1. Einleitung
Eine Benachrichtigung bedeutet, dass Benutzer im Falle von Problemen oder anderen Ereignissen im Monitoring von Checkmk aktiv informiert werden. Im häufigsten Fall geschieht das durch E-Mails. Es gibt aber auch viele andere Methoden, wie z.B. das Versenden von SMS oder die Weiterleitung an ein Ticketsystem. Checkmk bietet eine einfache Schnittstelle, um für eigene Benachrichtigungsmethoden Skripte zu schreiben.
Ausgangspunkt für jede Benachrichtigung an einen Benutzer ist ein vom Monitoring-Kern gemeldetes Ereignis. Wir nennen dies im Folgenden Monitoring-Ereignis, um Verwechslungen mit den Ereignissen zu vermeiden, die von der Event Console verarbeitet werden. Ein Monitoring-Ereignis bezieht sich immer auf einen bestimmten Host oder Service. Mögliche Typen von Monitoring-Ereignissen sind:
Ein Zustandswechsel, z.B. OK → WARN
Der Wechsel zwischen einem stetigen und einem
 unstetigen (flapping) Zustand
unstetigen (flapping) ZustandStart oder Ende einer
 Wartungszeit
WartungszeitDie
 Quittierung eines Problems durch einen Benutzer
Quittierung eines Problems durch einen BenutzerEine durch ein
 Kommando manuell ausgelöste Benachrichtigung
Kommando manuell ausgelöste BenachrichtigungDie Ausführung eines
 Alert Handlers
Alert HandlersEin Ereignis, das von der
 Event Console zur Benachrichtigung übergeben wurde
Event Console zur Benachrichtigung übergeben wurde
Checkmk verfügt über ein regelbasiertes System, mit dem Sie aus diesen Monitoring-Ereignissen Benutzerbenachrichtigungen erstellen lassen können, und mit dem Sie auch sehr anspruchsvolle Anforderungen umsetzen können. Eine einfache Benachrichtigung per E-Mail — wie sie in vielen Fällen zunächst völlig ausreicht — ist trotzdem schnell eingerichtet.
Dieser Artikel hier beschäftigt sich vor allem mit den Grundlagen und allgemeinen Dingen rund um das Thema Benachrichtigungen.
Wenn Sie stattdessen direkt mit der Umsetzung anfangen wollen: Checkmk unterscheidet generell zwei Formen der Einstellung von Benachrichtigungen. Einerseits werden die Regeln für Benachrichtigungen global definiert. Diese Regeln gelten ereignisabhängig für alle betroffenen Benutzer und Gruppen. Die Erstellung dieser Benachrichtigungen wird im im Artikel Benachrichtigungen per Regel einrichten beschrieben.
Gleichzeitig hat jeder Benutzer die Möglichkeit, die Einstellung der Benachrichtigungen individuell zu beeinflussen. So kann jemand zum Beispiel während einer Urlaubsperiode die Zustellung von Benachrichtigungen an die eigene Person deaktivieren. Wie diese persönlichen Einstellungen umgesetzt werden können, lesen Sie im Artikel Persönliche Benachrichtigungsregeln.
2. Benachrichtigen oder (noch) nicht benachrichtigen?
Grundsätzlich sind Benachrichtigungen optional und Sie können Checkmk durchaus auch ohne diese sinnvoll nutzen. Manche große Unternehmen haben eine Art Leitstand, in der das Monitoring-Team die Checkmk-Oberfläche ständig im Blick hat und keine zusätzlichen Benachrichtigungen benötigt. Wenn Sie noch im Aufbau Ihrer Checkmk-Umgebung sind, sollten Sie außerdem bedenken, dass Benachrichtigungen erst dann für Ihre Kollegen eine Hilfe sind, wenn keine oder nur selten Fehlalarme (false positives) produziert werden. Dazu müssen Sie erst einmal die Schwellwerte und alle anderen Einstellungen soweit im Griff haben, dass im Normalfall alle Zustände OK / UP sind oder mit anderen Worten: alles „grün“ ist.
Die Akzeptanz für das neue Monitoring ist schnell dahin, wenn es den Posteingang jeden Tag mit Hunderten nutzloser E-Mails flutet.
Folgendes Vorgehen hat sich bewährt:
Schritt 1: Feinjustieren Sie das Monitoring, indem Sie einerseits die durch Checkmk neu aufgedeckten, tatsächlichen Probleme beheben und andererseits Fehlalarme eliminieren. Tun Sie das, bis im Normalfall alles OK / UP ist. Im Leitfaden für Einsteiger finden Sie einige Empfehlungen, um typische Fehlalarme zu reduzieren.
Schritt 2: Schalten Sie Benachrichtigungen zunächst nur für sich selbst ein. Reduzieren Sie das „Rauschen“, welches durch sporadisch kurz auftretende Probleme verursacht wird. Passen Sie dazu weitere Schwellwerte an, nutzen Sie ggf. das prognosebasierte Monitoring, erhöhen Sie die Anzahl der Check-Versuche oder versuchen Sie es mit der verzögerten Benachrichtigung. Wenn es sich allerdings um tatsächliche Probleme handelt, sollten Sie deren Ursache finden, um sie in den Griff zu bekommen.
Schritt 3: Erst wenn in Ihrem eigenen Posteingang einigermaßen Ruhe eingekehrt ist, schalten Sie die Benachrichtigungen für Ihre Kollegen ein. Richten Sie dazu sinnvolle Kontaktgruppen ein, so dass jeder nur solche Benachrichtigungen bekommt, die ihn auch wirklich etwas angehen.
Das Ergebnis ist ein sehr nützliches System, das Ihnen und Ihren Kollegen hilft, mit relevanten Informationen Ausfallzeiten zu reduzieren.
3. Wann Benachrichtigungen erzeugt werden und wie man damit umgeht
3.1. Einleitung
Ein großer Teil der Komplexität im Benachrichtigungssystem von Checkmk liegt in den zahlreichen Tuning-Möglichkeiten, mit denen unwichtige Benachrichtigungen vermieden werden können. Die meisten davon betreffen Situationen, in denen bereits beim Auftreten der Monitoring-Ereignisse Benachrichtigungen verzögert oder unterdrückt werden. Auch gibt es eine im Monitoring-Kern eingebaute Intelligenz, die bestimmte Benachrichtigungen von Haus aus unterdrückt. Alle diese Aspekte wollen wir Ihnen in diesem Kapitel vorstellen.
3.2. Wartungszeiten
Während sich ein Host oder Service in einer Wartungszeit befindet, sind für dieses Objekt die Benachrichtigungen unterdrückt. Das ist — neben einer korrekten Berechnung von Verfügbarkeiten — der wichtigste Grund, warum man überhaupt eine Wartungszeit im Monitoring hinterlegt. Interessant sind dabei folgende Details:
Ist ein Host in Wartung, dann gelten automatisch auch alle seine Services als in Wartung, ohne dass man explizit eine Wartung für diese eintragen muss.
Endet die Wartungszeit eines Objekts, das während der Wartungszeit in einen Problemzustand gewechselt hat, dann werden für dieses Problem exakt beim Ablauf der Wartung nachträglich Benachrichtigungen ausgelöst.
Der Beginn und das Ende einer Wartungszeit selbst sind auch Monitoring-Ereignisse, für die Benachrichtigungen ausgelöst werden.
3.3. Benachrichtigungsperioden
Per Konfiguration können Sie für jeden Host und Service eine Benachrichtigungsperiode festlegen. Dies ist eine Zeitperiode, welche die Zeiträume festlegt, auf die Benachrichtigungen beschränkt werden sollen.
Die Konfiguration geschieht über die Regelsätze Notification period for hosts bzw. Notification period for services, die Sie schnell über die Suche im Setup-Menü finden können.
Ein Objekt, welches sich gerade nicht in seiner Benachrichtigungsperiode befindet, wird durch ein graues Pause-Zeichen ![]() markiert.
markiert.
Monitoring-Ereignisse zu einem Objekt, das sich gerade außerhalb seiner Benachrichtigungsperiode befindet, lösen keine Benachrichtigungen aus. Benachrichtigungen werden nachgeholt, wenn die Benachrichtigungsperiode wieder aktiv wird und der Host/Service sich immer noch in einem Problemzustand befindet. Dabei löst nur der jeweils letzte Zustand eine Benachrichtigung aus, auch wenn es außerhalb der Periode mehrere Zustandswechsel gab.
Übrigens gibt es auch bei den Benachrichtigungsregeln die Möglichkeit, Benachrichtigungen auf eine bestimmte Zeitperiode zu beschränken. Damit können Sie die Zeiträume zusätzlich einschränken. Allerdings werden Benachrichtigungen, die durch eine Regel mit Zeitbedingung verworfen wurden, später nicht automatisch nachgeholt!
3.4. Der Zustand des Hosts, auf dem ein Service läuft
Wenn ein Host komplett ausfällt oder zumindest für das Monitoring nicht erreichbar ist, können natürlich auch die Services des Hosts nicht mehr überwacht werden.
Aktive Checks werden dann in der Regel CRIT oder UNKNOWN, weil diese gezielt versuchen, den Host zu erreichen und dabei in einen Fehler laufen.
Alle anderen Checks — also die überwiegende Mehrheit — werden in so einem Fall ausgelassen und verharren in ihrem alten Zustand.
Sie werden mit der Zeit ![]() stale.
stale.
Natürlich wäre es sehr lästig, wenn alle Probleme von aktiven Checks in so einem Zustand Benachrichtigungen auslösen würden. Denn wenn z. B. ein Webserver nicht erreichbar ist — und dies auch schon als Benachrichtigung kommuniziert wurde --, wäre es wenig informativ, wenn nun auch für jeden einzelnen HTTP-Dienst, den dieser bereitstellt, eine E-Mail generiert würde.
Um dies zu vermeiden, erzeugt der Monitoring-Kern für Services grundsätzlich nur dann Benachrichtigungen, wenn der Host den Zustand UP hat. Das ist auch der Grund, warum die Erreichbarkeit von Hosts separat überprüft wird. Wenn Sie nichts anderes konfiguriert haben, geschieht dies durch einen Smart Ping bzw. Ping.
![]() Wenn Sie Checkmk Community verwenden (oder eine der kommerziellen Editionen mit Nagios als Kern), dann kann es in seltenen Fällen bei einem Host-Problem trotzdem zu einer Benachrichtigung aufgrund eines aktiven Services kommen.
Der Grund liegt darin, dass Nagios die Resultate von Host-Checks für eine kurze Zeit in der Zukunft als gültig betrachtet.
Wenn zwischen dem letzten erfolgreichen Ping an den Server und dem nächsten aktiven Check nur wenige Sekunden vergehen, kann es sein, dass Nagios den Host noch als UP wertet, obwohl dieser bereits DOWN ist.
Der Checkmk Micro Core (CMC) hingegen hält die Service-Benachrichtigung solange in Wartestellung, bis der Zustand des Hosts geklärt ist und vermeidet die unerwünschte Benachrichtigung so zuverlässig.
Wenn Sie Checkmk Community verwenden (oder eine der kommerziellen Editionen mit Nagios als Kern), dann kann es in seltenen Fällen bei einem Host-Problem trotzdem zu einer Benachrichtigung aufgrund eines aktiven Services kommen.
Der Grund liegt darin, dass Nagios die Resultate von Host-Checks für eine kurze Zeit in der Zukunft als gültig betrachtet.
Wenn zwischen dem letzten erfolgreichen Ping an den Server und dem nächsten aktiven Check nur wenige Sekunden vergehen, kann es sein, dass Nagios den Host noch als UP wertet, obwohl dieser bereits DOWN ist.
Der Checkmk Micro Core (CMC) hingegen hält die Service-Benachrichtigung solange in Wartestellung, bis der Zustand des Hosts geklärt ist und vermeidet die unerwünschte Benachrichtigung so zuverlässig.
3.5. Parent-Hosts
Stellen Sie sich vor, ein wichtiger Netzwerk-Router zu einem Unternehmensstandort mit Hunderten von Hosts fällt aus. Alle Hosts sind dann für das Monitoring nicht mehr erreichbar und gehen auf DOWN. Hunderte Benachrichtigungen werden ausgelöst. Nicht sehr schön.
Um das zu vermeiden, können Sie den Router als Parent-Host der Hosts definieren. Wenn es redundante Routen gibt, kann man auch mehrere Parents definieren. Sobald alle Parents auf DOWN gehen, werden die nicht mehr erreichbaren Hosts auf den Zustand UNREACH gesetzt und die darauf basierenden Benachrichtigungen werden unterdrückt. Das Problem mit dem Router selbst löst hingegen durchaus eine Benachrichtigung aus.
![]() Der CMC verhält sich intern übrigens geringfügig anders als Nagios.
Um Fehlalarme zu vermeiden, richtige Benachrichtigungen aber korrekt abzusetzen, achtet der CMC sehr genau auf die exakten Zeitpunkte der jeweiligen Host-Checks.
Scheitert ein Host-Check, so wartet der Kern zunächst das Ergebnis des Host-Checks der Parent-Hosts ab, bevor eine Benachrichtigung erzeugt wird.
Dieses Warten geschieht asynchron und ohne das übrige Monitoring zu beeinträchtigen.
Benachrichtigungen von Hosts können sich dadurch geringfügig verzögern.
Der CMC verhält sich intern übrigens geringfügig anders als Nagios.
Um Fehlalarme zu vermeiden, richtige Benachrichtigungen aber korrekt abzusetzen, achtet der CMC sehr genau auf die exakten Zeitpunkte der jeweiligen Host-Checks.
Scheitert ein Host-Check, so wartet der Kern zunächst das Ergebnis des Host-Checks der Parent-Hosts ab, bevor eine Benachrichtigung erzeugt wird.
Dieses Warten geschieht asynchron und ohne das übrige Monitoring zu beeinträchtigen.
Benachrichtigungen von Hosts können sich dadurch geringfügig verzögern.
4. Die Steuerung von Benachrichtigungen
4.1. Das Prinzip
Checkmk ist „ab Werk“ so eingerichtet, dass es bei einem Monitoring-Ereignis an jeden Kontakt des betroffenen Hosts oder Services eine Benachrichtigung per E-Mail versendet. Das ist sicher erst einmal sinnvoll, aber in der Praxis tauchen viele weitergehende Anforderungen auf, z. B.:
Unterdrücken bestimmter, wenig nützlicher Benachrichtigungen.
„Abonnieren“ von Benachrichtigungen zu Services, für die man kein Kontakt ist.
Benachrichtigen per E-Mail, SMS oder Pager, abhängig von der Tageszeit.
Eskalieren von Problemen nach einer bestimmten Zeit ohne Quittierung.
Eventuell keine Benachrichtigungen für WARN oder UNKNOWN erhalten.
Und vieles mehr …
Checkmk bietet Ihnen über einen regelbasierten Mechanismus maximale Flexibilität bei der Umsetzung solcher Anforderungen.
In der Benachrichtigungskonfiguration verwalten Sie die Kette der Benachrichtigungsregeln, welche festlegen, wer wie benachrichtigt werden soll. Bei jedem Monitoring-Ereignis wird diese Regelkette von oben nach unten durchlaufen. Jede Regel hat eine Bedingung, die entscheidet, ob die Regel überhaupt zur Anwendung kommt.
Ist die Bedingung erfüllt, legt die Regel zwei Dinge fest:
Eine Auswahl von Kontakten (Wer soll benachrichtigt werden?)
Eine Benachrichtigungsmethode (Wie soll benachrichtigt werden?), z. B. HTML-E-Mail, und dazu optional Parameter für die Methode
Wichtig: Anders als bei den Regeln für Hosts und Services geht die Auswertung hier auch nach einer zutreffenden Regel weiter. Die nachfolgenden Regeln können weitere Benachrichtigungen hinzufügen. Auch können Sie Benachrichtigungen wieder löschen, welche vorherige Regeln generiert haben.
Das Endergebnis der Regelauswertung ist eine Tabelle, die etwa folgenden Aufbau hat:
| Wer (Kontakt) | Wie (Methode) | Parameter der Methode |
|---|---|---|
Harry Hirsch |
|
|
Bruno Weizenkeim |
|
|
Bruno Weizenkeim |
SMS |
Nun wird pro Eintrag in dieser Tabelle das zur Methode gehörende Benachrichtigungsskript aufgerufen, welches die eigentliche Benutzerbenachrichtigung durchführt.
4.2. Benachrichtigungen abschalten
Per Regel abschalten
Über die Regelsätze Enable/disable notifications for hosts bzw. Enable/disable notifications for services können Sie Hosts und Services bestimmen, aufgrund derer grundsätzlich keine Benachrichtigungen erzeugt werden sollen. Wie oben erwähnt, unterbindet dann bereits der Kern die Benachrichtigungen. Eine Benachrichtigungsregel für ein „Abonnieren“ solcher Benachrichtigungen wäre wirkungslos, da diese ja gar nicht erzeugt werden.
Per Kommando abschalten
Es ist grundsätzlich möglich, die Benachrichtigungen bezogen auf einzelne Hosts und Services auch per Kommando vorübergehend abzuschalten.
Voraussetzung dafür ist allerdings, dass die Berechtigung Commands on host and services > Enable/disable notifications der Benutzerrolle zugewiesen ist. Standardmäßig ist dies für keine Rolle der Fall.
Mit zugewiesener Berechtigung können Sie Benachrichtigungen in den Host- oder Serviceansichten mit dem Kommando Commands > Enable/disable notifications abschalten (und später auch wieder einschalten):

Solche Hosts oder Services werden dann mit dem Symbol ![]() markiert.
markiert.
Da Kommandos im Gegensatz zu Regeln weder eine Konfigurationsberechtigung noch ein Aktivieren der Änderungen benötigen, können sie daher eine Lösung sein, um auf eine Situation schnell zu reagieren.
Wichtig: Im Gegensatz zu ![]() Wartungszeiten haben abgeschaltete Benachrichtigungen keinen Einfluss auf die Berechnung der Verfügbarkeit.
Wenn Sie also während eines ungeplanten Ausfalls einfach nur die Benachrichtigungen abschalten, aber Ihre Verfügbarkeitsberechnung nicht verfälschen möchten, sollten Sie keine Wartungszeiten dafür eintragen!
Wartungszeiten haben abgeschaltete Benachrichtigungen keinen Einfluss auf die Berechnung der Verfügbarkeit.
Wenn Sie also während eines ungeplanten Ausfalls einfach nur die Benachrichtigungen abschalten, aber Ihre Verfügbarkeitsberechnung nicht verfälschen möchten, sollten Sie keine Wartungszeiten dafür eintragen!
Global abschalten
Im Snapin Master control der Seitenleiste finden Sie einen Hauptschalter für die Benachrichtigungen (Notifications):

Dieser Schalter ist ausgesprochen nützlich, wenn Sie am System größere Änderungen vornehmen, durch die bei einem Fehler unter Umständen eine Vielzahl von Services auf CRIT geht. Sie ersparen sich so den Unmut Ihrer Kollegen über die vielen nutzlosen E-Mails. Vergessen Sie aber nicht, die Benachrichtigungen später wieder einzuschalten.
Im verteilten Monitoring gibt es diesen Schalter einmal pro Instanz. Ein Abschalten der Benachrichtigungen auf der Zentralinstanz lässt Benachrichtigungen auf den Remote-Instanzen weiterhin aktiviert — selbst wenn diese zur Zentralinstanz weitergeleitet und von dort zugestellt werden.
Wichtig: Benachrichtigungen, die angefallen wären, während die Benachrichtigungen abgeschaltet waren, werden beim Wiedereinschalten nicht nachgeholt.
4.3. Benachrichtigungen verzögern
Vielleicht haben Sie Services, die gelegentlich für kurze Zeit in einen Problemzustand gehen, der aber nur sehr kurz anhält und für Sie nicht kritisch ist. In solchen Fällen sind Benachrichtigungen sehr lästig, aber auch einfach zu unterdrücken. Dazu dienen die Regelsätze Delay host notifications und Delay service notifications.
Sie legen hier einen Zeitraum fest. Eine Benachrichtigung wird dann solange zurückgehalten, bis diese Zeit abgelaufen ist. Tritt vorher der OK / UP-Zustand wieder ein, so wird keine Benachrichtigung erzeugt. Natürlich bedeutet das aber dann auch, dass Sie im Falle eines wirklichen Problems erst mit einer Verzögerung benachrichtigt werden.
Viel besser als eine Verzögerung der Benachrichtigungen ist es natürlich, den eigentlichen Grund der sporadischen Probleme loszuwerden. Aber das ist eine andere Geschichte …
4.4. Mehrere Check-Versuche
Eine zur Verzögerung der Benachrichtigungen sehr ähnliche Methode ist es, mehrere Check-Versuche zu erlauben, wenn ein Service in einen Problemzustand geht. Dies geschieht über die Regelsätze Maximum number of check attempts for host bzw. Maximum number of check attempts for service.
Wenn Sie hier z. B. eine 3 einstellen, dann führt ein Check mit dem Resultat CRIT zunächst zu keiner Benachrichtigung.
Man spricht dann zunächst von einem weichen CRIT-Zustand (soft state).
Der harte Zustand (hard state) ist dann immer noch OK.
Erst wenn drei Versuche in Folge zu keinem OK-Zustand führen, wechselt der Service den harten Zustand und eine Benachrichtigung wird ausgelöst.
Im Gegensatz zur verzögerten Benachrichtigung haben Sie hier noch die Möglichkeit, sich Tabellenansichten zu definieren, welche solche Probleme ausblenden. Auch BI-Aggregate können so gebaut werden, dass nur die harten Zustände berücksichtigt werden, nicht die weichen.
4.5. Unstetige Hosts und Services
Wenn ein Host oder Service binnen kurzer Zeit mehrfach den Zustand ändert, so gilt er als unstetig (flapping). Dies ist sozusagen ein eigener Zustand. Die Idee dabei ist das Vermeiden von exzessiven Benachrichtigungen in Phasen, in denen ein Service nicht (ganz) stabil läuft. Auch in der Verfügbarkeitsberechnung können Sie solche Phasen speziell auswerten.
Unstetige Objekte werden mit dem Symbol ![]() markiert.
Während ein Objekt unstetig ist, erzeugen weitere Zustandswechsel keine Benachrichtigungen mehr.
Dafür wird aber jeweils eine Benachrichtigung ausgelöst, wenn das Objekt in den Zustand unstetig ein- oder austritt.
markiert.
Während ein Objekt unstetig ist, erzeugen weitere Zustandswechsel keine Benachrichtigungen mehr.
Dafür wird aber jeweils eine Benachrichtigung ausgelöst, wenn das Objekt in den Zustand unstetig ein- oder austritt.
Sie können die Erkennung von Unstetigkeiten auf folgende Arten beeinflussen:
Die Master control hat einen Hauptschalter für die Erkennung von Unstetigkeiten: Flap Detection
Über die Regelsätze Enable/disable flapping detection for hosts bzw. Enable/disable flapping detection for services können Sie Objekte von der Erkennung ausklammern.
In den kommerziellen Editionen können Sie mit Global settings > Monitoring core > Tuning of flap detection die Parameter der Unstetigkeitserkennung festlegen und sie mehr oder weniger empfindlich einstellen:

Blenden Sie die kontextsensitive Hilfe ein mit Help > Show inline help für Details zu den einstellbaren Werten.
5. Der Weg einer Benachrichtigung von Anfang bis Ende
5.1. Die Benachrichtigungshistorie
Zum Einstieg zeigen wir Ihnen, wie Sie sich in Checkmk die Historie der Benachrichtigungen auf Host- und Service-Ebene anzeigen lassen und so den Benachrichtigungsprozess nachverfolgen können.
Ein Monitoring-Ereignis, das Checkmk veranlasst, eine Benachrichtigung auszulösen, ist z. B. der Zustandswechsel eines Services. Diesen Zustandswechsel können Sie mit dem Kommando Fake check results zu Testzwecken manuell veranlassen.
Für einen Benachrichtigungstest können Sie einen Service auf diese Weise vom Zustand OK nach CRIT versetzen. Wenn Sie sich jetzt auf der Seite der Service-Details die Benachrichtigungen für diesen Service mit Service > Service notifications anzeigen lassen, sehen Sie die folgenden Einträge:
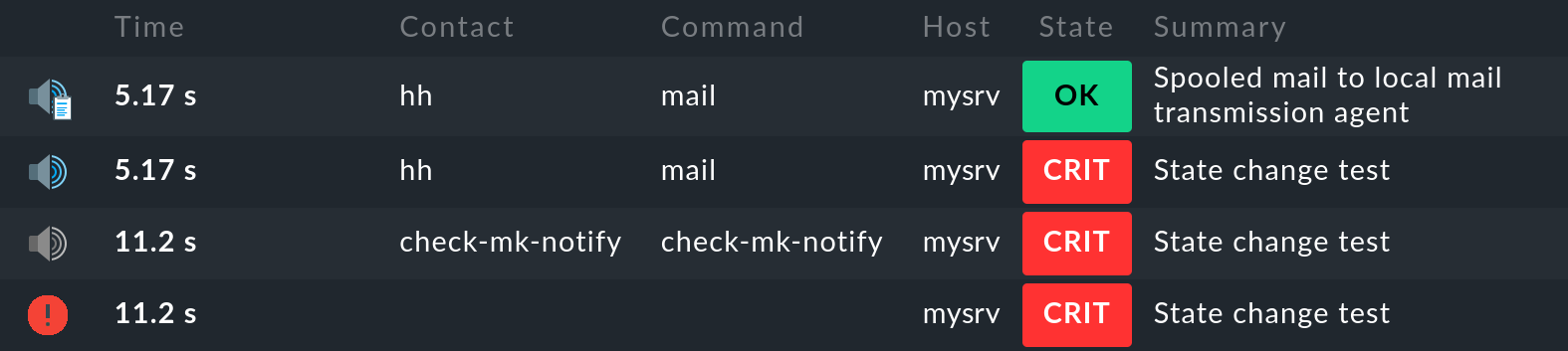
Der aktuellste Eintrag steht ganz oben in der Liste. Los ging es aber mit dem untersten, daher sehen wir uns die einzelnen Einträge von unten nach oben an:
Der Monitoring-Kern protokolliert das Monitoring-Ereignis des Zustandswechsels. Dabei zeigt das
 Symbol in der 1. Spalte den Zustand an (im Beispiel CRIT).
Symbol in der 1. Spalte den Zustand an (im Beispiel CRIT).Der Monitoring-Kern erzeugt eine
 Rohbenachrichtigung (raw notification).
Diese wird vom Kern an das Benachrichtigungsmodul übergeben, welches die Auswertung der Benachrichtigungsregeln durchführt.
Rohbenachrichtigung (raw notification).
Diese wird vom Kern an das Benachrichtigungsmodul übergeben, welches die Auswertung der Benachrichtigungsregeln durchführt.Die Auswertung der Regeln ergibt eine
 Benutzerbenachrichtigung (user notification) an den Benutzer
Benutzerbenachrichtigung (user notification) an den Benutzer hhmit der Methodemail.Das
 Benachrichtigungsergebnis (notification result) zeigt, dass die E-Mail erfolgreich an den SMTP-Server zur Auslieferung übergeben wurde.
Benachrichtigungsergebnis (notification result) zeigt, dass die E-Mail erfolgreich an den SMTP-Server zur Auslieferung übergeben wurde.
Um die Zusammenhänge von allen Einstellmöglichkeiten und Rahmenbedingungen genau zu verstehen und um eine sinnvolle Fehlerdiagnose zu ermöglichen, wenn mal eine Benachrichtigung nicht wie erwartet erfolgt oder ausbleibt, beschreiben wir im Folgenden alle Einzelheiten zum Ablauf einer Benachrichtigung mit allen beteiligten Komponenten.
Die Benachrichtigungshistorie, die wir oben für einen Service gezeigt haben, können Sie sich auch für einen Host anzeigen lassen: auf der Seite der Host-Details im Menü Host für den Host selbst (Menüeintrag Notifications of host) und auch für den Host mit all seinen Services (Notifications of host & services). |
5.2. Die Komponenten
Im Benachrichtigungssystem von Checkmk sind folgende Komponenten beteiligt:
| Komponente | Aufgabe | Log-Datei |
|---|---|---|
Nagios |
Monitoring-Kern von |
|
Monitoring-Kern der kommerziellen Editionen, der die gleiche Aufgabe erfüllt wie Nagios in Checkmk Community. |
|
|
Benachrichtigungsmodul |
Auswertung der Benachrichtigungsregeln, um aus einer Rohbenachrichtigung eine Benutzerbenachrichtigung zu erzeugen. Das Modul ruft die Benachrichtigungsskripte auf. |
|
Benachrichtigungs-Spooler (nur kommerzielle Editionen) |
Asynchrone Zustellung von Benachrichtigungen und zentralisierte Benachrichtigungen in verteilten Umgebungen. |
|
Benachrichtigungsskript |
Für jede Benachrichtigungsmethode gibt es ein Skript, welches die eigentliche Zustellung durchführt (z.B. eine HTML-E-Mail generiert und versendet). |
|
5.3. Der Monitoring-Kern
Rohbenachrichtigungen
Wie oben beschrieben, beginnt jede Benachrichtigung mit einem Monitoring-Ereignis im Monitoring-Kern. Wenn alle Bedingungen erfüllt sind und es grünes Licht für eine Benachrichtigung gibt, erzeugt der Kern eine Rohbenachrichtigung an den internen Hilfskontakt check-mk-notify. Die Rohbenachrichtigung enthält noch keine Angabe zu den eigentlichen Kontakten oder der Benachrichtigungsmethode.
In der Benachrichtigungshistorie des Services sieht eine Rohbenachrichtigung so aus:

Das Symbol ist ein
hellgrauer Lautsprecher.Als Kontakt wird
check-mk-notifyangegeben.Als Befehl wird
check-mk-notifyangegeben.
Die Rohbenachrichtigung geht dann an das Benachrichtigungsmodul von Checkmk, welches die Auswertung der Benachrichtigungsregeln übernimmt.
Dieses Modul wird von Nagios als externes Programm aufgerufen (cmk --notify).
Der CMC hält das Modul als permanenten Hilfsprozess in Bereitschaft (notification helper) und vermeidet so das Erzeugen von Prozessen, um Rechenzeit zu sparen.
Fehlerdiagnose im Monitoring-Kern Nagios
![]() Der in
Der in ![]() Checkmk Community verwendete Nagios-Kern protokolliert alle Monitoring-Ereignisse nach
Checkmk Community verwendete Nagios-Kern protokolliert alle Monitoring-Ereignisse nach ~/var/log/nagios.log.
Diese Datei ist gleichzeitig der Ort, wo die Benachrichtigungshistorie gespeichert wird, welche Sie auch in der GUI abfragen, wenn Sie z.B. die Benachrichtigungen eines Hosts oder Services sehen möchten.
Interessanter sind aber die Meldungen in der Datei ~/var/nagios/debug.log, welche Sie bekommen, wenn Sie in etc/nagios/nagios.d/logging.cfg die Variable debug_level auf 32 setzen.
Nach einem Core-Neustart …
… finden Sie nützliche Informationen über Gründe, warum Benachrichtigungen erzeugt oder unterdrückt wurden:
[1592405483.152931] [032.0] [pid=18122] ** Service Notification Attempt ** Host: 'localhost', Service: 'backup4', Type: 0, Options: 0, Current State: 2, Last Notification: Wed Jun 17 16:24:06 2020
[1592405483.152941] [032.0] [pid=18122] Notification viability test passed.
[1592405485.285985] [032.0] [pid=18122] 1 contacts were notified. Next possible notification time: Wed Jun 17 16:51:23 2020
[1592405485.286013] [032.0] [pid=18122] 1 contacts were notified.Fehlerdiagnose im Monitoring-Kern CMC
![]() In den kommerziellen Editionen finden Sie in der Log-Datei
In den kommerziellen Editionen finden Sie in der Log-Datei ~/var/log/cmc.log ein Protokoll des Monitoring-Kerns.
In der Standardeinstellung enthält dies keine Angaben zu Benachrichtigungen.
Sie können aber ein sehr detailliertes Logging einschalten, mit Global settings > Monitoring Core > Logging of the notification mechanics.
Der Kern gibt dann darüber Auskunft, warum er ein Monitoring-Ereignis für die Benachrichtigung an das Benachrichtigungsmodul weitergibt oder warum (noch) nicht:
Hinweis: Das eingeschaltete Logging zu Benachrichtigungen kann sehr viele Meldungen erzeugen. Es ist aber nützlich, wenn man später die Frage beantworten will, warum in einer bestimmten Situation keine Benachrichtigung erzeugt wurde.
5.4. Regelauswertung durch das Benachrichtigungsmodul
Nachdem der Kern eine Rohbenachrichtigung erzeugt hat, durchläuft diese die Kette der Benachrichtigungsregeln. Resultat ist die Benachrichtigungstabelle. Neben den Daten aus der Rohbenachrichtigung enthält jede Benutzerbenachrichtigung folgende zusätzliche Informationen:
Der Kontakt, der benachrichtigt werden soll
Die Methode für die Benachrichtigung
Die Parameter für diese Methode
Bei einer synchronen Zustellung wird jetzt pro Eintrag in der Tabelle das passende Benachrichtigungsskript aufgerufen. Bei einer asynchronen Zustellung wird die Benachrichtigung per Datei an den Benachrichtigungs-Spooler übergeben.
Analyse der Regelkette
Wenn Sie komplexere Regelwerke erstellen, stehen Sie sicher gelegentlich vor der Frage, welche Regeln denn nun für eine bestimmte Benachrichtigung greifen. Dazu bietet Checkmk unter Setup > Setup > Analyze recent notifications eine eingebaute Analysefunktion.
Im Analysemodus werden Ihnen standardmäßig die letzten zehn Rohbenachrichtigungen angezeigt, die das System erzeugt hat und welche die Regeln durchlaufen haben:
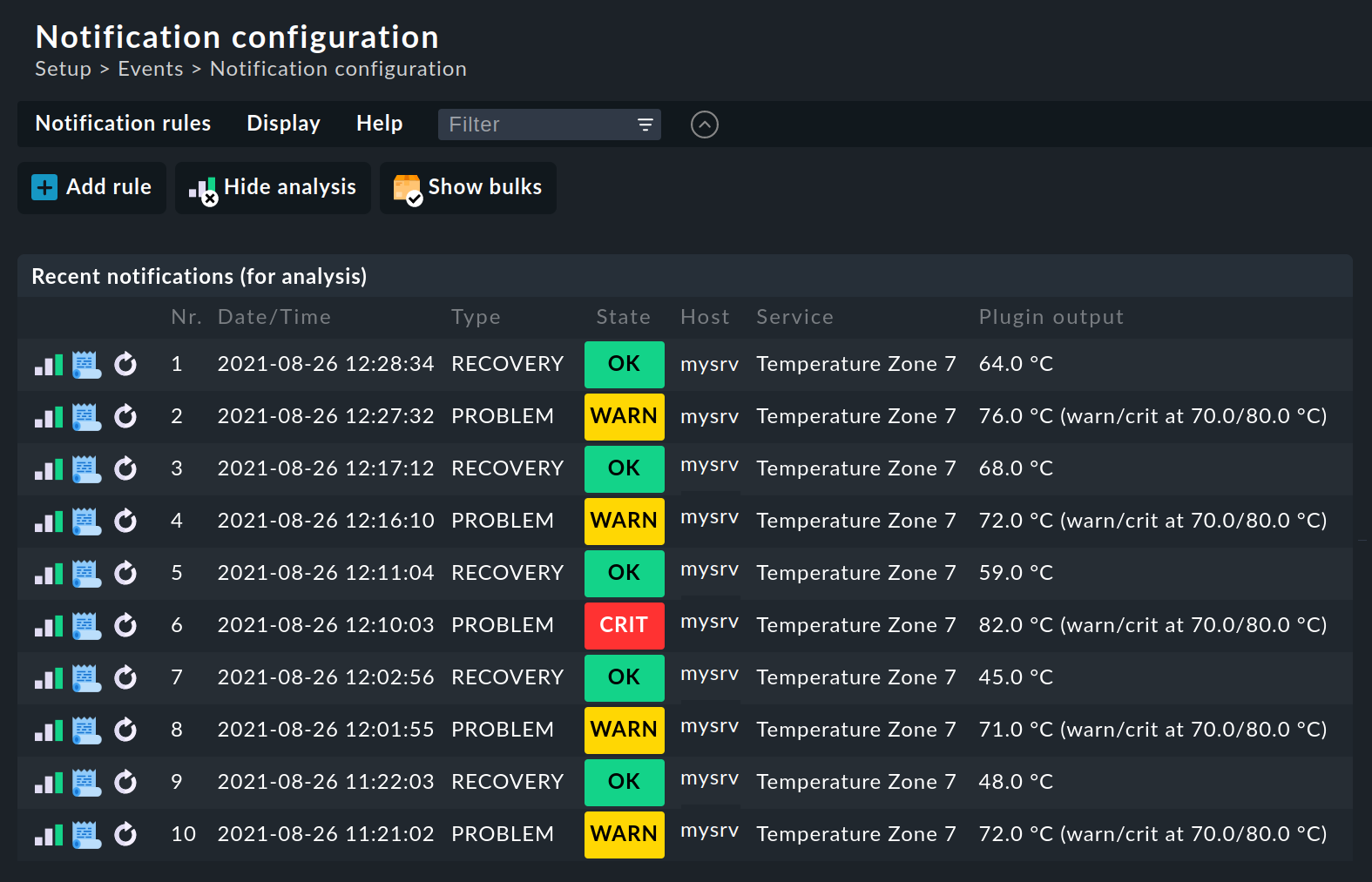
Sollten Sie für Ihre Analyse eine größere Menge an Rohbenachrichtigungen benötigen, können Sie die Anzahl über Global settings > Notifications > Store notifications for rule analysis erhöhen:

Für jede dieser Rohbenachrichtigungen stehen Ihnen drei Aktionen zur Verfügung:
|
Test der Regelkette, in dem für jede Regel geprüft wird, ob das Monitoring-Ereignis alle Bedingungen der Regel erfüllen würde. Im Anschluss an die Regeln wird dann die daraus resultierende Benachrichtigungstabelle angezeigt. |
|
Anzeige des kompletten Benachrichtigungskontexts. |
|
Wiederholung der Rohbenachrichtigung, als wäre das Monitoring-Ereignis jetzt aufgetreten. Ansonsten ist die Anzeige gleich wie bei der Analyse. Damit können Sie nicht nur die Bedingungen der Regel überprüfen, sondern auch testen, wie eine Benachrichtigung dann aussieht. |
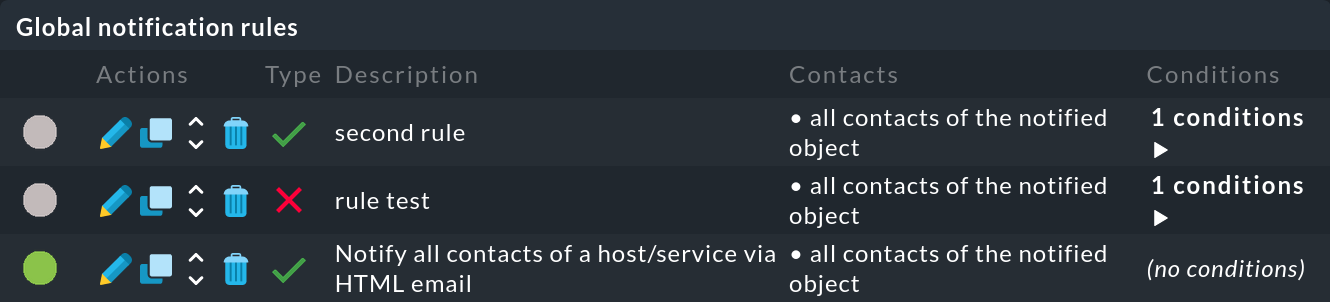
Fehlerdiagnose
Haben Sie den Test der Regelkette (![]() ) durchgeführt, so sehen Sie, welche Regeln auf ein Monitoring-Ereignis
) durchgeführt, so sehen Sie, welche Regeln auf ein Monitoring-Ereignis ![]() angewendet oder eben auch
angewendet oder eben auch ![]() nicht angewendet wurden:
nicht angewendet wurden:
Wurde eine Regel nicht angewendet, bewegen Sie die Maus über den grauen Kreis, um den Hinweistext (Mouse-Over-Text) zu sehen:
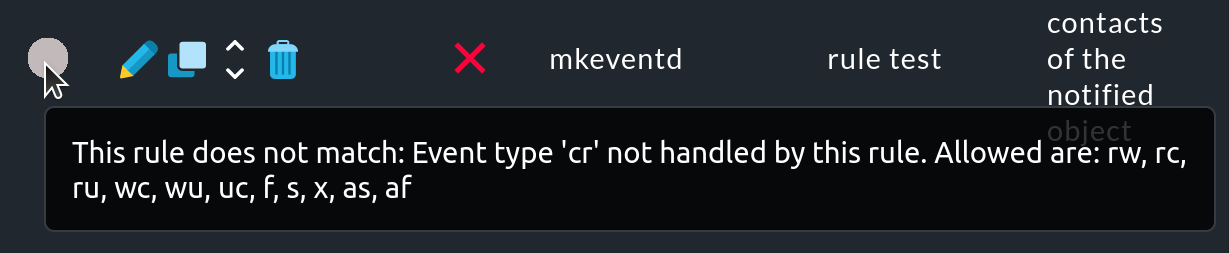
Dieser Mouse-Over-Text verwendet jedoch für die Ursachen einer nicht angewendeten Regel Abkürzungen. Diese beziehen sich auf die Bedingungen Host events bzw. Service events der Regel.
| Ereignistypen für Hosts | ||
|---|---|---|
Kürzel |
Bedeutung |
Beschreibung |
|
UP ➤ DOWN |
Setzt den Host-Zustand von UP auf DOWN |
|
UP ➤ UNREACHABLE |
Setzt den Host-Zustand von UP auf UNREACH |
|
DOWN ➤ UP |
Setzt den Host-Zustand von DOWN auf UP |
|
DOWN ➤ UNREACHABLE |
Setzt den Host-Zustand von DOWN auf UNREACH |
|
UNREACHABLE ➤ DOWN |
Setzt den Host-Zustand von UNREACH auf DOWN |
|
UNREACHABLE ➤ UP |
Setzt den Host-Zustand von UNREACH auf UP |
|
any ➤ UP |
Setzt jeden beliebigen Host-Zustand auf UP |
|
any ➤ DOWN |
Setzt jeden beliebigen Host-Zustand auf DOWN |
|
any ➤ UNREACHABLE |
Setzt jeden beliebigen Host-Zustand auf UNREACH |
|
Start or end of flapping state |
Anfang oder Ende eines unstetigen Zustands |
|
Start or end of a scheduled downtime |
Anfang oder Ende einer Wartungszeit |
|
Acknowledgment of problem |
Quittierung eines Problems |
|
Alert handler execution, successful |
Erfolgreiche Ausführung eines Alert Handlers |
|
Alert handler execution, failed |
Gescheiterte Ausführung eines Alert Handlers |
| Ereignistypen für Services | ||
|---|---|---|
Kürzel |
Bedeutung |
Beschreibung |
|
OK ➤ WARN |
Setzt den Service-Zustand von OK auf WARN |
|
OK ➤ OK |
Setzt den Service-Zustand von OK auf OK |
|
OK ➤ CRIT |
Setzt den Service-Zustand von OK auf CRIT |
|
OK ➤ UNKNOWN |
Setzt den Service-Zustand von OK auf UNKNOWN |
|
WARN ➤ OK |
Setzt den Service-Zustand von WARN auf OK |
|
WARN ➤ CRIT |
Setzt den Service-Zustand von WARN auf CRIT |
|
WARN ➤ UNKNOWN |
Setzt den Service-Zustand von WARN auf UNKNOWN |
|
CRIT ➤ OK |
Setzt den Service-Zustand von CRIT auf OK |
|
CRIT ➤ WARN |
Setzt den Service-Zustand von CRIT auf WARN |
|
CRIT ➤ UNKNOWN |
Setzt den Service-Zustand von CRIT auf UNKNOWN |
|
UNKNOWN ➤ OK |
Setzt den Service-Zustand von UNKNOWN auf OK |
|
UNKNOWN ➤ WARN |
Setzt den Service-Zustand von UNKNOWN auf WARN |
|
UNKNOWN ➤ CRIT |
Setzt den Service-Zustand von UNKNOWN auf CRIT |
|
any ➤ OK |
Setzt jeden beliebigen Service-Zustand auf OK |
|
any ➤ WARN |
Setzt jeden beliebigen Service-Zustand auf WARN |
|
any ➤ CRIT |
Setzt jeden beliebigen Service-Zustand auf CRIT |
|
any ➤ UNKNOWN |
Setzt jeden beliebigen Service-Zustand auf UNKNOWN |
Basierend auf diesen Hinweisen können Sie Ihre Regeln prüfen und überarbeiten.
Eine weitere wichtige Diagnosemöglichkeit ist die Log-Datei ~/var/log/notify.log.
Während Tests mit den Benachrichtigungen bietet sich dazu der beliebte Befehl tail -f an:
Mit Global settings > Notifications > Notification log level können Sie die Ausführlichkeit der Meldungen in drei Stufen steuern. Wenn Sie Full dump of all variables and command auswählen, so finden Sie in der Log-Datei eine komplette Auflistung aller Variablen, die dem Benachrichtigungsskript bereitgestellt werden:

Dies sieht dann z.B. so aus (Auszug):
2025-04-09 08:47:39,186 [10] [cmk.base.notify] Raw context:
CONTACTS=hh
HOSTACKAUTHOR=
HOSTACKCOMMENT=
HOSTADDRESS=127.0.0.1
HOSTALIAS=localhost
HOSTATTEMPT=1
HOSTCHECKCOMMAND=check-mk-host-smart5.5. Asynchrone Zustellung durch Benachrichtigungs-Spooler
![]() Eine mächtige Zusatzfunktion der kommerziellen Editionen ist der Benachrichtigungs-Spooler.
Dieser ermöglicht eine asynchrone Zustellung von Benachrichtigungen.
Was bedeutet asynchron in diesem Zusammenhang?
Eine mächtige Zusatzfunktion der kommerziellen Editionen ist der Benachrichtigungs-Spooler.
Dieser ermöglicht eine asynchrone Zustellung von Benachrichtigungen.
Was bedeutet asynchron in diesem Zusammenhang?
Synchrone Zustellung: Das Benachrichtigungsmodul wartet, bis das Benachrichtigungsskript fertig ausgeführt wurde. Sollte dies eine längere Ausführungszeit haben, stauen sich weitere Benachrichtigungen auf. Wird das Monitoring angehalten, gehen diese Benachrichtigungen verloren. Außerdem kann sich bei vielen Benachrichtigungen in kurzer Zeit ein Rückstau bis zum Kern bilden, so dass das Monitoring dadurch ins Stocken gerät.
Asynchrone Zustellung: Jede Benachrichtigung wird in einer Spool-Datei unter
~/var/check_mk/notify/spoolabgelegt. Es kann sich kein Stau bilden. Bei einem Stopp des Monitorings bleiben die Spool-Dateien erhalten und Benachrichtigungen werden später korrekt zugestellt. Das Abarbeiten der Spool-Dateien übernimmt der Benachrichtigungs-Spooler.
Eine synchrone Zustellung ist dann vertretbar, wenn das Benachrichtigungsskript schnell läuft und vor allem nicht in irgendeinen Timeout geraten kann. Bei Benachrichtigungsmethoden, die auf vorhandene Spooler zurückgreifen, ist das gegeben. Insbesondere bei E-Mail und SMS kommen Spool-Dienste vom System zum Einsatz. Das Benachrichtigungsskript übergibt eine Datei an den System-Spooler, wobei keine Wartezustände auftreten können.
Bei Verwendung der nachvollziehbaren Zustellung per SMTP oder anderer Skripte, welche Netzwerkverbindungen aufbauen, sollten Sie auf jeden Fall die asynchrone Zustellung einstellen. Dazu gehören auch Skripte, welche per HTTP Textnachrichten (SMS) über das Internet versenden. Die Timeouts bei der Verbindung zu einem Netzwerkdienst können bis zu mehrere Minuten lang sein und den oben beschriebenen Stau auslösen.
Die gute Nachricht: Die asynchrone Zustellung ist in Checkmk standardmäßig aktiviert.
Zum einen wird der Benachrichtigungs-Spooler (mknotifyd) beim Start der Instanz mitgestartet, was Sie mit dem folgenden Befehl überprüfen können:
Zum anderen ist in den globalen Einstellungen (Global settings > Notifications > Notification Spooling) die asynchrone Zustellung (Asynchronous local delivery by notification spooler) ausgewählt:

Fehlerdiagnose
Der Benachrichtigungs-Spooler pflegt eine eigene Log-Datei: ~/var/log/mknotifyd.log.
Diese verfügt über drei Log-Levels, die Sie unter Global settings > Notifications > Notification Spooler Configuration mit dem Parameter Verbosity of logging auswählen können.
Der Default steht auf Normal logging (only startup, shutdown and errors.
Bei der mittleren Stufe, Verbose logging (also spooled notifications), können Sie das Bearbeiten der Spool-Dateien sehen:
2025-04-09 08:47:37,928 [15] [cmk.mknotifyd] processing spoolfile: /omd/sites/mysite/var/check_mk/notify/spool/dad64e2e-b3ac-4493-9490-8be969a96d8d
2025-04-09 08:47:37,928 [20] [cmk.mknotifyd] running cmk --notify --log-to-stdout spoolfile /omd/sites/mysite/var/check_mk/notify/spool/dad64e2e-b3ac-4493-9490-8be969a96d8d
2025-04-09 08:47:39,848 [20] [cmk.mknotifyd] got exit code 0
2025-04-09 08:47:39,850 [20] [cmk.mknotifyd] processing spoolfile dad64e2e-b3ac-4493-9490-8be969a96d8d successful: success 250 - b'2.4.0 Ok: queued as 1D4FF7F58F9'
2025-04-09 08:47:39,850 [20] [cmk.mknotifyd] sending command LOG;SERVICE NOTIFICATION RESULT: hh;mysrv;CPU load;OK;mail;success 250 - b'2.4.0 Ok: queued as 1D4FF7F58F9';success 250 - b'2.0.0 Ok: queued as 1D4FF7F58F9'6. Nachvollziehbare Zustellung per SMTP
6.1. E-Mail ist nicht zuverlässig
![]() Das Monitoring ist nur nützlich, wenn man sich auch darauf verlassen kann.
Dazu gehört, dass Benachrichtigungen zuverlässig und zeitnah ankommen.
Nun ist die Zustellung von E-Mails hier leider nicht ganz ideal.
Denn der Versand geschieht üblicherweise durch Übergabe der E-Mail an den lokalen SMTP-Server.
Dieser versucht dann die E-Mail selbständig und asynchron zuzustellen.
Das Monitoring ist nur nützlich, wenn man sich auch darauf verlassen kann.
Dazu gehört, dass Benachrichtigungen zuverlässig und zeitnah ankommen.
Nun ist die Zustellung von E-Mails hier leider nicht ganz ideal.
Denn der Versand geschieht üblicherweise durch Übergabe der E-Mail an den lokalen SMTP-Server.
Dieser versucht dann die E-Mail selbständig und asynchron zuzustellen.
Bei einem vorübergehenden Fehler (z.B. falls der empfangende SMTP-Server nicht erreichbar ist) wird die E-Mail in eine Warteschlange versetzt und später ein erneuter Zustellversuch gestartet. Dieses „später“ ist dann in der Regel frühestens in 15-30 Minuten. Aber dann kann die Benachrichtigung eventuell schon viel zu spät sein!
Ist die E-Mail gar nicht zustellbar, so erzeugt der SMTP-Server eine hübsche Fehlermeldung in seiner Log-Datei und versucht, an den „Absender“ eine E-Mail über die gescheiterte Zustellung zu generieren. Aber das Monitoring-System ist kein richtiger Absender und kann auch keine E-Mails empfangen. In der Folge gehen solche Fehler dann einfach unter und Benachrichtigungen bleiben aus.
6.2. SMTP auf direktem Weg ermöglicht Fehlerauswertung
Die kommerziellen Editionen bieten die Möglichkeit einer nachvollziehbaren Zustellung per SMTP. Dabei wird bewusst auf eine Hilfe des lokalen Mailservers verzichtet. Anstelle dessen sendet Checkmk selbst die E-Mail direkt via SMTP zu Ihrem Smarthost und wertet die SMTP-Antwort auch selbst aus.
Dabei werden nicht nur SMTP-Fehler intelligent behandelt, es wird auch eine korrekte Zustellung genau protokolliert. Es ist ein bisschen wie ein Einschreiben: Checkmk bekommt quasi vom SMTP-Smarthost (empfangender Server) eine Quittung, dass die E-Mail übernommen wurde — inklusive einer Mail-ID.
Die praktische Einrichtung von Benachrichtigungen mit nachvollziehbarer Zustellung per SMTP finden Sie in den globalen Benachrichtigungsregeln und den persönlichen Benachrichtigungsregeln beschrieben.
6.3. SMS und andere Benachrichtigungsmethoden
Eine synchrone Zustellung inklusive Fehlermeldung und Nachvollziehbarkeit ist aktuell nur für HTML-E-Mails implementiert. Wie Sie in einem eigenen Benachrichtigungsskript einen Fehlerstatus zurückgeben können, erfahren Sie im Kapitel über das Schreiben von eigenen Skripten.
7. Benachrichtigungen in verteilten Systemen
In verteilten Umgebungen — also solchen mit mehr als einer Checkmk-Instanz — stellt sich die Frage, was mit Benachrichtigungen geschehen soll, die auf Remote-Instanzen erzeugt werden. Hier gibt es grundsätzlich zwei Möglichkeiten:
Lokale Zustellung
Zentrale Zustellung auf der Zentralinstanz (nur kommerzielle Editionen)
Einzelheiten dazu finden Sie im Artikel über das verteilte Monitoring.
8. Benachrichtigungsskripte
8.1. Das Prinzip
Benachrichtigungen können auf sehr vielfältige und individuelle Weise geschehen. Typische Fälle sind:
Übergabe von Benachrichtigungen an ein Ticket- oder externes Benachrichtigungssystem
Versand von SMS über verschiedene Internetdienste
Automatisierte Anrufe
Weiterleitung an ein übergeordnetes Monitoring-System
Aus diesem Grund bietet Checkmk eine sehr einfache Schnittstelle, mit der Sie selbst eigene Benachrichtigungsskripte schreiben können. Sie können diese in jeder von Linux unterstützten Programmiersprache schreiben — auch wenn Shell, Perl und Python zusammen hier sicher 95 % „Marktanteil“ haben.
Die von Checkmk mitgelieferten Skripte liegen unter ~/share/check_mk/notifications.
Dieses Verzeichnis ist Teil der Software und nicht für Änderungen vorgesehen.
Legen Sie eigene Skripte stattdessen in ~/local/share/check_mk/notifications ab.
Achten Sie darauf, dass sie ausführbar sind (chmod +x).
Sie werden dann automatisch gefunden und bei den Benachrichtigungsregeln als Methode zur Auswahl angeboten.
Möchten Sie ein mitgeliefertes Skript anpassen, so kopieren Sie es einfach von ~/share/check_mk/notifications nach ~/local/share/check_mk/notifications und machen dort Ihre Änderungen.
Wenn Sie dabei den Dateinamen beibehalten, ersetzt Ihr Skript automatisch die Originalversion und Sie müssen keine bestehenden Benachrichtigungsregeln anpassen.
Im Falle einer Benachrichtigung wird Ihr Skript mit den Rechten des Instanzbenutzers aufgerufen.
In Umgebungsvariablen, die mit NOTIFY_ beginnen, bekommt das Skript alle Informationen über den betreffenden Host/Service, das Monitoring-Ereignis, den zu benachrichtigenden Kontakt und die Parameter, die in der Benachrichtigungsregel angegeben wurden.
Texte, die das Skript in die Standardausgabe schreibt (mit print, echo, etc.), erscheinen in der Log-Datei des Benachrichtigungsmoduls ~/var/log/notify.log.
8.2. Nachvollziehbare Benachrichtigungen
Benachrichtigungsskripte haben die Möglichkeit, über den Exit Code mitzuteilen, ob ein wiederholbarer Fehler aufgetreten ist oder ein endgültiger:
| Exit Code | Bedeutung |
|---|---|
|
Das Skript wurde erfolgreich ausgeführt. |
|
Ein temporärer Fehler ist aufgetreten. Die Ausführung soll nach kurzer Zeit erneut probiert werden, bis die konfigurierte maximale Anzahl von Versuchen erreicht ist. Beispiel: HTTP-Verbindung zu SMS-Dienst konnte nicht aufgebaut werden. |
|
Ein endgültiger Fehler ist aufgetreten. Die Benachrichtigungen werden nicht wiederholt. Auf der GUI wird ein Benachrichtigungsfehler angezeigt. Der Fehler wird in der Historie des Hosts/Services angezeigt. Beispiel: der SMS-Dienst meldet den Fehler „Ungültige Authentifizierung“. |
Zudem wird in allen Fällen die Standardausgabe des Benachrichtigungsskripts zusammen mit dem Status in die Benachrichtigungshistorie des Hosts/Services eingetragen und ist somit über die GUI sichtbar.
Wichtig: Für Bulk-Benachrichtigungen steht die nachvollziehbare Benachrichtigung nicht zur Verfügung!
![]() Die Behandlung von Benachrichtigungsfehlern aus Sicht des Benutzers wird im Kapitel über die nachvollziehbare Zustellung per SMTP erklärt.
Die Behandlung von Benachrichtigungsfehlern aus Sicht des Benutzers wird im Kapitel über die nachvollziehbare Zustellung per SMTP erklärt.
8.3. Ein einfaches Beispielskript
Als Beispiel können Sie ein Skript erstellen, das alle Informationen zu der Benachrichtigung in eine Datei schreibt. Als Sprache kommt die Bash Linux-Shell zum Einsatz:
Danach machen Sie das Skript ausführbar:
Hier einige Erklärungen zum Skript:
In der ersten Zeile stehen
#!und der Pfad zum Interpreter der Skriptsprache (hier/bin/bash).In der zweiten Zeile steht nach dem Kommentarzeichen
#ein Titel für das Skript. Dieser wird bei der Auswahl der Benachrichtigungsmethode in der Regel angezeigt.Der Befehl
envgibt alle Umgebungsvariablen aus, die das Skript bekommen hat.Mit
grep NOTIFY_werden die Variablen von Checkmk herausgefiltert …… und mit
sortalphabetisch sortiert.> $OMD_ROOT/tmp/foobar.outschreibt das Ergebnis in die Datei~/tmp/foobar.outim Instanzverzeichnis.Das
exit 0wäre an dieser Stelle eigentlich überflüssig, da die Shell immer den Exit Code des letzten Befehls übernimmt. Dieser ist hierechound immer erfolgreich. Aber explizit ist immer besser.
8.4. Beispielskript testen
Damit das Skript verwendet wird, müssen Sie es in einer Benachrichtigungsregel als Methode einstellen.
Selbst geschriebene Skripte haben keine Parameterdeklaration.
Daher fehlen die ganzen Checkboxen, wie sie z.B. bei der Methode HTML Email angeboten werden.
Anstelle dessen können Sie eine Liste von Texten als Parameter angeben, die dem Skript als NOTIFY_PARAMETER_1, NOTIFY_PARAMETER_2 usw. bereitgestellt werden.
Für den Test übergeben Sie die Parameter Fröhn, Klabuster und Feinbein:
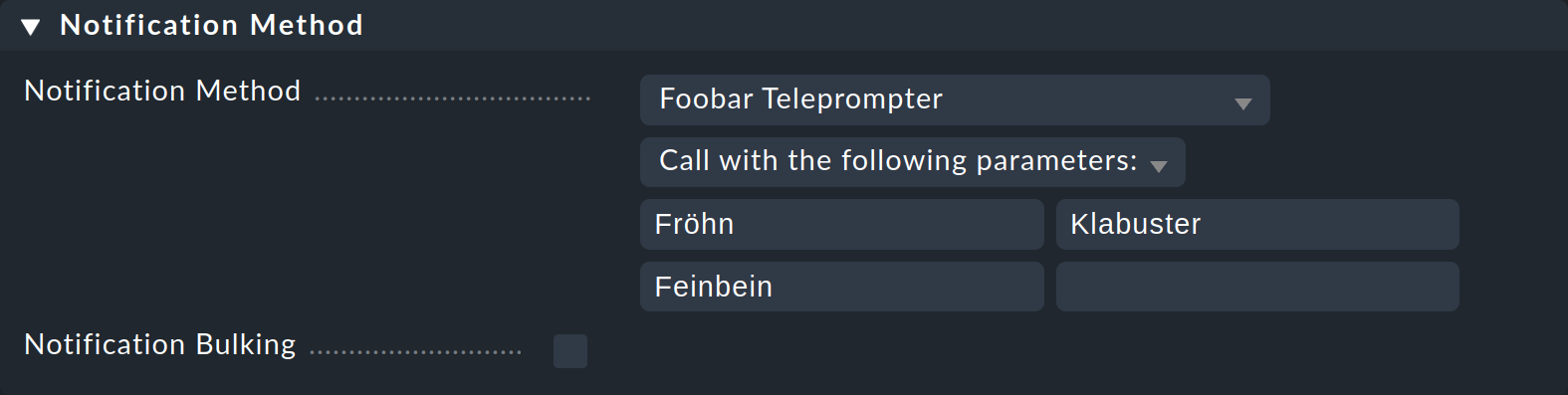
Nun setzen Sie zum Test den Service CPU load auf dem Host myserver auf CRIT — mit dem Kommando Fake check results.
In der Log-Datei des Benachrichtigungsmoduls ~/var/log/notify.log sehen Sie die Ausführung des Skripts samt Parametern und der erzeugten Spool-Datei:
2021-08-25 13:01:23,887 [20] [cmk.base.notify] Executing 1 notifications:
2021-08-25 13:01:23,887 [20] [cmk.base.notify] * notifying hh via foobar, parameters: Fröhn, Klabuster, Feinbein, bulk: no
2021-08-25 13:01:23,887 [20] [cmk.base.notify] Creating spoolfile: /omd/sites/mysite/var/check_mk/notify/spool/e1b5398c-6920-445a-888e-f17e7633de60Die Datei ~/tmp/foobar.out enthält nun eine alphabetische Liste aller Checkmk-Umgebungsvariablen, die Informationen über die Benachrichtigung beinhalten.
Dort können Sie sich orientieren, was für Werte für Ihr Skript zur Verfügung stehen. Hier die ersten zehn Zeilen:
Auch die Parameter lassen sich hier wiederfinden:
8.5. Umgebungsvariablen
Im obigen Beispiel haben Sie einige Umgebungsvariablen gesehen, die dem Skript übergeben wurden.
Welche Variablen genau bereitstehen, hängt ab von der Art der Benachrichtigung, der Checkmk-Version und -Edition und dem verwendeten Monitoring-Kern (CMC or Nagios).
Neben dem Trick mit dem Befehl env gibt es noch zwei weitere Wege zu einer vollständigen Liste aller Variablen:
Das Hochschalten des Log-Levels für
~/var/log/notify.logüber Global settings > Notifications > Notification log level.Bei Benachrichtigungen per HTML Email gibt es eine Checkbox Information to be displayed in the email body und dort die Option Complete variable list (for testing).
Folgendes sind die wichtigsten Variablen:
| Umgebungsvariable | Beschreibung |
|---|---|
|
Home-Verzeichnis der Instanz, z.B. |
|
Name der Instanz, z.B. |
|
Bei Host-Benachrichtigungen das Wort |
|
Benutzername (Login) des Kontakts |
|
E-Mail-Adresse des Kontakts |
|
Eintrag im Feld Pager des Benutzerprofils des Kontakts. Da das Feld meist nicht für einen bestimmten Zweck belegt ist, können Sie es einfach nutzen, um eine für die Benachrichtigung nötige Information pro Benutzer zu speichern. |
|
Datum der Benachrichtigung im ISO-8601-Format, z.B. |
|
Datum und Uhrzeit in der nicht-lokalisierten Standarddarstellung des Linux-Systems, z.B. |
|
Datum und Uhrzeit im ISO-Format, z.B. |
|
Name des betroffenen Hosts |
|
Ausgabe des Check-Plugins des Host-Checks, z.B. |
|
Eines der Worte |
|
Typ der Benachrichtigung, wie in der Einleitung dieses Artikels beschrieben. Er wird durch eines der folgenden Worte ausgedrückt: |
|
Alle Parameter des Skripts durch Leerzeichen getrennt |
|
Erster Parameter des Skripts |
|
Zweiter Parameter des Skripts, usw. |
|
Name des betroffenen Services. Bei Host-Benachrichtigungen ist diese Variable nicht vorhanden. |
|
Ausgabe des Check-Plugins des Service-Checks (nicht bei Host-Benachrichtigungen) |
|
Eines der Worte |
8.6. Bulk-Benachrichtigungen
Wenn Ihr Skript Bulk-Benachrichtigungen unterstützen soll, müssen Sie es speziell dafür präparieren, da hier dem Skript mehrere Benachrichtigungen auf einmal übergeben werden. Aus diesem Grund funktioniert dann auch die Übergabe per Umgebungsvariablen nicht mehr sinnvoll.
Deklarieren Sie Ihr Skript in der dritten Zeile im Kopf wie folgt, dann sendet das Benachrichtigungsmodul die Benachrichtigungen auf der Standardeingabe:
Auf der Standardeingabe werden dem Skript Blöcke von Variablen gesendet.
Jede Zeile hat die Form NAME=VALUE.
Blöcke werden getrennt durch Leerzeilen.
Das ASCII-Zeichen mit dem Code 1 (\a) wird verwendet, um innerhalb der Texte Zeilenumbrüche (newlines) darzustellen.
Der erste Block enthält eine Liste von allgemeinen Variablen (z.B. Aufrufparameter). Jeder weitere Block fasst die Variablen zu einer Benachrichtigung zusammen.
Am besten, Sie probieren das Ganze erst einmal mit einem einfachen Test aus, der die kompletten Daten in eine Datei schreibt und sehen sich an, wie die Daten gesendet werden. Dazu können Sie z.B. das folgende Benachrichtigungsskript nutzen:
Testen Sie das Skript wie oben beschrieben und aktivieren Sie zusätzlich in der Benachrichtigungsregel Notification Bulking.
8.7. Mitgelieferte Benachrichtigungsskripte
Im Auslieferungszustand stellt Checkmk bereits eine ganze Reihe Skripte bereit zur Anbindung an beliebte und weit verbreitete Instant-Messaging-Dienste, Incident-Management-Plattformen und Ticketsysteme. Wie Sie diese Skripte nutzen können, erfahren Sie in den folgenden Artikeln:
9. Dateien und Verzeichnisse
9.1. Pfade von Checkmk
| Pfad | Bedeutung |
|---|---|
|
Log-Datei des CMC. Falls das Debugging für Notifications eingeschaltet ist, finden Sie hier genaue Angaben, warum Benachrichtigungen (nicht) erzeugt wurden. |
|
Log-Datei des Benachrichtigungsmoduls |
|
Log-Datei des Benachrichtigungs-Spoolers |
|
Aktueller Zustand des Benachrichtigungs-Spoolers. Das ist hauptsächlich bei Benachrichtigungen in verteilten Umgebungen relevant. |
|
Debug-Log-Datei von Nagios. Schalten Sie Debug-Meldungen in |
|
Ablage der Spool-Dateien, die der Benachrichtigungs-Spooler bearbeiten soll. |
|
Bei temporären Fehlern verschiebt der Benachrichtigungs-Spooler die Dateien hierher und probiert es erst nach ein paar Minuten nochmal. |
|
Defekte Spool-Dateien werden hierher verschoben. |
|
Von Checkmk mitgelieferte Benachrichtigungsskripte. Ändern Sie hier nichts. |
|
Ablageort für eigene Benachrichtigungsskripte. Möchten Sie ein mitgeliefertes Skript anpassen, so kopieren Sie es von |
9.2. Log-Dateien des SMTP-Servers
Die Log-Dateien des SMTP-Servers sind Systemdateien und werden hier folglich mit absoluten Pfaden angegeben. Wo die Log-Datei genau liegt, hängt von Ihrer Linux-Distribution ab.
| Pfad | Bedeutung |
|---|---|
|
Log-Datei des SMTP-Servers unter Debian und Ubuntu |
|
Log-Datei des SMTP-Servers unter SUSE Linux Enterprise Server (SLES) |
|
Log-Datei des SMTP-Servers unter Red Hat Enterprise Linux (RHEL) |