This is a machine translation based on the English version of the article. It might or might not have already been subject to text preparation. If you find errors, please file a GitHub issue that states the paragraph that has to be improved. |
1. Le caratteristiche speciali di Checkmk Micro Core
Rispetto a Nagios, i vantaggi più significativi di Checkmk Micro Core sono le sue prestazioni più elevate e i tempi di reazione più veloci:
Smart Ping - Controlli intelligenti degli host
Processi ausiliari Check helper, Checkmk Fetcher e Checkmk Checker
Scheduler iniziale
Processo dei dati sulle prestazioni
Un paio di funzioni di Nagios non sono utilizzate o sono realizzate con una procedura diversa nel CMC. I dettagli a riguardo sono riportati nell'articolo sulla migrazione al CMC.
2. Smart Ping - Controlli intelligenti sugli host
Con Nagios la disponibilità degli host viene solitamente verificata tramite un Ping. A questo scopo, per ogni host viene eseguito un plug-in come check_ping o check_icmp una volta per intervallo di tempo (generalmente una volta al minuto). In questo modo vengono inviati, ad esempio, cinque pacchetti ping e si attende il loro ritorno. La creazione dei processi per l'esecuzione dei plug-in impegna risorse preziose della CPU. Inoltre, questi processi possono rimanere in arretrato per molto tempo se un host non è raggiungibile e bisogna sopportare lunghi timeout.
Al contrario, CMC esegue i controlli sugli host - a meno che non sia configurato diversamente - utilizzando una procedura chiamata Smart Ping.Smart Ping si basa su un componente interno chiamato icmpsender, che ha una propria implementazione del ping. Poiché Checkmk con CMC non si affida a un binario esterno, non è necessario generare un nuovo processo per ogni pacchetto ping inviato.
Inoltre, il comportamento predefinito di icmpsender è diverso da quello della sua controparte Nagios: invece di inviare pacchetti multipli in rapida serie che rimangono in attesa, icmpsender invia un solo pacchetto ICMP per host ogni n-secondi (configurazione predefinita a 6 secondi, configurabile tramite il set di regole di Normal check interval for host checks ). Questo comportamento riduce drasticamente il consumo di risorse e il traffico di dati.
Le risposte ai ping non sono esplicitamente attese. Il componente icmpreceiver di CMC è responsabile di decidere se lo stato di un host è UP o DOWN. Considera i pacchetti ping in arrivo da un host come un controllo riuscito dell'host e quindi lo segna di spunta come UP. Se non viene ricevuto alcun pacchetto da un host entro un tempo definito, questo host sarà contrassegnato come DOWN. Il timeout è preimpostato a 15 secondi (2,5 intervalli di tempo) e può essere modificato per host con il set di regole Settings for host checks via Smart PING.
Il componente icmpreceiver ascolta anche i pacchetti TCP SYN (sincronizzazione) e RST (reset) provenienti da un host. Quando riceve questi pacchetti, l'host viene considerato UP. Questo meccanismo può portare a stati irregolari degli host in infrastrutture in cui il traffico ICMP non è permesso ma il traffico TCP sì.
|
2.1. Nessun controllo on demand degli host
I controlli dell'host non servono solo a far scattare le notifiche in caso di guasto totale dell'host, ma anche a sopprimere le notifiche di problemi di servizio durante il periodo di inattività dell'host. I problemi di servizio possono sorgere e non essere responsabilità del servizio stesso, ma piuttosto di una condizione di guasto dell'host. Può accadere che un host sia effettivamente DOWN anche se il suo ultimo stato noto in Checkmk è UP, come risulta dal risultato dell'ultimo controllo dell'host. In questa condizione, più controlli di servizio potrebbero restituire problemi che dipendono dallo stato DOWN dell'host, con conseguente invio di notifiche di servizio - erroneamente. È quindi importante determinare prima la condizione di un host, in caso di problemi di servizio.
Il CMC risolve questo problema in modo molto semplice: se si verifica un problema di servizio e l'host si trova in uno stato UP, il CMC aspetterà il prossimo controllo dell'host. Dato che l'intervallo è molto breve (per impostazione predefinita), solo 6 secondi, il ritardo della notifica è trascurabile se l'host è ancora UP e quindi è necessario inviare la notifica per il servizio.
A titolo di esempio, prendiamo il caso di un plug-in di controllo di check_http che rilascia uno stato CRIT a causa dell'indisponibilità del servizio web interrogato. In questa situazione, dopo l'avvio del controllo del servizio, il componente icmpreceiver riceverà da questo server un pacchetto TCP RST(connessione rifiutata). Il CMC sa quindi con certezza che l'host è UP e può quindi inviare la notifica senza ritardi.
Lo stesso principio viene utilizzato per calcolare le interruzioni di rete se sono stati definiti degli host padre. Anche in questo caso le notifiche saranno a volte ritardate brevemente per attendere una verifica dello stato.
2.2. I vantaggi
Questa procedura offre una serie di vantaggi:
Carico di CPU praticamente insignificante derivante dai controlli degli host: anche senza un hardware particolarmente potente è possibile monitorare migliaia di host.
Nessun ostacolo al monitoraggio a causa di controlli on demand degli host se questi sono DOWN.
Nessun falso allarme da parte dei servizi quando lo stato di un host non è aggiornato.
C'è però uno svantaggio da non trascurare: i controlli host Smart Ping non generano dati sulle prestazioni (tempi di esecuzione dei pacchetti).
Per gli host in cui questi dati sono necessari, puoi semplicemente impostare un active check tramite ping con il set di regole Check hosts with PING (ICMP Echo Request).
2.3. Host non controllabili
In pratica, non tutti gli host possono essere controllati tramite ping. In questi casi, per il controllo dell'host possono essere utilizzati anche altri metodi di CMC, ad es. una connessione TCP. Poiché si tratta generalmente di eccezioni, non hanno un impatto negativo sulle prestazioni complessive. Il set di regole in questo caso è Host Check Command.
2.4. Problemi con i firewall
Esistono firewall che rispondono ai pacchetti di connessione TCP verso host inaccessibili con un pacchetto TCP RST. Il trucco sta nel fatto che il firewall non può registrarsi come mittente di questo pacchetto, ma deve specificare l'indirizzo IP dell'host di destinazione. Smart Ping visualizzerà questo pacchetto come un segno di vita e supporrà erroneamente che l'host di destinazione sia accessibile.
In questa (rara) situazione, tramite Global settings > Monitoring Core > Tuning of Smart PING hai la possibilità di attivare l'opzione Ignore TCP RST packets when determining host state. Oppure, con check_icmp puoi selezionare un ping convenzionale come verifica degli host interessati.
3. Processi ausiliari
Una lezione che deriva dalle scarse prestazioni di Nagios in ambienti di grandi dimensioni è che la creazione di processi è un'operazione che richiede risorse e tempo. La dimensione del processo padre è il fattore decisivo in questo caso. Per ogni esecuzione di un active check, il processo Nagios completo deve prima essere duplicato(biforcazione) prima di essere sostituito dal nuovo processo - il plug-in di controllo. Più host e servizi devono essere monitorati, più grande è questo processo e la biforcazione richiede rispettivamente più tempo. Nel frattempo, gli altri compiti del core devono aspettare - e in questo caso i core da 24 CPU non sono di grande aiuto.
3.1. Check helper
Per evitare il fork del core, durante l'avvio del programma il CMC crea un numero fisso di processi ausiliari molto snelli il cui compito è quello di avviare i plug-in di controllo attivi: i check helper.Non solo questi si biforcano molto più rapidamente, ma il fork si estende anche a tutti i core disponibili perché il core stesso non è più bloccato. In questo modo, l'esecuzione dei controlli attivi (es. check_http) - i cui tempi di esecuzione sono in realtà piuttosto brevi - viene notevolmente accelerata.
3.2. Checkmk Fetcher e Checkmk Checker
Il CMC compie un ulteriore passo avanti, perché in un ambiente Checkmk i check attivi rappresentano un'eccezione: qui si utilizzano principalmente i check basati su Checkmk, che richiedono un solo fork per host e per intervallo.
Per ottimizzare l'esecuzione di questi controlli, il CMC mantiene altri due tipi di processi ausiliari: i Checkmk Fetcher e i Checker.
I Checkmk Fetcher
recuperano le informazioni necessarie dagli host monitorati, cioè i dati dei servizi Check_MK e Check_MK Discovery. I fetcher si occupano quindi della comunicazione di rete con gli agenti Checkmk, gli agenti SNMP e gli agenti speciali. La raccolta di queste informazioni richiede un po' di tempo, ma con meno di 50 megabyte per processo la memoria è relativamente poca, quindi molti di questi processi possono essere configurati senza problemi. Tieni presente che i processi possono essere parzialmente o per nulla swappati e quindi devono essere sempre mantenuti nella memoria fisica. Il fattore limitante è la memoria disponibile nel server Checkmk.
I 50 megabyte indicati sono una stima per l'orientamento di base. Il valore effettivo può essere più alto in circostanze specifiche, ad es. perché è stato configurato l'IPMI sulla scheda di gestione. |
I Checkmk Checker
analizzano e valutano le informazioni raccolte dai Checkmk Fetcher e generano i risultati dei controlli per i servizi. I Checker hanno bisogno di molta memoria perché devono avere con sé la configurazione di Checkmk. Un processo di Checker occupa almeno circa 90 megabyte - tuttavia, potrebbe essere necessario un multiplo di questo valore, a seconda di come sono configurati i controlli. D'altra parte, i checker non causano alcun carico di rete e sono molto veloci nell'esecuzione. Il numero di checker dovrebbe essere pari a quello che il tuo server Checkmk può processare in parallelo. Di regola, questo numero corrisponde al numero di core del tuo server. Poiché i checker non sono legati all'IO, sono più efficaci se ogni checker ha un proprio core.
La divisione dei due diversi compiti di "raccolta" ed "esecuzione" tra Checkmk Fetcher e Checkmk Checker esiste dalla versione di Checkmk 2.0.0. In precedenza, esisteva un solo processo ausiliario responsabile di entrambi: i cosiddetti helper Checkmk.
Con il modello fetcher/checker, entrambi i compiti possono essere suddivisi tra due pool di processi separati: il recupero delle informazioni dalla rete con molti processi fetcher di piccole dimensioni e la verifica ad alta intensità di calcolo con pochi processi checker di grandi dimensioni. Di conseguenza, un CMC utilizza fino a quattro volte meno memoria a parità di prestazioni (controlli al secondo)!
3.3. Impostare correttamente il numero dei processi ausiliari
Per impostazione predefinita, vengono avviati 5 check helper, 13 Checkmk fetcher e 4 Checkmk Checker. Questi valori sono impostati in Global settings > Monitoring Core e possono essere personalizzati da te:
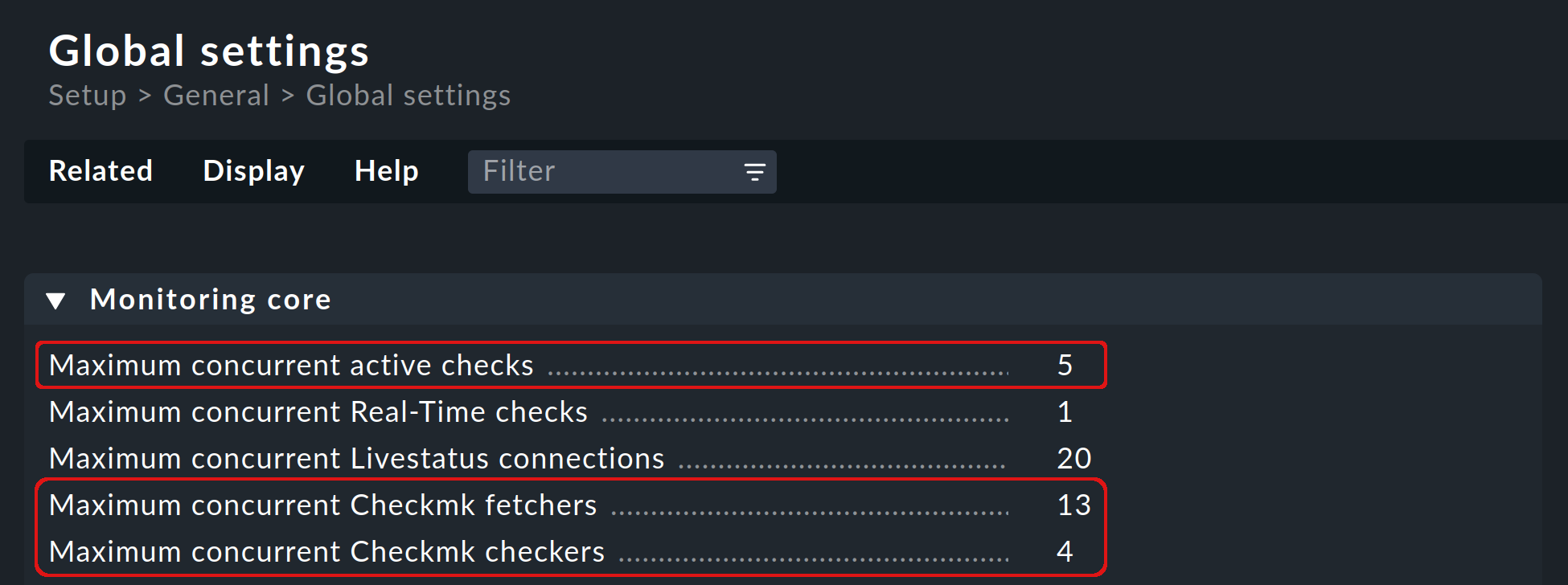
Per sapere se e come modificare i valori predefiniti, hai a disposizione diverse opzioni:
Nella barra laterale, lo snap-in Core statistics mostra la percentuale di utilizzo media degli ultimi 10-20 secondi:
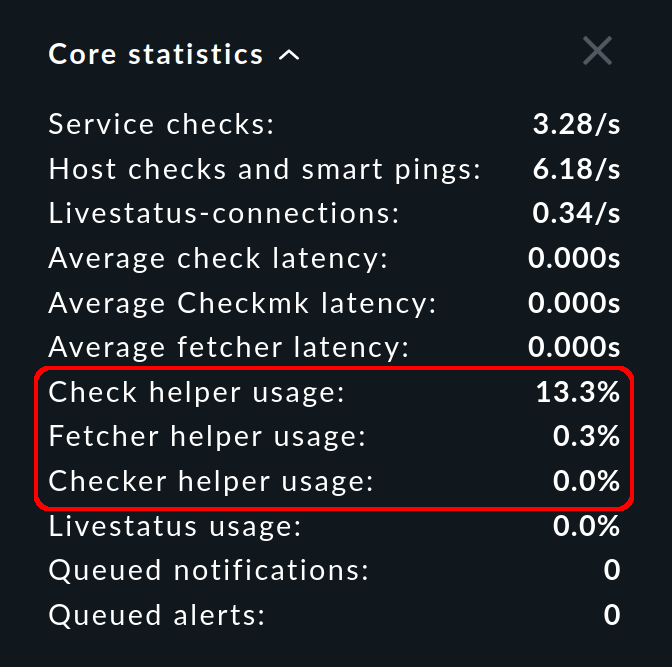
Per tutti i tipi di processi ausiliari, dovrebbero esserci sempre abbastanza processi per eseguire i controlli configurati. Se un pool viene utilizzato al 100%, i controlli non verranno eseguiti in tempo, la latenza aumenterà e gli stati dei servizi non saranno aggiornati.
L'utilizzo non dovrebbe superare l'80% pochi minuti dopo l'avvio di un sito. Per percentuali più elevate, dovresti aumentare il numero di processi. Poiché il numero necessario di Checkmk Fetcher cresce con il numero di host e servizi monitorati, è molto probabile che venga apportata una correzione. Tuttavia, fai attenzione a creare solo il numero di processi ausiliari realmente necessari, poiché ogni processo occupa risorse. Inoltre, tutti i processi ausiliari vengono inizializzati in parallelo all'avvio del CMC, il che può portare a picchi di carico.
Lo snap-in Core statistics ti mostra non solo l'utilizzo, ma anche la latenza. Per questi valori vale la semplice regola: più basso è, meglio è - e 0 secondi è quindi il valore migliore.
Puoi anche visualizzare i valori mostrati dallo snap-in per il tuo sito nei dettagli del servizio OMD <site_name> performance. |
In alternativa allo snap-in Core statistics, puoi anche far analizzare la tua configurazione da Checkmk, con Setup > Maintenance > Analyze configuration. Il vantaggio: in questo caso ottieni una valutazione immediata da Checkmk sullo stato dei processi ausiliari. Molto utile: se uno dei processi ausiliari non è OK, puoi aprire dal testo di aiuto l'opzione Global settings corrispondente per modificare il valore.
4. Pianificazione iniziale
Durante la schedulazione si definisce quali controlli devono essere eseguiti in quali intervalli di tempo. Nagios ha implementato numerose procedure che dovrebbero garantire una distribuzione regolare dei controlli nell'intervallo di tempo. Allo stesso modo, cercherà di distribuire le query da eseguire su un singolo sistema target in modo uniforme nell'intervallo di tempo.
Il CMC ha una propria procedura più semplice a questo scopo, che tiene conto del fatto che Checkmk contatta un host già una volta per intervallo. Inoltre, il CMC fa in modo che i nuovi controlli vengano eseguiti immediatamente e non distribuiti nell'arco di diversi minuti. Questo è molto comodo per l'utente, poiché un nuovo host verrà interrogato non appena la configurazione è stata attivata. Per evitare che un gran numero di nuovi controlli provochi un picco di carico, i nuovi controlli il cui numero supera un limite definibile possono essere distribuiti sull'intero intervallo. L'opzione per farlo si trova in Global settings > Monitoring Core > Initial Scheduling.
5. Elaborazione dei dati sulle prestazioni
Una funzione importante di Checkmk è l'elaborazione dei dati misurati, come l'utilizzo della CPU, e la loro conservazione per un lungo periodo di tempo. In Checkmk Raw viene utilizzato PNP4Nagios, che a sua volta si basa su RRDtool.
Il software svolge due funzioni:
La creazione e l'aggiornamento dei database Round Robin (RRD).
La rappresentazione grafica dei dati nella GUI.
Nel funzionamento del core di Nagios, la funzione di cui al punto 1 è un processo piuttosto lungo. A seconda del metodo, vengono utilizzati file di spool, script Perl e un processo ausiliario (npcd) scritto in C. Infine, i dati leggermente convertiti vengono scritti sul socket Unix del demone RRD cache.
Il CMC accorcia questa catena scrivendo direttamente al demone della cache RRD - tutti i passaggi intermedi vengono eliminati. Il parsing e la conversione dei dati nel formato dello strumento RRD vengono eseguiti direttamente in C++. Questo metodo è possibile e sensato al giorno d'oggi, poiché il demone della cache RRD ha già implementato un proprio spooling molto efficiente e, con l'aiuto dei file di spool, significa che nessun dato viene perso in caso di crash del sistema.
I vantaggi:
Riduzione del carico su disco e della CPU
Implementazione più semplice con una stabilità nettamente superiore
L'installazione di nuovi RRD viene eseguita dal CMC con un ulteriore helper, attivato da cmk --create-rrd. Questo crea file opzionalmente compatibili con PNP o con il nuovo formato Checkmk (solo per le nuove installazioni). Lo switch da Nagios a CMC non ha alcun effetto sui file RRD esistenti: questi verranno trasferiti senza problemi e continueranno ad essere mantenuti.
Nelle edizioni commerciali la visualizzazione grafica dei dati nella GUI è gestita direttamente dalla GUI di Checkmk, quindi non è coinvolto alcun componente di PNP4Nagios.