1. Introduction
Regular expressions — regex (or rarely regexp) — are used in Checkmk to specify service names and in many other situations.
They are patterns that match a certain text or do not match (non-match).
You can do many practical things with them, such as formulating flexible rules that apply to all services with foo or bar in their name.
Regular expressions are often confused with filename search patterns, since the special characters * and ?, as well as square and curly brackets, can exist in both.
In this article we will show you the most important functions of regular expressions, of course in the context of Checkmk. Since Checkmk uses two different components for regular expressions, sometimes the devil is in the detail. Essentially, the monitoring core uses the C library and all other components use Python 3. Where differences exist, we will explain them.
In Checkmk, regular expressions are allowed in input fields on various pages. If you are unsure, use the context-sensitive help via the Help menu (Help > Show inline help). There you can see whether regular expressions are permitted and how they can be used. |
When working with older plug-ins or plug-ins from external sources, it may happen that these may use Python 2 or Perl and deviate from the conventions described here.
In this article we will show you the most important capabilities of regular expressions — but by no means all of them. If the possibilities shown here do not go far enough, below you will find references where you can read all of the relevant details. And then there is always the internet.
If you want to program your own plug-ins that, for example, use regular expressions to find anomalies in log files, you can use this article as a basis. However, when searching in large volumes of data optimization of performance is an important aspect. If in doubt always consult the documentation for the regex library being used.
2. Working with regular expressions
In this section we use concrete examples to show how to work with regular expressions, from simple matches of single characters or strings, to complex groups of characters.
2.1. Alphanumeric characters
With regular expressions, it is always a question of whether a pattern matches a certain text (e.g. a service name). The simplest application example is a chain of alphanumeric characters. These (and the minus sign used as a hyphen) simply match themselves in an expression.
In input fields without a regular expression where an exact match is specified (mostly with host names), upper and lower case are always distinguished! |
2.2. The point ( . ) as a wild card
In addition to the 'plain text' character strings, there are a number of characters and character strings that have 'magic' functions.
The most important such character is the . (point).
It exactly matches any single arbitrary character:
| Regular Expression | Match | No Match |
|---|---|---|
|
|
|
|
|
|
2.3. Repetition of characters
One would very often like to define that a sequence of characters of a certain length may occur. For this purpose one specifies the number of repetitions of the preceding character in curly brackets:
| Regular Expression | Function | Match | No Match |
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
There are abbreviations for the last three above conditions:
* matches the preceding character any number of times, + matches at least one occurrence and ? matches at most one occurrence.
You can also use the period . with the repeat operators to search for a sequence of arbitrary characters in a more defined way:
| Regular Expression | Match | No Match |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
2.4. Character classes, numbers and letters
Character classes allow certain sections of the character set to be matched, for example, "here must come a digit". To do this, place all of the characters to be matched within square brackets. With a minus sign you can also specify ranges. Note: The sequence in the 7-bit ASCII character set applies.
For example, [abc] stands for exactly one of the characters a, b or c, and [0-9] for any digit — both can be combined.
Also a negation of the whole is possible — with a ^ in the parenthesis, [^abc] then stands for any character except a, b, c.
Character classes can of course be combined with other operators. Let’s start with some abstract examples:
| Character Class | Function |
|---|---|
|
Exactly one of the characters a, b, c. |
|
Exactly one digit, lower case letter or underscore. |
|
Any character except a, b, c. |
|
Exactly one character, ranging from a blank character to a hyphen, conforming to the ASCII standard. The following characters are in this range: |
|
A sequence of at least one and at most 20 letters and/or digits in any order. |
Here are some practical examples:
| Regular Expression | Match | No Match |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
If you need one of the characters |
2.5. Beginning and end — prefix, suffix and infix
In many cases it is necessary to distinguish between matches at the beginning, at the end or simply somewhere within a string.
For a match of the beginning of a string (prefix match) use the ^ (circumflex), for the end (suffix match) use the $ (dollar sign).
If neither of these operators is specified, most regular expression libraries use the infix-match as the default — it is searched for anywhere in the character string.
For exact matches, use both ^ and $.
| Regular Expression | Match | No Match |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
In monitoring and the Event Console, infix match is the standard. In monitoring, infix match is the standard. Expressions that occur anywhere in the text are found, i.e. the search for 'memory' also finds 'kernel memory'. In the Setup GUI, on the other hand, when comparing regular expressions with service names and other things, Checkmk basically checks whether the expression matches the beginning of the text (prefix match) — this is usually what you are looking for:
If you do need an infix match in places where prefix match is provided, simply extend your regular expression with .* at the beginning to match any prefixed string:
| Regular Expression | Match | No Match |
|---|---|---|
|
|
|
|
|
|
|
|
|
Tip: You can preface any search at the beginning of a string with ^ and any search within a string with .*,
the regular expression interpreters will ignore redundant symbols.
2.6. Masking special characters with a backslash
Since the point matches everything, it naturally also matches a point.
If you now want to match exactly one point, you have to mask it with a \ (backslash).
This applies analogously for all other special characters.
These are: \ . * + ? { } ( ) [ ] | & ^ and $.
Coding a \ backslash results in the special character following it being treated as a normal character:
| Regular Expression | Match | No Match |
|---|---|---|
|
|
|
|
|
|
|
|
|
Attention Python: Since in Python the backslash in the internal string representation is masked internally with another backslash, these two backslashes must be masked again, which leads to a total of four backslashes:
| Regular Expression | Match | No Match |
|---|---|---|
|
|
|
2.7. Alternative values
With the vertical line | you can define alternatives, i.e. use an OR operation:
1|2|3 matches 1, 2 or 3.
If you need such alternatives in the middle of an expression, group them within round brackets:
| Regular Expression | Match | No Match |
|---|---|---|
|
|
|
|
|
|
2.8. Match groups
Match groups (or capture groups) fulfill two functions:
The first function is the grouping of alternatives or partial matches, as shown in the previous example.
Nested groupings are also possible.
In addition, the repeat operators *, +, ? and {…} may be used preceded by round brackets.
Thus the expression (/local)?/share matches both /local/share and /share.
The second function is to 'capture' matched character groups in variables.
In the
Event Console (EC),
Business Intelligence (BI), in bulk renaming of hosts
and in piggyback mappings, there is the possibility of using the text part
corresponding to the regular expression in the first parenthesis as \1,
the part corresponding to the second parenthesis as \2, and so on.
The last example in the table shows the use of alternatives within a match group.
| Regular Expression | Text to be matched | Group 1 | Group 2 |
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
The following image shows such a renaming of multiple hosts in a single action.
All host names that match the regular expression server-(.*)\.local will be replaced by \1.servers.local.
Where the \1 stands exactly for the text 'captured' by the .* in the parenthesis:
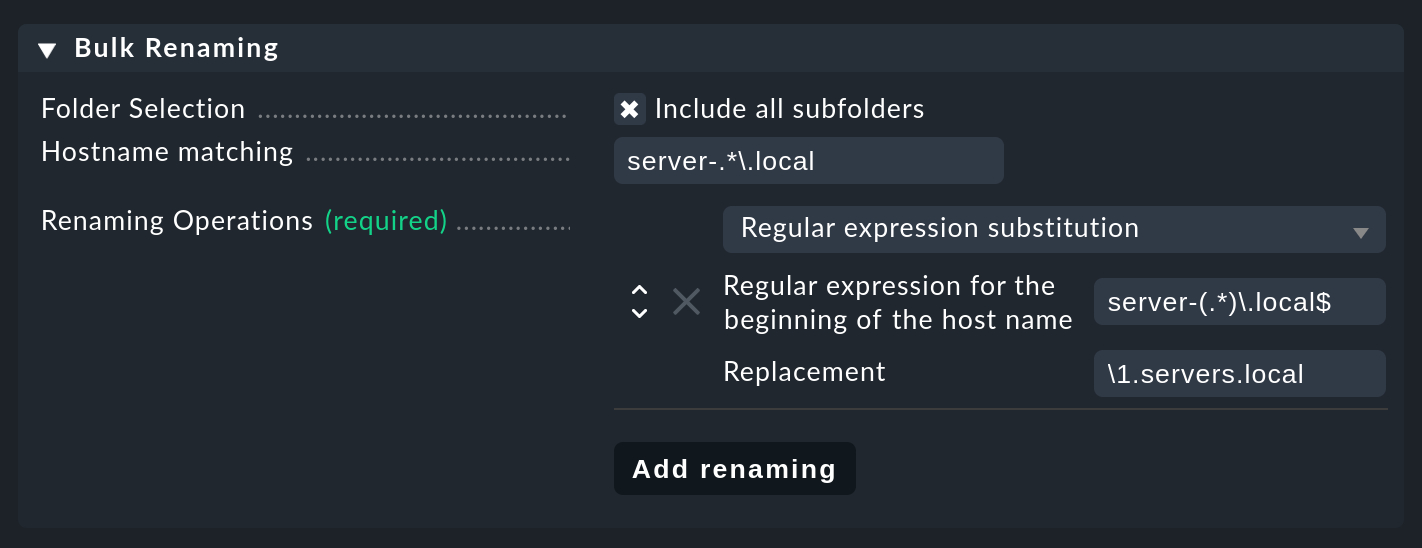
In the concrete example, server-lnx02.local is thus converted into lnx02.servers.local.
If a match group is not required to 'capture' character groups, for example if it is only used for structuring, ?: can be used to convert it into a non-capturing match group (non-capturing match group): (?:/local)?/share.
2.9. Inline flags
With inline flags, specific settings concerning the mode of evaluation can be made within a regular expression.
Most relevant for working with Checkmk is (?i), which switches to case-insensitive matching for expressions that are otherwise case-sensitive.
In very rare cases, you will also want to use (?s) and (?m) for working with multi-line strings.
Note that since version 3.11 Python expects inline flags either at the beginning of a regular expression - (?i)somestring — or specifying the scope — (?i:somestring).
Since Checkmk in some cases combines regular expressions internally for better performance, we strongly advise not to use inline flags at the beginning of a regular expression.
Instead, always use the notation with scope — which, when in doubt, extends to the entire regular expression:
(?i:somestring).
This is a variant of the non-capturing match group.
3. Table of special characters
Here you will find a list summarizing all of the special characters and regular expression functions used by Checkmk, as explained above:
|
matches any character. |
|
Evaluates the next special character as a normal character. |
|
The previous character must occur exactly five times. |
|
The previous character must occur at least five and at most ten times. |
|
The previous character may occur any number of times (corresponds to |
|
The previous character may occur any number of times, but must occur at least once (equivalent to |
|
The previous character may occur zero or once (equivalent to |
|
Represents exactly one of the characters |
|
Stands for exactly one of the characters |
|
Stands for exactly one digit, a lower case letter or the underscore. |
|
Stands for exactly one character except the single or double inverted comma. |
|
Matches the end of a text. |
|
Matches the beginning of a text. |
|
Matches |
|
Matches the sub-expression A to a match group. |
|
Changes the evaluation mode of the sub-expression A to case-insensitive via inline flag. |
|
Matches a tab stop (tabulator). This character often occurs in log files or CSV tables. |
|
Matches all spaces (ASCII uses 5 different types of space). |
The following characters must be masked by a backslash,
if they are to be used literally: \ . * + ? { } ( ) [ ] | & ^ $.
3.1. Unicode in Python 3
In particular, if proper names in comments or descriptive texts have been copied and pasted, and therefore Unicode characters or different types of spaces appear in the text, Python’s extended classes are very helpful:
|
Matches a tab stop (tabulator), partly in log files or CSV tables. |
|
Matches all spaces (Unicode supports 25 different spaces, ASCII 5). |
|
Invert from |
|
Matches all characters that are part of a word, i.e. letters, and in Unicode also accents, Chinese, Arabic or Korean glyphs. |
|
Inversion of |
In places in which Checkmk allows Unicode matching, \w is particularly useful when searching for similarly-spelled words in different languages, for example proper names that are sometimes written with and sometimes without an accent.
| Regular Expression | Match | No Match |
|---|---|---|
|
|
|
4. Testing regular expressions
The logic of regular expressions is not always easy to understand, especially in the case of nested match groups, and the question of the order and which end of the string is to be matched. Better than trial and error in Checkmk, there are two ways of testing regular expressions: Online services such as regex101.com prepare matches graphically and explain the order of evaluation in real time:
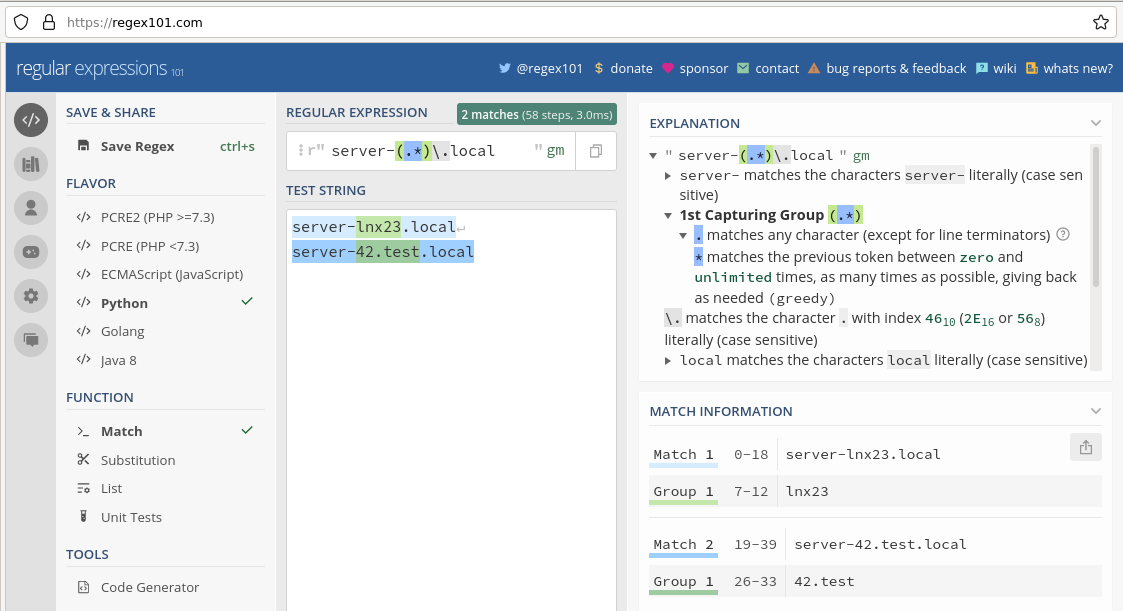
The second testing procedure is the Python prompt, which comes with every Python installation. With Linux and Mac OS Python 3 is usually pre-installed. Precisely because regular expressions at the Python prompt are evaluated exactly as in Checkmk, there are no discrepancies in an interpretation, even with complex nesting. With the test in the Python interpreter you are always on the safe side.
After opening, you have to import the module re.
In the example we switch the distinction between upper and lower case with re.IGNORECASE off:
To emulate the behavior of C’s regular expressions, which are also used in many Python components, you can restrict to ASCII:
>>> re.ASCII
re.ASCIINow you can use the function re.match() to directly match a regular expression against a string and output the match group:
group(0) stands for the whole match, and group(1) the match that is the first that matches the sub-expression enclosed within round brackets:
>>> x = re.match('M[ae]{1}[iy]{1}e?r', 'Meier')
>>> x.group(0)
'Meier'
>>> x = re.match('M[ae]{1}[iy]{1}e?r', 'Mayr')
>>> x.group(0)
'Mayr'
>>> x = re.match('M[ae]{1}[iy]{1}e?r', 'Myers')
>>> x.group(0)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
IndexError: no such group
>>> x = re.match('server-(.*)\.local', 'server-lnx23.local')
>>> x.group(0)
'server-lnx23.local'
>>> x.group(1)
'lnx23'5. Additional external documentation
Ken Thompson, one of the creators of Unix back in the 1960s, was the first to develop regular expressions in today’s form — among other things in the Unix command grep, which is still in use.
Since then, numerous extensions and dialects of regular expressions have been created — including extended regexes, Perl-compatible regexes as well as a very similar variant in Python.
In filters in views Checkmk uses POSIX extended regular expressions (extended REs).
These are evaluated in the monitoring core in C using the C-library’s regex function.
You can find a complete reference for this in the Linux manual page for regex(7):
In all other places, all of the functions of Python’s regular expressions are available. This includes, among other things the configuration rules, Event Console (EC) configuration rules and Business Intelligence (BI).
The regular expressions in Python are an extension of the extended REs and are very similar to those in Perl.
They support, for example, the so-called negative lookahead, a non-greedy * asterisk, or an enforcement of upper/lower case distinction.
The details of the capabilities of these regular expressions can be found in the Python online help for the re module, or in more detail in the Python online documentation:
A very detailed explanation of regular expressions can be found in a Wikipedia article.