This is a machine translation based on the English version of the article. It might or might not have already been subject to text preparation. If you find errors, please file a GitHub issue that states the paragraph that has to be improved. |
1. Introducción
1.1. ¿Debe intervenir la monitorización?
Se podría pensar que es obvio que un sistema de monitorización nunca debe intervenir en los eventos, sino que debe, bueno, monitorizar. Y probablemente sea una buena idea dejarlo así.
Sin embargo, hay que admitir que resulta atractiva la idea de que un sistema capaz de identificar problemas de forma fiable también podría corregirlos, siempre que pudiera funcionar automáticamente.
Se pueden imaginar fácilmente algunos ejemplos adecuados:
Reiniciar un servicio que se ha crash.
La activación de un recolector de basura si una Java-VM se está quedando sin memoria.
La reconstrucción de un canal VPN si está definitivamente muerto.
Si se puede aceptar esto, entonces hay que pensar de otra manera sobre la monitorización. De un sistema que simplemente observa y que "no es necesario" para las operaciones, un proceso paso a paso lleva a que la monitorización se convierta en un órgano vital del centro de datos.
Pero corregir los problemas no es lo único que la monitorización puede hacer automáticamente cuando identifica un problema. Muy útil, pero también inofensiva, es la colección de datos de diagnóstico adicionales en el momento de un fallo. Sin duda, se te ocurrirán de antemano otras muchas cuestiones para las que se podrían utilizar los alert handlers como punto de partida.
1.2. Manejadores de alerta en Checkmk
Los alert handlers son scripts que escribes tú mismo y que Checkmk ejecuta por ti en las ediciones comerciales si se detecta un problema o, más exactamente, si un host o servicio cambia de estado.
Los alert handlers son muy parecidos a las notificaciones y se configuran de forma similar, pero hay algunas diferencias importantes:
Los alert handlers son independientes de los tiempos de mantenimiento programados, periodos de notificación, reconocimientos y controles similares.
Los alert handlers se activarán al primer reintento (si se han configurado varios intentos de check).
Los alert handlers son independientes de los usuarios y de los grupos de contacto.
Los alert handlers sólo están disponibles en las ediciones comerciales.
También se puede decir que los gestores de alertas son de muy "bajo nivel". En cuanto un host o servicio cambie de estado, tus gestores de alertas configurados se activarán inmediatamente. De este modo, un gestor de alertas puede incluso realizar una reparación con éxito antes de que se genere una alerta real.
Naturalmente, como siempre en Checkmk, puedes utilizar reglas para definir las condiciones para las que debe ejecutarse un determinado handler. Puedes averiguar cómo hacerlo y todo lo demás sobre los handlers de alerta en este artículo.
Un consejo para los usuarios de Checkmk Raw: también puedes hacer que la monitorización ejecute acciones automáticamente. Utiliza para ello los "manejadores de eventos" de Nagios. Configúralos con archivos de configuración manual en la sintaxis de Nagios en ~/etc/nagios/conf.d/. Los manejadores de eventos están bien documentados. Puedes encontrar información de forma sencilla a través de Google.
2. Configurar los alert handlers
2.1. Guardar los scripts en el directorio correcto
Los alert handlers son scripts que se ejecutan en el servidor Checkmk. Deben guardarse en el directorio ~/local/share/check_mk/alert_handlers/, y pueden estar codificados en cualquier lenguaje compatible con Linux, por ejemplo, BASH, Python o Perl. No olvides hacer que los scripts sean ejecutables con chmod +x.
Si se inserta un comentario en la segunda línea del script (con un hash # ), éste aparecerá como nombre del script en la lista de selección de la regla:
#!/bin/bash
# Foobar handler for repairing stuff
...2.2. Un simple alert handler para probar
Al igual que con las notificaciones, el script obtiene toda la información del host o servicio como variables del entorno, todas las cuales empiezan por el prefijo ALERT_.
Para comprobar exactamente qué variables del entorno aparecen en el script, puedes utilizar el siguiente alert handler para hacer una prueba:
#!/bin/bash
# Dump all variables to ~/tmp/alert.out
env | grep ^ALERT_ | sort > $OMD_ROOT/tmp/alert.outenvmuestra todas las variables del entorno.grep ^ALERT_selecciona las que empiezan porALERT_.sortordena la lista resultante alfabéticamente.
2.3. Activación del alert handler
La activación del manejador se realiza mediante Setup > Events > Alert handlers.
Procede de la siguiente manera:
Guarda el script en
~/local/share/check_mk/alert_handlers/debug.Hazlo ejecutable con
chmod +x debug.Llama a la página de configuración mediante Setup > Events > Alert handlers.
Allí, define una nueva regla con Add rule.
El formulario para seleccionar el alert handler permite el acceso directo y muestra el título que se registra en la segunda línea del script. Además, puedes añadir argumentos, que introducirás en los campos de texto. Éstos se interpretarán como argumentos de línea de comandos en el script. En tu shell puedes acceder a ellos con $1, $2, etc.

Importante: Tras guardar la regla, el alert handler se activará inmediatamente y se ejecutará con cada cambio de estado de cualquier host o servicio.
2.4. Pruebas y diagnóstico de fallos
Para hacer pruebas, configura manualmente un servicio, por ejemplo, Fake check results a CRIT. Ahora se debería haber creado el archivo con las variables. Aquí tienes sus primeras veinte líneas:
OMD[mysite]:~$ head -n 20 ~/tmp/alert.out
ALERT_ALERTTYPE=STATECHANGE
ALERT_CONTACTNAME=check-mk-notify
ALERT_CONTACTS=
ALERT_DATE=2016-07-19
ALERT_HOSTADDRESS=127.0.0.1
ALERT_HOSTALIAS=myserver123
ALERT_HOSTATTEMPT=1
ALERT_HOSTCHECKCOMMAND=check-mk-host-smart
ALERT_HOSTCONTACTGROUPNAMES=all
ALERT_HOSTDOWNTIME=0
ALERT_HOSTFORURL=myserver123
ALERT_HOSTGROUPNAMES=check_mk
ALERT_HOSTNAME=myserver123
ALERT_HOSTNOTESURL=
ALERT_HOSTNOTIFICATIONNUMBER=1
ALERT_HOSTOUTPUT=Packet received via smart PING
ALERT_HOSTPERFDATA=
ALERT_HOSTPROBLEMID=0
ALERT_HOSTSHORTSTATE=UP
ALERT_HOSTSTATE=UPEl archivo de registro de la (no) ejecución del alert handler se encontrará en ~/var/log/alerts.log. La sección de ejecución del alert handler debug, para el servicio Filesystem / en el host myserver123tendrá el siguiente aspecto:
2016-07-19 15:17:22 Got raw alert (myserver123;Filesystem /) context with 60 variables
2016-07-19 15:17:22 Rule ''...
2016-07-19 15:17:22 -> matches!
2016-07-19 15:17:22 Executing alert handler debug for myserver123;Filesystem /
2016-07-19 15:17:22 Spawned event handler with PID 6004
2016-07-19 15:17:22 1 running alert handlers:
2016-07-19 15:17:22 PID: 6004, object: myserver123;Filesystem /
2016-07-19 15:17:24 1 running alert handlers:
2016-07-19 15:17:24 PID: 6004, object: myserver123;Filesystem /
2016-07-19 15:17:24 Handler [6004] for myserver123;Filesystem / exited with exit code 0.
2016-07-19 15:17:24 Output:Un par de consejos útiles más:
Los textos producidos por los alert handlers en la salida estándar aparecen en el archivo de registro junto a
Output:.También se registrará el código de salida del script (
exited with exit code 0).Los alert handlers resultan realmente útiles cuando ejecutan un comando en el host de destino. Checkmk ofrece una solución preparada para Linux que se explicará más adelante.
3. Configuración basada en reglas
Como se muestra en el ejemplo introductorio, los eventos que deben activar los gestores de alertas se definen mediante reglas. Esto funciona de forma totalmente análoga a las notificaciones, sólo que algo simplificada. En el ejemplo no especificamos ninguna condición, lo que naturalmente no es realista en la práctica. El siguiente ejemplo muestra una condición que un gestor de alertas define para hosts y servicios concretos:
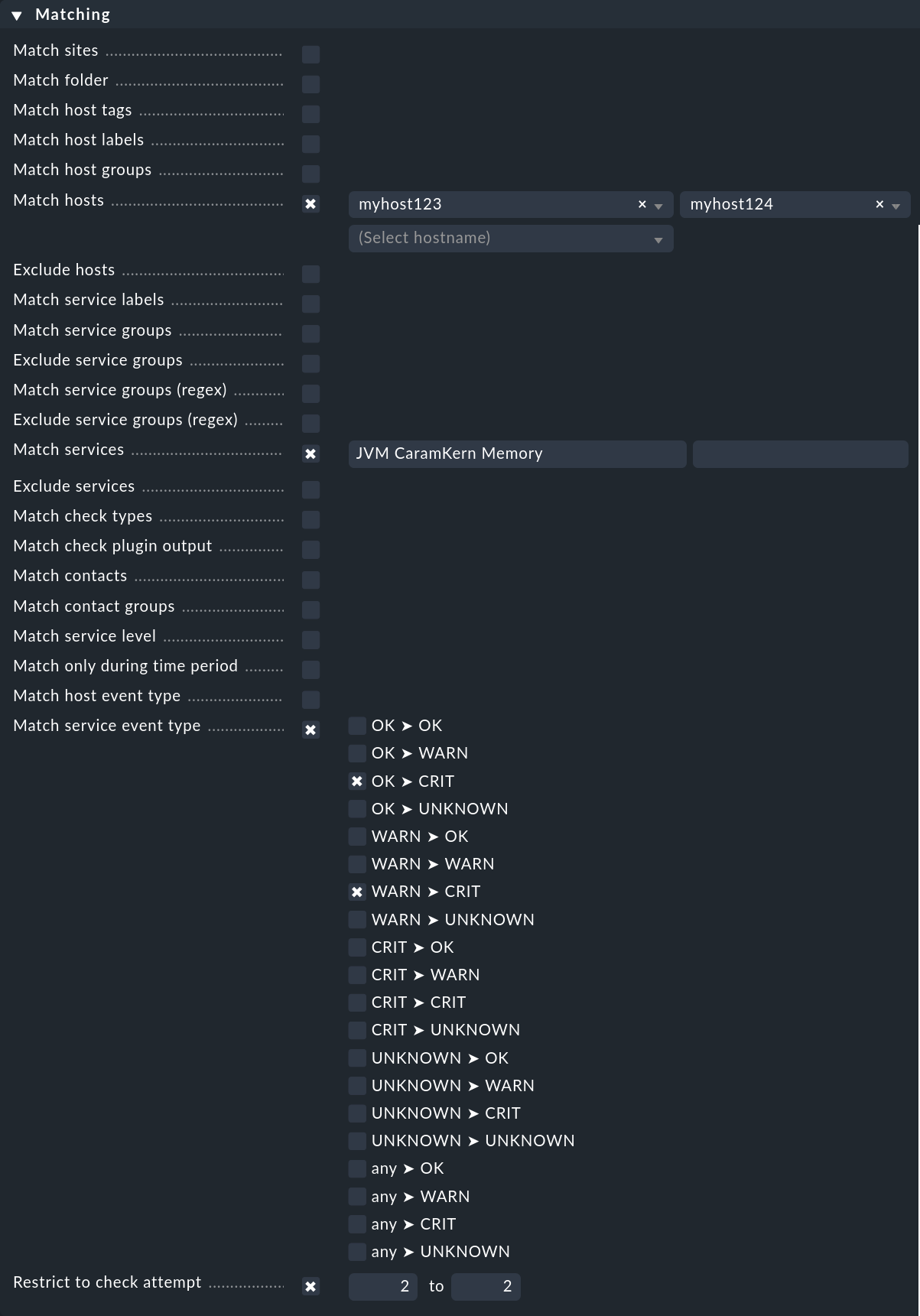
El alert handler sólo se activará
para los hosts
myhost123ymyhost124,para el servicio
JVM CaramKern Memory,si el estado cambia de OK o WARN a CRIT,
y sólo en el segundo intento de check.
Para que se active el gestor, en este ejemplo es necesario utilizar una regla Maximum number of check attempts for service para fijar el número mínimo de intentos de check en 2. Para suprimir una notificación en caso de que el recolector de basura tenga éxito, el número debe fijarse en 3, ya que si el gestor puede resolver el problema directamente tras el segundo intento, el tercer intento debería detectar un estado OK y, por tanto, no será necesaria ninguna otra notificación.
Nota: A diferencia de otros lugares de Checkmk, cada regla de alert handler se ejecutará si las condiciones coinciden. Aunque dos reglas llamen al mismo alert handler, éste se ejecutará dos veces. El asistente de alerta (que se explica en el capítulo siguiente) suprimirá la segunda ejecución con un mensaje de error, ya que el mismo alert handler no debe ejecutarse varias veces al mismo tiempo. Aun así, se recomienda configurar las reglas para que este caso no se produzca.
4. Cómo se ejecutan los alert handlers
4.1. Ejecución asíncrona
Los alert handlers se utilizan muy a menudo para conectarse remotamente a una máquina afectada mediante SSH u otro protocolo, y una vez allí ejecutar una acción controlada por script. Dado que esta máquina está experimentando un problema, no se puede excluir que la conexión tarde mucho tiempo o incluso que entre en timeout.
Para que la monitorización no se quede parada, ni se paralicen otros alert handlers durante este tiempo, por principio los alert handlers se ejecutan de forma asíncrona. Un proceso auxiliar -el asistente de alerta- se encarga de esta función, y es iniciado por la CMC. Para reducir la sobrecarga, esto sólo ocurre si se ha creado como mínimo una regla de alert handler. En el cmc.log verás entonces la siguiente línea:
2016-07-19 15:17:00 [5] Alert handlers have been switched onCon cada cambio de estado de un host o servicio, el asistente de alerta recibe una notificación de la CMC que contiene toda la información relevante para el evento. A continuación, evalúa todas las reglas de alerta y determina si se debe activar un alert handler. En caso afirmativo, se iniciará el script apropiado y se ejecutará en segundo plano como un proceso externo.
4.2. Detener el núcleo de monitorización
Cuando detengas la CMC (por ejemplo, a través de omd stop o apagando el servidor de monitorización), se abortarán todos los asistentes de alerta que aún se estén ejecutando, que no se repetirán más tarde, ya que ¿quién sabe cuándo será "más tarde"? Es posible que reiniciar un servicio o similar sea más perjudicial que útil!
4.3. Timeouts
Para protegerse de que se inicien demasiados procesos en caso de error, cuando se ejecuta un alert handler se aplica un timeout de 60 segundos (configurable). Al final de este tiempo el handler se detendrá. En detalle, esto significa que al final de un timeout se enviará una Señal 15 (SIGTERM) al handler. De esta forma tiene la posibilidad de detenerse limpiamente. Después de otros 60 segundos (doble timeout) se "terminará" finalmente con una Señal 9 (SIGKILL).
4.4. Superposición de
Checkmk impide la ejecución simultánea de asistentes de alerta si se aplican al mismo host/servicio y ejecutarían el mismo script con los mismos parámetros. Tal situación indica que el primer alert handler sigue ejecutándose y que no tendría sentido iniciar una segunda copia del mismo alert handler - el segundo alert handler se cancelaría instantáneamente y se identificaría como "fallido".
4.5. Códigos de salida y salidas
Las salidas y los códigos de salida del alert handler se evalúan de forma fiable y se devuelven al núcleo, donde se guardan en el historial de monitorización. Además, puedes activar una notificación (ver más abajo).
4.6. Ajustes globales
Hay una serie de ajustes globales para ejecutar los alert handlers:

El Alert handler log level influye en el registro en el archivo de registro del asistente de alerta (~/var/log/alerts.log).
4.7. Control maestro

Con un clic en el snap-in Master control puedes desactivar globalmente los alert handlers. Los alert handlers que se estén ejecutando no se verán afectados y se ejecutarán hasta su finalización.
No olvides volver a poner el pequeño interruptor en verde en cuanto sea posible! De lo contrario, podrías engañarte con la falsa sensación de seguridad de que la monitorización lo está arreglando todo...
5. Alert handlers en el historial
Los gestores de alertas crean entradas en el historial de monitorización. Con ello tienes una mejor trazabilidad en comparación con tener sólo el archivo de registro alerts.log. Se crea una entrada en cuanto se inicia un gestor de alertas y otra cuando finaliza.
Así, los gestores de alertas se consideran del mismo modo que los plugins de monitorización típicos, es decir, deben producir una línea de texto y devolver uno de los cuatro códigos de salida 0(OK), 1(WARN), 2(CRIT) o 3(UNKNOWN). Todos los errores que desde el principio impiden la ejecución de un gestor (aborto por ejecución duplicada, script ausente, timeout, etc.) se marcan automáticamente con UNKNOWN.
Por ejemplo - llamando a este manejador muy simple...
#!/bin/bash
# Dummy handler for testing
sleep 3
echo "Everything is fine again"
exit 0... produce un resultado como el anterior en el historial del servicio correspondiente (como siempre, el mensaje más reciente está en la parte superior):
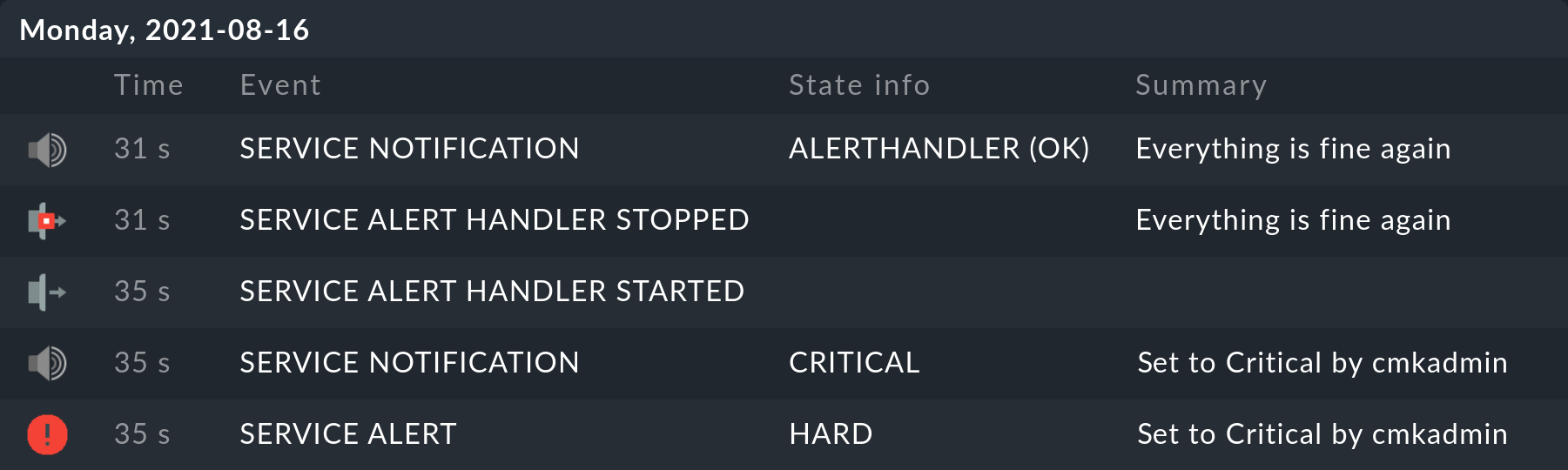
También existe una vista genérica Monitor > System > Alert handler executions, que proporciona una visualización global de todos los alert handlers en ejecución.
6. Notificación mediante alert handlers
La ejecución de un alert handler -o, más exactamente, la finalización de una ejecución- es un evento que desencadena una notificación. De este modo, puedes ser informado de que un alert handler ha completado su tarea. Hay dos tipos de eventos que puedes filtrar en una regla de notificación:
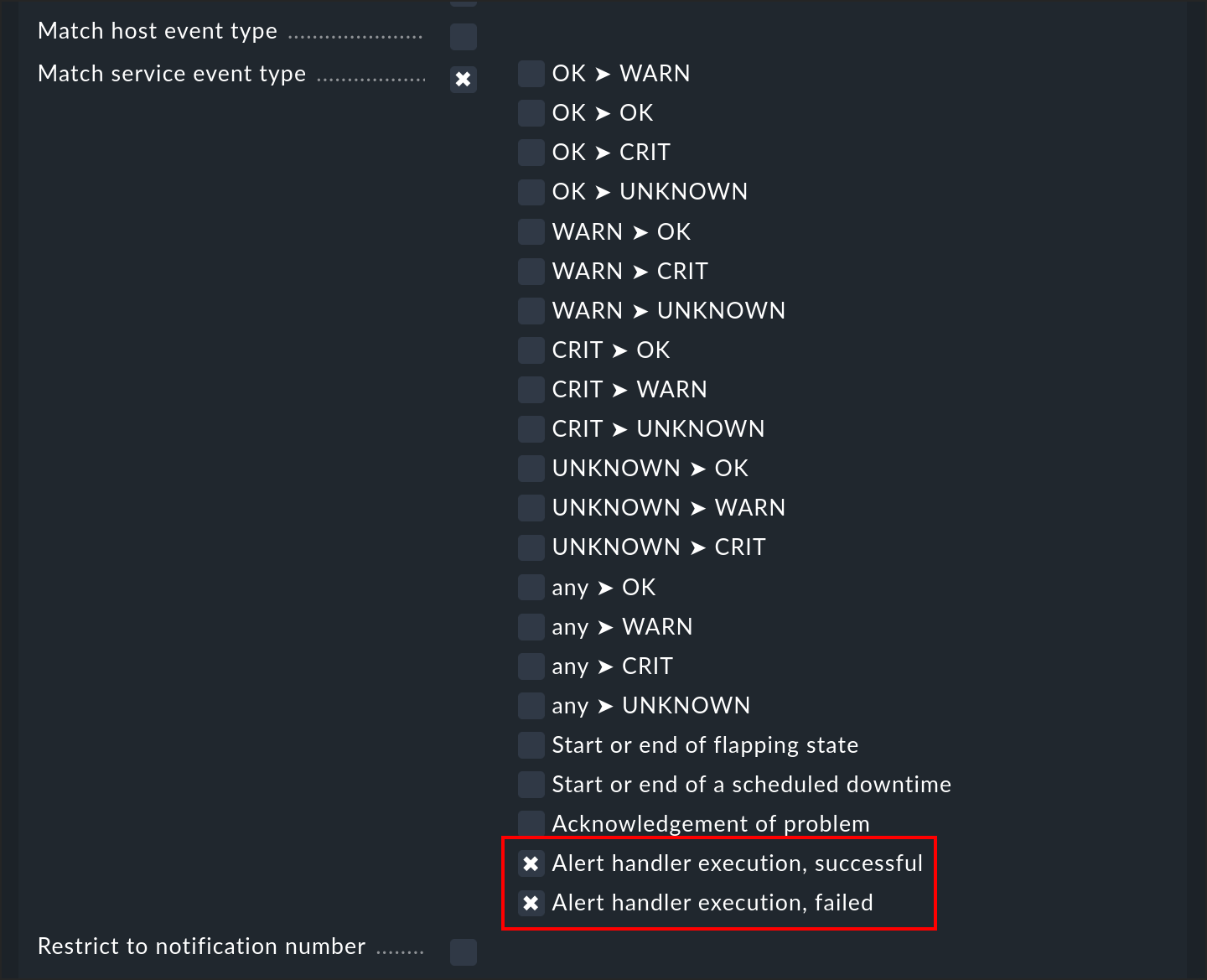
Así puedes diferenciar entre los handlers ejecutados con éxito (código de salida 0 - OK), y los fallos (todos los demás códigos). La notificación por correo electrónico de Checkmk no muestra el resultado del check, sino el resultado del alert handler.
7. Alert handler para cada ejecución de check
Normalmente, los alert handlers sólo se activan cuando cambia el estado de un host o de un servicio (o durante los intentos de reintento cuando se gestionan problemas). Las ejecuciones simples de un check sin cambio de estado no activan ningún alert handler.
Con Global settings > Alert handlers > Types of events that are being processed > All check executions! puedes hacer exactamente eso.Cada ejecución de un check puede activar potencialmente un alert handler. Puedes utilizarlo, por ejemplo, para transferir datos de la monitorización activa a otros sistemas.
Ten cuidado con esta configuración: iniciar procesos y llamar a scripts consume muchos recursos de la CPU. Checkmk puede ejecutar fácilmente 1000 comprobaciones por segundo, pero Linux no podría gestionar 1000 scripts de alert handler por segundo.
Para que esto sea útil, Checkmk ofrece la opción de escribir handlers de alerta como funciones de Python, que se ejecutan en línea, sin crear procesos. Estos handlers en línea pueden guardarse en el mismo directorio que los scripts de handler normales. El siguiente ejemplo de funcionamiento muestra la estructura de un handler en línea:
#!/usr/bin/python
# Inline: yes
# Do some basic initialization (optional)
def handle_init():
log("INIT")
# Called at shutdown (optional)
def handle_shutdown():
log("SHUTDOWN")
# Called at every alert (mandatory)
def handle_alert(context):
log("ALERT: %s" % context)Este script no tiene una función central, sino que simplemente define tres funciones, aunque sólo es necesaria la función handle_alert(). Ésta se llama tras la ejecución de cada check y en su argumento context recibe un diccionario de Python con variables como "HOSTNAME", "SERVICEOUTPUT", etc. Éstas representan las variables del entorno que también reciben los manejadores normales -aunque aquí sin el prefijo ALERT_. El ejemplo anterior puede utilizarse para ver el contenido de context.
Todas las salidas producidas por la función auxiliar log() se guardan en ~/var/log/alert.log. Las dos variables globales omd_root y omd_site se basan en el directorio de inicio y en el nombre del site de Checkmk, respectivamente.
Las funciones handle_init() y handle_shutdown() son invocadas por Checkmk al iniciar o detener el núcleo de monitorización y permiten una inicialización, por ejemplo, al establecer una conexión con una base de datos.
Información adicional:
Observa el
# Inline: yesen la segunda línea.El núcleo debe reiniciarse después de cada cambio en el script (
omd restart cmc).importse permiten comandos.Los asistentes de alerta Checkmk llaman a sus funciones de forma sincrónica. ¡Asegúrate de que no se producen estados de espera!
8. Ejecución remota en Linux
8.1. Principios básicos
Cada versión de Checkmk incluye un alert handler integrado que permite la ejecución fiable de scripts en sistemas Linux monitorizados. Las características más importantes de esta solución son:
Los scripts se invocan mediante SSH con restricción de comandos.
No se pueden utilizar comandos arbitrarios, sino sólo los definidos por ti.
Todo esto puede implementarse utilizando el Agent bakery.
Los alert handlers remotos de Linux constan de los siguientes elementos individuales:
El alert handler
linux_remotecon el títuloLinux via SSHen el servidor Checkmk.El script
mk-remote-alert-handleren el sistema de destino.Los scripts ("manejadores remotos") escritos por ti en el sistema de destino.
Las entradas en
.ssh/authorized_keyspara los usuarios del sistema de destino que los ejecutarán.Reglas en Setup > Agents > Windows, Linux, Solaris, AIX > Agent rules > Linux Agent > Remote alert handlers (Linux) que generan claves SSH.
Reglas del alert handler que llaman a
linux_remote.
8.2. Configuración
Suponiendo que se quiera ejecutar el script /etc/init.d/foo restart en el sistema Linux myserver123 cada vez que el servicio Proceso FOO se vuelva crítico (que ya hemos configurado), procede como sigue:
Codificación del manejador remoto
A continuación, escribe el script que se ejecutará en el sistema de destino. Como estamos trabajando con el Agent bakery, instala el script en el servidor Checkmk (¡no en el sistema de destino!). El directorio correcto para ello es ~/local/share/check_mk/agents/linux/alert_handlers. Aquí también el comentario de la segunda línea proporciona un título para la selección en la interfaz de usuario:
#!/bin/bash
# Restart FOO service
/etc/init.d/foo restart || {
echo "Could not restart FOO."
exit 2
}Haz que el script sea ejecutable:
OMD[mysite]:~$ cd local/share/check_mk/agents/linux/alert_handlers
OMD[mysite]:~$ chmod +x restart_fooNuestro script de ejemplo está construido de tal forma que, en caso de error, termina con un Código 2 para que el alert handler lo evalúe como CRIT.
Preparar el paquete agente con el gestor
Aquí describiremos el procedimiento con el Agent bakery. Más adelante encontrarás consejos para instalarlo a mano.
Define una regla en Setup > Agents > Windows, Linux, Solaris, AIX > Agent rules > Linux Agent > Remote alert handlers (Linux). En las propiedades se puede ver el manejador remoto Restart FOO service que acabas de definir. Selecciónalo para su instalación:
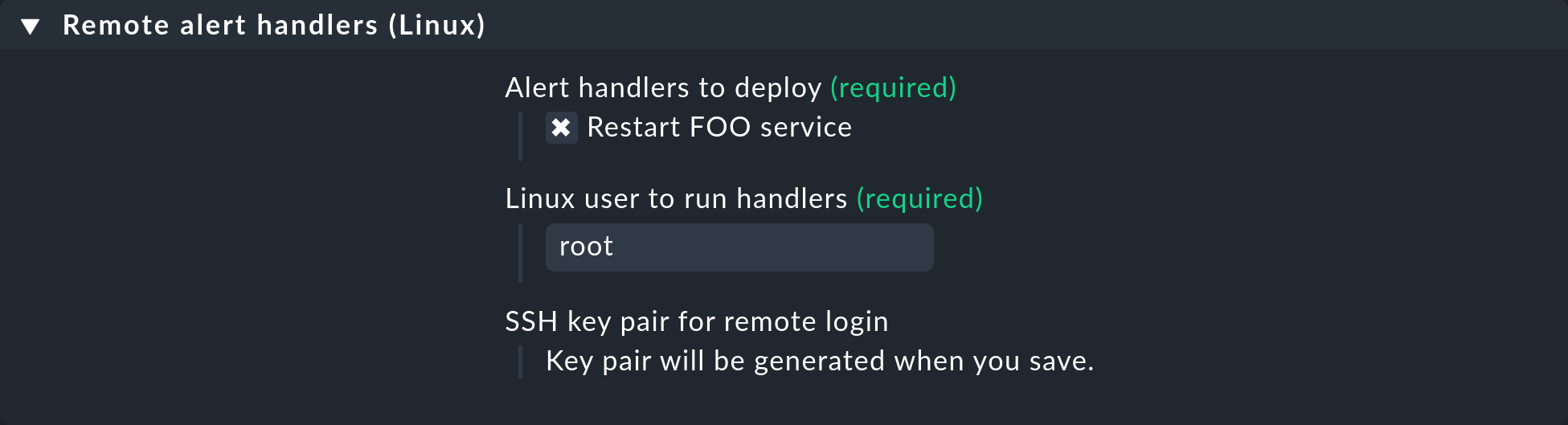
Una vez que lo hayas guardado, verás la regla en la lista: se ha generado automáticamente un par de claves SSH para llamar al manejador, cuya huella aparecerá en la regla. La propia huella se ha acortado para que quepa a lo ancho en esta captura de pantalla:
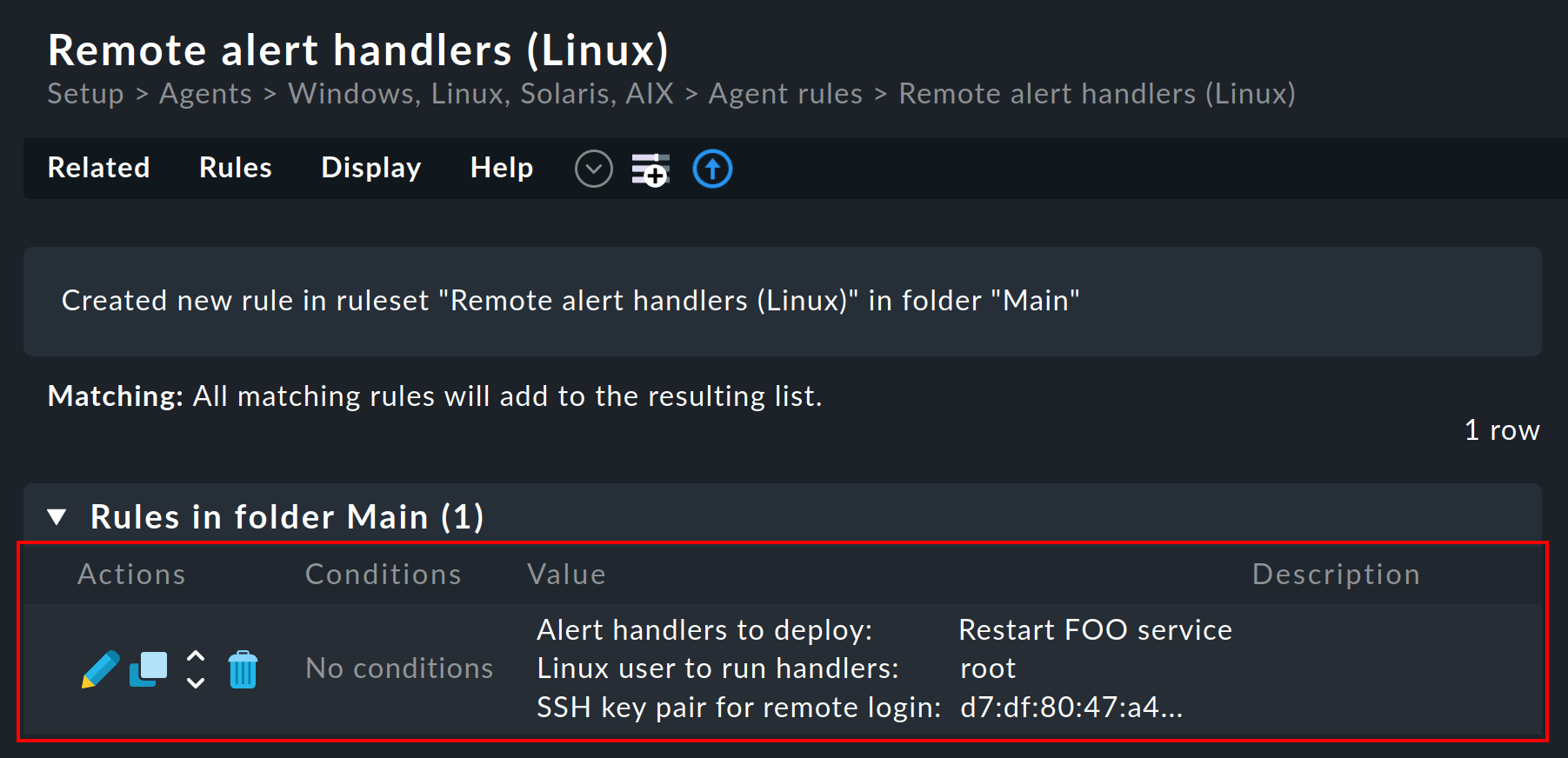
La clave pública está destinada al agente. La clave privada será requerida posteriormente por el servidor Checkmk para que un script instalado de este modo pueda ser llamado sin necesidad de introducir una contraseña.
También se puede utilizar otro usuario como root - naturalmente, sólo cuando tenga los derechos adecuados para la acción requerida. El agente Checkmk sólo instalará la clave SSH en los sistemas en los que ya exista este usuario.
Preparar el agente
Ahora hornea nuevos agentes con . En la lista de agentes listos debería aparecer ahora una entrada en la que se pueden ver tu manejador remoto y tu clave SSH. Aquí también se ha acortado la captura de pantalla. Esta vez por la cantidad de paquetes posibles que se pueden descargar:
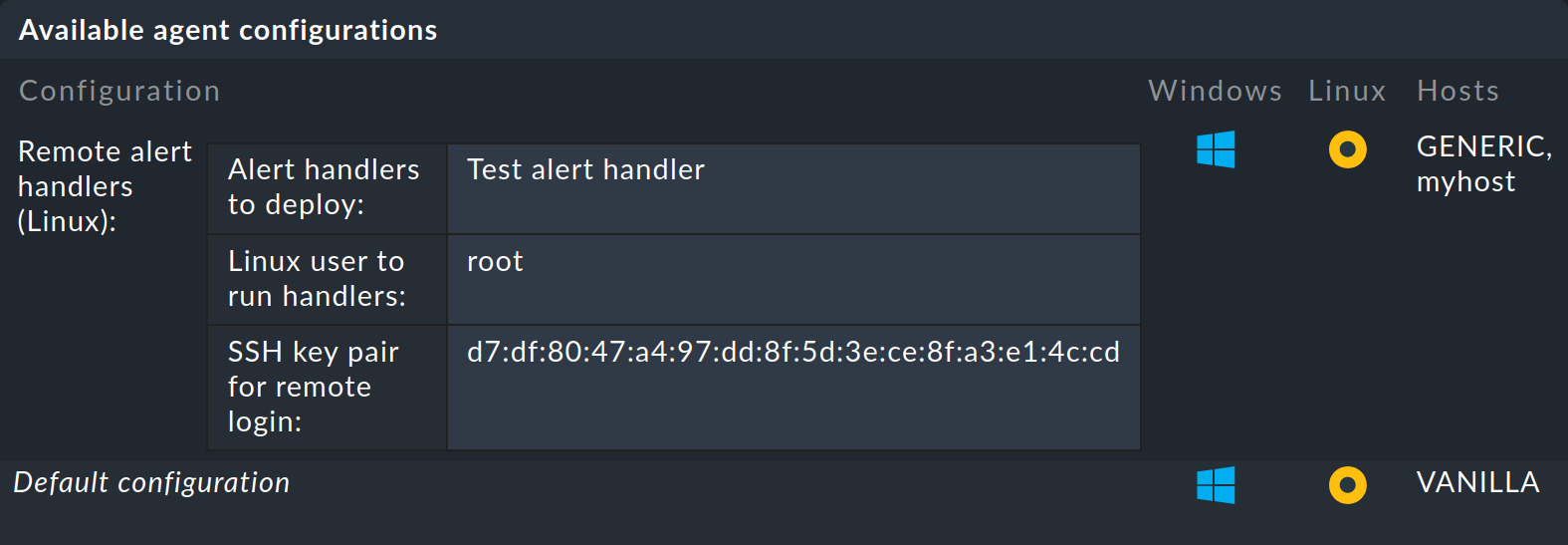
Instalar agente
A continuación, instala el paquete RPM o DEB en tu sistema de destino (la instalación del archivo TGZ no puede configurar la clave SSH y, por tanto, está incompleta). Con la instalación ocurren las siguientes cosas:
Se instalará tu script manejador remoto.
Se instalará el programa auxiliar
mk-remote-alert-handler.Para los usuarios seleccionados (aquí
root) se realizará una entrada enauthorized_keysque permitirá la ejecución del manejador.Se creará el directorio
.sshy el archivoauthorized_keyssegún sea necesario.
Con una instalación a través de DEB se verá algo así:
root@myserver123:~# dpkg -i check-mk-agent_2016.07.19-9d3ab34905da4934_all.deb
Selecting previously unselected package check-mk-agent.
(Reading database ... 515080 files and directories currently installed.)
Preparing to unpack ...check-mk-agent_2016.07.19-9d3ab34905da4934_all.deb ...
Unpacking check-mk-agent (2016.07.19-9d3ab34905da4934) ...
Setting up check-mk-agent (2016.07.19-9d3ab34905da4934) ...
Reloading xinetd...
* Reloading internet superserver configuration xinetd [ OK ]
Package 9d3ab34905da4934: adding SSH keys for Linux remote alert handlers for user root...Un vistazo a la configuración SSH para root revela:
root@myserver123:~# cat /root/.ssh/authorized_keys
command="/usr/bin/mk-remote-alert-handler restart_foo",no-port-forwarding,no-x11-forwarding,no-agent-forwarding ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAACAQCqoDVNFEbTqYEmhSZhUMvRy5SqGIPp1nE+EJGw1LITV/rej4AAiUUBYwMkeo5aBC6VOXkq78CdRuReSozec3krKkkwVbgYf98Wtc6N3WiljS85PLAVvPadJiJCkXFctbxyI2xeF5TQ1VKDRvzbBjXE9gjTnLWbPy77RC8SVXLoOQgabixpWQquIIdGyccPsWGTRgeI7Ua0lgWZQUJt7OIKQ0X7Syv2VHKJNqtW28IWu8y2hBEY/TERip5EQoNT/VclhHqjDG2y3F45PswcXD5in6y30EnfHGcwk+PD6fgp7jPGbO2+QBUwYgW67GmRpbaVQ97CqXFJvORNF+C6+O8DNweyH3ogspjfKvM7eN+M4NIJzjMRyNBMzqF3VmrMeqpzRjfFj2BS/8UbXGgHzZRapwrK3+GXX1pG49n77cIs+GWos9xb1DxX1pEu2tgQwRBBhYcTkk2eKkH18LKzFUyObxtQmf40C24cdQOp6USbwzsniqehsLIHH2unQ7bW6opF/GiaEjZamGbgsPOe8rmey5Vcd//e8cS+OsmcPZNybsTJpBeHpes+5bw0e1POw9GD9qptylrQLYIO5R467Ov8YlRFgYKyaDFHD40j5/JHPzmtp4vjH8Si7YZZOzvTRgBYEoEgbLS5dgdr/I5ZMRKfDPCpRUbGhp9kUEdGX99o5Q== mk-remote-alert-handler-9d3ab34905da4934Ten en cuenta que tu sistema podría estar configurado de modo que un acceso SSH como root no sea posible en general. En este caso, puedes ir a través de otro usuario y allí trabajar con sudo, que está configurado de modo que el comando deseado puede ejecutarse sin contraseña.
Llamar al manejador mediante una regla
Casi hemos alcanzado nuestro objetivo. El agente está listo. Ahora sólo falta una regla para invocar realmente al alert handler. El procedimiento es el descrito al principio de este artículo y se consigue mediante la creación de una regla adecuada. Esta vez elige Linux via SSH como handler, introduce el usuario para el que debe instalarse la clave SSH y selecciona tu alert handler remoto:
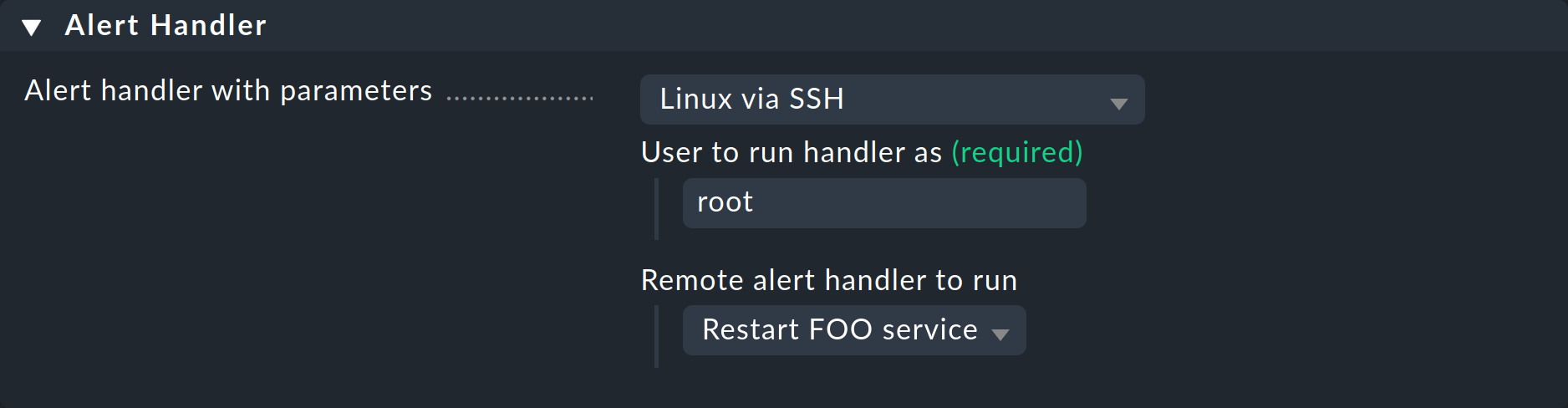
Establece también una condición sensata en la regla, ¡de lo contrario se intentará una conexión SSH con cada alerta de servicio!
Probando
Cuando, por ejemplo, ahora configures manualmente el servicio correspondiente como CRIT, en el historial del servicio verás en breve:
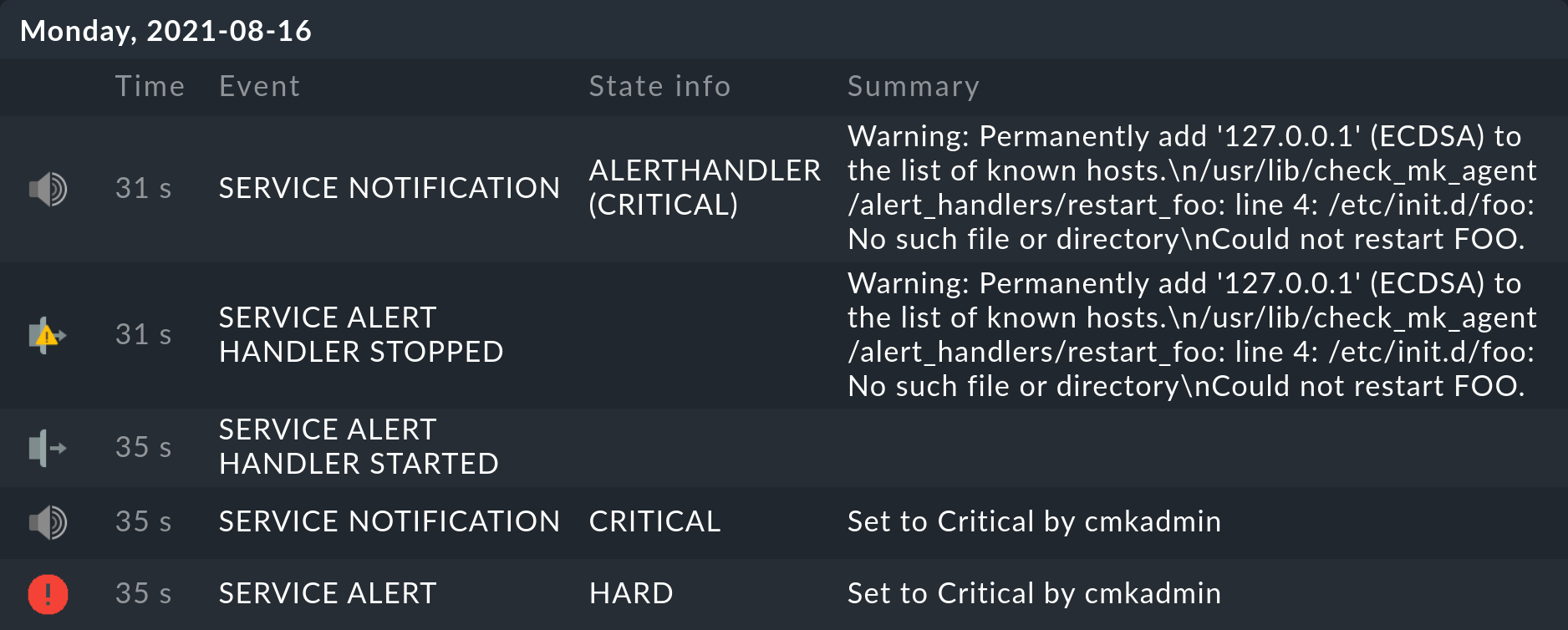
Naturalmente, si no existe el servicio foo, tampoco puede funcionar /etc/init.d/foo restart. Sin embargo, puede verse que este comando se ha procesado y también que se ha informado correctamente del estado de error. Asimismo, que Checkmk ha activado una notificación que fue detenida por un alert handler.
Por cierto, el mensaje Warning: Permanently added '127.0.0.1' (ECDSA) to the list of known hosts. es inofensivo y sólo aparece en el primer contacto con el host. Para evitar el laborioso intercambio manual de la clave del host, se llama a SSH con -o StrictHostKeyChecking=false. En la primera conexión, la clave se almacenará para su uso futuro.
8.3. Configuración sin Agent bakery
Por supuesto, la preparación manual de un agente también funciona. En tal caso, recomendamos realizar el procedimiento de Agent bakery en un sistema de prueba, y después examinar los datos relevantes y replicarlos manualmente en tu propio sistema. Puedes encontrar una lista de las rutas de los archivos aquí.
En este caso, también es importante que en el Agent bakery crees una regla para instalar el handler remoto, ¡porque en esta regla se generarán las claves SSH para el acceso y también para que las utilice el alert handler! La clave pública para la instalación en authorized_keys se encuentra en el archivo de configuración ~/etc/check_mk/conf.d/wato/rules.mk (o en una subcarpeta en rules.mk).
9. Ficheros y directorios
9.1. Rutas en el servidor Checkmk
| Ruta | Función |
|---|---|
|
Archivo de registro con todos los eventos relevantes para el alert handler (registrados por el asistente de alerta). |
|
Archivo de registro del núcleo. Aquí también se guarda parte de la información del alert handler. |
|
Guarda aquí tus propios alert handlers. |
|
Aquí se guarda el archivo de registro del historial de monitorización, que también evalúa el núcleo. |
|
Manejadores de alerta remotos para ser ejecutados en sistemas Linux. |
9.2. Rutas en el host Linux monitorizado
| Ruta | Función |
|---|---|
|
Script auxiliar para ejecutar los manejadores remotos. |
|
Manejadores remotos escritos por ti. |
|
Configuración SSH para el usuario |
|
Configuración SSH para un usuario |