1. Einleitung
![]() Für Checks, die Leistungswerte messen, ist es oft schwierig, die richtigen Schwellwerte festzulegen.
Während zu niedrige Werte WARN- oder CRIT-Zustände erzeugen, die nur vermeintlich Probleme anzeigen, bleibt es bei einer zu hohen Einstellung beim Zustand OK, was das Monitoring blind für Probleme macht.
Für Checks, die Leistungswerte messen, ist es oft schwierig, die richtigen Schwellwerte festzulegen.
Während zu niedrige Werte WARN- oder CRIT-Zustände erzeugen, die nur vermeintlich Probleme anzeigen, bleibt es bei einer zu hohen Einstellung beim Zustand OK, was das Monitoring blind für Probleme macht.
Nehmen wir als Beispiel den Service CPU load eines Linux-Hosts (oder analog Processor Queue eines Windows-Hosts): Sie haben vielleicht einen Server, der die meiste Zeit im Leerlauf ist, aber regelmäßig für einige kurze Zeiträume viel Rechenleistung benötigt. Nehmen wir weiter an, dass jeden Tag außer samstags und sonntags auf diesem Server von ca. 0:00 bis 7:00 Uhr morgens einige große Backup-Aufträge laufen. In dieser Zeit ist eine CPU-Auslastung von 10 (bei 20 Prozessorkernen) völlig normal. In der restlichen Zeit könnte sogar eine Auslastung von 3 verdächtig hoch sein.
In Checkmk haben Sie verschiedene Möglichkeiten, dieses Beispiel abzubilden. Eine davon ist, zuerst die Zeiträume mit unterschiedlicher Auslastung zu definieren und für diese Zeiten dann spezifische Schwellwerte festzulegen. Für unser Beispiel bedeutet das, zuerst eine neue Zeitperiode für die Zeit mit hoher Auslastung zu definieren (montags bis freitags von 0:00 bis 7:00 Uhr). Anschließend können Sie in einer Regel für den Service (CPU load bzw. Processor Queue) diese neue Zeitperiode auswählen und für diese abweichende (höhere) Schwellwerte festlegen.
Die Nutzung einer Zeitperiode hat den Vorteil, dass immer gut nachvollziehbar ist, warum ein WARN-/CRIT-Zustand zu einem bestimmten Zeitpunkt auftrat. Allerdings ist die manuelle Bindung von Schwellwerten an Zeitperioden auch etwas unflexibel und manchmal auch einfach viel zu umständlich.
![]() Falls Sie eine der kommerziellen Editionen einsetzen, steht Ihnen aber noch eine weitere Möglichkeit zur Verfügung, um das Problem zu lösen.
Sie heißt prognosebasiertes Monitoring (predictive monitoring), und dabei werden die Messdaten der Vergangenheit ausgewertet, um daraus eine Vorhersage zu berechnen, wie sich diese in Zukunft verhalten werden.
Falls Sie eine der kommerziellen Editionen einsetzen, steht Ihnen aber noch eine weitere Möglichkeit zur Verfügung, um das Problem zu lösen.
Sie heißt prognosebasiertes Monitoring (predictive monitoring), und dabei werden die Messdaten der Vergangenheit ausgewertet, um daraus eine Vorhersage zu berechnen, wie sich diese in Zukunft verhalten werden.
Einmal eingerichtet, ist die Vorhersage nicht mehr statisch, sondern passt sich mit der Zeit der sich ändernden Realität an: Die Prognose von heute ist übermorgen eine andere, weil übermorgen bereits die realen Werte von morgen einbezogen sind. Ohne Zeitreisen zu strapazieren, kann man es auch so ausdrücken: Checkmk lernt kontinuierlich dazu. Da die Schwellwerte für die WARN-/CRIT-Zustände stets relativ zu den prognostizierten Werten festgelegt werden, lernen die Schwellwerte ebenfalls mit.
2. Prognosebasiertes Monitoring einrichten
2.1. Vom Plugin-Namen zum Prognoseparameter
Eine ganze Reihe von Checkmk-Plugins unterstützt das prognosebasierte Monitoring. Im Folgenden finden Sie einige wichtige Beispiele:
Die Einstellungen für das prognosebasierte Monitoring finden Sie an der gleichen Stelle, an der Sie auch sonst Schwellwerte für einen Service einstellen. Dort finden Sie — sofern der betroffene Check dies unterstützt — die Auswahl Predictive levels (only on CMC).
2.2. Eine Regel für das prognosebasierte Monitoring erstellen
Für den Service CPU load des Linux-Hosts unseres Beispiels können Sie eine neue Regel mit dem Regelsatz CPU load (not utilization!) unter Service monitoring rules erstellen, den Sie am schnellsten mit der Suche im Setup-Menü finden.
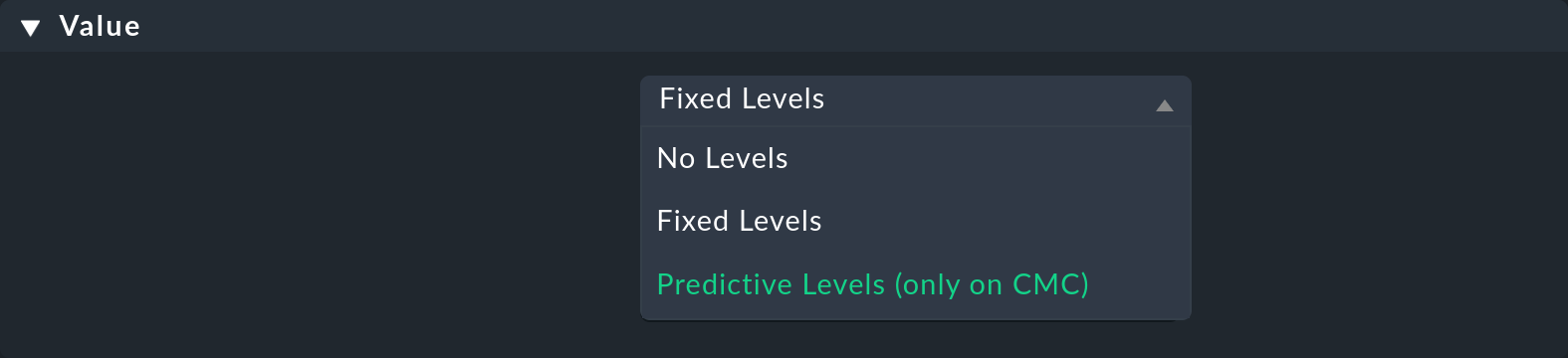
Im Abschnitt Value finden Sie Parameter auf Service-Ebene, für die Sie den Wert Predictive levels (only on CMC) auswählen können:
2.3. Referenzwerte der Vergangenheit auswählen
Nach der Auswahl von Predictive levels (only on CMC) werden die Parameter angezeigt, von denen wir zunächst die ersten beiden genauer vorstellen werden:
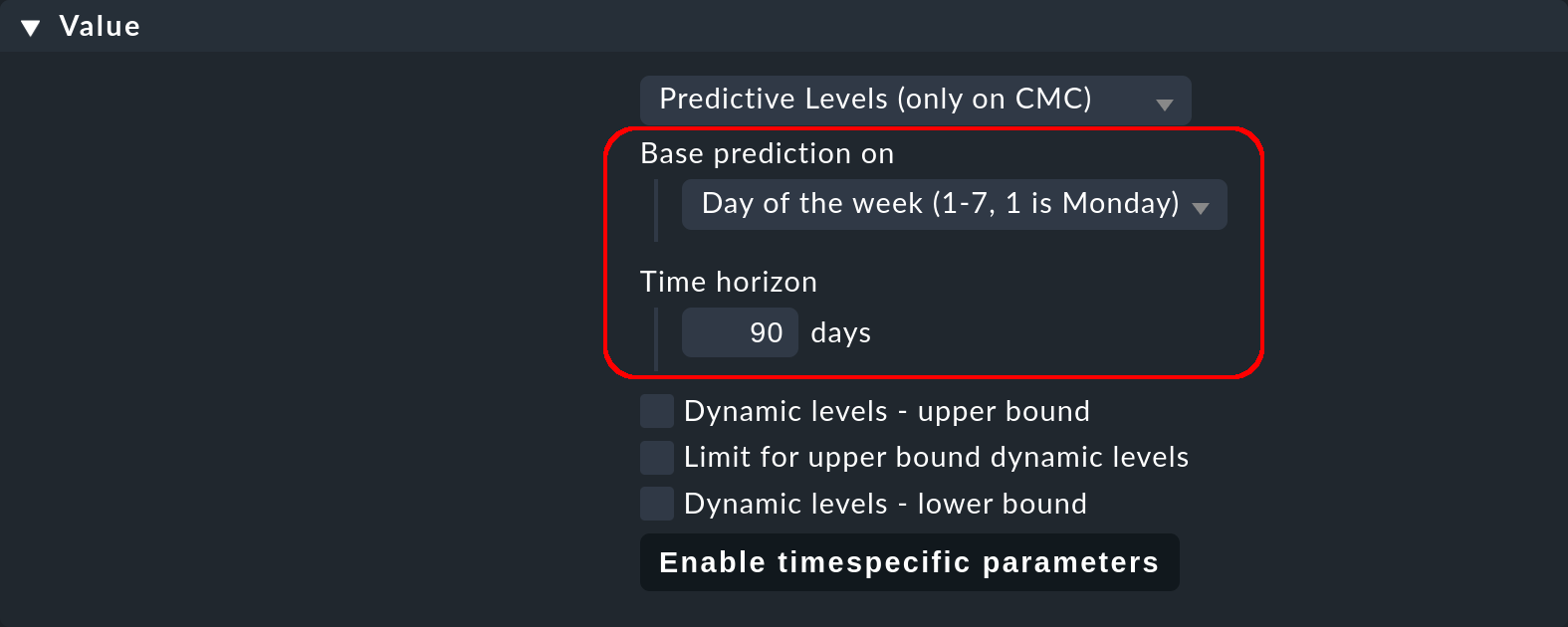
Mit Base prediction on legen Sie die Periodizität fest, in der die Wiederholung der Messdaten zu erwarten ist (monatlich, wöchentlich, täglich oder stündlich):
Day of the month: Die Messwerte jedes Monatstags werden miteinander verglichen, d.h. des 1., 2., 3., … jedes Monats.
Day of the week: Der Vergleich basiert auf den Wochentagen, d.h. für jeden Wochentag (montags, dienstags, mittwochs, etc.) wird eine andere Prognose erstellt. Dies ist meist die richtige Einstellung.
Hour of the day: Es werden die einzelnen Stunden jedes Tages verglichen, d.h. die Prognose wiederholt sich täglich.
Minute of the hour: Der Vergleich auf Minutenbasis und die stündliche Wiederholung ist in der Regel nur nützlich, um eine Prognose zu testen.
Im nächsten Parameter Time horizon geben Sie ein, bis zu wie vielen Tagen in der Vergangenheit Checkmk die Messdaten auswerten soll. Checkmk greift dabei auf die in den RRD-Dateien gespeicherten historischen Daten zu. Obwohl die Messdaten in den RRD-Dateien 4 Jahre lang gespeichert werden, macht es keinen Sinn, zu weit in die Vergangenheit zurückzugehen. Zum einen könnten sich die typischen Werte der jüngeren von denen der älteren Vergangenheit unterscheiden.
Zum anderen gibt es, je weiter Sie in die Vergangenheit zurückschauen, desto weniger Messdaten pro Zeiteinheit für den Vergleich. Das liegt daran, dass Checkmk die minütlich vorliegenden Messdaten in den RRD-Dateien standardmäßig in drei Phasen verdichtet, um Platz zu sparen: nach 2, 10 und nach 90 Tagen. Verdichtung bedeutet, dass aus mehreren Messdaten das Minimum, das Maximum und der Durchschnitt berechnet werden und diese berechneten Daten die ursprünglich gemessenen Daten ersetzen. Liegen die Messdaten der letzten beiden Tage in der vollen Auflösung von 1 Minute vor, so beträgt die Auflösung nach 2 Tagen 5 Minuten, nach 10 Tagen 30 Minuten und nach 90 Tagen 6 Stunden. Greift Checkmk für das prognosebasierte Monitoring auf historische Daten zu, wird von den drei gespeicherten Werten immer das Maximum genommen.
Für unseren Beispiel-Server mit der hohen Auslastung Montag bis Freitag nachts bietet es sich an, die wöchentliche Referenzperiode auszuwählen und einen Referenzzeitraum von (maximal) 90 Tagen. 90 Tage sind ein akzeptabler Kompromiss, da einerseits in diesem Zeitraum genügend Vergleichstage enthalten sind und andererseits die Messdaten in einer Auflösung von immerhin noch 30 Minuten vorliegen — sofern die Default-Werte nicht verändert wurden.
Wählen Sie als Base prediction on den Eintrag Day of the week aus und geben Sie als Time horizon 90 ein, so wie es das Bild oben zeigt.
Mit der Festlegung der wöchentlichen Referenzperiode für einen 90-Tage-Zeitraum in der Vergangenheit hat Checkmk die notwendigen Informationen, um die Referenzkurve zu berechnen. Dabei wird jeder Montag in der Zeitperiode ausgewertet (bei 90 Tagen sind es 12 Montage), jeder Messwert eines Montags mit den Messwerten der anderen Montage zur gleichen Uhrzeit verglichen und der Durchschnitt berechnet. Nach dem Montag kümmert sich Checkmk in gleicher Weise um die anderen Wochentage Dienstag bis Sonntag. Die so berechnete Referenzkurve der Vergangenheit wird dann fortgeschrieben und damit zur prognostizierten Referenzkurve für die Zukunft.
Die Werte, die zur Berechnung des Durchschnitts für die Referenzperiode hergenommen werden, können selbst bereits berechnete (d.h. nicht gemessene) Werte sein — je nach Auflösung der historischen Daten in den RRD-Dateien. |
Die von Checkmk auf Basis der beiden bisher festgelegten Parameter (Referenzperiode und Referenzzeitraum) berechnete Referenzkurve ist im folgenden Bild als schwarze Linie gezeichnet:
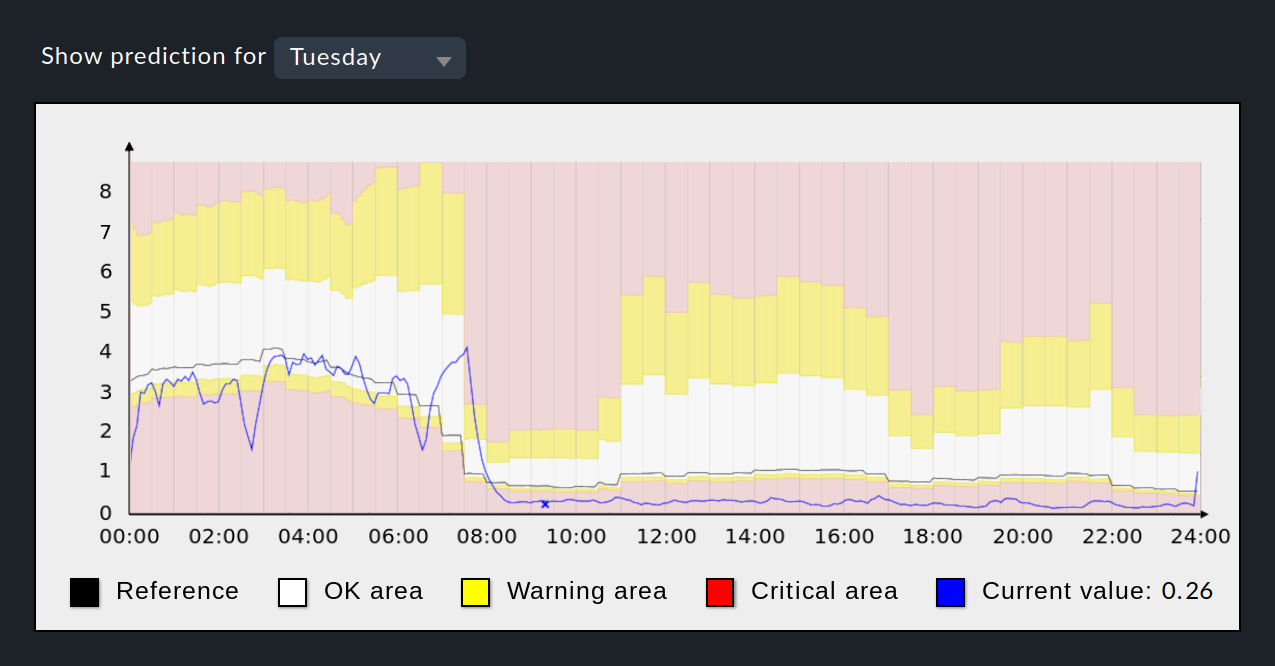
Dieses Bild zeigt als Vorgriff den Prognose-Graphen, den Sie sich nach der vollständig abgeschlossenen Einrichtung anzeigen lassen können. Außer der schwarzen Referenzkurve werden die aktuellen Werte als blaue Linie dargestellt — sofern sie in der dargestellten Zeitperiode verfügbar sind.
Was fehlt, um die Einrichtung abzuschließen, sind die Festlegungen der Schwellwerte für die Zustände WARN und CRIT, die im Graphen mit gelber und roter Hintergrundfarbe markiert sind. Um die Festlegung dieser Schwellwerte geht es im nächsten Abschnitt.
2.4. Schwellwerte für die Prognose festlegen
Die Schwellwerte für WARN und CRIT legen Sie in Abhängigkeit der in der Referenzkurve abgebildeten prognostizierten Werte fest.
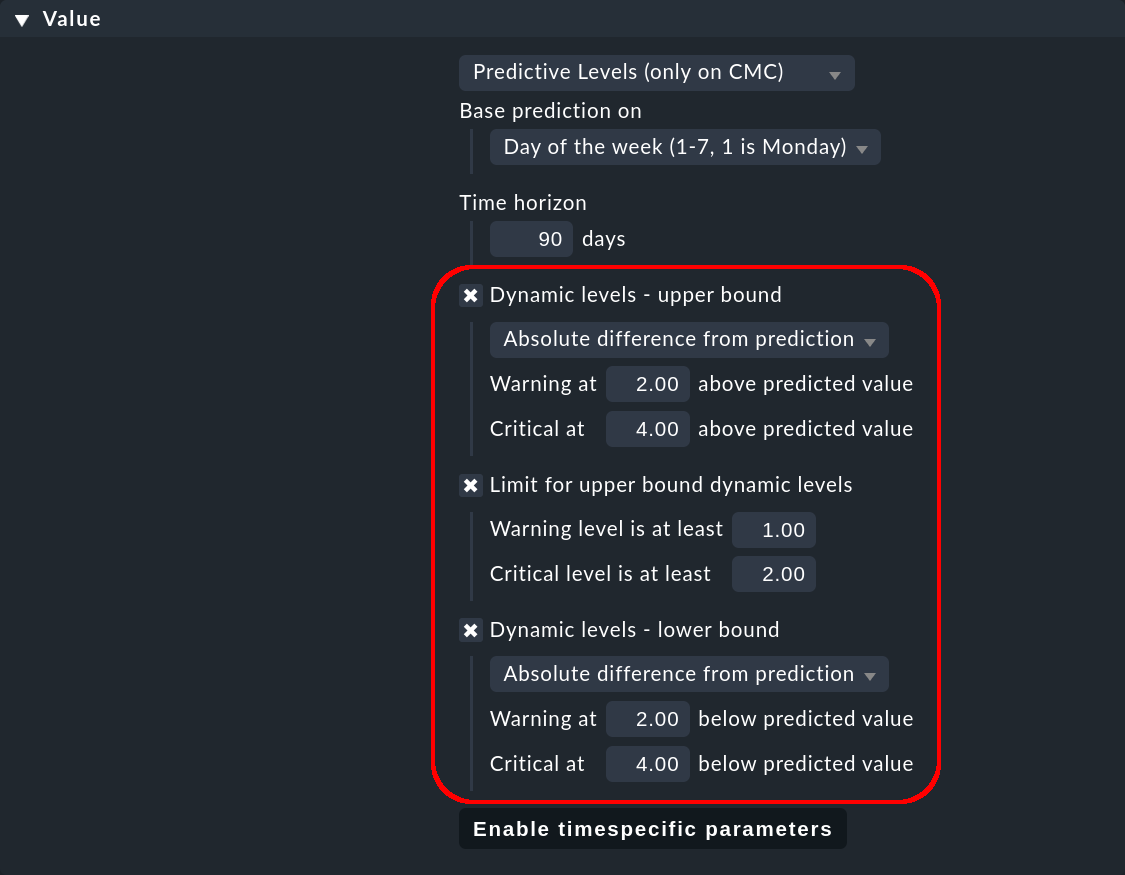
Um die Auswirkung der verschiedenen Parameterwerte zur Festlegung der Schwellwerte zu verdeutlichen, sehen wir uns einen einzigen Wert auf der Referenzkurve genau an. Wir nehmen an, dass der prognostizierte Wert des Services CPU load freitags um 3:30 Uhr 10 beträgt.
Für die oberen Schwellwerte gibt es den Parameter Dynamic levels - upper bound, für die unteren Schwellwerte Dynamic levels - lower bound. Für beide Parameter haben Sie 3 Auswahlmöglichkeiten, die in den folgenden 3 Abschnitten beschrieben werden.
Absolute Differenz zur Vorhersage
Mit Absolute difference from prediction werden die Schwellwerte berechnet, indem der prognostizierte Wert um einen festen, absoluten Wert erhöht bzw. vermindert wird.
Beispiel: Warning at 2.0 wird dazu führen, dass bei einem Wert über 12 und unter 8 eine Warnung angezeigt wird.
Relative Differenz zur Vorhersage
Mit Relative difference from prediction werden die Schwellwerte berechnet, indem der prognostizierte Wert um einen Prozentsatz erhöht bzw. vermindert wird.
Beispiel: Warning at 10.0 % wird dazu führen, dass bei einem Wert über 11 und unter 9 eine Warnung angezeigt wird.
In Relation zur Standardabweichung
Mit In relation to standard deviation werden die Schwellwerte berechnet, indem der prognostizierte Wert um ein Vielfaches der Standardabweichung erhöht bzw. vermindert wird. Die Standardabweichung gibt an, wie stark sich die Werte in einer Referenzperiode (z.B. freitags um 3:30 Uhr) unterscheiden.
Mit dieser Option ist die Berechnung der Schwellwerte nicht so einfach vorherzusagen, da Checkmk die Standardabweichung aus allen Messwerten der Referenzperiode intern kalkuliert. Zur Verdeutlichung der Auswirkung benötigen wir weitere Informationen über die 12 Messwerte der Referenzperiode freitags um 3:30 Uhr: Wir nehmen an, dass 10 Messwerte gleich 10 sind, einer 11 und einer 9. Die 12 Messwerte haben also den Mittelwert von 10 (was dem prognostizierten Wert entspricht), eine Varianz von ca. 0,167 und eine Standardabweichung von ca. 0,41. (Die Berechnungsdetails sparen wir uns hier, können aber auf verschiedenen Statistikseiten im Internet nachgelesen werden.)
Beispiel: Warning at 1.0 als Vielfaches der Standardabweichung wird dazu führen, dass bei einem Wert über 10,41 und unter 9,59 eine Warnung angezeigt wird.
Um ungewollte WARN-/CRIT-Zustände zu vermeiden, werden keine Schwellwerte angewendet, wenn die Standardabweichung undefiniert ist (z. B. weil es nur einen Messwert in der Referenzperiode gibt) oder Null ist (wenn alle Messwerte identisch sind).
Allgemein gilt die Regel: Je gleichmäßiger die Werte der Vergangenheit sind, desto geringer ist die Standardabweichung und desto strikter die Prognose. Diese Option bietet sich daher an, um Schwellwerte enger zu definieren für eine Referenzperiode mit stabilen, gleichmäßigen Werten.
Mindestwerte der oberen Schwellwerte
Schließlich haben Sie mit Limit for upper bound dynamic levels die Möglichkeit für die oberen Schwellwerte absolute Mindestwerte vorzugeben. Damit können Sie ungewollte WARN-/CRIT-Zustände vorbeugen für Zeiten, in denen die prognostizierten Werte sehr niedrig sind.
Beispiel: Ein Warning level von 2.0 wird dazu führen, dass eine Warnung nur bei einem Wert über 2 angezeigt wird, selbst wenn der obere Schwellwert für eine Warnung bei 1,5 liegt.
Darstellung der Schwellwerte im Prognose-Graphen
Die beispielhaft für einen Wert beschriebenen Auswirkungen berechnet Checkmk für alle Werte der Referenzkurve. Das Ergebnis sehen Sie im Prognose-Graphen, der im nächsten Kapitel noch genauer beschrieben wird. Im Graphen sind ober- und unterhalb der Referenzkurve die Kurven für die oberen und unteren Schwellwerte gezeichnet. Die Bereiche für WARN sind in gelb und für CRIT in rot eingefärbt.
Sie sollten die Bereiche für WARN und CRIT im Prognose-Graphen kritisch überprüfen, insbesondere wenn Sie die Schwellwerte aus der Standardabweichung berechnen lassen, da sich die der Standardabweichung zugrundeliegenden Werte nicht direkt aus der Checkmk-Oberfläche ablesen lassen. Durch die Prüfung und ggf. die Anpassung der Schwellwerte können Sie vermeiden, dass der Service zu häufig ungewollt die Zustände WARN oder CRIT annimmt.
Damit ist die Einrichtung des prognosebasierten Monitoring abgeschlossen. Im nächsten Kapitel erfahren Sie, wie sich die Einrichtung im Monitoring bemerkbar macht und wie Sie sich den Prognose-Graphen anzeigen lassen können.
3. Die Prognose analysieren
Haben Sie das prognosebasierte Monitoring für einen Service eingerichtet, die Änderungen aktiviert und hat Checkmk danach den Check für den Service einmal ausgeführt, wird das neue Symbol ![]() in der Service-Liste angezeigt:
in der Service-Liste angezeigt:
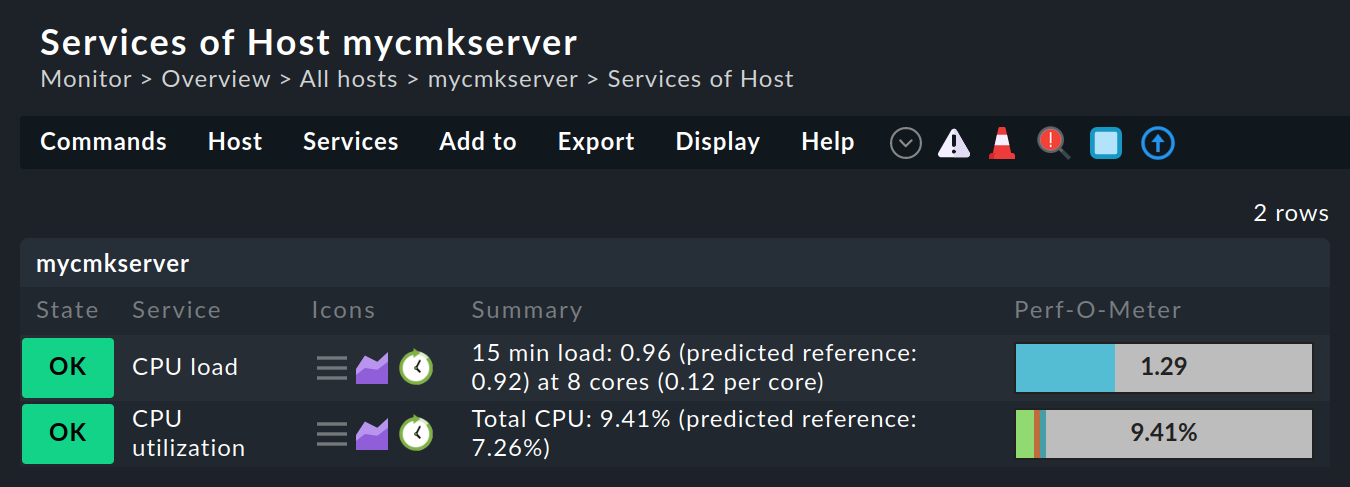
Insbesondere nach der Ersteinrichtung für einen Service kann es vorkommen, dass das Symbol fehlt, da noch nicht genügend Daten für die konfigurierte Prognose bereitstehen.
In diesem Fall wird in der Spalte Summary eine Meldung der Art |
Klicken Sie in der Service-Liste auf ![]() und eine grafische Darstellung des aktuellen Prognosezeitraums, der Prognose-Graph
(prediction graph), wird angezeigt:
und eine grafische Darstellung des aktuellen Prognosezeitraums, der Prognose-Graph
(prediction graph), wird angezeigt:
Im Graphen sehen Sie die Referenzkurve als schwarze Linie, die aktuellen Werte als blaue Linie und die Bereiche für die Zustände OK in weißer, für WARN in gelber und für CRIT in roter Hintergrundfarbe.
Der dargestellte Zeitraum orientiert sich an der ausgewählten Referenzperiode. Zum Beispiel können Sie sich bei einer wöchentliche Periode die einzelnen Wochentage ansehen und mit der Liste über dem Graphen zu einem anderen Tag wechseln. Mit dem speziellen Listeneintrag Everyday zeigt Ihnen der Graph die Durchschnittswerte aller Tage, für die Daten verfügbar sind.
Im Beispielgraphen ist die hohe Auslastung nachts und die niedrige Auslastung tagsüber zu erkennen. Von 0:00 bis 04:00 Uhr sind die aktuellen Werte (blaue Linie) niedriger als die prognostizierte Referenzkurve (schwarze Linie), und zwar so niedrig, dass die unteren Schwellwerte zeitweise unterschritten wurden und WARN-/CRIT-Zustände ausgelöst haben. Ähnlich ist das Verhalten im Zeitraum zwischen 08:30 und 23:30 Uhr, in der sich die blaue Linie konstant im unteren CRIT-Bereich befindet. Diese Zustände könnten in Zukunft durch höhere Werte für die unteren Schwellwerte vermieden werden.
Schließlich lässt sich aus dem Graphen ablesen, dass die oberen Schwellwerte auf der Standardabweichung basieren, denn zwischen 05:00 und 07:30 Uhr erhöhen sich tendenziell die oberen Schwellwerte bei gleichzeitig abnehmenden Werten in der Referenzkurve. Dieses Verhalten kann nur durch die Standardabweichung erklärt werden, da die anderen beiden Optionen (absoluter und prozentualer Wert) zu einer Veränderung der Schwellwerte in Richtung der Referenzkurve geführt hätten.
Wie beim erstmaligen Einrichten wird auch jede Änderung des prognosebasierten Monitoring erst nach einem neuen Check des Services wirksam.
Sie brauchen auf den nächsten regelmäßigen Check nicht zu warten, sondern können ihn manuell in der Service-Liste anstoßen mit dem Symbol |