In this article we explain the basic terms and concepts in Checkmk, such as host, service, user, contact group, notification, time period, scheduled downtime.
This is a machine translation based on the English version of the article. It might or might not have already been subject to text preparation. If you find errors, please file a GitHub issue that states the paragraph that has to be improved. |
In questo articolo spieghiamo i termini e i concetti di base di Checkmk, come host, servizio, utente, gruppo di contatto, notifica, periodo di notifica, tempo di manutenzione programmata.
1. Stati ed eventi
È importante capire le differenze di base tra stati ed eventi, soprattutto per un vantaggio pratico. La maggior parte dei sistemi classici di monitoraggio IT ruota intorno agli eventi. Un evento è qualcosa che si verifica in modo univoco in un momento particolare. Un buon esempio potrebbe essere un errore durante l'accesso all'unità X. Le fonti tipiche degli eventi sono i messaggi syslog, le trap SNMP, il registro eventi di Windows e le voci dei file di log. Gli eventi sono eventi quasi spontanei (autogenerati e asincroni).
Al contrario, uno stato descrive una situazione duratura, ad es. l'unità X è online. Per osservare lo stato di qualcosa, il sistema di monitoraggio deve eseguire regolarmente il polling. Come mostra l'esempio, nel monitoraggio è spesso possibile scegliere di lavorare con gli eventi o con gli stati.
Checkmk è in grado di lavorare sia con gli stati che con gli eventi ma, in caso di possibilità di scelta, darà sempre la priorità al monitoraggio basato sugli stati. Il motivo di questa scelta risiede nei numerosi vantaggi offerti da questo metodo, tra i quali ricordiamo:
Un errore nel monitoraggio stesso viene rilevato immediatamente, perché è evidente quando l'interrogazione dello stato non funziona più. Il non verificarsi di un messaggio, invece, non dà alcuna certezza che lo stato di monitoraggio stia ancora funzionando.
Checkmk stesso è in grado di controllare la frequenza con cui vengono interrogati gli stati. Non c'è il rischio di una tempesta di eventi in situazioni di errore globale.
Il controllo regolare in un arco di tempo fisso consente di acquisire le metriche per registrare la loro storia temporale.
Anche in situazioni caotiche - ad esempio un'interruzione di corrente in un data center - si ha sempre uno stato generale affidabile.
Per il processo degli eventi c'è anche la Console degli Eventi, specializzata nella correlazione e nella valutazione di un gran numero di eventi e perfettamente integrata nella piattaforma Checkmk.
2. Host e servizi
2.1. Gli host
Tutto in Checkmk ruota intorno agli host e ai servizi. Un host può essere molte cose, es:
Un server
Un dispositivo di rete (switch, router, load balancer).
Un dispositivo di misurazione con connessione IP (termometro, igrometro).
Qualsiasi altra cosa con un indirizzo IP
Un cluster di più host
Una macchina virtuale
Un container Docker
Nello stato di monitoraggio un host ha sempre uno dei seguenti stati:
| Stato | Colore | Significato |
|---|---|---|
UP |
verde |
L'host è accessibile attraverso la rete (in genere significa che risponde a un PING). |
DOWN |
rosso |
L'host non risponde alle richieste della rete e non è accessibile. |
NON RAGGIUNGIBILE |
arancione |
Il percorso verso l'host è attualmente bloccato per il monitoraggio, perché un router o uno switch nel percorso si è guastato. |
IN SOSP. |
grigio |
L'host è stato recentemente incluso nel monitoraggio, ma non è mai stato interrogato. A rigore questo non è un vero e proprio stato. |
Oltre allo stato, un host ha una serie di altri attributi che possono essere configurati dall'utente, ad es:
Un nome univoco
Un indirizzo IP
Opzionale - un alias, che non deve essere univoco
Opzionale - uno o più genitori
2.2. I genitori
Affinché il monitoraggio possa determinare lo stato di RAGGIUNGIBILE, deve sapere quale percorso può utilizzare per contattare ogni singolo host. A questo scopo, è possibile specificare uno o più cosiddetti host padre per ogni host. Ad esempio, se un server A visto dal monitoraggio può essere raggiunto solo tramite un router B, allora B è un host padre di A. In Checkmk vengono configurati solo i genitori diretti. Questo risulta in una struttura ad albero con il sito Checkmk al centro (mostrato qui come ):
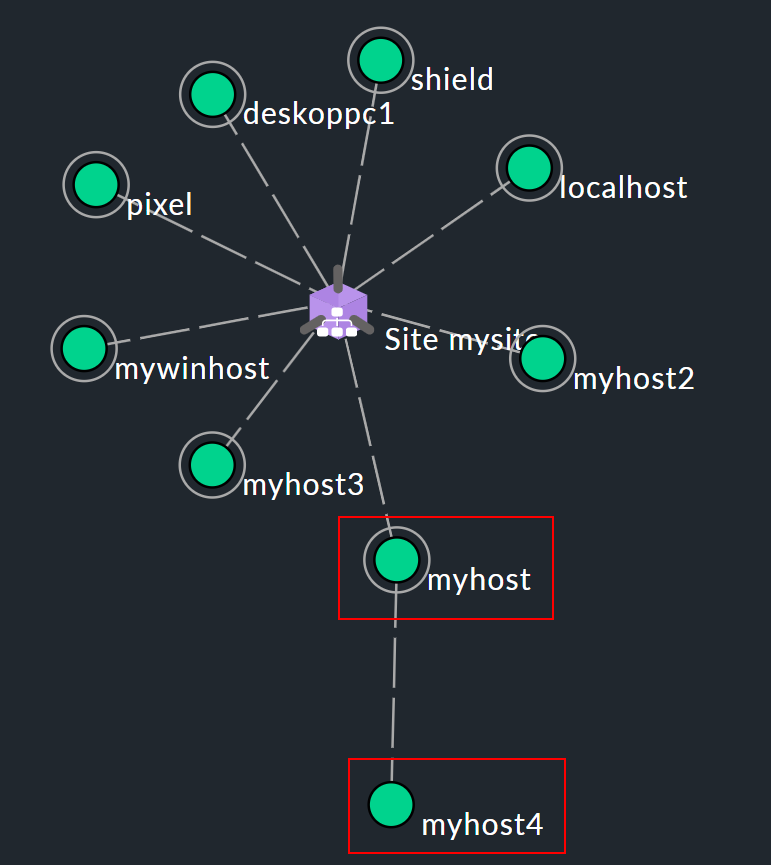
Supponiamo che nella topologia di rete mostrata sopra, gli host myhost e myhost4 non siano più raggiungibili. Il fallimento di myhost4 può essere spiegato dal fatto che myhost è fallito. Pertanto, myhost4 viene classificato come NON RAGGIUNGIBILE nel monitoraggio. Semplicemente non è possibile determinare chiaramente il motivo per cui Checkmk non riesce più a raggiungere myhost4 e lo stato DOWN sarebbe quindi fuorviante in alcune circostanze. NON RAGGIUNGIBILE ha invece l'effetto di sopprimere le notifiche per impostazione predefinita, il che è in fondo il compito più importante del concetto di genitorialità, ossia evitare notifiche di massa nell'evento in cui un intero segmento di rete dipendente diventa irraggiungibile per il monitoraggio a causa di un'interruzione in un singolo punto.
La prevenzione dei falsi allarmi è garantita anche dalla funzione del Checkmk Micro Core (CMC) utilizzata nelle edizioni commerciali. In questo caso, il cambio di stato di un host in avaria viene trattenuto per alcuni istanti e procede solo quando è certo che l'host padre è ancora raggiungibile. Se invece l'host padre è definitivamente DOWN, l'host passa a NON RAGGIUNGIBILE, senza che venga attivata alcuna notifica.
In alcuni casi un host potrebbe avere più genitori, ad esempio quando un router è in esecuzione ad alta disponibilità in un cluster. È sufficiente che Checkmk sia in grado di determinare in modo univoco lo stato dell'host quando uno di questi genitori è raggiungibile. Pertanto, quando un host ha più genitori e almeno uno di essi è UP, l'host è considerato raggiungibile nel monitoraggio. In altre parole, in questa situazione l'host non passerà automaticamente allo stato NON RAGGIUNGIBILE.
2.3. Servizi
Un host ha una serie di servizi. Un servizio può essere qualsiasi cosa - non confonderti con i servizi di Windows. Un servizio è qualsiasi parte o aspetto dell'host che può essere OK o non OK. Naturalmente lo stato può essere determinato solo se l'host è in stato UP.
Un servizio da monitorare può avere i seguenti stati:
| Stato | Colore | Significato |
|---|---|---|
OK |
verde |
Il servizio è completamente in ordine. Tutti i valori rientrano nel range consentito. |
WARN |
giallo |
Il servizio funziona normalmente, ma i suoi parametri non rientrano nell'intervallo ottimale. |
CRIT |
rosso |
Il servizio è fallito. |
SCONOSCIUTO |
arancione |
Lo stato del servizio non può essere determinato correttamente. L'agente di monitoraggio ha fornito dati difettosi o l'elemento monitorato è scomparso. |
IN SOSP. |
grigio |
Il servizio è stato incluso di recente e finora non ha fornito dati di monitoraggio. |
Per determinare quale condizione sia "peggiore", Checkmk utilizza la seguente sequenza:
OK → WARN → SCONOSCIUTO → CRIT
2.4. Controlli
Un controllo assicura che a un host o a un servizio possa essere assegnato uno stato. Quali siano questi stati è stato descritto nella sezione precedente. Servizi e controlli sono strettamente correlati. Per questo motivo a volte questi termini vengono utilizzati in modo intercambiabile, forse anche in questo manuale, anche se in realtà si tratta di cose diverse.
Nel Setup puoi visualizzare quale plug-in di controllo è responsabile di ogni servizio. Apri le proprietà di un host con Setup > Hosts e poi nel menu Hosts > Service Configuration l'elenco dei servizi per questo host. Poi usa Display > Show plugin names per visualizzare una nuova colonna che mostrerà il plug-in di controllo responsabile di ogni servizio:
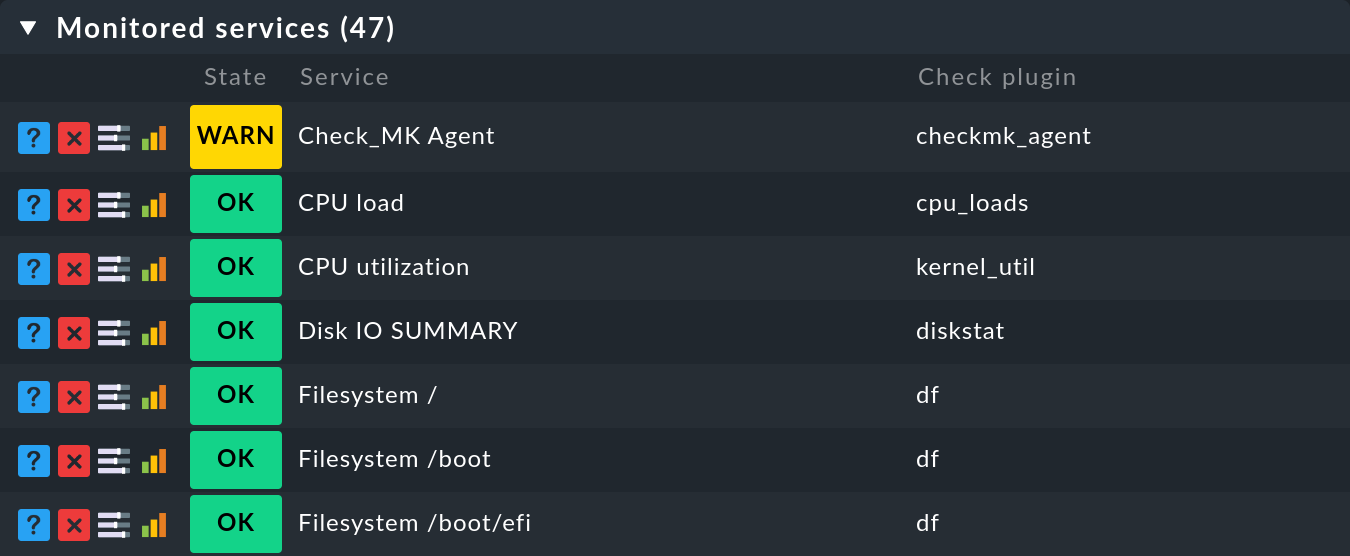
Come puoi vedere dall'esempio del plug-in di controllo df, un plug-in di controllo può essere responsabile di più di un servizio. Inoltre, i nomi del plug-in di controllo elencati nella colonna sono anche dei link che mostrano una descrizione del plug-in di controllo.
La connessione e la dipendenza tra servizi e controlli può essere vista anche nel monitoraggio. Nell'elenco dei servizi di un host in monitoraggio, puoi vedere che nel menu azione alla voce dell'elenco Reschedule c'è una freccia gialla per alcuni servizi (), ma una freccia grigia per la maggior parte degli altri (). Un servizio con la freccia gialla è basato su un active check:
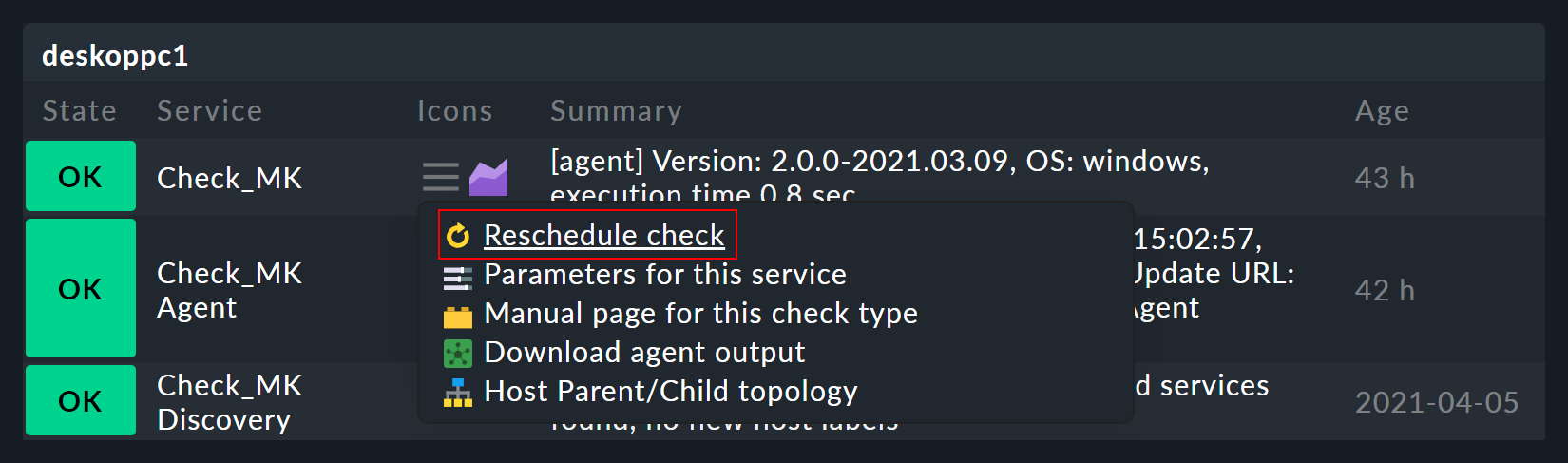
I servizi con la freccia grigia si basano su controlli passivi i cui dati vengono recuperati da un altro servizio, il servizio Check_MK. Questo avviene per motivi di prestazioni ed è una caratteristica speciale di Checkmk.
3. Gruppi di host e di servizi
Per migliorare la panoramica, puoi organizzare gli host in gruppi di host e i servizi in gruppi di servizi. Un host/servizio può anche far parte di più di un gruppo. La creazione di questi gruppi è facoltativa e non necessaria per la configurazione. Tuttavia, se ad esempio hai impostato la struttura delle cartelle in base alle località geografiche, potrebbe essere utile creare un gruppo di host Linux servers che raggruppa tutti i server Linux, indipendentemente dalla loro ubicazione.
Puoi trovare maggiori informazioni sui gruppi di host nell'articolo sulla strutturazione degli host e sui gruppi di servizi nell'articolo sui servizi.
4. Contatti e gruppi di contatto
Icontatti e i gruppi di contatti offrono la possibilità di assegnare persone a host e servizi. Un contatto è correlato a un nome utente o a un'interfaccia web. Tuttavia, la correlazione con host e servizi non avviene direttamente, bensì tramite gruppi di contatti.
In primo luogo, un contatto (ad esempio harri) viene assegnato a un gruppo di contatti (ad esempio linux-admins). In seguito, gli host o, se necessario, i singoli servizi possono essere assegnati al gruppo di contatti. In questo modo gli utenti, e allo stesso modo gli host e i servizi, possono essere assegnati a più gruppi di contatti.
Queste assegnazioni sono utili per una serie di motivi:
Chi è autorizzato a visualizzare qualcosa?
Chi è autorizzato a configurare e controllare quali host e servizi?
Chi riceve notifiche e per quali problemi?
Ad esempio, l'utente cmkadmin, che viene definito automaticamente con la creazione di un sito, ha sempre il permesso di visualizzare tutti gli host e i servizi, anche se cmkadmin non è un contatto. Questo è determinato dal suo ruolo di amministratore.
5. Utenti e ruoli
Mentre i contatti e i gruppi di contatti controllano chi è responsabile di un determinato host o servizio, i permessi sono controllati dai ruoli. Checkmk viene fornito con una serie di ruoli predefiniti da cui puoi ricavare altri ruoli in base alle tue esigenze. Ogni ruolo definisce un insieme di permessi che possono essere successivamente personalizzati. Il significato dei ruoli standard è il seguente:
| Ruolo | Descrizione |
|---|---|
|
Può vedere e fare tutto, ha tutti i permessi. |
|
Può vedere solo ciò per cui è un contatto. Può gestire gli host nelle cartelle a lui assegnate. Non può effettuare impostazioni globali. |
|
Può solo registrare l'agente Checkmk di un host con il server Checkmk, nient'altro. |
|
Può vedere tutto, ma non può configurare nulla o intervenire nel monitoraggio. |
6. Problemi, eventi e notifiche
6.1. Problemi gestiti e non gestiti
Checkmk identifica ogni host che non è UP e ogni servizio che non è OK come un problema. Un problema può avere due stati: non gestito e gestito. La procedura prevede che un nuovo problema venga inizialmente trattato come non gestito. Non appena qualcuno conferma il problema, questo viene segnalato come gestito e, non a caso, i problemi non gestiti sono quelli che non sono ancora stati presi in considerazione. La panoramica nella barra laterale differenzia quindi questi due tipi di problemi:
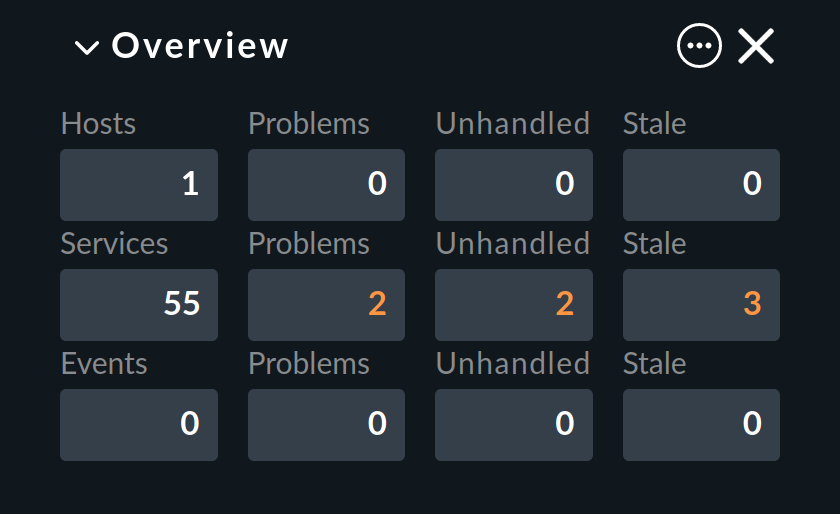
A proposito: i problemi di servizio provenienti da host che al momento non sono UP non vengono identificati come problemi.
Ulteriori dettagli sulla conferma dei problemi sono disponibili nell'articolo dedicato, " Confermare i problemi".
6.2. Notifiche
Quando lo stato di un host cambia (ad esempio da OK a CRIT), Checkmk registra un evento di monitoraggio. Questi eventi possono generare o meno una notifica. Checkmk è progettato in modo tale che ogni volta che un host o un servizio ha un problema, viene inviata un'e-mail ai contatti dell'oggetto (nota che l'utente cmkadmin, per impostazione predefinita, non è un contatto per nessun oggetto). Le notifiche possono essere personalizzate in modo molto flessibile. Le notifiche dipendono anche da una serie di parametri. La cosa più semplice è osservare i casi in cui le notifiche non vengono inviate. Le notifiche vengono soppresse ...
... quando le notifiche sono state disattivate a livello globale nel controllo Master
...quando le notifiche sono state disattivate nell'host/servizio
... quando le notifiche sono state disattivate per un particolare stato dell'host/servizio (es. nessuna notifica per WARN)
... quando il problema interessa un servizio il cui host è DOWN o NON RAGGIUNGIBILE
...quando il problema riguarda un host i cui genitori sono tutti DOWN o NON RAGGIUNGIBILE
... quando per l'host/servizio è stato impostato un periodo di notifica che non è attualmente attivo
... quando l'host/servizio è attualmente irregolare
... quando l'host/servizio si trova in un tempo di manutenzione programmata.
Se nessuno di questi prerequisiti per sopprimere le notifiche è soddisfatto, il nucleo di monitoraggio crea una notifica, che in un secondo momento passa attraverso una catena di regole. In queste regole puoi definire ulteriori criteri di esclusione e decidere chi deve essere notificato e in quale modulo (e-mail, SMS, ecc.).
Tutti i dettagli sulle notifiche si trovano nell'articolo dedicato alle notifiche.
6.3. Host e servizi irregolari
A volte capita che un servizio cambi continuamente e rapidamente le sue condizioni. Per evitare notifiche continue, Checkmk commuta tale servizio nello stato di flapping, come illustrato dal simbolo . Quando un servizio entra nello stato di flapping, viene generata una notifica che informa l'utente della situazione e silenzia ulteriori notifiche. Dopo un tempo adeguato, se non si verificano altri cambiamenti rapidi e se è evidente uno stato finale (buono o cattivo), lo stato di flapping scompare e riprendono le normali notifiche.
6.4. Tempi di manutenzione programmata
Se esegui lavori di manutenzione su un server, un dispositivo o un software, normalmente vorrai evitare le notifiche di potenziali problemi durante questo periodo. Inoltre, probabilmente vorrai avvisare i tuoi colleghi che i problemi che appaiono nel monitoraggio durante questo periodo possono essere temporaneamente ignorati.
A questo scopo puoi inserire una condizione di tempi di manutenzione programmata su un host o un servizio. Questo può essere fatto direttamente prima di iniziare il lavoro o in anticipo. I tempi di manutenzione programmata sono illustrati dai simboli:
Il servizio è in un tempo di manutenzione programmata. |
|
Anche i servizi il cui host è in tempo di manutenzione programmata sono contrassegnati da questo simbolo. |
Mentre un host o un servizio ha un tempo di manutenzione programmato:
Non verranno inviate notifiche.
I problemi non vengono visualizzati nello snap-in Overview.
Inoltre, quando desideri documentare in seguito le statistiche sulla disponibilità di host e servizi, è una buona idea includere i tempi di manutenzione programmata, che possono essere presi in considerazione nelle valutazioni successive della disponibilità.
6.5. Host e servizi obsoleti (in stallo)
Se lavori con Checkmk da un po' di tempo, è possibile che nelle visualizzazioni degli host e dei servizi vengano visualizzate delle ragnatele. Per i servizi, ad esempio, l'aspetto è questo:
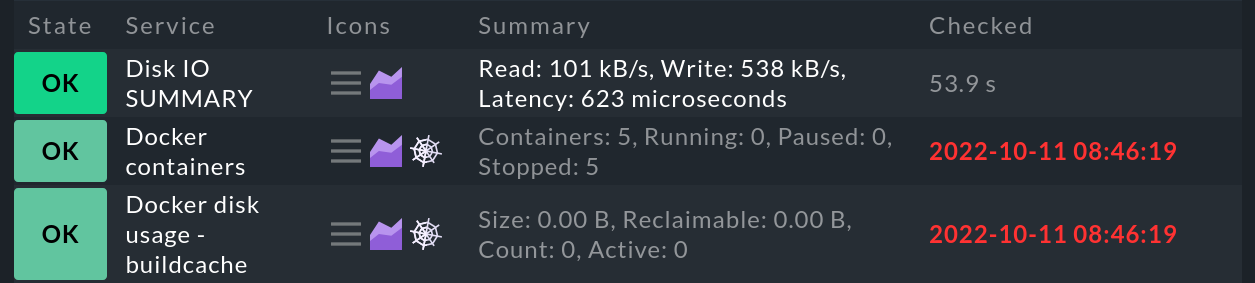
Queste ragnatele simboleggiano lo stato di stallo. Ogni volta che c'è un host o un servizio in stallo, questo verrà mostrato anche nello snap-in Overview che sarà ampliato dalla colonna Stale.
In generale, un host o un servizio viene contrassegnato come stallo quando Checkmk non riceve più informazioni aggiornate sul suo stato per un lungo periodo di tempo:
Un servizio diventa stallo: se un agente o anche solo un plug-in dell'agente si guasta - per qualsiasi motivo - in un periodo di tempo più lungo, l'agente non fornirà più dati aggiornati per la valutazione. I servizi il cui stato è determinato da controlli passivi non possono essere aggiornati, poiché dipendono dai dati dell'agente. I servizi rimangono nel loro ultimo stato, ma vengono contrassegnati come stallo dopo che è trascorso un certo periodo di tempo.
Un host diventa stallo: se il sito Host Check Command, che verifica la connettività dell'host, non fornisce risposte aggiornate, l'host mantiene l'ultimo stato determinato, ma viene contrassegnato come in stallo.
Puoi regolare il limite di tempo dopo il quale gli host e i servizi diventano in stallo. Per questo, leggi la sezione sugli intervalli di controllo.
7. Periodi di tempo

I periodi di tempo ricorrenti settimanali sono utilizzati in vari punti della configurazione. Un periodo di tempo tipico potrebbe chiamarsi working hours e includere gli orari dalle 8:00 alle 17:00 di ogni giorno, in tutti i giorni della settimana tranne il sabato e la domenica. Il periodo 24X7 è predefinito e include semplicemente tutti i giorni. I periodi di tempo possono anche includere eccezioni per alcuni giorni del calendario, ad es. per le festività bavaresi.
Alcuni punti importanti in cui vengono utilizzati i periodi di tempo sono:
Limitare gli orari in cui vengono effettuate le notifiche (periodo di notifica).
Limitazione dei tempi di esecuzione dei controlli(periodo di check).
Tempi di servizio per il calcolo della disponibilità (periodo di servizio).
Tempi entro i quali alcune regole della Console degli Eventi avranno effetto.
Puoi leggere come impostare i periodi nell'articolo sui periodi di tempo.
8. Periodi di check, intervalli di check e tentativi di check
8.1. Specificare i periodi di check
Puoi limitare i periodi di tempo in cui vengono eseguiti i controlli. I set di regole Check period for hosts, Check period for active services e Check period for passive Checkmk services servono a questo scopo. Usa queste regole per selezionare uno dei periodi di tempo disponibili come periodo di check.
8.2. Impostazione degli intervalli di controllo
I controlli vengono eseguiti a intervalli fissi nell'ambito del monitoraggio basato sullo stato. Checkmk utilizza un valore predefinito di un minuto per i controlli dei servizi e di 6 secondi per i controlli degli host con Smart Ping.
Questi intervalli predefiniti possono essere modificati utilizzando i set di regole Normal check interval for service checks e Normal check interval for host checks:
Aumenta l'intervallo per risparmiare risorse di CPU sul server Checkmk e sul sistema di destinazione.
Riduci a un intervallo più breve per ricevere più velocemente le notifiche e raccogliere i dati misurati a una risoluzione più elevata.
Se ora combini un periodo di check con un intervallo di check, puoi assicurarti che un controllo attivo venga eseguito esattamente una volta al giorno in un momento molto specifico. Ad esempio, se imposti l'intervallo di check a 24 ore e il periodo di check a 2:00 - 2:01 ogni giorno (cioè solo un minuto al giorno), Checkmk si assicurerà che il controllo venga effettivamente spostato in questa breve finestra temporale.
Lo stato dei servizi non sarà più aggiornato al di fuori di questo periodo di check definito e i servizi saranno contrassegnati come in stallo con il simbolo . Con l'impostazione globale Staleness value to mark hosts / services stale puoi definire il periodo di tempo che deve trascorrere prima che un host/servizio diventi in stallo. Questa impostazione si trova in Setup > General > Global settings > User interface:
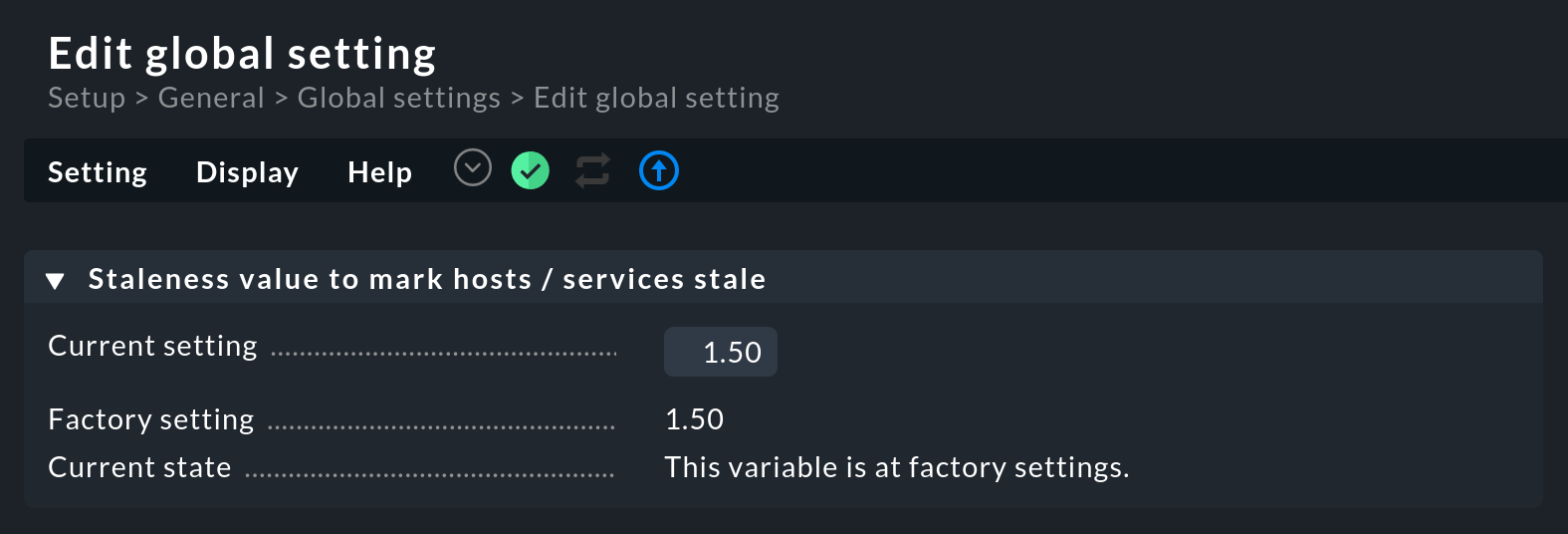
Questo fattore rappresenta n-volte l'intervallo di controllo. Quindi, se l'intervallo di controllo è impostato su un minuto (60 secondi), un servizio per il quale non ci sono nuovi risultati di controllo diventerà in stallo dopo 1,5 volte il tempo, cioè dopo 90 secondi.
8.3. Modificare i tentativi di verifica
Con l'aiuto dell'opzione tentativi di controllo puoi evitare le notifiche in caso di errori sporadici. In questo modo un controllo diventa per così dire meno sensibile. A questo scopo puoi utilizzare i set di regole Maximum number of check attempts for host e Maximum number of check attempts for service.
Se i tentativi di controllo sono impostati a 3, ad esempio, e il servizio corrispondente diventa CRIT, inizialmente non viene attivata alcuna notifica. Solo se anche i due controlli successivi producono un risultato non OK, il conteggio dei tentativi in corso aumenta a 3 e viene inviata la notifica.
Un servizio che si trova in questo stato intermedio - cioè non è OK ma non ha ancora raggiunto il numero massimo di tentativi di verifica - avrà uno stato soft. Solo uno stato hard attiverà effettivamente una notifica.
9. Panoramica dei simboli più importanti per host e servizi
La seguente tabella fornisce una breve panoramica dei simboli più importanti che appaiono accanto agli host e ai servizi:
Questo servizio è in un tempo di manutenzione programmata. |
|
Anche i servizi il cui host è in tempo di manutenzione programmata sono contrassegnati da questo simbolo. |
|
Questo host/servizio non rientra nel periodo di notifica. |
|
Le notifiche per questo host/servizio sono attualmente disabilitate. |
|
I controlli per questo servizio sono attualmente disabilitati. |
|
Lo stato di questo host/servizio è in stallo. |
|
Questo stato dell'host/servizio è irregolare. |
|
Questo host/servizio ha un problema confermato. |
|
Esiste un commento per questo host/servizio. |
|
Questo host/servizio fa parte di un'aggregazione BI. |
|
Qui puoi accedere direttamente alle impostazioni dei parametri del check. |
|
Solo per i servizi Logwatch: qui puoi accedere ai file di log memorizzati. |
|
Qui puoi accedere a un grafico della serie temporale dei valori misurati. |
|
Questo host/servizio contiene dati di inventario. Un clic su di esso mostra la relativa visualizzazione. |
|
Questo controllo è andato in crash. Cliccaci sopra per visualizzare e inviare un report sui crash. |