This is a machine translation based on the English version of the article. It might or might not have already been subject to text preparation. If you find errors, please file a GitHub issue that states the paragraph that has to be improved. |
1. Características especiales del Checkmk Micro Core
En comparación con Nagios, las ventajas más significativas del CMC son su mayor rendimiento y sus tiempos de reacción más rápidos. Tiene otras ventajas interesantes que debes conocer, las más importantes de las cuales son:
Smart Ping - Chequeos inteligentes de host.
Procesos auxiliares Check helper, Checkmk Fetcher y Checkmk Checker
Programación inicial
Proceso de datos de rendimiento
Un par de funciones de Nagios no se utilizan, o se consiguen mediante un procedimiento diferente en la CMC. Los detalles al respecto los encontrarás en el artículo sobre la migración a la CMC.
2. Smart Ping - Comprobaciones inteligentes de host
Con Nagios, la disponibilidad de los hosts suele comprobarse mediante Ping. Para ello, por cada host se ejecuta una vez por intervalo (generalmente, una vez por minuto) un Plugin como check_ping o check_icmp, que envía, por ejemplo, cinco paquetes ping y espera su retorno. La creación de los procesos para ejecutar los Plugins consume valiosos recursos de la CPU. Además, éstos pueden acumularse durante bastante tiempo si no se puede acceder a un host, y hay que soportar largos timeouts.
Por el contrario, CMC ejecuta comprobaciones de host -a menos que se configure lo contrario- mediante un procedimiento llamado Smart Ping.Smart Ping se basa en un componente interno llamado icmpsender, que tiene su propia implementación de ping. Como Checkmk con CMC no depende de un binario externo, no hay necesidad de generar un nuevo proceso para cada paquete de ping enviado.
Además, el comportamiento por defecto de icmpsender difiere de su homólogo de Nagios. En lugar de múltiples paquetes en series rápidas que se esperan, icmpsender sólo envía un paquete ICMP por host cada n segundos (por defecto 6 segundos, configurable mediante el conjunto de reglas Normal check interval for host checks ). Este comportamiento reduce drásticamente el consumo de recursos y el tráfico de datos.
Las respuestas a los pings no se esperan explícitamente. El componente icmpreceiver de CMC es responsable de decidir si el estado de un host es UP o DOWN. Considera los paquetes ping entrantes de un host como un checkmark de host con éxito y, por tanto, marca el host como UP. Si no se recibe ningún paquete de un host en un tiempo definido, este host se marcará como DOWN. El timeout está preestablecido en 15 segundos (intervalos de 2,5) y puede cambiarse por host con el conjunto de reglas Settings for host checks via Smart PING.
El componente icmpreceiver también escucha los paquetes TCP SYN (sincronización) y RST (reinicio) procedentes de un host. Cuando recibe dichos paquetes, el host se considera UP. Este mecanismo puede provocar estados inestables de los hosts en infraestructuras en las que no se permite el tráfico ICMP, pero sí el TCP.
|
2.1. No hay checks de host bajo demanda
Los checks de host no sólo sirven para activar notificaciones en caso de fallo total del host, sino también para suprimir notificaciones de problemas de servicio durante el tiempo de inactividad del host. Los problemas de servicio pueden surgir y no ser responsabilidad del servicio en sí, sino de una condición de fallo del host. Puede ocurrir que un host esté realmente DOWN aunque su último estado conocido en Checkmk sea UP según el resultado del último check del host. En tal condición, múltiples checks de servicio podrían devolver problemas que dependen del estado DOWN del host, lo que daría lugar al envío de notificaciones de servicio -erróneamente-. Por eso es importante determinar primero la condición de un host, en caso de problema de servicio.
La CMC resuelve este problema de forma muy sencilla: si surge un problema de servicio y el host está en estado UP, la CMC esperará al siguiente check del host. Como el intervalo es muy corto, de sólo (por defecto) 6 segundos, sólo hay un retraso insignificante hasta la notificación -si el host sigue UP y, por tanto, hay que enviar la notificación para el servicio.
Como ejemplo, tomemos el caso de un plugin de check_http que envía un estado CRIT, debido a que un servidor web consultado no está disponible. En esta situación, tras el inicio del check plugin, el componente icmpreceiver recibirá un paquete TCP RST(conexión rechazada) de este servidor. Por tanto, la CMC sabe con certeza que el propio host está UP y, por tanto, puede enviar la notificación sin retraso.
El mismo principio se utiliza cuando se calculan las interrupciones de la red si se han definido host padres. Aquí también las notificaciones se retrasarán a veces brevemente para esperar a que se verifique el estado.
2.2. Las ventajas
Este procedimiento ofrece una serie de ventajas:
La carga de CPU resultante de la monitorización de hosts es prácticamente insignificante: incluso sin un hardware especialmente potente, se pueden monitorizar miles de hosts.
No se frustra la monitorización por atascos en las comprobaciones de host bajo demanda si los hosts están DOWN.
Sin falsas alarmas de los servicios cuando el estado de un host no es el actual.
Sin embargo, no hay que silenciar una desventaja: los checks de host Smart Ping no generan datos de rendimiento (tiempos de ejecución de paquetes).
En los host en los que sean necesarios, sólo tienes que configurar un check activo mediante ping con el conjunto de reglas Check hosts with PING (ICMP Echo Request).
2.3. Host no pingables
En la práctica, no todos los hosts se pueden comprobar mediante ping. Para estos casos, también se pueden utilizar otros métodos de CMC para el check del host, por ejemplo, una conexión TCP. Como generalmente se trata de excepciones, no tienen un impacto negativo en el rendimiento general. El conjunto de reglas aquí es Host Check Command.
2.4. Problemas con los cortafuegos
Hay cortafuegos que responden a los paquetes de conexión TCP a hosts inaccesibles con un paquete TCP RST. El truco es que no se permite al cortafuegos registrarse como remitente de este paquete, sino que debe especificarse la dirección IP del host de destino. Smart Ping verá este paquete como una señal de vida y asumirá incorrectamente que el host de destino es accesible.
En una situación así (poco frecuente), a través de Global settings > Monitoring Core > Tuning of Smart PING tienes la posibilidad de activar la opción Ignore TCP RST packets when determining host state. O bien, con check_icmp puedes seleccionar un ping convencional como un host check para los hosts afectados.
3. Procesos auxiliares
Una lección extraída del bajo rendimiento de Nagios en entornos grandes es que la creación de procesos es una operación que consume muchos recursos y tiempo. El tamaño del proceso padre es el factor decisivo en este caso. Para cada ejecución de un check activo, primero hay que duplicar(bifurcar) el proceso Nagios completo antes de sustituirlo por el nuevo proceso: el check plugin. Cuantos más host y servicios haya que monitorizar, mayor será el tamaño de este proceso y más tardará en bifurcarse. Mientras tanto, las demás tareas del núcleo deben esperar, y aquí los núcleos de 24 CPU no son de mucha ayuda.
3.1. Check helper
Para evitar la bifurcación del núcleo, durante el inicio del programa la CMC crea un número fijo de procesos auxiliares muy reducidos cuya tarea es iniciar los plugins de comprobación activos: los check helper.Estos no sólo se bifurcan mucho más rápidamente, sino que la bifurcación también se amplía para cubrir todos los núcleos disponibles, porque el propio núcleo ya no está bloqueado. De este modo, la ejecución de las comprobaciones activas (por ejemplo, check_http) -cuyos tiempos de ejecución son en realidad bastante cortos- se acelera enormemente.
3.2. Checkmk Fetcher y Checkmk Checker
Sin embargo, la CMC va un paso más allá, porque en un entorno Checkmk las comprobaciones activas son más bien una excepción. Aquí se utilizan principalmente las comprobaciones basadas en Checkmk, en las que sólo se requiere un único fork por host e intervalo.
Para optimizar la ejecución de estas comprobaciones, la CMC mantiene otros dos tipos de procesos auxiliares: los Checkmk Fetcher y los Checkmk Checker.
Los Checkmk Fetcher
recuperan la información necesaria de los host monitorizados, es decir, los datos de los servicios Check_MK y Check_MK Discovery. De este modo, los fetchers se encargan de la comunicación de red con los agentes Checkmk, los agentes SNMP y los agentes especiales. La recopilación de esta información lleva cierto tiempo, pero con menos de 50 megabytes por proceso se dispone de relativamente poca memoria, por lo que muchos de estos procesos pueden configurarse sin problemas. Ten en cuenta que los procesos pueden intercambiarse parcialmente o no intercambiarse en absoluto, por lo que deben mantenerse siempre en la memoria física. El factor limitante aquí es la memoria disponible en el servidor Checkmk.
Los 50 megabytes mencionados son una estimación para una orientación básica. El valor real puede ser mayor en circunstancias concretas, por ejemplo, porque se haya configurado IPMI en la placa de gestión. |
El Checkmk Checker
analizan y evalúan la información recogida por los Checkmk Fetcher y generan los resultados de las comprobaciones de los servicios. Los Checkmk Checker necesitan mucha memoria porque deben llevar consigo la configuración de Checkmk. Un proceso de Checkmk Checker ocupa al menos unos 90 megabytes, aunque puede ser necesario un múltiplo de esa cantidad, según cómo estén configuradas las comprobaciones. Por otra parte, los verificadores no causan ninguna carga en la red y son muy rápidos en su ejecución. El número de verificadores sólo debe ser tan grande como tu servidor Checkmk pueda procesar en paralelo. Por regla general, este número corresponde al número de núcleos de tu servidor. Como los verificadores no están ligados a la E/S, son más eficaces si cada verificador tiene su propio núcleo.
La división de las dos tareas diferentes de "recopilación" y "ejecución" entre Checkmk Fetcher y Checkmk Checker existe desde la versión 2.0.0 de Checkmk. Antes, sólo había un tipo de proceso auxiliar que se encargaba de ambas: los llamados Checkmk helper.
Con el modelo fetcher/checker, ahora ambas tareas pueden dividirse en dos grupos de procesos separados: la recuperación de información de la red con muchos procesos fetcher pequeños y la comprobación, que requiere muchos cálculos, con unos pocos procesos checker grandes. Como resultado, ¡una CMC utiliza hasta cuatro veces menos memoria con el mismo rendimiento (comprobaciones por segundo)!
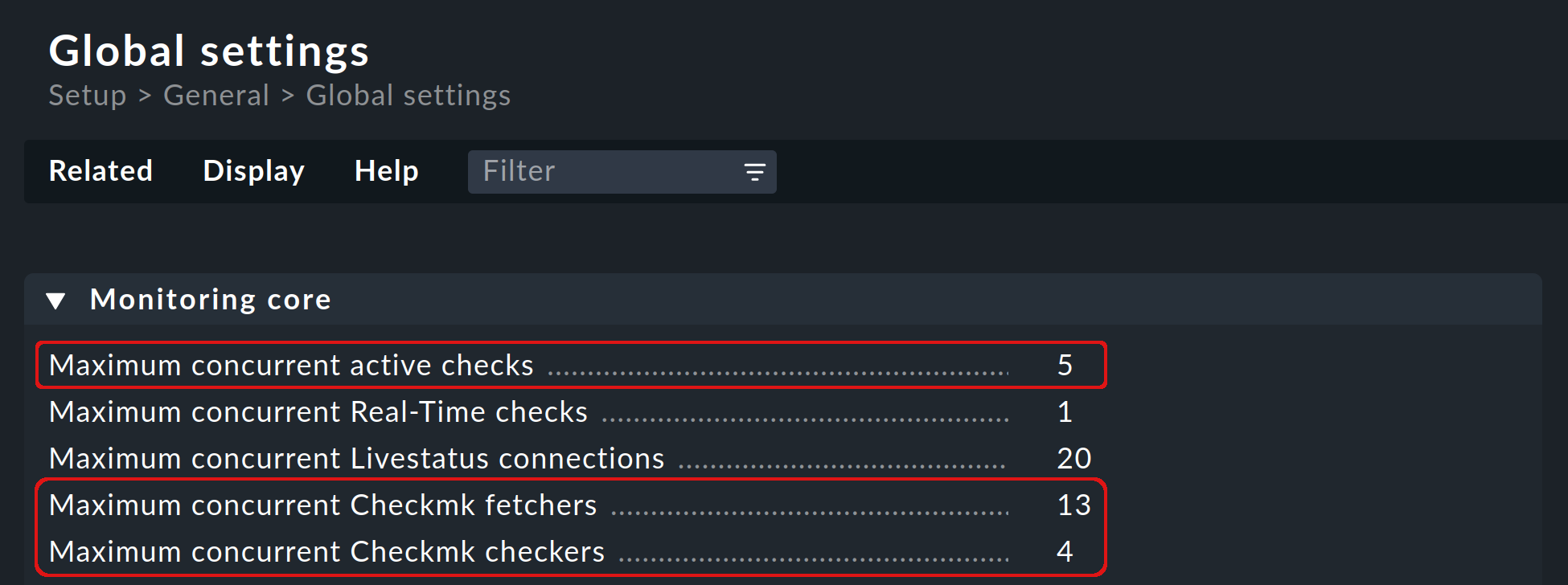
3.3. Establecer correctamente el número de procesos auxiliares
Por defecto, se inician 5 check helpers, 13 Checkmk fetcher y 4 Checkmk checker. Estos valores se configuran en Global settings > Monitoring Core y puedes personalizarlos:
Para saber si necesitas cambiar los valores por defecto y cómo hacerlo, tienes varias opciones:
En la barra lateral, el snap-in Core statistics te muestra el porcentaje de utilización promediado en los últimos 10-20 segundos:
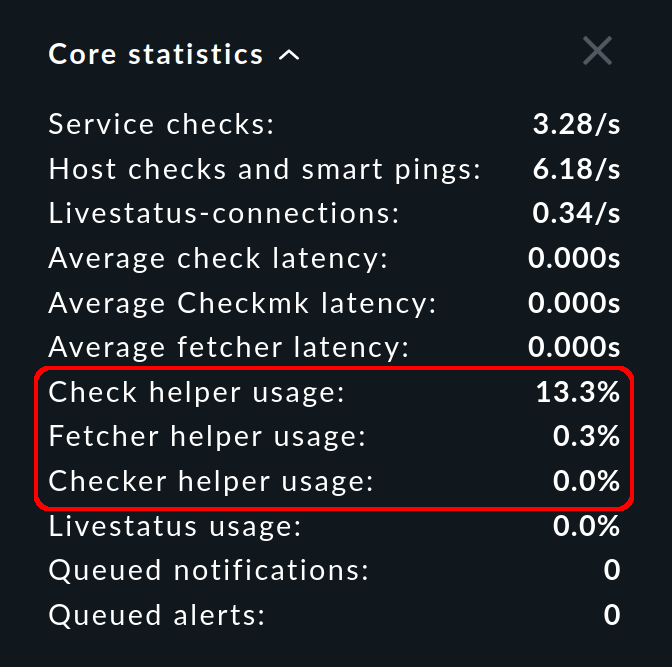
Para todos los tipos de procesos auxiliares, siempre debe haber suficientes procesos para ejecutar los checks configurados. Si un pool está siendo utilizado al 100 %, los checks no se ejecutarán a tiempo, la latencia crecerá y los estados de los servicios no estarán actualizados.
La utilización no debe superar el 80 % a los pocos minutos de iniciar un site. Para porcentajes superiores, debes aumentar el número de procesos. Dado que el número necesario de Checkmk Fetcher crece con el número de host y servicios monitorizados, lo más probable es que se trate de una corrección. Sin embargo, ten cuidado de crear sólo tantos procesos auxiliares como sean realmente necesarios, ya que cada proceso ocupa recursos. Además, todos los procesos auxiliares se inicializan en paralelo cuando se inicia la CMC, lo que puede provocar picos de carga.
El snap-in Core statistics te muestra no sólo la carga, sino también la latencia. Para estos valores, se aplica la regla simple: cuanto más bajo, mejor - y 0 segundos es, por tanto, lo mejor.
También puedes mostrar los valores mostrados en el snap-in para tu site en los detalles del servicio OMD <site_name> performance. |
Como alternativa al snap-in Core statistics, también puedes hacer que Checkmk analice tu configuración, con Setup > Maintenance > Analyze configuration. La ventaja: aquí obtienes una evaluación inmediata de Checkmk sobre cómo está el estado de los procesos auxiliares. Muy práctico es: si uno de los procesos auxiliares no está OK, puedes abrir desde el texto de ayuda la opción Global settings correspondiente para cambiar el valor.
4. Programación inicial
Durante la programación se define qué comprobaciones deben ejecutarse y a qué horas. Nagios ha implementado numerosos procedimientos que deberían garantizar que las comprobaciones se distribuyan regularmente a lo largo del intervalo. Asimismo, intentará distribuir las consultas que deben ejecutarse en un sistema de destino individual uniformemente a lo largo del intervalo.
Para ello, la CMC tiene su propio procedimiento, más sencillo, que tiene en cuenta que Checkmk ya contacta con un host una vez por intervalo. Además, la CMC se asegura de que los nuevos checks se ejecuten inmediatamente y no se distribuyan a lo largo de varios minutos. Esto es muy cómodo para el usuario, ya que se consultará a un nuevo host en cuanto se active la configuración. Para evitar que un gran número de nuevos checks provoque un pico de carga, los nuevos checks cuyo número supere un límite definible pueden distribuirse a lo largo de todo el intervalo. La opción para ello se encuentra en Global settings > Monitoring Core > Initial Scheduling.
5. Proceso de datos de rendimiento
Una función importante de Checkmk es el proceso de datos de medición, como la carga de la CPU, y su conservación durante un largo periodo de tiempo. En Checkmk Raw se utiliza para ello PNP4Nagios, que a su vez se basa en la herramienta RRDtool.
El software realiza dos funciones:
La creación y actualización de las Bases de Datos Round Robin (RRDs).
La representación gráfica de los datos en la GUI.
En una operación del núcleo de Nagios, la función mencionada en el punto 1. anterior es un proceso bastante largo. Según el método, se utilizan archivos spool, scripts de Perl y un proceso auxiliar (npcd) escrito en C. Por último, los datos ligeramente convertidos se escriben en el socket Unix del daemon de caché de RRD.
La CMC acorta esta cadena escribiendo directamente en el daemon de caché RRD: se prescinde de todos los pasos intermedios. El análisis sintáctico y la conversión de los datos al formato de la RRDtool se realizan directamente en C++. Este método es posible y sensato hoy en día, ya que el daemon de caché RRD ya ha implementado su propio spooling muy eficiente, y con la ayuda de los archivos de diario significa que no se pierden datos en caso de crash del sistema.
Las ventajas:
Reducción de la carga de E/S del disco y de la CPU
Implementación más sencilla con mucha más estabilidad
La instalación de nuevos RRD la realiza la CMC con un helper adicional, activado por cmk --create-rrd. Éste crea archivos opcionalmente compatibles con PNP, o con el nuevo formato Checkmk (sólo para nuevas instalaciones). El cambio de Nagios a CMC no afecta a los archivos RRD existentes: éstos se transferirán sin problemas y seguirán manteniéndose.
En las ediciones comerciales, la visualización gráfica de los datos en la GUI es gestionada directamente por la propia GUI de Checkmk, por lo que no interviene ningún componente de PNP4Nagios.