This is a machine translation based on the English version of the article. It might or might not have already been subject to text preparation. If you find errors, please file a GitHub issue that states the paragraph that has to be improved. |
1. Introduction
Checkmk Informatique décisionnelle — cela semble certes très ambitieux pour ce qui est, au fond, une chose simple. Ce nom décrit toutefois assez bien le noyau du module d’informatique décisionnelle de Checkmk. Il s’agit d’évaluer l’état global des applications critiques pour l’entreprise à partir des valeurs recueillies lors de la collection des états de nombreux composants individuels dans un environnement, et de présenter ces informations de manière claire.
Prenons l’exemple du service de courrier électronique, qui reste indispensable pour de nombreuses entreprises. Ce service repose sur le bon fonctionnement d’une multitude de composants matériels et logiciels — depuis des commutateurs spécifiques jusqu’aux services SMTP et IMAP, en passant par des services d’infrastructure tels que LDAP et DNS.
La défaillance d’un élément constitutif essentiel ne pose pas de problème si celui-ci a été conçu pour être redondant. À l’inverse, un problème peut survenir dans un service qui, à première vue, n’a rien à voir avec le courrier électronique, mais qui peut en réalité avoir des conséquences bien plus graves. Un simple coup d’œil à la liste des services dans Checkmk n’est pas toujours significatif — du moins pas pour tout le monde.
Checkmk BI vous permet de dégager un résumé de l’état de santé global d’une application à partir de l’état actuel des ordinateurs hôtes et services individuels. Les règles BI servent à définir, dans une structure arborescente, comment les différents éléments sont interdépendants. L’état global de chaque application peut alors être identifié comme «OK», «WARN» ou «CRIT». Les informations relatives à la condition et aux dépendances sont accessibles de différentes manières :
Affichage de l’état global d’une application dans l’interface graphique.
Le calcul de la disponibilité d'une application.
Des notifications en cas d’événement, voire de défaillance d’une application.
Analyse d'impact : un service est en état d'CRIT, quelles applications sont donc affectées ?
Planification des périodes de maintenance programmées et analyses de type « et si ? ».
De plus, il est possible d’utiliser la représentation arborescente dans BI pour obtenir une vue drill down de l’état d’un ordinateur hôte et de tous ses services.
Une caractéristique distinctive de la BI de Checkmk, contrairement aux outils comparables dans le domaine de la supervision, est que Checkmk fonctionne ici également avec une structure basée sur des règles. Cela vous permet de décrire de manière dynamique un nombre indéfini d’applications similaires à l’aide d’un ensemble générique de règles. Cela facilite considérablement le travail et aide à éviter les erreurs — en particulier dans des environnements très dynamiques.
2. Configuration, partie 1 : la première agrégation
2.1. Terminologie
Avant de vous lancer étape par étape dans la mise en œuvre pratique de la BI, vous devez d'abord connaître quelques termes :
Chaque application formalisée avec BI est appelée une agrégation, car un état global est agrégé à partir de nombreux états individuels.
Une agrégation est construite sous la forme d’un « arbre » d’objets. Ces objets sont appelés nœuds. Les nœuds finaux — les feuilles de l’arbre — sont les ordinateurs hôtes et les services de vos instances Checkmk. Les nœuds restants sont des objets BI créés artificiellement.
Chaque nœud est créé par une règle. Cela s’applique également aux racines de l’arbre — le nœud de niveau supérieur. Ces règles déterminent quels nœuds sont en connexion avec un autre nœud, et comment l’état des nœuds supérieurs doit être déterminé à partir de leurs états.
Le nœud supérieur d’une agrégation — la racine de l’arborescence — est également généré par une règle. De cette manière, une règle peut générer plusieurs agrégations.
2.2. Un exemple
La manière la plus simple de comprendre cela est d’utiliser un exemple concret.
Nous avons créé l’application Mystery spécialement pour illustrer cet article.
Supposons qu’il s’agisse d’une application importante au sein d’une organisation non spécifiée.
Entre autres, cinq serveurs et deux commutateurs réseau jouent un rôle important.
Afin que vous puissiez mieux comprendre notre exemple, nous utiliserons des noms simples tels que srv-mys-1 ou switch-1.
Le diagramme suivant donne un aperçu simple de la structure :
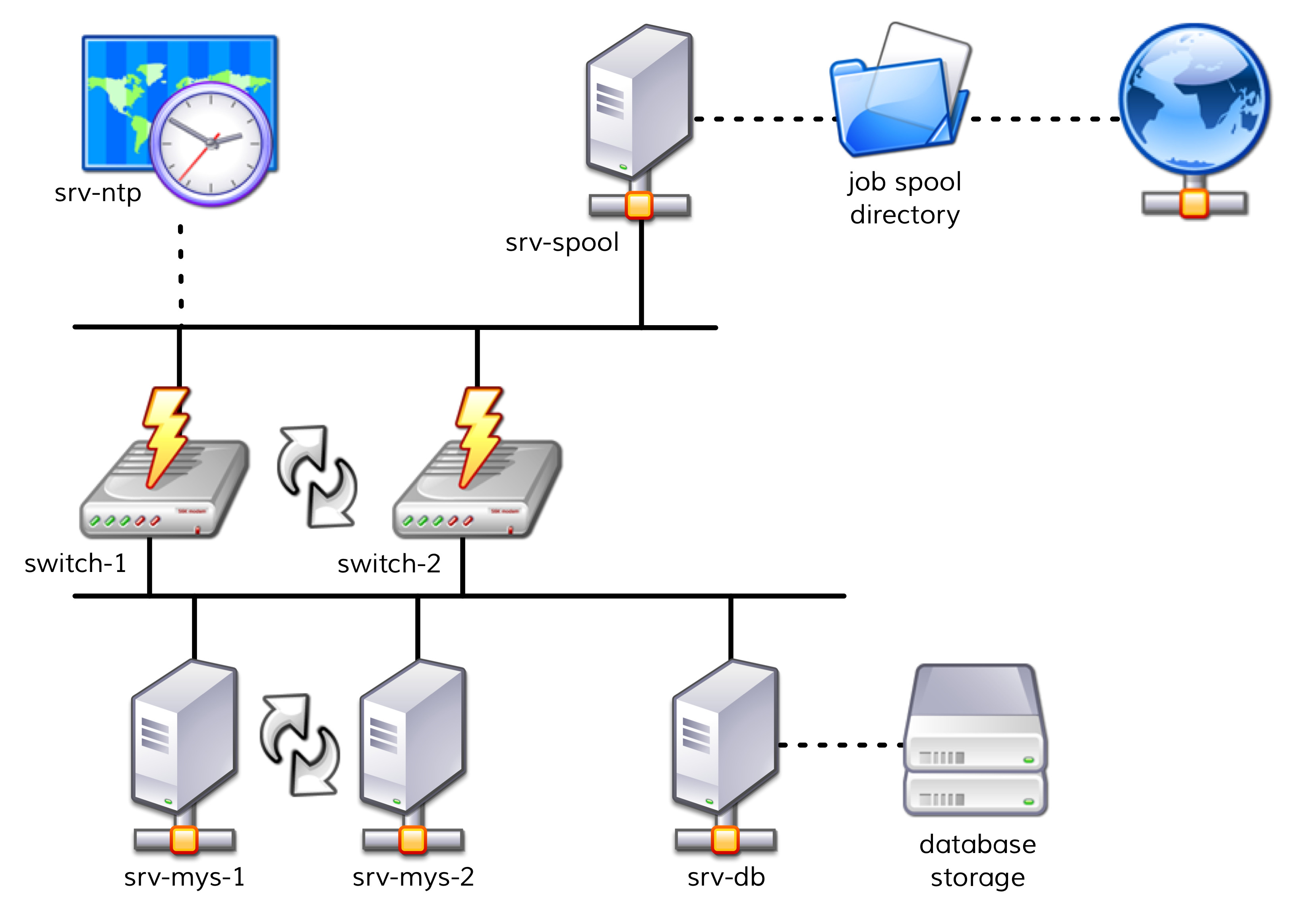
Les deux serveurs,
srv-mys-1etsrv-mys-2, forment un cluster redondant sur lequel l'application proprement dite s'exécute.srv-dbest un serveur de base de données qui stocke les données de l'application.switch-1etswitch-2sont deux routeurs redondants assurant la connexion du réseau de serveurs à un réseau de niveau supérieur.Chaque routeur est équipé d’une horloge
srv-ntpqui garantit une synchronisation horaire parfaite.De plus, l’
srv-spooldu serveur fonctionne ici et transmet les résultats calculés par l’application mystérieuse vers un répertoire de spool.Les données sont récupérées dans le répertoire de spool par un service parent mystérieux.
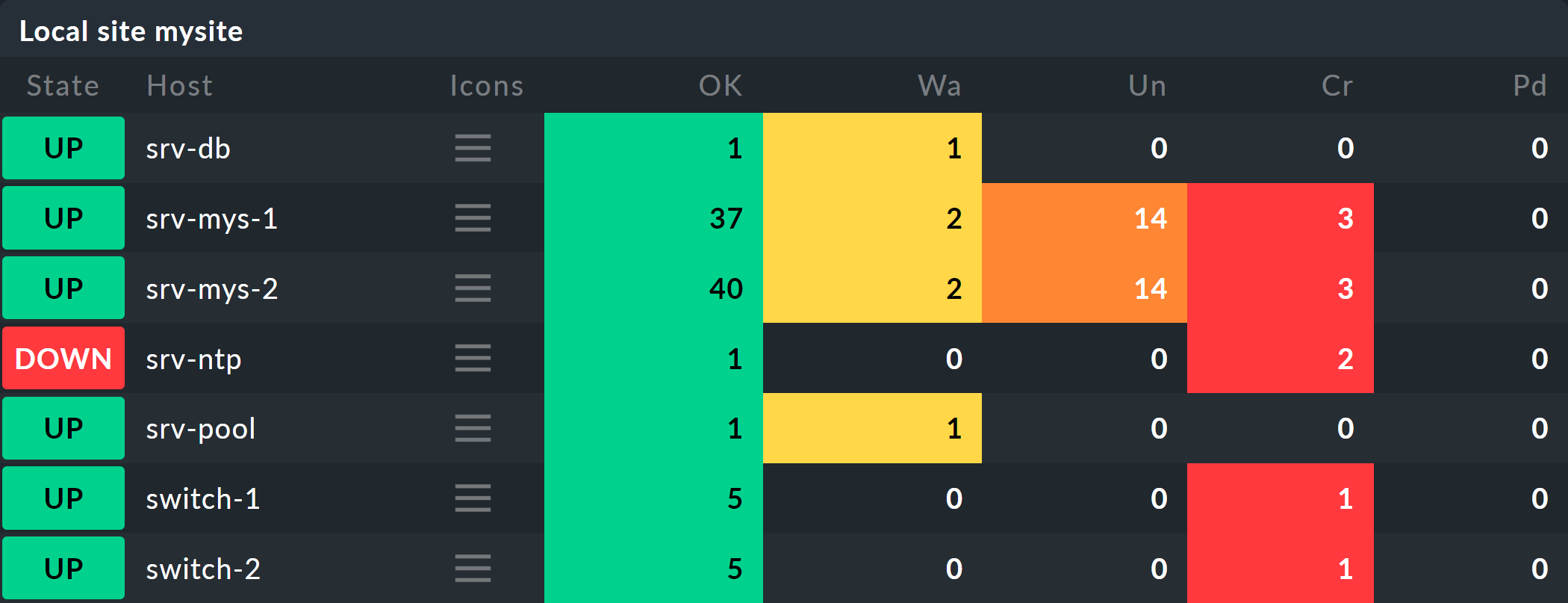
Si vous souhaitez suivre les étapes suivantes une par une, il vous suffit de reproduire les objets de supervision comme indiqué dans notre exemple. Pour un test, il suffit de cloner plusieurs fois un ordinateur hôte existant et de nommer les clones en conséquence. Plus tard, quelques services viendront s’ajouter au jeu, pour lesquels vous aurez alors le temps d’ajouter les ordinateurs hôtes correspondants à la supervision. Même là, vous pouvez encore tricher : grâce à de simples checks locaux, vous obtiendrez rapidement des services correspondants avec lesquels jouer.
Les ordinateurs hôtes apparaîtront alors comme suit dans la supervision :
2.3. Votre première règle BI
Commencez par quelque chose de simple — avec l’agrégation significative la plus simple possible — une agrégation ne comportant que deux nœuds.
Vous souhaitez ensuite résumer les états des ordinateurs hôtes switch-1 et switch-2.
L’agrégation doit s’appeler Network et doit être OK lorsque les deux commutateurs sont disponibles.
En cas de défaillance partielle, l’état doit passer à WARN, et si les deux commutateurs sont hors tension, à CRIT.
Pour commencer : configurez BI via Setup > Business Intelligence > Business Intelligence. La configuration des règles et des agrégations s’effectue au sein des packages de configuration — les packs BI. Ces packages sont non seulement pratiques car ils vous permettent de mieux gérer des configurations plus complexes — vous pouvez également appliquer des autorisations à un package et attribuer certains groupes de contacts — mais ils permettent même aux utilisateurs ne disposant pas de droits d’administrateur d’éditer certaines parties de la configuration. Mais nous y reviendrons plus tard…
La première fois que vous appelez le module BI, cela devrait ressembler à ceci :

Un paquet intitulé « Default Pack » est déjà présent. Celui-ci contient une démonstration d’une agrégation qui résume les données d’un ordinateur hôte.
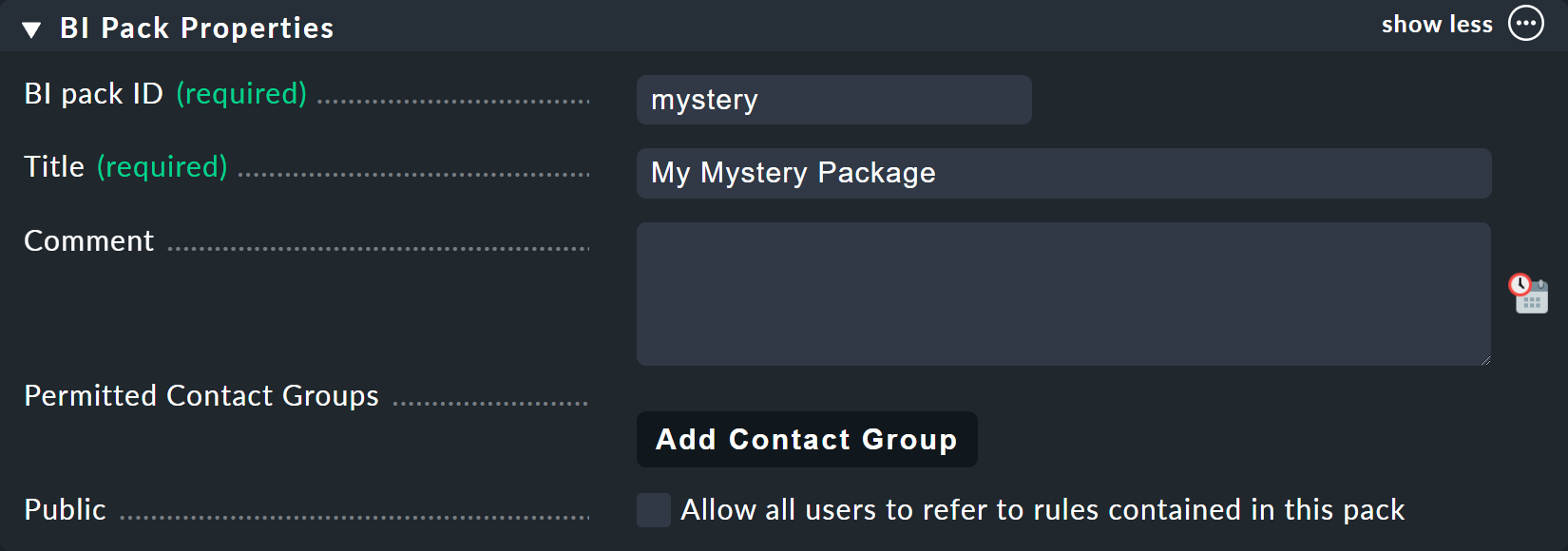
Pour cet exemple, il est préférable de créer un nouveau paquet — à l’aide du bouton « Add BI Pack » — que vous nommerez « Mystery ».
Comme toujours dans Checkmk, spécifiez un identifiant interne (mystery) qui ne pourra pas être modifié ultérieurement, ainsi qu’un titre descriptif.
L’option « Public » est nécessaire pour les autres utilisateurs s’il existe dans ce paquet des règles qu’ils souhaitent utiliser pour leurs propres règles ou agrégations.
Comme vous souhaitez probablement mener vos expériences seul et en toute tranquillité, laissez cette option désactivée :
Une fois la création terminée, vous trouverez bien sûr deux paquets dans la liste principale :

Chaque entrée est accompagnée d’une icône (![]() ) permettant d’éditer les propriétés,
et d’une icône permettant d’ouvrir le contenu réel du paquet (
) permettant d’éditer les propriétés,
et d’une icône permettant d’ouvrir le contenu réel du paquet (![]() ), où vous souhaitez vous rendre maintenant.
Une fois sur place, créez immédiatement votre première règle via Add rule.
), où vous souhaitez vous rendre maintenant.
Une fois sur place, créez immédiatement votre première règle via Add rule.
Comme toujours dans Checkmk, cette règle doit également disposer d’un identifiant unique et d’un titre. Le titre de la règle a non seulement une fonction de documentation, mais il sera également visible ultérieurement en tant que nom du nœud qui sera créé par cette règle :
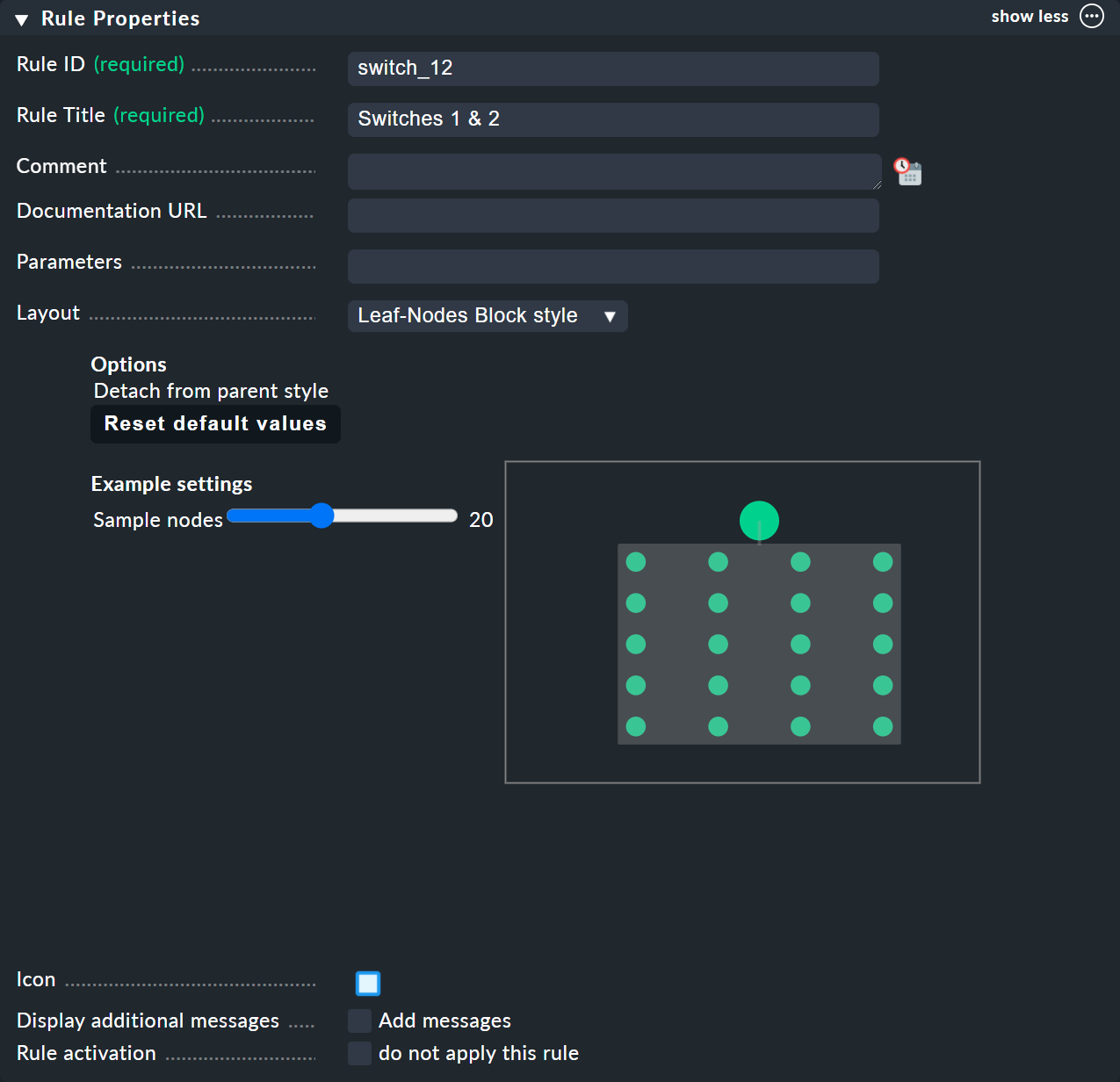
La case suivante s’intitule « Child Node Generation » et est la plus importante. C’est ici que vous spécifiez quels objets de ce nœud doivent être regroupés. Il peut s’agir soit d’autres nœuds BI — pour lesquels vous choisiriez une règle BI différente — soit d’objets sous supervision, c’est-à-dire des ordinateurs hôtes ou des services.
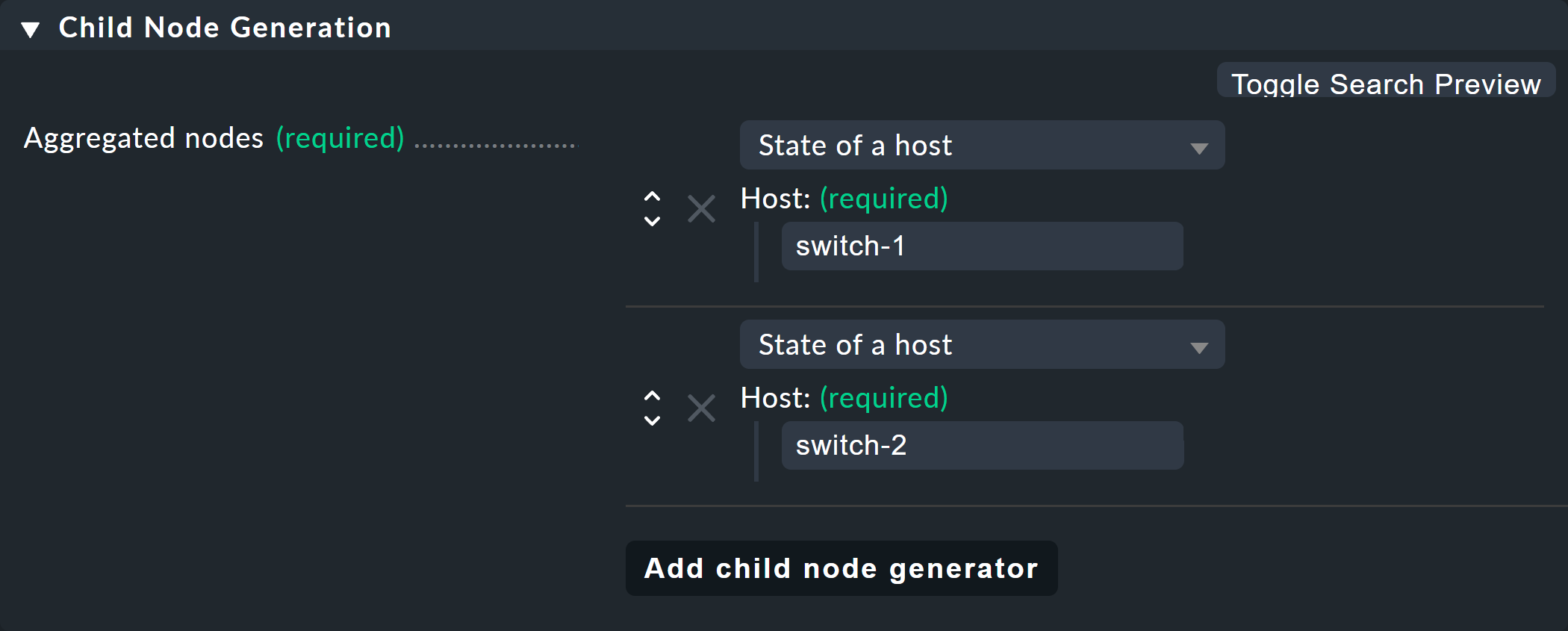
Pour le premier exemple, sélectionnez la deuxième variante (State of a host) et créez deux objets en tant qu’enfants, à savoir les deux hôtes switch-1 et switch-2.
Pour ce faire, utilisez le bouton « Add child node generator ».
Ici, vous choisissez naturellement « State of a host » et saisissez un nom pour chaque hôte :
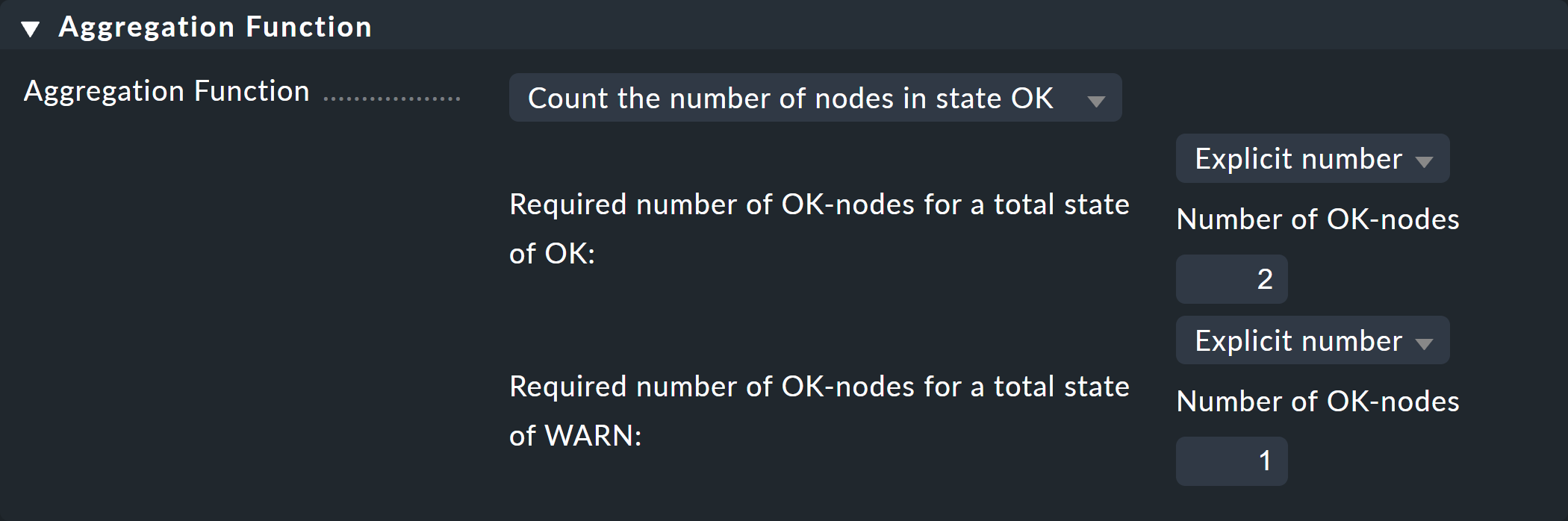
Dans la troisième et dernière case, Aggregation Function, vous spécifiez comment le statut de la supervision du nœud doit être calculé. La base pour cela est toujours la liste des états des sous-nœuds. Diverses relations logiques sont possibles.
L'option Best — take the best of all node states est présélectionnée. Cela signifierait que le nœud devient CRIT lorsque tous les sous-nœuds sont CRIT ou DOWN. Comme mentionné ci-dessus, cela ne devrait pas être le cas ici. Choisissez plutôt Count the number of nodes in state OK pour prendre comme référence le nombre de sous-nœuds ayant l'état OK. Ici, les chiffres 2 et 1 sont suggérés pour les valeurs seuils. C'est parfait, car c'est exactement ce dont vous avez besoin :
Si les deux commutateurs sont UP (ce qui est considéré comme OK), le nœud devrait alors également être OK.
Si un seul commutateur est en état « UP », l'état devient « WARN ».
Et lorsque les deux commutateurs sont DOWN, l'état devient CRIT.
Voici à quoi ressemblera le formulaire une fois rempli :
En cliquant sur « Create », vous obtiendrez votre première règle :

2.4. Votre première agrégation
Remarque — il est important de comprendre qu’une règle n’est pas encore une agrégation.
Checkmk ne peut pas encore savoir s’il s’agit de l’ensemble ou seulement d’une partie d’une arborescence plus grande.
Les véritables objets BI ne seront créés et ne deviendront visibles dans l’interface de suivi d'état que lorsque vous créerez une agrégation.
Pour ce faire, passez à la liste des agrégations « ![]() ».
».
Le bouton « ![]() » vous amène à un formulaire permettant de créer une nouvelle agrégation.
Il y a peu de champs à remplir ici.
Dans le champ « Aggregation groups », vous pouvez saisir le nom de votre choix.
Ces noms apparaissent ensuite dans l’interface de suivi d'état sous forme de groupes, sous lesquels toutes les agrégations partageant ce nom de groupe deviennent visibles.
Il s’agit en fait du même concept que pour les hashtags ou les mots-clés.
Vous pouvez également attribuer librement l’Aggregation ID, comme d’habitude, mais vous ne pourrez pas la modifier par la suite.
» vous amène à un formulaire permettant de créer une nouvelle agrégation.
Il y a peu de champs à remplir ici.
Dans le champ « Aggregation groups », vous pouvez saisir le nom de votre choix.
Ces noms apparaissent ensuite dans l’interface de suivi d'état sous forme de groupes, sous lesquels toutes les agrégations partageant ce nom de groupe deviennent visibles.
Il s’agit en fait du même concept que pour les hashtags ou les mots-clés.
Vous pouvez également attribuer librement l’Aggregation ID, comme d’habitude, mais vous ne pourrez pas la modifier par la suite.
Vous définissez le contenu de l'agrégation via Add new element. Sélectionnez le paramètre Call a rule et, dans Rule:, la règle que vous venez de créer (et avant le paquet de règles dans lequel elle se trouve).
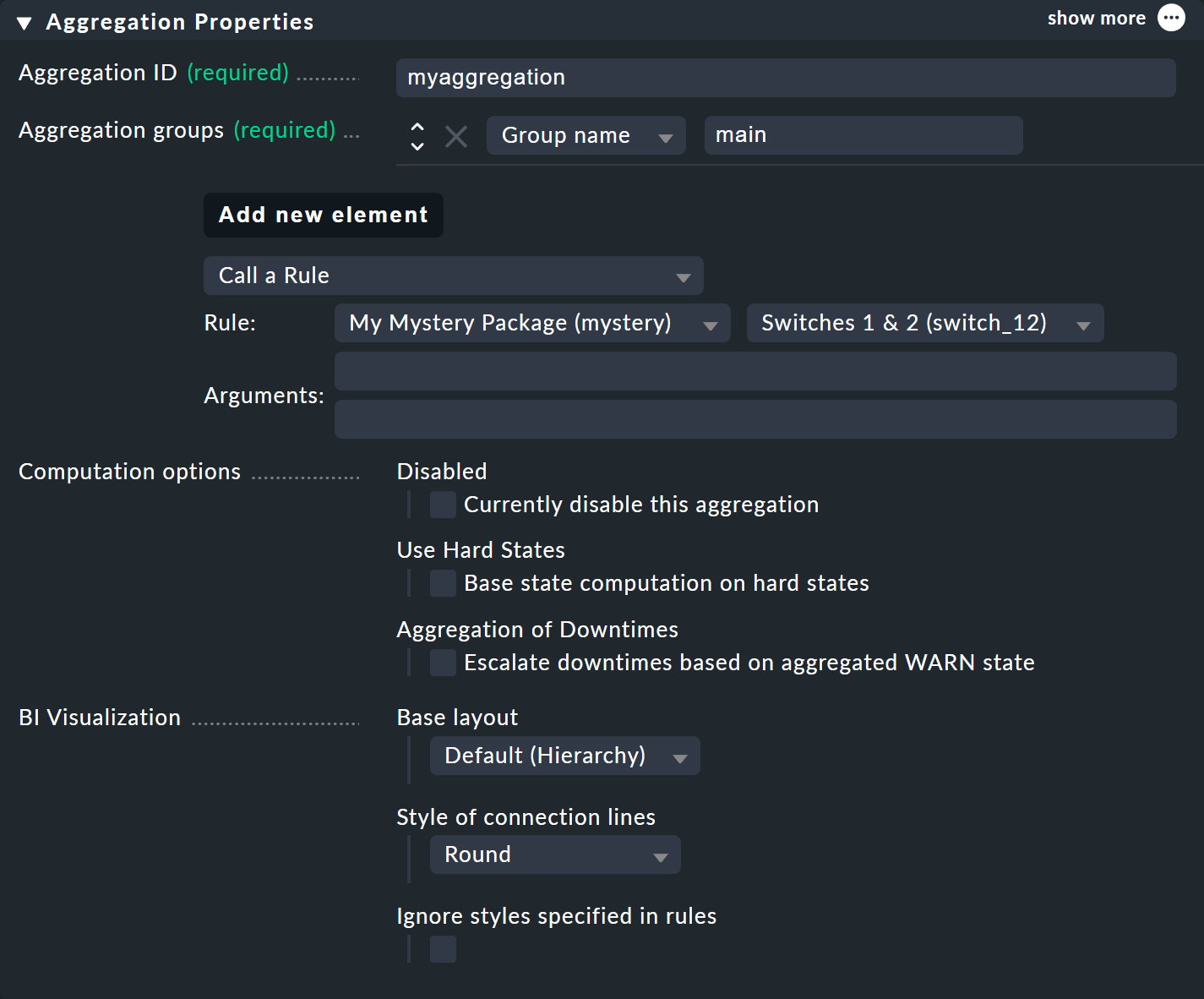
Si vous enregistrez maintenant l'agrégation via ![]() , vous avez terminé !
Votre première agrégation devrait désormais apparaître dans l'interface de suivi d'état — à condition que vous disposiez effectivement d'au moins un des ordinateurs hôtes,
, vous avez terminé !
Votre première agrégation devrait désormais apparaître dans l'interface de suivi d'état — à condition que vous disposiez effectivement d'au moins un des ordinateurs hôtes, switch-1 ou switch-2.
3. La BI en pratique, 1re partie : l'interface de suivi d'état
3.1. Affichage de toutes les agrégations
Si vous avez tout fait correctement, vous devriez désormais pouvoir voir votre première agrégation dans l'interface de suivi d'état. Le moyen le plus simple d'y parvenir est d'utiliser Monitor > Business Intelligence > All Aggregations :

Création de vues de tables pour la BI
Outre les vues BI prêtes à l'emploi, vous pouvez également créer vos propres vues. Pour ce faire, sélectionnez l'une des sources de données BI lors de la création d'une nouvelle vue. BI Aggregations fournit des informations sur les agrégations BI, BI Hostname Aggregations ajoute des filtres et des informations pour des hôtes individuels, BI Aggregations affected by one host affiche uniquement les agrégations liées à un seul hôte, et BI Aggregations for Hosts by Hostgroups vous permet de distinguer les groupes d'hôtes.
3.2. Utilisation de l'arborescence
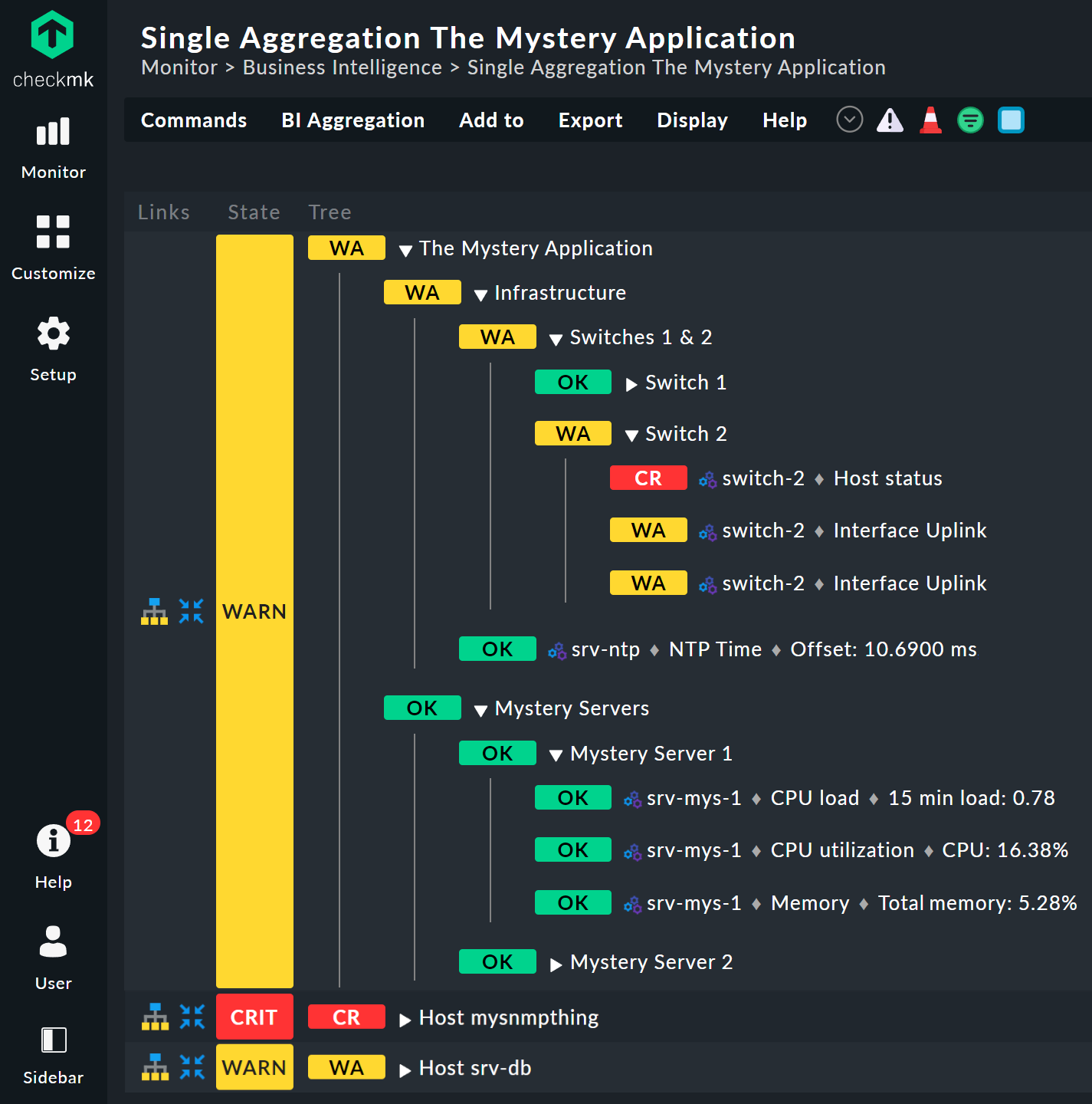
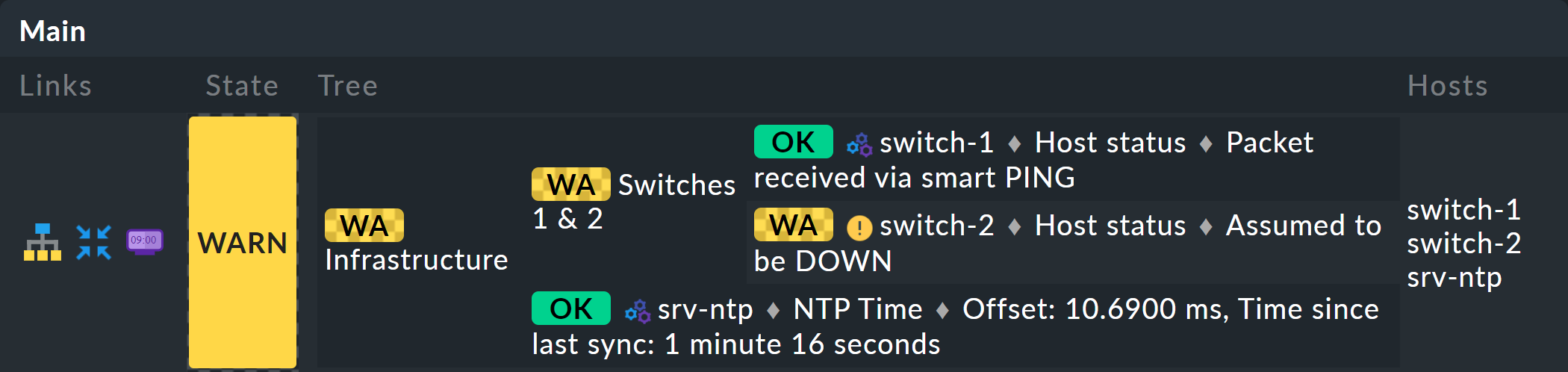
Examinez de plus près l'apparence de l'arborescence BI. L'exemple suivant montre votre mini-agrégation dans une situation où l'un des deux commutateurs est DOWN et l'autre UP. Comme souhaité, l'agrégation passe à l'état WARN :

Vous pouvez également constater que, afin de normaliser les ordinateurs hôtes et les services, l’ordinateur hôte DOWN est traité presque comme un service CRIT. De même, UP devient OK.
Les feuilles de l'arborescence indiquent les états des ordinateurs hôtes et des services. Le nom de domaine — et, pour les services, également le nom du service — est cliquable et vous redirige vers l'état actuel de l'objet correspondant. De plus, vous pouvez également voir la dernière sortie du plugin de supervision.
À gauche de chaque agrégation, vous trouverez deux icônes : ![]() et
et ![]() .
La première icône —
.
La première icône — ![]() — vous amène à une page qui affiche uniquement cette agrégation.
Cela s’avère naturellement très utile si vous avez créé plusieurs agrégations.
Cette fonction est, par exemple, particulièrement adaptée pour créer un signet.
— vous amène à une page qui affiche uniquement cette agrégation.
Cela s’avère naturellement très utile si vous avez créé plusieurs agrégations.
Cette fonction est, par exemple, particulièrement adaptée pour créer un signet.
![]() vous amène au calcul de la disponibilité.
Nous y reviendrons plus tard.
vous amène au calcul de la disponibilité.
Nous y reviendrons plus tard.
3.3. Essayer la BI : et si ?
À gauche du nom de domaine, vous trouverez une icône intéressante : ![]() .
Elle permet d’effectuer une analyse « et si ? ».
Le principe est simple :
en cliquant sur l’icône, l’objet passe à un autre état à titre de test — mais uniquement pour l’interface BI — pas dans la réalité !
Plusieurs clics vous feront passer de
.
Elle permet d’effectuer une analyse « et si ? ».
Le principe est simple :
en cliquant sur l’icône, l’objet passe à un autre état à titre de test — mais uniquement pour l’interface BI — pas dans la réalité !
Plusieurs clics vous feront passer de ![]() (OK) à
(OK) à ![]() (WARN), puis à
(WARN), puis à ![]() (CRIT) et
(CRIT) et ![]() (UNKNOWN), avant de revenir à
(UNKNOWN), avant de revenir à ![]() .
.
BI construit ensuite l'arborescence complète en fonction de l'état supposé.
Le graphique suivant illustre l'agrégation minimale en partant de l'hypothèse que, outre switch-1 qui est effectivement en panne, switch-2 serait également DOWN :

L'état global de l'agrégation passe ainsi de WARN à CRIT. Dans le même temps, la couleur de l'état est accompagnée d'un motif en check. Ce motif vous indique que l'état réel est en fait différent. Ce n'est pas toujours le cas, car certaines modifications apportées à un ordinateur hôte ou à un service ne sont plus pertinentes pour la condition globale — par exemple, si celui en question est déjà CRIT.
Vous pouvez utiliser cette analyse « et si ? » de plusieurs façons, par exemple :
Pour vérifier si l'agrégation BI réagit comme vous le souhaitez.
Lorsque vous prévoyez d'arrêter un composant pour maintenance.
Dans ce dernier cas, à titre de test, vous définissez l’état de l’appareil à entretenir ou de ses services sur « ![]() ».
Si l’agrégation dans son ensemble reste alors « OK », cela signifie que la défaillance peut actuellement être compensée par la redondance.
».
Si l’agrégation dans son ensemble reste alors « OK », cela signifie que la défaillance peut actuellement être compensée par la redondance.
3.4. Tester la BI à l'aide d'états fictifs
Il existe une autre façon de tester les agrégations BI : en modifiant directement l'état réel d'un objet. Ceci est particulièrement pratique dans un système de test.
À cette fin, les instructions disposent d’une instruction hôte/service nommée Fake check results.
Par défaut, celle-ci n’est disponible que pour le rôle Administrateur.
Cette méthode a été utilisée, par exemple, pour la création des captures d’écran utilisées dans cet article, où switch-1 a été défini sur DOWN.
C’est de là que provient le texte révélateur « Manually set to Down by cmkadmin ».

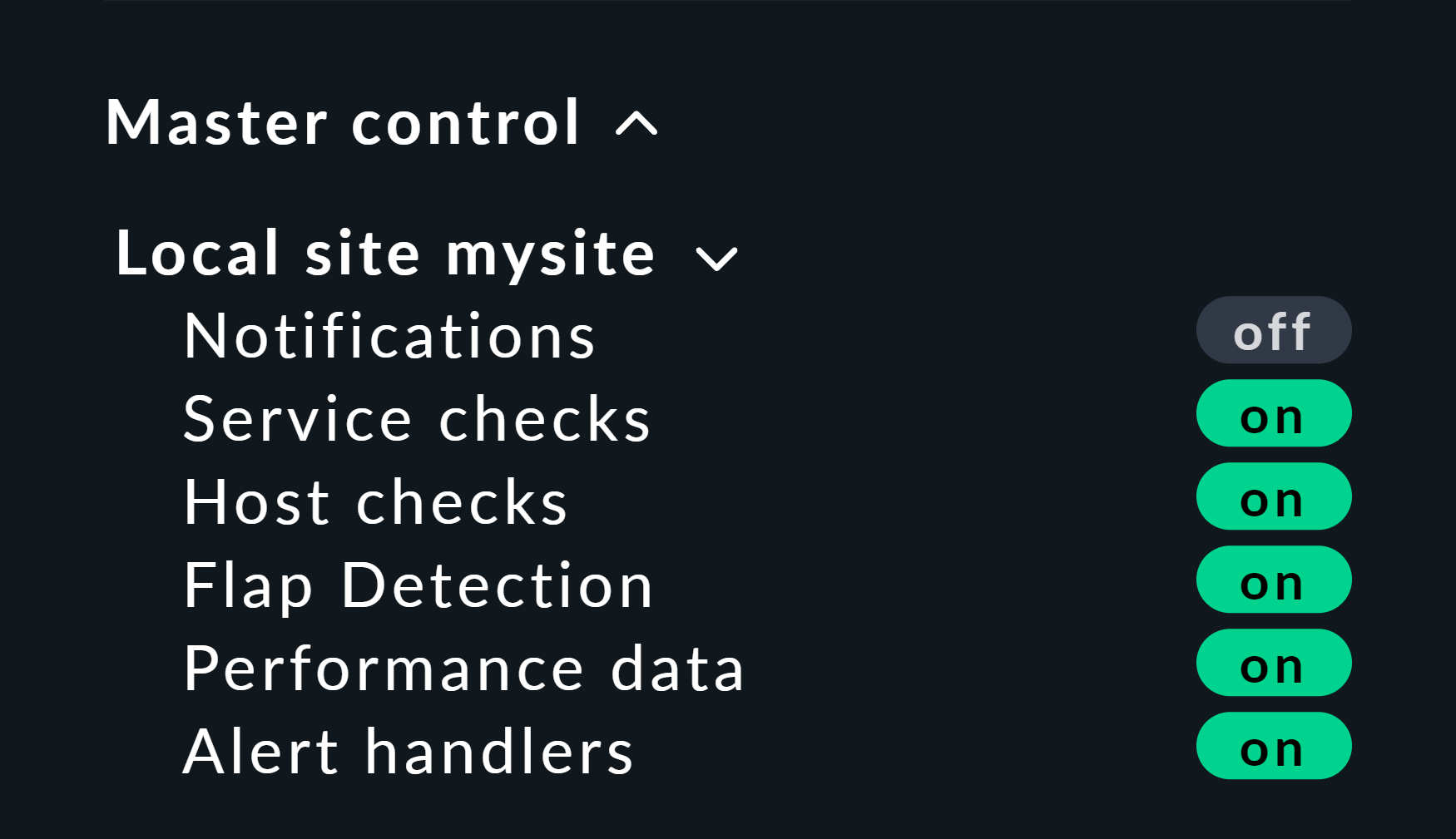
Voici une petite astuce utile : Si vous utilisez cette méthode, il est préférable de désactiver les vérifications actives pour les ordinateurs hôtes et services concernés, sinon, lors du prochain intervalle de vérification, ils reviendront immédiatement à leur état réel. Si vous êtes paresseux, effectuez simplement cette opération de manière globale via le snap-in « Master Control ». Mais n’oubliez surtout pas de la réactiver par la suite !
3.5. Groupes BI
Lors de la création de l'agrégation, nous avons brièvement abordé les possibilités disponibles pour le champ « Aggregation Groups ». Dans l'exemple, vous avez simplement confirmé l'Main suggérée ici. Vous êtes bien sûr entièrement libre dans l'attribution des noms, et vous pouvez également affecter une agrégation à plusieurs groupes.
Les groupes prennent toute leur importance lorsque le nombre d’agrégations dépasse ce que vous souhaitez afficher à l’écran. Pour accéder à un groupe, cliquez sur l’un des noms de groupe affichés sur la page « All aggregations » — dans notre exemple ci-dessus, il s’agit simplement de l’en-tête « Main ». Bien sûr, si vous ne disposez pour l’instant que de cette seule agrégation, cela ne changera pas grand-chose. Cependant, si vous y regardez de plus près, vous remarquerez que :
Le titre de la page s'appelle désormais « Aggregation group Main ».
L'en-tête du groupe « Main » a disparu.
Si vous souhaitez consulter cette vue plus souvent, il vous suffit de l'ajouter à vos favoris — de préférence avec l'élément « Bookmarks » dans la barre latérale.
3.6. De l'ordinateur hôte/service à l'agrégation
Une fois que vous avez configuré les agrégations BI, vous trouverez une nouvelle icône « ![]() » dans le menu contextuel de vos ordinateurs hôtes et services :
» dans le menu contextuel de vos ordinateurs hôtes et services :
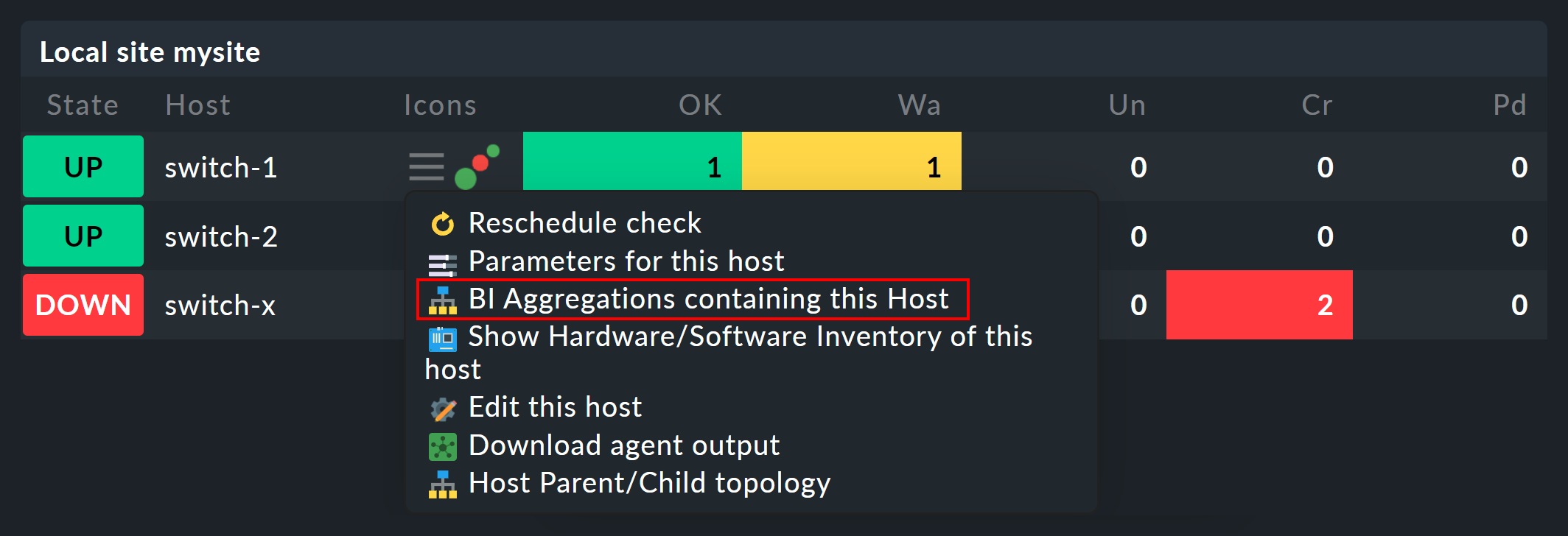
Cette icône vous permet d'accéder à la liste de toutes les agrégations dans lesquelles l'ordinateur hôte ou le service concerné est inclus.
4. Configuration, 2e partie : arborescences à plusieurs niveaux
Après ce premier aperçu de l'interface de suivi d'état BI, nous revenons à la configuration — car, bien sûr, vous ne pouvez pas vraiment impressionner qui que ce soit avec une agrégation BI aussi succincte.
Commencez par étendre l'arborescence d'un niveau, c'est-à-dire passer de deux niveaux (racine et feuilles) à trois niveaux (racine, niveau intermédiaire, feuilles). Pour ce faire, combinez votre nœud existant « Switches 1 & 2 » avec l'état de synchronisation horaire NTP pour former un nœud de niveau supérieur « Infrastructure ».
Mais une chose à la fois — tout d’abord, un aperçu du résultat :
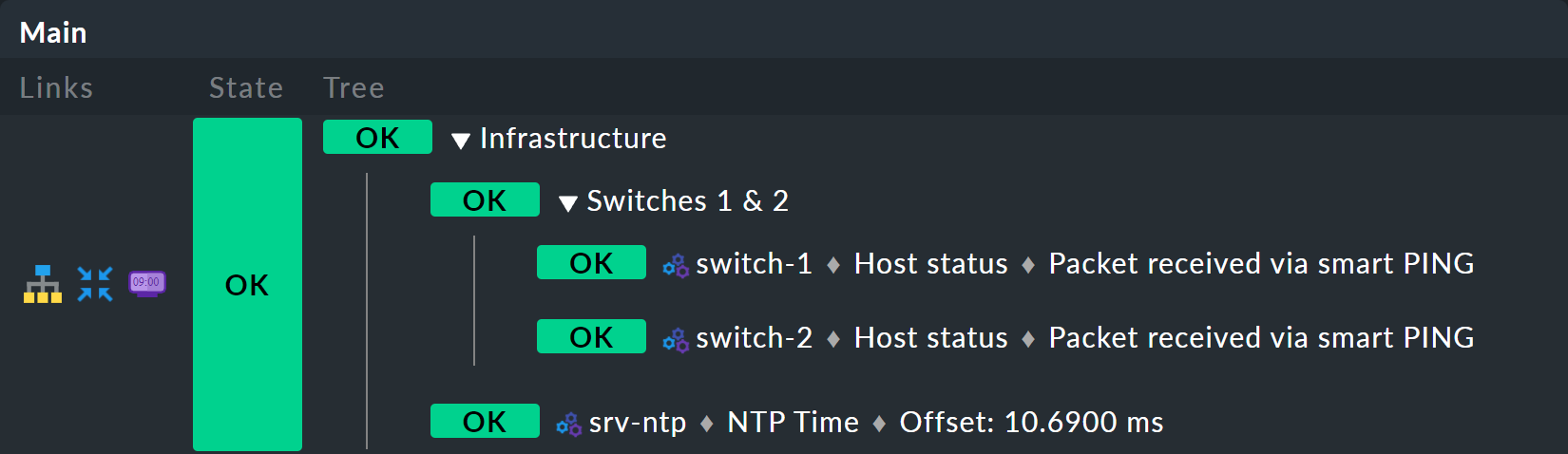
La condition préalable est qu’il existe un ordinateur hôte srv-ntp disposant d’un service nommé « NTP Time » :

Commencez par créer une règle BI dont le sous-nœud 1 reçoit la règle « Switches 1 & 2 », et dont le sous-nœud 2 reçoit directement le service NTP Time sur l’ordinateur hôte srv-ntp.
En haut de la règle, sélectionnez « infrastructure » comme ID de règle, et « Infrastructure » comme nom.
Il n’est pas nécessaire de saisir d’autres informations à ce stade :
C'est dans l'arborescence « Child Node Generation » que cela devient intéressant. La première entrée est désormais de type « Call a rule », et comme règle, choisissez celle que vous avez définie ci-dessus — afin de « suspendre » effectivement ces règles dans la sous-arborescence.
Le deuxième sous-nœud est de type « State of a service » ; choisissez ici votre service « NTP Time »
(veillez à respecter l'orthographe exacte, y compris les majuscules et les minuscules) et le service « NTP Time » par expression régulière :
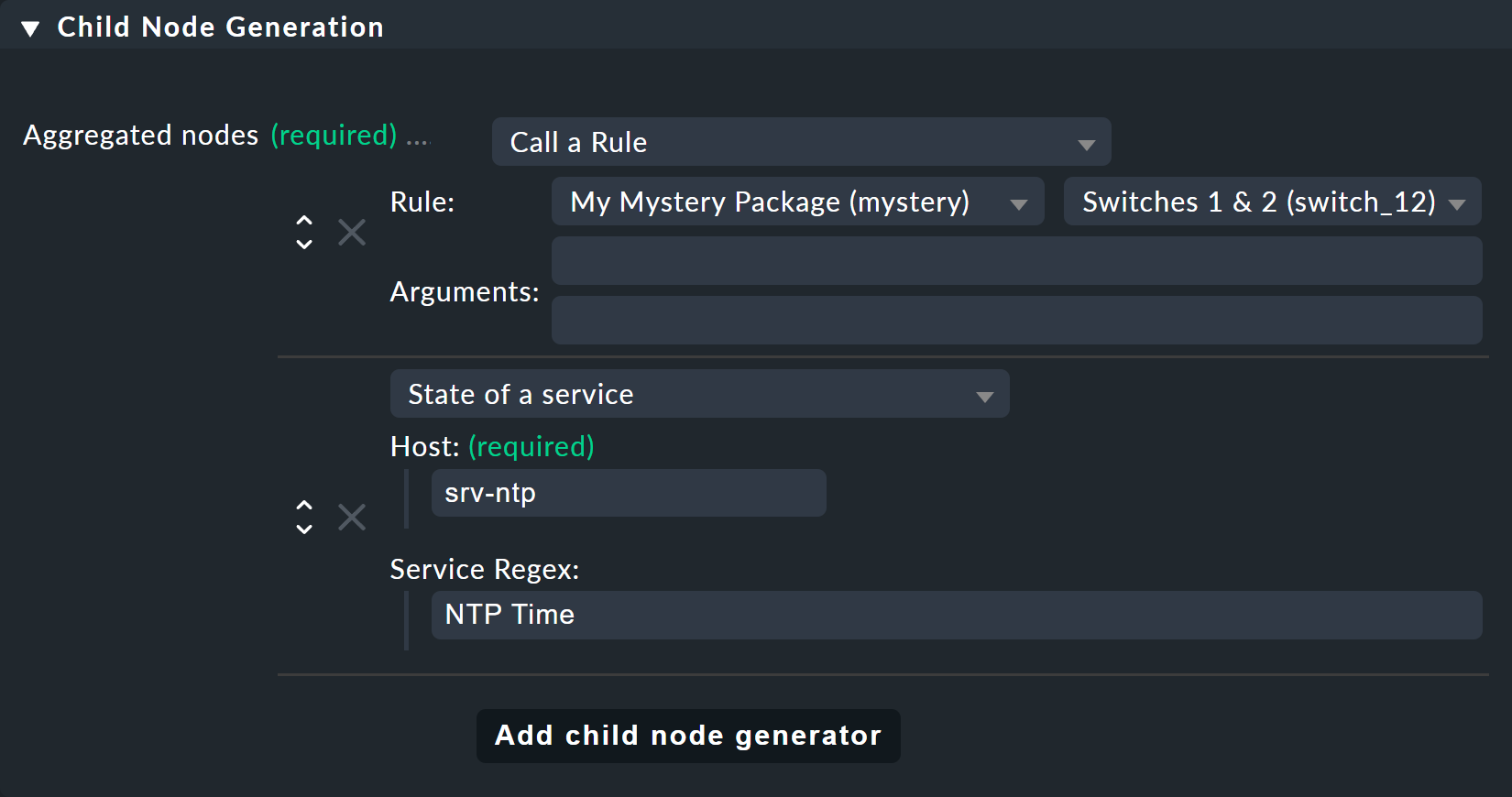
Cette fois-ci, définissez l'Aggregation Function dans la troisième case sur Worst — i.e., take the worst state of all nodes.
Dans cette fonction, l'état du nœud est donc dérivé de l'état le plus défavorable d'un service situé en dessous.
Dans ce cas, si NTP Time passe à CRIT, le nœud passe également à CRIT.
Bien sûr, pour rendre visible le nouvel arbre, plus grand, vous devrez à nouveau créer une agrégation. Il est préférable de simplement modifier l'agrégation existante afin que la nouvelle règle soit désormais utilisée :
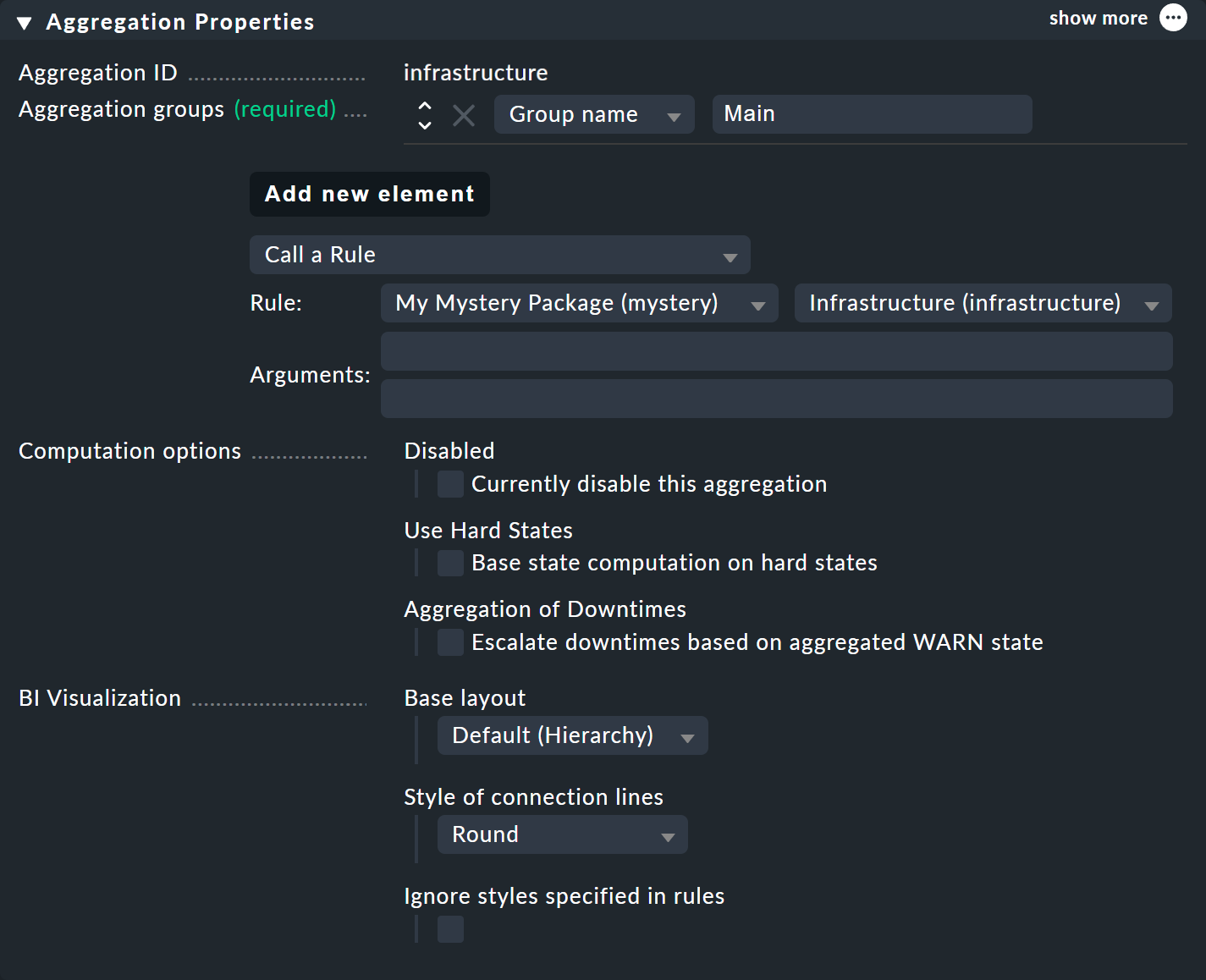
De cette manière, vous conservez une seule agrégation, qui se présente alors comme ci-dessous (cette fois-ci, les deux commutateurs sont de nouveau sur OK) :
5. La BI en pratique, 2e partie : autres modes d'affichage
5.1. Introduction
Maintenant que vous disposez d’une arborescence un peu plus intéressante, vous pouvez vous familiariser davantage avec les différentes options d’affichage proposées par Checkmk. Le point de départ pour celles-ci est l’option « Modify display options », accessible via le menu « Display ». Cela ouvre une case contenant diverses options. Le contenu de cette case correspond toujours aux éléments affichés sur la page. Dans le cas de la BI, vous disposez actuellement de quatre options :
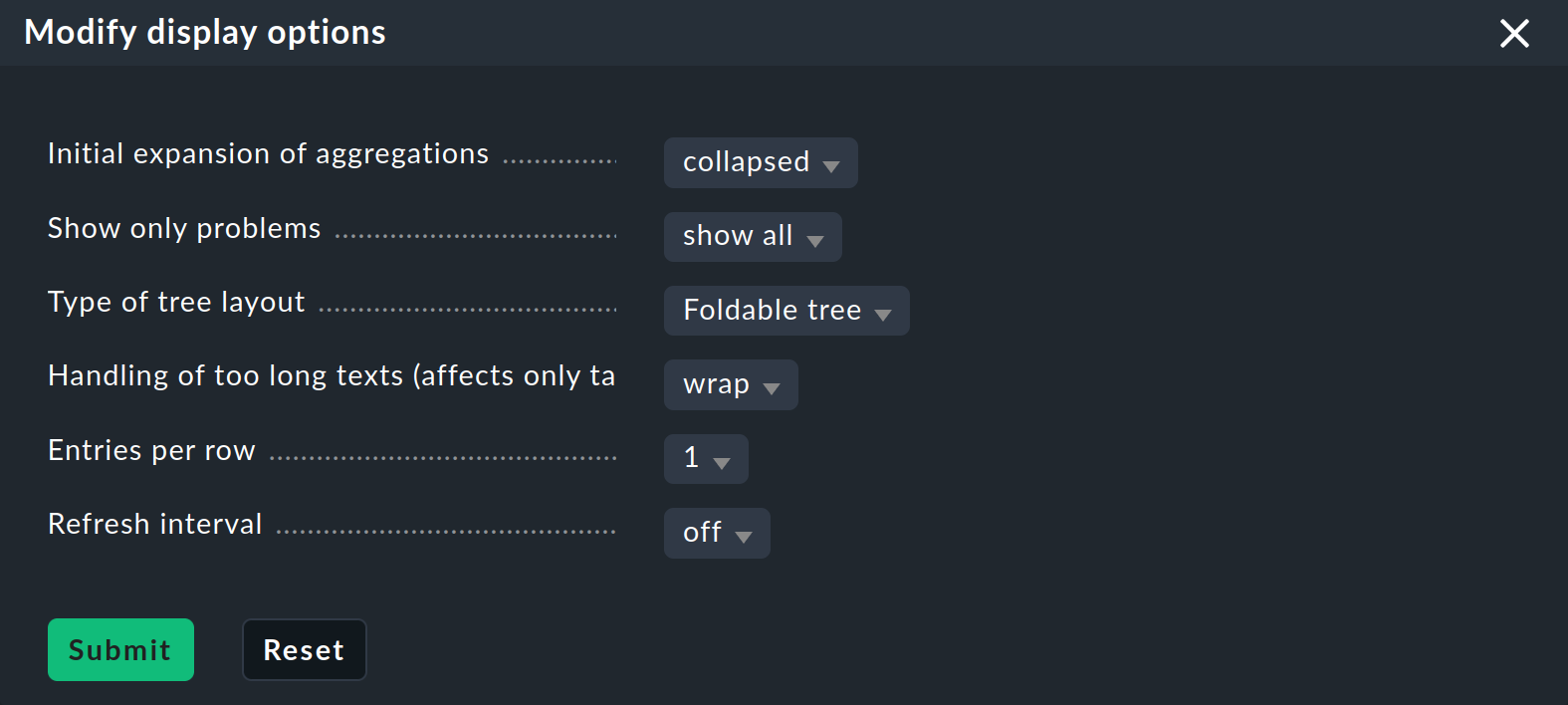
Développer ou réduire instantanément les arborescences
Si vous affichez non pas une seule agrégation, mais plusieurs, le paramètre « Initial expansion of aggregations » s’avère utile. Vous définissez ici le degré de déploiement des arborescences lors de leur premier affichage. Le choix va de « fermé » (collapsed) aux trois premiers niveaux, jusqu’à « complètement ouvert » (complete).
Afficher uniquement les problèmes
Si vous activez l'option « Show only problems », seules les branches qui ne sont pas en état « OK » seront affichées dans les arborescences. Le résultat ressemblera alors à ceci :

Types d'affichage des arborescences
Sous l'élément « Type of tree layout », vous trouverez plusieurs types d'affichage alternatifs pour l'arborescence. L'un d'entre eux s'appelle « Table: top down » et se présente comme suit :
L'affichage « Boxes » permet un gain de place considérable, en particulier si vous souhaitez visualiser de nombreux agrégats simultanément. Ici, chaque nœud est représenté par une case colorée qui peut être développée d'un simple clic. La structure arborescente n'est plus visible, mais vous pouvez rapidement cliquer pour localiser un problème, ce qui ne nécessite qu'un espace d'affichage minimal. Dans l'exemple ci-dessous, les cases sont entièrement développées :

5.2. Autres options
Enfin, vous pouvez définir une Refresh interval de 30, 60 ou 90 secondes et spécifier le nombre de colonnes via Entries per row.
5.3. Visualisation des agrégations BI
Outre les représentations tabulaires, Checkmk maîtrise également la visualisation des agrégations BI.
Vous pouvez ainsi visualiser les agrégations sous un angle nouveau, et parfois plus clair.
Vous trouverez l’BI Visualization via ![]() dans la vue des agrégations standard.
dans la vue des agrégations standard.

Vous pouvez déplacer librement l’arborescence en cliquant sur l’arrière-plan et zoomer sur l’ensemble de l’affichage à l’aide de la molette de la souris. Dès que le pointeur de la souris survole un nœud individuel, vous obtenez les informations d’état associées à ce nœud via une fenêtre contextuelle. Utilisez la molette de la souris pour zoomer sur la longueur des branches de l’arborescence.
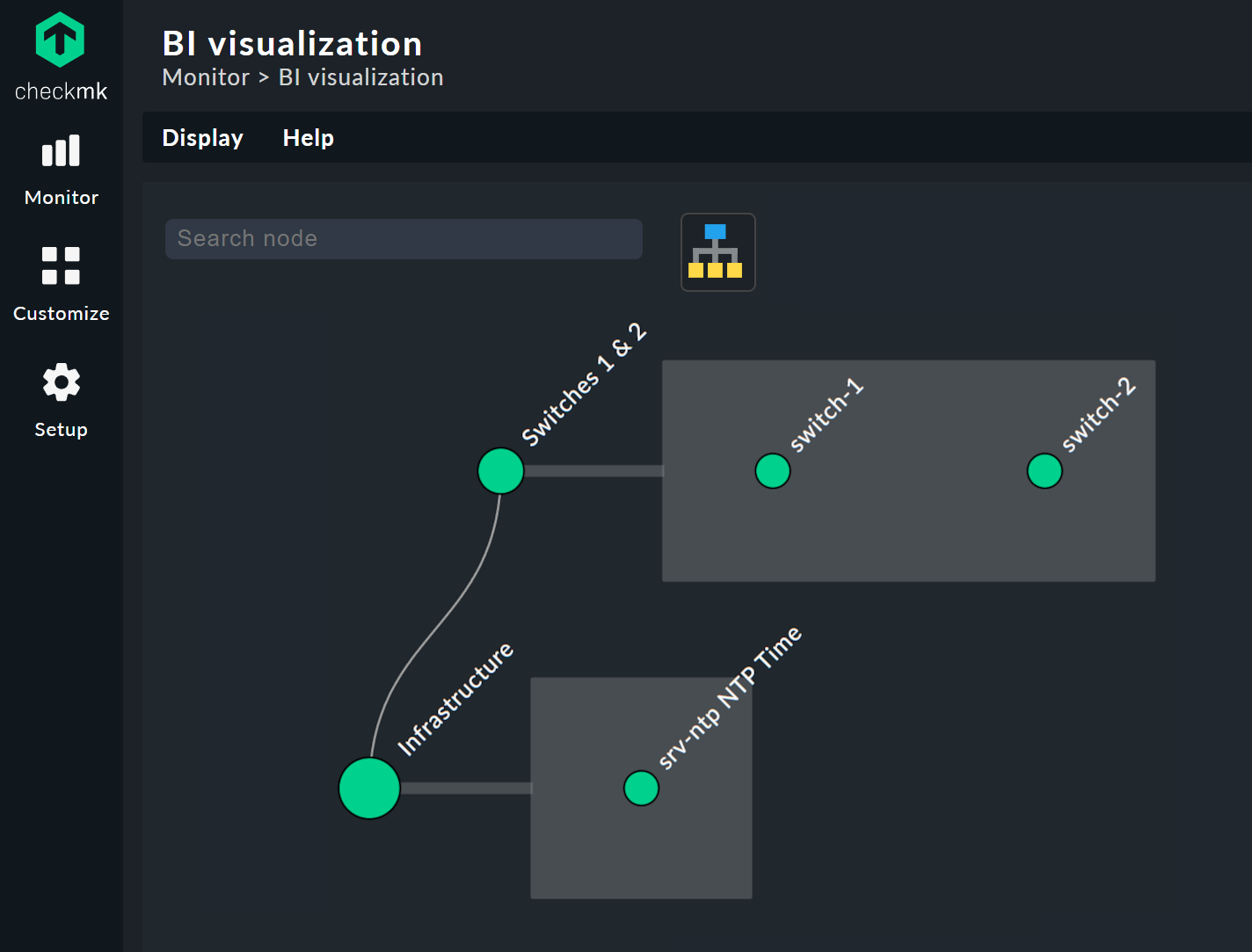
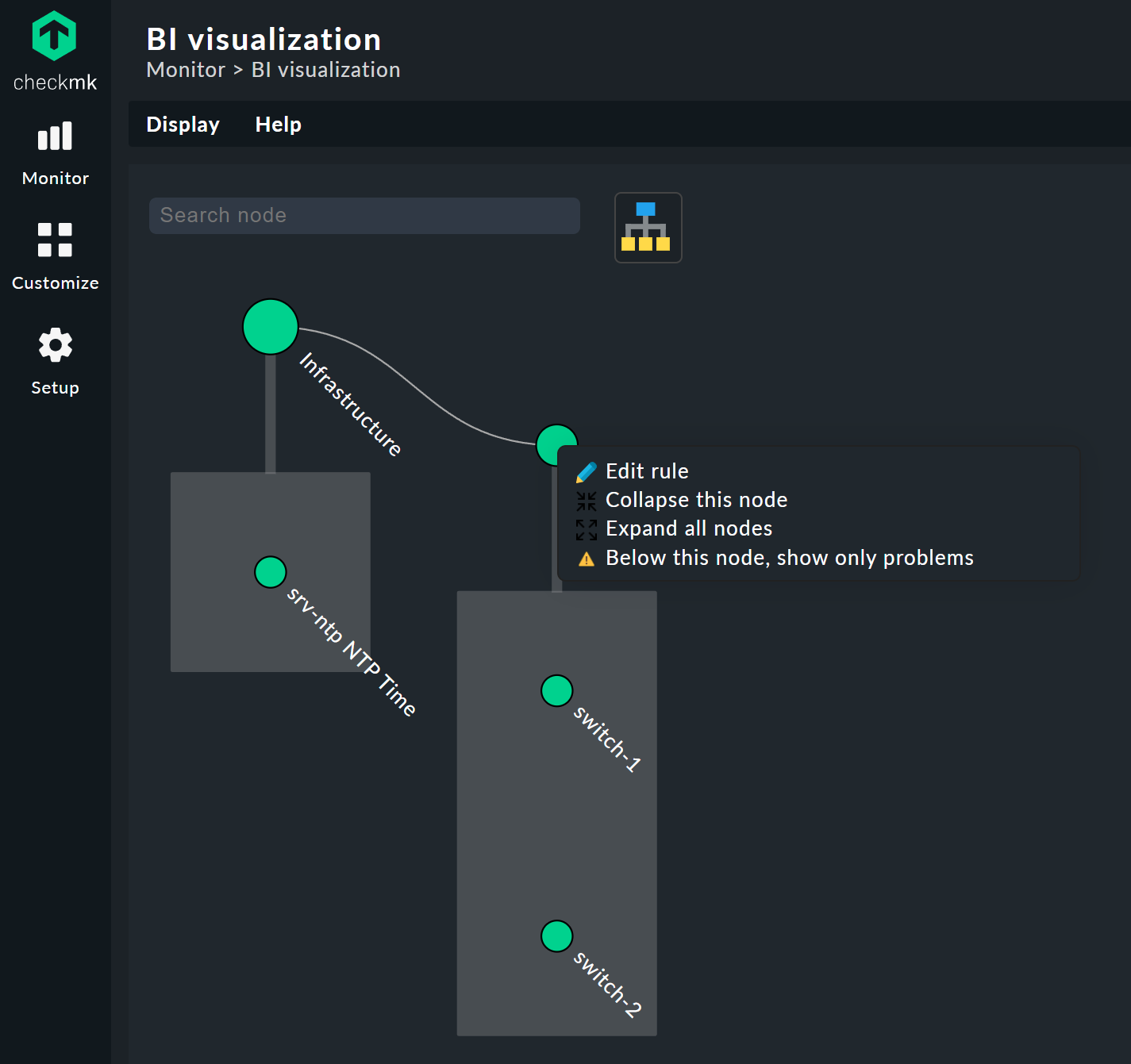
Cliquer sur les nœuds feuilles vous amène directement aux vues détaillées de l’ordinateur hôte ou du service. Un clic droit sur les autres nœuds — selon le type de nœud — donne accès aux options d’affichage et, par exemple, à la règle responsable elle-même — Edit rule dans l’image ci-dessous.
Personnalisation de l'affichage
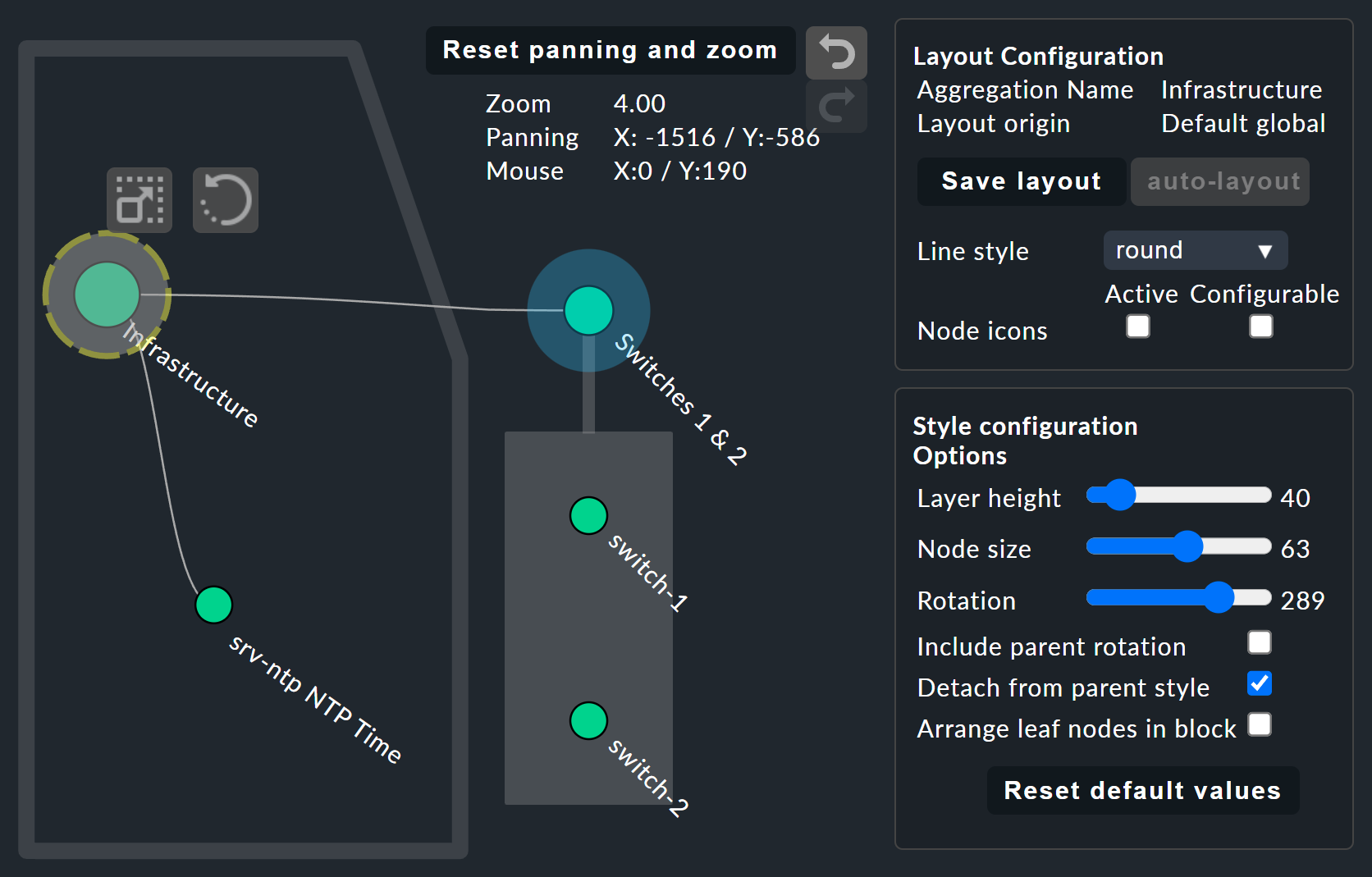
Les choses deviennent vraiment intéressantes avec l’Layout Designer, qui s’ouvre via l’![]() en haut, à côté du champ de recherche.
Tout d’abord, vous verrez deux nouveaux éléments — l’Layout Configuration, ainsi que deux nouvelles icônes à la racine —
en haut, à côté du champ de recherche.
Tout d’abord, vous verrez deux nouveaux éléments — l’Layout Configuration, ainsi que deux nouvelles icônes à la racine — ![]() et
et ![]() .
.
Dans une configuration, vous pouvez choisir entre différents types de lignes et activer l’option « Node icons ».
Cela affichera les icônes que vous pouvez spécifier dans les règles pour les agrégations BI dans la section « Aggregation Function »
(accessible directement via le menu contextuel du nœud).
À l’aide des icônes « ![]() » et «
» et « ![]() », l’arborescence peut être visualisée, puis pivotée ou redimensionnée en longueur et en largeur par glisser-déposer.
D’autres options d’affichage apparaissent également dans la case « Style configuration ».
Vous pouvez trouver celles qui conviennent le mieux à vos besoins en essayant simplement les différentes options disponibles.
», l’arborescence peut être visualisée, puis pivotée ou redimensionnée en longueur et en largeur par glisser-déposer.
D’autres options d’affichage apparaissent également dans la case « Style configuration ».
Vous pouvez trouver celles qui conviennent le mieux à vos besoins en essayant simplement les différentes options disponibles.
Les possibilités de personnalisation les plus étendues se trouvent dans les menus contextuels des nœuds, qui, en mode concepteur, proposent quatre affichages différents de la hiérarchie à partir de ce nœud :
Hierarchical style : le paramètre standard avec une hiérarchie simple.
Radial style : un format circulaire avec un secteur personnalisable du cercle.
Leaf-Nodes Block style : les nœuds feuilles sont affichés sous forme de groupe sur fond gris.
Free-Floating style : une mise en page dynamique avec des options telles que l'attraction, l'espacement et la longueur des branches.
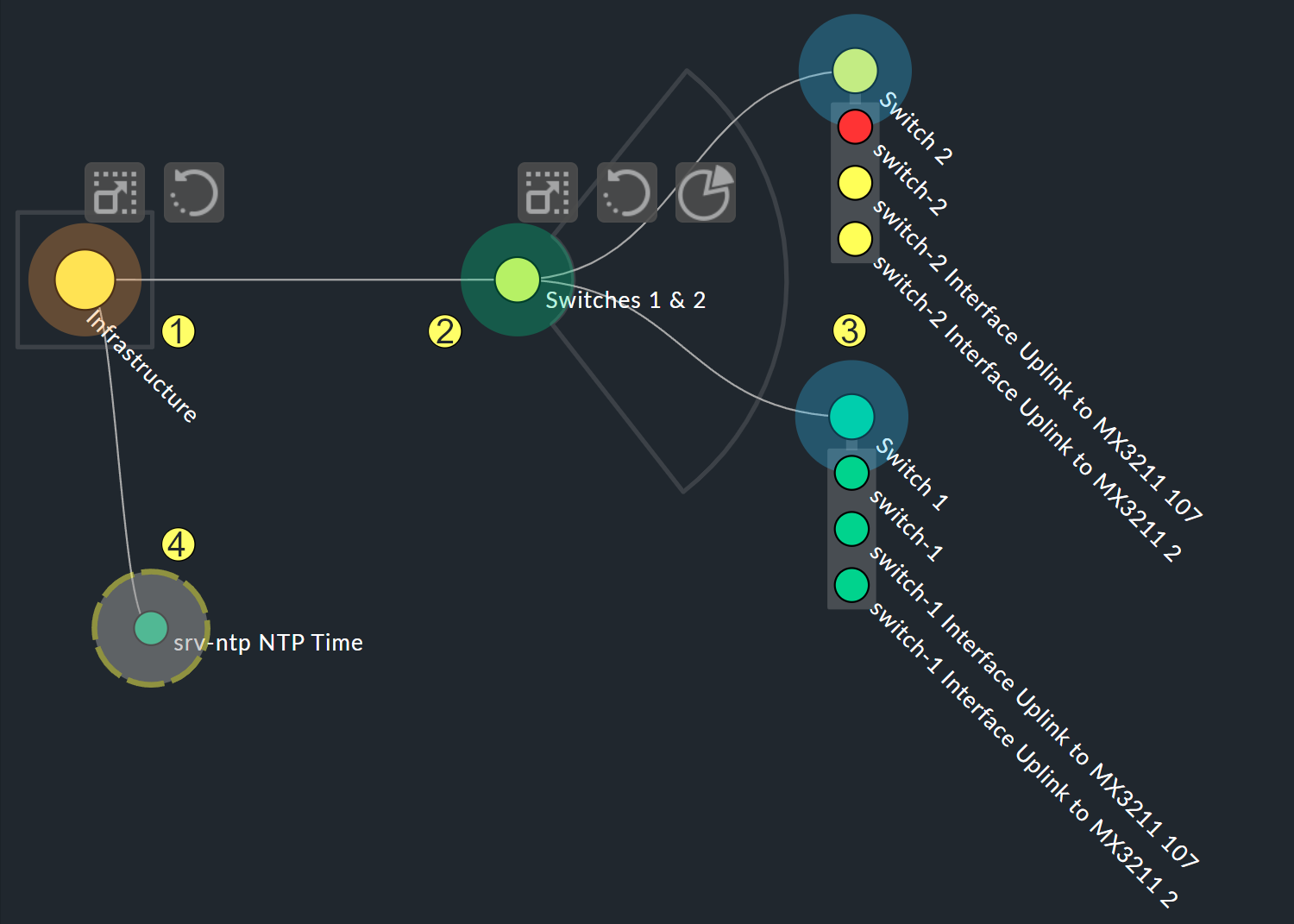
Les nœuds auxquels un style a été attribué peuvent être placés n'importe où.
Les options disponibles varient également en fonction du style : avec l'option Radial style, une troisième icône d'![]() apparaît au niveau du nœud racine, que vous pouvez utiliser pour limiter l'affichage à un secteur du cercle.
apparaît au niveau du nœud racine, que vous pouvez utiliser pour limiter l'affichage à un secteur du cercle.
Avec l’option « Detach from parent style », vous pouvez dissocier le style d’un nœud de celui de son nœud parent supérieur, puis configurer ces sous-nœuds différemment et les positionner librement. L’option « Include parent rotation » est également conçue de manière similaire pour vous permettre d’inclure ou d’exclure des nœuds parents lors de la rotation.
Ces options de style sont pour l’essentiel toutes intuitives — seule l’option « Free-Floating style » nécessite quelques explications. Il s’agit d’un système d’attraction et de répulsion, comme vous le connaissez dans les simulations gravitationnelles.
Center force strength |
Centre de gravité des nœuds. |
Repulsion force leaf |
Intensité de l'effet de répulsion des feuilles sur les autres nœuds. |
Repulsion force branches |
Intensité de la répulsion exercée par les nœuds sur les autres nœuds de la même branche. |
Link distance leaf |
Distance idéale entre le nœud feuille et le nœud précédent. |
Link distance branches |
Distance idéale entre le nœud de branche et le nœud précédent. |
Link strength |
Intensité avec laquelle la distance idéale est appliquée. |
Collision box leaf |
Taille de la zone du nœud feuille qui repousse les autres nœuds. |
Collision box branch/leaf |
Taille de la zone du nœud de branche qui repousse les autres nœuds. |
L'image suivante montre une branche dans l'Free-Floating style : les positions des feuilles individuelles sont déterminées de manière dynamique en fonction des options spécifiées.
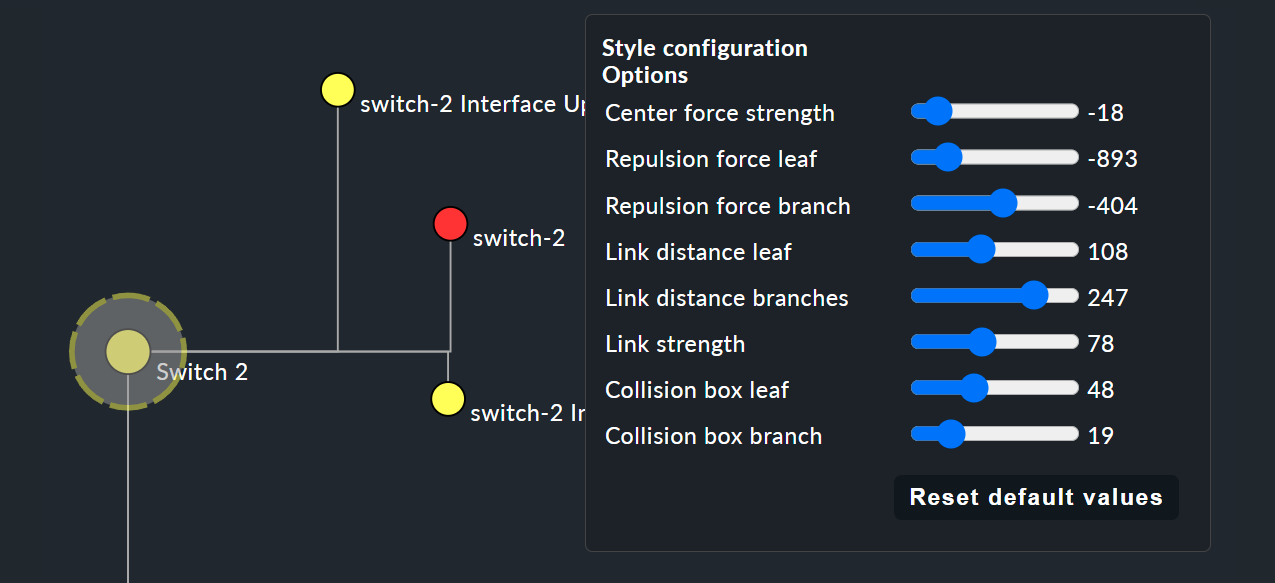
Spécification des styles de mise en page pour les règles BI
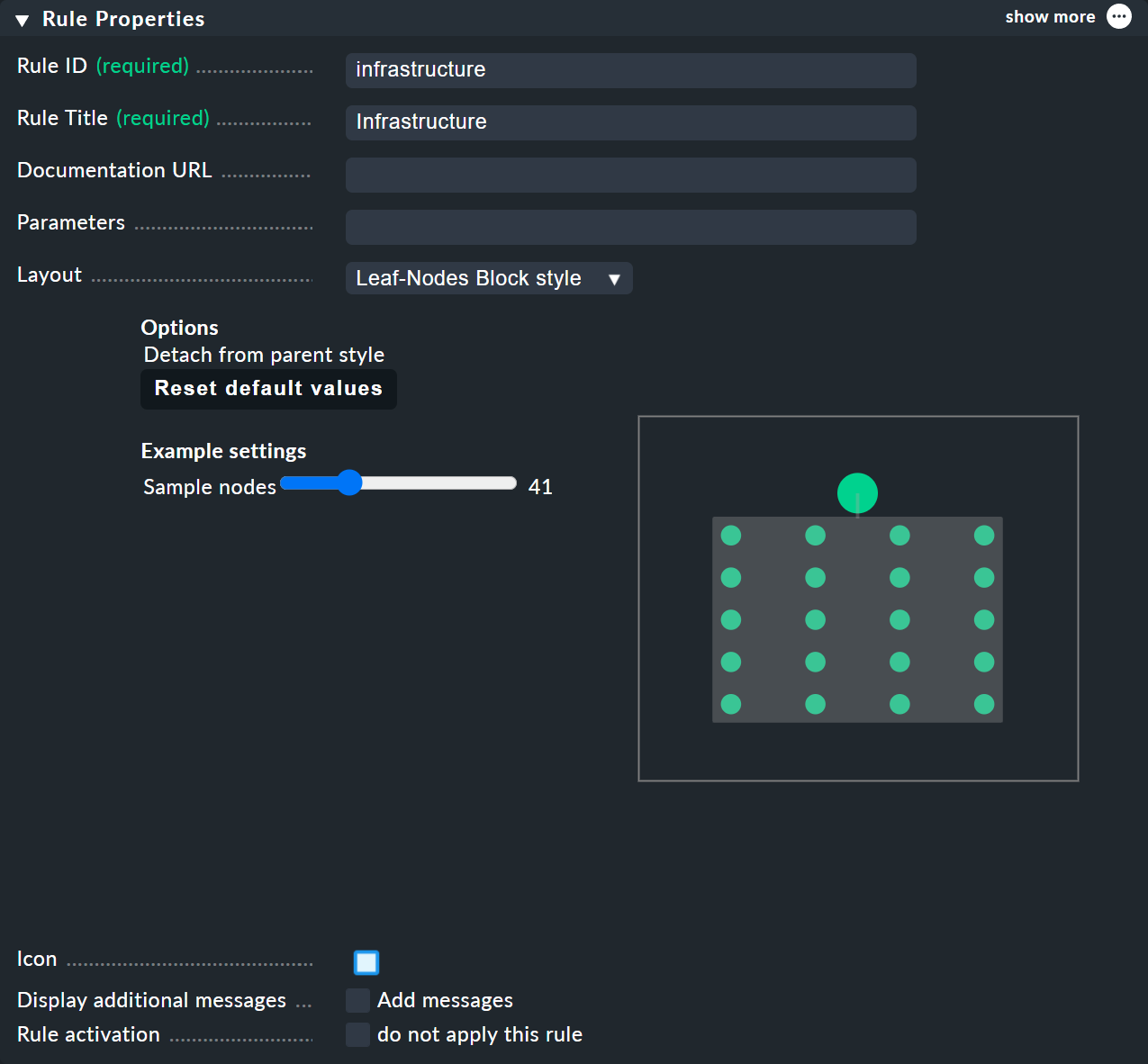
Pour les règles BI — auxquelles vous pouvez accéder depuis le menu contextuel des nœuds — dans le menu de l'Rule Properties vous pouvez attribuer les dispositions « Hierarchical », « Radial » ou « Leaf-Nodes Block », et définir de même les options correspondantes.
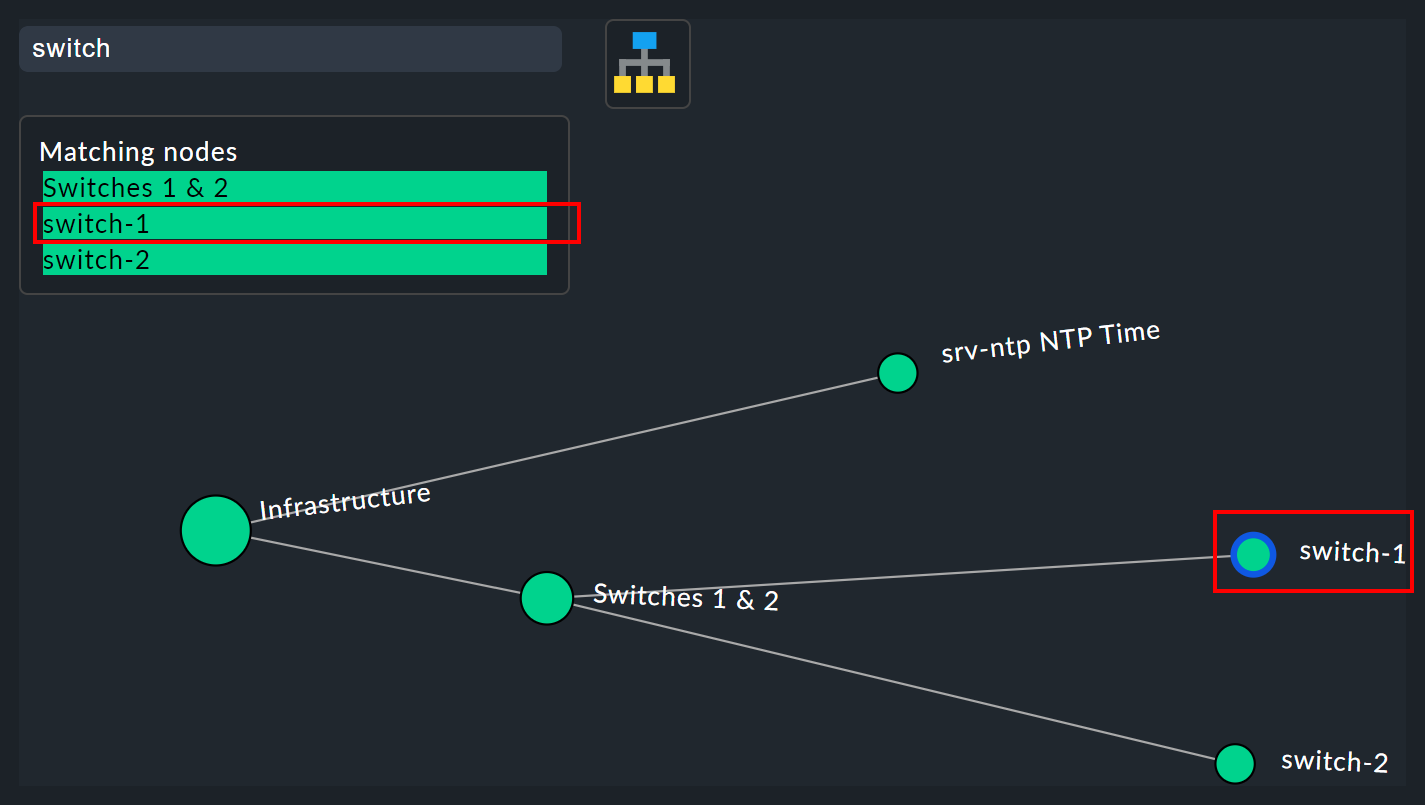
La fonction de recherche
La fonction de recherche est d’une aide précieuse avec les arborescences volumineuses. Dans le champ de recherche de l’Search node, il vous suffit de saisir une partie du nom du nœud souhaité pour obtenir une liste de résultats directement et en temps réel. Si vous passez ensuite la souris sur cette liste de suggestions, le nœud de l’arborescence situé sous le pointeur de la souris sera mis en évidence par une bordure bleue — cela facilite une première orientation. Cliquer sur un nœud de la liste centrera l’arborescence sur celui-ci. De cette manière, même dans les affichages comportant des centaines de nœuds, vous pouvez rapidement trouver la bonne section dans l’arborescence.
6. Configuration, 3e partie : variables, modèles, recherches
6.1. Une configuration plus intelligente
Poursuivons la configuration. Il est maintenant temps de passer aux choses sérieuses. Jusqu’à présent, l’exemple était si simple qu’il était possible de créer une liste individuelle de tous les objets de l’agrégation BI sans difficulté. Mais que se passe-t-il si les choses se compliquent ? Que faire si vous souhaitez définir de nombreuses dépendances récurrentes qui sont identiques ou similaires ? Que faire si une application comprend non pas un seul, mais plusieurs instances ? Que faire si vous souhaitez fusionner des centaines de services individuels d’une base de données en un seul nœud BI ?
Pour répondre à de telles exigences, vous aurez besoin de méthodes de configuration plus puissantes. Et c’est précisément ce qui distingue Checkmk BI des autres outils — et malheureusement, la courbe d’apprentissage est ici un peu plus raide. C’est également la raison pour laquelle Checkmk BI ne se prête pas à une configuration par « glisser-déposer ». Cependant, une fois que vous aurez découvert toutes ces possibilités, vous ne voudrez certainement plus vous en passer.
6.2. Paramètres
Commençons par les paramètres. Prenons la situation suivante : vous souhaitez non seulement savoir si les deux commutateurs sont UP, mais également connaître l’état des deux ports responsables de la liaison montante. D’une manière générale, cela dépend des quatre services suivants :
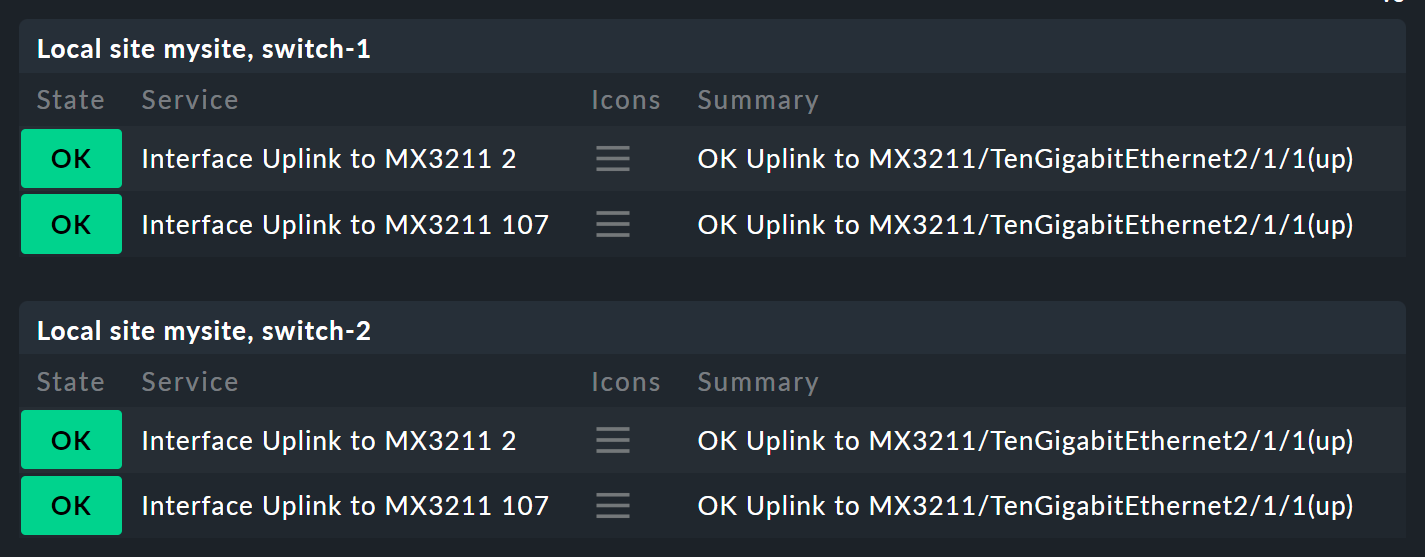
Le nœud Switch 1 & 2 doit désormais être étendu pour remplacer les deux états d’hôte des commutateurs 1 et 2, de sorte que chacun dispose d’un sous-nœud indiquant l’état d’hôte et les deux interfaces de liaison montante. Ces deux sous-nœuds devraient être Switch 1 ou Switch 2.
En fait, vous aurez désormais besoin de deux nouvelles règles — une pour chaque commutateur.
Il est préférable de procéder en créant une nouvelle règle d’switch, et de la doter d’un paramètre.
Ce paramètre est une variable que vous appelez lorsque vous appelez la règle depuis le nœud parent — qui, ici, peut être fournie par l’ancienne règle Switch 1 & 2.
Dans cet exemple, vous pouvez simplement passer soit un 1, soit un 2.
Le paramètre reçoit un nom que vous pouvez choisir librement.
Prenons ici, par exemple, le nom NUMBER.
L’orthographe en majuscules ici est purement arbitraire,
et si vous trouvez les minuscules plus esthétiques, vous êtes également libre de les utiliser.
L'en-tête de la règle ressemblera alors à ceci :
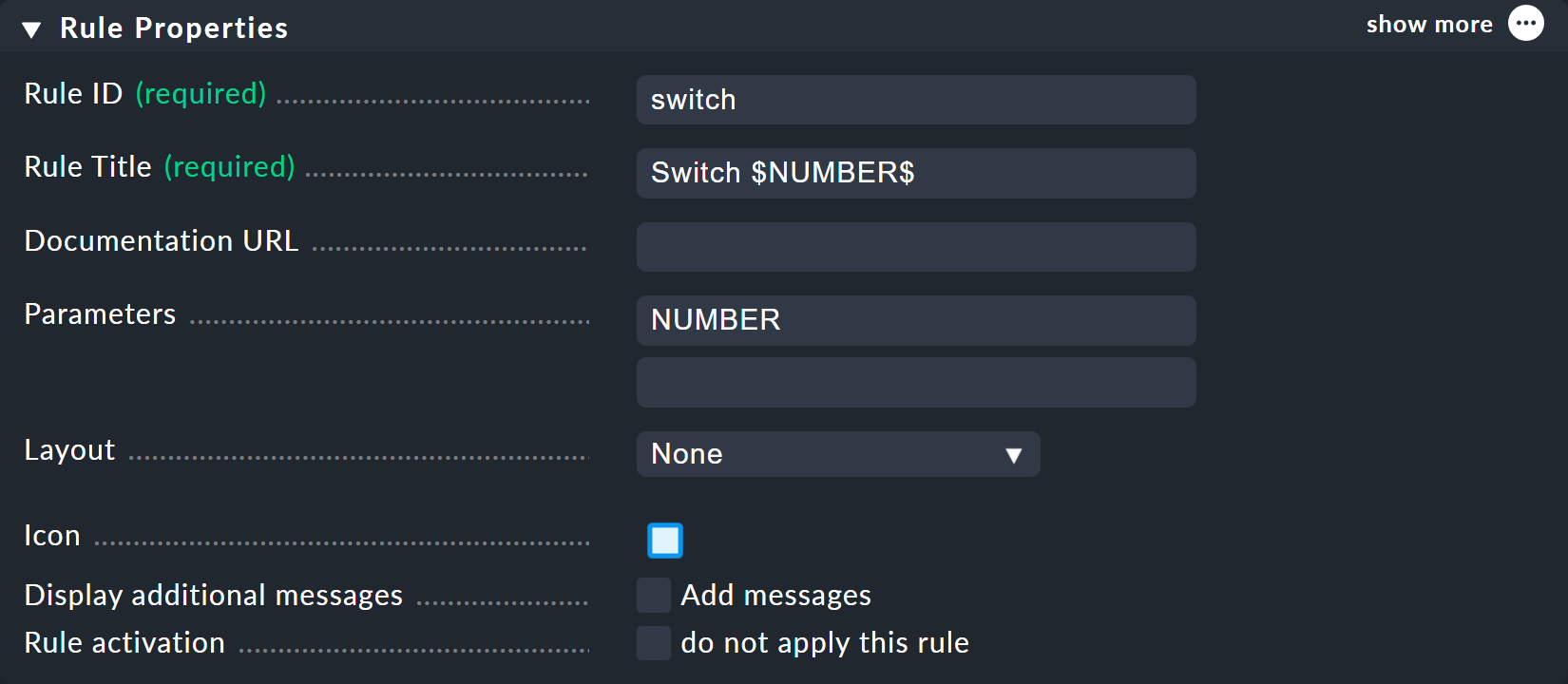
Vous pouvez choisir switch comme ID pour la nouvelle règle.
Dans le champ « Parameters », saisissez simplement le nom de la variable : NUMBER.
Il est également important que la variable soit utilisée dans l’Rule Title de la règle afin que les deux nœuds ne s’appellent pas simplement switch et aient ainsi le même nom.
Lors de l’utilisation de la variable, un signe dollar est ajouté au début et à la fin — comme c’est souvent le cas dans Checkmk.
En conséquence, les deux nœuds s’appelleront alors Switch 1 et Switch 2.
La correspondance de préfixe est le comportement par défaut pour les noms du service
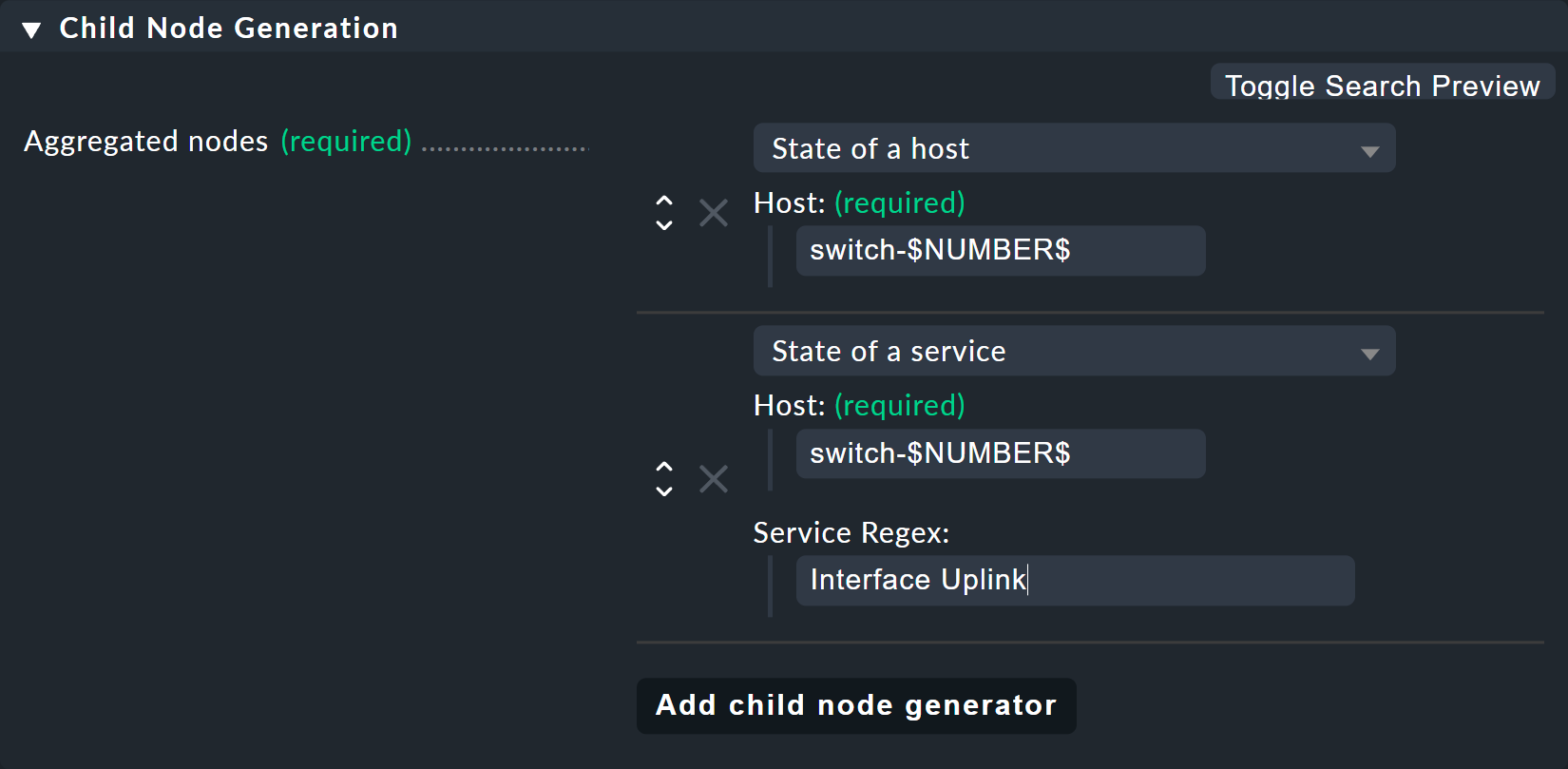
Pour l’Child node generator, la première chose à faire est d’insérer l’état de l’ordinateur hôte.
Au lieu de 1 ou 2 dans le nom de domaine, vous pouvez simplement utiliser votre variable, là encore avec un $ au début et à la fin.
Il en va de même pour les noms de domaine des interfaces de liaison montante.
Et voici la deuxième astuce : comme vous pouvez le deviner d’après la courte liste de services ci-dessus, les services de la liaison montante portent des noms différents sur chaque commutateur.
Mais cela ne pose aucun problème, car BI interprète toujours le nom du service comme une correspondance de préfixe à l’aide d’expressions régulières, de manière tout à fait analogue aux règles de service bien connues.
Ainsi, en écrivant simplement Interface Uplink, vous capturez tous les services sur l'ordinateur hôte concerné qui commencent par Interface Uplink:
À propos : en ajoutant $, vous pouvez désactiver le comportement lié au préfixe.
Dans les expressions régulières, $ signifie « Le texte doit s’arrêter ici ».
Ainsi, Interface 1$ ne saisit qu’Interface 1, et non pas, par exemple, Interface 10.
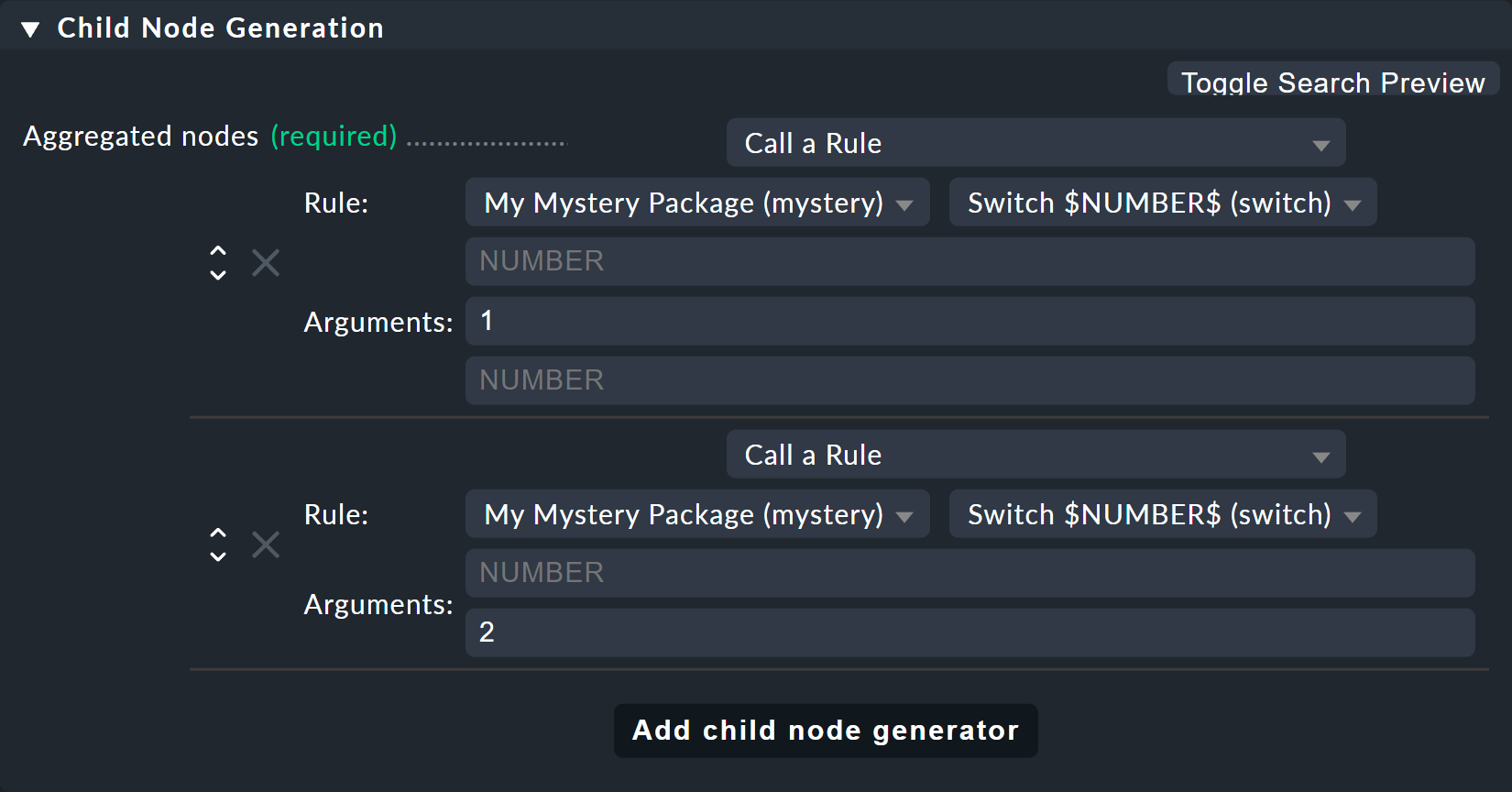
Modifiez maintenant l'ancienne règle Switch 1 & 2 de sorte qu’au lieu des états d’ordinateurs hôtes, cette nouvelle règle ne soit invoquée qu’une seule fois pour chacun des deux commutateurs.
Et c’est également ici que les valeurs 1 et 2 sont fournies comme paramètres pour la variable NUMBER :
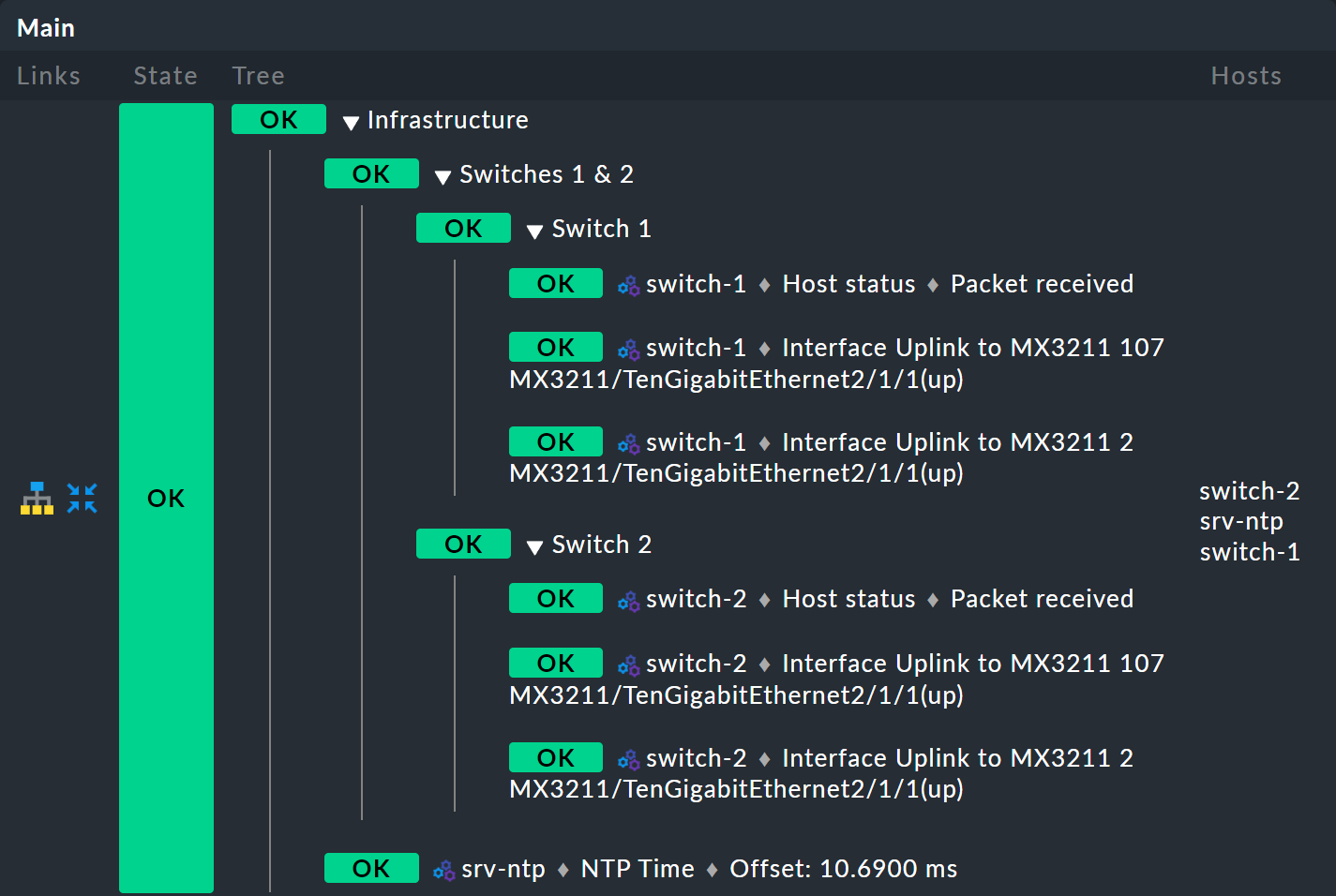
Et voilà — vous disposez désormais d’un joli arbre à trois niveaux :
6.3. Expressions régulières, objets manquants
Le sujet des expressions régulières mérite à nouveau qu’on s’y attarde. Lors de la correspondance du nom du service, nous avons tacitement sous-entendu au début qu’il ne s’agissait en principe que d’expressions régulières. Comme nous venons de le mentionner, il existe une correspondance de préfixe.
Ainsi, dans un nœud BI, si, par exemple, vous spécifiez disk sous « nom du service »,
tous les services de l’ordinateur hôte en question commençant par Disk seront capturés.
Les principes suivants s'appliquent généralement :
Si un nœud fait référence à des objets qui n'existent pas (actuellement), ceux-ci sont simplement omis.
Si un nœud devient vide, il sera omis.
Si le nœud racine d'une agrégation est également vide, l'agrégation elle-même sera omise.
Cela vous semble peut-être un peu audacieux au premier abord, car n’est-il pas risqué d’omettre simplement, sans commentaire, des éléments qui devraient être présents ?
Eh bien, avec le temps, vous remarquerez à quel point ce concept est pratique, car cela vous permettra d'écrire des règles « intelligentes » capables de réagir à des situations très différentes. Existe-t-il un service qui n'est pas présent sur toutes les instances d'une application ? Pas de problème : il ne sera pris en compte que s'il est présent. Ou bien des ordinateurs hôtes ou des services peuvent-ils être temporairement retirés de la supervision ? Ils disparaissent alors simplement de BI sans entraîner d'erreurs ou autres. BI n’est pas là pour vérifier si votre configuration de supervision est complète !
Soit dit en passant, ce principe s’applique également aux services explicitement définis,
puisque ceux-ci n’existent pas réellement, les noms des services étant toujours considérés comme des expressions régulières,
même s’ils ne contiennent pas de caractères spéciaux tels que .*.
Il s’agit toujours automatiquement d’un modèle de recherche.
6.4. Création d’un nœud à la suite d’une recherche
Mais vous pouvez encore automatiser davantage et, surtout, réagir avec souplesse aux changements.
Reprenons l’exemple des deux serveurs d’applications srv-mys-1 et srv-mys-2 de l’exemple précédent.
Votre arborescence devrait continuer à s’étendre.
Le nœud Infrastructure devrait passer au niveau 2.
Et en tant que racine définitive, il devrait y avoir une règle intitulée The Mystery Application sous laquelle tout sera regroupé.
À côté de Infrastructure, il devrait y avoir un nœud nommé Mystery Servers.
Les deux serveurs « mystères » (pour l’instant) sont censés être regroupés sous ce nœud.
Dans chacun d’eux, quelques services génériques sont intégrés à l’agrégation.
Le résultat devrait ressembler à ceci :
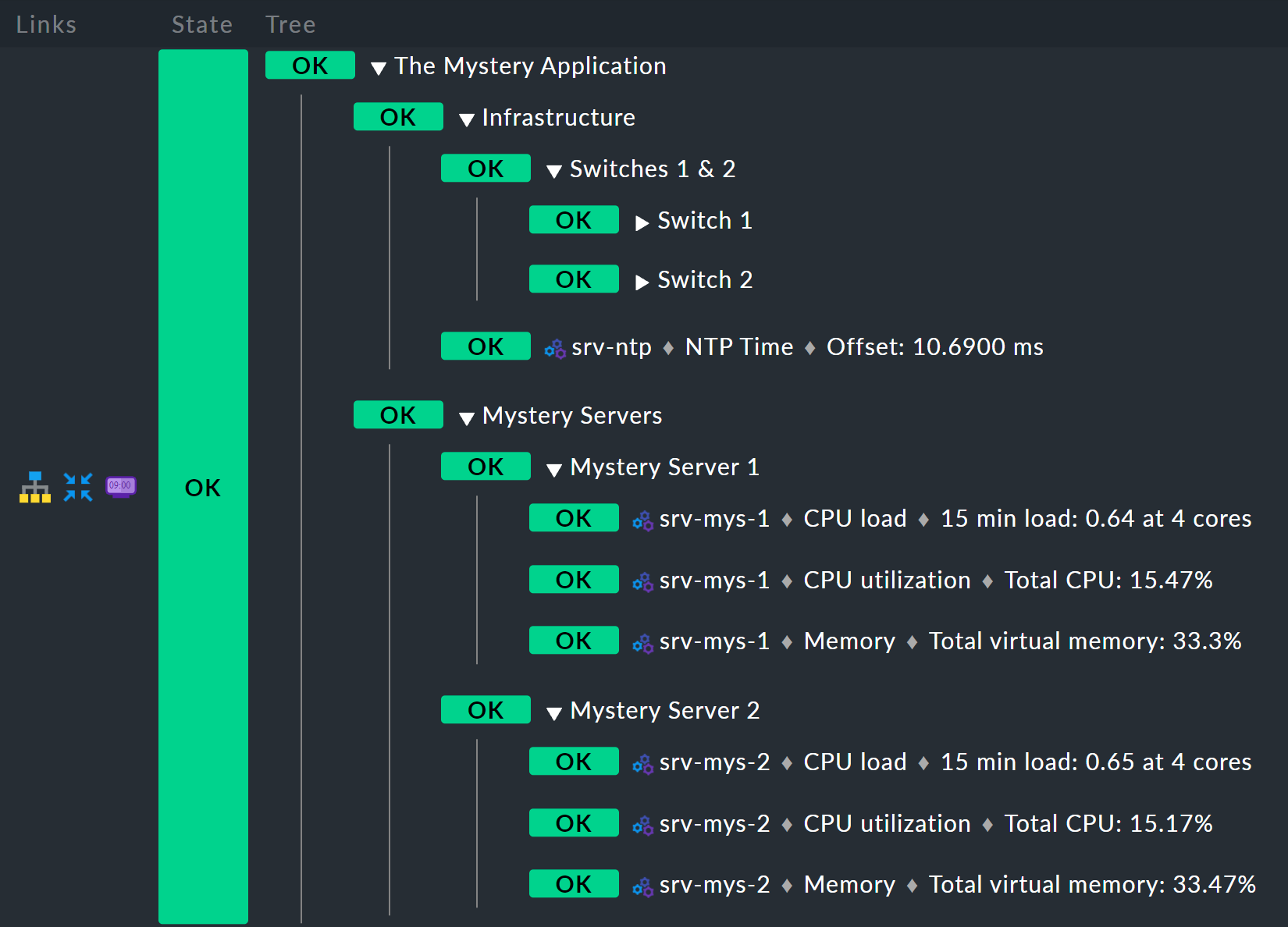
Règle de base : serveur mystérieux X
Commencez par le bas,
car c’est toujours la méthode la plus simple en BI.
Vous trouverez ci-dessous la nouvelle règle Mystery Server X.
Bien sûr, vous utilisez un paramètre afin de ne pas avoir besoin d’une règle distincte pour chaque serveur.
Vous pouvez à nouveau nommer ce paramètre NUMBER, par exemple.
Il devra ensuite prendre la valeur 1 ou 2.
Comme indiqué ci-dessus, vous devrez à nouveau saisir NUMBER dans l’en-tête à l’adresse Parameters.
Le générateur de nœuds enfants obtenu ressemblera à ceci :
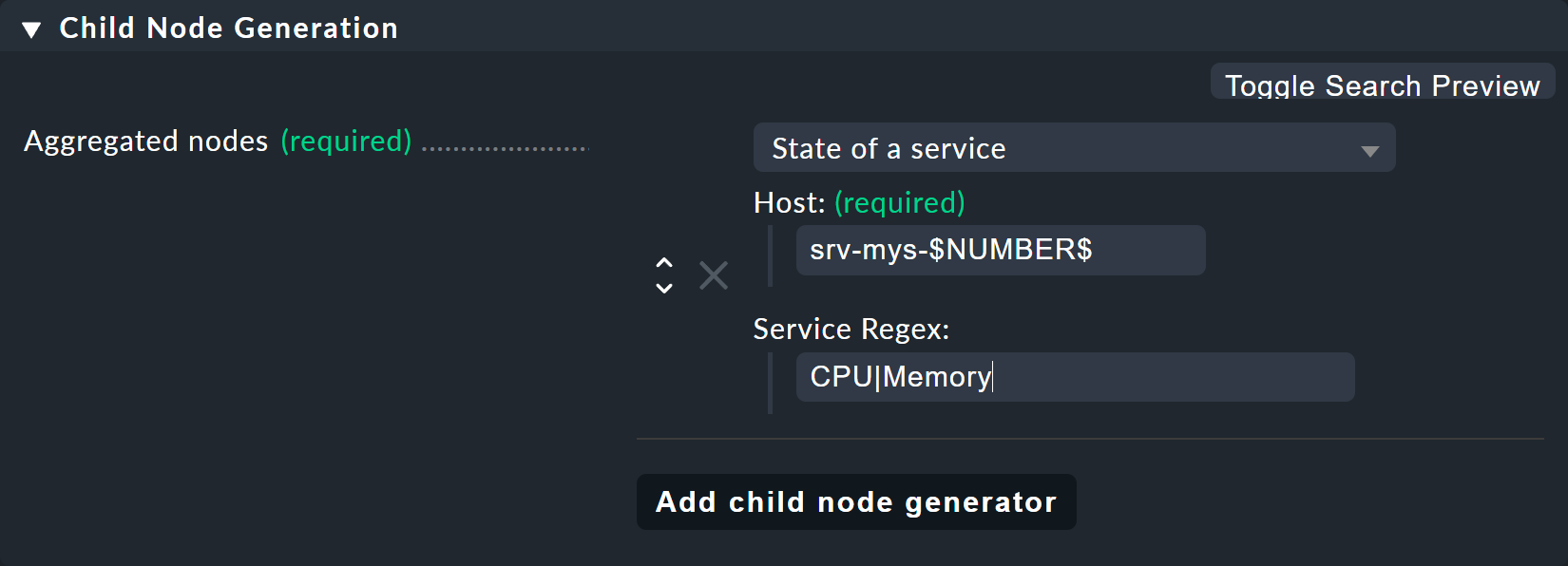
Ce qui suit est remarquable :
Le nom de domaine
srv-mys-$NUMBER$utilisera le nombre provenant du paramètre.Avec Service Regex, l'expression régulière sophistiquée
CPU|Memoryqui utilise une barre verticale pour autoriser des noms de service alternatifs (préfixes) est utilisée, et cela saisit tous les services commençant parCPUouMemory. Cela évite de dupliquer la configuration !
Soit dit en passant, cet exemple n’est bien sûr pas nécessairement parfait. Par exemple, l’état de l’ordinateur hôte lui-même n’a pas été enregistré du tout. Ainsi, si l’un des serveurs passe à DOWN, les services qui s’y trouvent deviendront obsolètes (passeront à stale), mais l’état restera OK, et l’agrégation ne « remarquera » pas cette défaillance. Si vous souhaitez connaître ce genre d’informations, vous devriez dans tous les cas enregistrer l’état de l’ordinateur hôte ainsi que les états de ses services.
Règle intermédiaire : serveurs mystères
Cette règle est intéressante : elle regroupe les deux serveurs mystères en un seul nœud. Il est désormais possible que le nombre de serveurs ne soit pas fixe, et qu’il y en ait parfois trois ou plus par la suite, ou bien qu’il y ait des dizaines d’instances dans l’application mystère, chacune avec un nombre différent de serveurs.
L'astuce réside dans le type de générateur de nœuds enfants « Create nodes based on a host search ». Celui-ci recherche les ordinateurs hôtes existants et crée des nœuds en fonction des ordinateurs trouvés. Voici à quoi cela ressemble :
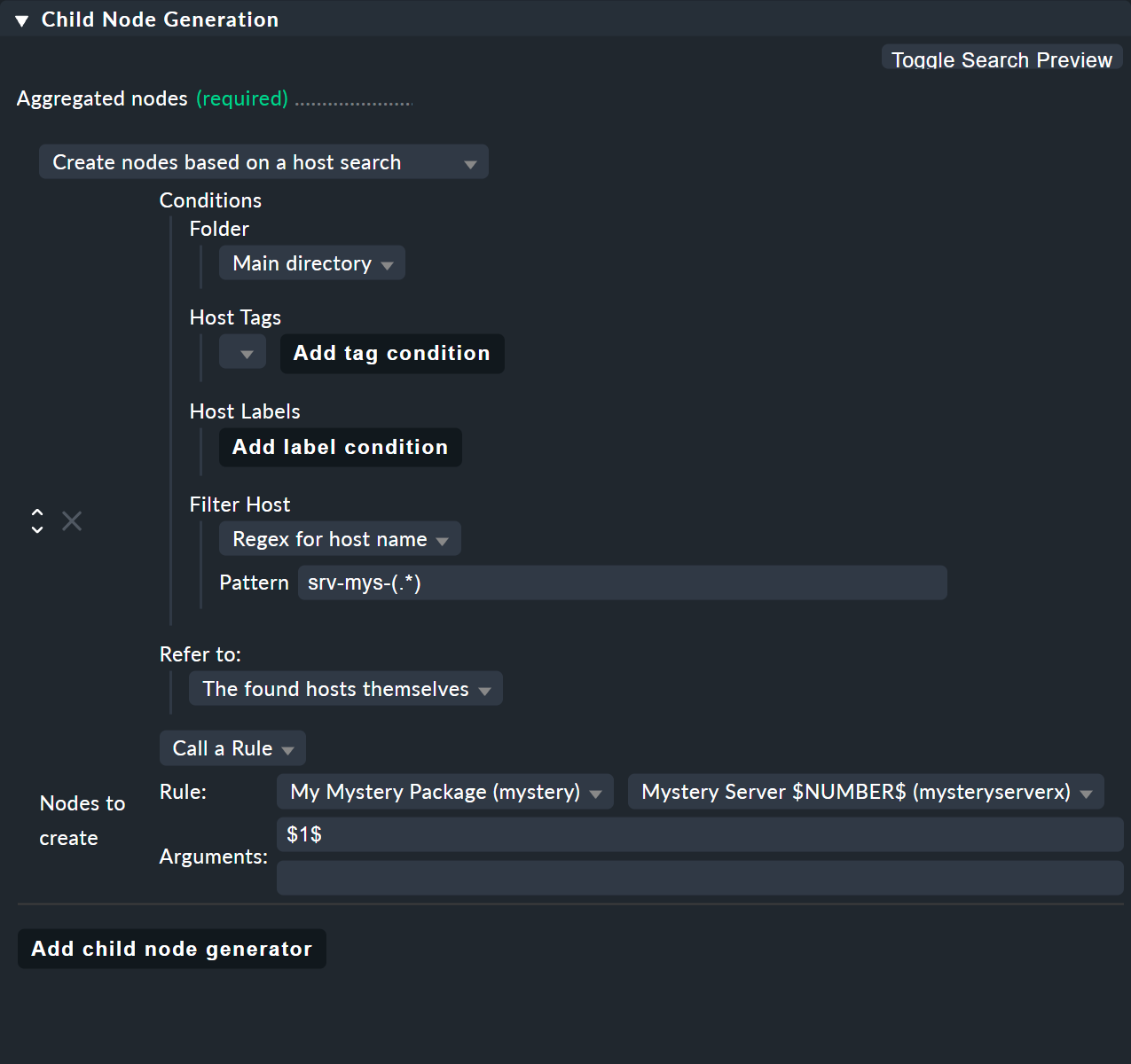
Le tout fonctionne ainsi :
Vous formulez une condition de recherche pour trouver des ordinateurs hôtes.
Un nœud enfant est créé pour chaque ordinateur hôte trouvé.
Vous pouvez extraire des parties des noms de domaine trouvés et les fournir en tant que paramètres.
La recherche n’est qu’un début.
Comme d’habitude, des balises de l’hôte sont disponibles.
Dans l’exemple, vous pouvez omettre cela et utiliser à la place l’srv-mys-(.*) d’expression régulière pour le nom de domaine.
Cela saisit tous les noms de domaine commençant par srv-mys-.
L’.* représente n’importe quelle chaîne de caractères.
Il est important que .* soit entre crochets, soit (.*).
Grâce aux parenthèses, la correspondance forme ce qu’on appelle un groupe de correspondance.
Ainsi, le texte qui correspond exactement à .* est capturé (et stocké) — ici 1 ou 2.
Les groupes de correspondance sont numérotés en interne.
Ici, il n’y en a qu’un seul, qui reçoit le numéro 1.
Vous pouvez ensuite accéder au texte correspondant à l’aide de $1$.
La recherche va désormais trouver deux ordinateurs hôtes :
| Nom de domaine |
Valeur pour$1$
|
|---|---|
|
1 |
|
2 |
Pour chaque ordinateur hôte trouvé, vous allez maintenant créer un sous-nœud à l'aide de la fonction Call a rule.
Sélectionnez la règle Mystery Server $NUMBER$ que vous venez de créer.
En tant qu'argument de NUMBER, passez désormais le groupe de correspondance : $1$.
La règle Mystery Server $NUMBER$ est désormais appelée deux fois : une fois avec 1 et une fois avec 2.
Si, à l’avenir, un nouveau serveur portant le nom srv-mys-3 est ajouté à la supervision, celui-ci apparaîtra automatiquement dans l’agrégation BI.
L’état de l’ordinateur hôte n’a aucune importance.
Même si le serveur est DOWN, il ne sera bien sûr pas supprimé de l’agrégation BI.
Certes, la courbe d'apprentissage est ici très raide. Cette méthode est vraiment complexe. Mais une fois que vous l'aurez essayée et comprise, vous réaliserez à quel point ce concept est puissant — et jusqu'à présent, nous n'avons fait qu'effleurer la surface des possibilités disponibles !
Règle du niveau supérieur
La nouvelle structure du nœud de niveau supérieur The Mystery Application est désormais simple : une nouvelle règle comportant deux nœuds enfants de type Call a rule est également nécessaire. Ces deux règles sont la règle existante Infrastructure et la règle Mystery Servers qui vient d’être créée.
6.5. Création d'un nœud avec recherche de service
Tout comme pour la recherche d'ordinateur hôte, il existe également un type de générateur de nœuds enfants appelé Create nodes based on a service search. Voici un exemple :
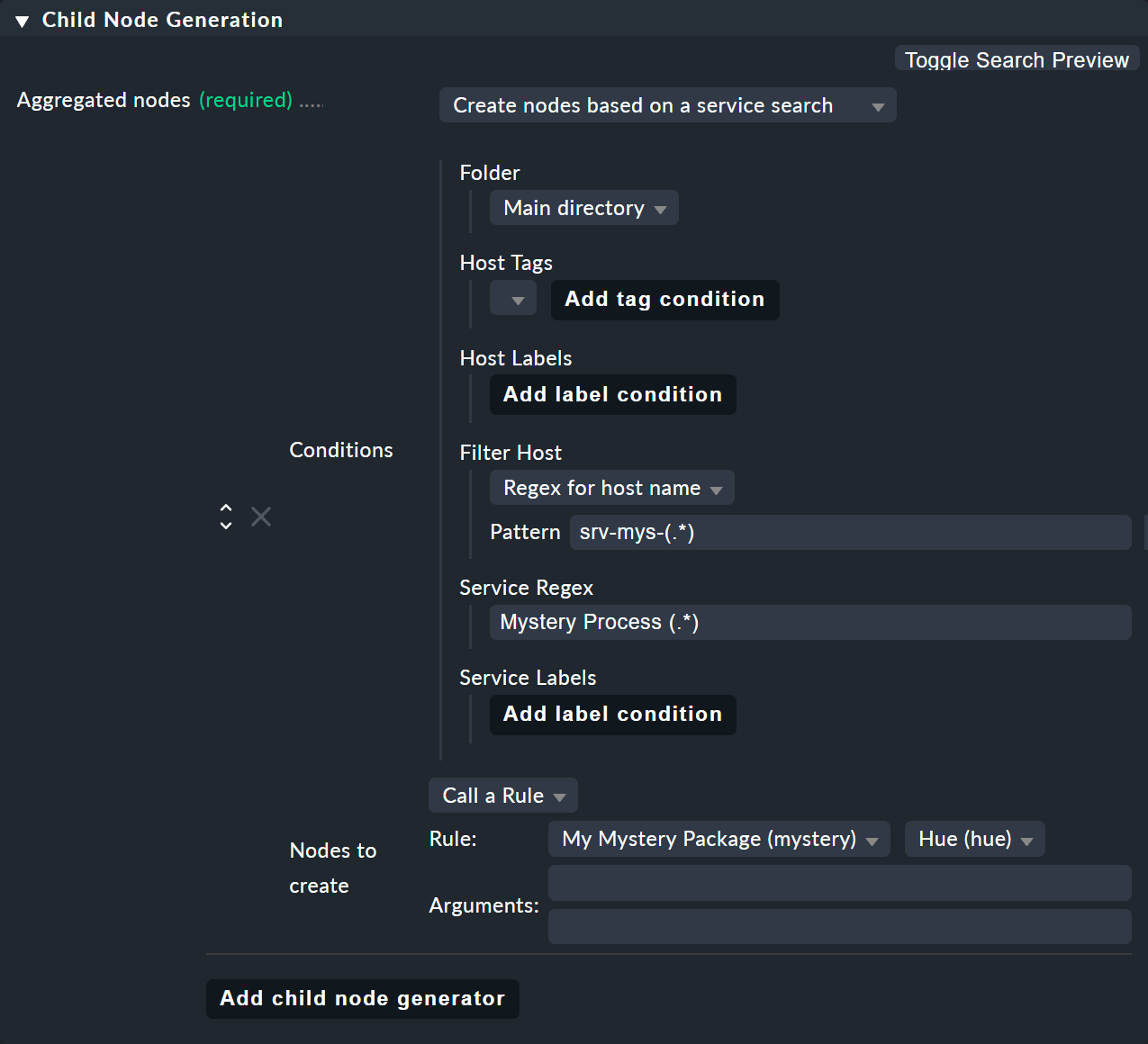
Vous pouvez utiliser () ici – en encadrant des expressions partielles – à la fois au niveau de l'ordinateur hôte et au niveau du service,
où :
Si vous choisissez « Regex for host name », vous devez définir exactement une expression entre parenthèses. Le texte de correspondance est alors fourni sous la forme «
$1$».Si vous choisissez All hosts, le nom de domaine complet sera fourni sous la forme
$1$.Vous pouvez utiliser plusieurs sous-groupes dans le nom du service. Les textes de correspondance associés sont fournis sous la forme
$2$,$3$, etc.
Et n'oubliez jamais que vous pouvez toujours utiliser ![]() pour obtenir de l'aide en ligne.
pour obtenir de l'aide en ligne.
6.6. Tous les autres services
Au cours de vos essais, vous êtes peut-être tombé sur le générateur de nœuds enfants State of remaining services. Celui-ci génère un nœud pour chacun des services de votre hôte qui n’ont pas encore été classés dans votre agrégation BI. Cela s’avère utile si vous utilisez BI pour regrouper les états de tous les services d’un hôte en groupes clairement organisés, comme c’est le cas dans notre exemple fourni.
7. L'agrégation d'ordinateurs hôtes prédéfinie
Comme nous venons de le mentionner, vous pouvez également utiliser BI pour présenter les services d’un ordinateur hôte de manière structurée. Vous regroupez tous les services dans une arborescence au sein d’une agrégation BI, et utilisez essentiellement la fonction «worst». L’état global d’un ordinateur hôte ne s’affichera alors que s’il y a un problème avec celui-ci — vous utilisez BI comme une méthode claire de «drill down».
À cette fin, Checkmk fournit déjà un ensemble prédéfini de règles qu’il vous suffit de déverrouiller.
Ces règles sont optimisées pour le rendu des services sur des ordinateurs hôtes Windows ou Linux,
mais vous pouvez bien sûr les personnaliser à votre guise.
Vous trouverez toutes ces règles dans le paquet de règles « Default ».
Comme d’habitude, accédez aux règles en cliquant sur « ![]() » :
» :

Vous y trouverez une liste de douze règles (résumées ici) :
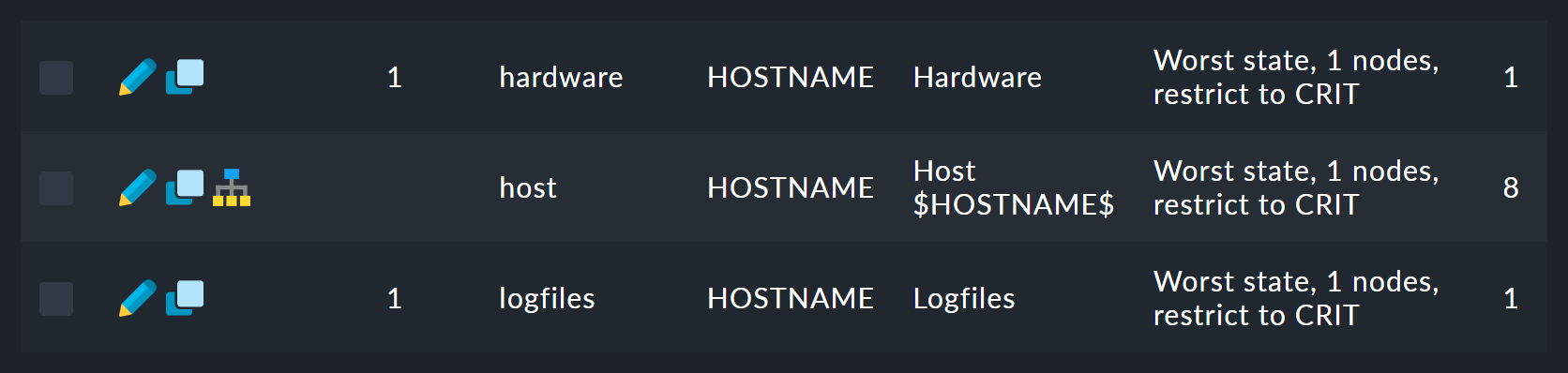
La première règle est celle de la racine de l'arborescence.
L'icône « ![]() » de cette règle vous amène à une vue arborescente.
Vous pouvez y voir comment les règles s'imbriquent les unes dans les autres :
» de cette règle vous amène à une vue arborescente.
Vous pouvez y voir comment les règles s'imbriquent les unes dans les autres :

De retour dans la liste des règles, le bouton « ![]() » (Aggregations) vous permet d’accéder à la liste des agrégations de ce package de règles — qui ne contient qu’une seule agrégation.
Dans les détails de l’agrégation (
» (Aggregations) vous permet d’accéder à la liste des agrégations de ce package de règles — qui ne contient qu’une seule agrégation.
Dans les détails de l’agrégation (![]() Details), il vous suffit de décocher la case à cocher « Currently disable this aggregation »
pour obtenir immédiatement, par ordinateur hôte, une agrégation intitulée «
Details), il vous suffit de décocher la case à cocher « Currently disable this aggregation »
pour obtenir immédiatement, par ordinateur hôte, une agrégation intitulée « Host myhost123 ».
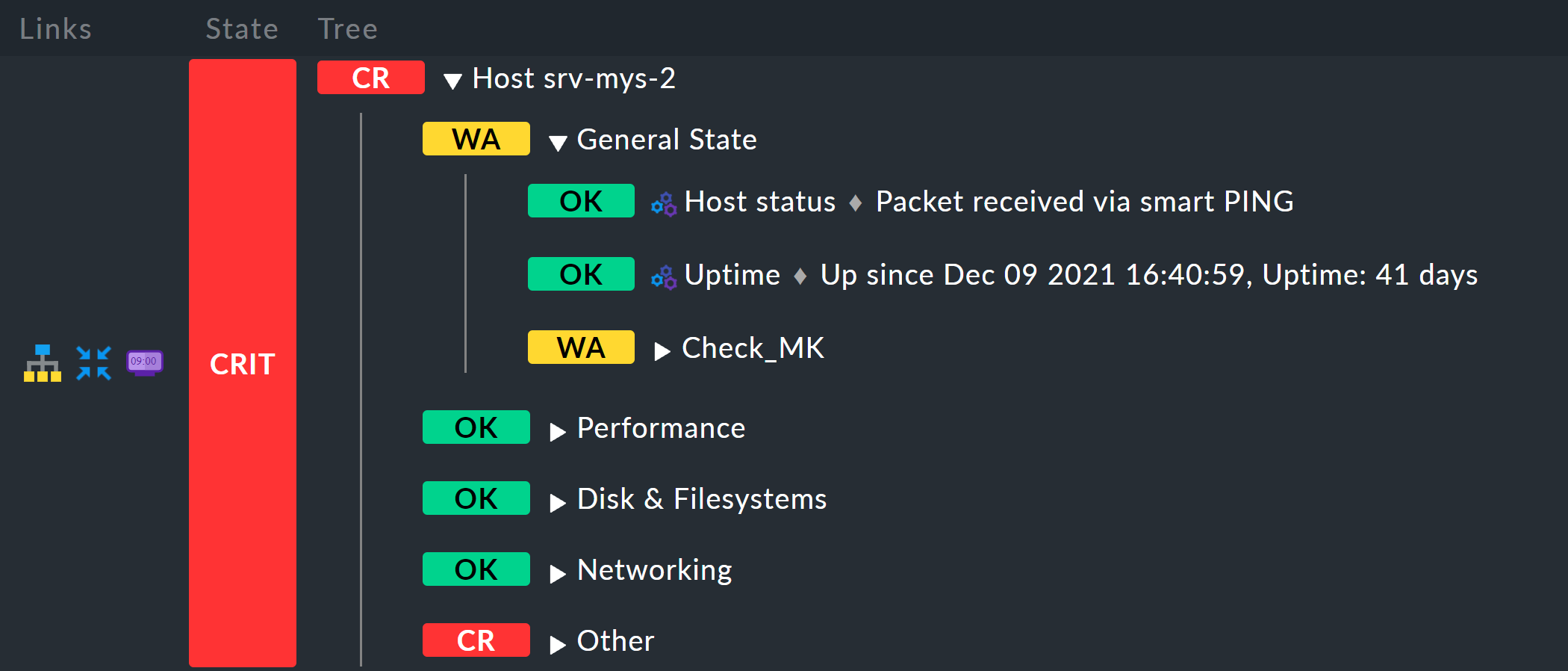
Le résultat ressemblera alors à ceci, par exemple :
8. Autorisations et visibilité
8.1. Autorisations d'édition
Revenons aux ensembles de règles. Pour toutes les actions d'édition dans BI, vous devez généralement disposer du rôle d'administrateur. Plus précisément, pour BI, il existe deux autorisations, qui se trouvent sous Setup > Users > Roles & permissions:

Dans le rôle d’utilisateur de supervision standard, seule la première de ces deux autorisations est active par défaut.
Les utilisateurs de supervision standard ne peuvent donc travailler que sur les ensembles de règles pour lesquels ils ont été définis comme contact.
Cette configuration s’effectue dans les détails de l’ensemble de règles sous ![]() .
.
Dans l’exemple suivant d’Permitted Contact Groups, le groupe de contact « The Mystery Admins » a été autorisé — ainsi, tous les membres de ce groupe peuvent désormais éditer les règles de ce paquet :
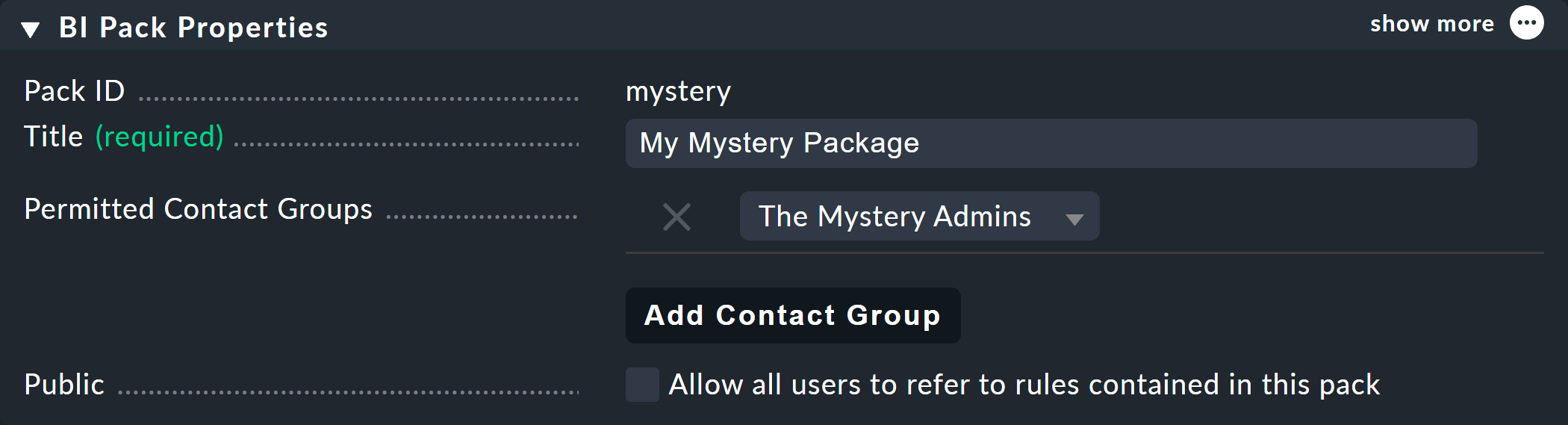
Par ailleurs, grâce à l’Public > Allow all users to refer to rules contained in this pack, vous pouvez autoriser d’autres utilisateurs à au moins utiliser les règles contenues ici — c’est-à-dire à définir (ailleurs) leurs propres règles — qui peuvent ensuite invoquer ces règles en tant que sous-nœuds.
8.2. Autorisations sur les ordinateurs hôtes et les services
Qu'en est-il de la visibilité effective des agrégations dans l'interface de suivi d'état ? Quels contacts sont autorisés à voir quoi ?
Eh bien, vous ne pouvez attribuer aucune autorisation dans les agrégations BI elles-mêmes. Cela s’effectue indirectement via la visibilité des ordinateurs hôtes et des services, et est régi par l’option « See all hosts and services » sous « Setup > Roles & Permissions: »

Dans le rôle «User», cette autorisation est désactivée par défaut. Les utilisateurs normaux ne peuvent voir que les hôtes et services partagés, et dans BI, cela se traduit par le fait qu’ils peuvent voir exactement toutes les agrégations BI qui contiennent au moins un hôte ou un service partagé. Ces agrégations ne contiennent toutefois que ces objets autorisés, et elles peuvent donc être quelque peu «allégées». Cela signifie en retour qu’elles peuvent présenter des états différents selon les utilisateurs.
Que cela soit une bonne ou une mauvaise chose dépend de ce que vous souhaitez. En cas de doute, vous pouvez activer ou désactiver cette autorisation et, en passant par BI, permettre à certains ou à tous les utilisateurs de voir les ordinateurs hôtes et les services pour lesquels ils ne sont pas des contacts — et ainsi vous assurer que l'état d'une agrégation BI est toujours le même pour tout le monde.
Bien sûr, toute cette question n’a d’importance que s’il existe effectivement des agrégations si hétéroclites que seuls certains utilisateurs sont contacts pour des parties spécifiques de celles-ci.
9. La BI en pratique, 3e partie : périodes de maintenance planifiées, confirmations
9.1. Le principe général
Comment BI gère-t-elle concrètement les périodes de maintenance planifiées pour ![]() ?
Nous avons longuement réfléchi à cette question et en avons discuté avec de nombreux utilisateurs ; voici le résultat :
?
Nous avons longuement réfléchi à cette question et en avons discuté avec de nombreux utilisateurs ; voici le résultat :
Vous ne pouvez pas placer une agrégation BI elle-même directement dans une période de maintenance planifiée — mais vous n’avez pas besoin de le faire, car…
la période de maintenance planifiée pour une agrégation BI est dérivée automatiquement de la période de maintenance planifiée pour les ordinateurs hôtes et les services de l'agrégation BI.
Pour comprendre selon quelle règle BI calcule l’état « en période de maintenance », il est utile de rappeler la véritable idée qui sous-tend les périodes de maintenance planifiées : l’objet en question fait actuellement l’objet de travaux. Des défaillances sont à prévoir. Même si l’objet est actuellement en état « OK », vous ne devez pas vous y fier. Il peut passer à l’état « CRIT » à tout moment. Ce phénomène est connu et documenté — il ne devrait donc pas déclencher de notification.
Ce principe peut être transposé tel quel dans BI : Dans l'agrégation, il peut y avoir quelques ordinateurs hôtes et services qui sont actuellement en période de maintenance. Que ceux-ci soient simplement « OK » ou « CRIT » n’a aucune importance, car c’est en réalité une coïncidence si, pendant la période de maintenance, les objets s’éteignent et se rallument parfois, ou non. Le simple fait qu’il y ait un objet en panne dans l’agrégation ne signifie pas immédiatement que l’application qui effectue l’affectation de l’agrégation est elle-même « menacée » et doit également être marquée comme « en période de maintenance ». L’application peut également disposer d’une redondance intégrée qui compense la défaillance des objets en période de maintenance. Ce n’est que si une telle défaillance conduisait effectivement à un état d’CRITe pour l’agrégation — c’est-à-dire s’il n’y a pas suffisamment de redondance et que l’agrégation est réellement menacée — que Checkmk la marquera comme « en période de maintenance ». Ici aussi, l’état actuel des objets n’a généralement aucune importance.
Pour être plus précis, la règle exacte est la suivante :
Si un état d’CRITion d’un ordinateur hôte/service entraînerait un état d’CRITion de l’agrégation, un état « en période de maintenance » de cet ordinateur hôte/service entraîne un état « en période de maintenance » pour l’agrégation.
Important : l’état réel actuel des ordinateurs hôtes/services ne joue aucun rôle dans le calcul — ce qui est en période de maintenance est considéré comme « in CRIT » dans la logique BI. Pourquoi ? Parce qu’un état « UP » ou « OK » pendant une période de maintenance planifiée est une pure coïncidence, par exemple si un ordinateur hôte signale « UP » pendant quelques secondes entre plusieurs redémarrages.
Et voici un autre exemple. Pour gagner de la place, voici une variante avec un seul serveur mystérieux au lieu de deux :
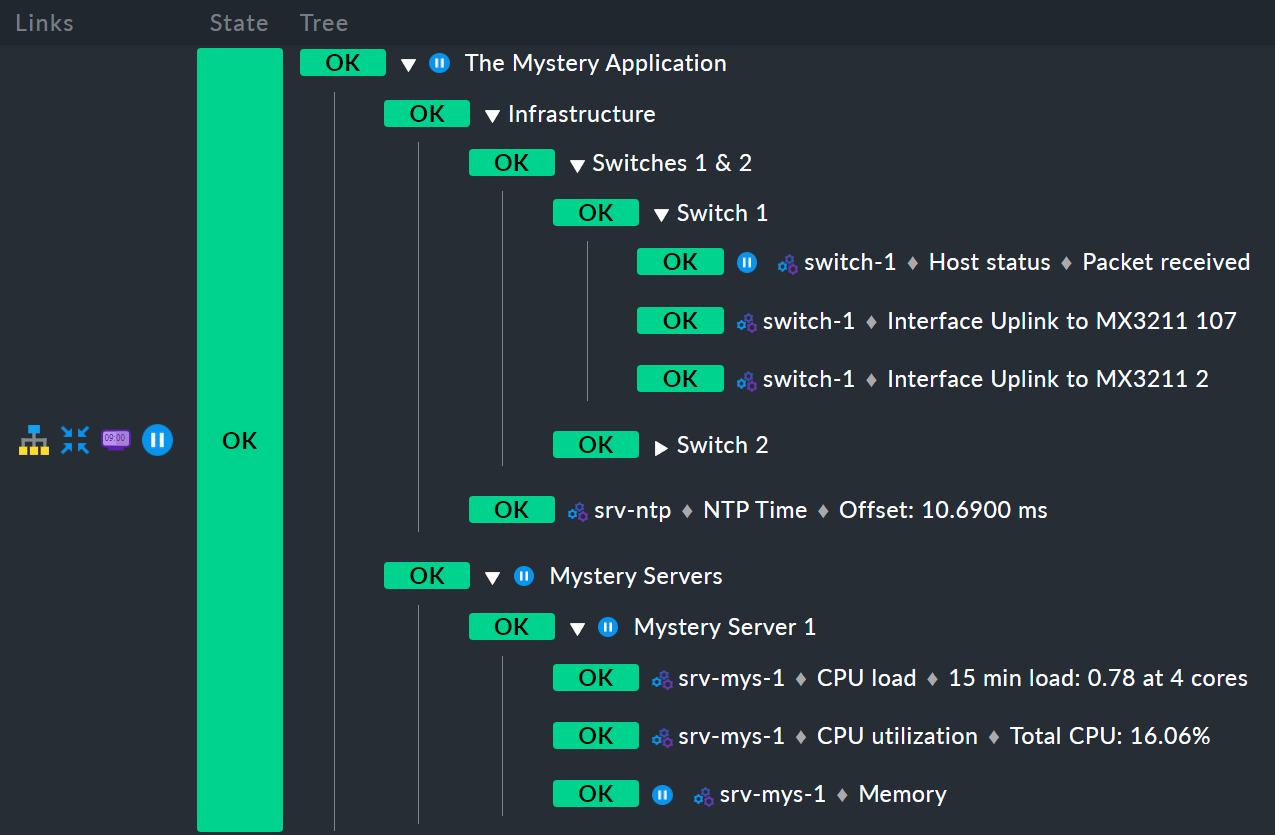
Tout d’abord, l’ordinateur hôte switch-1 est en période de maintenance.
Pour le nœud Infrastructure, cela n’a aucun effet, car switch-2 n’est pas en période de maintenance,
et donc Infrastructure n’est pas non plus en période de maintenance.
Il n’y a donc pas d’icône ![]() pour les périodes de maintenance dérivées.
pour les périodes de maintenance dérivées.
Cependant, le service Memory sur srv-mys-1 est également en période de maintenance.
Celui-ci n'est pas redondant.
La période de maintenance est donc héritée par le nœud parent Mystery Server 1, puis se propage jusqu'à Mystery Servers, et enfin jusqu'au nœud supérieur The Mystery Application.
Ce nœud supérieur sera donc également en période de maintenance.
9.2. Instruction « période de maintenance »
Nous avons indiqué plus haut qu’il n’était pas possible de mettre manuellement une agrégation BI en période de maintenance planifiée ?
Ce n’est qu’à moitié vrai, car il existe en réalité une instruction ![]() permettant de définir des périodes de maintenance planifiées dans les agrégations BI.
Mais cela ne fait rien de plus que d’enregistrer une entrée de période de maintenance pour chaque ordinateur hôte et service de l’agrégation.
Cela conduit bien sûr généralement à ce que l’agrégation elle-même soit signalée comme étant en période de maintenance,
mais il ne s’agit là que d’une procédure indirecte.
permettant de définir des périodes de maintenance planifiées dans les agrégations BI.
Mais cela ne fait rien de plus que d’enregistrer une entrée de période de maintenance pour chaque ordinateur hôte et service de l’agrégation.
Cela conduit bien sûr généralement à ce que l’agrégation elle-même soit signalée comme étant en période de maintenance,
mais il ne s’agit là que d’une procédure indirecte.
9.3. Options de réglage
Vous avez vu plus haut que le calcul des périodes de maintenance planifiées repose sur un état d'CRIT supposé. Dans les propriétés d'une agrégation, vous pouvez personnaliser l'algorithme de manière à ce qu'un nœud qui prend l'état d'WARN soit marqué comme étant en période de maintenance. L'option correspondante s'appelle « Escalate downtimes based on aggregated WARN state » :
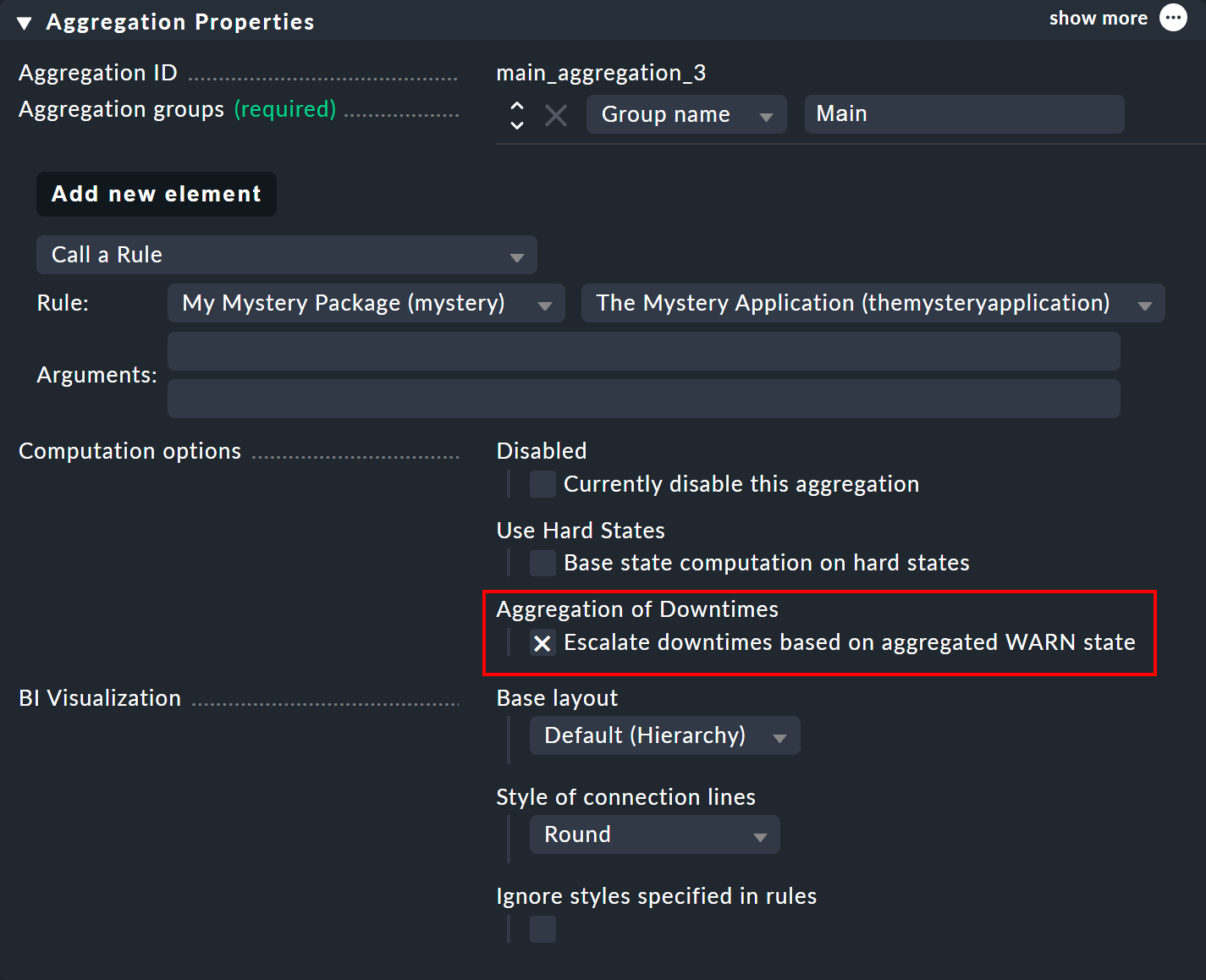
L'hypothèse de base reste que les objets en période de maintenance sont en état « CRIT ». La seule différence réside dans le fait que, selon la fonction d'agrégation, un état « CRIT » peut devenir un état « WARN » — comme ce fut le cas dans notre tout premier exemple avec Count the number of nodes in state OK. Ici, une période de maintenance planifiée aurait déjà été acceptée si un seul des deux commutateurs avait été en période de maintenance.
9.4. Confirmations
Tout comme pour le processus des périodes de maintenance planifiées, si un problème a été ![]() reconnu, l’information sera également
calculée automatiquement par BI.
Dans ce cas, l’état des objets joue certainement un rôle.
reconnu, l’information sera également
calculée automatiquement par BI.
Dans ce cas, l’état des objets joue certainement un rôle.
L'idée ici est de transposer le concept suivant dans BI :
Un objet présente un problème (WARN, CRIT), mais celui-ci est connu et quelqu'un y travaille (![]() ).
).
Vous pouvez calculer cela pour une agrégation comme suit :
Supposons que tous les ordinateurs hôtes et services pour lesquels des incidents ont été signalés (
 ) aient reçu la confirmation que les incidents ont été résolus (OK).
) aient reçu la confirmation que les incidents ont été résolus (OK).L'agrégation elle-même serait-elle alors à nouveau « OK » ? Dans ce cas précis, elle recevrait également une confirmation comme «
».
Toutefois, si l'agrégation devait rester en état « WARN » ou « CRIT », elle ne serait pas considérée comme ayant reçu la confirmation, car il y aurait alors au moins un problème important qui n'aurait pas reçu la confirmation, et l'état « OK » serait donc supprimé de l'agrégation.
À ce propos, l'![]() vous proposera une instruction permettant à l'agrégation BI de valider ses problèmes,
mais cela signifie uniquement que tous les ordinateurs hôtes et services détectés dans l'agrégation seront validés (uniquement ceux qui présentent actuellement des problèmes).
vous proposera une instruction permettant à l'agrégation BI de valider ses problèmes,
mais cela signifie uniquement que tous les ordinateurs hôtes et services détectés dans l'agrégation seront validés (uniquement ceux qui présentent actuellement des problèmes).
10. Rendre les modifications visibles
Les nœuds d'une agrégation peuvent parfois changer pendant le fonctionnement. En utilisant des agrégations figées, vous pouvez rendre ces changements visibles.
Voici un exemple : Un commutateur doté de 6 ports devrait être en état « OK » lorsque 5 de ses services/ports sont en état « OK ». Cependant, dans le cadre d'une mise à jour du micrologiciel, 2 des ports sont renommés et les services qui leur sont associés disparaissent de la supervision.
L'agrégation se composerait alors de 4 services présentant l'état « OK », mais l'agrégation elle-même serait « WARN » ou « CRIT » — sans fournir aucune indication sur la raison. C'est précisément là que les agrégations figées entrent en jeu : Vous figez l'état actuel, et vous pouvez ensuite cliquer pour créer une liste de ce qui a changé depuis lors, c'est-à-dire quels nœuds ont été ajoutés ou supprimés. En d'autres termes, alors que les règles d'une agrégation indiquent son état, les agrégations figées fournissent des informations sur les changements d'état.
10.1. Gel et comparaison
L'utilisation de la fonction de gel est très simple : Activez l'option « New aggregations are frozen » dans « Aggregation Properties ».
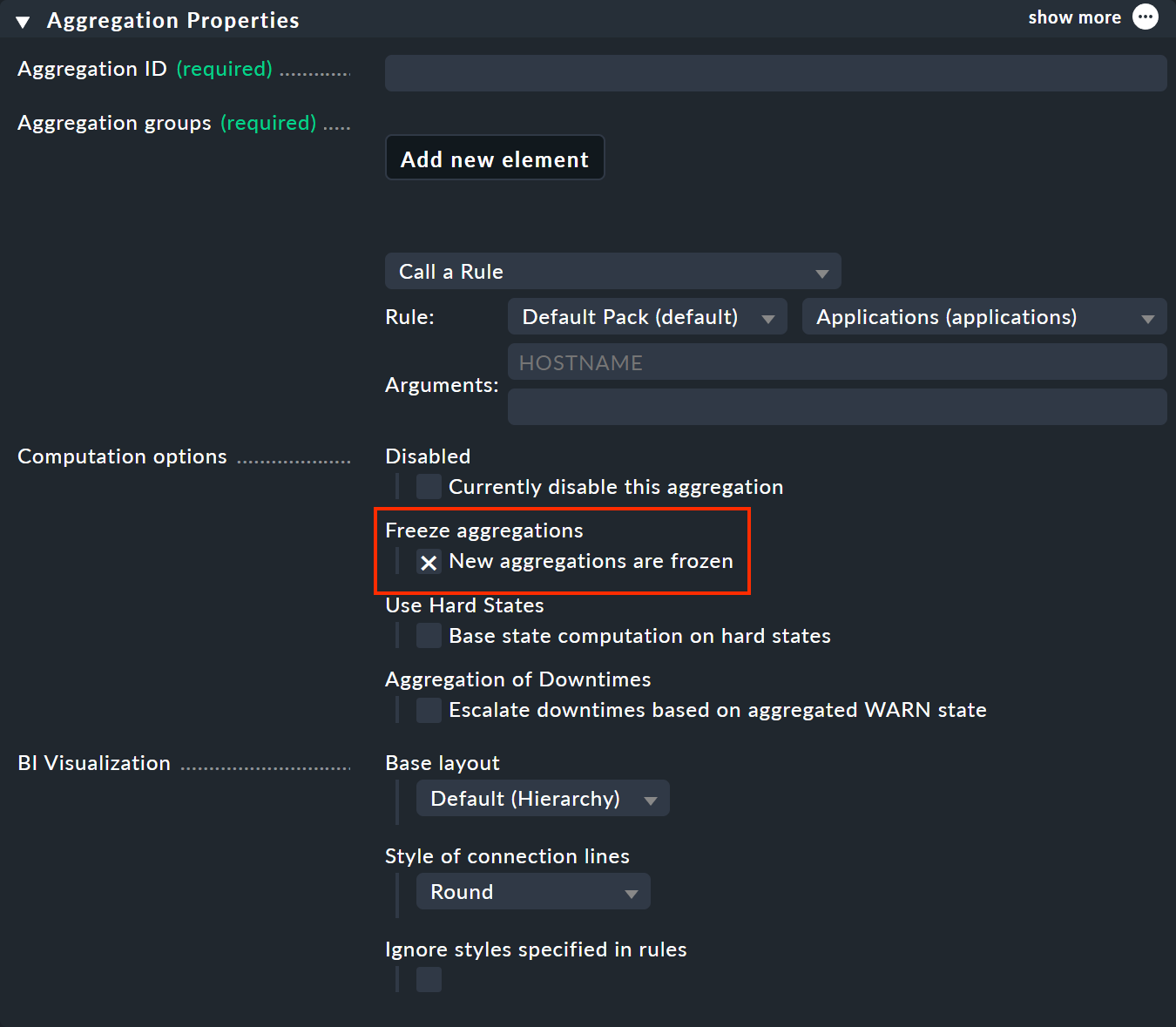
Cela gèlera l'agrégation lors de son enregistrement — et le fera chaque fois que la case sera cochée ; même si l'agrégation existait déjà auparavant (malgré la référence à « New aggregations … »). Pour débloquer le statut gelé, ne cochez pas la case en conséquence.
Dans la supervision, vous verrez désormais une nouvelle icône en forme de flocon de neige « ![]() » à côté de l’agrégation.
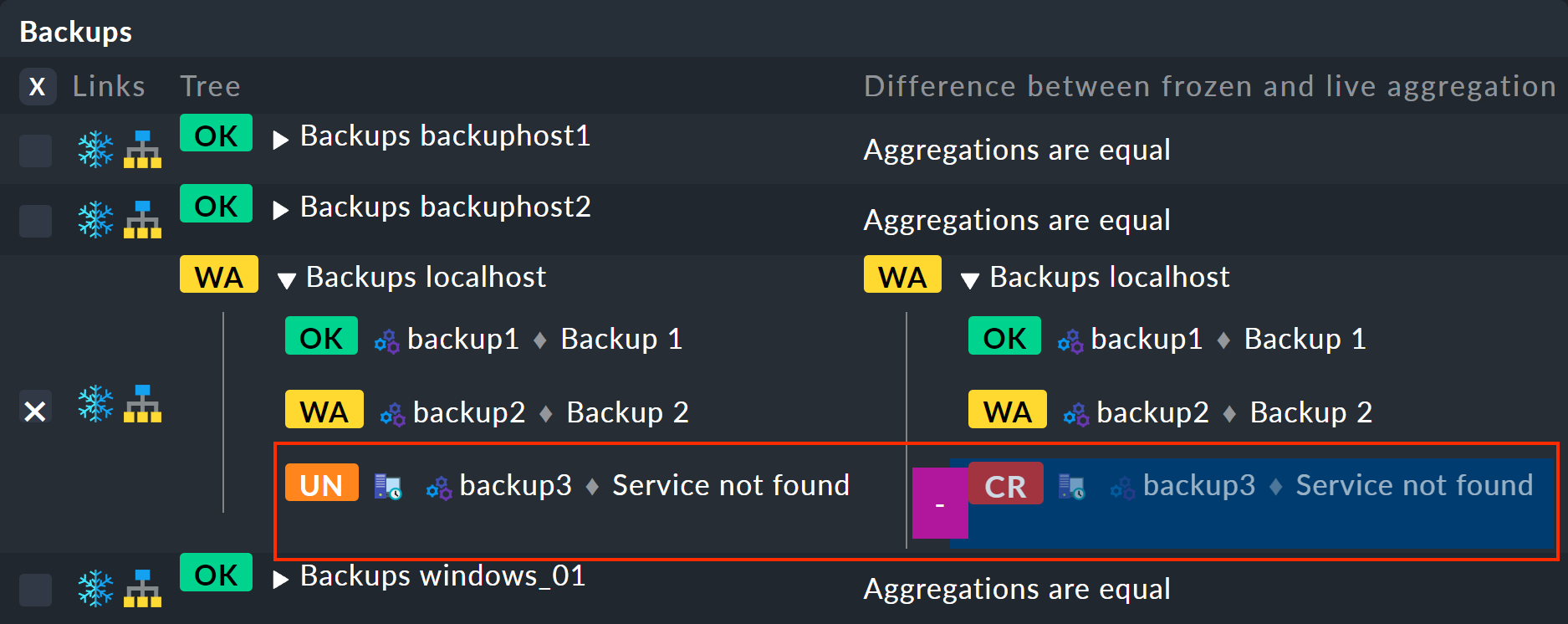
Cela vous mènera à la vue de la table affichant les différences :
à gauche, l’arborescence gelée ; à droite, l’arborescence actuelle avec les modifications mises en évidence (ici, la suppression du service backup3) :
» à côté de l’agrégation.
Cela vous mènera à la vue de la table affichant les différences :
à gauche, l’arborescence gelée ; à droite, l’arborescence actuelle avec les modifications mises en évidence (ici, la suppression du service backup3) :
Si vous souhaitez à nouveau geler l'état actuel, vous pouvez le faire via Commands > Freeze aggregations. Mais attention : il n'y a toujours qu'un seul état actuel gelé et aucun historique, y compris les états antérieurs.
11. Disponibilité
Tout comme pour les ordinateurs hôtes et les services, vous pouvez également consulter la disponibilité BI d'une ou plusieurs agrégations pour n'importe quelle période de temps passée. Pour ce faire, le module BI reconstitue l'état en se basant sur l'historique des ordinateurs hôtes et des services de l'agrégation pour chaque période de temps passée. Vous pouvez ainsi également calculer la disponibilité pour les périodes durant lesquelles l'agrégation n'était pas encore configurée !

Pour plus de détails sur la BI et la disponibilité, consultez la section consacrée à la BI dans l'article sur la disponibilité.
12. La BI dans le cadre d'une supervision distribuée
Que se passe-t-il réellement au niveau de la BI dans un environnement distribué ? C'est-à-dire lorsque les ordinateurs hôtes sont répartis sur plusieurs serveurs de supervision ?
La réponse est relativement simple : cela fonctionne — sans que vous ayez à vous en soucier. Comme la BI est un composant de l'interface graphique et qu'elle est fournie en standard avec une capacité de prise en charge des environnements distribués, cela est totalement transparent pour la BI.
Si un emplacement est actuellement indisponible ou si vous l'avez masqué manuellement depuis l'interface graphique, les ordinateurs hôtes de l'instance n'existent plus pour la BI. Cela signifie alors que :
les agrégations BI qui sont construites exclusivement à partir d'objets de cet emplacement disparaissent.
Les agrégations BI construites en partie à partir d’objets de cet emplacement sont allégées.
Dans ce dernier cas, cela peut bien sûr affecter l'état des agrégations concernées. Les effets précis que cela peut avoir dépendront de vos fonctions d'agrégation. Si, par exemple, vous avez utilisé partout « worst », l'état global reste simplement le même ou s'améliore, car les objets de l'emplacement qui n'existe plus pouvaient déjà avoir « WARN » ou « CRIT ». Bien sûr, d'autres états peuvent également se produire pour d'autres fonctions d'agrégation.
Il conviendra d’évaluer au cas par cas si ce comportement est pertinent pour votre opération. BI est en tout état de cause conçu de telle sorte que les objets inexistants ne puissent pas être inclus dans une agrégation BI, et ne puissent donc pas manquer, car toutes les règles BI fonctionnent — comme déjà expliqué ci-dessus — exclusivement avec des modèles de recherche.
13. Notifications, BI en tant que service
Est-il réellement possible de recevoir des notifications concernant les changements d'état dans les agrégations BI ? Eh bien, cela n'est pas directement possible à première vue, car la BI existe exclusivement dans l'interface graphique et n'a aucun lien avec la supervision proprement dite. Mais vous pouvez transformer les agrégations BI en services normaux, et ceux-ci peuvent bien sûr déclencher des notifications.
Vous pouvez utiliser l'agent spécial BI Aggregations à cet effet. Vous trouverez le jeu de règles approprié sous Setup > Agents > Other integrations > BI Aggregations. Commencez par créer une nouvelle entrée dans la case « BI Aggregations » avec « Add new entry ».
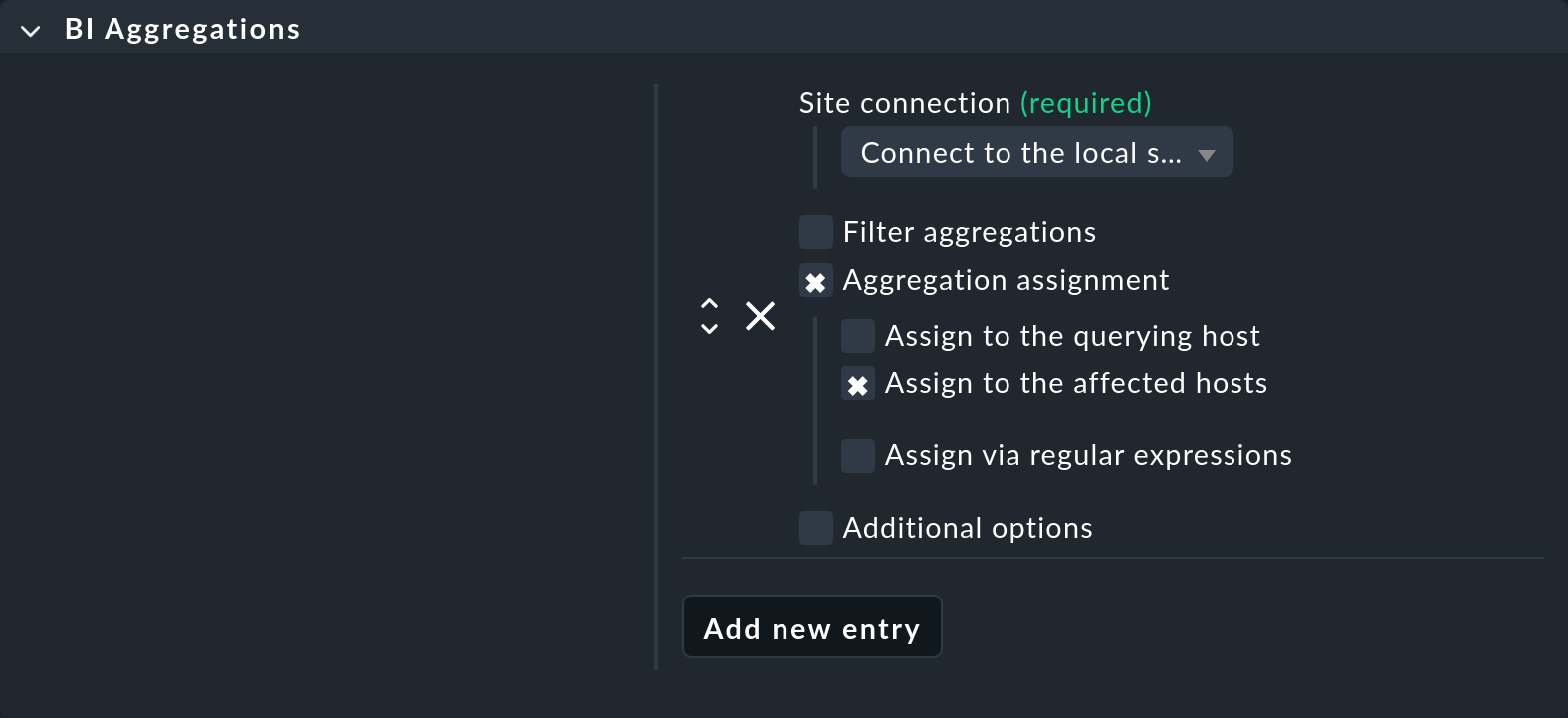
Vous pouvez y spécifier différentes options pour déterminer à quels ordinateurs hôtes les services doivent être ajoutés. Ceux-ci ne doivent pas nécessairement être rattachés à l’ordinateur hôte auquel l’agent spécial est affecté (Assign to the querying host). Il est également possible de les affecter aux ordinateurs hôtes inclus dans l’agrégation (Assign to the affected hosts). Cela n’a toutefois de sens que s’il s’agit d’un seul ordinateur hôte. Les expressions régulières et les substitutions vous offrent encore plus de flexibilité dans les affectations. L'ensemble est ensuite exécuté via le mécanisme de ferroutage.
Important : si l'ordinateur hôte auquel vous attribuez cette règle doit continuer à être supervisé via l'agent normal, assurez-vous dans ses paramètres que l'agent et les agents spéciaux sont exécutés :

Le nouveau service affiche alors — avec un délai pouvant aller jusqu’à un intervalle de check, bien sûr — l’état de l’agrégation. Voici deux exemples de nouveaux services, automatiquement complétés par le préfixe Aggr :

Comme d'habitude, vous pouvez attribuer ce service à des contacts et l'utiliser comme base pour les notifications.