1. Introduction
In Checkmk, notification means that users are actively informed in the case of problems or other events in the monitoring. This is most commonly achieved using emails. However, there are also many other methods, such as sending SMS or forwarding to a ticket system. Checkmk provides a simple interface for writing scripts for your own notification methods.
The starting point for any notification to a user is an event reported by the monitoring core. We call this a monitoring event in this article to avoid confusion with the events processed by the Event Console. A monitoring event is always related to a particular host or service. Possible types of monitoring events are:
A change of state, e.g. OK → WARN
The change between a steady and an
 unsteady (flapping) state.
unsteady (flapping) state.The start or end of a
 scheduled downtime.
scheduled downtime.The
 acknowledgment of a problem by a user.
acknowledgment of a problem by a user.A notification manually triggered by a
 command.
command.The execution of an
 alert handler.
alert handler.An event passed for notification from the
 Event Console.
Event Console.
Checkmk utilizes a rule-based system that allows you to create user notifications from these monitoring events — and this can also be used to implement very demanding requirements. A simple notification by email — which is entirely satisfactory in many cases — is nonetheless quick to set up.
This article mainly deals with the basics and general questions about notifications.
If instead you would like to start directly with the implementation: Checkmk generally distinguishes between two ways of defining notifications. On the one hand, the rules for notifications are defined globally. These rules apply to all affected users and groups depending on the event. The creation of these notifications is described under Setting up notifications by rules.
At the same time, each user has the option to influence the notification settings individually. For example, a contact person can deactivate the delivery of notifications to their own inbox while on vacation. You can read how these personal settings can be implemented in the article Personal notification rules.
2. To notify, or not (yet) to notify?
Notifications are basically optional, and Checkmk can still be used efficiently without them. Some large organizations have a sort of control panel in which an operations team has the Checkmk interface constantly under observation, and thus additional notifications are unnecessary. If your Checkmk environment is still under construction, it should be considered that notifications will only be of help to your colleagues when no — or only occasional — false alarms (false positives) are produced. One first needs to come to grips with the threshold values and all other settings, so that all states are OK / UP — or in other words: everything is ‘green’.
Acceptance of the new monitoring will quickly fade if every day the inbox is flooded with hundreds of useless emails.
The following procedure has been proven to be effective for the fine-tuning of notifications:
Step 1: Fine-tune the monitoring, on the one hand, by fixing any actual problems newly uncovered by Checkmk and, on the other hand, by eliminating false alarms. Do this until everything is ‘normally’ OK / UP. See the Beginner’s Guide for some recommendations for reducing typical false alarms.
Step 2: Next switch the notifications to be active only for yourself. Reduce the ‘static’ caused by sporadic, short duration problems. To do this, adjust further threshold values, use predictive monitoring if necessary, increase the number of check attempts or try delayed notifications. And of course if genuine problems are responsible, attempt to get these under control.
Step 3: Once your own inbox is tolerably peaceful, activate the notifications for your colleagues. Create efficient contact groups so that each contact only receives notifications relevant to them.
These procedures will result in a system which provides relevant information that assists in reducing outages.
3. When notifications are generated and how to deal with them
3.1. Introduction
A large part of the Checkmk notification system’s complexity is due to its numerous tuning options, with which unimportant notifications can be avoided. Most of these will be situations in which notifications are already being delayed or suppressed when they occur. Additionally, the monitoring core has a built-in intelligence that suppresses certain notifications by default. We would like to address all of these aspects in this chapter.
3.2. Scheduled downtimes
When a host or service is in a scheduled downtime the object’s notifications will be suppressed. This is – alongside a correct evaluation of availabilities — the most important reason for the actual provision of downtimes in monitoring. The following details are relevant to this:
If a host is flagged as having a scheduled downtime, then all of its services will also be automatically in scheduled downtime – without an explicit entry for them needing to be entered.
Should an object enter a problem state during a scheduled downtime, when the downtime ends as planned this problem will be retroactively notified precisely at the end of the downtime.
The beginning and the end of a scheduled downtime is itself a monitoring event which will be notified.
3.3. Notification periods
You can define a notification period for each host and service during configuration. This is a time period which defines the time frame within which the notification should be constrained.
The configuration is performed using the Monitoring Configuration > Notification period for hosts, or respectively the Notification period for services rule set, which you can quickly find via the search in the Setup menu.
An object that is not currently in a notification period will be flagged with a gray pause icon ![]() .
.
Monitoring events for an object that is not currently in its notification period will not be notified. Such notifications will be ‘reissued’ when the notification period is again active – if the host/service is still in a problem state. Only the latest state will be notified even if multiple changes to the object’s state have occurred during the time outside the notification period.
Incidentally, in the notification rules it is also possible to restrict a notification to a specific time period. In this way you can additionally restrict the time ranges. However, notifications that have been discarded due to a rule with time conditions will not automatically be repeated later!
3.4. The state of the host on which a service is running
If a host has completely failed, or is at least inaccessible to the monitoring, then obviously its services can no longer be monitored.
Active checks will then as a rule register CRIT or UNKNOWN, since these will be actively attempting to access the host and will thereby run into an error.
In such a situation all other checks — thus the great majority — will be omitted and will thus remain in their old state.
These will be flagged with the stale time icon ![]() .
.
It would naturally be very cumbersome if all active checks in such a state were to notify their problems. For example, if a web server is not reachable – and this has already been notified – it would not be very helpful to additionally generate an email for every single one of its dependent HTTP services.
To minimize such situations, as a basic principle the monitoring core only generates notifications for services if the host is in the UP state. This is also the reason why host accessibility is separately verified. If not otherwise configured, this verification will be achieved with a Smart Ping or ping.
![]() If you are using Checkmk Community (or one of the commercial editions with a Nagios core), in isolated cases it can nonetheless occur that a host problem
generates a notification for an active service.
The reason for this is that Nagios regards the results of host checks as still being valid for a short time into the future.
If even only a few seconds have elapsed between the last successful ping to the server and the next active check, Nagios can still assess the host as UP even though it is in fact DOWN.
In contrast, the Checkmk Micro Core (CMC) will hold the service notification in a ‘standby’ mode until the host state has been verified, thus reliably minimizing undesired notifications.
If you are using Checkmk Community (or one of the commercial editions with a Nagios core), in isolated cases it can nonetheless occur that a host problem
generates a notification for an active service.
The reason for this is that Nagios regards the results of host checks as still being valid for a short time into the future.
If even only a few seconds have elapsed between the last successful ping to the server and the next active check, Nagios can still assess the host as UP even though it is in fact DOWN.
In contrast, the Checkmk Micro Core (CMC) will hold the service notification in a ‘standby’ mode until the host state has been verified, thus reliably minimizing undesired notifications.
3.5. Parent hosts
Imagine that an important network router to a company location with hundreds of hosts fails. All of its hosts will then be unavailable to the monitoring and become DOWN. Hundreds of notifications will therefore be triggered. Not good.
In order to avoid such problems the router can be defined as a parent host for its hosts. If there are redundant hosts, multiple parents can also be defined. As soon as all parents enter a DOWN state, the hosts that are no longer reachable will be flagged with the UNREACH state and their notifications will be suppressed. The problem with the router itself will of course still be notified.
![]() By the way, the CMC operates internally in a slightly different manner to Nagios.
In order to reduce false alarms, but still process genuine notifications, the CMC pays very close attention to the exact times of the relevant host checks.
If a host check fails the core will wait for the result of the host check on the parent host before generating a notification.
This wait is asynchronous and has no effect on the general monitoring.
Notifications from hosts can thereby be subject to minimal delays.
By the way, the CMC operates internally in a slightly different manner to Nagios.
In order to reduce false alarms, but still process genuine notifications, the CMC pays very close attention to the exact times of the relevant host checks.
If a host check fails the core will wait for the result of the host check on the parent host before generating a notification.
This wait is asynchronous and has no effect on the general monitoring.
Notifications from hosts can thereby be subject to minimal delays.
4. Controlling notifications
4.1. The principle
Checkmk is configured ‘by default’ so that when a monitoring event occurs a notification email is sent to every contact for the affected host or service. This is certainly initially sensible, but in practice many further requirements arise, for example:
The suppression of specific, less useful notifications.
The ‘subscription’ to notifications from services for which one is not a contact.
A notification can be sent by email, SMS or pager, depending on the time of day.
The escalation of problems when no acknowledgment has been received beyond a certain time limit.
The option of no notification for the WARN or UNKNOWN states.
and much more …
Checkmk provides you with maximum flexibility in implementing such requirements via its rule-based mechanism.
In the notification configuration, you manage the chain of notification rules, which determine who should be notified and how. When any monitoring event occurs this rule chain will be run through from top to bottom. Each rule has a condition that decides whether the rule actually applies to the situation in question.
If the condition is satisfied the rule determines two things:
A selection of contacts (Who should be notified?).
A notification method (How to notify?), e.g. HTML email, and optionally, additional parameters for the chosen method.
Important: In contrast to the rules for hosts and services, here the evaluation also continues after the applicable rule has been satisfied. Subsequent rules can add further notifications. Notifications generated by preceding rules can also be deleted.
The end result of the rule evaluation will be table with a structure something like this:
| Who (contact) | How (method) | Parameters for the method |
|---|---|---|
Harry Hirsch |
|
|
Bruno Weizenkeim |
|
|
Bruno Weizenkeim |
SMS |
Now, for each entry in this table the notification script which actually executes the user notification appropriate to the method will be invoked.
4.2. Disabling notifications
Disabling using rules
With the Enable/disable notifications for hosts, or respectively, the Enable/disable notifications for services rule sets you can specify hosts and services for which generally no notifications are to be issued. As mentioned above the core then suppresses notifications. A subsequent notification rule that ‘subscribes’ to notifications for such services will be ineffective, as the notifications are simply not generated.
Disabling using commands
It is also possible to temporarily disable notifications for individual hosts or services via a command.
However, this requires that the permission Commands on host and services > Enable/disable notifications is assigned to the user role. By default, this is not the case for any role.
With the assigned permission, you can disable (and later enable) notifications from hosts and services with the Commands > Notifications command:

Such hosts or services will then be marked with an ![]() icon.
icon.
Since commands — in contrast to rules — require neither configuration permissions nor an activate changes, they can be a quick workaround for reacting promptly to a situation.
Important: In contrast to ![]() scheduled downtimes, disabled notifications have no influence on the availability evaluations.
If during an unplanned outage you really only want to disable the notifications without wishing to distort the availability statistics,
you should not register a scheduled downtime!
scheduled downtimes, disabled notifications have no influence on the availability evaluations.
If during an unplanned outage you really only want to disable the notifications without wishing to distort the availability statistics,
you should not register a scheduled downtime!
Disabling globally
In the Master control snap-in in the sidebar you will find a master switch for Notifications:

This switch is incredibly useful if you plan to make bigger system changes, during which an error could under the circumstances force many services into a CRIT state. You can use the switch to avoid upsetting your colleagues with a flood of useless emails. Remember to re-enable the notifications when you are finished.
Each site in a distributed monitoring has one of these switches. Switching off the central site’s notifications still allows remote sites to activate notifications — even though these are directed to and delivered from the central site.
Important: Notifications that would have been triggered during the time when notifications were disabled will not be repeated later when they are re-enabled.
4.3. Delaying notifications
You may possibly have services that occasionally enter a problem state for short periods, but the stops are very brief and are not critical for you. In such cases notifications are very annoying, but are easily suppressed. The Delay host notifications and Delay service notifications rule sets serve this situation.
You specify a time in minutes here — and a notification will be delayed until this time has expired. Should the OK / UP state occurs again before then, no notification will be triggered. Naturally this also means that the notification of a genuine problem will be delayed.
Obviously even better than delaying notifications would be the elimination of the actual cause of the sporadic problems — but that is of course another story…
4.4. Repeated check attempts
Another very similar method for delaying notifications is to allow multiple check attempts when a service enters a problem state. This is achieved with the Maximum number of check attempts for hosts, or respectively, the Maximum number of check attempts for service rule set.
If you set a value of 3 here, for example, a check with a CRIT result will at first not trigger a notification.
This is referred to as a CRIT soft state.
The hard state remains OK.
Only if three successive attempts return a not-OK-state will the service switch to the hard state and a notification be triggered.
In contrast to delayed notifications, here you have the option of defining views so that such problems are not displayed. A BI aggregation can also be constructed so that only hard states are included — not soft ones.
4.5. Flapping hosts and services
When a host or service frequently changes its state over a short time it is regarded as flapping. This is an actual state. The principle here is the reduction of excessive notifications during phases when a service is not (quite) running stably. Such phases can also be specially evaluated in the availability statistics.
Flapping objects are marked with the ![]() icon.
As long as an object is flapping, successive state changes trigger no further notifications.
A notification will however be triggered whenever the object enters or leaves the flapping state.
icon.
As long as an object is flapping, successive state changes trigger no further notifications.
A notification will however be triggered whenever the object enters or leaves the flapping state.
The system’s recognition of flapping can be influenced in the following ways:
The Master control has a main switch for controlling the detection of flapping (Flap Detection).
You can exclude objects from detection by using the Enable/disable flapping detection for hosts, or respectively, the Enable/disable flapping detection for services rule set.
In the commercial editions, using Global settings > Monitoring core > Tuning of flap detection you can define the parameters for flapping detection and set them to be more or less sensitive:

Show the context sensitive help with Help > Show inline help for details on the customizable values.
5. The path of a notification from beginning to end
5.1. The notification history
To get started, we will show you how to view the history of notifications at the host and service level in Checkmk to be able to track the notification process.
A monitoring event that causes Checkmk to trigger a notification is, for example, the change of state of a service. You can manually trigger this state change with the Fake check results command for testing purposes.
For a notification test, you can move a service from the OK state to CRIT in this way. If you now display the notifications for this service on the service details page with Service > Service notifications, you will see the following entries:
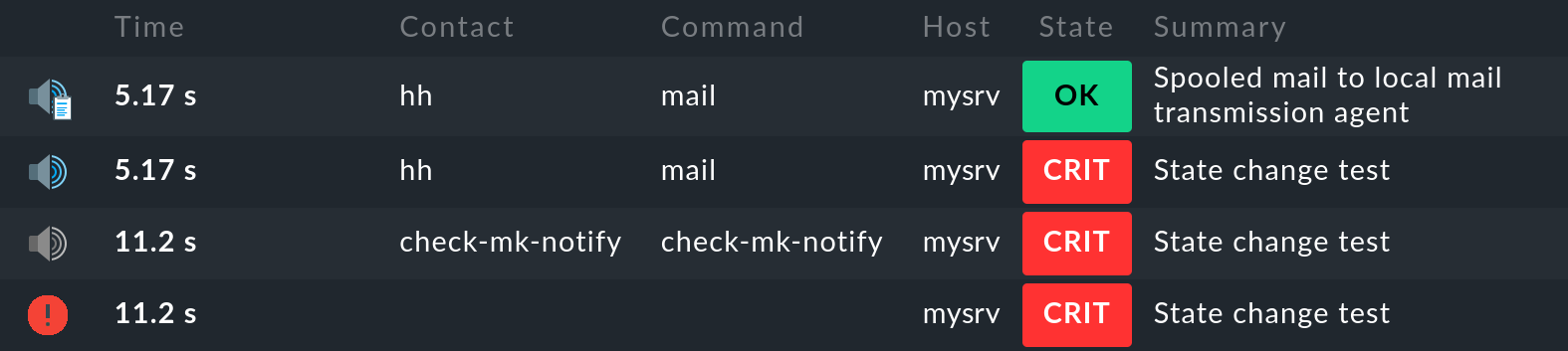
The most recent entry is at the top of the list. However, the first entry is at the bottom, so let’s look at the individual entries from bottom to top:
The monitoring core logs the monitoring event of the state change. The
 icon in the 1st column indicates the state (CRIT in the example).
icon in the 1st column indicates the state (CRIT in the example).The monitoring core generates a
 raw notification.
This is passed by the core to the notification module, which performs the evaluation of the applicable notification rules.
raw notification.
This is passed by the core to the notification module, which performs the evaluation of the applicable notification rules.The evaluation of the rules results in a
 user notification to the user
user notification to the user hhwith the methodmail.The
 notification result shows that the email was successfully handed over to the SMTP server for delivery.
notification result shows that the email was successfully handed over to the SMTP server for delivery.
To help in the correct understanding of the contexts for all of the various setting options and basic conditions, and to enable an accurate problem diagnosis when a notification appears or does not appear as expected, here we will describe all of the details of the notification process including all of the components involved.
The notification history that we have shown above for a service can also be displayed for a host: on the host details page in the Host menu for the host itself (Notifications of host menu item) and also for the host with all its services (Notifications of host & services). |
5.2. The components
The following components are involved in the Checkmk notification system:
| Component | Function | Log file |
|---|---|---|
Nagios |
The monitoring core in |
|
The monitoring core in the commercial editions that performs the same function as Nagios in Checkmk Community. |
|
|
Notification module |
Processes the notification rules in order to create a user notification from a raw notification. It calls up the notification scripts. |
|
Notification spooler (commercial editions only) |
Asynchronous delivery of notifications, and centralized notifications in distributed environments. |
|
Notification script |
For every notification method there is a script which processes the actual delivery (e.g., generates and sends an HTML email). |
|
5.3. The monitoring core
Raw notifications
As described above, every notification begins with a monitoring event in the monitoring core.
If all conditions have been satisfied and a ‘green light’ for a notification can be given, the core generates a raw notification to the internal check-mk-notify help contact.
The raw notification doesn’t yet contain details of the actual contacts or of the notification method.
The raw notification looks like this in the service’s notification history:

The icon is a
light-gray loudspeakercheck-mk-notifyis given as the contact.check-mk-notifyis given as the command.
The raw notification then passes to the Checkmk notification module, which processes the notification rules.
This module is called up as an external program by Nagios (cmk --notify).
The CMC keeps the module on standby as a permanent auxiliary process (notification helper), thus reducing process-creation and saving machine time.
Error diagnosis in the Nagios monitoring core
![]() The Nagios core used in
The Nagios core used in ![]() Checkmk Community logs all monitoring events to
Checkmk Community logs all monitoring events to ~/var/log/nagios.log.
This file is simultaneously the location where it stores the notification history — which is also queried using the
GUI if, for example, you wish to see a host’s or service’s notifications.
More interesting however are the messages you find in the ~/var/nagios/debug.log file which you receive if you set the debug_level
variable to 32 in etc/nagios/nagios.d/logging.cfg.
Following a core restart …
… you will find useful information on the reasons notifications were created or suppressed:
[1592405483.152931] [032.0] [pid=18122] ** Service Notification Attempt ** Host: 'localhost', Service: 'backup4', Type: 0, Options: 0, Current State: 2, Last Notification: Wed Jun 17 16:24:06 2020
[1592405483.152941] [032.0] [pid=18122] Notification viability test passed.
[1592405485.285985] [032.0] [pid=18122] 1 contacts were notified. Next possible notification time: Wed Jun 17 16:51:23 2020
[1592405485.286013] [032.0] [pid=18122] 1 contacts were notified.Error diagnosis in the CMC monitoring core
![]() In the commercial editions you can find a protocol from the monitoring core in the
In the commercial editions you can find a protocol from the monitoring core in the ~/var/log/cmc.log log file.
In the standard installation this file contains no information regarding notifications.
You can however activate a very detailed logging function with Global settings > Monitoring Core > Logging of the notification mechanics.
The core will then provide information on why — or why not (yet) — a monitoring event prompts it to pass a notification to the notification system:
Note: Turning on logging to notifications can generate a lot of messages. It is however useful when one later asks why a notification was not generated in a particular situation.
5.4. Rule evaluation by the notification module
Once the core has generated a raw notification, this runs through the chain of notification rules – resulting in a table of notifications. Alongside the data from the raw notification, every notification contains the following additional information:
The contact to be notified
The notification method
The parameters for this method
In a synchronous delivery, for every entry in the table an appropriate notification script will now be executed. In an asynchronous delivery a notification will be passed as a file to the notification spooler.
Analysis of the rule chain
When you create more complex rule regimes the question of which rules will apply to a specific notification will certainly come up. For this Checkmk provides a built-in analysis function under Setup > Setup > Analyze recent notifications.
In the analysis mode, by default the last ten raw notifications generated by the system and processed through the rules will be displayed:
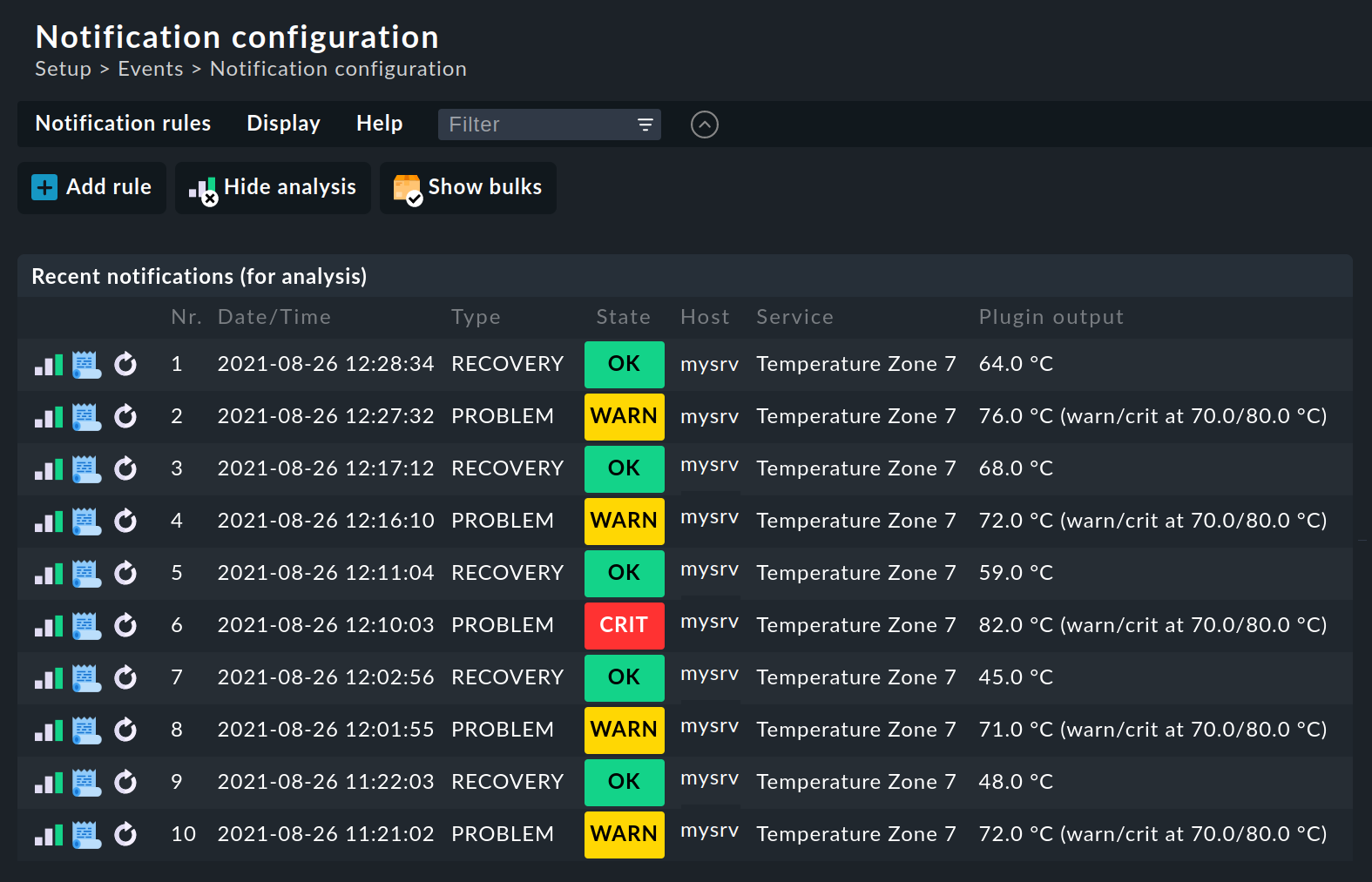
Should you need to analyze a larger number of raw notifications, you can easily increase the number stored for analysis via Global settings > Notifications > Store notifications for rule analysis:

For each of these raw notifications three actions will be available to you:
|
Tests the rule chain, in which every rule will be checked if all conditions for the rule have been satisfied for the selected monitoring event. The resulting table of notifications will be displayed with the rules. |
|
Displays the complete notification context. |
|
Repeats this raw notification as if it has just appeared. Otherwise the display is the same as in the analysis. With this you can not only check the rule’s conditions, but also test how a notification looks visually. |
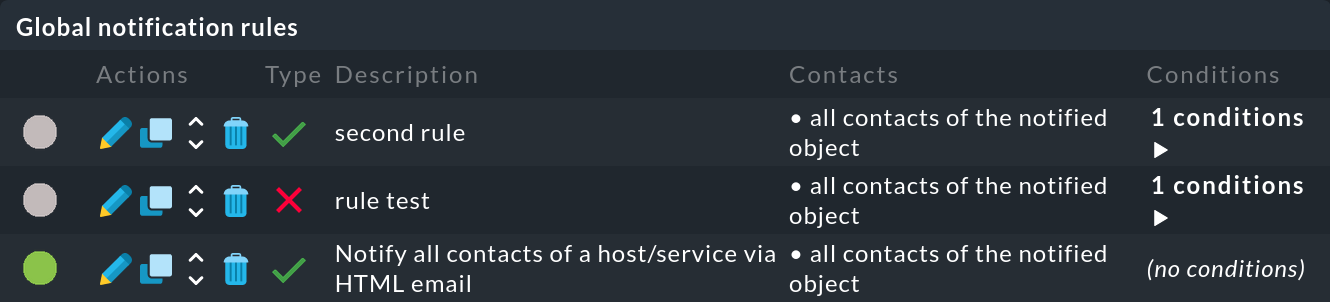
Error diagnosis
If you have performed the rule chain test (![]() ), you can see which rules
), you can see which rules ![]() have been applied or
have been applied or ![]() have not been applied to a monitoring event:
have not been applied to a monitoring event:
If a rule was not applied, move the mouse over the gray circle to see the hint (mouse-over text):
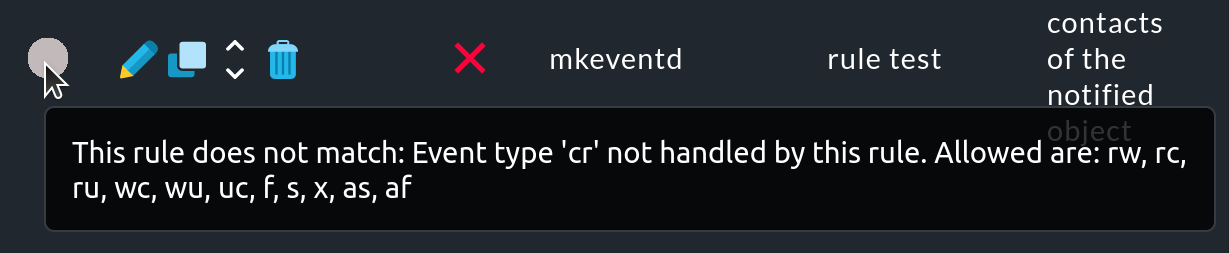
However, this mouse-over text uses abbreviations for the causes a rule was not applied. These refer to the Host events or Service events conditions of the rule.
| Host event types | ||
|---|---|---|
Abbreviation |
Meaning |
Description |
|
UP ➤ DOWN |
Host state changed from UP to DOWN |
|
UP ➤ UNREACHABLE |
Host state changed from UP to UNREACH |
|
DOWN ➤ UP |
Host state changed from DOWN to UP |
|
DOWN ➤ UNREACHABLE |
Host state changed from DOWN to UNREACH |
|
UNREACHABLE ➤ DOWN |
Host state changed from UNREACH to DOWN |
|
UNREACHABLE ➤ UP |
Host state changed from UNREACH to UP |
|
any ➤ UP |
Host state changed from any state to UP |
|
any ➤ DOWN |
Host state changed from any state to DOWN |
|
any ➤ UNREACHABLE |
Host state changed from any state to UNREACH |
|
Start or end of flapping state |
|
|
Start or end of a scheduled downtime |
|
|
Acknowledgment of problem |
|
|
Alert handler execution, successful |
|
|
Alert handler execution, failed |
|
| Service event types | ||
|---|---|---|
Abbreviation |
Meaning |
Description |
|
OK ➤ WARN |
Service state changed from OK to WARN |
|
OK ➤ OK |
Service state changed from OK to OK |
|
OK ➤ CRIT |
Service state changed from OK to CRIT |
|
OK ➤ UNKNOWN |
Service state changed from OK to UNKNOWN |
|
WARN ➤ OK |
Service state changed from WARN to OK |
|
WARN ➤ CRIT |
Service state changed from WARN to CRIT |
|
WARN ➤ UNKNOWN |
Service state changed from WARN to UNKNOWN |
|
CRIT ➤ OK |
Service state changed from CRIT to OK |
|
CRIT ➤ WARN |
Service state changed from CRIT to WARN |
|
CRIT ➤ UNKNOWN |
Service state changed from CRIT to UNKNOWN |
|
UNKNOWN ➤ OK |
Service state changed from UNKNOWN to OK |
|
UNKNOWN ➤ WARN |
Service state changed from UNKNOWN to WARN |
|
UNKNOWN ➤ CRIT |
Service state changed from UNKNOWN to CRIT |
|
any ➤ OK |
Service state changed from any state to OK |
|
any ➤ WARN |
Service state changed from any state to WARN |
|
any ➤ CRIT |
Service state changed from any state to CRIT |
|
any ➤ UNKNOWN |
Service state changed from any state to UNKNOWN |
Based on these hints you can check and revise your rules.
Another important diagnostic option is the log file ~/var/log/notify.log.
During tests with the notifications, the popular command tail -f is useful for this:
With Global settings > Notifications > Notification log level you can control the comprehensiveness of the notifications in three levels. Set this to Full dump of all variables and command, and in the log file you will find a complete listing of all of the variables available to the notification script:

For example, the list will appear like this (extract):
2025-04-09 08:47:39,186 [10] [cmk.base.notify] Raw context:
CONTACTS=hh
HOSTACKAUTHOR=
HOSTACKCOMMENT=
HOSTADDRESS=127.0.0.1
HOSTALIAS=localhost
HOSTATTEMPT=1
HOSTCHECKCOMMAND=check-mk-host-smart5.5. Asynchronous delivery via the notification spooler
![]() A powerful supplementary function of the commercial editions is the notification spooler.
This enables an asynchronous delivery of notifications.
What does asynchronous mean in this context?
A powerful supplementary function of the commercial editions is the notification spooler.
This enables an asynchronous delivery of notifications.
What does asynchronous mean in this context?
Synchronous delivery: The notification module waits until the notification script has finished executing. If this takes a long time to execute, more notifications will pile up. If monitoring is stopped, these notifications are lost. In addition, if many notifications are generated over a short period of time, a backlog may build up to the core, causing the monitoring to stall.
Asynchronous delivery: Every notification will be saved to a spool file under
~/var/check_mk/notify/spool. No jam can build up. If the monitoring is stopped the spool files will be retained and notifications can later be delivered correctly The notification spooler takes over the processing of the spool files.
A synchronous delivery is then feasible if the notification script runs quickly, and above all can’t lead to some sort of timeout. With notification methods that access existing spoolers that is a given. Spool services from the system can be used particularly with email and SMS. The notification script passes a file to the spooler — with this procedure no wait state can occur.
When using the traceable delivery via SMTP or other scripts which establish network connections, you should always employ asynchronous delivery. This also applies to scripts that send text messages (SMS) via HTTP over the internet. The timeouts when building a connection to a network service can take up to several minutes, causing a jam as described above.
The good news is that asynchronous delivery is enabled by default in Checkmk.
For one thing, the notification spooler (mknotifyd) is also started when the site is started, which you can check with the following command:
On the other hand, asynchronous delivery (Asynchronous local delivery by notification spooler) is selected in Global settings > Notifications > Notification Spooling:

Error diagnosis
The notification spooler maintains its own log file: ~/var/log/mknotifyd.log.
This possesses three log levels which can be set under Global settings > Notifications > Notification Spooler Configuration with the Verbosity of logging parameter.
The default is Normal logging (only startup, shutdown and errors.
In the middle level, Verbose logging (i.e. spooled notifications), the processing of the spool files can be seen:
2025-04-09 08:47:37,928 [15] [cmk.mknotifyd] processing spoolfile: /omd/sites/mysite/var/check_mk/notify/spool/dad64e2e-b3ac-4493-9490-8be969a96d8d
2025-04-09 08:47:37,928 [20] [cmk.mknotifyd] running cmk --notify --log-to-stdout spoolfile /omd/sites/mysite/var/check_mk/notify/spool/dad64e2e-b3ac-4493-9490-8be969a96d8d
2025-04-09 08:47:39,848 [20] [cmk.mknotifyd] got exit code 0
2025-04-09 08:47:39,850 [20] [cmk.mknotifyd] processing spoolfile dad64e2e-b3ac-4493-9490-8be969a96d8d successful: success 250 - b'2.4.0 Ok: queued as 1D4FF7F58F9'
2025-04-09 08:47:39,850 [20] [cmk.mknotifyd] sending command LOG;SERVICE NOTIFICATION RESULT: hh;mysrv;CPU load;OK;mail;success 250 - b'2.4.0 Ok: queued as 1D4FF7F58F9';success 250 - b'2.0.0 Ok: queued as 1D4FF7F58F9'6. Traceable delivery per SMTP
6.1. Email is not reliable
![]() Monitoring is only useful when one can rely on it.
This requires that notifications are received reliably and promptly.
Unfortunately email delivery is not completely ideal however.
The dispatch is usually processed by passing the email to the local SMTP server.
This attempts to deliver the email autonomously and asynchronously.
Monitoring is only useful when one can rely on it.
This requires that notifications are received reliably and promptly.
Unfortunately email delivery is not completely ideal however.
The dispatch is usually processed by passing the email to the local SMTP server.
This attempts to deliver the email autonomously and asynchronously.
With a temporary error (e.g., a case where the receiving SMTP server is not reachable) the email will be put into a queue and a later a new attempt will be made. This ‘later’ will as a rule be after 15-30 minutes. By then the notification could be far too late!
If the email really can’t be delivered the SMTP server creates a nice error message in its log file and attempts to generate an error email to the ‘sender’. But the monitoring system is not a real sender and also cannot receive emails. It follows that such errors simply disappear and notifications are then absent.
6.2. Using SMTP on a direct connection enables error analysis
The commercial editions provide the possibility of a traceable delivery via SMTP. This it intentionally does without the help of the local mail server. Instead Checkmk itself sends the email to your smarthost via SMTP, and then it evaluates the SMTP response itself.
In this way, not only are SMTP errors treated intelligently, but a correct delivery is also precisely documented. It is a bit like a registered letter: Checkmk receives a receipt from the SMTP smarthost (receiving server) verifying that the email has been accepted — including a mail ID.
The practical process for setting up notifications with traceable delivery via SMTP is described in global notification rules and in personal notification rules.
6.3. SMS and other notification methods
A synchronous delivery including error messages and traceability has to date only been implemented for HTML emails. How one can return an error status in a self-written notification script can be found in the chapter on writing your own scripts.
7. Notifications in distributed systems
In distributed environments — i.e., those with more than a single Checkmk site — the question arises of what to do with notifications generated on remote sites. In such a situation there are basically two possibilities:
Local delivery
Central delivery on the central site (commercial editions only)
Detailed information on this subject can be found in the article on distributed monitoring.
8. Notification scripts
8.1. The principle
Notification can occur in manifold and individual ways. Typical examples are:
Transfer of notifications to a ticket, or external notification system
The sending of an SMS over various internet services
Automated telephone calls
Forwarding to a higher, umbrella monitoring system
For this reason Checkmk provides a very simple interface which enables you to write your own notification scripts. These can be written in any Linux-supported programming language — even though Shell, Perl and Python together have 95 % of the ‘market’.
The standard scripts included with Checkmk can be found in ~/share/check_mk/notifications.
This directory is a component of the software and is not intended to be changed.
Instead, save your own scripts in ~/local/share/check_mk/notifications.
Ensure that your scripts are executable (chmod +x).
They will then be found automatically and made available for selection in the notification rules.
Should you wish to customize a standard script, simply copy it from ~/share/check_mk/notifications to ~/local/share/check_mk/notifications and there make your changes in the copy.
If you retain the original name, your script will be substituted automatically for the standard version and no changes will need to be made to the existing notification rules.
In the case of a notification your script will be called up with the site user’s permissions.
In environment variables, those that begin with NOTIFY_, the script will receive all of the information about the affected host/service, the monitoring event, the contacts to be notified, and the parameters specified in the notification rule.
Texts that the script writes to the standard output (with print, echo, etc.), appear in the notification module’s log file ~/var/log/notify.log.
8.2. Traceable notifications
Notification scripts have the option of using an exit code to communicate whether a replicable or final error has occurred:
| Exit code | Description |
|---|---|
|
The script was successfully executed. |
|
A temporary error has occurred. The execution should after a short wait be repeatedly reattempted, up until the configured maximum number of attempts has been reached. Example: an HTTP connection cannot be established with an SMS service. |
|
A final error has occurred. The notification will not be reattempted. A notification error will be displayed in the GUI. The error will be displayed in the host’s/service’s history. Example: the SMS service records an 'invalid authentication' error. |
Additionally, in all cases the standard output from the notification script, together with the status will be entered into the host’s/service’s notification history and will therefore be visible in the GUI.
Important: Traceable notifications are not available for bulk notifications!
![]() The treatment of notification errors from the user’s point of view will be explained in the chapter on traceable delivery via SMTP.
The treatment of notification errors from the user’s point of view will be explained in the chapter on traceable delivery via SMTP.
8.3. A simple script example
As an example you can create a script that writes all of the information about the notification to a file. The coding language is the Bash Linux shell:
Then make the script executable:
Here are a couple of explanations concerning the script:
In the first line is a
#!and the path to the script language’s interpreter (here/bin/bash).In the second line after the comment character
#is a title for the script. As a rule this will be shown when selecting the notification method.The
envcommand will output all environment variables received by the script.With
grep NOTIFY_the Checkmk variables will be filtered out …… and sorted alphabetically with
sort.> $OMD_ROOT/tmp/foobar.outwrites the result to the~/tmp/foobar.outfile within the site directory.The
exit 0would actually be superfluous in this location since the shell always takes the exit code from the last command. Here this isechoand is always successful — but explicit is always better.
8.4. Testing the example script
So that the script will be used you must define it as a method in a notification rule.
Self-written scripts have no parameter declaration, therefore all of the checkboxes such as those offered, for example, in the HTML Email method, will be missing.
Instead you can enter a list of texts as parameters that can be available as NOTIFY_PARAMETER_1, NOTIFY_PARAMETER_2, etc, to the script.
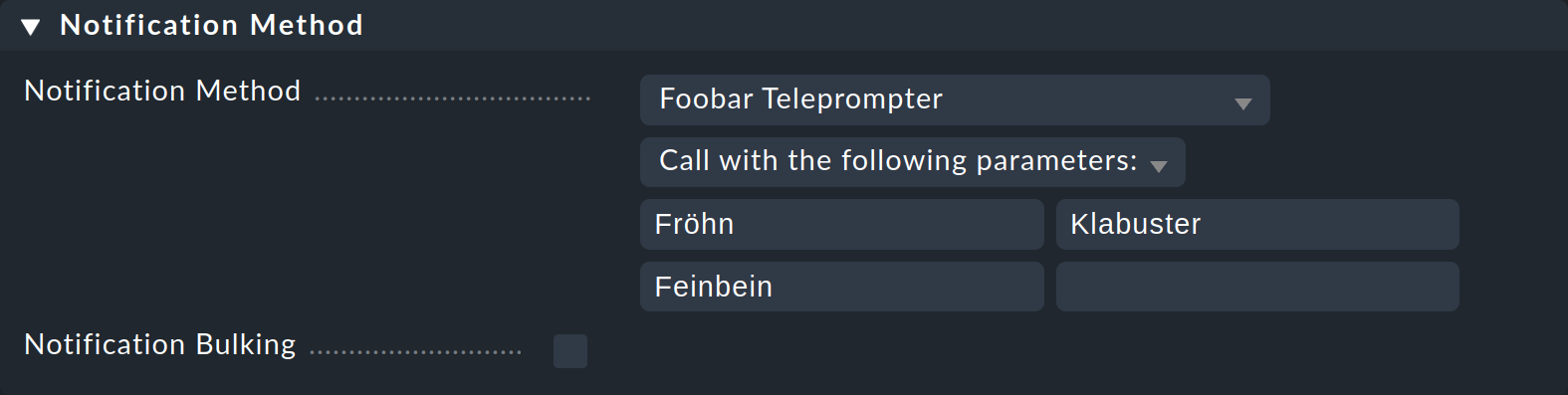
For a test provide the parameters Fröhn, Klabuster and Feinbein:
Now to test, set the service CPU load on the host myserver to CRIT — with the Fake check results command.
In the log file of the notification module ~/var/log/notify.log you then see the execution of the script including parameters and the generated spool file.:
2021-08-25 13:01:23,887 [20] [cmk.base.notify] Executing 1 notifications:
2021-08-25 13:01:23,887 [20] [cmk.base.notify] * notifying hh via foobar, parameters: Fröhn, Klabuster, Feinbein, bulk: no
2021-08-25 13:01:23,887 [20] [cmk.base.notify] Creating spoolfile: /omd/sites/mysite/var/check_mk/notify/spool/e1b5398c-6920-445a-888e-f17e7633de60The file ~/tmp/foobar.out will now contain an alphabetic list of all Checkmk environment variables that include information concerning the notification.
Here you can orient yourself with which values are available to your script.
Here are the first ten lines:
The parameters can also be found:
8.5. Environment variables
In the above example you have seen a number of environment variables that will be passed to the script.
Precisely which variables are available depends on the type of notification, the Checkmk version and edition and the monitoring core used (CMC or Nagios).
Alongside the trick with the env command there are two further ways of getting a complete list of all variables:
Changing up the log level for
~/var/log/notify.logvia Global settings > Notifications > Notification log level.For notifications per HTML Email there is a checkbox Information to be displayed in the email body with the Complete variable list (for testing) option.
Below is a list of the most important variables:
| Environment variable | Description |
|---|---|
|
Home directory of the site, e.g., |
|
Site name, e.g., |
|
For host notifications, the word |
|
Username (login) of the contact. |
|
The email address of the contact. |
|
Entry in the Pager field in the contact’s user profile. Since the field is not generally reserved for a specific purpose, you can simply use it for each user in order to save information required for notifications. |
|
Date of the notification in ISO-8601-Format, e.g., |
|
Date and time in the non-localized Linux system’s default display, e.g., |
|
Date and time in ISO-Format, e.g. |
|
Name of the affected host. |
|
Output of the host check’s check plug-in, e.g., |
|
One of the words: |
|
Notification type as described in the introduction to this article. This will be expressed by one of the following words: |
|
All of the script’s parameters separated by blanks. |
|
The script’s first parameter. |
|
The script’s second parameter, etc. |
|
Name of the service concerned. This variable is not present in host notifications. |
|
Output of the service check’s check plug-in (not for host notifications) |
|
One of the words: |
8.6. Bulk notifications
If your script should support bulk notifications, it will need to be specially prepared, since the script must deliver multiple notifications simultaneously. For this reason a delivery using environment variables also doesn’t function practicably.
Give your script a name in the third line in the header as below — the notification module will then send the notifications through the standard input:
Through the standard input the script will receive blocks of variables.
Each line has the form: NAME=VALUE.
Blocks are separated by blank lines.
The ASCII character with the code 1 (\a) is used to represent newlines within the text.
The first block contains a list of general variables (e.g., call parameters). Each subsequent block assembles the variables into a notification.
The best recommendation is to try it yourself with a simple test that writes the complete data to a file so that you can see how the data is sent. You can use the following notification script for this purpose:
Test the script as described above and additionally activate the Notification Bulking in the notification rule.
8.7. Supplied notification scripts
As delivered, Checkmk already provides a whole range of scripts for connecting to popular and widely used instant messaging services, incident management platforms and ticket systems. You can find out how to use these scripts in the following articles:
9. Files and directories
9.1. Paths of Checkmk
| File path | Function |
|---|---|
|
The CMC log file. If notification debugging is activated, here you will find precise information as to why notifications were, or were not generated. |
|
The notification module’s log file. |
|
The notification spooler’s log file. |
|
The current state of the notification spooler. This is primarily relevant for notifications in distributed environments. |
|
The Nagios debug log file. Switch on the debug messages in |
|
Storage location for the spool files to be processed by the notification spooler. |
|
With temporary errors the notification spooler moves the files to here and retries after a couple of minutes. |
|
Defective spool files will be moved to here. |
|
Notification scripts supplied as standard with Checkmk. Make no changes here. |
|
Storage location for your custom notification scripts. If you wish to customize a standard script, copy it from |
9.2. SMTP server log files
The SMTP server’s log files are system files and their absolute paths are listed here below. Precisely where the log files are stored will depend on your Linux distribution.
| Path | Function |
|---|---|
|
SMTP-server’s log file under Debian and Ubuntu |
|
SMTP-server’s log file under SUSE Linux Enterprise Server (SLES) |
|
SMTP-server’s log file under Red Hat Enterprise Linux (RHEL) |