This is a machine translation based on the English version of the article. It might or might not have already been subject to text preparation. If you find errors, please file a GitHub issue that states the paragraph that has to be improved. |
1. Introducción
Probablemente no todo el mundo entienda igual el término "monitorización distribuida". De hecho, la monitorización siempre está distribuida en varios ordenadores, a menos que el sistema de monitorización sólo se monitorice a sí mismo, lo que no sería muy útil.
Por tanto, en este Manual de usuario siempre nos referimos a monitorización distribuida cuando el sistema de monitorización en su conjunto está formado por más de un único site Checkmk. Hay varias buenas razones para dividir la monitorización en varios sites:
Rendimiento: La carga del procesador debería o debe repartirse entre varias máquinas.
Organización: Varios grupos diferentes deben poder administrar sus propios sites de forma independiente.
Disponibilidad: La monitorización en una ubicación debe funcionar independientemente de otras ubicaciones.
Seguridad: Los flujos de datos entre dos dominios de seguridad deben controlarse por separado y con precisión (DMZ, etc.)
Red: Las ubicaciones que sólo tienen conexiones de banda estrecha o poco fiables no se pueden monitorizar a distancia de forma fiable.
Checkmk admite varios procedimientos para implantar una monitorización distribuida. Checkmk controla algunos de ellos, ya que en gran medida es compatible con Nagios o se basa en él (si se ha instalado Nagios como núcleo). Esto incluye, por ejemplo, el procedimiento con mod_gearman. Comparado con el propio sistema de Checkmk, no ofrece ventajas y además es más engorroso de implantar. Por estas razones no lo recomendamos.
El procedimiento preferido por Checkmk se basa en Livestatus y en un entorno de configuración distribuido. Para situaciones con redes muy separadas, o incluso con una estricta transferencia unidireccional de datos de la periferia al centro, existe un método que utiliza Livedump o, respectivamente, CMCDump. Ambos métodos pueden combinarse.
2. Monitorización distribuida con Livestatus
2.1. Principios básicos
Estado central
Livestatus es una interfaz integrada en el núcleo de monitorizaciónque permite a otros programas externos consultar datos de estado y ejecutar comandos. Livestatus puede estar disponible a través de la red para que pueda acceder a él un site remoto de Checkmk. La interfaz de usuario de Checkmk utiliza Livestatus para combinar todos los sites conectados en una visión general. De este modo, parece un "gran" sistema de monitorización.
El siguiente diagrama muestra esquemáticamente la estructura de una monitorización con Livestatus distribuida en tres emplazamientos. El site central Checkmk se encuentra en el site central de proceso. Desde aquí se controlan directamente los sistemas centrales. Además, están el Site remoto 1 y el Site remoto 2, que se encuentran en otras redes y son controlados por sus sistemas locales:
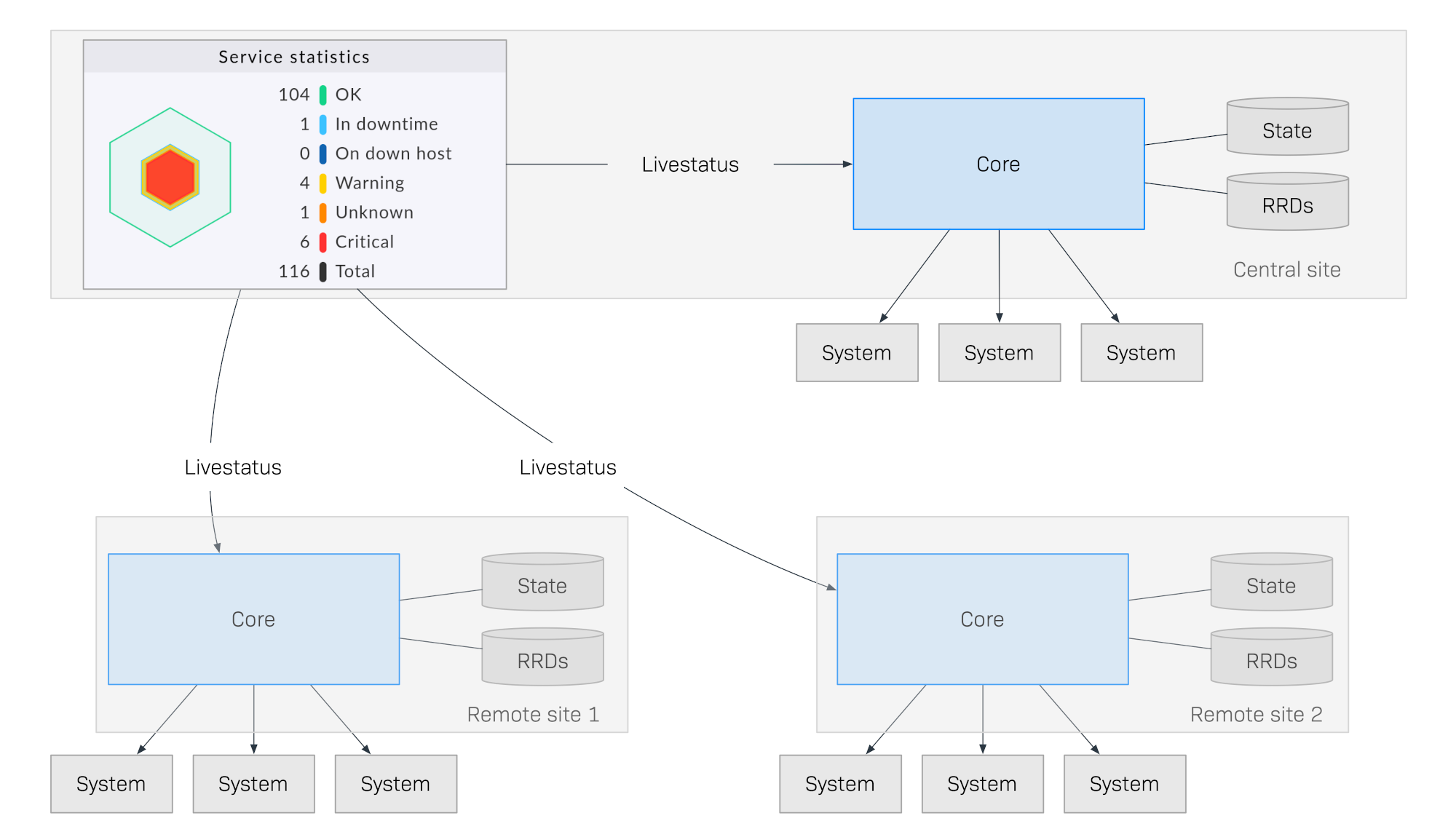
Lo que hace especial a este método es que el estado de monitorización de los sites remotos no se envía continuamente al site central. La GUI sólo recupera los datos en directo de los sitios remotos cuando los necesita un usuario del centro de control. A continuación, los datos se recopilan en una vista centralizada. Por tanto, no hay almacenamiento central de datos, ¡lo que ofrece enormes ventajas para la ampliación!
He aquí algunas de las ventajas de este método:
Escalabilidad: La monitorización en sí no genera ningún tráfico de red entre el site central y el remoto. De este modo se pueden conectar cientos de ubicaciones, o más.
Fiabilidad: Si falla una conexión de red a un site remoto, la monitorización local sigue funcionando con normalidad. No hay "agujero" en el registro de datos ni tampoco "atasco" de datos. La notificación local seguirá funcionando.
Simplicidad: Los sites pueden incorporarse o eliminarse muy fácilmente.
Flexibilidad: Los sites remotos siguen siendo autónomos y pueden utilizarse para el operador en su ubicación respectiva. Esto es especialmente interesante si nunca se permite que la "ubicación" acceda al resto de la monitorización.
Configuración centralizada
En un sistema distribuido utilizando Livestatus como el descrito anteriormente, es muy posible que los sites individuales puedan ser mantenidos independientemente por diferentes equipos, y que el site central sólo tenga la tarea de proporcionar un dashboard centralizado.
En el caso de que sean varios, o de que todos los sitios deban ser administrados por el mismo equipo, una configuración central es mucho más fácil de manejar. Checkmk apoya esto y se refiere a tal configuración como un entorno de configuración distribuida. Con esto, todos los host y servicios, usuarios y permisos, periodicidades y notificaciones, etc., se mantendrán y configurarán en el site central, y luego, dependiendo de sus tareas, se distribuirán automáticamente a los sites remotos.
Un sistema así no sólo tiene una visión general común del estado, sino también una configuración común, y efectivamente "se siente como un gran sistema".
Incluso puedes ampliar un sistema así con sites del visor dedicados, por ejemplo, que sirvan sólo como interfaces de estado para subáreas o grupos de usuarios concretos.
2.2. Instalación de una monitorización distribuida
La instalación de una monitorización distribuida mediante Livestatus/entorno de configuración distribuida se realiza en los siguientes pasos:
Primero instala el site central como se suele hacer para un site único
Instala los sites remotos, y activa Livestatus a través de la red
Integra los sites remotos en el site central utilizando Setup > General > Distributed monitoring
Para los host y servicios, especifica desde qué site deben ser monitorizados
Ejecuta un descubrimiento de servicios para los host migrados, y luego activa los cambios frescos
Instalación de un site central
No hay requisitos especiales para el site central. Esto significa que un site establecido desde hace tiempo puede ampliarse a una monitorización distribuida sin necesidad de modificaciones adicionales.
Instalar sites remotos y activar Livestatus a través de la red
Los sites remotos se generan como nuevos sites de la forma habitual con omd create. Esto tendrá lugar naturalmente en el servidor (remoto) destinado al site remoto respectivo.
Notas especiales:
Para los sites remotos, utiliza IDs únicos para tu monitorización distribuida.
La versión de Checkmk (por ejemplo, 2.2.0) de los sites remoto y central es la misma - sólo se admitenversiones mixtas para facilitar las actualizaciones.
Del mismo modo que Checkmk admite varios sites en un servidor, los sites remotos también pueden ejecutarse en el mismo servidor.
Aquí tienes un ejemplo para crear un site remoto con el nombre remote1:
root@linux# omd create remote1
Adding /opt/omd/sites/remote1/tmp to /etc/fstab.
Creating temporary filesystem /omd/sites/remote1/tmp...OK
Updating core configuration...
Generating configuration for core (type cmc)...
Starting full compilation for all hosts Creating global helper config...OK
Creating cmc protobuf configuration...OK
Executing post-create script "01_create-sample-config.py"...OK
Restarting Apache...OK
Created new site remote1 with version 2.2.0p1.cee.
The site can be started with omd start remote1.
The default web UI is available at http://myserver/remote1/
The admin user for the web applications is cmkadmin with password: lEnM8dUV
For command line administration of the site, log in with 'omd su remote1'
After logging in, you can change the password for cmkadmin with 'cmk-passwd cmkadmin'.El paso más importante ahora es habilitar Livestatus a través de TCP en la red. Ten en cuenta que Livestatus no es per se un protocolo seguro y sólo debe utilizarse dentro de una red segura (LAN segura, VPN, etc.). La habilitación aparece por omd config como usuario del site en un site detenido:
root@linux# su - remote1
OMD[remote1]:~$ omd configAhora selecciona Distributed Monitoring:
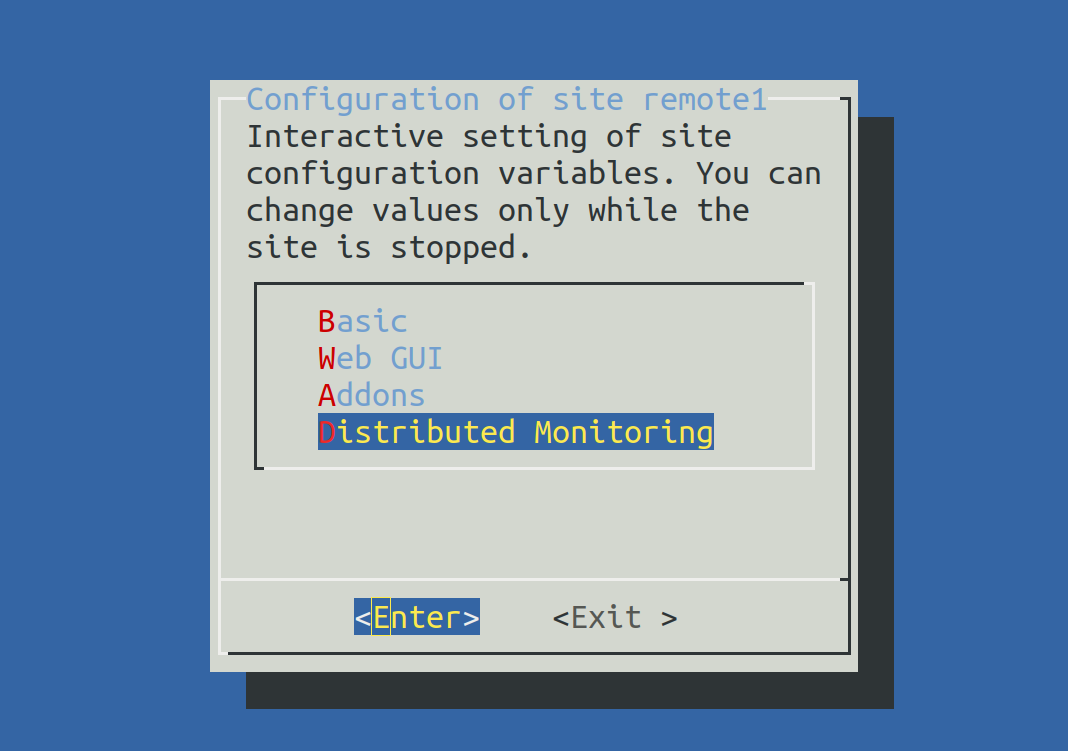
Establece LIVESTATUS_TCP en ‘on’ e introduce un número de puerto disponible paraLIVESTATUS_TCP_PORT que sea explícito en este servidor. El valor por defecto es 6557:
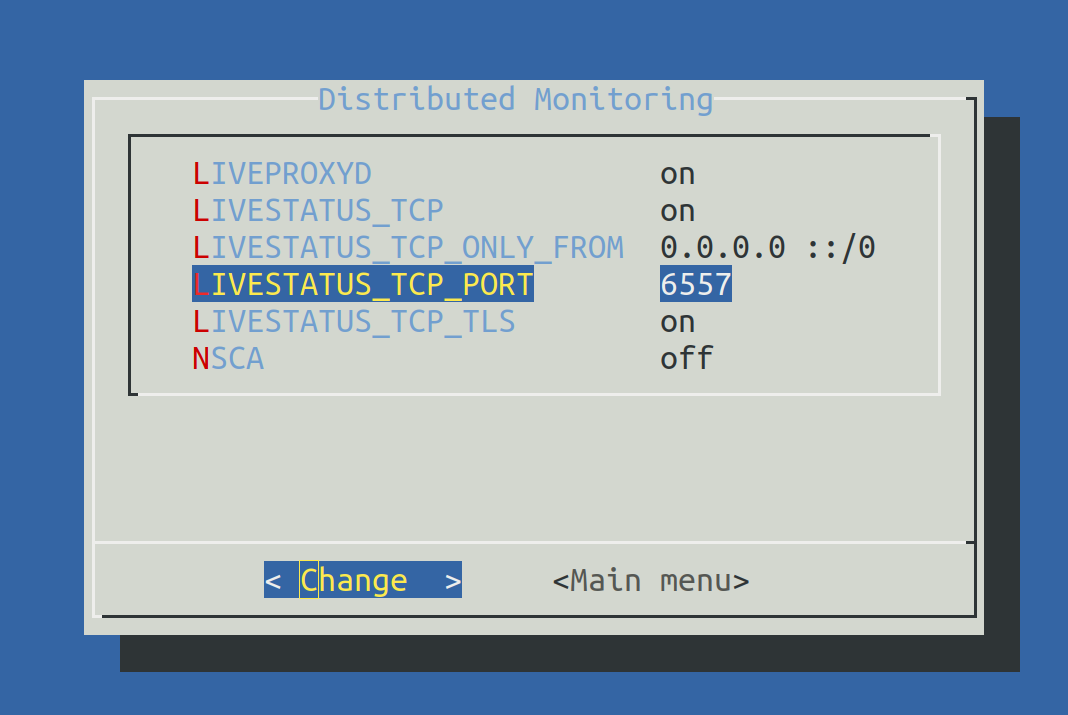
Después de guardar, inicia el site normalmente con omd start:
OMD[remote1]:~$ omd start
Temporary filesystem already mounted
Starting mkeventd...OK
Starting liveproxyd...OK
Starting mknotifyd...OK
Starting rrdcached...OK
Starting cmc...OK
Starting apache...OK
Starting dcd...OK
Starting redis...OK
Starting xinetd...OK
Initializing Crontab...OKConserva la contraseña para cmkadmin. Una vez que el remoto se haya subordinado al site central, todos los usuarios serán sustituidos igualmente por los del site central.
El remoto ya está listo. Compruébalo con netstat, que debería mostrar que el puerto 6557 está abierto. La conexión a este puerto la realiza un site del superservidor de internet xinetd, que se ejecuta directamente en el site:
root@linux# netstat -lnp | grep 6557
tcp6 0 0 :::6557 :::* LISTEN 10719/xinetdAsignación de sites remotos al site central
La configuración de la monitorización distribuida tiene lugar exclusivamente en el site central en el menú Setup > General > Distributed monitoring, y sirve para gestionar las conexiones a los sites individuales. Para esta función, el propio site central cuenta como site y ya está presente en la lista:

Utilizando Add connection, define ahora la conexión con el primer site remoto:

En Basic settings es importante utilizar el nombre EXACTO del site remoto -tal y como se definió con omd create- como Site ID. Como siempre, el alias puede definirse como se desee y también modificarse posteriormente.
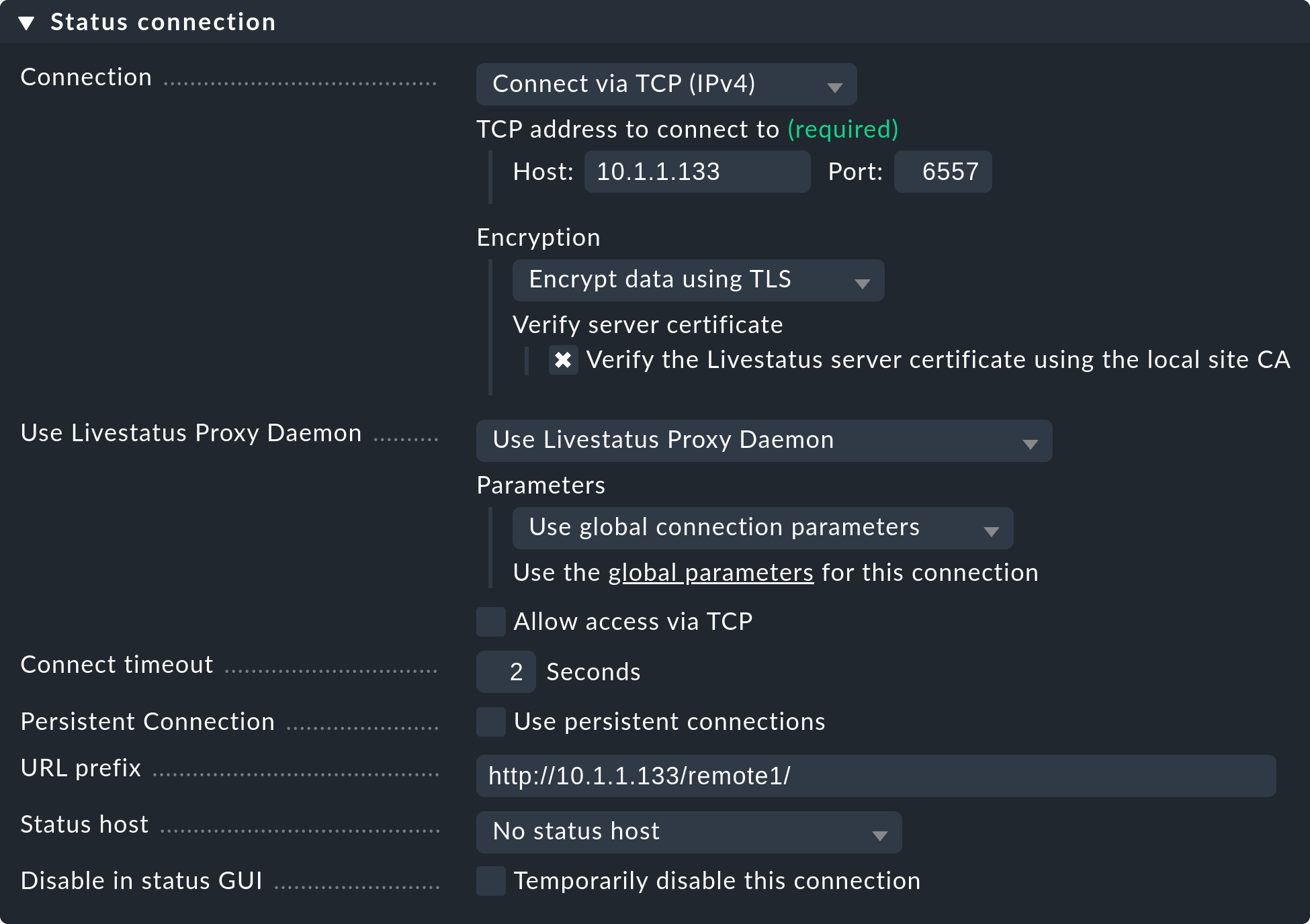
Los ajustes de Status connection determinan cómo consulta la central el estado de los sites remotos a través de Livestatus. El ejemplo de la captura de pantalla muestra una conexión con el método Connect via TCP(IPv4). Éste es el óptimo para conexiones estables con periodos de latencia cortos (como, por ejemplo, en una LAN). Más adelante hablaremos de los ajustes óptimos para conexiones WAN.
Introduce aquí la HTTP-URL a la interfaz web del remoto (sólo la parte que precede al componente check_mk/ ). Si básicamente accedes a Checkmk mediante HTTPS, sustituye aquí http por https. Encontrarás más información en la ayuda en línea o en el artículo sobre cómo proteger la interfaz web con HTTPS.
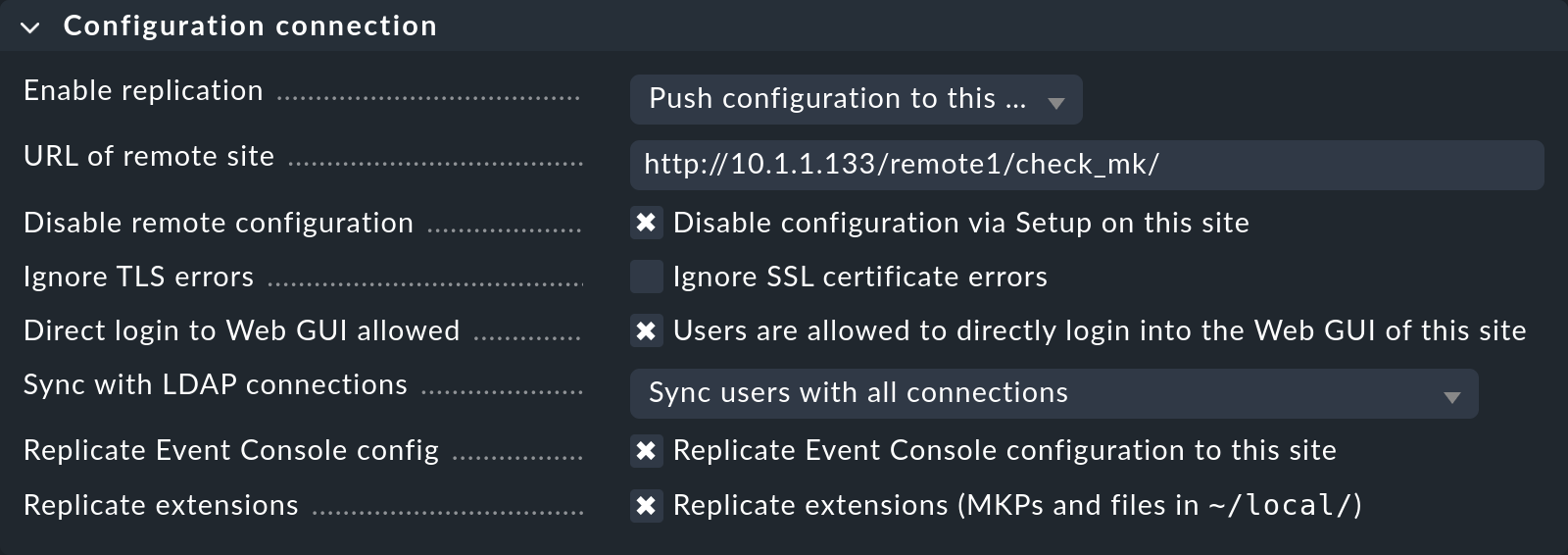
Replicar la configuración y utilizar así el entorno de configuración distribuido es, como hemos comentado en la introducción, opcional. Actívalo si deseas configurar el remoto con y desde el site central. En tal caso, selecciona la configuración exacta como se muestra en la imagen de arriba.
Es muy importante una configuración correcta de URL of remote site. La URL debe terminar siempre en /check_mk/. Se recomienda una conexión con HTTPS, siempre que el Apache del site remoto admita HTTPS, que debe instalarse manualmente en el remoto a nivel de Linux. Para el Appliance Checkmk, HTTPS puede configurarse mediante la interfaz de configuración basada en web. Si utilizas un certificado autofirmado, necesitarás la caja Ignore SSL certificate errors.
Una vez guardada la máscara, aparecerá un segundo site en la vista general:

El estado de monitorización del site remoto (hasta ahora) vacío está ahora correctamente integrado. Para poder utilizar el entorno de configuración distribuida sigues necesitando un login para el site remoto de Checkmk. Para ello, el site central intercambia un secreto de inicio de sesión generado aleatoriamente con el site remoto, a través del cual se realizará toda la comunicación futura. Posteriormente, ya no se utilizará el acceso cmkadmin en el site remoto.
Para iniciar sesión utiliza los datos de acceso cmkadmin y la contraseña correspondiente del site remoto. No olvides marcar la caja Confirm overwrite, antes de pulsar el botón Login:

Un inicio de sesión con éxito será reconocido:

Si se produce un error en el inicio de sesión, puede deberse a varias razones, por ejemplo:
El site remoto está parado.
El Multisite-URL of the remote site no se ha configurado correctamente.
No se puede acceder al sitio remoto con el nombre del host "del site central" especificado en la URL.
Las versiones de Checkmk del site central y del remoto son (demasiado) incompatibles.
Se ha introducido un ID de usuario y/o una contraseña inválidos.
Los puntos 1. y 2. pueden comprobarse fácilmente llamando manualmente a la URL del remoto en tu navegador.
Cuando todo haya ido bien, ejecuta Activate Changes. Esto te llevará, como siempre, a una vista general de los cambios aún no activados. Simultáneamente, la vista general también mostrará los estados de las conexiones Livestatus, así como los estados de sincronización del entorno de configuración distribuido de los sites individuales:
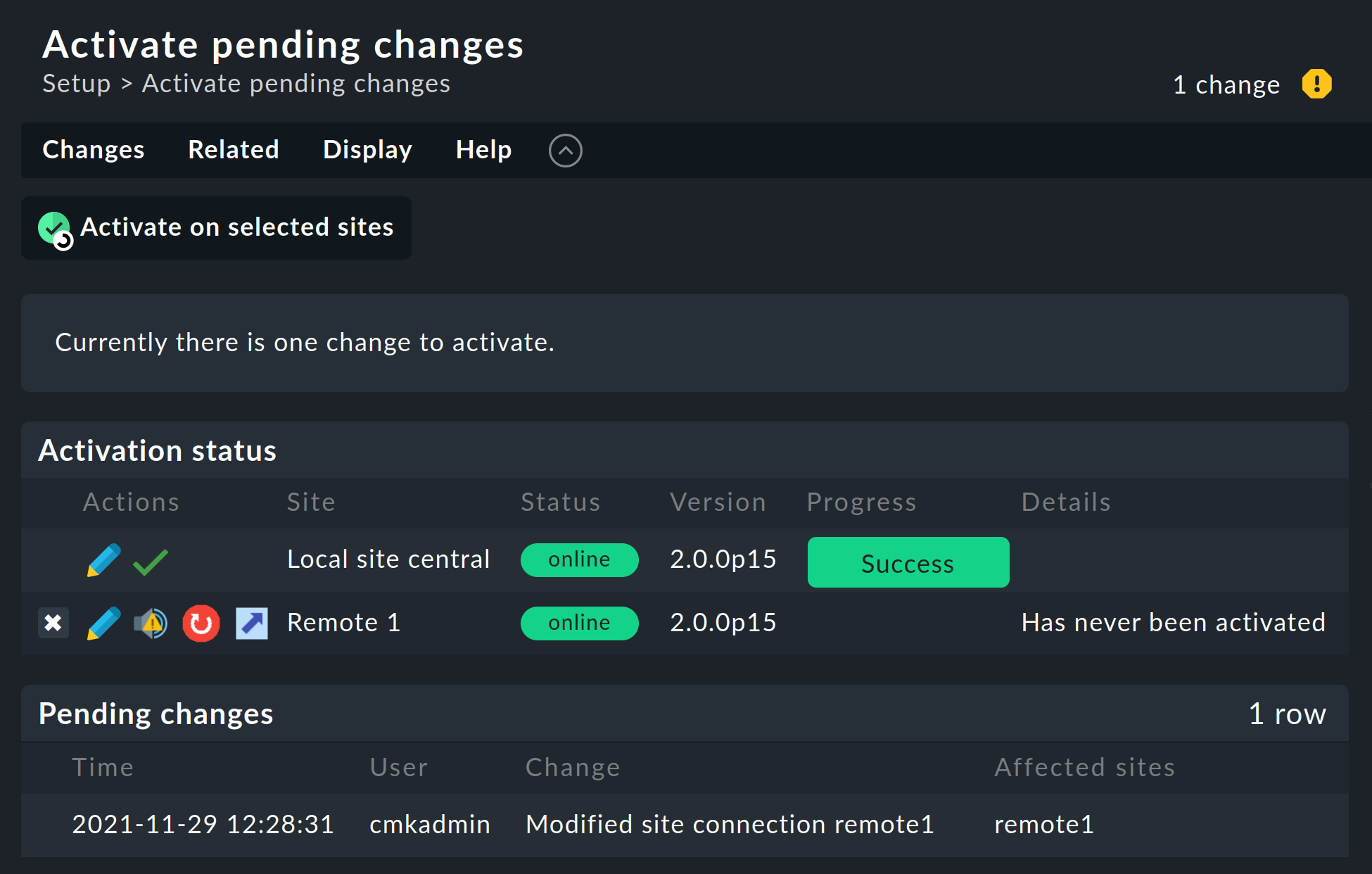
La columna Version muestra la versión de Livestatus del site correspondiente. Si utilizas la CMC como núcleo de Checkmk (ediciones comerciales), el número de versión del núcleo (que se muestra en la columna ‘Core’ ) es idéntico al de Livestatus. Si utilizas Nagios como núcleo (Checkmk edición Raw), aquí se mostrará el número de versión de Nagios.
Los siguientes símbolos muestran el estado de replicación del entorno de configuración:
Este site tiene cambios pendientes. La configuración coincide con el site central, pero no se han activado todos los cambios. Con el botón se puede realizar una activación específica para este site. |
|
La configuración de este site no es sincrónica y debe transferirse. Por supuesto, será necesario reiniciarla para activarla. Ambas funciones pueden realizarse pulsando el botón. |
En la columna Status se puede ver el estado de la conexión Livestatus para el site correspondiente. Esto se muestra a título meramente informativo, ya que la configuración no se transmite a través de Livestatus, sino a través de HTTP. Son posibles los siguientes valores:
Se puede acceder al site a través de Livestatus. |
|
No se puede acceder al site. Las consultas de Livestatus se están ejecutando en un timeout. Esto retrasa la carga de la página. Los datos de estado de este site no son visibles en la GUI. |
|
Actualmente no se puede acceder al site, pero esto se debe a la configuración de un host de estado o se conoce a través del proxy de Livestatus (ver más abajo). La inaccesibilidad no provoca Timeouts. Los datos de estado de este site no son visibles en la GUI. |
|
La conexión de Livestatus a este site ha sido desactivada temporalmente por el administrador (del site central). La configuración coincide con la caja check "Desactivar temporalmente esta conexión" en la configuración de esta conexión. |
Al hacer clic en el botón Activate on selected sites se sincronizarán ahora todos los sites y se activarán los cambios. Esto se realiza en paralelo, de modo que el tiempo total equivale al tiempo requerido por el site más lento. En el tiempo se incluye la creación de una instantánea de configuración para el site respectivo, la transmisión a través de HTTP, el desempaquetado de la instantánea en el site remoto y la activación de los cambios.
Importante: No salgas de la página antes de que se haya completado la sincronización en todos los sites - si sales de la página se interrumpirá la sincronización.
Especificar a los host y carpetas qué site debe monitorizarlos
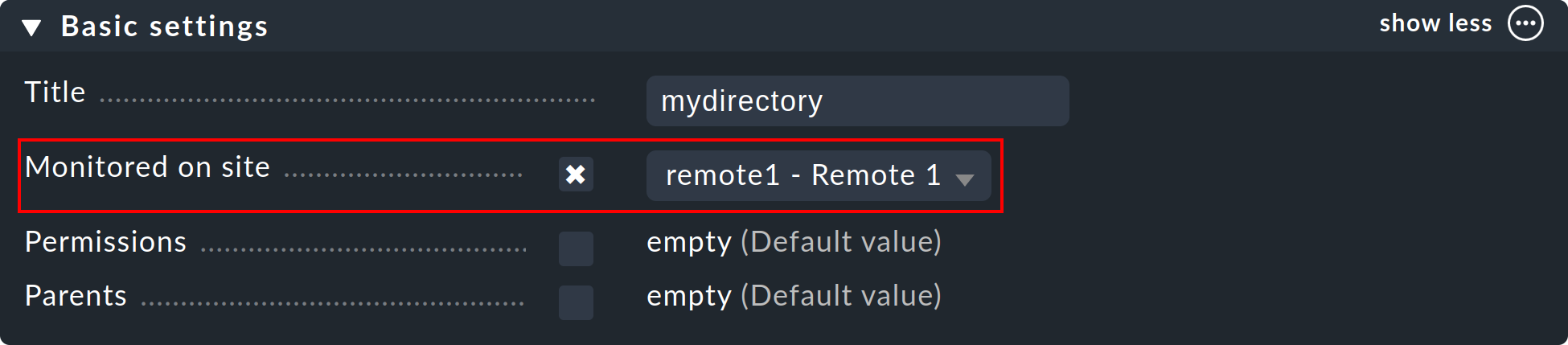
Una vez instalado tu entorno distribuido, puedes empezar a utilizarlo. En realidad, sólo tienes que indicar a cada host qué site debe monitorizarlo. Por defecto, se especifica el site central.
El atributo necesario para ello es ‘Monitored on site’. Puedes establecerlo individualmente para cada host. Naturalmente, esto también puede realizarse a nivel de carpeta:
Ejecutar un descubrimiento de servicios nuevo y activar cambios para los host migrados.
Añadir hosts funciona como de costumbre - aparte del hecho de que la monitorización y el descubrimiento de servicios se ejecutarán desde el site remoto correspondiente, no hay consideraciones especiales.
Al migrar hosts de un site a otro hay un par de puntos que debes tener en cuenta.No se transferirán los datos de estado actuales ni históricos del host.Sólo se conserva la configuración del host en el entorno de configuración. En efecto, es como si se hubiera eliminado el host de un site y se hubiera instalado de nuevo en el otro site:
Los servicios descubiertos automáticamente no se migrarán. Ejecuta un descubrimiento de servicios después de la migración.
Una vez reiniciados, los host y servicios aparecerán como PENDIENTES. Los problemas existentes pueden ser notificados de nuevo.
Se perderán los gráficos históricos. Esto puede evitarse moviendo manualmente los archivos RRD relevantes. Puedes encontrar la ubicación de los archivos en Archivos y directorios.
Se perderán los datos de disponibilidad y de eventos históricos. Desgraciadamente, no son fáciles de migrar, ya que los datos consisten en líneas sueltas en el registro de monitorización.
Si la continuidad del historial es importante para ti, al implantar la monitorización debes planificar cuidadosamente qué host se va a monitorizar y desde dónde.
2.3. Conexión de Livestatus con encriptación
A partir de la versión 1.6.0, las conexiones de Livestatus entre el site central y un site remoto pueden encriptarse. Para los sites recién creados no es necesario hacer nada más, ya que Checkmk se encarga de los pasos necesarios automáticamente. En cuanto utilices omd config para activar Livestatus, también se activa automáticamente la encriptación mediante TLS:
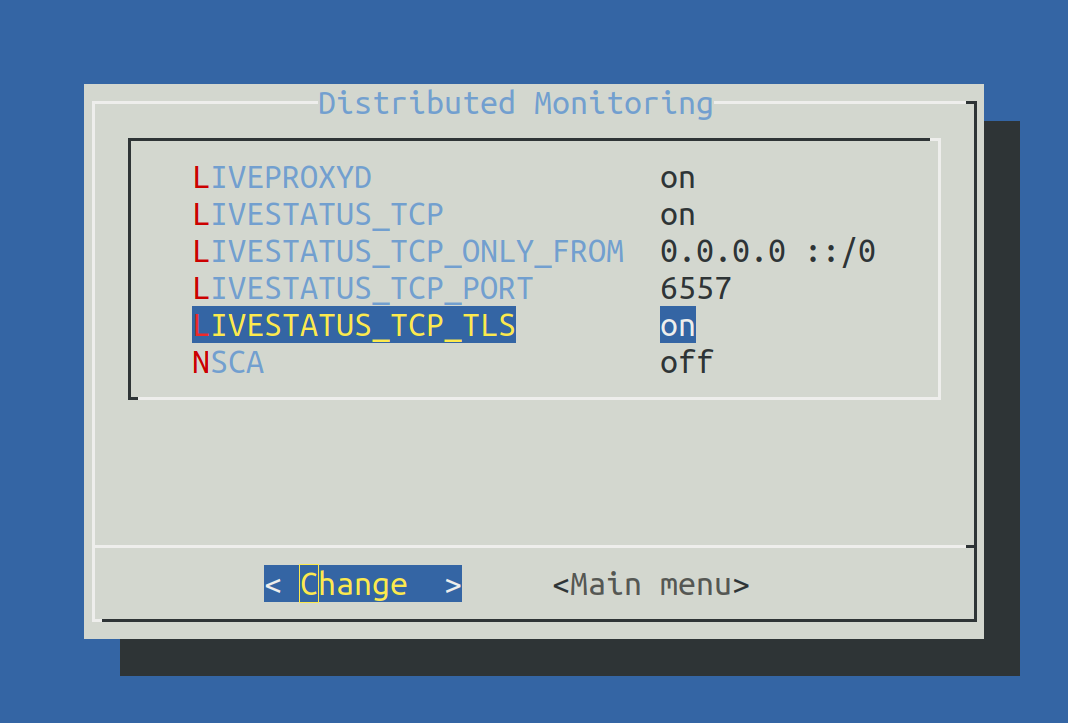
Por tanto, la configuración de la monitorización distribuida sigue siendo tan sencilla como hasta ahora. Para las nuevas conexiones a otros sites, se activa automáticamente la opciónEncryption.
Después de añadir el site remoto, te darás cuenta de dos cosas: en primer lugar, la conexión se marca como encriptada mediante este nuevo icono. Y en segundo lugar, Checkmk te indicará que la CA ya no confiará en el site remoto. Haz clic en para acceder a los detalles de los certificados utilizados. Un clic en te permite añadir cómodamente la CA a través de la interfaz web. A continuación, ambos certificados aparecerán en la lista como de confianza:
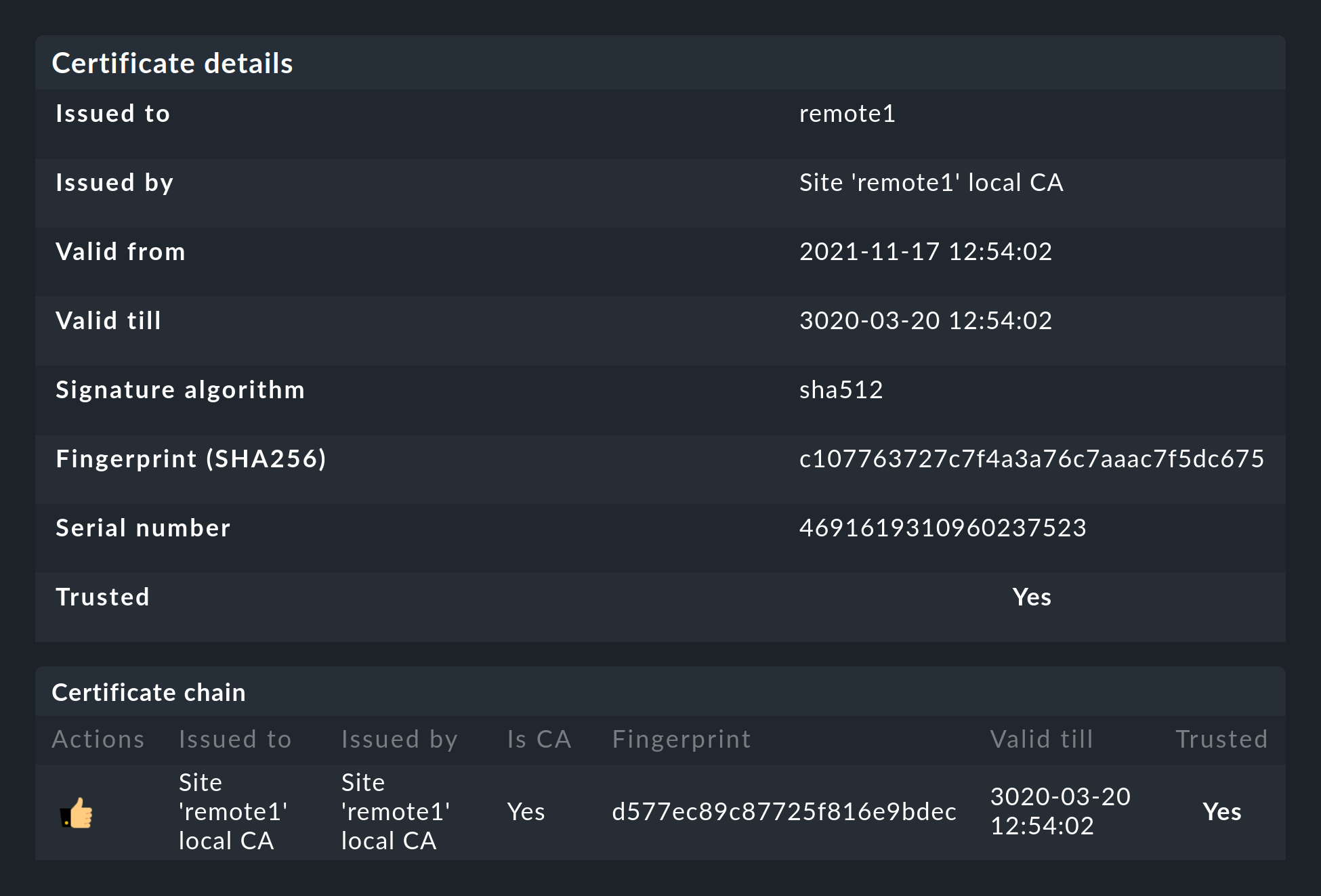
Detalles de las tecnologías utilizadas
Para lograr la encriptación, Checkmk utiliza el programa stunnel junto con su propio certificado y su propia Autoridad de Certificación (AC) para firmar el certificado. Estos se generarán individualmente de forma automática con un site nuevo y, por tanto, no son CAs o certificados estáticos predefinidos. Se trata de un factor de seguridad muy importante para evitar que los atacantes utilicen certificados falsos, ya que cualquier atacante podría acceder a una CA de acceso público.
Los certificados generados también tienen las siguientes propiedades:
Ambos certificados están en formato PEM. Los certificados firmados para el site también contienen la cadena de certificados completa.
Las claves utilizan RSA de 4096 bits, y el certificado está firmado con SHA512.
El certificado del site tiene una validez de 10 años.
El hecho de que el certificado estándar sea válido durante tanto tiempo evita de forma muy eficaz que tengas problemas de conexión que no puedas clasificar. Al mismo tiempo, es posible, por supuesto, que una vez que un certificado se ha visto comprometido, quede abierto durante mucho tiempo al abuso. Por tanto, si temes que un atacante acceda a la CA o al certificado de site firmado con ella, ¡reemplaza siempre ambos certificados (CA y site)!
Migración desde versiones anteriores
Durante una actualización de Checkmk, las dos opciones LIVESTATUS_TCP y LIVESTATUS_TCP_TLS nunca se cambian automáticamente. La activación automática de TLS podría acabar provocando que tus sites remotos ya no puedan ser consultados.
Si hasta ahora has estado utilizando Livestatus sin cifrar y ahora decides utilizar el cifrado, debes activarlo manualmente. Para ello, primero detén los sites afectados y luego activa TLS con el siguiente comando:
OMD[mysite]:~$ omd config set LIVESTATUS_TCP_TLS onComo los certificados se generaron automáticamente durante la actualización, el site utilizará inmediatamente la nueva función de encriptación. Para que puedas seguir accediendo al site desde el site central, comprueba que la opción Encryption está configurada como Encrypt data using TLS en el menú Setup > General > Distributed Monitoring:
El último paso es como el descrito anteriormente - de nuevo aquí primero tienes que marcar la CA del site remoto como de confianza.
2.4. Características especiales de una configuración distribuida
Una monitorización distribuida funciona a través de Livestatus de forma muy parecida a un sistema individual, pero tiene un par de características especiales:
Acceso a los host monitorizados
Todos los accesos a un host monitorizado se realizan sistemáticamente desde el site al que está asignado el host. Esto se aplica no sólo a la monitorización propiamente dicha, sino también al descubrimiento de servicios, la página de Diagnósticos, lasNotificaciones, los alert handlers y todo lo demás. Este punto es muy importante, ya que no se supone que el site central tenga realmente acceso a este host.
Especificar el site en vistas
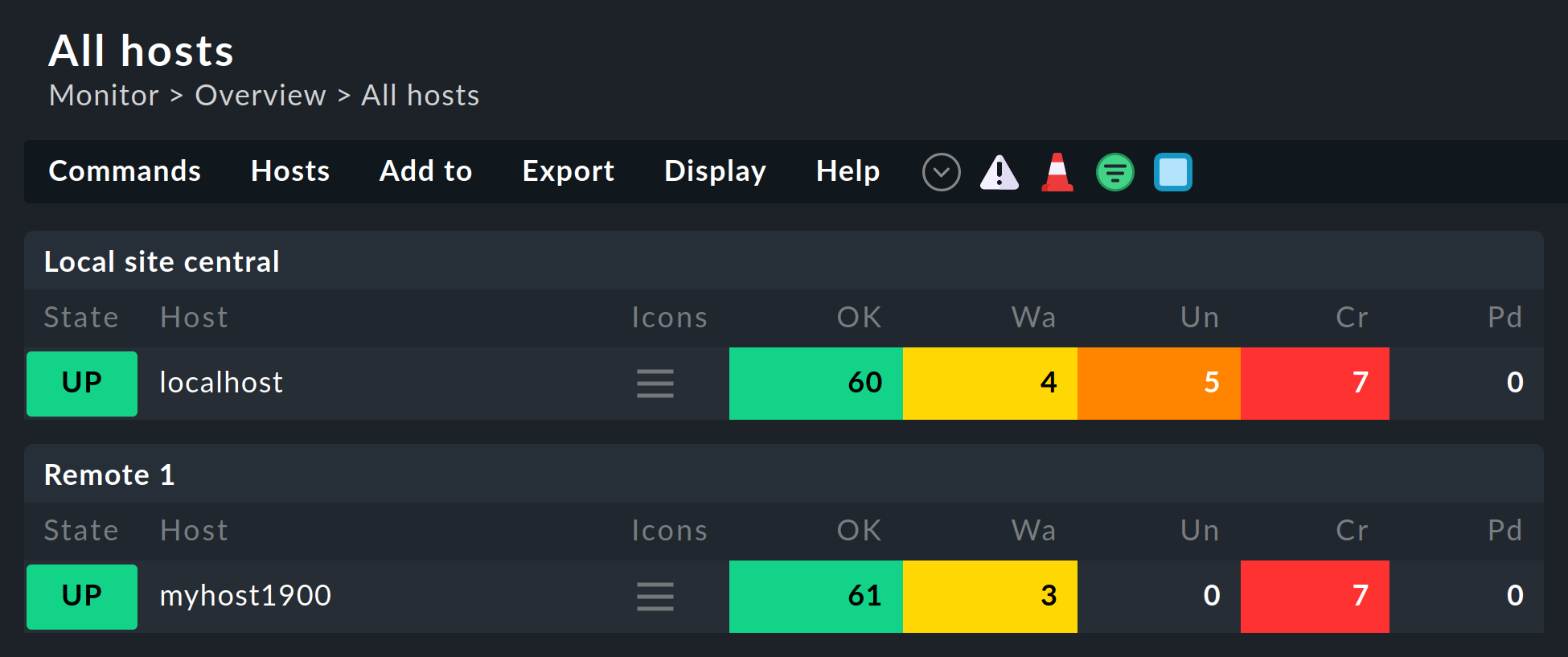
Algunas de las vistas estándar están agrupadas según el site desde el que se monitorizará el host - esto se aplica, por ejemplo, a All hosts:
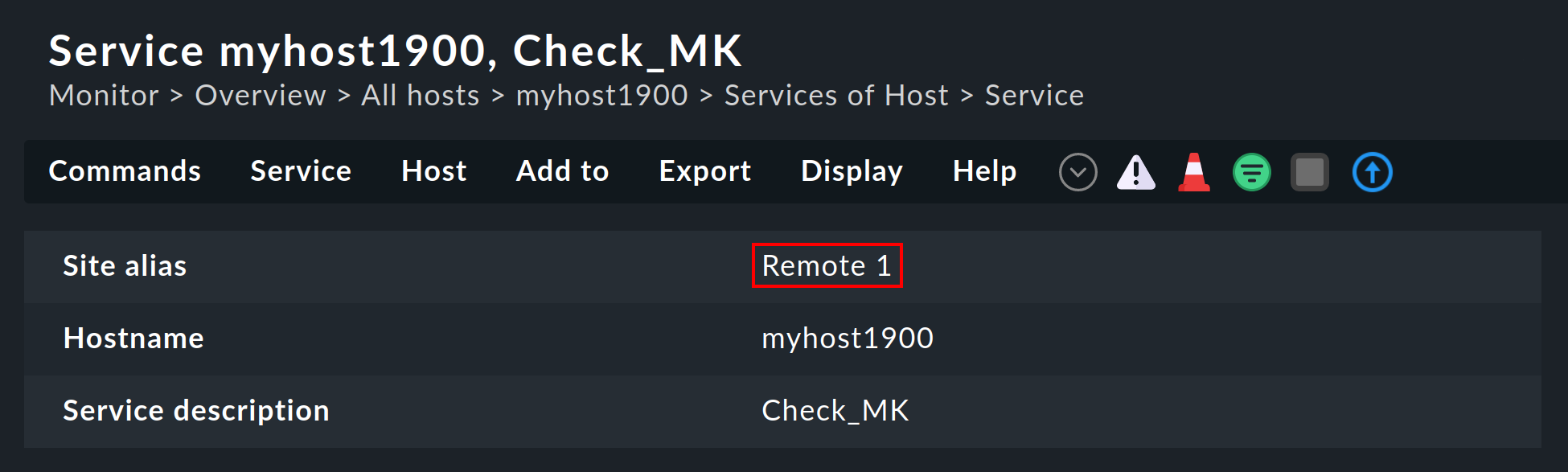
El site también se mostrará en los detalles del host o servicio:
Esta información suele estar disponible para utilizarla en una columna alcrear tus propias vistas. También hay un filtro con el que se puede filtrar una vista de tablas de host en un site concreto:
Snap-in de estado del site
Hay un snap-in Site status para la barra lateral que puede añadirse utilizando . Muestra el estado de los sitios individuales. También proporciona la opción de desactivar y volver a activar temporalmente un solo sitio haciendo clic en el estado - o todos los sitios a la vez haciendo clic en Disable all o Enable all.
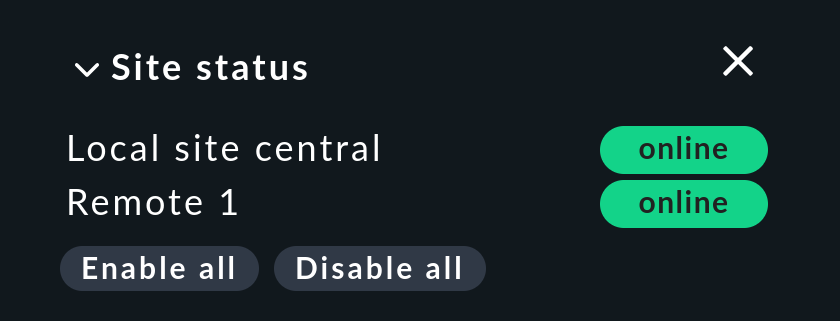
Los sitios desactivados se marcarán con el estado. Con esto también puedes desactivar un sitio que esté generando timeouts, evitando así timeouts superfluos. Esta desactivación no es lo mismo que desactivar la conexión Livestatus utilizando la configuración de conexión en Setup. Aquí la "desactivación" sólo afecta al usuario conectado en ese momento y tiene una función puramente visual. Al hacer clic en el nombre de un sitio se mostrará una vista de todos sus hosts.
Control maestro snap-in
En una monitorización distribuida, el snap-in Master control tiene un aspecto diferente.Cada site tiene su propio interruptor global:
Checkmk host de clúster
Si monitorizas con Checkmk HA-Cluster, los nodos individuales del clúster deben estar asignados al mismo site que el propio clúster. Esto se debe a que para determinar el estado de los servicios en clúster se accede a archivos de caché generados mediante la monitorización del nodo. Estos datos se encuentran localmente en el site correspondiente.
Datos piggyback (por ejemplo, ESXi)
Algunos check plugin utilizan datos piggyback, por ejemplo, para asignar los datos de monitorización recuperados de un host de ESXi a las máquinas virtuales individuales. Por la misma razón que en la monitorización de clústeres, en la monitorización distribuida el host "piggy" (portador), así como sus hosts dependientes, deben monitorizarse desde el mismo site. En el caso de ESXi, esto significa que las máquinas virtuales deben estar asignadas al mismo site en Checkmk que el sistema ESXi del que se recogen los datos de monitorización. Esto puede significar que es mejor sondear directamente el sistema host ESXi en lugar de sondear un vCenter global. Encontrarás más detalles al respecto en la documentación sobre la monitorización de ESXi.
Inventario de hardware/software
El inventario de hardware/software de Checkmk también funciona en entornos distribuidos. Para ello, los datos del inventario del directoriovar/check_mk/inventory deben transmitirse regularmente desde los remotos al site central. Por razones de rendimiento, la interfaz de usuario siempre accede a este directorio localmente.
En las ediciones comerciales, la sincronización se realiza automáticamente en todos los sites que están conectados mediante el proxy Livestatus.
Si realizas inventarios utilizando Checkmk Raw en sistemas distribuidos, el directorio debe reflejarse regularmente en el site central con tus propias herramientas (por ejemplo, con rsync).
Cambiar una contraseña
Incluso cuando todos los sites se monitorizan de forma centralizada, es muy posible, y a menudo también adecuado, iniciar sesión en la interfaz de un site individual. Por este motivo, Checkmk garantiza que la contraseña de un usuario sea siempre la misma para todos los sites.
Un cambio de contraseña realizado por el administrador tendrá efecto automáticamente en cuanto se comparta con todos los sites con Activate Changes.
Un cambio realizado por el propio usuario mediante la barra lateral de su configuración personal funciona de forma algo distinta. No puede ejecutarlo un Activate changes, ya que, por supuesto, el usuario no tiene autoridad general para esta función. En tal caso, Checkmk compartirá automáticamente la contraseña modificada en todos los sites, directamente después de guardarla, de hecho.
Como todos sabemos, las redes nunca están disponibles al 100 %. Si un site está inaccesible en el momento de un cambio de contraseña, no recibirá la nueva contraseña. Hasta que el administrador ejecute con éxito un Activate changes, o respectivamente, el siguiente cambio de contraseña con éxito, este site retendrá la antigua contraseña para el usuario. Un símbolo de estado informará al usuario del estado de la compartición de contraseñas a los sites individuales.
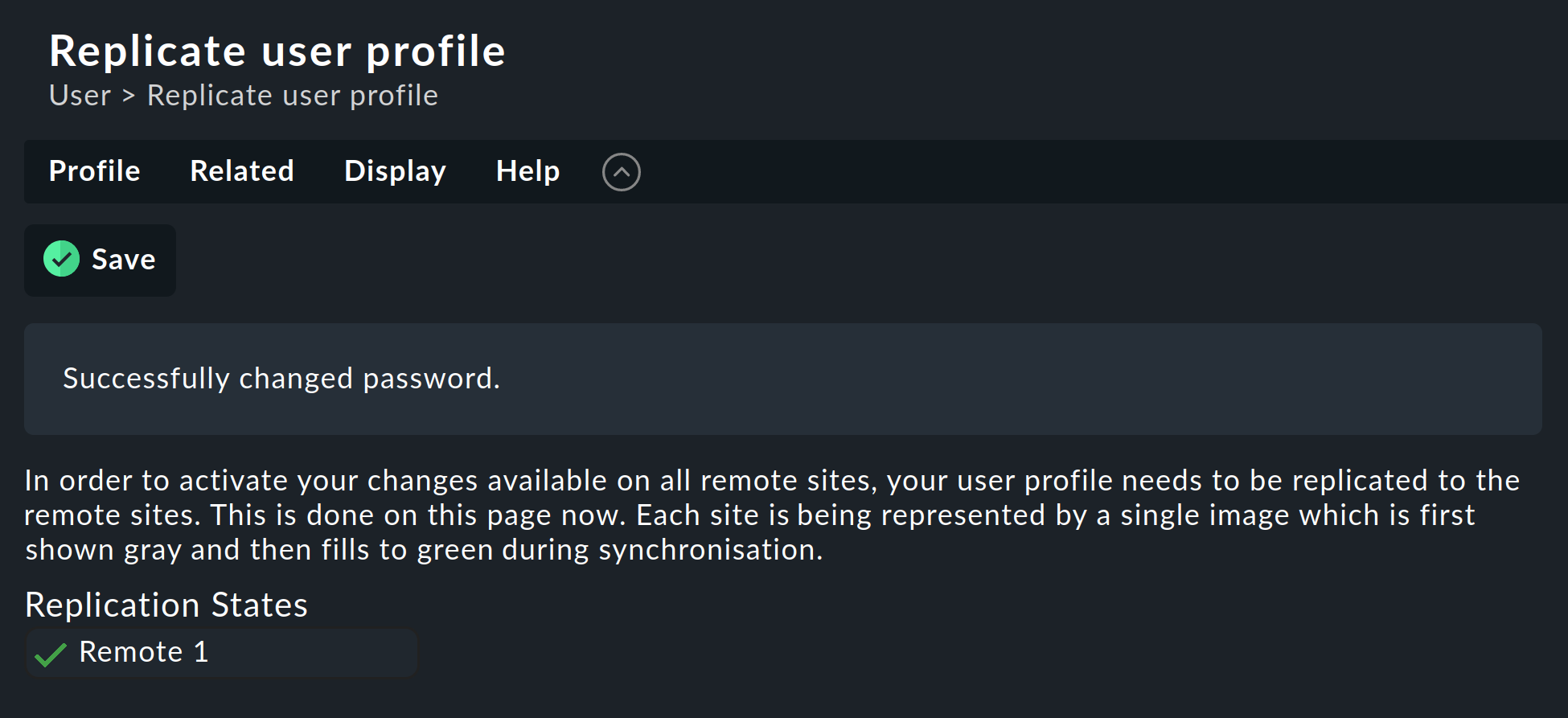
2.5. Anclaje de sitios existentes
Como ya se ha mencionado, los sitios existentes también pueden vincularse retrospectivamente a una monitorización distribuida. Siempre que se hayan cumplido las condiciones previas descritas anteriormente (versiones de Checkmk compatibles), esto se completará exactamente igual que para configurar un nuevo sitio remoto. Comparte Livestatus con TCP, luego añade el sitio a través de Setup > General > Distributed monitoring - ¡y ya está!
La segunda etapa -el cambio a una configuración centralizada- es algo más complicada. Antes de integrar el site en el entorno de configuración distribuida, como se ha descrito anteriormente, debes tener en cuenta que, al hacerlo, ¡se sobrescribirá toda la configuración local del site !
Si deseas asumir los host existentes, y posiblemente también las reglas, deberás seguir tres pasos:
Coincidencia con el esquema de tags del host.
Copia los directorios (host)
Edita las características en la carpeta principal
1. tags del host
Es evidente que las etiquetas del host utilizadas en el site remoto también deben ser conocidas por el site central para que puedan ser transferidas. Compruébalas antes de la migración y añade manualmente al site central las etiquetas que falten. Aquí es esencial que coincidan los tag-IDs - el título de la etiqueta es irrelevante.
2. Carpetas
A continuación, traslada los host y las reglas al entorno de configuración del site central. Esto sólo funciona para host y reglas en subcarpetas (es decir, no en la carpeta Main ). Los host de la carpeta principal deben trasladarse primero simplemente a una subcarpeta de un site remoto a través de Setup > Hosts > Hosts.
La migración propiamente dicha puede realizarse simplemente copiando los directorios apropiados. Cada carpeta del entorno de configuración corresponde a un directorio dentro de ~/etc/check_mk/conf.d/wato/. Estos pueden copiarse utilizando una herramienta de tu elección (por ejemplo, scp) desde el sitio remoto a la misma ubicación en el sitio central. Si ya existe allí un directorio con el mismo nombre, simplemente cámbiale el nombre. Ten en cuenta que los usuarios y grupos de Linux también son utilizados por el sitio central.
Tras la copia, los host aparecerán en el Setupdel sitio central, así como las reglas que hayas creado en estas carpetas. Con la copia también se incluirán las propiedades de las carpetas, que se encuentran en el directorio del archivo oculto .wato.
3. Editar y guardar una sola vez
Para que los atributos de las funciones de la carpeta padre del site central se hereden correctamente, como paso final tras la migración, las características de las carpetas padre deben abrirse y guardarse una vez - de este modo, los atributos del host estarán definidos de nuevo.
2.6. Configuración global específica del site
Una configuración centralizada significa, ante todo, que todos los sitios tienen una configuración común y (aparte de los host) la misma. Sin embargo, ¿cuál es la situación cuando los sitios individuales requieren una configuración global diferente? Un ejemplo podría ser la configuración de la CMC Maximum concurrent Checkmk checks. Podría ser que se requiriera una configuración personalizada para un site especialmente pequeño o especialmente grande.
Para estos casos existe una configuración global específica para cada site, a la que se accede mediante el símbolo del menú Setup > General > Distributed monitoring:

A través de este símbolo encontrarás una selección de todos los ajustes globales, aunque todo lo que definas aquí sólo será efectivo para el site elegido. Un valor que difiera de la norma se resaltará visualmente, y sólo se aplicará a este site:

2.7. Consola de eventos distribuida
La Consola de eventos procesa mensajes syslog, Traps SNMP y otros tipos de eventos de naturaleza asíncrona.
Checkmk también ofrece la opción de ejecutar una Consola de eventos distribuida. En ese caso, cada site ejecutará su propio proceso de eventos, que capturará los eventos de todos los host que se estén supervisando desde el site. De este modo, los eventos no se enviarán al sistema central, sino que permanecerán en los sites y sólo se recuperarán de forma centralizada. Esto se realiza de forma similar a lo que ocurre con los estados activos a través de Livestatus, y funciona tanto con Checkmk edición Raw como con las ediciones comerciales.
La conversión a una Consola de eventos distribuida según el nuevo esquema requiere los siguientes pasos:
En la configuración de la conexión, activa la opción (Replicate Event Console configuration to this site).
Cambia la ubicación de Syslog y los destinos de Trap SNMP de los host afectados al site remoto. Ésta es la tarea más laboriosa.
Si utilizas el conjunto de reglas Check event state in Event Console, vuelve a cambiarlo a Connect to the local Event Console.
Si utilizas el conjunto de reglas Logwatch Event Console Forwarding, cámbialo igualmente a la Consola de eventos local.
En la Consola de eventos Settings, vuelve a cambiar Access to event status via TCP por no access via TCP.
2.8. NagVis

El programa Open Source NagVis visualiza los datos de estado de la monitorización en mapas, diagramas y otros gráficos de elaboración propia. NagVis está integrado en Checkmk y se puede utilizar inmediatamente. El acceso es más sencillo a través del elemento de la barra lateral NagVis Maps. La integración de NagVis en Checkmk se describe en su propio artículo.
NagVis admite la monitorización distribuida a través de Livestatus de forma muy parecida a como lo hace Checkmk. Los enlaces a los sites individuales se denominan Backends. Checkmk configura automáticamente los backends de forma correcta para que puedas empezar a generar inmediatamente gráficos NagVis, también en monitorización distribuida.
Selecciona el backend correcto para cada objeto que coloques en un gráfico, es decir, el site de Checkmk desde el que se va a monitorizar el objeto. NagVis no puede encontrar el host o el servicio automáticamente, sobre todo por motivos de rendimiento. Por lo tanto, si mueves los hosts a un site remoto diferente, tendrás que actualizar los gráficos NagVis en consecuencia.
Puedes encontrar más detalles sobre los backend en la documentación aquí:NagVis.
3. Conexiones inestables o lentas
La vista de estado general de la interfaz del usuario permite un acceso siempre disponible y fiable a todos los sitios conectados. El único inconveniente es que la vista sólo puede mostrarse cuando todos los sitios han respondido. El proceso consiste siempre en que primero se envía una consulta de Livestatus (por ejemplo, "Lista de todos los servicios cuyo estado no es OK"). Entonces, la vista sólo puede mostrarse cuando el último sitio ha respondido.
Es molesto que un site no responda. Para tolerar interrupciones breves (por ejemplo, debidas al reinicio de un site o a la pérdida de un paquete TCP), la GUI espera un tiempo determinado antes de que se declare que un site está , y luego continúa procesando las respuestas de los sites restantes. Esto da lugar a una GUI "colgada". Por defecto, el timeout está fijado en 10 segundos.
Si esto ocurre ocasionalmente en tu red, deberías configurar o bien Status hosts o (aún mejor) el proxy Livestatus.
3.1. Host de estado
La configuración de hosts de Estado es el procedimiento recomendado con Checkmk Raw para reconocer conexiones defectuosas de forma fiable. La idea es sencilla: El site central monitoriza activamente la conexión con cada site remoto individual. Al menos dispondremos así de un sistema de monitorización! La GUI será entonces consciente de los sites inalcanzables y podrá excluirlos inmediatamente y marcarlos como . Así se minimizan los timeouts.
A continuación te explicamos cómo configurar un host de estado para una conexión:
Añade el host en el que se ejecuta el site remoto al site central en monitorización.
Introdúcelo como host de estado en la conexión con el remoto:
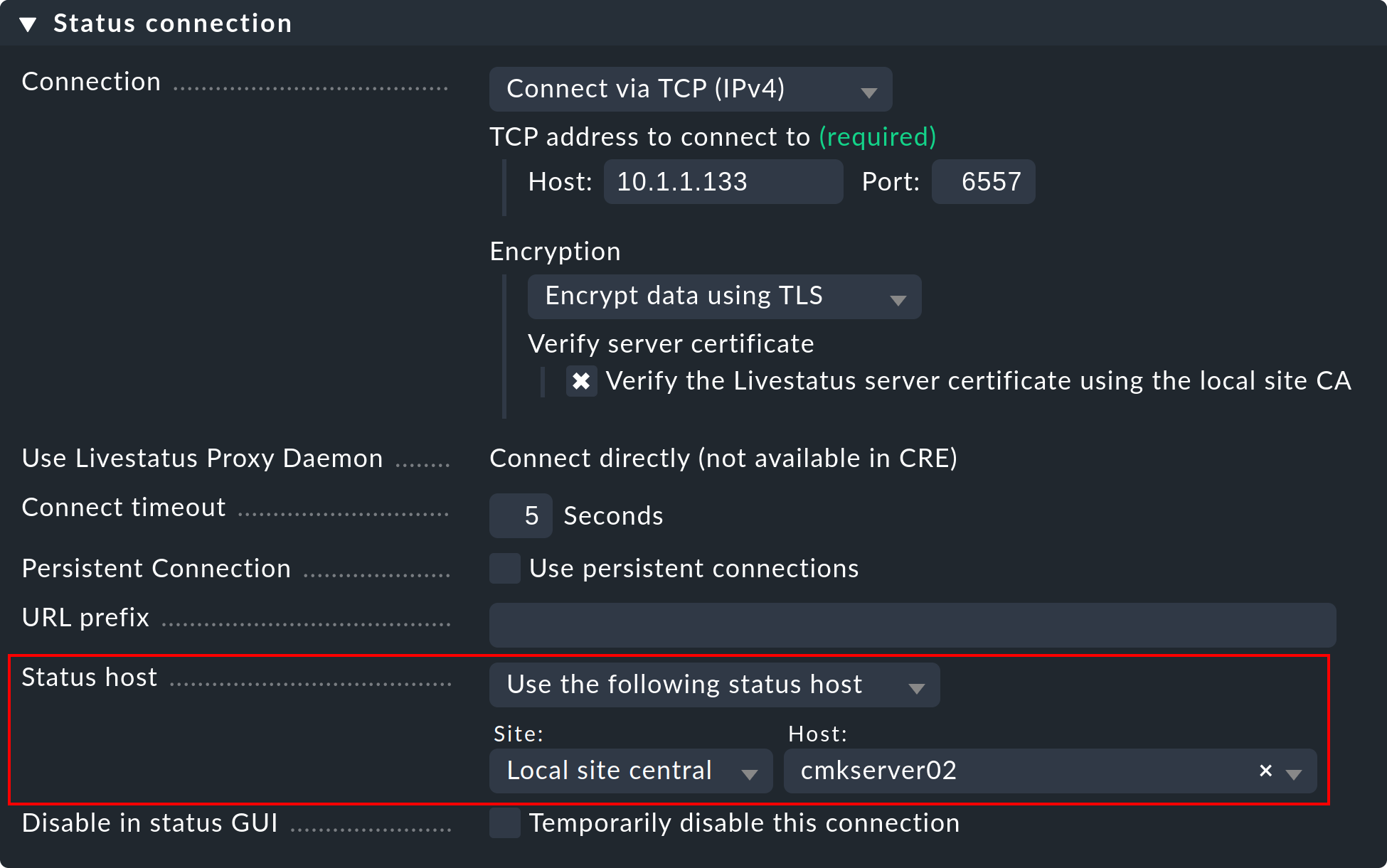
Ahora, una conexión fallida a un site remoto sólo puede provocar un breve cuelgue de la GUI, es decir, hasta que la monitorización lo reconozca. Reduciendo el intervalo de prueba del host de estado de los sesenta segundos por defecto a, por ejemplo, cinco segundos, puedes minimizar la duración de un cuelgue.
Si has configurado un host de estado, hay más estados posibles para las conexiones:
El ordenador en el que se ejecuta el site remoto acaba de ser inalcanzable para la monitorización porque un router está caído (el host de estado tiene un estado UNREACH ). |
|
El host de estado que supervisa la conexión con el sistema remoto aún no ha sido verificado por la monitorización (aún tiene un estado PENDIENTE ). |
|
El estado del host de estado tiene un valor inválido (esto no debería ocurrir nunca). |
En los tres casos se excluirá la conexión al site y se evitarán así los timeouts.
3.2. Conexiones persistentes
Con la caja check Use persistent connections puedes pedir a la GUI que mantenga las conexiones Livestatus establecidas con sites remotos permanentemente en estado "up", y que continúe utilizándolas para las consultas. Especialmente en conexiones con tiempos de entrega de paquetes más largos (por ejemplo, intercontinentales), esto puede hacer que la GUI responda notablemente mejor.
Dado que la GUI de Apache se comparte entre varios procesos independientes, se necesita una conexión para cada proceso Apache-Client que se ejecute simultáneamente. Si tienes muchos usuarios simultáneos, asegúrate de que la configuración tiene un número suficiente de conexiones Livestatus en el núcleo remoto de Nagios. Éstas se configuran en el archivo etc/mk-livestatus/nagios.cfg. El valor por defecto es veinte (num_client_threads=20).
Por defecto, Apache está configurado en Checkmk de modo que permite hasta 128 conexiones de usuario simultáneas. Esto se configura en la siguiente sección del archivo etc/apache/apache.conf:
<IfModule prefork.c>
StartServers 1
MinSpareServers 1
MaxSpareServers 5
ServerLimit 128
MaxClients 128
MaxRequestsPerChild 4000
</IfModule>Esto significa que, con una carga elevada, pueden iniciarse hasta 128 procesos Apache que, a su vez, generen y mantengan hasta 128 conexiones Livestatus. Si no se configura num_client_threads lo suficientemente alto, pueden producirse errores o un tiempo de respuesta muy lento en la GUI.
Para conexiones con LAN o con redes WAN rápidas aconsejamos noutilizar conexiones persistentes.
3.3. El proxy Livestatus
Con el proxy Livestatus, las ediciones comerciales disponen de un sofisticado mecanismo para detectar conexiones muertas. Además, optimiza especialmente el rendimiento de las conexiones con largos tiempos de ida y vuelta. Las ventajas del proxy Livestatus son:
Detección muy rápida y proactiva de los sites que no responden.
Almacenamiento local en caché de las consultas que proporcionan datos estáticos
Conexiones TCP permanentes, que requieren menos viajes de ida y vuelta y, en consecuencia, permiten respuestas mucho más rápidas desde sitios distantes (por ejemplo, EE.UU. ⇄ China).
Control preciso del número máximo de conexiones Livestatus necesarias
Permite el inventario de hardware/software en entornos distribuidos
Instalación
Instalar el proxy Livestatus es muy sencillo. Está activado por defecto en las ediciones comerciales, lo que se puede ver al iniciar un site:
OMD[central]:~$ omd start
Temporary filesystem already mounted
Starting mkeventd...OK
Starting liveproxyd...OK
Starting mknotifyd...OK
Starting rrdcached...OK
Starting cmc...OK
Starting apache...OK
Starting dcd...OK
Starting redis...OK
Starting stunnel...OK
Starting xinetd...OK
Initializing Crontab...OKSelecciona la opción 'Use Livestatus Proxy-Daemon' para la conexión a los sites remotos en lugar de 'Conectar vía TCP':
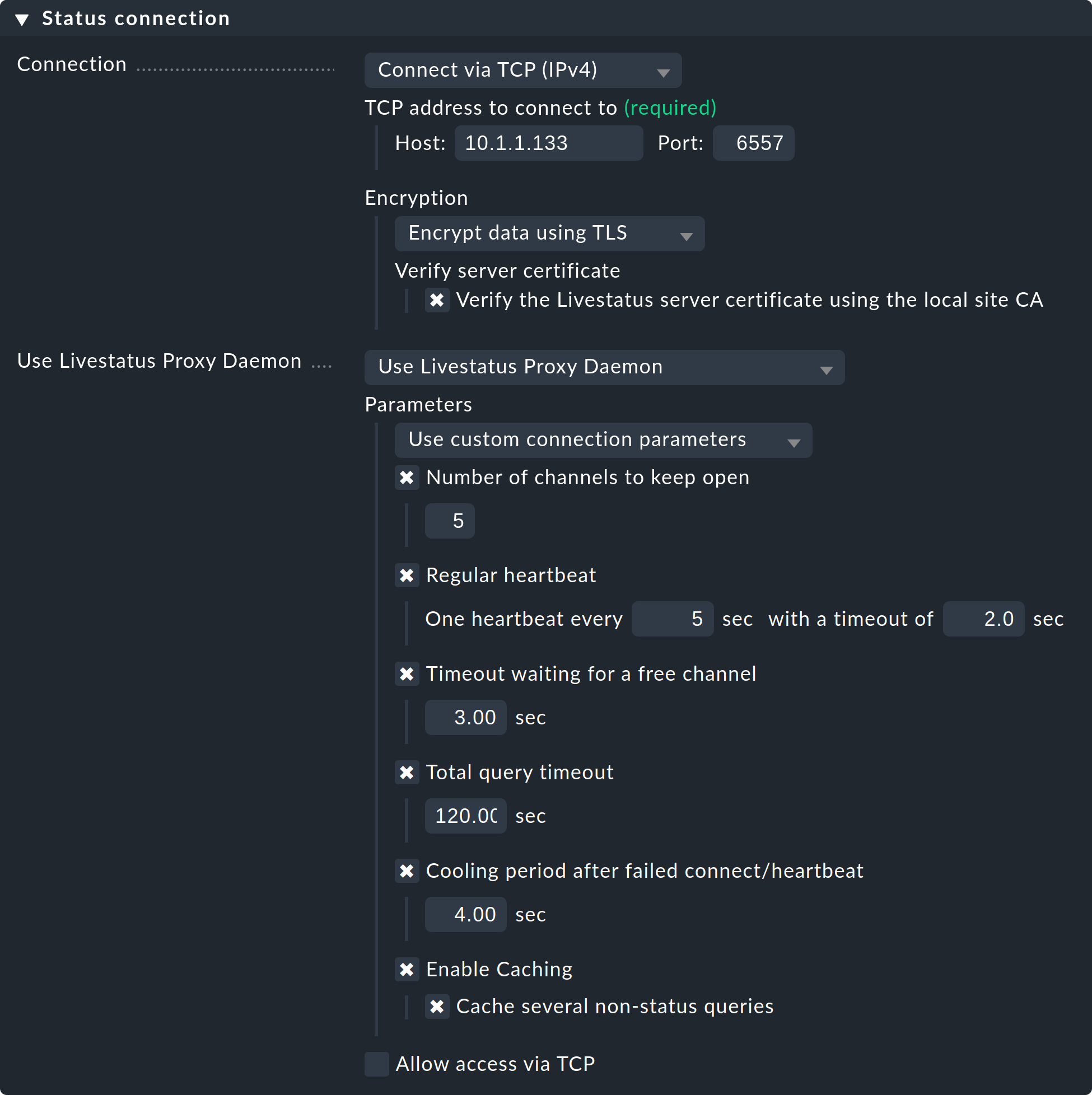
Los detalles de host y puerto son los de siempre. No hay que hacer ningún cambio en el site remoto. En Number of channels to keep open introduce el número de conexiones TCP paralelas que el proxy debe establecer y mantener con el site de destino.
El conjunto de conexiones TCP es compartido por todas las consultas de la GUI. El número de conexiones limita el número máximo de consultas que pueden procesarse simultáneamente, lo que indirectamente limita el número de usuarios. En situaciones en las que todos los canales estén reservados, esto no provocará inmediatamente un error. La GUI espera un tiempo determinado a que haya un canal libre. En realidad, la mayoría de las consultas sólo requieren unos milisegundos.
Si la GUI debe esperar más de Timeout waiting for a free channel por un canal, se interrumpirá con un error y el usuario recibirá un mensaje de error. En tal caso, debe aumentarse el número de conexiones. Ten en cuenta, sin embargo, que en el site remoto deben permitirse suficientes conexiones entrantes paralelas - por defecto está configurado a 20. Este ajuste se encuentra en las opciones globales enMonitoring core > Maximum concurrent Livestatus connections.
Regular heartbeat proporciona una monitorización activa constante de las conexiones directamente a nivel de protocolo. En el proceso, el proxy envía regularmente una simple consulta de Livestatus que debe ser respondida por el site remoto en el tiempo predeterminado (por defecto: 2 segundos). Con este método también se detectará una situación en la que el servidor de destino y el puerto TCP están realmente accesibles, pero el núcleo de monitorización ya no responde.
Si no aparece una respuesta, todas las conexiones se declararán "muertas" y, tras un tiempo de "enfriamiento" (por defecto: 4 segundos), se volverán a establecer. Todo esto tiene lugar de forma proactiva, es decir, sin que el usuario tenga que abrir una ventana GUI. De este modo, las interrupciones pueden detectarse rápidamente y, mediante una recuperación, las conexiones pueden restablecerse inmediatamente y, en el mejor de los casos, estar disponibles antes de que el usuario se dé cuenta de la interrupción.
Caching garantiza que las consultas estáticas sólo tengan que ser respondidas una vez por el site remoto, y que a partir de ese momento puedan ser respondidas directa y localmente, sin demora. Un ejemplo de ello es la lista de host monitorizados que requiere Quicksearch.
Diagnóstico de errores
El proxy Livestatus tiene su propio archivo de registro, que se encuentra en var/log/liveproxyd.log. En un site remoto correctamente configurado con cinco canales (estándar), tendrá un aspecto similar al siguiente:
2021-12-01 15:58:30,624 [20] ----------------------------------------------------------
2021-12-01 15:58:30,627 [20] [cmk.liveproxyd] Livestatus Proxy-Daemon (2.0.0p15) starting...
2021-12-01 15:58:30,638 [20] [cmk.liveproxyd] Configured 1 sites
2021-12-01 15:58:36,690 [20] [cmk.liveproxyd.(3236831).Manager] Reload initiated. Checking if configuration changed.
2021-12-01 15:58:36,692 [20] [cmk.liveproxyd.(3236831).Manager] No configuration changes found, continuing.
2021-12-01 16:00:16,989 [20] [cmk.liveproxyd.(3236831).Manager] Reload initiated. Checking if configuration changed.
2021-12-01 16:00:16,993 [20] [cmk.liveproxyd.(3236831).Manager] Found configuration changes, triggering restart.
2021-12-01 16:00:17,000 [20] [cmk.liveproxyd.(3236831).Manager] Restart initiated. Terminating site processes...
2021-12-01 16:00:17,028 [20] [cmk.liveproxyd.(3236831).Manager] Restart master processEl proxy Livestatus registra regularmente su estado en el archivo var/log/liveproxyd.state:
Current state:
[remote1]
State: ready
State dump time: 2021-12-01 15:01:15 (0:00:00)
Last reset: 2021-12-01 14:58:49 (0:02:25)
Site's last reload: 2021-12-01 14:26:00 (0:35:15)
Last failed connect: Never
Last failed error: None
Cached responses: 1
Channels:
9 - ready - client: none - since: 2021-12-01 15:01:00 (0:00:14)
10 - ready - client: none - since: 2021-12-01 15:01:10 (0:00:04)
11 - ready - client: none - since: 2021-12-01 15:00:55 (0:00:19)
12 - ready - client: none - since: 2021-12-01 15:01:05 (0:00:09)
13 - ready - client: none - since: 2021-12-01 15:00:50 (0:00:24)
Clients:
Heartbeat:
heartbeats received: 29
next in 0.2s
Inventory:
State: not running
Last update: 2021-12-01 14:58:50 (0:02:25)Y cuando un site esté detenido, el estado tendrá este aspecto
----------------------------------------------
Current state:
[remote1]
State: starting
State dump time: 2021-12-01 16:11:35 (0:00:00)
Last reset: 2021-12-01 16:11:29 (0:00:06)
Site's last reload: 2021-12-01 16:11:29 (0:00:06)
Last failed connect: 2021-12-01 16:11:33 (0:00:01)
Last failed error: [Errno 111] Connection refused
Cached responses: 0
Channels:
Clients:
Heartbeat:
heartbeats received: 0
next in -1.0s
Inventory:
State: not running
Last update: 2021-12-01 16:00:45 (0:10:50)Aquí el estado es 'starting'. Por tanto, el proxy está intentando establecer conexiones. Aún no hay canales. Durante este estado, las consultas al site se responderán con un error.
4. Livestatus en cascada
Como ya se ha mencionado en la introducción, es posible ampliar una monitorización distribuida para incluir sites del visor Checkmk dedicados que muestren los datos de monitorización de los sites remotos a los que, por sí mismos, no se puede acceder directamente. El único requisito para ello es que, por supuesto, el site central sea accesible. Técnicamente, esto se lleva a cabo mediante el proxy Livestatus. El site central recibe los datos del site remoto a través de Livestatus y actúa como proxy, es decir, puede pasar los datos a sites terceros. Puedes ampliar esta cadena como quieras, por ejemplo, conectando un segundo site del visor a través del primero.
Esto es práctico, por ejemplo, en un escenario como el siguiente: el site central da soporte a tres redes independientes-cliente1, cliente2 y cliente3-, y funciona él mismo en la red del operador1. Si la dirección del operador de la red del operador1 quisiera ver el estado de monitorización de los sites de los clientes, esto podría regularse, por supuesto, mediante un acceso desde el site central. Sin embargo, por razones técnicas y legales, el site central podría reservarse exclusivamente al personal responsable del mismo. Así, puede evitarse un acceso directo configurando un site del visor dedicado a ver los sites remotos. El site del visor muestra entonces los host y servicios de los sites conectados, pero su propia configuración permanece completamente vacía.
La configuración se hace en los ajustes de conexión de la monitorización distribuida, primero en el site central y luego en el site del visor (que en realidad no tiene por qué existir todavía).
En el site central, abre la configuración de conexión para el site remoto deseado a través de Setup > General > Distributed monitoring. En Use Livestatus Proxy Daemon, activa la opción Allow access via TCP e introduce un puerto disponible (aquí 6560). De este modo, el proxy Livestatus del site central se conecta al site remoto y abre un puerto para las peticiones del site del visor, que se reenvían al site remoto.
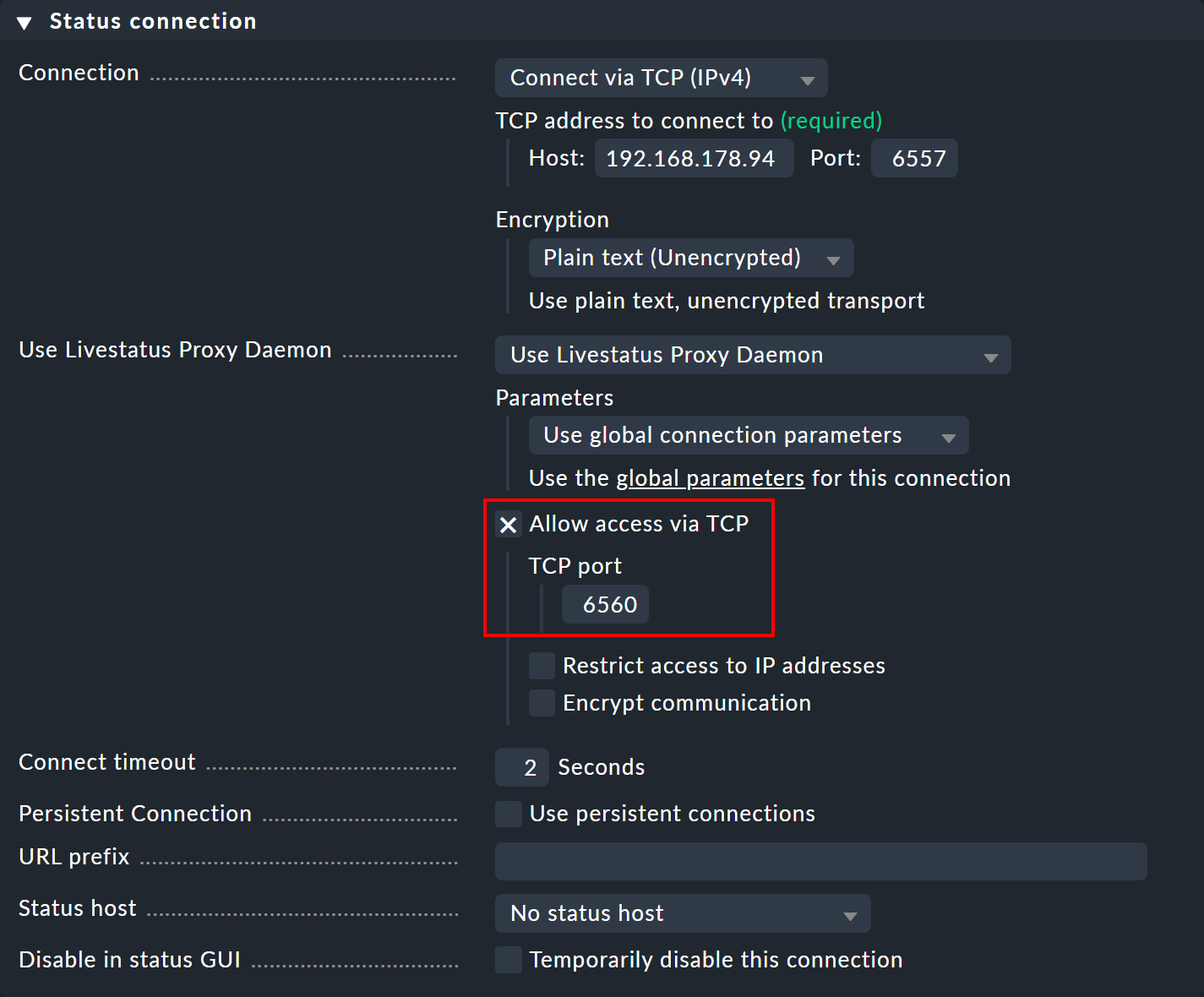
Ahora crea un site del visor y abre de nuevo la configuración de la conexión a través de Setup > General > Distributed monitoring. En el panel Basic settings introduce -como siempre para las conexiones en monitorización distribuida- el nombre exacto del site central como Site ID.

En el panel Status connection, introduce el site central como host - así como el puerto libre asignado manualmente (aquí 6560).
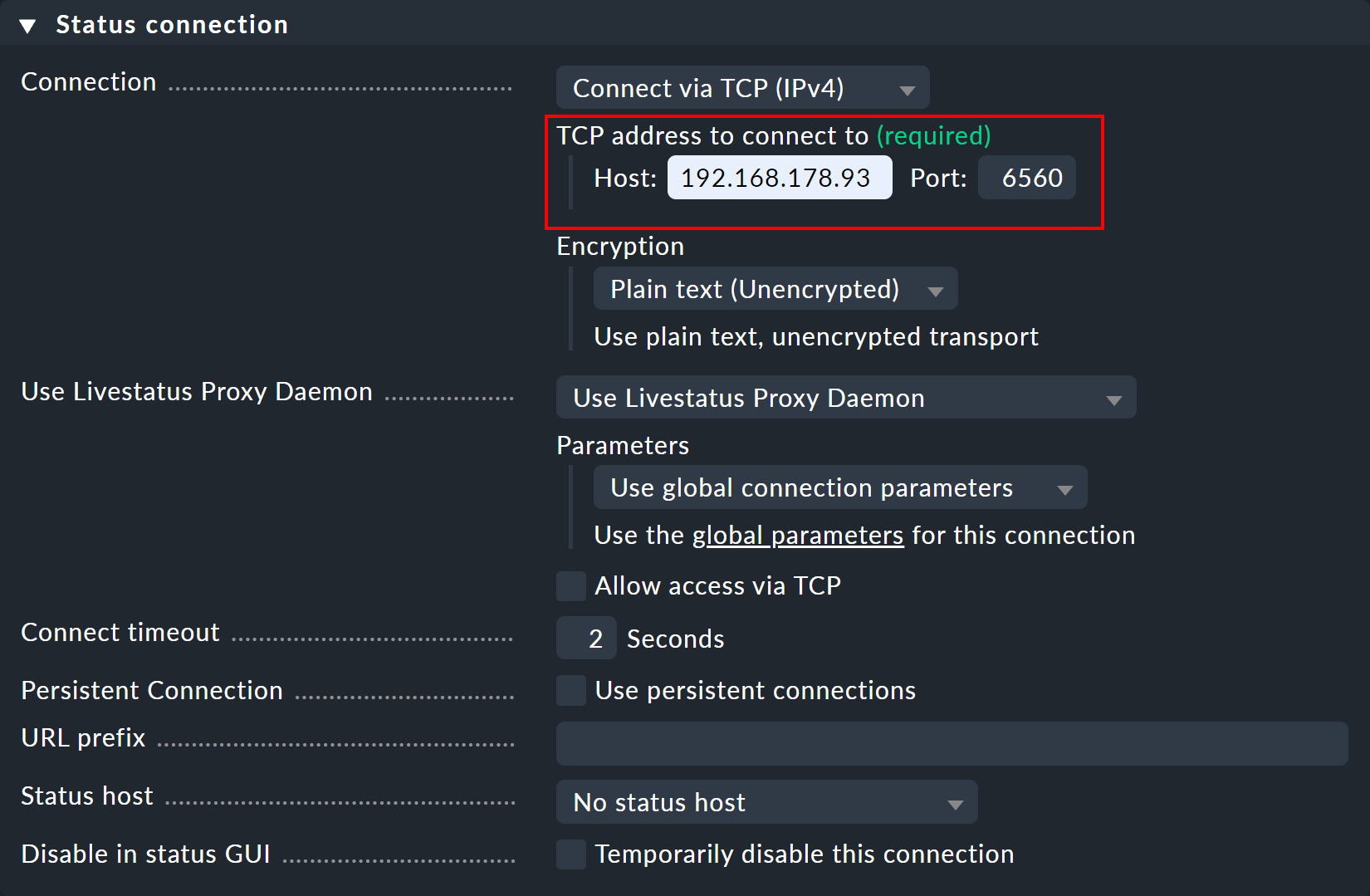
En cuanto se establezca la conexión, verás los host y servicios deseados en el site remoto en las vistas de monitorización del site del visor.
Si quieres continuar en cascada, también debes permitir el acceso TCP al proxy de Livestatus en el site del visor, como se hizo antes en el site central, esta vez con un puerto libre diferente.
5. Livedump y CMCDump
5.1. Motivación
El concepto de monitorización distribuida con Checkmk que se ha descrito hasta ahora es una solución buena y sencilla en la mayoría de los casos. Sin embargo, requiere acceso a la red desde el site central a los remotos. Hay situaciones en las que el acceso no es posible o no se desea, porque, por ejemplo:
Los sites remotos están en la red de tu cliente, a la que no tienes acceso.
Los sites remotos están en una zona de seguridad cuyo acceso está estrictamente prohibido.
Los sites remotos no tienen conexión de red permanente ni direcciones IP fijas, y métodos como el DNS dinámico no son una opción.
La monitorización distribuida con Livedump o, respectivamente, CMCDump adopta un enfoque bastante diferente. En primer lugar, los sitios remotos están conectados de tal modo que funcionan con total independencia del site central y se administran de forma descentralizada. Se prescinde de un entorno de configuración distribuida.
Todos los host y servicios del site remoto se replicarán como copias en el site central. Livedump/CMCDump puede ayudar generando una copia de la configuración de los sites remotos, que luego puede cargarse en el site central.
Ahora, durante la monitorización, en cada site remoto se escribirá en un archivo una copia del estado actual a intervalos predeterminados (por ejemplo, cada minuto), que se transmitirá al site central mediante un método definido por el usuario y se guardará allí como actualización del estado. No se ha proporcionado ni especificado ningún protocolo concreto para esta transferencia de datos. Podrían utilizarse todos los protocolos de transferencia que puedan automatizarse. No es imprescindible utilizar scp, ¡incluso es concebible una transferencia por correo electrónico!
Esta configuración difiere de una monitorización distribuida "normal" en lo siguiente:
La actualización de los estados y datos de rendimiento en el site central se retrasará.
El cálculo de la disponibilidad en el site central dará resultados mínimamente diferentes a un cálculo en el site remoto.
Los cambios de estado que se produzcan más rápidamente que el intervalo de actualización serán invisibles para el site central.
Si un site remoto está "muerto", los estados quedarán obsoletos en el site central: los servicios estarán "obsoletos", pero seguirán siendo visibles. Los datos de rendimiento y disponibilidad de este periodo de tiempo se "perderán" (pero seguirán estando disponibles en el site remoto).
Los comandos del site central, como Schedule downtimes y Acknowledge problems, no pueden transmitirse al site remoto.
El site central nunca puede acceder a los sites remotos.
El acceso a los detalles del archivo de registro mediante Logwatch es imposible.
La Consola de eventos no será compatible con Livedump/CMCDump.
Dado que los cambios de estado breves -dependiendo del intervalo periódico seleccionado en el site central- pueden no ser visibles, una notificación a través del site central no es lo ideal. Sin embargo, si el site central se utiliza como sitepuramente de visualización-como resumen central de todos los clientes, por ejemplo-, este método tiene definitivamente sus ventajas.
Por cierto, Livedump/CMCDump puede utilizarse simultáneamentecon la monitorización distribuida a través de Livestatus sin problemas. Algunos sites se conectan directamente a través de Livestatus, otros utilizan Livedump. Livedump también puede añadirse a uno de los sites remotos de Livestatus.
5.2. Instalar Livedump
Si vas a instalar Checkmk Raw (o las ediciones comerciales con núcleo Nagios), utiliza la herramienta livedump. El nombre deriva de Livestatus y volcado de estado.livedump se encuentra directamente en la ruta de búsqueda y, por tanto, está disponible como comando.
Haremos las siguientes suposiciones
el site remoto se ha configurado completamente y está monitorizando activamente host y servicios,
el site central se ha iniciado y está en funcionamiento,
al menos un host está siendo monitorizado localmente en el site central (porque el central se monitoriza a sí mismo).
Transferir la configuración
Primero, en el site remoto, crea una copia de las configuraciones de sus host y servicios en formato Nagios-configuration. También redirige la salida de livedump -TC a un archivo:
OMD[remote1]:~$ livedump -TC > config-remote1.cfgEl inicio del archivo será algo parecido a esto
define host {
name livedump-host
use check_mk_default
register 0
active_checks_enabled 0
passive_checks_enabled 1
}
define service {
name livedump-service
register 0
active_checks_enabled 0
passive_checks_enabled 1
check_period 0x0
}Transmite el archivo al site central, (por ejemplo con scp) y guárdalos allí en el directorio ~/etc/nagios/conf.d/ - aquí Nagios espera encontrar los datos de configuración de host y servicios. Selecciona un nombre de archivo que termine en.cfg, por ejemplo ~/etc/nagios/conf.d/config-remote1.cfg. Si es posible un acceso SSH desde el site remoto al site central, puede hacerse, por ejemplo, como se indica a continuación:
OMD[remote1]:~$ scp config-remote1.cfg central@myserver.mydomain:etc/nagios/conf.d/
central@myserver.mydomain's password:
config-remote1.cfg 100% 8071 7.9KB/s 00:00Ahora accede al site central y activa los cambios:
OMD[central]:~$ cmk -R
Generating configuration for core (type nagios)...OK
Validating Nagios configuration...OK
Precompiling host checks...OK
Restarting monitoring core...OKAhora todos los host y servicios del remoto deberían aparecer en el site central - inicialmente con el estado PEND, que conservarán por el momento:
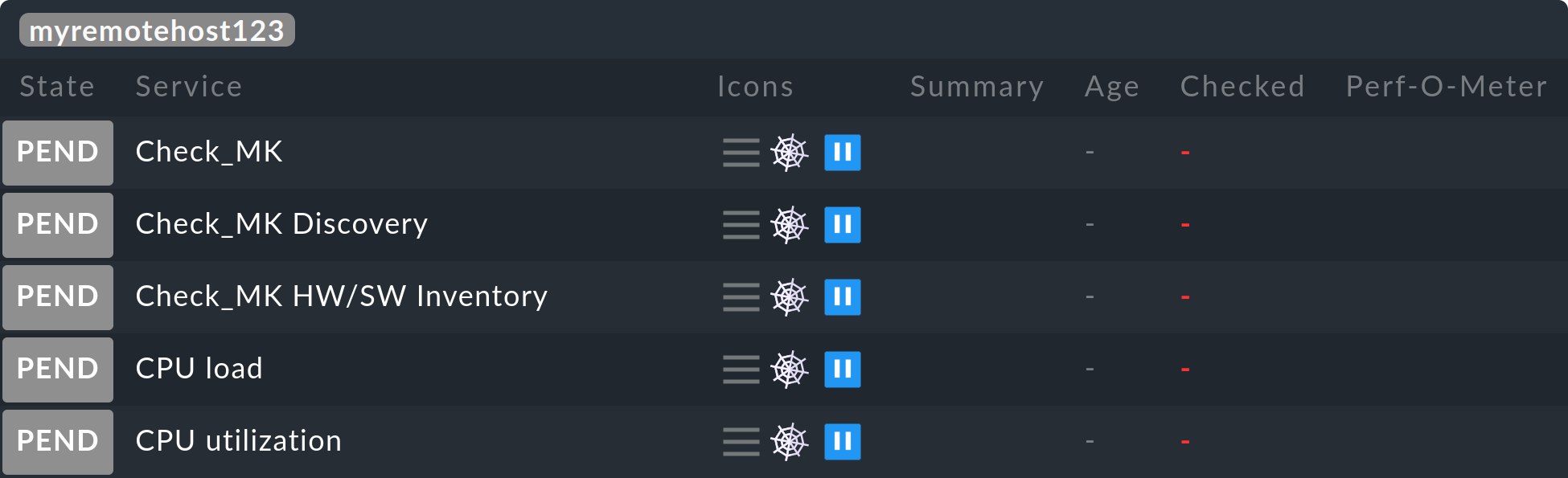
Nota:
Con la opción
-Tenlivedumpse crean definiciones de plantillas en Livedump a partir de las cuales extrae la configuración. Sin ellas, Nagios no puede iniciarse. Sin embargo, sólo puede estar presente una de ellas. Si importas una configuración desde otro site remoto , ¡no debe utilizar la opción-T!También es posible volcar la configuración en un Checkmk Micro Core (CMC), cuya importación requiere Nagios. Si la CMC se ejecuta en tu site central, utiliza CMCDump.
La copia y transferencia de la configuración debe repetirse para cada cambio en los host o servicios del site remoto.
Transferir el estado
Una vez que los host sean visibles en el site central, necesitaremos configurar una transmisión (regular) del estado de monitorización de los remotos. Crea de nuevo un archivo con livedump, pero esta vez sin opciones secundarias:
OMD[remote1]:~$ livedump > stateEste archivo contiene los estados de todos los host y servicios en un formato que Nagios puede leer directamente de los resultados de check. El inicio de este archivo es algo parecido a esto
host_name=myhost1900
check_type=1
check_options=0
reschedule_check
latency=0.13
start_time=1615521257.2
finish_time=16175521257.2
return_code=0
output=OK - 10.1.5.44: rta 0.066ms, lost 0%|rta=0.066ms;200.000;500.000;0; pl=0%;80;100;; rtmax=0.242ms;;;; rtmin=0.017ms;;;;Copia este archivo en el site central, en el directorio ~/tmp/nagios/checkresults . Importante: El nombre de este archivo debe empezar por c y tener siete caracteres. Con scp tendrá un aspecto parecido a éste:
OMD[remote1]:~$ scp state central@mycentral.mydomain:tmp/nagios/checkresults/caabbcc
central@mycentral.mydomain's password:
state 100% 12KB 12.5KB/s 00:00Por último, crea un archivo vacío en el site central con el mismo nombre y la extensión .ok. Con esto Nagios sabrá que el archivo de estado se ha transferido completamente y ahora se puede leer en él:
OMD[central]:~$ touch tmp/nagios/checkresults/caabbcc.okEl estado de los host/servicios remotos se actualizará inmediatamente en el site central:
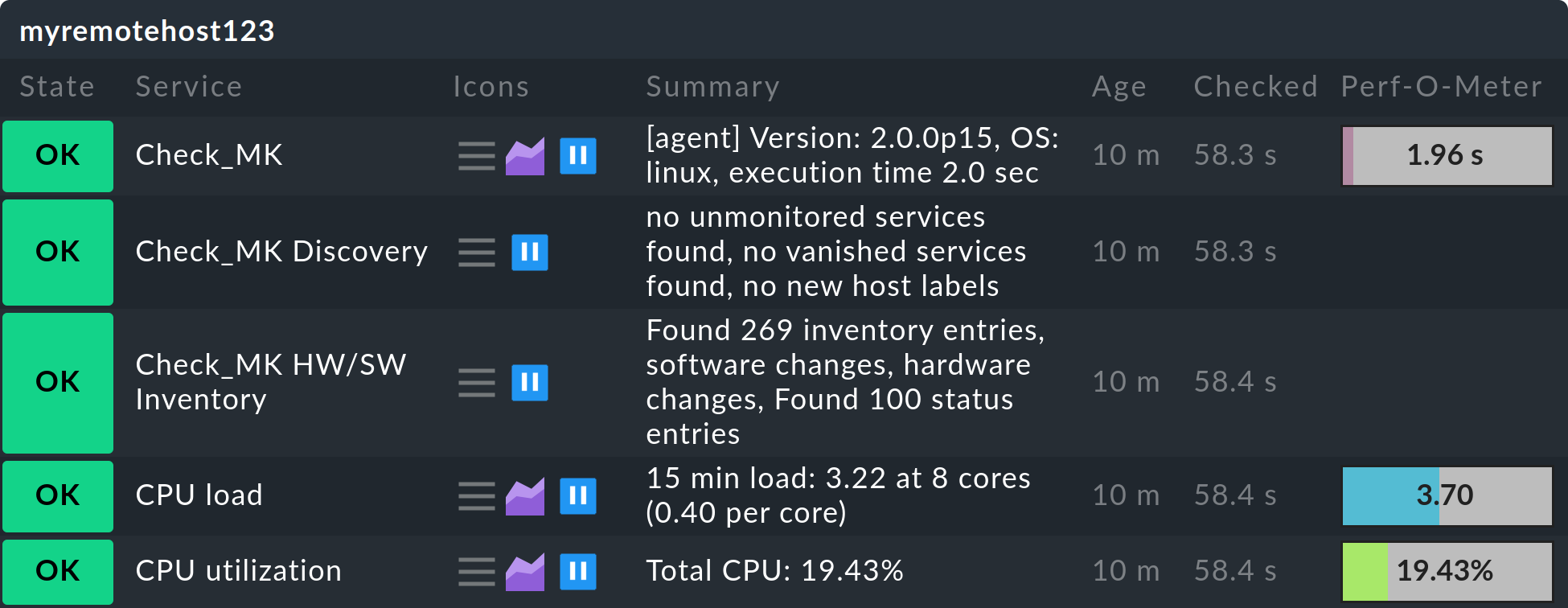
A partir de ahora, la transmisión del estado debe hacerse con regularidad. Lamentablemente, Livedump no admite esta tarea y tendrás que guionizarla tú mismo. El script livedump-ssh-recv se encuentra en ~/share/check_mk/doc/treasures/livedump, que puedes emplear para recibir las actualizaciones de Livedump (incluidas las de la configuración) en el site central por SSH. Para más detalles, consulta los comentarios del propio script.
El volcado de la configuración y del estado también puede restringirse utilizando filtros Livestatus. Por ejemplo, podrías limitar los host a los miembros del grupo del host mygroup:
OMD[remote1]:~$: livedump -H "Filter: host_groups >= mygroup" > statePuedes encontrar más información sobre Livedump en el archivo README del directorio ~/share/doc/check_mk/treasures/livedump.
5.3. Implementación de CMCDump
CMCDump es para Checkmk Micro Core lo que Livedumpes para Nagios y, por tanto, es la herramienta preferida para las ediciones comerciales. A diferencia de Livedump, CMCDump puede replicar el estado completo de hosts y servicios (Nagios no tiene las interfaces necesarias para esta tarea).
Para comparar: Livedump transfiere los siguientes datos:
Los estados actuales: PEND, OK, WARN, CRIT, UNKNOWN, UP, DOWN o UNREACH.
La salida de los Plugin de check
Los datos de rendimiento
CMCDump sincroniza además
La salida larga del Plugin
Si el objeto es actualmente inestable
Las marcas de tiempo de la última ejecución de check y del último cambio de estado
La duración de la ejecución del check
La latencia de la ejecución del check
El número de secuencia del intento de check actual y si el estado actual es "hard" o "soft".
Reconocimiento, si existe
Si el objeto está actualmente en un mantenimiento planificado.
Esto proporciona un reflejo mucho más preciso de la monitorización. Al importar el estado, la CMC no se limita a simular la ejecución de un check, sino que, utilizando una interfaz diseñada para esta tarea, transmite un estado preciso. Entre otras cosas, esto significa que en cualquier momento el centro de operaciones puede ver si se han reconocido problemas o si se han introducido tiempos de mantenimiento.
La instalación es casi idéntica a la de Livedump, pero es algo más sencilla, ya que no hay que preocuparse por posibles plantillas duplicadas o similares.
La copia de la configuración se realiza con cmcdump -C. Guarda este archivo en el site central en etc/check_mk/conf.d/. Debe utilizarse la extensión de archivo .mk:
OMD[remote1]:~$ cmcdump -C > config.mk
OMD[remote1]:~$ scp config.mk central@mycentral.mydomain:etc/check_mk/conf.d/remote1.mkActiva la configuración en el site central:
OMD[central]:~$ cmk -OAl igual que con Livedump, los host y servicios aparecerán ahora en el site central en estadoPEND. Sin embargo, verás por el símbolo que se trata de un objeto sombra. De este modo, se distingue de un objeto que está siendo monitorizado directamente en el site central o en un site remoto "normal":
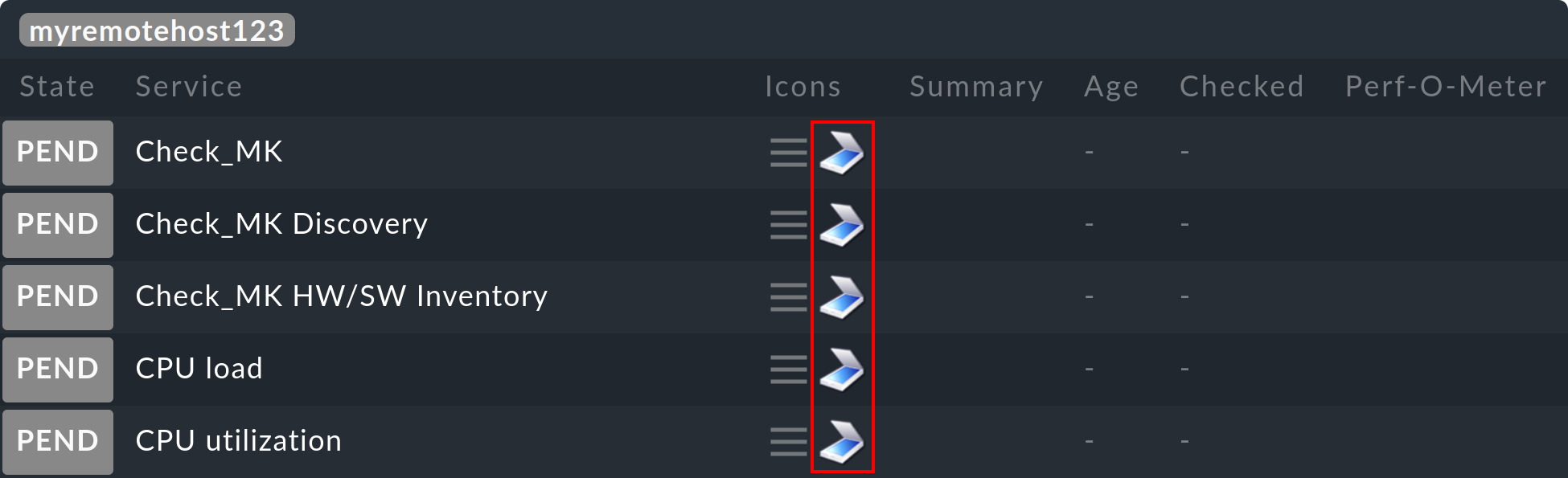
La generación normal del estado se realiza con cmcdump sin argumentos adicionales:
OMD[remote1]:~$ cmcdump > state
OMD[remote1]:~$ scp state central@mycentral.mydomain:tmp/state_remote1Para importar el estado al site central, el contenido del archivo debe escribirse en el UNIX-Sockettmp/run/live con ayuda de la herramienta unixcat.
OMD[central]:~$ unixcat tmp/run/live < tmp/state_remote1Si tienes una conexión desde el site remoto al site central mediante SSH sin contraseña, los tres comandos pueden combinarse en uno solo, y al hacerlo ni siquiera se crea un archivo temporal:
OMD[remote1]:~$ cmcdump | ssh central@mycentral.mydomain "unixcat tmp/run/live"¡Es muy sencillo! Pero, como ya se ha mencionado, ssh/scp no es el único método para transferir archivos, y una configuración o un estado pueden transferirse igual de bien utilizando el correo electrónico u otro protocolo deseado.
6. Notificaciones en entornos distribuidos
6.1. ¿Centralizadas o descentralizadas?
En un entorno distribuido se plantea la cuestión de desde qué sitio deben enviarse las notificaciones (por ejemplo, correos electrónicos): ¿desde los puestos remotos individuales o desde el site central? Hay argumentos a favor de ambos procedimientos.
Argumentos a favor del envío desde las remotas
Más sencillo de configurar
Sigue siendo posible una notificación local si el enlace al site central no está disponible
También funciona con Checkmk Raw
Argumentos para el envío desde el site central:
Las notificaciones pueden seguir procesándose en un sitio central (por ejemplo, reenviarse a un sistema de tickets)
los sites remotos no requieren configuración para correo electrónico o SMS
Para enviar un SMS por hardware sólo es necesario una vez: en el site central
6.2. Notificación descentralizada
No se requieren pasos especiales para una notificación descentralizada, ya que ésta es la configuración estándar. Cada notificación que se genera en un site remoto se ejecuta a través de la cadena de reglas de notificación que hay allí. Si implementas un entorno de configuración distribuido, estas reglas son las mismas en todos los sites. Las notificaciones resultantes de estas reglas se entregarán como de costumbre, para lo cual se habrán ejecutado localmente los scripts de notificación apropiados.
Simplemente hay que asegurarse de que se ha instalado correctamente el servicio adecuado en los sites -que se ha definido un smarthost para el correo electrónico, por ejemplo-, es decir, el mismo procedimiento que para configurar un site individual de Checkmk.
6.3. Notificación centralizada
Fundamentos
Las ediciones comerciales proporcionan un mecanismo integrado para las notificaciones centralizadas, que puede activarse individualmente para cada site remoto. Estos remotos dirigen todas las notificaciones al site central para su posterior procesamiento. De este modo, la notificación centralizada es independiente de si la monitorización distribuida se ha configurado de la forma estándar, o con CMCDump, o utilizando una mezcla de estos procedimientos. Técnicamente hablando, el servidor de notificación central ni siquiera necesita ser el "central". Esta tarea puede ser asumida por cualquier site Checkmk.
Si un site remoto se ha configurado como "reenviador", todas las notificaciones se reenviarán directamente al site central tal y como lo harían desde el núcleo, es decir, en formato raw. Una vez allí, se evaluarán las reglas de notificación que realmente deciden a quién se debe notificar y cómo. Los scripts de notificación necesarios se invocarán en el site central.
Configuración de las conexiones TCP
Los spoolers de notificación de los sites remoto y central (notificación) se comunican entre sí mediante TCP. Las notificaciones se envían del site remoto al central. La central reconoce a las remotas que se han recibido las notificaciones, lo que evita que se pierdan aunque se interrumpa la conexión TCP.
Hay dos alternativas para la construcción de una conexión TCP:
Se configura una conexión TCP de la central al site remoto. Aquí el remoto es el servidor TCP.
Se configura una conexión TCP desde el site remoto al site central. En este caso, el site central es el servidor TCP.
Por tanto, no hay nada que impida enviar notificaciones si, por motivos de red, sólo es posible establecer conexiones en una dirección concreta. Las conexiones TCP son supervisadas por el spooler con una señal de heartbeat y se restablecen inmediatamente cuando es necesario, no sólo en caso de notificación.
Dado que el site remoto y el central requieren ajustes globales diferentes, debes realizarajustes específicos para todos los remotos. La configuración del site central se realiza utilizando los ajustes globales normales. Nota: estos ajustes serán heredados automáticamente por todos los remotos para los que no se hayan definido ajustes específicos.
Veamos primero un ejemplo en el que el site central establece las conexiones TCP con los sites remotos.
Paso 1: En el site remoto, edita la configuración global específica del siteNotifications > Notification Spooler Configuration y activaAccept incoming TCP connections. Se recomendará el puerto TCP 6555 para las conexiones entrantes. Si no hay objeciones, adopta esta configuración.
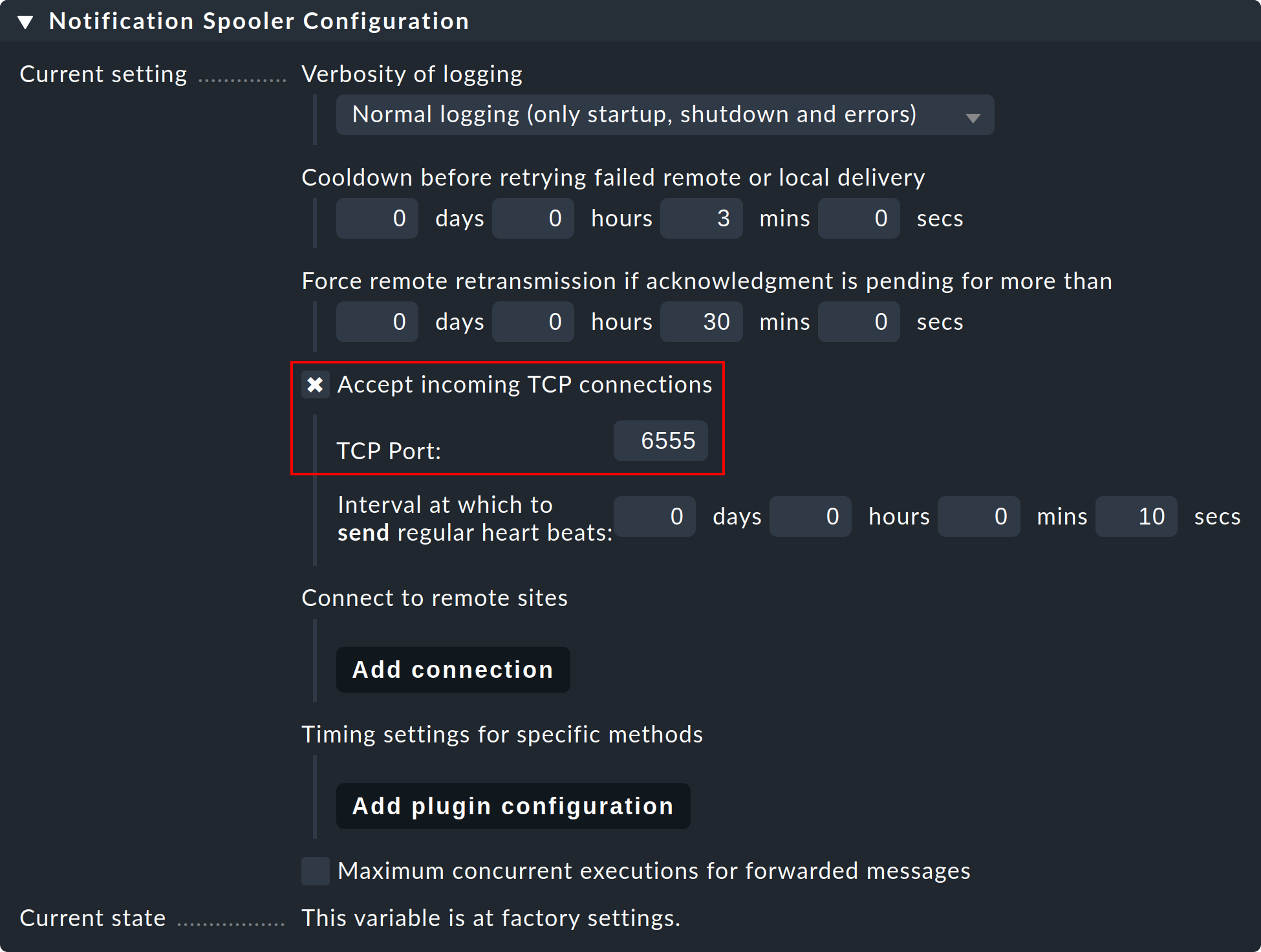
Paso 2: Ahora, del mismo modo, en el submenú Notification Spooling sólo en el site remoto, selecciona la opciónForward to remote site by notification spooler.

Paso 3: Ahora, en el site central- es decir, en la configuración global normal - configura la conexión con el site remoto (y luego con los remotos adicionales que sean necesarios):
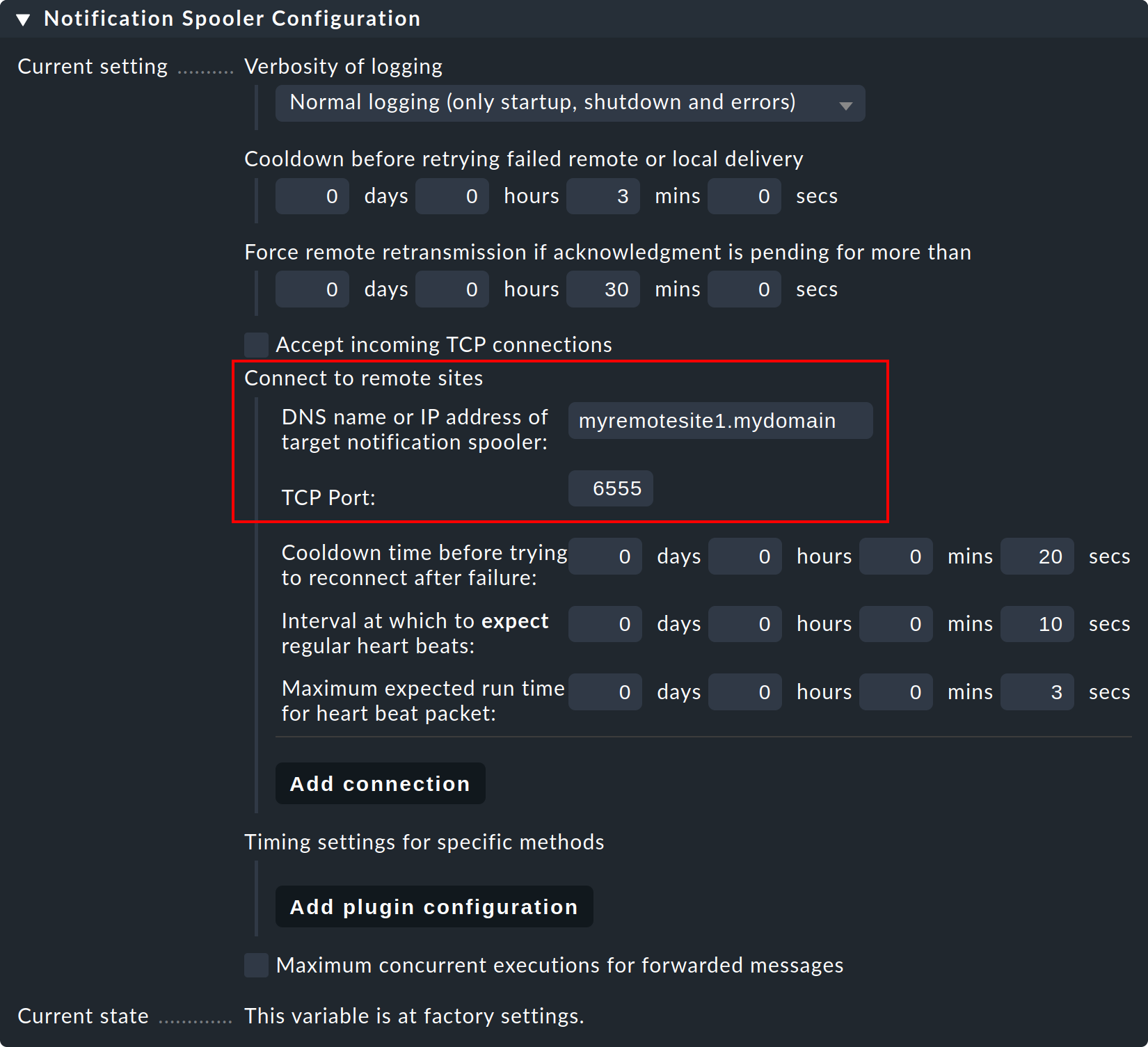
Paso 4: Establece la configuración global Notification Spooling enAsynchronous local delivery by notification spooler, para que las comunicaciones del site central también se procesen a través del mismo spooler central.

Paso 5: Activa los cambios.
Establecer conexiones desde un site remoto
Si la conexión TCP debe establecerse desde el site remoto, el procedimiento es idéntico, diferenciándose únicamente de la descripción anterior en que simplemente se intercambian los papeles de site central y remoto.
También es posible una mezcla de ambos procedimientos. En tal caso, el site central debe instalarse de modo que escuche las conexiones entrantes, además de conectarse a los sites remotos. Sin embargo, en cada relación central/remoto, ¡sólo uno de los dos puede establecer la conexión!
Prueba y diagnóstico
El spooler de notificación registra en el archivo var/log/mknotifyd.log. En la configuración del spooler se puede aumentar el nivel de registro para que se reciban más mensajes. Con un nivel de registro estándar se debería ver algo así en el site central:
2021-11-17 07:11:40,023 [20] [cmk.mknotifyd] -----------------------------------------------------------------
2021-11-17 07:11:40,023 [20] [cmk.mknotifyd] Check_MK Notification Spooler version 2.0.0p15 starting
2021-11-17 07:11:40,024 [20] [cmk.mknotifyd] Log verbosity: 0
2021-11-17 07:11:40,025 [20] [cmk.mknotifyd] Daemonized with PID 31081.
2021-11-17 07:11:40,029 [20] [cmk.mknotifyd] Connection to 10.1.8.44 port 6555 in progress
2021-11-17 07:11:40,029 [20] [cmk.mknotifyd] Successfully connected to 10.1.8.44:6555En todo momento, el archivo var/log/mknotifyd.state contiene el estado actual del spooler y de todas sus conexiones:
Connection: 10.1.8.44:6555
Type: outgoing
State: established
Status Message: Successfully connected to 10.1.8.44:6555
Since: 1637129500 (2021-11-17 07:11:40, 140 sec ago)
Connect Time: 0.002 secTambién existe una versión del mismo archivo en el site remoto. Allí la conexión tendrá un aspecto similar a éste
Connection: 10.22.4.12:56546
Type: incoming
State: established
Since: 1637129500 (2021-11-17 07:11:40, 330 sec ago)Para probarlo, selecciona cualquier servicio remoto monitorizado y ponlo manualmente en CRIT con el comando Fake check results.
Ahora, en el site central debería aparecer una notificación entrante en el archivo de registro de notificaciones (notify.log):
2021-11-17 07:59:36,231 ----------------------------------------------------------------------
2021-11-17 07:59:36,232 [20] [cmk.base.notify] Got spool file 307ad477 (myremotehost123;Check_MK) from remote host for local delivery.El mismo evento tendrá este aspecto en el site remoto:
2021-11-17 07:59:28,161 [20] [cmk.base.notify] ----------------------------------------------------------------------
2021-11-17 07:59:28,161 [20] [cmk.base.notify] Got raw notification (myremotehost123;Check_MK) context with 71 variables
2021-11-17 07:59:28,162 [20] [cmk.base.notify] Creating spoolfile: /omd/sites/remote1/var/check_mk/notify/spool/307ad477-b534-4cc0-99c9-db1c517b31fEn la configuración global puedes cambiar tanto el archivo de registro normal de notificaciones (notify.log) como el archivo de registro del spooler de notificación a un nivel de registro superior.
Monitorización de la cola de impresión
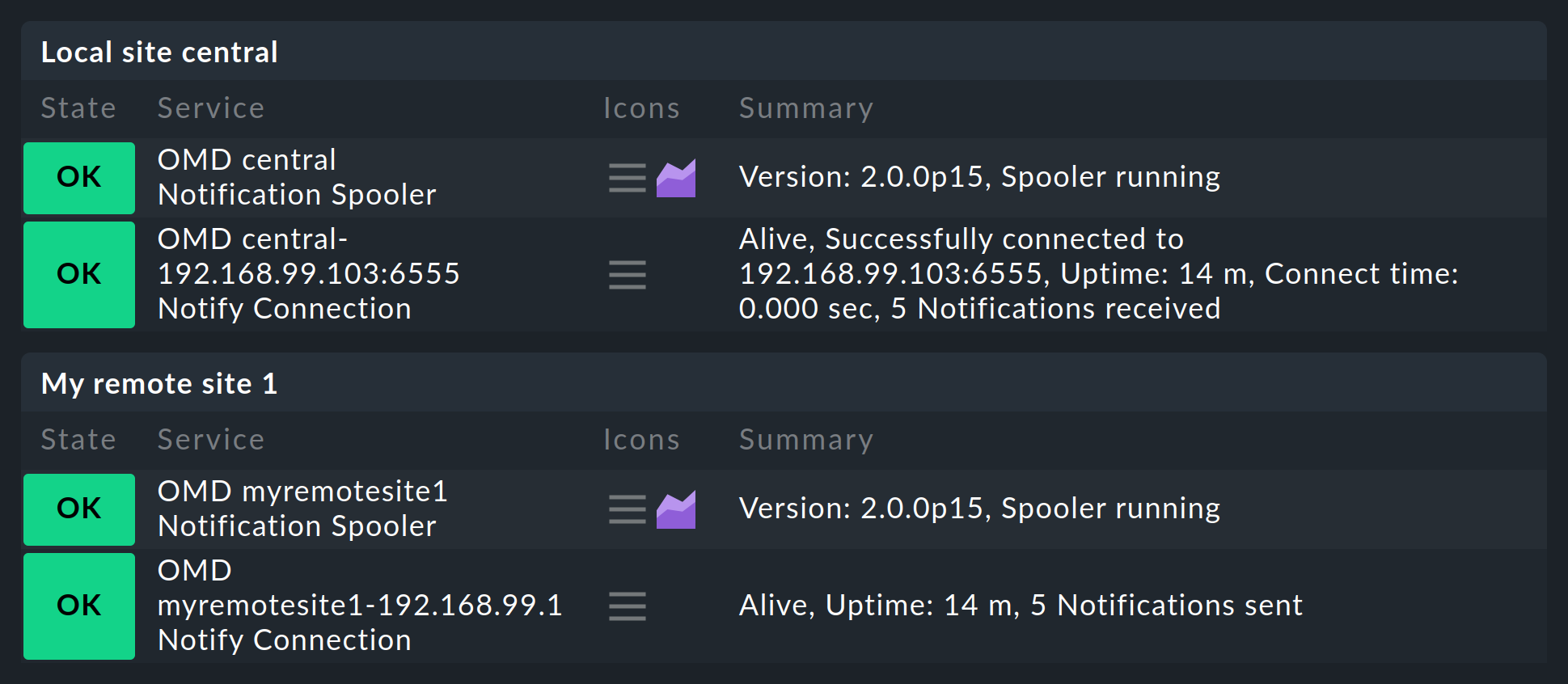
Una vez que hayas configurado todo como se ha descrito, te darás cuenta de que en el site central, y respectivamente en los remotos, se encontrará un nuevo servicio que definitivamente debe ser tenido en cuenta en la monitorización. Monitoriza el spooler de notificación y sus conexiones TCP, por lo que cada conexión será monitorizada dos veces: una por el site central y otra por el site remoto:
7. Un site central y sus sites remotos utilizan versiones distintas
Como regla general, las versiones de todos los sites remotos y del site central deben coincidir. Las excepciones a esta regla sólo se aplican durante la realización de actualizaciones. En este caso, hay que distinguir entre las siguientes situaciones:
7.1. Diferentes niveles de parche (pero la misma versión principal)
Por lo general, se permite que los niveles de parche (por ejemplo, p11) difieran sin problemas. Sin embargo, en raras ocasiones, incluso éstos pueden ser incompatibles entre sí, por lo que, en tal situación, debes mantener exactamente el mismo nivel de versión (por ejemplo, 2.0.0p11) en todos los sites para permitir que los sites funcionen juntos sin errores. Por tanto, anota siempre los cambios incompatibles de cada versión de parche en los Werks.
Como regla general -existen excepciones que se indican en los Werk- actualiza primero los site remotos y en último lugar el site central.
7.2. Diferentes versiones principales
Para ejecutar sin problemas actualizaciones mayores (por ejemplo, de 2.1.0 a 2.2.0) en grandes entornos distribuidos, a partir de la versión 2.0.0 Checkmk permite operaciones mixtas en las que los sites central y remoto pueden diferir en una versión mayor. Cuando realices una actualización, asegúrate de que primero actualizas los sites remotos. A continuación, actualiza el site central sólo cuando todos los sites remotos se hayan actualizado a la versión mayor.
De nuevo, ¡asegúrate de comprobar los Werks y las notas de actualización de la versión antes de iniciar la actualización! Siempre se requiere un nivel de parche específico (requisito previo) de la versión anterior en el site central para garantizar un funcionamiento mixto sin problemas.
Una característica especial en los entornos mixtos es la gestión centralizada de los paquetes de ampliación, que ahora pueden mantenerse en variantes tanto para la versión antigua como para la nueva de Checkmk. Los detalles al respecto se explican en el artículo sobre la gestión de los MKP.
8. Archivos y directorios
8.1. Ficheros de configuración
| Ruta | Descripción |
|---|---|
|
Aquí Checkmk almacena la configuración de las conexiones a los distintos sites. Si la interfaz se "cuelga" debido a un error en la configuración, de modo que queda inoperativa, puedes editar la entrada perturbadora directamente en el archivo. Sin embargo, si se activa el proxy Livestatus, posteriormente será necesario editar y guardar al menos una conexión, ya que sólo con esta acción se generará una configuración adecuada para este daemon. |
|
Configuración para el proxy Livestatus. Este archivo será generado de nuevo por Checkmk con cada alteración en la configuración de una monitorización distribuida. |
|
Configuración del spooler de notificación. Este archivo será generado por Checkmk al guardar la configuración global. |
|
Se crea en los sites remotos y garantiza que sólo monitorizan sus propios host. |
|
Ubicación de almacenamiento para los archivos de configuración de Nagios creados por el cliente con hosts y servicios. Son necesarios para utilizar Livedump en el site central. |
|
La configuración de Livestatus para el uso de Nagios como núcleo. Aquí puedes configurar el número máximo de conexiones simultáneas permitidas. |
|
La configuración de host y reglas para Checkmk. Almacena aquí los archivos de configuración generados por CMCDump. Sólo gestiona el subdirectorio |
|
Para los servicios encontrados por el descubrimiento de servicios. Siempre se almacenan localmente en el site remoto. |
|
Ubicación de la Base de datos Round Robin para archivar los datos de rendimiento cuando se utiliza el formato Checkmk-RRD (por defecto en las ediciones comerciales). |
|
Ubicación de la base de datos Round-Robin con el formato PNP4Nagios (Checkmk Raw) |
|
Archivo de registro de los proxies Livestatus. |
|
El estado actual de los proxies Livestatus en un formato legible. Este archivo se actualiza cada 5 segundos. |
|
Archivo de registro del sistema de notificaciones Checkmk. |
|
Archivo de registro del spooler de notificación. |
|
El estado actual del spooler de notificación de forma legible. Este archivo se actualiza cada 20 segundos. |