1. Introduction
Checkmk provides comprehensive options for the monitoring of Oracle databases. With the agent plug-in you can not only retrieve a database’s tablespaces or its active sessions, but also many other types of metrics. A complete list of monitoring options with our check plug-ins can be found in the Catalog of check plug-ins. We regularly add new plug-ins and update existing ones, so it is always worth looking in the catalog. Among others, Checkmk can monitor the following values:
To be able to monitor the databases only the agent plug-in is required in addition to the agent on the database server.
The Linux, Solaris, AIX and Windows operating systems are currently supported.
The agent plug-in for the Unix-like operating systems Linux, Solaris, AIX is called mk_oracle and for Windows mk_oracle.ps1.
No further additional software will be required for a monitoring, either on the Checkmk server or on the database server.
Many of the steps to set up monitoring are the same for both Linux and Windows. The differences are highlighted in the chapter on Setup under Linux, Solaris, AIX, and Windows. With the Agent Bakery feature of the commercial editions, you have the option of configuring the setup for different environments in one place.
2. Initial setup
The configuration files with sample content presented in this and the following chapters can be found on the Checkmk server — either via the command line or via the Checkmk web interface. In Checkmk Community select Setup > Agents and in the commercial editions Setup > Agents > Windows, Linux, Solaris, AIX > Related. In all editions you will find menu entries for the different operating systems. The configuration files can be found in the Example Configurations box.
2.1. Creating a database user
In principle, the first setup is quick and requires only three steps.
The first step, of course, is to have a user who is also allowed to query the databases.
Provided that you are not using Real Application Cluster (RAC), create a user in each database to be monitored.
How to access an instance differs depending on the installed operating system.
For Linux, you can do this, for example, by always first setting the relevant instance as an environment variable in which a user is to be created.
Normally you first switch to the oracle user,
but this can differ depending on the setup:
Then log on to the instance and create a user for the monitoring.
To get all of the data, the following permissions are required.
In the following example, the newly-created user is named checkmk.
You can also specify any other desired name:
You can find out exactly how the login to a specific instance works in the Oracle documentation.
Multi-tenant databases
You can also configure the login for multi-tenant databases.
This is usually performed in the configuration using a special user and with the prefix C##.
The assignment of permissions is a bit different as for regular users as you need to specify them for all current containers and for all future containers:
2.2. Creating the configuration
After you have created a user, the next step is to enable the agent plug-in to later receive this information. The simplest way is for you to define the same login data for all instances, and set a default in the configuration.
- Linux, Solaris, AIX
Create the configuration file
mk_oracle.cfgon the Oracle host:/etc/check_mk/mk_oracle.cfg# Syntax: # DBUSER='USERNAME:PASSWORD' DBUSER='checkmk:myPassword'- Windows
Create the configuration file
mk_oracle_cfg.ps1on the Oracle host. This file is a PowerShell script that sets the required variables:C:\ProgramData\checkmk\agent\config\mk_oracle_cfg.ps1# Syntax: # $DBUSER = @("USERNAME","PASSWORD") $DBUSER = @("checkmk","myPassword")
The standard user is all that the agent plug-in really requires. All other options that you can set in Unix-like systems or under Windows are optional.
2.3. Using the Oracle Wallet
As an alternative to specifying the user directly and with a password in a configuration file, you can also use the Oracle Wallet. This has the advantage that you no longer need to store the access data in an unencrypted form on the Checkmk server and on the Oracle host. So even if you have defined the configuration file’s access rights on the Oracle host to suit, the access data has nevertheless left the server and is located on the Checkmk server as long as you use the Agent Bakery.
The Oracle Wallet in turn stores the encrypted access data on the host to be monitored so that they can only be used, but no login data has to be made known explicitly. Checkmk can thus use this wallet so that the access data needs only be known to the database administrator (DBA). Create — or the DBA can create — a wallet on the appropriate server:
The agent plug-in will access this file later whenever a connection to an instance is to be established.
So that the necessary user data can also be found, you must enter this once in the wallet.
In the following example you thus add the user checkmk for the instance MYINST1:
For the agent plug-in to know where to look for the wallet, it must find two files.
The first file is sqlnet.ora in which the info for the wallet’s location can be found.
The second file — tnsnames.ora — defines the address of the instance so that it can also be addressed via its alias.
So that the agent plug-in can access these files you can specify the path under Linux, Solaris and AIX using the environment variable TNS_ADMIN.
This is especially useful if the files already exist.
Alternatively, you can create them explicitly.
Windows even requires that you specify them manually.
First create the sqlnet.ora file.
The agent plug-in alternatively searches in this file for the login data, so the correct file path to the wallet file you just created must be entered here.
Make sure that you set the SQLNET.WALLET_OVERRIDE parameter to TRUE:
LOG_DIRECTORY_CLIENT = /var/log/check_mk/oracle_client
DIAG_ADR_ENABLED = OFF
SQLNET.WALLET_OVERRIDE = TRUE
WALLET_LOCATION =
(SOURCE=
(METHOD = FILE)
(METHOD_DATA = (DIRECTORY=/etc/check_mk/oracle_wallet))
)Now the plug-in knows which credentials should be used.
So that it also accesses the correct address, create tnsnames.ora as the second file.
The exact syntax can be found in the Oracle documentation, but as an example the file could look like this:
MYINST1
(DESCRIPTION =
(ADDRESS = (PROTOCOL = TCP)(HOST = 127.0.0.1)(PORT = 1521))
(CONNECT_DATA =
(SERVER = DEDICATED)
(SERVICE_NAME = MYINST1_ALIAS)
)
)With this step you have created the prerequisites for removing the access data from the agent plug-in’s configuration file.
Instead of the access data, you simply enter a / (slash):
DBUSER='/:'You can of course add further access data to the wallet at a later date.
The tnsnames.ora file must then simply be amended as necessary.
Finally, change the permissions of the files and directories created manually in this section so that access rights on execution are correctly set.
The agent plug-in executed as root will switch to the owner of the Oracle binaries (such as $ORACLE_HOME/bin/sqlplus) before executing them.
As a minimum, the group of the owner of the Oracle binaries therefore needs read access to the manually created files in /etc/check_mk/.
In the following example, we assume that the group is oinstall.
The following commands change the group to oinstall:
These commands then ensure that the group can read the oracle_wallet directory and its contents:
The permissions should then look something like this:
The command output only shows the files and directories in question.
3. Setup for Linux, Solaris, AIX, and Windows
You can set up monitoring on Unix-like systems as well as Windows. However, some options are not available or only available to a limited extent on Windows. The following sections contain all of the information you need to set up monitoring in the various environments.
3.1. Plug-in and configuration paths
- Linux, Solaris, AIX
Under Unix-like systems Checkmk uses a uniform agent plug-in. On the one hand, this reduces maintenance effort, since SQL queries are not duplicated, and on the other hand you only need to pay attention to a single agent plug-in. On all supported systems the file paths for the agents are the same or very similar. Specifically, you need the following directories:
Operating system Plug-in path Configuration path Linux, Solaris, AIX
/usr/lib/check_mk_agent/plugins//etc/check_mk/Linux with
systemd/usr/lib/check_mk_agent/plugins/<Number>/etc/check_mk/AIX
/usr/check_mk/lib/plugins//usr/check_mk/conf/- Windows
On Windows, PowerShell is used as a scripting language to monitor Oracle databases. The functionality is similar to the agent plug-in under Unix-like systems, but contains only a part of this. To use the agent plug-in under Windows, you need PowerShell version 5.x or higher, as well as the following directories:
Operating system Plug-in path Configuration path Windows
C:\ProgramData\checkmk\agent\pluginsC:\ProgramData\checkmk\agent\config
3.2. Installing the agent plug-in
Once you have created a user in the initial setup and stored this in the configuration file, install the agent plug-in.
- Linux, Solaris, AIX
Copy the
mk_oraclefile from the Checkmk server’s directory~/share/check_mk/agents/plugins/to the Oracle host’s plug-in directory described above.
The agent plug-in for Unix-like systems
mk_oracledoes not work well withsystemd(see Werk #13732). On systems withsystemd, you must therefore run the agent plug-in asynchronously. This means that you do not install the agent plug-in directly under/usr/lib/check_mk_agent/plugins/, but in a subfolder/usr/lib/check_mk_agent/plugins/<Number>/.<Number>means the execution interval in seconds. We recommend execution once per minute, i.e./usr/lib/check_mk_agent/plugins/60/. When setting up via the Agent Bakery, you can do this using the Oracle rule’s option Host uses xinetd or systemd, which is set to xinetd by default.Be sure to make the agent plug-in executable:
- Windows
The agent plug-ins for Windows are stored on the host during the installation of the Checkmk agent for Windows. On the Oracle host, copy the file
mk_oracle.ps1from the directoryC:\Program Files (x86)\checkmk\service\plugins\into the plug-in directory described above. Alternatively, you can refer to the file in the installation path by updating the configuration file of the Checkmk agent.Special requirements
Windows normally prevents the execution of PowerShell scripts if they have not been signed. You can work around this problem very easily by modifying the policies for running PowerShell scripts for the user who is running the Checkmk agent:
This option is useful if for a short time you want to test a script or the general functionality of the Checkmk agent. To avoid compromising the security of your system, revert this setting on production servers after testing has been completed:
Understandably, you probably don’t want to change the guidelines every 60 seconds. You therefore set a permanent exception only for the relevant scripts. The configuration file of the agent plug-in must also be added to the exceptions. For easy readability, in this example the output has been completely omitted:
3.3. Advanced options
In the initial setup you have already learned about the first variables for getting monitoring data from their Oracle instances. However, depending on the application scenario, you will quickly need further possibilities for better, individual control of the monitoring for each instance. You will find these options in the following sections. Some of the options are only available in Unix-like environments.
Advanced user configuration
With the standard login you can use regular or possibly even all instances for a database. However, there are special cases in which you require individual access data for specific instances. In the configuration file you therefore have the following three options for specifying users:
| Parameter | Description |
|---|---|
|
The default if no individual access data has been defined for the database instance. |
|
Access data for a specific database instance — in this case for the instance |
|
Special access data for Automatic Storage Management (ASM). |
These variables additionally allow even more options apart from username and password.
You can also determine whether the user is a SYSDBA or SYSASM, on which combination of address and port the instance listens to, and even — for Unix-like systems — which TNS alias (TNSALIAS) should be used.
However, these specifications are always — unlike user and password — optional.
The configuration file created at the beginning can therefore be extended as follows, for example:
- Linux, Solaris, AIX
- /etc/check_mk/mk_oracle.cfg
# Syntax # DBUSER='USERNAME:PASSWORD:ROLE:HOST:PORT:TNSALIAS' DBUSER='checkmk:myPassword' DBUSER_MYINST1='cmk_specific1:myPassword1:SYSDBA:localhost:1521' DBUSER_MYINST2='cmk_specific2:myPassword2::localhost::INST2' ASMUSER='cmk_asm:myASMPassword:SYSASM'A few explanations for the above example:
You can define any number of individual access data. These are always preferred to the standard.
Each option is separated from the others by a
:(colon).If an optional field is omitted in the middle of the string, a colon must be coded, as with the
DBUSER_MYINST2entry, where no role and no port was specified.If after a certain point, no more optional fields are needed, you can omit the colons, as with the
ASMUSERentry, where neither host, port nor TNS alias was specified.
- Windows
- C:\ProgramData\checkmk\agent\config\mk_oracle_cfg.ps1
# Syntax # DBUSER = @("USERNAME", "PASSWORD", "ROLE", "HOST", "PORT") # Default # DBUSER = @("", "", "", "localhost", "1521") $DBUSER = @("checkmk", "myPassword", "SYSDBA", "localhost", "1521") @DBUSER_MYINST1 = @("cmk_specific1", "myPassword1", "", "10.0.0.73") @DBUSER_MYINST2 = @("cmk_specific2", "myPassword2", "SYSDBA", "localhost", "1531") @ASMUSER = @("cmk_asm", "myASMPassword", "SYSASM")A few explanations regarding the above example:
You can define any number of individual access data. These are always preferred to the standard.
Each option is defined in a list. The order of the entries is not arbitrary, so therefore the order may not be rearranged.
When an optional field remains unchanged but a field following it is to be edited, both fields must be specified correctly, as with the
DBUSER_MYINST2entry, where theHOSTis still set tolocalhosteven though only thePORTis to be changed.If optional fields are no longer needed after a certain point, they can be omitted, as with the
ASMUSERentry, in which only the user’s role was specified.If no special role is to be assigned to the user, but
HOSTorPORTis to be customized, simply enter a pair of inverted commas/double quotes ("") in this position.
Including or excluding instances
In some cases you may not want to include particular instances in the monitoring. This may be because it is only a playground for developers, or for other reasons. To make the configuration as simple as possible in individual situations, you have various options to entirely or partially exclude one or more instances:
- Linux, Solaris, AIX
Parameter Description ONLY_SIDSHere you can determine which instances are to be monitored. An instance is named by its system identifier (SID). This is a positive list, ignoring all instances that are not explicitly listed. This parameter is very useful if the number of instances to be monitored is smaller than the number of instances to be ignored.
SKIP_SIDSUnlike
ONLY_SIDS, this is a negative list where all instances are monitored except those explicitly listed here. This parameter is very suitable if the number of instances to be ignored is smaller than the number to be monitored.EXCLUDE_<SID>With this parameter you can partially exclude an instance by excluding certain sections of the instance from monitoring. In this way, you define a negative list of the sections of an instance. You can also exclude all sections with the value
ALLand and thus do the same as if you were to add the instance toSKIP_SIDS.
Important: For ASM SIDs you cannot use this procedure, however you can useSKIP_SIDS="+ASM1 …"instead.You will have already guessed: The order in which these parameters are processed determines the result. The entries are in fact processed per instance exactly in sequence as shown in the table above. Therefore if the variable
ONLY_SIDSis set,SKIP_SIDSis no longer evaluated nor is it checked whether theEXCLUDE_<SID>variable is set toALLfor this instance. IfONLY_SIDSis not set, the system proceeds according to the sequence. In case of doubt — that is, as the default behavior — the instance will be monitored accordingly.Below is an example in which all variables are set and what the behavior is like:
/etc/check_mk/mk_oracle.cfgONLY_SIDS='INST1 INST2 INST5' SKIP_SIDS='INST7 INST3 INST2' EXCLUDE_INST1='ALL' EXCLUDE_INST2='tablespaces rman'Since the positive list from the first line always has priority, the second and third lines are no longer evaluated. Only the fourth (last) line will be considered at a later date, since the instance is only to be partially evaluated here.
In practice, it makes sense to use only one of the variables to determine the number of instances to be monitored.
- Windows
Parameter Description ONLY_SIDSHere you can determine which instances are to be monitored. An instance is named by its system identifier (SID). This is a positive list, ignoring all instances that are not explicitly listed. This parameter is very useful if the number of instances to be monitored is smaller than the number of instances to be ignored.
EXCLUDE_<sid>Since the
SKIP_SIDSparameter is not available under Windows, you can only useEXCLUDE_<SID>to exclude instances and thus define a negative list. You do this by setting the value of the variable toALL. You can also use this parameter to partially exclude an instance by excluding certain sections of the instance from monitoring. In this way, you define a negative list of the sections of an instance.
Important: An (+ASM) cannot be completely deactivated with this option.The processing is done for each instance in the order shown in the table above. So first it is checked whether the instance is in
ONLY_SIDS, and only then whether certain sections are to be excluded. If the variableEXCLUDE_<SID>is set toALL, no section will be executed.Below is an example where each variable is shown once:
C:\ProgramData\checkmk\agent\config\mk_oracle_cfg.ps1$ONLY_SIDS = @("MYINST1", "MYINST3") $EXCLUDE_INST1 = "tablespaces rman" $EXCLUDE_INST3 = "ALL"Note that
ONLY_SIDSis a list, whereasEXCLUDE_INST1is a string containing sections separated by spaces.
Determining the data to be fetched
As you learned in the previous section, it is not only possible to disable instances completely, but also to only partially monitor them.
The operational requirements are diverse, and it is especially practical when it is undesirable to have certain long-running sections to be included in everything, or when only basic information from test instances is required, for example.
To restrict sections globally, set the corresponding variables directly — to restrict only certain instances you can slot in the EXCLUDE_<SID> variable which you have already learned about in the previous section.
The global variables are:
| Parameter | Description |
|---|---|
|
Sections that are to be queried synchronously, i.e. every time the agent runs. Since the query interval is 60 seconds by default, the SQL queries used must be run through correspondingly fast. If the variable is not specified, all sections are queried. |
|
Sections that are to be queried asynchronously, i.e. only every x minutes.
How long the data remains valid is determined by the |
|
Here for ASM sections the same mechanism applies as in the general description for the |
|
Here for ASM sections the same mechanism applies as in the general description for the |
|
This variable is used to determine how long asynchronously retrieved data remains valid. If the variable’s value is not specified, a default of 600 seconds (10 minutes) is used. Make sure that the time range is not shorter than the interval at which the Checkmk agent delivers the data (60 seconds by default). Otherwise, the data may be considered outdated and not delivered by the agent. |
|
Number of SIDs that are processed in parallel. The default value is 1. |
The mechanism therefore allows you to set a default in the configuration file and overwrite it for individual instances as required. A configuration could then look like this, for example:
- Linux, Solaris, AIX
- /etc/check_mk/mk_oracle.cfg
# DEFAULTS: # SYNC_SECTIONS="instance sessions logswitches undostat recovery_area processes recovery_status longactivesessions dataguard_stats performance locks" # ASYNC_SECTIONS="tablespaces rman jobs ts_quotas resumable" # SYNC_ASM_SECTIONS="instance processes" # ASYNC_ASM_SECTIONS="asm_diskgroup" # CACHE_MAXAGE=600 SYNC_ASM_SECTIONS='instance' ASYNC_SECTIONS='tablespaces jobs rman resumable' CACHE_MAXAGE=300 EXCLUDE_INST1='undostat locks' EXCLUDE_INST2='jobs' - Windows
- C:\ProgramData\checkmk\agent\config\mk_oracle_cfg.ps1
# DEFAULTS: # $SYNC_SECTIONS = @("instance", "sessions", "logswitches", "undostat", "recovery_area", "processes", "recovery_status", "longactivesessions", "dataguard_stats", "performance", "locks") # $ASYNC_SECTIONS = @("tablespaces", "rman", "jobs", "ts_quotas", "resumable") # $SYNC_ASM_SECTIONS = @("instance", "processes") # $ASYNC_ASM_SECTIONS = @("asm_diskgroup") # $CACHE_MAXAGE = 600 $SYNC_ASM_SECTIONS = @("instance") $ASYNC_SECTIONS = @("tablespaces", "jobs", "rman", "resumable") $CACHE_MAXAGE = 300 $EXCLUDE_INST1 = "undostat locks" $EXCLUDE_INST2 = "jobs'
As you can see in the example, only the instance section is queried for the ASM instances and a minimum set for the asynchronous sections is specified on all regular instances.
Additionally, on the INST1 instance the synchronous sections undostat and locks will be omitted.
Since the synchronous sections are not explicitly specified, all synchronous sections are retrieved from all other instances.
In the INST2 instance in turn, only three of the four asynchronous sections are queried, since jobs was additionally excluded.
And finally, the cache of 10 minutes is reduced to 5 minutes (300 seconds), as this is sufficient time to get all data.
If you define in the configuration file which sections you would like to retrieve, and by which method — you can also alter a asynchronous section to a synchronous section — you must specify all sections which should be executed in the respective area. |
For example, if you only want locks from the synchronous query, specify the entire synchronous list and simply omit locks:
- Linux, Solaris, AIX
- /etc/check_mk/mk_oracle.cfg
# Just exclude 'locks' from sync sections: SYNC_SECTIONS='instance sessions logswitches undostat recovery_area processes recovery_status longactivesessions dataguard_stats performance' - Windows
- C:\ProgramData\checkmk\agent\config\mk_oracle_cfg.ps1
# Just exclude 'locks' from sync sections: $SYNC_SECTIONS = @("instance", "sessions", "logswitches", "undostat", "recovery_area", "processes", "recovery_status", "longactivesessions", "dataguard_stats", "performance")
The same applies for the other three variables in which the sections can be determined.
Configuring TNS Alias and TNS_ADMIN (Linux, Solaris, AIX only)
The TNS alias is a user-friendly name for a database connection.
TNS stands for the Oracle network technology Transparent Network Substrate.
A TNS alias makes it possible to establish a connection to a database instance without having to enter the full connection details (such as host name, port number or service name) each time.
TNS aliases are defined in the file tnsnames.ora in Unix-like environments.
The section on Oracle Wallet contains an example of how to define a TNS alias.
TNS_ADMIN is an environment variable that points to the directory in which Oracle configuration files such as sqlnet.ora and tnsnames.ora are located.
By default, TNS_ADMIN is set by Oracle to $ORACLE_HOME/network/admin.
In the configuration file, you can assign a different path to TNS_ADMIN, as in the following example for a specific Oracle installation:
export TNS_ADMIN=/opt/oracle/product/19c/dbhome_1/network/admin/Only if the variable is not set at all, it is set by the agent plug-in to /etc/check_mk/.
Access rights on execution
- Linux, Solaris, AIX
For security reasons, the agent plug-in
mk_oracleno longer executes Oracle binaries under therootuser. This affects the programssqlplus,tnspingand — if available —crsctl. Instead,mk_oracle, for example, changes to the owner of the file$ORACLE_HOME/bin/sqlplusbefore executingsqlplus. This ensures that Oracle programs are only executed by a non-privileged user and thus prevents a malicious Oracle user from replacing a binary such assqlplusand running it asrootuser.
The execution of Oracle programs by a non-privileged user can lead to problems when using an Oracle wallet, as this user may not be able to access the wallet-specific files. The non-privileged user needs the permissions to read the files
$TNS_ADMIN/sqlnet.oraand$TNS_ADMIN/tnsnames.ora, to execute the wallet folder and to read the files in the wallet folder. You should not have any problems with the access rights as long as you have changed the group of the files and directories as described at the end of the section on Oracle Wallet.The agent plug-in helps you with the diagnosis and checks whether there are problems accessing the files mentioned and displays them in the connection test. The exact procedure for diagnosing and correcting access rights can be found in the Checkmk Knowledge Base.
- Windows
For security reasons, the agent plug-in
mk_oracle.ps1only executes Oracle binaries as administrator if these programs can only be changed by administrators. Administrators under Windows are the LocalSystem account and members of the built-inAdministratorsgroup. This applies to the programssqlplus.exe,tnsping.exeand — if available —crsctl.exe. The agent plug-inmk_oracle.ps1does not execute any of these programs if non-administrative users have one of the permissionsWrite,ModifyorFull controlfor the file. This prevents the security risk of non-privileged users executing programs as administrator.
You can find out in which patch version of Checkmk this change was made in Werk #15843.
If necessary, change the access rights by removing the above-mentioned permissions of non-administrative users for the programs. The agent plug-in helps you with the diagnosis and checks whether non-administrative users have access to the files mentioned and displays them in the connection test. The exact procedure for diagnosing and correcting access rights can be found in the Checkmk Knowledge Base.
If it is not possible for you to adjust the permissions for the Oracle programs securely, you can allow individual users and groups to run the programs:
C:\ProgramData\checkmk\agent\config\mk_oracle_cfg.ps1# Oracle plugin will allow users and groups in the list to have write access to the Oracle binaries $WINDOWS_SAFE_ENTRIES=@("NT AUTHORITY\Authenticated Users", "<Domain>\<User>")Only if there is no other way to ensure the Oracle monitoring you can switch off the access rights check as a final option.
If you disable the access rights check, the agent plug-in will no longer run securely.
C:\ProgramData\checkmk\agent\config\mk_oracle_cfg.ps1# Oracle plugin will not check if the used binaries are write-protected for non-admin users $SKIP_ORACLE_SECURITY_CHECK=1However, there is also another way to execute the agent plug-in — without administrator rights. You can customize the execution of the agent plug-in and run it under the local Windows group
Users, for example. To do this, edit the configuration filecheck_mk.user.ymlof the Windows agent, for example like this: In the commercial editions, you can have these entries created by the Agent Bakery with the agent rule Run plug-ins and local checks using non-system account.
In the commercial editions, you can have these entries created by the Agent Bakery with the agent rule Run plug-ins and local checks using non-system account.
3.4. Monitoring remote databases (Linux, Solaris, AIX only)
Under Unix-like systems, you can not only retrieve locally running instances, but also log on to remote ones and retrieve the databases running there. This, for example, is advantageous if you do not have access to the underlying system, but still want to monitor the database. It is also possible to monitor remote databases from a host on which the agent plug-in is running but no Oracle database.
For monitoring remote databases, the following requirements must be met on the host on which the agent plug-in is installed:
The Linux AIO access library is installed. Under Red Hat Enterprise Linux and binary compatible distributions the package is called
libaio.The Oracle Instant Client is installed.
The
sqlplusprogram already exists in the installation, or may have been installed as an extension package to the client.
As a rule, the conditions are already fulfilled if there is an Oracle installation on the host. Otherwise install the appropriate packages to do so.
In order for the agent plug-in to connect to the remote database, first store the access data in the configuration file.
These are similar to the specifications for DBUSER, which you will have already encountered in advanced user configuration.
However there are a number of additional mandatory specifications:
# Syntax:
# REMOTE_INSTANCE_[ID]='USER:PASSWORD:ROLE:HOST:PORT:PIGGYBACKHOST:SID:VERSION:TNSALIAS'
REMOTE_INSTANCE_1='check_mk:mypassword::myRemoteHost:1521:myOracleHost:MYINST3:11.2'
REMOTE_INSTANCE_myinst1='/:::myRemoteHost:1521::MYINST1:11.2:INST1'
REMOTE_ORACLE_HOME='/usr/lib/oracle/11.2/client64'In the example, two remote instances are being configured with two lines. So that each text line is unique, an ID is defined at the end of each variable. These can be freely-chosen — they just have to be unique for each configuration file. As you have probably already noticed, the port specification is now followed by further values. These are partly optional, and partly necessary to establish a connection.
The first new value PIGGYBACKHOST is set to myOracleHost for the MYINST3 instance.
This specification assigns the results from the query by the piggyback mechanism to the specified host.
If this is present as a host in Checkmk, the new services will appear there accordingly instead of on the host where the agent plug-in is running or from which the data was fetched.
You do not see this specification on the second instance MYINST1 — the assignment to another host is optional.
The second new value SID is the instance name.
Since the agent plug-in cannot see what instances are running on the remote host, a configuration line must be specified for each remote instance — this value is therefore required and thus not optional.
The third value VERSION is required and is also due to the fact that much metadata is only available if you are directly on the host.
Therefore the version specification can also not be omitted, and this determines which SQL queries can be passed to the instance.
In the example, both remote instances use version 11.2.
The fourth and last value TNSALIAS is again optional and can be used if you access the remote instance via the Oracle Wallet or the LDAP/Active Directory.
In the event that the instance responds only to a specific TNS alias, you can specify this alias here.
For the second remote instance, TNSALIAS has the value INST1.
To ensure that the sqlplus program is also found, use the REMOTE_ORACLE_HOME variable to specify where the Oracle client is located on the host that is runs the agent plug-in.
Only then are all resources available that are required for the queries.
When querying remote instances, there are some restrictions and special features:
Since you have explicitly entered the remote instances in the configuration file, you cannot exclude these instances using
SKIP_SIDS, and in return you do not need to include them usingONLY_SIDS.Instances with the same name (
SID) may not be assigned to the same host. This is especially relevant if you are fetching instances from multiple remote and/or local hosts where identical names are used.
4. Setting up with the Agent Bakery
![]() The setup can be greatly simplified in the commercial editions with the Agent Bakery,
because syntax errors in the configuration files are avoided, and adaptations to changing environments can be implemented more easily.
The main difference compared to a manual configuration is that you only need to work on the Oracle host at the command line if you want to make special Oracle-specific configurations.
You can perform the setup with the Agent Bakery for Linux, Solaris, AIX and Windows.
The setup can be greatly simplified in the commercial editions with the Agent Bakery,
because syntax errors in the configuration files are avoided, and adaptations to changing environments can be implemented more easily.
The main difference compared to a manual configuration is that you only need to work on the Oracle host at the command line if you want to make special Oracle-specific configurations.
You can perform the setup with the Agent Bakery for Linux, Solaris, AIX and Windows.
Nevertheless, you cannot configure all functions of the agent plug-in with the Agent Bakery, for example, if these are functions that require a major intervention and in-depth specialist knowledge. Accordingly, the custom SQL queries cannot be configured in the Agent Bakery.
Via Setup > Agents > Windows, Linux, Solaris, AIX and the Agents > Agent rules menu, you will find the page with the Oracle databases (Linux, Solaris, AIX, Windows) rule set. Create a new rule with Add rule. Here you will find all options available to you for configuring the agent plug-in:
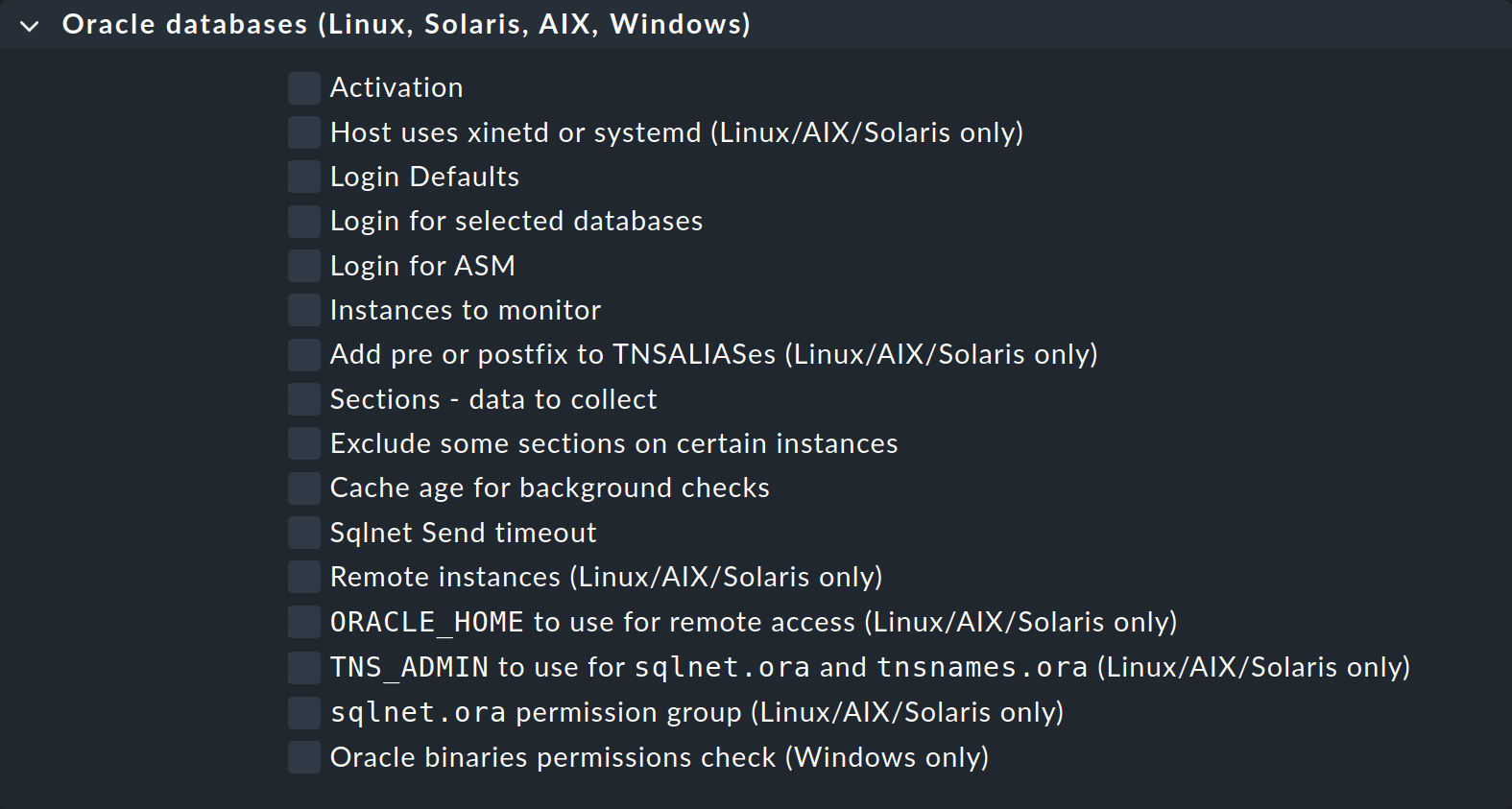
Many options will be familiar to you from the manual setup. As described there, there are options that are not available for all operating systems. The title of these options shows for which operating systems they can be used.
4.1. Configuring users
In the simplest configuration for a Unix-like operating system, the rule will look something like this:
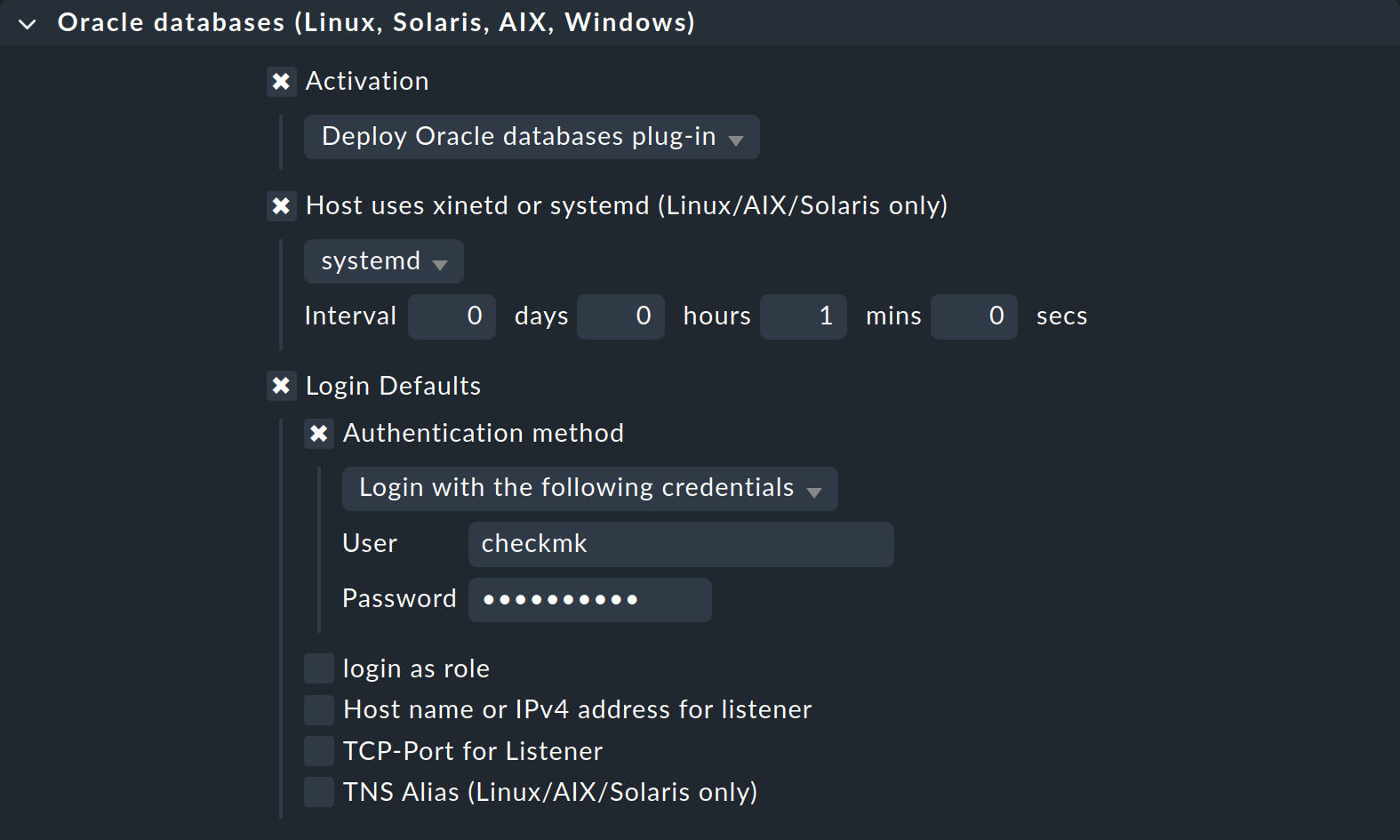
In the Agent Bakery you also have the option of creating standard users and creating exceptions for specific instances. The options separated by colons (for Linux & Co.) or as list entries (for Windows) in the configuration file can be found under Login Defaults as individual options, which you can then fill in accordingly. Of course, you can also use the Oracle Wallet here by simply changing Authentication method to Use manually created Oracle password wallet.
You can configure Automatic Storage Management (ASM) in the same way using the option Login for ASM, and enter the exceptions for specific instances under Login for selected databases, as described in advanced user configuration.
4.2. Advanced options
The following table lists the remaining options in the Oracle databases (Linux, Solaris, AIX, Windows) rule set, along with a reference to where to find a description of the option:
| Option | Description |
|---|---|
Host uses xinetd or systemd (Linux/AIX/Solaris only) |
This option must be activated for Unix-like systems with |
Instances to monitor |
This option combines several options in the configuration file that allow you to include or exclude instances for Linux, Solaris, AIX, or Windows include or exclude. |
Add pre or postfix to TNSALIASes (Linux/AIX/Solaris only) |
This option allows you to extend the TNS alias either globally or for a specific instance. |
Sections - data to collect |
All available sections are listed under this option, and these can be configured individually at global level.
They therefore correspond to the variables |
Exclude some sections on certain instances |
If you want to exclude only a few sections rather than the entire instance with |
Cache age for background checks |
Specify here how long asynchronous sections should remain valid. The default value is 600 seconds (10 minutes). |
Sqlnet Send timeout |
This option is added to the |
Remote instances (Linux/AIX/Solaris only) |
Configure remote instances with this option. It contains all elements of the configuration that you already know. To specify the variable’s ID, via Unique ID you can select from various options. You just have to make sure that the ID is unique within the configuration. |
ORACLE_HOME to use for remote access (Linux/AIX/Solaris only) |
Here you can determine where the agent plug-in finds the |
TNS_ADMIN to use for sqlnet.ora and tnsnames.ora (Linux/AIX/Solaris only) |
If the two files are located in a directory other than |
sqlnet.ora permission group (Linux/AIX/Solaris only) |
Enter here the Linux group of the non-privileged user who owns the Oracle binaries so that this user can read the |
Oracle binaries permissions check (Windows only) |
Here you can configure the access rights check for the Oracle binaries by allowing individual, non-administrative users and groups to execute the programs. You should only switch off the check if you know what you are doing. You can find more information on this topic in the Windows part of the Access rights during execution section. |
5. Clustered instances
5.1. Standby databases
Oracle supports so-called standby databases which can perform specified tasks, and which are usually simply copies of production or primary databases. These database concepts also require special monitoring mechanisms. You can find out more about these mechanisms in the following sections.
With Active Data Guard (ADG)
Once you have licensed and activated ADG, you do not need to make any changes to the configuration of the agent plug-in, since you can read from a standby instance at any time without having to interrupt the synchronization with the primary instance.
Without Active Data Guard (DG)
If the instances do not have ADG, the user with which the monitoring data from the standby instances is to be fetched needs the SYSDBA role.
This permission enables the user to fetch at least part of the data, even if the primary instance fails and the instance on the standby server has not yet been changed from MOUNTED to OPEN.
Assign the permission to the user who is authorized to retrieve the data from the instances. Important: How this works may differ from the following example. Here the role is assigned to the user as created in the initial setup example:
To enable the data to be queried by the agent plug-in on the standby server in case of an error, create the user on the primary instance, and then copy the password file to the standby server.
Finally, in the plug-in’s configuration file, set the role of the user to SYSDBA:
# Syntax:
# DBUSER='USER:PASSWORD:ROLE:HOST:PORT:TNSALIAS'
DBUSER='checkmk:myPassword:sysdba'Note that specifying a host, port, or TNS alias is optional, and can be omitted. In addition, the agent plug-in must of course be installed on the host of the primary instance as well as on the hosts of the standby instances.
Setting up cluster services
On Checkmk side, it is necessary — regardless of whether you are using ADG or DG — to customize the services and assign them to a cluster host. The corresponding check plug-ins have already been prepared to the extent that they can also be configured as cluster services. Create a cluster host in Checkmk and add the individual Oracle hosts on which the primary and standby instances are running to it as nodes. Then assign the following services to this cluster host:
ORA .* RMAN BackupORA .* JobORA .* Tablespaces
After this you will no longer need to worry about which instance the data comes from, and will have ensured seamless monitoring of the above-mentioned services — even in the event of a switchover of the primary instance.
5.2. Real Application Cluster (RAC)
Since there is a central storage for the data in a RAC, it is sufficient here to create the user for the agent plug-in only once. Only the agent plug-in needs to be installed and configured on each node of the Oracle cluster.
Important: Always set up the cluster’s nodes yourself, and do not query the Oracle SCAN listener. This is the only way to ensure that access via the agent plug-in works correctly.
Setting up cluster services
It also makes sense to set up cluster services for a RAC. In addition to the services that you assign to the cluster host under an (Active) Data Guard, you also assign the following services to the cluster host to ensure seamless monitoring in the event of a switch over:
ASM.* DiskgroupORA .* Recovery Area
6. Custom SQL queries (Custom SQLs)
6.1. Why custom SQL queries?
With its agent plug-in Checkmk already provides a large number of SQL queries with which you can monitor your database instances. To make these suitable for the widest possible range of technical and content requirements, they are of course kept in a very generalized form.
In order to be able to meet the individual requirements of each company for the monitoring of a specific database, Checkmk provides the possibility of creating your own custom SQL queries (custom SQLs for short) and having them retrieved with the agent plug-in. These custom SQL queries are then automatically recognized and monitored as own services in the Web interface.
It is only possible to use custom SQL queries under Linux, Solaris and AIX. This option is not available under Windows. |
6.2. Simple custom SQL queries
Writing SQL queries
The easiest way to connect such a SQL is to use the Oracle Database: Custom SQLs check plug-in.
To do this, first create the MyCustomSQL.sql file in the agent’s configuration directory on the host on which the SQL is to be executed.
The following is a dummy that illustrates the syntax:
The example shows on the one hand that you can define any number of statements in such a file. On the other hand, the syntax is very similar to that of a local check, especially with regard to metrics. In detail, this syntax is much more powerful here, because you can generate multi-line output, and this is then processed on the Checkmk server as a service. In principle, all lines are optional and do not need to be filled.
The possible keywords are in detail:
details: Here you can determine what should be output in the generated service’s Summary. This line is introduced with the keyword and a colon. The rest of the line is the output.perfdata: Metrics is passed with this keyword. Within a line, you can create any number of metrics — each separated by a space. You can also distribute the output of the metrics over several lines. Just always start with the keywordperfdata:.long: If the service should have a long output for the Details field, you can specify it here. You can also use this keyword multiple times to create multiple lines in the Details.exit: If the output should have a certain status, you can specify this here. The known assignments0,1,2,3are available for the statuses OK, WARN, CRIT, UNKNOWN.
You do not have to define the keyword |
Configuring the agent plug-in
Now that you have defined your first, very simple SQL, make it known to the agent plug-in mk_oracle.
This is done via the familiar configuration file, which you can expand accordingly:
SQLS_SECTIONS="mycustomsection1"
mycustomsection1 () {
SQLS_SIDS="INST1"
SQLS_DIR="/etc/check_mk"
SQLS_SQL="MyCustomSQL.sql"
}With the first option (SQLS_SECTIONS) you determine which individual sections you want to have executed.
Note that section here means a part of the agent plug-in output — and not a part of a database instance.
In the example, we have only specified one section (mycustomsection1) and then described it in more detail directly afterwards.
Each section is actually a small function called by the agent plug-in.
In this function you can then determine further details and specify for which instances (SQLS_SIDS) this section applies.
In addition, you also define where the file with the SQL statements is located (SQLS_DIR), and the name of this file (SQLS_SQL).
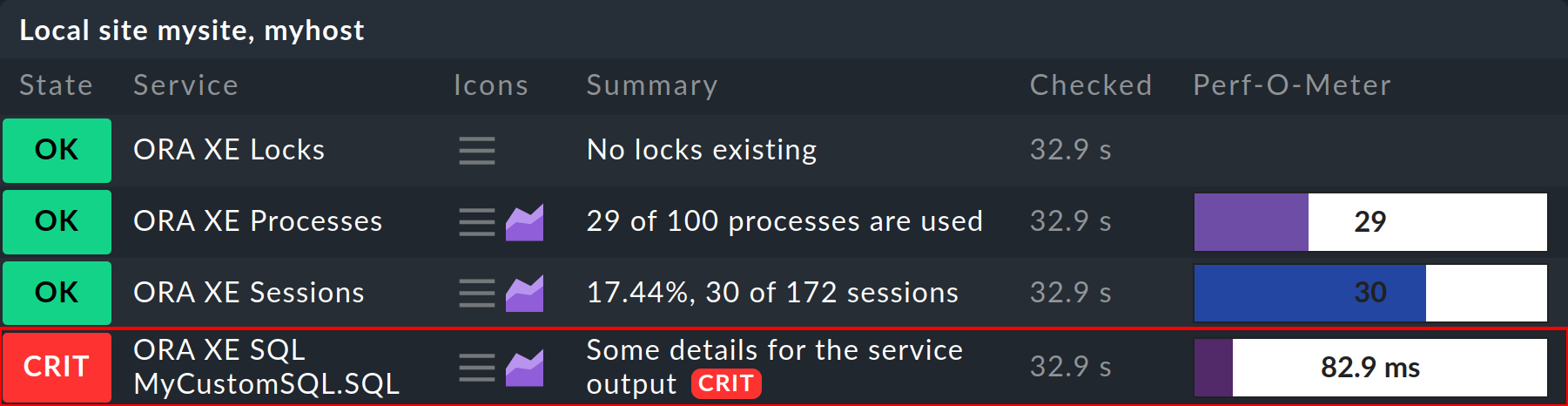
This simple configuration is sufficient to be able to see the result in Checkmk. To do this, perform a service discovery and activate the new service. Afterwards you will see this new service with the other services in the host overview:
6.3. Advanced options
The possibilities to monitor with custom SQL queries of course go beyond the simple example shown above.
In the following you will find an overview of the available variables that you can use in the mk_oracle.cfg configuration file.
For a detailed description, you can also call the agent plug-in mk_oracle with the --help option.
Variables that can only be set outside or only within a section function are marked accordingly. All others can be defined in both sections. If they are set outside of a section, they will apply globally to all sections. |
| Variable | Short description | Optional |
|---|---|---|
|
The self-defined section functions to be executed by the agent plug-in. |
No |
|
The instances that are to execute the section(s). |
No |
|
The path name of the directory in which the files with the custom SQL queries are stored. |
No |
|
The file that contains the SQL statements for a section. |
No |
|
The name of the section that you evaluate with an own check plug-in for the custom SQL queries. |
Yes |
|
The separator of the individual elements in a line of the output, defined as a decimal ASCII ID.
This variable can only be used in conjunction with the variable |
Yes |
|
Specifies a part of the generated service name.
By default, the service name is composed of SID and the file name with the custom SQL queries.
The value of this variable replaces the file name in the service name. |
Yes |
|
Performs the same task as |
Yes |
|
Defines an individual user for a section. |
Yes |
|
Defines the password of the user defined with |
Yes |
|
Only if the user defined with |
Yes |
|
Defines an individual TNS alias for a section. |
Yes |
6.4. Using your own check plug-ins
If the possibilities of the syntax described above are not sufficient, you can also use the SQLS_SECTION_NAME variable to output your own section names for one or more SQL queries and define your own separator with SQLS_SECTION_SEP.
However, this requires that you have also written an appropriate check plug-in and included it in your Checkmk site.
If you have written such a check plug-in, you are completely free to evaluate the output of the self-defined sections of the agent plug-in and can go your own way. Since this method is the most comprehensive, and also the most difficult, it is only mentioned here for completeness. It assumes that you know how to write an agent-based check plug-in and integrate it into the site. After that you assign the custom SQL queries with the variables to this check plug-in.
7. Diagnostic options
The mk_oracle agent plug-in (Linux, Solaris, AIX) or mk_oracle.ps1 (Windows) provides you with various options for error diagnosis.
The following sections contain information on diagnosis in the various environments.
7.1. Testing connections
If you have problems connecting to one or more instances on an Oracle server, the first thing you can do is to check basic parameters.
The connection test described below also checks whether the necessary access rights are set during execution. If access rights are missing, these are displayed with specific suggestions for rectification. The exact procedure for diagnosing and correcting access rights can be found in the Checkmk Knowledge Base.
- Linux, Solaris, AIX
If you start the agent plug-in with the
-toption, it displays the details of a connection. Note that the agent plug-in must be provided with the paths to its configuration file and to the plugin’s cached data beforehand. In the output the dummy sections have been omitted for readability.The following example is for a Linux server with
systemd, on which the agent plug-in is executed asynchronously every 60 seconds:On a Linux server with
xinetd, callmk_oraclefor the connection test as follows instead:Since this call is more likely to be made in the event of an error, you will then also receive further information: Both the connection string that was used for the connection and the first 100 characters of the error message that was returned during the connection attempt. With the help of this information, you can quickly identify simple configuration problems and then correct them accordingly.
- Windows
The agent plug-in does not accept any parameters under Windows. So to test the connection here, temporarily limit the sections to be retrieved to
instanceand activate theDEBUGoption:C:\ProgramData\checkmk\agent\config\mk_oracle_cfg.ps1# Syntax: # $DBUSER = @("USERNAME", "PASSWORD") $DBUSER = @("checkmk", "myPassword") SYNC_SECTIONS = @("instance") ASYNC_SECTIONS = @("") DEBUG = 1Then run the agent plug-in manually. You will get information about how the plug-in tries to access the instances. An output may then look like this, for example:
7.2. Logging
If the error cannot be found by checking a simple connection, the next step is to create a a log file, which logs all of the agent plug-in’s steps.
- Linux, Solaris, AIX
Do not forget the necessary environment variables here either.
In the following example, the output of the sections has also been omitted to improve readability.
Here is the call for a Linux server with
systemd, on which the agent plug-in is executed asynchronously every 60 seconds:Here is the call of
mk_oraclefor logging on a Linux server withxinetd:- Windows
Logging under Windows works similarly to the connection test described above. If the connection itself is stable, you can add the real sections back to the configuration file and then get a complete logging output.
You can use the generated log messages to identify very precisely on which line of the script the problem has occurred.
7.3. Debugging
If you cannot get to the problem, even with the help of the log, as a last option the agent plug-in provides the complete output of all steps for error analysis. This output is therefore the most comprehensive, and certainly the most difficult to read method to get to the cause of a problem, and should therefore only be used as a last resort.
- Linux, Solaris, AIX
The following is an example of debugging on a Linux server with
systemd, on which the agent plug-in is executed asynchronously every 60 seconds:Here is the call of
mk_oraclefor debugging on a Linux server withxinetd:
Sensitive data such as passwords is not masked in this output. Everything is therefore readable in plain text.
- Windows
In Windows you cannot pass arguments to the agent plug-in and must therefore manually enable tracing to obtain the complete output from all steps:
7.4. Error messages in Oracle log files
The database user for monitoring usually does not require the SYSDBA role.
However, note that the agent plug-in mk_oracle can generate error messages (not relevant for monitoring) with multi-tenant databases which may not be written to Oracle database log files due to a lack of the SYSDBA privilege.
This can then lead, for example, to Oracle error messages of type ORA-01031: insufficient privileges in an alert log file.
8. Files and directories
8.1. On the Oracle host
- Linux, Solaris, AIX
File path Description /usr/bin/check_mk_agentThe Checkmk agent that collects all data about the host.
/usr/lib/check_mk/plugins/mk_oracle/The Oracle agent plug-in in the usual directory for agent plug-ins. Note that the path name under AIX is slightly different:
/usr/check_mk/lib/plugins/mk_oracle/etc/check_mk/oracle.cfgThe configuration file for the agent plug-in. Again, AIX is different:
/usr/check_mk/conf/mk_oracle.cfg/etc/check_mk/sqlnet.oraThe configuration file required for the Oracle Wallet.
/etc/check_mk/tnsnames.oraThe configuration file which contains TNS aliases. Sample files are also located in the Oracle installation, but since the path differs from installation to installation, it cannot be specified in a standardized way.
- Windows
File path Description C:\Program Files (x86)\checkmk\service\check_mk_agent.exeThe Checkmk agent that collects all data about the host.
C:\ProgramData\checkmk\agent\plugins\mk_oracle.ps1The Oracle agent plug-in in the usual directory for agent plug-ins.
C:\ProgramData\checkmk\agent\config\mk_oracle_cfg.ps1The configuration file for the agent plug-in.
C:\ProgramData\checkmk\agent\config\sqlnet.oraThe configuration file required for the Oracle Wallet.
C:\ProgramData\checkmk\agent\config\tnsnames.oraThe configuration file which contains TNS aliases. Sample files are also located in the Oracle installation, but since the path differs from installation to installation, it cannot be specified in a standardized way.
8.2. On the Checkmk server
| File path | Description |
|---|---|
|
The agent plug-in for Unix-like systems, which fetches the data on the Oracle host. |
|
This agent plug-in for Unix-like systems provides data to an Oracle Cluster Manager. |
|
The agent plug-in for Windows, which fetches the data on the Oracle host. |
|
Here are sample configuration files for Unix-like systems in the files |
|
An example configuration file for Windows. |