1. Introduction
Check plug-ins are software modules written in Python that are executed on a Checkmk site and which create and evaluate the services on a host.
Checkmk includes over 2000 ready-made check plug-ins for all conceivable hardware and software. These plug-ins are maintained by the Checkmk team and new ones are added every week. In addition, there are further plug-ins on the Checkmk Exchange that are contributed by our users.
And yet it can always be the case that a device, an application or simply a certain metric, that is important to you is not yet covered by any of these existing plug-ins—perhaps simply because it is something that was developed in your organization and therefore no one else could have it. In the article on the introduction to developing extensions for Checkmk, you can find out what options are available to you.
This article shows you how to develop real check plug-ins for the Checkmk agent—including everything that goes with it. There is a separate article for SNMP-based check plug-ins.
When developing an agent-based check plug-in, you generally need two plug-ins: the agent plug-in on the monitored host, which provides the data, and the check plug-in on the Checkmk server, which evaluates this data. Both must be written together and optimized for each other. This is the only way they will work smoothly afterwards. |
1.1. The Check API documentation
Checkmk provides a Check API for programming check plug-ins. In Checkmk version 2.5.0, the Check API V2 is the current version. In this article, we will show you how to use Check API version 2 for the programming of plug-ins.
You can access the Check API documentation at any time via the Checkmk user interface: Help > Developer resources > Plug-in API references. In the new browser window, select Agent based ("Check API") > Version 2 in the left-side navigation bar:
Here you will not only find the documentation for the Check API in all supported versions, but also the documentation of all other APIs relevant for the creation of check plug-ins. In this article, we not only use the Check API, but also the Rulesets API V1 when creating a rule set and the Graphing API V1 when creating metric definitions.
Even without a running Checkmk site, you can view a copy of the plug-in API documentation at docs.checkmk.com/plugin-api. |
1.2. Prerequisites
If you are interested in programming check plug-ins, you will need the following:
Knowledge of the Python programming language.
Experience with Checkmk, especially when it comes to agents and checks.
Practice using Linux from the command line.
2. Writing an agent plug-in
If you are interested in programming plug-ins for Checkmk, it is very likely that you have already set up a Checkmk server. If you have done this, you have probably also monitored your Checkmk server itself as a host.
Here we will create a scenario in which it is useful if the Checkmk server and the host being monitored are identical. This allows us to use Livestatus queries from the host to obtain information about host groups provided by the Checkmk server.
In the example described, we will assume an organization with several locations:
Each of these locations is represented in Checkmk by a host group.
Each location has its own service team.
To ensure that the correct service team can be notified in the event of problems, each host must be assigned to a location—i.e. also to a host group. The aim of this example is to set up a check to ensure that no host has forgotten to assign a host group.
The whole process comprises two steps:
Read information for monitoring from the host. This is what this chapter is about.
Writing a check plug-in in the Checkmk site that evaluates this data. We will show this in the next chapter.
So, let’s go …
2.1. Retrieving and filtering information
The first step before writing any plug-in program is research! This means one needs to find out how to get the information you need for the monitoring.
For the example chosen, we use the fact that the Checkmk server is also the host. This means that initially it is sufficient to retrieve the status data via Livestatus, i.e. the data organized in tables that Checkmk holds about the monitored hosts and services in volatile memory.
Log in as a site user and query the information on the host groups with the following command:
The first line of the output contains the column names from the queried hostgroups table.
The semicolon acts as a separator.
The following lines then contain the contents of all columns, also separated by semicolons.
The output is already relatively confusing in this small example and contains information that is not relevant for our example.
In general, you should leave the interpretation of the data to Checkmk.
However, pre-filtering on the host can reduce the volume of data to be transferred if not all of it is actually required.
So in this case, restrict the query to the relevant columns (Columns), to the names of the host groups (name) and the hosts in those groups (members):
The Livestatus interface expects to receive all commands and headers in their own separate line.
The necessary line breaks are indicated by \n.
In this example, there are currently three host groups: two groups for the locations, and one for the check_mk group.
This contains a host called localhost.
The check_mk host group is a special feature within the host groups.
You have not created it yourself.
And you cannot actively add a host to this group.
So where does this host group come from?
As by definition every host in Checkmk must belong to a group, Checkmk assigns every host that you do not specifically assign to a group to the 'special' check_mk group as the default.
As soon as you have assigned a host to one of your own host groups, it will be removed by Checkmk from the check_mk group.
There is also no way to reassign a host to the check_mk host group.
Exactly these properties of the check_mk group are now used for our example:
Since each host should be assigned to a location, the host group check_mk should be empty.
If it is not empty, action is required, i.e. the hosts in it must be assigned to the host groups and thus to their appropriate locations.
2.2. Incorporate the command into the agent
Up until now, as a site user, you have used the lq command to display the information.
This is helpful for getting an understanding of the data.
However, in order to retrieve this data from the Checkmk server, the new command must become part of the Checkmk agent on the monitored host.
Theoretically, you could now directly edit the Checkmk agent in the /usr/bin/check_mk_agent file and include this part.
This method would however have the disadvantage that your new command would disappear again when the agent software is updated because this file will be overwritten during the update.
It is therefore better to create an agent plug-in.
All you need for this is an executable file that contains the command and which is located in the /usr/lib/check_mk_agent/plugins/ directory.
And one more thing is important: The data cannot be simply output. You will still need a section header. This is a specially formatted line that contains the name of the new agent plug-in. This section header allows Checkmk to later recognize where the data from the new agent plug-in begins and where the data from the preceding plug-in ends. It is easiest when the agent plug-in, section header and check plug-in have the same name—even if this is not mandatory.
So first of all, you will need a meaningful name for your new check plug-in.
This name may only contain lower case letters (only a-z, no umlauts, no accents), underscores and digits and must be unique.
Avoid name conflicts with existing check plug-ins.
If you are curious which names already exist, in a Checkmk site on the command line you can list these with cmk -L:
The output here only shows the first lines of the very long list. By using prefixes, the assignment of many check plug-ins can already be easily recognized here. The use of prefixes is therefore also recommended for your own check plug-ins. Incidentally, the second column shows how the respective check plug-in obtains its data.
A suitable name for the new check plug-in for our example is myhostgroups.
Now you have all of the information you need to create the script for the agent plug-in.
Create a new file myhostgroups as the root user in the /usr/lib/check_mk_agent/plugins/ directory:
What does this mean in detail?
The first line contains the 'shebang' (this is an abbreviation for sharp and bang, the latter being an abbreviation for the exclamation mark), by which Linux recognizes that it should execute the script with the specified shell.
To keep the script adaptable, two variables are introduced next:
the
columnsvariable, which currently contains the group names and the associated members,the
sitevariable, which contains the name of the Checkmk site.
Use the echo command to output the section header.
As the table columns are separated by a semicolon, use the addition sep(59) to specify that the semicolon is used as a separator for the data in the agent output.
The 59 stands for the ASCII character code 59, the semicolon.
Without this addition, the space character (ASCII character 32) would be used as a separator by default.
To be able to use the lq command, which is available to you as site user, in a script that is executed by the root user, prefix it with su.
It is possible that accessing |
One more point is important once you have created the file — make the file executable:
You can try out the agent plug-in directly by hand by entering the complete path as a command:
Host groups that do not contain any hosts are not listed here.
Our example uses a very simple shell script as an agent plug-in.
In many cases, you will want to use a scripting language or binary files that are easier to maintain.
Anything that is executable on the target system is permitted.
When using Python, there is one small detail to note:
If there is no |
2.3. Testing the agent
Testing and troubleshooting are the most important tasks when creating a functioning agent plug-in. It is best to proceed in three steps:
Try out the agent plug-in 'standalone'. You have just done this in the previous section.
Test the agent as a whole locally.
Retrieve the agent from the Checkmk server.
Testing the agent locally is very simple.
As root, call the check_mk_agent command:
The new section must appear somewhere in the very long output. Agent plug-ins are output by the agent at the end of processing.
You can scroll through the output by appending less (press the Spacebar to scroll, / to search and Q to exit):
Or you can search the output for the interesting lines.
For example, grep with -A has an option to output a few more lines after each hit.
This allows you to conveniently search and output the section:
The third and final test is then directly from the Checkmk site.
Include the host in the monitoring (for example as localhost), log in as the site user and then retrieve the agent data with cmk -d:
This should produce the same output as the previous command.
If this works, your agent is ready.
And what have you done for this?
You have created a short script under the path /usr/lib/check_mk_agent/plugins/myhostgroups and made it executable.
Everything that follows now only takes place on the Checkmk server: There you write the check plug-in.
3. Writing a simple check plug-in
Preparing the agent is only half the fun. Now you need to teach Checkmk how to handle the information from the new agent section, which services it should generate, when they should go to WARN or CRIT, etc. You can do all this by programming a check plug-in using Python.
3.1. Preparing the file
For your own check plug-ins you will find the base directory already prepared in the local hierarchy of the site directory.
This is ~/local/lib/python3/cmk_addons/plugins/.
The directory belongs to the site user and is therefore writable for you.
In this directory, the plug-ins are organized in plug-in families, whose directory names can be freely defined.
For example, all plug-ins relating to Cisco devices are stored in the cisco folder, likewise all plug-ins relating to your host groups are stored in the myhostgroups folder.
This convention allows all plug-ins belonging to the same family to share code — and is used in exactly the same way by the plug-ins that are delivered with Checkmk.
In this subdirectory <plug-in_family>, further subdirectories with predefined names are then created as required for the various APIs, e.g. agent_based for the Check API of agent-based check plug-ins.
In turn we will introduce further subdirectories for the Rulesets API and the Graphing API later.
Create the two subdirectories for the new agent-based check plug-in and then switch to them to work:
You can edit your check plug-in with any text editor installed on the Linux system.
Create the file myhostgroups.py for the check plug-in here.
The convention is that the file name reflects the name of the agent section.
It is mandatory that the file ends with .py, because from Checkmk version 2.0.0 the check plug-ins are always real Python modules.
An executable basic framework (Download at GitHub), which you will expand step by step in the following, looks like this:
First, you need to import the functions and classes required for the check plug-ins from Python modules.
For our example, we will only import what will be required or may be useful in the rest of this article.
Here, cmk.agent_based.v2 is used to specify that the modules from the Check API V2 are imported:
3.2. Writing the parse function
The parse function has the task of 'parsing' the 'raw' agent data, i.e. analyzing and splitting it up, and putting this data into a logically-structured form that is easy for all subsequent steps to process.
As shown in the section on testing the agent, the section supplied by the agent plug-in has the following structure:
<<<myhostgroups:sep(59)>>>
Hamburg;myhost11,myhost22,myhost33
Munich;myhost1,myhost2,myhost3
check_mk;localhostCheckmk already splits the lines of the section supplied by the agent plug-in into a list of lines based on the separator in the section header (in the example ;), these lines in turn are lists of words.
The following data structure is therefore available in Checkmk instead of the raw data from the agent plug-in:
In the inner list, the first element contains the name of the host group and the second the names of the hosts belonging to the group.
You can address all of this information, but only via its position in the data set. You would therefore always need to specify the number of square brackets and the 'sequence' number of the desired content(s) within each bracket. With larger volumes of data, this becomes increasingly complex and it becomes more and more difficult to maintain an overview.
At this point, a parse function offers clear advantages thanks to the structure it creates. It makes the code easier to read, the accesses are more performant and it is much easier to maintain an overview. It transforms the data structure supplied by Checkmk in such a way that you can address each of the individual values by name (or key) at will, and not be dependent on repeatedly searching through the array to find what you are looking for:
The convention is that the parse function is named after the agent section and begins with parse_.
It receives string_table as its only argument.
Note that you are not free to choose the argument here — it must be called exactly that.
With def you specify in Python that a function is to be defined below.
parsed = {} creates the dictionary with the improved data structure.
In our example, we will go through each line, element by element.
The host group followed by the members of the host group is taken from each line and assembled into an entry for the dictionary.
The dictionary is then returned with return parsed.
In the example shown above, you will find two commented-out lines. If you comment these later when testing the check plug-in, the data before and after executing the parse function will be displayed on the command line. This allows you to check whether the function really does what it is supposed to do. |
3.3. Creating the agent section
For this whole procedure to have any effect, you must create the new agent section with the new parse function.
This is the only way it will be recognized and taken into account by Checkmk.
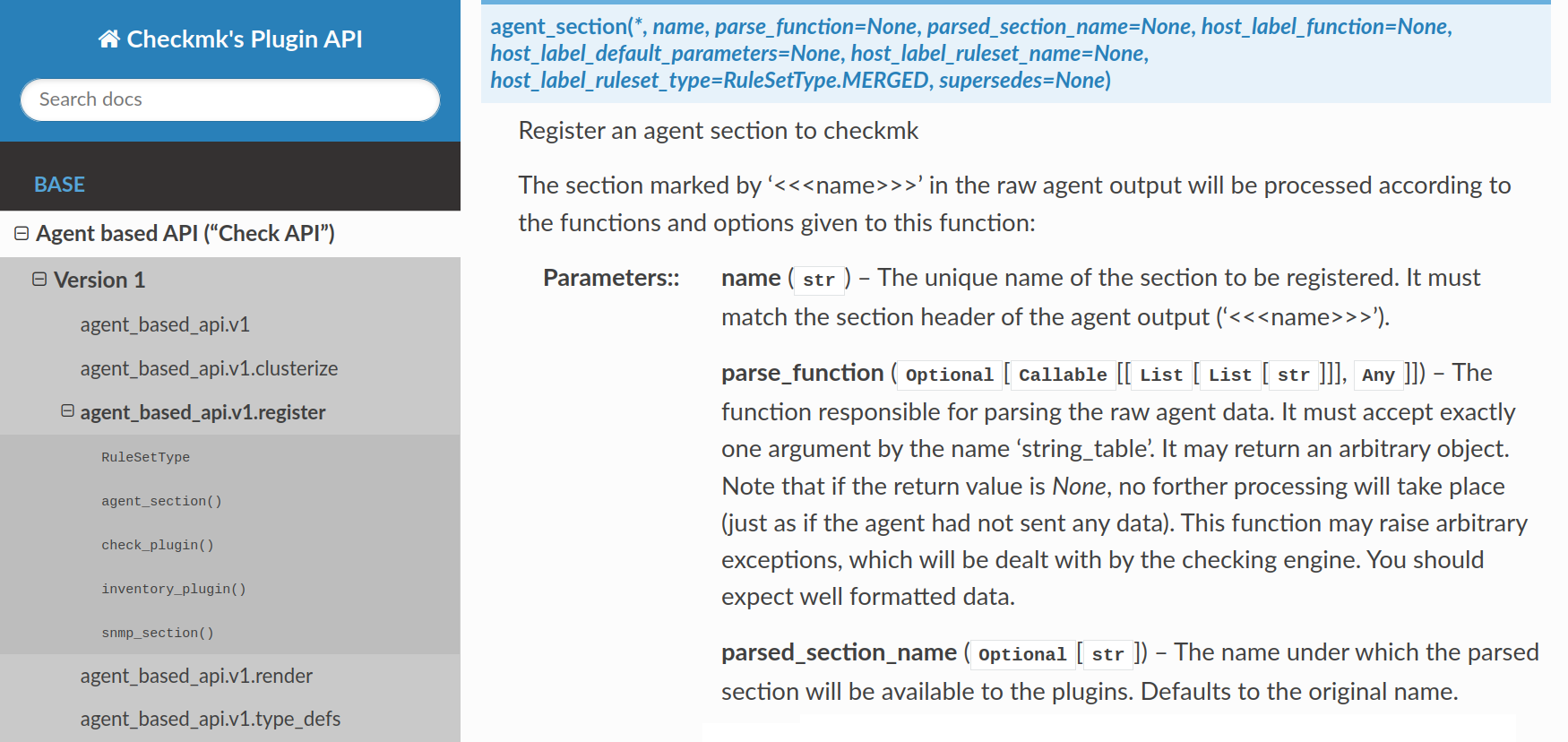
To do this, create the agent section as an instance of the AgentSection class:
Here it is important that the name of the section exactly matches the section header in the agent output.
From this moment on, every check plug-in that uses the myhostgroups section receives the return value from the parse function.
As a rule, this will be the check plug-in of the same name.
But other check plug-ins can also subscribe to this section, as we will show in the extension of the check plug-in.
By the way: If you want to know exactly, you can take a look at the Check API documentation at this point. There you will find a detailed description of this class—and also of the classes, functions and objects that will be used later in this article.
3.4. Creating a check plug-in
In order for Checkmk to recognize that there is a new check plug-in, it must be created.
This is done by creating an instance of the class CheckPlugin.
You must always specify at least four things:
name: The name of the check plug-in. The easiest way to do this is to use the same name as your new agent section. This way, the check defined later in the check function automatically knows which section it should evaluate.service_name: The name of the service as it should then appear in the monitoring.discovery_function: The function for discovering services of this type (more on this in a moment).check_function: The function for performing the actual check (more on this in a moment).
The name of the instance must begin with check_plugin_.
It then looks like this:
It is best not to try this out just yet, as you first need to write the discover_myhostgroups and check_myhostgroups functions.
These must appear in the source code before the creation of the agent section and check plug-in as described above.
If the Nagios core is used (always in the Checkmk Community), the following special characters are not permitted in the service name:
|
3.5. Writing the discovery function
A special feature of Checkmk is the automatic discovery of services to be monitored. For this to work, each check plug-in must define a function that uses the agent output to recognize whether a service of this type or which services of this type should be created for the host in question.
The discovery function is always called when a service discovery is carried out for a host.
It then decides whether or which services should be created.
In the standard case, it receives exactly one argument with the name section.
This contains the agent section data in a format prepared by the parse function.
Therefore, implement the following simple logic:
If the myhostgroups agent section exists, then also create a suitable service.
This will then automatically appear on all hosts on which the agent plug-in is deployed.
For check plug-ins that only create one service per host, no further information is required:
The discovery function must return an object of the service type for each service to be created using yield (not with return).
In Python, yield has the same function as return—both return a value to the calling function.
The decisive difference is that yield remembers how far the function has come in data processing.
The next call continues after the last yield statement—and does not start at the beginning again.
This means that not only the first hit is read out (as would be the case with return), but all hits in sequence (this advantage will become relevant later in our example with service discovery).
3.6. Writing the check function
You can now move on to the actual check function, which uses the current agent output to decide which state the service should assume and can output further information.
The aim of the check function is to set up a check that can be used to verify whether a host group has been assigned for any host.
To do this, it checks whether the check_mk host group contains hosts.
If this is the case, the service should receive the CRIT state.
If not, everything is OK and so is the state of the service.
Here is the implementation:
And now the explanation:
The check_myhostgroups() function first fetches the value belonging to the check_mk key into the attr variable.
Then the hosts variable is linked to the members value if it exists.
If there are no members, hosts remains empty.
This is followed by an if query for the actual evaluation:
If the
hostsvariable has content, i.e. thecheck_mkhost group is not empty, the state of the service goes to CRIT and an advisory text is output. This text also contains a list of the host names of all hosts that are in thecheck_mkhost group. The Python F-String is used to output the text with expressions, which is so named because the string is preceded by the letterf.If the
hostsvariable is empty, i.e. there are no hosts in thecheck_mkhost group, the state of the service instead changes to OK. In this case, an appropriate message text is also output.
Once the check function has been created, the check plug-in is ready.
The check plug-in and as well as the agent plug-in have been made available on GitHub.
3.7. Testing and activating the check plug-in
First, make sure your plug-in is syntactically correct:
Further testing and plug-in activation are performed on the command line using the cmk command.
First, try the service discovery with the -I option.
Adding the v option (for verbose) will generate detailed output.
The --detect-plugins option restricts command execution to this check plug-in and localhost to this specific host:
As planned, the service discovery recognizes a new service in the myhostgroups check plug-in.
Now you can try out the check contained in the check plug-in:
By executing the check, the state of the service found previously will be determined.
If everything went as expected, you can activate the changes. If not, you will find helpful information in the chapter on troubleshooting.
Finally, generate an updated configuration of the monitoring core and restart it:
In the Checkmk monitoring, you will now find the new service Host group check_mk at the host localhost:

check_mk is not empty, the service is CRIT
Congratulations on the successful creation of your first check plug-in!
4. Extending the check plug-in
4.1. Preparatory work
The recently completed first check plug-in is now to be extended step by step. So far, the agent plug-in has only provided information on the names and members within the host groups. In order to be able to evaluate the status of the hosts and the services running on them, for example, more data is required.
Extending the agent plug-in
You will first extend the agent plug-in once to collect all of the information that will be needed to extend the check plug-in in the following sections.
To find out what information Checkmk provides for host groups, you can query all available columns of the host group table with the following command as site user:
The output goes even further.
The table has almost 30 columns—and most of the columns even have names that are meaningful.
The following columns are of interest here:
Number of hosts per group (column num_hosts), number of hosts in the UP state (num_hosts_up), number of services of all hosts in the group (num_services) and number of services in the OK state (num_services_ok).
Now these new columns only need to be supplied by the agent. You can achieve this by extending the agent plug-in created in the previous chapter.
As the root user, edit the agent plug-in’s script.
Since the script has already put the configurable values into variables, it is sufficient to only change the line beginning with columns and enter the four additional columns retrieved there:
Run the script to verify this:
The four new values—each separated by a semicolon—now appear at the end of each line.
With this change, the agent plug-in now provides different data than before. At this point, it is important to make sure that with the changed data, the check plug-in still does what it is supposed to do.
Extending the parse function
In a check plug-in, the parse function is responsible for converting the data supplied by the agent plug-in. With writing the parse function, you have only considered two columns of the host group table. Now six columns are supplied instead of two. The parse function must therefore be customized to process the additional four columns.
As the site user, change the parse function in the myhostgroups.py file, which contains the check plug-in:
Everything between parsed = {} and return parsed has been changed here.
First, the columns to be processed are defined under their names as a column_names list.
A dictionary is then created in the for loop by generating the key-value pairs in each line from the column name and the value read.
This extension is not critical for the existing check function, as the data structure in the first two columns remains unchanged. Only additional columns are being provided, which are not (yet) evaluated in the check function.
Now that the new data can be processed, you will also use this data.
4.2. Service discovery
In the previous chapter you have built a very simple check that creates a service on a host. However, it is also very common for there to be several services from a single check on a host.
The most common example of this is a service for a file system on a host.
The check plug-in with the name df creates one service per file system on the host.
In order to distinguish these services, the mount point of the file system (for example /var) or the drive letter (for example C:) is incorporated into the name of the service.
This results in a service name such as Filesystem /var or Filesystem C:.
The word /var or C: is referred to here as an item.
We are therefore also talking about a check with items.
If you want to build a check with items, you must implement the following functions:
The discovery function must generate a service for each of the items that should be monitored on the host.
You must include the item in the service name using the placeholder
%s(e.g."Filesystem %s").The check function is called once, separately for each item, and receives this as an argument. From the agent data it must then fish out the relevant data for this item.
To test this in practice, you will create a separate service for each existing host group.
Since the myhostgroups check plug-in created in the previous chapter for checking the standard check_mk group should continue to function, this check plug-in remains as it is.
For the extension, create the new check plug-in myhostgroups_advanced in the existing file myhostgroups.py. — in the first step as previously by creating an instance of the class CheckPlugin.
Here you can find the old code and the new code highlighted:
So that the new check plug-in can be distinguished from the old one, it is given a unique name with myhostgroups_advanced.
The sections parameter determines the sections of the agent output that the check plug-in subscribes to.
Here, myhostgroups is used to specify that the new check plug-in uses the same data as the old one: the section of the agent plug-in prepared by the parse function.
The service name now contains the placeholder %s.
The name of the item is later inserted at this point by Checkmk.
In the last two lines, the names for the new discovery function and the new check function are defined, both of which still need to be written.
First to the discovery function, which now has the task of determining the items to be monitored—this is also entered in addition to the existing one:
As with previously, the discovery function receives the section argument.
The individual host groups are run through in a loop.
All host groups are of interest here—with the exception of check_mk, as this special host group has already been taken care of by the existing myhostgroups check plug-in.
Whenever an item is found, it is returned with yield, which creates an object of the type Service, that in turn receives the host group name as an item.
If the host is monitored later, the check function is called separately for each service—and therefore for each item.
This brings you to the definition of the check function for the new myhostgroups_advanced check plug-in.
The check function receives the item argument in addition to the section.
The first line of the function then looks like this:
The algorithm for the check function is simple: If the host group exists, the service is set to OK and the number and names of the hosts in the group are listed. The complete function for this:
The check result is delivered by returning an object of the class Result via yield.
This requires the parameters state and summary.
Here, state defines the state of the service (in the example OK) and summary the text that is displayed in the Summary of the service.
This is purely informative and is not evaluated further by Checkmk.
You can find out more about this in next section.
So far, so good. But what happens if the item you are looking for is not found? This can happen if a service has already been created for a host group in the past, but this host group has now disappeared — either because the host group still exists in Checkmk but no longer contains a host, or because it has been deleted completely. In both cases, this host group will no longer be present in the agent output.
The good news:
Checkmk takes care of this!
If a searched for item is not found, Checkmk automatically generates the result UNKNOWN - Item not found in monitoring data for the service.
This is intentional and a good thing.
If a searched item is not found, you can simply run Python out of the function and let Checkmk do its work.
Checkmk only knows that the item that was there before is now gone. Checkmk does not know the reason for this—but you do. It is therefore appropriate to not keep such knowledge to yourself and to intercept this condition in the check function and to display a helpful message.
What has changed?
The error condition is now handled first.
Therefore, check in the if branch if the item really does not exist, set the state to CRIT and exit the function with return.
In all other cases, return OK as before.
This means that you have adopted the disappearing host groups situation into the check function. Instead of UNKNOWN, the associated service will now be CRIT and contain information on the cause of the critical state.
This completes the new check plug-in as an extension of the old one.
The extended agent plug-in
and the extended file for the check plug-ins
can again be found on GitHub.
The latter contains the simple check plug-in myhostgroups from the previous chapter, the advanced parse function and the components of the new check plug-in myhostgroups_advanced with the creation of the check plug-in, the discovery function and the check function.
Note that the functions must always be defined before the creation of check plug-ins or agent sections so that there are no errors due to undefined function names.
As the new myhostgroups_advanced check plug-in provides new services, you must perform a service discovery for this check plug-in and activate the changes in order to see these services in the monitoring:

Proceed as described in the simple check plug-in chapter.
Do not execute the first two commands for myhostgroups, instead execute them for the new myhostgroups_advanced check plug-in.
4.3. Summary and details
In the monitoring of Checkmk, each service has a state—OK, WARN, etc.—as well as a line of text. This text is located in the Summary column—as can be seen in the previous screenshot—and therefore has the task of providing a brief summary of the service’s state. The concept is that this text should not exceed a length of 60 characters. That ensures a concise table display without annoying line breaks.
There is also the Details field, in which all details on the state of the service are displayed, which also includes all of the summary information. Clicking on the service opens the service page, in which the two fields Summary and Details can be seen alongside many others.
When calling yield Result(...), you can determine which information is so important that it should be displayed in the summary, and for which it is sufficient for it to appear in the details.
In our example, you have always used a call of the following type:
This means that the text defined as summary always appears in the Summary—and also in the Details.
You should therefore only use this for important information.
If a host group contains many hosts, the summary list can become very long—longer than the recommended 60 characters.
If a piece of information is of secondary importance, you can use details to specify that its text only appears in the details:
In the example above, the list of hosts is therefore only displayed in the Details. The Summary then only shows the number of hosts in the group:

In addition to summary and details, there is a third parameter.
With notice you specify that a text for a service in the OK is only displayed in the details—but also in the summary for all other states.
This makes it immediately clear from the summary why the service is not OK.
The notice parameter is not particularly useful if texts are permanently bound to states, as in our example so far.
In summary, this means:
The total text for the summary should not be longer than 60 characters for services that are OK.
Always use either
summaryornotice— at least one or the other, but not both.If required, add
detailsif the text for the details is to be an alternative.
4.4. Multiple partial results per service
To prevent the number of services on a host from increasing excessively, several partial results are often combined in one service. For example, the Memory service under Linux not only checks RAM and swap usage, but also shared memory, page tables and all sorts of other things.
The Check API provides a very convenient interface for this.
A check function can simply generate a result with yield as often as required.
The overall state of the service is then based on the worst partial result in the order OK → WARN → UNKNOWN → CRIT.
In the example, use this option to define two additional results for each service of the host groups in addition to the existing result. These evaluate the percentage of hosts in the UP state and the services in the OK state. You use the additional columns of the host group table previously defined in the agent output and the parse function.
Now expand the check function in stages from top to bottom:
The if branch remains unchanged, i.e. the new partial results only apply to host groups that also exist.
You then define five variables for the columns in the host group table contained in the section.
On the one hand, this increases readability and, on the other hand, you can convert the strings read into numbers with int() for the four columns that are still to be used for the calculation.
The only existing result remains (almost) unchanged:
Only the access in the Python 'F-String' to the expression that returns the value is now easier than previously, since the attr is already in the variable definitions.
Now to the actual core of the extension, the definition of a result that implements the following statement:
"The service of the host group is WARN when 90 % of the hosts are UP, and CRIT when 80 % of the hosts are UP."
The convention here is that the check goes to WARN or CRIT as soon as the threshold is reached—and not only when it is exceeded.
The Check API provides the auxiliary check_levels function for comparing a determined value with threshold values.
In the first line, the percentage is calculated from the total number and number of hosts in the UP state and stored in the hosts_up_perc variable.
The single slash (/) executes a floating point division, which ensures that the result is a float value.
This is useful because some of the functions used later on expect float as input.
In the second line, the result of the check_levels function is then returned as an object of the type Result, which can be found in the API documentation.
This function is fed with the percentage just calculated as a value (hosts_up_perc), the two lower threshold values (levels_lower), a label that precedes the output (label) and finally with notice_only=True.
The last parameter makes use of the notice parameter already introduced in the previous section for the Result() object.
With notice_only=True you specify that the text for the service is only displayed in the Summary if the state is not OK.
However, partial results that lead to a WARN or CRIT will in any case always be visible in the summary—regardless of the value of notice_only.
Finally, you define the third result in the same way as the second, which evaluates the percentage of services in the OK state:
This completes the check function.
The service for a host group now evaluates three results and displays the worst state from these in the monitoring, as in the following example:

4.5. Metrics
Not always, but often, checks deal with numbers — and these numbers are very often measured or calculated values.
In our example, the number of hosts in the host group (num_hosts) and the number of hosts in the UP state (num_hosts_up) are the measured values.
The percentage of hosts in the UP state (hosts_up_perc) is a value calculated from these values.
If such a value can then be displayed over a time range, it is also referred to as a metric.
With its built-in graphing system, Checkmk has a component for storing, evaluating and displaying such values. This is completely independent of the calculation of the OK, WARN and CRIT states.
In this example, you will define the two calculated values, hosts_up_perc and services_ok_perc, as metrics.
Metrics will be immediately visible in Checkmk’s graphical user interface without you having to do anything.
A graph is automatically generated for each metric.
Metrics are determined by the check function and returned as an additional result.
The easiest way is to add the metrics information to the check_levels() function in the call.
As a reminder, the lines with the check_levels() function call from the previous section follow here:
The two new arguments for the metric are metric_name and boundaries:
To keep things nice and simple and meaningful, for the name of the metric use the name of the variable in which the percentage is stored as a value.
You can use boundaries to provide the graphing system with information about the range of possible values.
This refers to the smallest and largest possible value.
In the case of a percentage, the limits of 0.0 and 100.0 are not too difficult to determine.
Both floating point numbers and integers (which are converted internally into floating point numbers) are permitted, but not strings.
If only one limit of the value range is defined, simply enter None for the other, for example boundaries = (0.0, None).
With this extension, the check_levels function now also returns an object of the type Metric via yield in addition to the Result.
You can now define the metric services_ok_perc in the same way.
The last lines of the check function will then look like this:
With the extended check function, both graphs are visible in the monitoring.
In the service list, the ![]() icon now shows that there are graphs for the service.
If you point to the icon with the mouse, the graphs will be displayed as a preview.
icon now shows that there are graphs for the service.
If you point to the icon with the mouse, the graphs will be displayed as a preview.
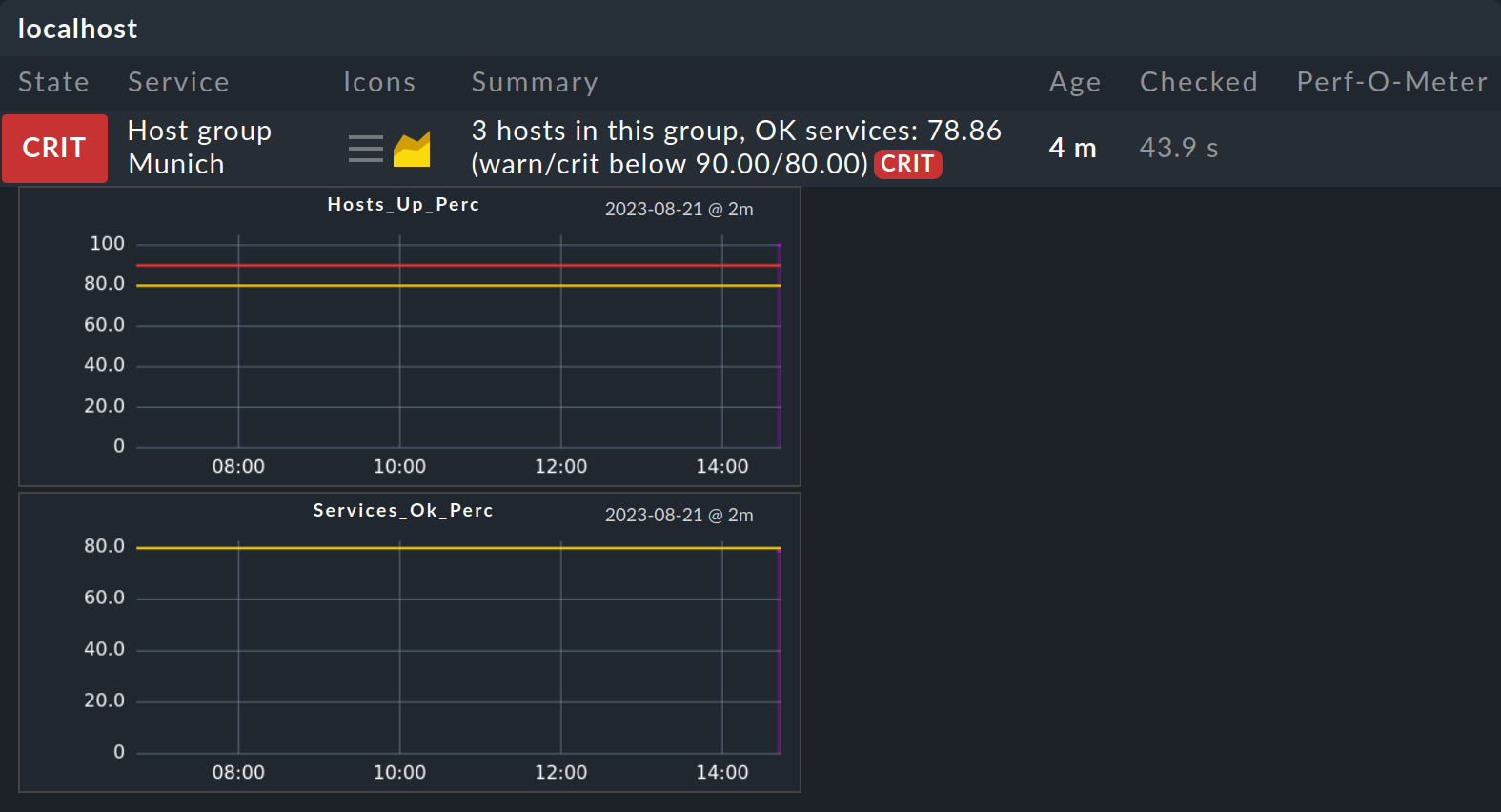
An overview of all graphs including their legends and more can be found in the service details.
But what do you do if the value for the desired metric has not been defined with the check_levels() function?
You can, of course, define a metric independently of a function call.
The Metric() object, which you can also create directly via its constructor, is used for this purpose.
The alternative definition of a metric for the value hosts_up_perc looks like this:
The arguments in Metric() are very similar to those in the function call shown above:
Mandatory are the first two arguments for the metric name and the value.
In addition, there are two optional arguments: levels for the threshold values WARN and CRIT and boundaries for the value range.
The specification of |
Now use the option of defining not only the two calculated values, but all measured values as metrics using Metric() — in our example, the four measured values from the host group table.
Limit yourself to the two obligatory specifications of metric name and value.
The four new lines complete the extension of the check function for metrics:
This increases the number of graphs per service, but also gives you the option of combining multiple metrics in a single graph, for example. We show these and other options in the section Customizing the display of metrics below.
In the example file at GitHub you can find the entire check function again.
5. Rule sets for check parameters
In the extended myhostgroups_advanced check plug-in you will have generated the WARN state if only 90 % of the hosts are UP, and CRIT for 80 %.
In this case, the numbers 90 and 80 are defined explicitly in the check function, or, as programmers would say, hard-coded.
In Checkmk, however, users are used to being able to configure such threshold values and other check parameters via rules.
For example, if a host group only has four members, then the two threshold values of 90 % and 80 % do not really fit well,
since the percentage will drop to 75 % as soon as the first host fails and the state will go directly to CRIT — without an intermediate WARN state.
Therefore, the check plug-in should now be modified so that it can be configured via the Setup interface. To do this, you will need a rule set.
To create a rule set for a check plug-in you exit from the check plug-in development and switch the directory, file and API. From Checkmk 2.3.0 the Rulesets API supports you in creating such rule sets for check plug-ins. The API documentation for rule sets can be found in your Checkmk site on the same page as the Check API under Rulesets > Version 1.
5.1. Defining a new rule set
To create a new rule set, first create a new subdirectory in the plug-in family’s directory ~/local/lib/python3/cmk_addons/plugins/myhostgroups/.
The name rulesets is predefined for this subdirectory:
In this directory, you then create a file for the definition of the rule set.
The name of the file should be based on that of the check plug-in and, like all plug-in files, must have the py extension.
For our example, the file name ruleset_myhostgroups.py is suitable.
Let’s take a step by step look at the structure of this file. First there are some import commands:
First, the classes for the texts are imported.
The second line makes a selection from the form specs, i.e. the basic elements for the GUI that are used in the rule set, for example, the binary selection (BooleanChoice), the multiple selection (Dictionary, DictElement), the definition of threshold values (SimpleLevel, LevelDirection, DefaultValue) and the input of floating point numbers (Float).
You only request the logical form elements here and leave the design of the GUI to Checkmk.
The last line imports the rule specs, which determine the area of application of the rule in Checkmk, i.e. here the definition of check parameters, the assignment to hosts and items and the storage under a topic.
As your check plug-in myhostgroups_advanced generates several services, import HostAndItemCondition here.
If your check does not generate a service, in other words does not have an item, import HostCondition instead.
Now come the actual definitions of the form for entering the check parameters. The user should be able to separately define the two threshold values for WARN and CRIT for both the number of hosts in the UP state and for the number of services in the OK state:
To do this, create a function that generates the dictionary. You can freely choose the name of the function; it is only required when creating the rule below. The name should begin with an underscore so that the function is not visible beyond the module boundary.
The return Dictionary() is mandatory.
Within it, use elements={} to create the elements of the dictionary, in the example hosts_up_lower and services_ok_lower.
The SimpleLevels parameter form is used to enter fixed threshold values.
In the form, you first define the title and floating point numbers for the values to be entered (form_spec_template).
Use LevelDirection.LOWER to specify that the status will change if the values fall below this level.
Finally, you can use prefill_fixed_levels to provide the users of the rule set with values instead of just empty input fields.
Note that these values displayed in the GUI are not the default values that are set further down in the creation of the check plug-in via check_default_parameters.
If you want to display the same default values in the GUI that also apply to the check function, you must keep the values consistent in both places.
Finally, create the new rule set using the imported and self-defined items.
This is done by creating a new instance of the CheckParameters class.
The name of this instance must begin with rule_spec_:
The following explanations apply:
The rule set’s
nameestablishes its connection to the check plug-ins. A check plug-in that wants to use this rule set must use this name as thecheck_ruleset_namewhen it is created. In order to keep track of a number of new rule sets, it is advisable to use a prefix in the name.titledefines the title of the rule set as it appears in the Checkmk GUI.The
topicdetermines where the rule set should appear in the Setup. With the value selected in the example, you will find the rule set under Setup > Services > Service monitoring rules in the box Various, where it is usually in good hands.Enter the name of the previously created function as
parameter_form.If your check does not use an item, the condition is
HostConditionand notHostAndItemCondition, as in the example above. With the title"Host group name"of the item, you define the label in the GUI with which you can restrict the rule to certain host groups.
5.2. Testing a rule set
Once you have created the file for the rule set, you should test whether everything works so far—still without a connection to the check plug-in.
Running cmk-validate-plugins will now confirm that the rule set itself is valid, but will warn that it has no effect yet.
To make the rule set visible, you must restart the Python processes that provide the graphical user interface. This is handled by restarting the Apache web server:
After that, the rule set can be found in Setup on the page mentioned above. However, you will only be able to find the default value using the search function in the Setup after restarting Redis:
The rule set you have just defined will look like this in the GUI:
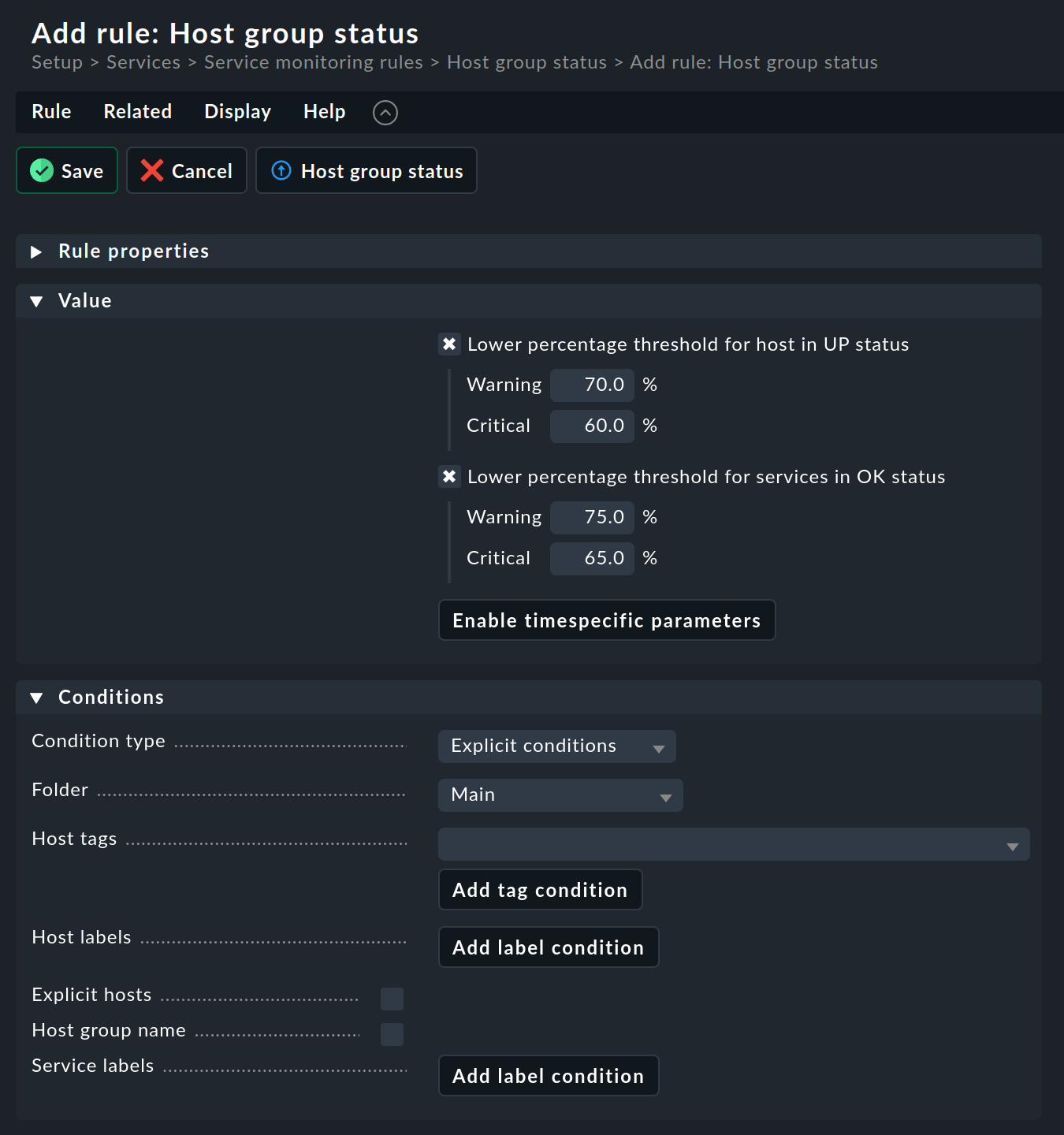
In the Conditions box, you will find the Host group name input field defined via the HostAndItemCondition for restricting the rule for host groups.
Create a rule and try out different values, as shown in the screenshot above. If this works without errors, you can now use the check parameters in the check function.
5.3. Connecting the rule set with the check plug-in
The freshly created rule set is now connected to the check plug-in provisionally completed in the previous chapter.
In order for the rule to take effect, you must allow the check plug-in to accept check parameters and tell it which rule should be used.
To do this, add two new lines to the check plug-in file when creating the myhostgroups_advanced check plug-in:
With the check_default_parameters entry, you can define the default values that apply as long as no rule has actually been created.
When converting the check plug-in for check parameters, this line must be present.
In the simplest case, pass an empty dictionary {}.
Secondly, enter check_ruleset_name, i.e. the name of the rule set.
This way Checkmk knows from which rule set the parameters are to be determined.
Now Checkmk will try to pass parameters to the check function.
For this to work, you must extend the check function so that it expects the params argument, which is inserted between item and section:
If you are building a check without an item, the item is omitted and params is at the beginning.
It is highly recommended to have the content of the variable params output with a print as a first test:
When the check plug-in is executed, the printed lines (one for each service) with the values defined by a rule will then look something like this:
When everything is ready and working correctly, remove the |
Now customize your check function further so that the passed parameters can take effect. Get the two dictionary elements defined in the rule with the name selected there from the parameters:
Further down in the check function, the previously hard-coded threshold values "fixed", (90.0, 80.0) are then replaced by the variables hosts_up_lower and services_ok_lower:
If a rule has been configured, you can now monitor the host groups of the example with the threshold values set via the GUI.
However, if no rule has been defined, this check function will crash, since the default parameters in the check plug-in will have not been filled, and the plug-in will generate a KeyError in the absence of a rule.
However, this problem can be solved if the default values are defined when the check plug-in is created:
You should always pass default values in this way (and not intercept the case of missing parameters in the check plug-in), as these default values can also be displayed in the Setup interface. For example, in the service discovery of a host, on the Services of host page, in the Display menu, there is the Show check parameters switch.
On GitHub you can find both the file with the rule set as well as the check plug-in extended by the rule set. |
5.4. Testing and enabling the extended check plug-in
The changes made in the previous chapter affect both the monitoring core and the graphical user interface, as well as its supporting processes.
Therefore, after running cmk-validate-plugins, you must first regenerate the configuration and then restart the site:
If you have a thorough understanding of the Checkmk process structure and know exactly which components will be affected by changes to your plug-in, you can limit the restart to specific services. For an overview, see the article Site services.
6. Customizing the metric displays
In the example above, you had the check plug-in myhostgroups_advanced generate metrics for all measured and calculated values.
We have presented two ways of doing this.
First, the metrics of the calculated values were created as part of the check_levels() function with the metric_name argument, for example like this:
Then you have generated the measured metrics directly with the Metric() object—for the number of services in the OK state, for example, like this:
Metrics will become immediately visible in the Checkmk graphical user interface without you having to do anything. There are, however, a few restrictions:
Matching metrics are not automatically combined in a graph, but each appears individually.
The metric will not have a proper title, instead the internal variable name of the metric is shown.
No unit is used that allows a meaningful representation (e.g. GB instead of individual bytes).
A color is selected at random.
A 'Perf-O-Meter', i.e. the graphic preview of the metric as a bar, does not automatically appear in the service list (for example in the view that shows all services of a host).
To complete the display of your metrics with such details, you will require metric definitions.
Just as for rule sets, as of Checkmk 2.3.0 there is also a separate API for metrics, graphs and Perf-O-Meters with the Graphing API. The documentation for the Graphing API can be found in your Checkmk site on the same page as the Check API, under Graphing > Version 1.
6.1. Creating a new metric definitions
The procedures for creating rule sets and metric definitions are very similar.
First create a new subdirectory with the default name graphing in your plug-in family directory ~/local/lib/python3/cmk_addons/plugins/myhostgroups/.
Then create a graphing file in this directory, e.g. graphing_myhostgroups.py.
First there are again some import commands:
For our example, you now define your own metric for the percentage of services in the OK state.
This is done by creating an instance of the class Metric.
This instance’s name must begin with metric_
Here is the explanation:
The metric name (here
services_ok_perc) must correspond to what the check function outputs.The
titleis the heading in the metric graph and replaces the previously used internal variable name.The available units (
unit) can be found in the API documentation, these all end inNotation, e.g.DecimalNotation,EngineeringScientificNotationorTimeNotation.The color names used in Checkmk for the
colordefinition can be found at GitHub.
This definition in the graphing file now ensures that the metric’s title, unit and color are displayed appropriately.
Similar to the creation of a rule set file, the graphing file must first be read before the change will be visible in the GUI. This is achieved by restarting the site’s Apache:
The metric graph will then look something like this in the Checkmk GUI:
6.2. Graphs with multiple metrics
If you want to combine several metrics in one graph (which is often very useful), you will need a graph definition that you can add to the graphing file created in the previous section.
For our example, the two metrics num_services and num_services_ok are to be displayed in a single graph.
The metric definitions for this are created in the same way as in the previous section for services_ok_perc and look as follows:
Now add a graph that draws these two metrics as lines.
This is done via an instance of the class Graph, whereby the instance’s name must again begin with a predefined prefix (graph_):
The parameter minimal_range describes the minimum range covered by the vertical axis of the graph, regardless of the actual values of the metric.
The vertical axis will be extended if the values exceed the minimum range, but it will never be smaller.
The result is the combined graph in the Checkmk GUI:
6.3. Metrics in the Perf-O-Meter
Would you like to display a Perf-O-Meter for a metric in the row of the service list? It could look like this, for example:

To create such a Perf-O-Meter, you will need another instance, this time of the class Perfometer, whose name begins with the prefix perfometer_:
Perf-O-Meters are a little trickier than graphs, as they have no legend. It is therefore difficult to display a range of values, especially when absolute values are being displayed. It is easier to display a percentage. This is also the case in the above example:
The metric names are entered in
segments, in this example the percentage of services in the OK state.The lower and upper limits are entered in
focus_range.Closedlimits are intended for metrics that can only accept values between the specified limits (here0and100).
Further, even more sophisticated options for implementing metrics in Perf-O-Meters can be found in the Graphing API documentation, for example, with the classes Bidirectional and Stacked, which allow several Perf-O-Meters to be displayed in one.
The graphing file for this chapter can be found at GitHub. Among other things, this file contains the metric definitions for the four measured values and the two calculated values.
7. Formatting numbers
Numbers are often output in the Summary and the Details of a service.
To make neat and correct formatting as easy as possible for you,
and also to standardize the output of all check plug-ins, there are helper functions for displaying the various types of sizes.
All of these are subfunctions of the render module and are therefore called with render..
For example, render.bytes(2000) results in the text 1.95 KiB.
What all of these functions have in common is that their value is shown in a so-called canonical or natural unit. This means you never have to think and there are no difficulties or errors when converting. For example, times are always given in seconds, and the sizes of hard disks, files, etc., are always given in bytes and not in kilobytes, kibibytes, blocks or other such confusion.
Use these functions even if you do not like the display that much. In any case, it will be standardized for the user. Future versions of Checkmk may be able to change the display or even make it configurable by the user, as is already the case with the temperature display, for example. Your check plug-in will then also benefit from this.
Before you can use the render function in your check plug-in, you must also import it:
Following this detailed description of all display functions (render functions), you will find a summary in the form of an easy to read table.
7.1. Times, time ranges, frequencies
Absolute time specifications (timestamps) are formatted with render.date() or render.datetime().
The information is always given as Unix time, i.e. in seconds from January 1, 1970, 00:00:00 UTC—the beginning of the Unix epoch.
This is also the format used by the Python function time.time().
The advantage with this representation is that it is very easy to calculate, for example the calculation of a time range, when the start and end times are known.
The formula is then simply duration = end - start.
These calculations work regardless of the time zone, daylight saving time changes, or leap years.
render.date() only outputs the date, render.datetime() adds the time.
The output is according to the current time zone in which the Checkmk server that is executing the check is located.
Examples:
| Call | Output |
|---|---|
|
|
|
|
|
|
|
|
Do not be surprised that render.datetime(0) does not output 00:00 as the time, but 01:00.
This is because we are writing this User Guide in the time zone for Germany—which is one hour ahead of standard UTC time (at least during standard time, because January 1st is not in daylight saving time).
For time ranges (or time spans) there is also the render.timespan() function.
This is given a duration in seconds and outputs it in human-readable form.
For larger time spans, seconds or minutes are omitted.
If you have a time span in a TimeDelta object, use the total_seconds() function to read out the number of seconds as a floating point number.
| Call | Output |
|---|---|
|
|
|
|
|
|
|
|
A frequency is effectively the reciprocal of time. The canonical unit is Hz, which means the same as 1 / sec (the reciprocal of one second). An example of its use is the clock rate of a CPU:
| Call | Output |
|---|---|
|
|
7.2. Bytes
Wherever working memory, files, hard disks, file systems and the like are concerned, the canonical unit is the byte. Since computers usually organize such things in powers of two, for example in units of 512, 1024 or 65,536 bytes, it became established right from the beginning, that a kilobyte is not 1000, and therefore a thousand times the unit, but 1024 (2 to the power of 10) bytes. This is admittedly illogical, but very practical because it usually results in round numbers. The legendary Commodore C64 had 64 kilobytes of memory and not 65.536.
Unfortunately, at some point hard disk manufacturers came up with the idea of specifying the sizes of their disks in units of 1000. Since the difference between 1000 and 1024 is 2.4 % for each size, and these are multiplied, a disk of size 1 GB (1024 times 1024 times 1024) suddenly becomes 1.07 GB. That sells better.
This annoying confusion still exists today and continues to produce errors. To alleviate this, the International Electrotechnical Commission (IEC) has defined new prefixes based on the binary system. Accordingly, today a kilobyte is officially 1000 bytes and a kibibyte is 1024 bytes (2 to the power of 10). In addition, one should say mebibyte, gibibyte and tebibyte. The abbreviations are then KiB, MiB, GiB and TiB.
Checkmk conforms to this standard and helps you with a number of customized render functions to ensure that you always produce the correct output.
For example, there is the render.disksize() function especially for hard disks and file systems, which produces its output in powers of 1000.
| Call | Output |
|---|---|
|
|
|
|
|
|
When it comes to the sizes of files, it is often customary to specify the exact size in bytes without rounding.
This has the advantage that you can see very quickly if a file has changed even minimally or that two files are (probably) the same.
The render.filesize() function is used for this:
| Call | Output |
|---|---|
|
|
|
|
|
|
If you want to output a value that is not the size of a hard disk or file, simply use the generic render.bytes().
With this you get the output in the 'classic' 1024 powers in the official notation:
| Call | Output |
|---|---|
|
|
|
|
|
|
7.3. Bandwidths, data rates
Networkers have their own terms and ways of expressing things. And as always, Checkmk makes every effort to adopt the conventional way of communicating in each domain. That is why there are three different render functions for data rates and speeds. What these all have in common is that the rates are passed in bytes per second, even if the actual output is in bits!
render.nicspeed() represents the maximum speed of a network card or a switch port.
As these are not measured values, there is no need for rounding.
Although no port can send individual bits, the data is in bits for historical reasons.
Important: Nevertheless, you must also pass bytes per second here!
| Call | Output |
|---|---|
|
|
|
|
render.networkbandwidth() is intended for an actually measured transmission speed in the network.
The input value is again bytes per second:
| Call | Output |
|---|---|
|
|
|
|
|
|
Where a network is not involved and data rates are still output, bytes are again common.
The most prominent case is the IO rates of hard disks.
The render.iobandwidth() function, which works with powers of 1000 in Checkmk, is used for this:
| Call | Output |
|---|---|
|
|
|
|
|
|
7.4. Percentages
The render.percent() function represents a percentage—rounded to two decimal places.
It is an exception to the other functions in that it does not pass the actual natural value—i.e. the ratio—but the real percentage.
For example, if something is half full, you do not have to pass 0.5 but 50.
Because it can sometimes be interesting to know whether a value is almost zero or exactly zero, values are marked by appending a ‘<’ character, for values that are greater than zero but less than 0.01 percent.
| Call | Output |
|---|---|
|
|
|
|
|
|
7.5. Summary
In conclusion, here is an overview of all render functions:
| Function | Input | Description | Output example |
|---|---|---|---|
|
Unix time |
Date |
|
|
Unix time |
Date and time |
|
|
Seconds |
Duration / age |
|
|
Hz |
Frequency (e.g. clock rate) |
|
|
Bytes |
Size of a hard disk, base 1000 |
|
|
Bytes |
Size of a file, full precision |
|
|
Bytes |
Size, base 1024 |
|
|
Bytes per second |
Network card speed |
|
|
Bytes per second |
Transmission speed |
|
|
Bytes per second |
IO bandwidths |
|
|
Percentage number |
Percentage, meaningfully-rounded |
|
8. Troubleshooting
The correct handling of errors (unfortunately) takes up a large part of any programming work. The good news is that the Check API already takes a lot of the work out of error handling. For some types of errors, it is therefore better not to handle them at all yourself.
If Python encounters a situation that is in any way unexpected, it reacts with a so-called exception. Here are a few examples:
You convert a string to a number with
int(), but the string does not contain a number, for exampleint("foo").You use
bar[4]to access the fifth element ofbar, but it only has four elements.You are calling a function that does not exist.
In order to decide how to tackle errors, it is first important to know the exact point in the code where an error occurs. You can use either the GUI or the command line for this—depending on where you are currently working.
8.1. Exceptions and crash reports in the GUI
If an exception occurs in monitoring or during service discovery in the Setup, the Summary contains references to the crash report that has just been created. It will look like this, for example:

Clicking on the ![]() icon displays a page with details in which you:
icon displays a page with details in which you:
can see the file in which the crash occurred,
receive all information about the crash, such as a list of the errors that occurred in the program (traceback), the current values of local variables, the agent output and much more, and
can send the report to us (Checkmk GmbH) as feedback.
The traceback helps you as a developer to decide whether there is an error in the program (e.g. the call of a non-existent function) or agent data that could not be processed as expected. In the first case you will want to correct the error, in the second case it often makes sense to do nothing.
Submitting the report is of course only useful for check plug-ins that are officially part of Checkmk. If you make your own plug-ins available to third parties, you can ask your users to send you the data.
8.2. Viewing exceptions on the command line
If you run your check plug-in using the command line, you will not receive any indication of the ID of any crash report generated. You will only see the summarized error message:
If you append the --debug option as an additional call parameter, you will receive the traceback from the Python interpreter:
If the error does not occur again the next time you call --debug, for example because a new agent output is available, you can also view the last crash reports in the file system:
There are two files in each of these folders:
crash.infocontains a Python dictionary with traceback and much more information. A glance at the file with the Pager is often sufficient.agent_outputcontains the complete agent output that was current at the time of the crash.
8.3. Custom debug output
In the examples shown above, we use the print() function to output the content of variables or the structure of objects for you as a developer.
These functions for debug output must be removed from the finished check plug-in.
As an alternative to removal, you can also have your debug output displayed only when the check plug-in is called from the console in debug mode.
To do this, import the debug object from the Checkmk toolbox and, if necessary, the pprint() formatting aid.
You can now produce debug output depending on the value of the debug object:
The debug object changed its path between Checkmk 2.3.0 and 2.4.0.
Instead of the previous location |
Note that any remaining debug output should be used sparingly and limited to hints that will help subsequent users with debugging. Obvious and foreseeable user errors (for example, that the contents of the agent section indicate that the agent plug-in has been incorrectly configured) should be answered with the UNKNOWN state and include explanatory notes in the summary.
8.4. Invalid agent output
The question is how you should react if the output from the agent is not in the form you actually expect—whether from the Checkmk agent or received via SNMP. Suppose you always expect three words per line, what should you do if you only get two words?
Well, if this is a permitted and known behavior by the agent, then of course you need to intercept this and work with a case distinction. However, if this is not actually allowed, then it is best to act as if the line always consists of three words, for example with the following parse function:
If there is a line that does not consist of exactly three words, an exception is generated and you receive the very helpful crash report just mentioned.
If you access keys in a dictionary that are expected to be missing occasionally, it can of course make sense to react accordingly.
This can be done by setting the service to CRIT or UNKNOWN and placing a note in the summary about the agent output that cannot be evaluated.
In any case, it is better to use the get() function of the dictionary for this than to catch the KeyError exception.
This is because get() returns an object of type None or an optional replacement to be passed as the second parameter if the key is not available:
8.5. Missing items
What if the agent outputs correct data, but the item to be checked is missing? Like this, for example:
If the item you are looking for is not included, the loop is run through and Python simply drops out at the end of the function without returning a result via yield.
And that is exactly the right approach!
Because Checkmk recognizes that the item to be monitored is missing and generates the correct status and a suitable standard text with UNKNOWN.
8.6. Testing with spool files
If you want to simulate particular agent outputs, files in the spool directory are very helpful. You can use these to test borderline cases that are otherwise difficult to recreate. Or you can directly use the agent output that led to a crash report to test changes to a check plug-in.
First deactivate your regular agent plug-in, for example by revoking its execution authorization.
Then create a file in the /var/lib/check_mk_agent/spool/ directory that contains the agent section (or expected agent sections) that your check plug-in expects, including the section header, and ends with Newline.
The next time the agent is called, the content of the spool file will be transferred instead of the output from the agent plug-in.
9. Files and directories
Please note that the symbolic links |
| File path | Description |
|---|---|
|
Base directory for storing plug-in files. |
|
Storage location for check plug-ins written according to the Check API V2. |
|
Storage location for rule set files created according to the Rulesets API. |
|
Storage location for graphing files created according to the Graphing API. |
|
This directory is located on a monitored Linux host. The Checkmk agent for Linux expects extensions of the agent (agent plug-ins) here. |