This is a machine translation based on the English version of the article. It might or might not have already been subject to text preparation. If you find errors, please file a GitHub issue that states the paragraph that has to be improved. |
1. Introduction
Tout le monde n’a sans doute pas la même conception du terme « supervision distribuée ». En réalité, la supervision est toujours répartie sur plusieurs ordinateurs, à moins que le système de supervision ne surveille uniquement lui-même — ce qui ne serait pas très utile.
Dans ce guide de l’utilisateur, nous faisons donc toujours référence à une supervision distribuée lorsque le système de supervision dans son ensemble se compose de plus d’une seule instance Checkmk. Il existe plusieurs bonnes raisons de répartir la supervision sur plusieurs sites :
Performances : la charge du processeur devrait, voire doit, être répartie sur plusieurs machines.
Organisation : différents groupes doivent pouvoir administrer leurs propres instances de manière indépendante.
Disponibilité : la supervision d’un site doit fonctionner indépendamment des autres sites.
Sécurité : les flux de données entre deux domaines de sécurité doivent être contrôlés séparément et avec précision (DMZ, etc.)
Réseau : les sites disposant uniquement d’une connexion à bande passante étroite ou peu fiable ne peuvent pas être soumis à une supervision à distance de manière fiable.
Checkmk prend en charge diverses procédures pour la mise en œuvre d’une supervision distribuée.
Checkmk contrôle certaines d’entre elles, car il est largement compatible avec Nagios ou basé sur ce dernier (si Nagios a été installé comme noyau du processeur).
Cela inclut par exemple la procédure avec mod_gearman.
Par rapport au système propre à Checkmk, cela n’offre aucun avantage et est également plus fastidieux à mettre en œuvre.
Pour ces raisons, nous ne le recommandons pas.
La procédure privilégiée par Checkmk repose sur Livestatus et un environnement de configuration distribué. Pour les situations où les réseaux sont très séparés, voire en cas de transfert de données strictement unidirectionnel de la périphérie vers le centre, il existe une méthode utilisant Livedump ou, respectivement, CMCDump. Ces deux méthodes peuvent être combinées.
2. Supervision distribuée avec Livestatus
2.1. Principes de base
État central
Livestatus est une interface intégrée au noyau de supervision qui permet à d’autres programmes externes d’interroger les données d’état et d’exécuter des instructions. Livestatus peut être mis à disposition sur le réseau afin d’être accessible depuis une instance Checkmk distante. L’interface utilisateur de Checkmk utilise Livestatus pour regrouper toutes les instances en un aperçu, qui ressemble alors à un seul et même grand système de supervision.
Le schéma suivant illustre la structure d’une supervision avec Livestatus répartie sur trois sites. L’instance centrale Checkmk se trouve sur le site de traitement central. C’est à partir de là que les systèmes centraux seront directement contrôlés. De plus, il existe l’instance distante 1 et l’instance distante 2, qui sont situées sur d’autres réseaux et contrôlées par leurs systèmes locaux :
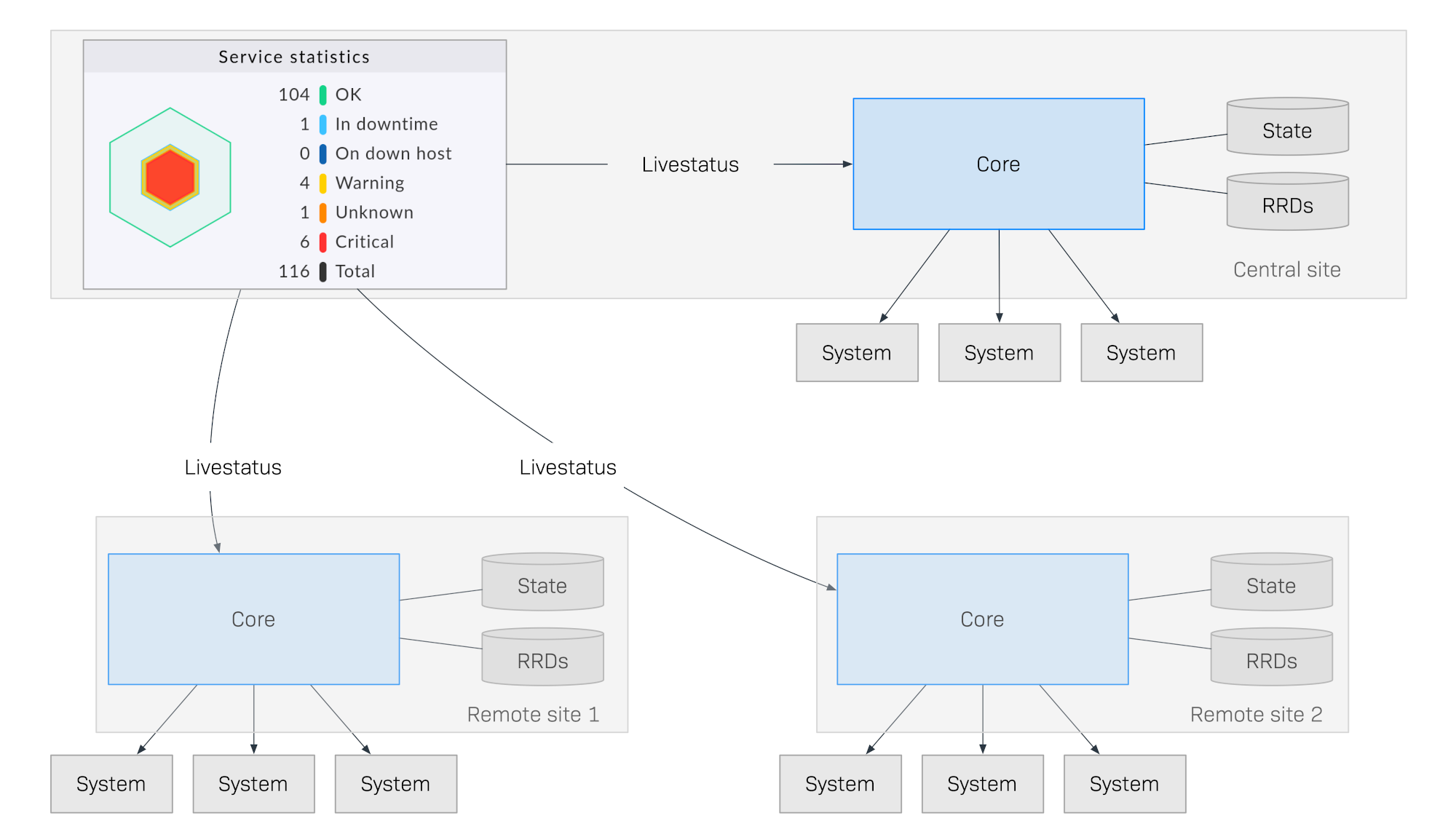
Ce qui rend cette méthode particulière, c’est que l’état de supervision des instances distantes n’est pas envoyé en continu vers l’instance centrale. L’interface graphique ne récupère les données en temps réel depuis les instances distantes que lorsque cela est demandé par un utilisateur du poste de contrôle. Les données sont ensuite compilées dans une vue centralisée. Il n’y a donc pas de stockage centralisé des données, ce qui offre d’énormes avantages pour la mise à l’échelle !
Voici quelques-uns des avantages de cette méthode :
Évolutivité : la supervision elle-même ne génère absolument aucun trafic réseau entre l’instance centrale et les instances distantes. De cette manière, des centaines d’instances, voire plus, peuvent être connectées.
Fiabilité : si une connexion réseau vers une instance distante est interrompue, la supervision locale continue néanmoins de fonctionner normalement. Il n’y a pas de « trou » dans l’enregistrement des données, ni d’« engorgement » des données. Une notification locale continuera de fonctionner.
Simplicité : les instances peuvent être très facilement ajoutées ou supprimées.
Flexibilité : les instances distantes restent autonomes et peuvent être utilisées pour le fonctionnement sur leur instance respective. Ceci est particulièrement intéressant si l’« emplacement » ne doit en aucun cas avoir accès au reste de la supervision.
Configuration centrale
Dans un système distribué utilisant Livestatus comme décrit ci-dessus, il est tout à fait possible que les instances individuelles soient gérées indépendamment par différentes équipes, et que l’instance centrale ait pour seule tâche de fournir un tableau de bord centralisé.
Dans le cas où plusieurs sites, voire tous, doivent être administrés par la même équipe, une configuration centralisée est beaucoup plus facile à gérer. Checkmk prend en charge cette approche et désigne une telle configuration sous le nom de « configuration centralisée ». Dans ce cas, tous les ordinateurs hôtes et services, les utilisateurs et autorisations, les périodes de temps, les notifications, etc., seront gérés dans l’Setup de l’instance centrale, puis automatiquement distribués aux instances distantes selon vos spécifications.
Un tel système offre non seulement un aperçu commun de l’état, mais aussi une configuration commune, et donne effectivement « l’impression d’un grand système ».
Vous pouvez même étendre ce système avec, par exemple, des instances de la visionneuse dédiées qui servent uniquement d’interfaces de suivi d’état pour des sous-domaines ou des groupes d’utilisateurs spécifiques.
2.2. Mise en place d’une supervision distribuée
L'installation d'une supervision distribuée à l'aide de Livestatus/central configuration s'effectue selon les étapes suivantes :
Commencez par installer l'instance centrale comme vous le feriez habituellement pour une instance unique
Installez les instances distantes et activez Livestatus via le réseau
Intégrez les instances distantes à l'instance centrale à l'aide de l'Setup > General > Distributed monitoring
Pour les ordinateurs hôtes et les services, précisez à partir de quelle instance ils doivent être supervisés
Exécutez la reconnaissance du service pour les ordinateurs hôtes migrés, puis activez les nouvelles modifications
Configuration de l'instance centrale
Aucune exigence particulière n'est imposée à l'instance centrale. Cela signifie qu'une instance existante de longue date peut être étendue à une supervision distribuée en ne nécessitant qu'une seule modification — nécessaire pour la gestion correcte des données ferroutées. Il vous suffit d'activer le hub ferroutage sur la page de configuration Setup > General > Global settings dans la section «Site management» :
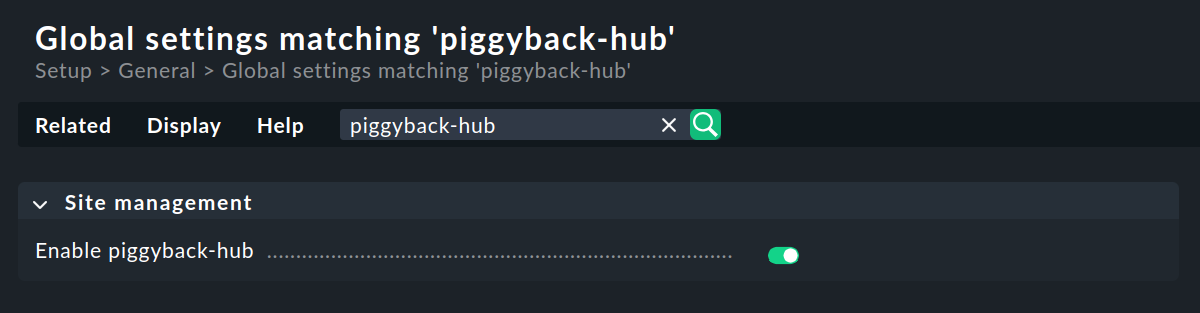
Activez ensuite les modifications, car l'activation ou la désactivation du hub de ferroutage nécessite le redémarrage de l'instance.
Configuration d’instances distantes et activation de Livestatus via le réseau
Les instances distantes sont ensuite générées comme de nouvelles instances de la manière habituelle via omd create.
Cette opération s'effectue naturellement sur le serveur (distant) destiné à l'instance distante concernée.
Remarques particulières :
Pour les instances distantes, utilisez des identifiants uniques pour votre supervision distribuée.
La version de Checkmk (par exemple 2.4.0) des instances distantes et de l’instance centrale est la même — les versions mixtes ne sont prises en charge que pour faciliter les mises à jour.
De la même manière que Checkmk prend en charge plusieurs instances sur un serveur, les instances distantes peuvent également fonctionner sur le même serveur.
Voici un exemple de création d'une instance distante nommée myremote1 avec le mot de passe t0p53cr3t pour l'administrateur de l'instance cmkadmin :
Les étapes les plus importantes consistent désormais à activer Livestatus via TCP pour le réseau et à activer également le hub de ferroutage ici.
Notez que Livestatus n’est pas en soi un protocole sécurisé et ne doit être utilisé que dans un réseau sécurisé (LAN sécurisé, VPN, etc.).
L’activation s’effectue en utilisant omd config en tant qu’utilisateur de l’instance alors que l’instance est arrêtée :
Sélectionnez maintenant Distributed Monitoring :
┌Configuration of site myremote1───┐ │ Interactive setting of site │ │ configuration variables. You can │ │ change values only while the │ │ site is stopped. │ │ ┌──────────────────────────────┐ │ │ │ Basic │ │ │ │ Web GUI │ │ │ │ Addons │ │ │ │ Distributed Monitoring │ │ │ │ │ │ │ └──────────────────────────────┘ │ ├──────────────────────────────────┤ │ <Enter> <Exit > │ └──────────────────────────────────┘
Définissez LIVESTATUS_TCP sur on , et pour LIVESTATUS_TCP_PORT, entrez un numéro de port non attribué qui soit unique sur ce serveur.
La valeur par défaut est 6557 :
┌────────────Distributed Monitoring──────────────┐ │ ┌────────────────────────────────────────────┐ │ │ │ LIVEPROXYD on │ │ │ │ LIVESTATUS_TCP on │ │ │ │ LIVESTATUS_TCP_ONLY_FROM 0.0.0.0 ::/0 │ │ │ │ LIVESTATUS_TCP_PORT 6557 │ │ │ │ LIVESTATUS_TCP_TLS on │ │ │ │ PIGGYBACK_HUB on │ │ │ │ │ │ │ └────────────────────────────────────────────┘ │ ├────────────────────────────────────────────────┤ │ < Change > <Main menu> │ └────────────────────────────────────────────────┘
Après avoir enregistré, démarrez l'instance comme d'habitude avec omd start :
Mémorisez le mot de passe pour cmkadmin.
Vous n'en aurez besoin que deux fois : d'abord pour activer le hub de ferroutage, puis pour établir la connexion entre l'instance distante et l'instance centrale.
Une fois que l'instance distante aura été subordonnée à l'instance centrale,
tous les utilisateurs seront de toute façon remplacés par ceux de l'instance centrale.
L'instance est désormais prête.
Un check avec netstat montre que le port 6557 est ouvert.
La connexion à ce port s'effectue avec une instance du superserver internet xinetd, qui s'exécute directement sur le site :
Connectez-vous maintenant une fois à l'instance distante en tant qu'utilisateur cmkadmin et activez le hub de ferroutage à l'aide des paramètres Setup > General > Global dans la section Site management :
Appliquez ensuite les modifications, car l'activation ou la désactivation du hub de ferroutage nécessite le redémarrage de l'instance.
Attribution des instances distantes à l'instance centrale
La configuration de la supervision distribuée s'effectue exclusivement sur l'instance centrale dans le menu Setup > General > Distributed monitoring, qui sert à gérer les connexions vers les différents sites. Pour cette fonction, l'instance centrale elle-même est considérée comme une instance et figure déjà dans la liste :

À l'aide de ![]() Add connection , définissez maintenant la connexion à la première instance distante :
Add connection , définissez maintenant la connexion à la première instance distante :

Dans l’Basic settings, il est important d’utiliser le nom EXACT de l’instance distante — tel que défini avec omd create — comme Site ID.
Comme toujours, l’alias peut être défini selon vos besoins et modifié ultérieurement.
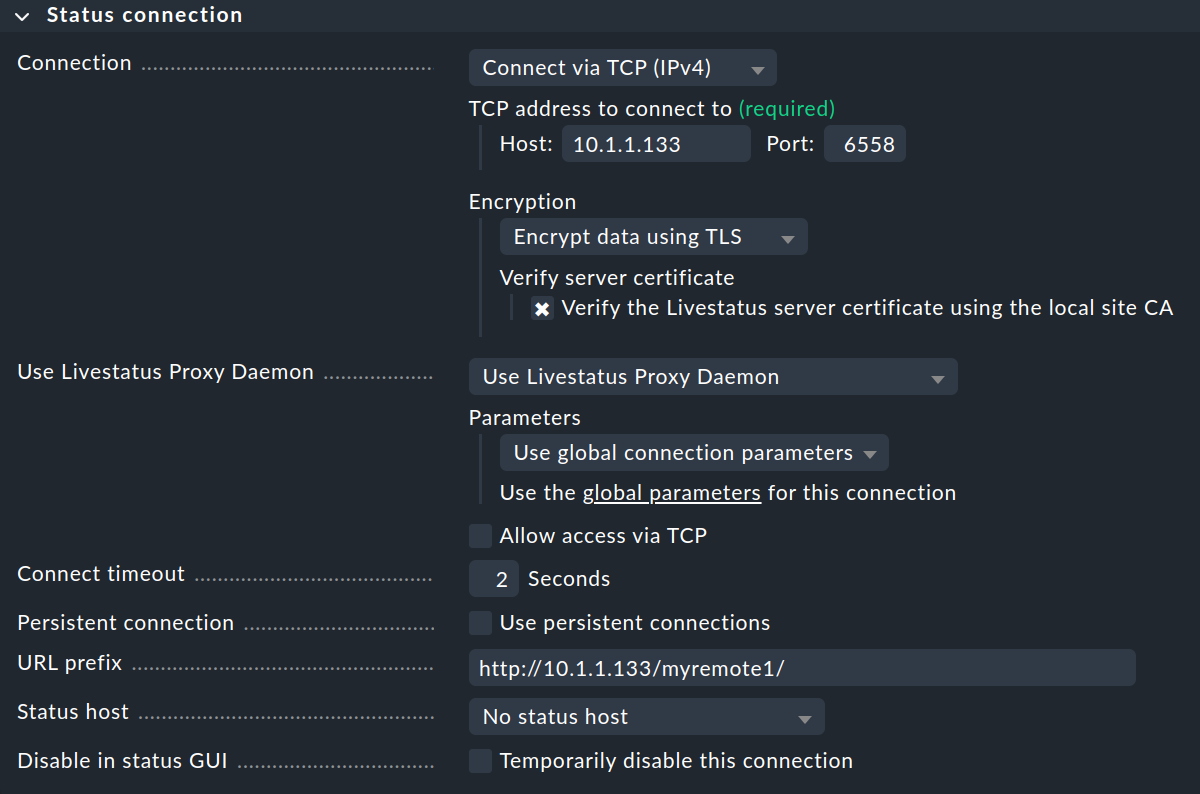
Les paramètres de l’Status connection déterminent la manière dont l’instance centrale interroge l’état des instances distantes via Livestatus. L’exemple de la capture d’écran montre une connexion utilisant la méthode Connect via TCP(IPv4). C’est la solution optimale pour des connexions stables avec de faibles niveaux de latence (comme, par exemple, dans un réseau local). Nous aborderons plus tard les paramètres optimaux pour les connexions WAN.
Saisissez ici l’URL HTTP de l’interface web de l’instance distante, sans le check_mk/ à la fin de l’URL.
Si vous accédez habituellement à Checkmk via HTTPS, remplacez ici http par https.
Vous trouverez de plus amples informations dans l’aide en ligne ![]() ou dans l’article consacré à la sécurisation de l’interface web avec HTTPS.
ou dans l’article consacré à la sécurisation de l’interface web avec HTTPS.
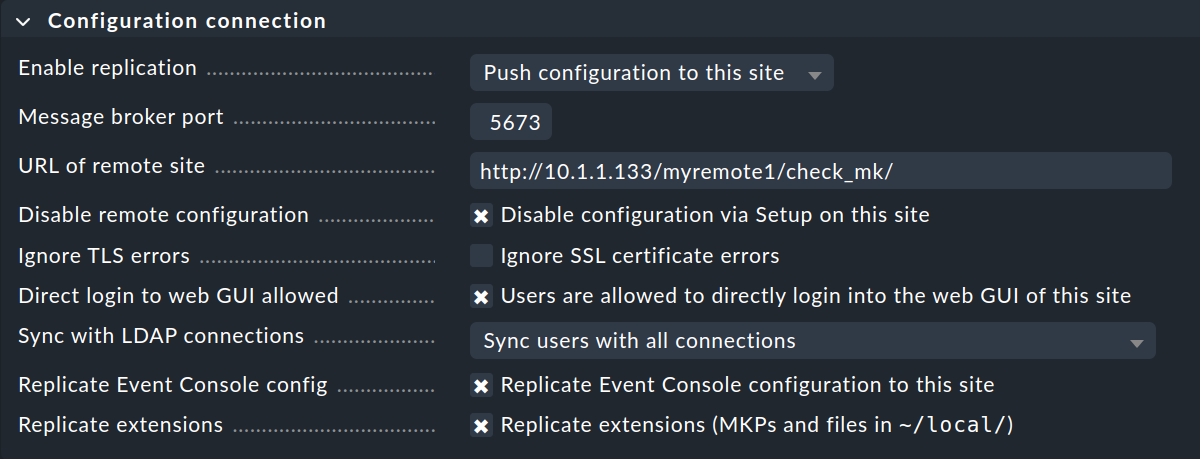
La réplication de la configuration et, par conséquent, l'utilisation de la configuration centrale sont, comme nous l'avons mentionné dans l'introduction, facultatives. Activez la réplication en sélectionnant Push configuration to this site si vous souhaitez configurer l'instance distante à partir de l'instance centrale. Dans ce cas, sélectionnez exactement les paramètres indiqués dans l'image ci-dessus.
Veillez à vérifier quelle adresse Message broker port vous devez spécifier.
Pour le savoir, connectez-vous à l’instance distante concernée et exécutez l’instruction omd config depuis la ligne de commande.
Accédez à la section Basic.
Ici, la variable RABBITMQ_PORT est celle qui vous intéresse.
┌─────────────────Basic───────────────────┐ │ ┌─────────────────────────────────────┐ │ │ │ ADMIN_MAIL │ │ │ │ AGENT_RECEIVER on │ │ │ │ AGENT_RECEIVER_PORT 8016 │ │ │ │ AUTOMATION_HELPER on │ │ │ │ AUTOSTART on │ │ │ │ CORE cmc │ │ │ │ RABBITMQ_DIST_PORT 25672 │ │ │ │ RABBITMQ_MANAGEMENT_PORT 15671 │ │ │ │ RABBITMQ_ONLY_FROM :: │ │ │ │ RABBITMQ_PORT 5671 │ │ │ │ TMPFS on │ │ │ │ │ │ │ └─────────────────────────────────────┘ │ ├─────────────────────────────────────────┤ │ < Change > <Main menu> │ └─────────────────────────────────────────┘
Ne vous méprenez pas : l’Message Broker Port est défini dans la variable |
Il est très important de configurer correctement l’URL of remote site.
L’URL doit toujours se terminer par /check_mk/. Une connexion via HTTPS est recommandée, à condition que le serveur Apache de l’instance distante prenne en charge le protocole HTTPS.
Celui-ci doit être installé manuellement sur l’instance distante au niveau du système d’exploitation Linux.
Pour la Checkmk Appliance, le protocole HTTPS peut être configuré à l’aide de l’interface de configuration Web.
Si vous utilisez un certificat auto-signé, vous devrez cocher la case « Ignore SSL certificate errors ».
Une fois le masque enregistré, une deuxième instance apparaîtra dans l'aperçu :

Le statut de supervision de l'instance distante (pour l'instant) vide est désormais correctement intégré.
Pour utiliser la configuration centrale, vous avez encore besoin d'un compte Login pour l'instance Checkmk distante.
À cette fin, l'instance centrale échange avec l'instance distante un secret de login généré aléatoirement, par l'intermédiaire duquel toutes les communications futures auront lieu.
Le compte cmkadmin sur l'instance distante ne sera par la suite plus utilisé.
Dans le formulaire suivant, utilisez comme identifiant cmkadmin et le mot de passe attribué lors de la création de l’instance distante.
À ce stade, confirmez que vous souhaitez remplacer les paramètres en cliquant sur «Confirm overwrite».

Un login réussi sera confirmé comme suit :

Si une erreur survient lors du login, cela peut être dû à plusieurs raisons – par exemple :
L'instance distante est actuellement arrêtée.
L'URL of remote site n'a pas été correctement configuré.
L'instance distante n'est pas accessible sous le nom de domaine « depuis l'instance centrale » spécifié dans l'URL.
Les versions de Checkmk de l'instance centrale et de l'instance distante sont (trop) incompatibles.
Un identifiant utilisateur et/ou un mot de passe non valide a été saisi.
Les deux premiers éléments de la liste peuvent être facilement vérifiés en appelant manuellement l'URL du site distant dans votre navigateur.
Une fois que tout a fonctionné, lancez Activate Changes. Comme toujours, cela vous mènera à un aperçu des modifications qui n’ont pas encore été activées. Parallèlement, l’aperçu affichera également les états des connexions Livestatus, ainsi que les états de synchronisation des différentes instances dans la configuration centrale :
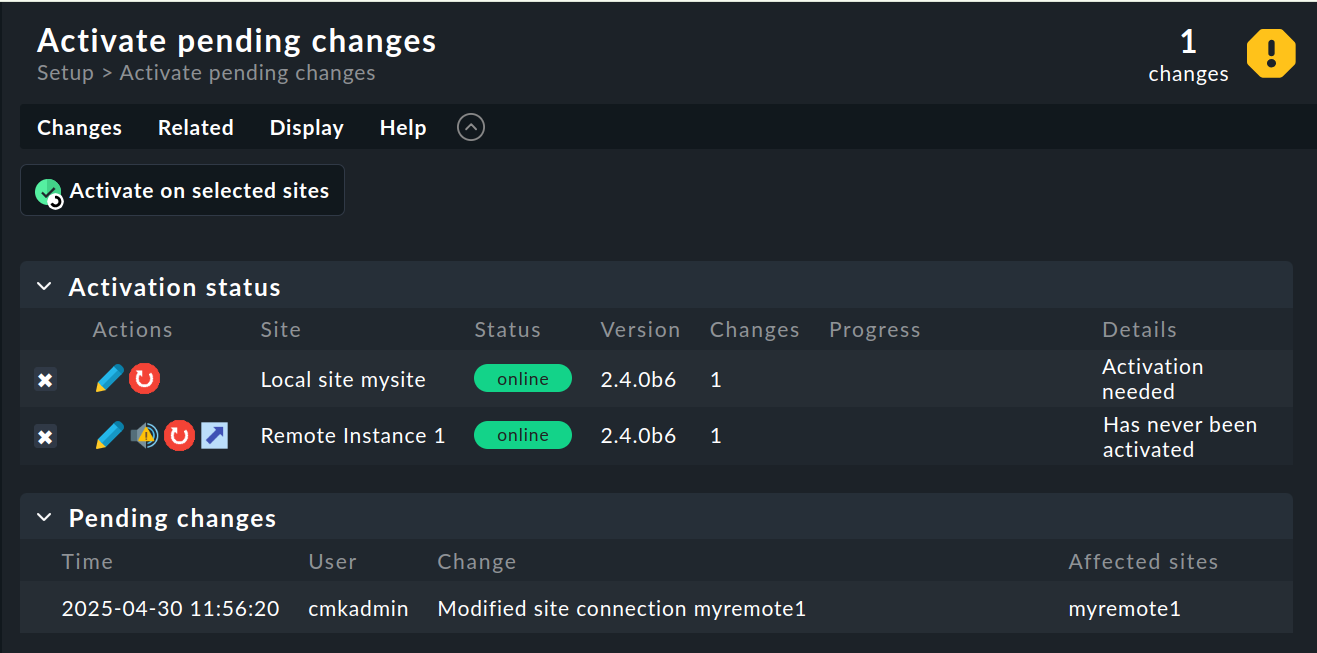
La colonne « Version » indique la version Livestatus de l’instance concernée. Lorsque vous utilisez le CMC comme noyau de Checkmk (éditions commerciales), le numéro de version du noyau (affiché dans la colonne « ‘Core’ ») est identique à celui de Livestatus. Si vous utilisez Nagios comme noyau (Checkmk Community), c’est le numéro de version de Nagios qui s’affiche ici.
Les icônes suivantes indiquent l'état de réplication de l'environnement de configuration :
|
Ce site présente des modifications en attente.
La configuration correspond à celle de l’instance centrale, mais toutes les modifications n’ont pas été activées.
Le bouton « |
|
La configuration de cette instance n'est pas synchronisée et doit être transférée.
Un redémarrage sera alors bien sûr nécessaire pour l'activer.
Ces deux fonctions peuvent être exécutées en cliquant sur le bouton « |
Dans la colonne « Status », vous pouvez voir l'état de la connexion Livestatus pour l'instance concernée. Cette information est fournie à titre purement indicatif, car la configuration n'est pas transmise via Livestatus, mais via HTTP. Les valeurs suivantes sont possibles :
|
L'instance est accessible via Livestatus. |
|
Le site n'est actuellement pas accessible. Les requêtes Livestatus sont en attente de timeout. Cela retarde le chargement de la page. Les données d'état de cette instance ne sont pas visibles dans l'interface graphique. |
|
Le site n'est actuellement pas accessible, mais cela est dû à la configuration d'un ordinateur hôte de statut ou est connu via le proxy Livestatus (voir ci-dessous). Cette inaccessibilité n'entraîne pas de timeouts. Les données de statut de ce site ne sont pas visibles dans l'interface graphique. |
|
La connexion Livestatus vers ce site a été temporairement désactivée par l’administrateur (de l’instance centrale). Ce paramètre correspond à la case à cocher « Temporarily disable this connection » dans les paramètres de cette connexion. |
Cliquer sur le bouton « ![]() » (Synchroniser toutes les instances) Activate on selected sites synchronisera alors toutes les instances et activera les modifications.
Cette opération s’effectue en parallèle, de sorte que la durée totale correspond au temps requis par l’instance la plus lente.
Ce temps comprend la création d’un snapshot de configuration pour l’instance concernée, la transmission via HTTP, la décompression du snapshot sur l’instance distante et l’activation des modifications.
» (Synchroniser toutes les instances) Activate on selected sites synchronisera alors toutes les instances et activera les modifications.
Cette opération s’effectue en parallèle, de sorte que la durée totale correspond au temps requis par l’instance la plus lente.
Ce temps comprend la création d’un snapshot de configuration pour l’instance concernée, la transmission via HTTP, la décompression du snapshot sur l’instance distante et l’activation des modifications.
Important : ne quittez pas la page avant que la synchronisation ne soit terminée sur toutes les instances — quitter la page interrompra la synchronisation.
Indiquer aux ordinateurs hôtes et aux dossiers quel site doit les superviser
Une fois votre environnement distribué installé, vous pouvez commencer à l'utiliser. Il vous suffit en fait d'indiquer à chaque ordinateur hôte par quelle instance il doit être supervisé. L'instance centrale est spécifiée par défaut.
L'attribut requis pour cela est « Monitored on site ». Vous pouvez le définir individuellement pour chaque ordinateur hôte. Cela peut bien sûr également être effectué au niveau des dossiers :

Exécution d'une nouvelle reconnaissance du service et activation des modifications pour les ordinateurs hôtes migrés
L'ajout d'ordinateurs hôtes s'effectue comme d'habitude — mis à part le fait que la supervision ainsi que la reconnaissance du service seront exécutées à partir de l'instance distante correspondante, il n'y a pas de considérations particulières.
Lors de la migration d’ordinateurs hôtes d’une instance vers une autre, il convient de tenir compte de plusieurs points. Ni les données d’état actuelles ni les données historiques de l’ordinateur hôte ne seront transférées. Seule la configuration de l’ordinateur hôte est conservée dans l’environnement de configuration. En effet, c’est comme si l’ordinateur hôte avait été supprimé d’une instance et nouvellement installé sur l’autre instance :
Les services détectés automatiquement ne seront pas migrés. Lancez la reconnaissance du service après la migration.
Une fois redémarrés, les ordinateurs hôtes et les services afficheront l'état PEND. Les problèmes existants peuvent par conséquent faire l'objet d'une nouvelle notification.
Les métriques historiques seront perdues. Vous pouvez éviter cela en déplaçant manuellement les fichiers RRD concernés. L'emplacement des fichiers se trouve dans Fichiers et répertoires.
Les données relatives à la disponibilité et aux événements historiques seront perdues. Celles-ci ne sont malheureusement pas faciles à migrer, car les données se composent de lignes individuelles dans le journal de supervision.
Si la continuité de l'historique est importante pour vous, lors de la mise en place de la supervision, vous devez planifier avec soin quel ordinateur hôte doit être surveillé et depuis quel emplacement.
2.3. Connexion de Livestatus avec cryptage
Les connexions Livestatus entre l’instance centrale et une instance distante peuvent être chiffrées.
Pour les instances nouvellement créées, aucune action supplémentaire n’est requise,
car Checkmk se charge automatiquement des étapes nécessaires.
Dès que vous utilisez ensuite omd config pour activer Livestatus, le chiffrement est également activé automatiquement par TLS :
┌────────────Distributed Monitoring──────────────┐ │ ┌────────────────────────────────────────────┐ │ │ │ LIVEPROXYD on │ │ │ │ LIVESTATUS_TCP on │ │ │ │ LIVESTATUS_TCP_ONLY_FROM 0.0.0.0 ::/0 │ │ │ │ LIVESTATUS_TCP_PORT 6557 │ │ │ │ LIVESTATUS_TCP_TLS on │ │ │ │ PIGGYBACK_HUB on │ │ │ │ │ │ │ └────────────────────────────────────────────┘ │ ├────────────────────────────────────────────────┤ │ < Change > <Main menu> │ └────────────────────────────────────────────────┘
La configuration de la supervision distribuée reste donc aussi simple qu’elle l’a toujours été. Pour les nouvelles connexions vers d’autres instances, l’option « Encryption » est alors automatiquement activée.
Après avoir ajouté l’instance distante, vous remarquerez deux choses : tout d’abord, la connexion est signalée comme cryptée par cette nouvelle icône « ![]() ».
Et ensuite, Checkmk vous indiquera que l’autorité de certification (CA) ne fait plus confiance à l’instance distante.
Cliquez sur «
».
Et ensuite, Checkmk vous indiquera que l’autorité de certification (CA) ne fait plus confiance à l’instance distante.
Cliquez sur « ![]() » pour accéder aux détails des certificats utilisés.
Un clic sur «
» pour accéder aux détails des certificats utilisés.
Un clic sur « ![]() » vous permet d’ajouter facilement l’autorité de certification via l’interface web.
Les deux certificats seront alors répertoriés comme fiables :
» vous permet d’ajouter facilement l’autorité de certification via l’interface web.
Les deux certificats seront alors répertoriés comme fiables :
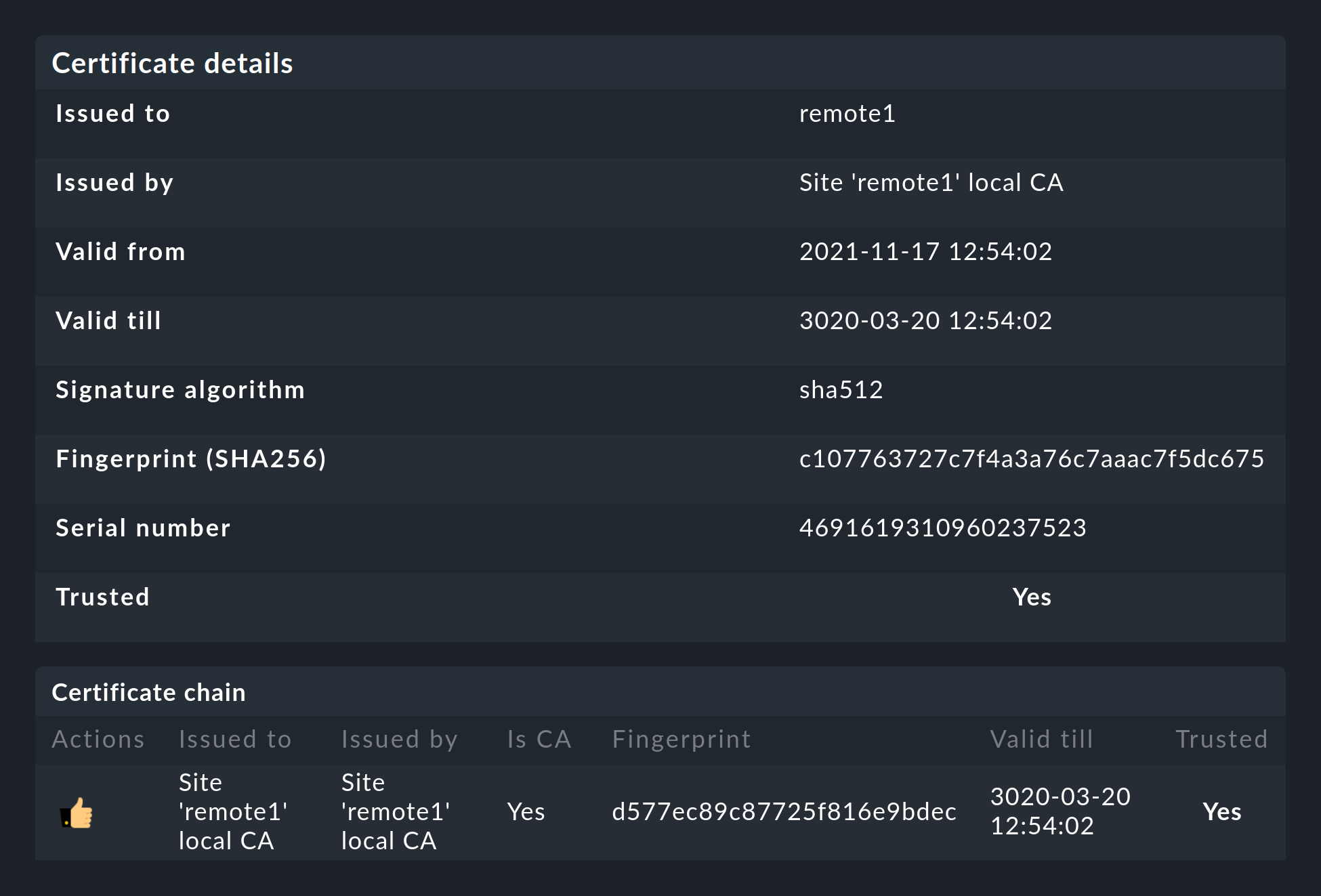
Détails des technologies utilisées
Pour assurer le chiffrement, Checkmk utilise le programme stunnel ainsi que son propre certificat et sa propre autorité de certification (CA) pour signer le certificat.
Ceux-ci seront générés automatiquement et individuellement lors de la création d’une nouvelle instance ; il ne s’agit donc pas de CA ou de certificats statiques prédéfinis.
Il s’agit là d’un facteur de sécurité très important pour empêcher l’utilisation de faux certificats par des attaquants, car ceux-ci pourraient alors accéder à une CA accessible au public.
Les certificats générés présentent également les propriétés suivantes :
Les deux certificats sont au format PEM. Les certificats signés pour l’instance contiennent également la chaîne de certificats complète.
Les clés utilisent un algorithme RSA de 4096 bits, et le certificat est signé à l'aide de SHA512
Le certificat de l’instance est valable pendant 10 ans.
Le fait que le certificat standard soit valable aussi longtemps vous évite très efficacement de rencontrer des problèmes de connexion que vous ne pourriez pas identifier. Dans le même temps, il est bien sûr possible qu’une fois qu’un certificat a été compromis, il reste exposé aux abus pendant une période proportionnellement longue. Ainsi, si vous craignez qu’un attaquant accède à l’autorité de certification ou au certificat de l’instance signé par celle-ci, remplacez toujours les deux certificats (autorité de certification et instance) !
Migration depuis des versions antérieures
Lors d'une mise à jour de Checkmk, les deux options LIVESTATUS_TCP et LIVESTATUS_TCP_TLS ne sont jamais modifiées automatiquement.
L'activation automatique du TLS pourrait en fin de compte empêcher toute interrogation de vos instances distantes.
Si vous utilisiez jusqu'à présent Livestatus sans cryptage et que vous décidez désormais d'utiliser le cryptage, vous devez l'activer manuellement. Pour ce faire, arrêtez d'abord les instances concernées, puis activez TLS à l'aide de l'instruction suivante :
Les certificats ayant été générés automatiquement lors de la mise à jour, l'instance utilise alors immédiatement la nouvelle fonctionnalité de chiffrement. Afin de pouvoir continuer à accéder à l'instance depuis l'instance centrale, vérifiez que l'option « Encryption » est définie sur « Encrypt data using TLS » dans le menu sous « Setup > General > Distributed Monitoring » : Vérifiez ce point et, si nécessaire, configurez l'option comme indiqué dans la capture d'écran suivante :
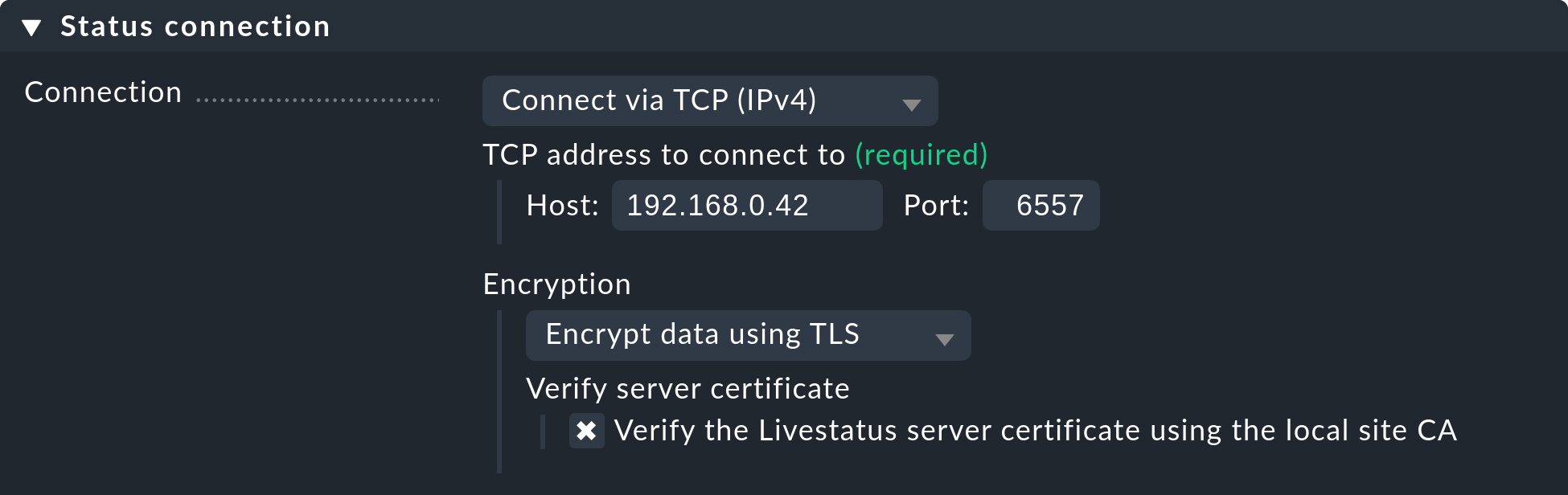
La dernière étape est celle décrite ci-dessus — là encore, vous devez d’abord marquer l’autorité de certification (CA) de l’instance distante comme étant de confiance.
2.4. Particularités d’une configuration centralisée
Une supervision distribuée fonctionne via Livestatus de manière très similaire à un système unique, mais elle présente tout de même quelques caractéristiques particulières :
Accès aux ordinateurs hôtes sous supervision
Tous les accès à un ordinateur hôte surveillé s’effectuent systématiquement à partir du site auquel l’ordinateur hôte est affecté. Cela s’applique non seulement à la supervision proprement dite, mais aussi à la reconnaissance du service, à la page Diagnostics, aux notifications, aux gestionnaires d’alertes et à tout le reste. Ce point est très important, car on ne part pas du principe que l’instance centrale a effectivement accès à cet ordinateur hôte.
Spécification de l'instance dans les vues de la table
Certaines vues standard sont regroupées en fonction de l’instance à partir de laquelle l’ordinateur hôte sera supervisé — cela s’applique, par exemple, à All hosts :
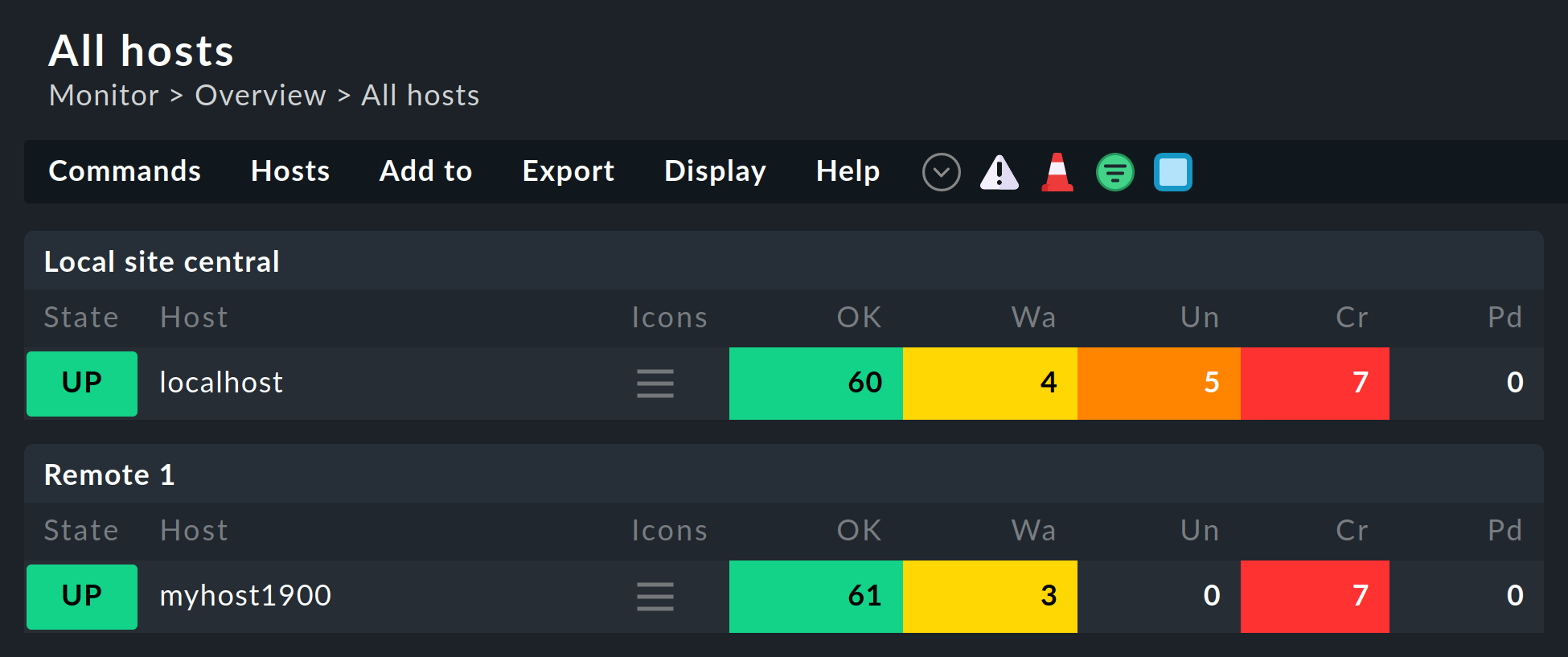
L’instance apparaîtra également dans les détails de l’ordinateur hôte ou du service :
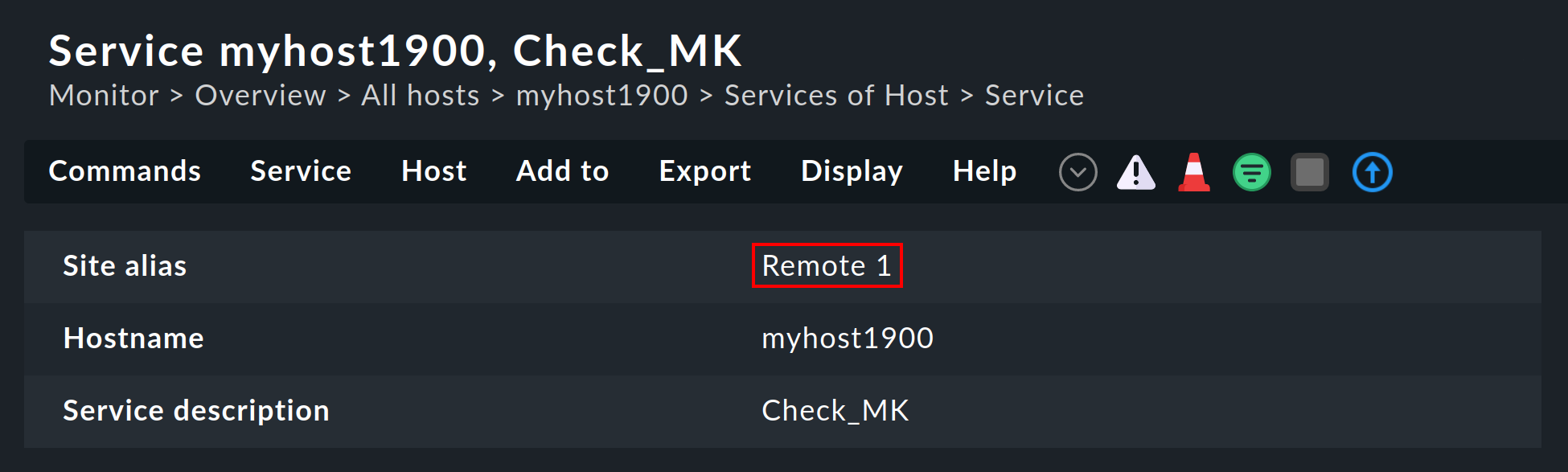
Ces informations sont généralement disponibles dans une colonne lorsque vous créez vos propres vues de la table. Il existe également un filtre permettant de filtrer les ordinateurs hôtes d'une instance spécifique :
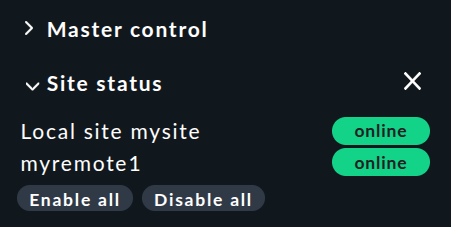
Snap-in « Site Status »
Il existe un snap-in enfichable « Site status » pour la barre latérale, que vous pouvez ajouter via ![]() .
Celui-ci affiche l’état de chaque instance.
Il offre également la possibilité de désactiver et de réactiver temporairement une instance individuelle en cliquant sur son état — ou toutes les instances à la fois en cliquant sur « Disable all » ou « Enable all ».
.
Celui-ci affiche l’état de chaque instance.
Il offre également la possibilité de désactiver et de réactiver temporairement une instance individuelle en cliquant sur son état — ou toutes les instances à la fois en cliquant sur « Disable all » ou « Enable all ».
Les sites désactivés seront signalés par le statut « ![]() ».
Cela vous permet également de désactiver un site
».
Cela vous permet également de désactiver un site ![]() qui génère des timeouts, évitant ainsi des timeouts superflus.
Cette désactivation n’est pas la même chose que la désactivation de la connexion Livestatus via la configuration de connexion dans Setup.
Ici, la « désactivation » n’affecte que l’utilisateur actuellement connecté et a une fonction purement visuelle.
Cliquer sur le nom d’un site affichera une vue de tous ses hôtes.
qui génère des timeouts, évitant ainsi des timeouts superflus.
Cette désactivation n’est pas la même chose que la désactivation de la connexion Livestatus via la configuration de connexion dans Setup.
Ici, la « désactivation » n’affecte que l’utilisateur actuellement connecté et a une fonction purement visuelle.
Cliquer sur le nom d’un site affichera une vue de tous ses hôtes.
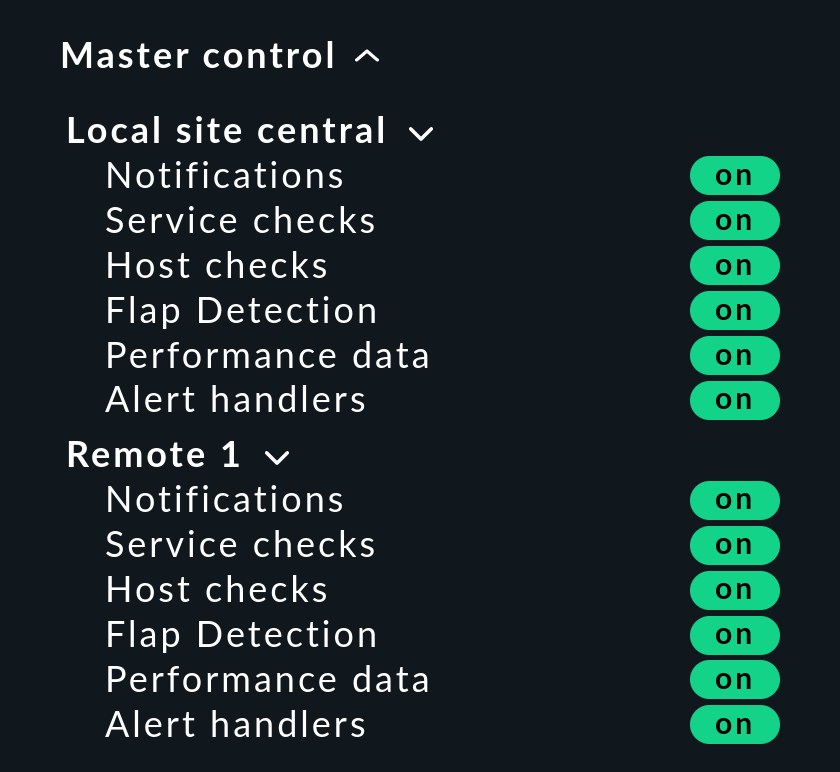
Componant logiciel de master control snap-in
Dans une supervision distribuée, le snap-in « Master control » présente une apparence différente. Chaque instance dispose de son propre commutateur global :
Ordinateurs hôtes du cluster Checkmk
Si vous effectuez une supervision avec un cluster HA Checkmk, les nœuds individuels du cluster doivent être affectés au même site que le cluster lui-même. En effet, la détermination de l’état des services en cluster nécessite l’accès à des fichiers de cache générés lors de la supervision du nœud. Ces données se trouvent localement sur le site concerné.
Données ferroutées
Certains plugins de supervision utilisent des données ferroutées, par exemple pour attribuer des données de supervision qui ont été « ferroutées » depuis un ordinateur hôte vers les machines virtuelles individuelles. Dans la supervision distribuée, l’hôte ferrouté — c’est-à-dire l’ordinateur hôte qui reçoit les données ferroutées — et les ordinateurs hôtes qui en dépendent — en tant que consommateurs effectifs des données ferroutées — ne sont pas toujours surveillés depuis la même instance. Dans ce cas, une attribution inter-sites des données ferroutées peut être activée.
Pour permettre cette communication, il vous suffit de vous assurer que le port du courtier de messages est correctement configuré sur toutes les instances participantes et que le hub de ferroutage est activé.
Vous devez checker cela au plus tard lorsque le message « Disabled » s’affiche ici :

Connexions peer-to-peer
Le trafic de données crée souvent un goulot d’étranglement dans la communication. Si les données sont transmises dans les deux sens entre tous les points, cela peut rapidement entraîner un afflux massif de données et donc une surcharge du réseau de communication. Il est donc conseillé de réduire le nombre de canaux de communication et de limiter l’échange de données principalement au réseau local. Ainsi, pour réduire la charge sur votre instance centrale ou pour optimiser le trafic réseau, vous pouvez également autoriser les instances distantes à communiquer directement entre elles (connexion peer-to-peer). Pour cela, les deux instances distantes doivent également avoir été configurées par l'instance centrale — c'est-à-dire que la fonction « Push configuration to this site » doit être activée pour les deux, comme décrit dans la section « Affectation de instances distantes à l'instance centrale ».
Dans l’Setup > General > Distributed monitoring, sélectionnez l’entrée « Connections > Add peer-to-peer message broker connection ». Attribuez ici un identifiant unique et sélectionnez les deux instances pour la connexion directe. Veillez à suivre les instructions de l’aide en ligne.
inventaire matériel/logiciel
L'inventaire matériel/logiciel de Checkmk fonctionne également dans les environnements distribués.
Pour cela, les données d'inventaire du répertoire ~/var/check_mk/inventory doivent être régulièrement transmises des instances distantes vers l'instance centrale.
Pour des raisons de performances, l'interface utilisateur accède toujours à ce répertoire localement.
Dans les éditions commerciales, la synchronisation s’effectue automatiquement sur toutes les instances connectées via le proxy Livestatus.
Si vous exécutez l'inventaire à l'aide de Checkmk Community dans des systèmes distribués, le répertoire doit être régulièrement répliqué vers l'instance centrale à l'aide de vos propres outils (par exemple, avec rsync).
Modification d’un mot de passe
Même lorsque toutes les instances sont sous supervision centralisée, il est tout à fait possible, et souvent approprié, de réaliser un login sur l’interface d’une instance individuelle. C’est pourquoi Checkmk veille à ce que le mot de passe d’un utilisateur soit toujours le même pour toutes les instances.
Un changement de mot de passe effectué par l'administrateur prendra effet automatiquement dès qu'il sera partagé sur toutes les instances via Activate pending changes.
Un changement effectué par l’utilisateur lui-même via la barre latérale ![]() dans ses paramètres personnels fonctionne de manière quelque peu différente.
Cela ne permet pas d’exécuter une commande `Activate pending changes`, car l’utilisateur ne dispose bien sûr pas d’autorisation générale pour cette fonction.
Dans un tel cas, Checkmk partagera automatiquement le mot de passe modifié sur toutes les instances — dès qu’il aura été enregistré, en fait.
dans ses paramètres personnels fonctionne de manière quelque peu différente.
Cela ne permet pas d’exécuter une commande `Activate pending changes`, car l’utilisateur ne dispose bien sûr pas d’autorisation générale pour cette fonction.
Dans un tel cas, Checkmk partagera automatiquement le mot de passe modifié sur toutes les instances — dès qu’il aura été enregistré, en fait.
Comme nous le savons tous, les réseaux ne sont jamais disponibles à 100 %. Si une instance est inaccessible au moment d’un changement de mot de passe, elle ne recevra pas le nouveau mot de passe. Jusqu’à ce que l’administrateur exécute avec succès une commande « Activate pending changes », ou respectivement jusqu’au prochain changement de mot de passe réussi, cette instance conservera l’ancien mot de passe pour l’utilisateur. Une icône d’état informera l’utilisateur de l’état du partage du mot de passe vers les différentes instances.
2.5. Connexion d'instances existantes
Comme mentionné ci-dessus, les instances existantes peuvent également être rattachées a posteriori à une supervision distribuée. Tant que les conditions préalables décrites ci-dessus sont remplies (versions Checkmk compatibles), cette opération s’effectuera exactement comme pour la configuration d’une nouvelle instance distante. Partagez Livestatus via TCP, puis ajoutez l’instance via Setup > General > Distributed monitoring – et le tour est joué !
La deuxième étape — le passage à une configuration centralisée — est un peu plus délicate. Avant d’intégrer l’instance dans l’environnement de configuration central comme décrit ci-dessus, sachez que cela entraînera l’écrasement de l’intégralité de la configuration locale de l’instance ! |
Si vous souhaitez reprendre les ordinateurs hôtes existants, et éventuellement les règles également, trois étapes seront nécessaires :
Faites correspondre le schéma des balises de l’hôte
Copiez les répertoires (ordinateurs hôtes)
Modifier les caractéristiques dans le dossier parent
1. Balises de l’hôte
Il va de soi que les balises de l’hôte utilisées sur l’instance distante doivent également être connues de l’instance centrale afin de pouvoir être transférées. Vérifiez-les avant la migration et ajoutez manuellement les balises manquantes à l’instance centrale. Il est ici essentiel que les identifiants de balise (Tag-ID) correspondent — le titre de la balise n'a aucune importance.
2. Dossiers
Ensuite, déplacez les ordinateurs hôtes et les règles vers l’environnement de configuration de l’instance centrale. Cela ne fonctionne que pour les ordinateurs hôtes et les règles situés dans des sous-dossiers (c’est-à-dire pas dans le dossier Main). Les ordinateurs hôtes du dossier Main doivent d’abord être simplement déplacés vers un sous-dossier de l’instance distante via Setup > Hosts > Hosts.
La migration proprement dite peut ensuite être effectuée très simplement en copiant les répertoires appropriés.
Chaque dossier de l’environnement de configuration correspond à un répertoire au sein de ~/etc/check_mk/conf.d/wato/.
Ceux-ci peuvent être copiés à l’aide d’un outil de votre choix (par exemple scp) depuis l’instance connectée vers le même emplacement sur l’instance centrale.
Si un répertoire portant le même nom existe déjà à cet emplacement, il suffit de le renommer.
Notez que les utilisateurs et groupes Linux sont également utilisés par l’instance centrale.
Une fois la copie effectuée, les ordinateurs hôtes apparaîtront dans le répertoire Setup de l'instance centrale, ainsi que les règles que vous avez créées dans ces dossiers.
Les propriétés des dossiers seront également incluses dans la copie.
Celles-ci se trouvent dans le répertoire du fichier caché .wato.
3. Édition et enregistrement uniques
Afin que les attributs des fonctions du dossier parent de l’instance centrale soient correctement hérités, la dernière étape après la migration consiste à ouvrir et à enregistrer une fois les caractéristiques des dossiers parents – les attributs de l’ordinateur hôte seront ainsi redéfinis.
2.6. Paramètres globaux spécifiques à l'instance
Une configuration centrale signifie avant tout que toutes les instances ont une configuration commune et (à l’exception des ordinateurs hôtes) identique. Quelle est toutefois la situation lorsque des instances individuelles nécessitent des paramètres globaux différents ? Un exemple pourrait être le paramètre CMC Maximum concurrent Checkmk checks. Il se peut qu’un paramètre personnalisé soit nécessaire pour une instance particulièrement petite ou particulièrement grande.
Dans de tels cas, il existe un paramètre global spécifique à l’instance.
Vous y accédez via l’icône « ![]() » dans le menu sous « Setup > General > Distributed monitoring » :
» dans le menu sous « Setup > General > Distributed monitoring » :

Cette icône vous permet d’accéder à une sélection de tous les paramètres globaux ― bien que tout ce que vous définissez ici ne s’applique qu’à l’instance sélectionnée. Une valeur s’écartant de la norme sera mise en évidence visuellement et ne s’appliquera qu’à cette instance :

2.7. Event Console distribuée
La Event Console traite les messages syslog, les traps SNMP et d'autres types d'événements de nature asynchrone.
Checkmk offre également la possibilité d’utiliser une Event Console distribuée.
Dans ce cas, chaque instance gère son propre traitement des événements, qui capture les événements provenant de tous les ordinateurs hôtes surveillés depuis cette instance.
Les événements ne sont donc pas envoyés au système central, mais restent sur les instances et ne sont récupérés qu’au niveau central.
Ce fonctionnement est similaire à celui des états actifs via Livestatus et est disponible à la fois dans Checkmk Community ![]() t dans les éditions commerciales.
t dans les éditions commerciales.
La conversion vers une Event Console distribuée selon le nouveau schéma nécessite les étapes suivantes :
Dans les paramètres de connexion, activez l'option (Replicate Event Console configuration to this site).
Faites passer l'emplacement syslog et les destinations trap SNMP des ordinateurs hôtes concernés vers l'instance distante. Il s'agit de la tâche la plus fastidieuse.
Si vous utilisez le jeu de règles « Check event state in Event Console », remettez-le sur « Connect to the local Event Console ».
Si vous utilisez le jeu de règles de gestion des événements, basculez-le également vers la Event Console locale.
Dans l'Event Console « Settings », remettez l'option « Access to event status via TCP » sur « no access via TCP ».
2.8. NagVis

Le programme libre NagVis visualise les données d'état issues de la supervision sur des cartes, des diagrammes et d'autres graphiques générés automatiquement. NagVis est intégré à Checkmk et peut être utilisé immédiatement. L'accès s'effectue le plus facilement via l'élément de la barre latérale « NagVis Maps ». L'intégration de NagVis dans Checkmk est décrite dans un article dédié.
NagVis prend en charge la supervision distribuée via Livestatus de la même manière que Checkmk. Les liens vers les instances individuelles sont appelés « backends ». Les backends sont automatiquement configurés correctement par Checkmk, ce qui permet de commencer immédiatement à générer des graphiques NagVis, y compris dans le cadre de la supervision distribuée.
Sélectionnez le backend approprié pour chaque objet que vous placez sur un graphique, c'est-à-dire l'instance Checkmk à partir de laquelle l'objet doit être supervisé. NagVis ne peut pas détecter automatiquement l'ordinateur hôte ou le service, principalement pour des raisons de performances. Par conséquent, si vous déplacez des ordinateurs hôtes vers une instance distante, vous devrez mettre à jour les graphiques NagVis en conséquence.
Vous trouverez plus de détails sur les backends dans la documentation ici : NagVis.
3. Connexions instables ou lentes
L'aperçu de l'état général dans l'interface utilisateur permet un accès toujours disponible et fiable à tous les sites connectés. Le seul inconvénient est qu'une vue ne peut s'afficher que lorsque toutes les instances ont répondu. Le processus consiste toujours à envoyer d'abord une requête Livestatus (par exemple : « Lister toutes les instances dont l'état n'est pas OK »). La vue ne peut alors s'afficher qu'une fois que la dernière instance a répondu.
C'est agaçant lorsqu'une instance ne répond pas du tout.
Pour tolérer de brèves interruptions (par exemple, dues au redémarrage d'une instance ou à la perte d'un paquet TCP), l'interface graphique attend un certain temps avant de déclarer une instance comme étant « ![]() », puis continue à traiter les réponses des instances restantes.
Cela entraîne un « blocage » de l'interface graphique.
Le timeout est fixé à 10 secondes par défaut.
», puis continue à traiter les réponses des instances restantes.
Cela entraîne un « blocage » de l'interface graphique.
Le timeout est fixé à 10 secondes par défaut.
Si cela se produit occasionnellement sur votre réseau, vous devriez configurer soit les ordinateurs hôtes de statut, soit (mieux encore) le proxy Livestatus.
3.1. Ordinateurs hôtes de statut
![]() La configuration des ordinateurs hôtes de statut est la procédure recommandée par la communauté Checkmk
La configuration des ordinateurs hôtes de statut est la procédure recommandée par la communauté Checkmk ![]() afin de détecter de manière fiable les connexions défectueuses.
Le principe est simple :
L’instance centrale surveille activement la connexion vers chaque instance distante.
Au moins, nous disposerons d’un système de supervision !
L’interface graphique sera alors informée des instances inaccessibles et pourra immédiatement les exclure et les signaler comme «
afin de détecter de manière fiable les connexions défectueuses.
Le principe est simple :
L’instance centrale surveille activement la connexion vers chaque instance distante.
Au moins, nous disposerons d’un système de supervision !
L’interface graphique sera alors informée des instances inaccessibles et pourra immédiatement les exclure et les signaler comme « ![]() ».
Les timeouts sont ainsi réduits au minimum.
».
Les timeouts sont ainsi réduits au minimum.
Voici comment configurer un ordinateur hôte de statut pour une connexion :
Ajoutez l'ordinateur hôte sur lequel l'instance distante est exécutée à l'instance centrale dans la supervision.
Entrez-le comme ordinateur hôte de statut dans la connexion vers le site distant :
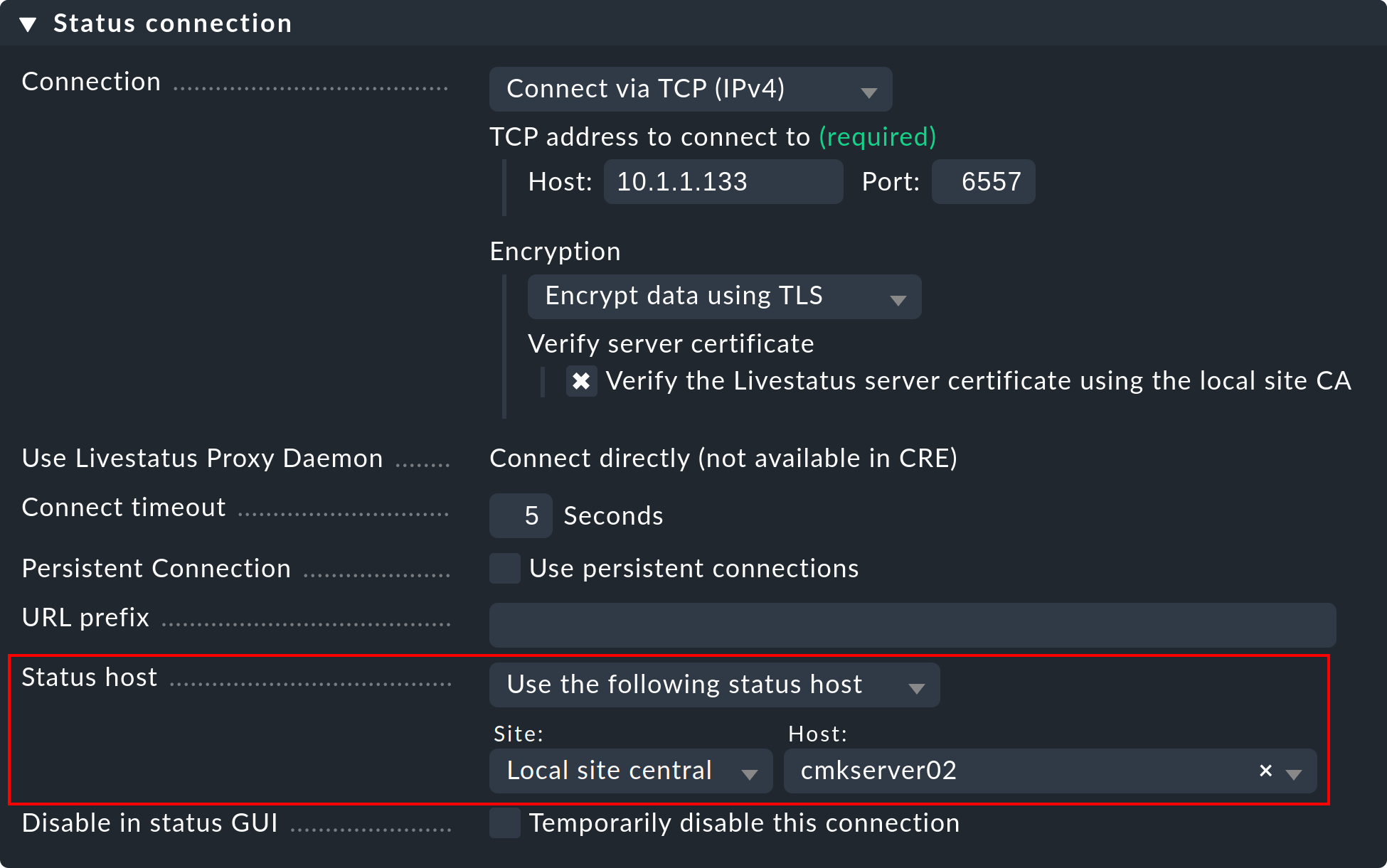
Une connexion échouée vers une instance distante ne peut désormais entraîner qu’un bref blocage de l’interface graphique — à savoir jusqu’à ce que la supervision l’ait détecté. En réduisant l’intervalle de vérification de l’ordinateur hôte de la valeur par défaut de soixante secondes à, par exemple, cinq secondes, vous pouvez minimiser la durée d’un blocage.
Si vous avez configuré un ordinateur hôte de statut, d'autres états sont possibles pour les connexions :
|
L'ordinateur sur lequel l'instance distante est exécutée est actuellement inaccessible à la supervision car un routeur est DOWN (l'ordinateur hôte présente un état « UNREACH »). |
|
L'ordinateur hôte qui surveille la connexion au système distant n'a pas encore été vérifié par la supervision (il est toujours dans l'état PEND). |
|
L'état de l'ordinateur hôte a une valeur non valide (cela ne devrait jamais se produire). |
Dans ces trois cas, la connexion à l'instance sera exclue et les timeouts seront ainsi évités.
3.2. Connexions persistantes
![]() La case à cocher « Use persistent connections » vous permet de demander à l’interface graphique de maintenir en permanence les connexions Livestatus établies vers les instances distantes dans un état « UP », et de continuer à les utiliser pour les requêtes.
Cela peut rendre l’interface graphique nettement plus réactive, en particulier pour les connexions présentant des temps de transit de paquets plus longs (par exemple, intercontinentales).
La case à cocher « Use persistent connections » vous permet de demander à l’interface graphique de maintenir en permanence les connexions Livestatus établies vers les instances distantes dans un état « UP », et de continuer à les utiliser pour les requêtes.
Cela peut rendre l’interface graphique nettement plus réactive, en particulier pour les connexions présentant des temps de transit de paquets plus longs (par exemple, intercontinentales).
Comme l’interface graphique Apache est partagée entre plusieurs processus indépendants, une connexion est requise pour chaque processus client Apache s’exécutant simultanément.
Si vous avez de nombreux utilisateurs simultanés, assurez-vous que la configuration prévoit un nombre suffisant de connexions Livestatus dans le noyau du processeur du site distant.
Celles-ci sont configurées dans le fichier ~/etc/mk-livestatus/nagios.cfg.
La valeur par défaut est vingt (num_client_threads=20).
Par défaut, Apache est configuré dans Checkmk de manière à autoriser jusqu’à 128 connexions utilisateur simultanées.
Cette configuration se trouve dans la section suivante du fichier ~/etc/apache/apache.conf :
Cela signifie qu’en cas de charge élevée, jusqu’à 128 processus Apache peuvent démarrer, ce qui génère et maintient alors jusqu’à 128 connexions Livestatus.
Si la valeur de num_client_threads n’est pas définie à un niveau suffisamment élevé, cela peut entraîner des erreurs ou une réponse très lente dans l’interface graphique.
Pour les connexions via un réseau local (LAN) ou des réseaux WAN rapides, nous vous recommandons de ne pas utiliser de connexions persistantes.
3.3. Le proxy Livestatus
![]() Grâce au proxy Livestatus, les éditions commerciales disposent d’un mécanisme sophistiqué de détection des connexions inactives.
De plus, il optimise tout particulièrement les performances des connexions présentant une durée de rotation des packs importante. Les avantages du proxy Livestatus sont les suivants :
Grâce au proxy Livestatus, les éditions commerciales disposent d’un mécanisme sophistiqué de détection des connexions inactives.
De plus, il optimise tout particulièrement les performances des connexions présentant une durée de rotation des packs importante. Les avantages du proxy Livestatus sont les suivants :
Détection très rapide et proactive des instances qui ne répondent pas
Mise en cache locale des requêtes fournissant des données statiques
Connexions TCP permanentes — qui nécessitent moins d'allers-retours et permettent par conséquent des réponses beaucoup plus rapides depuis des instances distantes (par exemple, États-Unis ⇄ Chine)
Contrôle précis du nombre maximal de connexions Livestatus requises
Permet l'inventaire matériel/logiciel dans des environnements distribués
Installation
L'installation du proxy Livestatus est très simple. Il est activé par défaut dans les éditions commerciales — ce qui est visible au démarrage d'une instance :
Sélectionnez le paramètre « Use Livestatus Proxy-Daemon » pour la connexion aux instances distantes au lieu de « Connect via TCP » :
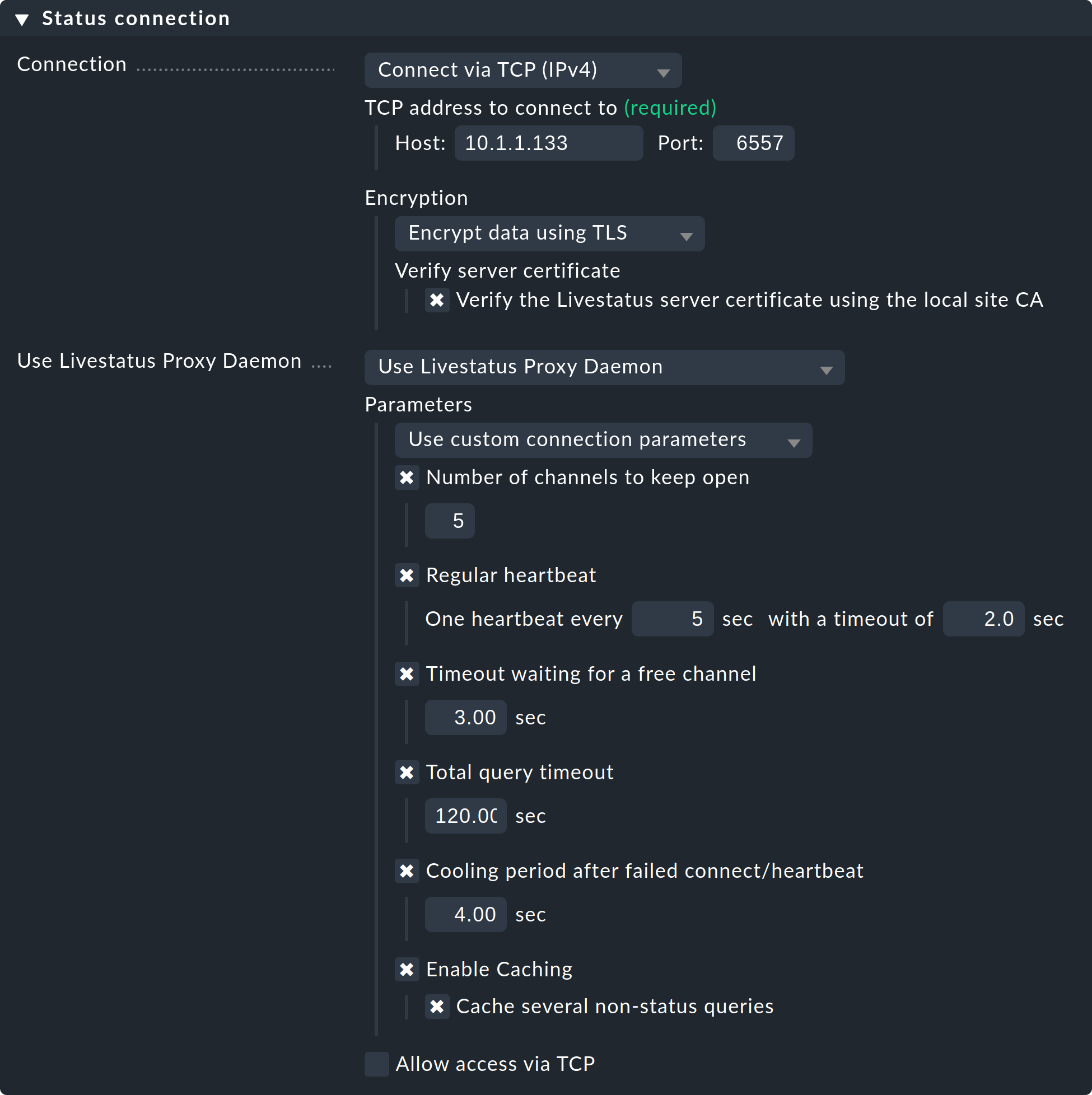
Les détails concernant l'ordinateur hôte et le port restent inchangés. Aucune modification ne doit être effectuée sur l'instance distante. Dans « Number of channels to keep open », saisissez le nombre de connexions TCP parallèles que le proxy doit établir et maintenir vers l'instance cible.
Le pool de connexions TCP est partagé par toutes les requêtes de l'interface graphique. Le nombre de connexions limite le nombre maximal de requêtes pouvant être traitées simultanément. Cela limite indirectement le nombre d'utilisateurs. Dans les situations où tous les canaux sont réservés, cela n'entraîne pas immédiatement une erreur. L'interface graphique attend un certain temps qu'un canal se libère. La plupart des requêtes ne nécessitent en réalité que quelques millisecondes.
Si l'interface graphique doit attendre plus longtemps qu'Timeout waiting for a free channel pour obtenir un canal, elle sera interrompue par une erreur et l'utilisateur recevra un message d'erreur. Dans ce cas, le nombre de connexions doit être augmenté. Sachez toutefois que l'instance distante doit autoriser un nombre suffisant de connexions entrantes parallèles — cette valeur est fixée à 20 par défaut. Ce paramètre se trouve dans les options globales sous « Monitoring core > Maximum concurrent Livestatus connections ».
La fonction « Regular heartbeat » assure une supervision constante des connexions directement au niveau du protocole. Dans ce cadre, le proxy envoie régulièrement une simple requête « Livestatus » à laquelle l’instance distante doit répondre dans un délai prédéfini (par défaut : 2 secondes). Cette méthode permet également de détecter une situation où le serveur cible et le port TCP sont effectivement joignables, mais où le noyau de supervision ne répond plus.
Si aucune réponse n’est reçue, toutes les connexions seront déclarées « mortes » et, après un délai de « refroidissement » (par défaut : 4 secondes), elles seront rétablies. Tout cela se déroule de manière proactive, c’est-à-dire sans que l’utilisateur ait besoin d’ouvrir une fenêtre d’interface graphique. De cette manière, les pannes peuvent être rapidement détectées, et grâce à une procédure de récupération, les connexions peuvent être immédiatement rétablies et, dans le meilleur des cas, être disponibles avant même qu’un utilisateur ne remarque la panne.
L’Cachinge garantit que les requêtes statiques ne nécessitent qu’une seule réponse de la part de l’instance distante et qu’à partir de ce moment-là, elles peuvent être traitées directement et localement, sans délai. La liste des ordinateurs hôtes surveillés requise par Quicksearch en est un exemple.
Diagnostic des erreurs
Le proxy Livestatus dispose de son propre fichier journal ~/var/log/liveproxyd.log.
Sur une instance distante correctement configurée avec cinq canaux (configuration standard), il ressemblera à ceci :
2025-04-30 15:58:30,624 [20] ----------------------------------------------------------
2025-04-30 15:58:30,627 [20] [cmk.liveproxyd] Livestatus Proxy-Daemon (2.4.0p24) starting...
2025-04-30 15:58:30,638 [20] [cmk.liveproxyd] Configured 1 sites
2025-04-30 15:58:36,690 [20] [cmk.liveproxyd.(3236831).Manager] Reload initiated. Checking if configuration changed.
2025-04-30 15:58:36,692 [20] [cmk.liveproxyd.(3236831).Manager] No configuration changes found, continuing.
2025-04-30 16:00:16,989 [20] [cmk.liveproxyd.(3236831).Manager] Reload initiated. Checking if configuration changed.
2025-04-30 16:00:16,993 [20] [cmk.liveproxyd.(3236831).Manager] Found configuration changes, triggering restart.
2025-04-30 16:00:17,000 [20] [cmk.liveproxyd.(3236831).Manager] Restart initiated. Terminating site processes...
2025-04-30 16:00:17,028 [20] [cmk.liveproxyd.(3236831).Manager] Restart master processLe proxy Livestatus enregistre régulièrement son état dans le fichier ~/var/log/liveproxyd.state :
Current state:
[myremote1]
State: ready
State dump time: 2025-04-30 15:01:15 (0:00:00)
Last reset: 2025-04-30 14:58:49 (0:02:25)
Site's last reload: 2025-04-30 14:26:00 (0:35:15)
Last failed connect: Never
Last failed error: None
Cached responses: 1
Channels:
9 - ready - client: none - since: 2025-04-30 15:01:00 (0:00:14)
10 - ready - client: none - since: 2025-04-30 15:01:10 (0:00:04)
11 - ready - client: none - since: 2025-04-30 15:00:55 (0:00:19)
12 - ready - client: none - since: 2025-04-30 15:01:05 (0:00:09)
13 - ready - client: none - since: 2025-04-30 15:00:50 (0:00:24)
Clients:
Heartbeat:
heartbeats received: 29
next in 0.2s
Inventory:
State: not running
Last update: 2025-04-30 14:58:50 (0:02:25)Et lorsqu'une instance est actuellement arrêtée, l'état se présentera comme suit :
----------------------------------------------
Current state:
[myremote1]
State: starting
State dump time: 2025-04-30 16:11:35 (0:00:00)
Last reset: 2025-04-30 16:11:29 (0:00:06)
Site's last reload: 2025-04-30 16:11:29 (0:00:06)
Last failed connect: 2025-04-30 16:11:33 (0:00:01)
Last failed error: [Errno 111] Connection refused
Cached responses: 0
Channels:
Clients:
Heartbeat:
heartbeats received: 0
next in -1.0s
Inventory:
State: not running
Last update: 2025-04-30 16:00:45 (0:10:50)Ici, l'état est « starting ».
Le proxy tente donc d'établir des connexions.
Il n'y a pas encore de canaux.
Dans cet état, les requêtes adressées à l'instance recevront une réponse d'erreur.
4. Mise en cascade de Livestatus
Comme déjà mentionné dans l’introduction, il est possible d’étendre la supervision distribuée pour inclure des instances de la visionneuse Checkmk dédiées qui affichent les données de supervision provenant d’instances distantes qui ne sont pas directement accessibles en eux-mêmes. La seule condition préalable est bien sûr que l’instance centrale soit accessible. Techniquement, cela est mis en œuvre via le proxy Livestatus. L'instance centrale reçoit les données de l'instance distante via Livestatus et agit elle-même comme un proxy, c'est-à-dire qu'elle peut transmettre les données à des instances de la visionneuse tierces. Vous pouvez étendre cette chaîne à votre guise, par exemple en connectant une deuxième instance de la visionneuse via la première.
Cela s’avère pratique, par exemple, dans un scénario tel que celui-ci : L’instance centrale prend en charge trois réseaux indépendants — client1, client2 et client3 — et est elle-même exploité au sein du réseau de l’opérateur1. Si la gestion de l’opérateur du réseau de l’opérateur1 souhaite consulter l’état de supervision des sites clients, cela pourrait bien sûr être géré via un accès depuis l’instance centrale. Pour des raisons techniques et juridiques, l’instance centrale pourrait toutefois être réservée exclusivement au personnel qui en est responsable. Un accès direct peut ainsi être évité en mettant en place une instance de la visionneuse dédiée à la consultation des instances distantes. L’instance de la visionneuse affiche alors les ordinateurs hôtes et les services des sites connectés, mais sa propre configuration reste entièrement vide.
La configuration s'effectue dans les paramètres de connexion de la supervision distribuée, d'abord sur l'instance centrale, puis sur l'instance de la visionneuse (qui n'a pas besoin d'exister pour l'instant).
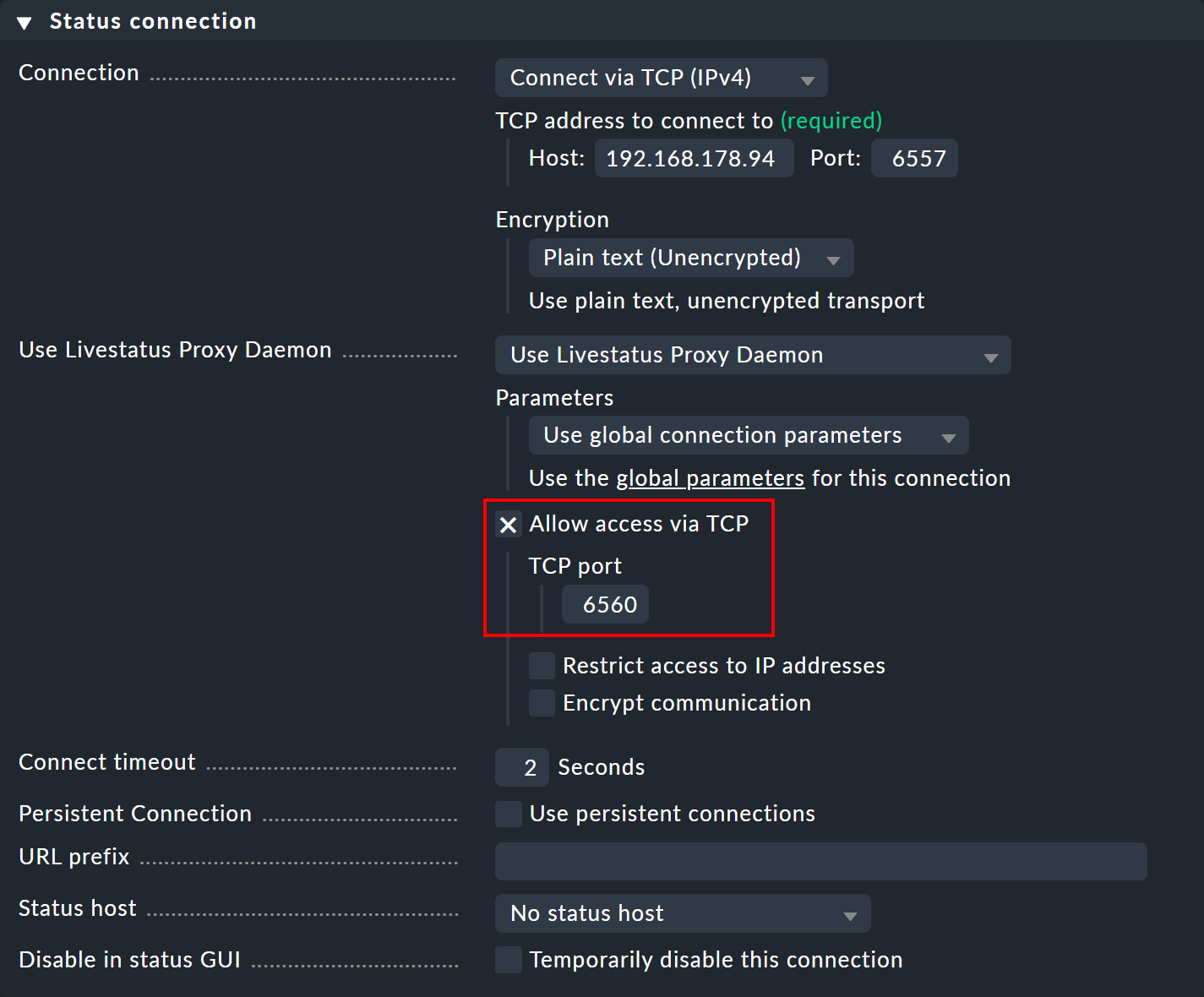
Sur l’instance centrale, ouvrez les paramètres de connexion de l’instance distante souhaitée via Setup > General > Distributed monitoring.
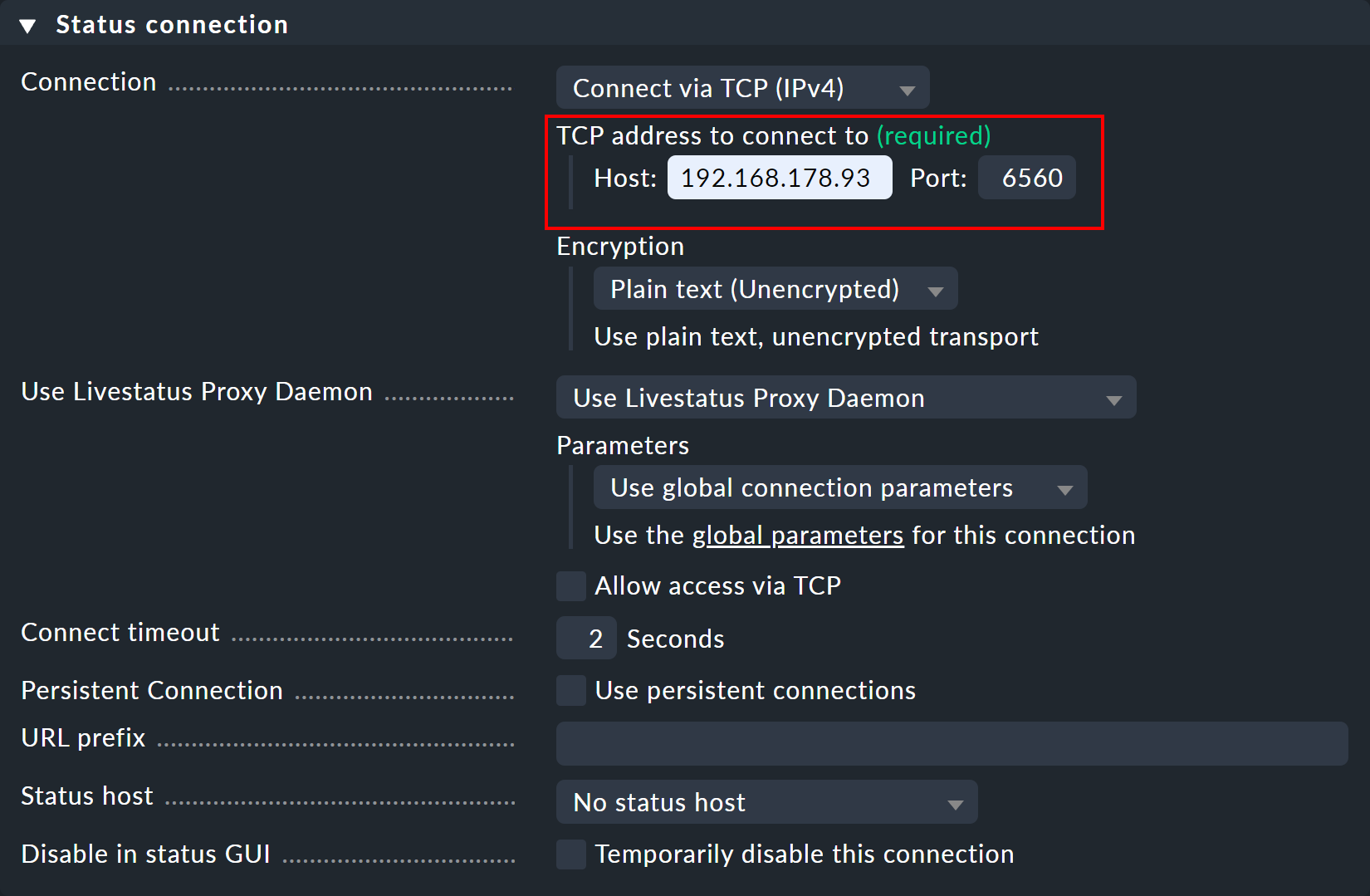
Sous « Use Livestatus Proxy Daemon », activez l’option « Allow access via TCP » et saisissez un port disponible (ici 6560).
De cette manière, le proxy Livestatus de l’instance centrale se connecte à l’instance distante et ouvre un port pour les requêtes provenant de l’instance de la visionneuse — qui sont ensuite transmises à l’instance distante.
Créez maintenant une instance de la visionneuse et ouvrez à nouveau les paramètres de connexion via Setup > General > Distributed monitoring. Dans Basic settings, saisissez — comme toujours pour les connexions dans la supervision distribuée — le nom exact de l’instance centrale comme Site ID.

Dans le panneau « 6560 », saisissez l’instance centrale comme ordinateur hôte — ainsi que le port libre attribué manuellement (ici ).
Dès que la connexion est établie, vous verrez les ordinateurs hôtes et services souhaités sur l’instance distante dans les vues de supervision de l’instance de la visionneuse.
Si vous souhaitez poursuivre la mise en cascade, vous devez également autoriser l'accès TCP au proxy Livestatus sur l'instance de la visionneuse, comme cela a été fait précédemment sur l'instance centrale, mais cette fois-ci avec un port libre différent.
5. Livedump et CMCDump
5.1. Motivation
Le concept de supervision distribuée avec Checkmk décrit jusqu’à présent constitue une solution simple et efficace dans la plupart des cas. Il nécessite toutefois un accès réseau entre l’instance centrale et les instances distantes. Il existe toutefois des situations dans lesquelles cet accès n’est pas possible ou n’est pas souhaitable, par exemple :
Les instances distantes se trouvent sur le réseau de votre client, auquel vous n'avez pas accès.
Les instances distantes se trouvent dans une zone de sécurité à laquelle l'accès est strictement interdit.
Les instances distantes ne disposent pas de connexion réseau permanente ou d'adresses IP fixes, et des méthodes telles que le DNS dynamique ne sont pas envisageables.
La supervision distribuée avec Livedump, ou respectivement CMCDump, adopte une approche tout à fait différente. Tout d’abord, les instances distantes sont configurées de manière à fonctionner de manière totalement indépendante de l’instance centrale et à être administrées de manière décentralisée. Il n’est donc pas nécessaire de disposer d’une configuration centrale.
Tous les ordinateurs hôtes et services de l’instance distante seront alors répliqués sous forme de copies sur l’instance centrale. Livedump/CMCDump peut vous aider en générant une copie de la configuration des instances distantes, qui peut ensuite être chargée sur l’instance centrale.
Désormais, pendant la supervision, sur chaque instance distante, une copie de l'état actuel sera enregistrée dans un fichier à des intervalles prédéterminés (par exemple, toutes les minutes).
Ce fichier sera transmis à l’instance centrale via une méthode définie par l’utilisateur et y sera enregistré en tant que mise à jour d’état.
Aucun protocole particulier n’a été fourni ou spécifié pour ce transfert de données.
Tous les protocoles de transfert pouvant être automatisés peuvent être utilisés.
Il n’est pas indispensable d’utiliser scp — même un transfert par courrier électronique est envisageable !
Une telle configuration diffère d’une supervision distribuée « normale » de la manière suivante :
L'actualisation des états et des données de performance à l'instance centrale sera différée.
Le calcul de la disponibilité sur l'instance centrale donnera des résultats légèrement différents de ceux obtenus sur l'instance distante.
Les changements d'état qui se produisent plus rapidement que l'intervalle d'actualisation seront invisibles pour l'instance centrale.
Si une instance distante est « hors service », les états deviendront obsolètes sur l’instance centrale — les services seront « obsolètes », mais resteront néanmoins visibles. Les données de performance et de disponibilité pour cette période de temps seront « perdues » (mais elles resteront disponibles sur l’instance distante).
Les instructions telles que « Schedule downtimes » et « Acknowledge problems » sur l’instance centrale ne peuvent pas être transmises à l’instance distante.
L'instance centrale ne peut jamais accéder aux instances distantes.
L'accès aux détails des fichiers journaux via logwatch est impossible.
La Event Console ne sera pas prise en charge par Livedump/CMCDump.
Étant donné que les changements d’état brefs — en fonction de l’intervalle périodique sélectionné sur l’instance centrale — peuvent ne pas être visibles, une notification via l’instance centrale n’est pas idéale. Si toutefois l’instance centrale est utilisée comme un simple site d’affichage — par exemple, pour un aperçu central de tous les clients — cette méthode présente clairement des avantages.
Par ailleurs, Livedump/CMCDump peut être utilisé simultanément avec la supervision distribuée via Livestatus sans aucun problème. Certains sites ont simplement une connexion directe avec Livestatus — d’autres utilisent Livedump. Livedump peut également être ajouté à l’une des instances distantes de Livestatus.
5.2. Installation de Livedump
![]() Si vous installez Checkmk Community (ou les éditions commerciales avec un noyau du processeur Nagios) sur
Si vous installez Checkmk Community (ou les éditions commerciales avec un noyau du processeur Nagios) sur ![]() , utilisez l’outil
, utilisez l’outil livedump.
Le nom est dérivé de Livestatus et de status dump.
livedumpse trouve directement dans le chemin d'accès et est donc disponible en tant que commande.
Nous partons des hypothèses suivantes :
l'instance distante a été entièrement configurée et effectue activement la supervision des ordinateurs hôtes et des services,
l'instance centrale a été démarrée et est en cours d'exécution,
au moins un ordinateur hôte est sous supervision locale à l'instance centrale (car l'instance centrale se surveille elle-même).
Transfert de la configuration
Tout d'abord, sur l'instance distante, créez une copie des configurations de ses ordinateurs hôtes et de ses services au format de configuration Nagios.
Redirigez également la sortie de la commande « livedump -TC » vers un fichier :
Le début du fichier ressemblera à ceci :
define host {
name livedump-host
use check_mk_default
register 0
active_checks_enabled 0
passive_checks_enabled 1
}
define service {
name livedump-service
register 0
active_checks_enabled 0
passive_checks_enabled 1
check_period 0x0
}Transférez le fichier vers l'instance centrale (par exemple, à l'aide d'scp) et enregistrez-le dans le répertoire ~/etc/nagios/conf.d/
– où Nagios s'attend à trouver les données de configuration des ordinateurs hôtes et des services.
Choisissez un nom de fichier se terminant par .cfg, par exemple ~/etc/nagios/conf.d/config-myremote1.cfg.
Si un accès SSH de l'instance distante vers l'instance centrale est possible, cela peut être effectué, par exemple, comme suit :
Connectez-vous maintenant à l’instance centrale et activez les modifications :
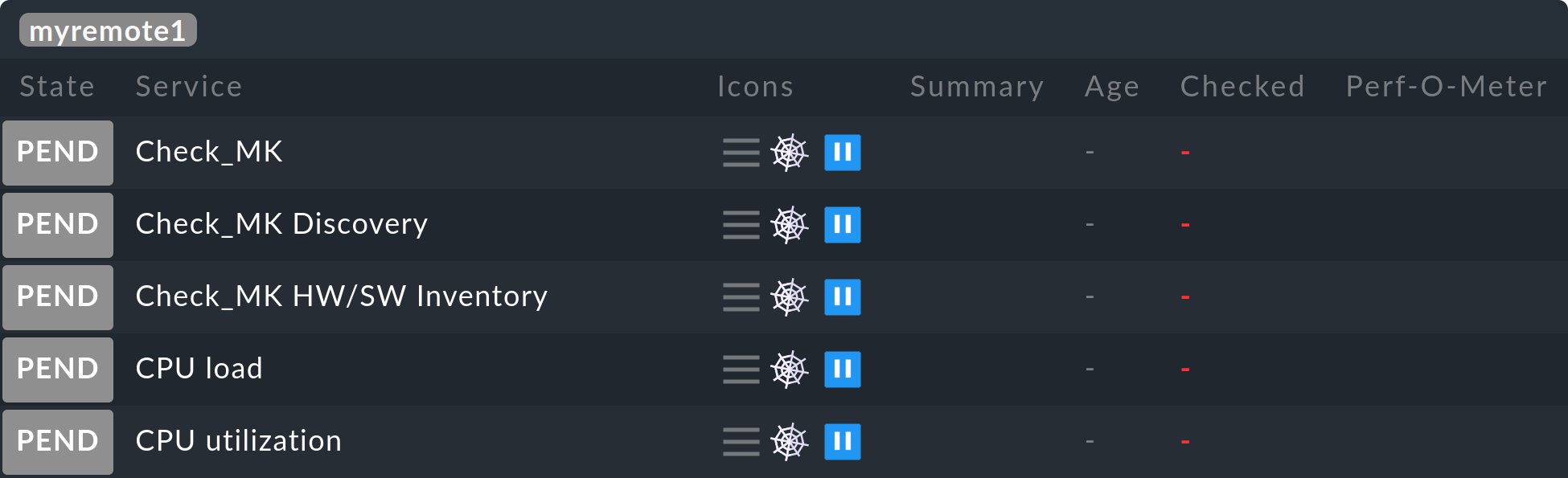
Tous les ordinateurs hôtes et services de la télécommande devraient désormais apparaître sur l'instance centrale – initialement avec l'état PEND, qu'ils conserveront pour le moment :
Remarques :
Avec l'option «
-T» dans l'livedump, des définitions de modèles sont créées dans Livedump, à partir desquelles la configuration est extraite. Sans celles-ci, Nagios ne peut pas être démarré. Cependant, une seule de ces options peut être présente. Si vous importez une configuration depuis une instance distante, celle-ci ne doit pas utiliser l'option «-T» !Une sauvegarde de la configuration est également possible sur un Checkmk Micro Core (CMC) — dont l'importation nécessite Nagios. Si le CMC est en cours d'exécution sur votre instance centrale, utilisez CMCDump.
La copie et le transfert de la configuration doivent être répétés à chaque modification apportée aux ordinateurs hôtes ou aux services sur l'instance distante.
Transfert de l'état
Une fois que les ordinateurs hôtes sont visibles sur l'instance centrale, il faudra effectuer la configuration d'une transmission (régulière) de l'état de supervision des instances distantes.
Créez à nouveau un fichier avec la commande `livedump`, mais cette fois sans options secondaires :
Ce fichier contient les états de tous les ordinateurs hôtes et services dans un format que Nagios peut lire directement à partir des résultats de check. Le début de ce fichier ressemble à ceci :
host_name=myhost1900
check_type=1
check_options=0
reschedule_check
latency=0.13
start_time=1615521257.2
finish_time=16175521257.2
return_code=0
output=OK - 10.1.5.44: rta 0.066ms, lost 0%|rta=0.066ms;200.000;500.000;0; pl=0%;80;100;; rtmax=0.242ms;;;; rtmin=0.017ms;;;;Copiez ce fichier sur l'instance centrale dans le répertoire ~/tmp/nagios/checkresults.
Important : le nom de ce fichier doit commencer par c et comporter sept caractères.
Avec scp, il ressemblera à ceci :
Enfin, créez un fichier vide sur l'instance centrale portant le même nom et l'extension .ok.
Grâce à cela, Nagios saura que le fichier d'état a été entièrement transféré et peut désormais être lu :
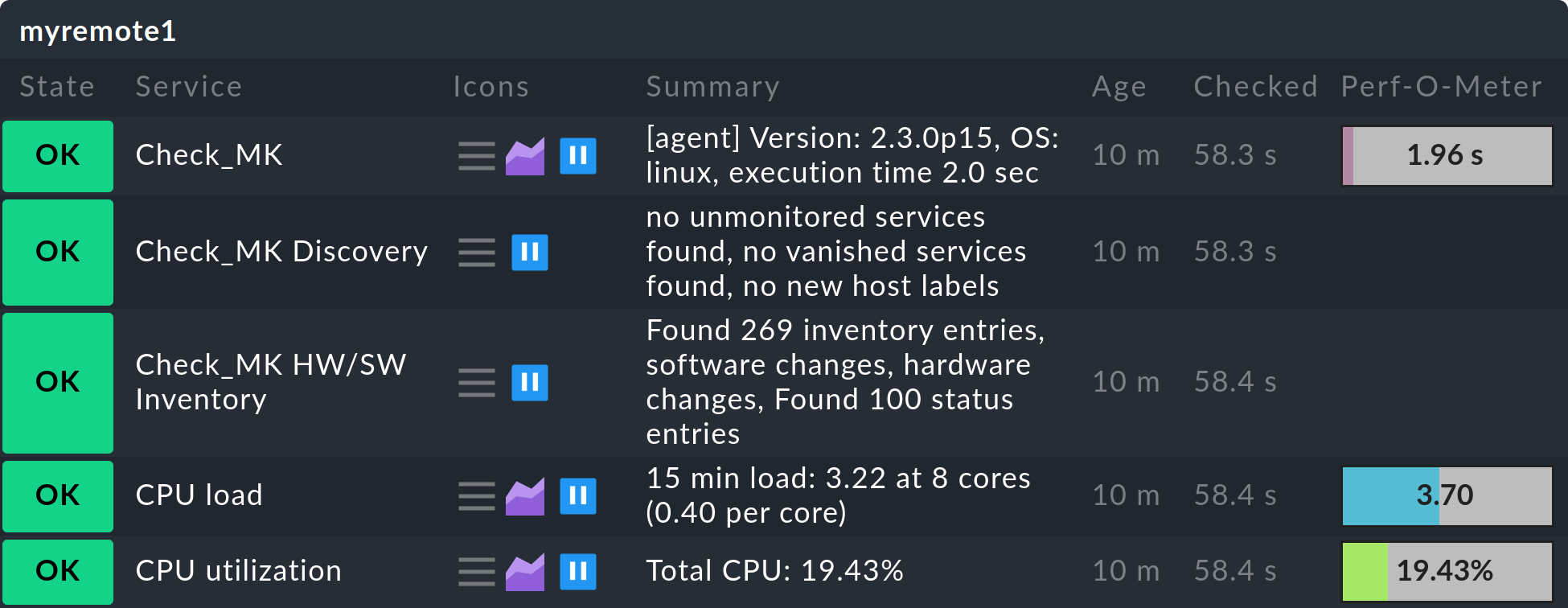
L'état des ordinateurs hôtes/services distants sera désormais immédiatement mis à jour sur l'instance centrale :
La transmission de l'état doit désormais être effectuée régulièrement.
Vous pouvez utiliser un script pour répéter les étapes décrites ci-dessus à des intervalles de votre choix.
Au lieu de copier les données via scp, votre script peut être exécuté directement depuis l'instance centrale afin de recevoir les données d'état ou de configuration via ssh.
Un script permettant d'effectuer ces actions est disponible sur GitHub dans le répertoire treasures.
Nous mettons ces fichiers à disposition dans le répertoire |
La configuration et le vidage d'état peuvent également être restreints à l'aide des filtres Livestatus.
Par exemple, vous pourriez limiter les ordinateurs hôtes aux membres du groupe d'hôtes « mygroup » :
5.3. Mise en œuvre de CMCDump
CMCDump est à Checkmk Micro Core ce que Livedump est à Nagios – c’est donc l’outil de prédilection pour les éditions commerciales. Contrairement à Livedump, CMCDump peut reproduire l’état complet des ordinateurs hôtes et des services (Nagios ne dispose pas des interfaces nécessaires pour cette tâche).
À titre de comparaison : Livedump transfère les données suivantes :
Les états actuels – c'est-à-dire PEND, OK, WARN, CRIT, UNKNOWN, UP, DOWN ou UNREACH
Résultats des plugins de supervision
Les données de performance
CMCDump synchronise en outre :
La sortie longue du plugin
Si l'objet est actuellement instable (
 )
)Les horodatages de la dernière exécution du check et du dernier changement d'état
La durée de l'exécution du check
La latence de l'exécution du check
Le numéro de séquence de la tentative de check en cours et si l'état actuel est « dur » ou « soft »
 Confirmé, le cas échéant
Confirmé, le cas échéantSi l'objet est actuellement en période de maintenance planifiée (
 ).
).
Cela offre un reflet beaucoup plus précis de la supervision. Lors de l’importation de l’état, le CMC ne se contente pas de simuler une exécution de vérification, mais transmet un état précis en utilisant une interface conçue à cet effet. Cela signifie notamment que le centre d’opérations peut à tout moment voir si des problèmes ont été confirmés ou si des périodes de maintenance ont été saisies.
L'installation est presque identique à celle de Livedump, mais elle est toutefois un peu plus simple puisqu'il n'est pas nécessaire de se soucier d'éventuels doublons de modèles ou autres.
La copie de la configuration s’effectue à l’aide de cmcdump -C.
Enregistrez ce fichier sur l’instance centrale dans ~/etc/check_mk/conf.d/.
L’extension de fichier .mk doit être utilisée :
Activez la configuration sur l'instance centrale :
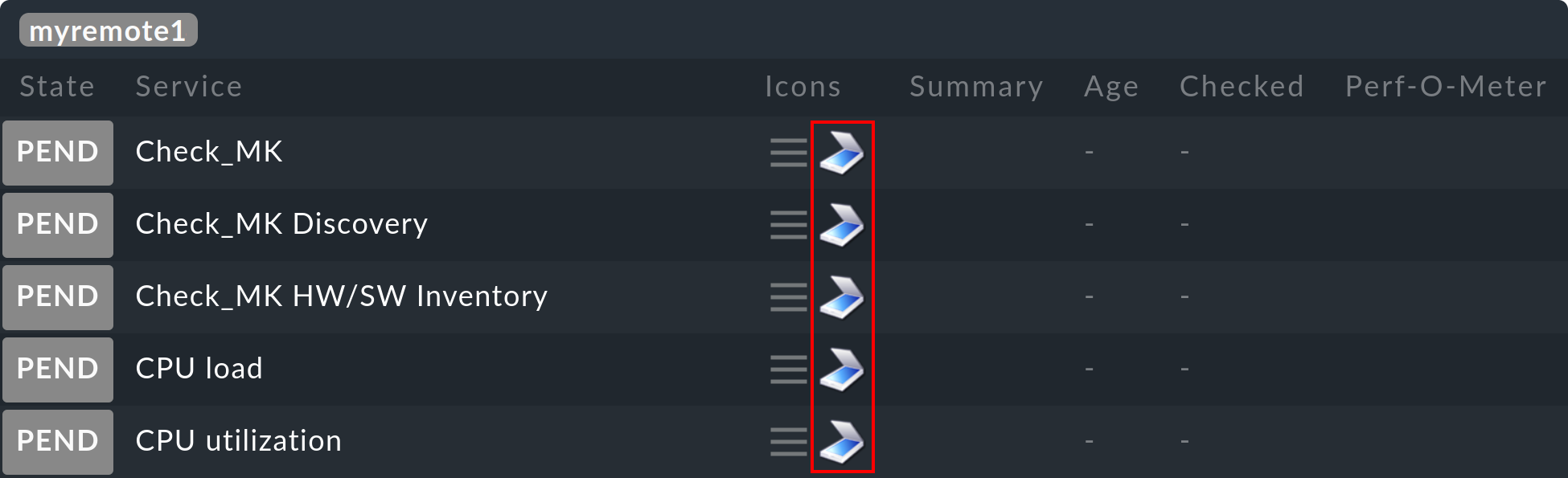
Comme avec Livedump, les hôtes et les services apparaîtront désormais sur l'instance centrale dans l'état PEND.
Vous verrez toutefois, grâce à l'icône ![]() , qu'il s'agit d'un objet fantôme.
Cela permet de le distinguer d'un objet surveillé directement sur l'instance centrale ou sur une instance distante « normale » :
, qu'il s'agit d'un objet fantôme.
Cela permet de le distinguer d'un objet surveillé directement sur l'instance centrale ou sur une instance distante « normale » :
La génération régulière du statut s'effectue avec la commande « cmcdump » sans arguments supplémentaires :
Pour importer l'état vers l'instance centrale, le contenu du fichier doit être écrit dans le socket Unix d'~/tmp/run/live à l'aide de l'outil unixcat.
Si vous disposez d'un accès depuis l'instance distante vers l'instance centrale via SSH sans mot de passe, les trois instructions peuvent être combinées en une seule — et, ce faisant, aucun fichier temporaire n'est créé :
C'est vraiment aussi simple que cela !
Mais, comme déjà mentionné, ssh / scp n'est pas la seule méthode pour transférer des fichiers, et une configuration ou un état peut tout aussi bien être transféré par courrier électronique ou via un autre protocole de votre choix.
6. Notifications dans les environnements distribués
6.1. Centralisé ou décentralisé ?
Dans un environnement distribué, la question se pose : depuis quelle instance les notifications (par exemple, les courriers électroniques) doivent-elles être envoyées : depuis les instances distantes individuelles ou depuis l’instance centrale ? Il existe des arguments en faveur des deux procédures.
Arguments en faveur de l'envoi depuis les instances distantes :
Plus simple à mettre en place
Une notification locale reste possible si la connexion à l'instance centrale n'est pas disponible
Fonctionne également avec l'
 e Checkmk Community
e Checkmk Community
Arguments en faveur de l'envoi depuis l'instance centrale :
Les notifications peuvent être traitées ultérieurement à un emplacement central (par exemple, être transférées vers un système de tickets)
les instances distantes ne nécessitent aucune configuration pour le courrier électronique ou les SMS
Pour l'envoi d'un SMS via du matériel, cette configuration n'est requise qu'une seule fois — à l'instance centrale
6.2. Notification décentralisée
Aucune étape particulière n’est requise pour une notification décentralisée, car il s’agit du paramétrage par défaut. Chaque notification générée sur une instance distante suit la chaîne de règles de notification qui y est définie. Si vous mettez en place une configuration centralisée, ces règles sont identiques sur toutes les instances. Les notifications résultant de ces règles seront transmises comme d’habitude, les scripts de notification appropriés ayant été exécutés localement.
Il suffit simplement de s’assurer que le service approprié a été correctement installé sur les instances — qu’un hôte intelligent a été défini pour le courrier électronique, par exemple — en d’autres termes, la même procédure que pour la configuration d’une instance Checkmk individuelle.
6.3. Notification centralisée
Principes fondamentaux
![]() Les éditions commerciales fournissent un mécanisme intégré de notifications centralisées qui peut être activé individuellement pour chaque instance distante.
Ces instances distantes acheminent alors toutes les notifications vers l’instance centrale pour traitement ultérieur.
La notification centralisée est ainsi indépendante du mode de configuration de la supervision distribuée : qu’elle soit standard, via CMCDump ou en combinant ces deux procédures.
Techniquement parlant, le serveur de notification central n’a même pas besoin d’être littéralement au « centre ».
Cette tâche peut être assurée par n’importe quelle instance Checkmk.
Les éditions commerciales fournissent un mécanisme intégré de notifications centralisées qui peut être activé individuellement pour chaque instance distante.
Ces instances distantes acheminent alors toutes les notifications vers l’instance centrale pour traitement ultérieur.
La notification centralisée est ainsi indépendante du mode de configuration de la supervision distribuée : qu’elle soit standard, via CMCDump ou en combinant ces deux procédures.
Techniquement parlant, le serveur de notification central n’a même pas besoin d’être littéralement au « centre ».
Cette tâche peut être assurée par n’importe quelle instance Checkmk.
Si une instance distante a été configurée en « transfert », toutes les notifications seront transférées directement vers l’instance centrale comme si elles provenaient du noyau du processeur — en fait, au format brut. Une fois sur place, les règles de notification détermineront qui doit effectivement être notifié et de quelle manière. Les scripts de notification requis seront exécutés sur l’instance centrale.
Configuration des connexions TCP
Les spouleurs de notification des instances distantes et de l’instance centrale (de notification) communiquent entre eux via TCP. Les notifications sont envoyées depuis les instances distantes vers l’instance centrale. L’instance centrale confirme la réception des notifications auprès des instances distantes, ce qui empêche toute perte de notifications même si la connexion TCP est interrompue.
Il existe deux alternatives pour l'établissement d'une connexion TCP :
Une connexion TCP est configurée de l’instance centrale vers l’instance distante. Dans ce cas, l’instance distante fait office de serveur TCP.
Une connexion TCP est configurée de l’instance distante vers l’instance centrale. Dans ce cas, l’instance centrale est le serveur TCP.
Par conséquent, rien n’empêche le transfert des notifications si, pour des raisons liées au réseau, l’établissement de connexions n’est possible que dans une direction spécifique. Les connexions TCP sont surveillées par le spooler à l’aide d’un signal de pulsation et sont immédiatement rétablies si nécessaire — et pas seulement en cas d’événement.
Étant donné que les instances distantes et l’instance centrale nécessitent des paramètres globaux différents pour le spooler, vous devez définir des paramètres spécifiques à chaque instance pour toutes les instances distantes. La configuration de l’instance centrale s’effectue à l’aide des paramètres globaux habituels. Remarque : ces paramètres seront automatiquement hérités par toutes les instances distantes pour lesquelles aucun paramètre spécifique n’a été défini.
Examinons d'abord un exemple dans lequel l'instance centrale établit les connexions TCP vers les instances distantes.
Étape 1 : Sur l’instance distante, modifiez le paramètre global spécifique à l’instance « Notifications > Notification Spooler Configuration » et activez l’option « Accept incoming TCP connections ». Le port TCP 6555 sera recommandé pour les connexions entrantes. Si vous n’avez aucune objection, adoptez ces paramètres.
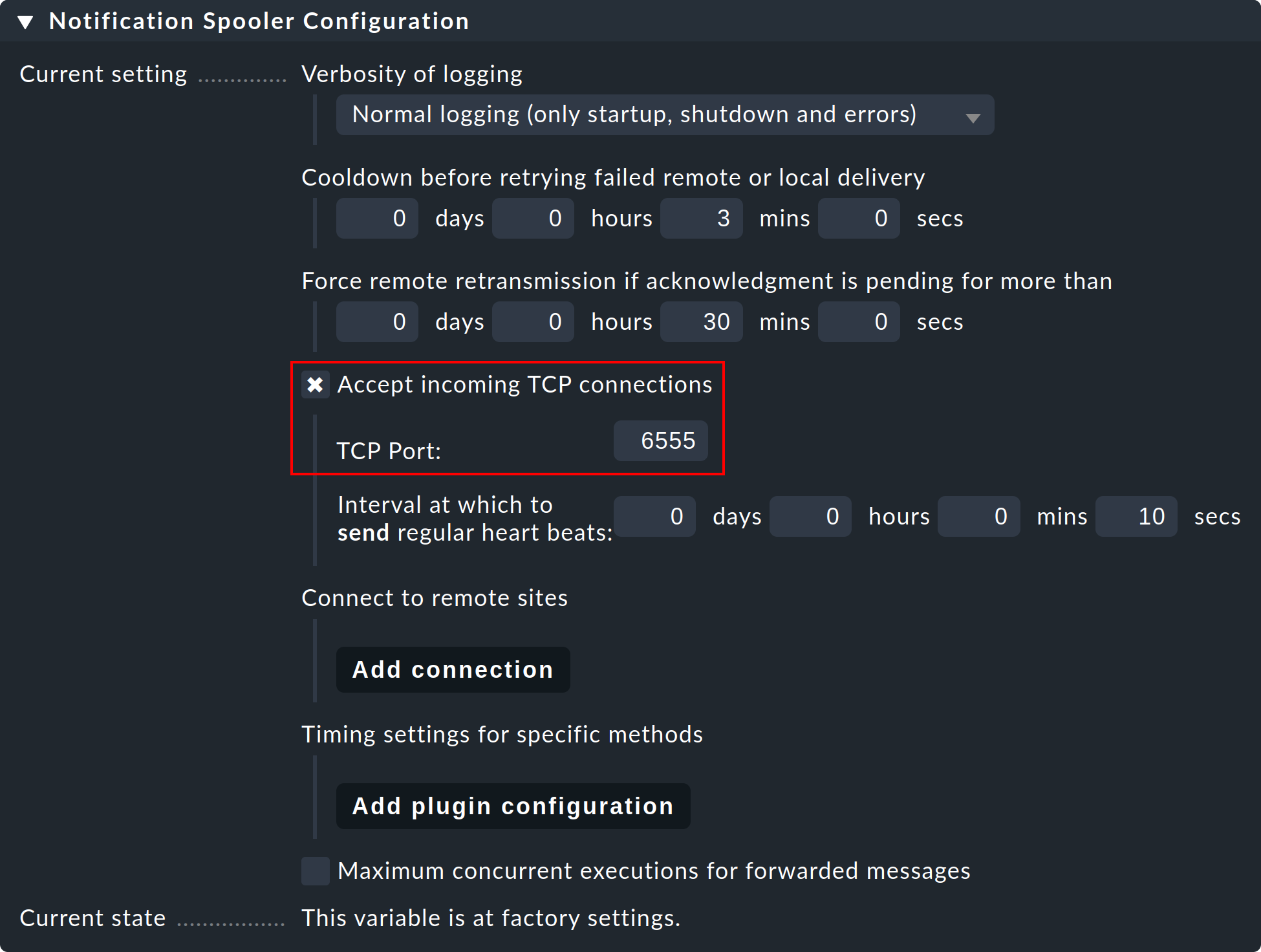
Étape 2 : À présent, de la même manière, dans le sous-menu « Notification Spooling » (Paramètres globaux) de l’instance distante uniquement, sélectionnez l’option « Forward to remote site by notification spooler » (Établir les connexions TCP vers les instances distantes).

Étape 3 : À présent, sur l'instance centrale — c'est-à-dire dans les paramètres globaux normaux —, configurez la connexion vers l'instance distante (puis vers d'autres instances distantes si nécessaire) :
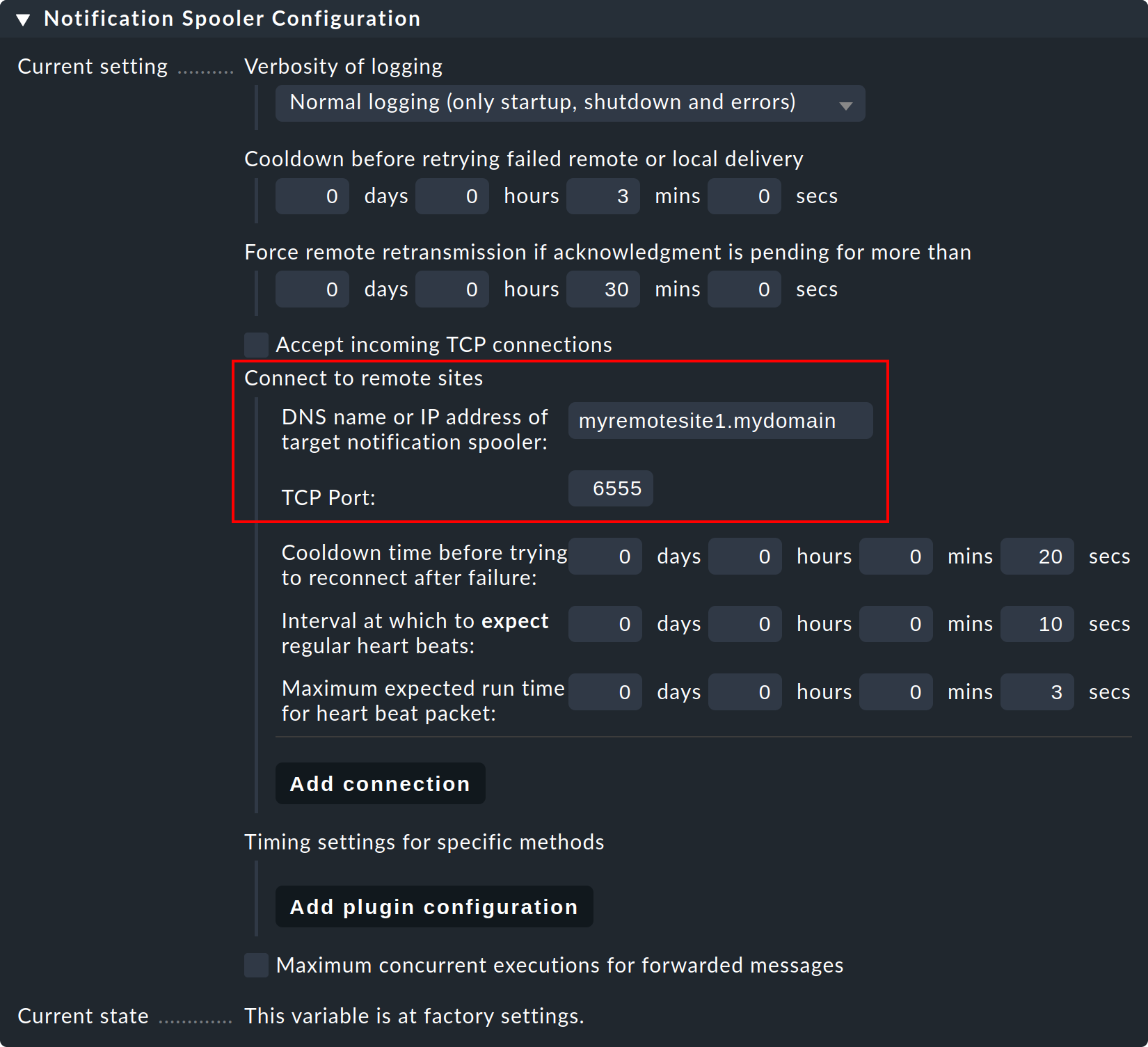
Étape 4 : Définissez le paramètre global « Notification Spooling » sur « Asynchronous local delivery by notification spooler », afin que les communications de l’instance centrale soient également traitées via le même spooler central.

Étape 5 : Activez les modifications.
Établissement de connexions à partir d’une instance distante
Si la connexion TCP doit être établie depuis l’instance distante vers l’extérieur, la procédure est identique, la seule différence par rapport à la description ci-dessus étant l’inversion des rôles entre l’instance centrale et l’instance distante.
Une combinaison des deux procédures est également possible. Dans ce cas, l’instance centrale doit être configurée de manière à écouter les connexions entrantes tout en se connectant aux instances distantes. Cependant, dans toute relation central/distant, seul l’un des deux est autorisé à établir la connexion !
Test et diagnostic
Le spouleur de notification consigne ses activités dans le fichier ~/var/log/mknotifyd.log.
Dans la configuration du spouleur, le niveau de journalisation peut être augmenté afin de recevoir davantage de messages.
Avec un niveau de journalisation standard, vous devriez voir quelque chose comme ceci sur l’instance centrale :
2025-04-30 07:11:40,023 [20] [cmk.mknotifyd] -----------------------------------------------------------------
2025-04-30 07:11:40,023 [20] [cmk.mknotifyd] Check_MK Notification Spooler version 2.4.0p24 starting
2025-04-30 07:11:40,024 [20] [cmk.mknotifyd] Log verbosity: 0
2025-04-30 07:11:40,025 [20] [cmk.mknotifyd] Daemonized with PID 31081.
2025-04-30 07:11:40,029 [20] [cmk.mknotifyd] Connection to 10.1.8.44 port 6555 in progress
2025-04-30 07:11:40,029 [20] [cmk.mknotifyd] Successfully connected to 10.1.8.44:6555À tout moment, le fichier ~/var/log/mknotifyd.state contient l'état actuel du spooler et de toutes ses connexions :
Connection: 10.1.8.44:6555
Type: outgoing
State: established
Status Message: Successfully connected to 10.1.8.44:6555
Since: 1637129500 (2025-04-30 07:11:40, 140 sec ago)
Connect Time: 0.002 secUne version de ce même fichier est également présente sur l’instance distante. Là-bas, la connexion ressemblera à ceci :
Connection: 10.22.4.12:56546
Type: incoming
State: established
Since: 1637129500 (2025-04-30 07:11:40, 330 sec ago)Pour effectuer un test, sélectionnez n'importe quel service distant sous supervision et définissez-le manuellement sur « CRIT » à l'aide de l'instruction « Fake check results ».
Une notification entrante devrait alors apparaître sur l’instance centrale dans le fichier journal des notifications (notify.log) :
2025-04-30 07:59:36,231 ----------------------------------------------------------------------
2025-04-30 07:59:36,232 [20] [cmk.base.notify] Got spool file 307ad477 (myremotehost123;Check_MK) from remote host for local delivery.Le même événement se présentera comme suit sur l'instance distante :
2025-04-30 07:59:28,161 [20] [cmk.base.notify] ----------------------------------------------------------------------
2025-04-30 07:59:28,161 [20] [cmk.base.notify] Got raw notification (myremotehost123;Check_MK) context with 71 variables
2025-04-30 07:59:28,162 [20] [cmk.base.notify] Creating spoolfile: /omd/sites/myremote1/var/check_mk/notify/spool/307ad477-b534-4cc0-99c9-db1c517b31fDans les paramètres généraux, vous pouvez définir un niveau de journalisation plus élevé à la fois pour le fichier journal normal des notifications (notify.log) et pour le fichier journal du spouleur de notification.
Supervision du spool
Une fois que vous aurez tout configuré comme décrit, vous remarquerez que sur l’instance centrale, et respectivement sur les instances distantes, un nouveau service apparaîtra qui devra impérativement être pris en compte dans la supervision. Celui-ci surveille le spouleur de notification et ses connexions TCP. Chaque connexion sera ainsi surveillée deux fois : une fois par l’instance centrale, et une fois par l’instance distante :
7. Lorsqu'une instance centrale et ses instances distantes utilisent des versions différentes
En règle générale, les versions de toutes les instances distantes et de l'instance centrale doivent correspondre. Les exceptions à cette règle ne s'appliquent que lors de la réalisation de mises à jour. Il convient ici de distinguer les situations suivantes :
7.1. Niveaux de correctifs différents (mais même version majeure)
Les niveaux de correctifs (par exemple p11) peuvent généralement différer sans poser de problème. Dans de rares cas, cependant, même ceux-ci peuvent être incompatibles entre eux ; dans une telle situation, vous devez donc maintenir exactement le même niveau de version (par exemple 2.4.0p11) sur toutes les instances afin de permettre à celles-ci de fonctionner ensemble sans erreur. Par conséquent, notez toujours les modifications incompatibles de chaque version de correctif dans les Werks.
En règle générale — des exceptions sont possibles et sont indiquées dans le Werks — mettez d'abord à jour les instances distantes et l'instance centrale en dernier.
7.2. Versions majeures différentes
Pour une exécution sans heurts des mises à jour majeures (par exemple de la version 2.3.0 à la version 2.4.0) dans les grands environnements distribués, à partir de la version 2.0.0, Checkmk autorise les opérations mixtes dans lesquelles les instances centraux et distantes peuvent présenter une version majeure différente. Lors d’une mise à jour, veillez à mettre à jour les instances distantes en premier. Vous ne mettrez à jour l’instance centrale qu’une fois que toutes les instances distantes auront été mises à jour vers la version supérieure.
Une fois encore, veillez à consulter les notes de mise à jour des Werk et des versions avant de lancer la mise à jour ! Un niveau de correctif spécifique (prérequis) de l'ancienne version est toujours requis sur l'instance centrale pour garantir un fonctionnement mixte sans problème.
Une fonctionnalité particulière des environnements mixtes est la gestion centralisée des paquets d'extension, qui peuvent désormais être conservés sous forme de variantes pour les versions anciennes et récentes de Checkmk. Les détails à ce sujet sont expliqués dans l'article consacré à la gestion des MKP.
8. Fichiers et répertoires
8.1. Fichiers de configuration
| Chemin d'accès | Description |
|---|---|
|
C'est ici que Checkmk stocke la configuration des connexions vers les différentes instances. Si l'interface « se bloque » en raison d'une erreur de configuration, rendant ainsi le système inutilisable, vous pouvez éditer directement l'entrée problématique dans le fichier. Si le proxy Livestatus est activé, il sera toutefois nécessaire d'éditer et d'enregistrer au moins une connexion, car ce n'est qu'ainsi qu'une configuration appropriée sera générée pour ce daemon. |
|
Configuration du proxy Livestatus. Ce fichier est généré à chaque modification de la configuration de la supervision distribuée. |
|
Configuration du spouleur de notification. Ce fichier est généré par Checkmk lors de l'enregistrement des paramètres globaux. |
|
Ce fichier est créé sur les instances distantes et garantit que celles-ci ne réalisent que la supervision de leurs propres ordinateurs hôtes. |
|
Emplacement de stockage des fichiers de configuration Nagios créés par le client, contenant les ordinateurs hôtes et les services. Ceux-ci sont nécessaires pour l'utilisation de Livedump sur l'instance centrale. |
|
Configuration de Livestatus pour l'utilisation de Nagios comme noyau du processeur. Vous pouvez y configurer le nombre maximal de connexions simultanées autorisées. |
|
Configuration des ordinateurs hôtes et des règles pour Checkmk. Stockez ici les fichiers de configuration générés par CMCDump. Seul le sous-répertoire |
|
Pour les services détectés par la reconnaissance du service. Ceux-ci sont toujours stockés localement sur l’instance distante. |
|
Emplacement de la base de donnée tourniquet (RRD) pour l'archivage des données de performance lors de l'utilisation du format Checkmk-RRD (par défaut avec les éditions commerciales) |
|
Emplacement de la base de données Round-Robin au format PNP4Nagios (Checkmk Community) |
|
Fichier journal pour les proxys Livestatus. |
|
L'état actuel des proxys Livestatus sous une forme lisible. Ce fichier est mis à jour toutes les 5 secondes. |
|
Fichier journal du système de notification Checkmk. |
|
Fichier journal du spouleur de notification. |
|
L'état actuel du spouleur de notification sous une forme lisible. Ce fichier est mis à jour toutes les 20 secondes. |