1. Grundprinzip
1.1. Der Blick in die Vergangenheit
Da Checkmk alle Hosts und Services in regelmäßigen Intervallen kontinuierlich überwacht, schafft es damit eine hervorragende Grundlage für spätere Auswertungen über deren Verfügbarkeit. Und nicht nur das — Sie können berechnen lassen, welchen Anteil der Zeit ein Objekt in einem bestimmten Zustand war, wie oft dieser Zustand aufgetreten ist, wie lange er am längsten angehalten hat und vieles mehr.
Jeder Berechnung liegen dabei eine Auswahl von Objekten und ein bestimmter Zeitraum der Vergangenheit zugrunde. Checkmk rekonstruiert dann für diesen Zeitraum den Verlauf des Zustands für jedes der ausgewählten Objekte. Pro Zustand werden die Zeiten aufsummiert und in einer Tabelle dargestellt. Das Ergebnis kann dann z.B. sein, dass der Zustand eines bestimmten Services zu 99,95 % OK war und zu 0,005 % WARN.
Dabei rechnet Checkmk auch Dinge wie Wartungszeiten, Service-Zeiten, nicht überwachte Zeiträume und andere Besonderheiten korrekt ab, erlaubt das Zusammenfassen von Zuständen, das Ignorieren von „kurzen Aussetzern“ und noch etliche weitere Anpassungsmöglichkeiten. Auch eine Verfügbarkeit von BI-Aggregaten ist möglich.
1.2. Mögliche Zustände
Durch die Einbeziehung von Wartungszeiten und ähnlichen Sonderzuständen gibt es theoretisch eine sehr große Zahl von möglichen Zustandskombinationen, wie z.B. CRIT + In Wartungszeit + In der Service-Zeit + Flapping. Da die meisten dieser Kombinationen nicht sehr nützlich sind, reduziert Checkmk sie auf eine kleine Zahl und geht dabei nach einem Prinzip von Prioritäten vor. Da in obigem Beispiel der Service in einer Wartungszeit war, gilt als Zustand einfach in scheduled downtime und der eigentliche Zustand wird ignoriert. Das reduziert die Anzahl der möglichen Zustände auf die Folgenden:
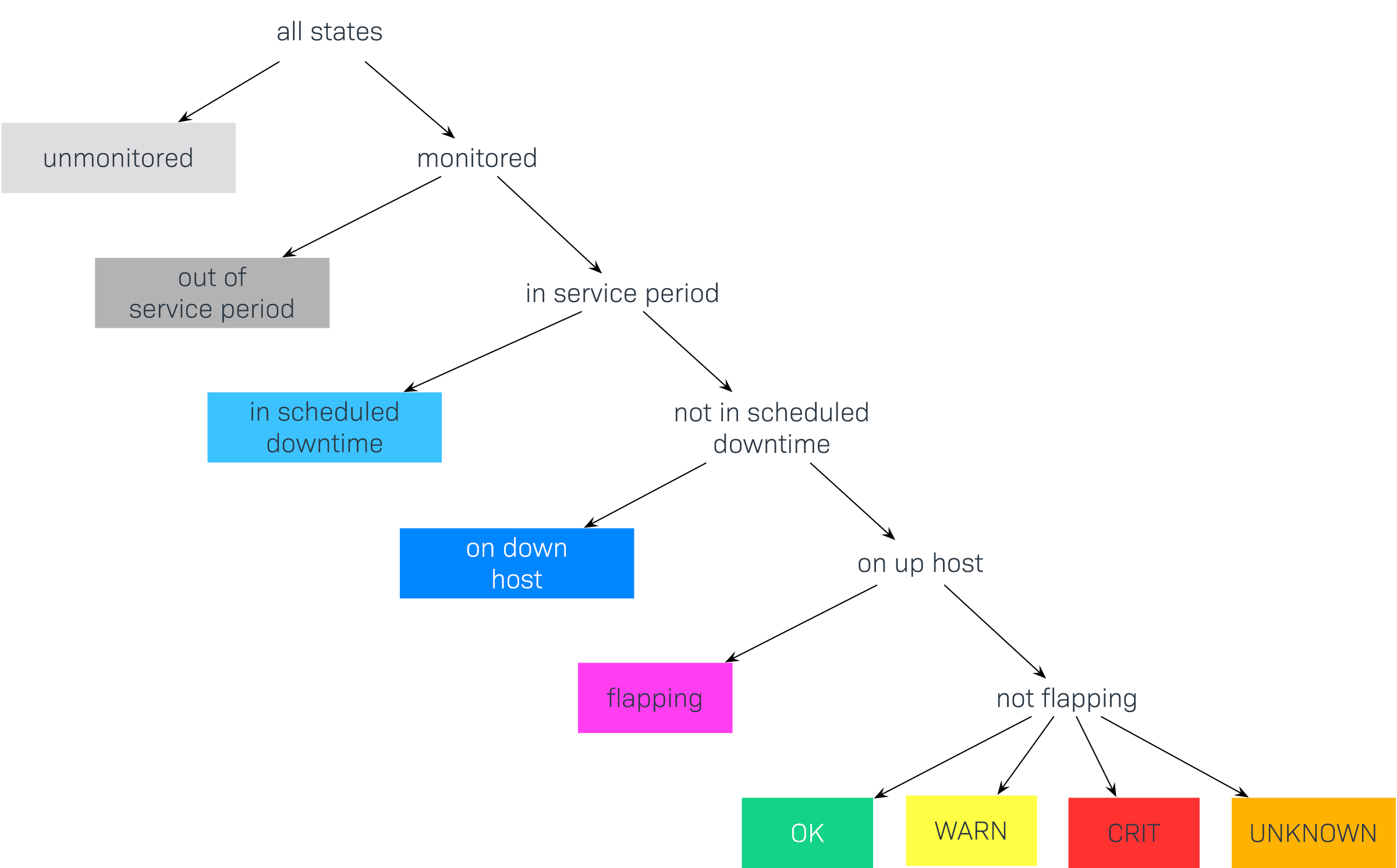
Diese Grafik zeigt auch die Reihenfolge, nach der Zustände priorisiert werden. Später werden wir zeigen, wie Sie manche der Zustände ignorieren oder zusammenfassen können. Hier die Zustände noch einmal im Detail:
| Zustand | Abkürzung | Bedeutung |
|---|---|---|
unmonitored |
N/A |
Zeiträume, während derer das Objekt nicht überwacht wurde. Dafür gibt es zwei mögliche Ursachen: Das Objekt war nicht Teil der Monitoring-Konfiguration, oder das Monitoring selbst ist für diesen Zeitraum nicht gelaufen. |
out of service period |
Das Objekt war außerhalb seiner |
|
in scheduled downtime |
Downtime |
Das Objekt war innerhalb einer |
on down host |
H.Down |
Diesen Zustand gibt es nur bei Services — und zwar wenn der Host des Services DOWN ist. Eine Überwachung des Services zu so einem Zeitpunkt ist nicht möglich. Bei den meisten Services ist dies gleichbedeutend damit, dass der Service CRIT ist — aber nicht bei allen! Zum Beispiel ist der Zustand eines Dateisystems (Filesystem-Check) sicher unabhängig davon, ob der Host erreichbar ist. |
flapping |
Phasen, in denen Zustand |
|
UP DOWN UNREACH |
Monitoring-Zustand von Hosts. |
|
OK WARN CRIT UNKNOWN |
Monitoring-Zustand von Services und BI-Aggregaten. |
2. Availability aufrufen
2.1. Von der Ansicht zur Auswertung
Das Erstellen einer Verfügbarkeitsauswertung ist sehr einfach. Rufen Sie zunächst eine beliebige Ansicht von Hosts, Services oder BI-Aggregaten auf. Dort finden Sie im Menü Services bzw. Hosts den Eintrag Availability, welcher Sie direkt zur Berechnung der Verfügbarkeit der ausgewählten Objekte bringt. Diese wird tabellarisch angezeigt:
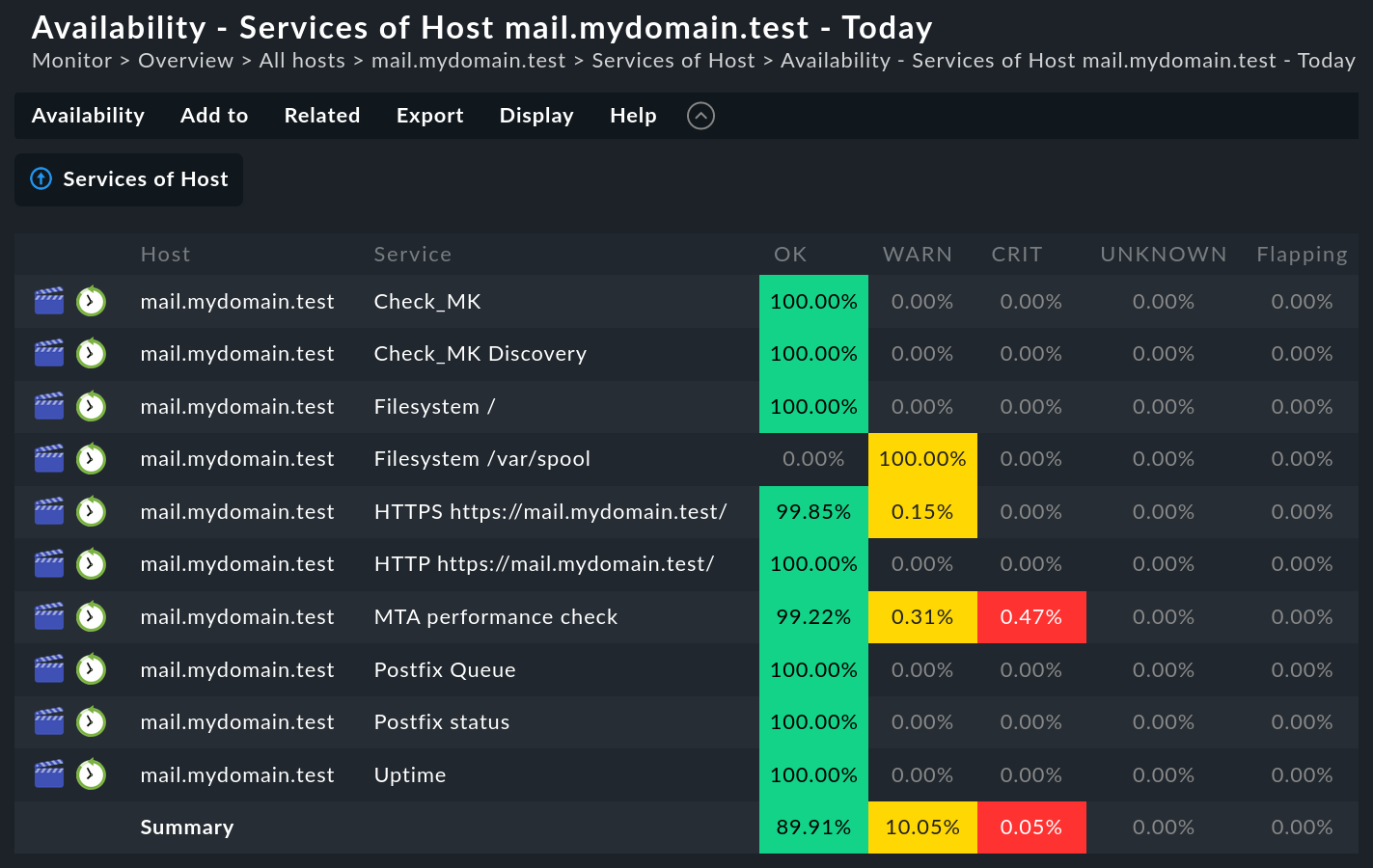
Die Tabelle zeigt die gleichen Objekte, die auch in der vorherigen Ansicht sichtbar waren. In jeder Spalte wird dargestellt, welchen Anteil des Abfragezeitraums das Objekt im besagten Zustand war. Die Darstellung ist per Default in Prozent mit zwei Kommastellen, aber das können Sie leicht umstellen.
Den Anfragezeitraum können Sie mit dem Menüeintrag Availability > Change display options > Time Range ändern. Dazu weiter unten mehr …
Sie haben die Möglichkeit, die Ansicht als PDF zu exportieren (nur kommerzielle Editionen). Auch ein Download der Daten in CSV-Format ist möglich (Export as CSV). Das sieht dann für obiges Beispiel so aus:
Host;Service;OK;WARN;CRIT;UNKNOWN;Flapping;H.Down;Downtime;N/A
mail.mydomain.test;Check_MK;100.00%;0.00%;0.00%;0.00%;0.00%;0.00%;0.00%;0.00%
mail.mydomain.test;Check_MK Discovery;100.00%;0.00%;0.00%;0.00%;0.00%;0.00%;0.00%;0.00%
mail.mydomain.test;Filesystem /;100.00%;0.00%;0.00%;0.00%;0.00%;0.00%;0.00%;0.00%
mail.mydomain.test;Filesystem /var/spool;0.00%;100.00%;0.00%;0.00%;0.00%;0.00%;0.00%;0.00%
mail.mydomain.test;HTTP https://mail.mydomain.test/;99.85%;0.15%;0.00%;0.00%;0.00%;0.00%;0.00%;0.00%
mail.mydomain.test;HTTPS https://mail.mydomain.test/;100.00%;0.00%;0.00%;0.00%;0.00%;0.00%;0.00%;0.00%
mail.mydomain.test;MTA performance check;99.23%;0.30%;0.46%;0.00%;0.00%;0.00%;0.00%;0.00%
mail.mydomain.test;Postfix Queue;100.00%;0.00%;0.00%;0.00%;0.00%;0.00%;0.00%;0.00%
mail.mydomain.test;Postfix status;100.00%;0.00%;0.00%;0.00%;0.00%;0.00%;0.00%;0.00%
mail.mydomain.test;Uptime;100.00%;0.00%;0.00%;0.00%;0.00%;0.00%;0.00%;0.00%
Summary;;89.91%;10.05%;0.05%;0.00%;0.00%;0.00%;0.00%;0.00%Mithilfe eines Automationsbenutzers, der sich über die URL
authentifizieren kann, können Sie so die Daten auch skriptgesteuert abrufen
(z.B. mit wget oder curl) und automatisiert verarbeiten.
2.2. Zeitleistendarstellung
In jeder Zeile finden Sie das Symbol ![]() . Dies bringt
Sie zu einer Zeitleistendarstellung des entsprechenden Objekts, in der genau
aufgeschlüsselt ist, welche Zustandswechsel es im Anfragezeitraum gab
(hier gekürzt):
. Dies bringt
Sie zu einer Zeitleistendarstellung des entsprechenden Objekts, in der genau
aufgeschlüsselt ist, welche Zustandswechsel es im Anfragezeitraum gab
(hier gekürzt):
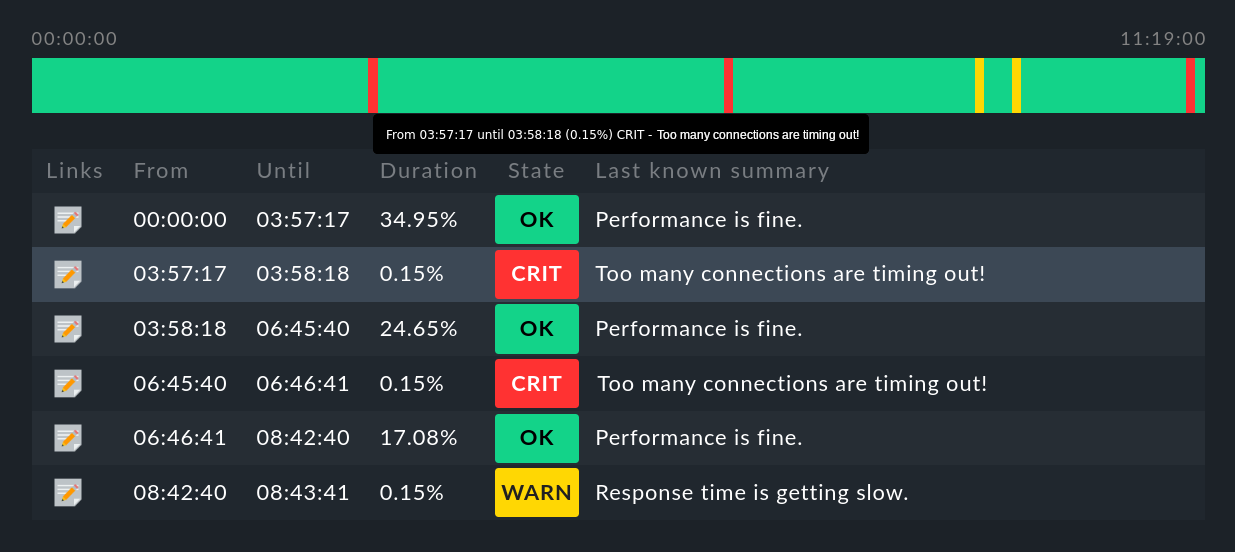
Dazu einige Hinweise:
Fahren Sie mit der Maus in der Zeitleistengrafik über einen Abschnitt, so wird dieser in der Tabellendarstellung hervorgehoben.
Auch in der Zeitleiste können Sie mit dem Menüeintrag Availability > Change display options bzw. Availability > Change computation options die Optionen für die Darstellung und Auswertung anpassen.
Mit dem Symbol
 erstellen Sie eine Anmerkung (Annotation) zu dem gewählten Abschnitt. Hier können Sie auch nachträglich Wartungszeiten angeben (mehr dazu gleich im nächsten Abschnitt).
erstellen Sie eine Anmerkung (Annotation) zu dem gewählten Abschnitt. Hier können Sie auch nachträglich Wartungszeiten angeben (mehr dazu gleich im nächsten Abschnitt).Bei der Verfügbarkeit von BI-Aggregaten können Sie mit dem
 Zauberstab eine Zeitreise zu dem Zustand des Aggregats im besagten Abschnitt machen. Mehr dazu weiter unten.
Zauberstab eine Zeitreise zu dem Zustand des Aggregats im besagten Abschnitt machen. Mehr dazu weiter unten.Mit dem Menüeintrag Availability > Timeline in der Hauptansicht können Sie die Zeitleisten von allen gewählten Objekten in einer einzigen langen Seite ansehen.
2.3. Anmerkungen und nachträgliche Wartungszeiten
Wie gerade erwähnt, bietet die Zeitleiste über das Symbol
![]() die Möglichkeit, für einen Zeitabschnitt eine
Anmerkung zu hinterlegen. Dahinter finden Sie ein bereits ausgefülltes Formular,
in dem Sie einen Kommentar eingeben können:
die Möglichkeit, für einen Zeitabschnitt eine
Anmerkung zu hinterlegen. Dahinter finden Sie ein bereits ausgefülltes Formular,
in dem Sie einen Kommentar eingeben können:
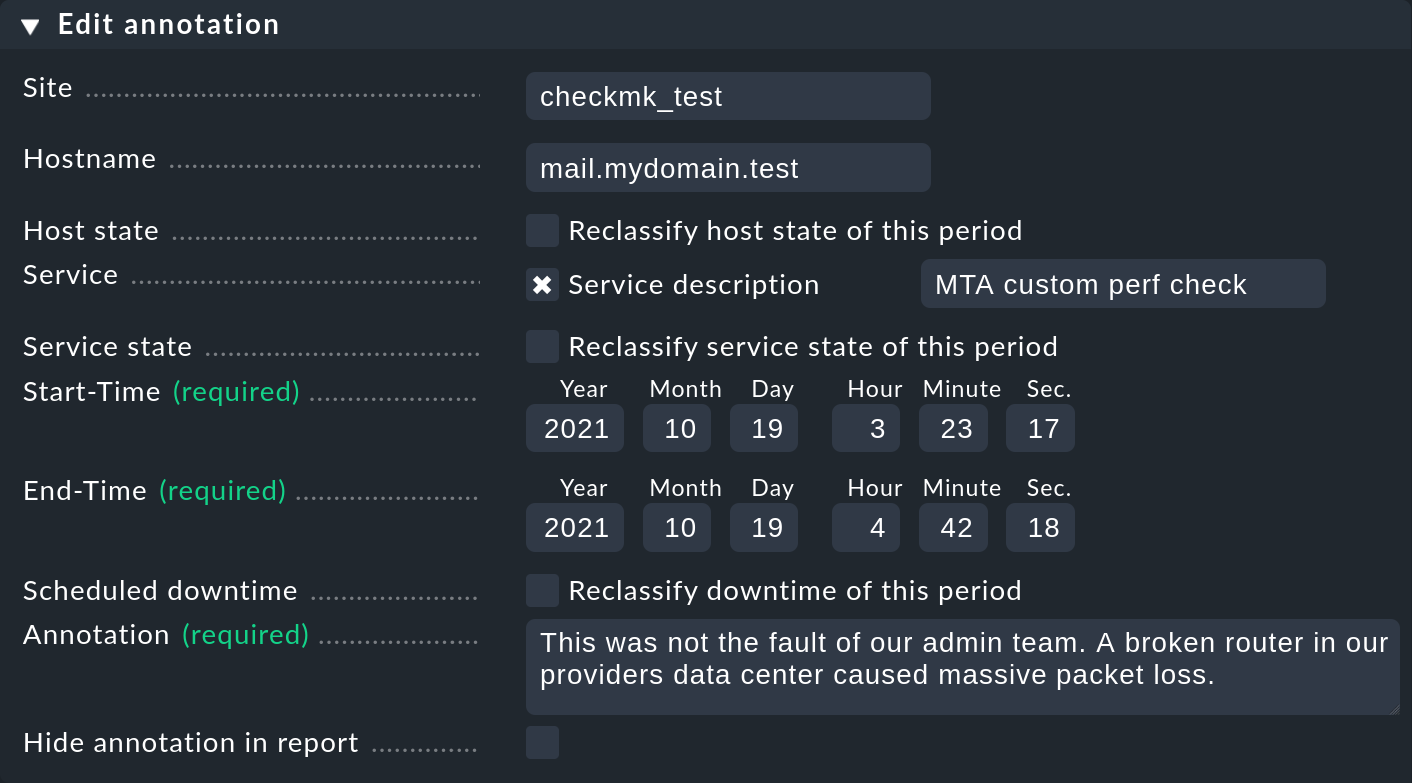
Dabei können Sie den Zeitraum auch anders festlegen und erweitern. Das ist z.B. praktisch, wenn Sie einen größeren Abschnitt annotieren möchten, der mehrere Zustandswechsel erlebt hat. Wenn Sie die Angabe eines Services weglassen, erzeugen Sie eine Anmerkung für einen Host. Diese bezieht sich automatisch auch auf alle Services des Hosts.
In jeder Verfügbarkeitsansicht werden automatisch alle Anmerkungen sichtbar, die zum Zeitraum und den Objekten passen, die dargestellt werden.
Aber Annotationen haben noch eine weitere Funktion: Sie können damit nachträglich Wartungszeiten eintragen oder umgekehrt auch entfernen. Die Verfügbarkeitsberechnung berücksichtigt diese Korrekturen wie ganz normale Wartungszeiten. Es gibt für so etwas mindestens zwei legitime Gründe:
Während des Betriebs kann es passieren, dass geplante Wartungszeiten nicht korrekt eingetragen wurden. Das sieht für die Verfügbarkeit natürlich schlecht aus. Durch nachträgliches Eintragen dieser Zeiten können Sie den Bericht richtigstellen.
Es gibt Benutzer, die bei einem spontanen Ausfall Wartungszeiten missbrauchen, um Benachrichtigungen abzustellen. Das verfälscht später die Auswertungen. Durch nachträgliches Entfernen der Wartungszeit können Sie das korrigieren.
Zum Umklassifizieren von Wartungszeiten wählen Sie einfach die Checkbox Reclassify downtime of this period:
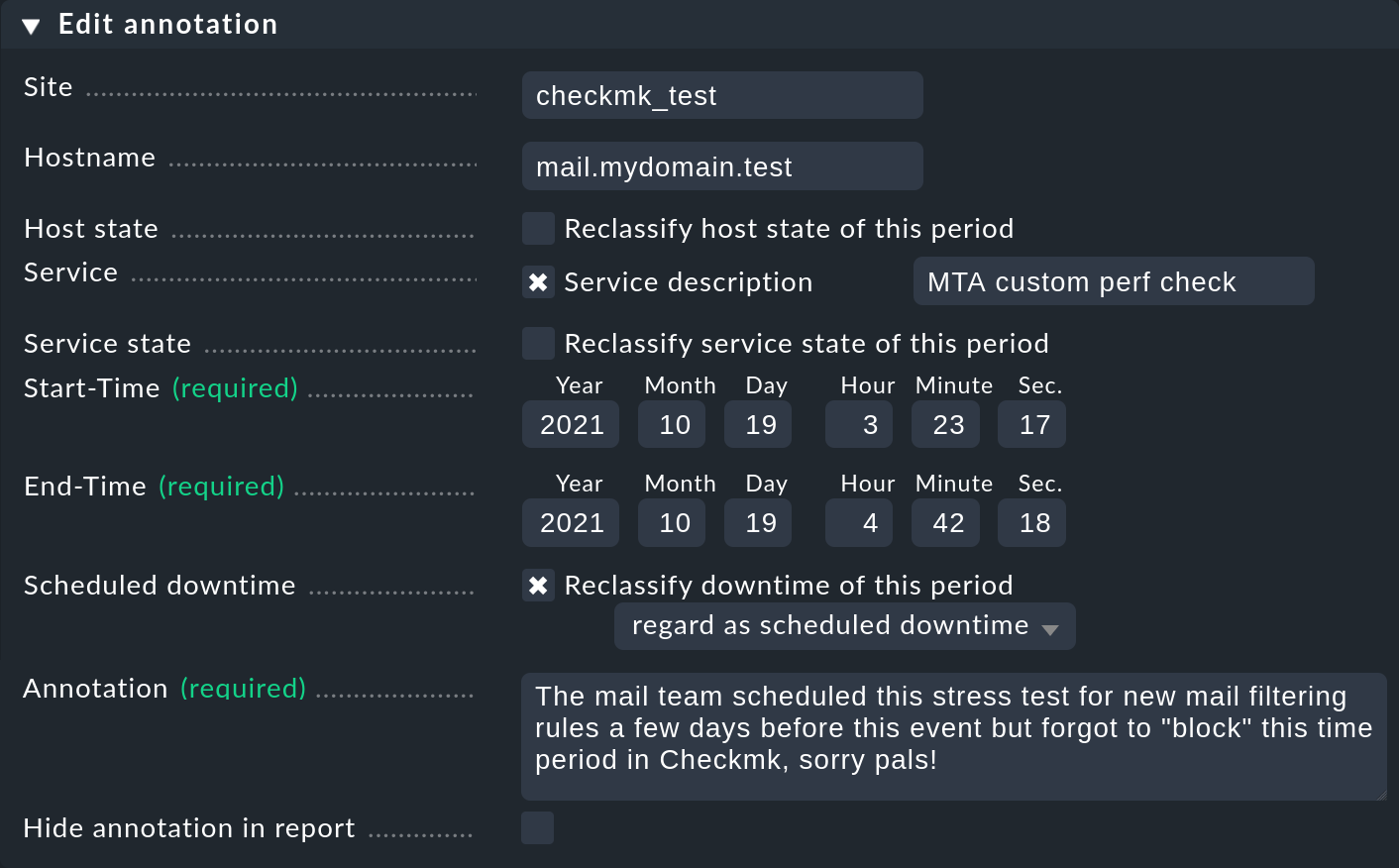
2.4. Monitoring-Historie anzeigen
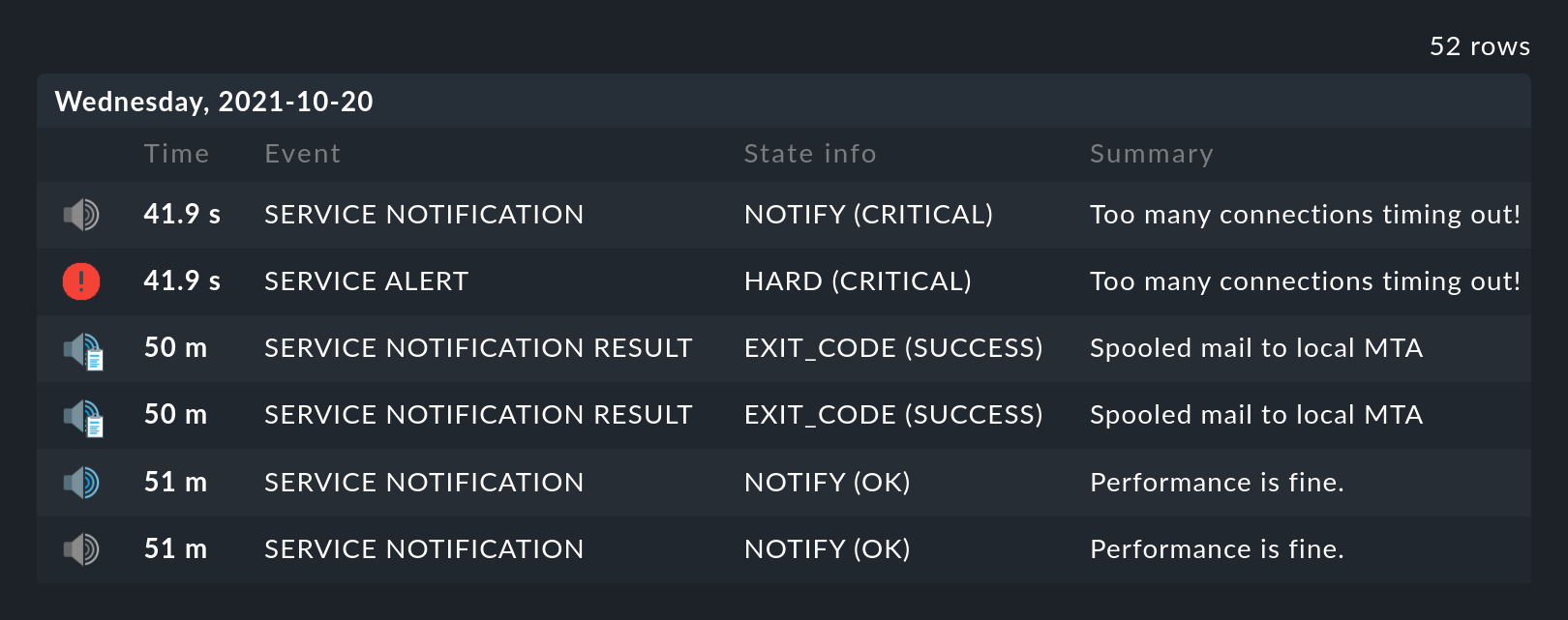
In der Verfügbarkeitstabelle finden Sie neben dem Symbol für die Zeitleiste
noch ein weiteres Symbol: ![]() . Dieses bringt Sie zur
Ansicht der Monitoring-Historie mit einem bereits ausgefüllten Filter
für das entsprechende Objekt und den Anfragezeitraum. Dort sehen Sie nicht
nur die Ereignisse, auf denen die Verfügbarkeitsberechnung basiert (die
Zustandswechsel), sondern auch die zugehörigen Benachrichtigungen und ähnliche
Ereignisse:
. Dieses bringt Sie zur
Ansicht der Monitoring-Historie mit einem bereits ausgefüllten Filter
für das entsprechende Objekt und den Anfragezeitraum. Dort sehen Sie nicht
nur die Ereignisse, auf denen die Verfügbarkeitsberechnung basiert (die
Zustandswechsel), sondern auch die zugehörigen Benachrichtigungen und ähnliche
Ereignisse:
Was Sie hier nicht sehen, ist der Zustand des Objekts am Anfang des Abfragezeitraums. Die Berechnung der Verfügbarkeit geht dazu noch weiter in die Vergangenheit zurück, um den Anfangszustand zuverlässig zu ermitteln.
3. Auswertungen anpassen
Sowohl die Berechnung als auch die Darstellung der Verfügbarkeit können Sie durch zahlreiche Optionen beeinflussen. Sie finden diese im Menüeintrag Availability > Change display options (Anzeigeoptionen ändern) respektive Availability > Change computation options (Berechnungsregeln ändern).
Nachdem Sie die Optionen geändert und mit Apply bestätigt haben, wird die Verfügbarkeit neu berechnet und dargestellt. Alle geänderten Optionen werden für Ihr Benutzerprofil als Default hinterlegt, so dass Sie beim nächsten Aufruf wieder die gleichen Einstellungen vorfinden.
Gleichzeitig sind die Optionen in der URL der aktuellen Seite kodiert. Wenn Sie also jetzt ein Lesezeichen auf die Seite speichern (z.B. mit dem praktischen Bookmarks-Element), dann sind die Optionen Teil von diesem und werden bei einem späteren Klick darauf genau so wieder hergestellt.
3.1. Auswahl des Zeitbereichs
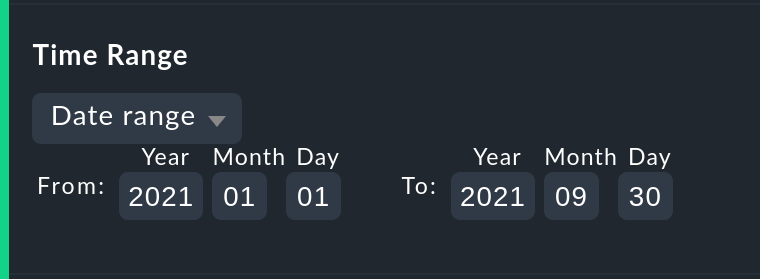
Die wichtigste und erste Option jeder Verfügbarkeitsauswertung ist natürlich der Zeitbereich, der betrachtet wird. Bei Date range können Sie einen exakten Zeitbereich mit Anfangs- und Enddatum festlegen. Dabei ist der letzte Tag bis 24:00 Uhr mit eingeschlossen.
Viel praktischer sind die relativen Zeitangaben wie z.B. Last week. Welcher Zeitraum genau angezeigt wird, hängt dabei (gewollt) vom Zeitpunkt ab, zu dem die Berechnung angestellt wird. Eine Woche geht hier übrigens immer von Montag 00:00 Uhr bis Sonntag 24:00 Uhr.
3.2. Optionen, die die Darstellung betreffen
Viele Optionen betreffen die Art, wie die Daten präsentiert werden, andere wiederum beeinflussen die Berechnungsmethode. Zunächst ein Blick auf die Darstellung:
Zeilen mit 100 % Verfügbarkeit ausblenden

Die Option Only show objects with outages begrenzt die Darstellung auf
solche Objekte, die überhaupt Ausfälle hatten (also Zeiten, zu denen der
Zustand nicht OK bzw. UP war). Das ist nützlich, wenn Sie bei einer
großen Zahl von Services nur die paar wenigen herauspicken wollen, bei denen
es ein Problem ab.
Beschriftungsoptionen
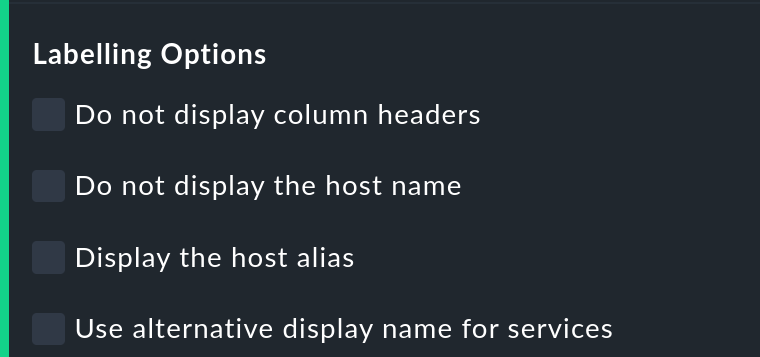
Die Labelling options erlauben es, verschiedene Beschriftungsfelder ein- oder umgekehrt auszuschalten. Manche der Optionen sind vor allem für das Reporting interessant. Zum Beispiel ist bei einem Bericht, der sowieso nur über einen Host geht, die Spalte mit dem Host-Namen eventuell überflüssig.
Die alternativen Anzeigenamen (alternative display names) von Services können Sie über eine Regel festlegen und damit z.B. wichtigen Services einen für den Leser Ihres Berichts aussagekräftigen Namen geben.
SLAs mit Schwellwerten farbig darstellen
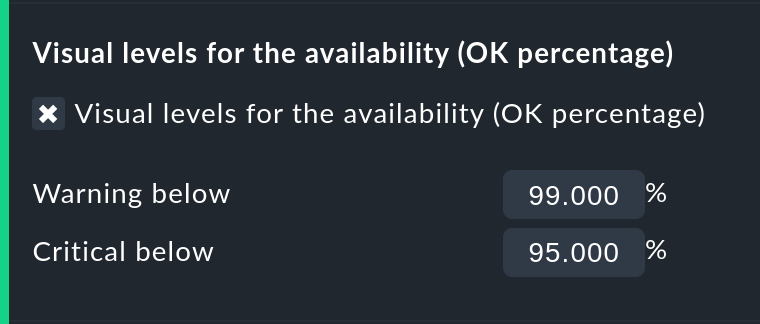
Mit den Visual levels können Sie Objekte optisch hervorheben, die eine bestimmte Verfügbarkeit im Anfragezeitraum unterschritten haben. Das betrifft ausschließlich die Spalte für den OK-Zustand. Diese ist normalerweise immer grün eingefärbt. Bei Unterschreitung der eingestellten Schwellen ändert sich die Farbe dieser Zelle dann auf Gelb bzw. Rot. Man kann das als sehr einfache SLA-Auswertung bezeichnen.
Anzahl und Dauer der einzelnen Ausfälle anzeigen
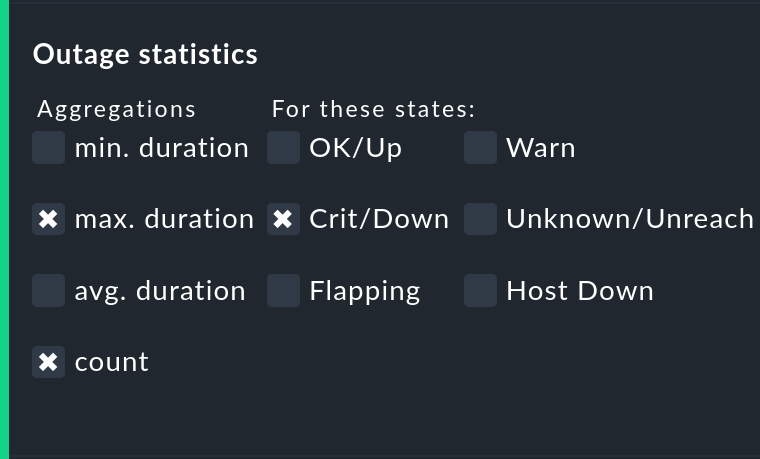
Die Option Outage statistics liefert zusätzliche Informationsspalten in der Verfügbarkeitstabelle. In der Abbildung wurden die Informationen max. duration und count für die Statusspalte Crit/Down aktiviert. Das bedeutet, dass Sie zu Ausfällen vom Zustand CRIT/DOWN jeweils die Anzahl der Vorfälle sowie die Dauer des längsten Vorfalls sehen.

In der Tabelle entstehen so zusätzliche Spalten.
Darstellung von Zeitangaben
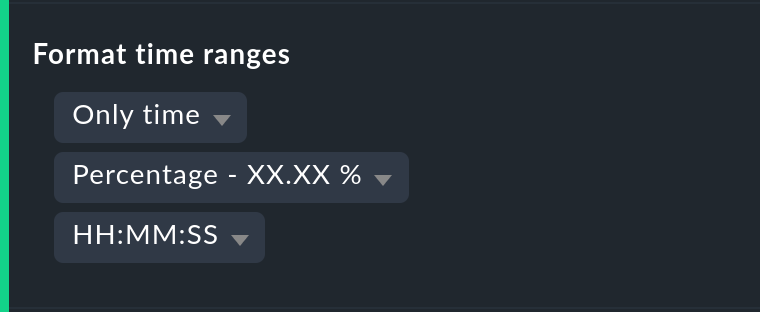
Nicht immer ist es sinnvoll, (Nicht-)Verfügbarkeiten in Prozent anzugeben. Die Option Format time ranges erlaubt das Umstellen auf eine Darstellung, in der Zeiträume in absoluten Zahlen gezeigt werden. Damit können Sie die Gesamtlänge der Ausfallzeiten auf die Minute genau sehen. Die Darstellung zeigt sogar Sekunden, aber bedenken Sie, dass das nur dann Sinn macht, wenn Sie die Überwachung auch im Sekundenraster durchführen und nicht wie üblich mit einem Check pro Minute. Auch die Genauigkeit der Angabe (Kommastellen in den Prozentwerten) können Sie hier bestimmen.
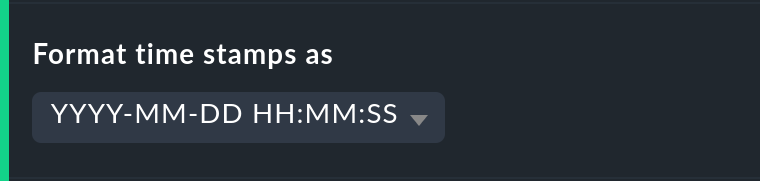
Die Formatierung von Zeitstempeln betrifft Angaben in der Zeitleiste (Timeline). Die Umstellung auf Unix-Epoch (Sekunden seit dem 1.1.1970) erleichtert die Zuordnung von Zeitbereichen zu den entsprechenden Stellen in den Logdateien der Monitoring-Historie.
Anpassen der Zusammenfassungszeile
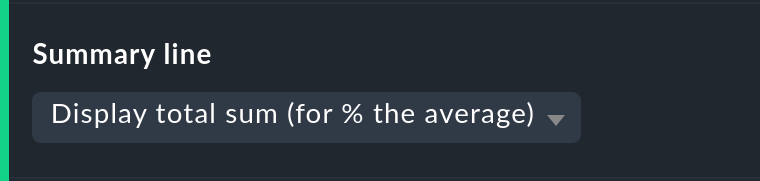
Die Zusammenfassung in der letzten Zeile der Tabelle können Sie hiermit nicht nur ein- und ausschalten. Sie können sich auch zwischen Summe und Durchschnitt entscheiden. Bei Spalten, die Prozentwerte enthalten, wird auch bei der Einstellung Display total sum ein Durchschnitt angezeigt, da es wenig sinnvoll ist, Prozentwerte zu addieren.
Kleine Zeitleiste einblenden
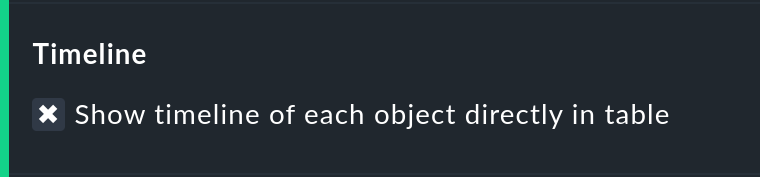
Diese Option fügt eine Miniaturversion der Zeitleiste direkt in die Ergebnistabelle ein. Sie entspricht dem grafischen Balken in der detaillierten Zeitleiste, ist aber kleiner und direkt in die Tabelle integriert. Außerdem ist sie maßstabsgetreu, damit Sie mehrere Objekte in der gleichen Tabelle vergleichen können.
Gruppierung nach Host, Host-Gruppe oder Service-Gruppe
Unabhängig von der Darstellung der Ansicht, von der Sie kommen, zeigt die Verfügbarkeit immer alle Objekte in einer gemeinsamen Tabelle. Sie können mit dieser Option eine Gruppierung nach Host, Host-Gruppe oder Service-Gruppe festlegen. Damit bekommen Sie auch pro Gruppe eine eigene Summary-Zeile.
Beachten Sie, dass bei einer Gruppierung nach Service-Gruppe Services mehrfach auftreten können. Das liegt daran, dass Services in mehreren Gruppen gleichzeitig enthalten sein können.
Nur die Verfügbarkeit anzeigen
Die Option Availability sorgt dafür, dass als einzige Spalte diejenige für den Zustand OK bzw. UP ausgegeben wird und diese den Titel Avail. bekommt. Damit wird ausschließlich die eigentliche Verfügbarkeit angezeigt. Sie können das mit den weiter unter gezeigten Möglichkeiten kombinieren, andere Zustände (z.B. WARN) auch dem OK-Zustand zuzurechnen und damit als verfügbar zu werten.
3.3. Gruppierung nach Zuständen
Die in der Einleitung beschriebenen Zustände können auf verschiedenste Arten angepasst und verdichtet werden. Auf diese Weise werden flexibel sehr unterschiedliche Arten von Auswertungen erstellt. Dafür gibt es verschiedene Optionen.
Behandlung von WARN, UNKNOWN und Host Down
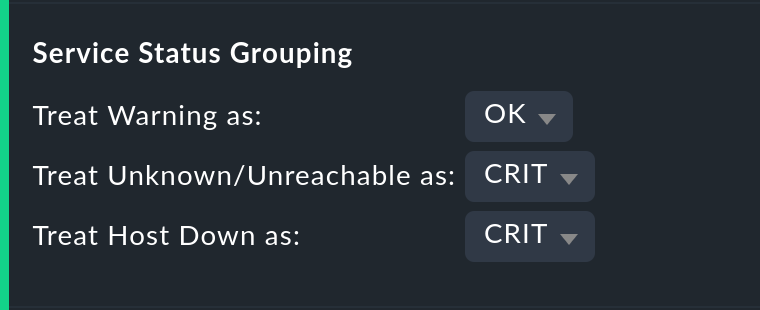
Die Option Service status grouping bietet die Möglichkeit, verschiedene „Zwischenzustände“ auf andere abzubilden. Ein häufiger Fall ist, dass man WARN zu OK dazuschlägt (wie in der Abbildung zu sehen). Wenn Sie an der eigentlichen Verfügbarkeit eines Service interessiert sind, kann dies durchaus sinnvoll sein. Denn WARN bedeutet ja meist, dass es noch kein wirkliches Problem gibt, dies aber bald der Fall sein könnte. So betrachtet muss dann WARN noch als verfügbar gelten. Bei Netzwerkdiensten wie einem HTTP-Server ist es sicherlich sinnvoll, Zeiten, in denen der Host DOWN ist, ebenso zu behandeln wie wenn der Service selbst CRIT ist.
Die durch die Umgruppierung weggefallenen Zustände fehlen dann natürlich auch in der Ergebnistabelle, welche dann weniger Spalten hat.
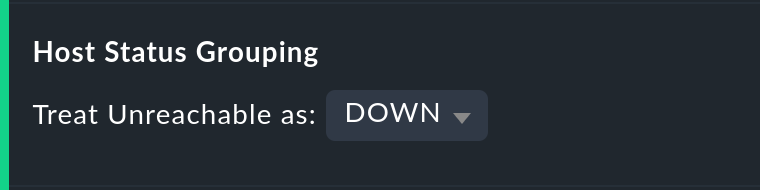
Die Option Host status grouping ist sehr ähnlich, betrifft aber Auswertungen der Verfügbarkeiten von Hosts. Der Zustand UNREACH bedeutet ja, dass ein Host aufgrund von Netzwerkproblemen nicht von Checkmk überwacht werden konnte. Sie können hier entscheiden, ob Sie das zum Zwecke der Verfügbarkeitsauswertung lieber als als UP oder DOWN werten möchten. Default ist, dass UNREACH als eigener Zustand gewertet wird.
Behandlung von nicht überwachten Zeiträumen und Flapping
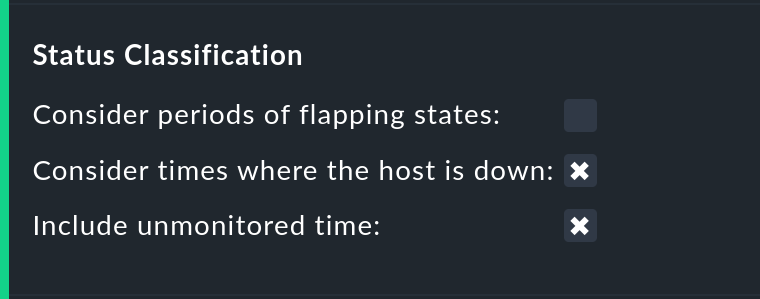
In der Option Status classification werden weitere Zusammenfassungen
vorgenommen. Die Checkbox Consider periods of flapping states ist per
Default an, womit Phasen häufiger Zustandswechsel einen eigenen Zustand bilden:
![]() unstetig. Die Idee dahinter ist, dass man gut sagen
kann, dass der betroffene Dienst während solcher Zeiten zwar immer wieder OK
ist, aber durch die häufigen Ausfälle trotzdem nicht nutzbar. Deaktivieren
Sie diese Option, so wird das Konzept „flapping“ komplett ignoriert und
der jeweils eigentliche Zustand kommt wieder zum Vorschein. Und die Spalte
flapping wird aus der Tabelle entfernt.
unstetig. Die Idee dahinter ist, dass man gut sagen
kann, dass der betroffene Dienst während solcher Zeiten zwar immer wieder OK
ist, aber durch die häufigen Ausfälle trotzdem nicht nutzbar. Deaktivieren
Sie diese Option, so wird das Konzept „flapping“ komplett ignoriert und
der jeweils eigentliche Zustand kommt wieder zum Vorschein. Und die Spalte
flapping wird aus der Tabelle entfernt.
Das Entfernen der Option Consider times where the host is down wirkt ähnlich. Sie schaltet das Konzept von Host down ab. Diese Option macht nur bei der Verfügbarkeit von Services Sinn. In Phasen, in denen der Host nicht UP ist, wird bei der Verfügbarkeit trotzdem der eigentliche Zustand des Services zugrunde gelegt — genauer gesagt der Zustand vom letzten Check bevor der Host unerreichbar wurde. Dies kann sinnvoll sein bei Services, bei denen es nicht um die Erreichbarkeit über das Netzwerk geht.
Ähnlich ist auch die Option Include unmonitored time. Stellen Sie sich vor, Sie machen eine Auswertung über den Februar und ein bestimmter Service ist erst am 15. Februar überhaupt in das Monitoring aufgenommen worden. Hat dieser deswegen eine Verfügbarkeit von nur 50 Prozent? In der Standardeinstellung (Option gesetzt) ist dies tatsächlich der Fall. Die fehlenden 50 Prozent aber nicht als Ausfall gewertet, sondern in einer eigenen Spalte mit dem Titel N/A aufsummiert. Ohne die Option beziehen sich 100 Prozent auf die Zeit vom 15. bis zum 28. Februar. Das bedeutet dann allerdings auch, dass eine Stunde Ausfall bei diesem Service prozentual doppelt so stark zu Buche schlägt wie der Ausfall eines Services, der den ganzen Monat über vorhanden war.
Behandlung von geplanten Wartungszeiten
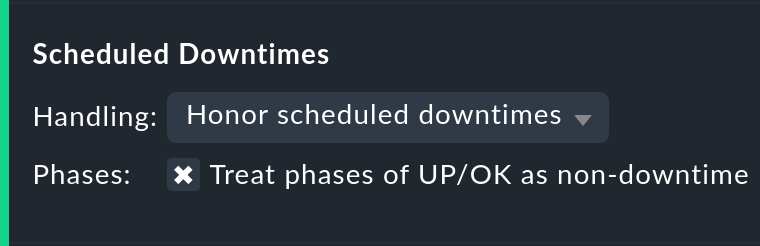
Mit der Option Scheduled Downtimes können Sie einstellen, wie sich Wartungszeiten in der Verfügbarkeitsauswertung auswirken:
Honor scheduled downtimes ist der Default. Hier werden Wartungszeichen als eigener Zustand in einer eigenen Spalte aufsummiert. Mit Treat phases of UP/OK as non-downtime können Sie die Zeiten, in denen der Service trotz Wartungszeit OK war, von der Wartungszeit abziehen.
Ignore scheduled downtimes ist, als wären überhaupt keine Wartungszeiten eingetragen gewesen. Ausfälle sind Ausfälle. Punkt. Aber natürlich auch nur dann, wenn es tatsächlich einen Ausfall gegeben hat.
Exclude scheduled downtimes sorgt dafür, dass die Wartungszeiten einfach aus dem Berechnungszeitraum ausgeschlossen werden. Die prozentuale Verfügbarkeit bezieht sich dann nur auf die Zeiten außerhalb der Wartung.
Zusammenfassen gleicher Phasen
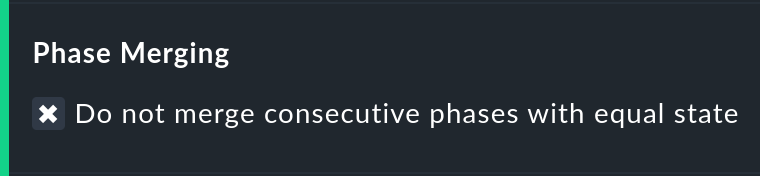
Durch das Umbiegen von Zuständen auf andere (z.B. aus WARN wird OK) kann es sein, dass aufeinanderfolgende Abschnitte der Zeitleiste eines Objekts den gleichen Zustand bekommen. Diese Abschnitte werden dann normalerweise zu einem einzigen zusammengefasst. Das ist meistens gut so und übersichtlich, hat aber Auswirkungen auf die Darstellung der Details in der Zeitleiste und eventuell auch auf die Zählung von Ereignissen mit der Option Outage statistics. Daher können Sie das Verschmelzen mit Do not merge consecutive phases with equal state abschalten.
3.4. Ignorieren kurzer Störungen
Manchmal werden Sie Überwachungen haben, die oft kurzzeitig ein Problem melden, das aber im Normalfall beim nächsten Check (nach einer Minute) schon wieder OK ist. Und Sie finden keinen Weg durch Anpassen von Schwellwerten oder Ähnlichem, das sauber in den Griff bekommen. Eine häufige Lösung ist dann das Setzen der Maximum number of check attempts von 1 auf 3, um mehrere Fehlversuche zu erlauben, bevor eine Benachrichtigung stattfindet. Dadurch ergibt sich das Konzept von Soft states — die Zustände WARN, CRIT und UNKNOWN vor Ablauf aller Versuche.
Von Anwendern, die dieses Feature einsetzen, werden wir gelegentlich gefragt, warum das Availability-Modul von Checkmk keine Funktion hat, um für die Berechnung nur Hard states zu verwenden. Der Grund ist: Es gibt eine bessere Lösung! Denn würde man die Hard states als Grundlage nehmen,
würden Ausfälle aufgrund der erfolglosen Versuche 1 und 2 zwei Minuten zu kurz gewertet, und
man könnte das Verhalten bei kurzen Ausfällen nicht nachträglich nachjustieren.
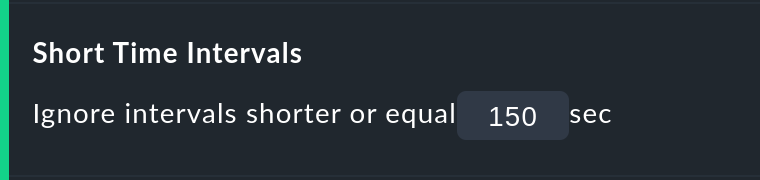
Die Option Short time Intervals ist viel flexibler und gleichzeitig sehr einfach. Sie legen schlicht eine Zeitdauer fest, unterhalb derer Zustände nicht gewertet werden.
Nehmen Sie an, Sie setzen den Wert auf 2,5 Minuten (150 Sekunden). Ist nun ein Service die ganze Zeit auf OK, geht dann 2 Minuten lang auf CRIT und dann wieder auf OK, so wird das kurze CRIT-Intervall einfach als OK gewertet! Das gilt allerdings auch umgekehrt! Ein kurzes OK innerhalb einer langen WARN-Phase wird dann ebenfalls als WARN gewertet.
Allgemein gesagt, werden kurze Abschnitte, bei denen vorher und nachher der gleiche Zustand herrscht, mit diesem gleichgesetzt. Bei einer Abfolge OK, dann 2 Minuten WARN, dann CRIT, bleibt das WARN bestehen, auch wenn dessen Dauer unterhalb der eingestellten Zeit liegt!
Bedenken Sie beim Festlegen der Zeit das bei Checkmk übliche Check-Intervall von einer Minute. Dadurch dauert jeder Zustand etwa das Vielfache einer Minute. Da die Antwortzeiten der Agenten leicht schwanken, können das auch leicht mal 61 oder 59 Sekunden sein. Daher ist es sicherer, wenn Sie als Wert keine ganze Minutenzahl eintragen, sondern einen Puffer einbauen (daher das Beispiel mit den 2,5 Minuten).
3.5. Einfluss von Zeitperioden
Eine wichtige Funktion der Verfügbarkeitsberechnung in den kommerziellen Editionen von Checkmk ist, dass Sie diese Berechnungen von Zeitperioden abhängig machen können. Damit können Sie für jeden Host oder Service individuelle Zeiten definieren. In diesen Zeiten wird der Host/Service als verfügbar erwartet und der Zustand dann zur Auswertung genutzt. Dafür hat jedes Objekt das Attribut Service period. Das Vorgehen ist wie folgt:
Definieren Sie für Ihre Service-Zeiten eine Zeitperiode.
Weisen Sie diese über den Regelsatz Host & Service parameters > Monitoring configuration > Service period for hosts bzw. … for services den Objekten zu.
Aktivieren Sie die Änderungen.
Nutzen Sie die Availability-Option Service time, um das Verhalten zu beeinflussen.
Hier gibt es drei einfache Möglichkeiten. Der Default Base report only on service times blendet die Zeiten außerhalb der definierten Service-Zeit komplett aus. Diese zählen damit auch nicht zu den 100 Prozent. Es werden nur die Zeiträume innerhalb der Service-Zeiten betrachtet. In der Zeitleistendarstellung sind die übrigen Zeiten grau dargestellt.
Base report only on none-service times macht das Gegenteil und berechnet quasi die inverse Darstellung: Wie gut war die Verfügbarkeit außerhalb der Service-Zeiten?
Und die dritte Option Include both service and non-service times deaktiviert das ganze Konzept der Service-Zeiten und zeigt die Auswertungen wieder für alle Zeiten von Montag bis Sonntag und 00:00 Uhr bis 24:00 Uhr.
Übrigens: Wenn ein Host nicht in der Service-Zeit ist, heißt das für Checkmk nicht automatisch, dass das auch für die Services auf dem Host gilt. Sie benötigen für Services immer eine eigene Regel in Service period for services.
Der Benachrichtigungszeitraum
Es gibt übrigens noch eine etwas verwandte Option: Notification period. Hier können Sie auch den Benachrichtigungszeitraum für die Auswertung heranziehen. Dieser ist aber eigentlich nur dafür gedacht, in bestimmten Zeiten keine Benachrichtigungen über Probleme zu erzeugen und deckt sich nicht unbedingt mit der Service-Zeit. Die Option wurde zu einer Zeit eingeführt, als die Software noch keine Service-Zeit kannte und ist nur noch aus Kompatibilitätsgründen vorhanden. Sie sollten Sie am besten nicht verwenden.
3.6. Begrenzung der Berechnungszeit
Bei der Berechnung der Verfügbarkeit muss die komplette Vergangenheit der
gewählten Objekte aufgerollt werden. Wie das im einzelnen geht, erfahren
Sie weiter unten. Vor allem in ![]() Checkmk Community kann die
Auswertung etwas Zeit beanspruchen, da dessen Kern keinen Cache für die benötigten
Daten hat und die textbasierten Logdateien durchsucht werden müssen.
Checkmk Community kann die
Auswertung etwas Zeit beanspruchen, da dessen Kern keinen Cache für die benötigten
Daten hat und die textbasierten Logdateien durchsucht werden müssen.
Damit eine allzu komplexe Anfrage — die eventuell aus Versehen aufgerufen wurden — nicht über sehr lange Zeit einen Apache-Prozess lahmlegt, die CPU übermäßig strapaziert und dabei „hängt“, gibt es zwei Optionen, welche die Dauer der Berechnung begrenzen. Beide sind per Default aktiviert:
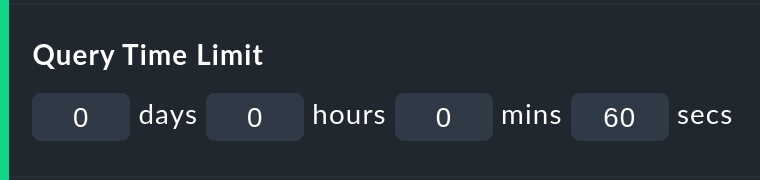
Das Query time limit begrenzt die Dauer der zugrundeliegenden Abfrage an den Monitoring-Kern auf eine bestimmte Zeit. Diese ist auf eine halbe Minute voreingestellt. Wird diese überschritten, wird die Auswertung abgebrochen und ein Fehler angezeigt. Wenn Sie sicher sind, dass die Auswertung länger dauern darf, können Sie dieses Timeout einfach hochsetzen.
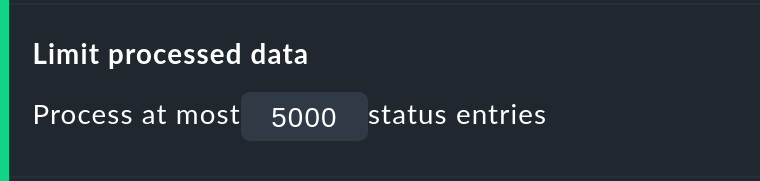
Die Option Limit processed data schützt Sie vor Auswertungen mit zu vielen Objekten. Hier wird ein Limit eingezogen, das analog zu dem in den Ansichten funktioniert. Wenn die Anfrage an den Monitoring-Kern mehr als 5000 Zeitabschnitte liefern würde, wird die Berechnung mit einer Warnung abgebrochen. Die Limitierung wird bereits im Kern durchgeführt — do wo die Daten beschafft werden.
4. Availability bei Business Intelligence
4.1. Grundprinzip
Ein starkes Feature der Verfügbarkeitsberechnung von Checkmk ist die Möglichkeit, die Verfügbarkeit von BI-Aggregaten zu berechnen. Ein Alleinstellungsmerkmal dabei ist, dass Checkmk dazu nachträglich anhand des Verlaufs der einzelnen Zustände von Hosts und Services Schritt für Schritt rekonstruiert, wie der Zustand des jeweiligen Aggregats zu einem bestimmte Zeitpunkt genau war.
Warum der ganze Aufwand? Warum nicht einfach das BI-Aggregat mit einem aktiven Check abfragen und dann dessen Verfügbarkeit anzeigen? Nun, der Aufwand hat für Sie eine ganze Menge Vorteile:
Sie können den Aufbau von BI-Aggregaten nachträglich anpassen und die Verfügbarkeit dann neu berechnen lassen.
Die Berechnung ist genauer, da nicht durch den aktiven Check eine Ungenauigkeit von +/- einer Minute entsteht.
Sie haben eine exzellente Analysefunktion, mit der Sie nachträglich untersuchen können, was denn damals genau zu einem Ausfall geführt hat.
Nicht zuletzt müssen Sie nicht extra einen Check einrichten.
4.2. Verfügbarkeit aufrufen
Das Aufrufen der Verfügbarkeitsansicht geht erst einmal analog zu den Hosts und
Services.
Sie wählen eine Ansicht mit einem oder mehreren BI-Aggregaten und wählen den Menüeintrag BI Aggregations > Availability aus.
Es gibt aber hier noch einen zweiten Weg: Jedes BI-Aggregat hat über das Symbol
![]() einen direkten Weg zu dessen Verfügbarkeit:
einen direkten Weg zu dessen Verfügbarkeit:
Die Auswertung an sich ist erst einmal analog zu der bei Services — allerdings ohne die Spalten Host down und flapping, da es diese Zustände bei BI nicht gibt:

4.3. Die Zeitreise
Der große Unterschied kommt in der ![]() Zeitleistenansicht. Folgendes Beispiel zeigt ein Aggregat von unserem
Demoserver, welches für einen sehr kurzen Abschnitt von gerade mal einer
Sekunde CRIT war (das wäre ein gutes Beispiel für die Option
Short time intervals).
Zeitleistenansicht. Folgendes Beispiel zeigt ein Aggregat von unserem
Demoserver, welches für einen sehr kurzen Abschnitt von gerade mal einer
Sekunde CRIT war (das wäre ein gutes Beispiel für die Option
Short time intervals).
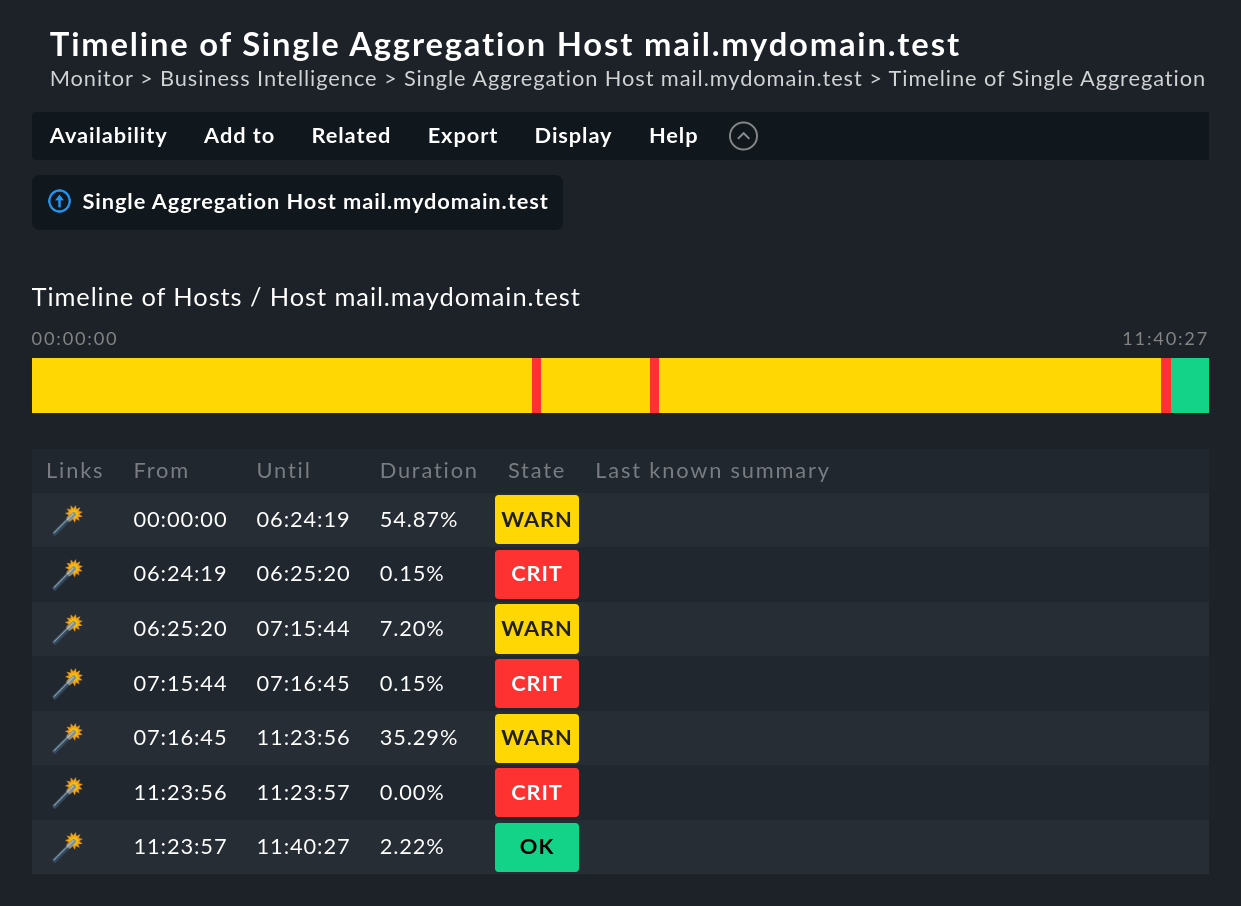
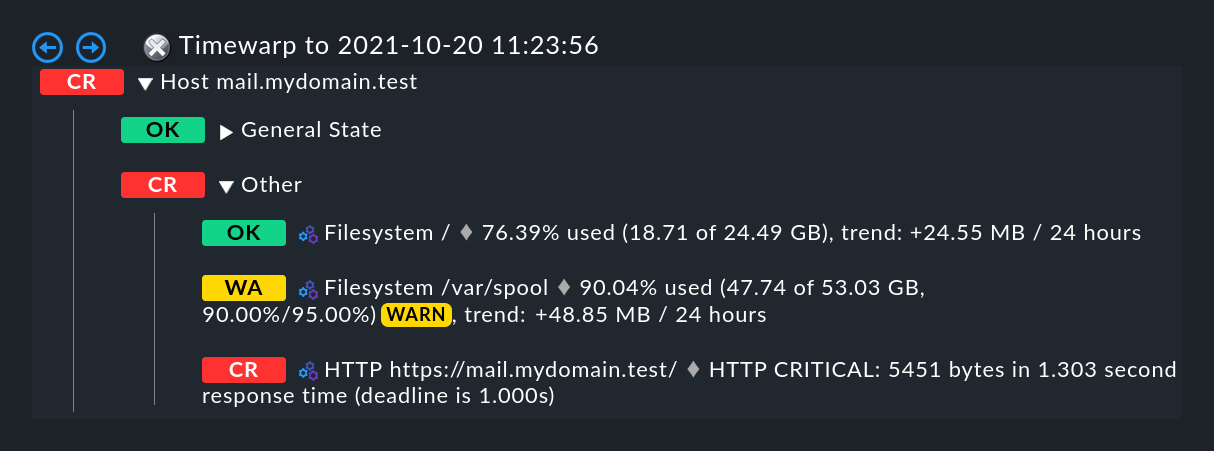
Wollen Sie wissen, was hier der Grund für den Ausfall war? Ein einfacher
Klick auf den ![]() Zauberstab genügt. Er ermöglicht
eine Zeitreise zu genau dem Zeitpunkt, an dem der Ausfall auftrat, und öffnet
eine Darstellung des BI-Aggregats zu jenem Zeitpunkt — in der folgenden
Abbildung bereits an der richtigen Stelle aufgeklappt:
Zauberstab genügt. Er ermöglicht
eine Zeitreise zu genau dem Zeitpunkt, an dem der Ausfall auftrat, und öffnet
eine Darstellung des BI-Aggregats zu jenem Zeitpunkt — in der folgenden
Abbildung bereits an der richtigen Stelle aufgeklappt:
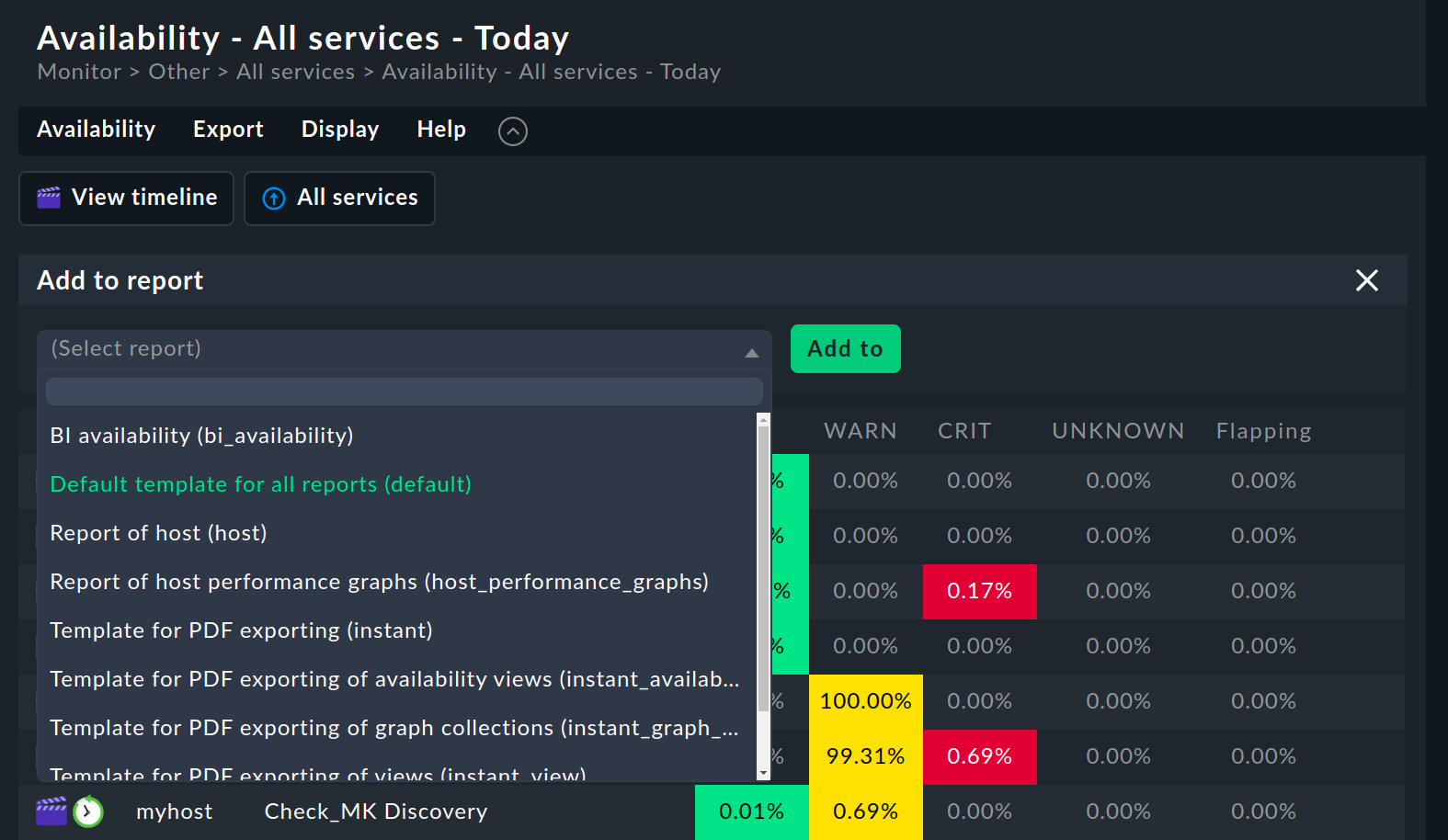
5. Verfügbarkeit in Berichten
Sie können Verfügbarkeitsansichten in Berichte einbinden. Der einfachste Weg führt über Export > Add to report in der Menüleiste. Wählen Sie den Bericht aus, dem Sie die Ansicht hinzufügen wollen und bestätigen Sie mit Add to.
Das Berichtselement Availability table fügt in den Bericht eine Verfügbarkeitsauswertung ein. Die ganzen oben genannten Optionen finden Sie dabei direkt als Parameter des Elements — wenn auch in einer optisch etwas anderen Darstellung:
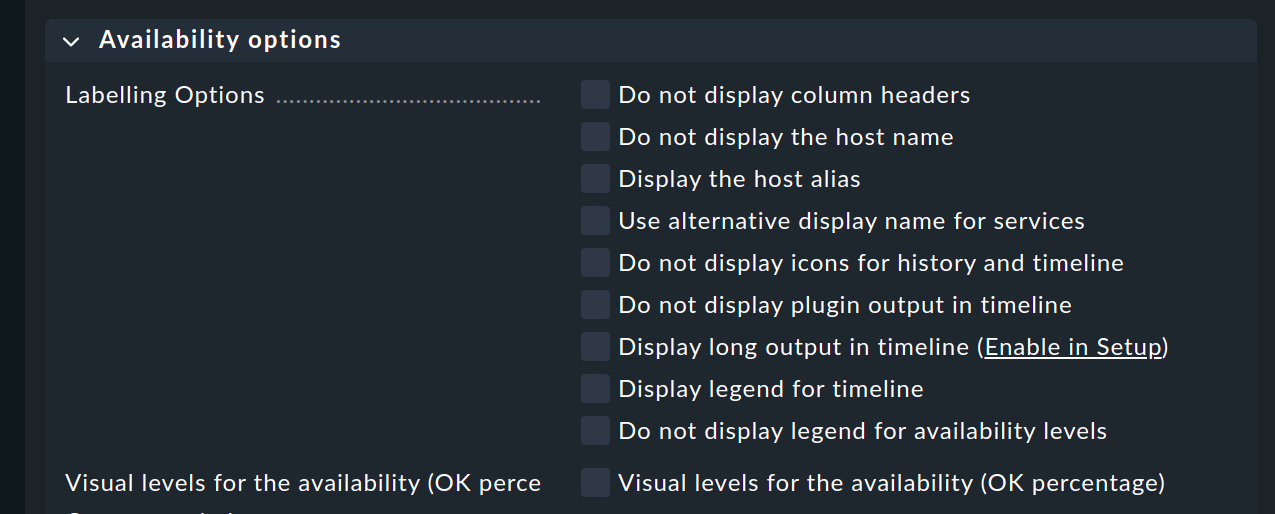
Eine Besonderheit ist die allerletzte Option:

Hier können Sie festlegen, welche Darstellung in den Bericht übernommen werden soll:
Die Tabelle der Verfügbarkeiten
Die grafische Darstellung der Zeitleiste
Die detaillierte Zeitleiste mit den einzelnen Abschnitten
Anders als bei der normalen interaktiven Ansicht, können Sie also hier im Bericht Tabelle und Zeitleiste gleichzeitig einbinden.
Eine zweite Besonderheit ist die fehlende Angabe für den Auswertungszeitraum; sie fehlt hier, weil sie automatisch vom Bericht vorgegeben wird.
Die Auswahl der Objekte wird wie bei allen Berichtselementen entweder vom Bericht übernommen oder im Element direkt festgelegt.
6. Technische Hintergründe
6.1. Wie die Berechnung funktioniert
Zur Berechnung der Verfügbarkeit greift Checkmk auf die Monitoring-Historie zurück. Es orientiert sich dabei an den Zustandswechseln. Wenn ein Service z.B. am 20.10.2021 um 17:14 Uhr auf CRIT geht und um 17:24 Uhr wieder auf OK, dann wissen Sie, dass er während dieser Zeitspanne 10 Minuten den Zustand CRIT hatte.
Diese Zustandswechsel sind in Form von Einträgen im Monitoring-Log
enthalten, haben den Typ HOST ALERT oder SERVICE ALERT
und sehen z.B. so aus:
[1634742874] SERVICE ALERT: mail.mydomain.com;Filesystem /var/spool;CRITICAL;HARD;1;CRIT - 95.9% used (206.96 of 215.81 GB), (warn/crit at 90.00/95.00%), trend: 0.00 B / 24 hoursDabei gibt es immer eine aktuelle Logdatei, die die Einträge der letzten Stunden oder Tage beinhaltet und ein Verzeichnis mit einem Archiv der früheren Zeiträume. Der Ort ist je nach verwendetem Monitoring-Kern unterschiedlich:
| Kern | aktuelle Datei | ältere Dateien |
|---|---|---|
|
|
|
|
|
Dabei greift die Benutzeroberfläche nicht direkt auf diese Dateien zu, sondern fragt sie mittels einer Livestatus-Abfrage vom Monitoring-Kern ab. Das ist unter anderem wichtig, weil in einem verteilten Monitoring die Dateien mit der Historie gar nicht auf dem gleichen System liegen wie die GUI.
Die Livestatus-Abfrage benutzt dabei die Tabelle statehist. Im
Gegensatz zur Tabelle log, welche einen „nackten“ Zugriff auf
die Historie bietet, wird hier die Tabelle statehist verwendet, weil
sie bereits erste aufwendige Berechnungsschritte durchführt. Sie übernimmt
unter anderem das Zurücklaufen in die Vergangenheit zur Ermittlung des
Anfangszustands und das Berechnen von Zeitabschnitten gleichen Zustands mit
Anfang, Ende und Dauer.
Das Verdichten der Zustände nach dem am Anfang beschriebenen Schema macht dann das Verfügbarkeitsmodul in der Benutzeroberfläche.
6.2. Der Availability Cache im CMC
Funktionsweise des Caches
![]() Bei Anfragen, die weit in die Vergangenheit zurückreichen, müssen
entsprechend viele Logdateien abgearbeitet werden. Das wirkt sich natürlich
negativ auf die Dauer der Berechnung aus. Aus dem Grund gibt es im Checkmk
Micro Core einen sehr effizienten Cache der Monitoring-Historie, welcher alle
wichtigen Informationen über die Zustandswechsel von Objekten bereits
direkt beim Start aus den Logdateien ermittelt, fest im RAM behält und
im laufenden Monitoring ständig aktualisiert. Folge ist, dass alle
Verfügbarkeitsanfragen direkt und sehr effizient aus dem RAM beantwortet
werden können und kein Dateizugriff mehr nötig ist.
Bei Anfragen, die weit in die Vergangenheit zurückreichen, müssen
entsprechend viele Logdateien abgearbeitet werden. Das wirkt sich natürlich
negativ auf die Dauer der Berechnung aus. Aus dem Grund gibt es im Checkmk
Micro Core einen sehr effizienten Cache der Monitoring-Historie, welcher alle
wichtigen Informationen über die Zustandswechsel von Objekten bereits
direkt beim Start aus den Logdateien ermittelt, fest im RAM behält und
im laufenden Monitoring ständig aktualisiert. Folge ist, dass alle
Verfügbarkeitsanfragen direkt und sehr effizient aus dem RAM beantwortet
werden können und kein Dateizugriff mehr nötig ist.
Das Parsen der Logdateien ist sehr schnell und erreicht bei ausreichend schnellen Platten bis zu 80 MB/s! Damit das Erstellen des Caches den Start des Monitorings nicht verzögert, geschieht dies zudem asynchron — und zwar von der Gegenwart in Richtung Vergangenheit. Sie werden also eine kurze Verzögerung lediglich dann feststellen, wenn Sie direkt nach dem Start der Checkmk-Instanz sofort eine Verfügbarkeitsanfrage über einen längeren Zeitraum machen. Dann kann es sein, dass der Cache noch nicht weit genug in die Vergangenheit zurückreicht und die GUI eine kleine Denkpause einlegen muss.
Bei einem Activate changes bleibt der Cache erhalten! Er muss nur bei einem echten (Neu-)Start von Checkmk neu berechnet werden — z.B. nach einem Booten des Servers oder nach einem Update von Checkmk.
Cache-Statistik
Wenn Sie neugierig sind, wie lange das Berechnen des Caches dauert, finden
Sie eine Statistik in der Logdatei ~/var/log/cmc.log. Hier ist ein
Beispiel von einem kleineren Monitoring-System:
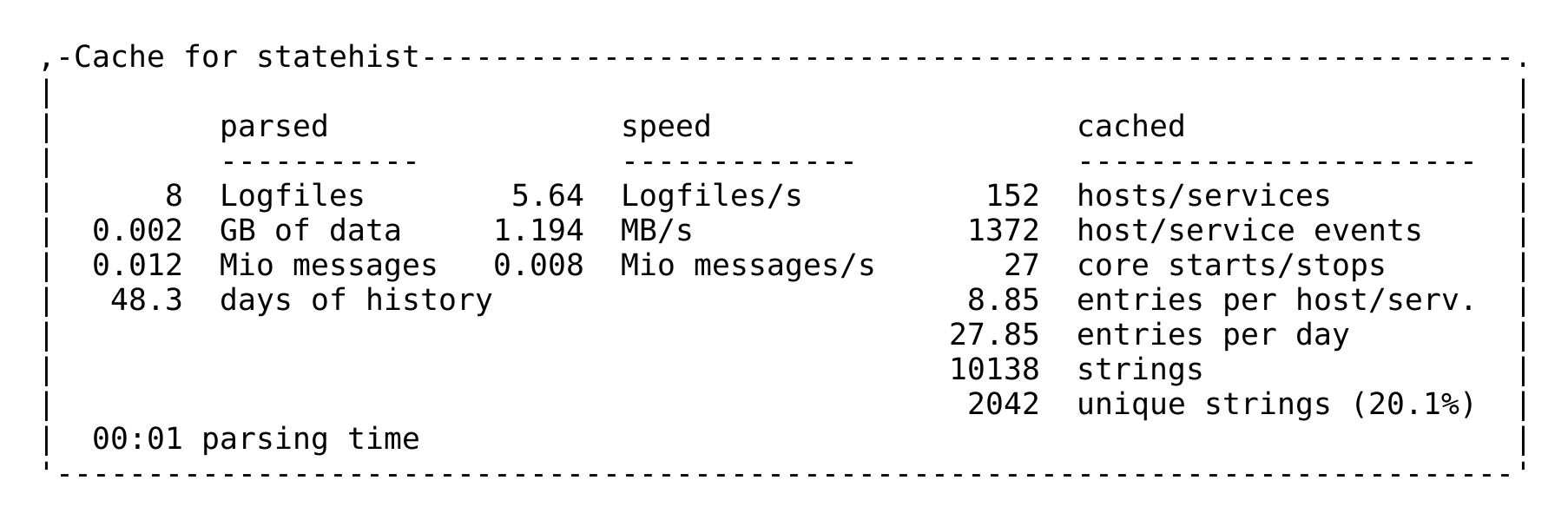
Den Cache justieren
Um den Speicherbedarf des Caches in Grenzen zu halten, ist dieser auf einen Horizont von 730 Tagen in die Vergangenheit limitiert. Dieses Limit ist definitiv — Anfragen, die weiter in die Vergangenheit gehen sind somit nicht nur langsamer, sondern ganz unmöglich. Sie können das mit der globalen Einstellung Global Settings > Monitoring Core > In-memory cache for availability data leicht anpassen:
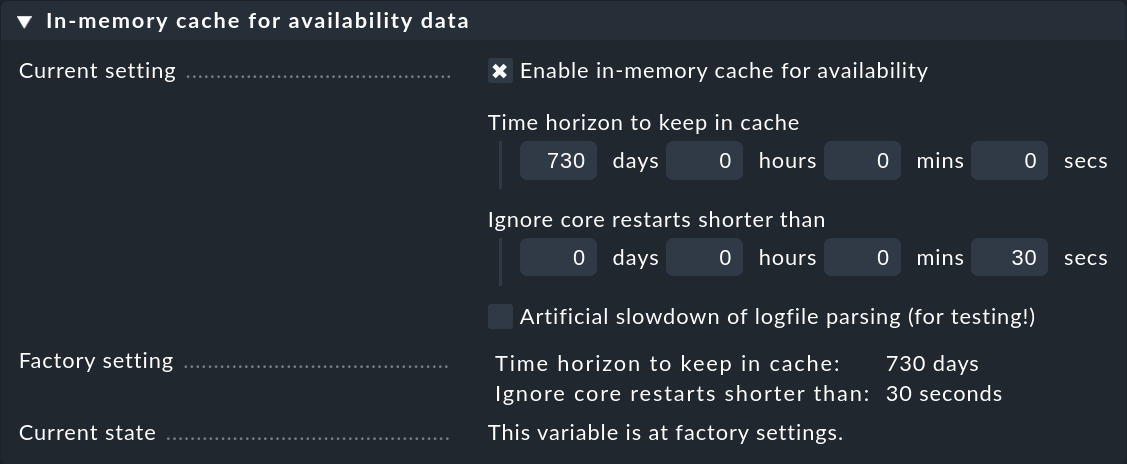
Neben dem Horizont für die Auswertung gibt es hier noch eine zweite interessante Einstellung: Ignore core restarts shorter than…. Denn ein Neustart des Cores (z.B. zum Zwecke eines Updates oder Server-Neustarts) führt ja faktisch zu Zeitabschnitten, die als unmonitored gelten. Auszeiten von bis zu 30 Sekunden werden dabei einfach ignoriert. Diese Zeit können Sie hier hochsetzen und auch längere Zeiten einfach ausblenden. Die Verfügbarkeitsauswertung geht dann davon aus, dass alle Hosts und Services den jeweils letzten ermittelten Zustand die ganze Zeit beibehalten haben.
7. Dateien und Verzeichnisse
| Pfad | Bedeutung |
|---|---|
|
Aktuelle Log-Datei der Monitoring-Historie beim CMC. |
|
Verzeichnis mit den älteren Log-Dateien der Historie. |
|
Logdatei des CMC, in dem die Statistik des Availability Caches zu sehen ist. |
|
Aktuelle Log-Datei der Monitoring-Historie von Nagios. |
|
Verzeichnis mit den älteren Log-Dateien bei Nagios. |
|
Hier werden die Anmerkungen und nachträglich angepassten Wartungszeiten zu Ausfällen gespeichert. Die Datei hat Python-Format und kann von Hand editiert werden. |