This is a machine translation based on the English version of the article. It might or might not have already been subject to text preparation. If you find errors, please file a GitHub issue that states the paragraph that has to be improved. |
1. Introduzione
Probabilmente non tutti hanno la stessa idea di cosa significhi "monitoraggio distribuito". In realtà il monitoraggio è sempre distribuito su più computer, a meno che il sistema di monitoraggio non stia monitorando solo se stesso — il che non sarebbe molto utile.
In questo manuale ci riferiamo quindi sempre a un monitoraggio distribuito quando il sistema di monitoraggio nel suo complesso è costituito da più di un singolo sito Checkmk. Ci sono diversi buoni motivi per distribuire il monitoraggio su più istanze:
Performance: il carico del processore dovrebbe, o deve, essere distribuito su più macchine.
Organizzazione: diversi gruppi dovrebbero poter amministrare le proprie istanze in modo indipendente.
Disponibilità: il monitoraggio in una sede dovrebbe funzionare indipendentemente dalle altre sedi.
Sicurezza: i flussi di dati tra due domini di sicurezza dovrebbero essere controllati in modo separato e preciso (DMZ, ecc.)
Rete: le sedi che dispongono solo di connessioni a banda stretta o inaffidabili non possono essere sottoposte a monitoraggio remoto affidabile.
Checkmk supporta diverse procedure per implementare il monitoraggio distribuito.
Checkmk gestisce alcune di queste poiché è in gran parte compatibile con, o basato su, Nagios (se Nagios è stato installato come core).
Questo include, ad esempio, la procedura con mod_gearman.
Rispetto al sistema proprio di Checkmk, questa non offre alcun vantaggio ed è anche più complicata da implementare.
Per questi motivi non la consigliamo.
La procedura preferita da Checkmk si basa su Livestatus e su un ambiente di configurazione distribuito. Per situazioni con reti molto separate, o anche un trasferimento dati rigorosamente unidirezionale dalla periferia al centro, esiste un metodo che utilizza Livedump o, rispettivamente, CMCDump. Entrambi i metodi possono essere combinati.
2. Monitoraggio distribuito con Livestatus
2.1. Principi di base
Stato centrale
Livestatus è un'interfaccia integrata nel nucleo di monitoraggio che permette ad altri programmi esterni di interrogare i dati di stato ed eseguire comandi. Livestatus può essere reso disponibile in rete in modo che sia accessibile da un sito Checkmk remoto. L'interfaccia utente di Checkmk usa Livestatus per combinare tutti i siti collegati in una panoramica generale, che poi assomiglia a un unico, grande sistema di monitoraggio.
Il diagramma seguente mostra schematicamente la struttura di un monitoraggio con Livestatus distribuito su tre sedi. Il sito Checkmk Central si trova nella sede di elaborazione centrale. Da qui i sistemi centrali saranno controllati direttamente. Inoltre, ci sono l'istanza remota 1 e l'istanza remota 2, che si trovano in altre reti e sono controllate dai rispettivi sistemi locali:
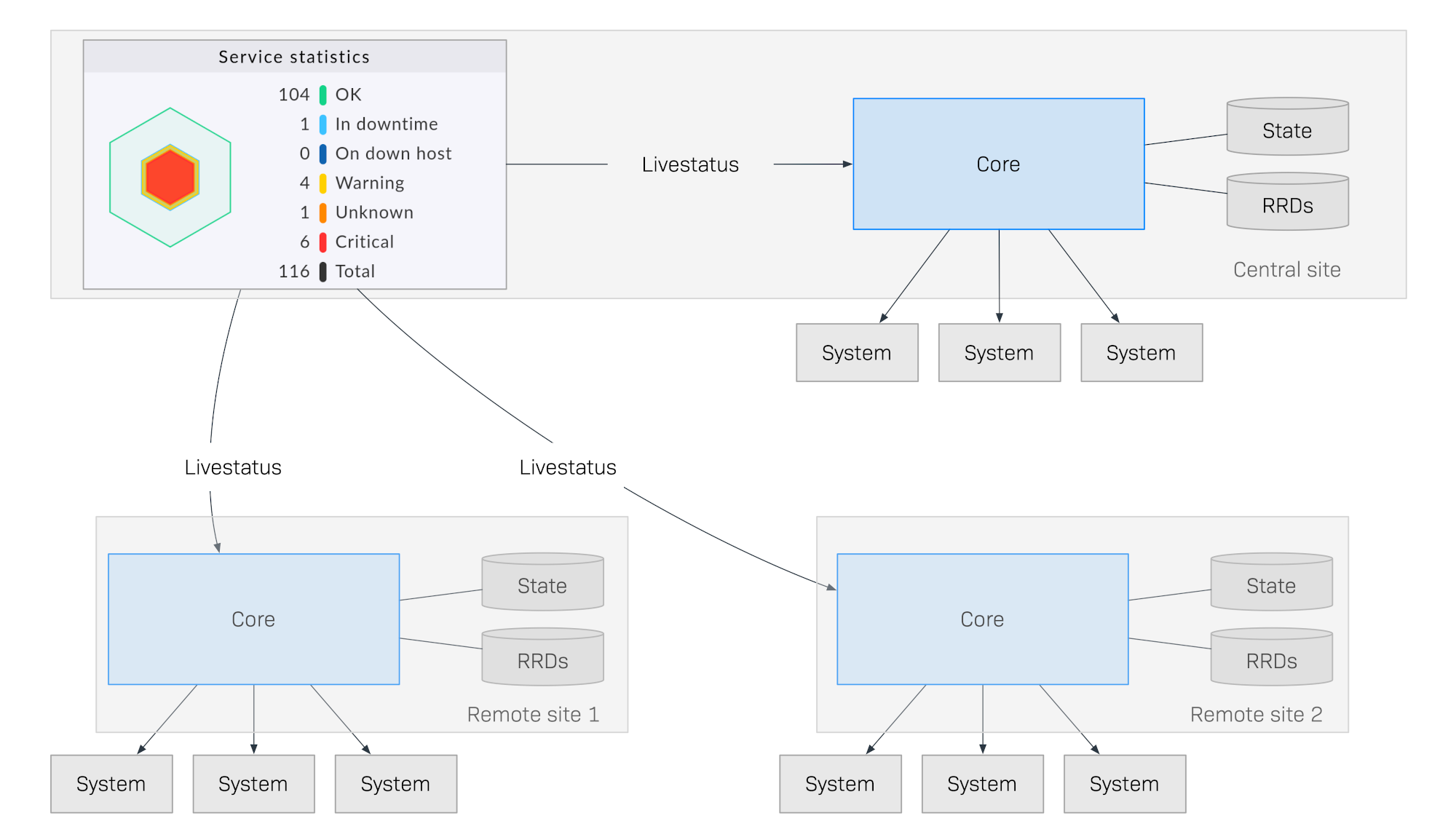
Ciò che rende speciale questo metodo è che lo stato di monitoraggio delle istanze remote non viene inviato continuamente all'istanza centrale. La GUI recupera i dati in tempo reale dalle istanze remote solo quando richiesto da un utente nel centro di controllo. I dati vengono quindi compilati in una visualizzazione centralizzata. Non c'è quindi alcuna archiviazione centrale dei dati, il che offre enormi vantaggi per il ridimensionamento!
Ecco alcuni dei vantaggi di questo metodo:
Scalabilità: il monitoraggio in sé non genera alcun traffico di rete tra l'istanza centrale e l'istanza remota. In questo modo è possibile effettuare connessioni tra centinaia di istanze, o anche di più.
Affidabilità: se la connessione di rete con un'istanza remota si interrompe, il monitoraggio locale continua comunque a funzionare normalmente. Non ci sono "lacune" nella registrazione dei dati né "congestioni" dei dati. Le notifiche locali continueranno a funzionare.
Semplicità: le istanze possono essere aggiunte o rimesse con estrema facilità.
Flessibilità: le istanze remote rimangono autonome e possono essere utilizzate per il funzionamento nella loro rispettiva sede. Ciò è particolarmente interessante se alla "sede" non deve mai essere consentito l'accesso al resto del sistema di monitoraggio.
Configurazione centrale
In un sistema distribuito che utilizza Livestatus come descritto sopra, è del tutto possibile che le istanze possano essere gestite in modo indipendente da team diversi, e che l'istanza centrale abbia solo il compito di fornire una dashboard centralizzata.
Nel caso in cui più istanze, o tutte le istanze, debbano essere amministrate dallo stesso team, una configurazione centrale è molto più facile da gestire. Checkmk supporta questa opzione e definisce tale configurazione come configurazione centrale. In questo modo tutti gli host e i servizi, gli utenti e i permessi, i periodi di tempo, le notifiche, ecc. saranno gestiti nell'Setupe dell'istanza centrale e poi distribuiti automaticamente alle istanze remote secondo le tue specifiche.
Un sistema di questo tipo non solo offre una panoramica comune dello stato, ma anche una configurazione comune, e di fatto "sembra un unico grande sistema".
Puoi persino estendere questo sistema con istanze-viewer dedicate, ad esempio, che fungono solo da interfacce di stato per sotto-aree o gruppi di utenti specifici.
2.2. Configurazione di un monitoraggio distribuito
L'installazione di un monitoraggio distribuito utilizzando Livestatus/central Setup si ottiene con i seguenti passaggi:
Per prima cosa effettua l'installazione dell'istanza centrale come si fa di solito per un singolo sito
Installa le istanze remote e abilita Livestatus tramite la rete
Integra le istanze remote nell'istanza centrale utilizzando Setup > General > Distributed monitoring
Per gli host e i servizi, specifica da quale istanza devono essere eseguiti i processi di monitoraggio
Esegui la scoperta del servizio per gli host migrati, quindi attiva le nuove modifiche
Configurazione dell'istanza centrale
Non ci sono requisiti particolari per l'istanza centrale. Questo significa che un'istanza già esistente può essere ampliata in un sistema di monitoraggio distribuito con una sola modifica, necessaria per handle correttamente i dati piggyback. Tutto quello che devi fare è abilitare l'hub piggyback nella pagina di configurazione Setup > General > Global settings nella sezione Site management:
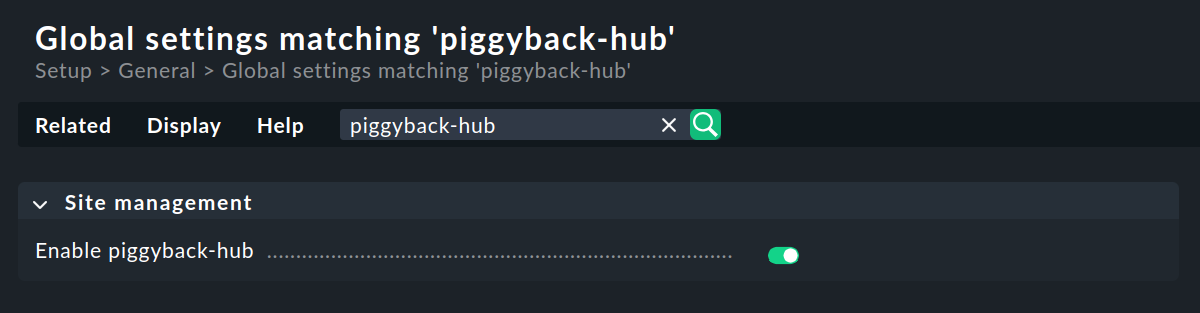
Quindi attiva le modifiche, poiché switchare l'hub piggyback richiede il riavvio dell'istanza.
Configurazione delle istanze remote e abilitazione di Livestatus tramite la rete
Le istanze remote vengono quindi generate come nuove istanze nel modo consueto con omd create.
Ciò avverrà naturalmente sul server (remoto) destinato alla rispettiva istanza remota.
Note speciali:
Per le istanze remote, usa ID univoci per il tuo monitoraggio distribuito.
La versione di Checkmk (ad es. 2.4.0) delle istanze remote e centrali è la stessa: le versioni miste sono supportate solo per facilitare gli aggiornamenti.
Proprio come Checkmk supporta più istanze su un server, anche le istanze remote possono essere eseguite sullo stesso server.
Ecco un esempio per creare un'istanza remota con il nome myremote1 e la password t0p53cr3t per l'amministratore dell'istanza cmkadmin:
I passaggi più importanti ora sono attivare Livestatus via TCP per la rete e abilitare anche l'hub piggyback qui.
Tieni presente che Livestatus non è di per sé un protocollo sicuro e dovrebbe essere usato solo all'interno di una rete sicura (LAN protetta, VPN, ecc.).
L'abilitazione si effettua usando omd config come utente dell’istanza mentre l’istanza è ferma:
Ora seleziona Distributed Monitoring:
┌Configuration of site myremote1───┐ │ Interactive setting of site │ │ configuration variables. You can │ │ change values only while the │ │ site is stopped. │ │ ┌──────────────────────────────┐ │ │ │ Basic │ │ │ │ Web GUI │ │ │ │ Addons │ │ │ │ Distributed Monitoring │ │ │ │ │ │ │ └──────────────────────────────┘ │ ├──────────────────────────────────┤ │ <Enter> <Exit > │ └──────────────────────────────────┘
Imposta LIVESTATUS_TCP su on e, per LIVESTATUS_TCP_PORT, inserisci un numero di porta non assegnato che sia unico su questo server.
Il valore predefinito è 6557:
┌────────────Distributed Monitoring──────────────┐ │ ┌────────────────────────────────────────────┐ │ │ │ LIVEPROXYD on │ │ │ │ LIVESTATUS_TCP on │ │ │ │ LIVESTATUS_TCP_ONLY_FROM 0.0.0.0 ::/0 │ │ │ │ LIVESTATUS_TCP_PORT 6557 │ │ │ │ LIVESTATUS_TCP_TLS on │ │ │ │ PIGGYBACK_HUB on │ │ │ │ │ │ │ └────────────────────────────────────────────┘ │ ├────────────────────────────────────────────────┤ │ < Change > <Main menu> │ └────────────────────────────────────────────────┘
Dopo aver salvato, avvia l'istanza come al solito con omd start:
Ricordati la password per cmkadmin.
Ti servirà solo due volte: prima per abilitare l'hub piggyback e poi per effettuare la connessione tra l'istanza remota e l'istanza centrale.
Una volta che l'istanza remota è stata subordinata all'istanza centrale,
tutti gli utenti saranno comunque sostituiti da quelli dell'istanza centrale.
L'istanza è ora pronta.
Un check con netstat mostra che la porta 6557 è aperta.
La connessione a questa porta viene effettuata con un'istanza del superserver internet xinetd , che gira direttamente sul sito:
Ora accedi una volta all'istanza remota come utente cmkadmin e attiva l'hub piggyback utilizzando le impostazioni Setup > General > Global nella sezione Site management:
Quindi attiva le modifiche, poiché switchare l'hub piggyback richiede il riavvio dell'istanza.
Assegnazione delle istanze remote all'istanza centrale
La configurazione del monitoraggio distribuito avviene esclusivamente sull'istanza centrale nel menu Setup > General > Distributed monitoring e serve per la gestione delle connessioni ai singoli siti. Per questa funzione, l'istanza centrale stessa conta come un sito ed è già presente nell'elenco:

Utilizzando ![]() Add connection , definisci ora la connessione all'istanza remota più vicina:
Add connection , definisci ora la connessione all'istanza remota più vicina:

In Basic settings è importante utilizzare il nome ESATTO dell’istanza remota — come definito in omd create — come Site ID.
Come sempre, l’alias può essere definito a piacere e modificato in un secondo momento.
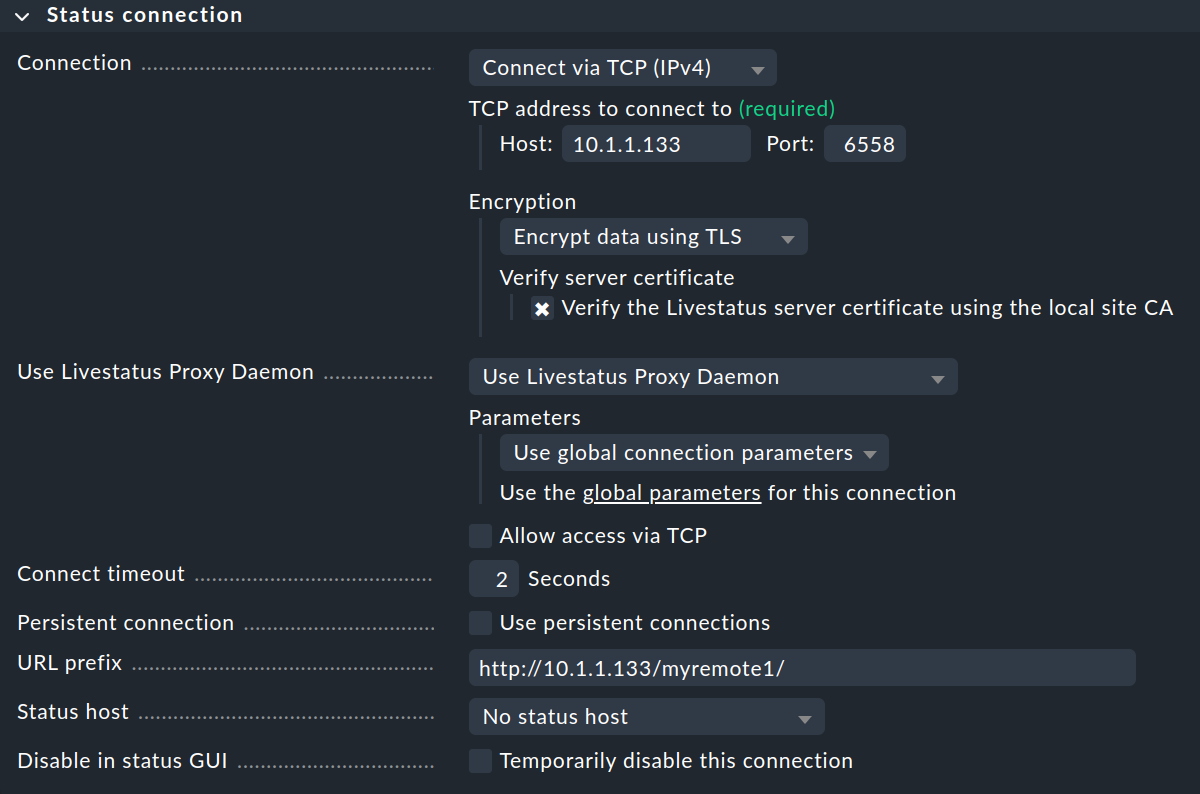
Le impostazioni dell'Status connection determinano il modo in cui l'istanza centrale interroga lo stato delle istanze remote tramite Livestatus. L'esempio nella schermata mostra una connessione con il metodo Connect via TCP(IPv4). Questo è l'ideale per connessioni stabili con tempi di latenza brevi (come, ad esempio, in una LAN). Parleremo delle impostazioni ottimali per le connessioni WAN più avanti.
Qui inserisci l'URL HTTP dell'interfaccia web dell'istanza remota, senza check_mk/ alla fine dell'URL.
Se di solito accedi a Checkmk tramite HTTPS, sostituisci qui http con https.
Trovi ulteriori informazioni nella guida online ![]() o nell'articolo sulla protezione dell'interfaccia web con HTTPS.
o nell'articolo sulla protezione dell'interfaccia web con HTTPS.
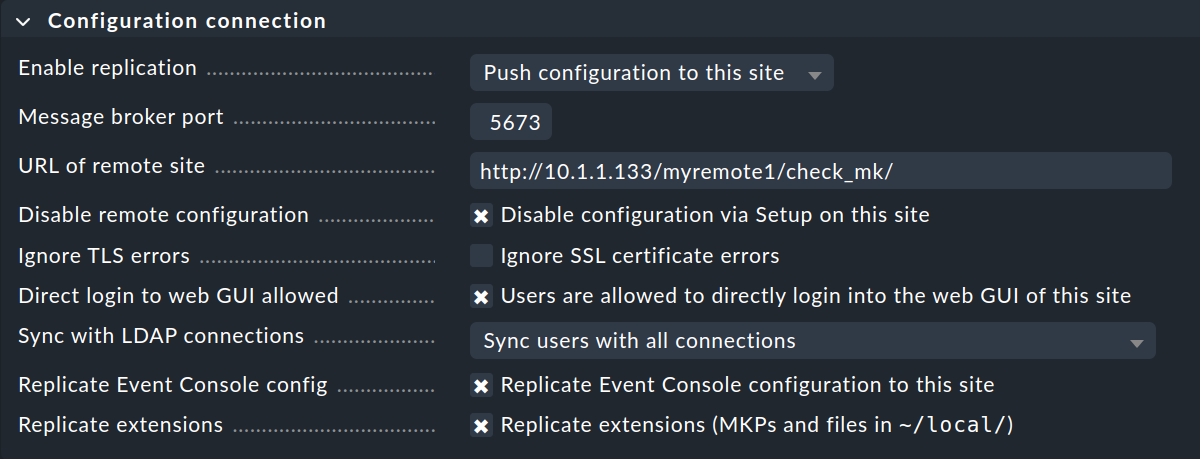
La replica della configurazione e quindi l'utilizzo del Setup centrale è, come abbiamo discusso nell'introduzione, facoltativo. Attiva la replica selezionando Push configuration to this site se desideri configurare l'istanza remota dall'istanza centrale. In tal caso, seleziona le impostazioni esatte come mostrato nell'immagine sopra.
Assicurati di verificare quale Message broker port devi specificare.
Per scoprirlo, accedi all'istanza remota e esegui omd config dalla riga di comando.
Vai alla sezione Basic.
Qui la variabile RABBITMQ_PORT è quella rilevante.
┌─────────────────Basic───────────────────┐ │ ┌─────────────────────────────────────┐ │ │ │ ADMIN_MAIL │ │ │ │ AGENT_RECEIVER on │ │ │ │ AGENT_RECEIVER_PORT 8016 │ │ │ │ AUTOMATION_HELPER on │ │ │ │ AUTOSTART on │ │ │ │ CORE cmc │ │ │ │ RABBITMQ_DIST_PORT 25672 │ │ │ │ RABBITMQ_MANAGEMENT_PORT 15671 │ │ │ │ RABBITMQ_ONLY_FROM :: │ │ │ │ RABBITMQ_PORT 5671 │ │ │ │ TMPFS on │ │ │ │ │ │ │ └─────────────────────────────────────┘ │ ├─────────────────────────────────────────┤ │ < Change > <Main menu> │ └─────────────────────────────────────────┘
Non confonderti: l'Message Broker Port è definito nella variabile |
È molto importante impostare correttamente l'URL of remote site.
L'URL deve sempre terminare con /check_mk/. Si consiglia una connessione HTTPS, a condizione che Apache sull'istanza remota supporti HTTPS.
Questo deve essere installato manualmente sull'istanza remota a livello di Linux.
Per Checkmk Appliance, HTTPS può essere configurato utilizzando l'interfaccia web di configurazione.
Se utilizzi un certificato self-signed, dovrai selezionare la casella di controllo Ignore SSL certificate errors.
Una volta salvata la maschera, nella panoramica apparirà una seconda istanza:

Lo stato di monitoraggio dell'istanza remota (finora) vuoto è ora correttamente integrato.
Per utilizzare la configurazione centrale hai ancora bisogno di un Login per l'istanza Checkmk remota.
A tal fine, l'istanza centrale scambia con l'istanza remota un segreto di login generato casualmente, attraverso il quale avverrà tutta la comunicazione futura.
L'account cmkadmin sull'istanza remota non verrà più utilizzato in seguito.
Nel seguente modulo, usa come Login credentials cmkadmin e la password assegnata al momento della creazione dell'istanza remota.
A questo punto, conferma che vuoi sovrascrivere le impostazioni cliccando su "Confirm overwrite".

Un login riuscito verrà riconosciuto in questo modo:

Se si verifica un errore durante il login, ciò potrebbe essere dovuto a diversi motivi – ad esempio:
L'istanza remota è attualmente inattiva.
L'URL of remote sitee non è stato configurato correttamente.
L'istanza remota non è raggiungibile con il nome host "dall'istanza centrale" specificato nell'URL.
Le versioni di Checkmk dell'istanza centrale e dell'istanza remota sono (troppo) incompatibili.
Sono stati inseriti un ID utente e/o una password non valide.
Le prime due voci dell’elenco possono essere facilmente verificate richiamando manualmente l’URL del sito remoto nel tuo browser.
Quando tutto è andato a buon fine, esegui Activate Changes. Questo, come sempre, ti porterà a una panoramica delle modifiche non ancora attive. Contemporaneamente, la panoramica mostrerà anche gli stati delle connessioni Livestatus, così come gli stati di sincronizzazione delle singole istanze nel Setup centrale:
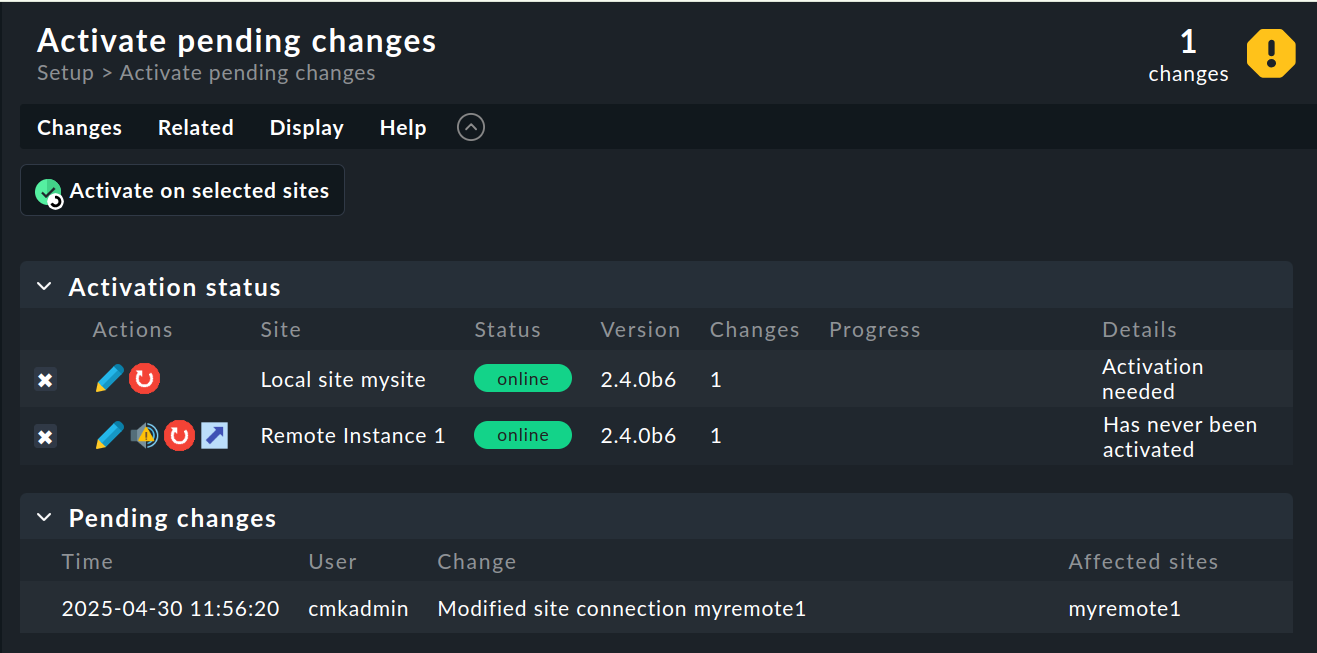
La colonna Version mostra la versione Livestatus dell’istanza corrispondente. Quando si utilizza il CMC come core di Checkmk (edizioni commerciali), il numero di versione del core (visualizzato nella colonna ‘Core’) è identico a quello di Livestatus. Se stai utilizzando Nagios come core (Comunità Checkmk), qui verrà visualizzato il numero di versione di Nagios.
I seguenti simboli mostrano lo stato di replica dell'ambiente di configurazione:
|
Questo sito presenta modifiche in sospeso.
La configurazione corrisponde all'istanza centrale, ma non tutte le modifiche sono state attivate.
Con il pulsante " |
|
La configurazione per questa istanza non è sincronizzata e deve essere trasferita.
Ovviamente sarà poi necessario un riavvio per attivarla.
Entrambe le funzioni possono essere eseguite con un clic sul pulsante " |
Nella colonna "Status" puoi vedere lo stato della connessione Livestatus per l'istanza in questione. Questo viene mostrato solo a titolo informativo, poiché la configurazione non viene trasmessa tramite Livestatus, ma piuttosto tramite HTTP. Sono possibili i seguenti valori:
|
L'istanza è raggiungibile tramite Livestatus. |
|
Il sito al momento non è raggiungibile. Le richieste Livestatus stanno andando in timeout. Questo rallenta il caricamento della pagina. I dati di stato per questo sito non sono visibili nella GUI. |
|
Il sito al momento non è raggiungibile, ma ciò è dovuto alla configurazione di un host di stato o è noto tramite il proxy Livestatus (vedi sotto). L'inaccessibilità non porta a timeout. I dati di stato per questo sito non sono visibili nella GUI. |
|
La connessione Livestatus a questa istanza è stata temporaneamente disattivata dall'amministratore (dell'istanza centrale). L'impostazione corrisponde alla box "Temporarily disable this connection" nelle impostazioni di questa connessione. |
Cliccando sul pulsante "![]() " (Sincronizza tutte le istanze) Activate on selected sites ora sincronizzerai tutte le istanze e attiverai le modifiche.
Questo viene eseguito in parallelo, quindi il tempo totale corrisponde al tempo richiesto dall'istanza più lenta.
Il tempo include la creazione di un'istantanea di configurazione per l'istanza corrispondente, la trasmissione via HTTP, la decompressione dell'istantanea sull'istanza remota e l'attivazione delle modifiche.
" (Sincronizza tutte le istanze) Activate on selected sites ora sincronizzerai tutte le istanze e attiverai le modifiche.
Questo viene eseguito in parallelo, quindi il tempo totale corrisponde al tempo richiesto dall'istanza più lenta.
Il tempo include la creazione di un'istantanea di configurazione per l'istanza corrispondente, la trasmissione via HTTP, la decompressione dell'istantanea sull'istanza remota e l'attivazione delle modifiche.
Importante: non abbandonare la pagina prima che la sincronizzazione sia stata completata su tutte le istanze — abbandonare la pagina interromperà la sincronizzazione.
Specificare agli host e alle cartelle quale istanza deve effettuare il monitoraggio
Una volta completata l'installazione del tuo ambiente distribuito, puoi iniziare a utilizzarlo. In realtà devi solo indicare a ciascun host da quale istanza deve essere monitorato. L'istanza centrale è specificata di default.
L'attributo richiesto per questo è Monitored on site. Puoi impostarlo individualmente per ogni host. Naturalmente, questo può essere eseguito anche a livello di cartella:

Eseguire una nuova scoperta del servizio e attivare le modifiche per gli host migrati
L'aggiunta di host funziona come al solito: a parte il fatto che sia il monitoraggio che la scoperta del servizio verranno eseguiti dalle rispettive istanze remote, non ci sono considerazioni particolari.
Quando si migrano host da un sito a un altro, ci sono un paio di punti da tenere a mente. Né i dati di stato attuali né quelli storici dell'host verranno trasferiti. Solo la configurazione dell'host viene mantenuta nell'ambiente di configurazione. In pratica è come se l'host fosse stato rimosso da un sito e reinstallato ex novo sull'altro sito:
I servizi rilevati automaticamente non verranno migrati. Esegui la scoperta del servizio dopo la migrazione.
Una volta riavviati, gli host e i servizi mostreranno lo stato IN SOSP. Di conseguenza, i problemi attualmente esistenti potrebbero essere segnalati nuovamente.
Le metriche storiche andranno perse. Questo può essere evitato spostando manualmente i file RRD pertinenti. La posizione dei file è indicata in File e directory.
I dati relativi alla disponibilità e agli eventi storici andranno persi. Purtroppo non è facile migrarli, poiché i dati consistono in singole righe nel log di monitoraggio.
Se la continuità della cronologia è importante per te, quando implementi il monitoraggio dovresti pianificare attentamente quale host deve essere monitorato e da dove.
2.3. Connessione di Livestatus con crittografia
Le connessioni Livestatus tra l'istanza centrale e un'istanza remota possono essere crittografate.
Per le istanze appena create non è necessario fare altro,
poiché Checkmk si occupa automaticamente dei passaggi necessari.
Non appena utilizzi omd config per attivare Livestatus, anche la crittografia viene attivata automaticamente tramite TLS:
┌────────────Distributed Monitoring──────────────┐ │ ┌────────────────────────────────────────────┐ │ │ │ LIVEPROXYD on │ │ │ │ LIVESTATUS_TCP on │ │ │ │ LIVESTATUS_TCP_ONLY_FROM 0.0.0.0 ::/0 │ │ │ │ LIVESTATUS_TCP_PORT 6557 │ │ │ │ LIVESTATUS_TCP_TLS on │ │ │ │ PIGGYBACK_HUB on │ │ │ │ │ │ │ └────────────────────────────────────────────┘ │ ├────────────────────────────────────────────────┤ │ < Change > <Main menu> │ └────────────────────────────────────────────────┘
La configurazione del monitoraggio distribuito rimane quindi semplice come lo è stata finora. Per le nuove connessioni ad altre istanze, l'opzione Encryption viene quindi abilitata automaticamente.
Dopo aver aggiunto l'istanza remota, noterai due cose: in primo luogo, la connessione è contrassegnata come crittografata da questo nuovo simbolo ![]() .
In secondo luogo, Checkmk ti segnalerà che la CA non considererà più attendibile l'istanza remota.
Clicca su
.
In secondo luogo, Checkmk ti segnalerà che la CA non considererà più attendibile l'istanza remota.
Clicca su ![]() per visualizzare i dettagli dei certificati utilizzati.
Cliccando su
per visualizzare i dettagli dei certificati utilizzati.
Cliccando su ![]() potrai aggiungere comodamente la CA tramite l'interfaccia web.
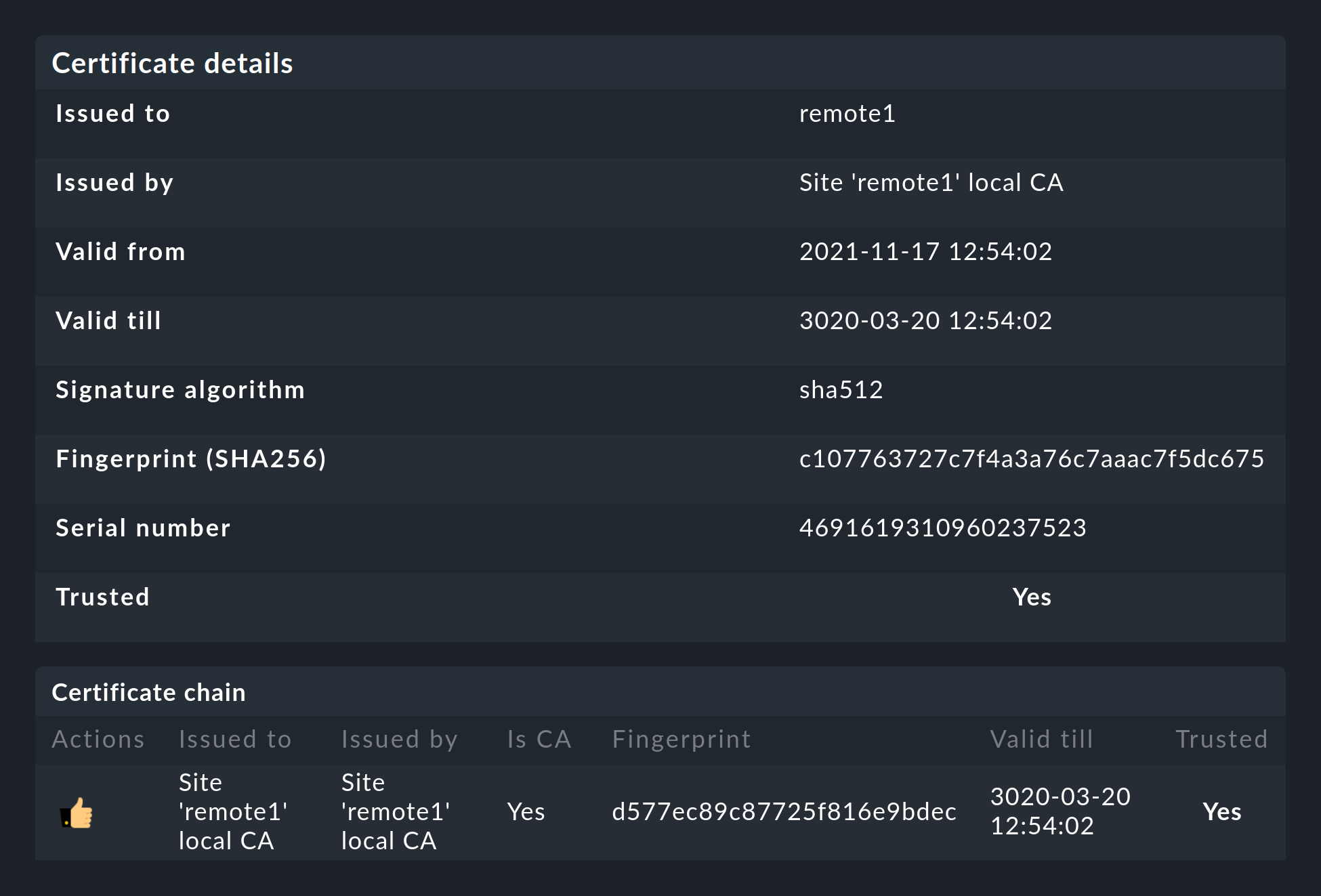
A quel punto entrambi i certificati saranno elencati come attendibili:
potrai aggiungere comodamente la CA tramite l'interfaccia web.
A quel punto entrambi i certificati saranno elencati come attendibili:
Dettagli sulle tecnologie utilizzate
Per ottenere la crittografia, Checkmk utilizza il programma stunnel insieme al proprio certificato e alla propria autorità di certificazione (CA) per firmare il certificato.
Questi vengono generati automaticamente in modo individuale con una nuova istanza e non sono quindi CA o certificati statici predefiniti.
Questo è un fattore di sicurezza molto importante per impedire che certificati falsi vengano utilizzati dagli hacker, poiché qualsiasi hacker potrebbe altrimenti ottenere l'accesso a una CA disponibile pubblicamente.
I certificati generati hanno anche le seguenti proprietà:
Entrambi i certificati sono in formato PEM. I certificati firmati per l'istanza contengono anche la catena di certificati completa.
Le chiavi utilizzano RSA a 4096 bit e il certificato è firmato con SHA512
Il certificato dell'istanza è valido per 10 anni.
Il fatto che il certificato standard sia valido per così tanto tempo impedisce in modo molto efficace di incorrere in problemi di connessione che non riesci a classificare. Allo stesso tempo è ovviamente possibile che, una volta che un certificato è stato compromesso, rimanga di conseguenza esposto ad abusi per un lungo periodo. Quindi, se temi che un hacker possa accedere alla CA o al certificato dell'istanza firmato con essa, sostituisci sempre entrambi i certificati (CA e istanza)!
Migrazione da versioni precedenti
Durante un aggiornamento di Checkmk, le due opzioni LIVESTATUS_TCP e LIVESTATUS_TCP_TLS non vengono mai modificate automaticamente.
L'attivazione automatica di TLS potrebbe alla fine impedire di interrogare le tue istanze remote.
Se finora hai utilizzato Livestatus senza crittografia e ora decidi di utilizzare la crittografia, devi attivarla manualmente. Per farlo, prima ferma le istanze interessate e poi attiva TLS con il seguente comando:
Poiché i certificati sono stati generati automaticamente durante l'aggiornamento, l'istanza utilizza immediatamente la nuova funzione di crittografia. Per poter continuare ad accedere all'istanza dal sito centrale, verifica che l'opzione "Encryption" sia impostata su "Encrypt data using TLS" nel menu sotto "Setup > General > Distributed Monitoring": Check questo e, se necessario, imposta l'opzione come mostrato nella seguente schermata:
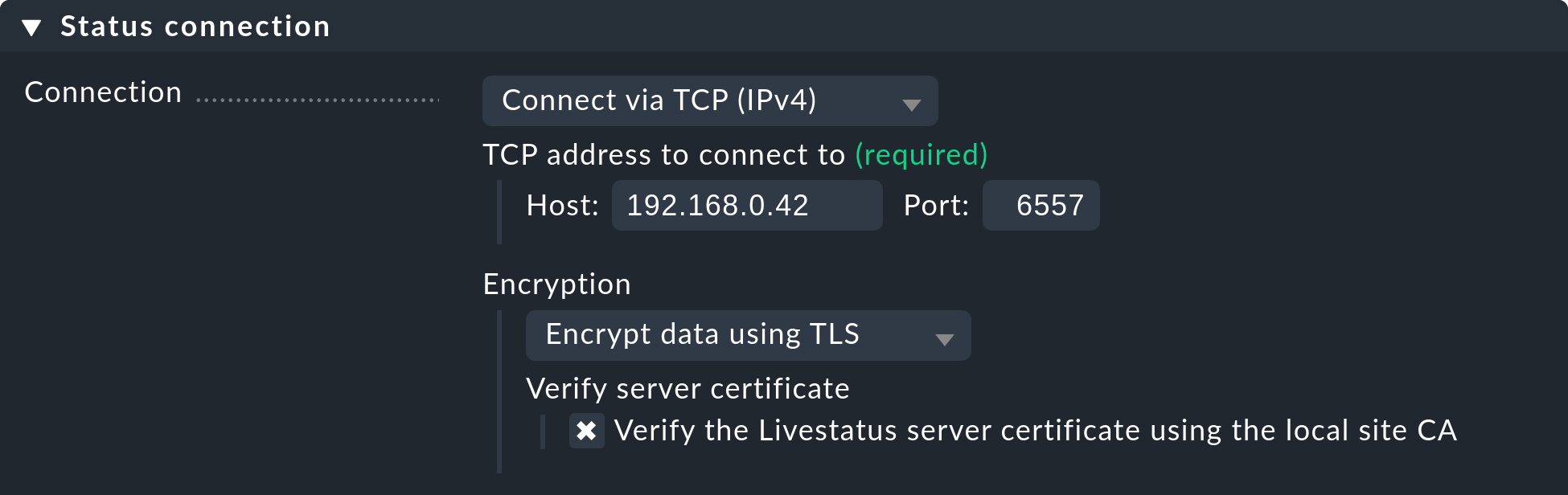
L'ultimo passaggio è quello descritto sopra: anche in questo caso devi prima contrassegnare la CA dell'istanza remota come attendibile.
2.4. Caratteristiche speciali di un Setup centrale
Un monitoraggio distribuito funziona tramite Livestatus in modo molto simile a un singolo sistema, ma presenta alcune caratteristiche speciali:
Accesso agli host sottoposti a monitoraggio
Tutti gli accessi a un host monitorato vengono effettuati in modo coerente dal sito a cui l'host è assegnato. Questo vale non solo per il monitoraggio vero e proprio, ma anche per la scoperta del servizio, la pagina Diagnostics, le notifiche, i gestori di avvisi e tutto il resto. Questo punto è molto importante poiché non si presume che l'istanza centrale abbia effettivamente accesso a questo host.
Specificare il sito nelle visualizzazioni
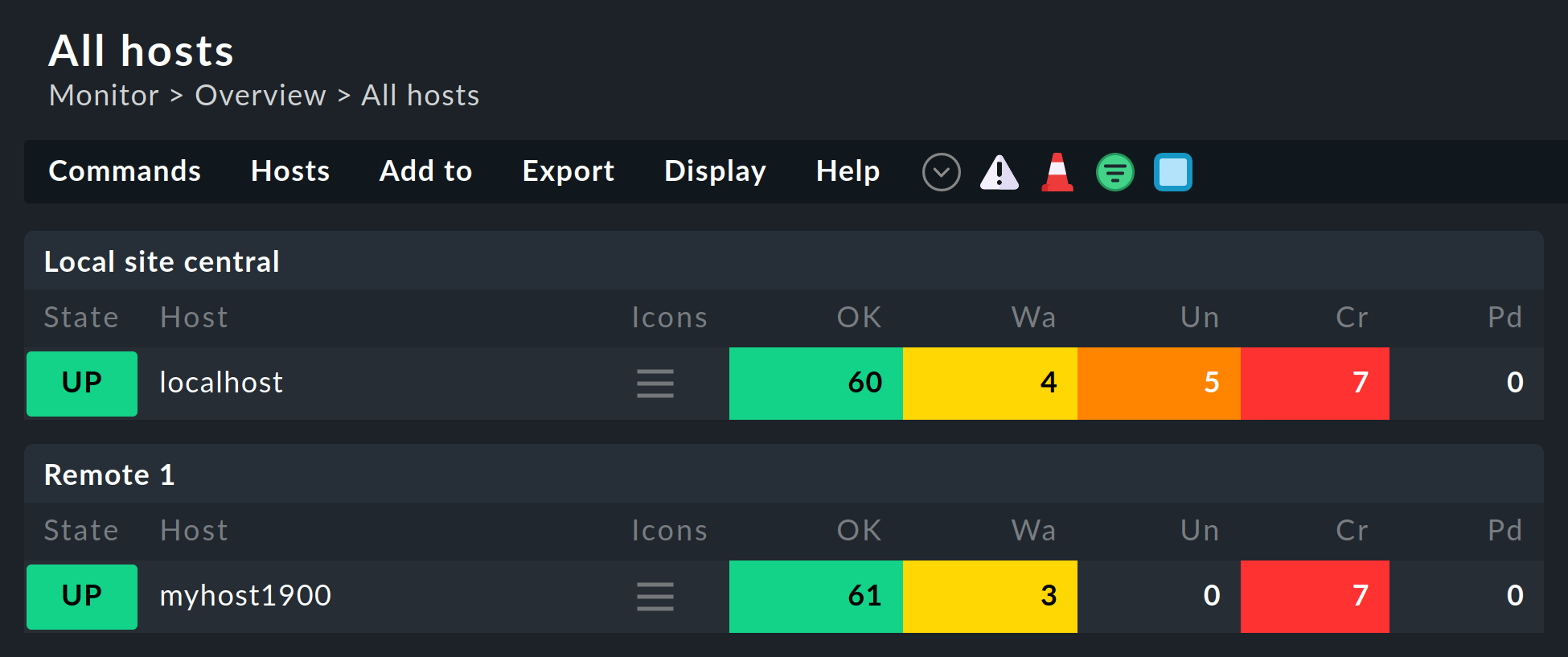
Alcune delle visualizzazioni standard sono raggruppate in base all'istanza da cui verrà effettuato il monitoraggio dell'host — questo vale, ad esempio, per All hosts:
Il sito verrà mostrato anche nei dettagli dell'host o del servizio:
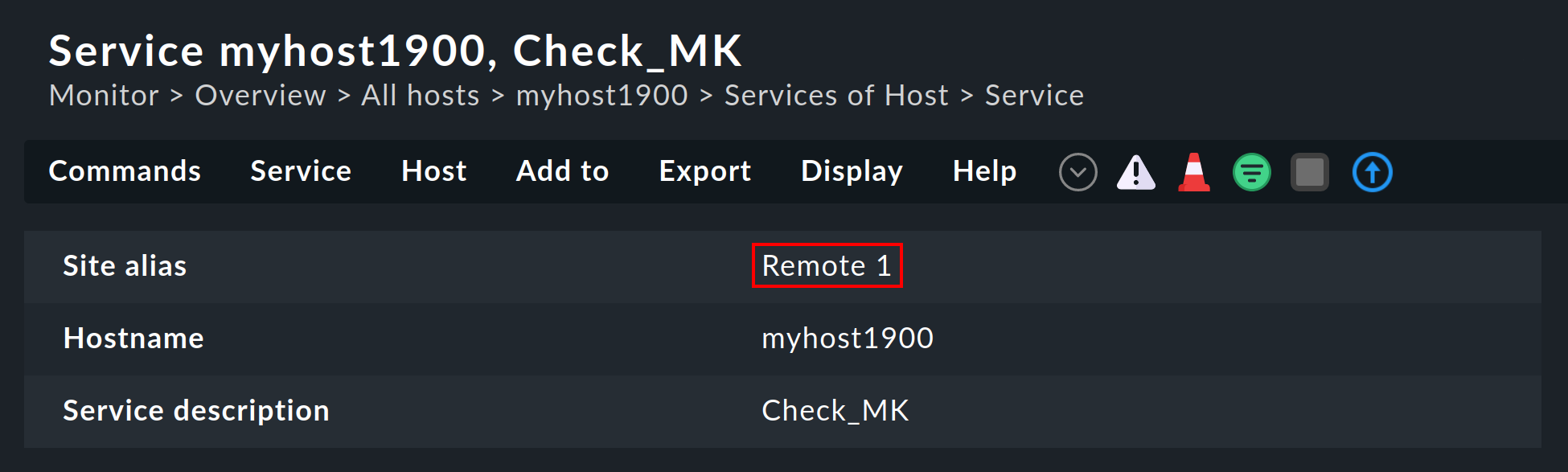
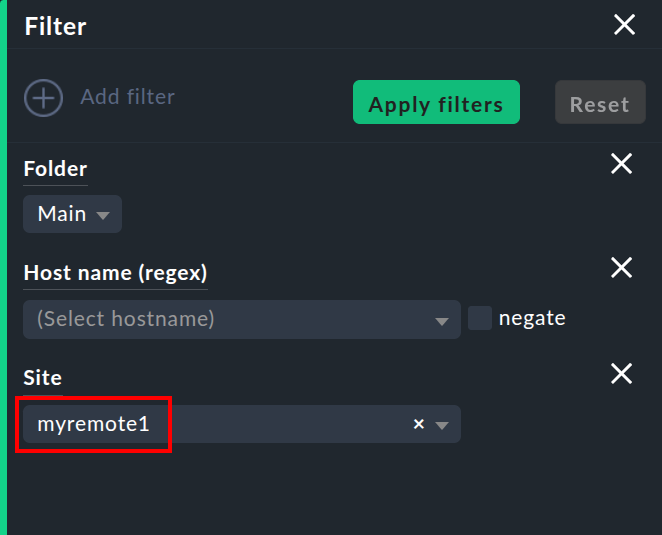
Queste informazioni sono generalmente disponibili per l'uso in una colonna quando crei le tue visualizzazioni personalizzate. C'è anche un filtro con cui è possibile filtrare una visualizzazione degli host su un'istanza specifica:
Snap-in dello stato dell'istanza
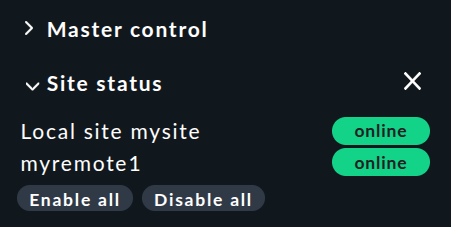
C'è uno snap-in "Site status" per la barra laterale che puoi aggiungere tramite ![]() .
Questo mostra lo stato delle singole istanze.
Offre anche la possibilità di disabilitare e riabilitare temporaneamente una singola istanza cliccando sullo stato — o tutte le istanze contemporaneamente cliccando su "Disable all" o "Enable all".
.
Questo mostra lo stato delle singole istanze.
Offre anche la possibilità di disabilitare e riabilitare temporaneamente una singola istanza cliccando sullo stato — o tutte le istanze contemporaneamente cliccando su "Disable all" o "Enable all".
I siti disabilitati saranno contrassegnati con lo stato "![]() ".
In questo modo puoi anche disabilitare un sito
".
In questo modo puoi anche disabilitare un sito ![]() che sta generando timeout, evitando così timeout superflui.
Questa disabilitazione non è la stessa cosa che disabilitare la connessione Livestatus utilizzando la configurazione della connessione in Setup.
Qui la "disabilitazione" riguarda solo l'utente attualmente connesso e ha una funzione puramente visiva.
Cliccando sul nome di un sito verrà visualizzata una visualizzazione di tutti i suoi host.
che sta generando timeout, evitando così timeout superflui.
Questa disabilitazione non è la stessa cosa che disabilitare la connessione Livestatus utilizzando la configurazione della connessione in Setup.
Qui la "disabilitazione" riguarda solo l'utente attualmente connesso e ha una funzione puramente visiva.
Cliccando sul nome di un sito verrà visualizzata una visualizzazione di tutti i suoi host.
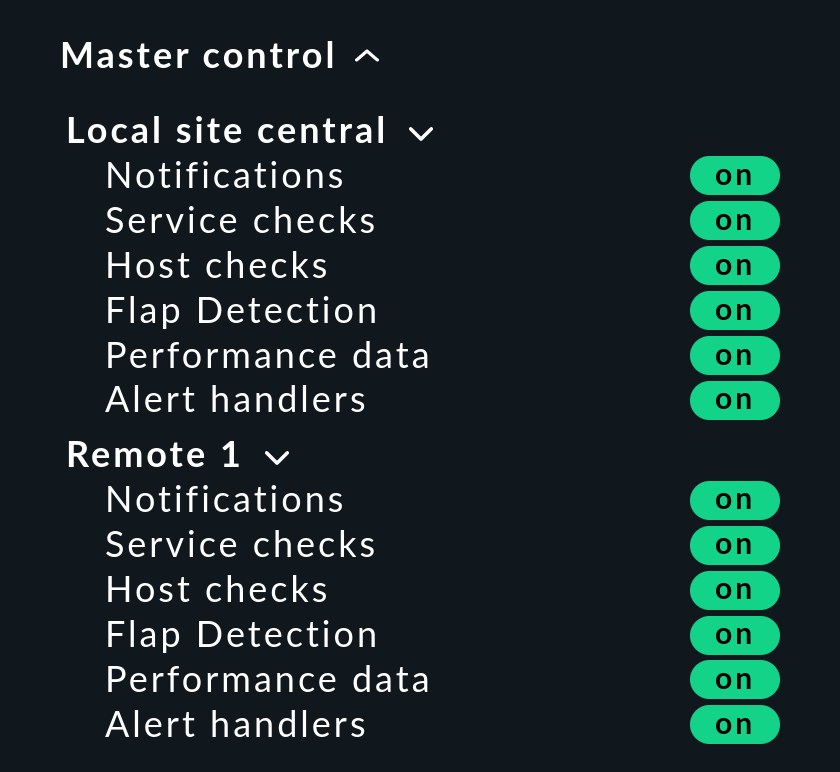
Snap-in di controllo master
In un monitoraggio distribuito, lo snap-in "Master control" ha un aspetto diverso. Ogni istanza ha il proprio switch globale:
Host del cluster Checkmk
Se monitori con il cluster HA di Checkmk, i singoli nodi del cluster devono essere assegnati allo stesso sito del cluster stesso. Questo perché per determinare lo stato dei servizi in cluster si accede ai file di cache generati dal monitoraggio del nodo. Questi dati si trovano localmente sull’istanza corrispondente.
Dati piggyback
Alcuni plug-in di controllo utilizzano i dati Piggyback, ad esempio per assegnare i dati di monitoraggio che sono stati "piggybackati" da un host alle singole macchine virtuali. Nel monitoraggio distribuito, l'host piggyback — ovvero l'host che riceve i dati piggyback — e gli host che dipendono da esso — in quanto effettivi consumatori dei dati piggyback — non sono sempre monitorati dallo stesso sito. In questi casi, è possibile attivare un'assegnazione cross-site dei dati piggyback.
Per abilitare tale comunicazione, devi solo assicurarti che la porta del broker di messaggi sia impostata correttamente su tutte le istanze partecipanti e che l'hub piggyback sia abilitato.
Dovresti checkare questo aspetto al più tardi quando vedi "Disabled" qui:

Connessioni peer-to-peer
Il traffico dati spesso crea un collo di bottiglia nella comunicazione. Se i dati vengono scambiati da ogni punto a ogni altro punto, questo può portare rapidamente a un enorme flusso di dati e quindi a un sovraccarico della rete di comunicazione. È quindi consigliabile ridurre il numero di canali di comunicazione e mantenere lo scambio di dati principalmente all’interno di una rete locale. Quindi, per ridurre il carico sull'istanza centrale o per ottimizzare il traffico di rete, puoi anche consentire alle istanze remote di comunicare direttamente tra loro (connessione peer-to-peer). Come prerequisito per questo, entrambe le istanze remote devono essere state configurate dall'istanza centrale, ovvero Push configuration to this site deve essere attivato per entrambe come descritto nella sezione Assegnazione delle istanze remote all'istanza centrale.
In Setup > General > Distributed monitoring seleziona la voce di menu "Connections > Add peer-to-peer message broker connection". Assegna qui un ID univoco e seleziona le due istanze per la connessione diretta. Assicurati di seguire le istruzioni nell'aiuto in linea.
inventario HW/SW
L'inventario HW/SW di Checkmk funziona anche in ambienti distribuiti.
A tal fine, i dati di inventario dalla directory ~/var/check_mk/inventory devono essere trasmessi regolarmente dalle istanze remote all'istanza centrale.
Per motivi di performance, l'interfaccia utente accede sempre a questa directory localmente.
Nelle edizioni commerciali la sincronizzazione viene eseguita automaticamente su tutte le istanze collegate tramite il proxy Livestatus.
Se esegui l'inventario utilizzando la Comunità Checkmk in sistemi distribuiti, la directory deve essere regolarmente replicata sull'istanza centrale con i tuoi strumenti (ad es. con rsync).
Modifica della password
Anche quando tutte le istanze sono sottoposte a monitoraggio centralizzato, è possibile e spesso anche opportuno effettuare il login sull'interfaccia di un'istanza singola. Per questo motivo Checkmk garantisce che la password di un utente sia sempre la stessa per tutte le istanze.
Una modifica della password effettuata dall'amministratore avrà effetto automaticamente non appena verrà condivisa con tutte le istanze tramite Activate pending changes.
Una modifica effettuata dall’utente stesso tramite la barra laterale ![]() nelle impostazioni personali funziona in modo leggermente diverso.
In questo caso non è possibile eseguire un comando Activate pending changes poiché l’utente, ovviamente, non dispone del permesso generale per questa funzione.
In tal caso Checkmk distribuirà automaticamente la password modificata a tutte le istanze — subito dopo che è stata salvata, in realtà.
nelle impostazioni personali funziona in modo leggermente diverso.
In questo caso non è possibile eseguire un comando Activate pending changes poiché l’utente, ovviamente, non dispone del permesso generale per questa funzione.
In tal caso Checkmk distribuirà automaticamente la password modificata a tutte le istanze — subito dopo che è stata salvata, in realtà.
Come tutti sappiamo, le reti non sono mai disponibili al 100%. Se un sito è non raggiungibile al momento della modifica della password, non riceverà la nuova password. Fino a quando l'amministratore non eseguirà con successo un Activate pending changes, o rispettivamente, fino alla successiva modifica della password riuscita, questo sito manterrà la vecchia password per l'utente. Un simbolo di stato informerà l'utente sullo stato della condivisione della password con le singole istanze.
2.5. Collegamento di istanze esistenti
Come menzionato sopra, anche le istanze esistenti possono essere collegate a posteriori a un monitoraggio distribuito. Purché siano soddisfatti i prerequisiti descritti sopra (versioni Checkmk compatibili), questa operazione verrà completata esattamente come per la configurazione di una nuova istanza remota. Condividi Livestatus con TCP, poi aggiungi l’istanza tramite Setup > General > Distributed monitoring – e il gioco è fatto!
La seconda fase — il passaggio a una configurazione centrale — è un po’ più complicata. Prima di integrare l’istanza nell’ambiente di configurazione centrale come descritto sopra, tieni presente che così facendo l’intera configurazione locale dell’istanza verrà sovrascritta! |
Se desideri acquisire gli host esistenti, e possibilmente anche le regole, saranno necessari tre passaggi:
Corrisponde lo schema dei tag host
Copia le directory (host)
Modifica le caratteristiche nella cartella principale
1. Tag host
È ovvio che i tag host utilizzati nell’istanza remota debbano essere noti anche all’istanza centrale affinché possano essere trasferiti. Checkali prima della migrazione e aggiungi manualmente all’istanza centrale eventuali tag mancanti. In questo caso è essenziale che gli ID dei tag corrispondano; il titolo del tag è irrilevante.
2. Cartelle
Successivamente, sposta gli host e le regole nell’ambiente di configurazione dell’istanza centrale. Questo funziona solo per gli host e le regole presenti nelle sottocartelle (cioè non nella cartella Main). Gli host nella cartella Main devono prima essere semplicemente spostati in una sottocartella dell’istanza remota tramite Setup > Hosts > Hosts.
La migrazione vera e propria può quindi essere effettuata semplicemente copiando le directory appropriate.
Ogni cartella nell'ambiente di configurazione corrisponde a una directory all'interno di ~/etc/check_mk/conf.d/wato/.
Queste possono essere copiate utilizzando uno strumento a tua scelta (ad es. scp) dall'istanza collegata alla stessa posizione nell'istanza centrale.
Se lì esiste già una directory con lo stesso nome, basta rinominarla.
Tieni presente che anche gli utenti e i gruppi Linux vengono utilizzati dall'istanza centrale.
Dopo la copia, gli host appariranno nell'istanza centrale in Setup, così come le regole che hai creato in queste cartelle.
Anche le proprietà delle cartelle saranno incluse nella copia.
Queste si trovano nella directory del file nascosto .wato.
3. Edizione e salvataggio una tantum
Affinché gli attributi delle funzioni della cartella principale dell’istanza centrale vengano ereditati correttamente, come passo finale dopo la migrazione, le caratteristiche delle cartelle principali devono essere aperte e salvate una volta – in questo modo gli attributi dell’host verranno ridefiniti.
2.6. Impostazioni globali specifiche per istanza
Un Setup centrale significa innanzitutto che tutte le istanze hanno una configurazione comune e (a parte gli host) identica. Ma cosa succede quando singole istanze richiedono impostazioni globali diverse? Un esempio potrebbe essere l’impostazione CMC Maximum concurrent Checkmk checks. Potrebbe essere necessaria un’impostazione personalizzata per un’istanza particolarmente piccola o particolarmente grande.
Per questi casi esiste un’impostazione globale specifica per l’istanza.
Ci si accede tramite il simbolo ![]() nel menu sotto Setup > General > Distributed monitoring:
nel menu sotto Setup > General > Distributed monitoring:

Tramite questo simbolo troverai una selezione di tutte le impostazioni globali, anche se qualsiasi cosa tu definisca qui sarà efficace solo per l'istanza scelta. Un valore che si discosta dallo standard verrà evidenziato visivamente e si applicherà solo a questa istanza:

2.7. Console degli Eventi distribuita
La Console degli Eventi elabora messaggi syslog, SNMP trap e altri tipi di eventi di natura asincrona.
Checkmk offre anche la possibilità di utilizzare una Console degli Eventi distribuita.
In questo modo, ogni istanza eseguirà la propria elaborazione degli eventi, acquisendo quelli provenienti da tutti gli host monitorati dall’istanza stessa.
Gli eventi non verranno quindi inviati al sistema centrale, ma rimarranno nelle istanze e saranno solo recuperati a livello centrale.
Questo funziona in modo simile a quanto avviene per gli stati attivi tramite Livestatus ed è disponibile sia nell’![]() , sia nelle edizioni commerciali di Checkmk.
, sia nelle edizioni commerciali di Checkmk.
Per passare a una Console degli Eventi distribuita secondo il nuovo schema, devi seguire questi passaggi:
Nelle impostazioni di connessione, attiva l'opzione (Replicate Event Console configuration to this site).
Switch la posizione syslog e le destinazioni SNMP trap per gli host interessati all'istanza remota. Questa è l'operazione più laboriosa.
Se utilizzi il set di regole Check event state in Event Console, switchalo su Connect to the local Event Console.
Se utilizzi il set di regole Logwatch Event Console Forwarding, switch anche questo sulla Console degli Eventi locale.
Nella Console degli Eventi Settings, switch l'Access to event status via TCP su no access via TCP.
2.8. NagVis

Il programma open source NagVis visualizza i dati di stato del monitoraggio su mappe, diagrammi e altri grafici generati automaticamente. NagVis è integrato in Checkmk e può essere utilizzato immediatamente. L'accesso più semplice avviene tramite l'elemento della barra laterale "NagVis Maps". L'integrazione di NagVis in Checkmk è descritta in un articolo a parte.
NagVis supporta il monitoraggio distribuito tramite Livestatus più o meno allo stesso modo di Checkmk. I collegamenti alle singole istanze sono indicati come back-end. I back-end vengono configurati automaticamente in modo corretto da Checkmk, così puoi iniziare subito a generare grafici NagVis, anche nel monitoraggio distribuito.
Seleziona il back-end corretto per ogni oggetto che inserisci in un grafico, ovvero il sito Checkmk da cui deve essere effettuato il monitoraggio dell'oggetto. NagVis non è in grado di trovare automaticamente l'host o il servizio, soprattutto per motivi di performance. Pertanto, se sposti gli host su un'istanza remota diversa, dovrai aggiornare di conseguenza i grafici NagVis.
Maggiori dettagli sui back-end sono disponibili nella documentazione qui: NagVis.
3. Connessioni instabili o lente
La panoramica generale dello stato nell'interfaccia utente garantisce un accesso sempre disponibile e affidabile a tutti i siti collegati. L'unico inconveniente è che una visualizzazione può essere visualizzata solo quando tutte le istanze hanno risposto. Il processo è sempre lo stesso: prima viene inviata una query Livestatus (ad esempio, "Elenca tutte le istanze il cui stato non è OK."). La visualizzazione può quindi essere visualizzata solo dopo che l'ultima istanza ha risposto.
È fastidioso quando un sito non risponde affatto.
Per tollerare brevi interruzioni (ad esempio, dovute al riavvio di un sito o alla perdita di un pacchetto TCP), la GUI attende un determinato tempo prima di dichiarare un sito come "![]() " e poi continua a elaborare le risposte delle istanze rimanenti.
Questo provoca un "blocco" della GUI.
Il timeout è impostato su 10 secondi per impostazione predefinita.
" e poi continua a elaborare le risposte delle istanze rimanenti.
Questo provoca un "blocco" della GUI.
Il timeout è impostato su 10 secondi per impostazione predefinita.
Se questo accade occasionalmente nella tua rete, dovresti configurare gli host di stato o (ancora meglio) il proxy Livestatus.
3.1. Host di stato
![]() La configurazione degli host di stato è la procedura raccomandata dall'
La configurazione degli host di stato è la procedura raccomandata dall'![]() a Comunità Checkmk per riconoscere in modo affidabile le connessioni difettose.
L'idea è semplice
L'istanza centrale monitora attivamente la connessione a ogni singola istanza remota.
Almeno avremo un sistema di monitoraggio a disposizione!
La GUI sarà quindi a conoscenza delle istanze non raggiungibili e potrà immediatamente escluderle e contrassegnarle come "
a Comunità Checkmk per riconoscere in modo affidabile le connessioni difettose.
L'idea è semplice
L'istanza centrale monitora attivamente la connessione a ogni singola istanza remota.
Almeno avremo un sistema di monitoraggio a disposizione!
La GUI sarà quindi a conoscenza delle istanze non raggiungibili e potrà immediatamente escluderle e contrassegnarle come "![]() ".
I timeout vengono così ridotti al minimo.
".
I timeout vengono così ridotti al minimo.
Ecco come configurare uno status host per una connessione:
Aggiungi l'host su cui è in esecuzione l'istanza remota al sito centrale nel monitoraggio.
Inseriscilo come host di stato nella connessione al sito remoto:
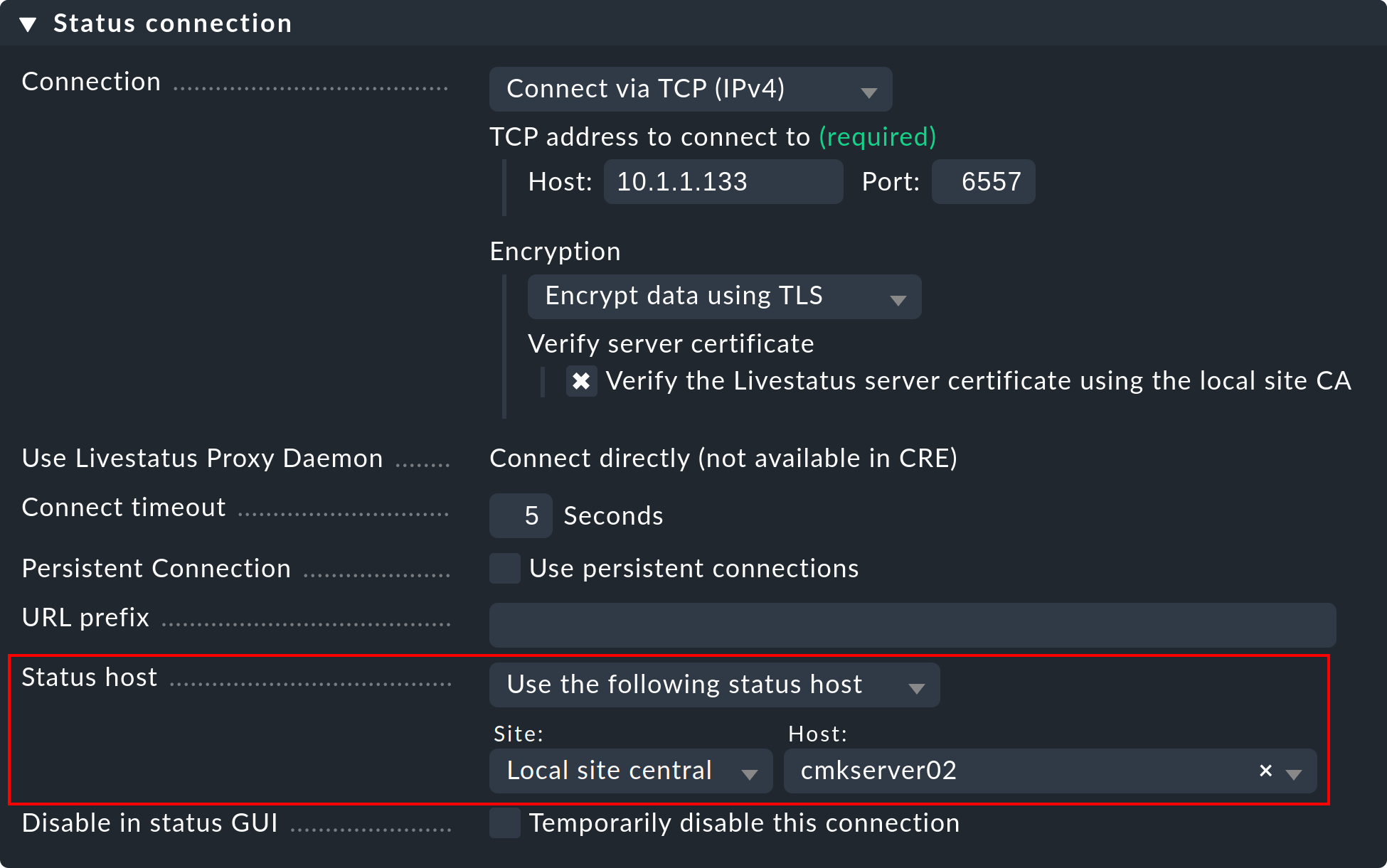
Una connessione fallita a un'istanza remota ora può portare solo a un breve blocco della GUI, ovvero fino a quando il monitoraggio non lo ha riconosciuto. Riducendo l'intervallo di verifica dell'host di stato da quello predefinito di sessanta secondi a, ad esempio, cinque secondi, puoi ridurre al minimo la durata di un blocco.
Se hai configurato un host di stato, ci sono ulteriori stati possibili per le connessioni:
|
Il computer su cui è in esecuzione l'istanza remota è al momento non raggiungibile dal monitoraggio perché un router è DOWN (l'host di stato ha uno stato "UNREACH"). |
|
L'host di stato che monitora la connessione al sistema remoto non è ancora stato verificato dal monitoraggio (ha ancora uno stato IN SOSP.). |
|
Lo stato dell'host ha un valore non valido (questo non dovrebbe mai verificarsi). |
In tutti e tre i casi la connessione al sito verrà esclusa, evitando così i timeout.
3.2. Connessioni persistenti
![]() Con la casella di controllo "Use persistent connections" puoi indicare alla GUI di mantenere le connessioni Livestatus stabilite con le istanze remote permanentemente in stato "up" e di continuare a utilizzarle per le query.
Soprattutto per le connessioni con tempi di risposta dei pacchetti più lunghi (ad es. intercontinentali), questo può rendere la GUI notevolmente più reattiva.
Con la casella di controllo "Use persistent connections" puoi indicare alla GUI di mantenere le connessioni Livestatus stabilite con le istanze remote permanentemente in stato "up" e di continuare a utilizzarle per le query.
Soprattutto per le connessioni con tempi di risposta dei pacchetti più lunghi (ad es. intercontinentali), questo può rendere la GUI notevolmente più reattiva.
Poiché la GUI di Apache è condivisa tra più processi indipendenti, è necessaria una connessione per ogni processo Apache-Client in esecuzione simultanea.
Se hai molti utenti simultanei, assicurati che la configurazione preveda un numero sufficiente di connessioni Livestatus nel core Nagios del remoto.
Queste sono configurate nel file ~/etc/mk-livestatus/nagios.cfg.
Il valore predefinito è venti (num_client_threads=20).
Per impostazione predefinita, Apache è configurato in Checkmk in modo da consentire fino a 128 connessioni utente simultanee.
Questo è configurato nella seguente sezione del file ~/etc/apache/apache.conf:
Ciò significa che in caso di carico elevato possono avviarsi fino a 128 processi Apache, che a loro volta generano e mantengono fino a 128 connessioni Livestatus.
Se il valore di num_client_threads non è impostato su un valore sufficientemente alto, potrebbero verificarsi errori o tempi di risposta molto lenti nella GUI.
Per le connessioni con LAN o con reti WAN veloci, ti consigliamo di non utilizzare connessioni persistenti.
3.3. Il proxy Livestatus
![]() Con il proxy Livestatus, le edizioni commerciali dispongono di un sofisticato meccanismo per rilevare le connessioni inattive.
Inoltre, ottimizza in modo particolare la performance delle connessioni con Round Trip Time lunghi. I vantaggi del proxy Livestatus sono:
Con il proxy Livestatus, le edizioni commerciali dispongono di un sofisticato meccanismo per rilevare le connessioni inattive.
Inoltre, ottimizza in modo particolare la performance delle connessioni con Round Trip Time lunghi. I vantaggi del proxy Livestatus sono:
Rilevamento molto veloce e proattivo delle istanze che non rispondono
Cache locale delle query che forniscono dati statici
Connessioni TCP permanenti — che richiedono meno round trip e di conseguenza consentono risposte molto più veloci da istanze distanti (ad es. USA ⇄ Cina)
Controllo preciso del numero massimo di connessioni Livestatus richieste
Consente l'inventario HW/SW in ambienti distribuiti
Installazione
Installare il proxy Livestatus è semplicissimo. È attivato di default nelle edizioni commerciali — come puoi vedere all'avvio di un'istanza:
Seleziona l'impostazione Use Livestatus Proxy-Daemon per la connessione alle istanze remote invece di Connect via TCP:
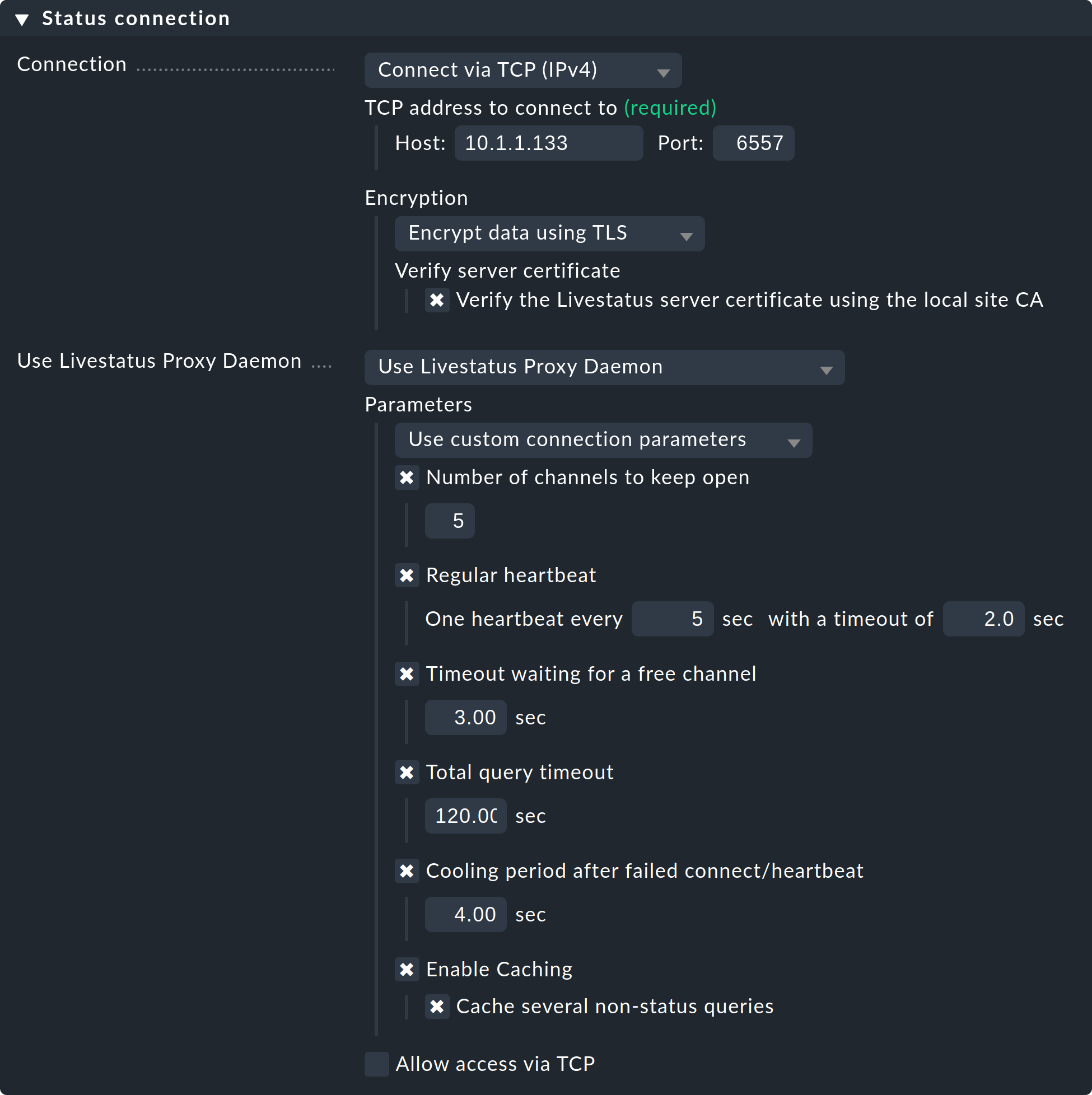
I dettagli relativi all'host e alla porta sono gli stessi di sempre. Non è necessario apportare modifiche sull'istanza remota. In "Number of channels to keep open" inserisci il numero di connessioni TCP parallele che il proxy deve stabilire e mantenere con il sito di destinazione.
Il pool di connessioni TCP è condiviso da tutte le richieste della GUI. Il numero di connessioni limita il numero massimo di query che possono essere elaborate contemporaneamente. Questo limita indirettamente il numero di utenti. In situazioni in cui tutti i canali sono occupati, ciò non porterà immediatamente a un errore. La GUI attende un determinato tempo per un canale libero. La maggior parte delle query richiede in realtà solo pochi millisecondi.
Se la GUI deve attendere più a lungo di unTimeout waiting for a free channele per un canale, verrà interrotta con un errore e l'utente riceverà un messaggio di errore. In tal caso, il numero di connessioni dovrebbe essere aumentato. Tieni presente, tuttavia, che sull'istanza remota devono essere consentite sufficienti connessioni in entrata parallele — questo valore è impostato su 20 per impostazione predefinita. Questa impostazione si trova nelle opzioni globali alla voce "Monitoring core > Maximum concurrent Livestatus connections".
L'Regular heartbeate fornisce un monitoraggio costantemente attivo delle connessioni direttamente a livello di protocollo. Durante il processo, il proxy invia regolarmente una semplice query Livestatus a cui l'istanza remota deve rispondere entro un tempo prestabilito (impostazione predefinita: 2 secondi). Con questo metodo viene rilevata anche una situazione in cui il server di destinazione e la porta TCP sono effettivamente raggiungibili, ma il nucleo di monitoraggio non risponde più.
Se la risposta non arriva, tutte le connessioni vengono dichiarate "morte" e, dopo un periodo di "cooldown" (impostazione predefinita: 4 secondi), vengono ristabilite. Tutto questo avviene in modo proattivo, cioè senza che tu debba aprire una finestra della GUI. In questo modo è possibile rilevare rapidamente le interruzioni e, tramite un recupero, le connessioni possono essere ristabilite immediatamente e, nel migliore dei casi, essere disponibili prima ancora che un utente si accorga dell'interruzione.
L'Cachinga garantisce che le query statiche debbano ricevere una risposta dall'istanza remota una sola volta e che, da quel momento in poi, possano essere gestite direttamente e localmente, senza ritardi. Un esempio è l'elenco degli host monitorati richiesto da Quicksearch.
Diagnosi degli errori
Il proxy Livestatus ha il proprio file di log ~/var/log/liveproxyd.log.
Su un'istanza remota configurata correttamente con cinque canali (standard) avrà un aspetto simile a questo:
2025-04-30 15:58:30,624 [20] ----------------------------------------------------------
2025-04-30 15:58:30,627 [20] [cmk.liveproxyd] Livestatus Proxy-Daemon (2.4.0p24) starting...
2025-04-30 15:58:30,638 [20] [cmk.liveproxyd] Configured 1 sites
2025-04-30 15:58:36,690 [20] [cmk.liveproxyd.(3236831).Manager] Reload initiated. Checking if configuration changed.
2025-04-30 15:58:36,692 [20] [cmk.liveproxyd.(3236831).Manager] No configuration changes found, continuing.
2025-04-30 16:00:16,989 [20] [cmk.liveproxyd.(3236831).Manager] Reload initiated. Checking if configuration changed.
2025-04-30 16:00:16,993 [20] [cmk.liveproxyd.(3236831).Manager] Found configuration changes, triggering restart.
2025-04-30 16:00:17,000 [20] [cmk.liveproxyd.(3236831).Manager] Restart initiated. Terminating site processes...
2025-04-30 16:00:17,028 [20] [cmk.liveproxyd.(3236831).Manager] Restart master processIl proxy Livestatus registra regolarmente il proprio stato nel file ~/var/log/liveproxyd.state:
Current state:
[myremote1]
State: ready
State dump time: 2025-04-30 15:01:15 (0:00:00)
Last reset: 2025-04-30 14:58:49 (0:02:25)
Site's last reload: 2025-04-30 14:26:00 (0:35:15)
Last failed connect: Never
Last failed error: None
Cached responses: 1
Channels:
9 - ready - client: none - since: 2025-04-30 15:01:00 (0:00:14)
10 - ready - client: none - since: 2025-04-30 15:01:10 (0:00:04)
11 - ready - client: none - since: 2025-04-30 15:00:55 (0:00:19)
12 - ready - client: none - since: 2025-04-30 15:01:05 (0:00:09)
13 - ready - client: none - since: 2025-04-30 15:00:50 (0:00:24)
Clients:
Heartbeat:
heartbeats received: 29
next in 0.2s
Inventory:
State: not running
Last update: 2025-04-30 14:58:50 (0:02:25)E quando un'istanza è attualmente ferma, lo stato sarà simile a questo:
----------------------------------------------
Current state:
[myremote1]
State: starting
State dump time: 2025-04-30 16:11:35 (0:00:00)
Last reset: 2025-04-30 16:11:29 (0:00:06)
Site's last reload: 2025-04-30 16:11:29 (0:00:06)
Last failed connect: 2025-04-30 16:11:33 (0:00:01)
Last failed error: [Errno 111] Connection refused
Cached responses: 0
Channels:
Clients:
Heartbeat:
heartbeats received: 0
next in -1.0s
Inventory:
State: not running
Last update: 2025-04-30 16:00:45 (0:10:50)Qui lo stato è "starting".
Il proxy sta quindi tentando di stabilire delle connessioni.
Non ci sono ancora canali.
In questo stato, le richieste all'istanza riceveranno una risposta di errore.
4. Livestatus a cascata
Come già accennato nell'introduzione, è possibile estendere un monitoraggio distribuito per includere istanze-viewer Checkmk dedicate che mostrano i dati di monitoraggio provenienti da istanze remote che di per sé non sono direttamente accessibili. L'unico prerequisito è che l'istanza centrale sia ovviamente accessibile. Tecnicamente, ciò viene implementato tramite il proxy Livestatus. L'istanza centrale riceve i dati dall'istanza remota tramite Livestatus e funge essa stessa da proxy, ovvero può trasmettere i dati a istanze terzi. Puoi estendere questa catena come desideri, ad esempio effettuando una connessione con un'altra istanza-viewer tramite la prima.
Ciò è pratico, ad esempio, in uno scenario come il seguente: L’istanza centrale supporta tre reti indipendenti — cliente1, cliente2 e cliente3 — ed è a sua volta gestita dall’operatore di rete1. Se la gestione dell’operatore della rete operatore1 volesse visualizzare lo stato di monitoraggio delle istanze dei clienti, ciò potrebbe ovviamente essere regolato tramite un accesso dall’istanza centrale. Per motivi tecnici e legali, tuttavia, l'istanza centrale potrebbe essere riservata esclusivamente al personale responsabile. È quindi possibile evitare un accesso diretto configurando un'istanza-viewer dedicata alla visualizzazione delle istanze remote. L'istanza-viewer mostra quindi gli host e i servizi sulle istanze collegate, ma la sua configurazione rimane completamente vuota.
La configurazione viene effettuata nelle impostazioni di connessione del monitoraggio distribuito, prima sull'istanza centrale, poi sull'instanza-viewer (che in realtà non deve ancora esistere).
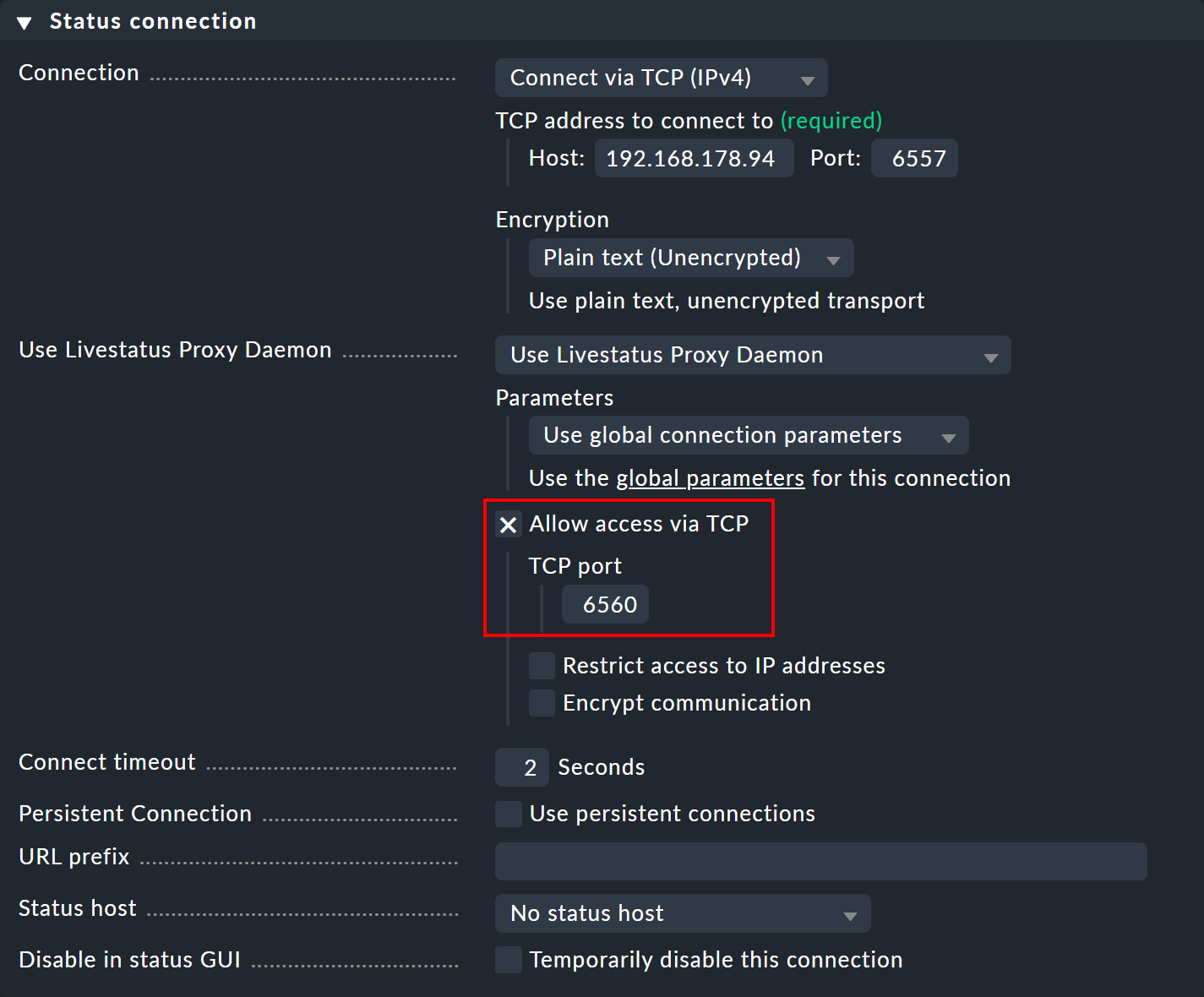
Sul sito centrale, apri le impostazioni di connessione per l'istanza remota desiderata tramite Setup > General > Distributed monitoring.
In "Use Livestatus Proxy Daemon" attiva l'opzione "Allow access via TCP" e inserisci una porta disponibile (qui 6560).
In questo modo, il proxy Livestatus sull'istanza centrale si connette all'istanza remota e apre una porta per le richieste provenienti dall'instanza-viewer, che vengono poi inoltrate all'istanza remota.
Ora crea un'instanza-viewer e apri nuovamente le impostazioni di connessione tramite Setup > General > Distributed monitoring. In Basic settings inserisci — come sempre per le connessioni nel monitoraggio distribuito — il nome esatto dell'istanza centrale come Site ID.

Nel pannello Status connection, inserisci l'istanza centrale come host — oltre alla porta libera assegnata manualmente (in questo caso 6560).
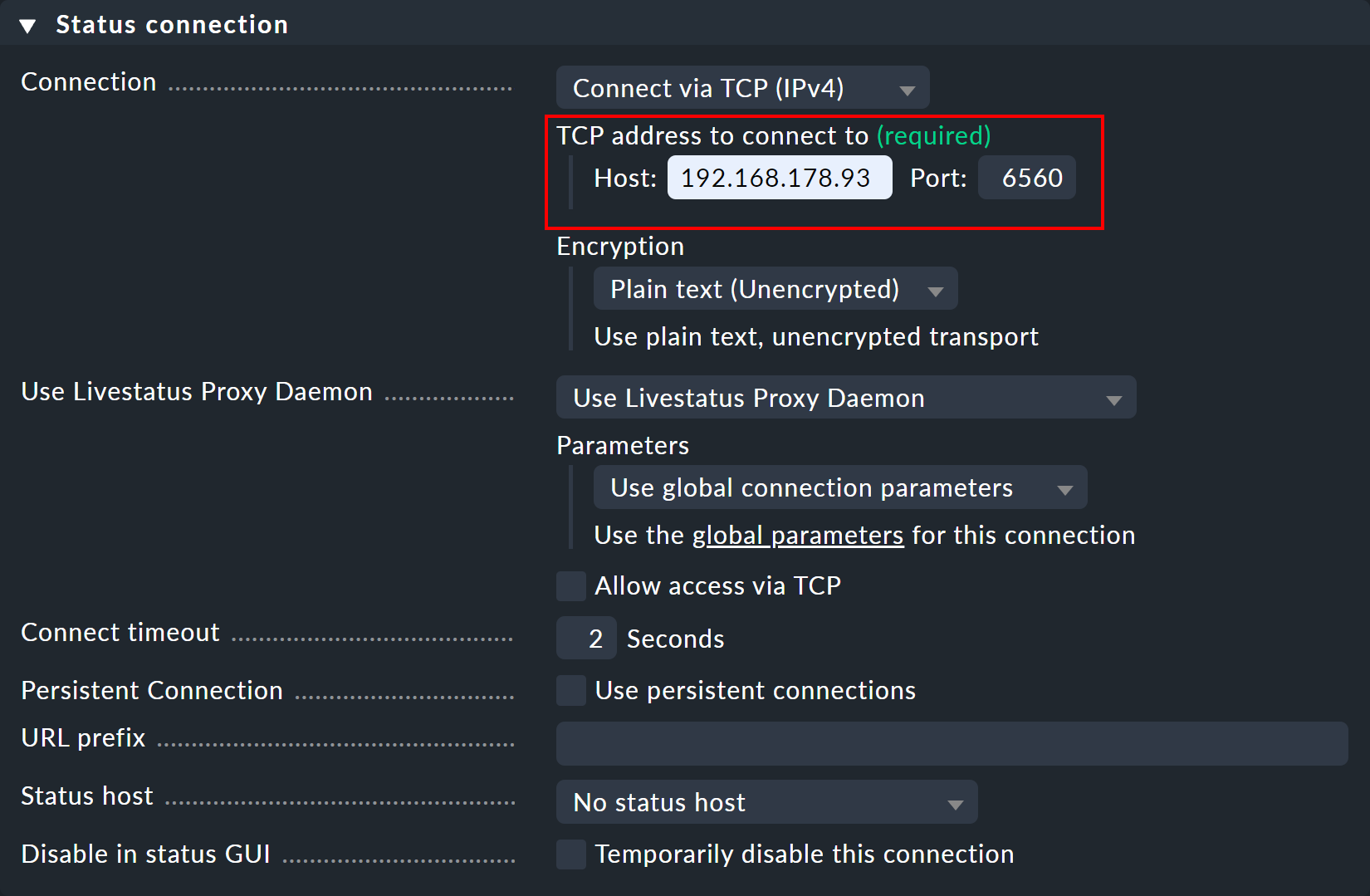
Non appena la connessione sarà stabilita, vedrai gli host e i servizi desiderati sull'istanza remota nelle viste di monitoraggio dell'istanza-viewer.
Se vuoi proseguire in cascata, devi anche consentire l'accesso TCP al proxy Livestatus sull'instanza-viewer, come fatto in precedenza sull'istanza centrale, questa volta con una porta libera diversa.
5. Livedump e CMCDump
5.1. Motivazione
Il concetto di monitoraggio distribuito con Checkmk descritto finora è una soluzione valida e semplice nella maggior parte dei casi. Tuttavia, richiede l'accesso di rete dall'istanza centrale alle istanze remote. Ci sono situazioni in cui l'accesso non è possibile o non è auspicabile, ad esempio perché:
Le istanze remote si trovano nella rete del tuo cliente, alla quale non hai accesso.
Le istanze remote si trovano in un'area di sicurezza alla quale l'accesso è severamente vietato.
Le istanze remote non dispongono di una connessione di rete permanente o di indirizzi IP fissi e metodi come il Dynamic DNS non sono un'opzione.
Il monitoraggio distribuito con Livedump, o rispettivamente CMCDump, adotta un approccio ben diverso. In primo luogo, le istanze remote sono collegate in modo tale da funzionare in modo completamente indipendente dall'istanza centrale e sono amministrate in modo decentralizzato. Si fa a meno di un Setup centrale.
Tutti gli host e i servizi delle istanze remote verranno quindi replicati come copie nell'istanza centrale. Livedump/CMCDump può aiutarti generando una copia della configurazione delle istanze remote che può poi essere caricata nell'istanza centrale.
Ora, durante il monitoraggio, su ogni istanza remota verrà scritta una copia dello stato attuale in un file a intervalli prestabiliti (ad es. ogni minuto).
Questo verrà trasmesso all'istanza centrale tramite un metodo definito dall'utente e verrà salvato lì come aggiornamento di stato.
Non è stato fornito o specificato alcun protocollo particolare per questo trasferimento di dati.
Si possono utilizzare tutti i protocolli di trasferimento che possono essere automatizzati.
Non è essenziale utilizzare scp — è ipotizzabile persino un trasferimento via e-mail!
Un Setup di questo tipo si differenzia da un monitoraggio distribuito "normale" nei seguenti modi:
L'aggiornamento degli stati e dei dati sulle prestazioni nell'istanza centrale subirà un ritardo.
Il calcolo della disponibilità sull'istanza centrale darà risultati leggermente diversi rispetto a un calcolo sull'istanza remota.
I cambiamenti di stato che avvengono più rapidamente dell'intervallo di aggiornamento non saranno visibili all'istanza centrale.
Se un'istanza remota è "morta", gli stati diventeranno obsoleti sull'istanza centrale — i servizi saranno "in stallo", ma comunque ancora visibili. I dati sulle prestazioni e sulla disponibilità per questo periodo di tempo andranno "persi" (ma saranno ancora disponibili sull'istanza remota).
Comandi come Schedule downtimes e Acknowledge problems sull'istanza centrale non possono essere trasmessi all'istanza remota.
L'istanza centrale non può mai accedere alle istanze remote.
L'accesso ai dettagli dei file di log tramite logwatch è impossibile.
La Console degli Eventi non sarà supportata da Livedump/CMCDump.
Poiché brevi cambiamenti di stato — a seconda dell’intervallo periodico selezionato sull’istanza centrale — potrebbero non essere visibili, una notifica tramite l’istanza centrale non è l’ideale. Se però l’istanza centrale viene utilizzata come istanza puramente di visualizzazione — ad esempio come panoramica centrale di tutti i clienti — questo metodo ha sicuramente i suoi vantaggi.
Per inciso, Livedump/CMCDump può essere utilizzato contemporaneamente al monitoraggio distribuito tramite Livestatus senza problemi. Alcuni siti sono semplicemente collegati direttamente tramite Livestatus, altri utilizzano Livedump. Livedump può anche essere aggiunto a una delle istanze remote di Livestatus.
5.2. Installazione di Livedump
![]() Se stai eseguendo l'installazione di Comunità Checkmk (o delle edizioni commerciali con un core Nagios) d
Se stai eseguendo l'installazione di Comunità Checkmk (o delle edizioni commerciali con un core Nagios) d![]() , usa lo strumento
, usa lo strumento livedump.
Il nome deriva da Livestatus e status dump.
livedumpsi trova direttamente nel percorso di ricerca ed è quindi disponibile come comando.
Partiamo dai seguenti presupposti:
l'istanza remota è stata completamente configurata e sta effettuando un monitoraggio attivo di host e servizi,
l'istanza centrale è stata avviata ed è in esecuzione,
almeno un host viene sottoposto a monitoraggio locale sull'istanza centrale (poiché l'istanza centrale monitora se stessa).
Trasferimento della configurazione
Per prima cosa, sull'istanza remota, crea una copia delle configurazioni dei suoi host e servizi nel formato di configurazione Nagios.
Inoltre, reindirizza l'output di livedump -TC in un file:
L'inizio del file sarà simile a questo:
define host {
name livedump-host
use check_mk_default
register 0
active_checks_enabled 0
passive_checks_enabled 1
}
define service {
name livedump-service
register 0
active_checks_enabled 0
passive_checks_enabled 1
check_period 0x0
}Trasmetti il file all'istanza centrale (ad es. con scp) e salvalo lì nella directory ~/etc/nagios/conf.d/
– dove Nagios si aspetta di trovare i dati di configurazione per host e servizi.
Scegli un nome file che finisca con .cfg , ad esempio ~/etc/nagios/conf.d/config-myremote1.cfg.
Se è possibile un accesso SSH dall'istanza remota all'istanza centrale, puoi procedere, ad esempio, come segue:
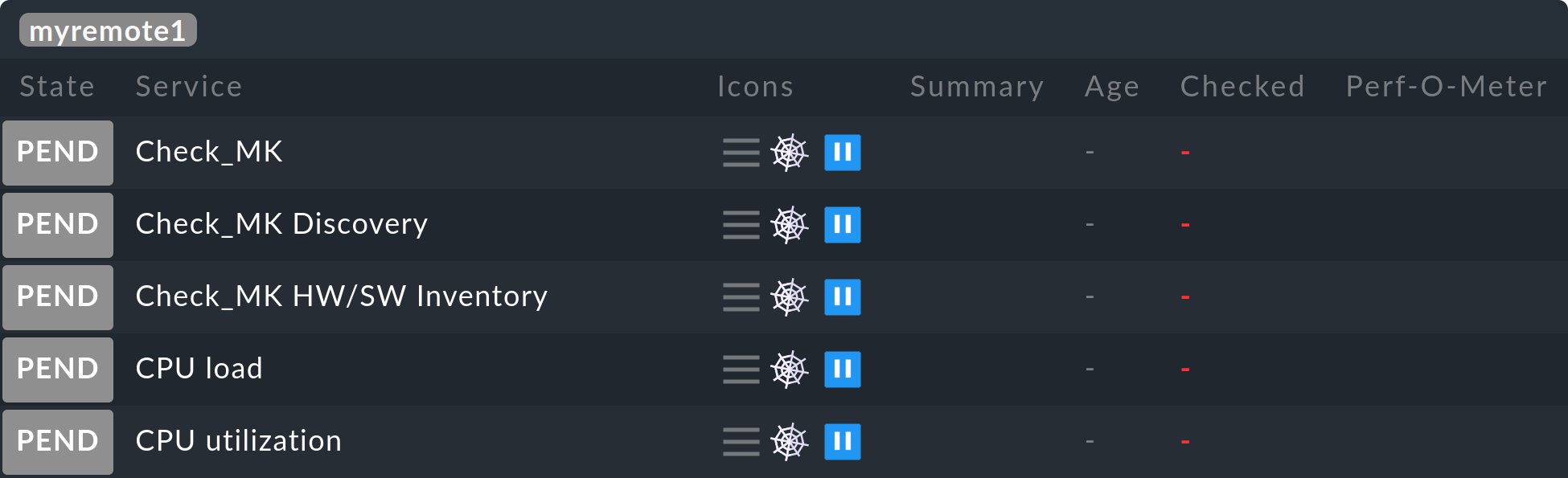
Ora accedi all'istanza centrale e attiva le modifiche:
Ora tutti gli host e i servizi del remote dovrebbero apparire nell’istanza centrale – inizialmente con lo stato IN SOSPENSIONE, che manterranno per il momento:
Note:
Con l'opzione "
-T" in "livedump", vengono create delle definizioni di template in Livedump da cui viene ricavata la configurazione. Senza queste, Nagios non può essere avviato. Tuttavia, può essercene solo una. Se importi una configurazione da un'istanza remota, questa non deve utilizzare l'opzione "-T"!È possibile anche un dump della configurazione su un Checkmk Micro Core (CMC) — la cui importazione richiede Nagios. Se il CMC è in esecuzione sull'istanza centrale, usa CMCDump.
La copia e il trasferimento della configurazione devono essere ripetuti per ogni modifica agli host o ai servizi sull'istanza remota.
Trasferimento dello stato
Una volta che gli host sono visibili nell'istanza centrale, dovremo impostare un Setup (regolare) dello stato di monitoraggio delle istanze remote.
Crea nuovamente un file con livedump, ma questa volta senza opzioni secondarie:
Questo file contiene gli stati di tutti gli host e i servizi in un formato che Nagios può leggere direttamente dai risultati dei check. L'inizio di questo file è simile a questo:
host_name=myhost1900
check_type=1
check_options=0
reschedule_check
latency=0.13
start_time=1615521257.2
finish_time=16175521257.2
return_code=0
output=OK - 10.1.5.44: rta 0.066ms, lost 0%|rta=0.066ms;200.000;500.000;0; pl=0%;80;100;; rtmax=0.242ms;;;; rtmin=0.017ms;;;;Copia questo file nell'istanza centrale nella directory ~/tmp/nagios/checkresults.
Importante: il nome di questo file deve iniziare con c ed essere lungo sette caratteri.
Con scp sarà simile a questo:
Infine, crea un file vuoto sull'istanza centrale con lo stesso nome e l'estensione .ok.
In questo modo Nagios saprà che il file di stato è stato trasferito completamente e potrà ora leggerlo:
Lo stato degli host/servizi remoti verrà ora aggiornato immediatamente sull'istanza centrale:
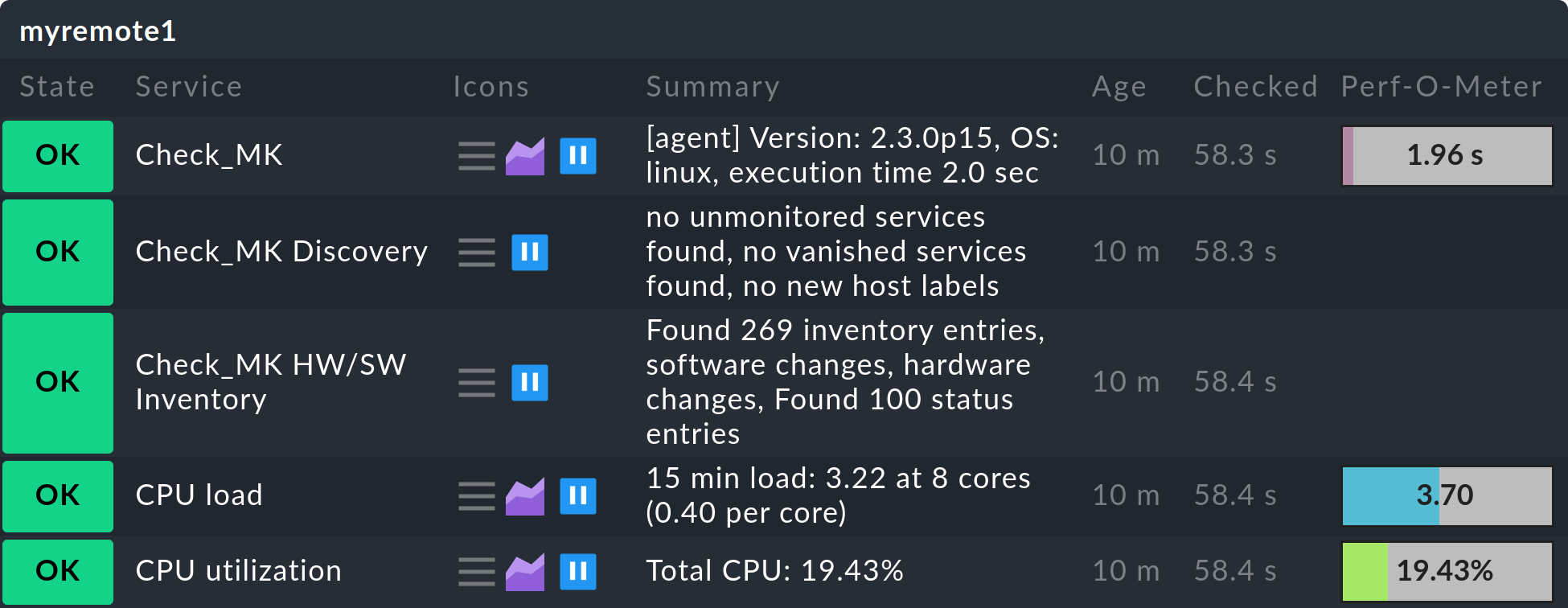
D'ora in poi la trasmissione dello stato deve essere effettuata regolarmente.
Puoi utilizzare uno script per eseguire ripetutamente i passaggi sopra descritti a intervalli di tua scelta.
Invece di copiare i dati tramite scp, il tuo script può essere eseguito direttamente dall'istanza centrale in modo che possa ricevere i dati di stato o di configurazione tramite ssh.
Uno script per eseguire queste azioni è disponibile su GitHub nella directory treasures.
Forniamo i file nella directory |
Il dump di configurazione e stato può anche essere limitato utilizzando i filtri Livestatus.
Ad esempio, potresti limitare gli host ai membri del gruppo di host mygroup:
5.3. Implementazione di CMCDump
CMCDump è per Checkmk Micro Core ciò che Livedump è per Nagios – ed è quindi lo strumento preferito per le edizioni commerciali. A differenza di Livedump, CMCDump può replicare lo stato completo di host e servizi (Nagios non dispone delle interfacce necessarie per questa operazione).
Per fare un confronto: Livedump trasferisce i seguenti dati:
Gli stati attuali – ovvero IN SOSP. , OK , WARN , CRIT , SCONOSCIUTO, UP , DOWN o UNREACH
I risultati dei plug-in di controllo
I dati sulla performance
CMCDump sincronizza inoltre:
L'output lungo del plug-in
Se l'oggetto è attualmente in uno stato irregolare (
 )
)I timestamp dell'ultima esecuzione del check e dell'ultimo cambiamento di stato
La durata dell'esecuzione del check
La latenza dell'esecuzione del check
Il numero di sequenza dell'attuale tentativo di check e se lo stato attuale è "hard" o "soft"
 confermato, se presente
confermato, se presenteSe l'oggetto si trova attualmente in un tempo di manutenzione programmata
 .
.
Questo offre un quadro molto più preciso del monitoraggio. Quando importa lo stato, il CMC non si limita a simulare l’esecuzione di un check, ma, utilizzando un’interfaccia progettata appositamente per questo compito, trasmette uno stato accurato. Tra le altre cose, questo significa che in qualsiasi momento il centro operativo può vedere se i problemi sono stati riconosciuti o se sono stati inseriti dei tempi di manutenzione programmati.
L'installazione è quasi identica a quella di Livedump, ma è comunque un po' più semplice poiché non è necessario preoccuparsi di possibili modelli duplicati o simili.
La copia della configurazione viene effettuata con cmcdump -C.
Salva questo file sull'istanza centrale in ~/etc/check_mk/conf.d/.
È necessario utilizzare l'estensione del file .mk:
Attiva la configurazione sull'istanza centrale:
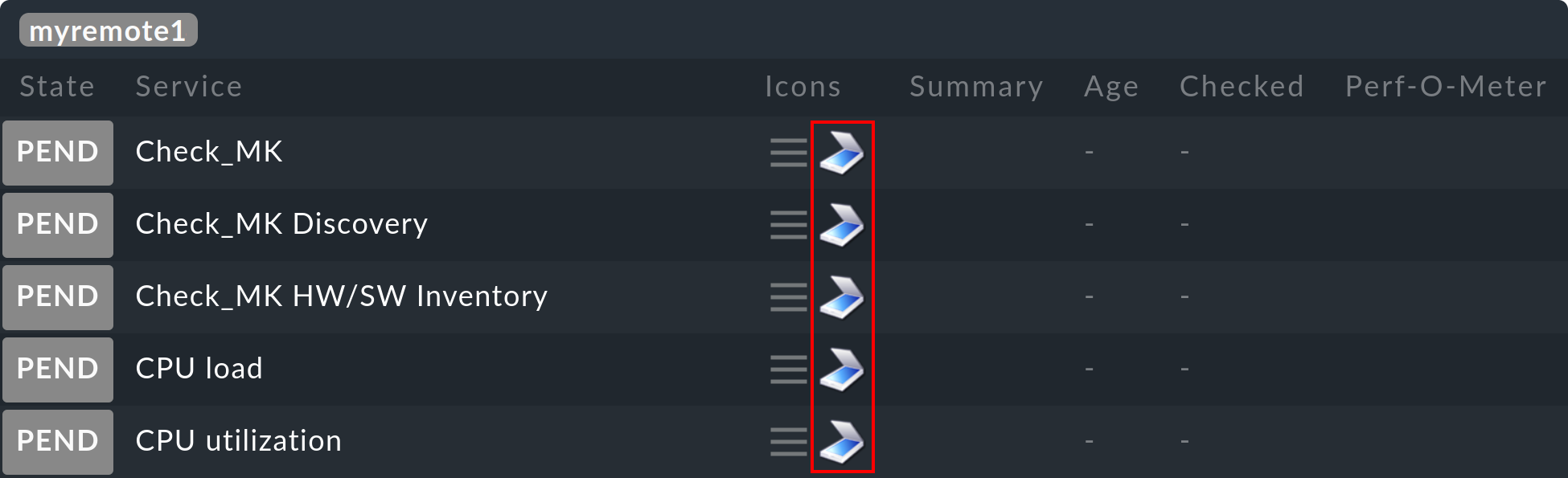
Come con Livedump, gli host e i servizi appariranno ora sull'istanza centrale nello stato IN SOSP.
Noterai tuttavia dal simbolo ![]() che si tratta di un oggetto shadow.
In questo modo è possibile distinguerlo da un oggetto monitorato direttamente sull'istanza centrale o su un'istanza remota "normale":
che si tratta di un oggetto shadow.
In questo modo è possibile distinguerlo da un oggetto monitorato direttamente sull'istanza centrale o su un'istanza remota "normale":
La generazione regolare dello stato si ottiene con cmcdump senza argomenti aggiuntivi:
Per importare lo stato nell'istanza centrale, il contenuto del file deve essere scritto nel socket Unix di ~/tmp/run/live con l'aiuto dello strumento unixcat.
Se hai accesso dall'istanza remota all'istanza centrale tramite SSH senza password, tutti e tre i comandi possono essere combinati in uno solo — e così facendo non viene creato nemmeno un file temporaneo:
È davvero semplicissimo!
Ma, come già accennato, ssh / scp non è l'unico metodo per trasferire file, e una configurazione o uno stato possono essere trasferiti altrettanto bene utilizzando l'e-mail o un altro protocollo desiderato.
6. Notifiche in ambienti distribuiti
6.1. Centralizzato o decentralizzato?
In un ambiente distribuito sorge la domanda: da quale sito dovrebbero essere inviate le notifiche (ad es. le e-mail): dai singoli siti remoti o dall'istanza centrale? Ci sono argomenti a favore di entrambe le procedure.
Argomenti a favore dell'invio dalle istanze remote:
Più semplice da configurare
È comunque possibile ricevere una notifica locale se il collegamento all'istanza centrale non è disponibile
Funziona anche con
 Comunità Checkmk
Comunità Checkmk
Argomenti a favore dell'invio dall'istanza centrale:
Le notifiche possono essere ulteriormente elaborate in una sede centrale (ad es. inoltrate a un sistema di ticket)
Le istanze remote non richiedono alcuna configurazione per e-mail o SMS
Per l'invio di un SMS tramite hardware, questa operazione è richiesta una sola volta, sull'istanza centrale
6.2. Notifiche decentralizzate
Non sono necessari passaggi speciali per una notifica decentralizzata, poiché questa è l'impostazione standard. Ogni notifica generata su un'istanza remota passa attraverso la catena di regole di notifica presente in quella istanza. Se implementi una configurazione centrale, queste regole sono le stesse su tutte le istanze. Le notifiche risultanti da queste regole verranno consegnate come al solito, per cui gli script di notifica appropriati saranno stati eseguiti localmente.
Bisogna semplicemente assicurarsi che il servizio appropriato sia stato installato correttamente sulle istanze — che sia stato definito uno smarthost per le e-mail, ad esempio — in altre parole, la stessa procedura utilizzata per configurare una singola istanza Checkmk.
6.3. Notifiche centralizzate
Nozioni fondamentali
![]() Le edizioni commerciali offrono un meccanismo integrato per le notifiche centralizzate che può essere attivato individualmente per ogni istanza remota.
Tali istanze remote inoltrano quindi tutte le notifiche all'istanza centrale per l'ulteriore elaborazione.
La notifica centralizzata è quindi indipendente dal fatto che il monitoraggio distribuito sia stato configurato in modo standard, con CMCDump o utilizzando una combinazione di queste procedure.
Tecnicamente parlando, il server di notifica centrale non deve nemmeno trovarsi letteralmente al “centro”.
Questo compito può essere svolto da qualsiasi istanza Checkmk.
Le edizioni commerciali offrono un meccanismo integrato per le notifiche centralizzate che può essere attivato individualmente per ogni istanza remota.
Tali istanze remote inoltrano quindi tutte le notifiche all'istanza centrale per l'ulteriore elaborazione.
La notifica centralizzata è quindi indipendente dal fatto che il monitoraggio distribuito sia stato configurato in modo standard, con CMCDump o utilizzando una combinazione di queste procedure.
Tecnicamente parlando, il server di notifica centrale non deve nemmeno trovarsi letteralmente al “centro”.
Questo compito può essere svolto da qualsiasi istanza Checkmk.
Se un'istanza remota è stata impostata su "inoltro", tutte le notifiche verranno inoltrate direttamente all'istanza centrale come se provenissero dal core — in pratica in formato grezzo. Una volta lì, le regole di notifica valuteranno chi deve essere effettivamente avvisato e in che modo. Gli script di notifica necessari verranno eseguiti sull'istanza centrale.
Configurazione delle connessioni TCP
Gli spooler di notifica delle istanze remote e centrali (di notifica) comunicano tra loro tramite TCP. Le notifiche vengono inviate dalle istanze remote all'istanza centrale. L'istanza centrale conferma alle istanze remote che le notifiche sono state ricevute, il che impedisce che le notifiche vadano perse anche se la connessione TCP viene interrotta.
Ci sono due alternative per la creazione di una connessione TCP:
Si configura una connessione TCP dall'istanza centrale a quella remota. In questo caso l'istanza remota è il server TCP.
Si configura una connessione TCP dall'istanza remota all'istanza centrale. In questo caso l'istanza centrale è il server TCP.
Di conseguenza, nulla impedisce l'inoltro delle notifiche se, per motivi di rete, è possibile stabilire connessioni solo in una direzione specifica. Le connessioni TCP sono monitorate dallo spooler tramite un segnale di heartbeat e vengono ristabilite immediatamente quando necessario — non solo in caso di evento.
Poiché le istanze remote e l'istanza centrale richiedono impostazioni globali diverse per lo spooler, devi definire impostazioni specifiche per tutte le istanze remote. La configurazione dell'istanza centrale viene eseguita utilizzando le normali impostazioni globali. Nota: queste impostazioni verranno automaticamente ereditate da tutte le istanze remote per le quali non sono state definite impostazioni specifiche.
Vediamo prima un esempio in cui l'istanza centrale stabilisce le connessioni TCP con le istanze remote.
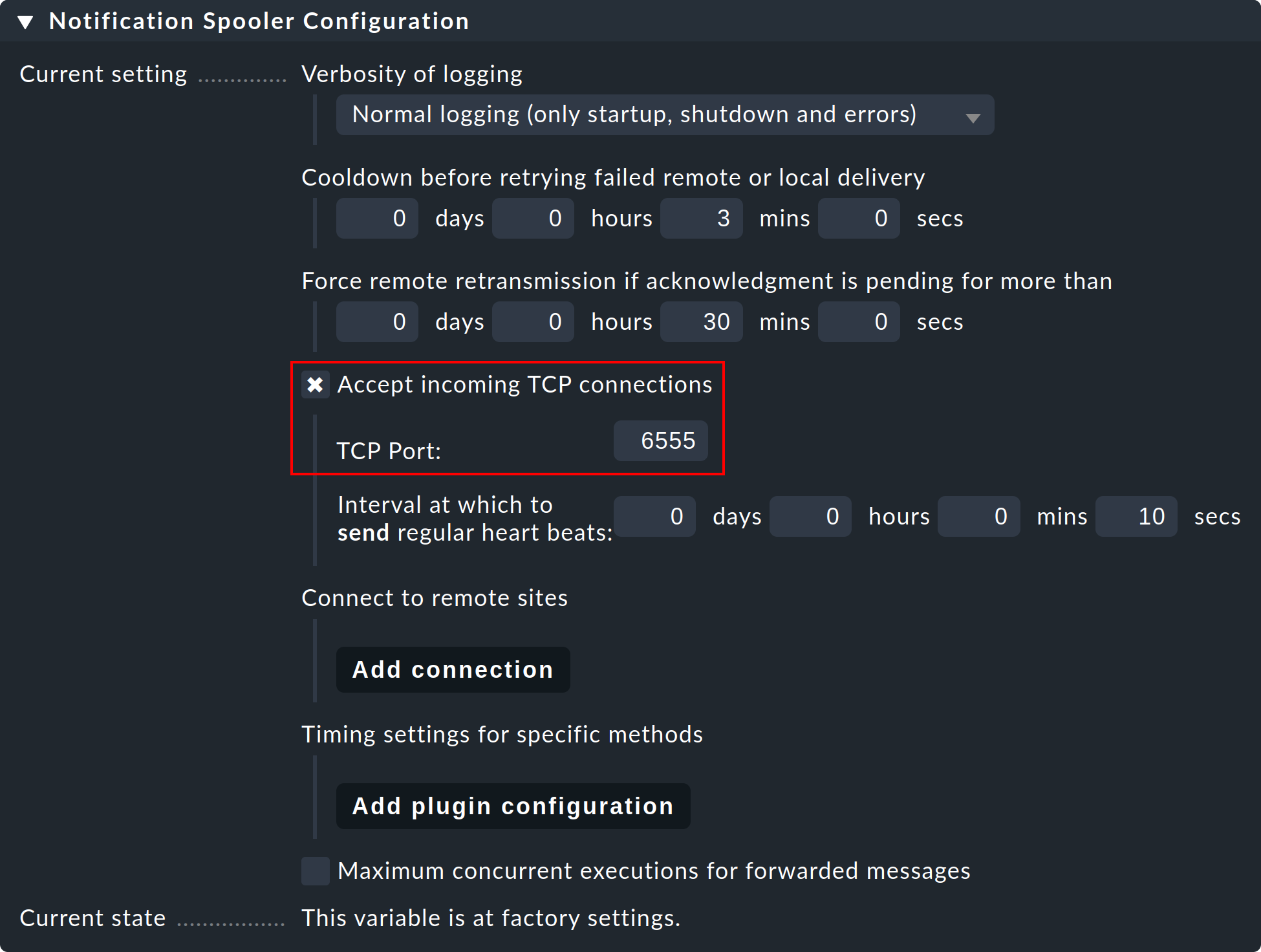
Passaggio 1: sull'istanza remota, modifica l'impostazione globale specifica dell'istanza "Notifications > Notification Spooler Configuration" e attiva "Accept incoming TCP connections". Per le connessioni in entrata verrà consigliata la porta TCP 6555. Se non ci sono obiezioni, adotta queste impostazioni.
Passo 2: Ora, allo stesso modo, nel sottomenu "Notification Spooling" solo sull'istanza remota, seleziona l'opzione "Forward to remote site by notification spooler".

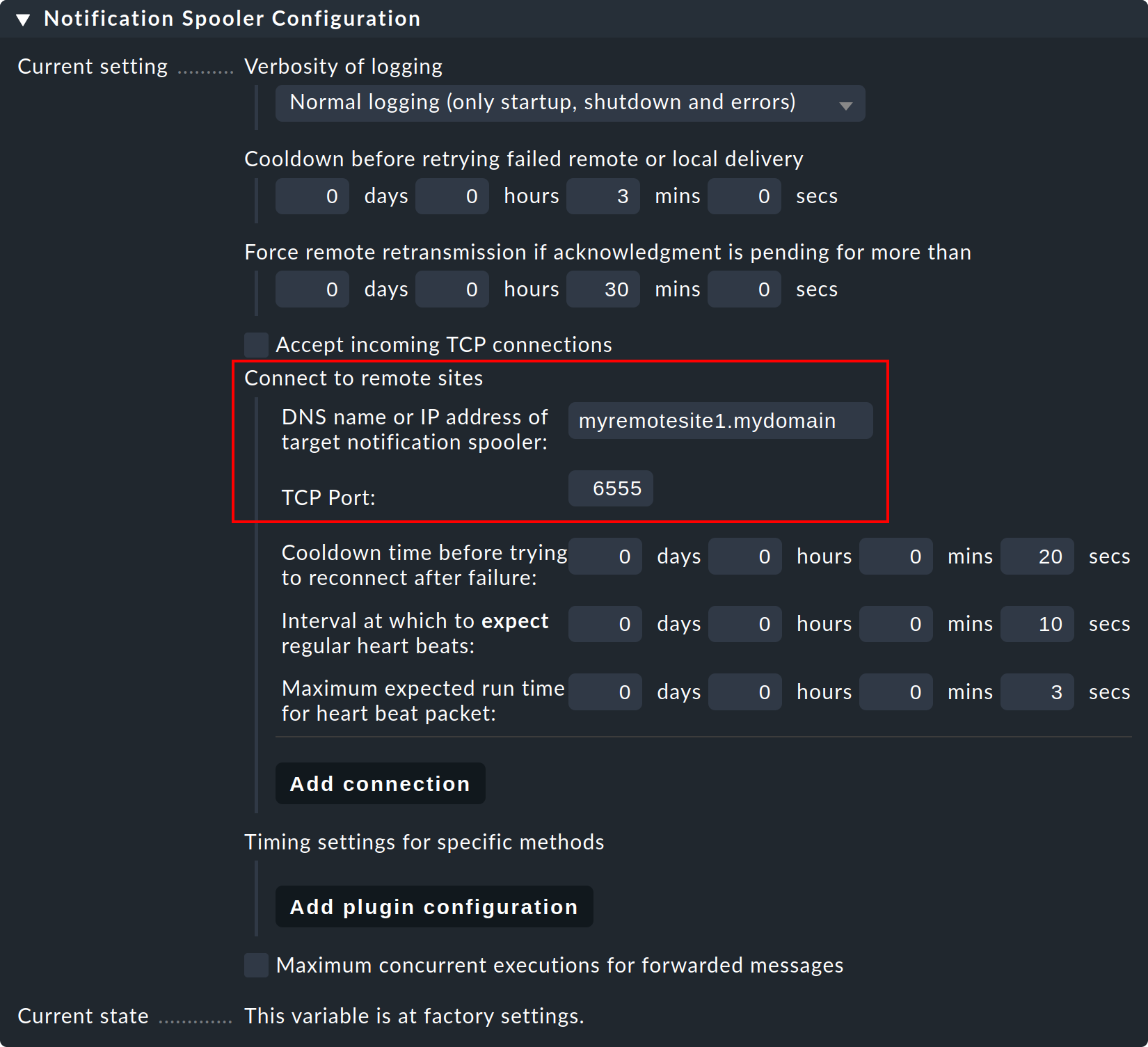
Passaggio 3: Ora, sull'istanza centrale — cioè nelle normali impostazioni globali — configura la connessione all'istanza remota (e poi a ulteriori istanze remote se necessario):
Passaggio 4: imposta l'impostazione globale "Notification Spooling" su "Asynchronous local delivery by notification spooler", in modo che anche le comunicazioni dell'istanza centrale vengano elaborate tramite lo stesso spooler centrale.

Passaggio 5: Attiva le modifiche.
Stabilire connessioni da un'istanza remota
Se la connessione TCP deve essere stabilita dall'istanza remota verso l'esterno, la procedura è identica, differendo dalla descrizione sopra riportata solo per lo scambio dei ruoli tra istanza centrale e istanza remota.
È possibile anche una combinazione delle due procedure. In tal caso, l'istanza centrale deve essere installata in modo da ascoltare le connessioni in entrata e da connettersi alle istanze remote. Tuttavia, in ogni relazione centrale/remota, solo uno dei due è autorizzato a stabilire la connessione!
Test e diagnostica
Lo spooler di notifica registra i log nel file ~/var/log/mknotifyd.log.
Nella configurazione dello spooler di notifica è possibile aumentare il livello di log in modo da ricevere più messaggi.
Con un livello di log standard dovresti vedere qualcosa di simile sull'istanza centrale:
2025-04-30 07:11:40,023 [20] [cmk.mknotifyd] -----------------------------------------------------------------
2025-04-30 07:11:40,023 [20] [cmk.mknotifyd] Check_MK Notification Spooler version 2.4.0p24 starting
2025-04-30 07:11:40,024 [20] [cmk.mknotifyd] Log verbosity: 0
2025-04-30 07:11:40,025 [20] [cmk.mknotifyd] Daemonized with PID 31081.
2025-04-30 07:11:40,029 [20] [cmk.mknotifyd] Connection to 10.1.8.44 port 6555 in progress
2025-04-30 07:11:40,029 [20] [cmk.mknotifyd] Successfully connected to 10.1.8.44:6555Il file ~/var/log/mknotifyd.state contiene sempre lo stato attuale dello spooler e di tutte le sue connessioni:
Connection: 10.1.8.44:6555
Type: outgoing
State: established
Status Message: Successfully connected to 10.1.8.44:6555
Since: 1637129500 (2025-04-30 07:11:40, 140 sec ago)
Connect Time: 0.002 secUna versione dello stesso file è presente anche sull'istanza remota. Lì la connessione apparirà più o meno così:
Connection: 10.22.4.12:56546
Type: incoming
State: established
Since: 1637129500 (2025-04-30 07:11:40, 330 sec ago)Per fare una prova, seleziona un servizio remoto monitorato e impostalo manualmente su CRIT con il comando Fake check results.
Ora sull'istanza centrale dovrebbe apparire una notifica in arrivo nel file di log delle notifiche (notify.log):
2025-04-30 07:59:36,231 ----------------------------------------------------------------------
2025-04-30 07:59:36,232 [20] [cmk.base.notify] Got spool file 307ad477 (myremotehost123;Check_MK) from remote host for local delivery.Lo stesso evento apparirà così sull'istanza remota:
2025-04-30 07:59:28,161 [20] [cmk.base.notify] ----------------------------------------------------------------------
2025-04-30 07:59:28,161 [20] [cmk.base.notify] Got raw notification (myremotehost123;Check_MK) context with 71 variables
2025-04-30 07:59:28,162 [20] [cmk.base.notify] Creating spoolfile: /omd/sites/myremote1/var/check_mk/notify/spool/307ad477-b534-4cc0-99c9-db1c517b31fNelle impostazioni globali puoi impostare sia il file di log normale per le notifiche (notify.log) sia il file di log dello spooler di notifica su un livello di log più alto.
Monitoraggio dello spooling
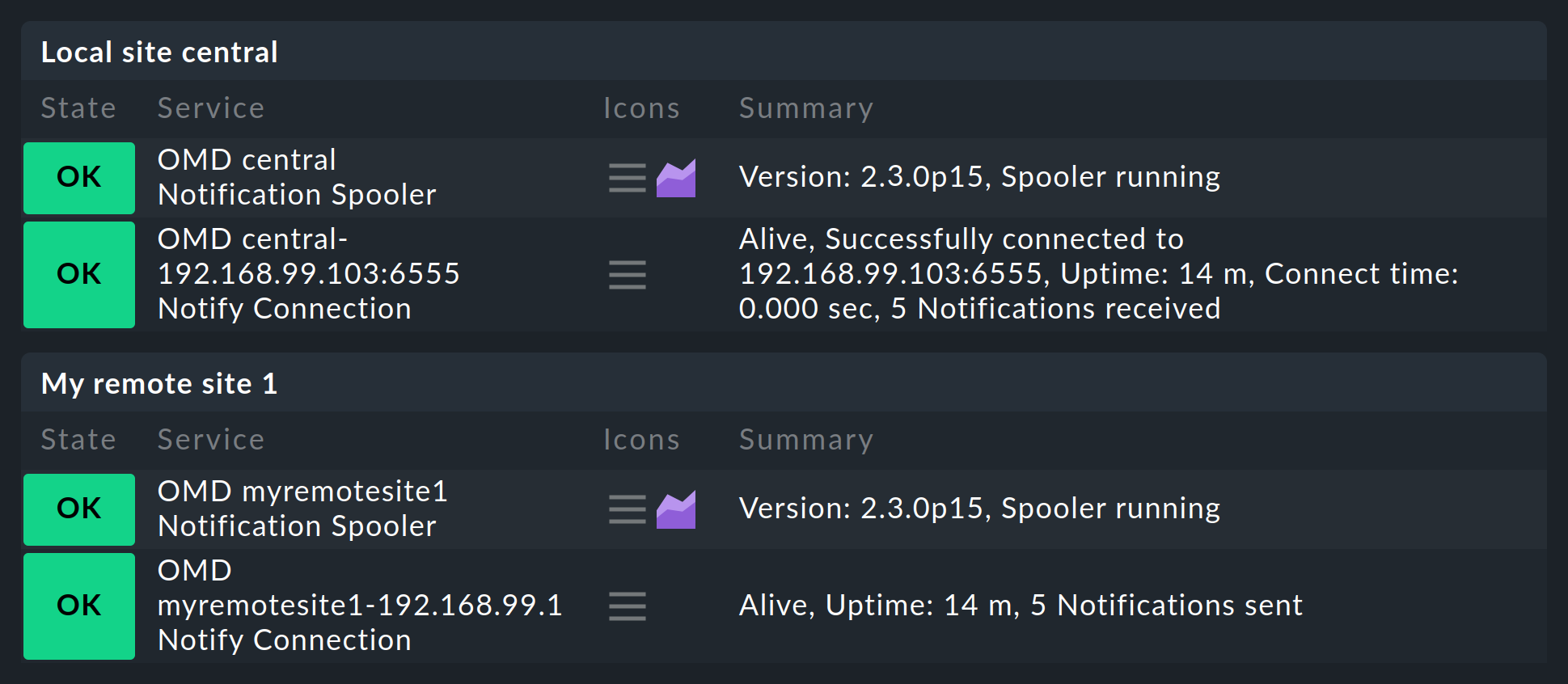
Una volta configurato tutto come descritto, noterai che sull'istanza centrale, e rispettivamente sulle istanze remote, sarà presente un nuovo servizio che deve assolutamente essere incluso nel monitoraggio. Questo monitora lo spooler di notifica e le sue connessioni TCP. Ogni connessione verrà quindi monitorata due volte: una volta dall'istanza centrale e una volta dall'istanza remota:
7. Quando un'istanza centrale e le sue istanze remote utilizzano versioni diverse
Come regola generale, le versioni di tutte le istanze remote e dell'istanza centrale devono corrispondere. Le eccezioni a questa regola si applicano solo durante la performance degli aggiornamenti. In questo caso, occorre distinguere tra le seguenti situazioni:
7.1. Livelli di patch diversi (ma stessa versione principale)
I livelli di patch (ad es. p11) possono generalmente differire senza problemi. In rari casi, tuttavia, anche questi possono essere incompatibili tra loro, quindi in una situazione del genere devi mantenere esattamente lo stesso livello di versione (ad es. 2.4.0p11) su tutte le istanze per consentire alle istanze di funzionare insieme senza errori. Pertanto, prendi sempre nota delle modifiche incompatibili per ciascuna versione patch nei Werks.
Come regola generale — sono possibili eccezioni, indicate nel Werks — aggiorna prima le istanze remote e per ultimi l'istanza centrale.
7.2. Versioni principali diverse
Per l’esecuzione senza intoppi di aggiornamenti principali (ad esempio da 2.3.0 a 2.4.0) in grandi ambienti distribuiti, a partire dalla versione 2.0.0 Checkmk consente operazioni miste in cui l’istanza centrale e le istanze remote possono differire di una versione principale. Quando esegui un aggiornamento, assicurati di aggiornare prima le istanze remote. Aggiorna poi l’istanza centrale solo quando tutte le istanze remote sono state aggiornate alla versione superiore.
Ricorda di controllare le note di aggiornamento di Werks e della versione prima di iniziare l'aggiornamento! Sul sito centrale è sempre richiesto un livello di patch specifico (prerequisito) della versione precedente per garantire un funzionamento misto senza problemi.
Una caratteristica speciale negli ambienti misti è la gestione centralizzata dei pacchetti di estensione, che ora possono essere mantenuti in varianti sia per le versioni precedenti che per quelle più recenti di Checkmk. I dettagli al riguardo sono spiegati nell'articolo sulla gestione degli MKP.
8. File e directory
8.1. File di configurazione
| Percorso | Descrizione |
|---|---|
|
Qui Checkmk memorizza la configurazione per le connessioni alle singole istanze. Se l'interfaccia si "blocca" a causa di un errore nella configurazione, rendendola inutilizzabile, puoi modificare direttamente nel file la voce che causa il problema. Se però il proxy Livestatus è attivato, sarà necessario modificare e salvare almeno una connessione, poiché solo così verrà generata una configurazione adeguata per questo daemon. |
|
Configurazione per il proxy Livestatus. Questo file verrà generato ex novo da Checkmk ad ogni modifica nella configurazione del monitoraggio distribuito. |
|
Configurazione per lo spooler di notifica. Questo file verrà generato da Checkmk al momento del salvataggio delle impostazioni globali. |
|
Viene creato sulle istanze remote e garantisce che queste eseguano solo il monitoraggio dei propri host. |
|
Percorso di archiviazione per i file di configurazione Nagios creati dal cliente con host e servizi. Questi sono necessari per l'utilizzo di Livedump sull'istanza centrale. |
|
La configurazione di Livestatus per l'utilizzo di Nagios come core. Qui puoi configurare il numero massimo di connessioni simultanee consentite. |
|
La configurazione di host e regole per Checkmk. Archivia qui i file di configurazione generati da CMCDump. Solo la sottodirectory |
|
Per i servizi individuati dalla scoperta del servizio. Questi vengono sempre memorizzati localmente sull'istanza remota. |
|
Posizione del database Round Robin (RRD) per l'archiviazione dei dati sulle prestazioni quando si utilizza il formato Checkmk-RRD (impostazione predefinita nelle edizioni commerciali) |
|
Posizione del database Round-Robin con il formato PNP4Nagios (Comunità Checkmk) |
|
File di log per i proxy Livestatus. |
|
Lo stato attuale dei proxy Livestatus in un formato leggibile. Questo file viene aggiornato ogni 5 secondi. |
|
File di log per il sistema di notifica Checkmk. |
|
File di log per lo spooler di notifica. |
|
Lo stato attuale dello spooler di notifica in un formato leggibile. Questo file viene aggiornato ogni 20 secondi. |