In diesem Artikel erläutern wir die grundlegenden Begriffe und Konzepte in Checkmk, wie z.B. Host, Service, Benutzer, Kontaktgruppe, Benachrichtigung, Zeitraum, Wartungszeit.
1. Zustände und Ereignisse
Zunächst ist es wichtig, die grundlegenden Unterschiede zwischen Zuständen und Ereignissen zu verstehen — und zwar aus ganz praktischem Nutzen. Die meisten klassischen IT-Monitoring-Systeme drehen sich um Ereignisse (Events). Ein Ereignis ist etwas zu einem ganz bestimmten Zeitpunkt einmalig Geschehenes. Ein gutes Beispiel wäre Fehler beim Zugriff auf Platte X. Übliche Quellen von Ereignissen sind Syslog-Meldungen, SNMP-Traps, das Windows-Event-Log und Einträge in Log-Dateien. Ereignisse passieren quasi spontan (von selbst, asynchron).
Dagegen beschreibt ein Zustand eine anhaltende Situation, z.B. Platte X ist online. Um den aktuellen Zustand von etwas zu überwachen, muss das Monitoring-System diesen regelmäßig abfragen. Wie das Beispiel zeigt, gibt es beim Monitoring oft die Wahl, ob man mit Ereignissen oder mit Zuständen arbeitet.
Checkmk beherrscht beide Disziplinen, gibt jedoch immer dort, wo die Wahl besteht, dem zustandsbasierten Monitoring den Vorzug. Der Grund liegt in den zahlreichen Vorteilen dieser Methode. Einige davon sind:
Ein Fehler in der Überwachung selbst wird sofort erkannt, weil es natürlich auffällt, wenn das Abfragen des Zustands nicht mehr funktioniert. Die Abwesenheit einer Meldung dagegen gibt keine Sicherheit, ob das Monitoring noch funktioniert.
Das Monitoring kann selbst steuern, mit welcher Rate Zustände abgerufen werden. Es gibt keine Gefahr eines Sturms an Event-Meldungen in systemweiten Problemsituationen.
Das regelmäßige Abfragen in einem festen Zeitraster ermöglicht das Erfassen von Metriken, um deren Zeitverlauf aufzuzeichnen.
Auch nach chaotischen Situationen — z.B. Stromausfall im Rechenzentrum — hat man immer einen zuverlässigen Gesamtzustand.
Man kann also sagen, dass das zustandsbasierte Monitoring bei Checkmk das normale ist. Für das Verarbeiten von Ereignissen gibt es daneben die Event Console. Diese ist auf das Korrelieren und Bewerten von großen Mengen an Ereignissen spezialisiert und nahtlos in das Monitoring mit Checkmk integriert.
2. Hosts und Services
2.1. Hosts
Alles in der Überwachung dreht sich um Hosts und Services. Wir haben uns lange Gedanken gemacht, wie man Host ins Deutsche übersetzen könnte und am Ende entschieden, dass wir den Begriff so belassen, um keine unnötige Verwirrung zu stiften. Denn ein Host kann vieles sein, z.B.:
Ein Server
Ein Netzwerkgerät (Switch, Router, Load Balancer)
Ein Messgerät mit IP-Anschluss (Thermometer, Luftfeuchtesensor)
Irgendetwas anderes mit einer IP-Adresse
Ein Cluster aus mehreren Hosts
Eine virtuelle Maschine
Ein Docker-Container
Im Monitoring hat ein Host immer einen der folgenden Zustände:
| Zustand | Farbe | Bedeutung |
|---|---|---|
UP |
grün |
Der Host ist über das Netzwerk erreichbar (in der Regel heißt das, dass er auf Ping antwortet). |
DOWN |
rot |
Der Host antwortet nicht auf Anfragen aus dem Netzwerk, ist nicht erreichbar. |
UNREACH |
orange |
Der Weg zu dem Host ist aktuell für das Monitoring versperrt, weil ein Router oder Switch auf dem Weg dorthin ausgefallen ist. |
PEND |
grau |
Der Host wurde frisch in die Überwachung aufgenommen und noch nie abgefragt. Genau genommen ist das aber kein Zustand. |
Neben dem Zustand hat ein Host noch einige Attribute, die vom Benutzer konfiguriert werden, z.B.:
Einen eindeutigen Namen
Eine IP-Adresse
Optional einen Alias-Namen, welcher nicht eindeutig sein muss
Optional einen oder mehrere Parents
2.2. Parents
Damit das Monitoring den Zustand UNREACH berechnen kann, muss es wissen, über welchen Weg es jeden einzelnen Host erreichen kann.
Dazu kann man bei jedem Host einen oder mehrere sogenannte Parent-Hosts angeben.
Wenn z.B. ein Server A vom Monitoring aus gesehen nur über einen Router B erreichbar ist, dann ist B ein Parent-Host von A.
In Checkmk konfiguriert werden dabei nur direkte Parents.
Daraus ergibt sich dann eine baumartige Struktur mit der Checkmk-Instanz in der Mitte (hier dargestellt als ![]() ):
):
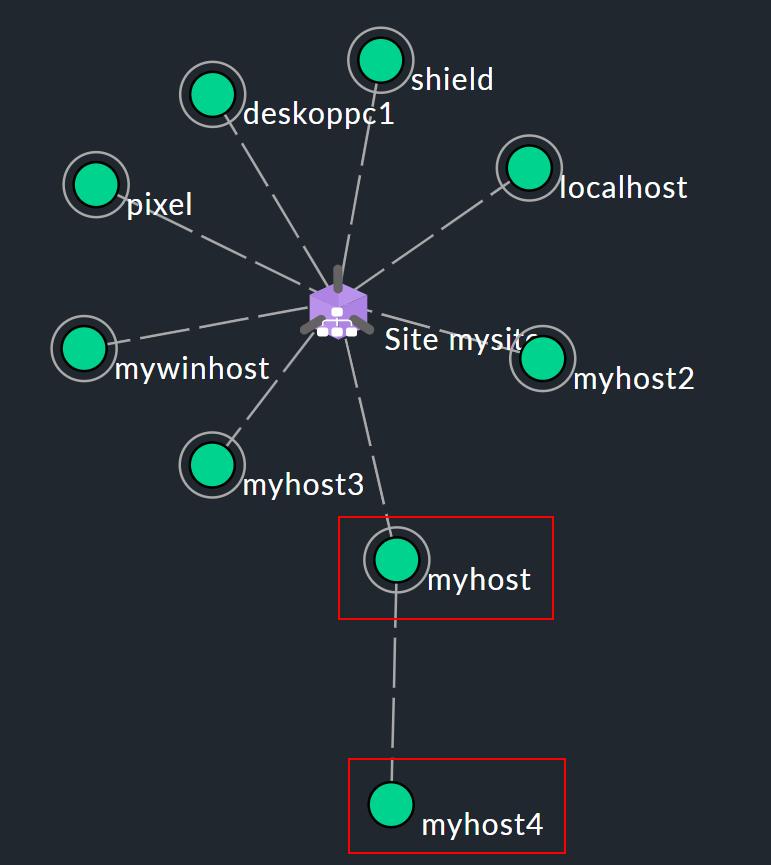
Nehmen wir an, dass in der oben gezeigten beispielhaften Netzwerktopologie die Hosts myhost und myhost4 nicht mehr erreichbar sind. Der Ausfall von myhost4 ist dadurch erklärbar, dass myhost ausgefallen ist. Daher wird myhost4 im Monitoring als UNREACH klassifiziert. Es ist schlicht nicht eindeutig feststellbar, weswegen Checkmk myhost4 nicht mehr erreichen kann und der Zustand DOWN wäre daher unter Umständen irreführend. Stattdessen bewirkt das UNREACH standardmäßig die Unterdrückung einer Benachrichtigung. Denn das ist die wichtigste Aufgabe des Konzepts der Parents: Die Vermeidung massenhafter Benachrichtigungen, falls ein ganzes Netzwerksegment aufgrund einer Unterbrechung für das Monitoring nicht mehr erreichbar ist.
Der Vermeidung von Fehlalarmen dient auch ein Feature des in den kommerziellen Editionen verwendeten Checkmk Micro Core (CMC). Hier wird der Zustandswechsel über einen ausgefallenen Host wenige Augenblicke zurückgehalten und findet erst dann statt, wenn gesichert ist, dass der Parent noch erreichbar ist. Falls der Parent dagegen sicher DOWN ist, wechselt der Host nach UNREACH — ohne dass benachrichtigt wird.
In manchen Fällen hat ein Host mehrere Parents, zum Beispiel, wenn ein Router hochverfügbar in einem Cluster betrieben wird. Für Checkmk reicht es, wenn einer dieser Parents erreichbar ist, um den Zustand des Hosts eindeutig zu bestimmen. Falls ein Host also mehrere Parents hat und zumindest einer dieser Parents UP ist, wird der Host im Monitoring als erreichbar betrachtet. Mit anderen Worten: In diesem Fall wird der Host nicht automatisch in den Zustand UNREACH wechseln.
2.3. Services
Ein Host hat eine Menge von Services. Ein Service kann alles Mögliche sein, verwechseln Sie das nicht mit den Diensten (services) von Windows. Ein Service ist irgendein Teil oder Aspekt des Hosts, der OK sein kann oder eben nicht. Der Zustand von Services kann natürlich immer nur dann abgefragt werden, wenn der Host im Zustand UP ist.
Folgende Zustände kann ein Service im Monitoring haben:
| Zustand | Farbe | Bedeutung |
|---|---|---|
OK |
grün |
Der Service ist vollständig in Ordnung. Alle Messwerte liegen im erlaubten Bereich. |
WARN |
gelb |
Der Service funktioniert normal, aber seine Parameter liegen außerhalb des optimalen Bereichs. |
CRIT |
rot |
Der Service ist ausgefallen, defekt. |
UNKNOWN |
orange |
Der Zustand des Services konnte nicht korrekt ermittelt werden. Der Monitoring-Agent hat fehlerhafte Daten geliefert oder die zu überwachende Sache ist ganz verschwunden. |
PEND |
grau |
Der Service ist gerade in die Überwachung aufgenommen worden und es gibt noch keine Monitoring-Daten. |
Wenn es darum geht, welcher Zustand „schlimmer“ ist, verwendet Checkmk folgende Reihenfolge:
OK → WARN → UNKNOWN → CRIT
2.4. Checks
Ein Check sorgt dafür, dass ein Host oder ein Service einen Zustand erhält. Welche Zustände das sein können, ist im vorherigen Abschnitt beschrieben. Services und Checks hängen eng miteinander zusammen. Daher werden sie manchmal, vielleicht sogar in diesem Handbuch, synonym verwendet, obwohl es doch verschiedene Dinge sind.
Im Setup können Sie sich anzeigen lassen, welches Check-Plugin für welchen Service zuständig ist. Öffnen Sie mit Setup > Hosts die Eigenschaften eines Hosts und dann im Menü Host > Run service discovery die Liste der Services dieses Hosts. Dann blenden Sie mit Display > Show plugin names eine neue Spalte ein, die Ihnen für jeden Service das zuständige Check-Plugin anzeigt:

Wie Sie am Beispiel des Check-Plugins df sehen, kann ein Check-Plugin für mehrere Services verantwortlich sein. Übrigens sind in der eingeblendeten Spalte die Namen der Check-Plugins Links, die Sie zur Beschreibung des Check-Plugins führen.
Der Zusammenhang und die Abhängigkeit von Services und Checks sind auch im Monitoring zu sehen.
In der Service-Liste eines Hosts im Monitoring können Sie feststellen, dass im ![]() Aktionsmenü beim Eintrag Reschedule bei einigen Services ein gelber Pfeil steht (
Aktionsmenü beim Eintrag Reschedule bei einigen Services ein gelber Pfeil steht (![]() ), bei den meisten anderen aber ein grauer Pfeil (
), bei den meisten anderen aber ein grauer Pfeil (![]() ).
Ein Service mit dem gelben Pfeil basiert auf einem aktiven Check:
).
Ein Service mit dem gelben Pfeil basiert auf einem aktiven Check:
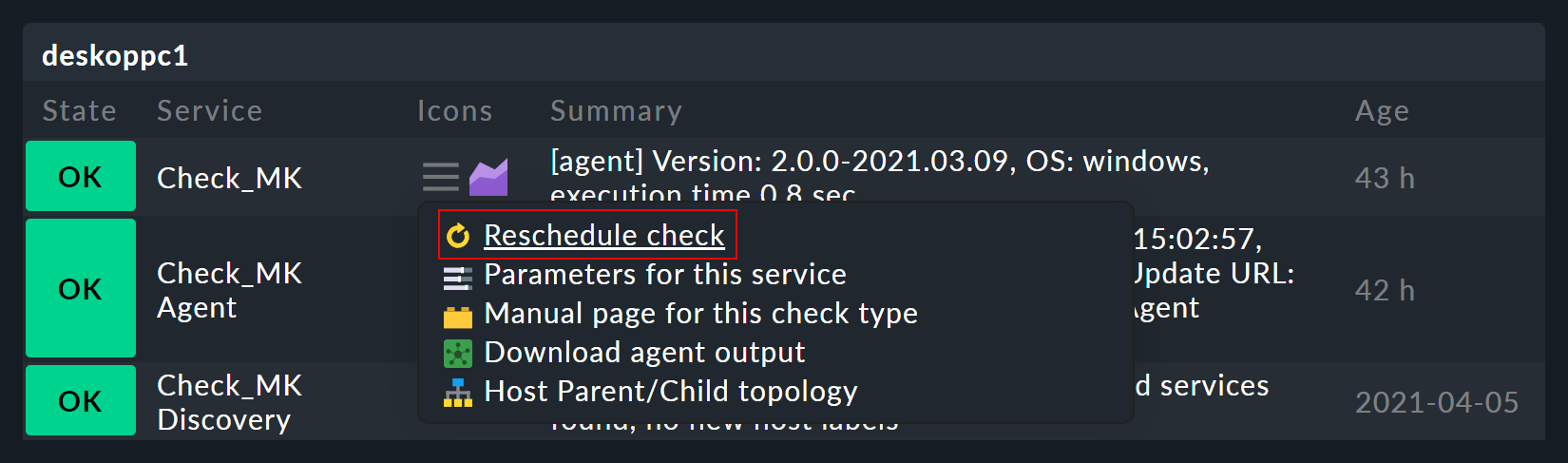
Solch ein aktiver Check wird von Checkmk direkt ausgeführt. Services mit dem grauen Pfeil basieren auf passiven Checks, deren Daten von einem anderen Service, dem Service Check_MK, geholt werden. Dies geschieht aus Gründen der Performance und stellt eine Besonderheit von Checkmk dar.
3. Host- und Service-Gruppen
Zur Verbesserung der Übersicht können Sie Hosts in Host-Gruppen und Services in Service-Gruppen organisieren.
Dabei kann ein Host/Service auch in mehreren Gruppen sein.
Die Erstellung dieser Gruppen ist optional und für die Konfiguration nicht notwendig.
Haben Sie aber z.B. die Ordnerstruktur nach geographischen Gesichtspunkten aufgebaut, dann kann eine Host-Gruppe Linux-Server sinnvoll sein, die alle Linux-Server zusammenfasst, egal an welchen Standorten diese stehen.
Mehr zu Host-Gruppen erfahren Sie im Artikel über die Strukturierung der Hosts und zu Service-Gruppen im Artikel über Services.
4. Kontakte und Kontaktgruppen
Kontakte und Kontaktgruppen bieten die Möglichkeit, Hosts und Services Personen zuzuordnen. Ein Kontakt entspricht einer Benutzerkennung der Weboberfläche. Die Zuordnung zu Hosts und Services geschieht jedoch nicht direkt, sondern über Kontaktgruppen.
Zunächst wird ein Kontakt (z.B. harri) einer Kontaktgruppe (z.B. linux-admins) zugeordnet.
Der Kontaktgruppe werden dann wieder Hosts oder nach Bedarf auch einzelne Services zugeordnet.
Dabei können sowohl Benutzer als auch Hosts und Services jeweils mehreren Kontaktgruppen zugeordnet sein.
Diese Zuordnung ist für mehrere Aspekte nützlich:
Wer darf was sehen?
Wer darf welche Hosts und Services konfigurieren und steuern?
Wer wird bei welchen Problemen benachrichtigt?
Der Benutzer cmkadmin, der beim Erzeugen einer Instanz automatisch angelegt wird, darf übrigens immer alle Hosts und Services sehen, auch wenn er kein Kontakt ist.
Dies ist durch seine Rolle als Administrator bedingt.
5. Benutzer und Rollen
Während über Kontakte und Kontaktgruppen gesteuert wird, welche Personen für einen bestimmten Host oder Service zuständig sind, werden die Berechtigungen über Rollen gesteuert. Checkmk wird dabei mit einigen vordefinierten Rollen ausgeliefert, von denen Sie später weitere Rollen ableiten können. Jede Rolle definiert eine Reihe von Berechtigungen, welche Sie anpassen können. Die Bedeutung der Standardrollen ist:
| Name der Rolle | Alias | Bedeutung |
|---|---|---|
|
Administrator |
Darf alles sehen und tun, hat alle Berechtigungen. |
|
Normal monitoring user |
Darf nur sehen, wofür er Kontakt ist. Darf Hosts verwalten in Ordnern, die ihm zugewiesen sind. Darf keine globalen Einstellungen machen. |
|
Agent registration user |
Darf nur den Checkmk-Agenten eines Hosts beim Checkmk-Server registrieren — sonst nichts. |
|
Guest user |
Darf alles sehen, aber nichts konfigurieren und auch nicht in das Monitoring eingreifen. |
|
Empty template for least privilege roles |
Darf gar nichts. |
6. Probleme, Ereignisse und Benachrichtigungen
6.1. Bearbeitete und unbehandelte Probleme
Checkmk bezeichnet jeden Host der nicht UP und jeden Service, der nicht OK ist, als ein Problem. Dabei kann ein Problem zwei Zustände haben: unbehandelt (unhandled) und bearbeitet (handled). Der Ablauf ist so, dass ein neues Problem zunächst als unbehandelt gilt. Sobald jemand das Problem im Monitoring bestätigt (quittiert, acknowledge), gilt es als bearbeitet. Man könnte auch sagen, dass die unbehandelten Probleme solche sind, um die sich noch niemand gekümmert hat. Der Overview in der Seitenleiste unterscheidet deswegen diese beiden Arten von Problemen:
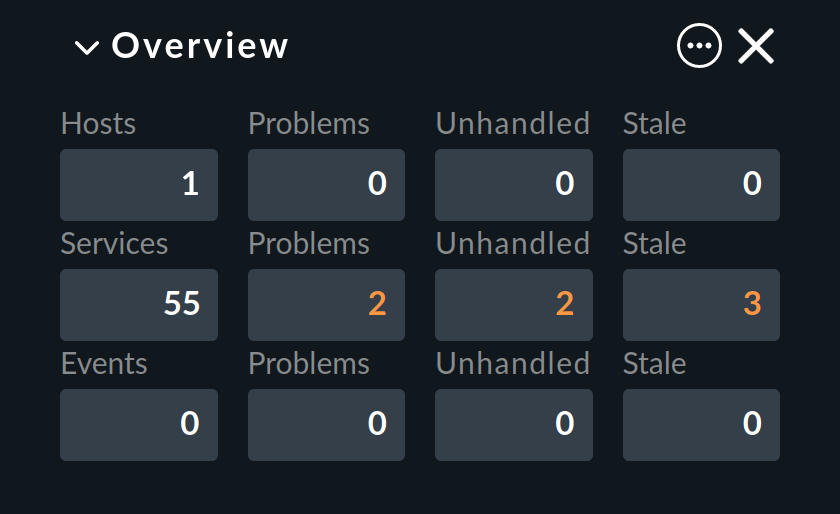
Übrigens: Service-Probleme von Hosts, die gerade nicht UP sind, werden hier nicht als Problem angezeigt.
Weitere Details zu den Quittierungen finden Sie in einem eigenen Artikel.
6.2. Benachrichtigungen
Wann immer sich der Zustand eines Hosts oder Services ändert (z.B. von OK auf CRIT), spricht Checkmk von einem Monitoring-Ereignis. So ein Ereignis kann — muss aber nicht — zu einer Benachrichtigung führen. Checkmk ist so voreingestellt, dass im Falle eines Problems von einem Host oder Service jeder Kontakt dieses Objekts per E-Mail benachrichtigt wird (beachten Sie hierbei, dass jeder neu erstellte Benutzer erst einmal kein Kontakt von irgendeinem Objekt ist). Dies kann aber sehr flexibel angepasst werden. Auch hängen die Benachrichtigungen von einigen Rahmenbedingungen ab. Am einfachsten ist es, wenn wir uns ansehen, in welchen Fällen nicht benachrichtigt wird. Benachrichtigungen werden unterdrückt, wenn:
Benachrichtigungen global im Master control ausgeschaltet wurden,
Benachrichtigungen bei dem Host/Service ausgeschaltet wurden,
der jeweilige Zustand bei dem Host/Service für Benachrichtigungen abgeschaltet ist (z.B. keine Benachrichtigung bei WARN),
das Problem einen Service betrifft, dessen Host DOWN oder UNREACH ist,
das Problem einen Host betrifft, dessen Parents alle DOWN oder UNREACH sind,
für den Host/Service ein Benachrichtigungszeitraum (notification period) definiert wurde, der gerade nicht aktiv ist,
der Host/Service gerade unstetig
 (flapping) ist,
(flapping) ist,sich der Host/Service gerade in einer Wartungszeit (scheduled downtime) befindet.
Wenn keine dieser Bedingungen für eine Unterdrückung erfüllt ist, erzeugt der Monitoring-Kern eine Benachrichtigung, welche dann im zweiten Schritt eine Kette von Regeln durchläuft. Dort können Sie dann noch weitere Ausschlusskriterien festlegen und entscheiden, wer auf welchem Wege benachrichtigt werden soll (E-Mail, SMS etc.).
Alle Einzelheiten rund um die Benachrichtigungen finden Sie in einem eigenen Artikel.
6.3. Unstetige Hosts und Services (Flapping)
Manchmal kommt es vor, dass sich der Zustand von einem Service in kurzen Abständen immer wieder ändert.
Um ständige Benachrichtigungen zu vermeiden, schaltet Checkmk so einen Service in den Zustand „unstetig“ (flapping).
Dies wird durch das Symbol ![]() illustriert.
illustriert.
Wenn ein Service in diesen Flapping-Zustand eintritt, wird eine Benachrichtigung generiert. Diese informiert, dass eben dieser Zustand eingetreten ist, und danach ist Ruhe. Wenn für eine angemessene Zeit kein weiterer Zustandswechsel geschieht — sich also alles beruhigt und endgültig zum Guten oder zum Schlechten gewendet hat — verschwindet dieser Zustand wieder und die normalen Benachrichtigungen setzen wieder ein.
6.4. Wartungszeiten (Scheduled downtimes)
Wenn Sie an einem Server, Gerät oder an einer Software Wartungsarbeiten vornehmen möchten, möchten Sie in der Regel Benachrichtigungen über Probleme in dieser Zeit vermeiden. Außerdem möchten Sie Ihren Kollegen eventuell signalisieren, dass Probleme, die das Monitoring anzeigt, vorübergehend ignoriert werden sollen.
Zu diesem Zweck können Sie zu einem Host oder Service Wartungszeiten (scheduled downtimes) eintragen. Diese können Sie entweder direkt beim Beginn der Arbeiten oder auch schon im Vorfeld eintragen. Wartungszeiten werden durch Symbole illustriert:
|
Der Host oder der Service befindet sich in einer Wartungszeit. |
|
Services, deren Hosts sich in einer Wartung befinden, werden mit diesem Symbol gekennzeichnet. |
Während ein Host oder Service in Wartungszeit ist,
werden keine Benachrichtigungen versendet,
werden Probleme nicht im Snapin Overview angezeigt.
Auch wenn Sie später Auswertungen über die Verfügbarkeit von Hosts oder Services machen möchten, ist es eine gute Idee Wartungszeiten einzutragen. Diese können dann später bei der Berechnung berücksichtigt werden.
6.5. Veraltete Hosts und Services (Stale)
Wenn Sie eine Weile mit Checkmk gearbeitet haben, kann es passieren, dass in Ihren Host- und Service-Ansichten Spinnennetze angezeigt werden. Für Services sieht das dann zum Beispiel so aus:
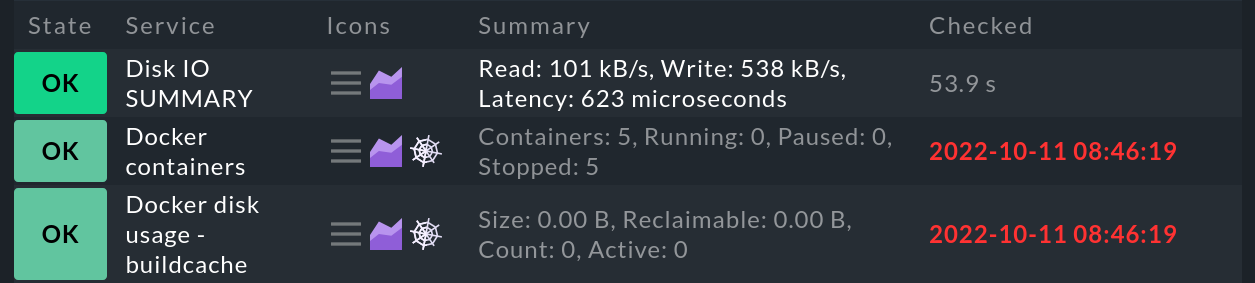
Diese Spinnennetze symbolisieren den Zustand veraltet (stale). Sobald es einen veralteten Host oder Service gibt, wird das auch im Snapin Overview angezeigt, das um die Spalte Stale erweitert wird.
Doch was bedeutet der Zustand stale genau? Generell wird ein Host oder Service als stale gekennzeichnet, wenn Checkmk über eine längere Zeit keine aktuellen Informationen über dessen Zustand mehr bekommt:
Ein Service wird stale: Fällt ein Agent oder auch nur ein Agentenplugin — aus welchen Gründen auch immer — über längere Zeit aus, so liefert der Agent keine aktuellen Daten mehr für die Auswertung. Services, deren Zustand von passiven Checks ermittelt wird, können nicht aktualisiert werden, da sie auf die Daten des Agenten angewiesen sind. Die Services verbleiben im jeweils letzten Zustand, werden aber nach Ablauf einer bestimmten Zeit als stale markiert.
Ein Host wird stale: Liefert das Host check command, mit dem die Erreichbarkeit des Hosts überprüft wird, keine aktuelle Antwort, behält der Host den letzten ermittelten Zustand bei — und wird dann aber als stale gekennzeichnet.
Sie können den Zeitraum anpassen, ab wann Hosts und Services stale werden. Lesen Sie hierzu den Abschnitt über Check-Intervalle.
7. Zeiträume (Time periods)

Wöchentlich wiederkehrende Zeiträume kommen an verschiedenen Stellen in der Konfiguration zum Einsatz.
Ein typischer Zeitraum könnte work hours heißen und die Zeiten von jeweils 8:00 bis 17:00 Uhr beinhalten, an allen Wochentagen außer Samstag und Sonntag.
Vordefiniert ist der Zeitraum 24X7, welcher einfach alle Zeiten einschließt.
Zeiträume können auch Ausnahmen für bestimmte Kalendertage enthalten — z.B. für die bayerischen Feiertage.
Einige wichtige Stellen, an denen Zeiträume zum Einsatz kommen, sind:
Begrenzung der Zeiten, innerhalb derer benachrichtigt wird (Benachrichtigungszeitraum, notification period).
Begrenzung der Zeiten, innerhalb derer Checks ausgeführt werden (Check-Zeitraum, check period).
Service-Zeiten für die Berechnung von Verfügbarkeit (Service-Zeitraum, service period).
Zeiten, innerhalb derer bestimmte Regeln in der Event Console greifen.
Wie Sie Zeiträume einstellen können, lesen Sie im Artikel Zeitperioden (Time Periods).
8. Check-Zeiträume, Check-Intervalle und Check-Versuche
8.1. Check-Zeiträume festlegen
Sie können die Zeiträume einschränken, in denen Checks ausgeführt werden. Dazu dienen die Regelsätze Check period for hosts, Check period for active services und Check period for passive Checkmk services. Mit diesen Regeln wählen Sie einen der verfügbaren Zeiträume (time periods) als Check-Zeitraum (check period) aus.
8.2. Check-Intervalle einstellen
Das Ausführen von Checks geschieht beim zustandsbasierten Monitoring in festen Intervallen. Checkmk verwendet als Standard für Service-Checks eine Minute, für Host-Checks mit Smart Ping 6 Sekunden.
Mit Hilfe der Regelsätze Normal check interval for service checks und Normal check interval for host checks kann dies geändert werden:
Auf einen längeren Wert, um CPU-Ressourcen auf dem Checkmk-Server und dem Zielsystem zu sparen.
Auf einen kürzeren Wert, um schneller Benachrichtigungen zu bekommen und Messdaten in einer höheren Auflösung einzusammeln.
Kombinieren Sie nun einen Check-Zeitraum mit einem Check-Intervall, so können Sie dafür sorgen, dass ein aktiver Check genau einmal am Tag zu einer ganz bestimmten Zeit ausgeführt wird. Setzen Sie z.B. das Check-Intervall auf 24 Stunden und den Check-Zeitraum auf 2:00 bis 2:01 Uhr an jedem Tag (also nur eine Minute pro Tag), dann wird Checkmk dafür sorgen, dass der Check auch wirklich in dieses kurze Zeitfenster verschoben wird.
Der Zustand der Services wird außerhalb des festgelegten Check-Zeitraums nicht mehr aktualisiert und die Services werden dann mit dem Symbol ![]() als veraltet (stale) gekennzeichnet.
Mit der globalen Einstellung Staleness value to mark hosts / services stale können Sie definieren, wie viel Zeit vergehen soll, bis ein Host/Service auf stale geht.
Diese Einstellung finden Sie unter Setup > General > Global settings > User interface:
als veraltet (stale) gekennzeichnet.
Mit der globalen Einstellung Staleness value to mark hosts / services stale können Sie definieren, wie viel Zeit vergehen soll, bis ein Host/Service auf stale geht.
Diese Einstellung finden Sie unter Setup > General > Global settings > User interface:
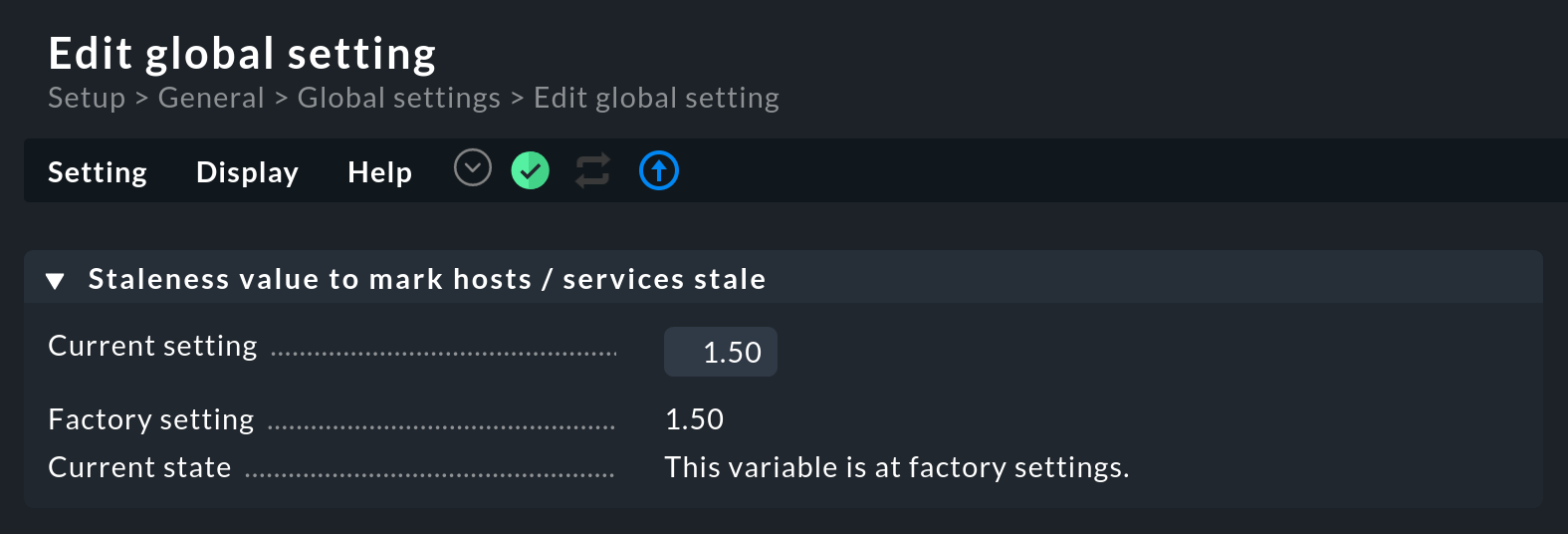
Dieser Faktor stellt das n-fache des Check-Intervalls dar. Ist also Ihr Check-Intervall auf eine Minute (60 Sekunden) eingestellt, so geht ein Service, für den es keine neuen Check-Ergebnisse gibt, nach der 1,5-fachen Zeit, somit nach 90 Sekunden, auf stale.
8.3. Check-Versuche anpassen
Mit Hilfe der Check-Versuche (check attempts) können Sie Benachrichtigungen bei sporadischen Fehlern vermeiden. Sie machen einen Check damit quasi weniger sensibel. Dazu können Sie die Regelsätze Maximum number of check attempts for host und Maximum number of check attempts for service nutzen.
Sind die Check-Versuche z.B. auf 3 eingestellt, und der entsprechende Service wird CRIT, dann wird zunächst noch keine Benachrichtigung ausgelöst. Erst wenn auch die nächsten beiden Checks ein Resultat liefern, das nicht OK ist, steigt die Nummer des aktuellen Versuchs auf 3 und die Benachrichtigung wird versendet.
Ein Service, der sich in diesem Zwischenzustand befindet — also nicht OK ist, aber die maximalen Anzahl der Check-Versuche noch nicht erreicht hat — hat einen „weichen Zustand“ (soft state). Nur ein „harter Zustand“ (hard state) löst eine Benachrichtigung aus.
9. Übersicht über die wichtigsten Host- und Service-Symbole
Folgende Tabelle gibt eine kurze Übersicht der wichtigsten Symbole, die Sie neben Hosts und Services finden:
|
Der Host oder der Service befindet sich in einer Wartungszeit. |
|
Services, deren Hosts sich in einer Wartung befinden, werden mit diesem Symbol gekennzeichnet. |
|
Dieser Host/Service ist gerade außerhalb seines Benachrichtigungszeitraums. |
|
Benachrichtigungen für diesen Host/Service sind gerade abgeschaltet. |
|
Checks dieses Services sind gerade abgeschaltet. |
|
Der Zustand dieses Hosts/Services ist veraltet (stale). |
|
Der Zustand dieses Hosts/Services ist unstetig (flapping). |
|
Dieser Host/Service hat ein Problem, das quittiert wurde. |
|
Zu diesem Host/Service gibt es einen Kommentar. |
|
Dieser Host/Service ist Teil eines BI-Aggregats. |
|
Hier gelangen Sie direkt zur Einstellung der Check-Parameter. |
|
Nur bei Logwatch-Services: Hier gelangen Sie zu den gespeicherten Log-Dateien. |
|
Hier gelangen Sie zum Zeitverlauf der aufgezeichneten Messwerte. |
|
Dieser Host besitzt HW-/SW-Inventurdaten. Ein Klickt bringt Sie zu deren Ansicht. |
|
Bei diesem Check ist ein Fehler aufgetreten. Über einen Klick können Sie einen Absturzbericht einsehen und absenden. |