This is a machine translation based on the English version of the article. It might or might not have already been subject to text preparation. If you find errors, please file a GitHub issue that states the paragraph that has to be improved. |
1. Introduzione
1.1. Gli eventi non sono stati
Lo stato principale dell'attività di Checkmk è il monitoraggio attivo degli stati.In qualsiasi momento, ogni servizio monitorato ha uno degli stati di monitoraggio, OK, WARN, CRIT o SCONOSCIUTO. Attraverso un polling regolare, il monitoraggio aggiorna costantemente il quadro della situazione attuale.
Un tipo di monitoraggio completamente diverso è quello che gestisce gli eventi. Un esempio di evento è un'eccezione che si verifica in un'applicazione. L'applicazione può rimanere nello stato di OK e continuare a funzionare correttamente, ma è successo qualcosa.
1.2. La Console degli Eventi
Con la Console degli Eventi (EC in breve), Checkmk offre un sistema completamente integrato per il monitoraggio degli eventi provenienti da fonti quali syslog, SNMP trap, file di log di Windows e applicazioni proprie. Gli eventi non sono semplicemente definiti come stati di monitoraggio, ma costituiscono una categoria a sé stante e vengono visualizzati come informazioni separate da Checkmk nella barra laterale Overview.
Internamente, gli eventi non vengono processati dal nucleo di monitoraggio, ma da un servizio separato: il daemon degli eventi (mkeventd).
La Console degli Eventi dispone anche di un archivio in cui è possibile cercare gli eventi passati. Tuttavia, va detto subito che questo non sostituisce un vero e proprio archivio dei log. Il compito della Console degli Eventi è quello di filtrare in modo intelligente un piccolo numero di messaggi rilevanti da un flusso di grandi dimensioni. È ottimizzata per la semplicità, la robustezza e il throughput, non per l'archiviazione di grandi volumi di dati.
Una breve descrizione delle funzionalità della CE:
Può ricevere messaggi direttamente tramite syslog o SNMP trap. Per questo motivo non è necessaria la configurazione dei servizi di sistema Linux corrispondenti.
Può anche valutare file di log basati su testo e registri eventi di Windows utilizzando gli agenti Checkmk.
Classifica i messaggi in base a catene di regole definite dall'utente.
Può correlare, riassumere, contare, annotare e riscrivere i messaggi e considerare le loro relazioni temporali.
Può eseguire azioni automatiche e inviare notifiche tramite Checkmk.
È completamente integrato nell'interfaccia utente di Checkmk.
È incluso e pronto all'uso in qualsiasi versione attuale del sistema Checkmk.
1.3. Terminologia
La Console degli Eventi riceve messaggi (per lo più sotto forma di registri eventi). Un messaggio è una riga di testo con una serie di possibili attributi aggiuntivi, ad es. un timestamp, un nome host, ecc:
Un messaggio viene trasformato in un evento solo se una regola ha effetto.
Le regole possono modificare il testo e altri attributi dei messaggi.
Più messaggi possono essere combinati in un unico evento.
I messaggi possono anche eliminare gli eventi in corso.
Si possono generare eventi artificiali se alcuni messaggi non vengono visualizzati.
Un evento può attraversare diverse fasi:
Apertura |
Lo stato "normale": Si è verificato qualcosa: l'operatore deve occuparsene. |
Confermato |
Il problema è stato confermato - questo è analogo ai problemi dello stato dell'host e del servizio nel monitoraggio basato sullo stato. |
Conteggio |
Il numero richiesto di messaggi specificati non è ancora arrivato: la situazione non è ancora problematica. L'evento non viene quindi ancora visualizzato dall'operatore. |
In ritardo |
È stato ricevuto un messaggio di errore, ma la Console degli Eventi sta ancora aspettando di ricevere il messaggio OK appropriato entro un tempo configurato. Solo allora l'evento verrà visualizzato dall'operatore. |
Chiuso |
L'evento è stato chiuso dall'operatore o automaticamente dal sistema e si trova solo nell'archivio. |
Un evento ha anche uno stato.A rigore, però, non si intende lo stato dell'evento stesso, ma piuttosto lo stato del servizio o del dispositivo che ha inviato l'evento. Per usare un'analogia con gli eventi di monitoraggio basati sullo stato, un evento può anche essere contrassegnato come OK, WARN, CRIT o SCONOSCIUTO.
2. Impostazione della Console degli Eventi
L'impostazione della Console degli Eventi è molto semplice, perché la Console degli Eventi è parte integrante di Checkmk e si attiva automaticamente.
Tuttavia, se vuoi ricevere messaggi syslog o SNMP trap attraverso la rete, devi attivarli separatamente. Il motivo è che entrambi i servizi devono aprire una porta UDP con un numero di porta specificamente identificato. E poiché solo un'istanza Checkmk per sistema può farlo, la ricezione attraverso la rete è disabilitata per impostazione predefinita.
I numeri di porta sono:
| Protocollo | Porta | Servizio |
|---|---|---|
UDP |
162 |
SNMP trap |
UDP |
514 |
Syslog |
TCP |
514 |
Syslog via TCP |
Il syslog via TCP è usato raramente, ma ha il vantaggio di garantire la trasmissione dei messaggi. Con UDP non si può mai garantire che i pacchetti arrivino effettivamente e né il syslog né le trap SNMP offrono conferme o una protezione simile contro i messaggi persi. Per poter utilizzare il syslog via TCP, il sistema di invio deve ovviamente essere in grado di inviare messaggi attraverso questa porta.
Nell'appliance Checkmk, puoi abilitare la ricezione di syslog/SNMP trap nella configurazione del sito. Altrimenti, usa semplicemente omd config. Puoi trovare l'impostazione necessaria sotto Addons:
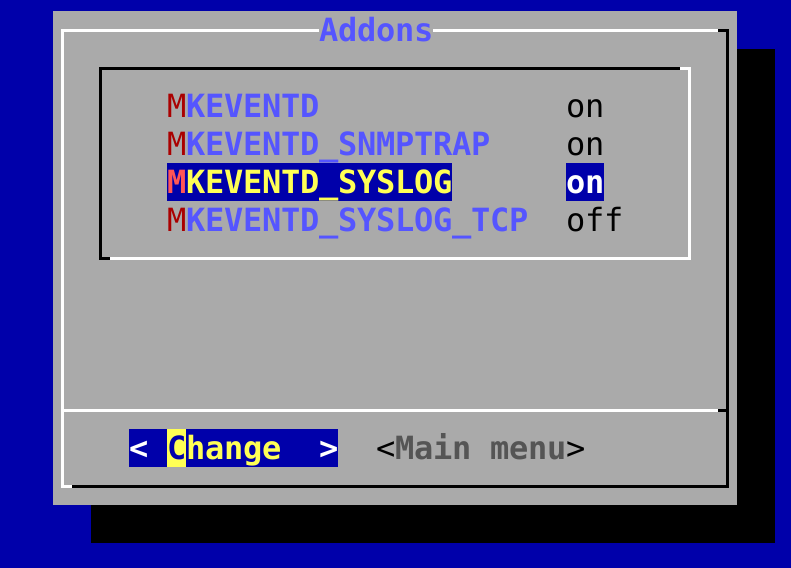
Su omd start puoi vedere nella riga che contiene mkeventd quali sono le interfacce esterne aperte dalla tua CE:
OMD[mysite]:~$ omd start
Creating temporary filesystem /omd/sites/mysite/tmp...OK
Starting mkeventd (builtin: syslog-udp,snmptrap)...OK
Starting liveproxyd...OK
Starting mknotifyd...OK
Starting rrdcached...OK
Starting cmc...OK
Starting apache...OK
Starting dcd...OK
Starting redis...OK
Initializing Crontab...OK3. I primi passi con la Console degli Eventi
3.1. Regole, regole, regole
All'inizio abbiamo accennato al fatto che la CE viene utilizzata per individuare e visualizzare i messaggi rilevanti. Purtroppo, però, la maggior parte dei messaggi, indipendentemente dal fatto che provengano da file di log, dal registro eventi di Windows o dal syslog, sono piuttosto insignificanti. Inoltre, non è d'aiuto quando i messaggi sono già stati preclassificati dal loro autore.
Ad esempio, nel syslog e nel registro eventi di Windows i messaggi sono classificati in qualcosa di simile a OK, WARN e CRIT. Ma il significato effettivo di WARN e CRIT può essere definito in modo soggettivo dal programmatore. E non si può nemmeno affermare con certezza che l'applicazione che ha prodotto il messaggio sia importante su questo computer. In breve: non puoi evitare di configurare quali messaggi ti sembrano un vero problema e quali possono essere semplicemente scartati.
Come ovunque in Checkmk, la configurazione avviene tramite regole, che vengono processate dall'EC per ogni messaggio in arrivo secondo il principio del "primo matching". La prima regola che viene applicata a un messaggio in arrivo ne decide il destino. Se non viene applicata alcuna regola, il messaggio verrà semplicemente scartato.
Poiché con il tempo si accumulano molte regole per la CE, queste sono organizzate in pacchetti. Il processo delle regole avviene pacchetto per pacchetto e all'interno di un pacchetto dall'alto verso il basso, quindi l'ordine di elaborazione dei pacchetti è importante.
3.2. Creare una regola semplice
Non sorprende che l'interfaccia di configurazione della CE si trovi nel menu Setup alla voce Events > Event Console. Out of the box, troverai solo il modulo Default rule pack, che in realtà non contiene alcuna regola. I messaggi in arrivo, come già detto, vengono scartati e non vengono nemmeno logati. Il modulo stesso si presenta così:
Inizia creando un nuovo pacchetto di regole con Add rule pack:
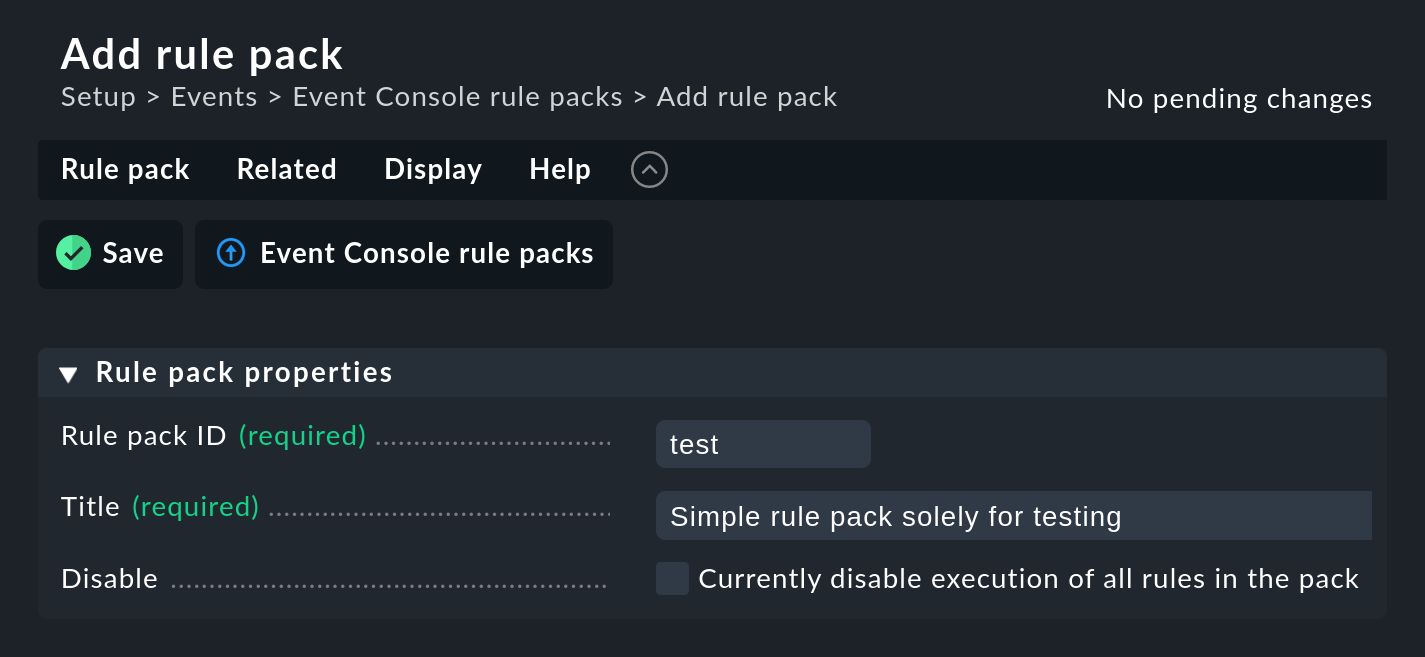
Come sempre, l'ID è un riferimento interno e non può essere modificato in seguito. Dopo aver salvato, troverai la nuova voce dell'elenco dei tuoi pacchetti di regole:
A questo punto puoi passare al pacchetto di regole ancora vuoto con e creare una nuova regola con Add rule. Compila solo il primo box con l'intestazione Rule Properties:
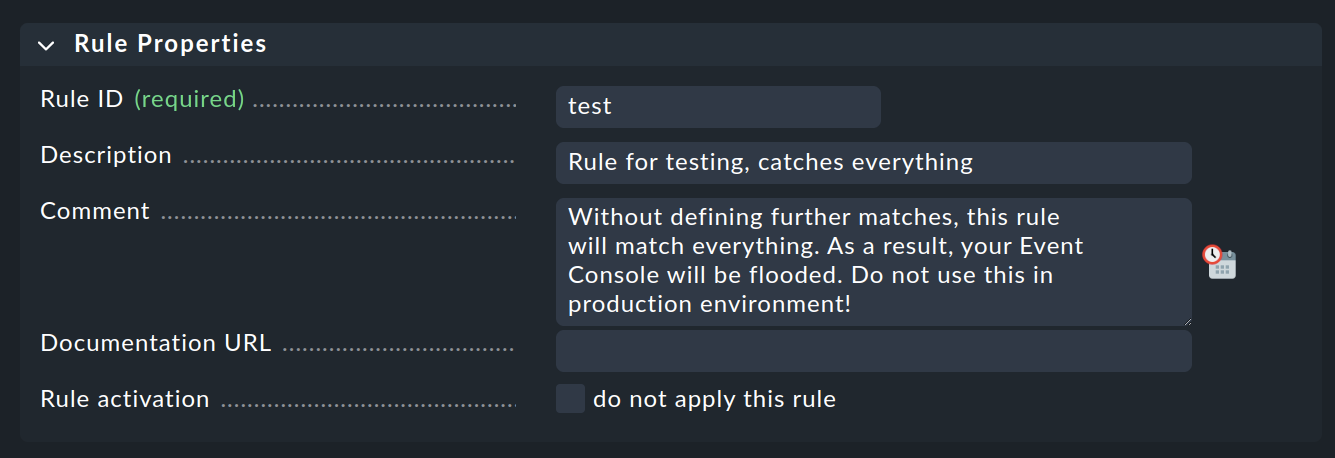
L'unica cosa necessaria è un ID univoco Rule ID. Questo ID sarà trovato in seguito nei file di log e sarà memorizzato insieme agli eventi generati. È quindi opportuno assegnare gli ID con nomi significativi in modo sistematico. Tutte le altre caselle sono facoltative. Questo vale soprattutto per le condizioni.
Importante: questa nuova regola è un esempio solo per i test e si applicherà a tutti gli eventi. Per questo motivo è importante che tu la rimuova in seguito o almeno la disattivi, altrimenti la tua Console degli Eventi sarà inondata da ogni messaggio inutile immaginabile e sarà praticamente inutile!
Attivare le modifiche
Come sempre in Checkmk, devi prima attivare le modifiche affinché diventino effettive. Questo non è uno svantaggio perché in questo modo, per le modifiche che riguardano diverse regole correlate, puoi specificare esattamente quando le regole devono essere "live". E prima puoi usare il sito Event Simulator per verificare che tutto funzioni come previsto.
Per prima cosa, clicca sul numero di modifiche accumulate in alto a destra della pagina.
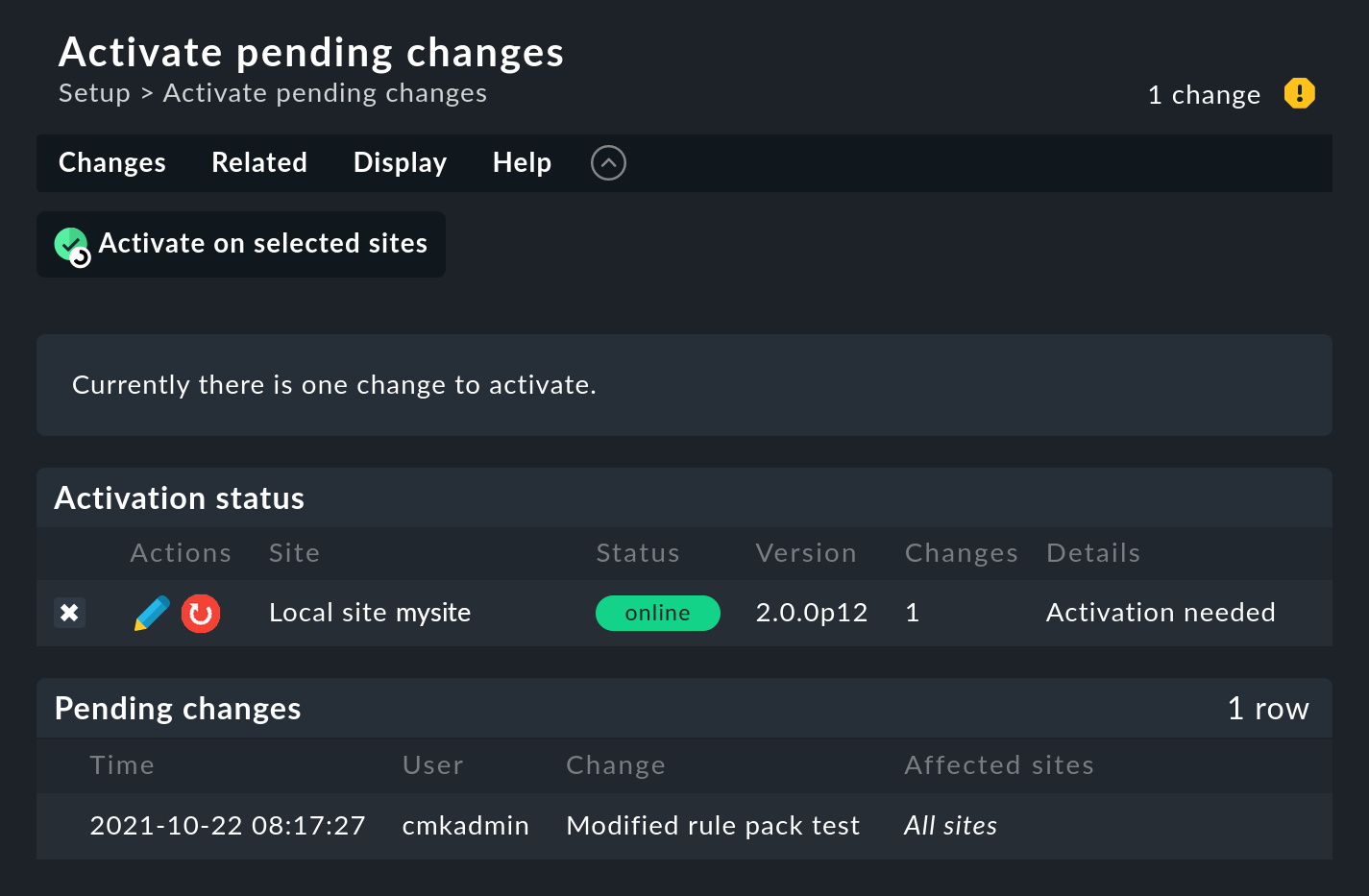
Poi clicca su Activate on selected sites per attivare le modifiche. La Console degli Eventi è progettata in modo tale che questa azione venga eseguita senza interruzioni. La ricezione dei messaggi in arrivo è garantita in ogni momento, in modo che nessun messaggio vada perso durante il processo.
Solo gli amministratori sono autorizzati ad attivare le modifiche nella Console eventi. Questo viene controllato tramite il permesso Activate changes for event console.
Testare la nuova regola
Per i test potresti ovviamente inviare messaggi tramite syslog o SNMP. Dovresti farlo anche in seguito, ma per un primo test è più pratico l'integrato Event Simulator di EC:
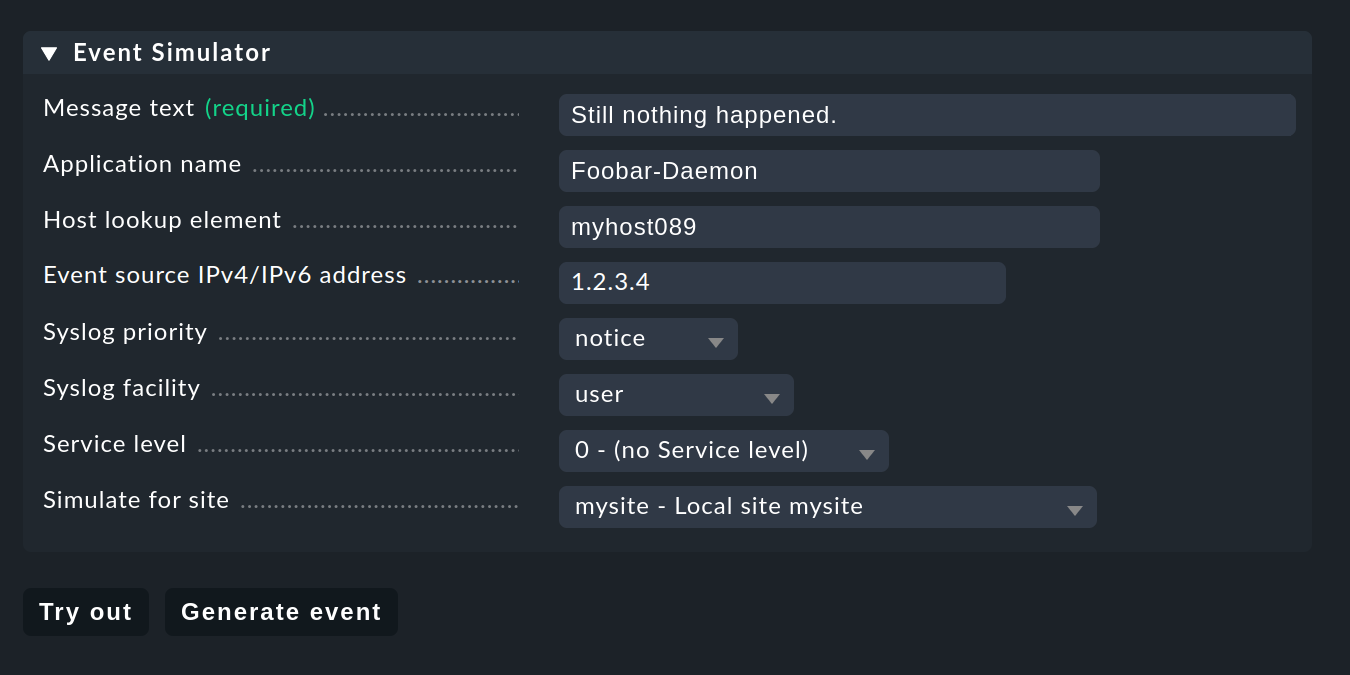
Qui hai due opzioni:Try out valuta sulla base del messaggio simulato quale delle regole corrisponderebbe. Se ti trovi nel livello superiore della GUI, i pacchetti di regole saranno evidenziati. Se ti trovi all'interno di un pacchetto di regole, le singole regole sono evidenziate. Ogni pacchetto o regola è contrassegnato da uno dei tre simboli seguenti:
Questa regola è la prima ad avere effetto sul messaggio e di conseguenza ne determina il destino. |
|
Questa regola avrebbe effetto, ma il messaggio è già stato trattato da una regola precedente. |
|
Questa regola non ha effetto. Molto utile: Se sposti il mouse sul pallino grigio, otterrai una spiegazione del perché la regola non è applicabile. |
Facendo clic su Generate event si ottiene quasi la stessa cosa di Try out, solo che ora il messaggio viene effettivamente generato.Tutte le azioni definite vengono effettivamente eseguite e l'evento viene visualizzato anche tra gli eventi aperti del monitoraggio. Puoi vedere il codice sorgente del messaggio generato nella conferma:

L'evento generato appare nel menu Monitor alla voce Event Console > Events:

Generare messaggi manualmente per i test
Per un primo test reale sulla rete, puoi facilmente inviare un messaggio syslog da un altro computer Linux a mano. Dato che il protocollo è così semplice, non hai nemmeno bisogno di un programma speciale: puoi semplicemente inviare i dati tramite netcat o nc utilizzando UDP. Il contenuto del pacchetto UDP consiste in una singola riga di testo. Se questo è conforme a una struttura specifica, la Console degli Eventi scompone i componenti in modo pulito:
user@host:~$ echo '<78>Dec 18 10:40:00 myserver123 MyApplication: It happened again.' | nc -w 0 -u 10.1.1.94 514Ma puoi anche inviare qualsiasi cosa: la CE la accetterà comunque e la valuterà come testo di un messaggio. Naturalmente mancheranno informazioni aggiuntive come l'applicazione, la priorità, ecc. Per motivi di sicurezza verrà assunto lo stato CRIT:
user@host:~$ echo 'This is no syslog message' | nc -w 0 -u 10.1.1.94 514All'interno dell'istanza Checkmk che esegue l'EC c'è una pipe denominata, nella quale puoi scrivere messaggi di testo localmente tramite echo. Questo è un metodo molto semplice per la connessione di un'applicazione locale e anche un modo per testare il processo dei messaggi:
OMD[mysite]:~$ echo 'Local application says hello' > tmp/run/mkeventd/eventsA proposito, è anche possibile inviare messaggi in formato syslog, in modo che tutti i campi dei dati dell'evento siano compilati in modo pulito.
3.3. Impostazioni della Console degli Eventi
La Console degli Eventi ha le sue impostazioni globali, che non si trovano insieme a quelle degli altri moduli, ma si trovano all'indirizzo Setup > Events > Event Console con il pulsante Settings.
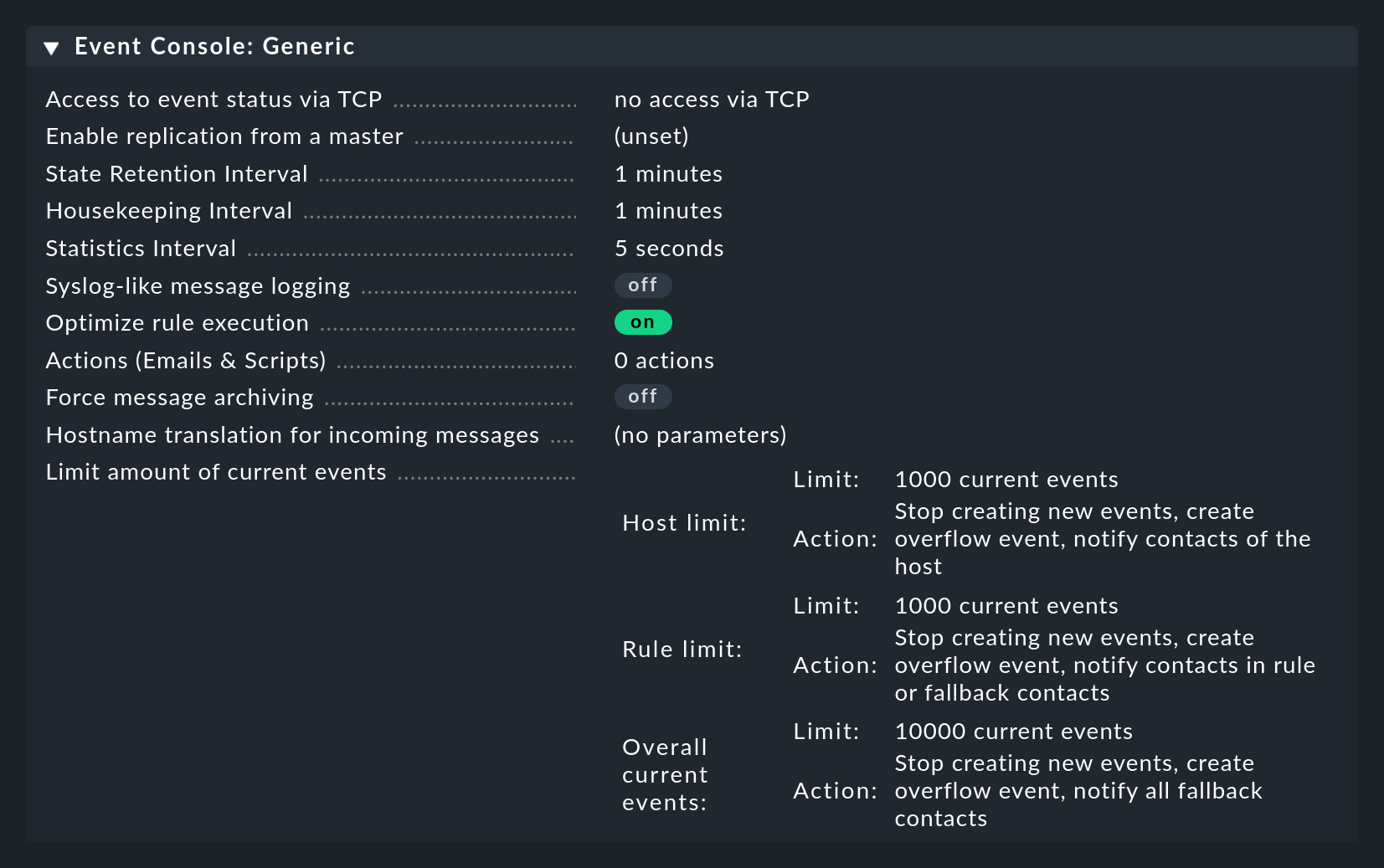
Come sempre, puoi trovare le spiegazioni delle singole impostazioni nell'aiuto inline e nei punti appropriati di questo articolo.
L'accesso alle impostazioni è possibile tramite il permesso Configuration of Event Console, che per impostazione predefinita è disponibile solo nel ruolo admin.
3.4. I permessi
Anche la Console degli Eventi ha una sezione dedicata ai ruoli e ai permessi:
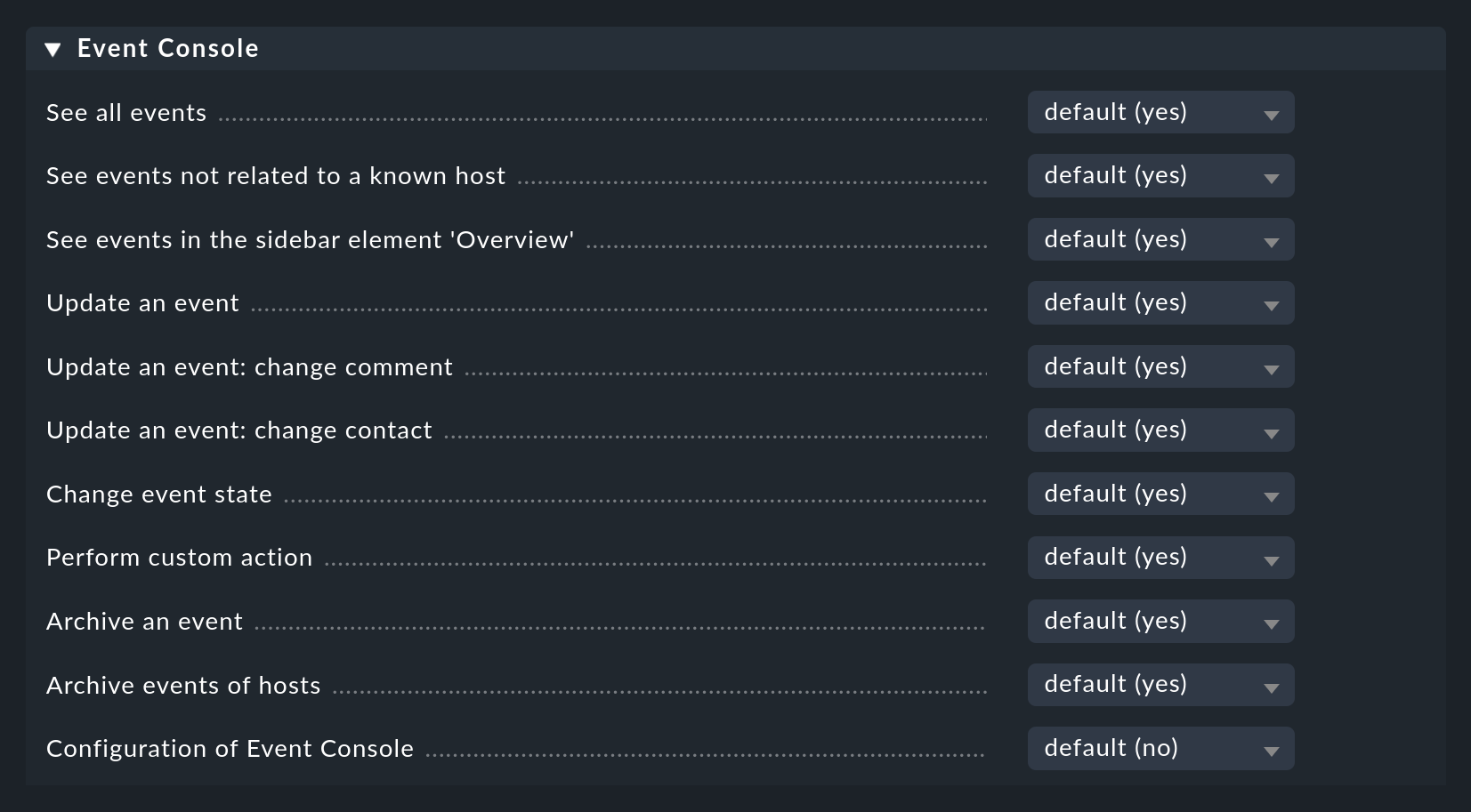
Alcuni di questi permessi saranno discussi in dettaglio nei punti appropriati di questo articolo.
3.5. Assegnazione dell'host nella Console degli Eventi
Una caratteristica speciale della Console degli Eventi è che, a differenza del monitoraggio basato sullo stato, gli host non sono al centro dell'attenzione. Gli eventi possono verificarsi senza un'assegnazione esplicita dell'host, cosa che in effetti è spesso desiderata. Tuttavia, un'assegnazione dovrebbe essere possibile per gli host che sono già in fase di monitoraggio attivo, in modo da accedere rapidamente alla panoramica dello stato quando si verifica un evento. O al più tardi, se gli eventi devono essere convertiti in stati, un'assegnazione corretta è essenziale.
La regola fondamentale per i messaggi ricevuti via syslog è che il nome host nel messaggio deve corrispondere al nome host nel monitoraggio. Questo si ottiene utilizzando il nome di dominio completamente qualificato (FQDN) / nome host completamente qualificato (FQHN), sia nella configurazione del syslog che nella denominazione dell'host in Checkmk. In Rsyslog puoi ottenere questo risultato utilizzando la direttiva globale $PreserveFQDN on.
Checkmk cerca di far corrispondere i nomi host degli eventi di monitoraggio a quelli del monitoraggio attivo nel modo più automatico possibile. Oltre al nome host, viene provato anche l'alias host. Se il nome breve viene trasmesso via syslog, l'assegnazione sarà corretta.
Una risoluzione a ritroso dell'indirizzo IP non avrebbe molto senso in questo caso, perché spesso vengono utilizzati server di log intermedi. Se la conversione dei nomi host in FQDN/FQHN o il reinserimento di molti alias richiede troppo tempo, puoi utilizzare l'impostazione della Console degli Eventi Hostname translation for incoming messages per tradurre i nomi host direttamente quando ricevi i messaggi. In questo modo hai numerose possibilità:
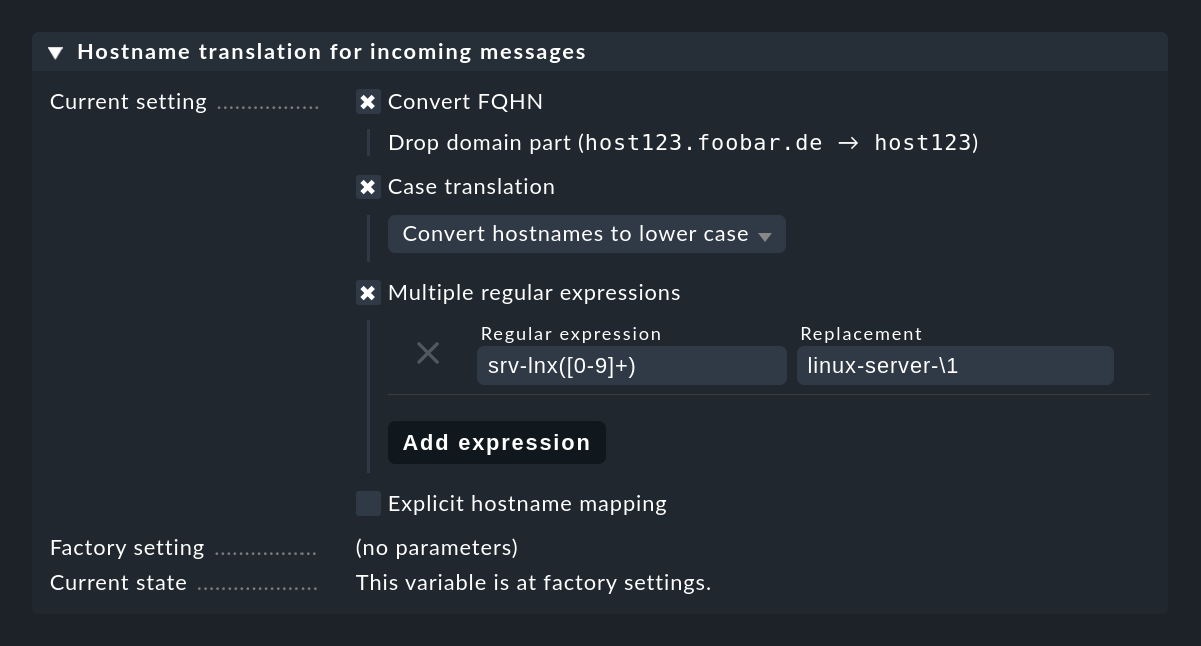
In particolare, se i nomi host sono espliciti, ma manca solo la parte del dominio utilizzata in Checkmk, una semplice regola ti aiuterà: (.*) diventa \1.mydomain.test. Nei casi in cui tutto questo non sia sufficiente, puoi utilizzare Explicit hostname mapping per specificare una tabella di nomi individuali e le rispettive traduzioni.
Importante: la conversione del nome viene eseguita prima della verifica delle condizioni della regola e quindi molto prima di un'eventuale riscrittura del nome host da parte dell'azione della regola Rewrite hostname nella riscrittura automatica del testo.
L'assegnazione è un po' più semplice con SNMP: in questo caso, l'indirizzo IP del mittente viene confrontato con gli indirizzi IP cache degli host nel monitoraggio; in altre parole, non appena sono disponibili controlli attivi regolari, come il controllo dell'accessibilità della porta Telnet o SSH di uno switch, i messaggi di stato di questo dispositivo inviati tramite SNMP saranno assegnati all'host corretto.
4. La Console degli Eventi nel monitoraggio
4.1. Visualizzazioni degli eventi
Gli eventi generati dalla Console degli Eventi vengono visualizzati in modo analogo agli host e ai servizi dell'ambiente di monitoraggio. Puoi trovare il punto di accesso a questa visualizzazione nel menu Monitor alla voce "Visualizzazioni". Event Console > Events:
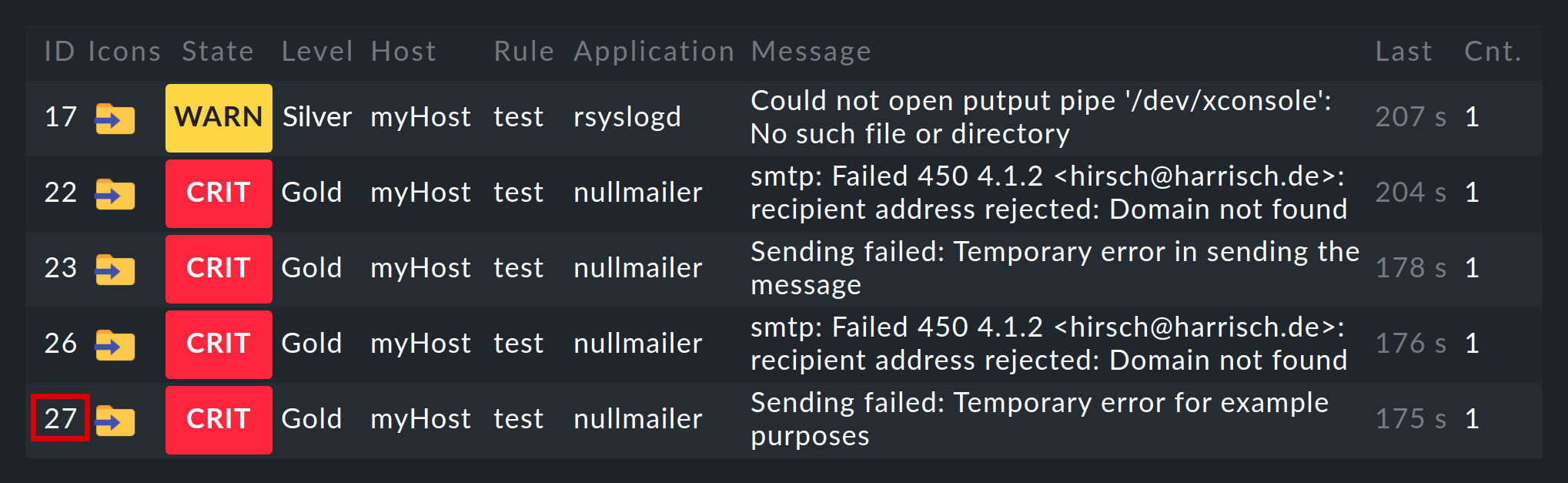
Puoi personalizzare la visualizzazione Events come qualsiasi altra. Puoi filtrare gli eventi visualizzati, eseguire comandi, ecc. Per maggiori dettagli, consulta l'articolo sulle visualizzazioni. Quando crei nuove visualizzazioni di eventi, gli eventi e la cronologia degli eventi sono disponibili come fonti di dati.
Cliccando sull'ID dell'evento (qui ad es. 27) potrai visualizzarne i dettagli:
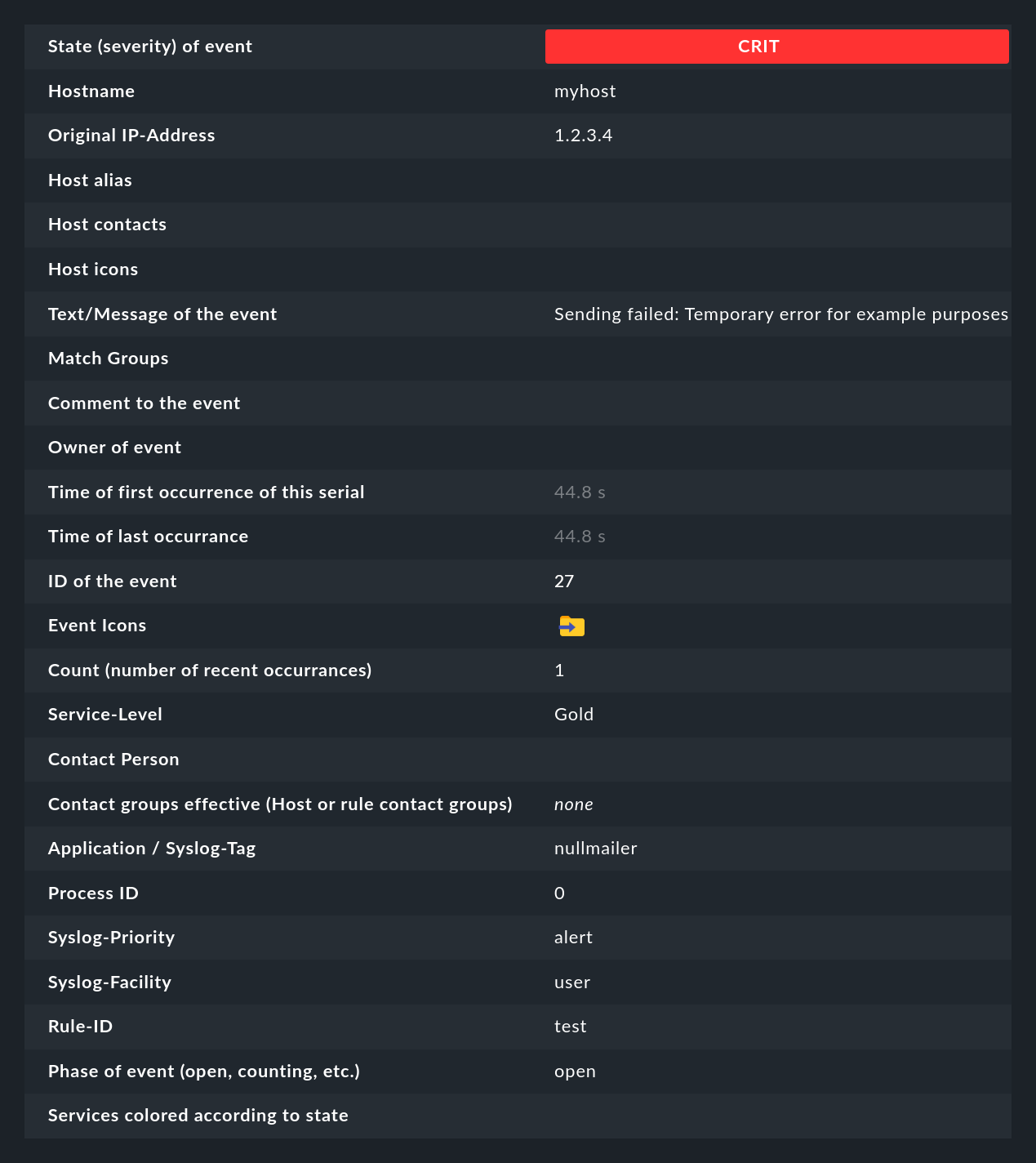
Come puoi vedere, un evento ha molti campi dati, il cui significato verrà spiegato poco a poco in questo articolo. I campi più importanti vanno comunque menzionati brevemente qui:
| Campo | Significato |
|---|---|
State (severity) of event |
Come accennato nell'introduzione, ogni evento è classificato come OK, WARN, CRIT o SCONOSCIUTO. Gli eventi con stato OK sono piuttosto insoliti. Questo perché la CE è stata progettata proprio per filtrare solo i problemi. Tuttavia, ci sono situazioni in cui un evento OK può avere senso. |
Text/Message of the event |
Il contenuto effettivo dell'evento: Un messaggio di testo. |
Hostname |
Il nome dell'host che ha inviato il messaggio. Questo non deve necessariamente essere un host monitorato attivamente da Checkmk. Tuttavia, se un host con quel nome esiste nel monitoraggio, il CE creerà automaticamente un collegamento. In questo caso, anche i campi Host alias, Host contacts e Host icons saranno riempiti e l'host apparirà con la stessa notazione del monitoraggio attivo. |
Rule-ID |
L'ID della regola che ha creato questo evento. Cliccando su questo ID si accede direttamente ai dettagli della regola. A proposito, l'ID viene conservato anche se la regola non esiste più. |
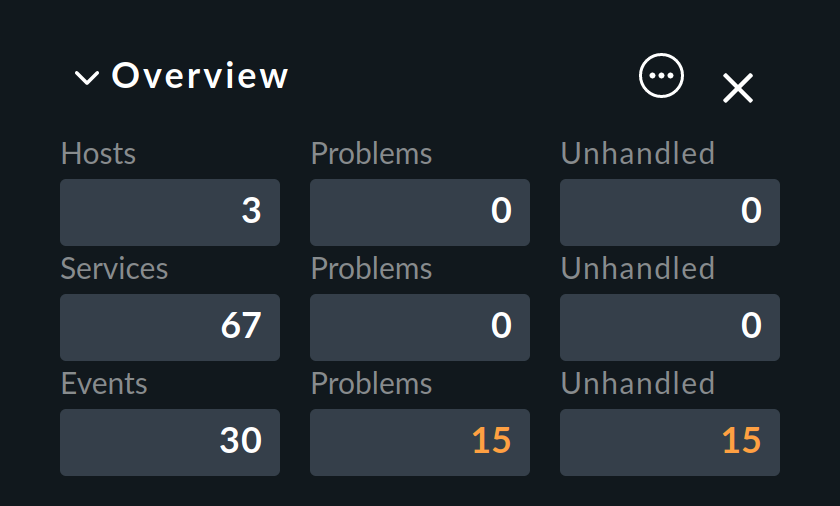
Come accennato all'inizio, gli eventi vengono visualizzati direttamente nella barra laterale Overview:
Qui vedrai tre numeri:
Events- tutti gli eventi aperti e confermati (corrisponde alla visualizzazione Event Console > Events )
Problems- di cui solo quelli con uno stato WARN / CRIT / SCONOSCIUTO
Unhandled- di questi solo quelli che non sono ancora stati confermati (per saperne di più, leggi qui di seguito).
4.2. Comandi e workflow degli eventi
Analogamente agli host e ai servizi, anche per gli eventi viene mappato un workflow semplice. Come al solito ciò avviene tramite i comandi, che si trovano nel menu Commands. Mostrando e selezionando con i checkbox puoi eseguire un comando su più eventi contemporaneamente. Come caratteristica speciale c'è l'archivio di uso frequente di un singolo evento direttamente tramite l'icona.
Per ognuno dei comandi c'è un permesso che puoi utilizzare per controllare per quale ruolo è consentita l'esecuzione del comando. Per impostazione predefinita tutti i comandi sono consentiti ai titolari dei ruoli admin e user.
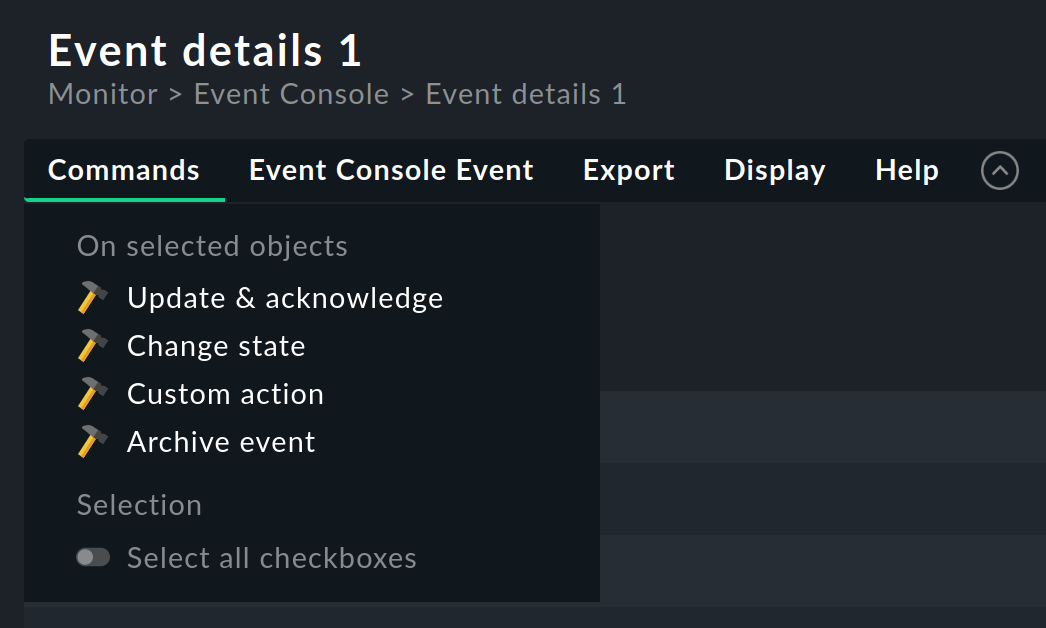
Sono disponibili i seguenti comandi:
Aggiorna e conferma
Il comando Update & Acknowledge visualizza la seguente area sopra l'elenco degli eventi:
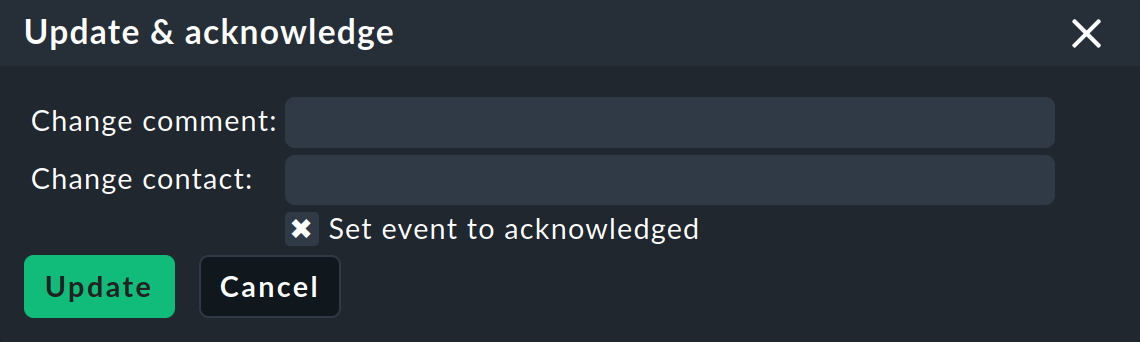
Con il pulsante Update puoi aggiungere in un'unica azione un commento all'evento, aggiungere un contatto e confermare l'evento. Il campo Change contact è intenzionalmente a testo libero. Qui puoi inserire anche cose come numeri di telefono. In particolare, questo campo non ha alcuna influenza sulla visibilità dell'evento nella GUI: è solo un campo di commento.
Il checkbox Set event to acknowledged fa sì che l'evento passi dalla fase open alla fase acknowledged e che d'ora in poi venga visualizzato come handled. Questo è analogo alla conferma dei problemi dell'host e del servizio.
Una successiva invocazione del comando con il checkbox deselezionato rimuove la conferma.
Cambia stato
Il comando Change State permette di cambiare manualmente lo stato di un evento, ad es. da CRIT a WARN.
Azione personalizzata
Con il comando Custom Action è possibile eseguire azioni liberamente definibili sugli eventi. Inizialmente è disponibile solo l'azione Send monitoring notification, che invia una notifica Checkmk che sarà gestita allo stesso modo di una notifica proveniente da un servizio di monitoraggio attivo. Questa passa attraverso le regole di notifica e può generare e-mail, un SMS o qualsiasi altra cosa tu abbia configurato di conseguenza. Vedi sotto per i dettagli sulla notifica da parte della CE.
Archiviare un evento
Il pulsante Archive Event rimuove in modo permanente un evento dall'elenco degli eventi aperti. Poiché tutte le azioni sugli eventi - compresa questa cancellazione - vengono registrate anche nell'archivio, sarai ancora in grado di accedere in seguito a tutte le informazioni sull'evento. Ecco perché non si parla di cancellazione, ma di archiviazione.
Puoi anche archiviare comodamente i singoli eventi dall'elenco degli eventi utilizzando .
4.3. Visibilità degli eventi
Il "problema" della visibilità
Per garantire la visibilità degli host e dei servizi nel monitoraggio per gli utenti normali, Checkmk utilizza i gruppi di contatto, che vengono assegnati agli host e ai servizi attraverso la configurazione della GUI, delle regole o delle cartelle.
Con la Console degli Eventi, questa assegnazione di eventi ai gruppi di contatto non esiste, perché semplicemente non si sa in anticipo quali messaggi verranno effettivamente ricevuti. Non si conosce nemmeno l'elenco degli host, perché i socket per syslog e SNMP sono accessibili da ogni parte. Per questo motivo, la Console degli Eventi include alcune funzioni speciali per definire la visibilità.
Inizialmente, tutti possono vedere tutto
Prima di tutto, quando si configurano i ruoli utente c'è il permesso Event Console > See all events. Questo è attivo per configurazione predefinita, in modo che gli utenti normali possano vedere tutti gli eventi!Questo è stato deliberatamente impostato per garantire che importanti messaggi di errore non cadano nel dimenticatoio a causa di una configurazione errata. Il primo passo per una visibilità più precisa è rimuovere questo permesso dal ruolo user.
Assegnazione agli host
Per garantire che la visibilità degli eventi sia il più possibile coerente con il resto del monitoraggio, la Console degli Eventi cerca il più possibile di far corrispondere gli host da cui riceve gli eventi a quelli configurati tramite la GUI di Setup. Ciò che sembra semplice è complicato nei dettagli. A volte il nome host non è presente nell'evento e si conosce solo l'indirizzo IP. In altri casi il nome host è scritto in modo diverso da quello presente nella GUI di Setup.
L'assegnazione avviene come segue:
Se l'evento non contiene alcun nome host, l'indirizzo IP viene utilizzato come nome host.
Il nome host dell'evento viene quindi confrontato in modo insensibile con tutti i nomi host, gli indirizzi host e gli indirizzi IP degli host presenti nel monitoraggio.
Se un host viene trovato in questo modo, i suoi gruppi di contatto vengono utilizzati per l'evento e questo viene usato per controllare la visibilità.
Se l'host non viene trovato, i gruppi di contatto, se configurati, vengono presi dalla regola che ha creato l'evento.
Se non ci sono gruppi, l'utente può vedere l'evento solo se ha il permesso Event Console > See events not related to a known host.
Puoi influenzare l'assegnazione in un punto: in particolare, se i gruppi di contatto sono definiti nella regola e l' host può essere assegnato, la mappatura ha solitamente la priorità. Puoi cambiare questo aspetto in una regola con l'opzione Precedence of contact groups:
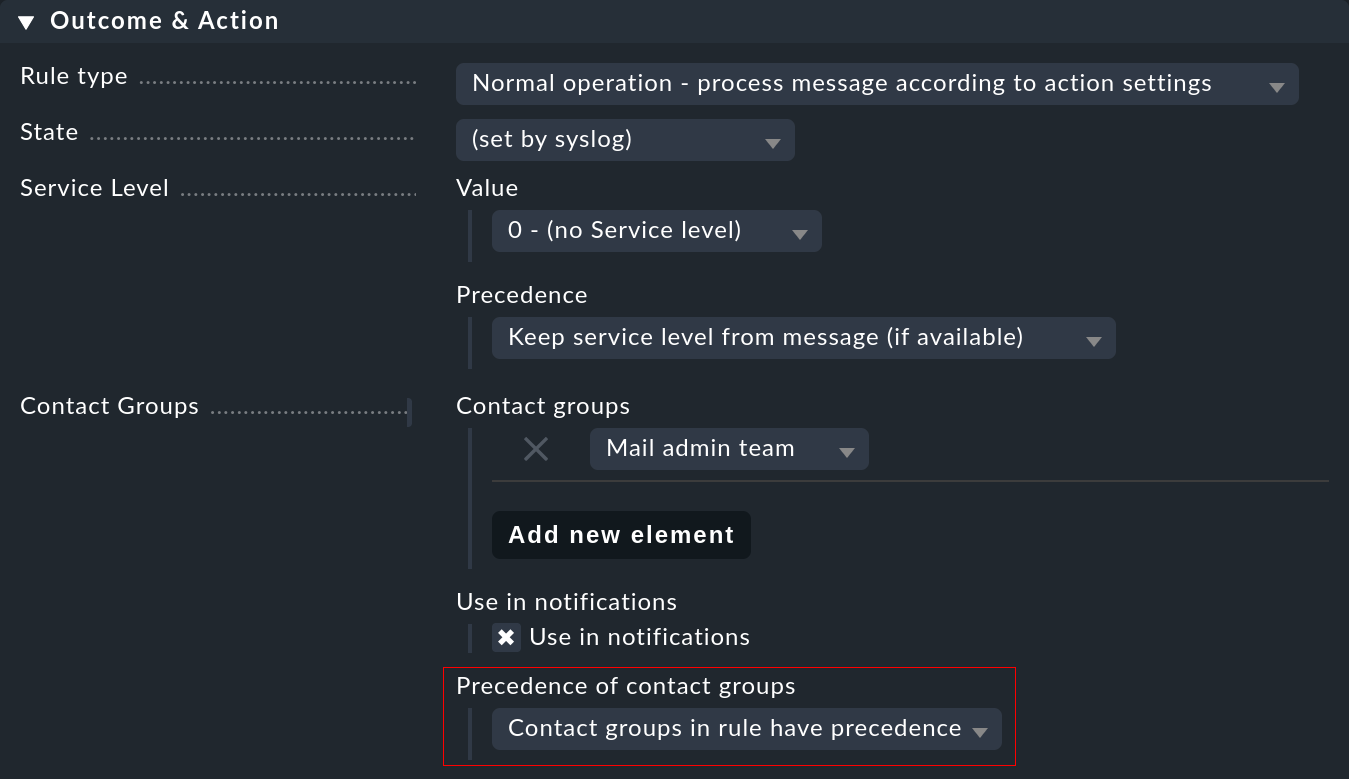
Inoltre, puoi impostare le regole di notifica direttamente nella regola: in questo modo è possibile dare priorità al tipo di evento rispetto alle normali responsabilità di un host.
4.4. Risoluzione dei problemi
Quale regola si applica e con quale frequenza?
Sia per i pacchetti di regole...
... sia per le singole regole ...

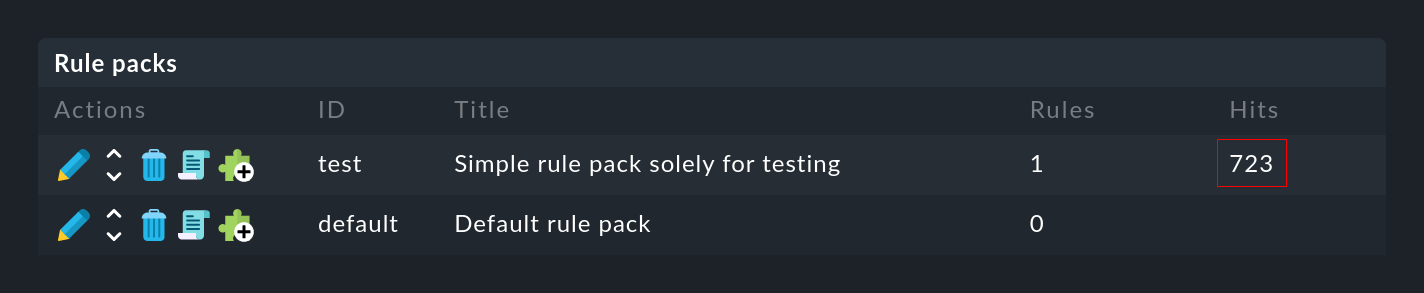
... nella colonna Hits troverai le informazioni sulla frequenza con cui il pacchetto o la regola ha già trovato un matching con un messaggio. Questo ti aiuta a eliminare o a riparare le regole inefficaci. Ma può essere interessante anche per le regole che hanno un matching molto frequente. Per ottenere prestazioni ottimali dall'EC, queste dovrebbero essere all'inizio della catena di regole. In questo modo puoi ridurre il numero di regole che l'EC deve testare per ogni messaggio.
Puoi azzerare i contatori in qualsiasi momento con la voce di menu Event Console > Reset counters.
Debug della valutazione delle regole
In Prova una regola hai già visto come utilizzare Event Simulator per verificare la valutazione delle tue regole. Puoi ottenere informazioni simili nel tempo di esecuzione per tutti i messaggi, se nelle impostazioni della Console degli Eventi imposti il valore da Debug rule execution a on.
Il file di log della Console degli Eventi si trova all'indirizzo var/log/mkeventd.log, in cui troverai il motivo esatto per cui una regola verificata non ha avuto effetto:
[1481020022.001612] Processing message from ('10.40.21.11', 57123): '<22>Dec 6 11:27:02 myserver123 exim[1468]: Delivery complete, 4 message(s) remain.'
[1481020022.001664] Parsed message:
application: exim
facility: 2
host: myserver123
ipaddress: 10.40.21.11
pid: 1468
priority: 6
text: Delivery complete, 4 message(s) remain.
time: 1481020022.0
[1481020022.001679] Trying rule test/myrule01...
[1481020022.001688] Text: Delivery complete, 4 message(s) remain.
[1481020022.001698] Syslog: 2.6
[1481020022.001705] Host: myserver123
[1481020022.001725] did not match because of wrong application 'exim' (need 'security')
[1481020022.001733] Trying rule test/myrule02n...
[1481020022.001739] Text: Delivery complete, 4 message(s) remain.
[1481020022.001746] Syslog: 2.6
[1481020022.001751] Host: myserver123
[1481020022.001764] did not match because of wrong textVa da sé che dovresti usare questo tipo di log intensivo solo quando necessario e con cautela: in un ambiente solo leggermente più complesso verranno generati enormi volumi di dati!
5. I pieni poteri delle regole
5.1. Le condizioni
La parte più importante di una regola EC è ovviamente la condizione (Matching Criteria). Solo se un messaggio soddisfa tutte le condizioni memorizzate nella regola, le azioni definite nella regola vengono eseguite e la valutazione del messaggio è così completata.
Informazioni generali sui confronti tra testi
Per tutte le condizioni che coinvolgono campi di testo, il testo di confronto viene sempre trattato come un'espressione regolare. Il confronto avviene sempre ignorando le maiuscole e le minuscole. Quest'ultima è un'eccezione alle convenzioni di Checkmk in altri moduli. Tuttavia, questo rende la formulazione delle regole più robusta, soprattutto perché i nomi host negli eventi non sono necessariamente coerenti nella loro ortografia se sono stati configurati su ogni host localmente piuttosto che centralmente. Questa eccezione è quindi molto utile in questo caso.
Inoltre, si applica sempre un match parziale, cioè un controllo del contenuto del testo di ricerca, per cui puoi salvare un .* all'inizio o alla fine del testo di ricerca.
C'è però un'eccezione: se nella corrispondenza con il nome host non viene utilizzata un'espressione regolare, ma un nome host esplicito, verrà verificata la corrispondenza esatta e non il contenuto.
Attenzione: Se il testo di ricerca contiene un punto (.), sarà considerato un'espressione regolare e si applicherà la ricerca parziale, ad esempio myhost.com corrisponderà anche a notmyhostide!
Gruppi di corrispondenza
Molto importante e utile è il concetto di gruppi di corrispondenza nel campo Text to match. Si tratta delle sezioni di testo che corrispondono alle espressioni parentetiche dell'espressione regolare.
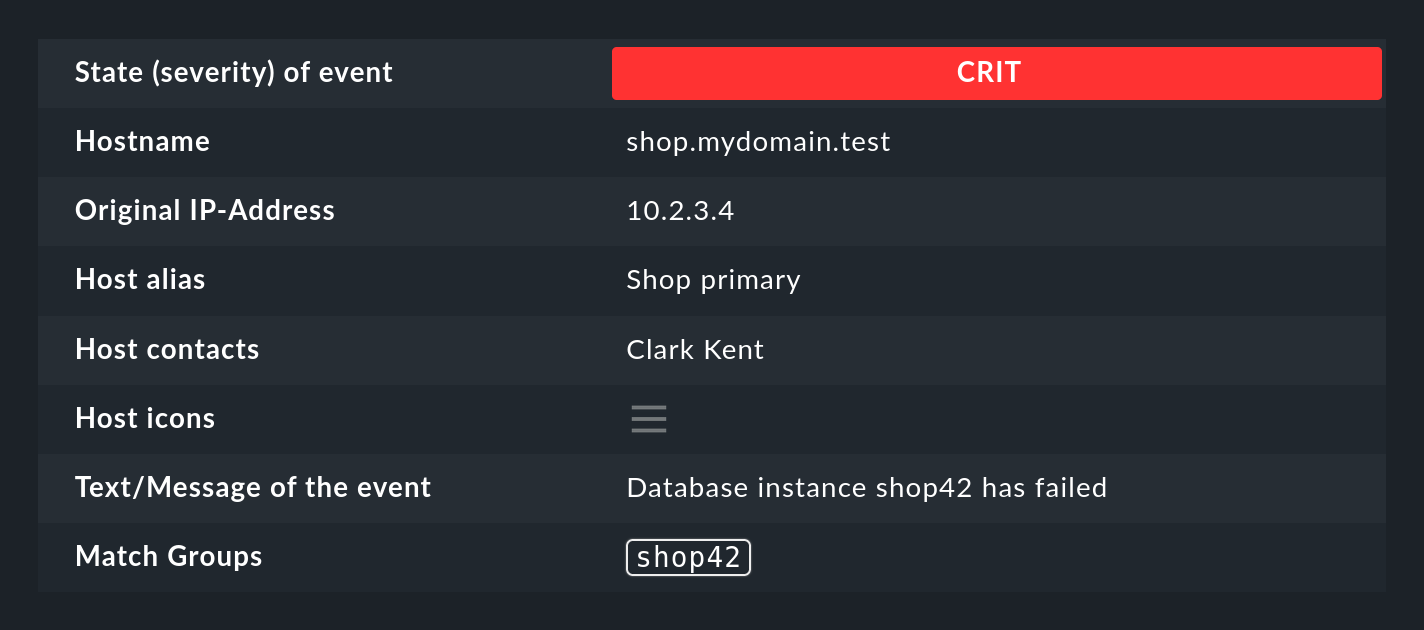
Supponiamo che tu voglia monitorare il seguente tipo di messaggio nel file di log di un database:
Database instance WP41 has failedIl campo WP41 è ovviamente variabile e sicuramente non vuoi formulare una regola separata per ogni istanza diversa. Per questo motivo, nell'espressione regolare utilizzi .*, che sta per qualsiasi stringa:
Database instance .* has failed
Se ora racchiudi la parte variabile tra parentesi tonde, la Console degli Eventi memorizzerà(catturerà) il valore effettivo per qualsiasi azione futura:
Database instance (.*) has failed
Dopo che la regola ha avuto successo, il primo gruppo di corrispondenza è ora impostato sul valore WP41 (o sull'istanza che ha prodotto l'errore).
Puoi vedere questi gruppi di corrispondenza nel sito Event Simulator se sposti il cursore sul pallino verde:

Puoi vedere i gruppi anche nei dettagli dell'evento generato:
Tra le altre cose, i gruppi di corrispondenza sono utilizzati per:
Riscrivere gli eventi
Eliminare automaticamente gli eventi
Il conteggio dei messaggi
A questo punto, un consiglio: ci sono situazioni in cui devi raggruppare qualcosa nell'espressione regolare ma non vuoi creare un gruppo di corrispondenza. Puoi farlo inserendo un ?: direttamente dopo la parentesi di apertura. Esempio: L'espressione one (.*) two (?:.*) three crea per una corrispondenza su one 123 two 456 three solo il gruppo di corrispondenza 123.
Indirizzo IP
Nel campo Match original source IP address puoi abbinare l'indirizzo IPv4 del mittente del messaggio. Specifica un indirizzo esatto o una rete nella notazione X.X.X.X/Y, ad es. 192.168.8.0/24 corrisponde a tutti gli indirizzi della rete 192.168.8.X.
Nota che la corrispondenza con l'indirizzo IP funziona solo se i sistemi di monitoraggio IT inviano direttamente alla Console degli Eventi. Se un altro server syslog intermedio connesso inoltra i messaggi, il suo indirizzo apparirà come mittente nel messaggio.
Priorità e struttura del syslog
I campi Match syslog priority e Match syslog facility sono informazioni standardizzate, originariamente definite dalle informazioni syslog. Internamente, un campo a 8 bit è diviso in 5 bit per la struttura (32 possibilità) e 3 bit per la priorità (8 possibilità).
Le 32 strutture predefinite erano un tempo destinate a qualcosa come un'applicazione, ma all'epoca la selezione non era molto lungimirante. Una delle strutture è uucp, un protocollo che all'inizio degli anni '90 dello scorso millennio era già quasi obsoleto.
Ma è un dato di fatto che ogni messaggio che arriva via syslog porta con sé una di queste strutture. In alcuni casi puoi anche assegnarle liberamente al momento dell'invio del messaggio, in modo da poterle filtrare in un secondo momento, il che è molto utile.
L'uso di strutture e priorità ha anche un aspetto legato alle prestazioni. Se definisci una regola che in ogni caso si applica solo ai messaggi che hanno tutti la stessa struttura o priorità, dovresti definirli anche nei filtri della regola. La Console degli Eventi può quindi bypassare queste regole in modo molto efficiente quando viene ricevuto un messaggio con valori diversi. Più regole sono impostate su questi filtri, meno confronti tra le regole sono necessari.
Invertire una corrispondenza
Il checkbox Negate match: Execute this rule if the upper conditions are not fulfilled. fa sì che la regola abbia effetto solo quando nessuna delle condizioni è soddisfatta. In realtà questo è utile solo nel contesto di due tipi di regola (Rule type nel box Outcome & Action della regola):
Do not perform any action, drop this message, stop processing.
Skip this rule pack, continue rule execution with next pack
Puoi trovare maggiori informazioni sui pacchetti di regole qui di seguito.
5.2. Effetto della regola
Tipo di regola: Eliminare o creare un evento
Quando una regola corrisponde, specifica cosa deve accadere con il messaggio. Questo viene fatto nel box Outcome & Action:
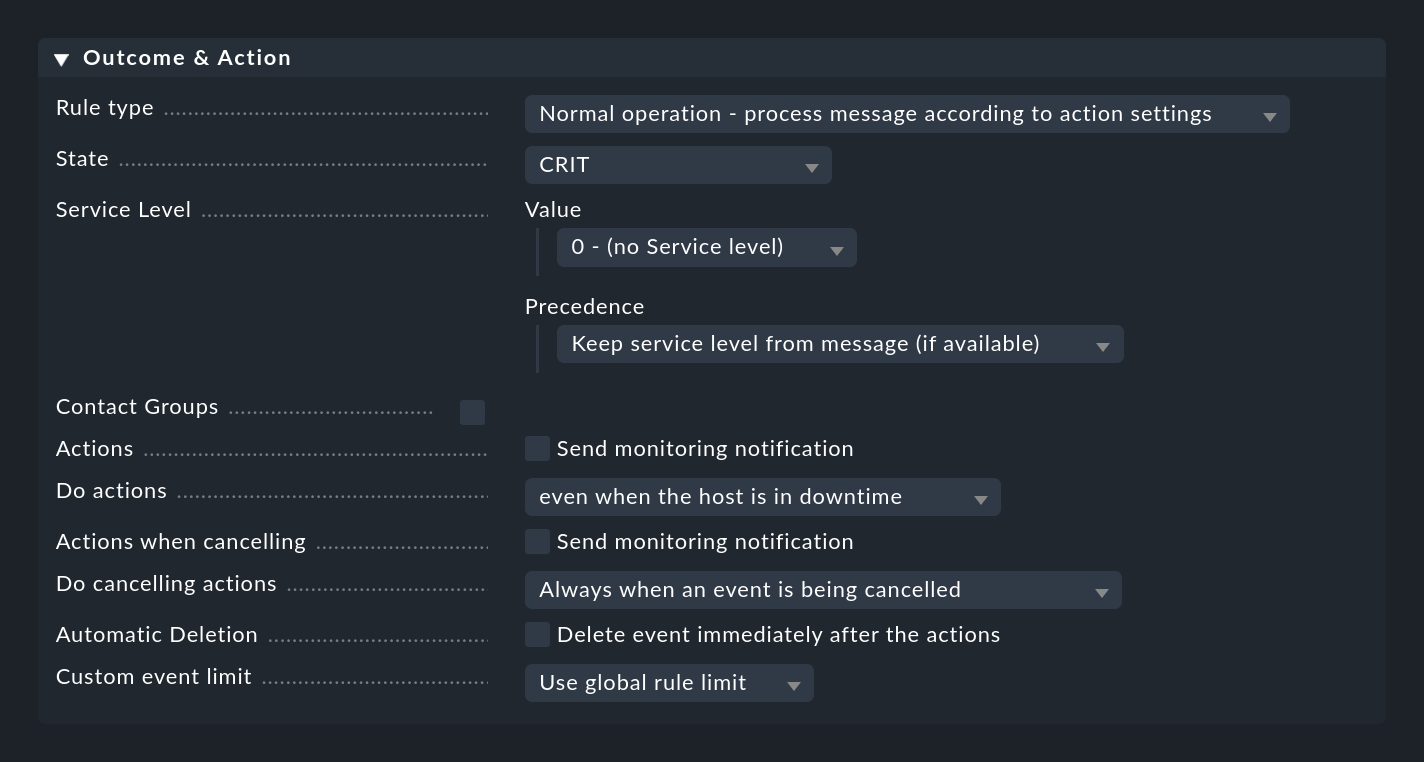
Il box Rule type può essere utilizzato per interrompere la valutazione del punto o per il pacchetto di regole corrente. In particolare, la prima opzione dovrebbe essere utilizzata per eliminare la maggior parte del "rumore" inutile utilizzando alcune regole specifiche all'inizio. Solo con le regole "normali" le altre opzioni di questo box vengono effettivamente valutate.
Impostazione dello stato
Con State la regola imposta lo stato dell'evento di monitoraggio. Nella regola questo stato sarà WARN o CRIT. Le regole che generano eventi OK possono essere interessanti in eccezione per rappresentare alcuni eventi in modo puramente informativo. In questo caso è interessante una combinazione con una scadenza automatica di questi eventi.
Oltre all'impostazione di uno stato esplicito, esistono altre due opzioni dinamiche. L'impostazione (set by syslog) si occupa della classificazione in base alla priorità del syslog. Questo funziona solo se il messaggio è già stato classificato in modo utilizzabile dal mittente. I messaggi ricevuti direttamente dal syslog conterranno una delle otto priorità RFC, mappate come segue:
| Priorità | ID | Stato | Definizione secondo syslog |
|---|---|---|---|
|
0 |
CRIT |
il sistema è inutilizzabile |
|
1 |
CRIT |
è necessaria un'azione immediata |
|
2 |
CRIT |
condizione critica |
|
3 |
CRIT |
errore |
|
4 |
WARN |
avviso |
|
5 |
OK |
normale, ma informazioni significative |
|
6 |
OK |
puramente informativo |
|
7 |
OK |
messaggio di debug |
Oltre ai messaggi syslog, i messaggi del registro eventi di Windows e i messaggi dei file di log che sono già stati classificati con il plug-in Checkmk logwatch sul sistema di destinazione, forniscono degli stati già pronti. Per le SNMP trap questo purtroppo non è disponibile.
Un metodo completamente diverso è quello di classificare il messaggio in base al testo stesso. Questo può essere fatto con l'impostazione (set by message text):
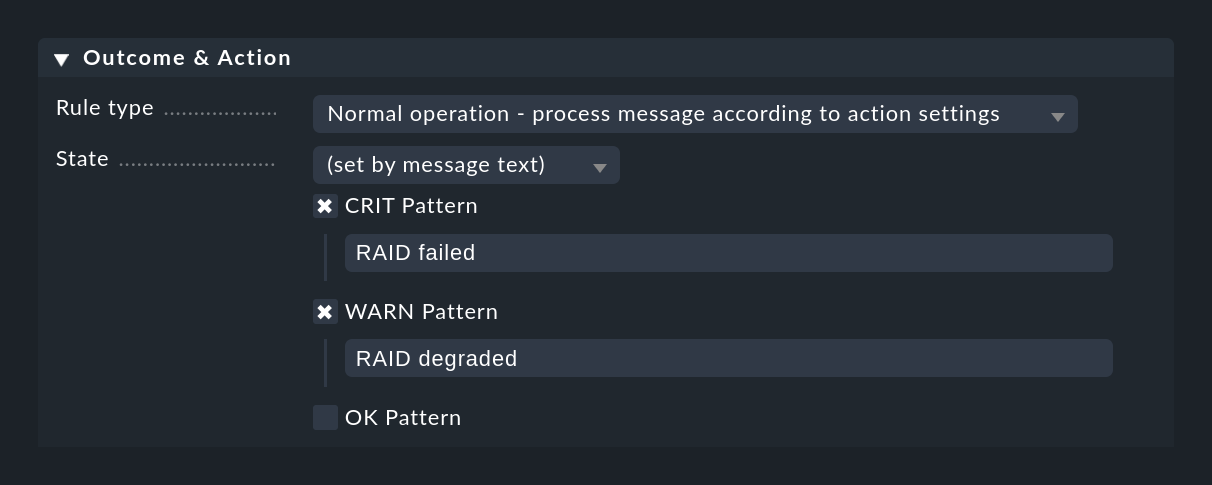
La corrispondenza con i testi configurati avviene solo dopo aver verificato la presenza di Text to match e delle altre condizioni della regola, in modo da non dover ripetere i controlli.
Se non viene trovato nessuno dei modelli configurati, l'evento restituisce lo stato SCONOSCIUTO.
Livelli del servizio
L'idea alla base del campo Service Level è che ogni host e ogni servizio di un'organizzazione abbia un certo livello di importanza, che può essere associato a un contratto di servizio specifico per l'host o il servizio. In Checkmk, puoi usare delle regole per assegnare tali livelli del servizio ai tuoi host e servizi e poi, ad esempio, far dipendere da essi le regole di notifica o i dashboard autodefiniti.
Poiché gli eventi non sono necessariamente correlati agli host o ai servizi, la Console degli Eventi ti permette di assegnare un livello del servizio a un evento utilizzando una regola. In seguito potrai filtrare le visualizzazioni degli eventi in base a questo livello.
Per impostazione predefinita, Checkmk definisce quattro livelli: 0 (nessun livello), 10 (argento), 20 (oro) e 30 (platino). Puoi modificare questa selezione in base alle tue esigenze nel sito Global settings > Notifications > Service Levels. Sono decisivi i numeri per la progettazione dei livelli, poiché i livelli vengono ordinati in base a questi numeri e confrontati anche in base all'importanza relativa.
Gruppi di contatto
I gruppi di contatto utilizzati per la visibilità saranno utilizzati anche per la notifica degli eventi. Qui puoi utilizzare delle regole per assegnare esplicitamente i gruppi di contatto agli eventi. I dettagli si trovano nel capitolo dedicato al monitoraggio.
Azioni
Le azioni sono molto simili ai gestori di avvisi per host e servizi. Qui puoi far eseguire uno script autodefinito all'apertura di un evento. I dettagli completi sulla descrizione delle azioni si trovano in una sezione separata.
Cancellazione automatica (archiviazione)
La cancellazione automatica (= archiviazione), che puoi impostare con Delete event immediately after the actions, fa sì che un evento non sia mai visibile nel monitoraggio. Questo è utile se vuoi attivare automaticamente solo alcune azioni o se vuoi archiviare solo alcuni eventi per poterli cercare in seguito.
5.3. Riscrittura automatica dei testi
Con la funzione Rewriting, una regola EC può riscrivere automaticamente i campi di testo di un messaggio e aggiungere annotazioni. Questa funzione viene configurata in un box separato:
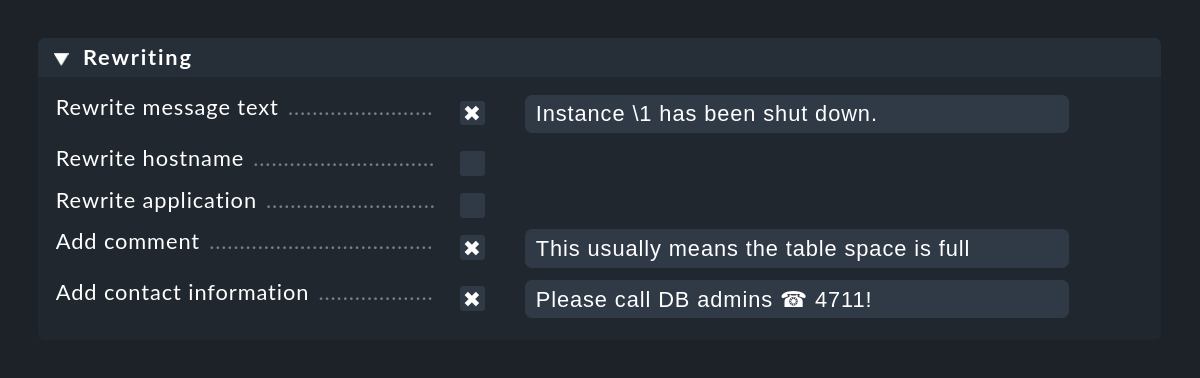
Durante la riscrittura, sono particolarmente importanti i gruppi di corrispondenza, che ti permettono di includere parti del messaggio originale nel nuovo testo. Puoi accedere ai gruppi durante la riscrittura come segue:
|
Sarà sostituito dal primo gruppo di corrispondenza del messaggio originale. |
|
Sarà sostituito dal secondo gruppo di corrispondenza del messaggio originale (ecc.). |
|
Sarà sostituito dall'intero messaggio originale. |
Nella schermata qui sopra, il nuovo testo del messaggio sarà codificato come Instance \1 has been shut down.Ovviamente, questo funziona solo se anche Text to match nella stessa regola dell'espressione di ricerca regolare ha almeno un'espressione di parentesi. Un esempio potrebbe essere es:

Altre note sulla riscrittura:
La riscrittura avviene dopo l' abbinamento e prima di eseguire le azioni.
L'abbinamento, la riscrittura e le azioni vengono sempre eseguite nella stessa regola. Non è possibile riscrivere un messaggio e poi processarlo con una regola successiva.
Le espressioni
\1,\2ecc. possono essere utilizzate in tutti i campi di testo, non solo in Rewrite message text.
5.4. Eliminazione automatica degli eventi
Alcune applicazioni o dispositivi sono così gentili da inviare un messaggio OK non appena il problema è stato risolto. Puoi configurare il CE in modo tale che in questo caso l'evento aperto dall'errore venga automaticamente chiuso. Questa operazione viene definita " eliminazione".
La figura seguente mostra una regola con la quale vengono ricercati i messaggi contenenti il testo database instance (.*) has failed. L'espressione (.*) rappresenta una stringa arbitraria che viene intrappolata in un gruppo di corrispondenza. L'espressione database instance (.*) recovery in progress, che si trova nel campo Text to cancel event(s) della stessa regola, chiuderà automaticamente gli eventi creati con questa regola quando viene ricevuto un messaggio corrispondente:
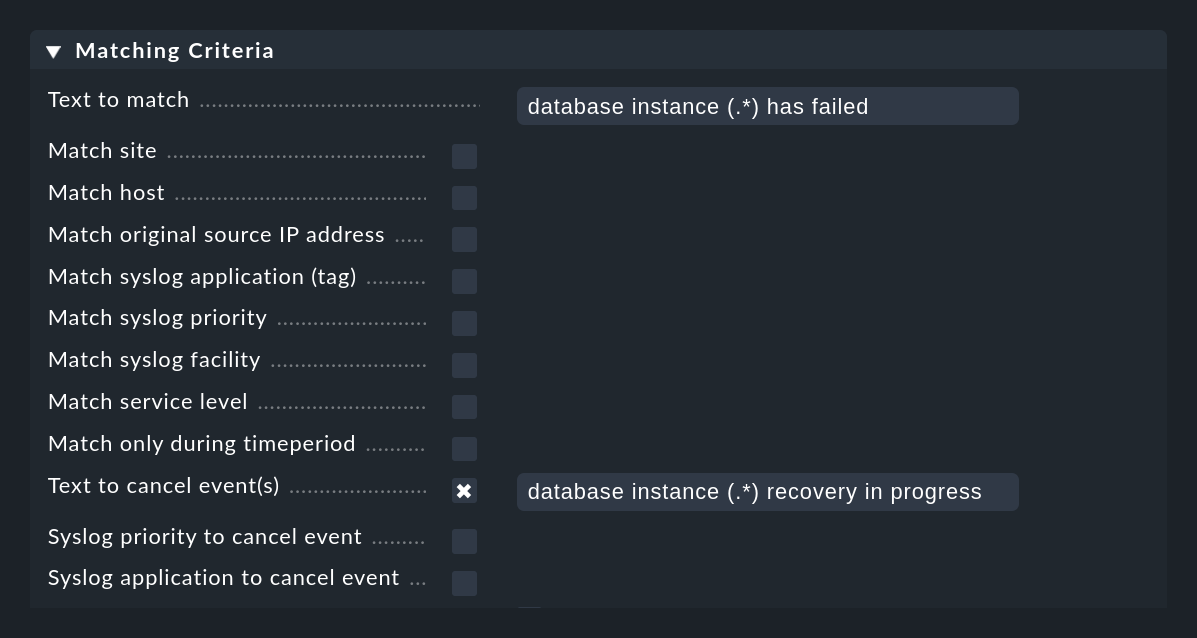
L'eliminazione automatica funziona finché viene ricevuto un messaggio il cui testo corrisponde a .
viene ricevuto un messaggio il cui testo corrisponde a Text to cancel event(s),
il valore catturato nel gruppo
(.*)è identico al gruppo di corrispondenza del messaggio originale,entrambi i messaggi provengono dallo stesso host e
si tratta della stessa applicazione (il campo Syslog application to cancel event ).
Il principio del gruppo di corrispondenza è molto importante in questo caso: dopo tutto, non avrebbe molto senso se il messaggio database instance TEST recovery in progress eliminasse un evento generato dal messaggio database instance PROD has failed, no?
Non commettere l'errore di utilizzare il segnaposto \1 in Text to cancel events(s). Questo non funziona: i segnaposto funzionano solo per la riscrittura.
In alcuni casi capita che un testo venga utilizzato sia per creare che per eliminare un evento. In questo caso, l'eliminazione ha la priorità.
Eseguire azioni quando si elimina un evento
Puoi anche fare in modo che le azioni vengano eseguite automaticamente quando un evento viene eliminato. È importante sapere che quando un evento viene eliminato, alcuni campi dell'evento vengono sovrascritti dai valori del messaggio OK prima che venga eseguita qualsiasi azione. In questo modo, i dati completi del messaggio OK sono disponibili nello script dell'azione. Inoltre, durante questa fase lo stato dell'evento viene contrassegnato come OK. In questo modo uno script dell'azione può rilevare un'eliminazione e puoi utilizzare lo stesso script per i messaggi di errore e OK (es. durante la connessione a un sistema di ticket).
I seguenti campi vengono sovrascritti dai dati del messaggio OK:
Il testo del messaggio
Il timestamp
L'ora dell'ultima occorrenza
la priorità del syslog
Tutti gli altri campi rimangono invariati, compreso l'ID dell'evento.
Eliminazione in combinazione con la riscrittura
Se utilizzi la riscrittura e l'annullamento nella stessa regola di eliminazione, devi fare attenzione alla riscrittura del nome host o dell'applicazione. Quando si annulla, la CE controlla sempre se il messaggio di annullamento corrisponde al nome host e all'applicazione dell'evento aperto. Se questi vengono riscritti, l'annullamento non funzionerà mai.
Per questo motivo, prima di eliminare l'evento, la Console degli Eventi simula una riscrittura del nome host e dell'applicazione per confrontare i testi pertinenti. Probabilmente è quello che ti aspetti.
Puoi anche approfittare di questo comportamento se il campo dell'applicazione nel messaggio di errore e nel successivo messaggio OK non corrispondono. In questo caso, riscrivi semplicemente il campo dell'applicazione con un valore fisso noto. In questo modo, infatti, il campo verrà ignorato.
Eliminazione in base alla priorità del syslog
Ci sono (purtroppo) situazioni in cui il testo dei messaggi di errore e di OK è assolutamente identico. Nella maggior parte dei casi lo stato effettivo non è codificato nel testo, ma nella priorità del syslog.
A questo scopo esiste l'opzione Syslog priority to cancel event. Inserisci ad esempio l'intervallo debug... notice. Tutte le priorità in questo intervallo sono normalmente considerate come aventi uno stato OK. Quando utilizzi questa opzione devi comunque inserire un testo adeguato nel campo Text to cancel event(s), altrimenti la regola corrisponderà a tutti i messaggi OK che riguardano la stessa applicazione.
5.5. Conteggio dei messaggi
Nel box Counting & Timing troverai delle opzioni per il conteggio di messaggi simili. L'idea è che alcuni messaggi siano rilevanti solo se si verificano troppo frequentemente o troppo raramente in determinati periodi di tempo.
Messaggi troppo frequenti
Puoi attivare il controllo dei messaggi che si verificano troppo spesso con l'opzione Count messages in interval:
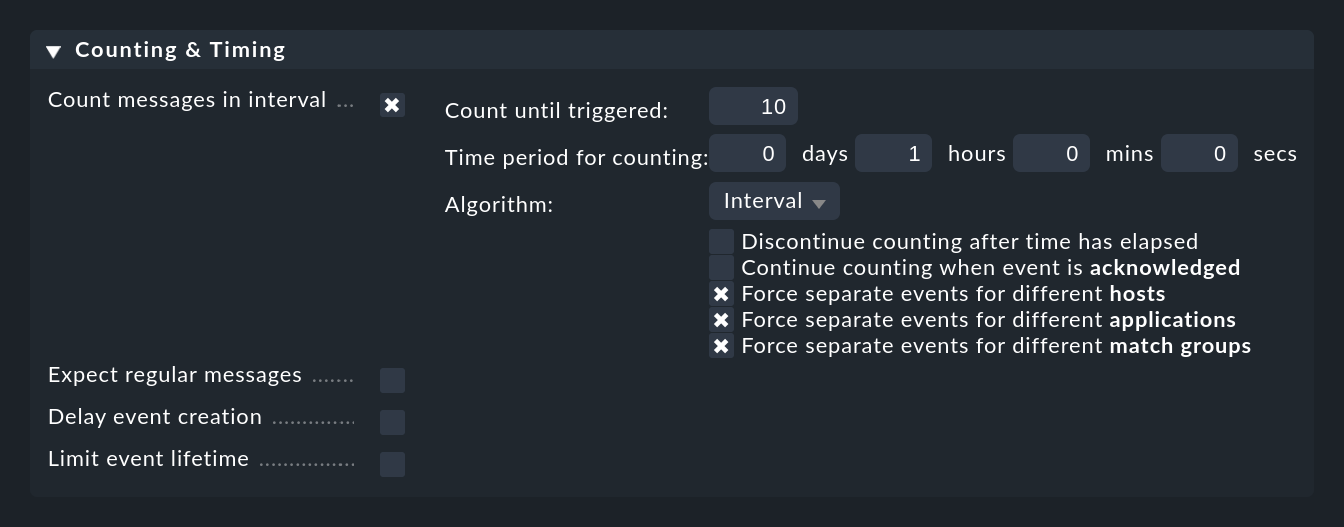
In questo caso, devi prima specificare un periodo di tempo all'indirizzo Time period for counting e il numero di messaggi che dovrebbero portare all'apertura di un evento all'indirizzo Count until triggered. Nell'esempio precedente, questo è impostato su 10 messaggi all'ora. Naturalmente non si tratta di 10 messaggi arbitrari, ma di messaggi che vengono abbinati alla regola.
Normalmente ha senso non contare tutti i messaggi corrispondenti a livello globale, ma solo quelli che si riferiscono alla stessa "causa". Per controllare questo aspetto, ci sono i tre checkbox per le opzioni con l'inizio parola (prefisso) Force separate events for different …. Questi sono preimpostati in modo tale che i messaggi vengano contati insieme solo se corrispondono in:
host
applicazione
Questo ti permette di formulare regole come "Se vengono ricevuti più di 10 messaggi all'ora dallo stesso host, dalla stessa applicazione e dallo stesso sito, allora...". A causa della regola, possono essere generati più eventi diversi.
Se, ad esempio, deselezioni tutti e tre i checkbox, il conteggio verrà effettuato solo a livello globale e la regola sarà in grado di generare un solo evento in totale!
A proposito, può essere utile inserire 1 come conteggio: in questo modo potrai controllare efficacemente le "tempeste di eventi". Se, ad esempio, in un breve lasso di tempo vengono ricevuti 100 messaggi dello stesso tipo, verrà comunque creato un solo evento. Nei dettagli dell'evento potrai vedere
l'ora in cui si è verificato il primo messaggio,
l'ora in cui si è verificato il messaggio più recente e
il numero totale di messaggi combinati in questo evento.
Quando il caso viene chiuso, tramite due checkbox puoi definire quando deve essere aperto un nuovo evento. Normalmente la conferma dell'evento crea una situazione per cui se vengono ricevuti altri messaggi, viene avviato un nuovo conteggio e si attiva un nuovo evento. Puoi disabilitare questa funzione con Continue counting when event is acknowledged.
L'opzione Discontinue counting after time has elapsed assicura che venga sempre aperto un evento separato per ogni periodo di confronto. Nell'esempio precedente è stata specificata una soglia di 10 messaggi all'ora. Se questa opzione è attivata, un massimo di 10 messaggi di un'ora verrà aggiunto a un evento già aperto. Non appena l'ora è trascorsa, se è stato ricevuto un numero sufficiente di messaggi verrà aperto un nuovo evento.
Ad esempio, se imposti il numero a 1 e l'intervallo di tempo a un giorno, vedrai al massimo un evento di questo tipo di messaggio al giorno.
L'impostazione di Algorithm può essere un po' sorprendente a prima vista, ma siamo realistici: cosa intendi effettivamente per "10 messaggi all'ora"?Quale ora si intende? Sempre ore intere del giorno? Potrebbe essere che nell'ultimo minuto di un'ora vengano ricevuti nove messaggi e altri nove nel primo minuto dell'ora successiva. In questo modo si ottengono 18 messaggi in soli due minuti di tempo trascorso, ma comunque meno di 10 all'ora, e quindi la regola non si applicherebbe. Non sembra molto ragionevole...
Poiché non esiste un'unica soluzione a questo problema, Checkmk fornisce tre diverse definizioni del significato esatto di "10 messaggi all'ora":
| Algoritmo | Funzionalità |
|---|---|
Interval |
L'intervallo di conteggio inizia dal primo messaggio corrispondente in arrivo. Viene generato un evento nella fase counting. Se il tempo specificato trascorre prima che il conteggio venga raggiunto, l'evento viene eliminato in modo silenzioso. Tuttavia, se il conteggio viene raggiunto prima dello scadere del tempo, l'evento viene aperto immediatamente (e vengono attivate le azioni configurate). |
Token Bucket |
Questo algoritmo non funziona con intervalli di tempo fissi, ma implementa un metodo spesso utilizzato nelle reti per il traffic shaping. Supponiamo di aver configurato 10 messaggi all'ora. Si tratta di una media di uno ogni 6 minuti. La prima volta che viene ricevuto un messaggio corrispondente, viene generato un evento nella fase counting e il conteggio viene impostato a 1. Per ogni messaggio successivo, il conteggio viene aumentato. Per ogni messaggio successivo, il contatore viene aumentato di 1. E ogni 6 minuti, il contatore viene nuovamente diminuito di 1, indipendentemente dal fatto che sia arrivato o meno un messaggio. Se il contatore scende di nuovo a 0, l'evento viene cancellato. Quindi l'evento viene attivato quando la media dei messaggi è stabilmente superiore a 10 all'ora. |
Dynamic Token Bucket |
Si tratta di una variante dell'algoritmo Token Bucket, in cui più il contatore è piccolo in un dato momento, più lentamente diminuisce. Nell'esempio precedente, se il contatore fosse stato 5, sarebbe diminuito solo ogni 12 minuti invece che ogni 6 minuti. L'effetto generale è che i tassi di notifica appena superiori a quello consentito apriranno un evento (e quindi riceveranno una notifica) molto più rapidamente. |
Quindi, quale algoritmo scegliere?
Interval è il più semplice da capire e più facile da seguire se in seguito vorrai eseguire un conteggio esatto nel tuo archivio syslog.
Token Bucket L'algoritmo di tipo "atipico", invece, è più intelligente e più "morbido". Ci sono meno anomalie ai margini degli intervalli.
Dynamic Token Bucket rende il sistema più reattivo e genera notifiche più velocemente.
Gli eventi che non hanno ancora raggiunto il numero stabilito sono latenti ma non visibili automaticamente dall'operatore. Sono nella fase counting. Puoi rendere visibili questi eventi con il filtro phase nella visualizzazione degli eventi:
Messaggi troppo infrequenti o mancanti
Così come l'arrivo di un particolare messaggio può indicare un problema, anche l'assenza di un messaggio può indicare un problema. Potresti aspettarti almeno un messaggio al giorno da un particolare lavoro. Se questo messaggio non arriva, probabilmente il lavoro non sta funzionando e dovrebbe essere risolto con urgenza.
Puoi configurare qualcosa di simile in Counting & Timing > Expect regular messages:
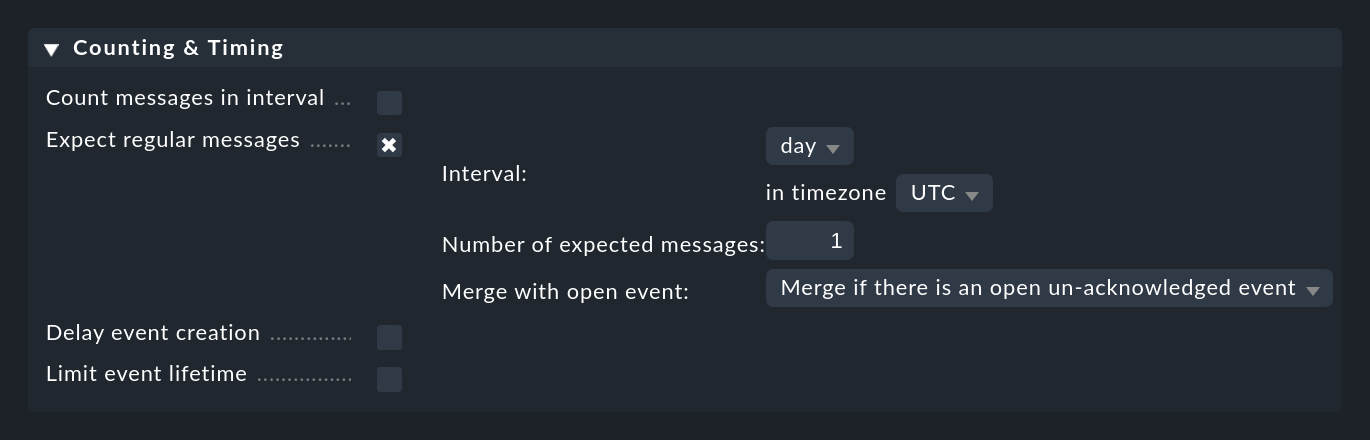
Come per il conteggio, devi specificare un periodo di tempo in cui ti aspetti che appaiano i messaggi. In questo caso, però, viene utilizzato un algoritmo completamente diverso, che a questo punto ha molto più senso. Il periodo di tempo è sempre allineato esattamente alle posizioni definite. Ad esempio, l'intervallo hour inizia sempre al minuto e al secondo zero. Hai a disposizione le seguenti opzioni:
| Intervallo | Allineamento |
|---|---|
10 seconds |
Su un numero di secondi divisibile per 10 |
minute |
Al minuto intero |
5 minutes |
Alle 0:00, 0:05, 0:10, ecc. |
15 minutes |
Alle 0:00, 0:15, 0:30, 0:45, ecc. |
hour |
All'inizio di ogni ora intera |
day |
Esattamente alle 00:00, ma in un fuso orario configurabile. Questo ti permette anche di dire che ti aspetti un messaggio tra le 12:00 e le 12:00 del giorno successivo. Ad esempio, se ti trovi nel fuso orario UTC +1, specifica UTC -11 hours. |
two days |
All'inizio di un'ora intera. Qui puoi specificare un offset del fuso orario da 0 a 47, riferito al 1970-01-01 00:00:00 UTC. |
week |
Alle 00:00 di giovedì mattina nel fuso orario UTC più l'offset, che puoi indicare in ore. Giovedì perché l'1/1/1970 - l'inizio dell'epoca - era un giovedì. |
Perché è così complicato? Questo serve a evitare falsi allarmi. Ad esempio, ti aspetti un messaggio da un backup al giorno? Sicuramente ci saranno piccole differenze nel tempo di esecuzione del backup, per cui i messaggi non vengono ricevuti esattamente a 24 ore di distanza. Ad esempio, se ti aspetti che il messaggio arrivi intorno a mezzanotte, più o meno un'ora o due, un intervallo dalle 12:00 alle 12:00 sarà molto più realistico di uno dalle 00:00 alle 00:00. Tuttavia, se il messaggio non dovesse apparire, riceverai una notifica solo alle 12:00 in punto.
Presenza multipla dello stesso problema
L'opzione Merge with open event è preimpostata in modo che, nel caso in cui lo stesso messaggio appaia ripetutamente, l'evento esistente venga aggiornato. Puoi modificare questa impostazione in modo che ogni volta venga aperto un nuovo evento.
5.6. Tempistiche
In Counting & Timing ci sono due opzioni che influenzano l'apertura e/o la chiusura automatica degli eventi.
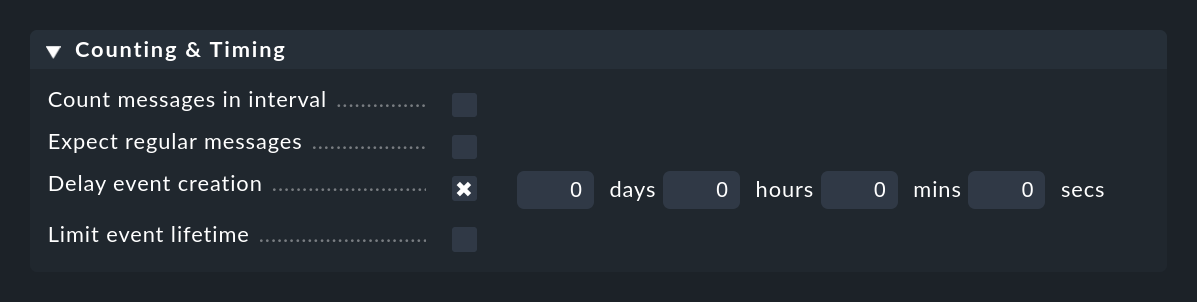
L'opzione Delay event creation è utile se lavori con l'annullamento automatico degli eventi. Impostando ad esempio un ritardo di 5 minuti, in caso di messaggio di errore l'evento creato rimarrà nello stato delayed per 5 minuti, nella speranza che il messaggio OK arrivi entro questo tempo. In questo caso, l'evento viene eliminato automaticamente e senza problemi e non compare nell'evento di monitoraggio. Se il tempo scade, invece, l'evento verrà aperto e verrà eseguita una qualsiasi delle azioni eventualmente definite:
Più o meno l'opposto viene fatto da Limit event lifetime, con il quale puoi fare in modo che gli eventi si chiudano automaticamente dopo un certo tempo. Questo è utile, ad esempio, per gli eventi informativi con stato OK che desideri visualizzare, ma per i quali non vuoi che il monitoraggio generi alcuna attività. Con lo "switch out" automatico ti risparmi la cancellazione manuale di questi messaggi:
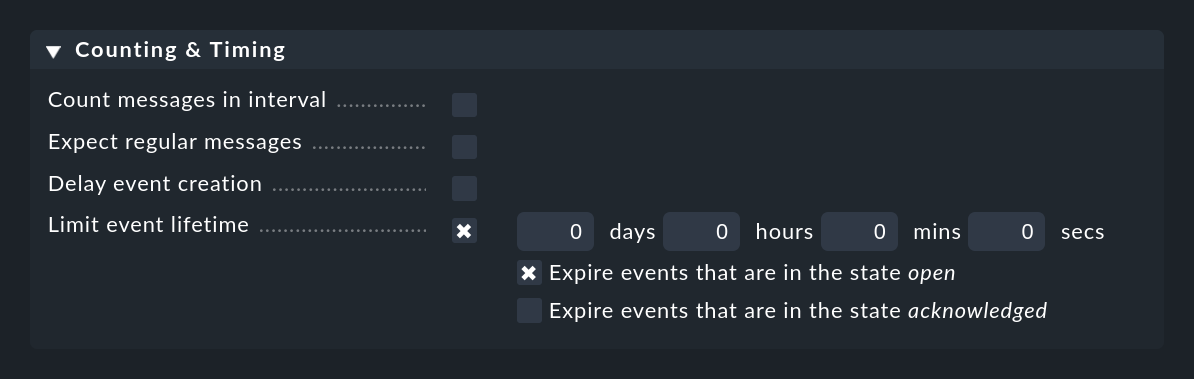
La conferma del messaggio interromperà lo switch out per il momento. Questo comportamento può essere controllato con i due checkbox.
5.7. Pacchetti di regole
I pacchetti di regole non solo hanno il beneficio di rendere le cose più gestibili, ma possono anche semplificare la configurazione di più regole simili e allo stesso tempo velocizzarne la valutazione.
Supponiamo di avere un set di 20 regole che ruotano tutte intorno al Registro eventi di Windows Security. Tutte queste regole hanno in comune il fatto di verificare la condizione di un certo testo nel campo dell'applicazione (il nome di questo file di log viene utilizzato nei messaggi di EC come Application). In questo caso, procedi come segue:
Crea il tuo pacchetto di regole.
Crea le 20 regole per Security in questo pacchetto o spostale lì (elenco di selezione Move to pack… sul lato destro della tabella delle regole).
Rimuovi la condizione dell'applicazione da tutte queste regole.
Crea come prima regola del pacchetto una regola per cui i messaggi escono immediatamente dal pacchetto se l'applicazione non è Security.
Questa regola di esclusione è strutturata come segue:
Matching Criteria > Match syslog application (tag) su
Security.Matching Criteria > Invert matching su Negate match: Execute this rule if the upper conditions are not fulfilled.
Outcome & Action > Rule type su Skip this rule pack, continue rule execution with next rule pack
Tutti i messaggi che non provengono dal log di sicurezza saranno "rifiutati" dalla prima regola di questo pacchetto. Questo non solo semplifica il resto delle regole del pacchetto, ma velocizza anche il processo, poiché nella maggior parte dei casi le altre regole non devono essere controllate affatto.
6. Azioni
6.1. Tipi di azioni
La Console degli Eventi include tre tipi di azioni che puoi eseguire manualmente o quando apri o elimini un evento:
Esecuzione di shell script scritti da te.
Invio di e-mail autodefinite.
Generare notifiche di Checkmk.
6.2. Shell script ed e-mail
Per prima cosa devi definire e-mail e script nelle impostazioni della Console degli Eventi, che puoi trovare alla voce Actions (Emails & Scripts):
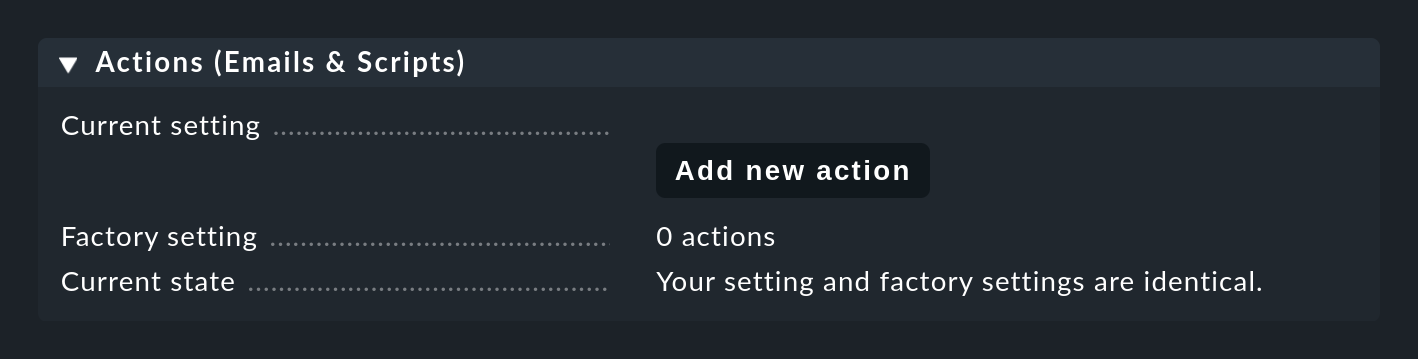
Esecuzione di script di shell
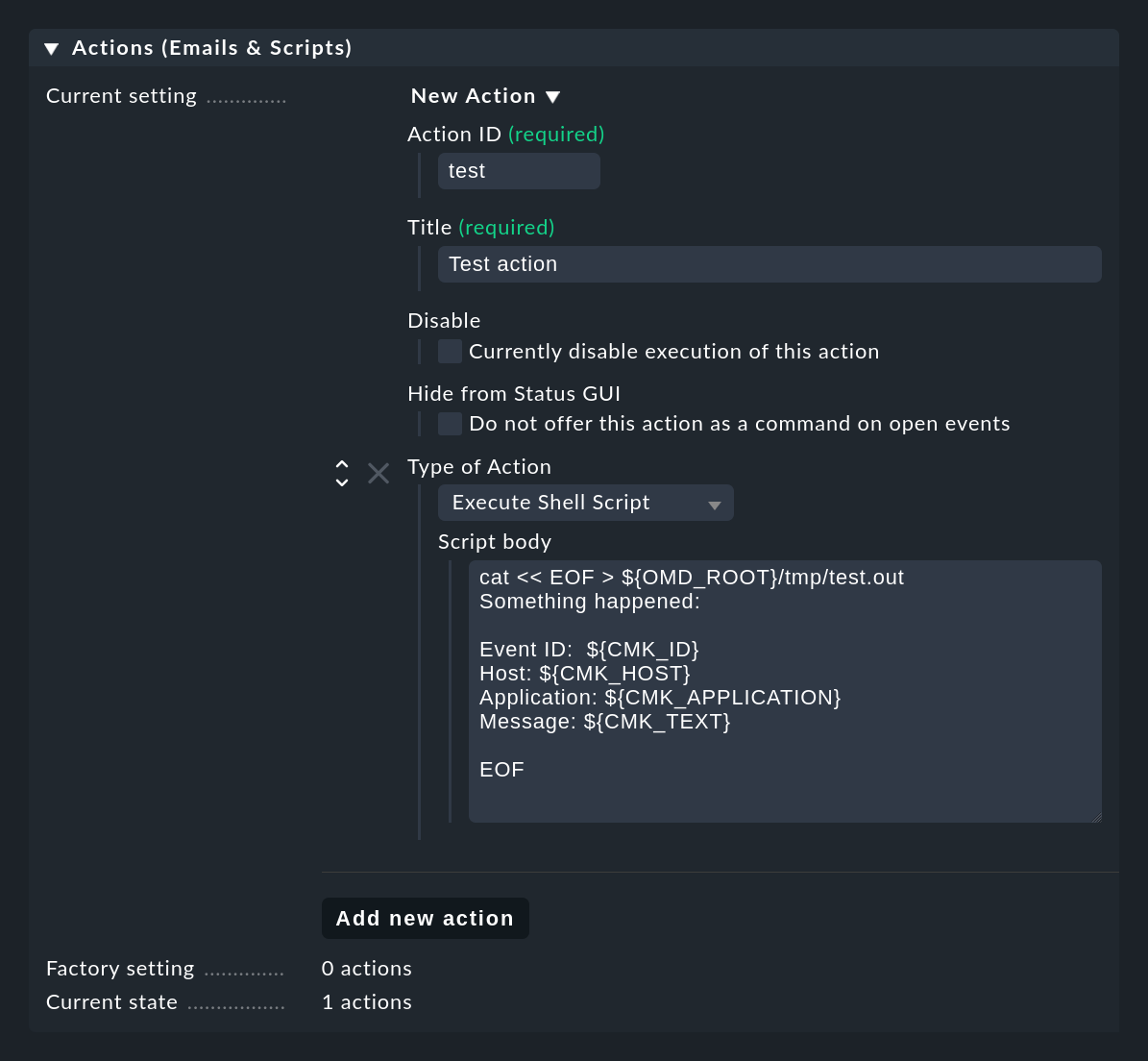
Con il pulsante Add new action puoi creare una nuova azione. L'esempio seguente mostra come creare un semplice shell script come azione del tipo Execute Shell Script. I dettagli degli eventi sono disponibili per lo script tramite variabili d'ambiente, ad esempio $CMK_ID dell'evento, $CMK_HOST, il testo completo $CMK_TEXT o il primo gruppo di corrispondenza come $CMK_MATCH_GROUP_1. Per un elenco completo delle variabili d'ambiente disponibili, consulta l'aiuto inline.
Le versioni precedenti di Checkmk consentivano l'uso di variabili d'ambiente e di macro come $TEXT$ che venivano sostituite prima dell'esecuzione dello script. A causa del pericolo che un aggressore possa iniettare comandi tramite un pacchetto UDP appositamente creato ed eseguito con i privilegi del processo Checkmk, non è consigliabile utilizzare le macro. Attualmente le macro sono ancora supportate per motivi di compatibilità, ma ci riserviamo il diritto di rimuoverle in una versione futura di Checkmk.
Lo script di esempio mostrato nella schermata crea il file tmp/test.out nella directory del sito in cui scrive un testo contenente i valori concreti delle variabili per il rispettivo ultimo evento:
cat << EOF > ${OMD_ROOT}/tmp/test.out
Something happened:
Event-ID: $CMK_ID
Host: $CMK_HOST
Application: $CMK_APPLICATION
Message: $CMK_TEXT
EOFGli script vengono eseguiti nel seguente ambiente:
/bin/bashviene utilizzato come interprete.Lo script viene eseguito come utente dell'istanza con la directory home del sito (es.
/omd/sites/mysite).Mentre lo script è in esecuzione, il processo di altri eventi viene interrotto!
Se il tuo script contiene tempi di attesa, puoi farlo eseguire in modo asincrono utilizzando lo spooler di Linux at. Per farlo, crea lo script in un file separato local/bin/myaction e avvialo con il comando at, ad es:
echo "$OMD_ROOT/local/bin/myaction '$HOST$' '$TEXT$' | at nowInvio di e-mail
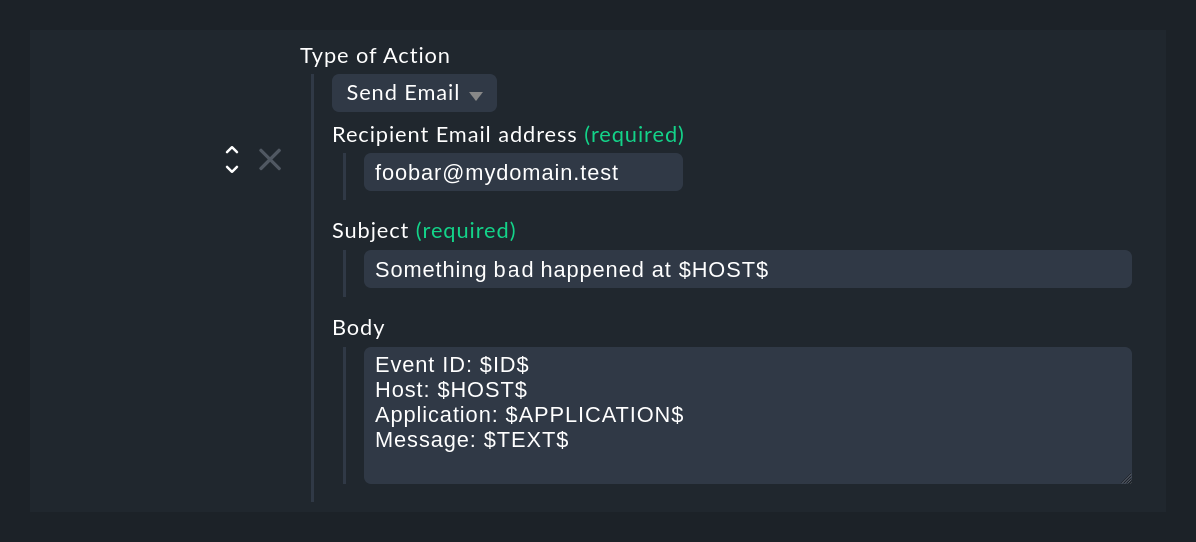
Il tipo di azione Send Email invia una semplice e-mail di testo. In realtà, potresti farlo anche con uno script, ad esempio utilizzando il comando da linea mail. Ma in questo modo è più comodo. Nota che i segnaposto sono ammessi anche nei campi Recipient email address e Subject.
6.3. Notifiche tramite Checkmk
Oltre all'esecuzione di script e all'invio di (semplici) e-mail, l'EC ha un terzo tipo di azione: l'invio di notifiche tramite il sistema di notifica Checkmk. Le notifiche possono essere generate dall'EC allo stesso modo delle notifiche di host e servizi del monitoraggio attivo. I vantaggi rispetto alle semplici e-mail descritte in precedenza sono evidenti:
Le notifiche sono configurate per il monitoraggio attivo e per quello basato su eventi, insieme in una posizione centrale.
Sono disponibili funzioni come le notifiche di massa, le e-mail HTML e altre utili funzioni.
Le regole di notifica personalizzate, la disattivazione delle notifiche e simili funzionano come al solito.
Il tipo di azione Send monitoring notification viene sempre processato automaticamente e non deve essere configurato.
Poiché gli eventi differiscono in qualche modo dai "normali" host o servizi, ci sono alcune particolarità nelle loro notifiche, che potrai conoscere in dettaglio nella sezione seguente.
Assegnazione agli host esistenti
Gli eventi possono provenire da qualsiasi host, indipendentemente dal fatto che sia configurato o meno nel monitoraggio attivo. Dopotutto, le porte syslog e SNMP sono aperte a tutti gli host della rete. Di conseguenza, gli attributi estesi dell'host come alias, tag degli host, contatti, ecc. non sono inizialmente disponibili. Questo è il motivo per cui le condizioni nelle regole di notifica non funzionano necessariamente come ti aspetteresti.
Ad esempio, al momento della notifica, la CE cerca di trovare un host all'interno dell'evento di monitoraggio attivo che corrisponda all'evento, utilizzando la stessa procedura utilizzata per la visibilità degli eventi. Se viene trovato un host, vengono presi i seguenti dati da questo host:
L'ortografia corretta del nome host.
L'alias dell'host
L'indirizzo IP primario configurato in Checkmk.
I tag dell'host
La cartella nella GUI di configurazione
L'elenco dei contatti e dei gruppi di contatto.
Di conseguenza, il nome host nella notifica elaborata potrebbe non corrispondere esattamente al nome host del messaggio originale. La codifica di testi di notifica conformi a quelli del monitoraggio attivo, tuttavia, semplifica la formulazione di regole di notifica uniformi che includono condizioni applicabili al nome host.
La mappatura viene effettuata in tempo reale inviando una query Livestatus al nucleo di monitoraggio che opera nello stesso sito dell'EC che ha ricevuto il messaggio. Ovviamente questo funziona solo se i messaggi syslog, le trap SNMP ecc. vengono sempre inviati al sito Checkmk in cui l'host viene monitorato attivamente!
Se la ricerca non funziona o l'host non può essere trovato, verranno accettati dati sostitutivi:
Nome host |
Il nome host dell'evento. |
Alias host |
Il nome host che verrà utilizzato come alias. |
Indirizzo IP |
Il campo dell'indirizzo IP contiene l'indirizzo del mittente originale del messaggio. |
Tag degli host |
L'host non riceverà alcun tag degli host. Se ci sono gruppi di tag host con tag vuoti, l'host adotta tali tag, ma altrimenti non riceve alcun tag dal gruppo. Tienilo presente quando definisci le condizioni relative ai tag degli host nelle regole di notifica. |
Cartella GUI di impostazione |
Nessuna cartella. Tutte le condizioni che si riferiscono a una cartella specifica non possono essere soddisfatte, anche nel caso della cartella Main. |
Contatti |
L'elenco dei contatti è vuoto. Se sono presenti dei contatti di riserva, verranno inseriti. |
Se l'host non può essere assegnato nell'evento di monitoraggio attivo, questo può ovviamente portare a problemi gestiti con le notifiche: da un lato a causa delle condizioni, che potrebbero non essere più valide, e dall'altro a causa della selezione dei contatti. In questi casi puoi modificare le regole di notifica in modo che le notifiche provenienti dalla Console degli Eventi vengano gestite in modo specifico utilizzando le loro regole. A questo scopo esiste una condizione separata con la quale puoi abbinare positivamente solo le notifiche CE o viceversa escluderle:
Campi di notifica rimanenti
Affinché le notifiche della CE passino attraverso il sistema di monitoraggio IT, la CE deve essere adattata al suo schema. Nel processo i campi dati tipici di una notifica vengono riempiti nel modo più efficace possibile. Abbiamo appena descritto come vengono determinati i dati dell'host. Altri campi sono:
Tipo di notifica |
Le notifiche della CE sono sempre considerate messaggi di servizio. |
Descrizione del servizio |
È il contenuto del campo Application dell'evento. Se questo campo è vuoto, verrà inserito |
Numero di notifica |
È fissato a |
Data/Ora |
Per gli eventi che vengono contati, è l'ora dell'ultimo messaggio associato all'evento. |
Output del plug-in |
Il contenuto testuale dell'evento. |
Stato del servizio |
Stato dell'evento, ad esempio OK, WARN, CRIT o SCONOSCIUTO. |
Stato precedente |
Poiché gli eventi non hanno uno stato precedente, OK viene sempre inserito qui per gli eventi normali e CRIT viene sempre inserito qui quando si elimina un evento. Questa regola è la più vicina a quella necessaria per le regole di notifica che hanno come condizione l'esatto cambiamento di stato. |
Definizione manuale dei gruppi di contatto
Come descritto in precedenza, potrebbe non essere possibile determinare automaticamente i contatti per un evento. In questi casi puoi specificare i gruppi di contatto direttamente nella regola CE da utilizzare per la notifica. È importante che tu non dimentichi di selezionare il box Use in notifications:
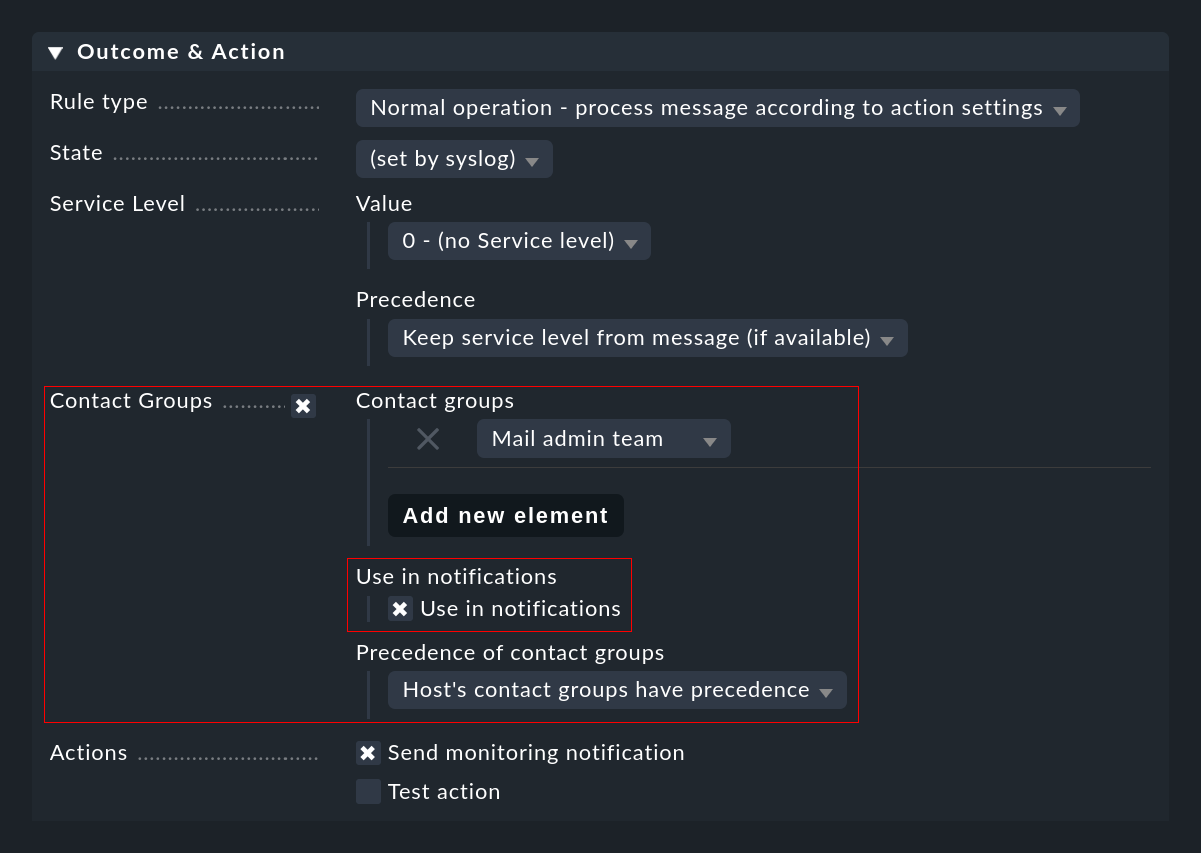
Switch globale per le notifiche
Esiste uno switch centrale per le notifiche nello snap-in Master control. Questo vale anche per le notifiche inoltrate dall'EC:

Come per l'assegnazione dell'host, l'interrogazione dello switch da parte dell'EC richiede l'accesso di Livestatus al nucleo di monitoraggio locale. Un'interrogazione riuscita può essere visualizzata nel file di log della Console degli Eventi:
[1482142567.147669] Notifications are currently disabled. Skipped notification for event 44Tempi di manutenzione programmata degli host
La Console degli Eventi è in grado di rilevare gli host che si trovano in un tempo di manutenzione programmata e non invia notifiche in queste situazioni. Il file di log avrà il seguente aspetto:
[1482144021.310723] Host myserver123 is currently in scheduled downtime. Skipping notification of event 433.Naturalmente, questo richiede che l'host venga trovato con successo nel monitoraggio attivo. Se ciò non avviene, si presume che l'host non sia in tempo di manutenzione programmata e in ogni caso verrà generata una notifica.
Macro aggiuntive
Quando scrivi i tuoi script di notifica, in particolare per le notifiche provenienti dalla Console degli Eventi, saranno disponibili alcune variabili aggiuntive che descrivono l'evento originale (a cui si accede come sempre con il prefisso NOTIFY_):
|
ID evento. |
|
ID della regola che ha creato l'evento. |
|
Priorità syslog come numero da |
|
Struttura syslog - anch'essa come numero. L'intervallo di valori va da |
|
Fase dell'evento. Poiché solo gli eventi aperti attivano azioni, questo valore dovrebbe essere |
|
Il campo del commento dell'evento. |
|
Il campo Owner. |
|
Il campo del commento con le informazioni di contatto specifiche dell'evento. |
|
L'ID del processo che ha inviato il messaggio (per gli eventi syslog). |
|
I gruppi di corrispondenza delle corrispondenze nella regola. |
|
I gruppi di contatto opzionali definiti manualmente nella regola. |
6.4. Esecuzione delle azioni
Nella sezione Comandi hai già imparato a conoscere l'esecuzione manuale delle azioni da parte dell'operatore. Più interessante è l'esecuzione automatica delle azioni, che puoi configurare con le regole EC nella sezione Outcome & Action:
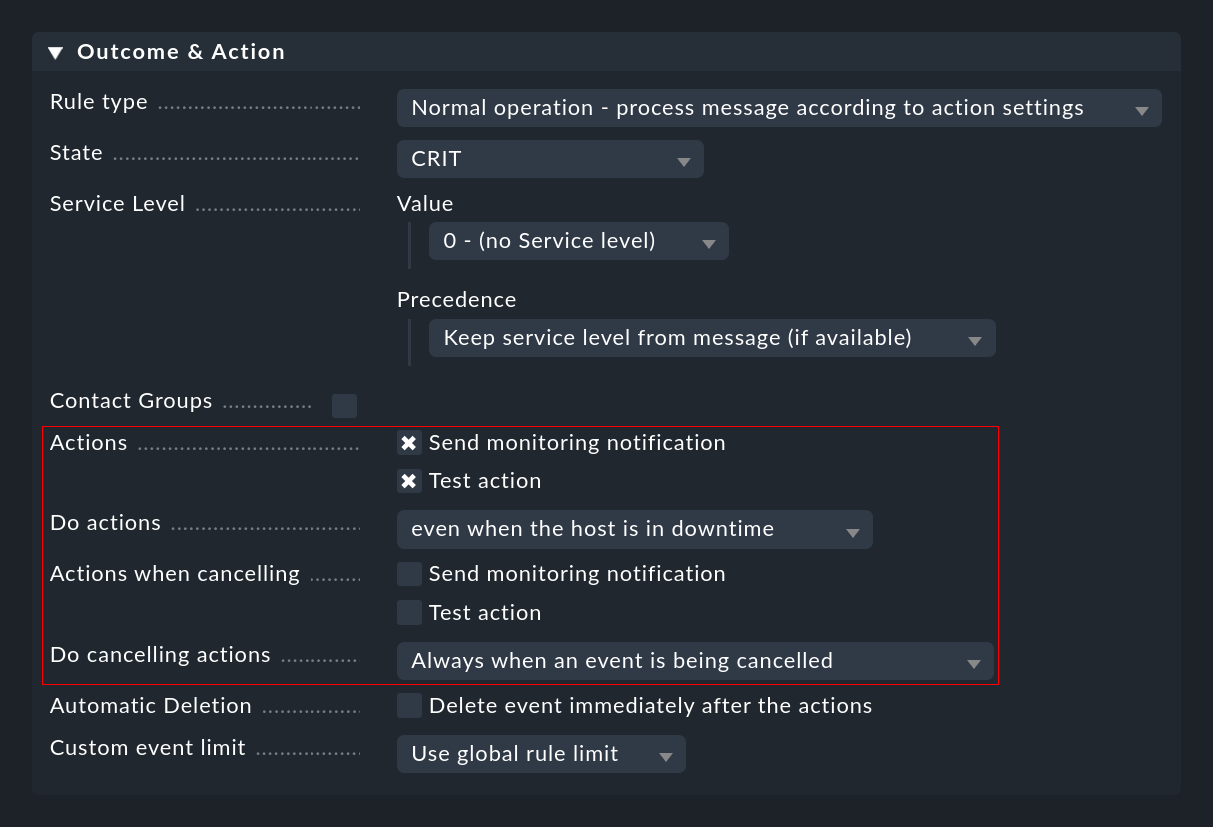
Qui puoi selezionare una o più azioni che verranno eseguite ogni volta che un evento viene aperto o annullato in base alla regola di eliminazione. Per quest'ultima puoi utilizzare l'elenco Do cancelling actions per specificare se l'azione deve essere eseguita solo se l'evento eliminato ha già raggiunto la fase open. Quando si utilizza il conteggio o il ritardo, può accadere che gli eventi che sono ancora nello stato di attesa e non ancora visibili all'utente vengano annullati.
L'esecuzione delle azioni viene registrata nel file di log var/log/mkeventd.log:
[1481120419.712534] Executing command: ACTION;1;cmkadmin;test
[1481120419.718173] Exitcode: 0Questi vengono anche scritti nell'archivio.
7. SNMP trap
7.1. Impostare la ricezione delle trap SNMP
Poiché la Console degli Eventi ha un proprio motore SNMP integrato, l'impostazione della ricezione delle trap SNMP è molto semplice. Non è necessario snmptrapd dal sistema operativo! Se è già in esecuzione, interrompilo.
Come descritto nella sezione dedicata alla configurazione della Console degli Eventi, usa omd config per abilitare il ricevitore di trappole in questo sito:
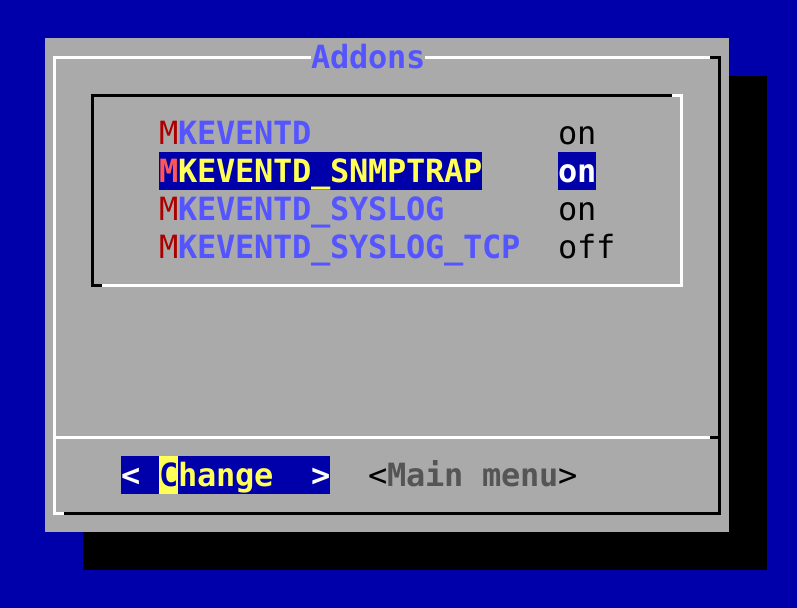
Poiché su ogni server la porta UDP per le trappole può essere utilizzata da un solo processo, questa operazione può essere eseguita solo in un'istanza Checkmk per ogni container. All'avvio del sito, nella riga contenente mkeventd puoi verificare se la ricezione delle trappole è stata abilitata:
OMD[mysite]:~$ omd start
Creating temporary filesystem /omd/sites/mysite/tmp...OK
Starting mkeventd (builtin: snmptrap)...OK
Starting liveproxyd...OK
Starting mknotifyd...OK
Starting rrdcached...OK
Starting cmc...OK
Starting apache...OK
Starting dcd...OK
Starting redis...OK
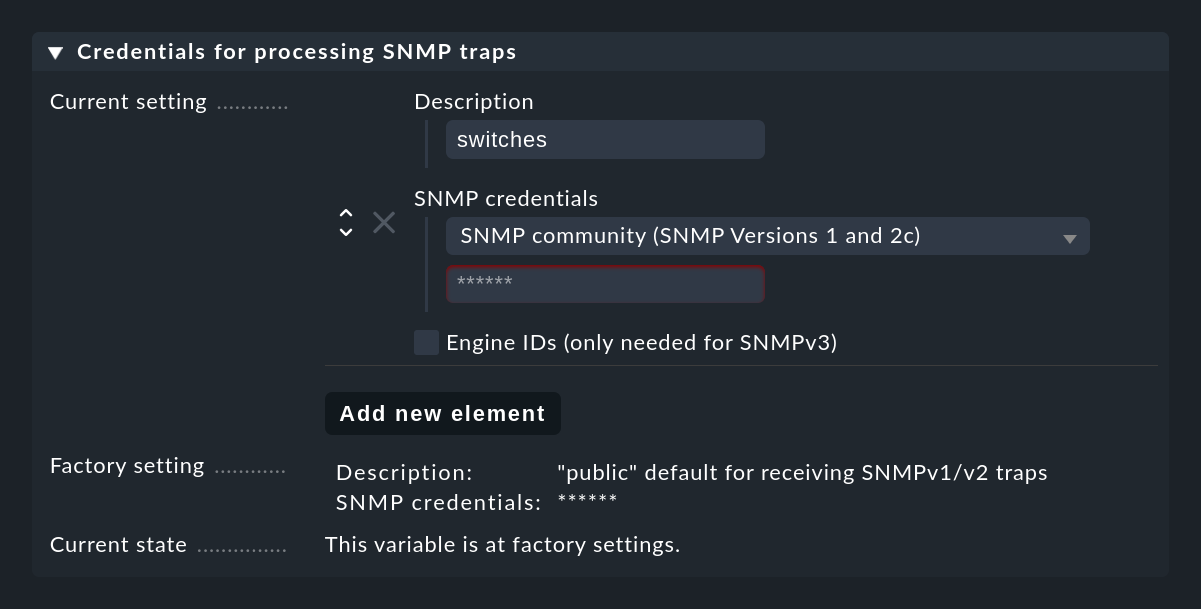
Initializing Crontab...OKAffinché le trap SNMP funzionino, il mittente e il destinatario devono essere d'accordo su alcune credentials. Nel caso di SNMP v1 e v2c si tratta di una semplice password, nota come "Community". Con la versione 3 sono necessarie altre credenziali, che si configurano nelle impostazioni della Console degli Eventi alla voce Credentials for processing SNMP traps. Puoi utilizzare il pulsante Add new element per impostare diverse credenziali che possono essere utilizzate in alternativa dai dispositivi:
La parte più complessa è ora, ovviamente, specificare l'indirizzo di destinazione per tutti i dispositivi da monitorare e configurare le credenziali.
7.2. Test
Purtroppo sono pochi i dispositivi che offrono funzionalità di test significative. Almeno puoi facilmente testare la ricezione delle trappole manualmente utilizzando la stessa Console degli Eventi inviando una trappola di prova, preferibilmente da un altro sistema Linux. Questo può essere fatto con il comando snmptrap. L'esempio seguente invia una trappola a 192.168.178.11. Il nome host del mittente è specificato dopo .1.3.6.1 e deve essere risolvibile o essere specificato come indirizzo IP (qui 192.168.178.30):
user@host:~$ snmptrap -v 1 -c public 192.168.178.11 .1.3.6.1 192.168.178.30 6 17 '' .1.3.6.1 s "Just kidding"Se nelle impostazioni hai impostato Log level su Verbose logging, potrai vedere la ricezione e la valutazione delle trappole nel file di log della CE:
[1482387549.481439] Trap received from 192.168.178.30:56772. Checking for acceptance now.
[1482387549.485096] Trap accepted from 192.168.178.30 (ContextEngineId "0x80004fb8054b6c617070666973636816893b00", ContextName "")
[1482387549.485136] 1.3.6.1.2.1.1.3.0 = 329887
[1482387549.485146] 1.3.6.1.6.3.1.1.4.1.0 = 1.3.6.1.0.17
[1482387549.485186] 1.3.6.1.6.3.18.1.3.0 = 192.168.178.30
[1482387549.485219] 1.3.6.1.6.3.18.1.4.0 =
[1482387549.485238] 1.3.6.1.6.3.1.1.4.3.0 = 1.3.6.1
[1482387549.485258] 1.3.6.1 = Just kiddingIn caso di credenziali errate, vedrai solo una singola riga:
[1482387556.477364] Trap received from 192.168.178.30:56772. Checking for acceptance now.Ecco come si presenta un evento generato da una trappola di questo tipo:

7.3. Trasformare i numeri in testo: Tradurre le trappole
SNMP è un protocollo binario ed è molto parsimonioso nelle descrizioni testuali dei messaggi. Il tipo di trap è comunicato internamente da una sequenza di numeri nei cosiddetti OID, che vengono visualizzati come sequenze di numeri separati da punti (es. 1.3.6.1.6.3.18.1.3.0).
Con l'aiuto dei cosiddetti file MIB, la Console degli Eventi può tradurre queste sequenze numeriche in testi: ad esempio, 1.3.6.1.6.3.18.1.3.0 diventa il testo SNMPv2-MIB::sysUpTime.0.
La traduzione delle trappole può essere attivata nelle impostazioni della Console degli Eventi:

La trappola di prova di cui sopra ora genera un evento leggermente diverso:

Se hai attivato l'opzione Add OID descriptions, il tutto diventa molto più dettagliato - e più confuso - ma aiuta a capire meglio cosa fa effettivamente una trappola:

7.4. Caricare le proprie MIB
Purtroppo, i vantaggi dell'open source non si sono ancora diffusi tra gli autori di file MIB e quindi noi del progetto Checkmk non siamo purtroppo in grado di fornire file MIB specifici per i provider. È preinstallata solo una piccola raccolta di MIB di base gratuite, che ad esempio prevede la traduzione di sysUpTime.
Tuttavia, puoi aggiungere questi file alla Console degli Eventi nel modulo SNMP MIBs for trap translation tramite la voce di menu Add one or multiple MIBs per caricare i tuoi file MIB, come è stato fatto di seguito con alcuni MIB di Netgear Smart Switch:
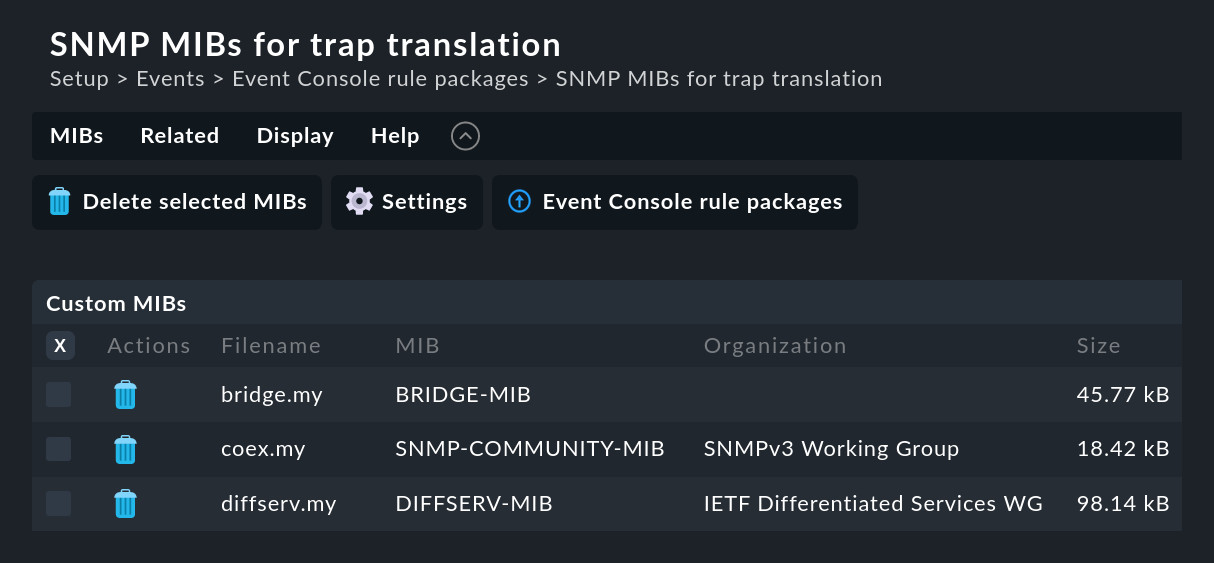
Note sulle MIB:
Invece di singoli file, puoi anche caricare file ZIP con raccolte di MIB in un'unica azione.
Le MIB hanno dipendenze tra loro. Le MIB mancanti ti verranno mostrate da Checkmk.
Le MIB caricate vengono utilizzate anche dalla linea di comando di
cmk --snmptranslate.
8. Monitoraggio dei file di log
L'agente Checkmk è in grado di analizzare i file di log tramite il plug-in logwatch. Questo plug-in fornisce innanzitutto il proprio monitoraggio dei file di log indipendentemente dalla Console degli Eventi, compresa la possibilità di confermare i messaggi direttamente nel monitoraggio. Esiste anche la possibilità di trasferire i messaggi trovati dal plug-in 1:1 nella Console degli Eventi.
Nell'agente Windows, il monitoraggio dei file di log è integrato in modo permanente, sotto forma di un plug-in per la valutazione dei file di testo e di uno per la valutazione dei registri eventi di Windows. Il plug-in mk_logwatch, codificato in Python, è disponibile per Linux e Unix. È possibile accedere a tutti e tre i plug-in tramite l'Agent bakery per impostarli o configurarli. A tal fine, utilizza i set di regole seguenti:
Text logfiles (Linux, Solaris, Windows)
Finetune Windows Eventlog monitoring
La configurazione precisa del plug-in Logwatch non è l'argomento di questo articolo, ma è importante che tu esegua il miglior pre-filtraggio possibile dei messaggi nel plug-in Logwatch stesso e che non invii semplicemente il contenuto completo dei file di testo alla Console degli Eventi.
Non confondere questo con la successiva riclassificazione tramite il set di regole Logfile patterns, che può cambiare solo lo stato dei messaggi già inviati dall'agente. Tuttavia, se hai già impostato questi modelli e vuoi semplicemente passare da logwatch alla Console degli Eventi, puoi mantenere i modelli. A questo scopo, le regole di inoltro (Logwatch Event Console Forwarding) includono l'opzione Reclassify messages before forwarding them to the EC.
In questo caso, tutti i messaggi passano attraverso un totale di tre catene di regole: sull'agente, attraverso la riclassificazione e nella Console degli Eventi!
Ora modifica logwatch in modo che i messaggi trovati dai plug-in non vengano più monitorati con il normale controllo di logwatch, ma semplicemente inoltrati 1:1 alla Console degli Eventi e lì processati. Questo avviene con il set di regole Logwatch Event Console Forwarding:
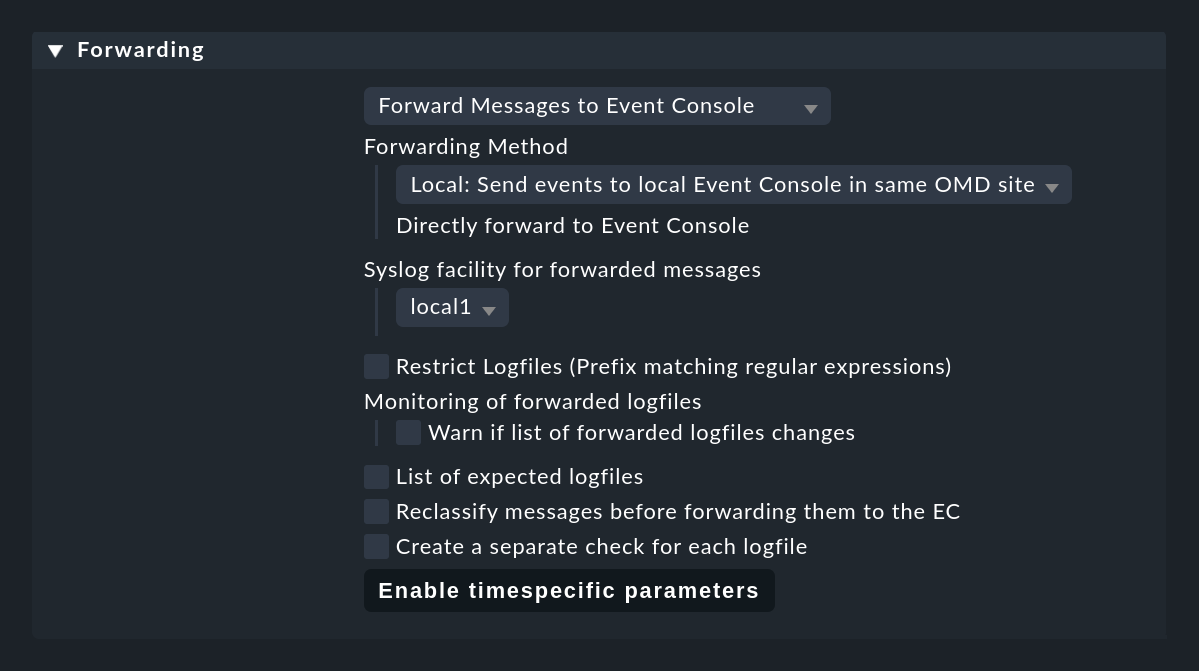
Alcune note a questo proposito:
Se hai un ambiente distribuito in cui ogni sito non ha una propria Console degli Eventi, i siti remoti devono inoltrare i messaggi al sito centrale tramite syslog. L'impostazione predefinita è UDP, ma non è un protocollo sicuro. Una soluzione migliore è utilizzare il syslog tramite TCP, ma dovrai abilitarlo nel sito centrale (omd config).
Per l'inoltro, specifica un qualsiasi Syslog facility. In questo modo potrai riconoscere facilmente i messaggi inoltrati nella CE. Le suite più adatte a questo scopo sono local0 e local7.
Con List of expected logfiles puoi monitorare l'elenco dei file di log attesi ed essere avvisato se alcuni file non vengono trovati come previsto.
Importante: salvare la regola da sola non serve a nulla. Questa regola diventa attiva solo durante la scoperta del servizio. Solo quando la eseguirai di nuovo, i servizi di logwatch precedenti verranno rimossi e verrà creato un nuovo servizio di nome Log Forwarding per ogni host.

Questo controllo ti indicherà anche se si verificano problemi durante l'inoltro alla Console degli Eventi.
8.1. Livello del servizio e priorità del syslog
Poiché i file di log inoltrati spesso non sono classificati come syslog a seconda del formato utilizzato, puoi definire la riclassificazione nel set di regole Logwatch Event Console Forwarding sotto Log Forwarding. Inoltre, nei set di regole che definisci come parte di Rule packs è sempre possibile impostare lo stato e i livelli del servizio individualmente.
9. Stato degli eventi nel monitoraggio attivo
Se vuoi anche vedere quali host nel monitoraggio attivo hanno attualmente eventi problematici aperti, puoi aggiungere un active check per ogni host che riassume lo stato attuale dell'evento. Per un host senza eventi aperti, l'aspetto sarà il seguente:

Se ci sono solo eventi in stato OK, il controllo mostra il loro numero, ma rimane verde:

Ecco un esempio di un caso con eventi aperti nello stato CRIT:

Puoi creare questo active check utilizzando una regola del set di regole Check event state in Event Console. Puoi anche specificare se gli eventi che sono già stati confermati debbano contribuire allo stato:
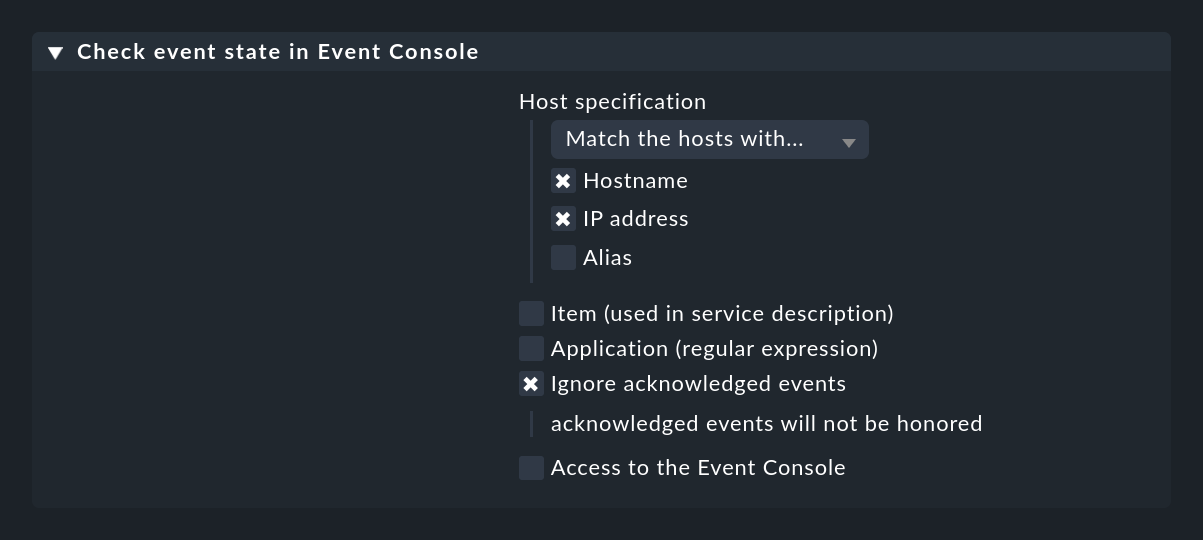
Con l'opzione Application (regular expression) puoi limitare il controllo agli eventi che hanno un testo specifico nel campo dell'applicazione. In questo caso può avere senso avere più di un controllo di eventi su un host e separare i controlli per applicazione. Affinché questi siano distinti per nome, è necessaria anche l'opzione Item (used in service description), che aggiunge un testo da te specificato al nome del servizio.
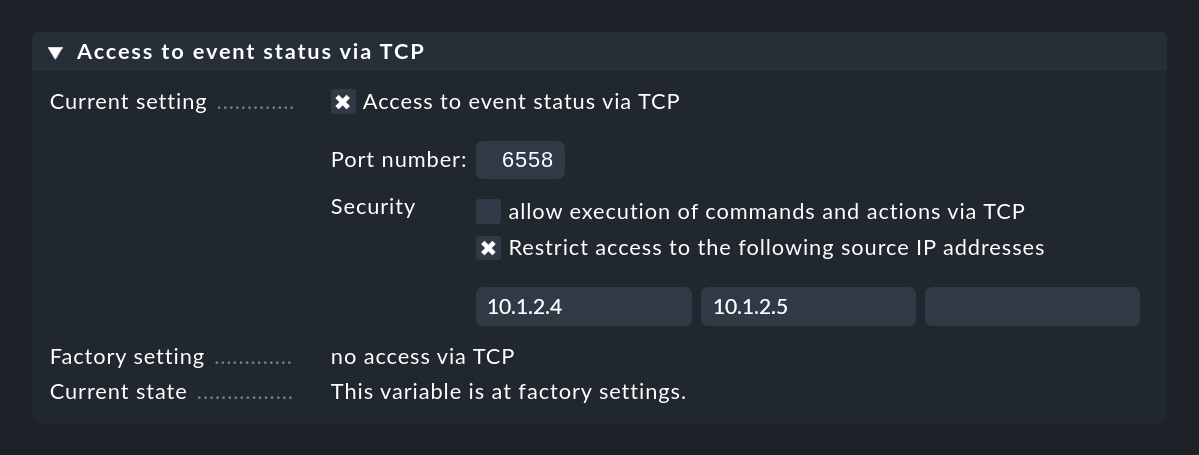
Se la tua Console degli Eventi non è in esecuzione sulla stessa istanza Checkmk di quella che sta monitorando l'host, devi impostare Access to Event Console per un accesso remoto via TCP:
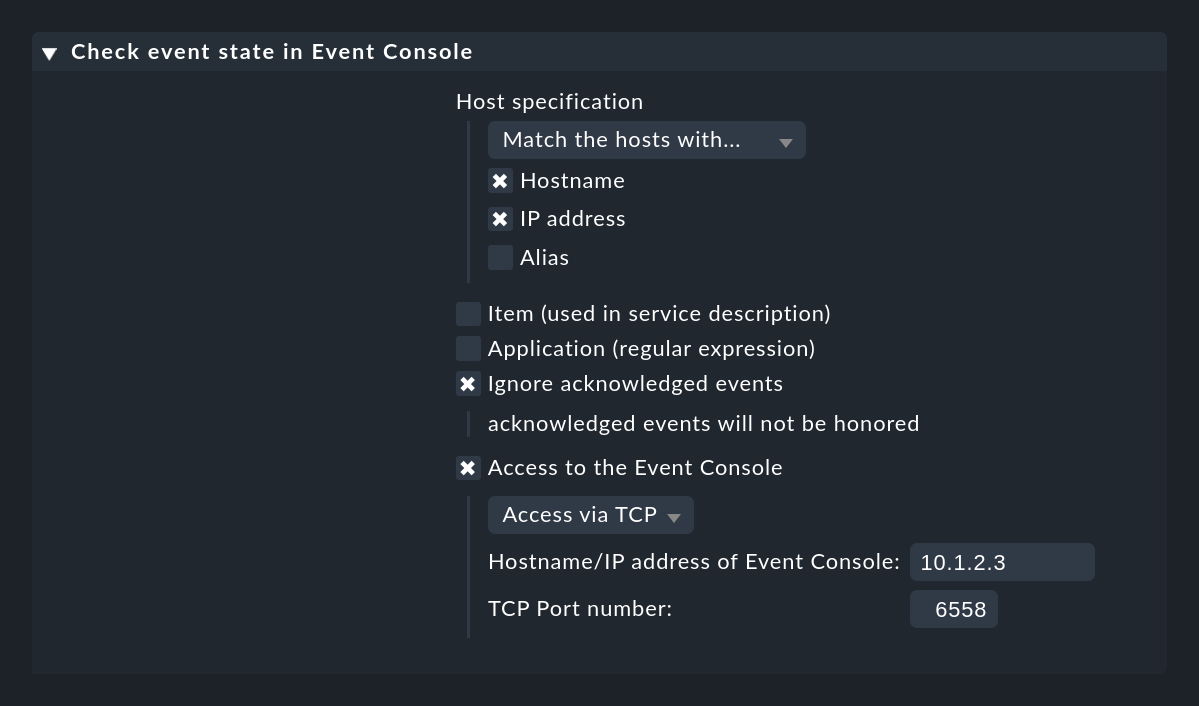
Affinché questo funzioni, la Console degli Eventi deve consentire l'accesso via TCP. Puoi configurarlo nelle impostazioni della Console degli Eventi a cui si deve accedere:
10. L'archivio
10.1. Come funziona l'archivio
La Console degli Eventi conserva un registro di tutte le modifiche che un evento subisce. Questo registro eventi può essere trovato in due modi:
Nella visualizzazione globale Recent event history, che puoi trovare in Monitor > Event Console.
Nei dettagli di un evento tramite la voce di menu Event Console Event > History of Event.
Nella visualizzazione globale c'è un filtro che mostra solo gli eventi delle ultime 24 ore, ma come al solito puoi personalizzare i filtri.
La figura seguente mostra la cronologia dell'evento 33, che ha subito un totale di quattro modifiche: prima l'evento è stato creato (NEW), poi lo stato è stato cambiato manualmente da OK a WARN (CHANGESTATE), quindi confermato con un commento aggiunto (UPDATE) e infine l'evento è stato archiviato/cancellato (DELETE):

L'archivio contiene i seguenti tipi di azione, visualizzati nella colonna Action:
| Tipo di azione | Descrizione |
|---|---|
|
L'evento è stato creato di recente (a causa di un messaggio ricevuto o di una regola che prevedeva un messaggio che non è stato visualizzato). |
|
L'evento è stato modificato dall'operatore (modifica del commento, delle informazioni di contatto, conferma). |
|
L'evento è stato archiviato. |
|
L'evento è stato eliminato automaticamente da un messaggio OK. |
|
Lo stato dell'evento è stato modificato dall'operatore. |
|
L'evento è stato archiviato automaticamente perché non è stata applicata alcuna regola e Force message archiving è stato abilitato nelle impostazioni globali. |
|
L'evento è stato archiviato automaticamente perché mentre si trovava nella fase counting, la regola associata è stata cancellata. |
|
L'evento è stato spostato da counting a open perché è stato raggiunto il numero di messaggi configurato. |
|
L'evento è stato archiviato automaticamente perché il numero di messaggi richiesto non è stato raggiunto in counting. |
|
L'evento è stato archiviato automaticamente perché mentre si trovava nella fase counting, la regola associata è stata modificata in "non contare". |
|
L'evento è stato aperto perché il ritardo configurato nella regola è scaduto. |
|
L'evento è stato archiviato automaticamente perché la sua durata configurata è scaduta. |
|
È stata inviata un'e-mail. |
|
È stata eseguita un'azione automatica (script). |
|
L'evento è stato archiviato automaticamente subito dopo l'apertura, perché questo era configurato nella regola corrispondente. |
10.2. Posizione dell'archivio
Come già detto, l'archivio della Console degli Eventi non è stato progettato come un archivio syslog a tutti gli effetti. Per semplificare al massimo l'implementazione e soprattutto l'amministrazione, è stato omesso un back-end del database. L'archivio viene invece scritto in semplici file di testo. Ogni voce consiste in una riga di testo, che contiene colonne separate da schede. Puoi trovare i file in ~/var/mkeventd/history:
OMD[mysite]:~$ ll var/mkeventd/history/
total 1328
-rw-rw-r-- 1 stable stable 131 Dec 4 23:59 1480633200.log
-rw-rw-r-- 1 stable stable 1123368 Dec 5 23:39 1480892400.log
-rw-rw-r-- 1 stable stable 219812 Dec 6 09:46 1480978800.logPer impostazione predefinita, un nuovo file viene avviato automaticamente ogni giorno. Nelle impostazioni della Console degli Eventi puoi personalizzare la rotazione del file. L'impostazione Event history logfile rotation ti permette di switchare a una rotazione settimanale.
I nomi dei file sono conformi al timestamp Unix del momento della creazione del file (secondi dall'1/1/1970 UTC).
I file vengono conservati per 365 giorni, a meno che tu non modifichi questa impostazione in Event history lifetime. Inoltre, i file vengono anche registrati dalla gestione centrale dello spazio su disco di Checkmk, che può essere configurata nelle impostazioni globali alla voce Site management. In questo caso, si applica il limite di tempo più breve impostato in ciascun caso. La gestione globale ha il vantaggio che, se lo spazio libero su disco diventa marginale, cancella automaticamente i dati storici di Checkmk in modo coerente, iniziando dai più vecchi.
Se dovessi avere problemi di spazio, puoi anche eliminare manualmente i file presenti nella directory o scambiarli. Non inserire file zippati o di altro tipo in questa directory.
10.3. Archiviazione automatica
Nonostante le limitazioni dei file di testo, è teoricamente possibile archiviare un gran numero di messaggi nella Console degli Eventi. La scrittura nei file di testo dell'archivio è molto performante, ma al costo di una ricerca meno efficiente in seguito. Poiché i file hanno come indice solo la periodicità della richiesta, per ogni richiesta devono essere letti e cercati tutti i file pertinenti.
Normalmente la CE scrive nell'archivio solo i messaggi per i quali è stato effettivamente aperto un evento. Puoi farlo in due modi diversi per estendere questa funzione a tutti gli eventi:
Crei una regola che corrisponda a tutti gli eventi (ulteriori) e in Outcome & actions attivi l'opzione Delete event immediately after the actions.
Attiva lo switch Force message archiving nelle impostazioni della Console degli Eventi.
Quest'ultima opzione garantisce che i messaggi che non sono soggetti a nessuna regola vengano comunque scritti nell'archivio (tipo di azione ARCHIVED).
11. Prestazioni e messa a punto
11.1. Elaborazione dei messaggi
Anche in tempi in cui i server hanno 64 core e 2 TB di memoria principale, le prestazioni del software giocano ancora un ruolo importante. Soprattutto nell'elaborazione degli eventi, i messaggi in arrivo possono andare persi in situazioni estreme.
Il motivo è che nessuno dei protocolli utilizzati (syslog, SNMP trap, ecc.) prevede un controllo del flusso: se migliaia di host inviano messaggi contemporaneamente ogni secondo, il ricevitore non ha alcuna possibilità di rallentarli.
Pertanto, in ambienti un po' più grandi, è importante tenere sotto controllo i tempi di processo dei messaggi. Questo dipende dal numero di regole definite e dalla loro struttura.
Misurare le prestazioni
Per misurare le prestazioni c'è uno snap-in separato per la barra laterale con il nome di Event Console Performance. Puoi includerlo come al solito con :
I valori mostrati qui sono medie dell'ultimo minuto circa. Una tempesta di eventi che dura solo pochi secondi non può essere letta direttamente qui, ma i numeri sono stati in qualche modo smussati e sono quindi più facili da leggere.
Per testare le massime prestazioni, puoi generare artificialmente una tempesta di messaggi non classificati (solo nel file system di prova!), ad esempio in un ciclo di shell scrivendo continuamente il contenuto di un file di testo nella pipe degli eventi.
OMD[mysite]:~$ while true ; do cat /etc/services > tmp/run/mkeventd/events ; doneLe letture più importanti dello snap-in hanno il seguente significato:
| Valore | Significato |
|---|---|
Received messages |
Numero di messaggi ricevuti al secondo. |
Rule tries |
Numero di regole provate. Questo dato fornisce informazioni preziose sull'efficienza della catena di regole, soprattutto in combinazione con il parametro successivo. |
Rule hits |
Numero di regole al secondo che vengono attualmente colpite. Queste possono anche essere regole che scartano i messaggi o che semplicemente li contano. Per questo motivo, non tutte le regole colpite producono un evento. |
Rule hit ratio |
Il rapporto tra Rule tries e Rule hits. In altre parole: Quante regole deve provare la CE prima che una (finalmente) abbia effetto. Nell'esempio riportato nella schermata, il tasso è allarmantemente basso. |
Created events |
Numero di nuovi eventi creati al secondo. Poiché la Console degli Eventi dovrebbe mostrare solo i problemi rilevanti (paragonabili ai problemi di host e di servizio del monitoraggio), il numero |
Processing time per message |
Qui puoi leggere il tempo impiegato per il processo di un messaggio. Attenzione: In generale, questo dato non è l'inverso di Received messages. Infatti, i tempi in cui la Console degli Eventi non ha avuto nulla da fare sono ancora mancanti, semplicemente perché non sono arrivati messaggi. In questo caso si misura il tempo reale trascorso tra l'arrivo di un messaggio e il completamento del processo. Puoi vedere approssimativamente quanti messaggi può gestire la CE in un determinato periodo di tempo. Nota anche che non si tratta di tempo di CPU, ma di tempo reale. In un sistema con un numero sufficiente di CPU libere, questi tempi sono più o meno gli stessi. Ma quando il sistema è talmente sotto carico che non tutti i processi ottengono sempre una CPU, il tempo reale può diventare molto più alto. |
Suggerimenti per la messa a punto
Puoi vedere quanti messaggi la Console degli Eventi può processare al secondo dal sito Processing time per message. Questo tempo è generalmente legato al numero di regole che devono essere provate prima che un messaggio venga processato. In questo caso hai diverse opzioni di ottimizzazione:
Le regole che escludono molti messaggi dovrebbero essere posizionate il più possibile all'inizio della catena di regole.
Utilizza i pacchetti di regole per raggruppare set di regole correlate. La prima regola di ogni pacchetto deve uscire immediatamente dal pacchetto se la condizione di base comune non è soddisfatta.
Per ogni combinazione di priorità e struttura, viene creata internamente una catena di regole separata in cui sono incluse solo le regole rilevanti per i messaggi di questa combinazione.
Ogni regola che contiene una condizione sulla priorità, sulla struttura o preferibilmente su entrambe, non sarà inclusa in tutte queste catene di regole, ma in modo ottimale solo in una. Ciò significa che la regola non deve essere controllata per i messaggi con una classificazione syslog diversa.
Dopo un riavvio, in ~/var/log/mkeventd.log vedrai una panoramica delle catene di regole ottimizzate:
[8488808306.233330] kern : emerg(112) alert(67) crit(67) err(67) warning(67) notice(67) info(67) debug(67)
[8488808306.233343] user : emerg(112) alert(67) crit(67) err(67) warning(67) notice(67) info(67) debug(67)
[8488808306.233355] mail : emerg(112) alert(67) crit(67) err(67) warning(67) notice(67) info(67) debug(67)
[8488808306.233367] daemon : emerg(120) alert(89) crit(89) err(89) warning(89) notice(89) info(89) debug(89)
[8488808306.233378] auth : emerg(112) alert(67) crit(67) err(67) warning(67) notice(67) info(67) debug(67)
[8488808306.233389] syslog : emerg(112) alert(67) crit(67) err(67) warning(67) notice(67) info(67) debug(67)
[8488808306.233408] lpr : emerg(112) alert(67) crit(67) err(67) warning(67) notice(67) info(67) debug(67)
[8488808306.233482] news : emerg(112) alert(67) crit(67) err(67) warning(67) notice(67) info(67) debug(67)
[8488808306.233424] uucp : emerg(112) alert(67) crit(67) err(67) warning(67) notice(67) info(67) debug(67)
[8488808306.233435] cron : emerg(112) alert(67) crit(67) err(67) warning(67) notice(67) info(67) debug(67)
[8488808306.233446] authpriv : emerg(112) alert(67) crit(67) err(67) warning(67) notice(67) info(67) debug(67)
[8488808306.233457] ftp : emerg(112) alert(67) crit(67) err(67) warning(67) notice(67) info(67) debug(67)
[8488808306.233469] (unused 12) : emerg(112) alert(67) crit(67) err(67) warning(67) notice(67) info(67) debug(67)
[8488808306.233480] (unused 13) : emerg(112) alert(67) crit(67) err(67) warning(67) notice(67) info(67) debug(67)
[8488808306.233498] (unused 13) : emerg(112) alert(67) crit(67) err(67) warning(67) notice(67) info(67) debug(67)
[8488808306.233502] (unused 14) : emerg(112) alert(67) crit(67) err(67) warning(67) notice(67) info(67) debug(67)
[8488808306.233589] local0 : emerg(112) alert(67) crit(67) err(67) warning(67) notice(67) info(67) debug(67)
[8488808306.233538] local1 : emerg(112) alert(67) crit(67) err(67) warning(67) notice(67) info(67) debug(67)
[8488808306.233542] local2 : emerg(112) alert(67) crit(67) err(67) warning(67) notice(67) info(67) debug(67)
[8488808306.233552] local3 : emerg(112) alert(67) crit(67) err(67) warning(67) notice(67) info(67) debug(67)
[8488808306.233563] local4 : emerg(112) alert(67) crit(67) err(67) warning(67) notice(67) info(67) debug(67)
[8488808306.233574] local5 : emerg(112) alert(67) crit(67) err(67) warning(67) notice(67) info(67) debug(67)
[8488808306.233585] local6 : emerg(112) alert(67) crit(67) err(67) warning(67) notice(67) info(67) debug(67)
[8488808306.233595] local7 : emerg(112) alert(67) crit(67) err(67) warning(67) notice(67) info(67) debug(67)
[8488808306.233654] snmptrap : emerg(112) alert(67) crit(67) err(67) warning(67) notice(67) info(67) debug(67)Nell'esempio precedente puoi vedere che in ogni caso ci sono 67 regole che devono essere controllate. Per i messaggi della struttura daemon sono rilevanti 89 regole, mentre solo per la combinazione daemon/emerg devono essere controllate 120 regole. Ogni regola che riceve una condizione sulla priorità o sulla struttura riduce ulteriormente il numero di 67 regole.
Ovviamente puoi impostare queste condizioni solo se sei sicuro che siano soddisfatte dai messaggi in questione!
11.2. Il conteggio degli eventi attuali
Anche il numero di eventi attualmente presenti può influire sulle prestazioni della CE, cioè quando va seriamente fuori controllo. Come già detto, la CE non deve essere vista come un sostituto di un archivio syslog, ma solo per visualizzare i "problemi attuali". La Console degli Eventi può certamente gestire diverse migliaia di problemi, ma non è questo il suo vero scopo.
Non appena il numero di eventi attuali supera i 5.000, le prestazioni iniziano a peggiorare sensibilmente. Da un lato, questo si nota nella GUI, che reagisce più lentamente alle richieste. Dall'altro, anche il processo diventa più lento, poiché in alcune situazioni i messaggi devono essere confrontati con tutti gli eventi attuali. Anche i requisiti di memoria possono diventare problematici.
Per motivi di prestazioni, la Console degli Eventi conserva sempre tutti gli eventi correnti nella RAM. Questi vengono scritti nel file ~/var/mkeventd/status una volta al minuto (regolabile) e al termine dell'elaborazione. Se il file diventa molto grande (ad es. oltre 50 megabyte), anche questo processo diventa sempre più lento. Puoi controllare rapidamente la dimensione attuale con ll. (alias di ls -alF):
OMD[mysite]:~$ ll -h var/mkeventd/status
-rw-r--r-- 1 mysite mysite 386K Dez 14 13:46 var/mkeventd/statusSe hai troppi eventi in corso a causa di una regola maldestra (es. una che fa matching su tutto), l'eliminazione manuale tramite GUI non è ragionevolmente possibile. In questo caso, la semplice cancellazione del file di stato sarà utile:
OMD[mysite]:~$ omd stop mkeventd
Stopping mkeventd...killing 17436......OK
OMD[mysite]:~$ rm var/mkeventd/status
OMD[mysite]:~$ omd start mkeventd
Starting mkeventd (builtin: syslog-udp)...OKAttenzione: Ovviamente tutti gli eventi in corso andranno persi, così come il contatore e gli altri stati memorizzati. In particolare, i nuovi eventi inizieranno nuovamente con l'ID 1.
Protezione automatica contro l'overflow
La Console degli Eventi ha una protezione automatica contro l'overflow che limita il numero di eventi correnti per host, per regola e a livello globale. Non vengono contati solo gli eventi aperti, ma anche quelli in altre fasi, come delayed o counting. Gli eventi archiviati non vengono contati.
Questo ti proteggerà nelle situazioni in cui, a causa di un problema sistematico sulla rete, migliaia di eventi critici si riversano e la Console degli Eventi si "spegnerebbe". Da un lato, questo impedisce un degrado delle prestazioni della Console degli Eventi, che dovrebbe contenere troppi eventi nella sua memoria principale. Dall'altro, la panoramica per l'operatore è (in qualche modo) protetta e gli eventi che non fanno parte della tempesta rimangono visibili.
Una volta raggiunto il limite, si verifica una delle seguenti azioni:
La creazione di nuovi eventi viene interrotta (per questo host, regola o a livello globale).
Lo stesso, ma in aggiunta viene creato un "evento di overflow".
Lo stesso, ma in aggiunta viene inviata una notifica ai contatti appropriati.
In alternativa a queste tre varianti, puoi anche eliminare l'evento più vecchio per fare spazio a quello nuovo.
I limiti e gli effetti associati al loro raggiungimento sono definiti nelle impostazioni della Console degli Eventi con Limit amount of current events. La figura seguente mostra l'impostazione predefinita:
Se hai abilitato un valore con …create overflow event, quando il limite viene raggiunto, verrà creato un singolo evento artificiale che informerà l'operatore della situazione di errore:
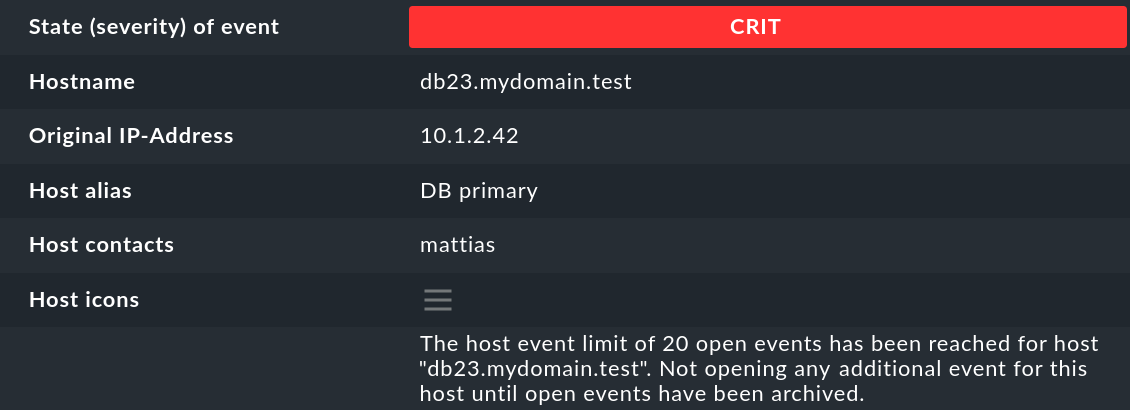
Se hai abilitato anche un valore con …notify contacts, i contatti appropriati saranno avvisati tramite notifica Checkmk. Questa notifica passerà attraverso le regole di notifica Checkmk. Queste regole non devono necessariamente seguire la selezione dei contatti della Console degli Eventi, ma possono modificarla. La tabella seguente mostra quali contatti vengono selezionati se hai impostato Notify all contacts of the notified host or service (che è il valore predefinito):
| Limite | Selezione dei contatti |
|---|---|
per host |
I contatti dell'host, che vengono determinati come per la notifica degli eventi tramite Checkmk. |
per regola |
Lascia vuoto il campo del nome host. Se nella regola sono stati definiti dei gruppi di contatto, questi verranno selezionati, altrimenti verranno applicati i contatti di riserva. |
Globale |
I contatti di riserva. |
11.3. Archivio troppo grande
Come mostrato sopra, la Console degli Eventi dispone di un archivio di tutti gli eventi e dei relativi processi, memorizzato in file di testo per facilitare l'implementazione e l'amministrazione.
I file di testo sono difficili da battere in termini di prestazioni quando si scrivono i dati, ad esempio utilizzando i database, solo con un enorme sforzo di ottimizzazione. Ciò è dovuto, tra gli altri fattori, all'ottimizzazione di questo tipo di accesso da parte di Linux e alla gerarchia completa della memoria dei dischi e delle SAN. Tuttavia, ciò va a discapito degli accessi in lettura: poiché i file di testo non hanno un indice, è necessaria una lettura completa quando si effettua una ricerca nei file.
Nella sua versione più semplice, la Console degli Eventi utilizza i nomi dei file di log come indice per l'ora degli eventi. Più si limita il periodo di tempo della ricerca, più veloce sarà la ricerca.
Tuttavia, è molto importante che il tuo archivio non diventi troppo grande. Se utilizzi la Console degli Eventi solo per processare messaggi di errore reali, questo non può accadere. Se cerchi di utilizzare la CE come sostituto di un vero archivio syslog, questo può portare a file molto grandi.
Se ti trovi in una situazione in cui il tuo archivio è diventato troppo grande, puoi semplicemente eliminare i file più vecchi in ~/var/mkeventd/history/. Inoltre, in Event history lifetime puoi generalmente limitare la durata dei dati in modo che l'eliminazione sia l'opzione predefinita in futuro. Per impostazione predefinita vengono archiviati 365 giorni. Forse puoi cavartela con molto meno.
11.4. Misurare le prestazioni nel tempo
Checkmk avvia automaticamente un servizio per ogni sito della Console degli Eventi, che registra i dati sulle prestazioni in curve e ti avvisa se si verificano degli overflow.
Se hai installato un agente Linux sul server di monitoraggio, il controllo verrà automaticamente trovato e impostato come di consueto:

Il controllo offre molti tipi di misurazioni interessanti, ad esempio il numero di messaggi in arrivo per ogni periodo di tempo e quanti di questi sono stati scartati:
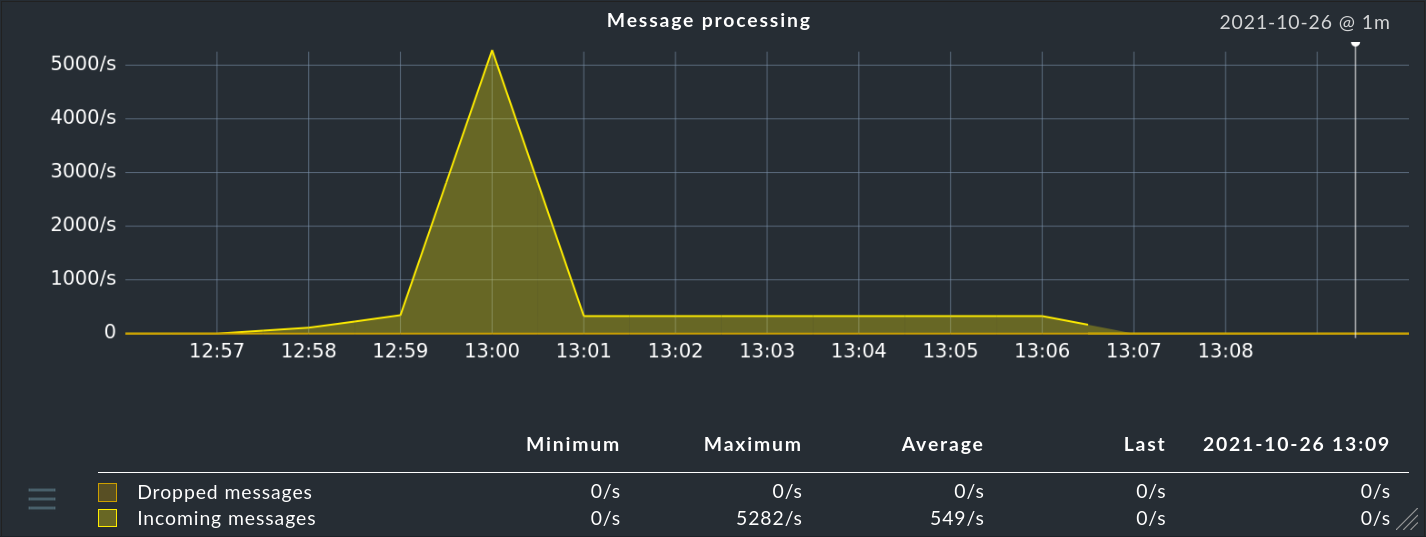
L'efficienza della catena di regole è rappresentata dal confronto tra le regole testate e quelle che hanno funzionato:
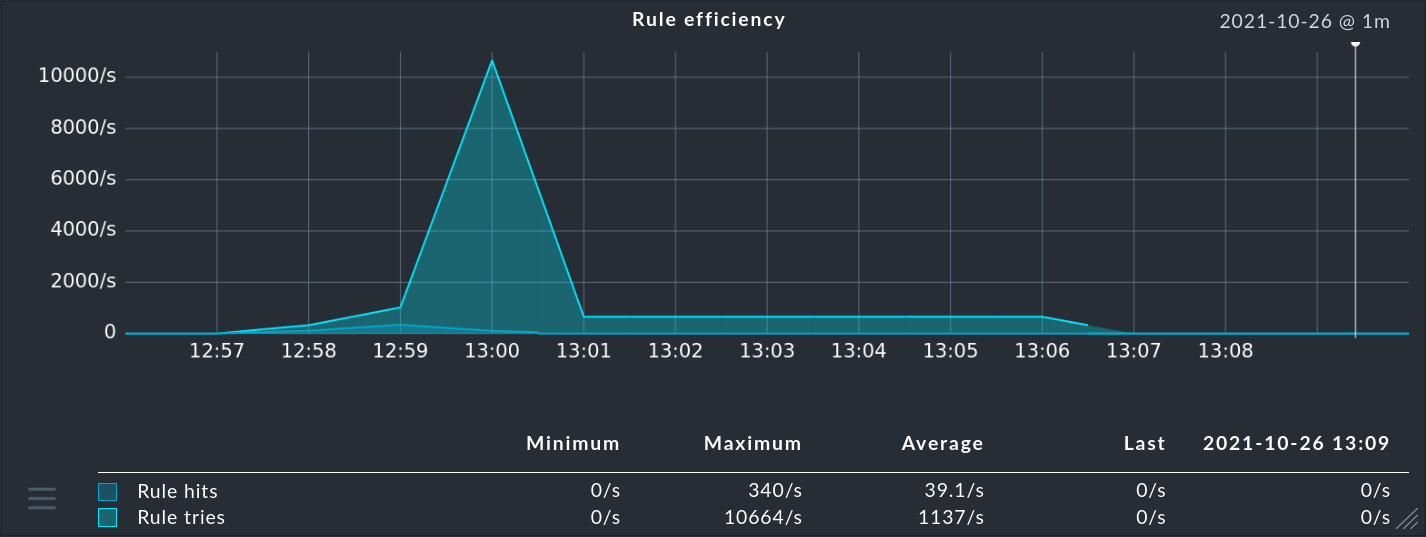
Questo grafico mostra il tempo medio necessario per il processo di un messaggio:
Ci sono anche molti altri grafici.
12. Monitoraggio distribuito
Per sapere come utilizzare la Console degli Eventi in un'installazione con più istanze Checkmk, consulta l'articolo sul monitoraggio distribuito.
13. L'interfaccia di stato
La Console degli Eventi, tramite il socket Unix ~/tmp/run/mkeventd/status, fornisce sia l'accesso allo stato interno che la possibilità di eseguire comandi. Il protocollo utilizzato è un sottoinsieme strettamente limitato di Livestatus. A questa interfaccia accede il nucleo di monitoraggio e passa i dati alla GUI per fornire un monitoraggio distribuito anche alla Console degli Eventi.
Le seguenti restrizioni si applicano al Livestatus semplificato della Console degli Eventi:
Le uniche intestazioni consentite sono
Filter:eOutputFormat:.Pertanto non è possibile effettuare KeepAlive e può essere effettuata una sola richiesta per connessione.
Sono disponibili le seguenti tabelle:
|
Elenco di tutti gli eventi correnti. |
|
Accesso all'archivio. Una query su questa tabella consente di accedere ai file di testo dell'archivio. Assicurati di utilizzare un filtro sull'orario di inserimento per evitare l'accesso completo a tutti i file. |
|
Stato e valori delle prestazioni dell'EC. Questa tabella ha sempre una riga esatta. |
I comandi possono essere scritti nel socket utilizzando unixcat con una sintassi molto semplice:
OMD[mysite]:~$ echo "COMMAND RELOAD" | unixcat tmp/run/mkeventd/statusSono disponibili i seguenti comandi:
|
Archivia un evento. Argomenti: ID dell'evento e abbreviazione dell'utente. |
|
Ricarica la configurazione. |
|
Esce dalla Console degli Eventi. |
|
Riapre il file di log. Questo comando è necessario per la rotazione del file di log. |
|
Cancella tutti gli eventi correnti e archiviati. |
|
Avvia un aggiornamento immediato del file |
|
Azzera i contatori delle regole (corrisponde alla voce di menu Event Console > Reset counters nella GUI). |
|
Esegue un aggiornamento da un evento. Gli argomenti sono nell'ordine l'id dell'evento, l'abbreviazione dell'utente, la conferma (0/1), il commento e le informazioni di contatto. |
|
Cambia gli stati OK / WARN / CRIT / SCONOSCIUTO di un evento. Gli argomenti sono l'ID dell'evento, l'abbreviazione dell'utente e la cifra di stato ( |
|
Esegue un'azione definita dall'utente su un evento. Gli argomenti sono l'ID dell'evento, l'abbreviazione dell'utente e l'ID dell'azione. L'ID speciale |
14. File e directory
| Percorso del file | Descrizione |
|---|---|
|
Cartella di lavoro del daemon degli eventi. |
|
Stato attuale completo della Console degli Eventi. Include principalmente tutti gli eventi attualmente aperti (e quelli in fase di transizione come counting ecc.). Nel caso di una configurazione errata che porta a molti eventi aperti, questo file può diventare enorme e ridurre drasticamente le prestazioni della CE. In questo caso puoi arrestare il servizio |
|
Posizione del file dell'archivio. |
|
File di log della Console degli Eventi. |
|
Le impostazioni globali della Console degli Eventi in sintassi Python. |
|
Tutti i pacchetti di regole e le regole configurate in sintassi Python. |
|
Una pipe denominata dove puoi scrivere messaggi direttamente con |
|
Un socket Unix che svolge lo stesso compito della pipe, ma che permette a più applicazioni di scrivervi contemporaneamente. Per scriverci è necessario il comando |
|
L'ID del processo corrente del daemon dell'evento mentre è in esecuzione. |
|
Un socket Unix che permette di interrogare lo stato attuale e di inviare comandi. Le richieste GUI vengono prima inviate al nucleo di monitoraggio, che poi accede a questo socket. |
|
File MIB caricati dall'utente per la traduzione di SNMP trap. |