1. Einleitung
1.1. Soll das Monitoring eingreifen?
Man möchte meinen, es sei offensichtlich, dass ein Monitoring-System niemals ins Geschehen eingreift, sondern eben nur überwacht. Und wahrscheinlich ist es auch eine gute Idee, es dabei zu belassen.
Nun ist es aber zugegeben eine verlockende Vorstellung, dass ein System, das zuverlässig Probleme erkennen kann, diese auch selbst behebt, sofern das automatisch geht.
Dafür finden sich leicht einige Beispiele:
Das Starten eines Dienstes, wenn dieser abgestürzt ist.
Das Auslösen eines Garbage Collectors, wenn der Speicher einer Java-VM knapp ist.
Das neue Aufbauen eines VPN-Kanals, wenn dieser definitiv tot ist.
Wer sich auf so etwas einlässt, muss natürlich Monitoring anders denken. Aus einem System, das einfach nur zuguckt und für den Betrieb „nicht notwendig“ ist, wird Schritt für Schritt ein lebenswichtiges Organ des Rechenzentrums.
Aber das Beheben von Problemen ist nicht das Einzige, was das Monitoring automatisiert tun kann, wenn es ein Problem feststellt. Ebenfalls sehr nützlich und gleichzeitig viel harmloser ist das Sammeln von zusätzlichen Diagnosedaten genau in dem Augenblick des Fehlers. Und sicher fallen Ihnen auf Anhieb noch etliche weitere Dinge ein, die Sie mit Alert Handlers anfangen können.
1.2. Alert Handlers in Checkmk
![]() Alert Handlers sind von Ihnen selbst geschriebene Skripte, die Checkmk in den kommerziellen Editionen für Sie ausführt, wenn ein Problem festgestellt wird — oder genauer ausgedrückt — wenn ein Host oder Service seinen Zustand ändert.
Alert Handlers sind von Ihnen selbst geschriebene Skripte, die Checkmk in den kommerziellen Editionen für Sie ausführt, wenn ein Problem festgestellt wird — oder genauer ausgedrückt — wenn ein Host oder Service seinen Zustand ändert.
Alert Handlers sind sehr ähnlich zu Benachrichtigungen und werden auch ähnlich konfiguriert, aber es gibt ein paar wichtige Unterschiede:
Alert Handlers sind unabhängig von Wartungszeiten, Benachrichtigungsperioden, Quittierungen und ähnlichen Einschränkungen.
Alert Handlers werden auch schon beim ersten Wiederholversuch aufgerufen (falls Sie mehrere Check-Versuche konfiguriert haben).
Alert Handlers sind unabhängig von Benutzern und Kontaktgruppen.
Alert Handlers gibt es nur in den kommerziellen Editionen.
Man kann auch sagen, dass Alert Handlers sehr „low level“ sind. Sobald ein Host oder Service seinen Status ändert, werden sofort die von Ihnen konfigurierten Alert Handlers aufgerufen. Auf diese Art kann ein Alert Handler auch erfolgreich etwas reparieren, bevor es überhaupt zu einem Alert kommt.
Natürlich können Sie — wie immer bei Checkmk — durch Regeln genaue Bedingungen festlegen, wann welcher Handler ausgeführt werden soll. Wie das geht und auch alles andere über Alert Handlers erfahren Sie in diesem Artikel.
![]() Ein Hinweis für Benutzer von
Ein Hinweis für Benutzer von ![]() Checkmk Community:
Auch Sie können das Monitoring automatisiert Aktionen ausführen lassen.
Verwenden Sie dazu die „Event Handlers“ von Nagios.
Konfigurieren Sie diese mit manuellen Konfigurationsdateien in Nagios-Syntax unterhalb von
Checkmk Community:
Auch Sie können das Monitoring automatisiert Aktionen ausführen lassen.
Verwenden Sie dazu die „Event Handlers“ von Nagios.
Konfigurieren Sie diese mit manuellen Konfigurationsdateien in Nagios-Syntax unterhalb von ~/etc/nagios/conf.d/.
Die Event Handlers sind gut dokumentiert.
Hinweise dazu finden Sie durch einfaches googeln.
2. Alert Handlers einrichten
2.1. Skripte in das richtige Verzeichnis legen
Alert Handlers sind Skripte, die auf dem Checkmk-Server ausgeführt werden.
Diese müssen im Verzeichnis ~/local/share/check_mk/alert_handlers/ liegen und können in jeder von Linux unterstützten Sprache geschrieben sein, z.B. in BASH, Python oder Perl.
Vergessen Sie nicht, die Skripte mit chmod +x ausführbar zu machen.
Wenn Sie im Skript in der zweiten Zeile einen Kommentar einfügen (mit einer Raute #), dann erscheint dieser als Name des Skripts in der Auswahlliste bei der Regel:
2.2. Ein einfacher Alert Handler zum Testen
Wie bei den Benachrichtigungen bekommt das Skript alle Informationen über den Host oder Service als Umgebungsvariablen, wobei diese hier alle mit dem Präfix ALERT_ beginnen.
Um zu testen, welche Umgebungsvariablen genau beim Skript ankommen, können Sie folgenden Alert Handler zum Testen verwenden:
envgibt alle Umgebungsvariablen aus.grep ^ALERT_wählt daraus diejenigen aus, die mitALERT_beginnen.sortsortiert dann die verbleibende Liste alphabetisch.
2.3. Alert Handler aktivieren
Die Aktivierung des Handlers erfolgt über Setup > Events > Alert handlers.
Gehen Sie wie folgt vor:
Legen Sie das obige Skript unter
~/local/share/check_mk/alert_handlers/debugab.Machen Sie es mit
chmod +x debugausführbar.Rufen Sie dann über Setup > Events die Konfiguration der Alert handlers auf.
Legen Sie dort mit Add rule eine neue Regel an.
Das Formular erlaubt eine direkte Auswahl des Alert Handlers.
Die zweite Zeile in dem ausgewählten Skript wird als Titel benutzt.
Zusätzlich können Sie Aufrufargumente mitgeben, die Sie in die Freitextfelder eintragen.
Diese kommen beim Skript als Befehlszeilenargumente an.
In der Shell können Sie darauf mit $1, $2 usw. zugreifen.

Nach dem Speichern der Regel ist der Alert Handler sofort wirksam und wird bei jeder Zustandsänderung irgendeines Hosts oder Services ausgeführt!
2.4. Test und Fehlerdiagnose
Zum Testen setzen Sie z.B. einen Service mit Fake check results von Hand auf CRIT. Nun sollte die Datei mit den Variablen angelegt worden sein. Hier die ersten 20 Zeilen davon:
Eine Log-Datei über die (Nicht-)Ausführung der Alert Handlers finden Sie unter ~/var/log/alerts.log.
Der Abschnitt für die Ausführung des Handlers debug für den Service Filesystem / auf dem Host myserver123 sieht etwa so aus:
2016-07-19 15:17:22 Got raw alert (myserver123;Filesystem /) context with 60 variables
2016-07-19 15:17:22 Rule ''...
2016-07-19 15:17:22 -> matches!
2016-07-19 15:17:22 Executing alert handler debug for myserver123;Filesystem /
2016-07-19 15:17:22 Spawned event handler with PID 6004
2016-07-19 15:17:22 1 running alert handlers:
2016-07-19 15:17:22 PID: 6004, object: myserver123;Filesystem /
2016-07-19 15:17:24 1 running alert handlers:
2016-07-19 15:17:24 PID: 6004, object: myserver123;Filesystem /
2016-07-19 15:17:24 Handler [6004] for myserver123;Filesystem / exited with exit code 0.
2016-07-19 15:17:24 Output:Noch einige nützliche Hinweise:
Texte, die der Alert Handler auf der Standardausgabe ausgibt, erscheinen in der Log-Datei neben
Output:.Auch der Exit Code des Skripts wird geloggt (
exited with exit code 0).Alert Handlers sind erst wirklich nützlich, wenn Sie auf dem Ziel-Host einen Befehl ausführen. Für Linux bietet Checkmk eine fertige Lösung, die weiter unten erklärt wird.
3. Regelbasierte Konfiguration
Wie im einführenden Beispiel gezeigt, legen Sie über Regeln fest, welche Ereignisse Alert Handlers auslösen sollen. Das Ganze funktioniert analog zu den Benachrichtigungen, nur etwas vereinfacht. Im Beispiel haben Sie überhaupt keine Bedingungen festgelegt, was in der Praxis natürlich unrealistisch ist. Folgendes Beispiel zeigt eine Bedingung, die einen Alert Handler für ganz bestimmte Hosts und Services festlegt:
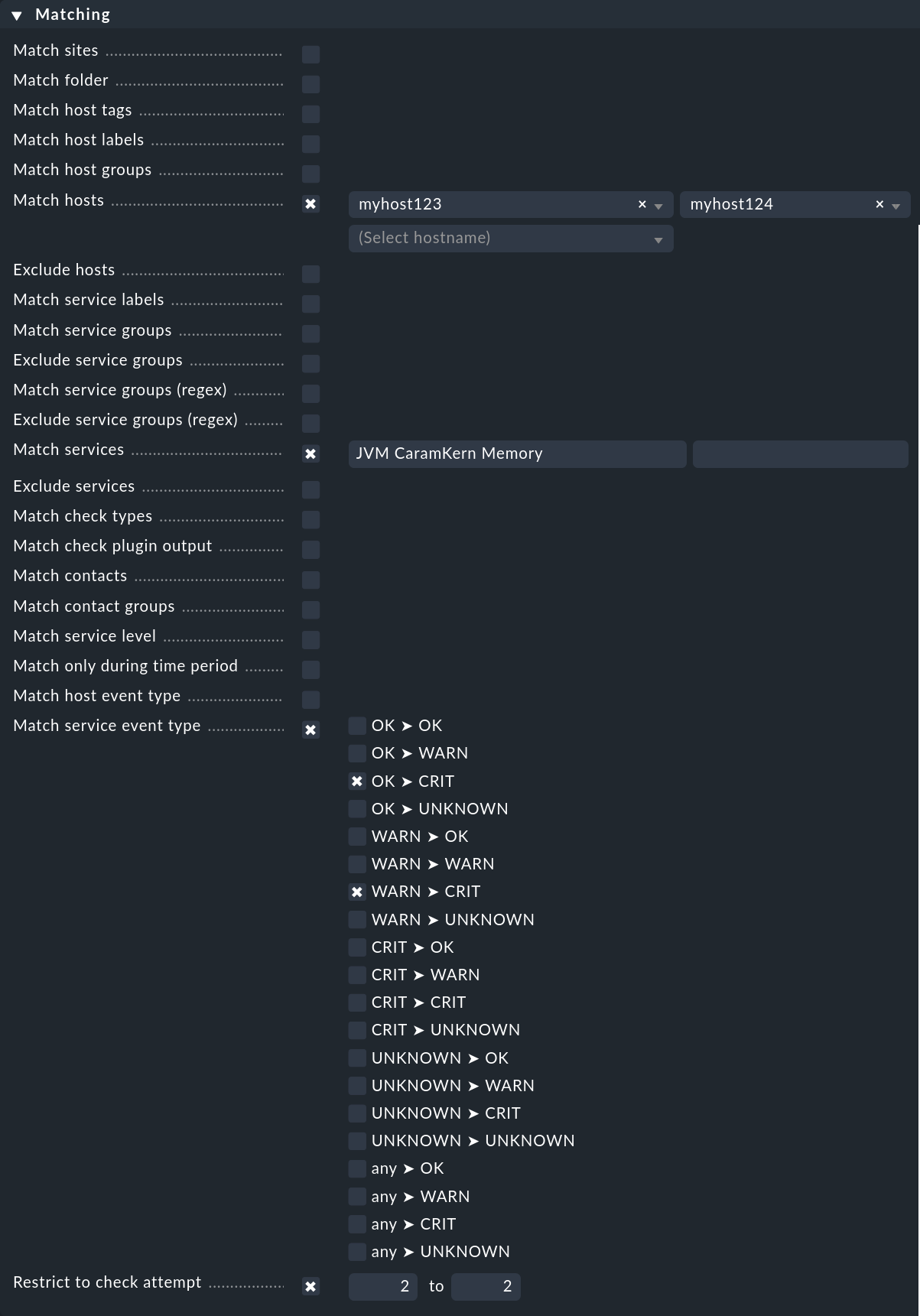
Der Alert Handler wird nur aufgerufen, wenn
einer der Hosts
myhost123odermyhost124betroffen ist,es um den Service
JVM CaramKern Memorygeht,der Zustand von OK oder WARN auf CRIT wechselt und
das alles beim zweiten Check-Versuch passiert.
Damit der Handler überhaupt aufgerufen wird, ist es in diesem Beispiel also notwendig, dass per Regel Maximum number of check attempts for service die Anzahl der Versuche mindestens auf 2 eingestellt wird. Um einen Alert im Falle eines erfolgreichen Garbage Collectors zu vermeiden, sollte die Anzahl auf 3 eingestellt werden. Denn wenn der Handler direkt nach dem zweiten Versuch das Problem beheben konnte, sollte der dritte Versuch wieder den Zustand OK feststellen und somit kein Alert mehr notwendig sein.
Anders als an anderen Stellen von Checkmk, wird bei den Alert Handlers jede Regel ausgeführt, deren Bedingung erfüllt ist. Sogar wenn zwei zutreffende Regeln jeweils den gleichen Handler auswählen, wird dieser also auch tatsächlich zweimal getriggert. Der Alert Helper (der im nächsten Kapitel beschrieben wird) wird dann die zweite Ausführung in der Regel wieder mit einer Fehlermeldung unterdrücken, da der gleiche Handler niemals mehrfach gleichzeitig laufen soll. Trotzdem ist es besser, wenn Sie Ihre Regeln so schreiben, dass dieser Fall nicht auftritt. |
4. Wie Alert Handlers ausgeführt werden
4.1. Asynchrone Ausführung
Sehr oft werden Alert Handlers dazu benutzt, sich remote per SSH oder einem anderen Protokoll auf der betroffenen Maschine anzumelden und dort skriptgesteuert eine Aktion auszuführen. Da die Maschine ja gerade ein Problem hat, ist es nicht ausgeschlossen, dass die Verbindung sehr lange dauert oder sogar in einen Timeout läuft.
Da während dieser Zeit natürlich weder das Monitoring stehen bleiben darf noch andere Alert Handlers aufgehalten werden dürfen, werden Alert Handlers grundsätzlich asynchron ausgeführt.
Verantwortlich dafür ist ein Hilfsprozess — der Alert Helper — welcher vom CMC automatisch gestartet wird.
Um Overhead zu vermeiden, geschieht dies allerdings nur, wenn Sie mindestens eine Regel für Alert Handlers angelegt haben.
Im cmc.log sehen Sie dann folgende Zeile:
2016-07-19 15:17:00 [5] Alert handlers have been switched onDer Alert Helper bekommt vom CMC bei jeder Zustandsänderung eines Hosts oder Services eine Benachrichtigung mit allen Informationen zu dem Ereignis. Nun wertet er alle Alert-Regeln aus und stellt so fest, ob ein Handler aufgerufen werden soll. Falls ja, wird das entsprechende Skript als externer Prozess gestartet und im Hintergrund ausgeführt.
4.2. Stoppen des Monitoring-Kerns
Wenn Sie den CMC stoppen (z.B. durch omd stop oder durch Herunterfahren des Monitoring-Servers), werden alle noch laufenden Alert Helper abgebrochen.
Diese werden später nicht wiederholt, denn wer weiß schon, wie viel später dieses „später“ sein wird.
Eventuell ist dann ein Neustart von einem Dienst oder dergleichen eher schädlich als nützlich!
4.3. Timeouts
Um sich im Fall eines Fehlers vor zu vielen Prozessen zu schützen, gilt für die Laufzeit eines Alert Handlers ein Timeout von (einstellbar) 60 Sekunden.
Nach Ablauf dieser Zeit wird der Handler beendet.
Im Detail heißt das, dass nach Ablauf des Timeouts ein Signal 15 (SIGTERM) an den Handler geschickt wird.
So hat dieser die Gelegenheit, sich sauber zu beenden.
Nach weiteren 60 Sekunden (doppelter Timeout) wird er dann mit Signal 9 (SIGKILL) endgültig „abgeschossen“.
4.4. Überlagerung
Checkmk verhindert die gleichzeitige Ausführung von Alert Helpers, wenn diese den gleichen Host/Service betreffen und das gleiche Skript mit den gleichen Parametern ausführen würden. So ein Fall deutet darauf hin, dass der erste Handler noch am Laufen ist und es keinen Sinn macht, einen zweiten gleichen Handler zu starten. Der zweite Handler wird dann sofort abgebrochen und als gescheitert gewertet.
4.5. Exit Codes und Ausgaben
Ausgaben und Exit Codes der Alert Handlers werden sauber ausgewertet, zum Kern zurück transportiert und dort in die Historie des Monitorings geschrieben. Außerdem können sie zu einer Benachrichtigung führen (siehe unten).
4.6. Globale Einstellungen
Für die Ausführung der Alert Handlers gibt es etliche globale Einstellungen:
![]](../images/alert_handlers_options.png)
Das Alert handler log level hingegen beeinflusst das Logging in der Alert Helper Log-Datei (~/var/log/alerts.log).
4.7. Master control

Mit einem Klick in das Snapin Master control können Sie Alert Handlers global deaktivieren. Bereits laufende Handlers sind davon nicht betroffen und werden noch fertig ausgeführt.
Vergessen Sie nicht, den kleinen Schalter beizeiten wieder auf grün zu stellen!
Sie könnten sich sonst zu Unrecht in Sicherheit wiegen, dass das Monitoring alles wieder repariert …
5. Alert Handlers in der Historie
Alert Handlers erzeugen Einträge in der Monitoring-Historie.
Damit haben Sie eine bessere Nachvollziehbarkeit, als allein durch die Log-Datei alerts.log.
Es wird ein Eintrag erzeugt, sobald ein Alert Handler gestartet wird und auch wenn er sich beendet.
Die Alert Handlers werden dabei so betrachtet wie klassische Monitoring-Plugins. Das heißt, sie sollen eine Zeile Text ausgeben und als Exit Code einen der vier Werte 0 (OK), 1 (WARN), 2 (CRIT) oder 3 (UNKNOWN) zurückgeben. Alle Fehler, die eine Ausführung des Handlers von vornherein verhindern (Abbruch wegen Doppelausführung, Skript nicht vorhanden, Timeout, etc.), werden automatisch mit UNKNOWN bewertet.
Der Aufruf von folgendem sehr einfachen Handler …
... sieht in der Historie des betroffenen Services dann z.B. so aus (wie immer sind die neuen Meldungen oben):
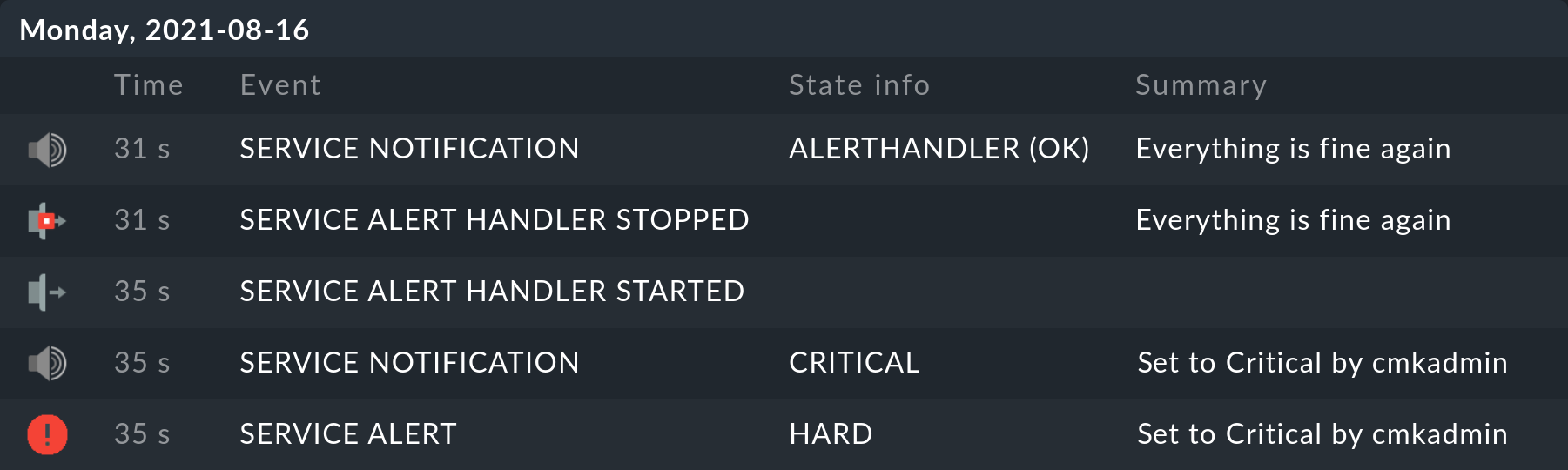
In der allgemeinen Ansicht Monitor > System > Alert handler executions werden zudem alle Ausführungen der Alert Handlers zusammen dargestellt.
6. Benachrichtigungen über Alert Handlers
Die Ausführung eines Alert Handlers — genauer gesagt die Beendigung der Ausführung — ist ein Ereignis, das zu einer Benachrichtigung führt. So können Sie sich informieren lassen, wenn ein Handler seine Arbeit verrichtet hat. Dazu gibt es zwei Ereignistypen, auf die Sie in einer Benachrichtigungsregel filtern können:
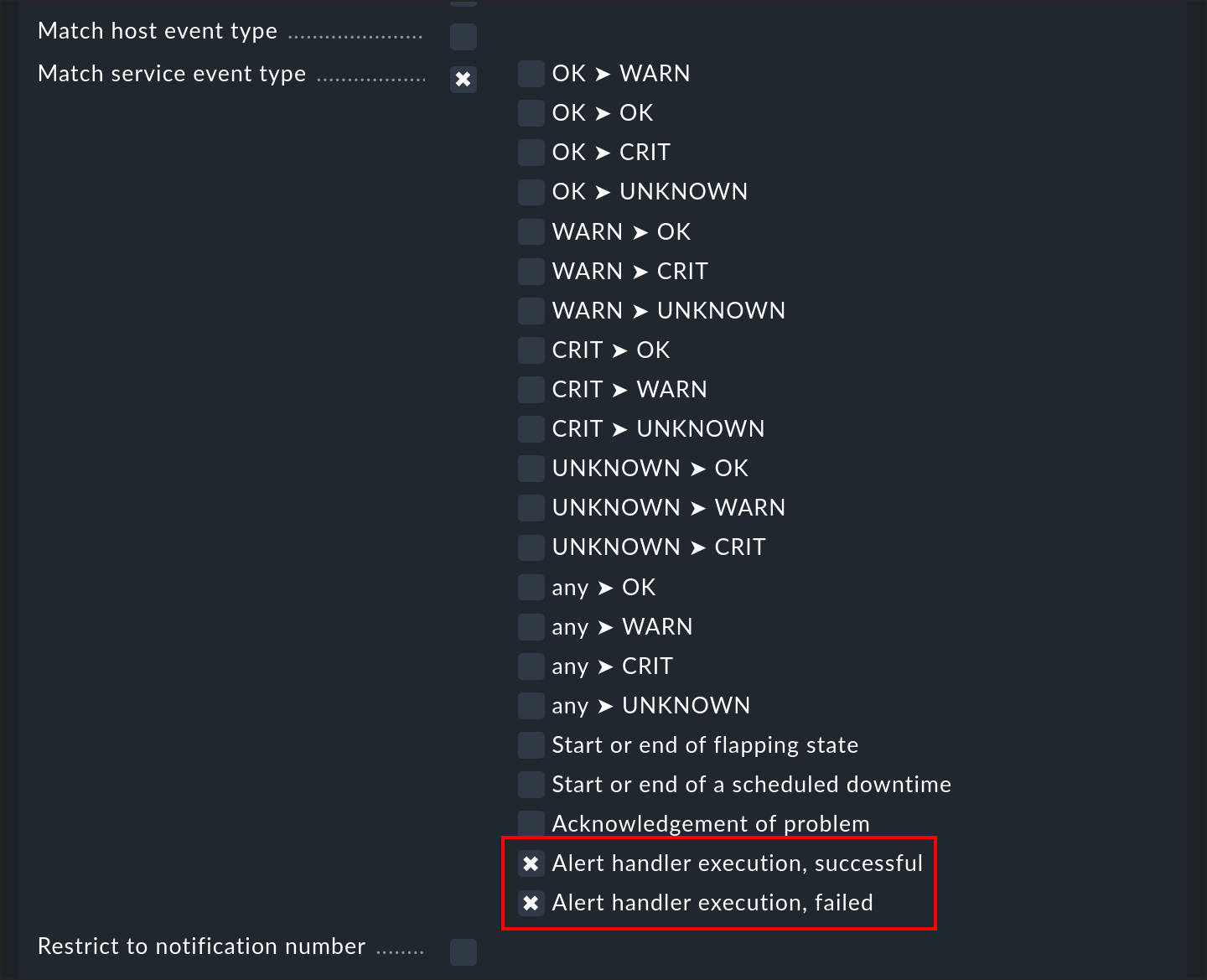
Sie können also auch zwischen erfolgreich ausgeführten Handlers (Exit Code 0 - OK) und gescheiterten (alle anderen Codes) unterscheiden. Die E-Mail-Benachrichtigung von Checkmk zeigt nicht die Ausgabe des Checks, sondern die Ausgabe des Alert Handlers.
7. Alert Handlers bei jeder Check-Ausführung
Normalerweise werden Alert Handlers nur aufgerufen, wenn sich der Zustand eines Hosts oder Services ändert (oder während der Wiederholversuche bei Problemen). Einfache Check-Ausführungen ohne Zustandsänderung lösen keinen Alert Handler aus.
Über die globale Einstellung Global settings > Alert handlers > Types of events that are being processed > All check executions! können Sie genau das umstellen. Jede Ausführung eines Checks löst dann potenziell Alert Handlers aus. Sie können das z.B. nutzen, um die laufenden Monitoring-Daten in andere Systeme zu übertragen.
Seien Sie mit dieser Einstellung vorsichtig! Das Starten von Prozessen und Aufrufen von Skripten sind sehr CPU-lastige Operationen. Checkmk kann spielend 1000 Checks pro Sekunde durchführen — aber 1000 Alert Handler-Skripte pro Sekunde schafft Linux ganz sicher nicht.
Um das Ganze dennoch sinnvoll möglich zu machen, bietet Checkmk die Möglichkeit, Alert Handlers als Python-Funktionen zu schreiben, welche dann inline laufen — ohne Prozesserzeugung. So einen Inline Handler legen Sie einfach im gleichen Verzeichnis ab wie die normalen Handler-Skripte. Folgendes funktionierendes Beispiel zeigt die Struktur eines Inline Handlers:
Das Skript hat keine Hauptfunktion, sondern definiert lediglich drei Funktionen.
Dabei ist nur die Funktion handle_alert() vorgeschrieben.
Sie wird nach jeder Check-Ausführung aufgerufen und bekommt im Argument context ein Python-Dictionary mit Variablen wie "HOSTNAME", "SERVICEOUTPUT" usw.
Dies entspricht den Umgebungsvariablen, die auch die normalen Handlers bekommen — allerdings ohne den Präfix ALERT_.
Sie können das Beispiel verwenden, um sich den Inhalt von context anzusehen.
Alle Ausgaben, die die Hilfsfunktion log() erzeugt, landen in ~/var/log/alert.log.
Die beiden globalen Variablen omd_root und omd_site sind gesetzt auf das Home-Verzeichnis bzw. den Namen der Checkmk-Instanz.
Die Funktionen handle_init() und handle_shutdown() werden von Checkmk beim Starten bzw. Stoppen des Monitoring-Kerns aufgerufen und ermöglichen Ihnen eine Initialisierung,
z.B. den Aufbau einer Verbindung zu einer Datenbank.
Weitere Hinweise:
Beachten Sie das
# Inline: yesin der zweiten Zeile.Nach jeder Änderung in dem Skript muss der Kern neu gestartet werden (
omd restart cmc).import-Befehle sind erlaubt.Der Alert Helper von Checkmk ruft Ihre Funktionen synchron auf. Achten Sie darauf, dass keine Wartezustände entstehen!
8. Remote-Ausführung unter Linux
8.1. Grundprinzipien
Jede Checkmk-Version bringt einen Alert Handler mit, der die sichere Ausführung von Skripten auf überwachten Linux-Systemen ermöglicht. Wichtigste Eigenschaften dieser Lösung sind:
Die Skripte werden per SSH mit Befehlsbeschränkung (command restriction) aufgerufen.
Es können keine beliebigen Befehle, sondern nur die von Ihnen definierten aufgerufen werden.
Das Ganze kann komplett mit der Agentenbäckerei aufgesetzt werden.
Die Linux Remote Alert Handlers bestehen aus folgenden Einzelteilen:
Der Alert Handler
linux_remotemit dem TitelLinux via SSHauf dem Checkmk-Server.Das Skript
mk-remote-alert-handlerauf dem Zielsystem.Von Ihnen geschriebene Skripte („Remote Handlers“) auf dem Zielsystem.
Einträge in
.ssh/authorized_keysdesjenigen Benutzers auf dem Zielsystem, der diese ausführen soll.Regeln in Setup > Agents > Windows, Linux, Solaris, AIX > Agent rules > Linux/UNIX agent options > Remote alert handlers (Linux), welche SSH-Schlüssel generieren.
Alert Handler-Regeln, welche
linux_remoteaufrufen.
8.2. Aufsetzen
Angenommen, Sie möchten auf dem Linux-System myserver123 das Skript /etc/init.d/foo restart ausführen, wann immer der Service Process FOO kritisch wird (welchen Sie bereits eingerichtet haben).
Gehen Sie wie folgt vor:
Remote Handler schreiben
Schreiben Sie zunächst das Skript, das auf dem Zielsystem ausgeführt werden soll.
Da Sie mit der Agentenbäckerei arbeiten, legen Sie das Skript auf dem Checkmk-Server an (nicht auf dem Zielsystem!).
Das korrekte Verzeichnis dafür ist ~/local/share/check_mk/agents/linux/alert_handlers.
Auch hier sorgt der Kommentar in der zweiten Zeile für einen Titel zur Auswahl in der Benutzeroberfläche:
Machen Sie das Skript ausführbar:
Das Beispielskript ist so gebaut, dass es sich im Fehlerfall mit dem Code 2 beendet, so dass der Alert Handler dies als CRIT werten wird.
Agentenpaket mit dem Handler vorbereiten
Wir beschreiben hier das Vorgehen mit der Agentenbäckerei. Hinweise für ein Aufsetzen von Hand finden Sie weiter unten.
Legen Sie eine Regel unter Setup > Agents > Windows, Linux, Solaris, AIX > Agent rules > Linux/UNIX agent options > Remote alert handlers (Linux) an.
Zur Erstellung dieser Regel benötigen Sie die Berechtigungen Rule sets und Add or modify executables.
In den Eigenschaften sehen Sie den Remote Handler Restart FOO service, den Sie gerade angelegt haben.
Wählen Sie diesen zur Installation aus:
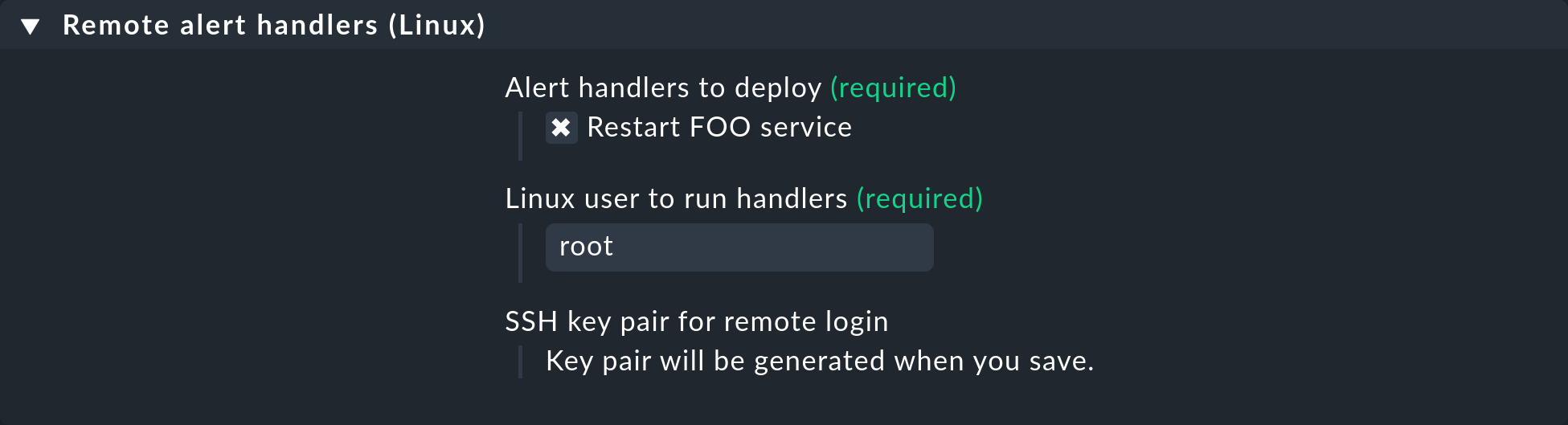
Nachdem Sie gespeichert haben, sehen Sie die Regel in der Liste: Es wurde automatisch ein SSH-Schlüsselpaar für den Aufruf des Handlers „ausgewürfelt“, dessen Fingerprint in der Regel angezeigt wird. In dem Screenshot wurde er aus Gründen der Darstellung gekürzt:
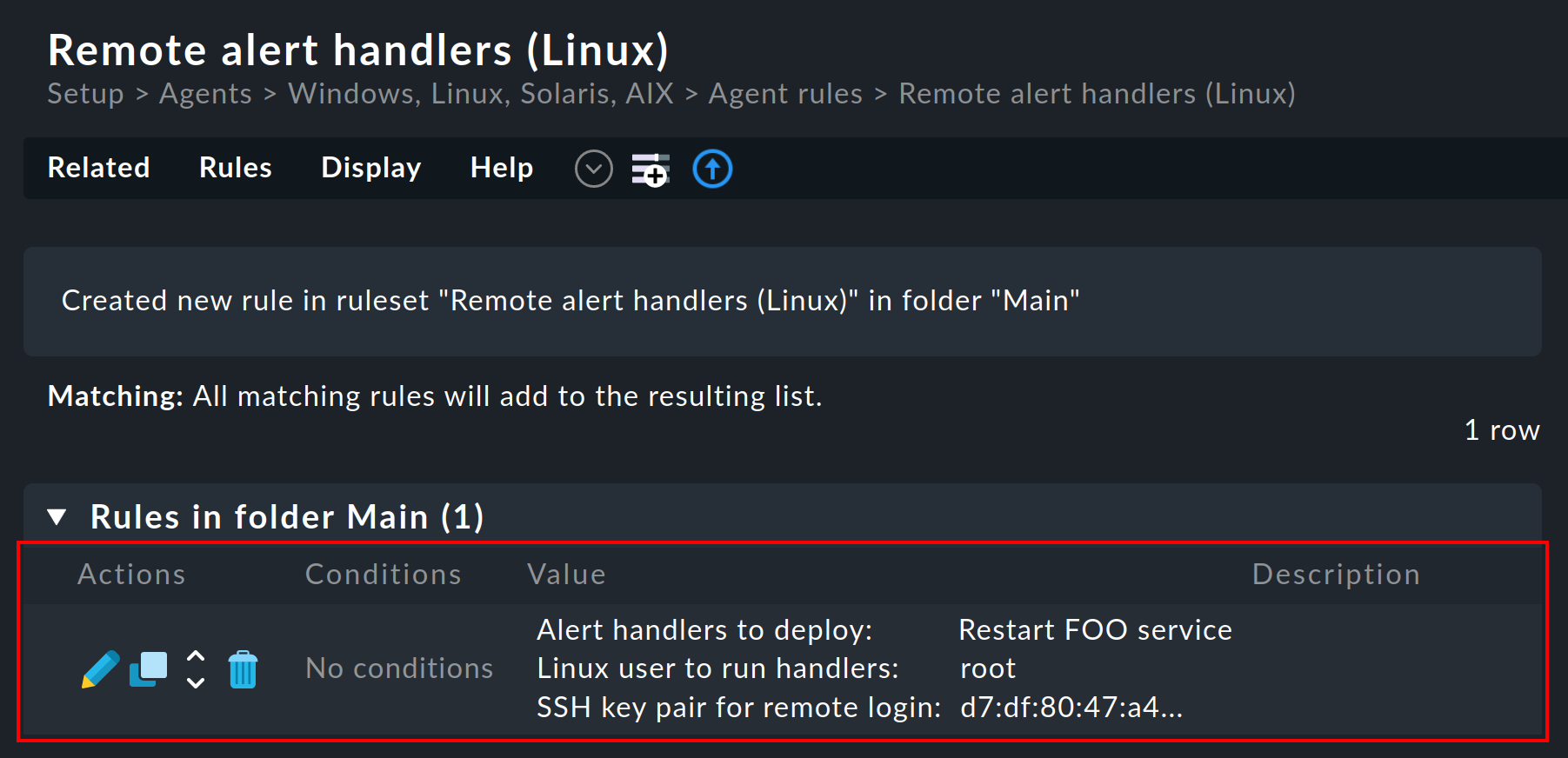
Der öffentliche Schlüssel ist für den Agenten vorgesehen. Der private Schlüssel wird vom Checkmk-Server später benötigt, um das so installierte Skript ohne Eingabe eines Passworts aufrufen zu können.
Sie können auch einen anderen Benutzer als root verwenden — natürlich nur, wenn dieser ausreichend Rechte für die benötigte Aktion hat.
Der Checkmk-Agent installiert den SSH-Schlüssel nur auf Systemen, auf denen dieser Benutzer bereits existiert.
Agent backen
Backen Sie nun neue Agenten mit ![]() .
In der Liste der fertigen Agenten muss nun ein Eintrag auftauchen, in dem Sie wieder Ihren Remote Handler und SSH-Schlüssel sehen.
Auch hier wurde der Screenshot — um die Anzahl der möglichen Pakete, die Sie herunterladen können — gekürzt:
.
In der Liste der fertigen Agenten muss nun ein Eintrag auftauchen, in dem Sie wieder Ihren Remote Handler und SSH-Schlüssel sehen.
Auch hier wurde der Screenshot — um die Anzahl der möglichen Pakete, die Sie herunterladen können — gekürzt:
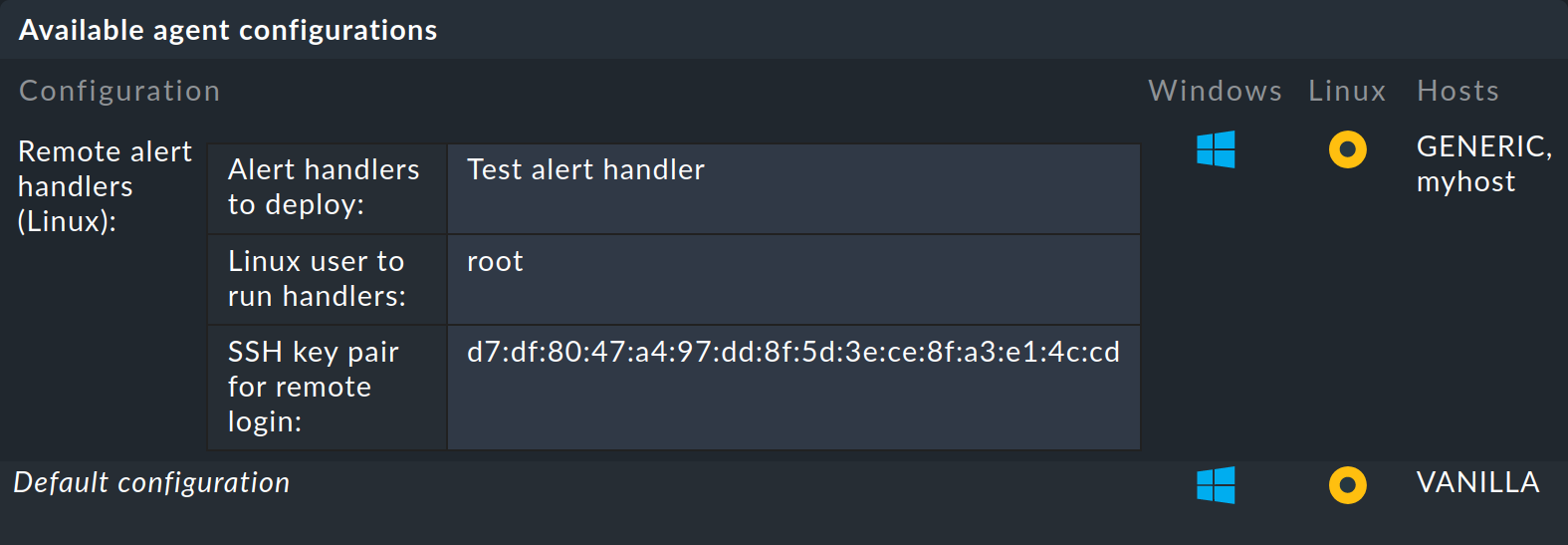
Agent installieren
Installieren Sie nun das RPM- oder DEB-Paket auf Ihrem Zielsystem (die Installation des TGZ-Archivs kann die SSH-Schlüssel nicht aufsetzen und ist deshalb unvollständig). Bei der Installation geschehen folgende Dinge:
Ihr Remote Handler-Skript wird installiert.
Das Hilfsprogramm
mk-remote-alert-handlerwird installiert.Beim gewählten Benutzer (hier
root) wird ein Eintrag inauthorized_keysgemacht, der die Ausführung des Handlers ermöglicht.Das Verzeichnis
.sshund die Dateiauthorized_keyswerden bei Bedarf automatisch angelegt.
Bei der Installation via DEB sieht das etwa so aus:
Ein Blick in die SSH-Konfiguration von root zeigt:
Beachten Sie noch, dass Ihr System eventuell so eingestellt ist, dass ein SSH-Zugriff als root generell nicht möglich ist.
In diesem Fall können Sie über einen anderen Benutzer gehen und dort mit sudo arbeiten, was so konfiguriert ist, dass der gewünschte Befehl ohne Passwort ausgeführt werden kann.
Handler per Regel aufrufen
Sie sind fast am Ziel.
Der Agent ist bereit.
Nun fehlt nur noch eine Regel, um den Alert Handler auch wirklich aufzurufen.
Das Vorgehen ist wie am Anfang dieses Artikels beschrieben und geschieht über das Anlegen einer entsprechenden Regel.
Wählen Sie als Handler dieses Mal Linux via SSH aus, tragen Sie den Benutzer ein, bei dem der SSH-Schlüssel installiert wurde, und wählen Sie Ihren Remote Handler aus:
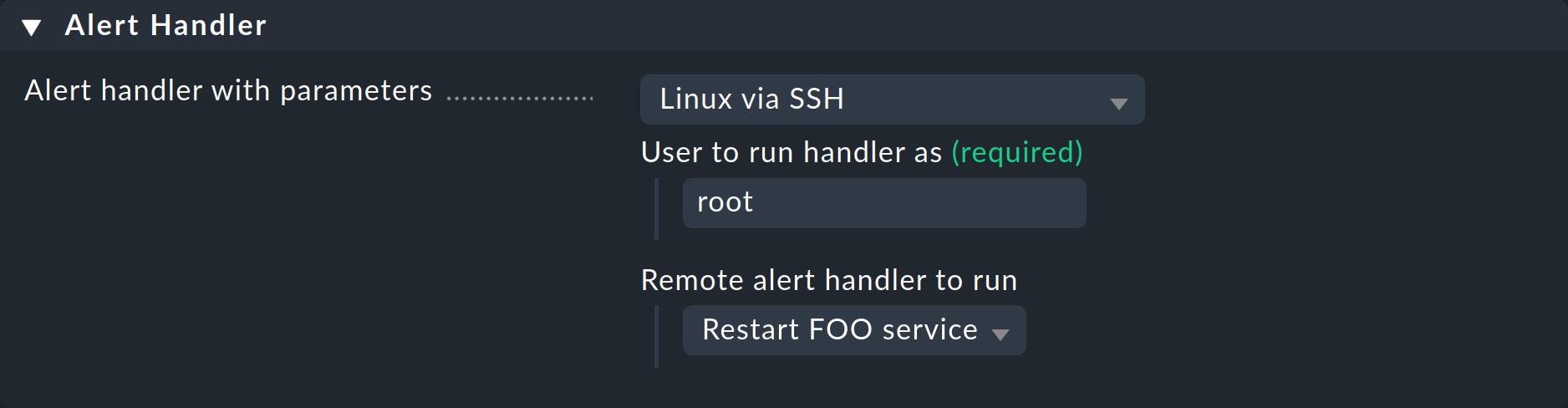
Setzen Sie auch eine sinnvolle Bedingung in der Regel, denn sonst wird bei jedem Service-Alert versucht, eine SSH-Verbindung zum Ziel-Host aufzubauen!
Test
Wenn Sie den betroffenen Service jetzt z.B. von Hand auf CRIT setzen, sehen Sie nach kurzer Zeit in der Historie des Services:
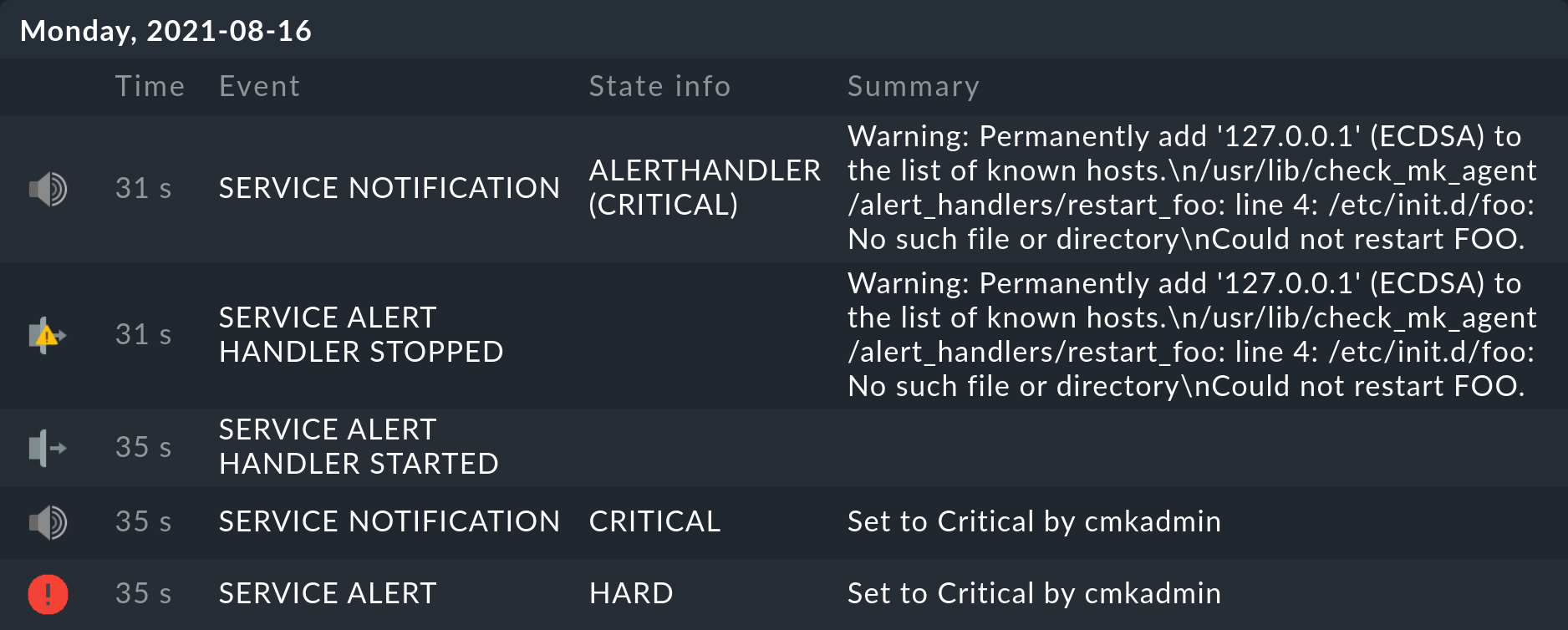
Da es natürlich keinen Dienst foo gibt, klappt auch /etc/init.d/foo restart nicht.
Aber Sie können daran sehen, dass dieser Befehl ausgeführt und auch der Fehlerstatus korrekt zurückgemeldet wurde.
Und Checkmk hat eine Benachrichtigung ausgelöst, da sich ein Alert Handler beendet hat.
Die Meldung Warning: Permanently added '127.0.0.1' (ECDSA) to the list of known hosts. ist übrigens harmlos und tritt nur beim ersten Kontakt mit dem Host auf.
Um den aufwendigen manuellen Austausch des Host Key zu vermeiden, wird SSH mit -o StrictHostKeyChecking=false aufgerufen.
Bei der ersten Verbindung wird der Schlüssel dann für die Zukunft gespeichert.
8.3. Aufsetzen ohne Agentenbäckerei
Ein Präparieren des Agenten von Hand geht natürlich auch. Für diesen Fall empfehlen wir, dass Sie auf einem Testsystem das Verfahren mit der Agentenbäckerei durchführen und sich dann die betroffenen Dateien ansehen und auf Ihrem System von Hand nachbauen. Eine Liste der Pfade finden Sie hier.
Wichtig dabei ist, dass Sie auch in diesem Fall in der Agentenbäckerei eine Regel für die Installation der Remote Handlers anlegen.
Denn in dieser Regel werden die SSH-Schlüssel für den Zugriff generiert und auch vom Alert Handler verwendet!
Den öffentlichen Schlüssel für die Installation in authorized_keys finden Sie in der Konfigurationsdatei ~/etc/check_mk/conf.d/wato/rules.mk (oder in rules.mk in einem Unterordner).
9. Dateien und Verzeichnisse
9.1. Pfade auf dem Checkmk-Server
| Pfad | Bedeutung |
|---|---|
|
Log-Datei mit allen Ereignissen rund um die Alert Handlers (vom Alert Helper geschrieben). |
|
Log-Datei des Kerns. Auch hier landen teilweise Informationen zu Alert Handlers. |
|
Legen Sie hier Ihre selbst geschriebenen Alert Handlers ab. |
|
Log-Datei der Monitoring-Historie, wird vom Kern geschrieben und auch ausgewertet. |
|
Remote Alert Handlers, die auf Linux-Systemen ausgeführt werden sollen. |
9.2. Pfade auf dem überwachten Linux-Host
| Pfad | Bedeutung |
|---|---|
|
Hilfsskript zur Ausführung der Remote Handlers. |
|
Von Ihnen geschriebene Remote Handlers. |
|
SSH-Konfiguration für den Benutzer |
|
SSH-Konfiguration für einen Benutzer |