This is a machine translation based on the English version of the article. It might or might not have already been subject to text preparation. If you find errors, please file a GitHub issue that states the paragraph that has to be improved. |
1. Les fausses alertes — un véritable fléau pour toute forme de supervision
La supervision n’est vraiment utile que si elle est précise. Le principal obstacle à son acceptation par vos collègues (et probablement par vous-même) réside dans les faux positifs — ou, en clair, les fausses alertes.
Nous avons constaté que certains débutants avec Checkmk ajoutaient de nombreux systèmes à la supervision en très peu de temps — peut-être parce que c’est si facile à faire dans Checkmk. Lorsqu’ils ont ensuite activé les notifications pour tous les utilisateurs, leurs collègues ont été submergés par des centaines de courriers électroniques par jour, et après seulement quelques jours, leur enthousiasme pour la supervision s’est pratiquement évanoui.
Même si Checkmk s’efforce réellement de définir des valeurs par défaut appropriées et fiables pour tous les paramètres possibles, il ne peut tout simplement pas savoir avec suffisamment de précision comment les choses devraient se passer dans votre environnement informatique en conditions normales. C’est pourquoi un peu de travail manuel de votre part est nécessaire pour effectuer un réglage fin de la supervision jusqu’à ce que même la dernière fausse alerte ne soit plus envoyée. En outre, Checkmk détectera également bon nombre de problèmes réels dont vous et vos collègues n’aviez pas encore soupçonné l’existence. Ceux-ci doivent eux aussi être correctement résolus en premier lieu — dans la réalité, et non dans la supervision !
Le principe suivant a fait ses preuves : la qualité avant la quantité — ou, en d'autres termes :
N'incluez pas trop d'ordinateurs hôtes à la fois dans la supervision.
Assurez-vous que tous les services qui ne présentent pas réellement de problème sont bien en ligne OK.
N'activez les notifications par courrier électronique ou SMS qu'après que Checkmk ait fonctionné de manière fiable pendant un certain temps, sans ou avec très peu de fausses alertes.
Les fausses alertes ne peuvent bien sûr se produire que lorsque la fonction de notification est activée. En résumé, ce qu’il nous faut faire ici, c’est désactiver la phase préliminaire des notifications et éviter les états critiques DOWN, WARN ou CRIT pour les problèmes non critiques. |
Dans les sections suivantes consacrées à la configuration, nous vous montrerons les options de réglage fin dont vous disposez — afin que tout ce qui ne pose pas de problème soit signalé en vert — et comment maîtriser les éventuelles coupures occasionnelles.
2. Configuration basée sur des règles
Avant de commencer la configuration, nous devons d'abord examiner brièvement les paramètres des ordinateurs hôtes et des services dans Checkmk. Checkmk ayant été développé pour des environnements vastes et complexes, cela s'effectue à l'aide de règles. Ce concept est très puissant et apporte également de nombreux avantages aux environnements plus modestes.
L'idée de base est que vous ne spécifiez pas explicitement chaque paramètre pour chaque service, mais que vous mettez en place quelque chose comme :
« Sur tous les serveurs Oracle de production, les systèmes de fichiers dont le nom commence par /var/ora/ et qui sont remplis à 90 % seront
WARN
et à 95 % seront
CRIT
».
Une telle règle permet de définir des valeurs seuils pour des milliers de systèmes de fichiers en une seule opération. Parallèlement, elle documente très clairement les directives de supervision applicables au sein de votre entreprise.
À partir d’une règle de base, vous pouvez ensuite définir des exceptions pour des cas particuliers séparément.
Une règle appropriée pourrait ressembler à ceci :
« Sur le serveur Oracle srvora123, le système de fichiers /var/ora/db01/, lorsqu’il est rempli à 96 %, sera
WARN
et à 98 %, il sera
CRIT
».
Cette règle d’exception est définie dans Checkmk de la même manière que la règle de base.
Chaque règle présente la même structure. Elle se compose toujours d’une condition et d’une valeur. Vous pouvez également ajouter une description et un commentaire pour documenter l’objectif de la règle.
Les règles sont organisées en jeux de règles. Pour chaque type de paramètre, Checkmk propose un jeu de règles adapté, vous permettant ainsi de choisir parmi plusieurs centaines de jeux de règles. Par exemple, il en existe un appelé « Filesystems (used space and growth) » qui définit les valeurs seuils pour tous les services effectuant la supervision des systèmes de fichiers. Pour mettre en œuvre l’exemple ci-dessus, vous devriez définir la règle de base et la règle d’exception à partir de ce jeu de règles. Pour déterminer quelles valeurs seuils sont valables pour un système de fichiers particulier, Checkmk passe en revue, dans l’ordre, toutes les règles valables pour la vérification. La première règle à laquelle la condition s’applique définit la valeur — dans ce cas, la valeur en pourcentage à laquelle la vérification du système de fichiers passe à l’état « WARN » ou « CRIT ».
3. Recherche de règles
Vous disposez de plusieurs options pour accéder aux jeux de règles dans Checkmk.
D'une part, vous pouvez trouver les jeux de règles dans le menu « Setup » (Règles et alertes) sous les thèmes correspondant aux objets pour lesquels il existe des jeux de règles (Hosts, Services et Agents) dans différentes catégories. Par exemple, il existe les entrées de jeux de règles suivantes pour les services : Service monitoring rules, Discovery rules, Enforced services, HTTP, TCP, Email, … et Other Services. Si vous sélectionnez l'une de ces entrées, les jeux de règles associés s'afficheront sur la page principale. Il peut s'agir d'une poignée d'entrées seulement, ou d'un très grand nombre, comme c'est le cas avec l'Service monitoring rules. Vous avez donc la possibilité de filtrer les résultats sur la page de résultats, dans le champ « Filter » des menus.
Si vous ne savez pas dans quelle catégorie se trouve le jeu de règles, vous pouvez également effectuer une recherche parmi toutes les règles en une seule fois, soit en utilisant le champ de recherche du menu de configuration, soit en ouvrant la page de recherche de règles via Setup > General > Rule search. Nous emprunterons cette dernière voie dans la section suivante, où nous présenterons le processus de création de règles.
Compte tenu du grand nombre de jeux de règles disponibles, il n’est pas toujours facile de trouver le bon, avec ou sans recherche.
Il existe toutefois une autre façon d’accéder aux règles appropriées pour un service existant.
Dans une vue incluant le service, cliquez sur l’option de menu « ![]() » et sélectionnez l’entrée « Parameters for this service » :
» et sélectionnez l’entrée « Parameters for this service » :
Vous accédez alors à une page à partir de laquelle vous pouvez consulter tous les jeux de règles pour ce service :
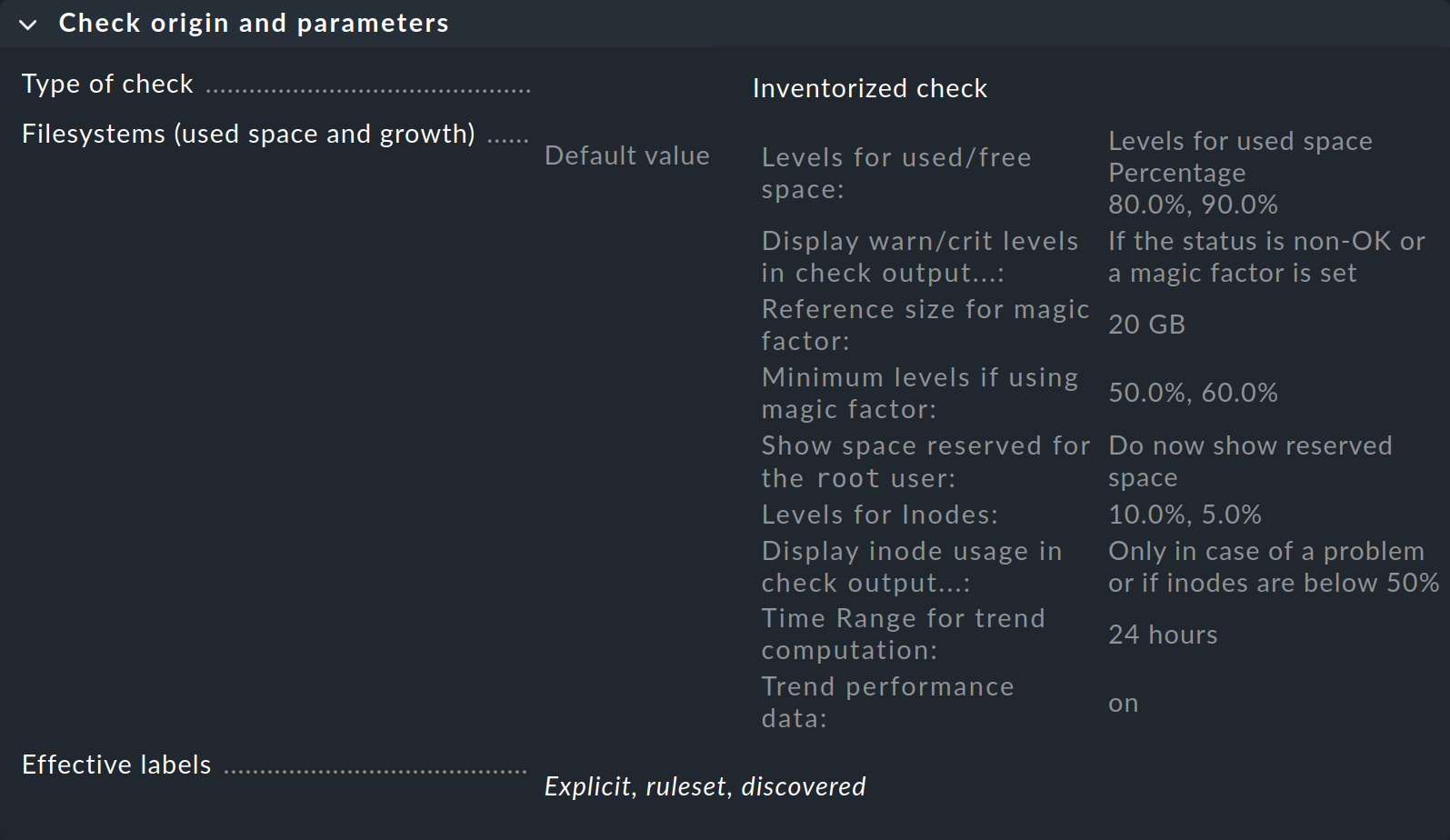
Dans la première case intitulée « Check origin and parameters », l'entrée « Filesystems (used space and growth) » vous mène directement à l'ensemble de règles relatives aux valeurs seuils de supervision du système de fichiers. Cependant, vous pouvez voir dans l'aperçu que Checkmk a déjà défini des valeurs par défaut ; vous n'avez donc besoin de créer une règle que si vous souhaitez modifier ces valeurs par défaut.
4. Création de règles
À quoi ressemble une règle dans la pratique ? La meilleure façon de commencer est de formuler la règle que vous souhaitez mettre en œuvre en une phrase, comme ceci : Sur tous les serveurs Oracle de production, les tablespaces DW20 et DW30 qui sont pleins à 90 % auront le statut « WARN » et à 95 % le statut « CRIT ».
Vous pouvez ensuite rechercher un jeu de règles approprié — dans cet exemple via la recherche de règles : Setup > General > Rule search. Cela ouvre une page dans laquelle vous pouvez rechercher « Oracle » ou « tablespace » (sans distinction de casse) et trouver tous les jeux de règles qui contiennent ce texte dans leur nom ou dans leur description (non illustré ici) :
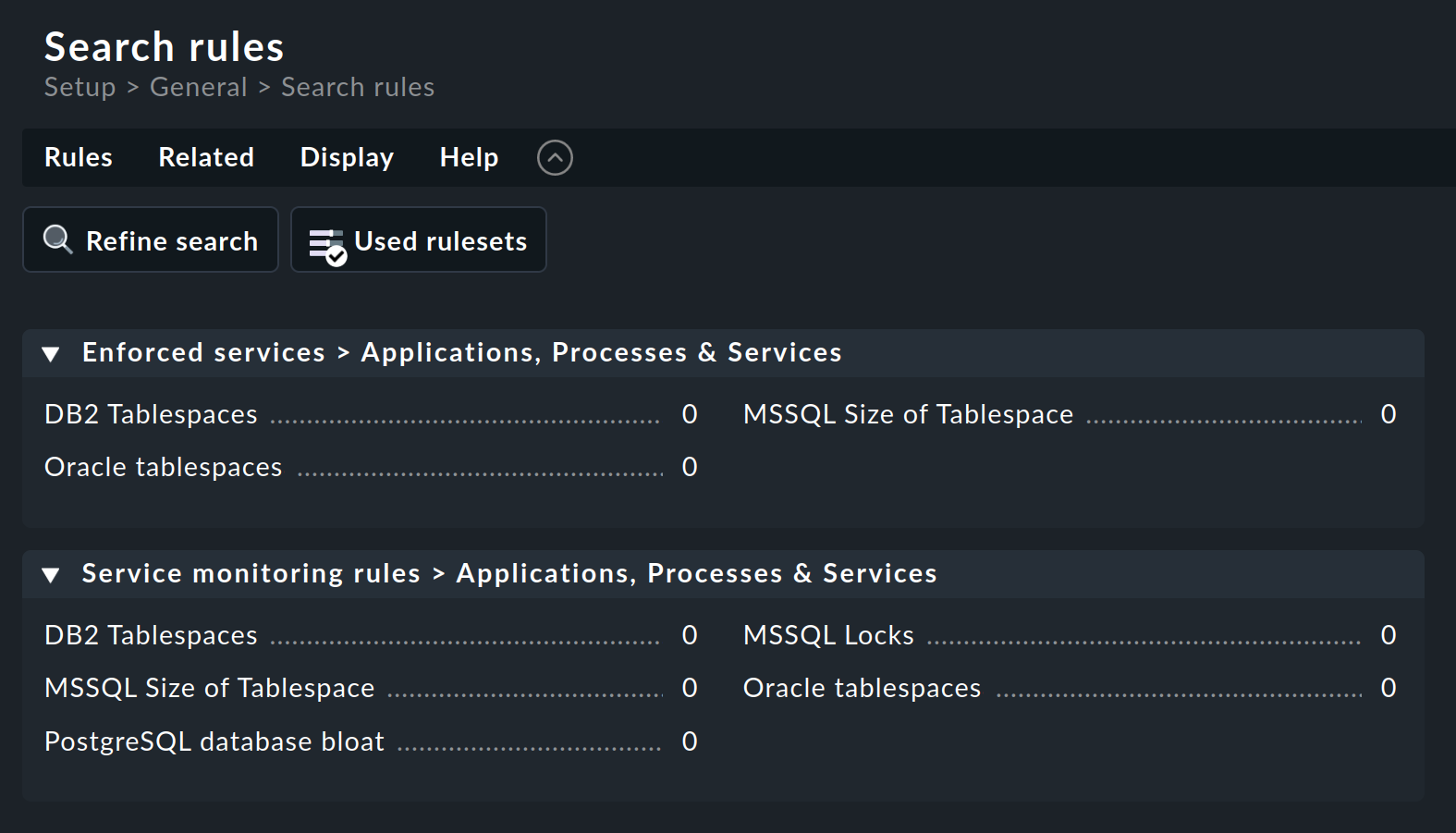
L'ensemble de règles « Oracle tablespaces » se trouve dans deux catégories.
Le nombre suivant le titre (ici « 0 » partout) indique le nombre de règles qui ont déjà été créées à partir de cet ensemble de règles.
Dans cet exemple, nous ne souhaitons pas la configuration de service imposée. Cliquez donc sur le nom dans la catégorie « Service monitoring rules » pour ouvrir la page d'aperçu du jeu de règles :
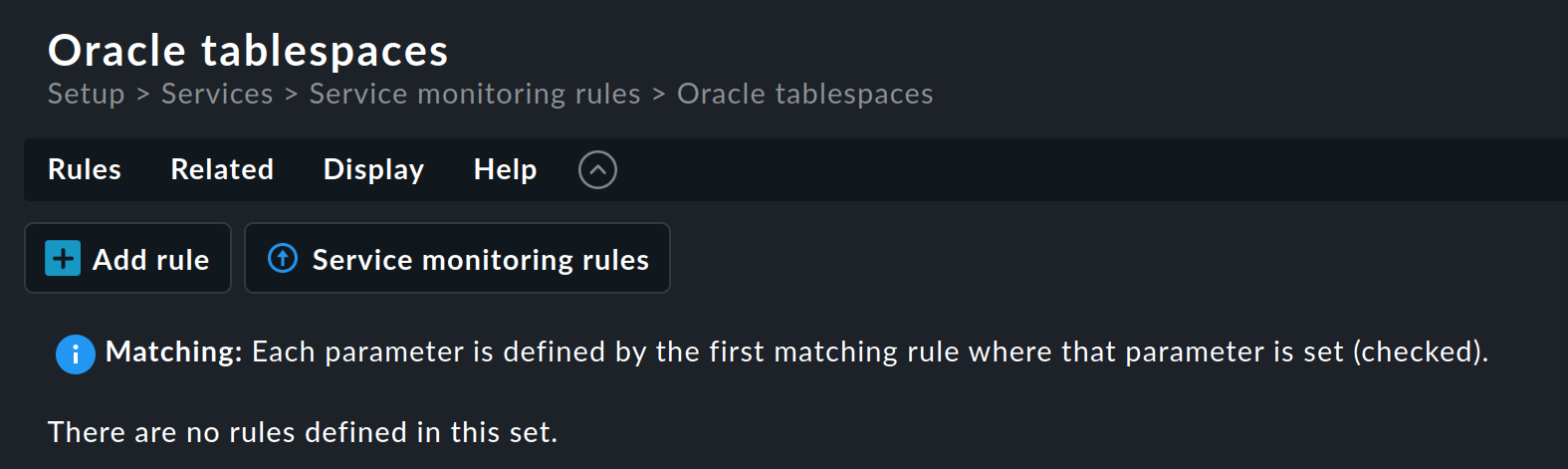
Ce jeu de règles ne contient encore aucune règle. Vous pouvez créer la première règle à l'aide du bouton « Add rule ». La création — puis l'édition ultérieure — de cette règle ouvre un formulaire comportant trois cases : « Rule properties », « Value » et « Conditions ». Nous allons examiner chacune de ces trois cases tour à tour.
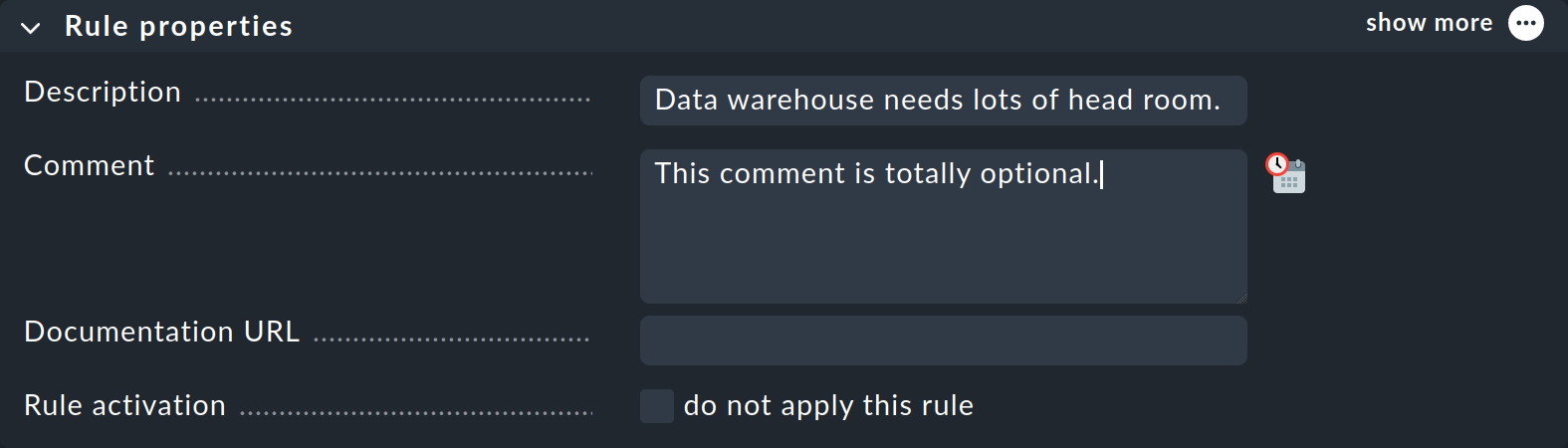
Dans la case « Rule properties », toutes les entrées sont facultatives. Outre les textes d’information, vous avez ici également la possibilité de désactiver temporairement une règle. C’est pratique, car cela vous évite parfois de supprimer et de recréer une règle si vous n’en avez temporairement pas besoin.
The content of the « Value » case depends, in each particular case, on the object of the regulation :
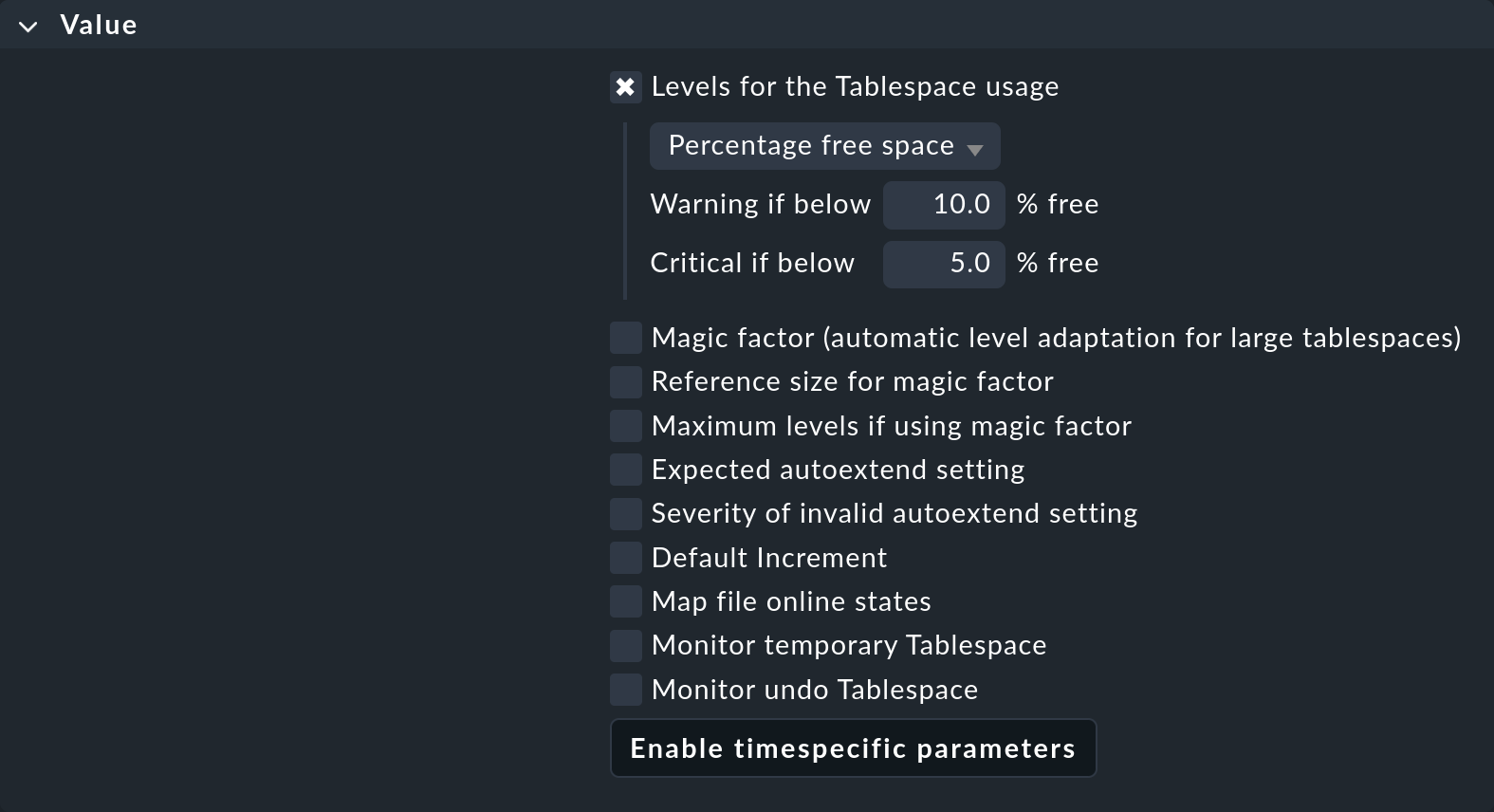
Comme vous pouvez le constater, cela peut représenter un nombre considérable de paramètres. L'exemple illustre un cas typique : chaque paramètre individuel peut être activé à l'aide d'une case à cocher, et la règle ne s'appliquera alors qu'à ce paramètre. Vous pouvez, par exemple, laisser un autre paramètre être déterminé par une règle différente si cela simplifie votre configuration. Dans cet exemple, seules les valeurs seuils pour le pourcentage d'espace libre dans le tablespace seront définies.
La case de dialogue « Conditions » (Configurer les conditions) peut sembler un peu plus déroutante à première vue :
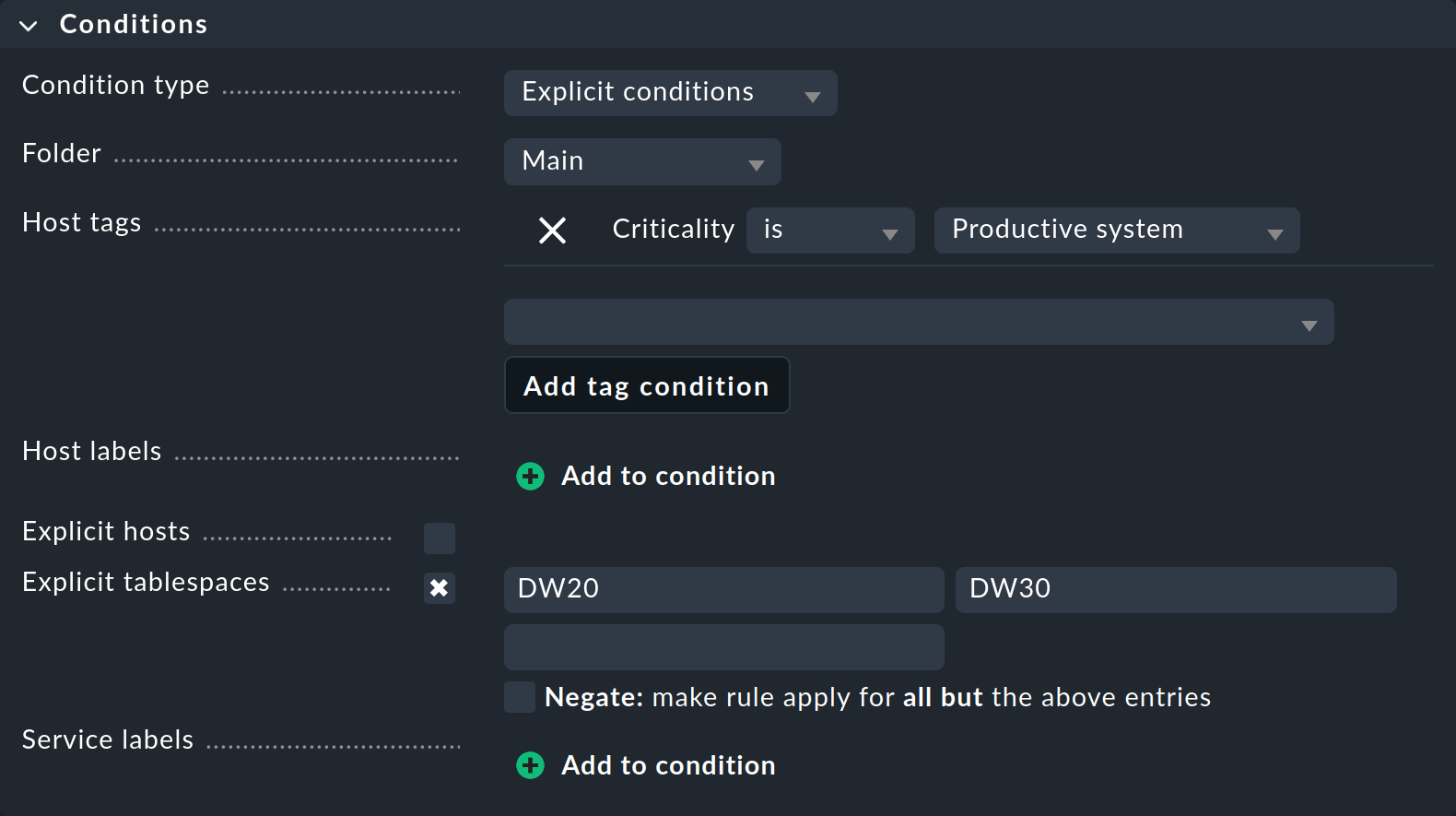
Dans cet exemple, nous n'aborderons que les paramètres dont nous avons absolument besoin pour définir cette règle spécifique :
Avec les Folder, vous spécifiez dans quel dossier la règle doit s'appliquer. Par exemple, si vous remplacez l'Main par défaut par Windows, la nouvelle règle s'appliquera uniquement aux ordinateurs hôtes situés directement dans ou sous le dossier Windows.
Les Host tags constituent une fonctionnalité très importante de Checkmk ; nous leur consacrerons donc une section distincte juste après celle-ci. À ce stade, vous utilisez l’une des balises de l’hôte prédéfinies pour spécifier que la règle ne doit s’appliquer qu’aux systèmes productifs. Sélectionnez d’abord le groupe de balises de l’hôte Criticality dans la liste, puis cliquez sur Add tag condition et sélectionnez la valeur Productive system.
Dans cet exemple, les conditions « Explicit tablespaces » sont très importantes, car elles limitent la règle à des services très spécifiques. Deux points sont importants ici :
Le nom de cette condition s'adapte au type de règle. Si elle s'intitule « Explicit services », précisez les noms des services concernés. Par exemple, l'un d'entre eux pourrait être «
Tablespace DW20», c'est-à-dire incluant le mot «Tablespace». Dans l'exemple présenté, cependant, Checkmk souhaite uniquement connaître le nom de l'espace de tablespace lui-même, d'où «DW20».Les textes saisis sont toujours saisis au début. La saisie de
DW20donne donc également accès à un tablespace fictifDW20A. Si vous souhaitez éviter cela, ajoutez le caractère$à la fin, c'est-à-direDW20$, car il s'agit de ce que l'on appelle des expressions régulières.
Vous trouverez une description détaillée de tous les autres paramètres ainsi qu’une explication détaillée du concept important des règles dans l’article consacré aux règles. Par ailleurs, vous pouvez en savoir plus sur l’Service labels, le dernier paramètre de l’image ci-dessus, dans l’article consacré aux étiquettes. |
Une fois toutes les entrées de la définition complétées, enregistrez la règle avec l'Save. Après l'enregistrement, il y aura exactement une nouvelle règle dans le jeu de règles :

Si, au lieu d’une seule règle, vous en utilisez plus tard des centaines, vous risquez de perdre l’aperçu. Afin de vous aider à garder un aperçu, Checkmk propose des entrées très utiles dans le menu « Related » sur chaque page répertoriant les règles. Cela vous permet d’afficher les règles utilisées sur l’instance actuelle (Used rulesets) et, de la même manière, celles qui ne sont pas utilisées du tout (Ineffective rules). |
5. Balises de l’hôte
5.1. Fonctionnement des balises de l’hôte
Dans la section précédente, nous avons vu un exemple de règle qui ne doit s'appliquer qu'aux systèmes productifs. Plus précisément, dans cette règle, nous avons défini une condition à l'aide de la balise de l’hôte Productive system. Pourquoi avons-nous défini cette condition sous forme de balise plutôt que de la définir simplement pour le dossier ? En effet, vous ne pouvez définir qu'une seule structure de dossiers, et chaque ordinateur hôte ne peut se trouver que dans un seul dossier. Mais un ordinateur hôte peut avoir de nombreuses balises différentes, et la structure de dossiers est tout simplement trop limitée et pas assez flexible pour cela.
En revanche, vous pouvez attribuer des balises de l’hôte aux hôtes aussi librement et arbitrairement que vous le souhaitez — quel que soit le dossier dans lequel se trouvent les hôtes. Vous pouvez ensuite faire référence à ces balises dans vos règles. Cela rend la configuration non seulement plus simple, mais aussi plus facile à comprendre et moins sujette aux erreurs que si vous deviez tout définir explicitement pour chaque ordinateur hôte.
Mais comment et où définissez-vous quels ordinateurs hôtes doivent avoir quelle balise ? Et comment pouvez-vous définir vos propres balises personnalisées ?
5.2. Définition des balises de l’hôte
Commençons par répondre à la deuxième question concernant les balises personnalisées. Tout d’abord, vous devez savoir que les balises sont organisées en groupes appelés « groupes de balises de l’hôte ». Prenons l’exemple de l’emplacement. Un groupe de balises pourrait s’appeler « Emplacement », et ce groupe pourrait contenir les balises « Munich », « Austin » et « Singapour ». En principe, chaque ordinateur hôte se voit attribuer exactement une balise de chaque groupe de balises. Ainsi, dès que vous définissez votre propre groupe de balises, chaque ordinateur hôte portera l’une des balises de ce groupe. Les ordinateurs hôtes pour lesquels vous n’avez pas sélectionné de balise dans le groupe se voient simplement attribuer la première par défaut.
Pour la définition des groupes de balises de l’hôte, consultez Setup > Hosts > Tags :
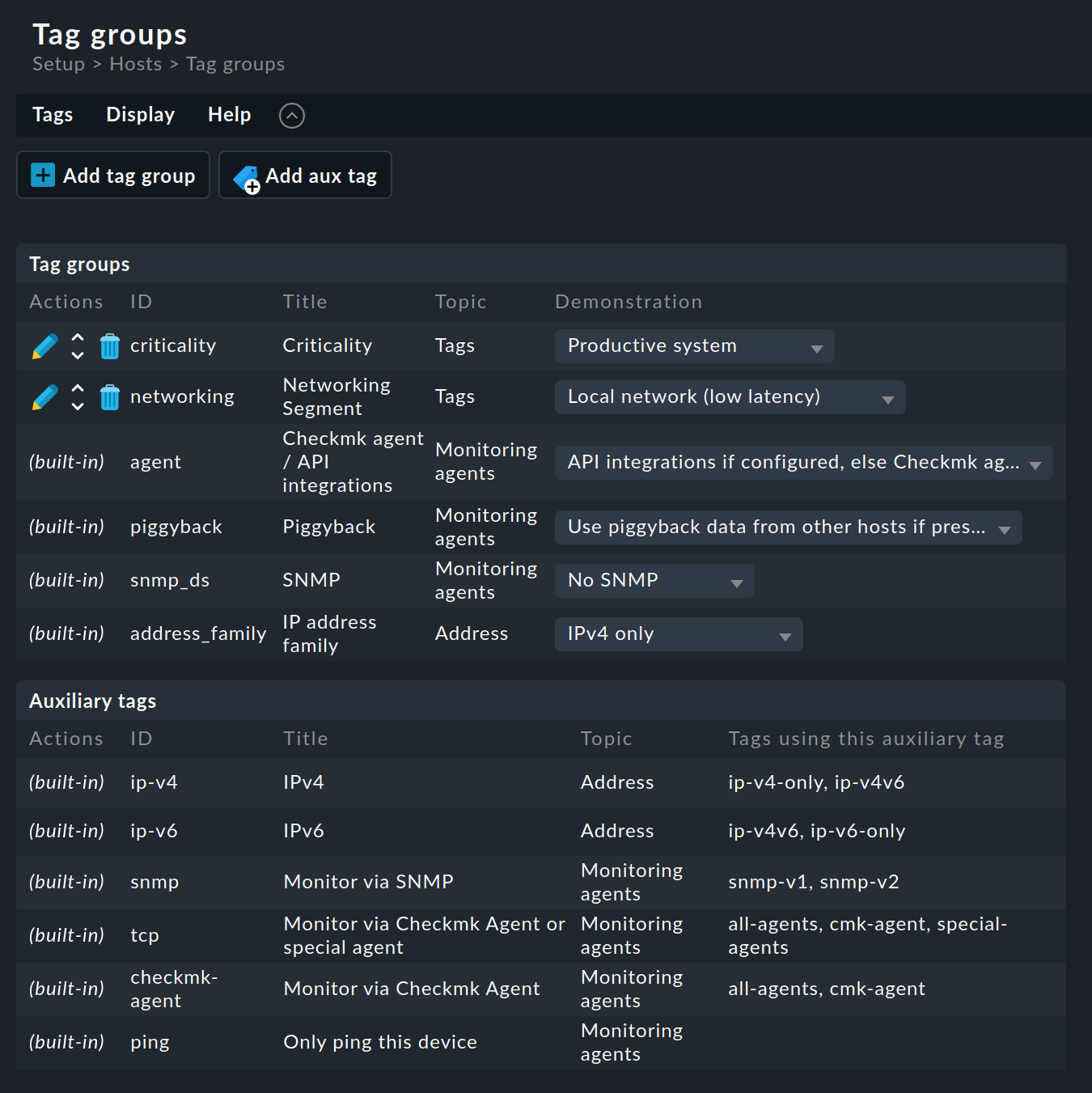
Comme vous pouvez le constater, certains groupes de balises ont déjà été prédéfinis. Vous ne pouvez pas modifier la plupart d'entre eux. Nous vous recommandons également de ne pas modifier les deux groupes d'exemple prédéfinis Criticality et Networking Segment. Il est préférable de définir vos propres groupes :
Cliquez sur Add tag group. Cela ouvre la page de création d’un nouveau groupe de balises. Dans le premier champ Basic settings, vous attribuez — comme c’est souvent le cas dans Checkmk — un identifiant interne qui sert de clé et qui ne peut pas être modifié ultérieurement. En plus de l’identifiant, vous définissez un titre descriptif, que vous pouvez modifier à tout moment par la suite. Avec Topic, vous pouvez déterminer où la balise sera proposée ultérieurement dans les propriétés de l’ordinateur hôte. Si vous créez un nouveau thème ici, la balise s’affichera dans une case distincte dans les propriétés de l’hôte.
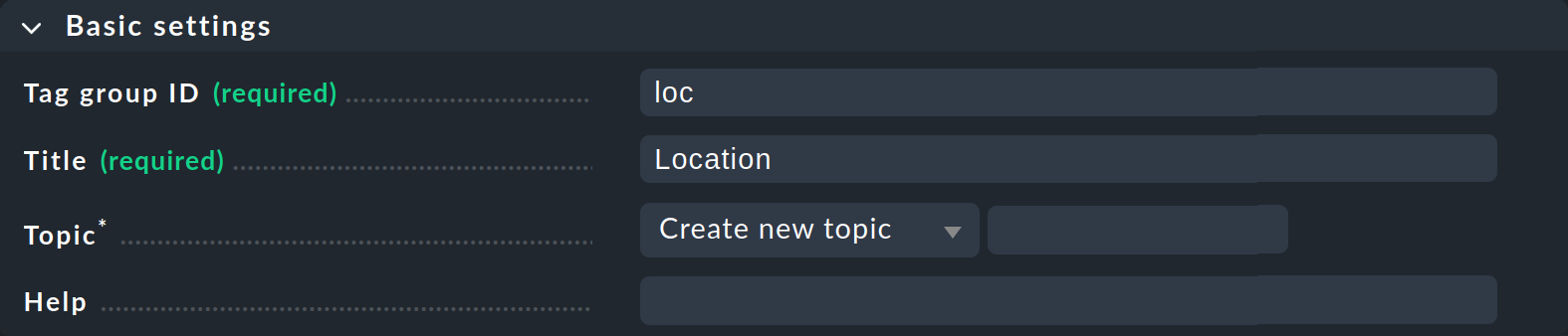
La deuxième case de dialogue, « Tag choices », concerne les balises proprement dites, c'est-à-dire les options de sélection du groupe. Cliquez sur « Add tag choice » pour créer une balise et attribuer un identifiant interne ainsi qu'un titre à chaque balise :
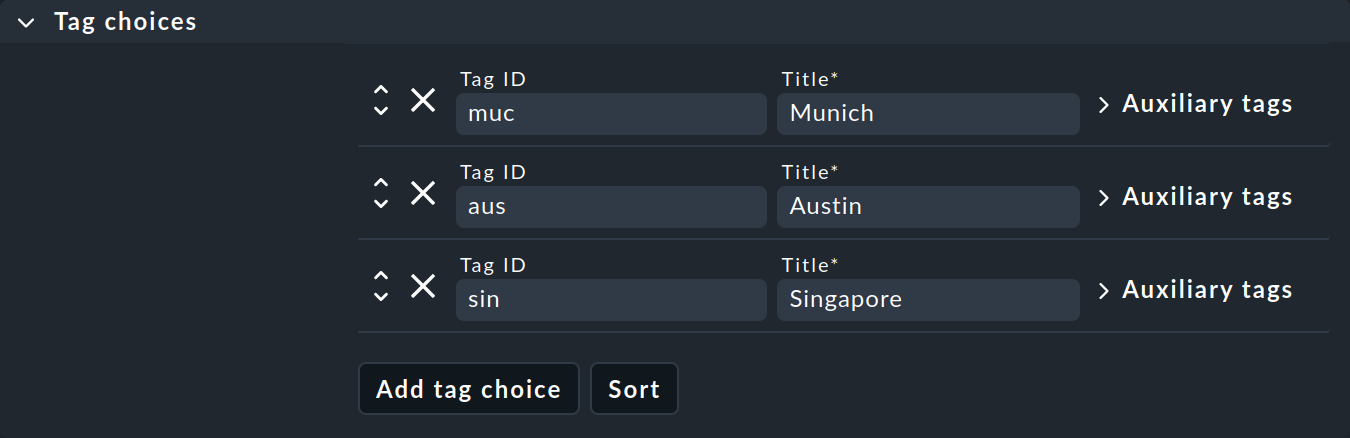
Remarques :
Les groupes ne comportant qu’une seule sélection sont également autorisés et peuvent même s’avérer utiles. La balise qu’ils contiennent est appelée « balise de la case à cocher » et apparaît alors dans les propriétés de l’hôte sous la forme d’une simple case à cocher. Chaque hôte disposera alors de cette balise — ou non, car les balises de la case à cocher sont désactivées par défaut.
À ce stade, vous pouvez ignorer les balises auxiliaires pour l'instant. Vous trouverez toutes les informations sur les balises auxiliaires en particulier et sur les balises de l’hôte en général dans l'article consacré aux balises de l’hôte.
Une fois que vous avez enregistré ce nouveau groupe de balises de l’hôte à l’aide de l’option «Save», vous pouvez commencer à l’utiliser.
5.3. Attribution d’une balise à un ordinateur hôte
Vous avez déjà vu comment attribuer des balises à un hôte — dans les propriétés de l’hôte lors de la création ou de l’édition d’un hôte. Dans la case « Custom attributes » — ou dans une case distincte si vous avez créé un « Topic » — le nouveau groupe de balises de l’hôte apparaîtra et vous pourrez y faire votre sélection et définir la balise pour l’hôte :
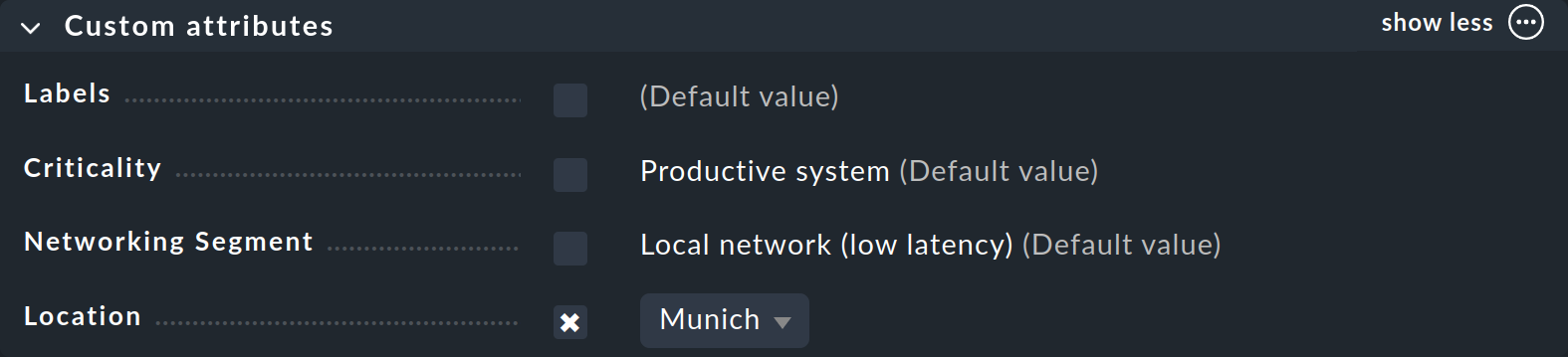
Maintenant que vous avez appris les principes importants de la configuration à l'aide de règles et de balises de l’hôte, nous aimerions vous donner, dans les sections suivantes, quelques conseils pratiques sur la manière de réduire les fausses alertes dans un nouveau système Checkmk.
6. Personnalisation des valeurs seuils du système de fichiers
Vérifiez les valeurs de seuil pour la supervision des systèmes de fichiers et ajustez-les si nécessaire. Nous avons déjà brièvement présenté les valeurs par défaut ci-dessus lors de la recherche de règles.
Par défaut, Checkmk utilise les valeurs seuils de 80 % pour WARN et de 90 % pour CRIT pour le niveau de remplissage des systèmes de fichiers. Or, 80 % d’un disque dur de 2 téraoctets correspondent tout de même à 400 gigaoctets — ce qui représente peut-être une marge un peu trop importante pour un avertissement. Voici donc quelques conseils concernant les systèmes de fichiers :
Créez vos propres règles dans le jeu de règles « Filesystems (used space and growth) ».
Les paramètres permettent de définir des valeurs seuils en fonction de la taille du système de fichiers. Pour ce faire, sélectionnez « Levels for used/free space > Levels for used space > Dynamic levels ». Grâce au bouton « Add new element », vous pouvez désormais définir vos propres valeurs seuil en fonction de la taille du disque.
C'est encore plus simple avec l'Magic factor, que nous présenterons dans le dernier chapitre.
7. Période de maintenance pour les ordinateurs hôtes
Certains serveurs sont redémarrés régulièrement, soit pour appliquer des correctifs, soit simplement parce que cela est prévu. Vous pouvez éviter les fausses alertes lors de ces opérations.
![]() Dans Checkmk Community, vous définissez d’abord une période de temps couvrant les heures de redémarrage.
Vous trouverez la marche à suivre dans l’article consacré aux périodes de temps.
Créez ensuite une règle dans chacun des jeux de règles « Notification period for hosts » et « Notification period for services » pour les ordinateurs hôtes concernés, puis sélectionnez-y la
période de temps précédemment définie.
La deuxième règle pour les services est nécessaire afin que les services qui passent en état « CRIT » pendant cette période ne déclenchent pas de notification.
Si des problèmes surviennent pendant cette période — et sont également résolus pendant cette même période — aucune notification ne sera déclenchée.
Dans Checkmk Community, vous définissez d’abord une période de temps couvrant les heures de redémarrage.
Vous trouverez la marche à suivre dans l’article consacré aux périodes de temps.
Créez ensuite une règle dans chacun des jeux de règles « Notification period for hosts » et « Notification period for services » pour les ordinateurs hôtes concernés, puis sélectionnez-y la
période de temps précédemment définie.
La deuxième règle pour les services est nécessaire afin que les services qui passent en état « CRIT » pendant cette période ne déclenchent pas de notification.
Si des problèmes surviennent pendant cette période — et sont également résolus pendant cette même période — aucune notification ne sera déclenchée.
![]() Dans les éditions commerciales, des périodes de maintenance planifiées régulières sont prévues à cet effet, que vous pouvez définir pour tous les ordinateurs hôtes concernés.
Dans les éditions commerciales, des périodes de maintenance planifiées régulières sont prévues à cet effet, que vous pouvez définir pour tous les ordinateurs hôtes concernés.
Une alternative à la création de périodes de maintenance pour les ordinateurs hôtes, que nous avons déjà décrite dans le chapitre consacré aux périodes de maintenance planifiées, est le jeu de règles « Recurring downtimes for hosts » (Périodes de maintenance planifiées) disponible dans les éditions commerciales. Cela présente le grand avantage que les ordinateurs hôtes ajoutés ultérieurement à la supervision bénéficient automatiquement de ces périodes de maintenance planifiées. |
8. Ignorer les ordinateurs hôtes hors tension
Le fait qu’un ordinateur soit éteint ne pose pas toujours de problème. Les imprimantes en sont un exemple classique. Il est tout à fait judicieux de les soumettre à la supervision avec Checkmk — certains utilisateurs organisent même la commande de toner à l’aide de Checkmk. En règle générale, toutefois, éteindre une imprimante avant la fermeture ne pose aucun problème. Il est toutefois tout simplement absurde que Checkmk envoie une notification à ce moment-là parce que l’ordinateur hôte correspondant à l’imprimante est en état « DOWN ».
Vous pouvez indiquer à Checkmk qu’il est tout à fait OK qu’un ordinateur hôte soit mis hors tension. Pour ce faire, recherchez l’ensemble de règles « Host check command », créez une nouvelle règle et définissez sa valeur sur « Always assume host to be up » :

Dans la case « Conditions », assurez-vous que cette règle ne s’applique réellement qu’aux ordinateurs hôtes concernés — en fonction de la structure que vous avez choisie. Par exemple, vous pouvez définir une balise de l’hôte et l’utiliser ici, ou vous pouvez définir la règle pour un dossier dans lequel se trouvent toutes les imprimantes.
Désormais, toutes les imprimantes s’afficheront toujours comme « en attente de réinitialisation », quel que soit leur état réel.
Cependant, les services de l'imprimante continueront d'être checkés, et tout timeout entraînerait un état « CRIT ». Pour éviter cela également, configurez une règle pour les ordinateurs hôtes concernés dans l'ensemble de règles « Status of the Checkmk services », dans lequel vous définissez respectivement les timeouts et les problèmes de connexion sur « OK » :
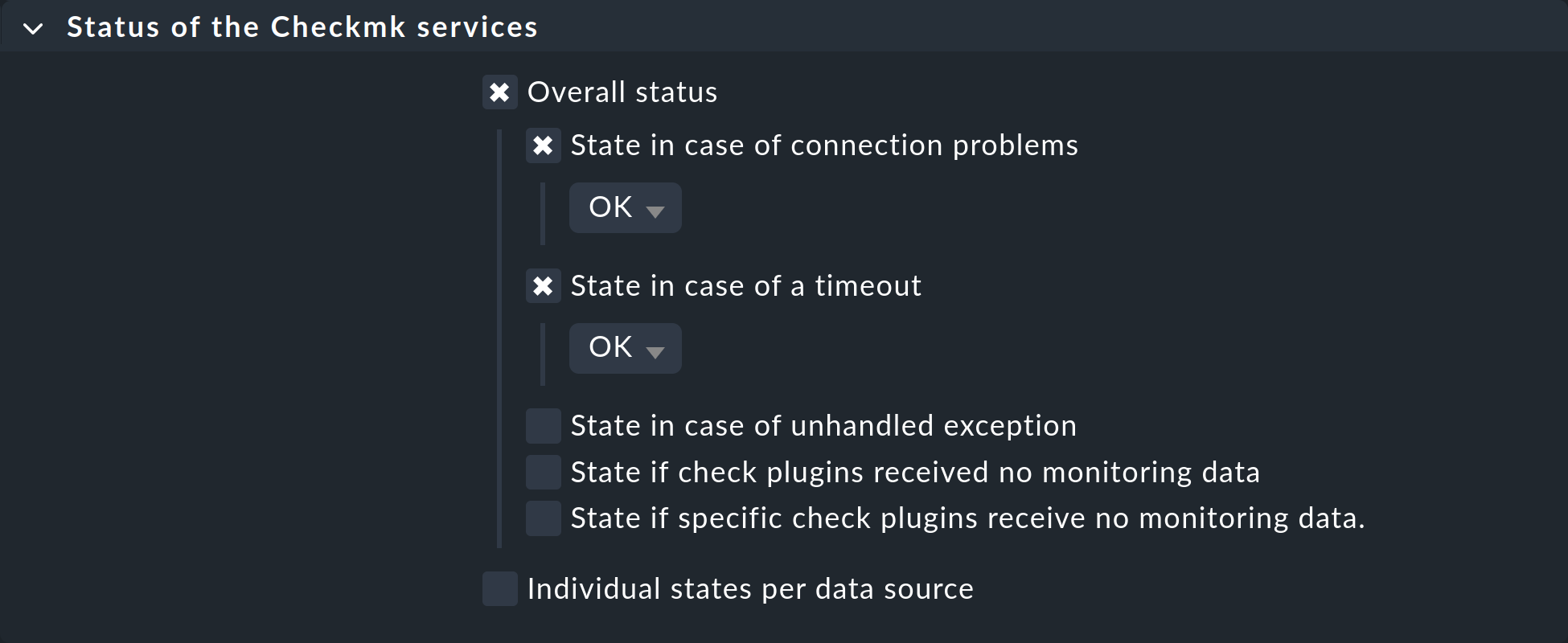
9. Configuration des ports du switch
Si vous effectuez la supervision d'un commutateur avec Checkmk, vous remarquerez que lors de la configuration du service, un service est automatiquement créé pour chaque port qui est UP à ce moment-là. Il s’agit d’un paramètre par défaut judicieux pour les commutateurs principaux et de distribution, c’est-à-dire ceux auxquels seuls des périphériques d’infrastructure ou des serveurs sont connectés. Cependant, pour les commutateurs auxquels sont connectés des terminaux tels que des postes de travail ou des imprimantes, cela entraîne d’une part des notifications en continu si un port tombe en panne, et d’autre part la détection constante de nouveaux services lorsqu’un port auparavant non surveillé devient actif.
Deux approches se sont avérées efficaces dans de telles situations. Tout d’abord, vous pouvez limiter la supervision aux uplink ports. Pour ce faire, créez une règle pour les services désactivés qui exclut les autres ports de la supervision.
La deuxième méthode est toutefois bien plus intéressante. Avec cette méthode, vous surveillez tous les ports, mais vous autorisez l'état « down » (désactivé). L'avantage est que vous bénéficiez d'une supervision des erreurs de transmission même pour les ports auxquels des terminaux sont connectés et pouvez ainsi détecter très rapidement les câbles de jonction défectueux ou les erreurs d'auto-négociation. Pour mettre en œuvre cette fonction, vous avez besoin de deux règles :
La première règle, « Network interface and switch port discovery », définit les conditions dans lesquelles les ports des switches doivent être supervisés. Créez une règle pour les switches souhaités et indiquez si des interfaces individuelles (Configure discovery of single interfaces) ou des groupes (Configure grouping of interfaces) doivent être détectés. Ensuite, sous « Conditions for this rule to apply > Match port states », activez « 2 - down » en plus de « 1 - up » :
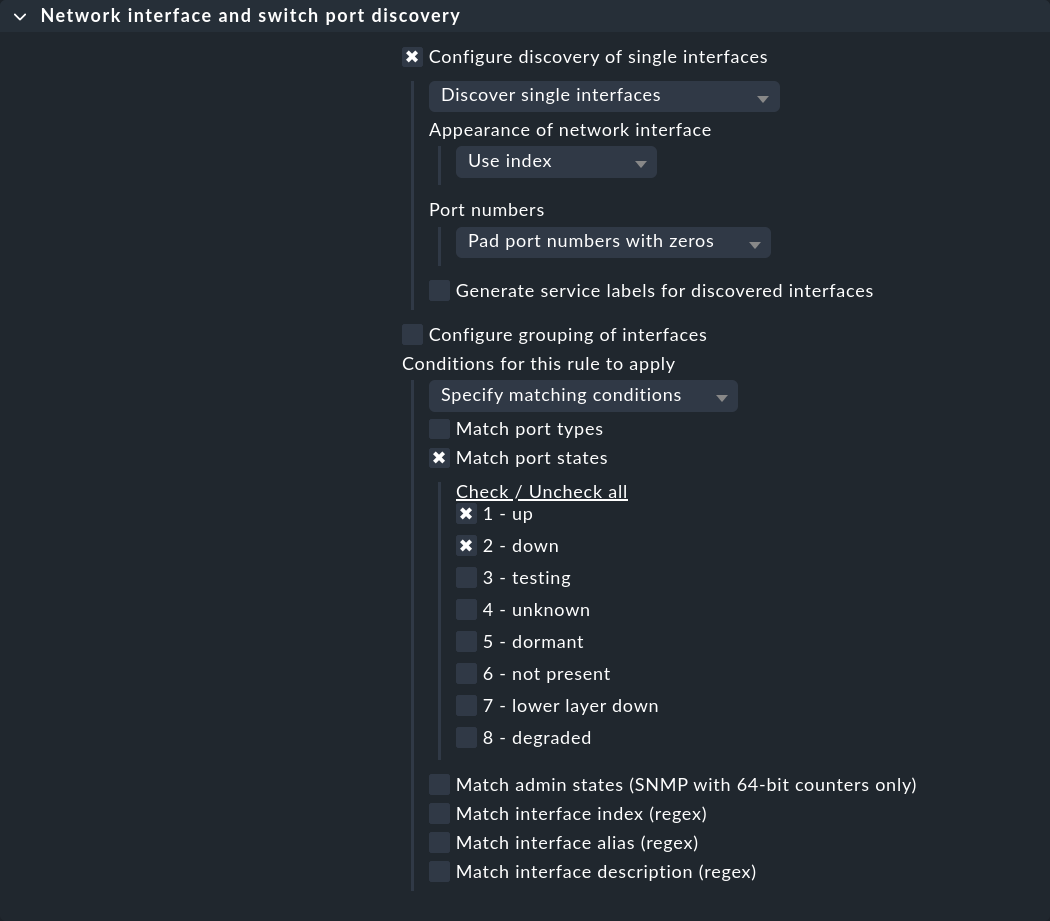
Dans la configuration des services des commutateurs, les ports en état « DOWN » seront désormais également affichés, et vous pourrez les ajouter à la liste des services sous supervision.
Avant d'activer la modification, vous aurez encore besoin de la deuxième règle qui garantit que cet état soit évalué comme «OK». Cet ensemble de règles s'appelle «Network interfaces and switch ports». Créez une nouvelle règle et activez l'option «Operational state», désactivez «Ignore the operational state» en dessous, puis activez les états «1 - up» et «2 - down» pour «Allowed operational states» (ainsi que tout autre état si nécessaire).
10. Désactivation définitive des services
Pour certains services qui ne peuvent tout simplement pas être configurés de manière fiable sur « OK », il est préférable de ne pas les superviser du tout. Dans ce cas, vous pouvez simplement supprimer manuellement les services de la supervision pour les ordinateurs hôtes concernés dans la reconnaissance du service (sur la page Services of host) en les configurant sur « Disabled » ou « Undecided ». Cependant, cette méthode est fastidieuse et source d’erreurs.
Il est bien préférable de définir des règles selon lesquelles certains services spécifiques ne seront systématiquement pas supervisés.
À cette fin, il existe un jeu de règles « Disabled services ».
Vous pouvez par exemple créer une règle et spécifier dans la condition que les systèmes de fichiers avec le point de montage « /var/test/ » ne doivent, par définition, pas être supervisés.
Si vous désactivez un service individuel dans la configuration des services d’un ordinateur hôte en cliquant sur « |
Vous trouverez plus d'informations à ce sujet dans l'article consacré à la configuration des services.
11. Détection des valeurs aberrantes à l'aide des valeurs moyennes
Les notifications sporadiques sont souvent générées par des valeurs seuils relatives à des métriques d’utilisation — telles que l’utilisation du processeur — qui ne sont dépassées que pendant un court instant. En règle générale, ces pics de courte durée ne posent pas de problème et ne devraient pas être signalés par la supervision.
C'est pourquoi de nombreux plugins de supervision proposent, dans leur configuration, une option permettant de calculer la moyenne de leurs métriques sur une période plus longue avant l'application des valeurs seuils. Un exemple en est le jeu de règles pour l'utilisation du processeur sur les systèmes non-Unix, appelé « CPU utilization for simple devices ». Pour cela, il existe le paramètre « Averaging for total CPU utilization » :
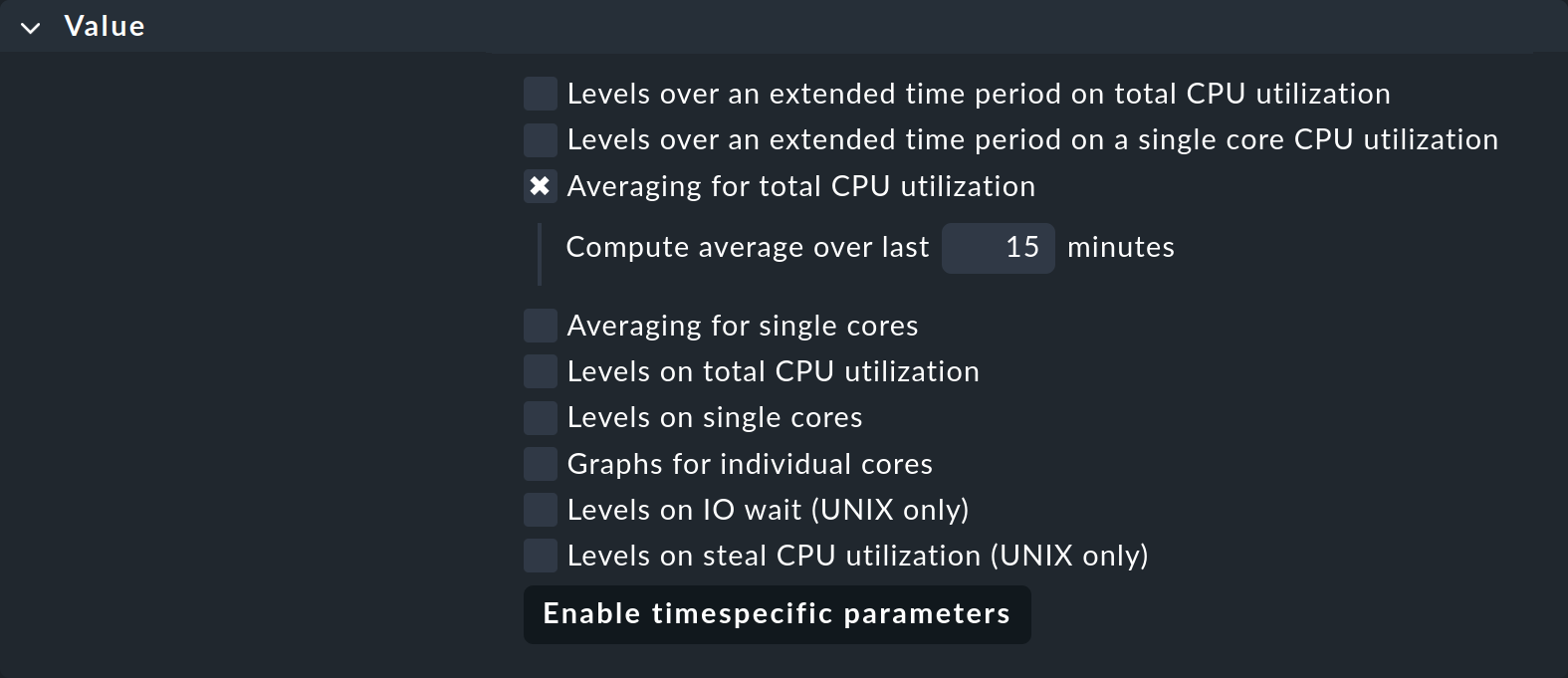
Si vous activez cette option et saisissez 15, l'utilisation du processeur sera d'abord moyennée sur une période de 15 minutes, et ce n'est qu'ensuite que les valeurs seuil seront appliquées à cette valeur moyenne.
12. Gestion des erreurs sporadiques
Lorsque rien d'autre ne fonctionne et que les services continuent de se connecter occasionnellement à WARN ou CRIT pendant un seul intervalle de check — c'est-à-dire pendant une minute —, il existe une dernière méthode pour éviter les fausses alertes : le jeu de règles « Maximum number of check attempts for service ».
Si vous créez une règle dans ce jeu de règles et que vous définissez sa valeur sur, par exemple, 3, un service passant de OK à WARN, par exemple, ne déclenchera pas encore de notification et n’apparaîtra pas encore comme un problème dans l’Overview.
L’état intermédiaire dans lequel se trouve désormais le service est appelé « soft state ».
Ce n’est que lorsque l’état reste « non OK » pendant trois vérifications consécutives — soit une durée totale d’un peu plus de deux minutes — qu’un problème persistant sera signalé.
Seul un état dur déclenchera une notification.
Il faut bien admettre que ce n’est pas une solution très satisfaisante. Vous devriez toujours essayer d’aller au fond du problème, mais parfois, les choses sont simplement ce qu’elles sont, et grâce au nombre de tentatives de check, vous disposez au moins d’un moyen viable de contourner ce genre de situations.
13. Maintenir la liste des services à jour
Dans tout centre de données, des travaux sont constamment effectués ; par conséquent, la liste des services à surveiller n’est jamais figée. Pour vous assurer de ne rien manquer, Checkmk configure automatiquement un service spécial pour vous sur chaque ordinateur hôte — ce service est appelé « Check_MK Discovery » :

Par défaut, toutes les deux heures, ce service checke si de nouveaux services — non encore sous supervision — ont été détectés ou si des services existants ont été supprimés. Si tel est le cas, le service passe à l’état « WARN ». Vous pouvez alors consulter la reconnaissance du service (sur la page « Services of host ») et mettre à jour la liste des services en fonction de l’état actuel.
Vous trouverez des informations détaillées sur cette vérification d’identification dans l’article consacré à la configuration des services. Vous y apprendrez également comment ajouter automatiquement des services non surveillés, ce qui facilite considérablement le travail dans le cadre d’une configuration à grande échelle.
Avec Monitor > System > Unmonitored services, vous pouvez afficher une vue de la table qui vous indique tous les services nouveaux ou supprimés. |