1. Einleitung
1.1. Cluster, Knoten und Cluster-Services
Bei der Bereitstellung wichtiger und geschäftskritischer Services wie Datenbanken oder Websites für den elektronischen Handel (E-commerce) werden Sie sich kaum darauf verlassen, dass der Host, auf dem diese Services laufen, ein langes, stabiles und absturzfreies Leben führen wird. Stattdessen werden Sie den Ausfall eines Hosts einkalkulieren und dafür sorgen, dass andere Hosts bereitstehen, um bei einem Ausfall die Services unmittelbar zu übernehmen (failover), sodass sich der Ausfall nach außen gar nicht bemerkbar macht.
Eine Gruppe von vernetzten Hosts, die zusammenarbeiten, um die gleiche Aufgabe zu erledigen, wird als Rechnerverbund oder Computer-Cluster oder kürzer als Cluster bezeichnet. Ein Cluster agiert nach außen als ein System und organisiert nach innen die Zusammenarbeit der Hosts, um die gemeinsame Aufgabe zu erfüllen.
Ein Cluster kann verschiedene Aufgaben übernehmen, zum Beispiel ein HPC-Cluster das Hochleistungsrechnen (high-performance computing), das unter anderem dann eingesetzt wird, wenn Berechnungen viel mehr Speicher benötigen, als auf einem Computer verfügbar ist. Falls der Cluster die Aufgabe hat, für Hochverfügbarkeit (high availability) zu sorgen, wird er auch als HA-Cluster bezeichnet. Um HA-Cluster geht es in diesem Artikel, d.h. wenn wir im Folgenden „Cluster“ schreiben, ist stets ein HA-Cluster gemeint.
Ein Cluster bietet einen oder mehrere Services nach außen an: die Cluster-Services, die manchmal auch als „geclusterte Services“ bezeichnet werden. In einem Cluster werden die Hosts, aus denen er besteht, als Knoten (nodes) bezeichnet. Zu einem bestimmten Zeitpunkt wird jeder Service von genau einem der Knoten bereitgestellt. Fällt ein Knoten des Clusters aus, werden alle Services, die für die Aufgabe des Clusters essentiell sind, auf einen der verbleibenden Knoten verschoben.
Um einen Failover transparent zu machen, stellen einige Cluster eine eigene Cluster-IP-Adresse zur Verfügung, die manchmal auch als virtuelle IP-Adresse bezeichnet wird. Die Cluster-IP-Adresse verweist stets auf den aktiven Knoten und steht stellvertretend für den gesamten Cluster. Im Falle eines Failover geht die IP-Adresse auf einen anderen, bisher passiven Knoten über, der dann zum aktiven Knoten wird. Dem Client, der mit dem Cluster kommuniziert, kann ein interner Failover egal sein: Er verwendet unverändert die gleiche IP-Adresse und braucht nicht umzuschalten.
Andere Cluster haben keine Cluster-IP-Adresse. Ein prominentes Beispiel sind Oracle-Datenbank-Cluster in vielen ihrer Varianten. Ohne Cluster-IP-Adresse muss der Client eine Liste der IP-Adressen aller Knoten führen, die den Service bereitstellen könnten. Fällt der aktive Knoten aus, muss der Client dies erkennen und auf denjenigen Knoten umschalten, der den Service nunmehr bereitstellt.
1.2. Das Monitoring eines Clusters
Checkmk ist einer der Clients, der mit dem Cluster kommuniziert. In Checkmk können alle Knoten eines Clusters eingerichtet und überwacht werden — unabhängig davon, wie die Cluster-Software intern den Status der einzelnen Knoten überprüft und, falls notwendig, einen Failover durchführt.
Die meisten Checks, die Checkmk auf den einzelnen Knoten eines Clusters ausführt, befassen sich mit den physischen Eigenschaften der Knoten, die unabhängig davon sind, ob der Host zu einem Cluster gehört oder nicht. Beispiele dafür sind CPU- und Speichernutzung, lokale Festplatten, physische Netzwerkschnittstellen und so weiter. Für die Abbildung der Cluster-Funktion der Knoten in Checkmk ist es aber notwendig, diejenigen Services zu identifizieren, die die Aufgabe des Clusters definieren und gegebenenfalls auf einen anderen Knoten übertragen werden: die Cluster-Services.
Checkmk hilft Ihnen dabei, die Cluster-Services zu überwachen. Was Sie tun müssen, ist:
Cluster erstellen
Cluster-Services auswählen
Service-Erkennung für alle beteiligten Hosts durchführen
Wie Sie dabei vorgehen, wird im nächsten Kapitel anhand der folgenden Beispielkonfiguration beschrieben:
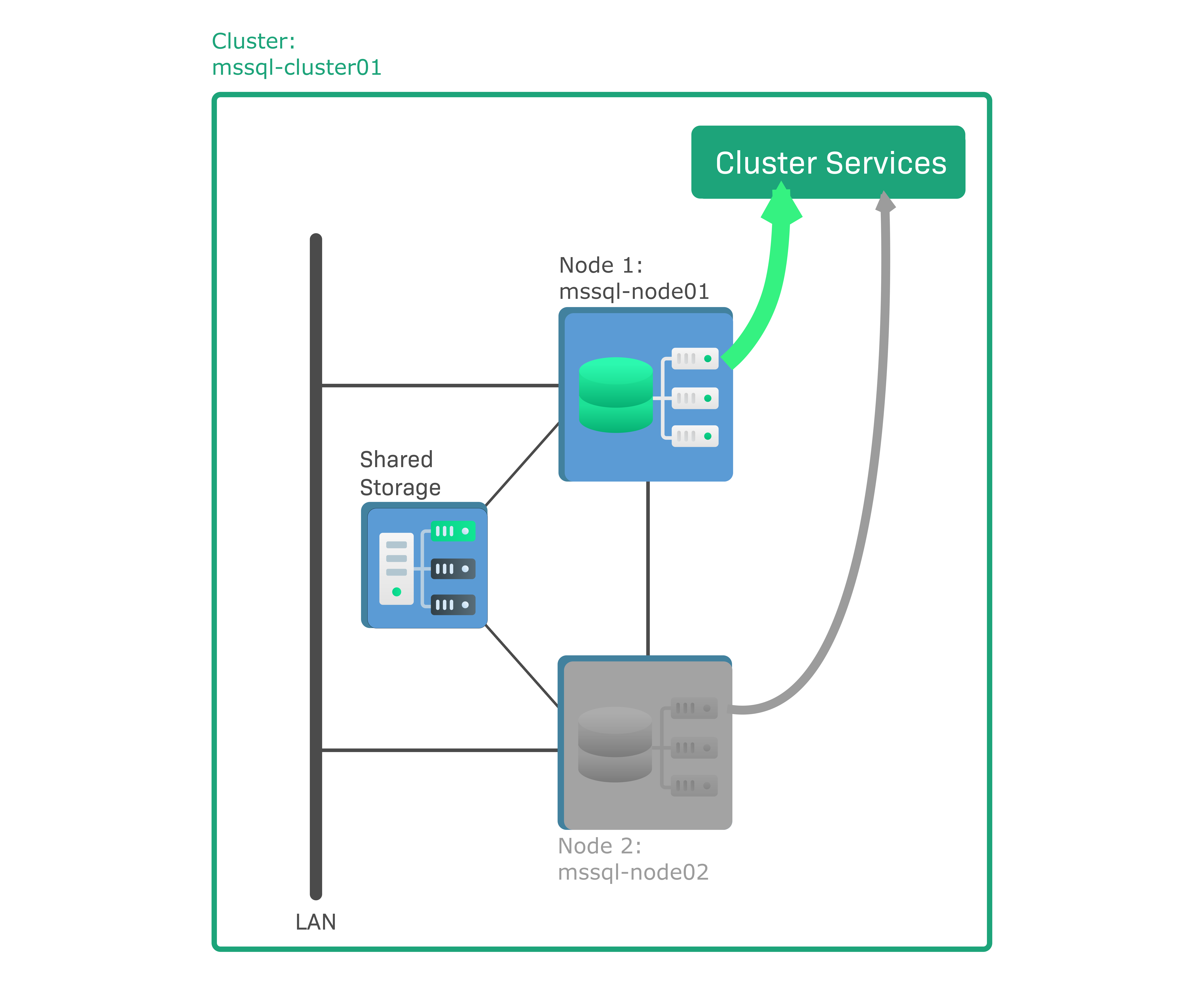
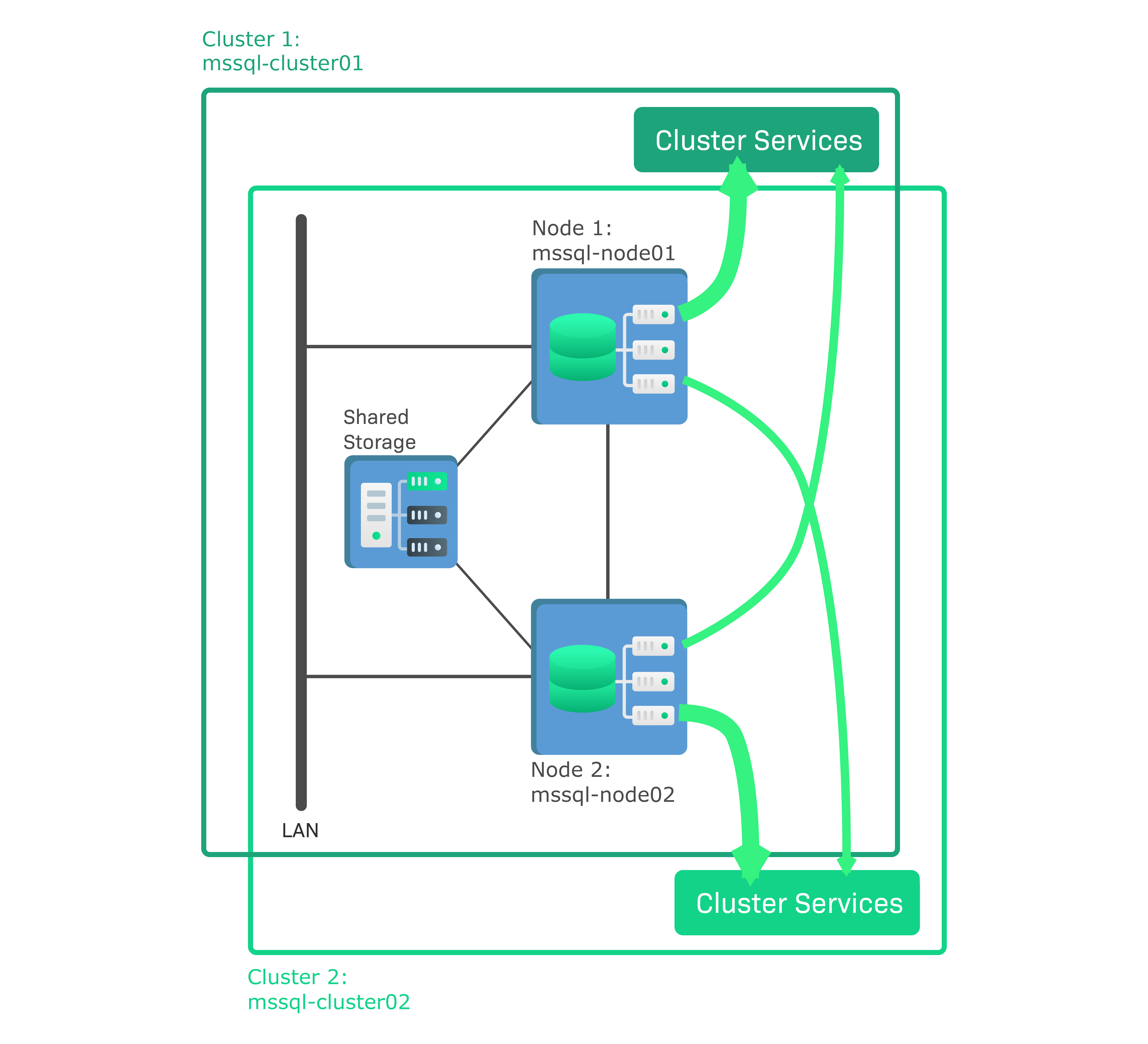
In Checkmk soll ein Windows Failover Cluster als HA-Cluster eingerichtet werden, der aus zwei Knoten mit installiertem Microsoft SQL (MS SQL) Server besteht. Es handelt sich dabei um einen sogenannten Aktiv/Passiv-Cluster, das heißt, nur auf einem, dem aktiven Knoten läuft eine Datenbankinstanz. Der andere Knoten ist passiv und wird nur im Fall eines Failover aktiv, fährt die Datenbankinstanz hoch und ersetzt den ausgefallenen Knoten. Die Daten der Datenbankinstanz werden nicht auf den Knoten selbst gespeichert, sondern auf einem gemeinsam genutzten Speichermedium, z.B. einem Storage Area Network (SAN), an das beide Knoten angeschlossen sind. Die Beispielkonfiguration besteht aus den folgenden Komponenten:
mssql-node01ist der aktive Knoten mit laufender Datenbankinstanz.mssql-node02ist der passive Knoten.mssql-cluster01ist der Cluster, dem beide Knoten angehören.
Anders als in diesem Beispiel ist es auch möglich, dass derselbe Knoten in mehreren Clustern enthalten ist. Im letzten Kapitel erfahren Sie anhand einer abgeänderten Beispielkonfiguration, wie Sie solche überlappenden Cluster konfigurieren.
2. Cluster und Cluster-Services einrichten
2.1. Cluster erstellen
In Checkmk werden die Knoten und der Cluster selbst als Hosts erstellt (Knoten-Hosts und Cluster-Hosts), wobei es für einen Cluster-Host einen speziellen Host-Typen gibt.
Vor der Einrichtung eines Cluster-Hosts gibt es folgendes zu beachten:
Der Cluster-Host ist ein virtueller Host, der mit Cluster-IP-Adresse konfiguriert werden soll, wenn diese existiert. In unserem Beispiel gehen wir davon aus, dass der Name des Cluster-Hosts über DNS auflösbar ist.
Cluster-Hosts können auf die gleiche Art und Weise konfiguriert werden wie „normale“ Hosts, zum Beispiel mit Host-Merkmalen oder Host-Gruppen.
Für alle beteiligten Hosts (damit sind stets der Cluster-Host und alle zugehörigen Knoten-Hosts gemeint) müssen die Datenquellen identisch konfiguriert werden, d.h. insbesondere dürfen nicht einige per Checkmk-Agent und andere per SNMP konfiguriert sein. Checkmk stellt sicher, dass ein Cluster-Host nur dann erstellt werden kann, wenn diese Voraussetzung erfüllt ist.
In einem verteilten Monitoring müssen alle beteiligten Hosts derselben Checkmk-Instanz zugeordnet sein.
Nicht alle Checks funktionieren in einer Cluster-Konfiguration. Bei denjenigen Checks, die die Cluster-Unterstützung implementiert haben, können Sie dies in der Handbuchseite des Plugins nachlesen. Zu den Handbuchseiten geht es im Menü Setup > Services > Catalog of check plug-ins.
In unserem Beispiel sind die beiden Knoten-Hosts mssql-node01 und mssql-node02 bereits als Hosts angelegt und eingerichtet.
Wie es so weit kommen konnte, können Sie im Artikel zur Überwachung von Windows-Servern nachlesen — und dort im Kapitel zur Erweiterung des Standard Windows-Agenten mit Plugins, für unser Beispiel den MS SQL Server-Plugins.
Starten Sie die Erstellung des Clusters im Menü Setup > Hosts > Hosts und dann im Menü Hosts > Add cluster:
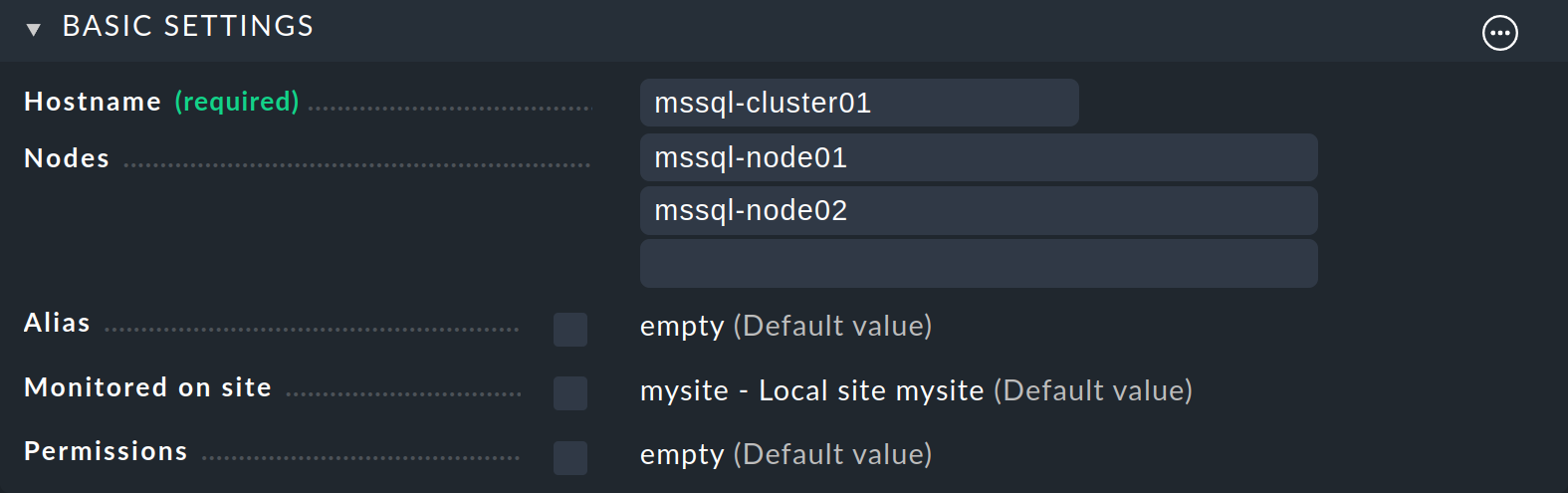
Geben Sie als Host name mssql-cluster01 ein und tragen Sie unter Nodes die beiden Knoten-Hosts ein.
Falls Sie es mit einem Cluster ohne Cluster-IP-Adresse zu tun haben, müssen Sie einen nicht ganz komfortablen Umweg gehen: Sie können im Kasten Network address für die IP address family den Eintrag No IP auswählen. Um aber zu verhindern, dass der Host im Monitoring auf DOWN geht, müssen Sie für diesen das standardmäßig eingestellte „Host check command“ über die gleichnamige Regel ändern: von Smart PING bzw. PING auf z.B. den Status eines der Services, die dem Cluster-Host im nächsten Abschnitt zugewiesen werden. Mehr Informationen zu den Host-Regelsätzen finden Sie im Artikel über Regeln. |
Schließen Sie die Erstellung mit Save & view folder ab und aktivieren Sie die Änderungen.
2.2. Cluster-Services auswählen
Checkmk kann nicht wissen, welche der auf einem Knoten laufenden Services lokale und welche Cluster-Services sind: Einige Dateisysteme können lokal sein, andere sind möglicherweise nur auf dem aktiven Knoten gemountet. Ähnliches gilt für Prozesse: Während der Windows-Dienst „Windows-Zeitgeber“ höchstwahrscheinlich auf allen Knoten läuft, wird eine bestimmte Datenbankinstanz nur auf dem aktiven Knoten verfügbar sein.
Statt Checkmk raten zu lassen, wählen Sie die Cluster-Services mit einer Regel aus.
Ohne Regel werden dem Cluster keine Services zugewiesen.
Für das Beispiel gehen wir davon aus, dass die Namen aller MS SQL Server Cluster-Services mit MSSQL beginnen und das Dateisystem des gemeinsam genutzten Speichermediums über das Laufwerk D: zugreifbar ist.
Starten Sie mit Setup > Hosts > Hosts und klicken Sie den Cluster-Namen an. Auf der Seite Properties of host wählen Sie im Menü Host > Clustered services. Sie landen auf der Seite des Regelsatzes Clustered services, auf der Sie eine neue Regel erstellen können. Dann erhalten Sie die Seite Add rule: Clustered services:
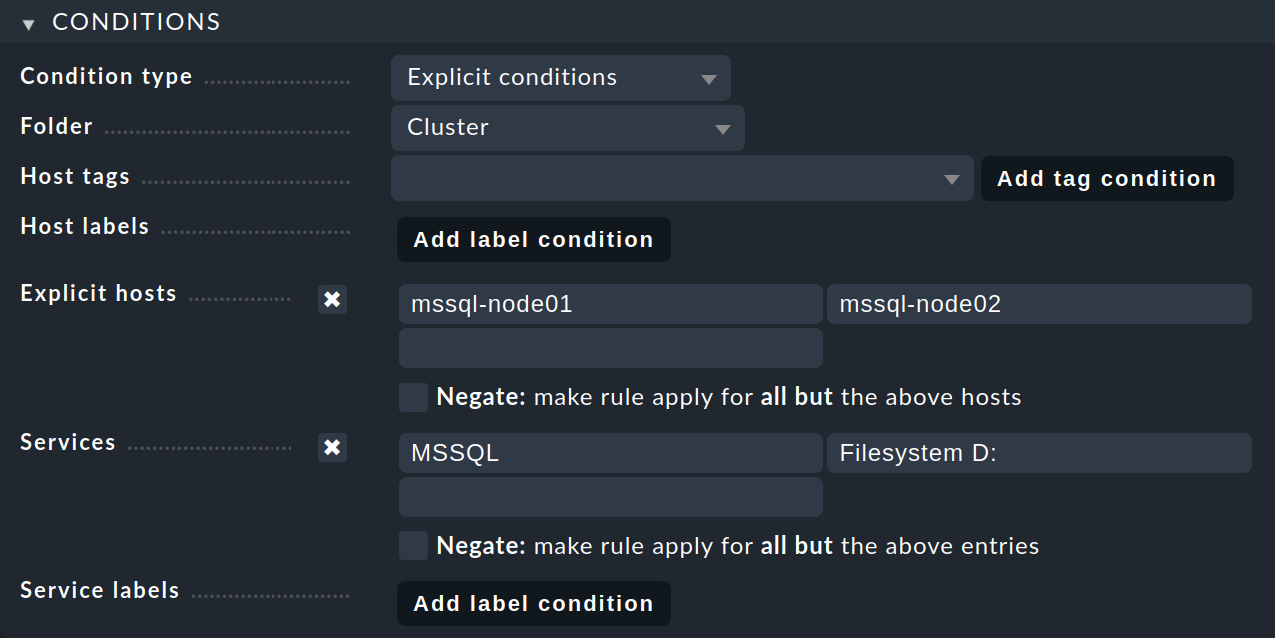
Unabhängig davon, ob und wie die Hosts in Ordner organisiert sind: Achten Sie darauf, dass Sie alle Regeln für Cluster-Services so erstellen, dass sie für die Knoten-Hosts gelten, auf denen die Services laufen. Für einen Cluster-Host ist eine solche Regel unwirksam.
Im Kasten Conditions wählen Sie unter Folder den Ordner aus, der die Knoten-Hosts enthält.
Aktivieren Sie Explicit hosts und tragen Sie den aktiven Knoten-Host mssql-node01 und den passiven Knoten-Host mssql-node02 ein.
Dann aktivieren Sie Services und machen dort zwei Einträge:
MSSQL für alle MS SQL-Services, deren Namen mit MSSQL beginnen, und Filesystem D: für das Laufwerk.
Die Eingaben werden als reguläre Ausdrücke interpretiert.
Alle Services, die nicht als Cluster-Services definiert sind, werden von Checkmk als lokale Services behandelt.
Schließen Sie die Erstellung der Regel mit Save ab und aktivieren Sie die Änderungen.
2.3. Service-Erkennung durchführen
Für alle beteiligten Hosts (Cluster- und Knoten-Hosts) muss zum Abschluss eine neue Service-Erkennung (discovery) durchgeführt werden, damit alle neu definierten Cluster-Services zuerst bei den Knoten entfernt und dann beim Cluster hinzugefügt werden.
Unter Setup > Hosts > Hosts markieren Sie zuerst alle beteiligten Hosts und wählen dann im Menü Hosts > On Selected hosts > Run bulk service discovery. Auf der Seite Bulk discovery sollte die erste Option Add unmonitored services and new host labels zum gewünschten Ergebnis führen.
Klicken Sie Start, um die Serviceerkennung für viele Hosts zu beginnen.
Nach erfolgreichem Abschluss, erkennbar an der Meldung Bulk discovery successful, verlassen Sie die Seite und aktivieren Sie die Änderungen.
Um herauszufinden, ob die Auswahl der Cluster-Services zum gewünschten Ergebnis geführt hat, können Sie sich alle Services auflisten, die nunmehr dem Cluster zugewiesen sind:
Unter Setup > Hosts > Hosts klicken Sie in der Host-Liste beim Eintrag des Cluster-Hosts auf das Symbol ![]() zum Bearbeiten der Services.
Auf der folgenden Seite Services of host werden unter Monitored services alle Cluster-Services aufgelistet:
zum Bearbeiten der Services.
Auf der folgenden Seite Services of host werden unter Monitored services alle Cluster-Services aufgelistet:
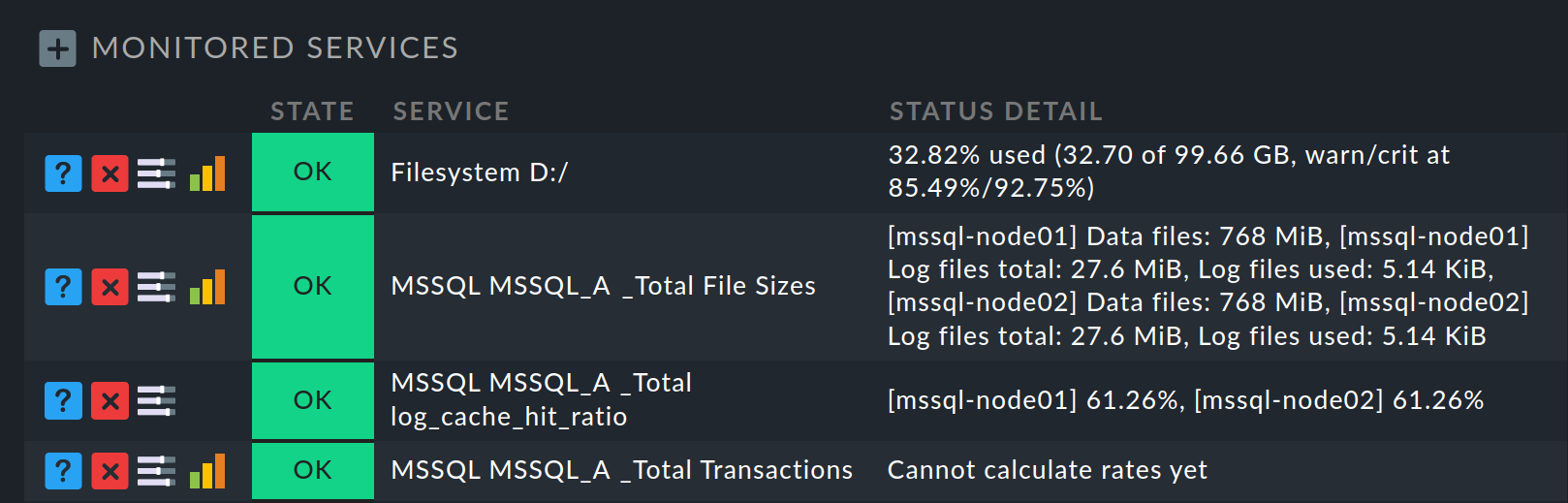
Auf der anderen Seite, bei den Knoten-Hosts, fehlen nunmehr genau die zum Cluster verschobenen Services in der Liste der überwachten Services. Am Knoten-Host finden Sie diese am Ende der Services-Liste im Abschnitt Monitored clustered services (located on cluster host):
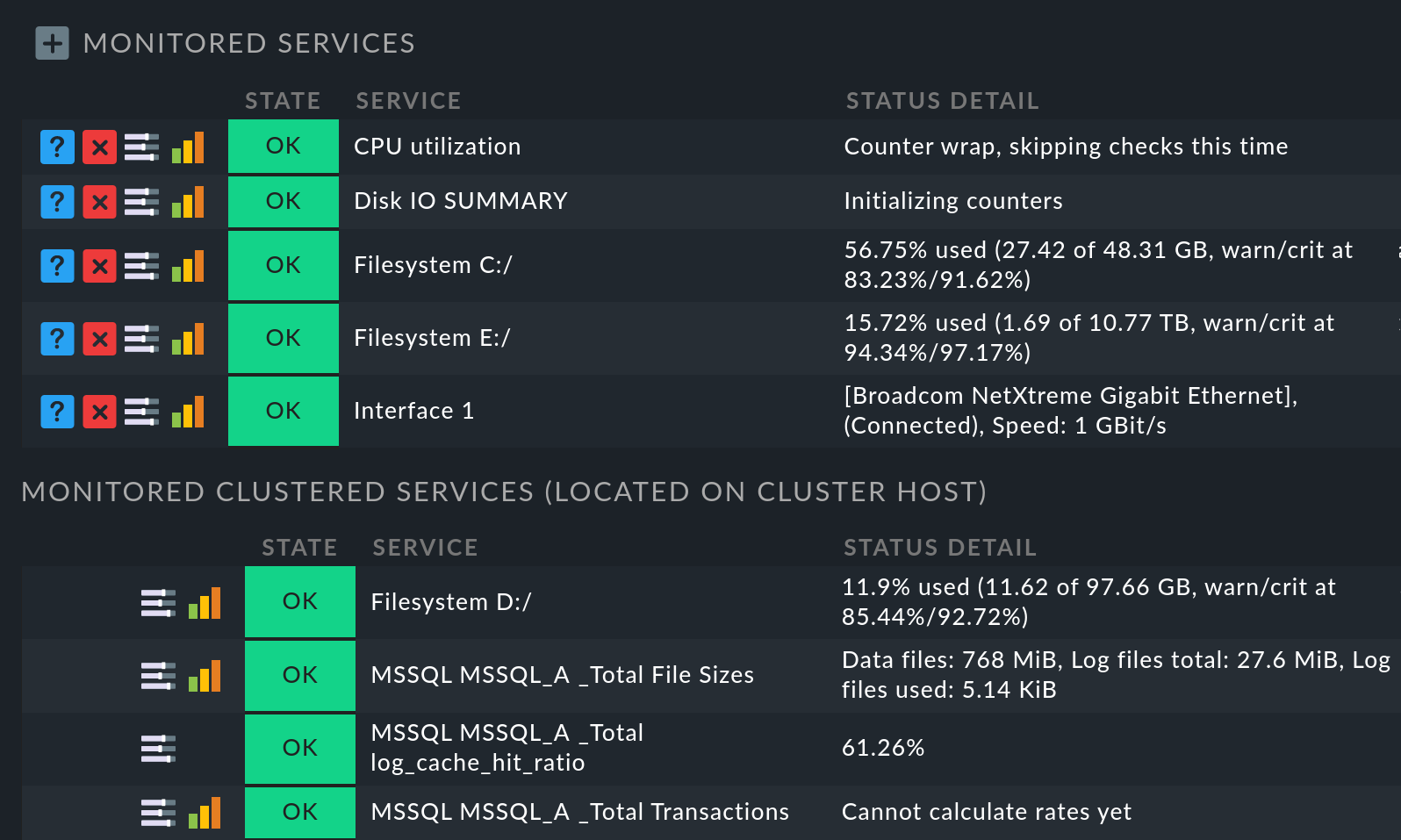
Falls Sie lokale Checks in einem Cluster ausführen, in dem die Regel Clustered services zur Anwendung kommt: Mit dem Regelsatz Local checks in Checkmk clusters können Sie das Ergebnis beeinflussen, indem Sie zwischen Worst state und Best state auswählen. |
2.4. Automatische Service-Erkennung
Wenn Sie die Service-Erkennung automatisch über den Discovery Check erledigen lassen, müssen Sie eine Besonderheit beachten. Der Discovery Check kann verschwundene Services automatisch löschen. Wandert ein geclusterter Service aber von einem Knoten zum anderen, könnte er fälschlicherweise als verschwunden registriert und dann gelöscht werden. Verzichten Sie hingegen auf diese Option, würden wiederum tatsächlich verschwundene Services niemals gelöscht.
3. Überlappende Cluster
Es ist möglich, dass mehrere Cluster einen oder auch mehrere Knoten gemeinsam nutzen. Man spricht dann von überlappenden Clustern. Bei überlappenden Clustern benötigen Sie eine spezielle Regel, um Checkmk mitzuteilen, welche Cluster-Services eines gemeinsam genutzten Knoten-Hosts welchem Cluster zugeordnet werden sollen.
Das prinzipielle Vorgehen beim Einrichten eines überlappenden Clusters werden wir im Folgenden vorstellen, indem wir das Beispiel des MS SQL Server Clusters von einem Aktiv/Passiv- zu einem Aktiv/Aktiv-Cluster abwandeln:
In dieser Konfiguration ist nicht nur MS SQL Server auf beiden Knoten-Hosts installiert, sondern auf jedem der beiden Knoten läuft eine eigene Datenbankinstanz. Beide Knoten greifen auf das gemeinsam genutzte Speichermedium zu, aber auf unterschiedlichen Laufwerken. Dieses Beispiel realisiert einen zu 100 % überlappenden Cluster, da die beiden Knoten beiden Clustern angehören.
Der Vorteil des Aktiv/Aktiv-Clusters besteht darin, dass die verfügbaren Ressourcen der beiden Knoten besser genutzt werden. Im Fall eines Failover wird die Aufgabe des ausgefallenen Knotens vom anderen Knoten übernommen, auf dem dann beide Datenbankinstanzen laufen.
Diese Beispielkonfiguration besteht somit aus den folgenden Komponenten:
mssql-node01ist der erste aktive Knoten mit der laufenden DatenbankinstanzMSSQL Instance1.mssql-node02ist der zweite aktive Knoten mit der laufenden DatenbankinstanzMSSQL Instance2.mssql-cluster01undmssql-cluster02sind die beiden Cluster, denen beide Knoten angehören.
Den 1. Schritt zur Einrichtung des Aktiv/Passiv-Clusters müssen Sie für einen Aktiv/Aktiv-Cluster nur leicht abwandeln:
Sie erstellen, wie oben beschrieben, den ersten Cluster mssql-cluster01.
Anschließend erstellen Sie den zweiten Cluster mssql-cluster02 mit denselben beiden Knoten-Hosts.
Im 2. Schritt nutzen Sie zur Auswahl der Cluster-Services statt des allgemeinen Regelsatzes Clustered services den speziell für überlappende Cluster geltenden Regelsatz Clustered services for overlapping clusters. Damit definieren Sie in einer Regel die Cluster-Services, die bei den Knoten-Hosts entfernt und dem ausgewählten Cluster zugeschlagen werden.
Für unser Beispiel mit 100 % Überlappung benötigen wir zwei dieser Regeln: Die erste Regel definiert die Cluster-Services der ersten Datenbankinstanz, die standardmäßig auf dem ersten Knoten-Host laufen. Da im Fall eines Failover diese Cluster-Services auf den zweiten Knoten-Host übertragen werden, weisen wir die Services beiden Knoten-Hosts zu. Die zweite Regel tut dies analog für den zweiten Cluster und die zweite Datenbankinstanz.
Starten wir mit der ersten Regel: Unter Setup > General > Rule search suchen Sie den Regelsatz Clustered services for overlapping clusters und klicken ihn an.
Erstellen Sie eine neue Regel.
Tragen Sie als Assign services to the following cluster den Cluster mssql-cluster01 ein:

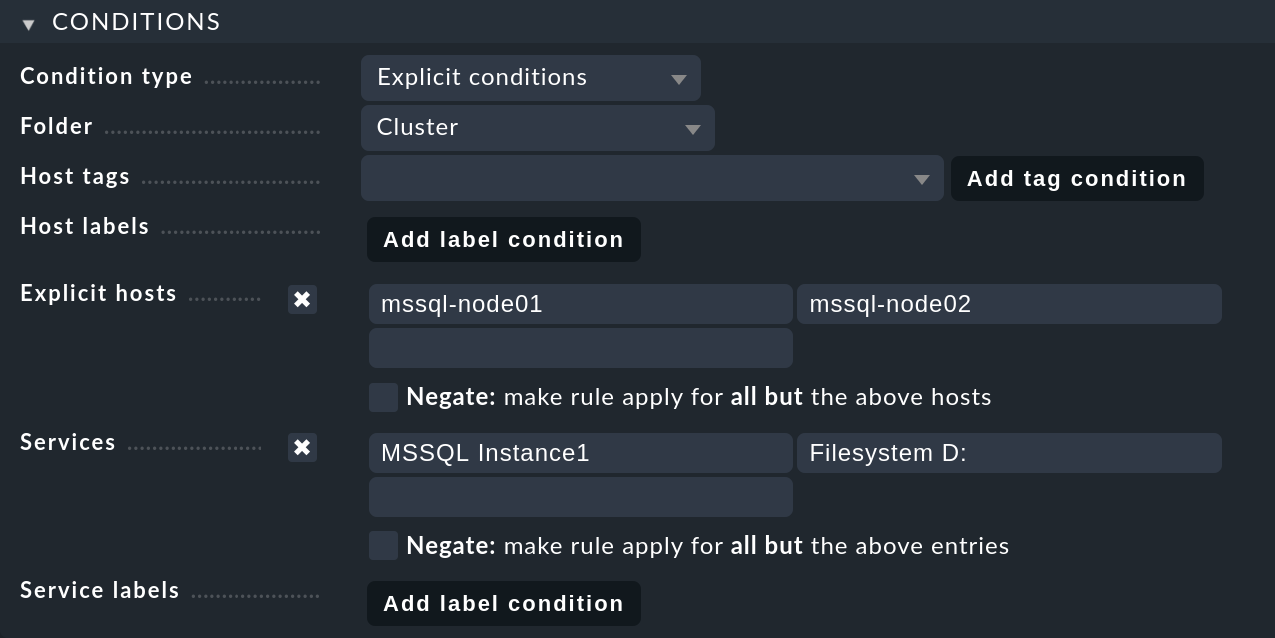
Im Kasten Conditions wählen Sie unter Folder wieder den Ordner aus, der die Knoten-Hosts enthält.
Aktivieren Sie Explicit hosts und tragen beide Knoten-Hosts ein.
Dann aktivieren Sie Services und machen Sie dort zwei Einträge:
MSSQL Instance1 für alle MS SQL-Services der ersten Datenbankinstanz und Filesystem D: für das Laufwerk:
Schließen Sie die Erstellung der ersten Regel mit Save ab.
Erstellen Sie anschließend gleich die zweite Regel, diesmal für den zweiten Cluster mssql-cluster02 und erneut für beide Knoten-Hosts.
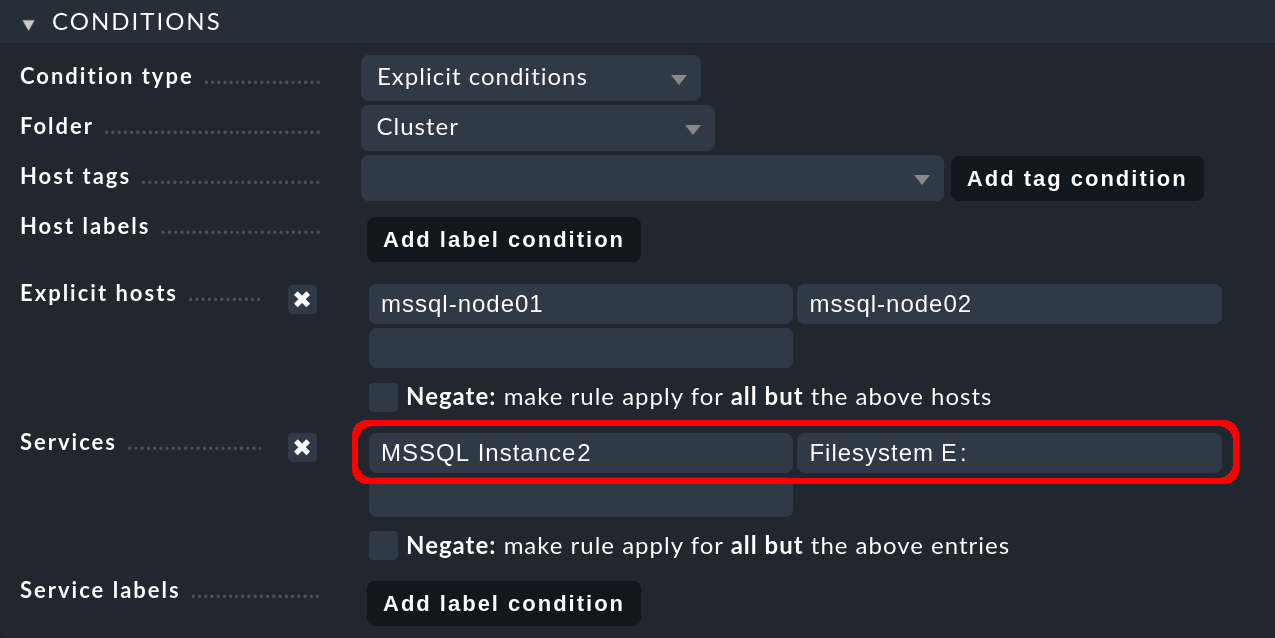
Unter Services tragen Sie jetzt MSSQL Instance2 ein für alle MS SQL-Services der zweiten Datenbankinstanz.
Der zweite Knoten-Host, auf dem die zweite Datenbankinstanz standardmäßig läuft, greift auf sein Speichermedium unter einem anderen Laufwerk zu, im folgenden Beispiel über das E: Laufwerk:
Sichern Sie auch diese Regel und aktivieren Sie dann die beiden Änderungen.
Führen Sie abschließend die Service-Erkennung als 3. und letzten Schritt genauso aus wie oben beschrieben: als Bulk discovery für alle beteiligten Hosts, d.h. die beiden Cluster-Hosts und die beiden Knoten-Hosts.
Falls mehrere Regeln einen Cluster-Service definieren, hat die spezifischere Regel Clustered services for overlapping clusters mit der expliziten Zuordnung zu einem bestimmten Cluster Vorrang vor der allgemeineren Regel Clustered Services. Für die beiden in diesem Artikel vorgestellten Beispiele bedeutet das: Durch die beiden zuletzt erstellten spezifischen Regeln würde die im ersten Beispiel erstellte allgemeine Regel nie zur Anwendung kommen. |