1. Einleitung
Neben dem eigentlichen System-Monitoring — nämlich der Erkennung von Problemen — ist Checkmk ein ausgezeichnetes Werkzeug zur Aufzeichnung und Analyse von unterschiedlichsten Messdaten, welche in IT-Umgebungen so anfallen können. Dazu gehören zum Beispiel:
Betriebssystem-Performance (Platten-IO, CPU- und Speicherauslastung, …)
Netzwerkgrößen (genutzte Bandbreite, Paketlaufzeiten, Fehlerraten, …)
Umgebungssensoren (Temperatur, Luftfeuchte, Luftdruck, …)
Nutzungsstatistiken (angemeldete Benutzer, Seitenabrufe, Sessions, …)
Qualitätskennzahlen von Anwendungen (z.B. Antwortzeiten von Webseiten)
Stromverbrauch und -qualität im Rechenzentrum (Ströme, Spannungen, Leistungen, Batteriegüte, …)
Anwendungsspezifische Daten (z.B. Länge von E-Mail-Warteschlangen von MS Exchange)
und vieles mehr …
Checkmk zeichnet grundsätzlich alle beim Monitoring anfallenden Messwerte über einen Zeitraum von (einstellbar) vier Jahren auf, so dass Sie nicht nur auf die aktuellen, sondern auch auf historische Messwerte zugreifen können. Um den Bedarf an Plattenplatz in Grenzen zu halten, werden die Daten mit zunehmendem Alter immer weiter verdichtet.
Die Metriken selbst werden von den einzelnen Check-Plugins ermittelt. Die Plugins legen somit auch fest, welche Metriken genau bereitgestellt werden.
![]() Die Oberfläche für die Visualisierung der historischen Messdaten basiert auf HTML5 und ist in den kommerziellen Editionen und in Checkmk Community identisch.
Ausschließlich in den kommerziellen Editionen können Sie erweiterte Funktionen wie PDF-Export, Graphensammlungen, benutzerdefinierte Graphen und Anbindung an externe Metrik-Datenbanken nutzen.
Die Oberfläche für die Visualisierung der historischen Messdaten basiert auf HTML5 und ist in den kommerziellen Editionen und in Checkmk Community identisch.
Ausschließlich in den kommerziellen Editionen können Sie erweiterte Funktionen wie PDF-Export, Graphensammlungen, benutzerdefinierte Graphen und Anbindung an externe Metrik-Datenbanken nutzen.
2. Zugriff über die GUI
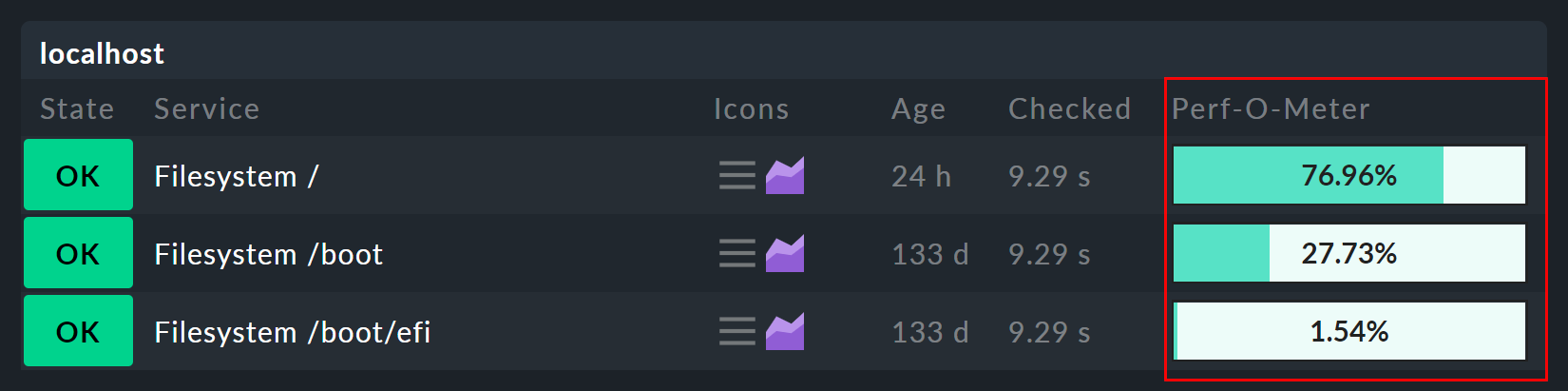
Die Messwerte eines Services werden in der GUI in drei verschiedenen Formen präsentiert. Die sogenannten Perf-O-Meter tauchen direkt in der Tabelle der Hosts oder Services auf und bieten einen schnellen Überblick und einen optischen Vergleich. Allerdings beschränken sich diese aus Platzgründen meist auf eine einzelne ausgewählte Metrik. Bei den Dateisystemen ist dies z.B. der prozentual belegte Platz:
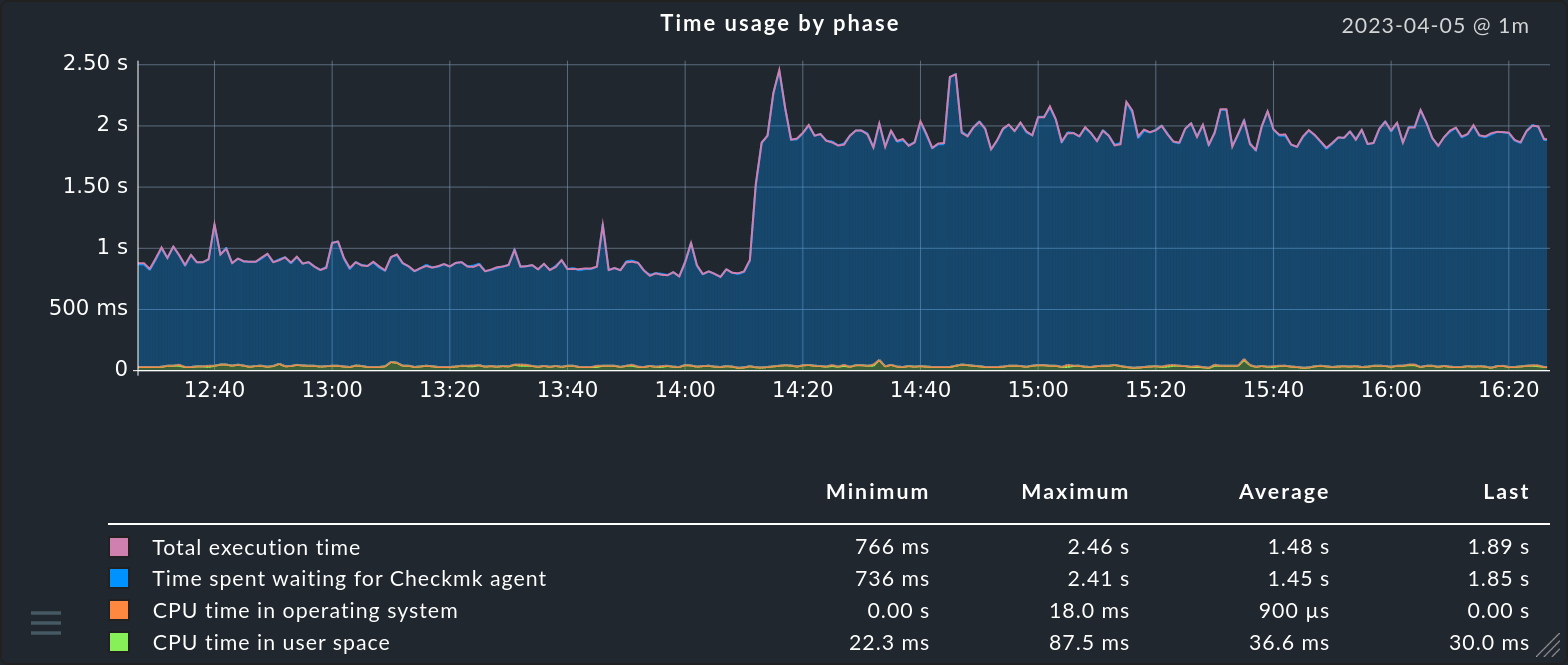
Alle Metriken eines Services im Zeitverlauf erhalten Sie, wenn Sie mit der Maus über das ![]() Graphsymbol fahren oder es anklicken.
Der @-Wert rechts oberhalb der Grafik zeigt dabei an, in welchem Intervall neue Daten geholt und ergänzt werden.
@ 1m steht zum Beispiel für ein Abfrageintervall von einer Minute.
Graphsymbol fahren oder es anklicken.
Der @-Wert rechts oberhalb der Grafik zeigt dabei an, in welchem Intervall neue Daten geholt und ergänzt werden.
@ 1m steht zum Beispiel für ein Abfrageintervall von einer Minute.
Die gleichen Graphen finden Sie zudem auch ganz einfach in den Details zu einem Host oder Service:
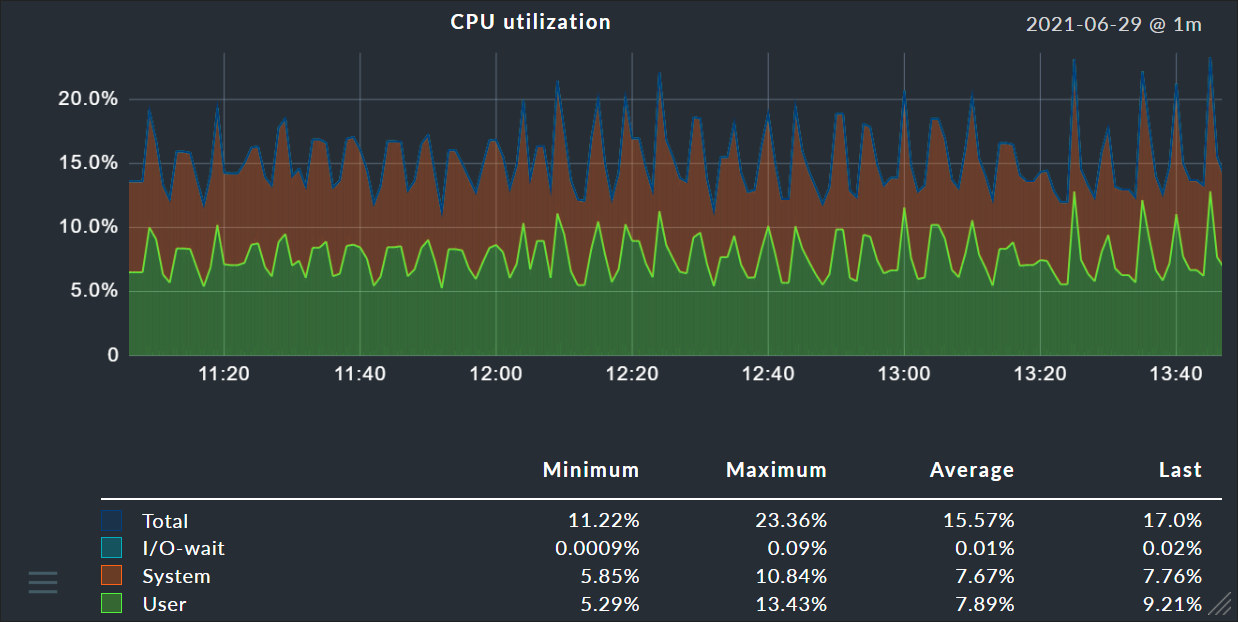
In den Details gibt es zudem eine Tabelle mit den aktuellen präzisen Messwerten für alle Metriken:

3. Interaktion mit dem Graphen
Sie können die Darstellung des Graphen auf verschiedene Arten interaktiv beeinflussen:
Durch Ziehen mit gedrückter Maustaste (panning oder dragging im Englischen) verschieben Sie den Zeitbereich (links/rechts) oder skalieren vertikal (hoch/runter).
Mit dem Mausrad zoomen Sie in die Zeit rein und raus.
Durch Ziehen an der rechten unteren Ecke verändern Sie die Größe des Graphen.
Ein Klick an eine Stelle im Graphen setzt eine "Stecknadel" (den Pin). Damit erfahren Sie die genaue zeitliche Lage eines Punkts und alle präzisen Messwerte zu diesem Zeitpunkt. Der exakte Zeitpunkt des Pins wird pro Benutzer gespeichert und in allen Graphen angezeigt.
Durch Anklicken einer Spaltenüberschrift stellen Sie die angezeigten Werte auf Minimum-, Maximum- oder Durchschnittswerte ein.
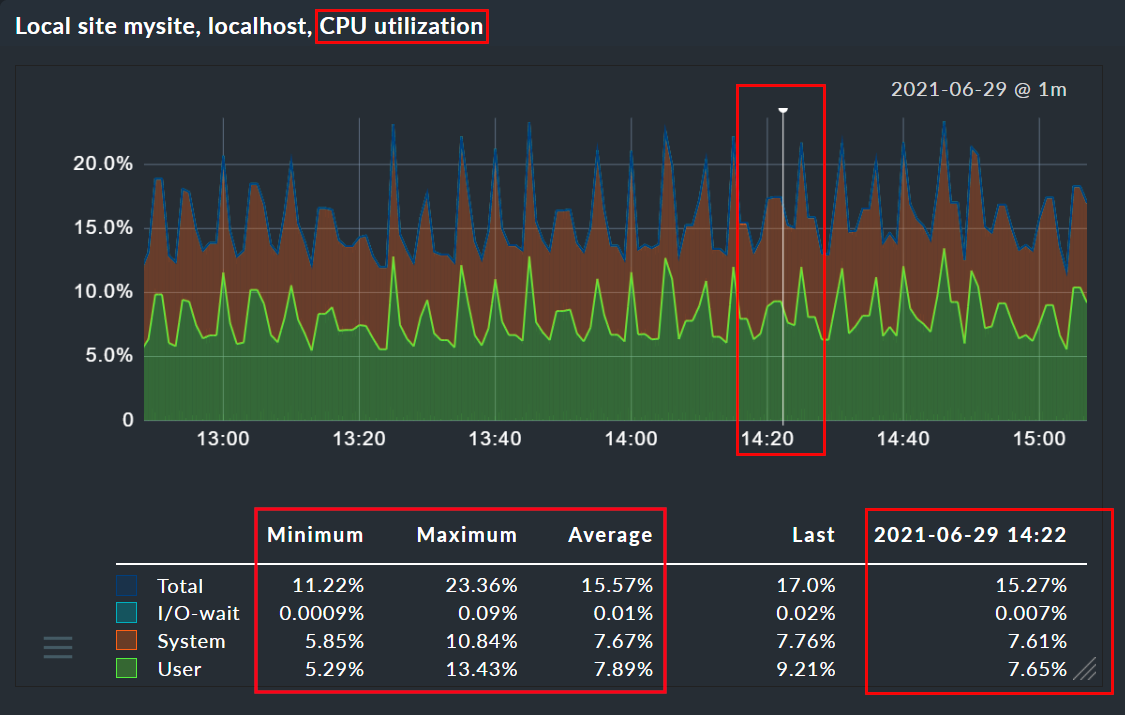
Wenn sich auf einer Seite mehrere Graphen befinden, so folgen auch alle anderen Graphen auf der Seite den gemachten Änderungen am gewählten Zeitbereich und des Pins. Somit sind die Werte immer vergleichbar. Auch eine Größenänderung wirkt sich auf alle Graphen aus. Der Abgleich geschieht allerdings erst beim nächsten Neuladen der Seite (sonst würde auch zwischenzeitlich ein ziemliches Chaos auf dem Bildschirm entstehen …).
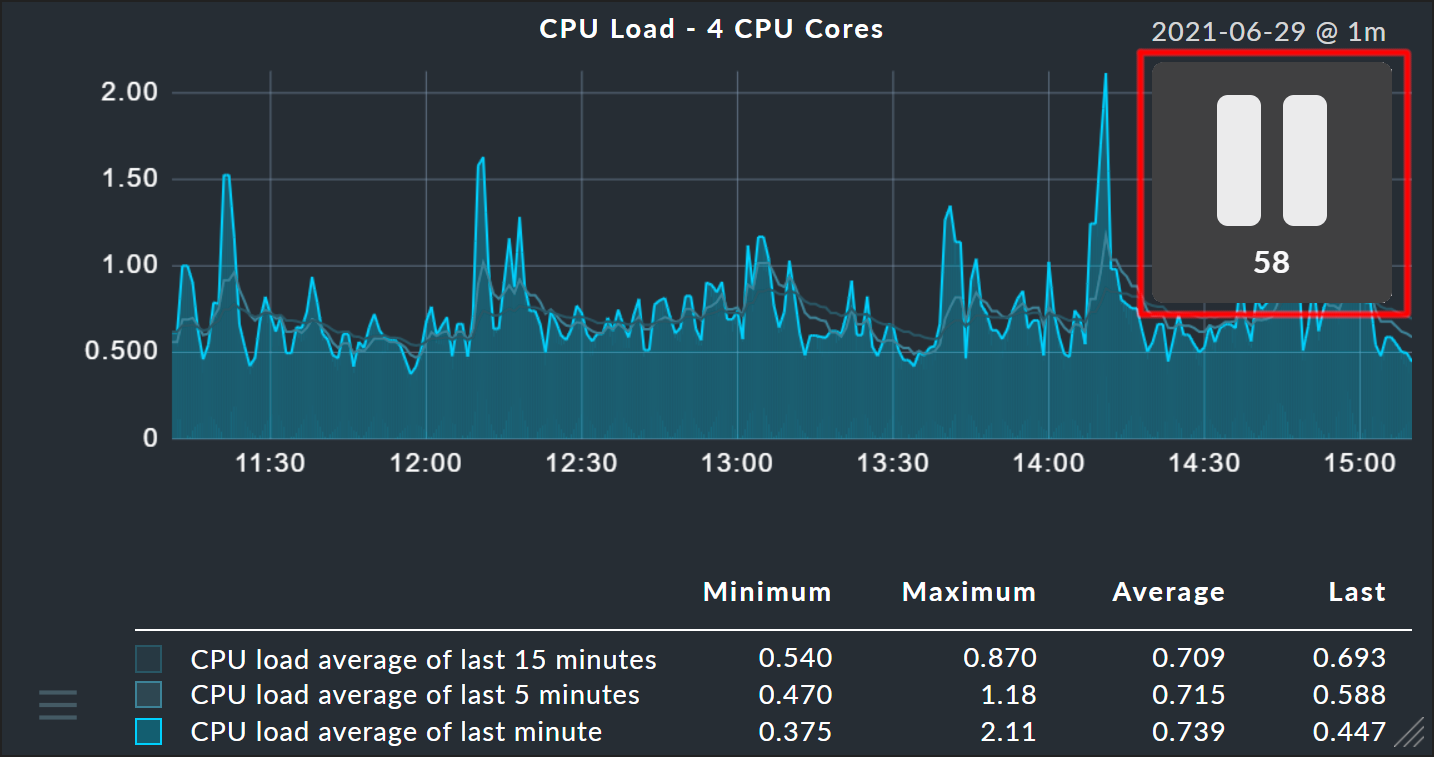
Sobald Sie die interaktiven Funktionen nutzen, also beispielsweise einen Pin setzen, erscheint auf dem Bildschirm ein großes Pause-Symbol und die Seitenaktualisierung setzt für 60 Sekunden aus. So wird Ihre Änderung im Graphen nicht sofort durch die Aktualisierung wieder rückgängig gemacht. Der Countdown wird immer wieder auf 60 Sekunden zurückgesetzt, wenn Sie erneut aktiv werden. Sie können den Countdown aber auch komplett abschalten, wenn Sie auf die Zahl klicken. Durch Klick auf das Pause-Symbol können Sie die Pause jederzeit wieder beenden.
4. Graphensammlungen (Graph collections)
![]() In den kommerziellen Editionen
können Sie mit dem
In den kommerziellen Editionen
können Sie mit dem ![]() Menü, das links unten im Graphen angezeigt wird, diesen an verschiedenen Stellen einbetten, z.B. in Berichte oder Dashboards.
Sehr nützlich ist dabei der Menübereich Add to graph collection.
In so eine Graphensammlung können Sie beliebig viele Graphen packen und diese dann später vergleichen oder auch als PDF exportieren.
Als Standard hat jeder Benutzer eine Graphensammlung mit dem Namen My graphs.
Sie können aber sehr einfach weitere anlegen und diese sogar für andere Benutzer sichtbar machen.
Das Vorgehen ist dabei exakt das Gleiche wie bei den Tabellenansichten.
Menü, das links unten im Graphen angezeigt wird, diesen an verschiedenen Stellen einbetten, z.B. in Berichte oder Dashboards.
Sehr nützlich ist dabei der Menübereich Add to graph collection.
In so eine Graphensammlung können Sie beliebig viele Graphen packen und diese dann später vergleichen oder auch als PDF exportieren.
Als Standard hat jeder Benutzer eine Graphensammlung mit dem Namen My graphs.
Sie können aber sehr einfach weitere anlegen und diese sogar für andere Benutzer sichtbar machen.
Das Vorgehen ist dabei exakt das Gleiche wie bei den Tabellenansichten.
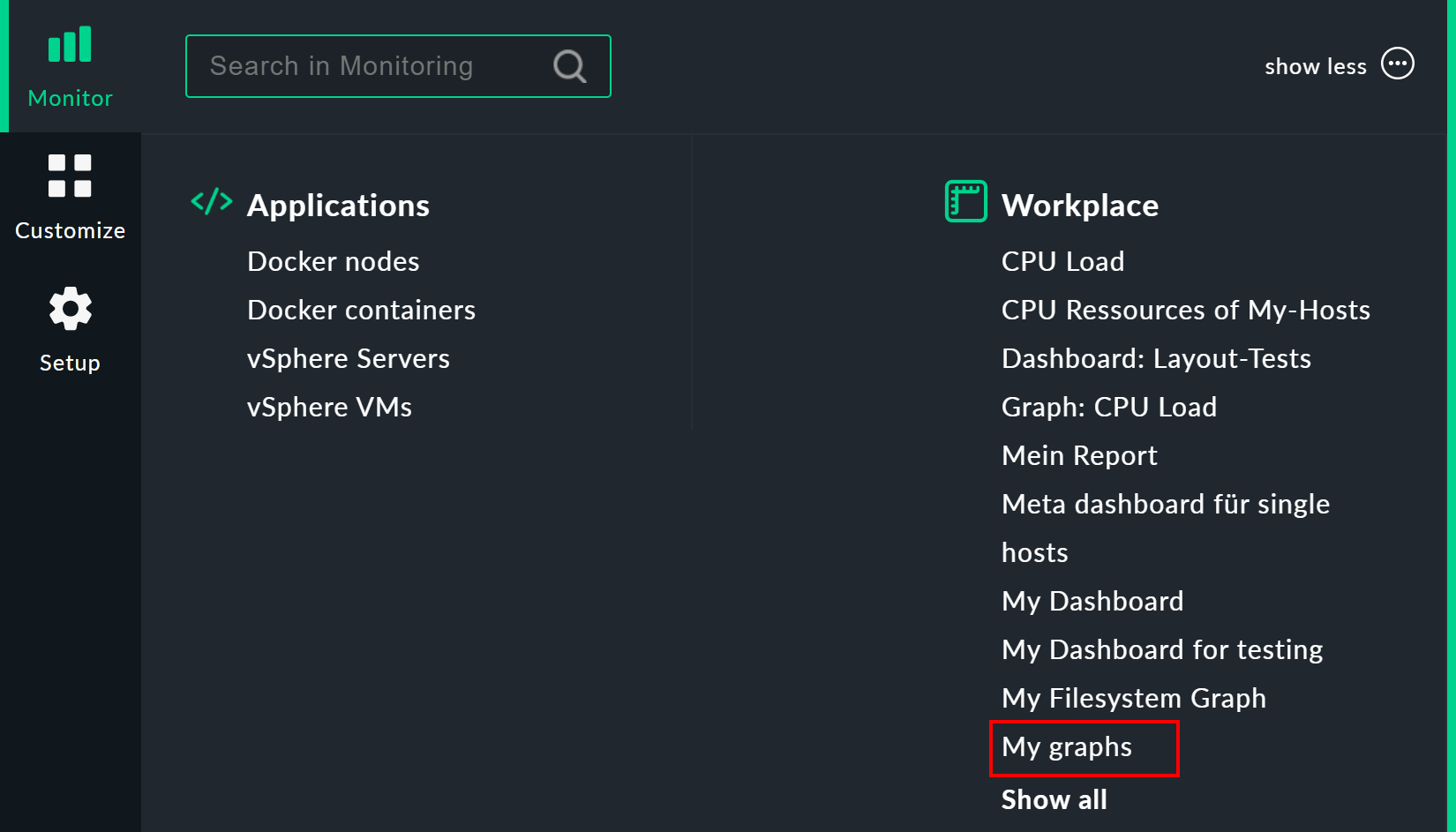
Sie gelangen zu Ihrer Graphensammlung über Monitor > Workplace > My graphs. Der Eintrag My graphs taucht erst auf, wenn Sie auch tatsächlich mindestens einen Graphen hinzugefügt haben.
Über Customize > Graphs > Graph collections kommen Sie zur Tabelle all Ihrer Graphensammlungen mit der Möglichkeit, weitere anzulegen, zu ändern usw.
5. Graphen anpassen (Graph tunings)
![]() In den kommerziellen Editionen
können Sie kleine Anpassungen an den eingebauten Graphen vornehmen und zwar über Customize > Graphs > Graph tunings.
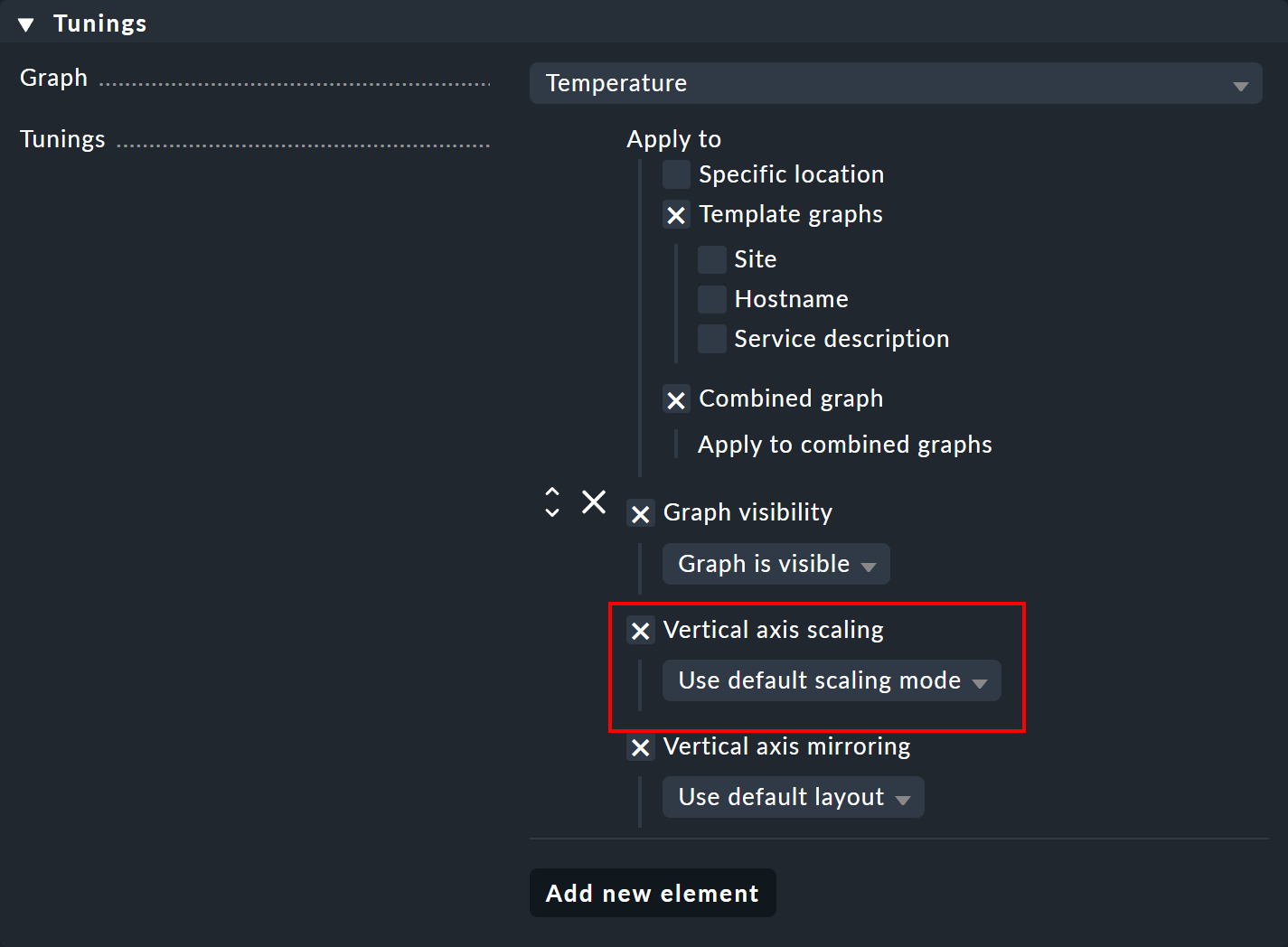
Diese Graph tunings ermöglichen Ihnen zum Beispiel, die Skalierung der Y-Achse für einen bestimmten Graphen zu verändern, über die Option Vertical axis scaling:
In den kommerziellen Editionen
können Sie kleine Anpassungen an den eingebauten Graphen vornehmen und zwar über Customize > Graphs > Graph tunings.
Diese Graph tunings ermöglichen Ihnen zum Beispiel, die Skalierung der Y-Achse für einen bestimmten Graphen zu verändern, über die Option Vertical axis scaling:
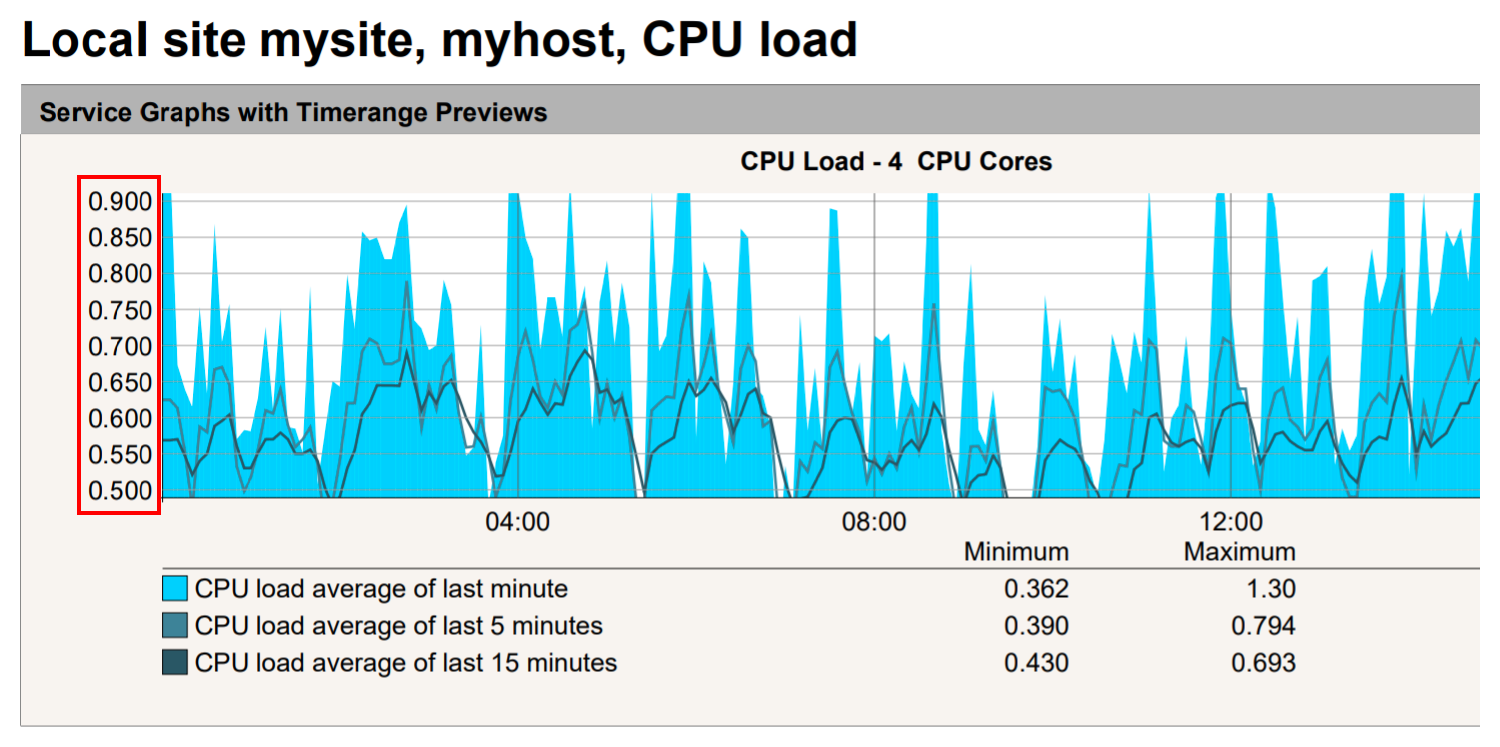
Diese Änderung ließe sich dann auch mit Apply to auf bestimmte Vorkommen des Graphen beschränken, beispielsweise in Dashboards. Im folgenden Bild sehen Sie eine Skalierung auf den Bereich 0.5 bis 0.9 in einem PDF-Bericht:
Darüber hinaus stehen Ihnen zwei weitere Optionen zur Verfügung: Über Graph visibility lässt sich ein Graph an bestimmten Orten explizit ein- oder ausblenden. Und Vertical axis mirroring ist nützlich bei Graphen, die Daten ober- und unterhalb der Zeitleiste (X-Achse) zeigen, wie etwa der Graph Disk throughput weiter unten: Dort lassen sich die Daten spiegeln, so dass also die vormals oberen Daten unterhalb der Zeitleiste angezeigt werden und umgekehrt.
Hinweis: Die Temperaturmaßeinheiten von Graphen und Perf-O-Metern können Nutzer individuell über ihr Profil festlegen. Die allgemeine Anpassung für Zusammenfassungen und Detailansichten erledigen Sie über den Service-Regelsatz Temperature.
6. Benutzerdefinierte Graphen (Custom graphs)
![]() Die kommerziellen Editionen bieten
einen grafischen Editor, mit dem Sie komplett eigene Graphen mit eigenen Berechnungsformeln erstellen können.
Damit ist es auch möglich, Metriken von verschiedenen Hosts und Services in einem Graphen zu kombinieren.
Die kommerziellen Editionen bieten
einen grafischen Editor, mit dem Sie komplett eigene Graphen mit eigenen Berechnungsformeln erstellen können.
Damit ist es auch möglich, Metriken von verschiedenen Hosts und Services in einem Graphen zu kombinieren.
Zu den benutzerdefinierten Graphen gelangen Sie z.B. über Customize > Graphs > Custom graphs.
Ein anderer Weg geht über die Metrik-Tabelle bei einem Service.
Dort gibt es bei jeder Metrik ein ![]() Menü mit einem Eintrag, um die Metrik zu einem benutzerdefinierten Graphen hinzuzufügen:
Menü mit einem Eintrag, um die Metrik zu einem benutzerdefinierten Graphen hinzuzufügen:
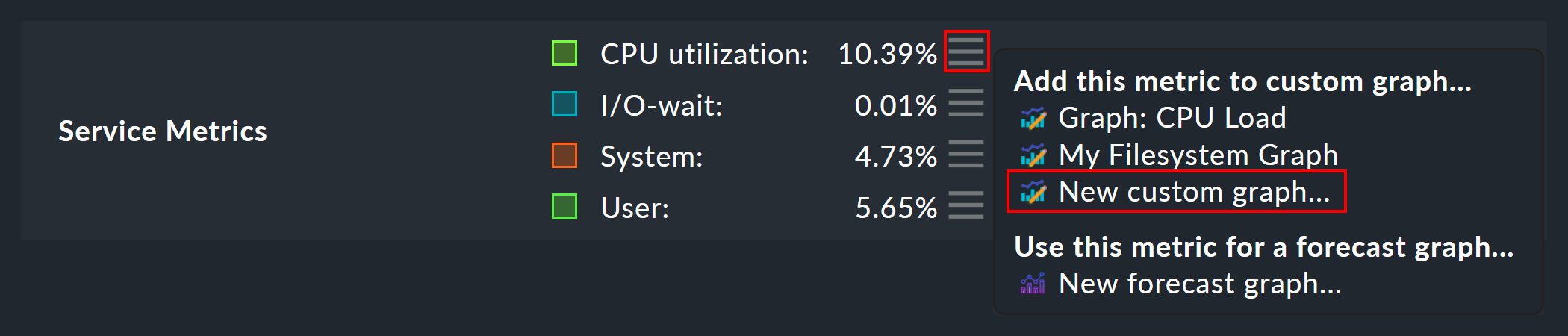
Folgende Abbildung zeigt die Liste der benutzerdefinierten Graphen (hier mit nur einem Eintrag):
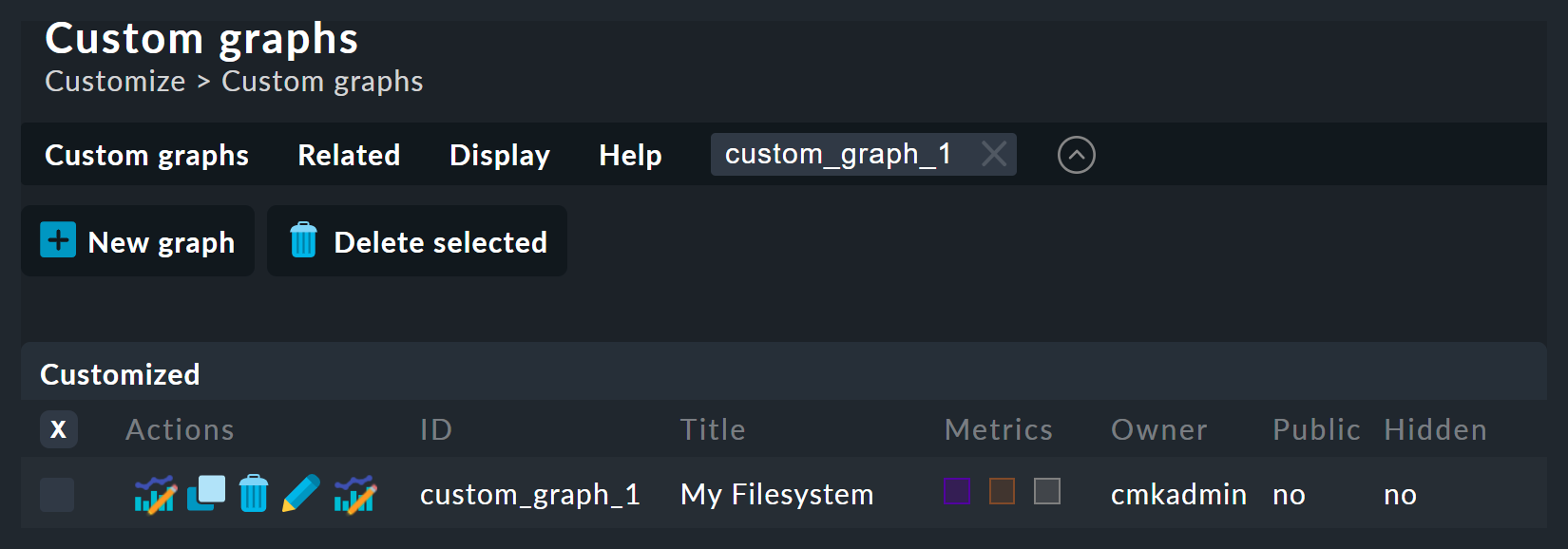
Bei jedem vorhandenen Graphen haben Sie fünf mögliche Operationen:
|
Zeigt den Graphen an. |
|
Öffnet die Eigenschaften dieses Graphen. Hier können Sie neben dem Titel auch Einstellungen zur Sichtbarkeit für andere Benutzer festlegen. Alles verhält sich exakt wie bei den Tabellenansichten. Wenn Sie Fragen zu einer der Einstellungen haben, können Sie sich die kontextsensitive Hilfe einblenden lassen mit Help > Show inline help. |
|
Hier gelangen Sie zum Graphdesigner, mit dem Sie die Inhalte verändern können. |
|
Erzeugt eine Kopie dieses Graphen. |
|
Löscht den Graphen. |
Beachten Sie, dass jeder benutzerdefinierte Graph — analog zu den Ansichten — eine eindeutige ID hat. Über diese wird der Graph in Berichten und Dashboards angesprochen. Wenn Sie die ID eines Graphen später ändern, gehen dadurch solche Referenzen verloren. Alle Graphen, die nicht hidden sind, werden standardmäßig unter Monitor > Workplace angezeigt.
6.1. Der Graphdesigner
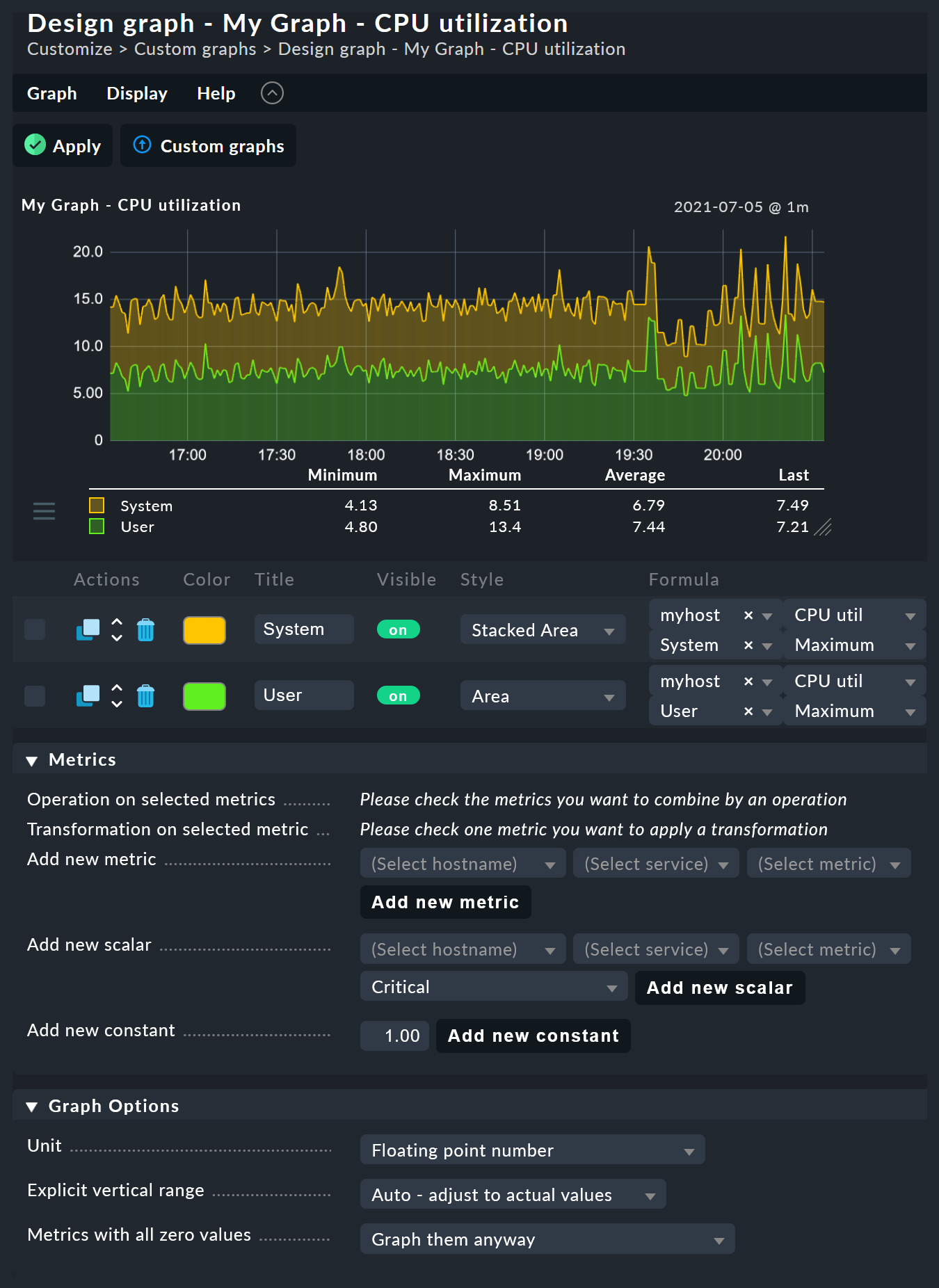
Der Graphdesigner ist in vier Bereiche unterteilt:
6.2. Vorschau des Graphen
Hier sehen Sie den Graphen exakt so, wie er auch später zu sehen sein wird. Sie können alle interaktiven Funktionen nutzen.
6.3. Liste der Graphlinien
Die im Graphen enthaltenen Kurven können hier direkt bearbeitet werden. Die Einstellungen sind direkt über einen Klick auf die betreffende Option bzw. durch Eingabe in das betreffende Textfeld veränderbar.
In der Spalte Actions finden Sie zu jeder angelegten Metrik einen ![]() Knopf zum Klonen derselben.
So können Sie fix Kurven kopieren und schlicht etwa den Host-Namen austauschen.
Knopf zum Klonen derselben.
So können Sie fix Kurven kopieren und schlicht etwa den Host-Namen austauschen.
Der Line style legt fest, wie der Wert im Graphen optisch gezeichnet wird. Dabei gibt es folgende Möglichkeiten:
Line |
Der Wert wird als Linie eingezeichnet. |
Area |
Der Wert wird als Fläche eingezeichnet. Beachten Sie, dass die Kurven Vorrang haben, die weiter oben in der Liste stehen, und so Kurven überdecken können, die weiter unten stehen. Wenn Sie Linien und Flächen kombinieren möchten, sollten die Flächen immer unten stehen. |
Stack |
Alle Kurven dieses Stils werden als Flächen gezeichnet und vom Wert her aufeinander gestapelt (also quasi addiert). Die obere Grenze dieses Stapels symbolisiert also die Summe aller beteiligten Kurven. |
Als weitere Möglichkeit können Sie zusätzlich die Option Mirrored aktivieren. Die betroffenen Darstellungen werden dann von der Nulllinie aus nach unten gezeichnet. Das ermöglicht eine Art von Graph, wie sie Checkmk generell für Input/Output-Graphen wie den folgenden verwendet:
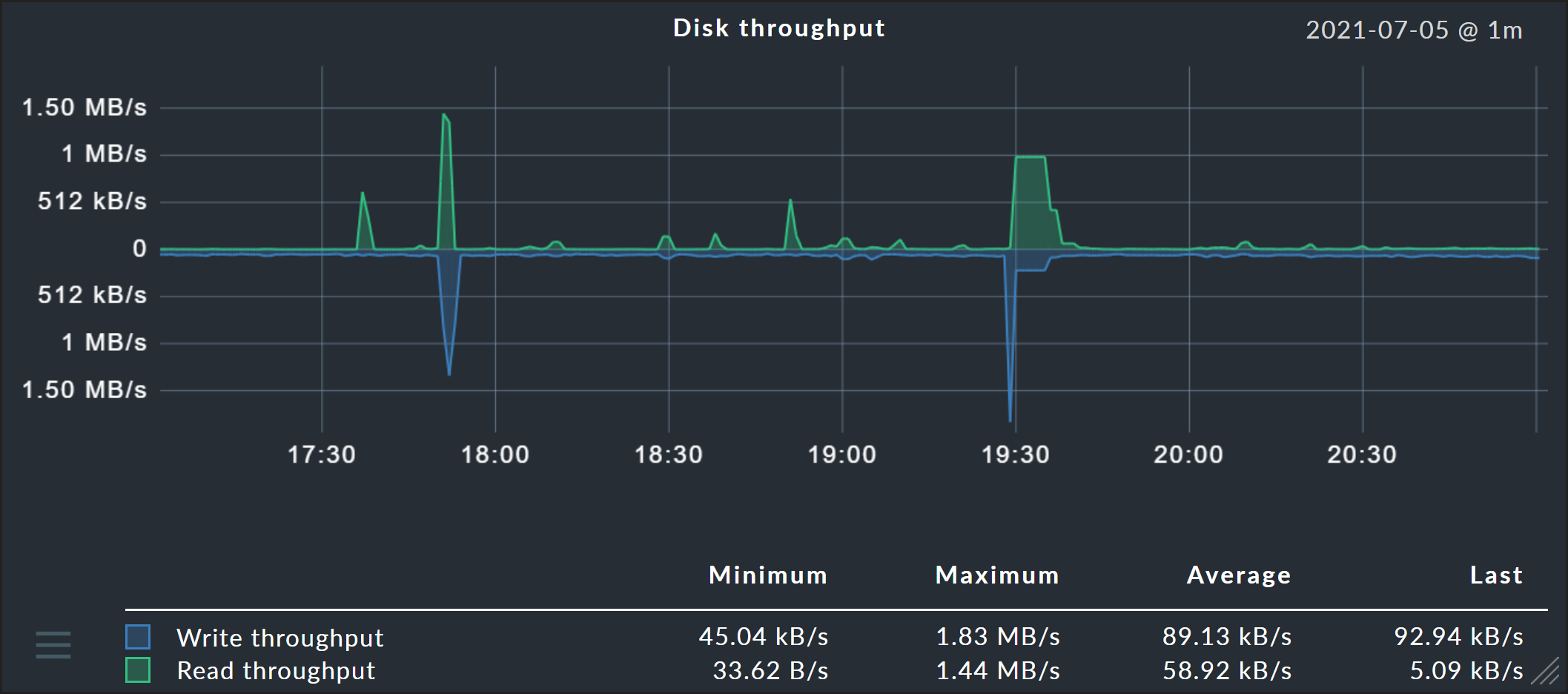
Über die Klapplisten in Formula können Sie jederzeit die Datenbasis der Graphen modifizieren.
6.4. Einen Graphen hinzufügen
Über die beiden Graph lines-Kästen können Sie neue Metriken zum Graphen hinzufügen.
Hier werden zwei Arten von Graph-Darstellungen unterschieden:
Graph lines (OpenTelemetry) und
Graph lines (Standard)
Einen neuen Graphen fügen Sie immer über einen Klick auf Add hinzu.
Eine Beschreibung der OpenTelemetry-Graphen finden Sie im Artikel zur OpenTelemetry.
Im Bereich der Standard-Graphen können Sie Metriken, Skalare und Konstanten erstellen. Sobald Sie im ersten Feld einer Metrik einen Host name ausgewählt haben, wird das zweite Feld mit der Liste der Services des Hosts gefüllt. Eine Auswahl des Service name füllt das dritte Feld mit der Liste der Metriken dieses Services. Im vierten und letzten Feld wählen Sie die Konsolidierungsfunktion. Zur Auswahl stehen Minimum, Maximum und Average. Diese Funktionen kommen immer dann zur Anwendung, wenn die Speicherung der Daten in den RRDs für den gewählten Zeitraum bereits verdichtet ist. In einem Bereich, wo z.B. nur noch ein Wert pro halber Stunde zur Verfügung steht, können Sie so wählen, ob Sie den größten, kleinsten oder durchschnittlichen Originalmesswert dieses Zeitraums einzeichnen möchten.
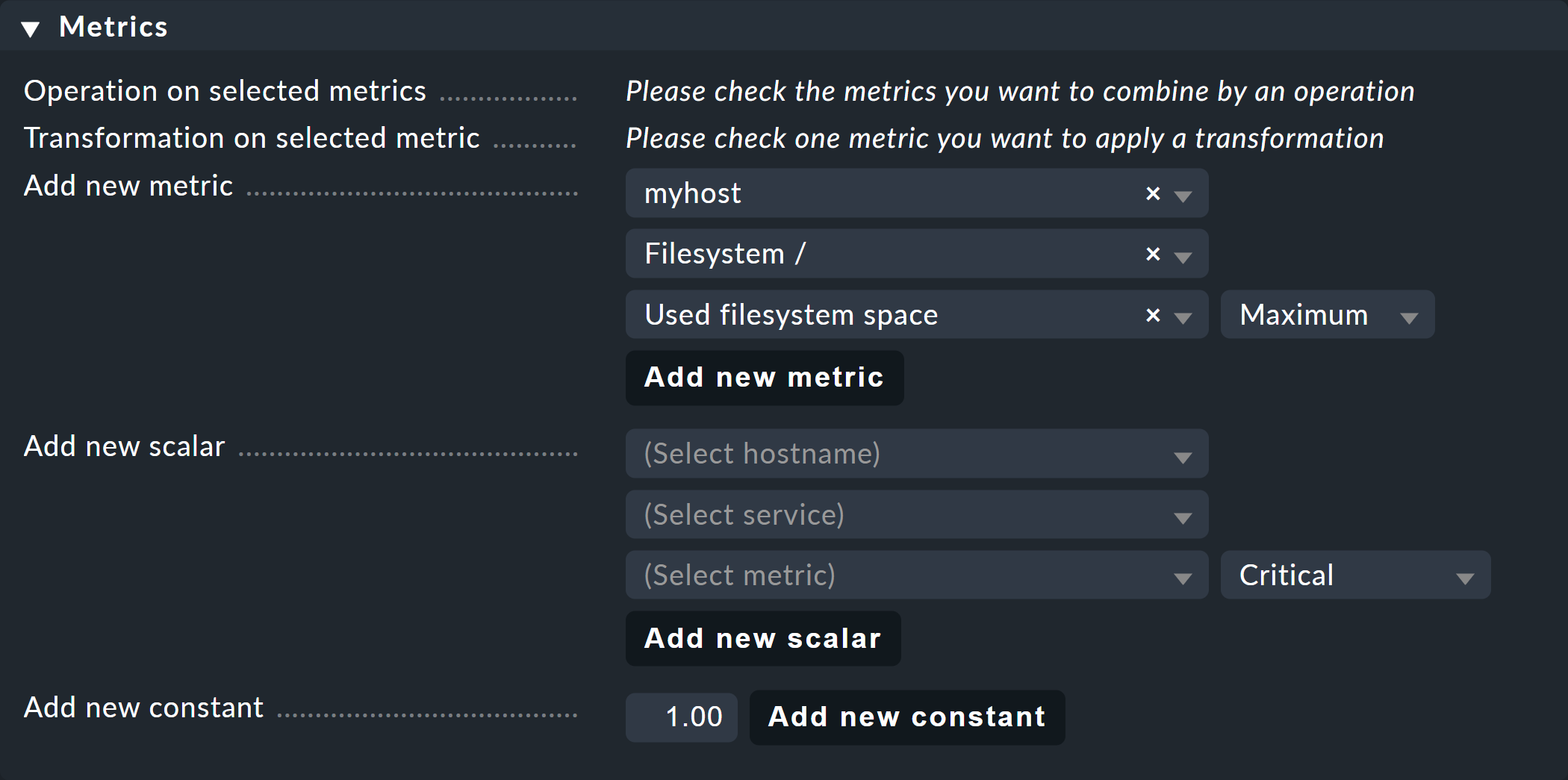
Auf die gleiche Art blenden Sie über den Scalar die Werte eines Services für WARN, CRIT, Maximum und Minimum als waagerechte Linien ein.
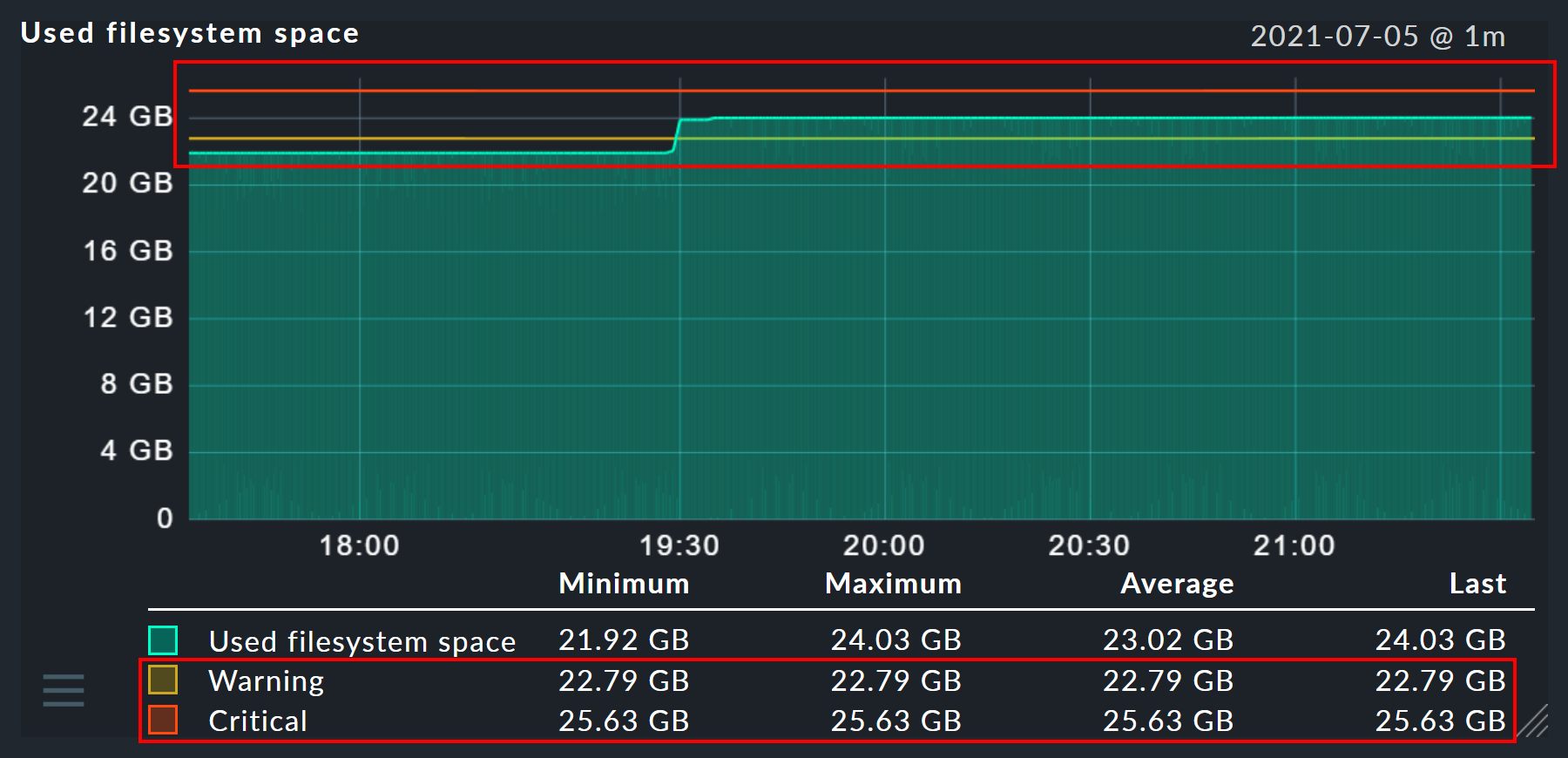
Sie können dem Graphen auch eine Konstante hinzufügen. Diese wird dann zunächst als waagerechte Linie angezeigt. Konstanten sind manchmal nötig zur Bildung von Berechnungsformeln. Dazu später mehr.
6.5. Graphoptionen
Hier finden Sie Optionen, die den Graphen als Ganzes betreffen.
Die Einheit (Unit) beeinflusst die Beschriftung der Achsen und der Legende. Der Standardwert Use unit of first entry legt fest, dass als Einheit der erste Eintrag des benutzerdefinierten Graphen mit einer bekannten Einheit verwendet wird. So ist die Einheit von Metriken und Skalaren stets bekannt, die von Konstanten jedoch nicht. Wenn kein Eintrag eine bekannte Einheit hat, wird der Graph ohne Einheitensymbol dargestellt. Wählen Sie stattdessen Custom aus, so öffnen sich weitere Einstellungen, mit denen Sie die Einheit selbst festlegen können. Beachten Sie, dass es zwar möglich, aber nicht sehr sinnvoll ist, zwei Metriken mit unterschiedlichen Einheiten in einem Graphen unterzubringen.
Unter Explicit range können Sie den vertikalen Bereich des Graphen voreinstellen. Normalerweise wird die Y-Achse so skaliert, dass alle Messwerte im gewählten Zeitraum genau in den Graphen passen. Wenn Sie einen Graphen für z.B. einen Prozentwert entwerfen, könnten Sie sich aber auch entscheiden, dass immer von 0 bis 100 dargestellt wird. Beachten Sie dabei, dass der Graph vom Benutzer (und auch Ihnen selbst) trotzdem mit der Maus skaliert werden kann und die Einstellung dann wirkungslos wird.
6.6. Rechnen mit Formeln
Der Graphdesigner ermöglicht es Ihnen, die einzelnen Kurven durch Rechenoperationen zu kombinieren. Folgendes Beispiel zeigt einen Graphen mit zwei Kurven: CPU utilization User und System.
Nehmen wir an, dass Sie für diesen Graphen nur die Summe von beiden interessiert. Dazu wählen Sie zunächst die beiden Kurven durch Ankreuzen ihrer Checkboxen aus. Sobald Sie das tun, erscheinen im Kasten Graph lines (Standard) in der Zeile Operations Knöpfe für alle wählbaren Verknüpfungen:
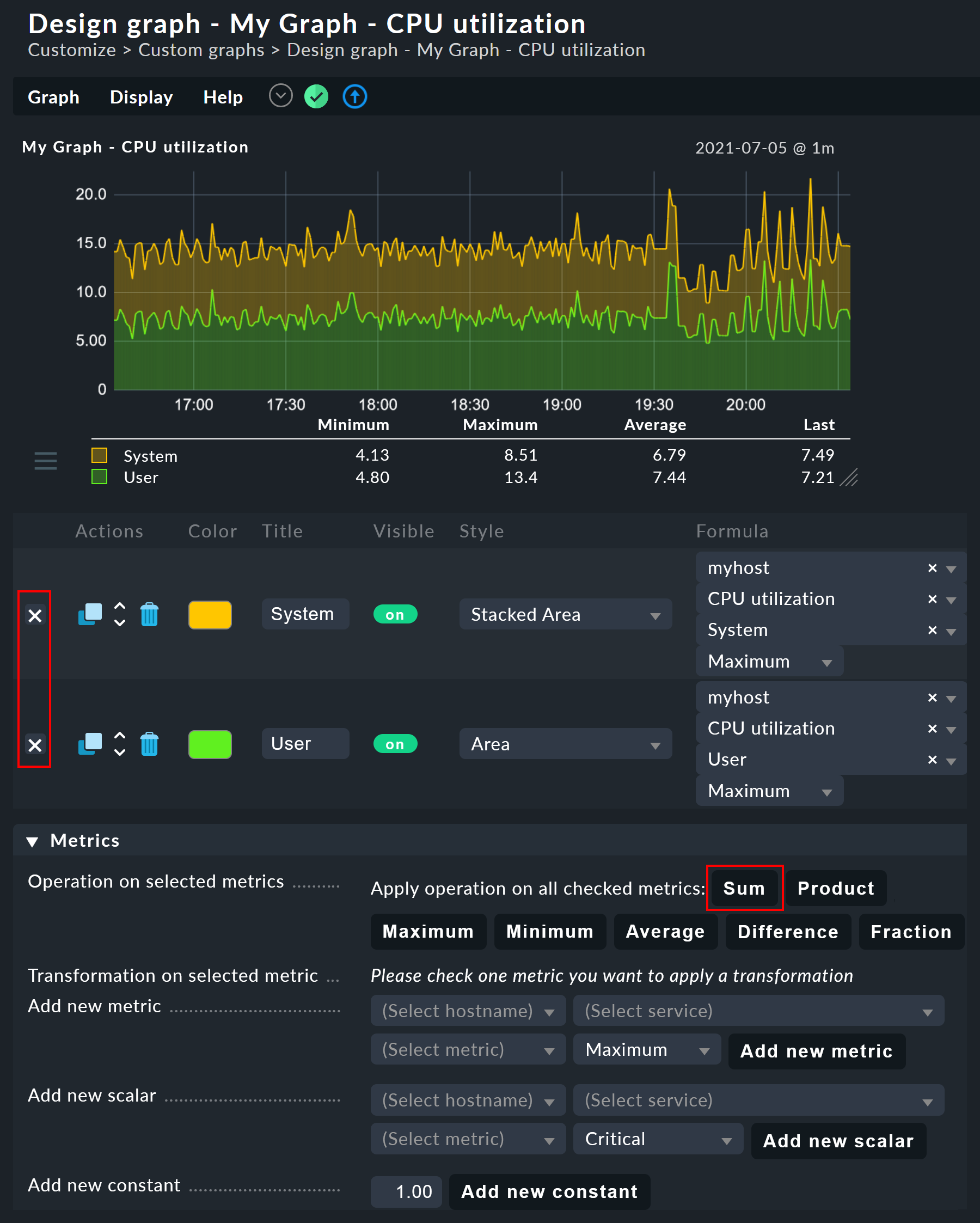
Ein Klick auf Sum kombiniert die beiden gewählten Zeilen zu einer neuen Kurve, deren Farbe der obersten ausgewählten Metrik entspricht.
Der Titel der neuen Kurve wird zu Sum of System, User.
Die Berechnungsformel wird in der Spalte Formula angezeigt.
Außerdem taucht ein neues ![]() Symbol auf:
Symbol auf:
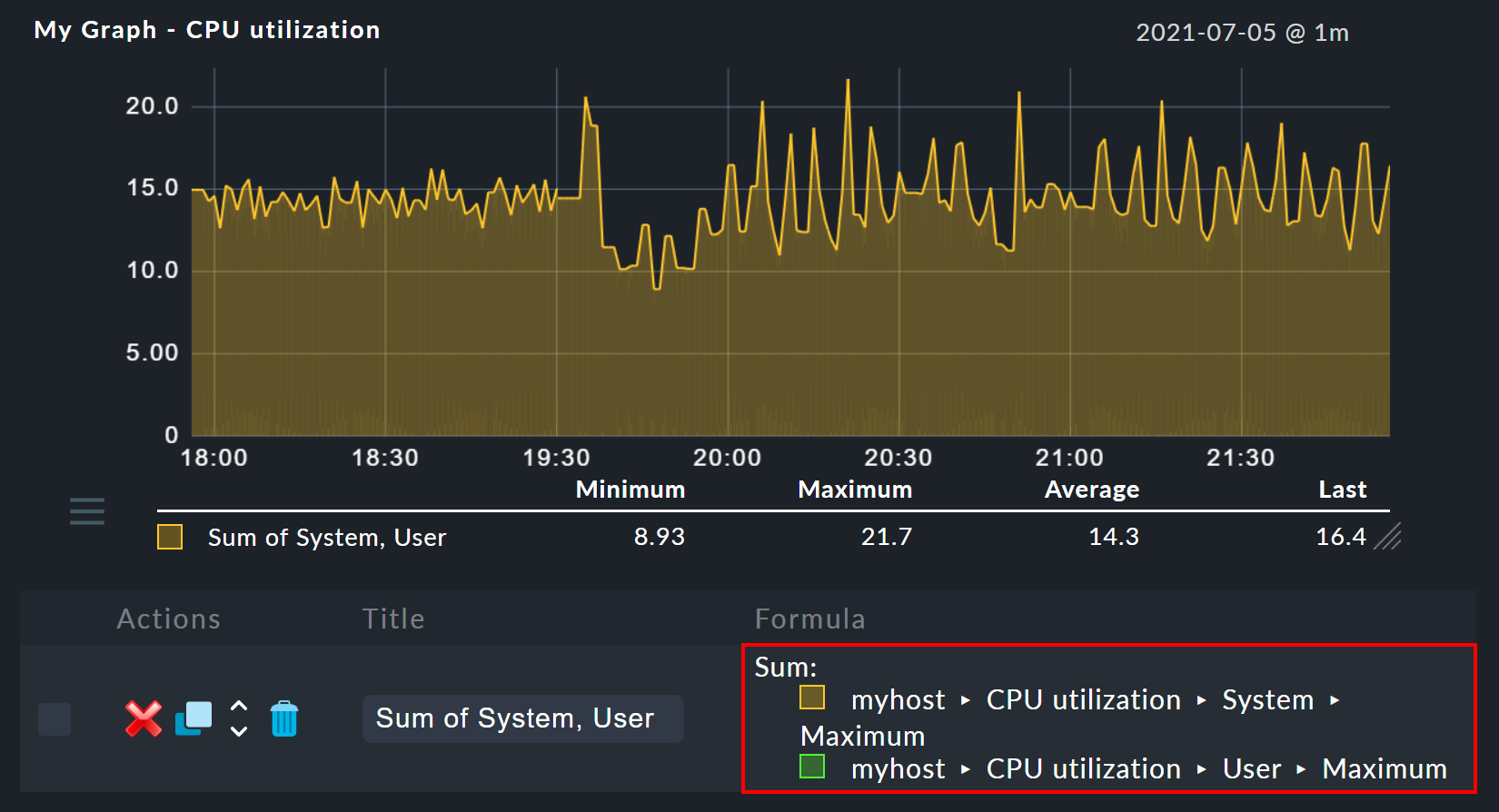
Durch einen Klick auf ![]() machen Sie die Operation quasi rückgängig, in dem Sie die Formel wieder auflösen — woraufhin die einzelnen enthaltenen Kurven wieder zum Vorschein kommen.
Weitere Hinweise zu den Rechenoperationen:
machen Sie die Operation quasi rückgängig, in dem Sie die Formel wieder auflösen — woraufhin die einzelnen enthaltenen Kurven wieder zum Vorschein kommen.
Weitere Hinweise zu den Rechenoperationen:
Manchmal ist es sinnvoll, Konstanten hinzuzufügen, um z.B. den Wert einer Kurve von der Zahl 100 abzuziehen.
Skalare können ebenfalls für Berechnungen genutzt werden.
Sie können die Operationen beliebig verschachteln.
7. InfluxDB, Graphite und Grafana
![]() Wenn Sie eine der kommerziellen Editionen einsetzen, so können Sie parallel zum in Checkmk eingebauten Graphing auch externe Metrikdatenbanken anbinden und die Metriken an InfluxDB oder Graphite senden.
Wenn Sie eine der kommerziellen Editionen einsetzen, so können Sie parallel zum in Checkmk eingebauten Graphing auch externe Metrikdatenbanken anbinden und die Metriken an InfluxDB oder Graphite senden.
In allen Editionen ist es außerdem möglich, Checkmk in Grafana zu integrieren und Metriken aus Checkmk in Grafana abrufen und anzeigen zu lassen.
8. Historische Messwerte in Tabellen
8.1. Um was geht es?
Wenn Sie die Messwerte der Vergangenheit betrachten, sind Sie manchmal nicht an deren genauem Verlauf interessiert, sondern eventuell nur an einer groben Zusammenfassung wie: Die durchschnittliche CPU-Auslastung der letzten 7 Tage. Das Ergebnis wäre dann einfach eine Zahl als Prozentwert wie 88 %.
Sie können in einer Tabelle von Hosts oder Services Spalten hinzufügen, welche den Durchschnitt, das Minimum, das Maximum oder andere Zusammenfassungen einer Metrik über einen bestimmten Zeitraum als Zahl darstellen. Das ermöglicht Ihnen dann auch Auswertungen, die nach diesen Spalten sortieren und so z.B. die Liste derjenigen ESXi-Hosts anzeigen, die im Vergleichszeitraum die geringste Auslastung hatten.
Um solche Messwerte in einer Ansicht anzuzeigen, gehen Sie so vor:
Wählen Sie eine bestehende Ansicht oder erstellen Sie eine neue.
Fügen Sie eine Spalte vom Typ Services: Metric History hinzu.
8.2. Ansicht erstellen
Zunächst benötigen Sie eine Ansicht, zu welcher die Spalten hinzugefügt werden sollen. Dies kann entweder eine Ansicht von Hosts oder von Services sein. Einzelheiten zum Anlegen oder Editieren von Ansichten finden Sie in dem Artikel über Ansichten.
Für das folgende Beispiel wählen wir die Ansicht All hosts, die Sie über Monitor > Hosts > All hosts öffnen können. Wählen Sie im Menü Display > Customize view. Das führt Sie zur Seite Clone view, mit der Sie sich die Ansicht nach Belieben zurechtkonfigurieren können.
Damit das Original All hosts nicht durch die Kopie überlagert wird, wählen Sie eine neue ID und auch einen neuen Titel, unter der die Ansicht später im Monitor-Menü angezeigt wird.
Dann entfernen Sie (optional) alle Spalten, die die Anzahl der Services in den verschiedenen Zuständen zeigen.
8.3. Spalte hinzufügen
Fügen Sie nun eine neue Spalte vom Typ Services: Metric History hinzu. Da dies eine Spalte für Services ist, benötigen Sie im Falle einer Host-Ansicht als erste Auswahl den Spaltentyp Joined column, welcher das Anzeigen einer Service-Spalte in einer Host-Tabelle ermöglicht. Bei einer Service-Ansicht reicht es, wenn Sie eine neue Column hinzufügen.
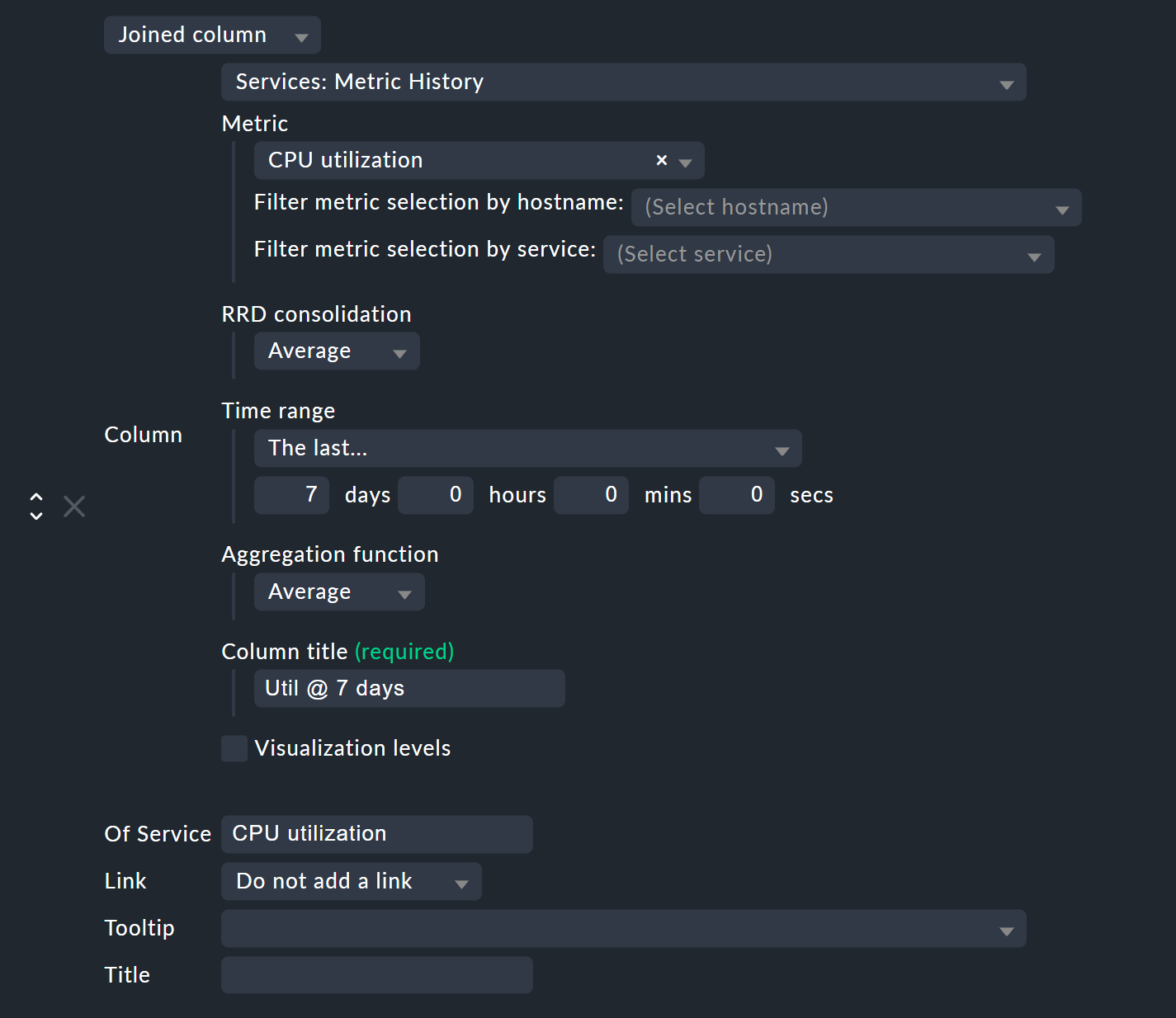
In Metric wählen Sie den Namen der Metrik aus, die historisch ausgewertet werden soll. Sollten Sie unsicher über den Namen der Metrik sein, finden Sie diesen in den Service-Details beim Eintrag Service Metrics:
Im Beispiel wählen wir die Metrik CPU utilization, welche hier zufällig gleich lautet wie der Name des Services.
Bei RRD consolidation wählen Sie am besten den gleichen Wert wie weiter unten bei Aggregation function, da es wenig sinnvoll ist, Dinge wie „das Minimum vom Maximum“ zu berechnen. Was es mit der Auswahlmöglichkeit bei RRDs auf sich hat, erfahren Sie im folgenden Kapitel über die Organisation der RRD-Daten.
Der Time range ist der Zeitraum in der Vergangenheit, über den Sie etwas erfahren wollen. In Beispiel sind es die letzten sieben Tage, was exakt 168 Stunden entspricht.
Column title ist dann der Spaltentitel, also zum Beispiel Util @ 7 days.
Wundern Sie sich nicht, dass später noch ein Feld mit dem Namen Title kommt.
Dieses sehen Sie nur dann, wenn hier eine Joined column benutzt wird, welche immer die Angabe eines Titels ermöglicht.
Lassen Sie den zweiten Titel einfach leer.
Zu guter Letzt geben Sie im Feld Of Service den Namen des Services ein, zu dem die oben gewählte Metrik gehört. Achten Sie auf die exakte Schreibweise des Services inklusive Groß- und Kleinschreibung.
Nach dem Speichern erhalten Sie jetzt eine neue Ansicht mit einer weiteren Spalte, welche die prozentuale CPU-Auslastung der letzten sieben Tage anzeigt:
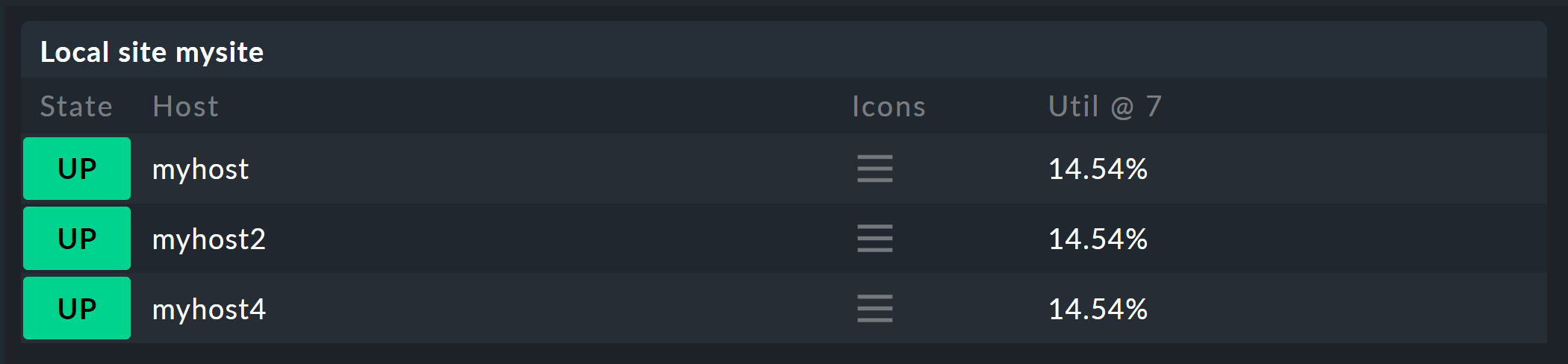
Hinweise
Sie können natürlich auch mehrere Spalten auf diese Art hinzufügen, z.B. für unterschiedliche Metriken oder unterschiedliche Zeiträume.
Bei Hosts, welche die Metrik oder den Service nicht haben, bleibt die Spalte leer.
Falls Sie mit einer Tabelle von Services arbeiten, benötigen Sie keine Joined Column. Allerdings können Sie dann pro Host in einer Zeile nur einen Service anzeigen.
9. Die Round-Robin-Datenbanken (RRDs)
Checkmk speichert alle Messwerte in dafür eigens entwickelten Datenbanken, sogenannten Round-Robin-Datenbanken (RRDs). Dabei kommt das RRDtool von Tobi Oetiker zum Einsatz, welches in Open-Source-Projekten sehr beliebt und weit verbreitet ist.
Die RRDs bieten gegenüber klassischen SQL-Datenbanken bei der Speicherung von Messwerten wichtige Vorteile:
RRDs speichern die Messdaten sehr kompakt und effizient.
Der Platzbedarf auf der Platte pro Metrik ist statisch. RRDs können weder wachsen noch schrumpfen. Der benötigte Plattenplatz kann gut geplant werden.
Die benötigte CPU- und Disk-Zeit pro Update ist immer gleich. RRDs sind (nahezu) echtzeitfähig, da es nicht zu Staus aufgrund von Reorganisationen kommen kann.
9.1. Organisation der Daten in den RRDs
Checkmk ist so voreingestellt, dass der Verlauf jeder Metrik über einen Zeitraum von vier Jahren aufgezeichnet wird. Die Grundauflösung ist dabei eine Minute. Dies ist deswegen sinnvoll, weil das Check-Intervall auf eine Minute voreingestellt ist und so von jedem Service genau einmal pro Minute neue Messwerte kommen.
Nun kann sich allerdings jeder ausrechnen, dass die Speicherung von einem Wert pro Minute über vier Jahre eine enorme Menge an Plattenplatz benötigen würde (obwohl die RRDs pro Messwert nur genau 8 Bytes benötigen). Aus diesem Grund werden die Daten mit der Zeit verdichtet. Die erste Verdichtung findet nach 48 Stunden statt. Ab diesem Zeitpunkt wird nur noch ein Wert pro fünf Minuten aufbewahrt. Die übrigen Stufen werden nach 10 Tagen und 90 Tagen umgesetzt:
| Phase | Dauer | Auflösung | Messwerte |
|---|---|---|---|
1 |
2 Tage |
1 Minute |
2880 |
2 |
10 Tage |
5 Minuten |
2880 |
3 |
90 Tage |
30 Minuten |
4320 |
4 |
4 Jahre |
6 Stunden |
5840 |
Jetzt stellt sich natürlich die Frage, wie denn nun fünf Werte sinnvoll zu einem einzigen konsolidiert werden sollen. Als Konsolidierungsfunktionen bieten sich das Maximum, das Minimum oder der Durchschnitt an. Was in der Praxis sinnvoll ist, hängt von der Anwendung oder Betrachtungsweise ab. Möchten Sie z.B. den Temperaturverlauf in einem Rechenzentrum über vier Jahre beobachten, wird Sie wahrscheinlich eher die maximale Temperatur interessieren, die je erreicht wurde. Bei der Messung von Zugriffszahlen auf eine Anwendung könnte der Durchschnitt interessieren.
Um maximal flexibel bei der späteren Auswertung zu sein, sind die RRDs von Checkmk so voreingestellt, dass sie einfach jeweils alle drei Werte speichern — also Minimum, Maximum und Durchschnitt. Pro Verdichtungsstufe und Konsolidierungsfunktion enthält die RRD einen ringförmigen Speicher — ein sogenanntes Round-Robin-Archiv (RRA). Im Standardaufbau gibt es insgesamt 12 RRAs. So benötigt das Standardschema von Checkmk genau 384 952 Bytes pro Metrik. Das ergibt sich aus 2880 + 2880 + 4320 + 5840 Messpunkten mal drei Konsolidierungsfunktionen mal acht Bytes pro Messwert, was genau 382 080 Bytes ergibt. Addiert man den Dateiheader von 2872 Bytes hinzu, ergibt sich die oben angegebene Größe von 384 952 Bytes.
Ein interessantes alternatives Schema wäre z.B. das Speichern von einem Wert pro Minute für ein komplettes Jahr. Dabei kann man einen kleinen Vorteil ausnutzen: Da die RRDs dann zu allen Zeiten die optimale Auflösung haben, können Sie auf die Konsolidierung verzichten und z.B. nur noch Average anlegen. So kommen Sie auf 365 x 24 x 60 Messwerte zu je 8 Bytes, was ziemlich genau 4 MB pro Metrik ergibt. Auch wenn die RRDs somit mehr als den zehnfachen Platz benötigen, ist die nötige "Disk I/O" sogar reduziert! Der Grund: Ein Update muss nicht mehr in 12 verschiedene RRAs geschrieben werden, sondern nur noch in eines.
9.2. Anpassen des RRD-Aufbaus
![]() Wenn Ihnen das voreingestellte Speicherschema nicht zusagt, so können Sie
dieses über Regelsätze ändern (sogar für Hosts oder
Services unterschiedlich). Den nötigen Regelsatz finden Sie am einfachsten über
die Regelsuche — also das Menü Setup. Geben Sie dort
einfach
Wenn Ihnen das voreingestellte Speicherschema nicht zusagt, so können Sie
dieses über Regelsätze ändern (sogar für Hosts oder
Services unterschiedlich). Den nötigen Regelsatz finden Sie am einfachsten über
die Regelsuche — also das Menü Setup. Geben Sie dort
einfach RRD in das Suchfeld ein. So finden Sie den Regelsatz
Configuration of RRD databases of services. Es gibt auch einen analogen Regelsatz
für Hosts, aber Hosts haben nur in Ausnahmefällen Messwerte. Folgendes Bild
zeigt die Regel mit den Standardeinstellungen:
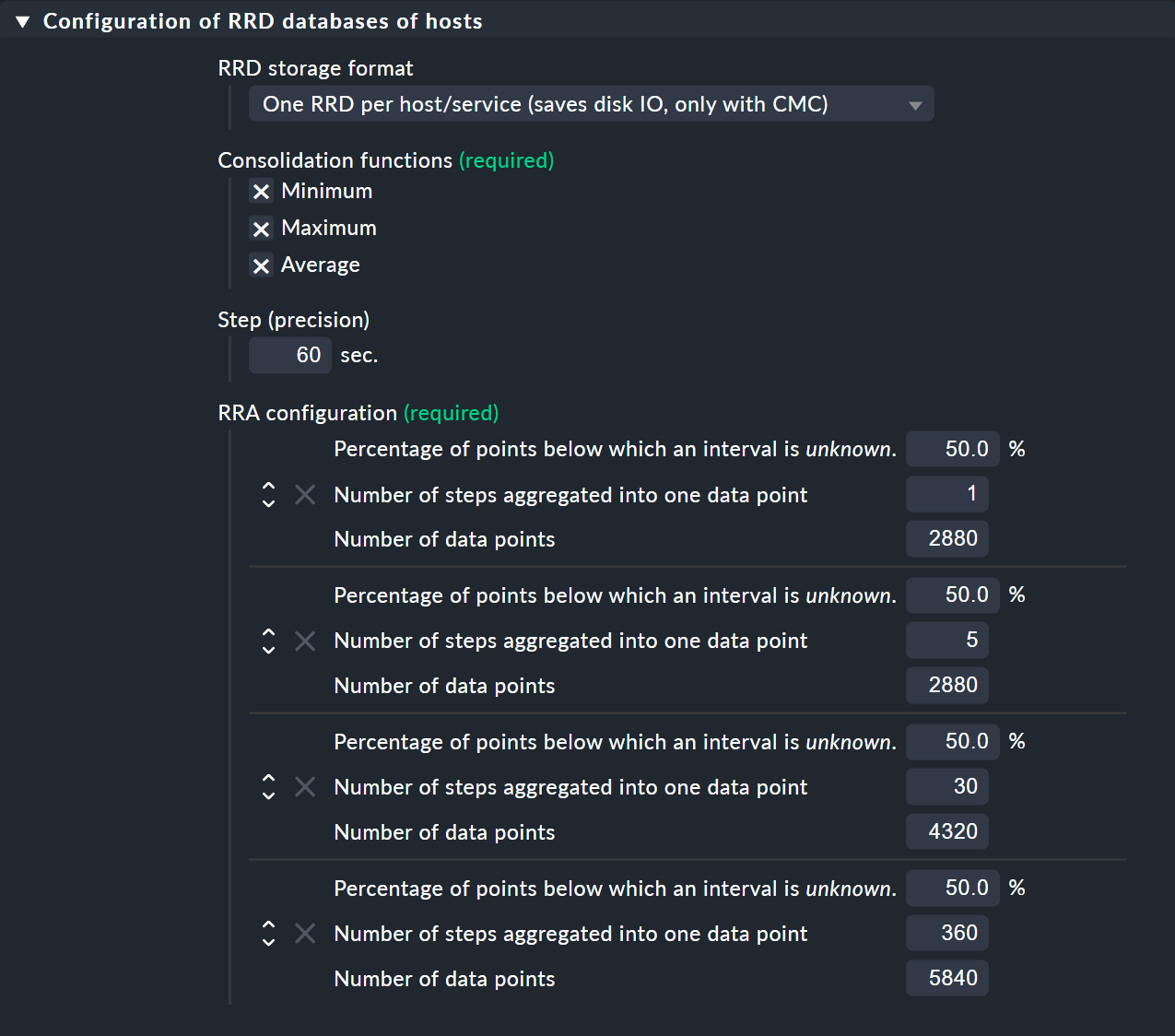
In den Abschnitten Consolidation functions und RRA configuration können Sie die Anzahl und Größe der Verdichtungsphasen bestimmen und festlegen, welche Konsolidierungen bereit gehalten werden sollen. Das Feld Step (precision) bestimmt die Auflösung in Sekunden, in der Regel 60 (eine Minute). Für Services mit einem Check-Interval von kleiner als einer Minute kann es sinnvoll sein, diese Zahl kleiner einzustellen. Beachten Sie dabei, dass die Angaben im Feld Number of steps aggregated into one data point dann nicht mehr Minuten bedeuten, sondern die in Step (precision) eingestellte Zeitspanne.
Jede Änderung des RRD-Aufbaus hat zunächst nur Einfluss auf
neu angelegte RRDs — sprich: wenn Sie neue Hosts oder Services in das
Monitoring aufnehmen. Sie können aber die bestehenden RRDs von Checkmk umbauen
lassen. Dazu dient der Befehl cmk-convert-rrds, bei welchem sich
immer die Option -v (verbose) anbietet. Checkmk kontrolliert dann
alle vorhandenen RRDs und baut diese nach Bedarf in das eingestellte
Zielformat um.
Um die Integrität der in den RRDs enthaltenen Daten sicherzustellen, stoppen Sie stets Ihre Instanz (mit |
Der Befehl ist intelligent genug, um RRDs zu erkennen, die bereits den richtigen Aufbau haben:
Wenn das neue Format eine höhere Auflösung oder zusätzliche Konsolidierungsfunktionen hat, werden die bestehenden Daten so gut es geht interpoliert, so dass die RRDs mit möglichst sinnvollen Werten gefüllt werden. Nur ist natürlich klar, dass wenn Sie z.B ab sofort nicht 2, sondern 5 Tage mit minutengenauen Werten haben möchten, die Genauigkeit der bestehenden Daten nicht nachträglich erhöht werden kann.
9.3. RRD-Speicherformat
![]() Die oben gezeigte Regel hat noch eine weitere Einstellung:
RRD storage format. Mit dieser können Sie zwischen zwei Methoden wählen, wie
Checkmk die RRDs erzeugt. Das Format One RRD per host/service
(oder kurz Checkmk-Format) speichert dabei alle Metriken
eines Hosts bzw. Services in einer einzigen RRD-Datei. Dies sorgt für ein
effizienteres Schreiben der Daten, da so immer ein kompletter Satz an Metriken
in einer einzigen Operation geschrieben werden kann. Diese Metriken liegen dann
in benachbarten Speicherzellen, was die Anzahl der Plattenblöcke reduziert, die
geschrieben werden müssen.
Die oben gezeigte Regel hat noch eine weitere Einstellung:
RRD storage format. Mit dieser können Sie zwischen zwei Methoden wählen, wie
Checkmk die RRDs erzeugt. Das Format One RRD per host/service
(oder kurz Checkmk-Format) speichert dabei alle Metriken
eines Hosts bzw. Services in einer einzigen RRD-Datei. Dies sorgt für ein
effizienteres Schreiben der Daten, da so immer ein kompletter Satz an Metriken
in einer einzigen Operation geschrieben werden kann. Diese Metriken liegen dann
in benachbarten Speicherzellen, was die Anzahl der Plattenblöcke reduziert, die
geschrieben werden müssen.
Sollten Ihre Checkmk-Instanzen mit einer kommerziellen Edition in einer älteren Version als 1.2.8 erzeugt worden sein, lohnt sich gegebenenfalls ein genauer Blick darauf, ob ihre Messdaten jemals in das aktuelle und weitaus performantere Format konvertiert worden sind. Sollten die Daten noch im alten Format vorliegen, können Sie diese über das Anlegen einer Regel im oben gezeigten Regelsatz auf das Checkmk-Format umstellen.
Auch hier benötigen Sie anschließend den Befehl cmk-convert-rrds, und auch hier gilt: Stoppen Sie stets Ihre Instanz, bevor Sie existierende RRDs konvertieren.
Wie Sie an der Warnung sehen können, lässt Checkmk die bestehenden Dateien
im alten Format zunächst liegen. Dies ermöglicht Ihnen im Zweifel eine Rückkehr
zu diesem Format, weil ein Konvertieren in die Rückrichtung nicht
möglich ist. Die Option --delete-rrds sorgt dafür, dass diese Kopien
nicht erzeugt bzw. nachträglich gelöscht werden. Sie können das Löschen
bequem später mit einem weiteren Aufruf des Befehls erledigen:
9.4. Der RRD-Cache-Daemon (rrdcached)
Um die Anzahl der nötigen Schreibzugriffe auf die Platte (drastisch) zu reduzieren, kommt ein Hilfsprozess zum Einsatz: der RRD-Cache-Daemon (rrdcached).
Er ist einer der automatisch gestarteten Instanzdienste.
Alle neuen Messwerte für die RRDs werden zunächst vom Checkmk Micro Core (kommerzielle Editionen) bzw. von NPCD (Checkmk Community)
an den rrdcached gesendet. Dieser schreibt die Daten zunächst nicht in die RRDs, sondern
merkt sie sich im Hauptspeicher, um sie später dann gesammelt in die jeweilige RRD
zu schreiben. So wird die Anzahl der Schreibzugriffe auf die Platte (oder in das SAN!)
deutlich reduziert.
Damit im Falle eines Neustarts keine Daten verloren gehen, werden die Updates zusätzlich in Journaldateien geschrieben. Dies bedeutet zwar auch Schreibzugriffe, aber da hier die Daten direkt hintereinander liegen, wird dadurch kaum IO erzeugt.
Damit der RRD-Cache-Daemon effizient arbeiten kann, benötigt er natürlich
viel Hauptspeicher. Die benötigte Menge hängt von der Anzahl Ihrer RRDs ab
und davon, wie lange Daten zwischengespeichert werden sollen. Letzteres können Sie in der
Datei ~/etc/rrdcached.conf einstellen. Die Standardeinstellung legt
eine Speicherung von 7200 Sekunden (zwei Stunden) plus eine Zufallsspanne
von 0-1800 Sekunden fest. Diese zufällige Verzögerung pro RRD verhindert
ein pulsierendes Schreiben und sorgt für eine gleichmäßige Verteilung
der IO über die Zeit:
# Tuning settings for the rrdcached. Please refer to rrdcached(1) for
# details. After changing something here, you have to do a restart
# of the rrdcached (reload is not sufficient)
# Data is written to disk every TIMEOUT seconds. If this option is
# not specified the default interval of 300 seconds will be used.
TIMEOUT=3600
# rrdcached will delay writing of each RRD for a random
# number of seconds in the range [0,delay). This will avoid too many
# writes being queued simultaneously. This value should be no
# greater than the value specified in TIMEOUT.
RANDOM_DELAY=1800
# Every FLUSH_TIMEOUT seconds the entire cache is searched for old values
# which are written to disk. This only concerns files to which
# updates have stopped, so setting this to a high value, such as
# 3600 seconds, is acceptable in most cases.
FLUSH_TIMEOUT=7200
# Specifies the number of threads used for writing RRD files. Increasing this
# number will allow rrdcached to have more simultaneous I/O requests into the
# kernel. This may allow the kernel to re-order disk writes, resulting in better
# disk throughput.
WRITE_THREADS=4Eine Änderung der Einstellungen in dieser Datei aktivieren Sie mit:
9.5. Dateien und Verzeichnisse
Hier ist eine Übersicht über die wichtigsten Dateien und Verzeichnisse, die mit Messdaten und RRDs zu tun haben (alle bezogen auf das Home-Verzeichnis der Instanz):
| Pfadname | Bedeutung |
|---|---|
|
RRDs im Checkmk-Format |
|
RRDs im alten Format (PNP) |
|
Journaldateien des RRD-Cache-Daemons |
|
Logdatei des RRD-Cache-Daemons |
|
Logdatei des Checkmk-Kerns (enthält ggf. Fehlermeldungen zu RRDs) |
|
Einstellungen für den RRD-Cache-Daemon |