This is a machine translation based on the English version of the article. It might or might not have already been subject to text preparation. If you find errors, please file a GitHub issue that states the paragraph that has to be improved. |
1. Tareas esenciales de monitorización
Ya has añadido hosts y has visto algunas herramientas importantes, y ahora estamos listos para empezar con la monitorización propiamente dicha. Al fin y al cabo, el objetivo de Checkmk no es ocuparse permanentemente de la configuración, sino proporcionar apoyo a las operaciones informáticas.
Es cierto que las vistas disponibles por defecto, o por ejemplo el snap-in Overview, ya te muestran con mucha precisión cuántos y qué problemas existen actualmente. Pero para modelar un Flujo de trabajo, es decir, "procedimientos sistemáticos de trabajo" con la monitorización, necesitas un poco más de información sobre:
el Reconocimiento de problemas
el envío de notificaciones en caso de problemas
el establecimiento de tiempos de mantenimiento programados
Este capítulo sólo trata del primero y del último de los puntos anteriores. Las notificaciones se tratarán más adelante en un capítulo aparte, ya que hay que hacer algunos preparativos especiales para este tema en concreto.
2. Reconocer problemas
En la Vista general ya hemos visto que los problemas pueden marcarse como no tratados o tratados. El Reconocimiento es la acción que convierte un problema no tratado en uno tratado. Esto no significa necesariamente que alguien esté trabajando en el problema. Algunos problemas desaparecen por sí solos. Pero el Reconocimiento ayuda a mantener una visión general y a establecer un Flujo de trabajo.
¿Qué ocurre exactamente cuando se reconoce un problema?
En Overview el problema ya no se contará en la columna Unhandled en el host o servicio.
En el dashboard tampoco se enumera ya el problema.
El objeto (host o servicio) se marca en las vistas con el símbolo .
Se realiza una entrada en el historial de objetos para que la acción pueda ser rastreada posteriormente.
Las notificaciones repetidas, si están configuradas, se detendrán.
¿Cómo se reconoce un problema?
Primero llama a una vista que contenga el problema. La forma más sencilla es utilizar las vistas predefinidas en los menús Monitor > Problems > Host problems o Service problems. Por cierto, casi puedes llegar a ellas más rápidamente haciendo clic en el recuento de problemas en Overview.
Puedes hacer clic en el host o servicio problemático de la lista y luego, en la página con sus detalles, realizar el Reconocimiento sólo para este host o servicio individual. Sin embargo, nos quedaremos en la página de la lista porque aquí tienes todas las opciones para reconocer sólo un problema o varios problemas a la vez.
No es raro que quieras reconocer varios problemas (relacionados) en una sola acción. Esto se hace fácilmente haciendo clic en Show checkboxes para mostrar una nueva primera columna en la lista, que contiene un checkbox delante de cada fila. Todos los checkboxes están desmarcados, ya que la selección es tuya: selecciona el checkbox de cada host o servicio sobre el que quieras actuar.
Importante: Si realizas una acción en una página con una lista sin casillas de verificación, esta acción se realizará para todas las entradas de la lista.
Ahora haz clic en Acknowledge problems, que mostrará el siguiente panel en la parte superior de la página:
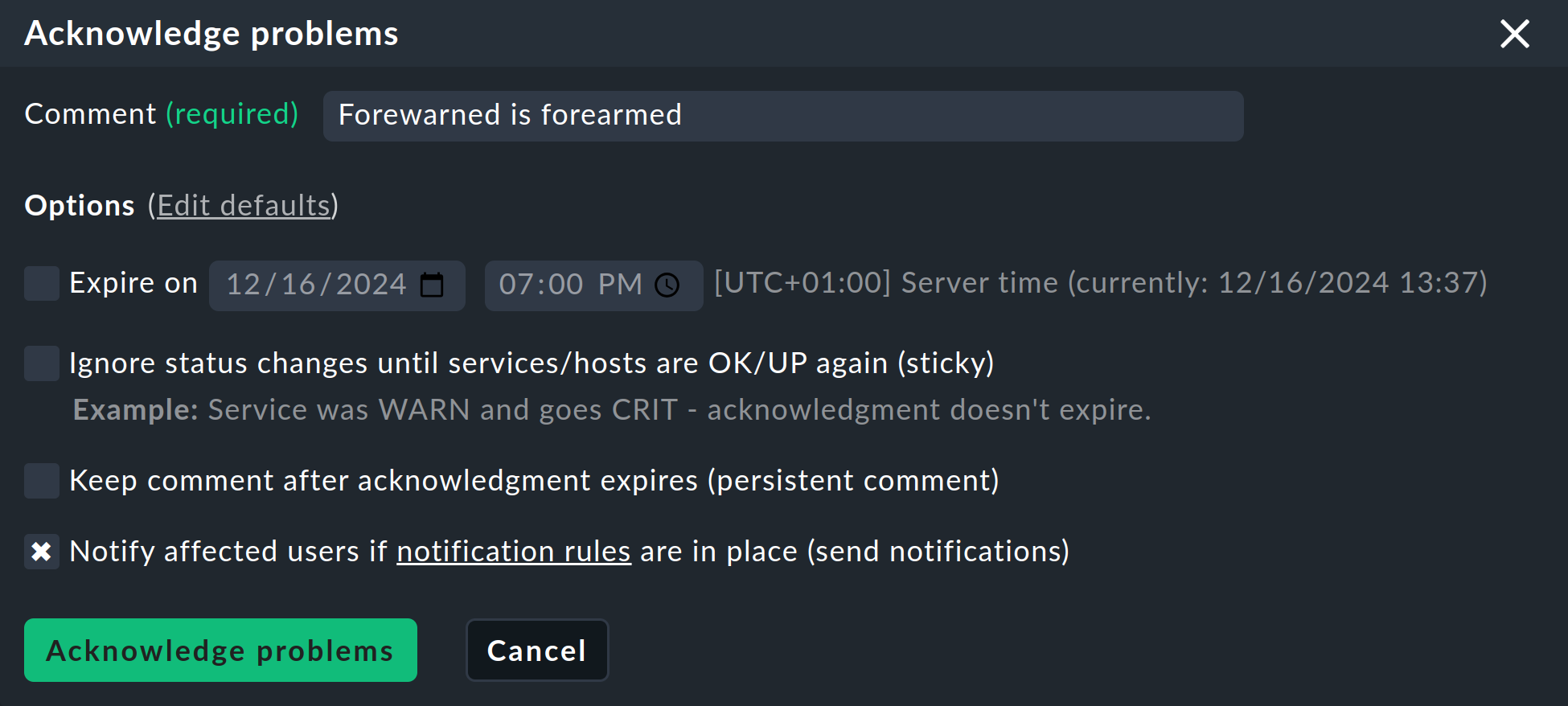
Introduce un comentario y haz clic en Acknowledge problems- y con la confirmación de la pregunta "¿Estás seguro?" ...
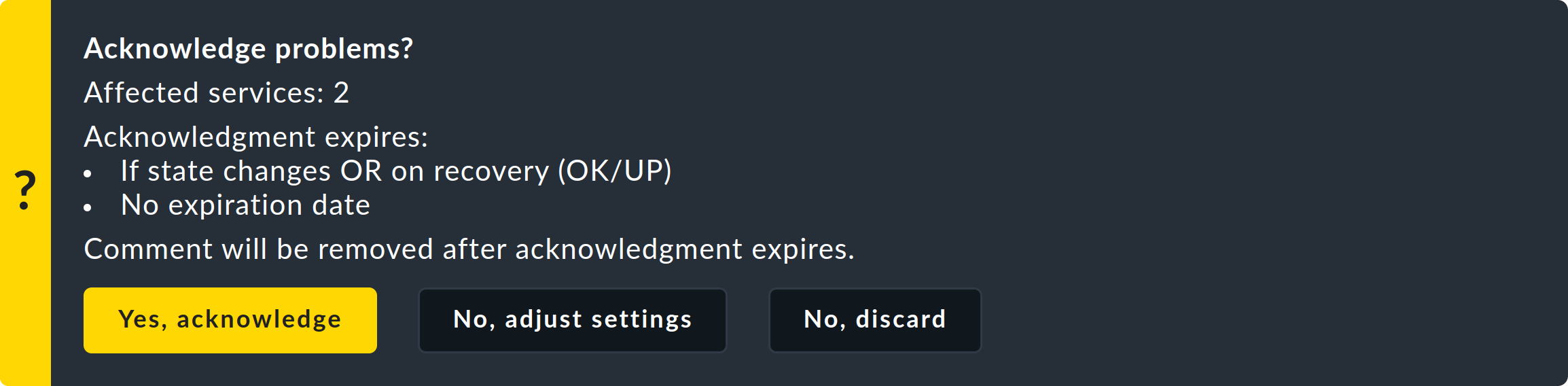
... todos los problemas seleccionados se marcarán como reconocidos.
Por último, un par de consejos:
También puedes eliminar un Reconocimiento con el botón Remove acknowledgement.
Los Reconocimientos pueden ejecutarse automáticamente. La opción Expire on sirve para este propósito, pero sólo es efectiva en las ediciones comerciales.
Para más información sobre todas las opciones de las acciones de Reconocimiento, consulta el artículo sobre Reconocimiento.
3. Establecer tiempos de mantenimiento programados
A veces las cosas no se "rompen" por accidente, sino a propósito, o para decirlo con un poco más de cuidado, se puede tolerar una interrupción necesaria. Después de todo, cada pieza de hardware o software necesita un mantenimiento ocasional, y durante ese trabajo es muy probable que el host o servicio respectivo en la monitorización entre en estado de DOWN o CRIT.
Para quienes deben reaccionar ante los problemas en Checkmk, es muy importante, por supuesto, que conozcan los tiempos de inactividad programados y no pierdan un tiempo valioso con "falsas alarmas". Para garantizarlo, Checkmk conoce el concepto de tiempo de mantenimiento programado (o tiempo de inactividad más corto).
De este modo, cuando un objeto deba someterse a mantenimiento, puedes establecer el tiempo de inactividad programado, ya sea inmediatamente o durante un tiempo planificado en el futuro.
Establecer tiempos de inactividad programados es muy similar al proceso de reconocimiento de problemas. Empiezas de nuevo con una vista que contenga el objeto deseado (host o servicio) para el que quieres establecer un tiempo de inactividad programado. Por ejemplo, puedes hacer clic en el total de host o servicios en Overview para obtener una lista de todos los objetos.
En la lista que se muestra, utiliza Show checkboxes para mostrar los checkbox y, a continuación, selecciona todas las entradas correspondientes.
Ahora haz clic en Schedule downtimes. Esto mostrará el siguiente panel en la parte superior de la página:
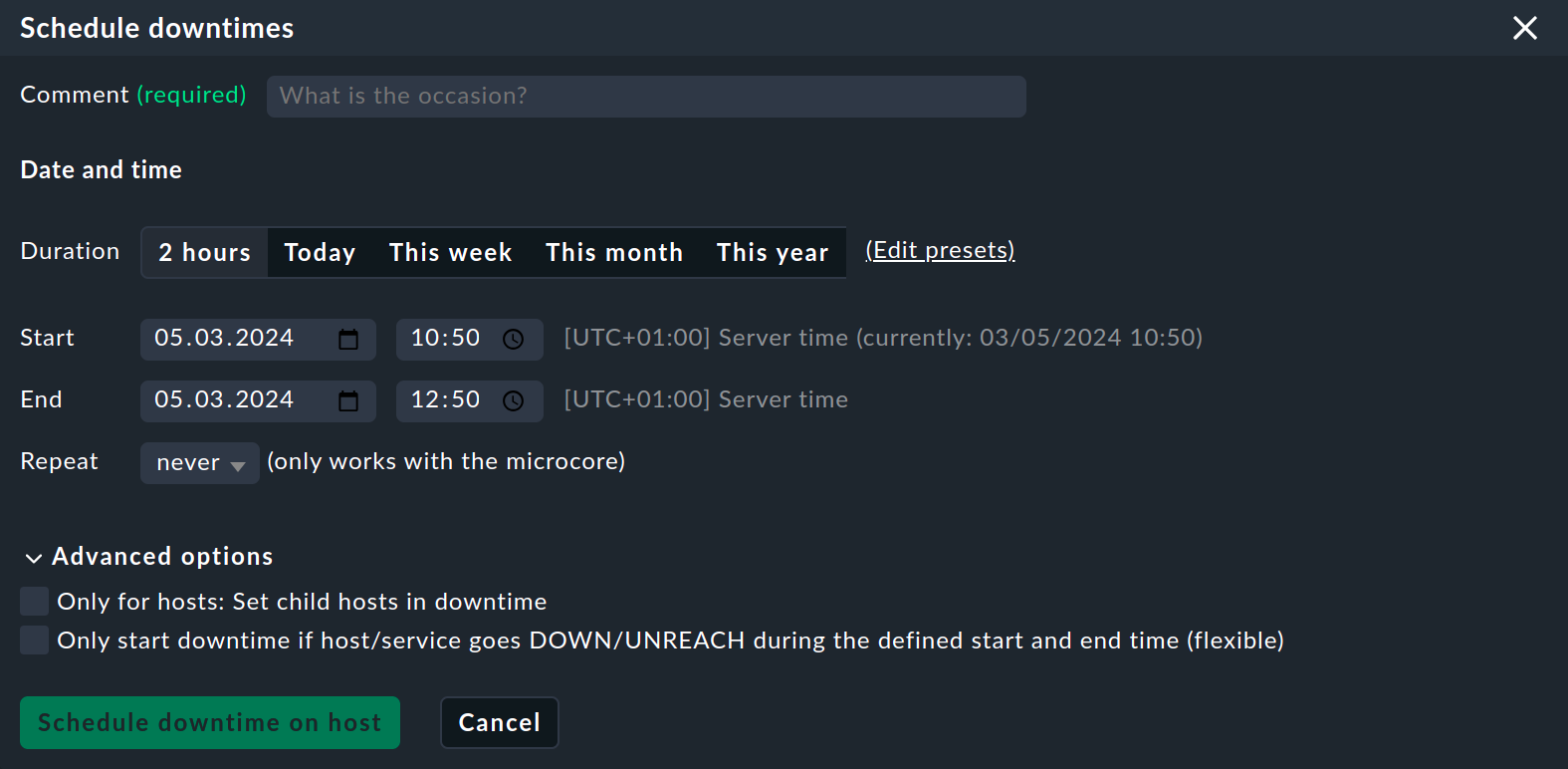
Hay toda una gama de opciones para los tiempos de inactividad programados. Debes introducir un comentario en cada caso. Existen numerosas opciones diferentes para definir el intervalo de tiempo: desde la simple 2 hours, que define el tiempo de inactividad de forma inmediata, hasta la especificación de un intervalo de tiempo explícito, que también puede utilizarse para definir un tiempo de inactividad en el futuro. A diferencia de los Reconocimientos, los tiempos de inactividad programados siempre tendrán una hora de finalización establecida de antemano.
Aquí tienes un par de consejos más:
Cuando programas un host para un tiempo de mantenimiento, todos sus servicios se programan automáticamente también, con lo que te ahorras el trabajo de tener que hacerlo dos veces.
En realidad, los tiempos de mantenimiento programados flexibles sólo comienzan cuando el objeto cambia a un estado distinto de OK.
Si utilizas una de las ediciones comerciales, también puedes definir tiempos de mantenimiento programados con regularidad, por ejemplo, para un reinicio obligatorio una vez a la semana.
Puedes obtener una visión general de los tiempos de mantenimiento programados en curso en Monitor > Overview > Scheduled downtimes.
Los efectos de un tiempo de mantenimiento programado son los siguientes:
En Overview, los hosts y servicios afectados dejan de aparecer como problemáticos.
En las vistas, el host o servicio seleccionado se marca con el cono de guía. Si un host con todos sus servicios se envía a tiempo de mantenimiento, los servicios obtienen el icono azul de pausa.
Para estos objetos, la notificación de problemas se desactiva durante el tiempo de mantenimiento programado.
Se activa una notificación especial al principio y al final de un tiempo de mantenimiento.
En el análisis de disponibilidad, los tiempos de mantenimiento programados se cuentan por separado.
Para una descripción detallada de todo lo anterior y otros aspectos, consulta el artículo sobre tiempos de mantenimiento programados.