This is a machine translation based on the English version of the article. It might or might not have already been subject to text preparation. If you find errors, please file a GitHub issue that states the paragraph that has to be improved. |
1. Introduzione
1.1. Il monitoraggio deve intervenire?
Si potrebbe pensare che sia ovvio che un sistema di monitoraggio non debba mai intervenire negli eventi, ma piuttosto che debba, beh, monitorare. E probabilmente è una buona idea lasciare le cose come stanno.
Tuttavia, l'idea che un sistema in grado di identificare in modo affidabile i problemi possa anche correggerli, a patto che funzioni in modo automatico, è indubbiamente interessante.
Si possono facilmente immaginare alcuni esempi calzanti:
Riavvio di un servizio che è andato in crash.
L'attivazione di un garbage collector se una Java-VM sta esaurendo la memoria.
La ricostruzione di un canale VPN se è definitivamente morto.
Se si riesce ad accettare questo, allora bisogna pensare in modo diverso al monitoraggio: da un sistema che semplicemente osserva e non è "necessario" per le operazioni di monitoraggio, un processo graduale porta il monitoraggio a diventare un organo vitale del data center.
Ma la correzione dei problemi non è l'unica cosa che il monitoraggio può fare automaticamente quando identifica un problema. Molto utile, ma anche innocua, è la raccolta di dati diagnostici aggiuntivi nel momento in cui si verifica un guasto. Senza dubbio potresti pensare a numerosi altri problemi per i quali si potrebbero usare i gestori di avvisi come punto di partenza.
1.2. Gestori di avvisi in Checkmk
I gestori di avvisi sono script che scrivi tu stesso e che vengono eseguiti da Checkmk nelle edizioni commerciali quando viene rilevato un problema o, più precisamente, quando un host o un servizio cambia stato.
I gestori di avvisi sono molto simili alle notifiche e sono configurati in modo simile, ma ci sono alcune importanti differenze:
I gestori di avvisi sono indipendenti dai tempi di manutenzione programmata, dai periodi di notifica, dalle conferme e da altri controller simili.
I gestori di avvisi si attivano al primo tentativo (se sono stati configurati più tentativi di check).
I gestori di avvisi sono indipendenti dagli utenti e dai gruppi di contatto.
I gestori di avvisi sono disponibili solo nelle edizioni commerciali.
Si può anche dire che i gestori di avvisi sono molto "di basso livello". Non appena un host o un servizio cambia stato, i gestori di avvisi configurati si attivano immediatamente. In questo modo un gestore di avvisi può persino eseguire una riparazione con successo prima che venga generato un avviso vero e proprio.
Naturalmente, come sempre in Checkmk, puoi utilizzare delle regole per definire le condizioni per le quali un particolare gestore deve essere eseguito. Puoi scoprire come fare questo e tutto il resto sui gestori di avvisi in questo articolo.
Un consiglio per gli utenti di Checkmk Raw: puoi anche fare in modo che il monitoraggio esegua automaticamente delle azioni, utilizzando i "gestori di eventi" di Nagios. Configura questi file di configurazione manuale nella sintassi di Nagios all'indirizzo ~/etc/nagios/conf.d/. I gestori di eventi sono ben documentati e le informazioni possono essere trovate semplicemente con Google.
2. Impostazione dei gestori di avvisi
2.1. Salvare gli script nella directory corretta
I gestori di avvisi sono script che vengono eseguiti sul server Checkmk. Devono essere salvati nella directory ~/local/share/check_mk/alert_handlers/ e possono essere codificati in qualsiasi linguaggio supportato da Linux, ad es. BASH, Python o Perl. Non dimenticare di rendere gli script eseguibili con chmod +x.
Se viene inserito un commento nella seconda riga dello script (con un hash # ), questo apparirà come nome dello script nell'elenco di selezione della regola:
#!/bin/bash
# Foobar handler for repairing stuff
...2.2. Un semplice gestore di avvisi da provare
Come per le notifiche, lo script ottiene tutte le informazioni relative all'host o al servizio come variabili d'ambiente, che iniziano tutte con il prefisso ALERT_.
Per verificare esattamente quali variabili d'ambiente appaiono nello script, puoi utilizzare il seguente gestore di avvisi per un test:
#!/bin/bash
# Dump all variables to ~/tmp/alert.out
env | grep ^ALERT_ | sort > $OMD_ROOT/tmp/alert.outenvvisualizza tutte le variabili d'ambiente.grep ^ALERT_seleziona quelle che iniziano conALERT_.sortordina l'elenco risultante in ordine alfabetico.
2.3. Attivazione del gestore di avvisi
L'attivazione del gestore avviene tramite Setup > Events > Alert handlers.
Procedi come segue:
Salva lo script in
~/local/share/check_mk/alert_handlers/debug.Rendilo eseguibile con
chmod +x debug.Richiama la pagina di configurazione con Setup > Events > Alert handlers.
Definisci una nuova regola con Add rule.
Il modulo per la selezione del gestore di avvisi consente l'accesso diretto e mostra il titolo che viene logato nella seconda riga dello script. Inoltre, puoi aggiungere degli argomenti che vengono inseriti nei campi di testo e che saranno interpretati come argomenti della riga di comando nello script. Nella tua shell puoi accedervi con $1, $2, ecc.

Importante: dopo aver salvato la regola, il gestore di avvisi sarà immediatamente attivo e verrà eseguito a ogni cambio di stato dell'host o del servizio!
2.4. Test e diagnosi dei guasti
Per effettuare un test, imposta manualmente un servizio, ad esempio Fake check results, su CRIT. A questo punto il file dovrebbe essere stato creato con le variabili. Ecco le prime venti righe:
OMD[mysite]:~$ head -n 20 ~/tmp/alert.out
ALERT_ALERTTYPE=STATECHANGE
ALERT_CONTACTNAME=check-mk-notify
ALERT_CONTACTS=
ALERT_DATE=2016-07-19
ALERT_HOSTADDRESS=127.0.0.1
ALERT_HOSTALIAS=myserver123
ALERT_HOSTATTEMPT=1
ALERT_HOSTCHECKCOMMAND=check-mk-host-smart
ALERT_HOSTCONTACTGROUPNAMES=all
ALERT_HOSTDOWNTIME=0
ALERT_HOSTFORURL=myserver123
ALERT_HOSTGROUPNAMES=check_mk
ALERT_HOSTNAME=myserver123
ALERT_HOSTNOTESURL=
ALERT_HOSTNOTIFICATIONNUMBER=1
ALERT_HOSTOUTPUT=Packet received via smart PING
ALERT_HOSTPERFDATA=
ALERT_HOSTPROBLEMID=0
ALERT_HOSTSHORTSTATE=UP
ALERT_HOSTSTATE=UPIl file di log per la (non) esecuzione del gestore di avvisi si troverà in ~/var/log/alerts.log. La sezione per l'esecuzione del gestore debug, per il servizio Filesystem / sull'host myserver123sarà simile a questa:
2016-07-19 15:17:22 Got raw alert (myserver123;Filesystem /) context with 60 variables
2016-07-19 15:17:22 Rule ''...
2016-07-19 15:17:22 -> matches!
2016-07-19 15:17:22 Executing alert handler debug for myserver123;Filesystem /
2016-07-19 15:17:22 Spawned event handler with PID 6004
2016-07-19 15:17:22 1 running alert handlers:
2016-07-19 15:17:22 PID: 6004, object: myserver123;Filesystem /
2016-07-19 15:17:24 1 running alert handlers:
2016-07-19 15:17:24 PID: 6004, object: myserver123;Filesystem /
2016-07-19 15:17:24 Handler [6004] for myserver123;Filesystem / exited with exit code 0.
2016-07-19 15:17:24 Output:Un altro paio di consigli utili:
I testi prodotti dai gestori di avvisi sull'uscita standard appaiono nel file di log insieme a
Output:.Anche il codice di uscita dello script viene logato (
exited with exit code 0).I gestori di avvisi diventano davvero utili quando eseguono un comando sull'host di destinazione. Checkmk offre una soluzione pronta per Linux che verrà spiegata più avanti.
3. Configurazione rule-based
Come mostrato nell'esempio introduttivo, gli eventi che devono attivare i gestori di avvisi sono definiti tramite regole di notifica. Questo funziona in modo del tutto analogo alle notifiche, solo un po' semplificato. Nell'esempio non abbiamo specificato alcuna condizione, il che naturalmente non è realistico nella pratica. L'esempio seguente mostra una condizione che un gestore di avvisi definisce per host e servizi specifici:
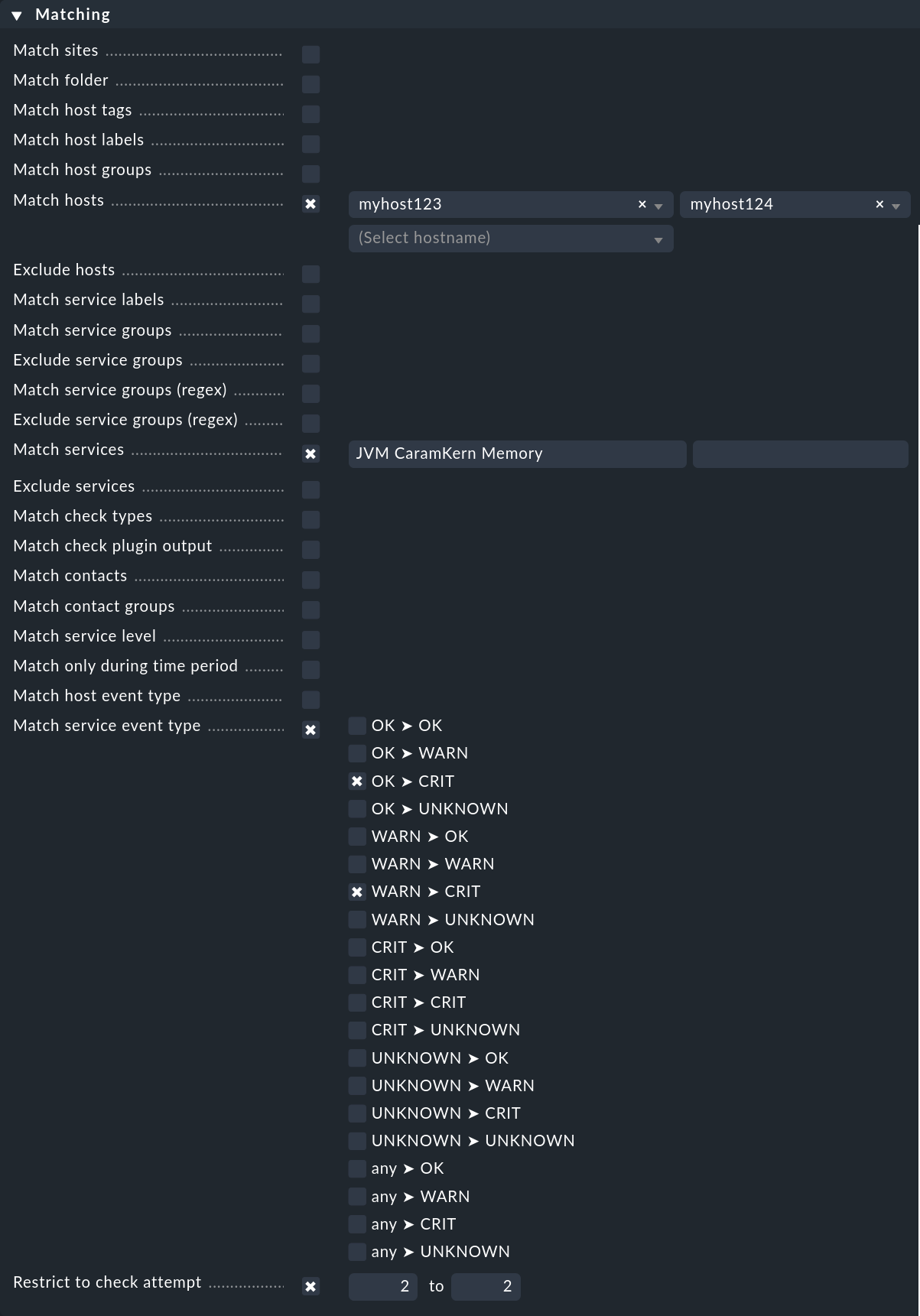
Il gestore di avvisi si attiverà soltanto
per gli host
myhost123emyhost124,per il servizio
JVM CaramKern Memory,se lo stato passa da OK o WARN a CRIT,
e solo al secondo tentativo di controllo.
Affinché l'handler si attivi, in questo esempio è necessario utilizzare la regola Maximum number of check attempts for service per impostare il numero minimo di tentativi di controllo a 2. Per sopprimere una notifica in caso di successo del garbage collector, il numero deve essere impostato a 3 - poiché se l'handler è in grado di risolvere il problema direttamente dopo il secondo tentativo, il terzo tentativo dovrebbe rilevare uno stato OK e quindi non saranno necessarie ulteriori notifiche.
Nota: a differenza di altri punti di Checkmk, ogni regola del gestore di avvisi verrà eseguita se le condizioni sono corrispondenti. Anche se due regole richiamano lo stesso gestore, questo verrà eseguito due volte. L'helper di avvisi (spiegato nel prossimo capitolo) sopprimerà la seconda esecuzione con un messaggio di errore, poiché lo stesso gestore non deve essere eseguito più volte allo stesso tempo. Si raccomanda comunque di impostare le regole in modo che questo caso non si presenti.
4. Come vengono eseguiti i gestori di avvisi
4.1. Esecuzione asincrona
I gestori di avvisi vengono spesso utilizzati per effettuare il log in a un computer interessato da remoto tramite SSH o un altro protocollo e, una volta lì, eseguire un'azione controllata da uno script. Poiché questo computer sta riscontrando un problema, non è da escludere che la connessione richieda molto tempo o addirittura vada in timeout.
Per evitare che il monitoraggio rimanga fermo o che altri gestori di avvisi si blocchino in questo lasso di tempo, in linea di principio i gestori di avvisi vengono eseguiti in modo asincrono. Un processo ausiliario - l'assistente agli avvisi - è responsabile di questa funzione e viene avviato dal CMC. Per ridurre l'overhead, questo avviene solo se è stata creata almeno una regola per il gestore di avvisi. Nel sito cmc.log vedrai quindi la seguente riga:
2016-07-19 15:17:00 [5] Alert handlers have been switched onAd ogni cambiamento di stato di un host o di un servizio, l'assistente agli avvisi riceve una notifica dal CMC contenente tutte le informazioni rilevanti per l'evento. Quindi valuta tutte le regole di notifica e determina se deve essere attivato un gestore di avvisi. In caso affermativo, lo script di notifica appropriato viene avviato ed eseguito in background come processo esterno.
4.2. Arresto del nucleo di monitoraggio
Quando si arresta il CMC (ad es. tramite omd stop o spegnendo il server di monitoraggio), tutti gli assistenti agli avvisi ancora in esecuzione vengono interrotti. Questi non verranno ripetuti in seguito, perché chi può sapere quando sarà il momento? È possibile che il riavvio di un servizio o simili possa essere più dannoso che utile!
4.3. Timeout
Per proteggersi dall'avvio di un numero eccessivo di processi in caso di errore, quando un gestore di avvisi è in esecuzione è in vigore un timeout di 60 secondi (impostabile) al termine del quale il gestore verrà arrestato. In dettaglio, ciò significa che al termine di un timeout verrà inviato al gestore un Segnale 15 (SIGTERM). In questo modo avrà la possibilità di arrestarsi in modo pulito. Dopo altri 60 secondi (timeout doppio) verrà "terminato" con un Segnale 9 (SIGKILL).
4.4. Sovrapposizione
Checkmk impedisce l'esecuzione simultanea di assistenti agli avvisi se si riferiscono allo stesso host/servizio e se eseguono lo stesso script con gli stessi parametri. Una situazione del genere indica che il primo gestore è ancora in esecuzione e che non ha senso avviare una seconda copia dello stesso gestore: il secondo gestore verrebbe immediatamente eliminato e identificato come "fallito".
4.5. Codici di uscita e output
Le uscite e i codici di uscita del gestore di avvisi vengono valutati in modo affidabile e restituiti al core, dove vengono salvati nella cronologia del monitoraggio. Inoltre puoi attivare una notifica (vedi sotto).
4.6. Impostazioni globali
Esistono diverse impostazioni globali per l'esecuzione dei gestori di avvisi:

L'opzione Alert handler log level influenza la registrazione nel file di log dell'assistente agli avvisi (~/var/log/alerts.log).
4.7. Controllo master

Con un clic nello snap-in Master control puoi disattivare i gestori di avvisi a livello globale. I gestori attualmente in esecuzione non saranno interessati e verranno eseguiti fino al completamento.
Non dimenticare di riportare il piccolo switch sul verde non appena possibile, altrimenti potresti essere ingannato dal falso senso di sicurezza che il monitoraggio stia sistemando ogni aspetto...
5. Gestori di avvisi nella cronologia
I gestori di avvisi creano voci nella cronologia del monitoraggio. In questo modo avrai una migliore tracciabilità rispetto al solo file di log alerts.log. Una voce viene creata non appena un gestore di avvisi inizia e un'altra quando termina.
I gestori di avvisi sono quindi considerati alla stregua dei tipici plug-in di monitoraggio: devono produrre una riga di testo e restituire uno dei quattro codici di uscita 0(OK), 1(WARN), 2(CRIT) o 3(SCONOSCIUTO). Tutti gli errori che fin dall'inizio impediscono l'esecuzione di un gestore di avvisi (aborto dovuto a un'esecuzione duplicata, script mancante, timeout, ecc.) vengono automaticamente contrassegnati con SCONOSCIUTO.
Ad esempio, chiamando questo semplice gestore...
#!/bin/bash
# Dummy handler for testing
sleep 3
echo "Everything is fine again"
exit 0... produce un risultato come sopra nella cronologia del servizio in questione (come sempre il messaggio più recente è in cima):
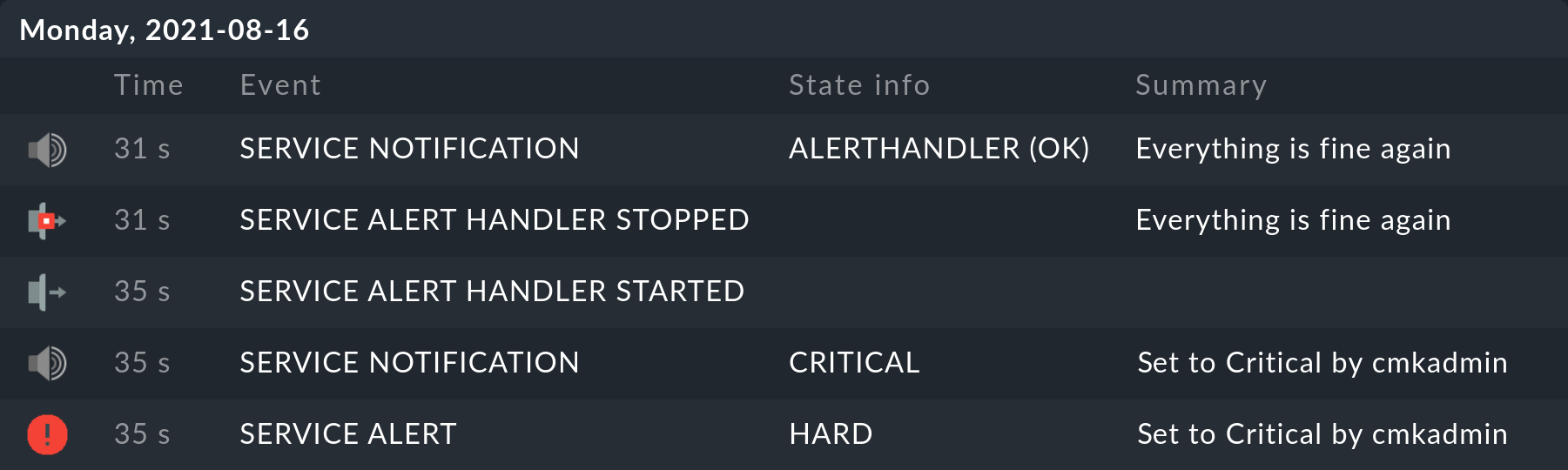
Esiste anche una visualizzazione generica Monitor > System > Alert handler executions, che fornisce una visualizzazione globale di tutti i gestori di avvisi in esecuzione.
6. Notifica tramite gestori di avvisi
L'esecuzione di un gestore di avvisi - o più esattamente il completamento di un'esecuzione - è un evento che attiva una notifica. In questo modo puoi essere informato che un gestore ha completato il suo compito. Esistono due tipi di eventi che puoi filtrare in una regola di notifica:
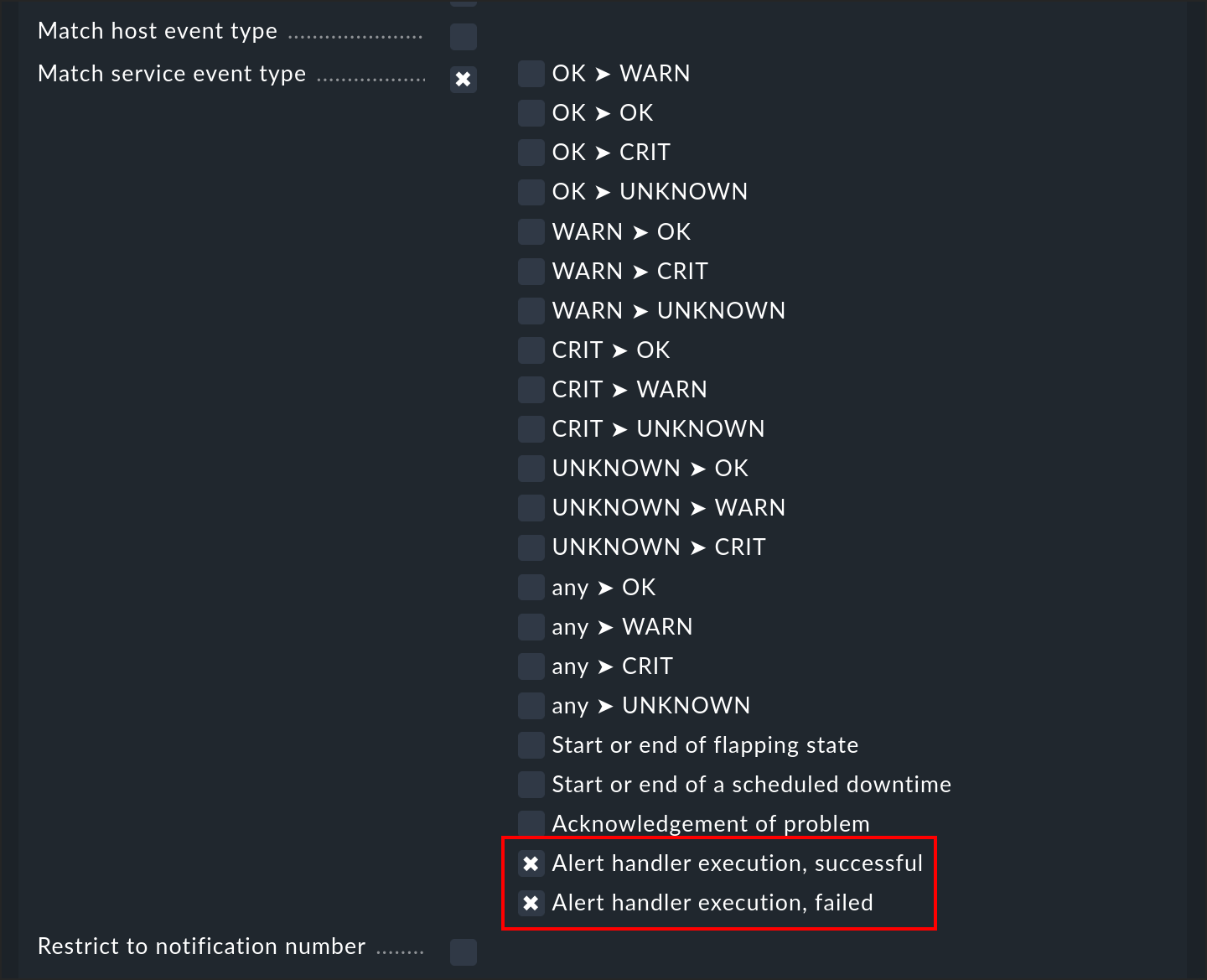
Puoi così distinguere tra gestori eseguiti con successo (codice di uscita 0 - OK) e fallimenti (tutti gli altri codici). La notifica e-mail di Checkmk non mostra l'esito del controllo, ma l'esito del gestore di avvisi.
7. Gestore di avvisi per ogni esecuzione di controllo
I gestori di avvisi vengono normalmente richiamati solo quando lo stato di un host o di un servizio cambia (o durante i tentativi di riprova quando si gestiscono dei problemi). Le semplici esecuzioni di controlli senza un cambiamento di stato non attivano alcun gestore di avvisi.
Con Global settings > Alert handlers > Types of events that are being processed > All check executions! puoi fare in modo che questo avvenga:ogni esecuzione di un controllo può potenzialmente attivare un gestore di avvisi. Ad esempio, puoi usarlo per trasferire i dati dal monitoraggio attivo ad altri sistemi.
L'avvio di processi e il richiamo di script consuma molte risorse della CPU. Checkmk può facilmente eseguire 1000 controlli al secondo, ma Linux non può certo gestire 1000 script di gestori di avvisi al secondo.
Per rendere tutto ciò possibile, Checkmk offre la possibilità di scrivere i gestori di avvisi come funzioni Python, che vengono eseguite in linea senza creare processi. Questi gestori in linea possono essere salvati nella stessa directory dei normali script. Il seguente esempio di funzionamento mostra la struttura di un gestore in linea:
#!/usr/bin/python
# Inline: yes
# Do some basic initialization (optional)
def handle_init():
log("INIT")
# Called at shutdown (optional)
def handle_shutdown():
log("SHUTDOWN")
# Called at every alert (mandatory)
def handle_alert(context):
log("ALERT: %s" % context)Questo script non ha una funzione centrale, ma definisce semplicemente tre funzioni, anche se è necessaria solo la funzione handle_alert(). Questa viene richiamata dopo l'esecuzione di ogni controllo e nel suo argomento context riceve un dizionario Python con variabili d'ambiente come "HOSTNAME", "SERVICEOUTPUT", ecc. Queste rappresentano le variabili d'ambiente che ricevono anche i normali gestori, ma in questo caso senza il prefisso ALERT_. L'esempio precedente può essere utilizzato per visualizzare il contenuto di context.
Tutti gli output prodotti dalla funzione ausiliaria log() vengono salvati in ~/var/log/alert.log. Entrambe le variabili globali omd_root e omd_site sono basate rispettivamente sulla directory home e sul nome dell'istanza Checkmk.
Le funzioni handle_init() e handle_shutdown() vengono richiamate da Checkmk all'avvio o all'arresto del nucleo di monitoraggio e consentono un'inizializzazione, ad esempio quando si stabilisce una connessione a un database.
Ulteriori informazioni:
Nota
# Inline: yesnella seconda riga.Il core deve essere riavviato dopo ogni modifica dello script (
omd restart cmc).importsono consentiti i comandi.Gli assistenti agli avvisi di Checkmk richiamano le tue funzioni in modo sincrono. Assicurati che non si verifichino stati di attesa!
8. Esecuzione remota in Linux
8.1. Principi di base
Ogni versione di Checkmk include un gestore di avvisi integrato che consente l'esecuzione affidabile degli script sui sistemi Linux monitorati. Le caratteristiche più importanti di questa soluzione sono:
Gli script vengono richiamati tramite SSH con limitazioni di comando.
Non possono essere utilizzati comandi arbitrari, ma solo quelli definiti dall'utente.
Tutto questo può essere implementato utilizzando l'agent bakery.
I gestori di avvisi remoti di Linux sono costituiti dai seguenti elementi:
Il gestore di avvisi
linux_remotecon il titoloLinux via SSHsul server Checkmk.Lo script
mk-remote-alert-handlersul sistema di destinazione.Gli script ("gestori remoti") scritti da te sul sistema di destinazione.
Voci in
.ssh/authorized_keysper gli utenti del sistema di destinazione che li eseguiranno.Regole in Setup > Agents > Windows, Linux, Solaris, AIX > Agent rules > Linux Agent > Remote alert handlers (Linux) che generano chiavi SSH.
Regole del gestore di avvisi che richiamano
linux_remote.
8.2. Impostazione
Supponendo di voler eseguire lo script /etc/init.d/foo restart sul sistema Linux myserver123 ogni volta che il servizio Process FOO diventa critico (che abbiamo già impostato), procedi come segue:
Codifica del gestore remoto
Successivamente, scrivi lo script da eseguire sul sistema di destinazione. Poiché stiamo lavorando con l'agent bakery, installa lo script sul server Checkmk (non sul sistema di destinazione!). La directory corretta è ~/local/share/check_mk/agents/linux/alert_handlers. Anche in questo caso, il commento nella seconda riga fornisce un titolo per la selezione nell'interfaccia utente:
#!/bin/bash
# Restart FOO service
/etc/init.d/foo restart || {
echo "Could not restart FOO."
exit 2
}Rendi lo script eseguibile:
OMD[mysite]:~$ cd local/share/check_mk/agents/linux/alert_handlers
OMD[mysite]:~$ chmod +x restart_fooIl nostro script di esempio è costruito in modo tale che, in caso di errore, termini con un codice 2 in modo che il gestore di avvisi lo valuti come CRIT.
Preparazione del pacchetto agente con il gestore
Qui descriveremo la procedura con l'agent bakery. I suggerimenti per l'installazione manuale sono riportati più avanti.
Definisci una regola sotto Setup > Agents > Windows, Linux, Solaris, AIX > Agent rules > Linux Agent > Remote alert handlers (Linux). Nelle proprietà è visibile il gestore remoto Restart FOO service che hai appena definito. Selezionalo per l'installazione:
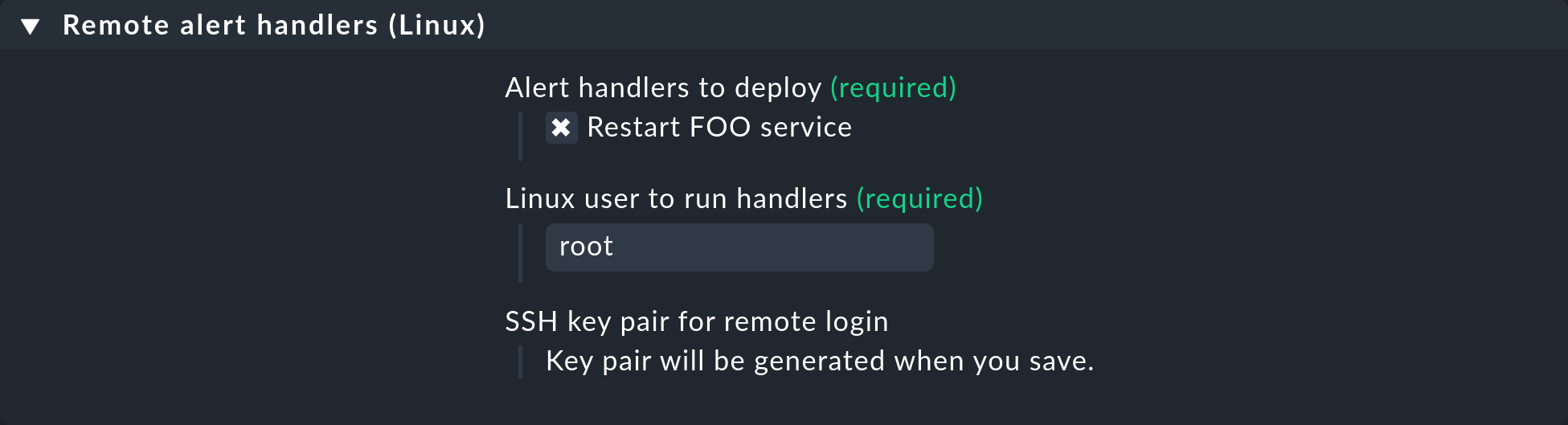
Una volta salvata, vedrai la regola nell'elenco: è stata generata automaticamente una coppia di chiavi SSH per richiamare l'handler, la cui impronta digitale apparirà nella regola. L'impronta digitale stessa è stata accorciata per adattarsi alla larghezza di questa schermata:
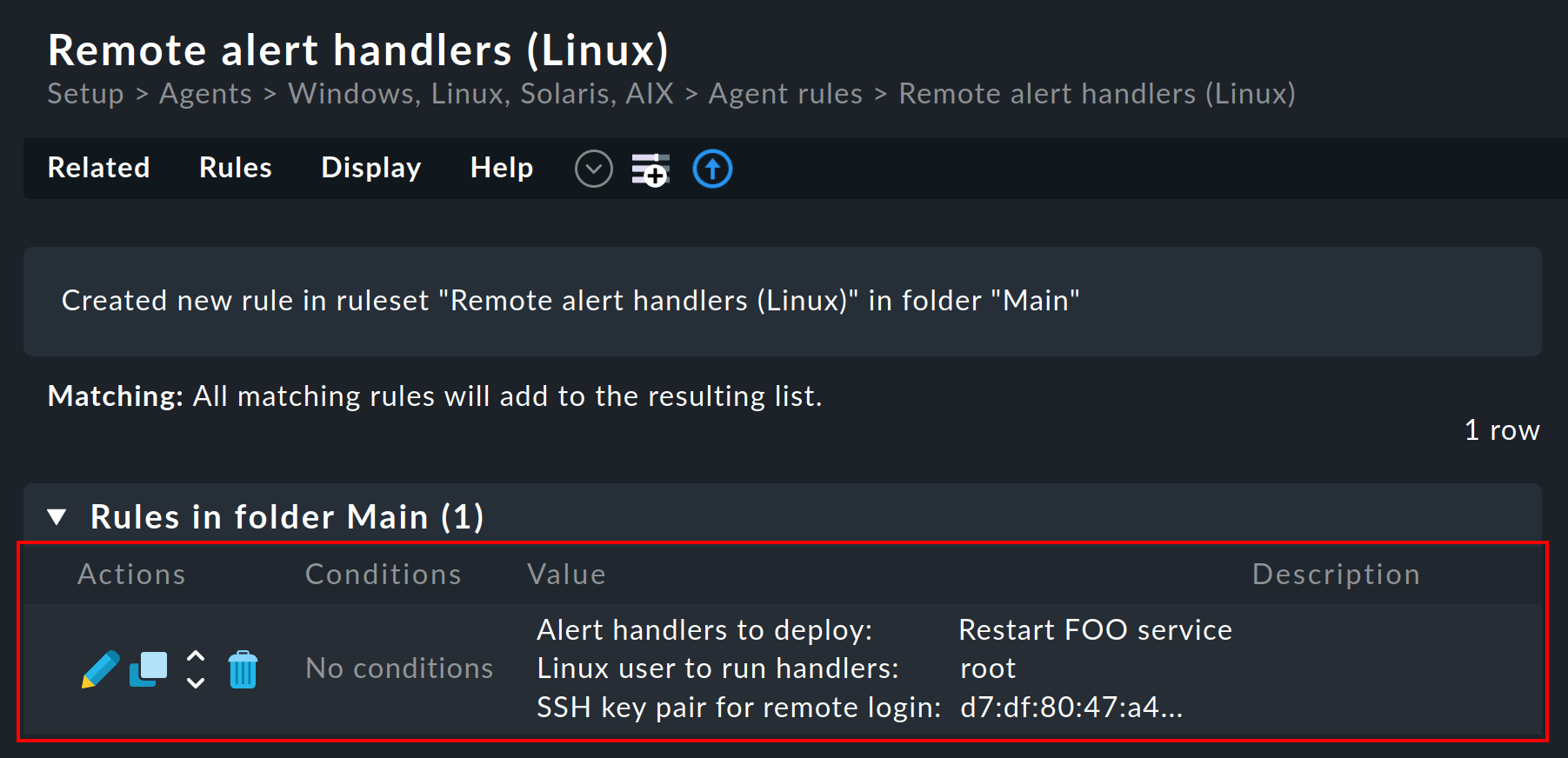
La chiave pubblica è destinata all'agente Checkmk, mentre la chiave privata sarà richiesta dal server Checkmk per poter richiamare uno script così installato senza dover inserire una password.
Si può anche utilizzare un altro utente come root - naturalmente solo se ha i diritti appropriati per l'azione richiesta. L'agente Checkmk installerà la chiave SSH solo sui sistemi in cui questo utente è già presente.
Baked agent
Ora prepara nuovi agenti con . Nell'elenco degli agenti pronti dovrebbe comparire una voce in cui sono visibili il gestore remoto e la chiave SSH. Anche in questo caso la schermata è stata accorciata. Questa volta per la quantità di pacchetti che possono essere scaricati:
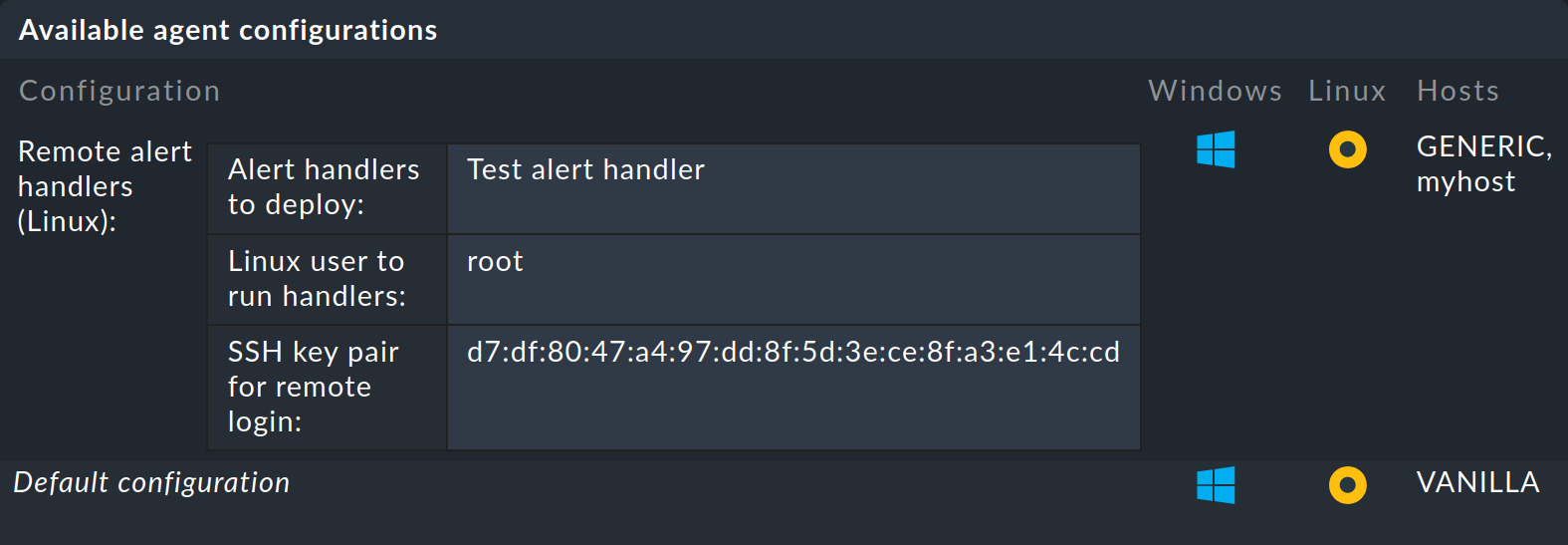
Installa l'agente
Successivamente, installa il pacchetto RPM o DEB sul tuo sistema di destinazione (l'installazione dell'archivio TGZ non può configurare la chiave SSH ed è quindi incompleta). Con l'installazione si verificano le seguenti cose:
Viene installato lo script del gestore remoto.
Viene installato il programma ausiliario
mk-remote-alert-handler.Per alcuni utenti selezionati (in questo caso
root) verrà creata una voce inauthorized_keysche abiliterà l'esecuzione del gestore.La directory
.sshe il fileauthorized_keysverranno creati come necessario.
In caso di installazione tramite DEB, l'aspetto sarà il seguente:
root@myserver123:~# dpkg -i check-mk-agent_2016.07.19-9d3ab34905da4934_all.deb
Selecting previously unselected package check-mk-agent.
(Reading database ... 515080 files and directories currently installed.)
Preparing to unpack ...check-mk-agent_2016.07.19-9d3ab34905da4934_all.deb ...
Unpacking check-mk-agent (2016.07.19-9d3ab34905da4934) ...
Setting up check-mk-agent (2016.07.19-9d3ab34905da4934) ...
Reloading xinetd...
* Reloading internet superserver configuration xinetd [ OK ]
Package 9d3ab34905da4934: adding SSH keys for Linux remote alert handlers for user root...Uno sguardo alla configurazione SSH di root rivela:
root@myserver123:~# cat /root/.ssh/authorized_keys
command="/usr/bin/mk-remote-alert-handler restart_foo",no-port-forwarding,no-x11-forwarding,no-agent-forwarding ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAACAQCqoDVNFEbTqYEmhSZhUMvRy5SqGIPp1nE+EJGw1LITV/rej4AAiUUBYwMkeo5aBC6VOXkq78CdRuReSozec3krKkkwVbgYf98Wtc6N3WiljS85PLAVvPadJiJCkXFctbxyI2xeF5TQ1VKDRvzbBjXE9gjTnLWbPy77RC8SVXLoOQgabixpWQquIIdGyccPsWGTRgeI7Ua0lgWZQUJt7OIKQ0X7Syv2VHKJNqtW28IWu8y2hBEY/TERip5EQoNT/VclhHqjDG2y3F45PswcXD5in6y30EnfHGcwk+PD6fgp7jPGbO2+QBUwYgW67GmRpbaVQ97CqXFJvORNF+C6+O8DNweyH3ogspjfKvM7eN+M4NIJzjMRyNBMzqF3VmrMeqpzRjfFj2BS/8UbXGgHzZRapwrK3+GXX1pG49n77cIs+GWos9xb1DxX1pEu2tgQwRBBhYcTkk2eKkH18LKzFUyObxtQmf40C24cdQOp6USbwzsniqehsLIHH2unQ7bW6opF/GiaEjZamGbgsPOe8rmey5Vcd//e8cS+OsmcPZNybsTJpBeHpes+5bw0e1POw9GD9qptylrQLYIO5R467Ov8YlRFgYKyaDFHD40j5/JHPzmtp4vjH8Si7YZZOzvTRgBYEoEgbLS5dgdr/I5ZMRKfDPCpRUbGhp9kUEdGX99o5Q== mk-remote-alert-handler-9d3ab34905da4934Tieni presente che il tuo sistema potrebbe essere configurato in modo tale che l'accesso SSH come root non sia generalmente possibile. In questo caso puoi accedere tramite un altro utente e lavorare con sudo, che è configurato in modo tale che il comando desiderato possa essere eseguito senza password.
Chiamare il gestore utilizzando una regola
Abbiamo quasi raggiunto il nostro obiettivo: l'agent è pronto. Ora manca solo una regola per chiamare effettivamente il gestore di avvisi. La procedura è quella descritta all'inizio di questo articolo e si ottiene attraverso la creazione di una regola appropriata. Questa volta scegli Linux via SSH come gestore di avvisi, inserisci l'utente per il quale deve essere installata la chiave SSH e seleziona il tuo gestore remoto:
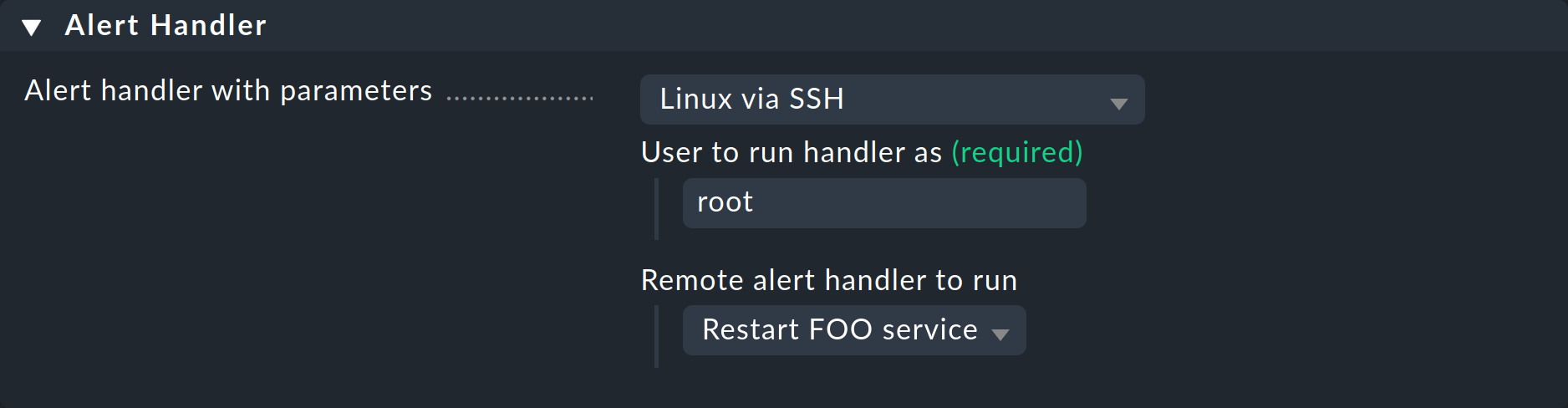
Imposta anche una condizione sensata nella regola, altrimenti ad ogni avviso di servizio verrà tentata una connessione SSH!
Test
Quando, ad esempio, imposti manualmente il servizio in questione su CRIT, nella cronologia del servizio vedrai subito:
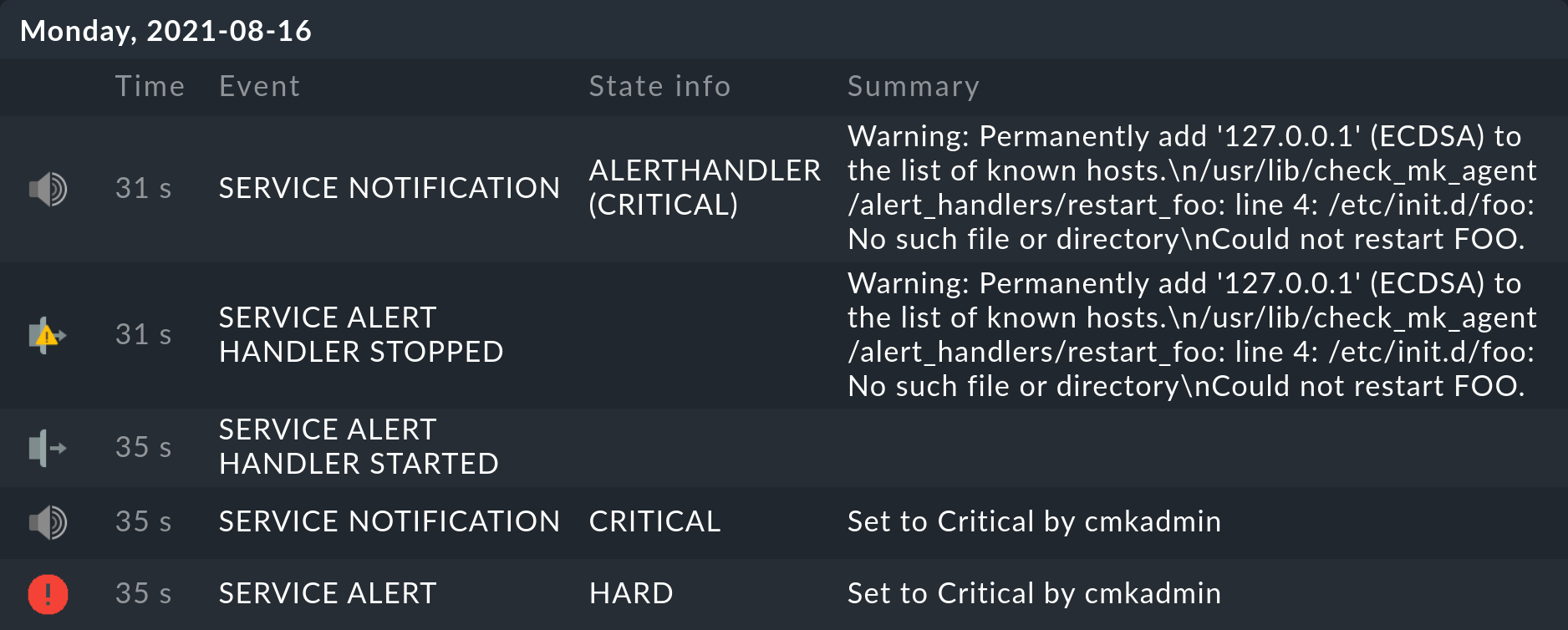
Naturalmente, se non esiste il servizio foo, anche /etc/init.d/foo restart non può funzionare. Si può comunque vedere che questo comando è stato processato e che lo stato del servizio è stato riportato correttamente. Allo stesso modo, Checkmk ha attivato una notifica che è stata fermata da un gestore di avvisi.
Il messaggio Warning: Permanently added '127.0.0.1' (ECDSA) to the list of known hosts. è comunque innocuo e appare solo al primo contatto con l'host. Per evitare il lungo scambio manuale della chiave dell'host, SSH viene chiamato con -o StrictHostKeyChecking=false. Alla prima connessione la chiave viene memorizzata per un uso futuro.
8.3. Impostazione senza agent bakery
Naturalmente, la preparazione manuale di un agente funziona anche. In questo caso, ti consigliamo di eseguire la procedura Agent bakery su un sistema di prova, quindi di esaminare i dati rilevanti e di replicarli manualmente sul tuo sistema. Un elenco dei percorsi dei file è disponibile qui.
In questo caso è importante che nell'Agent bakery tu crei una regola per l'installazione del gestore remoto, perché in questa regola verranno generate le chiavi SSH per l'accesso e per l'utilizzo da parte del gestore di avvisi! La chiave pubblica per l'installazione in authorized_keys si trova nel file di configurazione di ~/etc/check_mk/conf.d/wato/rules.mk (o in una sottocartella di rules.mk).
9. File e directory
9.1. Percorsi sul server Checkmk
| Percorso | Funzione |
|---|---|
|
File di log con tutti gli eventi rilevanti per il gestore di avvisi (registrati dall'assistente agli avvisi). |
|
File di log per il core. Qui vengono memorizzate anche alcune informazioni relative ai gestori di avvisi. |
|
Salva qui i gestori di avvisi scritti da te. |
|
Qui viene memorizzato il file di log della cronologia di monitoraggio e viene anche valutato dal core. |
|
Gestori di avvisi remoti da eseguire su sistemi Linux. |
9.2. Percorsi sull'host Linux monitorato
| Percorso | Funzione |
|---|---|
|
Script ausiliario per l'esecuzione dei gestori remoti. |
|
Gestori remoti scritti dall'utente. |
|
Configurazione SSH per l'utente |
|
Configurazione SSH per un utente |