This is a machine translation based on the English version of the article. It might or might not have already been subject to text preparation. If you find errors, please file a GitHub issue that states the paragraph that has to be improved. |
1. Il principio di base
1.1. Uno sguardo al passato
Poiché Checkmk monitora continuamente tutti gli host e i servizi a intervalli regolari, fornisce una base eccezionale per la valutazione successiva della loro disponibilità. E non solo: è anche possibile calcolare per quale percentuale di un determinato periodo di tempo un oggetto si è trovato in uno o più stati specifici, con quale frequenza si è verificato questo stato, la durata del suo arresto più lungo e molto altro ancora.
Ogni calcolo si basa su una selezione di oggetti e su un determinatoperiodo di tempo nel passato. Checkmk ricostruisce quindi, all'interno di questo intervallo di tempo, una sequenza cronologica degli stati di tutti gli oggetti selezionati. Per ogni stato, i tempi vengono sommati e visualizzati in una tabella. Questa tabella può, ad esempio, mostrare che un particolare servizio ha sperimentato stati del 99,95% OK e dello 0,005% WARN nel periodo di tempo definito.
Nell'effettuare questi calcoli, Checkmk tiene conto correttamente anche di fattori come i tempi di manutenzione programmata, i tempi di inattività del servizio, i periodi di tempo non monitorati e altri fattori speciali, permette di riassumere gli stati e di ignorare le "brevi interruzioni". Sono inoltre disponibili numerose opzioni di personalizzazione e la possibilità di effettuare aggregazioni BI.
1.2. Stati possibili
Grazie all'inclusione dei tempi di manutenzione programmata e di altri stati speciali simili, esiste in teoria un gran numero di combinazioni possibili di stati, ad esempio: Poiché la maggior parte di queste combinazioni non sono molto utili, Checkmk le riduce a un numero ridotto e procede secondo un principio di priorità. Poiché nell'esempio precedente il servizio si trovava in un tempo di manutenzione programmata, si applica semplicemente lo stato in scheduled downtime e lo stato attuale viene ignorato. Questo riduce l'elenco dei possibili stati ai seguenti:
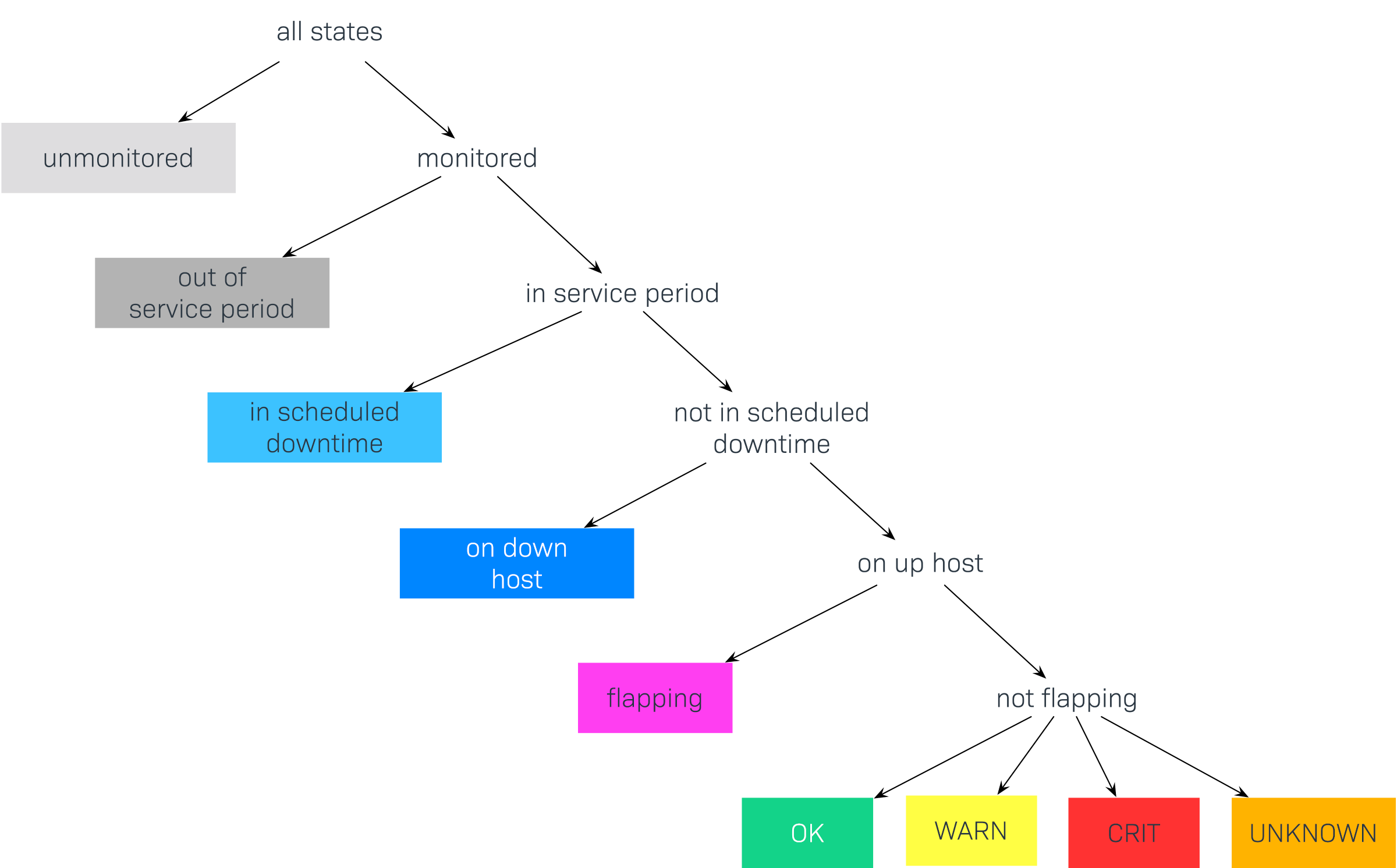
Questo grafico mostra l'ordine di priorità degli stati. Più avanti mostreremo come alcuni stati possano essere ignorati o combinati. Ecco di nuovo gli stati in dettaglio:
| Stato | Abbreviazione | Descrizione |
|---|---|---|
unmonitored |
N/D |
Periodi di tempo durante i quali l'oggetto non è stato monitorato. Le ragioni possono essere due: l'oggetto non era presente nella configurazione del monitoraggio oppure il monitoraggio stesso non era in esecuzione nel periodo di tempo specificato. |
out of service period |
L'oggetto si trovava al di fuori del suo periodo di servizio, ovvero quando la sua disponibilità era "irrilevante". Puoi trovare maggiori informazioni sui periodi di servizio più avanti. |
|
in scheduled downtime |
Downtime |
L'oggetto si trovava in un tempo di manutenzione programmata Downtime . Questo stato viene assunto anche per i servizi i cui host si trovano in un tempo di manutenzione programmata. |
on down host |
H.Down |
Questo stato è disponibile solo per i servizi - quando l'host del servizio è (down). Il monitoraggio del servizio in questo momento non è possibile. Per la maggior parte dei servizi questo ha lo stesso significato di un servizio in CRIT, ma non per tutti! Ad esempio, lo stato di un servizio (File system-Check) è sicuramente indipendente dall'accessibilità dell'host. |
flapping |
Fasi in cui lo stato è irregolare, ovvero quelle fasi in cui si verificano molti cambiamenti di stato in un breve lasso di tempo. |
|
UP DOWN NON RAGGIUNGIBILE |
Stati di monitoraggio degli host |
|
OK AVVERTIRE CRIT SCONOSCIUTO |
Stati di monitoraggio per i servizi e le aggregazioni BI |
2. Recupero della disponibilità
2.1. Dalla visualizzazione all'analisi
Generare un'analisi della disponibilità è molto semplice. Per prima cosa recupera una qualsiasivisualizzazione di host, servizi o aggregazioni BI. Troverai nel menu Services o Hosts la voce di menu Availability, che ti porterà direttamente al calcolo della disponibilità degli oggetti selezionati. I dati verranno visualizzati sotto forma di tabella:
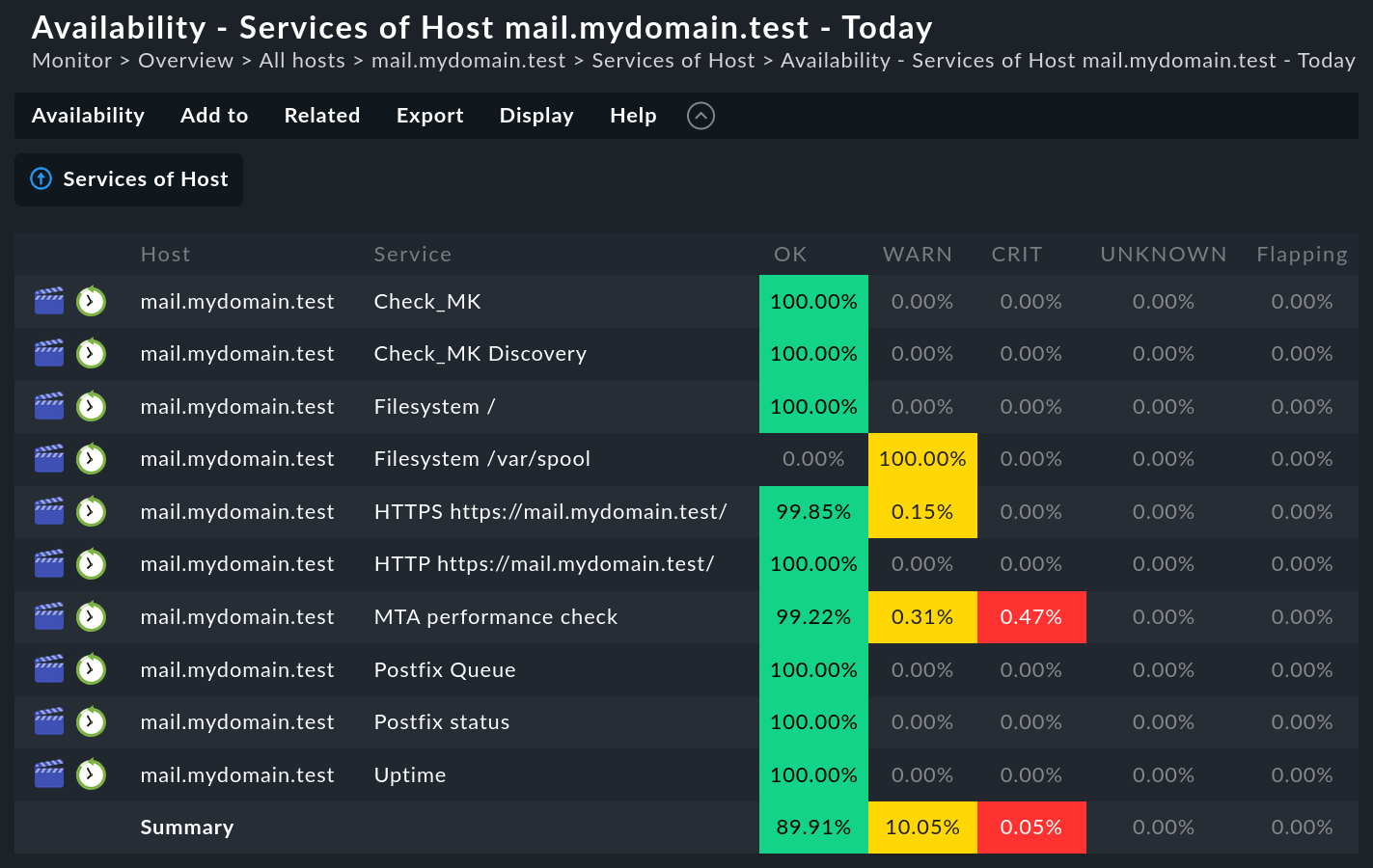
La tabella mostra gli stessi oggetti visualizzati nella visualizzazione precedente. In ogni colonna è indicata la percentuale del periodo di tempo richiesto in cui un oggetto si trovava nello stato oggetto dell'interrogazione. Il valore è indicato in percentuale, con due cifre decimali per impostazione predefinita, che puoi anche personalizzare facilmente.
L'interrogazione del periodo di tempo può essere personalizzata con la voce di menu Availability > Change display options > Time Range Più avanti...
Hai la possibilità di ricevere la tabella in formato PDF (solo per le edizioni commerciali). È anche possibile scaricare i dati in formato CSV (Export as CSV). L'aspetto sarà il seguente per l'esempio precedente:
Host;Service;OK;WARN;CRIT;UNKNOWN;Flapping;H.Down;Downtime;N/A
mail.mydomain.test;Check_MK;100.00%;0.00%;0.00%;0.00%;0.00%;0.00%;0.00%;0.00%
mail.mydomain.test;Check_MK Discovery;100.00%;0.00%;0.00%;0.00%;0.00%;0.00%;0.00%;0.00%
mail.mydomain.test;Filesystem /;100.00%;0.00%;0.00%;0.00%;0.00%;0.00%;0.00%;0.00%
mail.mydomain.test;Filesystem /var/spool;0.00%;100.00%;0.00%;0.00%;0.00%;0.00%;0.00%;0.00%
mail.mydomain.test;HTTP https://mail.mydomain.test/;99.85%;0.15%;0.00%;0.00%;0.00%;0.00%;0.00%;0.00%
mail.mydomain.test;HTTPS https://mail.mydomain.test/;100.00%;0.00%;0.00%;0.00%;0.00%;0.00%;0.00%;0.00%
mail.mydomain.test;MTA performance check;99.23%;0.30%;0.46%;0.00%;0.00%;0.00%;0.00%;0.00%
mail.mydomain.test;Postfix Queue;100.00%;0.00%;0.00%;0.00%;0.00%;0.00%;0.00%;0.00%
mail.mydomain.test;Postfix status;100.00%;0.00%;0.00%;0.00%;0.00%;0.00%;0.00%;0.00%
mail.mydomain.test;Uptime;100.00%;0.00%;0.00%;0.00%;0.00%;0.00%;0.00%;0.00%
Summary;;89.91%;10.05%;0.05%;0.00%;0.00%;0.00%;0.00%;0.00%Con l'aiuto di un utente automazione, che può autenticare se stesso tramite l'URL, puoi anche recuperare i dati - ad es. conwget o curl) - e processare automaticamente i dati sotto il controllo di script.
2.2. Visualizzazione della timeline
Questo pulsante, che si trova in ogni riga della tabella, ti porta alla visualizzazione della timeline dell'oggetto in questione, in cui sono indicati con precisione gli elementi che si sono verificati nel periodo di tempo specificato (qui abbreviato):
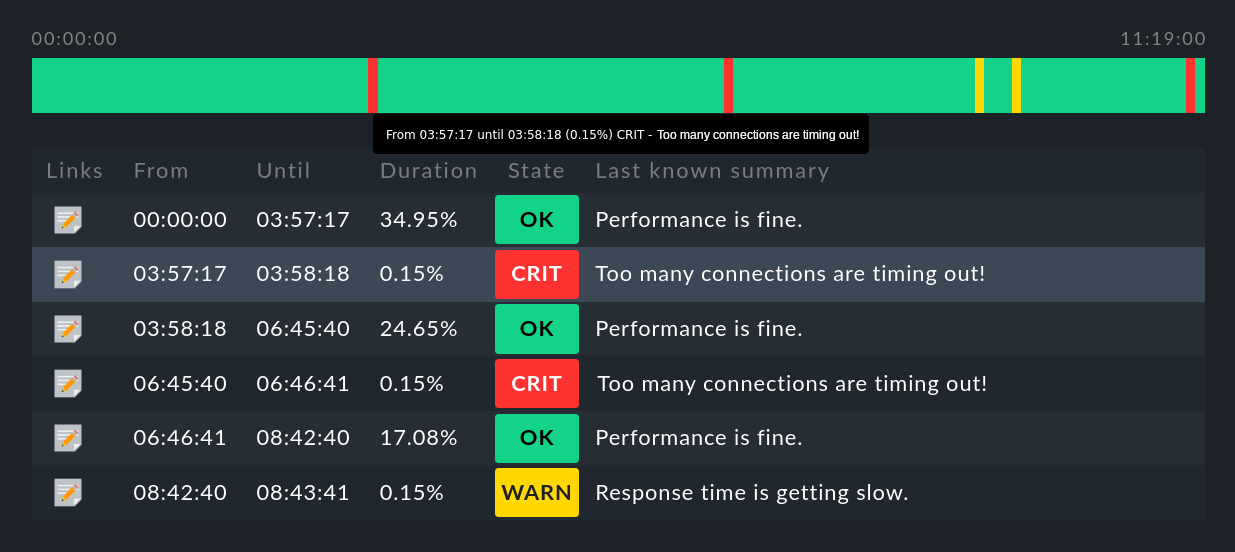
Alcuni suggerimenti utili:
Passa il cursore del mouse su un simbolo della linea temporale nella riga di un oggetto nella visualizzazione, questo verrà evidenziato nella visualizzazione della tabella.
Sempre nella linea temporale, puoi utilizzare le voci di menu Availability > Change display options o Availability > Change computation options per personalizzare le opzioni di visualizzazione e valutazione.
Con il simbolo puoi aggiungere un Annotation all'elemento selezionato. Qui puoi anche pubblicare retrospettivamente i tempi di manutenzione programmata (maggiori informazioni nella prossima sezione).
Per quanto riguarda la disponibilità di aggregazioni BI, con il simbolo della bacchetta magica puoi viaggiare nel tempo fino allo stato dell'aggregato per la fetta di tempo in questione. Maggiori informazioni in seguito.
Utilizzando la voce di menu Availability > Timeline nella pagina principale, puoi visualizzare le cronologie di tutti gli oggetti selezionati in un'unica lunga pagina.
2.3. Annotazioni e successivi tempi di manutenzione programmata
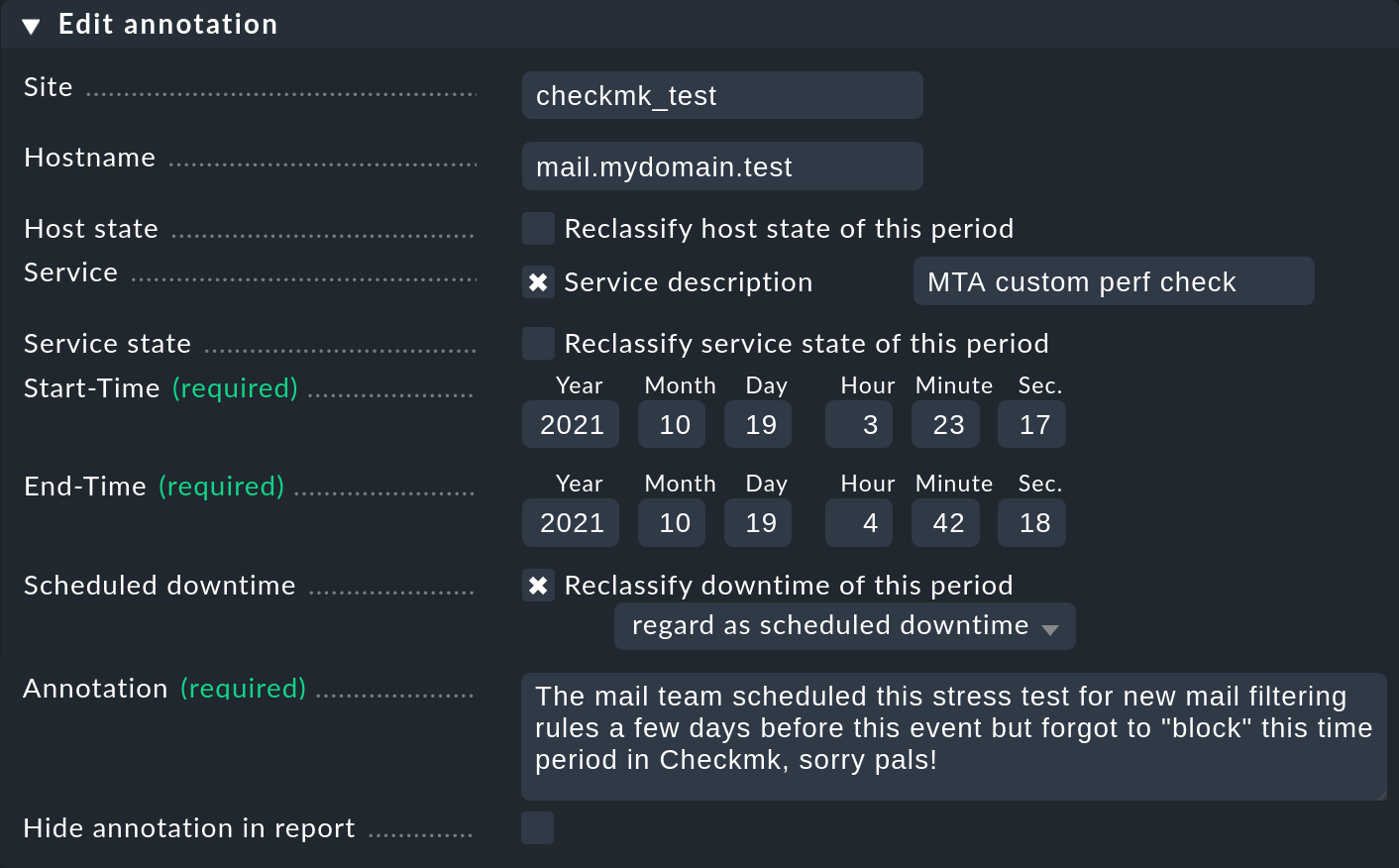
Come appena accennato, con il simbolo le linee temporali offrono la possibilità di aggiungere un'annotazione a un periodo di tempo. Viene fornito un modulo precompilato ("Proprietà") in cui è possibile inserire dei commenti:
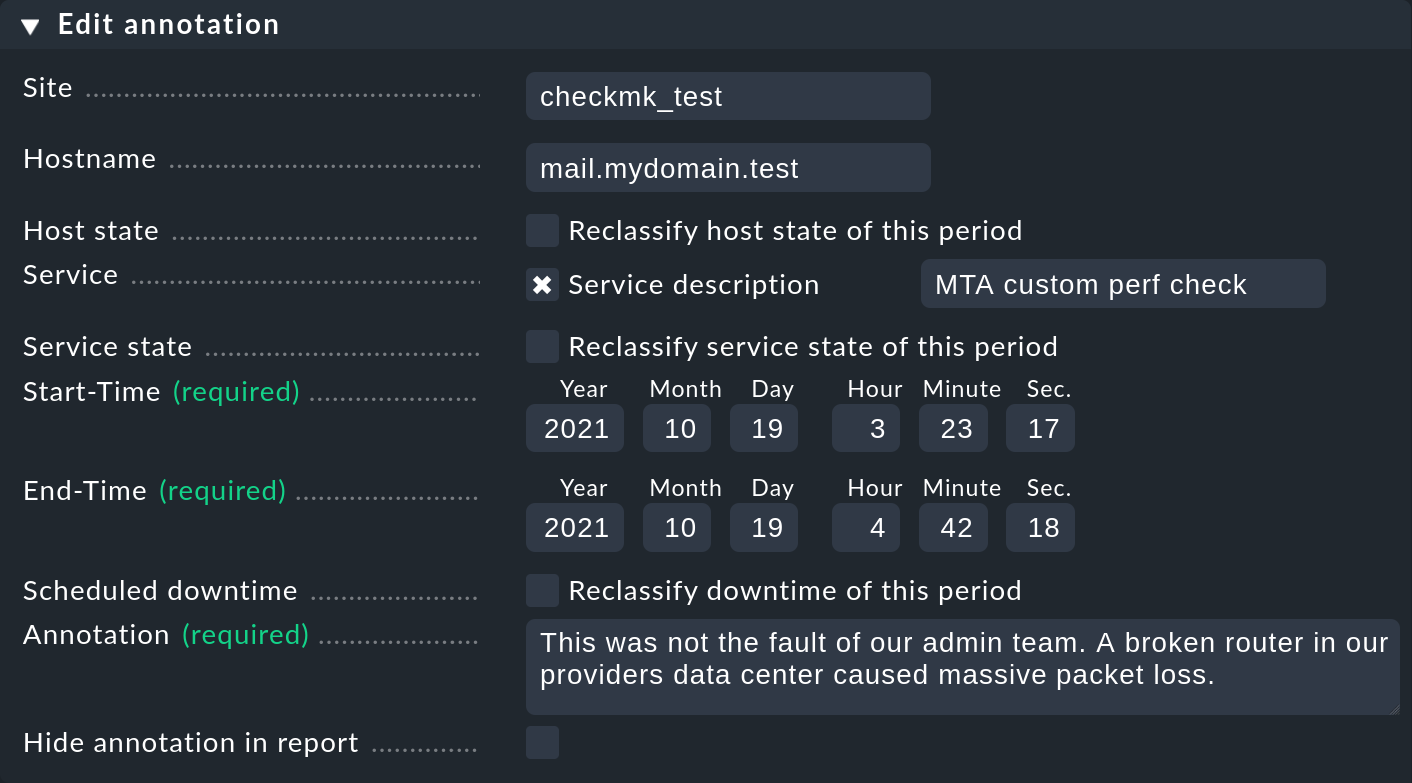
In questo modo puoi definire ed estendere il periodo di tempo con valori diversi a seconda delle esigenze. Questo è pratico, ad esempio, se desideri annotare un intervallo di tempo più ampio che ha subito ripetuti cambiamenti di stato. Se non inserisci un servizio, l'annotazione verrà creata per l'host e sarà automaticamente collegata a tutti i servizi dell'host.
In ogni visualizzazione della disponibilità, tutte le annotazioni applicabili al periodo di tempo e agli oggetti visualizzati saranno automaticamente visibili.
Ma le annotazioni hanno una funzione aggiuntiva: i tempi di inattività possono essere inseriti a posteriori o, al contrario, rimossi. L'analisi della disponibilità tiene conto di queste correzioni esattamente come avviene per i tempi di manutenzione programmata "normali". Ci sono almeno due giustificazioni legittime per questo:
Durante le operazioni può succedere che i tempi di manutenzione programmata vengano inseriti in modo errato. Questo ovviamente è negativo per l'accuratezza delle statistiche di disponibilità. L'inserimento retrospettivo di questi tempi permette di correggere il report.
Ci sono utenti che utilizzano erroneamente i tempi di manutenzione programmata durante un'interruzione spontanea per sopprimere una notifica. Questo corrompe di fatto l'analisi successiva. Questo può essere corretto a posteriori cancellando il tempo di manutenzione programmata errato.
Per riclassificare i tempi di manutenzione programmata, basta selezionare il checkbox Reclassify downtime of this period:
2.4. Visualizzazione dello storico del monitoraggio
Nella tabella della disponibilità, accanto al simbolo della linea temporale si trova un altro simbolo: . Questo ti porta a unavisualizzazione della cronologia dell'oggetto con un filtro precompilato per l'oggetto in questione e il periodo di tempo per la query. Qui potrai vedere non solo l'evento su cui si basa l'analisi della disponibilità (i cambiamenti di stato), ma anche le notifiche associate e gli eventi simili:
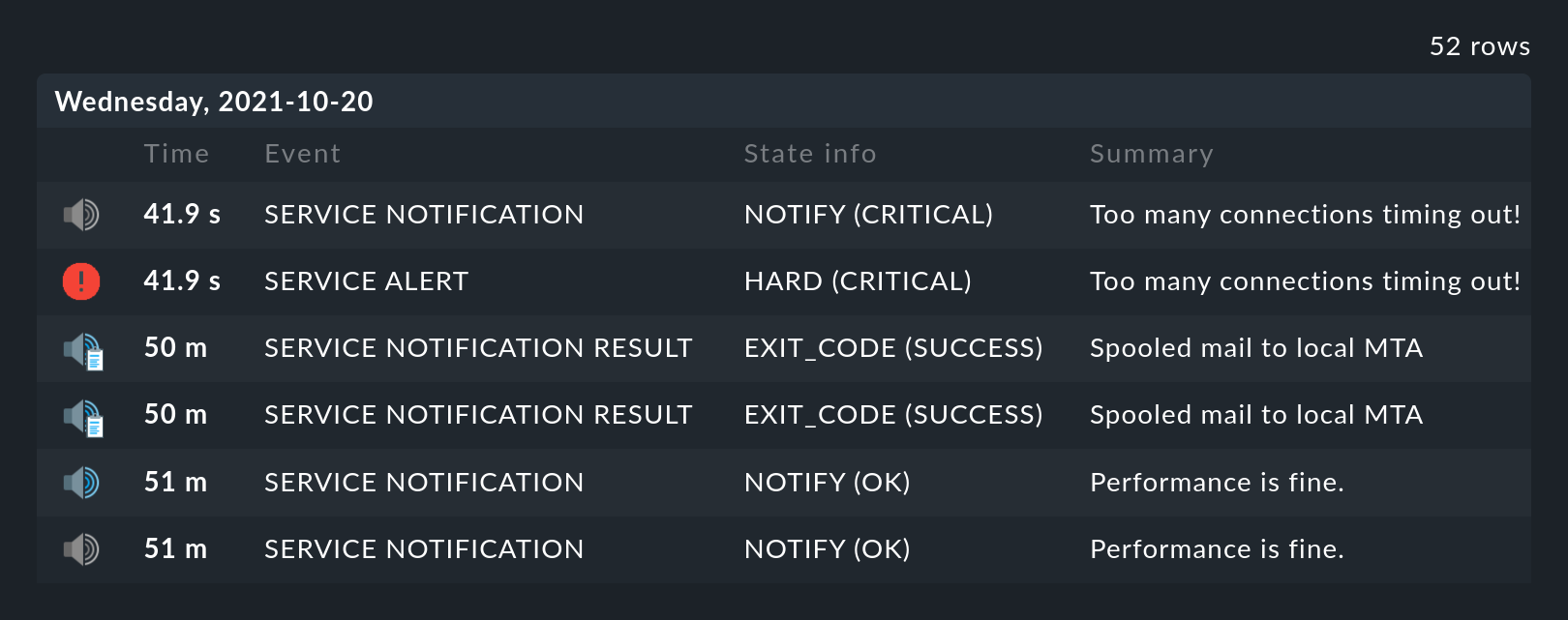
Ciò che non è visibile è lo stato dell'oggetto all'inizio del periodo di tempo della query. Il calcolo della disponibilità guarda ancora più indietro nel passato per determinare in modo affidabile lo stato iniziale.
3. Opzioni di calcolo
Oltre al calcolo vero e proprio, la visualizzazione della disponibilità può essere controllata attraverso numerose opzioni, disponibili alle voci di menu Availability > Change display options e Availability > Change computation options.
Una volta modificate le opzioni e confermate con Apply, la disponibilità verrà ricalcolata e visualizzata. Tutte le opzioni modificate verranno memorizzate nel profilo dell'utente come predefinite, in modo che le query successive utilizzino le stesse impostazioni.
Allo stesso tempo, le opzioni saranno codificate nell'URL della pagina corrente. Se ora salvi un segnalibro nella pagina, ad es. utilizzando il pratico elementoBookmarks, le opzioni faranno parte di questo elemento e, se cliccate successivamente, saranno generate esattamente nello stesso modo.
3.1. Scelta del periodo di tempo
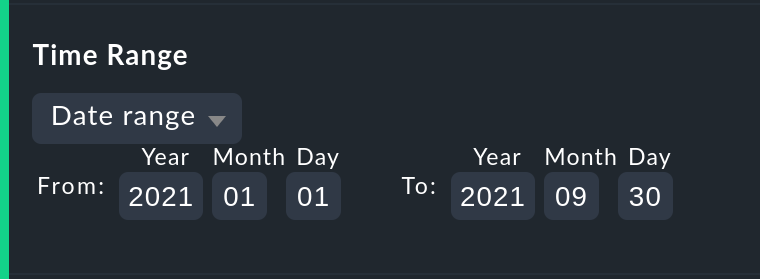
La prima e più importante opzione in qualsiasi calcolo di disponibilità è ovviamente il periodo di tempo da esaminare. In Date range è possibile specificare un periodo di tempo con date precise di inizio e fine. L'ultimo giorno - fino alle 24:00 - sarà incluso.
Molto più pratiche sono le specifiche temporali relative, come ad esempioLast week. L'esatto periodo di tempo che verrà visualizzato - intenzionalmente - dipende dal momento in cui viene effettuato il calcolo. Nota: in questo caso "una settimana" si riferisce sempre a un intervallo di tempo compreso tra le 00:00 di lunedì e le 24:00 di domenica.
3.2. Opzioni che influenzano le visualizzazioni
Molte opzioni influenzano il formato delle visualizzazioni, mentre altre influenzano a loro volta i metodi di calcolo. Per cominciare, diamo un'occhiata alle visualizzazioni:
Nascondi le linee con disponibilità del 100

L'opzione Only show objects with outages limita la visualizzazione agli oggetti che hanno effettivamente subito un'interruzione, cioè ai momenti in cui lo stato non era OK o UP. Questo è utile nel caso in cui ci sia un gran numero di servizi, tra i quali sono interessanti solo quei pochi che hanno effettivamente problemi.
Opzioni di etichetta
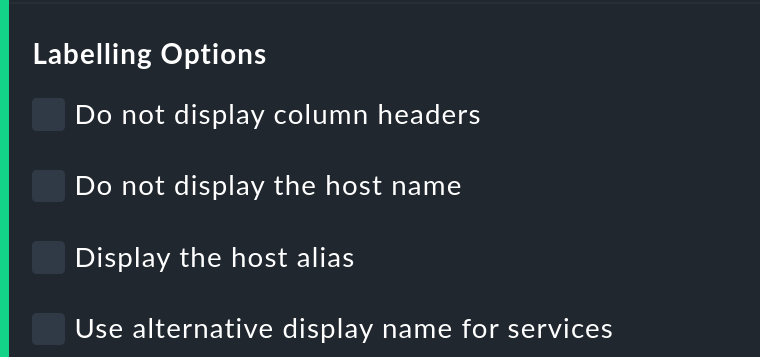
Il sito Labelling options permette di attivare o disattivare diversi campi etichetta. Alcune opzioni sono interessanti soprattutto per il Reporting: se, ad esempio, si deve produrre un report per un singolo host, la colonna del nome host non è necessaria.
Il sito alternative display names per i servizi può essere definito con delleregole; utilizzando queste, ad esempio, è possibile assegnare ai nomi del servizio importanti un nome esplicito e significativo per il lettore del report.
Usare i colori nella visualizzazione degli SLA con threshold
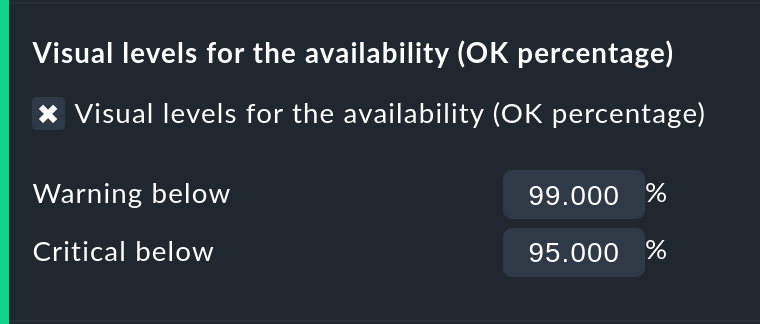
Con Visual levels puoi evidenziare gli oggetti che non hanno mantenuto una disponibilità specifica nel periodo di tempo richiesto. Questo vale solo per la colonna relativa allo stato OK. Se non si raggiunge la soglia definita, il colore di questa cella passa da verde a giallo o a rosso. Questa potrebbe essere descritta come una panoramica SLA molto semplice.
Visualizzazione del numero e della durata delle interruzioni individuali
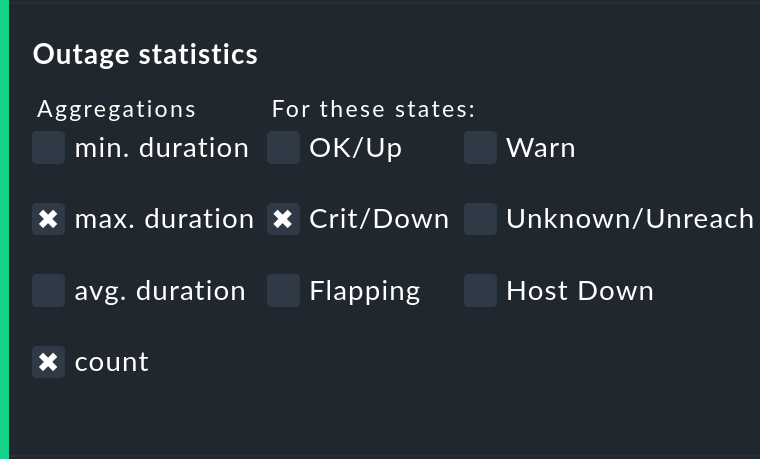
L'opzione Outage statistics fornisce ulteriori colonne di informazioni nella tabella della disponibilità. Nella schermata sottostante si può notare che le informazioni aggiuntive di max. duration e count sono state attivate per la colonna di stato di Crit/Down. Ciò significa che per le interruzioni con stato CRIT/DOWN vengono mostrati rispettivamente il numero di incidenti e la durata dell'incidente più lungo.

Nella tabella verranno create queste colonne aggiuntive.
Visualizzazione delle specifiche temporali
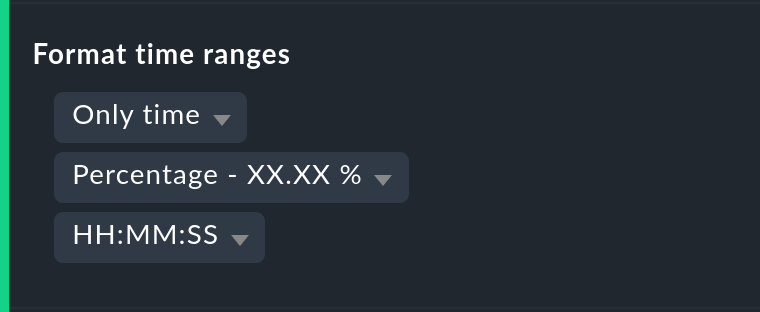
Non è sempre saggio specificare le (dis)disponibilità come percentuali. L'opzione Format time ranges permette di passare a una visualizzazione che presenta i periodi di tempo come valori assoluti. In questo modo la durata totale delle interruzioni può essere visualizzata al minuto esatto. Il display mostra anche i secondi, ma si noti che questo ha senso solo se il monitoraggio viene effettuato a intervalli di un secondo e non come di consueto con un controllo al minuto. Allo stesso modo è possibile definire la precisione della specifica (il numero di decimali nei valori percentuali).
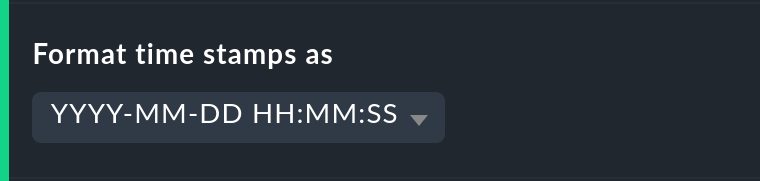
La formattazione delle marche temporali si applica alle impostazioni di Timeline. Il passaggio alle epoche Unix (secondi trascorsi dall'1.1.1970) semplifica la correlazione dei periodi di tempo alle posizioni appropriate nei dati di log della cronologia di monitoraggio.
Personalizzazione della riga di riepilogo
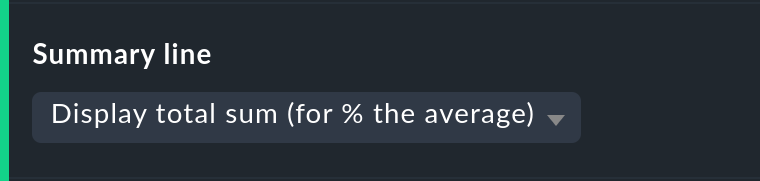
Non solo è possibile attivare/disattivare il riepilogo nell'ultima riga della tabella, ma è anche possibile decidere tra una somma totale e una media. Per le colonne che contengono un valore percentuale, utilizzando l'impostazione Sum verrà mostrata una media, poiché l'aggiunta di valori percentuali ha poco senso.
Mostra la linea temporale piccola
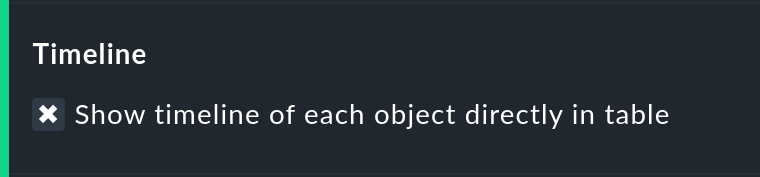
Questa opzione aggiunge una versione in miniatura della linea temporale della disponibilitàdirettamente nella tabella dei risultati. Corrisponde alla barra grafica della timeline dettagliata, ma è più piccola e integrata direttamente nella tabella. Inoltre, è fedele alla scala, in modo da poter confrontare più oggetti nella stessa tabella.
Raggruppamento per host, gruppo di host o gruppo di servizi
Indipendentemente dalla visualizzazione da cui provieni, la disponibilità mostra sempre tutti gli oggetti in una tabella comune. Con questa opzione puoi selezionare un raggruppamento per host, per gruppo di host o per gruppo di servizi: ogni gruppo avrà la sua linea Summary.
Nota che con il raggruppamento per gruppo di servizi, i servizi possono apparire moltiplicati, poiché possono essere assegnati a più gruppi contemporaneamente.
Visualizza solo la disponibilità
L'opzione Availability fa sì che venga visualizzata solo la colonna relativa agli stati OK o UP, con il titolo Avail.. In questo modo verrà mostrata solo la disponibilità actual. Questa opzione può essere combinata con le altre opzioni spiegate di seguito, con altri stati (es. WARN) e può includere anche lo stato OK e quindi essere valutata come disponibile.
3.3. Raggruppamento di stati
Gli stati descritti nell'introduzione possono essere personalizzati e condensati in molti modi. In questo modo è possibile generare in modo flessibile moduli di valutazione molto diversi tra loro. Esistono varie opzioni per questo scopo.
Gestione degli stati WARN, SCONOSCIUTO e Host Down
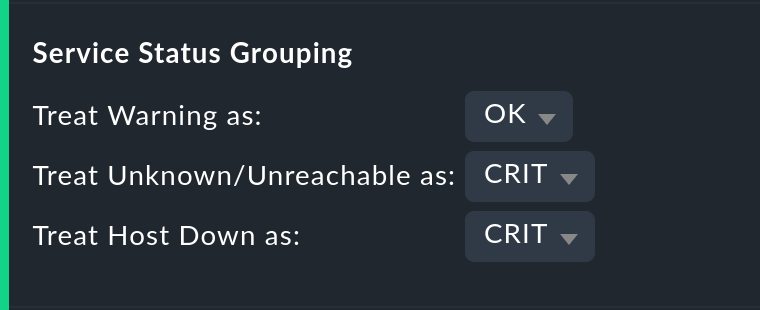
L'opzione Service status grouping offre la possibilità di mostrare vari "stati intermedi". Una situazione comune è quella di forzare il trattamento di WARN come OK. Questo può essere molto utile se sei interessato alladisponibilità effettiva di un servizio. Spesso WARN non significa ancora che esiste un problema reale, ma che potrebbe svilupparsi presto. Quindi, visto in questo modo, WARN deve essere considerato come disponibile. Con i servizi di rete come un server HTTP, è sicuramente sensato trattare i tempi in cui l'host è DOWN allo stesso modo di quando il servizio è CRIT.
Gli stati omessi a causa del raggruppamento saranno ovviamente assenti anche dalla tabella dei risultati, che avrà meno colonne.
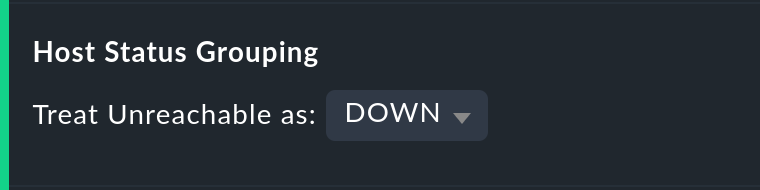
L'opzione Host status grouping è molto simile, ma riguarda la disponibilità degli host. Lo stato NON RAGGIUNGIBILE significa che un host, a causa di problemi di rete, non può essere monitorato da Checkmk. In queste situazioni, ai fini del calcolo della disponibilità, puoi decidere se trattare lo stato NON RAGGIUNGIBILE come UP o DOWN. L'impostazione predefinita è quella di trattare NON RAGGIUNGIBILE come uno stato a sé stante.
Gestione dei periodi di tempo non monitorati e dell'irregolare
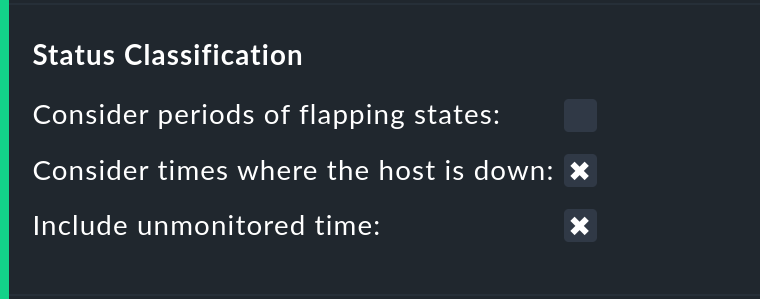
L'opzione Status classification prevede ulteriori riepiloghi. Il box Consider periods of flapping states è attivo per impostazione predefinita: con questa opzione le fasi di frequenti cambiamenti di stato costituiscono uno stato a sé stante: l'irregolare. L'idea alla base è che, anche se si può dire che in questi momenti il servizio interessato torna sempre allo stato OK, a causa delle frequenti interruzioni il servizio è di fatto inutilizzabile. Disattivando questa opzione, il concetto di "irregolare" verrà completamente ignorato e riapparirà il rispettivo stato effettivo; anche la colonna flappingverrà rimossa dalla tabella.
La rimozione dell'opzione Consider times where the host is down funziona in modo simile. Il concetto di Host down viene disattivato. Questa opzione ha senso solo per la disponibilità dei servizi. Nelle fasi in cui l'host non è UP, lo stato effettivo del servizio verrà preso come base per la disponibilità - o più precisamente, lo stato dell'ultimo Check prima che l'host diventasse non disponibile. Questo può essere sensato con servizi per i quali l'accessibilità alla rete non è rilevante.
Anche l'opzione Include unmonitored time è simile. Supponiamo che si debba effettuare un'analisi per il mese di febbraio e che un determinato servizio sia presente nel monitoraggio solo dal 15 febbraio. Questo servizio ha quindi una disponibilità del 50%? Con l'impostazione predefinita - opzione attiva- questo sarà effettivamente il caso. Il 50 % mancante non sarà valutato come un'interruzione, ma sarà sommato in una colonna a sé stante sotto il titolo N/A. Senza l'opzione corrisponderà al 100% del tempo dal 15 al 28 febbraio, ma ciò significa che un'interruzione di un'ora per questo servizio sarà considerata una percentuale doppia rispetto a un servizio monitorato per tutto il mese.
Gestione dei tempi di manutenzione programmata
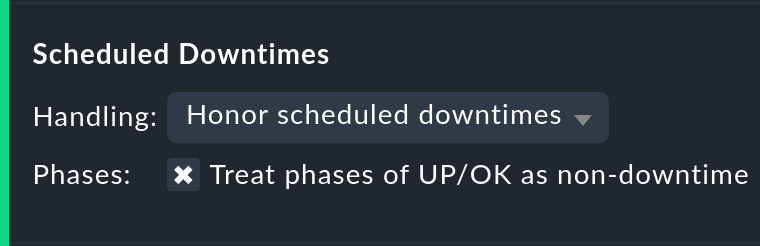
Con l'opzione Scheduled Downtimes puoi specificare come itempi di manutenzione programmata influiscono sull'analisi della disponibilità:
Honor scheduled downtimes è il valore predefinito. In questo caso i tempi di manutenzione programmata saranno trattati come uno stato a sé stante e riassunti in una colonna a sé stante. Con Treat phases of UP/OK as non-downtime puoi sottrarre i tempi in cui, nonostante il tempo di manutenzione programmata, il servizio era OK.
Ignore scheduled downtimes viene trattato come se non fosse stato inserito alcun tempo di manutenzione programmata. Le interruzioni sono interruzioni, punto e basta. Ovviamente solo se si è verificata davvero un'interruzione.
Exclude scheduled downtimes significa che i tempi di manutenzione programmata vengono semplicemente esclusi dal periodo di tempo analizzato. La percentuale di disponibilità corrisponde quindi ai tempi al di fuori dei tempi di manutenzione programmata.
Unire fasi uguali
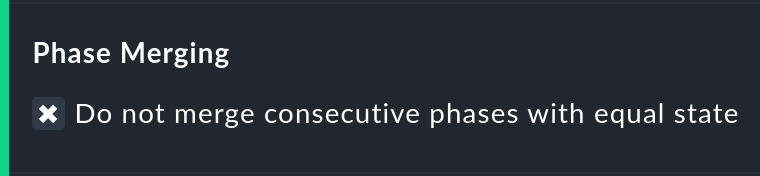
Attraverso la conversione di uno stato in un altro (es. da WARN a OK) può accadere che sezioni consecutive della timeline di un oggetto abbiano lo stesso stato. In genere queste sezioni vengono unite in un'unica sezione. Questo è generalmente positivo e chiaro, ma ha un effetto sulla visualizzazione dei dettagli nella timeline e forse anche sul conteggio degli eventi con l'opzione Outage statistics. Puoi quindi disattivare questo unire con l'opzioneDo not merge consecutive phases with equal state.
3.4. Ignorare brevi interruzioni
A volte i monitoraggi producono messaggi di problemi momentanei, ma in condizioni normali l'oggetto è già OK nel momento in cui viene eseguito il controllo successivo (dopo un minuto) - e non è stato trovato un modo, attraverso la regolazione di threshold o simili, per risolvere questi casi. Una soluzione comune è quella di impostare il parametroMaximum number of check attempts da 1 a 3 per consentire un numero maggiore di guasti prima che venga attivata una notifica. È stato quindi sviluppato il concetto di Soft states, ovvero gli stati WARN, CRIT oSCONOSCIUTO, a condizione che non siano stati "esauriti" tutti i tentativi consentiti.
Di tanto in tanto gli utenti che utilizzano questa funzione ci chiedono perché il modulo di disponibilità di Checkmk non ha una funzione per calcolare solo Hard states. Il motivo è che esiste una soluzione migliore! Esiste una soluzione migliore: si potrebbero utilizzare gli hard state come base...
... in modo che le interruzioni reali, dovute al fallimento del primo e del secondo tentativo di verifica, vengano valutate come due minuti in meno.
... e non si potrebbe riadattare retrospettivamente il comportamento per le interruzioni brevi.
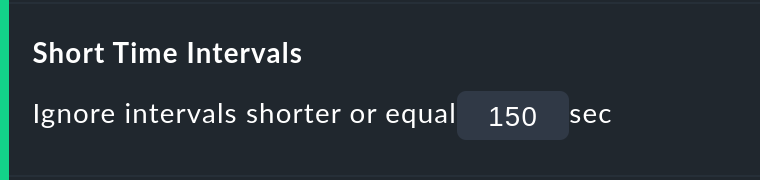
L'opzione Short time Intervals è molto più flessibile e allo stesso tempo molto semplice. Basta definire un periodo di tempo che deve essere superato prima che gli stati vengano valutati.
Supponiamo che il valore di tempo sia stato impostato a 2,5 minuti (150 secondi). Se un servizio è stato continuamente OK, poi è stato CRIT per 2 minuti e poi è tornato ad essere OK, il breve intervallo di tempo CRIT sarà semplicemente valutato come OK! Tra l'altro, funziona anche la situazione opposta! Un breve OK all'interno di una lungafase WARN verrà valutato come WARN.
In generale, brevi intervalli di tempo in cui prima e dopo prevale lo stesso stato riceveranno lo stesso stato. Per una sequenza di OK, poi un WARN di 2 minuti, seguito da CRIT, il WARNpersisterà, anche se la sua durata è inferiore a quella definita!
Quando definisci il tempo, tieni presente che in Checkmk l'intervallo di tempo standard è di un minuto. Quindi ogni stato ha una durata multipla dicirca un minuto. Poiché i tempi di risposta effettivi dell'agente variano leggermente, è facile che si tratti di 61 o 59 secondi. Per questo motivo è meglio non inserire i minuti esatti per il valore, ma piuttosto includere un buffer: ecco l'esempio con 2,5 minuti.
3.5. Effetti dei periodi di tempo
Una funzione importante dei calcoli di disponibilità nelle edizioni commerciali di Checkmk è che questi calcoli possono dipendere da periodi di tempo. In questo modo è possibile definire dei periodi di tempo per ogni singolo host o servizio. In questi periodi ci si aspetta che l'host/servizio sia disponibile e lo stato viene quindi utilizzato per i calcoli. Per questo motivo ogni oggetto ha l'attributo Service period. La procedura è la seguente:
Definisci un periodo di tempo per i tempi di servizio.
Assegnali agli oggetti con i set di regole Host & Service parameters > Monitoring configuration > Service period for hosts o … for services.
Attiva le modifiche.
Utilizza l'opzione Service time Disponibilità per controllare il comportamento:
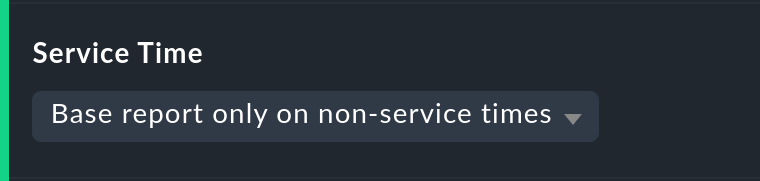
In questo caso ci sono tre semplici possibilità. L'opzione predefinitaBase report only on service times nasconde gli orari al di fuori degli orari di servizio definiti. Questi tempi nascosti non vengono conteggiati per raggiungere il 100 %. Solo i periodi di tempo all'interno dei tempi di servizio saranno effettivamente considerati. Nella visualizzazione della timeline i tempi rimanenti saranno "grigi".
Base report only on non-service times esegue il contrario e calcola la visualizzazione inversa: Quanto è stata buona la disponibilitàal di fuori degli orari di servizio?
La terza opzione Include both service and non-service times disattiva il concetto completo di orari di servizio e mostra i calcoli per tutti gli orari che vanno dalle 00:00 del lunedì alle 24:00 della domenica.
A proposito: Se un host non rientra nell'orario di servizio, per Checkmk nonsignifica automaticamente che questo vale anche per i servizi dell'host. I servizi richiedono sempre una regola propria in Service period for services.
Il periodo di notifica
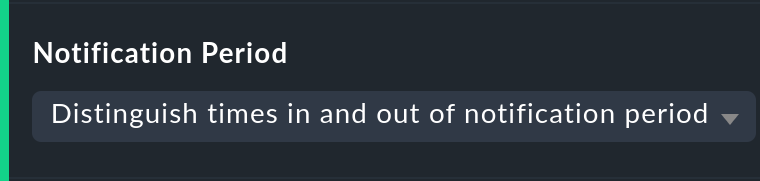
Esiste un'altra opzione correlata: Notification period. Qui si può anche scegliere il periodo di notifica per la valutazione. In realtà questa opzione è stata concepita solo per evitare che per determinati periodi di tempo vengano generate notifiche per problemi e non copre necessariamente il periodo di servizio. Questa opzione è stata introdotta in passato quando il software-as-a-service non funzionava ancora e oggi è stata mantenuta solo per motivi di compatibilità. È meglio non utilizzarla.
3.6. Limitare il tempo di calcolo
Quando si calcola la disponibilità, è necessario riaprire la cronologia completa dell'oggetto selezionato. Per sapere come funziona in dettaglio, leggipiù avanti. Soprattutto in Checkmk Raw, l'analisi può richiedere un po' di tempo, poiché il suo core non ha una cache per i dati richiesti e i dati di log basati sul testo devono essere cercati in sequenza.
Affinché una query eccessivamente complessa, che potrebbe essere stata avviata involontariamente, non blocchi un processo Apache, non consumi CPU e quindi non si "blocchi", esistono due opzioni per limitare la durata del calcolo. Entrambe sono attivate per impostazione predefinita:
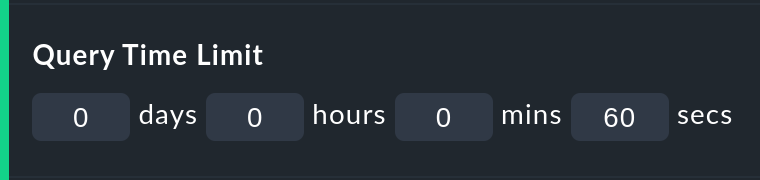
Query time limit limita la durata della query sottostante al nucleo di monitoraggio a un tempo specifico. Se questo tempo viene superato, l'analisi verrà interrotta e verrà evidenziato un errore. Se sei sicuro che l'analisi possa essere eseguita più a lungo, aumenta il timeout manualmente.
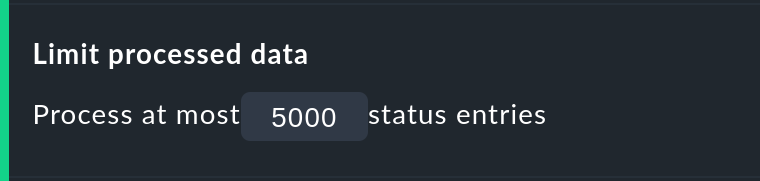
L'opzione Limit processed data protegge dai calcoli con molti oggetti. In questo caso verrà applicato un limite analogo a quello dellevisualizzazioni. Se la query al nucleo di monitoraggio produrrà più di 5000 periodi di tempo, il calcolo verrà interrotto con un avviso. La limitazione sarà stata pre-processata nel nucleo, dove vengono raccolti i dati.
4. Disponibilità in Business Intelligence
4.1. Il principio di base
Una potente caratteristica del calcolo della disponibilità di Checkmk è la possibilità di calcolare la disponibilità dalle aggregazioni BI. La grande attrattiva è che a questo scopo Checkmk ricostruisce retroattivamente lo stato preciso dei rispettivi aggregati in un determinato momento utilizzando i protocolli degli stati dei singoli host e servizi.
Perché tanto tempo e fatica? Perché non basta interrogare l'aggregazione BI con un Check attivo e mostrarne la disponibilità? Questo sforzo comporta una serie di vantaggi per l'utente:
La costruzione delle aggregazioni BI può essere adattata retrospettivamente e quindi la disponibilità può essere ricalcolata.
Il calcolo è più preciso, poiché non utilizzando un active check non si genera un'imprecisione di +/- un minuto.
È disponibile un'eccellente funzione di analisi, grazie alla quale è possibile indagare in modo retrospettivo la causa esatta di un'interruzione.
Inoltre, non è necessario creare un controllo aggiuntivo.
4.2. Recupero della disponibilità
Il recupero della visualizzazione della disponibilità è inizialmente analogo a quello degli host e dei servizi. Seleziona una visualizzazione con una o più aggregazioni BI e seleziona la voce di menu BI Aggregations > Availability. Qui c'è anche un secondo metodo: ogni aggregazione BI ha un percorso diretto alla sua disponibilità utilizzando il simbolo:
Il calcolo è inizialmente analogo a quello dei servizi, ma senza le colonne Host down e flapping, poiché questi stati non esistono per la BI:

4.3. Viaggio nel tempo
La grande differenza sta nella visualizzazione della linea temporale. L'esempio seguente mostra un aggregato nel nostro server demo, che è stato CRITper un brevissimo intervallo di tempo di un secondo (questo sarebbe un buon esempio per l'uso dell'opzione Short time intervals ).
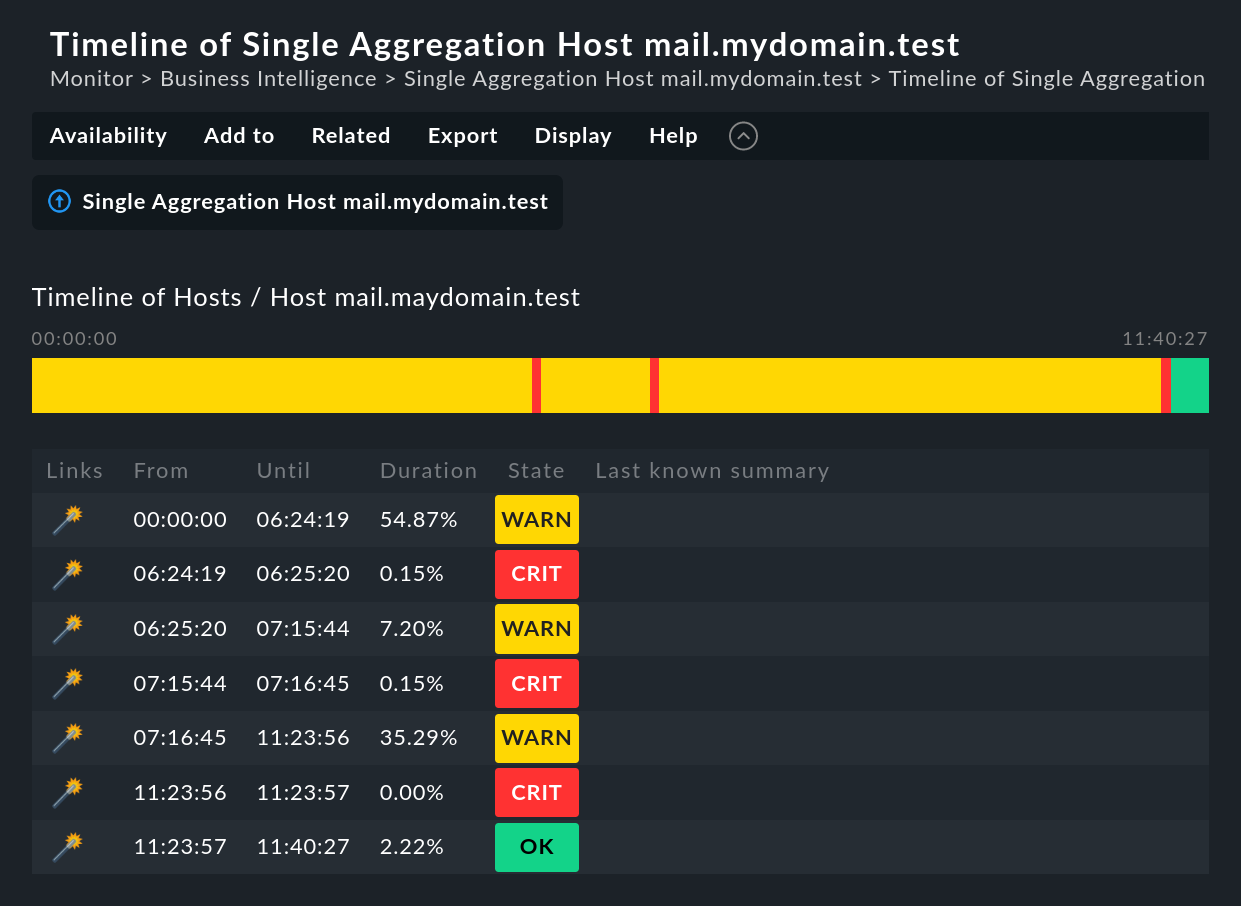
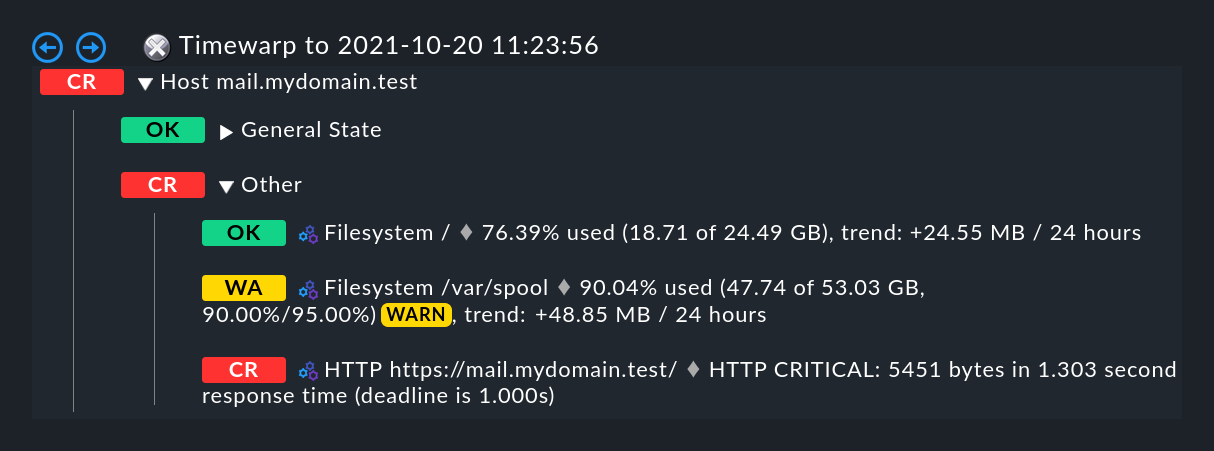
Vuoi sapere qual è stata la causa dell'interruzione? Basta un semplice clic sulla bacchetta magica. Questo permette di viaggiare nel tempo fino al momento esatto in cui si è verificata l'interruzione e apre una visualizzazione dell'aggregazione BI in quel momento - nell'immagine seguente, già aperta nella posizione corretta:
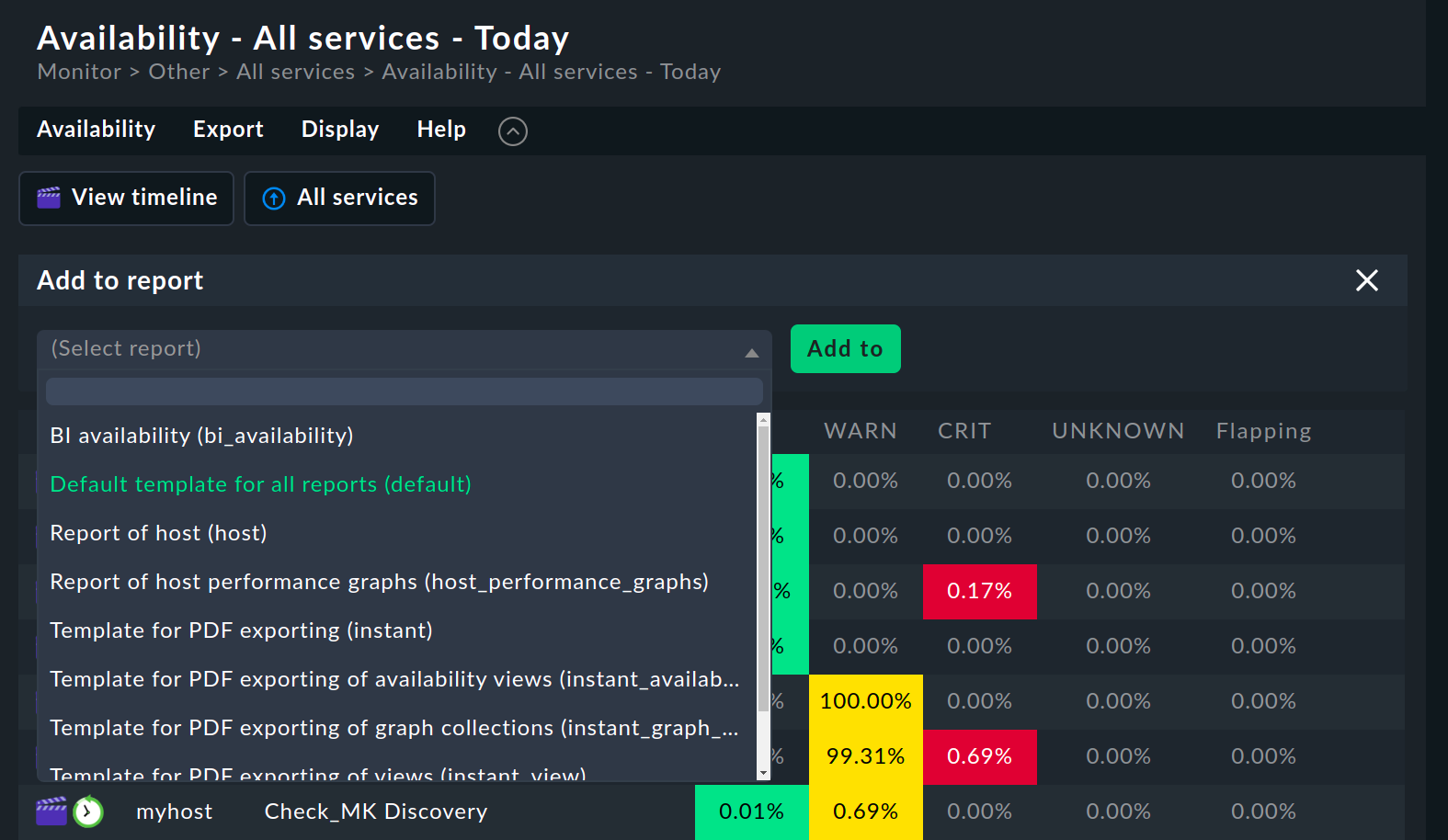
5. Disponibilità nei report
Le visualizzazioni della disponibilità possono essere inserite nei report. Il modo più semplice è tramite Export > Add to report nella barra del menu. Seleziona il report a cui vuoi aggiungere la visualizzazione e conferma con Add to.
L'elemento del report Availability table inserisce un'analisi della disponibilità nel report. Tutte le opzioni discusse in precedenza si trovano come parametri direttamente nell'elemento, anche se con un modulo leggermente diverso:
L'ultima opzione è speciale:

Qui puoi specificare quale visualizzazione deve essere aggiunta al report:
La tabella delle disponibilità
La visualizzazione grafica della linea temporale
La timeline in dettaglio con i singoli periodi di tempo.
A differenza delle normali visualizzazioni interattive, in questo caso puoi incorporare contemporaneamente tabelle e linee temporali nei report.
Una seconda caratteristica è la possibilità di specificare il periodo di tempo della valutazione, opzione che qui manca perché viene predeterminata automaticamente dal report.
La selezione dell'oggetto, come per ogni elemento del report, è adottata dal report o predefinita direttamente nell'elemento.
6. Background tecnico
6.1. Come funzionano i calcoli
Per calcolare la disponibilità, Checkmk accede agli archivi dei log della cronologia di monitoraggio e per farlo si orienta sui cambiamenti di stato. Se, ad esempio, alle 17:14 del 20/10/2021 un servizio cambia il suo stato in CRIT e poi alle 17:24 torna a OK, allora saprai che in questo periodo di tempo di 10 minuti il servizio era in stato CRIT.
Questi cambiamenti di stato vengono registrati nel log di monitoraggio, hanno il tipo di avvisoHOST ALERT o SERVICE ALERT e hanno un aspetto simile a questo, ad esempio:
[1634742874] SERVICE ALERT: mail.mydomain.com;Filesystem /var/spool;CRITICAL;HARD;1;CRIT - 95.9% used (206.96 of 215.81 GB), (warn/crit at 90.00/95.00%), trend: 0.00 B / 24 hoursEsiste sempre un file di log corrente che include le voci relative all'attività più recente fino al momento attuale, oltre a una directory con un archivio dei periodi precedenti. La posizione di questi file varia a seconda del nucleo di monitoraggio in uso:
| Core | File corrente | File più vecchi |
|---|---|---|
Nagios |
|
|
|
|
L'interfaccia utente non accede direttamente a questi file, ma li interroga utilizzando una query Livestatus emessa dal nucleo di monitoraggio. Tra gli altri fattori, questo è importante perché in unmonitoraggio distribuito i file di cronologia non sono memorizzati sullo stesso sistema del GUI.
La query Livestatus utilizza la tabella statehist. A differenza della tabella log, che fornisce un accesso "nudo" alla cronologia, in questo caso viene utilizzata la tabella statehist perché ha già eseguito le fasi iniziali di calcolo che richiedono molto tempo. Tra le altre cose, si assume il compito di controllare la cronologia per determinare lo stato iniziale e di calcolare i periodi di tempo con lo stesso stato, con il loro inizio, la loro durata e la loro fine.
La procedura di condensazione degli stati viene eseguita nella panoramica dell'utente dal Modulo Disponibilità, come descritto all'inizio di questo articolo.
6.2. La cache della disponibilità in CMC
Come funziona la cache
Per le query che risalgono al passato, è necessario processare molti file di log. Questo ovviamente ha un effetto negativo sulla durata del calcolo. Per questo motivo, nel Checkmk Micro Core è presente una cache molto efficiente della cronologia di monitoraggio, in cui fin dall'inizio tutte le informazioni importanti sui cambiamenti di stato degli oggetti sono già state determinate dai file di log conservati nella RAM, e che viene continuamente aggiornata durante il monitoraggio attivo. La conseguenza di ciò è che tutte le query sulla disponibilità possono essere risposte direttamente e in modo molto efficiente dalla RAM e quindi non è necessario un ulteriore accesso.
L'analisi dei file di log è molto rapida e con dischi rigidi adeguatamente veloci può raggiungere una velocità di elaborazione fino a 80 MB/sec! Per evitare che la creazione della cache ritardi l'inizio del monitoraggio, questa operazione viene eseguita in modo asincrono, dal presente al passato. Si noterà un breve ritardo se, subito dopo l'avvio dell'istanza Checkmk, viene avviata immediatamente un'interrogazione sulla disponibilità che copre un lungo periodo di tempo. In una situazione del genere è possibile che la cache non arrivi ancora abbastanza indietro nel passato e che la GUI abbia bisogno di qualche istante per pensarci.
Con Activate changes la cache viene mantenuta! Solo con un effettivo (ri)avvio di Checkmk sarà necessario generarla nuovamente, ad esempio in seguito a un riavvio del server o a un aggiornamento di Checkmk.
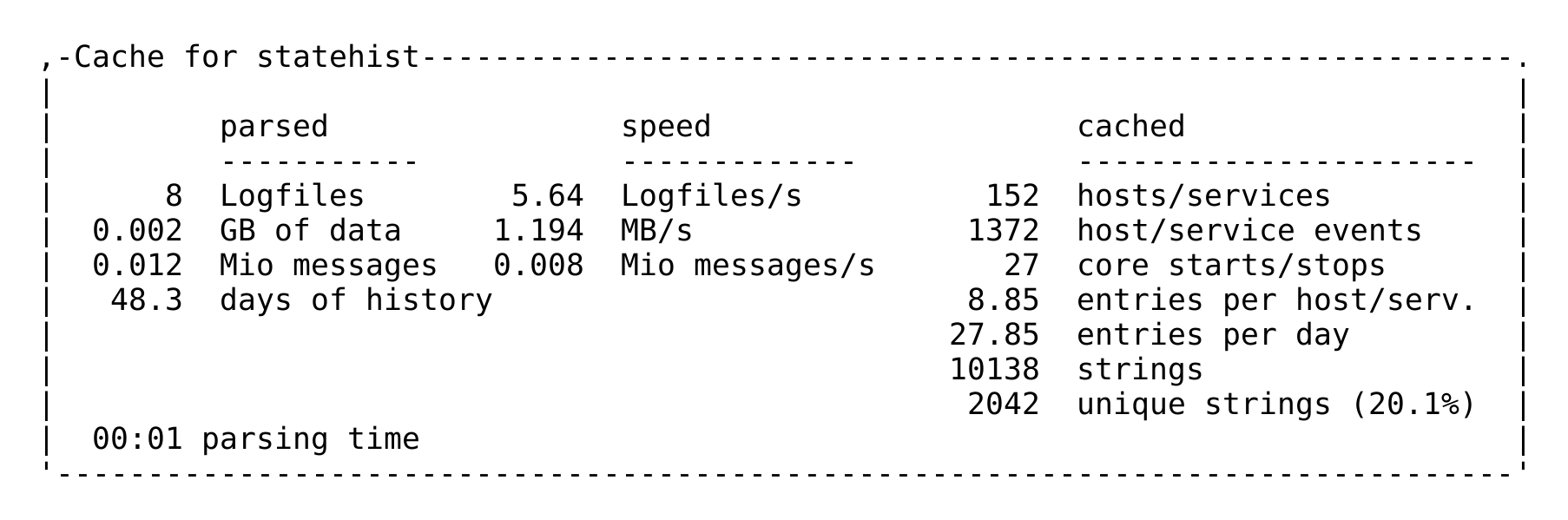
Statistiche sulla cache
Se sei curioso di sapere quanto tempo può richiedere la generazione di una cache, puoi trovare una statistica nel file di log var/log/cmc.log. Ecco un esempio tratto da un sistema di monitoraggio più piccolo:
Regolazione della cache
Per tenere sotto controllo i requisiti di archiviazione della cache, questa è limitata a un orizzonte di 730 giorni nel passato. Questo limite è fisso, quindi le query che vanno più indietro nel tempo non sono solo più lente, ma anche impossibili. Questo limite può essere facilmente personalizzato utilizzando l'impostazione globale Global Settings > Monitoring Core > In-memory cache for availability data:
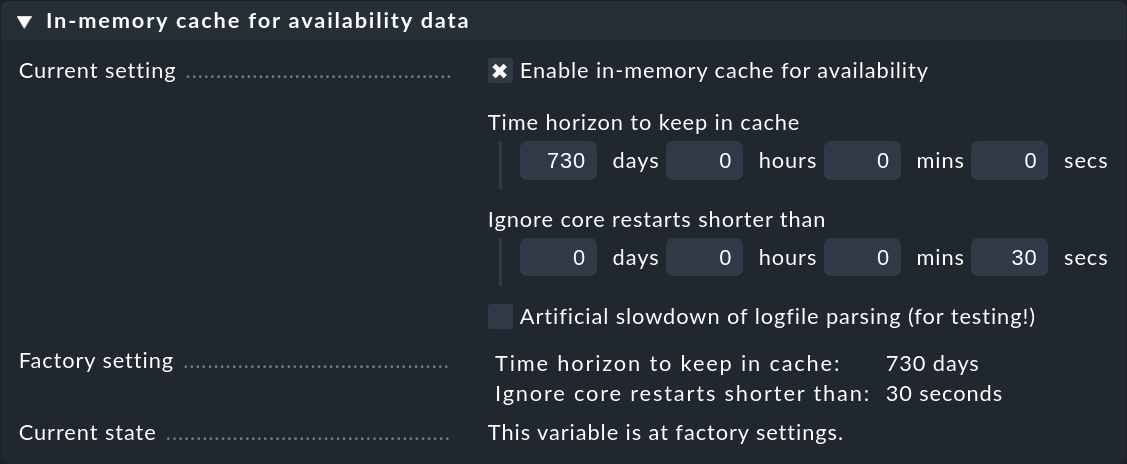
Oltre all'orizzonte di calcolo, esiste una seconda interessante impostazione: Ignore core restarts shorter than…. Un nuovo avvio del core (ad es. per un aggiornamento o un riavvio del server) produce effettivamente periodi di tempo che vengono conteggiati come unmonitored. Le interruzioni fino a 30 secondi saranno quindi semplicemente ignorate. Questo tempo può essere aumentato e i tempi più lunghi possono anche essere semplicemente soppressi. Il calcolo della disponibilità presuppone che tutti gli host e i servizi abbiano mantenuto i loro ultimi stati comunicati per tutto il tempo.
7. File e directory
| Percorso dei file | Funzione |
|---|---|
|
File di log corrente per lo storico del monitoraggio nel CMC |
|
Directory con i file di log più vecchi della cronologia |
|
Il file di log del CMC, in cui è possibile visualizzare le statistiche della cache di disponibilità. |
|
Il file di log corrente della cronologia di monitoraggio di Nagios |
|
Directory con i file di log più vecchi in Nagios |
|
Qui vengono memorizzate le annotazioni e i tempi di manutenzione programmata modificati a posteriori per le interruzioni. Il file è in formato Python e può essere modificato manualmente. |