This is a machine translation based on the English version of the article. It might or might not have already been subject to text preparation. If you find errors, please file a GitHub issue that states the paragraph that has to be improved. |
1. Falsas alarmas: fatales para cualquier monitorización
La monitorización sólo es realmente útil si es precisa. El mayor obstáculo para su aceptación por los compañeros (y probablemente por ti mismo) son los falsos positivos, o, en lenguaje llano, las falsas alarmas.
Con algunos principiantes en Checkmk, hemos visto cómo han añadido muchos sistemas a la monitorización en poco tiempo -quizá porque es muy fácil hacerlo en Checkmk-. Cuando poco después activaron las notificaciones para todos los usuarios, sus colegas se vieron inundados con cientos de correos electrónicos al día, y al cabo de sólo unos días su entusiasmo por la monitorización quedó efectivamente destruido.
Aunque Checkmk se esfuerce realmente por definir valores por defecto adecuados y sólidos para todos los ajustes posibles, no puede saber con suficiente precisión cómo deberían ser las cosas en tu entorno de TI en condiciones normales. Por tanto, se requiere un poco de trabajo manual por tu parte para ajustar la monitorización hasta que no se envíe ni la última falsa alarma. Aparte de eso, Checkmk también encontrará bastantes problemas reales que ni tú ni tus colegas habéis sospechado todavía. Éstos también deben remediarse primero adecuadamente, ¡en la realidad, no en la monitorización!
El siguiente principio ha demostrado su eficacia: primero la calidad, luego la cantidad, o dicho de otro modo:
No incluyas demasiados host a la vez en la monitorización.
Asegúrate de que todos los servicios que realmente no tienen ningún problema están en OK de forma fiable.
Activa las notificaciones por correo electrónico o SMS sólo cuando Checkmk lleve un tiempo funcionando de forma fiable sin falsas alarmas o con muy pocas.
Por supuesto, las falsas alarmas sólo pueden producirse cuando la función de notificación está activada. Así que, básicamente, lo que tenemos que hacer aquí es desactivar la fase preliminar de las notificaciones y evitar los estados críticos DOWN, WARN o CRIT para los problemas no críticos. |
En los siguientes capítulos sobre configuración, te mostraremos qué opciones de ajuste preciso tienes -para que todo lo que no cause problemas esté en verde- y cómo tener bajo control las caídas ocasionales.
2. Configuración basada en reglas
Antes de empezar a configurar, debemos examinar brevemente la configuración de host y servicios en Checkmk. Como Checkmk se desarrolló para entornos grandes y complejos, esto se hace mediante reglas. Este concepto es muy potente y aporta muchas ventajas también a los entornos más pequeños.
La idea básica es que no especifiques explícitamente cada parámetro para cada servicio, sino que implementes algo como:'En todos los servidores productivos de Oracle, los sistemas de archivos con el prefijo /var/ora/ al 90 % de llenado serán WARN y al 95 % serán CRIT'.
Una regla de este tipo puede establecer umbrales para miles de sistemas de archivos con una sola acción. Al mismo tiempo, también documenta muy claramente qué directivas de monitorización se aplican en tu empresa.
A partir de una regla básica, puedes definir excepciones para casos individuales por separado. Una regla adecuada podría tener este aspecto:'En el servidor Oracle srvora123, el sistema de archivos /var/ora/db01/ al 96 % de llenado será WARN y al 98 % será CRIT'. Esta regla de excepción se establece en Checkmk del mismo modo que la regla básica.
Cada regla tiene la misma estructura. Siempre consta de una condición y un valor. También puedes añadir una descripción y un comentario para documentar la finalidad de la regla.
Las reglas se organizan en conjuntos de reglas. Para cada tipo de parámetro, Checkmk tiene preparado un conjunto de reglas adecuado, por lo que puedes elegir entre varios cientos de conjuntos de reglas. Por ejemplo, hay uno llamado Filesystems (used space and growth) que establece los umbrales para todos los servicios que monitorizan sistemas de archivos. Para implementar el ejemplo anterior, establecerías la regla básica y la regla de excepción a partir de este conjunto de reglas. Para determinar qué umbrales son válidos para un sistema de archivos concreto, Checkmk recorre secuencialmente todas las reglas válidas para el check. La primera regla para la que se aplica la condición establece el valor: en este caso, el valor porcentual a partir del cual el check del sistema de archivos se convierte en WARN o CRIT.
3. Encontrar reglas
Tienes varias opciones para acceder a los conjuntos de reglas en Checkmk.
Por un lado, puedes encontrar los conjuntos de reglas en el menú Setup bajo los temas de los objetos para los que existen conjuntos de reglas (Hosts, Services y Agents) en diferentes categorías. Por ejemplo, existen las siguientes entradas de conjuntos de reglas para servicios:Service monitoring rules, Discovery rules, Enforced services, HTTP, TCP, Email, … y Other Services. Si seleccionas una de estas entradas, se listarán en la página principal los conjuntos de reglas asociados, que pueden ser sólo unos pocos, o muchos, muchísimos, como en el caso de Service monitoring rules. Por tanto, tienes la posibilidad de filtrar en la página de resultados - en el campo Filter de la barra de menú.
Si no estás seguro de en qué categoría se encuentra el conjunto de reglas, también puedes buscar en todas las reglas de una sola vez, utilizando el campo de búsqueda del Menú de configuración o abriendo la página de búsqueda de reglas a través de Setup > General > Rule search. Tomaremos esta última vía en el siguiente capítulo, en el que presentaremos el proceso de creación de reglas.
Con el gran número de conjuntos de reglas disponibles, no siempre es fácil encontrar el adecuado, con o sin búsqueda. Sin embargo, hay otra forma de acceder a las reglas adecuadas para un servicio existente. En una vista de tabla que incluya el servicio, haz clic en la opción de menú y selecciona la entrada Parameters for this service:
Aparecerá una página desde la que podrás acceder a todos los conjuntos de reglas de este servicio:
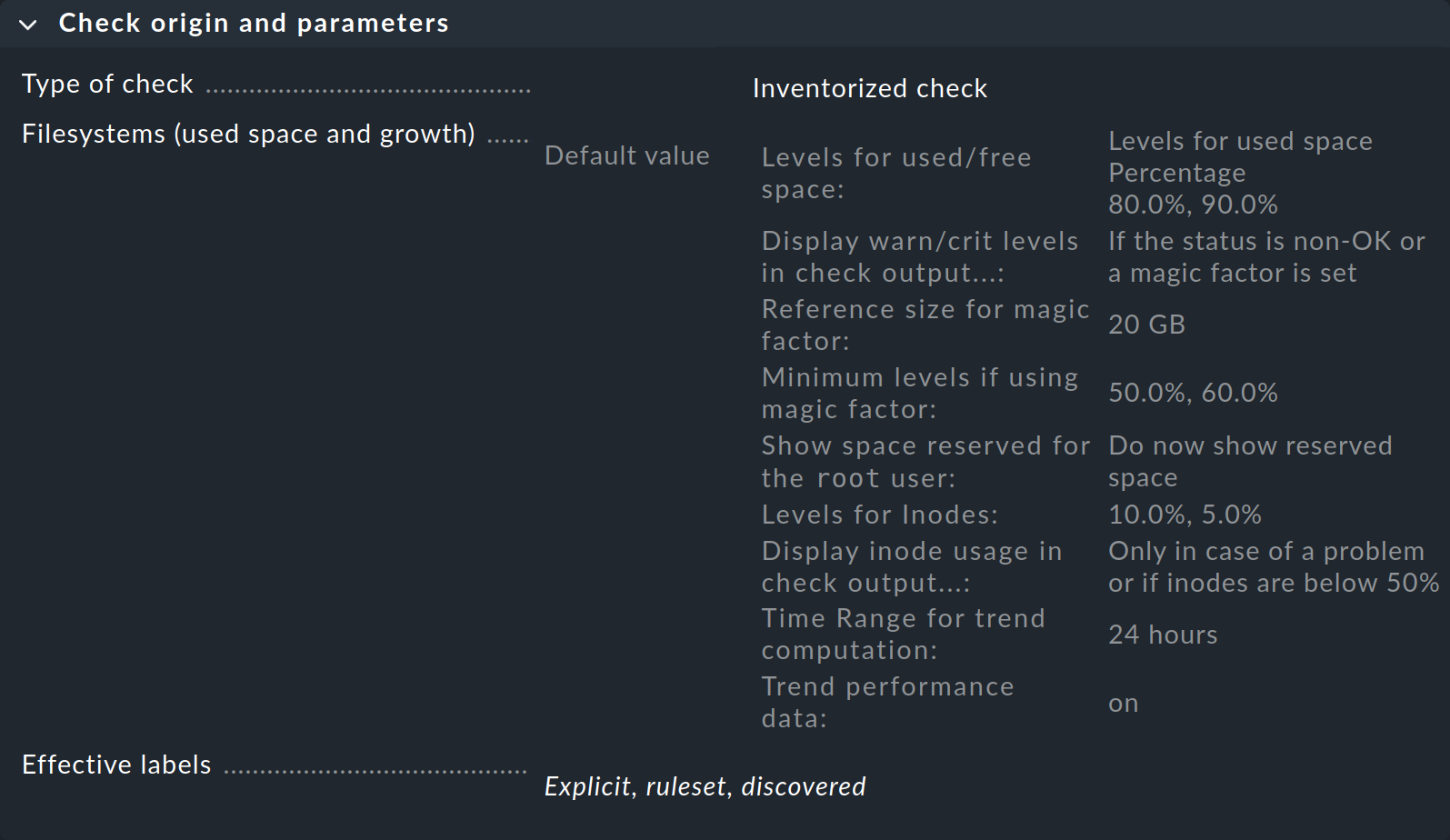
En la primera caja titulada Check origin and parameters, la entrada Filesystems (used space and growth) te lleva directamente al conjunto de reglas para los umbrales de monitorización del sistema de archivos. Sin embargo, puedes ver en la vista general que Checkmk ya ha establecido valores por defecto, por lo que sólo tienes que crear una regla si quieres modificar esos valores por defecto.
4. Crear reglas
¿Qué aspecto tiene una regla en la práctica? La mejor forma de empezar es formular la regla que quieres aplicar en una frase, como ésta:"En todos los servidores Oracle de producción, los tablespaces DW20 y DW30 al 90 % de llenado tendrán un estado WARN y al 95 % un estado CRIT".
A continuación, puedes buscar un conjunto de reglas adecuado, en este ejemplo mediante la búsqueda de reglas: Setup > General > Rule search. Se abre una página en la que puedes buscar "Oracle" o "tablespace" (sin distinguir mayúsculas de minúsculas) y encontrar todos los conjuntos de reglas que contengan este texto en su nombre o en su descripción (no se muestra aquí):
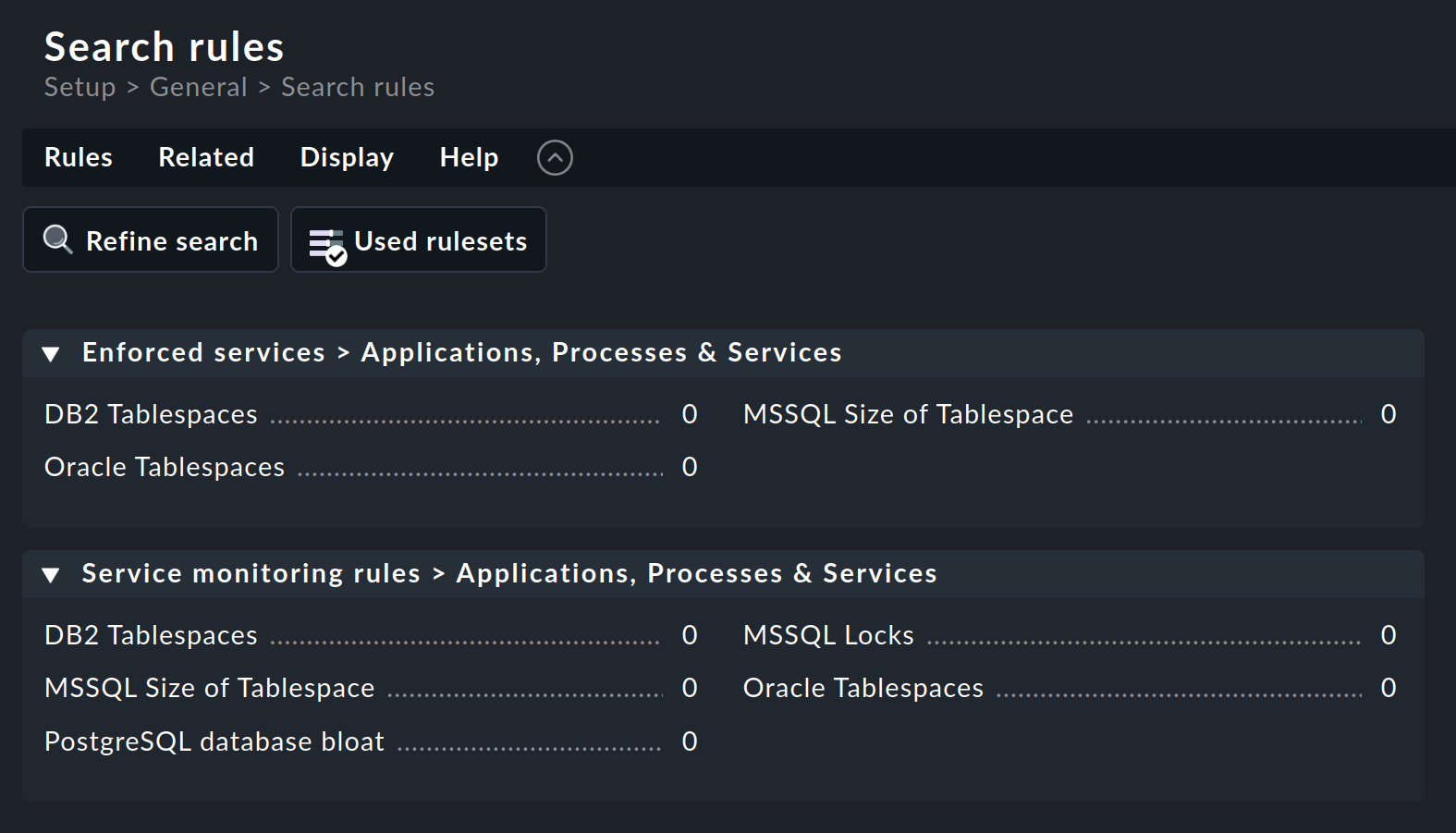
El conjunto de reglas Oracle Tablespaces se encuentra en dos categorías. El número que sigue al título (aquí en todas partes 0) muestra el número de reglas que ya se han creado a partir de este conjunto de reglas.
Por lo tanto, haz clic en el nombre de la categoría Service monitoring rules para abrir la página de resumen del conjunto de reglas:
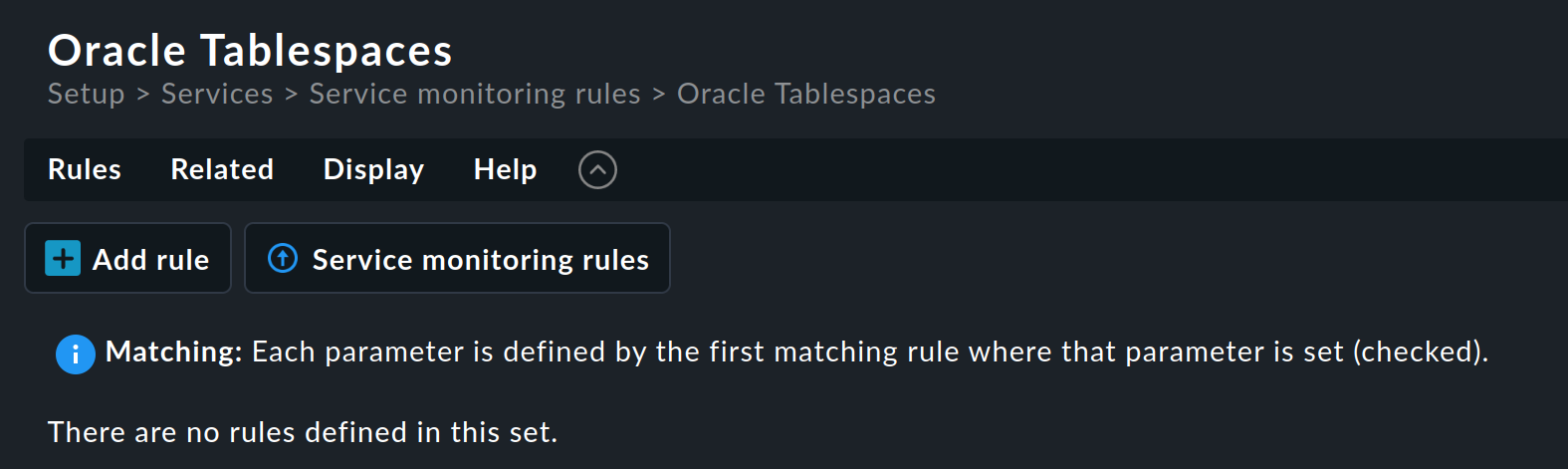
Este conjunto de reglas aún no contiene ninguna regla. Puedes crear la primera regla con el botón Add rule. Al crear -y posteriormente editar- esta regla, se abre un formulario con tres casillas: Rule properties Value y Conditions. Veremos cada una de estas tres sucesivamente.
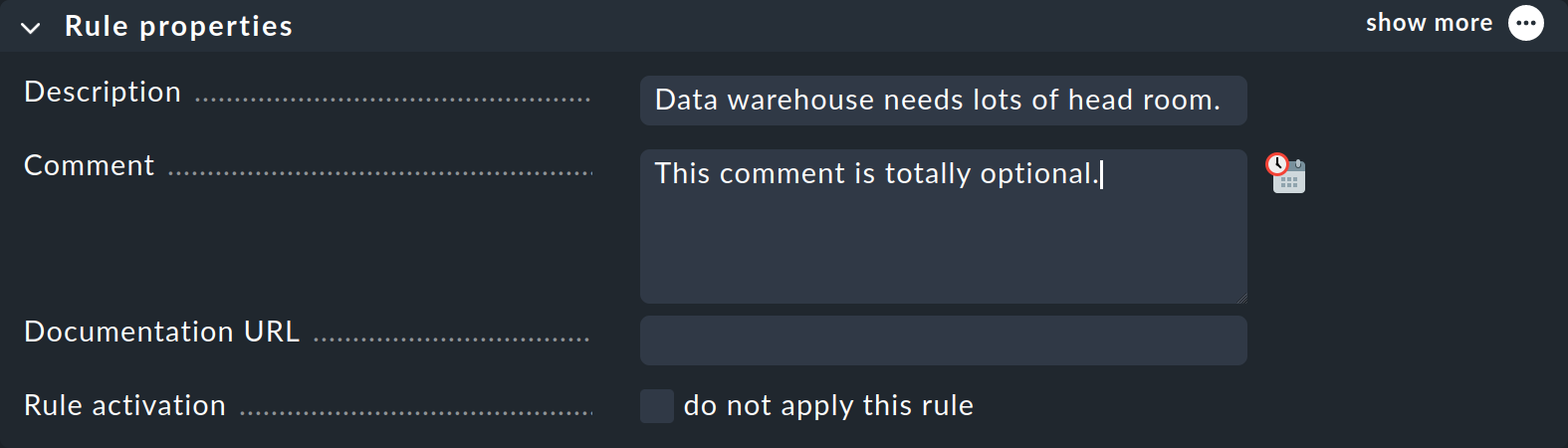
En la caja Rule properties, todas las entradas son opcionales. Además de los textos informativos, aquí también tienes la opción de desactivar temporalmente una regla. Esto es práctico porque a veces puedes evitar borrar y volver a crear una regla si temporalmente no la necesitas.
Lo que encuentres en la caja Value depende en cada caso concreto del contenido de lo que se está regulando:
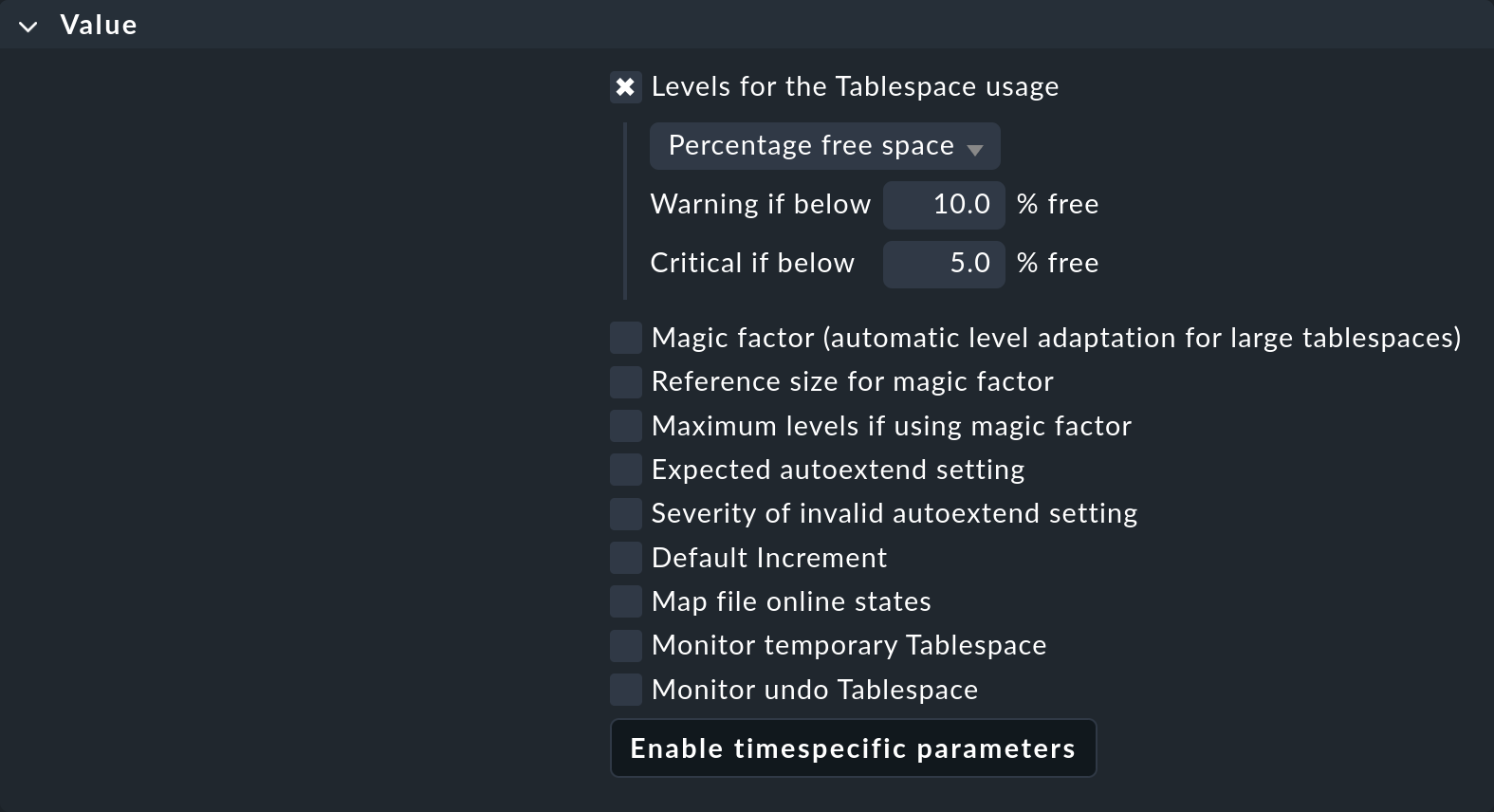
Como puedes ver, puede tratarse de un buen número de parámetros. El ejemplo muestra un caso típico: cada parámetro individual puede activarse mediante un checkbox, y entonces la regla sólo se aplicará a este parámetro. Puedes, por ejemplo, dejar que otro parámetro sea determinado por una regla diferente si eso simplifica tu configuración. En este ejemplo, sólo se definirán los valores umbrales para el porcentaje de espacio libre en el tablespace.
La caja Conditions para establecer las condiciones parece un poco más confusa a primera vista:
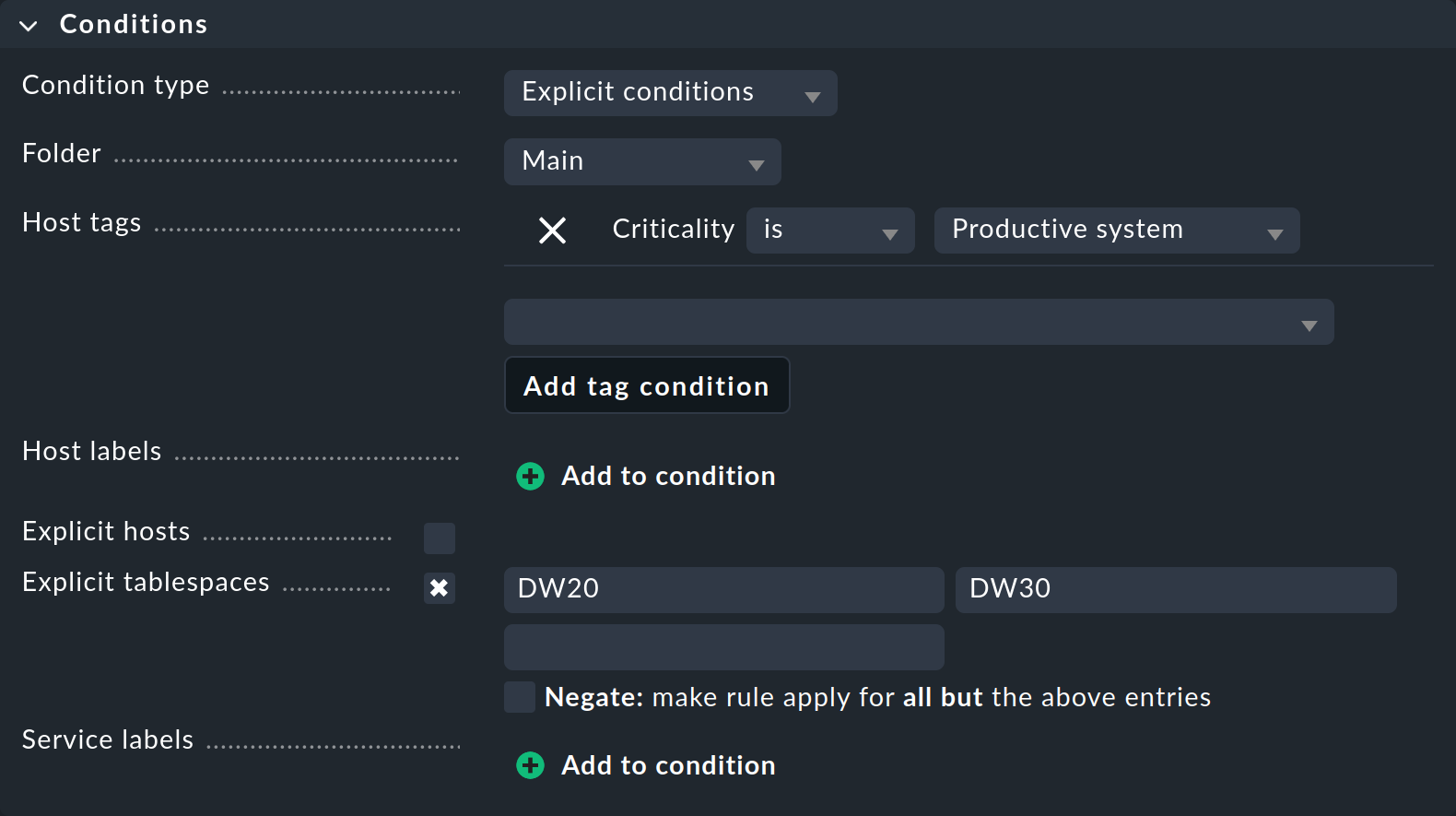
En este ejemplo sólo entraremos en los parámetros absolutamente necesarios para definir esta regla concreta:
Con Folder especificas en qué carpeta debe aplicarse la regla. Por ejemplo, si cambias el valor por defecto de Main por Windows, la nueva regla sólo se aplicará a los host situados directamente dentro o debajo de la carpeta Windows.
Los Host tags son una función muy importante en Checkmk, por lo que les dedicaremos un capítulo aparte justo después de éste. En este punto, utilizas uno de los tags predefinidos del host para especificar que la regla sólo debe aplicarse a los sistemas productivos. Primero selecciona el grupo de tags del host Criticality de la lista, luego haz clic en Add tag condition y selecciona el valor Productive system.
Muy importante en este ejemplo son los Explicit tablespaces, que restringen la regla a servicios muy concretos. Aquí hay dos puntos importantes:
El nombre de esta condición se adapta al tipo de regla. Si dice Explicit services, especifica los nombres de los servicios en cuestión. Por ejemplo, podría ser
Tablespace DW20, es decir, incluyendo la palabraTablespace. En el ejemplo mostrado, sin embargo, Checkmk sólo quiere saber el nombre del tablespace en sí, por lo tantoDW20.Los textos introducidos siempre coinciden con el principio. Por tanto, la entrada de
DW20también accede a un tablespace ficticioDW20A. Si quieres evitarlo, añade el carácter$al final, es decir,DW20$, ya que se trata de las llamadas expresiones regulares.
Puedes encontrar una descripción detallada de todos los demás parámetros y una explicación detallada del importante concepto de reglas en el artículo sobre reglas. Por cierto, puedes obtener más información sobre Service labels, el último parámetro de la imagen anterior, en el artículo sobre etiquetas. |
Una vez completadas todas las entradas de la definición, guarda la regla con Save. Después de guardarla, habrá exactamente una nueva regla en el conjunto de reglas:

Si en lugar de con una regla, más adelante trabajas con cientos, existe el peligro de perder una visión de conjunto. Por eso, para ayudarte a mantener una visión de conjunto, Checkmk proporciona entradas muy útiles en el menú Related en cada página que enumera reglas. Con esto puedes mostrar las reglas utilizadas en el site actual (Used rulesets) y, de forma similar, las que no se utilizan en absoluto (Ineffective rules). |
5. Tags del host
5.1. Cómo funcionan los tags del host
En el capítulo anterior vimos un ejemplo de regla que sólo debería aplicarse a los sistemas productivos. Más concretamente, en esa regla definimos una condición utilizando la etiqueta tag del host Productive system. ¿Por qué definimos la condición como una etiqueta y no la establecimos simplemente para la carpeta? Bueno, sólo puedes definir una única estructura de carpetas, y cada host sólo puede estar en una carpeta. Pero un host puede tener muchas etiquetas diferentes, y la estructura de carpetas es simplemente demasiado limitada y no lo suficientemente flexible para ello.
En cambio, puedes asignar tags del host a los hosts tan libre y arbitrariamente como quieras -independientemente de la carpeta en la que se encuentren los hosts-. Luego puedes hacer referencia a estos tags en tus reglas. Esto hace que la configuración no sólo sea más sencilla, sino también más fácil de entender y menos propensa a errores que si tuvieras que definirlo todo explícitamente para cada host.
Pero, ¿cómo y dónde defines qué host debe tener qué tag? ¿Y cómo puedes definir tus propios tags personalizados?
5.2. Definir tags del host
Empecemos con la respuesta a la segunda pregunta sobre las etiquetas personalizadas. En primer lugar, debes saber que las etiquetas se organizan en grupos denominados grupos de tags de host. Tomemos como ejemplo la ubicación. Un grupo de tags podría denominarse Ubicación, y este grupo podría contener las etiquetas Múnich, Austin y Singapur. Básicamente, a cada host se le asigna exactamente una etiqueta de cada grupo de tags. Por tanto, en cuanto definas tu propio grupo de tags, cada host llevará una de las etiquetas de este grupo. A los hosts para los que no hayas seleccionado una etiqueta del grupo simplemente se les asigna la primera por defecto.
Para definir los grupos de tags de host, consulta Setup > Hosts > Tags:
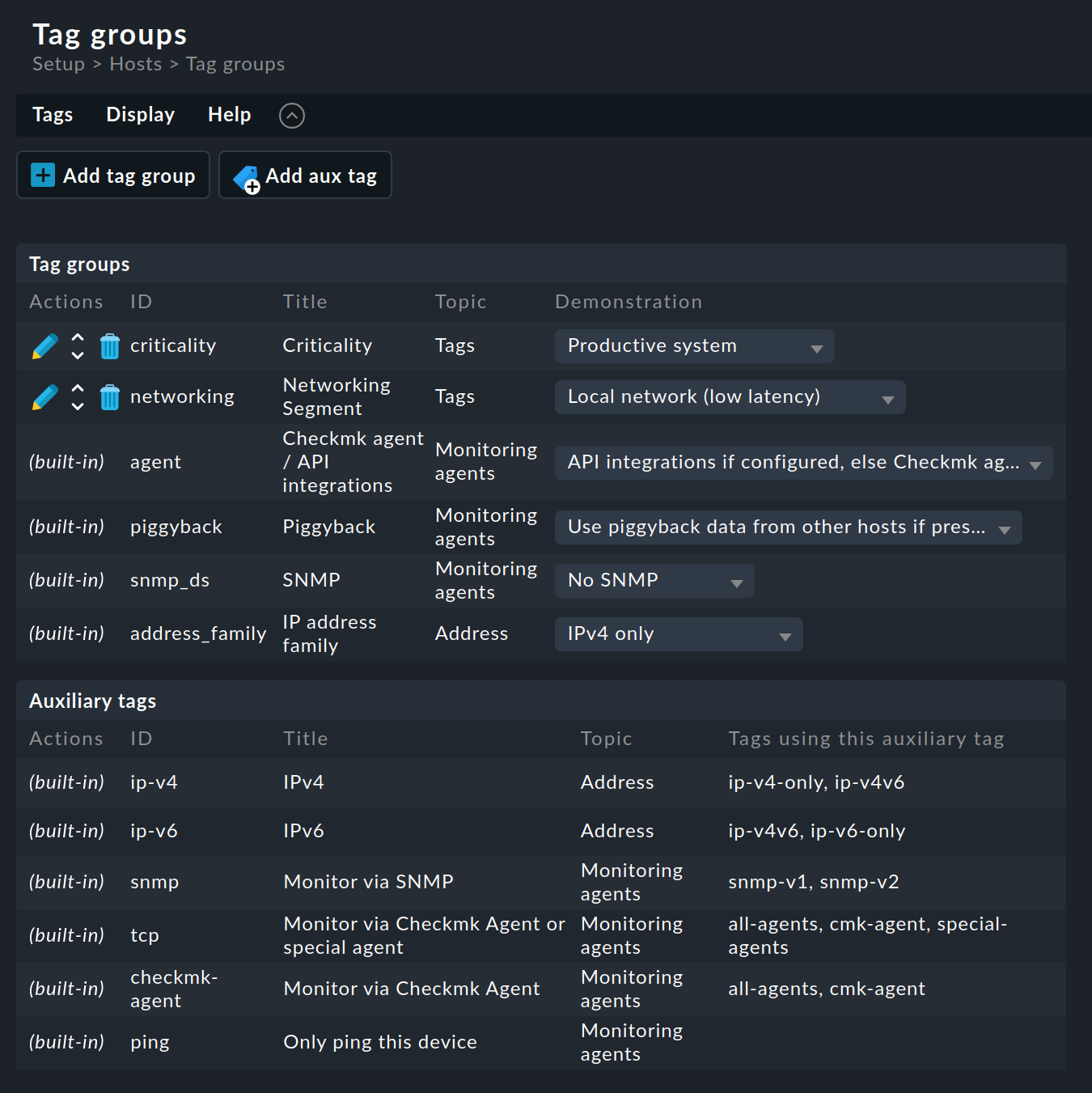
Como puedes ver, algunos grupos de tags ya están predefinidos. No puedes cambiar la mayoría de ellos. También te recomendamos que no toques los dos grupos de ejemplo predefinidos Criticality y Networking Segment. Es mejor que definas tus propios grupos:
Haz clic en Add tag group. Se abrirá la página para crear un nuevo grupo de tags. En la primera casilla Basic settings asignas -como tantas veces en Checkmk- un ID interno que sirve como clave y que no se puede cambiar más tarde. Además del ID, defines un título descriptivo, que puedes cambiar más tarde. Con Topic puedes determinar dónde se ofrecerá el tag más tarde en las propiedades del host. Si creas un nuevo tema aquí, el tag se mostrará en una caja aparte en las propiedades del host.
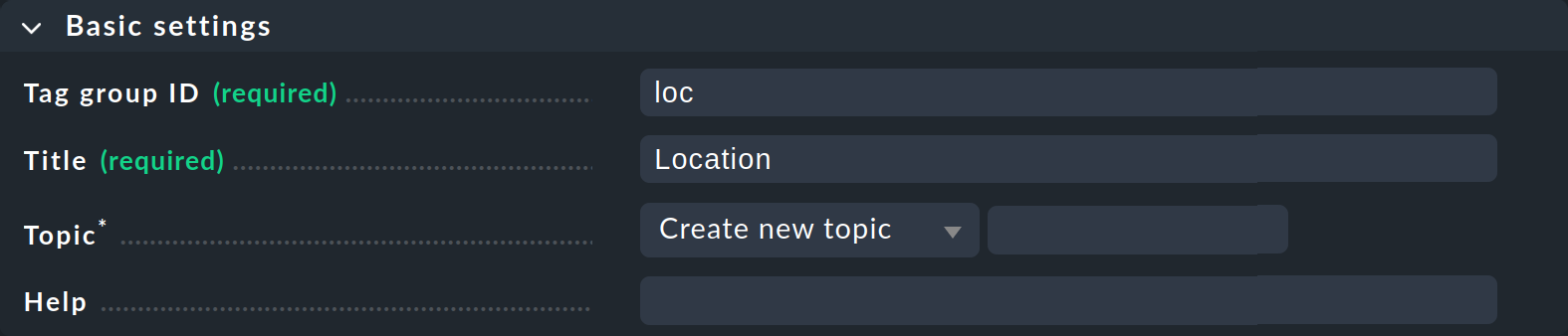
La segunda caja Tag choices se refiere a los tags propiamente dichos, es decir, a las opciones de selección en el grupo. Haz clic en Add tag choice para crear un tag y asignar un ID interno y un título a cada tag:
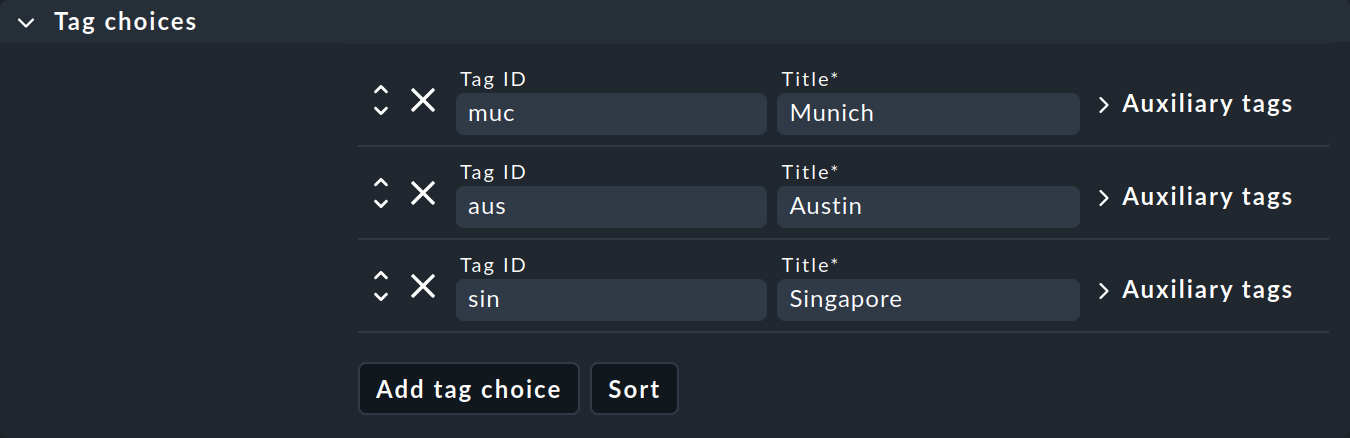
Notas:
Los grupos con una sola selección también están permitidos e incluso pueden ser útiles. La etiqueta que contiene se conoce como checkbox tag y aparece en las propiedades del host como una simple casilla de verificación. Cada host tendrá entonces la etiqueta, o no, porque las checkbox tags están desactivadas por defecto.
En este punto, puedes ignorar por ahora las tags auxiliares. Puedes obtener toda la información sobre las tags auxiliares en particular y sobre las tags del host en general en el artículo sobre las tags del host.
Una vez que hayas guardado este nuevo grupo de tags del host con Save, puedes empezar a utilizarlo.
5.3. Asignar un tag a un host
Ya has visto cómo asignar tags a un host -en las propiedades del host al crear o editar un host-. En la caja Custom attributes -o en otra aparte si has creado un Topic - aparecerá el nuevo grupo de tags del host y allí podrás hacer tu selección y establecer el tag para el host:
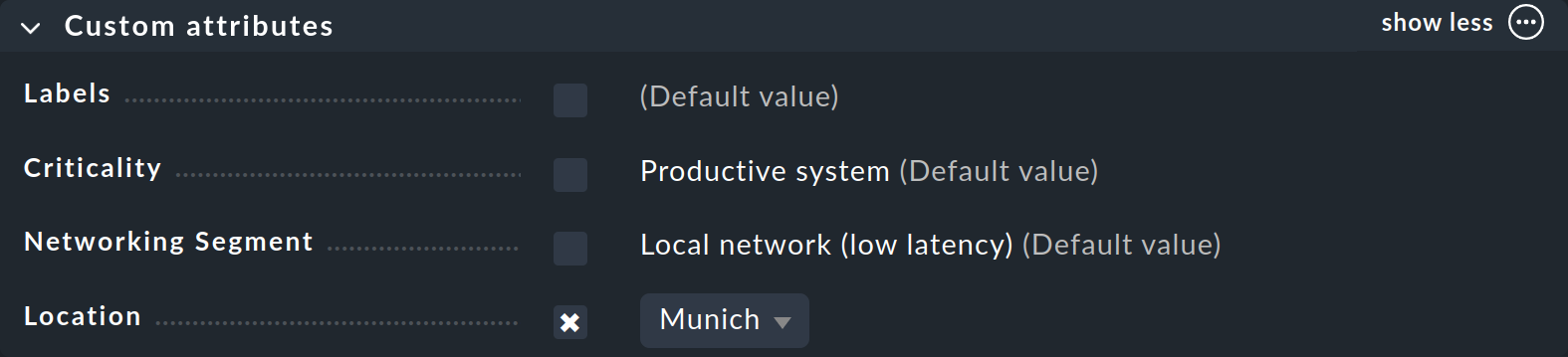
Ahora que has aprendido los principios importantes de la configuración con reglas y tags del host, en los capítulos restantes nos gustaría darte algunas directrices prácticas sobre cómo reducir las falsas alarmas en un nuevo sistema Checkmk.
6. Personalizar los umbrales del sistema de archivos
Check los valores por defecto para la monitorización de los sistemas de archivos y ajústalos si es necesario. Ya hemos mostrado brevemente los valores por defecto anteriormente en la búsqueda de reglas.
Por defecto, Checkmk toma los umbrales del 80 % para WARN y del 90 % para CRIT para el nivel de llenado de los sistemas de archivos. Ahora bien, el 80 % para un disco duro de 2 terabytes son 400 gigabytes, después de todo, quizá un poco demasiado búfer para una advertencia. Así que aquí tienes algunos consejos sobre el tema de los sistemas de archivos:
Crea tus propias reglas en el conjunto de reglas Filesystems (used space and growth).
Los parámetros permiten umbrales que dependen del tamaño del sistema de archivos. Para ello, selecciona Levels for used/free space > Levels for used space > Dynamic levels. Con el botón Add new element ya puedes definir tus propios valores umbrales por tamaño de disco.
Es aún más fácil con el botón Magic factor, que presentaremos en el último capítulo.
7. Enviar hosts a tiempo de mantenimiento
Algunos servidores se reinician con regularidad, ya sea para aplicar parches o simplemente porque se supone que deben hacerlo. Puedes evitar las falsas alarmas en esos momentos de dos formas:
En Checkmk Raw, define primero un periodo de tiempo que abarque las horas del reinicio. Puedes averiguar cómo hacerlo en el artículo sobre periodos de tiempo. A continuación, crea una regla en cada uno de los conjuntos de reglas Notification period for hosts y Notification period for services para los host afectados y selecciona allí el periodo de tiempo definido previamente. La segunda regla para los servicios es necesaria para que los servicios que pasen a CRIT durante este tiempo no activen una notificación. Si los problemas se producen dentro de este periodo de tiempo -y también se resuelven dentro del mismo-, no se activará ninguna notificación.
En las ediciones comerciales hay tiempos de mantenimiento programados para este fin, que puedes establecer para cualquier host afectado.
Una alternativa a la creación de tiempos de inactividad para los host, que ya hemos descrito en el capítulo sobre tiempos de inactividad programados, es el conjunto de reglas Recurring downtimes for hosts de las ediciones comerciales, que tiene la gran ventaja de que los host que se añadan posteriormente a la monitorización recibirán automáticamente estos tiempos de inactividad programados. |
8. Ignorar hosts apagados
No siempre es un problema que un ordenador esté apagado. Las impresoras son un ejemplo clásico. Su monitorización con Checkmk tiene mucho sentido; algunos usuarios incluso organizan la reordenación del tóner mediante Checkmk. Sin embargo, por regla general, apagar una impresora antes de la hora de cierre no es un problema. Sin embargo, carece de sentido cuando en ese momento Checkmk avisa debido a que el host correspondiente a la impresora está DOWN.
Puedes decirle a Checkmk que está perfectamente OK que un host esté apagado. Para ello, busca el conjunto de reglas Host check command, crea una nueva regla y establece su valor en Always assume host to be up:

En la caja Conditions, asegúrate de que esta regla sólo se aplica realmente a los host apropiados, dependiendo de la estructura que hayas elegido. Por ejemplo, puedes definir un tag del host y utilizarlo aquí, o puedes establecer la regla para una carpeta en la que se encuentren todas las impresoras.
Ahora, todas las impresoras se mostrarán siempre como UP, sea cual sea su estado real.
Sin embargo, se seguirán comprobando los servicios de la impresora, y cualquier timeout resultaría en un estado CRIT. Para evitarlo también, configura una regla para los host afectados en el conjunto de reglas Status of the Checkmk services, en la que establezcas los timeouts y los problemas de conexión en OK respectivamente:
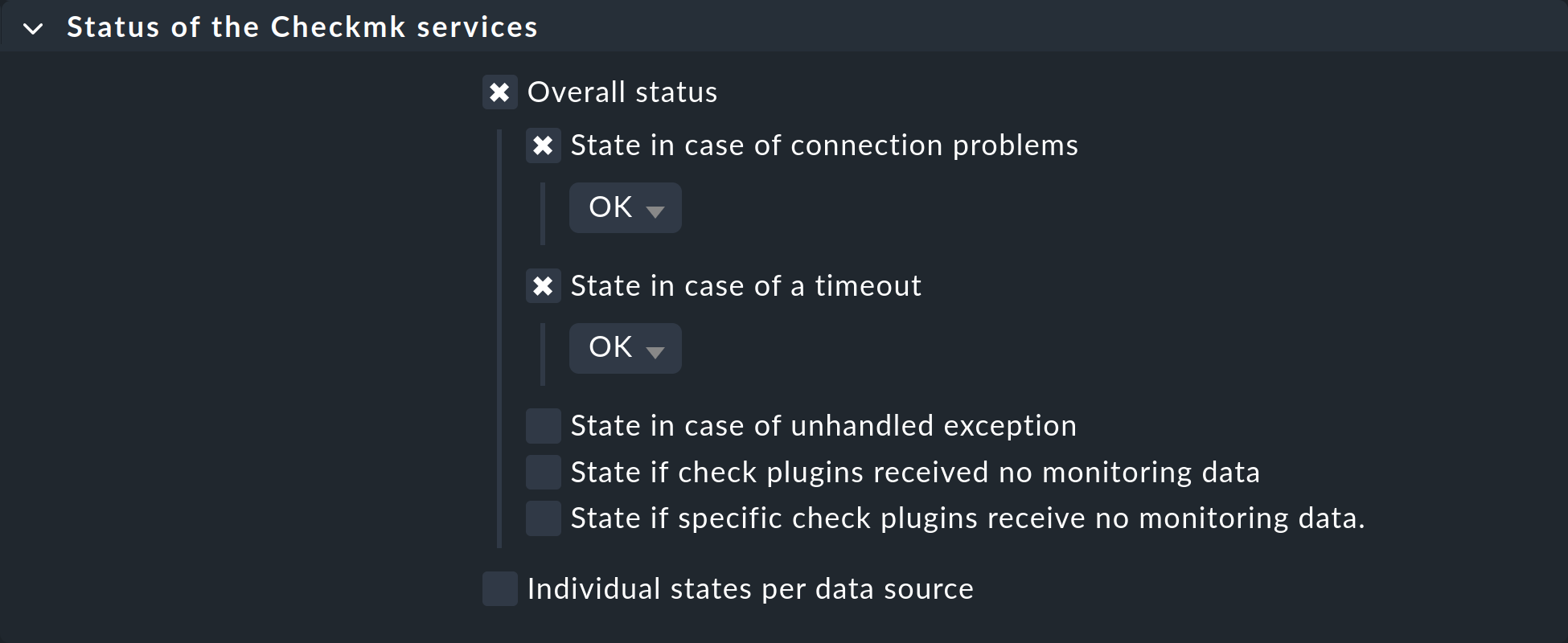
9. Configurar los puertos del switch
Si monitorizas un switch con Checkmk, te darás cuenta de que, durante la configuración del servicio, se crea automáticamente un servicio para cada puerto que esté activo en ese momento. Se trata de una configuración por defecto sensata para los switches core y de distribución, es decir, aquellos a los que sólo se conectan dispositivos de infraestructura o servidores. Sin embargo, en el caso de los switches a los que se conectan dispositivos finales, como estaciones de trabajo o impresoras, esto provoca, por un lado, notificaciones continuas si un puerto se cae y, por otro, que se encuentren continuamente nuevos servicios porque se sube un puerto que antes no estaba monitorizado.
Hay dos métodos que han dado buenos resultados en estas situaciones. En primer lugar, puedes restringir la monitorización a los puertos uplink. Para ello, crea una regla para los servicios desactivados que excluya de la monitorización a los demás puertos.
Sin embargo, el segundo método es mucho más interesante. Con este método monitorizas todos los puertos, pero permites que DOWN sea un estado válido. La ventaja es que dispondrás de monitorización de errores de transmisión incluso para los puertos a los que están conectados los dispositivos finales y, de este modo, podrás detectar muy rápidamente cables de parche en mal estado o errores en la autonegociación. Para implementar esta función, necesitas dos reglas:
El primer conjunto de reglas Network interface and switch port discovery define las condiciones en las que se van a monitorizar los puertos del switch. Crea una regla para los switches deseados y selecciona si se van a descubrir interfaces individuales (Configure discovery of single interfaces), o grupos (Configure grouping of interfaces). A continuación, en Conditions for this rule to apply > Match port states, activa 2 - down además de 1 - up:
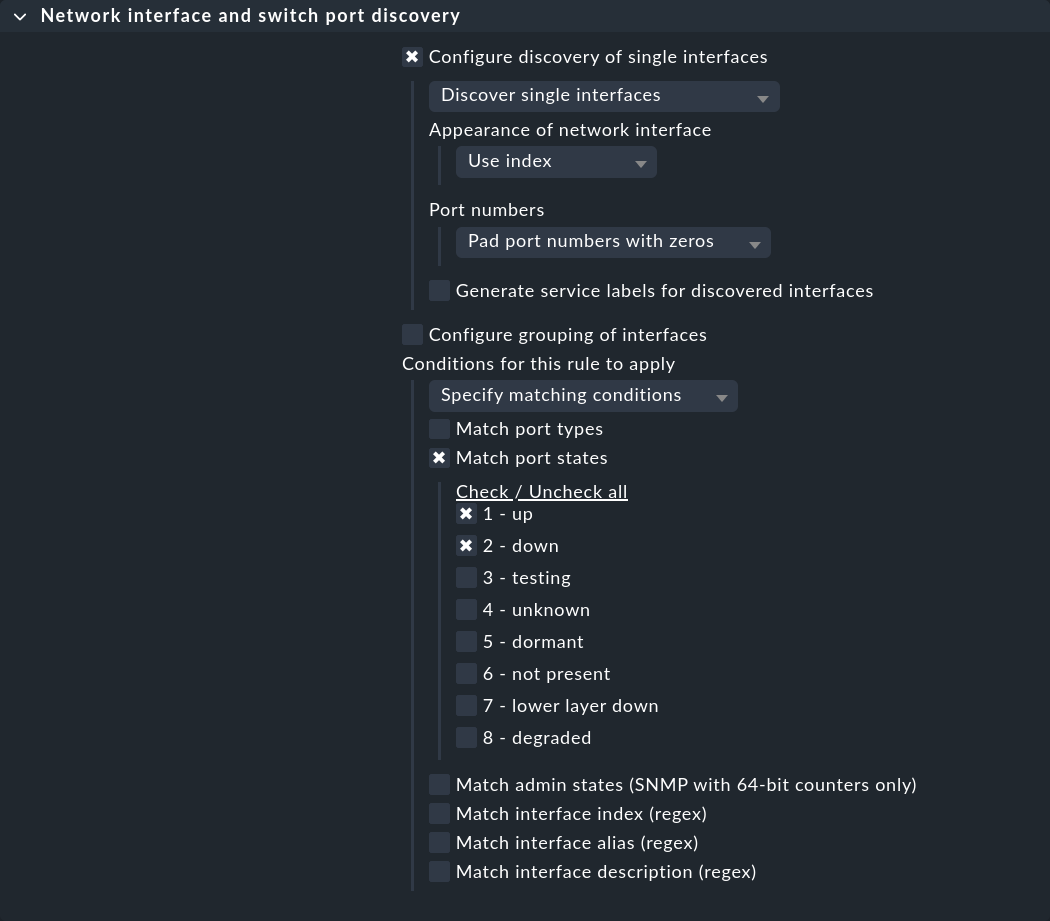
En la configuración de servicios de los switches, ahora también se presentarán los puertos con el estado DOWN, y podrás añadirlos a la lista de servicios monitorizados.
Antes de activar el cambio, aún necesitarás la segunda regla que garantice que este estado se evalúa como OK. Este conjunto de reglas se llama Network interfaces and switch ports. Crea una nueva regla y activa la opción Operational state, desactiva Ignore the operational state debajo de ella y, a continuación, activa los estados 1 - up y 2 - down para el Allowed operational states (y cualquier otro estado que sea necesario).
10. Desactivar servicios permanentemente
Para algunos servicios que simplemente no se pueden configurar de forma fiable como OK, es mejor no monitorizarlos en absoluto. En este caso, podrías simplemente eliminar manualmente los servicios de la monitorización para los host afectados en la configuración de servicios (en la página Services of host ) configurándolos como Disabled o Undecided. Sin embargo, este método es engorroso y propenso a errores.
Es mucho mejor definir reglas según las cuales determinados servicios no serán monitorizados sistemáticamente. Para ello existe el conjunto de reglas Disabled services. Aquí puedes, por ejemplo, crear una regla y especificar en la condición que los sistemas de archivos con el punto de montaje /var/test/ no sean monitorizados por definición.
Si desactivas un servicio individual en la configuración de servicios de un host haciendo clic en , se crea automáticamente una regla para el host en este mismo conjunto de reglas. Puedes editar esta regla manualmente y, por ejemplo, eliminar el nombre explícito del host. El servicio afectado quedará desactivado en todos los hosts. |
Puedes leer más información sobre esto en el artículo sobre configuración de servicios.
11. Detección de valores atípicos mediante valores medios
Las notificaciones esporádicas suelen generarse por valores umbrales en las métricas de utilización -como la utilización de la CPU-que sólo se superan durante un breve periodo de tiempo. Por regla general, esos breves picos no son un problema y no deben ser reprobados por la monitorización.
Por esta razón, bastantes plugins de check tienen la opción en su configuración de que sus métricas se promedien durante un periodo de tiempo más largo antes de aplicar los umbrales. Un ejemplo de ello es el conjunto de reglas para la utilización de la CPU en sistemas no Unix llamado CPU utilization for simple devices. Para ello existe el parámetro Averaging for total CPU utilization:
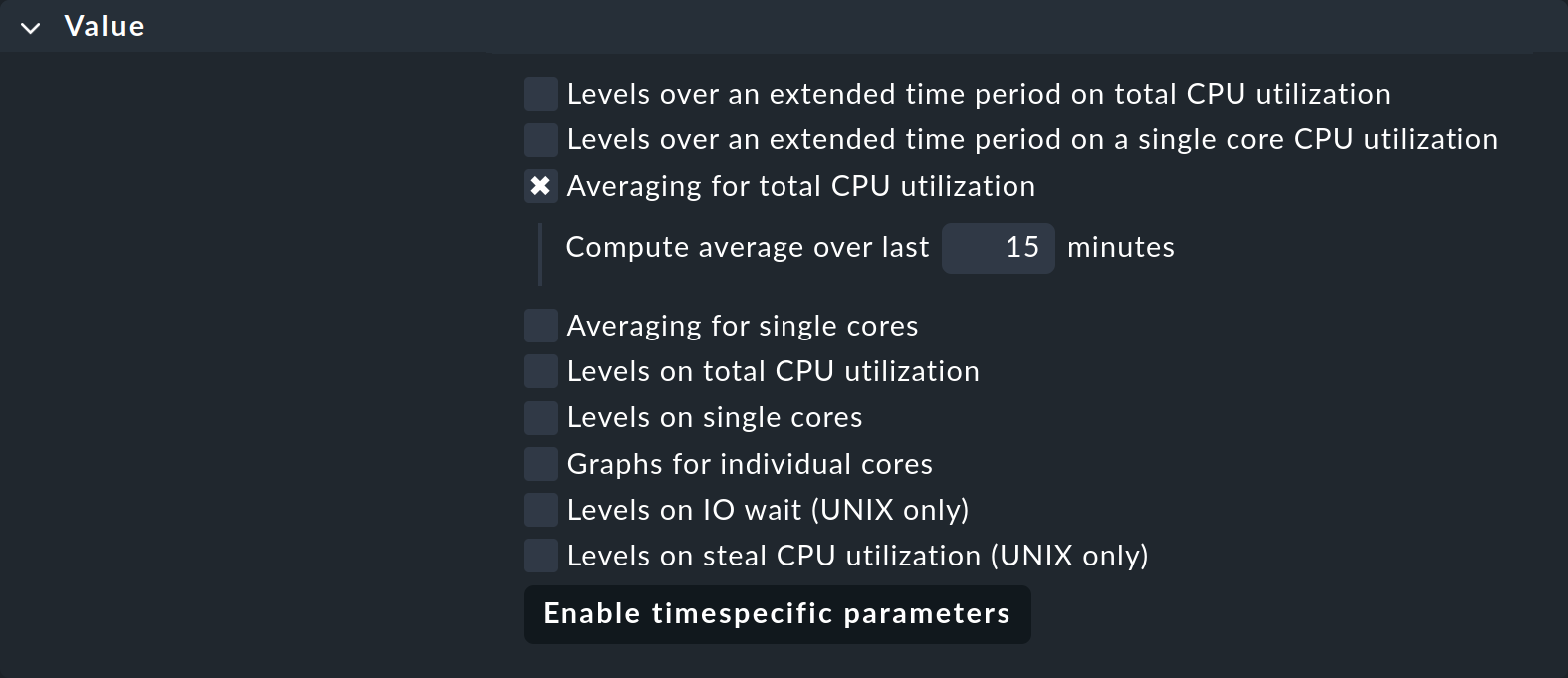
Si lo activas e introduces 15, la utilización de la CPU se promediará primero durante un periodo de 15 minutos y sólo después se aplicarán los valores umbrales a este valor medio.
12. Gestión de errores esporádicos
Cuando nada más ayuda y los servicios siguen pasando esporádicamente a WARN o CRIT durante un único intervalo de check -es decir, durante un minuto-, existe un último método para evitar las falsas alarmas: el conjunto de reglas Maximum number of check attempts for service.
Si creas una regla en ese conjunto de reglas y estableces su valor en, por ejemplo, 3, un servicio que pase de OK a WARN, por ejemplo, aún no activará una notificación y aún no se mostrará como problema en el cuadro de diálogo OverviewEl estado intermedio en el que se encontrará el servicio se denomina soft state. Sólo cuando el estado siga sin ser OK durante tres checks consecutivos -lo que supone una duración total de algo más de dos minutos- se informará de un problema persistente. Sólo un hard state activará una notificación.
Hay que admitir que no es una solución atractiva. Siempre debes intentar llegar a la raíz de cualquier problema, pero a veces las cosas son como son, y con el número de intentos de check al menos tienes una forma viable de evitar esas situaciones.
13. Mantener actualizada la lista de servicios
En cualquier centro de datos se trabaja constantemente, por lo que la lista de servicios a monitorizar nunca permanecerá estática. Para asegurarte de que no se te pasa nada por alto, Checkmk configura automáticamente un servicio especial para ti en cada host: este servicio se conoce como Check_MK Discovery:

Por defecto, cada dos horas este servicio comprueba si se han encontrado nuevos servicios -aún no monitorizados- o si se han dado de baja servicios existentes. Si es así, el servicio pasa a WARN. Entonces puedes llamar a la configuración del servicio (en la página Services of host ) y volver a poner la lista de servicios en el estado actual.
Encontrarás información detallada sobre este "Discovery Check " en el artículo sobre la configuración de servicios. Allí también puedes aprender cómo puedes hacer que se añadan automáticamente servicios no supervisados, lo que facilita mucho el trabajo en una configuración grande.
Con Monitor > System > Unmonitored services puedes llamar a una vista de tabla que te muestra los servicios nuevos o dados de baja. |