This is a machine translation based on the English version of the article. It might or might not have already been subject to text preparation. If you find errors, please file a GitHub issue that states the paragraph that has to be improved. |
1. El principio básico
1.1. Una mirada al pasado
Como Checkmk monitoriza continuamente todos los host y servicios a intervalos regulares, proporciona una base excepcional para la evaluación posterior de su disponibilidad. Y no sólo eso: también se puede calcular durante qué porcentaje de un intervalo de tiempo determinado un objeto estuvo en un estado o estados especificados, con qué frecuencia se produjo este estado, la duración de su parada más larga, y mucho más.
Cada cálculo se basa en una selección de objetos y unintervalo de tiempo especificadoen el pasado. A continuación, Checkmk reconstruye, dentro de este intervalo de tiempo, una secuencia cronológica de los estados de todos los objetos seleccionados. Por estado, se sumarán los tiempos y se mostrarán en una tabla. Esta tabla puede, por ejemplo, mostrar que un servicio concreto experimentó estados de 99,95 % OK, y 0,005 % WARN en el intervalo de tiempo definido.
Al realizar estos cálculos, Checkmk también tiene en cuenta correctamente factores como los tiempos de mantenimiento programados, los tiempos de inactividad del servicio, los intervalos de tiempo no supervisados y otros factores especiales, permite resumir los estados e ignorar las "interrupciones breves". También dispone de numerosas opciones de personalización y de la posibilidad de realizar Agregaciones BI.
1.2. Estados posibles
Mediante la inclusión de tiempos de mantenimiento programados y estados especiales similares, existe en teoría un gran número de combinaciones posibles de estados, por ejemplo: CRIT + En tiempo de inactividad programado + En tiempo de mantenimiento + Inestable. Como la mayoría de estas combinaciones no son muy útiles, Checkmk las reduce a un número pequeño y, al hacerlo, procede según un principio de prioridades. Como en el ejemplo anterior el servicio estaba en tiempo de inactividad programado, simplemente se aplica el estado in scheduled downtime, y se ignora el estado real. Esto reduce la lista de estados posibles a los siguientes:
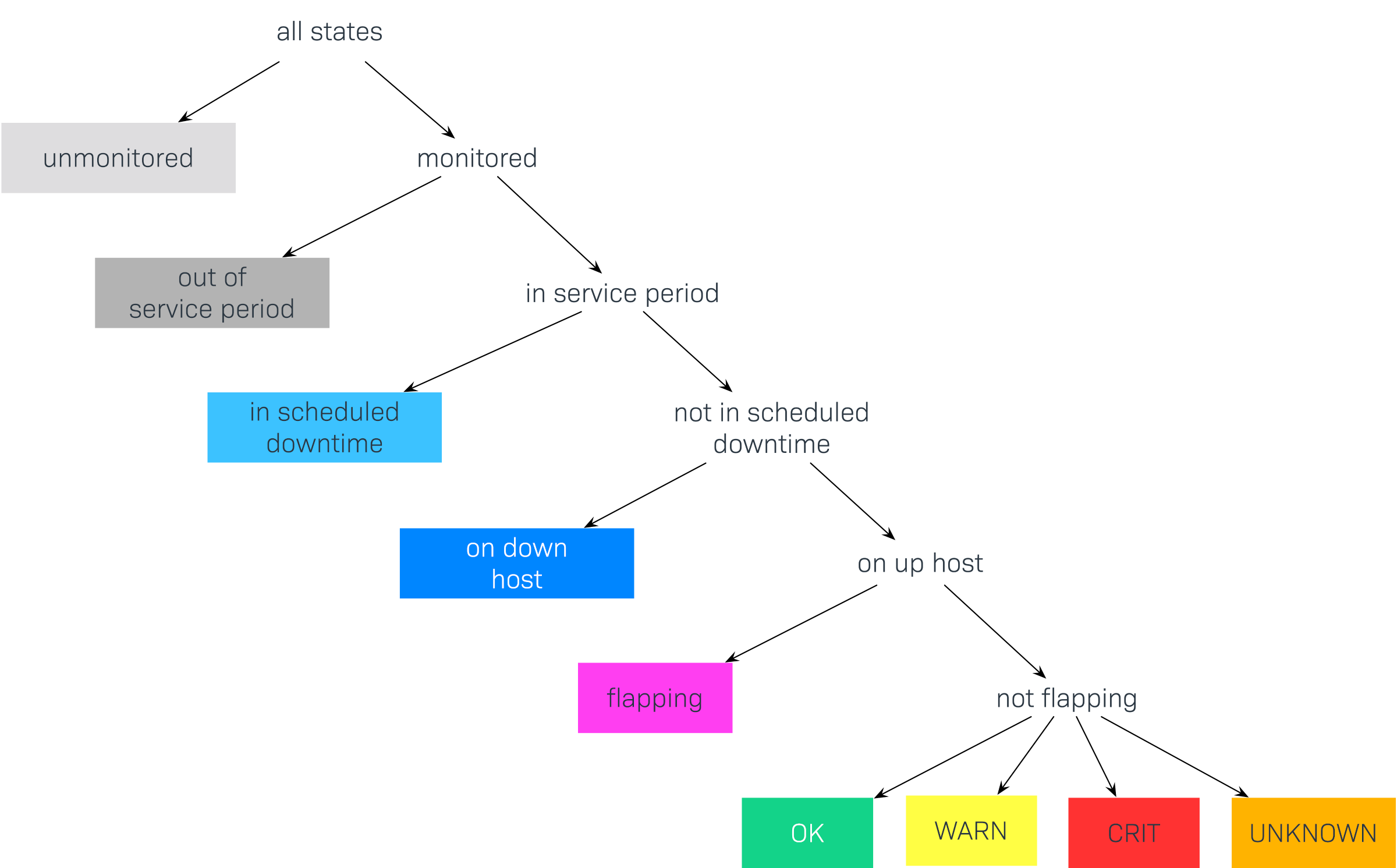
Este gráfico muestra el orden de prioridad de los estados. Más adelante mostraremos cómo se pueden ignorar o combinar algunos estados. Aquí están de nuevo los estados, en detalle:
| Estado | Abreviatura | Descripción |
|---|---|---|
unmonitored |
NO DISPONIBLE |
Intervalos de tiempo durante los cuales el objeto no estaba siendo monitorizado. Hay dos posibles razones para ello: el objeto no estaba en la configuración de la monitorización, o la propia monitorización no se estaba ejecutando durante el intervalo de tiempo especificado. |
out of service period |
El objeto estaba fuera de su periodo de servicio, es decir, cuando su disponibilidad era "irrelevante". Más adelante encontrarás más información sobre los periodos de servicio. |
|
in scheduled downtime |
Downtime |
El objeto estaba en un periodo de tiempo de mantenimiento programado Tiempo de inactividad . Este estado también se asumirá para los servicios cuyos hosts estén en un tiempo de mantenimiento programado. |
on down host |
H.Down |
Este estado sólo está disponible para los servicios - cuando el host del servicio está (caído). Una monitorización del servicio en este momento no es posible. Para la mayoría de los servicios esto tiene el mismo significado que si el servicio está CRIT- ¡pero no para todos! Por ejemplo, el estado de un (File system-Check) es ciertamente independiente de la accesibilidad del host. |
flapping |
Fases en las que el estado es inestable- es decir, aquellas fases durante las cuales se han experimentado muchos cambios de estado en un breve lapso de tiempo. |
|
UP DOWN UNREACH |
Estados de monitorización de los host |
|
OK WARN CRIT DESCONOCIDO |
Estados de monitorización para servicios y Agregaciones BI |
2. Recuperación de la disponibilidad
2.1. De la vista de tabla al análisis
Generar un análisis de disponibilidad es muy sencillo. Primero recupera cualquiervista de host, servicios o Agregaciones BI. Allí encontrarás en el menú Services o en Hosts el item Availability, que te lleva directamente al cálculo de la disponibilidad de los objetos seleccionados. Los datos se mostrarán en forma de tabla:
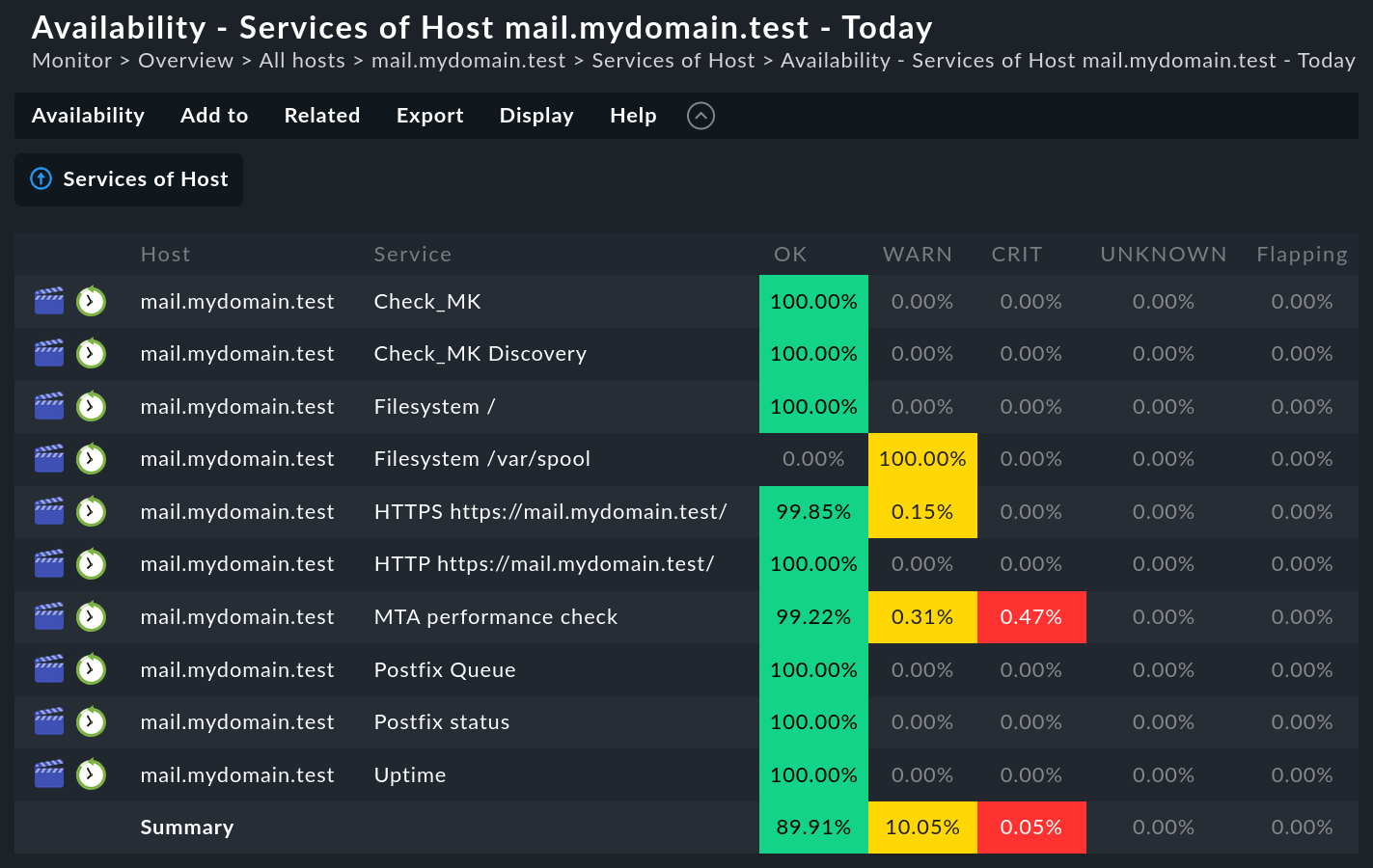
La tabla muestra los mismos objetos que se veían en la vista anterior. En cada columna se muestra la proporción del intervalo de tiempo solicitado en que un objeto se encontraba en el estado consultado. El valor se da en forma de porcentaje, por defecto con dos decimales, que también puedes personalizar fácilmente.
La consulta del intervalo de tiempo se puede personalizar con la opción de menú Availability > Change display options > Time Range item de menú. Más sobre esto más adelante...
Tienes la opción de recibir la tabla en formato PDF (sólo ediciones comerciales). También es posible descargar los datos en formato CSV (Export as CSV). Tendrá el siguiente aspecto para el ejemplo anterior:
Host;Service;OK;WARN;CRIT;UNKNOWN;Flapping;H.Down;Downtime;N/A
mail.mydomain.test;Check_MK;100.00%;0.00%;0.00%;0.00%;0.00%;0.00%;0.00%;0.00%
mail.mydomain.test;Check_MK Discovery;100.00%;0.00%;0.00%;0.00%;0.00%;0.00%;0.00%;0.00%
mail.mydomain.test;Filesystem /;100.00%;0.00%;0.00%;0.00%;0.00%;0.00%;0.00%;0.00%
mail.mydomain.test;Filesystem /var/spool;0.00%;100.00%;0.00%;0.00%;0.00%;0.00%;0.00%;0.00%
mail.mydomain.test;HTTP https://mail.mydomain.test/;99.85%;0.15%;0.00%;0.00%;0.00%;0.00%;0.00%;0.00%
mail.mydomain.test;HTTPS https://mail.mydomain.test/;100.00%;0.00%;0.00%;0.00%;0.00%;0.00%;0.00%;0.00%
mail.mydomain.test;MTA performance check;99.23%;0.30%;0.46%;0.00%;0.00%;0.00%;0.00%;0.00%
mail.mydomain.test;Postfix Queue;100.00%;0.00%;0.00%;0.00%;0.00%;0.00%;0.00%;0.00%
mail.mydomain.test;Postfix status;100.00%;0.00%;0.00%;0.00%;0.00%;0.00%;0.00%;0.00%
mail.mydomain.test;Uptime;100.00%;0.00%;0.00%;0.00%;0.00%;0.00%;0.00%;0.00%
Summary;;89.91%;10.05%;0.05%;0.00%;0.00%;0.00%;0.00%;0.00%Con la ayuda de un usuario de automatización, que puede autenticarse a través de la URL, también puedes recuperar datos -por ejemplo, conwget o curl) - y procesarlos automáticamente bajo el control del script.
2.2. Visualización de la línea de tiempo
Este botón te lleva a una visualización de la línea de tiempo del objeto correspondiente, en la que se detalla con precisión qué cambio(s) de estado se produjo(n) en el intervalo de tiempo especificado (abreviado aquí):
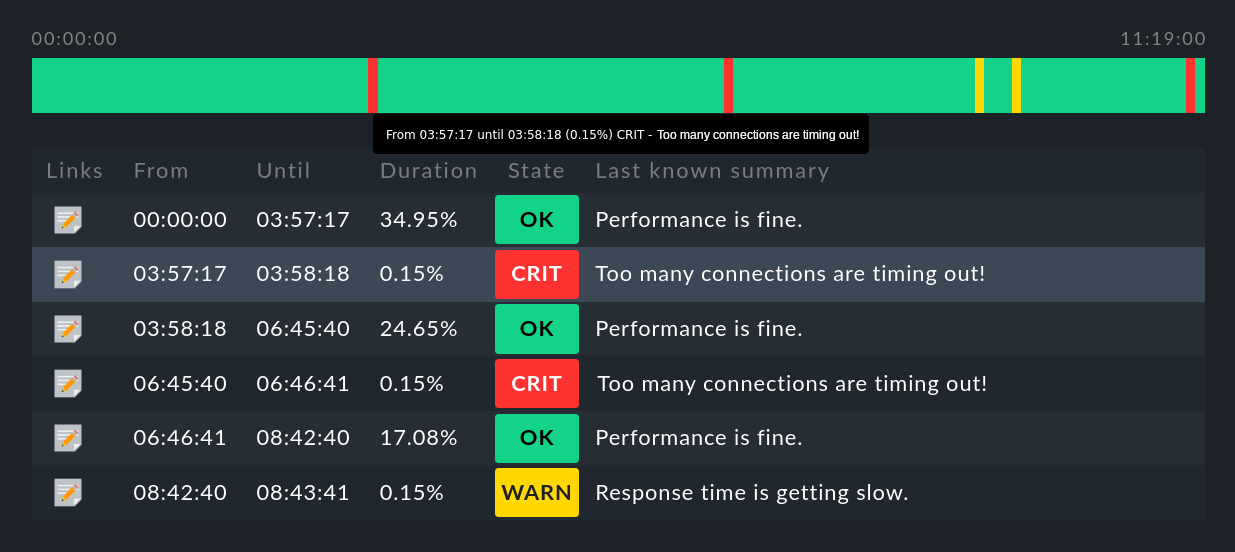
Algunos consejos útiles:
Pasa el puntero del ratón por encima de un símbolo de la línea de tiempo de un objeto en la visualización, éste se resaltará en la visualización de la tabla.
También en la línea de tiempo, puedes utilizar los elementos de menú Availability > Change display options o Availability > Change computation options para personalizar las opciones de visualización y evaluación.
Con el símbolo puedes añadir un Annotation al item seleccionado. Aquí también puedes contabilizar retrospectivamente los tiempos de mantenimiento (más sobre esto en la próxima sección).
En la disponibilidad de Agregaciones BI, con el símbolo de la varita mágica puedes viajar en el tiempo al estado de la agregación para el tramo de tiempo en cuestión. Más sobre esto más adelante.
Con el elemento de menú Availability > Timeline de la vista principal, puedes ver las líneas de tiempo de todos los objetos seleccionados en una única y larga página.
2.3. Anotaciones y tiempos de mantenimiento posteriores
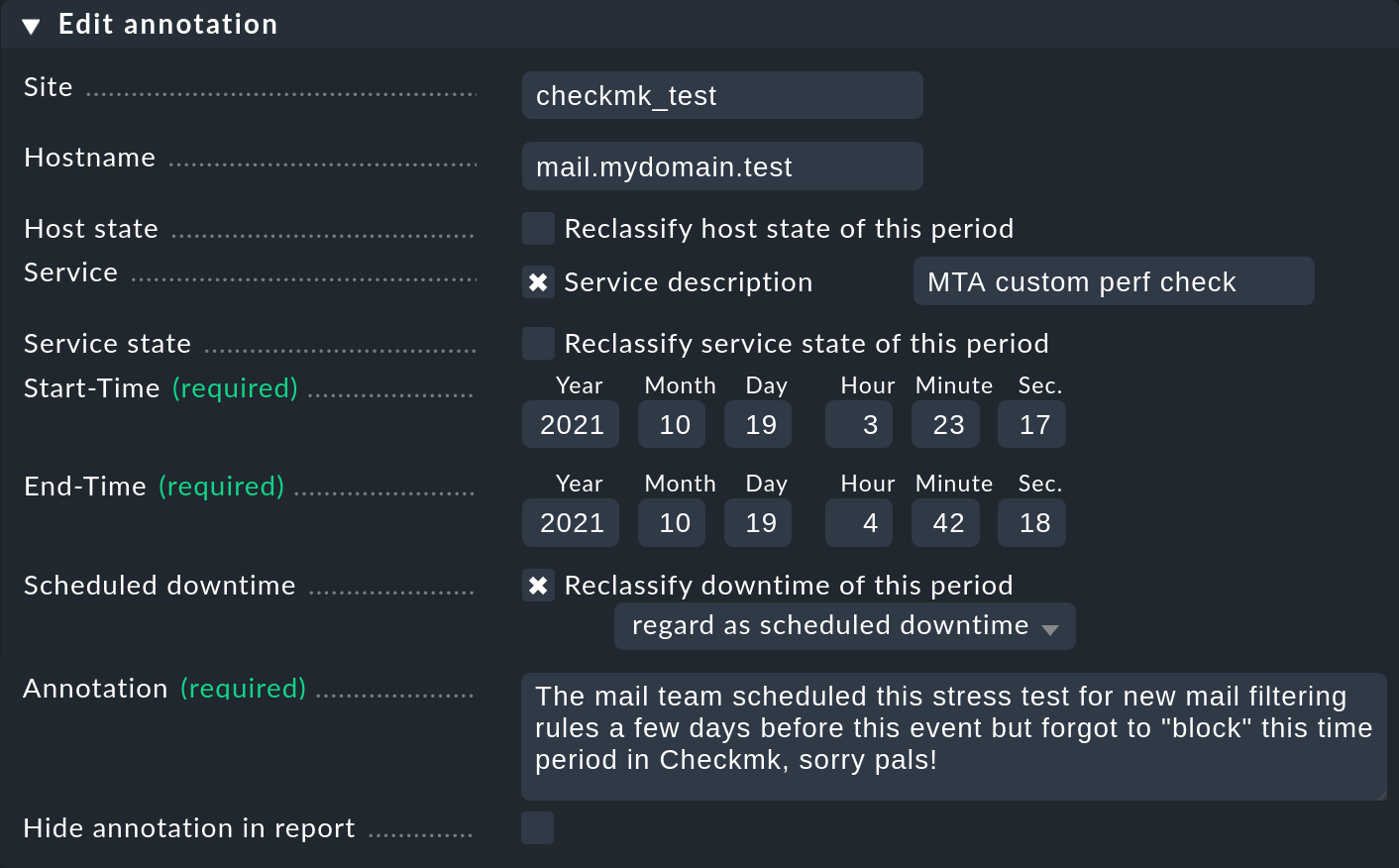
Como acabamos de mencionar, con el símbolo las líneas de tiempo ofrecen la posibilidad de añadir una anotación a un periodo de tiempo. Se proporciona un formulario precargado ("Propiedades") en el que se pueden introducir comentarios:
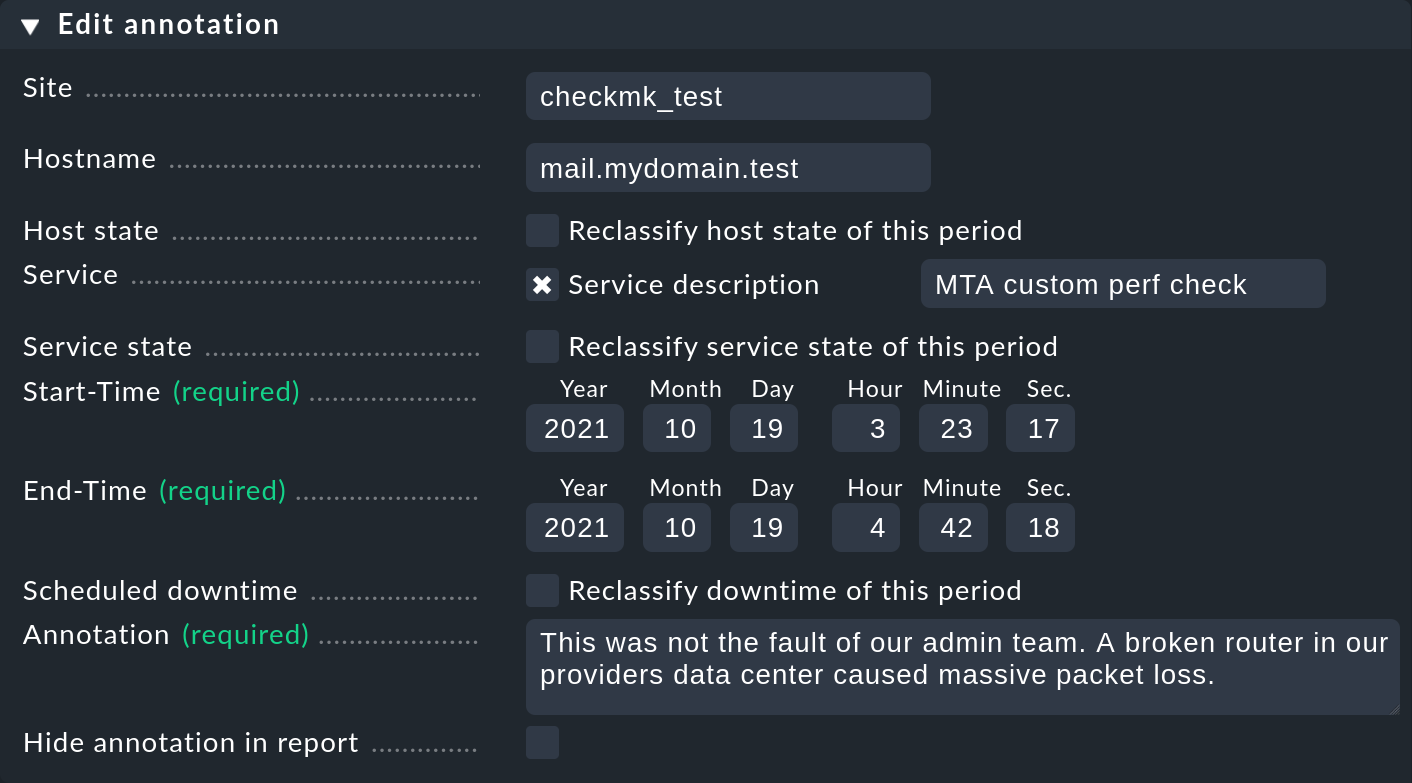
Con él puedes definir y ampliar el intervalo de tiempo con diferentes valores, según sea necesario. Esto resulta práctico, por ejemplo, si deseas anotar un intervalo de tiempo mayor que haya experimentado cambios de estado repetidos. Si omites introducir un servicio, la anotación se creará para el host, y se relacionará automáticamente con todos los servicios del host.
En cada vista de tabla de disponibilidad serán visibles automáticamente todas las anotaciones aplicables al intervalo de tiempo y a los objetos visualizados.
Pero las anotaciones tienen una función adicional. Los tiempos de mantenimiento pueden introducirse a posteriori o, por el contrario, eliminarse. El análisis de disponibilidad tiene en cuenta estas correcciones exactamente igual que con los tiempos de mantenimiento "normales". Hay al menos dos justificaciones legítimas para ello:
Durante el funcionamiento, puede ocurrir que los tiempos de mantenimiento previstos se introduzcan incorrectamente. Por supuesto, esto es perjudicial para la exactitud de las estadísticas de disponibilidad. La introducción retrospectiva de estos tiempos permite rectificar los informes.
Hay usuarios que utilizan incorrectamente los tiempos de mantenimiento durante una interrupción espontánea para suprimir una notificación. Esto corrompe el análisis posterior. Se puede corregir a posteriori borrando el tiempo de mantenimiento erróneo.
Para reclasificar los tiempos de mantenimiento, simplemente selecciona el checkbox Reclassify downtime of this period:
2.4. Visualización del historial de monitorización
En la tabla de disponibilidad, junto al símbolo de la línea de tiempo se encuentra otro símbolo: . Esto te lleva a unavista del historial de monitorización con un filtro pre-rellenado para el objeto relevante y el intervalo de tiempo para la consulta. Aquí no sólo verás el evento en el que se basa el análisis de disponibilidad (los cambios de estado), sino también las notificaciones asociadas y eventos similares:
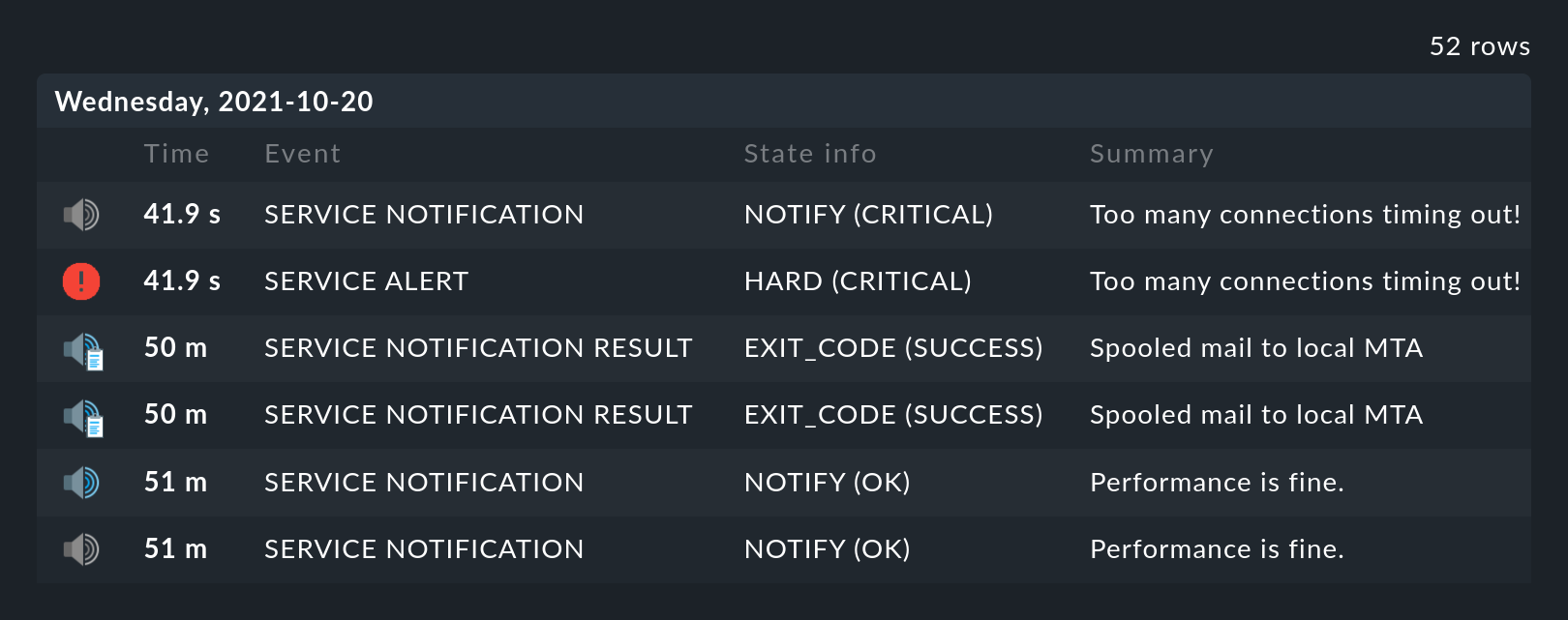
Lo que no se ve aquí es el estado del objeto al inicio del periodo de tiempo de la consulta. El cálculo de la disponibilidad mira aún más atrás en el pasado para determinar con fiabilidad el estado inicial.
3. Opciones de cálculo
Además del propio cálculo, la visualización de la disponibilidad puede controlarse mediante numerosas opciones, que encontrarás en los elementos de menú Availability > Change display options y Availability > Change computation options respectivamente.
Una vez modificadas las opciones y confirmadas con Apply, se recalculará y mostrará la disponibilidad. Todas las opciones modificadas se almacenarán en el perfil del usuario como predeterminadas, de modo que las consultas posteriores utilizarán la misma configuración.
Al mismo tiempo, las opciones se codificarán en la URL de la página actual. Si ahora guardas un Marcador en la página -por ejemplo, utilizando el práctico elementoBookmarks- las opciones formarán parte de éste, y cuando se haga clic en él posteriormente se generarán exactamente de la misma manera.
3.1. Elegir el intervalo de tiempo
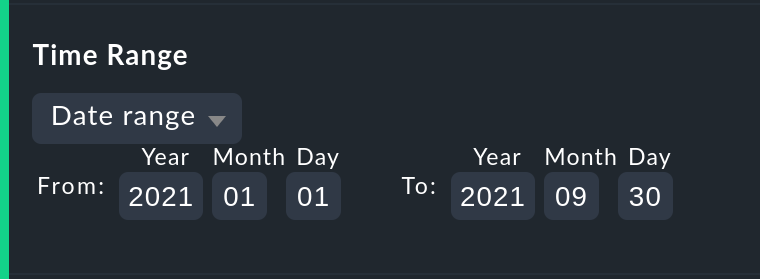
La primera y más importante opción en cualquier cálculo de disponibilidad es, por supuesto, el intervalo de tiempo que se va a examinar. En Date range se puede especificar un intervalo de tiempo con fechas precisas de inicio y fin. Se incluirá el último día -hasta las 24:00-.
Mucho más prácticas son las especificaciones horarias relativas, como, por ejemplo,Last week. El intervalo de tiempo exacto que se mostrará -intencionadamente- depende del momento en que se realice el cálculo. Nota - aquí "una semana" siempre se refiere a un intervalo desde las 00:00 del lunes hasta las 24:00 del domingo.
3.2. Opciones que afectan a las visualizaciones
Muchas opciones influyen en el formato de las visualizaciones, mientras que otras, a su vez, influyen en los métodos de cálculo. Para empezar, veamos las visualizaciones:
Ocultar líneas con disponibilidad del 100

La opción Only show objects with outages limita la visualización a los objetos que realmente tienen cortes, es decir, los momentos en los que el estado no era OK o UP. Esto es útil cuando hay un gran número de servicios, de los que sólo interesan los pocos que realmente tienen problemas.
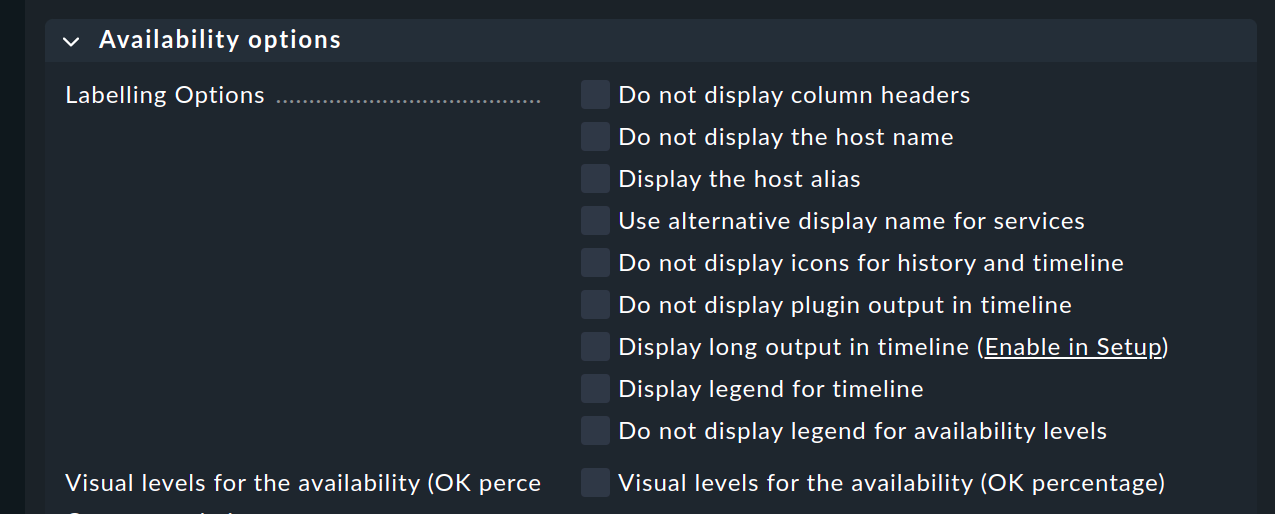
Opciones de etiquetado
La página Labelling options permite activar o desactivar varios campos de etiquetado. Algunas de las opciones son interesantes sobre todo para los Informes. Si, por ejemplo, se va a elaborar un informe para un único host, la columna para el nombre del host no es realmente necesaria.
Las alternative display names para los servicios pueden definirse mediante unaregla, y al utilizarlas, por ejemplo, se puede dar a las visualizaciones de servicios importantes un nombre explícito y significativo para el lector del informe.
Utilizar colores en la visualización de ANS con umbrales
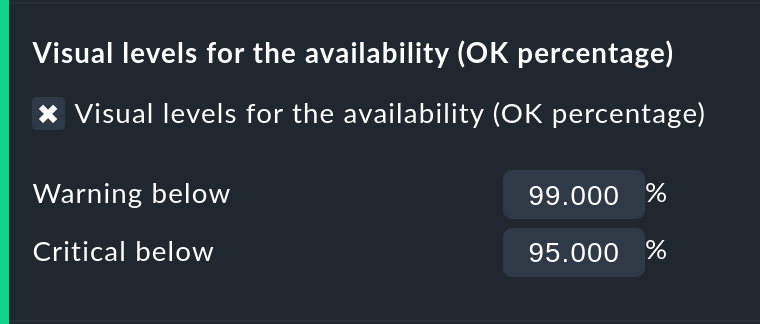
Con Visual levels puedes resaltar los objetos que no han mantenido una disponibilidad especificada dentro del intervalo de tiempo consultado. Esto sólo se aplica a la columna del estado OK. Normalmente siempre es verde. Un déficit del umbral definido hará que el color de esta celda cambie de verde a amarillo, o a rojo. Esto podría describirse como una vista general de ANS muy simple.
Visualización del número y duración de las interrupciones individuales
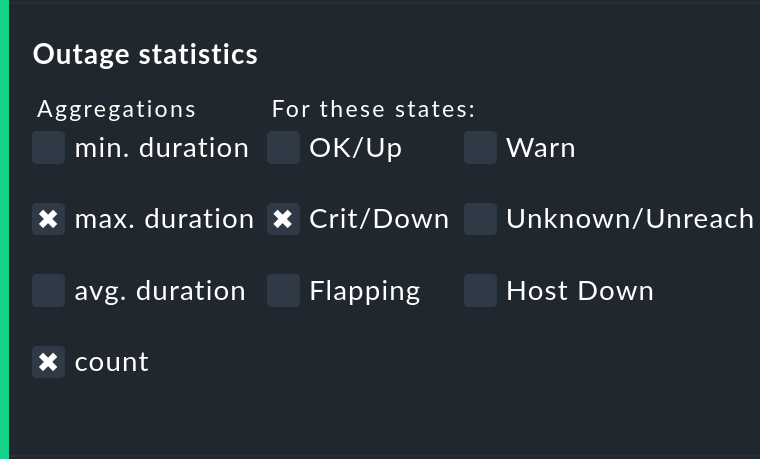
La opción Outage statistics proporciona columnas de información adicionales en la tabla de disponibilidad. En la captura de pantalla siguiente se puede ver que la información adicional para max. duration y count se ha activado para la columna de estado Crit/Down. Esto significa que para las interrupciones con estado CRIT/DOWN, se muestra el número de incidencias, así como la duración de la incidencia más larga respectivamente.

En la tabla se crearán estas columnas adicionales.
Visualización de la especificación de tiempo
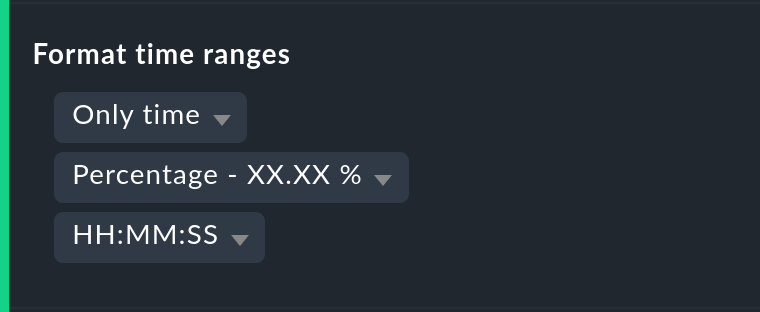
No siempre es prudente especificar las (in)disponibilidades como porcentajes. La opción Format time ranges permite cambiar a una visualización que presenta los intervalos de tiempo como valores absolutos. Con esto se puede ver la duración total de las interrupciones hasta el minuto exacto. La visualización muestra incluso los segundos, pero ten en cuenta que esto sólo tiene sentido si la monitorización se realiza a intervalos de un segundo, y no como es habitual con un check por minuto. Asimismo, se puede definir la precisión de la especificación (el número de decimales en los valores porcentuales).
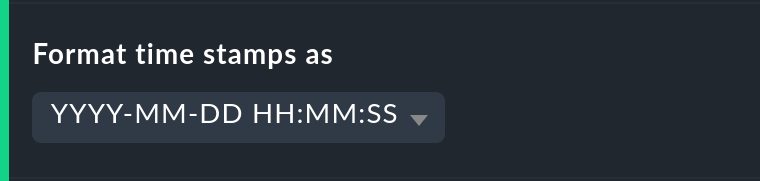
El formato de las marcas de tiempo se aplica a las opciones de Timeline. El cambio a UNIX-Epochs (segundos transcurridos desde el 1.1.1970) simplifica la correlación de los intervalos de tiempo con las ubicaciones adecuadas en los datos de registro del historial de monitorización.
Personalizar la línea de resumen
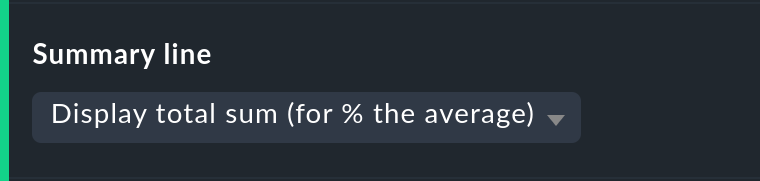
Con esto no sólo puedes activar/desactivar el resumen en la última línea de la tabla, sino que también puedes decidir entre una suma total o una media. Para las columnas que contengan un valor porcentual, si utilizas la opción Sum se mostrará una media, ya que añadir valores porcentuales no tiene mucho sentido.
Mostrar la línea de tiempo en pequeño
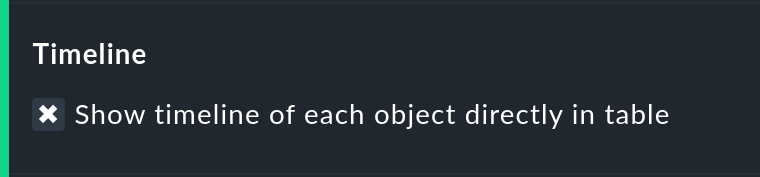
Esta opción añade una versión en miniatura de la línea de tiempode disponibilidad directamente a la tabla de resultados. Se corresponde con la barra gráfica de la línea de tiempo detallada, pero es más pequeña y se integra directamente en la tabla. Además, es fiel a la escala, por lo que se pueden comparar varios objetos en la misma tabla.
Agrupación por host, grupo del host o grupo de servicio
Independientemente de la visualización de la que procedas, la disponibilidad siempre muestra todos los objetos en una tabla común. Con esta opción puedes seleccionar una agrupación por host, por grupo del host o por grupo de servicio -cada grupo tendrá entonces su propia Summary-línea.
Ten en cuenta que con una agrupación por grupo de servicio, los servicios pueden aparecer multiplicados, ya que los servicios pueden asignarse a varios grupos simultáneamente.
Mostrar sólo la disponibilidad
La opción Availability garantiza que sólo se mostrará la columna de los estados OK o UP-con el título Avail.. De esta forma, sólo se mostrará la disponibilidad actual. Esta opción puede combinarse con las otras opciones que se explican a continuación, con otros estados (por ejemplo, WARN), y también puede incluir el estado OK y así ser evaluado como disponible.
3.3. Agrupación de estados
Los estados descritos en la introducción pueden personalizarse y condensarse de muchas maneras. De este modo se pueden generar de forma flexible formas de evaluación muy diferentes. Hay varias opciones para ello.
Manejo de los estados WARN, UNKNOWN y Host DOWN
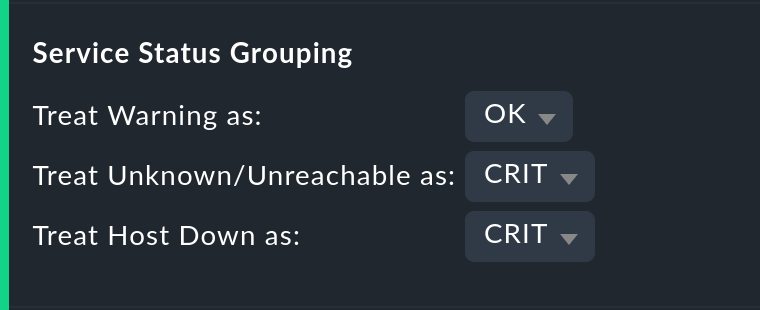
La opción Service status grouping ofrece la posibilidad de mostrar varios "estados intermedios". Una situación habitual es forzar que WARN se trate como OK, lo que puede ser muy útil si te interesa conocer ladisponibilidad real de un servicio. A menudo, WARN no significa que exista todavía un problema real, sino que podría desarrollarse pronto. Así pues, visto de este modo, WARN debe considerarse como disponible. Con servicios de red como un servidor HTTP, es ciertamente sensato tratar los tiempos durante los cuales el host está DOWN del mismo modo que cuando el servicio está CRIT.
Por supuesto, los estados que se omitan debido a la reagrupación también faltarán en la tabla de resultados, que tendrá menos columnas.
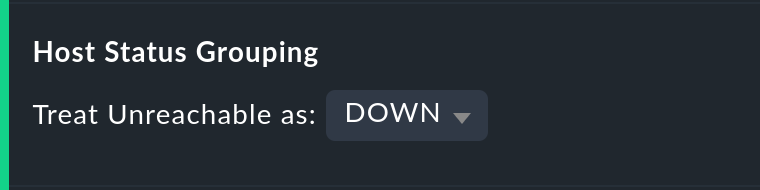
La opción Host status grouping es muy similar, pero se refiere a la disponibilidad de los host. El estado UNREACH significa que un host, debido a problemas de red, no puede ser monitorizado por Checkmk. En tales situaciones, a efectos de los cálculos de disponibilidad puedes decidir si prefieres tratar el estado UNREACH como UP o DOWN. El valor por defecto es tratar UNREACH como su propio estado.
Tratamiento de los periodos de tiempo no supervisados y de la inestabilidad
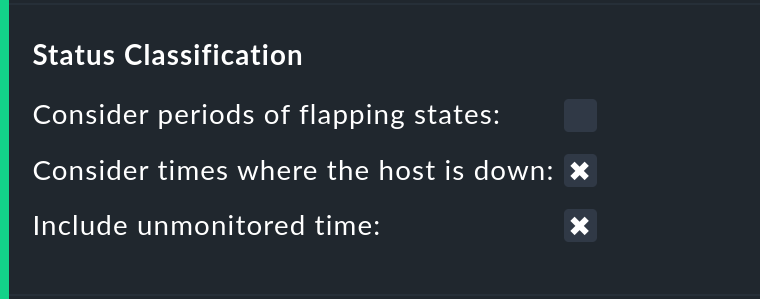
En la opción Status classification se realizarán más resúmenes. La caja Consider periods of flapping states está activada por defecto - con ella las fases de cambios de estado frecuentes constituyen su propio estado: - "inestable". La idea subyacente es que, aunque puede decirse que en esos momentos el servicio afectado siempre vuelve al estado OK, debido a las frecuentes interrupciones el servicio es efectivamente inutilizable. Al desactivar esta opción, el concepto de "inestable" se ignorará por completo, y volverá a aparecer el estado real respectivo - y la columna flappingtambién se eliminará de la tabla.
Eliminar la opción Consider times where the host is down funciona de forma similar. Se desactiva el concepto de Host down. Esta opción sólo tiene sentido para la disponibilidad de los servicios. En las fases en las que el host no esté UP, se tomará como base para la disponibilidad el estado real del servicio -o, más exactamente, el estado del último check antes de que el host dejara de estar disponible-. Esto puede ser sensato con servicios para los que su accesibilidad a través de la red no es relevante.
La opción Include unmonitored time también es similar. Supongamos que hay que hacer un análisis para febrero, y que un servicio concreto sólo ha estado en la monitorización desde el 15 de febrero. ¿Tiene entonces este servicio una disponibilidad de sólo el 50 %? Con la configuración por defecto -opción activa-esto será realmente así. El 50 % que falta no se valorará como interrupción, sino que se sumará en su propia columna bajo el título N/A. Sin la opción, corresponderá al 100 % del tiempo del 15 al 28 de febrero, lo que significa que una interrupción de una hora de este servicio se reflejará como el doble del porcentaje de un servicio que ha sido monitorizado durante todo el mes.
Gestión de los tiempos de mantenimiento programados
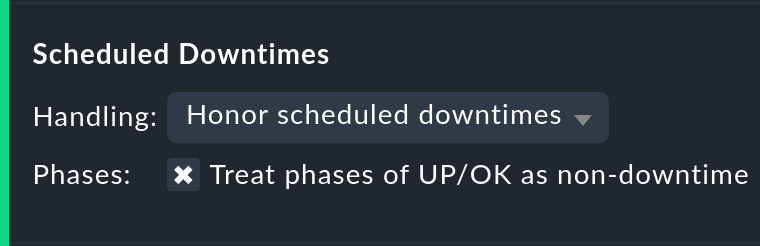
Con la opción Scheduled Downtimes puedes especificar cómo afectanlos tiempos de mantenimiento programados al análisis de disponibilidad:
Honor scheduled downtimes es el valor por defecto. Aquí los tiempos de mantenimiento se tratarán como un estado propio y se resumirán en su propia columna. Con Treat phases of UP/OK as non-downtime puedes restar los tiempos durante los cuales, a pesar del tiempo de mantenimiento, el servicio estaba OK.
Ignore scheduled downtimes se trata como si no se hubiera introducido ningún tiempo de mantenimiento. Las interrupciones son interrupciones y punto. Por supuesto, sólo si se ha producido realmente una interrupción.
Exclude scheduled downtimes significa que los tiempos de mantenimiento programados simplemente se excluyen del periodo de tiempo analizado. El porcentaje de disponibilidad corresponde entonces a los tiempos fuera de los tiempos de mantenimiento programados.
Agrupar fases iguales
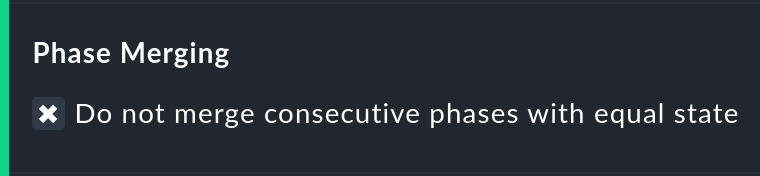
Mediante la conversión de un estado a otro (por ejemplo, de WARN a OK) puede ocurrir que secciones consecutivas de la línea temporal de un objeto tengan el mismo estado. Normalmente, estas secciones se agruparán en una sola sección. En general, esto es bueno y está claro, pero afecta a la visualización de los detalles en la línea de tiempo, y posiblemente también al recuento de eventos con la opción Outage statistics. Por tanto, puedes desactivar esta agrupación con la opciónDo not merge consecutive phases with equal state.
3.4. Ignorar las interrupciones breves
A veces la monitorización suele producir mensajes de problemas momentáneos, pero en condiciones normales el objeto ya está OK para cuando se ejecuta el siguiente check (al cabo de un minuto) - y no se ha encontrado ninguna forma mediante el ajuste de umbrales o similares de controlar bien estos casos. Una solución habitual es establecer el umbralMaximum number of check attempts de 1 a 3 para permitir más fallos antes de que se active una notificación. Así se ha desarrollado el concepto de Soft states, es decir, los estados WARN, CRIT oUNKNOWN, siempre que no se hayan "agotado" todos los intentos permitidos.
A veces, los usuarios que utilizan esta función nos preguntan por qué el Módulo de Disponibilidad de Checkmk no tiene una función para calcular utilizando sólo Hard states. La razón es la siguiente: Hay una solución mejor! Se podrían utilizar los hard states como base...
... de modo que las interrupciones reales, debidas a los intentos fallidos del primer y segundo check, se evaluaran como dos minutos de menos.
... y no se podría reajustar retrospectivamente el comportamiento para las interrupciones cortas.
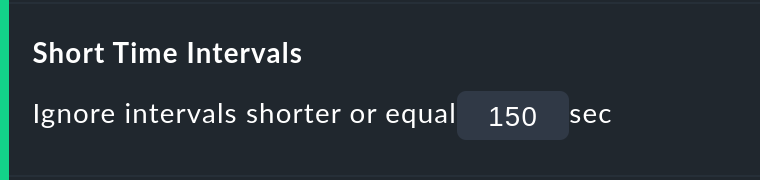
La opción Short time Intervals es mucho más flexible y al mismo tiempo muy sencilla. Basta con definir un tiempo que debe superarse para que se evalúen los estados.
Supongamos que el valor de tiempo se ha fijado en 2,5 minutos (150 segundos). Si un servicio ha estado continuamente OK, luego está CRIT durante 2 minutos, y después vuelve a estar OK, ¡el breve intervalo CRIT simplemente se evaluará como OK! La situación contraria, por cierto, ¡también funciona! Un breve OK dentro de una largafase WARN también se considerará WARN.
En general, los intervalos cortos en los que antes y después prevalezca el mismo estado, recibirán ese mismo estado. Para una secuencia de OK, luego un WARN de 2 minutos, seguido de CRIT, el WARNpersistirá, ¡aunque fuera de una duración inferior a la definida!
Ten en cuenta, al definir el tiempo, que en Checkmk el intervalo de check estándar es de un minuto. Por tanto, cada estado tiene una duración de múltiplos deaproximadamente un minuto. Como los tiempos de respuesta reales del agente varían ligeramente, esto puede ser fácilmente 61 ó 59 segundos, por lo que es más seguro no introducir minutos exactos para el valor, sino incluir un búfer -de ahí el ejemplo con 2,5 minutos.
3.5. Efecto de los periodos de tiempo
Una función importante de los cálculos de disponibilidad en las ediciones comerciales de Checkmk es que estos cálculos pueden depender de periodos de tiempo. Con esto se pueden definir periodicidades para cada host o servicio individual. En estas periodicidades se espera que el host/servicio esté disponible y el estado se utiliza entonces para los cálculos. Por tanto, cada objeto tiene el atributo Service period. El procedimiento es el siguiente:
Define un periodo de tiempo para los tiempos de servicio.
Asígnalos a los objetos con los conjuntos de reglas Host & Service parameters > Monitoring configuration > Service period for hosts o respectivamente … for services.
Activa los cambios.
Utiliza la opción de disponibilidad Service time para controlar el comportamiento:
Aquí hay tres posibilidades sencillas. Por defecto,Base report only on service times oculta los tiempos fuera de los tiempos de servicio definidos. Estos tiempos ocultos no cuentan para el 100 %. Sólo se tendrán en cuenta los intervalos de tiempo dentro de los tiempos de servicio. En la visualización de la línea de tiempo, los tiempos restantes aparecerán "en gris".
Base report only on non-service times realiza lo contrario y, en efecto, calcula la visualización inversa: ¿Cómo de buena era la disponibilidadfuera de los tiempos de servicio?
La tercera opción Include both service and non-service times desactiva el concepto completo de tiempos de servicio y muestra los cálculos para todos los tiempos desde las 00:00 del lunes hasta las 24:00 del domingo.
Por cierto: Si un host no está en el tiempo de servicio, para Checkmk nosignifica automáticamente que esto también se aplique a los servicios del host. Los servicios siempre requieren su propia regla en Service period for services.
El periodo de notificación
Por cierto, hay otra opción relacionada: Notification period. Aquí también se puede recurrir al periodo de notificación de la evaluación. En realidad, sólo se concibió para que en determinados momentos no se generaran notificaciones por problemas, y no cubre necesariamente el tiempo de servicio. Esta opción se introdujo en el pasado, cuando el software aún no trabajaba con un tiempo de servicio, y hoy en día sólo se ha mantenido por motivos de compatibilidad. Es mejor no utilizarla.
3.6. Limitar el tiempo de cálculo
Al calcular la disponibilidad, hay que volver a abrir el historial completo del objeto seleccionado.Más adelante se explica en detalle cómo funciona. Especialmente en Checkmk Raw, el análisis puede llevar cierto tiempo, ya que su núcleo no tiene caché para los datos necesarios y hay que buscar secuencialmente en los datos de registro basados en texto.
Para que una consulta excesivamente compleja -que posiblemente se haya iniciado sin querer- no atasque un proceso Apache, consuma CPU y, por tanto, se "cuelgue", existen dos opciones para limitar la duración del cálculo. Ambas están activadas por defecto:
La Query time limit limita la duración de la consulta subyacente al núcleo de monitorización a un tiempo determinado. Si se supera este tiempo, el análisis se interrumpirá y se mostrará un mensaje de error. Si estás seguro de que el análisis se puede ejecutar durante más tiempo, simplemente aumenta el timeout manualmente.
La opción Limit processed data protege de los cálculos con muchos objetos. Aquí se aplicará un límite que funciona de forma análoga al de lasvistas. Si la consulta al núcleo de monitorización produce más de 5000 periodos de tiempo, el cálculo se interrumpirá con un aviso. La limitación se habrá preprocesado en el núcleo, donde se recogen los datos.
4. Disponibilidad en Business Intelligence
4.1. El principio básico
Una potente característica del cálculo de disponibilidad de Checkmk es la posibilidad de calcular la disponibilidad a partir de agregaciones BI. El gran atractivo aquí es que, para ello, Checkmk reconstruye retroactivamente el estado preciso de los respectivos agregados en un momento determinado utilizando los protocolos de los estados de los host y servicios individuales.
¿Por qué tanto tiempo y esfuerzo? ¿Por qué no limitarse a consultar la Agregación BI con un Check activo, y luego mostrar su disponibilidad? Bueno, el esfuerzo tiene bastantes ventajas para el usuario:
La construcción de las Agregaciones BI se puede adaptar a posteriori, y entonces se puede recalcular la disponibilidad.
El cálculo es más preciso, ya que al no utilizar un check activo no se genera una imprecisión de +/- un minuto.
Se dispone de una excelente función de análisis, con la que se puede investigar retrospectivamente la causa exacta de una interrupción.
Y lo que es más importante, no hay que crear un check adicional.
4.2. Recuperación de la disponibilidad
La recuperación de la vista de disponibilidad es inicialmente análoga a la de los host y servicios. Selecciona una vista con una o varias agregaciones BI, y selecciona el elemento de menú BI Aggregations > Availability. Aquí también hay un segundo método: cada agregación BI tiene una ruta directa a su disponibilidad mediante el símbolo:
En sí mismo, el cálculo es inicialmente análogo al de los servicios, pero sin las columnas Host down y flapping, ya que estos estados no existen para BI:

4.3. Recorrido temporal
La gran diferencia está en la vista de tabla temporal. El siguiente ejemplo muestra un agregado en nuestro servidor de demostración, que fue CRITdurante un intervalo muy breve de un segundo (éste sería un buen ejemplo para el uso de la opción Short time intervals ).
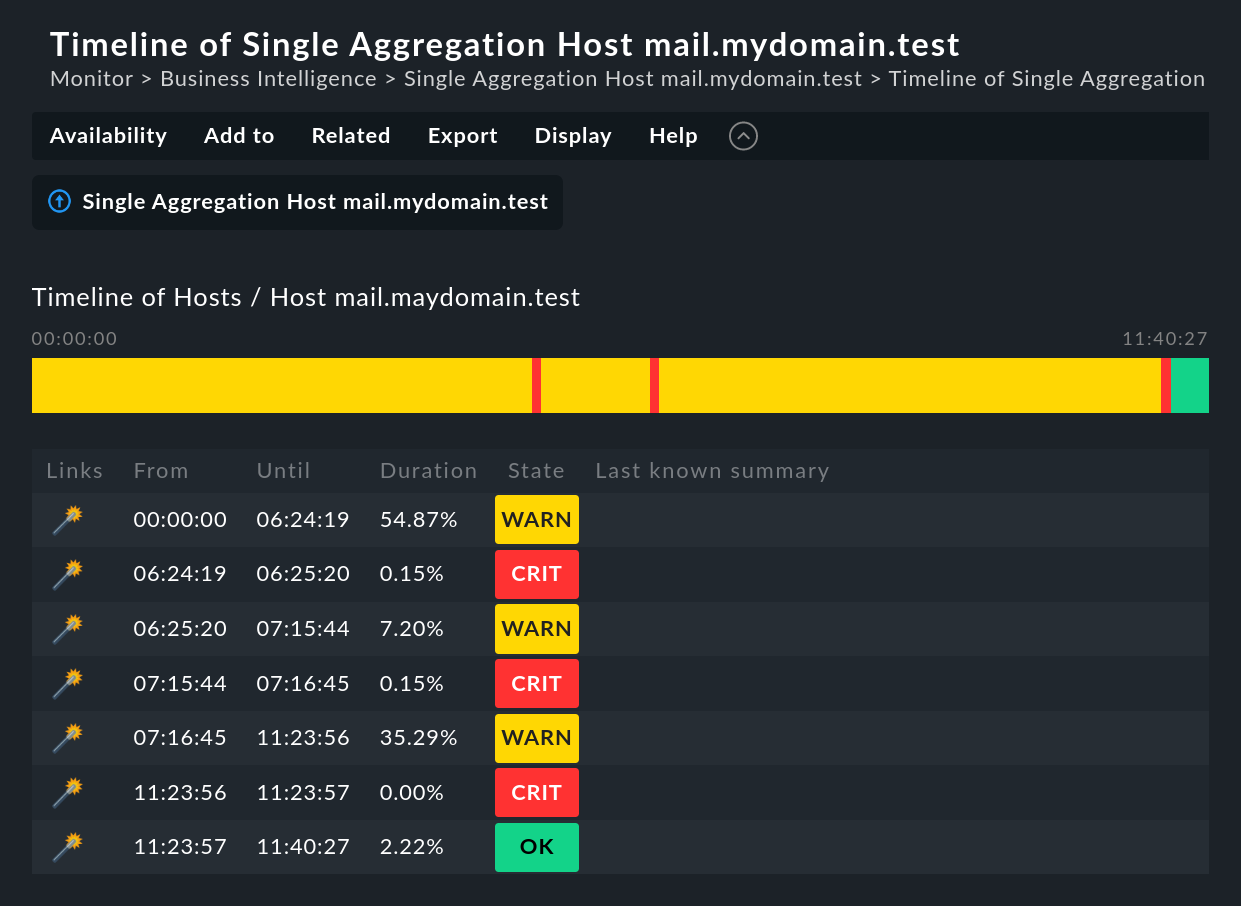
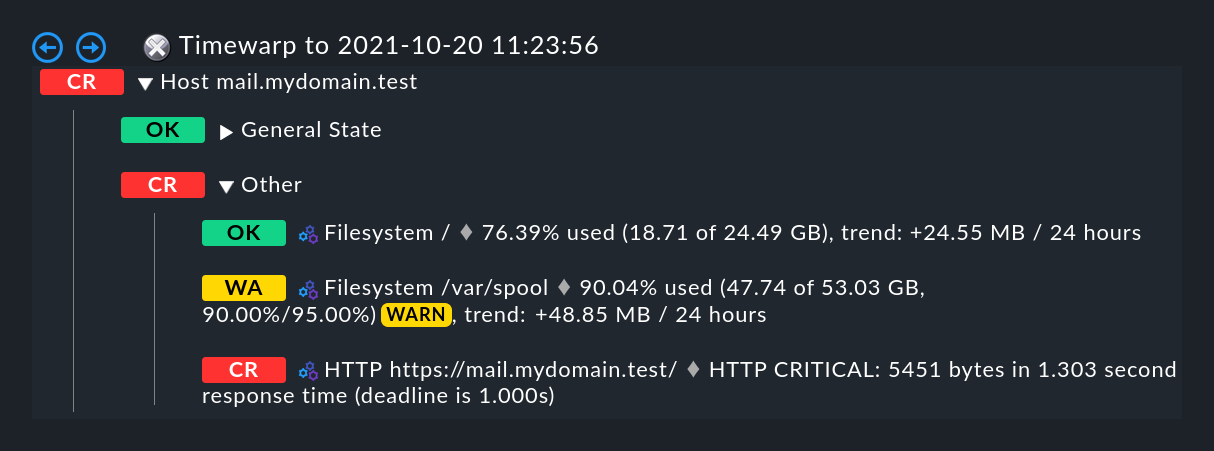
¿Quieres saber cuál fue la causa de la interrupción? Basta con un simple clic en la varita mágica. Esto permite un viaje en el tiempo hasta el momento exacto en que se produjo la interrupción, y abre una visualización de la Agregación BI en ese momento -en la imagen siguiente, ya abierta en el lugar correcto-:
5. Disponibilidad en informes
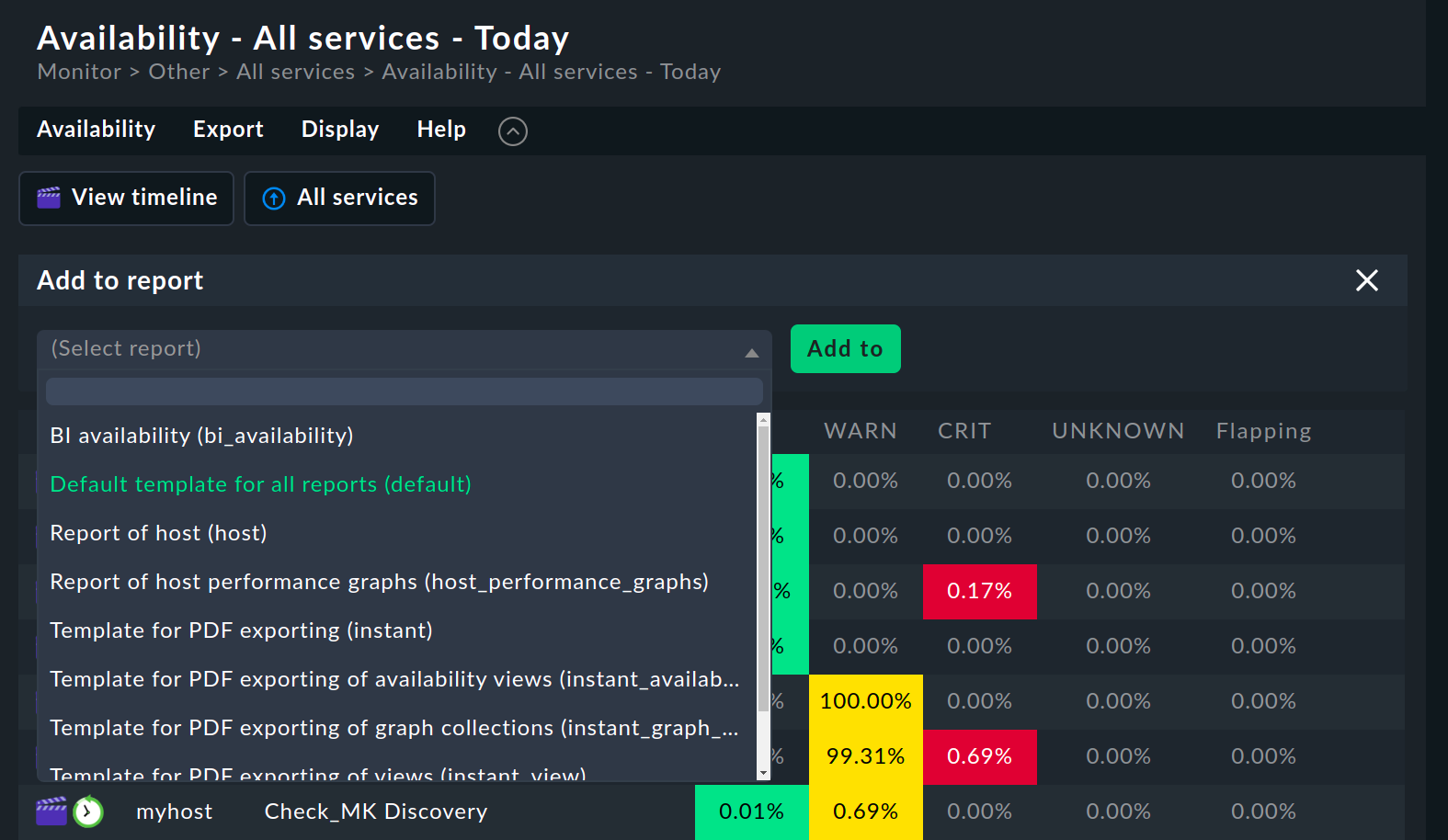
Las vistas de disponibilidad pueden incrustarse en los informes. La forma más sencilla es a través de Export > Add to report en la barra de menú. Selecciona el informe al que quieres añadir la vista y confirma con Add to.
El elemento de informe Availability table inserta un análisis de disponibilidad en el informe. Todas las opciones comentadas anteriormente se pueden encontrar como parámetros directamente en el elemento, aunque en una forma gráfica ligeramente diferente:
La última opción es especial:

Aquí puedes especificar qué visualización debe añadirse al informe:
La tabla de disponibilidad
La visualización gráfica de la línea de tiempo
La línea de tiempo en detalle con los periodos de tiempo individuales
A diferencia de las vistas interactivas normales, aquí puedes incrustar simultáneamente tablas y líneas de tiempo en los informes.
Una segunda característica es la especificación del periodo de tiempo de evaluación, opción que aquí no existe, porque el informe la predetermina automáticamente.
La selección del objeto, como en todos los elementos del informe, se adopta del informe o se predefine directamente en el elemento.
6. Antecedentes técnicos
6.1. Cómo funcionan los cálculos
Para calcular la disponibilidad, Checkmk accede a los historiales de monitorización archivados, y para ello se orienta a los cambios de estado. Si, por ejemplo, a las 17:14 del 20/10/2021 un servicio cambia su estado a CRIT, y luego a las 17:24 vuelve a cambiar a OK, entonces sabes que durante ese periodo de tiempo de 10 minutos el servicio estuvo en estado CRIT.
Estos cambios de estado se registran en el registro de monitorización, tienen el tipo de alertaHOST ALERT o SERVICE ALERT, y tienen el siguiente aspecto, por ejemplo:
[1634742874] SERVICE ALERT: mail.mydomain.com;Filesystem /var/spool;CRITICAL;HARD;1;CRIT - 95.9% used (206.96 of 215.81 GB), (warn/crit at 90.00/95.00%), trend: 0.00 B / 24 hoursSiempre hay un archivo de registro actual que incluye entradas para la actividad más reciente hasta el momento actual, así como un directorio con un archivo de los periodos anteriores. La ubicación de estos archivos varía, dependiendo del núcleo de monitorización en uso:
| Núcleo | Archivo actual | Archivos anteriores |
|---|---|---|
Nagios |
|
|
|
|
La interfaz de usuario no accede directamente a estos archivos, sino que los consulta mediante una consulta Livestatus emitida desde el núcleo de monitorización. Entre otros factores, esto es importante porque en unamonitorización distribuida los archivos del historial no se almacenan en el mismo sistema que la GUI.
La consulta Livestatus utiliza la tabla statehist. A diferencia de la tabla log, que proporciona un acceso "desnudo" al historial, aquí se utiliza la tabla statehist porque ya ha realizado los pasos iniciales de cálculo, que consumen mucho tiempo. Entre otras cosas, asume la tarea de retroceder en el historial para determinar el estado inicial, y el cálculo de periodos de tiempo con el mismo estado, con sus inicios, duraciones y finales.
El procedimiento de condensación de los estados se realiza en la visión general del usuario mediante el Módulo de Disponibilidad, como se describe al principio de este artículo.
6.2. La caché de disponibilidad en CMC
Cómo funciona la caché
Para las consultas que se remontan muy atrás en el tiempo, hay que procesar muchos archivos de registro en consecuencia. Obviamente, esto tiene un efecto negativo en la duración del cálculo. Por eso, en el Checkmk Micro Core hay un caché muy eficaz del historial de monitorización, en el que desde el principio ya se ha determinado toda la información importante sobre los cambios de estado de los objetos a partir de los archivos de registro guardados en la RAM, y que se actualiza continuamente en la monitorización activa. La consecuencia de esto es que todas las consultas de disponibilidad pueden responderse directamente y de forma muy eficaz desde la RAM, por lo que no es necesario ningún otro acceso.
El análisis sintáctico de los archivos de registro es muy rápido, y con discos duros adecuadamente rápidos se puede alcanzar una velocidad de proceso de ¡hasta 80 MB/seg! Para que la creación de la caché no retrase el inicio de la monitorización, ésta se realiza de forma asíncrona: de hecho, del presente al pasado. Se notará un pequeño retraso si inmediatamente después del inicio del site Checkmk se inicia una consulta de disponibilidad que cubra un largo intervalo de tiempo. En tal situación, es posible que el caché aún no llegue lo suficientemente lejos en el pasado, y que la GUI necesite unos instantes para pensar en ello.
Con un Activate changes, ¡la caché se conserva! Sólo será necesario volver a generarla cuando se (re)inicie Checkmk, por ejemplo, cuando se reinicie el servidor o se actualice Checkmk.
Estadísticas de la caché
Si tienes curiosidad por saber cuánto tiempo puede tardar la generación de un caché, puedes encontrar una estadística en el archivo de registro var/log/cmc.log. Aquí tienes un ejemplo de un sistema de monitorización más pequeño:
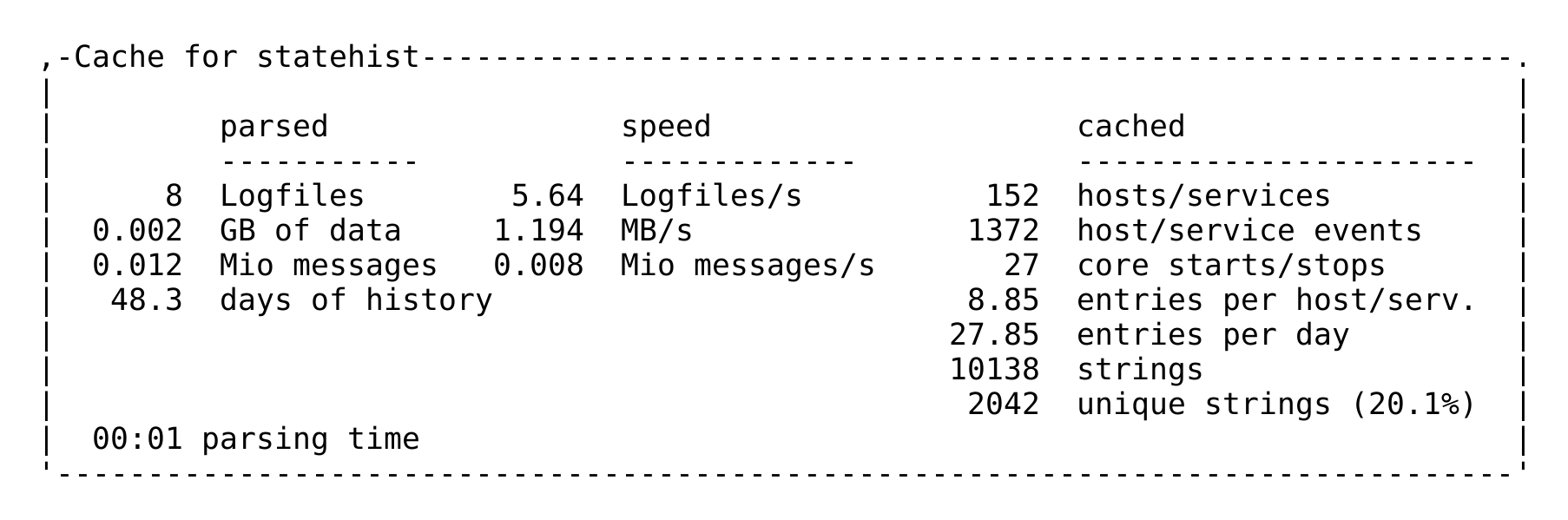
Ajuste de la caché
Para mantener bajo control las necesidades de almacenamiento de la caché, ésta se limita a un horizonte de hasta 730 días en el pasado. Este límite es fijo, por lo que las consultas que se remontan más atrás en el pasado no sólo son más lentas, sino que son imposibles. Esto se puede personalizar fácilmente utilizando la configuración global Global Settings > Monitoring Core > In-memory cache for availability data:
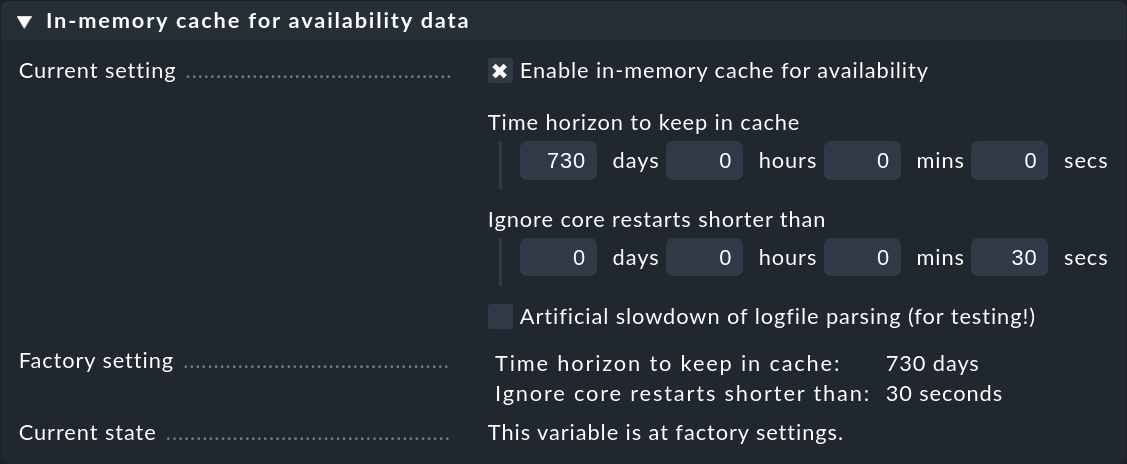
Además del horizonte de cálculo, existe un segundo ajuste interesante: Ignore core restarts shorter than…. Un nuevo inicio del núcleo (por ejemplo, con motivo de una actualización o de un reinicio del servidor) produce en realidad periodos de tiempo que cuentan como unmonitored. De este modo, las interrupciones de hasta 30 segundos simplemente se ignorarán. Este tiempo puede aumentarse y los tiempos más largos también pueden simplemente suprimirse. El cálculo de la disponibilidad supondrá entonces que todos los host y servicios han mantenido durante todo ese tiempo sus respectivos últimos estados comunicados.
7. Archivos y directorios
| Ruta del archivo | Función |
|---|---|
|
Archivo de registro actual del historial de monitorización en la CMC |
|
Directorio con los archivos de registro más antiguos del historial |
|
El archivo de registro de la CMC, en el que se pueden ver las estadísticas del caché de disponibilidad |
|
El archivo de registro actual del historial de monitorización de Nagios |
|
El directorio con los archivos de registro más antiguos de Nagios |
|
Aquí se almacenan las anotaciones y los tiempos de mantenimiento programados modificados retrospectivamente para las interrupciones. El archivo tiene formato Python y se puede editar manualmente. |