This is a machine translation based on the English version of the article. It might or might not have already been subject to text preparation. If you find errors, please file a GitHub issue that states the paragraph that has to be improved. |
1. Falsi allarmi: letali per qualsiasi sistema di monitoraggio
Il monitoraggio è davvero utile solo se è preciso. Il principale ostacolo all'accettazione da parte dei colleghi (e probabilmente anche da parte tua) sono i falsi positivi — o, in parole povere, i falsi allarmi.
Abbiamo visto alcuni principianti di Checkmk aggiungere molti sistemi al monitoraggio in poco tempo — forse perché in Checkmk è così facile farlo. Quando poco dopo hanno attivato le notifiche per tutti gli utenti, i loro colleghi sono stati sommersi da centinaia di e-mail al giorno e, dopo solo pochi giorni, il loro entusiasmo per il monitoraggio è stato praticamente distrutto.
Anche se Checkmk si impegna davvero a definire valori predefiniti adeguati e validi per tutte le impostazioni possibili, semplicemente non può sapere con sufficiente precisione come dovrebbero essere le cose nel tuo ambiente IT in condizioni normali. Pertanto, è necessario un po' di lavoro manuale da parte tua per regolare il monitoraggio fino a quando non verrà inviato nemmeno l'ultimo falso allarme. A parte questo, Checkmk individuerà anche parecchi problemi reali che tu e i tuoi colleghi non avevate ancora sospettato. Anche questi devono essere prima risolti correttamente — nella realtà, non nel monitoraggio!
Il seguente principio si è dimostrato valido: prima la qualità, poi la quantità — o, in altre parole:
Non includere troppi host nel monitoraggio tutti in una volta.
Assicurati che tutti i servizi che non presentano realmente alcun problema siano affidabili e in OK.
Attiva le notifiche via e-mail o SMS solo dopo che Checkmk ha funzionato in modo affidabile per un po' di tempo senza o con pochissimi falsi allarmi.
I falsi allarmi possono ovviamente verificarsi solo quando la funzione di notifica è attivata. Quindi, in sostanza, quello che dobbiamo fare qui è disattivare la fase preliminare delle notifiche ed evitare gli stati critici DOWN, WARN o CRIT per i problemi non critici. |
Nelle seguenti sezioni sulla configurazione ti mostreremo quali opzioni per regolare la configurazione hai a disposizione — in modo che tutto ciò che non causa problemi sia verde — e come tenere sotto controllo eventuali interruzioni occasionali.
2. Configurazione rule-based
Prima di iniziare la configurazione, dobbiamo dare un'occhiata veloce alle impostazioni di host e servizi in Checkmk. Dato che Checkmk è stato sviluppato per ambienti grandi e complessi, questo viene fatto usando delle regole. Questo concetto è molto potente e offre molti vantaggi anche agli ambienti più piccoli.
L'idea di base è che non devi specificare esplicitamente ogni singolo parametro per ogni servizio, ma implementare qualcosa del tipo: "
Su tutti i server Oracle di produzione, i file system con il prefisso /var/ora/ che raggiungono il 90% di riempimento saranno
WARN
e al 95% saranno
CRIT
".
Una regola del genere può impostare soglie per migliaia di file system con una sola azione. Allo stesso tempo, documenta anche in modo molto chiaro quali politiche di monitoraggio si applicano nella tua azienda.
Partendo da una regola di base, puoi poi definire separatamente delle eccezioni per singoli casi.
Una regola adeguata potrebbe essere questa:
'Sul server Oracle srvora123, il file system /var/ora/db01/, quando è pieno al 96%, sarà
WARN
e al 98% sarà
CRIT
'.
Questa regola di eccezione viene impostata in Checkmk allo stesso modo della regola di base.
Ogni regola ha la stessa struttura. È sempre composta da una condizione e da un valore. Puoi anche aggiungere una descrizione e un commento per documentare lo scopo della regola.
Le regole sono organizzate in set di regole. Per ogni tipo di parametro, Checkmk ha un set di regole adatto già pronto, quindi puoi scegliere tra diverse centinaia di set di regole. Ad esempio, ce n'è uno chiamato "Filesystems (used space and growth)" che imposta le soglie per tutti i servizi che effettuano il monitoraggio dei file system. Per implementare l’esempio sopra riportato, dovresti impostare la regola di base e la regola di eccezione da questo set di regole. Per determinare quali soglie sono valide per un particolare file system, Checkmk passa in sequenza attraverso tutte le regole valide per il controllo. La prima regola per cui si applica la condizione imposta il valore — in questo caso, il valore percentuale al quale il controllo del file system diventa WARN o CRIT.
3. Ricerca delle regole
Hai diverse opzioni per accedere ai set di regole in Checkmk.
Da un lato, puoi trovare i set di regole nel menu "Setup" sotto i temi relativi agli oggetti per i quali esistono set di regole (Hosts, Services e Agents) in diverse categorie. Ad esempio, per i servizi sono disponibili le seguenti voci relative ai set di regole: Service monitoring rules, Discovery rules, Enforced services, HTTP, TCP, Email, … e Other Services. Se selezioni una di queste voci, i set di regole associati verranno elencati nella pagina principale. Potrebbero essere solo pochi, oppure moltissimi, come nel caso dell'Service monitoring rules. Per questo motivo, hai la possibilità di filtrare i risultati nella pagina dei risultati, nel campo "Filter" della barra del menu.
Se non sei sicuro in quale categoria si trovi il set di regole, puoi anche cercare tra tutte le regole in una volta sola, utilizzando il campo di ricerca nel menu di configurazione oppure aprendo la pagina di ricerca delle regole tramite Setup > General > Rule search. Seguiremo quest’ultima strada nella sezione seguente, in cui introdurremo il processo di creazione delle regole.
Con il gran numero di set di regole disponibili, non è sempre facile trovare quello giusto, con o senza ricerca.
Tuttavia, c'è un altro modo per accedere alle regole appropriate per un servizio esistente.
In una visualizzazione che include il servizio, clicca sull'opzione di menu ![]() e seleziona la voce Parameters for this service:
e seleziona la voce Parameters for this service:
Verrà visualizzata una pagina dalla quale potrai accedere a tutti i set di regole per questo servizio:
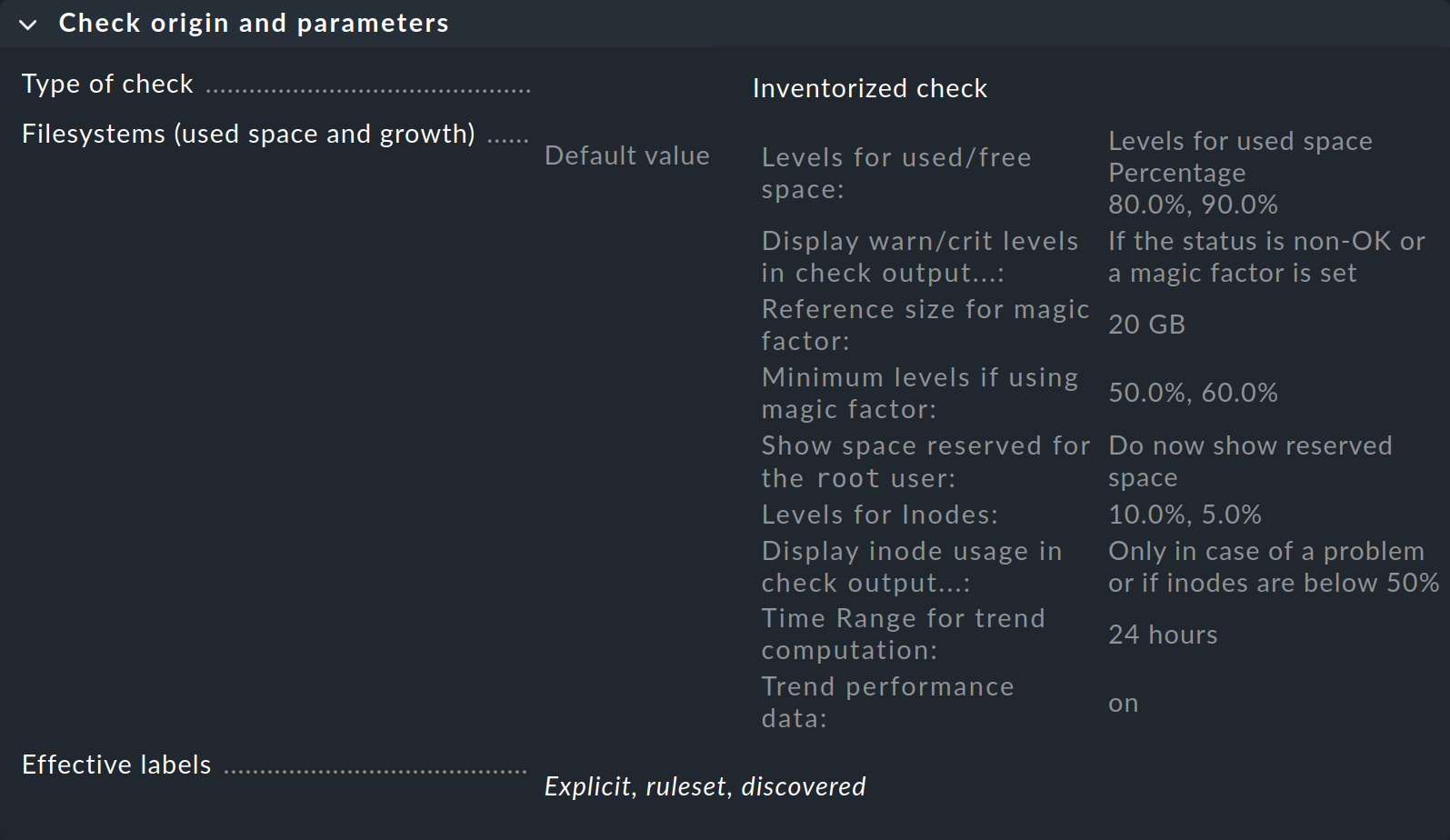
Nella prima box intitolata "Check origin and parameters", la voce "Filesystems (used space and growth)" ti porta direttamente al set di regole per le soglie di monitoraggio del file system. Tuttavia, puoi vedere nella panoramica che Checkmk ha già impostato dei valori predefiniti, quindi devi creare una regola solo se vuoi modificare tali valori predefiniti.
4. Creazione delle regole
Come si presenta una regola nella pratica? Il modo migliore per iniziare è formulare la regola che vuoi implementare in una frase, in questo modo: Su tutti i server Oracle di produzione, i tablespace DW20 e DW30 al 90% di riempimento avranno lo stato WARN e al 95% lo stato CRIT.
Puoi quindi cercare un set di regole appropriato — in questo esempio tramite la ricerca per regola: Setup > General > Rule search. Si aprirà una pagina in cui potrai cercare "Oracle" o "tablespace" (senza distinzione tra maiuscole e minuscole) e trovare tutti i set di regole che contengono questo testo nel nome o nella descrizione (non mostrato qui):
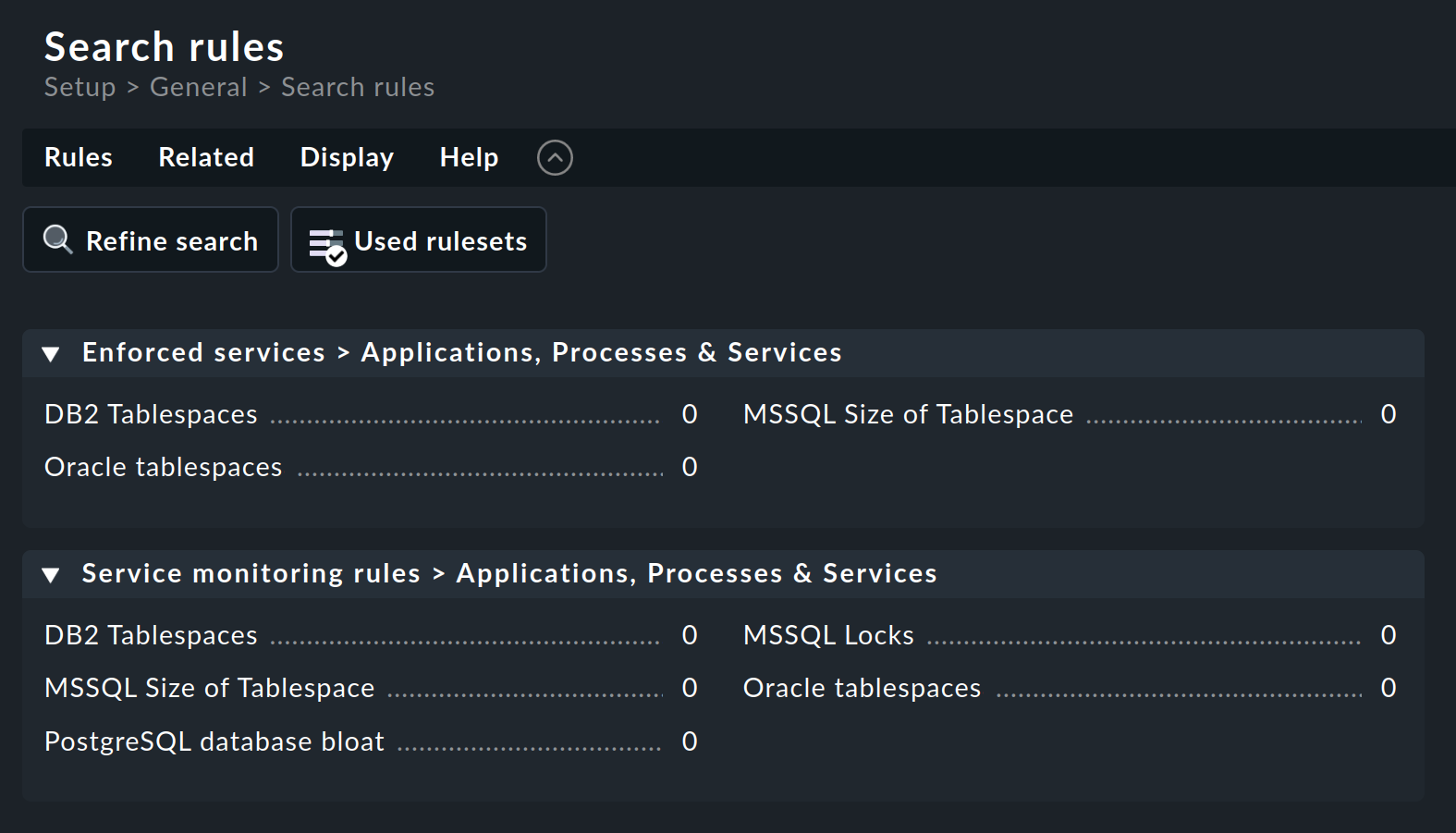
Il set di regole Oracle tablespaces si trova in due categorie.
Il numero che segue il titolo (qui ovunque 0) indica il numero di regole già create da questo set di regole.
In questo esempio, non vogliamo l'impostazione del servizio forzata. Pertanto, clicca sul nome nella categoria "Service monitoring rules" per aprire la pagina di panoramica del set di regole:
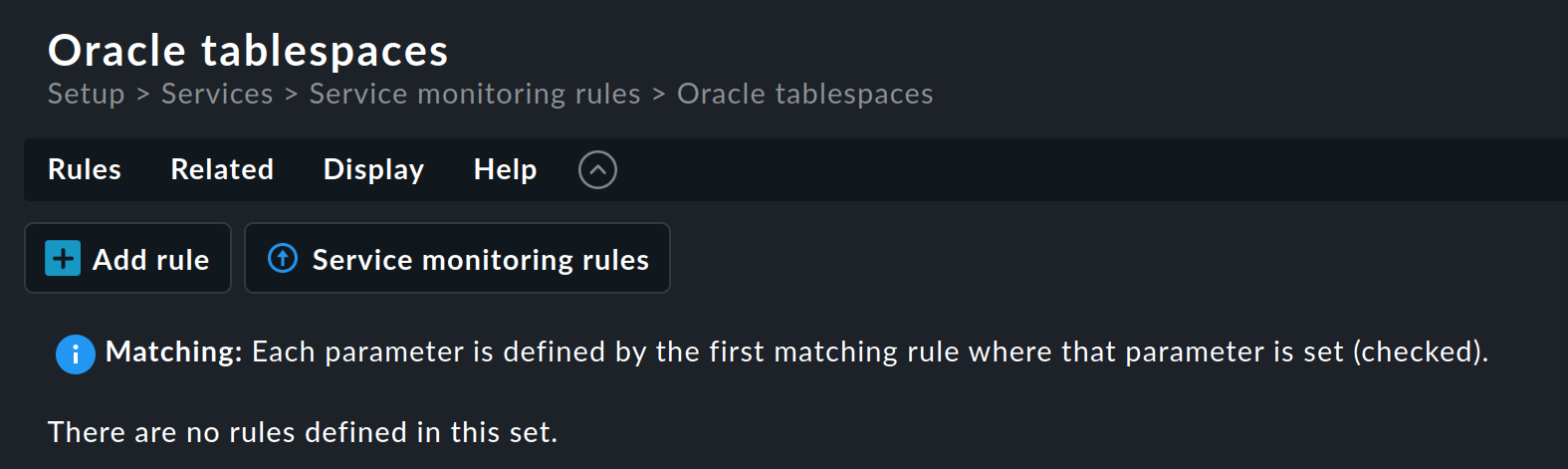
Questo set di regole non contiene ancora alcuna regola. Puoi creare la prima regola con il pulsante "Add rule". La creazione — e la successiva modifica — di questa regola apre un modulo con tre box: "Rule properties", "Value" e "Conditions". Esamineremo ciascuna di queste tre a turno.
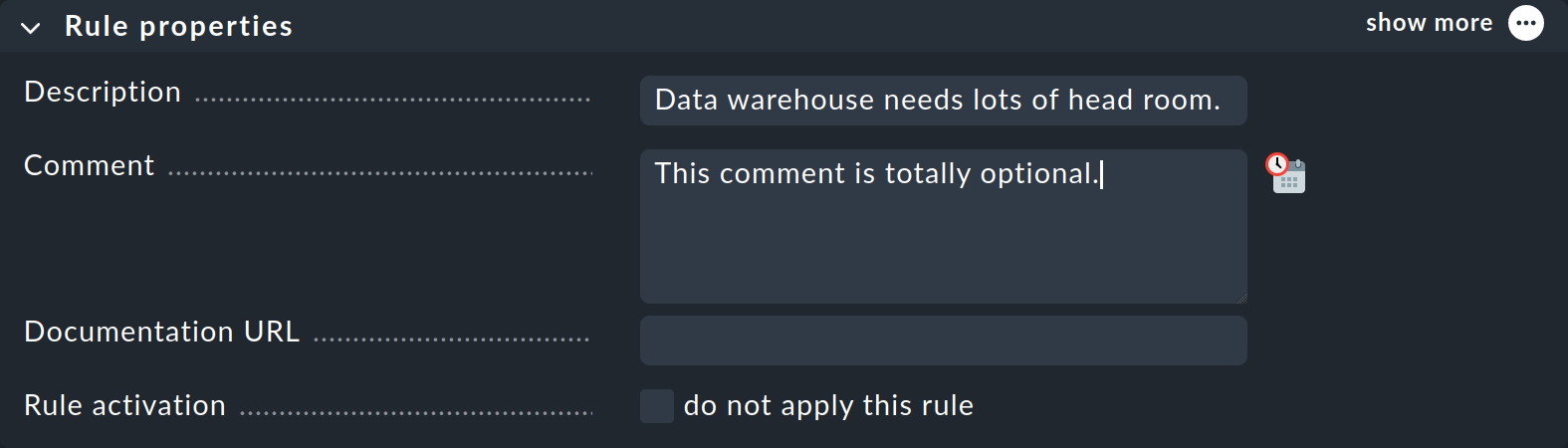
Nella box "Rule properties", tutti i campi sono facoltativi. Oltre ai testi informativi, qui hai anche la possibilità di disattivare temporaneamente una regola. Questo è utile perché a volte puoi evitare di cancellare e ricreare una regola se temporaneamente non ne hai bisogno.
Ciò che trovi nella box "Value" dipende, in ogni caso specifico, dal contenuto di ciò che viene regolato:
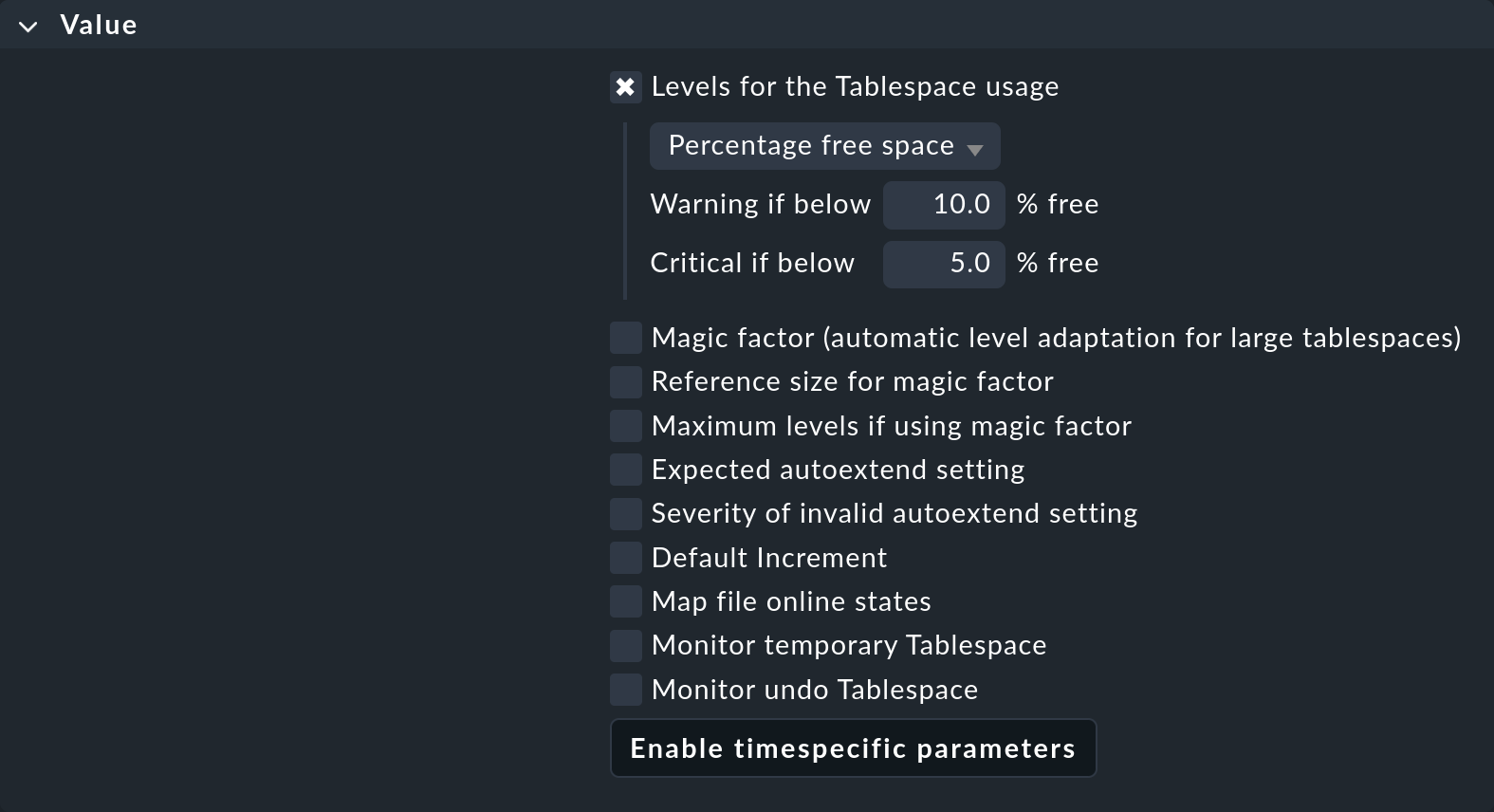
Come puoi vedere, i parametri possono essere piuttosto numerosi. L'esempio mostra un caso tipico: ogni singolo parametro può essere attivato tramite una checkbox e la regola si applicherà quindi solo a quel parametro. Puoi, ad esempio, lasciare che un altro parametro sia determinato da una regola diversa se ciò semplifica la tua configurazione. In questo esempio, verranno definiti solo i valori di threshold per la percentuale di spazio libero nel tablespace.
La box "Conditions" per l'impostazione delle condizioni sembra un po' più complicata a prima vista:
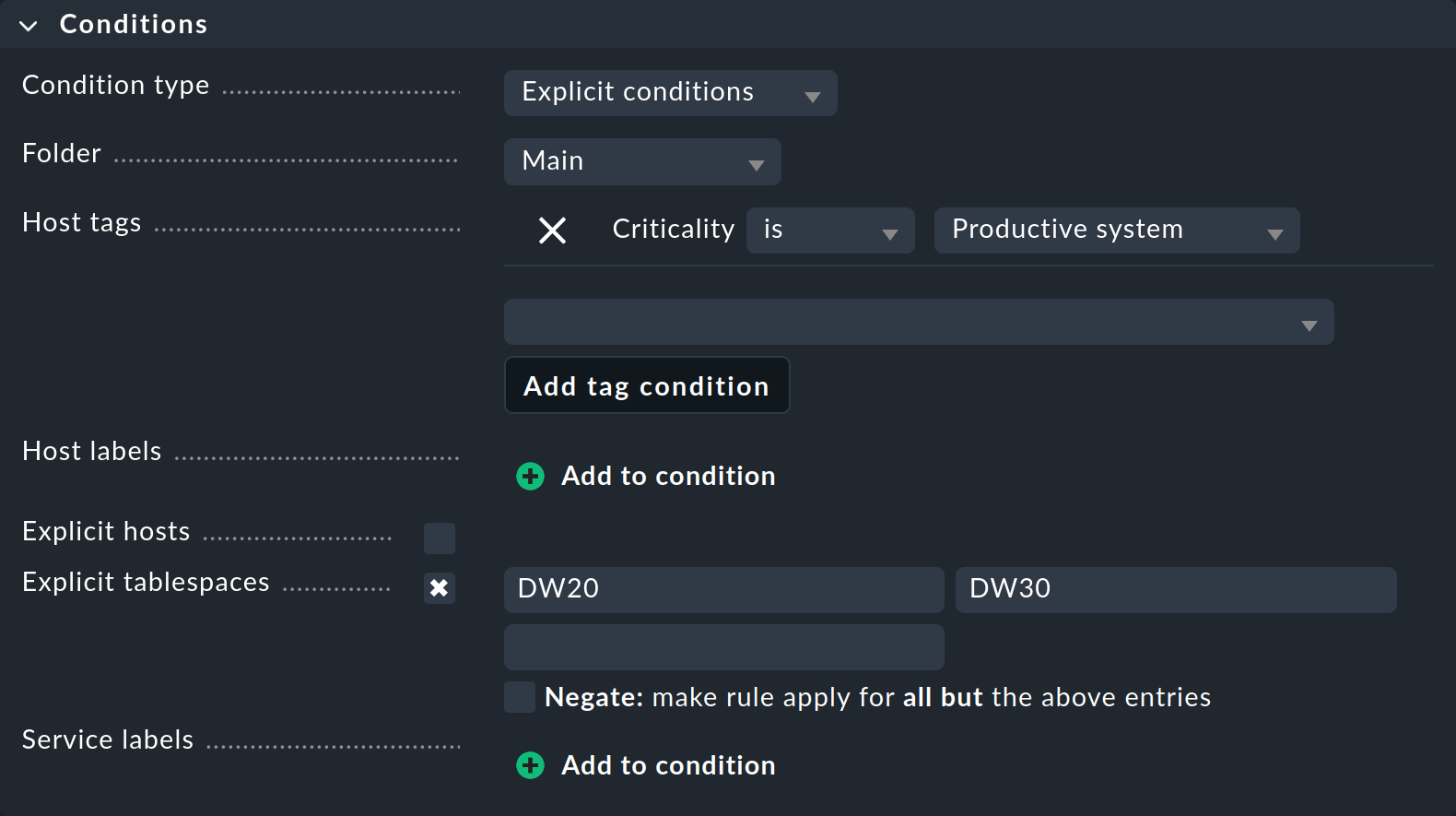
In questo esempio ci limiteremo ai parametri che ci servono assolutamente per definire questa regola specifica:
Con Folder specifichi in quale cartella deve essere applicata la regola. Ad esempio, se cambi l'Maine predefinita in Windows, la nuova regola si applicherà solo agli host che si trovano direttamente nella cartella Windows o nelle sottocartelle.
Gli Host tags sono una funzionalità molto importante in Checkmk, quindi dedicheremo loro una sezione a parte subito dopo questa. A questo punto, usa uno dei tag host predefiniti per specificare che la regola si applichi solo ai sistemi di produzione. Seleziona prima il gruppo di tag host Criticality dall'elenco, poi clicca su Add tag condition e seleziona il valore Productive system.
In questo esempio sono molto importanti le condizioni "Explicit tablespaces", che limitano la regola a servizi molto specifici. Due punti sono importanti qui:
Il nome di questa condizione si adatta al tipo di regola. Se c'è scritto Explicit services, specifica i nomi dei servizi interessati. Ad esempio, uno di questi potrebbe essere
Tablespace DW20, ovvero includendo la parolaTablespace. Nell'esempio mostrato, tuttavia, Checkmk vuole solo conoscere il nome del tablespace stesso, quindiDW20.I testi inseriti corrispondono sempre all'inizio. L'inserimento di
DW20accede quindi anche a un tablespace fittizioDW20A. Se vuoi evitare questo, aggiungi il carattere$alla fine, cioèDW20$, perché si tratta di cosiddette espressioni regolari.
Una descrizione dettagliata di tutti gli altri parametri e una spiegazione approfondita dell'importante concetto di regole è disponibile nell'articolo sulle regole. A proposito, puoi saperne di più sull'Service labels, l'ultimo parametro nell'immagine sopra, nell'articolo sulle etichette. |
Una volta completate tutte le voci per la definizione, salva la regola con l'Save. Dopo il salvataggio, ci sarà esattamente una nuova regola nel set di regole:

Se invece di lavorare con una sola regola, in seguito ne utilizzerai centinaia, c'è il rischio di perdere la panoramica. Per aiutarti a mantenere una panoramica, Checkmk fornisce voci molto utili nel menu Related su ogni pagina che elenca le regole. In questo modo puoi visualizzare le regole utilizzate nell'istanza corrente (Used rulesets) e, analogamente, quelle che non vengono utilizzate affatto (Ineffective rules). |
5. Tag host
5.1. Come funzionano i tag host
Nella sezione precedente abbiamo visto un esempio di regola che dovrebbe applicarsi solo ai sistemi di produzione. Più precisamente, in quella regola abbiamo definito una condizione utilizzando il tag host Productive system. Perché abbiamo definito la condizione come tag e non l’abbiamo semplicemente impostata per la cartella? Beh, puoi definire solo una singola struttura di cartelle e ogni host può trovarsi solo in una cartella. Ma un host può avere molti tag diversi e la struttura delle cartelle è semplicemente troppo limitata e non abbastanza flessibile per questo.
Al contrario, puoi assegnare tag host in modo libero e arbitrario come preferisci, indipendentemente dalla cartella in cui si trovano gli host. Puoi poi fare riferimento a questi tag host nelle tue regole. Questo rende la configurazione non solo più semplice, ma anche più facile da capire e meno soggetta a errori rispetto a se dovessi definire tutto esplicitamente per ogni host.
Ma come e dove si definisce quali host devono avere quale tag? E come puoi definire i tuoi tag personalizzati?
5.2. Definizione dei tag host
Cominciamo con la risposta alla seconda domanda sui tag personalizzati. Prima di tutto, devi sapere che i tag sono organizzati in gruppi chiamati gruppi di tag host. Prendiamo come esempio la posizione. Un gruppo di tag potrebbe chiamarsi Posizione e questo gruppo potrebbe contenere i tag Monaco, Austin e Singapore. In sostanza, a ogni host viene assegnato esattamente un tag da ciascun gruppo di tag. Quindi, non appena definisci il tuo gruppo di tag, ogni host avrà uno dei tag di questo gruppo. Agli host per i quali non hai selezionato un tag dal gruppo viene semplicemente assegnato il primo per impostazione predefinita.
Per la definizione dei gruppi di tag host, consulta Setup > Hosts > Tags:
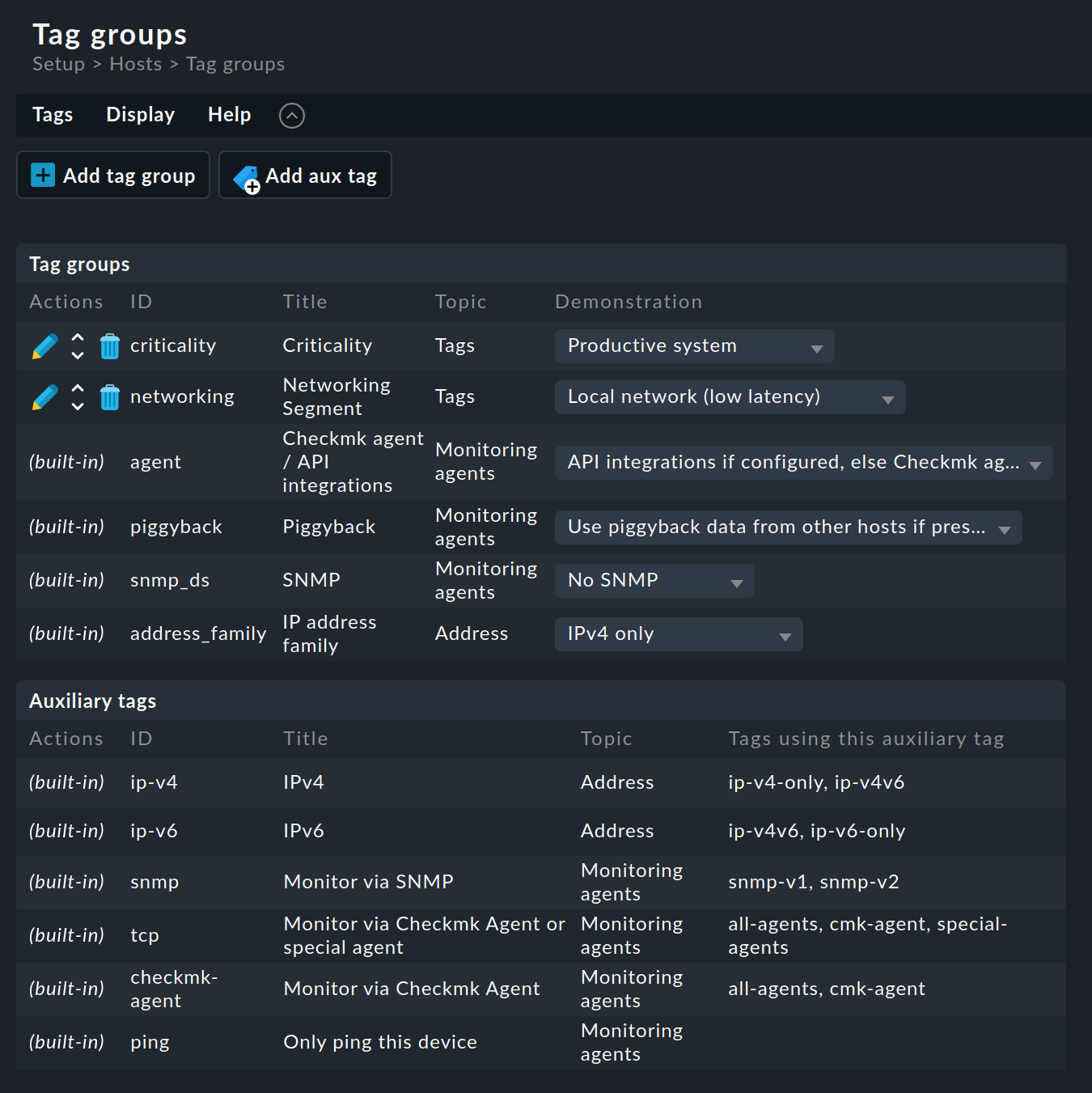
Come puoi vedere, alcuni gruppi di tag sono già stati predefiniti. Non puoi modificare la maggior parte di questi. Ti consigliamo inoltre di non modificare i due gruppi di esempio predefiniti Criticality e Networking Segment. È meglio definire i tuoi gruppi:
Clicca su Add tag group. Si aprirà la pagina per la creazione di un nuovo gruppo di tag. Nella prima box Basic settings assegni — come spesso accade in Checkmk — un ID interno che funge da chiave e che non può essere modificato in seguito. Oltre all’ID, definisci un titolo descrittivo, che potrai modificare in qualsiasi momento. Con Topic puoi determinare dove il tag verrà visualizzato in seguito nelle proprietà dell’host. Se crei un nuovo tema qui, il tag verrà visualizzato in una box separata nelle proprietà dell'host.
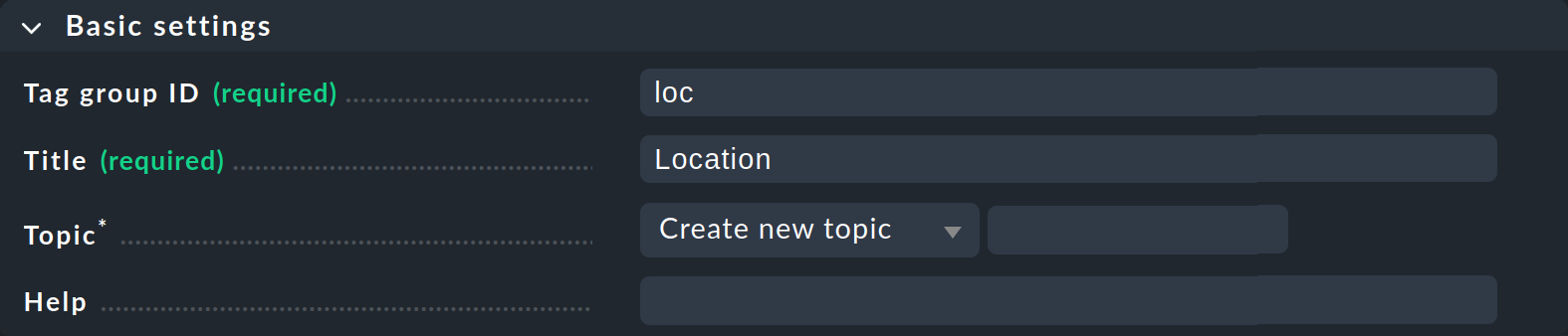
La seconda box, "Tag choices", riguarda i tag effettivi, ovvero le opzioni di selezione nel gruppo di tag. Clicca su "Add tag choice" per creare un tag e assegnare un ID interno e un titolo a ciascun tag:
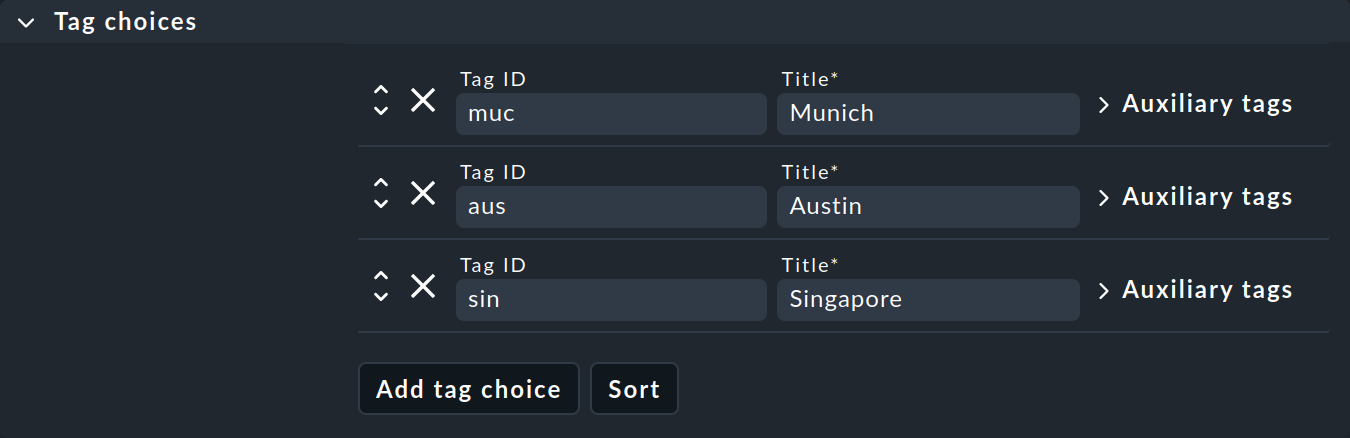
Note:
Sono ammessi anche gruppi con una sola selezione e possono persino essere utili. Il tag in essi contenuto è noto come tag della checkbox e appare quindi nelle proprietà dell'host semplicemente come una checkbox. Ogni host avrà quindi il tag — o meno, poiché i tag della checkbox sono disabilitati per impostazione predefinita.
A questo punto, puoi ignorare i tag ausiliari per ora. Puoi trovare tutte le informazioni sui tag ausiliari in particolare e sui tag host in generale nell'articolo sui tag host.
Una volta salvato questo nuovo gruppo di tag host con Save, puoi iniziare a utilizzarlo.
5.3. Assegnazione di un tag a un host
Hai già visto come assegnare i tag a un host — nelle proprietà dell’host durante la creazione o la modifica di un host. Nella box “Custom attributes” — o in una box separata se hai creato un “Topic” — apparirà il nuovo gruppo di tag host e lì potrai effettuare la tua selezione e impostare il tag per l’host:
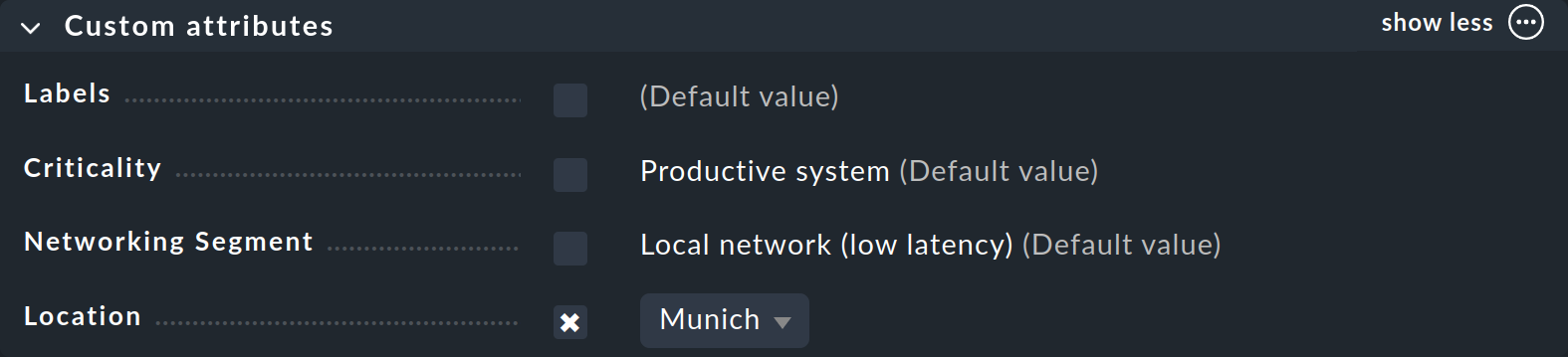
Ora che hai imparato i principi fondamentali della configurazione con regole e tag host, nelle sezioni restanti vorremmo darti alcune linee guida pratiche su come ridurre i falsi allarmi in un nuovo sistema Checkmk.
6. Personalizzazione delle soglie del file system
Controlla i valori di soglia per il monitoraggio dei file system e modificali se necessario. Abbiamo già mostrato brevemente i valori predefiniti sopra, nella ricerca delle regole.
Per impostazione predefinita, Checkmk utilizza le soglie dell'80% per WARN e del 90% per CRIT per il livello di riempimento dei file system. Ora, l'80% di un disco rigido da 2 terabyte corrisponde comunque a 400 gigabyte — forse un margine un po' troppo ampio per un avviso. Ecco quindi alcuni consigli sui file system:
Crea le tue regole nel set di regole "Filesystems (used space and growth)".
I parametri consentono di impostare soglie che dipendono dalle dimensioni del file system. Per farlo, seleziona "Levels for used/free space > Levels for used space > Dynamic levels". Con il pulsante "Add new element" puoi ora definire i tuoi valori di soglia in base alle dimensioni del disco.
È ancora più facile con l'Magic factor, che presenteremo nel capitolo finale.
7. Messa in tempo di manutenzione programmata degli host
Alcuni server vengono riavviati regolarmente, sia per applicare patch sia semplicemente perché è previsto. In questi casi puoi evitare i falsi allarmi.
![]() Nella Comunità Checkmk devi prima definire un periodo di tempo che copra gli orari del riavvio.
Puoi scoprire come farlo nell’articolo sui periodi di tempo.
Poi crea una regola in ciascuno dei set di regole Notification period for hosts e Notification period for services per gli host interessati e seleziona lì il
periodo di tempo definito in precedenza.
La seconda regola per i servizi è necessaria affinché eventuali servizi che entrano in stato di “CRIT” durante questo periodo non attivino una notifica.
Se si verificano problemi all’interno di questo lasso di tempo — e vengono risolti entro lo stesso lasso di tempo — non verrà attivata alcuna notifica.
Nella Comunità Checkmk devi prima definire un periodo di tempo che copra gli orari del riavvio.
Puoi scoprire come farlo nell’articolo sui periodi di tempo.
Poi crea una regola in ciascuno dei set di regole Notification period for hosts e Notification period for services per gli host interessati e seleziona lì il
periodo di tempo definito in precedenza.
La seconda regola per i servizi è necessaria affinché eventuali servizi che entrano in stato di “CRIT” durante questo periodo non attivino una notifica.
Se si verificano problemi all’interno di questo lasso di tempo — e vengono risolti entro lo stesso lasso di tempo — non verrà attivata alcuna notifica.
![]() Nelle edizioni commerciali sono previsti dei tempi di manutenzione programmati a questo scopo, che puoi impostare per qualsiasi host interessato.
Nelle edizioni commerciali sono previsti dei tempi di manutenzione programmati a questo scopo, che puoi impostare per qualsiasi host interessato.
Un'alternativa alla creazione di tempi di manutenzione programmati per gli host, che abbiamo già descritto nel capitolo sui tempi di manutenzione programmati, è il set di regole "Recurring downtimes for hosts" presente nelle edizioni commerciali. Questa ha il grande vantaggio che gli host aggiunti al monitoraggio in un secondo momento ricevono automaticamente questi tempi di manutenzione programmati. |
8. Ignorare gli host spenti
Non è sempre un problema quando un computer è spento. Le stampanti sono un classico esempio. Il monitoraggio delle stampanti con Checkmk ha perfettamente senso: alcuni utenti organizzano persino il riordino del toner usando Checkmk. Di norma, però, spegnere una stampante prima dell'orario di chiusura non è un problema. È semplicemente inutile, però, quando a questo punto Checkmk invia una notifica perché l'host corrispondente alla stampante è in stato "DOWN".
Puoi indicare a Checkmk che va benissimo che un host venga spento. Per farlo, trova il set di regole "Host check command", crea una nuova regola e imposta il suo valore su "Always assume host to be up":

Nella box "Conditions", assicurati che questa regola venga applicata solo agli host appropriati, a seconda della struttura che hai scelto. Ad esempio, puoi definire un tag host e utilizzarlo qui, oppure puoi impostare la regola per una cartella in cui si trovano tutte le stampanti.
Ora, tutte le stampanti verranno sempre visualizzate come "UP", indipendentemente dal loro stato effettivo.
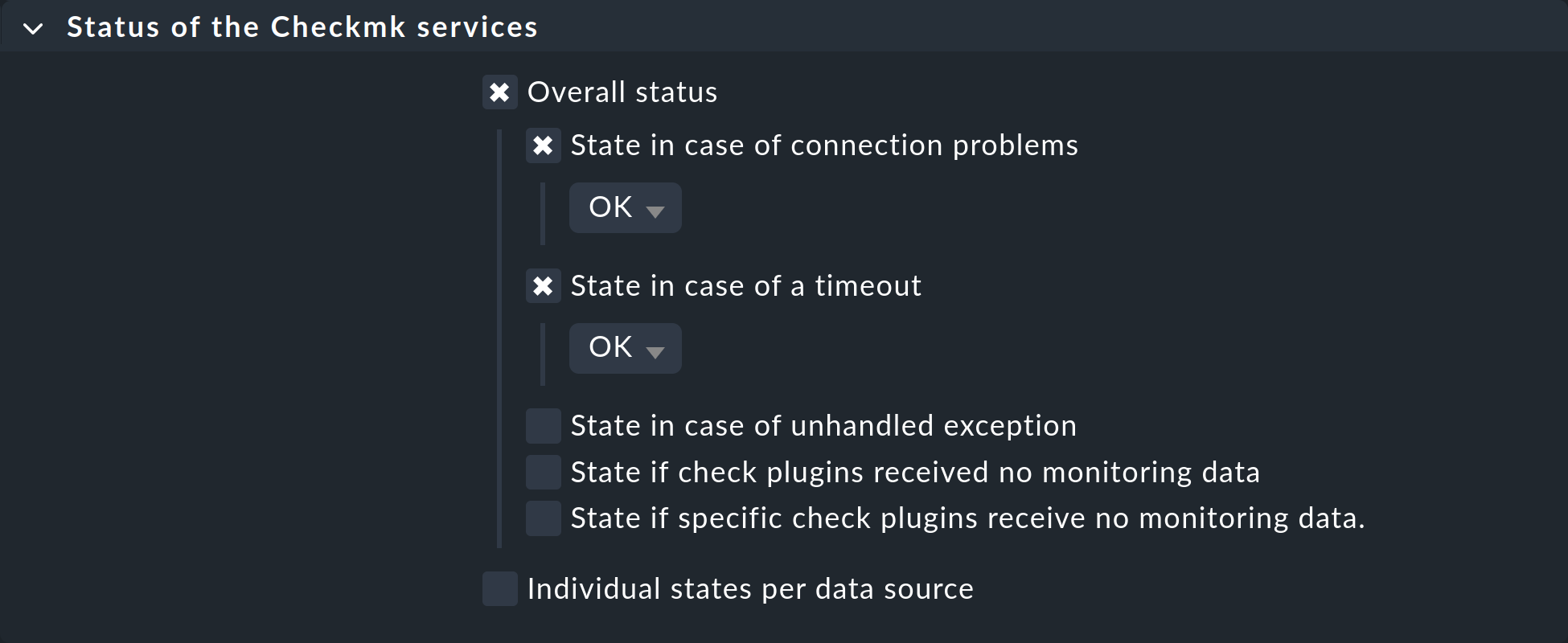
Tuttavia, i servizi della stampante continueranno a essere controllati e qualsiasi timeout comporterà uno stato "CRIT". Per evitare anche questo, configura una regola per gli host interessati nel set di regole "Status of the Checkmk services", in cui imposti rispettivamente i timeout e i problemi di connessione su "OK":
9. Configurazione delle porte dello switch
Se effettui il monitoraggio di uno switch con Checkmk, noterai che durante la configurazione del servizio viene creato automaticamente un servizio per ogni porta UP in quel momento. Si tratta di un'impostazione predefinita sensata per gli switch core e di distribuzione, ovvero quelli a cui sono collegati solo dispositivi di infrastruttura o server. Tuttavia, per gli switch a cui sono collegati dispositivi finali come workstation o stampanti, ciò comporta da un lato notifiche continue se una porta si disattiva e, dall'altro, la continua individuazione di nuovi servizi quando una porta precedentemente non monitorata si attiva.
Due approcci si sono dimostrati efficaci in tali situazioni. In primo luogo, puoi limitare il monitoraggio alle porte uplink. Per farlo, crea una regola per i servizi disabilitati che escluda le altre porte dal monitoraggio.
Tuttavia, il secondo metodo è molto più interessante. Con questo metodo monitori tutte le porte, ma consenti che lo stato "down" sia considerato valido. Il vantaggio è che avrai il monitoraggio degli errori di trasmissione anche per le porte a cui sono collegati dispositivi terminali e potrai così individuare molto rapidamente cavi patch difettosi o errori nell'auto-negoziazione. Per implementare questa funzione, hai bisogno di due regole:
Il primo set di regole, impostato in Network interface and switch port discovery, definisce le condizioni in base alle quali devono essere eseguiti il monitoraggio delle porte dello switch. Crea una regola per gli switch desiderati e seleziona se devono essere rilevate singole interfacce (Configure discovery of single interfaces) o gruppi (Configure grouping of interfaces). Quindi, in Conditions for this rule to apply > Match port states, attiva 2 - down oltre a 1 - up:
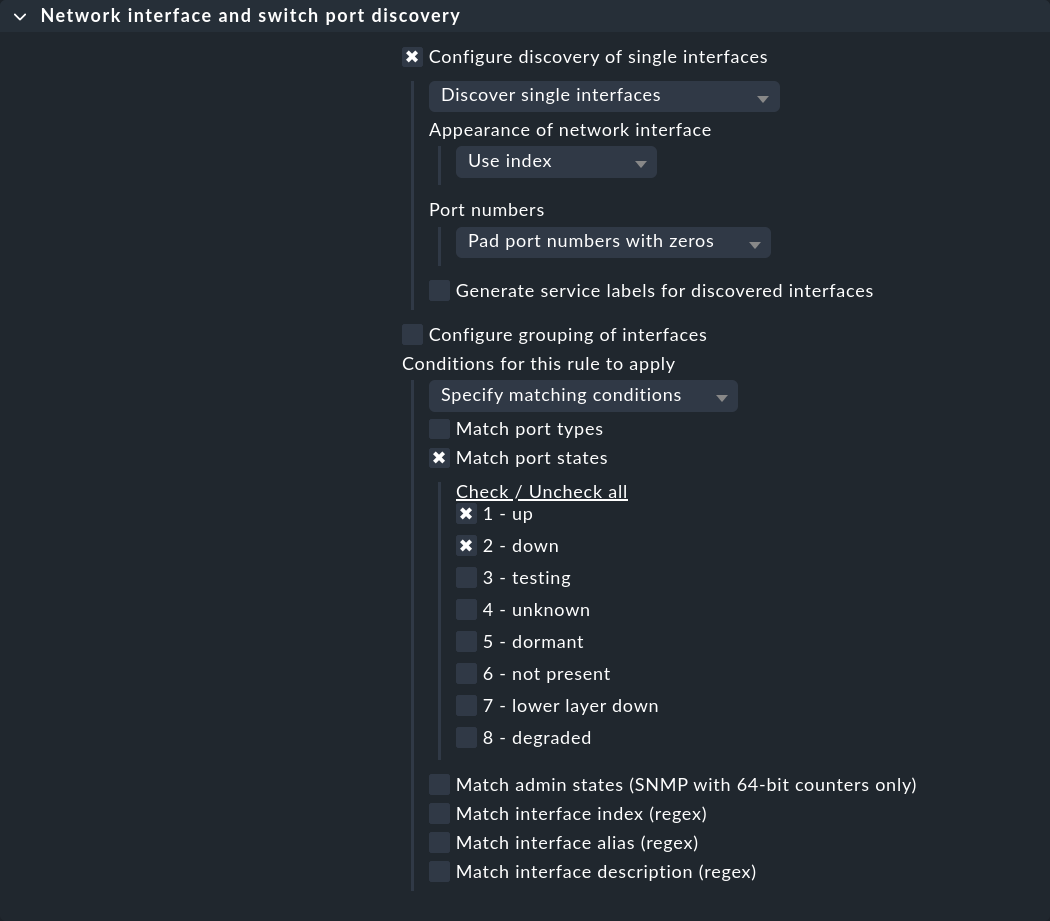
Nella configurazione dei servizi degli switch, ora verranno visualizzate anche le porte con stato "DOWN" e potrai aggiungerle all'elenco dei servizi monitorati.
Prima di attivare la modifica, avrai ancora bisogno della seconda regola che assicura che questo stato venga valutato come "OK". Questo set di regole si chiama "Network interfaces and switch ports". Crea una nuova regola e attiva l'opzione "Operational state", disattiva "Ignore the operational state" sotto di essa e poi attiva gli stati "1 - up" e "2 - down" per "Allowed operational states" (e qualsiasi altro stato che possa essere richiesto).
10. Disattivazione definitiva dei servizi
Per alcuni servizi che semplicemente non possono essere impostati in modo affidabile su "OK", è meglio non monitorarli affatto. In questo caso, potresti semplicemente rimuovere manualmente i servizi dal monitoraggio per gli host interessati nella scoperta del servizio (nella pagina "Services of host") impostandoli su "Disabled" o "Undecided". Tuttavia, questo metodo è macchinoso e soggetto a errori.
È molto meglio definire delle regole in base alle quali determinati servizi non vengano sistematicamente monitorati.
A questo scopo esiste il set di regole "Disabled services".
Qui puoi, ad esempio, creare una regola e specificare nella condizione che i file system con il mount point /var/test/ non debbano essere sottoposti a monitoraggio per definizione.
Se disattivi un singolo servizio nella configurazione dei servizi di un host cliccando su |
Puoi trovare ulteriori informazioni al riguardo nell'articolo sulla configurazione dei servizi.
11. Individuare i valori anomali utilizzando i valori medi
Spesso le notifiche sporadiche sono generate dai valori di threshold delle metriche di utilizzo — come l'utilizzo della CPU — che vengono superati solo per un breve periodo. Di norma, questi brevi picchi non sono un problema e non dovrebbero essere segnalati dal monitoraggio.
Per questo motivo, molti plug-in di controllo hanno un'opzione nella loro configurazione che permette di calcolare la media delle metriche su un periodo di tempo più lungo prima di applicare le soglie. Un esempio è il set di regole per l'utilizzo della CPU nei sistemi non Unix chiamato "CPU utilization for simple devices". Per questo c'è il parametro "Averaging for total CPU utilization":
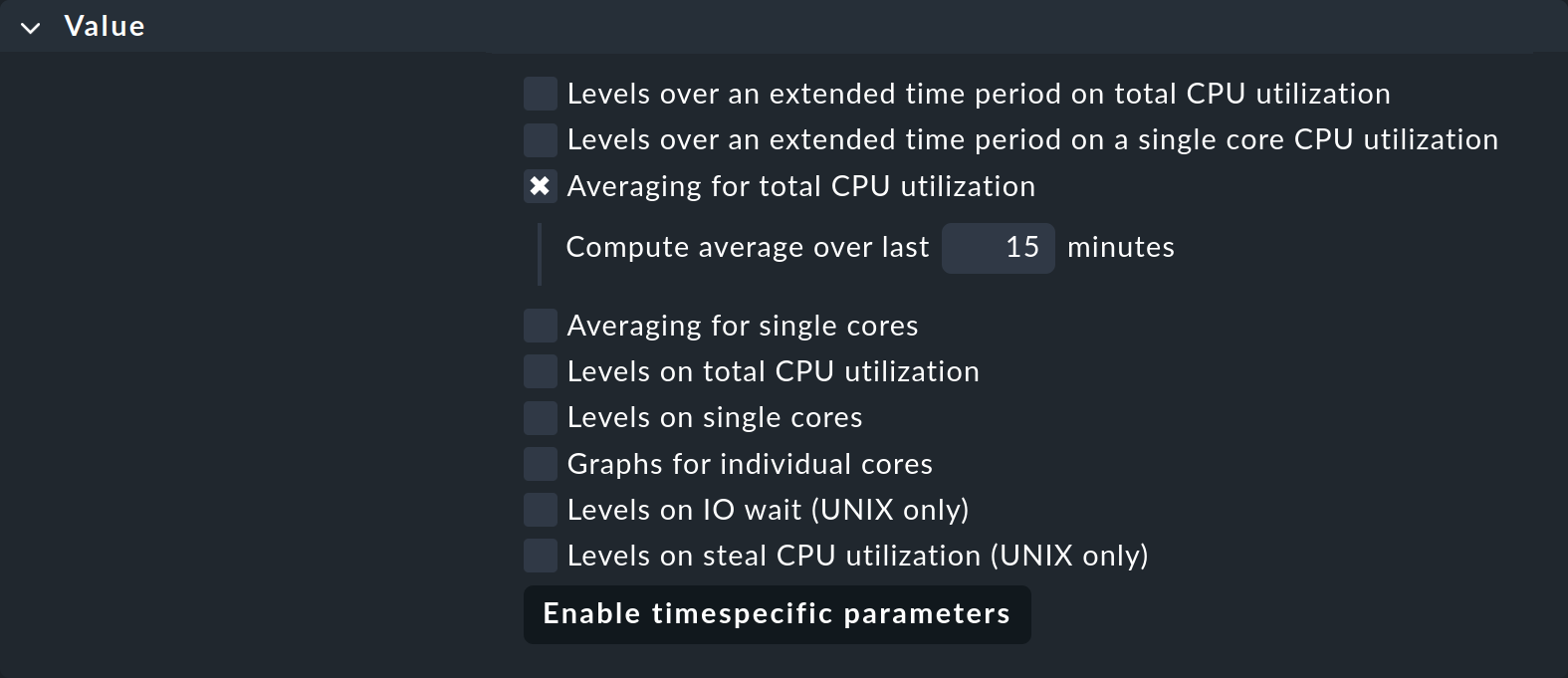
Se lo attivi e inserisci 15, l'utilizzo della CPU verrà prima calcolato come media su un periodo di 15 minuti e solo successivamente i valori di threshold verranno applicati a questo valore medio.
12. Gestione degli errori sporadici
Quando nient'altro funziona e i servizi continuano a collegarsi occasionalmente a WARN o CRIT per un singolo intervallo di controllo — cioè per un minuto — c'è un ultimo metodo per evitare i falsi allarmi: il set di regole Maximum number of check attempts for service.
Se crei una regola in quel set di regole e imposti il suo valore, ad esempio, su 3, un servizio che passa da OK a WARN, per esempio, non attiverà ancora una notifica e non verrà ancora visualizzato come un problema nell'Overview.
Lo stato intermedio in cui si troverà ora il servizio è chiamato stato soft.
Solo quando lo stato rimane non OK per tre controlli consecutivi — ovvero una durata totale di poco più di due minuti — verrà segnalato un problema persistente.
Solo uno stato "hard state" attiverà una notifica.
Certo, non è una soluzione ideale. Dovresti sempre cercare di arrivare alla radice di qualsiasi problema, ma a volte le cose stanno semplicemente così, e con il numero di check hai almeno un modo praticabile per aggirare tali situazioni.
13. Mantenere aggiornato l'elenco dei servizi
In ogni data center il lavoro è in continuo svolgimento, quindi l'elenco dei servizi da monitorare non rimane mai statico. Per assicurarti di non perdere nulla, Checkmk configura automaticamente un servizio speciale su ogni host: questo servizio è noto come "Check_MK Discovery":

Per impostazione predefinita, ogni due ore questo servizio verifica se sono stati individuati nuovi servizi — non ancora monitorati — o se servizi esistenti sono stati rimossi. In tal caso, il servizio passa a “WARN”. Puoi quindi richiamare la scoperta del servizio (nella pagina “Services of host”) e aggiornare l’elenco dei servizi allo stato attuale.
Puoi trovare informazioni dettagliate su questo discovery check nell'articolo sulla configurazione dei servizi. Lì puoi anche scoprire come aggiungere automaticamente i servizi non monitorati, il che semplifica notevolmente il lavoro in una configurazione di grandi dimensioni.
Con Monitor > System > Unmonitored services puoi richiamare una visualizzazione che mostra eventuali servizi nuovi o eliminati. |