1. Monitorización de la utilización individual de la CPU en todos los núcleos
Checkmk configura automáticamente un servicio, tanto en Linux como en Windows, que monitoriza el uso medio de la CPU en el transcurso del último minuto. Por un lado, esto tiene sentido, pero por otro no reconoce algunos errores, por ejemplo, que un único proceso se desboque y utilice continuamente una CPU al 100 %. En un sistema con 16 CPUs, sin embargo, una CPU sólo contribuye en un 6,25 % al rendimiento general, por lo que incluso en el caso extremo descrito, se registra una utilización total de sólo el 6,25 %, lo que no activa una notificación.
Por esta razón, Checkmk ofrece la opción (para Linux y para Windows) de monitorizar individualmente todas las CPU disponibles y determinar si alguno de sus núcleos está constantemente ocupado durante un periodo de tiempo más largo. Configurar este check ha resultado ser una buena idea.
Para configurar este check para tus servidores Windows, necesitas para el servicio CPU utilization el conjunto de reglas CPU utilization for simple devices, que puedes encontrar en Service monitoring rules. Este conjunto de reglas es responsable de la monitorización de todas las CPU, pero también tiene esta opción: Levels over an extended time period on a single core CPU utilization.
Crea una regla nueva y activa en ella sólo esta opción:
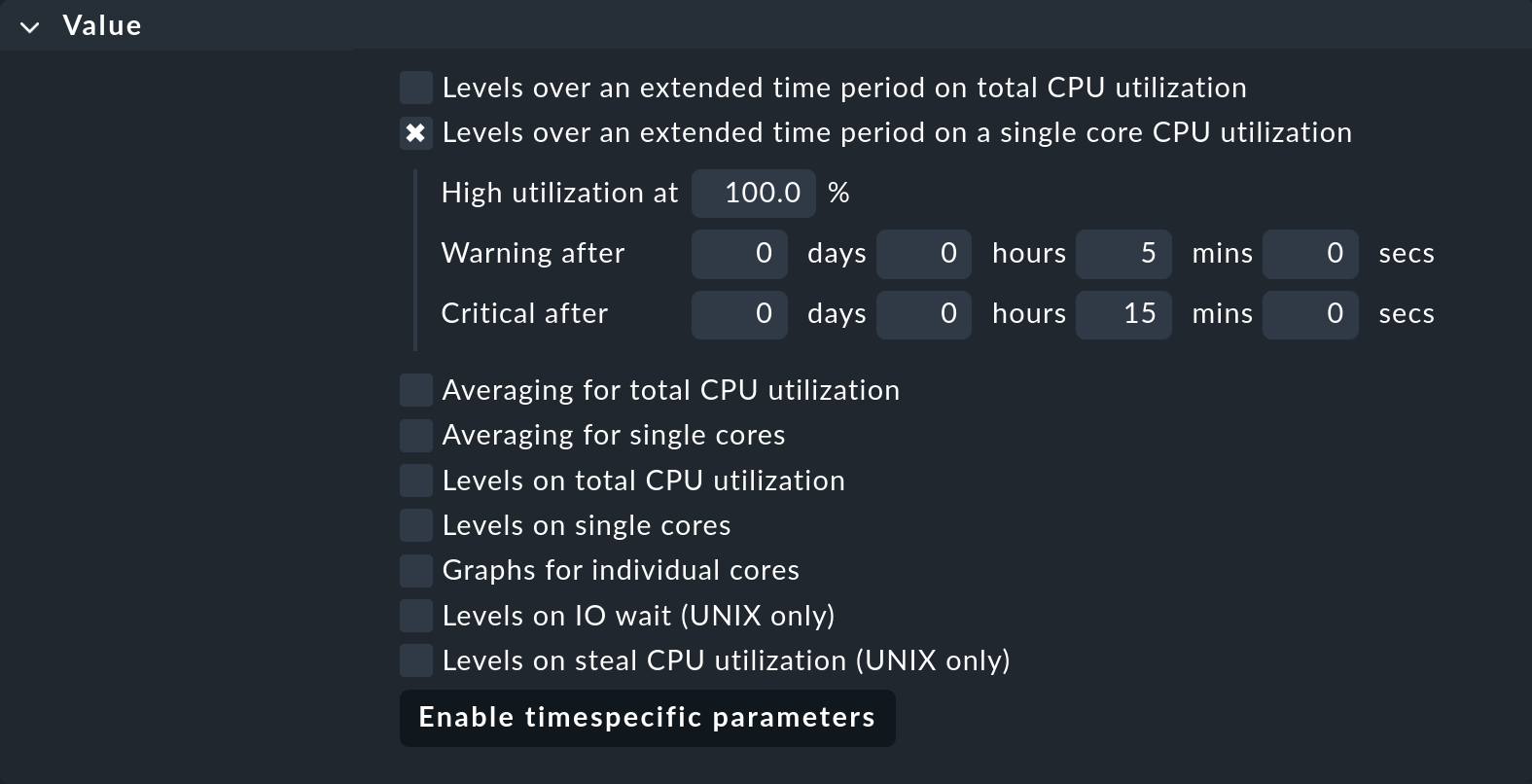
Define la condición para que sólo se aplique a los servidores Windows, por ejemplo utilizando una carpeta o tag del host adecuados. Esta regla no afectará a otras reglas del mismo conjunto de reglas si establecen otras opciones, como los umbrales para la utilización total de la CPU.
Para los servidores Linux, esto es responsabilidad del conjunto de reglas CPU utilization on Linux/UNIX, en el que puedes establecer la misma opción.
This is a machine translation based on the English version of the article. It might or might not have already been subject to text preparation. If you find errors, please file a GitHub issue that states the paragraph that has to be improved. |
2. Monitorización de los servicios de Windows
Por defecto, Checkmk no monitoriza ningún servicio de tus servidores Windows. ¿Por qué no? Sencillamente porque Checkmk no sabe qué servicios son importantes para ti.
Si no quieres tomarte la molestia de determinar manualmente para cada servidor qué servicios son importantes, también puedes configurar un check que simplemente compruebe si todos los servicios con el tipo de inicio "automático" se están ejecutando. Además, se te puede informar de si se están ejecutando servicios que se iniciaron manualmente -desordenados, por así decirlo-. Éstos dejarán de ejecutarse tras un reinicio, lo que podría ser un problema.
Para ponerlo en práctica, primero necesitas el conjunto de reglas Windows Services, que puedes encontrar en Service monitoring rules, utilizando la función de búsqueda Setup > General > Rule search, por ejemplo. La opción crucial de la nueva regla es Services states. Actívala y añade tres nuevos elementos para los estados de los servicios:
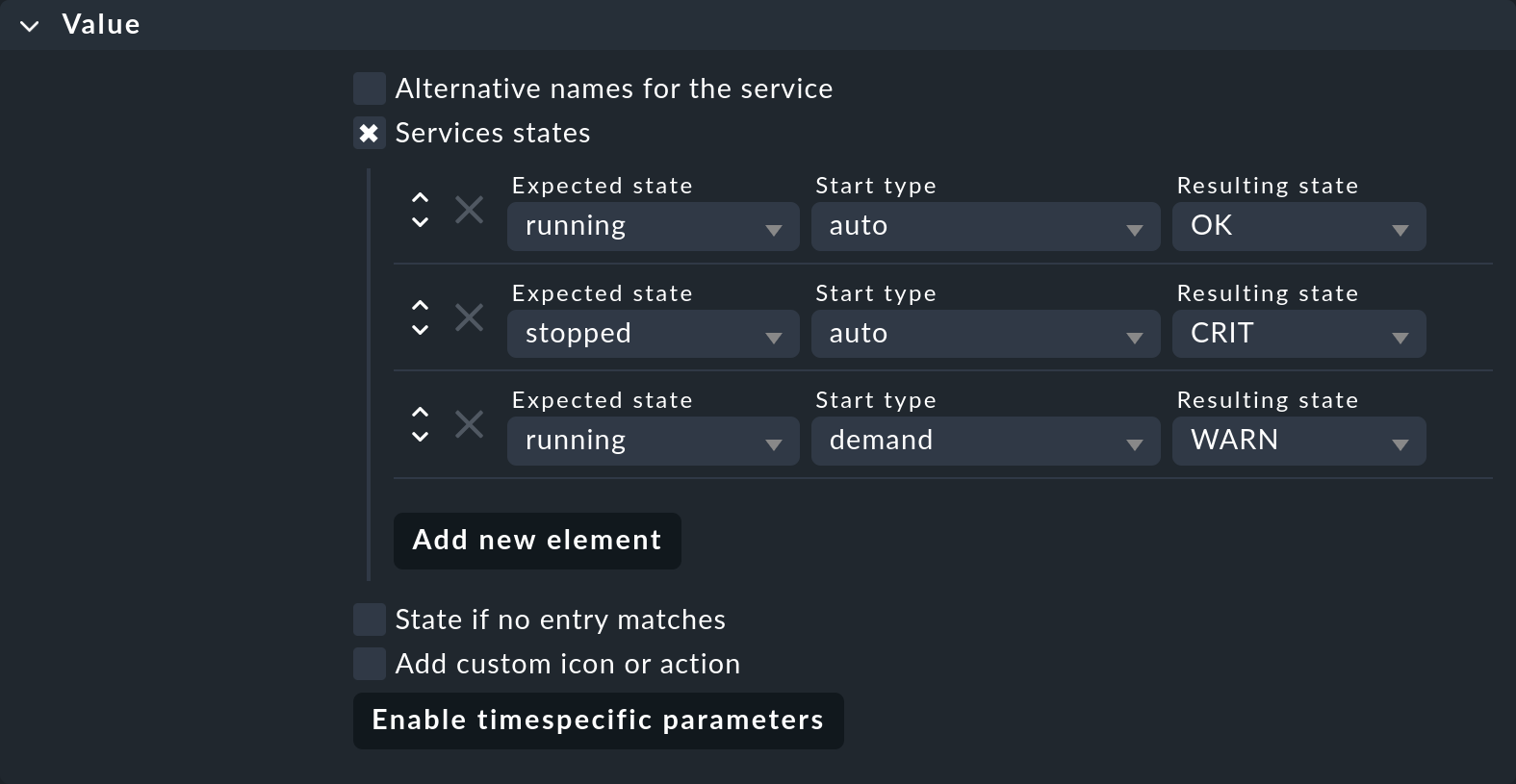
Esto te permite implementar la siguiente monitorización:
Un servicio con el tipo de inicio auto, y que está en ejecución, se considera OK.
Un servicio con el tipo de inicio auto que no se está ejecutando se considera CRIT.
Un servicio con el tipo de inicio demand, y que está en ejecución, se considera WARN.
Sin embargo, esta regla sólo se aplica a los servicios que se están monitorizando realmente. Por tanto, necesitamos un segundo paso y una segunda regla, esta vez del conjunto de reglas Windows service discovery, con la que defines qué servicios de Windows debe monitorizar Checkmk como servicios.
Cuando crees esta regla, puedes introducir primero la expresión regular .* en la opción Services (Regular Expressions), que se aplicará a todos los servicios.
Después de guardar la regla, pasa a la configuración de servicios de un host adecuado, donde encontrarás un gran número de servicios nuevos, uno por cada servicio de Windows.
Para limitar el número de servicios monitorizados a los que te interesen, vuelve a la regla y afina los términos de búsqueda según sea necesario, distinguiendo entre mayúsculas y minúsculas. He aquí un ejemplo de selección personalizada de servicios:
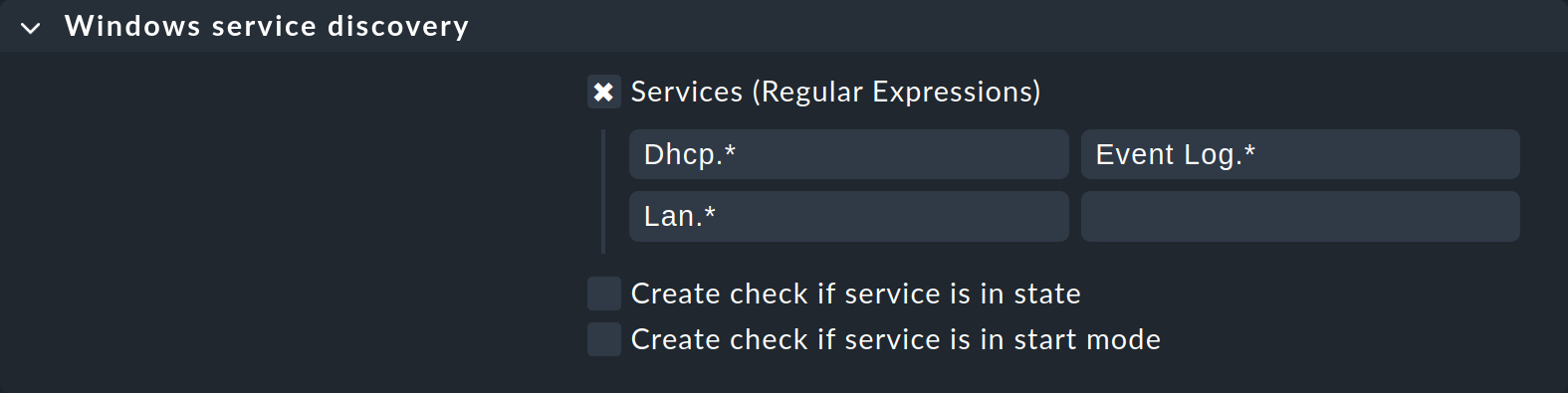
Si previamente has incluido servicios que no coinciden con las nuevas expresiones de búsqueda ahora en la monitorización, aparecerán como desaparecidos en la configuración de servicios. Con el botón Rescan puedes limpiar el aire y hacer que se vuelva a crear toda la lista de servicios.
3. Monitorización de las conexiones a internet
El acceso de tu organización a internet es, sin duda, muy importante para todos. La monitorización de la conexión a "internet" es un poco difícil de implementar, ya que implica a miles de millones de ordenadores que podrían (con suerte) ser accesibles... o no. No obstante, puedes establecer un sistema de monitorización eficaz, basado en el siguiente plan de construcción:
Selecciona varios ordenadores en internet que normalmente deberían ser accesibles mediante un comando
pingy anota sus direcciones IP.Crea un nuevo host en Checkmk, por ejemplo con el nombre
internety configúralo como sigue: En IPv4 address introduce una de las direcciones IP anotadas. En Additional IPv4 addresses introduce las direcciones IP restantes. En Monitoring agents, habilita Checkmk agent / API integrations y selecciona No API integrations, no Checkmk agent allí. Guarda el host sin descubrimiento de servicios.Crea una nueva regla a partir del conjunto de reglas Check hosts with PING (ICMP Echo Request) que sólo se aplique al nuevo host
internet(por ejemplo, a través de la condición Explicit hosts, o de un tag del host coincidente). Configura la regla como sigue: Habilita Service Description e introduceInternet connection. Habilita Alternate address to ping y selecciona Ping all IPv4 addresses allí. Habilita Number of positive responses required for OK state e introduce1.Crea otra regla que también sólo se aplique al host
internet, esta vez a partir del conjunto de reglas Host Check Command. Allí, selecciona como Host Check Command la opción Use the status of the service… e introduceInternet connectioncomo nombre -el mismo nombre que elegiste como nombre del servicio en el paso anterior.
Si ahora activas los cambios, obtendrás el nuevo host internet con el servicio único Internet connection en la monitorización.
Si al menos uno de los destinos ping es alcanzable, el host tendrá el estado UP y el servicio tendrá el estado OK. Al mismo tiempo, el servicio te proporciona datos de rendimiento para el tiempo medio de ida y vuelta de los paquetes(promedio de ida y vuelta) y la pérdida de paquetes para cada una de las direcciones IP especificadas. Esto te dará una indicación de la calidad de tu conexión a lo largo del tiempo:

El cuarto y último paso del procedimiento anterior es necesario para que el host no entre en estado DOWN si la primera dirección IP no es alcanzable a través de |
4. Monitorización de servicios HTTP/HTTPS
Supongamos que quieres comprobar la accesibilidad de un sitio web o servicio web. El agente Checkmk no ofrece una solución en este caso, ya que no muestra esta información y, además, puede que ni siquiera tengas la posibilidad de instalar un agente en el servidor.
La solución es el llamado check activo, que no se realiza mediante un agente, sino contactando directamente con un protocolo de red en el host de destino, en este caso HTTP(S).
El procedimiento es el siguiente
Crea un nuevo host para el servidor web, por ejemplo para
checkmk.com. En Monitoring agents, activa la opción Checkmk agent / API integrations y selecciona No API integrations, no Checkmk agent. Guarda el host sin descubrimiento de servicios.Crea una nueva regla a partir del conjunto de reglas Check HTTP web service, que sólo se aplique al nuevo host (por ejemplo, mediante la condición Explicit hosts).
En la caja Value encontrarás numerosas opciones para realizar el check. El principio es el siguiente: define un nuevo endpoint para cada URL a comprobar. Se crea un servicio para cada endpoint. A continuación, define el nombre del servicio (por ejemplo,
Basic webserver health) y, si es necesario, un prefijo (HTTPoHTTPS) para el endpoint.-
También puedes hacer ajustes adicionales en la caja Value que hay debajo de los endpoints. Por ejemplo, puedes utilizar Response time para establecer el servicio en WARN o CRIT si el tiempo de respuesta es demasiado lento y utilizar Certificate validity para comprobar el periodo de validez del certificado. Con Search for strings puedes comprobar si un determinado texto aparece en la respuesta, es decir, en la página entregada. Esto te permite comprobar una parte relevante del contenido para que un simple mensaje de error del servidor no se interprete como una respuesta positiva.
Puedes definir estos ajustes de forma idéntica para todos los endpoints o individualmente para cada endpoint.

Puedes encontrar información muy útil sobre todas las opciones disponibles en la ayuda en línea.
Guarda la regla y activa los cambios.
Ahora tendrás un nuevo host con los servicios que hayas especificado que check el acceso a través de HTTP(S):

Por supuesto, también puedes realizar este check en un host que ya esté siendo monitorizado con Checkmk a través de un agente. En este caso, no es necesario crear el host y sólo tendrás que crear la regla para el host. |
5. Personalizar "mágicamente" los umbrales del sistema de archivos
Encontrar buenos umbrales para la monitorización de sistemas de archivos puede ser tedioso. Al fin y al cabo, un umbral del 90 % es demasiado bajo para un disco duro muy grande y quizá ya sea demasiado marginal para uno pequeño. Ya hemos presentado la posibilidad de establecer umbrales en función del tamaño de un sistema de archivos en el capítulo sobre el ajuste preciso de la monitorización, y hemos insinuado entonces que Checkmk ofrece otra opción aún más inteligente: el factor mágico.
El factor mágico se configura así:
En el conjunto de reglas Filesystems (used space and growth), crea una sola regla.
En esta regla, activa Levels for used/free space y deja los umbrales por defecto en 80 % o 90 % sin modificar.
Además, activa Magic factor (automatic level adaptation for large filesystems) y confirma el valor por defecto de 0,80.
Establece también Reference size for magic factor en 20 GB. Como 20 GB es el valor por defecto, tendrá efecto incluso sin que actives explícitamente la opción.
El resultado tendrá este aspecto:
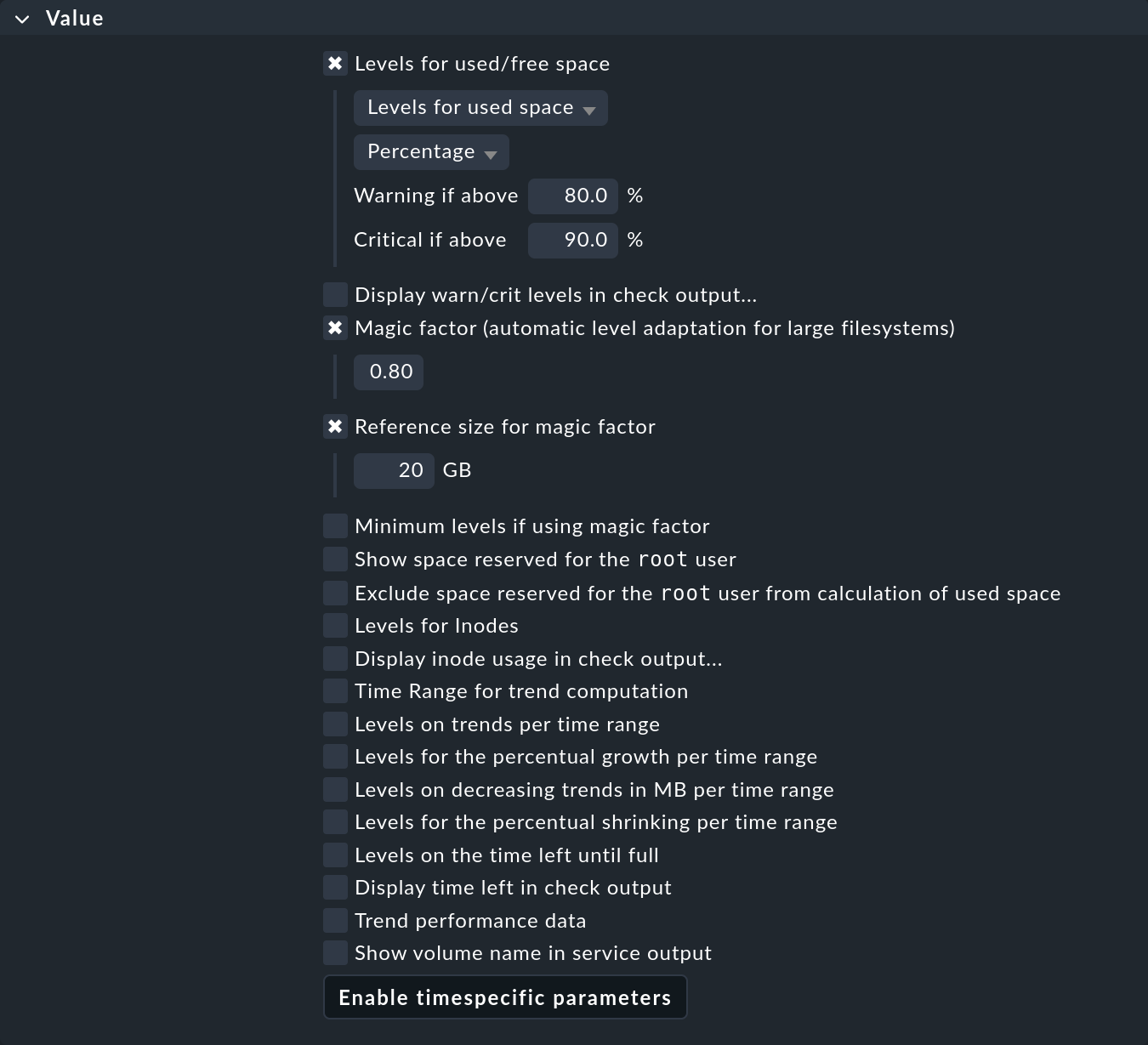
Si ahora guardas esta regla y activas el cambio, tendrás valores umbrales que varían automáticamente en función del tamaño del sistema de archivos:
Los sistemas de archivos que tengan un tamaño exacto de 20 GB reciben los umbrales 80 % / 90 %.
Los sistemas de archivos de menos de 20 GB tienen umbrales más bajos.
Los sistemas de archivos de más de 20 GB tienen umbrales más altos.
El factor (aquí 0,80) determina cuánto se ajustan los valores. Un factor de 1,0 no cambia nada, y todos los sistemas de archivos obtienen los mismos valores. Los valores por defecto para Checkmk utilizados en este capítulo han demostrado su eficacia en la práctica con muchísimas instalaciones.
Puedes ver exactamente qué umbrales se aplican a cada servicio en su Summary:
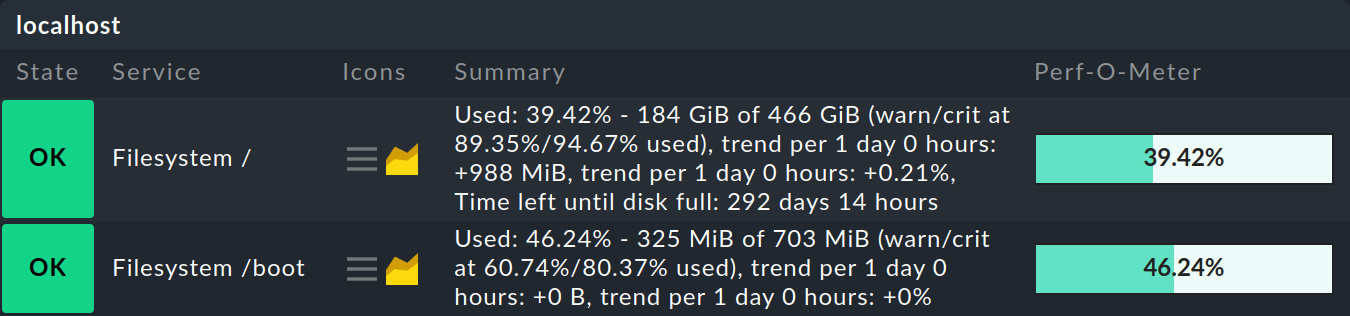
La siguiente tabla muestra algunos ejemplos del efecto del factor mágico con un valor de referencia de 20 GB / 80 %:
| Factor mágico | 5 GB | 10 GB | 20 GB | 50 GB | 100 GB | 300 GB | 800 GB |
|---|---|---|---|---|---|---|---|
1.0 |
80 % |
80 % |
80 % |
80 % |
80 % |
80 % |
80 % |
0.9 |
77 % |
79 % |
80 % |
82 % |
83 % |
85 % |
86 % |
0.8 |
74 % |
77 % |
80 % |
83 % |
86 % |
88 % |
90 % |
0.7 |
70 % |
75 % |
80 % |
85 % |
88 % |
91 % |
93 % |
0.6 |
65 % |
74 % |
80 % |
86 % |
89 % |
93 % |
95 % |
0.5 |
60 % |
72 % |
80 % |
87 % |
91 % |
95 % |
97 % |
Con este capítulo sobre el factor mágico, concluimos nuestra guía para principiantes. Esperamos que hayas podido establecer una base sólida para tu sistema Checkmk, con o sin magia. Para casi todos los temas que hemos tratado en esta guía para principiantes, encontrarás información más detallada en otros artículos del Manual de usuario.
¡Te deseamos mucho éxito con Checkmk en el futuro!