This is a machine translation based on the English version of the article. It might or might not have already been subject to text preparation. If you find errors, please file a GitHub issue that states the paragraph that has to be improved. |
1. Introduzione
Le espressioni regolari -regex (o raramente regexp) - sono utilizzate in Checkmk per specificare i nomi dei servizi e in molte altre situazioni. Si tratta di schemi che corrispondono a un certo testo o che non corrispondono(non-match). Puoi fare molte cose pratiche con esse, come ad esempio formulare regole flessibili che si applicano a tutti i servizi con foo o bar nel loro nome.
Le espressioni regolari vengono spesso confuse con i modelli di ricerca dei nomi di file, poiché i caratteri speciali * e ?, così come le parentesi quadre e graffe, possono essere presenti in entrambi.
In questo articolo ti mostreremo le funzioni più importanti delle espressioni regolari, ovviamente nel contesto di Checkmk. Dato che Checkmk utilizza due componenti diversi per le espressioni regolari, a volte il diavolo si nasconde nei dettagli. Essenzialmente, il nucleo di monitoraggio utilizza la libreria C e tutti gli altri componenti utilizzano Python 3. Ti spiegheremo le differenze che esistono.
Suggerimento: in Checkmk le regexp sono consentite nei campi di input di varie pagine. Se non sei sicuro, utilizza l'aiuto contestuale tramite il menu Help (Help > Show inline help). Lì potrai vedere se le espressioni regolari sono consentite e come possono essere utilizzate.
Quando lavori con vecchi plug-in o plug-in provenienti da fonti esterne, può capitare che questi utilizzino Python 2 o Perl e si discostino dalle convenzioni qui descritte.
In questo articolo ti mostreremo le funzionalità più importanti delle espressioni regolari, ma non tutte. Se le possibilità mostrate non sono sufficienti, qui di seguito troverai dei riferimenti dove potrai leggere tutti i dettagli del caso. E poi c'è sempre internet.
Se vuoi programmare i tuoi plug-in che, ad esempio, utilizzano le espressioni regolari per trovare anomalie nei file di log, puoi utilizzare questo articolo come base. Tuttavia, quando si effettuano ricerche su grandi volumi di dati, l'ottimizzazione delle prestazioni è un aspetto importante. In caso di dubbi, consulta sempre la documentazione della libreria regex utilizzata.
2. Lavorare con le espressioni regolari
In questa sezione utilizziamo esempi concreti per mostrare come lavorare con le espressioni regolari, da semplici corrispondenze di singoli caratteri o stringhe a complessi gruppi di corrispondenza.
2.1. Caratteri alfanumerici
Con le espressioni regolari si tratta sempre di stabilire se un modello corrisponde a un determinato testo (ad es. il nome del servizio). L'esempio di applicazione più semplice è una catena di caratteri alfanumerici. Questi (e il segno meno usato come trattino) corrispondono semplicemente a se stessi in un'espressione.
Quando si effettua una ricerca nell'ambiente di monitoraggio, Checkmk di solito non fa distinzione tra maiuscole e minuscole. Nella maggior parte dei casi, l'espressione CPU load corrisponde al testo CPU load così come a cpu LoAd. Laricerca nell'ambiente di configurazione, invece, di solito fa distinzione tra maiuscole e minuscole. Sono possibili eccezioni giustificate a questi standard, descritte nell'aiuto inline.
Attenzione: Nei campi di input senza espressione regolare in cui è specificata una corrispondenza esatta (soprattutto per i nomi host), le maiuscole e le minuscole sono sempre distinte!
2.2. Il punto ( . ) come carattere jolly
Oltre alle stringhe di caratteri del "testo normale", esistono diversi caratteri e stringhe di caratteri che hanno funzioni "magiche". Il carattere più importante è . (punto) checorrisponde esattamente a qualsiasi carattere arbitrario:
| Espressione regolare | Corrispondenza | Nessuna corrispondenza |
|---|---|---|
|
|
|
|
|
|
2.3. Ripetizione di caratteri
Molto spesso si desidera definire la possibilità di ripetere una sequenza di caratteri di una certa lunghezza. A questo scopo si specifica il numero di ripetizioni del carattere precedente tra parentesi graffe:
| Espressione regolare | Funzione | Corrispondenza | Nessuna corrispondenza |
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Esistono abbreviazioni per le ultime tre condizioni:* corrisponde al carattere precedente un numero qualsiasi di volte, + corrisponde ad almeno una occorrenza e ? corrisponde al massimo a una occorrenza.
Puoi anche utilizzare la periodicità . con gli operatori di ripetizione per cercare una sequenza di caratteri arbitrari in modo più definito:
| Espressione regolare | Corrispondenza | Nessuna corrispondenza |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
2.4. Classi di caratteri, numeri e lettere
Le classi di caratteri permettono di abbinare determinate sezioni del set di caratteri, ad esempio "deve arrivare una cifra". Per farlo, inserisci tutti i caratteri da abbinare tra parentesi quadre. Con il segno meno puoi anche specificare degli intervalli.Nota: si applica la sequenza del set di caratteri ASCII a 7 bit.
Ad esempio, [abc] indica esattamente uno dei caratteri a, b o c, mentre [0-9] indica qualsiasi cifra; entrambi possono essere combinati. È possibile anche la negazione dell'insieme: con ^ tra le parentesi, [^abc] indica qualsiasi carattere eccetto a, b, c.
Le classi di caratteri possono ovviamente essere combinate con altri operatori: iniziamo con alcuni esempi astratti:
| Classe di caratteri | Funzione |
|---|---|
|
Esattamente uno dei caratteri a, b, c. |
|
Esattamente una cifra, una lettera minuscola o un trattino basso. |
|
Qualsiasi carattere tranne a, b, c. |
|
Esattamente un carattere, da un carattere vuoto a un trattino, conforme allo standard ASCII. I seguenti caratteri rientrano in questo intervallo: |
|
Una sequenza di almeno una e al massimo 20 lettere e/o cifre in qualsiasi ordine. |
Ecco alcuni esempi pratici:
| Espressione regolare | Corrispondenza | Nessuna corrispondenza |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Nota: se hai bisogno di uno dei caratteri -, [ o ], dovrai usare un trucco. Scrivi - (segno meno) alla fine della classe- come già mostrato nell'esempio precedente. Quando si valutano le espressioni regolari, il segno meno, se non si trova in mezzo a tre caratteri, non viene valutato come operatore, ma esattamente come questo carattere.
Se necessario, inserisci una parentesi quadra di chiusura come primo carattere della classe e una parentesi di apertura come secondo carattere. Poiché non sono ammesse classi vuote, la parentesi quadra di chiusura viene interpretata come un carattere normale. Una classe con questi caratteri speciali avrebbe il seguente aspetto: []-], o rispettivamente [][-] se è necessaria anche la parentesi quadra di apertura.
2.5. Inizio e fine - prefisso, suffisso e infisso
In molti casi è necessario distinguere tra corrispondenze all'inizio, alla fine o semplicemente all'interno di una stringa. Per una corrispondenza all'inizio di una stringa (match prefisso) usa ^ (circonflesso), per la fine (match suffisso) usa $ (segno del dollaro). Se nessuno di questi operatori viene specificato, la maggior parte delle librerie di espressioni regolari usa il match parziale (infisso) come impostazione predefinita: viene cercato in qualsiasi punto della stringa di caratteri. Per le corrispondenze esatte, usa sia ^ che $.
| Espressione regolare | Corrispondenza | Nessuna corrispondenza |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
Nota: nel monitoraggio e nella Console degli Eventi, la corrispondenza infix è lo standard. Le espressioni che si verificano in qualsiasi punto del testo vengono trovate, ad esempio la ricerca di "memoria" trova anche "memoria del kernel". Nella GUI, invece, quando si confrontano le espressioni regolari con i nomi del servizio e altri elementi, Checkmk controlla fondamentalmente se l'espressione corrisponde all'inizio parola (match prefisso) - questo è di solito ciò che stai cercando:
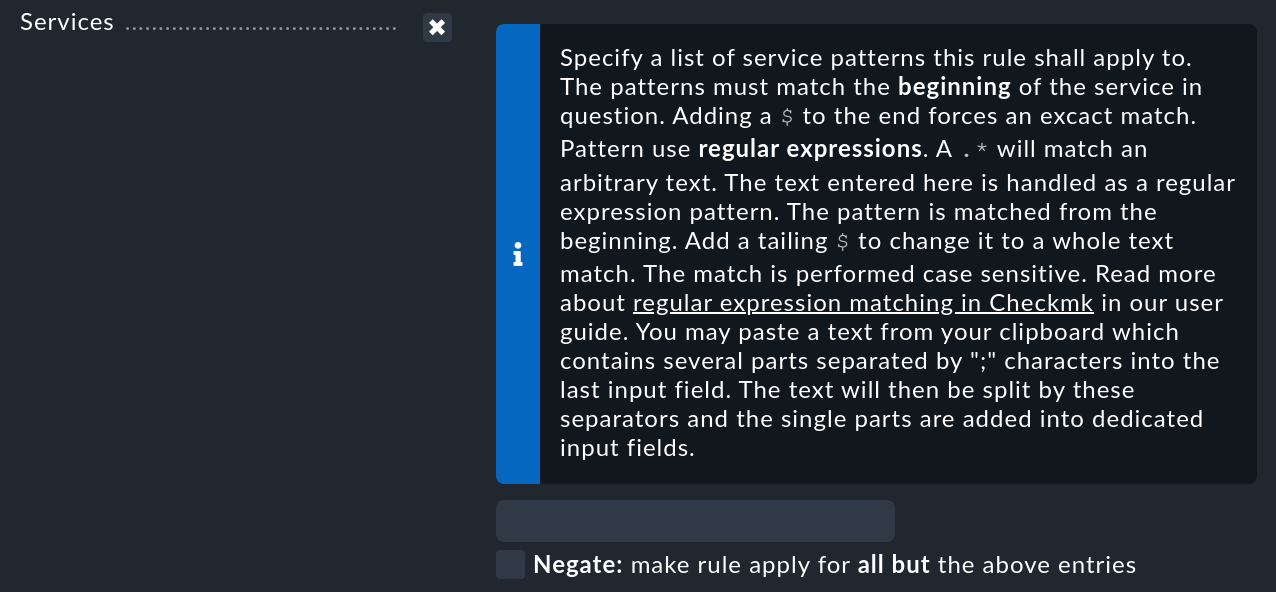
Se hai bisogno di un match parziale nei punti in cui è prevista la corrispondenza con il prefisso, estendi semplicemente la tua espressione regolare con .* all'inizio per far corrispondere qualsiasi stringa con prefisso:
| Espressione regolare | Corrispondenza | Nessuna corrispondenza |
|---|---|---|
|
|
|
|
|
|
|
|
|
Suggerimento: puoi precedere qualsiasi ricerca all'inizio di una stringa con ^ e qualsiasi ricerca all'interno di una stringa con .*; gli interpreti delle espressioni regolari ignoreranno i simboli ridondanti.
2.6. Mascherare i caratteri speciali con un backslash
Dato che il punto corrisponde a tutto, naturalmente corrisponde anche a un punto. Se vuoi corrispondere esattamente a un punto, devi mascherarlo con un \ (backslash). Questo vale analogamente per tutti gli altri caratteri speciali: \ . * + ? { } ( ) [ ] | & ^ e $. La codifica di un backslash \ fa sì che il carattere speciale che lo segue venga trattato come un carattere normale:
| Espressione regolare | Corrispondenza | Nessuna corrispondenza |
|---|---|---|
|
|
|
|
|
|
|
|
|
Attenzione a Python: Poiché in Pythonil backslash nella rappresentazione interna della stringa viene mascherato internamente con un altro backslash, questi due backslash devono essere nuovamente mascherati, il che porta a un totale di quattro backslash:
| Espressione regolare | Corrispondenza | Nessuna corrispondenza |
|---|---|---|
|
|
|
2.7. Valori alternativi
Con la linea verticale | puoi definire delle alternative, cioè utilizzare un'operazione OR:1|2|3 corrisponde a 1, 2 o 3. Se hai bisogno di tali alternative al centro di un'espressione, raggruppale tra parentesi tonde:
| Espressione regolare | Corrispondenza | Nessuna corrispondenza |
|---|---|---|
|
|
|
|
|
|
2.8. Gruppi di corrispondenza
Igruppi di corrispondenza (o gruppi di cattura) svolgono due funzioni: la prima è il raggruppamento di alternative o di corrispondenze parziali, come mostrato nell'esempio precedente. Sono possibili anche raggruppamenti annidati. Inoltre, gli operatori di ripetizione *, +, ? e {...} possono essere utilizzati preceduti da parentesi tonde. Così l'espressione (/local)?/share corrisponde sia a /local/share che a /share.
Nella Console degli Eventi (EC), nella Business Intelligence (BI), nella rinominazione in blocco degli hoste nelle mappature piggyback, è possibile utilizzare la parte di testo corrispondente all'espressione regolare nella prima parentesi come \1, la parte corrispondente alla seconda parentesi come \2 e così via. L'ultimo esempio della tabella mostra l'uso di alternative all'interno di un gruppo di corrispondenza.
| Espressione regolare | Testo da abbinare | Gruppo 1 | Gruppo 2 |
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
L'immagine seguente mostra la ridenominazione di più host in un'unica azione: tutti i nomi host che corrispondono all'espressione regolare server-(.*)\.local saranno sostituiti da \1.servers.local, dove \1 corrisponde esattamente al testo "catturato" da .* nella parentesi:
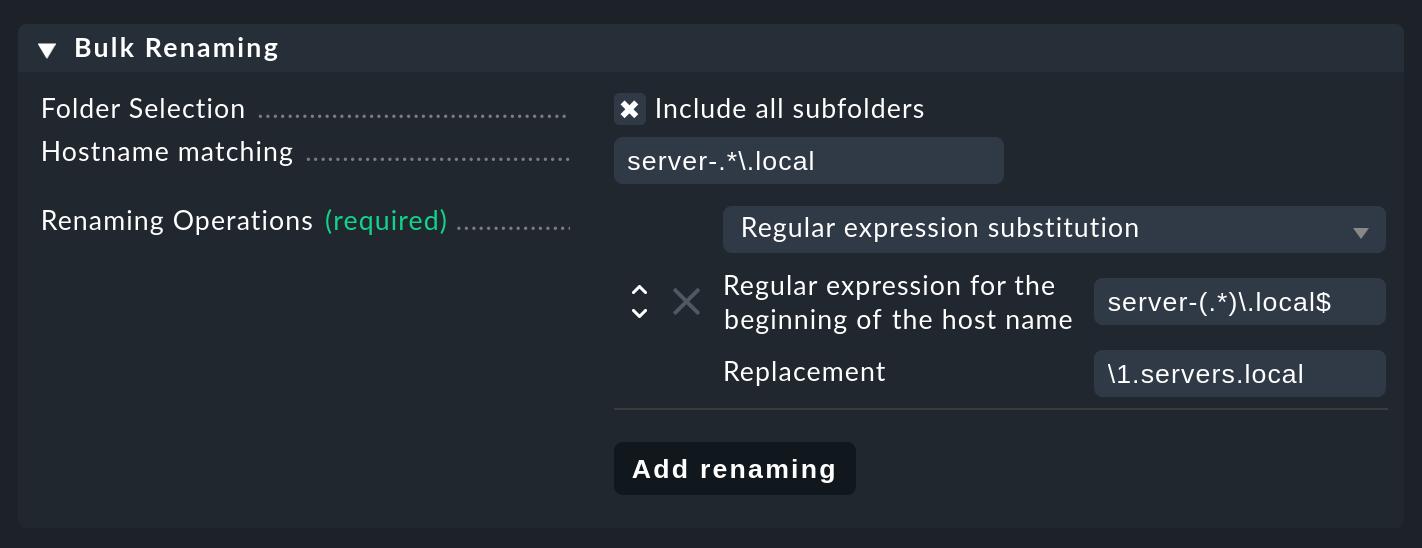
Nell'esempio concreto, server-lnx02.local viene quindi convertito in lnx02.servers.local.
Se un gruppo di corrispondenza non deve "catturare" gruppi di caratteri, ad esempio se viene utilizzato solo per la strutturazione, è possibile utilizzare ?: per convertirlo in un gruppo di corrispondenza non catturante(gruppo di corrispondenza non catturante): (?:/local)?/share.
2.9. Flag in linea
Con i flag in linea è possibile effettuare impostazioni specifiche relative alla modalità di valutazione all'interno di un'espressione regolare. Il più importante per lavorare con Checkmk è (?i), che passa alla corrispondenza senza distinzione tra maiuscole e minuscole per le espressioni altrimenti sensibili alle maiuscole e minuscole. In casi molto rari, potrai anche utilizzare (?s) e (?m) per lavorare con stringhe multilinea.
Nota che dalla versione 3.11 Python si aspetta che i flag inline siano all'inizio di un'espressione regolare - (?i)somestring- o che ne specifichino l'ambito -(?i:somestring). Poiché Checkmk in alcuni casi combina internamente le espressioni regolari per migliorare le prestazioni, ti consigliamo vivamente di non utilizzare i flag inline all'inizio di un'espressione regolare, ma di utilizzare sempre la notazione con ambito- che, in caso di dubbio, si estende all'intera espressione regolare:
(?i:somestring).
Questa è una variante del gruppo di corrispondenza non catturante.
3. Tabella dei caratteri speciali
Qui troverai un elenco che riassume tutti i caratteri speciali e le funzioni delle espressioni regolari utilizzate da Checkmk, come spiegato in precedenza:
|
corrisponde a qualsiasi carattere. |
|
Valuta il carattere speciale successivo come un carattere normale. |
|
Il carattere precedente deve comparire esattamente cinque volte. |
|
Il carattere precedente deve comparire da un minimo di cinque a un massimo di dieci volte. |
|
Il carattere precedente può comparire un numero qualsiasi di volte (corrisponde a |
|
Il carattere precedente può comparire un numero qualsiasi di volte, ma deve comparire almeno una volta (corrisponde a |
|
Il carattere precedente può comparire zero o una volta (equivalente a |
|
Rappresenta esattamente uno dei caratteri |
|
Rappresenta esattamente uno dei caratteri |
|
Rappresenta esattamente una cifra, una lettera minuscola o il trattino basso. |
|
Rappresenta esattamente un carattere tranne la virgola singola o doppia. |
|
Corrisponde alla fine di un testo. |
|
Corrisponde all'inizio di un testo. |
|
Corrisponde a |
|
Abbina la sottoespressione A a un gruppo di corrispondenza. |
|
Cambia la modalità di valutazione della sottoespressione A in case-insensitive tramite il flag inline. |
|
Corrisponde a una tabulazione (tabulatore). Questo carattere è spesso presente nei file di log o nelle tabelle CSV. |
|
Corrisponde a tutti gli spazi (ASCII utilizza 5 tipi diversi di spazi). |
I seguenti caratteri devono essere mascherati da una barra rovesciata, se devono essere utilizzati letteralmente: \ . * + ? { } ( ) [ ] | & ^ $.
3.1. Unicode in Python 3
In particolare, se i nomi propri nei commenti o nei testi descrittivi sono stati copiati e incollati e quindi nel testo compaiono caratteri Unicode o diversi tipi di spazi, le classi estese di Python sono molto utili:
|
Corrisponde a un tab stop (tabulatore), in parte nei file di log o nelle tabelle CSV. |
|
Corrisponde a tutti gli spazi (Unicode supporta 25 spazi diversi, ASCII 5). |
|
Inverte da |
|
Corrisponde a tutti i caratteri che fanno parte di una parola, cioè le lettere e in Unicode anche gli accenti, i glifi cinesi, arabi o coreani. |
|
Inversione di |
Nei luoghi in cui Checkmk permette la corrispondenza con Unicode, \w è particolarmente utile quando si cercano parole dallo stesso significato in lingue diverse, ad esempio nomi propri che a volte sono scritti con e a volte senza accento.
| Espressione regolare | Corrispondenza | Nessuna corrispondenza |
|---|---|---|
|
|
|
4. Testare le espressioni regolari
La logica delle espressioni regolari non è sempre facile da capire, soprattutto nel caso di gruppi di corrispondenza annidati, e la questione dell'ordine e di quale estremità della stringa deve essere abbinata. Meglio dei tentativi e degli errori in Checkmk, ci sono due modi per testare le espressioni regolari: servizi online come regex101.com preparano le corrispondenze graficamente e spiegano l'ordine di valutazione in tempo reale:
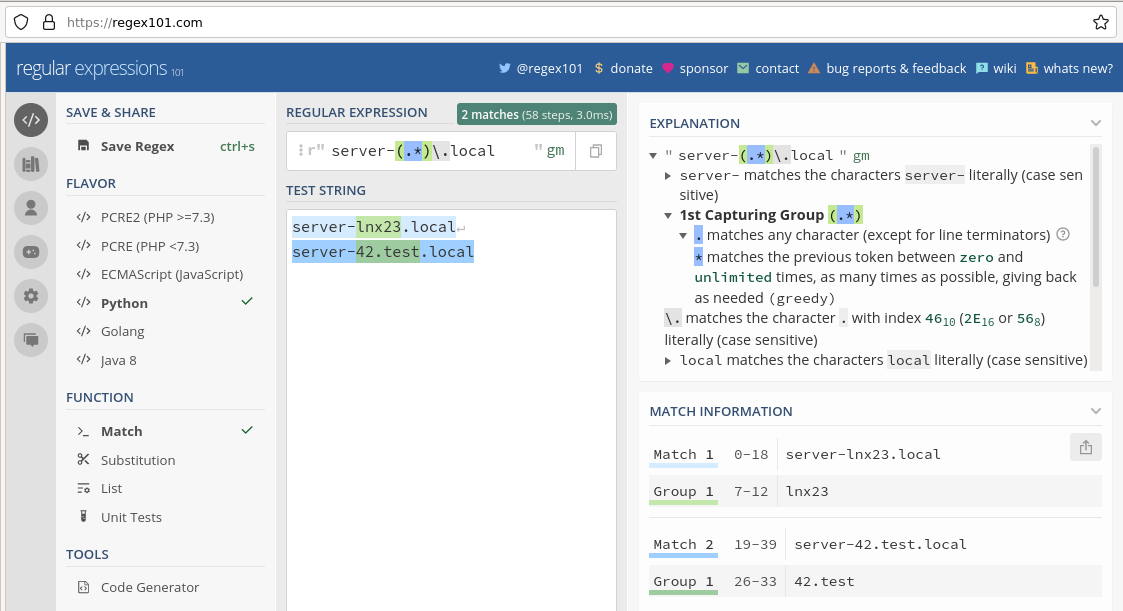
La seconda procedura di test è il prompt di Python, che viene fornito in ogni installazione di Python. Su Linux e Mac OS Python 3 è solitamente preinstallato. Proprio perché le espressioni regolari nel prompt di Python vengono valutate esattamente come in Checkmk, non ci sono discrepanze nell'interpretazione, anche in caso di annidamenti complessi. Con il test nell'interprete di Python vai sempre sul sicuro.
Dopo l'apertura, devi importare il modulo re. Nell'esempio, switchiamo la distinzione tra maiuscole e minuscole con re.IGNORECASE off:
OMD[mysite]:~$ python3
Python 3.8.10 (default, Jun 2 2021, 10:49:15)
[GCC 9.4.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import re
>>> re.IGNORECASE
re.IGNORECASEPer emulare il comportamento delle espressioni regolari del C, utilizzate anche in molti componenti di Python, puoi limitarti all'ASCII:
>>> re.ASCII
re.ASCIIOra puoi usare la funzione re.match() per confrontare direttamente un'espressione regolare con una stringa e ottenere il gruppo di corrispondenza:group(0) indica l'intera corrispondenza e group(1) la prima corrispondenza con la sottoespressione racchiusa tra parentesi tonde:
>>> x = re.match('M[ae]{1}[iy]{1}e?r', 'Meier')
>>> x.group(0)
'Meier'
>>> x = re.match('M[ae]{1}[iy]{1}e?r', 'Mayr')
>>> x.group(0)
'Mayr'
>>> x = re.match('M[ae]{1}[iy]{1}e?r', 'Myers')
>>> x.group(0)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
IndexError: no such group
>>> x = re.match('server-(.*)\.local', 'server-lnx23.local')
>>> x.group(0)
'server-lnx23.local'
>>> x.group(1)
'lnx23'5. Documentazione esterna aggiuntiva
Ken Thompson, uno dei creatori di UNIX negli anni '60, è stato il primo a sviluppare le espressioni regolari nel modulo odierno, tra l'altro nel comando Unix grep, che è ancora in uso. Da allora sono state create numerose estensioni e dialetti delle espressioni regolari, tra cui le regex estese, le regex compatibili con Perl e una variante molto simile in Python.
Nei filtri in visualizzazione Checkmk utilizza le espressioni regolari estese POSIX (extended REs), che vengono valutate nel nucleo di monitoraggio in C utilizzando la funzione regex del C-library. Puoi trovare un riferimento completo a questa funzione nella pagina man di Linux per regex(7):
OMD[mysite]:~$ man 7 regex
REGEX(7) Linux Programmer's Manual REGEX(7)
NAME
regex - POSIX.2 regular expressions
DESCRIPTION
Regular expressions ("RE"s), as defined in POSIX.2, come in two forMFS:
modern REs (roughly those of egrep; POSIX.2 calls these "extended" REs)
and obsolete REs (roughly those of *ed*(1); POSIX.2 "basic" REs). Obso-
lete REs mostly exist for backward compatibility in some old programs;In tutti gli altri luoghi sono disponibili tutte le funzioni delle espressioni regolari di Python, tra cui le regole di configurazione, la Console degli Eventi (EC) e la Business Intelligence (BI).
Le espressioni regolari di Python sono un'estensione delle RE estese e sono molto simili a quelle di Perl. Supportano, ad esempio, il cosiddetto lookahead negativo, l'asterisco non avido di * o l'applicazione della distinzione tra maiuscole e minuscole. I dettagli sulle funzionalità di queste espressioni regolari possono essere trovati nella guida online di Python per il modulo re o, più in dettaglio, nella documentazione online di Python:
OMD[mysite]:~$ pydoc3 re
Help on module re:
NAME
re - Support for regular expressions (RE).
MODULE REFERENCE
https://docs.python.org/3.8/library/re
The following documentation is automatically generated from the Python
source files. It may be incomplete, incorrect or include features that
are considered implementation detail and may vary between Python
implementations. When in doubt, consult the module reference at the
location listed above.
DESCRIPTION
This module provides regular expression matching operations similar to
those found in Perl. It supports both 8-bit and Unicode strings; both
the pattern and the strings being processed can contain null bytes and
characters outside the US ASCII range.
Regular expressions can contain both special and ordinary characters.
Most ordinary characters, like "A", "a", or "0", are the simplest
regular expressions; they simply match themselves. You can
concatenate ordinary characters, so last matches the string 'last'.Una spiegazione molto dettagliata delle espressioni regolari si trova in un articolo diWikipedia.