1. CPU-Auslastung aller Kerne einzeln überwachen
Checkmk richtet sowohl unter Linux als auch unter Windows automatisch einen Service ein, der die durchschnittliche CPU-Auslastung der letzten Minute ermittelt. Dies ist einerseits sinnvoll, erkennt aber andererseits einige Fehler nicht, beispielsweise den, dass ein einzelner Prozess Amok läuft und permanent eine CPU mit 100 % belastet. Bei einem System mit 16 CPUs trägt eine CPU aber nur mit 6,25 % zur Gesamtleistung bei, und so wird selbst im geschilderten Extremfall nur eine Auslastung von 6,25 % gemessen — was dann nicht zu einer Benachrichtigung führt.
Deswegen bietet Checkmk die Möglichkeit (für Linux und für Windows), alle vorhandenen CPUs einzeln zu überwachen und festzustellen, ob einer der Kerne über längere Zeit permanent ausgelastet ist. Diesen Check einzurichten hat sich als gute Idee herausgestellt.
Um diese Überprüfung für Ihre Windows-Server einzurichten, benötigen Sie für den Service CPU utilization den Regelsatz CPU utilization for simple devices, den Sie unter den Service monitoring rules finden. Dieser Regelsatz ist für die Überwachung aller CPUs zuständig — hat aber auch diese Option im Angebot: Levels over an extended time period on a single core CPU utilization.
Erstellen Sie eine neue Regel und aktivieren Sie darin nur diese Option:
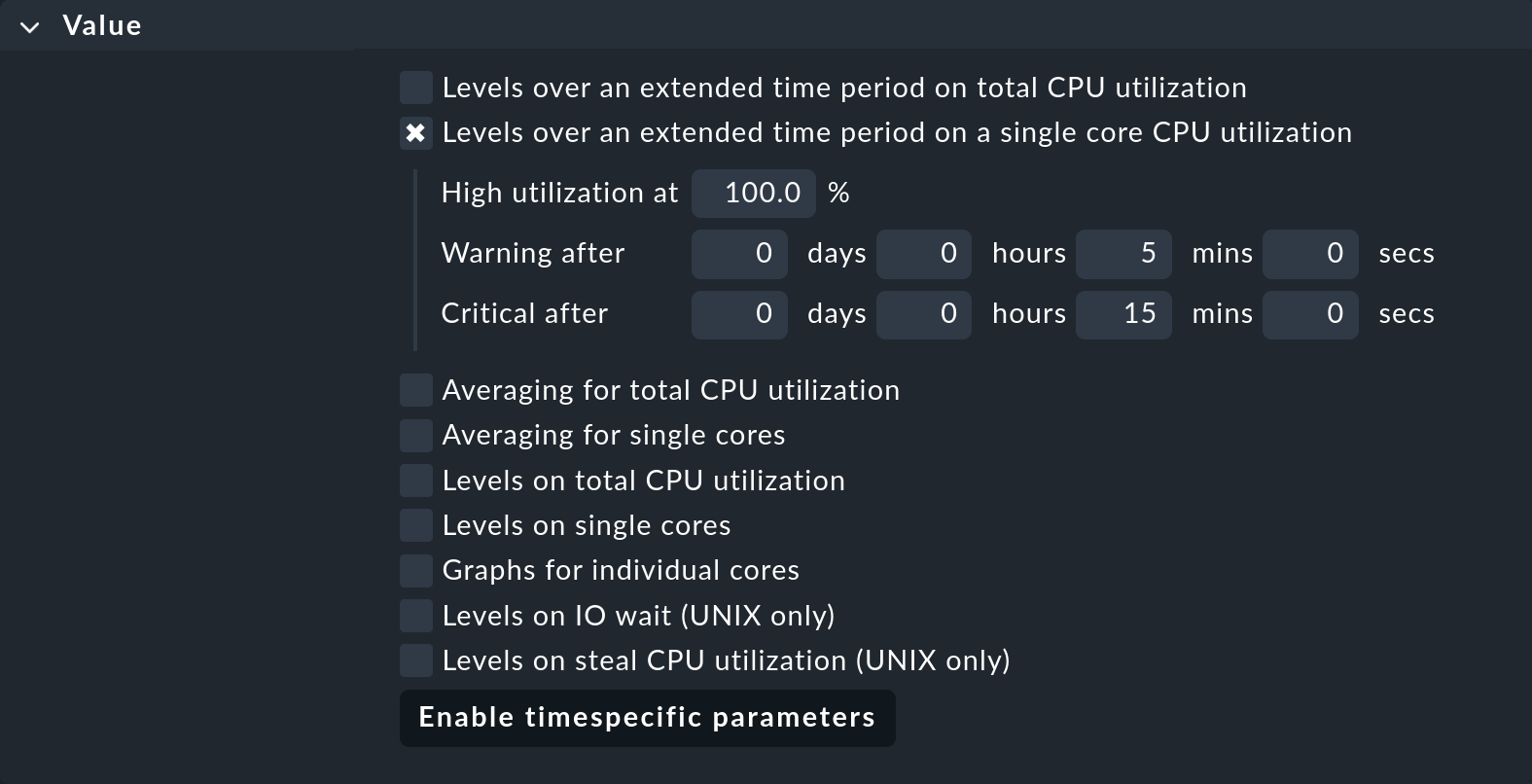
Definieren Sie die Bedingung so, dass sie nur für die Windows-Server greift, z.B. durch einen geeigneten Ordner oder ein Host-Merkmal. Diese Regel wird andere Regeln des gleichen Regelsatzes nicht beeinflussen, wenn diese andere Optionen festlegen, z.B. die Schwellwerte für die Gesamtauslastung.
Bei Linux-Servern ist dafür der Regelsatz CPU utilization on Linux/Unix zuständig, in dem Sie die gleiche Option setzen können.
2. Windows-Dienste überwachen
In der Voreinstellung überwacht Checkmk auf Ihren Windows-Servern keine Dienste. Warum nicht? Nun, weil Checkmk nicht weiß, welche Dienste für Sie wichtig sind.
Wenn Sie sich nicht die Mühe machen wollen, für jeden Server von Hand festzulegen, welche Dienste dort wichtig sind, können Sie auch einen Check einrichten, der einfach überprüft, ob alle Dienste mit der Startart „automatisch“ auch wirklich laufen. Zusätzlich können Sie sich informieren lassen, ob Dienste laufen, die manuell — quasi außer der Reihe — gestartet wurden. Diese werden nach einem Reboot nicht mehr laufen, was ein Problem sein kann.
Um dies umzusetzen, benötigen Sie zunächst den Regelsatz Windows Services, den Sie unter den Service monitoring rules finden, z.B. über die Suchfunktion Setup > General > Rule search. Die entscheidende Option in der neuen Regel lautet Services states. Aktivieren Sie diese und fügen Sie drei neue Elemente für die Zustände der Dienste hinzu:
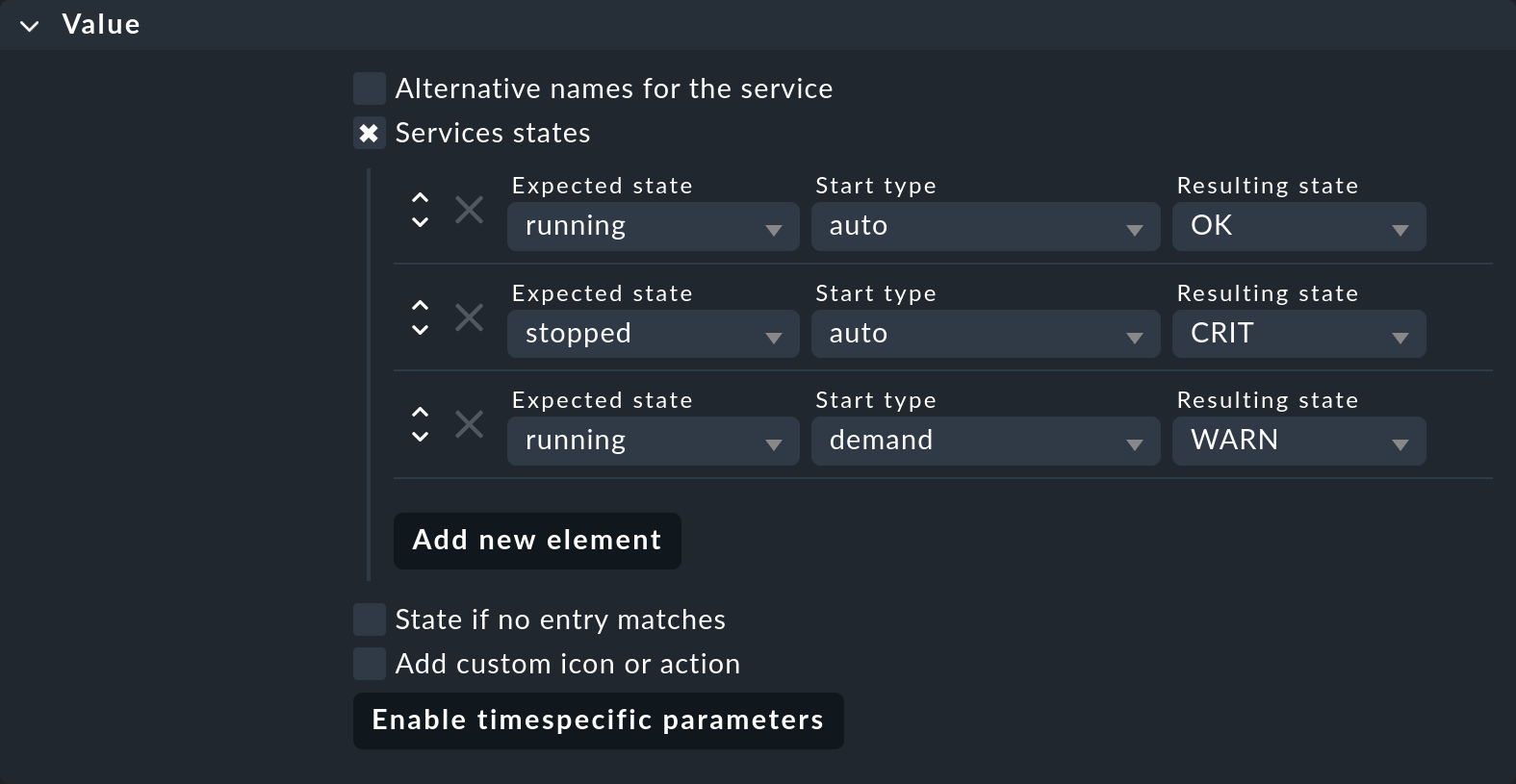
Dadurch erreichen Sie folgende Überwachung:
Ein Dienst mit der Startart auto, der läuft, gilt als OK.
Ein Dienst mit der Startart auto, der nicht läuft, gilt als CRIT.
Ein Dienst mit der Startart demand, der läuft, gilt als WARN.
Diese Regel gilt allerdings nur für Dienste, die auch wirklich überwacht werden. Daher benötigen Sie noch einen zweiten Schritt und eine zweite Regel, diesmal aus dem Regelsatz Windows service discovery, mit der Sie festlegen, welche Windows-Dienste Checkmk als Services überwachen soll.
Wenn Sie diese Regel anlegen, können Sie zunächst bei der Option Services (regular expressions) den regulären Ausdruck .* eingeben, der auf alle Services zutrifft.
Nach dem Sichern der Regel wechseln Sie für einen passenden Host in die Service-Konfiguration. Dort werden Sie eine große Zahl von neuen Services finden — für jeden Windows-Dienst einen.
Um die Anzahl der überwachten Services auf die für Sie interessanten einzuschränken, kehren Sie zu der Regel zurück und verfeinern die Suchausdrücke nach Bedarf. Dabei wird Groß- und Kleinschreibung unterschieden. Hier ist ein Beispiel für eine angepasste Service-Auswahl:
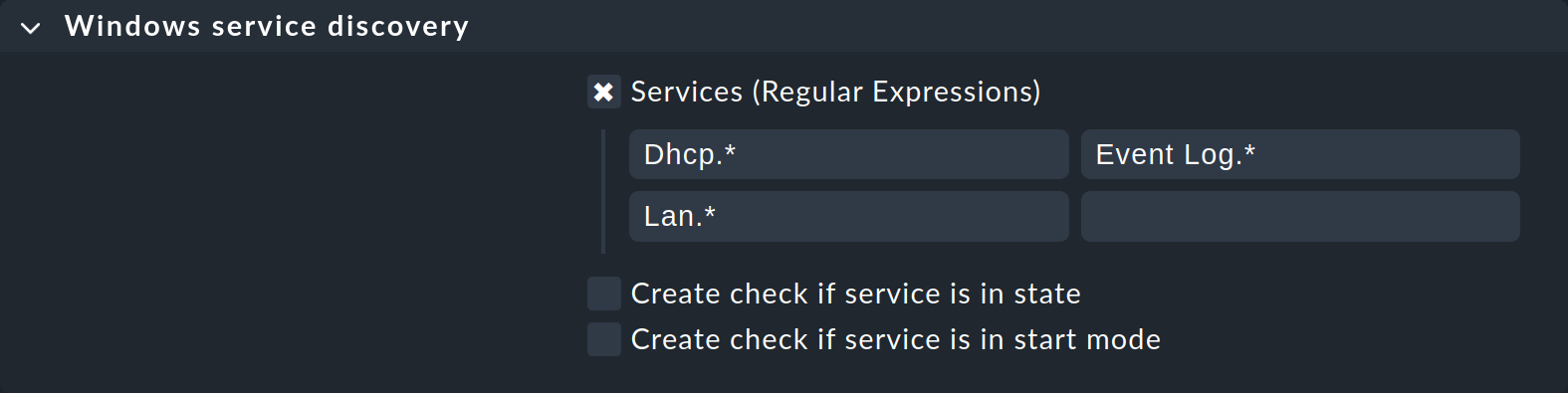
Sollten Sie Services, die den neuen Suchausdrücken nicht entsprechen, zuvor schon in die Überwachung aufgenommen haben, erscheinen diese jetzt in der Service-Konfiguration als fehlend. Mit dem Knopf Rescan können Sie reinen Tisch machen und die ganze Service-Liste neu erstellen lassen.
3. Internetverbindung überwachen
Der Zugang Ihrer Firma zum Internet ist sicherlich für alle sehr wichtig. Die Überwachung der Verbindung zu „dem Internet“ ist dabei etwas schwierig umzusetzen, da es um Milliarden von Rechnern geht, die (hoffentlich) erreichbar sind — oder eben nicht. Sie können aber trotzdem effizient eine Überwachung einrichten, nach folgendem Bauplan:
Wählen Sie mehrere Rechner im Internet, die normalerweise per
ping-Befehl erreichbar sein sollten, und notieren Sie deren IP-Adressen.Legen Sie in Checkmk einen neuen Host an, etwa mit dem Namen
internetund konfigurieren diesen wie folgt: Als IPv4 address geben Sie eine der notierten IP-Adressen ein. Unter Additional IPv4 addresses tragen Sie die restlichen IP-Adressen ein. Aktivieren Sie unter Monitoring agents die Option Checkmk agent / API integrations und wählen dort No API integrations, no Checkmk agent aus. Speichern Sie den Host ohne Service-Erkennung.Erstellen Sie eine neue Regel aus dem Regelsatz Check hosts with ping (ICMP echo request), die nur für den neuen Host
internetgreift (z.B. über die Bedingung mit Explicit hosts oder einem passenden Host-Merkmal). Konfigurieren Sie die Regel wie folgt: Aktivieren Sie Service name und geben SieInternet connectionein. Aktivieren Sie Alternative address to ping und wählen Sie dort Ping all IPv4 addresses aus. Aktivieren Sie Number of positive responses required for OK state und tragen Sie1ein.Erstellen Sie eine weitere Regel, die ebenfalls nur für den Host
internetgilt, diesmal aus dem Regelsatz Host check command. Wählen Sie dort als Host check command die Option Use the status of the service… und tragen Sie als NamenInternet connectionein, den Sie im vorherigen Schritt als Service-Namen gewählt haben.
Wenn Sie jetzt die Änderungen aktivieren, erhalten Sie im Monitoring den neuen Host internet mit dem einzigen Service Internet connection.
Wenn mindestens eines der Ping-Ziele erreichbar ist, hat der Host den Status UP und der Service den Status OK. Gleichzeitig erhalten Sie beim Service für jede der eingetragenen IP-Adressen Messdaten für die durchschnittliche Paketumlaufzeit (round trip average) und den Paketverlust. Damit erhalten Sie einen Anhaltspunkt für die Qualität Ihrer Verbindung im Laufe der Zeit:

Der letzte und vierte Schritt in obiger Prozedur ist notwendig, damit der Host nicht den Zustand DOWN erhält, falls die erste IP-Adresse nicht per |
4. HTTP/HTTPS-Dienste überwachen
Nehmen wir an, Sie wollen die Erreichbarkeit einer Website oder eines Webdienstes prüfen. Der Checkmk-Agent bietet hier keine Lösung, da er diese Information nicht anzeigt — und außerdem haben Sie vielleicht gar nicht die Möglichkeit, den Agenten auf dem Server zu installieren.
Die Lösung ist ein sogenannter aktiver Check. Das ist einer, der nicht per Agent durchgeführt wird, sondern direkt durch das Kontaktieren eines Netzwerkprotokolls beim Ziel-Host — in diesem Fall HTTP(S).
Das Vorgehen ist wie folgt:
Legen Sie einen neuen Host für den Webserver an, z.B. für
checkmk.com. Aktivieren Sie unter Monitoring agents die Option Checkmk agent / API integrations und wählen dort No API integrations, no Checkmk agent aus. Speichern Sie den Host ohne Service-Erkennung.Erstellen Sie eine neue Regel aus dem Regelsatz Check HTTP web service ,die nur für den neuen Host greift (z.B. über die Bedingung Explicit hosts).
Im Kasten Value finden Sie zahlreiche Optionen zur Durchführung des Checks. Das Prinzip dabei ist: Für jede zu überprüfende URL definieren Sie einen neuen Endpunkt. Pro Endpunkt wird ein Service erzeugt. Den Service-Namen (z. B.
Basic webserver health) und gegebenenfalls einen Präfix (HTTPoderHTTPS) legen Sie beim Endpunkt fest.-
Ebenfalls im Kasten Value, unterhalb der Endpunkte, können Sie zusätzliche Einstellungen vornehmen. So können Sie per Response time den Service auf WARN oder CRIT setzen lassen, wenn die Antwortzeit zu langsam ist und mit Certificate validity die Gültigkeitsdauer des Zertifikats überprüfen. Mit Search for strings können Sie prüfen lassen, ob in der Antwort — also in der gelieferten Seite — ein bestimmter Text vorkommt. Damit können Sie einen relevanten Teil des Inhalts prüfen, damit nicht eine simple Fehlermeldung des Servers als positive Antwort gewertet wird.
Diese Einstellungen können Sie identisch für alle Endpunkte festlegen oder für jeden Endpunkt individuell.

Für alle verfügbaren Optionen finden Sie in der Inline-Hilfe sehr nützliche Informationen.
Speichern Sie die Regel und aktivieren Sie die Änderungen.
Sie bekommen jetzt einen neuen Host mit den von Ihnen festgelegten Services, die den Zugriff per HTTP(S) prüfen:

Sie können diesen Check natürlich auch auf einem Host durchführen, der bereits mit Checkmk per Agent überwacht wird. In diesem Fall entfällt das Anlegen des Hosts und Sie müssen nur die Regel für den Host erstellen. |
5. Dateisystem-Schwellwerte magisch anpassen
Gute Schwellwerte für die Überwachung von Dateisystemen zu finden, kann mühsam sein. Denn eine Schwelle von 90 % ist bei einer sehr großen Festplatte viel zu niedrig und bei einer kleinen vielleicht schon zu knapp. Wir hatten bereits im Kapitel über die Feinjustierung des Monitoring die Möglichkeit vorgestellt, Schwellwerte in Abhängigkeit von der Dateisystemgröße festzulegen — und angedeutet, dass Checkmk eine weitere, noch schlauere Option im Angebot hat: den Magic Factor.
Den Magic Factor richten Sie so ein:
Im Regelsatz File systems (used space and growth) legen Sie nur eine einzige Regel an.
In dieser Regel aktivieren Sie Levels for used/free space und lassen den Standard der Schwellwerte 80 % bzw. 90 % unverändert.
Zusätzlich aktivieren Sie Magic factor (automatic level adaptation for large filesystems) und akzeptieren den Standardwert von 0.8.
Setzen Sie ferner Reference size for magic factor auf 20 GB. Da 20 GB der Standardwert ist, wird er wirksam, auch ohne dass Sie die Option explizit aktivieren.
Das Ergebnis sieht dann so aus:
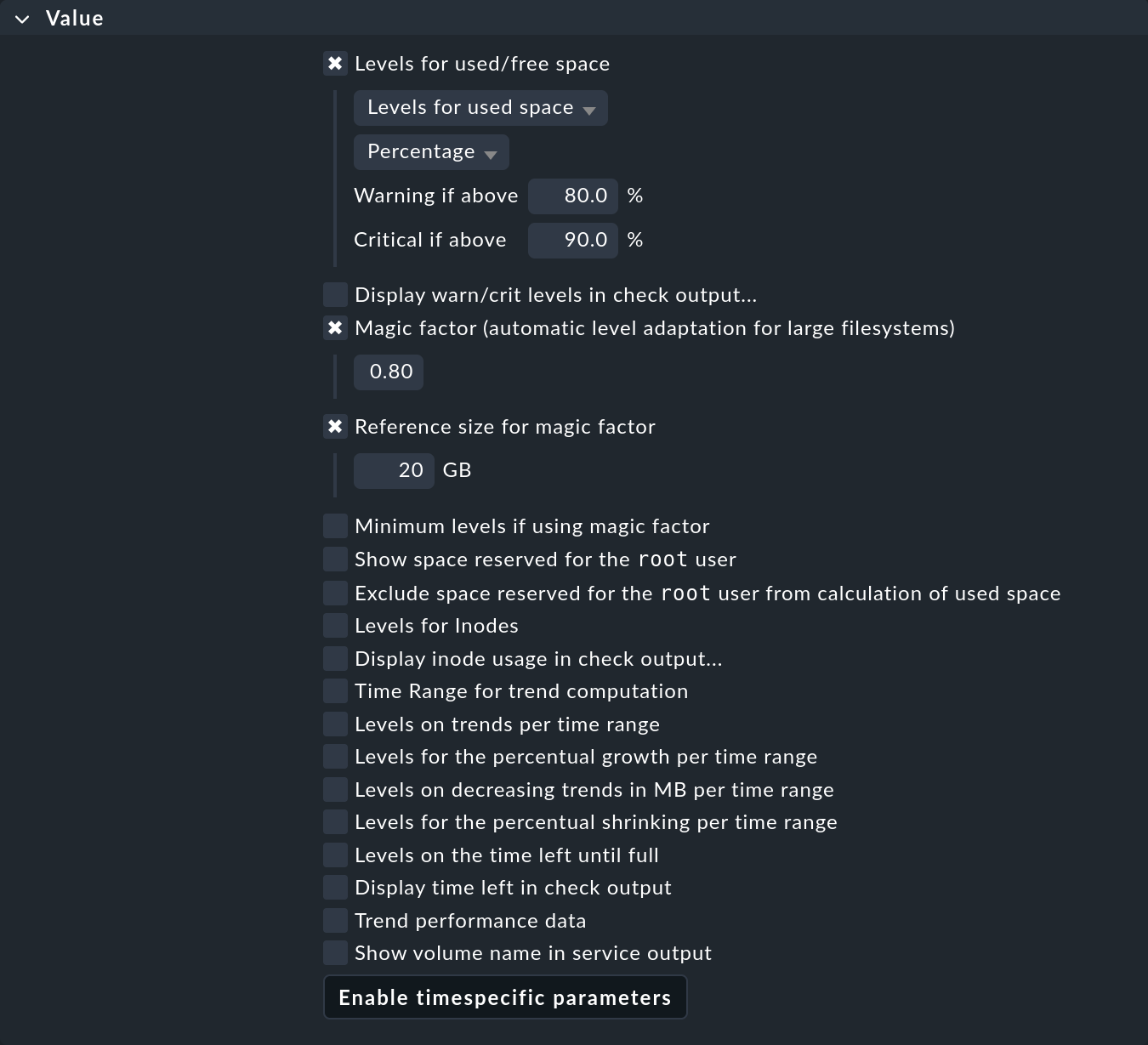
Wenn Sie jetzt die Regel sichern und die Änderung aktivieren, erhalten Sie Schwellwerte, die automatisch von der Größe des Dateisystems abhängen:
Dateisysteme, die genau 20 GB groß sind, erhalten die Schwellwerte 80 % / 90 %.
Dateisysteme, die kleiner als 20 GB sind, erhalten niedrigere Schwellwerte.
Dateisysteme, die größer als 20 GB sind, erhalten höhere Schwellwerte.
Wie hoch die Schwellwerte genau sind, ist — nun ja — magisch! Über den Faktor (hier 0.8) bestimmen Sie, wie stark die Werte verbogen werden. Ein Faktor von 1.0 ändert gar nichts, und alle Dateisysteme bekommen die gleichen Werte. Kleinere Werte verbiegen die Schwellwerte stärker. Die in diesem Abschnitt angewendeten Standardwerte von Checkmk haben sich in der Praxis bei sehr vielen Installationen bewährt.
Welche Schwellen genau gelten, können Sie bei jedem Service in seiner Zusammenfassung (Summary) sehen:
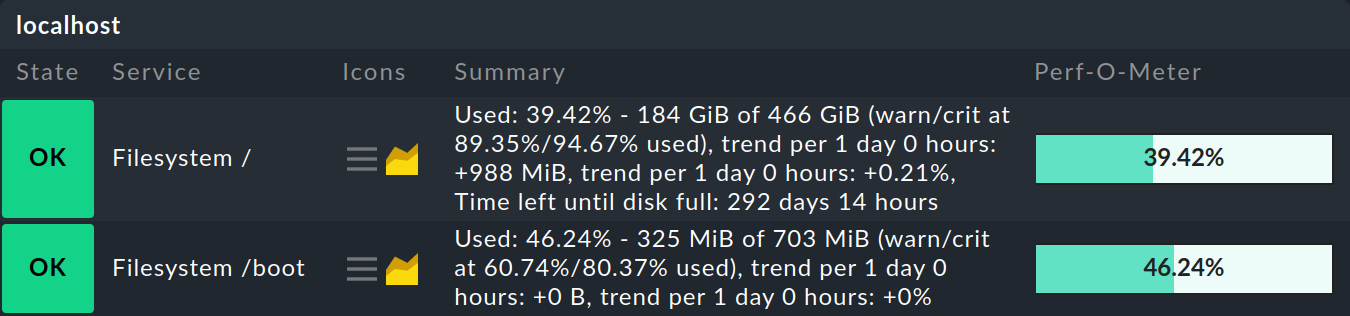
Die folgende Tabelle zeigt einige Beispiele für die Auswirkung des Magic Factor bei einer Referenz von 20 GB / 80 %:
| Magic Factor | 5 GB | 10 GB | 20 GB | 50 GB | 100 GB | 300 GB | 800 GB |
|---|---|---|---|---|---|---|---|
1.0 |
80 % |
80 % |
80 % |
80 % |
80 % |
80 % |
80 % |
0.9 |
77 % |
79 % |
80 % |
82 % |
83 % |
85 % |
86 % |
0.8 |
74 % |
77 % |
80 % |
83 % |
86 % |
88 % |
90 % |
0.7 |
70 % |
75 % |
80 % |
85 % |
88 % |
91 % |
93 % |
0.6 |
65 % |
74 % |
80 % |
86 % |
89 % |
93 % |
95 % |
0.5 |
60 % |
72 % |
80 % |
87 % |
91 % |
95 % |
97 % |
Mit dem Magic Factor schließen wir den Leitfaden für Einsteiger ab.
Wenn Sie sich jetzt erstmal eine Pause gönnen wollen, können Sie sich abmelden. In der Checkmk-Navigationsleiste finden Sie im User-Menü den Eintrag Logout. |
Wir hoffen, dass Sie es geschafft haben, Ihr Checkmk grundlegend einzurichten — mit oder ohne Magie. Für fast alle Themen, die wir in diesem Leitfaden behandelt haben, finden Sie vertiefende Informationen in anderen Artikeln des Handbuchs.
Wir wünschen viel Erfolg mit Checkmk!