This is a machine translation based on the English version of the article. It might or might not have already been subject to text preparation. If you find errors, please file a GitHub issue that states the paragraph that has to be improved. |
1. Introducción
1.1. Los eventos no son estados
La tarea principal de Checkmk es la monitorización activa de estados.En cualquier momento, cada servicio monitorizado tiene uno de los estados OK, WARN, CRIT o UNKNOWN. Mediante sondeos regulares, la monitorización actualiza constantemente su imagen de la situación actual.
Un tipo de monitorización completamente diferente es la que gestiona eventos. Un ejemplo de evento es una excepción que se produce en una aplicación. La aplicación puede permanecer en el estado OK y seguir ejecutándose correctamente, pero algo ha ocurrido.
1.2. La Consola de eventos
Con la Consola de eventos (abreviada EC), Checkmk proporciona un sistema totalmente integrado para monitorizar eventos procedentes de fuentes como syslog, traps SNMP, registros de eventos de Windows, archivos de registro y aplicaciones propias. Los eventos no se definen simplemente como estados, sino que forman una categoría propia y, de hecho, Checkmk los muestra como información independiente en la barra lateral Overview.
Internamente, los eventos no son procesados por el núcleo de monitorización, sino por un servicio independiente: el daemon de eventos (mkeventd).
La Consola de eventos también tiene un archivo en el que puedes buscar eventos pasados. Sin embargo, hay que decir de entrada que esto no es un sustituto de un archivo de registros adecuado. La tarea de la Consola de eventos es el filtrado inteligente de un pequeño número de mensajes relevantes de un gran flujo. Está optimizada para la simplicidad, la robustez y el rendimiento, no para almacenar grandes volúmenes de datos.
Un breve resumen de la funcionalidad de la CE:
Puede recibir mensajes directamente a través de syslog o de Trap SNMP, por lo que no es necesario configurar los correspondientes servicios del sistema Linux.
También puede evaluar archivos de registro basados en texto y registros de eventos de Windows mediante los agentes Checkmk.
Clasifica los mensajes basándose en cadenas de reglas definidas por el usuario.
Puede correlacionar, resumir, contar, anotar y reescribir mensajes, así como considerar sus relaciones temporales.
Puede realizar acciones automatizadas y enviar notificaciones a través de Checkmk.
Está totalmente integrado en la interfaz de usuario de Checkmk.
Está incluido y listo para usar en cualquier versión actual del sistema Checkmk.
1.3. Terminología
La Consola de eventos recibe mensajes (la mayoría en forma de mensajes de registro). Un mensaje es una línea de texto con una serie de posibles atributos adicionales, por ejemplo, una marca de tiempo, un nombre del host, etc. Si el mensaje es relevante, puede convertirse directamente en un evento con los mismos atributos, pero:
Un mensaje sólo se convertirá en evento si entra en vigor una regla.
Las reglas pueden editar el texto y otros atributos de los mensajes.
Se pueden combinar varios mensajes en un evento.
Los mensajes también pueden cancelar eventos en curso.
Se pueden generar eventos artificiales si determinados mensajes no aparecen.
Un evento puede pasar por varias fases:
Abierto |
El estado "normal": Ha ocurrido algo: el operador debe atenderlo. |
Reconocido |
Se ha reconocido el problema: es análogo a los problemas de host y servicio de la monitorización basada en el estado. |
Contando |
Aún no ha llegado el número necesario de mensajes especificados: la situación aún no es problemática. Por tanto, el evento aún no se muestra al operador. |
Retrasado |
Se ha recibido un mensaje de error, pero la Consola de eventos aún está esperando si se recibirá el mensaje OK correspondiente en un tiempo configurado. Sólo entonces se mostrará el evento al operador. |
Cerrado |
El evento ha sido cerrado por el operador o automáticamente por el sistema y sólo se encuentra en el archivo. |
Un evento también tiene un estado.Sin embargo, estrictamente hablando, no se refiere al estado del evento en sí, sino al estado del servicio o dispositivo que envió el evento. Para utilizar una analogía con la monitorización basada en el estado, un evento también puede marcarse como OK, WARN, CRIT o UNKNOWN.
2. Configuración de la Consola de eventos
Configurar la Consola de eventos es muy sencillo, porque la Consola de eventos es parte integrante de Checkmk y se activa automáticamente.
Sin embargo, si quieres recibir mensajes syslog o traps SNMP a través de la red, debes activarlos por separado. El motivo es que ambos servicios necesitan abrir un puerto UDP con un número de puerto específicamente identificado. Y como sólo puede hacerlo un site de Checkmk por sistema, la recepción a través de la red está desactivada por defecto.
Los números de puerto son
| Protocolo | Puerto | Servicio |
|---|---|---|
UDP |
162 |
Trap SNMP |
UDP |
514 |
Syslog |
TCP |
514 |
Syslog vía TCP |
Syslog vía TCP se utiliza poco, pero tiene la ventaja de que la transmisión de mensajes está asegurada. Con UDP nunca se puede garantizar que los paquetes lleguen realmente. Y ni Syslog ni los traps SNMP ofrecen Reconocimientos o protecciones similares contra mensajes perdidos. Para poder utilizar syslog vía TCP, el sistema emisor debe, por supuesto, poder enviar mensajes a través de este puerto.
En el appliance Checkmk, puedes activar la recepción de syslog/SNMP traps en la configuración del site. Si no, utiliza simplemente omd config. Puedes encontrar la configuración necesaria en Addons:
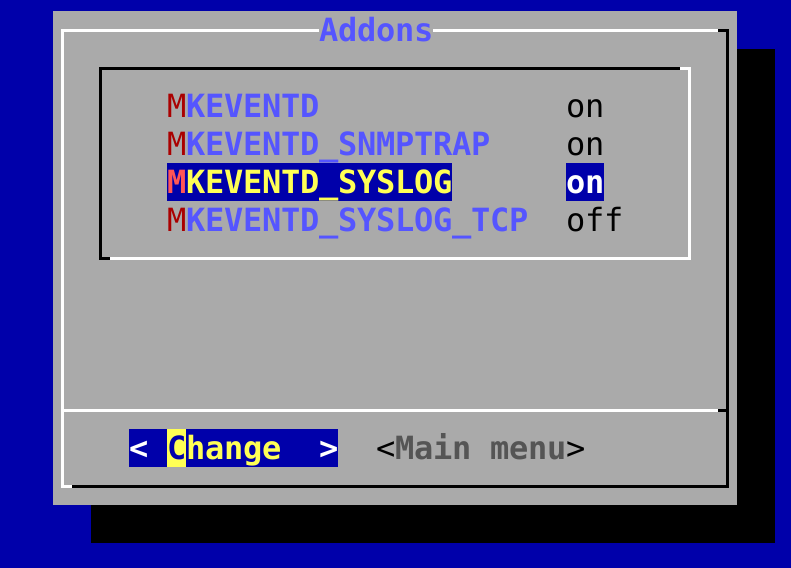
En omd start puedes ver en la línea que contiene mkeventd qué interfaces externas tiene abiertas tu CE:
OMD[mysite]:~$ omd start
Creating temporary filesystem /omd/sites/mysite/tmp...OK
Starting mkeventd (builtin: syslog-udp,snmptrap)...OK
Starting liveproxyd...OK
Starting mknotifyd...OK
Starting rrdcached...OK
Starting cmc...OK
Starting apache...OK
Starting dcd...OK
Starting redis...OK
Initializing Crontab...OK3. Los primeros pasos con la Consola de eventos
3.1. Reglas, reglas, reglas
Al principio se mencionó que la CE se utiliza para pescar y mostrar mensajes relevantes. Sin embargo, el hecho desafortunado es que la mayoría de los mensajes -independientemente de si proceden de archivos de texto, del Registro de Eventos de Windows o del syslog- carecen de importancia. Tampoco ayuda cuando los mensajes ya han sido preclasificados por su creador.
Por ejemplo, en Syslog y en el Registro de eventos de Windows los mensajes se clasifican en algo parecido a OK, WARN y CRIT. Pero lo que significan realmente WARN y CRIT puede definirlo subjetivamente su programador. Y ni siquiera se puede afirmar definitivamente que la aplicación que ha producido el mensaje sea importante en este ordenador. En resumen: no puedes evitar tener que configurar qué mensajes te parecen un problema real y cuáles puedes descartar sin más.
Como en todas partes en Checkmk, la configuración se realiza mediante reglas, que son procesadas por el CE para cada mensaje entrante según el principio de "primera coincidencia". La primera regla que se aplica a un mensaje entrante decide su destino. Si no se aplica ninguna regla, el mensaje simplemente se descartará en silencio.
Como con el tiempo se suelen acumular muchas reglas para la CE, éstas se organizan en paquetes. El procesamiento de las reglas se hace paquete a paquete y dentro de un paquete de arriba abajo, por lo que el orden de procesamiento de estos paquetes es importante.
3.2. Crear una regla sencilla
No es sorprendente que la interfaz de configuración de la CE se encuentre en el menú Setup, en Events > Event Console. Out of the box, sólo encontrarás Default rule pack, que en realidad no contiene ninguna regla. Por tanto, como ya se ha dicho, los mensajes entrantes se descartan y tampoco se registran. El módulo en sí tiene el siguiente aspecto:
Empieza creando un nuevo paquete de reglas con Add rule pack:
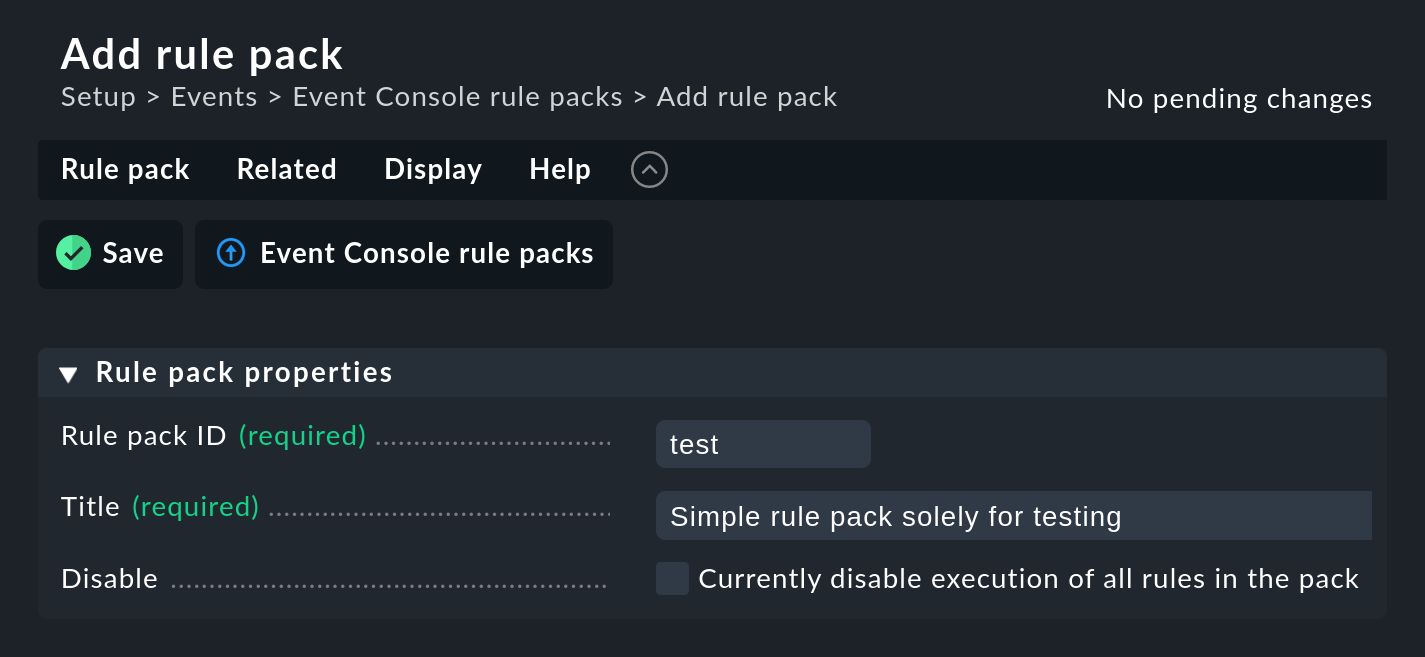
Como siempre, el ID es una referencia interna y no se puede cambiar más tarde. Después de guardar, encontrarás la nueva entrada en la lista de tus paquetes de reglas:
Ahora puedes cambiar al paquete de reglas aún vacío con y crear una nueva regla con Add rule. Aquí sólo tienes que rellenar la primera caja con el encabezamiento Rule Properties:
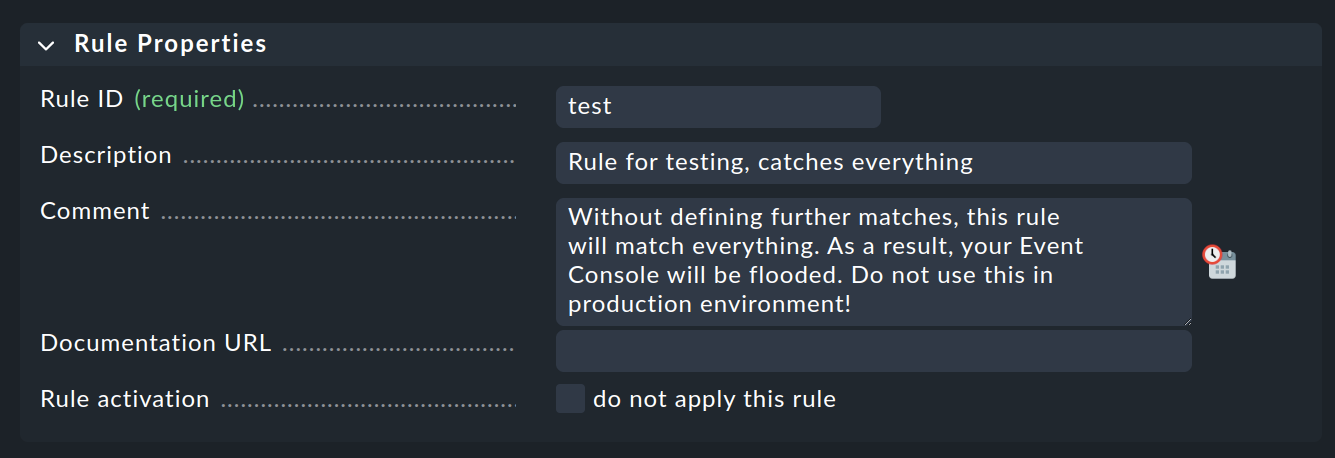
Lo único necesario es un identificador único Rule ID. Este identificador se encontrará más tarde en los archivos de registro, y se almacenará con los eventos generados. Por tanto, es sensato asignar los identificadores con nombres significativos de forma sistemática. Todas las demás cajas son opcionales. Esto es especialmente cierto para las condiciones.
Importante: Esta nueva regla es sólo un ejemplo para pruebas y se aplicará a todos los eventos, por lo que también es importante que después la elimines o al menos la desactives, de lo contrario tu Consola de eventos se inundará de todos los mensajes sin sentido imaginables y ¡será prácticamente inútil!
Activar cambios
Como siempre en Checkmk, primero debes activar cambios para que surtan efecto. Esto no es un inconveniente, porque así, en el caso de cambios que afecten a varias reglas relacionadas, puedes especificar exactamente cuándo deben "activarse" las reglas. Y antes puedes utilizar la página Event Simulator para comprobar si todo se ajusta a lo previsto.
Primero, haz clic en el número de cambios acumulados en la parte superior derecha de la página.
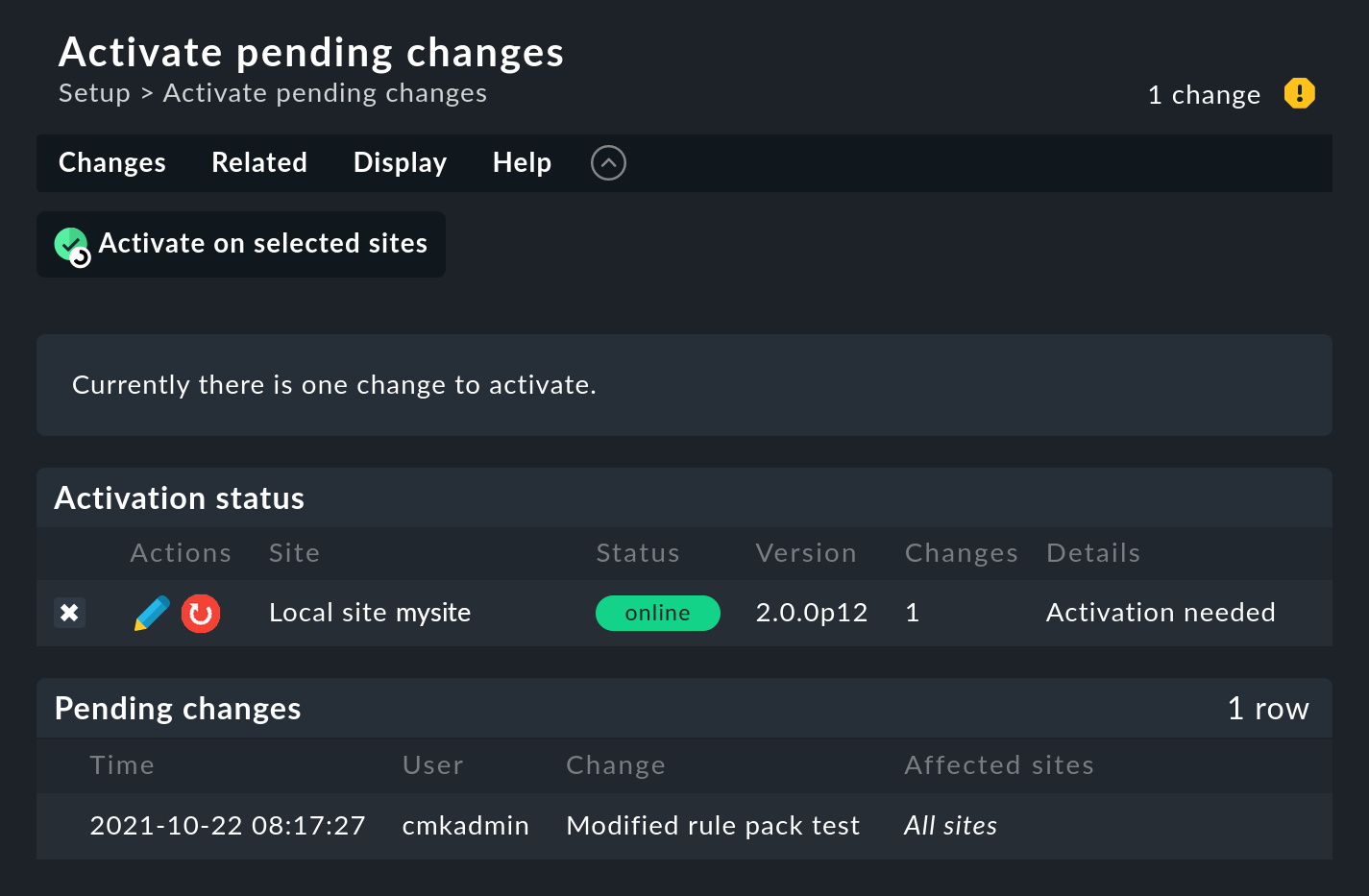
A continuación, haz clic en Activate on selected sites para activar el cambio. La Consola de eventos está diseñada de tal forma que esta acción se ejecuta sin interrupciones. La recepción de mensajes entrantes está garantizada en todo momento, de modo que no se puede perder ningún mensaje en el proceso.
Sólo los administradores pueden activar cambios en la CE. Esto se controla mediante el permiso Activate changes for event console.
Probar la nueva regla
Por supuesto, ahora puedes enviar mensajes a través de Syslog o SNMP para hacer pruebas, pero para una primera prueba es más práctico el Event Simulator integrado en la CE:
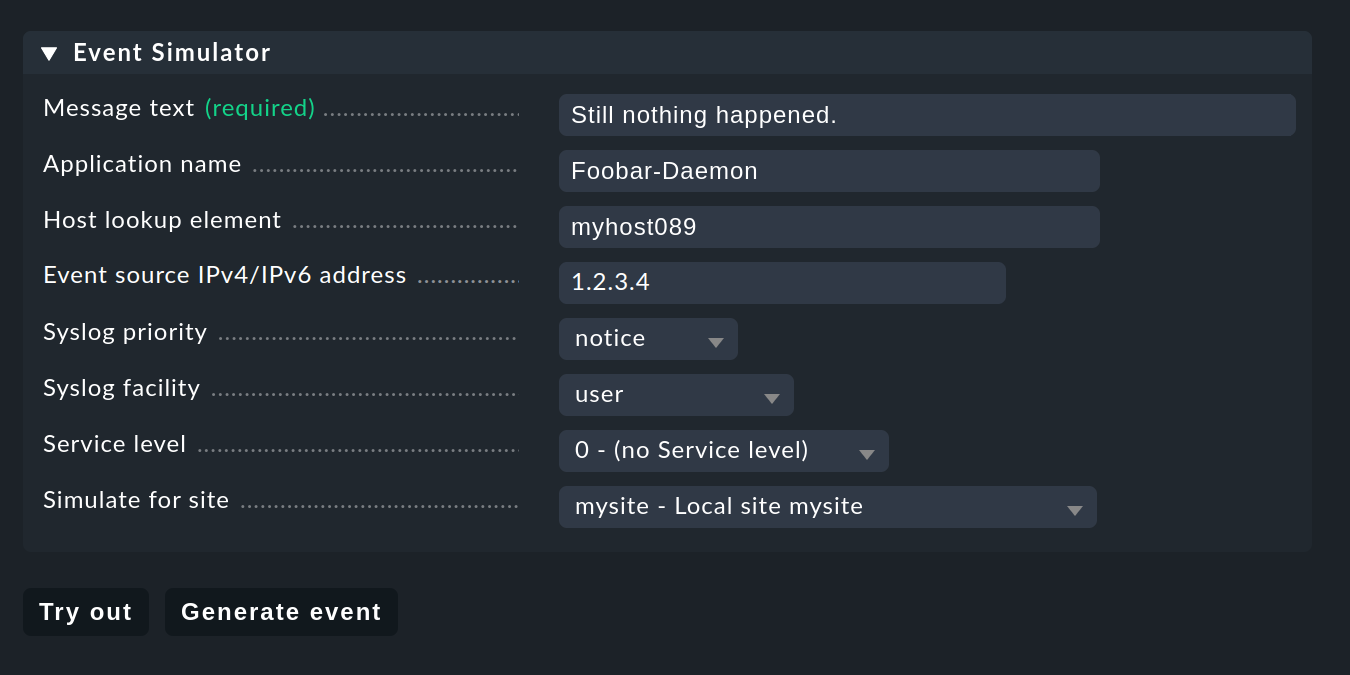
Aquí tienes dos opciones:Try out evalúa en función del mensaje simulado cuál de las reglas coincidiría. Si estás en el nivel superior de la GUI de configuración de la CE, se resaltarán los paquetes de reglas. Si estás dentro de un paquete de reglas, se resaltarán las reglas individuales. Cada paquete o regla está marcado con uno de los tres símbolos siguientes:
Esta regla es la primera en surtir efecto sobre el mensaje y, en consecuencia, determina su destino. |
|
Esta regla tendría efecto, pero el mensaje ya ha sido tratado por una regla anterior. |
|
Esta regla no tiene efecto. Muy práctico: Si pasas el ratón por encima de la bola gris, obtendrás una explicación de por qué no se aplica la regla. |
Hacer clic en Generate event hace prácticamente lo mismo que Try out, sólo que ahora el mensaje se genera realmente.Cualquier acción definida se ejecuta realmente. Y el evento también aparecerá en los eventos abiertos en la monitorización. Puedes ver el código fuente del mensaje generado en la confirmación:

El evento generado aparece en el menú Monitor en Event Console > Events:

Generación manual de mensajes para pruebas
Para una primera prueba real a través de la red, puedes enviar fácilmente a mano un mensaje syslog desde otro ordenador Linux. Como el protocolo es tan sencillo, ni siquiera necesitas un programa especial, simplemente puedes enviar los datos a través de netcat o nc utilizando UDP. El contenido del paquete UDP consiste en una sola línea de texto. Si se ajusta a una estructura específica, la Consola de eventos desglosa los componentes limpiamente:
user@host:~$ echo '<78>Dec 18 10:40:00 myserver123 MyApplication: It happened again.' | nc -w 0 -u 10.1.1.94 514Pero también puedes enviar simplemente cualquier cosa. En ese caso, la CE lo aceptará igualmente y sólo lo evaluará como un texto de mensaje. Por supuesto, faltará información adicional como la aplicación, la prioridad, etc. Por motivos de seguridad, se asumirá el estado CRIT:
user@host:~$ echo 'This is no syslog message' | nc -w 0 -u 10.1.1.94 514Dentro del site Checkmk que ejecuta la CE hay una tubería con nombre, en la que puedes escribir mensajes de texto localmente a través de echo. Éste es un método muy sencillo para conectar una aplicación local y también una forma de probar el proceso de los mensajes:
OMD[mysite]:~$ echo 'Local application says hello' > tmp/run/mkeventd/eventsPor cierto, aquí también es posible enviar en formato syslog, para que todos los campos de los datos del evento se rellenen limpiamente.
3.3. Configuración de la Consola de eventos
La Consola de eventos tiene sus propios ajustes globales, que no se encuentran con los de los otros módulos, sino en Setup > Events > Event Console con el botón Settings.
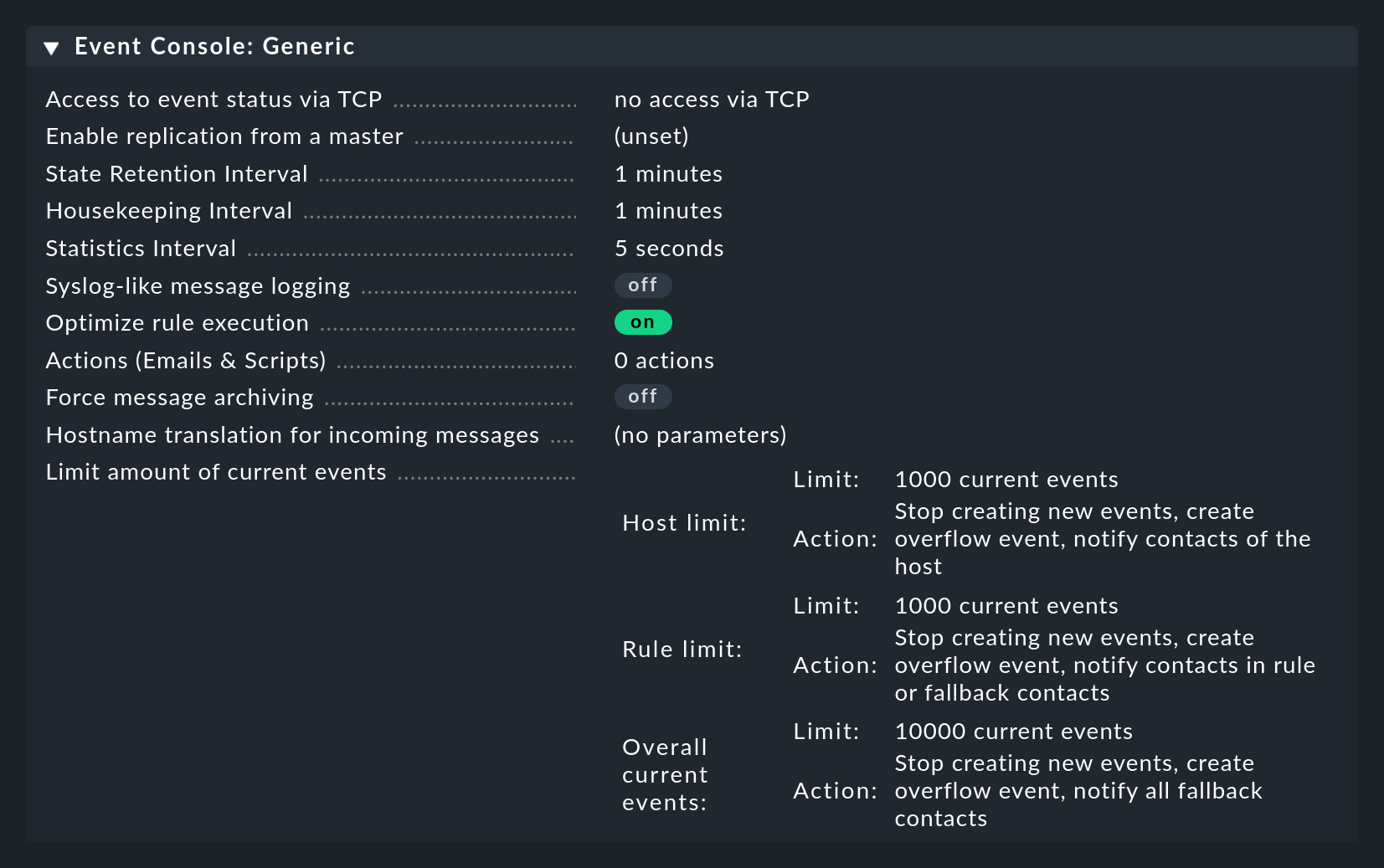
Como siempre, puedes encontrar explicaciones de los ajustes individuales en la ayuda en línea y en los lugares apropiados de este artículo.
El acceso a los ajustes es posible a través del permiso Configuration of Event Console, que por defecto sólo está disponible en el rol admin.
3.4. Permisos
La Consola de eventos también tiene su propia sección de roles y permisos:
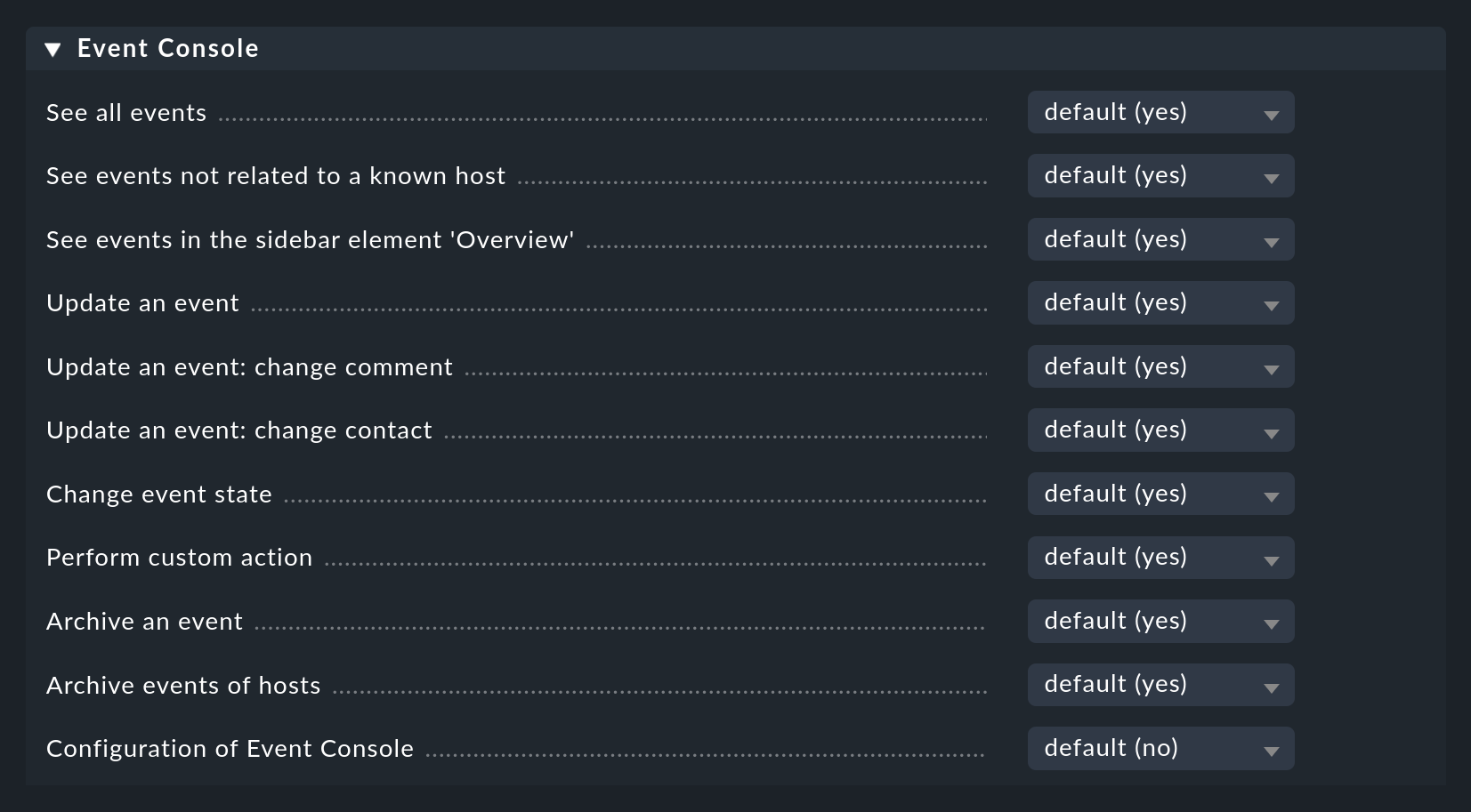
Hablaremos de algunos de estos permisos con más detalle en los lugares apropiados de este artículo.
3.5. Asignación de host en la Consola de eventos
Una característica especial de la Consola de eventos es que, a diferencia de la monitorización basada en el estado, los hosts no son el centro de atención. Los eventos pueden ocurrir sin ninguna asignación explícita de host, lo que de hecho se desea a menudo. Sin embargo, una asignación debe ser posible para los hosts que ya están en monitorización activa, con el fin de acceder rápidamente a la visión general del estado cuando se produce un evento. O como muy tarde, si los eventos se van a convertir en estados, es esencial una asignación correcta.
La regla fundamental para los mensajes recibidos a través de syslog es que el nombre del host en el mensaje se corresponda con el nombre del host en la monitorización. Esto se consigue utilizando el nombre de dominio completo (FQDN) / nombre de host completo (FQHN), tanto en tu configuración de syslog como en la asignación de nombres de host en Checkmk. En Rsyslog puedes conseguirlo utilizando la directiva global $PreserveFQDN on.
Checkmk intenta hacer coincidir los nombres del host de los eventos con los de la monitorización activa lo mejor que puede de forma automática. Además del nombre del host, también se intenta el alias del host. Si el nombre abreviado se transmite a través de syslog, la asignación será correcta.
Una resolución hacia atrás de la dirección IP no tendría mucho sentido en este caso, porque a menudo se utilizan servidores de registro intermedios. Si la conversión de los nombres del host a FQDN/FQHN o la reintroducción de muchos alias lleva demasiado tiempo, puedes utilizar la configuración de la Consola de eventos Hostname translation for incoming messages para traducir los nombres del host directamente al recibir los mensajes. De este modo tienes numerosas posibilidades:
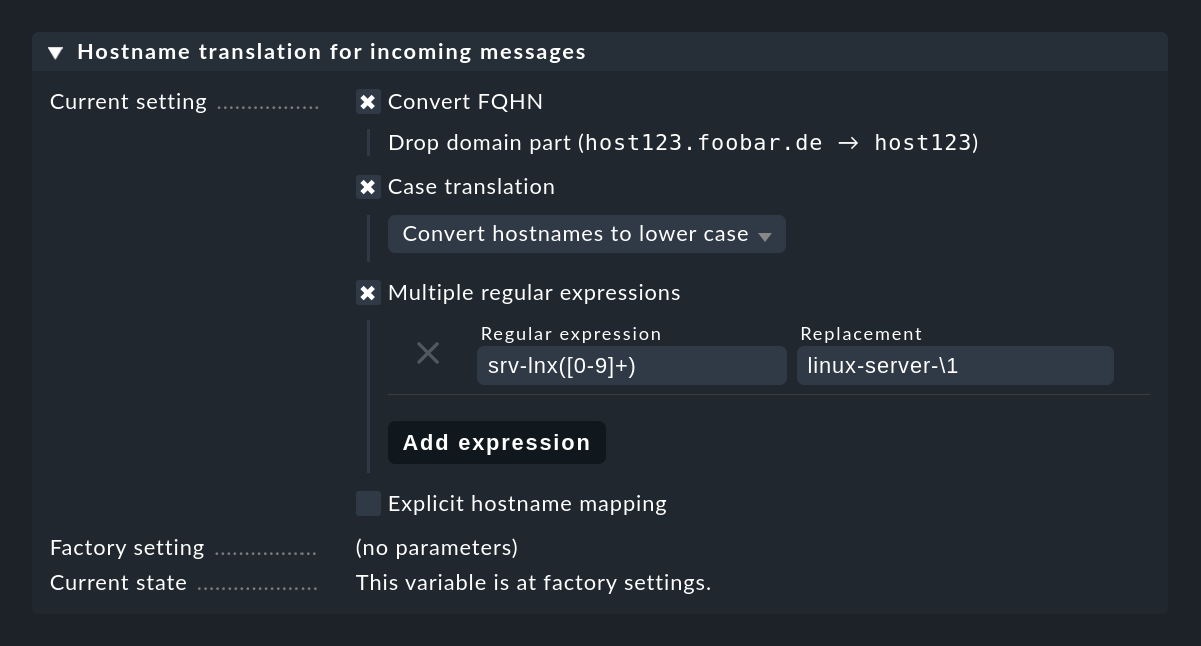
El método más flexible es trabajar con expresiones regulares, que permiten una búsqueda y sustitución inteligente dentro de los nombres del host. En particular, si los nombres del host son explícitos, pero sólo falta la parte del dominio utilizada en Checkmk, una simple regla ayuda: (.*) se convierte en \1.mydomain.test. En los casos en que todo esto no sea suficiente, puedes utilizar Explicit hostname mapping para especificar una tabla de nombres individuales y sus respectivas traducciones.
Importante: la conversión del nombre se realiza antes de comprobar las condiciones de la regla y, por tanto, mucho antes de una posible reescritura del nombre del host por la acción de la regla Rewrite hostname en la reescritura automática de texto.
La asignación es algo más sencilla con SNMP. Aquí la dirección IP del remitente se compara con las direcciones IP en caché de los hosts en la monitorización - es decir, tan pronto como estén disponibles los checks activos regulares, como la comprobación de accesibilidad del puerto Telnet o SSH en un switch, los mensajes de estado de este dispositivo enviados a través de SNMP se asignarán al host correcto.
4. La Consola de eventos en monitorización
4.1. Vistas de eventos
Los eventos generados por la Consola de eventos se muestran de forma análoga a los host y servicios del entorno de monitorización. Puedes encontrar el punto de entrada para ello en el menú Monitor en Event Console > Events:
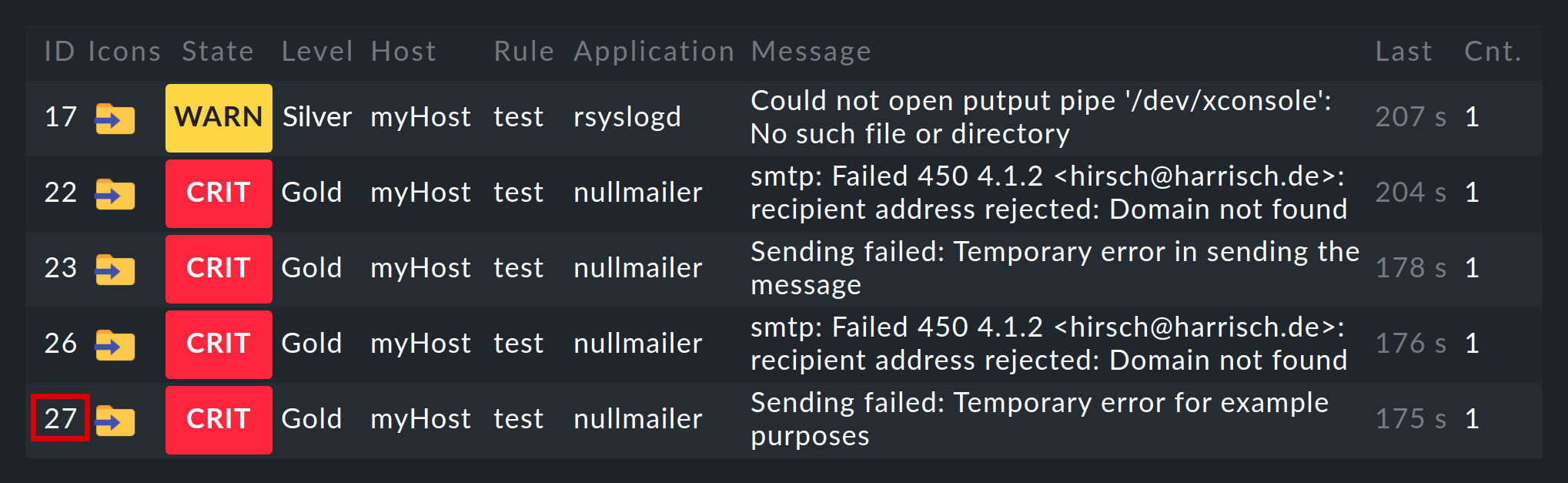
Puedes personalizar la vista mostrada Events como cualquier otra. Puedes filtrar los eventos mostrados, ejecutar comandos, etc. Para más detalles, consulta el artículo sobre vistas. Cuando creas nuevas vistas de eventos, los eventos y el historial de eventos están disponibles como fuentes de datos.
Un clic en el ID del evento (aquí, por ejemplo, 27) te mostrará sus detalles:
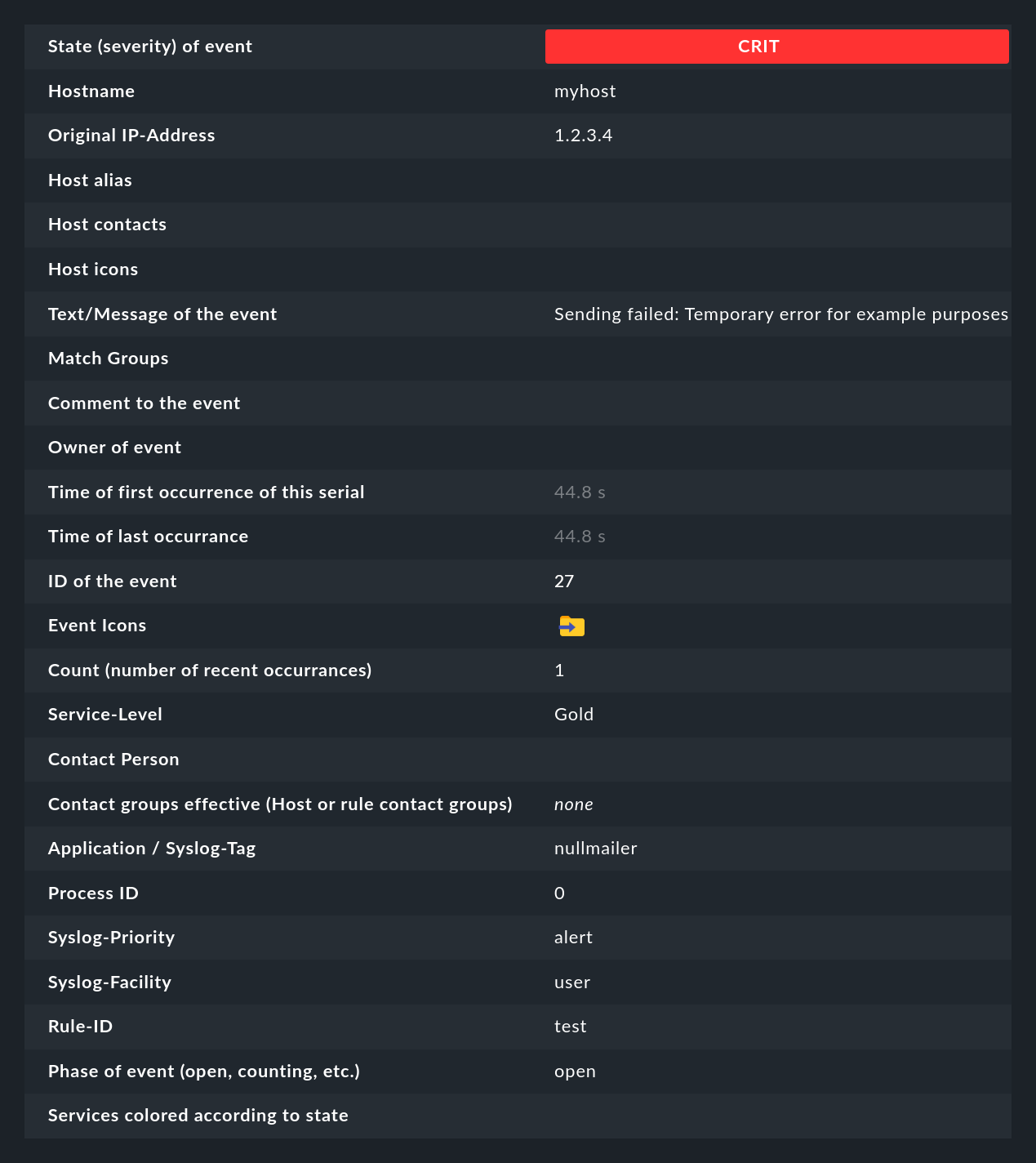
Como puedes ver, un evento tiene bastantes campos de datos, cuyo significado explicaremos poco a poco en este artículo. No obstante, los campos más importantes deben mencionarse brevemente aquí:
| Campo | Significado |
|---|---|
State (severity) of event |
Como se ha mencionado en la introducción, cada evento se clasifica como OK, WARN, CRIT o UNKNOWN. Los eventos de estado OK son bastante inusuales. Esto se debe a que la CE está diseñada precisamente para filtrar sólo los problemas. Sin embargo, hay situaciones en las que un evento OK puede tener sentido. |
Text/Message of the event |
El contenido real del evento: Un mensaje de texto. |
Hostname |
El nombre del host que envió el mensaje. No tiene que ser necesariamente un host que esté siendo monitorizado activamente por Checkmk. Sin embargo, si existe un host con ese nombre en la monitorización, la CE creará automáticamente un enlace. En este caso, los campos Host alias, Host contacts y Host icons también se rellenarán y el host aparecerá en la misma notación que en la monitorización activa. |
Rule-ID |
El ID de la regla que creó este evento. Si haces clic en este ID, accederás directamente a los detalles de la regla. Por cierto, el ID se conserva aunque la regla deje de existir mientras tanto. |
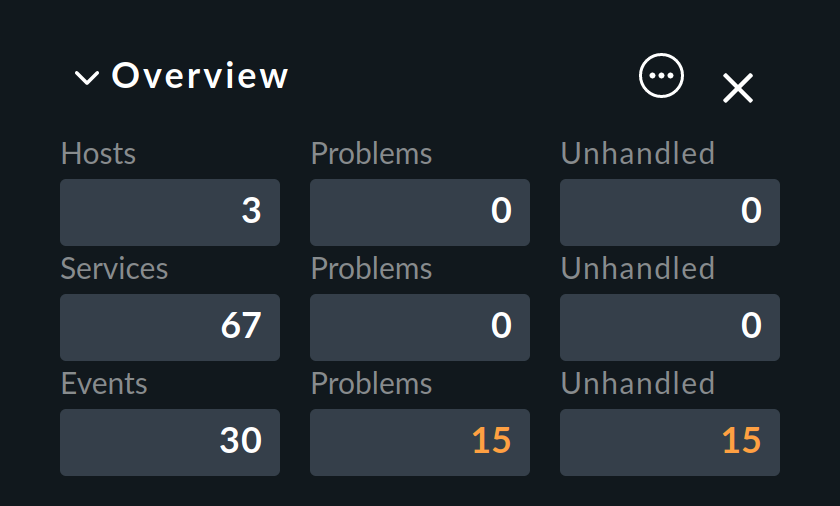
Como se mencionó al principio, los eventos se muestran directamente en la Overview de la barra lateral:
Aquí verás tres números
Events- todos los eventos abiertos y reconocidos (corresponde a la vista de tabla Event Console > Events )
Problems- de los cuales sólo aquellos con estado WARN / CRIT / UNKNOWN
Unhandled- de éstos, de nuevo, sólo los que aún no han sido reconocidos (más sobre esto dentro de un momento)
4.2. Comandos y Flujo de trabajo de los eventos
De forma análoga a lo que ocurre con los host y los servicios, también para los eventos se asigna un flujo de trabajo sencillo. Como es habitual, esto se hace mediante comandos, que se encuentran en el menú Commands. Mostrando y seleccionando con checkboxes puedes ejecutar un comando en varios eventos simultáneamente. Como característica especial está el archivo de uso frecuente de un solo evento directamente a través del icono.
Para cada uno de los comandos hay un permiso, que puedes utilizar para controlar para qué rol está permitida la ejecución del comando. Por defecto, todos los comandos están permitidos para los titulares de los roles admin y user.
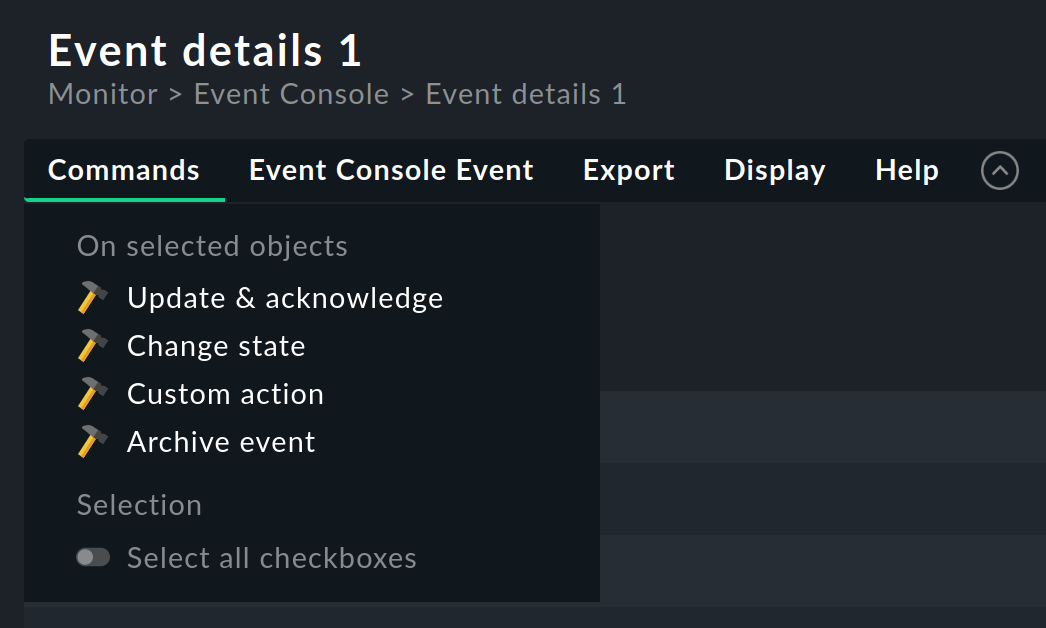
Están disponibles los siguientes comandos:
Actualización y Reconocimiento
El comando Update & Acknowledge muestra la siguiente zona encima de la lista de eventos:
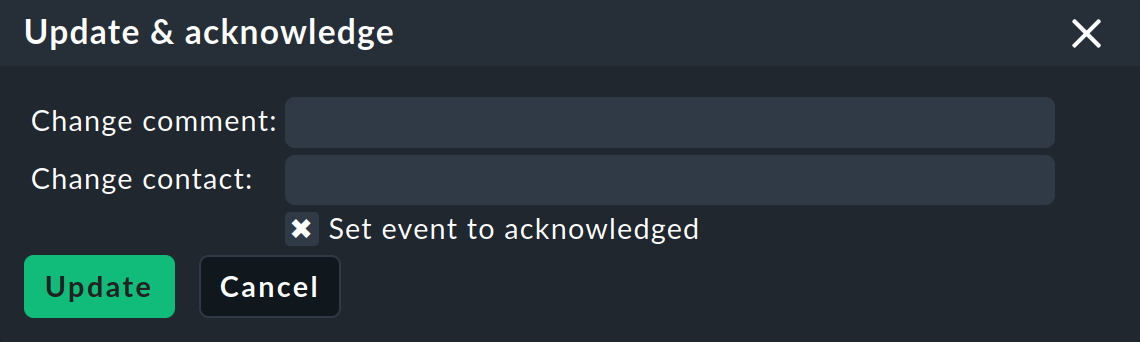
Con el botón Update puedes, en una sola acción, añadir un comentario al evento, añadir una persona de contacto y reconocer el evento. El campo Change contact es intencionadamente de texto libre. Aquí también puedes introducir cosas como números de teléfono. En particular, este campo no influye en la visibilidad del evento en la GUI - es puramente un campo de comentario.
El checkbox Set event to acknowledged hará que el evento pase de la fase open a acknowledged, y en adelante se mostrará como handled. Esto es análogo al Reconocimiento de problemas de host y de servicio.
La invocación posterior del comando con el checkbox desmarcado elimina el Reconocimiento.
Cambiar estado
El comando Change State permite cambiar manualmente el estado de un evento, por ejemplo, de CRIT a WARN.
Acción personalizada
Con el comando Custom Action, se pueden ejecutar acciones libremente definibles sobre los eventos. Inicialmente, sólo está disponible la acción Send monitoring notification. Ésta enviará una notificación Checkmk que se gestionará de la misma forma que la de un servicio activamente monitorizado. Ésta pasa por las reglas de notificación y puede generar correos electrónicos, un SMS o lo que hayas configurado en consecuencia. Consulta más abajo los detalles sobre la notificación por la CE.
Archivar evento
El botón Archive Event elimina permanentemente un evento de la lista de eventos abiertos. Dado que todas las acciones sobre los eventos -incluida esta eliminación- se registran también en el archivo, podrás seguir accediendo posteriormente a toda la información sobre el evento. Por eso no hablamos de eliminar, sino de archivar.
También puedes archivar cómodamente eventos individuales de la lista de eventos utilizando .
4.3. Visibilidad de los eventos
El "problema" de la visibilidad
Para proporcionar visibilidad de los host y servicios en la monitorización para usuarios normales, Checkmk utiliza grupos de contacto. Estos grupos se asignan a los host y servicios mediante la configuración de la GUI, reglas o carpetas.
Con la Consola de eventos, la situación es que esa asignación de eventos a grupos de contacto no existe, porque sencillamente no se sabe de antemano qué mensajes se van a recibir realmente. Ni siquiera se conoce la lista de hosts, porque los sockets para Syslog y SNMP son accesibles desde todas partes. Por eso, la Consola de eventos incluye algunas funciones especiales para definir la visibilidad.
Inicialmente, todo el mundo puede verlo todo
En primer lugar, al configurar los roles de usuario aparece el permiso Event Console > See all events. ¡Está activo por defecto, de modo que los usuarios normales pueden ver todos los eventos!Esto se establece deliberadamente para garantizar que los mensajes de error importantes no se queden por el camino debido a una configuración incorrecta. El primer paso para una visibilidad más precisa es eliminar este permiso del rol user.
Asignación a host
Para que la visibilidad de los eventos sea lo más coherente posible con el resto de la monitorización, la Consola de eventos intenta, en la medida de lo posible, hacer coincidir los hosts de los que recibe eventos con los hosts configurados a través de la GUI de Configuración. Lo que parece sencillo es complicado en los detalles. A veces falta el nombre del host en el evento y sólo se conoce la dirección IP. En otros casos, el nombre del host está escrito de forma distinta a la que aparece en la GUI de Configuración.
La asignación se realiza del siguiente modo:
Si no se encuentra ningún nombre del host en el evento, se utiliza su dirección IP como nombre del host.
A continuación, el nombre del host en el evento se compara caso por caso con todos los nombres de host, direcciones del host y direcciones IP de los hosts en la monitorización.
Si se encuentra un host de esta forma, se utilizan sus grupos de contacto para el evento, y esto se utiliza para controlar la visibilidad.
Si no se encuentra el host, los grupos de contacto -si están configurados allí- se toman de la regla que creó el evento.
Si tampoco hay grupos almacenados allí, el usuario sólo podrá ver el evento si tiene el permiso Event Console > See events not related to a known host.
Puedes influir en la asignación en un punto: a saber, si los grupos de contacto están definidos en la regla y se puede asignar el host, el mapeo suele tener prioridad. Puedes cambiar esto en una regla con la opción Precedence of contact groups:
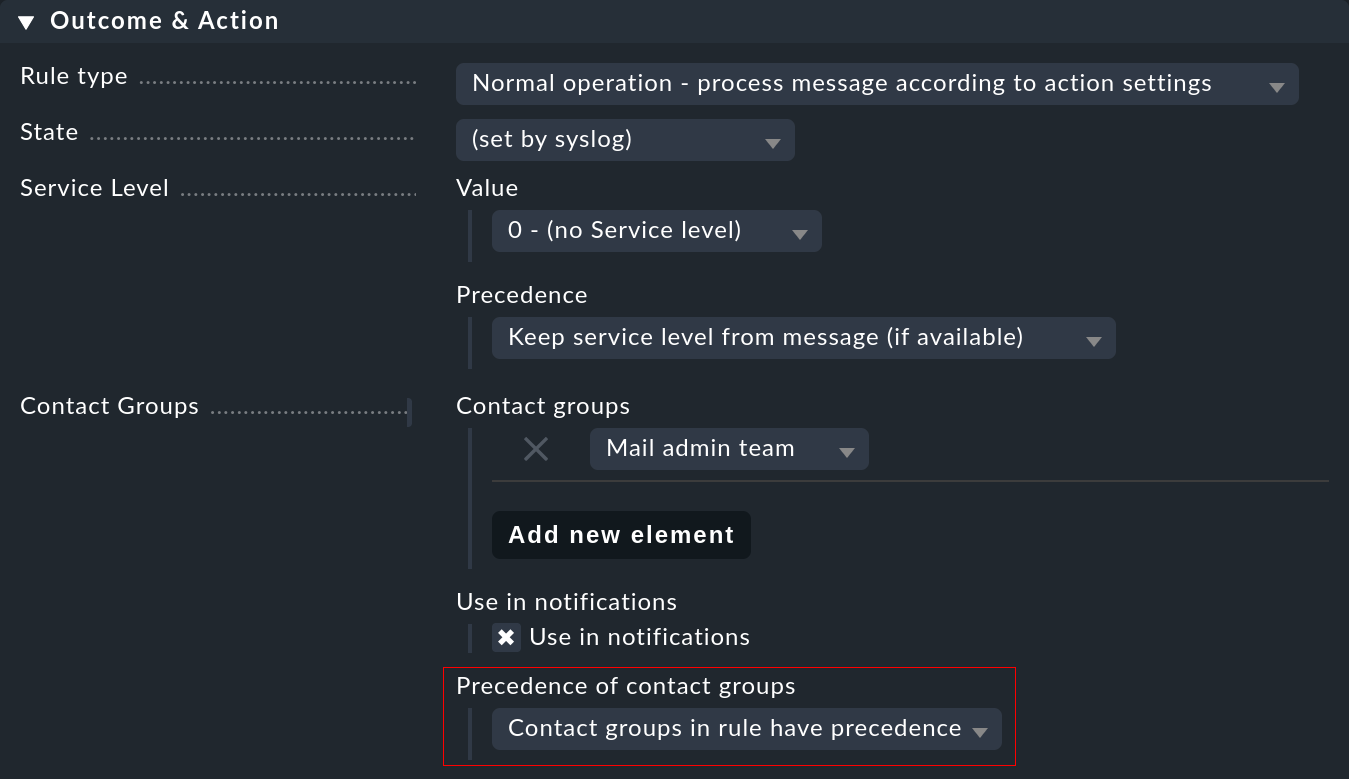
Además, puedes hacer ajustes directamente en la regla para la notificación. Esto permite dar prioridad al tipo de evento sobre las responsabilidades habituales de un host.
4.4. Solución de problemas
¿Qué regla se aplica y con qué frecuencia?
Tanto para los paquetes de reglas ...
... como para las reglas individuales ...

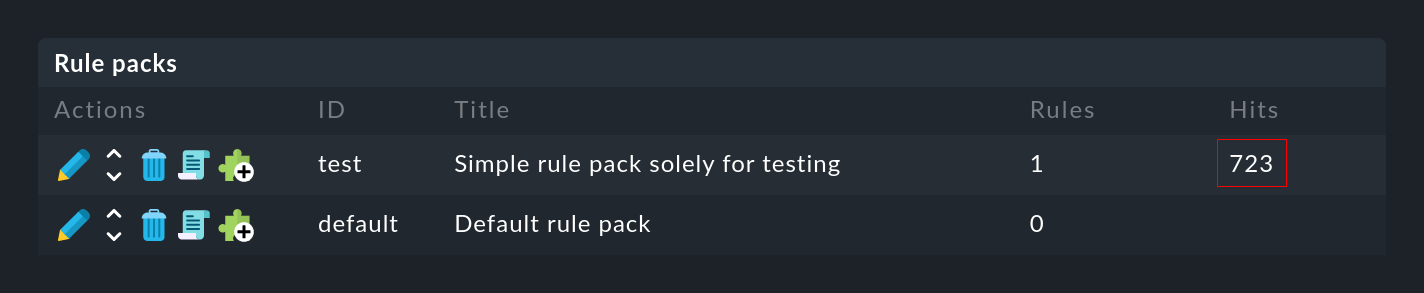
... en la columna Hits encontrarás la información sobre la frecuencia con la que el paquete o la regla ya ha coincidido con un mensaje. Esto te ayuda a eliminar o reparar las reglas ineficaces. Pero también puede ser interesante para las reglas que coinciden muy a menudo. Para un rendimiento óptimo de la CE, éstas deben estar al principio de la secuencia de reglas. De esta forma puedes reducir el número de reglas que la CE tiene que probar en cada mensaje.
Puedes restablecer los contadores en cualquier momento con el elemento de menú Event Console > Reset counters.
Depurar la evaluación de reglas
En Probar una regla ya has visto cómo puedes utilizar Event Simulator para comprobar las evaluaciones de tus reglas. Puedes obtener información similar en tiempo de ejecución para todos los mensajes, si en los ajustes de la Consola de eventos estableces el valor de Debug rule execution a on.
El archivo de registro de la Consola de eventos se encuentra en var/log/mkeventd.log, en el que encontrarás la razón exacta por la que alguna regla verificada no surtió efecto:
[1481020022.001612] Processing message from ('10.40.21.11', 57123): '<22>Dec 6 11:27:02 myserver123 exim[1468]: Delivery complete, 4 message(s) remain.'
[1481020022.001664] Parsed message:
application: exim
facility: 2
host: myserver123
ipaddress: 10.40.21.11
pid: 1468
priority: 6
text: Delivery complete, 4 message(s) remain.
time: 1481020022.0
[1481020022.001679] Trying rule test/myrule01...
[1481020022.001688] Text: Delivery complete, 4 message(s) remain.
[1481020022.001698] Syslog: 2.6
[1481020022.001705] Host: myserver123
[1481020022.001725] did not match because of wrong application 'exim' (need 'security')
[1481020022.001733] Trying rule test/myrule02n...
[1481020022.001739] Text: Delivery complete, 4 message(s) remain.
[1481020022.001746] Syslog: 2.6
[1481020022.001751] Host: myserver123
[1481020022.001764] did not match because of wrong textHuelga decir que debes utilizar este registro intensivo sólo cuando sea necesario y con precaución. ¡En un entorno sólo ligeramente más complejo se generarán enormes volúmenes de datos!
5. El pleno poder de las reglas
5.1. Las condiciones
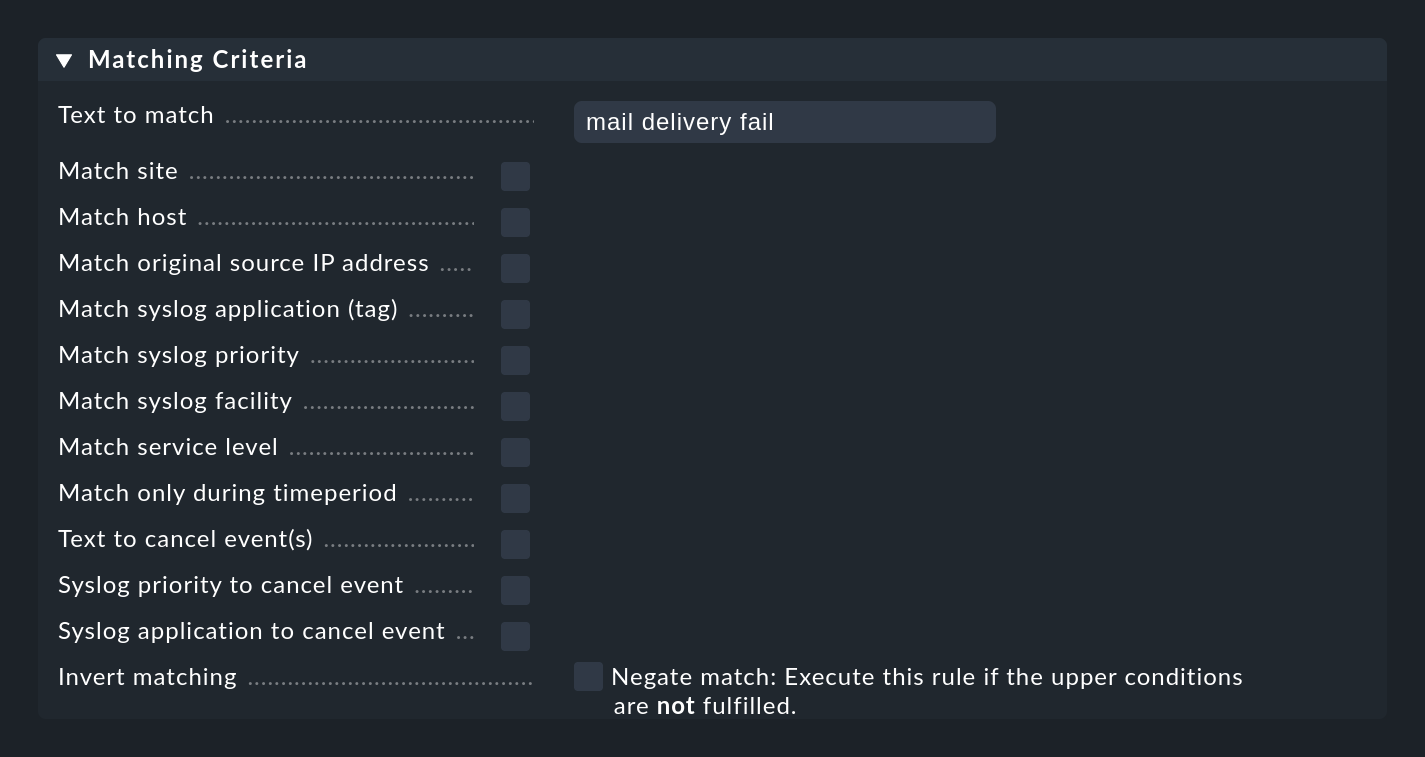
La parte más importante de una regla CE es, por supuesto, la condición (Matching Criteria). Sólo si un mensaje cumple todas las condiciones almacenadas en la regla, se ejecutan las acciones definidas en la regla y se completa así la evaluación del mensaje.
Información general sobre las comparaciones de texto
Para todas las condiciones que implican campos de texto, el texto de comparación siempre se trata como una expresión regular. La comparación siempre tiene lugar ignorando mayúsculas/minúsculas. Esto último es una excepción a las convenciones de Checkmk en otros módulos. Sin embargo, esto hace que la formulación de las reglas sea más robusta, especialmente porque los nombres del host en los eventos no son necesariamente consistentes en su ortografía si se han configurado en cada host localmente en lugar de centralmente. Por tanto, esta excepción es muy útil aquí.
Además, siempre se aplica una concordancia infix, es decir, un check del contenido del texto de búsqueda, por lo que puedes guardar un .* al principio o al final del texto de búsqueda.
Sin embargo, hay una excepción: si no se utiliza una expresión regular en la coincidencia con el nombre del host, sino un nombre del host explícito, se comprobará si hay coincidencia exacta y no si está contenido.
Atención: ¡Si el texto de búsqueda contiene un punto (.), se considerará una expresión regular y se aplicará la búsqueda infix, por ejemplo, mihost.com coincidirá también, por ejemplo, con notmyhostide!
Grupos de concordancia
Muy importante y útil aquí es el concepto de grupos de concordancia en el campo Text to match. Se refiere a las secciones de texto que coinciden con las expresiones entre paréntesis de la expresión regular.
Supongamos que quieres monitorizar el siguiente tipo de mensaje en el archivo de registro de una base de datos:
Database instance WP41 has failedEl WP41 es, por supuesto, variable y seguramente no querrás formular una regla distinta para cada instancia diferente, por lo que utilizarás .* en la expresión regular, que significa cualquier cadena:
Database instance .* has failed
Si ahora encierras la parte variable entre corchetes, la Consola de eventos memorizará(capturará) el valor real para cualquier acción futura:
Database instance (.*) has failed
Tras una coincidencia correcta de la regla, el primer grupo de concordancia se fija ahora en el valor WP41 (o en la instancia que haya producido el error).
Puedes ver estos grupos de concordancia en Event Simulator si pasas el cursor por encima de la bola verde:

También puedes ver los grupos en los detalles del evento generado:
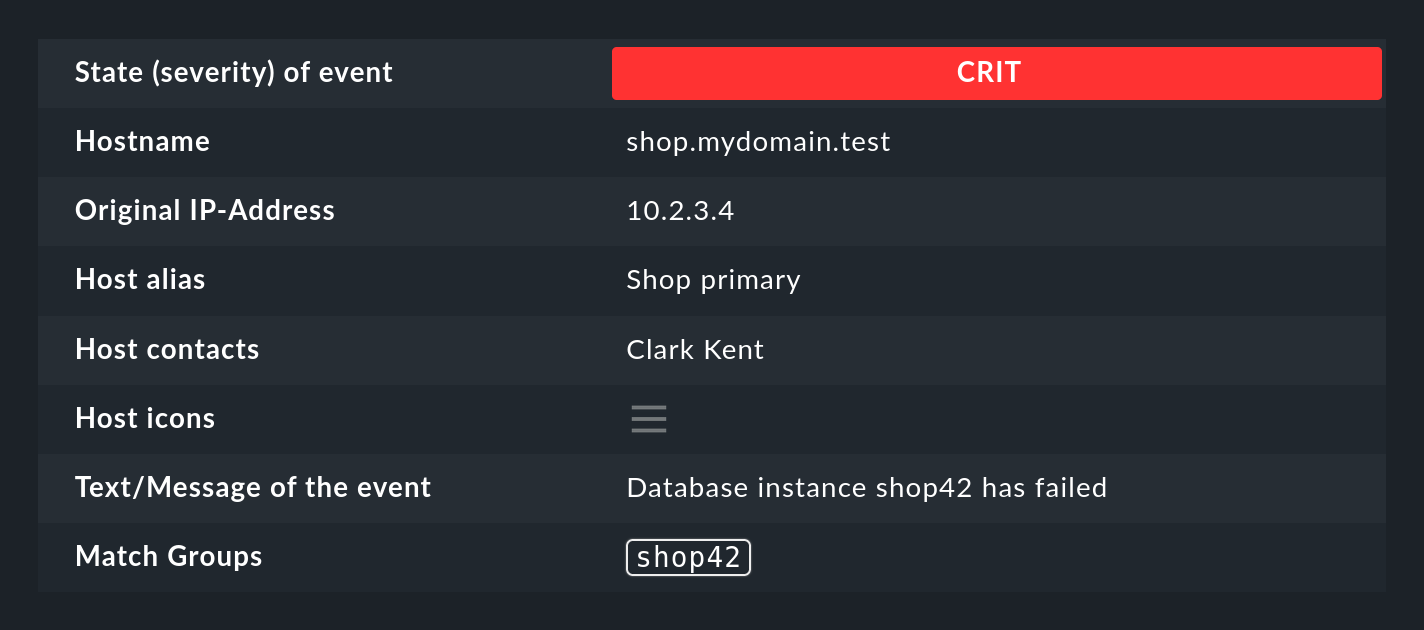
Entre otras cosas, los grupos de concordancia se utilizan para:
Reescribir eventos
Cancelar eventos automáticamente
El recuento de mensajes
Llegados a este punto, un consejo: Hay situaciones en las que necesitas agrupar algo en la expresión regular pero no quieres crear un grupo de concordancia. Puedes hacerlo colocando un ?: justo después del paréntesis de apertura. Ejemplo: La expresión one (.*) two (?:.*) three crea para una coincidencia en one 123 two 456 three sólo el único grupo de concordancia 123.
Dirección IP
En el campo Match original source IP address puedes coincidir con la dirección IPv4 del remitente del mensaje. Especifica una dirección exacta o una red en la notación X.X.X.X/Y, por ejemplo 192.168.8.0/24 para coincidir con todas las direcciones de la red 192.168.8.X.
Ten en cuenta que la coincidencia en la dirección IP sólo funciona si los sistemas monitorizados envían directamente a la Consola de eventos. Si otro servidor de syslog intermedio conectado está reenviando los mensajes, su dirección aparecerá en su lugar como remitente en el mensaje.
Prioridad y facilidad del syslog
Los campos Match syslog priority y Match syslog facility son información estandarizada, definida originalmente por la información Syslog. Internamente, un campo de 8 bits se divide en 5 bits para la facilidad (32 posibilidades) y 3 bits para la prioridad (8 posibilidades).
Las 32 facilidades predefinidas se pensaron en su día para algo como una aplicación, pero la selección no se hizo con mucha visión de futuro en aquel momento. Una de las facilidades es uucp, un protocolo que a principios de los 90 del milenio pasado ya estaba casi obsoleto.
Pero es un hecho que cada mensaje que llega a través de syslog lleva una de estas facilidades. En algunos casos también puedes asignarlas libremente al enviar el mensaje, para poder filtrarlas después, lo que resulta bastante útil.
El uso de la facilidad y la prioridad también tiene un aspecto de rendimiento. Si defines una regla que, en cualquier caso, sólo se aplica a los mensajes que tienen todos la misma facilidad o prioridad, debes definirlas adicionalmente en los filtros de la regla. La Consola de eventos podrá entonces omitir estas reglas de forma muy eficiente cuando se reciba un mensaje con valores diferentes. Cuantas más reglas tengan establecidos estos filtros, menos comparaciones de reglas serán necesarias.
Invertir una coincidencia
El checkbox Negate match: Execute this rule if the upper conditions are not fulfilled. hace que la regla sólo tenga efecto cuando no se cumpla ninguna de las condiciones. En realidad, esto sólo es útil en el contexto de dos tipos de reglas (Rule type en la caja Outcome & Action de la regla):
Do not perform any action, drop this message, stop processing.
Skip this rule pack, continue rule execution with next pack
A continuación puedes obtener más información sobre los paquetes de reglas.
5.2. Efecto de la regla
Tipo de regla: Cancelar o crear un evento
Cuando una regla coincide, especifica lo que debe ocurrir con el mensaje. Esto se hace en la caja Outcome & Action:
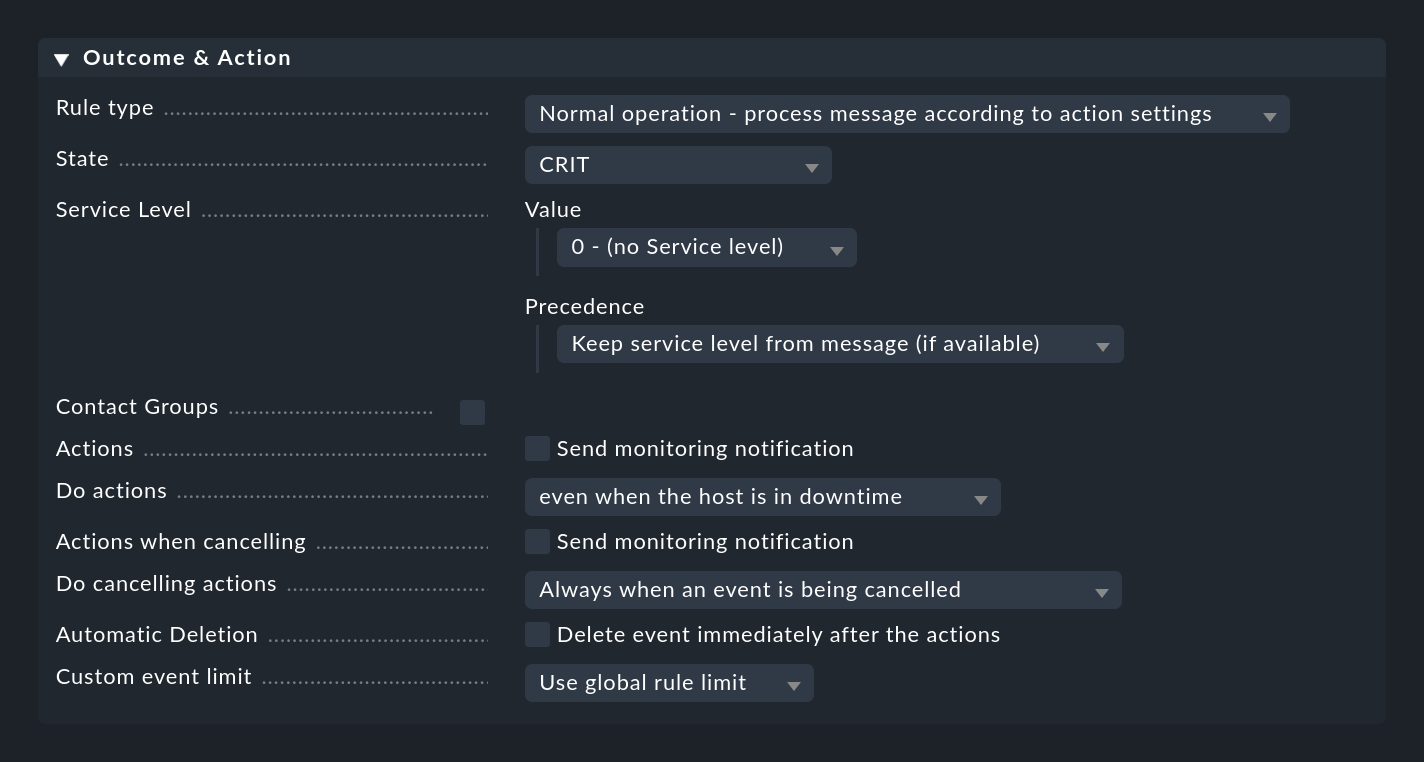
El Rule type se puede utilizar para abortar la evaluación en el punto por completo o para el paquete de reglas actual. Especialmente la primera opción se debe utilizar para deshacerse de la mayor parte del "ruido" inútil utilizando unas pocas reglas específicas al principio. Sólo con las reglas "normales" se evalúan realmente las otras opciones de esta caja.
Establecer el estado
En State, la regla establece el estado del evento en la monitorización. En la regla, este estado será WARN o CRIT. Las reglas que generan eventos OK pueden ser interesantes en excepciones para representar determinados eventos de forma puramente informativa. En tal caso, resulta interesante una combinación con una caducidad automática de estos eventos.
Además de establecer un estado explícito, hay dos opciones más dinámicas. La opción (set by syslog) asume la clasificación basada en la prioridad syslog. Esto sólo funciona si el mensaje ya ha sido clasificado utilizable por el remitente. Los mensajes recibidos directamente por syslog contendrán una de las ocho prioridades RFC, que se mapean de la siguiente manera:
| Prioridad | ID | Estado | Definición según syslog |
|---|---|---|---|
|
0 |
CRIT |
sistema inutilizable |
|
1 |
CRIT |
se requiere acción inmediata |
|
2 |
CRIT |
condición crítica |
|
3 |
CRIT |
error |
|
4 |
ADVERTENCIA |
advertencia |
|
5 |
OK |
normal, pero información significativa |
|
6 |
OK |
puramente informativo |
|
7 |
OK |
mensaje de depuración |
Además de los mensajes syslog, los mensajes del Registro de eventos de Windows y los mensajes de los archivos de texto que ya se han clasificado con el Plugin Checkmk logwatch en el sistema de destino, proporcionan estados listos para usar. Para los Trap SNMP, lamentablemente, esto no está disponible.
Un método completamente distinto es clasificar el mensaje basándose en el propio texto, lo que puede hacerse con la configuración (set by message text):
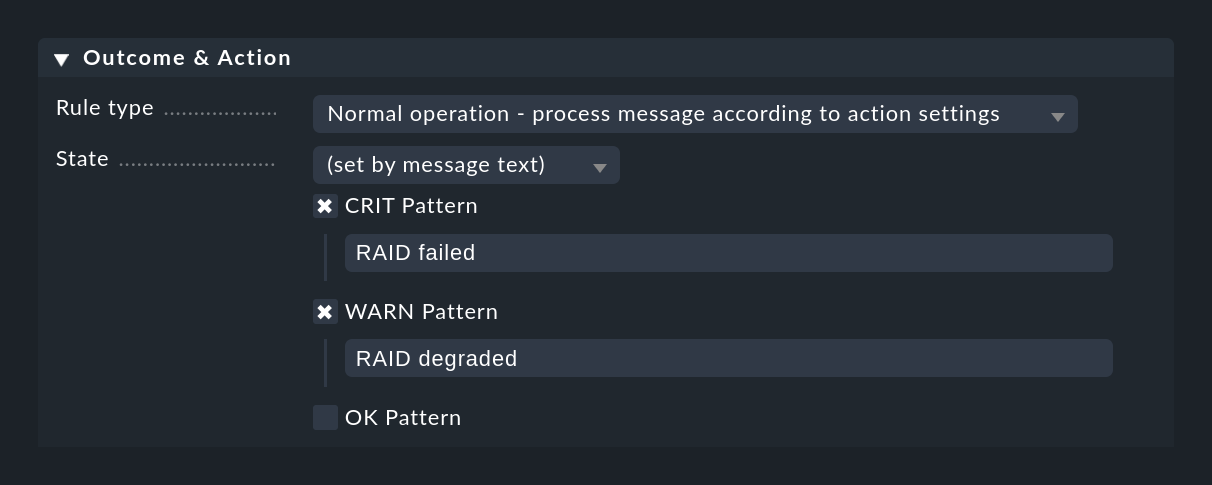
La coincidencia con los textos configurados aquí sólo se produce después de comprobar Text to match y de que se hayan comprobado las demás condiciones de la regla, de modo que no tengas que repetir esas comprobaciones.
Si no se encuentra ninguno de los patrones configurados, el evento devuelve el estado UNKNOWN.
Niveles de servicio
La idea que subyace en el campo Service Level es que cada host y cada servicio de una organización tiene un determinado nivel de importancia, que puede asociarse a un acuerdo de servicio específico para el host o el servicio. En Checkmk, puedes utilizar reglas para asignar dichos niveles de servicio a tus hosts y servicios y luego, por ejemplo, hacer que la notificación o los dashboards autodefinidos dependan de ello.
Dado que los eventos no se correlacionan necesariamente con los host o servicios, la Consola de eventos te permite asignar un nivel de servicio a un evento mediante una regla. Posteriormente, puedes filtrar las vistas de eventos utilizando este nivel.
Por defecto, Checkmk define cuatro niveles: 0 (sin nivel), 10 (plata), 20 (oro) y 30 (platino). Puedes cambiar esta selección según necesites en Global settings > Notifications > Service Levels. Son decisivos los números que designan los niveles, ya que los niveles se ordenan por estos números y también se comparan según la importancia relativa.
Grupos de contacto
Los grupos de contacto utilizados para la visibilidad también se utilizarán para la notificación de eventos. Aquí puedes utilizar reglas para asignar grupos de contacto explícitamente a los eventos. Encontrarás más detalles en el capítulo sobre monitorización.
Acciones
Las acciones son muy similares a los Alert handlers para host y servicios. Aquí puedes hacer que se ejecute un script autodefinido cuando se abra un evento. Más adelante, en una sección aparte, encontrarás información detallada sobre las acciones.
Borrado automático (archivado)
El borrado automático (= archivado), que puedes configurar con Delete event immediately after the actions, garantiza que un evento no sea visible en la monitorización en absoluto. Esto es útil si sólo quieres activar algunas acciones automáticamente o si sólo quieres archivar ciertos eventos para poder buscarlos más tarde.
5.3. Reescritura automática de textos
Con la función Rewriting, una regla CE puede reescribir automáticamente los campos de texto de un mensaje y añadir anotaciones. Esto se configura en una caja aparte:
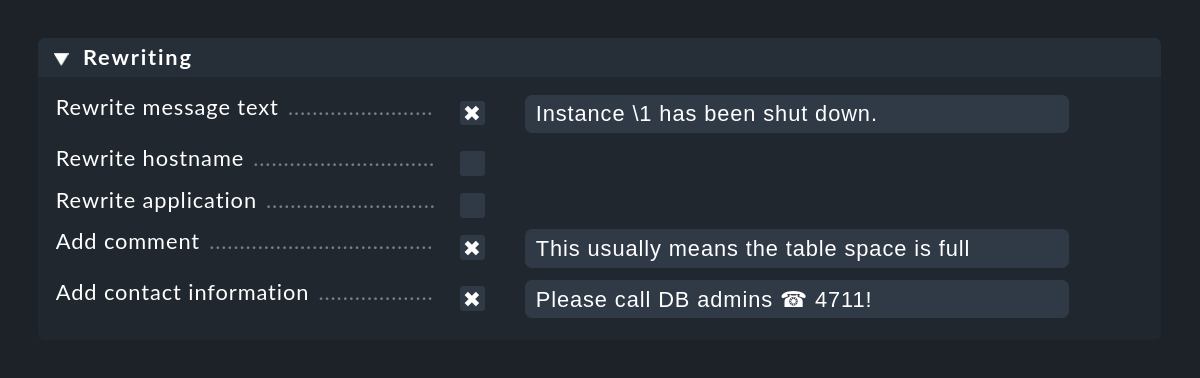
Al reescribir, son especialmente importantes los grupos de coincidencia, que te permiten incluir partes del mensaje original en el nuevo texto. Puedes acceder a los grupos al reescribir del siguiente modo:
|
Será sustituido por el primer grupo de concordancia del mensaje original. |
|
Se sustituirá por el segundo grupo de concordancia del mensaje original (etc.). |
|
Se sustituirá por el mensaje original completo. |
En la captura de pantalla anterior, el texto del nuevo mensaje se codificará como Instance \1 has been shut down.. Por supuesto, esto sólo funciona si el Text to match de la misma regla de la expresión de búsqueda regular también tiene al menos una expresión entre paréntesis. Un ejemplo de esto sería, por ejemplo

Algunas notas más sobre la reescritura:
La reescritura se realiza después de la coincidencia y antes de realizar acciones.
Las coincidencias, la reescritura y las acciones se realizan siempre en la misma regla. No es posible reescribir un mensaje y luego procesarlo con una regla posterior.
Las expresiones
\1,\2etc. se pueden utilizar en todos los campos de texto, no sólo en Rewrite message text.
5.4. Cancelación automática de eventos
Algunas aplicaciones o dispositivos tienen la amabilidad de enviar posteriormente un mensaje OK adecuado en cuanto se ha resuelto el problema. Puedes configurar la CE de forma que, en tal caso, el evento abierto por el error se cierre automáticamente, lo que se denomina cancelar.
La siguiente figura muestra una regla con la que se buscan mensajes que contengan el texto database instance (.*) has failed. La expresión (.*) representa una cadena arbitraria que está atrapada en un grupo de coincidencia. La expresión database instance (.*) recovery in progress, que está en el campo Text to cancel event(s) de la misma regla, cerrará automáticamente los eventos creados con esta regla cuando se reciba un mensaje que coincida:
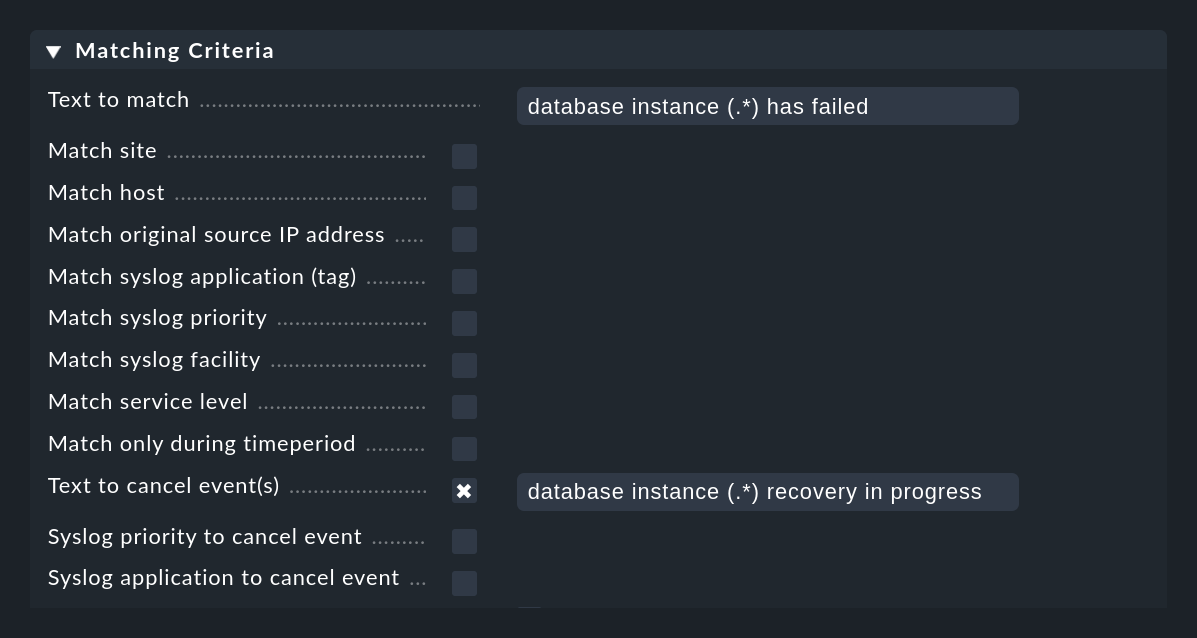
La cancelación automática funciona siempre que
se reciba un mensaje cuyo texto coincida con Text to cancel event(s),
el valor capturado aquí en el grupo
(.*)es idéntico al grupo de concordancia del mensaje original,ambos mensajes procedan del mismo host, y
se trata de la misma aplicación (el campo Syslog application to cancel event ).
El principio del grupo de concordancia es muy importante aquí. Después de todo, no tendría mucho sentido que el mensaje database instance TEST recovery in progress cancelara un evento que había sido generado por el mensaje database instance PROD has failed, ¿verdad?
No cometas el error de utilizar el marcador de posición \1 en Text to cancel events(s). ¡Esto NO funciona! Estos marcadores de posición sólo sirven para reescribir.
En algunos casos ocurre que un texto se utiliza tanto para crear como para cancelar un evento. En tal caso, cancelar tiene prioridad.
Ejecutar acciones al cancelar
También puedes hacer que se ejecuten acciones automáticamente cuando se cancela un evento. Es importante saber que cuando se cancela un evento, una serie de campos de datos del evento se sobrescriben con valores del mensaje OK antes de que se ejecute ninguna acción. De este modo, los datos completos del mensaje OK están disponibles en el script de acción. Además, durante esta fase, el estado del evento se marca como OK. De este modo, un script de acción puede detectar una anulación y puedes utilizar el mismo script para mensajes de error y OK (por ejemplo, cuando te conectas a un sistema de tickets).
Los siguientes campos se sobrescriben a partir de los datos del mensaje OK:
El texto del mensaje
La marca de tiempo
La hora de la última aparición
La prioridad syslog
Todos los demás campos permanecen inalterados, incluido el ID del evento.
Cancelar en combinación con reescribir
Si utilizas la reescritura y la cancelación en la misma regla, debes tener cuidado al reescribir el nombre del host o la aplicación. Al cancelar, la CE siempre comprueba si el mensaje de cancelación coincide con el nombre del host y la aplicación del evento abierto. Pero si éstos se reescribiesen, la cancelación nunca funcionaría.
Por lo tanto, antes de cancelar el evento, la Consola de eventos simula una reescritura del nombre del host y de la aplicación para comparar los textos relevantes. Esto es probablemente lo que esperarías.
También puedes aprovechar este comportamiento si el campo de aplicación del mensaje de error y el posterior mensaje OK no coinciden. En este caso, simplemente reescribe el campo de aplicación a un valor fijo conocido, lo que de hecho conduce al resultado de que este campo será ignorado.
Cancelación basada en la prioridad del syslog
Hay situaciones (por desgracia) en las que el texto de los mensajes de error y OK es absolutamente idéntico. En la mayoría de los casos, el estado real no está codificado en el texto, sino en la prioridad del syslog.
Para ello existe la opción Syslog priority to cancel event. Introduce aquí el intervalo debug... notice, por ejemplo. Normalmente se considera que todas las prioridades de este intervalo tienen un estado OK. Cuando utilices esta opción, debes introducir igualmente un texto adecuado en el campo Text to cancel event(s), ya que de lo contrario la regla coincidirá con todos los mensajes OK que afecten a la misma aplicación.
5.5. Contar mensajes
En la caja Counting & Timing encontrarás opciones para contar mensajes similares. La idea es que algunos mensajes sólo son relevantes si ocurren con demasiada frecuencia o con muy poca frecuencia dentro de periodos de tiempo especificados.
Mensajes demasiado frecuentes
Puedes activar el check de mensajes que ocurren con demasiada frecuencia con la opción Count messages in interval:
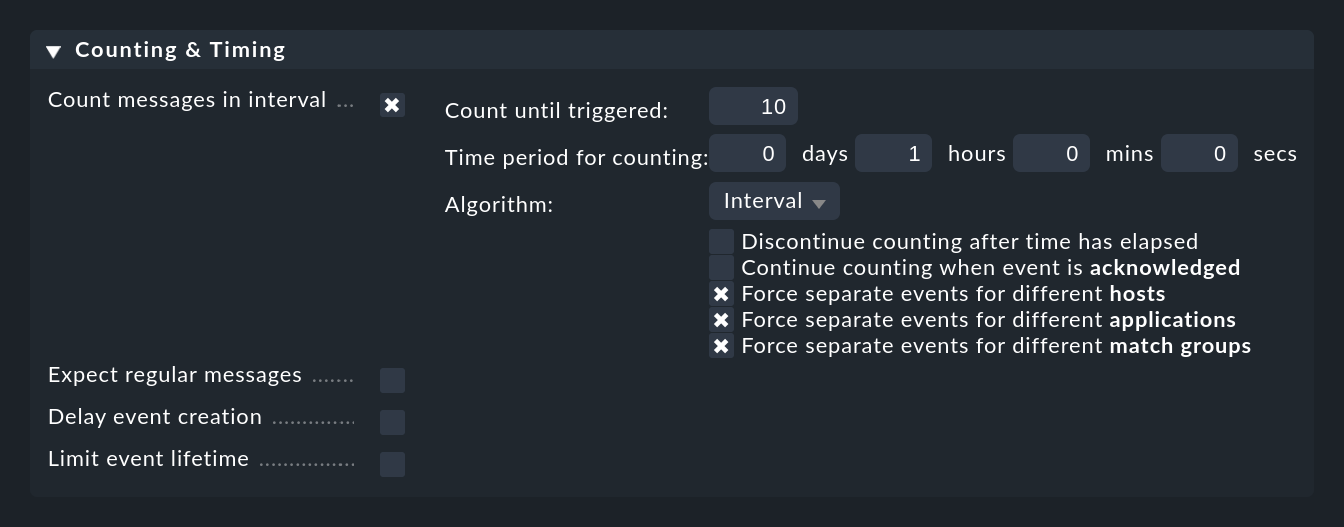
Aquí especificas primero un periodo de tiempo en Time period for counting y el número de mensajes que deben provocar la apertura de un evento en Count until triggered. En el ejemplo anterior, esto se establece en 10 mensajes por hora. Por supuesto, no se trata de 10 mensajes arbitrarios, sino de mensajes que coinciden con la regla.
Normalmente, tiene sentido no contar globalmente todos los mensajes coincidentes, sino sólo los que se refieren a la misma "causa". Para controlar esto, existen los tres checkbox de las opciones prefijadas por Force separate events for different …. Están preconfigurados de tal forma que los mensajes sólo se cuentan juntos si coinciden en:
host
aplicación
Esto te permite formular reglas como "Si se reciben más de 10 mensajes por hora del mismo host, la misma aplicación y allí el mismo site, entonces..." Debido a la regla, esto puede dar lugar a que se generen varios eventos diferentes.
Si, por ejemplo, desmarcas los tres checkbox, el recuento se hará sólo globalmente y la regla sólo podrá generar un evento en total.
Por cierto, puede tener sentido introducir 1 como recuento. De este modo podrás controlar eficazmente las "tormentas de eventos". Si, por ejemplo, en un breve espacio de tiempo se reciben 100 mensajes del mismo tipo, sólo se creará un evento. Verás en los detalles del evento
la hora en que se produjo el primer mensaje,
la hora en que se produjo el mensaje más reciente, y
el número total de mensajes combinados en este evento.
A continuación, mediante dos checkbox puedes definir cuándo debe abrirse un nuevo evento. Normalmente, el Reconocimiento del evento crea una situación en la que, si se reciben más mensajes, se inicia un nuevo recuento y se activa un nuevo evento. Puedes desactivar esta función con Continue counting when event is acknowledged.
La opción Discontinue counting after time has elapsed garantiza que siempre se abra un evento distinto para cada periodo de comparación. En el ejemplo anterior, se especificó un umbral de 10 mensajes por hora. Si esta opción está activada, se añadirá un máximo de 10 mensajes de una hora a un evento ya abierto. En cuanto haya transcurrido la hora, si se ha recibido un número suficiente de mensajes, se abrirá un nuevo evento.
Por ejemplo, si estableces el número en 1 y el intervalo de tiempo en un día, sólo verás un máximo de un evento de este tipo de mensaje al día.
La configuración de Algorithm puede resultar un poco sorprendente a primera vista, pero seamos realistas: ¿qué quieres decir realmente con "10 mensajes por hora"? ¿A qué hora te refieres con eso? ¿Siempre a horas completas del día? Podría ser que en el último minuto de una hora se recibieran nueve mensajes, y otros nueve en el primer minuto de la hora siguiente. Eso hace entonces 18 mensajes en sólo dos minutos de tiempo transcurrido, pero siguen siendo menos de 10 por hora, por lo que la regla no se aplicaría. Eso no suena muy razonable...
Como no hay una solución única a este problema, Checkmk proporciona tres definiciones diferentes de lo que debe significar exactamente "10 mensajes por hora":
| Algoritmo | Funcionalidad |
|---|---|
Interval |
El intervalo de recuento comienza en el primer mensaje de coincidencia entrante. Se genera un evento en la fase counting. Si transcurre el tiempo especificado antes de que se alcance el recuento, el evento se elimina silenciosamente. Sin embargo, si se alcanza el recuento antes de que expire el tiempo, el evento se abre inmediatamente (y se desencadenan las acciones que se hayan configurado). |
Token Bucket |
Este algoritmo no funciona con intervalos de tiempo fijos, sino que implementa un método que se utiliza a menudo en las redes para dar forma al tráfico. Supongamos que has configurado 10 mensajes por hora. Es decir, una media de uno cada 6 minutos. La primera vez que se recibe un mensaje coincidente, se genera un evento en la fase counting y el recuento se establece en 1. Por cada mensaje posterior, se aumenta en 1. Y cada 6 minutos, el contador vuelve a disminuir en 1, independientemente de que haya llegado un mensaje o no. Si el contador vuelve a bajar a 0, el evento se borra. Por tanto, el activador se dispara cuando la tasa media de mensajes es permanentemente superior a 10 por hora. |
Dynamic Token Bucket |
Se trata de una variante del algoritmo Token Bucket, en el que cuanto más pequeño es el contador en un momento dado, más lentamente disminuye. En el ejemplo anterior, si el contador fuera 5, sólo disminuiría cada 12 minutos en lugar de cada 6 minutos. El efecto general de esto es que las tasas de notificación justo por encima de la tasa permitida abrirán un evento (y por tanto serán notificadas) mucho más rápido. |
Entonces, ¿qué algoritmo debes elegir?
Interval es el más sencillo de entender y más fácil de seguir si más adelante quieres realizar un recuento exacto en tu archivo syslog.
Token Bucket por otro lado es más inteligente y "suave". Hay menos anomalías en los bordes de los intervalos.
Dynamic Token Bucket hace que el sistema sea más reactivo y genere notificaciones más rápidamente.
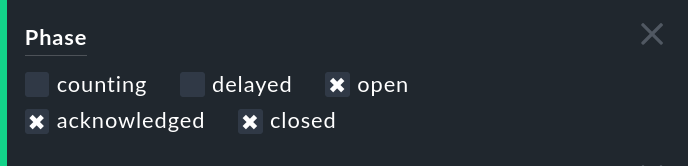
Los eventos que aún no han alcanzado el número establecido, están latentes pero no son visibles automáticamente para el operador. Están en la fase counting. Puedes hacer visibles estos eventos con el filtro phase en la vista de tabla:
Mensajes demasiado infrecuentes o ausentes
Al igual que la llegada de un mensaje concreto puede significar un problema, la ausencia de un mensaje también puede significar un problema. Puedes esperar al menos un mensaje al día de un trabajo concreto. Si este mensaje no llega, es probable que el trabajo no esté funcionando y deba arreglarse urgentemente.
Puedes configurar algo así en Counting & Timing > Expect regular messages:
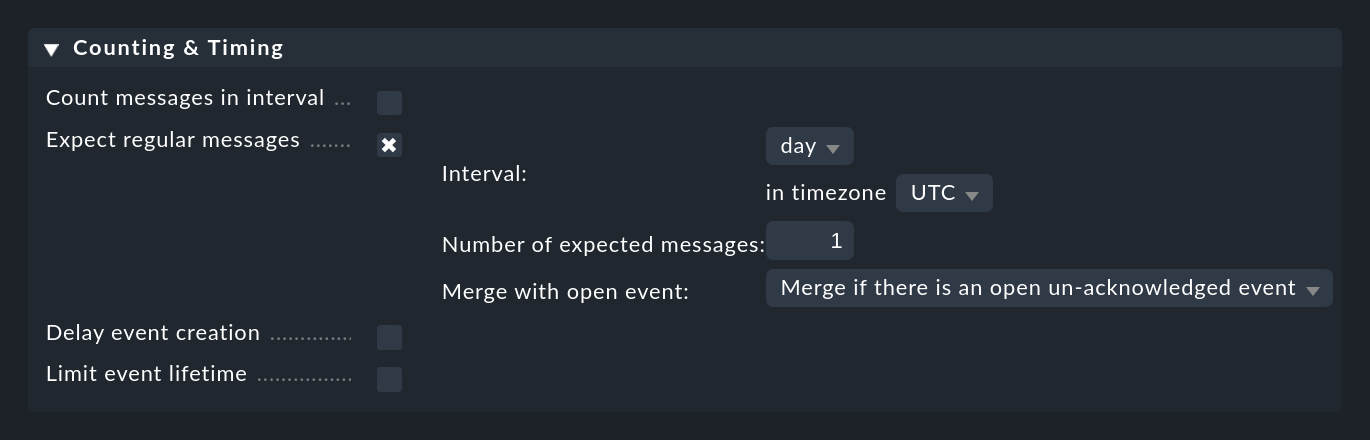
Al igual que con el recuento, tienes que especificar un periodo de tiempo en el que esperas que aparezca el mensaje o mensajes. Aquí, sin embargo, se utiliza un algoritmo completamente diferente, que tiene mucho más sentido en este punto. La periodicidad siempre se alinea exactamente con las posiciones definidas. Por ejemplo, el intervalo hour siempre comienza en el minuto y segundo cero. Tienes las siguientes opciones:
| Intervalo | Alineación |
|---|---|
10 seconds |
En un número de segundos divisible por 10 |
minute |
En el minuto completo |
5 minutes |
A las 0:00, 0:05, 0:10, etc. |
15 minutes |
A las 0:00, 0:15, 0:30, 0:45, etc. |
hour |
Al principio de cada hora completa |
day |
Exactamente a las 00:00, pero en una zona horaria configurable. Esto también te permite decir que esperas un mensaje entre las 12:00 y las 12:00 del día siguiente. Por ejemplo, si tú mismo estás en la zona horaria UTC +1, especifica UTC -11 hours. |
two days |
Al principio de una hora completa. Aquí puedes especificar un desfase horario de 0 a 47, referido a 1970-01-01 00:00:00 UTC. |
week |
A las 00:00 de la mañana del jueves en la zona horaria UTC más el desfase, que puedes indicar en horas. Jueves porque el 1/1/1970, el inicio de la "época", fue un jueves. |
¿Por qué es tan complicado? Para evitar falsas alarmas. ¿Esperas un mensaje de copia de seguridad al día, por ejemplo? Seguramente habrá ligeras diferencias en el tiempo de ejecución de la copia de seguridad, de modo que los mensajes no se reciban exactamente con 24 horas de diferencia. Por ejemplo, si esperas que el mensaje llegue hacia medianoche, más o menos una hora o dos, un intervalo de 12:00 a 12:00 será mucho más realista que uno de 00:00 a 00:00. Sin embargo, si el mensaje no aparece, sólo recibirás una notificación a las 12:00 del mediodía.
Múltiples apariciones del mismo problema
La opción Merge with open event está preconfigurada de forma que, en caso de que aparezca repetidamente el mismo mensaje, se actualizará el evento existente. Puedes modificarlo para que se abra un nuevo evento cada vez.
5.6. Temporización
En Counting & Timing hay dos opciones que afectan a la apertura y/o cierre automático de eventos.
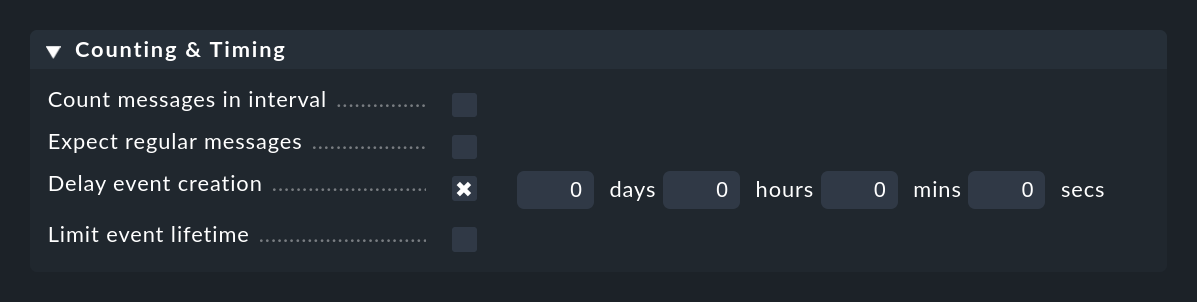
La opción Delay event creation es útil si trabajas con la cancelación automática de eventos. Establece, por ejemplo, un retraso de 5 minutos, entonces, en el caso de un mensaje de error, el evento creado permanecerá en el estado delayed durante 5 minutos, con la esperanza de que el mensaje OK llegue en ese tiempo. Si es así, el evento se cerrará automáticamente y sin complicaciones, y no aparecerá en la monitorización. Sin embargo, si el tiempo expira, el evento se abrirá y se ejecutará cualquiera de sus posibles acciones definidas:
Más o menos lo contrario se hace con Limit event lifetime. Con esto puedes hacer que los eventos se cierren automáticamente después de un tiempo determinado. Esto es útil, por ejemplo, para eventos informativos con un estado OK que te gustaría mostrar, pero para los que no quieres que la monitorización genere ninguna actividad. Al "apagarse" automáticamente te ahorras la eliminación manual de tales mensajes:
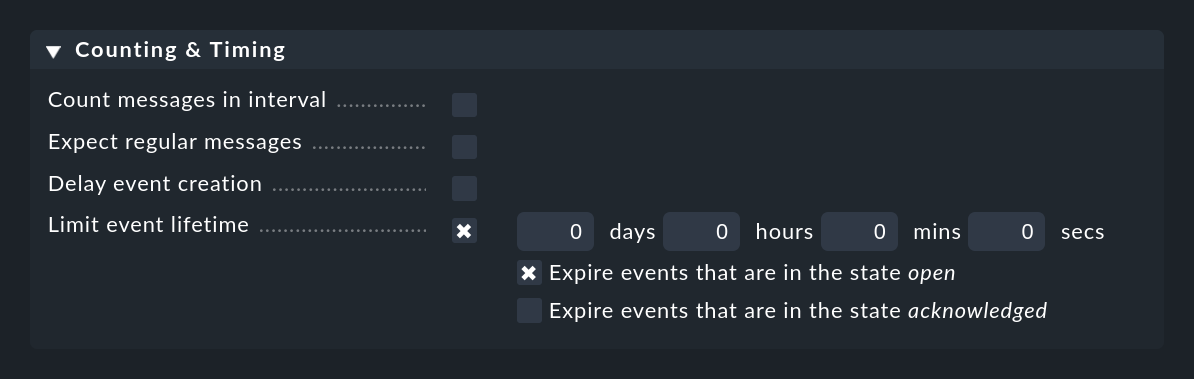
Reconociendo el mensaje se detendrá la desconexión por el momento. Este comportamiento se puede controlar con los dos checkbox.
5.7. Paquetes de reglas
Los paquetes de reglas no sólo tienen la ventaja de hacer las cosas más manejables, sino que también pueden simplificar la configuración de múltiples reglas similares y, al mismo tiempo, acelerar la evaluación.
Supongamos que tienes un conjunto de 20 reglas que giran todas en torno al registro de eventos de Windows Security. Todas estas reglas tienen en común que comprueban en la condición un determinado texto en el campo de aplicación (el nombre de este archivo de registro se utiliza en los mensajes de la CE como Application). En tal caso, procede como sigue:
Crea tu propio paquete de reglas.
Crea las 20 reglas para Security en este paquete o muévelas allí (lista de selección Move to pack… a la derecha de la tabla de reglas).
Elimina la condición sobre la aplicación de todas estas reglas.
Crea como primera regla del paquete una regla por la que los mensajes salgan inmediatamente del paquete si la aplicación no es Security.
Esta regla de exclusión se estructura como sigue:
Matching Criteria > Match syslog application (tag) en
Security.Matching Criteria > Invert matching en Negate match: Execute this rule if the upper conditions are not fulfilled.
Outcome & Action > Rule type en Skip this rule pack, continue rule execution with next rule pack
Cualquier mensaje que no proceda del registro de seguridad será "rechazado" por la primera regla de este paquete. Esto no sólo simplifica el resto de reglas del paquete, sino que también acelera el proceso, ya que en la mayoría de los casos no es necesario comprobar las demás reglas en absoluto.
6. Acciones
6.1. Tipos de acciones
La Consola de eventos incluye tres tipos de acciones, que puedes ejecutar manualmente o al abrir o cancelar eventos:
Ejecución de scripts shell escritos por ti mismo.
Envío de correos electrónicos autodefinidos.
Generación de notificaciones Checkmk
6.2. Scripts shell y correos electrónicos
Primero debes definir los correos electrónicos y los scripts en la configuración de la Consola de eventos, que encontrarás en la entrada Actions (Emails & Scripts):
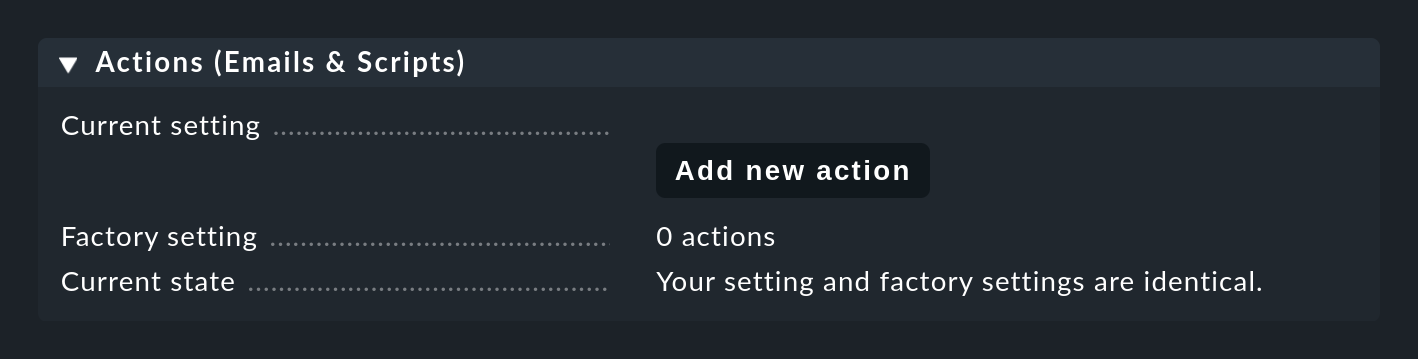
Ejecutar scripts shell
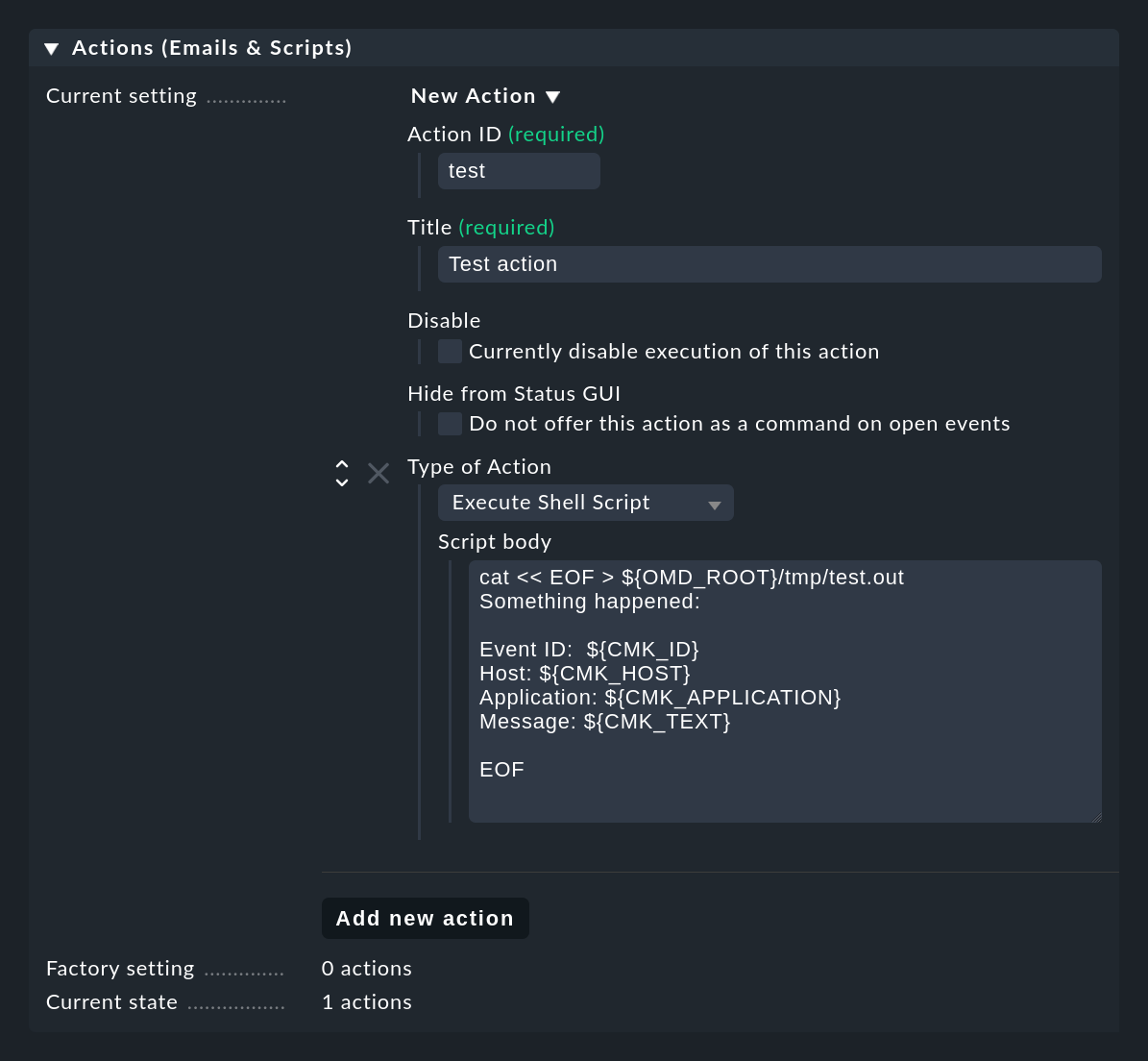
Con el botón Add new action puedes crear una nueva acción. El siguiente ejemplo muestra cómo crear un simple script shell como una acción del tipo Execute Shell Script. Los detalles de los eventos están disponibles para el script a través de variables de entorno, por ejemplo la $CMK_ID del evento, la $CMK_HOST, el texto completo $CMK_TEXT o el primer grupo de coincidencia como $CMK_MATCH_GROUP_1. Para obtener una lista completa de las variables de entorno disponibles, consulta la ayuda en línea.
Las versiones anteriores de Checkmk permitían variables del entorno, así como macros como $TEXT$, que se sustituían antes de ejecutar el script. Debido al peligro de que un atacante pueda inyectar comandos a través de un paquete UDP especialmente diseñado que se ejecute con los privilegios del proceso de Checkmk, no debes hacer uso de macros. Actualmente, las macros siguen admitiéndose por motivos de compatibilidad, pero nos reservamos el derecho a eliminarlas en una versión futura de Checkmk.
El script de ejemplo que se muestra en la captura de pantalla crea el archivo tmp/test.out en el directorio del site, en el que escribe un texto que contiene los valores concretos de las variables para el último evento correspondiente:
cat << EOF > ${OMD_ROOT}/tmp/test.out
Something happened:
Event-ID: $CMK_ID
Host: $CMK_HOST
Application: $CMK_APPLICATION
Message: $CMK_TEXT
EOFLos scripts se ejecutan en el siguiente entorno:
/bin/bashse utiliza como intérprete.El script se ejecuta como usuario del site con el directorio de inicio del site (por ejemplo,
/omd/sites/mysite).¡Mientras se ejecuta el script se detiene el proceso de otros eventos!
Si es posible que tu script contenga tiempos de espera, puedes hacer que se ejecute de forma asíncrona utilizando el spooler de Linux at. Para ello, crea el script en un archivo separado local/bin/myaction e inícialo con el comando at, por ejemplo:
echo "$OMD_ROOT/local/bin/myaction '$HOST$' '$TEXT$' | at nowEnviar correos electrónicos
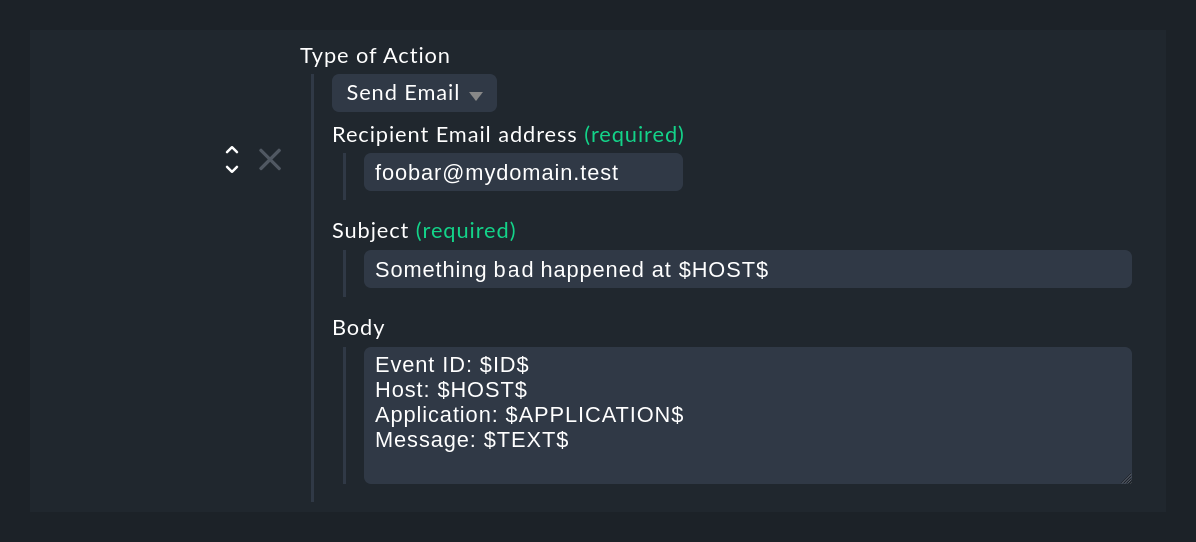
El tipo de acción Send Email envía un simple correo electrónico de texto. En realidad, también podrías hacerlo con un script, por ejemplo utilizando el comando de línea de comandos mail. Pero de esta forma es más cómodo. Ten en cuenta que también se permiten marcadores de posición en los campos Recipient email address y Subject.
6.3. Notificaciones a través de Checkmk
Además de ejecutar scripts y enviar correos electrónicos (simples), la CE tiene un tercer tipo de acción: enviar notificaciones a través del sistema de notificaciones Checkmk. La CE puede generar notificaciones de la misma forma que las notificaciones de host y servicios de la monitorización activa. Las ventajas en comparación con los simples correos electrónicos descritos anteriormente son obvias:
La notificación se configura para la monitorización activa y la basada en eventos, juntas en una ubicación central.
Dispone de funciones como notificaciones masivas, correos electrónicos HTML y otras funciones útiles.
Las reglas de notificación definidas por el usuario, la desactivación de notificaciones y similares funcionan como de costumbre.
El tipo de acción Send monitoring notification siempre procesa automáticamente y no necesita ser configurado.
Como los eventos difieren algo de los host o servicios "normales", hay algunas peculiaridades en sus notificaciones, que puedes conocer con más detalle en la siguiente sección.
Asignación a hosts existentes
Los eventos pueden proceder de cualquier host, independientemente de si están configurados en la monitorización activa o no. Al fin y al cabo, los puertos syslog y SNMP están abiertos a todos los hosts de la red. Como resultado, los atributos extendidos del host, como alias, tags del host, contactos, etc., no están disponibles inicialmente. Por eso, en particular, las condiciones de las reglas de notificación no funcionan necesariamente como cabría esperar.
Por ejemplo, al notificar, la CE intenta encontrar un host dentro de la monitorización activa que coincida con el evento. Para ello se utiliza el mismo procedimiento que para la visibilidad de los eventos. Si se encuentra un host de este tipo, se toman los siguientes datos de este host
La ortografía correcta del nombre del host.
El alias del host
La dirección IP principal configurada en Checkmk.
Los tags del host
La carpeta en la GUI de Configuración
La lista de contactos y grupos de contacto
Como resultado, el nombre del host en la notificación procesada puede no coincidir exactamente con el nombre del host en el mensaje original. Sin embargo, la codificación de los textos de notificación que se ajustan a los de la monitorización activa simplifica la formulación de reglas de notificación uniformes que incluyen condiciones que se aplican al nombre del host.
El mapeo se realiza en tiempo real enviando una consulta Livestatus al core de monitorización que se ejecuta en el mismo site que el CE que recibió el mensaje. Por supuesto, ¡esto sólo funciona si los mensajes syslog, Trap SNMP, etc. se envían siempre al site Checkmk en el que se está monitorizando activamente el host!
Si la consulta no funciona o no se puede encontrar el host, se aceptarán datos sustitutivos:
Nombre del host |
El nombre del host del evento. |
Alias del host |
El nombre del host que se utilizará como alias. |
Dirección IP |
El campo dirección IP contiene la dirección del remitente original del mensaje. |
Tags del host |
El host no recibirá ningún tag del host. Si tienes grupos de tags de host con tags vacíos, el host adoptará esos tags, pero de lo contrario no tendrá tags del grupo. Ten esto en cuenta cuando definas condiciones referentes a tags del host en las reglas de notificación. |
Configurar carpeta GUI |
Sin carpeta. Todas las condiciones que van a una carpeta específica son, por tanto, incumplibles, incluso en el caso de la carpeta principal. |
Contactos |
La lista de contactos está vacía. Si hay contactos de reserva, se introducirán. |
Si no se puede asignar el host en la monitorización activa, esto puede dar lugar, por supuesto, a problemas con las notificaciones. Por un lado, debido a las condiciones, que entonces pueden dejar de aplicarse, y también debido a la selección de contactos. Para estos casos, puedes modificar tus reglas de notificación, de modo que las notificaciones de la Consola de eventos se gestionen específicamente utilizando sus propias reglas. Para ello hay una condición independiente con la que puedes hacer coincidir positivamente sólo a las notificaciones de la CE, o viceversa, excluirlas:
Campos de notificación restantes
Para que las notificaciones de la CE pasen a través del sistema de notificación de la monitorización activa, la CE debe adaptarse para ajustarse a su esquema. En el proceso, los campos de datos típicos de una notificación se rellenan de la forma más eficaz posible. Acabamos de describir cómo se determinan los datos del host. Otros campos son:
Tipo de notificación |
Las notificaciones de la CE siempre se consideran mensajes de servicio. |
Descripción del servicio |
Es el contenido del campo Application del evento. Si este campo está vacío, se introducirá |
Número de notificación |
Está fijado en |
Fecha/Hora |
Para los eventos contabilizados, es la hora de la última aparición de un mensaje asociado al evento. |
Salida del Plugin |
El contenido textual del evento. |
Estado del servicio |
Estado del evento, es decir, OK, WARN, CRIT o UNKNOWN. |
Estado anterior |
Dado que los eventos no tienen estado previo, aquí se introduce siempre OK para los eventos normales, y CRIT cuando se cancela un evento. Esta regla es lo más parecido a lo que se necesita para las reglas de notificación que tienen una condición sobre el cambio de estado exacto. |
Definir manualmente grupos de contacto
Como se ha descrito anteriormente, puede que no sea posible determinar automáticamente los contactos para un evento. En tales casos, puedes especificar los grupos de contacto directamente en la regla de notificación que se va a utilizar. Es importante que no olvides marcar la caja Use in notifications:
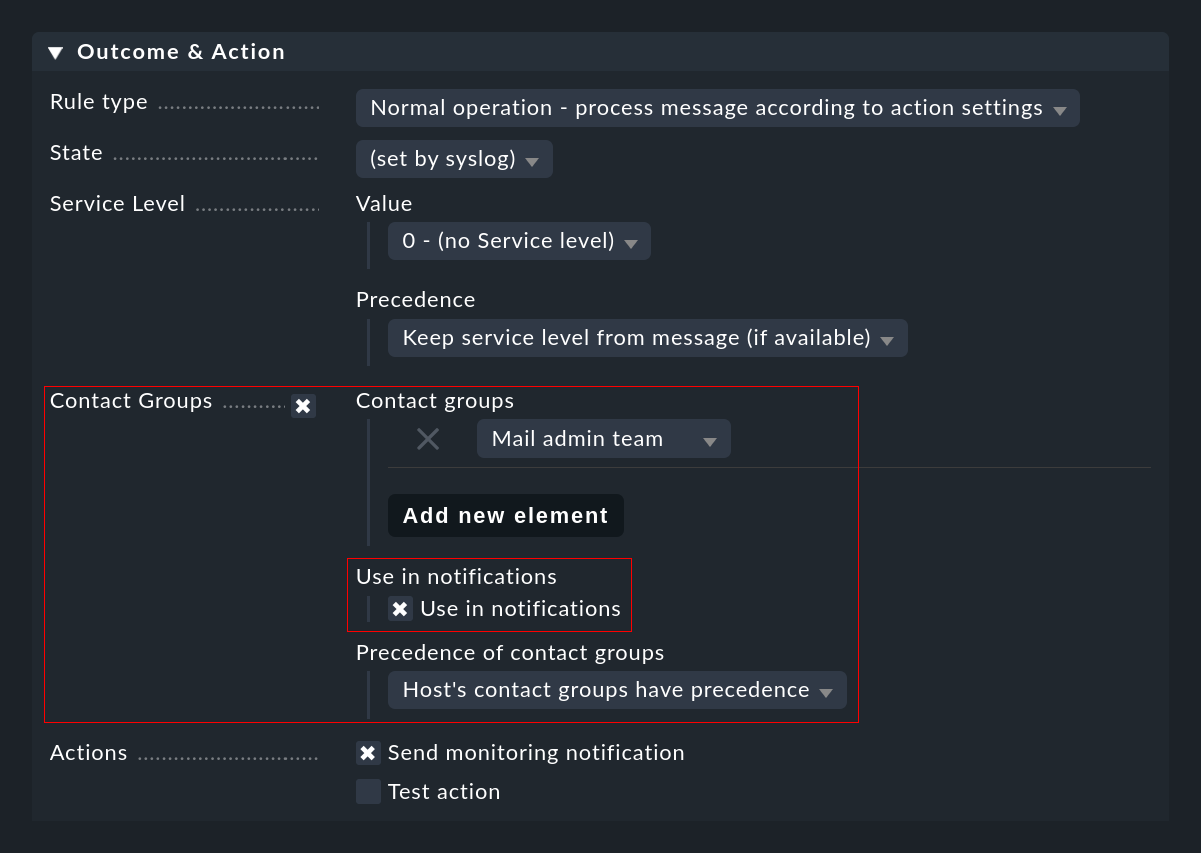
Conmutador global para notificaciones
Existe un conmutador central para notificaciones en el snap-in Master control. Esto también se aplica a las notificaciones reenviadas por la CE:

Al igual que con la asignación de host, la consulta del conmutador por parte de la CE requiere el acceso de Livestatus al núcleo local de monitorización. Una consulta realizada con éxito puede verse en el archivo de registro de la Consola de Eventos:
[1482142567.147669] Notifications are currently disabled. Skipped notification for event 44Tiempos de mantenimiento programados del host
La Consola de eventos es capaz de detectar host que se encuentran en un tiempo de mantenimiento programado y no envía notificaciones en tales situaciones. En el archivo de registro tendrá el siguiente aspecto:
[1482144021.310723] Host myserver123 is currently in scheduled downtime. Skipping notification of event 433.Por supuesto, esto también requiere que el host se encuentre correctamente en la monitorización activa. Si esto no se consigue, se asume que el host no está en tiempo de mantenimiento y, en cualquier caso, se generará una notificación.
Macros adicionales
Cuando escribas tus propios scripts de notificación, especialmente para las notificaciones procedentes de la Consola de eventos, dispondrás de una serie de variables adicionales que describen el evento original (a las que se accede como siempre con el prefijo NOTIFY_):
|
ID del evento. |
|
ID de la regla que creó el evento. |
|
Prioridad del syslog como un número desde |
|
Facilidad de syslog - también como un número. El rango de valores va de |
|
Fase del evento. Como sólo los eventos abiertos desencadenan acciones, debe ser |
|
El campo de comentario del evento. |
|
El campo Owner. |
|
El campo de comentario con la información de contacto específica del evento. |
|
El ID del proceso que envió el mensaje (para eventos syslog). |
|
Los grupos de concordancia de coincidencias en la regla. |
|
Los grupos de contacto opcionales definidos manualmente en la regla. |
6.4. Ejecutar acciones
Más arriba en Comandos ya has aprendido sobre la ejecución manual de acciones por parte del operador. Más emocionante es la ejecución automática de acciones, que puedes configurar con reglas CE en la sección Outcome & Action:
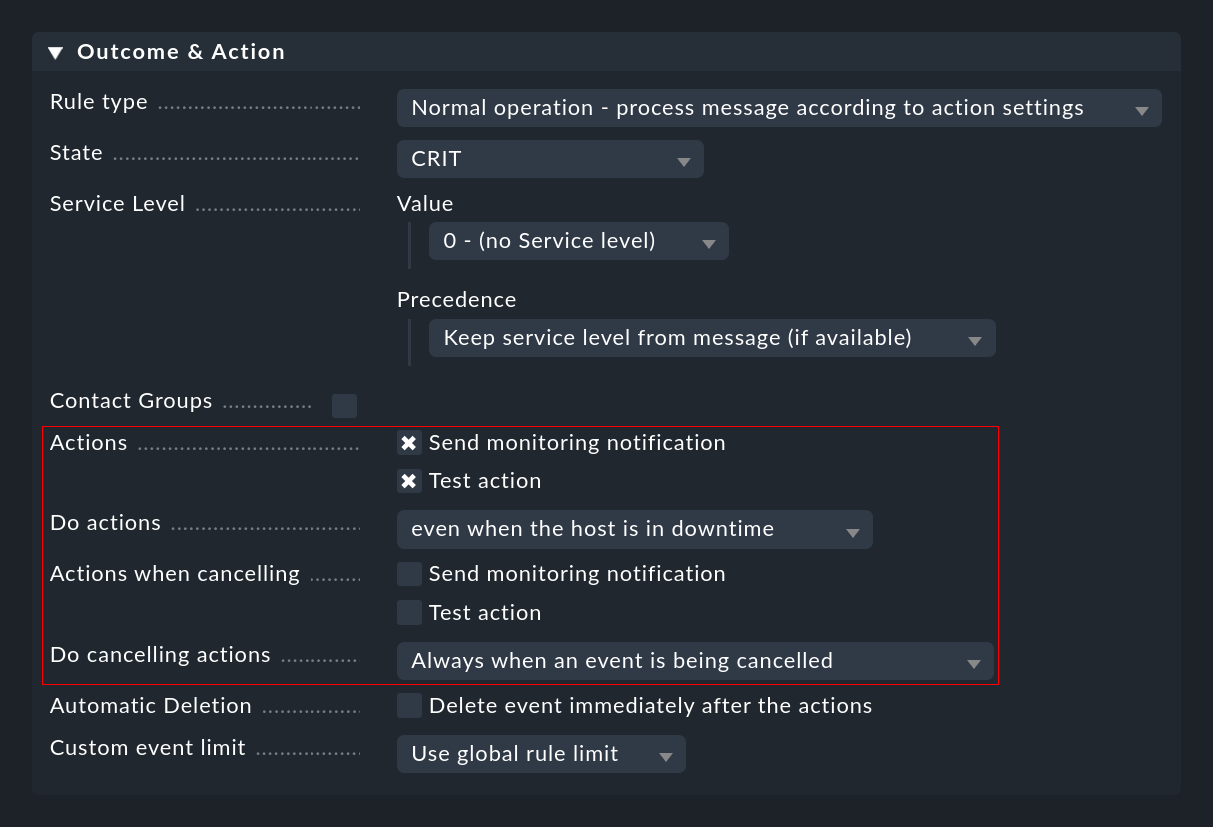
Aquí puedes seleccionar una o más acciones que se ejecutarán siempre que se abra o cancele un evento en función de la regla. Para esto último puedes utilizar la lista Do cancelling actions para especificar si la acción sólo debe ejecutarse si el evento cancelado ya ha llegado a la fase open. Al utilizar el recuento o el retraso puede ocurrir que se cancelen eventos que aún están en estado de espera y todavía no son visibles para el usuario .
La ejecución de las acciones se registra en el archivo de registro var/log/mkeventd.log:
[1481120419.712534] Executing command: ACTION;1;cmkadmin;test
[1481120419.718173] Exitcode: 0También se escriben en el archivo.
7. Traps SNMP
7.1. Configurar la recepción de traps SNMP
Como la Consola de eventos tiene su propio motor SNMP integrado, configurar la recepción de traps SNMP es muy sencillo. No necesitas snmptrapd del sistema operativo. Si ya lo tienes en ejecución, detenlo.
Como se describe en la sección sobre la configuración de la Consola de eventos, utiliza omd config para activar el receptor de trampas en este site:
Dado que en cada servidor el puerto UDP para las trampas sólo puede ser utilizado por un proceso, esto sólo puede hacerse en un site Checkmk por ordenador. Al iniciar el site, en la línea que contiene mkeventd puedes comprobar si se ha habilitado la recepción de trampas:
OMD[mysite]:~$ omd start
Creating temporary filesystem /omd/sites/mysite/tmp...OK
Starting mkeventd (builtin: snmptrap)...OK
Starting liveproxyd...OK
Starting mknotifyd...OK
Starting rrdcached...OK
Starting cmc...OK
Starting apache...OK
Starting dcd...OK
Starting redis...OK
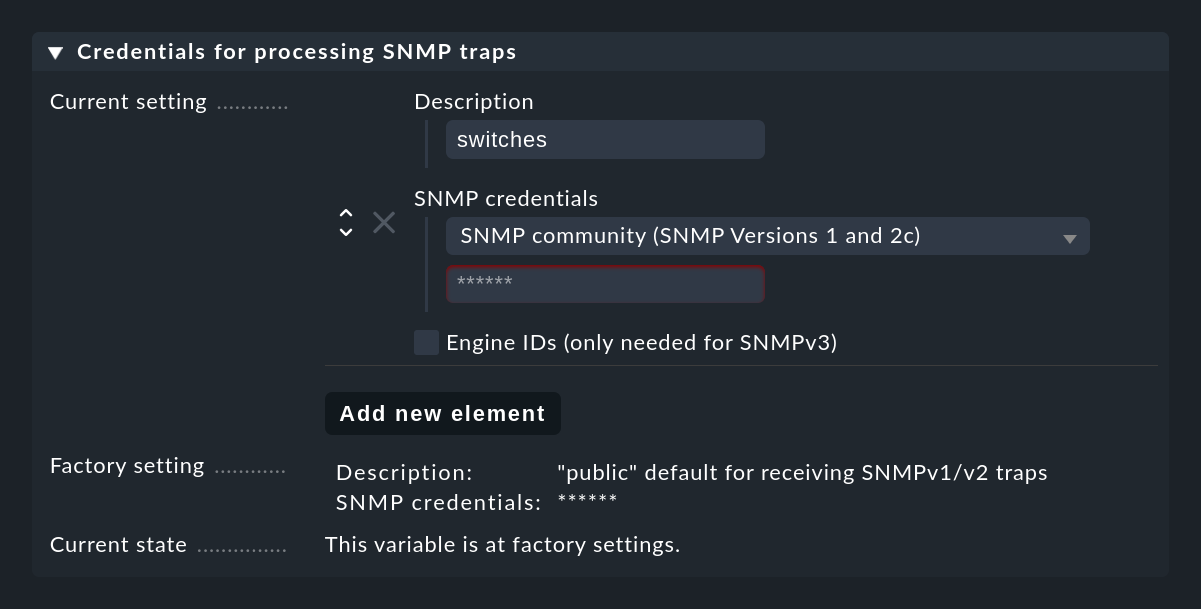
Initializing Crontab...OKPara que los traps SNMP funcionen, el emisor y el receptor deben estar de acuerdo en ciertas credentials. En el caso de SNMP v1 y v2c se trata de una simple contraseña, que se conoce como "Comunidad". Con la versión 3 necesitas algunas credenciales más. Estas credenciales se configuran en los ajustes de la Consola de eventos, en Credentials for processing SNMP traps. Puedes utilizar el botón Add new element para configurar varias credenciales diferentes que los dispositivos pueden utilizar como alternativas:
La parte mucho más compleja es ahora, por supuesto, especificar la dirección de destino de todos los dispositivos que se van a monitorizar y configurar aquí también las credenciales.
7.2. Probando
Lamentablemente, muy pocos dispositivos ofrecen capacidades de prueba significativas. Al menos, puedes probar fácilmente la recepción de trampas manualmente utilizando la propia Consola de eventos enviando una trampa de prueba, preferiblemente desde otro sistema Linux. Esto puede hacerse con el comando snmptrap. El siguiente ejemplo envía una trampa a 192.168.178.11. El nombre del host del remitente se especifica después de .1.3.6.1 y debe ser resoluble o especificarse como una dirección IP (aquí 192.168.178.30):
user@host:~$ snmptrap -v 1 -c public 192.168.178.11 .1.3.6.1 192.168.178.30 6 17 '' .1.3.6.1 s "Just kidding"Si has configurado Log level como Verbose logging en los ajustes, podrás ver la recepción y evaluación de las trampas en el archivo de registro de la CE:
[1482387549.481439] Trap received from 192.168.178.30:56772. Checking for acceptance now.
[1482387549.485096] Trap accepted from 192.168.178.30 (ContextEngineId "0x80004fb8054b6c617070666973636816893b00", ContextName "")
[1482387549.485136] 1.3.6.1.2.1.1.3.0 = 329887
[1482387549.485146] 1.3.6.1.6.3.1.1.4.1.0 = 1.3.6.1.0.17
[1482387549.485186] 1.3.6.1.6.3.18.1.3.0 = 192.168.178.30
[1482387549.485219] 1.3.6.1.6.3.18.1.4.0 =
[1482387549.485238] 1.3.6.1.6.3.1.1.4.3.0 = 1.3.6.1
[1482387549.485258] 1.3.6.1 = Just kiddingEn caso de credenciales incorrectas, sólo verás una única línea:
[1482387556.477364] Trap received from 192.168.178.30:56772. Checking for acceptance now.Y así es como se ve un evento generado por una trampa de este tipo:

7.3. Convertir números en texto: Traducir traps
SNMP es un protocolo binario y es muy parco en descripciones textuales de los mensajes. El tipo de trap se comunica internamente mediante una secuencia de números en los llamados OID, que se muestran como secuencias de números separadas por puntos (por ejemplo, 1.3.6.1.6.3.18.1.3.0).
Con la ayuda de los llamados archivos MIB, la Consola de eventos puede traducir estas secuencias numéricas en textos. Así, por ejemplo, 1.3.6.1.6.3.18.1.3.0 se convierte en el texto SNMPv2-MIB::sysUpTime.0.
La traducción de las trampas puede activarse en los ajustes de la Consola de eventos:

La trampa de prueba anterior genera ahora un evento ligeramente distinto:

Si has activado la opción Add OID descriptions, todo se vuelve mucho más detallado -y más confuso-. Sin embargo, ayuda a comprender mejor lo que hace realmente una trampa:

7.4. Cargar tus propias MIB
Lamentablemente, las ventajas del código abierto aún no se han extendido a los autores de archivos MIB, por lo que nosotros, desde el proyecto Checkmk, lamentablemente no podemos ofrecer archivos MIB específicos de un proveedor. Sólo viene preinstalada una pequeña colección de MIB básicas gratuitas que, por ejemplo, ofrece una traducción de sysUpTime.
Sin embargo, puedes añadir estos archivos a la Consola de eventos del módulo SNMP MIBs for trap translation a través de la entrada de menú Add one or multiple MIBs para cargar tus propios archivos MIB, como se ha hecho a continuación con algunos MIB de los Smart Switches de Netgear:
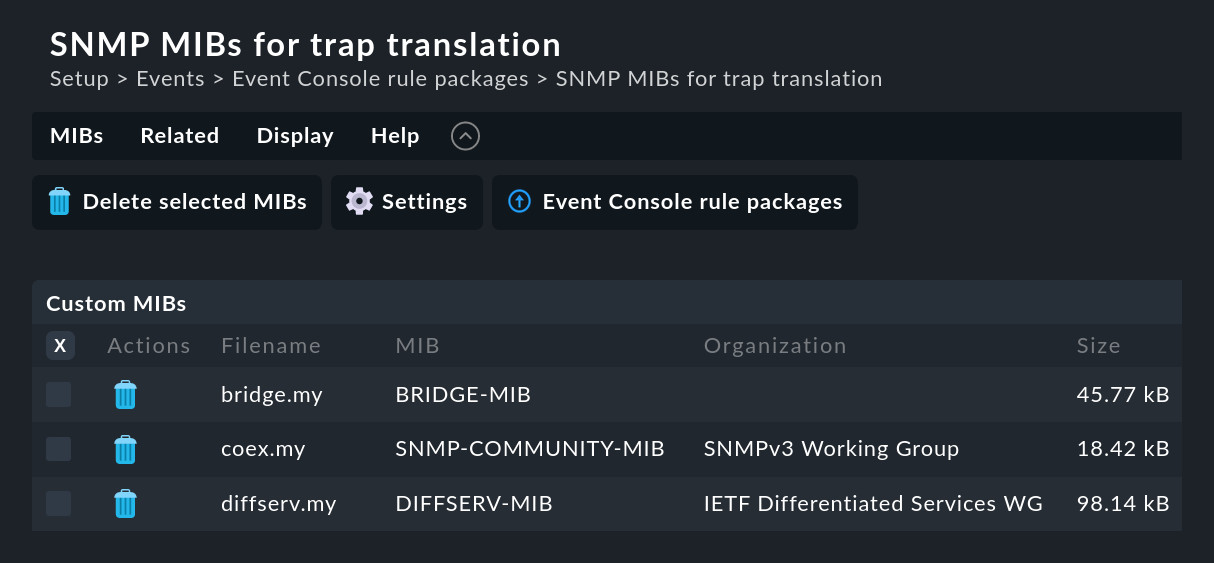
Notas sobre las MIBs:
En lugar de archivos sueltos, también puedes subir archivos ZIP con colecciones de MIB en una sola acción.
Las MIB tienen dependencias entre sí. Checkmk te mostrará las MIB que falten.
Las MIB cargadas también se utilizan en la línea de comando mediante
cmk --snmptranslate.
8. Monitorización de archivos de registro
El agente Checkmk puede analizar los archivos de registro mediante el plugin de logwatch. Este plugin proporciona, en primer lugar, su propia monitorización de los archivos de registro independientemente de la Consola de eventos, incluida la posibilidad de reconocer los mensajes directamente en la monitorización. También existe la posibilidad de transferir los mensajes encontrados por el plugin 1:1 a la Consola de eventos.
En el agente de Windows, la monitorización de archivos de registro está permanentemente integrada, en forma de un plugin para la evaluación de archivos de texto y otro para la evaluación de registros de eventos de Windows. El plugin mk_logwatch, codificado en Python, está disponible para Linux y Unix. Se puede acceder a los tres a través de Agent bakery para su instalación o configuración. Utiliza para ello los siguientes conjuntos de reglas:
Text logfiles (Linux, Solaris, Windows)
Finetune Windows Eventlog monitoring
La configuración precisa del Plugin Logwatch no es objeto de este artículo. Lo importante, sin embargo, es que sigas realizando el mejor prefiltrado posible de los mensajes en el propio Plugin Logwatch y no te limites a enviar el contenido completo de los archivos de texto a la Consola de eventos.
No confundas esto con la reclasificación posterior a través del conjunto de reglas Logfile patterns. Esto sólo puede cambiar el estado de los mensajes que ya han sido enviados por el agente. Sin embargo, si ya has configurado estas plantillas y quieres pasar simplemente de Logwatch a la Consola de eventos, puedes mantener los patrones. Para ello, las reglas de reenvío (Logwatch Event Console Forwarding) incluyen la opción Reclassify messages before forwarding them to the EC.
En este caso, todos los mensajes pasan por un total de tres secuencias de reglas: en el agente, a través de la reclasificación y ¡en la Consola de eventos!
Ahora cambia Logwatch de forma que los mensajes encontrados por los plugins ya no se controlen con el check plugin normal de Logwatch, sino que simplemente se reenvíen 1:1 a la Consola de eventos y se procesen allí. Esto se hace con el conjunto de reglas Logwatch Event Console Forwarding:
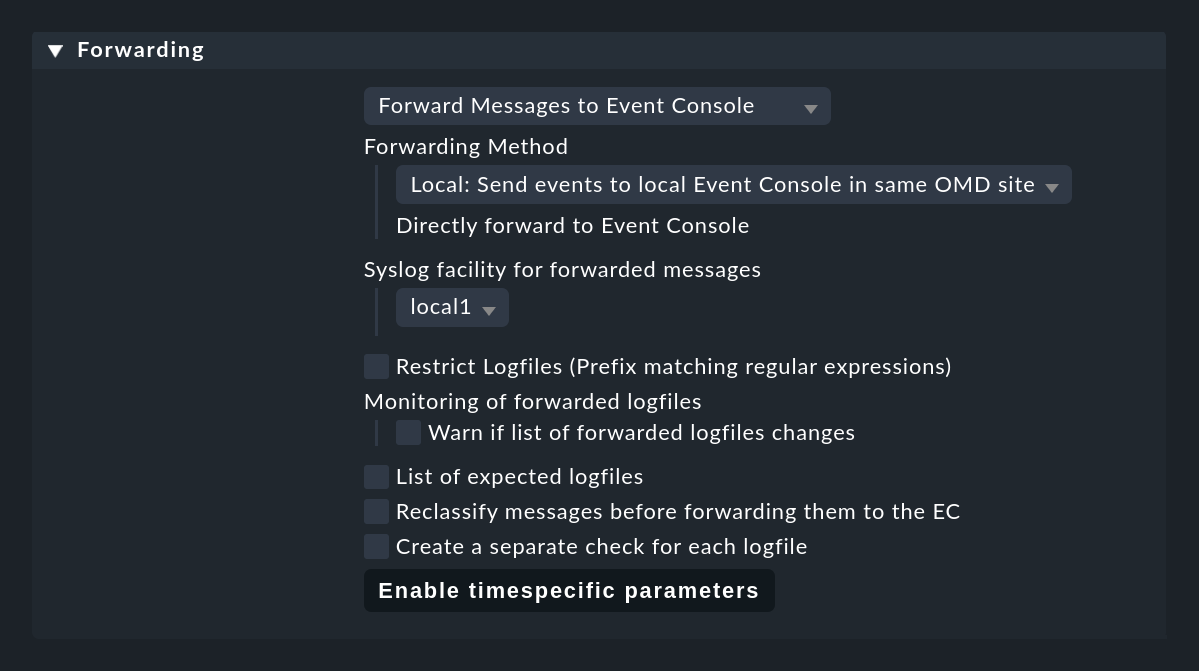
Algunas notas al respecto:
Si tienes un entorno distribuido en el que cada site no tiene su propia Consola de eventos, los sites remotos deben reenviar sus mensajes al site central a través de syslog. El valor predeterminado para esto es UDP, sin embargo, no es un protocolo seguro. Una solución mejor es utilizar syslog a través de TCP, pero tendrás que habilitarlo en el site central (omd config).
Cuando reenvíes, especifica cualquier Syslog facility. De este modo podrás reconocer fácilmente los mensajes reenviados en la CE. Muy adecuados para ello son local0 a local7.
Con List of expected logfiles puedes monitorizar la lista de archivos de registro esperados y recibir un aviso si ciertos archivos no se encuentran como se esperaba.
Importante: Guardar la regla por sí sola no consigue nada. Esta regla sólo se activa durante un descubrimiento de servicios. Sólo cuando vuelvas a ejecutarla, se eliminarán los servicios anteriores de Logwatch y, en su lugar, se creará un nuevo servicio llamado Log Forwarding para cada host.

Este check también te mostrará más adelante si se produce algún problema al reenviarlo a la Consola de eventos.
8.1. Nivel de servicio y prioridades de syslog
Como los archivos de registro reenviados a menudo carecen de clasificación syslog en función del formato utilizado, puedes definir la reclasificación en el conjunto de reglas Logwatch Event Console Forwarding en Log Forwarding. Además, en los conjuntos de reglas que definas como parte de Rule packs siempre es posible establecer el estado y los niveles de servicio individualmente.
9. Estado de los eventos en la monitorización activa
Si también quieres ver qué host de la monitorización activa tienen actualmente eventos problemáticos abiertos, puedes añadir un check activo para cada host que resuma el estado actual del evento del host. Para un host sin eventos abiertos, tendrá el siguiente aspecto:

Si sólo hay eventos en estado OK, el check muestra su número, pero permanece verde:

He aquí un ejemplo de un caso con eventos abiertos en estado CRIT:

Creas este check activo utilizando una regla del conjunto de reglas Check event state in Event Console. También puedes especificar si los eventos que ya han sido reconocidos deben seguir contribuyendo al estado o no:
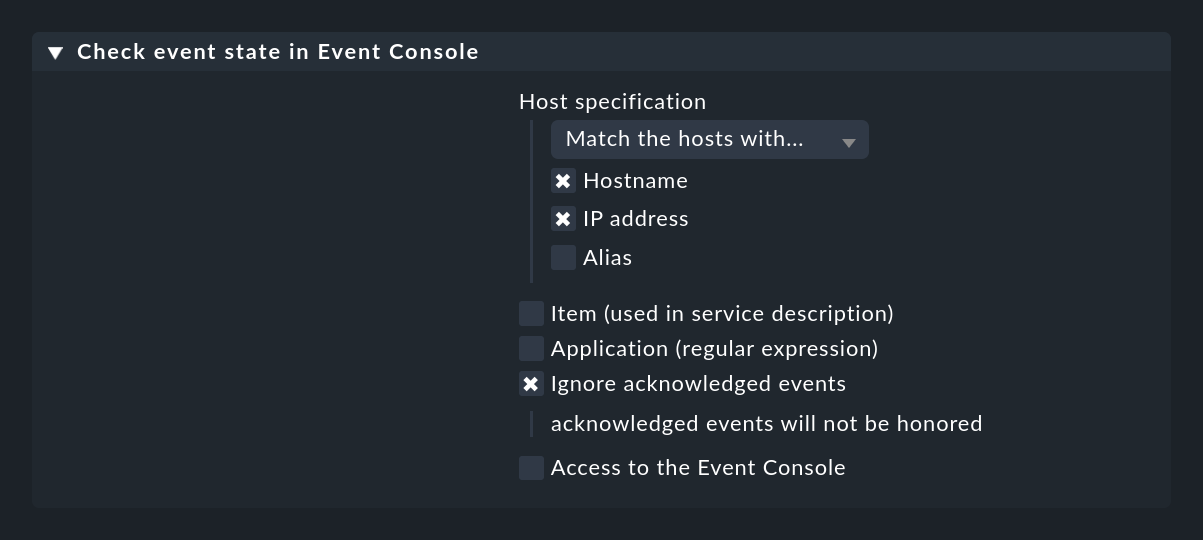
Con la opción Application (regular expression) puedes restringir el check a los eventos que tengan un texto específico en el campo aplicación. En este caso puede tener sentido tener más de un check de eventos en un host y separar los checks por aplicación. Para que se distingan por su nombre, también necesitas la opción Item (used in service description), que añade un texto que tú especifiques al nombre del servicio.
Si tu Consola de eventos no se está ejecutando en el mismo site Checkmk que el que también está monitorizando el host, necesitas configurar Access to Event Console para un acceso remoto vía TCP:
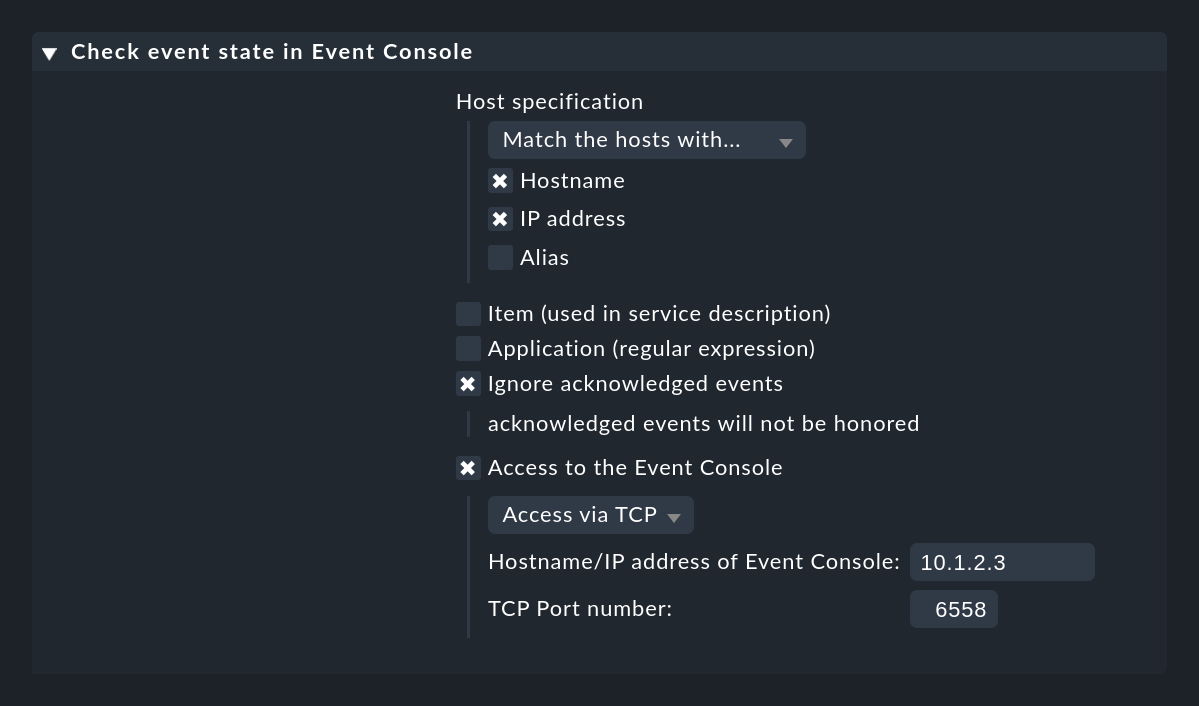
Para que esto funcione, la Consola de eventos debe permitir el acceso vía TCP. Puedes configurarlo en los ajustes de la Consola de eventos a la que se va a acceder:
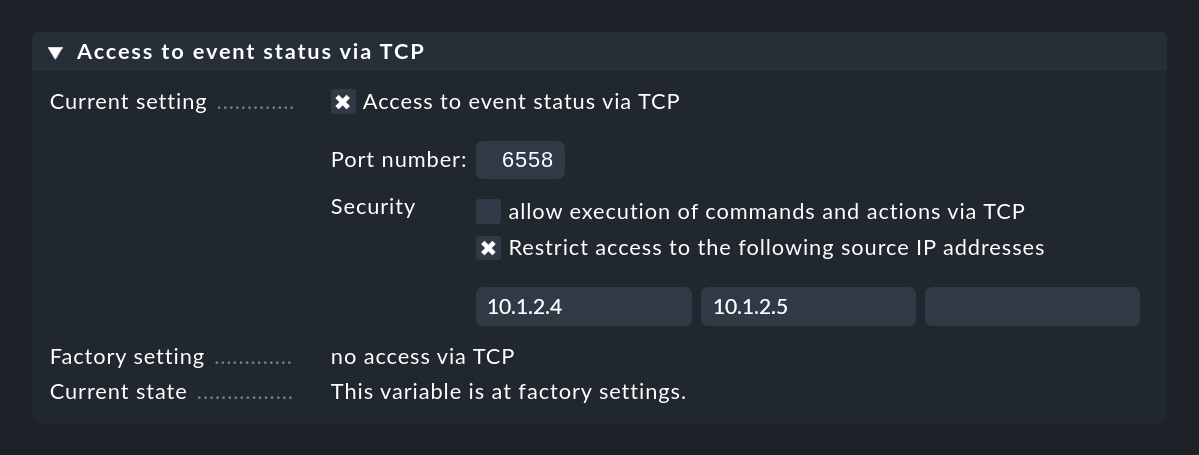
10. El archivo
10.1. Cómo funciona el archivo
La Consola de eventos mantiene un registro de todos los cambios que experimenta un evento. Este registro puede encontrarse de dos formas:
En la vista de tabla global Recent event history, que puedes encontrar en Monitor > Event Console.
En los detalles de un evento a través del elemento de menú Event Console Event > History of Event.
En la vista de tabla global hay un filtro que sólo muestra los eventos de las últimas 24 horas. Sin embargo, como es habitual, puedes personalizar los filtros.
La siguiente figura muestra el historial del evento 33, que ha sufrido un total de cuatro cambios. Primero se creó el evento (NEW), luego se cambió manualmente el estado de OK a WARN (CHANGESTATE), después se reconoció con un comentario añadido (UPDATE), y finalmente se archivó/eliminó el evento (DELETE):

El archivo contiene los siguientes tipos de acción que se muestran en la columna Action:
| Tipo de acción | Descripción |
|---|---|
|
El evento se creó de nuevo (debido a un mensaje recibido o a una regla que esperaba un mensaje que no apareció). |
|
El evento fue editado por el operador (cambio de comentario, información de contacto, Reconocimiento). |
|
El evento fue archivado. |
|
El evento se canceló automáticamente mediante un mensaje OK. |
|
El operador cambió el estado del evento. |
|
El evento se archivó automáticamente porque no se aplicó ninguna regla y Force message archiving estaba activado en la configuración global. |
|
El evento se archivó automáticamente porque mientras estaba en la fase counting, se eliminó su regla asociada. |
|
El evento se movió de counting a open porque se alcanzó el número de mensajes configurado. |
|
El evento se archivó automáticamente porque no se alcanzó el número de mensajes requerido en counting. |
|
El evento se archivó automáticamente porque mientras estaba en la fase counting, su regla asociada se cambió a "no contar". |
|
El evento se abrió porque expiró el retraso configurado en la regla. |
|
El evento se archivó automáticamente porque su tiempo de vida configurado había expirado. |
|
Se envió un correo electrónico. |
|
Se ejecutó una acción automática (script). |
|
El evento se archivó automáticamente inmediatamente después de abrirse, porque así estaba configurado en su regla correspondiente. |
10.2. Ubicación del archivo
Como ya se ha mencionado, el archivo de la Consola de eventos no se ha diseñado como un archivo syslog completo. Para que la implementación y, especialmente, la administración sean lo más sencillas posible, se ha omitido un backend de base de datos. En su lugar, el archivo se escribe en archivos de texto sencillos. Cada entrada consta de una línea de texto, que contiene columnas separadas por pestañas. Puedes encontrar los archivos en ~/var/mkeventd/history:
OMD[mysite]:~$ ll var/mkeventd/history/
total 1328
-rw-rw-r-- 1 stable stable 131 Dec 4 23:59 1480633200.log
-rw-rw-r-- 1 stable stable 1123368 Dec 5 23:39 1480892400.log
-rw-rw-r-- 1 stable stable 219812 Dec 6 09:46 1480978800.logPor defecto, se inicia automáticamente un nuevo archivo cada día. En los ajustes de la Consola de eventos puedes personalizar la rotación del archivo. El ajuste Event history logfile rotation te permite cambiar a una rotación semanal.
Los nombres de los archivos se ajustan a la marca de tiempo Unix de la hora de creación del archivo (segundos desde el 1/1/1970 UTC).
Los archivos se conservan durante 365 días, a menos que lo cambies en el ajuste Event history lifetime. Además, los archivos también son registrados por la gestión central de espacio en disco de Checkmk, que se puede configurar en los Ajustes globales en Site management. En este caso, se aplica el límite de tiempo más corto establecido en cada caso. La gestión global tiene la ventaja de que, si el espacio libre en disco se vuelve marginal, borra automáticamente los datos históricos de Checkmk de forma coherente, empezando por los más antiguos.
Si tienes problemas de espacio, también puedes eliminar manualmente los archivos del directorio o intercambiarlos. No pongas archivos comprimidos ni de ningún otro tipo en este directorio.
10.3. Archivo automático
A pesar de las limitaciones de los ficheros de texto, teóricamente es posible archivar un gran número de mensajes en la Consola de eventos. La escritura en los ficheros de texto del archivo es muy eficaz, pero a costa de una búsqueda posterior menos eficiente. Puesto que los ficheros sólo tienen como índice el periodo de solicitud, para cualquier solicitud hay que leer y buscar completamente todos los ficheros relevantes.
Normalmente, la CE sólo escribirá en el archivo aquellos mensajes para los que realmente se haya abierto un evento, pero puedes hacerlo de dos formas distintas para ampliarlo a todos los eventos:
Creas una regla que coincida con todos los eventos (posteriores) y en Outcome & actions activas la opción Delete event immediately after the actions.
Activas el interruptor Force message archiving en la configuración de la Consola de eventos.
Esto último garantiza que los mensajes que no estén sujetos a ninguna regla se escriban, no obstante, en el archivo (tipo de acción ARCHIVED).
11. Rendimiento y puesta a punto
11.1. 11.1. Proceso de mensajes
Incluso en tiempos en que los servidores tienen 64 núcleos y 2 TB de memoria principal, el rendimiento del software sigue siendo importante. Especialmente en el proceso de eventos, los mensajes entrantes pueden perderse en situaciones extremas.
La razón es que ninguno de los protocolos utilizados (Syslog, Trap SNMP, etc.) prevé el control de flujo. Si miles de host envían simultáneamente mensajes cada segundo, el receptor no tiene ninguna posibilidad de ralentizarlos.
Por eso, en entornos algo más grandes, es importante que vigiles los tiempos de proceso de los mensajes, lo que depende del número de reglas que hayas definido y de cómo estén estructuradas.
Medir el rendimiento
Para medir tu rendimiento existe un snap-in independiente para la barra lateral con el nombre Event Console Performance. Puedes incluirlo de la forma habitual con :
Los valores que se muestran aquí son promedios de aproximadamente el último minuto. Una tormenta de eventos que dure sólo unos segundos no puede leerse aquí directamente, pero las cifras se han suavizado un poco y, por tanto, son más fáciles de leer.
Para probar el máximo rendimiento, puedes generar artificialmente una tormenta de mensajes sin clasificar (¡por favor, sólo en el sistema de pruebas!), por ejemplo, en un bucle de shell escribiendo continuamente el contenido de un archivo de texto en la tubería de eventos.
OMD[mysite]:~$ while true ; do cat /etc/services > tmp/run/mkeventd/events ; doneLas lecturas más importantes del snap-in tienen el siguiente significado:
| Valor | Significado |
|---|---|
Received messages |
Número de mensajes recibidos actualmente por segundo. |
Rule tries |
Número de reglas que se intentan. Esto proporciona información valiosa sobre la eficacia de la secuencia de reglas, especialmente junto con el siguiente parámetro. |
Rule hits |
Número de reglas por segundo que están golpeando actualmente. También puede tratarse de reglas que descartan mensajes o que simplemente cuentan. Por lo tanto, no todas las reglas golpeadas dan lugar a un evento. |
Rule hit ratio |
La relación entre Rule tries y Rule hits. En otras palabras: Cuántas reglas tiene que probar la CE antes de que una (finalmente) surta efecto. En el ejemplo de la captura de pantalla, la tasa es alarmantemente pequeña. |
Created events |
Número de nuevos eventos creados por segundo. Dado que la Consola de eventos sólo debe mostrar problemas relevantes (comparables a los problemas de host y servicio de la monitorización), ¡el número |
Processing time per message |
Aquí puedes leer cuánto tiempo se tardó en procesar un mensaje. Atención: En general, no es la inversa de Received messages. Porque faltan los tiempos en los que la Consola de eventos no tuvo nada que hacer, simplemente porque no entraron mensajes. Aquí se mide realmente el tiempo real puro transcurrido entre la llegada de un mensaje y la finalización del proceso. Puedes ver aproximadamente cuántos mensajes puede gestionar la CE en un tiempo determinado. Ten en cuenta también que no se trata de tiempo de CPU, sino de tiempo real. En un sistema con suficientes CPUs libres, estos tiempos son aproximadamente los mismos. Pero en cuanto el sistema esté tan cargado que no todos los procesos obtengan siempre una CPU, el tiempo real puede llegar a ser mucho mayor. |
Consejos de ajuste
Puedes ver cuántos mensajes puede procesar por segundo la Consola de eventos en Processing time per message. Este tiempo suele estar relacionado con el número de reglas que hay que probar antes de procesar un mensaje. Aquí tienes varias opciones de optimización:
Las reglas que excluyen muchos mensajes deben colocarse, en la medida de lo posible, al principio de la secuencia de reglas.
Trabaja con paquetes de reglas para agrupar conjuntos de reglas relacionadas. La primera regla de cada paquete debe abandonar el paquete inmediatamente si no se cumple la condición base común.
Además, hay una optimización en la CE basada en la prioridad y la facilidad del syslog. Para cada combinación de prioridad y facilidad, se crea internamente una secuencia de reglas independiente en la que sólo se incluyen las reglas que son relevantes para los mensajes de esta combinación.
Cada regla que contenga una condición sobre la prioridad, la facilidad o, preferiblemente, ambas, no se incluirá en todas estas cadenas de reglas, sino, de forma óptima, sólo en una. Esto significa que no es necesario comprobar la regla para mensajes con una clasificación syslog diferente.
Tras un reinicio, en ~/var/log/mkeventd.log verás un resumen de las cadenas de reglas optimizadas:
[8488808306.233330] kern : emerg(112) alert(67) crit(67) err(67) warning(67) notice(67) info(67) debug(67)
[8488808306.233343] user : emerg(112) alert(67) crit(67) err(67) warning(67) notice(67) info(67) debug(67)
[8488808306.233355] mail : emerg(112) alert(67) crit(67) err(67) warning(67) notice(67) info(67) debug(67)
[8488808306.233367] daemon : emerg(120) alert(89) crit(89) err(89) warning(89) notice(89) info(89) debug(89)
[8488808306.233378] auth : emerg(112) alert(67) crit(67) err(67) warning(67) notice(67) info(67) debug(67)
[8488808306.233389] syslog : emerg(112) alert(67) crit(67) err(67) warning(67) notice(67) info(67) debug(67)
[8488808306.233408] lpr : emerg(112) alert(67) crit(67) err(67) warning(67) notice(67) info(67) debug(67)
[8488808306.233482] news : emerg(112) alert(67) crit(67) err(67) warning(67) notice(67) info(67) debug(67)
[8488808306.233424] uucp : emerg(112) alert(67) crit(67) err(67) warning(67) notice(67) info(67) debug(67)
[8488808306.233435] cron : emerg(112) alert(67) crit(67) err(67) warning(67) notice(67) info(67) debug(67)
[8488808306.233446] authpriv : emerg(112) alert(67) crit(67) err(67) warning(67) notice(67) info(67) debug(67)
[8488808306.233457] ftp : emerg(112) alert(67) crit(67) err(67) warning(67) notice(67) info(67) debug(67)
[8488808306.233469] (unused 12) : emerg(112) alert(67) crit(67) err(67) warning(67) notice(67) info(67) debug(67)
[8488808306.233480] (unused 13) : emerg(112) alert(67) crit(67) err(67) warning(67) notice(67) info(67) debug(67)
[8488808306.233498] (unused 13) : emerg(112) alert(67) crit(67) err(67) warning(67) notice(67) info(67) debug(67)
[8488808306.233502] (unused 14) : emerg(112) alert(67) crit(67) err(67) warning(67) notice(67) info(67) debug(67)
[8488808306.233589] local0 : emerg(112) alert(67) crit(67) err(67) warning(67) notice(67) info(67) debug(67)
[8488808306.233538] local1 : emerg(112) alert(67) crit(67) err(67) warning(67) notice(67) info(67) debug(67)
[8488808306.233542] local2 : emerg(112) alert(67) crit(67) err(67) warning(67) notice(67) info(67) debug(67)
[8488808306.233552] local3 : emerg(112) alert(67) crit(67) err(67) warning(67) notice(67) info(67) debug(67)
[8488808306.233563] local4 : emerg(112) alert(67) crit(67) err(67) warning(67) notice(67) info(67) debug(67)
[8488808306.233574] local5 : emerg(112) alert(67) crit(67) err(67) warning(67) notice(67) info(67) debug(67)
[8488808306.233585] local6 : emerg(112) alert(67) crit(67) err(67) warning(67) notice(67) info(67) debug(67)
[8488808306.233595] local7 : emerg(112) alert(67) crit(67) err(67) warning(67) notice(67) info(67) debug(67)
[8488808306.233654] snmptrap : emerg(112) alert(67) crit(67) err(67) warning(67) notice(67) info(67) debug(67)En el ejemplo anterior puedes ver que, en cualquier caso, hay 67 reglas que deben comprobarse. Para los mensajes de la instalación daemon son relevantes 89 reglas, sólo para la combinación daemon/emerg deben comprobarse 120 reglas. Cada regla que recibe una condición sobre la prioridad o la instalación reduce aún más el número de 67.
Por supuesto, ¡sólo puedes establecer estas condiciones si estás seguro de que las cumplen los mensajes correspondientes!
11.2. El recuento de eventos actuales
El número de eventos actuales también puede afectar al rendimiento de la CE, es decir, cuando se descontrola gravemente. Como ya se ha dicho, la CE no debe considerarse como un sustituto de un archivo syslog, sino sólo para mostrar los "problemas actuales". La Consola de eventos puede gestionar ciertamente varios miles de problemas, pero ése no es su verdadero propósito.
En cuanto el número de eventos actuales supera unos 5.000, el rendimiento empieza a deteriorarse notablemente. Por un lado, esto se nota en la GUI, que reacciona más lentamente a las peticiones. Por otro, el proceso también se vuelve más lento, ya que en algunas situaciones hay que comparar los mensajes con todos los eventos actuales. Los requisitos de memoria también pueden llegar a ser problemáticos.
Por razones de rendimiento, la Consola de eventos siempre guarda todos los eventos actuales en la RAM. Éstos se escriben en el archivo ~/var/mkeventd/status una vez por minuto (ajustable) y al finalizar el procesamiento. Si éste se hace muy grande (por ejemplo, más de 50 megabytes), este proceso también se hace cada vez más lento. Puedes comprobar rápidamente el tamaño actual con ll. (alias de ls -alF):
OMD[mysite]:~$ ll -h var/mkeventd/status
-rw-r--r-- 1 mysite mysite 386K Dez 14 13:46 var/mkeventd/statusSi tienes demasiados eventos actuales debido a una regla torpe (por ejemplo, una que coincide en todo), no es razonablemente posible una eliminación manual a través de la GUI. En este caso, simplemente eliminar el archivo de estado ayudará:
OMD[mysite]:~$ omd stop mkeventd
Stopping mkeventd...killing 17436......OK
OMD[mysite]:~$ rm var/mkeventd/status
OMD[mysite]:~$ omd start mkeventd
Starting mkeventd (builtin: syslog-udp)...OKAtención: Por supuesto, se perderán todos los eventos actuales, así como el contador almacenado y otros estados. En particular, los nuevos eventos volverán a empezar con el ID 1.
Protección automática contra desbordamiento
La Consola de eventos tiene una protección automática contra el "desbordamiento", que limita el número de eventos actuales por host, por regla y globalmente. No sólo se cuentan los eventos abiertos, sino también los eventos en otras fases, como delayed o counting. Los eventos archivados no se cuentan.
Esto te protegerá en situaciones en las que, debido a un problema sistemático en tu red, se estén inundando miles de eventos críticos y la Consola de eventos se "apagaría". Por un lado, esto evita una degradación del rendimiento de la Consola de eventos, que tendría que retener demasiados eventos en su memoria principal. Por otro lado, la Vista general para el operador está (en cierto modo) protegida y los eventos que no forman parte de la tormenta permanecen visibles.
Una vez alcanzado el límite, se producirá una de las siguientes acciones:
Se detiene la creación de nuevos eventos (para este host, regla o globalmente).
Lo mismo, pero además se crea un "evento de desbordamiento".
Lo mismo, pero además se notifica a los contactos apropiados.
Como alternativa a las tres variantes anteriores, también puedes hacer que se elimine el evento más antiguo para dejar espacio al nuevo.
Los límites, así como el efecto asociado al alcanzarlos, se definen en la configuración de la Consola de eventos con Limit amount of current events. La siguiente figura muestra la configuración por defecto:
Si has habilitado un valor con …create overflow event, cuando se alcance el límite, se creará un único evento artificial, informando al operador de la situación de error:
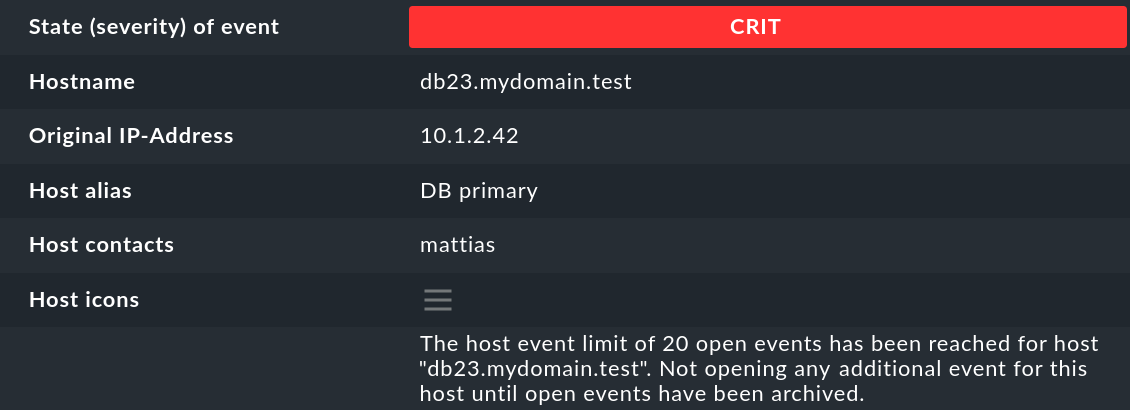
Si además has habilitado un valor con …notify contacts, se notificará a los contactos adecuados mediante la notificación de Checkmk. Esa notificación pasará por las reglas de notificación de Checkmk. Estas reglas no tienen por qué seguir la selección de contactos de la Consola de eventos, pero pueden modificarla. La siguiente tabla muestra qué contactos se seleccionan si has configurado Notify all contacts of the notified host or service (que es la configuración por defecto):
| Límite | Selección de contactos |
|---|---|
por host |
Los contactos del host, que se determinan del mismo modo que para la notificación de eventos a través de Checkmk. |
por regla |
Deja vacío el campo nombre del host. Si se definen grupos de contacto en la regla, se seleccionarán; de lo contrario, se aplicarán los contactos de reserva. |
Global |
Los contactos alternativos. |
11.3. Archivo demasiado grande
Como se muestra arriba, la Consola de eventos tiene un archivo de todos los eventos y sus pasos de proceso, que se almacena en archivos de texto para facilitar su implementación y administración.
Los archivos de texto son difíciles de superar en cuanto a rendimiento al escribir datos, por ejemplo, utilizando bases de datos, sólo con un enorme esfuerzo de optimización. Esto se debe, entre otros factores, a la optimización de este tipo de acceso por parte de Linux y a la completa jerarquía de memoria de los discos y las SAN. Sin embargo, esto es a costa de los accesos de lectura. Como los archivos de texto no tienen índice, es necesaria una lectura completa al buscar en los archivos.
En su forma más simple, la Consola de eventos utiliza los nombres de los archivos de registro como índice para el tiempo de los eventos. Cuanto más limites el periodo de consulta, más rápida será la búsqueda.
Sin embargo, es muy importante que tu archivo no se haga demasiado grande. Si utilizas la Consola de eventos sólo para procesar mensajes de error reales, esto no puede ocurrir realmente. Si intentas utilizar la CE como sustituto de un archivo syslog real, esto puede dar lugar a archivos muy grandes.
Si te encuentras con una situación en la que tu archivo se ha hecho demasiado grande, puedes simplemente borrar los archivos más antiguos en ~/var/mkeventd/history/. Además, en Event history lifetime puedes limitar generalmente la vida útil de los datos para que su borrado sea el predeterminado en el futuro. Por defecto se almacenan 365 días. Tal vez puedas arreglártelas con bastante menos.
11.4. Medir el rendimiento a lo largo del tiempo
Checkmk inicia automáticamente un servicio para cada site de la Consola de eventos, que registra sus datos de rendimiento en curvas y también te avisa si se producen desbordamientos.
Siempre que hayas instalado un agente Linux en el servidor de monitorización, el check se encontrará automáticamente y se configurará como de costumbre:

El check viene con muchos tipos de mediciones interesantes, por ejemplo, el número de mensajes entrantes por cada periodo de tiempo y cuántos de ellos se descartaron:
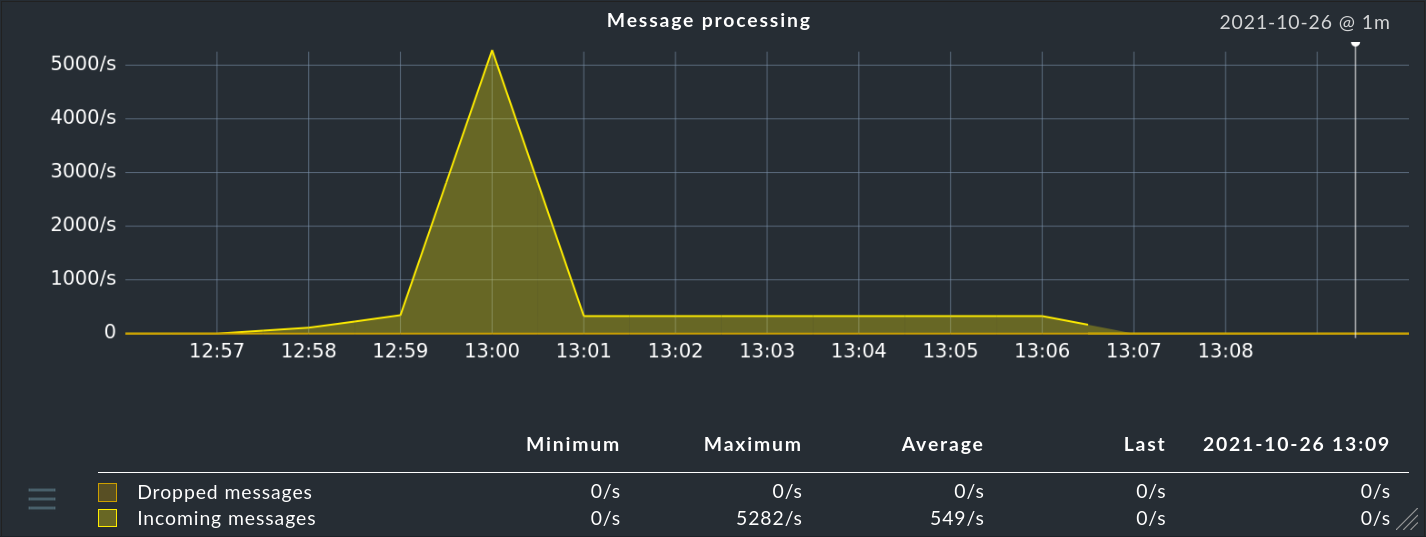
La eficacia de tu secuencia de reglas se representa mediante una comparación entre las reglas comprobadas y las que funcionaron:
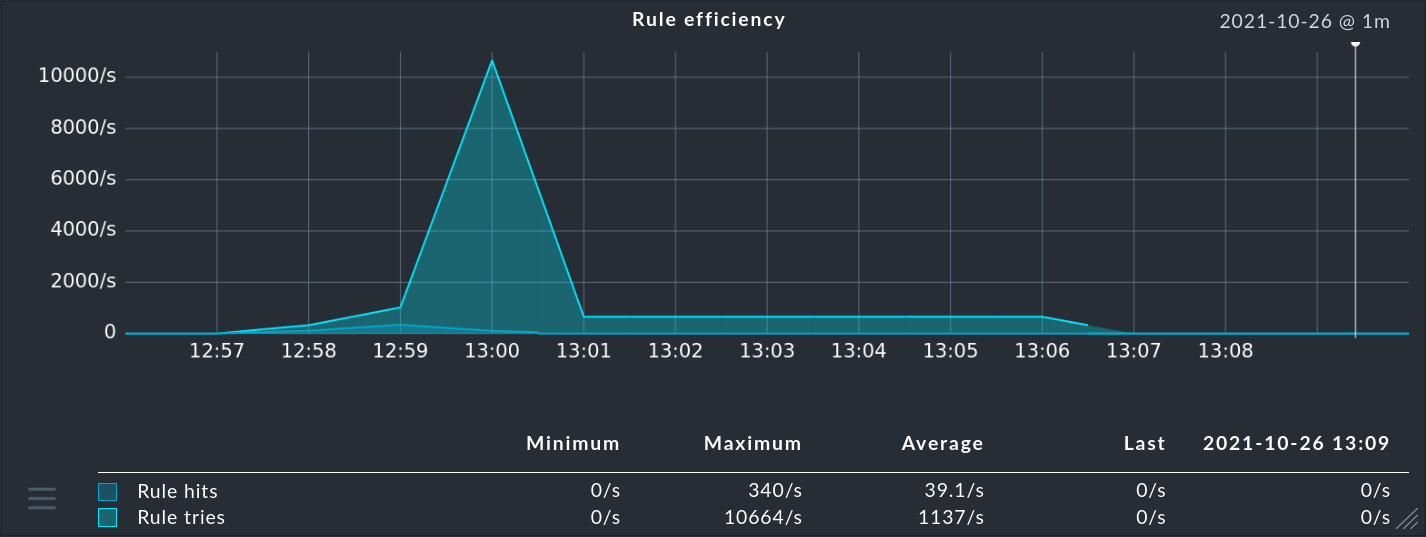
Este gráfico muestra el tiempo medio que se tarda en procesar un mensaje:
También hay bastantes gráficos adicionales.
12. Monitorización distribuida
Cómo utilizar la Consola de eventos en una instalación con varios sitios Checkmk, consulta el artículo sobre monitorización distribuida.
13. La interfaz de estado
La Consola de eventos a través del socket Unix ~/tmp/run/mkeventd/status proporciona tanto acceso al estado interno como la posibilidad de ejecutar comandos. El protocolo utilizado aquí es un subconjunto de Livestatus muy restringido. A esta interfaz accede el núcleo de monitorización y pasa los datos a la GUI para proporcionar también una monitorización distribuida para la Consola de eventos.
Las siguientes restricciones se aplican al Livestatus simplificado de la Consola de eventos:
Las únicas cabeceras permitidas son
Filter:yOutputFormat:.Por lo tanto, no es posible KeepAlive y sólo se puede realizar una solicitud por conexión.
Están disponibles las siguientes tablas:
|
Lista de todos los eventos actuales. |
|
Acceso al archivo. Una consulta en esta tabla accederá a los ficheros de texto del archivo. Asegúrate de utilizar un filtro sobre la hora de la entrada para evitar el acceso completo a todos los archivos. |
|
Valores de estado y rendimiento de la CE. Esta tabla siempre tiene exactamente una fila. |
Se pueden escribir comandos en el socket utilizando unixcat con una sintaxis muy sencilla:
OMD[mysite]:~$ echo "COMMAND RELOAD" | unixcat tmp/run/mkeventd/statusEstán disponibles los siguientes comandos:
|
Archiva un evento. Argumentos: ID del evento y abreviatura del usuario. |
|
Recarga la configuración. |
|
Sale de la Consola de eventos. |
|
Reabre el archivo de registro. Este comando es necesario para la rotación del archivo de registro. |
|
Borra todos los eventos actuales y archivados. |
|
Inicia una actualización inmediata del archivo |
|
Restablece los contadores de aciertos de regla (corresponde al elemento de menú Event Console > Reset counters de la GUI de configuración). |
|
Ejecuta una actualización a partir de un evento. Los argumentos son, por orden, identificador del evento, abreviatura del usuario, Reconocimiento (0/1), comentario e información de contacto. |
|
Cambia los estados OK / WARN / CRIT / UNKNOWN de un evento. Los argumentos son el ID del evento, la abreviatura del usuario y el dígito de estado ( |
|
Ejecuta una acción definida por el usuario sobre un evento. Los argumentos son el ID del evento, la abreviatura del usuario y el ID de la acción. El ID especial |
14. Archivos y directorios
| Ruta del archivo | Descripción |
|---|---|
|
Directorio de trabajo del daemon de eventos. |
|
Estado actual completo de la Consola de eventos. Incluye principalmente todos los eventos abiertos en ese momento (y los que están en fase de transición, como counting, etc.). En caso de una configuración errónea que provoque muchos eventos abiertos, este archivo puede llegar a ser enorme y reducir drásticamente el rendimiento de la CE. En tal situación, puedes detener el servicio |
|
Ubicación del archivo. |
|
Archivo de registro de la Consola de eventos. |
|
La configuración global de la Consola de eventos en sintaxis Python. |
|
Todos tus paquetes de reglas y reglas configurados en sintaxis de Python. |
|
Una tubería con nombre en la que puedes escribir mensajes directamente con |
|
Un socket Unix que realiza la misma función que la tubería, pero permite que varias aplicaciones escriban en él simultáneamente. Para escribir en él, necesitas el comando |
|
El ID del proceso actual del daemon de eventos mientras se está ejecutando. |
|
Un socket Unix que permite consultar el estado actual y enviar comandos. Las peticiones GUI van primero al núcleo de monitorización, que accede a este socket. |
|
Archivos MIB cargados por ti para la traducción de Trap SNMP. |