1. Einleitung
Die Services sind das eigentliche Fleisch im Monitoring-System. Jeder Einzelne von ihnen repräsentiert ein wichtiges Rädchen in Ihrer komplexen IT-Landschaft. Der Nutzen des ganzen Monitorings steht und fällt damit, wie treffsicher und sinnvoll die Services konfiguriert sind. Schließlich soll das Monitoring zuverlässig melden, wenn sich irgendwo ein Problem abzeichnet, aber auf der anderen Seite falsche und nutzlose Benachrichtigungen unbedingt vermeiden.
Bei der Konfiguration der Services zeigt Checkmk seine vielleicht größte Stärke: Es verfügt über ein einzigartiges und sehr mächtiges System für eine automatische Erkennung und Konfiguration von Services. Sie müssen mit Checkmk nicht jeden einzelnen Service über Schablonen und Einzelzuweisungen definieren. Denn Checkmk kann die Liste der zu überwachenden Services sehr zuverlässig automatisch ermitteln und vor allem auch aktuell halten. Das spart nicht nur sehr viel Zeit — es macht das Monitoring auch genauer. Denn es stellt sicher, dass die täglichen Änderungen im Rechenzentrum auch immer zeitnah im Monitoring abgedeckt werden und kein wichtiger Dienst ohne Monitoring bleibt.
Die Service-Erkennung in Checkmk basiert auf einem wichtigen Grundprinzip: der Trennung des Was vom Wie:
Was soll überwacht werden? → Das Dateisystem
/varauf dem Hostmyserver01Wie soll es überwacht werden? → Bei 90 % belegtem Platz WARN, bei 95 % CRIT
Das Was wird bei der Service-Erkennung automatisch ermittelt. Es
setzt sich aus dem Host-Namen (myserver01), dem
Check-Plugin (df: Dateisystemcheck
unter Linux) und dem Item (/var) zusammen. Check-Plugins, die auf
einem Host maximal einen Service erzeugen können, benötigen kein Item
(z.B. das Check-Plugin für die CPU-Ausnutzung). Das Ergebnis der Erkennung
ist eine Tabelle, die Sie sich so vorstellen können:
| Host | Check-Plugin | Item |
|---|---|---|
|
|
|
|
|
|
|
|
|
… |
… |
… |
|
|
|
… |
… |
… |
Das Wie — also die Schwellwerte/Check-Parameter für die
einzelnen Services — wird unabhängig davon über Regeln
konfiguriert. Sie können z.B. eine Regel aufstellen, dass alle Dateisysteme mit
dem Mount-Punkt /var mit den Schwellwerten 90 % / 95 % überwacht werden,
ohne sich dabei Gedanken machen zu müssen, auf welchen Hosts denn nun
überhaupt so ein Dateisystem existiert. Das ist es, was die Konfiguration mit
Checkmk so einfach und übersichtlich macht!
Einige wenige Services können nicht über eine automatische Erkennung eingerichtet werden. Dazu gehören z.B. Checks, die per HTTP bestimmte Webseiten abrufen sollen. Diese werden per Regeln angelegt; wie, erfahren Sie im Artikel über die aktiven Checks.
Die Möglichkeiten von Checkmk, sich selber zu überwachen, werden im Artikel Das eigene System überwachen aufgeführt.
2. Services eines Hosts im Setup
2.1. Host neu aufnehmen
Nachdem Sie einen neuen Host im Setup aufgenommen haben, ist der nächste Schritt, die Liste der Services aufzurufen. Hierbei läuft bereits das erste Mal die Service-Erkennung für den Host, gleichzeitig wird die Erreichbarkeit der Datenquellen geprüft. Sie können diese Liste auch jederzeit später wieder aufrufen, um die Erkennung neu zu starten oder Anpassungen an der Konfiguration vorzunehmen. Sie erreichen die Service-Liste auf verschiedene Arten:
über den Knopf
 Save & run service discovery in den Properties of host im Setup
Save & run service discovery in den Properties of host im Setupin der Menüleiste der Properties of host über Host > Run service discovery
über das Symbol
 in der Liste der Hosts in einem Ordner im Setup
in der Liste der Hosts in einem Ordner im Setupüber den Eintrag
Run service discovery im Aktionsmenü des Services Check_MK Discovery eines Hosts
Wenn der Host gerade neu aufgenommen wurde, ist noch kein Service konfiguriert und daher erscheinen alle gefundenen Services in der Rubrik Undecided services - currently not monitored:
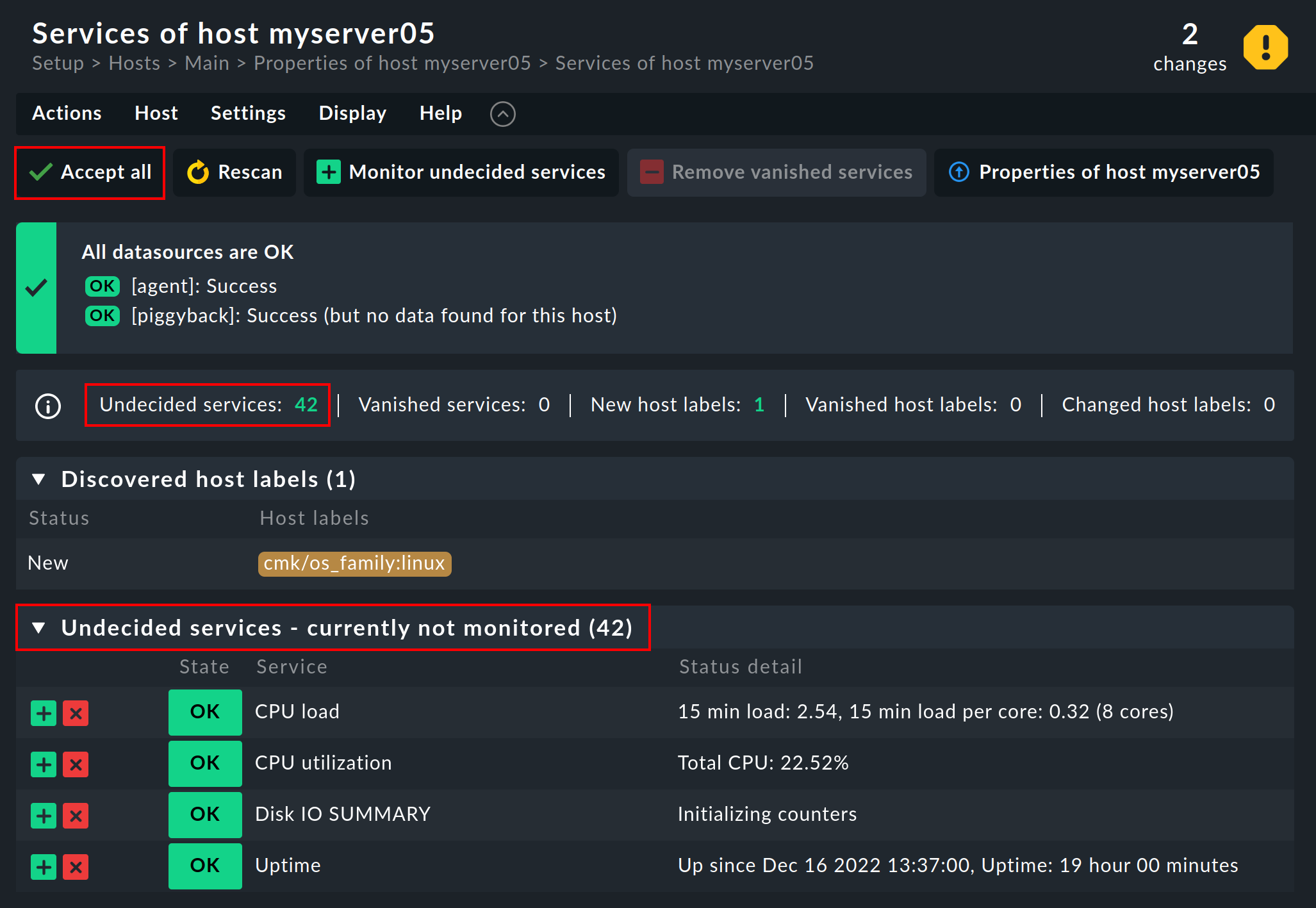
Der übliche Weg ist nun einfach das Hinzufügen der Services über den Knopf ![]() Accept all.
Auf diese Weise werden zeitgleich auch alle neuen Host-Labels mit aufgenommen.
Danach ein Activate changes und schon ist der Host samt Services im Monitoring.
Accept all.
Auf diese Weise werden zeitgleich auch alle neuen Host-Labels mit aufgenommen.
Danach ein Activate changes und schon ist der Host samt Services im Monitoring.
2.2. Fehlende Services hinzufügen
Bei einem Host, der bereits überwacht wird, sieht diese Liste anders aus. Anstelle von Undecided services - currently not monitored sehen Sie Monitored services. Sollte Checkmk allerdings feststellen, dass es auf dem Host etwas gibt, das aktuell nicht überwacht wird, aber überwacht werden sollte, dann sieht das etwa so aus:
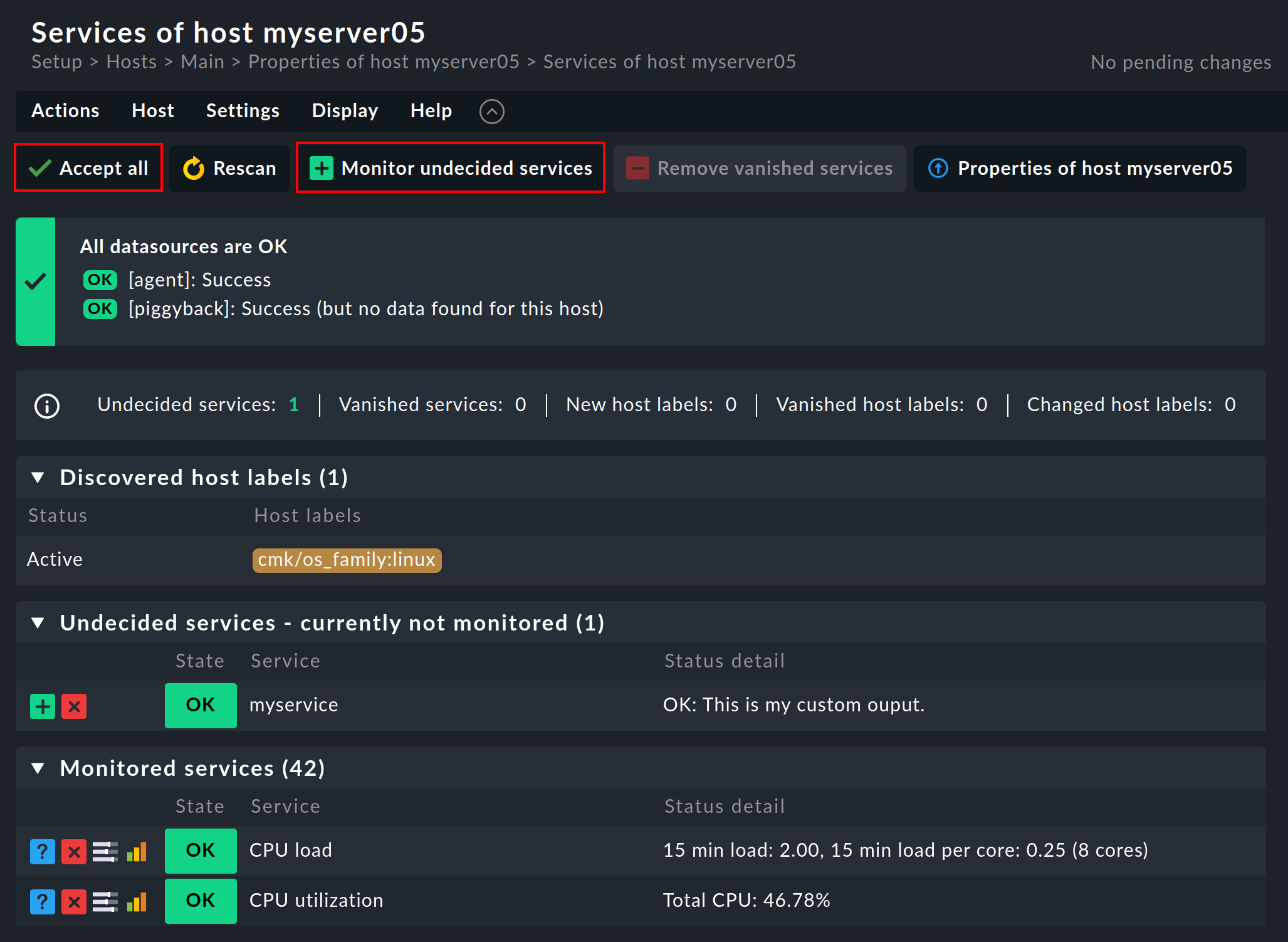
Ein Klick auf ![]() Monitor undecided services oder auf
Monitor undecided services oder auf ![]() Accept all fügt abermals alle fehlenden Services hinzu, so dass die Überwachung wieder vollständig ist. Wenn Sie nur manche der fehlenden Services aufnehmen möchten, können Sie in den jeweiligen Zeilen auf den Knopf
Accept all fügt abermals alle fehlenden Services hinzu, so dass die Überwachung wieder vollständig ist. Wenn Sie nur manche der fehlenden Services aufnehmen möchten, können Sie in den jeweiligen Zeilen auf den Knopf ![]() für Move to monitored services klicken.
für Move to monitored services klicken.
2.3. Verschwundene Services
Im Rechenzentrum können Dinge nicht nur neu auftauchen, sondern auch verschwinden. Eine Datenbankinstanz wird abgeschafft, eine LUN ausgehängt, ein Dateisystem entfernt u.s.w. Checkmk erkennt solche Services dann automatisch als verschwunden (vanished). In der Service-Liste sieht das z.B. so aus:

Der einfachste Weg um diese Services loszuwerden ist erneut ein Klick auf ![]() Accept all.
Alternativ können Sie die verschwundenen Services auch über den Knopf
Accept all.
Alternativ können Sie die verschwundenen Services auch über den Knopf ![]() Remove vanished services entfernen.
Achtung: Der Grund für das Verschwinden kann durchaus auch ein Problem sein!
Das Verschwinden eines Dateisystems kann ja auch bedeuten, dass dieses aufgrund eines Fehlers nicht gemountet werden konnte.
Und für solche Fälle ist das Monitoring schließlich da!
Sie sollten den Service also nur dann entfernen, wenn Sie wissen, dass hier eine Überwachung auch wirklich keinen Sinn mehr macht.
Remove vanished services entfernen.
Achtung: Der Grund für das Verschwinden kann durchaus auch ein Problem sein!
Das Verschwinden eines Dateisystems kann ja auch bedeuten, dass dieses aufgrund eines Fehlers nicht gemountet werden konnte.
Und für solche Fälle ist das Monitoring schließlich da!
Sie sollten den Service also nur dann entfernen, wenn Sie wissen, dass hier eine Überwachung auch wirklich keinen Sinn mehr macht.
2.4. Ungewünschte Services loswerden
Nicht alles, was Checkmk findet, möchten Sie auch unbedingt überwachen. Zwar arbeitet die Erkennung durchaus zielgerichtet und kann schon viel Unnützes im Vorfeld ausschließen. Doch woher soll Checkmk z.B. wissen, dass eine bestimmte Datenbankinstanz nur zum „Herumspielen“ eingerichtet wurde und nicht produktiv ist? Sie können solche Services auf zwei Arten loswerden:
Vorübergehendes Abschalten von Services
Um bestimmte Services vorübergehend aus dem Monitoring zu entfernen, klicken Sie entweder auf das Symbol ![]() .
Hiermit wird der Service wieder in die Liste der Undecided services verschoben.
Oder Sie deaktivieren den Service gänzlich, indem Sie am Anfang der Zeile auf
.
Hiermit wird der Service wieder in die Liste der Undecided services verschoben.
Oder Sie deaktivieren den Service gänzlich, indem Sie am Anfang der Zeile auf ![]() klicken.
Und natürlich, wie immer Activate changes nicht vergessen.
klicken.
Und natürlich, wie immer Activate changes nicht vergessen.
Das Ganze ist allerdings nur für vorübergehende und kleinere Maßnahmen gedacht. Denn die so abgewählten Services werden von Checkmk dann wieder als missing angemahnt. Und der Discovery Check (den wir Ihnen weiter unten zeigen) wird ebenfalls nicht glücklich damit sein. Außerdem ist das in einer Umgebung mit ein paar zigtausend Services einfach zu viel Arbeit und nicht wirklich praktikabel …
Permanentes Abschalten von Services
Viel eleganter und dauerhafter ist das permanente Ignorieren von Services mit Hilfe des Regelsatzes Disabled services. Hier können Sie nicht nur einzelne Services vom Monitoring ausschließen, sondern Regeln wie „Auf dem Host myserver01 sollen keine Services überwacht werden, die mit myservice beginnen.“ formulieren.
Sie erreichen die Regel über Setup > Services > Discovery rules > Discovery and Checkmk settings > Disabled services.
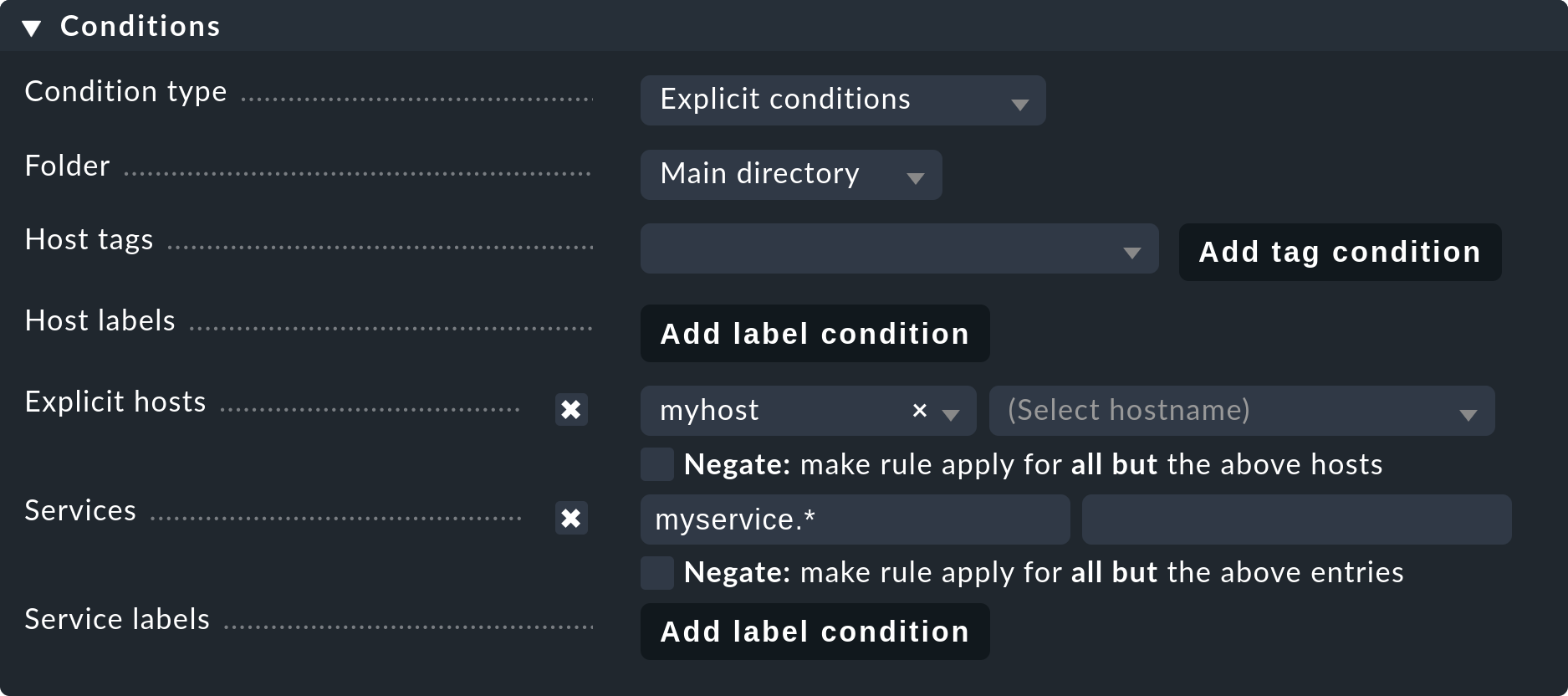
Wenn Sie die Regel speichern und erneut auf die Serviceliste des Hosts gehen, finden Sie die stillgelegten Services gemeinsam mit manuell deaktivierten Services unter Disabled services.
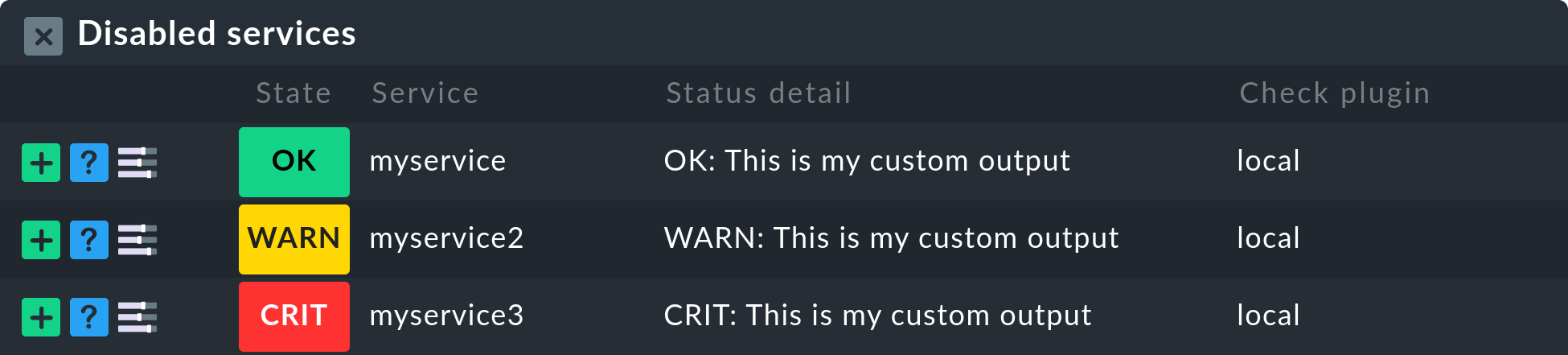
2.5. Services auffrischen
Es gibt einige Check-Plugins, die sich während der Erkennung Dinge merken. So merkt sich z.B. das Plugin für Netzwerkinterfaces die Geschwindigkeit, auf die das Interface während der Erkennung eingestellt war. Warum? Um Sie zu warnen, falls sich diese ändert! Es ist selten ein gutes Zeichen, wenn ein Interface mal auf 10 Mbit/s, mal auf 1 Gbit/s eingestellt ist — eher ein Hinweis auf eine fehlerhafte Autonegotiation.
Was aber, wenn diese Änderung gewollt ist und von nun an als OK gelten soll?
Entfernen Sie entweder den Service über das Symbol
![]() für Move to undecided services und
fügen Sie ihn anschließend wieder hinzu. Dazu müssen Sie nach dem Entfernen
einmal speichern. Oder Sie frischen alle Services des Hosts auf, indem Sie in
der Menüleiste auf Actions > Remove all and find new klicken. Das
ist natürlich viel bequemer — geht aber nur, wenn Sie nicht einzelne Services
im Fehlerzustand behalten wollen.
für Move to undecided services und
fügen Sie ihn anschließend wieder hinzu. Dazu müssen Sie nach dem Entfernen
einmal speichern. Oder Sie frischen alle Services des Hosts auf, indem Sie in
der Menüleiste auf Actions > Remove all and find new klicken. Das
ist natürlich viel bequemer — geht aber nur, wenn Sie nicht einzelne Services
im Fehlerzustand behalten wollen.
2.6. Host- und Service-Labels aktualisieren
Über die Menüleiste haben Sie über Actions > Host labels > Update host labels bzw. Actions > Services > Update host labels auch die Möglichkeit nur die Liste der zugehörigen Host- und Service-Labels zu aktualisieren.
Sollte es mal notwendig sein nur einzelne (neue) Service-Labels aufzunehmen bzw. zu aktualisieren, dann ist dies in der Zeile des jeweiligen Service im Kasten Changed services durch Anklicken von ![]() möglich.
möglich.
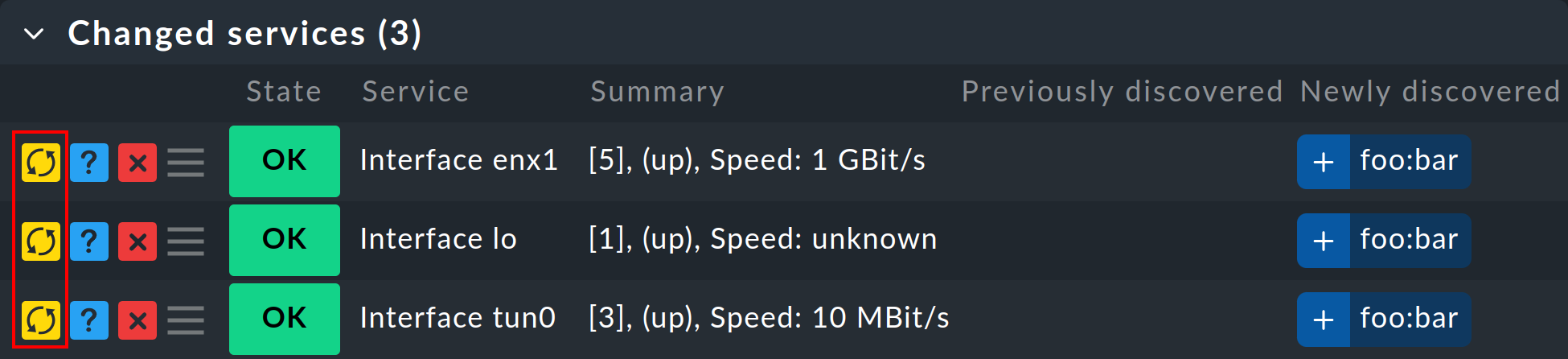
2.7. Besonderheiten bei SNMP
Bei Geräten, die per SNMP überwacht werden, gibt es ein paar Sonderheiten. Diese erfahren Sie im Artikel über SNMP.
3. Bulk-Erkennung — Service-Erkennung für viele Hosts gleichzeitig
Wenn Sie die Erkennung für mehrere Hosts auf einmal machen wollen, können Sie sich die Arbeit mit Bulk-Aktionen von Checkmk erleichtern. Wählen Sie zunächst aus, auf welchen Hosts die Erkennung durchgeführt werden soll. Dazu haben Sie mehrere Möglichkeiten:
In einem Ordner die Checkboxen bei einzelnen Hosts ankreuzen und dann in der Menüleiste auf Hosts > On selected hosts > Run bulk service discovery drücken.
Mit der Host-Suche im Setup Hosts suchen, alle gefundenen mit einem Klick auf das Kreuz
 auswählen und wieder in der Menüleiste über Hosts > On selected hosts > Run bulk service discovery gehen.
auswählen und wieder in der Menüleiste über Hosts > On selected hosts > Run bulk service discovery gehen.In einem Ordner in der Menüleiste auf Hosts > In this folder > Run bulk service discovery klicken.
Bei der dritten Variante können Sie die Service-Erkennung auch rekursiv in allen Unterordnern ausführen lassen. In allen drei Fällen gelangen Sie im nächsten Schritt zu folgendem Dialog:
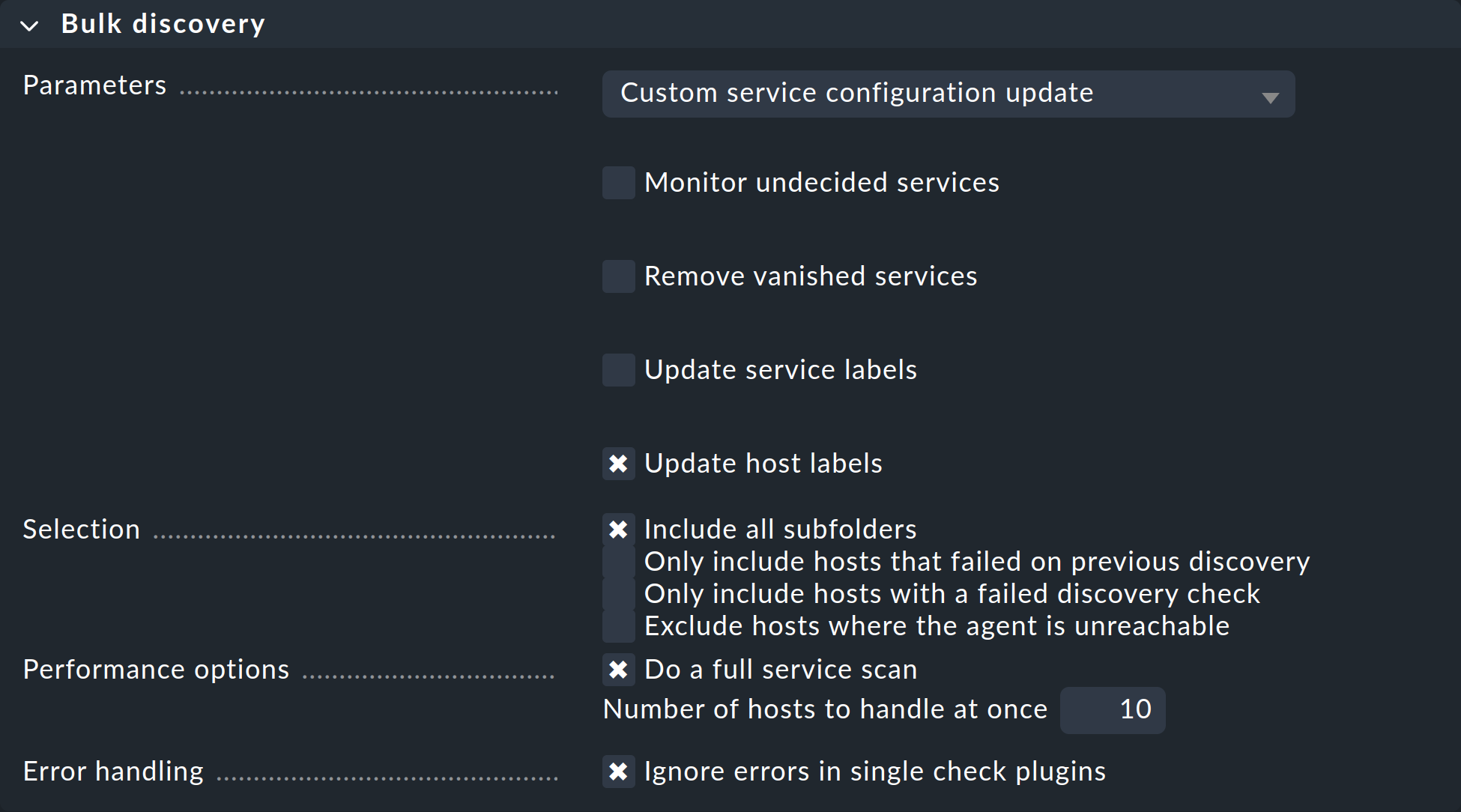
Im Drop-down-Menü Parameters ist die Option Custom service configuration update vorausgewählt. Die vier Checkboxen darunter bieten genau die Möglichkeiten, die Sie auch in der Service-Liste im Setup haben und die wir schon weiter oben erläutert haben. Im Drop-down-Menü haben Sie zusätzlich noch die Möglichkeit Refresh all services (tabula rasa) auszuwählen.
Unter Selection können Sie die Auswahl der Hosts noch mal steuern. Das ist vor allem dann sinnvoll, wenn Sie diese nicht per Checkboxen, sondern über den Ordner ausgewählt haben. Die meisten Optionen zielen auf eine Beschleunigung der Discovery hin:
Include all subfolders |
Wenn Sie die Service-Erkennung für einen Ordner gestartet haben, dann ist diese Option überhaupt nur verfügbar und standardmäßig aktiv. Die Service-Erkennung wird dann auch bei allen Hosts in den Unterordnern des aktuell geöffneten Ordners durchgeführt. |
Only include hosts that failed on previous discovery |
Hosts, bei denen eine frühere Service-Erkennung per Bulk-Aktion fehlgeschlagen ist (z.B. weil der Host zu dem Zeitpunkt nicht erreichbar war), werden von Checkmk mit dem Symbol |
Only include hosts with a failed discovery check |
Dies schränkt die Erkennung auf solche Hosts ein, bei denen der Discovery Check angeschlagen hat. Wenn Sie mit dem Discovery Check arbeiten, ist das eine gute Methode, um das Discovery von vielen Hosts massiv zu beschleunigen. Die Kombination mit der Option Refresh all services (tabula rasa) macht hier allerdings weniger Sinn, da dies den Status von bestehenden Services verfälschen kann. |
Exclude hosts where the agent is unreachable |
Hosts, die nicht erreichbar sind, verursachen beim Discovery Wartezeiten durch Verbindungs-Timeouts. Dies kann das Discovery einer größeren Zahl von Hosts stark verlangsamen. Wenn die Hosts aber schon im Monitoring sind und dieses weiß, dass die Hosts DOWN sind, können Sie diese hiermit überspringen und die Timeouts somit vermeiden. |
Die Performance options sind so voreingestellt, dass immer ein vollständiger Service-Scan durchgeführt wird. Wenn Sie nicht auf neue Plugins aus sind, können Sie die Erkennung durch Wegnahme der Option beschleunigen.
Die eingestellte 10 unter Number of hosts to handle at once
bedeutet, dass immer zehn Hosts auf ein mal bearbeitet werden. Intern geschieht
das mit einem HTTP-Request. Sollten Sie Probleme mit Timeouts haben, weil
einzelne Hosts sehr lange zum Erkennen brauchen, können Sie versuchen,
diese Zahl kleiner einzustellen (zulasten der Gesamtdauer).
Sobald Sie den Dialog bestätigen, geht es los und Sie können den Fortschritt beobachten:
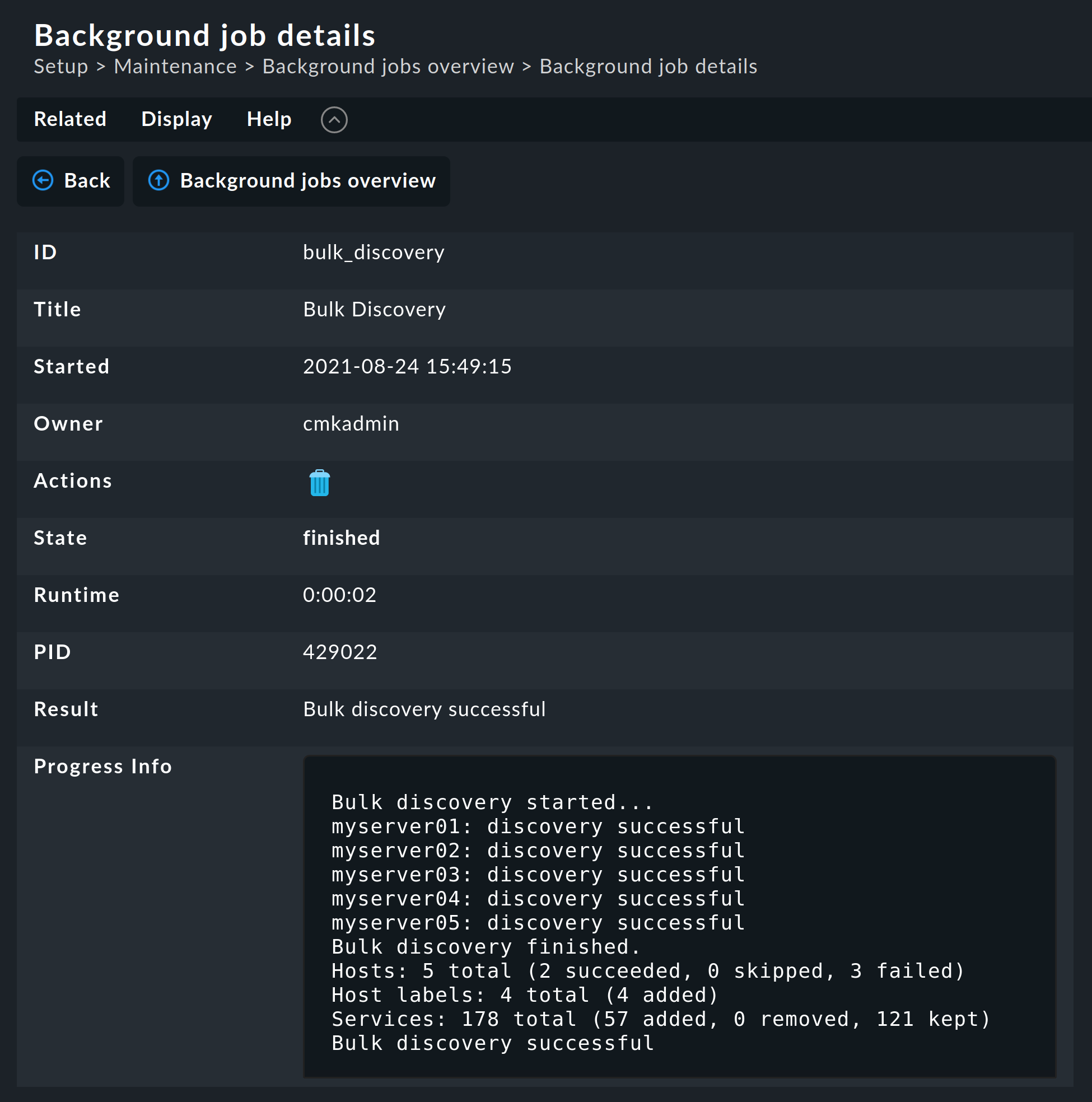
4. Check-Parameter von Services
Viele der Check-Plugins können über Parameter konfiguriert werden. Die häufigste Anwendung ist das Setzen von Schwellwerten für WARN und CRIT. Parameter können aber auch deutlich komplexer aufgebaut sein, wie das Beispiel der Temperaturüberwachung mit Checkmk zeigt:
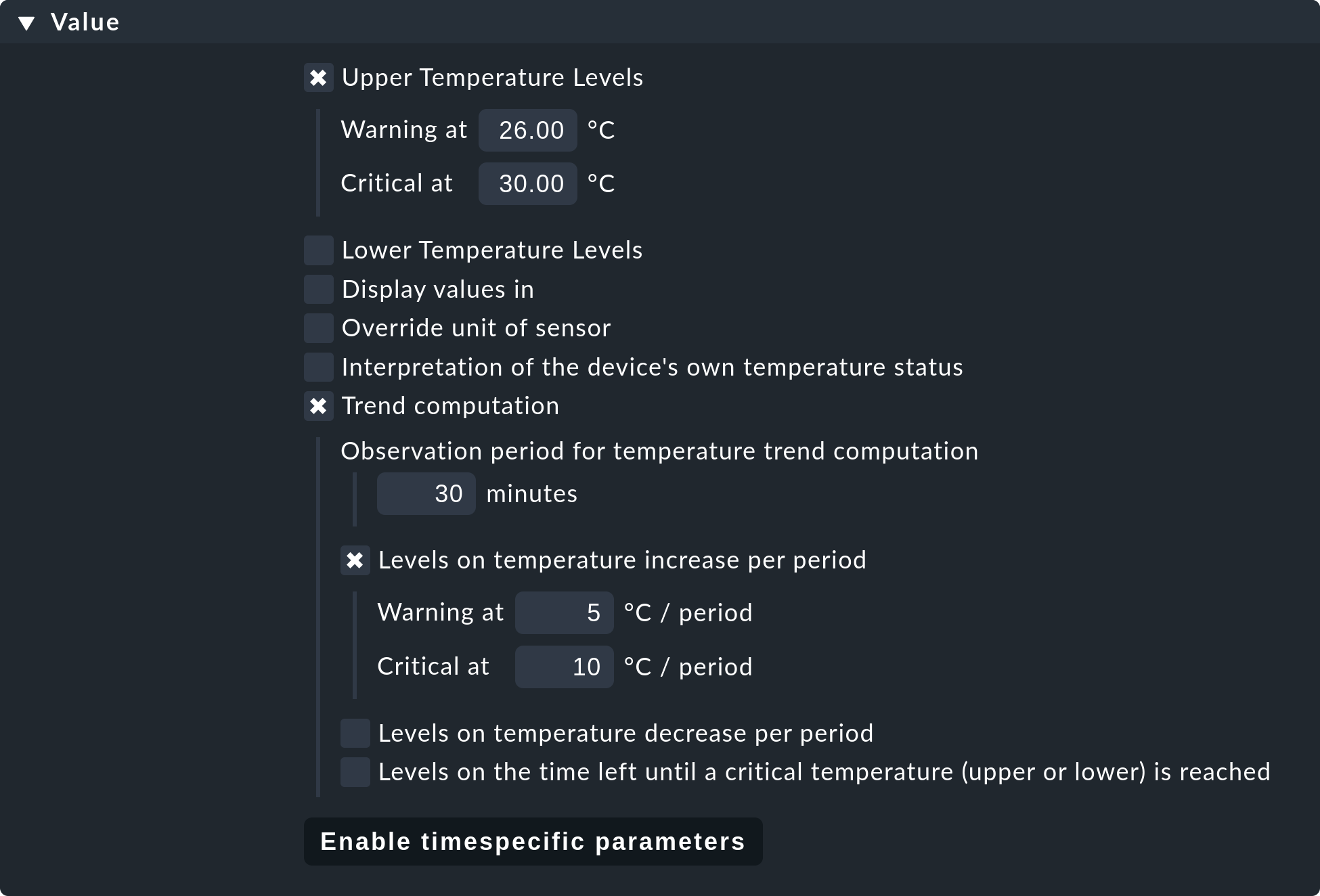
Die Check-Parameter für einen Service werden in drei Schritten gebildet:
Jedes Plugin hat Standardwerte für die Parameter.
Manche Plugins setzen Werte während der Erkennung (siehe oben).
Parameter können über Regeln gesetzt werden.
Dabei haben Parameter aus Regeln Vorrang vor den bei der Erkennung gesetzten und diese wiederum Vorrang für den Defaultwerten. Bei komplexen Parametern, bei denen per Checkbox einzelne Unterparameter festgelegt werden (wie im Beispiel mit der Temperatur), gilt diese Vorrangregel für jeden einzelnen Unterparameter separat. Wenn Sie also per Regel nur einen der Unterparameter anpassen, bleiben die anderen auf ihren jeweiligen Defaultwerten. So können Sie z.B mit einer Regel die Trendberechnung der Temperatur aktivieren und mit einer anderen die Temperaturschwellwerte für einen konkreten Sensor einstellen. Der komplette Parametersatz wird dann aus beiden Regeln zusammengesetzt.
Welche Parameter ein Service am Ende genau hat, erfahren Sie in der
Parameterseite des Services. Diese erreichen Sie in der Serviceliste eines Hosts
über das Symbol für die Check-Parameter ![]() . Wenn Sie
die Parameter von allen Services direkt in der Service-Tabelle sehen möchten,
können Sie diese mit über die Menüleiste Display > Details > Show
check parameters einblenden. Das sieht dann etwa so aus:
. Wenn Sie
die Parameter von allen Services direkt in der Service-Tabelle sehen möchten,
können Sie diese mit über die Menüleiste Display > Details > Show
check parameters einblenden. Das sieht dann etwa so aus:

5. Anpassen der Service-Erkennung
Wie Sie die Service-Erkennung konfigurieren, um nicht erwünschte Services auszublenden, haben wir bereits weiter oben gezeigt. Es gibt aber für etliche Check-Plugins noch weitere Regelsätze, die das Verhalten der Discovery bei diesen Plugins beeinflussen. Dabei gibt es nicht nur Einstellungen zum Weglassen von Items, sondern auch solche, die positiv Items finden oder zu Gruppen zusammenfassen. Auch die Benennung von Items ist manchmal ein Thema — z.B. bei den Switchports, Netzwerkschnittstellen, wo Sie sich entscheiden können, anstelle der Interface-ID deren Description oder Alias als Item (und damit im Service-Namen) zu verwenden.
Alle Regelsätze, die mit der Service-Erkennung zu tun haben, finden Sie unter Setup > Services > Discovery rules. Bitte verwechseln Sie diese Regelsätze nicht mit denen, die zum Parametrieren der eigentlichen Services gedacht sind. Etliche Plugins haben in der Tat zwei Regelsätze — einen für die Erkennung und einen für die Parameter. Dazu gleich ein paar Beispiele.
5.1. Überwachung von Prozessen
Es wäre wenig sinnvoll, wenn Checkmk einfach für jeden Prozess, den es auf einem Host findet, einen Service für die Überwachung einrichten würde. Die meisten Prozesse sind entweder nicht interessant oder sogar nur vorübergehend vorhanden. Und auf einem normalen Linux-Server laufen mindestens Hunderte von Prozessen.
Zum Überwachen von Prozessen müssen Sie daher mit erzwungenen Services arbeiten oder — und das ist viel eleganter — der Service-Erkennung mit dem Regelsatz Process discovery sagen, nach welchen Prozessen sie Ausschau halten soll. So können Sie immer dann, wenn auf einem Host bestimmte interessante Prozesse gefunden werden, dafür automatisch eine Überwachung einrichten lassen.
Folgende Abbildung zeigt eine Regel im Regelsatz Process discovery,
welche nach Prozessen sucht, die das Programm /usr/sbin/apache2
ausführen. In diesem Beispiel wird für jeden unterschiedlichen
Betriebssystembenutzer, für den ein solcher Prozess gefunden wird,
ein Service erzeugt (Grab user from found processes). Der Name des Services
wird Apache %u, wobei das %u durch den Benutzernamen ersetzt
wird. Als Schwellwerte für die Anzahl der Prozessinstanzen werden 1/1 (untere)
bzw. 30/60 (obere) verwendet:
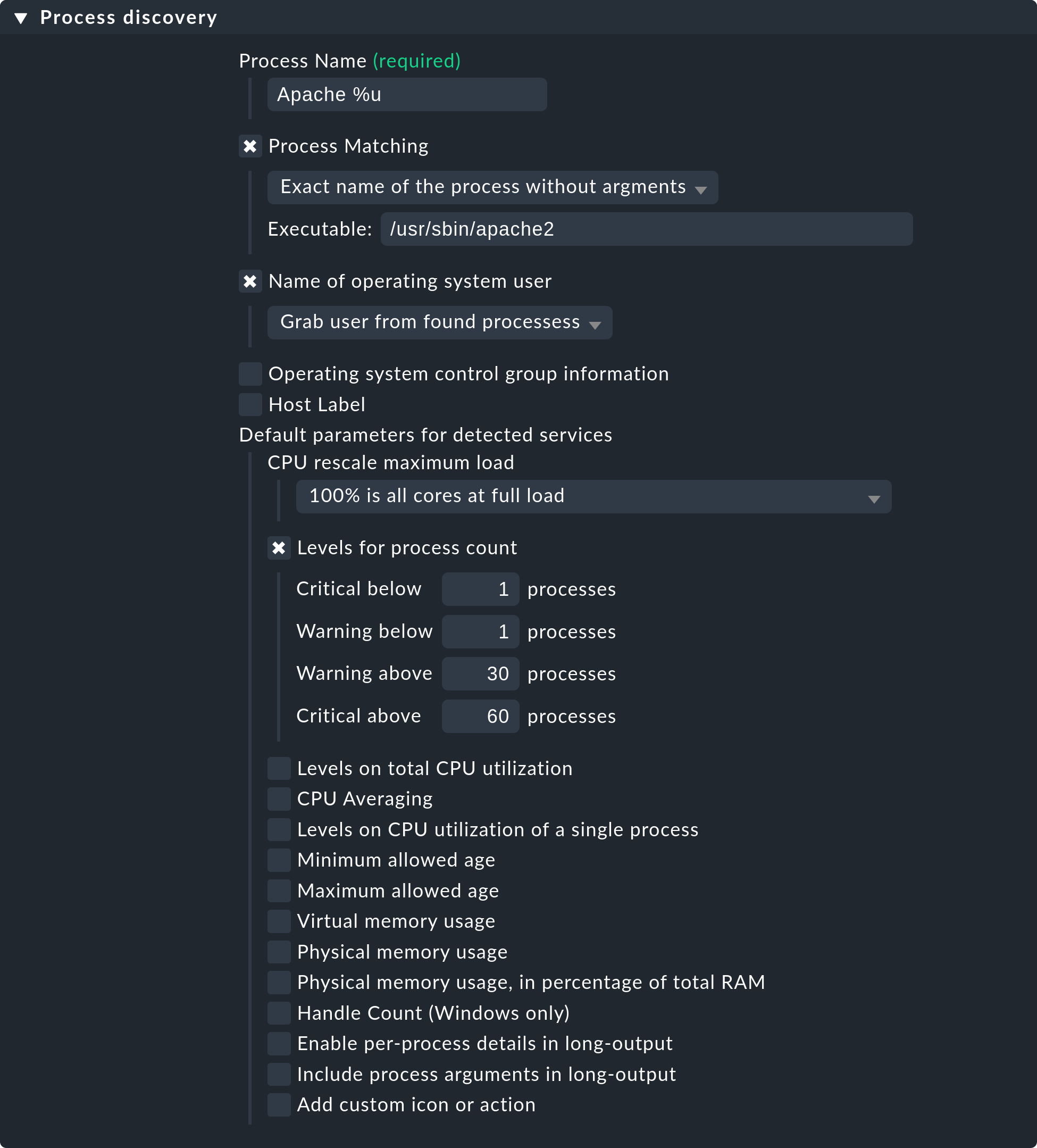
Bitte beachten Sie, dass die festgelegten Schwellwerte Default parameters for detected services heißen. Denn Sie können diese — wie bei allen anderen Services auch — per Regel festlegen. Zur Erinnerung: Obige Regel konfiguriert die Erkennung der Services — also das Was. Sind die Services erst mal vorhanden, so ist eigentlich die Regelkette State and count of processes für die Schwellwerte zuständig.
Die Tatsache, dass Sie schon bei der Erkennung Schwellwerte festlegen können, ist nur der Bequemlichkeit geschuldet. Und es gibt auch einen Haken: Änderungen in der Erkennungsregel haben erst bei der nächsten Erkennung Einfluss. Wenn Sie also Schwellwerte ändern, müssen Sie die Erkennung nochmal ausführen. Wenn Sie aber die Regel nur zum eigentlichen Finden verwenden (also das Was), und den Regelsatz State and count of processes für das Wie verwenden, haben Sie dieses Problem nicht.
Um bestimmte oder einzelne Prozesse auf einem Windows-Host zu überwachen, muss
im Feld Executable tatsächlich nur der Dateiname ohne Pfad angegeben
werden. In Windows finden Sie diesen Namen im Reiter Details des Windows Task
Managers. In der Regel Process discovery könnte das für den Prozess
svchost dann wie folgt aussehen:
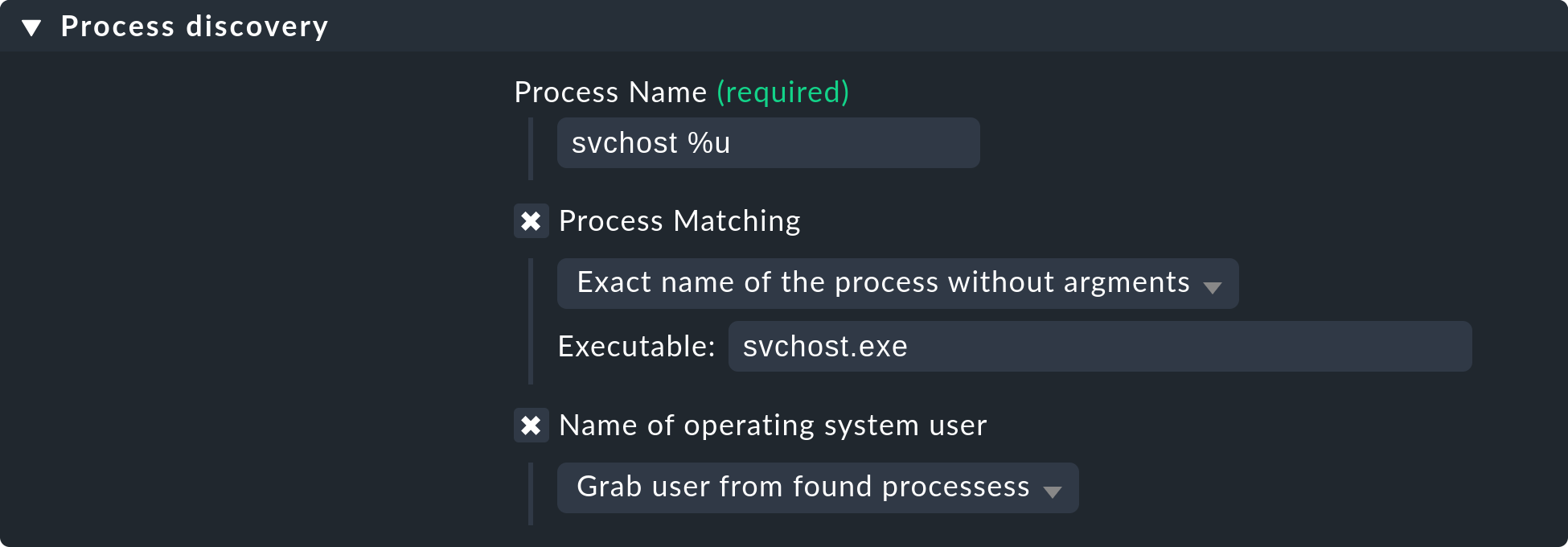
Weitere Details zur Prozesserkennung finden Sie in der Inline-Hilfe dieses Regelsatzes. Diese aktivieren Sie über Help > Show inline help in der Menüleiste.
5.2. Überwachung von Windows-Diensten
Das Erkennen und Parametrieren der Überwachung von Windows-Services geht analog zu den Prozessen und wird über die Regelsätze Windows service discovery (Was) bzw. Windows services (Wie) gesteuert. Hier ist ein Beispiel für eine Regel, die nach zwei Diensten Ausschau hält:
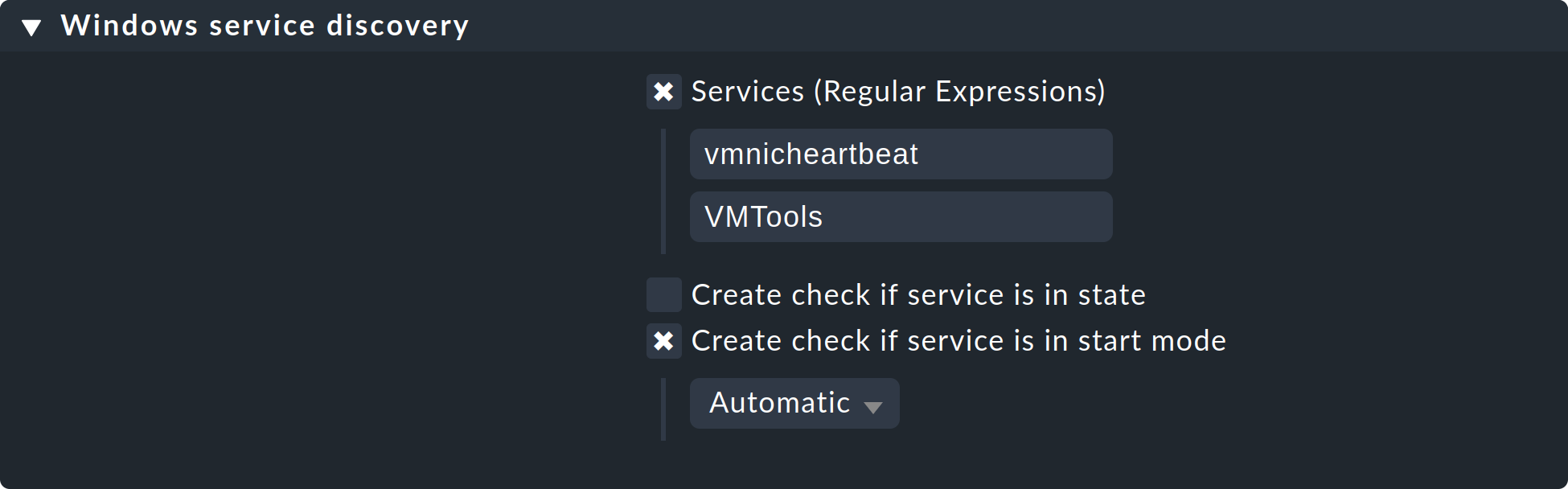
Genau wie bei den Prozessen ist auch hier die Service-Erkennung nur eine Option. Wenn Sie anhand von Host-Merkmalen und Ordnern präzise Regeln formulieren können, auf welchen Hosts bestimmte Dienste erwartet werden, können Sie auch mit erzwungenen Services arbeiten. Das ist dann unabhängig von der tatsächlich vorgefundenen Situation — allerdings kann das deutlich mehr Aufwand sein, da Sie unter Umständen viele Regeln brauchen, um genau abzubilden, auf welchem Host welche Dienste erwartet werden.
5.3. Überwachung von Switchports
Checkmk verwendet für die Überwachung von Netzwerkschnittstellen von Servern und für die Ports von Ethernet-Switches die gleiche Logik. Vor allem bei den Switchports sind die vorhandenen Optionen für die Steuerung der Service-Erkennung interessant, auch wenn (im Gegensatz zu den Prozessen und Windows-Diensten) die Erkennung auch erst mal ohne Regel funktioniert. Per Default überwacht Checkmk nämlich automatisch alle physikalischen Ports, die gerade den Zustand UP haben. Der Regelsatz dazu heißt Network interface and switch port discovery und bietet zahlreiche Einstellmöglichkeiten, die hier nur gekürzt dargestellt sind:
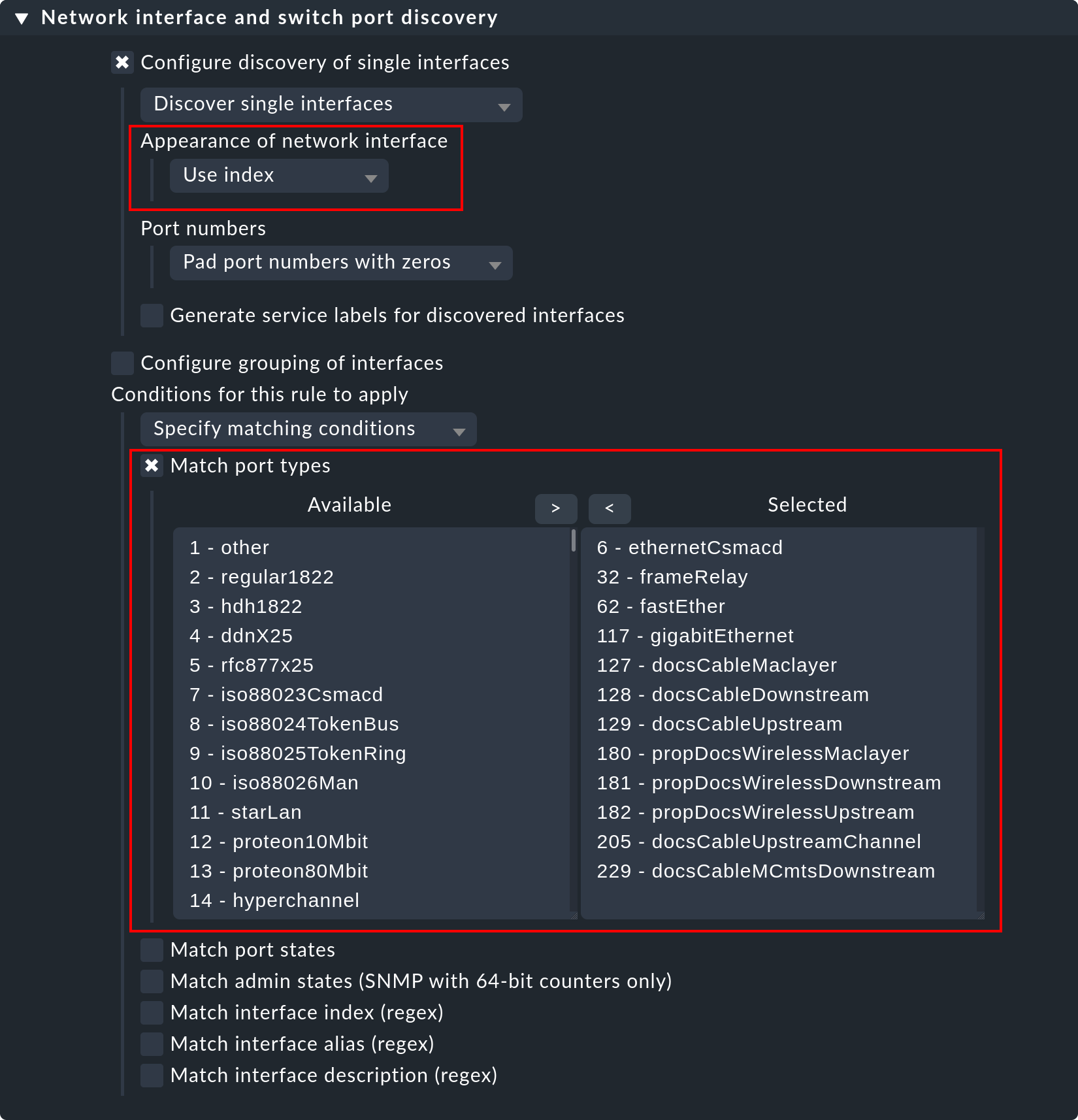
Am wichtigsten sind folgende Möglichkeiten:
Im Abschnitt Appearance of network interface können Sie bestimmen, wie das Interface im Service-Namen erscheinen soll. Sie haben hier die Wahl zwischen Use description, Use alias und Use index.
Match port types ermöglicht das Einschränken oder Ausweiten der überwachten Interfacetypen oder -namen.
6. Einrichtung von Services erzwingen
Es gibt einige Situationen, in denen eine automatische Service-Erkennung nicht sinnvoll ist. Das ist immer dann der Fall, wenn Sie das Einhalten einer bestimmte Richtlinie erzwingen möchten. Wie Sie im vorherigen Kapitel gesehen haben, können Sie Überwachung von Windows-Diensten automatisch einrichten lassen, wenn diese gefunden werden. Was ist aber, wenn schon das Fehlen eines solchen Diensts ein Problem darstellt? Beispiele:
Auf jedem Windows-Host soll ein bestimmter Virenscanner installiert sein.
Auf jedem Linux-Host soll NTP konfiguriert sein.
In solchen Fällen können Sie das Anlegen von Services erzwingen. Den Einstiegspunkt dafür finden Sie unter sind die Setup > Services > Enforced services. Dahinter verbirgt sich eine Sammlung von Regelsätzen, welche exakt die gleichen Namen haben, wie diejenigen Regelsätze, mit denen auch Parameter für diese Checks konfiguriert werden.
Die Regeln unterscheiden sich jedoch in zwei Punkten:
Es sind Regeln für Hosts, nicht für Services. Die Services werden ja erst durch die Regeln erzeugt.
Da keine Erkennung stattfindet, müssen Sie selbst das Check-Plugin auswählen, das für den Check verwendet werden soll.
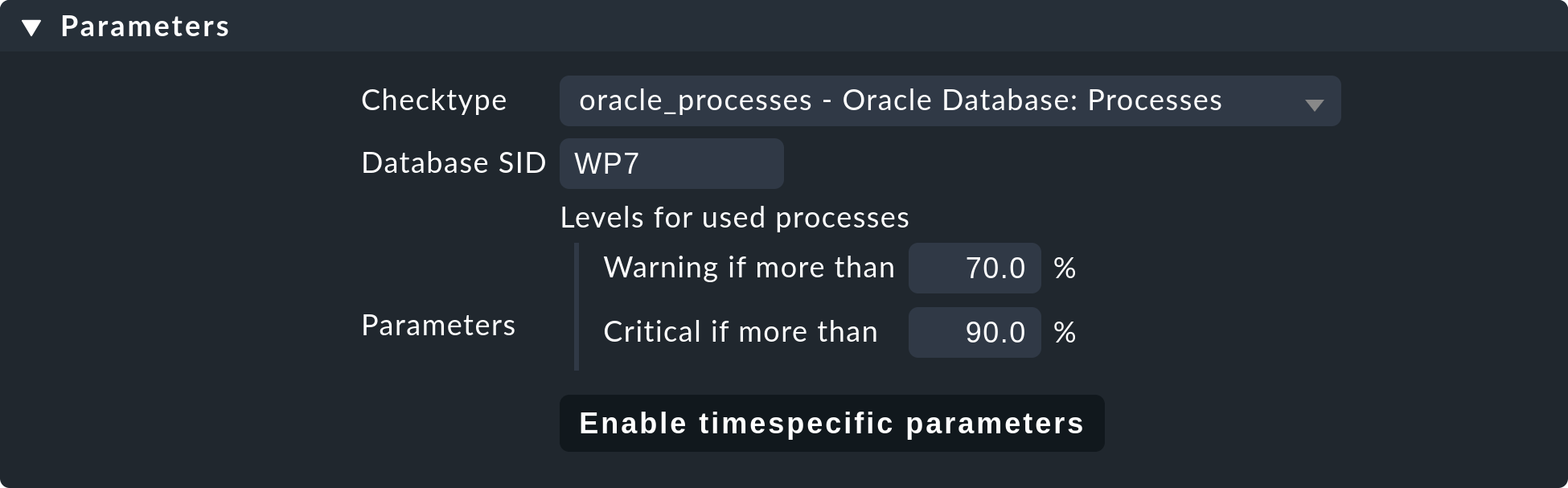
Folgendes Beispiel zeigt den Rumpf der Regel State of NTP time synchronisation unter Enforced services:

Neben den Schwellwerten legen Sie hier auch das Check-Plugin fest
(z.B. chrony oder ntp_time). Bei Check-Plugins, die ein
Item benötigen, müssen Sie auch dieses angeben. Dies ist z.B. beim Plugin
oracle_processes notwendig, welches die Angabe der zu überwachenden
Datenbank-SID benötigt:
Der so definierte manuelle Service wird auf allen Hosts angelegt, auf die diese Regel greift. Für die eigentliche Überwachung gibt es jetzt drei Fälle:
Der Host ist korrekt aufgesetzt und der Service geht auf OK.
Der Agent liefert die Information, dass der gefragte Dienst nicht läuft oder ein Problem hat. Dann geht der Service auf CRIT oder auf UNKNOWN.
Der Agent stellt überhaupt keine Informationen bereit, z.B. weil NTP überhaupt nicht installiert ist. Dann bleibt der Service auf PEND und der Service Check_MK geht auf WARN, mit dem Hinweis, dass die entsprechende Sektion in den Agentendaten fehlt.
Die meisten Regelsätze im Modul Enforced services werden Sie nie benötigen und sind nur der Vollständigkeit halber vorhanden. Die häufigsten Fälle für erzwungene Services sind:
Überwachung von Windows-Diensten (Regelsatz: Windows Services)
Überwachung von Prozessen (Regelsatz: State and count of processes)
7. Der Discovery Check
In der Einleitung haben wir versprochen, dass Checkmk die Liste der Services nicht nur automatisch ermitteln, sondern auch aktuell halten kann. Natürlich wäre dafür eine Möglichkeit, dass Sie ab und zu von Hand eine Bulk-Erkennung über alle Hosts durchführen.
7.1. Automatisches Prüfen auf nicht überwachte Services
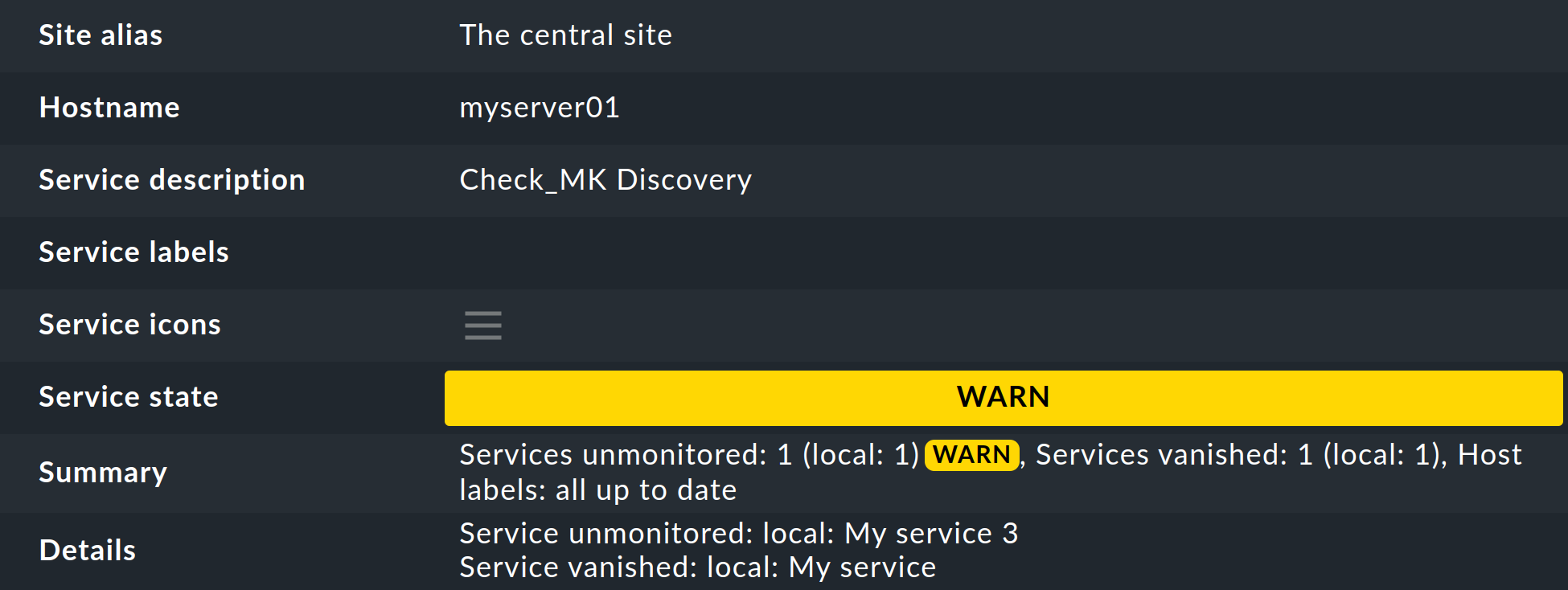
Viel besser ist dafür aber ein regelmäßiger Discovery Check, welcher von Checkmk bei neuen Instanzen automatisch eingerichtet wird. Dieser Service Check_MK Discovery existiert für jeden Host und meldet sich mit einer Warnung, wenn er nicht überwachte Dinge findet:

Die Einzelheiten zu den nicht überwachten oder verschwundenen Services finden Sie auf der Seite mit den Details des Services Check_MK Discovery im Feld Details:
Zu der Service-Liste des Hosts im Setup gelangen Sie bequem über das ![]() Aktionsmenü des Check_MK Discovery Services
und den Eintrag
Aktionsmenü des Check_MK Discovery Services
und den Eintrag ![]() Run service discovery.
Run service discovery.
Das Parametrieren des Discovery Checks geht sehr einfach über den Regelsatz Periodic service discovery. In einer frischen Instanz werden Sie hier bereits eine global wirksame Regel mit den folgenden Einstellungen vorfinden:
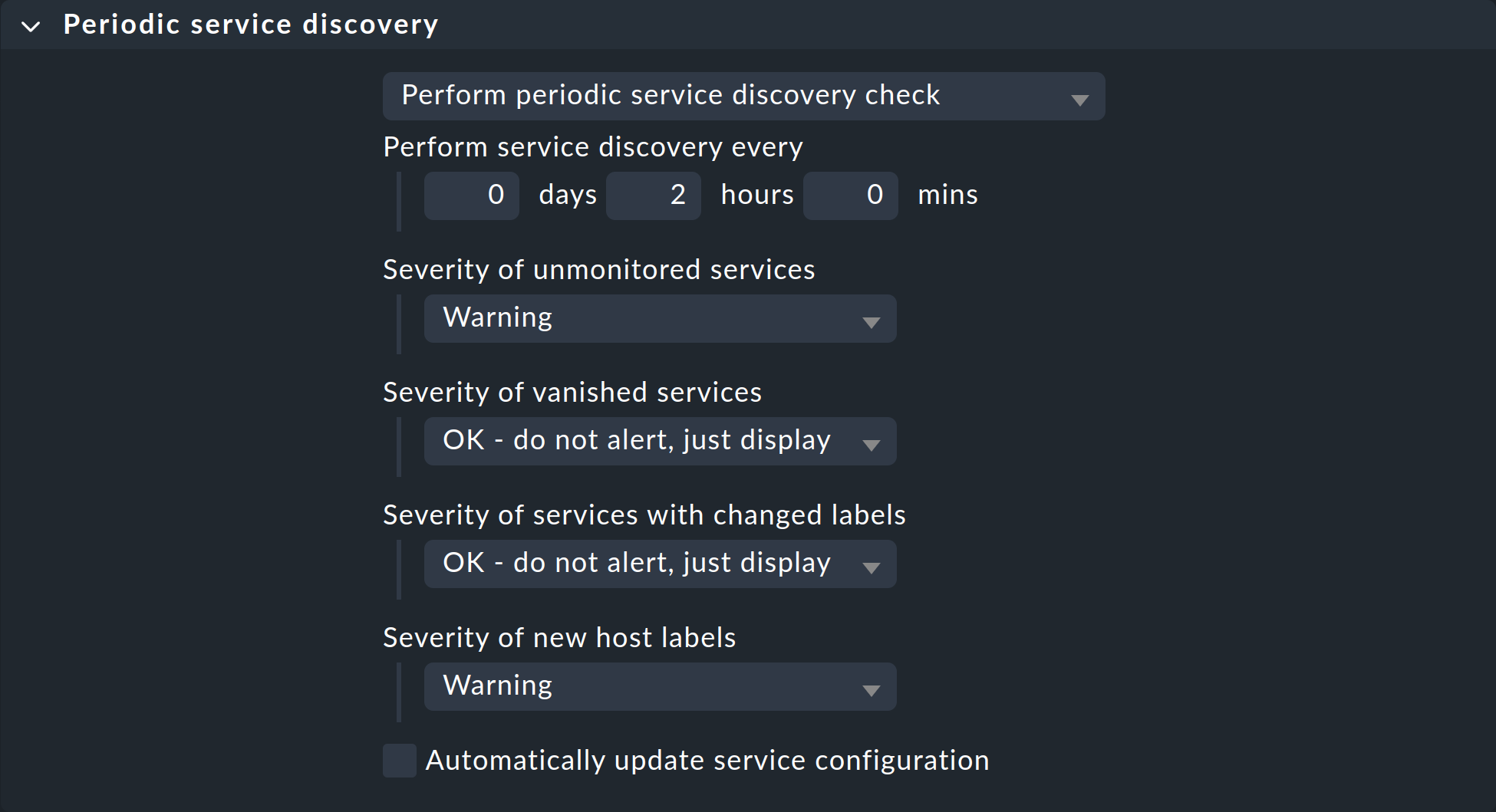
Neben dem Intervall, in dem der Check laufen soll, können Sie auch noch den Monitoring-Zustand auswählen — für die Fälle von nicht überwachten Services, verschwundenen Services, geänderten Service-Labels und neuen Host-Labels.
7.2. Services automatisch hinzufügen
Sie können den Discovery Check fehlende Services automatisch hinzufügen lassen. Dazu aktivieren Sie die Option Automatically update service configuration. Nun werden weitere Optionen sichtbar.

Neben dem Hinzufügen können Sie bei Parameters auch auswählen, verschwundene Services zu entfernen oder sogar alle bestehenden Services zu entfernen und komplett neu zu erkennen. Letztere Option finden Sie im Drop-down-Menü unter der Bezeichnung Refresh all services and host labels (tabula rasa). Beide Optionen sind mit Vorsicht zu genießen! Ein verschwundener Service kann auf ein Problem hindeuten! Der Discovery Check wird so einen Service dann einfach entfernen und Sie im Glauben wiegen, dass alles in Ordnung ist. Der Refresh ist besonders gefährlich. So übernimmt z.B. der Check für Switchports nur solche Ports in das Monitoring, die UP sind. Ports mit Status DOWN gelten dann als verschwunden und würden vom Discovery Check ohne Rückfrage weggeräumt!
Ein weiteres Problem gilt es noch zu bedenken: Das Hinzufügen von Services oder gar das automatische Activate Changes kann Sie als Admin bei Ihrer Arbeit am System stören, wenn Sie gerade beim Konfigurieren sind. Es kann theoretisch passieren, dass Sie gerade dabei sind, an Regeln und Einstellungen zu arbeiten und just in dem Augenblick ein Discovery Check Ihre Änderungen aktiviert. Denn in Checkmk können immer nur alle Änderungen auf einmal aktiviert werden! Um dies zu verhindern, können Sie die Uhrzeiten, in denen so etwas geschieht, z.B. in die Nacht legen. Die obige Abbildung zeigt dafür ein Beispiel.
Unter Vanished clustered services können Sie geclusterte Services separat handhaben. Die Besonderheit hier: Wenn ein geclusterter Service von einem Node auf den anderen wechselt, könnte er kurzzeitig als verschwunden angesehen und entsprechend ungewollt gelöscht werden. Verzichten Sie hingegen auf diese Option, würden wiederum tatsächlich verschwundene Services niemals gelöscht.
Die Einstellung Group discovery and activation for up to sorgt dafür, dass nicht jeder einzelne Service, der neu gefunden wird, sofort ein Activate Changes auslöst, sondern eine bestimmte Zeit gewartet wird, um gleich mehrere Änderungen in einem Rutsch zu aktivieren. Denn selbst wenn der Discovery Check auf ein Intervall von zwei Stunden oder mehr eingestellt ist, gilt das nur für jeden Host separat. Die Checks laufen nicht für alle Hosts gleichzeitig — und das ist auch gut so, denn der Discovery Check braucht erheblich mehr Ressourcen als ein normaler Check.
8. Passive Services
Passive Services sind solche, die nicht von Checkmk aktiv angestoßen werden, sondern bei denen regelmäßig von außen neue Check-Ergebnisse eingeschleust werden. Dies geschieht in der Regel über die Befehls-Pipe des Cores. Hier ist ein Schritt-für-Schritt-Vorgehen für das Einrichten eines passiven Services:
Zunächst müssen Sie den Service dem Kern bekannt machen. Dies geschieht mit dem gleichen Regelsatz wie bei den eigenen aktiven Checks, nur dass Sie die Command line weglassen:
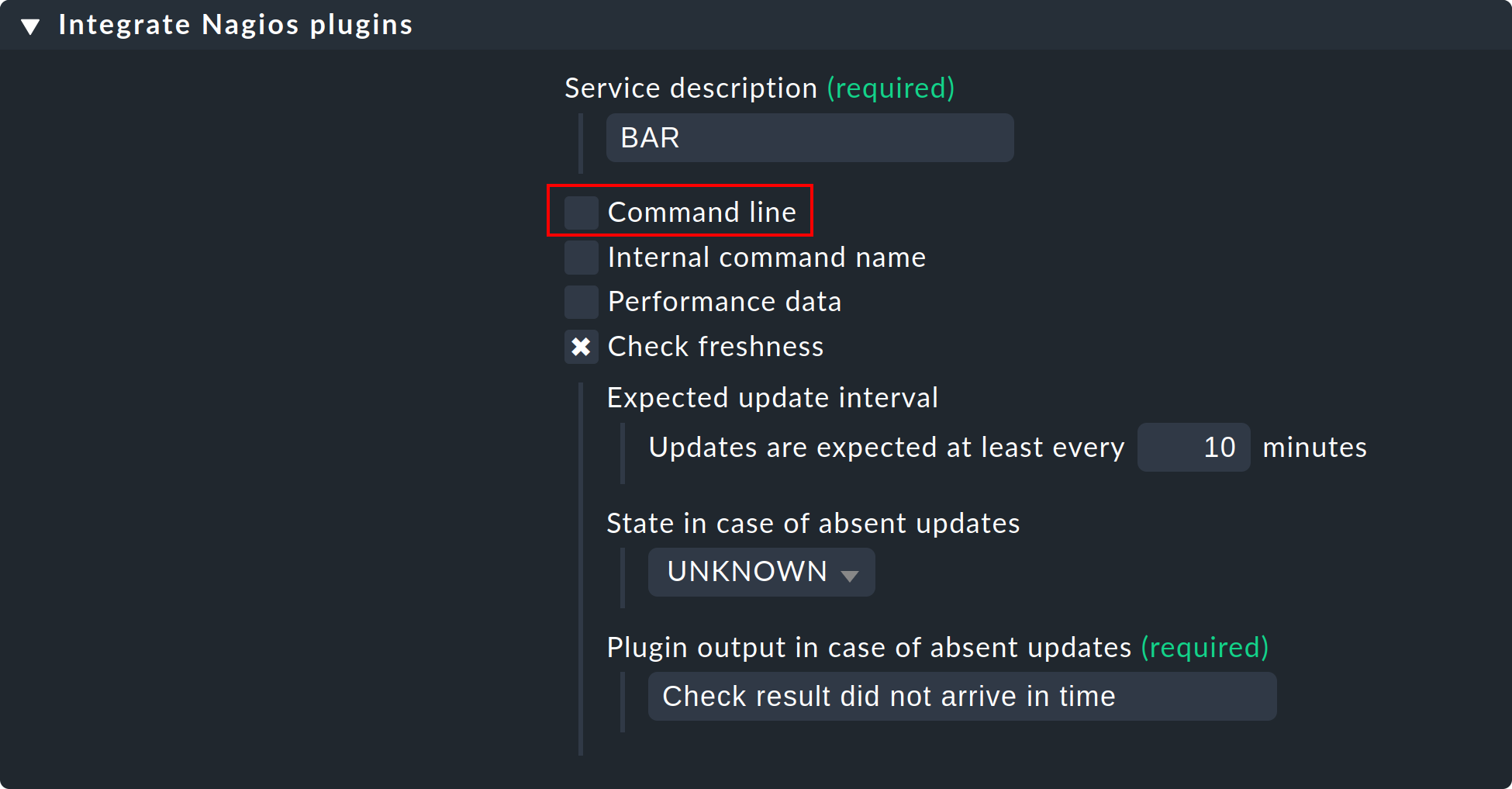
Die Abbildung zeigt auch, wie Sie prüfen lassen können, ob regelmäßig Check-Ergebnisse eingehen. Wenn dies für länger als 10 Minuten ausbleibt, so wird der Service hier automatisch auf UNKNOWN gesetzt.
Nach einem Activate Changes beginnt der neue Service sein Leben im Zustand PEND:

Das Senden der Check-Ergebnisse geschieht nun auf der Befehlszeile durch
ein echo des Befehls PROCESS_SERVICE_CHECK_RESULT in die
Befehls-Pipe ~/tmp/run/nagios.cmd.
Die Syntax entspricht den bei Nagios üblichen Konventionen — inklusive eines
aktuellen Zeitstempels in eckigen Klammern. Als Argumente nach dem Befehl
brauchen Sie den Host-Namen (z.B. myhost) und den gewählten
Service-Namen (im Beispiel BAR). Die beiden weiteren Argumente sind
wieder der Status (0 … 3) und die Plugin-Ausgabe. Den
Zeitstempel erzeugen Sie mit $(date +%s):
Nun zeigt der Service ohne Verzögerung den neuen Status:

9. Service-Erkennung auf der Befehlszeile
So schön eine GUI ist, so praktisch ist doch manchmal noch die gute alte Befehlszeile — sei es zum Automatisieren oder einfach zum schnellen Arbeiten für den geübten Benutzer.
Die Service-Erkennung können Sie auf der Befehlszeile mit dem Befehl cmk -I auslösen.
Dabei gibt es ein paar verschiedene Spielarten. Bei allen empfehlen wir die Option -v,
damit Sie sehen, was genau passiert. Ohne -v verhält sich Checkmk nach guter alter
Unix-Tradition: Solange alles gut geht, schweigt es.
Mit einem einfachen -I suchen Sie auf allen Hosts nach neuen Services:
Sie können nach dem -I auch einen oder mehrere Host-Namen angeben, um nur diese zu untersuchen.
Das hat gleich noch einen zweiten Effekt. Während ein -I auf allen Hosts
grundsätzlich nur mit zwischengespeicherten Daten arbeitet, holt Checkmk bei der
expliziten Angabe von einem Host immer frische Daten!
Alternativ können Sie über Tags filtern:
Damit würde das Discovery für alle Hosts mit dem Host-Merkmal mytag durchgeführt.
Filtern mit Tags steht für alle cmk-Optionen zur Verfügung, die mehrere Hosts akzeptieren.
Mit den Optionen --cache bzw. --no-cache können Sie die Verwendung
von Cache auch explizit bestimmen.
Zusätzliche Ausgaben bekommen Sie mit einem zweiten -v. Bei SNMP-basierten Geräten
können Sie dann sogar jede einzelne OID sehen, die vom Gerät geholt wird:
Ein komplettes Erneuern der Services (Tabula Rasa) machen Sie mit einem Doppel- -II:
Sie können das Ganze auch auf ein einzelnes Check-Plugin einschränken. Die Option dazu
lautet --detect-plugins= und muss vor dem Host-Namen stehen:
Wenn Sie fertig sind, können Sie mit cmk -O (bei Nagios als Kern cmk -R)
die Änderungen aktivieren:
Und wenn Sie mal bei einer Discovery auf einen Fehler stoßen …
… dann können Sie mit einem zusätzlichen --debug einen genauen Python Aufrufstapel (stack trace) der
Fehlerstelle bekommen:
9.1. Optionen im Überblick
Hier noch mal alle Optionen auf einen Blick:
|
Neue Services erkennen. |
|
Alle Services verwerfen und neu erkennen (Tabula Rasa). |
|
Verbose: Hosts und gefundene Services anzeigen. |
|
Very verbose: genaues Protokoll von allen Operationen anzeigen. |
|
Erkennung (und auch Tabula Rasa) nur für das gewählte Check-Plugin durchführen. |
|
Erkennung (und auch Tabula Rasa) nur für Hosts mit dem gewählten Host-Merkmal durchführen. |
|
Verwendung von Cache-Dateien erzwingen (sonst nur bei fehlender Host-Angabe). |
|
Frische Daten holen (sonst nur bei Angabe von Host-Name). |
|
Im Fehlerfall abbrechen und den kompletten Aufrufstapel von Python anzeigen. |
|
Änderungen aktivieren (kommerzielle Editionen mit CMC als Kern). |
|
Änderungen aktivieren (Checkmk Community bzw. Nagios als Kern). |
9.2. Speicherung in Dateien
Das Ergebnis der Service-Erkennung — also die eingangs genannte Tabelle
von Host-Name, Check-Plugin, Item und erkannten Parametern — finden Sie im
Verzeichnis var/check_mk/autochecks. Dort existiert für jeden Host
eine Datei, welche die automatisch erkannten Services speichert. Solange
Sie die Python-Syntax der Datei nicht verletzen, können Sie einzelne Zeilen
auch von Hand löschen oder ändern. Ein Löschen der Datei entfernt
alle Services und setzt diese quasi wieder auf „unmonitored“.
[
{'check_plugin_name': 'cpu_loads', 'item': None, 'parameters': (5.0, 10.0), 'service_labels': {}},
{'check_plugin_name': 'cpu_threads', 'item': None, 'parameters': {}, 'service_labels': {}},
{'check_plugin_name': 'diskstat', 'item': 'SUMMARY', 'parameters': {}, 'service_labels': {}},
{'check_plugin_name': 'kernel_performance', 'item': None, 'parameters': {}, 'service_labels': {}},
{'check_plugin_name': 'kernel_util', 'item': None, 'parameters': {}, 'service_labels': {}},
{'check_plugin_name': 'livestatus_status', 'item': 'myremotesite', 'parameters': {}, 'service_labels': {}},
{'check_plugin_name': 'lnx_thermal', 'item': 'Zone 0', 'parameters': {}, 'service_labels': {}},
{'check_plugin_name': 'mem_linux', 'item': None, 'parameters': {}, 'service_labels': {}},
{'check_plugin_name': 'mknotifyd', 'item': 'mysite', 'parameters': {}, 'service_labels': {}},
{'check_plugin_name': 'mknotifyd', 'item': 'myremotesite', 'parameters': {}, 'service_labels': {}},
{'check_plugin_name': 'mounts', 'item': '/', 'parameters': ['errors=remount-ro', 'relatime', 'rw'], 'service_labels': {}},
{'check_plugin_name': 'omd_apache', 'item': 'mysite', 'parameters': {}, 'service_labels': {}},
{'check_plugin_name': 'omd_apache', 'item': 'myremotesite', 'parameters': {}, 'service_labels': {}},
{'check_plugin_name': 'tcp_conn_stats', 'item': None, 'parameters': {}, 'service_labels': {}},
{'check_plugin_name': 'timesyncd', 'item': None, 'parameters': {}, 'service_labels': {}},
{'check_plugin_name': 'uptime', 'item': None, 'parameters': {}, 'service_labels': {}},
]10. Service-Gruppen
10.1. Wofür Service-Gruppen?
Bis hierher haben Sie erfahren, wie Sie Services ins Monitoring aufnehmen. Nun macht es wenig Sinn, sich Listen mit Tausenden Services anzuschauen oder immer über Host-Ansichten zu gehen. Wenn Sie beispielsweise alle Dateisystem- oder Update-Services gemeinsam beobachten wollen, können Sie in ähnlicher Weise Gruppen bilden, wie das mit Host-Gruppen möglich ist.
Service-Gruppen ermöglichen Ihnen auf einfache Art, über Ansichten und NagVis-Karten deutlich mehr Ordnung ins Monitoring zu bringen und gezielte Benachrichtigungen und Alert Handler zu schalten.
Übrigens: Sie könnten entsprechende Ansichten fast immer auch rein über die Ansichten-Filter konstruieren — Service-Gruppen sind aber einfacher und übersichtlicher zu handeln.
10.2. Service-Gruppen anlegen
Sie finden Service-Gruppen unter Setup > Services > Service groups.
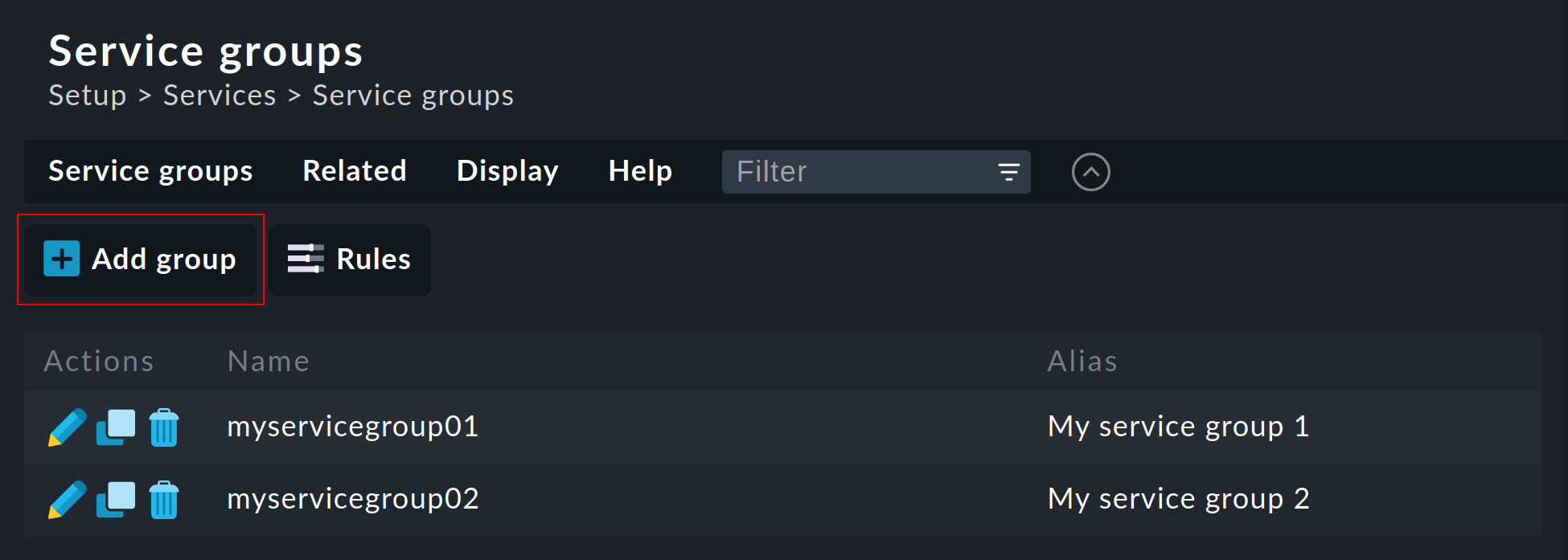
Das Anlegen einer Service-Gruppe ist simpel: Legen Sie über ![]() Add group eine neue Gruppe an und vergeben Sie einen später nicht
mehr veränderbaren Namen sowie einen aussagekräftigen Alias.
Add group eine neue Gruppe an und vergeben Sie einen später nicht
mehr veränderbaren Namen sowie einen aussagekräftigen Alias.
10.3. Services in Service-Gruppe aufnehmen
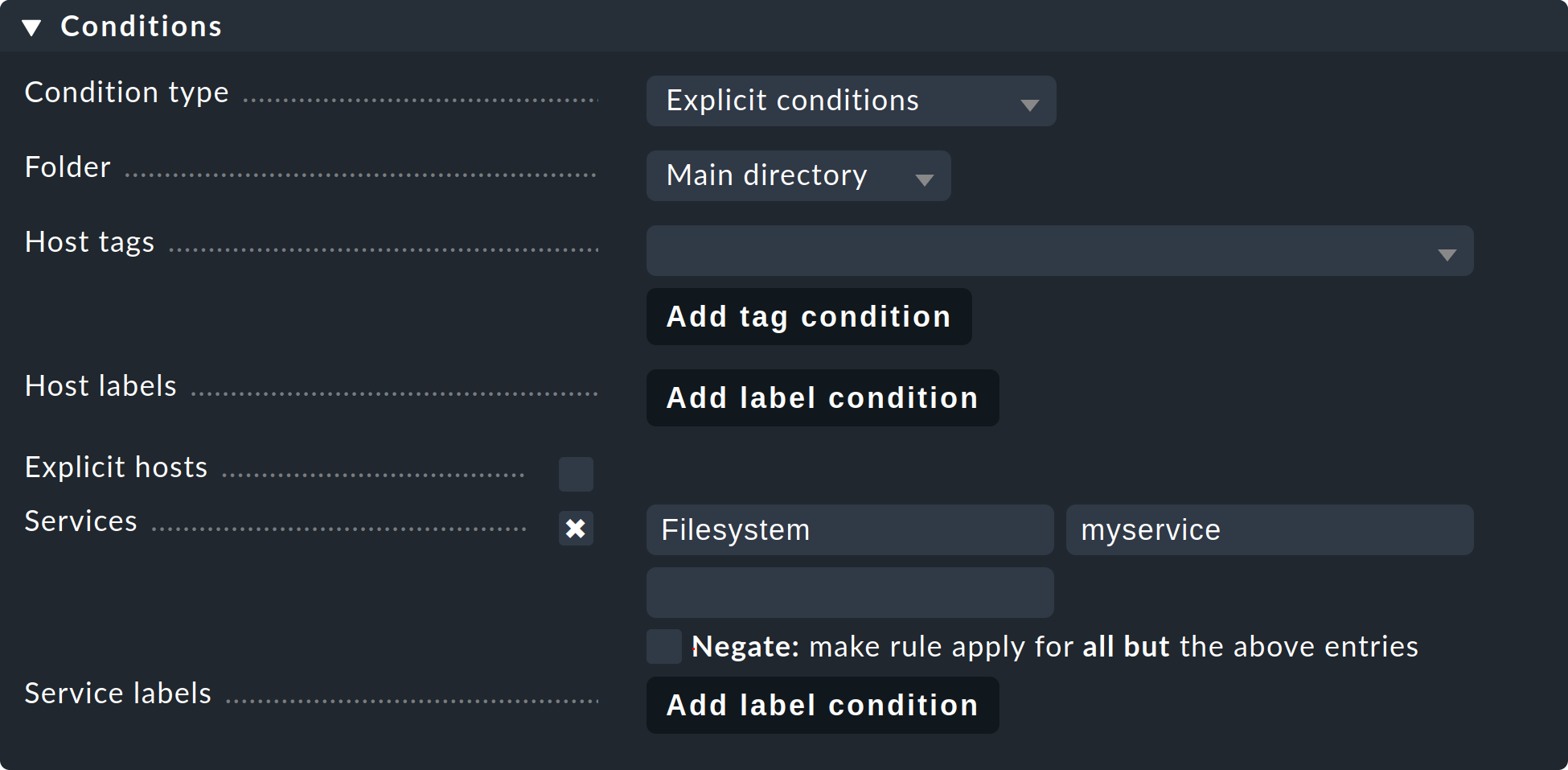
Für die Zuordnung von Services in Service-Gruppen benötigen Sie den Regelsatz Assignment of services to service groups. In der Übersicht Ihrer Service-Gruppen (Setup > Services > Service Groups), finden Sie diese Regel am schnellsten und zwar über die Menüleiste und dort die Punkte Service Groups > Assign to group > Rules. Alternativ können Sie die Regel natürlich auch über die Regelsuche im Setup-Menü finden, oder sich über Setup > Services > Service monitoring rules > Various > Assignment of services to service groups durchklicken. Erstellen Sie nun über Create rule in folder eine neue Regel im gewünschten Ordner. Zunächst legen Sie fest, welcher Service-Gruppe Services zugeordnet werden sollen, hier beispielsweise myservicegroup beziehungsweise dessen Alias My service group 1.

Der spannende Teil folgt nun im Bereich Conditions. Zum einen dürfen
Sie hier über Ordner, Host-Merkmale und explizite Host-Namen Einschränkungen
abseits der Services vornehmen. Zum anderen nennen Sie eben die Services, die
Sie gerne gruppiert hätten, beispielsweise Filesystem und
myservice, um eine Gruppe mit Dateisystemen zu erstellen. Die Angabe
der Services erfolgt hier in Form Regulärer Ausdrücke. So
können Sie Gruppen ganz exakt definieren.
10.4. Service-Gruppen eines Services prüfen
Die Zuordnungen von Services können Sie auf der Detailseite eines jeweiligen Service prüfen. Hier finden Sie, standardmäßig weit unten, die Zeile Service groups the service is member of.

10.5. Service-Gruppen einsetzen
Zum Einsatz kommen die Service-Gruppen wie bereits erwähnt an mehreren Stellen: zum Beispiel in Ansichten, NagVis-Karten, Alert Handler und Benachrichtigungen. Bei neuen Ansichten ist hier wichtig, dass Sie als Datenquelle die Service groups setzen. Im Views-Widget finden Sie natürlich auch vordefinierte Ansichten für Service-Gruppen, zum Beispiel eine übersichtliche Zusammenfassung:
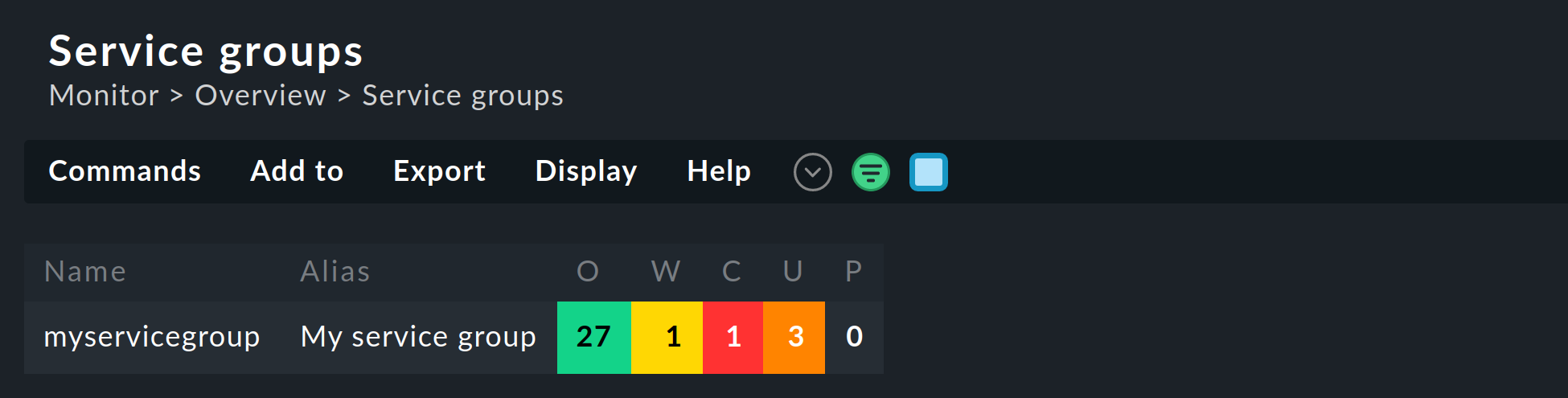
Mit einem Klick auf die Service-Gruppennamen gelangen Sie zur vollständigen Ansicht aller Services der jeweiligen Gruppe.
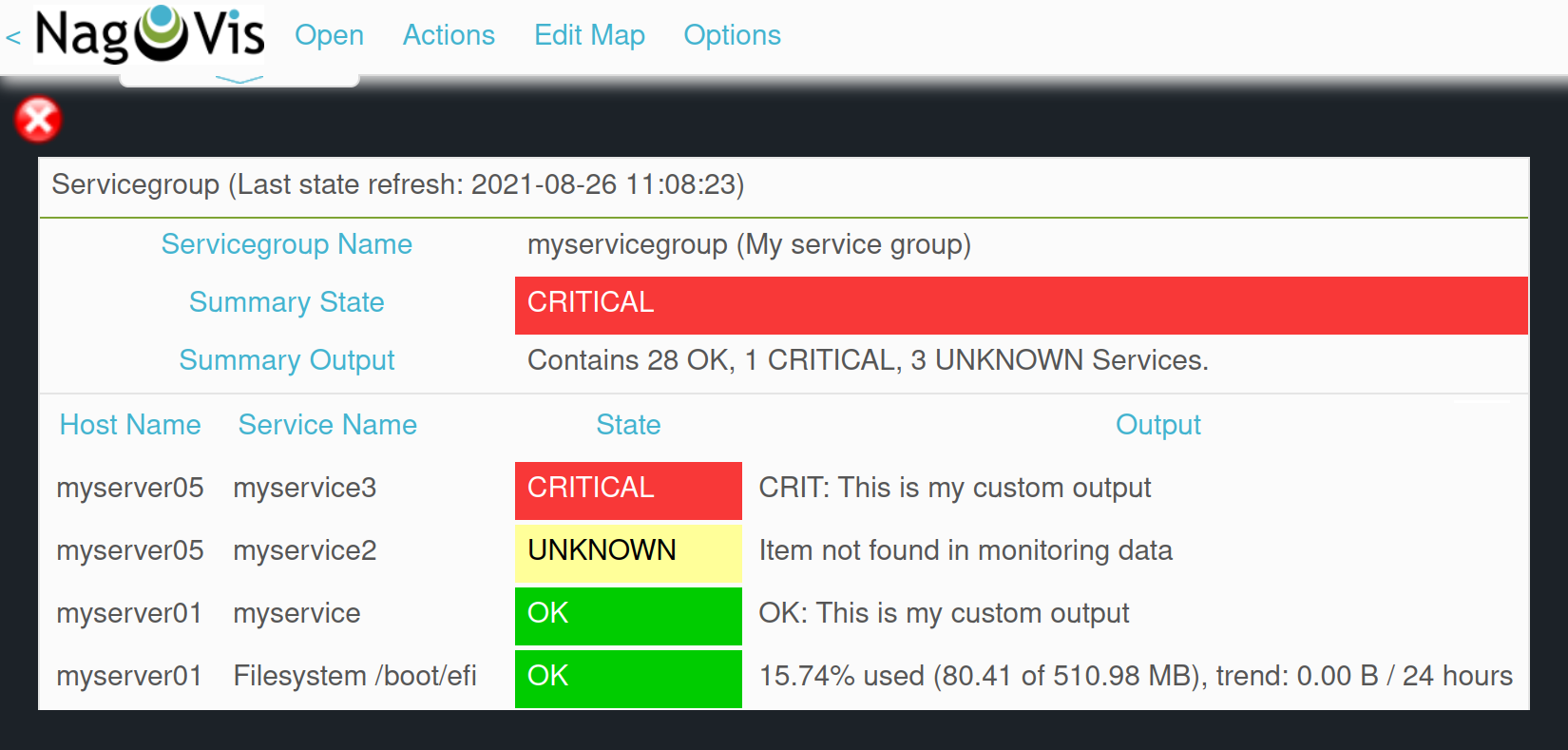
Wenn Sie Service-Gruppen in NagVis-Karten einsetzen, bekommen Sie als Ergebnis beispielsweise Zusammenfassungen von Service-Gruppen per Hover-Menü über ein einzelnes Icon:
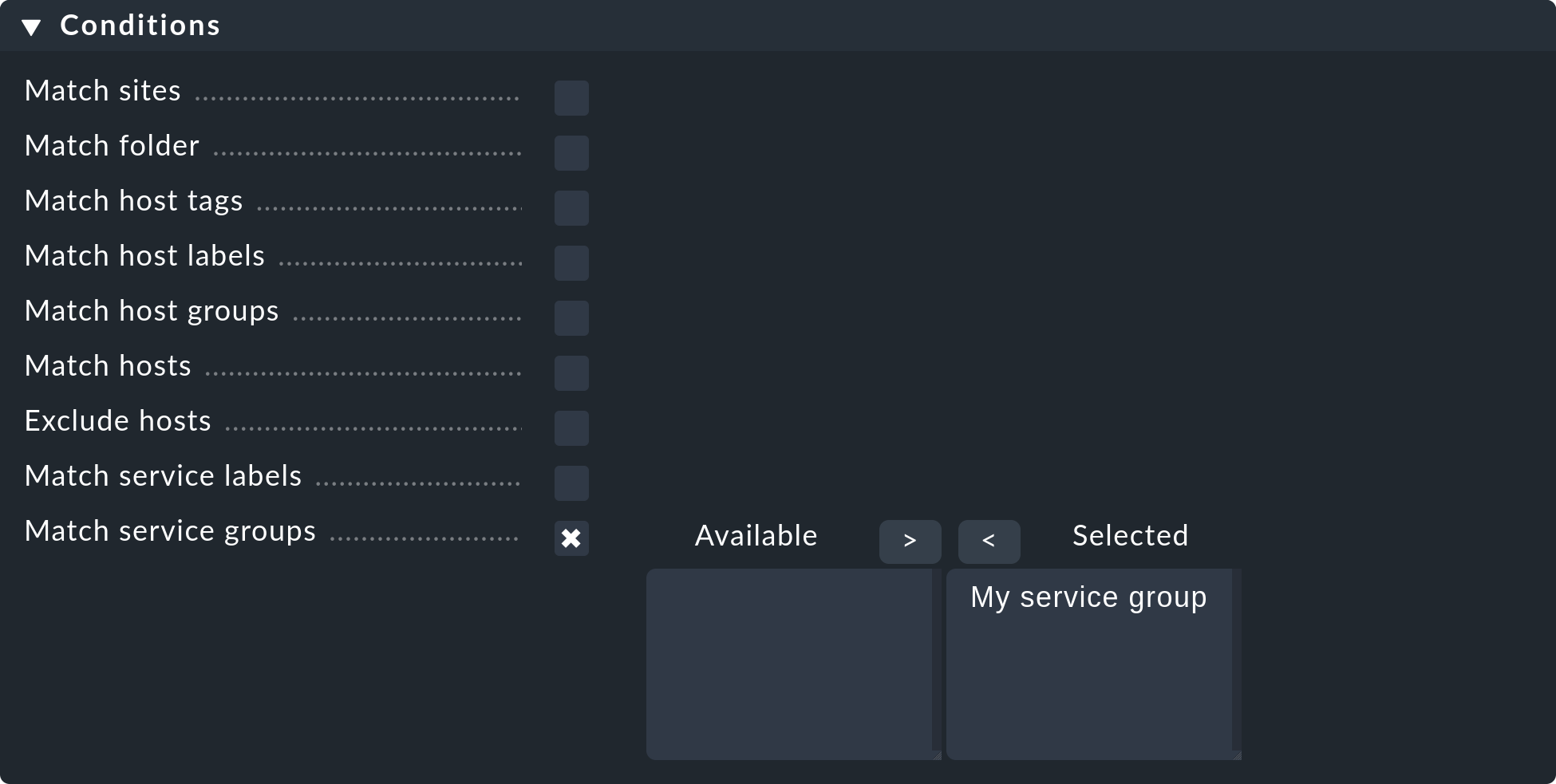
Wenn Sie Service-Gruppen in Benachrichtigungen und Alert Handlers nutzen, stehen sie als Bedingungen/Filter zur Verfügung, von denen Sie einen oder mehrere nutzen können:
11. Mehr über Check-Plugins
11.1. Kurze Beschreibung der Funktionsweise
Check-Plugins werden benötigt, um die Services in Checkmk zu erstellen. Jeder
Service greift auf ein Check-Plugin zurück, um seinen Status zu ermitteln,
Metriken zu erstellen/pflegen usw. Dabei kann ein solches Plugin einen oder
mehrere Services pro Host erstellen. Damit mehrere Services vom gleichen
Plugin unterschieden werden können, wird ein Item benötigt. So ist
z.B. beim Service Filesystem /var das Item der Text /var. Bei
Plugins, die pro Host maximal einen Service anlegen können (z.B. CPU
utilization), ist das Item leer und nicht sichtbar.
11.2. Verfügbare Check-Plugins
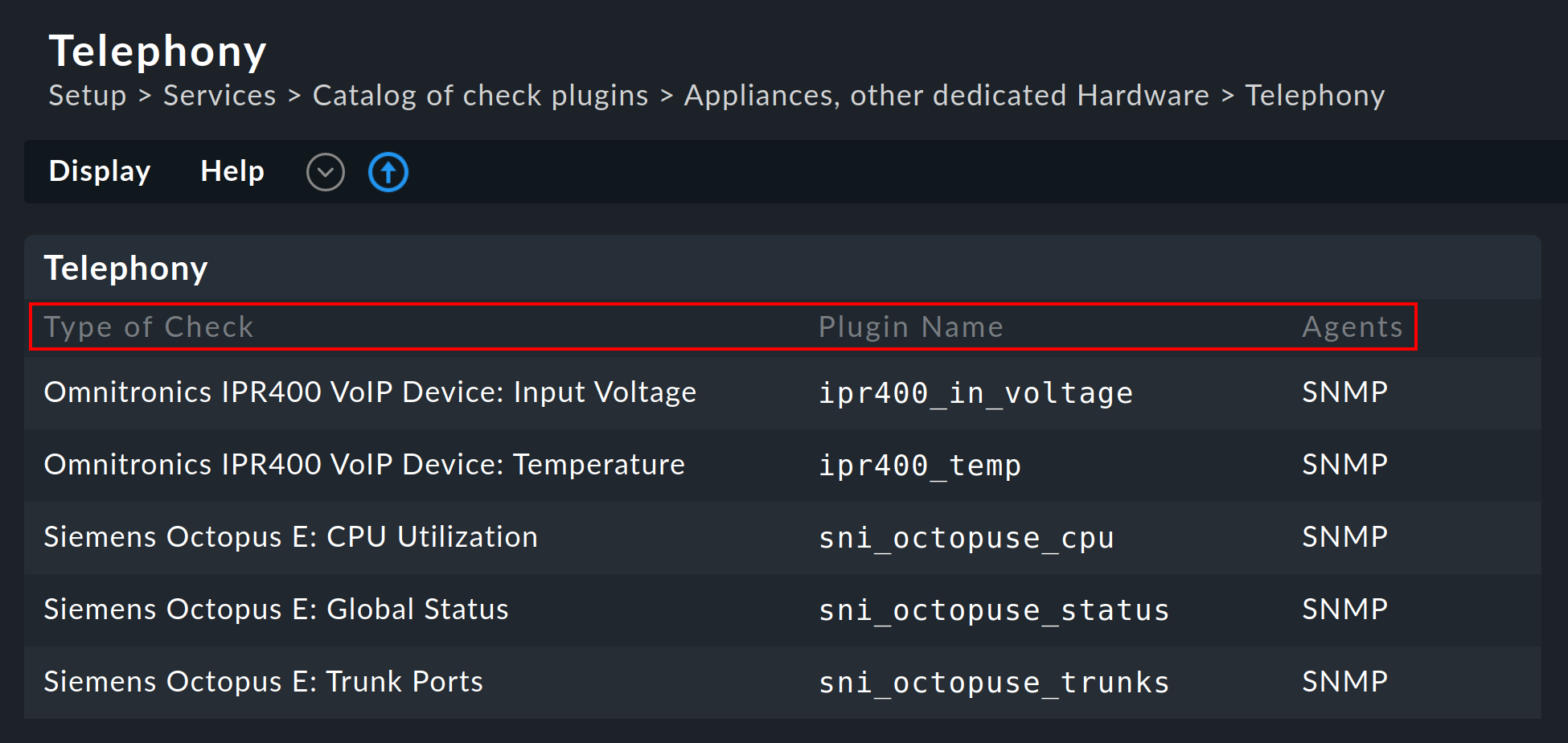
Eine Liste aller verfügbaren Check-Plugins finden Sie unter Setup > Services > Catalog of check plugins. Hier können Sie nach verschiedenen Kategorien gefiltert die einzelnen Plugins durchsuchen:

Zu jedem Plugin werden drei Spalten ausgegeben, die die Servicebeschreibung (Type of Check), den Namen des Check-Plugins (Plugin Name) und die kompatiblen Datenquellen (Agents) enthalten: