This is a machine translation based on the English version of the article. It might or might not have already been subject to text preparation. If you find errors, please file a GitHub issue that states the paragraph that has to be improved. |
1. Introducción
Las expresiones regulares-regex (o raramente regexp)- se utilizan en Checkmk para especificar nombres de servicios y en muchas otras situaciones. Son patrones que coinciden con un texto determinado o no coinciden(no coinciden). Puedes hacer muchas cosas prácticas con ellas, como formular reglas flexibles que se apliquen a todos los servicios que tengan foo o bar en su nombre.
Las expresiones regulares se confunden a menudo con los patrones de búsqueda de nombres de archivo, ya que los caracteres especiales * y ?, así como los corchetes y las llaves, pueden existir en ambos.
En este artículo te mostraremos las funciones más importantes de las expresiones regulares, por supuesto en el contexto de Checkmk. Como Checkmk utiliza dos componentes diferentes para las expresiones regulares, a veces el diablo está en los detalles. Esencialmente, el núcleo de monitorización utiliza la biblioteca C y todos los demás componentes utilizan Python 3. Donde existan diferencias, las explicaremos.
Consejo: En Checkmk se permiten las expresiones regulares en los campos de entrada de varias páginas. Si no estás seguro, utiliza la ayuda contextualizada a través del menú Help (Help > Show inline help). Allí podrás ver si se permiten las expresiones regulares y cómo se pueden utilizar.
Cuando trabajes con Plugins antiguos o de fuentes externas, puede ocurrir que éstos utilicen Python 2 o Perl y se desvíen de las convenciones aquí descritas.
En este artículo te mostraremos las capacidades más importantes de las expresiones regulares, pero ni mucho menos todas. Si las posibilidades que te mostramos aquí no van lo suficientemente lejos, más abajo encontrarás referencias donde podrás leer todos los detalles relevantes. Y luego siempre está internet.
Si quieres programar tus propios Plugin que, por ejemplo, utilicen expresiones regulares para encontrar anomalías en archivos de registro, puedes utilizar este artículo como base. Sin embargo, cuando se realizan búsquedas en grandes volúmenes de datos, la optimización del rendimiento es un aspecto importante. En caso de duda, consulta siempre la documentación de la biblioteca de expresiones regulares que estés utilizando.
2. Trabajar con expresiones regulares
En esta sección utilizamos ejemplos concretos para mostrar cómo trabajar con expresiones regulares, desde simples coincidencias de caracteres individuales o cadenas, hasta complejos grupos de caracteres.
2.1. Caracteres alfanuméricos
Con las expresiones regulares, siempre se trata de saber si un patrón coincide con un texto determinado (por ejemplo, el nombre de un servicio). El ejemplo de aplicación más sencillo es una cadena de caracteres alfanuméricos. Éstos (y el signo menos utilizado como guión) simplemente coinciden entre sí en una expresión.
Cuando se busca en el entorno de monitorización, Checkmk no suele distinguir entre mayúsculas y minúsculas. En la mayoría de los casos, la expresión CPU load coincide tanto con el texto CPU load como con cpu LoAd. En cambio, cuandose busca en el entorno de configuración, sí suele distinguir entre mayúsculas y minúsculas. Existen excepciones justificadas a estas normas, que se describen en la ayuda en línea.
Atención: En los campos de entrada sin expresión regular en los que se especifica una coincidencia exacta (sobre todo con nombres del host), ¡siempre se distingue entre mayúsculas y minúsculas!
2.2. El punto ( . ) como comodín
Además de las cadenas de caracteres de "texto plano", hay una serie de caracteres y cadenas de caracteres que tienen funciones "mágicas". El más importante de estos caracteres es el . (punto).Coincide exactamente con cualquier carácter arbitrario:
| Expresión regular | Coincidencia | Sin coincidencia |
|---|---|---|
|
|
|
|
|
|
2.3. Repetición de caracteres
Muy a menudo se desea definir que puede darse una secuencia de caracteres de una longitud determinada. Para ello se especifica el número de repeticiones del carácter precedente entre llaves:
| Expresión regular | Función | Coincidencia | Sin coincidencia |
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Existen abreviaturas para las tres últimas condiciones anteriores:* coincide con el carácter precedente cualquier número de veces, + coincide al menos una vez y ? coincide como máximo una vez.
También puedes utilizar el punto . con los operadores de repetición para buscar una secuencia de caracteres arbitraria de forma más definida:
| Expresión regular | Coincidencia | Sin coincidencia |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
2.4. Clases de caracteres, números y letras
Las clases de caracteres permiten hacer coincidir determinadas secciones del juego de caracteres, por ejemplo, "aquí tiene que venir un dígito". Para ello, coloca todos los caracteres a coincidir entre corchetes. Con un signo menos también puedes especificar rangos.Nota: Se aplica la secuencia del juego de caracteres ASCII de 7 bits.
Por ejemplo, [abc] representa exactamente uno de los caracteres a, b o c, y [0-9] cualquier dígito- ambos pueden combinarse. También es posible una negación del conjunto - con un ^ en el paréntesis, [^abc] representa entonces cualquier carácter excepto a, b, c.
Por supuesto, las clases de caracteres pueden combinarse con otros operadores. Empecemos con algunos ejemplos abstractos:
| Clase de caracteres | Función |
|---|---|
|
Exactamente uno de los caracteres a, b, c. |
|
Exactamente un dígito, letra minúscula o guión bajo. |
|
Cualquier carácter excepto a, b, c. |
|
Exactamente un carácter, desde un espacio en blanco hasta un guión, conforme a la norma ASCII. Los siguientes caracteres están dentro de este rango: |
|
Una secuencia de al menos una y como máximo 20 letras y/o dígitos en cualquier orden. |
Aquí tienes algunos ejemplos prácticos:
| Expresión regular | Coincidencia | Sin coincidencia |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Nota: Si necesitas uno de los caracteres -, [ o ], tendrás que utilizar un truco. Escribe el - (signo menos) al final de la clase, como ya se ha mostrado en el ejemplo anterior. Al evaluar las expresiones regulares, el signo menos, si no está en medio de tres caracteres, no se evalúa como un operador, sino exactamente como este carácter.
Si es necesario, inserta un corchete de cierre como primer carácter de la clase, y un corchete de apertura como segundo carácter. Como no se permiten clases vacías, el corchete de cierre se interpreta entonces como un carácter normal. Una clase con estos caracteres especiales tendría el siguiente aspecto: []-], o respectivamente [][-] si también se necesita el corchete de apertura.
2.5. Principio y final - prefijo, sufijo e infijo
En muchos casos es necesario distinguir entre coincidencias al principio, al final o simplemente en algún lugar de una cadena. Para una coincidencia al principio de una cadena (coincidencia de prefijo) utiliza el ^ (circunflejo), para el final (coincidencia de sufijo) utiliza el $ (signo del dólar). Si no se especifica ninguno de estos operadores, la mayoría de las bibliotecas de expresiones regulares utilizan la coincidencia infija por defecto: se busca en cualquier lugar de la cadena de caracteres. Para coincidencias exactas, utiliza tanto ^ como $.
| Expresión regular | Coincidencia | Sin coincidencia |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
Nota: En la monitorización y la Consola de eventos, la concordancia infix es el estándar. Se encuentran las expresiones que aparecen en cualquier parte del texto, es decir, la búsqueda de "memoria" también encuentra "memoria del núcleo". En la GUI de configuración, por otro lado, al comparar expresiones regulares con nombres de servicios y otras cosas, Checkmk básicamente comprueba si la expresión coincide con el principio del texto (concordancia de prefijo) - esto es normalmente lo que estás buscando:
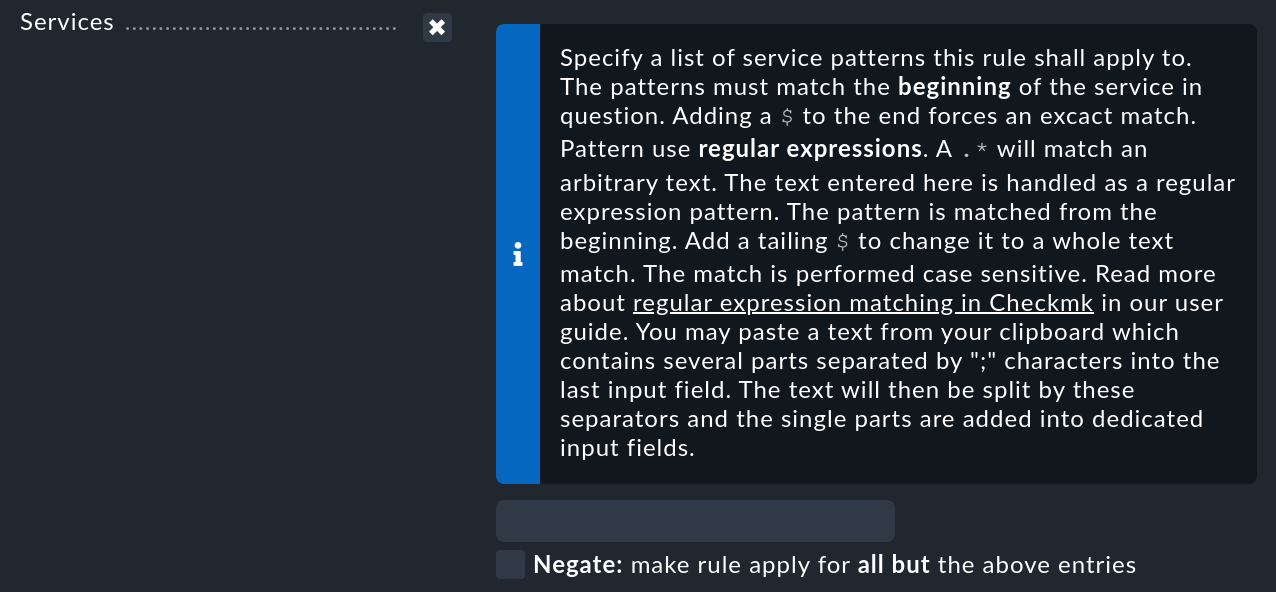
Si necesitas una concordancia infix en lugares donde se proporciona concordancia de prefijo, simplemente amplía tu expresión regular con .* al principio para que coincida con cualquier cadena prefijada:
| Expresión regular | Coincidencia | Sin coincidencia |
|---|---|---|
|
|
|
|
|
|
|
|
|
Consejo: Puedes prefijar cualquier búsqueda al principio de una cadena con ^ y cualquier búsqueda dentro de una cadena con .*, los intérpretes de expresiones regulares ignorarán los símbolos redundantes.
2.6. Enmascarar caracteres especiales con una barra invertida
Como el punto coincide con todo, naturalmente también coincide con un punto. Si ahora quieres que coincida exactamente con un punto, tienes que enmascararlo con una \ (barra invertida). Esto se aplica análogamente a todos los demás caracteres especiales, que son: \ . * + ? { } ( ) [ ] | & ^ y $. Si codificas una \ barra invertida , el carácter especial que le sigue se tratará como un carácter normal:
| Expresión regular | Coincidencia | Sin coincidencia |
|---|---|---|
|
|
|
|
|
|
|
|
|
Atención Python: Como en Pythonla barra invertida en la representación interna de la cadena se enmascara internamente con otra barra invertida, estas dos barras invertidas deben enmascararse de nuevo, lo que lleva a un total de cuatro barras invertidas:
| Expresión regular | Coincidencia | Sin coincidencia |
|---|---|---|
|
|
|
2.7. Valores alternativos
Con la línea vertical | puedes definir alternativas, es decir, utilizar una operación OR:1|2|3 coincide con 1, 2 ó 3. Si necesitas este tipo de alternativas en medio de una expresión, agrúpalas entre corchetes:
| Expresión regular | Coincidencia | Sin coincidencia |
|---|---|---|
|
|
|
|
|
|
2.8. Grupos de coincidencia
Losgrupos de concordancia (o grupos de captura) cumplen dos funciones: La primera función es la agrupación de coincidencias alternativas o parciales, como se muestra en el ejemplo anterior. También son posibles las agrupaciones anidadas. Además, se pueden utilizar los operadores de repetición *, +, ? y {...} precedidos de corchetes. Así, la expresión (/local)?/share coincide tanto con /local/share como con /share.
La segunda función es "capturar" grupos de caracteres coincidentes en variables. En la Consola de eventos (CE), Business Intelligence (BI), en el renombramiento masivo de hosty en los mapeos piggyback, existe la posibilidad de utilizar la parte de texto correspondiente a la expresión regular del primer paréntesis como \1, la parte correspondiente al segundo paréntesis como \2, etc. El último ejemplo de la tabla muestra el uso de alternativas dentro de un grupo de coincidencia.
| Expresión regular | Texto a coincidir | Grupo 1 | Grupo 2 |
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
La siguiente imagen muestra un cambio de nombre de varios host en una sola acción. Todos los nombres del host que coincidan con la expresión regular server-(.*)\.local se sustituirán por \1.servers.local. Donde \1 corresponde exactamente al texto "capturado" por .* en el paréntesis:
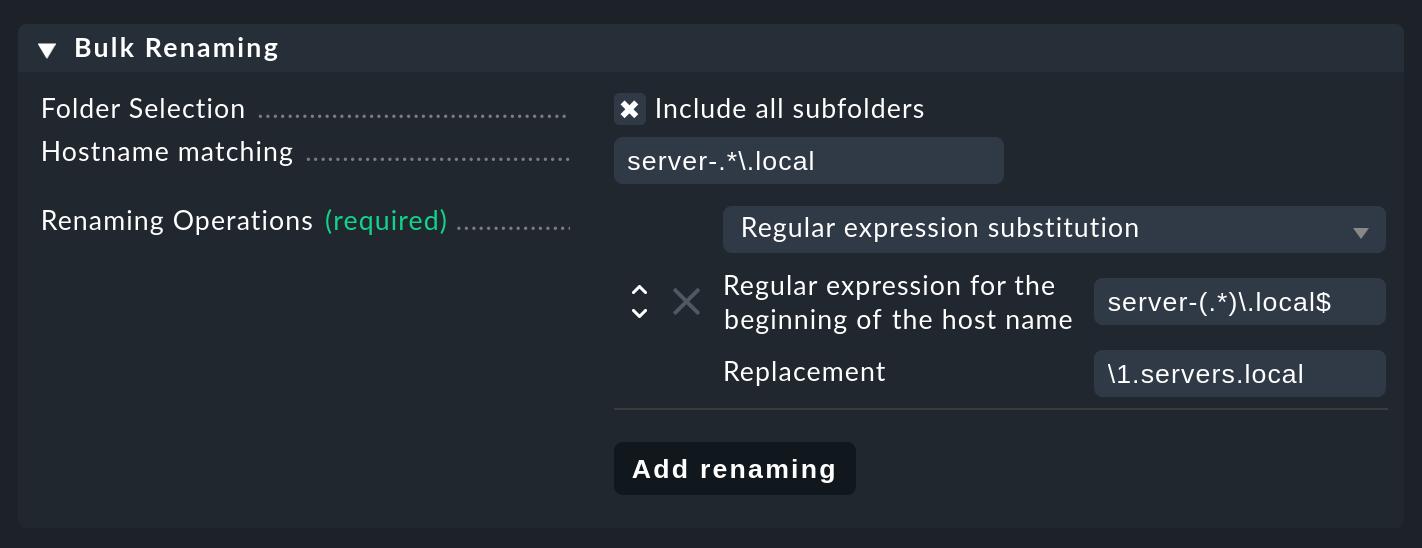
En el ejemplo concreto, server-lnx02.local se convierte así en lnx02.servers.local.
Si no es necesario que un grupo de concordancia "capture" grupos de caracteres, por ejemplo si sólo se utiliza para estructurar, se puede utilizar ?: para convertirlo en un grupo de concordancia queno capture: (?:/local)?/share.
2.9. Banderas en línea
Con las banderas en línea, se pueden realizar ajustes específicos relativos al modo de evaluación dentro de una expresión regular. La más relevante para trabajar con Checkmk es (?i), que cambia a coincidencia insensible a mayúsculas/minúsculas para expresiones que, de otro modo, distinguirían entre mayúsculas y minúsculas. En casos muy raros, también querrás utilizar (?s) y (?m) para trabajar con cadenas de varias líneas.
Ten en cuenta que, desde la versión 3.11, Python espera los indicadores en línea al principio de una expresión regular ( (?i)somestring) o especificando el ámbito((?i:somestring)). Dado que, en algunos casos, Checkmk combina internamente las expresiones regulares para mejorar el rendimiento, te recomendamos encarecidamente que no utilices indicadores en línea al principio de una expresión regular, sino que utilices siempre la notación con ámbito, que, en caso de duda, se extiende a toda la expresión regular:
(?i:somestring).
Se trata de una variante del grupo de concordancia sin alcance.
3. Tabla de caracteres especiales
Aquí encontrarás una lista que resume todos los caracteres especiales y las funciones de expresión regular que utiliza Checkmk, tal y como se ha explicado anteriormente:
|
Coincide con cualquier carácter. |
|
Evalúa el siguiente carácter especial como un carácter normal. |
|
El carácter anterior debe aparecer exactamente cinco veces. |
|
El carácter anterior debe aparecer un mínimo de cinco y un máximo de diez veces. |
|
El carácter anterior puede aparecer cualquier número de veces (corresponde a |
|
El carácter anterior puede aparecer cualquier número de veces, pero debe aparecer al menos una vez (equivale a |
|
El carácter anterior puede aparecer cero o una vez (equivalente a |
|
Representa exactamente uno de los caracteres |
|
Representa exactamente uno de los caracteres |
|
Representa exactamente un dígito, una letra minúscula o el guión bajo. |
|
Representa exactamente un carácter , excepto la coma invertida simple o doble. |
|
Coincide con el final de un texto. |
|
Coincide con el principio de un texto. |
|
Coincide con |
|
Hace coincidir la subexpresión A con un grupo de concordancia. |
|
Cambia el modo de evaluación de la subexpresión A a insensible a mayúsculas y minúsculas mediante la bandera inline. |
|
Coincide con un tabulador. Este carácter suele aparecer en archivos de registro o tablas CSV. |
|
Coincide con todos los espacios (ASCII utiliza 5 tipos diferentes de espacio). |
Los siguientes caracteres deben enmascararse con una barra invertida, si se van a utilizar literalmente: \ . * + ? { } ( ) [ ] | & ^ $.
3.1. Unicode en Python 3
En particular, si se han copiado y pegado nombres propios en comentarios o textos descriptivos, y por tanto aparecen en el texto caracteres Unicode o diferentes tipos de espacios, las clases extendidas de Python son muy útiles:
|
Coincide con una tabulación (tabulador), en parte en archivos de registro o tablas CSV. |
|
Coincide con todos los espacios (Unicode admite 25 espacios diferentes, ASCII 5). |
|
Invierte de |
|
Coincide con todos los caracteres que forman parte de una palabra, es decir, letras, y en Unicode también acentos, glifos chinos, árabes o coreanos. |
|
Inversión de |
En los lugares en los que Checkmk permite la coincidencia Unicode, \w es especialmente útil cuando se buscan palabras escritas de forma similar en distintos idiomas, por ejemplo nombres propios que a veces se escriben con acento y a veces sin acento.
| Expresión regular | Coincidencia | Sin coincidencia |
|---|---|---|
|
|
|
4. Probar expresiones regulares
La lógica de las expresiones regulares no siempre es fácil de entender, sobre todo en el caso de los grupos de concordancia anidados, y la cuestión del orden y el extremo de la cadena que debe coincidir. Mejor que la prueba y error en Checkmk, hay dos formas de probar las expresiones regulares: Los servicios en línea como regex101.com preparan las coincidencias gráficamente y explican el orden de evaluación en tiempo real:
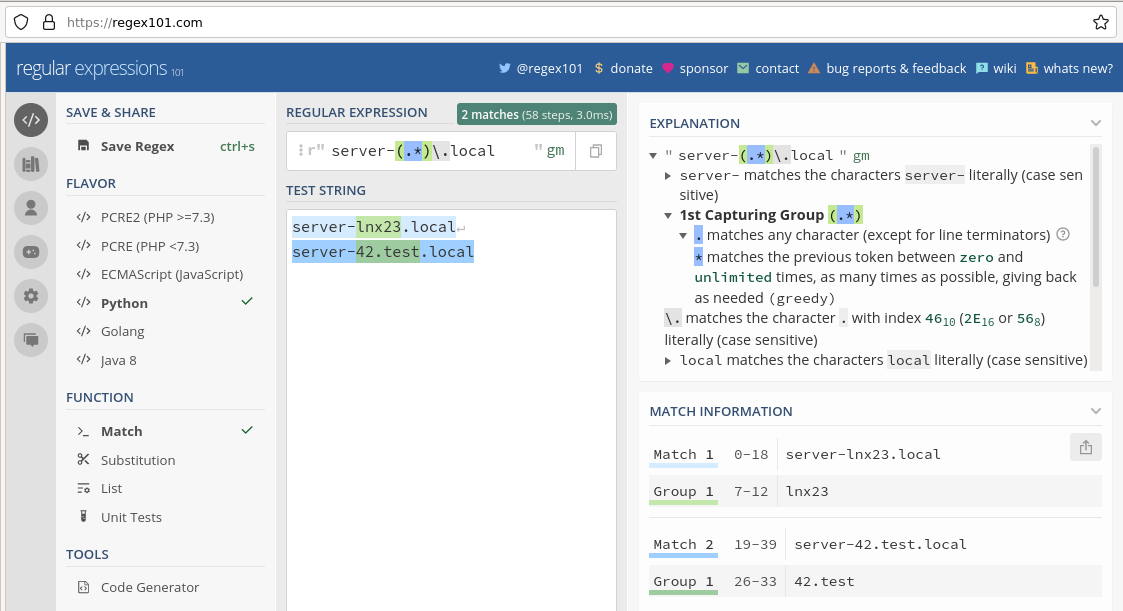
El segundo procedimiento de prueba es el intérprete de Python, que viene con cada instalación de Python. En Linux y Mac OS, Python 3 suele estar preinstalado. Precisamente porque las expresiones regulares en el intérprete de Python se evalúan exactamente igual que en Checkmk, no hay discrepancias en la interpretación, ni siquiera con anidamientos complejos. Con la prueba en el intérprete de Python siempre vas sobre seguro.
Después de abrirlo, tienes que importar el módulo re. En el ejemplo cambiamos la distinción entre mayúsculas y minúsculas con re.IGNORECASE desactivado:
OMD[mysite]:~$ python3
Python 3.8.10 (default, Jun 2 2021, 10:49:15)
[GCC 9.4.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import re
>>> re.IGNORECASE
re.IGNORECASEPara emular el comportamiento de las expresiones regulares de C, que también se utilizan en muchos componentes de Python, puedes restringirlas a ASCII:
>>> re.ASCII
re.ASCIIAhora puedes utilizar la función re.match() para hacer coincidir directamente una expresión regular con una cadena y obtener el grupo de concordancia:group(0) representa la coincidencia completa, y group(1) la coincidencia que es la primera que coincide con la subexpresión encerrada entre corchetes:
>>> x = re.match('M[ae]{1}[iy]{1}e?r', 'Meier')
>>> x.group(0)
'Meier'
>>> x = re.match('M[ae]{1}[iy]{1}e?r', 'Mayr')
>>> x.group(0)
'Mayr'
>>> x = re.match('M[ae]{1}[iy]{1}e?r', 'Myers')
>>> x.group(0)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
IndexError: no such group
>>> x = re.match('server-(.*)\.local', 'server-lnx23.local')
>>> x.group(0)
'server-lnx23.local'
>>> x.group(1)
'lnx23'5. Documentación externa adicional
Ken Thompson, uno de los creadores de UNIX en los años 60, fue el primero en desarrollar las expresiones regulares en su forma actual, entre otras cosas, en el comando Unix grep, que aún se utiliza. Desde entonces, se han creado numerosas extensiones y dialectos de las expresiones regulares, como las expresiones regulares extendidas, las expresiones regulares compatibles con Perl y una variante muy similar en Python.
En los filtros de las vistas, Checkmk utiliza expresiones regulares extendidas POSIX (extended REs). Éstas se evalúan en el núcleo de monitorización en C utilizando la función regex de la biblioteca C. Puedes encontrar una referencia completa al respecto en la página man de Linux para regex(7):
OMD[mysite]:~$ man 7 regex
REGEX(7) Linux Programmer's Manual REGEX(7)
NAME
regex - POSIX.2 regular expressions
DESCRIPTION
Regular expressions ("RE"s), as defined in POSIX.2, come in two forMFS:
modern REs (roughly those of egrep; POSIX.2 calls these "extended" REs)
and obsolete REs (roughly those of *ed*(1); POSIX.2 "basic" REs). Obso-
lete REs mostly exist for backward compatibility in some old programs;En todos los demás sitios, están disponibles todas las funciones de las expresiones regulares de Python. Esto incluye, entre otras cosas, las reglas de configuración, la Consola de eventos (CE) y la Business Intelligence (BI).
Las expresiones regulares de Python son una extensión de las ER ampliadas y son muy similares a las de Perl. Admiten, por ejemplo, el llamado lookahead negativo, un asterisco * no codicioso, o una aplicación de la distinción mayúsculas/minúsculas. Los detalles de las capacidades de estas expresiones regulares pueden encontrarse en la ayuda en línea de Python para el módulo re, o con más detalle en la documentación en línea de Python:
OMD[mysite]:~$ pydoc3 re
Help on module re:
NAME
re - Support for regular expressions (RE).
MODULE REFERENCE
https://docs.python.org/3.8/library/re
The following documentation is automatically generated from the Python
source files. It may be incomplete, incorrect or include features that
are considered implementation detail and may vary between Python
implementations. When in doubt, consult the module reference at the
location listed above.
DESCRIPTION
This module provides regular expression matching operations similar to
those found in Perl. It supports both 8-bit and Unicode strings; both
the pattern and the strings being processed can contain null bytes and
characters outside the US ASCII range.
Regular expressions can contain both special and ordinary characters.
Most ordinary characters, like "A", "a", or "0", are the simplest
regular expressions; they simply match themselves. You can
concatenate ordinary characters, so last matches the string 'last'.Puedes encontrar una explicación muy detallada de las expresiones regulares en un artículo deWikipedia.