This is a machine translation based on the English version of the article. It might or might not have already been subject to text preparation. If you find errors, please file a GitHub issue that states the paragraph that has to be improved. |
1. はじめに
Checkmk ビジネスインテリジェンス — これは、基本的に単純なことを表現するには、確かに非常に高尚な言葉です。 しかし、この名前は、Checkmk のBIモジュールのコアを非常によく表現しています。 これは、環境内の多くの個々のコンポーネントの状態から収集した値に基づいて、ビジネスに不可欠なアプリケーションの全体的な状態を評価し、それを明確に表現するものです。
多くの企業にとって依然として欠かせない電子メールサービスを例にとってみましょう。 このサービスは、特定のスイッチ、SMTP および IMAP サービス、LDAP や DNS などのインフラストラクチャサービスなど、さまざまなハードウェアおよびソフトウェアコンポーネントの正しい機能に基づいています。
重要な構成要素の 1 つが故障しても、それが冗長設計になっていれば問題はありません。 一方、一見電子メールとは無関係に見えるサービスでも、実際にはより深刻な影響をもたらす問題が発生する可能性があります。 Checkmk のサービスリストを単に確認するだけでは、必ずしも意味があるとは限りません。
Checkmk BIを使用すると、個々のホストおよびサービスの現在の状態から、アプリケーションの全体的な健康状態の要約を導き出すことができます。 BI ルールは、さまざまなエレメントが相互にどのように依存しているかを、ツリー構造で定義するために使用されます。 各アプリケーションの全体的な状態は、OK 、WARN 、またはCRIT として識別できます。 条件および依存関係に関する情報は、さまざまな方法でアクセスできます。
GUI でのアプリケーションの全体的な状態の表示。
アプリケーションの可用性の計算。
問題、あるいはアプリケーションの障害発生時の通知。
影響分析:サービスが「CRIT 」状態にある場合、どのアプリケーションが影響を受けるか?
スケジュールダウンタイムの計画および「もしもの場合」の分析。
さらに、BI のツリー表示を使用して、ホストとそのすべてのサービスの状態を「ドリルダウン」ビューで表示することもできます。
監視分野の同種のツールとは異なり、Checkmk の BI の特徴は、ルールベースの構造を採用していることです。 これにより、一般的なルールセットを使用して、類似のアプリケーションをいくつでも動的に記述することができます。 これにより、作業が大幅に容易になり、特に非常にダイナミックな環境においてミスを防ぐことができます。
2. 構成パート 1: 最初の集約
2.1. 用語
BIの実践的な適用を段階的に開始する前に、まずいくつかの用語を理解しておく必要があります:
BI で形式化された各アプリケーションは、多くの個々の状態から全体的な状態がアグリゲーションされるため、アグリゲーションと呼ばれます。
アグリゲーションは、オブジェクトの「ツリー」として構築されます。 これらのオブジェクトはノードと呼ばれます。 エンドノード(ツリーの葉)は、Checkmk サイトのホストおよびサービスです。 残りのノードは、人工的に作成された BI オブジェクトです。
各ノードはルールによって作成されます。 これは、ツリーのルート(最上位のノード)にも当てはまります。 これらのルールは、どのノードが別のノードに接続されるか、およびそれらの状態から上位のノードの状態をどのように決定するかを決定します。
集約のトップノード(ツリーのルート)も、ルールによって生成されます。 このようにして、1 つのルールで複数の集約を生成することができます。
2.2. 例
これを理解する最も簡単な方法は、具体的な例を使用することです。
この記事のデモンストレーション用に、Mystery Applicationを特別に作成しました。
これは、不特定の組織における重要なアプリケーションであると仮定します。
とりわけ、5 台のサーバーと 2 台のネットワークスイッチが重要な役割を果たしています。
この例をよりよく理解するために、srv-mys-1 やswitch-1 などの単純な名前を使用します。
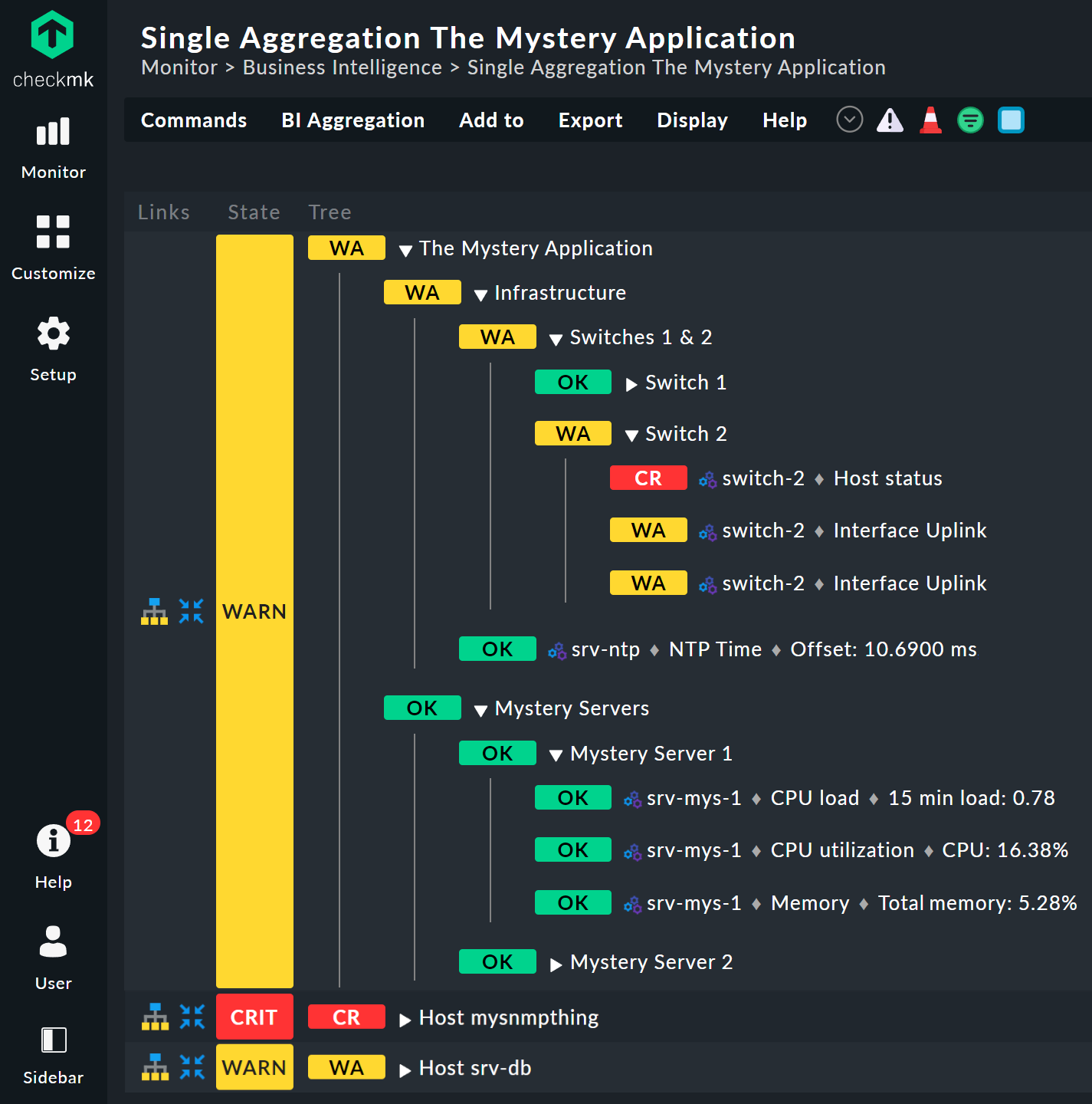
次の図は、この構造の概要を示しています。
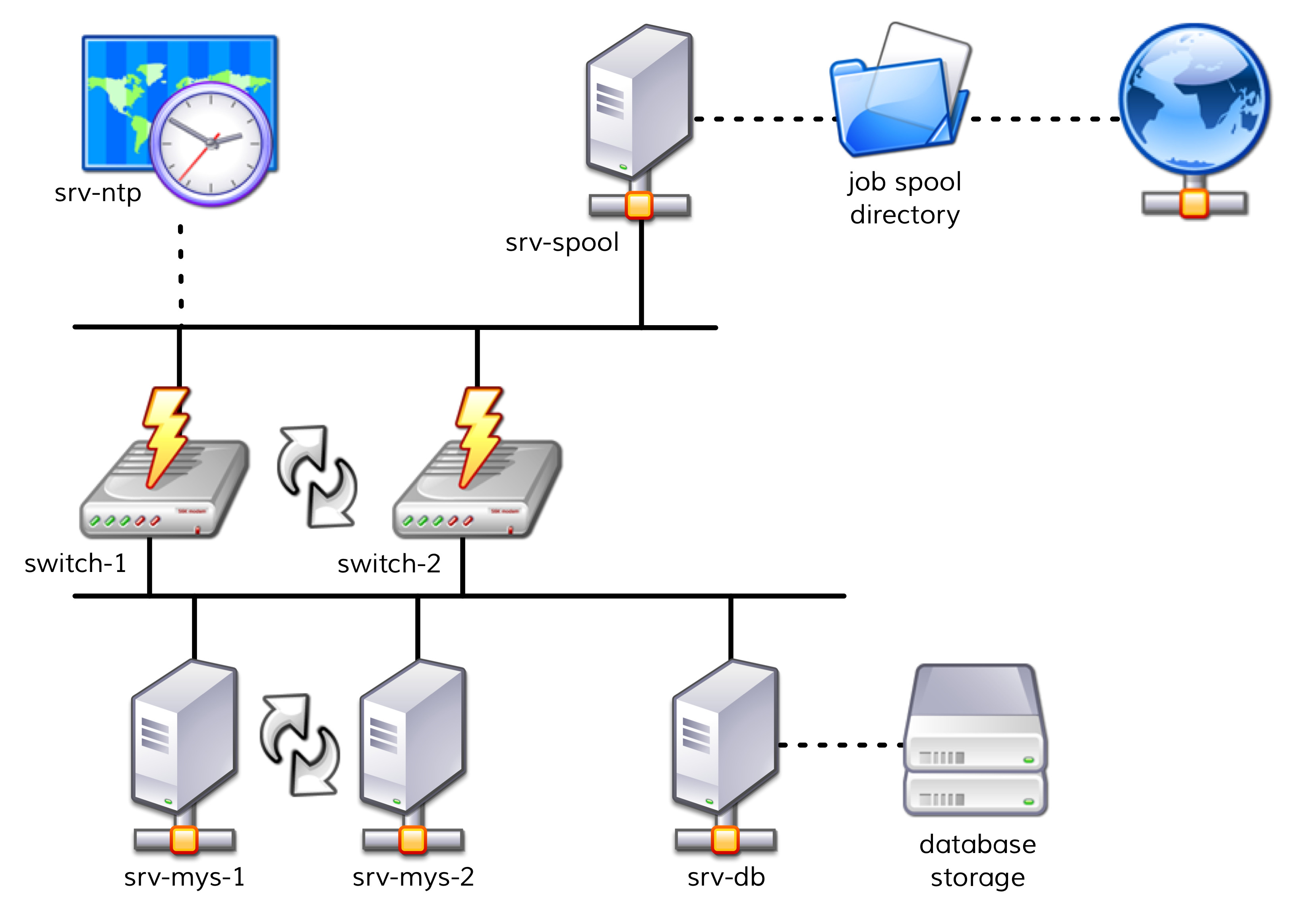
2 台のサーバー、
srv-mys-1とsrv-mys-2は、実際のアプリケーションが実行される冗長クラスタを形成しています。srv-dbは、アプリケーションのデータを格納するデータベースサーバーです。switch-1および は、サーバーネットワークを上位ネットワークに接続する 2 つの冗長ルーターです。switch-2各ルーターには、正確に同期した時刻を保証するタイマー
srv-ntpが搭載されています。さらに、サーバー
srv-spoolがここで動作し、謎めいたアプリケーションによって計算された結果をスプールディレクトリに渡します。スプールディレクトリから、データは謎の親サービスによって取得されます。
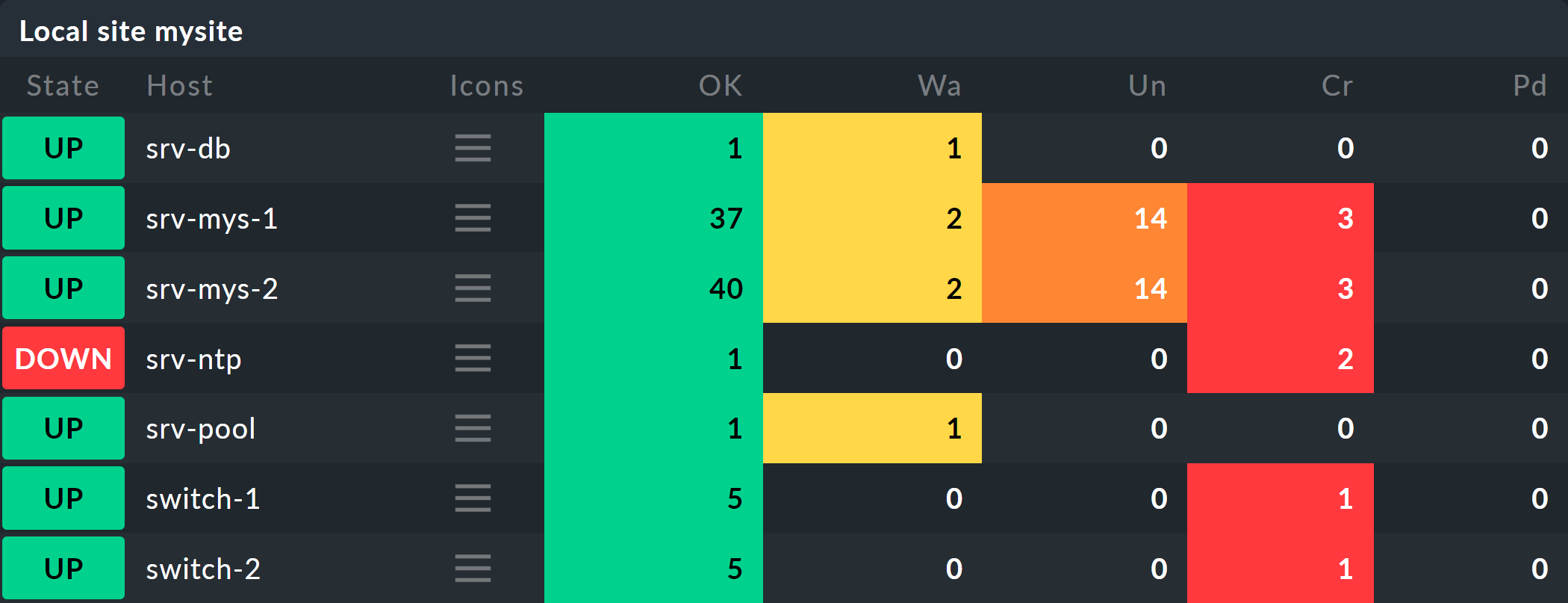
以下の手順を 1 つずつ実行したい場合は、この例に示すように、監視オブジェクトを複製してください。 次の手順を 1 つずつ実行する場合は、例に示すように、既存のホストを複数回複製し、複製に適切な名前を付けるだけで十分です。 後で、いくつかのサービスを追加する必要がありますが、その時点で、監視に適切なホストを追加する時間があります。 ここでも、またごまかすことができます。 簡単なローカルチェックを行うと、すぐに一致するサービスを見つけることができます。
ホストは、監視画面では次のように表示されます。
2.3. 最初の BI ルール
まずは、できるだけ単純で意味のある集約、つまり 2 つのノードだけの集約という、簡単なものから始めましょう。
次に、ホストswitch-1 およびswitch-2 の状態をまとめます。
この集約は「Network」と名付け、両方のスイッチが利用可能な場合は「OK 」となるように設定します。
一部が故障した場合は、状態は「WARN 」となり、両方のスイッチがオフの場合は「CRIT 」となります。
開始:Setup > Business Intelligence > Business Intelligence を使用して BI を設定します。 ルールおよびアグリゲーションの設定は、設定パッケージ(BI パック)内で実行されます。 これらのパッケージは、より複雑な設定を適切に管理できるだけでなく、パッケージに許可を適用して特定の連絡先グループを割り当てたり、管理者権限のないユーザーにも設定の一部を編集する許可を与えたりすることができるため、実用性に優れています。 詳細については、後で説明します。
BI モジュールを初めて呼び出すと、次のような画面が表示されます。

Default Pack という名前のパッケージがすでに存在しています。 このパッケージには、個々のホストのデータを要約する集約のデモが含まれています。
この例では、[Add BI Pack ] ボタンを使用して、新しいパッケージを作成し、その名前を「Mystery 」と指定するのが最適です。
Checkmk ではいつものように、後で変更できない内部 ID (mystery) と、わかりやすいタイトルを指定します。
このパッケージに、他のユーザーが自分のルールや集約に使用したいルールがある場合、そのユーザーには [Public ] オプションが必要です。
おそらくは、一人で静かに実験を行いたいでしょうから、このオプションは使用不能のままにしておいてください。
作成後、メインリストに 2 つのパッケージが表示されます。

各エントリには、プロパティを編集するためのアイコン () と パッケージの実際のコンテンツを開くためのアイコン () があります。 ここでは、まず、Add rule から最初のルールを作成してください。
Checkmk ではいつものように、このルールにも一意の ID とタイトルが必要です。 ルールのタイトルは、ドキュメント機能だけでなく、後でこのルールによって作成されるノードの名前としても表示されます。
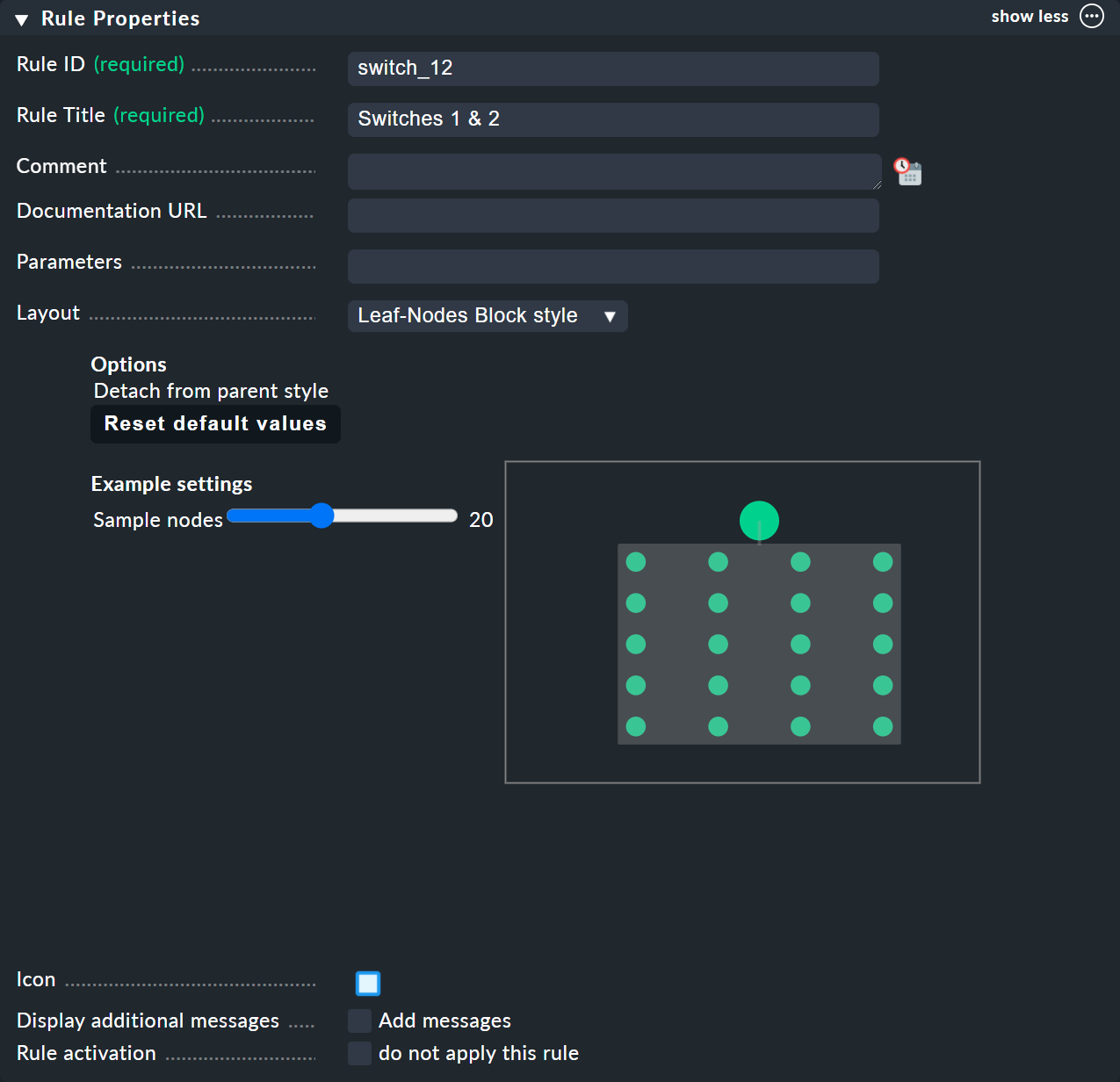
次のボックスは「Child Node Generation 」という名前で、最も重要です。 ここでは、このノード内のどのオブジェクトを要約するかを指定します。 これは、別の BI ルールを選択する他の BI ノード、または監視対象オブジェクト(ホストやサービス)のいずれかになります。
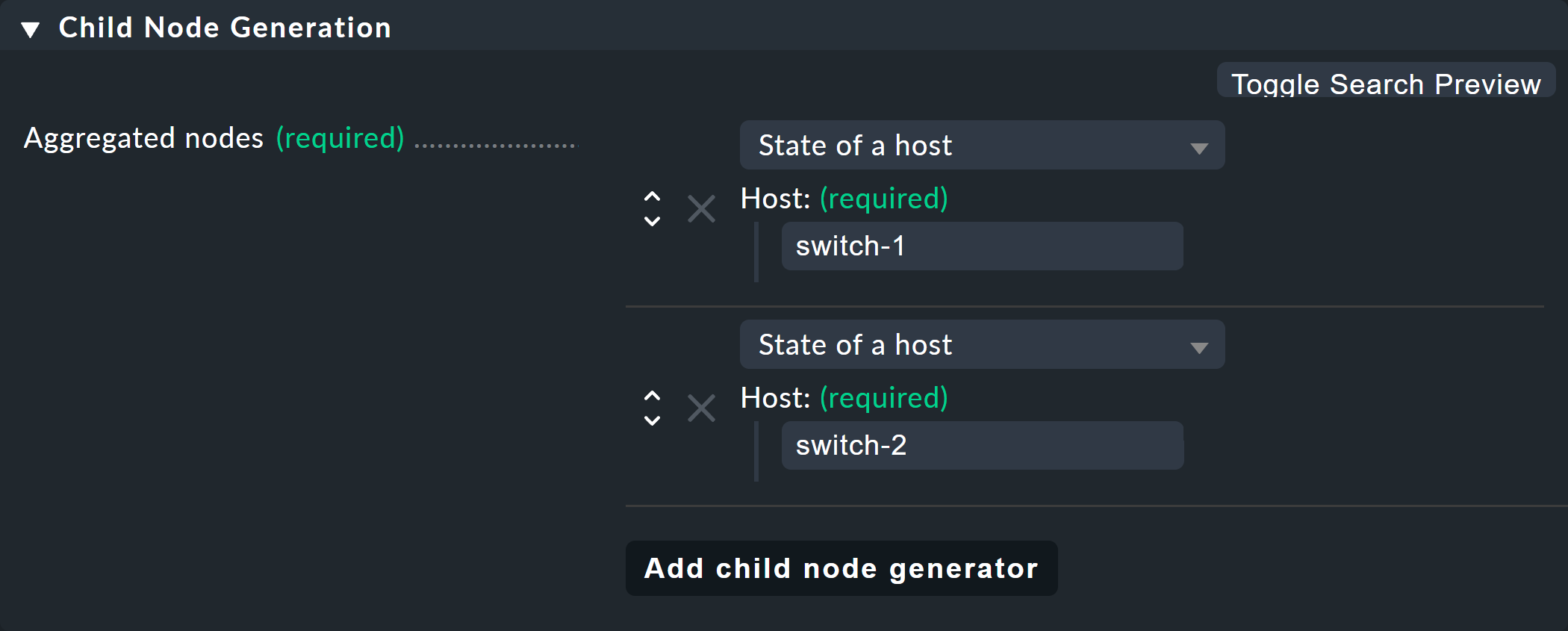
最初の例では、2 番目の選択肢 (State of a host) を選択し、2 つのオブジェクトを子供として作成します。つまり、2 つのホストswitch-1 およびswitch-2 です。
これは、Add child node generator ボタンを使用して行います。
ここでは、当然のことながらState of a host を選択し、各ホストの名前を入力します。
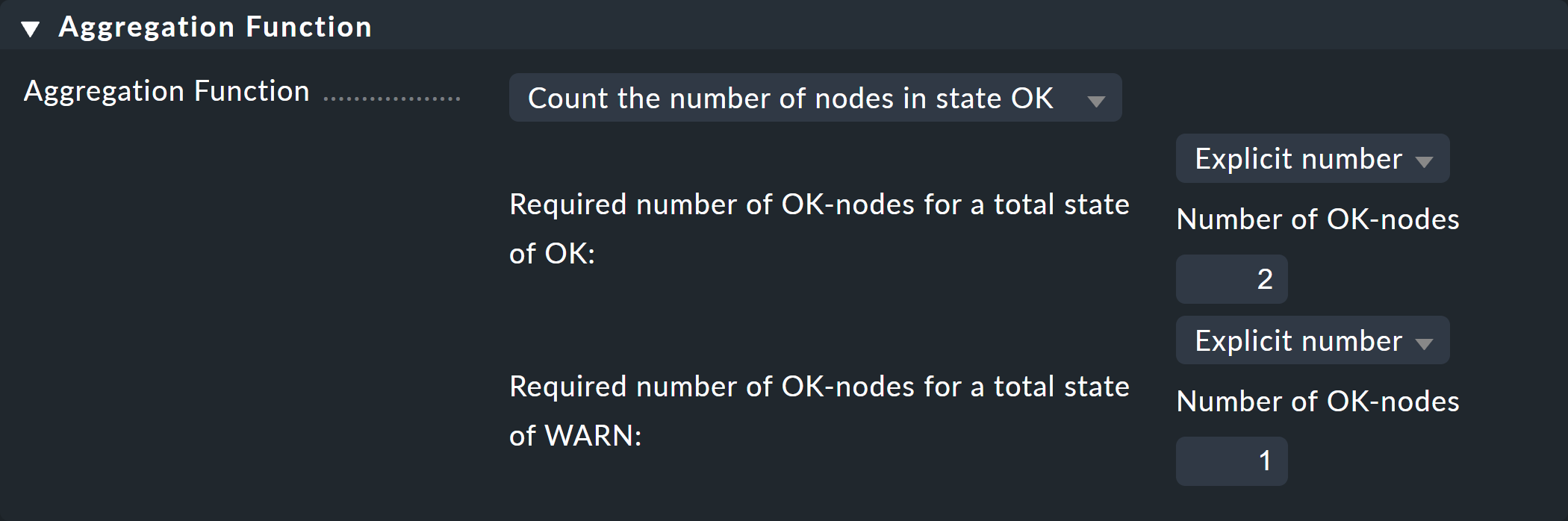
3 番目の最後のボックス「Aggregation Function 」では、ノードの監視状態をどのように計算するかを指定します。 これは、常にサブノードの状態のリストに基づいて行われます。 さまざまな論理リンクが可能です。
事前選択されているのは、Best — take the best of all node states です。 これは、すべてのサブノードがCRIT またはDOWN の場合、ノードはCRIT になることを意味します。 前述のように、ここではそうはなりません。 代わりに、Count the number of nodes in state OK を選択して、状態OK のサブノードの数を基準としてください。 ここでは、閾値として 2 と 1 が提案されています。 これは、まさに必要な設定であるため、最適です。
両方のスイッチがUP (これはOK として扱われます)の場合、ノードもOK になります。
1 つのスイッチだけがUP の場合、状態はWARN になります。
そして、両方のスイッチがDOWN の場合、状態はCRIT になります。
完成したフォームは、次のようになります。
Create をクリックすると、最初のルールが作成されます。

2.4. 初めての集約
注 — ルールはまだアグリゲーションではないことを理解しておくことが重要です。 Checkmk は、これがすべてなのか、それともより大きなツリーの一部なのかをまだ認識できません。 実際の BI オブジェクトは、アグリゲーションを作成すると、ステータスインターフェイスに作成され、表示されます。 これを行うには、アグリゲーションのリストに切り替えます。
ボタンをクリックすると、新しい集約を作成するためのフォームが表示されます。 ここで入力する項目はほとんどありません。Aggregation groups で、任意の名前を指定できます。 この名前は、ステータスインターフェイスにグループとして表示され、そのグループ名を持つすべての集約が表示されます。 これは、ハッシュタグやキーワードと同じ概念です。Aggregation ID も通常どおり自由に割り当てることができますが、後で変更することはできません。
集約の内容は、Add new element で定義します。Call a rule 設定を選択し、Rule: で、先ほど作成したルール(およびそのルールが属するルールパッケージ)を選択します。
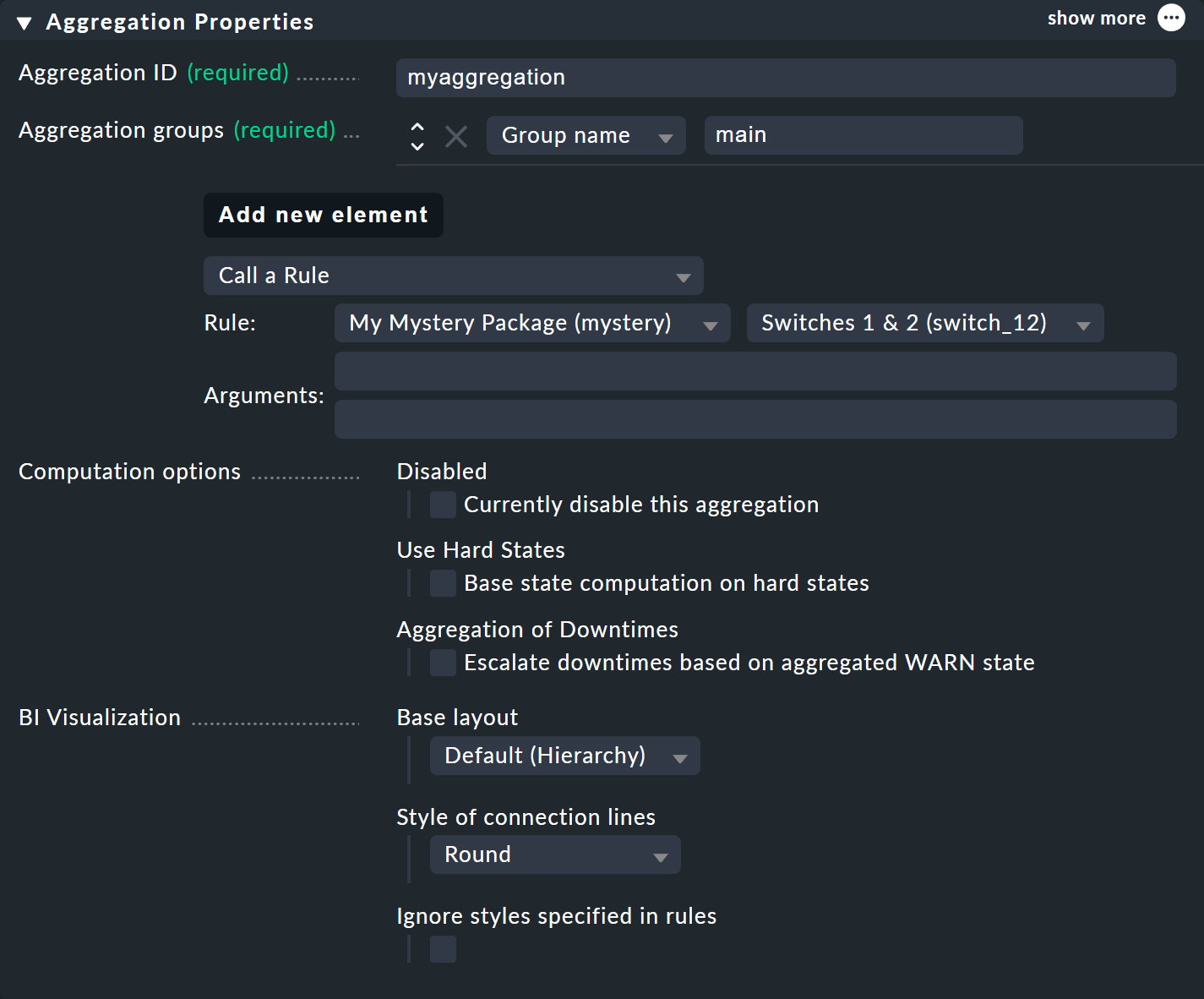
ここで、で集約を保存すれば完了です。
最初の集約がステータスインターフェイスに表示されます。ただし、switch-1 またはswitch-2 のホストが少なくとも 1 つ存在することが前提です。
3. BI の運用パート 1:ステータスインターフェイス
3.1. すべての集計の表示
すべて正しく実行すると、ステータスインターフェイスに最初の集計が表示されます。 最も簡単な方法は、Monitor > Business Intelligence > All Aggregations を使用することです。

BI 用のビューの作成
既製の BI ビューに加えて、独自のビューを作成することもできます。 これを行うには、新しいビューを作成する際にBI データソースのいずれかを選択します。BI Aggregations は、アグリゲーションに関する情報を提供します。BI Hostname Aggregations は、個々のホストに関するフィルタと情報を追加します。BI Aggregations affected by one host は、1 つのホストに関連するアグリゲーションのみを表示します。BI Aggregations for Hosts by Hostgroups は、ホストグループを区別することができます。
3.2. ツリーとの作業
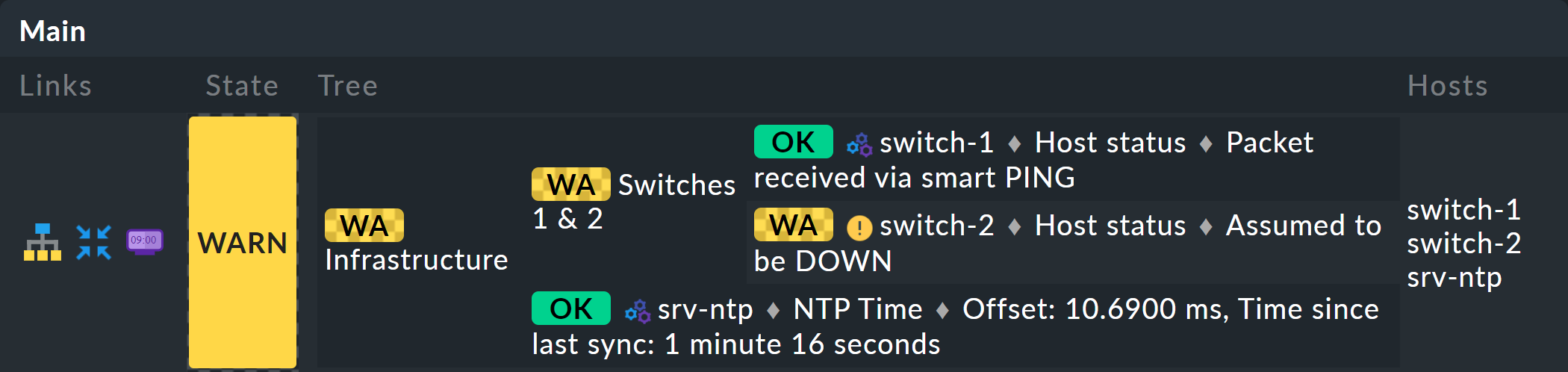
BI ツリーの表示を詳しく見てみましょう。 次の例は、2 つのスイッチのうち 1 つがDOWN 、もう 1 つがUP である場合の、ミニアグリゲーションの表示です。 希望どおり、アグリゲーションはWARN 状態になります。

また、ホストとサービスを標準化するために、DOWN のホストは、CRIT のサービスとほぼ同じように扱われていることがわかります。 同様に、UP は、それに応じてOK になります。
ツリーの葉は、ホストおよびサービスの状態を示しています。 ホスト名(およびサービスの場合はサービス名)はクリック可能で、対応するオブジェクトの現在の状態に移動します。 さらに、チェックプラグインからの最後の出力も確認できます。
各集約の左側には、2 つのアイコン と があります。 最初のアイコン をクリックすると、その集約のみを表示するページに移動します。 これは、複数の集約を作成した場合に主に役立ちます。 たとえば、ブックマークとして最適です。 をクリックすると、可用性の計算に移動します。 これについては後で詳しく説明します。
3.3. BI の試行:もしも?
ホスト名の左側には、興味深いアイコンがあります。 これは「もし、もし」の分析を行うためのものです。 その考え方は簡単です。 このアイコンをクリックすると、オブジェクトが別の状態にテスト的に切り替わります。ただし、これは BI インターフェース上でのみ行われ、実際の状態には影響はありません。 アイコンを複数回クリックすると、 (OK) から (WARN)、 (CRIT)、 (UNKNOWN) を経て、 に戻ります。
BI は、想定される状態に基づいて完全なツリーを構築します。
次の図は、実際に失敗したswitch-1 の他に、switch-2 もDOWN であると仮定した場合の最小のアグリゲーションを示しています。

これにより、集約の全体的な状態は、WARN からCRIT に変化します。 同時に、状態の色はチェックパターンで強調表示されます。 このパターンは、実際の状態が実際には異なることを示しています。 ホストまたはサービスの一部の変更は、全体的な条件とは関係がなくなる場合があるため、これは常に当てはまるわけではありません。たとえば、問題のホストまたはサービスがすでにCRIT である場合などです。
この「もし」の分析は、次のようなさまざまな方法で利用できます。
BI アグリゲーションが希望どおりに反応するかどうかをテストする場合。
メンテナンスのためにコンポーネントをシャットダウンするプランを立てている場合。
後者のシナリオでは、テストとして、サービス対象デバイスまたはそのサービスをに設定します。 その後、アグリゲーション全体がOK のままの場合、その障害は現在、冗長性によって補完されていることを意味します。
3.4. 偽の状態を使用した BI のテスト
BI アグリゲーションをテストする別の方法があります。 それは、オブジェクトの実際の状態を直接変更する方法です。 これは、テストシステムで特に実用的です。
この目的のために、コマンドには Fake check results というホスト/サービスコマンドがあります。
デフォルトでは、これは管理者ロールでのみ使用できます。
この方法は、たとえば、この記事で使用しているスクリーンショットの作成に使用されています。このスクリーンショットでは、switch-1 がDOWN に設定されています。
これが、Manually set to Down by cmkadmin というテキストが表示される理由です。

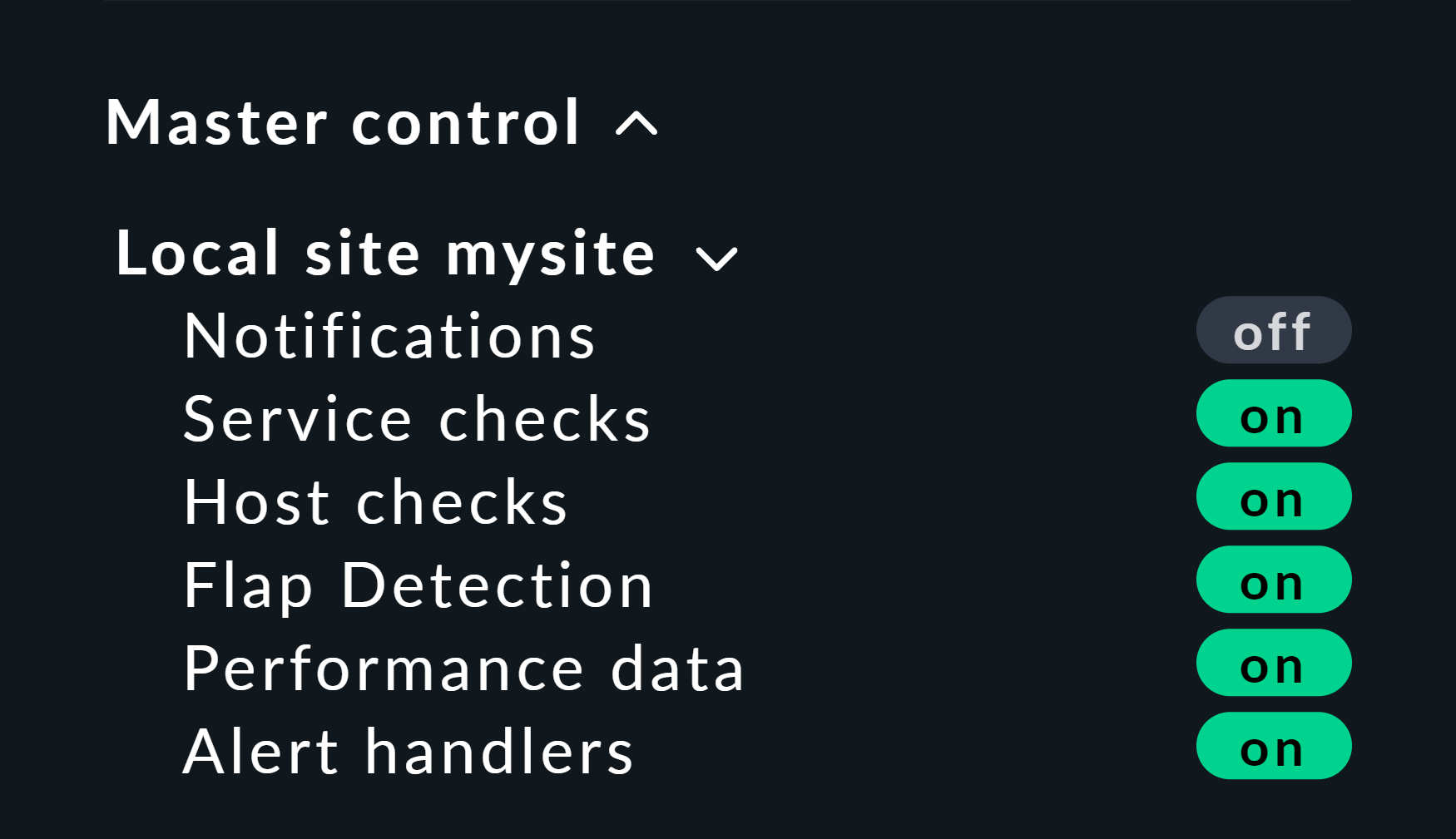
ここに役立つヒントがあります。 この方法を使用する場合は、関連するホストおよびサービスのアクティブチェックを無効にしておくことをお勧めします。 そうしないと、次のチェック間隔で、それらはすぐに実際の状態に戻ってしまいます。 面倒であれば、Master Control スナップインを使用して、グローバルに無効にしてください。 ただし、後で必ず有効に戻すことを忘れないでください。
3.5. BI グループ
集約を作成する際、Aggregation Groups 入力の可用性について簡単に説明しました。 例では、ここで提案されたMain を確認しました。 名前は自由に設定でき、集約を複数のグループに割り当てることも可能です。
グループは、表示したい集約の数が増えた場合に重要になります。 グループに移動するには、All aggregations ページに表示されているグループ名をクリックします。上記の例では、単に「Main 」の見出しをクリックします。 もちろん、現時点でこの単一の集約しかない場合は、ほとんど変化はありません。 しかし、よく見ると、次のようなことに気づくでしょう:
ページのタイトルが「Aggregation group Main 」に変更されています。
グループ見出し「Main 」が消えています。
このビューを頻繁に表示したい場合は、ブックマークに登録してください。サイドバーのBookmarks エレメントをブックマークに登録するとよいでしょう。
3.6. ホスト/サービスから集約へ
BI アグリゲーションを設定すると、ホストおよびサービスのコンテキストメニューに新しいアイコンが表示されます。
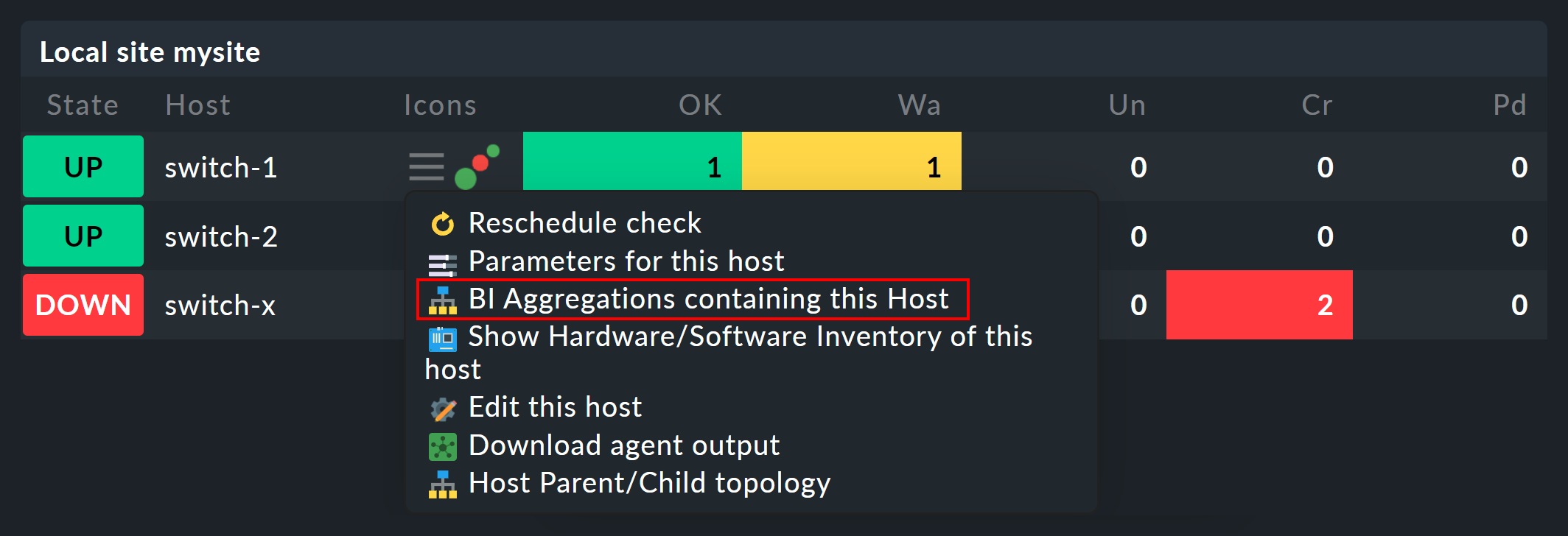
このアイコンをクリックすると、影響を受けるホストまたはサービスが含まれるすべてのアグリゲーションのリストが表示されます。
4. 設定パート 2: マルチレベルツリー
BI ステータスインターフェイスの簡単な紹介を終えましたので、設定に戻りましょう。もちろん、このようなミニアグリゲーションでは、誰をも感動させることはできません。
まず、ツリーを 1 レベル拡張します。つまり、2 レベル (ルートとリーフ) から 3 レベル (ルート、中間レベル、リーフ) に拡張します。 これを行うには、既存のノード「スイッチ 1 および 2」を NTP 時刻同期ステータスと組み合わせて、最上位ノード「インフラストラクチャ」を作成します。
しかし、一つずつ進めましょう。まず、結果のプレビューを確認します:
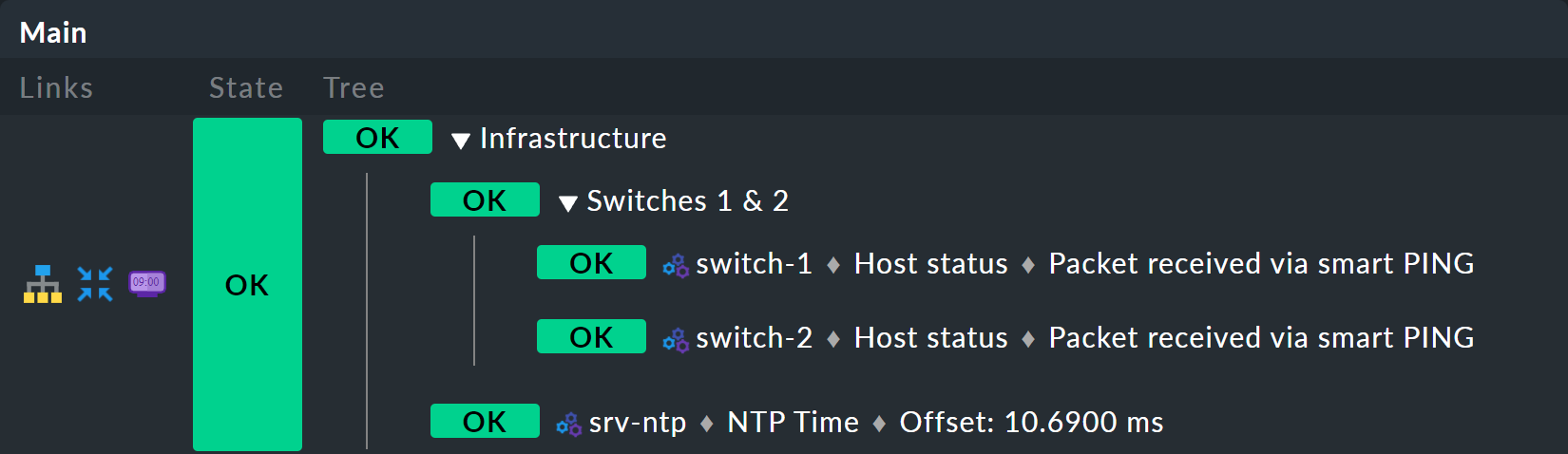
前提条件として、NTP Time というサービスを持つホストsrv-ntp があることです。

まず、サブノード 1 としてルール「Switches 1 & 2」を受信し、サブノード 2 としてsrv-ntp ホストのNTP Time サービスを直接受信する BI ルールを作成します。
ルールの最上部で、ルール ID として「infrastructure 」を選択し、その名前として「Infrastructure 」を選択します。
この時点では、これ以上の情報を入力する必要はありません。
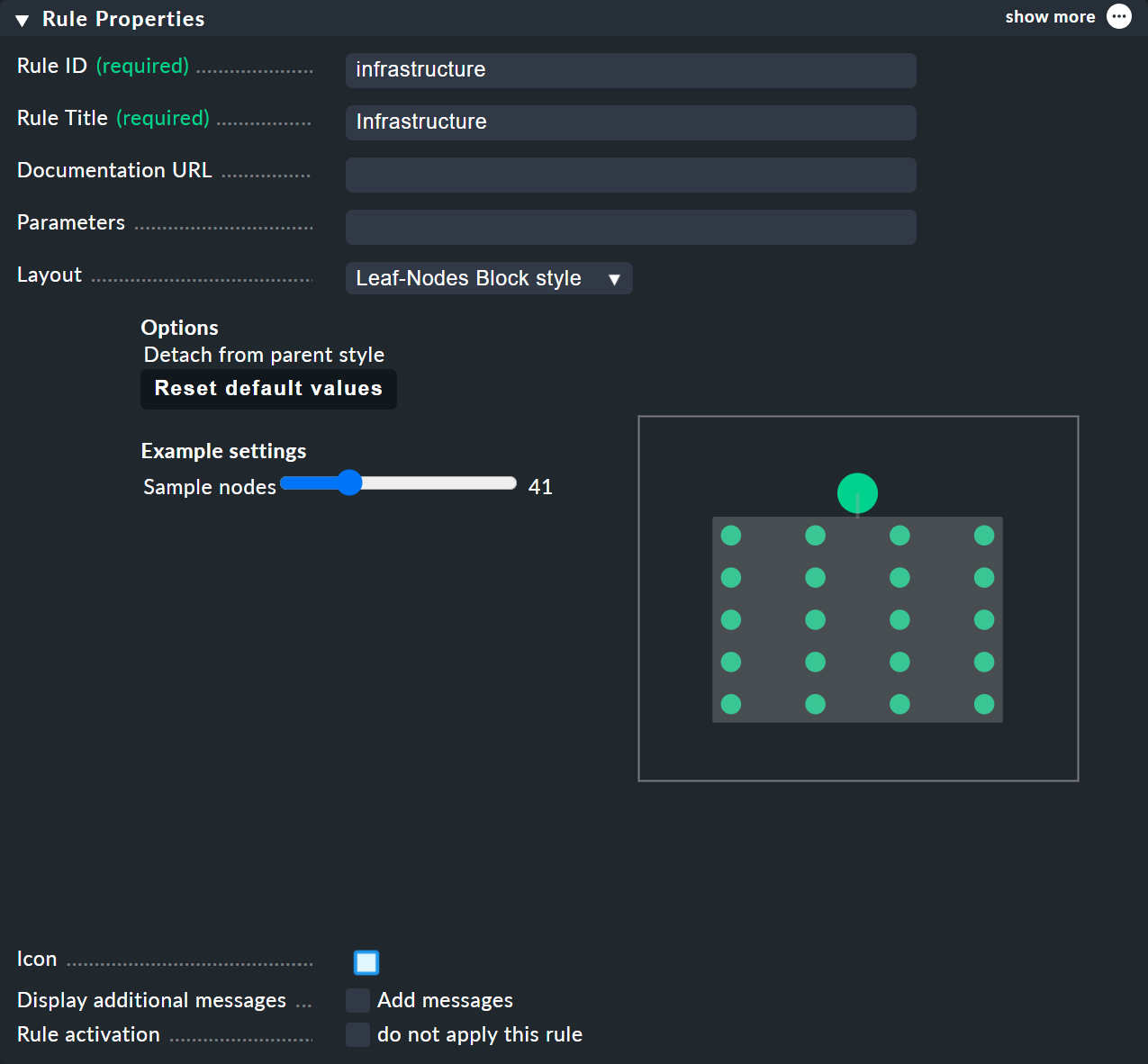
Child Node Generation で興味深い部分になります。 最初のエントリはCall a rule タイプになり、ルールとして上記のルールを選択します。これにより、これらのルールがサブツリーに効果的に「ぶら下げ」られます。
2 番目のサブノードはState of a service タイプです。ここでは、NTP Time サービス
(大文字と小文字を含む、正確なスペルに注意してください)と、正規表現によるNTP Time サービスを選択します。
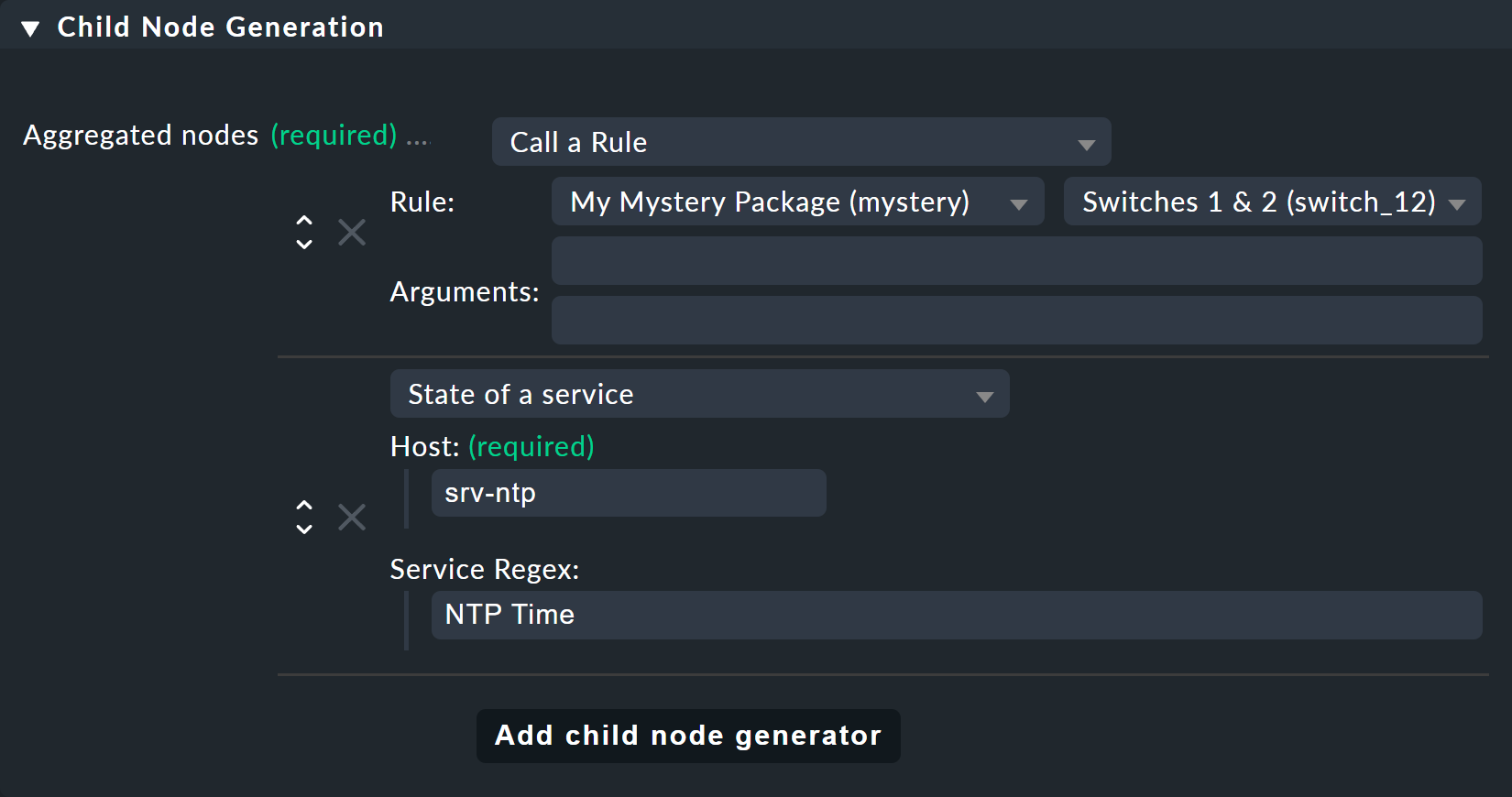
今回は、3 番目のボックスの「Aggregation Function 」を「Worst — i.e., take the worst state of all nodes 」に設定します。
この関数では、ノードの状態は、その下にあるサービスの最悪の状態から導出されます。
この場合、NTP Time がCRIT になった場合、ノードもCRIT になります。
もちろん、新しい、より大きなツリーを表示するには、もう一度集約を作成する必要があります。 既存の集約を変更して、これからは新しいルールが使用されるようにするのが最善です。
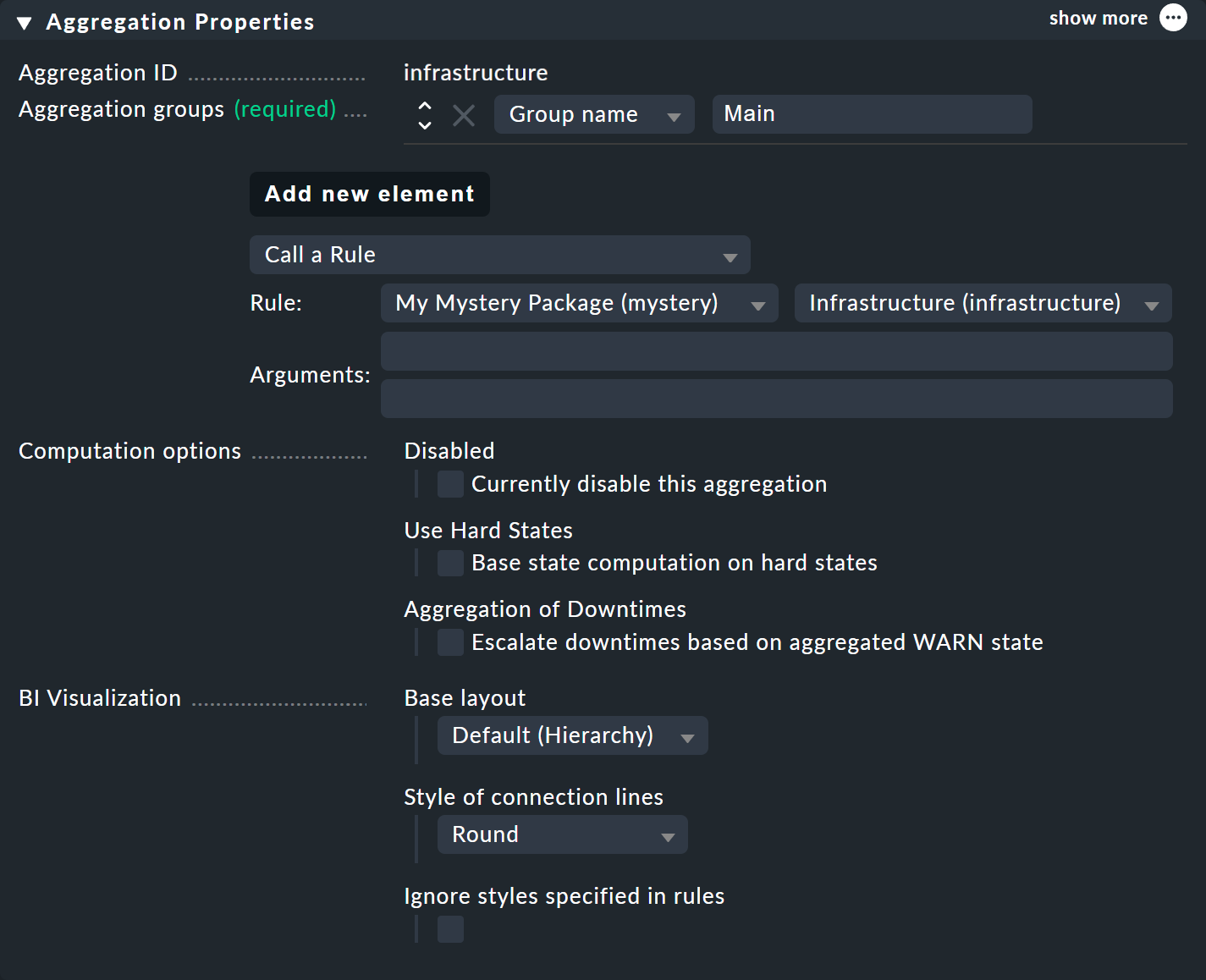
こうすることで、単一の集約を使用することになり、結果は以下のように表示されます(この場合は、両方のスイッチがOK に戻っています)。
5. BI の運用パート 2:代替表示
5.1. 概要
少し興味深いツリーができたところで、CMK が提供するさまざまな表示オプションについてもう少し詳しく見ていきましょう。 これらのオプションは、Display メニューからアクセスできるModify display options から開始します。 これにより、さまざまなオプションを含むボックスが開きます。 ボックスの内容は、ページに表示されているエレメントに常に一致しています。 BI の場合、現在 4 つのオプションがあります。
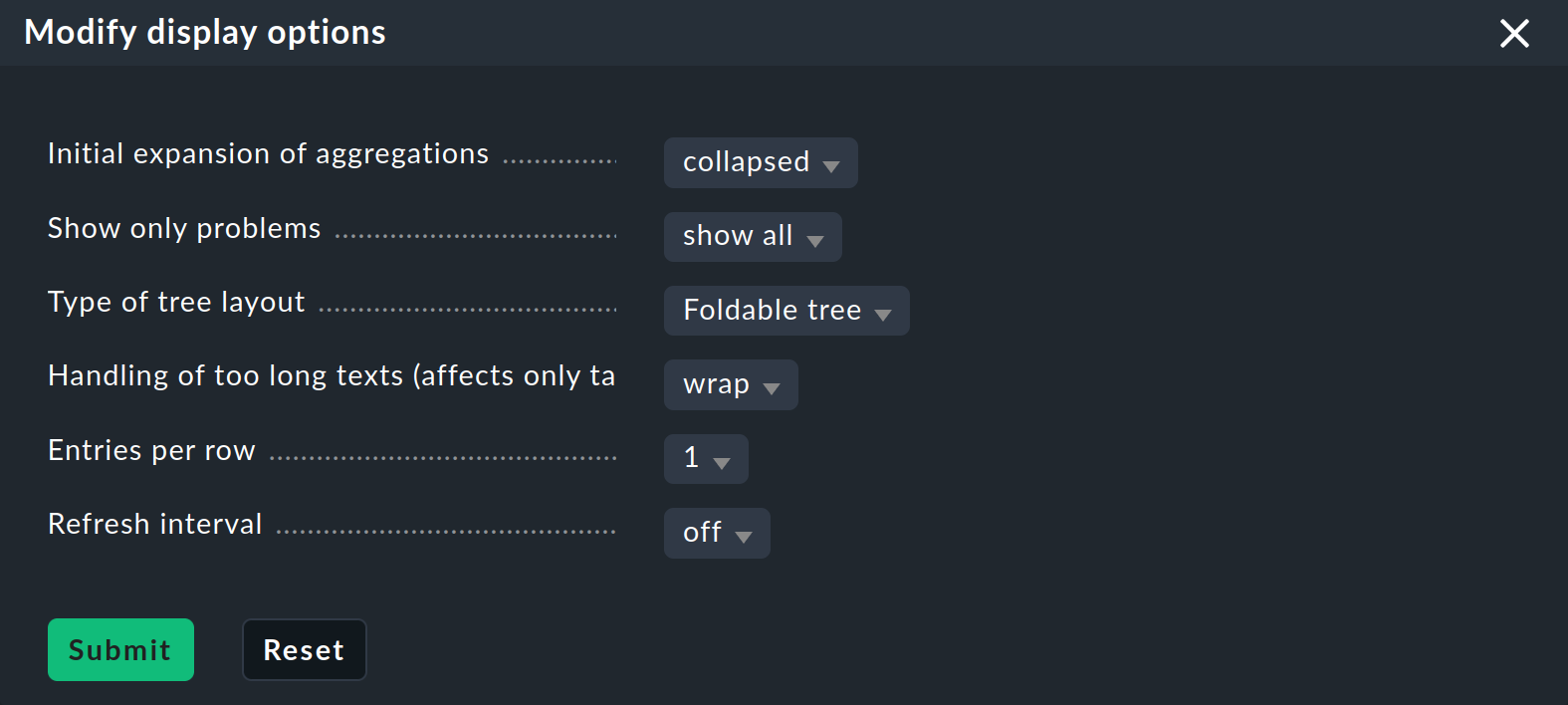
ツリーを即座に展開または折りたたむ
1 つの集約だけでなく、複数の集約を表示する場合は、Initial expansion of aggregations (ツリーの展開レベル)の設定が便利です。 ここでは、最初に表示するときにツリーを展開するレベルを定義します。 選択範囲は、閉じた状態(collapsed )から最初の 3 レベルまで、完全に開いた状態(complete )まであります。
問題のみを表示
「Show only problems 」オプションを有効にすると、OK 状態ではないブランチのみがツリーに表示されます。 この場合、次のように表示されます:

ツリーの表示タイプ
Type of tree layout (問題の表示)項目には、ツリーを表示するいくつかの代替タイプがあります。 そのうちの 1 つはTable: top down (セベリティ)と呼ばれ、次のように表示されます。
Boxes 表示は、特に多くの集約を同時に表示したい場合に、非常にスペースを節約できます。 ここでは、各ノードはクリックで展開できる色付きのボックスになっています。 ツリー構造は表示されなくなりますが、クリックするだけで問題の位置をすばやく見つけることができ、表示に必要なスペースも最小限で済みます。 この例では、ボックスが完全に展開されています。

5.2. 追加のオプション
最後に、Refresh interval を30、60、または90秒に設定し、Entries per row で列数を指定できます。
5.3. BI アグリゲーションの視覚化
表形式の表示に加え、Checkmk は BI アグリゲーションの視覚化もマスターしています。 アグリゲーションを新しい視点から、より明確に表示することができます。BI Visualization は、通常のアグリゲーションビューの からアクセスできます。

背景をクリックするとツリーを自由に移動でき、マウスホイールで表示全体を拡大縮小できます。 マウスポインタを個々のノードに置くと、そのノードに関連する状態情報がホバーウィンドウに表示されます。 マウスホイールでツリーの枝の長さを拡大縮小できます。
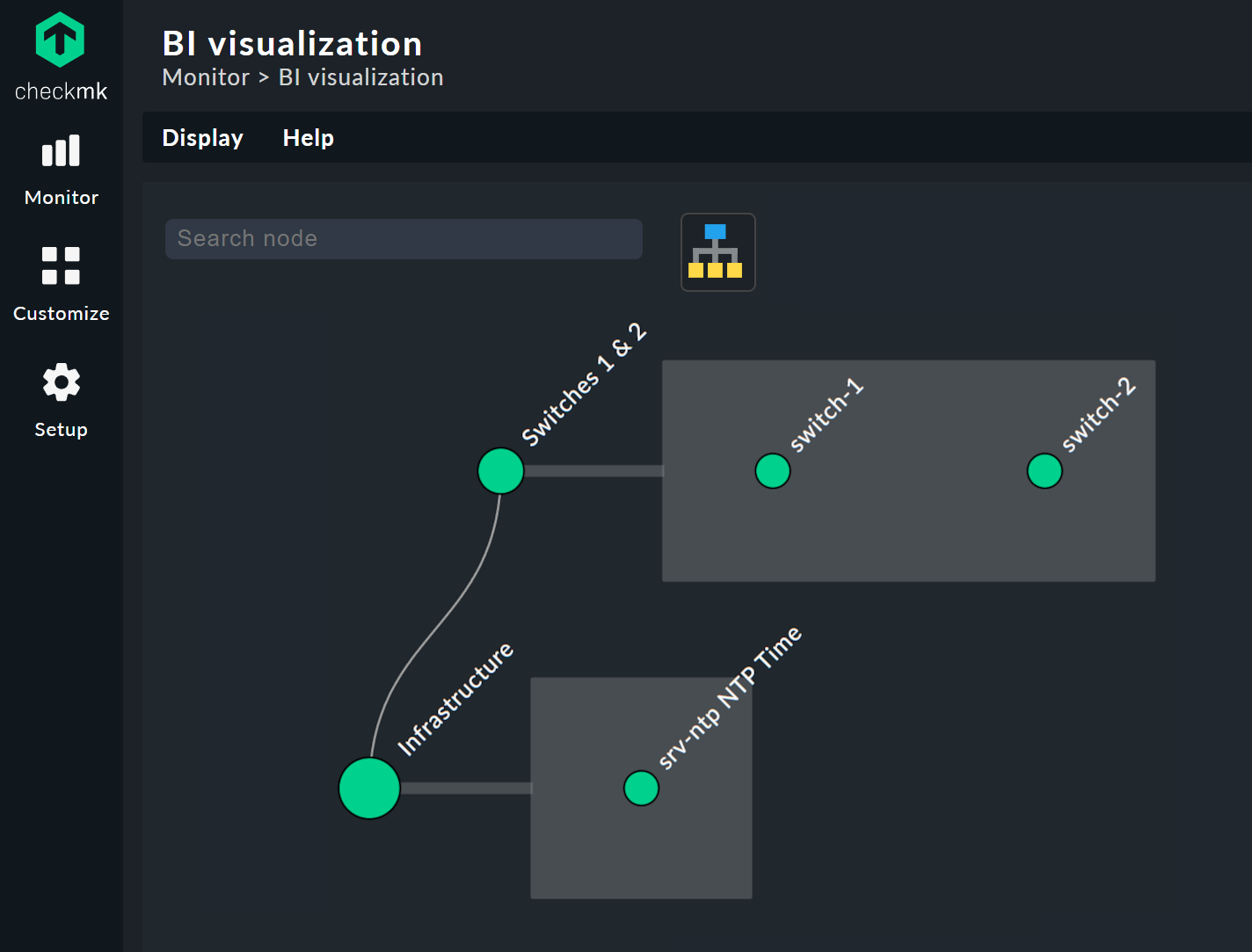
リーフノードをクリックすると、ホストまたはサービスの詳細ビューに直接移動します。 他のノードを右クリックすると、ノードのタイプに応じて、表示オプションや、たとえば、責任のあるルール自体(下の画像では「Edit rule 」)にアクセスできます。
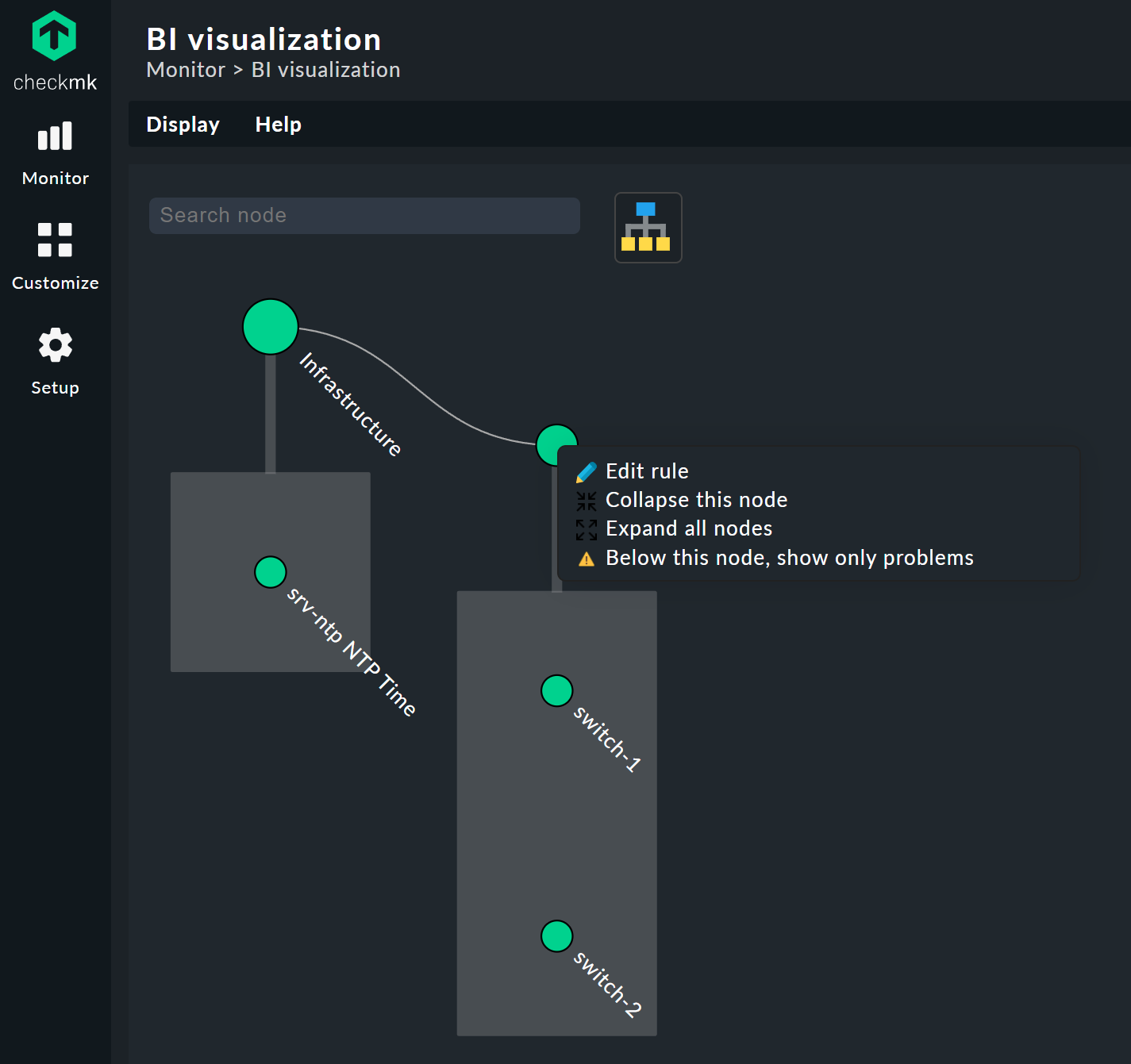
表示のカスタマイズ
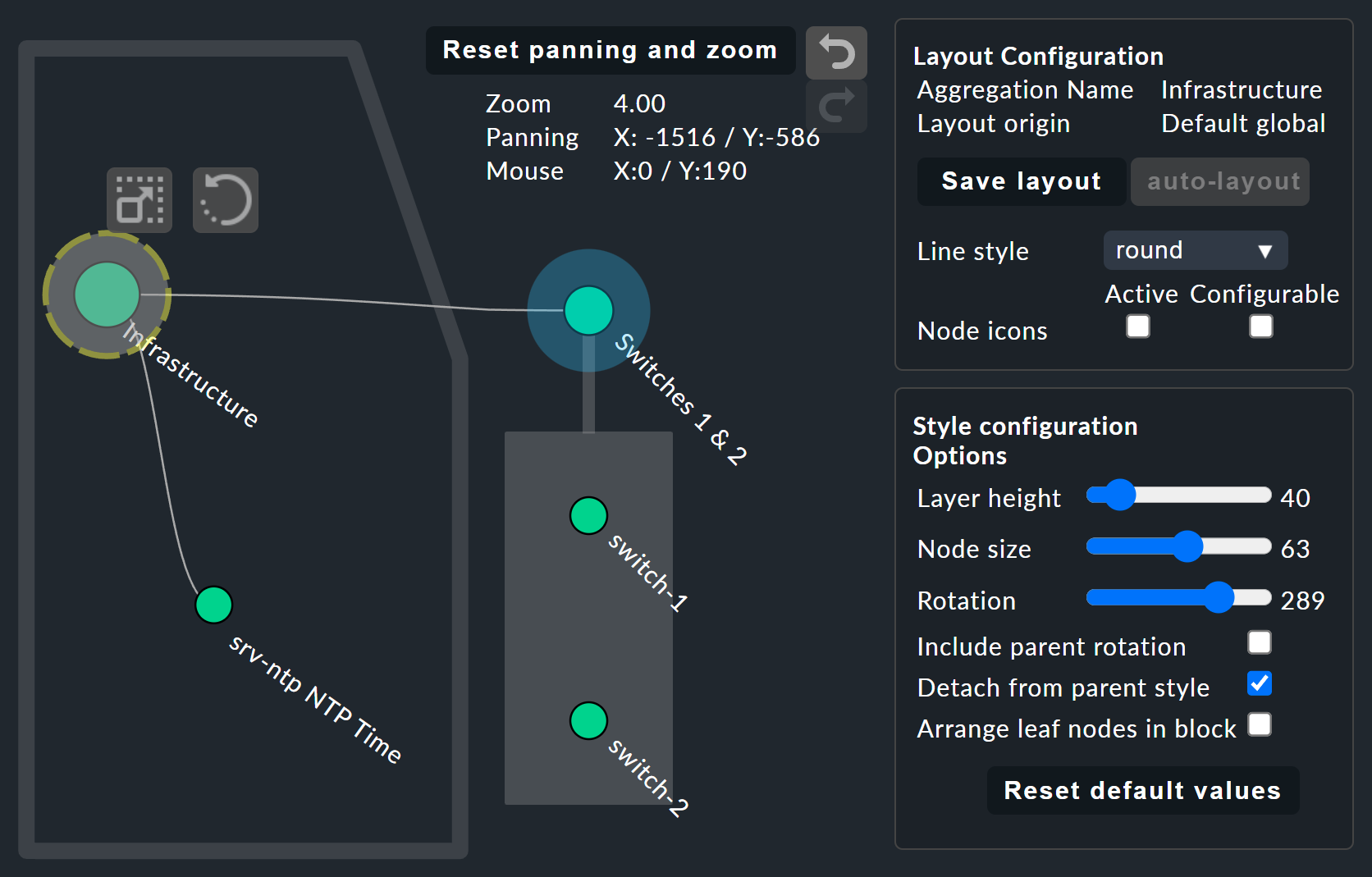
検索フィールドの上部にある をクリックして開く [Layout Designer] で、いよいよ興味深い部分に入ります。 まず、2 つの新しい項目、Layout Configuration と、ルートに 2 つの新しいアイコン と が表示されます。
設定では、さまざまな種類の線を選択し、Node icons を有効にすることができます。 これにより、Aggregation Functionセクションの BI アグリゲーションのルールで指定できるアイコンが表示されます (これは、ノードのコンテキストメニューから直接アクセスできます)。 アイコンとアイコンを使用してツリーを表示し、クリック&ドラッグで回転、または縦横のサイズを変更することができます。Style configuration ボックスには、その他の表示オプションも表示されます。 利用可能なオプションを試すことで、ご要件に最も適した設定を見つけることができます。
最もカスタマイズ可能なのは、ノードのコンテキストメニューです。デザイナーモードでは、このノードの階層について 4 種類の表示を選択できます。
Hierarchical style: シンプルな階層表示の標準設定です。
Radial style: 円のセクターをカスタマイズ可能な円形フォーマット。
Leaf-Nodes Block style: リーフノードは、灰色の背景のグループとして表示されます。
Free-Floating style: 吸引、間隔、枝の長さなどのオプションを備えた動的レイアウト。
スタイルが割り当てられたノードは、任意の場所に配置することができます。 使用可能なオプションもスタイルによって異なります。Radial style では、ルートノードに 3 つ目の アイコン があり、これを使用して表示を円のセクターに制限することができます。
Detach from parent style オプションを使用すると、ノードのスタイルをその親ノードのスタイルから切り離し 、これらのサブノードを別々に設定して自由に配置することができます。Include parent rotation も同様に、回転時に親ノードを含めるか除外するかを選択することができます。
これらのスタイルオプションは、基本的にすべて自明ですが、Free-Floating style についてのみ説明が必要です。 これは、重力シミュレーションで知られる引力および反発力のシステムです。
Center force strength |
ノードの重心です。 |
Repulsion force leaf |
他のノードに対する葉の反発力の強さです。 |
Repulsion force branches |
同じブランチ内の他のノードに対するノードの反発の強さ。 |
Link distance leaf |
葉ノードから前のノードまでの理想的な距離。 |
Link distance branches |
分岐ノードから前のノードまでの理想的な距離。 |
Link strength |
理想的な距離が強制される強度。 |
Collision box leaf |
他のノードを反発する葉ノード領域のサイズ。 |
Collision box branch/leaf |
他のノードを反発するブランチノード領域のサイズ。 |
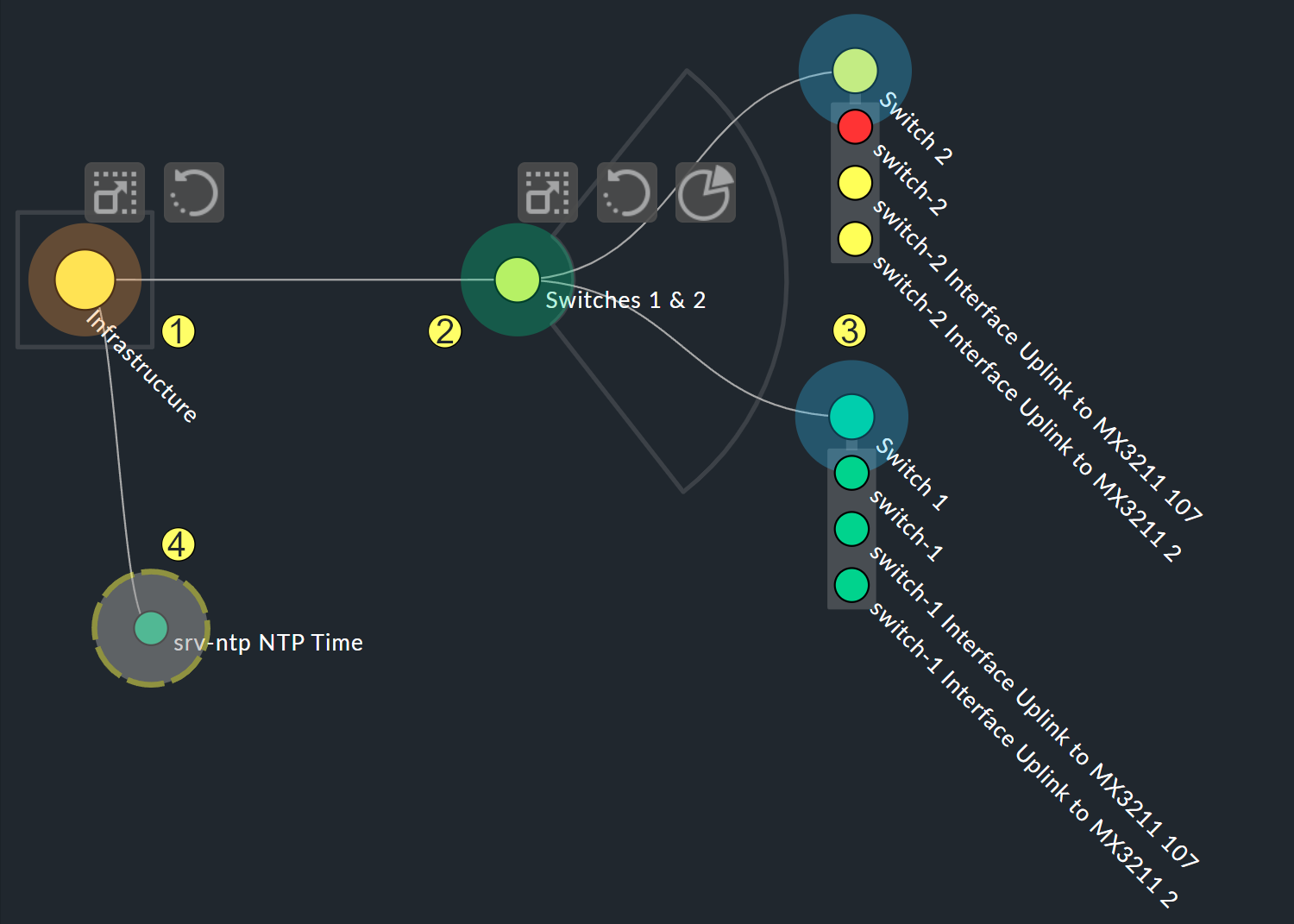
以下の画像は、Free-Floating styleのブランチを示しています — 個々の葉の位置は、指定されたオプションに応じて動的に決定されます。
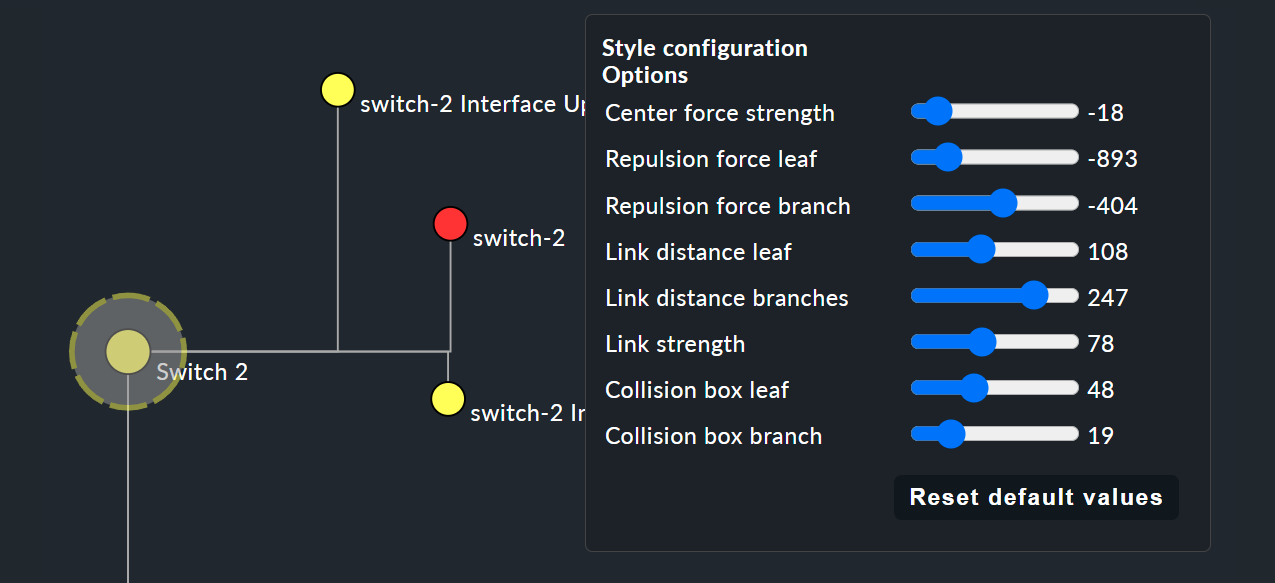
BI ルール用のレイアウトスタイルの指定
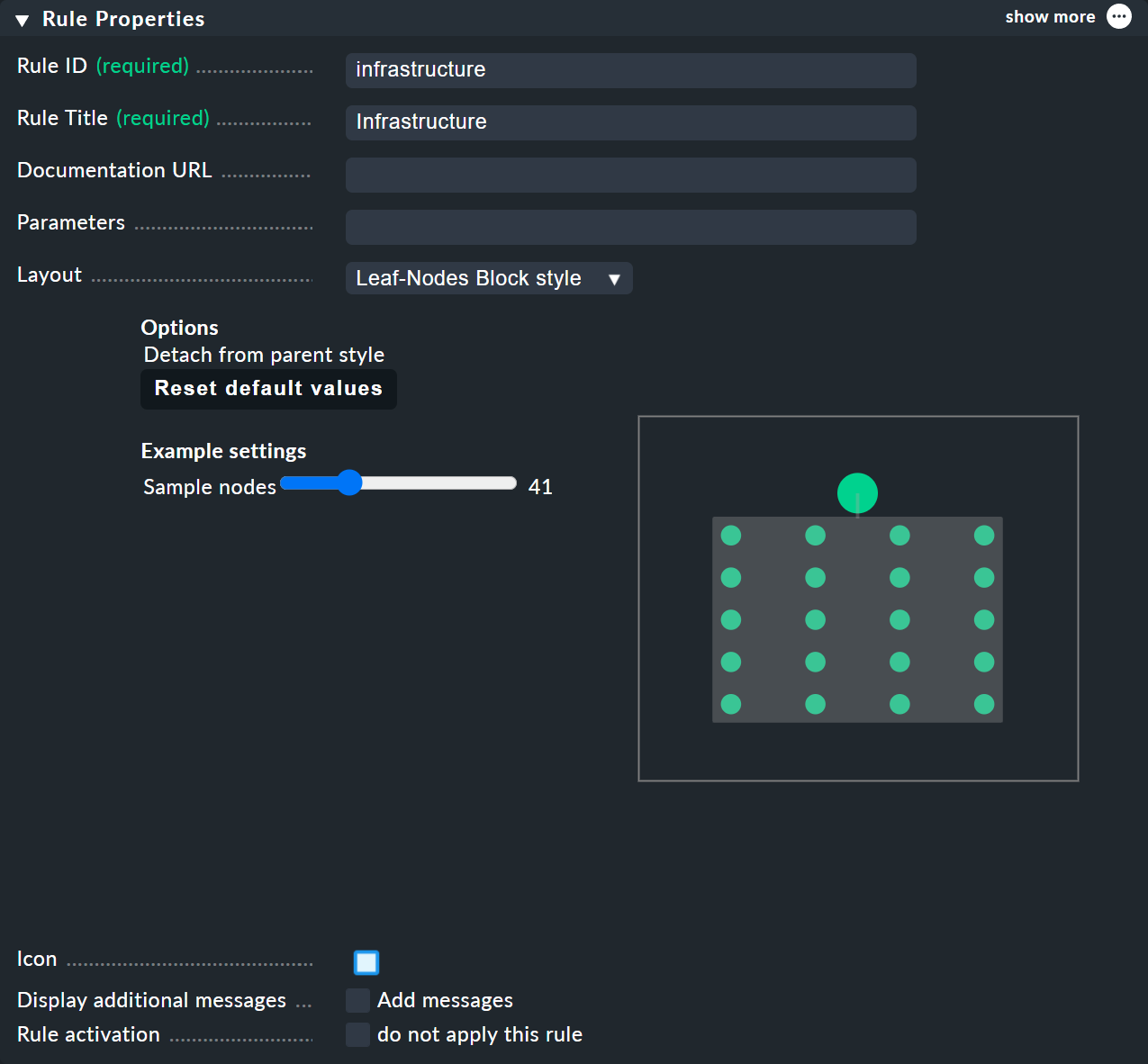
Rule Properties メニューのノードのコンテキストメニューからアクセスできる BI ルールではHierarchical 、Radial 、Leaf-Nodes Block のレイアウトを割り当て、関連するオプションを設定することができます。
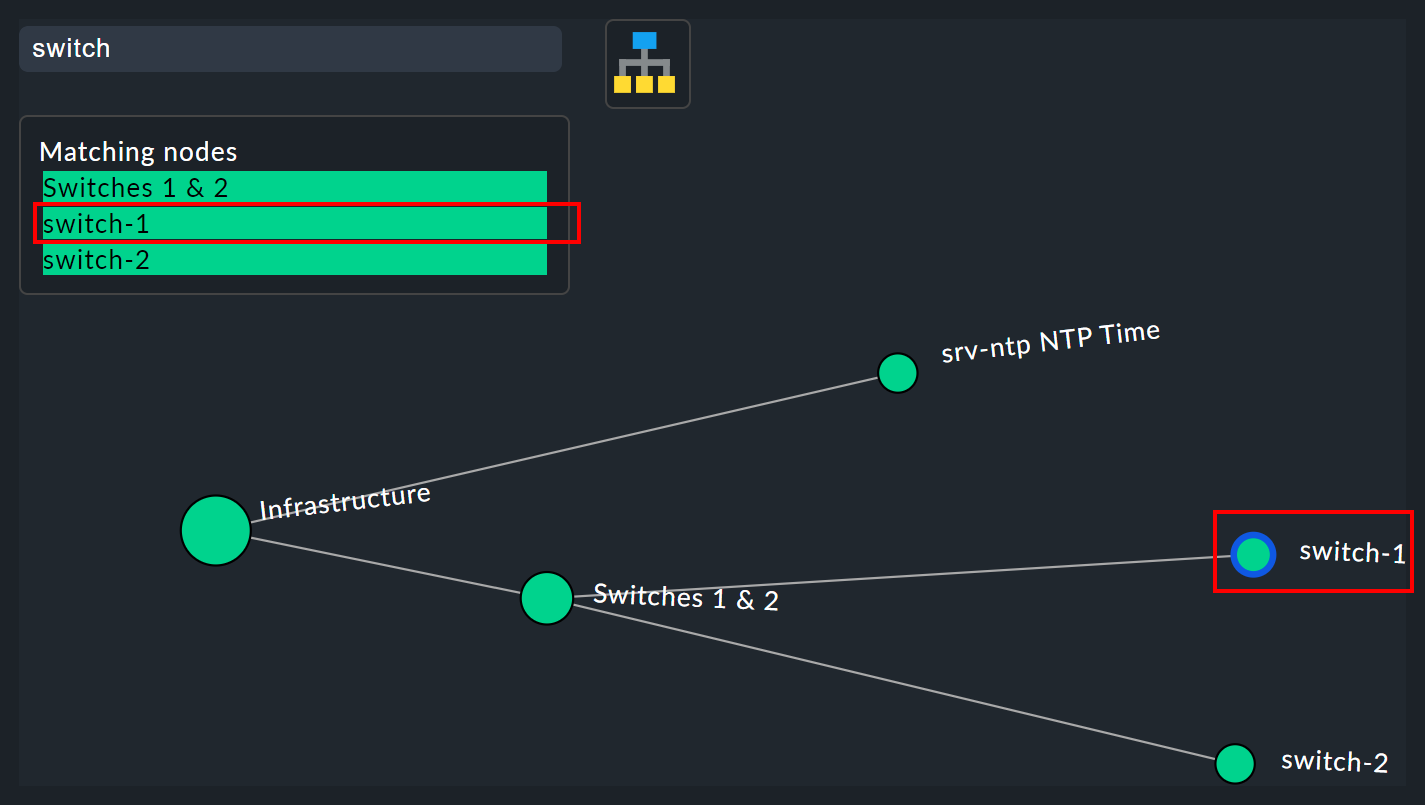
検索機能
検索機能は、大規模なツリーで非常に役立ちます。Search node の検索フィールドに、目的のノードの名前の部分を入力するだけで、一致するリストが直接、リアルタイムで表示されます。 この候補リストをマウスでなぞると、マウスポインタの下のツリーのノードが青い枠で強調表示されます。これにより、最初の位置確認が簡単になります。 リスト内のノードをクリックすると、そのノードがツリーの中心に表示されます。 このようにして、何百ものノードがある表示でも、インフラストラクチャ内の目的のセクションをすばやく見つけることができます。
6. 設定パート 3: 変数、テンプレート、検索
6.1. より高度な設定
設定を続けます。 いよいよ本題に入ります。 これまでの例はとても単純で、アグリゲーション内のすべてのオブジェクトを個別にリストアップすることが難なくできました。 しかし、より複雑になった場合はどうでしょうか? 同じまたは類似の依存関係を何度も繰り返し作成したい場合はどうでしょうか? アプリケーションが 1 つではなく複数のサイトを含む場合はどうでしょうか? データベースの何百もの個別サービスを 1 つの BI ノードにマージしたい場合はどうでしょうか?
このような要件には、より強力な設定方法が必要になります。 そして、まさにこれが Checkmk BI が他のツールと一線を画す点であり、残念ながら、この点に関しては学習曲線が少し急になります。 また、Checkmk BI で「ドラッグアンドドロップ」による設定ができない理由もここにあります。 しかし、その可能性を知ったら、きっと手放せなくなるでしょう。
6.2. パラメーター
まず、パラメータから始めましょう。 次のような状況を考えてみてください。 2 つのスイッチがUP であるかどうかだけでなく、アップリンクを担当する 2 つのポートの状態も知りたいとします。 これは、全体としては次の 4 つのサービスに依存しています。
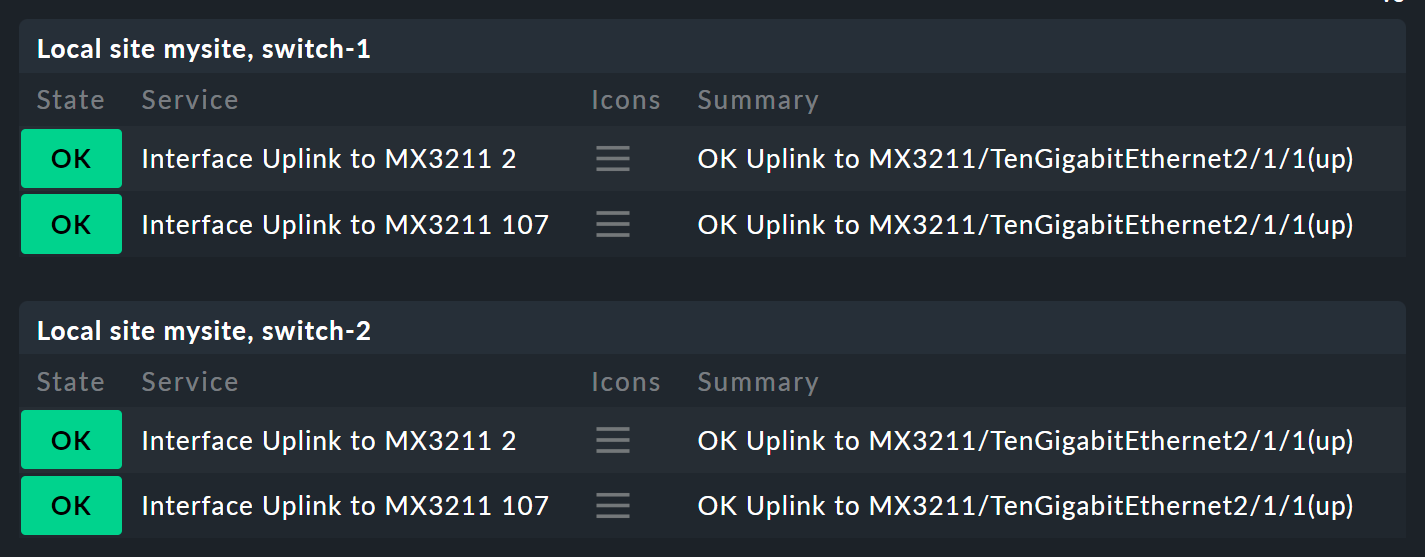
ここで、ノードSwitch 1 & 2 を拡張して、スイッチ 1 および 2 の 2 つのホスト状態を置き換え、それぞれにホスト状態と2 つのアップリンクインターフェースを示すサブノード を追加します。 この 2 つのサブノードは、Switch 1 またはSwitch 2 である必要があります。
実際には、2 つの新しいルール(スイッチごとに 1 つずつ)が必要になります。
新しいswitch ルールを作成し、それにパラメータを設定してこれを行うのが良いでしょう。
このパラメータは、親ノードからルールを呼び出すときに呼び出す変数です。ここでは、古いSwitch 1 & 2 ルールから提供することができます。
この例では、1 または2 のいずれかを渡すだけで済みます。
パラメータには、自由に名前をつけることができます。
ここでは、NUMBER という名前を使用します。
大文字のスペルは、ここではまったく任意です。
小文字の方が美しいと思う場合は、小文字を使用してもかまいません。
ルールの見出しは、次のように表示されます。
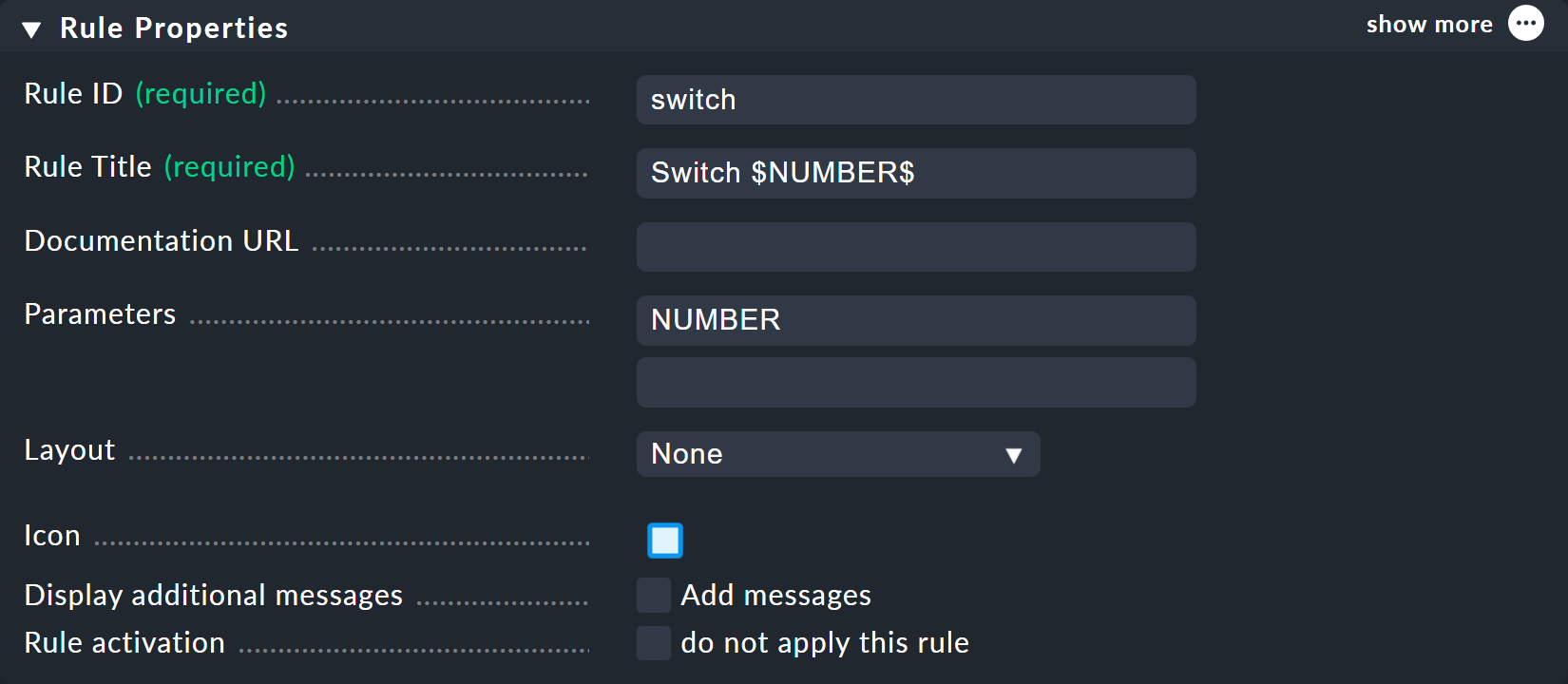
新しいルールの ID として「switch 」を選択できます。Parameters には、変数の名前「NUMBER 」を入力してください。
ここで重要なのは、変数がルールの「Rule Title 」で使用されていることです。そうしないと、両方のノードが「switch 」と呼ばれ、同じ名前になってしまうからです。
変数を使用する場合は、Checkmk の多くの場所で通常どおり、先頭と末尾にドル記号を付けます。
その結果、2 つのノードは「Switch 1 」と「Switch 2 」と呼ばれます。
サービス名には、デフォルトでプレフィックス一致が設定されています。
Child node generator の場合、まず最初にホストの状態を挿入する必要があります。
ホスト名に「1 」や「2 」の代わりに、変数を使用することができます。この場合も、変数の先頭と末尾に「$ 」を付けます。
アップリンクインターフェースのホスト名についても同様です。
ここで 2 つ目のトリックがあります。上の小さなサービスリストからご想像のとおり、アップリンクのサービスはスイッチごとに異なる名前が付けられています。
しかし、BI はサービス名を正規表現を使用してプレフィックス一致として解釈するため、これは問題ではありません。これは、よく知られているサービスルールとまったく同じです。
したがって、Interface Uplink と記述するだけで、Interface Uplinkで始まる、それぞれのホスト上のすべてのサービスをキャッチすることができます。
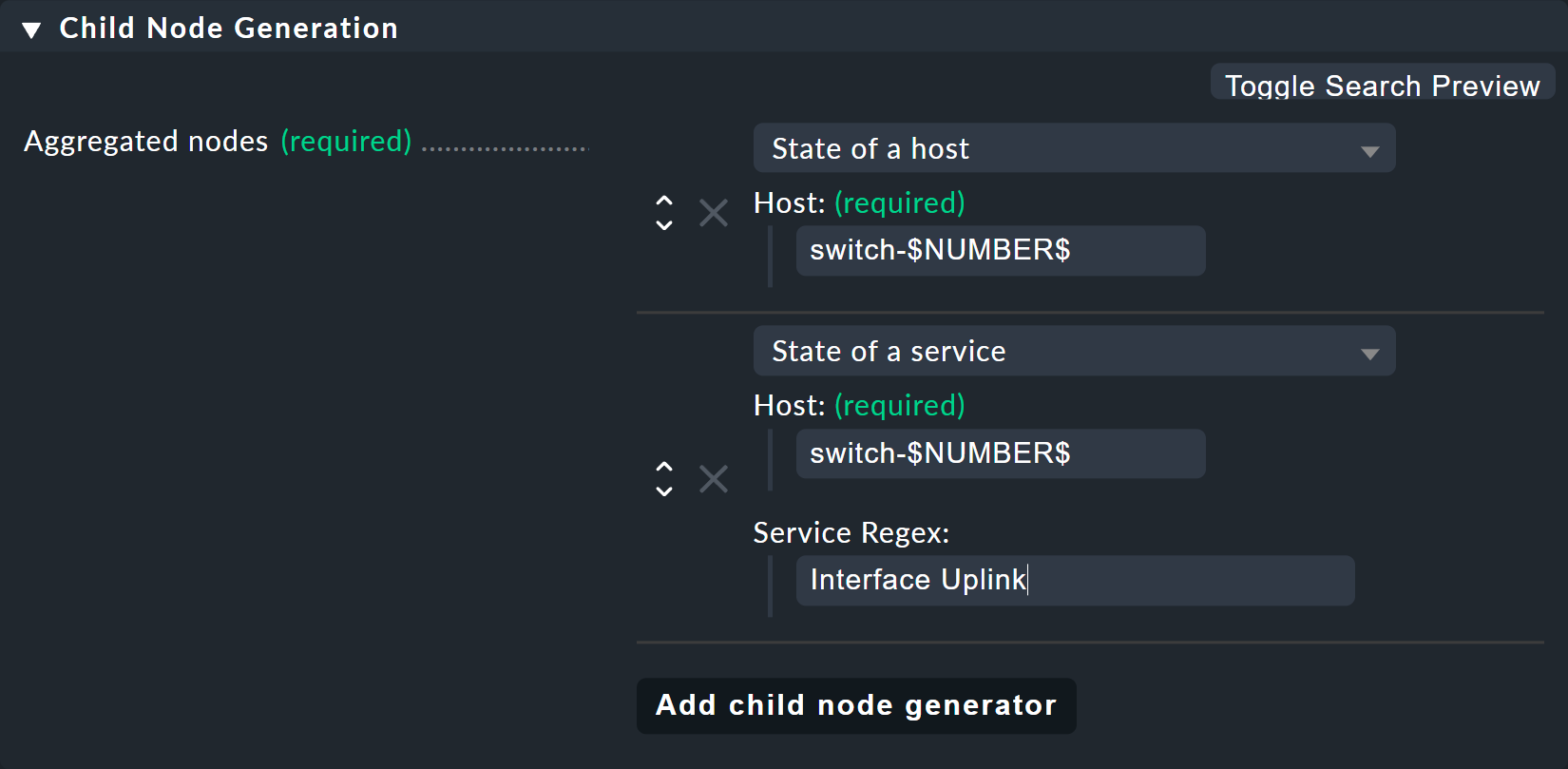
ちなみに、$ を追加すると、プレフィックスの動作を無効にすることができます。
正規表現では、$ は「テキストはここで終了しなければならない」という意味です。
したがって、Interface 1$ はInterface 1 とのみ一致し、たとえばInterface 10 とは一致しません。
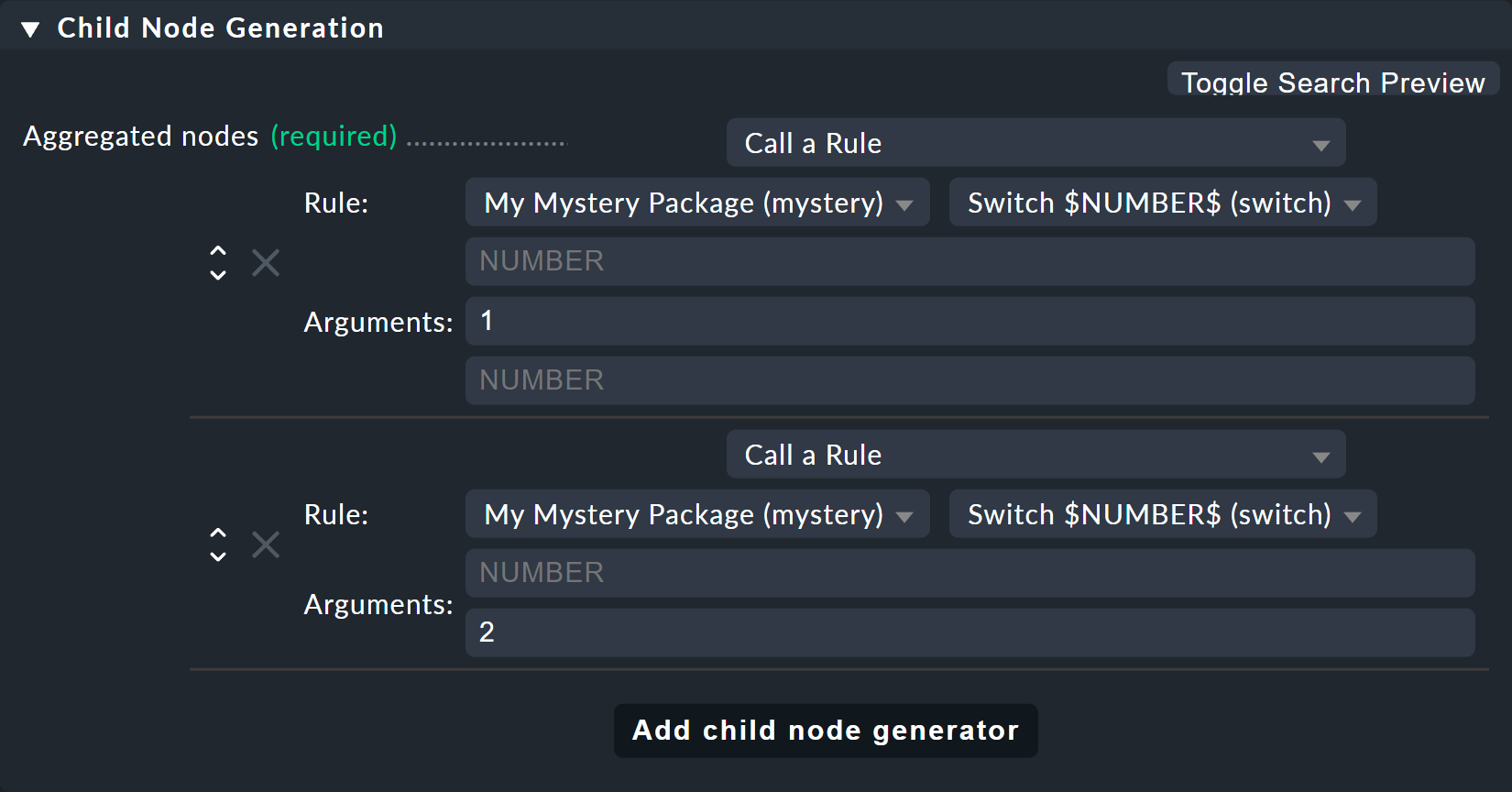
次に、古いSwitch 1 & 2 ルールを変更して、ホストの代わりに、この新しいルールが2つのスイッチのそれぞれに対して1回だけ呼び出されるようにします。
また、ここで、1 および2 という値が、変数NUMBER のパラメータとして指定されています。
これで、3 つのレベルからなるきれいなツリーができました。
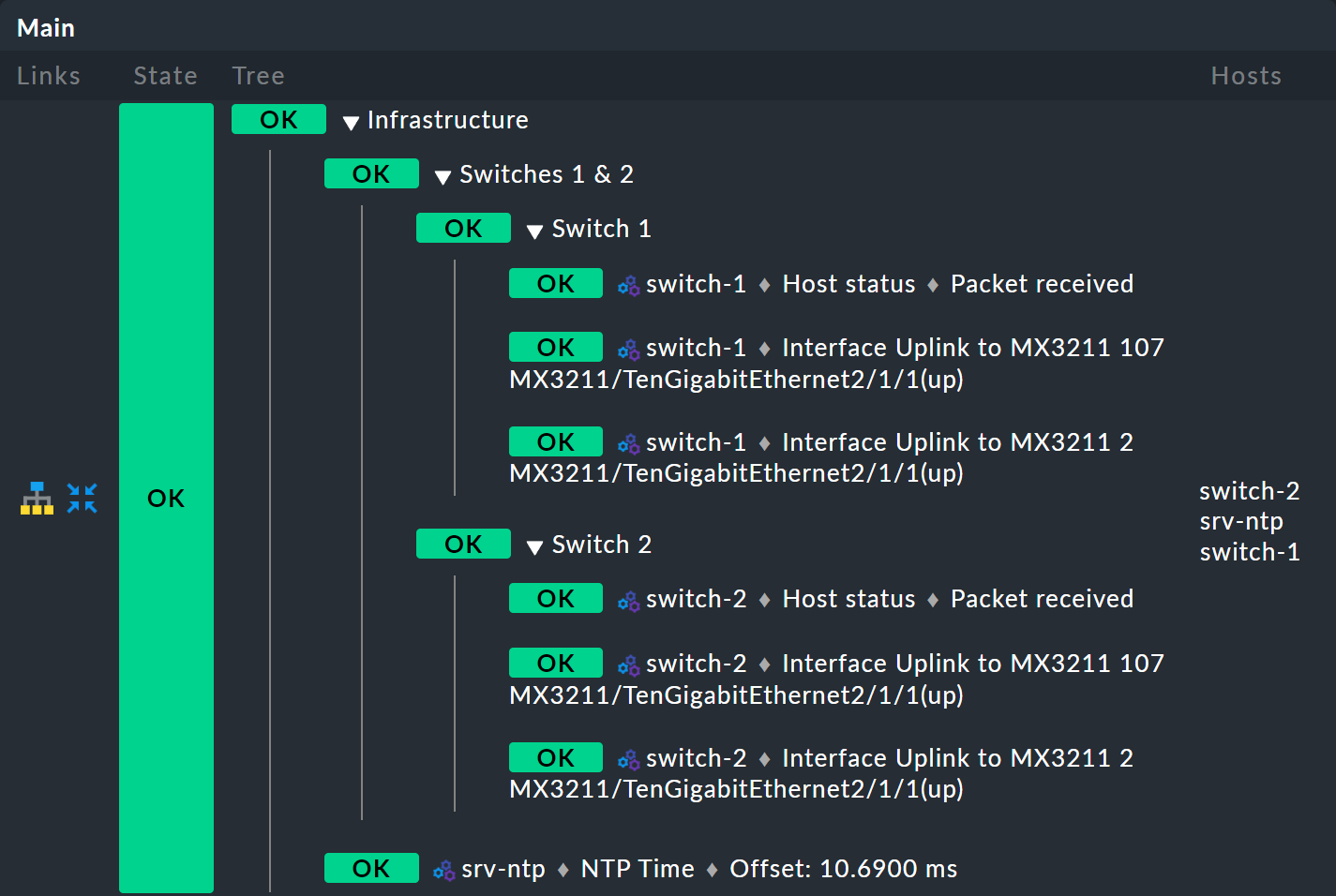
6.3. 正規表現、欠落オブジェクト
正規表現については、もう一度詳しく見ておく価値があります。 サービス名の一致では、基本的に正規表現のみに関係することを暗黙のうちに前提としていました。 前述のように、プレフィックス一致があります。
したがって、BI ノードで、たとえばサービス名にdisk を指定した場合、Disk で始まる、当該ホストのすべてのサービスがキャプチャされます。
以下の原則が一般的に適用されます:
ノードが(現在)存在しないオブジェクトを参照している場合、それらは単に省略されます。
ノードが空になった場合は、そのノードは省略されます。
集約のルートノードも空の場合、その集約自体が省略されます。
これは、最初は少し大胆すぎると思われるかもしれません。 なぜなら、存在すべき項目をコメントも付けずに単に省略することは危険ではないのか、と。
しかし、この概念がどれほど実用的であるかは、時間が経てばお分かりになると思います。 この概念により、さまざまな状況に対応できる「スマート」なルールを作成することができるからです。 アプリケーション内のすべてのサイトに存在しないサービスがありますか? 問題ありません。そのサービスが存在するかどうかのみが考慮されます。 ホストやサービスを監視から一時的に除外することはできますか? その場合は、エラーなどになることなく、BI から単に消えるだけです。 BI は、監視設定が完全であるかどうかを確認するためのものではありません。
ちなみに、この原則は明示的に定義されたサービスにも適用されます。
サービス名は、.* などの特殊文字が含まれていなくても、常に正規表現としてビューされるため、実際には存在しないからです。
これは常に自動的に検索パターンになります。
6.4. 検索結果としてノードを作成する
しかし、さらに自動化を進め、とりわけ変更に柔軟に対応することは可能です。
例で示した 2 つのアプリケーションサーバーsrv-mys-1 およびsrv-mys-2 の例を続けてみましょう。
ツリーは引き続き拡大します。Infrastructure ノードはレベル 2 に移動します。
そして、最終的なルートとして、The Mystery Application というタイトルのルールを設定し、その下にすべてを配置します。Infrastructure の横に、Mystery Servers という名前のノードを作成します。
このノードの下に、現在 2 台の不明なサーバーを配置します。
それぞれに、いくつかの汎用サービスがアグリゲーションされます。
結果は次のようになります。
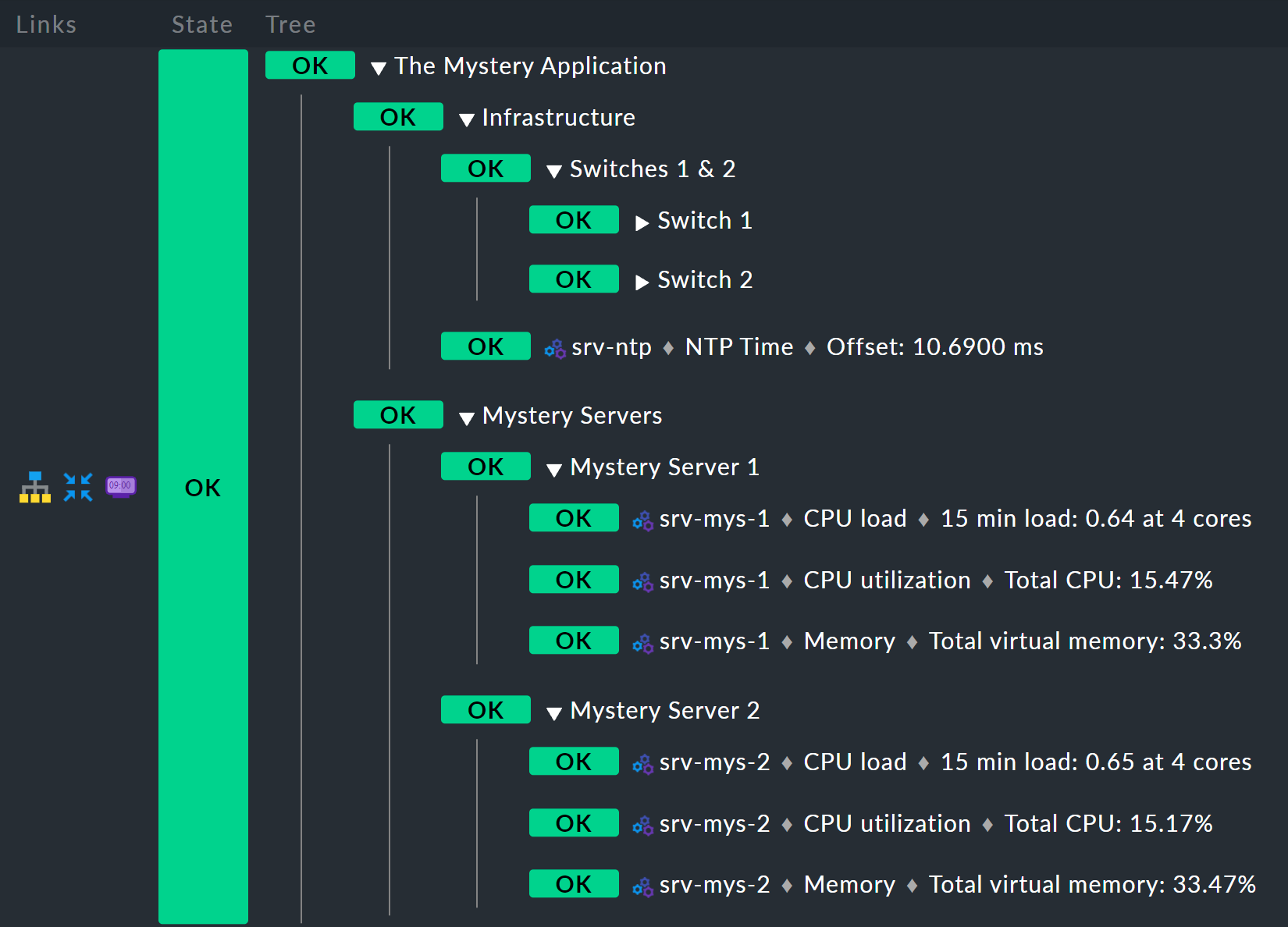
一番下のルール:謎のサーバー X
BI では、常に下から始めるのが最も簡単な方法です。
以下は、新しいMystery Server X ルールです。
もちろん、サーバーごとに個別のルールを設定する必要がないよう、パラメータを使用します。
パラメータの名前は、たとえば「NUMBER 」とすることができます。
このパラメータには、後で「1 」または「2 」の値を設定します。
上記と同様に、Parameters のヘッダーに「NUMBER 」を再度入力する必要があります。
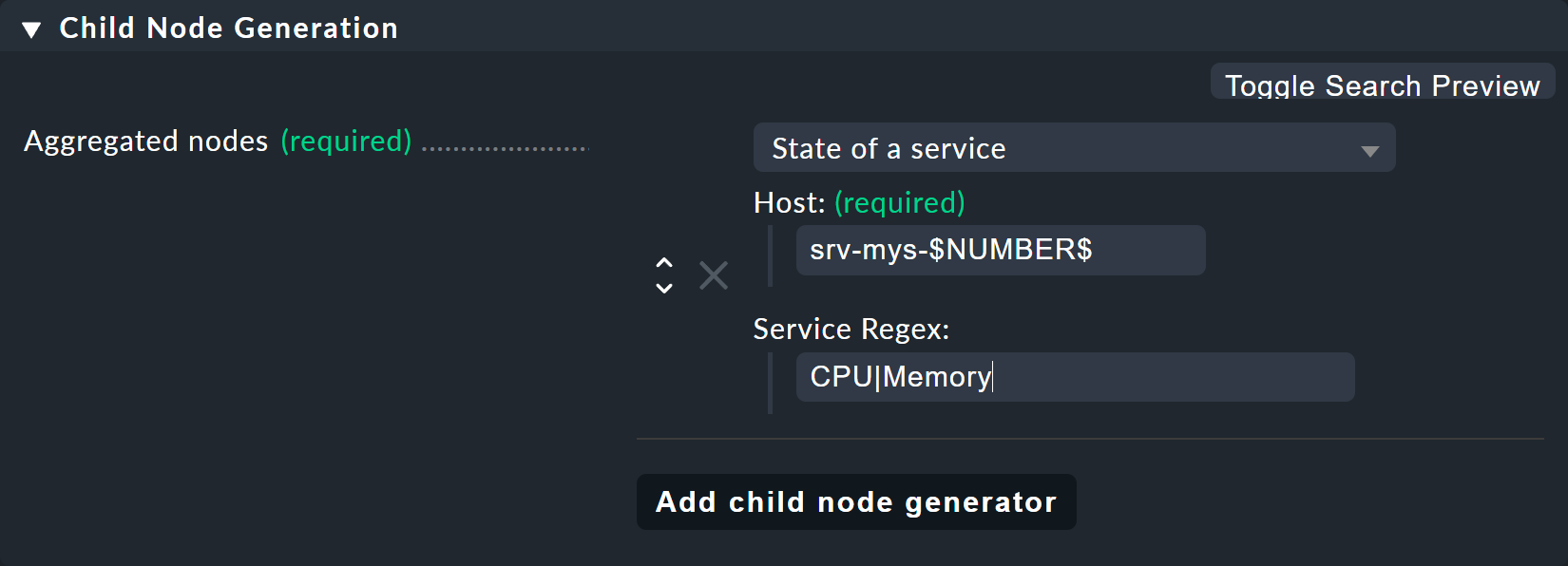
その結果、次のような子ノードジェネレータが生成されます。
その結果、子ノードジェネレータは次のようになります。
以下は注目すべき点です:
ホスト名
srv-mys-$NUMBER$は、パラメータの番号を使用します。Service Regex では、縦棒を使用して代替サービス名 (プレフィックス) を許可する、洗練された正規表現
CPU|Memoryが使用されており、これはCPUまたはMemoryで始まるすべてのサービスと一致します。 これにより、設定が 2 倍になることを回避できます。
ちなみに、この例は、もちろん必ずしも完璧というわけではありません。 たとえば、ホスト自体の状態はまったく記録されていません。 したがって、サーバーの 1 つがDOWN になった場合、このサーバー上のサービスは廃止されます (stale になります) が、状態はOK のままとなり、集約は障害を「認識」しません。 このようなことを知りたい場合は、サービスの状態だけでなく、ホストの状態も記録しておく必要があります。
中間ルール: 謎のサーバー
このルールは興味深いものです。2 つのミステリーサーバーを 1 つのノードにまとめます。 これで、サーバーの数が固定ではなく、後で 3 つ以上になる場合や、ミステリーアプリケーションに数十のサイトがあり、それぞれサーバーの数が異なる場合にも対応可能になります。 このトリックは、子ノードジェネレータのタイプ xml-ph-0000@deepl.internal にあります。
その秘訣は、子ノードジェネレータのタイプCreate nodes based on a host search にあります。 これは、既存のホストを検索し、見つかったホストに基づいてノードを作成します。 これは次のように表示されます。
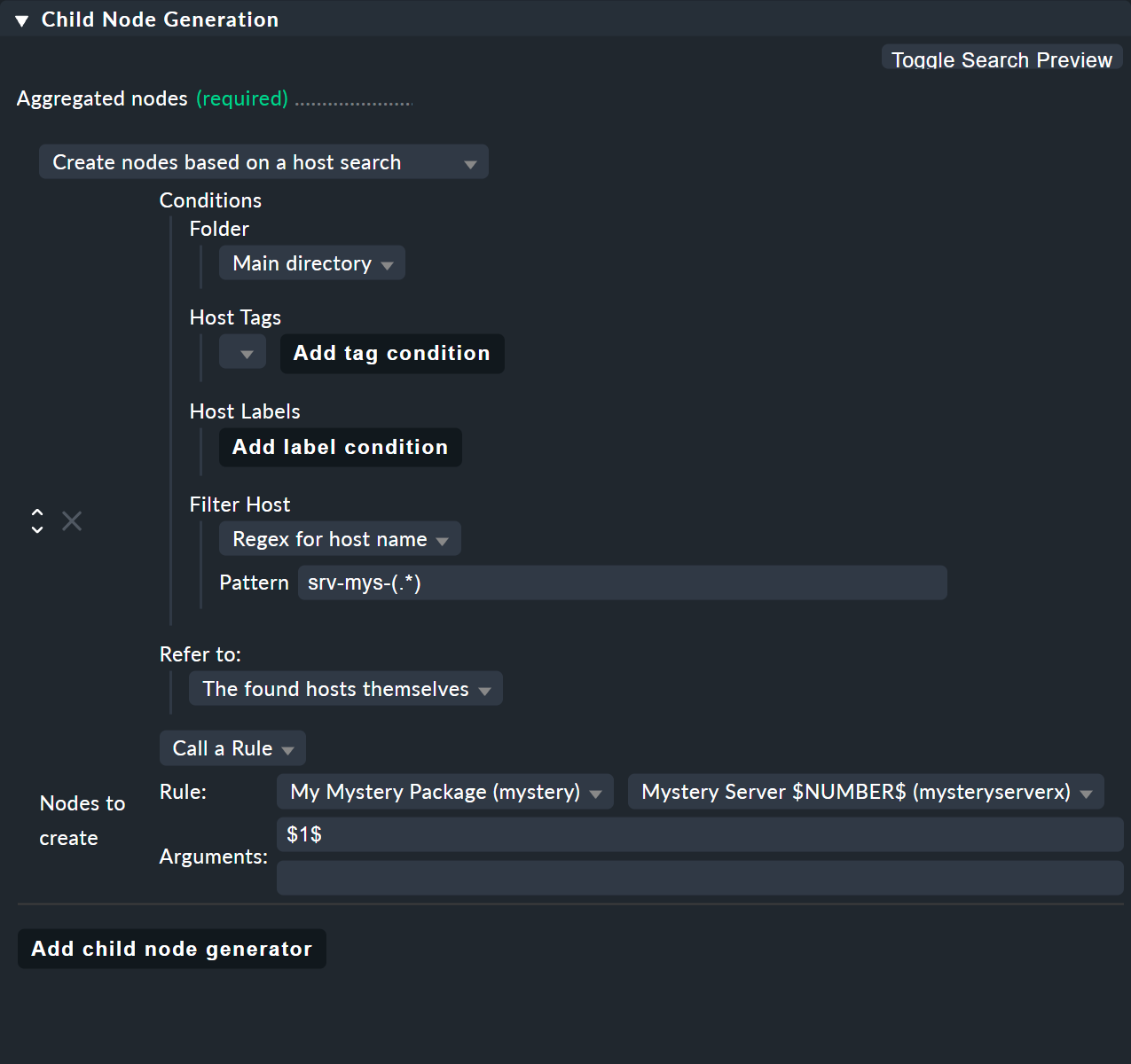
全体は次のように機能します:
ホストを見つけるための検索条件を策定します。
見つかったホストごとに子ノードが作成されます。
見つかったホスト名の一部を切り取り、それをパラメータとして指定することができます。
検索は始まりにすぎません。
通常どおり、ホストタグを使用できます。
この例では、ホストタグを省略し、代わりにホスト名として正規表現srv-mys-(.*) を使用しています。
これは、srv-mys- で始まるすべてのホスト名と一致します。.* は、任意の文字列を表します。
.* を括弧で囲むことが重要です。つまり、(.*) とします。
括弧を使用することで、一致は、いわゆるグループを形成します。
これにより、.* と完全に一致するテキストが取得(および保存)されます。ここでは、1 または2 です。
マッチグループは内部で番号が付けられます。
ここでは、番号 1 が 1 つだけ割り当てられています。
後で、$1$ で一致したテキストにアクセスできます。
これで、2 つのホストが検索されます。
| ホスト名 |
$1$の値 |
|---|---|
|
1 |
|
2 |
見つかった各ホストに対して、Call a rule 関数を使用してサブノードを作成します。
先ほど作成したルール「Mystery Server $NUMBER$ 」を選択します。NUMBER の引数として、マッチグループ「$1$ 」を渡します。
これで、サブルールMystery Server $NUMBER$ が 2 回呼び出されます。1 回目は1 で、2 回目は2 で呼び出されます。
今後、srv-mys-3 という名前の新しいサーバーが監視に追加された場合、これは BI アグリゲーションに自動的に表示されます。
ホストの状態は関係ありません。
サーバーがDOWN であっても、もちろんアグリゲーションから削除されることはありません。
確かに、ここでは学習曲線が非常に急です。 この方法は実に複雑です。 しかし、一度試してみて理解すれば、このコンセプト全体の威力を実感できるでしょう。そして、ここではまだ、利用可能な可能性のほんの一部にしか触れていません。
トップレベルルール
新しいトップレベルノードThe Mystery Application は、非常にシンプルになりました。Call a rule タイプの子ノードが 2 つある新しいルールが追加で必要になります。 この 2 つのルールは、既存のInfrastructure ルールと、新しく作成したMystery Servers ルールです。
6.5. サービス検索を使用してノードを作成する
ホスト検索と同様に、Create nodes based on a service search という子ジェネレータタイプもあります。 以下に例を示します。
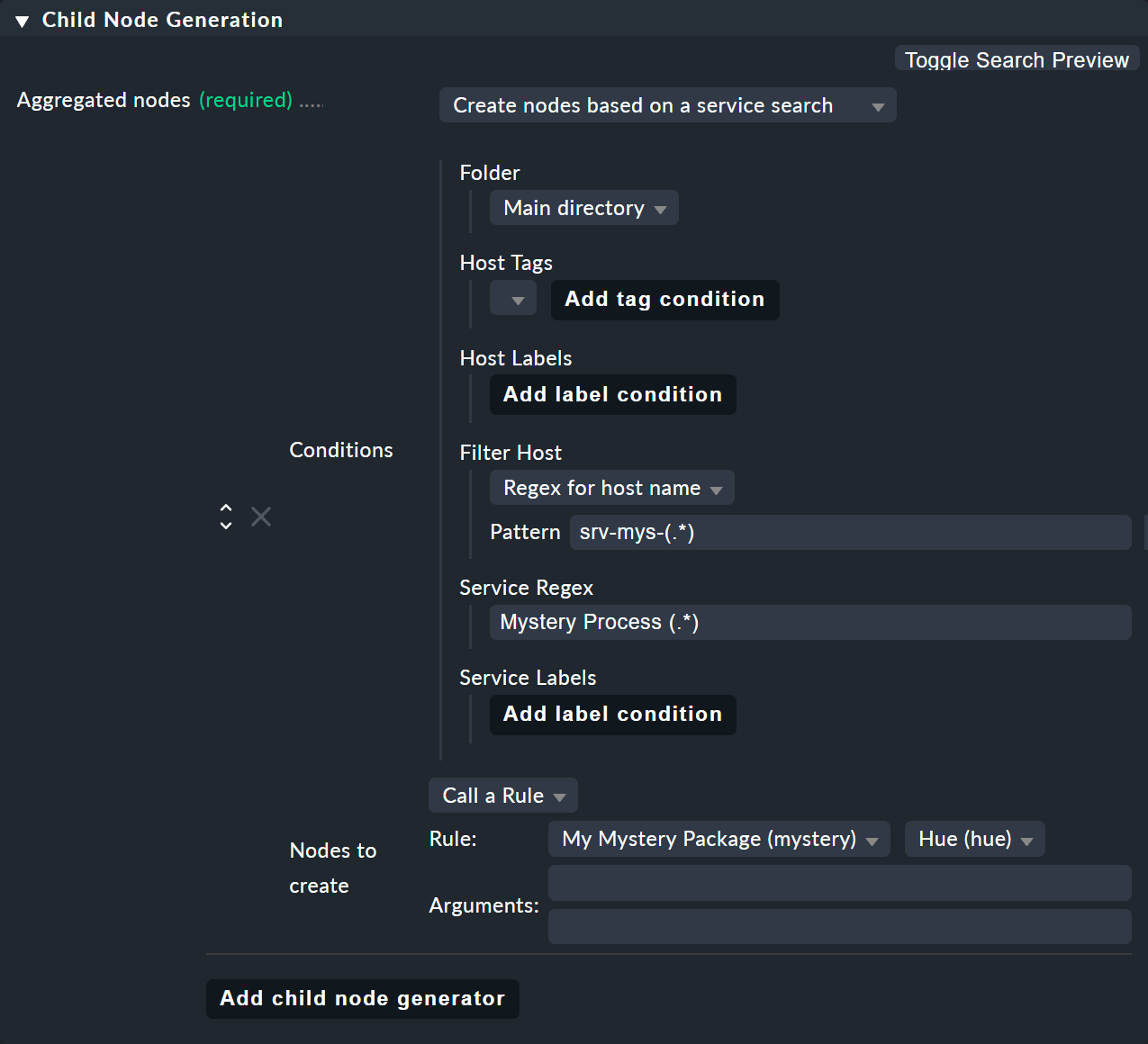
ここでは、() (部分式を括る)をホストとサービスの両方で使用できます。
ここで、
Regex for host name を選択した場合は、括弧で囲んだ式を 1 つだけ定義する必要があります。 一致したテキストは、
$1$として提供されます。All hosts を選択した場合、ホスト名全体が
$1$として提供されます。サービス名には複数のサブグループを使用できます。 関連する一致テキストは、
$2$、$3$などとして提供されます。
また、インラインヘルプはいつでも を使用して表示できることをお忘れなく。
6.6. その他のサービス
試みるうちに、子ジェネレータState of remaining services に遭遇したかもしれません。 これは、BI アグリゲーションにまだ分類されていないホストのサービスに対してノードを生成します。 これは、BI を使用してホストのすべてのサービスの状態を、付属の例のように、わかりやすく整理されたグループに結合する場合に便利です。
7. 事前定義されたホストの集約
前述のように、BI を使用して、ホストのサービスを構造化された形で提供することもできます。 すべてのサービスを 1 つのツリーにアグリゲーションとして結合し、基本的にはworst 機能を使用します。 これにより、ホストに問題がある場合のみ、ホストの全体的な状態が表示されます。BI は、わかりやすい「ドリルダウン」の方法として使用できます。
この目的のために、Checkmk には、ロックを解除するだけで使用できる、あらかじめ定義されたルールセットが用意されています。 これらのルールは、Windows または Linux ホスト上のサービスのレンダリングに最適化されていますが 、もちろん、お好みに応じてカスタマイズすることもできます。 すべてのルールは、Default ルールパッケージに含まれています。 通常どおり、をクリックしてルールにアクセスしてください。

12 個のルール(ここでは省略)のリストが表示されます。
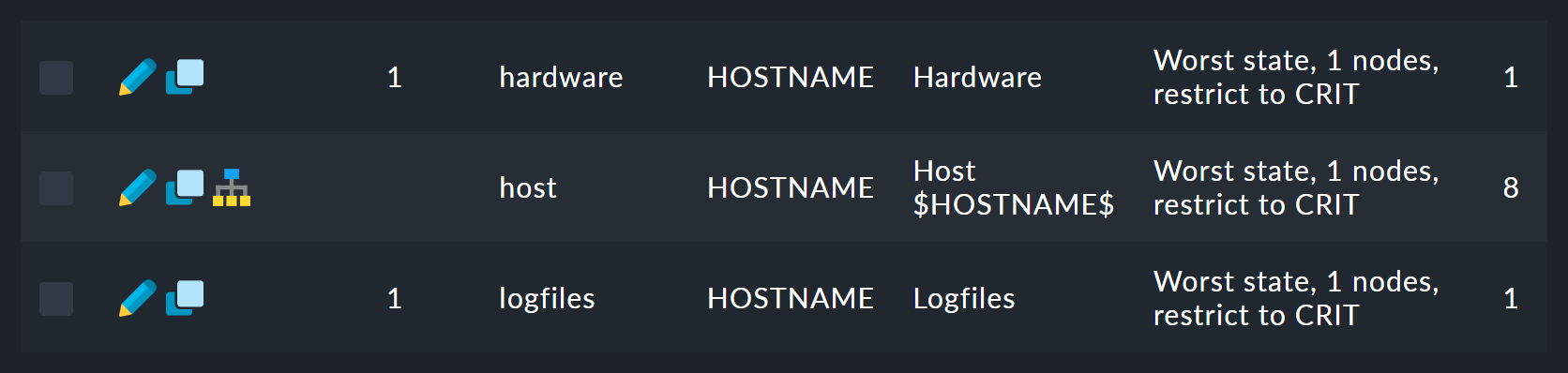
最初のルールは、ツリーのルートに対するルールです。 このルールの アイコンをクリックすると、ツリービューが表示されます。 ここでは、ルールが互いにどのようにネストされているかを確認できます。

ルールリストに戻り、Aggregations ボタンをクリックすると、このルールパッケージの集約のリストにアクセスできます。このパッケージには 1 つの集約のみが含まれています。
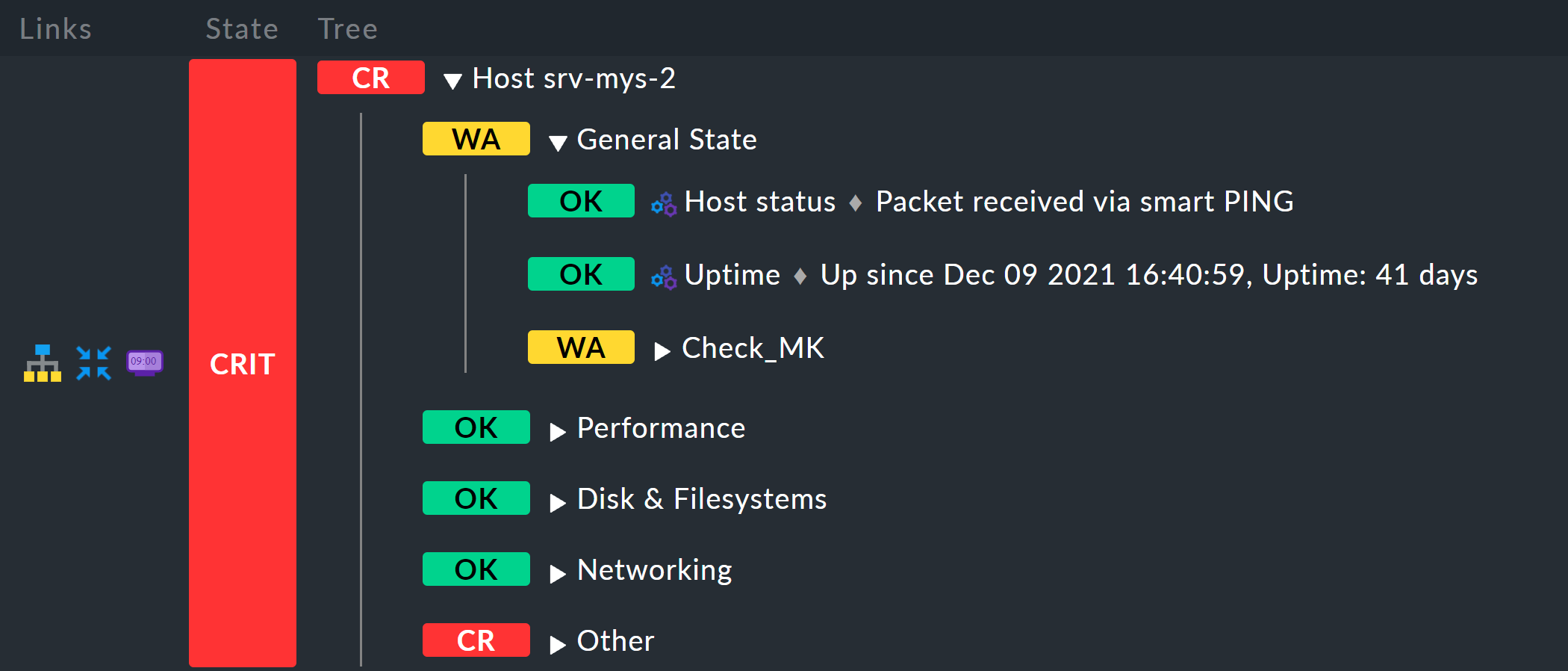
Details で、Currently disable this aggregationのチェックボックスをオフにすると
、ホストごとに、Host myhost123 というタイトルの集約がすぐに表示されます。
その結果は、たとえば次のようになります。
8. 許可および表示
8.1. 編集の許可
再び、ルールパッケージに戻ります。 BI でのすべての編集操作には、通常、管理者ロールが必要です。 より正確には、BI には 2 つの許可があり、これらはSetup > Users > Roles & permissions:

通常の監視ユーザーロールでは、2 つの許可のうち最初の 1 つだけがデフォルトで有効になっています。 したがって、通常の監視ユーザーは、自分が連絡先として定義されているルールパッケージでのみ作業することができます。 これは、[ルールパッケージの詳細] で設定します。
次の例「Permitted Contact Groups 」では、連絡先グループ「The Mystery Admins 」が認可されています。したがって、このグループのすべてのメンバーは、このパッケージのルールを編集できるようになりました。
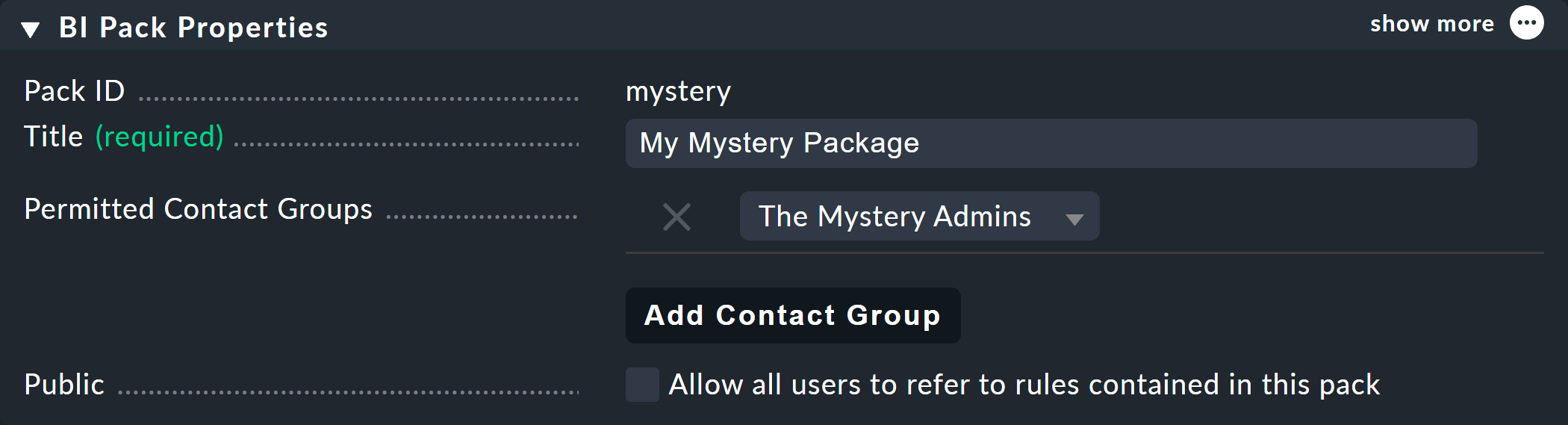
ちなみに、Public > Allow all users to refer to rules contained in this pack を使用すると、他のユーザーに、ここに含まれるルールを少なくとも使用(つまり、他の場所で独自のルールを定義)することを許可し、そのルールをサブノードとして呼び出すことができます。
8.2. ホストおよびサービスの許可
ステータスインターフェイスでの集約の実際の表示状況はどうなっていますか? どの連絡先が何かを見ることができますか?
BI アグリゲーション自体には、権限を割り当てることはできません。 これは、ホストおよびサービスの表示設定によって間接的に行われ 、See all hosts and services のオプションによって制御されます。Setup > Roles & Permissions:

User ロールでは、この許可はデフォルトで使用不能になっています。 通常のユーザーは、共有ホストおよびサービスのみを表示できます。 BI では、これらは、少なくとも 1 つの共有ホストまたはサービスを含む BI アグリゲーションをすべて正確に表示できる形で表現されます。 ただし、このようなアグリゲーションには、認可されたオブジェクトのみが含まれるため、多少「薄め」になる場合があります。 つまり、ユーザーによって状態が異なる場合があります。
これが良いか悪いかは、お客様の要望によって異なります。 疑問がある場合は、許可を切り替えて、BI を経由して、一部のユーザーまたはすべてのユーザーが、連絡先ではないホストおよびサービスを表示できるようにし、アグリゲーションの状態がすべての人にとって常に同じになるようにすることができます。
もちろん、この問題は、実際には、一部のユーザーだけがその特定の部分の連絡先となっている、非常にカラフルにまとめられた集約がある場合にのみ問題になります。
9. BI の運用パート 3:スケジュールダウンタイム、承認
9.1. 概要
BIはスケジュールダウンタイムを実際にどのように管理するのでしょうか? この問題について、弊社では熟考を重ね、多くのユーザーと議論を重ねた結果、以下の結論に達しました。
BI アグリゲーション自体をスケジュールダウンタイムに直接設定することはできませんが、その必要はありません。
BI アグリゲーションのスケジュールダウンタイムは、アグリゲーションのホストおよびサービスのスケジュールダウンタイムから自動的に導出されます。
BI が「ダウンタイム中」の状態を計算するルールを理解するには、スケジュールダウンタイムの実際の考え方を再確認しておくと役立ちます。 問題のオブジェクトは現在処理中です。障害が発生する可能性があります。オブジェクトが現在「OK 」であっても、そのオブジェクトに依存してはなりません。オブジェクトはいつでも「CRIT 」になる可能性があります。これは既知であり、文書化されています。したがって、通知はトリガーされないはずです。
この考え方は、BI にそのまま適用できます。 アグリゲーションには、現在ダウンタイム中のホストやサービスがいくつかあるかもしれません。 これらがOK であるかCRIT であるかは問題ではありません。メンテナンス作業中にオブジェクトが時々オフになったりオンになったりするのは、実際には偶然であるからです。 集約にダウンタイムオブジェクトがあるからといって、その集約をマッピングするアプリケーション自体が「脅威にさらされている」とすぐに判断して、「ダウンタイム中」とマークする必要はありません。 アプリケーションには、ダウンタイム中のオブジェクトの障害を補う冗長性がインストールされている場合もあります。 そのような障害が実際に集約の「CRIT 」状態につながる場合、つまり、冗長性が不十分で集約が実際に脅威にさらされている場合にのみ、Checkmk はそれを「ダウンタイム中」とマークします。 ここでも、オブジェクトの現在の状態は一般的に問題ではありません。
より簡潔に言えば、正確なルールは次のとおりです。
ホスト/サービスの「CRIT 」状態が、アグリゲーションの「CRIT 」状態につながる場合 そのホスト/サービスの「in downtime」状態は、アグリゲーションの「in downtime」状態になります。
重要:ホスト/サービスの実際の現在の状態は計算には影響しません。ダウンタイムにあるものは、BI ロジックでは「CRIT 」とみなされます。 なぜでしょうか? スケジュールされたダウンタイム中に「UP 」または「OK 」の状態になることは、まったくの偶然であるからです。たとえば、ホストが、複数の再起動の間に数秒間「UP 」を報告した場合などです。
ここに別の例があります。 スペースを節約するため、2 台の謎のサーバーではなく、1 台のみの場合のバリエーションです。
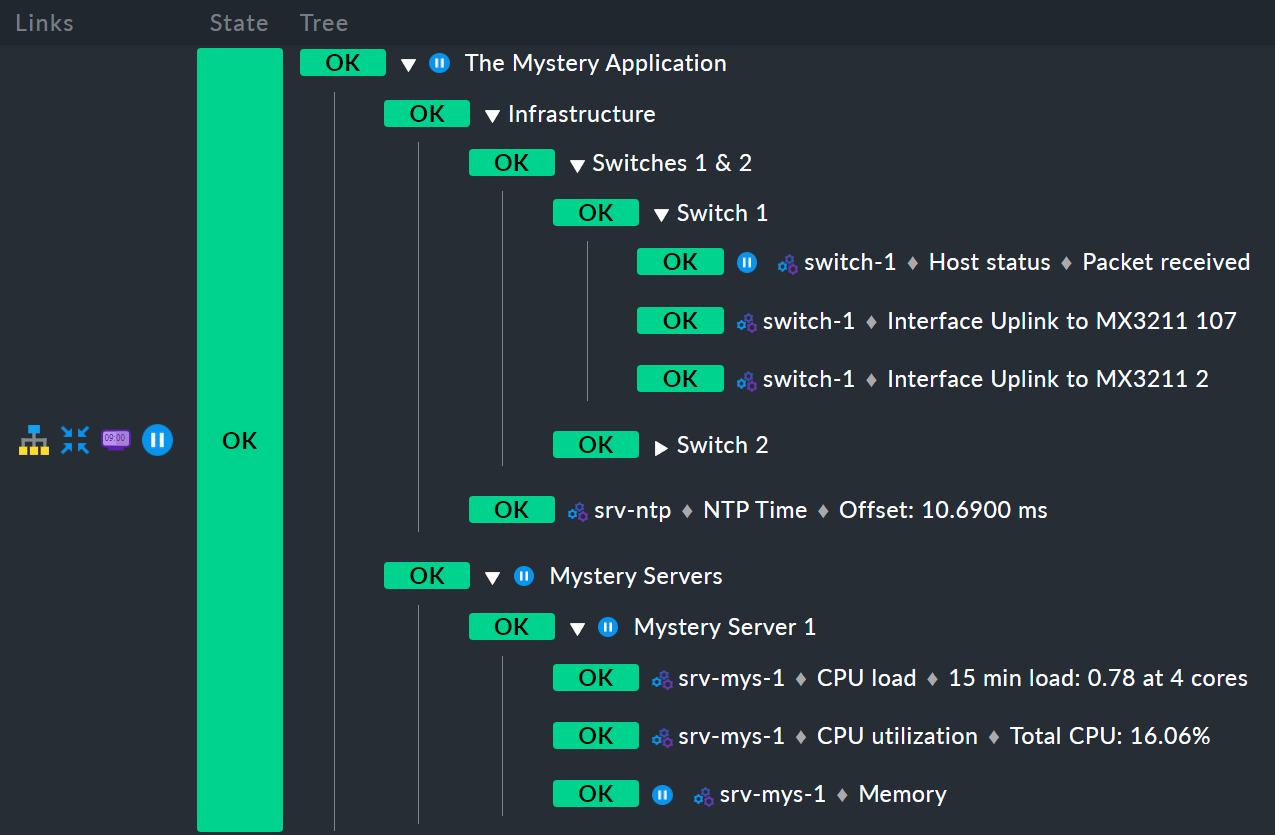
まず、ホストswitch-1 がダウンタイム中です。Infrastructure ノードには、これは影響しません。switch-2 はダウンタイム中ではないため、Infrastructure もダウンタイム中ではないからです。
したがって、派生ダウンタイムを示すアイコンは表示されません。
しかし、srv-mys-1 のサービスMemory もダウンタイム中です。
これは冗長ではありません。
したがって、ダウンタイムは親ノードMystery Server 1 に継承され、Mystery Servers まで続き、最終的には最上位ノードThe Mystery Application まで続きます。
したがって、この最上位ノードもダウンタイムになります。
9.2. スケジュールダウンタイムコマンド
BI アグリゲーションをスケジュールダウンタイムに手動で設定することはできない、と上記で述べました。 しかし、実際には BI アグリゲーションでスケジュールダウンタイムを設定するコマンドがあるため、これは半分しか真実ではありません。 ただし、このコマンドは、アグリゲーション内の各ホストおよびサービスについてダウンタイムエントリを記録するだけです。 もちろん、これにより通常、アグリゲーション自体がダウンタイムとしてフラグが付けられますが 、これは間接的な手順にすぎません。
9.3. チューニングオプション
上記で、スケジュールダウンタイムの計算は、CRIT 状態を想定して行われていることを説明しました。 集約のプロパティでは、WARN 状態を想定するノードをダウンタイムとしてマークするように、アルゴリズムをカスタマイズすることができます。 このオプションは、Escalate downtimes based on aggregated WARN state と呼ばれています。
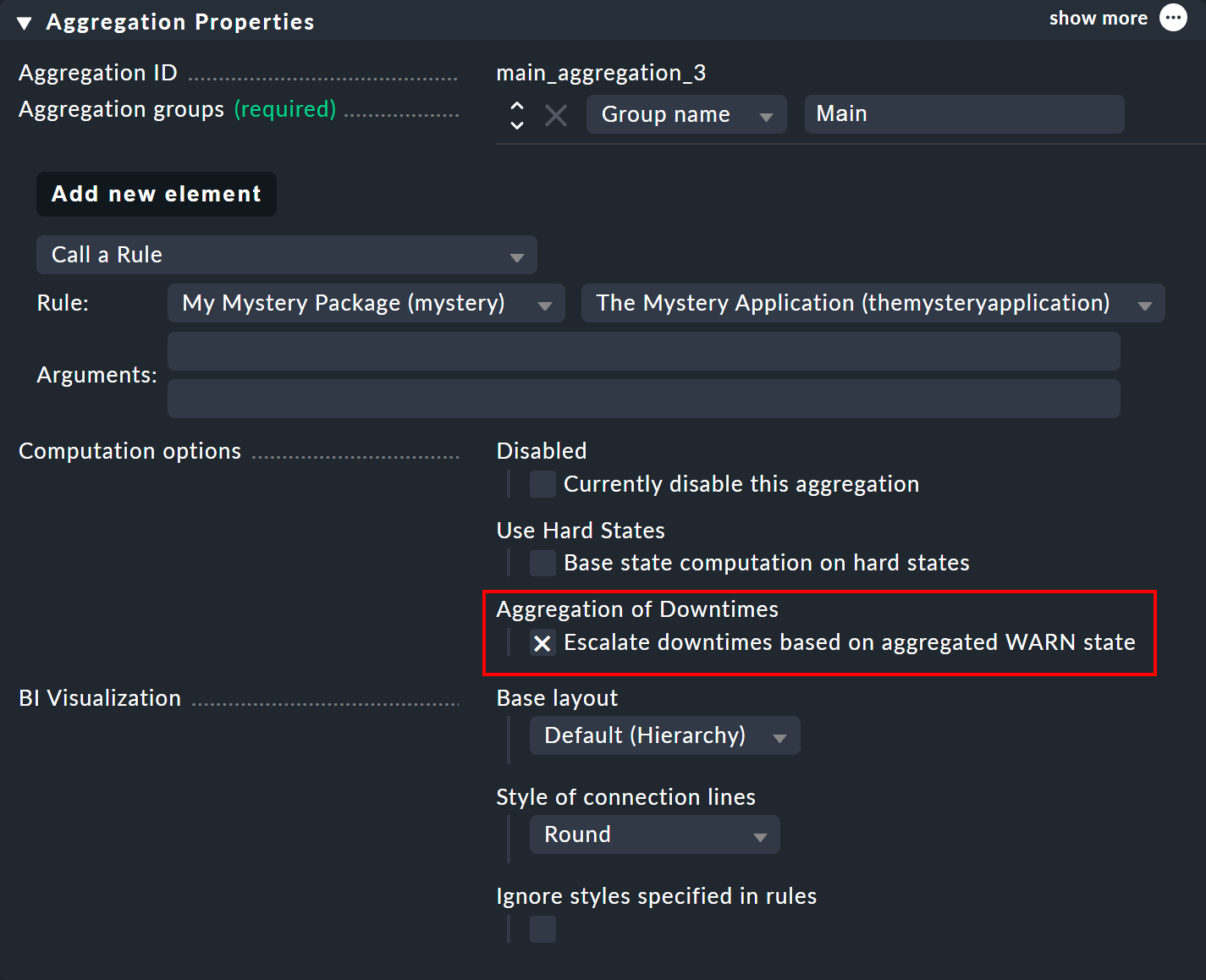
ダウンタイム中のオブジェクトは「CRIT 」であるという基本的な仮定は変わりません。 唯一の違いは、CRIT がWARNになることができる集約関数がある場合です。これは、最初の例「Count the number of nodes in state OK 」の場合でした。 この場合、2 つのスイッチのうち 1 つだけがダウンタイム中であれば、スケジュールダウンタイムはすでに受け入れられていたことになります。
9.4. 承認
スケジュールダウンタイムのプロセスとよく似ていますが、問題が承認された場合、その情報も BI によって自動的に計算されます。 この場合、オブジェクトの状態は確かに重要な役割を果たします。
ここでの考え方は、次の概念を BI に転送することです。 オブジェクトに問題があります (WARN 、CRIT) が、この問題は認識されており、誰かが対応しています ()。
この状態をアグリゲーションとして計算するには、次のようにします:
問題の承認を受けたすべてのホストおよびサービスが再びOK になったと仮定します。
すると、集約自体は再びOK になりますか? まさにこのような場合、それは として承認されます。
ただし、集約がWARN またはCRIT のままの場合、それは承認されたとはみなされません。 なぜなら、その場合は、承認されていない重要な問題が少なくとも 1 つ存在することになり、その結果、OK 状態が集約から削除されるからです。
ちなみに、BI アグリゲーションの問題を承認するためのコマンドも表示されますが、 これは、アグリゲーションで検出されたすべてのホストおよびサービス(現在問題のあるもののみ)が承認されることを意味するだけです。
10. 変更を可視化する
集約内のノードは、動作中に変更される場合があります。 凍結集約を使用すると、そのような変更を表示することができます。
以下に例を示します。 6 ポートのスイッチは、そのサービス/ポートのうち 5 つがOK の場合、OK である必要があります。 しかし、ファームウェアのアップデートの一環として、2 つのポートの名前が変更され、関連するサービスが監視から消えました。
その結果、アグリゲーションはOK 状態の 4 つのサービスで構成されますが、アグリゲーション自体はWARN またはCRITとなり、その理由を示す表示は一切ありません。 ここで、凍結アグリゲーションが役立ちます。 現在の状態を凍結し、後でクリックして、それ以降に変更された内容、つまり追加または削除されたノードをリスト表示することができます。 つまり、アグリゲーションのルールはその状態を示すのに対し、凍結アグリゲーションは状態の変化に関する情報を提供します。
10.1. 凍結と比較
凍結機能の使用は非常に簡単です: Aggregation Properties で「New aggregations are frozen 」オプションを有効にします。
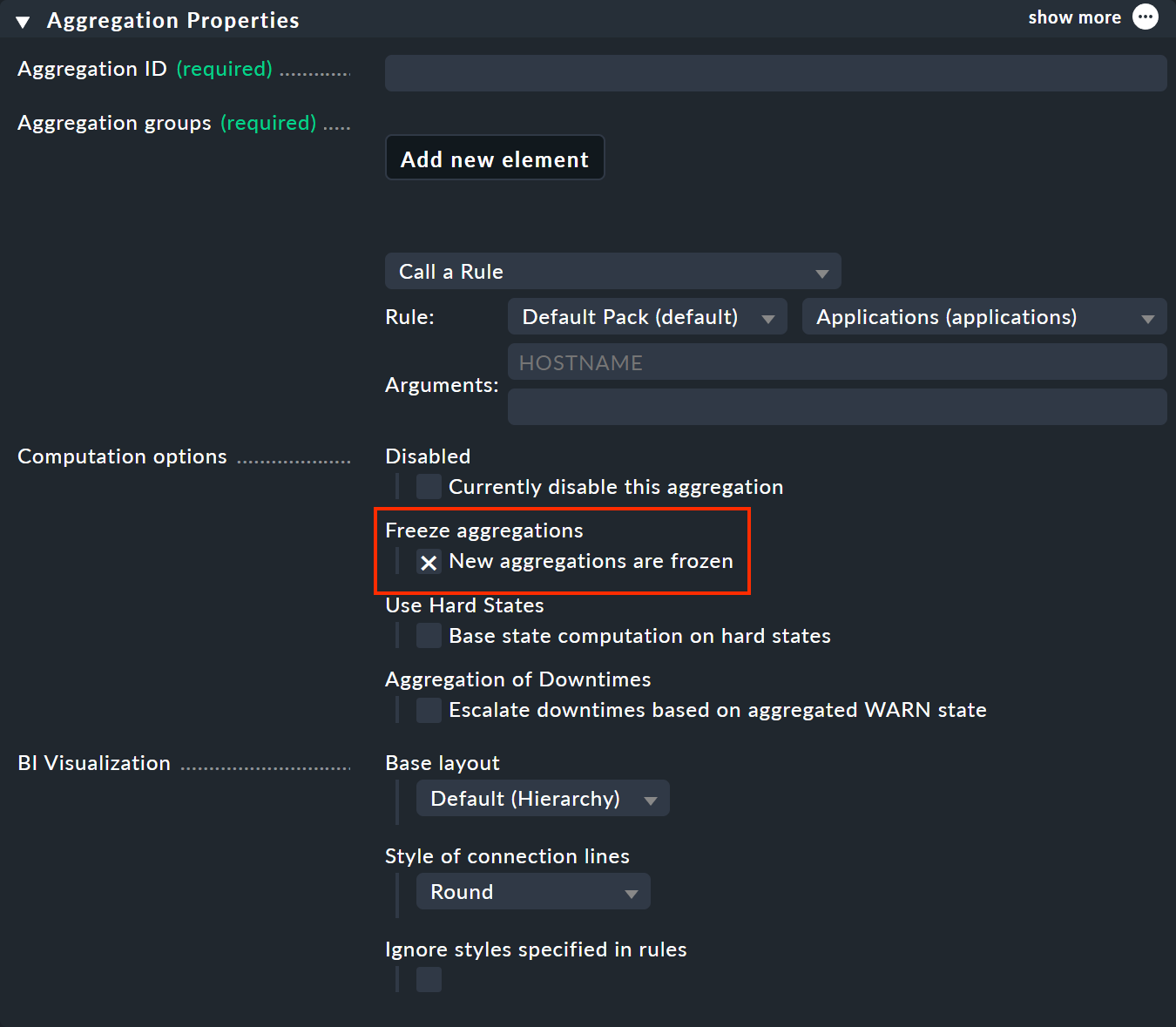
これにより、保存時に集約が凍結されます。また、チェックマークが新たに設定されるたびに、集約が凍結されます。 集約が以前に存在していた場合でも(New aggregations … を参照している場合でも)、凍結されます。 凍結状態を解除するには、チェックマークを削除してください。
監視では、集約の横に新しい雪の結晶アイコンが表示されます。 これをクリックすると、相違点を表示するビューに移動します。 左側に凍結されたツリー、右側に変更が強調表示された現在のツリー(ここでは、backup3 サービスの削除)が表示されます。
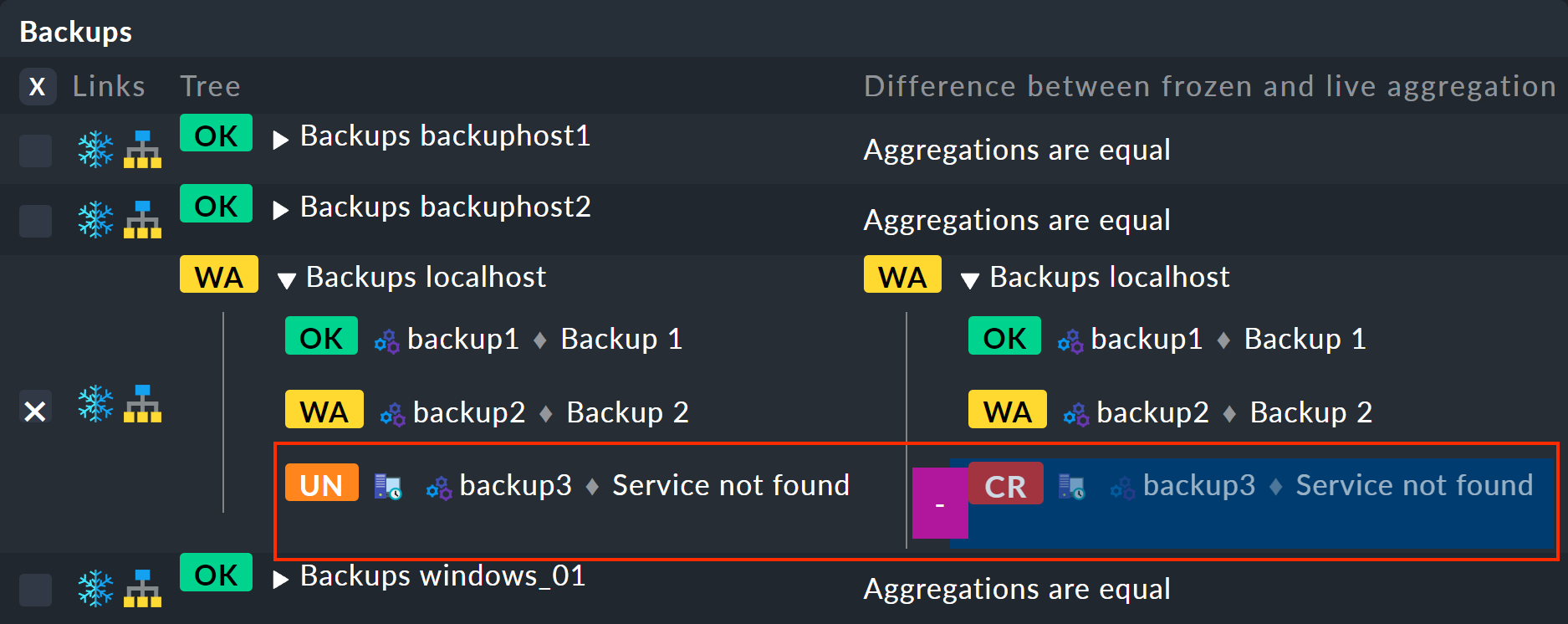
現在の状態を再び凍結したい場合は、Commands > Freeze aggregations から実行できます。 ただし、注意してください。凍結された現在の状態は常に 1 つだけで、古い状態を含むヒストリーは保存されません。
11. 可用性

12. 分散監視における BI
分散環境における BI では、実際には何が起こっているのでしょうか? つまり、ホストが複数の監視サーバーに分散している場合です。
答えは比較的簡単です。 何も気にする必要はありません。 BI は GUI のコンポーネントであり、標準で分散環境対応機能が付属しているため、BI にはまったく影響がありません。
ある場所が現在利用できない場合や、GUI から手動で非表示にした場合、そのサイトのホストは BI にとって存在しなくなります。 つまり、
この場所にあるオブジェクトのみから構築された BI アグリゲーションは消えます。
この場所のオブジェクトの一部から構築された BI アグリゲーションは、削減されます。
後者の場合、当然ながら、影響を受ける集計の状態に影響を与える可能性があります。 具体的な影響は、ご使用の集計関数に依存します。 例えば、worst をすべての集計関数で使用している場合、全体的な状態は同じままか、または改善されます。 これは、存在しなくなった場所のオブジェクトが既にWARN またはCRIT が設定されていたためです。 他の集計関数を使用している場合、異なる状態が発生する可能性もあります。
この動作がお客様の業務に実用的であるかどうかは、個々のケースで評価する必要があります。 BI は、存在しないオブジェクトがアグリゲーションに含まれないように、したがって見落とされることがないよう構築されています。 これは、前述のように、すべての BI ルールが検索パターンでのみ機能するためです。
13. 通知、サービスとしての BI
BI アグリゲーションの状態変化を実際に通知することはできますか? BI は GUI 内にのみ存在し、実際の監視とは関係がないため、最初は直接通知することはできません。 しかし、BI アグリゲーションを通常のサービスに変換することで、 もちろん通知をトリガーすることができます。
このためには、スペシャルエージェント「BI Aggregations 」を使用できます。 適切なルールセットは、「Setup > Agents > Other integrations > BI Aggregations 」にあります。 まず、「BI Aggregations 」ボックスに、「Add new entry 」という新しいエントリを作成します。
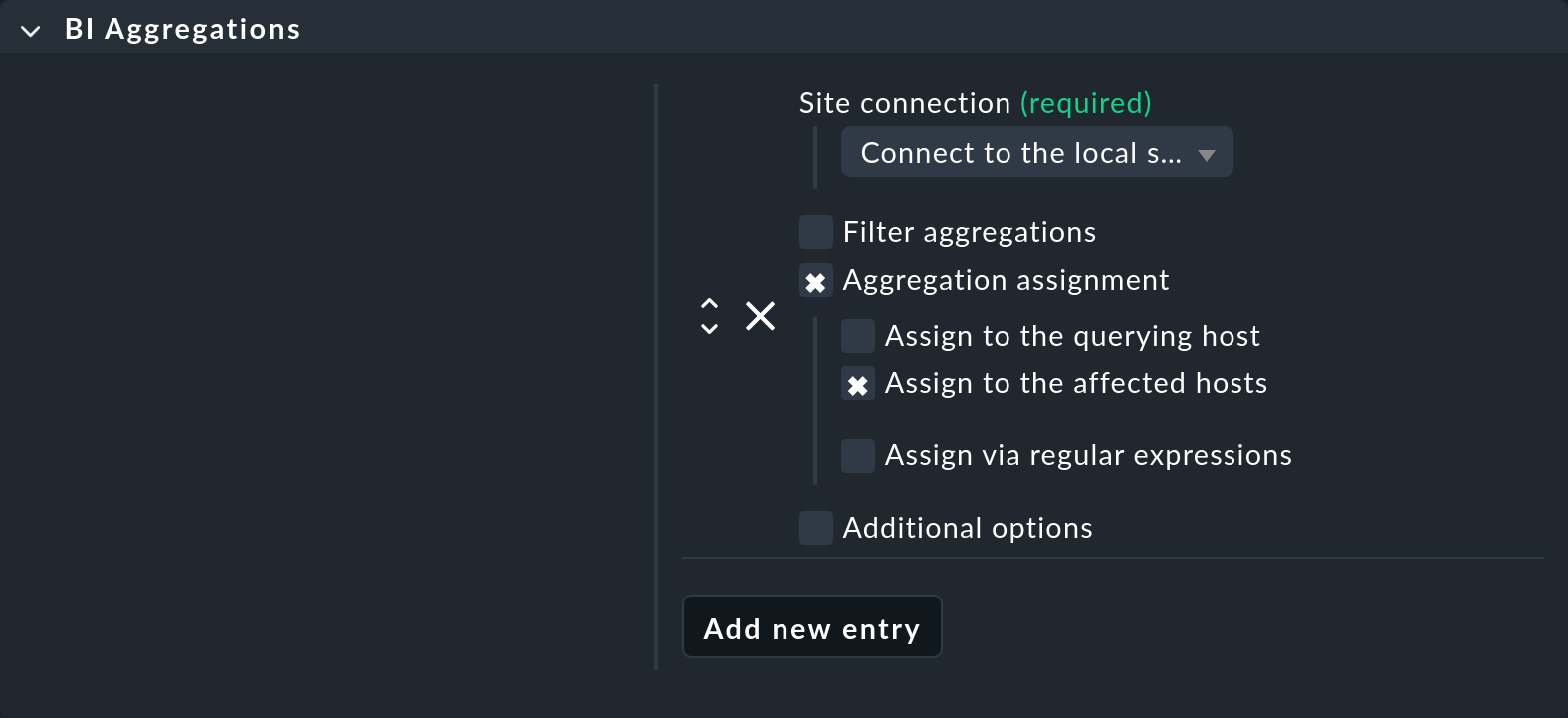
ここでは、サービスを追加するホストについて、さまざまなオプションを指定できます。 これらのオプションは、スペシャルエージェントが割り当てられているホスト(Assign to the querying host )に必ずしも関連付けられている必要はありません。 集約に含まれているホスト(Assign to the affected hosts )にも割り当てることができます。 ただし、これは 1 つのホストのみに関係する場合にのみ意味があります。 正規表現および置換を使用すると、割り当てをさらに柔軟に行うことができます。 その後、ピギーバックメカニズムによって全体が実行されます。
重要:このルールを割り当てるホストを通常のエージェントで監視し続ける場合は、 その設定で、エージェントとスペシャルエージェントが実行されるようにしてください。

新しいサービスは、もちろん最大 1 チェック間隔の遅延で、集約の状態を表示します。 以下は、プレフィックスAggr が自動的に追加される 2 つの新しいサービスの例です。

通常どおり、このサービスを連絡先に割り当てて、通知の基礎として使用することができます。