This is a machine translation based on the English version of the article. It might or might not have already been subject to text preparation. If you find errors, please file a GitHub issue that states the paragraph that has to be improved. |
1. Introducción
1.1. Clústeres, nodos y servicios de clúster
Al distribuir servicios críticos y de misión crítica, como bases de datos o sitios web de comercio electrónico, es poco probable que confíes en que el host que ejecuta esos servicios tenga una vida larga, estable y sin sobresaltos. Más bien, tendrás en cuenta el posible fallo de un host y te asegurarás de que otros hosts estén en espera para hacerse cargo de los servicios inmediatamente en caso de fallo(o Failover), de modo que el fallo ni siquiera sea perceptible para el mundo exterior.
Un grupo de hosts conectados en red que trabajan juntos para realizar la misma tarea se denomina red informática o clúster informático, o más sencillamente, clúster. Un clúster actúa y aparece como un único sistema externamente y organiza sus hosts internamente para que trabajen juntos para realizar la tarea común.
Un clúster puede realizar varias tareas, por ejemplo, un clúster HPC puede realizar computación de alto rendimiento, que se utiliza, entre otros escenarios, cuando los cálculos requieren mucha más memoria de la que está disponible en un solo ordenador. Si el clúster tiene la tarea de proporcionar alta disponibilidad, también se denomina clúster HA. Este artículo se ocupa de los clústeres HA, es decir, cuando nos referimos a un "clúster" en el texto siguiente, siempre nos referimos a un clúster HA.
Un clúster ofrece uno o varios servicios al mundo exterior: los servicios del clúster, a veces denominados "servicios en clúster". En un clúster, los hosts que lo componen se denominan nodos. En un momento dado, cada servicio es proporcionado por uno solo de los nodos. Si falla algún nodo del clúster, todos los servicios esenciales para la misión del clúster se trasladan a uno de los otros nodos.
Para que la conmutación por error sea transparente, algunos clústeres proporcionan su propia dirección IP de clúster, que a veces también se denomina dirección IP virtual. La dirección IP de clúster siempre se refiere al nodo activo y es representativa de todo el clúster. En caso de conmutación por error, la dirección IP se transfiere a otro nodo previamente pasivo, que pasa a ser el nodo activo. El cliente que se comunica con el clúster puede ser ajeno a una conmutación por error interna: utiliza la misma dirección IP sin cambios y no tiene que hacer por sí mismo ninguna conmutación.
Otros clústeres no tienen una dirección IP de clúster. Los clústeres de bases de datos Oracle en muchas de sus variantes son un ejemplo destacado. Sin una dirección IP de clúster, el cliente debe mantener una lista de direcciones IP de todos los nodos que podrían prestar el servicio. Si el nodo activo falla, el cliente debe detectarlo y cambiar al nodo que ahora presta el servicio.
1.2. Monitorización de un clúster
Checkmk es uno de los clientes que se comunica con el clúster. En Checkmk se pueden configurar y monitorizar todos los nodos de un clúster, independientemente de cómo el software del clúster compruebe internamente el estado de los nodos individuales y, si es necesario, realice un Failover.
La mayoría de los checks que Checkmk realiza en los nodos individuales de un clúster tienen que ver con las propiedades físicas de los nodos, que son independientes de que el host pertenezca o no a un clúster. Algunos ejemplos son la carga de CPU y memoria, los discos locales, las interfaces físicas de red, etc. Sin embargo, para mapear la función de clúster de los nodos en Checkmk, es necesario identificar aquellos servicios que definen la tarea del clúster y puede ser necesario transferir a otro nodo: los servicios de clúster.
Checkmk te ayuda a monitorizar los servicios del clúster. Lo que tienes que hacer es
Crear el clúster.
Selecciona los servicios del clúster.
Realizar un descubrimiento de servicios para todos los host asociados.
En el capítulo siguiente se describe cómo proceder utilizando la siguiente configuración de ejemplo:
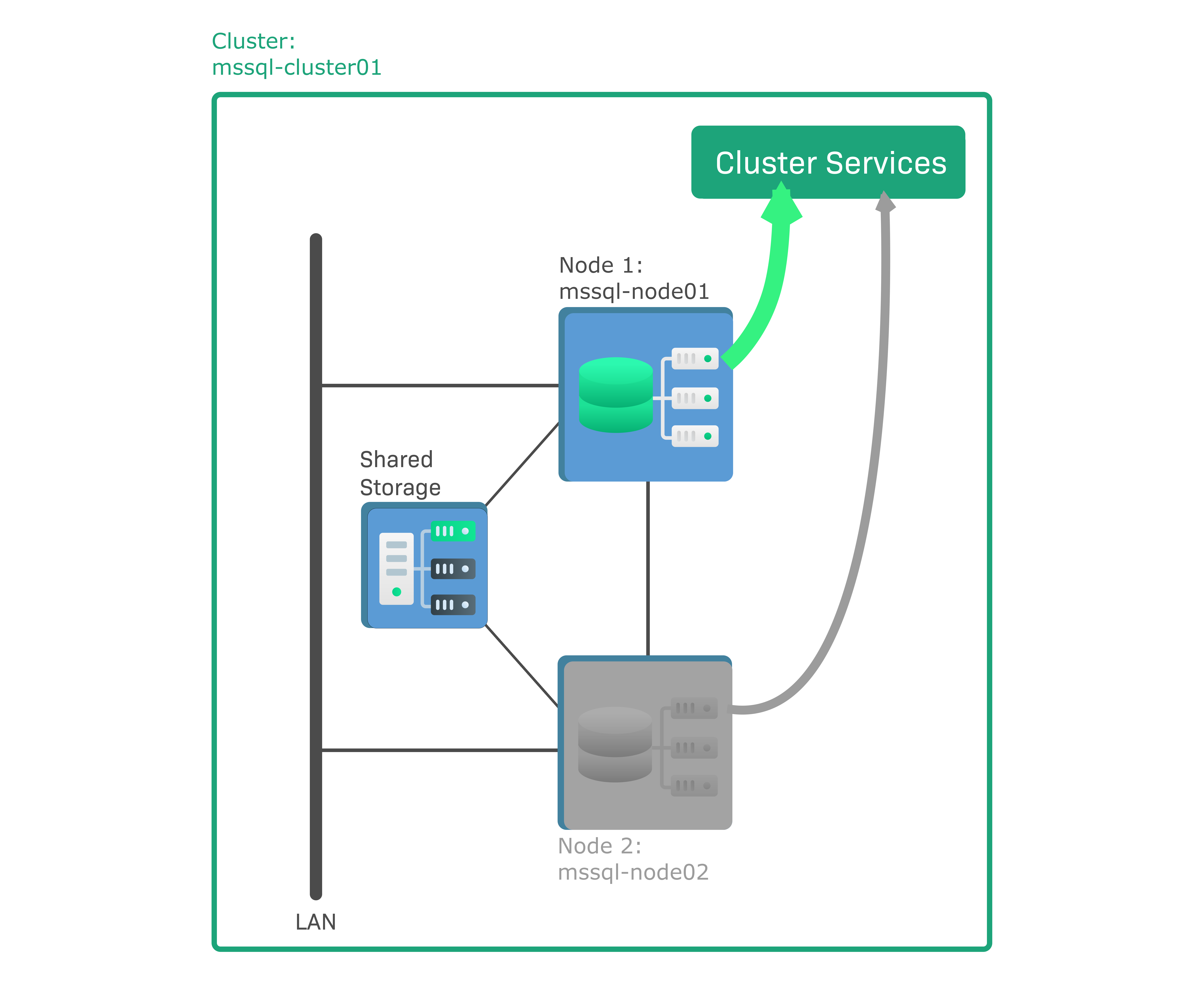
En Checkmk, hay que configurar un clúster de Failover de Windows como clúster de HA formado por dos nodos con servidores Microsoft SQL (MS SQL) instalados. Se trata de un clúster denominado activo/pasivo, lo que significa que sólo uno, el nodo activo, ejecuta una instancia de base de datos. El otro nodo es pasivo y sólo se activa en caso de Failover, cuando arranca la instancia de base de datos y sustituye al nodo que ha fallado. Los datos de la instancia de base de datos no se almacenan en los propios nodos, sino en un medio de almacenamiento compartido, por ejemplo una red de área de almacenamiento (SAN), a la que están conectados ambos nodos. La configuración de ejemplo consta de los siguientes componentes
mssql-node01es el nodo activo que ejecuta una instancia de base de datos activa.mssql-node02es el nodo pasivo.mssql-cluster01es el clúster al que pertenecen ambos nodos.
A diferencia de este ejemplo, también es posible que un mismo nodo esté incluido en más de un clúster. En el último capítulo aprenderás a configurar esos clústeres superpuestos utilizando una configuración de ejemplo modificada.
2. Configuración de clústeres y servicios de clúster
2.1. Crear un clúster
En Checkmk, los nodos y el propio clúster se crean como hosts (hosts de nodo y hosts de clúster), con un tipo de host especial definido para un host de clúster.
Aquí tienes algunos puntos a tener en cuenta antes de configurar un host de clúster:
El host de clúster es un host virtual que debe configurarse con una dirección IP de clúster, si existe. En nuestro ejemplo, suponemos que el nombre del host de clúster se puede resolver mediante DNS.
Los hosts de clúster pueden configurarse del mismo modo que los hosts "normales", por ejemplo con tags del host o grupos de host.
Para todos los hosts participantes (esto significa siempre el host de clúster y todos los hosts de sus nodos asociados), las fuentes de datos deben configurarse de forma idéntica, es decir, en particular, algunos no pueden configurarse mediante un agente Checkmk y otros mediante SNMP. Checkmk garantiza que sólo se pueda crear un host de clúster si se cumple este requisito.
En una monitorización distribuida, todos los host participantes deben estar asignados al mismo site Checkmk.
No todos los checks funcionan en una configuración de clúster. Para aquellos checks que tienen implementado el soporte de clúster, puedes leer sobre ello en la página del manual del plugin. Puedes acceder a las páginas del manual desde el menú Setup > Services > Catalog of check plugins.
En nuestro ejemplo, los dos nodos hosts mssql-node01 y mssql-node02 ya han sido creados y configurados como hosts. Para saber cómo llegar hasta aquí, consulta el artículo sobre monitorización de servidores Windows, y allí el capítulo sobre ampliación del agente estándar de Windows con Plugin, para nuestro ejemplo los Plugin de MS SQL Server.
Inicia la creación del clúster desde el menú Setup > Hosts > Hosts y después desde el menú Hosts > Add cluster:
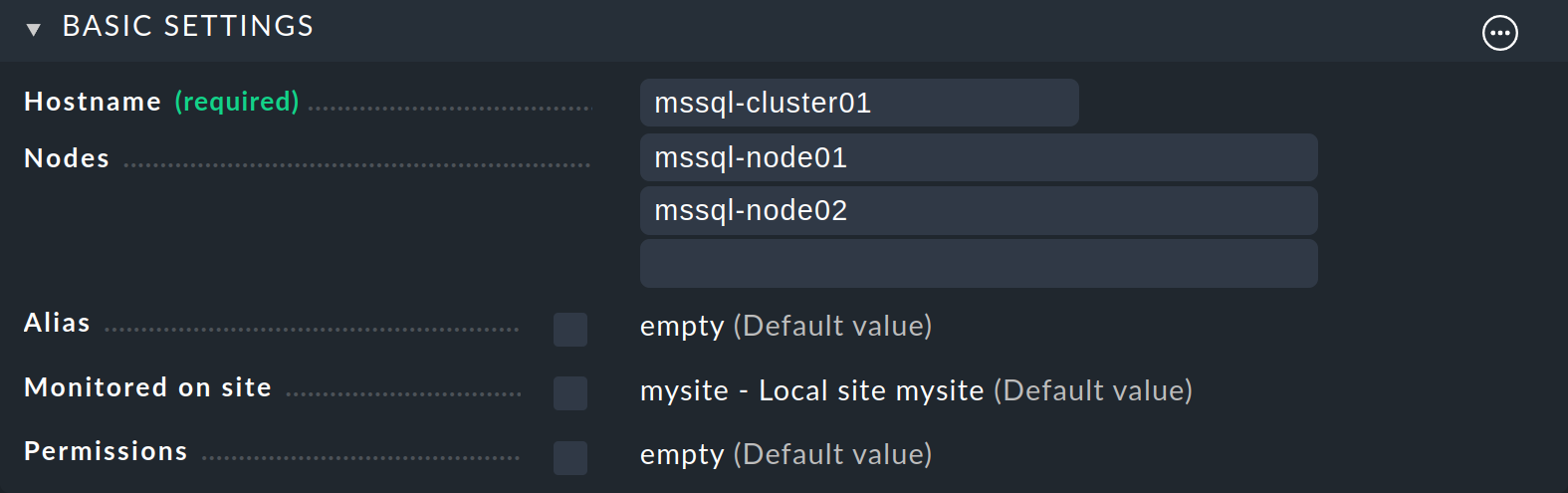
Introduce mssql-cluster01 como Hostname, e introduce los dos nodos host en Nodes.
Nota: Si se trata de un clúster sin dirección IP de clúster, tendrás que dar un rodeo no tan cómodo, seleccionando No IP en la caja Network Address para el IP Address Family. Pero para evitar que el host quede DOWN en la monitorización, debes cambiar el "comando de chequeo del host" por defecto para ello mediante la regla del mismo nombre -de Smart PING o PING a, por ejemplo, el estado de uno de los servicios que se va a asignar al host de clúster-, como se explicará en la siguiente sección. Para más información sobre conjuntos de reglas de host, consulta el artículo sobre reglas.
Completa la creación con Save & view folder y activa los cambios.
2.2. Seleccionar los servicios del clúster
Checkmk no puede saber cuáles de los servicios que se ejecutan en un nodo son locales y cuáles son servicios de clúster: algunos sistemas de archivos pueden ser locales, otros pueden estar montados sólo en el nodo activo. Lo mismo ocurre con los procesos: Mientras que es muy probable que el servicio "Temporizador de Windows" se esté ejecutando en todos los nodos, una determinada instancia de base de datos sólo estará disponible en el nodo activo.
En lugar de hacer que Checkmk adivine, selecciona los servicios del clúster con una regla. Sin una regla, no se asignará ningún servicio al clúster. En este ejemplo supondremos que los nombres de todos los servicios de clúster de MS SQL Server empiezan porMSSQL y que se puede acceder al sistema de archivos del dispositivo de almacenamiento compartido a través de la unidad D:.
Comienza con Setup > Hosts > Hosts y haz clic en el nombre del clúster. En la página Properties of host, selecciona del menú Hosts > Clustered services. Llegarás a la página del conjunto de reglas Clustered services, donde podrás crear una nueva regla.
Independientemente de si los hosts están organizados en carpetas y de cómo lo estén, asegúrate de crear cualquier regla para los servicios del clúster de modo que se aplique a los hosts de los nodos en los que se ejecutan los servicios. Una regla de este tipo es ineficaz para un host de clúster.
En Create rule in folder, selecciona la carpeta que contiene los hosts de nodo. Accederás a la página New rule: Clustered services:
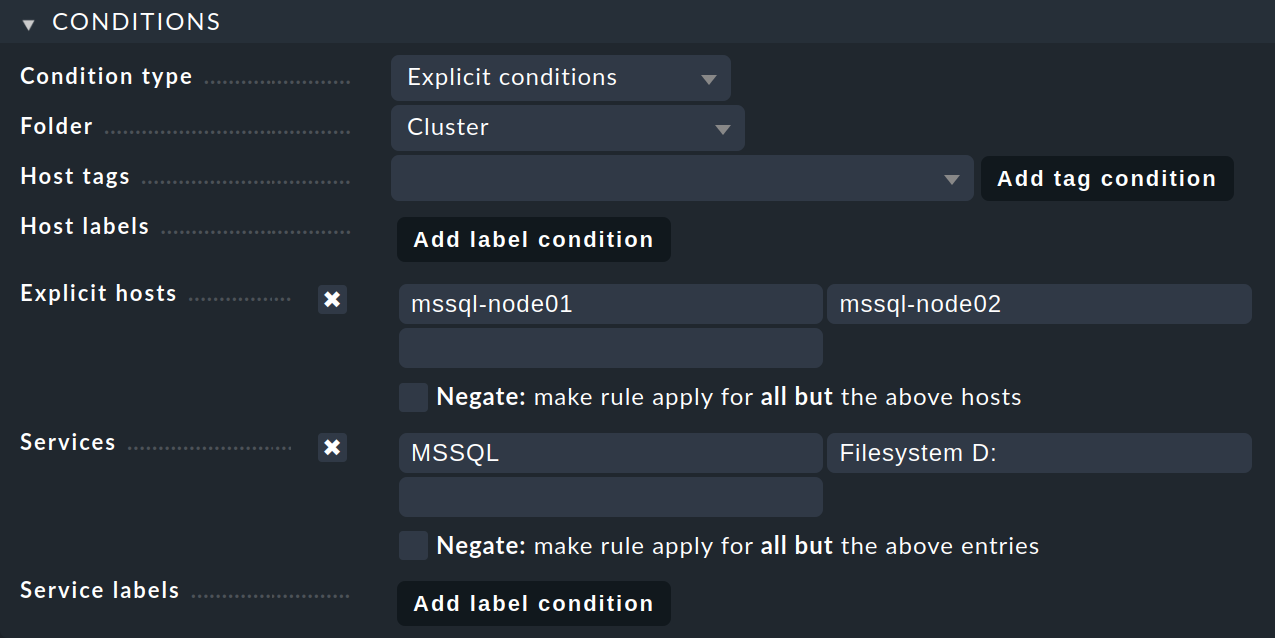
En la caja Conditions, activa Explicit hosts e introduce el host de nodo activo mssql-node01 y el host de nodo pasivo mssql-node02. A continuación, activa Services y haz dos entradas allí: MSSQL para todos los servicios MS SQL cuyo nombre empiece por MSSQL y Filesystem D: para la unidad. Las entradas se interpretan como expresiones regulares.
Todos los servicios que no estén definidos como servicios de clúster serán tratados como servicios locales por Checkmk.
Termina de crear la regla con Save y activa los cambios.
2.3. Realiza un descubrimiento de servicios
Para todos los hosts participantes (hosts de clúster y de nodo), hay que realizar al final un nuevodescubrimiento de servicios para que todos los servicios de clúster recién definidos se eliminen primero de los nodos y se añadan después al clúster.
En Setup > Hosts > Hosts, selecciona primero todos los host implicados y, a continuación, selecciona en el menú Hosts > On Selected hosts > Run bulk service discovery. En la página Bulk discovery, la primera opción Add unmonitored services and new host labels debería producir el resultado deseado.
Haz clic en Start para iniciar eldescubrimiento de servicios para varios host. Una vez completado con éxito - indicado por el mensajeBulk discovery successful - sal y activa los cambios.
Para saber si la selección de los servicios del clúster ha dado el resultado deseado, puedes listar todos los servicios que ahora están asignados al clúster: En Setup > Hosts > Hosts, en la lista de hosts, en la entrada del host de clúster, haz clic en el icono para editar los servicios. En la página siguiente Services of host todos los servicios del clúster están listados en Monitored services:
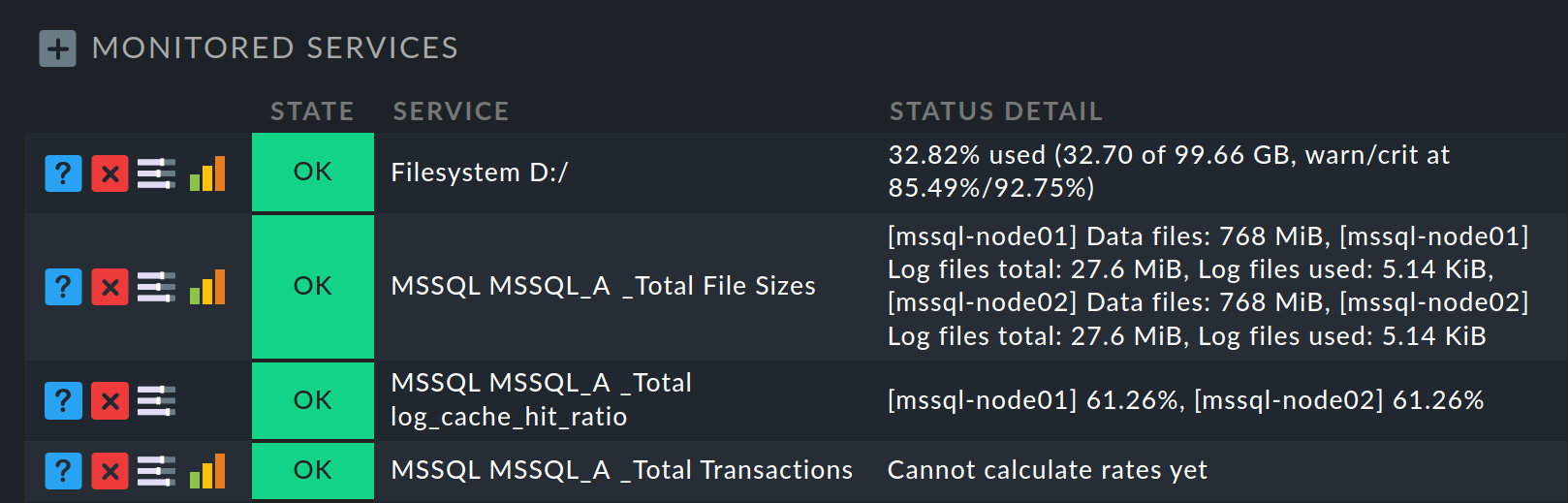
En cambio, en los hosts de nodo, los mismos servicios que se han trasladado al clúster ahora no aparecerán en la lista de servicios monitorizados. En el host de nodo, puedes encontrarlos de nuevo mirando al final de la lista de servicios en la secciónMonitored clustered services (located on cluster host):
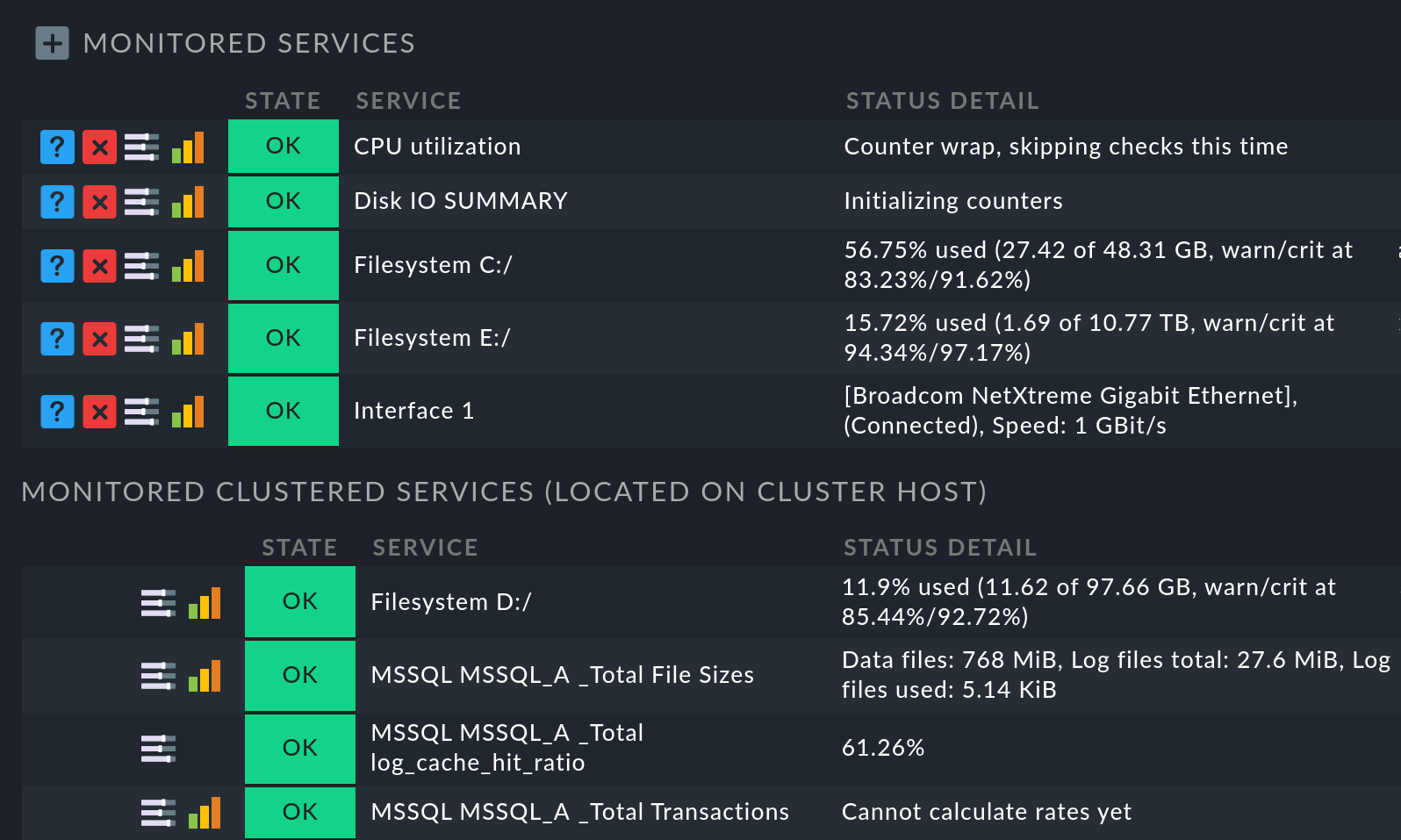
Consejo: Si ejecutas local check en un clúster en el que se ha aplicado la reglaClustered services, puedes utilizar el conjunto de reglasLocal checks in Checkmk clusters para influir en el resultado, eligiendo entre Worst state y Best state.
2.4. Descubrimiento automático de servicios
Si dejas que el descubrimiento de servicios se realice automáticamente mediante el Discovery Check, debes tener en cuenta un aspecto especial. El Discovery Check puede eliminar automáticamente los servicios que desaparecen. Sin embargo, si un servicio agrupado se desplaza de un nodo a otro, podría registrarse incorrectamente como desaparecido y luego eliminarse. Por otra parte, si omites esta opción, los servicios que realmente desaparecieran nunca se eliminarían.
3. Superposición de clústeres
Es posible que varios clústeres compartan uno o varios nodos. Se habla entonces de clústeres solapados. Para los clústeres solapados, necesitas una regla especial para indicar a Checkmk qué servicios de clúster de un host de nodo compartido deben asignarse a qué clúster.
A continuación presentaremos el procedimiento básico para configurar un clúster solapado modificando el ejemplo del clúster de MS SQL Server de un clúster activo/pasivo a uno activo/activo:
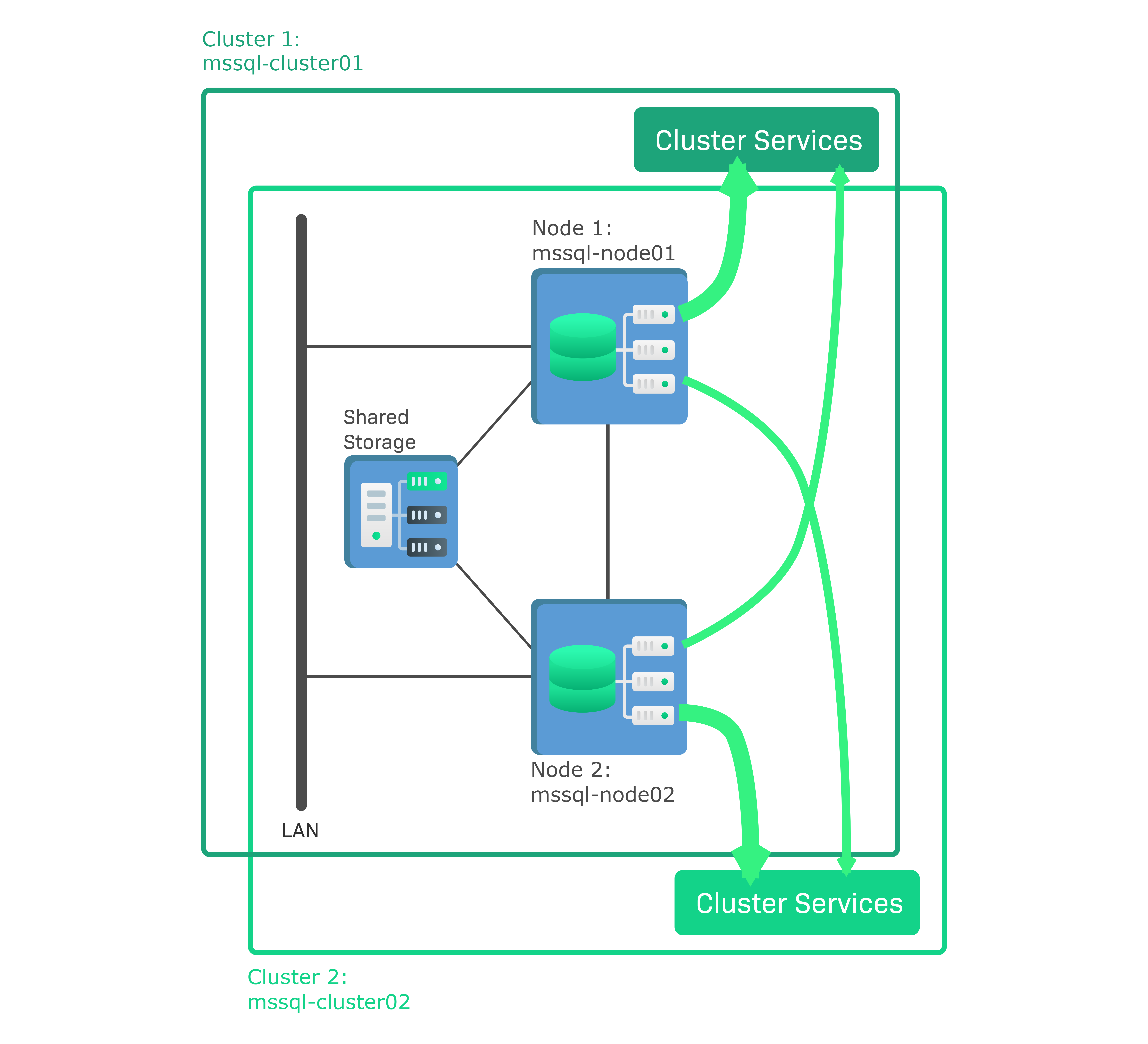
En esta configuración, no sólo se instala MS SQL Server en los dos nodos anfitriones, sino que se ejecuta una instancia de base de datos independiente en cada uno de los dos nodos. Ambos nodos acceden al medio de almacenamiento compartido, pero en unidades diferentes. Este ejemplo implementa un clúster solapado al 100 %, porque los dos nodos pertenecen a ambos clústeres.
La ventaja del clúster activo/activo es que se aprovechan mejor los recursos disponibles de los dos nodos. En caso de Failover, la tarea del nodo que ha fallado es asumida por el nodo alternativo, que entonces ejecuta ambas instancias de la base de datos.
Así pues, esta configuración de ejemplo consta de los siguientes componentes
mssql-node01es el primer nodo activo que ejecuta actualmente la instancia de base de datosMSSQL Instance1.mssql-node02es el segundo nodo activo que ejecuta actualmente la instancia de base de datosMSSQL Instance2.mssql-cluster01ymssql-cluster02son los dos clústeres a los que pertenecen ambos nodos.
Sólo tienes que modificar ligeramente el primer paso para configurar el clúster activo/pasivo para un clúster activo/activo: Creas el primer clústermssql-cluster01 como se ha descrito anteriormente. Luego creas el segundo clústermssql-cluster02 con los mismos dos nodos host.
En el segundo paso, en lugar de utilizar el conjunto de reglas general Clustered services para seleccionar los servicios del clúster, utiliza el conjunto de reglas creado especialmente para clústeres solapados Clustered services for overlapping clusters. Esto te permite definir en una regla los servicios de clúster que se eliminarán de los hosts de nodo y se añadirán al clúster seleccionado.
Para nuestro ejemplo con un solapamiento del 100 % necesitamos dos de estas reglas: La primera regla define los servicios de clúster de la primera instancia de base de datos, que se ejecutan en el primer host de nodo por defecto. Como en caso de Failover estos servicios de clúster se transfieren al segundo host de nodo, asignamos los servicios a ambos hosts de nodo. La segunda regla hace lo mismo para el segundo clúster y la segunda instancia de base de datos.
Empecemos por la primera regla: En Setup > General > Rule search busca el conjunto de reglas Clustered services for overlapping clusters y haz clic en él. En Create rule in folder selecciona de nuevo la carpeta que contiene los hosts de nodo.
En Assign services to the following cluster introduce el clúster mssql-cluster01:

En la caja Conditions, activa Explicit hosts e introduce los dos hosts de los nodos. A continuación, activa Services y haz dos entradas allí: MSSQL Instance1
para todos los servicios MS SQL de la primera instancia de base de datos, y Filesystem D: para la unidad:
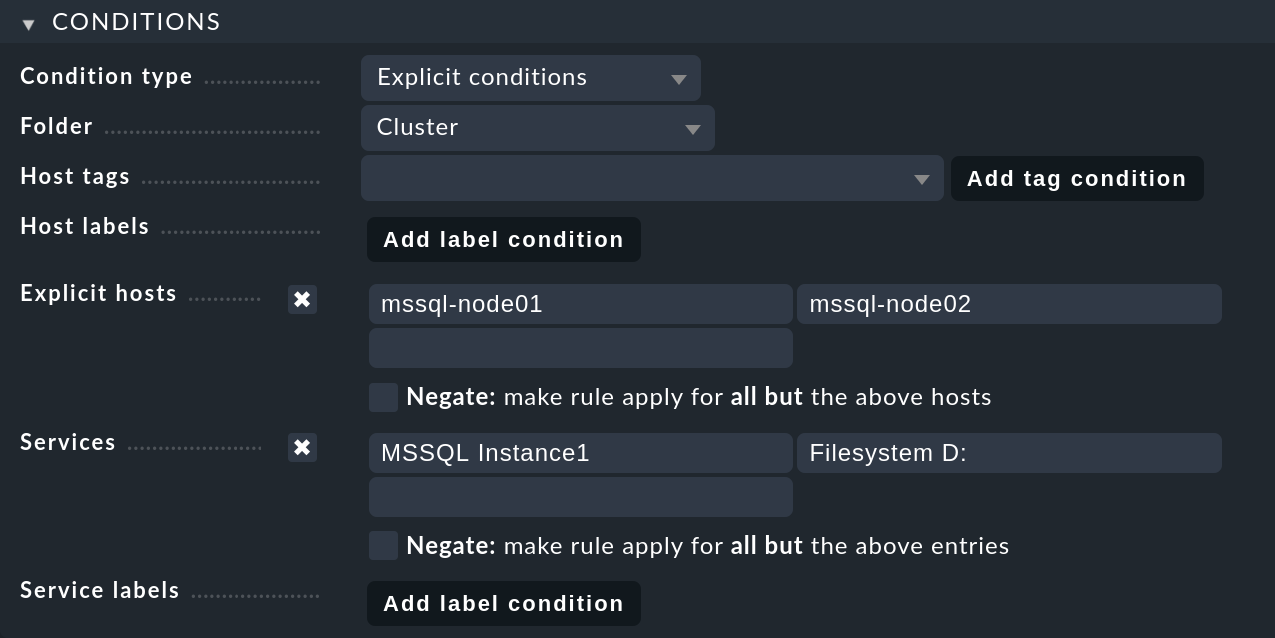
Termina la creación de la primera regla con Save.
A continuación, crea la segunda regla, esta vez para el segundo clúster mssql-cluster02y de nuevo para ambos nodos host. En Services introduce ahoraMSSQL Instance2 para todos los servicios MS SQL de la segunda instancia de base de datos. El host del segundo nodo, en el que se ejecuta por defecto la segunda instancia de base de datos, accede a su medio de almacenamiento en una unidad diferente, en el ejemplo siguiente a través de la unidad E::
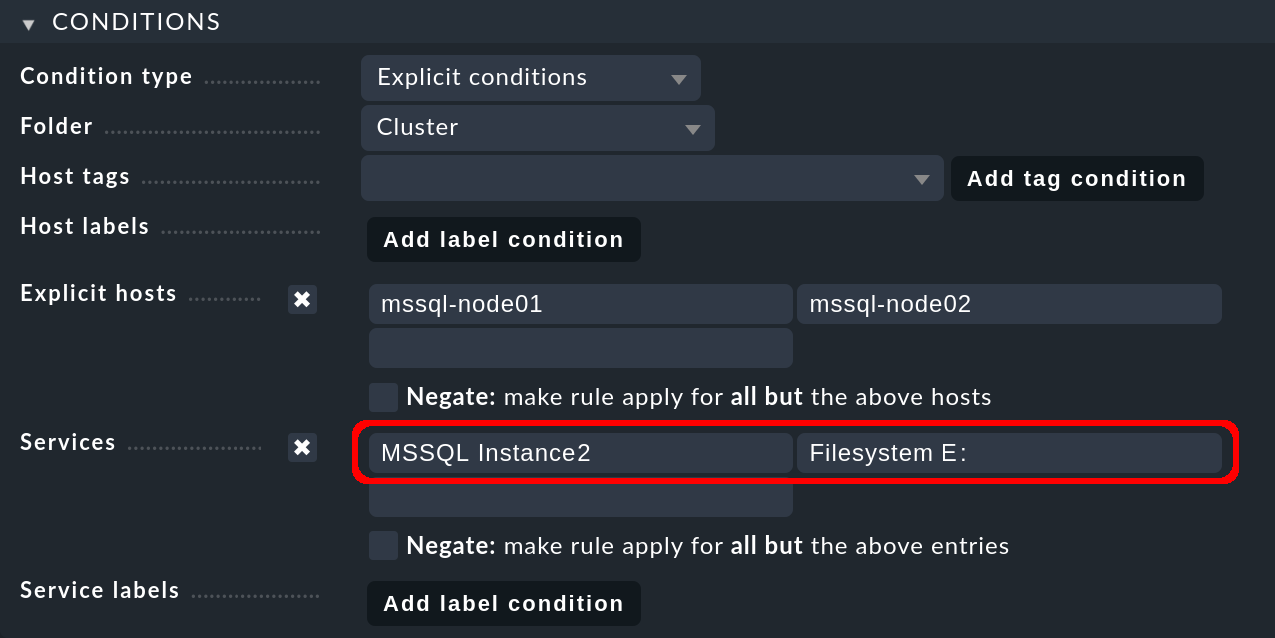
Guarda también esta regla y activa los dos cambios.
Por último, realiza un descubrimiento de servicios como tercer y último paso, del mismo modo que se ha descrito anteriormente: como Bulk discovery para todos los hosts asociados, es decir, los dos hosts de clúster y los dos hosts de nodo.
Nota: Si varias reglas definen un servicio de clúster, la regla más específicaClustered services for overlapping clusters con la asignación explícita a un clúster específico tiene prioridad sobre la regla más generalClustered services. Para los dos ejemplos presentados en este artículo, esto significa que las dos últimas reglas específicas creadas nunca permitirían que se aplicara la regla general creada en el primer ejemplo.