In this article we explain the basic terms and concepts in Checkmk, such as host, service, user, contact group, notification, time period, scheduled downtime.
This is a machine translation based on the English version of the article. It might or might not have already been subject to text preparation. If you find errors, please file a GitHub issue that states the paragraph that has to be improved. |
En este artículo explicamos los términos y conceptos básicos de Checkmk, como host, servicio, usuario, grupo de contacto, notificación, periodo de tiempo, tiempo de mantenimiento programado.
1. Estados y eventos
Es importante comprender las diferencias básicas entre estados y eventos, y sobre todo por una ventaja muy práctica. La mayoría de los sistemas clásicos de monitorización informática giran en torno a eventos. Un evento es algo que ocurre de forma única en un momento determinado. Un buen ejemplo sería un error al acceder a la unidad X. Las fuentes típicas de eventos son los mensajes syslog, los traps SNMP, el registro de eventos de Windows y las entradas de archivos de registro. Los eventos son sucesos casi espontáneos (autogenerados, asíncronos).
En cambio, un estado describe una situación sostenida, por ejemplo, la unidad X está en línea. Para observar el estado de algo, el sistema de monitorización debe sondearlo periódicamente. Como muestra el ejemplo, en monitorización a menudo es posible elegir trabajar con eventos o con estados.
Checkmk puede acomodar tanto estados como eventos, pero, cuando se puede elegir, siempre dará prioridad a la monitorización basada en estados. La razón de ello radica en las numerosas ventajas que ofrece este método. Algunas de ellas son:
Un error en la propia monitorización se detecta de inmediato, porque es obvio que se nota cuando la consulta de estado deja de funcionar. La no aparición de un mensaje, en cambio, no da ninguna certeza de que la monitorización siga funcionando.
El propio Checkmk puede controlar el ritmo de sondeo de los estados, por lo que no hay riesgo de tormenta de eventos en situaciones de error global.
El check regular en un marco temporal fijo permite capturar métricas para registrar su historial temporal.
Incluso en situaciones caóticas -un fallo eléctrico en un centro de datos, por ejemplo- siempre se dispone de un estado global fiable.
Bien puede decirse que la monitorización basada en el estado de Checkmk es la norma. Para procesar eventos existe también la Consola de eventos, especializada en la correlación y evaluación de grandes cantidades de eventos y perfectamente integrada en la plataforma Checkmk.
2. Hosts y servicios
2.1. Host
Todo en Checkmk gira en torno a los host y los servicios. Un host puede ser muchas cosas, por ejemplo
Un servidor
Un dispositivo de red (conmutador, router, equilibrador de carga)
Un dispositivo de medición con conexión IP (termómetro, higrómetro)
Cualquier otra cosa con una dirección IP
Un clúster de varios hosts
Una máquina virtual
Un contenedor Docker
En la monitorización, un host siempre tiene uno de los siguientes estados:
| Estado | Color | Significado |
|---|---|---|
ARRIBA |
verde |
El host es accesible a través de la red (generalmente significa que responde a un PING). |
ABAJO |
rojo |
El host no responde a las consultas de red, no es accesible. |
UNREACH |
naranja |
La ruta al host está actualmente bloqueada para la monitorización, porque ha fallado un router o conmutador en la ruta. |
PENDIENTE |
gris |
El host ha sido recientemente incluido en la monitorización, pero nunca antes ha sido sondeado. En sentido estricto, no se trata realmente de un estado. |
Junto con el estado, un host tiene otra serie de atributos que el usuario puede configurar, por ejemplo
Un nombre único
Una dirección IP
Opcional - un alias, que no debe ser único
Opcional - uno o más padres
2.2. Padres
Para que la monitorización pueda determinar el estado UNREACH, debe saber qué ruta puede utilizar para ponerse en contacto con cada host individual. Para ello, se pueden especificar uno o más hosts denominados padres para cada host. Por ejemplo, si sólo se puede llegar a un servidor A visto desde la monitorización a través de un router B, entonces B es un host padre de A. En Checkmk sólo se configuran los padres directos. Esto da como resultado una estructura en forma de árbol con el site de Checkmk en el medio (mostrado aquí como ):
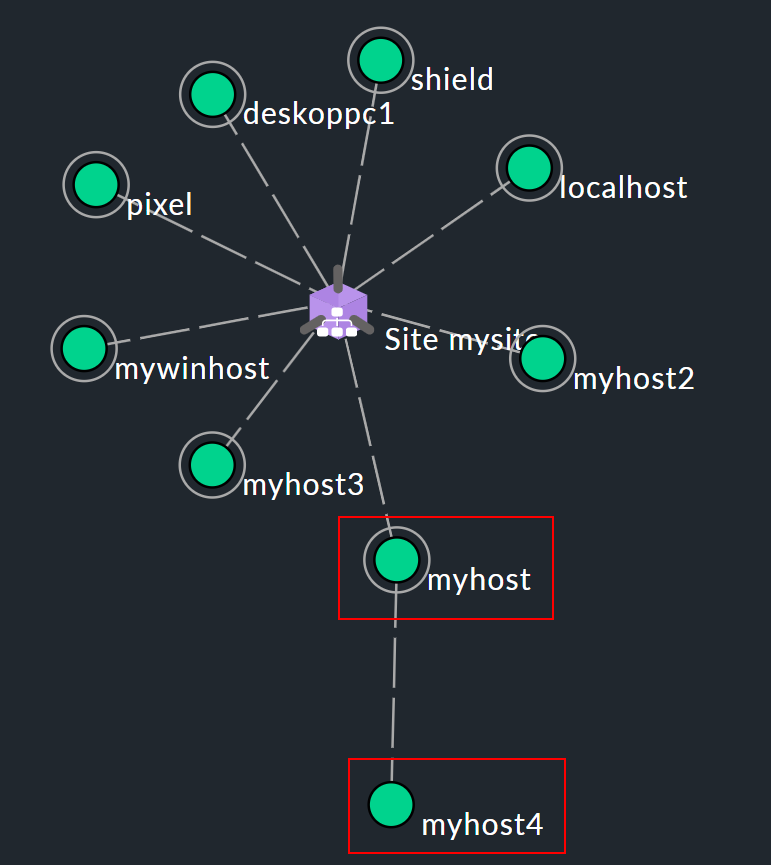
Supongamos que, en el ejemplo de topología de red mostrado anteriormente, los hosts myhost y myhost4 ya no son accesibles. El fallo de myhost4 puede explicarse por el hecho de que myhost ha fallado. Por tanto, myhost4 se clasifica como UNREACH en la monitorización. Simplemente no es posible determinar claramente por qué Checkmk ya no puede llegar a myhost4, por lo que el estado DOWN sería engañoso en algunas circunstancias. En cambio, el UNREACH tiene el efecto de suprimir las notificaciones por defecto. Al fin y al cabo, ésta es la tarea más importante del concepto de padres, es decir, evitar las notificaciones masivas en caso de que todo un segmento de red dependiente quede inalcanzable para la monitorización debido a una interrupción en un único punto.
La función Checkmk Micro Core (CMC) utilizada en las ediciones comerciales también sirve para evitar las falsas alarmas. En este caso, el cambio de estado de un host averiado se retiene unos instantes y sólo se produce cuando se tiene la certeza de que el padre aún está accesible. Si, por el contrario, el padre está definitivamente DOWN, el host pasará a UNREACH, sin que se active una notificación.
En algunos casos, un host puede tener varios padres, por ejemplo, cuando un router se ejecuta en alta disponibilidad en un clúster. Basta con que Checkmk pueda determinar de forma única el estado del host cuando uno de estos padres está alcanzable. Así, cuando un host tiene varios padres y al menos uno de ellos está UP, el host se considera alcanzable en la monitorización. En otras palabras, en tal situación, el host no pasará automáticamente al estado UNREACH.
2.3. Servicios
Un host tiene una serie de servicios. Un servicio puede ser cualquier cosa -no confundas esto con los servicios en Windows-. Un servicio es cualquier parte o aspecto del host que puede estar OK, o no OK. Naturalmente, el estado sólo puede determinarse si el host está en estado UP.
Un servicio en monitorización puede tener los siguientes estados:
| Estado | Color | Significado |
|---|---|---|
OK |
verde |
El servicio está totalmente en orden. Todos los valores están dentro de su rango permitido. |
WARN |
amarillo |
El servicio funciona normalmente, pero sus parámetros están fuera de su rango óptimo. |
CRIT |
rojo |
El servicio ha fallado. |
DESCONOCIDO |
naranja |
No se puede determinar correctamente el estado del servicio. El agente de monitorización ha entregado datos defectuosos o el elemento monitorizado ha desaparecido. |
PENDIENTE |
gris |
El servicio se ha incluido recientemente y hasta ahora no ha proporcionado datos de monitorización. |
Para determinar qué condición es "peor", Checkmk utiliza la siguiente secuencia:
OK → WARN → UNKNOWN → CRIT
2.4. Chequeos
Un check garantiza que se pueda asignar un estado a un host o a un servicio. En la sección anterior se describe qué estados pueden ser. Los servicios y los checks están estrechamente relacionados. Por eso, a veces se utilizan estos términos indistintamente, incluso en este Manual de usuario, aunque en realidad son cosas distintas.
En la Configuración puedes mostrar qué check plugin es responsable de cada servicio. Abre las propiedades de un host con Setup > Hosts y luego en el menú Hosts > Service Configuration la lista de los servicios de este host. A continuación, utiliza Display > Show plugin names para mostrar una nueva columna que mostrará el check plugin responsable de cada servicio:
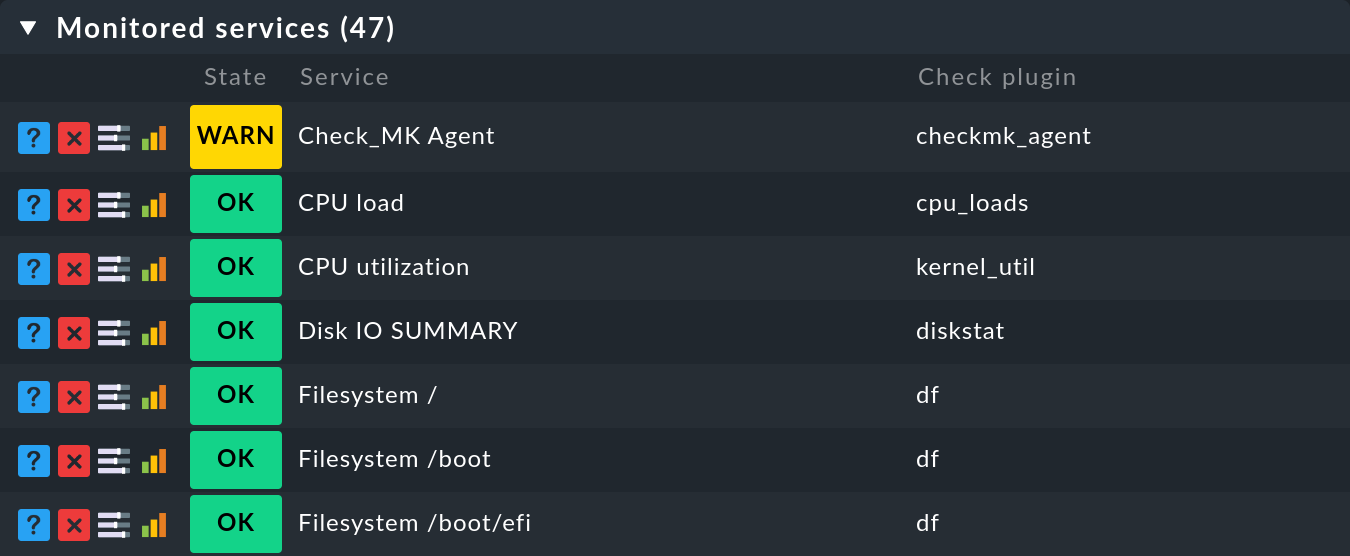
Como puedes ver en el ejemplo del plugin de comprobación df, un plugin de comprobación puede ser responsable de más de un servicio. Por cierto, los nombres de los plugins de comprobación que aparecen en la columna son también enlaces que muestran una descripción del plugin de comprobación.
La conexión y dependencia de servicios y comprobaciones también puede verse en la monitorización. En la lista de servicios de un host en monitorización, puedes ver que en el menú de acción de la entrada Reschedule, hay una flecha amarilla para algunos servicios (), pero una flecha gris para la mayoría de los demás (). Un servicio con la flecha amarilla se basa en una comprobación activa:
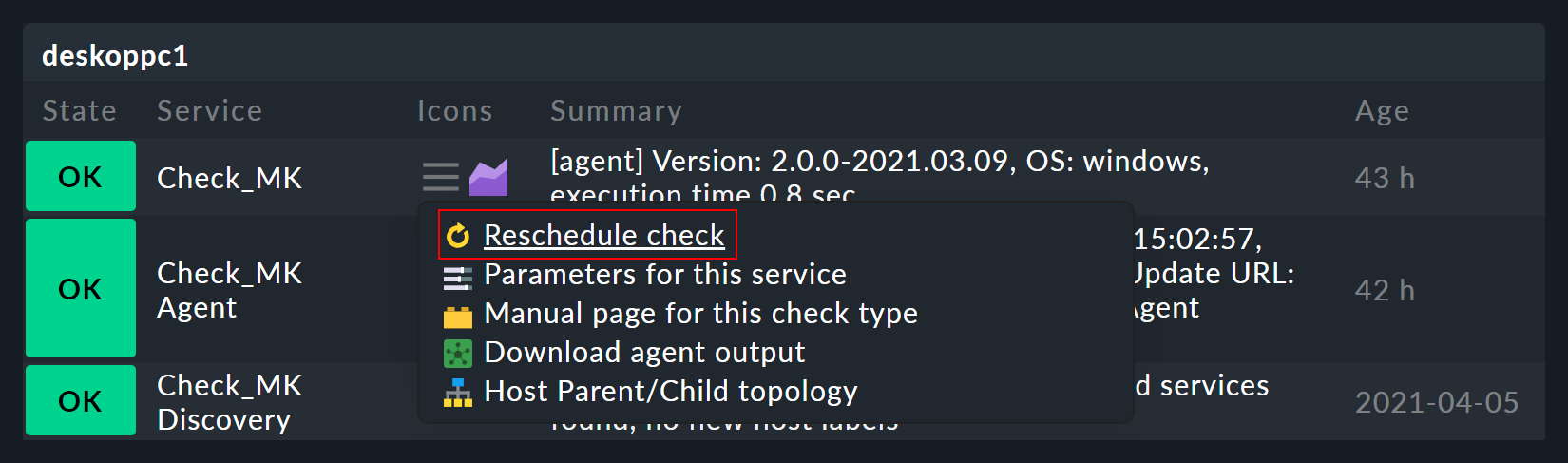
Los servicios con la flecha gris se basan en comprobaciones pasivas cuyos datos se obtienen de otro servicio, el servicio Check_MK. Esto se hace por razones de rendimiento y es una característica especial de Checkmk.
3. Grupos del host y de servicios
Para mejorar la vista general, puedes organizar los host en grupos de host y los servicios en grupos de servicios. Un host/servicio también puede estar en más de un grupo. La creación de estos grupos es opcional y no es necesaria para la configuración. Sin embargo, si por ejemplo has configurado la estructura de carpetas según ubicaciones geográficas, puede ser útil crear un grupo de host Linux servers que agrupe a todos los servidores Linux, independientemente de dónde se encuentren.
Puedes obtener más información sobre los grupos del host en el artículo sobre la estructuración de hosts y sobre los grupos de servicio en el artículo sobre servicios.
4. Contactos y grupos de contacto
Loscontactos y los grupos de contacto ofrecen la posibilidad de asignar personas a hosts y servicios. Un contacto se correlaciona con un nombre de usuario o una interfaz web. Sin embargo, la correlación con hosts y servicios no se produce directamente, sino a través de grupos de contacto.
En primer lugar, se asigna un contacto (por ejemplo, harri) a un grupo de contacto (por ejemplo, linux-admins). A continuación, se pueden asignar hosts -o, si es necesario, servicios individuales- al grupo de contacto. De este modo, los usuarios, y también los hosts y servicios, pueden asignarse a varios grupos de contacto.
Estas asignaciones son útiles por varias razones:
¿Quién está autorizado a ver algo?
¿Quién está autorizado a configurar y controlar qué host y servicios?
¿Quién recibe notificaciones y para qué problemas?
Por cierto, el usuario cmkadmin, que se define automáticamente al crear un site, siempre tiene permiso para ver todos los host y servicios, aunque cmkadmin no sea un contacto. Esto se determina a través de su función como administrador.
5. Usuarios y roles
Mientras que los contactos y los grupos de contacto controlan quién es el responsable de un host o servicio concreto, los permisos se controlan mediante roles. Checkmk se suministra con una serie de roles predefinidos a partir de los cuales puedes derivar posteriormente otros roles según necesites. Cada rol define un conjunto de permisos que luego se pueden personalizar. El significado de los roles estándar es el siguiente
| Función | Descripción |
|---|---|
|
Puede ver y hacer todo, tiene todos los permisos. |
|
Sólo puede ver aquello de lo que es contacto. Puede administrar host en carpetas asignadas a ellos. No puede hacer ajustes globales. |
|
Sólo puede registrar el agente Checkmk de un host en el servidor Checkmk, nada más. |
|
Puede verlo todo, pero no puede configurar nada ni intervenir en la monitorización. |
6. Problemas, eventos y notificaciones
6.1. Problemas tratados y no tratados
Checkmk identifica cada host que no está UP y cada servicio que no está OK como un problema. Un problema puede tener dos estados: no tratado y tratado. El procedimiento es que un problema nuevo se trata primero como no tratado. En cuanto alguien reconozca (confirme) el problema, se marcará como tratado, y no es de extrañar, los problemas no tratados son los que aún no han sido atendidos. Por tanto, la Vista general de la barra lateral diferencia estos dos tipos de problemas:
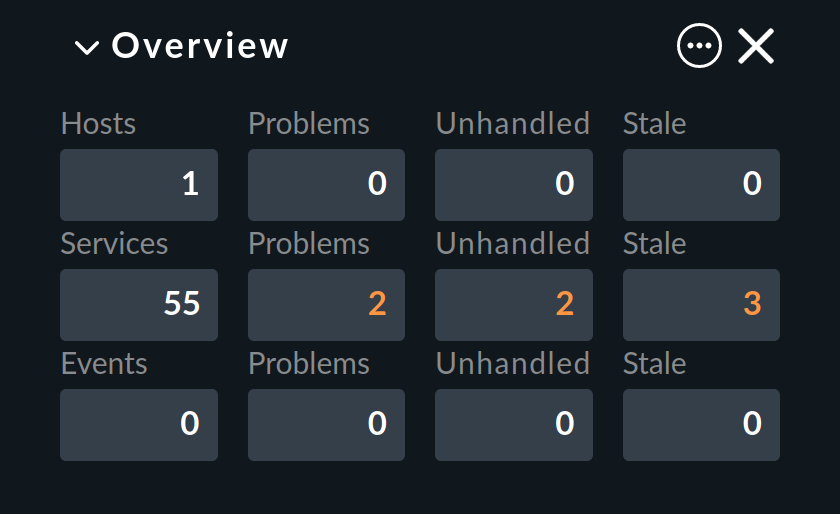
Por cierto: los problemas de servicio de host que actualmente no están UP no se identifican como problemas.
Puedes encontrar más detalles sobre los Reconocimientos en su propio artículo, Reconocer problemas.
6.2. Notificaciones
Cuando cambia el estado de un host (por ejemplo, de OK a CRIT), Checkmk registra un evento de monitorización. Estos eventos pueden generar o no una notificación. Checkmk está diseñado de tal forma que, siempre que un host o un servicio tenga un problema, se envía un correo electrónico a los contactos del objeto (ten en cuenta que el usuario de cmkadmin, por defecto, no es un contacto para ningún objeto). Sin embargo, se pueden personalizar de forma muy flexible. Las notificaciones también dependen de una serie de parámetros. Lo más sencillo es ver los casos en los que no se envían notificaciones. Las notificaciones se suprimen ...
...cuando las notificaciones se han desactivado globalmente en el Control maestro
...cuando se han desactivado las notificaciones en el host/servicio
...cuando se han desactivado las notificaciones para un estado concreto del host/servicio (por ejemplo, no hay notificaciones para WARN)
...cuando el problema afecta a un servicio cuyo host está DOWN o UNREACH
...cuando el problema afecta a un host, cuyos padres están todos DOWN o UNREACH
...cuando para el host/servicio se ha establecido un periodo de notificación que no está activo actualmente
...cuando el host/servicio está actualmente inestable
...cuando el host/servicio está actualmente en un tiempo de mantenimiento programado
Si no se cumple ninguno de estos requisitos previos para suprimir las notificaciones, el núcleo de monitorización crea una notificación, que en un segundo paso pasa por una cadena de reglas. En estas reglas puedes definir más criterios de exclusión y decidir a quién se debe notificar y de qué forma (correo electrónico, SMS, etc.).
Puedes encontrar todos los detalles sobre las notificaciones en su propio artículo sobre Notificaciones.
6.3. Host y servicios inestables
A veces ocurre que un servicio cambia de estado de forma rápida y continua. Para evitar las notificaciones continuas, Checkmk pone dicho servicio en estado inestable. Esto se ilustra con el icono Cuando un servicio entra en estado inestable, se genera una notificación que informa al usuario de la situación y silencia las notificaciones posteriores. Después de un tiempo adecuado, si no se producen más cambios rápidos y es evidente un estado final (bueno o malo), el estado inestable desaparece y se reanudan las notificaciones normales.
6.4. Tiempos de mantenimiento programados
Si realizas tareas de mantenimiento en un servidor, dispositivo o software, normalmente querrás evitar posibles notificaciones de problemas durante este tiempo. Además, probablemente querrás avisar a tus compañeros de que los problemas que aparezcan en la monitorización durante este tiempo pueden ser ignorados temporalmente.
Para ello, puedes introducir una condición de tiempos de mantenimiento programados en un host o servicio. Esto puede hacerse directamente antes de iniciar el trabajo, o con antelación. Los tiempos de mantenimiento programados se ilustran con los iconos:
El servicio está en un tiempo de mantenimiento programado. |
|
El host está en un tiempo de mantenimiento programado. Los servicios cuyo host está en un tiempo de mantenimiento programado también están marcados con este icono. |
Mientras un host o servicio tenga un tiempo de mantenimiento programado:
No se enviarán notificaciones.
Los problemas no se mostrarán en el snap-in Overview.
Además, cuando quieras documentar posteriormente estadísticas sobre la disponibilidad de host y servicios, es una buena idea incluir los tiempos de mantenimiento programados, ya que pueden tenerse en cuenta en posteriores evaluaciones de la disponibilidad.
6.5. Host y servicios obsoletos (obsoletos)
Si llevas tiempo trabajando con Checkmk, es posible que aparezcan telarañas en tus vistas de host y servicios. En el caso de los servicios, por ejemplo, tiene este aspecto:
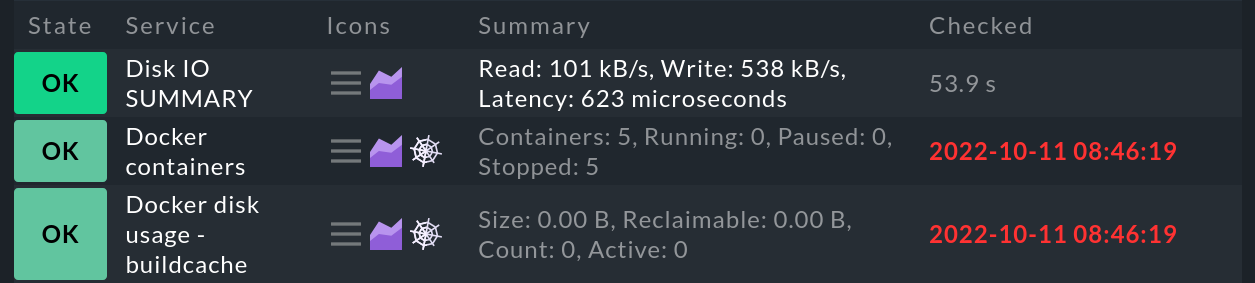
Estas telarañas simbolizan el estado obsoleto. Siempre que haya un host o un servicio obsoleto, también se mostrará en el complemento Overview snap-in, que se ampliará con la columna Stale.
Pero, ¿qué significa exactamente el estado obsoleto? En general, un host o servicio se marca como obsoleto cuando Checkmk deja de recibir información actualizada sobre su estado durante un periodo de tiempo prolongado:
Un servicio se vuelve obsoleto: Si un agente o incluso sólo un plugin de agente falla -por el motivo que sea- durante un periodo de tiempo más largo, el agente dejará de proporcionar datos actuales para su evaluación. Los servicios cuyo estado se determina mediante comprobaciones pasivas no pueden actualizarse, ya que dependen de los datos del agente. Los servicios permanecen en su último estado, pero se marcan como obsoletos una vez transcurrido cierto tiempo.
Un host se vuelve obsoleto: Si el Host Check Command, que comprueba la conectividad del host, no proporciona una respuesta actualizada, el host conserva el último estado determinado, pero entonces se marca como obsoleto.
Puedes ajustar el límite de tiempo tras el cual los host y los servicios se vuelven obsoletos. Para ello, lee la sección sobre intervalos de check.
7. Periodos de tiempo

Los periodos de tiempo recurrentes semanales se utilizan en varios lugares de la configuración. Un periodo de tiempo típico podría llamarse working hours e incluir las horas de 8:00 a 17:00 cada día, en todos los días de la semana excepto el sábado y el domingo. El periodo 24X7 está predefinido, que simplemente incluye todos los días. Los periodos de tiempo también pueden incluir excepciones para determinados días del calendario, por ejemplo, para los días festivos de Baviera.
Algunos puntos importantes en los que se utilizan periodos de tiempo son:
Limitar el periodo de notificación.
Limitación del periodo de ejecución de los checks(periodo de check).
Tiempos de servicio para calcular la disponibilidad (periodo de servicio).
Tiempos en los que surtirán efecto determinadas reglas de la Consola de eventos.
Puedes leer cómo establecer periodos en el artículo Periodos de tiempo.
8. Periodos de check, intervalos de check e intentos de check
8.1. Especificar periodos de check
Puedes restringir los periodos de tiempo en los que se ejecutan los checks. Los conjuntos de reglas Check period for hosts, Check period for active services y Check period for passive Checkmk services sirven para este propósito. Utiliza estas reglas para seleccionar uno de los periodos de tiempo disponibles como periodo de check.
8.2. Establecer intervalos de check
Las comprobaciones se ejecutan a intervalos fijos dentro de la monitorización basada en el estado. Checkmk utiliza por defecto un minuto para las comprobaciones de servicio y 6 segundos para las comprobaciones de host con un Smart Ping.
Estos valores predeterminados pueden anularse utilizando los conjuntos de reglas Normal check interval for service checks y Normal check interval for host checks:
Aumentar a un intervalo más largo para ahorrar recursos de CPU en el servidor Checkmk y en el sistema de destino.
Reducir a un intervalo más corto para recibir notificaciones más rápidamente y recoger datos de medición con mayor resolución.
Si ahora combinas un periodo de check con un intervalo de check, puedes asegurarte de que un check activo se ejecuta precisamente una vez al día a una hora muy concreta. Por ejemplo, si estableces el intervalo de check en 24 horas y el periodo de check en 2:00 a 2:01 cada día (es decir, sólo un minuto al día), Checkmk se asegurará de que el check se desplaza realmente a esta breve ventana de tiempo.
El estado de los servicios ya no se actualizará fuera de este periodo de check definido y los servicios se marcarán como obsoletos con el icono Con el ajuste global Staleness value to mark hosts / services stale puedes definir cuánto tiempo debe pasar antes de que un host/servicio pase a obsoleto. Este ajuste se encuentra en Setup > General > Global settings > User interface:
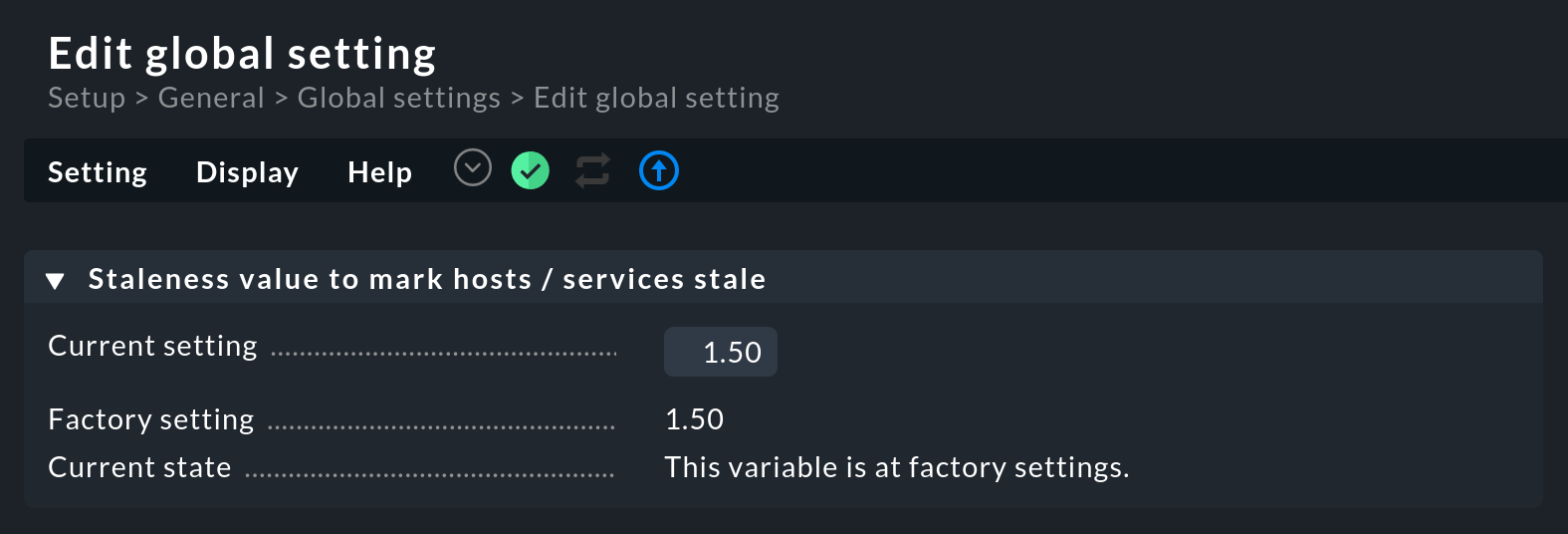
Este factor representa n veces el intervalo de chequeo. Así, si tu intervalo de chequeo está fijado en un minuto (60 segundos), un servicio para el que no haya nuevos resultados de chequeo pasará a obsoleto después de 1,5 veces el tiempo, es decir, después de 90 segundos.
8.3. Modificar los intentos de check
Con la ayuda de la opción intentos de comprobación puedes evitar notificaciones en caso de errores esporádicos. Esto hace que una comprobación sea menos sensible, por así decirlo. Para ello puedes utilizar los conjuntos de reglas Maximum number of check attempts for host y Maximum number of check attempts for service.
Si los intentos de comprobación se fijan en 3, por ejemplo, y el servicio correspondiente se convierte en CRIT, inicialmente no se activará ninguna notificación. Sólo si las dos comprobaciones siguientes también producen un resultado que no es OK, el recuento de los intentos actuales aumentará a 3 y se enviará la notificación.
Un servicio que se encuentre en este estado intermedio -es decir, que no esté OK pero que aún no haya alcanzado el número máximo de intentos de check- tendrá un soft state. Sólo un hard state activará realmente una notificación.
9. Vista general de los iconos de host y servicios más importantes
La siguiente tabla proporciona una breve vista general de los iconos más importantes que aparecen junto a los host y servicios:
Este servicio está en un tiempo de mantenimiento programado. |
|
Este host está en un tiempo de mantenimiento programado. Los servicios cuyo host está en un tiempo de mantenimiento programado también están marcados con este símbolo. |
|
Este host/servicio está actualmente fuera de su periodo de notificaciones. |
|
Las notificaciones para este host/servicio están actualmente desactivadas. |
|
Los checks de este servicio están desactivados. |
|
Este estado del host/servicio es obsoleto. |
|
Este estado del host/servicio es inestable. |
|
Este host/servicio tiene un problema reconocido. |
|
Hay un comentario para este host/servicio |
|
Este host/servicio forma parte de una Agregación BI. |
|
Aquí puedes acceder directamente a la configuración de los parámetros de check. |
|
Sólo para servicios Logwatch: aquí puedes acceder a los archivos de registro almacenados. |
|
Aquí puedes acceder a un gráfico de la serie temporal de los valores medidos. |
|
Este host/servicio tiene datos de inventario. Un clic sobre él muestra la vista de tabla relacionada. |
|
Este check se ha crasheado. Pulsa sobre él para ver y enviar un informe de fallos. |