This is a machine translation based on the English version of the article. It might or might not have already been subject to text preparation. If you find errors, please file a GitHub issue that states the paragraph that has to be improved. |
1. Introducción
Probablemente no todo el mundo entiende lo mismo por «monitorización distribuida». De hecho, la monitorización siempre se distribuye entre varios ordenadores, a menos que el sistema de monitorización solo se esté monitorizando a sí mismo, lo cual no sería muy útil.
Por eso, en este Manual de usuario siempre hablamos de monitorización distribuida cuando el sistema de monitorización en su conjunto consta de más de un sitio de Checkmk. Hay varias buenas razones para dividir la monitorización entre varios sitios:
Rendimiento: la carga del procesador debería, o debe, repartirse entre varias máquinas.
Organización: Los distintos grupos deberían poder administrar sus propios sites de forma independiente.
Disponibilidad: La monitorización en una ubicación debería funcionar independientemente de otras ubicaciones.
Seguridad: los flujos de datos entre dos dominios de seguridad deben controlarse de forma separada y precisa (DMZ, etc.).
Red: Las ubicaciones que solo tienen conexiones de banda estrecha o poco fiables no pueden realizarse de forma remota tareas de monitorización con fiabilidad.
Checkmk admite varios procedimientos para implementar una monitorización distribuida.
Checkmk controla algunos de ellos, ya que es en gran medida compatible con Nagios o se basa en él (si se ha instalado Nagios como core de monitorización).
Esto incluye, por ejemplo, el procedimiento con mod_gearman.
En comparación con el propio sistema de Checkmk, esto no ofrece ventajas y además es más engorroso de implementar.
Por estas razones, no lo recomendamos.
El procedimiento preferido por Checkmk se basa en Livestatus y un entorno de configuración distribuido. Para situaciones con redes muy separadas, o incluso una transferencia de datos estrictamente unidireccional desde la periferia hacia el centro, existe un método que utiliza Livedump o, respectivamente, CMCDump. Ambos métodos se pueden combinar.
2. Monitorización distribuida con Livestatus
2.1. Principios básicos
Estado central
Livestatus es una interfaz integrada en el core de monitorización que permite a otros programas externos consultar datos de estado y ejecutar comandos. Livestatus puede estar disponible a través de la red para que pueda acceder a él un sitio Checkmk remoto. La interfaz de usuario de Checkmk utiliza Livestatus para combinar todos los sitios conectados en una vista general, que entonces se asemeja a un único y gran sistema de monitorización.
El siguiente diagrama muestra esquemáticamente la estructura de una monitorización con Livestatus distribuida en tres ubicaciones. El sitio central de Checkmk se encuentra en el sitio de procesamiento central. Desde aquí se controlarán directamente los sistemas centrales. Además, están el site remoto 1 y el site remoto 2, que se encuentran en otras redes y son controlados por sus sistemas locales:
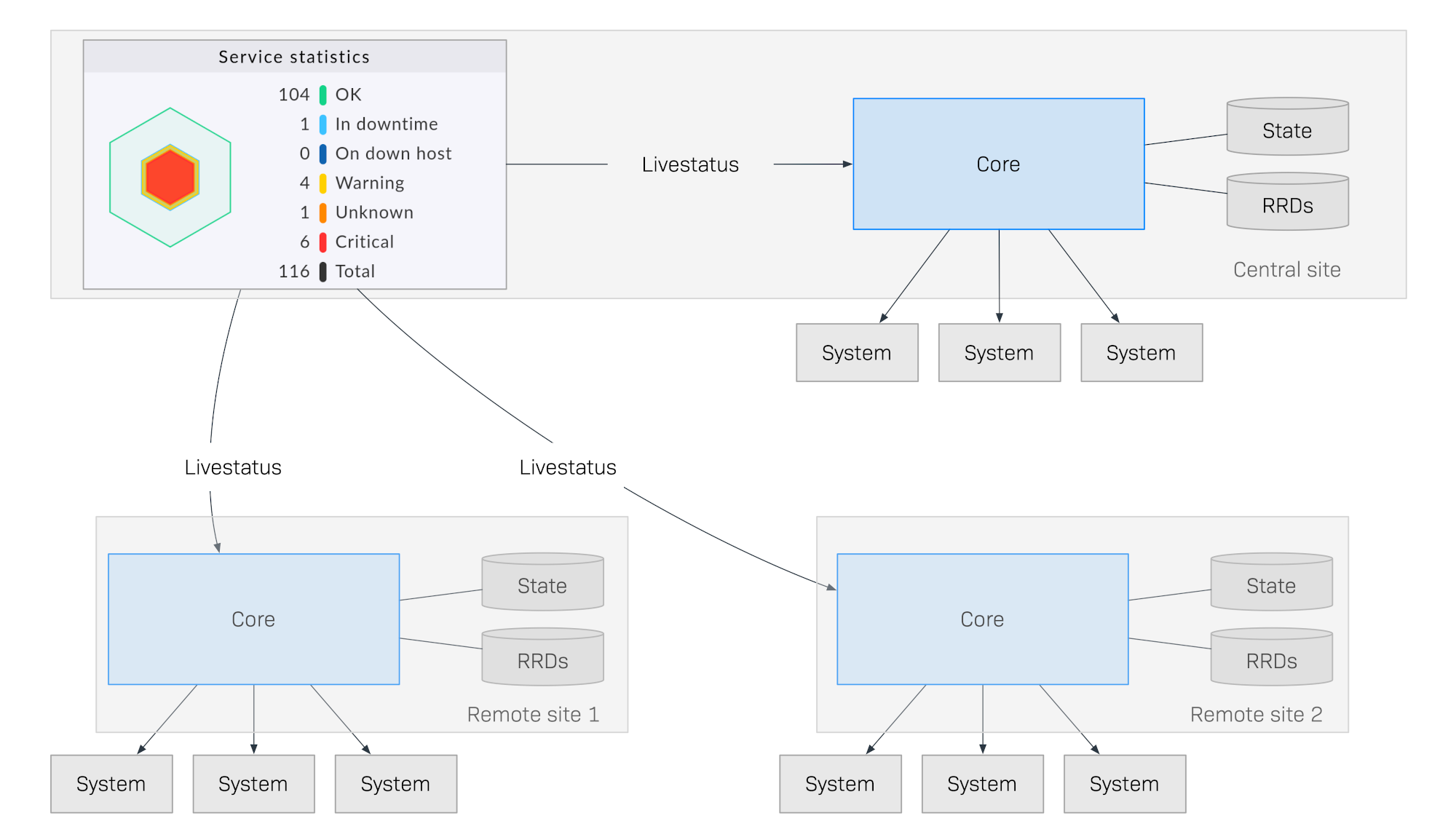
Lo que hace especial a este método es que el estado de monitorización de los sitios remotos no se envía continuamente al sitio central. La GUI solo recupera datos en tiempo real de los sitios remotos cuando lo solicita un usuario del centro de control. A continuación, los datos se recopilan en una vista centralizada. Por lo tanto, no hay un almacenamiento central de datos, ¡lo que ofrece enormes ventajas para la escalabilidad!
Estas son algunas de las ventajas de este método:
Escalabilidad: La monitorización en sí misma no genera ningún tráfico de red entre el site central y el remoto. De esta forma, se pueden establecer conexiones entre cientos de ubicaciones, o incluso más.
Fiabilidad: si falla la conexión de red con un site remoto, la monitorización local sigue funcionando con normalidad. No hay «lagunas» en el registro de datos ni «atascos» de datos. Las notificaciones locales seguirán funcionando.
Simplicidad: Los sites se pueden añadir o eliminar muy fácilmente.
Flexibilidad: Los sites remotos siguen siendo autónomos y se pueden utilizar para el funcionamiento en su respectiva ubicación. Esto resulta especialmente interesante si no se debe permitir en ningún caso que la «ubicación» acceda al resto del sistema de monitorización.
Configuración central
En un sistema distribuido que utiliza Livestatus como se ha descrito anteriormente, es muy posible que los distintos sitios puedan ser mantenidos de forma independiente por diferentes equipos, y que el site central solo tenga la tarea de proporcionar un dashboard centralizado.
En el caso de que varios sitios, o todos ellos, deban ser administrados por el mismo equipo, una configuración central es mucho más fácil de manejar. Checkmk admite esto y se refiere a dicha configuración como una configuración central. Con esto, todos los hosts y servicios, usuarios y permisos, periodos de tiempo, notificaciones, etc., se mantendrán en el «Setup» del site central y luego se distribuirán automáticamente a los sitios remotos según tus especificaciones.
Este sistema no solo ofrece una vista general común del estado, sino también una configuración común, y da la sensación de ser «un gran sistema».
Incluso puedes ampliar este sistema con sitios del visor dedicados, por ejemplo, que sirvan únicamente como interfaces de estado para subáreas o grupos de usuarios específicos.
2.2. Configuración de una monitorización distribuida
La instalación de una monitorización distribuida mediante Livestatus/configuración central se realiza siguiendo estos pasos:
Primero instala el site central como se hace habitualmente para un solo site
Instala los sitios remotos y activa Livestatus a través de la red
Integra los sitios remotos en el site central usando Setup > General > Distributed monitoring
Para los hosts y los servicios, especifica desde qué site se van a realizar las operaciones de monitorización
Ejecuta el descubrimiento de servicios para los hosts migrados y, a continuación, activa los cambios recientes
Configuración del site central
No hay requisitos especiales para el site central. Esto significa que un site ya establecido puede ampliarse a una monitorización distribuida con solo una única modificación, necesaria para el correcto manejo de los datos piggyback. Todo lo que tienes que hacer es habilitar el hub piggyback en la página de configuración Setup > General > Global settings, en la sección «Site management»:
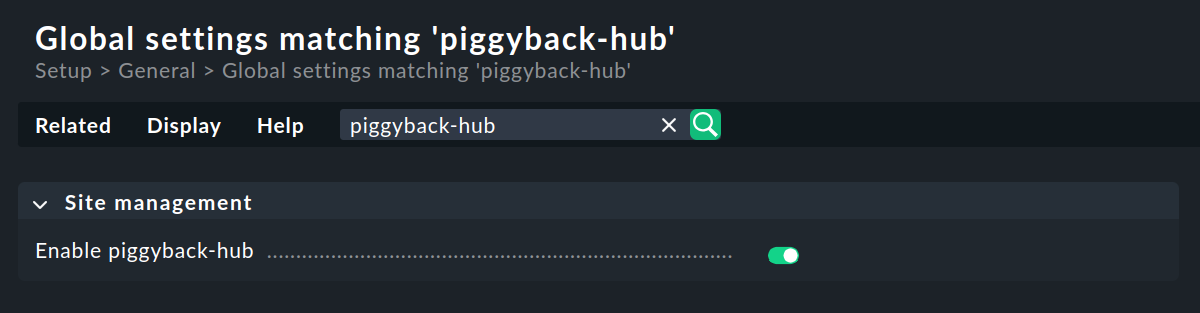
A continuación, activa los cambios, ya que para activar o desactivar el hub piggyback es necesario reiniciar el site.
Configuración de sitios remotos y activación de Livestatus a través de la red
Los sitios remotos se generan entonces como nuevos sitios de la forma habitual con omd create.
Esto se llevará a cabo, naturalmente, en el servidor (remoto) destinado al sitio remoto correspondiente.
Notas especiales:
Para los sitios remotos, utiliza ID únicos para tu monitorización distribuida.
La versión de Checkmk (p. ej., 2.4.0) de los sitios remotos y centrales es la misma; solo se admiten versiones mixtas para facilitar las actualizaciones.
Del mismo modo que Checkmk admite múltiples sitios en un servidor, los sitios remotos también pueden ejecutarse en el mismo servidor.
Aquí tienes un ejemplo para crear un site remoto con el nombre myremote1 y la contraseña t0p53cr3t para el administrador del site cmkadmin:
Los pasos más importantes ahora son activar Livestatus a través de TCP para la red y habilitar también el concentrador piggyback aquí.
Ten en cuenta que Livestatus no es en sí mismo un protocolo seguro y solo debe utilizarse dentro de una red segura (LAN protegida, VPN, etc.).
La habilitación se realiza utilizando omd config como usuario del site mientras el site está detenido:
Ahora selecciona Distributed Monitoring:
┌Configuration of site myremote1───┐ │ Interactive setting of site │ │ configuration variables. You can │ │ change values only while the │ │ site is stopped. │ │ ┌──────────────────────────────┐ │ │ │ Basic │ │ │ │ Web GUI │ │ │ │ Addons │ │ │ │ Distributed Monitoring │ │ │ │ │ │ │ └──────────────────────────────┘ │ ├──────────────────────────────────┤ │ <Enter> <Exit > │ └──────────────────────────────────┘
Configura LIVESTATUS_TCP en on y, en LIVESTATUS_TCP_PORT, introduce un número de puerto no asignado que sea único en este servidor.
El valor predeterminado es 6557:
┌────────────Distributed Monitoring──────────────┐ │ ┌────────────────────────────────────────────┐ │ │ │ LIVEPROXYD on │ │ │ │ LIVESTATUS_TCP on │ │ │ │ LIVESTATUS_TCP_ONLY_FROM 0.0.0.0 ::/0 │ │ │ │ LIVESTATUS_TCP_PORT 6557 │ │ │ │ LIVESTATUS_TCP_TLS on │ │ │ │ PIGGYBACK_HUB on │ │ │ │ │ │ │ └────────────────────────────────────────────┘ │ ├────────────────────────────────────────────────┤ │ < Change > <Main menu> │ └────────────────────────────────────────────────┘
Después de guardar, inicia el site como de costumbre con omd start:
Recuerda la contraseña de cmkadmin.
Solo la necesitarás dos veces: primero para habilitar el hub piggyback y luego para establecer la conexión entre el site remoto y el site central.
Una vez que el site remoto se haya subordinado al site central,
todos los usuarios serán sustituidos por los del site central de todos modos.
La instancia ya está lista.
Una check con netstat muestra que el puerto 6557 está abierto.
La conexión a este puerto se realiza con una instancia del súper servidor de internet xinetd, que se ejecuta directamente en el site:
Ahora inicia sesión una vez en el site remoto como usuario cmkadmin y activa el concentrador piggyback utilizando la configuración de Setup > General > Global en la sección Site management:
A continuación, activa los cambios, ya que para encender o apagar el concentrador piggyback es necesario reiniciar el site.
Asignación de sitios remotos al sitio central
La configuración de la monitorización distribuida se realiza exclusivamente en el site central, en el menú «Setup > General > Distributed monitoring», y sirve para gestionar las conexiones con los sitios individuales. Para esta función, el propio site central cuenta como un sitio y ya aparece en la lista:

Mediante ![]() Add connection, define ahora la conexión con el primer site remoto:
Add connection, define ahora la conexión con el primer site remoto:

En Basic settings es importante utilizar el nombre EXACTO del site remoto —tal y como se define en omd create— como Site ID.
Como siempre, el alias se puede definir como se desee y también se puede cambiar más adelante.
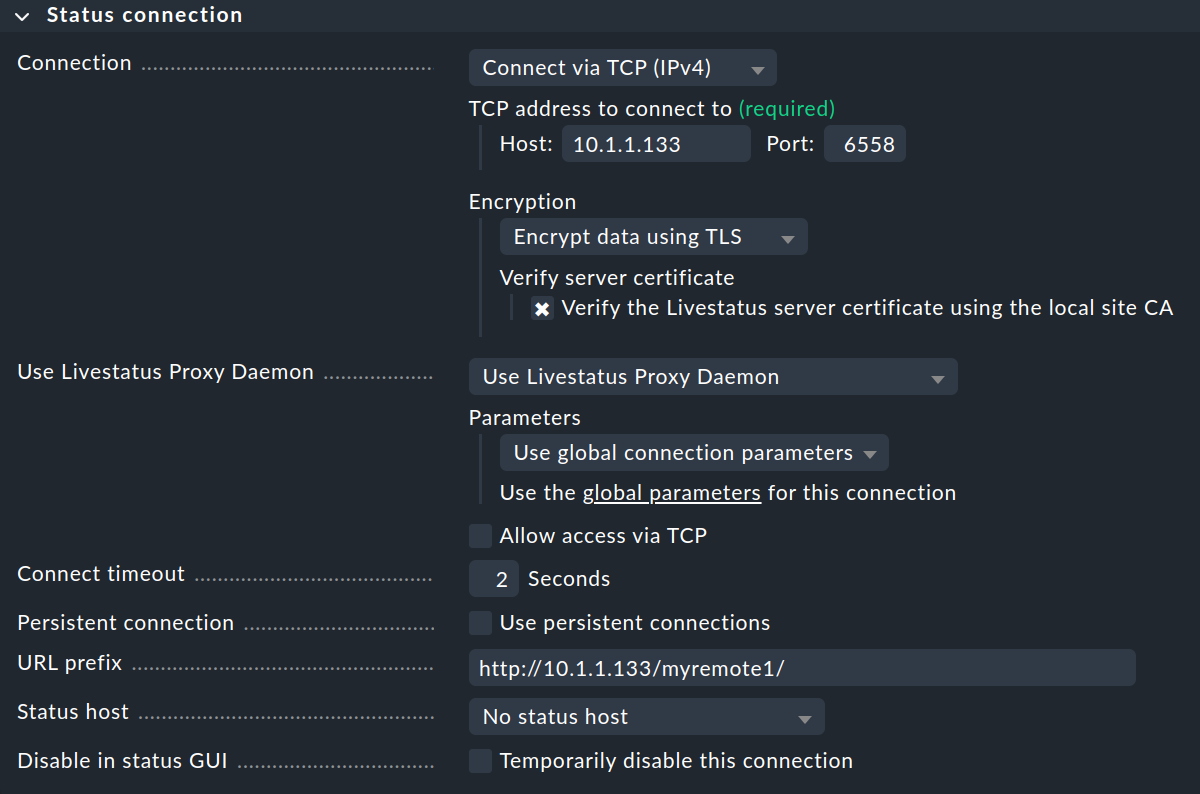
La configuración de Status connection determina cómo el sitio central consulta el estado de los sitios remotos a través de Livestatus. El ejemplo de la captura de pantalla muestra una conexión con el método Connect via TCP(IPv4). Esta es la opción óptima para conexiones estables con tiempos de latencia cortos (como, por ejemplo, en una LAN). Más adelante hablaremos de la configuración óptima para conexiones WAN.
Introduce aquí la URL HTTP de la interfaz web del site remoto, sin el check_mk/ al final de la URL.
Si normalmente accedes a Checkmk a través de HTTPS, sustituye aquí el http por https.
Puedes encontrar más información en la ayuda en línea ![]() o en el artículo sobre cómo proteger la interfaz web con HTTPS.
o en el artículo sobre cómo proteger la interfaz web con HTTPS.
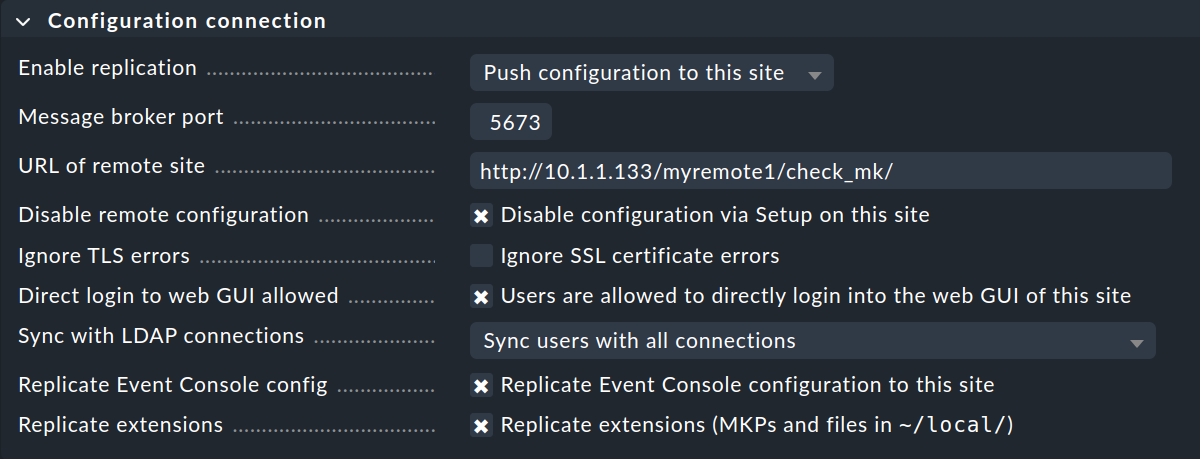
Replicar la configuración y, por lo tanto, utilizar la configuración central es, como comentamos en la introducción, opcional. Activa la replicación seleccionando Push configuration to this site si deseas configurar el sitio remoto desde el site central. En tal caso, selecciona los ajustes exactos que se muestran en la imagen de arriba.
Asegúrate de checkear qué Message broker port debes especificar.
Para averiguarlo, inicia sesión en el site remoto correspondiente y ejecuta omd config desde la línea de comandos.
Ve a la sección Basic.
Aquí, la variable RABBITMQ_PORT es la relevante.
┌─────────────────Basic───────────────────┐ │ ┌─────────────────────────────────────┐ │ │ │ ADMIN_MAIL │ │ │ │ AGENT_RECEIVER on │ │ │ │ AGENT_RECEIVER_PORT 8016 │ │ │ │ AUTOMATION_HELPER on │ │ │ │ AUTOSTART on │ │ │ │ CORE cmc │ │ │ │ RABBITMQ_DIST_PORT 25672 │ │ │ │ RABBITMQ_MANAGEMENT_PORT 15671 │ │ │ │ RABBITMQ_ONLY_FROM :: │ │ │ │ RABBITMQ_PORT 5671 │ │ │ │ TMPFS on │ │ │ │ │ │ │ └─────────────────────────────────────┘ │ ├─────────────────────────────────────────┤ │ < Change > <Main menu> │ └─────────────────────────────────────────┘
No te confundas: Message Broker Port se define aquí en la variable |
Es muy importante que la configuración de URL of remote site sea correcta.
La URL siempre debe terminar en /check_mk/. Se recomienda una conexión con HTTPS, siempre que el Apache del sitio remoto admita HTTPS.
Esto debe instalarse manualmente en el sitio remoto a nivel de Linux.
En el caso de la Appliance Checkmk, HTTPS se puede configurar mediante la interfaz de configuración web.
Si utilizas un certificado autofirmado, tendrás que marcar la casilla «Ignore SSL certificate errors».
Una vez guardada la máscara, aparecerá un segundo site en la Vista general:

El estado de monitorización del sitio remoto (hasta ahora) vacío ya está correctamente integrado.
Para utilizar la configuración central, sigues necesitando una cuenta Login para el sitio Checkmk remoto.
Para ello, el site central intercambia un secreto de inicio de sesión generado aleatoriamente con el sitio remoto, a través del cual se llevará a cabo toda la comunicación futura.
La cuenta cmkadmin en el sitio remoto ya no se utilizará a partir de ahora.
En el siguiente formulario, utiliza como Login credentials cmkadmin y la contraseña asignada al crear el site remoto.
En este punto, confirma que deseas sobrescribir la configuración haciendo clic en «Confirm overwrite».

Si el inicio de sesión se realiza correctamente, se realizará un reconocimiento de la siguiente manera:

Si se produce un error al realizar el inicio de sesión, esto podría deberse a varias razones, por ejemplo:
El site remoto está actualmente detenido.
El URL of remote site no se ha configurado correctamente.
No se puede acceder al sitio remoto con el nombre del host «desde el site central» especificado en la URL.
Las versiones de Checkmk del site central y del site remoto son (demasiado) incompatibles.
Se ha introducido un ID de usuario y/o una contraseña inválida.
Las dos primeras entradas de la lista se pueden comprobar fácilmente accediendo manualmente a la URL del sitio remoto en tu navegador.
Cuando todo haya salido bien, ejecuta Activate Changes. Esto te llevará, como siempre, a una vista general de los cambios aún no activados. Al mismo tiempo, la vista general también mostrará los estados de las conexiones de Livestatus, así como los estados de sincronización de cada sitio en la configuración central:
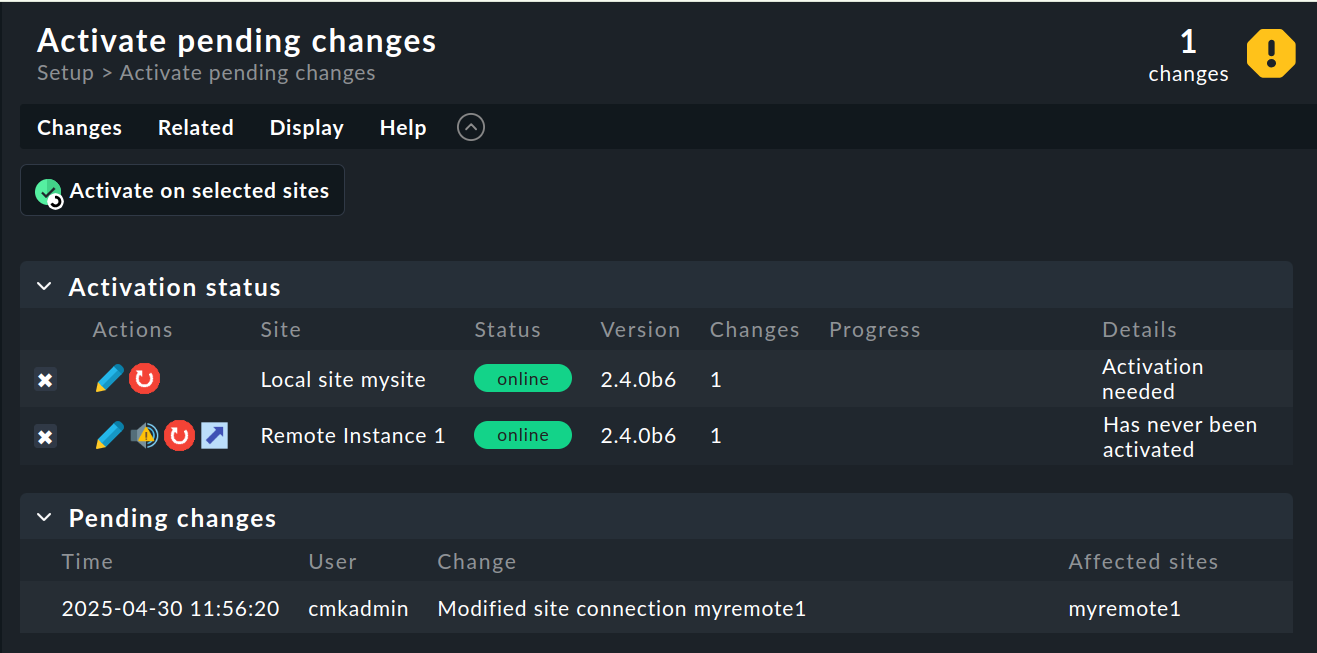
La columna «Version» muestra la versión de Livestatus del site correspondiente. Si utilizas el CMC como core de Checkmk (ediciones comerciales), el número de versión del core (que se muestra en la columna «‘Core’») es idéntico al de Livestatus. Si utilizas Nagios como core (Checkmk Community), aquí se mostrará el número de versión de Nagios.
Los siguientes iconos muestran el estado de replicación del entorno de configuración:
|
Este sitio tiene cambios pendientes.
La configuración tiene una coincidencia con la del site central, pero no se han activado todos los cambios.
Con el botón « |
|
La configuración de este site no está sincronizada y debe transferirse.
Por supuesto, será necesario reiniciar para activarla.
Ambas funciones se pueden realizar con un clic en el botón « |
En la columna «Status» se puede ver el estado de la conexión de Livestatus para el site en cuestión. Esto se muestra solo a título informativo, ya que la configuración no se transmite a través de Livestatus, sino por HTTP. Los siguientes valores son posibles:
|
Se puede acceder al site a través de Livestatus. |
|
No se puede acceder al site en este momento. Las consultas de Livestatus están agotando el timeout. Esto retrasa la carga de la página. Los datos de estado de este site no se ven en la GUI. |
|
Actualmente no se puede acceder al site, pero esto se debe a la configuración de un host de estado o se conoce a través del proxy de Livestatus (ver más abajo). La inaccesibilidad no provoca tiempos de timeout. Los datos de estado de este site no son visibles en la GUI. |
|
El administrador (del site central) ha desactivado temporalmente la conexión de Livestatus a este sitio. La configuración coincide con la casilla de verificación «Temporarily disable this connection» en los ajustes de esta conexión. |
Al hacer clic en el botón «![]() » (Actualizar todos los sitios) Activate on selected sites, se sincronizarán todos los sitios y se activarán los cambios.
Esto se realiza en paralelo, por lo que el tiempo total equivale al tiempo que tarda el sitio más lento.
En ese tiempo se incluye la creación de una instantánea de configuración para el sitio correspondiente, la transmisión por HTTP, la descompresión de la instantánea en el site remoto y la activación de los cambios.
» (Actualizar todos los sitios) Activate on selected sites, se sincronizarán todos los sitios y se activarán los cambios.
Esto se realiza en paralelo, por lo que el tiempo total equivale al tiempo que tarda el sitio más lento.
En ese tiempo se incluye la creación de una instantánea de configuración para el sitio correspondiente, la transmisión por HTTP, la descompresión de la instantánea en el site remoto y la activación de los cambios.
Importante: No salgas de la página antes de que la sincronización se haya completado en todos los sites; si sales de la página, se interrumpirá la sincronización.
Especificar a los hosts y carpetas qué site debe realizar la monitorización de ellos
Una vez instalado tu entorno distribuido, puedes empezar a utilizarlo. En realidad, solo tienes que indicar a cada host qué site debe supervisarlo. El site central se especifica por defecto.
El atributo necesario para esto es Monitored on site. Puedes configurarlo individualmente para cada host. Por supuesto, esto también se puede hacer a nivel de carpeta:

Ejecutar un nuevo descubrimiento de servicios y activar cambios para los hosts migrados
Añadir hosts funciona como de costumbre: aparte del hecho de que la monitorización y el descubrimiento de servicios se ejecutarán desde el site remoto correspondiente, no hay que tener en cuenta nada especial.
Al migrar hosts de un sitio a otro, hay un par de puntos que debes tener en cuenta. No se transferirán ni los datos de estado actuales ni los históricos del host. Solo se conserva la configuración del host en el entorno de configuración. En la práctica, es como si el host se hubiera eliminado de un sitio y se hubiera instalado de nuevo en el otro:
Los servicios detectados automáticamente no se migrarán. Ejecuta el descubrimiento de servicios después de la migración.
Una vez reiniciados, los hosts y los servicios mostrarán el estado PEND. Como resultado, es posible que se notifiquen de nuevo los problemas existentes actualmente.
Se perderán las métricas históricas. Esto se puede evitar moviendo manualmente los archivos RRD pertinentes. La ubicación de los archivos se puede encontrar en Archivos y directorios.
Se perderán los datos de disponibilidad y de eventos históricos. Lamentablemente, estos no son fáciles de migrar, ya que los datos consisten en líneas individuales en el registro de monitorización.
Si la continuidad del historial es importante para ti, al implementar la monitorización debes planificar cuidadosamente qué host se va a monitorizar y desde dónde.
2.3. Conexión de Livestatus con cifrado
Las conexiones de Livestatus entre el site central y un site remoto se pueden cifrar.
Para los sitios recién creados no hay que hacer nada más,
ya que Checkmk se encarga automáticamente de los pasos necesarios.
En cuanto utilices omd config para activar Livestatus, el cifrado también se activa automáticamente mediante TLS:
┌────────────Distributed Monitoring──────────────┐ │ ┌────────────────────────────────────────────┐ │ │ │ LIVEPROXYD on │ │ │ │ LIVESTATUS_TCP on │ │ │ │ LIVESTATUS_TCP_ONLY_FROM 0.0.0.0 ::/0 │ │ │ │ LIVESTATUS_TCP_PORT 6557 │ │ │ │ LIVESTATUS_TCP_TLS on │ │ │ │ PIGGYBACK_HUB on │ │ │ │ │ │ │ └────────────────────────────────────────────┘ │ ├────────────────────────────────────────────────┤ │ < Change > <Main menu> │ └────────────────────────────────────────────────┘
Por lo tanto, la configuración de la monitorización distribuida sigue siendo tan sencilla como hasta ahora. Para nuevas conexiones a otros sitios, la opción «Encryption» se habilita automáticamente.
Después de añadir el sitio remoto, notarás dos cosas: en primer lugar, la conexión aparece marcada como cifrada con este nuevo icono de ![]() .
Y en segundo lugar, Checkmk te indicará que la CA ya no confía en el sitio remoto.
Haz clic en
.
Y en segundo lugar, Checkmk te indicará que la CA ya no confía en el sitio remoto.
Haz clic en ![]() para ver los detalles de los certificados utilizados.
Con un clic en
para ver los detalles de los certificados utilizados.
Con un clic en ![]() puedes añadir cómodamente la CA a través de la interfaz web.
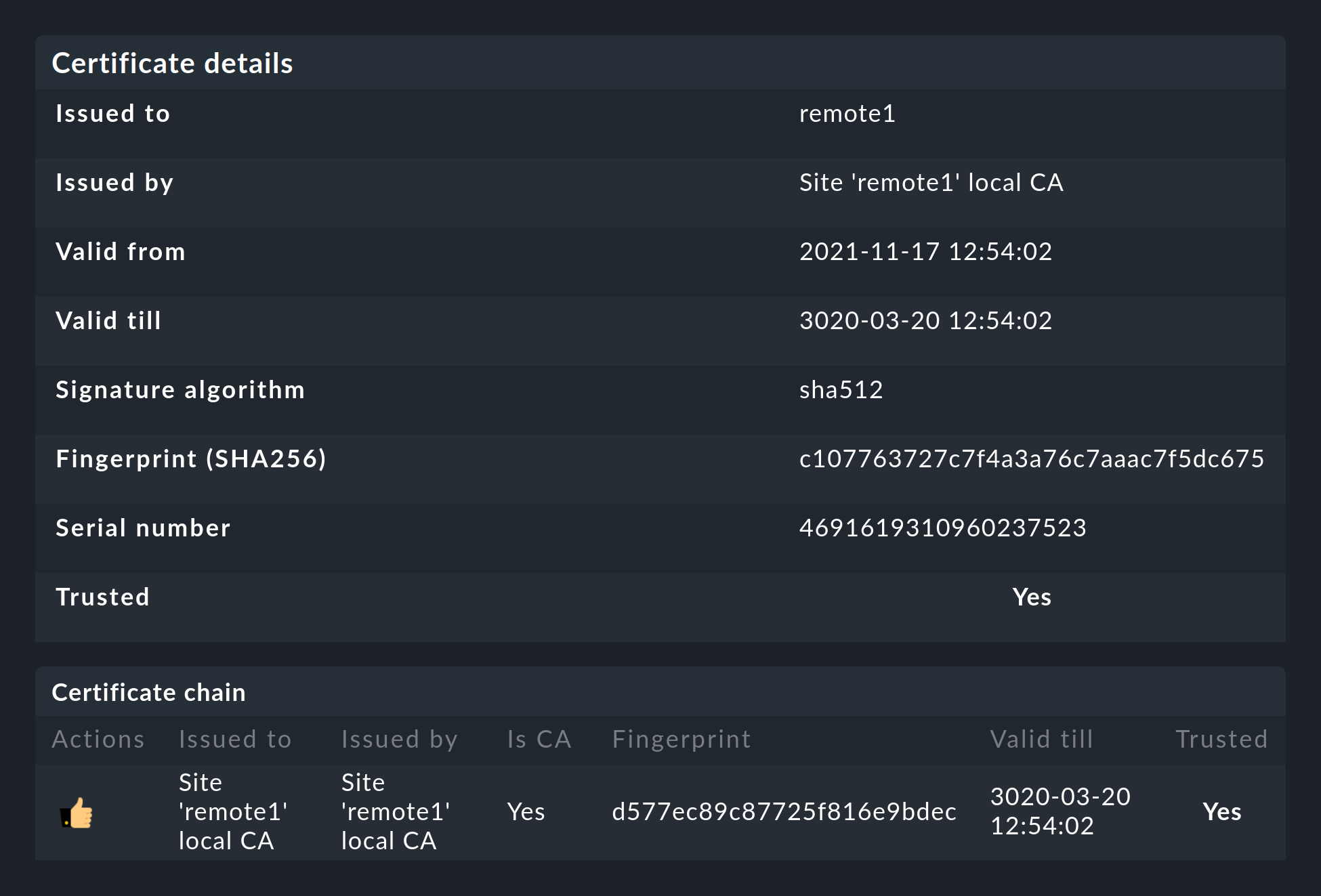
Entonces ambos certificados aparecerán en la lista como de confianza:
puedes añadir cómodamente la CA a través de la interfaz web.
Entonces ambos certificados aparecerán en la lista como de confianza:
Detalles de las tecnologías utilizadas
Para llevar a cabo el cifrado, Checkmk utiliza el programa stunnel junto con su propio certificado y su propia autoridad de certificación (CA) para firmar el certificado.
Estos se generan automáticamente de forma individual con cada nuevo site y, por lo tanto, no son CA ni certificados estáticos predefinidos.
Este es un factor de seguridad muy importante para evitar que los atacantes utilicen certificados falsos, ya que cualquier atacante podría entonces acceder a una CA disponible públicamente.
Los certificados generados también tienen las siguientes propiedades:
Ambos certificados están en formato PEM. Los certificados firmados para el site también contienen la cadena de certificados completa.
Las claves utilizan RSA de 4096 bits, y el certificado se firma con SHA512
El certificado del site tiene una validez de 10 años.
El hecho de que el certificado estándar sea válido durante tanto tiempo evita de forma muy eficaz que surjan problemas de conexión que no puedas identificar. Al mismo tiempo, por supuesto, es posible que, una vez que un certificado se haya visto comprometido, esté expuesto al abuso durante ese mismo tiempo. Así que, si temes que un atacante pueda acceder a la CA o al certificado del sitio firmado con ella, ¡sustituye siempre ambos certificados (el de la CA y el del sitio)!
Migración desde versiones anteriores
Durante una actualización de Checkmk, las dos opciones LIVESTATUS_TCP y LIVESTATUS_TCP_TLS nunca se modifican automáticamente.
La activación automática de TLS podría acabar provocando que ya no se puedan consultar tus sitios remotos.
Si hasta ahora has estado utilizando Livestatus sin cifrar y ahora decides utilizar el cifrado, debes activarlo manualmente. Para ello, primero detén los sitios afectados y, a continuación, activa TLS con el siguiente comando:
Dado que los certificados se generaron automáticamente durante la actualización, el sitio utilizará inmediatamente la nueva función de cifrado. Para que puedas seguir accediendo al sitio desde el site central, comprueba que la opción «Encryption» esté configurada en «Encrypt data using TLS» en el menú bajo «Setup > General > Distributed Monitoring»: Comprueba esto y, si es necesario, configura la opción como se muestra en la siguiente captura de pantalla:
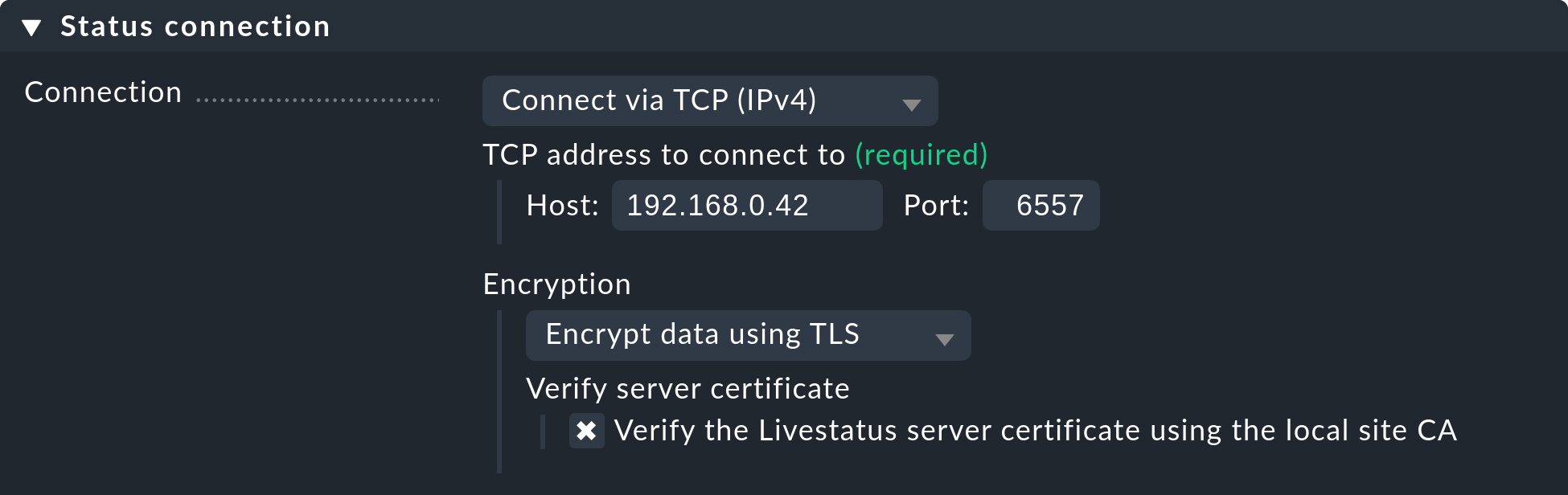
El último paso es el descrito anteriormente; aquí también tienes que marcar primero la CA del site remoto como de confianza.
2.4. Características especiales de una configuración central
Una monitorización distribuida funciona a través de Livestatus de forma muy similar a un sistema único, pero tiene un par de características especiales:
Acceso a los hosts sujetos a monitorización
Todos los accesos a un host supervisado se realizan siempre desde el sitio al que está asignado el host. Esto se aplica no solo a la monitorización propiamente dicha, sino también al descubrimiento de servicios, la página de Diagnósticos, las notificaciones, los alert handlers y todo lo demás. Este punto es muy importante, ya que no se da por sentado que el site central tenga realmente acceso a este host.
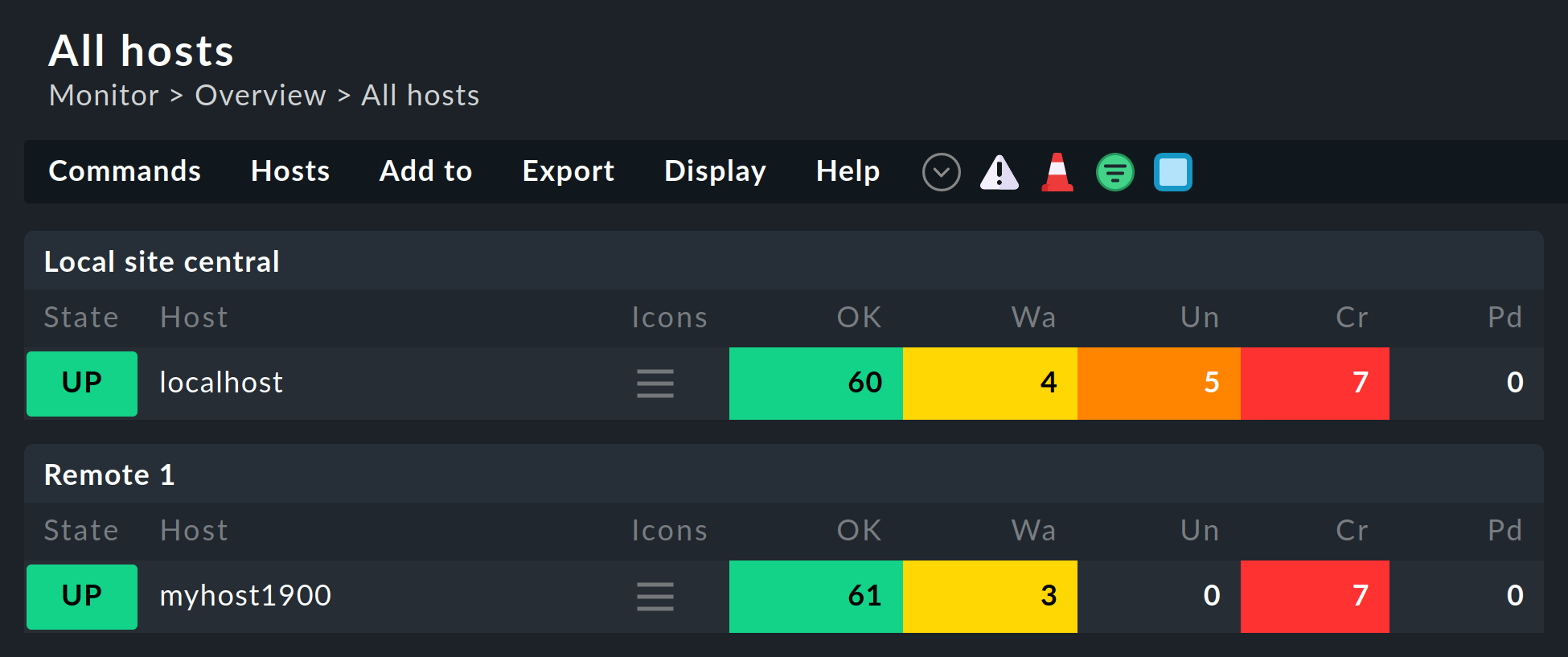
Especificación del site en las vistas de tabla
Algunas de las vistas estándar se agrupan según el site desde el que se realizará la monitorización del host; esto se aplica, por ejemplo, a All hosts:
El site también aparecerá en los detalles del host o del servicio:
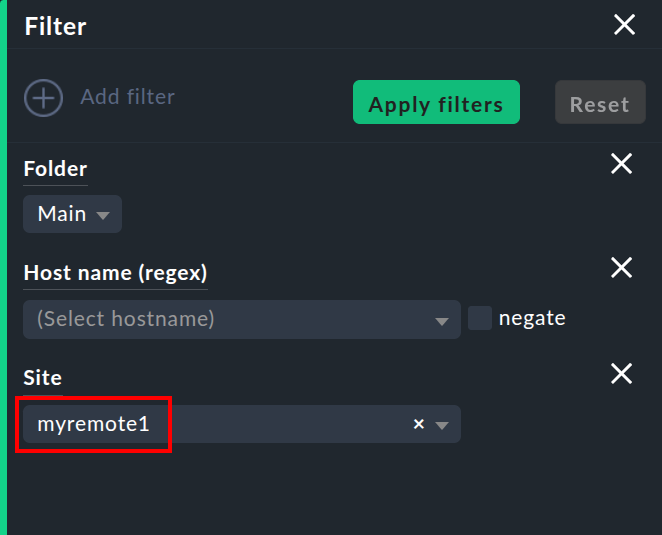
Esta información suele estar disponible para usarla en una columna al crear tus propias vistas de tabla. También hay un filtro con el que se puede filtrar una vista de tabla de los hosts de un site específico:
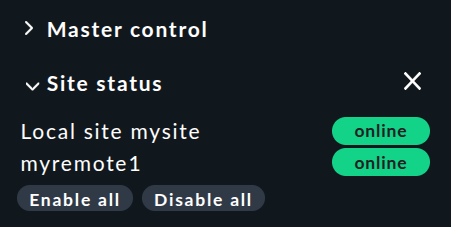
Componente snap-in de estado del site
Hay un snap-in de Site status para la barra lateral que se puede añadir usando ![]() .
Esto muestra el estado de cada sitio.
También ofrece la opción de desactivar y volver a activar temporalmente un solo sitio haciendo clic en el estado, o todos los sitios a la vez haciendo clic en «Disable all» o «Enable all».
.
Esto muestra el estado de cada sitio.
También ofrece la opción de desactivar y volver a activar temporalmente un solo sitio haciendo clic en el estado, o todos los sitios a la vez haciendo clic en «Disable all» o «Enable all».
Los sitios desactivados aparecerán marcados con el estado «![]() ».
Con esto también puedes desactivar un sitio de
».
Con esto también puedes desactivar un sitio de ![]() que esté generando tiempos de espera, evitando así tiempos de espera innecesarios.
Esta desactivación no es lo mismo que desactivar la conexión de Livestatus mediante la configuración de conexión en Setup.
Aquí, la «desactivación» solo afecta al usuario que está conectado actualmente y tiene una función puramente visual.
Al hacer clic en el nombre de un sitio, se mostrará una vista de tabla de todos sus hosts.
que esté generando tiempos de espera, evitando así tiempos de espera innecesarios.
Esta desactivación no es lo mismo que desactivar la conexión de Livestatus mediante la configuración de conexión en Setup.
Aquí, la «desactivación» solo afecta al usuario que está conectado actualmente y tiene una función puramente visual.
Al hacer clic en el nombre de un sitio, se mostrará una vista de tabla de todos sus hosts.
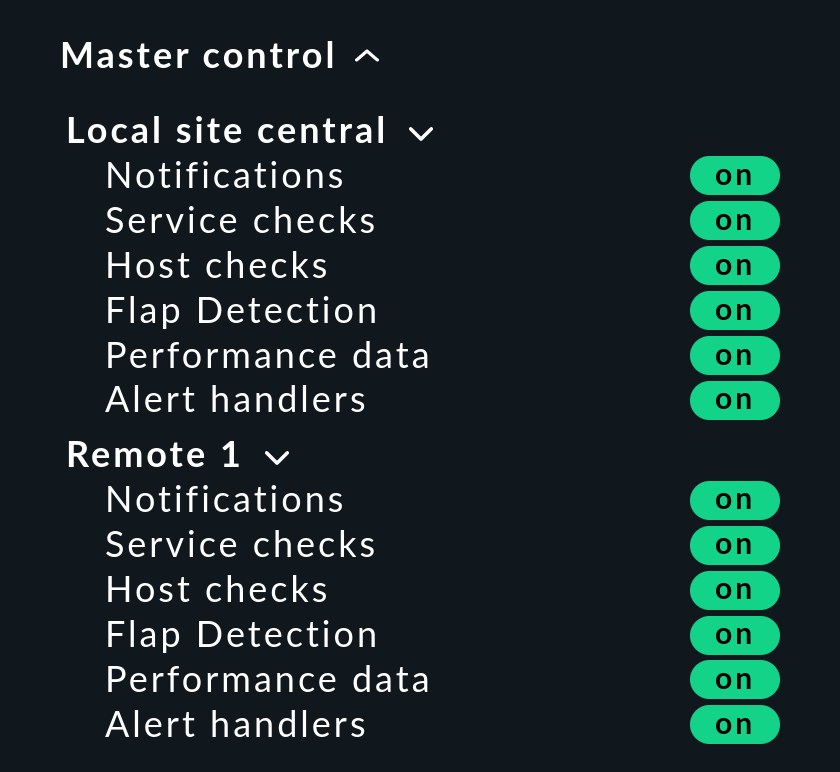
Complemento de control maestro snap-in
En una monitorización distribuida, el snap-in «Master control» tiene un aspecto diferente. Cada sitio tiene su propio switch global:
Hosts del clúster de Checkmk
Si supervisas con un clúster HA de Checkmk, los nodos individuales del clúster deben asignarse al mismo sitio que el propio clúster. Esto se debe a que, para determinar el estado de los servicios en clúster, se accede a archivos de caché generados mediante la monitorización del nodo. Estos datos se encuentran localmente en el sitio correspondiente.
Datos piggyback
Algunos check plugins utilizan datos piggyback, por ejemplo, para asignar datos de monitorización que se han «acoplado» desde un host a las máquinas virtuales individuales. En la monitorización distribuida, el host piggyback —es decir, el host que recibe los datos piggyback— y los hosts que dependen de él —como consumidores reales de los datos piggyback— no siempre se monitorizan desde el mismo site. En estos casos, se puede activar una asignación de datos piggyback entre sitios.
Para habilitar esta comunicación, solo tienes que asegurarte de que el puerto del broker de mensajes esté configurado correctamente en todos los sites participantes y de que el piggyback hub esté habilitado.
Deberías check esto a más tardDisablede que veas aquí:

Conexiones punto a punto
El tráfico de datos suele crear un cuello de botella en la comunicación. Si los datos van y vienen de un punto a otro, esto puede provocar rápidamente una avalancha de datos y, por lo tanto, una sobrecarga de la red de comunicación. Por eso, es recomendable reducir el número de canales de comunicación y mantener el intercambio de datos principalmente dentro de una red local. Así pues, para reducir la carga en tu sitio central u optimizar el tráfico de red, también puedes permitir que los sitios remotos se comuniquen directamente entre sí (conexión entre pares). Como requisito previo para ello, ambos sitios remotos deben haber sido configurados por el sitio central, es decir, Push configuration to this site debe estar activado para ambos tal y como se describe en la sección Asignación de sitios remotos al sitio central.
En Setup > General > Distributed monitoring, selecciona el elemento de menú «Connections > Add peer-to-peer message broker connection». Asigna aquí un ID único y selecciona los dos sitios para la conexión directa. Asegúrate de seguir las instrucciones de la ayuda en línea.
inventario de HW/SW
El inventario de HW/SW de Checkmk también funciona en entornos distribuidos.
Para ello, los datos de inventario del directorio ~/var/check_mk/inventory deben transmitirse regularmente desde los sitios remotos al site central.
Por motivos de rendimiento, la interfaz de usuario siempre accede a este directorio de forma local.
En las ediciones comerciales, la sincronización se lleva a cabo automáticamente en todos los sitios conectados mediante el proxy Livestatus.
Si ejecutas el inventario con Checkmk Community en sistemas distribuidos, debes replicar el directorio regularmente en el site central con tus propias herramientas (por ejemplo, con rsync).
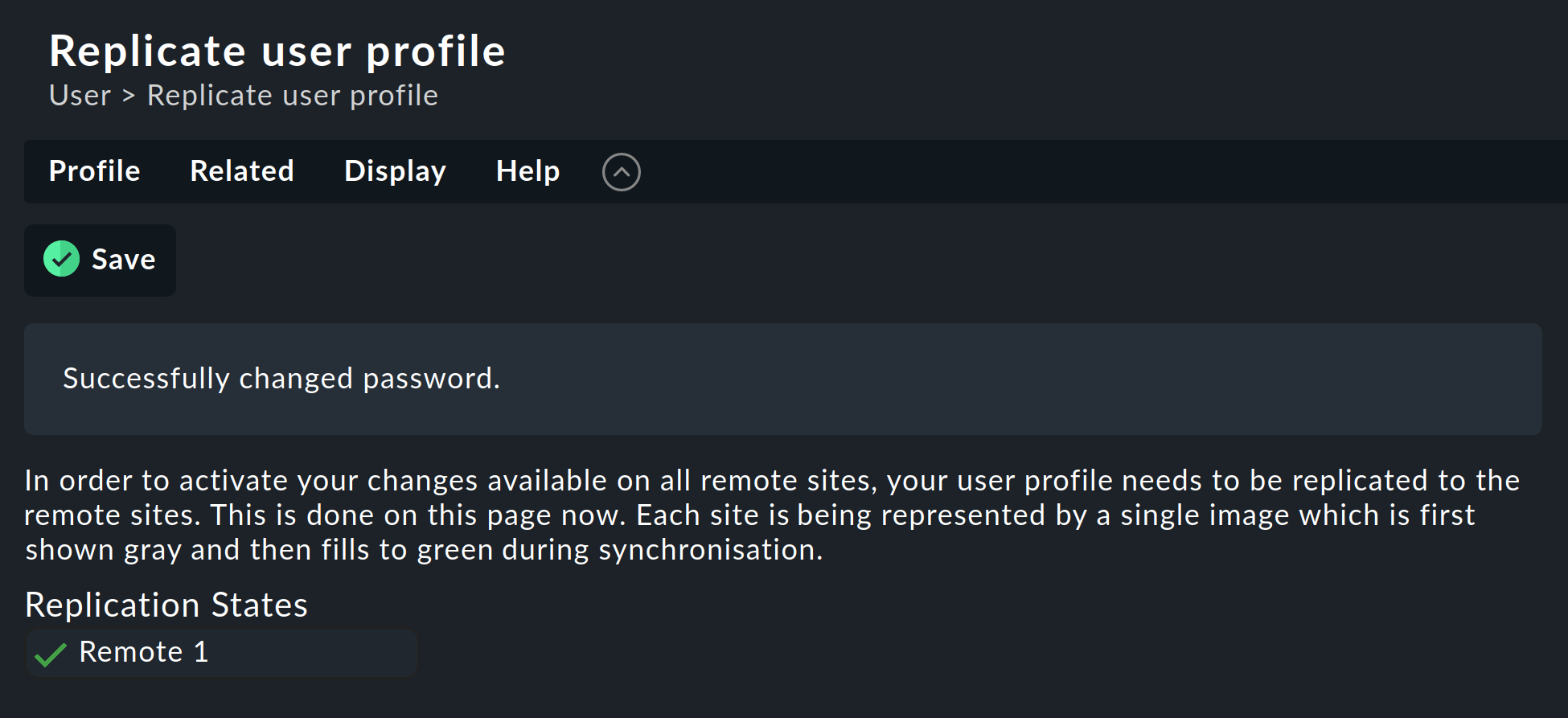
Cambiar una contraseña
Incluso cuando todos los sitios se realizan tareas de monitorización de forma centralizada, es perfectamente posible realizar un inicio de sesión en la interfaz de un sitio individual y, a menudo, también es lo más adecuado. Por este motivo, Checkmk garantiza que la contraseña de un usuario sea siempre la misma en todos los sitios.
Un cambio de contraseña realizado por el administrador surtirá efecto automáticamente tan pronto como se comparta con todos los sitios mediante Activate pending changes.
Un cambio realizado por el propio usuario a través de la barra lateral de ![]() en su configuración personal funciona de forma algo diferente.
Esto no puede ejecutar un comando «Activate pending changes», ya que el usuario, por supuesto, no tiene permiso general para esta función.
En tal caso, Checkmk compartirá automáticamente la contraseña cambiada en todos los sitios, de hecho, justo después de que se haya guardado.
en su configuración personal funciona de forma algo diferente.
Esto no puede ejecutar un comando «Activate pending changes», ya que el usuario, por supuesto, no tiene permiso general para esta función.
En tal caso, Checkmk compartirá automáticamente la contraseña cambiada en todos los sitios, de hecho, justo después de que se haya guardado.
Como todos sabemos, las redes nunca están disponibles al 100 %. Si no se puede acceder a un sitio en el momento del cambio de contraseña, este no recibirá la nueva contraseña. Hasta que el administrador ejecute correctamente un comando «Activate pending changes», o hasta el siguiente cambio de contraseña que se realice con éxito, este sitio mantendrá la contraseña antigua para el usuario. Un icono de estado informará al usuario del estado de la sincronización de la contraseña en los sitios individuales.
2.5. Vinculación de sitios existentes
Como se ha mencionado anteriormente, los sitios existentes también se pueden vincular retrospectivamente a una monitorización distribuida. Siempre que se cumplan las condiciones previas descritas anteriormente (versiones compatibles de Checkmk), esto se completará exactamente igual que para configurar un nuevo site remoto. Comparte Livestatus con TCP, luego añade el sitio a través de Setup > General > Distributed monitoring, ¡y listo!
La segunda etapa —el cambio a una configuración centralizada— es algo más complicada. Antes de integrar el sitio en el entorno de configuración central como se ha descrito anteriormente, debes tener en cuenta que, al hacerlo, ¡se sobrescribirá toda la configuración local del sitio! |
Si deseas hacerte cargo de los hosts existentes, y posiblemente también de las reglas, serán necesarios tres pasos:
Haz la coincidencia del esquema de los tags de los hosts
Copia los directorios (de host)
Edita las características en la carpeta principal
1. Tags del host
Es obvio que las etiquetas del host utilizadas en el sitio remoto también deben ser conocidas por el site central para que puedan transferirse. Checklas antes de la migración y añade manualmente al site central cualquier etiqueta que falte. Aquí es esencial que haya coincidencia entre los ID de las etiquetas; el título de la etiqueta es irrelevante.
2. Carpetas
A continuación, mueve los hosts y las reglas al entorno de configuración del site central. Esto solo funciona para los hosts y las reglas que están en subcarpetas (es decir, no en la carpeta Main). Los hosts de la Carpeta principal deben moverse primero a una subcarpeta del site remoto a través de Setup > Hosts > Hosts.
La migración propiamente dicha se puede realizar de forma muy sencilla copiando los directorios correspondientes.
Cada carpeta del entorno de configuración se corresponde con un directorio dentro de ~/etc/check_mk/conf.d/wato/.
Estos se pueden copiar utilizando la herramienta que prefieras (por ejemplo, scp) desde el sitio vinculado a la misma ubicación en el site central.
Si ya existe allí un directorio con el mismo nombre, simplemente cámbiale el nombre.
Ten en cuenta que el site central también utiliza los usuarios y grupos de Linux.
Tras la copia, los hosts aparecerán en el site central Setup, así como las reglas que hayas creado en estas carpetas.
Las propiedades de las carpetas también se incluirán en la copia.
Estas se pueden encontrar en el directorio del archivo oculto .wato.
3. Edición y guardado únicos
Para que los atributos de las funciones de la carpeta principal del site central se hereden correctamente, como paso final tras la migración, debes abrir y guardar una vez las características de las carpetas principales ; de este modo, se volverán a definir los atributos del host.
2.6. Ajustes globales específicos de cada site
Una configuración centralizada significa, ante todo, que todos los sitios tienen una configuración común y (aparte de los hosts) idéntica. ¿Qué ocurre, sin embargo, cuando sitios individuales requieren ajustes globales diferentes? Un ejemplo podría ser el ajuste CMC Maximum concurrent Checkmk checks. Podría darse el caso de que se requiera un ajuste personalizado para un sitio especialmente pequeño o especialmente grande.
Para estos casos, existe una configuración global específica para cada sitio.
Se accede a ella a través del icono ![]() en el menú, en «Setup > General > Distributed monitoring»:
en el menú, en «Setup > General > Distributed monitoring»:

A través de este icono encontrarás una selección de todas las configuraciones globales, aunque cualquier cosa que definas aquí solo será efectiva para el site elegido. Un valor que se desvíe del estándar se resaltará visualmente y solo se aplicará a este site:

2.7. Consola de eventos distribuida
La Consola de eventos procesa mensajes syslog, Traps SNMP y otros tipos de eventos de naturaleza asíncrona.
Checkmk también ofrece la opción de ejecutar una Consola de eventos distribuida.
De este modo, cada sitio ejecutará su propio procesamiento de eventos, que capturará los eventos de todos los hosts supervisados desde ese sitio.
Por lo tanto, los eventos no se enviarán al sistema central, sino que permanecerán en los sitios y solo se recuperarán de forma centralizada.
Esto se lleva a cabo de manera similar a como se hace con los estados activos a través de Livestatus, y funciona tanto con Checkmk Community ![]() como con las ediciones comerciales.
como con las ediciones comerciales.
Para pasar a una Consola de eventos distribuida según el nuevo esquema, hay que seguir estos pasos:
En la configuración de la conexión, activa la opción (Replicate Event Console configuration to this site).
Switch la ubicación de syslog y los destinos de Trap SNMP de los hosts afectados al site remoto. Esta es la tarea más laboriosa.
Si utilizas el conjunto de reglas Check event state in Event Console, switchlo a Connect to the local Event Console.
Si utilizas el conjunto de reglas de Logwatch Event Console Forwarding, switchalo también a la Consola de eventos local.
En la Consola de eventos «Settings», switch el «Access to event status via TCP» de nuevo a «no access via TCP».
2.8. NagVis

El programa Open Source NagVis visualiza los datos de estado de la monitorización en mapas, diagramas y otros gráficos generados por él mismo. NagVis está integrado en Checkmk y se puede usar de inmediato. La forma más fácil de acceder es a través del elemento de la barra lateral «NagVis Maps». La integración de NagVis en Checkmk se describe en un artículo aparte.
NagVis admite la monitorización distribuida a través de Livestatus prácticamente de la misma manera que Checkmk. Los enlaces a los sitios individuales se denominan backends. Checkmk configura automáticamente los backends de forma correcta para que puedas empezar a generar gráficos de NagVis de inmediato, incluso en la monitorización distribuida.
Selecciona el backend correcto para cada objeto que coloques en un gráfico, es decir, el site de Checkmk desde el que se va a realizar la monitorización del objeto. NagVis no puede encontrar el host o el servicio automáticamente, sobre todo por motivos de rendimiento. Por lo tanto, si trasladas hosts a un site remoto diferente, tendrás que actualizar los gráficos de NagVis en consecuencia.
Puedes encontrar más detalles sobre los backends en la documentación aquí: NagVis.
3. Conexiones inestables o lentas
La vista general del estado en la interfaz de usuario permite un acceso siempre disponible y fiable a todos los sitios conectados. El único inconveniente es que la vista de tabla solo se puede mostrar cuando todos los sitios han respondido. El proceso siempre es el siguiente: primero se envía una consulta de Livestatus (por ejemplo, «Mostrar todos los servicios cuyo estado no sea OK»). La vista de tabla solo se puede mostrar una vez que el último sitio haya respondido.
Es molesto cuando un sitio no responde en absoluto.
Para tolerar breves interrupciones (por ejemplo, debido al reinicio de un sitio o a la pérdida de un paquete TCP), la GUI espera un tiempo determinado antes de declarar que un sitio está «![]() », y luego continúa procesando las respuestas de los sitios restantes.
Esto provoca que la GUI se «cuelgue».
El timeout está fijado en 10 segundos por defecto.
», y luego continúa procesando las respuestas de los sitios restantes.
Esto provoca que la GUI se «cuelgue».
El timeout está fijado en 10 segundos por defecto.
Si esto ocurre de vez en cuando en tu red, deberías configurar hosts de Status o (mejor aún) el proxy Livestatus.
3.1. Hosts de estado
![]() La configuración de los hosts de estado es el procedimiento recomendado por la comunidad de Checkmk
La configuración de los hosts de estado es el procedimiento recomendado por la comunidad de Checkmk ![]() para detectar conexiones defectuosas de forma fiable.
La idea es sencilla:
El site central supervisa activamente la conexión con cada site remoto individual.
¡Al menos tendremos un sistema de monitorización disponible!
De este modo, la GUI detectará los sitios inaccesibles y podrá excluirlos inmediatamente y marcarlos como «
para detectar conexiones defectuosas de forma fiable.
La idea es sencilla:
El site central supervisa activamente la conexión con cada site remoto individual.
¡Al menos tendremos un sistema de monitorización disponible!
De este modo, la GUI detectará los sitios inaccesibles y podrá excluirlos inmediatamente y marcarlos como «![]() ».
Así se minimizan los tiempos de timeout.
».
Así se minimizan los tiempos de timeout.
A continuación te explicamos cómo configurar un host de estado para una conexión:
Añade el host en el que se ejecuta el site remoto al site central en la monitorización.
Introduce esto como host de estado en la conexión con el sitio remoto:
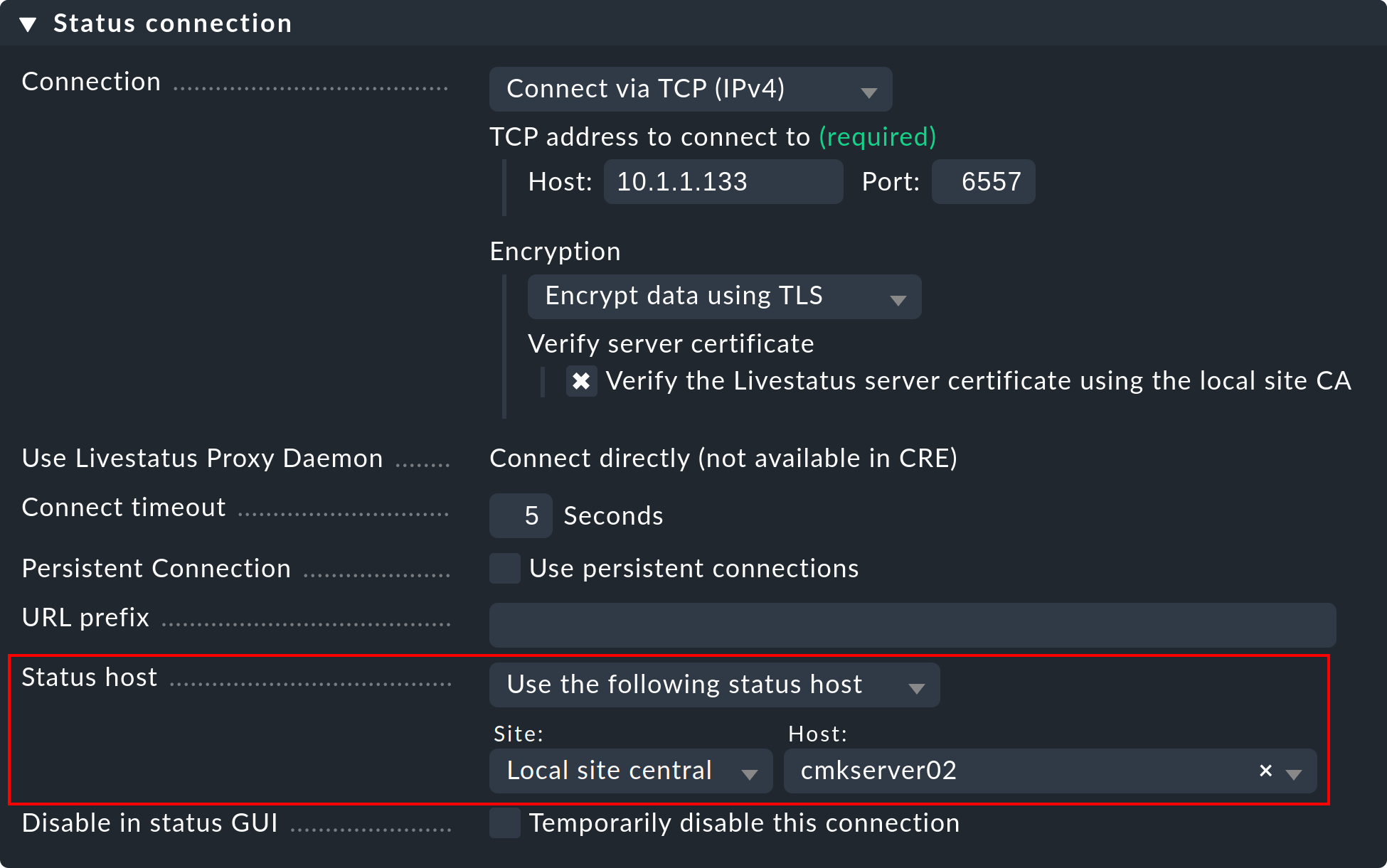
Ahora, una conexión fallida a un site remoto solo puede provocar un breve bloqueo de la GUI, es decir, hasta que la monitorización lo haya detectado. Al reducir el intervalo de comprobación del host de estado de los sesenta segundos predeterminados a, por ejemplo, cinco segundos, puedes minimizar la duración del bloqueo.
Si has configurado un host de estado, existen otros estados posibles para las conexiones:
|
El ordenador en el que se ejecuta el site remoto no es accesible para el sistema de monitorización en este momento porque un router está caído (el host de estado tiene el estado «UNREACH»). |
|
El host de estado que supervisa la conexión con el sistema remoto aún no ha sido verificado por la monitorización (todavía tiene un estado PEND). |
|
El estado del host de estado tiene un valor inválido (esto nunca debería ocurrir). |
En los tres casos, la conexión al site será excluida y así se evitarán los tiempos de timeout.
3.2. Conexiones persistentes
![]() Con la caja de verificación «Use persistent connections» puedes indicar a la GUI que mantenga las conexiones Livestatus establecidas con los sitios remotos permanentemente en estado «UP» y que siga utilizándolas para las consultas.
Especialmente en el caso de conexiones con tiempos de respuesta de paquetes más largos (por ejemplo, intercontinentales), esto puede hacer que la GUI sea notablemente más receptiva.
Con la caja de verificación «Use persistent connections» puedes indicar a la GUI que mantenga las conexiones Livestatus establecidas con los sitios remotos permanentemente en estado «UP» y que siga utilizándolas para las consultas.
Especialmente en el caso de conexiones con tiempos de respuesta de paquetes más largos (por ejemplo, intercontinentales), esto puede hacer que la GUI sea notablemente más receptiva.
Dado que la GUI de Apache se comparte entre varios procesos independientes, se requiere una conexión para cada proceso de cliente de Apache que se ejecute simultáneamente.
Si tienes muchos usuarios simultáneos, asegúrate de que la configuración cuente con un número suficiente de conexiones Livestatus en el core de Nagios del sitio remoto.
Estas se configuran en el archivo ~/etc/mk-livestatus/nagios.cfg.
El valor predeterminado es veinte (num_client_threads=20).
Por defecto, Apache está configurado en Checkmk para permitir hasta 128 conexiones de usuario simultáneas.
Esto se configura en la siguiente sección del archivo ~/etc/apache/apache.conf:
Esto significa que, bajo una carga elevada, pueden iniciarse hasta 128 procesos de Apache, lo que a su vez genera y mantiene hasta 128 conexiones Livestatus.
Si no se establece un valor lo suficientemente alto para num_client_threads, pueden producirse errores o una respuesta muy lenta en la GUI.
Para conexiones con LAN o con redes WAN rápidas, recomendamos no utilizar conexiones persistentes.
3.3. El proxy de Livestatus
![]() Con el proxy de Livestatus, las ediciones comerciales cuentan con un sofisticado mecanismo para detectar conexiones inactivas.
Además, optimiza especialmente el rendimiento de las conexiones con tiempos de ida y vuelta largos. Las ventajas del proxy de Livestatus son:
Con el proxy de Livestatus, las ediciones comerciales cuentan con un sofisticado mecanismo para detectar conexiones inactivas.
Además, optimiza especialmente el rendimiento de las conexiones con tiempos de ida y vuelta largos. Las ventajas del proxy de Livestatus son:
Detección muy rápida y proactiva de sitios que no responden
Caché local de consultas que proporcionan datos estáticos
Conexiones TCP permanentes, que requieren menos idas y vueltas y, por lo tanto, permiten respuestas mucho más rápidas desde sitios lejanos (p. ej., EE. UU. ⇄ China)
Control preciso del número máximo de conexiones Livestatus necesarias
Permite el inventario de HW/SW en entornos distribuidos
Instalación
Instalar el proxy de Livestatus es muy sencillo. Viene activado por defecto en las ediciones comerciales, lo cual se puede ver al iniciar un site:
Selecciona la configuración «Use Livestatus Proxy-Daemon» para la conexión a los sitios remotos en lugar de «Connect via TCP»:
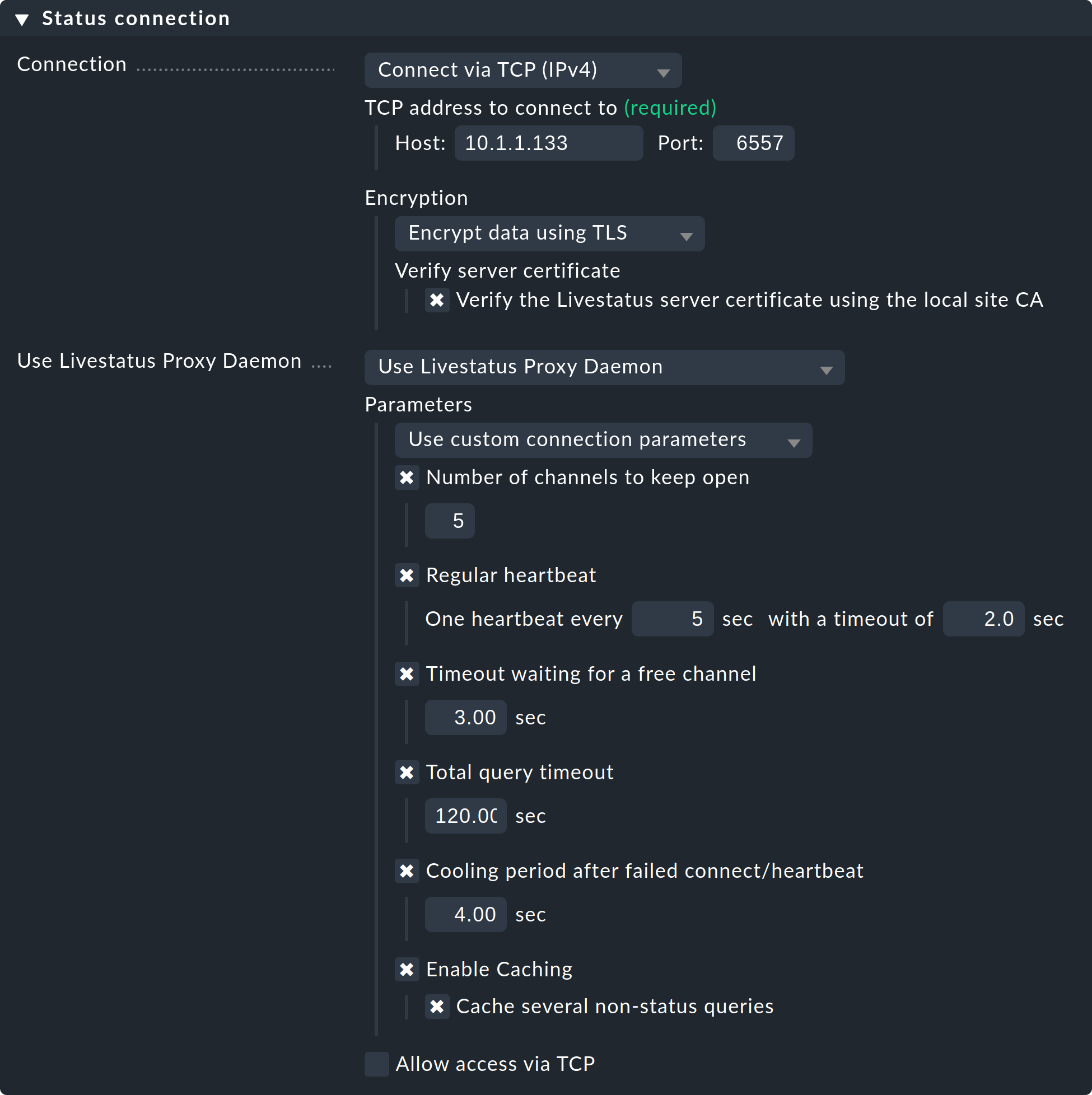
Los detalles del host y el puerto son los de siempre. No hay que hacer ningún cambio en el site remoto. En Number of channels to keep open, introduce el número de conexiones TCP paralelas que el proxy debe establecer y mantener con el sitio de destino.
El grupo de conexiones TCP es compartido por todas las consultas de la GUI. El número de conexiones limita el número máximo de consultas que se pueden procesar simultáneamente. Esto limita indirectamente el número de usuarios. En situaciones en las que todos los canales están reservados, esto no provocará un error de inmediato. La GUI espera un tiempo determinado a que haya un canal libre. La mayoría de las consultas solo requieren unos pocos milisegundos.
Si la GUI tiene que esperar más de unTimeout waiting for a free channele por un canal, se interrumpirá con un error y el usuario recibirá un mensaje de error. En tal caso, se debe aumentar el número de conexiones. Ten en cuenta, sin embargo, que en el site remoto se deben permitir suficientes conexiones entrantes paralelas; esto está configurado en 20 por defecto. Esta configuración se encuentra en las opciones globales, en «Monitoring core > Maximum concurrent Livestatus connections».
El «Regular heartbeat» proporciona una monitorización constante de las conexiones directamente a nivel de protocolo. En este proceso, el proxy envía regularmente una sencilla consulta «Livestatus» a la que el site remoto debe responder en un tiempo predeterminado (por defecto: 2 segundos). Con este método, también se detectará una situación en la que el servidor de destino y el puerto TCP sean realmente accesibles, pero el core de monitorización ya no responda.
Si no llega ninguna respuesta, todas las conexiones se declararán «muertas» y, tras un tiempo de «enfriamiento» (por defecto: 4 segundos), se volverán a establecer. Todo esto ocurre de forma proactiva, es decir, sin que el usuario tenga que abrir una ventana de la GUI. De esta forma, las interrupciones se detectan rápidamente y, mediante una recuperación, las conexiones se restablecen de inmediato y, en el mejor de los casos, están disponibles antes incluso de que el usuario se dé cuenta de la interrupción.
El «Caching» garantiza que las consultas estáticas solo tengan que ser respondidas una vez por el site remoto y, a partir de ese momento, puedan responderse directamente y de forma local, sin demora. Un ejemplo de esto es la lista de hosts supervisados que requiere Quicksearch.
Diagnóstico de errores
El proxy Livestatus tiene su propio archivo de registro: ~/var/log/liveproxyd.log.
En un site remoto correctamente configurado con cinco canales (estándar), tendrá un aspecto similar a este:
2025-04-30 15:58:30,624 [20] ----------------------------------------------------------
2025-04-30 15:58:30,627 [20] [cmk.liveproxyd] Livestatus Proxy-Daemon (2.4.0p24) starting...
2025-04-30 15:58:30,638 [20] [cmk.liveproxyd] Configured 1 sites
2025-04-30 15:58:36,690 [20] [cmk.liveproxyd.(3236831).Manager] Reload initiated. Checking if configuration changed.
2025-04-30 15:58:36,692 [20] [cmk.liveproxyd.(3236831).Manager] No configuration changes found, continuing.
2025-04-30 16:00:16,989 [20] [cmk.liveproxyd.(3236831).Manager] Reload initiated. Checking if configuration changed.
2025-04-30 16:00:16,993 [20] [cmk.liveproxyd.(3236831).Manager] Found configuration changes, triggering restart.
2025-04-30 16:00:17,000 [20] [cmk.liveproxyd.(3236831).Manager] Restart initiated. Terminating site processes...
2025-04-30 16:00:17,028 [20] [cmk.liveproxyd.(3236831).Manager] Restart master processEl proxy de Livestatus registra regularmente su estado en el archivo ~/var/log/liveproxyd.state:
Current state:
[myremote1]
State: ready
State dump time: 2025-04-30 15:01:15 (0:00:00)
Last reset: 2025-04-30 14:58:49 (0:02:25)
Site's last reload: 2025-04-30 14:26:00 (0:35:15)
Last failed connect: Never
Last failed error: None
Cached responses: 1
Channels:
9 - ready - client: none - since: 2025-04-30 15:01:00 (0:00:14)
10 - ready - client: none - since: 2025-04-30 15:01:10 (0:00:04)
11 - ready - client: none - since: 2025-04-30 15:00:55 (0:00:19)
12 - ready - client: none - since: 2025-04-30 15:01:05 (0:00:09)
13 - ready - client: none - since: 2025-04-30 15:00:50 (0:00:24)
Clients:
Heartbeat:
heartbeats received: 29
next in 0.2s
Inventory:
State: not running
Last update: 2025-04-30 14:58:50 (0:02:25)Y cuando un site está actualmente detenido, el estado se verá así:
----------------------------------------------
Current state:
[myremote1]
State: starting
State dump time: 2025-04-30 16:11:35 (0:00:00)
Last reset: 2025-04-30 16:11:29 (0:00:06)
Site's last reload: 2025-04-30 16:11:29 (0:00:06)
Last failed connect: 2025-04-30 16:11:33 (0:00:01)
Last failed error: [Errno 111] Connection refused
Cached responses: 0
Channels:
Clients:
Heartbeat:
heartbeats received: 0
next in -1.0s
Inventory:
State: not running
Last update: 2025-04-30 16:00:45 (0:10:50)Aquí el estado es «starting».
El proxy está, por lo tanto, intentando establecer conexiones.
Aún no hay canales.
Durante este estado, las consultas al site se responderán con un error.
4. Livestatus in cascada
Como ya se mencionó en la introducción, es posible ampliar la monitorización distribuida para incluir sitios del visor dedicados de Checkmk que muestren los datos de monitorización de sitios remotos a los que, por sí mismos, no se puede acceder directamente. El único requisito previo para esto es que, por supuesto, se pueda acceder al site central. Técnicamente, esto se implementa a través del proxy de Livestatus. El site central recibe datos del site remoto a través de Livestatus y actúa a su vez como proxy, es decir, puede reenviar los datos a terceros sitios. Puedes ampliar esta cadena como desees, por ejemplo, conectando un segundo site del visor a través del primero.
Esto resulta práctico, por ejemplo, en un escenario como el siguiente: El site central da soporte a tres redes independientes —cliente1, cliente2 y cliente3— y, a su vez, es gestionado por el operador de red1. Si la dirección del operador de la red del operador1 quisiera ver el estado de la monitorización de los sitios de los clientes, esto podría, por supuesto, regularse mediante un acceso desde el site central. Sin embargo, por razones técnicas y legales, el site central podría estar reservado exclusivamente para el personal responsable del mismo. Así, se puede evitar un acceso directo configurando un site del visor dedicado a ver los sitios remotos. El site del visor muestra entonces los hosts y servicios de los sitios conectados, pero su propia configuración permanece completamente vacía.
La configuración se realiza en los ajustes de conexión de la monitorización distribuida, primero en el site central y luego en el site del visor (que, de hecho, aún no tiene por qué existir).
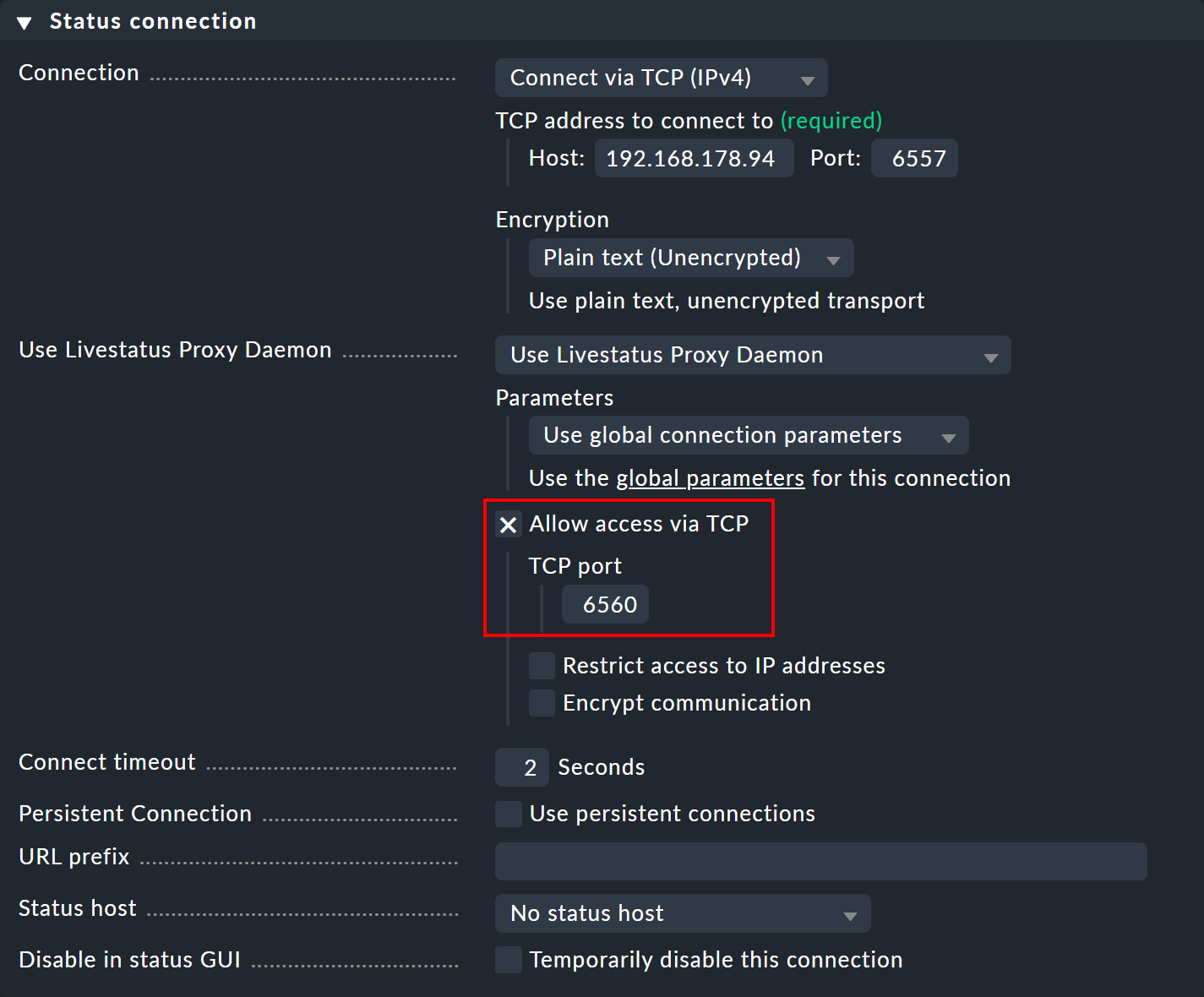
En el sitio central, abre la configuración de conexión del sitio remoto deseado a través de Setup > General > Distributed monitoring.
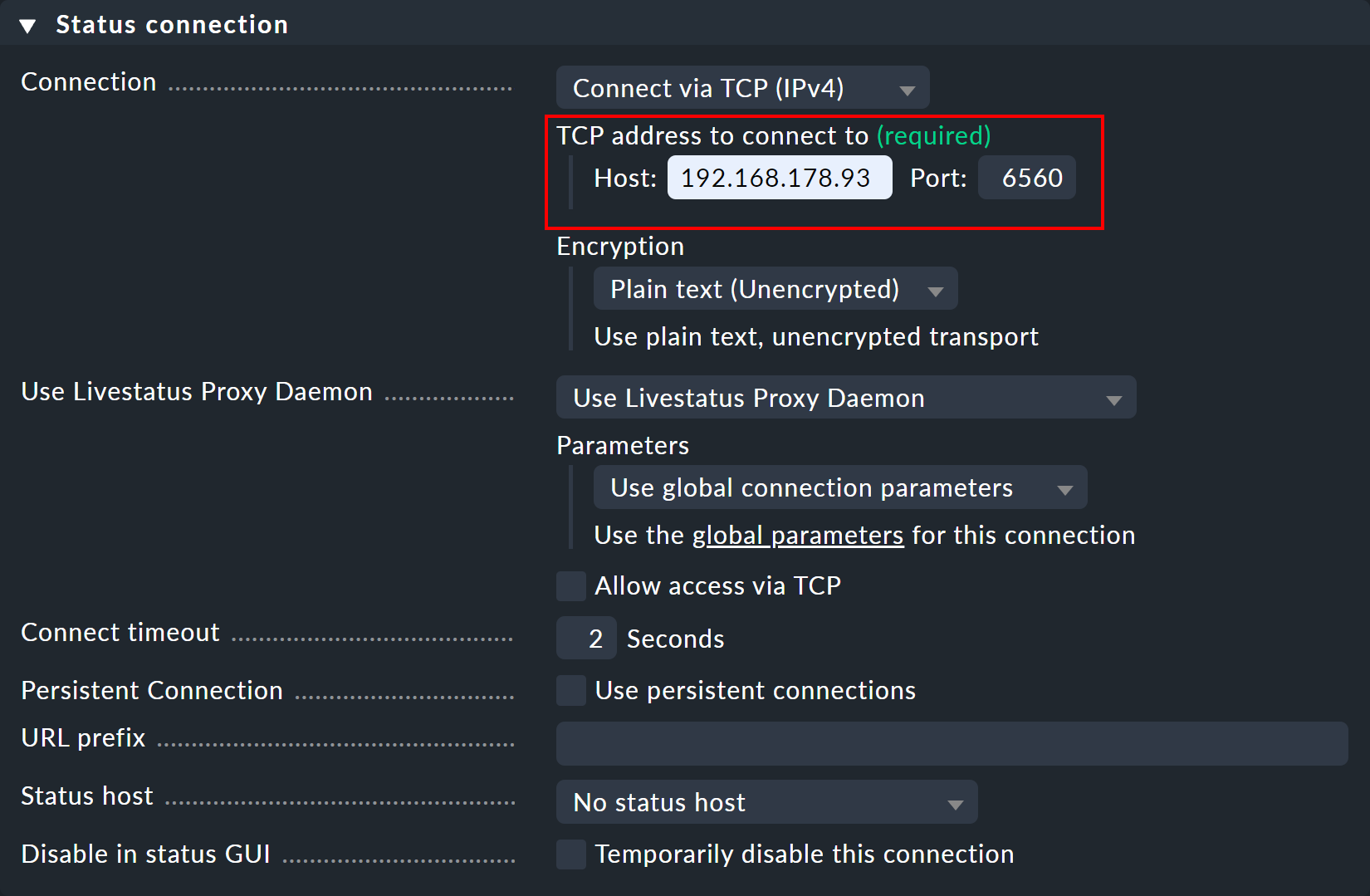
En «Use Livestatus Proxy Daemon», activa la opción «Allow access via TCP» e introduce un puerto disponible (en este caso, 6560).
De esta forma, el proxy de Livestatus del sitio central se conecta al sitio remoto y abre un puerto para las solicitudes del site del visor, que luego se reenvían al sitio remoto.
Ahora crea un site del visor y vuelve a abrir la configuración de conexión a través de Setup > General > Distributed monitoring. En Basic settings introduce —como siempre para las conexiones en la monitorización distribuida— el nombre exacto del site central como Site ID.

En el panel «Status connection», introduce el site central como host, así como el puerto libre asignado manualmente (en este caso, «6560»).
En cuanto se establezca la conexión, verás los hosts y servicios deseados del site remoto en las vistas de monitorización del site del visor.
Si quieres seguir con la configuración en cascada, también debes permitir el acceso TCP al proxy de Livestatus en el site del visor, tal y como se hizo antes en el site central, esta vez con un puerto libre diferente.
5. Livedump y CMCDump
5.1. Motivación
El concepto de monitorización distribuida con Checkmk que se ha descrito hasta ahora es una solución buena y sencilla en la mayoría de los casos. Sin embargo, requiere acceso de red desde el sitio central a los sitios remotos. Hay situaciones en las que el acceso no es posible o no es deseable, por ejemplo:
Los sitios remotos se encuentran en la red de tu cliente, a la que no tienes acceso.
Los sitios remotos se encuentran en una zona de seguridad a la que el acceso está estrictamente prohibido.
Los sitios remotos no tienen conexión de red permanente ni direcciones IP fijas, y métodos como el DNS dinámico no son una opción.
La monitorización distribuida con Livedump, o CMCDump, adopta un enfoque bastante diferente. En primer lugar, los sitios remotos están conectados de tal manera que funcionan de forma totalmente independiente del site central y se administran de forma descentralizada. Se prescinde de una configuración central.
Todos los hosts y servicios del sitio remoto se replicarán entonces como copias en el sitio central. Livedump/CMCDump puede ayudar generando una copia de la configuración de los sitios remotos que luego se puede cargar en el sitio central.
Ahora, durante la monitorización, en cada site remoto se escribirá una copia del estado actual en un archivo a intervalos predeterminados (por ejemplo, cada minuto).
Esto se transmitirá al site central mediante un método definido por el usuario y se guardará allí como una actualización de estado.
No se ha proporcionado ni especificado ningún protocolo concreto para esta transferencia de datos.
Se pueden utilizar todos los protocolos de transferencia que se puedan automatizar.
No es imprescindible utilizar scp; ¡incluso se podría hacer una transferencia por correo electrónico!
Esta configuración se diferencia de una monitorización distribuida «normal» en los siguientes aspectos:
La actualización de los estados y los datos de rendimiento en el site central se retrasará.
El cálculo de la disponibilidad en el site central dará resultados mínimamente diferentes a los de un cálculo en el site remoto.
Los cambios de estado que se produzcan más rápido que el intervalo de actualización serán invisibles para el site central.
Si un sitio remoto está «muerto», los estados quedarán obsoletos en el site central —los servicios estarán «obsoletos», pero seguirán siendo visibles—. Los datos de rendimiento y disponibilidad de este periodo de tiempo se «perderán» (pero seguirán estando disponibles en el sitio remoto).
Los comandos como «Schedule downtimes» y «Acknowledge problems» en el site central no se pueden transmitir al site remoto.
El site central nunca puede acceder a los sitios remotos.
No se podrá acceder a los detalles de los archivos de registro mediante logwatch.
La Consola de eventos no será compatible con Livedump/CMCDump.
Dado que los cambios de estado breves —dependiendo de la periodicidad seleccionada en el sitio central— pueden no ser visibles, una notificación a través del sitio central no es lo ideal. Sin embargo, si el sitio central se utiliza como un sitio puramente de visualización —por ejemplo, como una vista general central de todos los clientes—, este método tiene sin duda sus ventajas.
Por cierto, Livedump/CMCDump se puede utilizar simultáneamente junto con la monitorización distribuida a través de Livestatus sin problemas. Algunos sitios están conectados directamente a través de Livestatus; otros utilizan Livedump. Livedump también se puede añadir a uno de los sitios remotos de Livestatus.
5.2. Instalación de Livedump
![]() Si estás instalando una comunidad Checkmk (
Si estás instalando una comunidad Checkmk (![]() ) o las ediciones comerciales con un core Nagios, usa la herramienta
) o las ediciones comerciales con un core Nagios, usa la herramienta livedump.
El nombre viene de Livestatus y status dump.
livedumpse encuentra directamente en la ruta de búsqueda y, por lo tanto, está disponible como comando.
Partiremos de las siguientes premisas:
el site remoto está completamente configurado y realiza la monitorización activa de los hosts y los servicios,
el site central se ha iniciado y está en funcionamiento,
se está realizando la monitorización local de al menos un host en el site central (ya que el site central se monitoriza a sí mismo).
Transferencia de la configuración
Primero, en el site remoto, crea una copia de las configuraciones de sus hosts y servicios en el formato de configuración de Nagios.
Además, redirige la salida de livedump -TC a un archivo:
El inicio del archivo tendrá un aspecto similar a este:
define host {
name livedump-host
use check_mk_default
register 0
active_checks_enabled 0
passive_checks_enabled 1
}
define service {
name livedump-service
register 0
active_checks_enabled 0
passive_checks_enabled 1
check_period 0x0
}Envía el archivo al site central (por ejemplo, con scp) y guárdalo allí en el directorio ~/etc/nagios/conf.d/
– donde Nagios espera encontrar los datos de configuración de los hosts y servicios.
Elige un nombre de archivo que termine en .cfg, por ejemplo, ~/etc/nagios/conf.d/config-myremote1.cfg.
Si es posible acceder por SSH desde el sitio remoto al site central, puedes hacerlo, por ejemplo, como se muestra a continuación:
Ahora inicia sesión en el site central y activa los cambios:
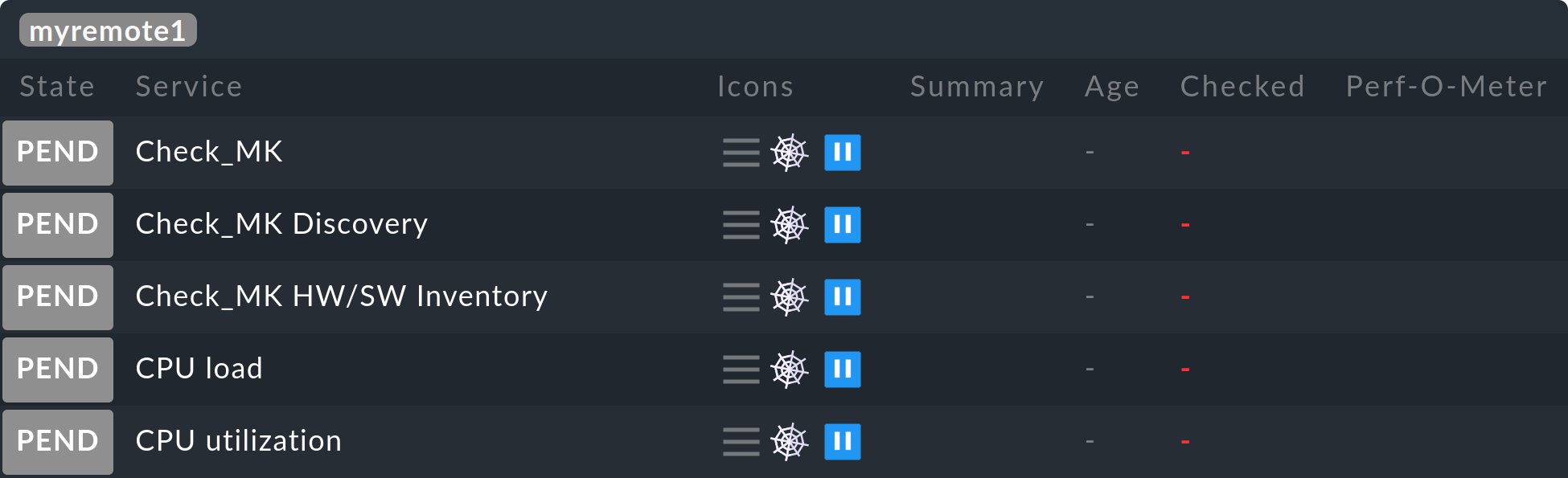
Ahora todos los hosts y servicios del control remoto deberían aparecer en el site central, inicialmente con el estado PEND, que mantendrán por el momento:
Notas:
Con la opción «
-T» en «livedump», se crean definiciones de plantilla en Livedump a partir de las cuales se extrae la configuración. Sin ellas, Nagios no se puede iniciar. Sin embargo, solo puede haber una de ellas. Si importas una configuración desde otro site remoto, ¡no debe usar la opción «-T»!También es posible realizar un volcado de la configuración en un Checkmk Micro Core (CMC), cuya importación requiere Nagios. Si el CMC se está ejecutando en tu site central, utiliza CMCDump.
La copia y la transferencia de la configuración deben repetirse cada vez que se produzca un cambio en los hosts o servicios del site remoto.
Transferencia del estado
Una vez que los hosts sean visibles en el site central, tendremos que configurar una transmisión (periódica) del estado de monitorización de los remotos.
Vuelve a crear un archivo con `livedump`, pero esta vez sin opciones secundarias:
Este archivo contiene los estados de todos los hosts y servicios en un formato que Nagios puede leer directamente a partir de los resultados de las checkings. El inicio de este archivo tiene un aspecto similar a este:
host_name=myhost1900
check_type=1
check_options=0
reschedule_check
latency=0.13
start_time=1615521257.2
finish_time=16175521257.2
return_code=0
output=OK - 10.1.5.44: rta 0.066ms, lost 0%|rta=0.066ms;200.000;500.000;0; pl=0%;80;100;; rtmax=0.242ms;;;; rtmin=0.017ms;;;;Copia este archivo en el site central, en el directorio ~/tmp/nagios/checkresults.
Importante: El nombre de este archivo debe empezar por c y tener siete caracteres.
Con scp, tendrá un aspecto similar a este:
Por último, crea un archivo vacío en el site central con el mismo nombre y la extensión .ok.
Con esto, Nagios sabrá que el archivo de estado se ha transferido por completo y ya se puede leer:
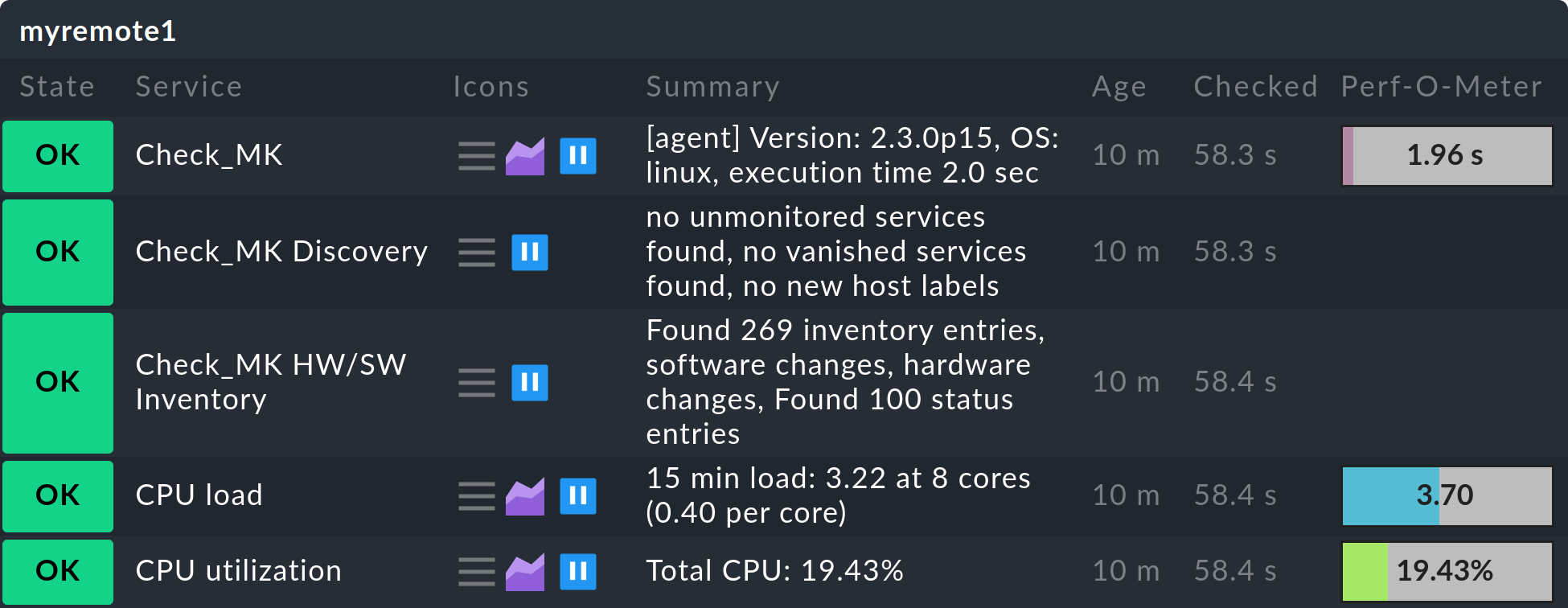
El estado de los hosts/servicios remotos se actualizará ahora inmediatamente en el site central:
A partir de ahora, la transmisión del estado debe realizarse con regularidad.
Puedes utilizar un script para repetir los pasos descritos anteriormente a intervalos que elijas.
En lugar de copiar los datos a través de scp, tu script se puede ejecutar directamente desde el site central para que pueda recibir datos de estado o configuración a través de ssh.
Hay un script para realizar estas acciones disponible en GitHub, en el directorio treasures.
Proporcionamos los archivos del directorio |
La configuración y el volcado de estado también se pueden restringir utilizando los filtros de Livestatus.
Por ejemplo, podrías limitar los hosts a los miembros del grupo del host mygroup:
5.3. Implementación de CMCDump
CMCDump es para Checkmk Micro Core lo que Livedump es para Nagios, por lo que es la herramienta preferida para las ediciones comerciales. A diferencia de Livedump, CMCDump puede replicar el estado completo de los hosts y servicios (Nagios no dispone de las interfaces necesarias para esta tarea).
A modo de comparación: Livedump transfiere los siguientes datos:
Los estados actuales, es decir, PEND, OK, WARN, CRIT, UNKNOWN, UP, DOWN o UNREACH
Los resultados de los check plugins
Los datos de rendimiento
CMCDump sincroniza además:
La salida larga del Plugin
Si el objeto está actualmente en un estado inestable (
 )
)Las marcas de tiempo de la última ejecución del check y del último cambio de estado
La duración de la ejecución de la check
La latencia de la ejecución de la check
El número de secuencia del intento de check actual y si el estado actual es «hard» o «soft»
 Reconocimiento, si procede
Reconocimiento, si procedeSi el objeto se encuentra actualmente en un tiempo de mantenimiento programado
 .
.
Esto ofrece una visión mucho más precisa de la monitorización. Al importar el estado, el CMC no se limita a simular una ejecución de comprobación, sino que, mediante una interfaz diseñada para esta tarea, transmite un estado preciso. Entre otras cosas, esto significa que el centro de operaciones puede ver en cualquier momento si se han realizado reconocimientos de problemas o si se han introducido tiempos de mantenimiento programados.
La instalación es casi idéntica a la de Livedump, pero es algo más sencilla, ya que no hay que preocuparse por posibles plantillas duplicadas o similares.
La copia de la configuración se realiza con cmcdump -C.
Guarda este archivo en el site central en ~/etc/check_mk/conf.d/.
Debes usar la extensión de archivo .mk:
Activa la configuración en el site central:
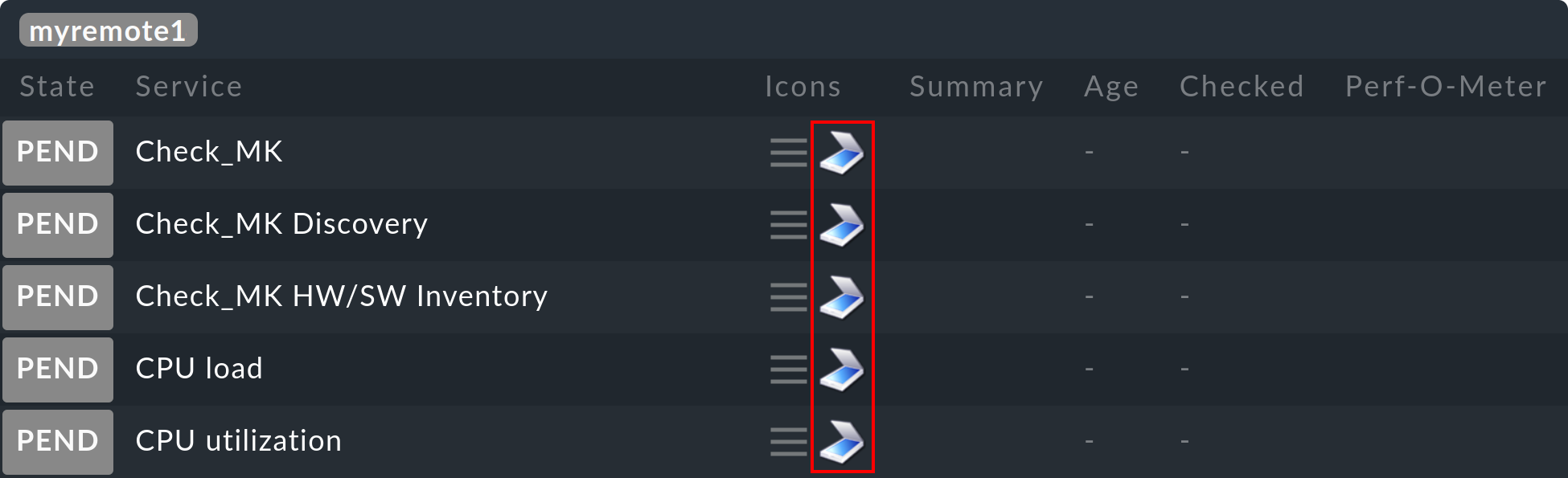
Al igual que con Livedump, los hosts y los servicios aparecerán ahora en el sitio central en estado PEND.
Sin embargo, verás por el icono ![]() que se trata de un objeto sombra.
De esta forma se puede distinguir de un objeto que se supervisa directamente en el sitio central o en un site remoto «normal»:
que se trata de un objeto sombra.
De esta forma se puede distinguir de un objeto que se supervisa directamente en el sitio central o en un site remoto «normal»:
La generación regular del estado se consigue con cmcdump sin argumentos adicionales:
Para importar el estado al site central, el contenido del archivo debe escribirse en el socket Unix de ~/tmp/run/live con la ayuda de la herramienta unixcat.
Si tienes acceso desde el sitio remoto al site central vía SSH sin contraseña, los tres comandos se pueden combinar en uno solo —y al hacerlo ni siquiera se crea un archivo temporal:
¡Es así de sencillo!
Pero, como ya se ha mencionado, ssh / scp no es el único método para transferir archivos, y una configuración o un estado se pueden transferir igual de bien mediante correo electrónico u otro protocolo que se desee.
6. Notificaciones en entornos distribuidos
6.1. ¿Centralizado o descentralizado?
En un entorno distribuido surge la pregunta: ¿desde qué sitio deben enviarse las notificaciones (por ejemplo, los correos electrónicos): desde cada uno de los sitios remotos o desde el site central? Hay argumentos a favor de ambos procedimientos.
Argumentos a favor de enviarlas desde los sitios remotos:
Más fácil de configurar
Se puede seguir recibiendo notificaciones locales aunque no haya conexión con el site central
También funciona con
 Checkmk Community
Checkmk Community
Argumentos a favor del envío desde el site central:
Las notificaciones se pueden procesar posteriormente en una ubicación central (por ejemplo, reenviarlas a un sistema de tickets)
los sitios remotos no necesitan configuración para el correo electrónico o los SMS
Para enviar un SMS a través del hardware, esto solo es necesario una vez: en el site central
6.2. Notificación descentralizada
No se requieren pasos especiales para una notificación descentralizada, ya que esta es la configuración estándar. Cada notificación que se genera en un sitio remoto pasa por la cadena de reglas de notificación de ese sitio. Si implementas una configuración centralizada, estas reglas son las mismas en todos los sitios. Las notificaciones resultantes de estas reglas se entregarán como de costumbre, para lo cual se habrán ejecutado localmente los scripts de notificación correspondientes.
Solo hay que asegurarse de que el servicio adecuado se haya instalado correctamente en los sitios —por ejemplo, que se haya definido un smarthost para los correos electrónicos—, es decir, el mismo procedimiento que para configurar un site Checkmk individual.
6.3. Notificación centralizada
Fundamentos
![]() Las ediciones comerciales ofrecen un mecanismo integrado para notificaciones centralizadas que se puede activar individualmente para cada sitio remoto.
Estos sitios remotos envían entonces todas las notificaciones al site central para su posterior procesamiento.
La notificación centralizada es, por lo tanto, independiente de si la monitorización distribuida se ha configurado de la forma estándar, con CMCDump o mediante una combinación de estos procedimientos.
Técnicamente hablando, el servidor de notificaciones central ni siquiera tiene que estar literalmente en el «centro».
Esta tarea puede asumirla cualquier sitio de Checkmk.
Las ediciones comerciales ofrecen un mecanismo integrado para notificaciones centralizadas que se puede activar individualmente para cada sitio remoto.
Estos sitios remotos envían entonces todas las notificaciones al site central para su posterior procesamiento.
La notificación centralizada es, por lo tanto, independiente de si la monitorización distribuida se ha configurado de la forma estándar, con CMCDump o mediante una combinación de estos procedimientos.
Técnicamente hablando, el servidor de notificaciones central ni siquiera tiene que estar literalmente en el «centro».
Esta tarea puede asumirla cualquier sitio de Checkmk.
Si un sitio remoto se ha configurado en «reenvío», todas las notificaciones se reenviarán directamente al sitio central tal y como lo harían desde el core —prácticamente en formato sin procesar—. Una vez allí, las reglas de notificación evaluarán a quién se debe notificar realmente y cómo. Los scripts de notificación necesarios se ejecutarán en el sitio central.
Configuración de las conexiones TCP
Los spoolers de notificaciones de los sitios remotos y centrales (de notificaciones) se comunican entre sí a través de TCP. Las notificaciones se envían desde los sitios remotos al sitio central. El sitio central realiza un Reconocimiento a los remotos para indicar que se han recibido las notificaciones, lo que evita que se pierdan incluso si se interrumpe la conexión TCP.
Hay dos alternativas para establecer una conexión TCP:
Se configura una conexión TCP del site central al remoto. En este caso, el site remoto es el servidor TCP.
Se configura una conexión TCP del sitio remoto al sitio central. En este caso, el sitio central es el servidor TCP.
Por lo tanto, no hay ningún obstáculo para reenviar notificaciones si, por motivos de red, solo es posible establecer conexiones en una dirección específica. Las conexiones TCP son supervisadas por el spooler mediante una señal de latido y se restablecen inmediatamente cuando es necesario, no solo en el evento de una notificación.
Dado que los sitios remotos y el sitio central requieren ajustes globales diferentes para el spooler, debes realizar ajustes específicos para cada sitio en todos los sitios remotos. La configuración del sitio central se realiza utilizando los ajustes globales habituales. Nota: estos ajustes serán heredados automáticamente por todos los sitios remotos para los que no se hayan definido ajustes específicos.
Veamos primero un ejemplo en el que el site central establece las conexiones TCP con los sitios remotos.
Paso 1: En el site remoto, edita la configuración global específica del site «Notifications > Notification Spooler Configuration» y activa «Accept incoming TCP connections». Se recomendará el puerto TCP 6555 para las conexiones entrantes. Si no hay objeciones, adopta esta configuración.
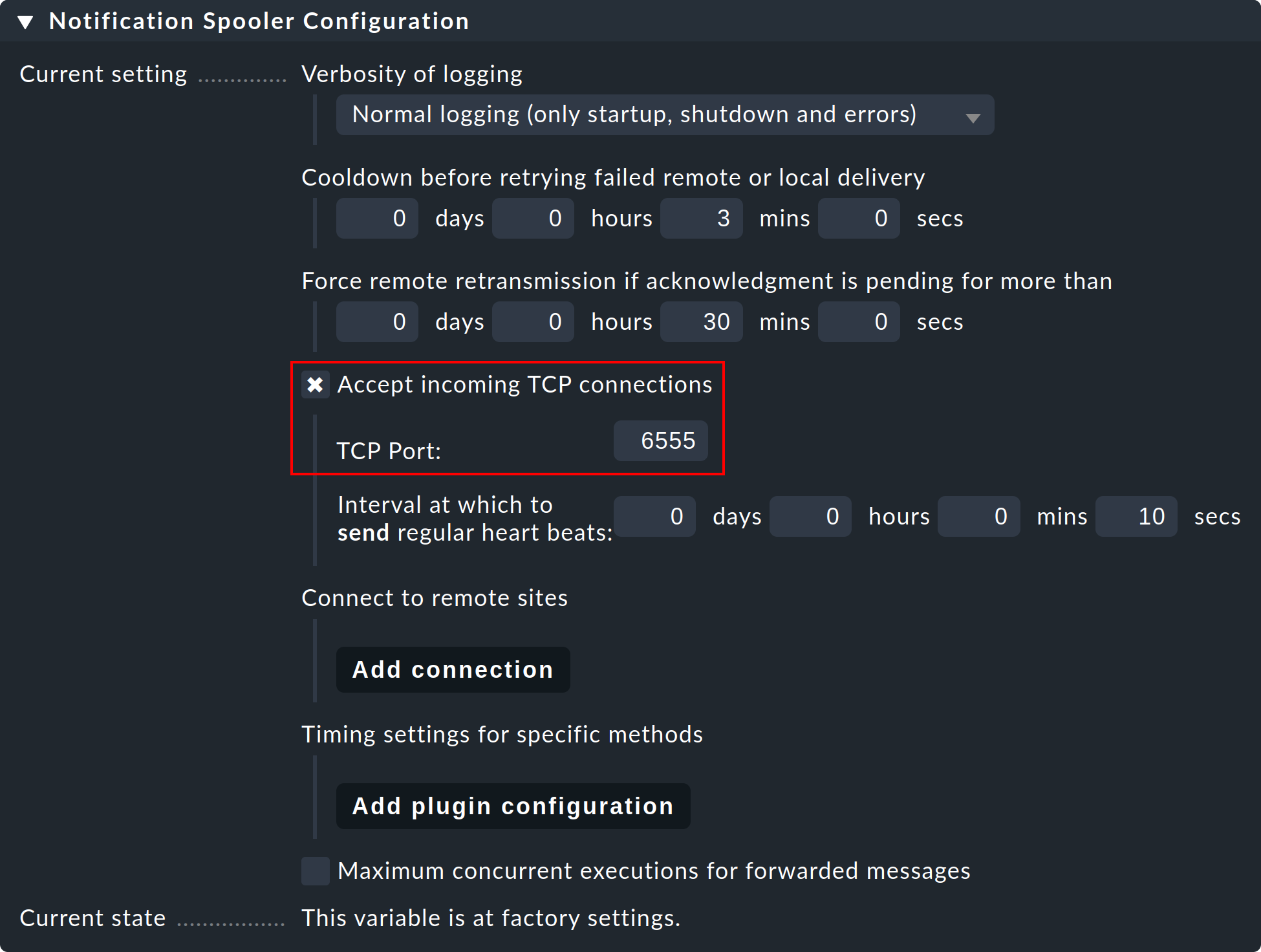
Paso 2: Ahora, del mismo modo, en el submenú «Notification Spooling» solo en el site remoto, selecciona la opción «Forward to remote site by notification spooler».

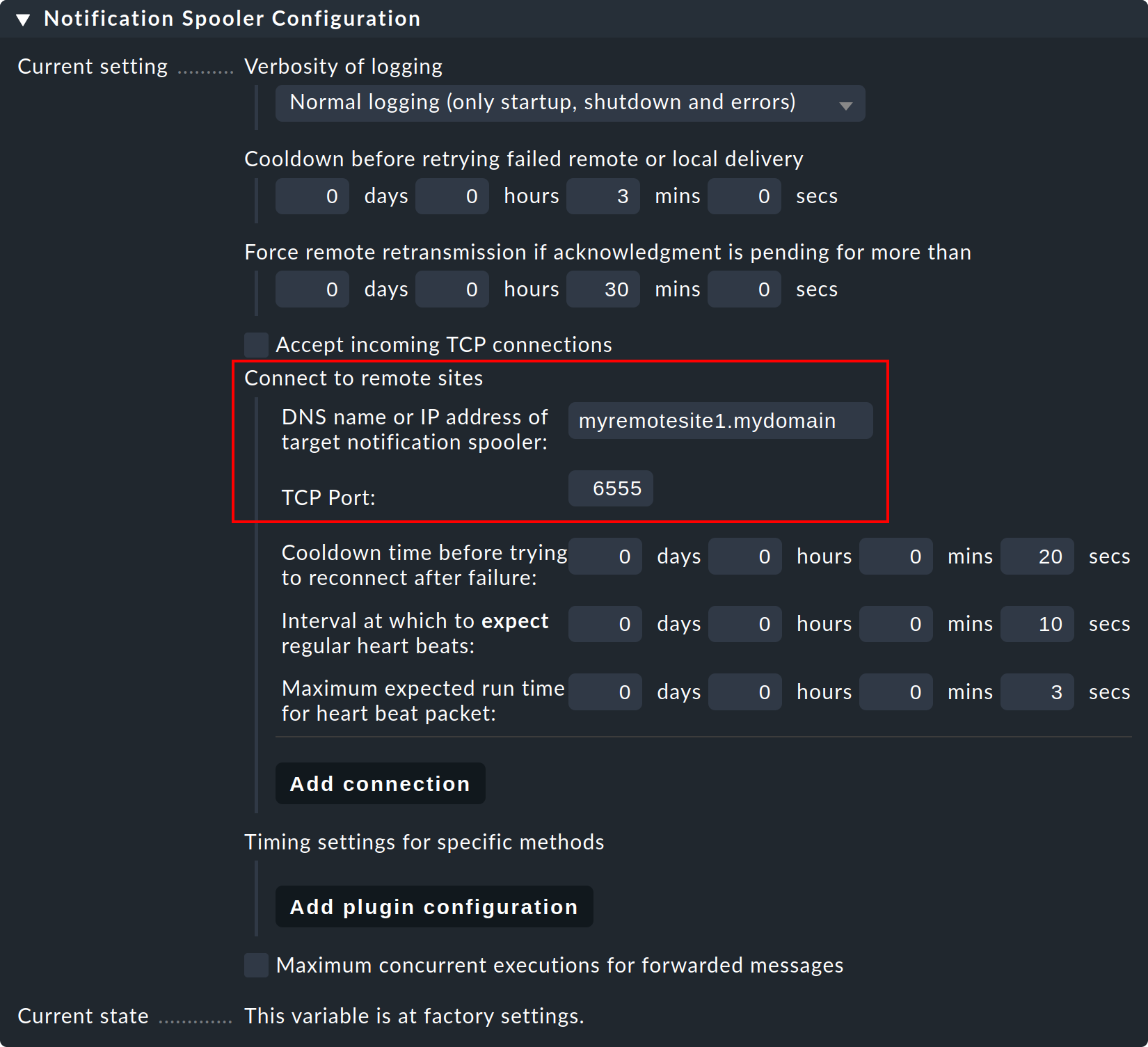
Paso 3: Ahora, en el site central —es decir, en la configuración global normal—, configura la conexión con el site remoto (y luego con otros sitios remotos según sea necesario):
Paso 4: Establece la configuración global «Notification Spooling» en «Asynchronous local delivery by notification spooler», para que las comunicaciones del site central también se procesen a través del mismo spooler central.

Paso 5: Activa los cambios.
Establecimiento de conexiones desde un sitio remoto
Si la conexión TCP debe establecerse desde el sitio remoto hacia fuera, el procedimiento es idéntico, diferenciándose de la descripción anterior únicamente por el simple intercambio de los roles de site central y remoto.
También es posible una combinación de los dos procedimientos. En tal caso, el site central debe configurarse para que escuche las conexiones entrantes y también se conecte a los sitios remotos. Sin embargo, en toda relación central/remota, ¡solo uno de los dos puede establecer la conexión!
Prueba y diagnóstico
El spooler de notificación registra los mensajes en el archivo ~/var/log/mknotifyd.log.
En la configuración del spooler se puede aumentar el nivel de registro para recibir más mensajes.
Con un nivel de registro estándar, deberías ver algo como esto en el site central:
2025-04-30 07:11:40,023 [20] [cmk.mknotifyd] -----------------------------------------------------------------
2025-04-30 07:11:40,023 [20] [cmk.mknotifyd] Check_MK Notification Spooler version 2.4.0p24 starting
2025-04-30 07:11:40,024 [20] [cmk.mknotifyd] Log verbosity: 0
2025-04-30 07:11:40,025 [20] [cmk.mknotifyd] Daemonized with PID 31081.
2025-04-30 07:11:40,029 [20] [cmk.mknotifyd] Connection to 10.1.8.44 port 6555 in progress
2025-04-30 07:11:40,029 [20] [cmk.mknotifyd] Successfully connected to 10.1.8.44:6555En todo momento, el archivo ~/var/log/mknotifyd.state contiene el estado actual del spooler y todas sus conexiones:
Connection: 10.1.8.44:6555
Type: outgoing
State: established
Status Message: Successfully connected to 10.1.8.44:6555
Since: 1637129500 (2025-04-30 07:11:40, 140 sec ago)
Connect Time: 0.002 secTambién hay una versión del mismo archivo en el site remoto. Allí, la conexión tendrá un aspecto similar a este:
Connection: 10.22.4.12:56546
Type: incoming
State: established
Since: 1637129500 (2025-04-30 07:11:40, 330 sec ago)Para probarlo, selecciona cualquier servicio remoto sujeto a monitorización y configúralo manualmente en CRIT con el comando Fake check results.
Ahora, en el site central, debería aparecer una notificación entrante en el archivo de registro de notificaciones (notify.log):
2025-04-30 07:59:36,231 ----------------------------------------------------------------------
2025-04-30 07:59:36,232 [20] [cmk.base.notify] Got spool file 307ad477 (myremotehost123;Check_MK) from remote host for local delivery.El mismo evento se verá así en el site remoto:
2025-04-30 07:59:28,161 [20] [cmk.base.notify] ----------------------------------------------------------------------
2025-04-30 07:59:28,161 [20] [cmk.base.notify] Got raw notification (myremotehost123;Check_MK) context with 71 variables
2025-04-30 07:59:28,162 [20] [cmk.base.notify] Creating spoolfile: /omd/sites/myremote1/var/check_mk/notify/spool/307ad477-b534-4cc0-99c9-db1c517b31fEn la configuración global puedes cambiar tanto el archivo de registro normal para las notificaciones (notify.log) como el archivo de registro del spooler de notificación a un nivel de registro más alto.
Monitorización del spool
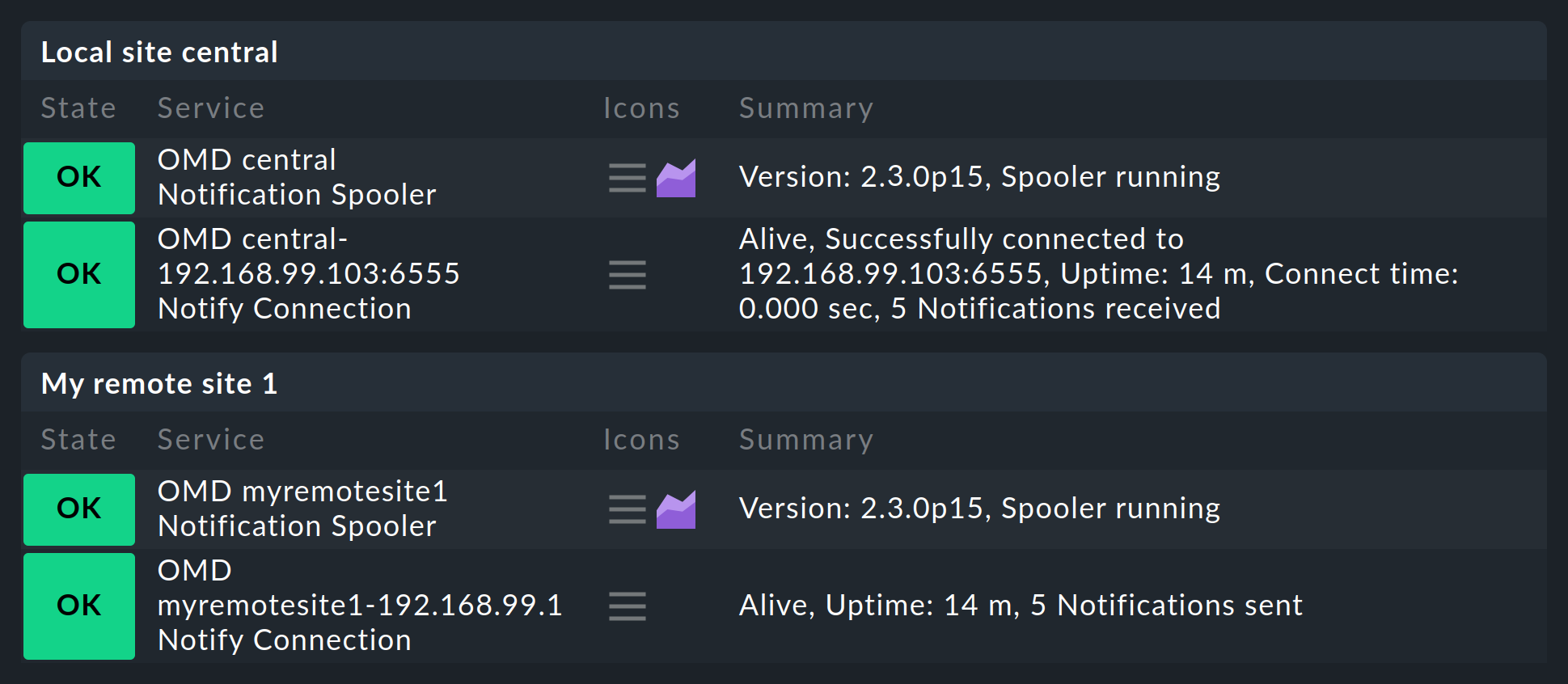
Una vez que hayas configurado todo tal y como se describe, verás que en el site central, y respectivamente en los remotos, aparecerá un nuevo servicio que sin duda debes incluir en la monitorización. Este supervisa el spooler de notificación y sus conexiones TCP. De este modo, cada conexión se supervisará dos veces: una vez por el site central y otra por el site remoto:
7. Cuando un sitio central y sus sitios remotos utilizan versiones diferentes
Por regla general, las versiones de todos los sitios remotos y del site central deben coincidir. Las excepciones a esta regla solo se aplican durante la realización de actualizaciones. En este caso, hay que distinguir entre las siguientes situaciones:
7.1. Niveles de parches diferentes (pero misma versión principal)
Por lo general, se permite que los niveles de parche (p. ej., p11) difieran sin problemas. Sin embargo, en casos excepcionales, incluso estos pueden ser incompatibles entre sí, por lo que en tal situación debes mantener exactamente el mismo nivel de versión (p. ej., 2.4.0p11) en todos los sites para que estos puedan funcionar juntos sin errores. Por lo tanto, toma siempre nota de los cambios incompatibles de cada versión de parche en los Werks.
Como regla general —aunque hay excepciones, que se indican en el Werks—, actualiza primero los sitios remotos y deja el sitio central para el final.
7.2. Versiones principales diferentes
Para que las actualizaciones mayores (por ejemplo, de la 2.3.0 a la 2.4.0) se ejecuten sin problemas en entornos distribuidos de gran tamaño, a partir de la versión 2.0.0 Checkmk permite operaciones mixtas en las que el sitio central y los sitios remotos pueden diferir en una versión mayor. Cuando realices una actualización, asegúrate de actualizar primero los sitios remotos. A continuación, actualiza el sitio central solo cuando todos los sitios remotos se hayan actualizado a la versión superior.
¡Asegúrate de consultar las notas de actualización de Werks y de la versión antes de iniciar la actualización! Siempre se requiere un nivel de parche específico (requisito previo) de la versión anterior en el site central para garantizar un funcionamiento mixto sin problemas.
Una característica especial de los entornos mixtos es la gestión centralizada de los paquetes de extensión, que ahora se pueden mantener en variantes tanto para las versiones antiguas como para las nuevas de Checkmk. Los detalles al respecto se explican en el artículo sobre la gestión de MKP.
8. Archivos y directorios
8.1. Archivos de configuración
| Ruta | Descripción |
|---|---|
|
Aquí es donde Checkmk guarda la configuración de las conexiones a los sitios individuales. Si la interfaz se «cuelga» debido a un error en la configuración, de modo que deja de funcionar, puedes realizar la edición de la entrada problemática directamente en el archivo. Sin embargo, si el proxy de Livestatus está activado, posteriormente será necesario realizar la edición y el guardado de al menos una conexión, ya que solo con esta acción se generará una configuración adecuada para este daemon. |
|
Configuración del proxy Livestatus. Checkmk generará este archivo de nuevo cada vez que se modifique la configuración de la monitorización distribuida. |
|
Configuración del spooler de notificación. Checkmk generará este archivo al guardar la configuración global. |
|
Se crea en los sitios remotos y garantiza que solo realicen la monitorización de sus propios hosts. |
|
Ubicación de almacenamiento para los archivos de configuración de Nagios creados por el cliente con hosts y servicios. Estos son necesarios para el uso de Livedump en el site central. |
|
La configuración de Livestatus para usar Nagios como core. Aquí puedes configurar el número máximo de conexiones simultáneas permitidas. |
|
La configuración de hosts y reglas para Checkmk. Guarda aquí los archivos de configuración generados por CMCDump. Solo el subdirectorio |
|
Para los servicios detectados por el descubrimiento de servicios. Estos siempre se almacenan localmente en el site remoto. |
|
Ubicación de la base de datos Round Robin (RRD) para archivar los datos de rendimiento cuando se utiliza el formato Checkmk-RRD (el predeterminado en las ediciones comerciales) |
|
Ubicación de la base de datos Round-Robin con el formato PNP4Nagios (Comunidad Checkmk) |
|
Archivo de registro para los proxies de Livestatus. |
|
El estado actual de los proxies de Livestatus en un formato legible. Este archivo se actualiza cada 5 segundos. |
|
Archivo de registro del sistema de notificaciones de Checkmk. |
|
Archivo de registro del spooler de notificación. |
|
El estado actual del spooler de notificación en un formato legible. Este archivo se actualiza cada 20 segundos. |