1. The Checkmk Micro Core’s special features
The most significant advantages of CMC are its higher performance and faster response times compared to the monitoring core of the open-source project Nagios, It has further interesting advantages of which you should be aware — the most important of which are:
Smart Ping — Intelligent host checks
Auxiliary processes Check helper, Checkmk fetcher and Checkmk checker
Initial Scheduling
Processing of performance data
A couple of Nagios' functions are not used, or are achieved using a different procedure in the CMC. The details on this can be found in the article on the migration to the CMC.
2. Smart Ping — Intelligent host checks
With Nagios the availability of hosts is usually verified using a Ping.
For this purpose, for every host a plug-in such as check_ping or check_icmp is executed once per interval (generally once per minute).
This sends, for example, five ping packets and waits for their return.
Creating the processes for executing the plug-ins ties up valuable CPU resources.
Furthermore, these can form a backlog for quite a long time if a host is not reachable, and long timeouts must be endured.
By contrast, CMC runs host checks — unless otherwise configured — using a procedure called Smart Ping.
Smart Ping relies on an internal component called icmpsender, which has its own ping implementation.
Since Checkmk with CMC does not rely on an external binary, there is no need to spawn a new process for each ping packet sent.
Additionally the default behavior of icmpsender differs from its Nagios counterpart.
Instead of multiple packets in rapid series that are waited upon, icmpsender sends only one ICMP packet per host every n-seconds (the default is 6 seconds, configurable via the Normal check interval for host checks rule set).
This behavior drastically reduces resource consumption and data traffic.
The responses to the pings are not explicitly waited-for.
The CMC’s icmpreceiver component is responsible for deciding whether the state of a host is UP or DOWN.
The CMC treats incoming ping packets from a host as a successful host check and thus marks the host as UP.
If no packet is received from a host within a defined time, this host will be flagged as DOWN.
The timeout is preset to 15 seconds (2.5 intervals) and can be changed per host with the Settings for host checks via Smart PING rule set.
The icmpreceiver component also listens to TCP SYN (synchronization) and RST (reset) packets coming from a host.
When it receives such packets, the host is considered UP.
This mechanism can lead to flapping states of hosts in infrastructures where ICMP traffic is not allowed but TCP traffic is.
|
2.1. No on-demand host checks
Host checks not only serve to trigger notifications in the case of a total host failure, but also to suppress notifications of service problems during a host’s planned downtime. Service problems can arise and not be the responsibility of the service itself, but rather of a failure condition of the host. It can happen that a host is actually DOWN even if its last known state in Checkmk is UP as per the last host check result. In such condition multiple service checks could returns problems that depend on the hosts DOWN state, resulting in sending service notifications — erroneously. In the event of a service problem it is therefore important to first determine the condition of the service’s host.
The CMC solves this problem very simply: if a service problem arises and the host is in an UP state, CMC will wait for the next host check. Due to the interval being very short at only (by default) 6 seconds, there is only a negligible delay to a notification — if the host is still UP and therefore the notification needs to be sent for the service.
As an example, let’s take the case of a check_http plug-in delivering a CRIT state, due to a queried web server being unavailable.
In this situation, following the start of the service check a TCP RST packet (connection refused) will be received from this server by the icmpreceiver component.
The CMC therefore knows for certain that the host itself is UP and it can thus send the notification without delay.
The same principle is utilized when calculating network outages if parent hosts have been defined. Here as well notifications will at times be delayed briefly in order to wait for a verified state.
2.2. The advantages
This procedure yields a number of advantages:
Virtually insignificant CPU load resulting from host checks — even without particularly powerful hardware umpteen thousand hosts can be monitored.
No thwarting of monitoring by on-demand host check jams if hosts are DOWN.
No false alarms from services when a host state is not current.
One disadvantage should not be hushed-up however: the Smart Ping host checks generate no performance data (packet runtimes).
On hosts where these are required you can simply set up an active check via ping with the Check hosts with PING (ICMP Echo Request) rule set.
2.3. Unpingable hosts
In practice, not all hosts are checkable by ping. For these cases other methods in CMC can also be used for the host check, e.g., a TCP connection. Because these are generally exceptions they have no negative impact on the overall performance. The rule set here is Host check command.
2.4. Problems with firewalls
There are firewalls that answer TCP connection packets to inaccessible hosts with a TCP RST packet. The trick is that the firewall is not permitted to register itself as the sender of this packet, rather the target host’s IP address must be specified. Smart Ping will view this packet as a sign of life and incorrectly assume that the target host is accessible.
In such a (rare) situation, via Global settings > Monitoring core > Tuning of Smart PING you have the possibility of activating the Ignore TCP RST packets when determining host state option.
Or, with check_icmp you can select a conventional ping as a host check for the affected hosts.
3. Auxiliary processes
A lesson from the poor performance of Nagios in larger environments is that creating processes is a resource and time consuming operation. The size of the parent process is the decisive factor here. For every execution of an active check the complete Nagios process must first be duplicated (forked) before it is replaced by the new process — the check plug-in. The more hosts and services to be monitored, the larger this process and the fork respectively takes longer. In the meantime the core’s other tasks must wait — and here 24-CPU cores are not much help.
3.1. Check helper
In order to avoid forking the core, during the program start the CMC creates a fixed number of very lean auxiliary processes whose task is to start the active check plug-ins: the check helpers.
Not only do these fork much more quickly, but the forking also scales-up to cover all available cores because the core itself is no longer blocked.
In this way, the execution of active checks (e.g. check_http) — whose runtimes are actually quite short — is greatly accelerated.
3.2. Checkmk fetcher and Checkmk checker
The CMC goes a significant step further however — because in a Checkmk environment active checks are rather an exception. Here Checkmk-based checks — in which only a single fork per host and interval is required — are primarily used.
To optimize the execution of these checks, the CMC maintains two other types of auxiliary processes: the Checkmk fetchers and the Checkmk checkers.
The Checkmk fetchers
The Checkmk fetchers retrieve the required information from the monitored hosts, i.e. the data from the Check_MK and Check_MK Discovery services. The fetchers thus take over the network communication with the Checkmk agents, SNMP agents and the special agents. Gathering this information takes some time, but with typically less than 50 megabytes required per process — which is relatively little memory — multiple processes can be configured without problems. Keep in mind that the processes can be partially or not at all swapped out and thus must always be kept in physical memory. The limiting factor here is the available memory in the Checkmk server.
The 50 megabytes mentioned above are an estimate for basic orientation. The actual value may be higher under specific circumstances — e.g. because IPMI has been configured on the management board. |
The Checkmk checkers
The Checkmk checkers analyze and evaluate the information collected by the Checkmk fetchers and generate the check results for the services. The checkers need a lot of memory because they must include the Checkmk configuration. A checker process occupies at least about 90 megabytes — however, a multiple of this may be necessary, depending on how the checks are configured. On the other hand, the checkers do not generate any network load and execute very quickly. The number of checkers should only be as large as your Checkmk server can process in parallel. As a rule, this number corresponds to the number of cores in your server. Since the checkers are not IO-bound, they are most effective if each checker has its own core.
The division of the two different 'collect' and 'execute' tasks between the Checkmk fetcher and the Checkmk checker exists since Checkmk version 2.0.0. Previously there was only one auxiliary process type that was responsible for both — the so-called Checkmk helpers.
With the fetcher/checker model, both tasks are now divided into two separate pools of processes: retrieving information from the network with many small fetcher processes and the computationally-intensive checking with a few large checker processes. As a result, a CMC uses up to four times less memory for the same performance (checks per second)!
3.3. Setting the number of auxiliary processes correctly
The number of check helpers (active checks), Checkmk fetchers and Checkmk checkers started by default are defined under Global settings > Monitoring core and can be customized by you:
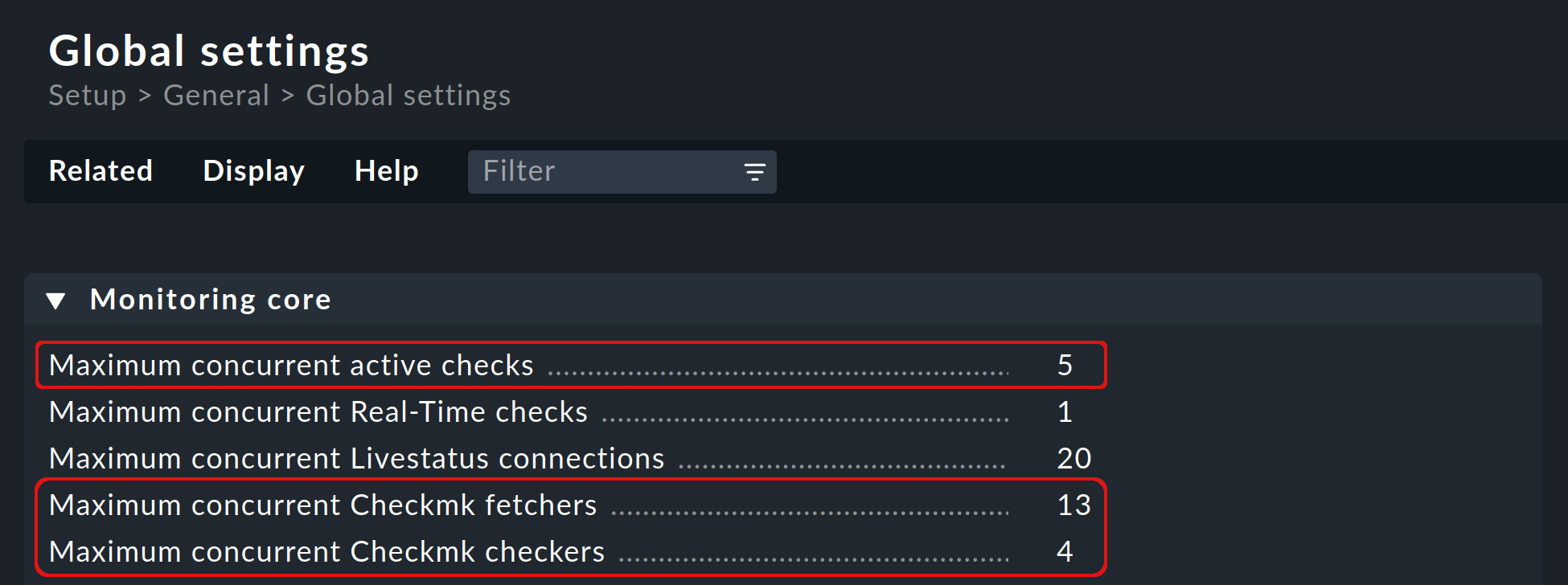
To find out if and how you need to change the default values, you have several options:
In the sidebar, the Core statistics snap-in shows you the percentage utilization averaged over the last 10-20 seconds:
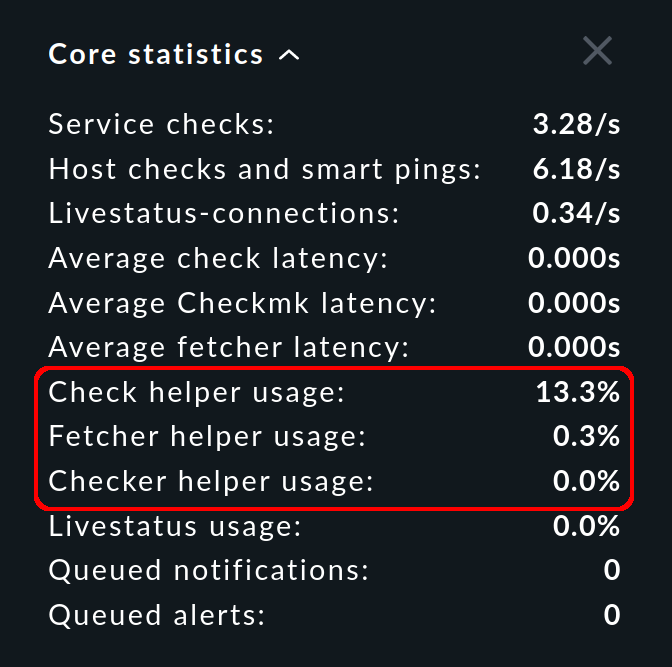
For all auxiliary process types, there should always be enough processes to run the configured checks. If a pool is being 100 % utilized, the checks will not be executed in time, the latency will grow and the states of the services will not be up to date.
The usage should not exceed 80 % a few minutes after starting a site. For higher percentages, you should increase the number of processes. Since the necessary number of Checkmk fetchers grows with the number of monitored hosts and services, a correction is most likely here. However, be careful to create only as many auxiliary processes as are really needed, as each process occupies resources. In addition, all auxiliary processes are initialized in parallel when the CMC is started, which can lead to load peaks.
The Core statistics snap-in shows you not only the usage, but also the latency. For these values, the simple rule applies: the lower, the better — and 0 seconds is therefore best.
You can also display the values shown in the snap-in for your site in the details of the OMD <site_name> performance service. |
As an alternative to the Core statistics snap-in, you can also have your configuration analyzed by Checkmk, with Setup > Maintenance > Analyze configuration. The advantage here is that you get an immediate evaluation from Checkmk of the state of the auxiliary processes. It is very handy that if one of the auxiliary processes is not OK, from the help text you can open the corresponding Global settings option to change the process’s value.
4. Initial scheduling
During scheduling it is defined which checks should be run at what times. Nagios has implemented numerous procedures that should ensure that the checks are regularly distributed over the interval. Nagios will likewise attempt to distribute the queries to be run uniformly on an individual target system over the interval.
The CMC has its own, simpler procedure for this purpose. This takes into account that Checkmk already contacts a host once per interval. Furthermore, the CMC ensures that new checks are immediately executed and not distributed over several minutes. This is very convenient for the user since a new host will be queried as soon as the configuration has been activated. In order to avoid a large number of new checks causing a load spike, new checks whose number exceeds a definable limit can be distributed over the entire interval. The option for this can be found under Global settings > Monitoring core > Initial scheduling.
5. Processing of performance data
An important function of Checkmk is the processing of measurement data, such as CPU utilization, and its retention for a long time period. In Checkmk Community, PNP4Nagios is used for this, which in turn is based on the RRDtool.
The software performs two functions:
The creation and updating of the Round Robin Databases (RRDs).
The graphic representation of the data in the GUI.
In a Nagios core operation the function mentioned in point 1. above is quite a long process.
Depending on the method, spool files, Perl scripts and an auxiliary process (npcd) written in C is used.
Finally, partly converted data is written to the RRD cache daemon’s Unix socket.
The CMC shortens this chain by writing directly to the RRD cache daemon — all intermediate steps are dispensed with. Parsing, and converting the data to the RRDtool’s format is performed directly in C++. This method is possible and sensible nowadays as the RRD cache daemon has already implemented its own very efficient spooling, and with the aid of journal files this means that no data is lost in the event of a system crash.
The advantages:
Reduced Disk-I/O and CPU load
Simpler implementation with markedly more stability
The CMC creates new RRDs using another helper, which is called via cmk-create-rrd.
This helper creates the files either in a format compatible with PNP or, alternatively, in the new Checkmk format (only applies to new installations).
Switching from Nagios to CMC therefore has no effect on existing RRD files.
These continue to be maintained seamlessly.
In the commercial editions the graphic display of the data in the GUI is handled directly by Checkmk’s GUI itself, so that no PNP4Nagios component is involved.