This is a machine translation based on the English version of the article. It might or might not have already been subject to text preparation. If you find errors, please file a GitHub issue that states the paragraph that has to be improved. |
1. Introducción
En Checkmk, notificación significa que se informa activamente a los usuarios en caso de problemas u otros eventos de monitorización. Esto se consigue normalmente mediante correos electrónicos. Sin embargo, también existen muchos otros métodos, como el envío de SMS o el reenvío a un sistema de tickets. Checkmk proporciona una interfaz sencilla para escribir scripts para tus propios métodos de notificación.
El punto de partida de cualquier notificación a un usuario es un evento del que informa el núcleo de monitorización. En el siguiente artículo lo llamaremos evento de monitorización para evitar confusiones con los eventos procesados por la Consola de eventos. Un evento de monitorización siempre está relacionado con un host o servicio concreto. Los posibles tipos de eventos de monitorización son:
Un cambio de estado, por ejemplo OK → WARN
El cambio entre un estado estable y uno inestable(inestable).
El inicio o fin de un tiempo de mantenimiento programado.
El Reconocimiento de un problema por parte de un usuario.
Una notificación activada manualmente por un comando .
La ejecución de un alert handler.
Un evento pasado para notificación desde la Consola de eventos .
Checkmk utiliza un sistema basado en reglas que te permite crear notificaciones de usuario a partir de estos eventos de monitorización, y esto también puede utilizarse para implementar requisitos muy exigentes. Una simple notificación por correo electrónico -que es totalmente satisfactoria en muchos casos- es, sin embargo, rápida de configurar.
2. ¿Notificar o (todavía) no notificar?
Las notificaciones son básicamente opcionales, y Checkmk puede seguir utilizándose eficazmente sin ellas. Algunas grandes organizaciones tienen una especie de panel de control en el que un equipo de operaciones tiene la interfaz de Checkmk constantemente bajo observación, por lo que las notificaciones adicionales son innecesarias. Si tu entorno Checkmk aún está en construcción, hay que tener en cuenta que las notificaciones sólo serán útiles para tus compañeros cuando no se produzcanfalsas alarmas (falsos positivos), o sólo se produzcan ocasionalmente. Primero hay que familiarizarse con los valores umbrales y con todos los demás ajustes, para que todos los estados sean OK / UP, o dicho de otro modo: que todo esté "en verde".
La aceptación de la nueva monitorización se desvanecerá rápidamente si cada día la bandeja de entrada se inunda con cientos de correos electrónicos inútiles.
El siguiente procedimiento ha demostrado su eficacia para el ajuste preciso de las notificaciones:
Paso 1: Ajusta la monitorización, por un lado, solucionando los problemas reales recién descubiertos por Checkmk y, por otro, eliminando las falsas alarmas. Hazlo hasta que todo esté "normalmente" OK / UP. Consulta la guía para principiantes para ver algunas recomendaciones para reducir las típicas falsas alarmas.
Paso 2: A continuación, cambia las notificaciones para que sólo estén activas para ti. Reduce la "estática" causada por problemas esporádicos y de corta duración. Para ello, ajusta más los valores umbrales, utiliza la monitorización predictiva si es necesario, aumenta el número de intentos de check o prueba a retrasar las notificaciones. Y, por supuesto, si los responsables son problemas auténticos, intenta tenerlos bajo control.
Paso 3: Una vez que tu propia bandeja de entrada esté tolerablemente tranquila, activa las notificaciones para tus colegas. Crea grupos de contacto eficaces para que cada contacto sólo reciba las notificaciones que le conciernan.
Estos procedimientos darán como resultado un sistema que proporciona información relevante que ayuda a reducir las interrupciones.
3. Notificaciones sencillas por correo electrónico
Una notificación por correo electrónico enviada por Checkmk en formato HTML tiene el siguiente aspecto:
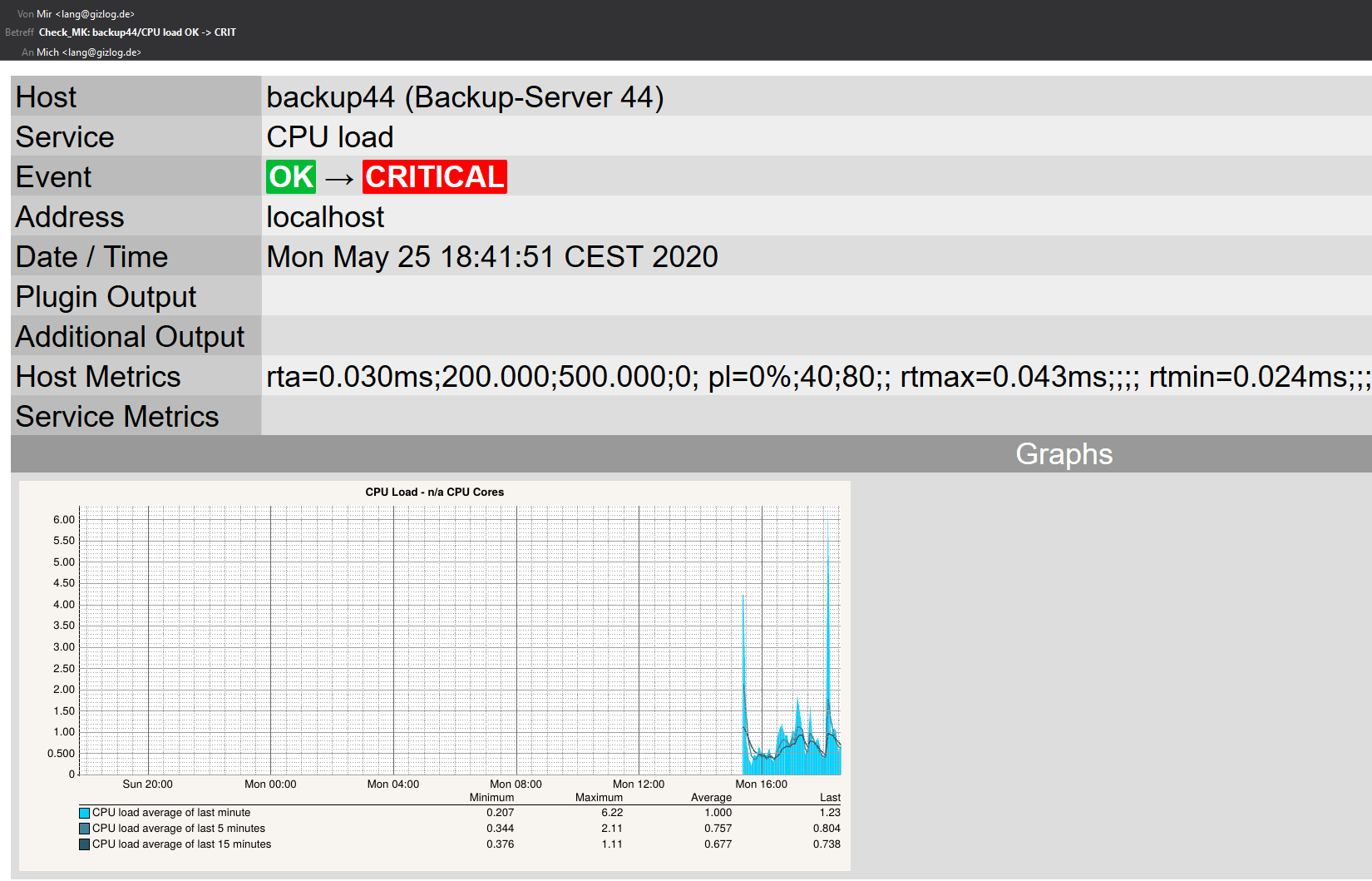
Como puede verse en el ejemplo, el correo electrónico también contiene las lecturas actuales del servicio afectado.
Antes de recibir un correo electrónico de este tipo de Checkmk, son necesarios algunos preparativos, que se describen a continuación.
3.1. Requisitos previos
En la configuración por defecto de Checkmk, un usuario recibirá notificaciones por correo electrónico cuando se cumplan los siguientes requisitos previos:
El servidor Checkmk está configurado para enviar correos electrónicos.
El usuario tiene configurada una dirección de correo electrónico.
El usuario es miembro de un grupo de contacto y, por tanto, es un contacto.
Se produce un evento de monitorización en un host o servicio asignado a este grupo de contacto, que activa una notificación.
3.2. Configurar el envío de correo en Linux
Para que el envío de correos electrónicos se realice correctamente, tu servidor Checkmk debe tener una configuración de servidor SMTP en funcionamiento. Dependiendo de tu distribución de Linux, ésta podría utilizar, por ejemplo, Postfix, Qmail, Exim o Nullmailer. La configuración se implementará con los recursos de tu distribución de Linux.
Por lo general, la configuración se limita a registrar un "smarthost" (también conocido como servidor de retransmisión SMTP) al que se dirigirán todos los correos electrónicos. Éste será el servidor de correo SMTP interno de tu empresa. Por regla general, los smarthost no requieren autenticación en una LAN, lo que simplifica las cosas. En algunas distribuciones, el smarthost se consultará durante la instalación. Con el appliance Checkmk se puede configurar el smarthost cómodamente a través de la interfaz web.
Puedes probar el envío de correos electrónicos fácilmente con el comando mail en la línea de comandos. Dado que existen numerosas implementaciones diferentes para este comando en Linux, para su estandarización Checkmk proporciona la versión del proyecto Heirloom mailx directamente en la ruta de búsqueda del usuario del site (como ~/bin/mail). El archivo de configuración correspondiente es ~/etc/mail.rc. La mejor forma de probarlo es como usuario del site, ya que los script de notificación se ejecutarán posteriormente con los mismos permisos.
El contenido del correo electrónico se lee de la entrada estándar, el asunto se especifica con -s, y la dirección del destinatario simplemente se añade como argumento al final de la línea de comando:
OMD[mysite]:~$ echo "content" | mail -s test-subject harry.hirsch@example.comEl correo electrónico debería entregarse sin demora. Si esto no funciona, puedes encontrar información en el archivo de registro del servidor SMTP en el directorio /var/log (ver archivos y directorios).
3.3. Dirección de correo electrónico y grupo de contacto
La dirección de correo electrónico y el grupo de contacto de un usuario se definen en la administración de usuarios:
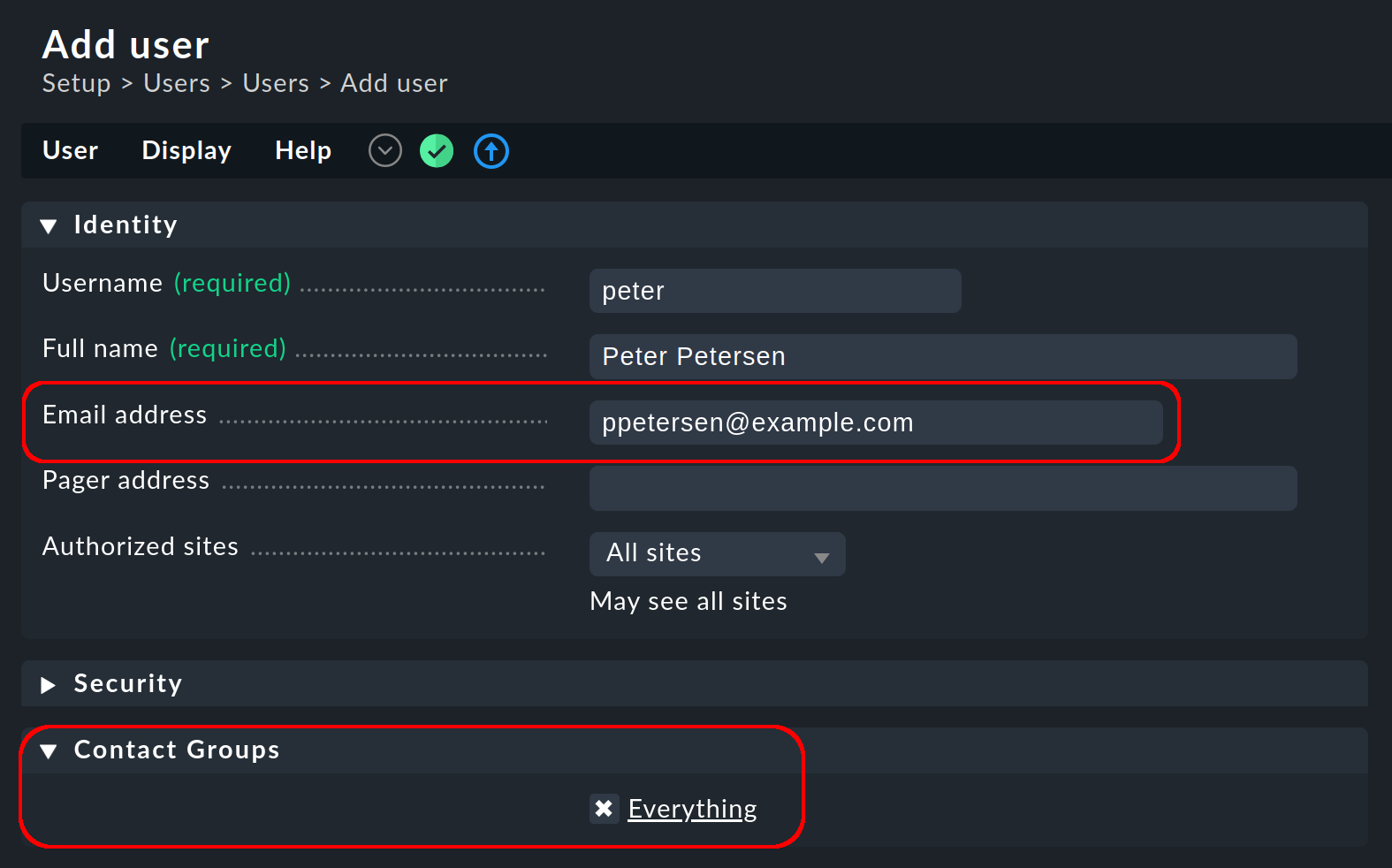
En un site Checkmk recién generado, inicialmente sólo existe el grupo de contacto Everything. Los miembros de este grupo son automáticamente responsables de todos los host y servicios, y serán notificados de cada evento de monitorización relevante por correo electrónico.
Nota: Si tu instalación de Checkmk se ha generado con una versión anterior, es posible que este grupo también se llame Everybody. Sin embargo, esto es ilógico, ya que este grupo no contiene a todos los usuarios, sino a todos los hosts. Aparte de la diferencia de nombres, la función es la misma.
3.4. Casos especiales: Sistema de tickets, mensajero y motor de eventos
En lugar de correo electrónico o SMS, también puedes enviar notificaciones a un sistema de tickets (como Jira o ServiceNow), a un mensajero (Slack, Mattermost) o a un motor de eventos (Consola de eventos). Hay un método de notificación distinto para cada uno de estos casos especiales, que puede seleccionarse en la regla de notificación. Sin embargo, debes tener en cuenta los dos puntos siguientes al crear la regla:
Cuando selecciones contactos, asegúrate de que las notificaciones sólo se envían a un contacto, por ejemplo, seleccionando un único usuario. Con los métodos de notificación para sistemas de tickets, etc., la selección del contacto sólo sirve para especificar que se envíen notificaciones. Sin embargo, las notificaciones no se envían al usuario seleccionado, sino al sistema de tickets. Ten en cuenta que una selección de contactos mediante grupos de contactos, todos los contactos de un objeto o similar suele generar varias notificaciones idénticas para un evento, que luego acaban en el sistema de tickets dos, tres o incluso más veces.
Si se cumple el primer punto, pero el usuario se utiliza en varias reglas de notificación para el mismo método, sólo se aplica la última regla en cada caso, por lo que es aconsejable crear un usuario funcional distinto para cada una de estas reglas de notificación.
3.5. Prueba de las reglas de notificación
|
En Checkmk 2.3.0 Test notifications puedes probar todas las reglas de notificación y enviar notificaciones por correo electrónico. Si quieres probar el envío real de cualquier cosa que no sea correo electrónico, puedes seguir utilizando Fake check results. |
Para probar las reglas de notificación, Checkmk ofrece una herramienta inteligente con Test notifications. Puedes utilizarla para simular una notificación para un host o servicio y reconocer cuáles de tus reglas de notificación son eficaces. Además de la simulación, también puedes hacer que se envíe la notificación por correo electrónico.
La forma más rápida de acceder a la prueba de notificación es a través de Setup > Events > Notifications y del botón Test notifications. Además, hay otras opciones de llamada desde algunas vistas de monitorización (lista de servicios y detalles de servicios) y en la Configuración (propiedades del host), en cada caso en el menú Host > Test notifications.
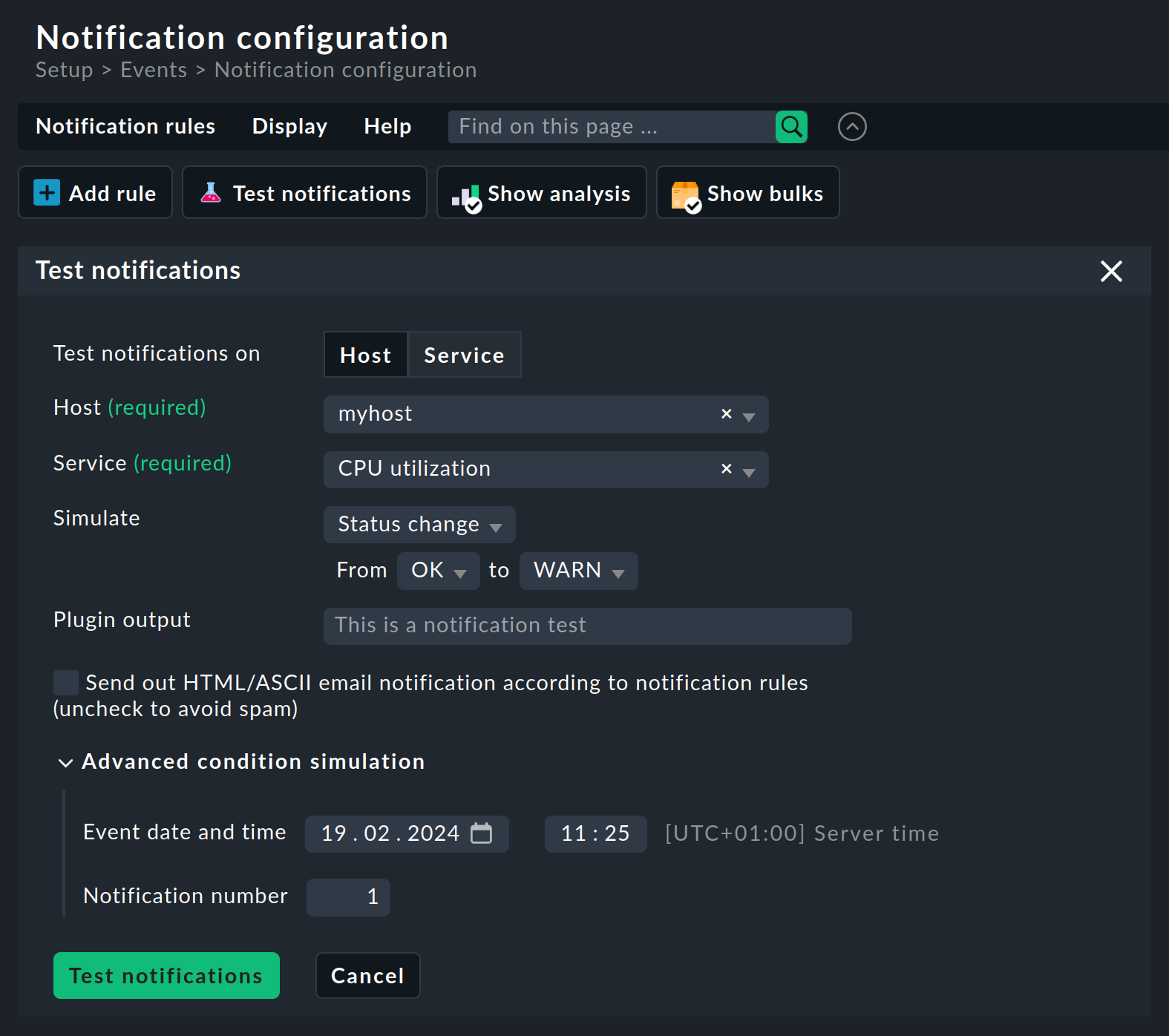
En primer lugar, haz clic en uno de los dos botones para decidir si la notificación es para un Host o un Service. A continuación, selecciona de qué host o servicio debe ser. Puedes añadir una descripción del evento en Plugin output. Como evento puedes seleccionar un cambio de estado o el inicio de un tiempo de mantenimiento programado. Utiliza el checkbox Send out HTML/ASCII email notification according to notification rules para especificar si la notificación sólo se simula o se envía realmente.
Por último, en Advanced condition simulation hay otras dos opciones con las que puedes definir el tiempo y el número de notificaciones. Esto te permite probar reglas de notificación que sólo se aplican durante un periodo determinado (por ejemplo, fuera del horario laboral) o que inician una escalada tras un número especificado de notificaciones repetidas.
Haz clic en Test notifications para iniciar la prueba - y también el envío de correo electrónico, si has seleccionado esta opción. El diálogo Test notifications se oculta y se muestran los resultados:
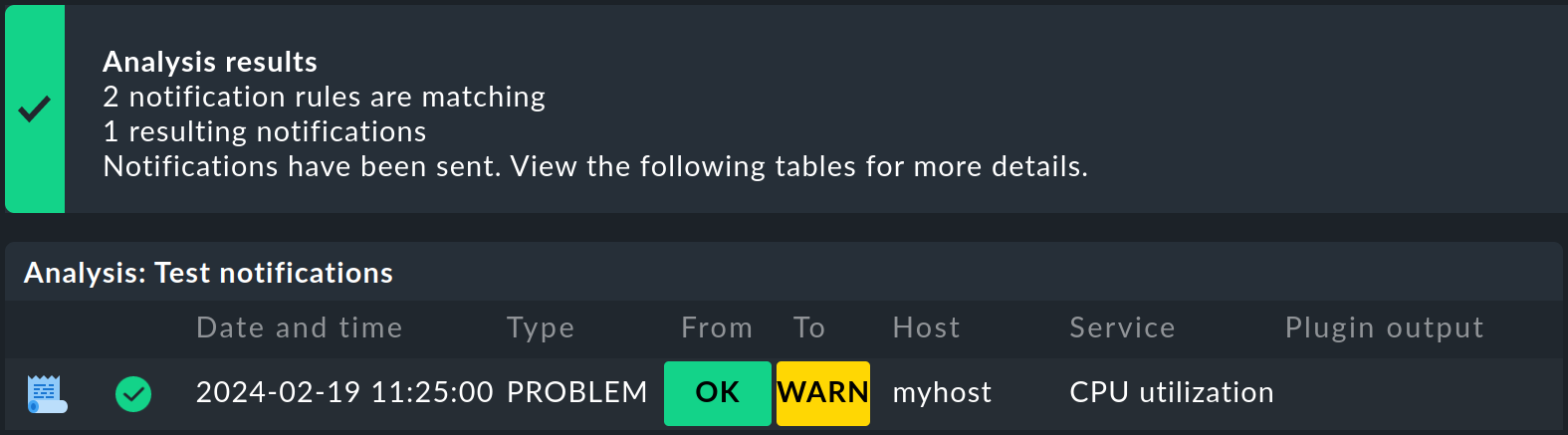
En primer lugar aparece el resumen. En Analysis results puedes ver cuántas reglas de notificación se aplican y cuántas notificaciones se derivan de ellas. Si has seleccionado Enviar notificación, aquí aparece el mensaje correspondiente Notifications have been sent, que debe dar lugar inmediatamente a un correo electrónico para este problema.
La línea inferior resume las notificaciones generadas a partir de tus entradas. Haciendo clic en el icono, puedes mostrar el contexto de la notificación. Esto te permite ver las variables del entorno y sus valores que son válidos en el contexto de esta notificación.
A continuación, las dos secciones siguientes muestran más detalles:
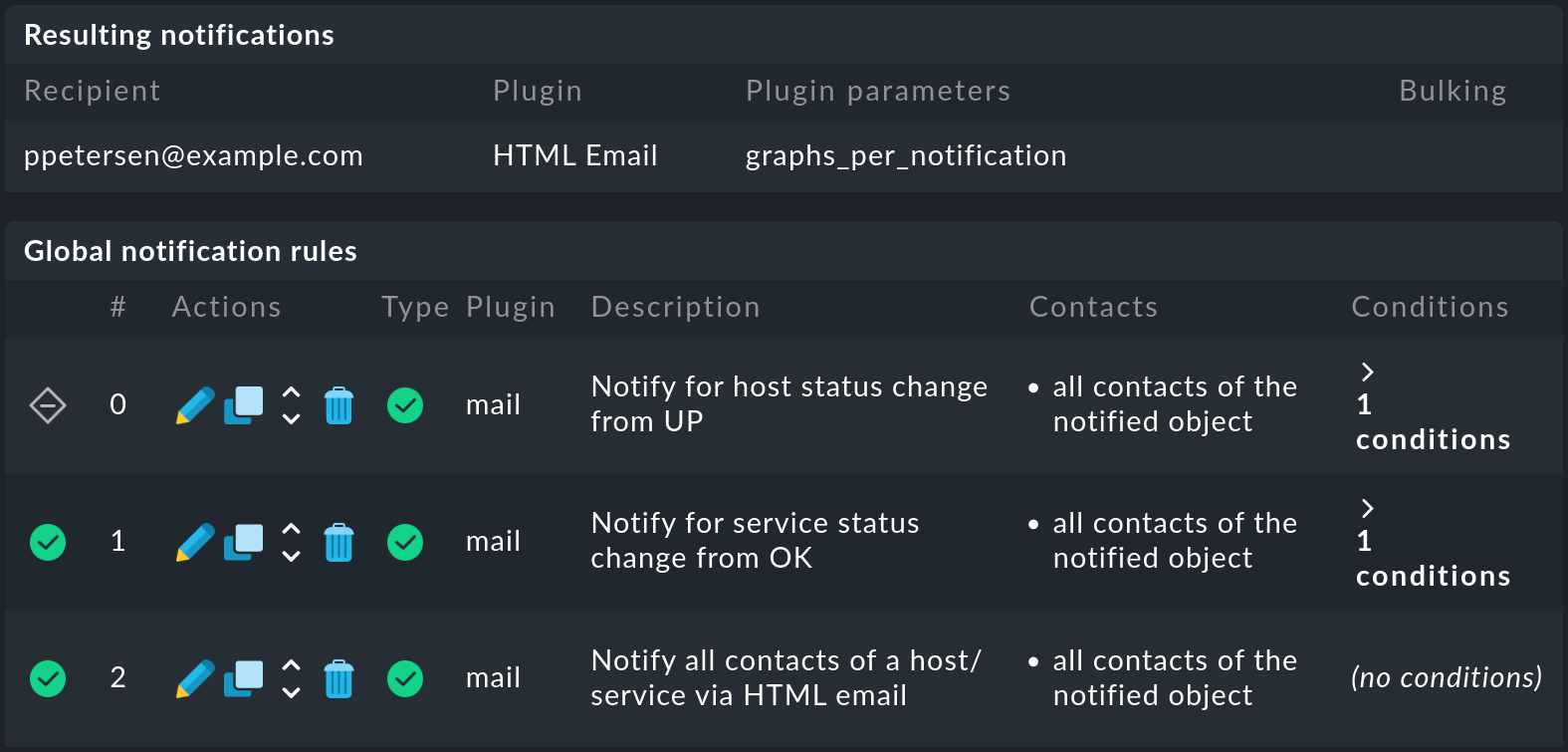
En Resulting notifications puedes ver a quién y cómo se envían las notificaciones. También recibirás esta información sobre la simulación si no has seleccionado enviar la notificación.
En Global notification rules se enumeran las reglas de notificación, que se presentan con más detalle en el capítulo siguiente. En este punto, sólo es importante la primera columna de la tabla, que utiliza iconos para indicar cuáles de las reglas se aplican y cuáles no . En el ejemplo, la primera regla no se aplica porque evalúa los cambios de estado de los host, pero el evento es un cambio de estado de un servicio.
Como de costumbre, puedes seguir activando notificaciones directamente a través de la GUI como alternativa a la comprobación de notificaciones mediante simulación, por ejemplo, con los comandos Send custom notification y Fake check results. |
3.6. Ajuste preciso del correo electrónico HTML
Al enviar correos electrónicos HTML, puede que desees añadir información adicional o definir de forma flexible una dirección de respuesta (Reply to) a un contacto concreto para cualquier consulta. Para ello, existe la regla Setup > Services > Service monitoring rules > Parameters for HTML Email, y en las reglas de notificación el método de notificación de correo electrónico HTML. Con estas reglas puedes añadir una serie de parámetros, como la dirección de respuesta, campos adicionales con detalles o texto libre formateado como HTML.
Ten en cuenta que en el campo Add HTML section above table (e.g. title, description…), por motivos de seguridad, sólo se permite un pequeño conjunto de tags HTML, que son los siguientes
| Tag | Función | Consejos |
|---|---|---|
|
Se permite cuando se combina con los atributos |
|
|
||
|
||
|
||
|
Obsoleto. ¡No utilices este tag! |
|
|
||
|
||
|
||
|
Desaprobado. ¡No utilices este tag! |
|
|
Se conservan los espacios y las sangrías. |
|
|
||
|
||
|
||
|
Utilízalo sólo dentro de las siguientes listas |
|
|
||
|
Como es habitual con todas las reglas de Checkmk, es posible una aplicación de granulación muy fina, de modo que puedas individualizar un conjunto detallado de notificaciones a hosts y servicios según tus necesidades.
4. Control de las notificaciones mediante reglas
4.1. El principio
Checkmk está configurado "por defecto" para que, cuando se produzca un evento de monitorización, se envíe un correo electrónico de notificación a todos los contactos del host o servicio afectado. Esto es, sin duda, sensato en un principio, pero en la práctica surgen muchos otros requisitos, por ejemplo:
La supresión de notificaciones específicas menos útiles.
La "suscripción" a notificaciones de servicios de los que no se es contacto
Una notificación puede enviarse por correo electrónico, SMS o buscapersonas, según la hora del día
La escalada de problemas cuando no se ha recibido ningún Reconocimiento más allá de un cierto límite de tiempo
La opción de NO notificación para los estados WARN o UNKNOWN
y mucho más ...
Checkmk te proporciona la máxima flexibilidad en la aplicación de estos requisitos mediante su mecanismo basado en reglas. Introduce la configuración con Setup > Events > Notifications.
Nota: Cuando abras la página Notification configuration por primera vez, verás una advertencia sobre la "dirección de correo electrónico de reserva" no configurada. Puedes ignorar este aviso por el momento. Hablaremos de ello más adelante.
En la configuración de notificación, gestionas la cadena de reglas de notificación, que determinan a quién se debe notificar y cómo. Cuando se produce cualquier evento de monitorización, esta cadena de reglas se ejecuta de arriba abajo. Cada regla tiene una condición que decide si la regla se aplica realmente a la situación en cuestión.
Si se cumple la condición, la regla determina dos cosas:
Una selección de contactos(¿A quién se debe notificar?).
Un método de notificación (¿Cómo notificar?), por ejemplo, correo electrónico HTML, y opcionalmente, parámetros adicionales para el método elegido.
Importante: A diferencia de las reglas para host y servicios, aquí la evaluación también continúa después de que se haya cumplido la regla aplicable. Las reglas posteriores pueden añadir más notificaciones. Las notificaciones generadas por las reglas anteriores también se pueden eliminar.
El resultado final de la evaluación de las reglas será una tabla con una estructura parecida a ésta
| Quién (contacto) | Cómo (método) | Parámetros del método |
|---|---|---|
Harry Hirsch |
Correo electrónico |
|
Bruno Weizenkeim |
Correo electrónico |
|
Bruno Weizenkeim |
SMS |
Ahora, para cada entrada de esta tabla se invocará el script de notificación que realmente ejecuta la notificación al usuario adecuada al método.
4.2. La regla predefinida inicial
Si tienes un Checkmk recién instalado, se habrá predefinido precisamente una regla:

Esta regla define el comportamiento por defecto descrito anteriormente. Su estructura es la siguiente
Condición |
Ninguna, es decir, la regla se aplica a todos los eventos de monitorización |
Método |
Envía un correo electrónico en formato HTML (con gráficos métricos incrustados) |
Contacto |
Todos los contactos del host/servicio afectado |
Como de costumbre, puedes editar la regla , clonarla (copiarla) , eliminarla o crear una regla nueva. Cuando tengas más de una regla, puedes cambiar su orden de proceso arrastrándolas y soltándolas con el icono .
Nota: Los cambios en las reglas de notificación no requieren su activación, sino que entran en vigor inmediatamente.
4.3. Estructura de las reglas de notificación
A continuación te presentamos la estructura general de las reglas de notificación con las definiciones de las propiedades generales, métodos, contactos y condiciones.
Propiedades generales
Como en todas las reglas de Checkmk, aquí puedes incluir una descripción y un comentario para la regla, o incluso desactivar temporalmente la regla.
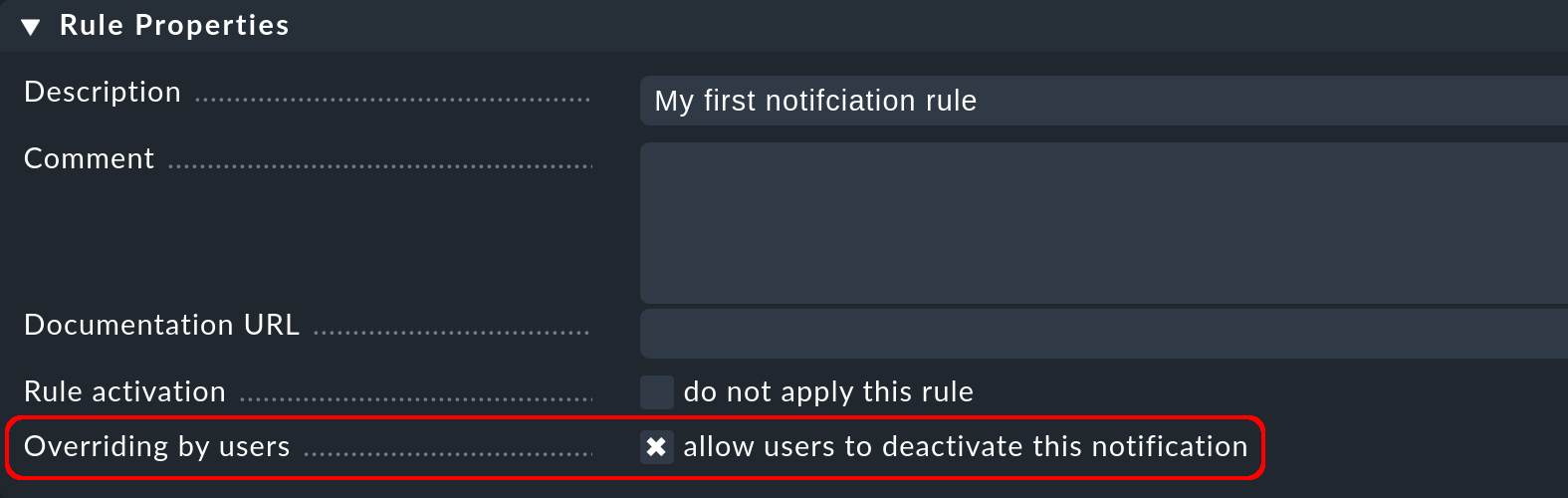
La opción Overriding by users está activada por defecto. activada. Permite a los usuarios "darse de baja" de las notificaciones generadas por esta regla. Te mostramos cómo hacerlo con las notificaciones definidas por el usuario.
Método de notificación
El método de notificación especifica la técnica que se utilizará para enviar la notificación, por ejemplo, con correo electrónico HTML.
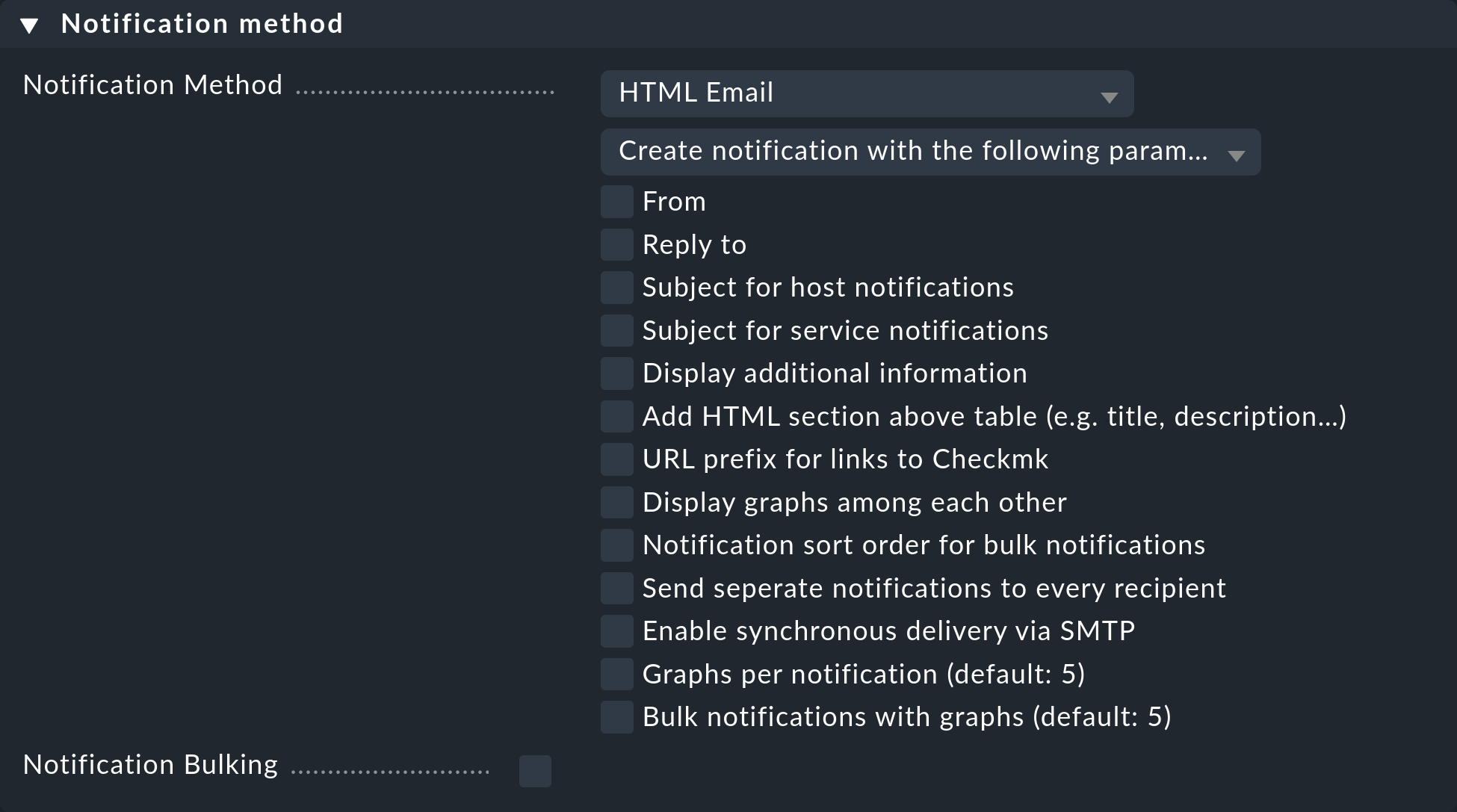
Cada método se realiza mediante un script. Checkmk incluye varios scripts. También puedes escribir fácilmente tus scripts personalizados en cualquier lenguaje de programación que desees para implementar notificaciones especiales, por ejemplo, para redirigir una notificación a tu propio sistema de tickets.
Un método puede incluir parámetros, como permitir que el método que envía correos electrónicos ASCII y HTML establezca explícitamente la dirección del remitente (From:), por ejemplo.
Antes de realizar los ajustes directamente en la regla de notificación, debes saber que los parámetros de los métodos de notificación también se pueden especificar mediante reglas para host y servicios: En Setup > Services > Service monitoring rules, en la sección Notifications, encontrarás un conjunto de reglas para cada método de notificación, que puedes utilizar para definir los mismos ajustes - y como es habitual, pueden depender del host o del servicio.
Las definiciones de parámetros en las reglas de notificación permiten variar estos ajustes en casos individuales. Así, por ejemplo, puedes definir un asunto global para tu correo electrónico, pero también definir un asunto alternativo con una regla de notificación individual.
En lugar de parámetros, también puedes seleccionar Cancel previous notifications, con lo que se eliminarán todas las notificaciones de este método de reglas anteriores. Para más información, consulta el tema Eliminar notificaciones.
Nota: Para muchos métodos de notificación para el reenvío a otros sistemas, encontrarás información más detallada en artículos separados. La lista de artículos se encuentra en el capítulo sobre scripts de notificación.
Seleccionar contactos
El procedimiento más habitual es que las notificaciones se envíen a todos los usuarios que se hayan registrado como contacto para el host/servicio correspondiente. Éste es el procedimiento "normal" y lógico, ya que también a través de los contactos se define qué objetos recibe cada usuario en su pantalla GUI -en realidad, aquellos objetos de los que el usuario es responsable.
Puedes marcar varias opciones en la selección de contactos y ampliar así la notificación a más contactos:
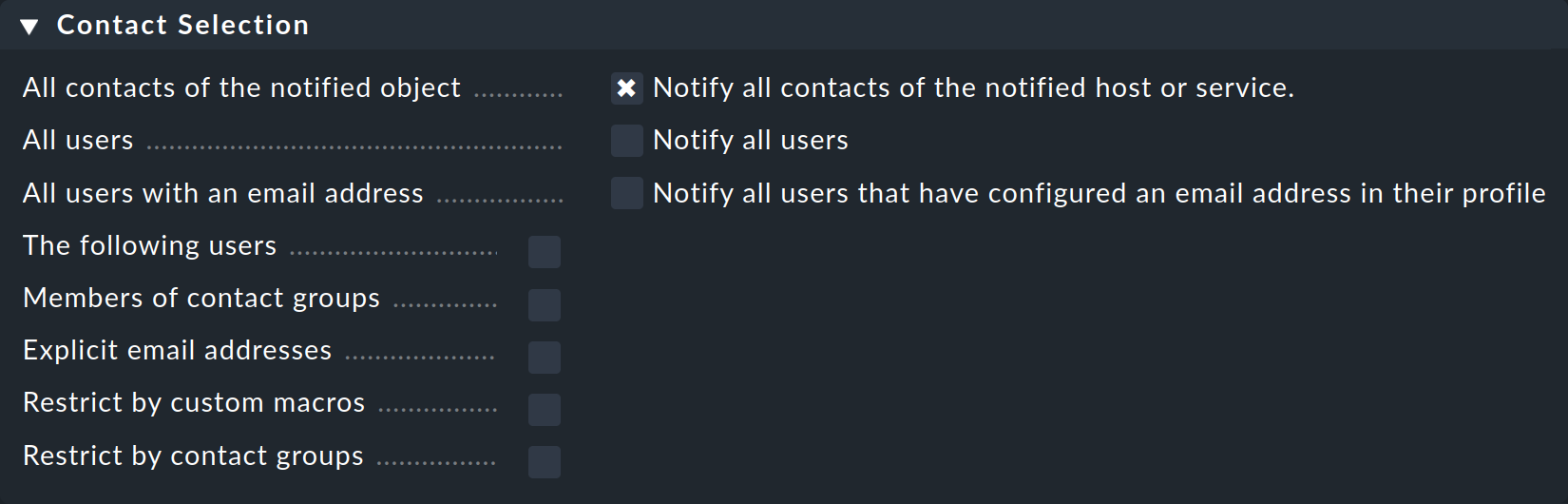
Checkmk eliminará automáticamente los contactos duplicados. Para que la regla tenga sentido, debe haber al menos una selección.
Las dos opciones de Restrict by… funcionan de forma algo diferente. Aquí se restringirán de nuevo los contactos seleccionados con las otras opciones. Con ellas también puedes crear un operador Y entre grupos de contacto, por ejemplo, para que se envíen notificaciones a todos los contactos que sean miembros de los grupos Linux y Data center.
Introduciendo Explicit email addresses puedes notificar a personas que de hecho no están nominadas como usuarios en Checkmk. Por supuesto, esto sólo tiene sentido cuando se utiliza en el método de notificación que realmente envía correos electrónicos.
Si, en el método elegido, has seleccionado Cancel previous notifications, las notificaciones sólo se eliminarán para el contacto seleccionado aquí.
Nota: Cuando utilices un sistema de tickets, un mensajero o un motor de eventos como método de notificación, debes observar también las notas sobre estos casos especiales.
Condiciones
Las condiciones determinan cuándo se utilizará una regla. Para su comprensión, es importante recordar que el origen es siempre un evento de monitorización en un host o servicio concreto.
Las condiciones se refieren a
a los atributos estáticos del objeto - por ejemplo, si el nombre del servicio contiene el texto
/tmp,con el estado actual o el cambio de estado, por ejemplo, si el servicio acaba de cambiar de OK a CRIT,
o con cosas completamente distintas, por ejemplo, si elperiodo de tiempo "tiempo de trabajo" está activo en ese momento.
Hay dos puntos importantes que debes tener en cuenta al establecer las condiciones:
Si no se ha definido ninguna condición, la regla tendrá efecto para cada evento de monitorización.
En cuanto selecciones una sola condición, la regla sólo tendrá efecto si se cumplen todas las condiciones. Todas las condiciones seleccionadas están vinculadas con Y. Sólo hay una excepción a esta importante regla, que trataremos más adelante y no consideraremos ahora.
Esto significa que debes prestar mucha atención a si las condiciones que has elegido pueden cumplirse al mismo tiempo para que se active una notificación para el caso deseado.
Supongamos que quieres que se active una notificación cuando se produzca un evento de monitorización de un servicio que empiece por el nombre NTP en un host de la carpeta Main:
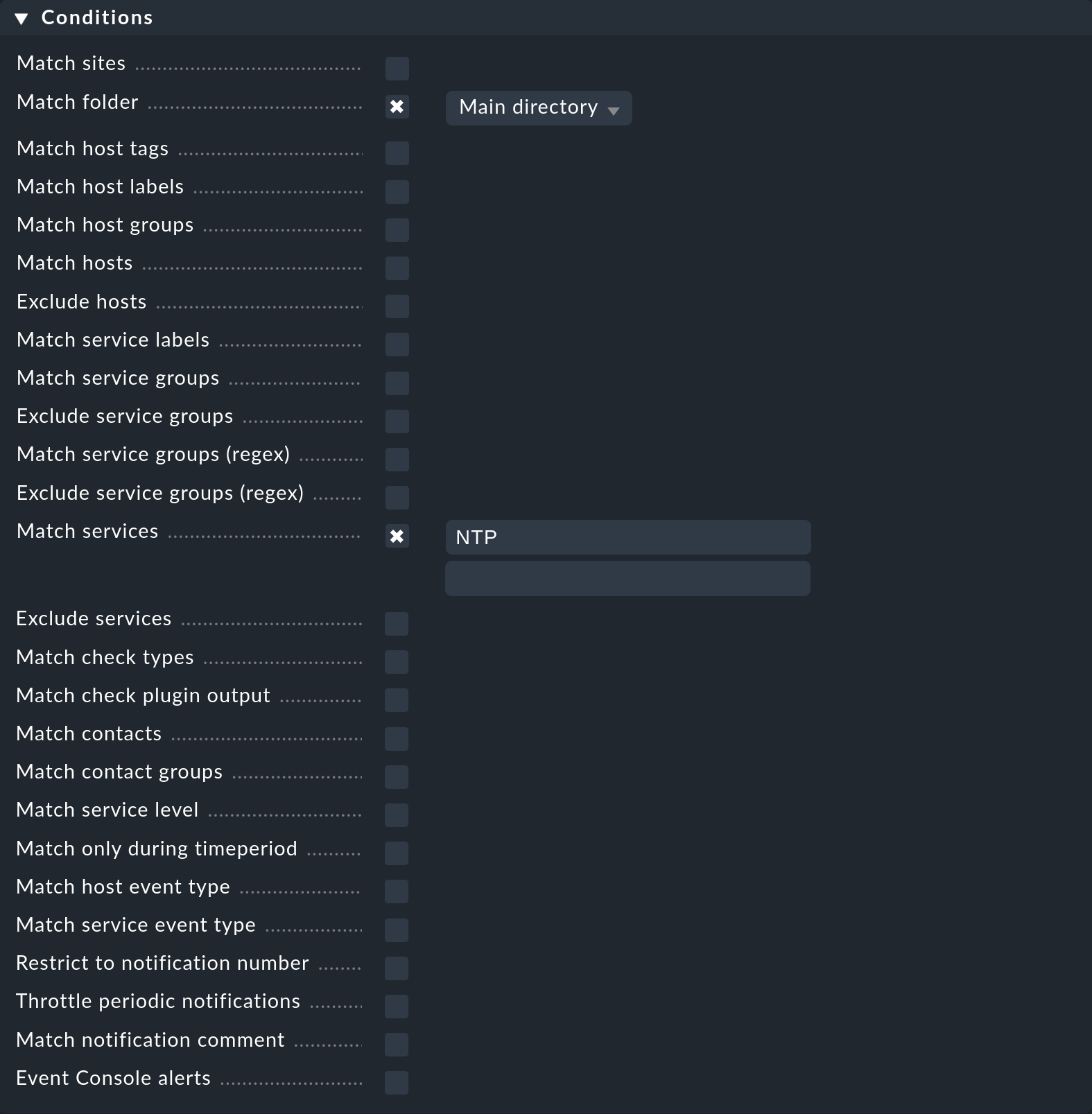
Supongamos además que esta condición se amplía ahora notificando también todos los cambios de estado de un host al estado DOWN:

El resultado de esta regla de notificación con las tres condiciones individuales es que nunca se producirá una notificación, porque ningún evento de monitorización contendrá el cambio de estado de un host y el nombre del servicio con NTP.
La siguiente nota se repite en este Manual de usuario de vez en cuando. Sin embargo, en conexión con la configuración de tus notificaciones, conviene insistir de nuevo: muestra la ayuda contextualizada con Help > Show inline help para obtener detalles sobre el efecto de las distintas condiciones. El siguiente extracto de la ayuda contextualizada para la opción Match services ilustra muy bien el comportamiento:"Nota: Las notificaciones del host nunca coincidirán con esta regla, si se utiliza esta opción".
La excepción a la operación AND
Sólo si un evento de monitorización satisface todas las condiciones configuradas, se aplicará la regla de notificación. Como ya se ha dicho, hay una excepción importante a esta regla general: para las condiciones Match host event type y Match service event type:
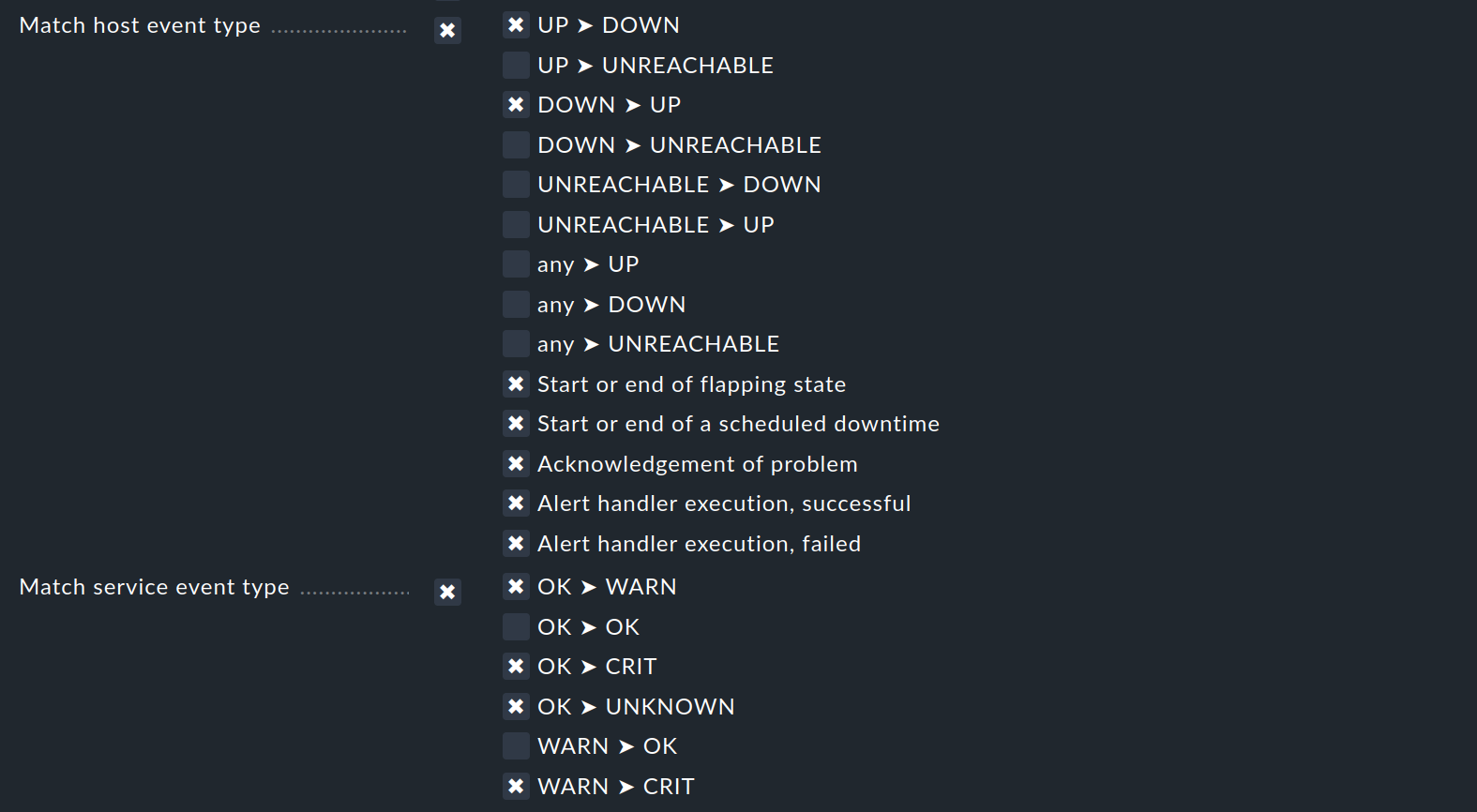
Si sólo seleccionas Match host event type, la regla no coincidirá con ningún evento de servicio. Lo mismo ocurre si seleccionas Match service event type y eventos de host. Sin embargo, si activas ambas condiciones, la regla coincidirá si el tipo de evento está activado en cualquiera de las dos listas de checkbox. En este caso excepcional, estas condiciones no se vincularán con un "Y" lógico, sino con un "O". De este modo, puedes administrar las notificaciones de host y de servicio con una sola regla.
Otro consejo sobre las condiciones Match contacts y Match contact groups:
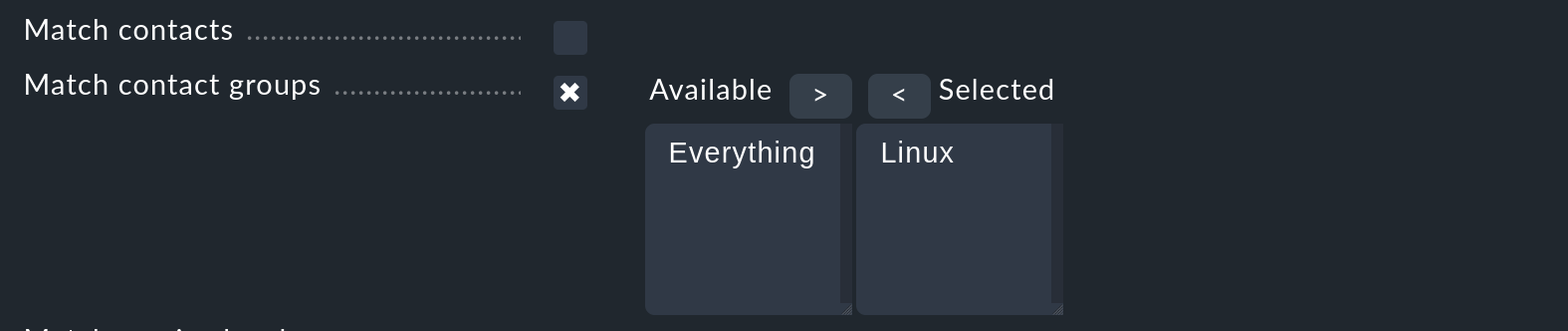
La condición que se check aquí es si el host/servicio en cuestión tiene una determinada asignación de contactos. Esto puede utilizarse para implementar funciones como "Las notificaciones de host en el grupo de contacto Linux nunca deben enviarse por SMS". Esto no tiene nada que ver con la selección de contactos descrita anteriormente.
4.4. Cancelar notificaciones
Como ya se ha mencionado en la selección del método de notificación, también encontrarás la opción de selección Cancel previous notifications. Para poder entender el funcionamiento de una regla de este tipo, lo mejor es visualizar la tabla de notificaciones. Suponiendo que el proceso de las reglas para un evento de monitorización concreto se ha completado parcialmente, y que debido a una serie de reglas se han activado las tres notificaciones siguientes:
| Quién (contacto) | Cómo (método) |
|---|---|
Harry Hirsch |
Correo electrónico |
Bruno Weizenkeim |
Correo electrónico |
Bruno Weizenkeim |
SMS |
Ahora viene la siguiente regla con el método SMS y la selección Cancel previous notifications. La selección de contactos elige el grupo "Windows", al que pertenece Bruno Weizenkeim. Como resultado de esta regla, la entrada "Bruno Weizenkeim / SMS" se elimina de la tabla, que queda así:
| Quién (contacto) | Cómo (método) |
|---|---|
Harry Hirsch |
Correo electrónico |
Bruno Weizenkeim |
Correo electrónico |
Si una regla posterior vuelve a definir una notificación por SMS para Bruno, esta regla tendrá prioridad y el SMS se añadirá de nuevo a la tabla.
En resumen:
Las reglas pueden suprimir (borrar) notificaciones específicas.
Las reglas de supresión deben ir después de las reglas que crean las notificaciones.
Una regla de supresión no "borra" realmente una regla precedente, sino que suprime las notificaciones generadas por (posiblemente varias) reglas precedentes.
Las reglas posteriores pueden restablecer las notificaciones suprimidas anteriormente.
4.5. ¿Qué ocurre si no se aplica ninguna regla?
Quien configura también puede cometer errores. Un posible error en la configuración de la notificación podría ser que se descubriera un problema crítico de monitorización, pero que no entrara en vigor ni una sola regla de notificación.
Para protegerte de un caso así, Checkmk te ofrece la opción Fallback email address for notifications. La encontrarás en Setup > General > Global settings, en la sección Notifications. Introduce aquí una dirección de correo electrónico. Esta dirección de correo electrónico recibirá entonces las notificaciones a las que no se aplique ninguna regla de notificación.
Nota: También puedes hacer que un usuario sea el destinatario en su configuración personal. La dirección de correo electrónico almacenada con el usuario se utilizará como dirección de reserva.
Sin embargo, la dirección alternativa sólo se utilizará si no se aplica ninguna regla, ¡no cuando no se haya activado ninguna notificación! Como mostramos en el capítulo anterior, la supresión explícita de notificaciones es deseable, no es un error de configuración.
La introducción de una dirección alternativa se "recomendará" en la página Notification configuration con una advertencia en pantalla:

Si -por el motivo que sea- sólo quieres librarte de la advertencia, pero al mismo tiempo no quieres recibir correos electrónicos en la dirección de reserva, introduce primero una dirección de reserva de todos modos y luego crea una nueva regla como primera regla, que elimine todas las notificaciones anteriores. Esta regla no es efectiva en la configuración de notificaciones, ya que aquí todavía no se han creado notificaciones. Pero con esto puedes asegurarte de que al menos una regla se aplicará siempre, permitiendo así eliminar esta advertencia.
Desaconsejamos explícitamente este enfoque, ya que podrías pasar por alto lagunas en tu secuencia de reglas.
5. Notificaciones definidas por el usuario
5.1. Vista general
Una función útil del sistema de notificaciones de Checkmk es aquella con la que los usuarios -incluso sin derechos de administrador- pueden personalizar las notificaciones. Los usuarios pueden:
Añadir notificaciones que de otro modo no recibirían ("suscribirse")
Eliminar notificaciones que de otro modo recibirían (si no están restringidas)
Personalizar los parámetros de notificación
Desactivar completamente sus notificaciones
5.2. Reglas de notificación definidas por el usuario
El punto de entrada desde el punto de vista del usuario es el menú Usuario, y allí la entrada Notification rules. En la página Your personal notification rules, se puede crear una nueva regla con Add rule.
Las reglas personalizadas se estructuran como las reglas normales, con una diferencia: no contienen una selección de contacto. El propio usuario se selecciona automáticamente como contacto. Esto significa que un usuario sólo puede añadir o eliminar notificaciones para sí mismo.
Sin embargo, el usuario sólo puede borrar notificaciones si la opción allow users to deactivate this notification está activada en la regla que las crea:
En el orden de las reglas de notificación, las reglas personalizadas siempre vienen después de las reglas globales y, por tanto, pueden ajustar la tabla de notificaciones que se ha generado hasta el momento. Así pues, salvo en el caso del bloqueo por eliminación que acabamos de describir, las reglas globales siempre se aplican como la configuración por defecto que puede personalizar el usuario.
Si quieres impedir totalmente la personalización, puedes revocar el permiso General Permissions > Edit personal notification settings del rol user.
Como administrador, puedes mostrar todas las reglas de usuario si en el menú seleccionas Display > Show user rules:
Después de las reglas globales, se enumeran las reglas de usuario, que también puedes editar con .
5.3. Desactivar temporalmente las notificaciones
La desactivación completa de las notificaciones por parte de un usuario está protegida con el permiso General Permissions > Disable all personal notifications, que está establecido por defecto en no para el rol de usuario user. Un usuario sólo verá los checkbox correspondientes en su configuración personal si asignas explícitamente este derecho al rol user:
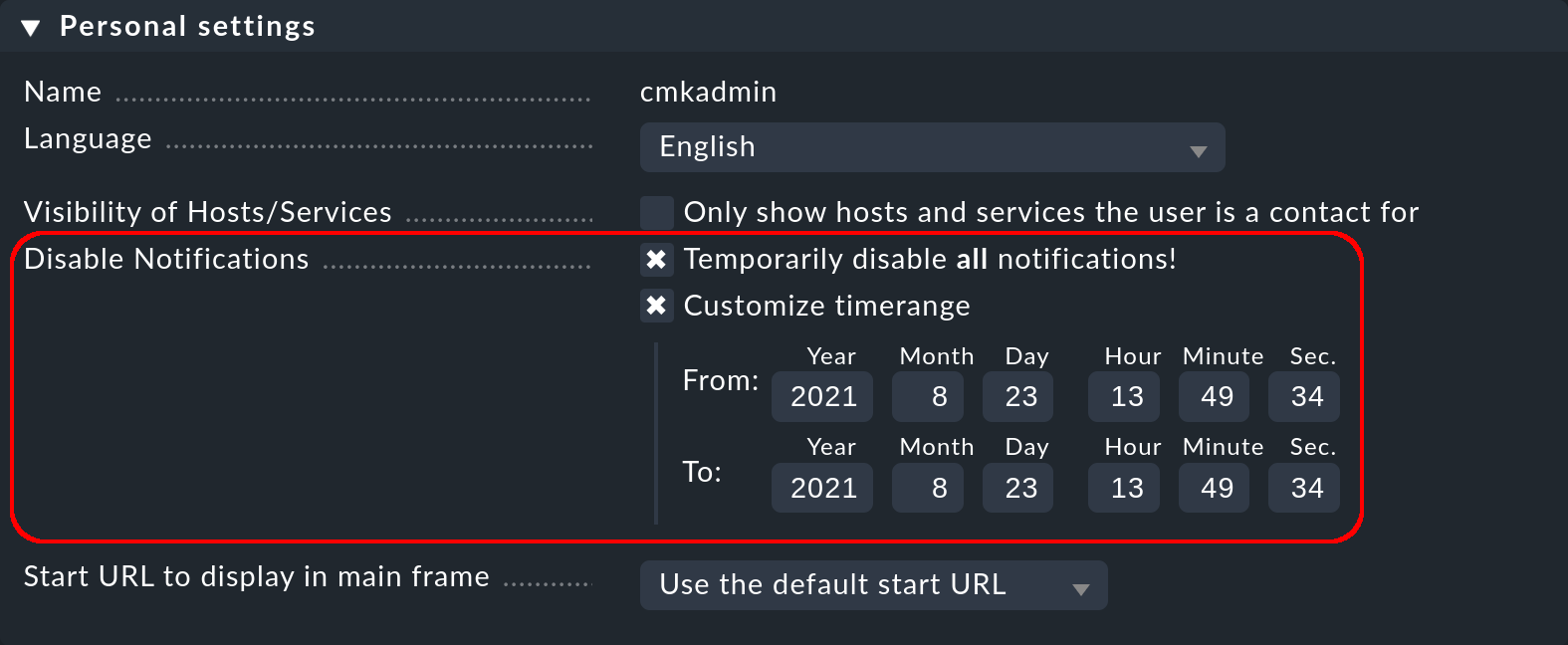
Como administrador con acceso a la configuración personal del usuario, puedes llevar a cabo acciones de desactivación en nombre del usuario, incluso si el permiso descrito anteriormente no está presente. Puedes encontrar esta configuración en Setup > Users > Users y luego en las propiedades del perfil del usuario. Con esto, por ejemplo, puedes silenciar muy rápidamente las notificaciones de un compañero de vacaciones, sin necesidad de alterar la configuración real.
6. Cuándo se generan las notificaciones y cómo gestionarlas
6.1. Introducción
Gran parte de la complejidad del sistema de notificaciones de Checkmk se debe a sus numerosas opciones de ajuste, con las que se pueden evitar notificaciones sin importancia. Además, el núcleo de monitorización tiene una inteligencia integrada que suprime determinadas notificaciones por defecto. En este capítulo queremos tratar todos estos aspectos.
6.2. Tiempos de mantenimiento programados
Cuando un host o un servicio se encuentra en un tiempo de mantenimiento programado, se suprimirán las notificaciones del objeto. Ésta es -junto con una evaluación correcta de las disponibilidades- la razón más importante para la provisión real de tiempos de mantenimiento en la monitorización. Los siguientes detalles son relevantes al respecto:
Si un host está marcado como en tiempo de mantenimiento programado, todos sus servicios también estarán automáticamente en tiempo de mantenimiento programado, sin que sea necesario introducir una entrada explícita para ellos.
Si un objeto entra en estado de problema durante un tiempo de mantenimiento programado, cuando el tiempo de mantenimiento termine según lo previsto, este problema se notificará retroactivamente precisamente al final del tiempo de mantenimiento.
El inicio y el final de un tiempo de inactividad programado es en sí mismo un evento de monitorización que será notificado.
6.3. Periodos de notificación
Puedes definir un periodo de notificación para cada host y servicio durante la configuración. Se trata de un periodo de tiempo que define el marco temporal en el que debe limitarse la notificación.
La configuración se realiza utilizando el Monitoring Configuration > Notification period for hosts, o respectivamente el conjunto de reglas Notification period for services, que puedes encontrar rápidamente mediante la búsqueda en el Menú de configuración. Un objeto que no se encuentre actualmente en un periodo de notificación se marcará con un icono de pausa gris .
No se notificarán los eventos de monitorización de un objeto que no esté actualmente en su periodo de notificación. Dichas notificaciones se "reemitirán" cuando el periodo de notificación vuelva a estar activo, si el host/servicio sigue en estado problemático. Sólo se notificará el estado más reciente, aunque se hayan producido múltiples cambios en el estado del objeto durante el tiempo transcurrido fuera del periodo de notificación.
Por cierto, en las reglas de notificación también es posible restringir una notificación a un periodo de tiempo concreto. De esta forma puedes restringir adicionalmente los intervalos de tiempo. Sin embargo, ¡las notificaciones que se hayan descartado debido a una regla con condiciones de tiempo no se repetirán automáticamente más adelante!
6.4. El estado del host en el que se está ejecutando un servicio
Si un host ha fallado por completo, o al menos es inaccesible para la monitorización, es obvio que sus servicios ya no se pueden monitorizar. Los checksactivos registrarán entonces, por regla general, CRIT o UNKNOWN, ya que estarán intentando acceder activamente al host y, por tanto, se encontrarán con un error. En tal situación, todos los demás checks -por tanto, la gran mayoría- se omitirán y, por tanto, permanecerán en su estado anterior. Éstos se marcarán con el icono de tiempo stale.
Naturalmente, sería muy engorroso que todas las comprobaciones activas en tal estado notificaran sus problemas. Por ejemplo, si un servidor web no es accesible -y esto ya se ha notificado- no sería muy útil generar adicionalmente un correo electrónico para cada uno de sus servicios HTTP dependientes.
Para minimizar estas situaciones, como principio básico, el núcleo de monitorización sólo genera notificaciones para los servicios si el host está en estado UP. Ésta es también la razón por la que la accesibilidad al host se verifica por separado. Si no se configura de otro modo, esta verificación se conseguirá con un Smart Ping o ping.
Si utilizas Checkmk Raw (o una de las ediciones comerciales con núcleo Nagios), en casos aislados puede ocurrir, no obstante, que un problema en el host genere una notificación para un servicio activo. El motivo es que Nagios considera que los resultados de las comprobaciones del host siguen siendo válidos durante un breve periodo de tiempo en el futuro. Si sólo han transcurrido unos segundos entre el último ping con éxito al servidor y la siguiente comprobación activa, Nagios puede seguir evaluando el host como UP aunque en realidad esté DOWN. En cambio, el Checkmk Micro Core (CMC) mantendrá la notificación del servicio en modo "espera" hasta que se haya verificado el estado del host, minimizando así de forma fiable las notificaciones no deseadas.
6.5. Padres host
Imagina que falla un importante router de la red de una empresa con cientos de hosts. Todos sus hosts dejarán de estar disponibles para la monitorización y pasarán a estar DOWN. Por tanto, se activarán cientos de notificaciones. Esto no es bueno.
Para evitar estos problemas, el router puede definirse como host padre para sus hosts. Si hay hosts redundantes, también pueden definirse varios padres. En cuanto todos los padres entren en estado DOWN, los hosts que ya no estén accesibles se marcarán con el estado UNREACH y se suprimirán sus notificaciones. El problema con el propio router seguirá notificándose, por supuesto.
Por cierto, la CMC funciona internamente de un modo ligeramente distinto a Nagios. Para reducir las falsas alarmas, pero seguir procesando notificaciones auténticas, presta mucha atención a los tiempos exactos de los correspondientes checks de host. Si falla un check de host, el núcleo esperará al resultado del check de host en el host padre antes de generar una notificación. Esta espera es asíncrona y no tiene ningún efecto en la monitorización general. De este modo, las notificaciones de los hosts pueden sufrir retrasos mínimos.
6.6. Desactivar notificaciones mediante reglas
Con los conjuntos de reglas Enable/disable notifications for hosts, o Enable/disable notifications for services, respectivamente, puedes especificar host y servicios para los que, en general, no deben emitirse notificaciones. Como ya se ha dicho, el núcleo suprime las notificaciones. Una regla de notificación posterior que se "suscriba" a las notificaciones de dichos servicios no será efectiva, ya que las notificaciones simplemente no se generan.
6.7. Desactivar notificaciones mediante comandos
También es posible desactivar temporalmente las notificaciones para host o servicios individuales mediante un comando.
Sin embargo, esto requiere que el permiso Commands on host and services > Enable/disable notifications esté asignado al rol de usuario. Por defecto, este no es el caso para ningún rol.
Con el permiso asignado, puedes desactivar (y posteriormente activar) las notificaciones de hosts y servicios con el comando Commands > Notifications:

Dichos host o servicios se marcarán con un icono.
Dado que los comandos -a diferencia de las reglas- no requieren permisos de configuración ni activar cambios, pueden ser una solución rápida para reaccionar rápidamente ante una situación.
Importante: A diferencia de los tiempos de inactividad programados, las notificaciones desactivadas no influyen en las evaluaciones de disponibilidad. Si durante una interrupción no planificada sólo quieres desactivar las notificaciones sin querer distorsionar las estadísticas de disponibilidad, ¡no debes registrar un tiempo de mantenimiento programado!
6.8. Desactivar las notificaciones globalmente
En el snap-in Master control de la barra lateral encontrarás un interruptor master para Notifications:

Este interruptor es increíblemente útil si planeas hacer cambios mayores en el sistema, durante los cuales un error podría, dadas las circunstancias, forzar a muchos servicios a entrar en estado CRIT. Puedes utilizar el interruptor para evitar molestar a tus colegas con una avalancha de correos electrónicos inútiles. Recuerda volver a activar las notificaciones cuando hayas terminado.
Cada site de una monitorización distribuida tiene uno de estos conmutadores. Desactivar las notificaciones del site central sigue permitiendo que los sites remotos activen las notificaciones, aunque éstas se dirijan y envíen desde el site central.
Importante: Las notificaciones que se hubieran activado durante el tiempo en que las notificaciones estuvieron desactivadas no se repetirán más tarde cuando se vuelvan a activar.
6.9. Retrasar notificaciones
Es posible que tengas servicios que de vez en cuando entran en estado de problema durante periodos cortos, pero las paradas son muy breves y no son críticas para ti. En estos casos, las notificaciones son muy molestas, pero se suprimen fácilmente. Los conjuntos de reglas Delay host notifications y Delay service notifications sirven para esta situación.
Aquí especificas un tiempo en minutos, y la notificación se retrasará hasta que haya transcurrido ese tiempo. Si el estado OK / UP vuelve a producirse antes de ese momento, no se activará ninguna notificación. Naturalmente, esto también significa que se retrasará la notificación de un verdadero problema.
Obviamente, aún mejor que retrasar las notificaciones sería eliminar la causa real de los problemas esporádicos, pero eso es, por supuesto, otra historia...
6.10. Intentos repetidos de check
Otro método muy similar para retrasar las notificaciones es permitir múltiples intentos de check cuando un servicio entra en estado problemático. Esto se consigue con el conjunto de reglas Maximum number of check attempts for hosts, o respectivamente, Maximum number of check attempts for service.
Si estableces aquí un valor de 3, por ejemplo, un check con resultado CRIT no desencadenará en un primer momento una notificación. Esto se denomina CRIT soft state. El hard state sigue siendo OK. Sólo si tres intentos sucesivos devuelven un estado no OK, el servicio pasará al hard state y se desencadenará una notificación.
A diferencia de las notificaciones diferidas, aquí tienes la opción de definir vistas para que no se muestren estos problemas. También se puede construir una Agregación BI para que sólo se incluyan los hard states, no los soft.
6.11. Host y servicios inestables
Cuando un host o un servicio cambia frecuentemente de estado en poco tiempo, se considera que está aleteando. Se trata de un estado real. El principio en este caso es la reducción de notificaciones excesivas durante las fases en las que un servicio no funciona (del todo) de forma estable. Estas fases también pueden evaluarse especialmente en las estadísticas de disponibilidad.
Los objetos inestables se marcan con el icono . Mientras un objeto sea inestable, los cambios de estado sucesivos no activan más notificaciones. Sin embargo, se activará una notificación cada vez que el objeto entre o salga del estado inestable.
El reconocimiento del estado inestable por parte del sistema puede verse influido de las siguientes formas:
El Master control tiene un interruptor principal para controlar la detección del aleteo (Flap Detection).
Puedes excluir objetos de la detección utilizando el conjunto de reglas Enable/disable flapping detection for hosts, o respectivamente, Enable/disable flapping detection for services.
En las ediciones comerciales, utilizando Global settings > Monitoring Core > Tuning of flap detection puedes definir los parámetros de detección de inestabilidad y configurarlos para que sean más o menos sensibles:

Muestra la ayuda contextualizada con Help > Show inline help para más detalles sobre los valores personalizables.
6.12. Notificaciones repetidas periódicamente y escalado
Para algunos sistemas, puede tener sentido no limitarse a una única notificación cuando un problema persiste durante un periodo de tiempo más largo, por ejemplo, para hosts cuya etiqueta del host Criticality esté configurada como Business critical.
Configurar notificaciones repetidas periódicamente
Checkmk puede configurarse para que se emitan notificaciones sucesivas a intervalos fijos, hasta que se haya reconocido o solucionado el problema.
La configuración para ello se encuentra en Periodic notifications during host problems, o respectivamente, en el conjunto de reglas Periodic notifications during service problems:

Una vez activada esta opción, para un problema persistente, Checkmk activará notificaciones periódicas a los intervalos configurados. Estas notificaciones recibirán un número creciente que empezará por 1 (para la notificación inicial).
Las notificaciones periódicas no sólo son útiles para recordar un problema (y molestar al operador), sino que también proporcionan una base para las escaladas, lo que significa que, tras un tiempo definido, una notificación puede escalarse a otros destinatarios.
Configurar escaladas y entenderlas
Para establecer una escalada, crea una regla de notificación adicional que utilice la condición Restrict to notification number.

Si introduces de 3 a 99999 como rango para el número secuencial, esta regla surtirá efecto a partir de la tercera notificación. El escalado puede realizarse seleccionando otro método, (por ejemplo, SMS), o puede notificar a otras personas (selección de contactos).
Con la opción Throttle periodic notifications, después de un tiempo determinado se puede reducir el ritmo de repetición de las notificaciones, de modo que, por ejemplo, al principio se puede enviar un correo electrónico cada hora, y más tarde se puede reducir a un correo electrónico al día.
Con varias reglas de notificación, puedes construir un modelo de escalada. Pero, ¿cómo funcionará luego esta escalada en la práctica? ¿A quién se notifica y cuándo? He aquí un ejemplo, implementado con una regla para las notificaciones repetidas periódicamente, así como con tres reglas de notificación: Por ejemplo:
En caso de que se detecte un problema en un servicio, se activará una notificación en forma de correo electrónico cada 60 minutos hasta que el problema se resuelva o se reconozca.
Las notificaciones uno a cinco van a las dos personas responsables del servicio.
Las notificaciones seis a diez también se envían al jefe de equipo correspondiente.
A partir de la notificación once, en cambio, se envía un correo diario a la dirección de la empresa.
A las 9 de la mañana, se produce un problema en las instalaciones. Se notifica el problema a los dos empleados responsables, pero no responden (por el motivo que sea). Así pues, a las 10, 11, 12 y a las 13 horas, cada uno de ellos recibe nuevos correos electrónicos. A partir de la sexta notificación, a las 14 horas, el jefe de equipo también recibe un correo electrónico; sin embargo, el problema sigue sin cambiar. A las 15, 16, 17 y 18 horas, se envían nuevos correos electrónicos a los miembros del equipo y al jefe de equipo.
A las 19.00 horas, entra en vigor el tercer nivel de escalada: a partir de ese momento, ya no se envían más correos electrónicos a los miembros del equipo ni al jefe de equipo, sino que la dirección de la empresa recibe un correo electrónico todos los días a las 19.00 horas hasta que se resuelva el problema.
En cuanto se haya solucionado el problema y el servicio en Checkmk vuelva a estar OK, se enviará automáticamente un "todo correcto" al último grupo de personas notificado: así, en el ejemplo anterior, si el problema se soluciona antes de las 14:00, a los dos miembros del equipo; si se soluciona entre las 14:00 y las 19:00, a los miembros del equipo y al jefe de equipo; y después de las 19:00, sólo a la dirección de la empresa.
7. La ruta de una notificación de principio a fin
7.1. El historial de notificaciones
Para empezar, te mostraremos cómo ver el historial de notificaciones a nivel de host y de servicio en Checkmk para poder seguir el proceso de notificación.
Un evento de monitorización que hace que Checkmk active una notificación es, por ejemplo, el cambio de estado de un servicio. Puedes activar manualmente este cambio de estado con el comando Fake check results para realizar pruebas.
Para una prueba de notificación, puedes mover un servicio del estado OK a CRIT de esta forma. Si ahora visualizas las notificaciones de este servicio en la página de detalles del servicio con Service > Service Notifications, verás las siguientes entradas:
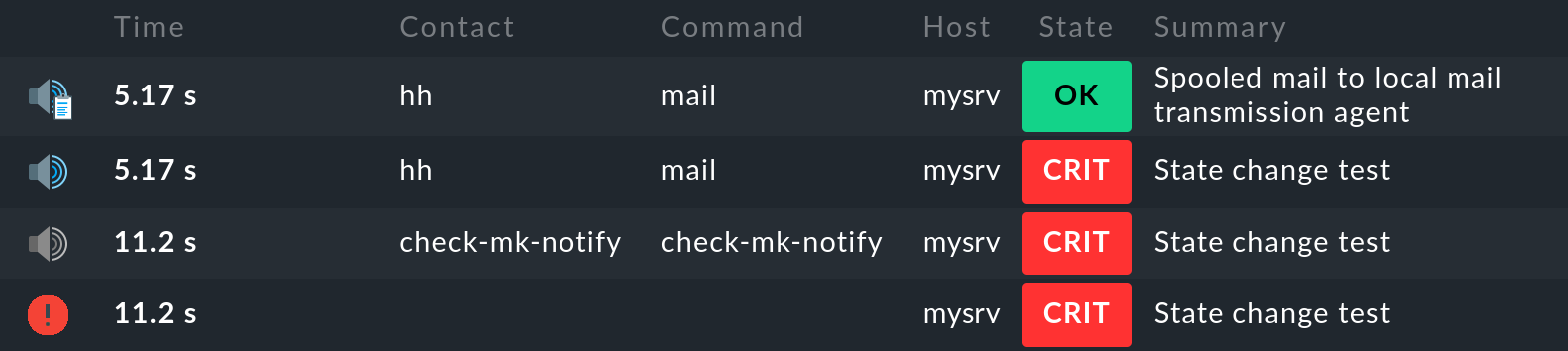
La entrada más reciente está al principio de la lista. Sin embargo, la primera entrada está al final, así que veamos las entradas individuales de abajo a arriba:
El núcleo de monitorización registra el evento de monitorización del cambio de estado. El icono de la 1ª columna indica el estado(CRIT en el ejemplo).
El núcleo de monitorización genera una notificación raw . El núcleo la pasa al módulo de notificación, que realiza la evaluación de las reglas de notificación aplicables.
La evaluación de las reglas da como resultado una notificación al usuario
hhcon el métodomail.El resultado de la notificación muestra que el correo electrónico se entregó correctamente al servidor SMTP para su entrega.
Para ayudar a la correcta comprensión de los contextos de las distintas opciones de configuración y condiciones básicas, y para permitir un diagnóstico preciso del problema cuando una notificación aparece o no como se esperaba, describiremos aquí todos los detalles del proceso de notificación, incluyendo todos los componentes implicados.
Nota: El historial de notificaciones que hemos mostrado anteriormente para un servicio también puede mostrarse para un host: en la página de detalles del host en el menú Host para el propio host ( elemento de menúNotifications of host ) y también para el host con todos sus servicios (Notifications of host & services).
7.2. Los componentes
En el sistema de notificación Checkmk intervienen los siguientes componentes:
| Componente | Función | Archivo de registro |
|---|---|---|
Nagios |
El núcleo de monitorización de Checkmk Raw que detecta eventos de monitorización y genera notificaciones raw. |
|
El núcleo de monitorización en las ediciones comerciales que realiza la misma función que Nagios en Checkmk edición Raw. |
|
|
Módulo de notificación |
Procesa las reglas de notificación para crear una notificación de usuario a partir de una notificación raw. Llama a los script de notificación. |
|
Spooler de notificación (sólo ediciones comerciales) |
Envío asíncrono de notificaciones y notificaciones centralizadas en entornos distribuidos. |
|
Script de notificación |
Para cada método de notificación hay un script que procesa la entrega real (por ejemplo, genera y envía un correo electrónico HTML). |
|
7.3. El núcleo de monitorización
Notificaciones raw
Como se ha descrito anteriormente, cada notificación comienza con un evento de monitorización en el núcleo de monitorización. Si se han cumplido todas las condiciones y se puede dar "luz verde" a una notificación, el núcleo genera una notificación raw al contacto de ayuda interno de check-mk-notify. La notificación raw aún no contiene detalles de los contactos reales ni del método de notificación.
La notificación raw tiene este aspecto en el historial de notificaciones del servicio:

El icono es un altavoz gris claro
check-mk-notifycomo contacto.check-mk-notifycomo comando de notificación.
La notificación raw pasa entonces al módulo de notificación Checkmk, que procesa las reglas de notificación. Este módulo es llamado como programa externo por Nagios (cmk --notify). La CMC, por su parte, mantiene el módulo en espera como proceso auxiliar permanente(notification helper), con lo que se reduce la creación de procesos y se ahorra tiempo de máquina.
Diagnóstico de errores en el núcleo de monitorización de Nagios
El núcleo de Nagios utilizado en Checkmk Raw registra todos los eventos de monitorización en ~/var/log/nagios.log. Este archivo es al mismo tiempo la ubicación donde almacena el historial de notificaciones, que también se consulta mediante la GUI si, por ejemplo, quieres ver las notificaciones de un host o servicio.
Sin embargo, son más interesantes los mensajes que se encuentran en el archivo ~/var/nagios/debug.log y que recibes si ajustas la variable debug_levela 32 en etc/nagios/nagios.d/logging.cfg.
Tras un reinicio del núcleo ...
OMD[mysite]:~$ omd restart nagios... encontrarás información útil sobre las razones por las que se crearon o suprimieron notificaciones:
[1592405483.152931] [032.0] [pid=18122] ** Service Notification Attempt ** Host: 'localhost', Service: 'backup4', Type: 0, Options: 0, Current State: 2, Last Notification: Wed Jun 17 16:24:06 2020
[1592405483.152941] [032.0] [pid=18122] Notification viability test passed.
[1592405485.285985] [032.0] [pid=18122] 1 contacts were notified. Next possible notification time: Wed Jun 17 16:51:23 2020
[1592405485.286013] [032.0] [pid=18122] 1 contacts were notified.Diagnóstico de errores en el núcleo de monitorización CMC
En las ediciones comerciales puedes encontrar un protocolo del núcleo de monitorización en el archivo de registro ~/var/log/cmc.log. En la instalación estándar, este archivo no contiene información relativa a las notificaciones. Sin embargo, puedes activar una función de registro muy detallada con Global settings > Monitoring Core > Logging of the notification mechanics.. El núcleo proporcionará entonces información sobre por qué -o por qué no (todavía)- un evento de monitorización le lleva a pasar una notificación al sistema de notificaciones:
OMD[mysite]:~$ tail -f var/log/cmc.log
+2021-08-26 16:12:37 [5] [core 27532] Executing external command: PROCESS_SERVICE_CHECK_RESULT;mysrv;CPU load;1;test
+2021-08-26 16:12:43 [5] [core 27532] Executing external command: LOG;SERVICE NOTIFICATION: hh;mysrv;CPU load;WARNING;mail;test
+2021-08-26 16:12:52 [5] [core 27532] Executing external command: LOG;SERVICE NOTIFICATION RESULT: hh;mysrv;CPU load;OK;mail;success 250 - b'2.0.0 Ok: queued as 482477F567B';success 250 - b'2.0.0 Ok: queued as 482477F567B'Nota: Activar el registro de notificaciones puede generar muchos mensajes. Sin embargo, es útil cuando más adelante se pregunta por qué no se generó una notificación en una situación concreta.
7.4. Evaluación de reglas por el módulo de notificación
Una vez que el núcleo ha generado una notificación raw, ésta se ejecuta a través de la cadena de reglas de notificación, lo que da como resultado una tabla de notificaciones. Junto a los datos de la notificación raw, cada notificación contiene la siguiente información adicional:
El contacto a notificar
El método de notificación
Los parámetros de este método
En una entrega síncrona, por cada entrada de la tabla se ejecutará un script de notificación apropiado. En una entrega asíncrona, la notificación se pasará como un archivo al spooler de notificación.
Análisis de la secuencia de reglas
Cuando crees regímenes de reglas más complejos, seguramente surgirá la cuestión de qué reglas se aplicarán a una notificación concreta. Para ello, Checkmk proporciona una función de análisis integrada en la página Notifications configuration, a la que puedes acceder con el elemento de menú Display > Show analysis.
En el modo de análisis, se mostrarán por defecto las diez últimas notificaciones raw generadas por el sistema y procesadas a través de las reglas:
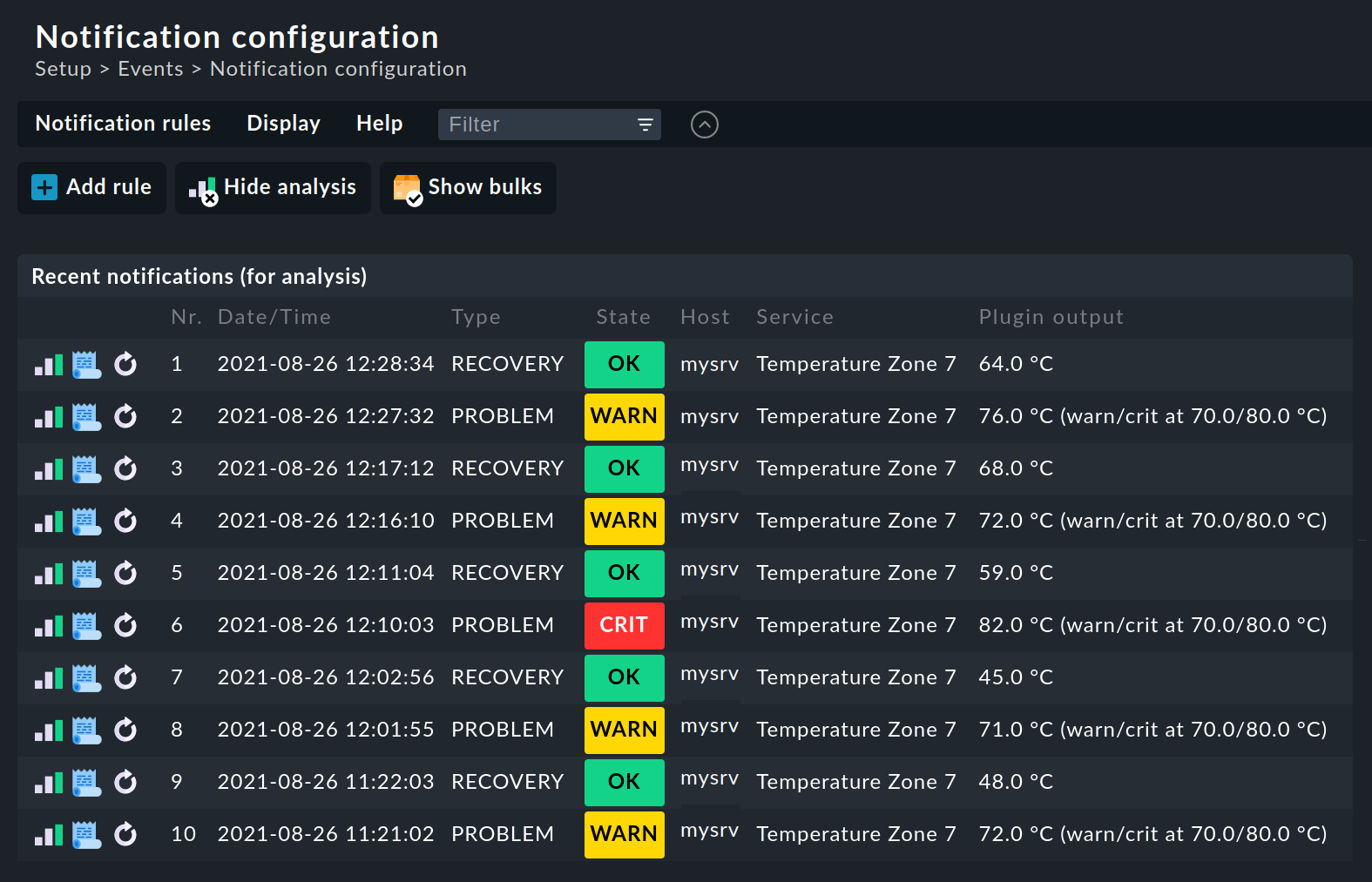
Si necesitas analizar un número mayor de notificaciones raw, puedes aumentar fácilmente el número almacenado para el análisis a través de Global settings > Notifications > Store notifications for rule analysis:

Para cada una de estas notificaciones raw dispondrás de tres acciones:
Comprueba la secuencia de reglas, en la que cada regla se comprobará si se han cumplido todas las condiciones de la regla para el evento de monitorización seleccionado. La tabla de notificaciones resultante se mostrará con las reglas. |
|
Muestra el contexto completo de la notificación. |
|
Repite esta notificación raw como si acabara de aparecer. De lo contrario, la visualización es la misma que en el análisis. Con esto no sólo puedes comprobar las condiciones de la regla, sino también comprobar el aspecto visual de una notificación. |
Diagnóstico de errores
Si has realizado la prueba de la secuencia de reglas (), puedes ver qué reglas se han aplicado o no a un evento de monitorización:
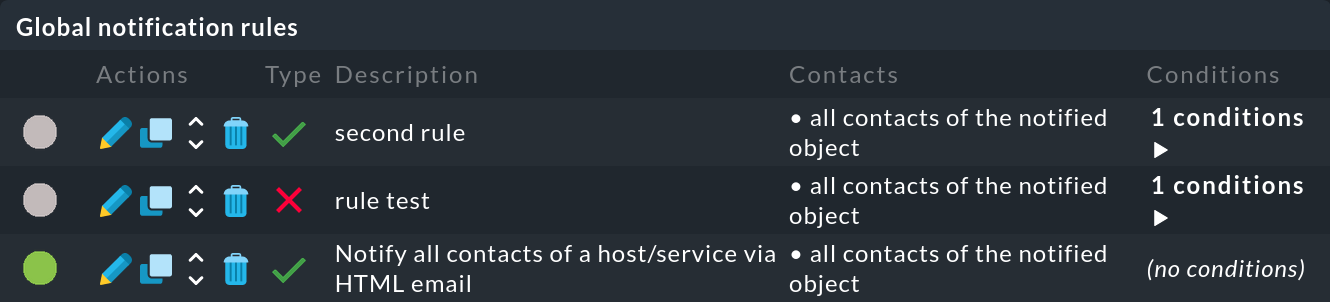
Si no se ha aplicado una regla, pasa el ratón sobre el círculo gris para ver la sugerencia (texto al pasar el ratón):
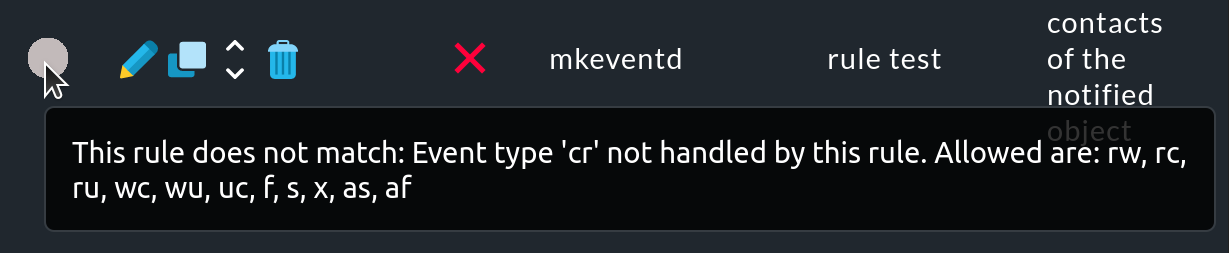
Sin embargo, este texto sobre el ratón utiliza abreviaturas para las causas por las que no se aplicó una regla, que se refieren a las condiciones Match host event type o Match service event type de la regla.
| Tipos de eventos de host | ||
|---|---|---|
Abreviatura |
Significado |
Descripción |
|
UP ➤ DOWN |
El estado del host ha cambiado de UP a DOWN |
|
UP ➤ INALCANZABLE |
Estado del host cambiado de UP a UNREACH |
|
ABAJO ➤ ARRIBA |
Estado del host cambiado de ABAJO a ARRIBA |
|
DOWN ➤ INALCANZABLE |
Estado del host cambiado de DOWN a UNREACH |
|
INALCANZABLE ➤ DOWN |
Estado del host cambiado de UNREACH a DOWN |
|
INALCANZABLE ➤ UP |
Estado del host cambiado de UNREACH a UP |
|
cualquiera ➤ UP |
Estado del host cambiado de cualquier estado a UP |
|
cualquiera ➤ DOWN |
Estado del host cambiado de cualquier estado a DOWN |
|
cualquiera ➤ UNREACHABLE |
Estado del host cambiado de cualquier estado a UNREACH |
|
Inicio o fin de un estado inestable |
|
|
Inicio o fin de un tiempo de mantenimiento programado |
|
|
Reconocimiento del problema |
|
|
Ejecución del alert handler, correcta |
|
|
Ejecución del alert handler, fallida |
|
| Tipos de eventos de servicio | ||
|---|---|---|
Abreviatura |
Significado |
Descripción |
|
OK ➤ WARN |
El estado del servicio ha cambiado de OK a WARN |
|
OK ➤ OK |
El estado del servicio ha cambiado de OK a OK |
|
OK ➤ CRIT |
Estado del servicio cambiado de OK a CRIT |
|
OK ➤ UNKNOWN |
Estado del servicio cambiado de OK a UNKNOWN |
|
WARN ➤ OK |
Estado del servicio cambiado de WARN a OK |
|
WARN ➤ CRIT |
Estado del servicio cambiado de WARN a CRIT |
|
WARN ➤ UNKNOWN (DESCONOCIDO) |
Estado del servicio cambiado de WARN a UNKNOWN |
|
CRIT ➤ OK |
Estado del servicio cambiado de CRIT a OK |
|
CRIT ➤ WARN |
Estado del servicio cambiado de CRIT a WARN |
|
CRIT ➤ DESCONOCIDO |
Estado del servicio cambiado de CRIT a UNKNOWN |
|
UNKNOWN ➤ OK |
Estado del servicio cambiado de UNKNOWN a OK |
|
UNKNOWN ➤ WARN |
Estado del servicio cambiado de UNKNOWN a WARN |
|
UNKNOWN ➤ CRIT |
Estado del servicio cambiado de UNKNOWN a CRIT |
|
cualquiera ➤ OK |
Estado del servicio cambiado de cualquier estado a OK |
|
cualquiera ➤ WARN |
Estado del servicio cambiado de cualquier estado a WARN |
|
cualquiera ➤ CRIT |
Estado del servicio cambiado de cualquier estado a CRIT |
|
cualquiera ➤ UNKNOWN |
Estado del servicio cambiado de cualquier estado a UNKNOWN |
Basándote en estas pistas, puedes comprobar y revisar tus reglas.
Otra opción de diagnóstico importante es el archivo de registro ~/var/log/notify.log. Durante las pruebas con las notificaciones, el popular comando tail -f es útil para ello:
OMD[mysite]:~$ tail -f var/log/notify.log
2021-08-26 17:11:58,914 [20] [cmk.base.notify] Analysing notification (mysrv;Temperature Zone 7) context with 71 variables
2021-08-26 17:11:58,915 [20] [cmk.base.notify] Global rule 'Notify all contacts of a host/service via HTML email'...
2021-08-26 17:11:58,915 [20] [cmk.base.notify] -> matches!
2021-08-26 17:11:58,915 [20] [cmk.base.notify] - adding notification of hh via mail
2021-08-26 17:11:58,916 [20] [cmk.base.notify] Executing 1 notifications:
2021-08-26 17:11:58,916 [20] [cmk.base.notify] * would notify hh via mail, parameters: smtp, graphs_per_notification, notifications_with_graphs, bulk: noCon Global settings > Notifications > Notification log level puedes controlar la exhaustividad de las notificaciones en tres niveles. Establécelo en Full dump of all variables and command, y en el archivo de registro encontrarás una lista completa de todas las variables disponibles para el script de notificación:

Por ejemplo, la lista aparecerá así (extracto):
2021-08-26 17:24:54,709 [10] [cmk.base.notify] Raw context:
CONTACTS=hh
HOSTACKAUTHOR=
HOSTACKCOMMENT=
HOSTADDRESS=127.0.0.1
HOSTALIAS=localhost
HOSTATTEMPT=1
HOSTCHECKCOMMAND=check-mk-host-smart7.5. Envío asíncrono a través del spooler de notificación
Una potente función complementaria de las ediciones comerciales es el spooler de notificación, que permite una entrega asíncrona de las notificaciones. ¿Qué significa asíncrona en este contexto?
Entrega sincrónica: El módulo de notificación espera hasta que el script de notificación haya terminado de ejecutarse. Si tarda mucho en ejecutarse, se acumulan más notificaciones. Si se detiene la monitorización, estas notificaciones se pierden. Además, si se generan muchas notificaciones en un corto periodo de tiempo, puede acumularse una acumulación en el núcleo, provocando que se paralice la monitorización.
Entrega asíncrona: Cada notificación se guardará en un archivo spool en
~/var/check_mk/notify/spool. No puede acumularse ningún atasco. Si se detiene la monitorización, los archivos spool se conservarán y las notificaciones podrán entregarse correctamente más adelante. El spooler de notificación se encarga del proceso de los archivos spool.
Una entrega sincrónica es entonces factible si el script de notificación se ejecuta rápidamente y, sobre todo, no puede dar lugar a algún tipo de timeout. Con los métodos de notificación que acceden a los spoolers existentes, esto es un hecho. Los servicios de spool del sistema pueden utilizarse especialmente con el correo electrónico y los SMS. El script de notificación pasa un archivo al spooler: con este procedimiento no puede producirse ningún estado de espera.
Cuando utilices la entrega rastreable a través de SMTP u otros scripts que establezcan conexiones de red, debes emplear siempre la entrega asíncrona. Esto también se aplica a los scripts que envían mensajes de texto (SMS) a través de HTTP por internet. Los timeout al establecer una conexión con un servicio de red pueden tardar hasta varios minutos, provocando un atasco como el descrito anteriormente.
La buena noticia es que la entrega asíncrona está activada por defecto en Checkmk. Por un lado, el spooler de notificación (mknotifyd) también se inicia cuando se inicia el site, lo que puedes comprobar con el siguiente comando:
OMD[mysite]:~$ omd status mknotifyd
mknotifyd: running
-----------------------
Overall state: runningPor otro lado, la entrega asíncrona (Asynchronous local delivery by notification spooler) está seleccionada en Global settings > Notifications > Notification Spooling:

Diagnóstico de errores
El spooler de notificación mantiene su propio archivo de registro: ~/var/log/mknotifyd.log. Éste posee tres niveles de registro que pueden establecerse en Global settings > Notifications > Notification Spooler Configuration con el parámetro Verbosity of logging. En el nivel intermedio, Verbose logging (i.e. spooled notifications), puede verse el proceso de los archivos spool:
2021-08-26 18:05:02,928 [15] [cmk.mknotifyd] processing spoolfile: /omd/sites/mysite/var/check_mk/notify/spool/dad64e2e-b3ac-4493-9490-8be969a96d8d
2021-08-26 18:05:02,928 [20] [cmk.mknotifyd] running cmk --notify --log-to-stdout spoolfile /omd/sites/mysite/var/check_mk/notify/spool/dad64e2e-b3ac-4493-9490-8be969a96d8d
2021-08-26 18:05:05,848 [20] [cmk.mknotifyd] got exit code 0
2021-08-26 18:05:05,850 [20] [cmk.mknotifyd] processing spoolfile dad64e2e-b3ac-4493-9490-8be969a96d8d successful: success 250 - b'2.0.0 Ok: queued as 1D4FF7F58F9'
2021-08-26 18:05:05,850 [20] [cmk.mknotifyd] sending command LOG;SERVICE NOTIFICATION RESULT: hh;mysrv;CPU load;OK;mail;success 250 - b'2.0.0 Ok: queued as 1D4FF7F58F9';success 250 - b'2.0.0 Ok: queued as 1D4FF7F58F9'8. Notificaciones masivas
8.1. Vista general
Todo el que trabaja con monitorización ha experimentado algún problema aislado que desencadena una auténtica avalancha de notificaciones (sucesivas). El principio del padre (host ) es una forma de reducirlas en determinadas circunstancias, pero desgraciadamente no ayuda en todos los casos.
Puedes tomar un ejemplo del propio proyecto Checkmk: una vez al día creamos paquetes de instalación de Checkmk para cada distribución de Linux compatible. Nuestra propia monitorización de Checkmk está configurada de modo que tenemos un servicio que sólo está OK si se ha construido correctamente el número correcto de paquetes. A veces puede ocurrir que un error general en el software obstaculice el empaquetado, provocando que 43 servicios entren en estado de CRIT simultáneamente.
Hemos configurado las notificaciones de forma que, en tal caso, sólo se envíe un único correo electrónico con una lista de las 43 notificaciones en secuencia, lo que, naturalmente, es más claro que 43 correos electrónicos individuales, y también reduce el riesgo de que "en el fragor de la batalla" se pase por alto un 44º correo electrónico perteneciente a otro problema muy distinto.
El modo de funcionamiento de esta notificación masiva es muy sencillo. Cuando se produce una notificación, al principio se retendrá durante un breve periodo de tiempo. Las notificaciones posteriores que se produzcan durante este tiempo se añadirán inmediatamente en el mismo correo electrónico. Esta recogida puede definirse para cada regla. Así, por ejemplo, durante el día puedes operar con correos electrónicos individuales, pero durante la noche con una notificación masiva. Si se activa una notificación masiva, generalmente se te ofrecerán las siguientes opciones:
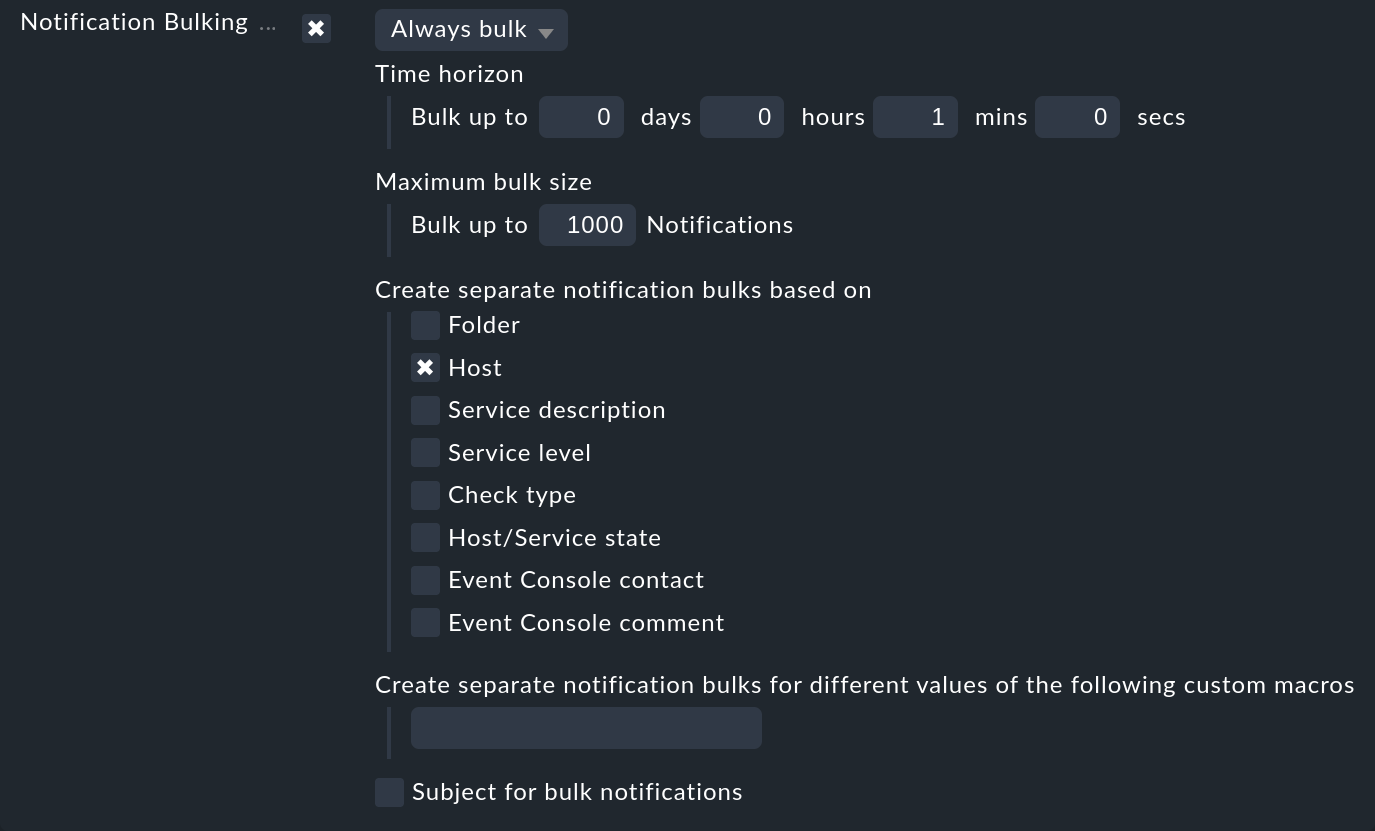
El tiempo de espera puede configurarse como se desee. En muchos casos, basta con un minuto, ya que para entonces, como muy tarde, deberían haber aparecido todos los problemas relacionados. Por supuesto, puedes establecer un tiempo mayor, pero eso provocará un retraso fundamental en las notificaciones.
Como, naturalmente, no tiene sentido meterlo todo en el mismo saco, puedes especificar qué grupos de problemas deben notificarse colectivamente. La opción Host se utiliza con mucha frecuencia, ya que garantiza que sólo se agrupen las notificaciones del mismo host.
Aquí tienes algunos datos adicionales sobre las notificaciones masivas:
Si se activa la agrupación en una regla, la activación puede ser desactivada por una regla posterior - y viceversa.
La notificación masiva siempre tiene lugar por contacto. Cada contacto tiene su propio "bote de colección privado" en vigor.
Puedes limitar el tamaño del bote (Maximum bulk size). Una vez alcanzado el máximo, se enviará inmediatamente la notificación masiva.
8.2. Notificaciones masivas y periodos de tiempo
¿Qué ocurre cuando una notificación está dentro del periodo de notificación, pero la notificación masiva que la contiene -y que llega algo más tarde- está fuera del periodo de notificación? La situación inversa también es posible...
Aquí se aplica un principio muy simple: todas las configuraciones que restringen las notificaciones a periodos de tiempo sólo son válidas para la notificación real. La notificación masiva posterior siempre se entregará independientemente de todos los periodos de tiempo.
9. Entrega rastreable por SMTP
9.1. El correo electrónico no es fiable
La monitorización sólo es útil cuando se puede confiar en ella. Para ello, es necesario que las notificaciones se reciban de forma fiable y rápida. Por desgracia, la entrega por correo electrónico no es del todo ideal. El envío suele procesarse pasando el correo electrónico al servidor SMTP local, que intenta entregarlo de forma autónoma y asíncrona.
Si se produce un error temporal (por ejemplo, si no se puede acceder al servidor SMTP receptor), el correo electrónico se pondrá en cola y más tarde se hará un nuevo intento. Este "más tarde" será, por regla general, al cabo de 15-30 minutos. Para entonces, ¡la notificación podría llegar demasiado tarde!
Si realmente no se puede entregar el correo electrónico, el servidor SMTP crea un bonito mensaje de error en su archivo de registro e intenta generar un correo electrónico de error para el "remitente". Pero el sistema de monitorización no es un remitente real y tampoco puede recibir correos electrónicos, por lo que tales errores simplemente desaparecen y entonces no hay notificaciones.
Importante: ¡las notificaciones rastreables no están disponibles para las notificaciones masivas!
9.2. El uso de SMTP en una conexión directa permite el análisis de errores
Las ediciones comerciales ofrecen la posibilidad de un envío rastreable mediante SMTP. Esto lo hace intencionadamente sin la ayuda del servidor de correo local. En su lugar, el propio Checkmk envía el correo electrónico a tu smarthost mediante SMTP, y luego evalúa él mismo la respuesta SMTP.
De este modo, no sólo se tratan los errores SMTP de forma inteligente, sino que también se documenta con precisión una entrega correcta. Es un poco como una carta certificada: Checkmk recibe un recibo del smarthost SMTP (servidor receptor) que verifica que el correo electrónico ha sido aceptado, incluyendo un ID de correo.
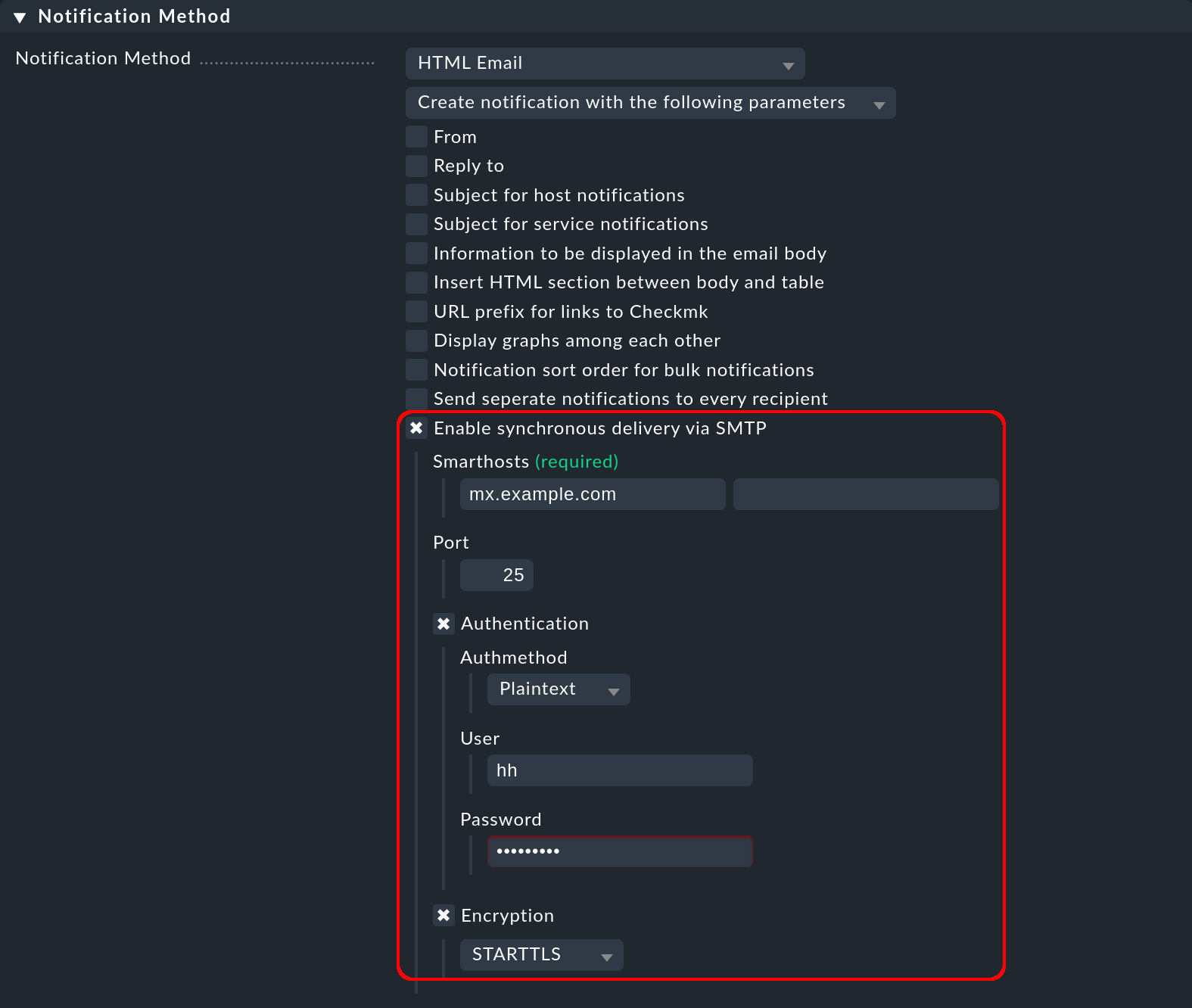
9.3. Entrega sincrónica para correos electrónicos HTML
Puedes seleccionar y configurar la entrega rastreable vía SMTP para el método de notificación correo electrónico HTML introduciendo el smarthost (con nombre y número de puerto) y los datos de acceso y el método de encriptación:
En el historial del servicio en cuestión, podrás hacer un seguimiento exacto de la entrega. Aquí tienes un ejemplo en el que un servicio -con fines de prueba- se configuró manualmente como CRIT. La captura de pantalla siguiente muestra las notificaciones de este servicio, que puedes visualizar en la página de detalles del servicio con Service > Service Notifications:
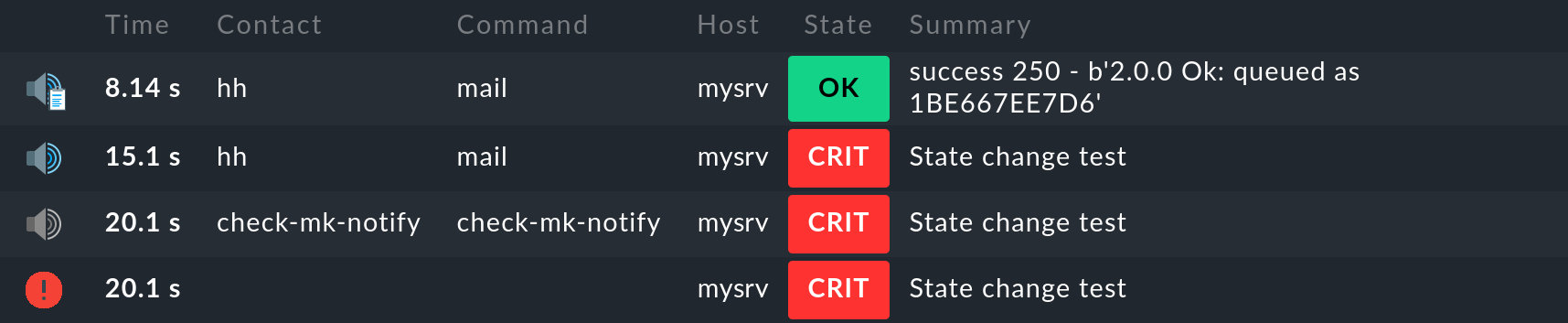
Aquí verás los cuatro pasos individuales en la secuencia cronológica de abajo a arriba, como ya los hemos presentado en el capítulo sobre el historial de notificaciones. La diferencia importante es que ahora puedes ver en la entrada superior que el correo electrónico se entregó correctamente al smarthost y su respuesta es success.
También puedes seguir los pasos individuales en el archivo notify.log. Las siguientes líneas pertenecen al último paso y contienen la respuesta del servidor SMTP:
2021-08-26 10:02:22,016 [20] [cmk.base.notify] Got spool file d3b417a5 (mysrv;CPU load) for local delivery via mail
2021-08-26 10:02:22,017 [20] [cmk.base.notify] executing /omd/sites/mysite/share/check_mk/notifications/mail
2021-08-26 10:02:29,538 [20] [cmk.base.notify] Output: success 250 - b'2.0.0 Ok: queued as 1BE667EE7D6'El Message-ID 1BE667EE7D6 aparecerá en el archivo de registro del smarthost. Allí -si te preocupa- podrás investigar dónde ha llegado el correo electrónico. En cualquier caso, podrás demostrar que, y cuándo, el correo electrónico se envió correctamente desde Checkmk.
Repitamos la prueba anterior, pero esta vez con una contraseña falsamente configurada para la transferencia SMTP al smarthost. Aquí puedes ver en texto plano el mensaje de error SMTP Error: authentication failed del smarthost:
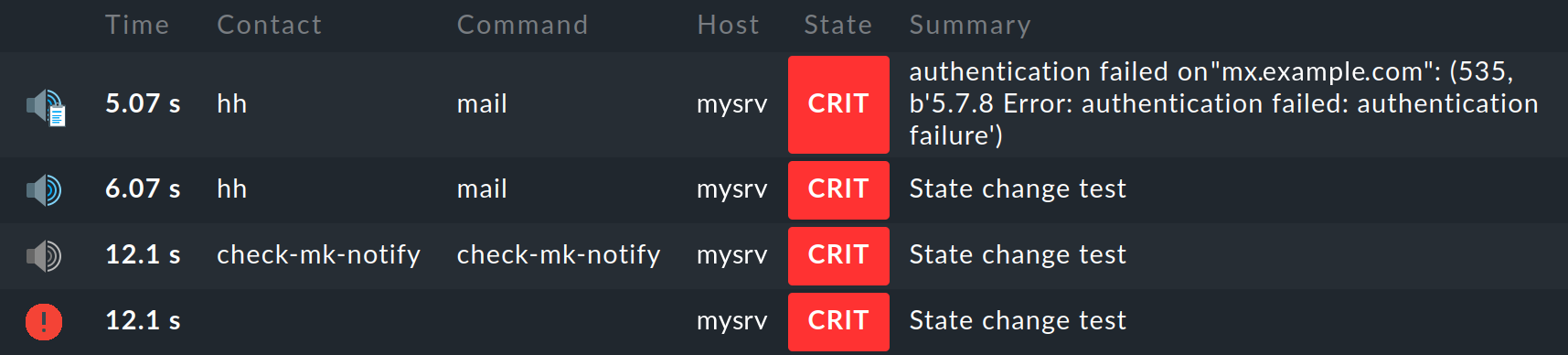
¿Qué se puede hacer con las notificaciones fallidas? Una vez más, notificar por correo electrónico no parece una buena solución. En su lugar, Checkmk muestra una clara advertencia con color de fondo rojo en la Vista general:
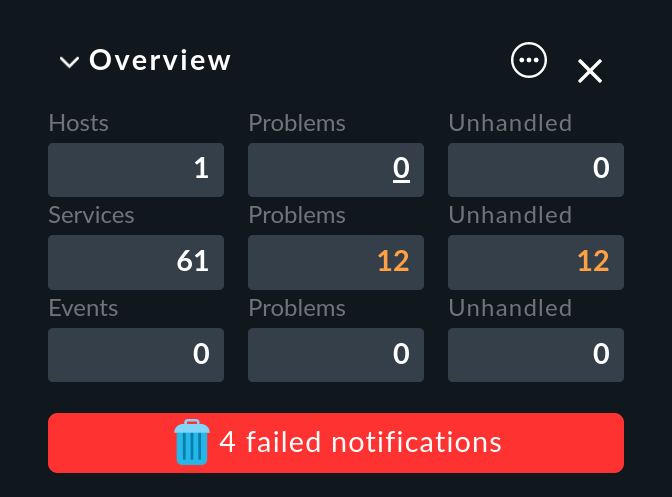
Aquí puedes
Hacer clic en el texto … failed notifications para ver una lista de las entregas fallidas.
Hacer clic en el icono para confirmar estos mensajes y eliminar el aviso haciendo clic en Confirm en la Vista general que se abre.
Importante: Ten en cuenta que la entrega directa por SMTP en situaciones de error puede hacer que el script de notificación se ejecute durante mucho tiempo y provocar un timeout. Por este motivo, te recomendamos encarecidamente que utilices el spooler de notificación y que selecciones una entrega asíncrona de notificaciones.
La conducta con errores repetibles (como un timeout SMTP) puede definirse con Global settings > Notifications > Notification spooler configuration por método de notificación:
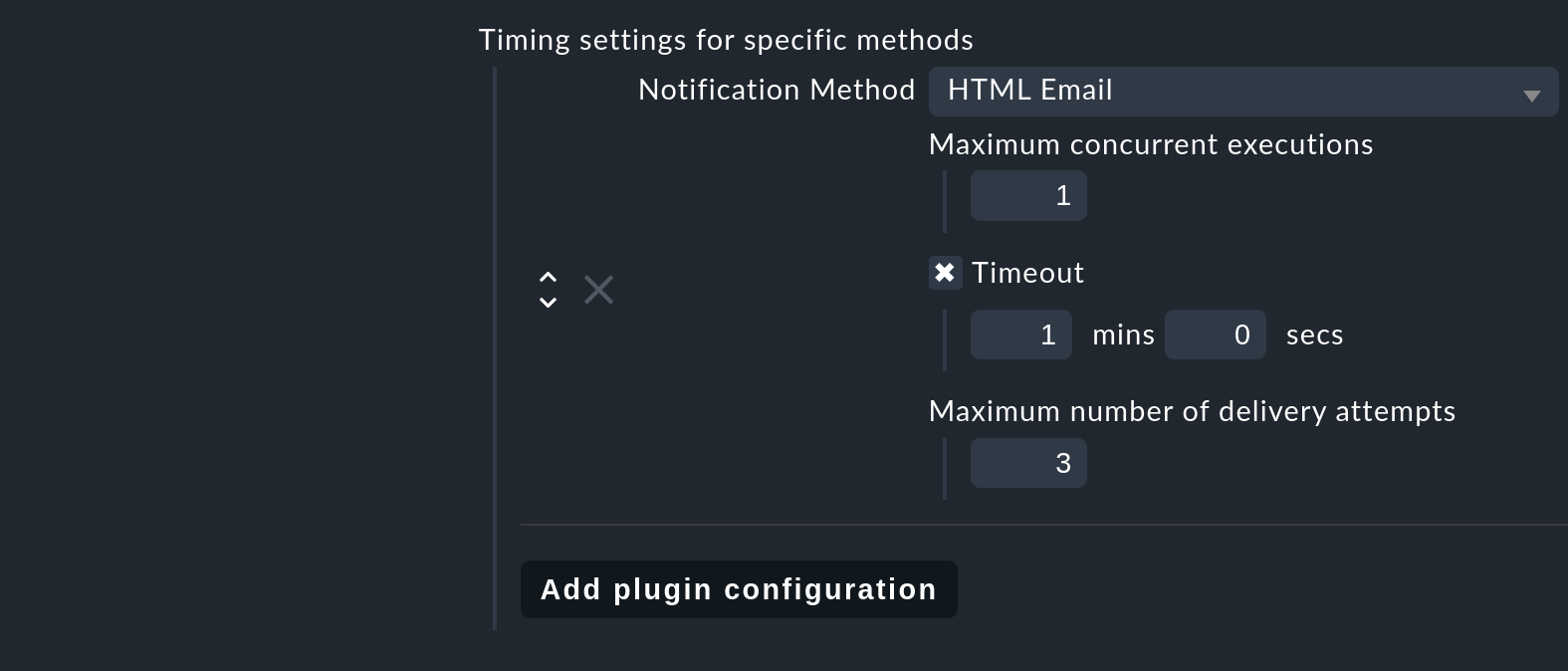
Junto a un timeout opcional (el predeterminado es de 1 minuto) y un número máximo de reintentos, también se puede definir si se permite que el script se ejecute varias veces en paralelo y envíe así múltiples notificaciones (Maximum concurrent executions). Si el script de notificación es muy lento, puede tener sentido una ejecución en paralelo; sin embargo, el script debe estar programado de modo que las ejecuciones múltiples se ejecuten limpiamente (y, por ejemplo, que el script no se reserve ciertos datos para sí mismo).
Un envío múltiple en paralelo a través de SMTP no plantea problemas, ya que el servidor de destino puede gestionar varias conexiones en paralelo, lo que no ocurre cuando el envío se realiza directamente desde un SMS a través de un módem sin un spooler adicional, por lo que en este caso se debe mantener la configuración 1.
9.4. SMS y otros métodos de notificación
Hasta la fecha, sólo se ha implementado una entrega síncrona que incluya mensajes de error y trazabilidad para los correos electrónicos HTML. En el capítulo sobre cómo escribir tus propios scripts encontrarás cómo devolver un estado de error en un script de notificación escrito por ti mismo.
10. Notificaciones en sistemas distribuidos
En los entornos distribuidos, es decir, en los que hay más de un site Checkmk, se plantea la cuestión de qué hacer con las notificaciones generadas en sites remotos. En tal situación hay básicamente dos posibilidades:
Entrega local
Entrega central en el site central (sólo ediciones comerciales)
Encontrarás información detallada sobre este tema en el artículo sobre monitorización distribuida.
11. Scripts de notificación
11.1. El principio
La notificación puede producirse de múltiples e individuales maneras. Ejemplos típicos son:
La transferencia de notificaciones a un ticket, o a un sistema de notificación externo
El envío de un SMS a través de diversos servicios de internet
Llamadas telefónicas automatizadas
Reenvío a un sistema de monitorización superior y paraguas
Por esta razón, Checkmk proporciona una interfaz muy sencilla que te permite escribir tus propios scripts de notificación, que pueden escribirse en cualquier lenguaje de programación compatible con Linux, aunque Shell, Perl y Python tienen juntos el 95 % del "mercado".
Los scripts estándar incluidos en Checkmk se encuentran en ~/share/check_mk/notifications. Este directorio es un componente del software y no debe modificarse. En su lugar, guarda tus propios scripts en ~/local/share/check_mk/notifications. Asegúrate de que tus scripts son ejecutables (chmod +x). Entonces se encontrarán automáticamente y estarán disponibles para su selección en las reglas de notificación.
Si deseas personalizar un script estándar, simplemente cópialo de ~/share/check_mk/notifications a ~/local/share/check_mk/notifications y realiza allí tus cambios en la copia. Si conservas el nombre original, tu script será sustituido automáticamente por la versión estándar y no será necesario realizar ningún cambio en las reglas de notificación existentes.
Con el software se incluyen algunos scripts de ejemplo más en ~/share/doc/check_mk/treasures/notifications. Puedes utilizarlos como plantillas para la personalización. La configuración generalmente se realizará directamente en el script -en los comentarios encontrarás consejos al respecto.
En el caso de una notificación, se llamará a tu script con los permisos del usuario del site. En las variables del entorno, (las que empiezan por NOTIFY_), recibirá toda la información sobre el host/servicio afectado, el evento de monitorización, los contactos a notificar y los parámetros especificados en la regla de notificación.
Los textos que el script escriba en la salida estándar (con print, echo, etc.), aparecerán en el archivo de registro del módulo de notificación ~/var/log/notify.log.
11.2. Notificaciones rastreables
Los script de notificación tienen la opción de utilizar un código de salida para comunicar si se ha producido un error replicable o final:
| Código de salida | Función |
|---|---|
|
El script se ha ejecutado correctamente. |
|
Se ha producido un error temporal. La ejecución debe reintentarse repetidamente tras una breve espera, hasta alcanzar el número máximo de intentos configurado. Ejemplo: no se puede establecer una conexión HTTP con un servicio SMS. |
|
Se ha producido un error final. No se reintentará la notificación. Se mostrará un error de notificación en la GUI. El error se mostrará en el historial del host/servicio. Ejemplo: el servicio SMS registra un error de "autenticación inválida". |
Además, en todos los casos, la salida estándar del script de notificación, junto con el estado, se introducirá en el historial de notificaciones del host/servicio y, por tanto, será visible en la GUI.
Importante: ¡Las notificaciones rastreables no están disponibles para las notificaciones masivas!
El tratamiento de los errores de notificación desde el punto de vista del usuario se explicará en el capítulo sobre el envío rastreable a través de SMTP.
11.3. Un simple script de ejemplo
Como ejemplo, puedes crear un script que escriba toda la información sobre la notificación en un archivo. El lenguaje de codificación es el shell de Linux Bash:
#!/bin/bash
# Foobar Teleprompter
env | grep NOTIFY_ | sort > $OMD_ROOT/tmp/foobar.out
echo "Successfully written $OMD_ROOT/tmp/foobar.out"
exit 0A continuación, haz que el script sea ejecutable:
OMD[mysite]:~$ chmod +x local/share/check_mk/notifications/foobarAquí tienes un par de explicaciones sobre el script:
En la primera línea hay un
#!y la ruta al intérprete del lenguaje de script (aquí/bin/bash).En la segunda línea después del carácter de comentario
#hay un título para el script. Por regla general, se mostrará al seleccionar el método de notificación.El comando
envmostrará todas las variables del entorno recibidas por el script.Con
grep NOTIFY_se filtrarán las variables Checkmk ...... y ordenadas alfabéticamente con
sort.> $OMD_ROOT/tmp/foobar.outescribe el resultado en el archivo~/tmp/foobar.outdentro del directorio del site.En realidad, el
exit 0sería superfluo en esta ubicación, ya que el shell siempre toma el código de salida del último comando. Aquí esechoy siempre tiene éxito - pero explícito siempre es mejor.
11.4. Probar el script de ejemplo
Para que el script sea utilizado, debes definirlo como un método en una regla de notificación. Los scripts escritos por ti mismo no tienen declaración de parámetros, por lo que faltarán todos los checkbox como los que se ofrecen, por ejemplo, en el método HTML Email. En su lugar, puedes introducir una lista de textos como parámetros que pueden estar disponibles como NOTIFY_PARAMETER_1, NOTIFY_PARAMETER_2, etc, para el script. Para una prueba, proporciona los parámetros Fröhn, Klabuster y Feinbein:
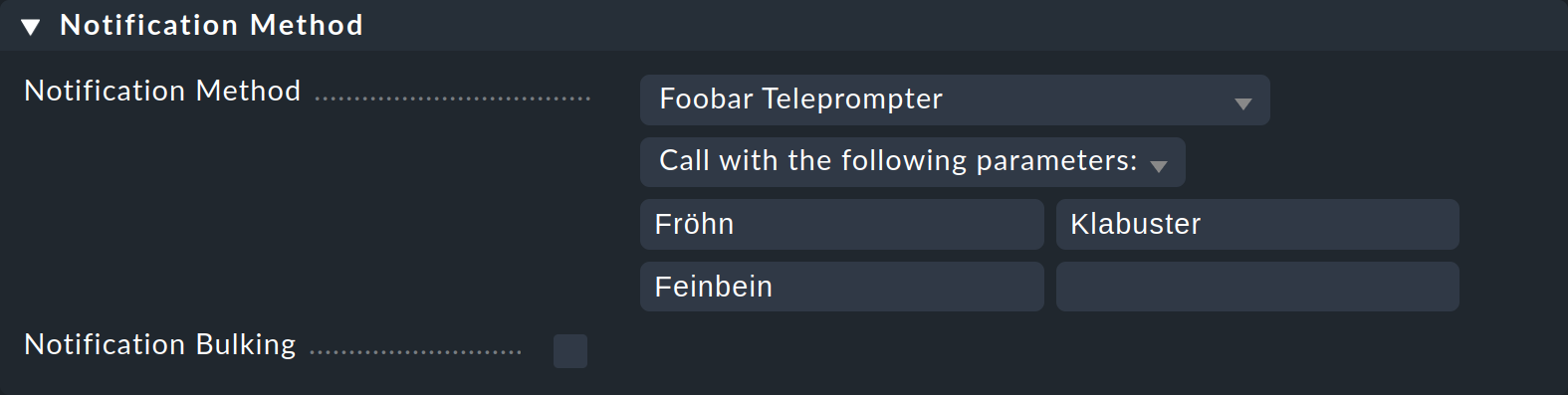
Ahora para probar, establece el servicio CPU load en el host myserver a CRIT- con el comando Fake check results. En el archivo de registro del módulo de notificación ~/var/log/notify.log verás entonces la ejecución del script incluyendo los parámetros y el archivo spool generado.:
2021-08-25 13:01:23,887 [20] [cmk.base.notify] Executing 1 notifications:
2021-08-25 13:01:23,887 [20] [cmk.base.notify] * notifying hh via foobar, parameters: Fröhn, Klabuster, Feinbein, bulk: no
2021-08-25 13:01:23,887 [20] [cmk.base.notify] Creating spoolfile: /omd/sites/mysite/var/check_mk/notify/spool/e1b5398c-6920-445a-888e-f17e7633de60El archivo ~/tmp/foobar.out contendrá ahora una lista alfabética de todas las variables del entorno Checkmk que incluyen información relativa a la notificación. Aquí puedes orientarte con qué valores están disponibles para tu script. He aquí las diez primeras líneas:
OMD[mysite]:~$ head tmp/foobar.out
NOTIFY_ALERTHANDLERNAME=debug
NOTIFY_ALERTHANDLEROUTPUT=Arguments:
NOTIFY_ALERTHANDLERSHORTSTATE=OK
NOTIFY_ALERTHANDLERSTATE=OK
NOTIFY_CONTACTALIAS=Harry Hirsch
NOTIFY_CONTACTEMAIL=harryhirsch@example.com
NOTIFY_CONTACTNAME=hh
NOTIFY_CONTACTPAGER=
NOTIFY_CONTACTS=hh
NOTIFY_DATE=2021-08-25También puedes encontrar los parámetros:
OMD[mysite]:~$ grep PARAMETER tmp/foobar.out
NOTIFY_PARAMETERS=Fröhn Klabuster Feinbein
NOTIFY_PARAMETER_1=Fröhn
NOTIFY_PARAMETER_2=Klabuster
NOTIFY_PARAMETER_3=Feinbein11.5. Variables del entorno
En el ejemplo anterior has visto una serie de variables del entorno que se pasarán al script. Exactamente qué variables están disponibles depende del tipo de notificación, de la versión y edición de Checkmk y del core de monitorización utilizado(CMC o Nagios). Junto al truco con el comando env hay otras dos formas de obtener una lista completa de todas las variables:
Cambiando UP el nivel de registro para
notify.logmediante Global settings > Notifications > Notification log level.Para las notificaciones por HTML Email hay un checkbox Information to be displayed in the email body con la opción Complete variable list (for testing).
A continuación hay una lista de las variables más importantes:
| Variable del entorno | Significado |
|---|---|
|
Directorio de inicio del site, por ejemplo, |
|
Nombre del site, por ejemplo, |
|
Para notificaciones de host, la palabra |
|
Nombre de usuario (inicio de sesión) del contacto. |
|
La dirección de correo electrónico del contacto. |
|
La entrada en el campo Pager del perfil de usuario del contacto. Como este campo no suele estar reservado para un fin concreto, puedes utilizarlo simplemente para cada usuario con el fin de guardar la información necesaria para las notificaciones. |
|
Fecha de la notificación en formato ISO-8601, por ejemplo, |
|
Fecha y hora en la visualización por defecto del sistema Linux no localizado, por ejemplo, |
|
Fecha y hora en formato ISO, por ejemplo |
|
Nombre del host afectado. |
|
Salida del plugin de check plugin del host, por ejemplo, |
|
Una de las palabras |
|
Tipo de notificación, tal y como se describe en la introducción de este artículo. Se expresará mediante una de las siguientes palabras: |
|
Todos los parámetros del script separados por espacios en blanco. |
|
El primer parámetro del script. |
|
El segundo parámetro del script, etc. |
|
Nombre del servicio en cuestión. Esta variable no está presente en las notificaciones de host. |
|
Salida del plugin de check plugin del servicio (no para las notificaciones del host). |
|
Una de las palabras |
11.6. Notificaciones masivas
Si tu script debe soportar notificaciones masivas, tendrá que estar especialmente preparado, ya que el script debe entregar múltiples notificaciones simultáneamente. Por esta razón, una entrega utilizando variables del entorno tampoco funciona de forma práctica.
Dale un nombre a tu script en la tercera línea de la cabecera, como se indica a continuación: el módulo de notificación enviará entonces las notificaciones a través de la entrada estándar:
#!/bin/bash
# My Bulk Notification
# Bulk: yesA través de la entrada estándar, el script recibirá bloques de variables. Cada línea tiene la forma: NAME=VALUE. Los bloques están separados por líneas en blanco. El carácter ASCII con el código 1 (\a) se utiliza para representar nuevas líneas dentro del texto.
El primer bloque contiene una lista de variables generales (por ejemplo, parámetros de llamada). Cada bloque posterior reúne las variables en una notificación.
La mejor recomendación es que lo pruebes tú mismo con una prueba sencilla que escriba los datos completos en un archivo para que puedas ver cómo se envían los datos. Para ello, puedes utilizar el siguiente script de notificación:
#!/bin/bash
# My Bulk Notification
# Bulk: yes
cat > $OMD_ROOT/tmp/mybulktest.outPrueba el script como se ha descrito anteriormente y activa además el Notification Bulking en la regla de notificación.
11.7. Scripts de notificación suministrados
Tal y como se entrega, Checkmk ya proporciona toda una serie de scripts para conectarse a servicios de mensajería instantánea, plataformas de gestión de incidencias y sistemas de tickets populares y ampliamente utilizados. Puedes averiguar cómo utilizar estos scripts en los siguientes artículos:
12. Probar notificaciones con Fake check results
Para probar los métodos de notificación distintos del correo electrónico, puedes simplemente establecer manualmente un servicio OK a CRIT. Esto puede hacerse con el comando Fake check results, que puedes encontrar en la lista de servicios del menú Commands. Si el comando no está visible en la lista, haz clic una vez en el botón Show more.
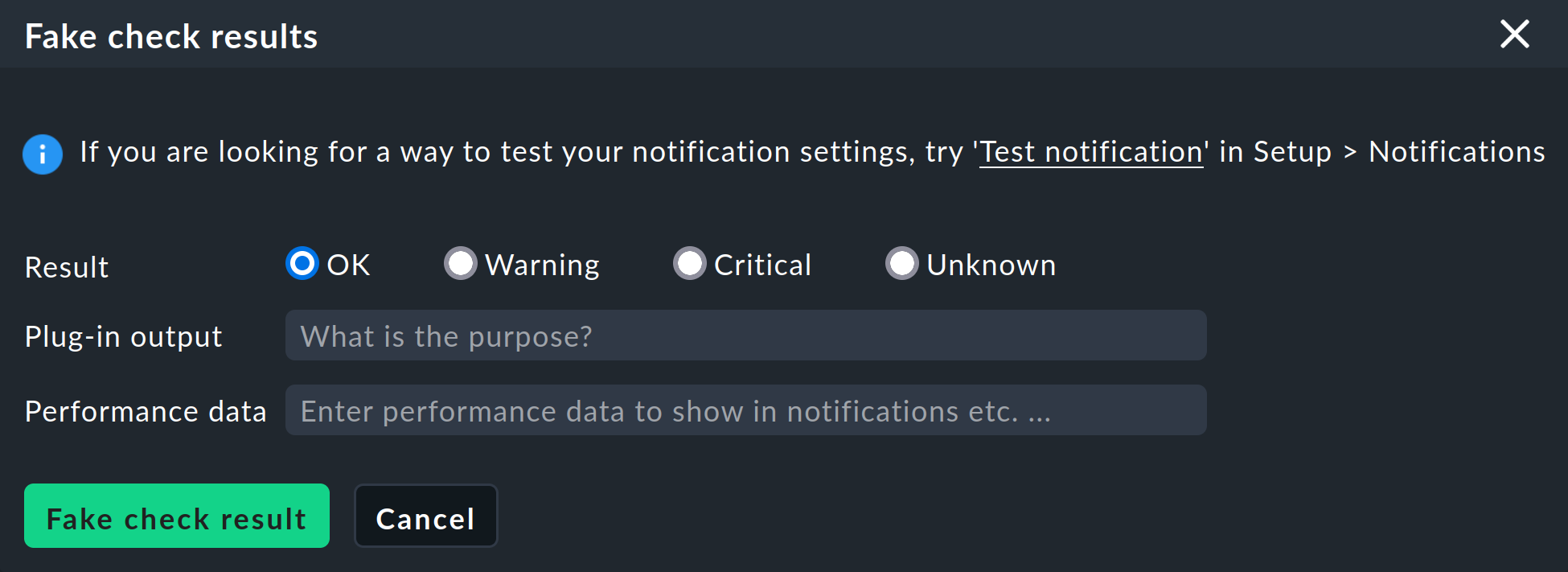
Si se cumplen todas las condiciones de una de tus reglas de notificación, se ejecuta el método de notificación establecido para esta regla. En el siguiente check regular, el servicio debería volver a OK, activando así una nueva notificación, esta vez de recuperación.
Ten en cuenta que durante estas pruebas, al realizar cambios frecuentes en su estado, el servicio entrará después de un tiempo en estado inestable. Los cambios de estado posteriores ya no activarán las notificaciones. En el snap-in Control maestro de la barra lateral puedes desactivar temporalmente la detección de inestabilidad (Flap Detection).
Alternativamente, también puedes enviar un Custom notification- también mediante un comando:
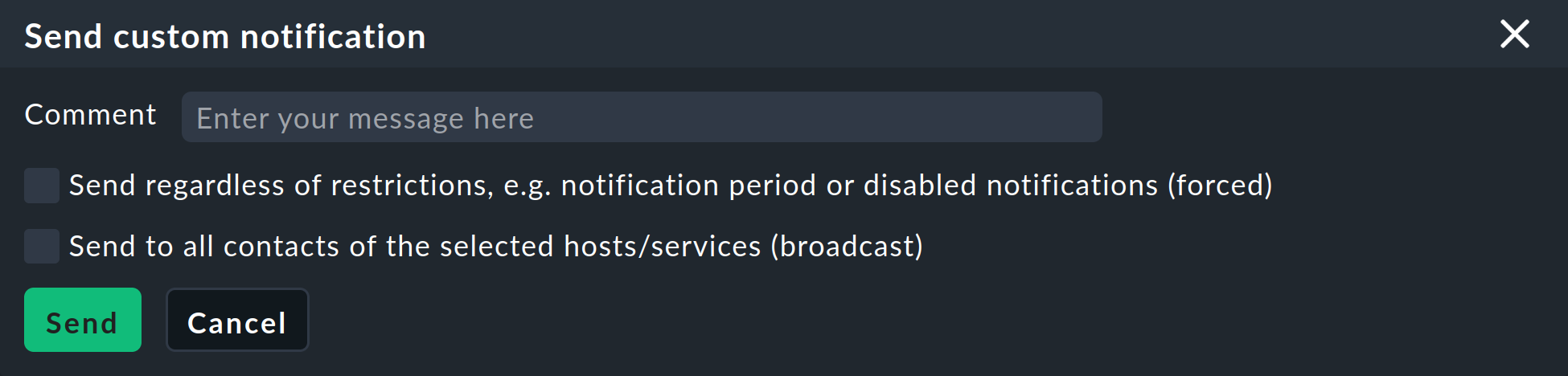
Esto no altera el estado del servicio afectado. Sin embargo, esta notificación generada es de otro tipo y -dependiendo de tus reglas de notificación- puede comportarse de forma diferente.
13. Archivos y directorios
13.1. Rutas de Checkmk
| Ruta del archivo | Función |
|---|---|
|
El archivo de registro de la CMC. Si está activada la depuración de notificaciones, aquí encontrarás información precisa sobre por qué se generaron o no notificaciones. |
|
El archivo de registro del módulo de notificación. |
|
El archivo de registro del spooler de notificación. |
|
El estado actual del spooler de notificación. Esto es importante sobre todo para las notificaciones en entornos distribuidos. |
|
El archivo de registro de depuración de Nagios. Activa los mensajes de depuración en |
|
Ubicación de almacenamiento de los archivos spool que procesará el spooler de notificación. |
|
En caso de errores temporales, el spooler de notificación mueve los archivos aquí y vuelve a intentarlo al cabo de un par de minutos. |
|
Los archivos spool defectuosos se moverán aquí. |
|
Scripts de notificación suministrados de serie con Checkmk. No hagas cambios aquí. |
|
Ubicación de almacenamiento para tus scripts de notificación definidos por el usuario. Si deseas personalizar un script estándar, cópialo de |
|
Otros script de notificación que puedes personalizar ligeramente y utilizar. |
13.2. Archivos de registro del servidor SMTP
Los archivos de registro del servidor SMTP son archivos de sistema y sus rutas absolutas se enumeran a continuación. La ubicación exacta de los archivos de registro dependerá de tu distribución de Linux.
| Ruta | Función |
|---|---|
|
Archivo de registro del servidor SMTP en Debian y Ubuntu |
|
Archivo de registro del servidor SMTP en SUSE Linux Enterprise Server (SLES) |
|
Archivo de registro del servidor SMTP en Red Hat Enterprise Linux (RHEL) |