This is a machine translation based on the English version of the article. It might or might not have already been subject to text preparation. If you find errors, please file a GitHub issue that states the paragraph that has to be improved. |
1. 偽アラーム − あらゆる監視にとって致命的な問題
監視は、正確である場合にのみ真に有用です。 同僚(そしておそらくあなた自身)が監視を受け入れる上で最大の障害となるのは、偽陽性、つまり 偽アラームです。
Checkmk を始めたばかりのユーザーの中には、Checkmk では設定が簡単すぎるため、短期間に多くのシステムを監視対象に追加してしまう方がいます。 その後、すべてのユーザーに通知を有効にすると、同僚は 1 日に何百通もの電子メールに埋もれてしまい、わずか数日で監視に対する熱意は完全に失われてしまいます。
Checkmk は、考えられるすべての設定に対して適切かつ妥当なデフォルト値を定義するために真摯に取り組んでいますが、お客様の IT 環境における通常の条件下で何がどのように動作するかを正確に把握することは不可能です。 そのため、最後の偽アラームが送信されなくなるまで、監視を微調整するために、お客様側で少しの手作業が必要となります。 それとは別に、Checkmk は、お客様やお客様の同僚がまだ気付いていない、かなりの数の実際の問題も発見します。 これらも、まず適切に修正する必要があります。もちろん、監視ではなく、現実の世界でです。
以下の原則が有効であることが証明されています - まず品質、次に量 — つまり:
一度にあまりにも多くのホストを監視対象に含めないでください。
実際に問題のないすべてのサービスが確実に「OK 」であることを確認してください。
Checkmk がしばらくの間、偽アラームがまったく発生しないか、ごくわずかにしか発生しない状態で安定して動作していることを確認してから、電子メールまたは SMS による通知を有効にしてください。
もちろん、偽アラームは通知機能がオンになっている場合にのみ発生します。 つまり、ここでは、通知の予備段階をオフにし、重要ではない問題に対して「DOWN 」、「WARN 」、または「CRIT 」という重要な状態にならないようにする必要があります。 |
以下の設定に関するセクションでは、問題の原因とならないものがすべて緑色になるように、微調整のオプションと、時折発生するドロップアウトを制御する方法について説明します。
2. ルールベースの構成
設定を始める前に、まず Checkmk におけるホストおよびサービスの設定について簡単に説明します。 Checkmk は大規模で複雑な環境向けに開発されているため、この設定はルールを使用して行います。 このコンセプトは非常に強力で、小規模な環境にも多くのメリットをもたらします。
基本的な考え方は、すべてのサービスについてすべてのパラメータを明示的に指定するのではなく、次のような設定を行うことです。
「すべての Oracle 本番サーバーで、プレフィックスが/var/ora/ のファイルシステムが 90% 満杯になった場合は WARN 、95% 満杯になった場合は CRIT 」というルールを設定します。
このようなルールでは、1 つのアクションで数千のファイルシステムの閾値を設定できます。 同時に、社内で適用される監視ポリシーも非常に明確に文書化されます。
基本ルールに基づいて、個々のケースの例外を個別に定義することができます。
適切なルールは、次のように指定します。
「Oracle サーバーsrvora123 において、ファイルシステム/var/ora/db01/ が 96% になった時点で WARN となり 、98% になった時点で CRITとなります」。
この例外ルールは、基本ルールと同じ方法で Checkmk で設定します。
各ルールは、同じ構造になっています。 ルールは、常に条件と 値で構成されています。 ルールの目的を文書化するために、説明やコメントを追加することもできます。
ルールはルールセットで整理されます。 Checkmk には、各パラメータの種類に適したルールセットが用意されており、数百ものルールセットから選択することができます。 たとえば、ファイルシステムを監視するすべてのサービスの閾値を設定する「Filesystems (used space and growth) 」というルールセットがあります。 上記の例を実装するには、このルールセットから基本ルールと例外ルールを設定します。 特定のファイルシステムに対してどの閾値が有効であるかを判断するために、Checkmk はチェックに対して有効なすべてのルールを順番に調べます。 条件に適用される最初のルールが値を設定します。この例では、ファイルシステムチェックがWARN またはCRIT になる割合の値です。
3. ルールを見つける
Checkmk では、ルールセットにアクセスするためのさまざまなオプションがあります。
1 つは、ルールセットがあるオブジェクトのトピックス(Hosts 、Services 、Agents )の「Setup 」メニューで、ルールセットをさまざまなカテゴリに分類して検索する方法です。 たとえば、サービスには、Service monitoring rules 、Discovery rules 、Enforced services 、HTTP, TCP, Email, … 、Other Services というルールセットエントリがあります。 これらのエントリのいずれかを選択すると、関連するルールセットがメインページに一覧表示されます。 これはごくわずかな数でも、 のように非常に多くの場合もあります。 その数はごくわずかである場合もあれば、Service monitoring rules のように非常に多い場合もあります。 そのため、結果ページで、メニューバーの「Filter 」フィールドでフィルタリングすることができます。
ルールセットがどのカテゴリにあるか不明な場合は、セットアップメニューの検索フィールドを使用するか、Setup > General > Rule search でルール検索ページを開いて、すべてのルールを一度に検索することもできます。 次のセクションでは、後者の方法を使用して、ルール作成のプロセスを紹介します。
利用可能なルールセットの数が多いため、検索を使用しても、適切なルールを見つけるのは必ずしも容易ではありません。 ただし、既存のサービスに適切なルールにアクセスする別の方法があります。 サービスを含むビューで、メニューオプションをクリックし、[Parameters for this service ] エントリを選択します。
このサービスに関するすべてのルールセットにアクセスできるページが表示されます。
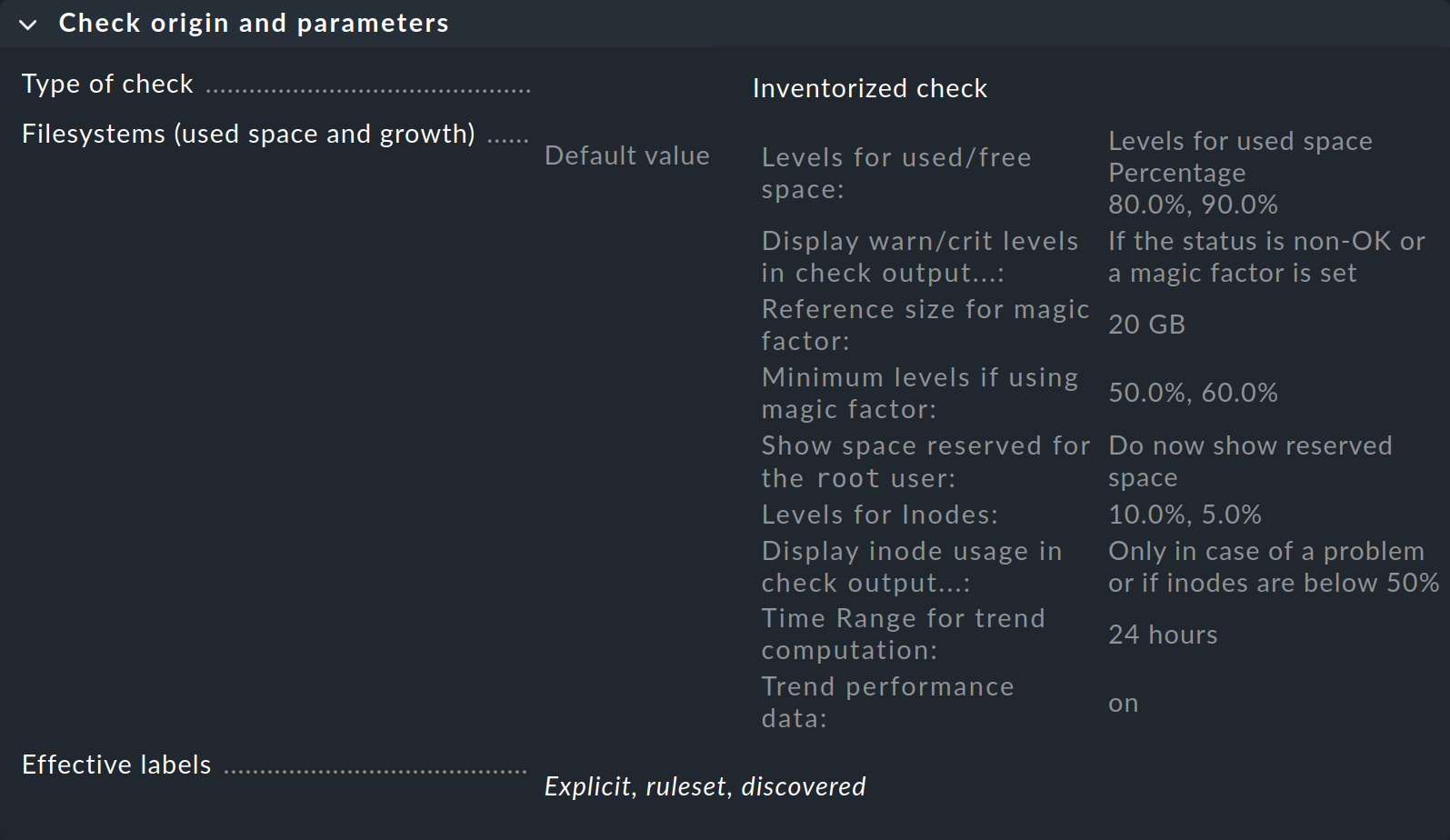
最初の「Check origin and parameters 」というボックスの「Filesystems (used space and growth) 」をクリックすると、ファイルシステムの監視閾値に関するルールセットに直接移動します。 ただし、概要には Checkmk がすでにデフォルト値を設定していることが表示されます。したがって、これらのデフォルト値を変更する場合にのみ、ルールを作成する必要があります。
4. ルールを作成する
ルールは実際にはどのように見えるのでしょうか? まず、実装したいルールを次のような文章で表現してみるのが最善です。 すべての本番 Oracle サーバーで、テーブルスペース DW20 および DW30 が 90% いっぱいになった時点で「WARN 」ステータスになり、95% いっぱいになった時点で「CRIT 」ステータスになります。
次に、適切なルールセットを検索します。この例では、ルール検索「Setup > General > Rule search 」を使用します。 これにより、[Oracle] または [tablespace] (大文字小文字は区別されません)を検索し、そのテキストが名前または説明に含まれるすべてのルールセットを見つけることができるページが開きます(ここでは表示されていません)。
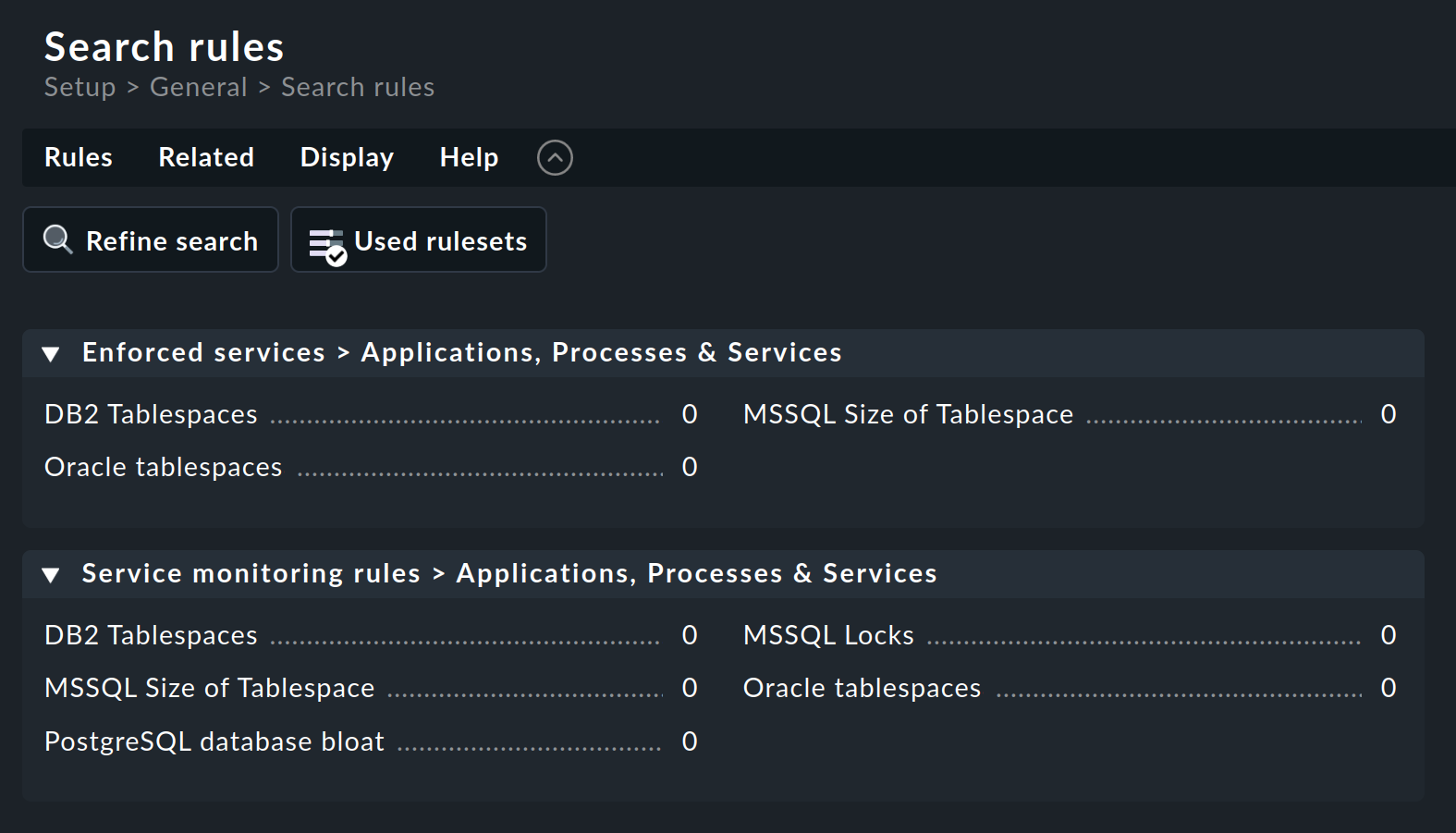
Oracle tablespaces ルールセットは 2 つのカテゴリで見つかります。
タイトル(ここではすべて0 )の後の数字は、このルールセットからすでに作成されているルールの数を示しています。
この例では、強制サービスセットアップ は必要ありません。 そのため、[Service monitoring rules ] カテゴリ内の名前をクリックして、ルールセットの概要ページを開きます。
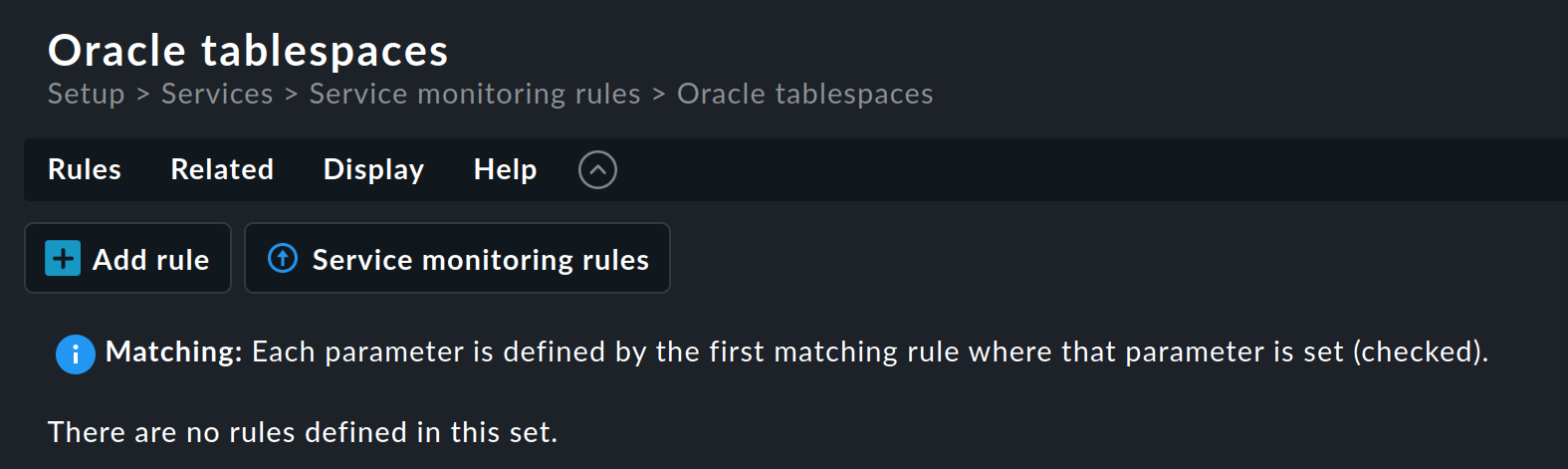
このルールセットにはまだルールは含まれていません。 最初のルールは、[Add rule ] ボタンで作成できます。 このルールを作成(および後で編集)すると、3 つのボックス(Rule properties 、Value 、Conditions )を含むフォームが開きます。 これら 3 つについて、順番に説明します。
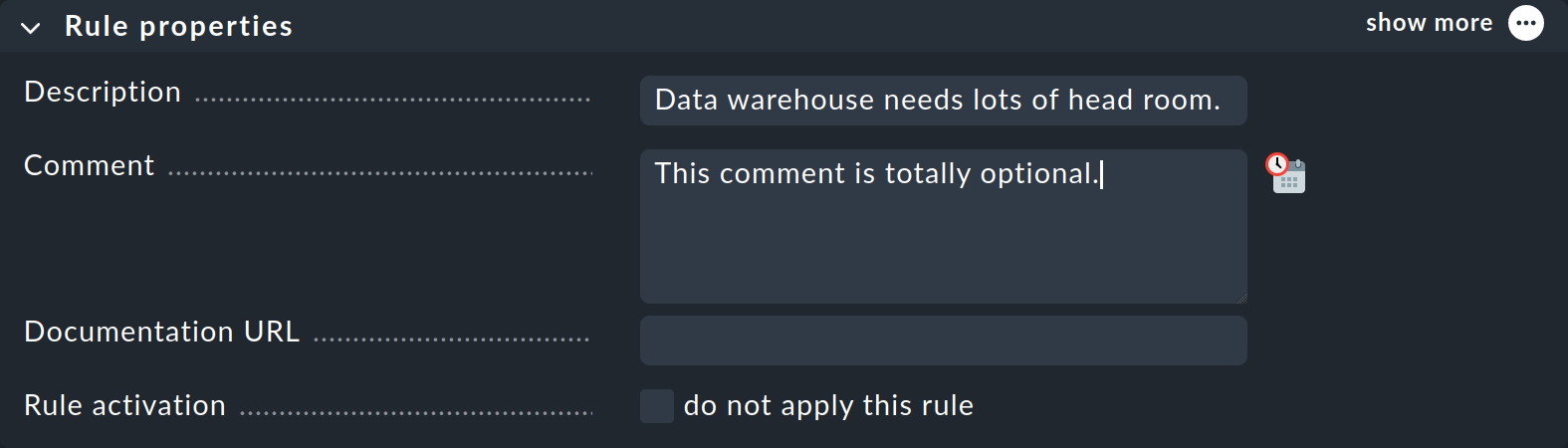
「Rule properties 」ボックスでは、すべての入力はオプションです。 情報テキストに加えて、ここではルールを一時的に無効にするオプションもあります。 これは、一時的にルールが必要ない場合に、ルールを削除して再作成する手間を省くことができるため、便利です。
Value ボックスの内容は、規制の対象となる内容によってそれぞれ異なります。
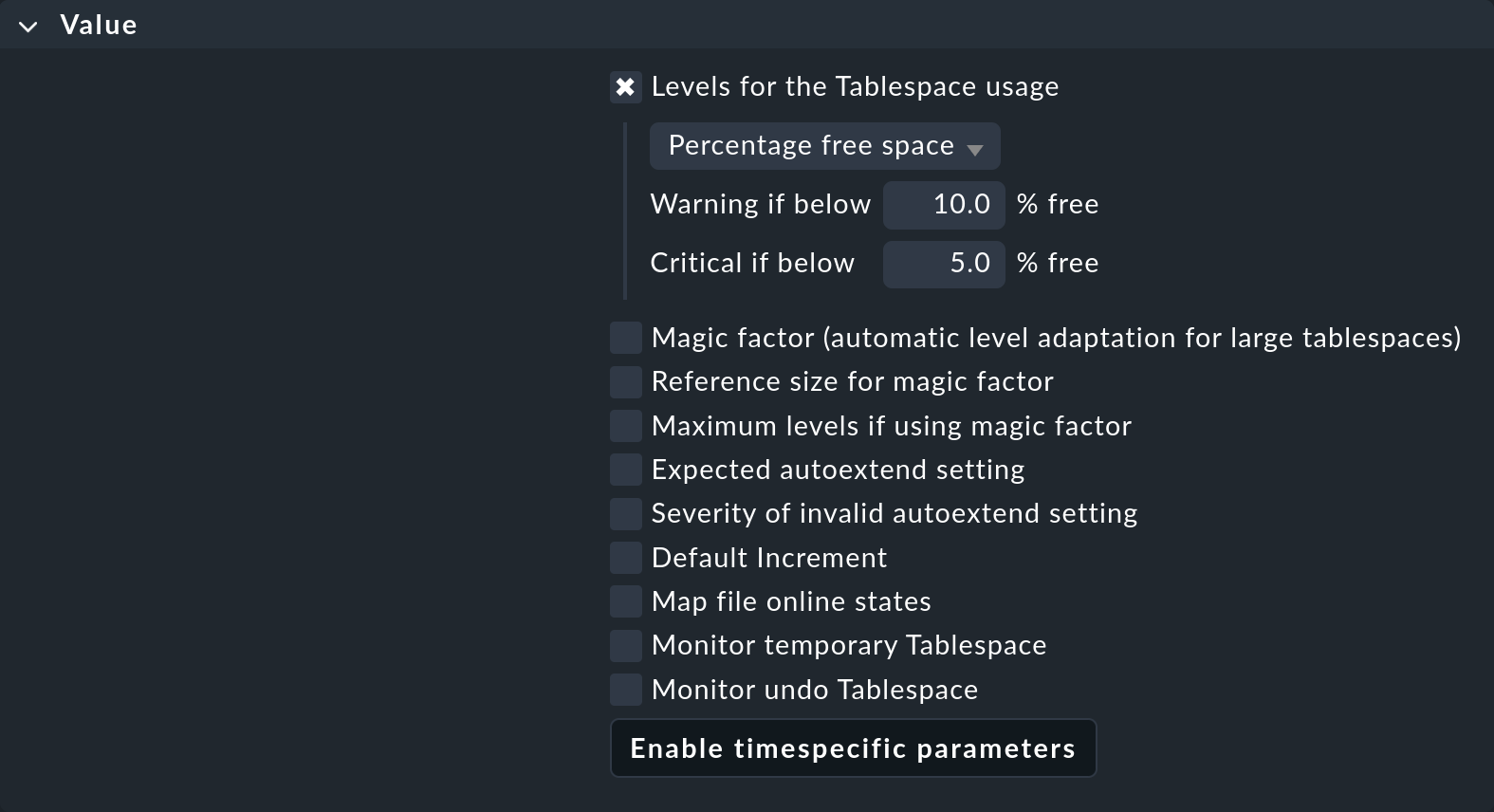
ご覧のとおり、パラメータの数はかなり多くなる場合があります。 この例は典型的なケースです。個々のパラメータはチェックボックスで有効にすることができ、そのルールは、そのパラメータにのみ適用されます。 たとえば、設定を簡略化するために、別のルールで別のパラメータを決定することができます。 この例では、テーブルスペースの空き容量の閾値のみを設定しています。
条件を設定するための [Conditions ] ボックスは、一見すると少しわかりにくいかもしれません。
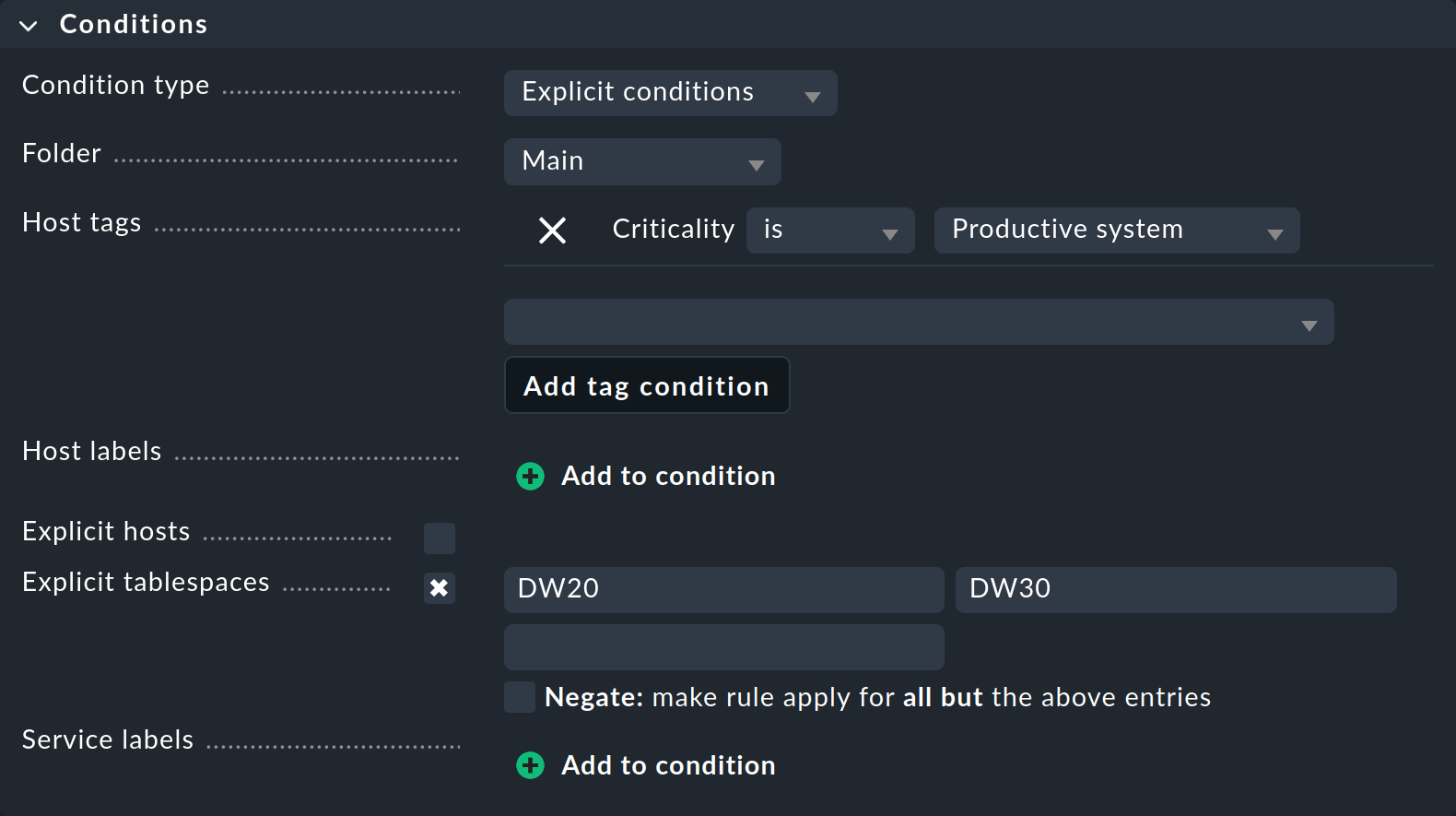
この例では、この特定のルールを定義するために絶対に必要なパラメータのみについて説明します。
「Folder 」では、ルールを適用するフォルダを指定します。 たとえば、デフォルトの「Main 」を「Windows 」に変更すると、新しいルールは「Windows 」フォルダに直接、またはその下にあるホストにのみ適用されます。
Host tags は Checkmk の非常に重要な機能であるため、このセクションの直後に、 について別のセクションを設けて説明します。 この時点で、定義済みホストタグの 1 つを使用して、ルールを本番システムにのみ適用するように指定します。 まず、リストからホストタググループ「Criticality 」を選択し、「Add tag condition 」をクリックして「Productive system 」の値を選択します。
この例で非常に重要なのは、ルールを非常に特定のサービスに制限するExplicit tablespaces です。 ここで重要な点は 2 つあります。
この条件の名前は、ルールのタイプに合わせて変更してください。Explicit services と表示されている場合は、関連するサービスの名前を指定してください。 たとえば、
Tablespace DW20という名前があります。つまり、Tablespaceという単語が含まれています。 ただし、この例では、Checkmk はテーブルスペース自体の名前のみを知りたいので、DW20と指定します。入力したテキストは、常に先頭部分と一致する部分を探します。 したがって、
DW20と入力すると、架空のテーブルスペースDW20Aにもアクセスしてしまいます。 これを防ぐには、$文字を末尾に追加します。つまり、DW20$と入力します。これらは、いわゆる正規表現です。
その他のすべてのパラメータの詳細および重要なルール概念の詳細については、ルールに関する記事をご覧ください。 ちなみに、上の画像で最後のパラメータであるService labels については、ラベルに関する記事で詳しく説明しています。 |
定義のすべての入力が完了したら、Save でルールを保存します。 保存すると、ルールセットに新しいルールが 1 つだけ追加されます。

1 つのルールではなく、後で数百のルールを扱う場合、全体像を見失ってしまう危険があります。 そのため、概要を把握しやすくするために、Checkmk では、ルールを一覧表示するすべてのページの「Related 」メニューに、非常に役立つエントリを用意しています。 これを使用すると、現在のサイトで使用されているルール (Used rulesets)、およびまったく使用されていないルール (Ineffective rules) を表示できます。 |
5. ホストタグ
5.1. ホストタグの仕組み
前のセクションでは、本番システムにのみ適用されるルールの例を見ました。 具体的には、そのルールでは、Productive system ホストタグを使用して条件を定義しました。 なぜ、条件をタグとして定義し、フォルダに設定しなかったのでしょうか? それは、フォルダ構造は 1 つしか定義できず、各ホストは 1 つのフォルダにしか配置できないからです。 しかし、ホストには複数のタグを割り当てることができます。そのため、フォルダ構造では制限が多く、柔軟性に欠けます。
一方、ホストタグは、ホストがどのフォルダにあるかに関係なく、自由に任意にホストに割り当てることができます。 そして、ルールでこれらのタグを参照することができます。 これにより、設定が単純になるだけでなく、各ホストにすべてを明示的に定義する場合に比べ、理解しやすく、エラーも発生しにくくなります。
しかし、どのホストにどのタグを割り当てるかを、どのように、どこで定義すればよいのでしょうか? また、独自のカスタマイズしたタグを定義するにはどうすればよいのでしょうか?
5.2. ホストタグの定義
まず、カスタマイズしたタグに関する 2 つ目の質問から答えましょう。 まず、タグはホストタググループと呼ばれるグループに整理されていることを知っておく必要があります。 場所を例にとって考えてみましょう。 タググループには「Location」という名前を付け、このグループには「Munich」、「Austin」、「Singapore」というタグを含めることができます。 基本的に、各ホストには各タググループから1 つのタグだけが割り当てられます。 したがって、独自のタググループを定義すると、各ホストにはこのグループ内のタグの 1 つが割り当てられます。 グループからタグを選択していないホストには、デフォルトで最初のタグが割り当てられます。
ホストタググループの定義については、Setup > Hosts > Tags をご覧ください。
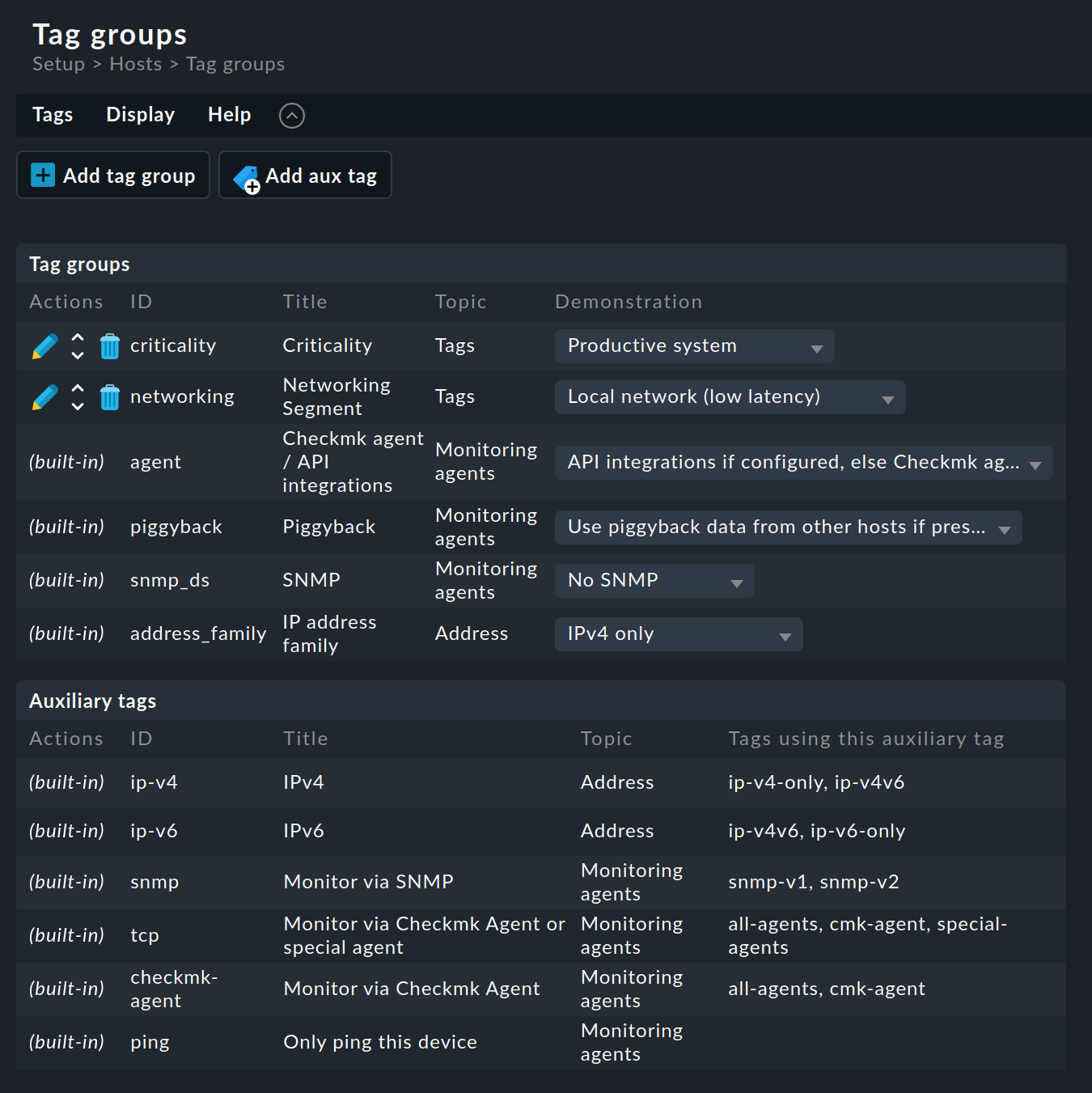
ご覧のとおり、一部のタググループはすでに定義済みです。 これらのほとんどは変更できません。 また、定義済みの 2 つのサンプルグループ「Criticality 」および「Networking Segment 」は変更しないことをお勧めします。 独自のグループを定義することをお勧めします。
Add tag group をクリックします。 新しいタググループを作成するためのページが開きます。 最初のボックスBasic settings では、Checkmk でよく使用される、キーとして機能し、後で変更できない内部 ID を割り当てます。 ID の他に、後でいつでも変更できる説明的なタイトルも定義します。Topic では、ホストプロパティでタグが後で表示される場所を決定できます。 ここで新しいトピックを作成すると、そのタグはホストプロパティの別のボックスに表示されます。
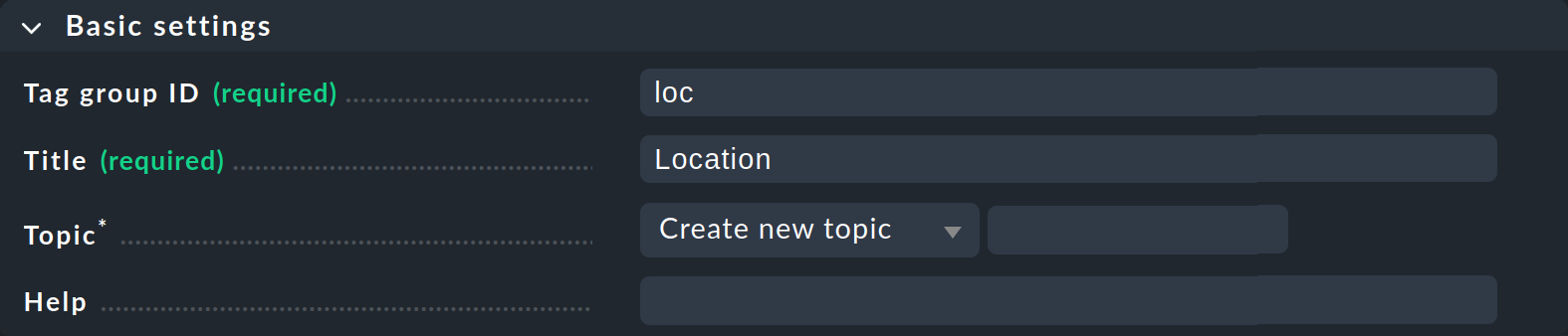
2 番目のボックス「Tag choices 」は、実際のタグ、つまりグループ内の選択オプションに関するものです。 「Add tag choice 」をクリックしてタグを作成し、各タグに内部 ID とタイトルを割り当てます。
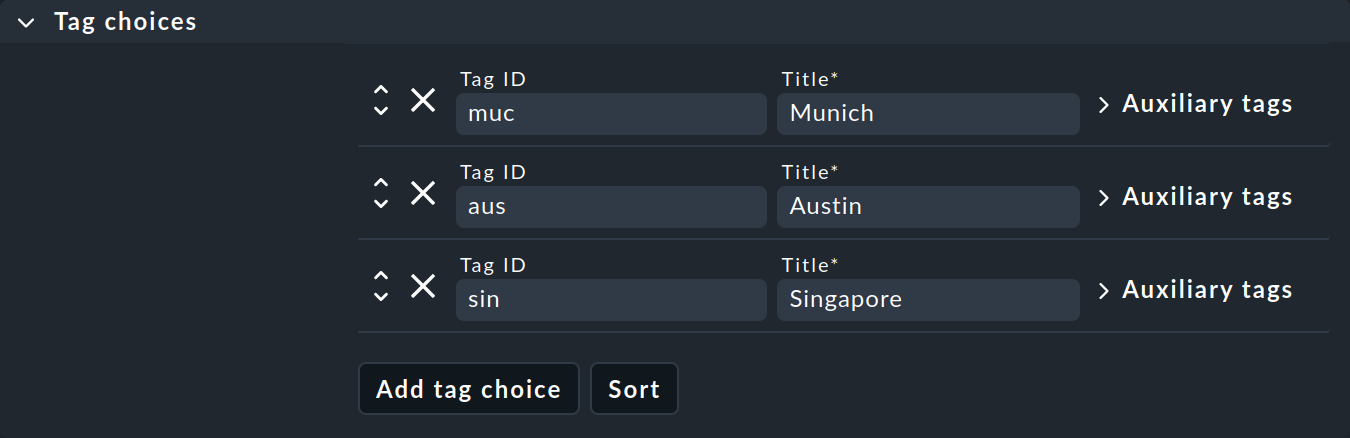
注意事項:
1 つしか選択できないグループも作成でき、場合によっては便利です。 そのグループに含まれるタグはチェックボックスタグと呼ばれ、ホストのプロパティにはチェックボックスとして表示されます。 各ホストにはそのタグが付けられます。ただし、チェックボックスタグはデフォルトで使用不能になっているため、タグは表示されません。
この時点では、補助タグは無視してかまいません。 補助タグに関する詳細情報、およびホストタグに関する一般的な情報は、ホストタグに関する記事をご覧ください。
この新しいホストタググループを [Save] で保存すると、使用を開始できます。
5.3. ホストにタグを割り当てる
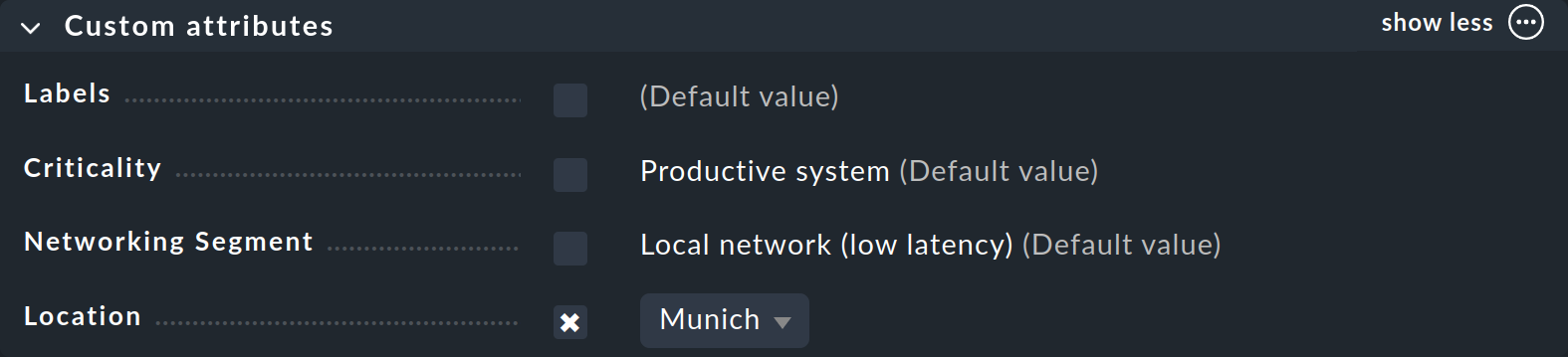
ホストにタグを割り当てる方法は、ホストの作成または編集時のホストプロパティで既に説明しました。Custom attributes ボックス(Topic を作成した場合は別のボックス)に、新しいホストタググループが表示されます。そこで選択して、ホストのタグを設定できます。
ルールとホストタグを使用した設定の重要な原則について学びましたので、残りのセクションでは、新しい Checkmk システムで偽アラームを削減するための実践的なガイドラインをご紹介します。
6. ファイルシステムの閾値のカスタマイズ
ファイルシステムの監視の閾値をチェックし、必要に応じて調整します。 デフォルト値は、ルールの検索で既に簡単に紹介しました。
デフォルトでは、Checkmk はファイルシステムのフィルレベルについて、WARN で 80%、CRIT で 90% を閾値として採用しています。 しかし、2 テラバイトのハードディスクの場合、80% は結局 400 ギガバイトになります。これは、警告を発するバッファとしては少し多すぎるかもしれません。 そこで、ファイルシステムに関するヒントをいくつかご紹介します。
Filesystems (used space and growth) ルールセットで独自のルールを作成してください。
このパラメータでは、ファイルシステムのサイズに応じて閾値を設定することができます。 これを行うには、[Levels for used/free space > Levels for used space > Dynamic levels] を選択します。Add new element ボタンを使用して、ディスクサイズごとに独自の閾値を設定することができます。
最終章でご紹介する「Magic factor 」を使用すると、さらに簡単に設定できます。
7. ホストをダウンタイムに送る
一部のサーバーは、パッチを適用するため、あるいは単に予定通り、定期的に再起動されます。 このような場合、偽アラームを回避することができます。
Checkmk Raw では、まず、再起動の時間帯を含む期間を設定します。 その方法については、期間に関する記事をご覧ください。 次に、影響を受けるホストのルールセット「Notification period for hosts 」および「Notification period for services 」にそれぞれルールを作成し、 で、先ほど設定した期間を選択します。 この期間にCRIT になったサービスが通知をトリガーしないようにするには、サービスに対する 2 つ目のルールが必要です。 この時間枠内に問題が発生し、その問題も同時間枠内に解決された場合、通知はトリガーされません。
商業版では、この目的のために、影響を受けるホストに設定できる定期的なスケジュールダウンタイムがあります。
ホストのダウンタイムを作成する代わりに、スケジュールダウンタイムの章で説明した、商業版に搭載されているRecurring downtimes for hosts ルールセットを使用することもできます。 この方法には、後で監視に追加されたホストが、これらのスケジュールダウンタイムを自動的に受け取るという大きな利点があります。 |
8. スイッチがオフになっているホストを無視する
コンピュータの電源がオフになっている場合、必ずしも問題になるとは限りません。 プリンタは、その典型的な例です。 Checkmk でこれらを監視することは、非常に理にかなっています。一部のユーザーは、Checkmk を使用してトナーの注文を整理しています。 ただし、原則として、閉店前にプリンタの電源をオフにすることは問題ではありません。 しかし、この時点で、プリンタの対応するホストがDOWN になったために Checkmk が通知するのは、まったく意味がありません。
ホストの電源がオフになっていてもまったく問題がないことを Checkmk に指示することができます。 これを行うには、Host check command ルールセットを見つけ、新しいルールを作成し、その値をAlways assume host to be up に設定します。

Conditions ボックスで、このルールが、選択した構造に応じて、適切なホストにのみ適用されるようにしてください。 たとえば、ホストタグを定義してここで使用したり、すべてのプリンタが置かれているフォルダにルールを設定したりすることができます。
これで、すべてのプリンターは実際のステータスに関係なく、常に「UP」として表示されます。
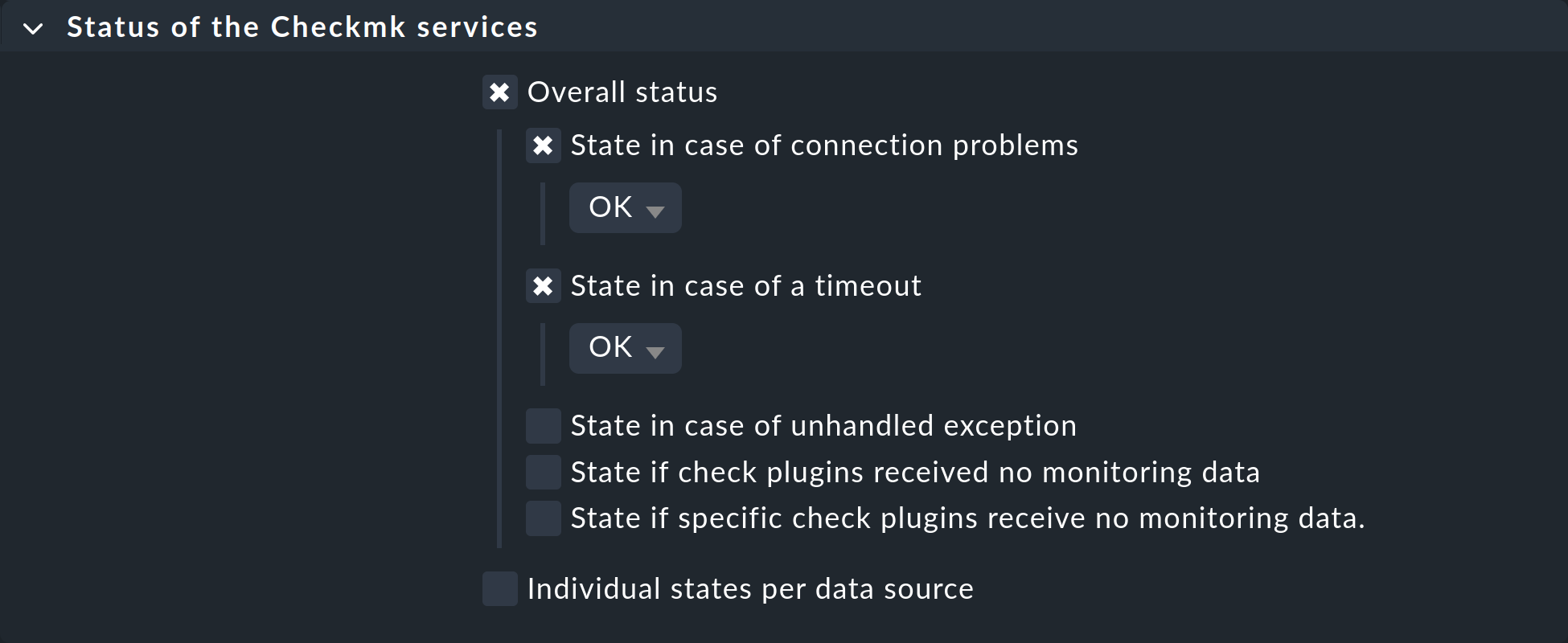
ただし、プリンタのサービスは引き続きチェックされ、タイムアウトが発生すると、CRIT 状態になります。 これを回避するには、Status of the Checkmk services ルールセットで、影響を受けるホストのルールを設定し、タイムアウトと接続の問題をそれぞれOK に設定します。
9. スイッチポートの設定
Checkmk でスイッチを監視する場合、サービス設定中に、その時点でUPになっている各ポートに対してサービスが自動的に作成されます。 これは、インフラストラクチャデバイスやサーバーのみに接続されているコアスイッチやディストリビューションスイッチには、妥当なデフォルト設定です。 しかし、ワークステーションやプリンターなどのエンドデバイスが接続されているスイッチの場合、ポートがダウンすると通知が継続的に送信される一方、これまで監視対象ではなかったポートがアップすると、新しいサービスが継続的に検出されます。
このような状況では、2 つのアプローチが有効であることが証明されています。 まず、監視をアップリンクポートに制限することができます。 これを行うには、使用不能なサービスに対して、他のポートを監視から除外するルールを作成します。
しかし、2 番目の方法の方がはるかに興味深い方法です。 この方法では、すべてのポートを監視しますが、ダウンを有効な状態として許容します。 この方法の利点は、エンドデバイスが接続されているポートでも伝送エラーを監視できるため、不良のパッチケーブルやオートネゴシエーションのエラーを非常に迅速に検出できることです。 この機能を実装するには、2 つのルールが必要です。
最初のルールセット「Network interface and switch port discovery 」は、スイッチポートを監視する条件を定義します。 目的のスイッチのルールを作成し、個々のインターフェース (Configure discovery of single interfaces) またはグループ (Configure grouping of interfaces) を検出するかを選択します。 次に、「Conditions for this rule to apply > Match port states 」で、「1 - up 」に加えて「2 - down 」を有効にします。
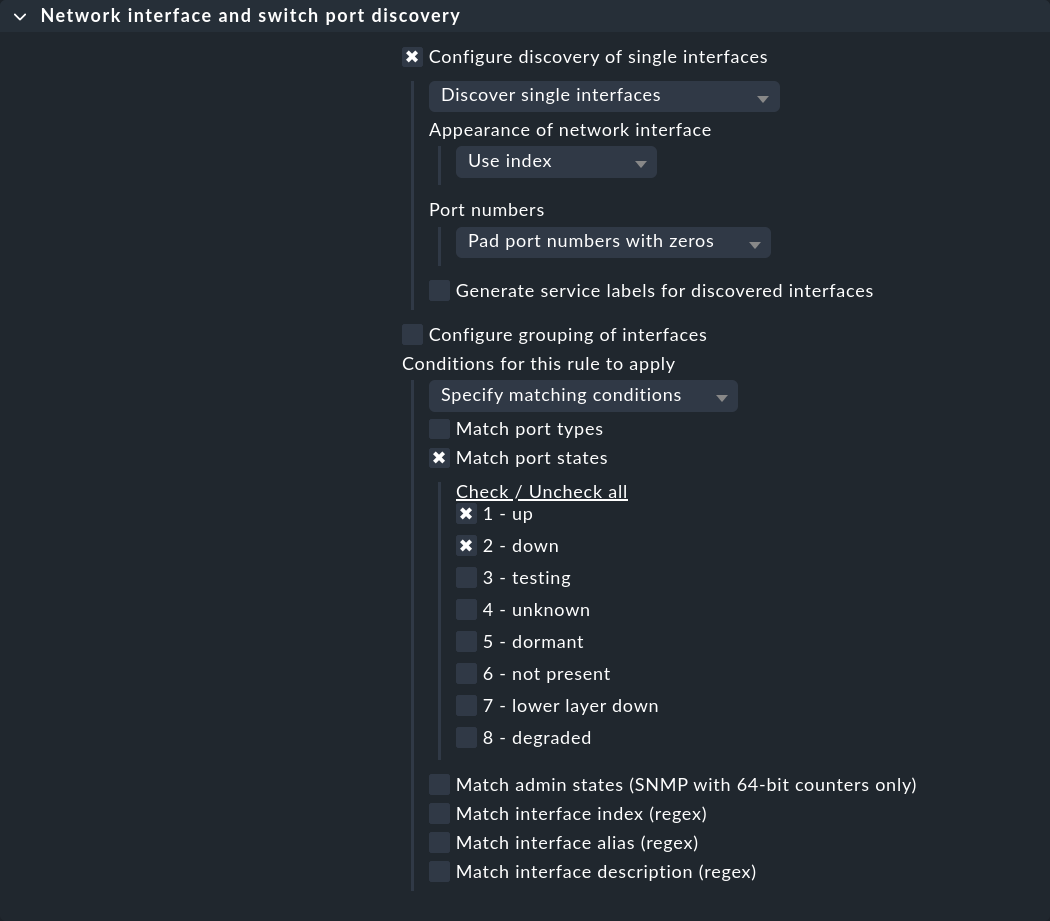
スイッチのサービス設定では、ダウン状態のポートも表示されるようになり、これらを監視サービスのリストに追加することができます。
変更をアクティブにする前に、この状態が「OK 」として評価されるようにする 2 つ目のルールが必要です。 このルールセットは「Network interfaces and switch ports 」と呼ばれます。 新しいルールを作成し、「Operational state 」オプションをアクティブにし、その下の「Ignore the operational state 」を非アクティブにして、「1 - up 」および「2 - down 」の状態を「Allowed operational states 」(および必要に応じてその他の状態)に対してアクティブにします。
10. サービスを永久的に使用不能にする
OK に確実に設定できない一部のサービスについては、監視をまったく行わない方がよいでしょう。 この場合、サービスディスカバリー(Services of host ページ)で、影響を受けるホストの監視から、そのサービスをDisabled またはUndecided に設定して、手動で削除することができます。 ただし、この方法は面倒で、ミスも発生しやすいです。
特定のサービスを体系的に監視しないルールを定義する方がはるかに望ましいです。
この目的のために、Disabled services ルールセットがあります。
ここでは、たとえば、ルールを作成し、条件として、マウントポイントが/var/test/ のファイルシステムは、定義上監視対象としないことを指定することができます。
ホストのサービス設定で をクリックして個々のサービスを無効にすると、このルールセットに、そのホストに対するルールが自動的に作成されます。 このルールは手動で編集して、たとえば、明示的なホスト名を削除することができます。 これにより、影響を受けるサービスはすべてのホストで使用不能になります。 |
詳細については、サービスの設定に関する記事をご覧ください。
11. 平均値を使用して外れ値を検出する
CPU 使用率などの利用率メトリックの閾値によって、短時間だけ閾値を超えたために、散発的な通知が生成されることがよくあります。 通常、このような一時的なピークは問題ではないため、監視によってエラーとして検出されるべきではありません。
このため、多くのチェックプラグインでは、閾値を適用する前に、メトリックを一定期間にわたって平均化するオプションが設定されています。 その一例が、Unix 以外のシステムの CPU 使用率に関するルールセット「CPU utilization for simple devices 」です。 このルールセットには、「Averaging for total CPU utilization 」というパラメータがあります。
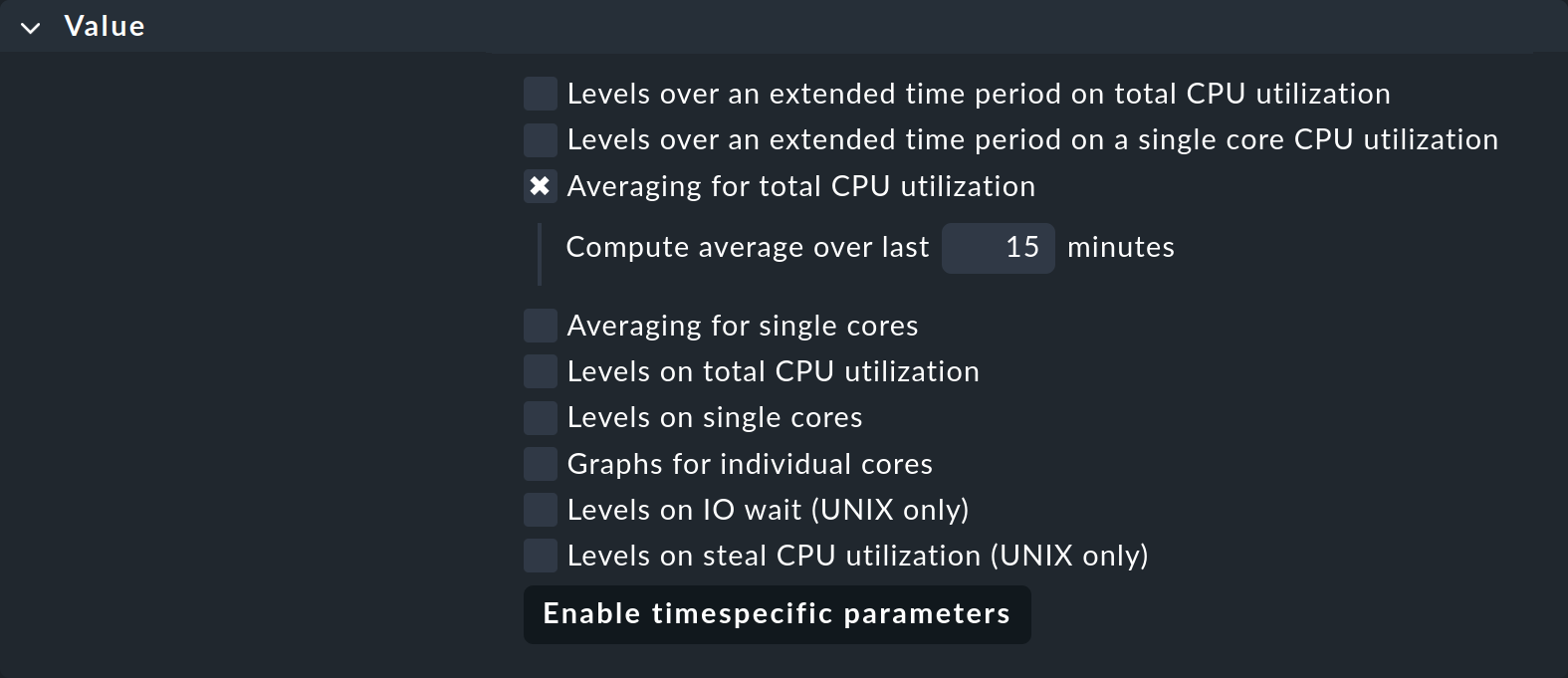
これを有効にして「15 」と入力すると、CPU 使用率はまず 15 分間の平均値が算出され、その平均値に閾値が適用されます。
12. 散発的なエラーの管理
他の何も効果がなく、サービスが 1 回のチェック間隔(1 分間)に 1 回だけWARN またはCRIT にアクセスし続ける場合、偽アラームを防ぐ最後の方法として、Maximum number of check attempts for service ルールセットがあります。
そのルールセットにルールを作成し、その値をたとえば3 に設定すると、たとえばOK からWARN に移行したサービスは、まだ通知をトリガーせず、問題として表示されません。 Overviewに問題として表示されません。
サービスが現在ある中間状態は、ソフトステートと呼ばれます。
3 回連続のチェックで状態が「OK 」のままの場合(合計 2 分強)、永続的な問題としてレポートされます。
ハードステートのみ通知がトリガーされます。
これは確かに魅力的な解決策ではありません。 問題の原因を常に突き止めようとするべきですが、状況によっては、その状況を受け入れるしかない場合もあります。チェックの試行回数を増やすことで、少なくともそのような状況を回避する現実的な手段を得ることができます。
13. サービスのリストを最新情報に更新
データセンターでは常に作業が行われているため、監視するサービスのリストは決して固定されたままではありません。 何も見逃さないよう、Checkmk は各ホストに特別なサービスを自動的に設定します。このサービスは、Check_MK Discovery と呼ばれています。

デフォルトでは、このサービスは 2 時間ごとに、新しい(まだ監視対象になっていない)サービスが発見されたか、既存のサービスが削除されたかをチェックします。 その場合は、そのサービスはWARN に移動します。 その後、サービスディスカバリー(Services of host ページ)を呼び出し、サービスリストを現在の状態に戻すことができます。
このディスカバリーチェックの詳細については、サービスの設定に関する記事をご覧ください。 また、監視対象外のサービスを自動的に追加する方法も紹介しています。これにより、大規模な設定での作業が大幅に容易になります。
Monitor > System > Unmonitored services を使用すると、新しいサービスや削除されたサービスを表示するビューを呼び出すことができます。 |