This is a machine translation based on the English version of the article. It might or might not have already been subject to text preparation. If you find errors, please file a GitHub issue that states the paragraph that has to be improved. |
1. Introducción
Para los checks que miden valores de rendimiento, a menudo es difícil establecer los umbrales correctos. Mientras que los valores demasiado bajos crean estados WARN o CRIT que sólo supuestamente indican problemas, establecerlos demasiado altos los deja en estado OK, lo que provoca que la monitorización sea ciega a los problemas.
Tomemos como ejemplo el servicio CPU load en un host Linux (o, de forma similar, Processor Queue en un host Windows): puedes tener un servidor que esté inactivo la mayor parte del tiempo, pero regularmente, durante unos breves periodos de tiempo todos los días, excepto los sábados y domingos, de 0:00 a 7:00 de la mañana aproximadamente, se ejecutan en este servidor algunos trabajos de copia de seguridad de gran tamaño. Durante este tiempo, una carga de la CPU de 10 (con 20 núcleos) es completamente normal. Durante el resto del tiempo, incluso una carga de 3 podría ser sospechosamente alta.
En Checkmk tienes varias posibilidades para poner en práctica este ejemplo. Una de ellas es definir primero los periodos de tiempo con las distintas cargas de trabajo y, a continuación, establecer valores umbrales específicos para estos periodos. En nuestro ejemplo, esto significa definir primero un nuevo periodo de tiempo para el tiempo con carga alta (de lunes a viernes de 0:00 a 7:00). A continuación, puedes especificar una regla para el servicio (CPU load o Processor Queue). Selecciona este nuevo periodo de tiempo y establece valores umbrales diferentes (más altos) para él.
Utilizar un periodo de tiempo tiene la ventaja de que siempre es fácil entender por qué se produjo un estado WARN/CRIT a una hora determinada. Sin embargo, la vinculación manual de los valores umbrales a periodos de tiempo también es algo inflexible y, a veces, simplemente demasiado complicada.
Si utilizas una de las ediciones comerciales, hay otra forma de resolver este problema: se llama monitorización predictiva, y consiste en evaluar los datos para obtener una predicción de cómo se comportarán en el futuro.
Una vez establecida, la predicción no permanece estática, sino que se adapta a la realidad cambiante a lo largo del tiempo:la predicción de hoy para pasado mañana no permanecerá invariable, porque se habrán incluido los valores reales de mañana para pasado mañana. Sin entrar en viajes en el tiempo (¡agotadores!), el proceso también puede expresarse así: Checkmk aprende continuamente. Como los valores umbrales para los estados WARN/CRIT siempre se establecen en relación con los valores de predicción, los valores umbrales también aprenden junto con la predicción.
2. Aplicación de la monitorización predictiva
2.1. Del Nombre del plugin al parámetro de predicción
Toda una serie de Plugins Checkmk admiten la monitorización predictiva. A continuación encontrarás algunos ejemplos importantes:
Los ajustes para la monitorización predictiva se encuentran en el mismo lugar donde, por lo demás, estableces los umbrales de un servicio. Allí encontrarás la selección Predictive Levels (only on CMC), si el check en cuestión lo admite.
2.2. Crear una regla para la monitorización predictiva
Para el servicio CPU load en el host Linux de nuestro ejemplo, puedes crear una nueva regla con el conjunto de reglas CPU load (not utilization!) en Service monitoring rules, que puedes encontrar más rápidamente buscando en el Menú de configuración.
En la sección Value encontrarás el parámetro sobre el nivel de servicio para el que puedes seleccionar el valor Predictive Levels (only on CMC):
2.3. Selección de valores de referencia anteriores
Tras seleccionar Predictive Levels (only on CMC) se muestran los parámetros, de los que primero presentaremos los dos primeros con más detalle:
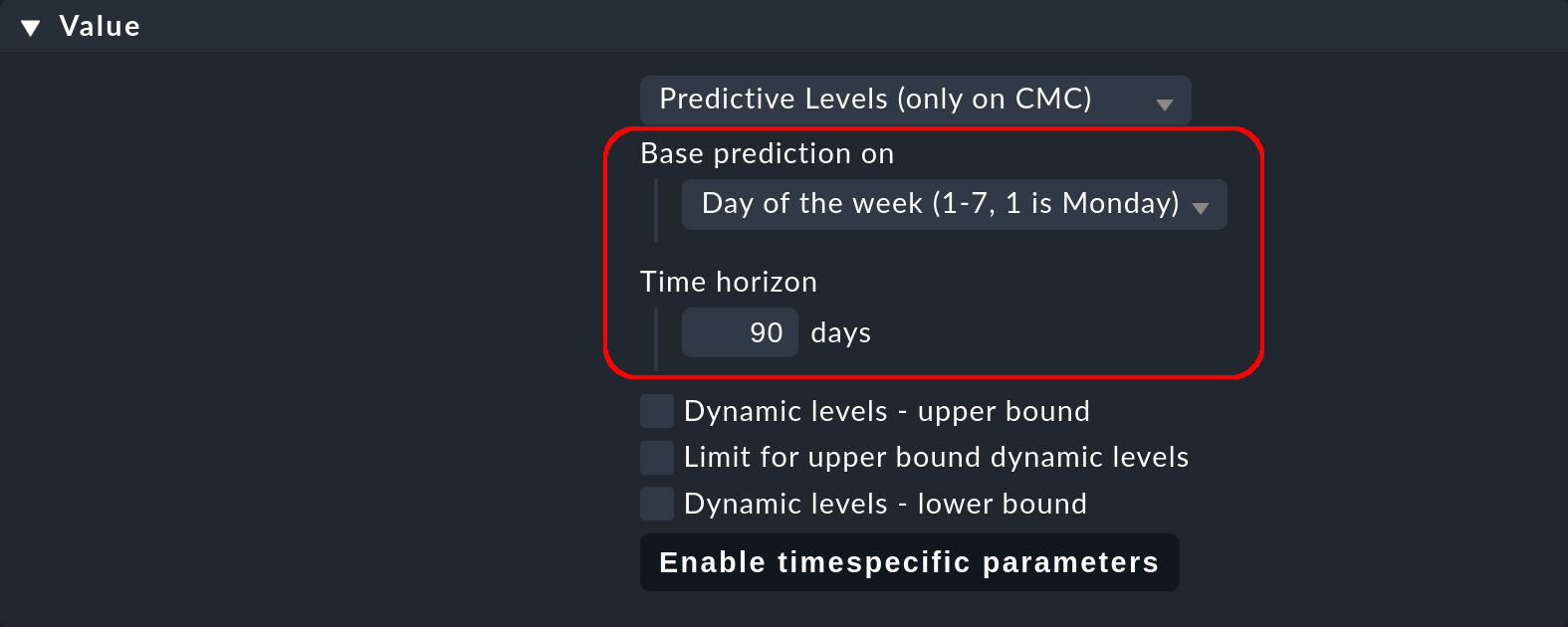
Con Base prediction on defines la periodicidad en la que se espera la repetición de los datos de medición (mensual, semanal, diaria u horaria):
Day of the month: Los valores medidos de cada día del mes se comparan entre sí, es decir, el 1º, 2º, 3º, etc. de cada mes.
Day of the week: La comparación se basa en los días de la semana, es decir, se hace una predicción diferente para cada día de la semana (lunes, martes, miércoles, etc.). Ésta suele ser la configuración correcta.
Hour of the day: Se comparan las horas individuales de cada día, es decir, la predicción se repite diariamente.
Minute of the hour: La comparación por minutos y la repetición horaria sólo suelen ser útiles para probar una predicción.
En el siguiente parámetro Time horizon introduce hasta cuántos días en el pasado debe evaluar Checkmk los datos de medición. Checkmk accede a los datos históricos almacenados en los archivos RRD. Aunque los datos de medición de los archivos RRD se almacenan durante 4 años, no tiene sentido retroceder demasiado en el pasado. Por un lado, los valores típicos del pasado reciente pueden diferir de los del pasado más lejano.
Por otra parte, cuanto más atrás en el tiempo mires, menos datos de medición por unidad de tiempo habrá para comparar. Esto se debe a que , por defecto, Checkmk comprime los datos de medición disponibles de cada minuto en los archivos RRD en tres fases para ahorrar espacio: después de 2, 10 y después de 90 días. La compresión significa que el mínimo, el máximo y la media se calculan a partir de múltiples datos de medición y estos datos calculados sustituyen a los datos de medición originales. Si los datos medidos de los dos últimos días están disponibles en la resolución completa de 1 minuto, la resolución es de 5 minutos después de 2 días, 30 minutos después de 10 días y 6 horas después de 90 días. Si Checkmk accede a los datos históricos para la monitorización predictiva, siempre se toma el máximo de los tres valores almacenados.
Para nuestro servidor de ejemplo, con una gran carga de trabajo de lunes a viernes por la noche, es aconsejable seleccionar el periodo de referencia semanal y un intervalo de tiempo de referencia de (como máximo) 90 días. 90 días es un compromiso aceptable, ya que, por un lado, este intervalo contiene suficientes días de comparación y, por otro, los datos de medición siguen estando disponibles con una resolución de 30 minutos, siempre que no se hayan modificado los valores por defecto.
Selecciona como Base prediction on la entrada Day of the week e introduce como Time horizon 90 como muestra la imagen de arriba.
Al establecer el periodo de referencia semanal para un intervalo de 90 días en el pasado, Checkmk dispone de la información necesaria para calcular la curva de referencia. Esto implica evaluar cada lunes del periodo de tiempo (para 90 días hay 12 lunes), comparar el valor medido de cada lunes con los valores medidos de los demás lunes a la misma hora y calcular la media. Después del lunes, Checkmk trata los demás días de la semana de martes a domingo de la misma manera. La curva de referencia así calculada para el pasado se actualiza y se convierte así en la curva de referencia proyectada para el futuro.
Los valores utilizados para calcular la media del periodo de referencia pueden ser valores calculados (es decir, no medidos), dependiendo de la resolución de los datos históricos de los archivos RRD. |
La curva de referencia calculada por Checkmk a partir de los dos parámetros definidos hasta ahora (periodo de referencia e intervalo de tiempo de referencia) se dibuja como una línea negra en la siguiente imagen:
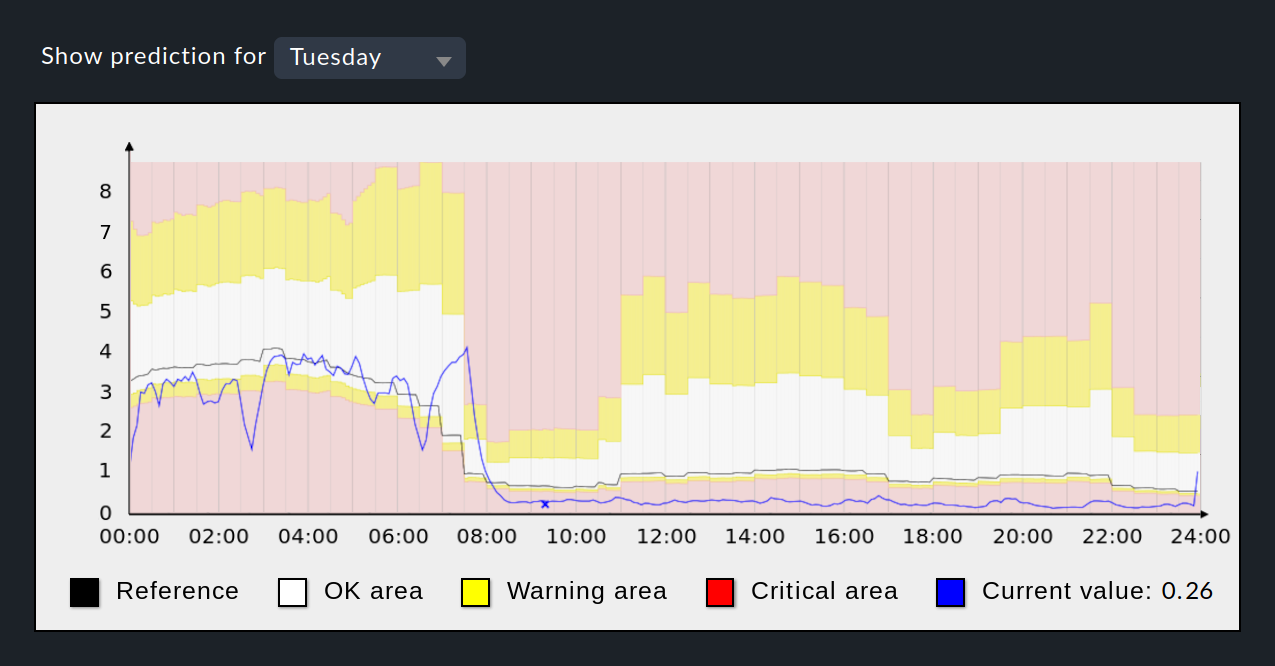
Como vista previa, esta imagen muestra el gráfico de predicción, que puedes visualizar una vez completada la configuración. Aparte de la curva de referencia negra, los valores actuales se muestran como una línea azul, si están disponibles en el intervalo de tiempo mostrado.
Lo que falta para completar la configuración son las definiciones de los valores umbrales para los estados WARN y CRIT, que se marcan en el gráfico con colores de fondo amarillo y rojo. La siguiente sección trata de la definición de estos umbrales.
2.4. Definición de umbrales para la predicción
Define los valores umbrales para WARN y CRIT en función de los valores de predicción mostrados en la curva de referencia.
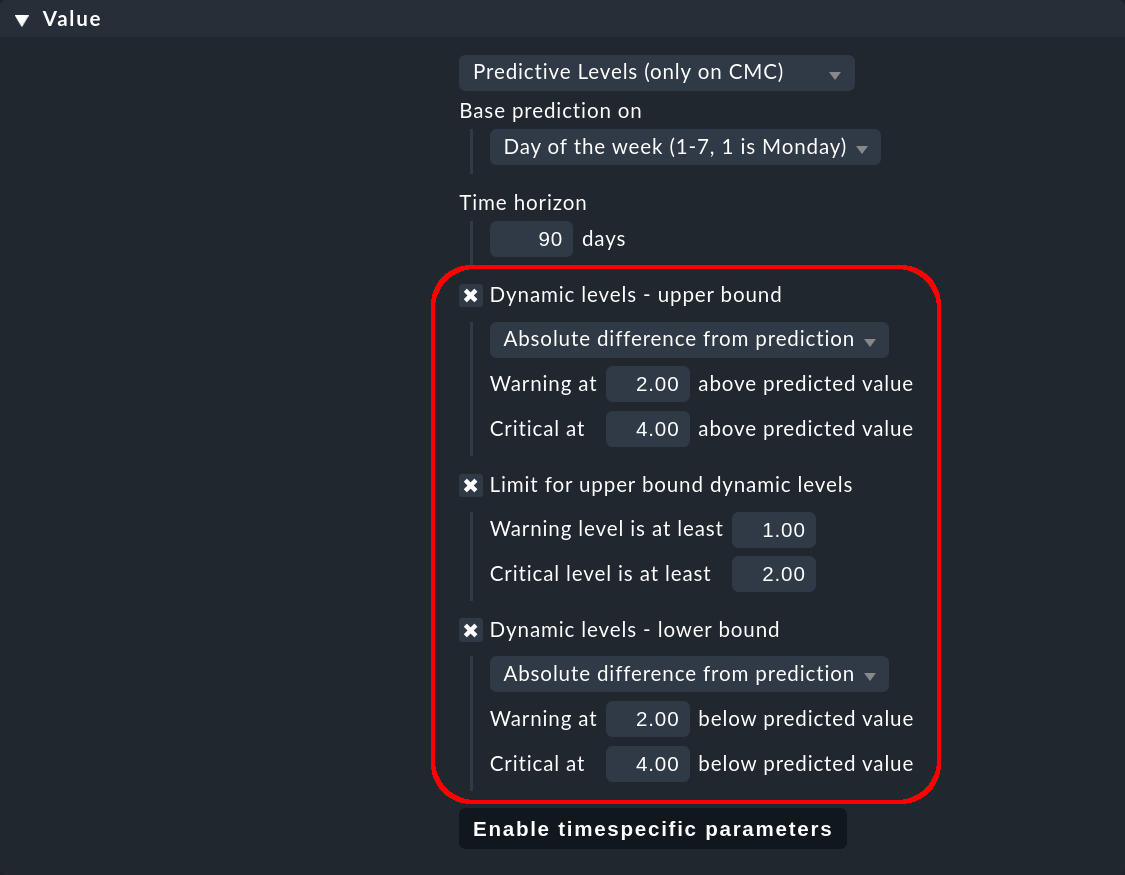
Para ilustrar el efecto de los distintos valores de los parámetros utilizados para definir los umbrales, veamos de cerca un único valor de la curva de referencia. Supondremos que el valor de predicción del servicio CPU load es 10 a las 3:30 h de los viernes.
Para los umbrales superiores existe el parámetro Dynamic levels — upper bound, y para los umbrales inferioresDynamic levels — lower bound. Para ambos parámetros tienes tres opciones, que se describen en las tres secciones siguientes.
Diferencia absoluta respecto a la predicción
Con este valor, los umbrales se calculan aumentando o disminuyendo el valor de predicción en un valor absoluto fijo. Ejemplo: Warning at 2.00 hará que se muestre un aviso si el valor es superior a 12 e inferior a 8.
Diferencia relativa respecto a la predicción
Con este valor, los umbrales se calculan aumentando o disminuyendo el valor de predicción en un porcentaje. Ejemplo: Warning at 10.0 % hará que se muestre un aviso si el valor es superior a 11 e inferior a 9.
En relación con la desviación estándar
Con este valor, los umbrales se calculan aumentando o disminuyendo el valor predicho en un múltiplo de la desviación estándar. La desviación estándar indica cuánto difieren los valores en un periodo de referencia (por ejemplo, los viernes a las 3:30 h).
Con esta opción, el cálculo de los valores umbrales no es tan fácil de predecir, porque Checkmk calcula internamente la desviación estándar a partir de todos los valores medidos del periodo de referencia. Para ilustrar el efecto, necesitamos más información sobre las 12 mediciones del periodo de referencia de los viernes a las 3:30 h: suponemos que 10 mediciones son iguales a 10, una es 11 y otra es 9. Por tanto, las 12 mediciones tienen un valor medio de 10 (que corresponde al valor de predicción), una varianza de aproximadamente 0,167 y una desviación estándar de aproximadamente 0,41. (Nos ahorraremos aquí los detalles del cálculo, pero puedes consultar diversas páginas de estadísticas en internet).
Ejemplo: Warning at 1.00 como múltiplo de la desviación estándar hará que se muestre un WARN si el valor es superior a 10,41 e inferior a 9,59.
Para evitar estados WARN/CRIT no deseados, no se aplican umbrales si la desviación estándar no está definida (por ejemplo, porque sólo hay un valor medido en el periodo de referencia) o es cero (si todos los valores medidos son idénticos).
En general, se aplica la siguiente regla: cuanto más constantes son los valores del pasado, menor es la desviación estándar y más estricta es la predicción. Por tanto, esta opción es útil para definir umbrales más estrechos para un periodo de referencia con valores estables y uniformes.
Valores umbrales superiores mínimos
Por último, con Limit for upper bound dynamic levels tienes la posibilidad de establecer valores mínimos absolutos para los valores umbrales superiores. Esto te permite evitar estados WARN/CRIT no deseados para momentos en los que los valores de predicción son muy bajos.
Ejemplo: Un Warning level de 2.00 hará que se muestre una WARN sólo si el valor es superior a 2, aunque el umbral superior para una WARN sea 1,5.
Gráfico de predicción con valores umbrales
Los efectos descritos como ejemplo para un valor son calculados por Checkmk para todos los valores de la curva de referencia. Puedes ver el resultado en el gráfico de predicción, que se describirá con más detalle en el capítulo siguiente. El gráfico muestra las curvas de los valores umbral superior e inferior por encima y por debajo de la curva de referencia. Las zonas para WARN están coloreadas en amarillo y para CRIT en rojo.
Debes comprobar cuidadosamente los rangos para WARN y CRIT en el gráfico de predicción, especialmente si tienes los umbrales calculados a partir de la desviación estándar, ya que los valores subyacentes a la desviación estándar no se pueden leer directamente desde la interfaz de usuario de Checkmk. Comprobando y, si es necesario, ajustando los niveles, puedes evitar que el servicio tenga involuntariamente los estados WARN o CRIT con demasiada frecuencia.
Esto completa la implementación de la monitorización predictiva. En el próximo capítulo aprenderás cómo se puede observar la configuración en la monitorización, y cómo puedes visualizar el gráfico de predicción.
3. Analizar los pronósticos
Si has configurado la monitorización basada en predicciones para un servicio, activa los cambios y, una vez que Checkmk haya realizado un check para este servicio, aparecerá el nuevo icono en la lista de servicios:
Especialmente tras la configuración inicial de un servicio, puede faltar este icono porque no se dispone de datos suficientes para la predicción configurada. En este caso, aparece un mensaje del tipo |
Haz clic en la lista de servicios y aparecerá una representación gráfica del intervalo de tiempo de predicción actual -gráfico de predicción:
En el gráfico de predicción verás la curva de referencia como una línea negra, los valores actuales como una línea azul, y los rangos para los estados OK en blanco, para WARN en amarillo, y para CRIT con un color de fondo rojo.
El intervalo de tiempo mostrado se basa en el periodo de referencia seleccionado. Por ejemplo, si tienes un periodo semanal, puedes ver los días individuales de la semana y utilizar la lista desplegable situada encima del gráfico para cambiar de día. Con la entrada de lista especial Everyday, el gráfico te mostrará los valores medios de todos los días de los que hay datos disponibles.
En el gráfico del ejemplo, se puede ver la alta utilización de la capacidad por la noche y la baja utilización de la capacidad durante el día. De 0:00 a 04:00 horas, los valores actuales (línea azul) son inferiores a la curva de referencia de predicción (línea negra) -de hecho, tan bajos que los valores umbrales inferiores se estaban reduciendo intermitentemente, provocando estados WARN/CRIT-. También es visible el intervalo entre las 08:30 y las 23:30 horas, cuando la línea azul está constantemente en el intervalo CRIT inferior. Este estado podría evitarse en el futuro mediante valores más altos para los umbrales inferiores.
Por último, el gráfico muestra que los umbrales superiores se basan en la desviación estándar, porque entre las 05:00 y las 07:30 horas los umbrales superiores tienden a aumentar, mientras que los valores de la curva de referencia disminuyen. Este comportamiento sólo puede explicarse por la desviación estándar, ya que las otras dos opciones (valor absoluto y porcentual) habrían provocado un ajuste de los valores umbrales en el sentido de la curva de referencia.
Al igual que en la configuración inicial, cualquier cambio en la monitorización predictiva sólo se hará efectivo tras un nuevo check del servicio. No es necesario que esperes al siguiente check periódico, sino que puedes activar uno manualmente desde la lista de servicios con el icono y el elemento de menú Reschedule 'Check_MK' service. |