This is a machine translation based on the English version of the article. It might or might not have already been subject to text preparation. If you find errors, please file a GitHub issue that states the paragraph that has to be improved. |
1. Introduzione
1.1. Cluster, nodi e servizi del cluster
Quando distribuisci servizi critici e mission-critical, come database o servizi web di e-commerce, è improbabile che tu faccia affidamento sul fatto che l'host che esegue tali servizi abbia una vita lunga, stabile e priva di errori. Piuttosto, dovrai tenere conto del possibile guasto di un host e assicurarti che altri host siano in standby per assumere immediatamente i servizi in caso di guasto(o failover), in modo che il guasto non sia nemmeno percepibile dal mondo esterno.
Un gruppo di host collegati in rete che lavorano insieme per svolgere lo stesso compito è chiamato rete di computer o cluster di computer o, più semplicemente, cluster. Un cluster agisce e appare come un unico sistema all'esterno e organizza i suoi host all'interno per lavorare insieme per svolgere il compito comune.
Un cluster può svolgere diversi compiti, ad esempio un cluster HPC può eseguire il calcolo ad alte prestazioni, utilizzato, tra l'altro, quando i calcoli richiedono una quantità di memoria molto superiore a quella disponibile su un singolo computer. Se il cluster ha il compito di fornire high availability, viene anche chiamato cluster HA. In questo articolo ci occupiamo dei cluster HA, vale a dire che quando ci riferiamo a un "cluster" nel testo seguente, intendiamo sempre un cluster HA.
Un cluster offre uno o più servizi al mondo esterno: i servizi del cluster, talvolta indicati come "servizi del cluster". In un cluster, gli host che lo compongono sono chiamati nodi. In qualsiasi momento, ogni servizio è fornito da uno solo dei nodi. Se un nodo del cluster si guasta, tutti i servizi essenziali per la missione del cluster vengono spostati su uno degli altri nodi.
Per rendere trasparente qualsiasi failover, alcuni cluster forniscono un proprio indirizzo IP del cluster, a volte indicato anche come indirizzo IP virtuale. L'indirizzo IP del cluster si riferisce sempre al nodo attivo ed è rappresentativo dell'intero cluster. In caso di failover, l'indirizzo IP viene trasferito a un altro nodo, precedentemente passivo, che diventa il nodo attivo. Il client che comunica con il cluster può essere ignaro di un failover interno: utilizza lo stesso indirizzo IP invariato e non deve effettuare alcuno switch.
Altri cluster non hanno un indirizzo IP del cluster: i cluster di database Oracle, in molte delle loro varianti, ne sono un esempio lampante. Senza un indirizzo IP del cluster, il client deve mantenere un elenco di indirizzi IP di tutti i nodi che potrebbero fornire il servizio. Se il nodo active-active si guasta, il client deve rilevarlo e passare al nodo che ora fornisce il servizio.
1.2. Monitoraggio di un cluster
Checkmk è uno dei client che comunica con il cluster. In Checkmk è possibile impostare e monitorare tutti i nodi del cluster, indipendentemente dal modo in cui il software del cluster controlla internamente lo stato dei singoli nodi e, se necessario, esegue un failover.
La maggior parte dei controlli che Checkmk esegue sui singoli nodi del cluster riguarda le proprietà fisiche dei nodi, che sono indipendenti dall'appartenenza dell'host del cluster o meno. Ad esempio, l'utilizzo della CPU e della memoria, i dischi locali, le interfacce fisiche di rete e così via. Tuttavia, per mappare la funzione dei nodi del cluster in Checkmk, è necessario identificare i servizi che definiscono il compito del cluster e che potrebbero rendere necessario il trasferimento a un altro nodo: i servizi del cluster.
Checkmk ti aiuta a monitorare i servizi del cluster. Quello che devi fare è:
Creare il cluster.
Selezionare i servizi del cluster.
Eseguire una scoperta del servizio per tutti gli host associati.
Il modo in cui procedere è descritto nel prossimo capitolo utilizzando la seguente configurazione di esempio:
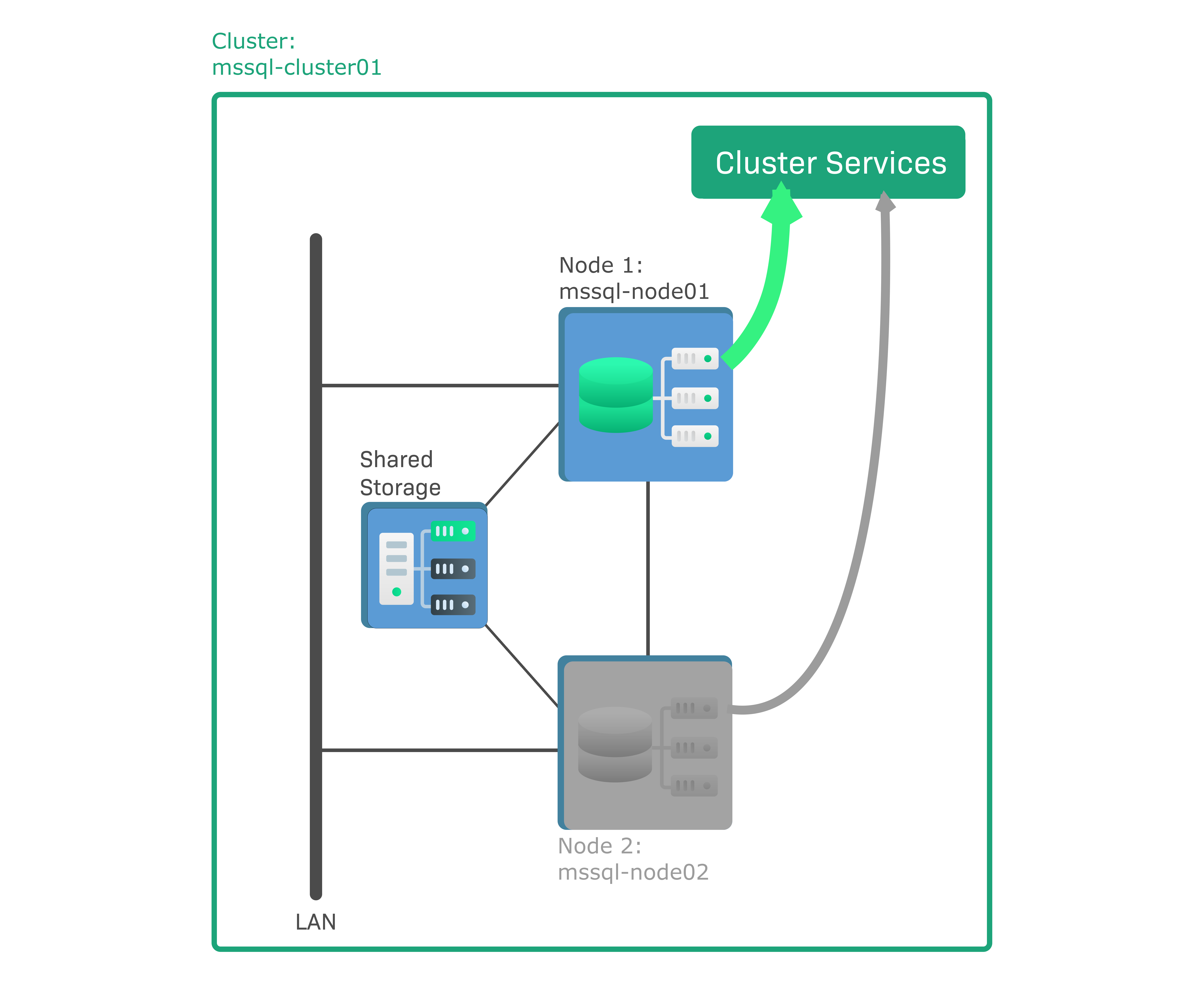
In Checkmk, un cluster failover di Windows deve essere configurato come un cluster HA composto da due nodi con Microsoft SQL (MS SQL) Server installato. Si tratta di un cosiddetto cluster active-passive, il che significa che solo uno, il nodo attivo, esegue un'istanza del database. L'altro nodo è passivo e diventa attivo solo in caso di failover, quando avvia l'istanza del database e sostituisce il nodo guasto. I dati dell'istanza di database non sono archiviati sui nodi stessi, ma su un supporto di archiviazione condiviso, ad es. una rete SAN (Storage Area Network), a cui entrambi i nodi sono connessi. La configurazione di esempio è composta dai seguenti componenti:
mssql-node01è il nodo attivo che esegue un'istanza di database attiva.mssql-node02è il nodo passivo.mssql-cluster01è il nodo del cluster a cui appartengono entrambi i nodi.
A differenza di questo esempio, è possibile che lo stesso nodo sia incluso in più di un cluster. Nell'ultimo capitolo imparerai a configurare questi cluster sovrapposti utilizzando una configurazione di esempio modificata.
2. Impostazione dei cluster e dei servizi cluster
2.1. Creare un cluster
In Checkmk, i nodi e il cluster stesso vengono creati come host (host del nodo e host del cluster), con un tipo di host speciale definito per l'host del cluster.
Ecco alcuni punti da considerare prima di configurare un host del cluster:
L'host del cluster è un host virtuale da configurare con un indirizzo IP del cluster, se presente. Nel nostro esempio, assumiamo che il nome host del cluster sia risolvibile tramite DNS.
Gli host del cluster possono essere configurati come gli host "normali", ad esempio con tag degli host o gruppi di host.
Per tutti gli host partecipanti (il che significa sempre l'host del cluster e tutti gli host dei nodi associati), le fonti di dati devono essere configurate in modo identico; in particolare, alcune non possono essere configurate tramite un agente Checkmk e altre tramite SNMP. Checkmk assicura che un host del cluster può essere creato solo se questo requisito è soddisfatto.
In un monitoraggio distribuito tutti gli host partecipanti devono essere assegnati alla stessa istanza Checkmk.
Non tutti i controlli funzionano in una configurazione cluster. Per i controlli che hanno implementato il supporto per i cluster, puoi leggere le informazioni nella pagina del manuale del plugin. Puoi accedere alle pagine del manuale dal menu Setup > Services > Catalog of check plugins.
Nel nostro esempio, i due host mssql-node01 e mssql-node02 sono già stati creati e impostati come host. Per sapere come arrivare a questo punto, consulta l'articolo sul monitoraggio dei server Windowse il capitolo sull'estensione dell'agente standard di Windows con i plug-in, nel nostro esempio i plug-in di MS SQL Server.
Avvia la creazione del cluster dal menu Setup > Hosts > Hosts e poi dal menu Hosts > Add cluster:
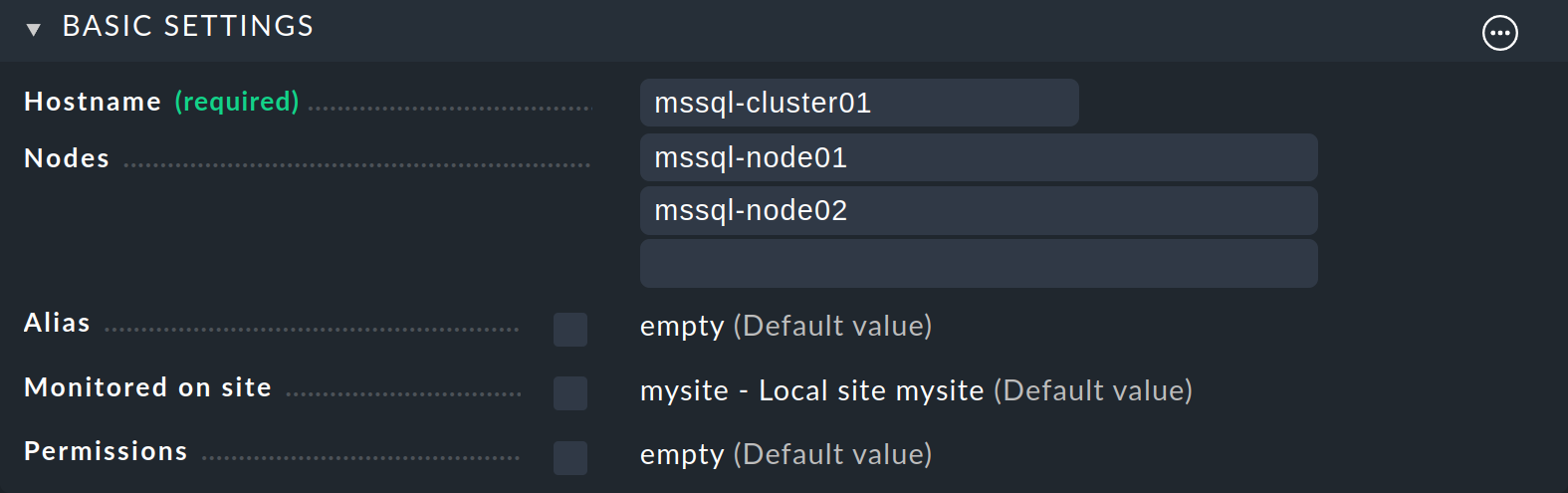
Inserisci mssql-cluster01 come Hostname e inserisci i due host dei nodi in Nodes.
Nota: se hai a che fare con un cluster senza un indirizzo IP del cluster, dovrai fare una deviazione non troppo comoda, selezionando No IP nel box Network Address per IP Address Family. Ma per evitare che l'host vada DOWN nel monitoraggio, devi cambiare il "comando di controllo dell'host" predefinito tramite l'omonima regola - da Smart PING o PING a, ad esempio, lo stato di uno dei servizi che devono essere assegnati all'host del cluster - come verrà spiegato nella sezione successiva. Per maggiori informazioni sui set di regole dell'host, consulta la sezione sulle regole.
Completa la creazione con Save & view folder e attiva le modifiche.
2.2. Selezionare i servizi del cluster
Checkmk non può sapere quali servizi in esecuzione su un nodo sono locali e quali sono servizi del cluster: alcuni file system possono essere locali, altri possono essere montati solo sul nodo active-active. Lo stesso vale per i processi: Mentre il servizio "Windows Timer" è molto probabilmente in esecuzione su tutti i nodi, una particolare istanza di database sarà disponibile solo sul nodo attivo.
Invece di far tirare a indovinare Checkmk, seleziona i servizi del cluster con una regola. Senza una regola, nessun servizio verrà assegnato al cluster. In questo esempio assumeremo che i nomi di tutti i servizi del cluster MS SQL Server inizino conMSSQL e che il file system del dispositivo di archiviazione condivisa sia accessibile tramite l'unità D:.
Inizia con Setup > Hosts > Hosts e clicca sul nome del cluster. Nella pagina Properties of host seleziona dal menu Hosts > Clustered services. Arriverai alla pagina del set di regole Clustered services dove potrai creare una nuova regola.
Indipendentemente dal fatto che gli host siano organizzati in cartelle, assicurati di creare regole per i servizi del cluster in modo che si applichino agli host del nodo su cui vengono eseguiti i servizi. Una regola del genere è inefficace per un host del cluster.
In Create rule in folder, seleziona la cartella che contiene gli host del nodo e verrai indirizzato alla pagina New rule: Clustered services:
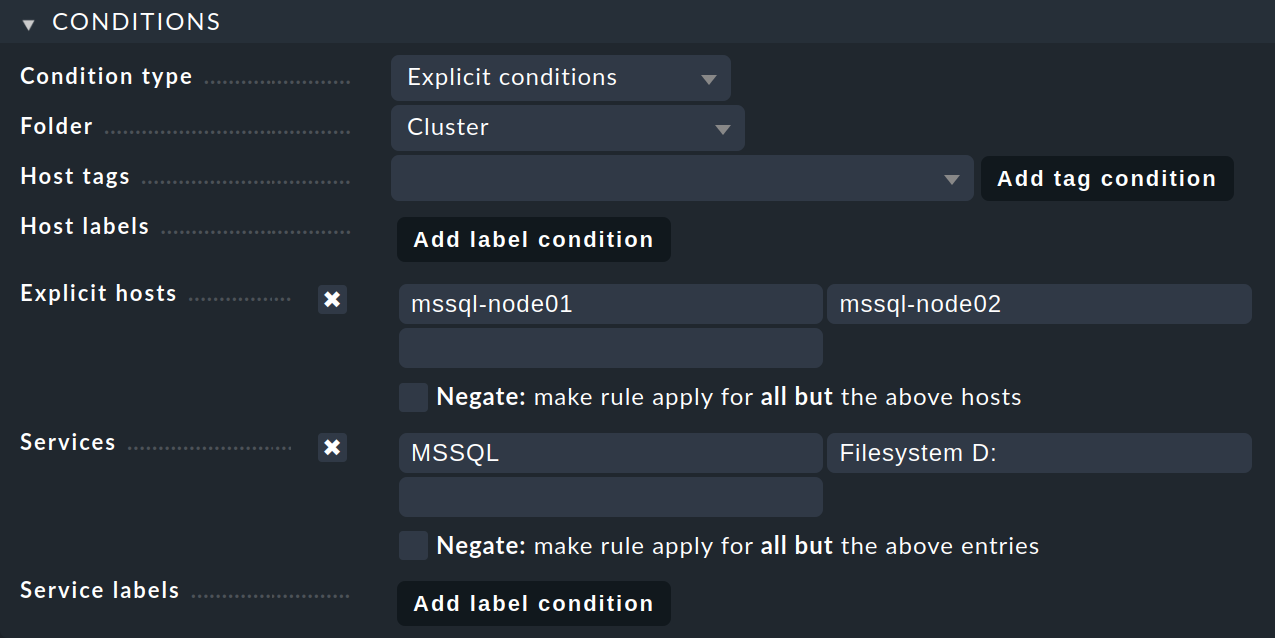
Nel box Conditions, attiva Explicit hosts e inserisci l'host del nodo attivo mssql-node01 e l'host del nodo passivo mssql-node02. Poi attiva Services e inserisci due voci: MSSQL per tutti i servizi MS SQL il cui nome inizia con MSSQL e Filesystem D: per l'unità. Le voci vengono interpretate come espressioni regolari.
Tutti i servizi che non sono definiti come servizi cluster saranno trattati da Checkmk come servizi locali.
Termina la creazione della regola con Save e attiva le modifiche.
2.3. Eseguire la scoperta del servizio
Per tutti gli host partecipanti (host del cluster e host del nodo), è necessario eseguire una nuovascoperta del servizio alla fine, in modo che tutti i servizi del cluster appena definiti vengano prima rimossi dai nodi e poi aggiunti al cluster.
In Setup > Hosts > Hosts, seleziona prima tutti gli host coinvolti e poi seleziona dal menu Hosts > On Selected hosts > Run bulk service discovery. Nella pagina Bulk discovery, la prima opzione Add unmonitored services and new host labels dovrebbe produrre il risultato desiderato.
Clicca su Start per iniziare lascoperta del servizio per più host. Una volta completata con successo, come indicato dal messaggioBulk discovery successful, esci e attiva le modifiche.
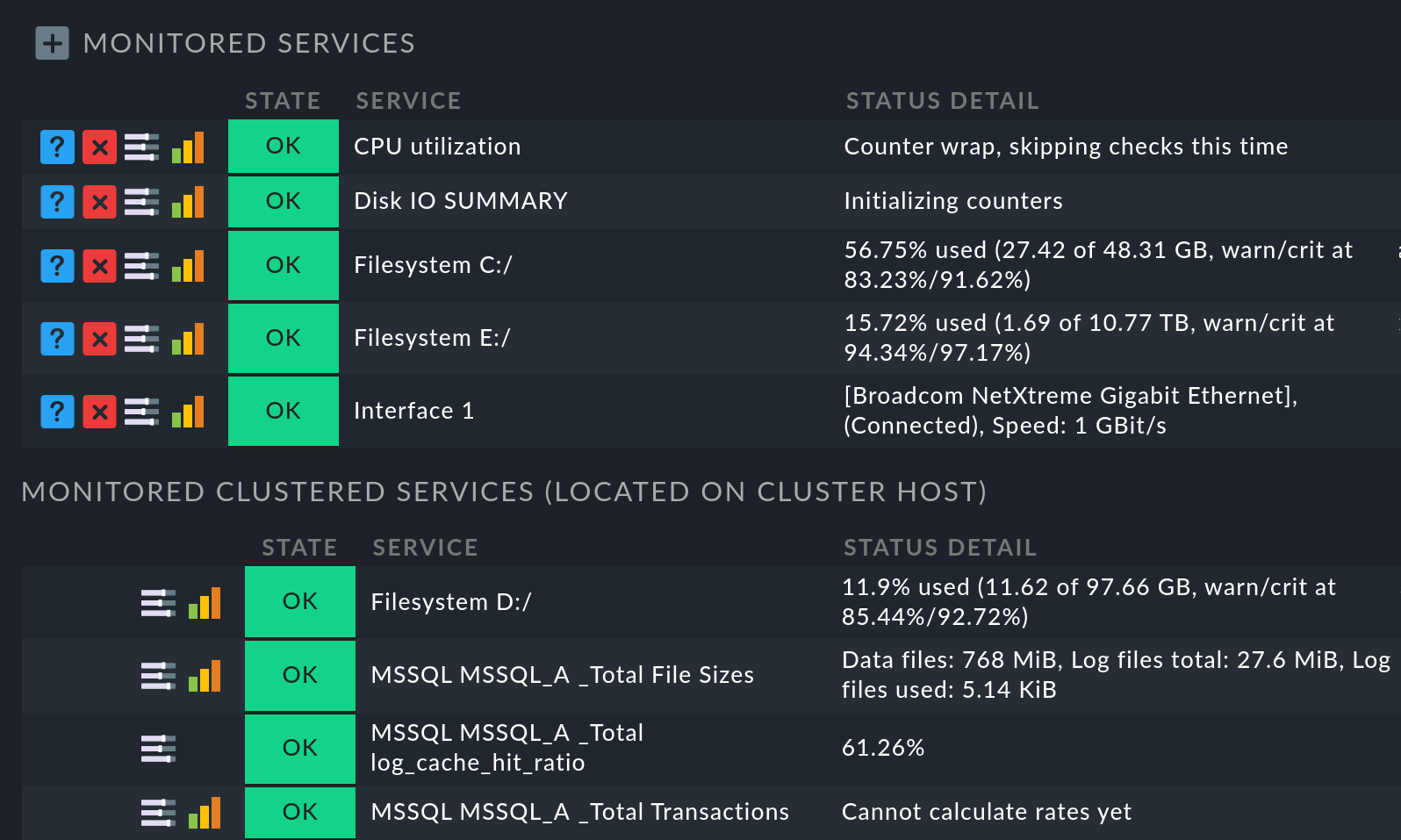
Per verificare se la selezione dei servizi del cluster ha portato al risultato desiderato, puoi elencare tutti i servizi che ora sono assegnati al cluster: in Setup > Hosts > Hosts, nell'elenco degli host alla voce dell'elenco degli host del cluster clicca sul simbolo per modificare i servizi. Nella pagina successiva Services of host tutti i servizi del cluster sono elencati in Monitored services:
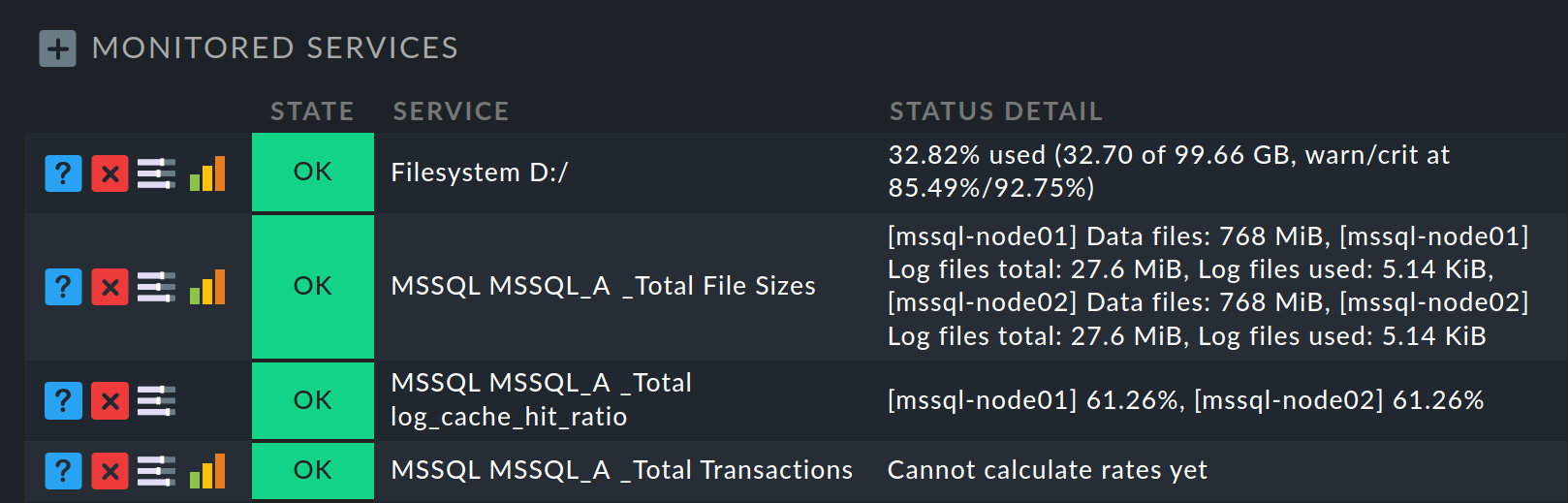
D'altra parte, per gli host del cluster, i servizi che sono stati spostati nel cluster non saranno più presenti nell'elenco dei servizi monitorati. Sull'host nodo, puoi ritrovarli guardando la fine dell'elenco dei servizi nella sezioneMonitored clustered services (located on cluster host):
Suggerimento: se esegui i check locali in un cluster in cui è stata applicata la regolaClustered services, puoi utilizzare il set di regoleLocal checks in Checkmk clusters per influenzare il risultato scegliendo tra Worst state e Best state.
2.4. Scoperta automatica del servizio
Se lasci che la scoperta del servizio avvenga automaticamente tramite il Discovery Check, devi considerare un aspetto particolare. Discovery Check può eliminare automaticamente i servizi che scompaiono. Tuttavia, se un servizio del cluster si sposta da un nodo all'altro, potrebbe essere erroneamente registrato come scomparso e quindi eliminato. D'altra parte, se ometti questa opzione, i servizi effettivamente scomparsi non saranno mai eliminati.
3. Sovrapposizione di cluster
È possibile che diversi cluster condividano uno o più nodi. In questo caso si parla di cluster sovrapposti. Per i cluster sovrapposti, è necessaria una regola speciale per indicare a Checkmk quali servizi del cluster di un host del cluster condiviso devono essere assegnati a quale cluster.
Di seguito presenteremo la procedura di base per la configurazione di un cluster sovrapposto modificando l'esempio del cluster MS SQL Server da un cluster active-passive a un cluster active-active:
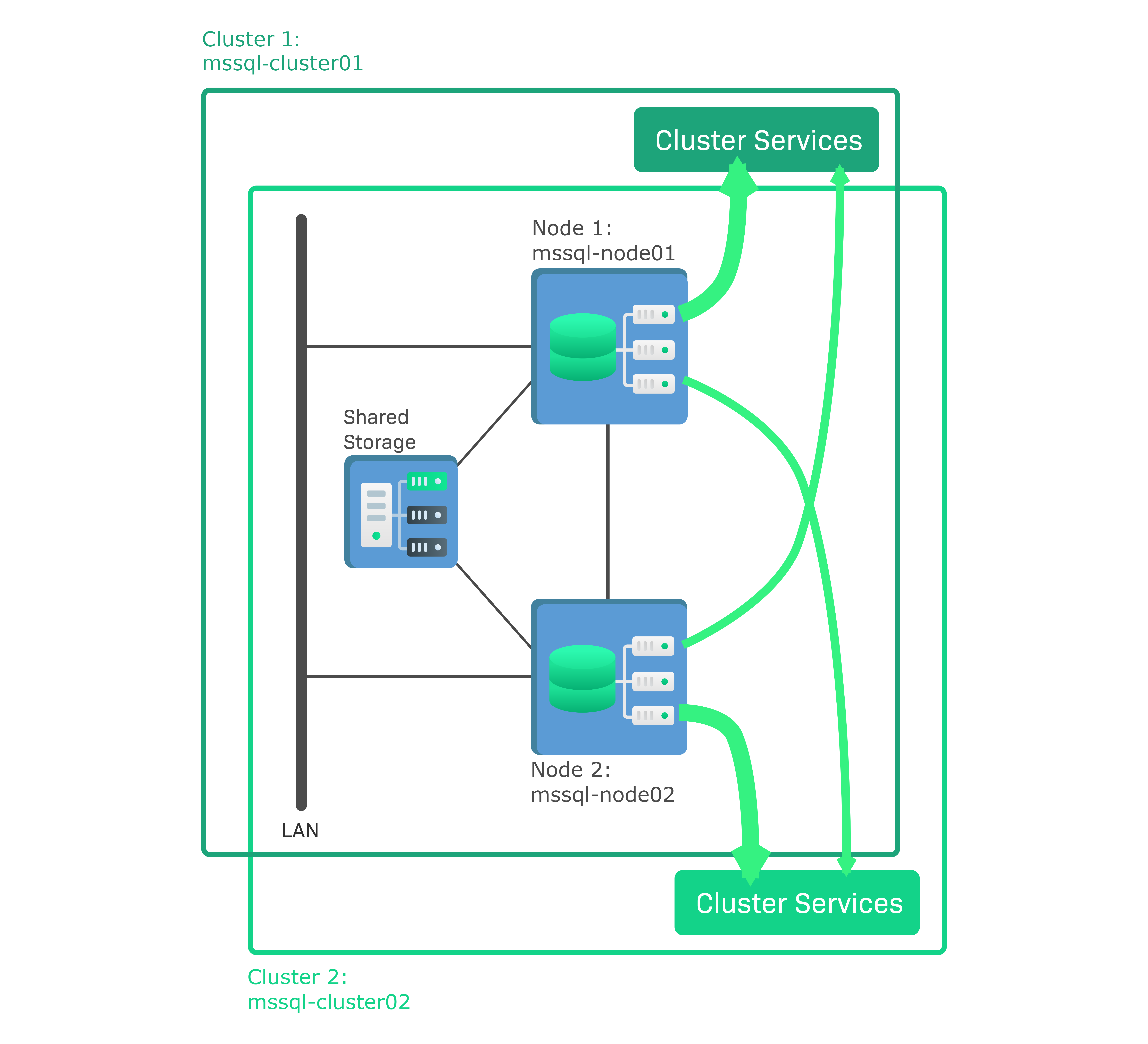
In questa configurazione, non solo MS SQL Server è installato su entrambi gli host del cluster, ma su ognuno dei due nodi è in esecuzione un'istanza di database separata. Entrambi i nodi accedono al supporto di archiviazione condiviso, ma su unità diverse. Questo esempio implementa un cluster sovrapposto al 100% perché i due nodi appartengono a entrambi i cluster.
Il vantaggio del cluster active-active è che le risorse disponibili dei due nodi vengono utilizzate meglio. In caso di failover, l'attività del nodo guasto viene assunta dal nodo alternativo, che esegue entrambe le istanze del database.
Questa configurazione di esempio è composta dai seguenti componenti:
mssql-node01è il primo nodo attivo che esegue l'istanza del databaseMSSQL Instance1.mssql-node02è il secondo nodo attivo che esegue l'istanza del databaseMSSQL Instance2.mssql-cluster01emssql-cluster02sono i due nodi del cluster a cui appartengono i due nodi.
Devi solo modificare leggermente il primo passo per la configurazione del cluster active-passive per un cluster active-active: Crea il primo clustermssql-cluster01 come descritto sopra. Poi crei il secondo clustermssql-cluster02 con gli stessi due host del cluster.
Nel secondo passo, invece di utilizzare il set di regole generale Clustered services per selezionare i servizi del cluster, utilizza il set di regole creato appositamente per i cluster sovrapposti Clustered services for overlapping clusters. Questo ti permette di definire in una regola i servizi del cluster che verranno rimossi dagli host del cluster e aggiunti al cluster selezionato.
Per il nostro esempio con una sovrapposizione del 100% abbiamo bisogno di due di queste regole: La prima regola definisce i servizi del cluster della prima istanza del database, che per impostazione predefinita vengono eseguiti sul primo host del cluster. Poiché in caso di failover questi servizi del cluster vengono trasferiti all'host del secondo nodo, assegniamo i servizi a entrambi i nodi. La seconda regola fa lo stesso per il secondo cluster e la seconda istanza del database.
Iniziamo con la prima regola: Sotto Setup > General > Rule search trova il set di regole Clustered services for overlapping clusters e cliccaci sopra. Sotto Create rule in folder seleziona nuovamente la cartella che contiene gli host nodo.
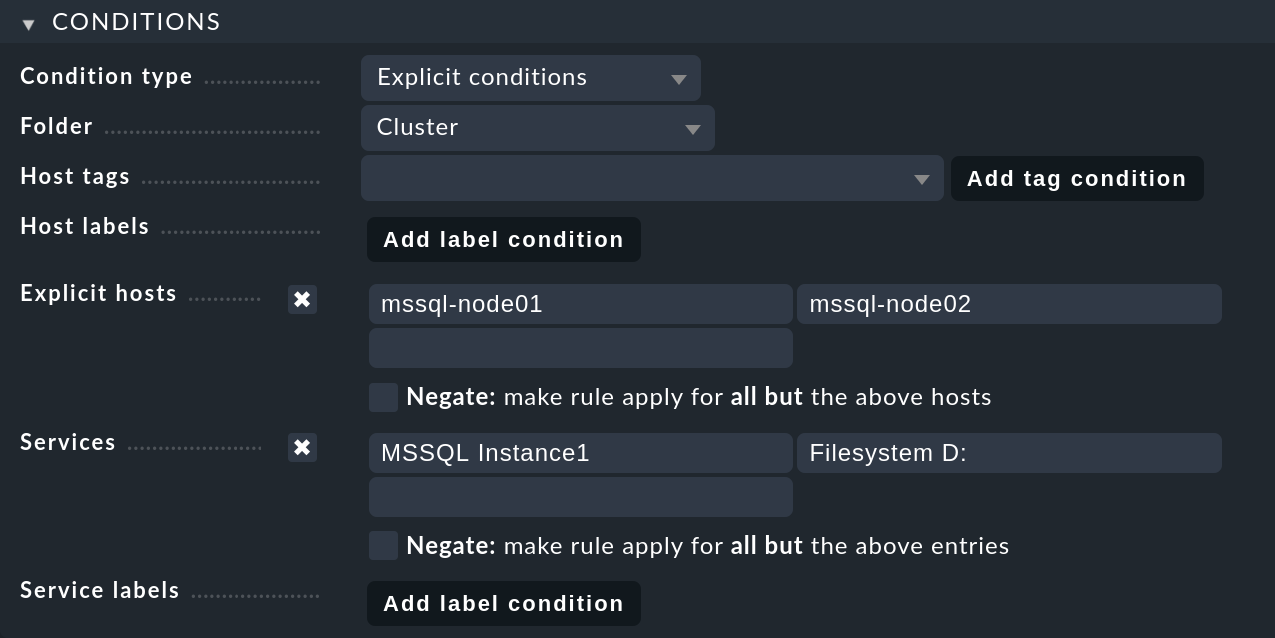
In Assign services to the following cluster inserisci il cluster mssql-cluster01:

Nel box Conditions, attiva Explicit hosts e inserisci entrambi gli host dei nodi. Successivamente, attiva Services e inserisci due voci: MSSQL Instance1
per tutti i servizi MS SQL della prima istanza del database e Filesystem D: per l'unità:
Termina la creazione della prima regola con Save.
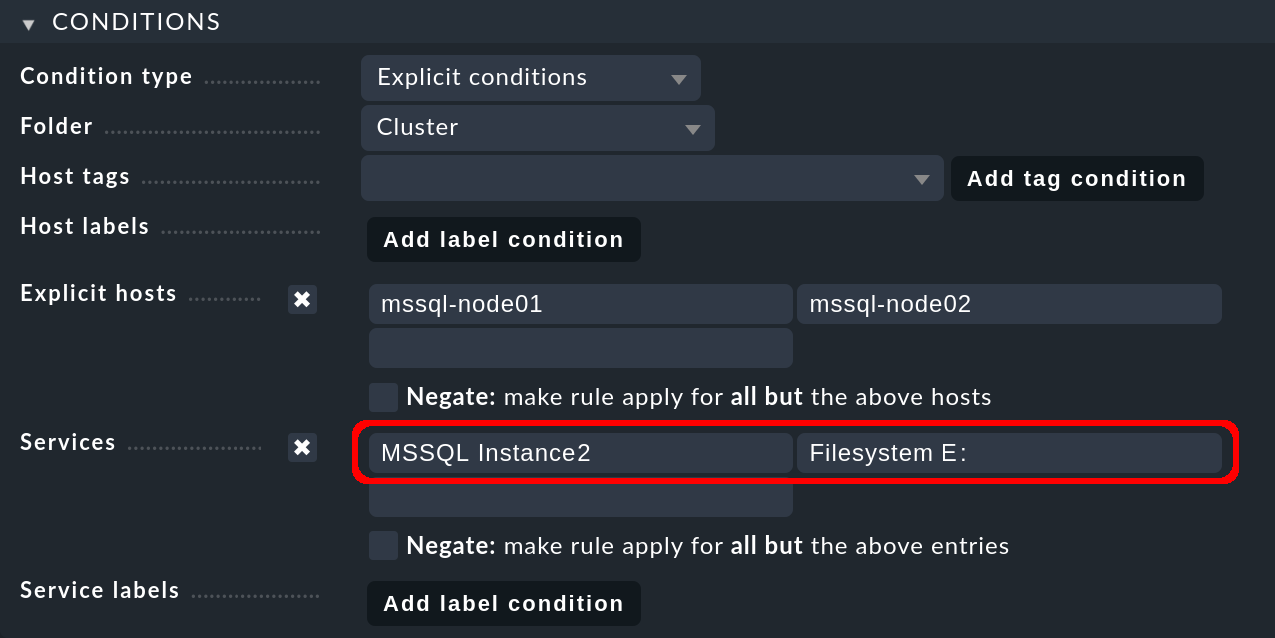
Poi crea la seconda regola, questa volta per il secondo cluster mssql-cluster02e di nuovo per entrambi gli host del cluster. Sotto Services inserisci oraMSSQL Instance2 per tutti i servizi MS SQL della seconda istanza del database. Il secondo host nodo, su cui gira per impostazione predefinita la seconda istanza del database, accede al suo supporto di memorizzazione su un'unità diversa, nell'esempio seguente tramite l'unità E::
Salva anche questa regola e attiva le due modifiche.
Infine, come terzo e ultimo passo, esegui una scoperta del servizio nello stesso modo descritto in precedenza: Bulk discovery per tutti gli host associati, cioè i due host del cluster e i due host del nodo.
Nota: se più regole definiscono un servizio cluster, la regola più specificaClustered services for overlapping clusters con l'assegnazione esplicita a un cluster specifico ha la precedenza sulla regola più generaleClustered services. Per i due esempi presentati in questo articolo, ciò significa che le ultime due regole specifiche create non permetteranno mai di applicare la regola generale creata nel primo esempio.