This is a machine translation based on the English version of the article. It might or might not have already been subject to text preparation. If you find errors, please file a GitHub issue that states the paragraph that has to be improved. |
1. Introduzione
Checkmk Business Intelligence: ammettiamolo, suona un po' pretenzioso per qualcosa che in fondo è piuttosto semplice. Questo nome, però, descrive piuttosto bene il core del modulo Business Intelligence di Checkmk. Si tratta di valutare lo stato generale delle applicazioni critiche per l'azienda sulla base dei valori raccolti dalla raccolta degli stati di molti singoli componenti in un ambiente, e di presentarli in modo chiaro.
Prendiamo ad esempio il servizio e-mail, che è ancora indispensabile per molte aziende. Questo servizio si basa sul corretto funzionamento di una varietà di componenti hardware e software — da switch specifici, ai servizi SMTP e IMAP, fino a servizi di infrastruttura come LDAP e DNS.
Il guasto di un elemento essenziale non è un problema se è stato progettato per essere ridondante. Al contrario, può verificarsi un problema in un servizio che a prima vista non ha nulla a che fare con l’e-mail, ma che in realtà può avere effetti molto più gravi. Una semplice occhiata all’elenco dei servizi in Checkmk non è sempre significativa — almeno non per tutti.
Checkmk BI ti permette di ricavare un riepilogo dello stato generale di un'applicazione dall'attuale stato dei singoli host e servizi. Le regole BI vengono utilizzate per definire — in una struttura ad albero — come i vari elementi sono interdipendenti. Lo stato generale di ciascuna applicazione può quindi essere identificato come OK, WARN o CRIT. È possibile accedere alle informazioni sulla condizione e sulle dipendenze in vari modi:
Visualizzazione dello stato complessivo di un'applicazione nella GUI.
Il calcolo della disponibilità di un'applicazione.
Notifiche in caso di eventi di problemi o addirittura di guasti di un'applicazione.
Analisi dell'impatto: un servizio è in uno stato "CRIT" — quindi quali applicazioni ne sono interessate?
Pianificazione dei tempi di manutenzione programmati e analisi "what if?".
Inoltre, c'è la possibilità di utilizzare la rappresentazione ad albero nella BI per una visualizzazione "drill down" dello stato di un host e di tutti i suoi servizi.
Una caratteristica distintiva della BI di Checkmk, a differenza di strumenti simili nel campo del monitoraggio, è che qui Checkmk lavora anche con una struttura rule-based. Questo ti permette di descrivere dinamicamente un numero indefinito di applicazioni simili con un insieme generico di regole. Ciò facilita enormemente il lavoro e aiuta a evitare errori — specialmente in ambienti molto dinamici.
2. Configurazione, parte 1: la prima aggregazione
2.1. Terminologia
Prima di iniziare passo dopo passo con l'applicazione pratica della BI, devi prima conoscere alcuni termini:
Ogni applicazione formalizzata con BI viene chiamata aggregazione BI, poiché uno stato complessivo viene aggregato da molti stati individuali.
Un'aggregazione è costruita come un "albero" di oggetti. Questi oggetti sono chiamati nodi. I nodi finali — le foglie dell'albero — sono gli host e i servizi nelle tue istanze Checkmk. I nodi rimanenti sono oggetti BI creati artificialmente.
Ogni nodo viene creato da una regola. Questo vale anche per le radici dell'albero — il nodo di livello superiore. Queste regole determinano quali nodi sono in connessione con un altro nodo e come, a partire dai loro stati, si debba determinare lo stato dei nodi superiori.
Anche il nodo principale di un’aggregazione — la radice dell’albero — viene generato da una regola. In questo modo una regola può generare più aggregazioni.
2.2. Un esempio
Il modo più semplice per capirlo è usare un esempio concreto.
Abbiamo creato l'applicazione Mystery appositamente come dimostrazione per questo articolo.
Supponiamo che si tratti di un'applicazione importante in un'organizzazione non specificata.
Tra le altre cose, cinque server e due switch di rete svolgono ruoli importanti.
Per aiutarti a capire meglio il nostro esempio, useremo nomi semplici come srv-mys-1 o switch-1.
Il diagramma seguente offre una semplice panoramica della struttura:
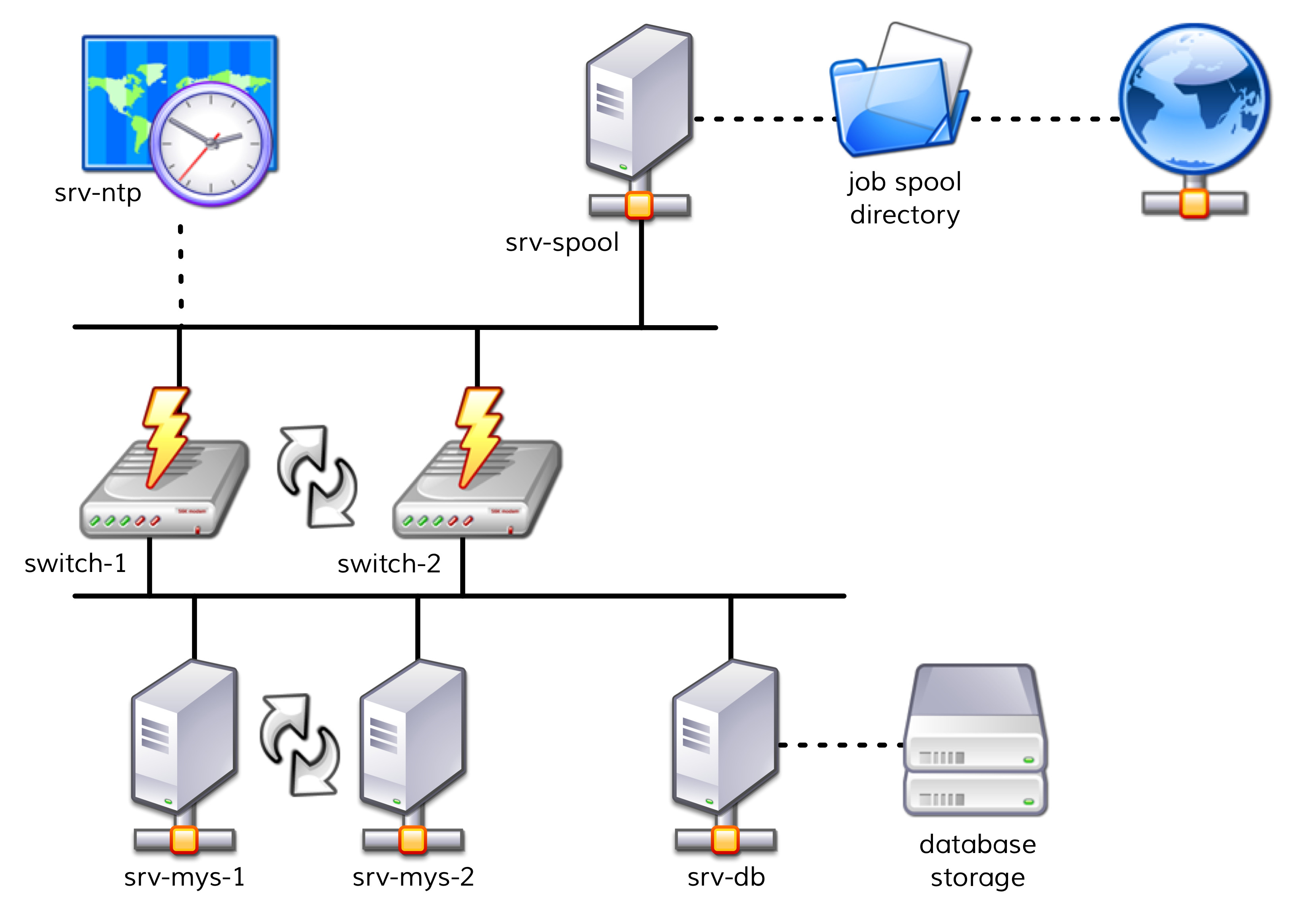
I due server,
srv-mys-1esrv-mys-2, formano un cluster ridondante su cui gira l'applicazione vera e propria.srv-dbè un server di database che memorizza i dati dell'applicazione.switch-1eswitch-2sono due router ridondanti che forniscono la connessione tra la rete dei server e una rete di livello superiore.In ogni router c'è un timer
srv-ntpche garantisce un tempo perfettamente sincronizzato.Inoltre, il server
srv-spoolopera qui e trasferisce i risultati calcolati dall'applicazione misteriosa in una directory di spool.Dalla directory di spool i dati vengono prelevati da un misterioso servizio padre.
Se vuoi seguire i passaggi seguenti uno per uno, puoi semplicemente replicare gli oggetti di monitoraggio come mostrato nel nostro esempio. Per un test è sufficiente clonare più volte un host esistente e denominare i cloni di conseguenza. In seguito ci saranno alcuni servizi da aggiungere al gioco, per i quali avrai poi tempo di aggiungere gli host corrispondenti al monitoraggio. Anche lì puoi barare di nuovo: con semplici check locali otterrai rapidamente servizi che corrispondono con cui giocare.
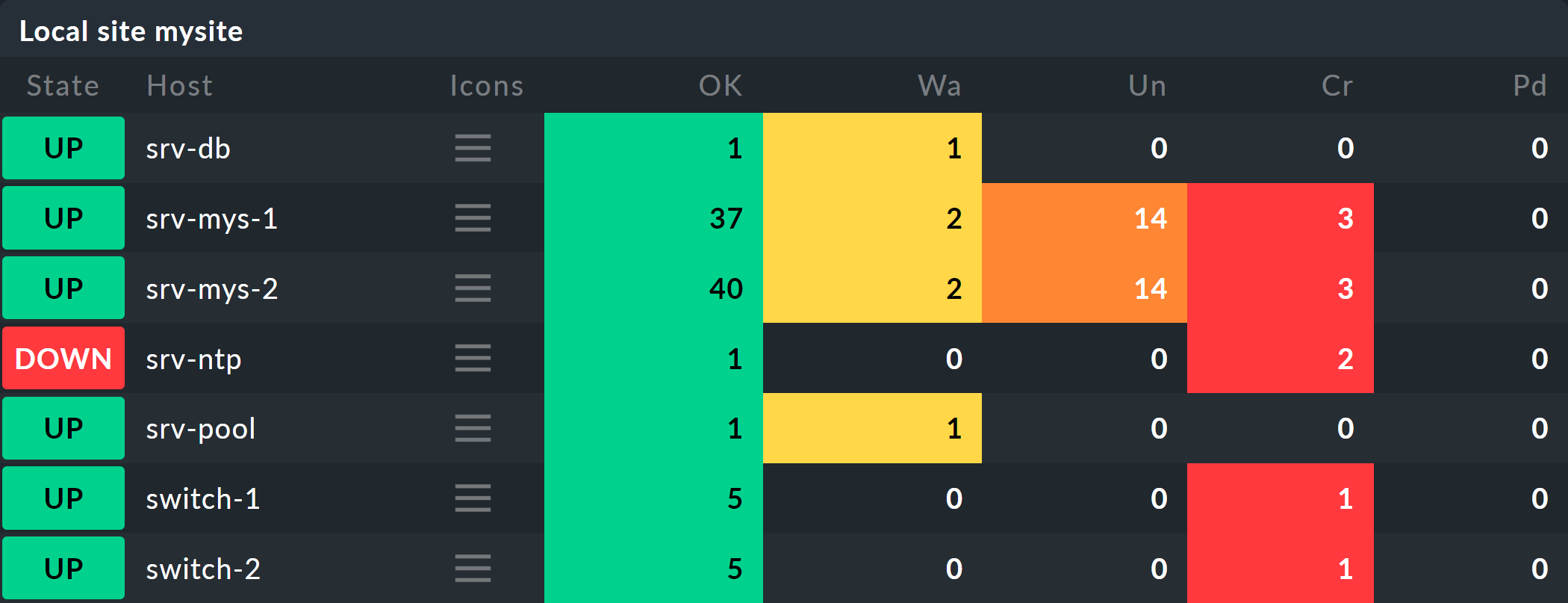
Gli host appariranno quindi più o meno così nel monitoraggio:
2.3. La tua prima regola BI
Inizia con qualcosa di semplice — con l'aggregazione significativa più semplice possibile — un'aggregazione con solo due nodi.
Vuoi quindi riassumere gli stati degli host switch-1 e switch-2.
L'aggregazione dovrebbe chiamarsi Network e dovrebbe essere OK quando entrambi gli switch sono disponibili.
In caso di guasto parziale, lo stato dovrebbe passare a WARN, e se entrambi gli switch sono spenti, CRIT.
Per iniziare: configura BI tramite Setup > Business Intelligence > Business Intelligence. La configurazione delle regole e delle aggregazioni BI viene eseguita all’interno dei pacchetti di configurazione, i pacchetti BI. Questi pacchetti non sono solo pratici perché ti permettono di gestire meglio configurazioni più complesse, ma puoi anche applicare permessi a un pacchetto e assegnare determinati gruppi di contatti, e persino consentire agli utenti senza diritti di amministratore di modificare parti della configurazione. Ma ne parleremo più avanti…
La prima volta che chiami il modulo BI dovrebbe apparire qualcosa del genere:

È già presente un pacchetto intitolato Default Pack. Questo contiene una demo per un'aggregazione che riassume i dati di un singolo host.
Per questo esempio è meglio creare un nuovo pacchetto — con il pulsante “Add BI Pack” — che chiamerai “Mystery”.
Come sempre in Checkmk, specifica un ID interno (mystery) che non potrà essere modificato in seguito, e un titolo descrittivo.
L’opzione “Public” è necessaria agli altri utenti se in questo pacchetto ci sono regole che vogliono utilizzare per le loro regole o aggregazioni.
Dato che probabilmente vorrai fare i tuoi esperimenti da solo in tutta tranquillità, lascia questa opzione disabilitata:
Dopo la creazione troverai ovviamente due pacchetti nell'elenco principale:

Accanto a ogni voce c'è un simbolo (![]() ) per modificare le proprietà,
e un simbolo per aprire il contenuto effettivo del pacchetto (
) per modificare le proprietà,
e un simbolo per aprire il contenuto effettivo del pacchetto (![]() ), che è dove vuoi andare ora.
Una volta lì, crea subito la tua prima regola tramite Add rule.
), che è dove vuoi andare ora.
Una volta lì, crea subito la tua prima regola tramite Add rule.
Come sempre in Checkmk, anche questa regola deve avere un ID univoco e un titolo. Il titolo della regola non ha solo una funzione di documentazione, ma in seguito sarà visibile anche come nome del nodo che verrà creato da questa regola:
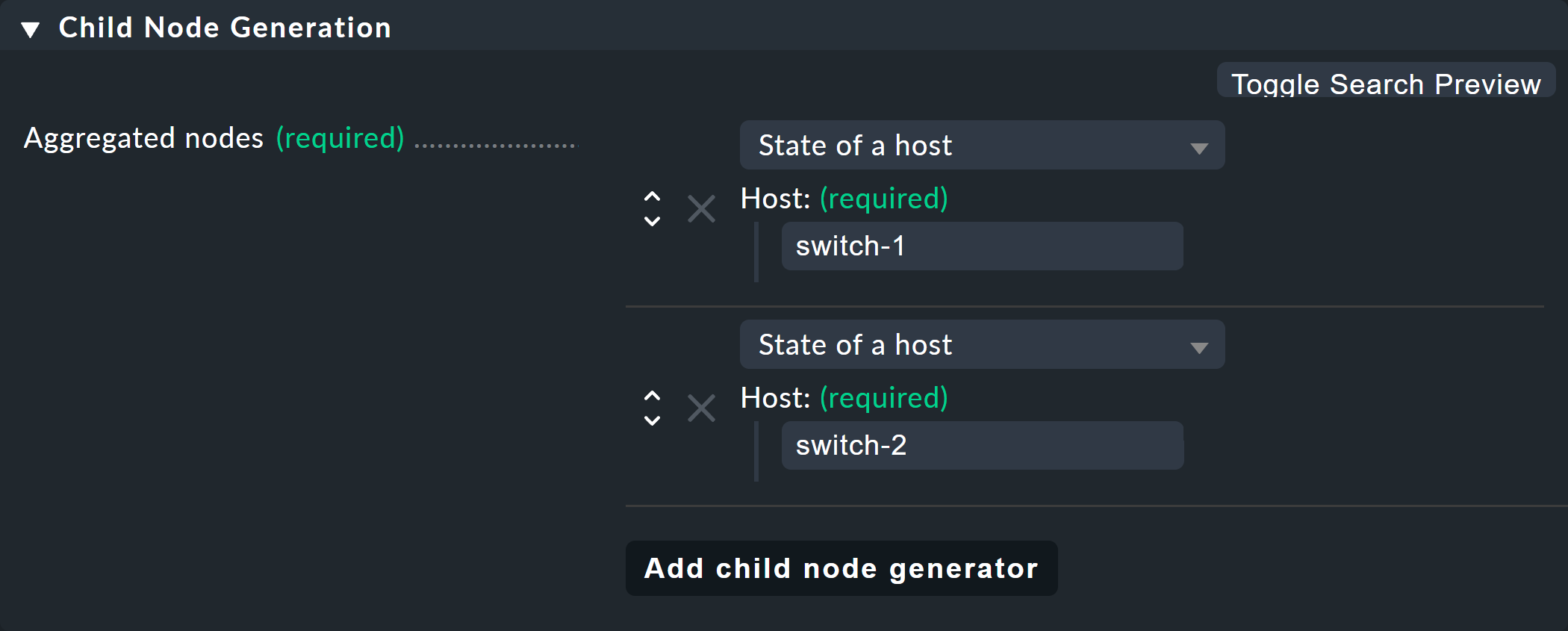
La box successiva si chiama Child Node Generation ed è la più importante. Qui specifichi quali oggetti in questo nodo devono essere riepilogati. Può trattarsi di altri nodi BI — per i quali sceglieresti una regola BI diversa — oppure di oggetti sottoposti a monitoraggio, ovvero host o servizi.
Per il primo esempio seleziona la seconda variante (State of a host) e crea due oggetti come figli, ovvero i due host switch-1 e switch-2.
Questo si fa con il pulsante Add child node generator.
Qui ovviamente scegli State of a host e inserisci un nome per ogni host:
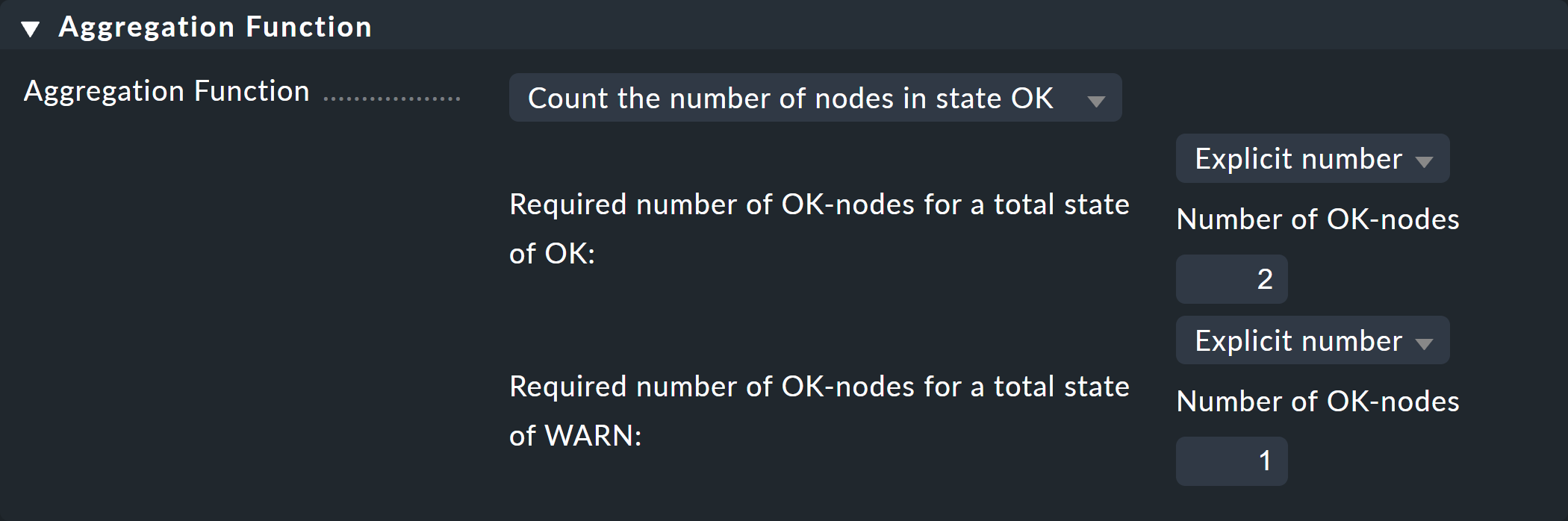
Nella terza e ultima box, Aggregation Function, specifichi come deve essere calcolato lo stato di monitoraggio del nodo. La base per questo è sempre l'elenco degli stati dei sottonodi. Sono possibili vari collegamenti logici.
L'impostazione predefinita è Best — take the best of all node states. Ciò significa che il nodo diventa CRIT quando tutti i sottonodi sono CRIT o DOWN. Come accennato sopra, in questo caso non dovrebbe essere così. Scegli invece Count the number of nodes in state OK per utilizzare come parametro di riferimento il numero di sottonodi con stato OK. Qui vengono suggeriti i numeri 2 e 1 come thresholds. Questo è ottimo perché è esattamente ciò di cui hai bisogno:
Se entrambi i switch sono UP (questo viene considerato come OK), anche il nodo dovrebbe essere OK.
Se solo uno dei switch è UP, lo stato diventa WARN.
E quando entrambi i switch sono DOWN, lo stato diventa CRIT.
Ecco come apparirà il modulo una volta compilato:
Con un clic su Create avrai la tua prima regola:

2.4. La tua prima aggregazione
Nota: è importante capire che una regola non è ancora un'aggregazione.
Checkmk non può ancora sapere se si tratta di tutto o solo di una parte di un albero più grande.
I veri oggetti BI verranno creati e diventeranno visibili nell'interfaccia di stato solo quando creerai un'aggregazione BI.
Per farlo, switch all'elenco delle aggregazioni BI "![]() ".
".
Il pulsante "![]() " ti porta a un modulo per creare una nuova aggregazione.
Qui c'è poco da compilare.
Nel campo "Aggregation groups" puoi specificare qualsiasi nome a tua scelta.
Questi nomi appariranno poi nell'interfaccia di stato come gruppi, sotto i quali saranno visibili tutte le aggregazioni che condividono quel nome di gruppo.
In realtà si tratta dello stesso concetto degli hashtag o delle keyword.
Puoi anche assegnare liberamente l'Aggregation ID come al solito, ma non potrai cambiarlo in seguito.
" ti porta a un modulo per creare una nuova aggregazione.
Qui c'è poco da compilare.
Nel campo "Aggregation groups" puoi specificare qualsiasi nome a tua scelta.
Questi nomi appariranno poi nell'interfaccia di stato come gruppi, sotto i quali saranno visibili tutte le aggregazioni che condividono quel nome di gruppo.
In realtà si tratta dello stesso concetto degli hashtag o delle keyword.
Puoi anche assegnare liberamente l'Aggregation ID come al solito, ma non potrai cambiarlo in seguito.
Definisci il contenuto dell'aggregazione tramite Add new element. Seleziona l'impostazione Call a rule e in Rule: la regola che hai appena creato (e prima del pacchetto di regole in cui si trova).
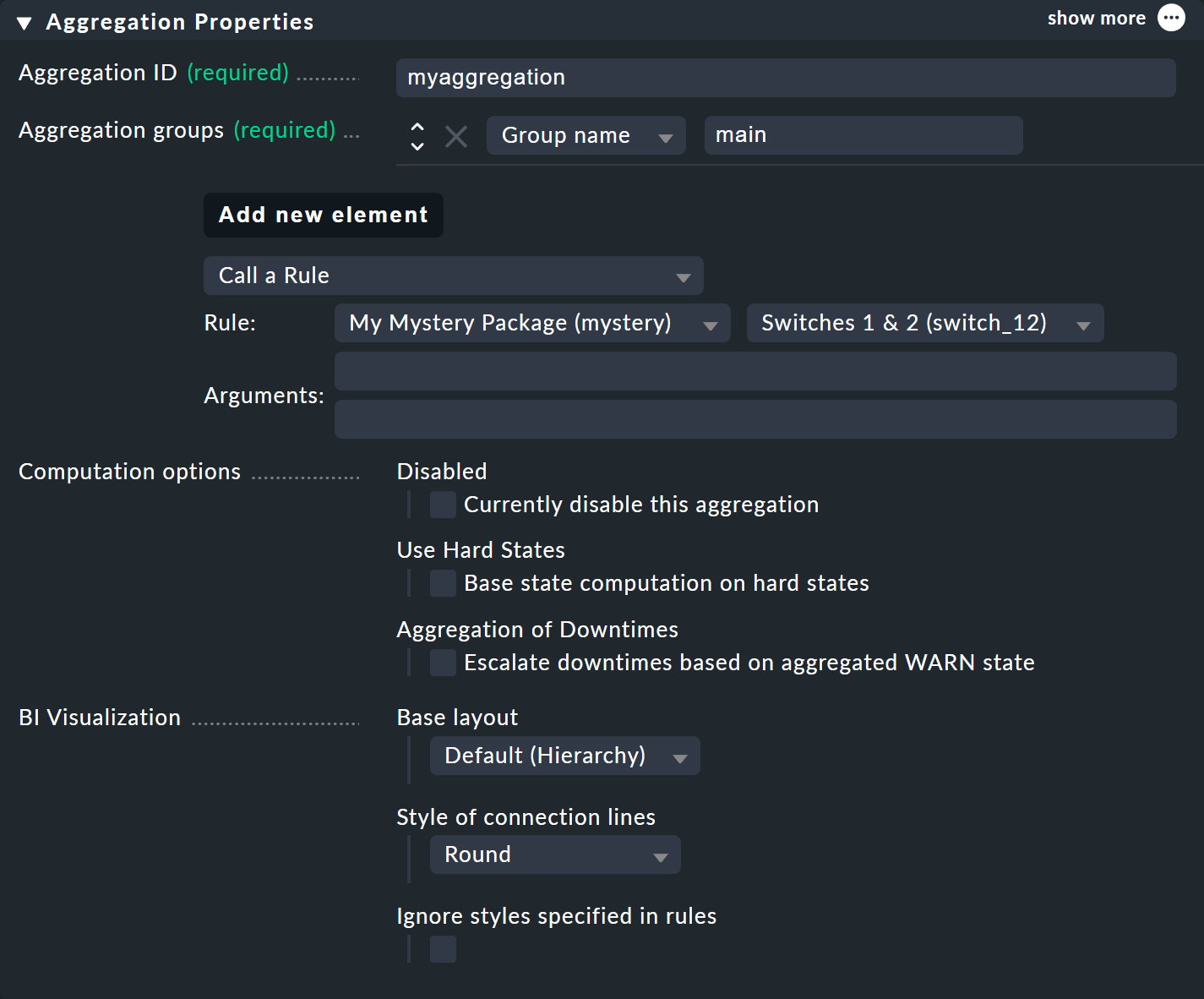
Se ora salvi l'aggregazione con "![]() ", il gioco è fatto!
La tua prima aggregazione dovrebbe ora apparire nell'interfaccia di stato, ammesso che tu disponga effettivamente di almeno uno degli host,
", il gioco è fatto!
La tua prima aggregazione dovrebbe ora apparire nell'interfaccia di stato, ammesso che tu disponga effettivamente di almeno uno degli host, switch-1 o switch-2.
3. La BI in azione – Parte 1: l'interfaccia di stato
3.1. Visualizzazione di tutte le aggregazioni
Se hai fatto tutto correttamente, ora dovresti vedere la tua prima aggregazione nell'interfaccia di stato. Il modo più semplice per farlo è tramite Monitor > Business Intelligence > All Aggregations:

Creazione di visualizzazioni per la BI
Oltre alle visualizzazioni BI già pronte, puoi anche crearne di personalizzate. Per farlo, seleziona una delle sorgenti dati BI quando crei una nuova visualizzazione. BI Aggregations fornisce informazioni sulle aggregazioni BI, BI Hostname Aggregations aggiunge filtri e informazioni per singoli host, BI Aggregations affected by one host mostra solo le aggregazioni relative a un singolo host e BI Aggregations for Hosts by Hostgroups ti permette di distinguere tra gruppi di host.
3.2. Utilizzo dell'albero
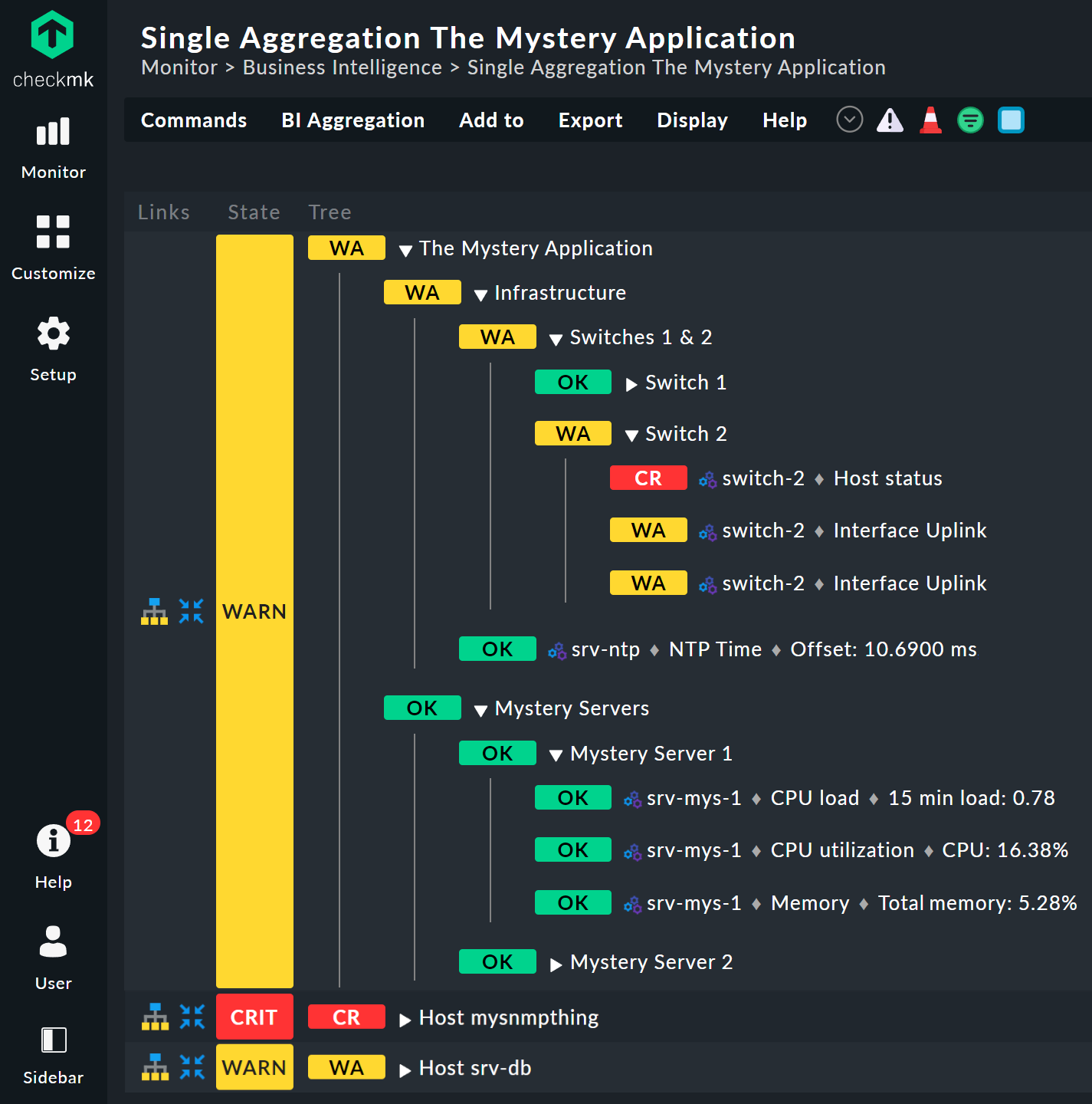
Dai un'occhiata più da vicino all'aspetto dell'albero BI. L'esempio seguente mostra la tua mini-aggregazione in una situazione in cui uno dei due switch è DOWN e l'altro UP. Come desiderato, l'aggregazione entra nello stato WARN:

Puoi anche notare che, per standardizzare host e servizi, l'host che è DOWN viene trattato quasi come un servizio che è CRIT. Allo stesso modo, UP diventa di conseguenza OK.
Le foglie dell'albero mostrano gli stati degli host e dei servizi. Il nome host — e per i servizi anche il nome del servizio — è cliccabile e ti porta allo stato attuale dell'oggetto corrispondente. Inoltre, puoi anche vedere l'ultimo output del plug-in di controllo.
A sinistra di ogni aggregazione troverai due simboli: ![]() e
e ![]() .
Con il primo simbolo —
.
Con il primo simbolo — ![]() — si arriva a una pagina che mostra solo quella singola aggregazione.
Questo è naturalmente utile soprattutto se hai creato più di un’aggregazione.
È, ad esempio, perfetto come segnalibro.
— si arriva a una pagina che mostra solo quella singola aggregazione.
Questo è naturalmente utile soprattutto se hai creato più di un’aggregazione.
È, ad esempio, perfetto come segnalibro.
![]() ti porterà al calcolo della disponibilità.
Ne parleremo più avanti.
ti porterà al calcolo della disponibilità.
Ne parleremo più avanti.
3.3. Prova la BI: e se...?
A sinistra del nome host troverai un simbolo interessante: ![]() .
Questa consente un'analisi "what if?".
L'idea alla base è semplice:
facendo clic sul simbolo, l'oggetto switcherà a un altro stato a titolo di test — ma solo per l'interfaccia BI — non nella realtà!
Cliccando più volte passerai da
.
Questa consente un'analisi "what if?".
L'idea alla base è semplice:
facendo clic sul simbolo, l'oggetto switcherà a un altro stato a titolo di test — ma solo per l'interfaccia BI — non nella realtà!
Cliccando più volte passerai da ![]() (OK) a
(OK) a ![]() (WARN),
(WARN), ![]() (CRIT) e
(CRIT) e ![]() (SCONOSCIUTO) per poi tornare a
(SCONOSCIUTO) per poi tornare a ![]() .
.
BI costruisce quindi l'albero completo in base allo stato ipotizzato.
Il grafico seguente mostra l'aggregazione minima partendo dal presupposto che, oltre a switch-1 che ha effettivamente fallito, anche switch-2 sia DOWN:

Lo stato complessivo dell'aggregazione passa quindi da WARN a CRIT. Allo stesso tempo, il colore dello stato è accompagnato da un motivo a quadretti. Questo motivo ti indica che lo stato reale è in realtà diverso. Non è sempre così, perché alcune modifiche in un host o in un servizio non sono più rilevanti per la condizione complessiva — ad esempio, se quello in questione è già CRIT.
Puoi utilizzare questa analisi "what if?" in diversi modi, ad esempio:
Per verificare se l'aggregazione BI reagisce nel modo desiderato.
Quando si pianifica di spegnere un componente per manutenzione.
In quest'ultimo scenario, come test imposti il dispositivo da sottoporre a manutenzione o i suoi servizi su "![]() ".
Se l'intera aggregazione rimane quindi "OK", significa che il guasto può essere attualmente compensato dalla ridondanza.
".
Se l'intera aggregazione rimane quindi "OK", significa che il guasto può essere attualmente compensato dalla ridondanza.
3.4. Testare la BI utilizzando stati fittizi
C'è un altro modo per testare le aggregazioni BI: modificando direttamente lo stato effettivo di un oggetto. Questo è particolarmente pratico in un sistema di test.
A questo scopo, i comandi dispongono di un comando host/servizio denominato Fake check results.
Per impostazione predefinita, questo è disponibile solo per il ruolo di Amministratore.
Questo metodo è stato utilizzato, ad esempio, per la creazione degli screenshot utilizzati in questo articolo, dove switch-1 è stato impostato su DOWN.
Da qui deriva il testo rivelatore Manually set to Down by cmkadmin.

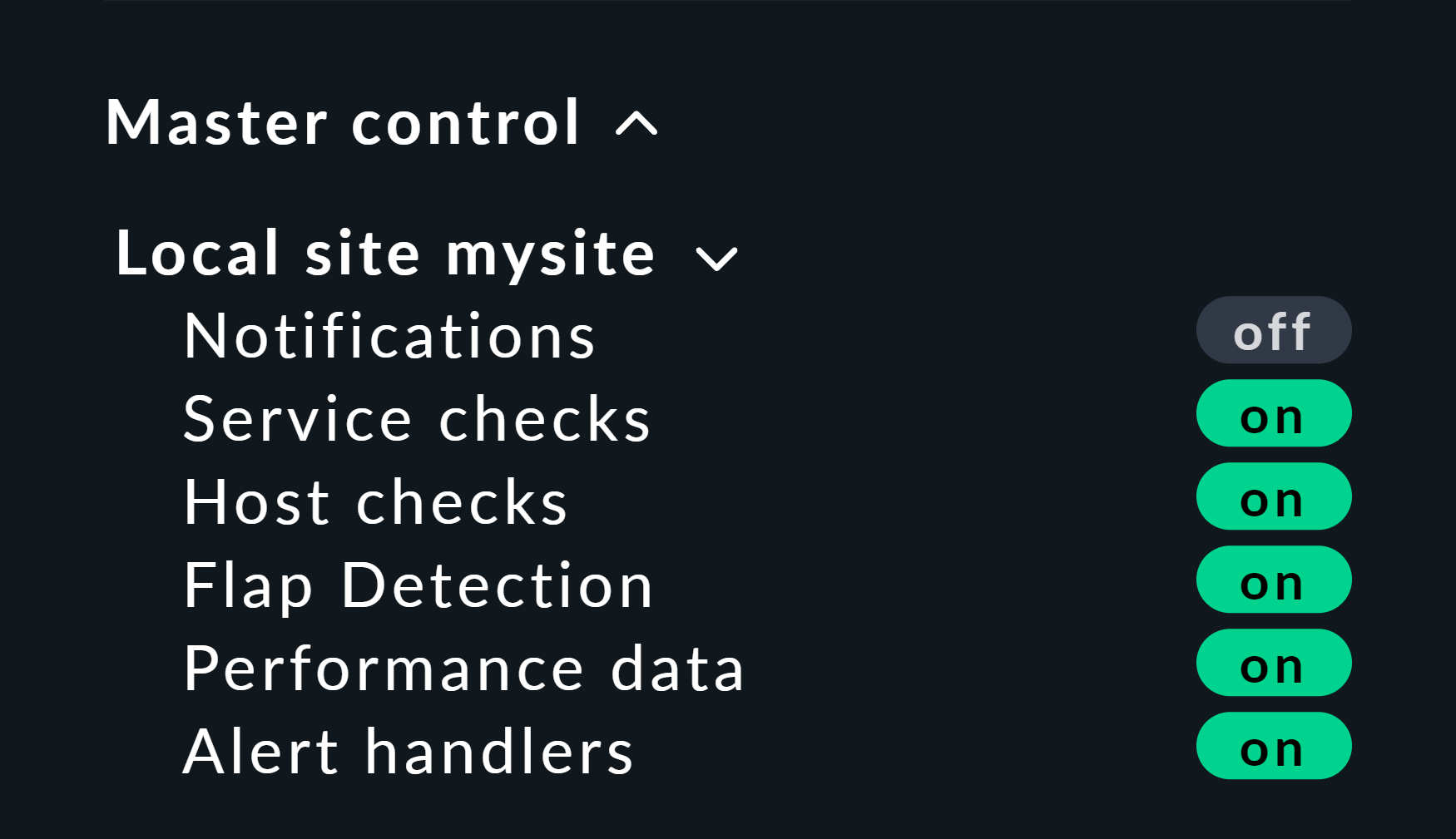
Ecco un piccolo suggerimento utile: Se lavori con questo metodo, è meglio disabilitare gli active checks per gli host e i servizi interessati, altrimenti al prossimo intervallo di controllo torneranno immediatamente al loro stato effettivo. Se sei pigro, fallo semplicemente a livello globale tramite lo snap-in Master Control. Ma non dimenticare mai di riattivarlo dopo!
3.5. Gruppi BI
Durante la creazione dell'aggregazione abbiamo accennato brevemente alle possibilità disponibili per l'input Aggregation Groups. Nell'esempio hai semplicemente confermato l'Maine suggerita qui. Ovviamente sei completamente libero nell'assegnazione dei nomi e puoi anche assegnare un'aggregazione a più gruppi.
I gruppi diventano importanti quando il numero di aggregazioni supera quello che vuoi visualizzare su uno schermo. Puoi accedere a un gruppo cliccando su uno dei nomi dei gruppi visualizzati nella pagina "All aggregations" — nel nostro esempio sopra, semplicemente sull'intestazione "Main". Ovviamente, se finora hai solo questa singola aggregazione, non cambierà molto. Tuttavia, se guardi attentamente, ti accorgerai che:
Il titolo della pagina ora è Aggregation group Main.
L'intestazione del gruppo Main è scomparsa.
Se vuoi visitare questa visualizzazione più spesso, basta aggiungerla ai preferiti — preferibilmente con l'elemento Bookmarks nella barra laterale.
3.6. Da host/servizio ad aggregazione
Una volta configurate le aggregazioni BI, nel menu contestuale dei tuoi host e servizi troverai un nuovo simbolo "![]() ":
":
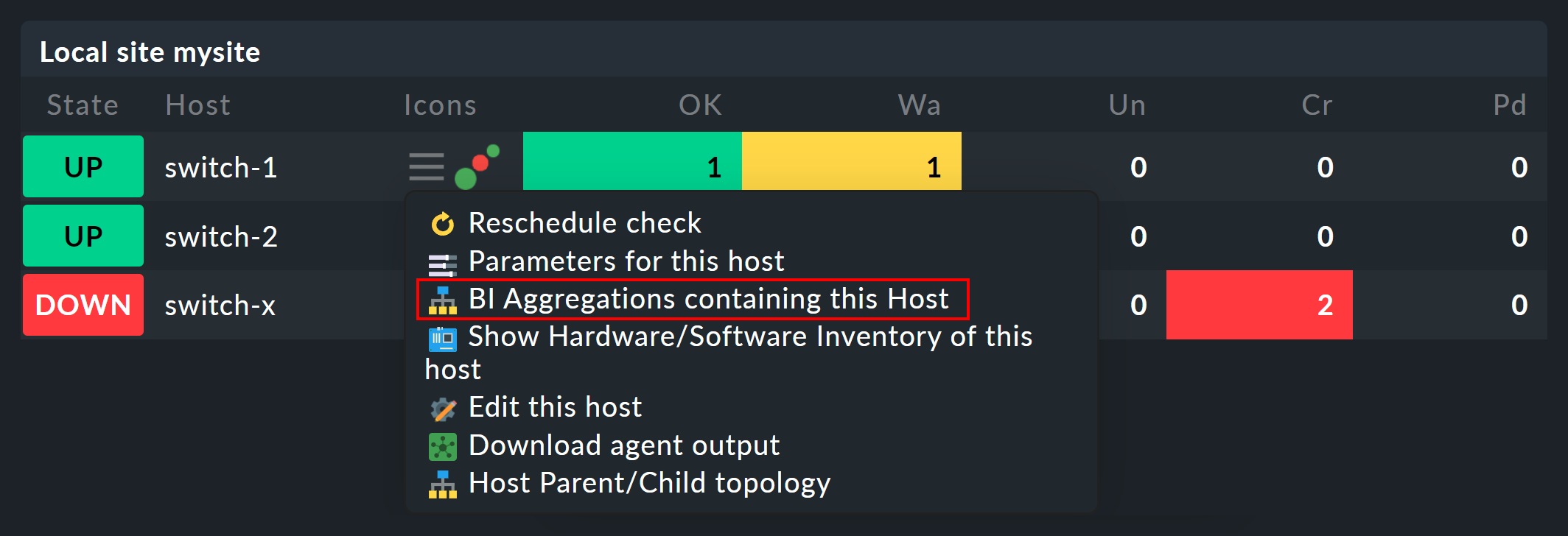
Questo simbolo ti porta all'elenco di tutte le aggregazioni in cui è incluso l'host o il servizio in questione.
4. Configurazione, parte 2: alberi a più livelli di livello
Dopo questa prima breve panoramica dell'interfaccia di stato BI, torniamo alla configurazione — perché ovviamente non puoi davvero impressionare nessuno con un'aggregazione BI così ridotta.
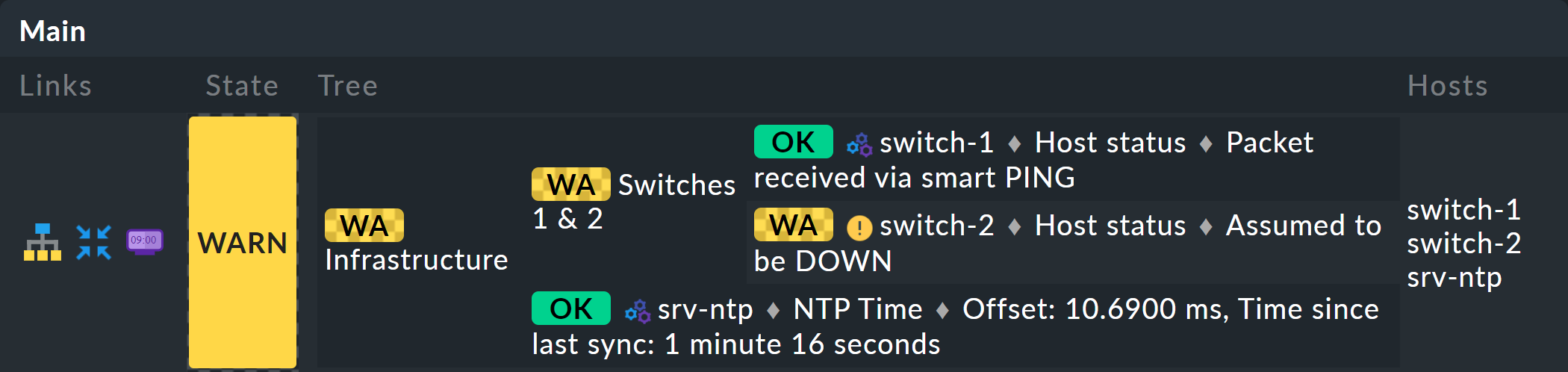
Si inizia estendendo l'albero di un livello, cioè da due livelli (radice e foglie) a tre livelli (radice, livello intermedio, foglie). Per farlo, combina il nodo esistente "Switches 1 & 2" con lo stato di sincronizzazione temporale NTP in un nodo di primo livello "Infrastruttura".
Ma una cosa alla volta: prima di tutto, un'anteprima del risultato:
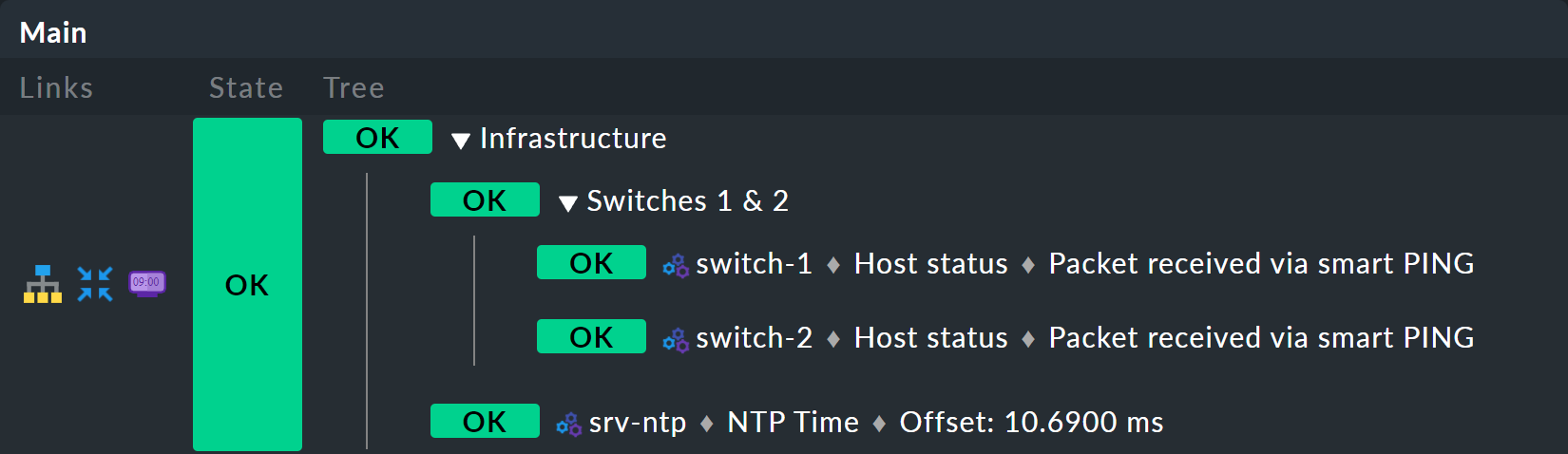
Il prerequisito è che esista un host srv-ntp che abbia un servizio denominato NTP Time:

Per prima cosa crea una regola BI che come sottonodo 1 riceva la regola "Switches 1 & 2" e come sottonodo 2 riceva direttamente il servizio NTP Time nell'host srv-ntp.
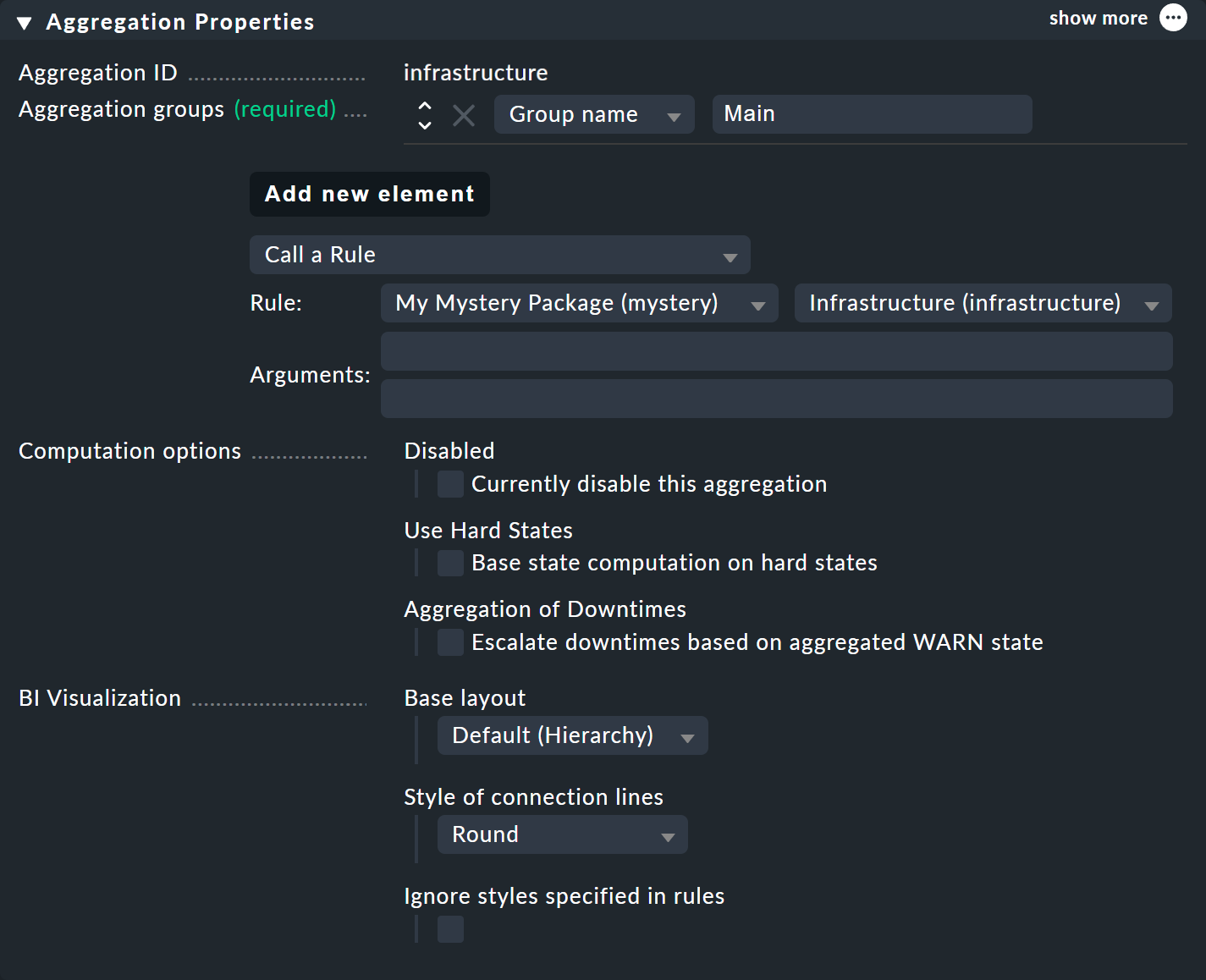
In cima alla regola, seleziona infrastructure come ID della regola e Infrastructure come nome.
A questo punto non è necessario inserire altre informazioni:
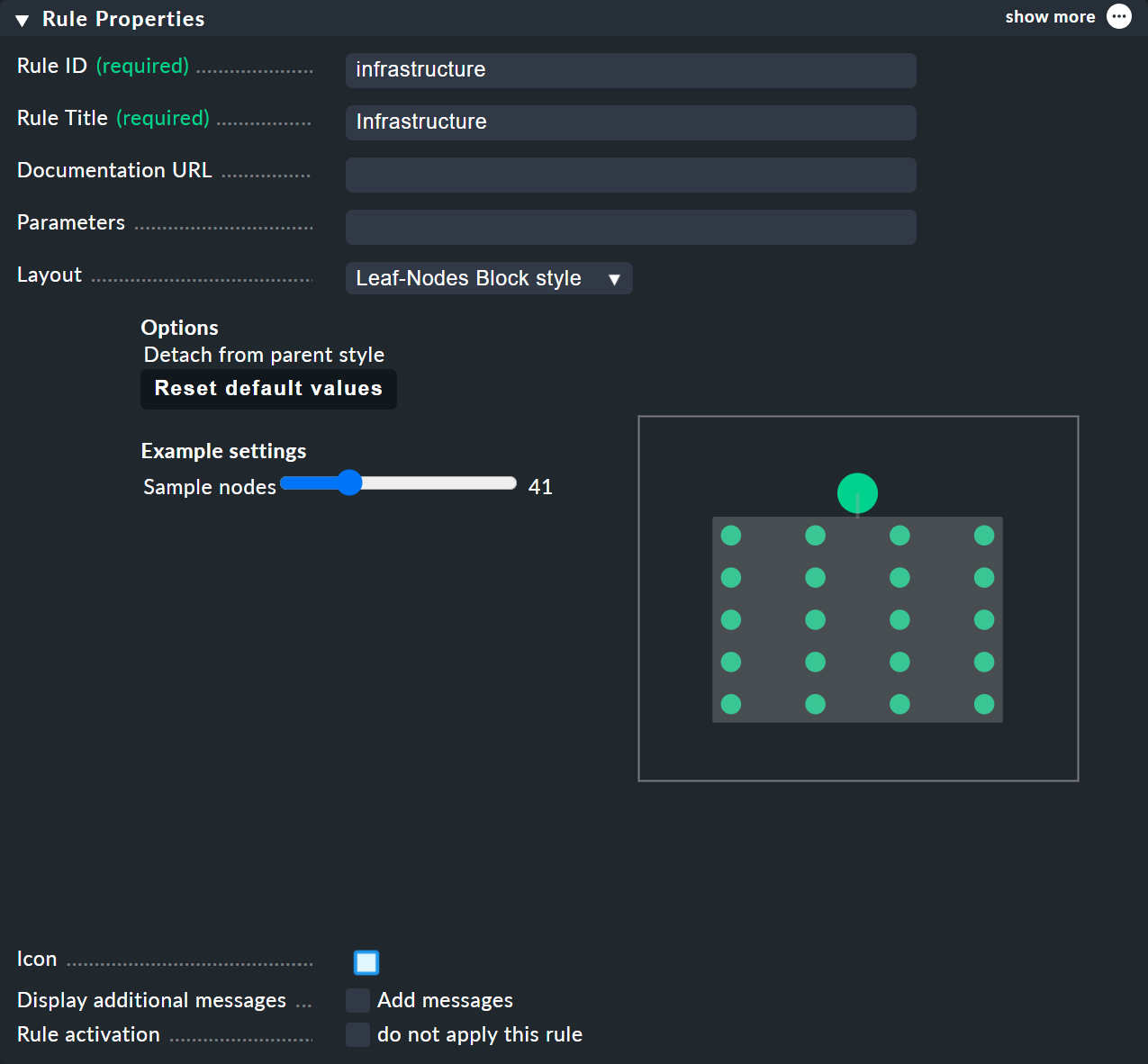
È nell'Child Node Generation che la cosa si fa interessante. La prima voce è ora di tipo Call a rule e, come regola, scegli la tua regola da quelle sopra indicate, in modo da "appendere" effettivamente queste regole nella sottostruttura.
Il secondo sottonodo è di tipo "State of a service" e qui scegli il tuo servizio "NTP Time"
(fai attenzione all'ortografia esatta, inclusi i caratteri maiuscoli e minuscoli) e il servizio "NTP Time" tramite regex:
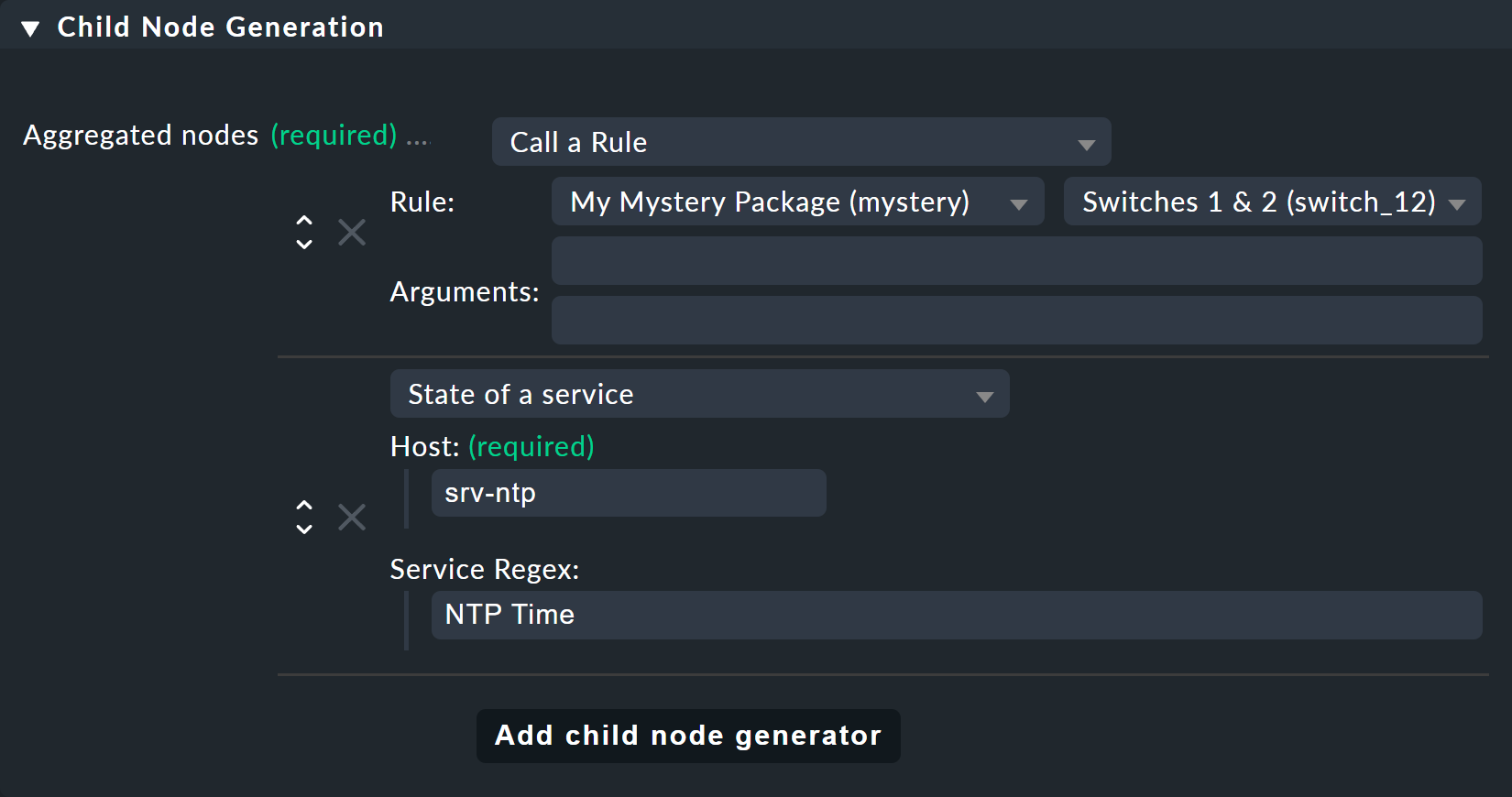
Questa volta imposta Aggregation Function nella terza box su Worst — i.e., take the worst state of all nodes.
In questa funzione lo stato del nodo viene quindi derivato dallo stato peggiore di un servizio sottostante.
In questo caso, se NTP Time passa a CRIT, anche il nodo passa a CRIT.
Ovviamente, per rendere visibile il nuovo albero, più grande, dovrai creare nuovamente un’aggregazione. La cosa migliore è semplicemente modificare l’aggregazione esistente in modo che d’ora in poi venga utilizzata la nuova regola:
In questo modo ti attieni a un'unica aggregazione, che appare quindi come di seguito (questa volta entrambi i switch sono tornati su OK):
5. La BI in azione – Parte 2: visualizzazioni alternative
5.1. Introduzione
Ora che hai un albero un po' più interessante, puoi avvicinarti un po' di più alle varie opzioni di visualizzazione offerte da Checkmk. Il punto di partenza sono le "Modify display options", a cui puoi accedere tramite il menu "Display". Si aprirà una box con varie opzioni. Il contenuto della box corrisponde sempre agli elementi visualizzati nella pagina. Nel caso della BI, al momento sono disponibili quattro opzioni:
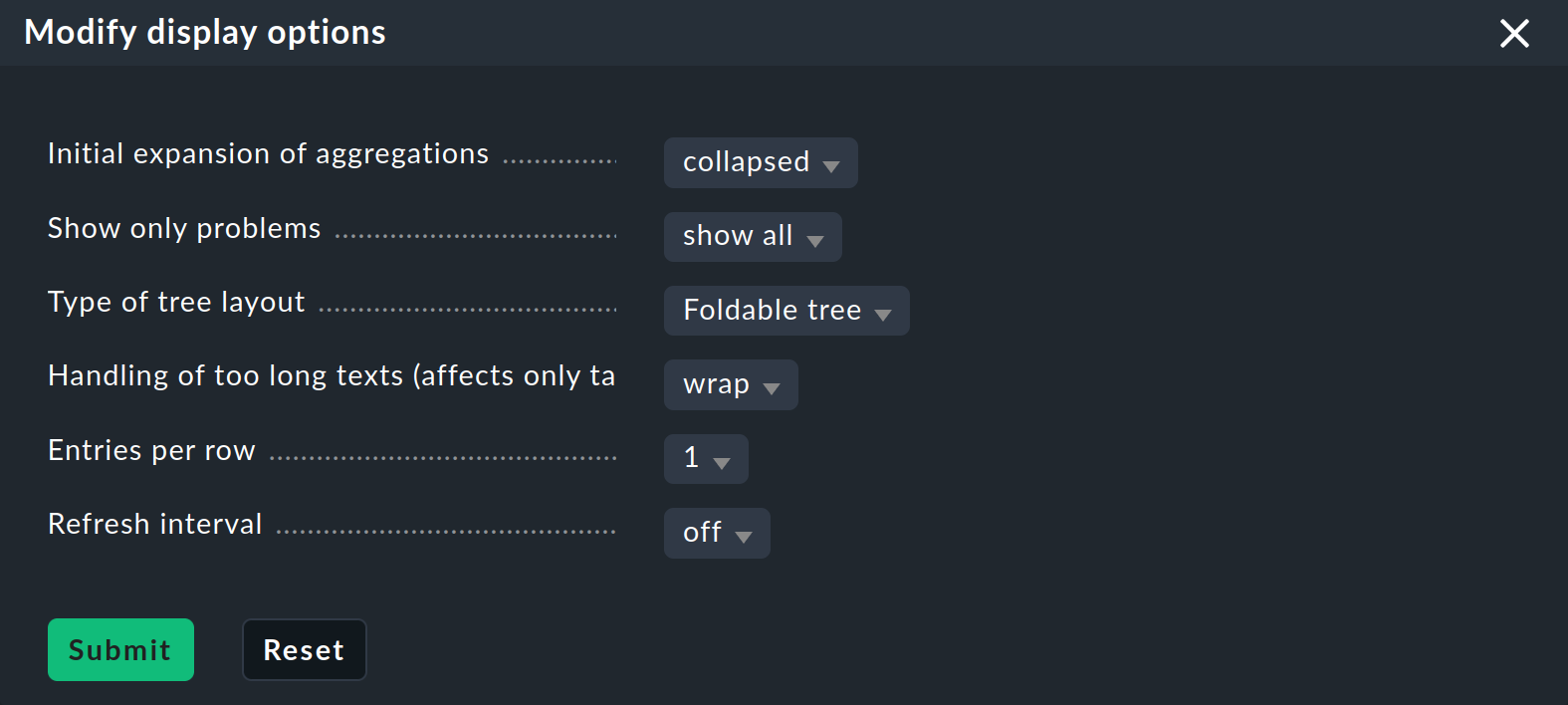
Espandi o comprimi immediatamente gli alberi
Se visualizzi non solo una singola aggregazione, ma molte, allora l'impostazione Initial expansion of aggregations è utile. Qui definisci fino a che punto gli alberi devono essere espansi quando vengono visualizzati per la prima volta. La selezione va da chiuso (collapsed) ai primi tre livelli, fino a completamente aperto (complete).
Mostra solo i problemi
Se abiliti l'opzione "Show only problems", negli alberi verranno visualizzati solo i rami che non hanno lo stato "OK". Il risultato sarà simile a questo:

Tipi di visualizzazione dell'albero
Sotto l'elemento Type of tree layout troverai diversi tipi di visualizzazione alternativi per l'albero. Uno di questi si chiama Table: top down e ha questo aspetto:
La visualizzazione "Boxes" è estremamente salvaspazio, specialmente se vuoi vedere molti aggregati contemporaneamente. Qui ogni nodo è una box colorata che può essere espansa con un clic. La struttura ad albero non è più visibile, ma puoi cliccare rapidamente per individuare un problema, richiedendo solo uno spazio minimo per farlo. Qui nell'esempio le box sono completamente aperte:

5.2. Altre opzioni
Infine, puoi impostare un intervallo di aggiornamento (Refresh interval) di 30, 60 o 90 secondi e specificare il numero di colonne tramite "Entries per row".
5.3. Visualizzazione delle aggregazioni BI
Oltre alle rappresentazioni tabellari, Checkmk è in grado di gestire anche la visualizzazione delle aggregazioni BI.
Puoi visualizzare le aggregazioni da una nuova prospettiva e, in alcuni casi, in modo più chiaro.
Troverai l'BI Visualizatione tramite ![]() nella visualizzazione delle aggregazioni standard.
nella visualizzazione delle aggregazioni standard.

Puoi spostare liberamente l'albero cliccando sullo sfondo e ridimensionare l'intera visualizzazione utilizzando la rotella del mouse. Non appena il puntatore del mouse si trova sopra un singolo nodo, ottieni le informazioni sullo stato associate al nodo tramite una finestra a comparsa. Usa la rotella del mouse per ridimensionare la lunghezza dei rami dell'albero.
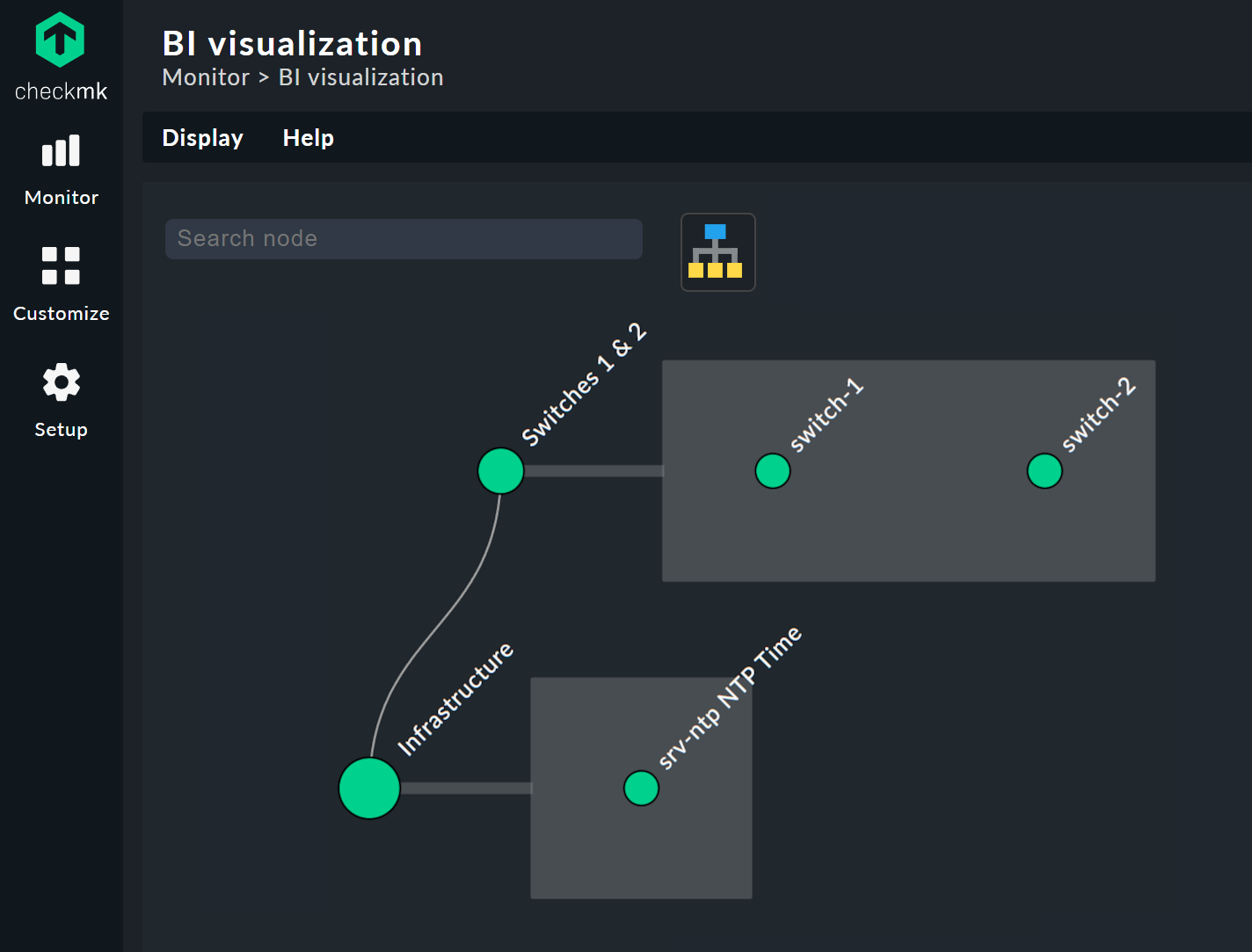
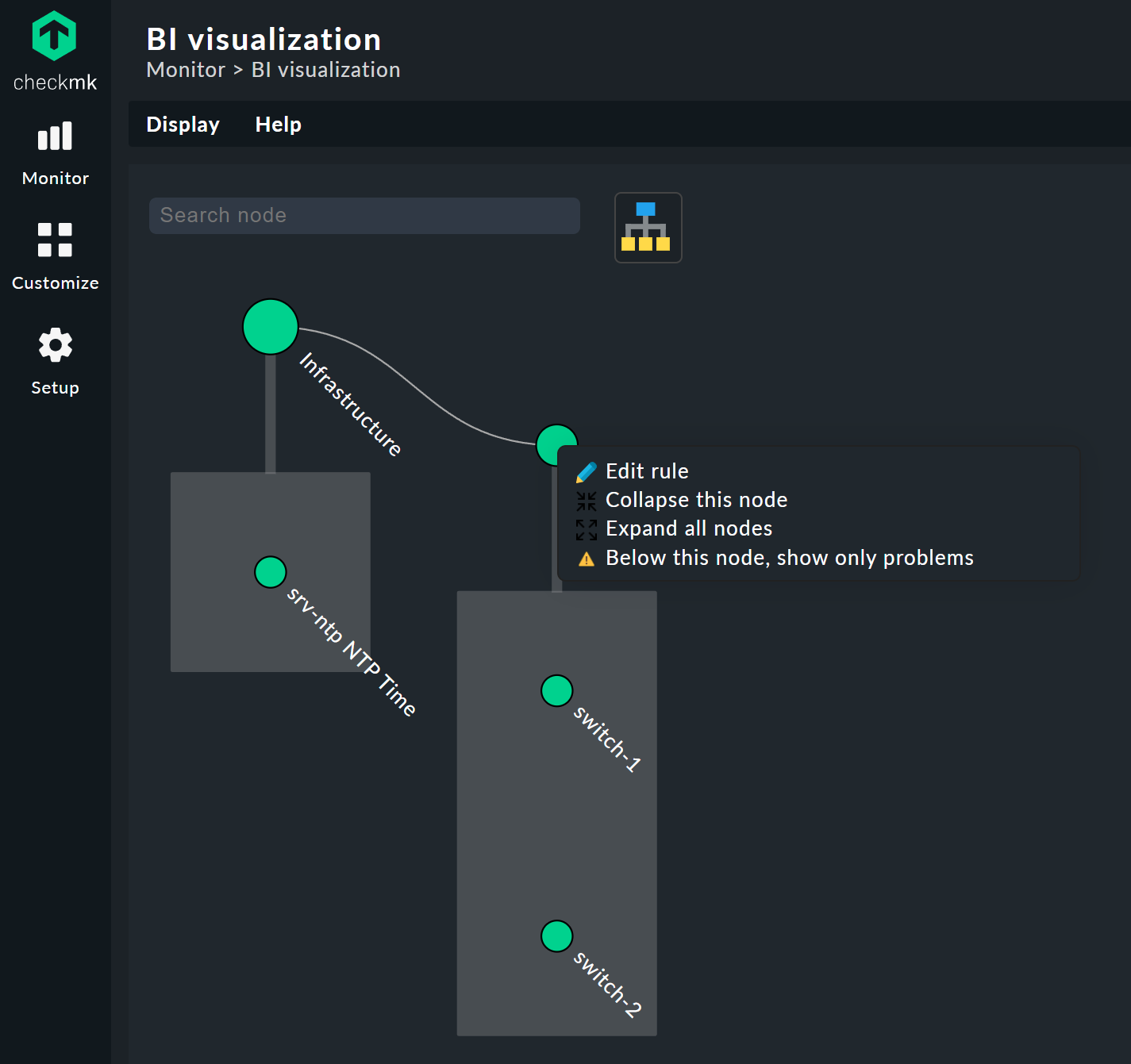
Cliccando sui nodi foglia si accede direttamente alle visualizzazioni dettagliate dell'host o del servizio. Un clic destro sugli altri nodi — a seconda del tipo di nodo — dà accesso alle opzioni di visualizzazione e, ad esempio, alla regola responsabile stessa — Edit rule nell'immagine qui sotto.
Personalizzazione della visualizzazione
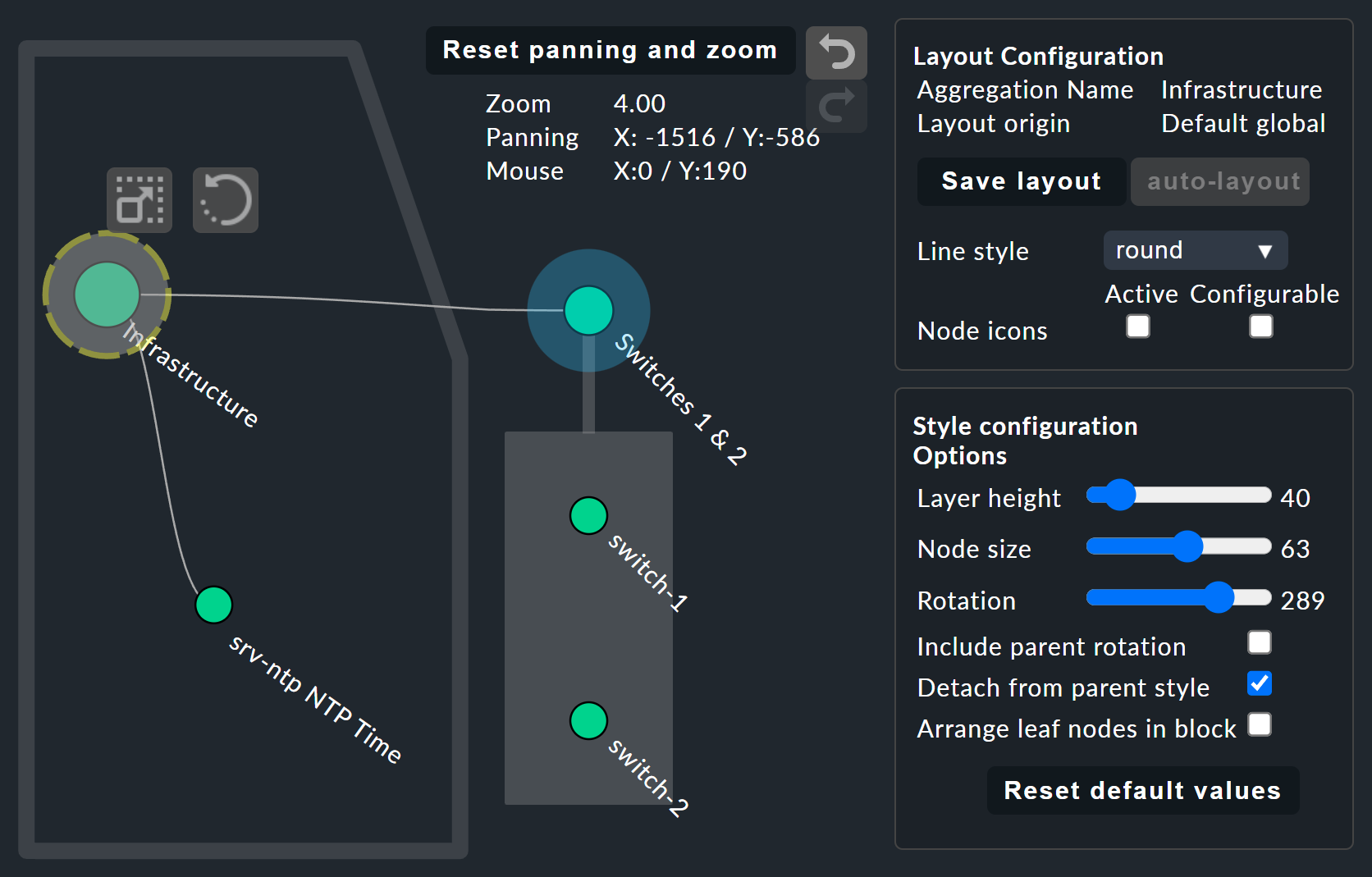
Le cose si fanno davvero interessanti con l’Layout Designer, che si apre con l’![]() in alto, accanto al campo di ricerca.
Per prima cosa, vedrai due nuovi elementi — l’Layout Configuration, e due nuovi simboli alla radice —
in alto, accanto al campo di ricerca.
Per prima cosa, vedrai due nuovi elementi — l’Layout Configuration, e due nuovi simboli alla radice — ![]() e
e ![]() .
.
In una configurazione puoi scegliere tra diversi tipi di linea e attivare l'Node icons.
Questo mostrerà i simboli che puoi specificare nelle regole per le aggregazioni BI nella sezione Aggregation Function
(a cui puoi accedere direttamente tramite il Menù contestuale del nodo).
Usando i simboli ![]() e
e ![]() puoi visualizzare l'albero e, tramite clic e trascinamento, ruotarlo o ridimensionarlo in lunghezza e larghezza.
Ulteriori opzioni di visualizzazione compaiono anche nella box Style configuration.
Puoi trovare quelle più adatte alle tue esigenze semplicemente provando ciò che è disponibile.
puoi visualizzare l'albero e, tramite clic e trascinamento, ruotarlo o ridimensionarlo in lunghezza e larghezza.
Ulteriori opzioni di visualizzazione compaiono anche nella box Style configuration.
Puoi trovare quelle più adatte alle tue esigenze semplicemente provando ciò che è disponibile.
Le maggiori possibilità di personalizzazione si trovano nei menu contestuali dei nodi, che in modalità designer offrono quattro diverse visualizzazioni della gerarchia a partire da questo nodo:
Hierarchical style: L'impostazione standard con una gerarchia semplice.
Radial style: Un formato circolare con un settore personalizzabile del cerchio.
Leaf-Nodes Block style: I nodi foglia vengono mostrati come un gruppo con uno sfondo grigio.
Free-Floating style: Un layout dinamico con opzioni quali attrazione, spaziatura, lunghezza dei rami.
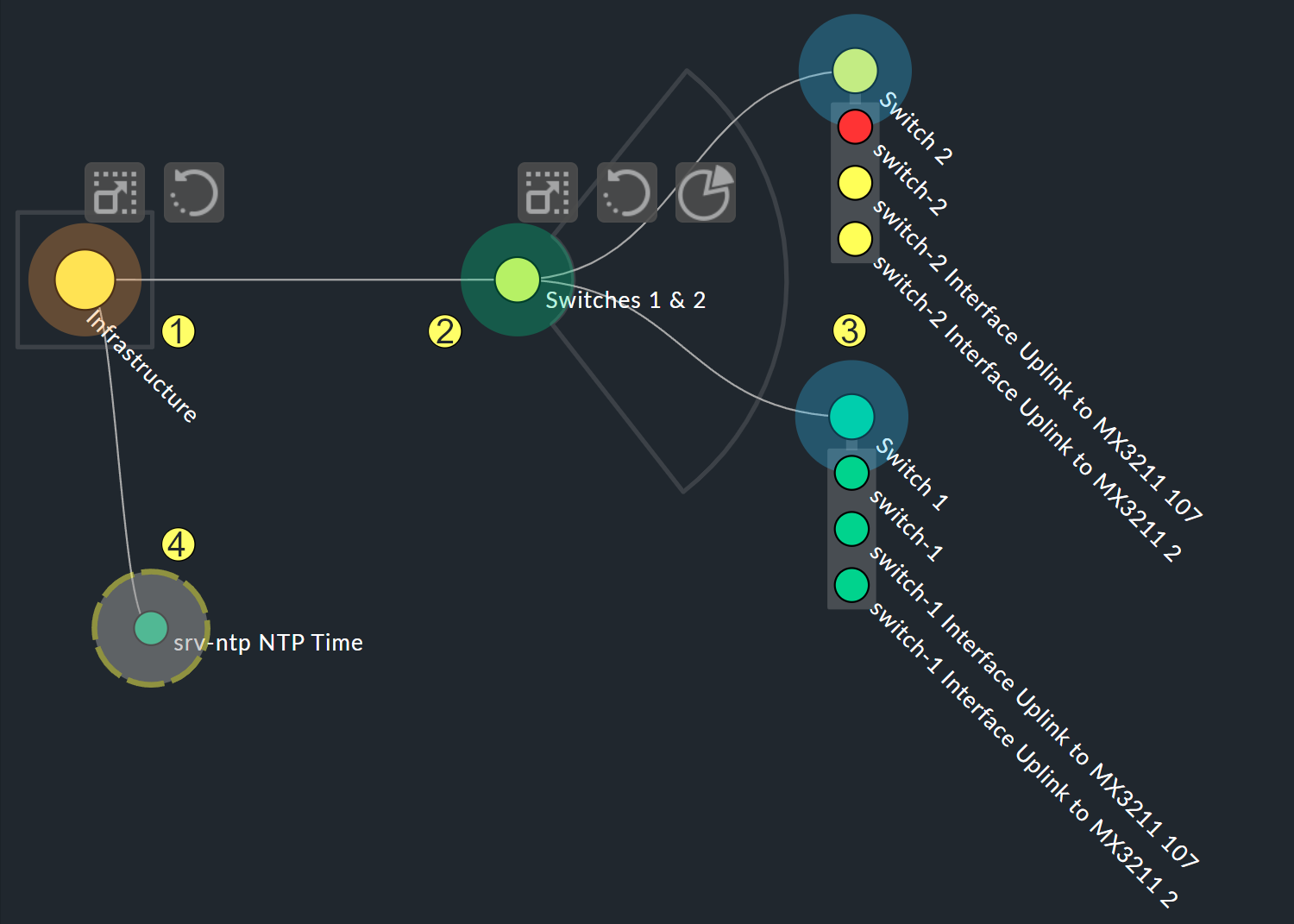
I nodi a cui è stato assegnato uno stile possono essere posizionati ovunque.
Le opzioni disponibili variano anche a seconda dello stile: con Radial style, nel nodo radice c'è un terzo simbolo ![]() che puoi usare per limitare la visualizzazione a un settore del cerchio.
che puoi usare per limitare la visualizzazione a un settore del cerchio.
Con l'opzione "Detach from parent style" puoi separare lo stile di un nodo dallo stile del suo nodo padre superiore, quindi configurare questi sottonodi in modo diverso e posizionarli liberamente. "Include parent rotation" ha uno scopo simile: ti permette di includere o escludere i nodi padre durante la rotazione.
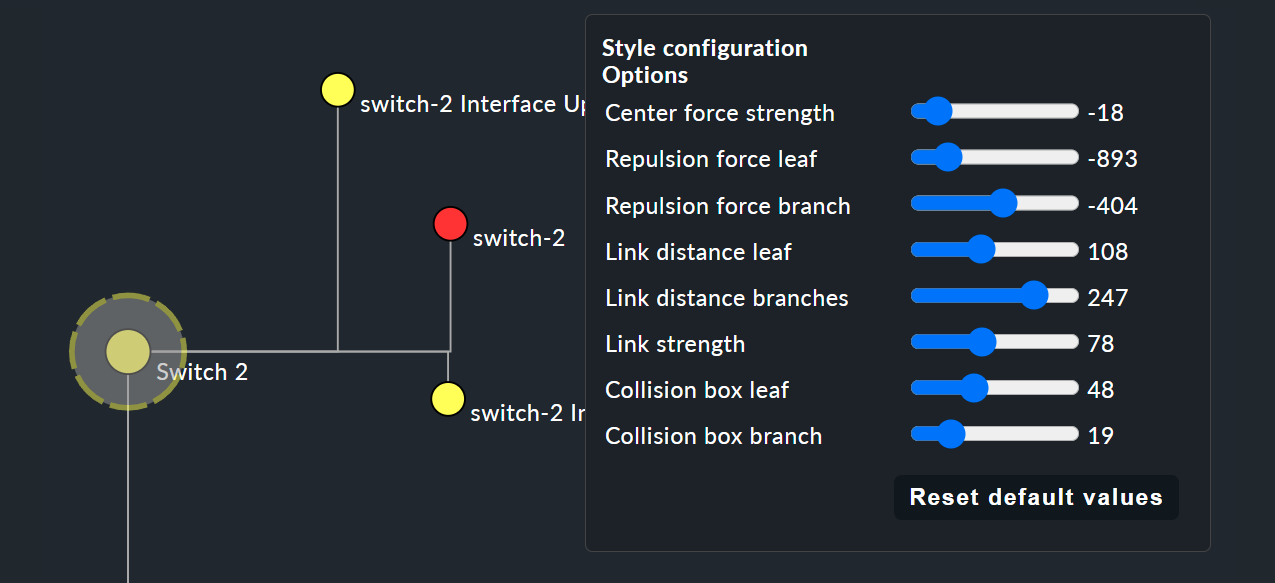
Queste opzioni di stile sono fondamentalmente tutte intuitive — solo l’opzione “Free-Floating style” richiede qualche spiegazione. Si tratta di un sistema di attrazione e repulsione simile a quello che conosci dalle simulazioni gravitazionali.
Center force strength |
Centro di gravità dei nodi. |
Repulsion force leaf |
Intensità dell'effetto di repulsione delle foglie sugli altri nodi. |
Repulsion force branches |
Intensità della repulsione dai nodi verso gli altri nello stesso ramo. |
Link distance leaf |
Distanza ideale dal nodo foglia al nodo precedente. |
Link distance branches |
Distanza ideale dal nodo del ramo al nodo precedente. |
Link strength |
Intensità con cui viene applicata la distanza ideale. |
Collision box leaf |
Dimensione dell'area del nodo foglia che respinge gli altri nodi. |
Collision box branch/leaf |
Dimensione dell'area del nodo di ramo che respinge gli altri nodi. |
L'immagine seguente mostra un ramo nell'Free-Floating style: le posizioni delle singole foglie vengono determinate dinamicamente in base alle opzioni specificate.
Specificare gli stili di layout per le regole BI
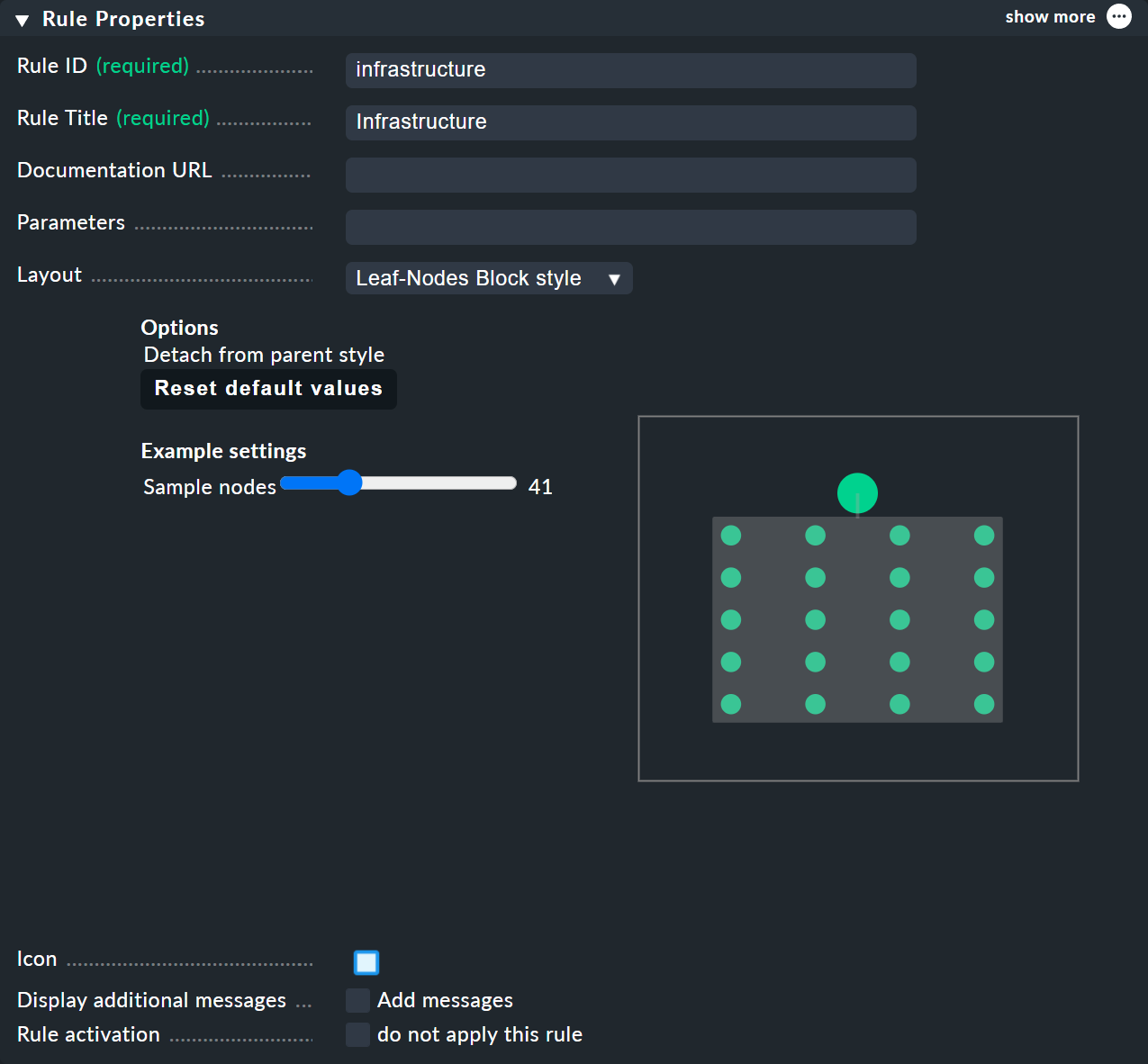
Per le regole BI — a cui puoi accedere dal Menù contestuale dei nodi — nel menu dell'Rule Properties puoi assegnare i layout "Hierarchical", "Radial" o "Leaf-Nodes Block" e, allo stesso modo, impostare le opzioni pertinenti.
La funzione di ricerca
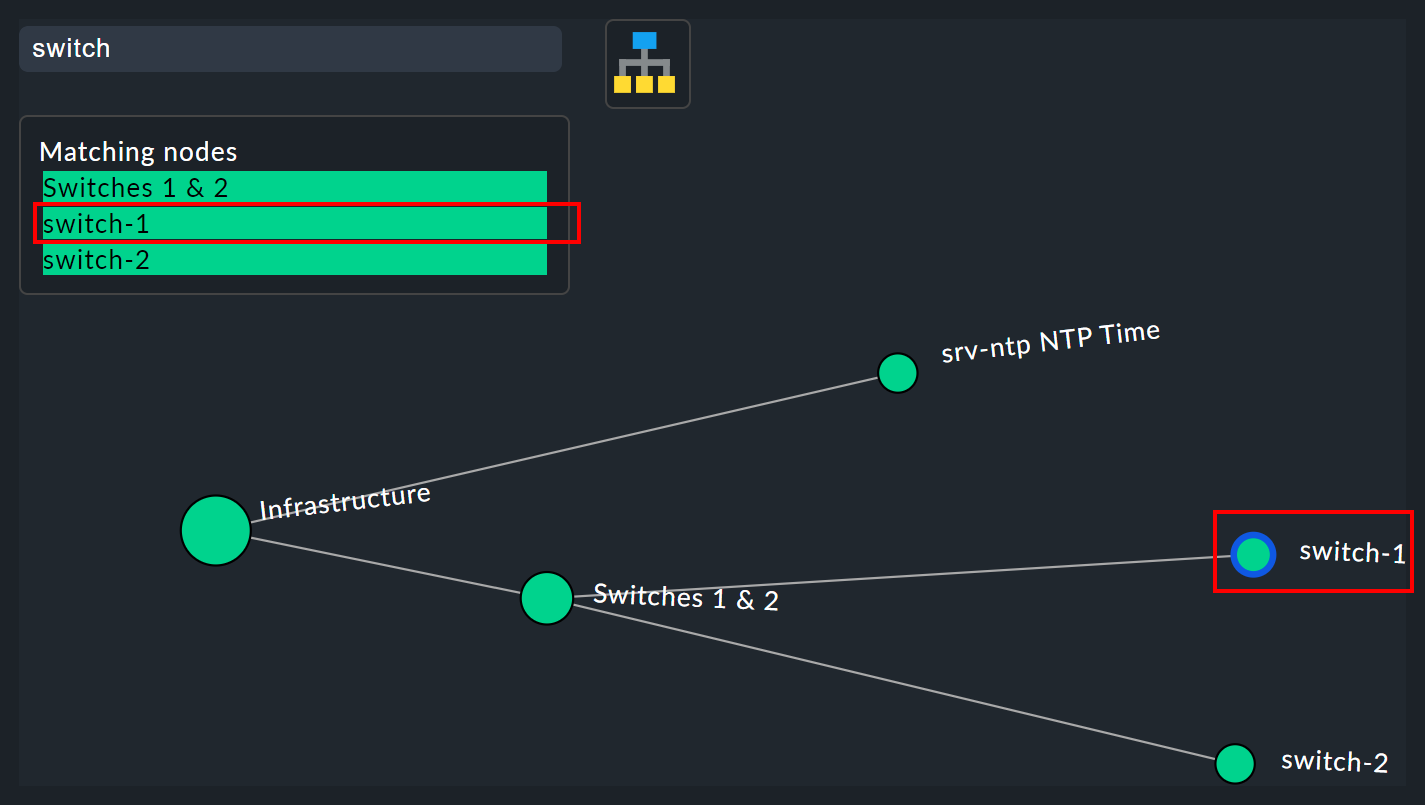
La funzione di ricerca è di enorme aiuto con alberi di grandi dimensioni. Nel campo di ricerca di Search node puoi semplicemente inserire una parte del nome del nodo desiderato e ottenere un elenco di risultati direttamente e in tempo reale. Se ora passi con il mouse su questo elenco di suggerimenti, il nodo dell'albero sotto il puntatore del mouse verrà evidenziato da un bordo blu: questo facilita un primo orientamento. Cliccando su un nodo nell'elenco, l'albero verrà centrato su quel punto. In questo modo, anche nelle visualizzazioni con centinaia di nodi, puoi trovare rapidamente la sezione giusta nell'albero.
6. Configurazione - Parte 3: variabili, modelli, ricerche
6.1. Configurazione più intelligente
Continuiamo con la configurazione. Ora è il momento di mettersi davvero al lavoro. Finora l'esempio è stato così semplice che è stato possibile creare un elenco di tutti gli oggetti nell'aggregazione BI senza difficoltà. Ma cosa succede se le cose si complicano? Cosa succede se vuoi formulare molte dipendenze ricorrenti che sono uguali o simili? Cosa succede se un'applicazione include non una, ma più istanze? Cosa succede se dovessi voler unire centinaia di singoli servizi di un database in un unico nodo BI?
Per tali requisiti avrai bisogno di metodi di configurazione più potenti. E questi sono esattamente ciò che distingue Checkmk BI dagli altri strumenti — e purtroppo qui la curva di apprendimento è un po’ più ripida. È anche il motivo per cui Checkmk BI non si lascia configurare tramite “trascina”. Una volta che avrai scoperto le possibilità, però, non vorrai più farne a meno.
6.2. Parametri
Cominciamo dai parametri. Prendiamo la seguente situazione: non vuoi solo sapere se i due switch sono UP, ma vuoi anche conoscere lo stato delle due porte responsabili dell'uplink. In generale, questo dipende dai seguenti quattro servizi:
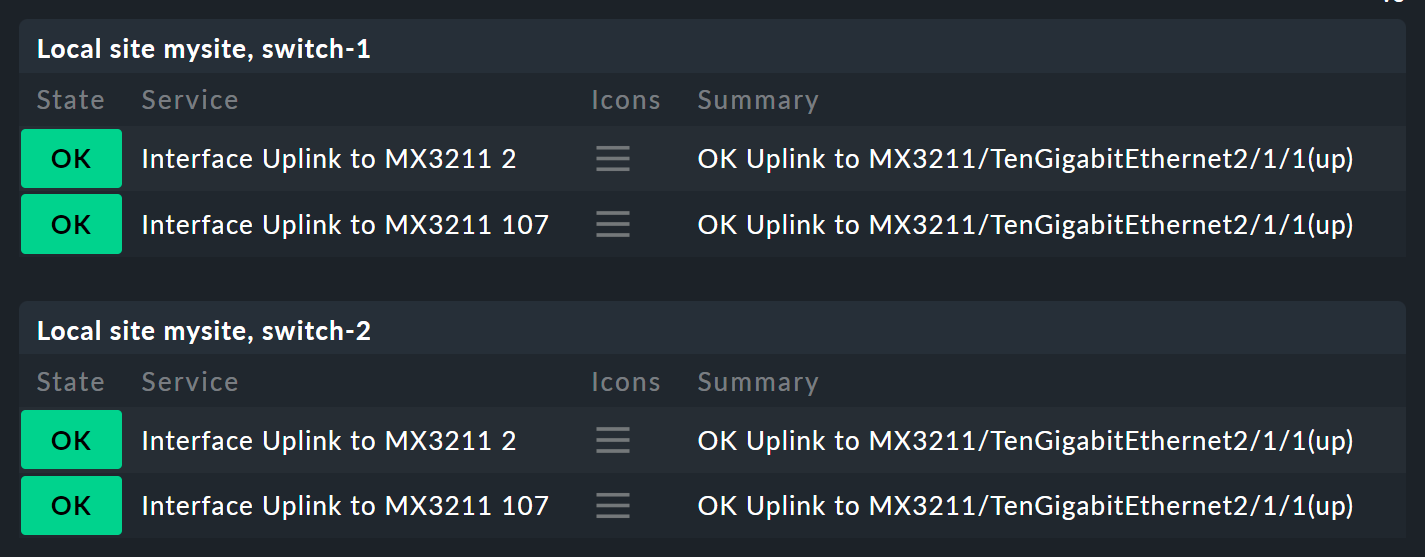
Ora il nodo Switch 1 & 2 dovrebbe essere esteso per sostituire i due stati dello host degli switch 1 e 2, in modo che ciascuno abbia un sottonodo che mostri lo stato dello host e le due interfacce uplink. Questi due sottonodi dovrebbero essere Switch 1 o Switch 2.
In realtà ora avrai bisogno di due nuove regole: una per ogni switch.
È meglio farlo creando una nuova regola switch e dotandola di un parametro.
Questo parametro è una variabile che chiami quando chiami la regola dal nodo padre — che qui può essere fornito dalla vecchia regola Switch 1 & 2.
In questo esempio puoi semplicemente passare un 1 o un 2.
Il parametro riceve un nome che puoi scegliere liberamente.
Prendi qui, ad esempio, il nome NUMBER.
L'ortografia con le lettere maiuscole qui è puramente arbitraria,
e se trovi le lettere minuscole più belle sei libero di usare anche quelle.
L'intestazione della regola avrà quindi questo aspetto:
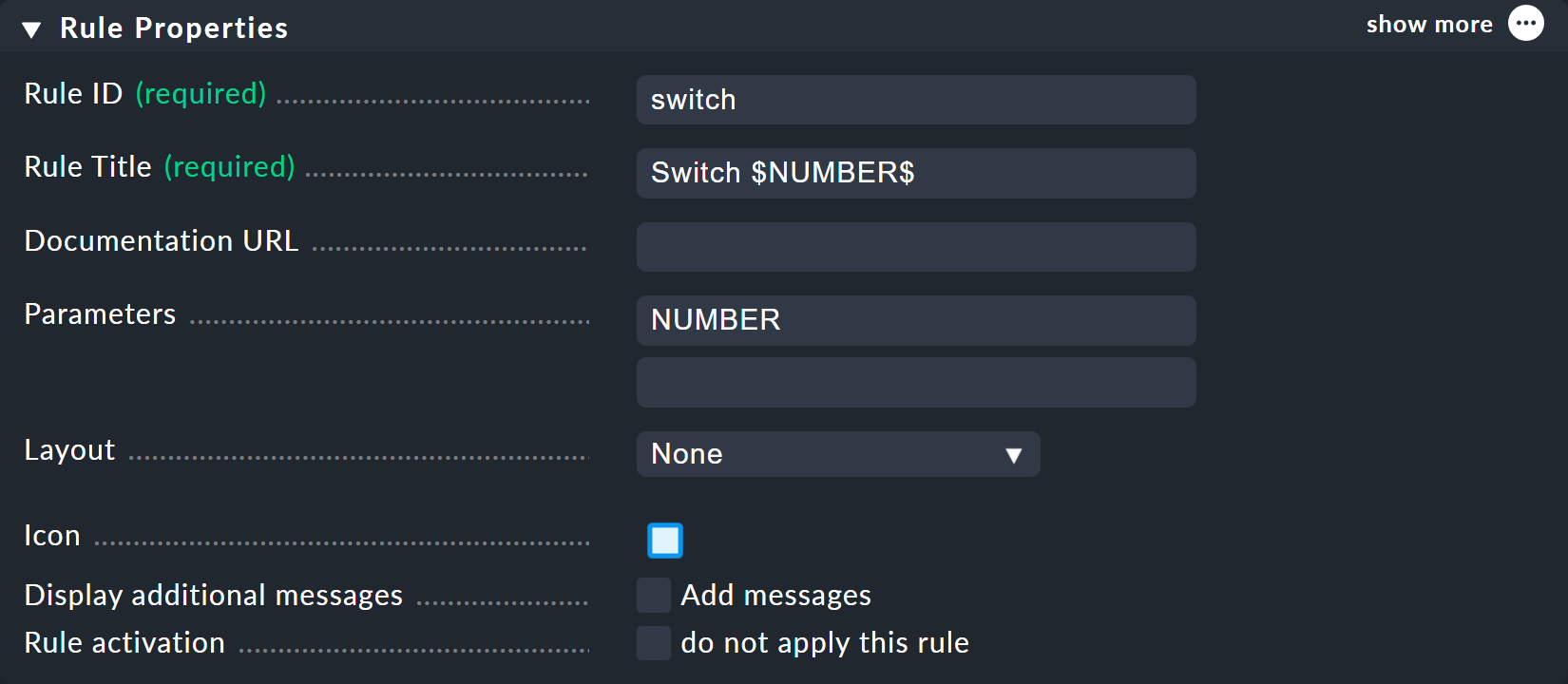
Puoi scegliere switch come ID per la nuova regola.
In Parameters inserisci semplicemente il nome della variabile: NUMBER.
È importante anche che la variabile venga utilizzata nell’Rule Titlee della regola, in modo che entrambi i nodi non si chiamino semplicemente switch e abbiano quindi lo stesso nome.
Quando si utilizza la variabile, vengono inseriti un simbolo del dollaro all’inizio e alla fine, come è consuetudine in molti punti di Checkmk.
Di conseguenza, i due nodi si chiameranno Switch 1 e Switch 2.
Il match inizio parola (prefisso) è l'impostazione predefinita per i nomi dei servizi
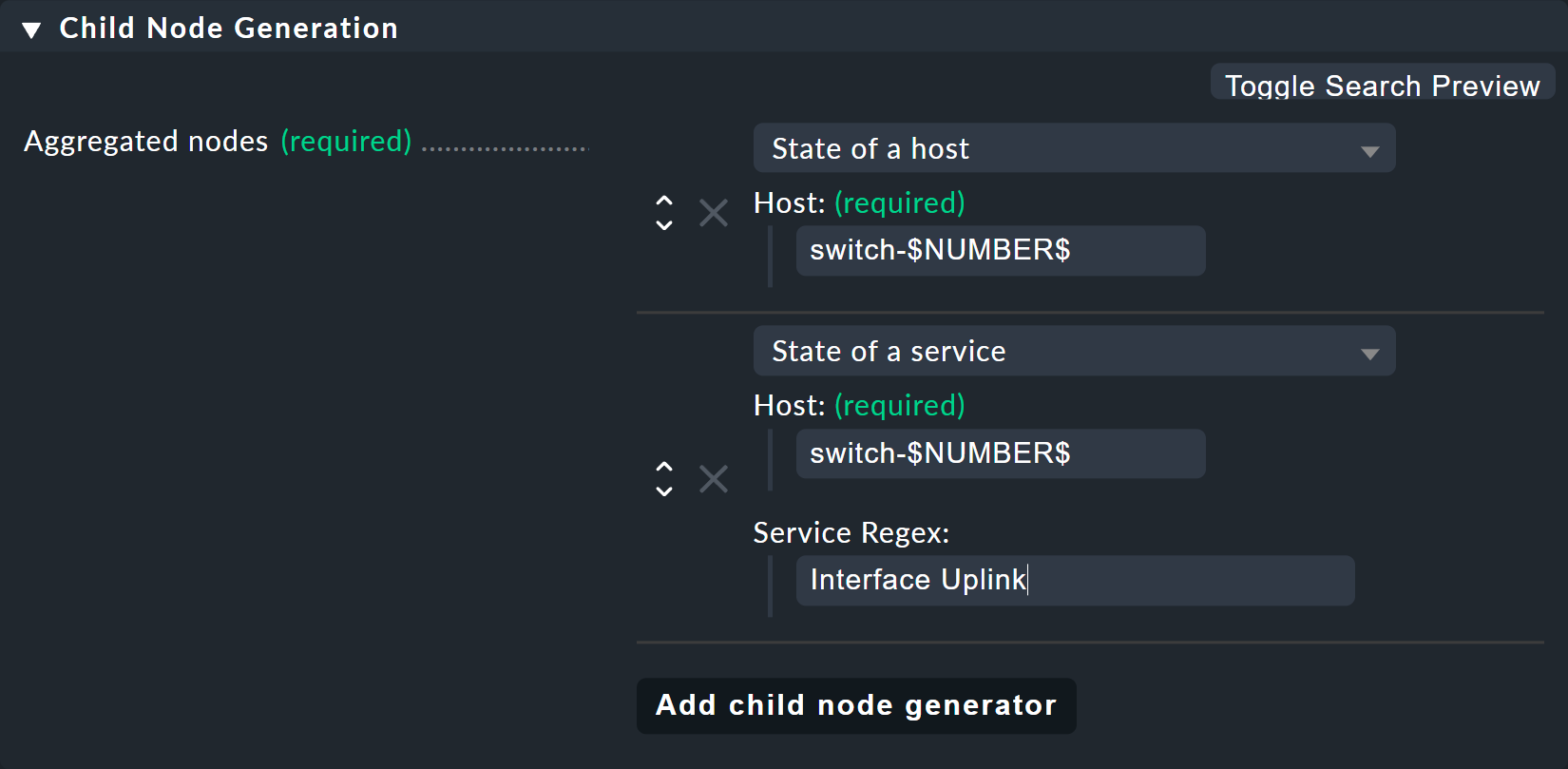
Per l'Child node generator, la prima cosa da fare è inserire lo stato dello host.
Invece di 1 o 2 nel nome host, puoi semplicemente usare la tua variabile, sempre con un $ all'inizio e alla fine.
Lo stesso vale per i nomi host delle interfacce uplink.
Ed ecco il secondo trucco: come puoi intuire dall'elenco breve di servizi visto sopra, i servizi per l'uplink hanno nomi diversi su ogni switch.
Ma non è un problema, perché BI interpreta sempre il nome del servizio come una corrispondenza inizio parola (prefisso) usando espressioni regolari, in modo del tutto analogo alle ben note regole di servizio.
Quindi, semplicemente scrivendo Interface Uplink, intercetti tutti i servizi sul rispettivo host che iniziano con Interface Uplink:
A proposito: aggiungendo $ puoi disabilitare il comportamento del prefisso.
Nelle espressioni regolari, $ significa "Il testo deve terminare qui".
Quindi Interface 1$ corrisponde solo a Interface 1 e non, ad esempio, a Interface 10.
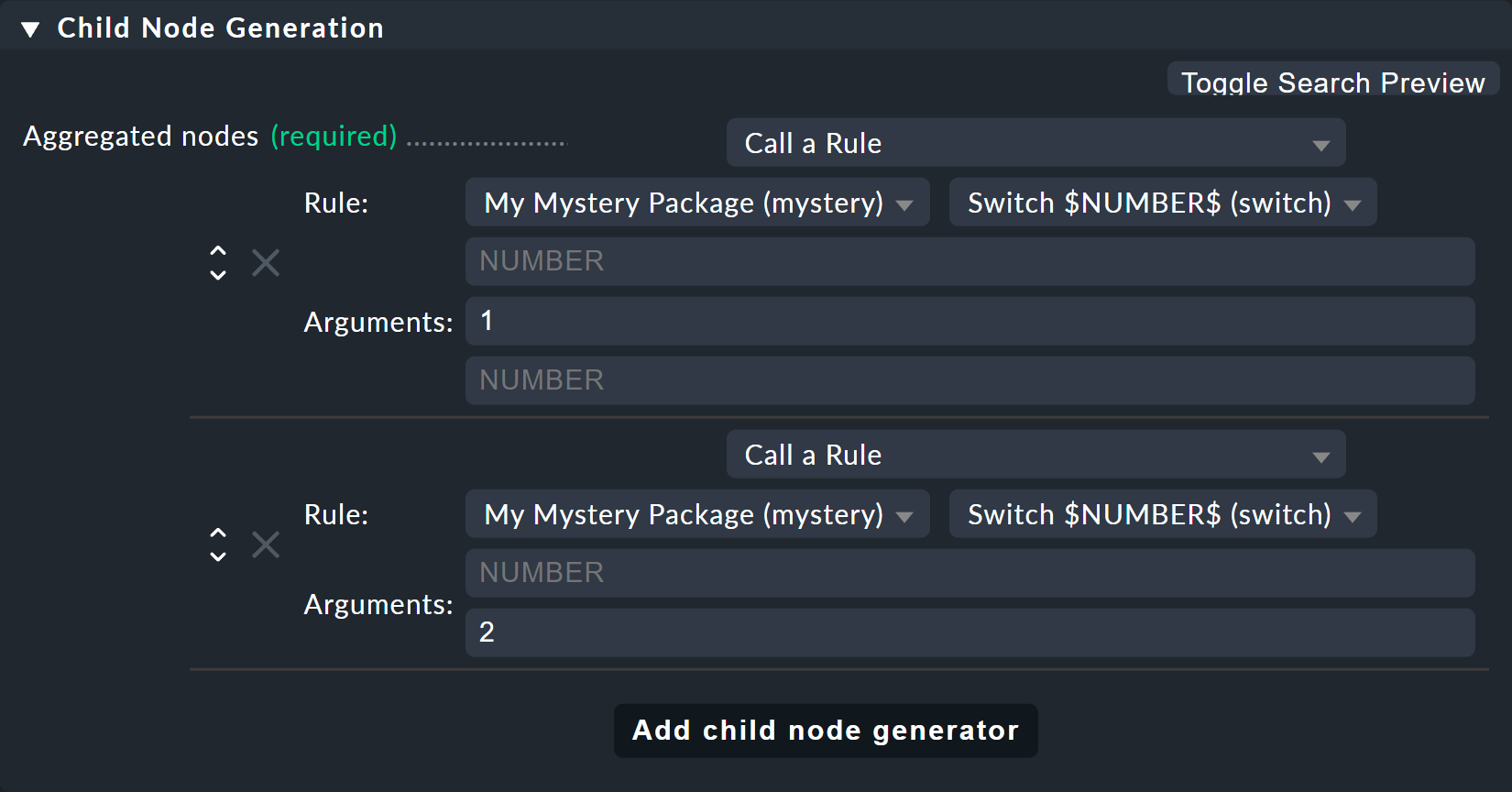
Ora modifica la vecchia regola Switch 1 & 2 in modo che, invece degli stati dello host, questa nuova regola venga invocata solo una volta per ciascuno dei due switch.
Ed è qui che vengono forniti anche i valori 1 e 2 come parametri per la variabile NUMBER:
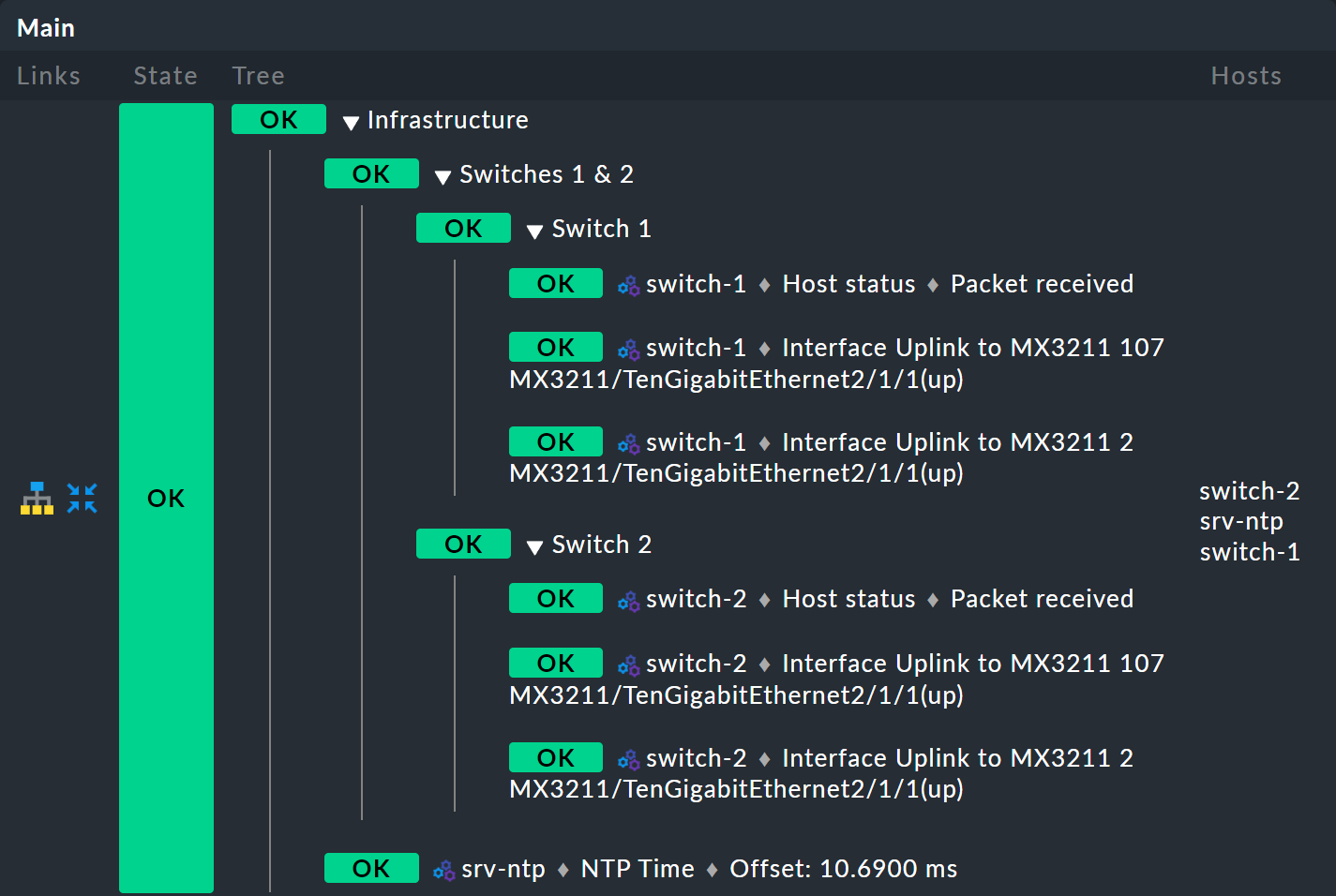
Et voilà: ora hai un bel tree a tre livelli:
6.3. Espressioni regolari, oggetti mancanti
Vale la pena dare un'altra occhiata alle espressioni regolari. Quando abbiamo abbinato il nome del servizio all'inizio, abbiamo sottinteso che si trattasse fondamentalmente solo di espressioni regolari. Come appena detto, c'è una corrispondenza inizio parola (prefisso).
Quindi, in un nodo BI, se ad esempio sotto il nome del servizio specifichi disk,
verranno catturati tutti i servizi dell’host in questione che iniziano con Disk.
In generale si applicano i seguenti principi:
Se un nodo fa riferimento a oggetti che (attualmente) non esistono, questi vengono semplicemente omessi.
Se un nodo diventa vuoto, verrà omesso.
Se anche il nodo radice di un'aggregazione è vuoto, l'aggregazione stessa verrà omessa.
Forse all’inizio ti sembrerà un po’ azzardato, perché non è rischioso omettere semplicemente, senza commenti, elementi che dovrebbero essere presenti?
Beh, col tempo noterai quanto sia pratico questo concetto, perché ti permetterà di scrivere regole "intelligenti" in grado di reagire a situazioni molto diverse. C'è un servizio che non esiste in tutte le istanze all'interno di un'applicazione? Nessun problema: verrà preso in considerazione solo se è presente. Oppure gli host o i servizi possono essere temporaneamente rimossi dal monitoraggio? In tal caso scompariranno semplicemente dal BI senza causare errori o simili. BI non serve a verificare se la tua configurazione di monitoraggio è completa!
A proposito: questo principio vale anche per i servizi definiti esplicitamente,
poiché questi in realtà non esistono perché i nomi dei servizi sono sempre visualizzati come espressioni regolari
anche se non contengono caratteri speciali come .*.
Si tratta sempre automaticamente di un modello di ricerca.
6.4. Creazione di un nodo come risultato di una ricerca
Ma puoi comunque automatizzare ulteriormente e, soprattutto, reagire in modo flessibile ai cambiamenti.
Continua con l'esempio dei due server applicativi srv-mys-1 e srv-mys-2 dell'esempio.
Il tuo albero dovrebbe continuare a crescere.
Il nodo Infrastructure dovrebbe scivolare al livello 2.
E come radice definitiva, dovrebbe esserci una regola con il titolo The Mystery Application sotto la quale sarà appeso tutto.
Accanto a Infrastructure dovrebbe esserci un nodo chiamato Mystery Servers.
I due server misteriosi (attualmente) dovrebbero essere appesi sotto questo nodo.
In ciascuno di essi entrano nell'aggregazione alcuni servizi generici.
Il risultato dovrebbe apparire così:
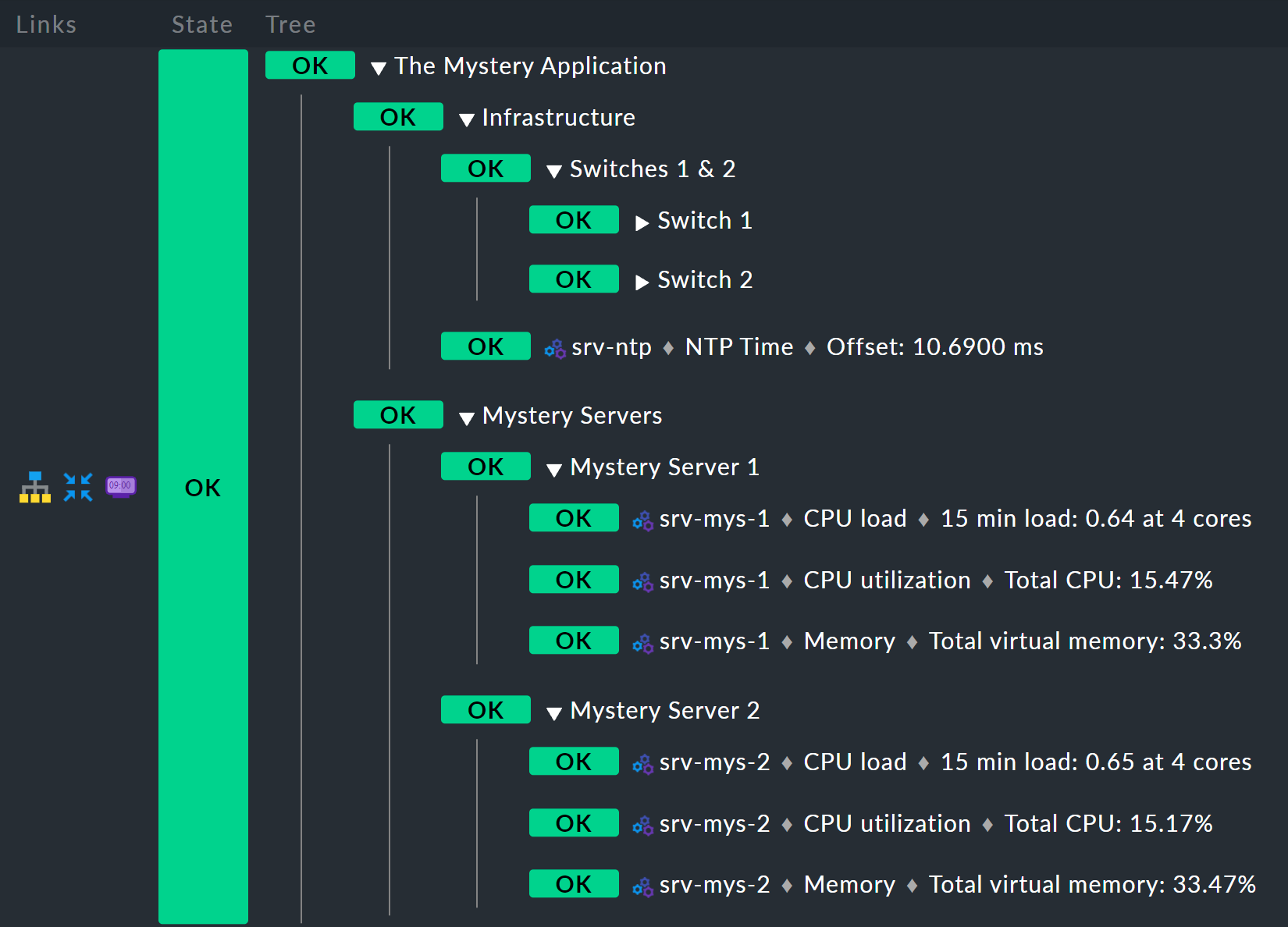
Regola inferiore: server misterioso X
Inizia dal basso,
perché è sempre il modo più semplice in BI.
Di seguito c'è la nuova regola Mystery Server X.
Ovviamente usa un parametro in modo da non aver bisogno di una regola separata per ogni server.
Puoi chiamare il parametro, ad esempio, NUMBER.
In seguito dovrebbe avere il valore 1 o 2.
Come già fatto sopra, dovrai inserire nuovamente NUMBER nell'intestazione in Parameters.
Il generatore di nodi figli risultante avrà questo aspetto:
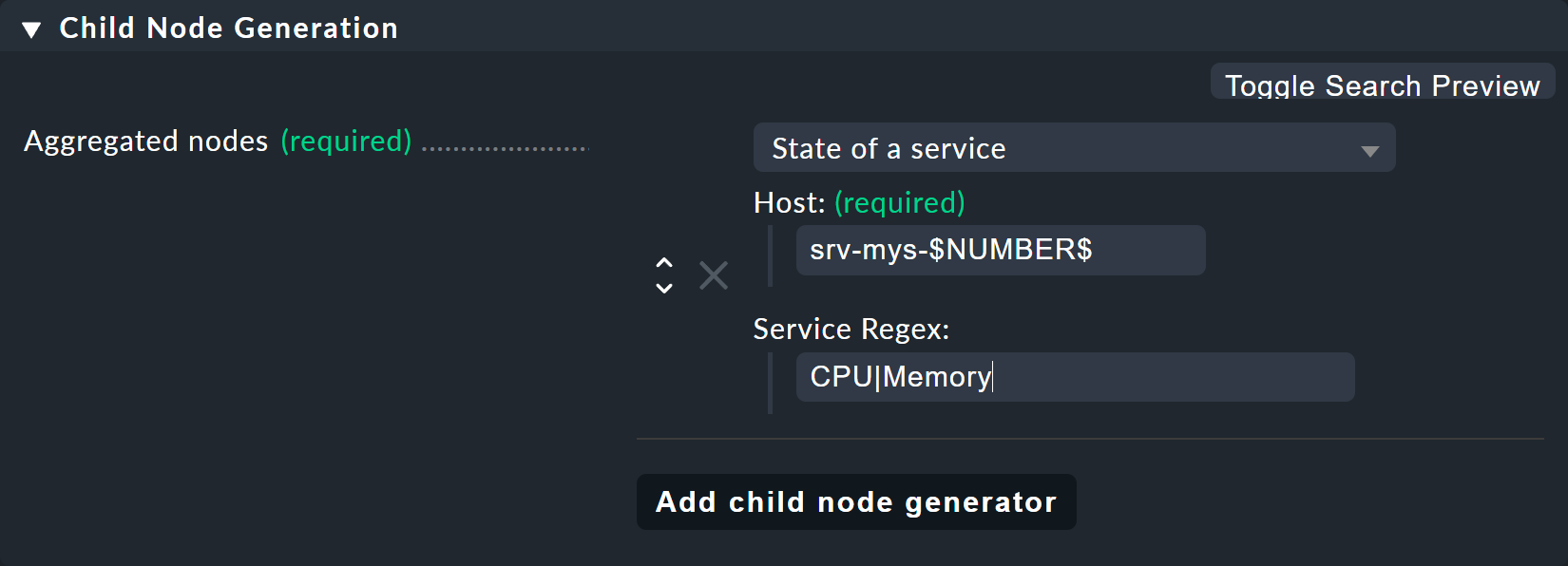
Quello che segue è degno di nota:
Il nome host
srv-mys-$NUMBER$utilizzerà il numero del parametro.Con Service Regex, viene utilizzata la sofisticata espressione regolare
CPU|Memoryche utilizza una barra verticale per consentire nomi dei servizi alternativi (prefissi), e questo corrisponde a tutti i servizi che iniziano conCPUoMemory. Questo evita di dover duplicare la configurazione!
Per inciso, questo esempio non è ovviamente perfetto. Ad esempio, lo stato dell'host stesso non è stato registrato affatto. Quindi, se uno dei server diventa DOWN, i servizi su di esso diventeranno obsoleti (diventeranno stale), ma lo stato rimarrà OK e l'aggregazione non "noterà" quel guasto. Se vuoi sapere qualcosa del genere, dovresti in ogni caso registrare lo stato dell'host oltre agli stati dei suoi servizi.
Regola intermedia: server misteriosi
Questa regola è interessante: riassume i due server misteriosi in un unico nodo. Ora dovrebbe essere possibile che il numero di server non sia fisso, e in seguito a volte ce ne possano essere tre o più, oppure potrebbe essere che ci siano dozzine di istanze nell'applicazione misteriosa, ciascuna con un numero diverso di server.
Il trucco sta nel tipo di generatore di nodi figli Create nodes based on a host search. Questo cerca gli host esistenti e crea nodi in base agli host trovati. Funziona così:
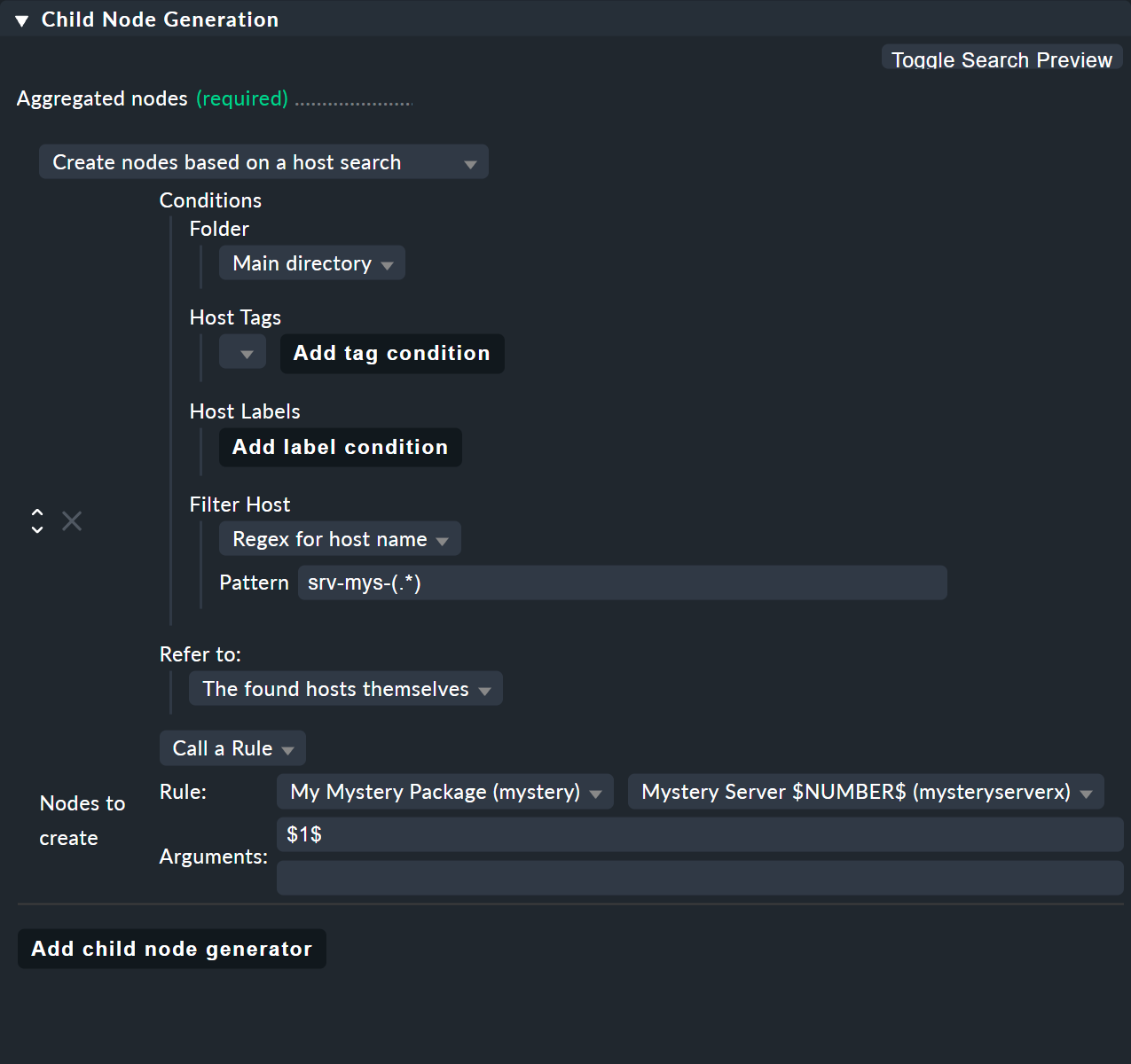
Il tutto funziona così:
Formuli una condizione di ricerca per trovare gli host.
Viene creato un nodo figlio per ogni host trovato.
Puoi estrarre parti dai nomi host trovati e fornirle come parametri.
La ricerca è solo l'inizio.
Come al solito, sono disponibili dei tag host.
Nell'esempio puoi ometterli e usare invece l'srv-mys-(.*)e di espressione regolare per il nome host.
Questo corrisponde a tutti i nomi host che iniziano con srv-mys-.
L'.*e sta per qualsiasi stringa.
È importante che .* sia racchiuso tra parentesi, quindi (.*).
Usando le parentesi, la corrispondenza forma un cosiddetto gruppo di corrispondenza.
In questo modo viene catturato (e memorizzato) il testo che corrisponde in modo esatto a .* — qui 1 o 2.
I gruppi di corrispondenza sono numerati internamente.
Qui ce n'è solo uno che riceve il numero 1.
Puoi poi accedere in seguito al testo corrispondente con $1$.
La ricerca troverà ora due host:
| Nome host |
Valore per$1$
|
|---|---|
|
1 |
|
2 |
Per ogni host trovato creerai ora un sottonodo con la funzione Call a rule.
Seleziona la regola Mystery Server $NUMBER$ che hai appena creato.
Come argomento per NUMBER passa ora il gruppo di corrispondenza: $1$.
Ora la sottoregola Mystery Server $NUMBER$ viene chiamata due volte: una volta con 1 e una volta con 2.
Se in futuro un nuovo server con il nome srv-mys-3 viene aggiunto al monitoraggio, questo apparirà automaticamente nell'aggregazione BI.
Lo stato dell'host non ha importanza.
Anche se il server è DOWN, ovviamente non verrà rimosso dall'aggregazione.
Certo, la curva di apprendimento qui è molto ripida. Questo metodo è davvero complesso. Ma una volta che l'avrai provato e compreso, ti renderai conto di quanto sia potente l'intero concetto — e finora abbiamo solo sfiorato la superficie delle possibilità disponibili!
Regola di primo livello
Il nuovo nodo di primo livello The Mystery Application è ora semplice: è necessaria una nuova regola che abbia due nodi figli di tipo Call a rule. Queste due regole sono la regola esistente Infrastructure e la regola appena creata Mystery Servers.
6.5. Creazione di un nodo con ricerca del servizio
Analogamente alla ricerca dell'host, esiste anche un tipo di generatore figlio chiamato Create nodes based on a service search. Ecco un esempio:
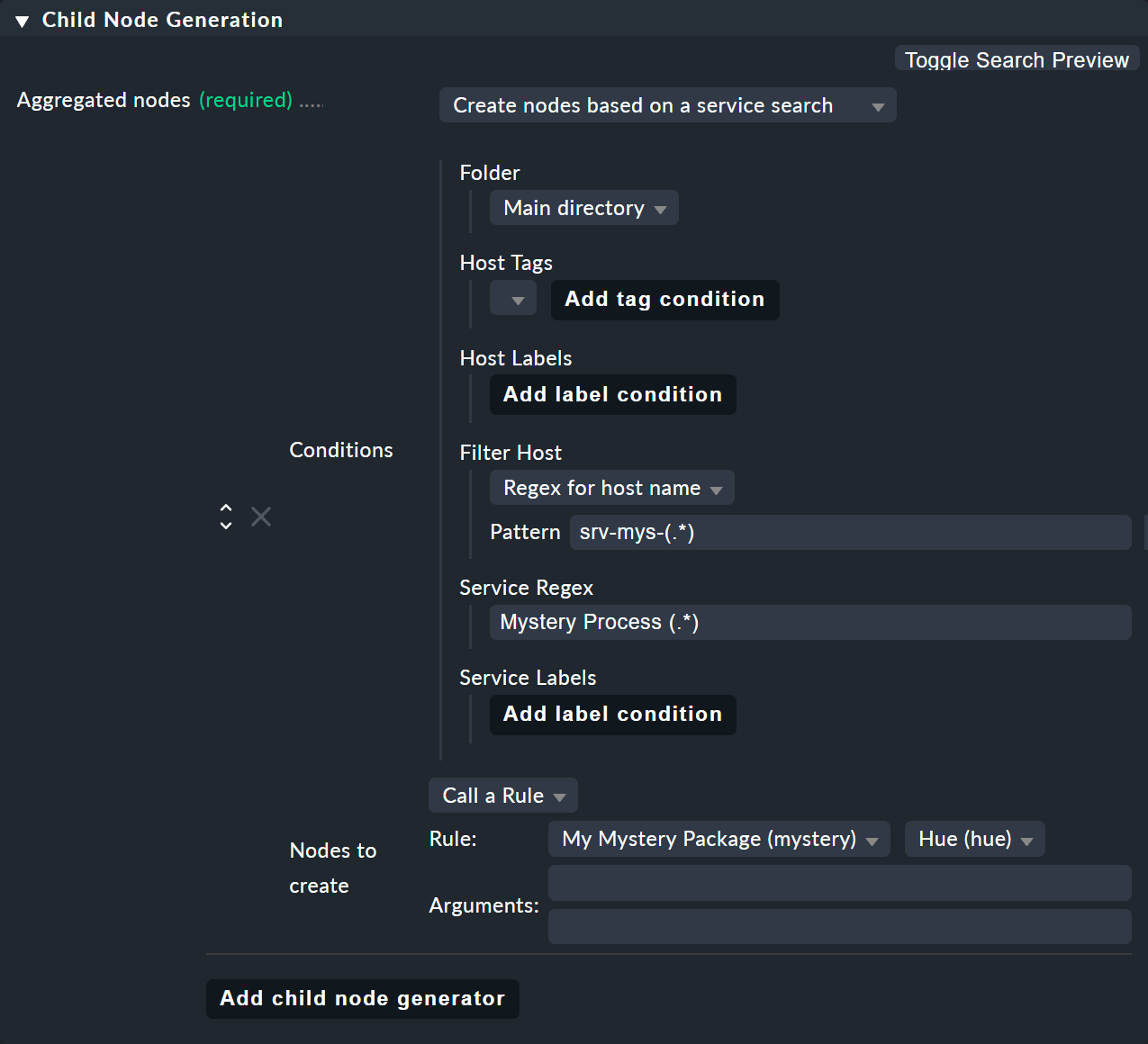
Qui puoi usare () – racchiudendo espressioni parziali – sia a livello di host che di servizio,
dove:
Se scegli "Regex for host name", devi definire esattamente un'espressione tra parentesi. Il testo corrispondente viene quindi fornito come "
$1$".Se scegli All hosts, il nome host completo verrà fornito come
$1$.Puoi usare diversi sottogruppi nel nome del servizio. I testi di corrispondenza associati vengono forniti come
$2$,$3$e così via.
E non dimenticare mai che puoi sempre usare ![]() per ottenere l'aiuto in linea.
per ottenere l'aiuto in linea.
6.6. Tutti gli altri servizi
Nei tuoi tentativi potresti esserti imbattuto nel generatore di figli State of remaining services. Questo genera un nodo per qualsiasi servizio del tuo host che non sia stato ancora ordinato nella tua aggregazione BI. Questo è utile se usi BI per combinare gli stati di tutti i servizi di un host in gruppi chiaramente organizzati, come avviene nel nostro esempio incluso.
7. L'aggregazione predefinita degli host
Come appena accennato, puoi anche usare BI per fornire i servizi di un host in modo strutturato. Combini tutti i servizi in un unico albero in un'aggregazione BI e, in pratica, usi la funzione "worst". Lo stato complessivo di un host verrà quindi visualizzato solo se c'è un problema con l'host: usi BI come un chiaro metodo di "esamina".
A questo scopo Checkmk fornisce già un insieme predefinito di regole che devi solo sbloccare.
Queste regole sono ottimizzate per il rendering dei servizi su host Windows o Linux,
ma ovviamente puoi personalizzarle a tuo piacimento.
Puoi trovare tutte le regole nel pacchetto di regole "Default".
Come al solito, accedi alle regole cliccando su "![]() ":
":

Lì troverai un elenco di dodici regole (qui abbreviate):
La prima regola è quella per la radice dell'albero.
Il simbolo "![]() " di questa regola ti porta a una visualizzazione ad albero.
Qui puoi vedere come le regole sono annidate l'una nell'altra:
" di questa regola ti porta a una visualizzazione ad albero.
Qui puoi vedere come le regole sono annidate l'una nell'altra:

Tornando all’elenco delle regole, con il pulsante “![]() ” (Aggregations) puoi accedere all’elenco delle aggregazioni in questo pacchetto di regole — che consiste di una sola aggregazione.
Nei dettagli dell’aggregazione (
” (Aggregations) puoi accedere all’elenco delle aggregazioni in questo pacchetto di regole — che consiste di una sola aggregazione.
Nei dettagli dell’aggregazione (![]() Details) basta deselezionare la checkbox “Currently disable this aggregation”
e otterrai immediatamente, per ogni host, un’aggregazione intitolata “
Details) basta deselezionare la checkbox “Currently disable this aggregation”
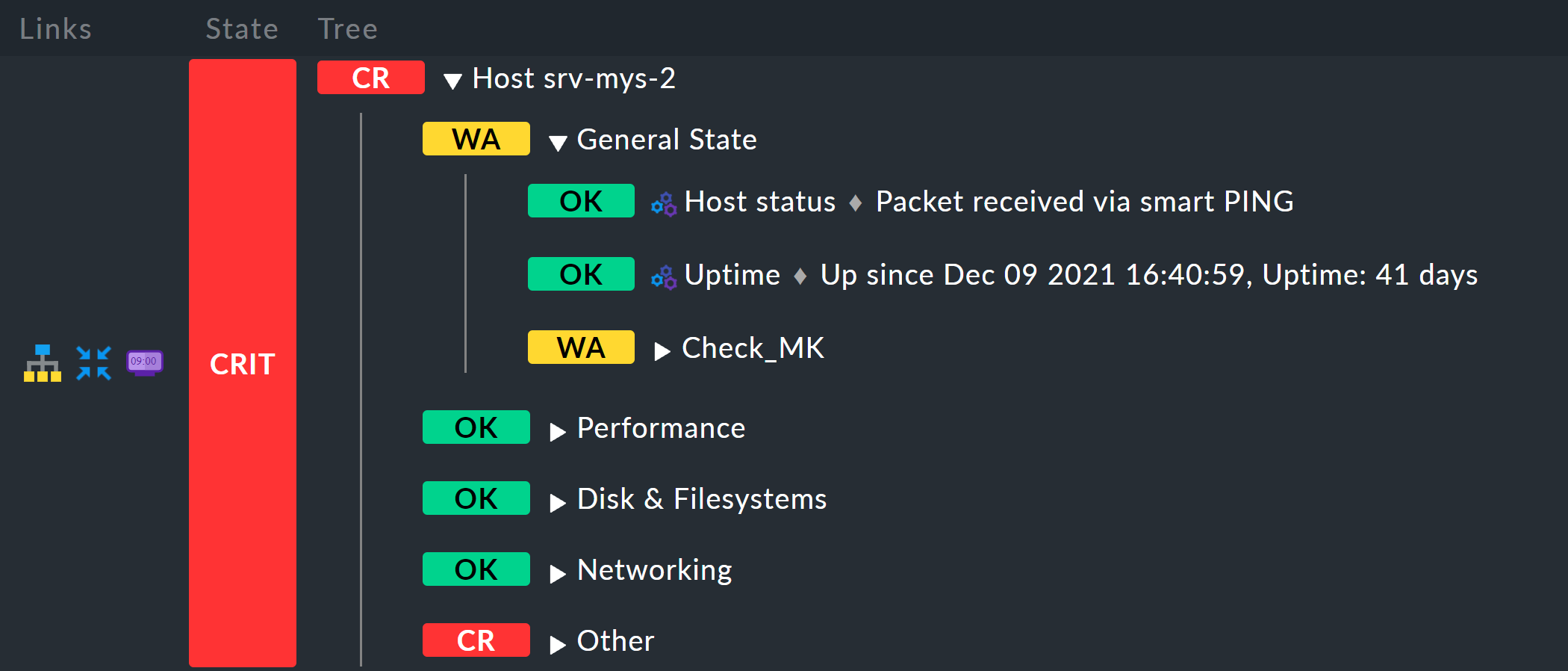
e otterrai immediatamente, per ogni host, un’aggregazione intitolata “Host myhost123”.
Il risultato sarà quindi simile a questo, ad esempio:
8. Permessi e visibilità
8.1. Permessi per l'edizione
Torniamo ancora una volta ai pacchetti di regole. Per tutte le azioni di modifica in BI di solito devi avere il ruolo di amministratore. Più precisamente, per BI ci sono due permessi, che trovi in Setup > Users > Roles & permissions:

Nel ruolo utente di monitoraggio normale, solo il primo dei due permessi è attivo per impostazione predefinita.
Gli utenti di monitoraggio normali possono quindi lavorare solo in quei pacchetti di regole per i quali sono stati definiti come contatto.
Questo si fa in ![]() Dettagli del pacchetto di regole.
Dettagli del pacchetto di regole.
Nell'esempio seguente di Permitted Contact Groups, il gruppo di contatto The Mystery Admins è stato autorizzato: quindi tutti i membri di questo gruppo possono ora modificare le regole in questo pacchetto:
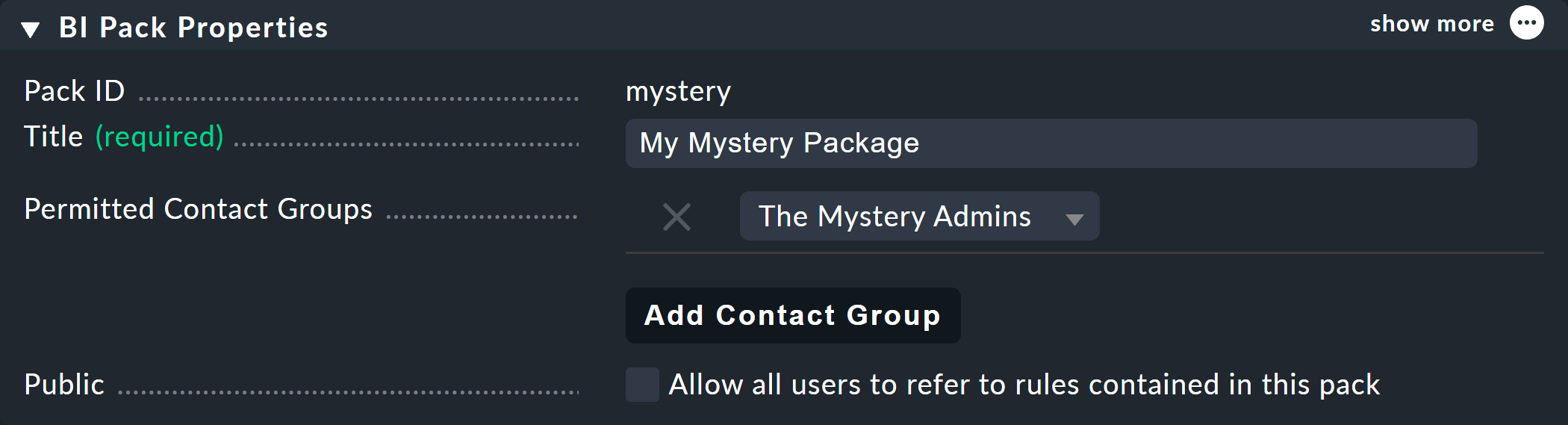
A proposito, con l'Public > Allow all users to refer to rules contained in this pack puoi consentire ad altri utenti almeno di utilizzare le regole qui contenute — ovvero di definire (altrove) le proprie regole — che possono poi richiamare queste regole come sottonodi.
8.2. Permessi su host e servizi
Qual è la situazione riguardo alla visibilità effettiva delle aggregazioni nell'interfaccia di stato? Quali contatti sono autorizzati a vedere qualcosa?
Beh, non puoi assegnare alcun permesso nelle aggregazioni BI stesse. Questo viene fatto indirettamente attraverso la visibilità degli host e dei servizi, ed è regolato dall'opzione See all hosts and services in Setup > Roles & Permissions:

Nel ruolo "User", questa autorizzazione è disabilitata per impostazione predefinita. Gli utenti normali possono vedere solo host e servizi condivisi, e in BI questo si traduce nel fatto che possono vedere esattamente tutte le aggregazioni BI che contengono almeno un host o un servizio condiviso. Tali aggregazioni, tuttavia, contengono solo questi oggetti autorizzati e potrebbero quindi risultare un po' "svuotate". E questo a sua volta significa che possono avere stati diversi a seconda degli utenti.
Che questo sia un bene o un male dipende da ciò che desideri. In caso di dubbio puoi attivare il permesso e, passando per BI, consentire ad alcuni o a tutti gli utenti di vedere host e servizi per i quali non sono contatti — assicurandoti così che lo stato di un'aggregazione sia sempre lo stesso per tutti.
Ovviamente tutta questa questione ha importanza solo se ci sono effettivamente aggregazioni così eterogenee che solo alcuni utenti sono contatti solo per parti specifiche di esse.
9. La BI in azione - Parte 3: tempi di manutenzione programmati, conferme
9.1. L'idea generale
In che modo BI gestisce effettivamente il tempo di manutenzione programmata dell'![]() ?
Ci abbiamo riflettuto a lungo e ne abbiamo discusso con molti utenti: il risultato è il seguente:
?
Ci abbiamo riflettuto a lungo e ne abbiamo discusso con molti utenti: il risultato è il seguente:
Non puoi inserire direttamente un’aggregazione BI in un tempo di manutenzione programmata, ma non è necessario farlo, perché…
il tempo di manutenzione programmato per un'aggregazione BI viene derivato automaticamente dal tempo di manutenzione programmato degli host e dei servizi dell'aggregazione.
Per capire con quale regola BI calcola lo stato "in downtime", è utile ricordare qual è la vera idea alla base delle tempe di manutenzione programmate: l'oggetto in questione è attualmente in fase di lavorazione. Sono prevedibili dei guasti. Anche se l'oggetto è attualmente "OK", non dovresti fare affidamento su di esso. Può diventare "CRIT" in qualsiasi momento. Questo è noto e documentato — non dovrebbe quindi attivare una notifica.
Questo concetto può essere trasferito 1:1 in BI: Nell'aggregazione BI potrebbero esserci alcuni host e servizi attualmente in tempo di manutenzione programmata. Che questi siano semplicemente OK o CRIT non ha importanza, perché in realtà è una coincidenza se durante i lavori di manutenzione gli oggetti a volte si spengono e si riaccendono, o meno. Solo perché nell'aggregazione c'è un oggetto in tempo di manutenzione programmata non significa immediatamente che l'applicazione che effettua la mappatura dell'aggregazione sia essa stessa "minacciata" e debba essere contrassegnata come "in tempo di manutenzione programmata". L'applicazione può anche avere una ridondanza installata che compensa il guasto degli oggetti in tempo di manutenzione programmata. Solo se tale guasto portasse effettivamente a uno stato di "CRIT" per l'aggregazione — quindi se non c'è abbastanza ridondanza e l'aggregazione è davvero a rischio — solo allora Checkmk la contrassegnerà come "in tempo di manutenzione programmata". Anche in questo caso, lo stato attuale degli oggetti in genere non ha importanza.
Per dirla in modo più conciso, la regola esatta è la seguente:
Se uno stato "CRIT" di un host/servizio comporterebbe uno stato "CRIT" dell'aggregazione, uno stato "in tempo di manutenzione programmata" di quell'host/servizio comporta uno stato "in tempo di manutenzione programmata" per l'aggregazione.
Importante: lo stato attuale reale degli host/servizi non ha alcun ruolo nel calcolo — ciò che è in tempo di manutenzione programmata viene considerato come "CRIT" nella logica BI. Perché? Perché uno stato "UP" o "OK" durante una manutenzione programmata è pura coincidenza, ad esempio se un host segnala "UP" per pochi secondi tra un riavvio e l'altro.
Ed ecco un altro esempio. Per risparmiare spazio, questa è una variante con un solo server misterioso invece di due:
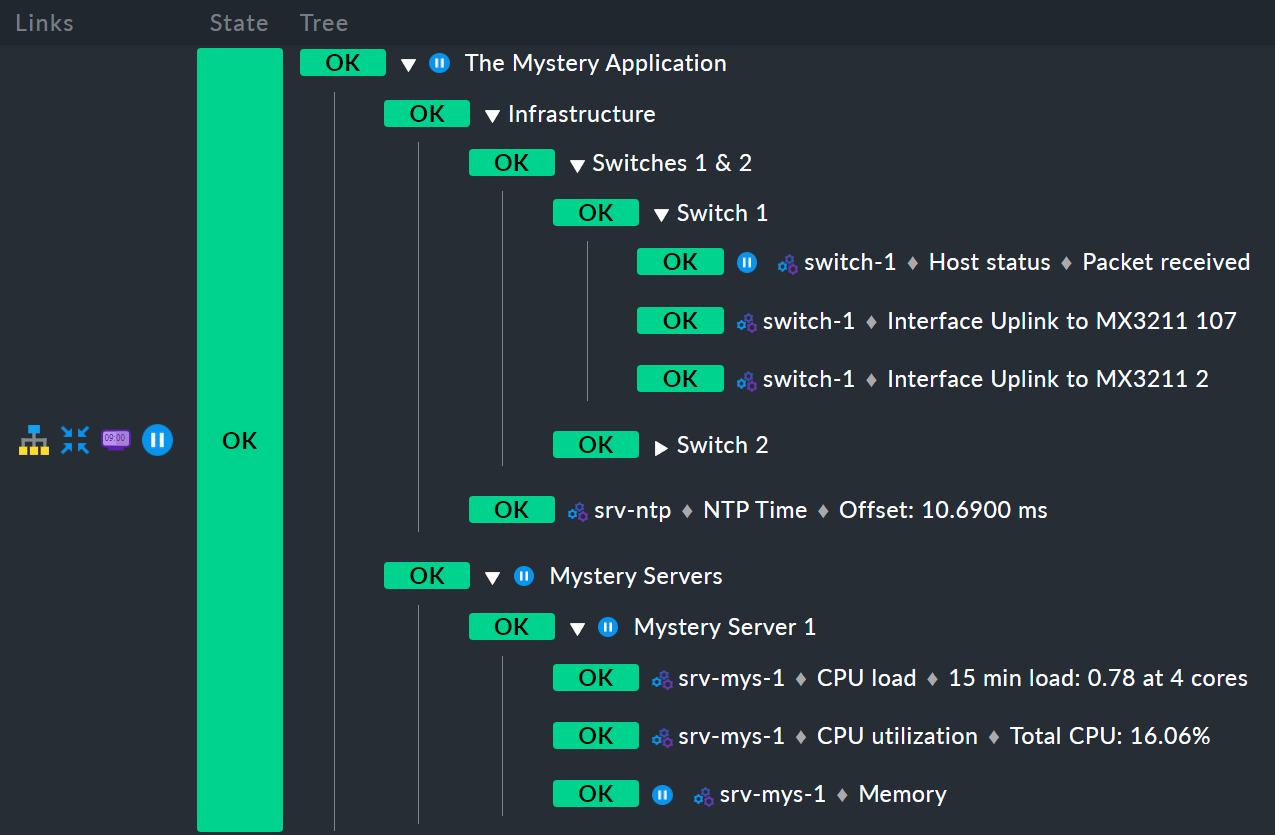
In primo luogo, l'host switch-1 è in tempo di manutenzione programmata.
Per il nodo Infrastructure questo non ha alcun effetto, perché switch-2 non è in tempo di manutenzione programmata,
e quindi anche Infrastructure non è in tempo di manutenzione programmata.
Non c'è quindi il simbolo ![]() per i tempi di manutenzione programmata derivati.
per i tempi di manutenzione programmata derivati.
Tuttavia, anche il servizio Memory su srv-mys-1 è in tempo di manutenzione programmata.
Questo non è ridondante.
Il tempo di manutenzione programmata viene quindi ereditato dal nodo padre Mystery Server 1, per poi proseguire fino a Mystery Servers e infine al nodo principale The Mystery Application.
Anche questo nodo principale sarà quindi in tempo di manutenzione programmata.
9.2. Comando per i periodi di tempo di manutenzione programmata
Abbiamo scritto sopra che non è possibile inserire manualmente un'aggregazione BI in un periodo di tempo di manutenzione programmata?
Questo è vero solo a metà, poiché in realtà esiste un comando ![]() per impostare periodi di tempo di manutenzione programmata nelle aggregazioni BI.
Ma questo non fa altro che registrare una voce di tempo di manutenzione per ogni host e servizio nell'aggregazione.
Questo ovviamente porta solitamente a contrassegnare l'aggregazione stessa come inattiva,
ma si tratta solo di una procedura indiretta.
per impostare periodi di tempo di manutenzione programmata nelle aggregazioni BI.
Ma questo non fa altro che registrare una voce di tempo di manutenzione per ogni host e servizio nell'aggregazione.
Questo ovviamente porta solitamente a contrassegnare l'aggregazione stessa come inattiva,
ma si tratta solo di una procedura indiretta.
9.3. Opzioni di ottimizzazione
Come hai visto sopra, il calcolo del tempo di manutenzione programmata si basa su uno stato "CRIT" ipotizzato. Nelle proprietà di un'aggregazione puoi personalizzare l'algoritmo in modo che un nodo che assume lo stato "WARN" venga contrassegnato come in tempo di manutenzione programmata. L'opzione per farlo si chiama "Escalate downtimes based on aggregated WARN state":
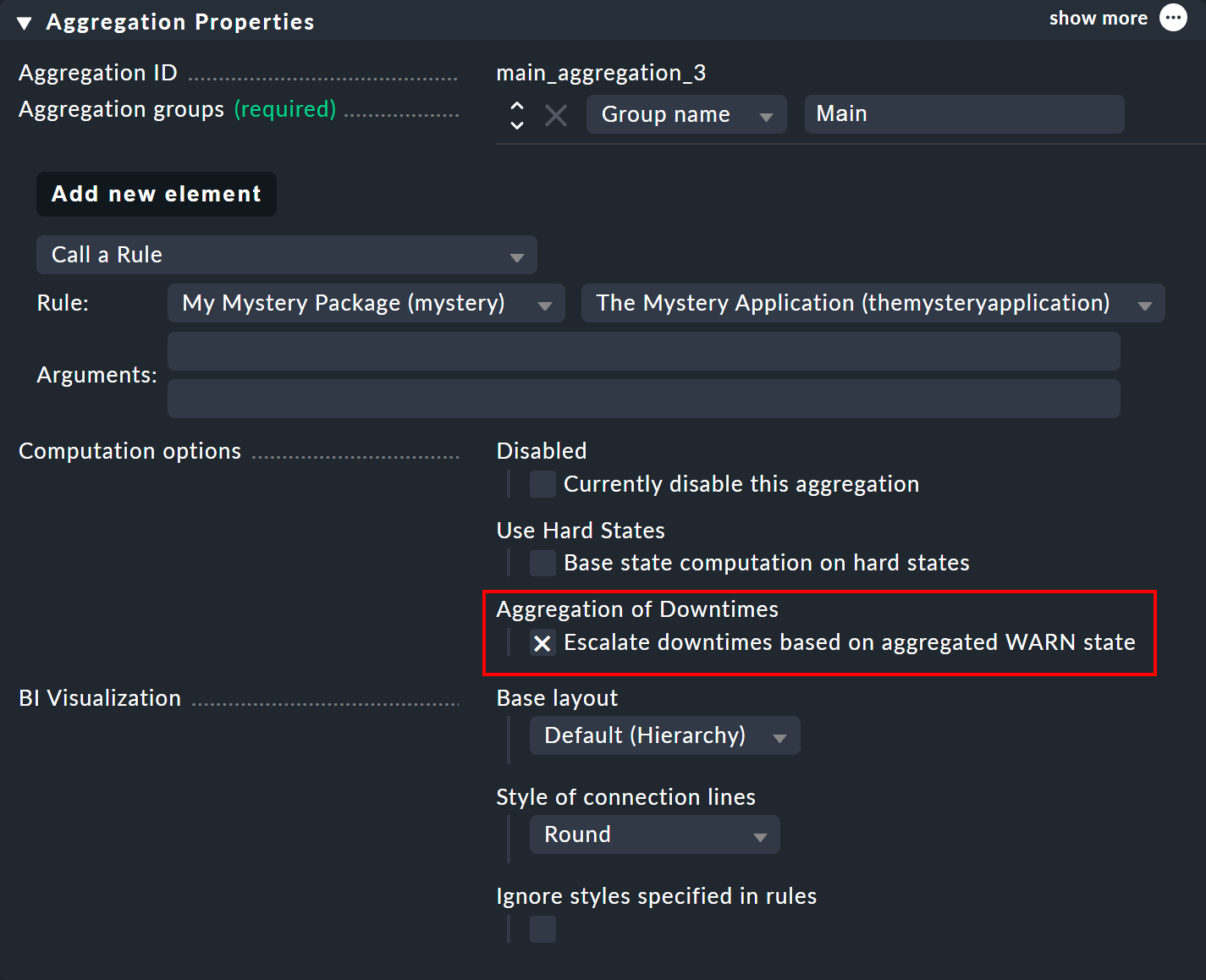
L'ipotesi di base rimane che gli oggetti in tempo di manutenzione programmata siano CRIT. C'è solo una differenza nel caso in cui, a causa della funzione di aggregazione, un CRIT possa diventare un WARN — come nel nostro primissimo esempio con Count the number of nodes in state OK. Qui una tempo di manutenzione programmata sarebbe già stato accettato se solo uno dei due switch fosse stato in tempo di manutenzione programmata.
9.4. Riconoscimenti
In modo molto simile al processo con le tempistiche di manutenzione programmate, se un problema è stato ![]() confermato, l'informazione verrà
calcolata automaticamente anche da BI.
In questo caso lo stato degli oggetti gioca sicuramente un ruolo.
confermato, l'informazione verrà
calcolata automaticamente anche da BI.
In questo caso lo stato degli oggetti gioca sicuramente un ruolo.
L'idea è quella di trasferire il seguente concetto al BI:
Un oggetto presenta un problema (WARN , CRIT), ma questo è noto e qualcuno ci sta lavorando (![]() ).
).
Puoi calcolarlo per un'aggregazione come segue:
Supponiamo che tutti gli host e i servizi che hanno problemi confermati come
 siano di nuovo OK.
siano di nuovo OK.Allora l'aggregazione stessa tornerebbe ad essere OK? Proprio in questo caso verrebbe effettuato il riconoscimento come
.
Tuttavia, se l'aggregazione dovesse rimanere in stato "WARN" o "CRIT", allora non verrebbe considerata come confermata, perché in tal caso ci sarebbe almeno un problema importante che non è stato confermato, e quindi lo stato "OK" verrebbe rimosso dall'aggregazione.
A proposito, l'![]() ti offrirà un comando per far sì che l'aggregazione BI riconosca i propri problemi,
ma questo significa solo che tutti gli host e i servizi rilevati nell'aggregazione verranno riconosciuti (solo quelli che attualmente presentano problemi).
ti offrirà un comando per far sì che l'aggregazione BI riconosca i propri problemi,
ma questo significa solo che tutti gli host e i servizi rilevati nell'aggregazione verranno riconosciuti (solo quelli che attualmente presentano problemi).
10. Rendere visibili le modifiche
I nodi all'interno di un'aggregazione a volte possono cambiare durante il funzionamento. Usando le aggregazioni congelate puoi rendere visibili tali modifiche.
Ecco un esempio: Uno switch con 6 porte dovrebbe essere "OK" quando 5 dei suoi servizi/porte sono "OK". Tuttavia, nell'ambito di un aggiornamento del firmware, 2 delle porte vengono rinominate e i servizi associati scompaiono dal monitoraggio.
L'aggregazione consisterebbe quindi in 4 servizi con lo stato "OK", ma l'aggregazione stessa risulterebbe "WARN" o "CRIT" — senza fornire alcuna indicazione del motivo. È proprio qui che entrano in gioco le aggregazioni congelate: congeli lo stato attuale e in seguito puoi cliccare per creare un elenco di ciò che è cambiato da allora, ovvero quali nodi sono stati aggiunti o rimossi. In altre parole, mentre le regole di un'aggregazione indicano il suo stato, le aggregazioni congelate forniscono informazioni sui cambiamenti di stato.
10.1. Congelamento e confronto
Usare la funzione di congelamento è molto semplice: Abilita l'opzione "New aggregations are frozen" in "Aggregation Properties".
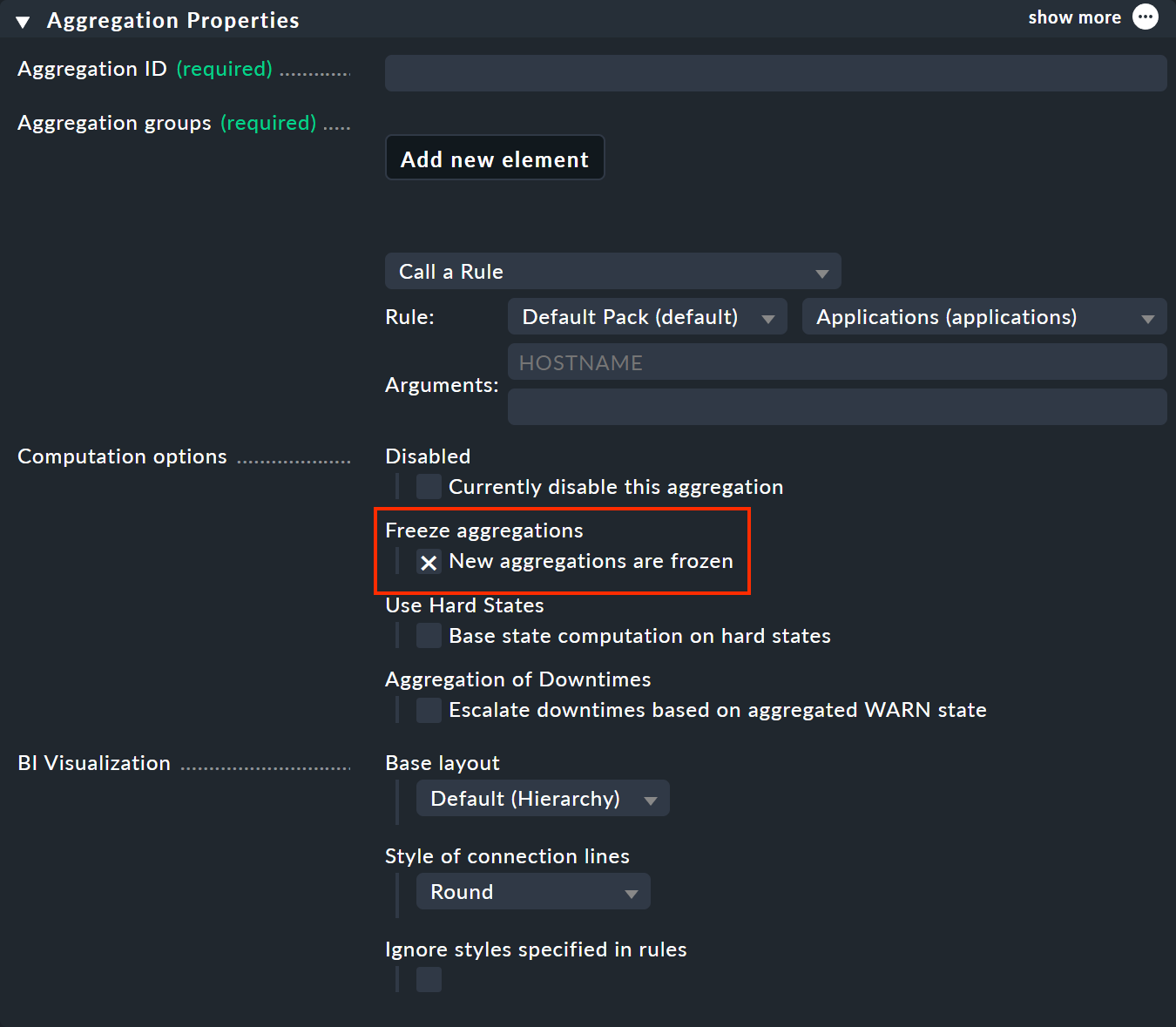
Questo congelerà l'aggregazione al momento del salvataggio — e lo farà ogni volta che il segno di spunta viene impostato di nuovo; anche se l'aggregazione esisteva già in precedenza (nonostante il riferimento a "New aggregations …"). Per sbloccare lo stato congelato, rimuovi il segno di spunta.
Nel monitoraggio, vedrai ora un nuovo simbolo a forma di fiocco di neve "![]() " accanto all'aggregazione.
Questo ti porterà alla visualizzazione che mostra le differenze:
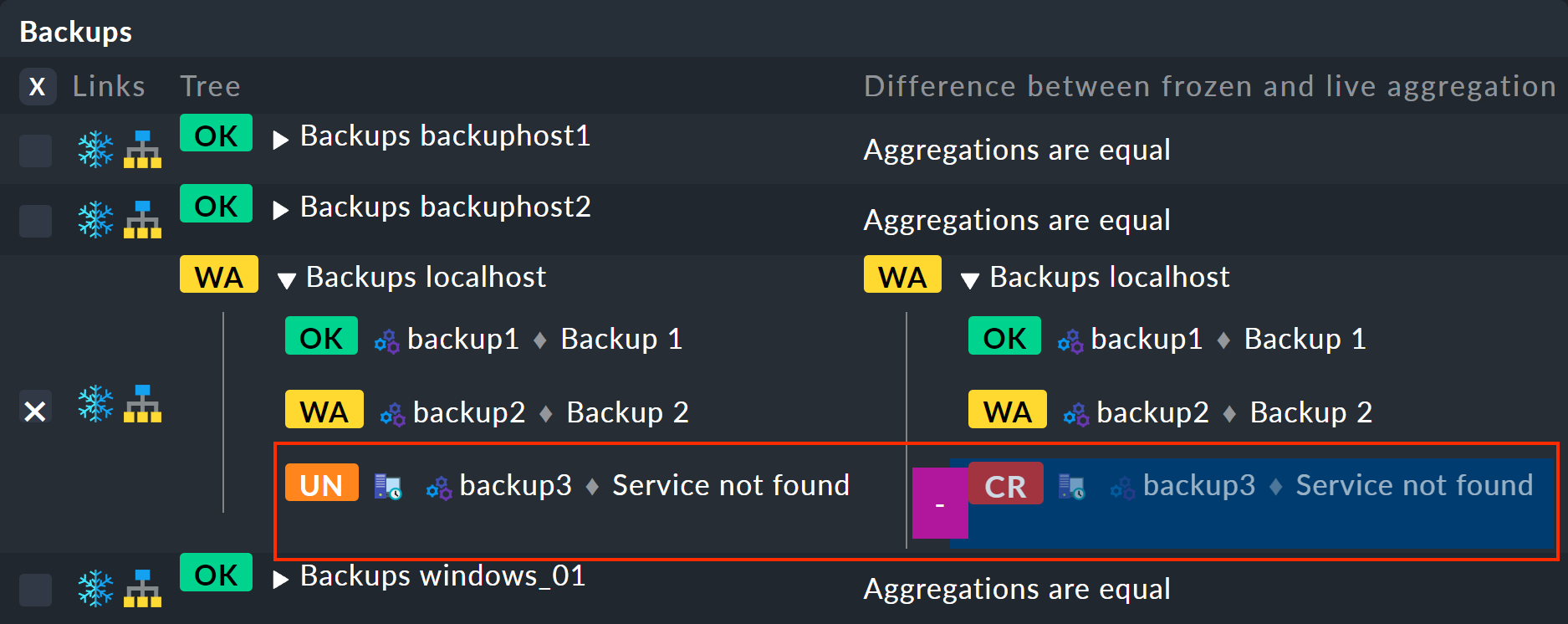
A sinistra l'albero congelato, a destra l'albero attuale con le modifiche evidenziate (in questo caso la rimozione del servizio backup3):
" accanto all'aggregazione.
Questo ti porterà alla visualizzazione che mostra le differenze:
A sinistra l'albero congelato, a destra l'albero attuale con le modifiche evidenziate (in questo caso la rimozione del servizio backup3):
Se vuoi congelare nuovamente lo stato attuale, puoi farlo tramite Commands > Freeze aggregations. Ma fai attenzione: c'è sempre e solo uno stato attuale congelato e nessuna cronologia, inclusi gli stati precedenti.
11. Disponibilità
Proprio come per gli host e i servizi, puoi anche accedere alla disponibilità BI di una o più aggregazioni per qualsiasi periodo di tempo passato. Per farlo, il modulo BI ricostruisce lo stato in base alla cronologia degli host e dei servizi dell'aggregazione per ogni periodo di tempo passato. In questo modo puoi calcolare la disponibilità anche per quei periodi in cui l'aggregazione non era ancora configurata!

Per tutti i dettagli su BI e disponibilità, consulta la sezione dedicata alla BI nell'articolo sulla disponibilità.
12. BI nel monitoraggio distribuito
Cosa succede effettivamente nella BI in un ambiente distribuito? Cioè, quando gli host sono distribuiti su più server di monitoraggio?
La risposta è relativamente semplice: funziona, senza che tu debba prestare attenzione a nulla. Poiché BI è un componente della GUI e, di default, viene fornito con funzionalità di supporto all'ambiente distribuito, è completamente trasparente per BI.
Se una posizione è attualmente non disponibile o è stata nascosta manualmente dalla GUI, le istanze del sito non esistono più per la BI. Ciò significa quindi che:
le aggregazioni BI costruite esclusivamente da oggetti in questa posizione scompaiono.
Le aggregazioni BI costruite parzialmente da oggetti presenti in questa posizione vengono ridotte.
In quest’ultimo caso, ovviamente, ciò può influire sullo stato delle aggregazioni interessate. Quali effetti ciò possa avere dipenderà dalle tue funzioni di aggregazione. Se, ad esempio, hai utilizzato ovunque worst, lo stato complessivo rimane semplicemente lo stesso o migliora, poiché gli oggetti nella posizione non più esistente potrebbero aver già avuto WARN o CRIT. Naturalmente possono verificarsi anche altri stati per altre funzioni di aggregazione.
Se questo comportamento sia pratico o meno per la tua operazione dovrà essere valutato caso per caso. BI è comunque strutturato in modo tale che gli oggetti inesistenti non possano essere inclusi in un'aggregazione BI e quindi non possano mancare, poiché tutte le regole BI funzionano — come già spiegato sopra — esclusivamente con modelli di ricerca.
13. Notifiche, BI come servizio
È davvero possibile ricevere notifiche sui cambiamenti di stato nelle aggregazioni BI? Beh... a prima vista non è direttamente possibile, dato che la BI esiste esclusivamente nella GUI e non ha alcuna relazione con il monitoraggio vero e proprio. Ma puoi trasformare le aggregazioni BI in normali servizi, e questi a loro volta possono ovviamente attivare delle notifiche.
Per farlo puoi usare l'special agent BI Aggregations. Troverai il set di regole appropriato in Setup > Agents > Other integrations > BI Aggregations. Per prima cosa crea una nuova voce nella box BI Aggregations con Add new entry.
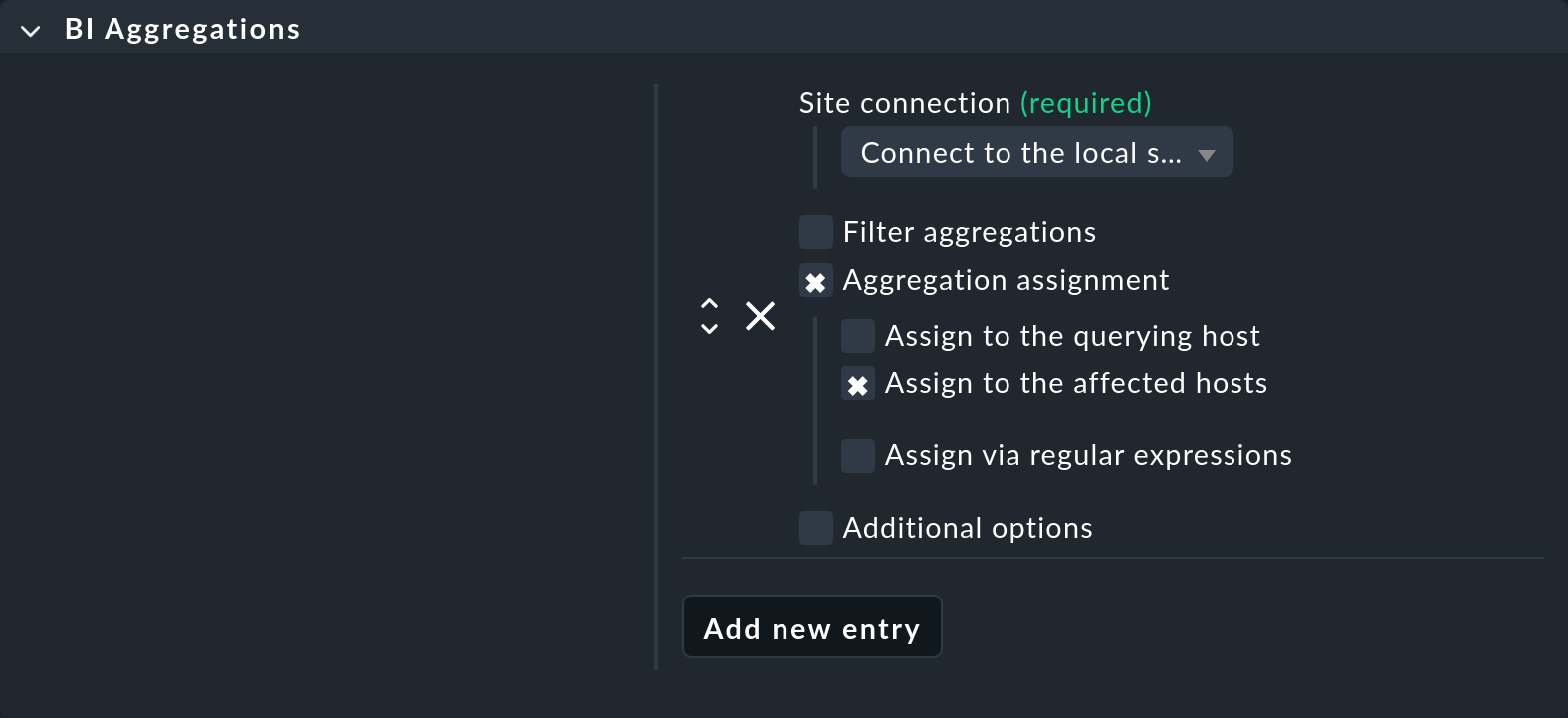
Qui puoi specificare diverse opzioni per stabilire a quali host aggiungere i servizi. Non devono necessariamente essere collegati all'host a cui è assegnato l'special agent (Assign to the querying host). È anche possibile assegnarli agli host inclusi nell'aggregazione (Assign to the affected hosts). Questo però ha senso solo se si tratta di un singolo host. Le espressioni regolari e le sostituzioni possono rendere le assegnazioni ancora più flessibili. Il tutto viene poi eseguito tramite il meccanismo piggyback.
Importante: se l'host a cui assegni questa regola deve continuare a essere monitorato tramite l'agente normale, assicurati nelle sue impostazioni che l'agente e gli special agents siano in esecuzione:

Il nuovo servizio mostra quindi — ovviamente con un ritardo massimo pari a un intervallo di check — lo stato dell'aggregazione. Ecco due esempi di nuovi servizi, integrati automaticamente dal prefisso Aggr:

Come al solito, puoi assegnare questo servizio ai contatti e utilizzarlo come base per le notifiche.