1. Besonderheiten des Checkmk Micro Cores
Die wichtigsten Vorteile des CMC liegen in seiner höheren Performance und seinen schnelleren Reaktionszeiten verglichen mit dem Monitoring-Kern des Open-Source-Projekts Nagios. Es gibt jedoch auch darüber hinaus einige interessante Besonderheiten, die Sie kennen sollten. Die wichtigsten sind:
Smart Ping - Intelligente Host-Checks
Hilfsprozesse Check-Helper, Checkmk-Fetcher und Checkmk-Checker
Initiales Scheduling
Verarbeitung von Messdaten
Einige Funktionen von Nagios sind im CMC nicht oder anders umgesetzt. Die Details finden Sie im Artikel zur Migration auf den CMC.
2. Smart Ping – Intelligente Host-Checks
Bei Nagios ist es üblich, die Erreichbarkeit von Hosts mittels eines Ping zu prüfen.
Dazu wird für jeden Host einmal pro Intervall (in der Regel eine Minute) ein Plugin wie check_ping oder check_icmp aufgerufen.
Dieses sendet dann z.B. fünf Ping-Pakete und wartet auf deren Rückkehr.
Das Erzeugen der Prozesse für den Aufruf der Plugins bindet wertvolle CPU-Ressourcen.
Zudem sind diese recht lange blockiert, falls ein Host nicht erreichbar ist und lange Timeouts abgewartet werden müssen.
Der CMC führt Host-Checks hingegen — soweit nicht anders konfiguriert — mit einem Verfahren namens Smart Ping aus.
Smart Ping basiert auf einer internen Komponente namens icmpsender, die ihre eigene Ping-Implementierung hat.
Da Checkmk mit CMC nicht auf ein externes Binary angewiesen ist, muss nicht für jedes gesendete Ping-Paket ein neuer Prozess gestartet werden,
Außerdem unterscheidet sich das Standardverhalten von icmpsender von seinem Nagios-Gegenstück.
Anstelle mehrerer Pakete in schneller Folge, auf die gewartet wird, sendet icmpsender nur ein ICMP-Paket pro Host alle n-Sekunden (der Standardwert von 6 Sekunden ist mit dem Regelsatz Normal check interval for host checks konfigurierbar).
Dieses Verhalten reduziert den Ressourcenverbrauch und Datenverkehr drastisch.
Die Antworten auf die Pings werden nicht explizit abgewartet.
Die CMC-Komponente icmpreceiver ist für die Entscheidung zuständig, ob der Zustand eines Hosts UP oder DOWN ist.
Sie bewertet eingehende Ping-Pakete von einem Host als erfolgreichen Host-Check und kennzeichnet den Host somit als UP.
Wenn innerhalb einer bestimmten Zeit kein Paket von einem Host empfangen wird, wird dieser Host als DOWN markiert.
Das Timeout ist auf 15 Sekunden (2,5 Intervalle) voreingestellt und kann pro Host mit dem Regelsatz Settings for host checks via Smart PING geändert werden.
Die Komponente icmpreceiver lauscht auch auf TCP SYN (synchronization) und RST (reset) Pakete, die von einem Host kommen.
Wenn sie solche Pakete empfängt, wird der Host als UP betrachtet.
Dieser Mechanismus kann zu schwankenden (flapping) Zuständen von Hosts in Infrastrukturen führen, in denen ICMP-Verkehr nicht erlaubt ist, TCP-Verkehr aber schon.
|
2.1. Keine Host-Checks auf Abruf
Host-Checks dienen nicht nur der Benachrichtigung bei einem Totalausfall eines Hosts, sondern auch dazu, Benachrichtigungen zu Service-Problemen während der Zeit des Host-Ausfalls zu unterdrücken. Service-Probleme können auftreten, ohne dass der Service selbst dafür verantwortlich ist, sondern eher ein Fehlerzustand des Hosts. Es kann vorkommen, dass ein Host tatsächlich DOWN ist, auch wenn sein letzter bekannter Zustand in Checkmk UP ist, wie das Ergebnis des letzten Host-Checks zeigt. In einem solchen Fall könnten mehrere Service-Checks Probleme zurückgeben, die vom DOWN-Zustand des Hosts abhängen und Benachrichtigungen für die Services — fälschlicherweise — versendet werden. Daher ist es wichtig, im Falle eines Service-Problems zuerst den Zustand des Hosts zu bestimmen.
Der CMC löst dieses Problem sehr einfach: Wenn ein Service-Problem auftritt und der Host sich im Zustand UP befindet, wartet der CMC auf den nächsten Host-Check. Da das Intervall mit (standardmäßig) 6 Sekunden sehr kurz ist, gibt es nur eine vernachlässigbare Verzögerung bis zu einer Benachrichtigung — falls der Host weiterhin UP ist und daher die Benachrichtigung für den Service gesendet werden muss.
Nehmen wir folgendes Beispiel: Ein check_http-Plugin liefert einen CRIT-Zustand, weil der abgefragte Webserver nicht erreichbar ist.
In diesem Fall wurde nach dem Beginn des Service-Checks ein TCP-RST-Paket (connection refused) von diesem Server von der Komponente icmpreceiver empfangen.
Der CMC weiß daher mit Sicherheit, dass der Host selbst UP ist und kann die Benachrichtigung ohne Verzögerung versenden.
Das gleiche Prinzip wird beim Berechnen von Netzwerkausfällen angewendet, wenn Parent-Hosts definiert sind. Auch hier werden Benachrichtigungen teilweise kurz zurückgehalten, um einen gesicherten Zustand abzuwarten.
2.2. Der Nutzen
Durch dieses Verfahren ergibt sich eine Reihe von Vorteilen:
Nahezu vernachlässigbare CPU-Last durch Host-Checks: Es können selbst ohne besonders leistungsfähige Hardware Zigtausende von Hosts überwacht werden.
Kein Ausbremsen des Monitorings durch blockierende Host-Checks auf Abruf, falls Hosts DOWN sind.
Keine Fehlalarme von Services bei nicht aktuellem Host-Zustand.
Ein Nachteil soll dabei nicht verschwiegen werden: Die Host-Checks via Smart Ping erzeugen keine Performance-Daten (Paketlaufzeiten).
Für Hosts, bei denen Sie diese benötigen, können Sie einfach einen aktiven Check per Ping einrichten mit dem Regelsatz Check hosts with PING (ICMP Echo Request).
2.3. Nicht Ping-bare Hosts
In der Praxis sind nicht alle Hosts durch Ping überprüfbar. Für diese Fälle kann man auch im CMC andere Methoden für den Host-Check verwenden, z.B. einen TCP-Connect. Da dies Ausnahmen von der Regel sind, wirken sie sich nicht negativ auf die Gesamtperformance aus. Der Regelsatz dazu lautet Host check command.
2.4. Probleme mit Firewalls
Es gibt Firewalls, die TCP-Verbindungspakete an nicht erreichbare Hosts mit einem TCP-RST-Paket beantworten. Das Trickreiche ist dabei, dass die Firewall als Absender dieser Pakete nicht sich selbst eintragen darf, sondern die IP-Adresse des Ziel-Hosts angeben muss. Smart Ping wird dieses Paket als Lebenszeichen werten und somit zu Unrecht annehmen, dass der Ziel-Host erreichbar ist.
In so einer (seltenen) Situation haben Sie die Möglichkeit, mit Global settings > Monitoring core > Tuning of Smart PING die
Option Ignore TCP RST packets when determining host state zu aktivieren.
Oder Sie wählen für die betroffenen Hosts als Host-Check einen klassischen Ping mit check_icmp.
3. Hilfsprozesse
Eine Lehre aus der schlechten Performance von Nagios in größeren Umgebungen ist, dass das Erzeugen von Prozessen eine teure Operation ist. Entscheidend hierbei ist vor allem die Größe des Mutterprozesses. Bei jeder Ausführung eines aktiven Checks muss zunächst der komplette Nagios-Prozess dupliziert werden (fork), bevor er durch den neuen Prozess — das Check-Plugin — ersetzt wird. Je mehr Hosts und Services überwacht werden, desto größer ist dieser Prozess und desto länger dauert der Fork. Da der Prozess während dessen auch noch blockiert ist, bleiben auch die anderen Aufgaben des Prozessorkerns liegen — da helfen auch keine 24 CPU-Kerne.
3.1. Check-Helper
Um das Forken des Kerns zu vermeiden, erzeugt der CMC beim Programmstart eine festgelegte Anzahl sehr schlanker Hilfsprozesse, deren Aufgabe das Starten der aktiven Check-Plugins ist: die Check-Helper.
Nicht nur forken diese viel schneller, das Forken skaliert auch noch über alle vorhandenen CPU-Kerne, da der Prozessorkern selbst nicht mehr blockiert wird.
Dadurch wird das Ausführen von aktiven Checks (z.B. check_http), deren eigentliche Laufzeit recht kurz ist, stark beschleunigt.
3.2. Checkmk-Fetcher und Checkmk-Checker
Der CMC geht noch einen wesentlichen Schritt weiter. Denn in einer Checkmk-Umgebung sind aktive Checks eher die Ausnahme. Hier kommen hauptsächlich Checkmk-basierte Checks zum Einsatz, bei denen pro Host und Intervall nur noch ein Fork notwendig ist.
Um die Ausführung dieser Checks zu optimieren, unterhält der CMC noch zwei weitere Typen von Hilfsprozessen: die Checkmk-Fetcher und die Checkmk-Checker.
Die Checkmk-Fetcher
Die Checkmk-Fetcher rufen die benötigten Informationen von den überwachten Hosts ab, das heißt, die Daten der Services Check_MK und Check_MK Discovery. Die Fetcher übernehmen damit die Netzwerkkommunikation mit den Checkmk-Agenten, SNMP-Agenten und den Spezialagenten. Das Sammeln dieser Informationen benötigt etwas Zeit, aber mit normalerweise weniger als 50 Megabytes pro Prozess vergleichsweise wenig Arbeitsspeicher. Es können also viele dieser Prozesse ohne Probleme konfiguriert werden. Bedenken Sie dennoch, dass die Prozesse teilweise oder gar nicht in den Swap ausgelagert werden können und damit immer im physischen Speicher gehalten werden müssen. Der limitierende Faktor ist hier der verfügbare Arbeitsspeicher des Checkmk-Servers.
Bei den 50 Megabytes handelt es sich um eine Schätzung, die der grundsätzlichen Orientierung dienen soll. Unter bestimmten Umständen (z.B. bei der Konfiguration von IPMI im Management board) kann der Wert auch höher sein. |
Die Checkmk-Checker
Die Checkmk-Checker analysieren und bewerten die von den Checkmk-Fetchern gesammelten Informationen und erzeugen die Check-Resultate für die Services. Die Checker benötigen viel Arbeitsspeicher, da sie die Checkmk-Konfiguration mit dabei haben müssen. Ein Checker-Prozess belegt mindestens ca. 90 Megabytes — es kann aber auch ein Vielfaches davon notwendig sein, je nachdem wie die Checks konfiguriert sind. Dafür verursachen die Checker keine Netzwerklast und sind sehr schnell in der Ausführung. Die Anzahl der Checker sollte nur so groß sein, wie Ihr Checkmk-Server parallel Prozesse abarbeiten kann. Im Regelfall entspricht diese Zahl der Anzahl an Prozessorkernen Ihres Servers. Da die Checker nicht IO-gebunden sind, sind sie am effektivsten, wenn jeder Checker seinen eigenen Prozessorkern erhält.
Die Aufteilung der beiden unterschiedlichen Aufgaben „Sammeln“ und „Ausführen“ auf Checkmk-Fetcher und Checkmk-Checker gibt es seit der Checkmk-Version 2.0.0. Vorher gab es nur einen Hilfsprozesstyp, der für beides zuständig war — die sogenannten Checkmk-Helper.
Mit dem Fetcher/Checker-Modell werden nunmehr beide Aufgaben auf zwei separate Pools von Prozessen aufgeteilt: das Abrufen der Informationen aus dem Netzwerk mit vielen kleinen Fetcher-Prozessen und die rechenintensive Überprüfung mit wenigen großen Checker-Prozessen. Dadurch benutzt ein CMC bei gleicher Leistung (Checks pro Sekunde) bis zu viermal weniger Arbeitsspeicher!
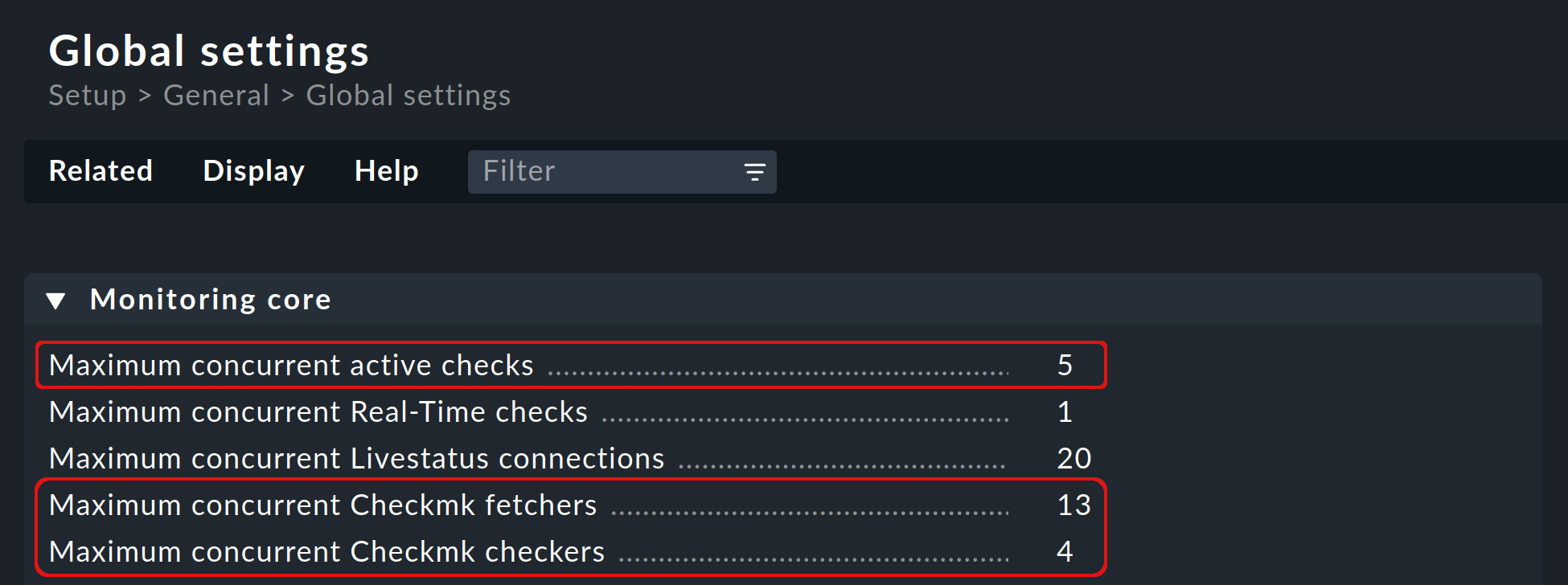
3.3. Zahl der Hilfsprozesse richtig einstellen
Die Zahl der standardmäßig gestarteten Check-Helper (active checks), Checkmk-Fetcher und Checkmk-Checker werden unter Global settings > Monitoring core festgelegt und können von Ihnen angepasst werden:
Um herauszufinden, ob und wie Sie die Standardwerte verändern müssen, haben Sie mehrere Möglichkeiten:
In der Seitenleiste zeigt Ihnen das Snapin Core statistics die prozentuale Auslastung im Durchschnitt der letzten 10-20 Sekunden:
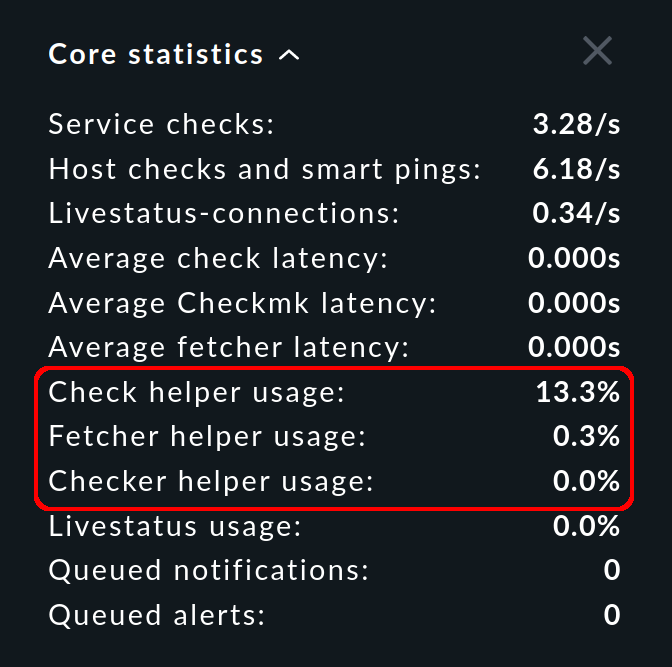
Für alle Hilfsprozesstypen gilt: Es sollten immer genügend Prozesse vorhanden sein, um die konfigurierten Prüfungen durchzuführen. Wenn ein Pool zu 100 % ausgelastet ist, werden die Checks nicht rechtzeitig ausgeführt, die Latenzzeit wächst und die Zustände der Services sind nicht aktuell.
Die Auslastung (usage) sollte wenige Minuten nach dem Start einer Instanz 80 % nicht überschreiten. Bei höheren Prozentwerten sollten Sie die Anzahl der Prozesse erhöhen. Da die notwendige Anzahl der Checkmk-Fetcher mit der Zahl der überwachten Hosts und Services wächst, ist hier eine Korrektur am wahrscheinlichsten. Achten Sie jedoch darauf, nur so viele Hilfsprozesse zu erzeugen, wie wirklich benötigt werden, da jeder Prozess Ressourcen belegt. Außerdem werden alle Hilfsprozesse beim Start des CMC parallel initialisiert, was zu Lastspitzen führen kann.
Das Snapin Core statistics zeigt Ihnen aber nicht nur die Auslastung, sondern auch die Latenzzeiten (latency). Für diese Werte gilt die simple Regel: Je niedriger, desto besser — und am allerbesten sind daher 0 Sekunden.
Die im Snapin gezeigten Werte können Sie sich für Ihre Instanz auch in den Details des Services OMD <site_name> performance anzeigen lassen. |
Alternativ zum Snapin Core statistics können Sie sich auch Ihre Konfiguration von Checkmk analysieren lassen, mit Setup > Maintenance > Analyze configuration. Der Vorteil: Hier erhalten Sie von Checkmk sofort die Bewertung, wie es um den Zustand der Hilfsprozesse steht. Sehr praktisch ist: Sollte einer der Hilfsprozesse nicht OK sein, können Sie aus dem Hilfetext gleich die zugehörige Option in den Global settings öffnen, um den Wert zu ändern.
4. Initiales Scheduling
Beim Scheduling wird festgelegt, welche Checks zu welcher Zeit ausgeführt werden sollen. Nagios hat hier mehrere Verfahren implementiert, die dafür sorgen sollen, dass die Checks gleichmäßig über die Zeit verteilt werden. Dabei wird auch versucht, die Abfragen, die auf einem einzelnen Zielsystem laufen, über das Intervall zu verteilen.
Der CMC hat hier ein eigenes, einfacheres Verfahren. Dies trägt dem Umstand Rechnung, dass Checkmk einen Host ohnehin nur einmal pro Intervall kontaktiert. Außerdem sorgt der CMC dafür, dass neue Checks sofort ausgeführt werden und nicht über mehrere Minuten verteilt. Für den Anwender ist das sehr angenehm, da ein neu aufgenommener Host sofort nach dem Aktivieren der Konfiguration abgefragt wird. Um eine Lastspitze bei einer großen Zahl von neuen Checks zu vermeiden, werden neue Checks, die eine bestimmte einstellbare Zahl überschreiten, auf das ganze Intervall verteilt. Die Option dafür finden Sie unter Global settings > Monitoring core > Initial scheduling.
5. Verarbeitung von Messdaten
Eine wichtige Funktion von Checkmk ist das Verarbeiten von Messdaten, wie z.B. CPU-Auslastung, und deren Speicherung über einen längeren Zeitraum. In Checkmk Community kommt dabei PNP4Nagios zum Einsatz, welches wiederum auf dem RRDtool aufsetzt.
Die Software erledigt zwei Aufgaben:
Das Anlegen und Aktualisieren der Round-Robin-Datenbanken (RRDs).
Die grafische Darstellung der Daten in der GUI.
Bei Verwendung des Nagios-Kerns läuft der erste Part über einen recht langen Weg.
Je nach Methode kommen dabei Spool-Dateien, Perl-Skripte und ein Hilfsprozess (npcd) zum Einsatz, der in C geschrieben ist.
Am Ende werden leicht umgewandelte Daten in das Unix-Socket des RRD-Cache-Daemons geschrieben.
Der CMC kürzt diese Kette ab, indem er direkt zum RRD-Cache-Daemon schreibt — alle Zwischenschritte werden ausgelassen. Das Parsen der Daten und Umwandeln in das Format des RRDtools erfolgt direkt in C++. Dieses Verfahren ist heute möglich und sinnvoll, da der RRD-Cache-Daemon ohnehin sein eigenes sehr effizientes Spooling implementiert und mithilfe von Journaldateien auch bei einem Absturz des Systems keine Daten verliert.
Die Vorteile:
Einsparen von Disk-I/O und CPU.
Einfachere Implementierung mit deutlich mehr Stabilität.
Das Neuanlegen von RRDs erledigt der CMC mit einem weiteren Helper, der per cmk-create-rrd aufgerufen wird.
Dieser legt die Dateien wahlweise kompatibel zu PNP an oder alternativ im neuen Checkmk-Format (gilt nur für Neuinstallationen).
Ein Wechsel von Nagios auf CMC hat daher keinen Einfluss auf bestehende RRD-Dateien.
Diese werden nahtlos weiter gepflegt.
In den kommerziellen Editionen übernimmt die grafische Darstellung der Daten direkt die GUI von Checkmk selbst, so dass keine Komponente von PNP4Nagios mehr beteiligt ist.