1. Fehlalarme — der Tod jedes Monitorings
Ein Monitoring ist nur dann wirklich nützlich, wenn es präzise ist. Das größte Hindernis für die Akzeptanz bei Kollegen (und wohl auch bei Ihnen selbst) sind dabei false positives — oder auf gut deutsch Fehlalarme.
Bei einigen Checkmk-Einsteigern haben wir erlebt, wie diese in kurzer Zeit sehr viele Systeme in die Überwachung aufgenommen haben — vielleicht deswegen, weil das in Checkmk so einfach geht. Als sie dann kurz danach die Benachrichtigungen für alle aktiviert hatten, wurden die Kolleginnen mit Hunderten von E-Mails pro Tag überflutet, und bereits nach wenigen Tagen war die Begeisterung für das Monitoring nachhaltig gestört.
Auch wenn Checkmk sich wirklich Mühe gibt, für alle möglichen Einstellungen sinnvolle und vernünftige Standardwerte zu definieren, kann es einfach nicht präzise genug wissen, wie es in Ihrer IT-Umgebung unter Normalzuständen zugehen soll. Deswegen ist von Ihrer Seite ein bisschen Handarbeit erforderlich, um das Monitoring feinzujustieren (fine-tuning), bis auch der letzte Fehlalarm gar nicht erst gesendet wird. Abgesehen davon wird Checkmk auch etliche wirkliche Probleme finden, von denen Sie und Ihre Kolleginnen noch nichts geahnt haben. Auch die gilt es zuerst einmalig zu beheben — und zwar in der Realität, nicht im Monitoring!
Bewährt hat sich folgender Grundsatz: erst Qualität, dann Quantität — oder anders ausgedrückt:
Nehmen Sie nicht zu viele Hosts auf einmal ins Monitoring auf.
Sorgen Sie dafür, dass alle Services, bei denen nicht wirklich ein Problem besteht, zuverlässig auf OK sind.
Aktivieren Sie die Benachrichtigungen per E-Mail oder SMS erst, wenn Checkmk eine Zeit lang zuverlässig ohne oder mit sehr wenigen Fehlalarmen läuft.
Fehlalarme können natürlich nur bei eingeschalteten Benachrichtigungen entstehen. Worum es im Folgenden also geht, ist es die Vorstufe der Benachrichtigungen abzustellen und die kritischen Zustände DOWN, WARN und CRIT für unkritische Probleme zu vermeiden. |
Welche Möglichkeiten zur Feinjustierung Sie haben (damit all das grün wird, was keine Probleme verursacht), und wie Sie gelegentliche Aussetzer in den Griff bekommen, zeigen Ihnen die folgenden Abschnitte zur Konfiguration.
2. Regelbasiert konfigurieren
Bevor Sie mit der Konfiguration starten, geben wir Ihnen eine kurze Einführung zum Thema, wie Sie die Einstellungen von Hosts und Services in Checkmk festlegen. Da Checkmk für große und komplexe Umgebungen entwickelt wurde, geschieht das anhand von Regeln. Dieses Konzept ist sehr leistungsfähig und bringt auch in kleineren Umgebungen viele Vorteile.
Die Grundidee ist, dass Sie nicht für jeden Service jeden einzelnen Parameter explizit festlegen, sondern so etwas umsetzen wie:
„Auf allen produktiven Oracle-Servern werden Dateisysteme mit dem Präfix /var/ora/ bei 90 % Füllgrad WARN und bei 95 % CRIT.“
So eine Regel kann mit einem Schlag Schwellwerte für Tausende von Dateisystemen festlegen. Gleichzeitig dokumentiert sie auch sehr übersichtlich, welche Überwachungsrichtlinien in Ihrem Unternehmen gelten.
Basierend auf einer Grundregel können Sie dann Ausnahmen für Einzelfälle gesondert festlegen.
Eine passende Regel könnte so aussehen:
„Auf dem Oracle-Server srvora123 wird das Dateisystem /var/ora/db01/ bei 96 % Füllgrad WARN und bei 98 % CRIT.“
Diese Ausnahmeregel wird in Checkmk in der gleichen Art und Weise wie die Grundregel festgelegt.
Jede Regel hat den gleichen Aufbau. Sie besteht immer aus einer Bedingung und einem Wert. Zusätzlich können Sie noch eine Beschreibung und einen Kommentar hinterlegen, um den Sinn der Regel zu dokumentieren.
Die Regeln sind in Regelsätzen (rule sets) organisiert. Für jede Art von Parameter hat Checkmk einen passenden Regelsatz parat, sodass Sie aus mehreren hundert Regelsätzen auswählen können. So gibt es etwa einen mit dem Namen File systems (used space and growth), der die Schwellwerte für alle Services festlegt, die Dateisysteme überwachen. Um das obige Beispiel umzusetzen, würden Sie aus diesem Regelsatz die Grundregel und die Ausnahmeregel festlegen. Um festzustellen, welche Schwellwerte für ein bestimmtes Dateisystem gültig sind, geht Checkmk alle für den Check gültigen Regeln der Reihe nach durch. Die erste Regel, bei der die Bedingung zutrifft, legt den Wert fest — also in diesem Fall den Prozentwert, bei dessen Erreichen der Dateisystemcheck WARN oder CRIT wird.
3. Regeln finden
Sie haben verschiedene Möglichkeiten zum Zugriff auf das Regelwerk von Checkmk.
Zum einen finden Sie die Regelsätze im Setup-Menü unter den Themen der Objekte, für die es Regelsätze gibt (Hosts, Services und Agents) in verschiedenen Kategorien. Für Services gibt es z.B. die folgenden Einträge mit Regelsätzen: Service monitoring rules, Discovery rules, Enforced services, HTTP, TCP, Email, … und Other Services. Wenn Sie einen dieser Einträge auswählen, werden Ihnen die zugehörigen Regelsätze auf der Hauptseite aufgelistet. Das können eine Handvoll sein, aber auch sehr, sehr viele wie bei den Service monitoring rules. Daher haben Sie auf der Ergebnisseite die Möglichkeit zu filtern: im Filter-Feld der Menüleiste.
Wenn Sie sich unsicher sind, in welcher Kategorie der Regelsatz zu finden ist, können Sie auch gleich alle Regeln durchsuchen, indem Sie entweder die Suche im Setup-Menü nutzen oder über Setup > General > Rule search die Seite zur Regelsuche öffnen. Wir werden den letztgenannten Weg im folgenden Abschnitt gehen, in dem es um die Erstellung einer Regel geht.
Bei der großen Anzahl der verfügbaren Regelsätze ist es mit oder ohne Suche nicht immer einfach, den richtigen zu finden.
Es gibt aber noch einen anderen Weg, mit dem Sie auf die passenden Regeln für einen bereits existierenden Service zugreifen können.
Klicken Sie in einer Tabellenansicht mit dem Service auf das ![]() Menü und wählen Sie den Eintrag Parameters for this service:
Menü und wählen Sie den Eintrag Parameters for this service:
Sie erhalten eine Seite, von der aus Sie Zugriff auf alle Regelsätze dieses Services haben:
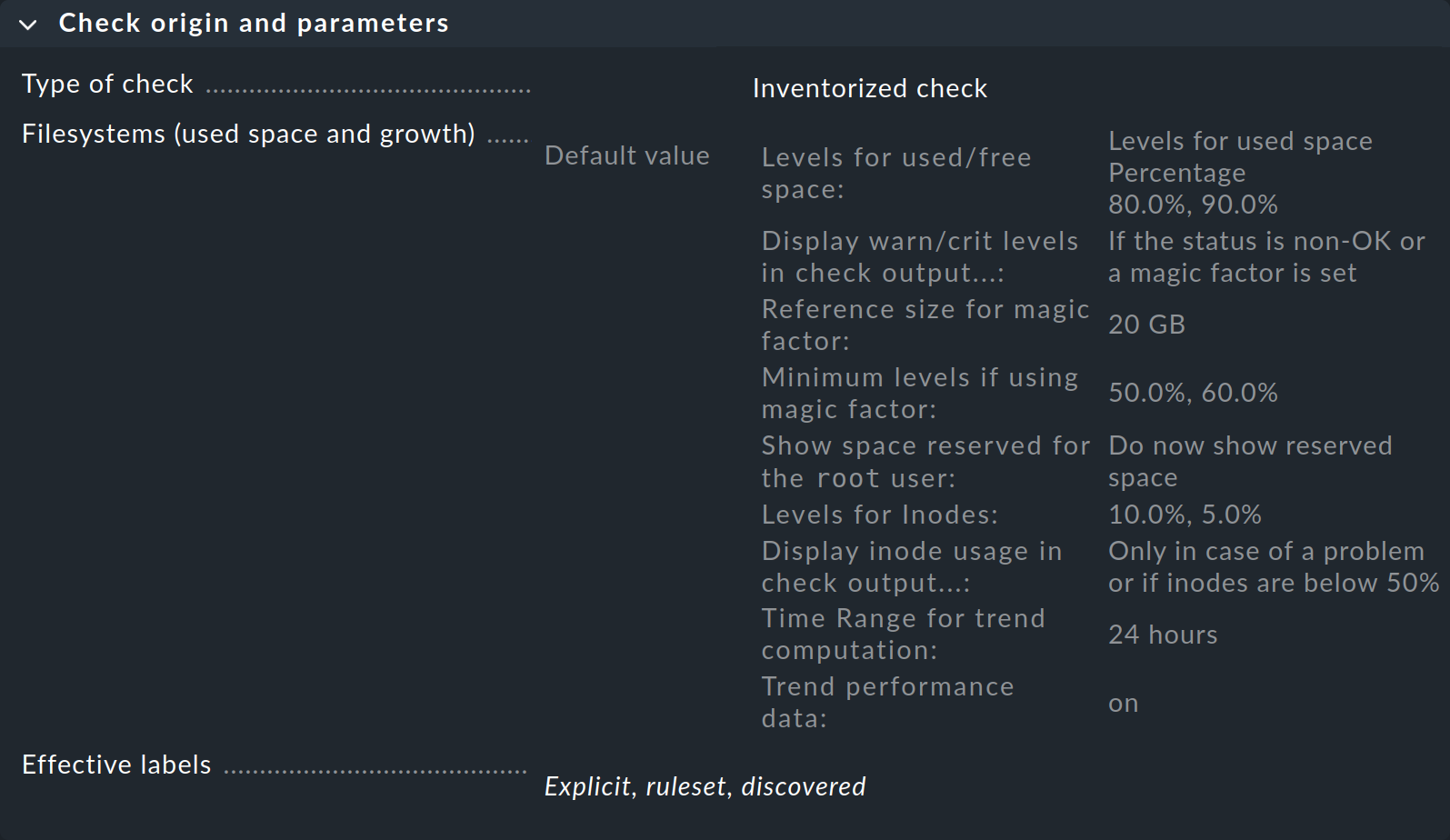
Im ersten Kasten mit dem Titel Check origin and parameters führt Sie der Eintrag File systems (used space and growth) direkt zum Regelsatz für die Schwellwerte der Dateisystemüberwachung. Sie können aber in der Übersicht sehen, dass Checkmk bereits Standardwerte festgelegt hat, sodass Sie eine Regel nur dann erstellen müssen, wenn Sie die Standardwerte ändern wollen.
4. Regeln erstellen
Wie sieht das mit den Regeln nun in der Praxis aus? Am besten starten Sie damit, die Regel, die Sie umsetzen wollen, in einem Satz zu formulieren, etwa in diesem: „Auf allen produktiven Oracle-Servern werden die Tablespaces DW20 und DW30 bei 90 % Füllgrad WARN und bei 95 % CRIT.“
Dann suchen Sie sich den passenden Regelsatz — in diesem Beispiel über die Regelsuche: Setup > General > Rule search. Dies öffnet eine Seite, in der Sie nach „Oracle“ oder nach „tablespace“ suchen können (Groß- und Kleinschreibung spielen keine Rolle) und alle Regelsätze finden, die diesen Text im Namen oder in der (hier unsichtbaren) Beschreibung enthalten:
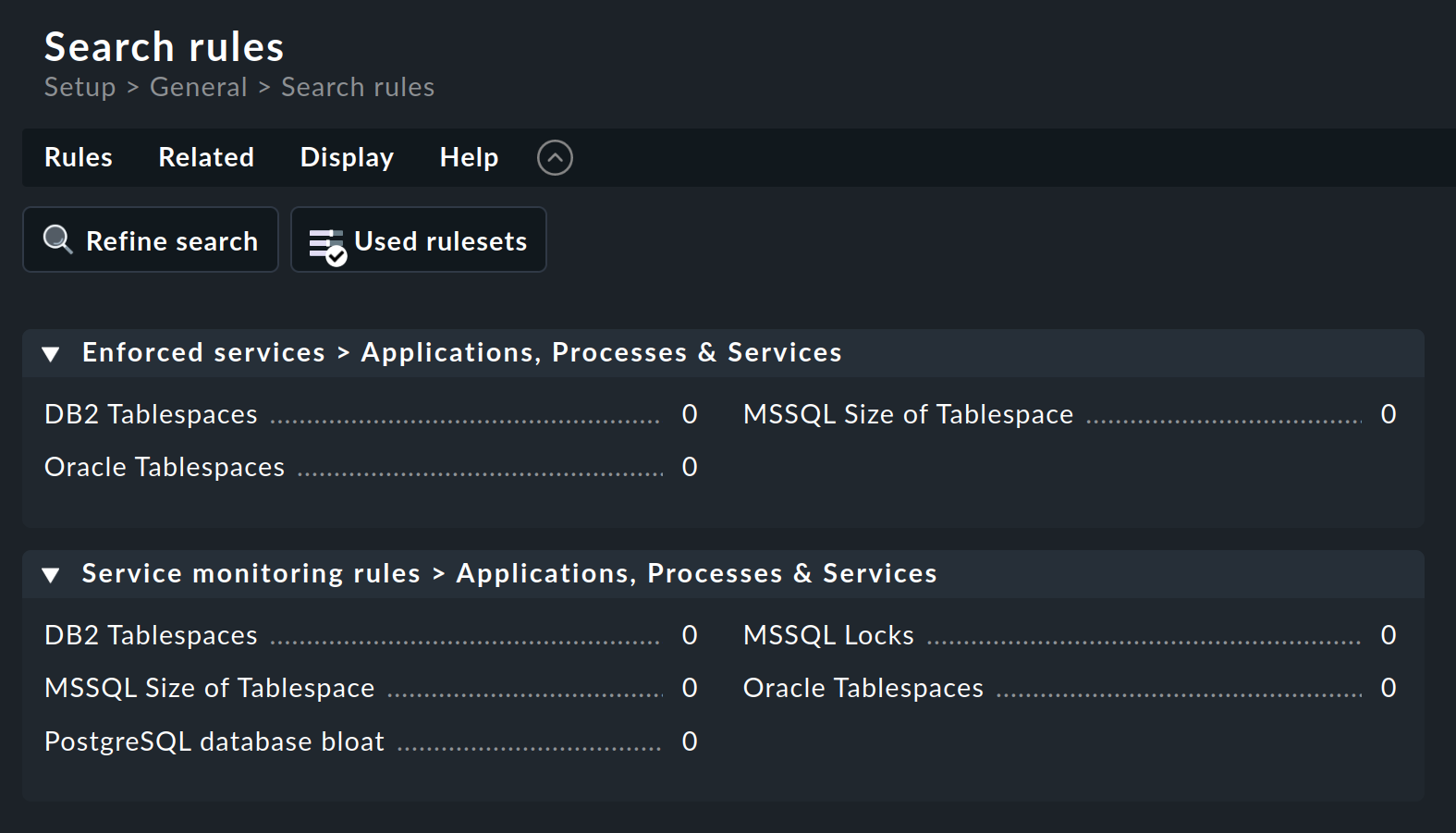
Der Regelsatz Oracle tablespaces wird in zwei Kategorien gefunden.
Die Zahl hinter dem Titel (hier überall 0) zeigt die Anzahl der Regeln, die aus diesem Regelsatz bereits erstellt wurden.
In diesem Beispiel soll nicht die Einrichtung eines Services erzwungen werden (enforced service). Klicken Sie daher auf den Namen in der Kategorie Service monitoring rules. Sie landen dann auf dieser Seite:
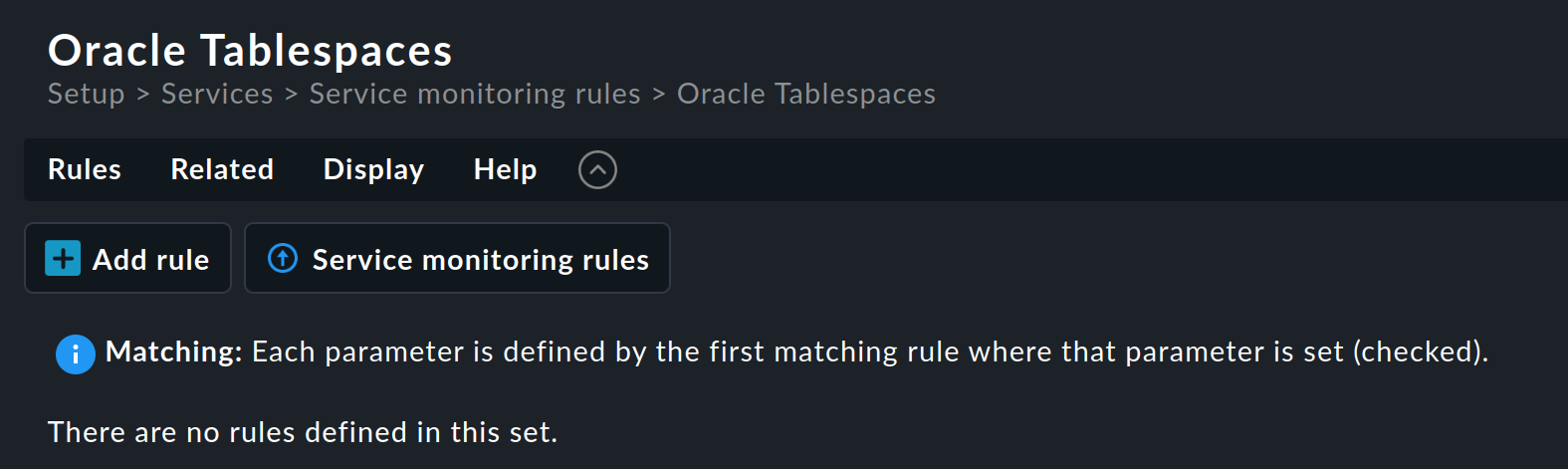
Der Regelsatz enthält noch keine Regeln. Sie können die erste mit dem Knopf Add rule erstellen. Das Anlegen (und auch das spätere Bearbeiten) der Regel bringt Sie zu einem Formular mit drei Kästen Rule properties, Value und Conditions. Wir werden uns die drei nacheinander vornehmen.
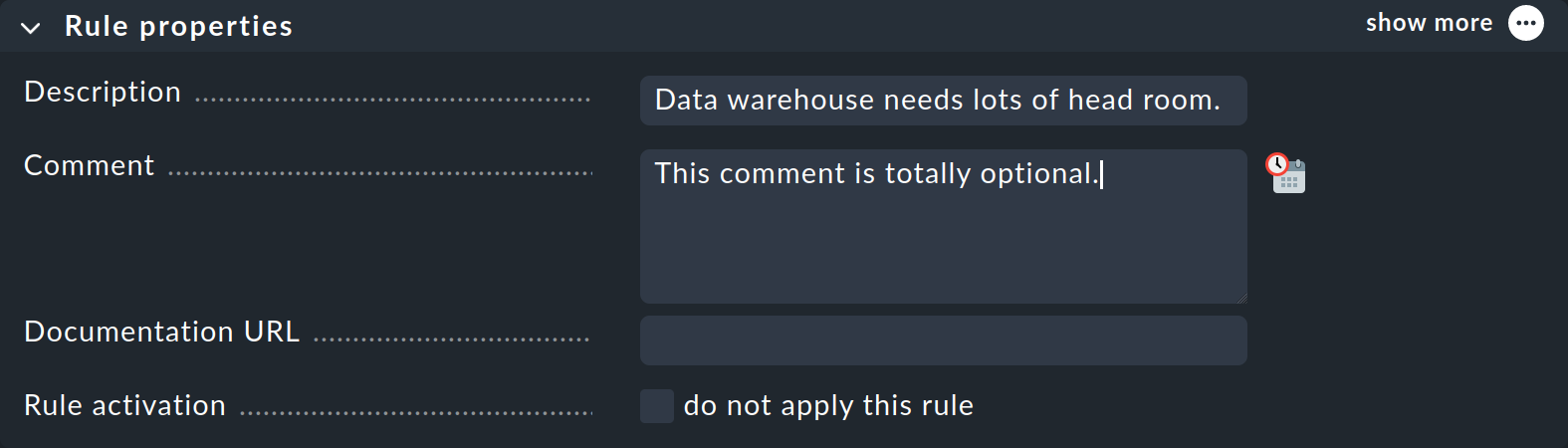
Im Kasten Rule properties sind alle Angaben optional. Neben den informativen Texten haben Sie hier auch die Möglichkeit, eine Regel vorübergehend zu deaktivieren. Das ist praktisch, denn so vermeiden Sie manchmal ein Löschen und Neuanlegen, wenn Sie eine Regel vorübergehend nicht benötigen.
Was Sie im Kasten Value finden, hängt individuell vom Inhalt dessen ab, was gerade geregelt wird:
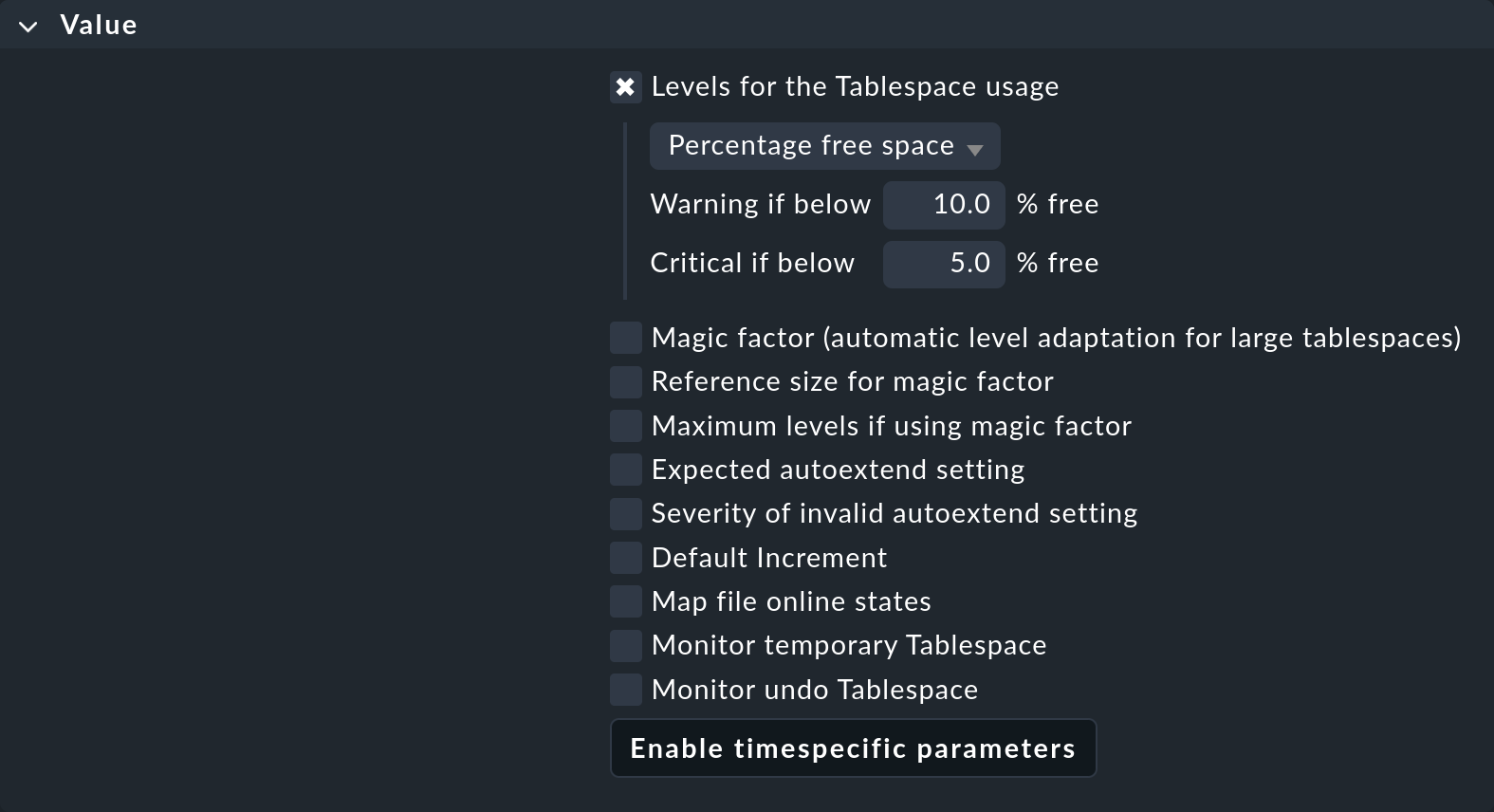
Wie Sie sehen, kann das schon eine ganze Menge an Parametern sein. Das Beispiel zeigt einen typischen Fall: Jeder einzelne Parameter kann per Checkbox aktiviert werden, und die Regel legt dann auch nur diesen fest. Sie können z.B. einen anderen Parameter von einer anderen Regel bestimmen lassen, wenn das Ihre Konfiguration vereinfacht. Im Beispiel werden nur die Schwellwerte für den prozentualen freien Platz im Tablespace definiert.
Nun folgt der Kasten Conditions zur Festlegung der Bedingungen:
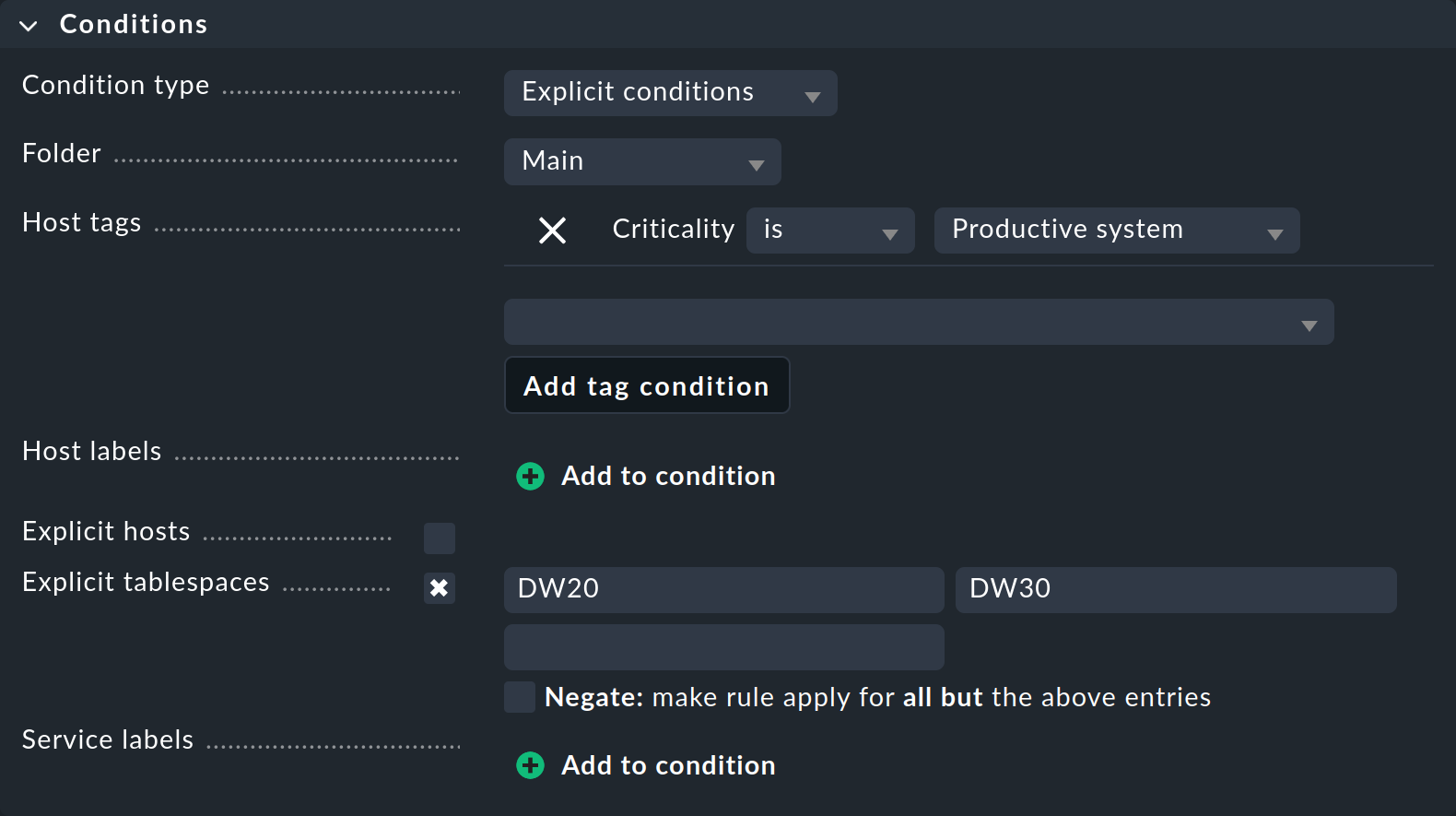
Wir gehen nur auf die Parameter ein, die für die Festlegung der Beispielregel unbedingt benötigt werden:
Mit Folder legen Sie fest, in welchem Ordner die Regel gelten soll. Wenn Sie die Voreinstellung Main z.B. auf Windows ändern, so gilt die neue Regel nur für Hosts, die direkt im oder unterhalb vom Ordner Windows liegen.
Die Host-Merkmale (Host tags) sind ein ganz wichtiges Feature von Checkmk, deshalb widmen wir ihnen im Folgenden noch einen eigenen Abschnitt. An dieser Stelle nutzen Sie eines der vordefinierten Host-Merkmale aus, um festzulegen, dass die Regel nur für Produktivsysteme gelten soll. Dazu aktivieren Sie zuerst Host tags und wählen dann in der Liste die Host-Merkmalsgruppe Criticality aus. In den beiden Listen, die dann eingeblendet werden, wählen Sie is und Productive system aus.
Sehr wichtig für das Beispiel sind die Explicit tablespaces, welche die Regel auf ganz bestimmte Services einschränken. Dazu sind zwei Anmerkungen wichtig:
Der Name dieser Bedingung passt sich dem Regeltyp an. Wenn hier Explicit services steht, geben Sie die Namen der betroffenen Services an. Ein solcher könnte z.B.
Tablespace DW20lauten — also inklusive des WortsTablespace. Im gezeigten Beispiel hingegen möchte Checkmk von Ihnen lediglich den Namen des Tablespaces selbst wissen, also z.B.DW20.Die eingegebenen Texte werden immer gegen den Anfang gematcht. Die Eingabe von
DW20greift also auch auf einen fiktiven TablespaceDW20A. Wenn Sie das verhindern möchten, hängen Sie das Zeichen$an das Ende an, alsoDW20$, denn es handelt sich hier um sogenannte reguläre Ausdrücke.
Die detaillierte Beschreibung aller anderen Parameter für Bedingungen und eine ausführliche Erklärung zum wichtigen Konzept der Regeln finden Sie im Artikel über Regeln. Mehr zu den Service labels, dem letzten Parameter im obigen Bild, erfahren Sie übrigens im Artikel über Labels. |
Nachdem alle Eingaben zur Festlegung komplett sind, sichern Sie die Regel mit Save.

Wenn Sie statt mit einer später mit Hunderten von Regeln arbeiten, droht die Gefahr, den Überblick zu verlieren. Checkmk bietet auf jeder Seite, die Regeln auflistet, im Menü Related sehr hilfreiche Einträge an, um den Überblick zu behalten: Sie können sich die in der aktuellen Instanz genutzten Regeln anzeigen lassen (Used rulesets) und umgekehrt auch die, die gar nicht genutzt werden (Ineffective rules). |
5. Host-Merkmale
5.1. So funktionieren Host-Merkmale
Im vorherigen Abschnitt haben Sie ein Beispiel für eine Regel gesehen, die nur für „produktive“ Systeme gelten soll. Genauer gesagt haben Sie in der Regel eine Bedingung über das Host-Merkmal (host tag) Productive system definiert. Warum wurde die Bedingung als Merkmal definiert und nicht einfach für den Ordner festgelegt? Nun, Sie können nur eine einzige Ordnerstruktur definieren, und jeder Host kann nur in einem Ordner sein. Es gibt aber viele unterschiedliche Merkmale, die ein Host haben kann. Dafür ist die Ordnerstruktur zu beschränkt und nicht flexibel genug.
Dagegen können Sie Host-Merkmale den Hosts völlig frei und beliebig zuordnen — egal, in welchem Ordner sich die Hosts befinden. In Ihren Regeln können Sie sich dann auf diese Merkmale beziehen. Das macht die Konfiguration nicht nur einfacher, sondern auch leichter verständlich und weniger fehleranfällig, als wenn Sie für jeden Host alles explizit festlegen würden.
Aber wie und wo legt man nun fest, welche Hosts welche Merkmale haben sollen? Und wie können Sie eigene Merkmale definieren?
5.2. Host-Merkmale definieren
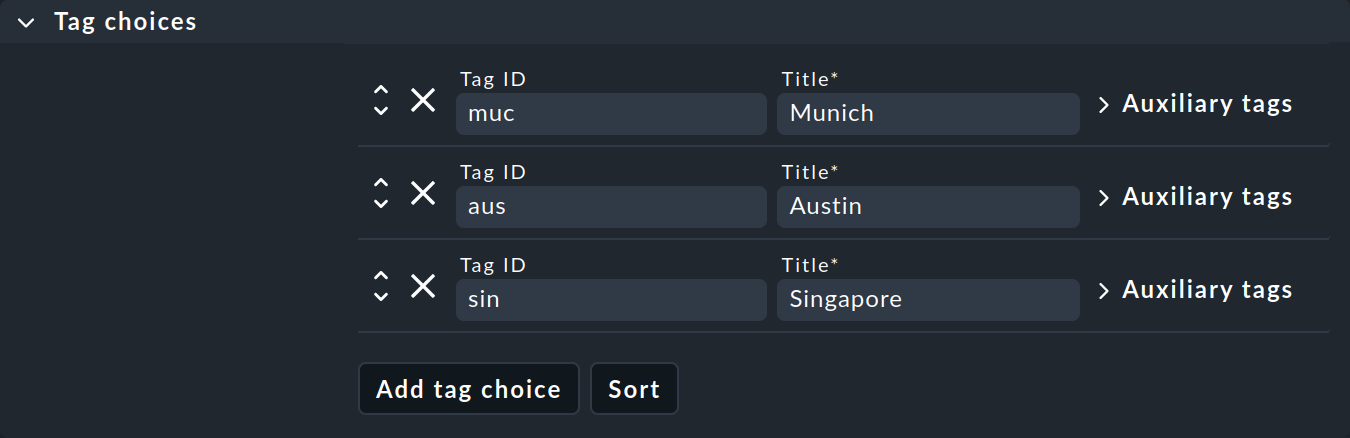
Beginnen wir mit der Antwort auf die zweite Frage nach eigenen Merkmalen. Zunächst müssen Sie wissen, dass Merkmale in Gruppen organisiert sind, den sogenannten Host-Merkmalsgruppen (host tag groups). Nehmen Sie als Beispiel den Standort (location). Eine Merkmalsgruppe könnte Location heißen, und diese Gruppe könnte die Merkmale Munich, Austin und Singapore enthalten. Grundsätzlich gilt dabei, dass jedem Host aus jeder Merkmalsgruppe genau ein Merkmal zugewiesen wird. Sobald Sie also eine eigene Merkmalsgruppe definieren, trägt jeder Host eines der Merkmale aus dieser Gruppe. Hosts, bei denen Sie kein Merkmal aus der Gruppe gewählt haben, bekommen einfach per Default das erste zugewiesen.
Die Definition der Host-Merkmalsgruppen finden Sie unter Setup > Hosts > Tags:
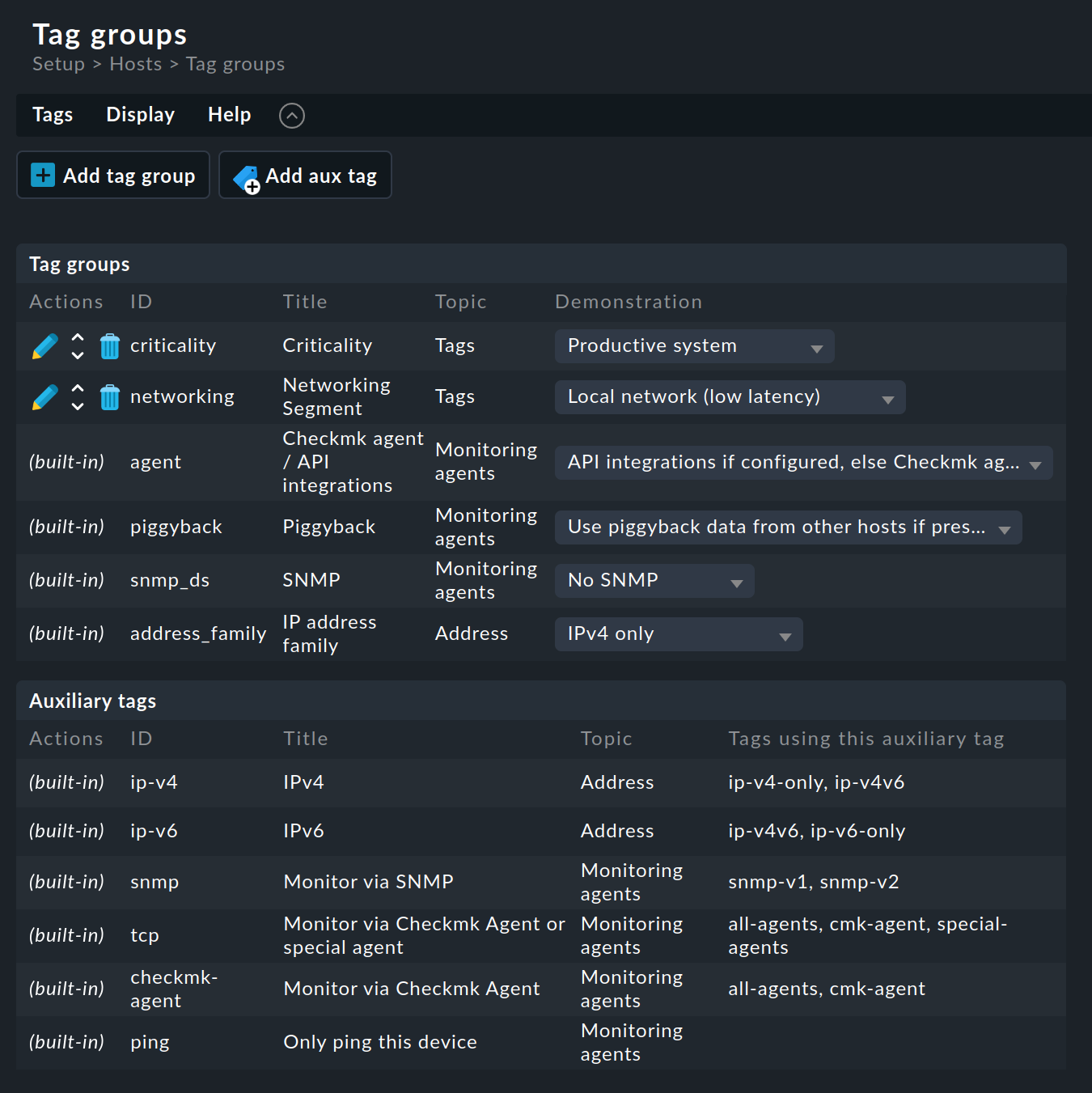
Wie Sie sehen, sind einige Merkmalsgruppen bereits vordefiniert. Die meisten davon können Sie nicht ändern. Wir empfehlen Ihnen außerdem, die beiden vordefinierten Beispielgruppen Criticality und Networking Segment nicht anzutasten. Definieren Sie lieber Ihre eigenen Gruppen:
Klicken Sie auf Add tag group. Dies öffnet die Seite zum Erstellen einer neuen Merkmalsgruppe. Im ersten Kasten Basic settings vergeben Sie — wie so oft in Checkmk — eine interne ID, die als Schlüssel dient und später nicht mehr geändert werden kann. Zusätzlich zur ID legen Sie einen sprechenden Titel fest, den Sie später jederzeit ändern können. Mit Topic können Sie das Thema bestimmen, unter dem das Merkmal bei den Eigenschaften des Hosts später angeboten wird. Wenn Sie hier ein neues Topic erstellen, wird das Merkmal bei den Host-Eigenschaften in einem eigenen Kasten angezeigt.
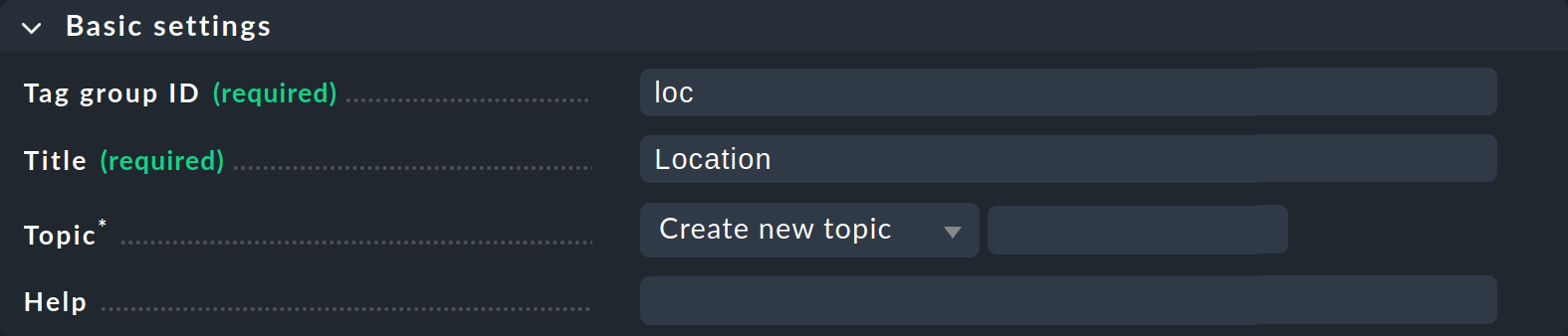
Im zweiten Kasten Tag choices geht es um die eigentlichen Merkmale, also die Auswahlmöglichkeiten der Gruppe. Klicken Sie Add tag choice, um ein Merkmal zu erstellen und vergeben Sie auch hier pro Merkmal eine interne ID und einen Titel:
Hinweise:
Auch Gruppen mit nur einer einzigen Auswahl sind erlaubt und sogar sinnvoll. Das darin enthaltene Merkmal heißt Checkbox-Merkmal (checkbox tag) und erscheint dann in den Host-Eigenschaften als eben eine Checkbox. Jeder Host hat dann das Merkmal — oder eben nicht, denn Checkbox-Merkmale sind standardmäßig deaktiviert.
An dieser Stelle können Sie die Hilfsmerkmale (auxiliary tags) erstmal ignorieren. Sie erhalten alle Informationen zu Hilfsmerkmalen im Speziellen und zu Host-Merkmalen im Allgemeinen im Artikel über Host-Merkmale.
Sobald Sie mit Save die neue Host-Merkmalsgruppe gesichert haben, können Sie sie nutzen.
5.3. Ein Merkmal einem Host zuordnen
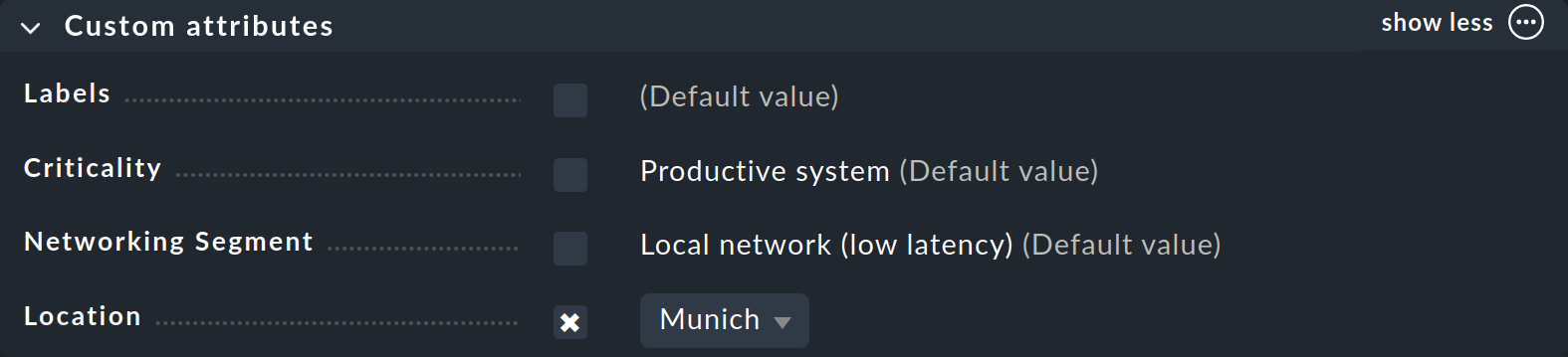
Wie Sie einem Host Merkmale zuordnen, haben Sie schon gesehen: in den Host-Eigenschaften beim Erstellen oder Bearbeiten eines Hosts. Im Kasten Custom attributes (oder in einem eigenen, falls Sie ein Topic erstellt haben) taucht nun die neue Host-Merkmalsgruppe auf, und Sie können für den Host die Auswahl treffen und das Merkmal festlegen:
Nachdem Sie jetzt die wichtigen Prinzipien der Konfiguration mit Regeln und Host-Merkmalen kennengelernt haben, möchten wir Ihnen in den restlichen Abschnitten einige konkrete Empfehlungen geben, um in einem neuen Checkmk-System Fehlalarme zu reduzieren.
6. Dateisystem-Schwellwerte anpassen
Überprüfen Sie die Schwellwerte für die Überwachung von Dateisystemen und passen Sie diese gegebenenfalls an. Die Standardwerte hatten wir bereits weiter oben bei der Suche nach Regeln kurz gezeigt.
Standardmäßig nimmt Checkmk beim Füllgrad von Dateisystemen die Schwellen 80 % für WARN und 90 % für CRIT. Nun sind 80 % bei einer 2 Terabytes großen Festplatte immerhin 400 Gigabytes — vielleicht ein bisschen viel Puffer für eine Warnung. Daher hier ein paar Tipps zum Thema Dateisysteme:
Legen Sie Ihre eigenen Regeln an im Regelsatz File systems (used space and growth).
Die Parameter erlauben Schwellwerte, die von der Größe des Dateisystems abhängen. Wählen Sie dazu Levels for used/free space > Levels for used space > Dynamic levels. Mit dem Knopf Add new element definieren Sie jetzt pro Plattengröße eigene Schwellwerte.
Noch einfacher geht es mit dem Magic factor, den wir im letzten Kapitel vorstellen.
7. Hosts in die Wartung schicken
Manche Server werden turnusmäßig neu gestartet — sei es, um Patches einzuspielen oder einfach, weil das so vorgesehen ist. Sie können Fehlalarme zu diesen Zeiten vermeiden.
![]() In Checkmk Community definieren Sie zunächst eine Zeitperiode (time period), welche die Zeiten des Reboots abdeckt.
Wie das geht, erfahren Sie im Artikel über Zeitperioden.
Danach legen Sie jeweils eine Regel in den Regelsätzen Notification period for hosts und Notification period for services für die betroffenen Hosts an und wählen dort die zuvor definierte Zeitperiode aus.
Die zweite Regel für die Services ist nötig, damit auch Services, die in dieser Zeit auf CRIT gehen, keine Benachrichtigungen auslösen.
Falls nun während dieser Zeiten Probleme auftreten (und rechtzeitig wieder verschwinden), werden keine Benachrichtigungen ausgelöst.
In Checkmk Community definieren Sie zunächst eine Zeitperiode (time period), welche die Zeiten des Reboots abdeckt.
Wie das geht, erfahren Sie im Artikel über Zeitperioden.
Danach legen Sie jeweils eine Regel in den Regelsätzen Notification period for hosts und Notification period for services für die betroffenen Hosts an und wählen dort die zuvor definierte Zeitperiode aus.
Die zweite Regel für die Services ist nötig, damit auch Services, die in dieser Zeit auf CRIT gehen, keine Benachrichtigungen auslösen.
Falls nun während dieser Zeiten Probleme auftreten (und rechtzeitig wieder verschwinden), werden keine Benachrichtigungen ausgelöst.
![]() In den kommerziellen Editionen gibt es regelmäßige Wartungszeiten für diesen Zweck, die Sie für die betroffenen Hosts setzen können.
In den kommerziellen Editionen gibt es regelmäßige Wartungszeiten für diesen Zweck, die Sie für die betroffenen Hosts setzen können.
Eine Alternative zur Erstellung von Wartungszeiten für Hosts, die wir im Kapitel über Checkmk im Monitoring schon beschrieben haben, ist in den kommerziellen Editionen der Regelsatz Recurring downtimes for hosts. Dieser hat den großen Vorteil, dass auch Hosts, die erst später in die Überwachung aufgenommen werden, automatisch diese Wartungszeiten erhalten. |
8. Abgeschaltete Hosts ignorieren
Nicht immer ist es ein Problem, wenn ein Rechner abgeschaltet wird. Ein klassisches Beispiel sind Drucker. Diese mit Checkmk zu überwachen ist durchaus sinnvoll. Manche Anwender organisieren sogar die Nachbestellung von Toner mit Checkmk. In aller Regel ist aber das Ausschalten eines Druckers vor Feierabend kein Problem. Dumm ist nur, wenn Checkmk hier benachrichtigt, weil der entsprechende Host DOWN ist.
Sie können Checkmk mitteilen, dass es völlig in Ordnung ist, wenn ein Host ausgeschaltet ist. Dazu suchen Sie den Regelsatz Host check command, erstellen eine neue Regel und setzen Sie den Wert auf Always assume host to be up:

Stellen Sie im Kasten Conditions sicher, dass diese Regel wirklich nur auf die passenden Hosts angewendet wird — je nach der von Ihnen gewählten Struktur. Sie können dazu z.B. ein Host-Merkmal definieren und hier nutzen oder Sie können die Regel über einen Ordner festlegen, in dem sich alle Drucker befinden.
Jetzt werden alle Drucker grundsätzlich als UP angezeigt — egal, wie ihr Status tatsächlich ist.
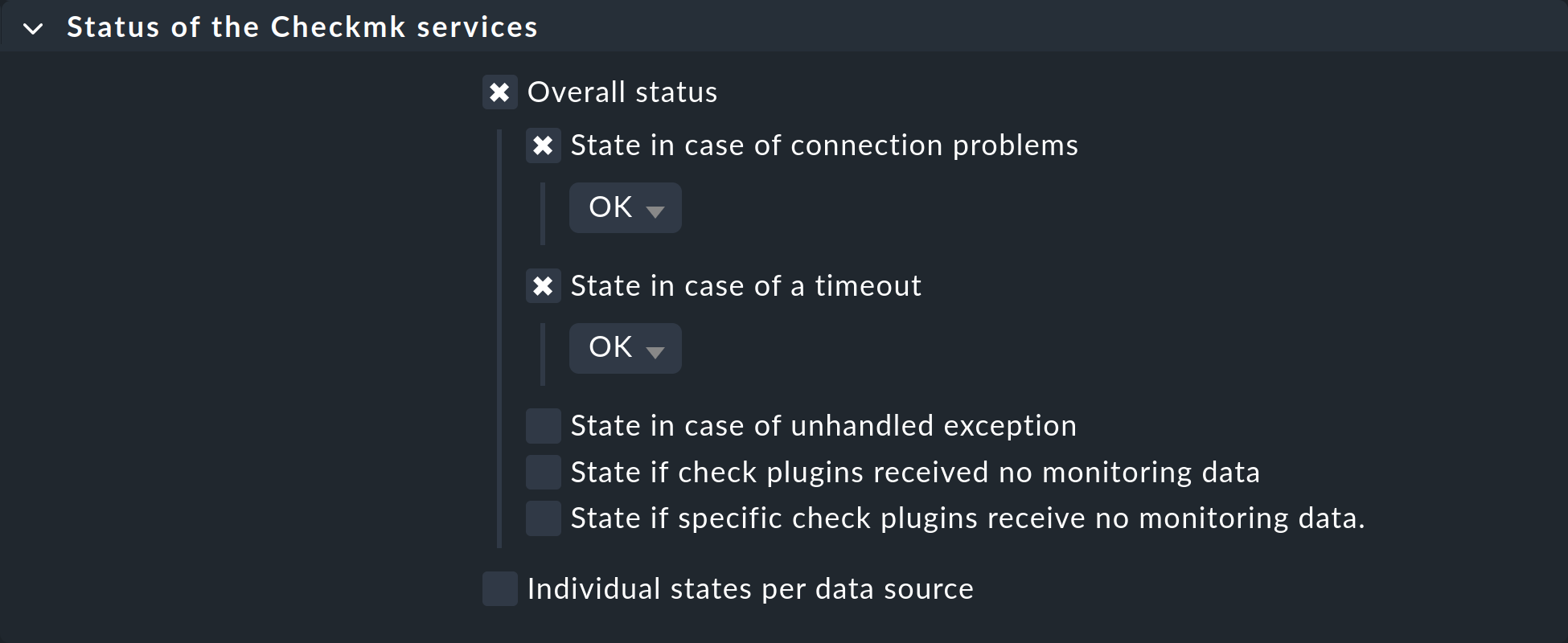
Die Services des Druckers werden allerdings weiterhin geprüft und ein Timeout würde zu einem CRIT Zustand führen. Um auch dies zu vermeiden, konfigurieren Sie für die betroffenen Hosts im Regelsatz Status of the Checkmk services eine Regel, in der Sie Timeouts und Verbindungsprobleme jeweils auf OK setzen:
9. Switch Ports konfigurieren
Wenn Sie mit Checkmk einen Switch überwachen, dann werden Sie feststellen, dass bei der Service-Konfiguration automatisch für jeden Port, der zu dem Zeitpunkt up ist, ein Service angelegt wird. Dies ist eine sinnvolle Standardeinstellung für Core und Distribution Switches — also solche, an denen nur Infrastrukturgeräte oder Server angeschlossen sind. Bei Switches, an denen Endgeräte wie Arbeitsplätze oder Drucker angeschlossen sind, führt das aber einerseits zu ständigen Benachrichtigungen, falls ein Port auf down geht, und andererseits zu ständig neu gefundenen Services, weil ein bisher nicht überwachter Port umgekehrt up geht.
Hier haben sich zwei Vorgehensweisen bewährt. So können Sie erstens die Überwachung auf die Uplink-Ports beschränken. Dazu legen Sie eine Regel bei den deaktivierten Services an, welche die anderen Ports von der Überwachung ausschließt.
Viel interessanter ist jedoch die zweite Methode: Hier überwachen Sie zwar alle Ports, erlauben aber den Zustand down als gültigen Zustand. Der Vorteil: Auch für Ports, an denen Endgeräte hängen, haben Sie eine Überwachung der Übertragungsfehler und erkennen so sehr schnell schlechte Patchkabel oder Fehler in der Autonegotiation. Um das umzusetzen, benötigen Sie zwei Regeln:
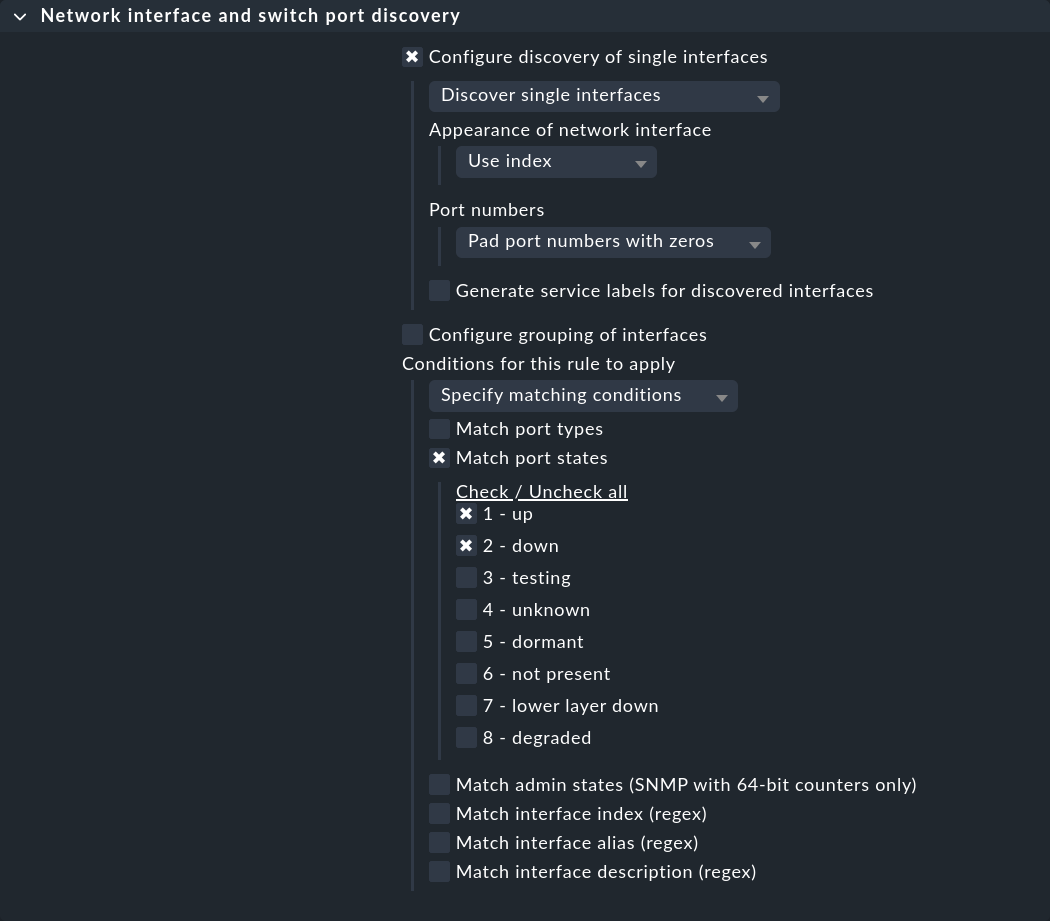
Der erste Regelsatz Network interface and switch port discovery legt fest, unter welchen Bedingungen Switch Ports überwacht werden sollen. Legen Sie eine Regel für die gewünschten Switches an und wählen Sie aus, ob einzelne Schnittstellen (Configure discovery of single interfaces) oder Gruppen (Configure grouping of interfaces) gefunden werden sollen. Aktivieren Sie dann unter Conditions for this rule to apply > Specify matching conditions > Match port states zusätzlich zu 1 - up auch 2 - down:
In der Service-Konfiguration der Switches werden nun auch die Ports mit dem Zustand down angeboten, und Sie können sie zur Liste der überwachten Services hinzufügen.
Bevor Sie die Änderung aktivieren, benötigen Sie noch die zweite Regel, die dafür sorgt, dass dieser Zustand als OK gewertet wird. Der Regelsatz heißt Network interfaces and switch ports. Erstellen Sie eine neue Regel und aktivieren Sie die Option Operational state, deaktivieren Sie darunter Ignore the operational state und aktivieren Sie dann bei den Allowed operational states die Zustände 1 - up und 2 - down (und eventuell weitere Zustände).
10. Services dauerhaft deaktivieren
Bei manchen Services, die einfach nicht zuverlässig auf OK zu bekommen sind, ist es am Ende besser, sie gar nicht zu überwachen. Hier könnten Sie nun einfach bei den betroffenen Hosts in der Service-Konfiguration (auf der Seite Services of host) die Services manuell aus der Überwachung herausnehmen, indem Sie sie auf Disabled oder Undecided setzen. Dies ist aber umständlich und fehleranfällig.
Viel besser ist es, wenn Sie Regeln definieren, nach denen bestimmte Services systematisch nicht überwacht werden.
Dafür gibt es den Regelsatz Disabled services.
Hier können Sie z.B. eine Regel anlegen und in der Bedingung festlegen, dass Dateisysteme mit dem Mount-Punkt /var/test/ grundsätzlich nicht überwacht werden sollen.
Wenn Sie in der Service-Konfiguration eines Hosts einen einzelnen Service durch Klick auf |
Weitere Informationen können Sie im Artikel über die Konfiguration von Services nachlesen.
11. Durch Mittelwert Ausreißer abfangen
Ein Grund für sporadische Benachrichtigungen sind oft Schwellwerte auf Auslastungsmetriken, wie z.B. die CPU-Auslastung (CPU utilization), die nur kurzfristig überschritten werden. In der Regel sind solche kurzen Spitzen kein Problem und sollten vom Monitoring auch nicht bemängelt werden.
Aus diesem Grund haben eine ganze Reihe von Check-Plugins in ihrer Konfiguration die Möglichkeit, dass die Messwerte vor der Anwendung der Schwellen über einen längeren Zeitraum gemittelt werden. Ein Beispiel dafür ist der Regelsatz für die CPU-Auslastung für nicht-Unix-Systeme mit dem Namen CPU utilization for simple devices. Hier gibt es den Parameter Averaging for total CPU utilization:
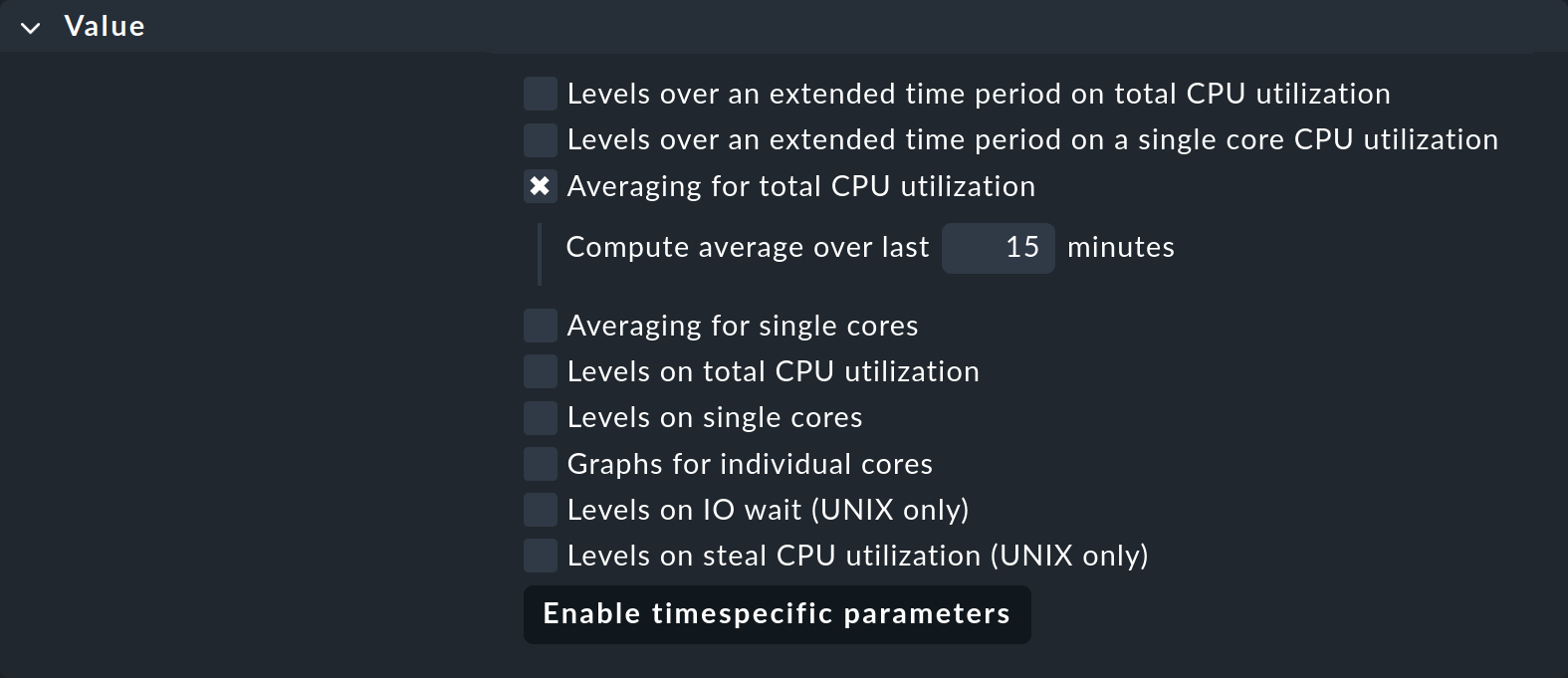
Wenn Sie diesen aktivieren und 15 eintragen, wird die CPU-Auslastung zunächst über einen Zeitraum von 15 Minuten gemittelt und die Schwellwerte erst danach auf diesen Mittelwert angewendet.
12. Sporadische Fehler kontrollieren
Wenn alles nichts hilft und Services immer wieder gelegentlich für einen einzelnen Check (also für eine Minute) auf WARN oder CRIT gehen, gibt es eine letzte Methode, die Fehlalarme verhindert: den Regelsatz Maximum number of check attempts for service.
Legen Sie dort eine Regel an und setzen Sie den Wert z.B. auf 3, so wird ein Service, der z.B. von OK auf WARN geht, zunächst noch keine Benachrichtigungen auslösen und auch im Overview noch nicht als Problem angezeigt werden.
Der Zwischenzustand, in dem sich der Service befindet, wird als „weicher Zustand“ (soft state) bezeichnet.
Erst wenn der Zustand in drei aufeinanderfolgenden Checks (was insgesamt dann knapp über zwei Minuten dauert) nicht OK ist, wird das hartnäckige Problem gemeldet.
Nur ein harter Zustand (hard state) löst eine Benachrichtigung aus.
Das ist zugegeben keine schöne Lösung. Sie sollten immer versuchen, das Problem an der Wurzel zu packen, aber manchmal sind die Dinge einfach so, wie sie sind, und mit der Anzahl der Check-Versuche haben Sie für solche Fälle zumindest einen gangbaren Weg zur Umgehung.
13. Liste der Services aktuell halten
In einem Rechenzentrum wird ständig gearbeitet, und so wird die Liste der zu überwachenden Services nie konstant bleiben. Damit Sie dabei möglichst nichts übersehen, richtet Checkmk für Sie automatisch einen besonderen Service auf jedem Host ein. Dieser heißt Check_MK Discovery:

Dieser prüft in der Voreinstellung alle zwei Stunden, ob neue (noch nicht überwachte) Services gefunden oder bestehende weggefallen sind. Ist dies der Fall, so geht der Service auf WARN. Sie können dann die Service-Konfiguration aufrufen (auf der Seite Services of host) und die Liste der Services wieder auf den aktuellen Stand bringen.
Detaillierte Informationen zu diesem Discovery Check erhalten Sie im Artikel über die Konfiguration von Services. Dort erfahren Sie auch, wie Sie nicht überwachte Services automatisch hinzufügen lassen können, was die Arbeit in großen Konfiguration erheblich erleichtert.
Über Monitor > System > Unmonitored services können Sie sich eine Ansicht aufrufen, die Ihnen die neuen und weggefallenen Services anzeigt. |