This is a machine translation based on the English version of the article. It might or might not have already been subject to text preparation. If you find errors, please file a GitHub issue that states the paragraph that has to be improved. |
1. Introduzione
In Checkmk, per notifica si intende l'informazione attiva degli utenti in caso di problemi o di altri eventi di monitoraggio. Il metodo più comunemente utilizzato è quello delle e-mail, ma esistono anche altri metodi, come l'invio di SMS o l'inoltro a un sistema di ticket. Checkmk fornisce una semplice interfaccia per la scrittura di script per i propri metodi di notifica.
Il punto di partenza per qualsiasi notifica a un utente è un evento segnalato dal nucleo di monitoraggio. Nel seguente articolo chiameremo questo evento di monitoraggio per evitare confusione con gli eventi processati dalla Console degli Eventi. Un evento di monitoraggio è sempre legato a un particolare host o servizio. I possibili tipi di eventi di monitoraggio sono:
Un cambiamento di stato, ad es. OK → WARN
Il passaggio da uno stato stabile a uno irregolare(flap).
L'inizio o la fine di un tempo di manutenzione programmato.
La conferma di un problema da parte di un utente.
Una notifica attivata manualmente da un comando .
L'esecuzione di un gestore di avvisi .
Un evento passato per la notifica dalla Console degli Eventi .
Checkmk utilizza una notifica rule-based che ti permette di creare notifiche per l'utente a partire da questi eventi di monitoraggio e che può essere utilizzata anche per implementare requisiti molto esigenti. Una semplice notifica via e-mail, che in molti casi è del tutto soddisfacente, è comunque veloce da impostare.
2. Notificare o non notificare (ancora)?
Le notifiche sono fondamentalmente facoltative e Checkmk può essere utilizzato in modo efficiente anche senza di esse. Alcune grandi organizzazioni hanno una sorta di pannello di controllo in cui un team operativo tiene costantemente sotto controllo l'interfaccia di Checkmk e quindi le notifiche aggiuntive non sono necessarie. Se il tuo ambiente Checkmk è ancora in fase di costruzione, è bene considerare che le notifiche saranno utili ai tuoi colleghi solo quando non si produrrannofalsi allarmi (falsi positivi) o se ne produrranno solo occasionalmente. Per prima cosa è necessario prendere confidenza con i valori di soglia e con tutte le altre impostazioni, in modo che tutti gli stati siano OK / UP- o in altre parole: tutto è "verde".
L'accettazione del nuovo monitoraggio svanirà rapidamente se ogni giorno la casella di posta elettronica sarà invasa da centinaia di e-mail inutili.
La seguente procedura si è dimostrata efficace per la messa a punto delle notifiche:
Fase 1: metti a punto il monitoraggio, da un lato risolvendo i problemi reali appena scoperti da Checkmk e, dall'altro, eliminando i falsi allarmi. Procedi in questo modo fino a quando tutto è "normalmente" OK / UP. Consulta la Guida per principianti per alcuni consigli su come ridurre i falsi allarmi tipici.
Fase 2: Successivamente, switcha le notifiche in modo che siano attive solo per te stesso. Riduci la "staticità" causata da problemi sporadici e di breve durata. A tal fine, regola altri valori di threshold, utilizza il monitoraggio predittivo se necessario, aumenta il numero di tentativi di check o prova le notifiche ritardate. E naturalmente, se sono responsabili di problemi reali, cerca di tenerli sotto controllo.
Fase 3: una volta che la tua casella di posta elettronica è tollerabilmente tranquilla, attiva le notifiche per i tuoi colleghi. Crea gruppi di contatto efficienti in modo che ogni contatto riceva solo le notifiche che lo riguardano.
Queste procedure daranno vita a un sistema in grado di fornire informazioni rilevanti che contribuiranno a ridurre le interruzioni.
3. Semplici notifiche via e-mail
Una notifica via e-mail inviata da Checkmk in formato HTML ha un aspetto simile a questo:
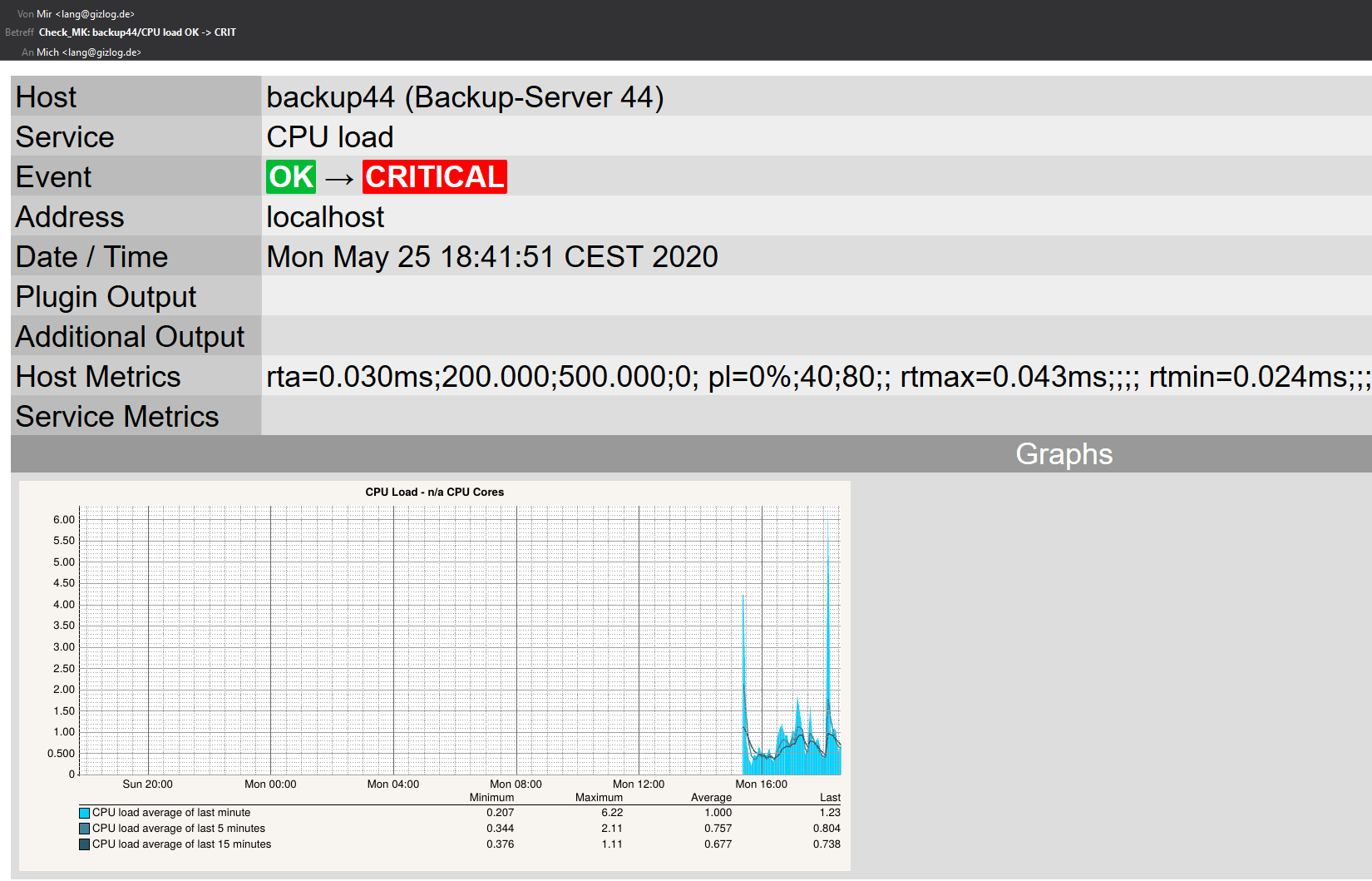
Come si può vedere nell'esempio, l'e-mail contiene anche le letture attuali del servizio interessato.
Prima di ricevere un'e-mail di questo tipo da Checkmk, sono necessari alcuni preparativi, descritti di seguito.
3.1. Prerequisiti
Nella configurazione predefinita di Checkmk, un utente riceve notifiche via e-mail quando sono soddisfatti i seguenti prerequisiti:
Il server Checkmk ha una configurazione funzionante per l'invio di e-mail.
L'utente ha un indirizzo e-mail configurato.
L'utente è membro di un gruppo di contatto e quindi è un contatto.
Si verifica un evento di monitoraggio su un host o un servizio assegnato a questo gruppo di contatto, che attiva una notifica.
3.2. Impostazione dell'invio di posta elettronica in Linux
Per inviare con successo le e-mail, il tuo server Checkmk deve avere una configurazione funzionante del server SMTP. A seconda della tua distribuzione Linux, questo potrebbe utilizzare, ad esempio, Postfix, Qmail, Exim o Nullmailer. La configurazione sarà implementata con le risorse della tua distribuzione Linux.
In genere la configurazione si limita alla registrazione di uno "smarthost" (noto anche come server SMTP relay) a cui verranno indirizzate tutte le e-mail. Questo sarà il server SMTP interno della tua azienda. Di regola gli smarthost non richiedono l'autenticazione in una LAN, il che semplifica le cose. In alcune distribuzioni lo smarthost viene interrogato durante l'installazione. Con l'appliance Checkmk è possibile configurare lo smarthost comodamente tramite l'interfaccia web.
Puoi testare facilmente l'invio di e-mail con il comando mail sulla linea di comando. Poiché esistono numerose implementazioni diverse di questo comando in Linux, per standardizzarlo Checkmk fornisce la versione del progetto Heirloom mailx direttamente nel percorso di ricerca dell'utente del sito (come ~/bin/mail). Il file di configurazione corrispondente è ~/etc/mail.rc. Il modo migliore per testare è come utente dell'istanza, poiché gli script di notifica verranno eseguiti con gli stessi permessi.
Il contenuto dell'e-mail viene letto dallo standard input, l'oggetto viene specificato con -s e l'indirizzo del destinatario viene semplicemente aggiunto come argomento alla fine della riga di comando:
OMD[mysite]:~$ echo "content" | mail -s test-subject harry.hirsch@example.comL'e-mail dovrebbe essere consegnata senza ritardi. Se non funziona, puoi trovare informazioni nel file di log del server SMTP nella directory /var/log (vedi file e directory).
3.3. Indirizzo e-mail e gruppo di contatto
L'indirizzo e-mail e il gruppo di contatto di un utente sono definiti nell'amministrazione dell'utente:
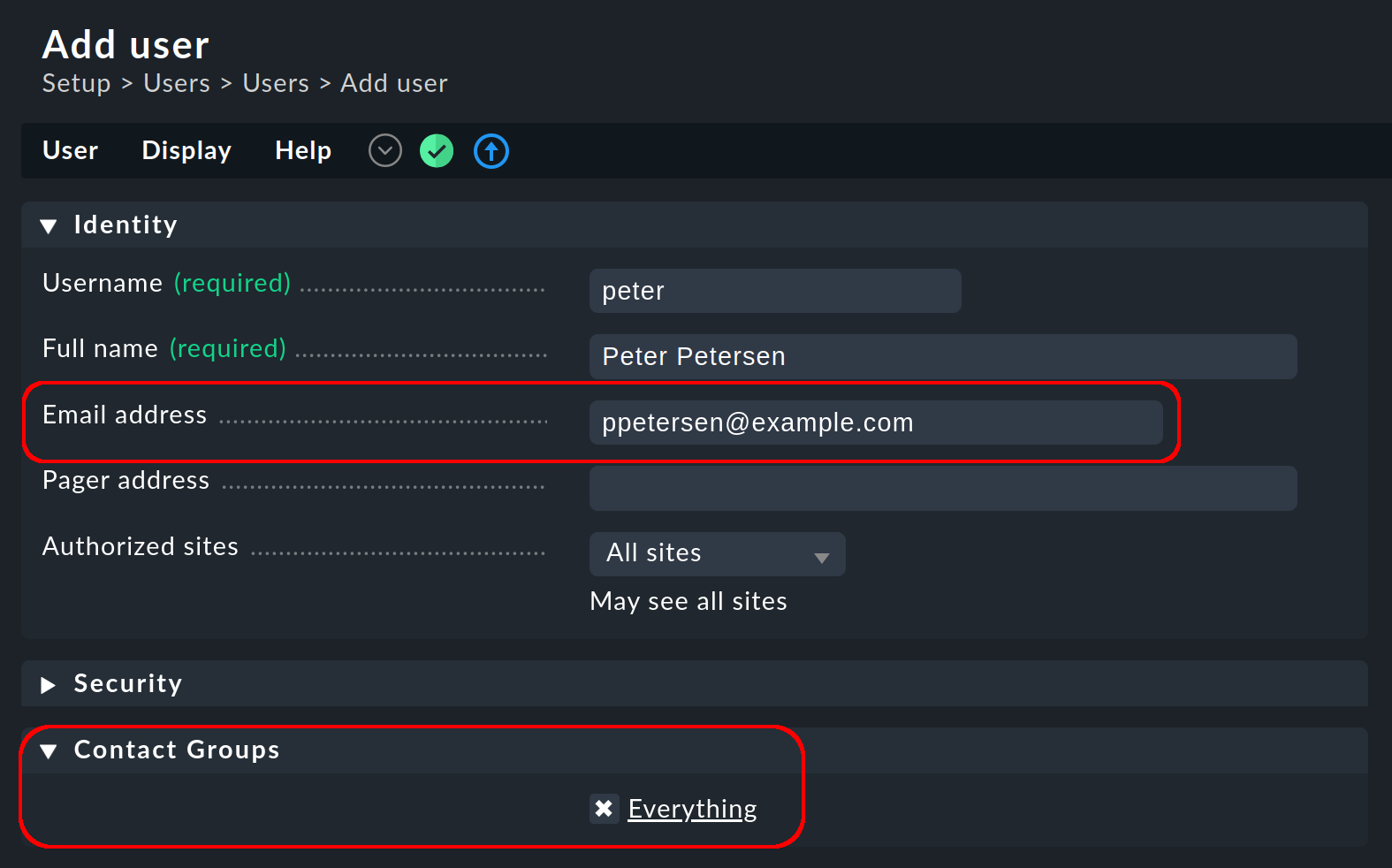
In un'istanza Checkmk appena creata, inizialmente esiste solo il gruppo di contatto Everything. I membri di questo gruppo sono automaticamente responsabili di tutti gli host e i servizi e riceveranno una notifica via e-mail di ogni evento di monitoraggio rilevante.
Nota: se la tua installazione di Checkmk è stata generata con una versione precedente, questo gruppo potrebbe anche chiamarsi Everybody. Ciò è tuttavia illogico, poiché questo gruppo non contiene tutti gli utenti, bensì tutti gli host. A parte i nomi diversi, la funzione è la stessa.
3.4. Casi speciali: Sistema di ticket, messenger e motore di eventi
Invece di e-mail o SMS, puoi inviare notifiche a un sistema di ticket (come Jira o ServiceNow), a un messenger (Slack, Mattermost) o a un motore di eventi (Console degli Eventi). Esiste un metodo di notifica separato per ognuno di questi casi speciali, che può essere selezionato nella regola di notifica. Tuttavia, devi tenere presente i due punti seguenti quando crei la regola:
Quando selezioni i contatti, assicurati che le notifiche vengano inviate a un solo contatto, ad esempio selezionando un solo utente. Con i metodi di notifica per i sistemi di ticket, ecc. la selezione del contatto serve solo a specificare l' invio delle notifiche, che però non vengono inviate all'utente selezionato, ma al sistema di ticket. Tieni presente che una selezione di contatti tramite gruppi di contatti, tutti i contatti di un oggetto o simili genera di solito diverse notifiche identiche per un evento, che poi finiscono nel sistema di ticket due, tre o anche più volte.
Se il primo punto è soddisfatto, ma l'utente è utilizzato in più regole di notifica per lo stesso metodo, allora si applica solo l'ultima regola in ogni caso. È quindi consigliabile creare un utente funzionale separato per ciascuna di queste regole di notifica.
3.5. Testare le regole di notifica
|
In Checkmk 2.3.0 Test notifications puoi testare tutte le regole di notifica e inviare notifiche via e-mail. Se vuoi testare l'effettivo invio di qualcosa di diverso dalle e-mail, puoi comunque utilizzare i risultati di Fake check. |
Per testare le regole di notifica, Checkmk offre uno strumento intelligente con Test notifications. Puoi usarlo per simulare una notifica per un host o un servizio e riconoscere quali regole di notifica sono efficaci. Oltre alla simulazione, puoi anche inviare una notifica e-mail.
Il modo più rapido per accedere al test di notifica è tramite Setup > Events > Notifications e il pulsante Test notifications. Inoltre, ci sono altre opzioni di chiamata da alcune visualizzazioni nel Monitoraggio (elenco dei servizi e dettagli dei servizi) e nel Menu di configurazione (proprietà degli host), in ogni caso nel menu Host > Test notifications.
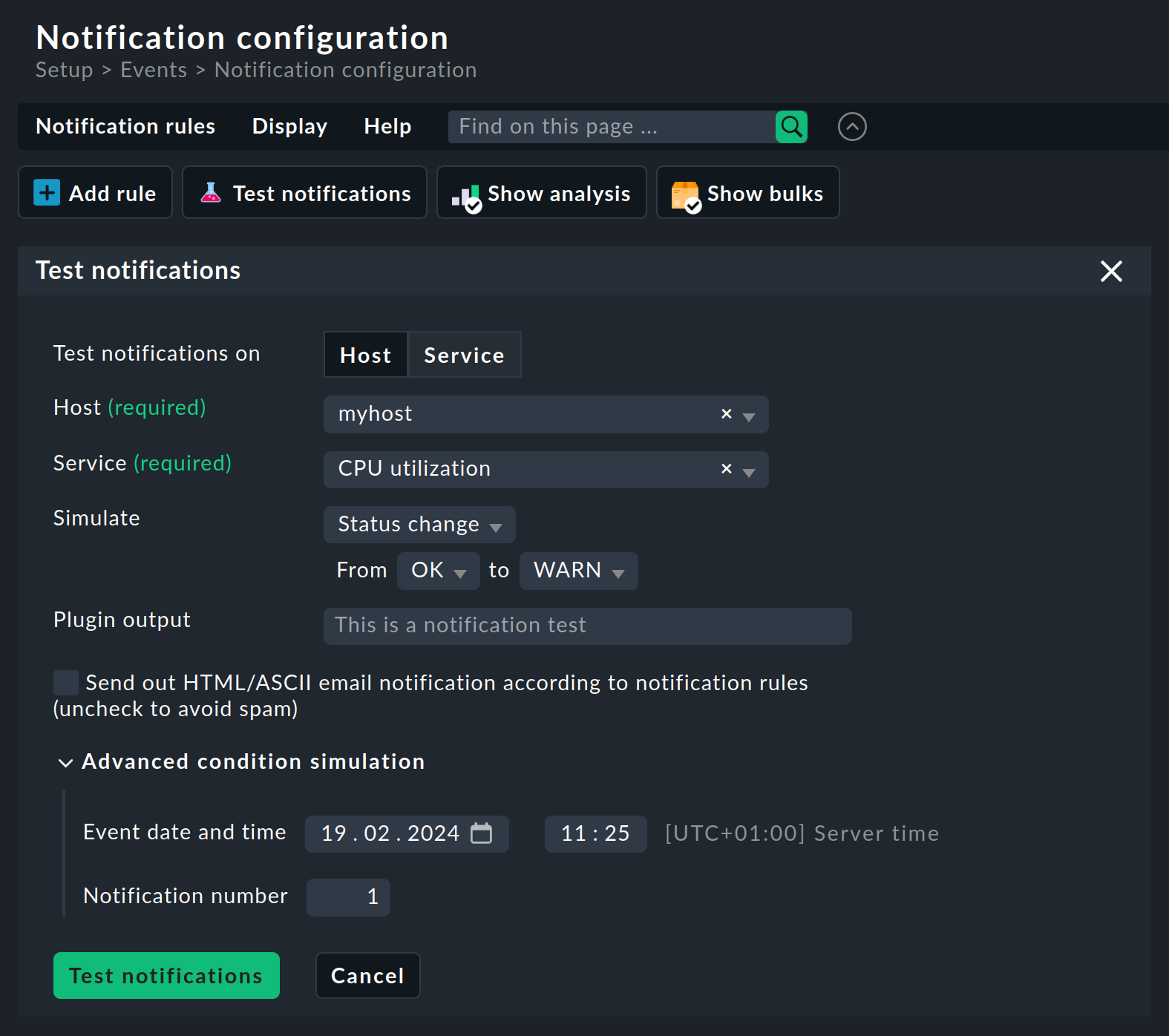
Per prima cosa, clicca su uno dei due pulsanti per decidere se la notifica è per un Host o un Service. Poi seleziona quale host o servizio deve essere. Puoi aggiungere una descrizione del servizio a Plugin output. Come evento puoi selezionare un cambiamento di stato o l'inizio di un tempo di manutenzione programmato. Usa il checkbox Send out HTML/ASCII email notification according to notification rules per specificare se la notifica è solo simulata o effettivamente inviata.
Infine, alla voce Advanced condition simulation ci sono altre due opzioni con cui puoi definire l'orario e il numero di notifiche. Questo ti permette di testare regole di notifica che si applicano solo in un determinato periodo di tempo (es. al di fuori dell'orario di lavoro) o che avviano un'escalation dopo un determinato numero di notifiche ripetute.
Clicca su Test notifications per avviare il test e anche l'invio dell'e-mail, se hai selezionato questa opzione. La finestra di dialogo Test notifications viene nascosta e vengono mostrati i risultati:
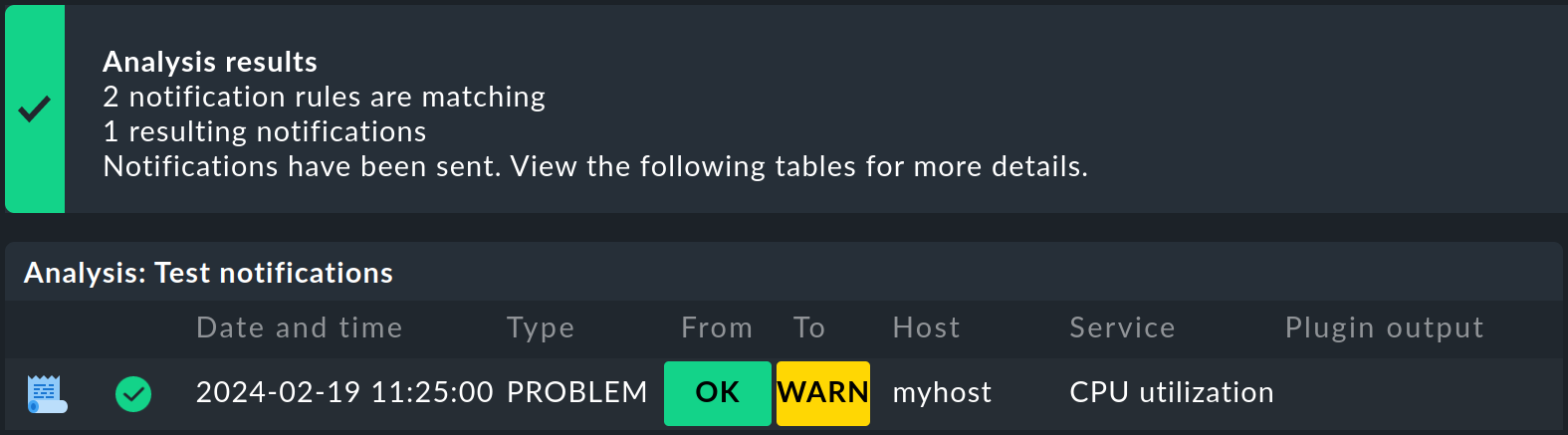
Sotto Analysis results puoi vedere quante regole di notifica si applicano e quante notifiche ne derivano. Se hai selezionato Invia notifica, viene visualizzato il messaggio corrispondente Notifications have been sent. Questo deve portare immediatamente a un'e-mail per questo problema.
La riga sottostante riassume le notifiche generate dalle tue voci. Cliccando sul simbolo, puoi visualizzare il contesto della notifica, che ti permette di vedere le variabili d'ambiente e i loro valori validi nel contesto di questa notifica.
Le due sezioni successive mostrano ulteriori dettagli:
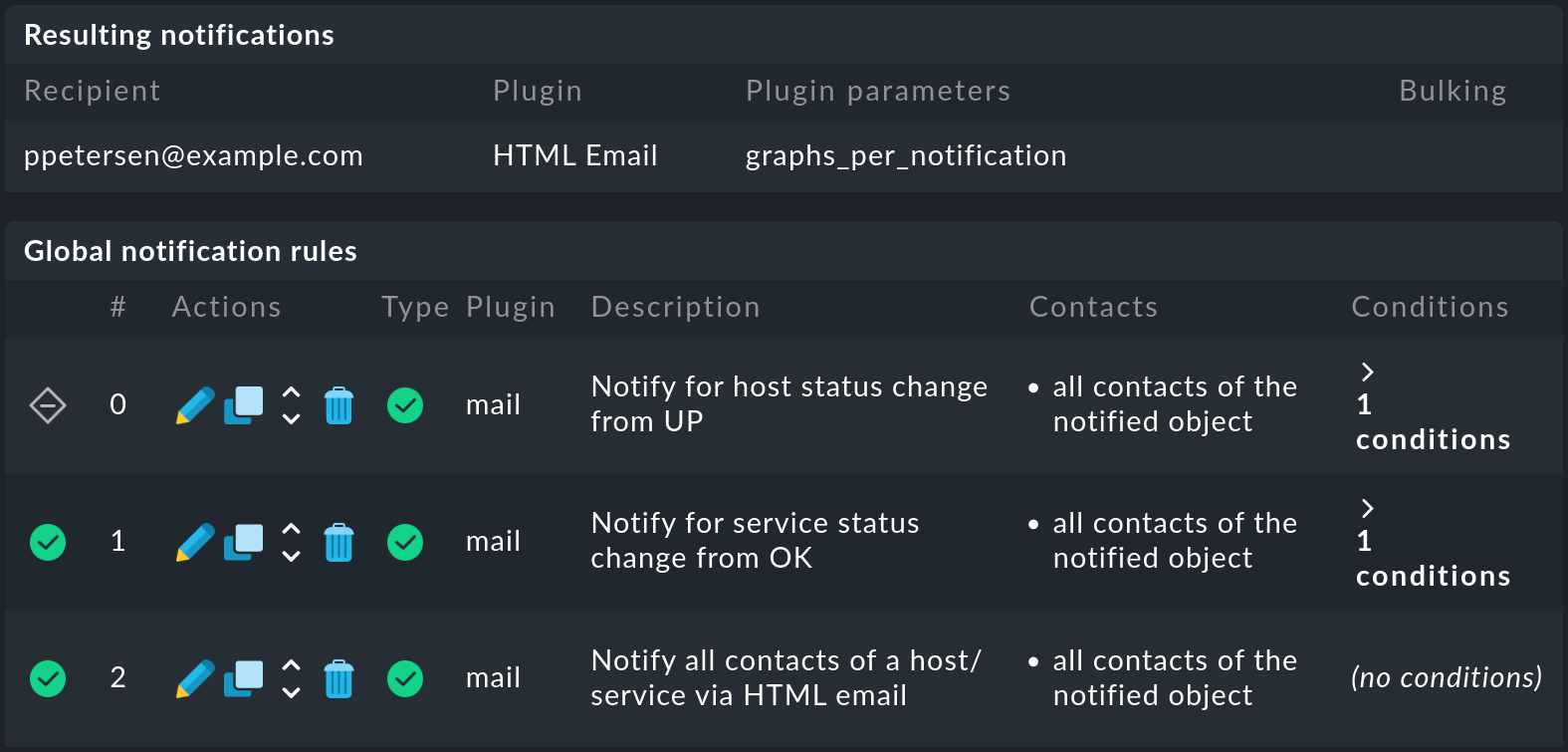
In Resulting notifications puoi vedere a chi e come vengono inviate le notifiche. Riceverai queste informazioni sulla simulazione anche se non hai selezionato l'invio della notifica.
In Global notification rules sono elencate le regole di notifica, presentate in modo più dettagliato nel prossimo capitolo. A questo punto, è importante solo la prima colonna della tabella, che utilizza dei simboli per indicare quali regole si applicano e quali no. Nell'esempio, la prima regola non si applica perché valuta i cambiamenti di stato degli host, ma l'evento è un cambiamento di stato di un servizio.
Come al solito, puoi continuare ad attivare le notifiche direttamente tramite la GUI in alternativa al test delle notifiche tramite la simulazione, ad es. con i comandi Send custom notification e Fake check results. |
3.6. Mettere a punto le e-mail HTML
Quando invii un'e-mail HTML, potresti voler aggiungere informazioni aggiuntive o definire in modo flessibile un indirizzo e-mail di risposta (Reply to) a un contatto specifico per qualsiasi domanda. A questo scopo, esiste la regola Setup > Services > Service monitoring rules > Parameters for HTML Email e nelle regole di notifica il metodo di notifica dell'e-mail HTML. Con queste regole puoi aggiungere una serie di parametri come l'indirizzo e-mail di risposta, campi aggiuntivi con dettagli o testo libero formattato come HTML.
Nota che nel campo Add HTML section above table (e.g. title, description…), per motivi di sicurezza, sono consentiti solo una piccola serie di tag HTML, che sono:
| Tag | Funzione | Suggerimenti |
|---|---|---|
|
Consentito se combinato con gli attributi |
|
|
||
|
||
|
||
|
Deprecato. Non usare questo tag! |
|
|
||
|
||
|
||
|
Deprecato. Non usare questo tag! |
|
|
Gli spazi e i rientri sono conservati. |
|
|
||
|
||
|
||
|
Da utilizzare solo all'interno dei seguenti elenchi |
|
|
||
|
Come di consueto con tutte le regole di Checkmk, è possibile un'applicazione a grana molto fine, in modo da poter personalizzare un set dettagliato di notifiche agli host e ai servizi a seconda delle esigenze.
4. Controllare le notifiche con le regole di notifica
4.1. Il principio
Checkmk è configurato "di default" in modo che quando si verifica un evento di monitoraggio venga inviata un'e-mail di notifica a tutti i contatti dell'host o del servizio interessato. Questo è certamente ragionevole all'inizio, ma nella pratica sorgono molti altri requisiti, ad esempio:
La soppressione di notifiche specifiche e meno utili.
L'abbonamento alle notifiche di servizi per i quali non si è contatto.
Le notifiche possono essere inviate tramite e-mail, SMS o cercapersone, a seconda dell'ora del giorno.
L'escalation dei problemi quando non si riceve alcuna conferma oltre un certo limite di tempo.
L'opzione di NESSUNA notifica per gli stati WARN o SCONOSCIUTO
e molto altro ancora...
Checkmk ti offre la massima flessibilità nell'implementazione di tali requisiti grazie al suo meccanismo rule-based. Accedi alla configurazione con Setup > Events > Notifications.
Nota: quando richiami la pagina Notification configuration per la prima volta, vedrai un avviso relativo all '"indirizzo e-mail di riserva" non configurato. Per il momento puoi ignorare questo avviso. Approfondiremo l'argomento più avanti.
Nella configurazione delle notifiche, gestisci la catena di regole di notifica che determinano chi deve essere avvisato e come. Quando si verifica un evento di monitoraggio, questa catena di regole viene percorsa da cima a fondo. Ogni regola ha una condizione che decide se la regola si applica effettivamente alla situazione in questione.
Se la condizione è soddisfatta, la regola determina due cose:
Una selezione di contatti(chi deve essere notificato?).
Un metodo di notifica(Come notificare?), ad esempio un'e-mail HTML e, facoltativamente, parametri aggiuntivi per il metodo scelto.
Importante: a differenza delle regole per host e servizi, in questo caso la valutazione continua anche dopo che la regola di notifica applicabile è stata soddisfatta. Le regole successive possono aggiungere altre notifiche. Le notifiche generate dalle regole precedenti possono anche essere eliminate.
Il risultato finale della valutazione delle regole sarà una tabella con una struttura simile a questa:
| Chi (contatto) | Come (metodo) | Parametri per il metodo |
|---|---|---|
Harry Hirsch |
|
|
Bruno Weizenkeim |
|
|
Bruno Weizenkeim |
SMS |
Ora, per ogni voce di questa tabella verrà invocato lo script di notifica che esegue la notifica all'utente appropriata al metodo di notifica.
4.2. La regola iniziale predefinita
Se hai una Checkmk appena installata, è stata predefinita una regola:

Questa regola definisce il comportamento predefinito sopra descritto. È strutturata come segue:
Condizione |
Nessuna, cioè la regola si applica a tutti gli eventi di monitoraggio. |
Metodo |
Invia un'e-mail in formato HTML (con grafici metrici incorporati) |
Contatti |
Tutti i contatti dell'host/servizio interessato. |
Come al solito, puoi modificare la regola, clonarla (copiarla), eliminarla o crearne una nuova. Una volta che hai più di una regola, puoi cambiare il loro ordine di elaborazione trascinandole con il simbolo.
Nota: le modifiche alle regole di notifica non richiedono l'attivazione delle modifiche, ma hanno effetto immediato.
4.3. Struttura delle regole di notifica
Di seguito presentiamo la struttura generale delle regole di notifica con le definizioni delle proprietà generali, dei metodi, dei contatti e delle condizioni.
Proprietà generali
Come per tutte le regole di Checkmk, qui puoi inserire una descrizione e un commento per la regola o anche disattivarla temporaneamente.
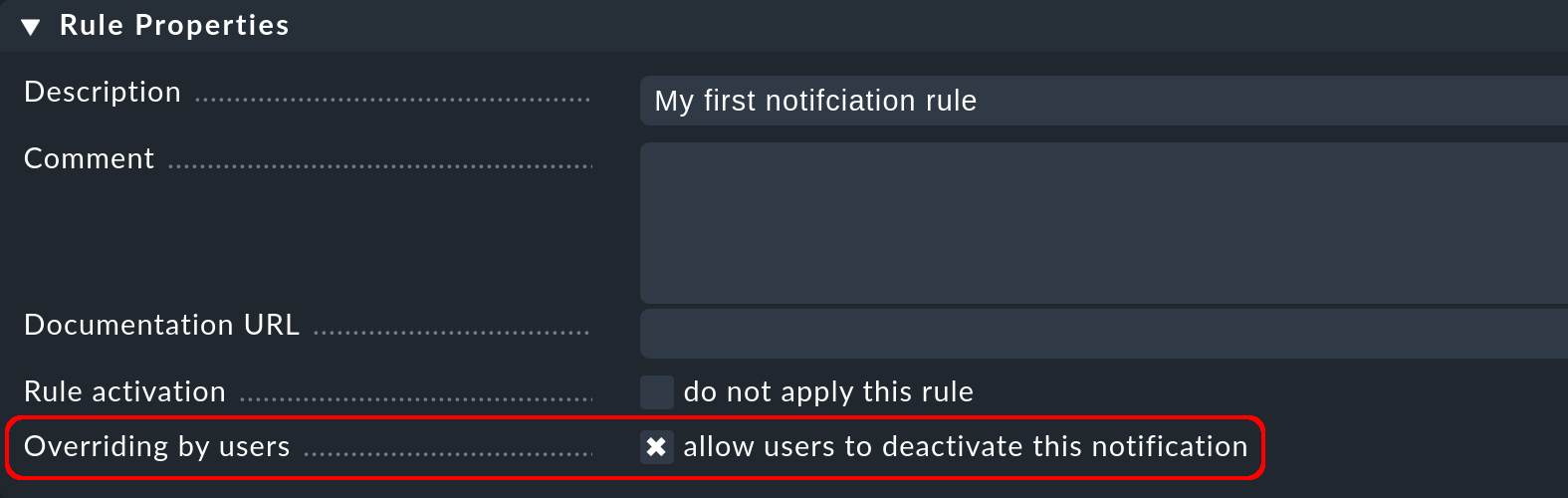
L'opzione Overriding by users è attivata per impostazione predefinita. attivata. Permette agli utenti di "cancellarsi" dalle notifiche generate da questa regola. Ti mostriamo come farlo con le notifiche personalizzate.
Metodo di notifica
Il metodo di notifica specifica la tecnica da utilizzare per inviare la notifica, ad es. con un'e-mail HTML.
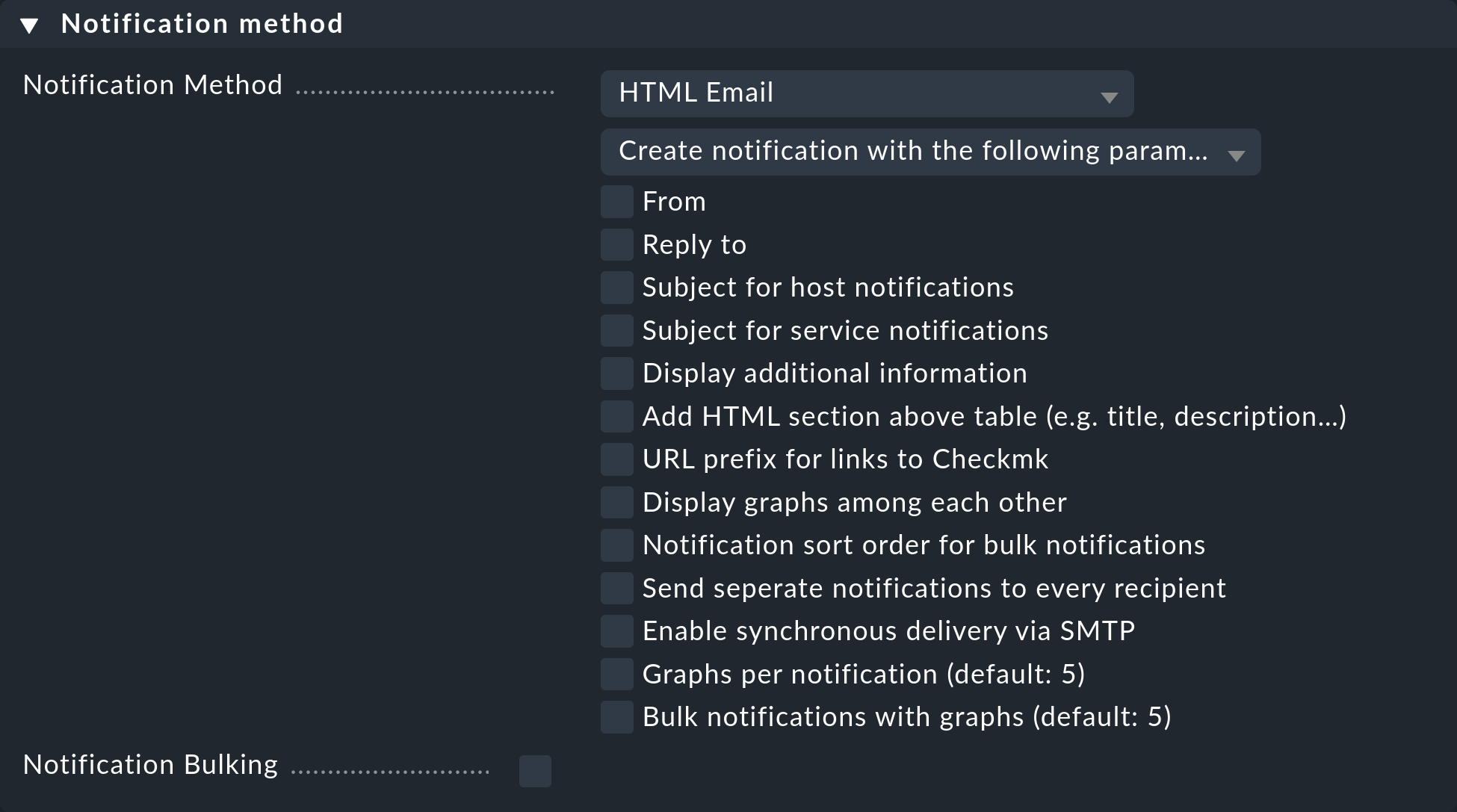
Ogni metodo di notifica è realizzato tramite uno script. Checkmk include una serie di script. Puoi anche scrivere facilmente script personalizzati in qualsiasi linguaggio di programmazione desiderato per implementare notifiche speciali, ad esempio per reindirizzare una notifica al tuo sistema di ticket.
Un metodo può includere dei parametri, come ad esempio permettere al metodo che invia e-mail ASCII e HTML di impostare esplicitamente l'indirizzo del mittente (From:).
Prima di effettuare le impostazioni direttamente nella regola di notifica, è bene sapere che i parametri dei metodi di notifica possono essere specificati anche tramite regole per host e servizi: in Setup > Services > Service monitoring rules, nella sezione Notifications, troverai un set di regole per ogni metodo di notifica, che potrai utilizzare per definire le stesse impostazioni e, come al solito, possono dipendere dall'host o dal servizio.
La definizione di parametri nelle regole di notifica permette di variare queste impostazioni nei singoli casi: ad esempio, puoi definire un oggetto globale per la tua e-mail, ma anche un oggetto alternativo con una regola di notifica individuale.
Al posto dei parametri puoi anche selezionare Cancel previous notifications - con il quale verranno cancellate tutte le notifiche di questo metodo da regole precedenti. Per saperne di più, consulta il tema Cancellare le notifiche.
Nota: per molti metodi di notifica per l'inoltro ad altri sistemi, troverai informazioni più dettagliate in articoli separati. L'elenco degli articoli si trova nel capitolo sugli script di notifica.
Selezionare i contatti
La procedura più comune prevede che le notifiche vengano inviate a tutti gli utenti che sono stati registrati come contatti per il rispettivo host/servizio. Questa è la procedura "normale" e logica, poiché è anche attraverso i contatti che si definiscono gli oggetti che ogni utente riceve nella visualizzazione della GUI - in pratica gli oggetti di cui l'utente è responsabile.
Puoi selezionare diverse opzioni nella selezione dei contatti ed estendere così la notifica a più contatti:
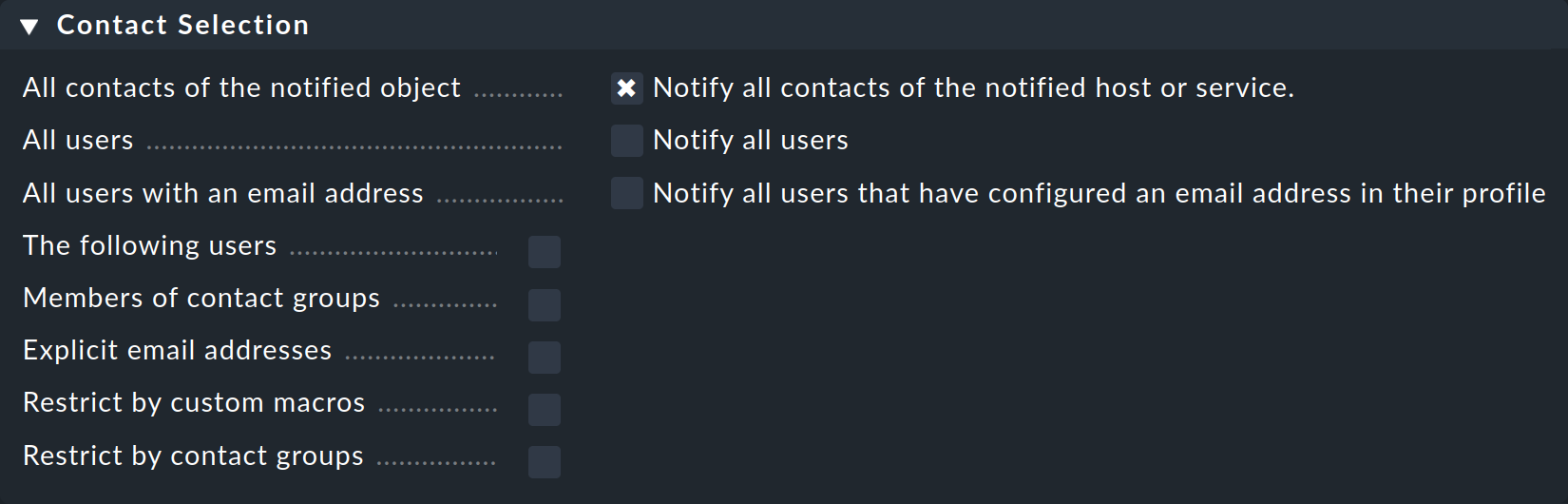
Checkmk eliminerà automaticamente i contatti duplicati. Affinché la regola abbia senso, deve essere effettuata almeno una selezione.
Le due opzioni Restrict by… funzionano in modo diverso: anche in questo caso i contatti selezionati con le altre opzioni saranno limitati. Con queste opzioni puoi anche creare un operatore AND tra gruppi di contatti, ad esempio per consentire l'invio di notifiche a tutti i contatti che sono membri di entrambi i gruppi Linux e Data center.
Inserendo Explicit email addresses puoi inviare notifiche a persone che in realtà non sono state nominate utenti in Checkmk. Questo ovviamente ha senso solo se utilizzato nel metodo di notifica che invia effettivamente le e-mail.
Se nel metodo scelto hai selezionato Cancel previous notifications, le notifiche verranno eliminate solo per il contatto selezionato.
Nota: se utilizzi un sistema di ticket, un messenger o un motore di eventi come metodo di notifica, devi osservare le note relative a questi casi speciali.
Condizioni
Le condizioni determinano quando una regola verrà utilizzata. Per la comprensione è importante ricordare che la fonte è sempre un evento di monitoraggio su un host o un servizio concreto.
Le condizioni riguardano
gli attributi statici dell'oggetto, ad esempio se il nome del servizio contiene il testo
/tmp,con lo stato corrente o il cambiamento di stato, ad es. se il servizio è appena passato da OK a CRIT,
o con cose completamente diverse, ad esempio se ilperiodo di "tempo di lavoro" è attualmente attivo.
Ci sono due punti importanti da considerare quando si impostano le condizioni:
Se non sono state definite condizioni, la regola avrà effetto per ogni evento di monitoraggio.
Non appena selezioni anche una sola condizione, la regola entra in vigore solo se tutte le condizioni sono soddisfatte. Tutte le condizioni selezionate sono collegate con AND. C'è solo un'eccezione a questa importante regola, di cui parleremo più avanti e che non considereremo ora.
Ciò significa che devi prestare molta attenzione al fatto che le condizioni che hai scelto possano essere soddisfatte contemporaneamente in modo da attivare una notifica per il caso desiderato.
Supponiamo che tu voglia attivare una notifica quando si verifica un evento di monitoraggio per un servizio che inizia con il nome NTP su un host della cartella Main:
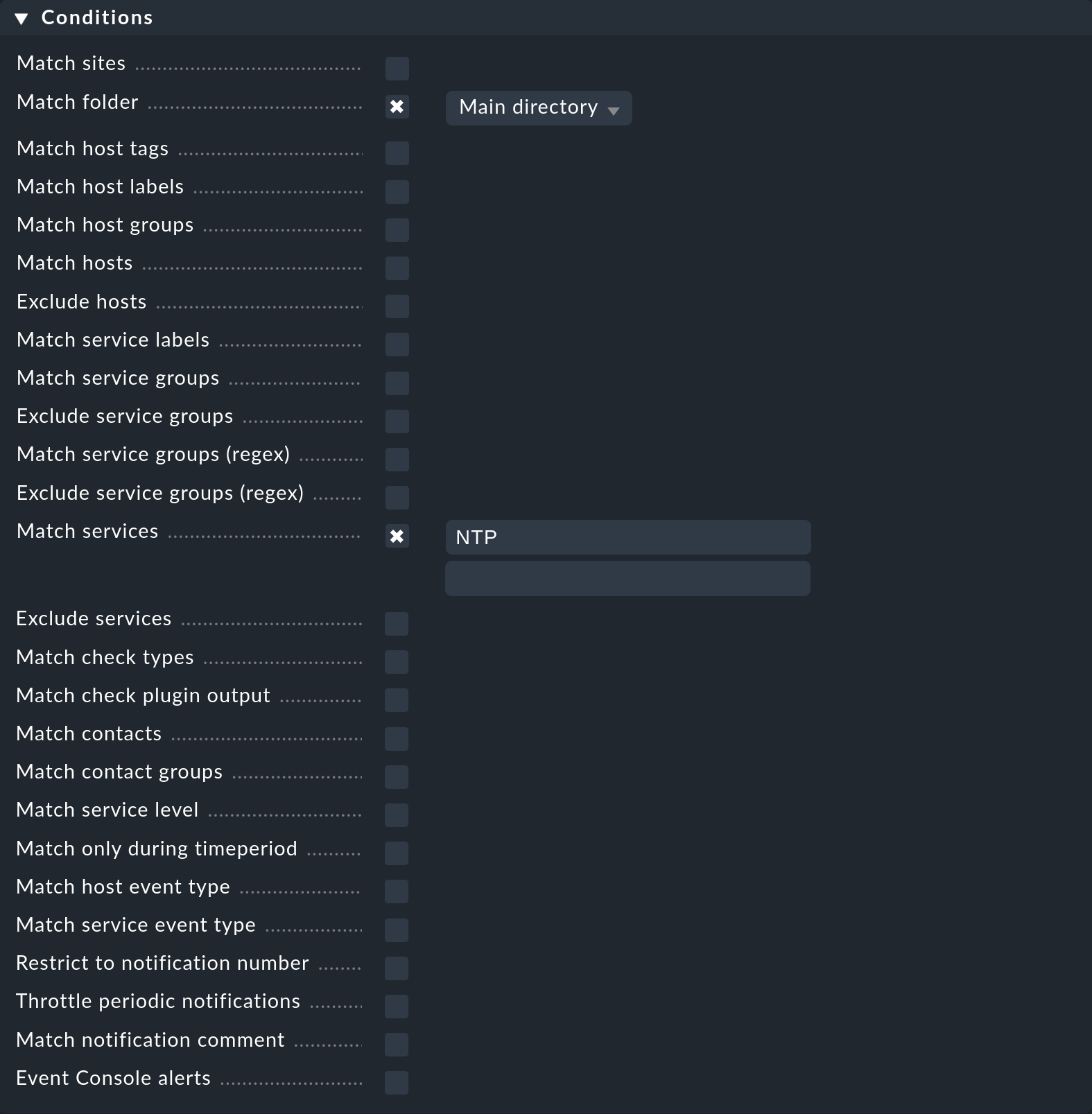
Supponiamo inoltre che questa condizione venga estesa per notificare anche tutti i cambiamenti di stato di un host nello stato DOWN:

Il risultato di questa regola di notifica con le tre condizioni singole è che non si verificherà mai una notifica, perché nessun evento di monitoraggio conterrà il cambiamento di stato di un host e il nome del servizio con NTP.
La seguente nota viene ripetuta di tanto in tanto in questo manuale d'uso. Tuttavia, in connessione con la configurazione delle tue notifiche, va sottolineato ancora una volta: mostra l'aiuto contestuale con Help > Show inline help per ottenere dettagli sull'effetto delle varie condizioni. Il seguente estratto dall'aiuto contestuale per l'opzione Match services illustra molto bene il comportamento: "Nota: le notifiche dell'host non corrisponderanno mai a questa regola, se si utilizza questa opzione."
L'eccezione all'operazione AND
Solo se un evento di monitoraggio soddisfa tutte le condizioni configurate, la regola di notifica verrà applicata. Come già detto, esiste un'importante eccezione a questa regola generale: le condizioni Match host event type e Match service event type:
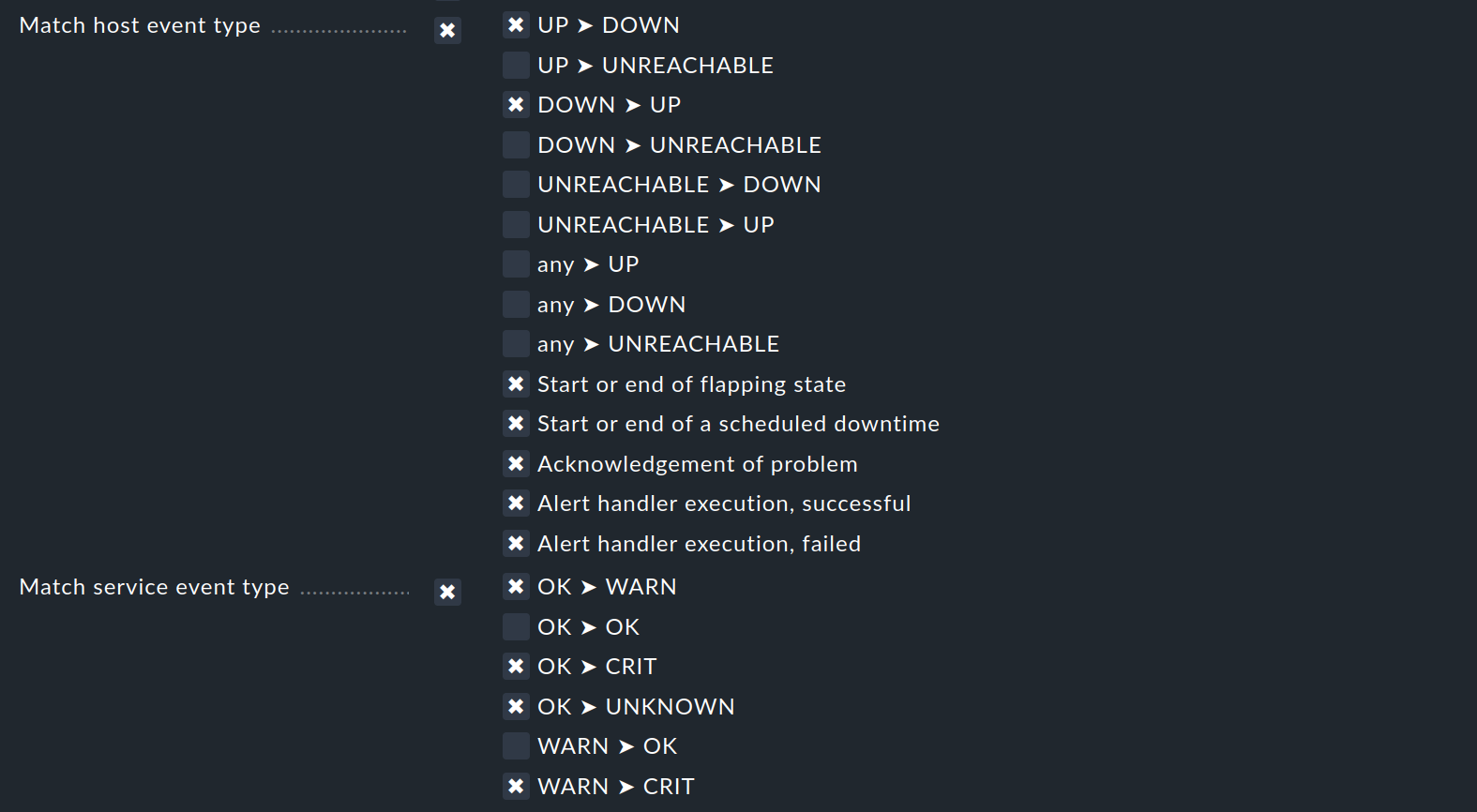
Se selezioni solo Match host event type, la regola non corrisponderà a nessun singolo evento di servizio. Allo stesso modo, questo vale per la selezione di Match service event type e degli eventi host. Se invece attivi entrambe le condizioni, la regola corrisponderà se il tipo di evento è attivato in uno qualsiasi dei due elenchi di checkbox. In questo caso eccezionale, le condizioni non saranno collegate con un "AND" logico, ma piuttosto con un "OR". In questo modo puoi amministrare le regole di notifica di host e servizi con un'unica regola.
Un ulteriore suggerimento sulle condizioni di Match contacts e Match contact groups:
La condizione verificata in questo caso è se l'host/servizio in questione ha un determinato gruppo di contatti. Questo può essere utilizzato per implementare funzioni come "Le notifiche del gruppo di host nel gruppo di contatti Linux non devono mai essere inviate via SMS". Questo non ha nulla a che fare con la selezione dei contatti descritta in precedenza.
4.4. Eliminare le notifiche
Come già accennato nella selezione del metodo di notifica, troverai anche l'opzione di selezione Cancel previous notifications. Per poter comprendere il funzionamento di una regola di questo tipo, è meglio visivamente visualizzare la tabella delle notifiche. Supponendo che il processo delle regole per un evento concreto di monitoraggio sia parzialmente completato e che a causa di una serie di regole siano state attivate le seguenti tre notifiche:
| Chi (contatto) | Come (metodo) |
|---|---|
Harry Hirsch |
|
Bruno Weizenkeim |
|
Bruno Weizenkeim |
SMS |
Ora viene applicata una regola successiva con il metodo SMS e la selezione Cancel previous notifications. La selezione del contatto sceglie il gruppo 'Windows', di cui fa parte Bruno Weizenkeim. Come risultato di questa regola, la voce 'Bruno Weizenkeim / SMS' viene rimossa dalla tabella, che appare così:
| Chi (contatto) | Come (metodo) |
|---|---|
Harry Hirsch |
|
Bruno Weizenkeim |
Se una regola successiva dovesse definire nuovamente un SMS di notifica per Bruno, questa regola avrà la priorità e l'SMS verrà aggiunto nuovamente alla tabella.
Per riassumere:
Le regole possono sopprimere (eliminare) notifiche specifiche.
Le regole di cancellazione devono essere successive alle regole di notifica.
Una regola di eliminazione non "cancella" effettivamente una regola precedente, ma sopprime le regole di notifica generate dalle regole (eventualmente multiple) precedenti.
Le regole successive possono ripristinare le notifiche precedentemente soppresse.
4.5. Cosa succede se nessuna regola è applicabile?
Chi configura può anche commettere degli errori. Un possibile errore nella configurazione delle notifiche potrebbe essere quello di scoprire un problema di monitoraggio critico, ma di non applicare nessuna regola di notifica.
Per proteggerti da questa eventualità, Checkmk offre l'impostazione Fallback email address for notifications che si trova sotto Setup > General > Global settings nella sezione Notifications. Inserisci qui un indirizzo e-mail che riceverà le notifiche per le quali non si applica alcuna regola di notifica.
Nota: in alternativa, puoi anche rendere un utente il destinatario nelle sue impostazioni personali. L'indirizzo e-mail memorizzato con l'utente viene utilizzato come indirizzo di riserva.
Tuttavia, l'indirizzo di riserva sarà utilizzato solo se non si applica alcuna regola di notifica, non quando non è stata attivata alcuna notifica! Come abbiamo mostrato nel capitolo precedente, la soppressione esplicita delle notifiche è voluta, non è un errore di configurazione.
L'inserimento di un indirizzo di ripiego sarà "consigliato" nella pagina Notification configuration con un avviso sullo schermo:

Se, per qualsiasi motivo, vuoi eliminare l'avviso, ma allo stesso tempo non vuoi ricevere e-mail all'indirizzo di riserva, inserisci comunque un indirizzo di riserva e poi crea una nuova regola come prima regola, che cancella tutte le notifiche precedenti. Questa regola non ha effetto sulla configurazione delle notifiche, in quanto non sono ancora state create notifiche. Tuttavia, in questo modo puoi assicurarti che almeno una regola venga sempre applicata, permettendo così di eliminare l'avviso.
Ti sconsigliamo esplicitamente di adottare questo approccio, in quanto potresti perdere delle lacune nella catena di regole.
5. Notifiche personalizzate
5.1. Panoramica
Una funzione utile del sistema di notifiche di Checkmk è quella che permette agli utenti - anche senza diritti di amministratore - di personalizzare le notifiche. Gli utenti possono:
aggiungere notifiche che altrimenti non riceverebbero ("sottoscrizione")
Eliminare le notifiche che altrimenti riceverebbero (se non limitate)
personalizzare i parametri delle notifiche
Disattivare completamente le notifiche.
5.2. Regole di notifica personalizzata
Il punto di accesso dal punto di vista dell'utente è il menu Utente, dove si trova la voce Notification rules. Nella pagina Your personal notification rules è possibile creare una nuova regola con Add rule.
Le regole personalizzate sono strutturate come le regole normali, con una differenza: non contengono la selezione di un contatto. L'utente stesso viene automaticamente selezionato come contatto. Questo significa che l'utente può aggiungere o eliminare notifiche solo per se stesso.
Tuttavia, l'utente può eliminare le notifiche solo se l'opzione allow users to deactivate this notification è attivata nella regola di notifica che le crea:
Nell'ordine delle regole di notifica, le regole personalizzate vengono sempre dopo le regole globali e quindi possono modificare la tabella delle notifiche che è stata generata fino a quel momento. Quindi, ad eccezione del blocco dell'eliminazione appena descritto, le regole globali sono sempre valide come impostazione predefinita che può essere personalizzata dall'utente.
Se vuoi impedire del tutto la personalizzazione, puoi revocare il permesso General Permissions > Edit personal notification settings del ruolo user.
Come amministratore, puoi visualizzare tutte le regole utente se nel menu selezioni Display > Show user rules:
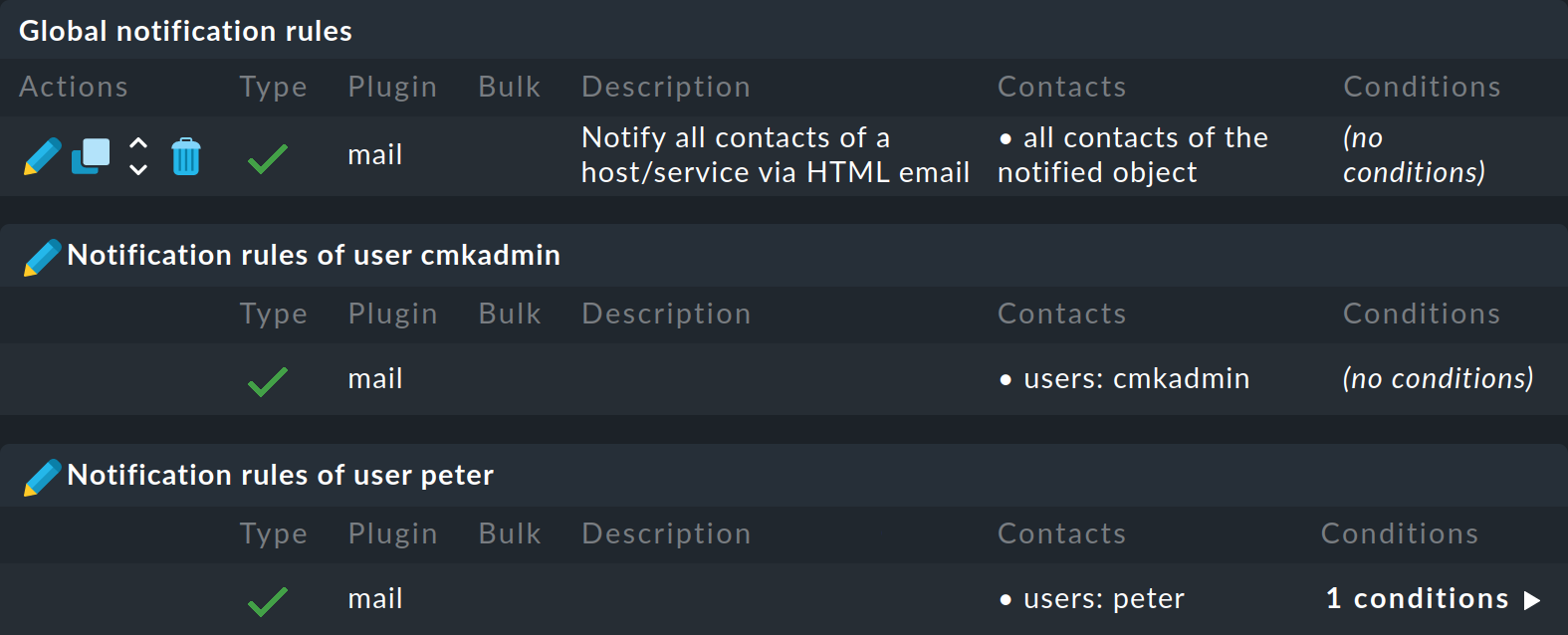
Dopo le regole globali, vengono elencate le regole utente, che puoi anche modificare con .
5.3. Disabilitare temporaneamente le notifiche
La disattivazione completa delle notifiche da parte di un utente è protetta dal permesso General Permissions > Disable all personal notifications, che per impostazione predefinita è impostato su no per il ruolo utente user. Un utente vedrà i checkbox corrispondenti nelle sue impostazioni personali solo se assegnerai esplicitamente questo diritto al ruolo user:
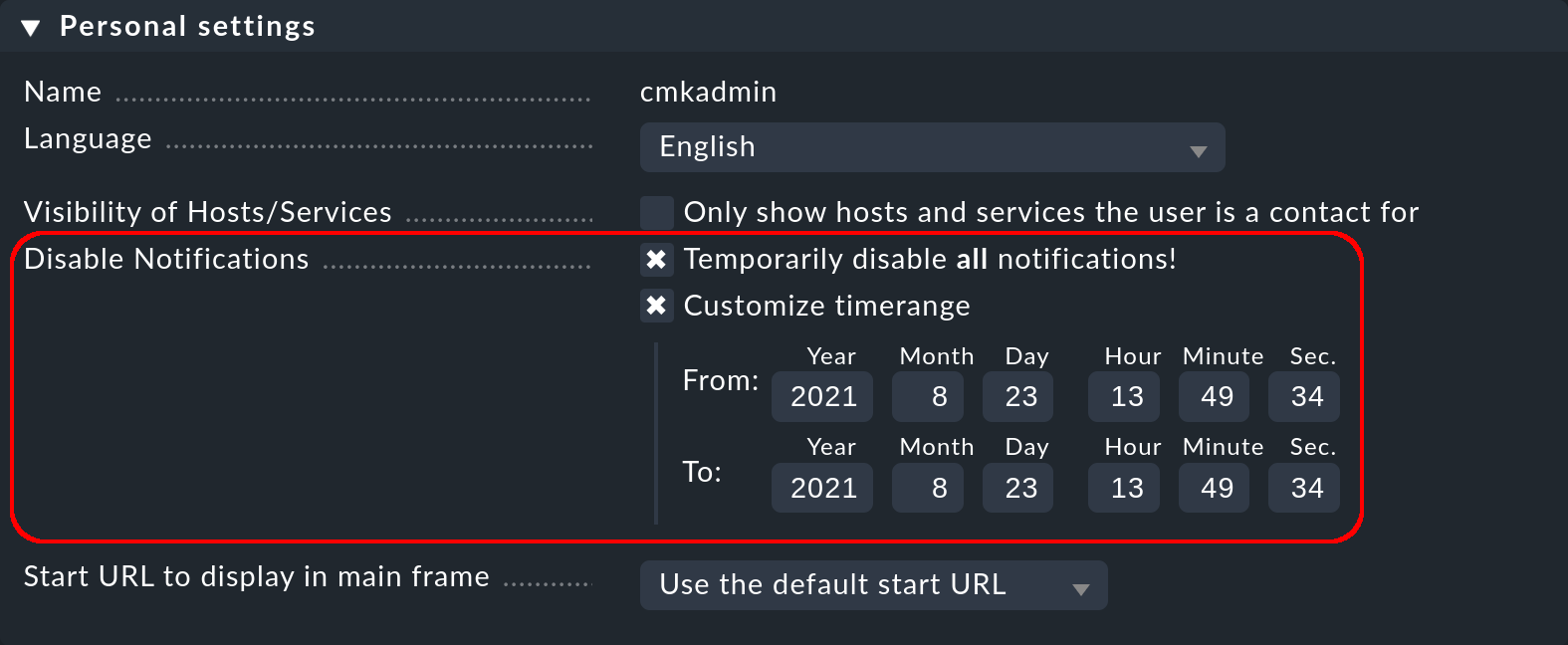
In qualità di amministratore con accesso alle impostazioni personali dell'utente, puoi eseguire azioni di disabilitazione per conto dell'utente, anche se il permesso descritto sopra non è presente. Puoi trovare questa impostazione alla voce Setup > Users > Users e poi nelle proprietà del profilo dell'utente. In questo modo, ad esempio, puoi silenziare molto rapidamente le notifiche di un collega in vacanza, senza dover modificare la configurazione attuale.
6. Quando vengono generate le notifiche e come gestirle
6.1. Introduzione
Gran parte della complessità del sistema di notifiche di Checkmk è dovuta alle sue numerose opzioni di regolazione, con le quali è possibile evitare le notifiche non importanti. La maggior parte di queste situazioni è costituita da situazioni in cui le notifiche vengono già ritardate o soppresse quando si verificano. Inoltre, il nucleo di monitoraggio IT ha un'intelligenza integrata che sopprime alcune notifiche per impostazione predefinita. In questo capitolo vorremmo affrontare tutti questi aspetti.
6.2. Tempi di manutenzione programmata
Quando un host o un servizio si trova in un periodo di inattività programmata, le notifiche dell'oggetto vengono soppresse. Questo è, insieme alla corretta valutazione delle disponibilità, il motivo più importante per cui il tempo di manutenzione programmata è previsto nel monitoraggio. I dettagli seguenti sono rilevanti a questo proposito:
Se un host viene segnalato come inattività programmata, anche tutti i suoi servizi saranno automaticamente in tempo di manutenzione programmata, senza che sia necessario inserire una voce esplicita.
Se un oggetto entra in uno stato problematico durante un tempo di inattività programmata, quando il tempo di inattività termina come previsto, questo problema verrà notificato retroattivamente proprio alla fine del tempo di manutenzione programmata.
L'inizio e la fine di un tempo di manutenzione programmato sono di per sé un evento di monitoraggio che verrà notificato.
6.3. Periodi di notifica
Durante la configurazione puoi definire un periodo di notifica per ogni host e servizio. Si tratta di un periodo di tempo che definisce l'arco temporale entro il quale la notifica deve essere limitata.
La configurazione viene eseguita utilizzando il sito Monitoring Configuration > Notification period for hosts o, rispettivamente, il set di regole Notification period for services, che puoi trovare rapidamente tramite la ricerca nel menu di configurazione. Un oggetto che non si trova al momento in un periodo di notifica sarà contrassegnato da un simbolo grigio di pausa.
Gli eventi di monitoraggio per un oggetto che non si trova nel periodo di notifica non verranno notificati. Tali notifiche verranno "riemesse" quando il periodo di notifica sarà di nuovo attivo - se l'host/servizio si trova ancora in uno stato problematico. Verrà notificato solo lo stato più recente, anche se si sono verificate più modifiche allo stato dell'oggetto durante il periodo di tempo al di fuori del periodo di notifica.
Tra l'altro, nelle regole di notifica è anche possibile limitare una notifica a un periodo di tempo specifico. In questo modo puoi limitare ulteriormente i periodi di tempo. Tuttavia, le notifiche che sono state scartate a causa di una regola di notifica con condizioni temporali non verranno automaticamente ripetute in seguito!
6.4. Lo stato dell'host su cui è in esecuzione un servizio
Se un host è completamente fallito, o comunque inaccessibile al monitoraggio, ovviamente i suoi servizi non possono più essere monitorati. Icheck attivi registreranno di regola CRIT o SCONOSCIUTO, poiché questi tenteranno attivamente di accedere all'host e quindi incorreranno in un errore. In questa situazione, tutti gli altri check - quindi la maggior parte - saranno omessi e rimarranno nel loro vecchio stato di monitoraggio. Questi saranno contrassegnati dal simbolo stale time.
Sarebbe naturalmente molto complicato se tutti i check attivi in questo stato dovessero notificare i loro problemi: ad esempio, se un server web non è raggiungibile - e questo è già stato notificato - non sarebbe molto utile generare un'e-mail per tutti i servizi HTTP che ne dipendono.
Per ridurre al minimo queste situazioni, come principio di base il nucleo di monitoraggio genera notifiche per i servizi solo se l'host si trova nello stato della verifica UP. Questo è anche il motivo per cui l'accessibilità dell'host viene verificata separatamente. Se non è configurato diversamente, questa verifica viene effettuata con uno Smart Ping o un ping.
Se utilizzi Checkmk Raw (o una delle edizioni commerciali con core Nagios), in casi isolati può comunque accadere che un problema dell'host generi una notifica per un servizio attivo. Il motivo è che Nagios considera i risultati dei controlli dell'host come ancora validi per un breve periodo di tempo nel futuro. Se sono trascorsi anche solo pochi secondi tra l'ultimo ping riuscito al server e il successivo active check, Nagios può ancora valutare l'host come UP anche se in realtà è DOWN. Al contrario, il Checkmk Micro Core (CMC) manterrà la notifica del servizio in modalità "standby" fino alla verifica dello stato dell'host, riducendo così in modo affidabile le notifiche indesiderate.
6.5. Host padre
Immagina che un importante router di rete di un'azienda con centinaia di host si guasti: tutti i suoi host non saranno disponibili per il monitoraggio e diventeranno DOWN. Si attiveranno quindi centinaia di notifiche. Non è una buona cosa.
Per evitare questi problemi, il router può essere definito come host padre per i suoi host. Se ci sono host ridondanti, si possono definire anche più genitori. Non appena tutti i genitori entrano in uno stato DOWN, gli host che non sono più raggiungibili saranno contrassegnati con lo stato NON RAGGIUNGIBILE e le loro notifiche saranno soppresse. Il problema del router stesso sarà ovviamente notificato.
A proposito, il CMC opera internamente in modo leggermente diverso rispetto a Nagios. Per ridurre i falsi allarmi e processare comunque le notifiche autentiche, presta molta attenzione agli orari esatti dei controlli dell'host in questione. Se un controllo dell'host fallisce, il core attende il risultato del controllo dell'host sull'host padre prima di generare una notifica. Questa attesa è asincrona e non ha alcun effetto sul nucleo di monitoraggio generale. Le notifiche dagli host possono quindi subire ritardi minimi.
6.6. Disabilitare le notifiche con le regole di notifica
Con i set di regole Enable/disable notifications for hosts o Enable/disable notifications for services puoi specificare host e servizi per i quali in generale non devono essere emesse notifiche. Come già detto, il core sopprime le notifiche. Una regola di notifica successiva che "sottoscrive" le notifiche per questi servizi sarà inefficace, in quanto le notifiche non verranno semplicemente generate.
6.7. Disabilitare le notifiche con i comandi
È anche possibile disabilitare temporaneamente le notifiche per singoli host o servizi tramite un comando.
Tuttavia, questo richiede che il permesso Commands on host and services > Enable/disable notifications sia assegnato al ruolo dell'utente. Per impostazione predefinita, questo non avviene per nessun ruolo.
Con il permesso assegnato, puoi disabilitare (e successivamente abilitare) le notifiche di host e servizi con il comando Commands > Notifications:

Tali host o servizi saranno contrassegnati da un simbolo.
Poiché i comandi, a differenza delle regole, non richiedono né permessi di configurazione né l'attivazione di modifiche, possono essere una soluzione rapida per reagire prontamente a una situazione.
Importante: a differenza dei tempi di inattività programmati, le notifiche disabilitate non hanno alcuna influenza sulle valutazioni di disponibilità. Se durante un'interruzione non programmata vuoi davvero solo disabilitare le notifiche senza voler alterare le statistiche di disponibilità, non devi registrare un tempo di manutenzione programmata!
6.8. Disabilitare le notifiche a livello globale
Nello snap-in Master control nella barra laterale troverai uno switch master per Notifications:

Questo switch è incredibilmente utile se hai intenzione di apportare grandi modifiche al sistema, durante le quali un errore potrebbe costringere molti servizi in uno stato CRIT. Puoi usare questo switch per evitare di turbare i tuoi colleghi con una marea di e-mail inutili. Ricordati di riattivare le notifiche quando hai finito.
Ogni sito di un monitoraggio distribuito dispone di uno di questi switch. Disattivando le notifiche del sito centrale, i siti remoti possono comunque attivare le notifiche, anche se queste sono dirette e consegnate dal sito centrale.
Importante: le notifiche che sarebbero state attivate durante il periodo in cui le notifiche sono state disabilitate non saranno ripetute in seguito quando saranno riattivate.
6.9. Ritardare le notifiche
Può capitare di avere servizi che occasionalmente entrano in uno stato problematico per brevi periodi, ma le interruzioni sono molto brevi e non sono critiche per l'utente. In questi casi le notifiche sono molto fastidiose, ma possono essere facilmente soppresse. I set di regole Delay host notifications e Delay service notifications servono a questa situazione.
Qui specifichi un tempo in minuti e la notifica sarà ritardata fino allo scadere di questo tempo. Se lo stato OK / UP si ripresenta prima di allora, non verrà attivata alcuna notifica. Naturalmente questo significa anche che la notifica di un problema reale sarà ritardata.
Ovviamente, ancora meglio del ritardo delle notifiche sarebbe l'eliminazione della causa effettiva dei problemi sporadici, ma questa è ovviamente un'altra storia...
6.10. Tentativi di controllo ripetuti
Un altro metodo molto simile per ritardare le notifiche è quello di consentire più tentativi di controllo quando un servizio entra in uno stato problematico. Questo si ottiene con il set di regole Maximum number of check attempts for hosts o, rispettivamente, Maximum number of check attempts for service.
Se ad esempio imposti un valore di riferimento di 3, un controllo con risultato CRIT inizialmente non farà scattare una notifica. Questo viene definito stato soft CRIT. Lo stato hard rimane OK. Solo se tre tentativi successivi restituiscono uno stato non OK, il servizio passa allo stato hard e scatta una notifica.
A differenza delle notifiche ritardate, in questo caso hai la possibilità di definire delle visualizzazioni in modo che questi problemi non vengano visualizzati. Un'aggregazione BI può anche essere costruita in modo da includere solo gli stati hard e non quelli soft.
6.11. Host e servizi irregolari
Quando un host o un servizio cambia frequentemente il suo stato in un breve lasso di tempo, viene considerato irregolare. Si tratta di uno stato vero e proprio. Il principio è quello di ridurre le notifiche eccessive durante le fasi in cui un servizio non funziona (del tutto) in modo stabile. Tali fasi possono essere valutate in modo particolare nelle statistiche di disponibilità.
Gli oggetti irregolari sono contrassegnati da un simbolo. Finché un oggetto è irregolare, i successivi cambiamenti di stato non attivano ulteriori notifiche. Tuttavia, una notifica viene attivata ogni volta che l'oggetto entra o esce dallo stato irregolare.
Il riconoscimento dell'irregolare da parte del sistema può essere influenzato nei seguenti modi:
Il sito Master control dispone di uno switch principale per controllare il rilevamento dell'irregolare (Flap Detection).
Puoi escludere gli oggetti dal riconoscimento utilizzando il set di regole Enable/disable flapping detection for hosts o, rispettivamente, il set di regole Enable/disable flapping detection for services.
Nelle edizioni commerciali, utilizzando Global settings > Monitoring Core > Tuning of flap detection puoi definire i parametri per il rilevamento degli irregolari e impostarli come più o meno sensibili:

Mostra l'aiuto contestuale di Help > Show inline help per maggiori dettagli sui valori personalizzabili.
6.12. Notifiche ripetute periodicamente e escalation
Per alcuni sistemi, può avere senso non limitarsi a una singola notifica quando un problema persiste per un periodo di tempo più lungo, ad esempio per gli host il cui tag host Criticality è impostato su Business critical.
Impostazione di notifiche a ripetizione periodica
Checkmk può essere impostato in modo che vengano emesse notifiche successive a intervalli fissi, finché il problema non viene confermato o risolto.
L'impostazione di questa opzione si trova nel set di regole Periodic notifications during host problems o, rispettivamente, Periodic notifications during service problems:

Una volta attivata questa opzione, per un problema persistente, Checkmk invierà notifiche periodiche agli intervalli configurati. Queste notifiche riceveranno un numero crescente a partire da 1 (per la notifica iniziale).
Le notifiche periodiche non sono utili solo per ricordare un problema (e per infastidire l 'operatore), ma forniscono anche una base per le escalation: ciò significa che dopo un periodo di tempo definito una notifica può essere inoltrata ad altri destinatari.
Impostare le escalation e comprenderle
Per impostare un'escalation, crea una regola di notifica aggiuntiva che utilizzi la condizione Restrict to notification number.

Se inserisci da 3 a 99999 come intervallo per il numero sequenziale, questa regola di notifica entra in vigore a partire dalla terza notifica. L'escalation può essere eseguita selezionando un altro metodo di notifica (es. SMS) oppure può notificare altre persone (selezione del contatto).
Con l'opzione Throttle periodic notifications, dopo un certo periodo di tempo la frequenza di ripetizione delle notifiche può essere ridotta in modo che, ad esempio, all'inizio si possa inviare un'e-mail ogni ora e successivamente si possa ridurre a un'e-mail al giorno.
Con più regole di notifica, puoi costruire un modello di escalation, ma come funzionerà in pratica questa escalation? Chi viene avvisato e quando? Ecco un esempio, implementato con una regola di notifica periodica e tre regole di notifica: Ad esempio:
In caso di rilevamento di un problema in un servizio, verrà attivata una notifica sotto forma di e-mail ogni 60 minuti finché il problema non sarà risolto o confermato.
Le notifiche da uno a cinque vengono inviate alle due persone responsabili del servizio.
Le notifiche da sei a dieci vengono inviate anche al responsabile del team interessato.
Dalla notifica undici in poi, una mail giornaliera viene invece inviata alla direzione dell'azienda.
Alle 9 del mattino si verifica un problema presso l'impianto. I due dipendenti responsabili vengono avvisati del problema ma non rispondono (per qualsiasi motivo). Quindi alle 10, 11, 12 e alle 13 ricevono ciascuno una nuova e-mail. A partire dalla sesta notifica delle 14, anche il team leader riceve un'e-mail, ma il problema non cambia. Alle 15, 16, 17 e 18 vengono inviate altre e-mail ai membri del team e al team leader.
Alle 19:00 entra in vigore il terzo livello di escalation: d'ora in poi non verranno più inviate e-mail ai membri del team o al team leader, ma la direzione dell'azienda riceverà un'e-mail ogni giorno alle 19:00 fino alla risoluzione del problema.
Non appena il problema è stato risolto e il servizio in Checkmk torna ad essere OK, viene inviato automaticamente un "via libera" all'ultimo gruppo di persone che ha ricevuto la notifica: nell'esempio precedente, se il problema viene risolto prima delle 14:00, ai due membri del team; se il problema viene risolto tra le 14:00 e le 19:00, ai membri del team e al team leader; e dopo le 19:00, solo alla direzione aziendale.
7. Il percorso di una notifica dall'inizio alla fine
7.1. La cronologia delle notifiche
Per iniziare, ti mostreremo come visualizzare la cronologia delle notifiche a livello del servizio e dell'host in Checkmk per poter seguire il processo di notifica.
Un evento di monitoraggio che fa scattare una notifica in Checkmk è, ad esempio, il cambiamento di stato di un servizio. Puoi scatenare manualmente questo cambiamento di stato con il comando Fake check results a scopo di test.
Per un test di notifica, puoi spostare un servizio dallo stato OK a CRIT in questo modo. Se ora visualizzi le notifiche di questo servizio nella pagina dei dettagli del servizio con Service > Service Notifications, vedrai le seguenti voci:
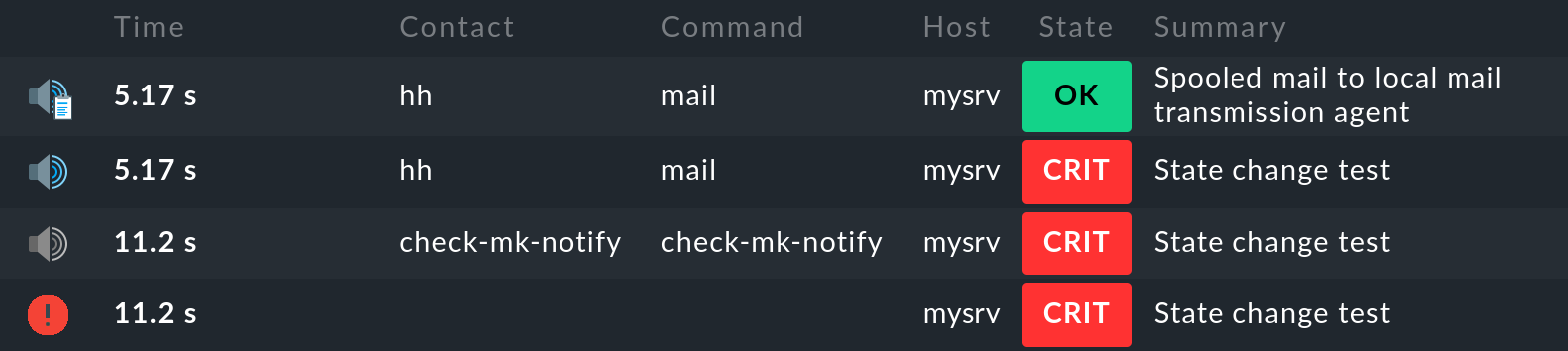
La voce più recente è in cima all'elenco. Tuttavia, la prima voce si trova in basso, quindi analizziamo le singole voci dal basso verso l'alto:
Il nucleo di monitoraggio registra l'evento di monitoraggio del cambiamento di stato. Il simbolo nella prima colonna indica lo stato(CRIT nell'esempio).
Il nucleo di monitoraggio genera una notifica grezza . Questa viene passata dal core al modulo di notifica, che esegue la valutazione delle regole di notifica applicabili.
La valutazione delle regole di notifica genera una notifica all 'utente
hhcon il metodomail.Il risultato della notifica mostra che l'e-mail è stata consegnata con successo al server SMTP per la consegna.
Per aiutare a comprendere correttamente il contesto delle varie opzioni di impostazione e delle condizioni di base e per consentire una diagnosi accurata dei problemi quando una notifica appare o non appare come previsto, qui descriveremo tutti i dettagli del processo di notifica, compresi tutti i componenti coinvolti.
Nota: la cronologia delle notifiche che abbiamo mostrato sopra per un servizio può essere visualizzata anche per un host: nella pagina dei dettagli dell'host nel menu Host per l'host stesso (voce di menuNotifications of host ) e anche per l'host con tutti i suoi servizi (Notifications of host & services).
7.2. I componenti
Il sistema di notifica di Checkmk coinvolge i seguenti componenti:
| Componente | Funzione | File di log |
|---|---|---|
Nagios |
Il nucleo di monitoraggio di Checkmk Raw che rileva gli eventi di monitoraggio e genera notifiche grezze. |
|
Il nucleo di monitoraggio delle edizioni commerciali che svolge la stessa funzione di Nagios in Checkmk Raw. |
|
|
Modulo di notifica |
Processa le regole di notifica per creare una notifica utente da una notifica grezza. Richiama gli script di notifica. |
|
Spooler di notifica (solo edizioni commerciali) |
Consegna asincrona di notifiche e notifiche centralizzate in ambienti distribuiti. |
|
Script di notifica |
Per ogni metodo di notifica c'è uno script che processa l'effettiva consegna (es. genera e invia un'e-mail HTML). |
|
7.3. Il nucleo di monitoraggio
Notifiche grezze
Come descritto in precedenza, ogni notifica inizia con un evento di monitoraggio nel nucleo di monitoraggio. Se tutte le condizioni sono state soddisfatte e si può dare il "via libera" a una notifica, il nucleo genera una notifica grezza al contatto interno di assistenza check-mk-notify. La notifica grezza non contiene ancora dettagli sui contatti effettivi o sul metodo di notifica.
La notifica grezza appare così nella cronologia delle notifiche del servizio:

Il simbolo è un altoparlante di colore grigio chiaro.
check-mk-notifyè indicato come contatto.check-mk-notifyè indicato come comando di notifica.
La notifica grezza passa quindi al modulo di notifica Checkmk, che elabora le regole di notifica. Questo modulo viene richiamato come programma esterno da Nagios (cmk --notify). Il CMC, invece, mantiene il modulo in standby come processo ausiliario permanente(helper Checkmk), riducendo così la creazione di processi e risparmiando tempo macchina.
Diagnosi degli errori nel nucleo di monitoraggio di Nagios
Il core di Nagios utilizzato in Checkmk Raw registra tutti gli eventi di monitoraggio in ~/var/log/nagios.log. Questo file è anche la posizione in cui viene memorizzata la cronologia delle notifiche, che viene anche interrogata tramite la GUI se, ad esempio, desideri vedere le notifiche di un host o di un servizio.
Più interessanti sono invece i messaggi che si trovano nel file ~/var/nagios/debug.log e che si ricevono se si imposta la variabile debug_levelsu 32 in etc/nagios/nagios.d/logging.cfg.
Dopo un riavvio del core ...
OMD[mysite]:~$ omd restart nagios... troverai informazioni utili sui motivi per cui le notifiche sono state create o soppresse:
[1592405483.152931] [032.0] [pid=18122] ** Service Notification Attempt ** Host: 'localhost', Service: 'backup4', Type: 0, Options: 0, Current State: 2, Last Notification: Wed Jun 17 16:24:06 2020
[1592405483.152941] [032.0] [pid=18122] Notification viability test passed.
[1592405485.285985] [032.0] [pid=18122] 1 contacts were notified. Next possible notification time: Wed Jun 17 16:51:23 2020
[1592405485.286013] [032.0] [pid=18122] 1 contacts were notified.Diagnosi degli errori nel nucleo di monitoraggio CMC
Nelle edizioni commerciali puoi trovare un protocollo del nucleo di monitoraggio nel file di log ~/var/log/cmc.log. Nell'installazione standard questo file non contiene informazioni relative alle notifiche. Puoi tuttavia attivare una funzione di log molto dettagliata con Global settings > Monitoring Core > Logging of the notification mechanics.. Il nucleo fornirà quindi informazioni sul perché - o perché (ancora) - un evento di monitoraggio lo spinge a passare una notifica al sistema di monitoraggio:
OMD[mysite]:~$ tail -f var/log/cmc.log
+2021-08-26 16:12:37 [5] [core 27532] Executing external command: PROCESS_SERVICE_CHECK_RESULT;mysrv;CPU load;1;test
+2021-08-26 16:12:43 [5] [core 27532] Executing external command: LOG;SERVICE NOTIFICATION: hh;mysrv;CPU load;WARNING;mail;test
+2021-08-26 16:12:52 [5] [core 27532] Executing external command: LOG;SERVICE NOTIFICATION RESULT: hh;mysrv;CPU load;OK;mail;success 250 - b'2.0.0 Ok: queued as 482477F567B';success 250 - b'2.0.0 Ok: queued as 482477F567B'Nota: l 'attivazione del log per le notifiche può generare molti messaggi, ma è utile quando in seguito ci si chiede perché non è stata generata una notifica in una particolare situazione.
7.4. Valutazione delle regole di notifica da parte del modulo di notifica
Una volta che il core ha generato una notifica grezza, questa passa attraverso la catena di regole di notifica, dando vita a una tabella di notifiche. Oltre ai dati della notifica grezza, ogni notifica contiene le seguenti informazioni aggiuntive:
Il contatto da notificare
Il metodo di notifica
I parametri di questo metodo
In caso di consegna sincrona, per ogni voce della tabella verrà eseguito uno script di notifica appropriato. In caso di consegna asincrona, la notifica verrà passata come file allo spooler di notifica.
Analisi della catena di regole
Quando crei regole di notifica più complesse, ti chiederai quali regole si applicheranno a una specifica notifica. Per questo Checkmk offre una funzione di analisi integrata nella pagina Notifications configuration, che puoi raggiungere con la voce di menu Display > Show analysis.
Nella modalità di analisi, per impostazione predefinita, vengono visualizzate le ultime dieci notifiche grezze generate dal sistema e processate attraverso le regole di notifica:
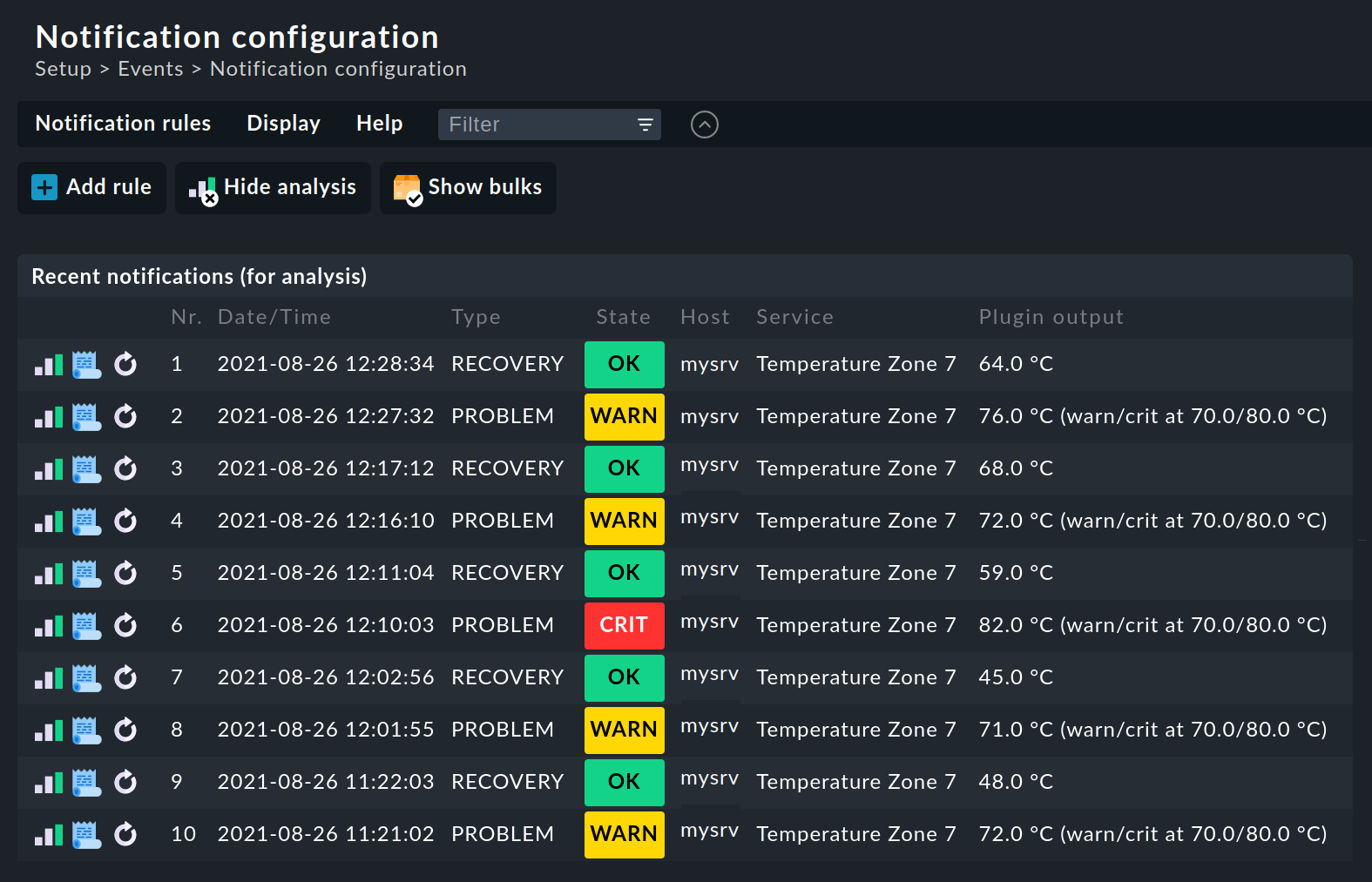
Se hai bisogno di analizzare un numero maggiore di notifiche grezze, puoi facilmente aumentare il numero di notifiche memorizzate per l'analisi tramite Global settings > Notifications > Store notifications for rule analysis:

Per ognuna di queste notifiche grezze sono disponibili tre azioni:
Verifica la catena di regole, in cui ogni regola viene controllata se tutte le condizioni della regola sono state soddisfatte per l'evento di monitoraggio selezionato. La tabella delle notifiche risultante verrà visualizzata con le regole di notifica. |
|
Visualizza il contesto completo della notifica. |
|
Ripete la notifica grezza come se fosse appena apparsa. Altrimenti la visualizzazione è la stessa dell'analisi. In questo modo puoi non solo verificare le condizioni della regola di notifica, ma anche testare la visualizzazione di una notifica. |
Diagnosi degli errori
Se hai eseguito il test della catena di regole (), puoi vedere quali regole sono state applicate o meno a un evento di monitoraggio:
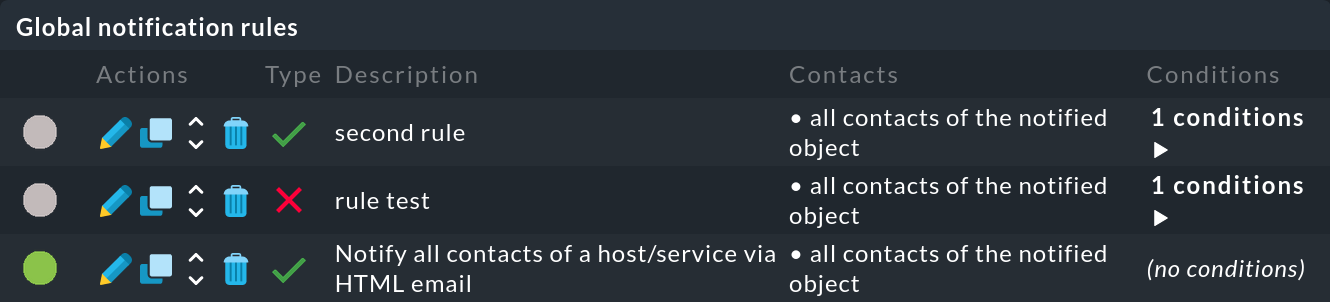
Se una regola non è stata applicata, muovi il mouse sul cerchio grigio per vedere il suggerimento (testo di passaggio del mouse):
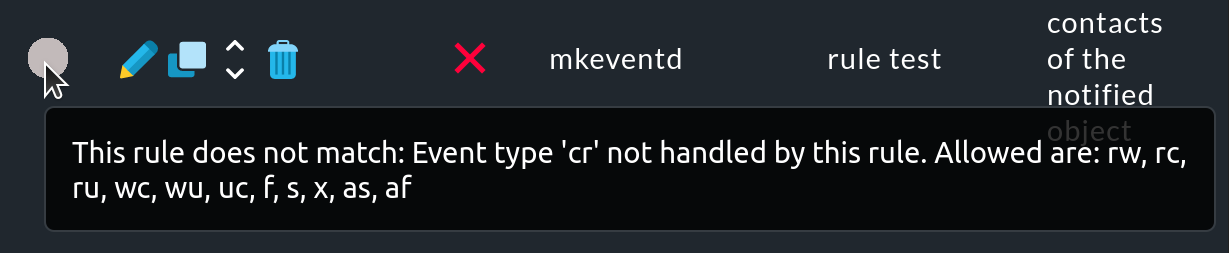
Tuttavia, questo testo utilizza delle abbreviazioni per indicare le condizioni per cui una regola non è stata applicata, che si riferiscono alle condizioni Match host event type o Match service event type della regola.
| Tipi di eventi host | ||
|---|---|---|
Abbreviazione |
Significato |
Descrizione |
|
UP ➤ DOWN |
Stato dell'host cambiato da UP a DOWN |
|
UP ➤ NON RAGGIUNGIBILE |
Stato dell'host cambiato da UP a NON RAGGIUNGIBILE |
|
DOWN ➤ UP |
Stato dell'host cambiato da DOWN a UP |
|
DOWN ➤ NON RAGGIUNGIBILE |
Stato host cambiato da DOWN a NON RAGGIUNGIBILE |
|
NON RAGGIUNGIBILE ➤ DOWN |
Stato host cambiato da NON RAGGIUNGIBILE a DOWN |
|
NON RAGGIUNGIBILE ➤ UP |
Stato dell'host cambiato da NON RAGGIUNGIBILE a UP |
|
qualsiasi ➤ UP |
Stato dell'host cambiato da qualsiasi stato a UP |
|
qualsiasi ➤ DOWN |
Stato dell'host cambiato da qualsiasi stato a DOWN |
|
qualsiasi ➤ NON RAGGIUNGIBILE |
Stato dell'host cambiato da qualsiasi stato a NON RAGGIUNGIBILE |
|
Inizio o fine dello stato di irregolare |
|
|
Inizio o fine di un tempo di manutenzione programmata |
|
|
Conferma del problema |
|
|
Esecuzione del gestore di avvisi con successo |
|
|
Esecuzione del gestore di avvisi, fallita |
|
| Tipi di eventi del servizio | ||
|---|---|---|
Abbreviazione |
Significato |
Descrizione |
|
OK ➤ WARN |
Stato del servizio cambiato da OK a WARN |
|
OK ➤ OK |
Stato del servizio cambiato da OK a OK |
|
OK ➤ CRIT |
Stato del servizio cambiato da OK a CRIT |
|
OK ➤ SCONOSCIUTO |
Stato del servizio cambiato da OK a SCONOSCIUTO |
|
WARN ➤ OK |
Stato del servizio cambiato da WARN a OK |
|
WARN ➤ CRIT |
Stato del servizio cambiato da WARN a CRIT |
|
WARN ➤ SCONOSCIUTO |
Stato del servizio cambiato da WARN a SCONOSCIUTO |
|
CRIT ➤ OK |
Stato del servizio cambiato da CRIT a OK |
|
CRIT ➤ WARN |
Stato del servizio cambiato da CRIT a WARN |
|
CRIT ➤ SCONOSCIUTO |
Stato del servizio cambiato da CRIT a SCONOSCIUTO |
|
SCONOSCIUTO ➤ OK |
Stato del servizio cambiato da SCONOSCIUTO a OK |
|
SCONOSCIUTO ➤ WARN |
Stato del servizio cambiato da SCONOSCIUTO a WARN |
|
SCONOSCIUTO ➤ CRIT |
Stato del servizio cambiato da SCONOSCIUTO a CRIT |
|
qualsiasi ➤ OK |
Stato del servizio cambiato da qualsiasi stato a OK |
|
qualsiasi ➤ WARN |
Stato del servizio cambiato da qualsiasi stato a WARN |
|
qualsiasi ➤ CRIT |
Stato del servizio cambiato da qualsiasi stato a CRIT |
|
qualsiasi ➤ SCONOSCIUTO |
Stato del servizio cambiato da qualsiasi stato a SCONOSCIUTO |
Sulla base di questi suggerimenti puoi controllare e rivedere le tue regole.
Un'altra importante opzione diagnostica è il file di log ~/var/log/notify.log. Durante i test con le notifiche, il famoso comando tail -f è utile per questo:
OMD[mysite]:~$ tail -f var/log/notify.log
2021-08-26 17:11:58,914 [20] [cmk.base.notify] Analysing notification (mysrv;Temperature Zone 7) context with 71 variables
2021-08-26 17:11:58,915 [20] [cmk.base.notify] Global rule 'Notify all contacts of a host/service via HTML email'...
2021-08-26 17:11:58,915 [20] [cmk.base.notify] -> matches!
2021-08-26 17:11:58,915 [20] [cmk.base.notify] - adding notification of hh via mail
2021-08-26 17:11:58,916 [20] [cmk.base.notify] Executing 1 notifications:
2021-08-26 17:11:58,916 [20] [cmk.base.notify] * would notify hh via mail, parameters: smtp, graphs_per_notification, notifications_with_graphs, bulk: noCon Global settings > Notifications > Notification log level puoi controllare la completezza delle notifiche in tre livelli: impostalo su Full dump of all variables and command e nel file di log troverai un elenco completo di tutte le variabili disponibili per lo script di notifica:

Ad esempio, l'elenco apparirà come segue (estratto):
2021-08-26 17:24:54,709 [10] [cmk.base.notify] Raw context:
CONTACTS=hh
HOSTACKAUTHOR=
HOSTACKCOMMENT=
HOSTADDRESS=127.0.0.1
HOSTALIAS=localhost
HOSTATTEMPT=1
HOSTCHECKCOMMAND=check-mk-host-smart7.5. Consegna asincrona tramite lo spooler di notifica
Una potente funzione aggiuntiva delle edizioni commerciali è lo spooler di notifica, che permette di inviare le notifiche in modo asincrono. Cosa significa asincrono in questo contesto?
Consegna sincrona: Il modulo di notifica aspetta che lo script di notifica abbia finito di essere eseguito. Se l'esecuzione richiede molto tempo, si accumuleranno altre notifiche. Se il monitoraggio viene interrotto, queste notifiche andranno perse. Inoltre, se vengono generate molte notifiche in un breve periodo di tempo, è possibile che si crei un arretrato fino al core, causando un blocco del monitoraggio.
Consegna asincrona: Ogni notifica viene salvata in un file di spool all'indirizzo
~/var/check_mk/notify/spool. Non è possibile che si crei un inceppamento. Se il monitoraggio viene interrotto, i file di spool verranno conservati e le notifiche potranno essere consegnate correttamente in seguito. Lo spooler di notifica si occupa del processo dei file di spool.
La consegna sincrona è possibile se lo script di notifica viene eseguito rapidamente e soprattutto non può causare timeout. Con i metodi di notifica che accedono agli spooler esistenti, questo è un dato di fatto. I servizi di spool del sistema possono essere utilizzati in particolare con le e-mail e gli SMS. Lo script di notifica passa un file di spool allo spooler: con questa procedura non può verificarsi alcuno stato di attesa.
Quando utilizzi la consegna tracciabile via SMTP o altri script che stabiliscono connessioni di rete, dovresti sempre utilizzare la consegna asincrona. Questo vale anche per gli script che inviano messaggi di testo (SMS) via HTTP su internet. I timeout durante la creazione di una connessione a un servizio di rete possono durare fino a diversi minuti, causando l'inceppamento descritto sopra.
La buona notizia è che l'invio asincrono è abilitato per impostazione predefinita in Checkmk. Da un lato, lo spooler di notifica (mknotifyd) viene avviato all'avvio dell'istanza Checkmk, cosa che puoi verificare con il seguente comando:
OMD[mysite]:~$ omd status mknotifyd
mknotifyd: running
-----------------------
Overall state: runningD'altra parte, la consegna asincrona (Asynchronous local delivery by notification spooler) è selezionata in Global settings > Notifications > Notification Spooling:

Diagnosi degli errori
Lo spooler di notifica mantiene un proprio file di log: ~/var/log/mknotifyd.log. Questo possiede tre livelli di log che possono essere impostati in Global settings > Notifications > Notification Spooler Configuration con il parametro Verbosity of logging. Nel livello intermedio, Verbose logging (i.e. spooled notifications), è possibile vedere il processo dei file di spool:
2021-08-26 18:05:02,928 [15] [cmk.mknotifyd] processing spoolfile: /omd/sites/mysite/var/check_mk/notify/spool/dad64e2e-b3ac-4493-9490-8be969a96d8d
2021-08-26 18:05:02,928 [20] [cmk.mknotifyd] running cmk --notify --log-to-stdout spoolfile /omd/sites/mysite/var/check_mk/notify/spool/dad64e2e-b3ac-4493-9490-8be969a96d8d
2021-08-26 18:05:05,848 [20] [cmk.mknotifyd] got exit code 0
2021-08-26 18:05:05,850 [20] [cmk.mknotifyd] processing spoolfile dad64e2e-b3ac-4493-9490-8be969a96d8d successful: success 250 - b'2.0.0 Ok: queued as 1D4FF7F58F9'
2021-08-26 18:05:05,850 [20] [cmk.mknotifyd] sending command LOG;SERVICE NOTIFICATION RESULT: hh;mysrv;CPU load;OK;mail;success 250 - b'2.0.0 Ok: queued as 1D4FF7F58F9';success 250 - b'2.0.0 Ok: queued as 1D4FF7F58F9'8. Notifiche di massa
8.1. Panoramica
A tutti coloro che lavorano con il monitoraggio è capitato di avere un problema isolato che ha scatenato una vera e propria marea di notifiche (successive). Il principio degli host padre è un modo per ridurle in determinate circostanze, ma purtroppo non è utile in tutti i casi.
Puoi prendere esempio dal progetto Checkmk stesso: una volta al giorno creiamo i pacchetti di installazione di Checkmk per ogni distribuzione Linux supportata. Il nostro stato di monitoraggio di Checkmk è impostato in modo tale da avere un servizio che è OK solo se il numero giusto di pacchetti è stato costruito correttamente. A volte può succedere che un errore generale nel software ostacoli l'impacchettamento, causando il passaggio simultaneo di 43 servizi in uno stato CRIT.
Abbiamo configurato le notifiche in modo tale che, in questo caso, venga inviata un'unica e-mail che elenca tutte le 43 notifiche in sequenza. Questo è naturalmente più chiaro di 43 e-mail singole e riduce anche il rischio che "nella foga della battaglia" si perda una 44esima e-mail relativa a un altro problema.
La modalità di funzionamento di questa notifica di massa è molto semplice. Quando si verifica una notifica, in un primo momento questa viene trattenuta per un breve periodo di tempo. Le notifiche successive che si verificano durante questo lasso di tempo vengono immediatamente aggiunte alla stessa e-mail. Questa raccolta può essere definita per ogni regola di notifica. Quindi, ad esempio, durante il giorno puoi operare con e-mail singole, ma durante la notte con una notifica di massa. Se viene attivata una notifica di massa, in genere ti verranno offerte le seguenti opzioni:
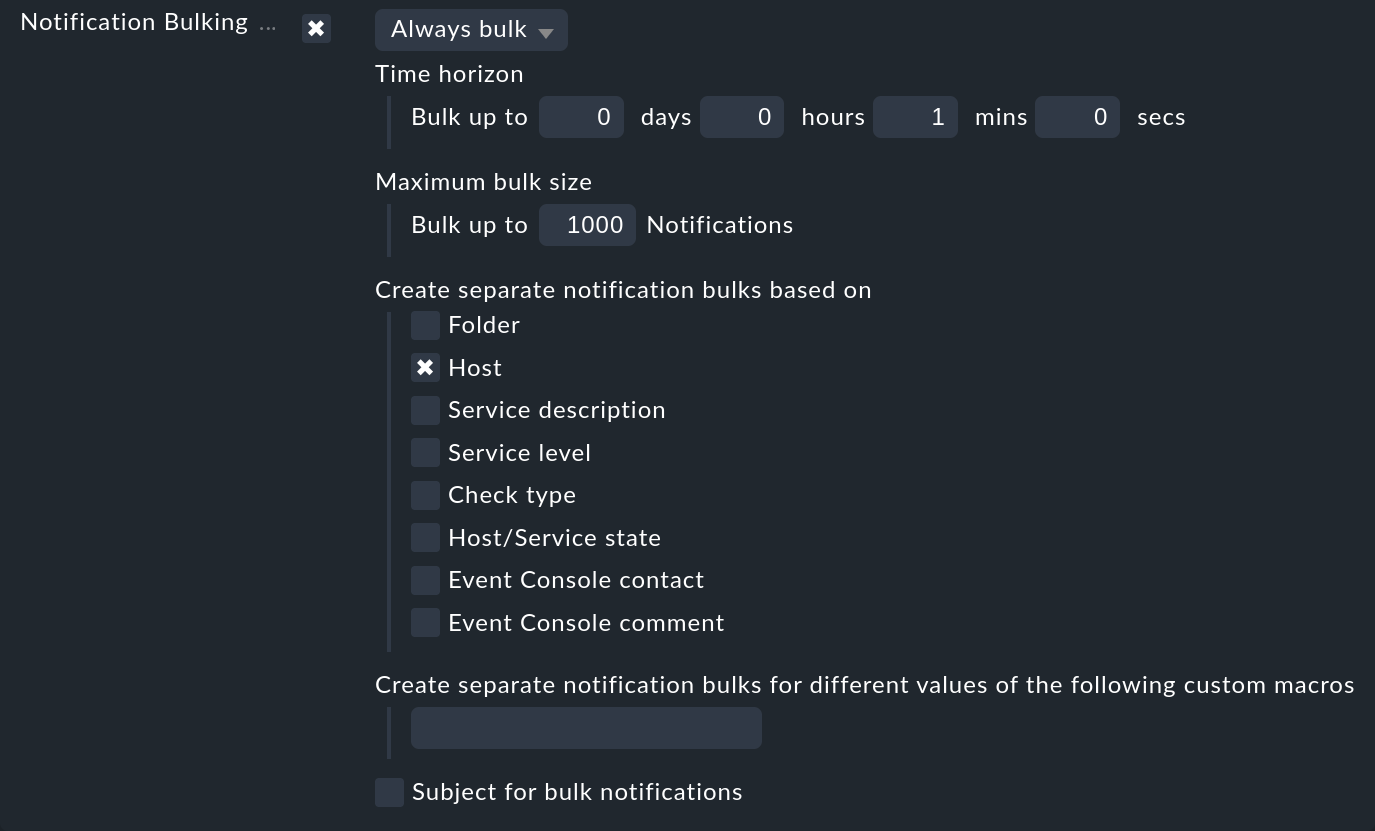
Il tempo di attesa può essere configurato a piacimento. In molti casi è sufficiente un minuto, in quanto al più tardi a quell'ora dovrebbero essere comparsi tutti i problemi relativi. Naturalmente puoi impostare un tempo più lungo, ma questo comporterà un ritardo fondamentale nelle notifiche.
Dato che naturalmente non ha senso buttare tutto in un unico piatto, puoi specificare quali gruppi di problemi devono essere notificati collettivamente. L'opzione Host è molto utilizzata: in questo modo si garantisce che vengano raggruppate solo le notifiche provenienti dallo stesso host.
Ecco alcune informazioni aggiuntive sulle notifiche di massa:
Se il raggruppamento è attivato in una regola, l'attivazione può essere disattivata da una regola successiva e viceversa.
La notifica di massa avviene sempre per contatto. Ogni contatto ha un proprio "vaso di raccolta privato".
Puoi limitare la dimensione del vaso (Maximum bulk size). Una volta raggiunto il limite massimo, la notifica di massa verrà inviata immediatamente.
8.2. Notifiche di massa e periodi di tempo
Cosa succede quando una notifica rientra nel periodo di notifica, ma la notifica di massa che la contiene - e che arriva un po' più tardi - non rientra nel periodo di notifica? È possibile anche la situazione inversa...
In questo caso si applica un principio molto semplice: tutte le configurazioni che limitano le notifiche a periodi di tempo sono valide solo per la notifica vera e propria. La successiva notifica di massa sarà sempre consegnata indipendentemente da tutti i periodi di tempo.
9. Consegna tracciabile per SMTP
9.1. L'e-mail non è affidabile
Il monitoraggio è utile solo se si può fare affidamento su di esso. Ciò richiede che le notifiche intelligenti vengano ricevute in modo affidabile e tempestivo. Purtroppo, però, la consegna delle e-mail non è del tutto ideale. L'invio viene solitamente processato passando l'e-mail al server SMTP locale, che tenta di consegnarla in modo autonomo e asincrono.
In caso di errore temporaneo (ad es. se il server SMTP ricevente non è raggiungibile) l'e-mail viene messa in coda e in seguito viene effettuato un nuovo tentativo. Questo "in seguito" avviene di regola dopo 15-30 minuti. A quel punto la notifica potrebbe essere troppo tardi!
Se l'e-mail non può essere consegnata, il server SMTP crea un messaggio di errore nel suo file di log e tenta di generare un'e-mail di errore al "mittente". Ma il sistema di monitoraggio IT non è un vero mittente e non può ricevere e-mail. Ne consegue che tali errori scompaiono semplicemente e le notifiche sono assenti.
Importante: le notifiche tracciabili non sono disponibili per le notifiche di massa!
9.2. L'utilizzo dell'SMTP in connessione diretta consente l'analisi degli errori
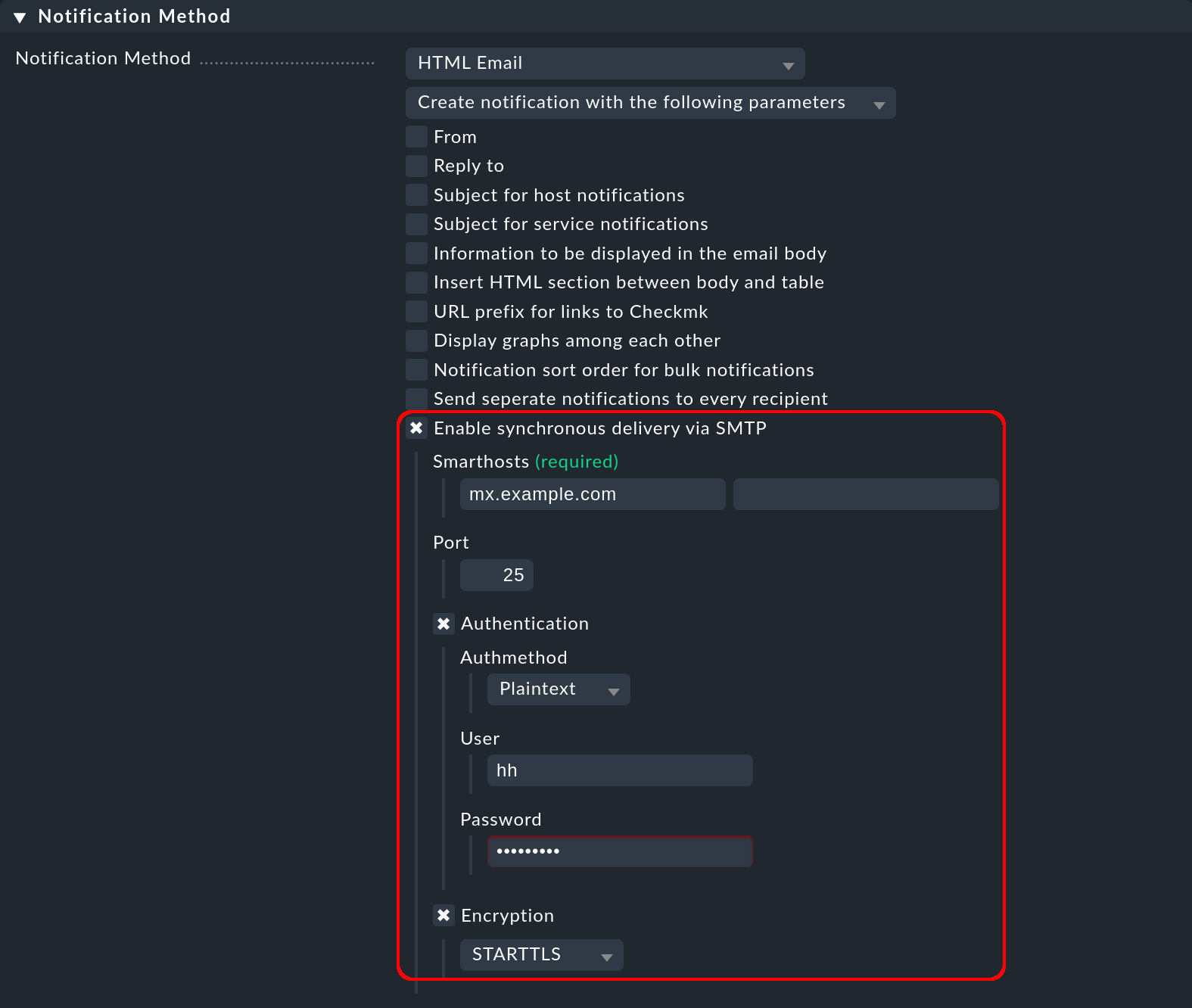
Le edizioni commerciali offrono la possibilità di effettuare una consegna tracciabile tramite SMTP, senza l'aiuto del server Checkmk locale: Checkmk stesso invia l'e-mail al tuo smarthost tramite SMTP e poi valuta la risposta SMTP.
In questo modo, non solo gli errori SMTP vengono trattati in modo intelligente, ma anche la consegna corretta viene documentata con precisione. È un po' come una lettera raccomandata: Checkmk riceve una ricevuta dallo smarthost SMTP (server ricevente) che verifica che l'e-mail sia stata accettata, compreso un ID di posta.
9.3. Consegna sincrona per le e-mail HTML
Puoi selezionare e configurare la consegna tracciabile via SMTP per il metodo di notifica delle e-mail HTML inserendo lo smarthost (con nome e numero di porta) e i dati di accesso e il metodo di crittografia:
Nella cronologia del servizio in questione, puoi quindi tracciare esattamente la consegna. Ecco un esempio in cui un servizio - a scopo di test - è stato impostato manualmente su CRIT. Lo screenshot qui sotto mostra le notifiche di questo servizio, che puoi visualizzare nella pagina dei dettagli del servizio con Service > Service Notifications:
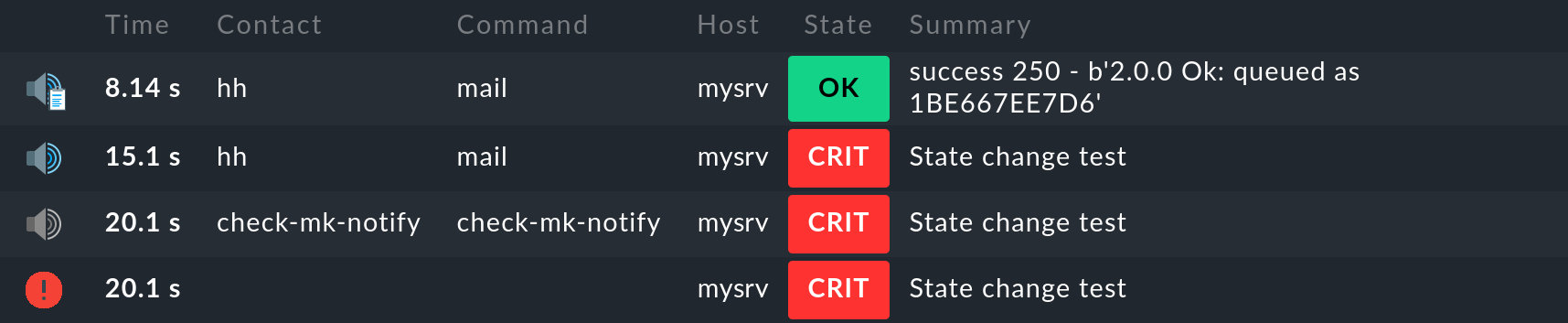
Qui vedrai i quattro singoli passaggi nella sequenza cronologica dal basso verso l'alto, come li abbiamo già presentati nel capitolo sulla cronologia delle notifiche. La differenza importante è che ora puoi vedere nella voce più in alto che l'e-mail è stata consegnata con successo allo smarthost e la sua risposta è success.
Puoi anche seguire i singoli passaggi nel file notify.log. Le righe seguenti appartengono all'ultimo passaggio e contengono la risposta del file server SMTP:
2021-08-26 10:02:22,016 [20] [cmk.base.notify] Got spool file d3b417a5 (mysrv;CPU load) for local delivery via mail
2021-08-26 10:02:22,017 [20] [cmk.base.notify] executing /omd/sites/mysite/share/check_mk/notifications/mail
2021-08-26 10:02:29,538 [20] [cmk.base.notify] Output: success 250 - b'2.0.0 Ok: queued as 1BE667EE7D6'Il Message-ID 1BE667EE7D6 apparirà nel file di log dello smarthost. In questo modo, se sei preoccupato, potrai verificare dove è arrivata l'e-mail. In ogni caso potrai dimostrare che, e quando, l'e-mail è stata inviata correttamente da Checkmk.
Ripetiamo il test di cui sopra, ma questa volta con una password falsamente configurata per il trasferimento SMTP allo smarthost. Qui puoi vedere in chiaro il messaggio di errore SMTP Error: authentication failed dallo smarthost:
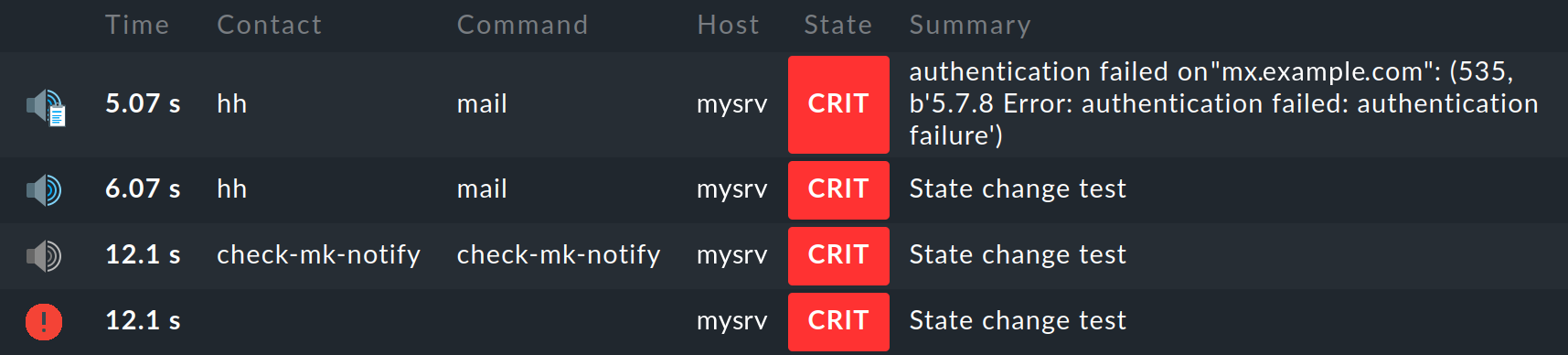
Cosa si può fare per le notifiche fallite? Anche in questo caso, la notifica via e-mail non sembra essere una buona soluzione, ma Checkmk mostra un chiaro avviso con sfondo rosso nella panoramica:
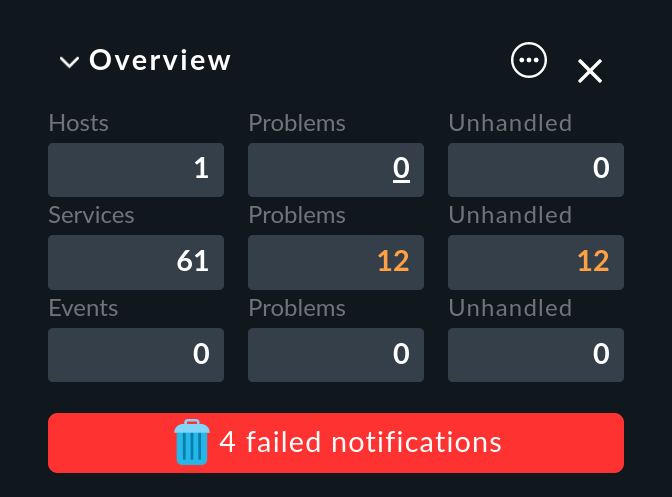
Qui puoi:
Cliccare sul testo … failed notifications per avere un elenco delle consegne non riuscite.
Cliccare sul simbolo per confermare questi messaggi e rimuovere l'avviso cliccando su Confirm nella panoramica che si apre.
Importante: Nota che l'invio diretto tramite SMTP in caso di errore può portare lo script di notifica ad essere eseguito per molto tempo e a causare un timeout. Per questo motivo ti consigliamo di utilizzare lo spooler di notifica e di selezionare un invio asincrono delle notifiche.
La condotta con errori ripetibili (come un timeout SMTP) può essere definita con Global settings > Notifications > Notification spooler configuration per metodo di notifica:
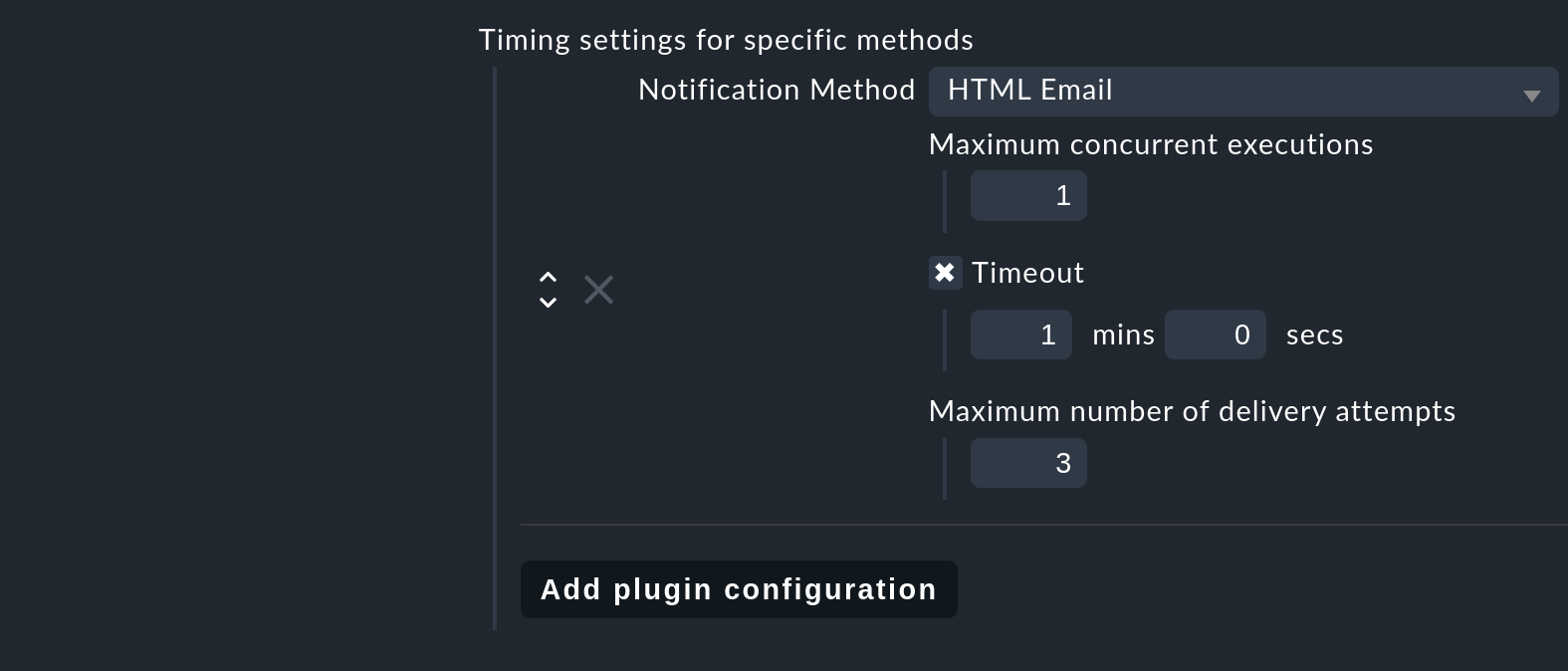
Oltre a un timeout opzionale (il valore predefinito è di 1 minuto) e a un numero massimo di tentativi, si può anche definire se lo script può essere eseguito più volte in parallelo e quindi inviare più notifiche (Maximum concurrent executions). Se lo script di notifica è molto lento, l'esecuzione in parallelo può avere senso, ma lo script deve essere programmato in modo che le esecuzioni multiple avvengano in modo pulito (e, ad esempio, che lo script non riservi alcuni dati per sé).
Una consegna multipla e parallela tramite SMTP non presenta problemi, poiché il server di destinazione è in grado di gestire più connessioni parallele. Questo non è certamente il caso quando si consegna direttamente da SMS tramite un modem senza uno spooler aggiuntivo, e in questo caso è necessario attenersi all'impostazione 1.
9.4. SMS e altri metodi di notifica
Finora la consegna sincrona con messaggi di errore e tracciabilità è stata implementata solo per le e-mail HTML. Per sapere come restituire uno stato di errore in uno script di notifica scritto da te, consulta il capitolo sulla scrittura dei tuoi script.
10. Notifiche in sistemi distribuiti
In ambienti distribuiti, cioè con più di un'istanza Checkmk, si pone il problema di cosa fare con le notifiche generate da istanze remote. In questa situazione ci sono fondamentalmente due possibilità:
Consegna locale
Consegna centrale sul sito centrale (solo edizioni commerciali).
Informazioni dettagliate su questo argomento sono disponibili nell'articolo sul monitoraggio distribuito.
11. Script di notifica
11.1. Il principio
Le notifiche possono avvenire in modi diversi e individuali. Esempi tipici sono:
Trasferimento di notifiche a un ticket o a un sistema di notifica esterno.
L'invio di un SMS tramite vari servizi internet.
Chiamate telefoniche automatiche
Inoltro a un sistema di monitoraggio superiore, a ombrello.
Per questo motivo Checkmk offre un'interfaccia molto semplice che ti permette di scrivere i tuoi script di notifica, che possono essere scritti in qualsiasi linguaggio di programmazione supportato da Linux, anche se Shell, Perl e Python detengono insieme il 95% del "mercato".
Gli script standard inclusi in Checkmk si trovano in ~/share/check_mk/notifications. Questa directory è un componente del software e non deve essere modificata. Salva invece i tuoi script in ~/local/share/check_mk/notifications. Assicurati che i tuoi script siano eseguibili (chmod +x). Verranno quindi trovati automaticamente e resi disponibili per la selezione nelle regole di notifica.
Se desideri personalizzare uno script standard, è sufficiente copiarlo da ~/share/check_mk/notifications a ~/local/share/check_mk/notifications e apportare le modifiche nella copia. Se mantieni il nome originale, il tuo script verrà sostituito automaticamente alla versione standard e non sarà necessario apportare modifiche alle regole di notifica esistenti.
Altri script di esempio sono inclusi nel software all'indirizzo ~/share/doc/check_mk/treasures/notifications. Puoi utilizzarli come modelli per la personalizzazione. In genere la configurazione avviene direttamente nello script: nei commenti troverai suggerimenti in merito.
Nel caso di una notifica, lo script verrà richiamato con i permessi dell'utente dell'istanza. Nelle variabili d'ambiente(quelle che iniziano con NOTIFY_), riceverà tutte le informazioni sull'host/servizio interessato, l'evento di monitoraggio, i contatti da avvisare e i parametri specificati nella regola di notifica.
I testi che lo script di notifica scrive sullo standard output (con print, echo, ecc.) vengono visualizzati nel file di log del modulo di notifica ~/var/log/notify.log.
11.2. Notifiche tracciabili
Gli script di notifica hanno la possibilità di utilizzare un codice di uscita per comunicare se si è verificato un errore replicabile o definitivo:
| Codice di uscita | Funzione |
|---|---|
|
Lo script è stato eseguito con successo. |
|
Si è verificato un errore temporaneo. Dopo una breve attesa, l'esecuzione deve essere ripetuta fino al raggiungimento del numero massimo di tentativi configurato. Esempio: non è possibile stabilire una connessione HTTP con un servizio SMS. |
|
Si è verificato un errore finale. La notifica non verrà ritentata. Un errore di notifica verrà visualizzato nella GUI. L'errore verrà visualizzato nella cronologia dell'host o del servizio. Esempio: il servizio SMS registra un errore di "autenticazione non valida". |
Inoltre, in tutti i casi l'output standard dello script di notifica, insieme allo stato, verrà inserito nella cronologia delle notifiche dell'host o del servizio e sarà quindi visibile nella GUI.
Importante: le notifiche tracciabili non sono disponibili per le notifiche di massa!
Il trattamento degli errori di notifica dal punto di vista dell'utente sarà spiegato nel capitolo sulla consegna tracciabile via SMTP.
11.3. Un semplice script di esempio
Come esempio puoi creare uno script che scrive tutte le informazioni sulla notifica in un file. Il linguaggio di codifica è la shell Linux Bash:
#!/bin/bash
# Foobar Teleprompter
env | grep NOTIFY_ | sort > $OMD_ROOT/tmp/foobar.out
echo "Successfully written $OMD_ROOT/tmp/foobar.out"
exit 0Quindi rendi lo script eseguibile:
OMD[mysite]:~$ chmod +x local/share/check_mk/notifications/foobarEcco un paio di spiegazioni sullo script:
Nella prima riga c'è un
#!e il percorso dell'interprete del linguaggio di script (qui/bin/bash).Nella seconda riga, dopo il carattere di commento
#c'è il titolo dello script. Di regola questo viene mostrato quando si seleziona il metodo di notifica.Il comando
envvisualizza tutte le variabili d'ambiente ricevute dallo script.Con
grep NOTIFY_le variabili di Checkmk verranno filtrate...... e ordinate alfabeticamente con
sort.> $OMD_ROOT/tmp/foobar.outscrive il risultato nel file~/tmp/foobar.outall'interno della directory del sito.Il file
exit 0sarebbe in realtà superfluo in questa posizione poiché la shell prende sempre il codice di uscita dell'ultimo comando. In questo caso si tratta diechoe va sempre a buon fine, ma è sempre meglio se è esplicito.
11.4. Testare lo script di esempio
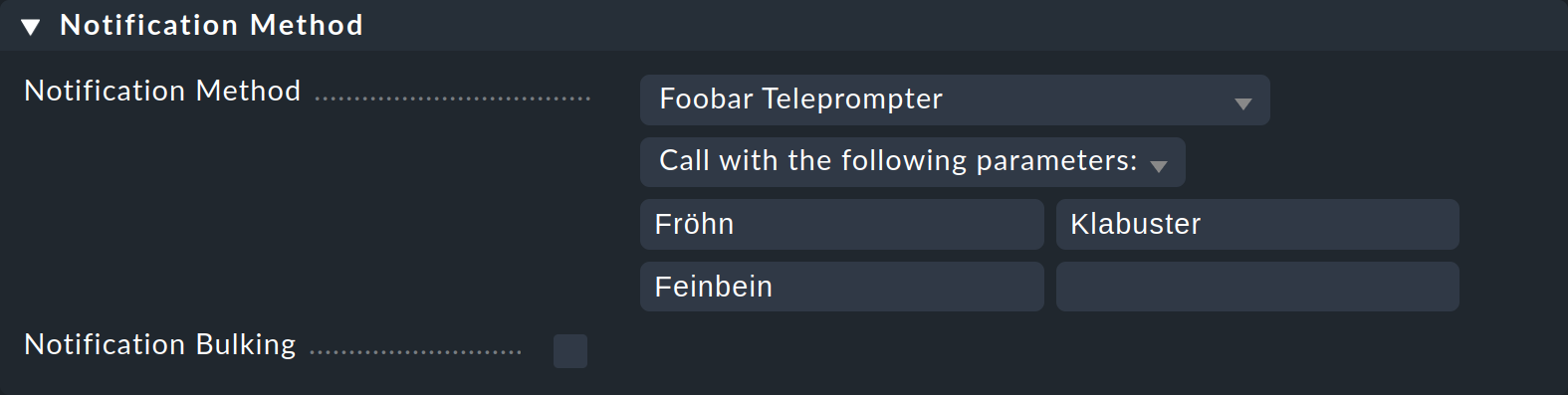
Affinché lo script venga utilizzato, devi definirlo come metodo in una regola di notifica. Gli script scritti in proprio non hanno una dichiarazione dei parametri, quindi tutti i checkbox come quelli offerti, ad esempio, nel metodo HTML Email, saranno assenti. Invece puoi inserire un elenco di testi come parametri che possono essere disponibili come NOTIFY_PARAMETER_1, NOTIFY_PARAMETER_2, ecc. Per un test fornisci i parametri Fröhn, Klabuster e Feinbein:
Per fare un test, imposta il servizio CPU load sull'host myserver su CRIT- con il comando Fake check results. Nel file di log del modulo di notifica ~/var/log/notify.log vedrai l'esecuzione dello script, compresi i parametri e il file di spool generato:
2021-08-25 13:01:23,887 [20] [cmk.base.notify] Executing 1 notifications:
2021-08-25 13:01:23,887 [20] [cmk.base.notify] * notifying hh via foobar, parameters: Fröhn, Klabuster, Feinbein, bulk: no
2021-08-25 13:01:23,887 [20] [cmk.base.notify] Creating spoolfile: /omd/sites/mysite/var/check_mk/notify/spool/e1b5398c-6920-445a-888e-f17e7633de60Il file ~/tmp/foobar.out conterrà ora un elenco alfabetico di tutte le variabili d'ambiente di Checkmk che includono informazioni relative alla notifica. Qui puoi orientarti sui valori disponibili per il tuo script di notifica. Ecco le prime dieci righe:
OMD[mysite]:~$ head tmp/foobar.out
NOTIFY_ALERTHANDLERNAME=debug
NOTIFY_ALERTHANDLEROUTPUT=Arguments:
NOTIFY_ALERTHANDLERSHORTSTATE=OK
NOTIFY_ALERTHANDLERSTATE=OK
NOTIFY_CONTACTALIAS=Harry Hirsch
NOTIFY_CONTACTEMAIL=harryhirsch@example.com
NOTIFY_CONTACTNAME=hh
NOTIFY_CONTACTPAGER=
NOTIFY_CONTACTS=hh
NOTIFY_DATE=2021-08-25Si possono trovare anche i parametri:
OMD[mysite]:~$ grep PARAMETER tmp/foobar.out
NOTIFY_PARAMETERS=Fröhn Klabuster Feinbein
NOTIFY_PARAMETER_1=Fröhn
NOTIFY_PARAMETER_2=Klabuster
NOTIFY_PARAMETER_3=Feinbein11.5. Variabili d'ambiente
Nell'esempio precedente hai visto una serie di variabili d'ambiente che verranno passate allo script. Le variabili disponibili dipendono esattamente dal tipo di notifica, dalla versione e dall'edizione di Checkmk e dal nucleo di monitoraggio utilizzato(CMC o Nagios). Oltre al trucco del comando env, ci sono altri due modi per ottenere un elenco completo di tutte le variabili:
Modificando il livello di log per
notify.logtramite Global settings > Notifications > Notification log level.Per le notifiche di HTML Email c'è un checkbox Information to be displayed in the email body con l'opzione Complete variable list (for testing).
Di seguito è riportato un elenco delle variabili più importanti:
| Variabile d'ambiente | Significato |
|---|---|
|
Directory home del sito, ad es. |
|
Nome del sito, ad es. |
|
Per le notifiche dell'host, la parola |
|
Nome utente (login) del contatto. |
|
L'indirizzo e-mail del contatto. |
|
Inserimento del campo Pager nel profilo utente del contatto. Poiché questo campo non è generalmente riservato a uno scopo specifico, puoi semplicemente utilizzarlo per ogni utente al fine di salvare le informazioni necessarie per le notifiche. |
|
Data della notifica in formato ISO-8601, ad es. |
|
Data e ora nella visualizzazione predefinita del sistema Linux non localizzato, ad es. |
|
Data e ora in formato ISO, ad es. |
|
Nome dell'host interessato. |
|
Output del plug-in di controllo dell'host, ad es. |
|
Una delle parole: |
|
Tipo di notifica come descritto nell'introduzione di questo articolo. Questo sarà espresso da una delle seguenti parole: |
|
Tutti i parametri dello script separati da spazi vuoti. |
|
Il primo parametro dello script. |
|
Il secondo parametro dello script, ecc. |
|
Nome del servizio interessato. Questa variabile non è presente nelle notifiche host. |
|
Output del plug-in di controllo del servizio (non per le notifiche host) |
|
Una delle parole: |
11.6. Notifiche di massa
Se il tuo script deve supportare le notifiche di massa, dovrà essere preparato in modo particolare, poiché lo script deve inviare più notifiche contemporaneamente. Per questo motivo, anche l'invio tramite variabili d'ambiente non funziona in modo pratico.
Dai un nome allo script di notifica nella terza riga dell'intestazione, come indicato di seguito: il modulo di notifica invierà le notifiche attraverso lo standard input:
#!/bin/bash
# My Bulk Notification
# Bulk: yesAttraverso lo standard input lo script riceverà blocchi di variabili. Ogni riga ha il modulo: NAME=VALUE. I blocchi sono separati da righe vuote. Il carattere ASCII con il codice 1 (\a) viene utilizzato per rappresentare le linee nuove all'interno del testo.
Il primo blocco contiene un elenco di variabili generali (es. parametri di chiamata). Ogni blocco successivo assembla le variabili in una notifica.
Il consiglio migliore è quello di provare tu stesso con un semplice test che scriva i dati completi su un file in modo da poter vedere come vengono inviati i dati. A questo scopo puoi utilizzare il seguente script di notifica:
#!/bin/bash
# My Bulk Notification
# Bulk: yes
cat > $OMD_ROOT/tmp/mybulktest.outProva lo script di notifica come descritto sopra e attiva anche il sito Notification Bulking nella regola di notifica.
11.7. Script di notifica in dotazione
Checkmk fornisce già una serie di script per la connessione a servizi di messaggistica istantanea, piattaforme di gestione degli incidenti e sistemi di ticket molto diffusi. Puoi scoprire come utilizzare questi script nei seguenti articoli:
12. Testare le notifiche con Fake check results
Per testare i metodi di notifica diversi dall'e-mail puoi semplicemente impostare manualmente un servizio OK su CRIT. Questo può essere fatto con il comando Fake check results, che puoi trovare nell'elenco dei servizi nel menu Commands. Se il comando non è visibile nell'elenco, clicca una volta sul pulsante Show more.
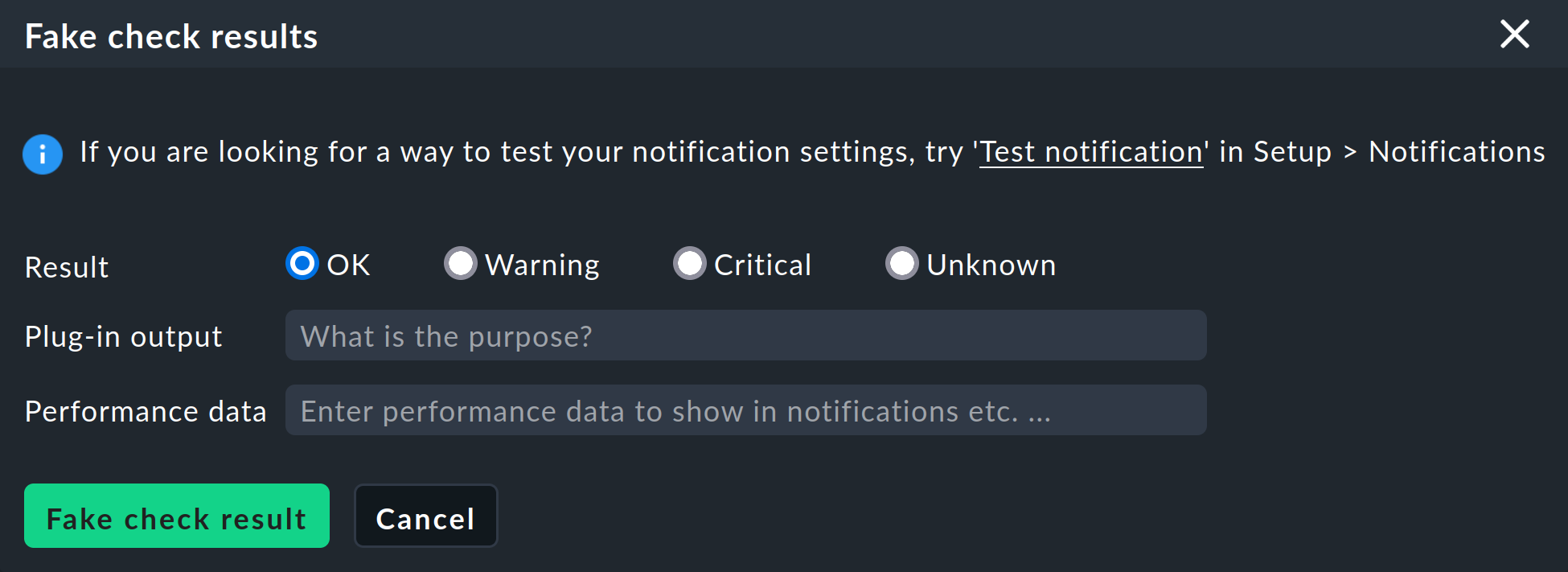
Se tutte le condizioni di una delle tue regole di notifica sono soddisfatte, viene eseguito il metodo di notifica impostato per questa regola. Al prossimo controllo regolare il servizio dovrebbe tornare a OK, innescando così una nuova notifica, questa volta di recupero.
Tieni presente che durante questi test, modificando frequentemente il suo stato, dopo un po' di tempo il servizio entrerà nello stato di irregolare. I successivi cambiamenti di stato non faranno più scattare le notifiche. Nello snap-in del controllo master sulla barra laterale puoi disattivare temporaneamente il rilevamento dell'irregolare (Flap Detection).
In alternativa, puoi anche inviare un Custom notification, sempre tramite un comando:
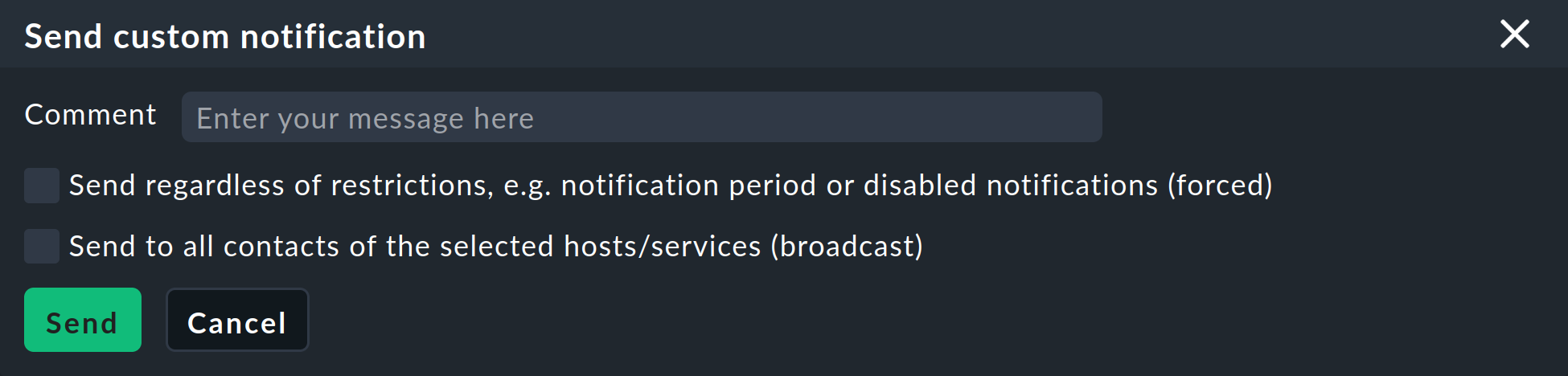
Questa notifica generata è di tipo diverso e, a seconda delle regole di notifica, può comportarsi in modo diverso.
13. File e directory
13.1. Percorsi di Checkmk
| Percorso del file | Funzione |
|---|---|
|
Il file di log del CMC. Se il debug delle notifiche è attivato, qui troverai informazioni precise sul perché le notifiche sono state o non sono state generate. |
|
Il file di log del modulo di notifica. |
|
Il file di log dello spooler di notifica. |
|
Lo stato attuale dello spooler di notifica. Questo è importante soprattutto per le notifiche in ambienti distribuiti. |
|
Il file di log di debug di Nagios. Attiva i messaggi di debug in |
|
Posizione di archiviazione dei file di spool da processare da parte dello spooler di notifica. |
|
In caso di errori temporanei, lo spooler di notifica sposta i file in questa posizione e riprova dopo un paio di minuti. |
|
I file di spool difettosi verranno spostati qui. |
|
Gli script di notifica sono forniti di serie con Checkmk. Non apportare modifiche qui. |
|
Luogo di archiviazione degli script di notifica personalizzati. Se desideri personalizzare uno script standard, copialo da |
|
Altri script di notifica personalizzati che puoi utilizzare. |
13.2. I file di log del server SMTP
I file di log del server SMTP sono file di sistema e i loro percorsi assoluti sono elencati qui di seguito. La posizione esatta dei file di log dipende dalla tua distribuzione Linux.
| Percorso | Funzione |
|---|---|
|
File di log del server SMTP in Debian e Ubuntu |
|
File di log di SMTP-server in SUSE Linux Enterprise Server (SLES) |
|
File di log del server SMTP in Red Hat Enterprise Linux (RHEL) |