This is a machine translation based on the English version of the article. It might or might not have already been subject to text preparation. If you find errors, please file a GitHub issue that states the paragraph that has to be improved. |
1. Introducción
Checkmk Business Intelligence: hay que reconocer que suena muy pomposo para algo que, en el fondo, es bastante sencillo. Sin embargo, este nombre describe bastante bien la esencia del módulo de Business Intelligence de Checkmk. Se trata de evaluar el estado general de las aplicaciones críticas para el negocio basándose en los valores recopilados a partir del estado de muchos componentes individuales de un entorno, y de presentarlos de forma clara.
Tomemos como ejemplo el servicio de correo electrónico, que sigue siendo indispensable para muchas empresas. Este servicio se basa en el correcto funcionamiento de diversos componentes de hardware y software —desde switches específicos hasta servicios SMTP e IMAP, pasando por servicios de infraestructura como LDAP y DNS.
El fallo de un componente esencial no supone un problema si se ha diseñado para ser redundante. Por el contrario, puede surgir un problema en un servicio que, a primera vista, no tiene nada que ver con el correo electrónico, pero que, de hecho, puede tener consecuencias mucho más graves. Echar un simple vistazo a la lista de servicios en Checkmk no siempre resulta significativo, al menos no para todo el mundo.
Checkmk BI te permite obtener un resumen del estado general de una aplicación a partir del estado actual de los hosts y servicios individuales. Las reglas BI se utilizan para definir —en una estructura de árbol— cómo se interrelacionan los distintos elementos. El estado general de cada aplicación puede identificarse entonces como «OK», «WARN» o «CRIT». Se puede acceder a la información sobre la condición y las dependencias de varias maneras:
Una visualización del estado general de una aplicación en la GUI.
Cálculo de la disponibilidad de una aplicación.
Notificaciones en caso de un evento, o incluso un fallo de una aplicación.
Análisis de impacto: un servicio está en estado «CRIT» (en espera), ¿qué aplicaciones se ven afectadas?
Planificación del tiempo de mantenimiento programado y análisis de «¿qué pasaría si...?».
Además, existe la posibilidad de utilizar la representación en árbol de BI para profundizar en la vista del estado de un host y de todos sus servicios.
Una característica distintiva del BI de Checkmk, a diferencia de herramientas comparables en el campo de la monitorización, es que aquí Checkmk también trabaja con una estructura basada en reglas. Esto te permite describir dinámicamente un número indefinido de aplicaciones similares con un conjunto genérico de reglas. Esto facilita enormemente el trabajo y ayuda a evitar errores, especialmente en entornos muy dinámicos.
2. Configuración, parte 1: la primera agregación
2.1. Terminología
Antes de empezar paso a paso con la aplicación práctica de BI, primero tendrás que conocer algunos términos:
Cada aplicación formalizada con BI se denomina agregación BI, ya que se agrega un estado general a partir de muchos estados individuales.
Una agregación se construye como un «árbol» de objetos. Estos objetos se llaman nodos. Los nodos finales —las hojas del árbol— son los hosts y los servicios de tus sitios de Checkmk. Los nodos restantes son objetos de BI creados artificialmente.
Cada nodo se crea mediante una regla. Esto también se aplica a las raíces del árbol —el nodo de nivel superior—. Estas reglas determinan qué nodos están conectados a otro nodo y cómo se debe determinar el estado de los nodos superiores a partir de sus estados.
El nodo superior de una agregación —la raíz del árbol— también se genera mediante una regla. De esta forma, una regla puede generar múltiples agregaciones.
2.2. Un ejemplo
La forma más fácil de entender esto es con un ejemplo concreto.
Hemos creado la aplicación Mystery específicamente como demostración para este artículo.
Supongamos que se trata de una aplicación importante en una organización no especificada.
Entre otras cosas, cinco servidores y dos switches desempeñan un papel importante.
Para que puedas entender mejor nuestro ejemplo, usaremos nombres sencillos como srv-mys-1 o switch-1.
El siguiente diagrama ofrece una vista general sencilla de la estructura:
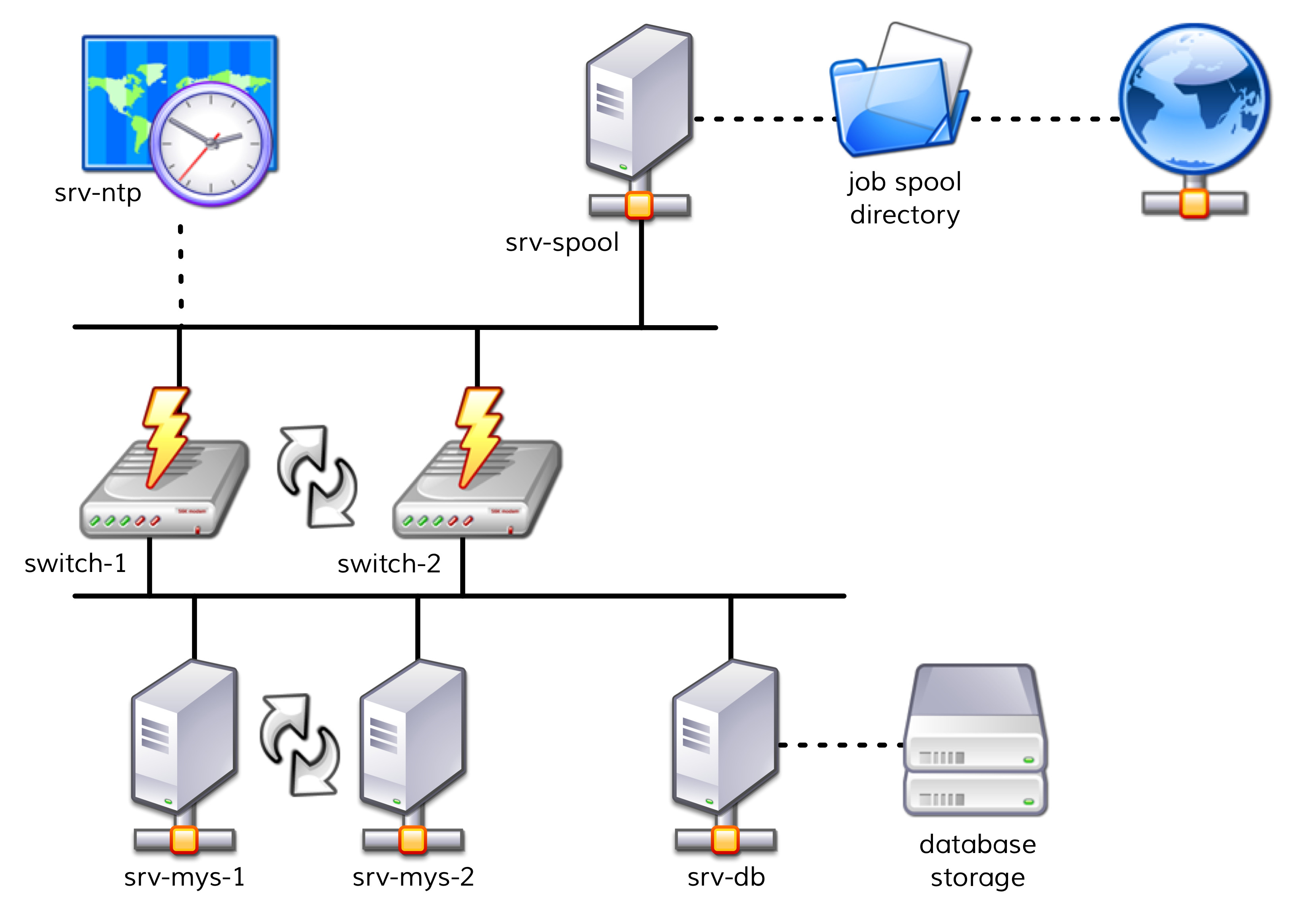
Los dos servidores,
srv-mys-1ysrv-mys-2, forman un clúster redundante en el que se ejecuta la aplicación propiamente dicha.srv-dbes un servidor de base de datos que almacena los datos de la aplicación.switch-1yswitch-2son dos routers redundantes que establecen la conexión entre la red de servidores y una red superior.En cada router hay un temporizador
srv-ntpque garantiza una sincronización horaria exacta.Además, el servidor
srv-spoolopera aquí y envía los resultados calculados por la misteriosa aplicación a un directorio de spool.Desde el directorio de spool, un misterioso servicio principal recoge los datos.
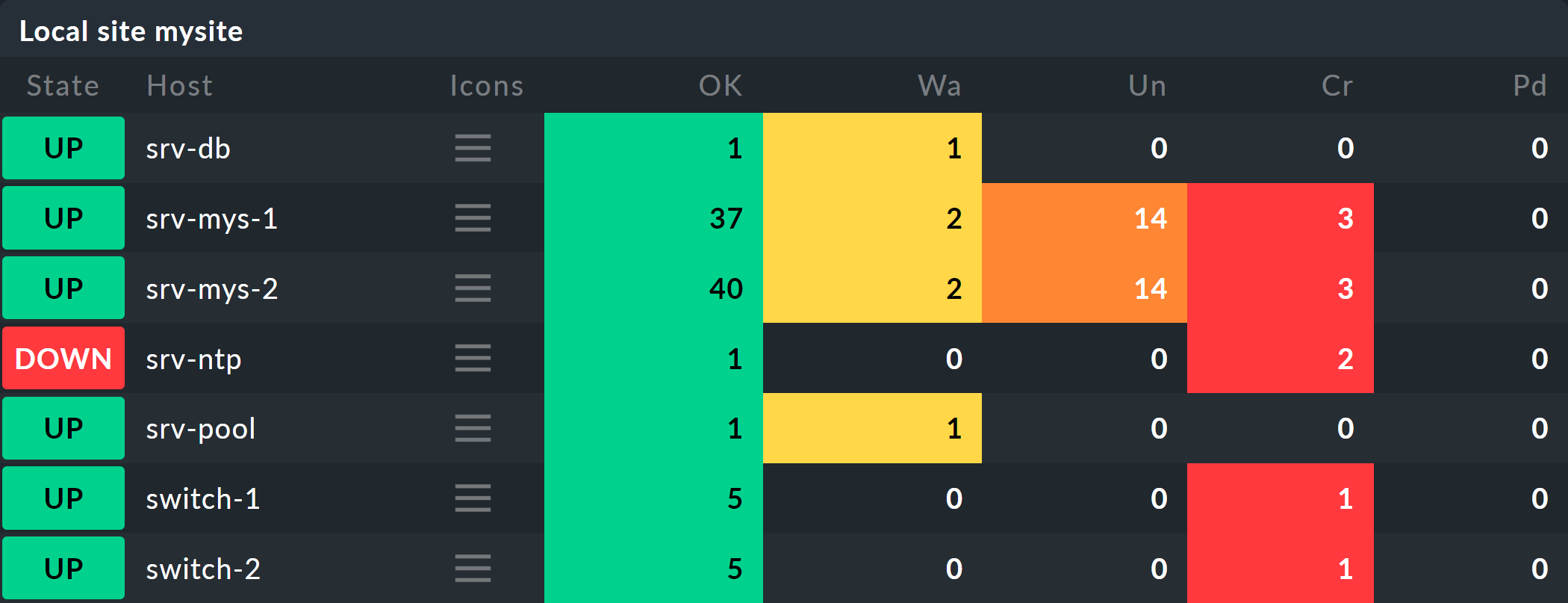
Si quieres seguir los siguientes pasos uno por uno, simplemente puedes replicar los objetos de monitorización tal y como se muestra en nuestro ejemplo. Para una prueba, basta con que clones varias veces un host existente y les pongas nombre a los clones como corresponda. Más adelante habrá que añadir algunos servicios al juego, para lo cual tendrás tiempo de añadir los hosts pertinentes a la monitorización. Incluso ahí puedes volver a hacer trampa: con simples local checks conseguirás rápidamente servicios que coincidan con los que quieres probar.
Los hosts se verán entonces más o menos así en la monitorización:
2.3. Tu primera regla BI
Empieza con algo sencillo —con la agregación significativa más simple posible—: una agregación con solo dos nodos.
A continuación, querrás resumir los estados de los hosts switch-1 y switch-2.
La agregación debería llamarse «Network» y debería estar en «OK» cuando ambos switches estén disponibles.
En caso de un fallo parcial, el estado debería pasar a «WARN», y si ambos switches están apagados, a «CRIT».
Para empezar: configura BI a través de Setup > Business Intelligence > Business Intelligence. La configuración de las reglas y las agregaciones se realiza dentro de los paquetes de configuración: los paquetes BI. Estos paquetes no solo son prácticos porque te permiten gestionar mejor configuraciones más complejas, sino que también puedes aplicar permisos a un paquete y asignar ciertos grupos de contactos, e incluso permitir a usuarios sin derechos de administrador editar partes de la configuración. Pero hablaremos más de eso más adelante…
La primera vez que accedas al módulo BI debería verse algo así:

Ya existe un paquete titulado «Default Pack». Este contiene una demostración de una agregación que resume los datos de un host individual.
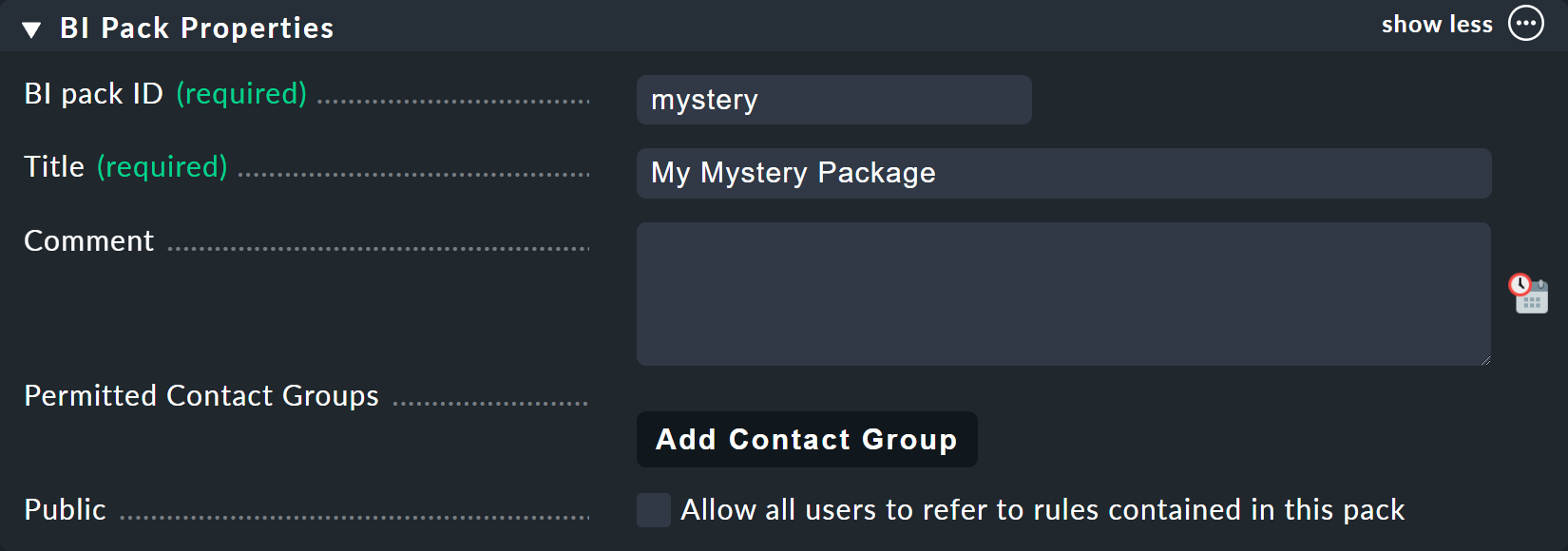
Para este ejemplo, lo mejor es crear un nuevo paquete —con el botón «Add BI Pack»— al que llamarás «Mystery».
Como siempre en Checkmk, especifica un ID interno (mystery) que no se puede cambiar más adelante, y un título descriptivo.
La opción «Public» es necesaria para otros usuarios si hay reglas en este paquete que quieran usar para sus propias reglas o agregaciones.
Como probablemente quieras hacer tus experimentos a solas y en paz, deja esta opción desactivada:
Tras la creación, encontrarás, por supuesto, dos paquetes en la lista principal:

Junto a cada entrada hay un icono (![]() ) para realizar la edición de las propiedades,
y un icono para abrir el contenido real del paquete (
) para realizar la edición de las propiedades,
y un icono para abrir el contenido real del paquete (![]() ), que es donde quieres ir ahora.
Una vez allí, crea tu primera regla directamente a través de Add rule.
), que es donde quieres ir ahora.
Una vez allí, crea tu primera regla directamente a través de Add rule.
Como siempre en Checkmk, esta regla también necesita tener un ID único y un título. El título de la regla no solo tiene una función de documentación, sino que más adelante también será visible como el nombre del nodo que creará esta regla:
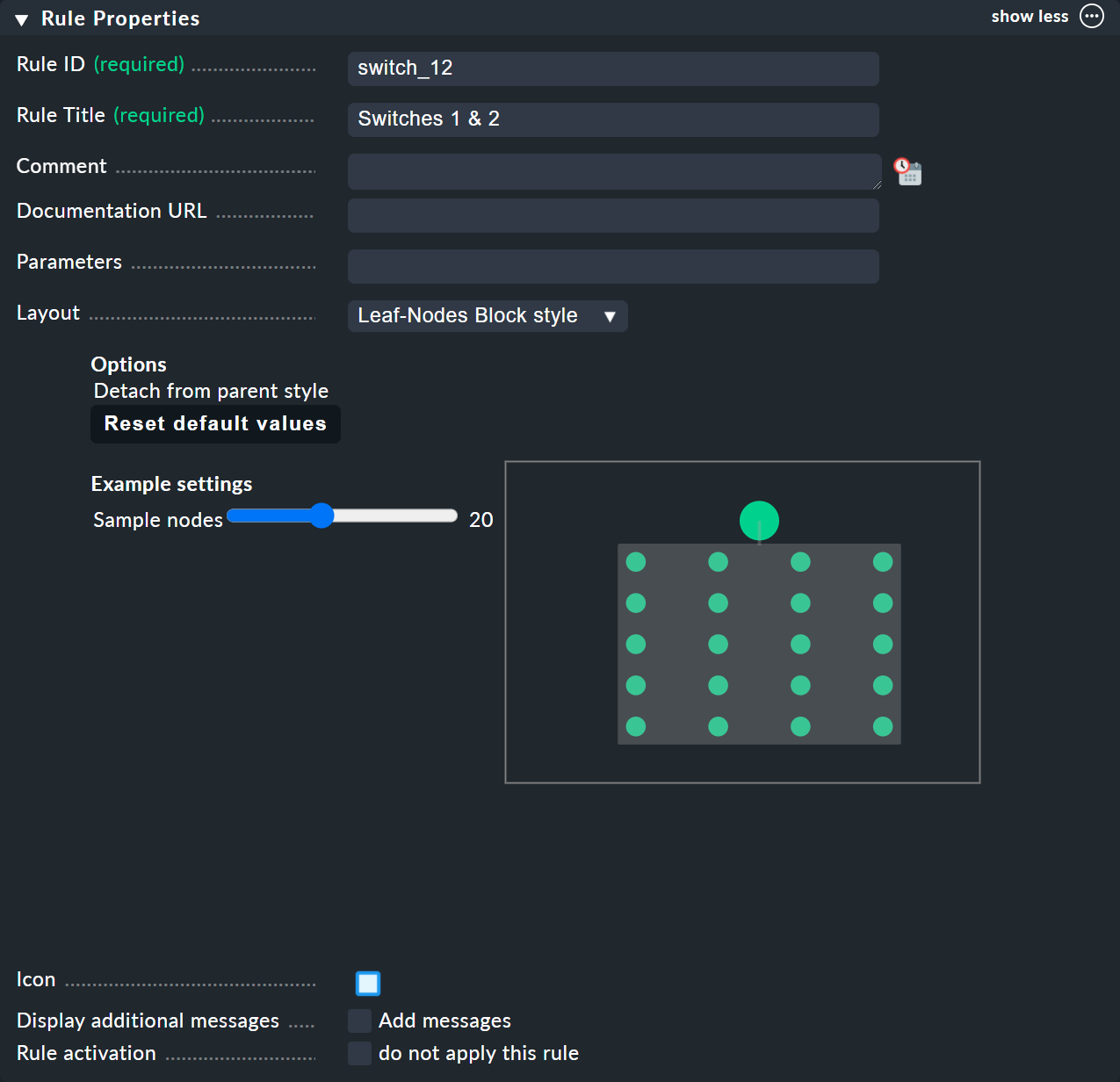
El siguiente cuadro se llama «Child Node Generation» y es el más importante. Aquí especificas qué objetos de este nodo deben resumirse. Pueden ser otros nodos de BI —para los que elegirías una regla BI diferente— u objetos sujetos a la monitorización, es decir, hosts o servicios.
Para el primer ejemplo, selecciona la segunda variante (State of a host) y crea dos objetos como hijos, concretamente los dos hosts switch-1 y switch-2.
Esto se hace con el botón «Add child node generator».
Aquí, naturalmente, eliges «State of a host» e introduces un nombre para cada host:
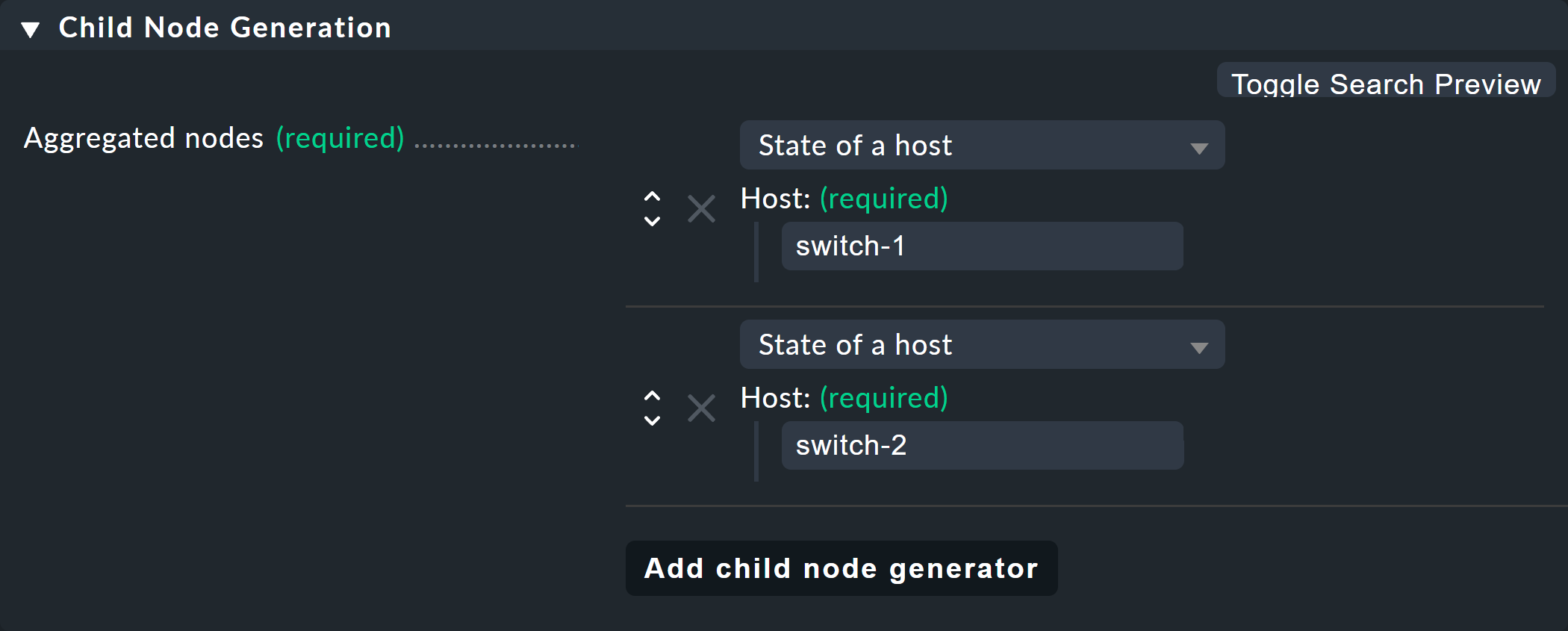
En la tercera y última caja, Aggregation Function, especificas cómo se debe calcular el estado de monitorización del nodo. La base para ello es siempre la lista de estados de los subnodos. Hay varios enlaces lógicos posibles.
La opción preseleccionada es Best — take the best of all node states. Eso significaría que el nodo pasa a ser CRIT cuando todos los subnodos son CRIT o DOWN. Como se ha mencionado anteriormente, este no debería ser el caso aquí. Elige en su lugar Count the number of nodes in state OK para tomar como referencia el número de subnodos con el estado OK. Aquí se sugieren los números 2 y 1 como umbrales. Esto es genial porque es exactamente lo que necesitas:
Si ambos switches están en UP (esto se trata como OK), el nodo también debería estar en OK.
Si solo un switch está en «UP», el estado pasa a ser «WARN».
Y cuando ambos switches están en DOWN, el estado pasa a ser CRIT.
Así es como se verá el formulario una vez completado:
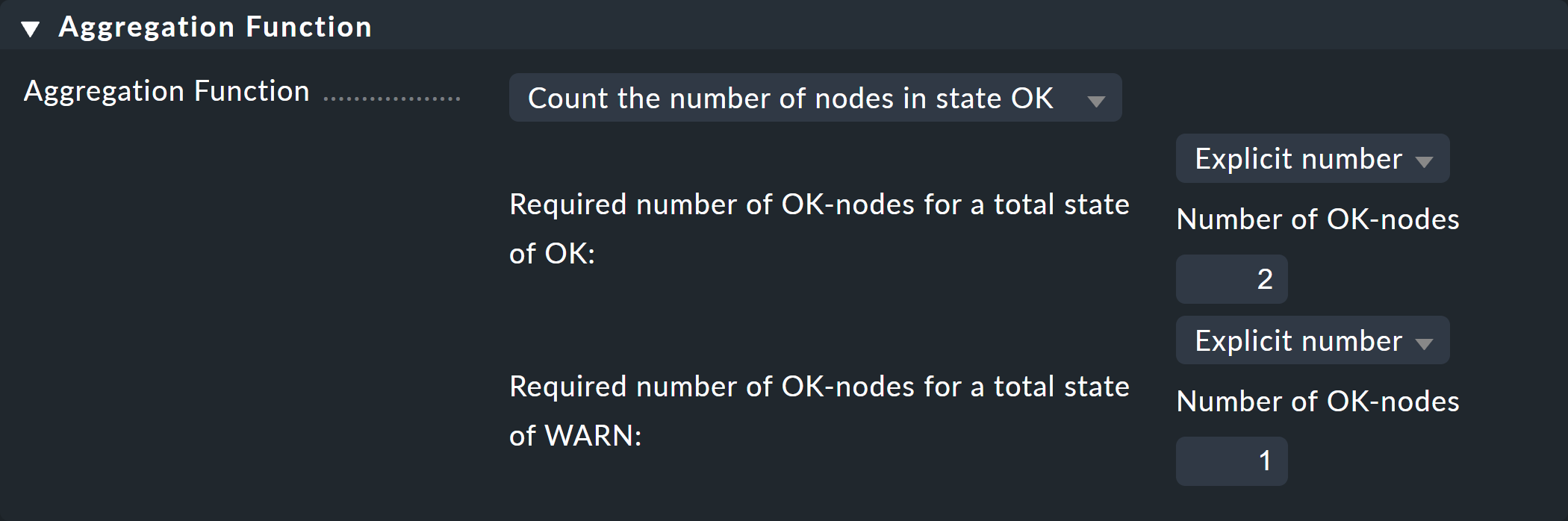
Con un clic en «Create» tendrás tu primera regla:

2.4. Tu primera agregación
Nota: es importante entender que una regla aún no es una agregación.
Checkmk aún no puede saber si esto es todo o solo parte de un árbol más grande.
Los objetos BI reales solo se crearán y serán visibles en la interfaz de estado cuando crees una agregación.
Para ello, switch a la lista de agregaciones «![]() ».
».
El botón «![]() » te lleva a un formulario para crear una nueva agregación.
Aquí hay poco que rellenar.
En el campo «Aggregation groups» puedes especificar cualquier nombre que elijas.
Estos nombres aparecerán luego en la interfaz de estado como grupos, bajo los cuales se harán visibles todas aquellas agregaciones que compartan este nombre de grupo.
En realidad, se trata del mismo concepto que con los hashtags o las palabras clave.
También puedes asignar libremente el «Aggregation ID» como de costumbre, pero no podrás cambiarlo más adelante.
» te lleva a un formulario para crear una nueva agregación.
Aquí hay poco que rellenar.
En el campo «Aggregation groups» puedes especificar cualquier nombre que elijas.
Estos nombres aparecerán luego en la interfaz de estado como grupos, bajo los cuales se harán visibles todas aquellas agregaciones que compartan este nombre de grupo.
En realidad, se trata del mismo concepto que con los hashtags o las palabras clave.
También puedes asignar libremente el «Aggregation ID» como de costumbre, pero no podrás cambiarlo más adelante.
Defines el contenido de la agregación a través de Add new element. Selecciona la configuración Call a rule y, en Rule:, la regla que acabas de crear (y antes del paquete de reglas en el que se encuentra).
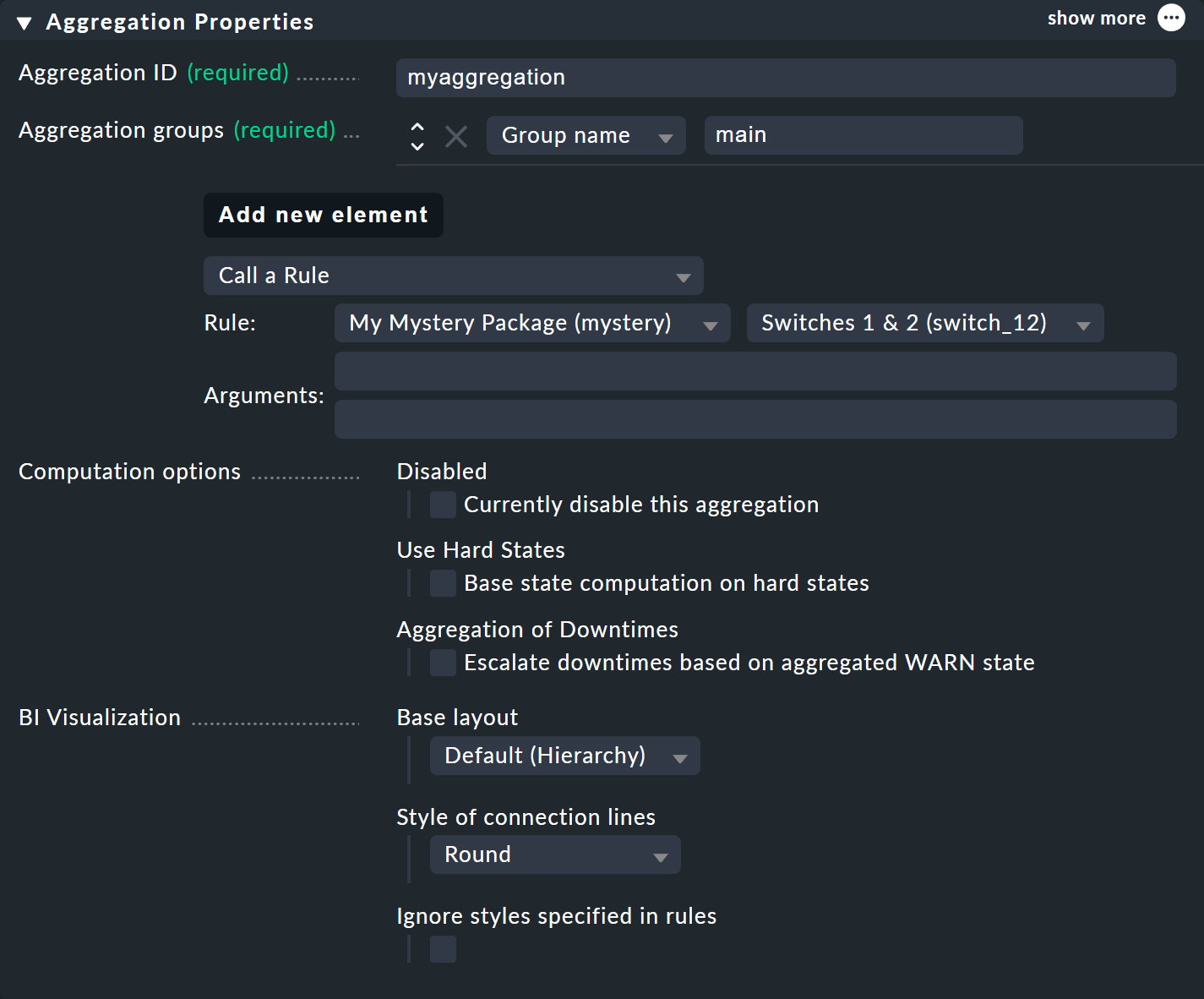
Si ahora guardas la agregación con «![]() », ¡ya está!
Tu primera agregación debería aparecer ahora en la interfaz de estado, siempre y cuando tengas al menos uno de los hosts,
», ¡ya está!
Tu primera agregación debería aparecer ahora en la interfaz de estado, siempre y cuando tengas al menos uno de los hosts, switch-1 o switch-2.
3. La BI en la práctica, parte 1: la interfaz de estado
3.1. Visualización de todas las agregaciones
Si has hecho todo correctamente, ahora podrás ver tu primera agregación en la interfaz de estado. La forma más fácil de hacerlo es a través de Monitor > Business Intelligence > All Aggregations:

Creación de vistas de tabla para BI
Además de las vistas de tabla de BI ya preparadas, también puedes crear las tuyas propias. Para ello, selecciona una de las fuentes de datos de BI al crear una nueva vista de tabla. BI Aggregations proporciona información sobre las Agregaciones BI, BI Hostname Aggregations añade filtros e información para hosts individuales, BI Aggregations affected by one host muestra solo las Agregaciones BI relacionadas con un único host, y BI Aggregations for Hosts by Hostgroups te permite distinguir entre grupos del host.
3.2. Trabajar con el árbol
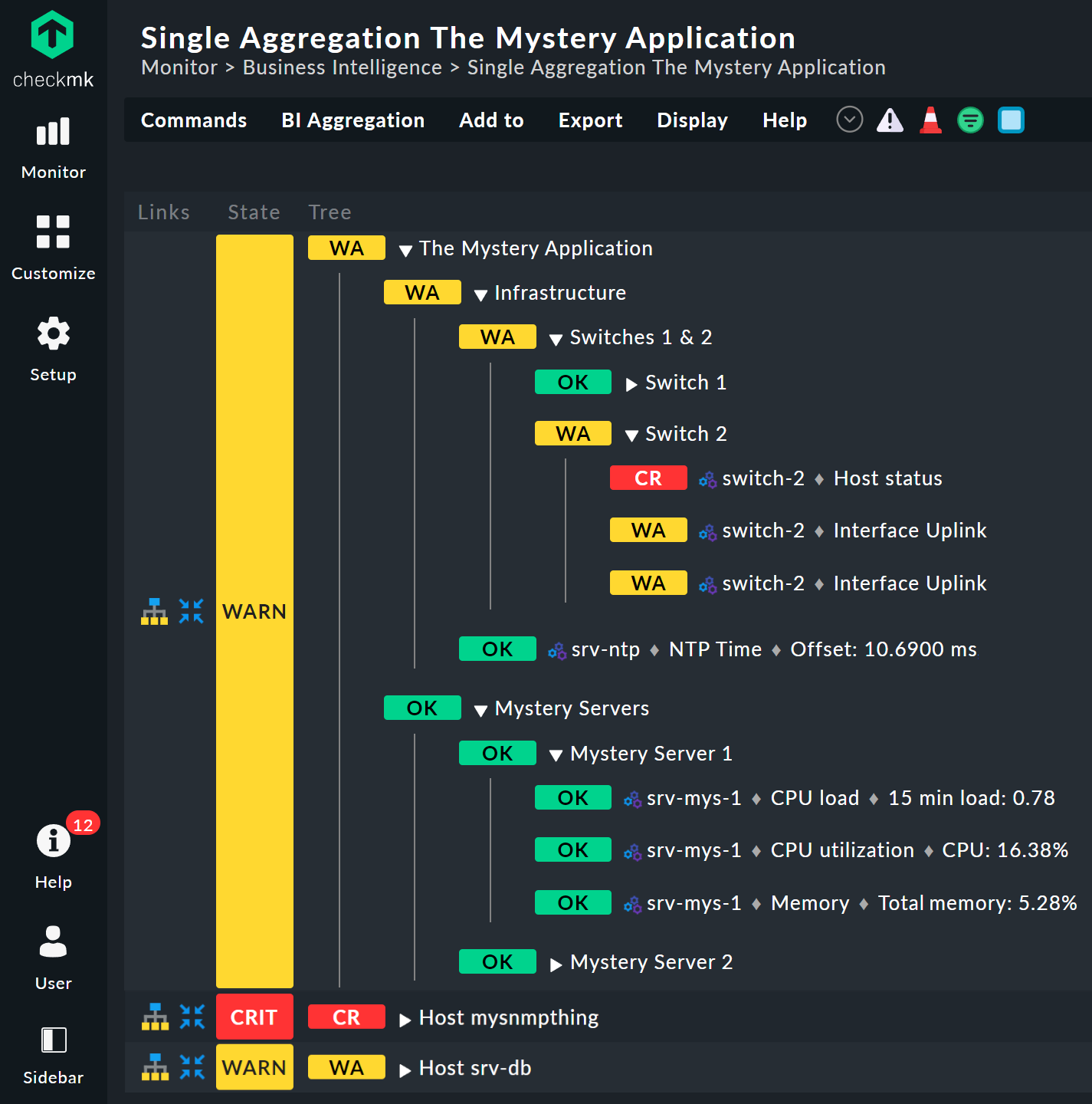
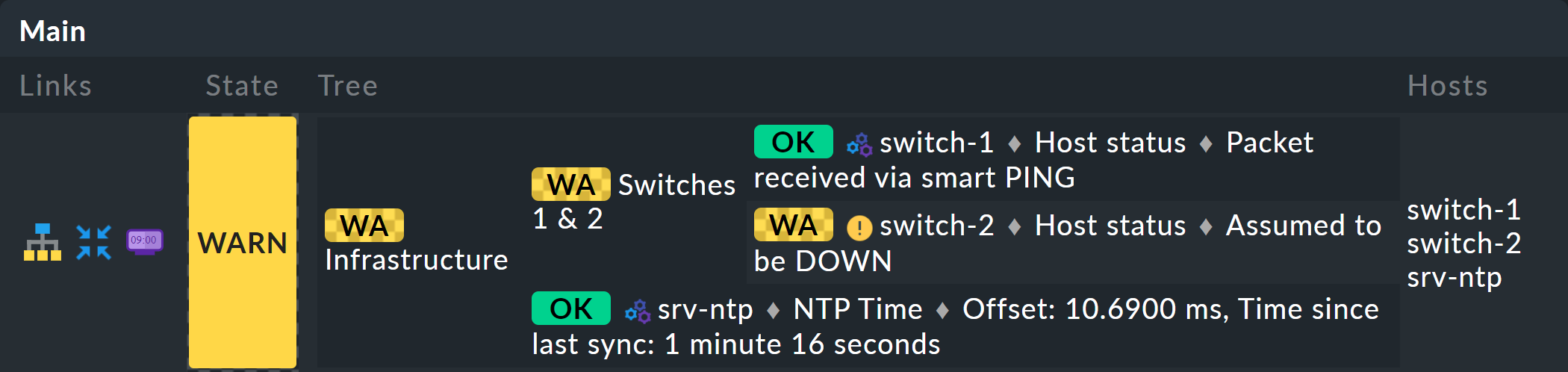
Echa un vistazo más de cerca al aspecto del árbol de BI. El siguiente ejemplo muestra tu miniagregación en una situación en la que uno de los dos switches es DOWN y el otro UP. Tal y como deseabas, la agregación entra en el estado WARN:

También puedes ver que, para estandarizar los hosts y los servicios, el host que es DOWN se trata casi como un servicio que es CRIT. Del mismo modo, UP se convierte en OK.
Las hojas del árbol muestran los estados de los hosts y los servicios. El nombre del host —y, en el caso de los servicios, también el nombre del servicio— es clicable y te lleva al estado actual del objeto correspondiente. Además, también puedes ver el último resultado del check plugin.
A la izquierda de cada agregación encontrarás dos iconos: ![]() y
y ![]() .
Con el primer icono —
.
Con el primer icono —![]() — accedes a una página que muestra solo esa única agregación.
Esto resulta útil, naturalmente, sobre todo si has creado más de una agregación.
Esto es, por ejemplo, muy adecuado como marcador.
— accedes a una página que muestra solo esa única agregación.
Esto resulta útil, naturalmente, sobre todo si has creado más de una agregación.
Esto es, por ejemplo, muy adecuado como marcador.
![]() te llevará al cálculo de la disponibilidad.
Más sobre esto más adelante.
te llevará al cálculo de la disponibilidad.
Más sobre esto más adelante.
3.3. Probando BI: ¿y si...?
A la izquierda del nombre del host encontrarás un icono interesante: ![]() .
Esto permite realizar un análisis de «¿y si…?»
La idea es sencilla:
al hacer clic en el icono, el objeto switchará a otro estado a modo de prueba —aunque solo para la interfaz de BI—, ¡no en la realidad!
Varios clics te llevarán de
.
Esto permite realizar un análisis de «¿y si…?»
La idea es sencilla:
al hacer clic en el icono, el objeto switchará a otro estado a modo de prueba —aunque solo para la interfaz de BI—, ¡no en la realidad!
Varios clics te llevarán de ![]() (OK) pasando por
(OK) pasando por ![]() (WARN),
(WARN), ![]() (CRIT) y
(CRIT) y ![]() (UNKNOWN) de vuelta a
(UNKNOWN) de vuelta a ![]() .
.
A continuación, BI construye el árbol completo basándose en el estado supuesto.
El siguiente gráfico muestra la agregación mínima bajo la suposición de que, además de switch-1, que realmente ha fallado, switch-2 también sería DOWN:

El estado general de la agregación pasa así de WARN a CRIT. Al mismo tiempo, el color del estado viene acompañado de un patrón de cuadros. Este patrón te indica que el estado real es, en realidad, diferente. Esto no siempre es así, porque algunos cambios en un host o servicio ya no son relevantes para la condición general; por ejemplo, si el en cuestión ya está CRIT.
Puedes usar este análisis de «¿y si...?» de varias maneras, por ejemplo:
Para comprobar si la Agregación BI reacciona como tú quieres.
Cuando planees apagar un componente para realizar mantenimiento.
En este último caso, como prueba, configuras el dispositivo que se va a reparar o sus servicios como «![]() ».
Si entonces toda la agregación sigue siendo «OK», eso significa que, en ese momento, la redundancia puede compensar el fallo.
».
Si entonces toda la agregación sigue siendo «OK», eso significa que, en ese momento, la redundancia puede compensar el fallo.
3.4. Probar BI usando estados falsos
Hay otra forma de probar las agregaciones BI: cambiando directamente el estado real de un objeto. Esto resulta especialmente práctico en un sistema de pruebas.
Para ello, los comandos cuentan con un comando de host/servicio llamado Fake check results.
Por defecto, solo está disponible para el rol de Administrador.
Este método se ha utilizado, por ejemplo, para crear las capturas de pantalla de este artículo, en las que switch-1 se ha establecido en DOWN.
De ahí viene el texto revelador «Manually set to Down by cmkadmin».

Aquí tienes un pequeño consejo útil: Si trabajas con este método, es mejor desactivar las comprobaciones activas de los hosts y servicios relevantes, de lo contrario, en el siguiente intervalo de comprobación volverán inmediatamente a su estado real. Si eres un poco vago, hazlo a nivel global a través del snap-in «Master Control». Pero... ¡no te olvides nunca de volver a activarlo después!
3.5. Grupos de BI
Al crear la agregación, abordamos brevemente las posibilidades disponibles para la entrada «Aggregation Groups». En el ejemplo, simplemente confirmaste el nombre sugerido «Main» aquí. Por supuesto, tienes total libertad a la hora de asignar nombres, y también puedes asignar una agregación a varios grupos.
Los grupos cobran importancia cuando el número de agregaciones supera lo que quieres mostrar en una pantalla. Accedes a un grupo haciendo clic en uno de los nombres de grupo que aparecen en la página «All aggregations»; en nuestro ejemplo anterior, simplemente en el encabezado «Main». Por supuesto, si hasta ahora solo tienes esta única agregación, no cambiará gran cosa. Sin embargo, si te fijas bien, te darás cuenta de que:
El título de la página ahora es «Aggregation group Main».
El encabezado del grupo «Main» ha desaparecido.
Si quieres visitar esta vista de tabla más a menudo, simplemente añádela a tus favoritos, preferiblemente con el elemento «Bookmarks» en la barra lateral.
3.6. De host/servicio a agregación
Una vez que hayas configurado las agregaciones BI, en el menú de contexto de tus hosts y servicios encontrarás un nuevo icono de «![]() »:
»:
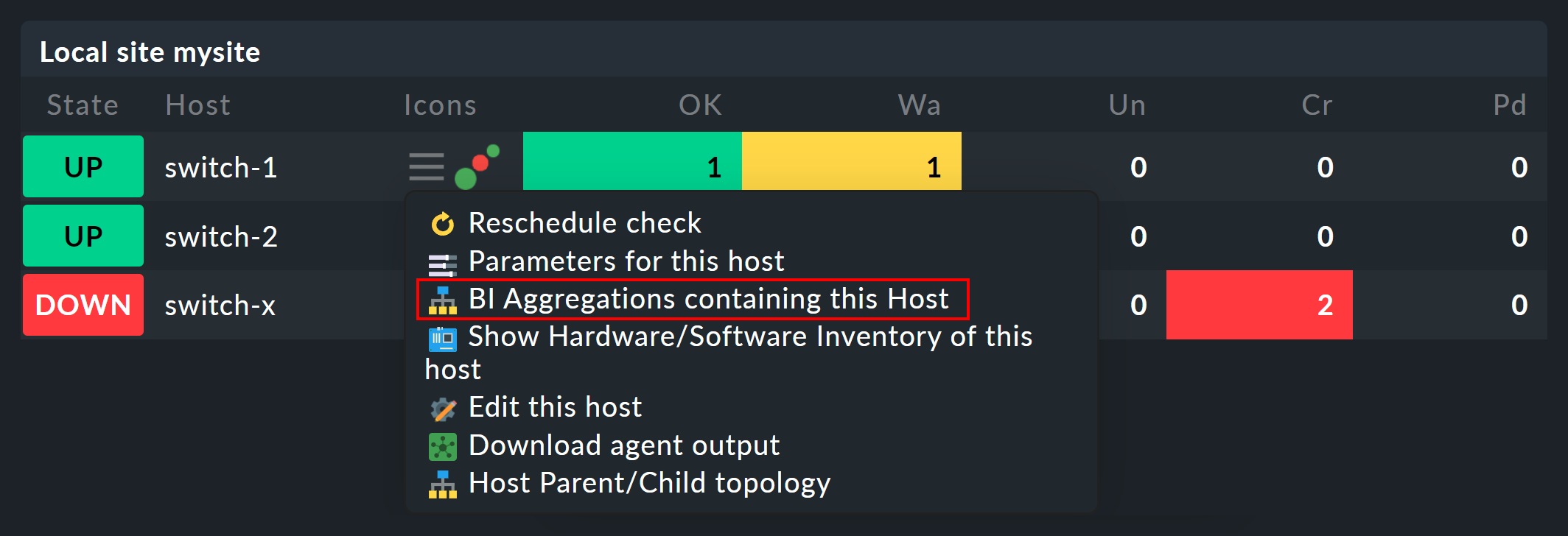
Este icono te lleva a la lista de todas las agregaciones en las que se incluye el host o servicio en cuestión.
4. Configuración, parte 2: árboles de varios niveles
Tras esta primera impresión general de la interfaz de estado de BI, volvemos a la configuración, porque, claro, no puedes impresionar a nadie con una agregación BI tan pequeña.
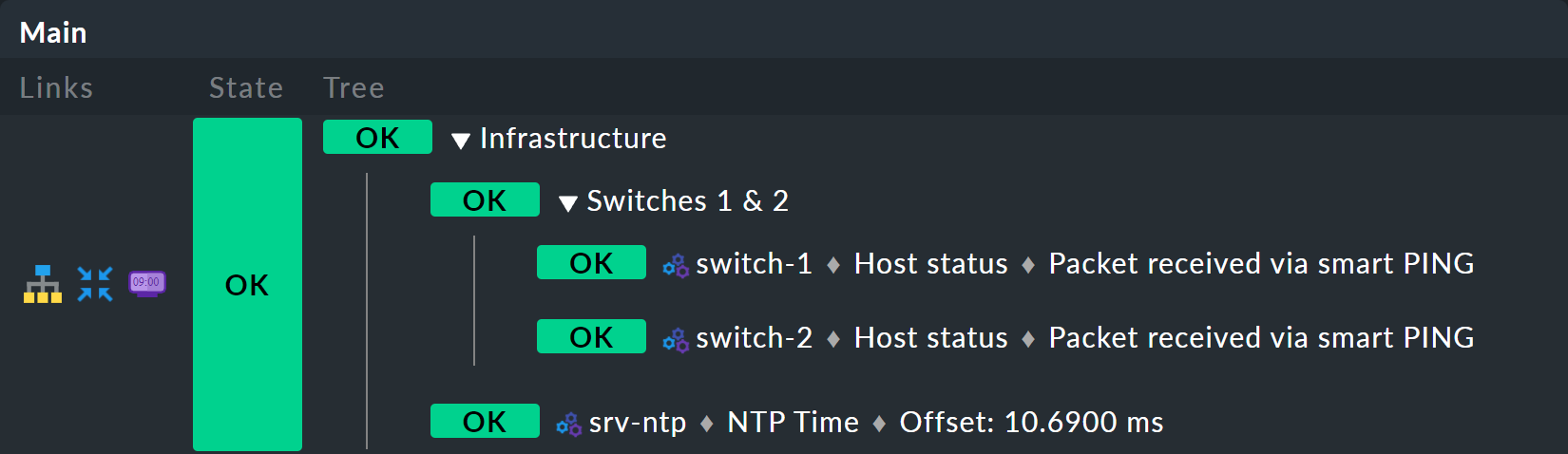
Empieza ampliando el árbol en un nivel, es decir, de dos niveles (raíz y hojas) a tres niveles (raíz, nivel intermedio, hojas). Para ello, combina tu nodo existente «Switches 1 y 2» con el estado de sincronización horaria NTP en un nodo de nivel superior «Infraestructura».
Pero vamos paso a paso: primero, un avance del resultado:
El requisito previo es que haya un host srv-ntp que tenga un servicio llamado NTP Time:

Primero crea una regla BI que, como subnodo 1, reciba la regla «Switches 1 & 2», y como subnodo 2 reciba directamente el servicio NTP Time en el host srv-ntp.
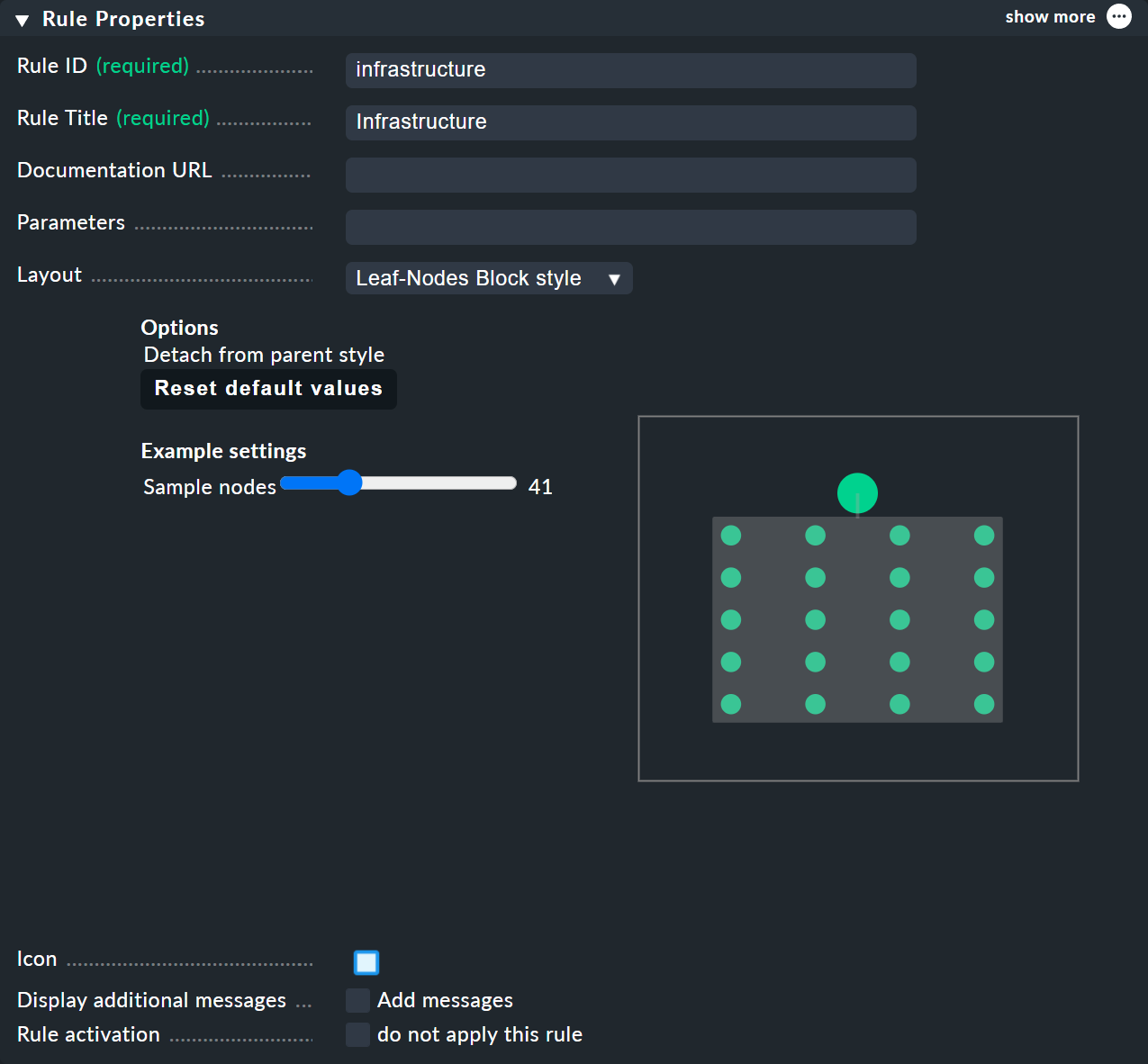
En la parte superior de la regla, selecciona infrastructure como ID de la regla y Infrastructure como su nombre.
No es necesario introducir más información en este momento:
En el Child Node Generation es donde se pone interesante. La primera entrada es ahora del tipo Call a rule, y como regla elige la tuya de las anteriores, de modo que realmente «cuelgues» estas reglas de forma efectiva en el subárbol.
El segundo subnodo es del tipo «State of a service», y aquí elige tu servicio «NTP Time»
(presta atención a la ortografía exacta, incluyendo mayúsculas y minúsculas) y el servicio «NTP Time» mediante expresión regular:
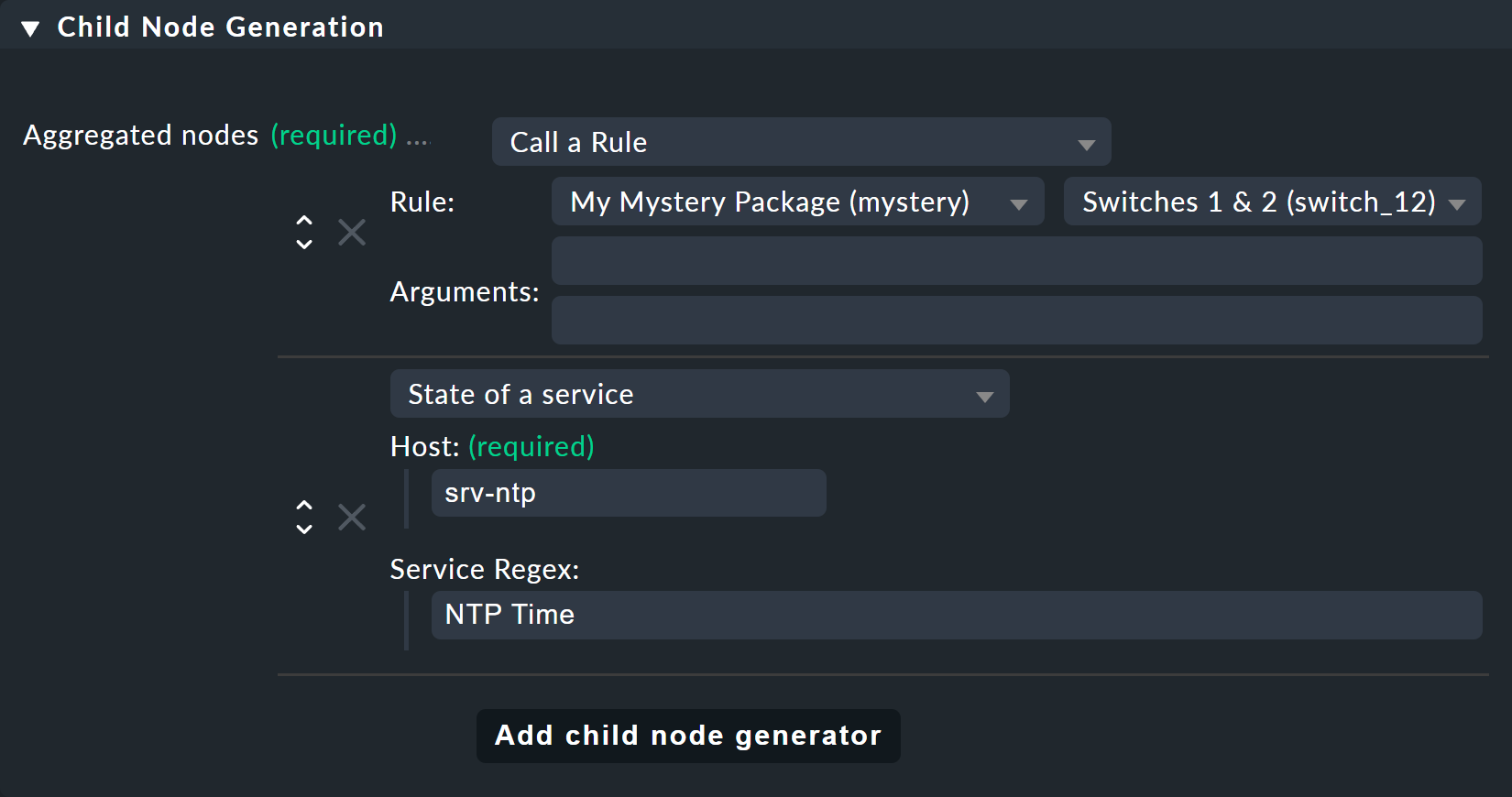
Esta vez, configura el Aggregation Function en la tercera caja como Worst — i.e., take the worst state of all nodes.
En esta función, el estado del nodo se deriva así del peor estado de un servicio situado debajo de él.
En este caso, si NTP Time pasa a CRIT, el nodo también pasa a CRIT.
Por supuesto, para que el nuevo árbol, más grande, sea visible, tendrás que volver a crear una agregación. Lo mejor es simplemente cambiar la agregación existente para que, a partir de ahora, se utilice la nueva regla:
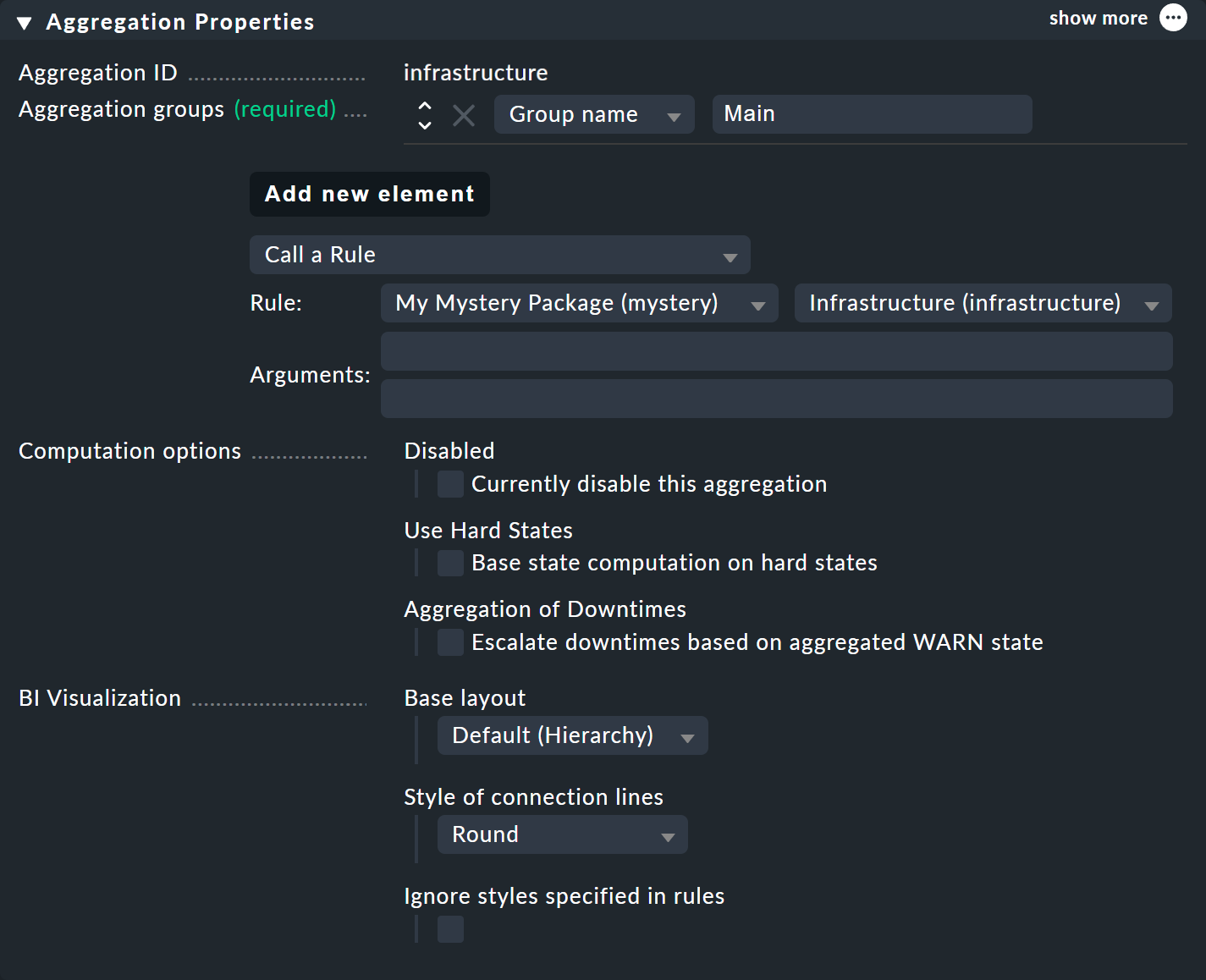
De esta forma te quedas con una sola agregación, que entonces queda como se muestra a continuación (esta vez ambos switches vuelven a estar en OK):
5. La BI en la práctica, parte 2: visualizaciones alternativas
5.1. Introducción
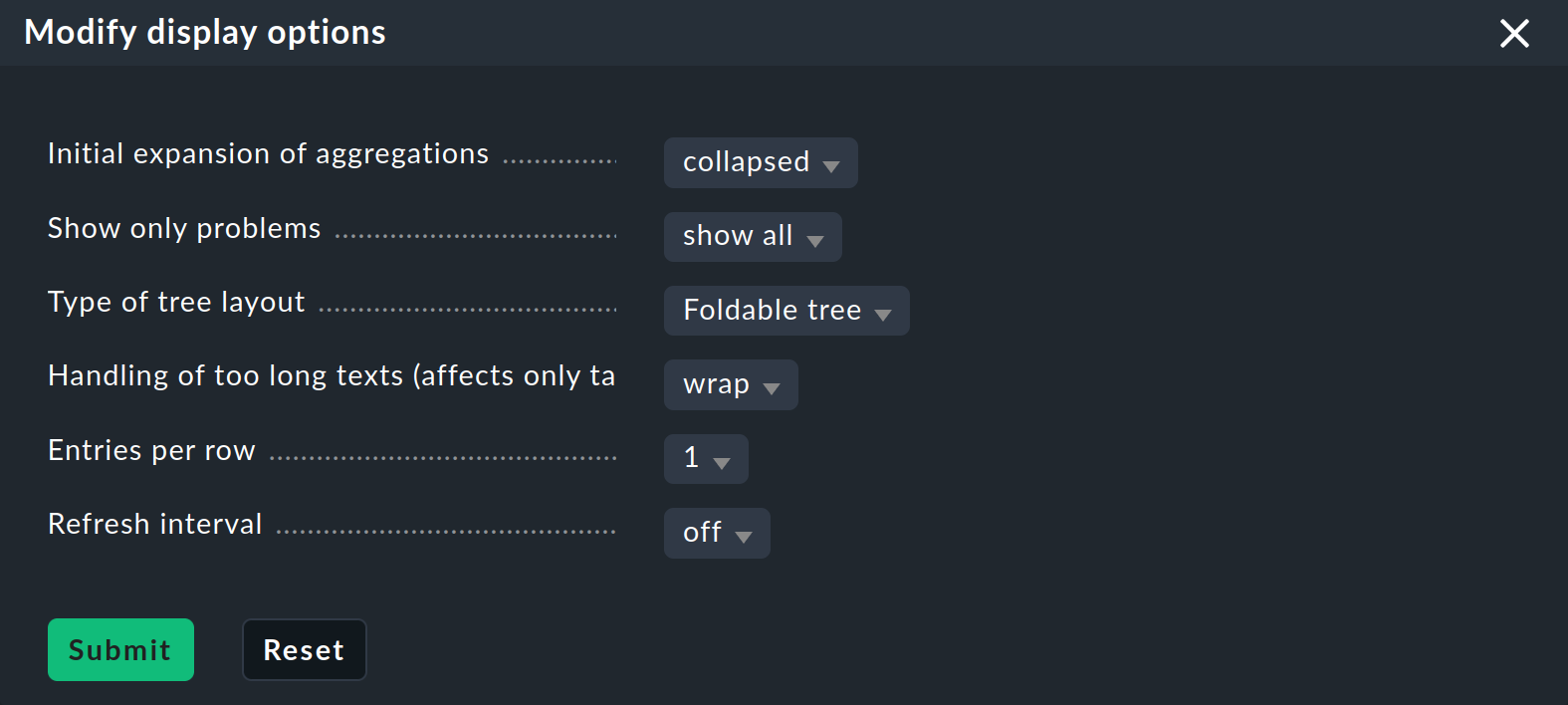
Ahora que tienes un árbol un poco más interesante, puedes acercarte un poco más a las diversas opciones de visualización que ofrece Checkmk. El punto de partida para ello son las «Modify display options», a las que puedes acceder a través del menú «Display». Esto abre una caja con varias opciones. El contenido de la caja siempre se ajusta a los elementos que se muestran en la página. En el caso de BI, actualmente puedes encontrar cuatro opciones:
Expandir o contraer árboles al instante
Si no muestras una sola agregación, sino muchas, la configuración «Initial expansion of aggregations» te resultará útil. Aquí defines hasta qué punto deben desplegarse los árboles cuando se muestran por primera vez. La selección va desde cerrado (collapsed) pasando por los tres primeros niveles, hasta completamente abierto (complete).
Mostrar solo problemas
Si activas la opción «Show only problems», en los árboles solo se mostrarán las ramas que no tengan el estado «OK». El resultado será el siguiente:

Tipos de visualización de árboles
En el item «Type of tree layout» encontrarás varios tipos de visualización alternativos para el árbol. Uno de ellos se llama «Table: top down» y tiene este aspecto:
La visualización «Boxes» ahorra muchísimo espacio, sobre todo si quieres ver muchos agregados a la vez. Aquí cada nodo es una caja de color que se puede expandir con un clic. La estructura de árbol ya no es visible, pero puedes hacer clic rápidamente para localizar un problema, lo que solo requiere un espacio mínimo en la pantalla. En este ejemplo, las cajas están completamente desplegadas:

5.2. Más opciones
Por último, puedes establecer un intervalo de actualización (Refresh interval) de 30, 60 o 90 segundos y especificar el número de columnas mediante Entries per row.
5.3. Visualización de agregaciones BI
Además de las representaciones tabulares, Checkmk también domina la visualización de agregaciones BI.
Puedes ver las agregaciones desde una nueva perspectiva y, a veces, con mayor claridad.
Encontrarás el BI Visualization a través de ![]() en la vista de tabla habitual.
en la vista de tabla habitual.

Puedes mover el árbol libremente haciendo clic en el fondo y ajustar el tamaño de toda la pantalla con la rueda del ratón. En cuanto pasas el puntero del ratón por encima de un nodo concreto, aparece una ventana emergente con la información de estado asociada a ese nodo. Usa la rueda del ratón para ajustar la longitud de las ramas del árbol.
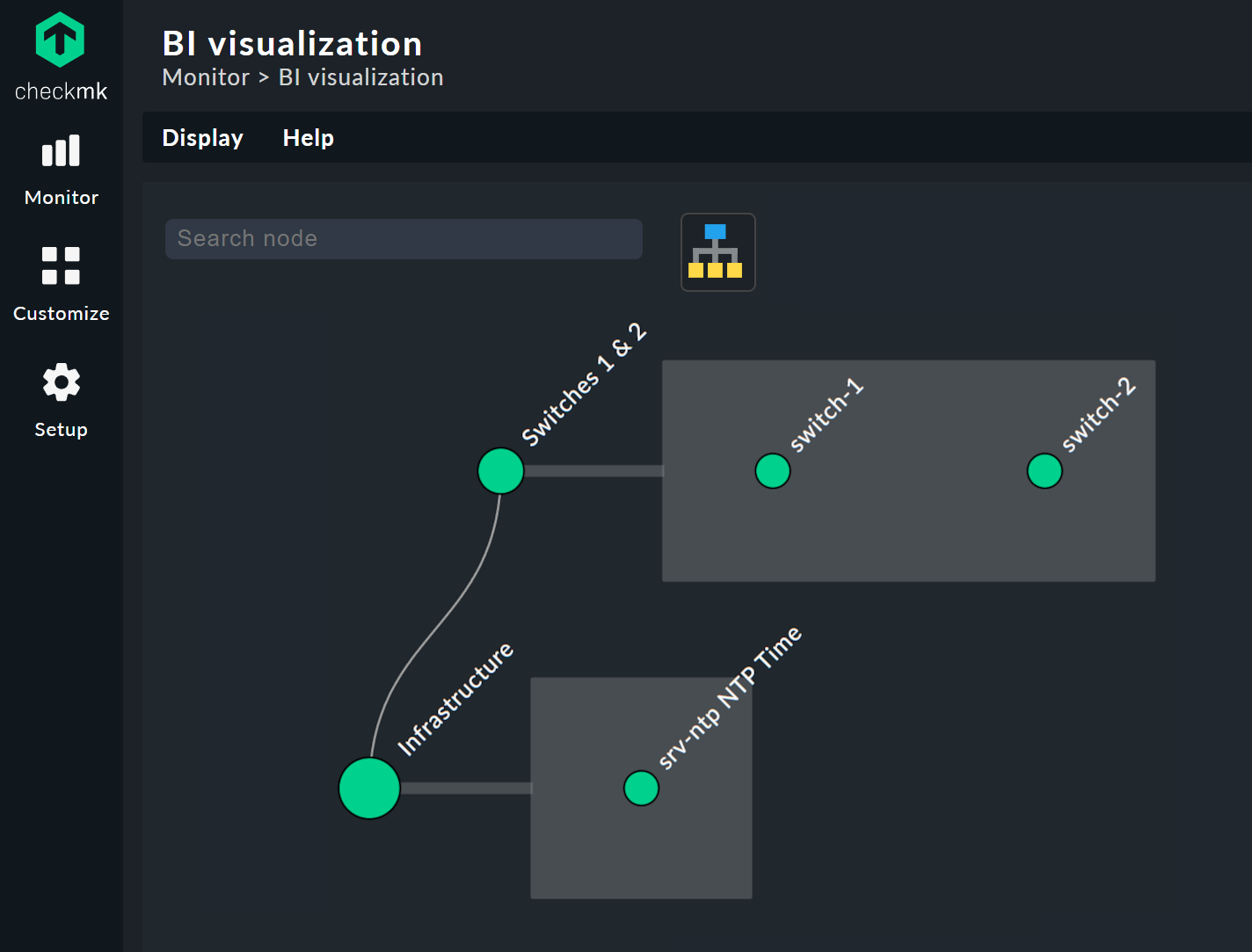
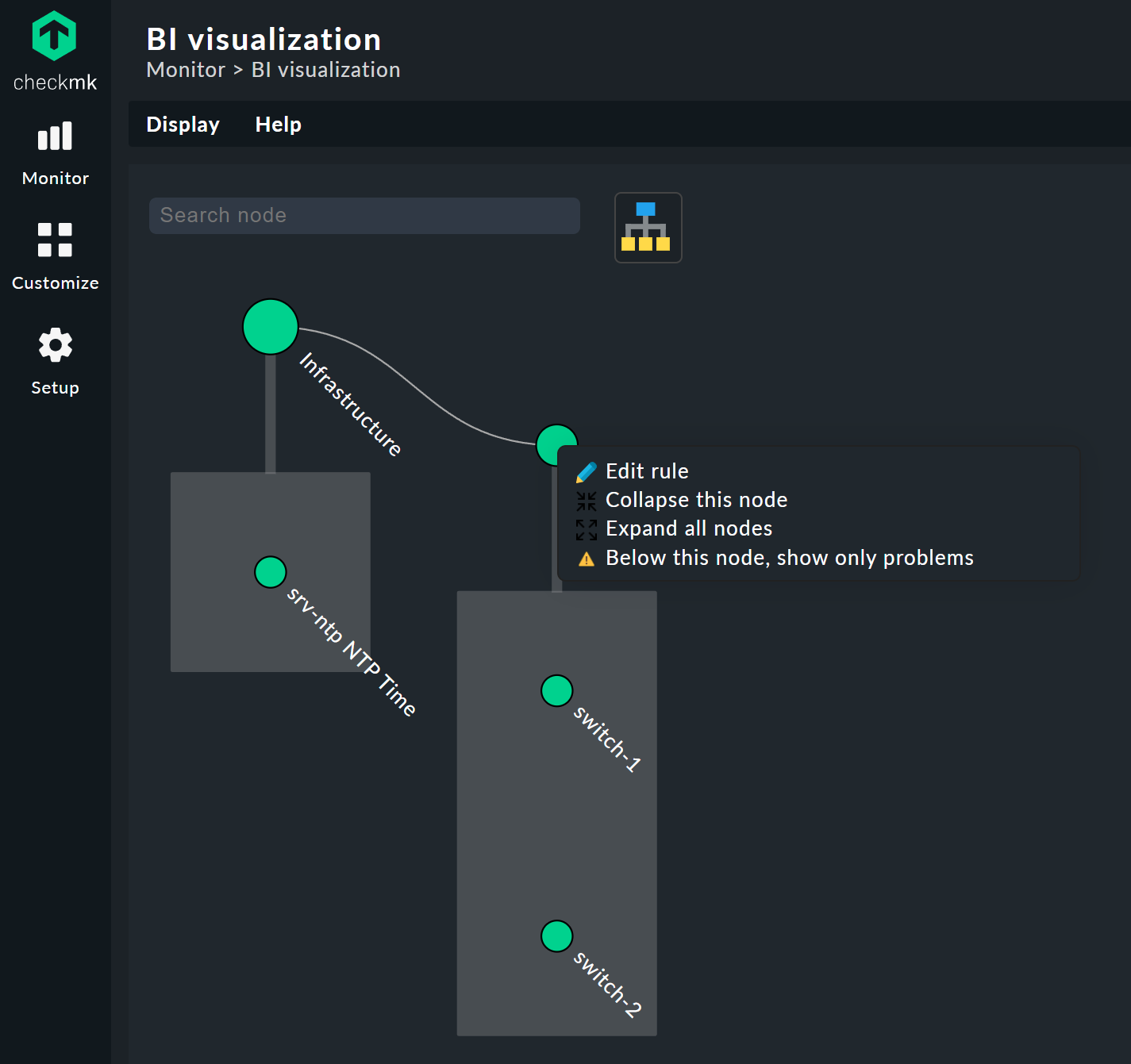
Al hacer clic en los nodos hoja, accederás directamente a las vistas detalladas del host o del servicio. Al hacer clic con el botón derecho en los demás nodos —dependiendo del tipo de nodo— podrás acceder a las opciones de visualización y, por ejemplo, a la propia regla responsable —Edit rule, en la imagen de abajo.
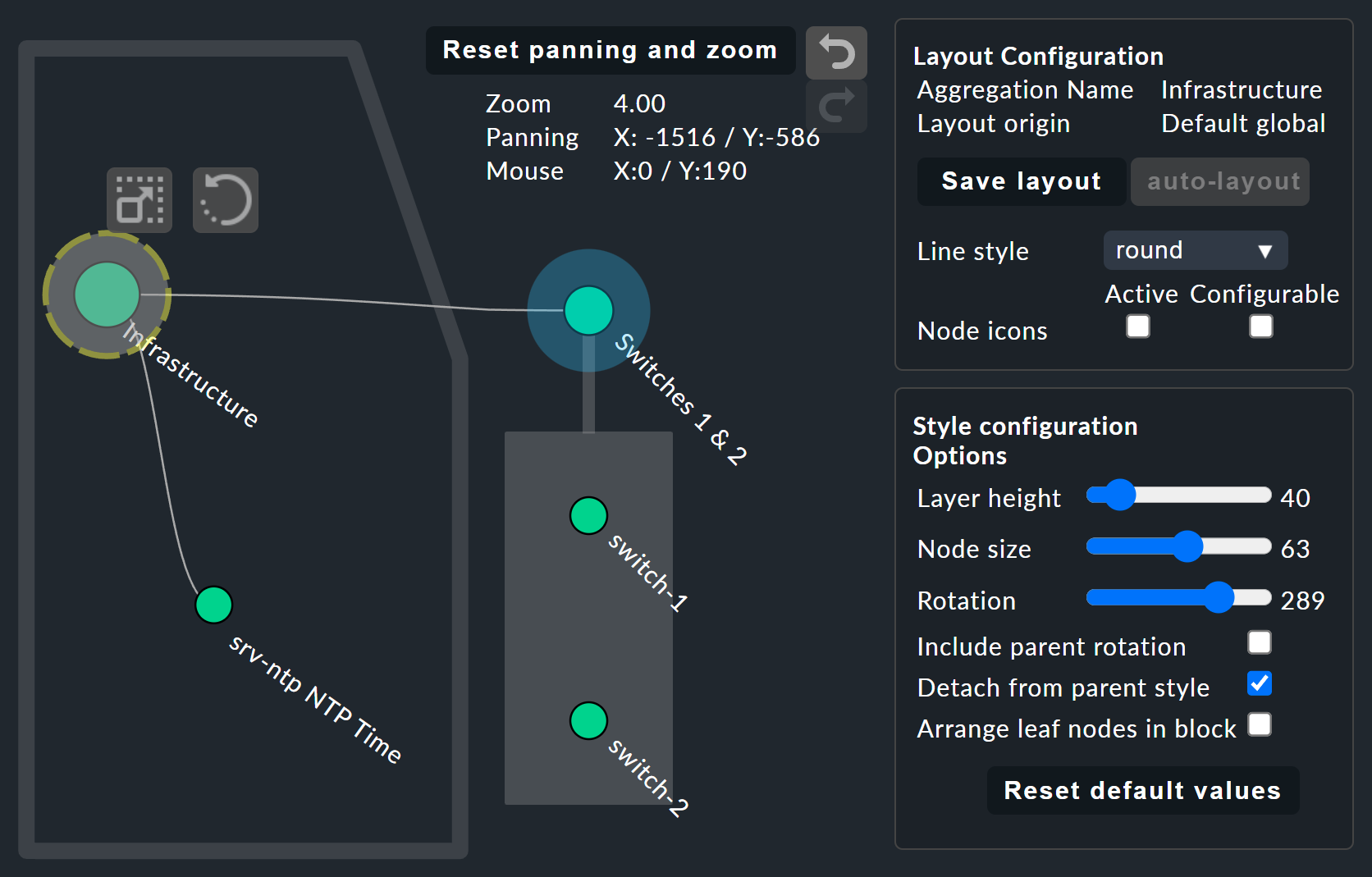
Personalización de la visualización
La cosa se pone realmente interesante con el Layout Designer, que se abre con un ![]() en la parte superior, junto al campo de búsqueda.
En primer lugar, verás dos items nuevos —el Layout Configuration— y dos iconos nuevos en la raíz —
en la parte superior, junto al campo de búsqueda.
En primer lugar, verás dos items nuevos —el Layout Configuration— y dos iconos nuevos en la raíz —![]() y
y ![]() .
.
En la configuración puedes elegir entre diferentes tipos de línea y activar la función «Node icons».
Esto mostrará los iconos que puedes especificar en las reglas para las Agregaciones BI en la sección «Aggregation Function»
(a la que puedes acceder directamente a través del menú de contexto del nodo).
Con los iconos «![]() » y «
» y «![]() » puedes ver el árbol y, haciendo clic y arrastrando, girarlo o cambiar su longitud y anchura.
En la caja «Style configuration» también aparecen otras opciones de visualización.
Puedes encontrar las que mejor se adapten a tus necesidades simplemente probando las opciones disponibles.
» puedes ver el árbol y, haciendo clic y arrastrando, girarlo o cambiar su longitud y anchura.
En la caja «Style configuration» también aparecen otras opciones de visualización.
Puedes encontrar las que mejor se adapten a tus necesidades simplemente probando las opciones disponibles.
Las mayores posibilidades de personalización se encuentran en los menús contextuales de los nodos, que en el modo de diseño ofrecen cuatro visualizaciones diferentes de la jerarquía a partir de este nodo:
Hierarchical style: La configuración estándar con una jerarquía simple.
Radial style: Un formato circular con un sector personalizable del círculo.
Leaf-Nodes Block style: Los nodos hoja se muestran como un grupo con fondo gris.
Free-Floating style: Un diseño dinámico con opciones como atracción, espaciado y longitud de las ramas.
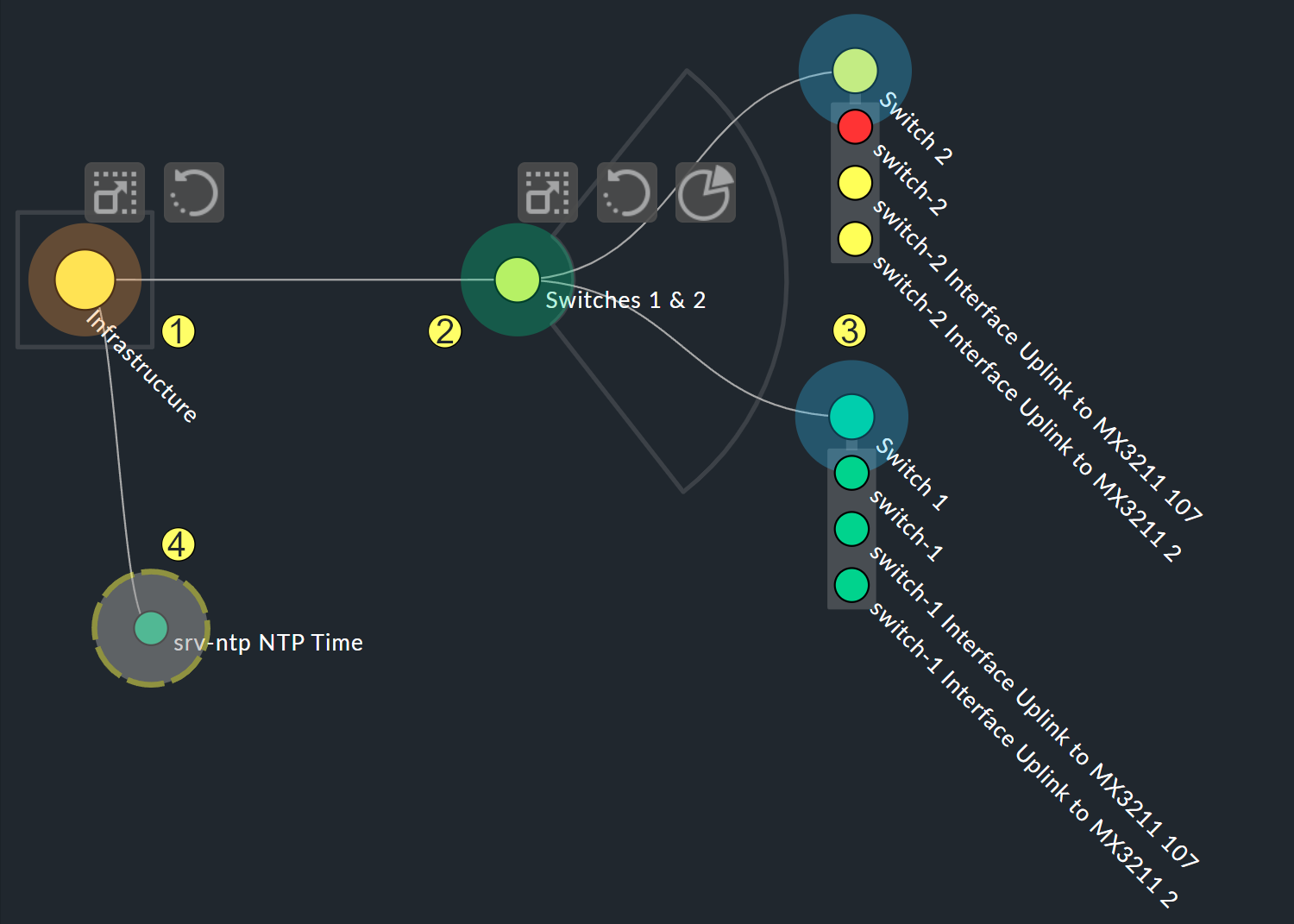
Los nodos a los que se les ha asignado un estilo se pueden colocar en cualquier lugar.
Las opciones disponibles también varían según el estilo: con Radial style, en el nodo raíz hay un tercer icono ![]() que puedes usar para limitar la visualización a un sector del círculo.
que puedes usar para limitar la visualización a un sector del círculo.
Con la opción «Detach from parent style» puedes separar el estilo de un nodo del estilo de su nodo padre superior, para luego configurar estos subnodos de forma diferente y colocarlos libremente. «Include parent rotation» tiene un propósito similar: te permite incluir o excluir nodos padres al rotar.
Estas opciones de estilo son básicamente todas intuitivas; solo «Free-Floating style» necesita alguna explicación. Se trata de un sistema de atracción y repulsión, como el que conoces de las simulaciones gravitatorias.
Center force strength |
Centro de gravedad de los nodos. |
Repulsion force leaf |
Intensidad del efecto de repulsión de las hojas sobre otros nodos. |
Repulsion force branches |
Intensidad de la repulsión de los nodos hacia otros de la misma rama. |
Link distance leaf |
Distancia ideal del nodo hoja al nodo anterior. |
Link distance branches |
Distancia ideal del nodo de rama al nodo anterior. |
Link strength |
Intensidad con la que se aplica la distancia ideal. |
Collision box leaf |
Tamaño del área del nodo hoja que repele a otros nodos. |
Collision box branch/leaf |
Tamaño del área del nodo de rama que repele a otros nodos. |
La siguiente imagen muestra una rama en el árbol de decisión (Free-Floating style): las posiciones de las hojas individuales se determinan dinámicamente en función de las opciones especificadas.
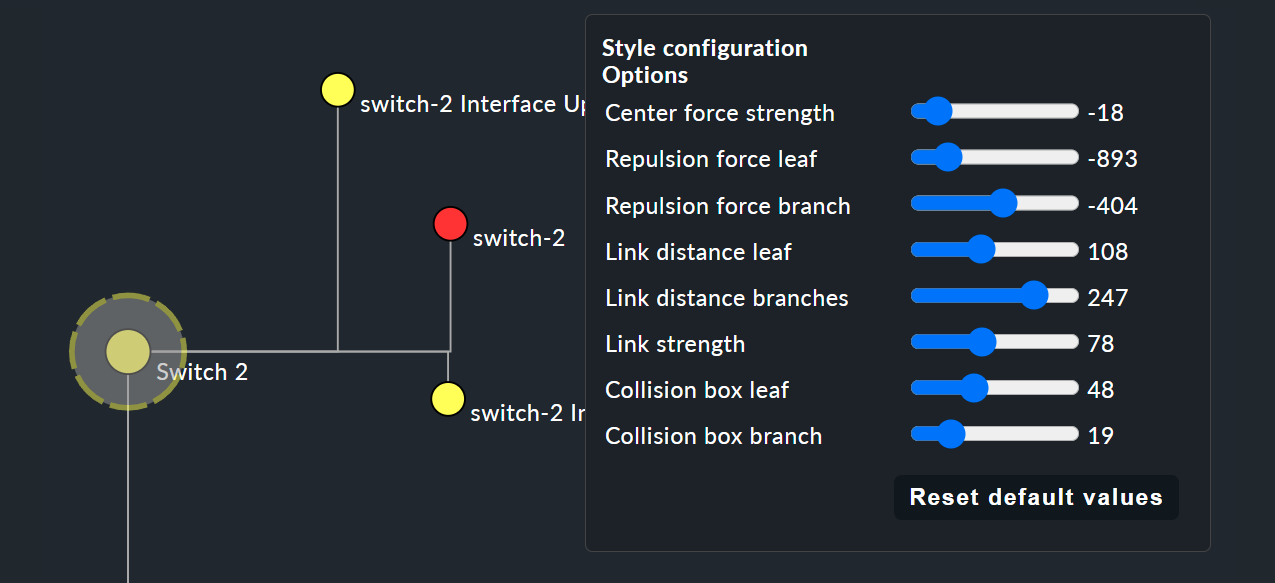
Especificar estilos de diseño para reglas BI
Para las reglas BI —a las que puedes acceder desde el menú de contexto de los nodos— en el menú «Rule Properties» puedes asignar los diseños «Hierarchical», «Radial» o «Leaf-Nodes Block», y configurar las opciones correspondientes.
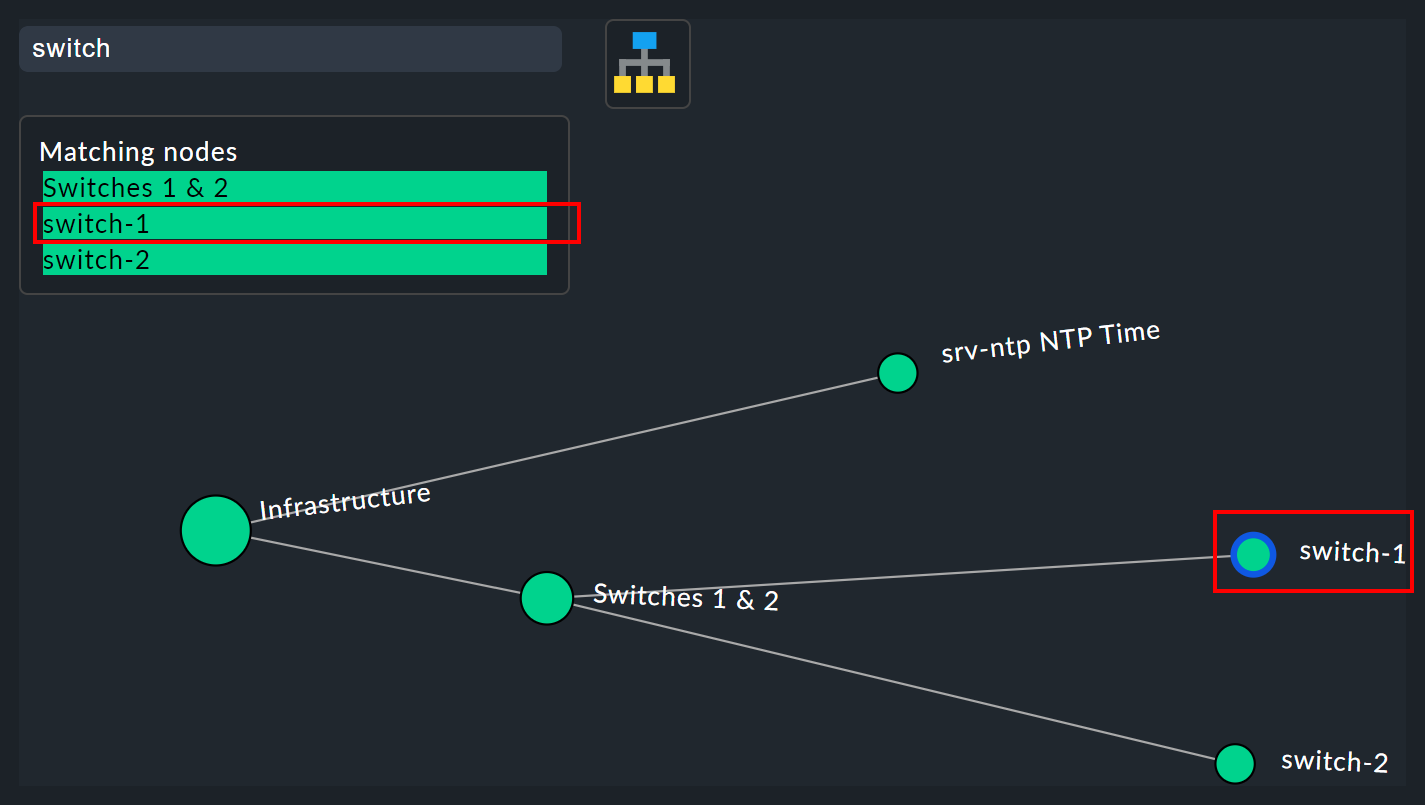
La función de búsqueda
La función de búsqueda es de gran ayuda con árboles más grandes. En el campo de búsqueda de «Search node» (Nodos y nodos de subárbol) puedes simplemente introducir una parte del nombre del nodo deseado y obtener una lista de resultados directamente y en tiempo real. Si ahora pasas el ratón por esta lista de sugerencias, el nodo del árbol situado bajo el puntero del ratón se resaltará con un borde azul, lo que facilita una primera orientación. Al hacer clic en un nodo de la lista, el árbol se centrará en ese punto. De esta manera, incluso en pantallas con cientos de nodos, podrás encontrar rápidamente la sección correcta en la estructura.
6. Configuración, parte 3: variables, plantillas, búsquedas
6.1. Configuración más inteligente
Continuemos con la configuración. Ahora es el momento de ponernos manos a la obra de verdad. Hasta ahora, el ejemplo ha sido tan sencillo que ha sido posible enumerar individualmente todos los objetos de la agregación BI sin dificultad. Pero, ¿y si las cosas se complican? ¿Y si quieres formular muchas dependencias recurrentes que son iguales o similares? ¿Y si una aplicación incluye no uno, sino varios sites? ¿Y si quisieras agrupar cientos de servicios individuales de una base de datos en un solo nodo de BI?
Para este tipo de requisitos necesitarás métodos de configuración más potentes. Y esto es precisamente lo que distingue a Checkmk BI de otras herramientas —y, por desgracia, aquí la curva de aprendizaje es un poco más pronunciada. También es la razón por la que Checkmk BI no permite configurarse mediante «arrastrar y soltar». Sin embargo, una vez que conozcas las posibilidades, seguro que no querrás prescindir de ellas.
6.2. Parámetros
Empecemos por los parámetros. Imagina la siguiente situación: no solo quieres saber si los dos switches están UP, sino que también quieres conocer el estado de los dos puertos responsables del enlace ascendente. En términos generales, esto depende de los siguientes cuatro servicios:
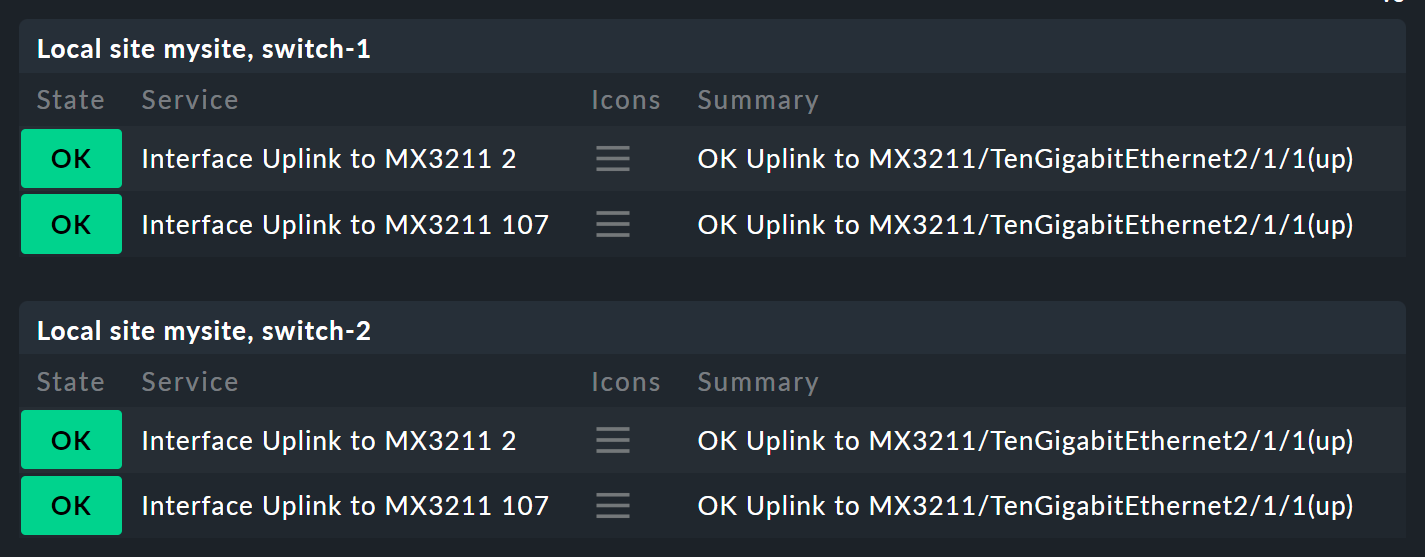
Ahora, el nodo Switch 1 & 2 debería ampliarse para sustituir los dos estados de host de los switches 1 y 2, de modo que cada uno tenga un subnodo que muestre el estado del host y las dos interfaces de enlace ascendente. Estos dos subnodos deberían ser Switch 1 o Switch 2.
De hecho, ahora necesitarás dos reglas nuevas: una para cada switch.
Es mejor hacerlo creando una nueva regla switch y dotándola de un parámetro.
Este parámetro es una variable que invocas cuando llamas a la regla desde el nodo padre —que aquí puede ser proporcionada por la antigua regla Switch 1 & 2.
En este ejemplo, puedes simplemente pasar un 1 o un 2.
El parámetro recibe un nombre que puedes elegir libremente.
Toma aquí, por ejemplo, el nombre NUMBER.
El uso de mayúsculas aquí es puramente arbitrario,
y si te parecen más bonitas las minúsculas, también eres libre de usarlas.
El título de la regla quedará así:
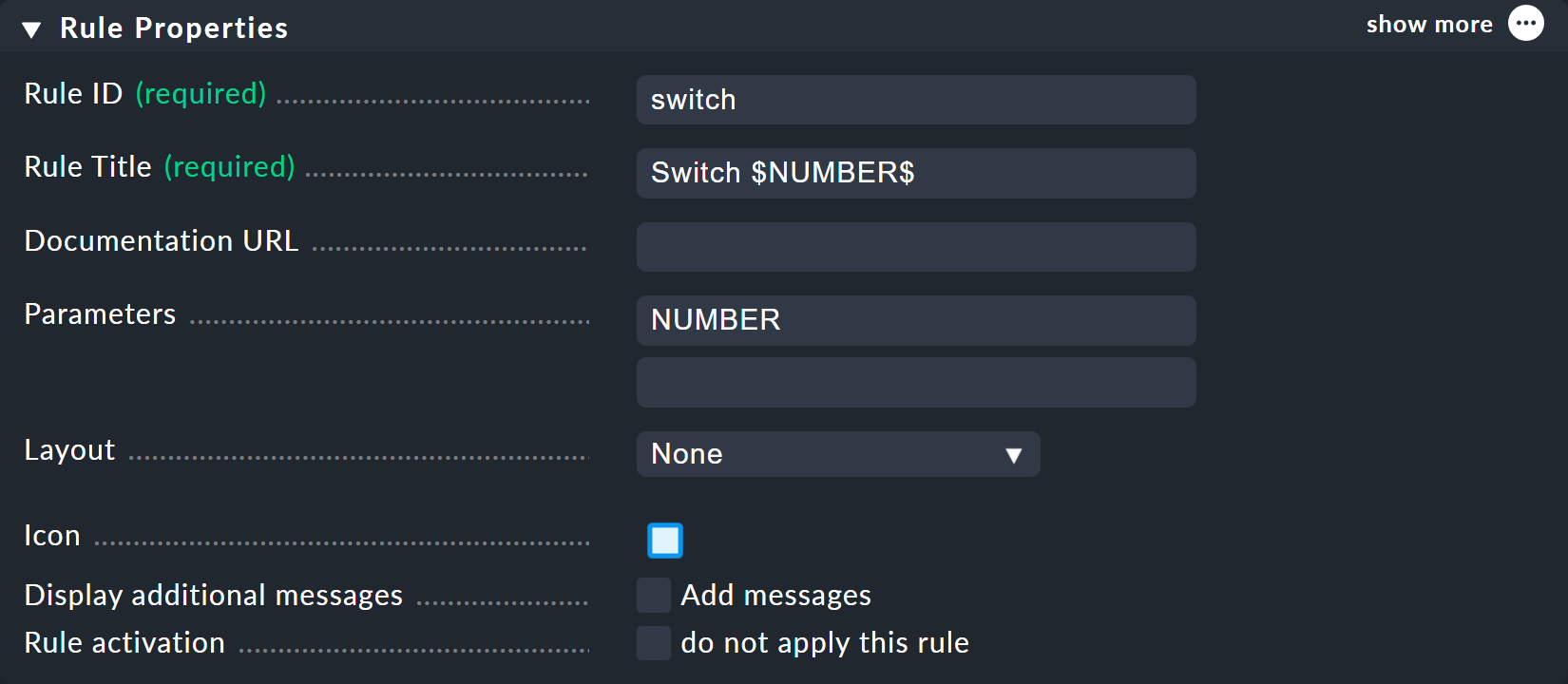
Puedes elegir switch como ID para la nueva regla.
En Parameters, simplemente introduce el nombre de la variable: NUMBER.
Ahora también es importante que la variable se utilice en el Rule Title de la regla, para que ambos nodos no se llamen simplemente switch y, por lo tanto, tengan el mismo nombre.
Al utilizar la variable, se añade un signo de dólar al principio y al final, como es habitual en muchos lugares de Checkmk.
Como resultado, los dos nodos se llamarán Switch 1 y Switch 2.
La concordancia de prefijo es la opción predeterminada para los nombres del servicio
Para el Child node generator, lo primero que hay que hacer es insertar el estado del host.
En lugar de 1 o 2 en el nombre del host, puedes usar simplemente tu variable, de nuevo con un $ al principio y al final.
Lo mismo ocurre con los nombres de host de las interfaces de enlace ascendente.
Y aquí viene el segundo truco, porque, como puedes imaginar por la pequeña lista de servicios que has visto arriba, los servicios para el enlace ascendente tienen nombres diferentes en cada switch.
Pero eso no es ningún problema, porque BI siempre interpreta el nombre del servicio como una concordancia de prefijo usando expresiones regulares, de forma totalmente análoga a las conocidas reglas de servicio.
Así que con solo escribir Interface Uplink, capturas todos los servicios del host correspondiente que empiezan por Interface Uplink:
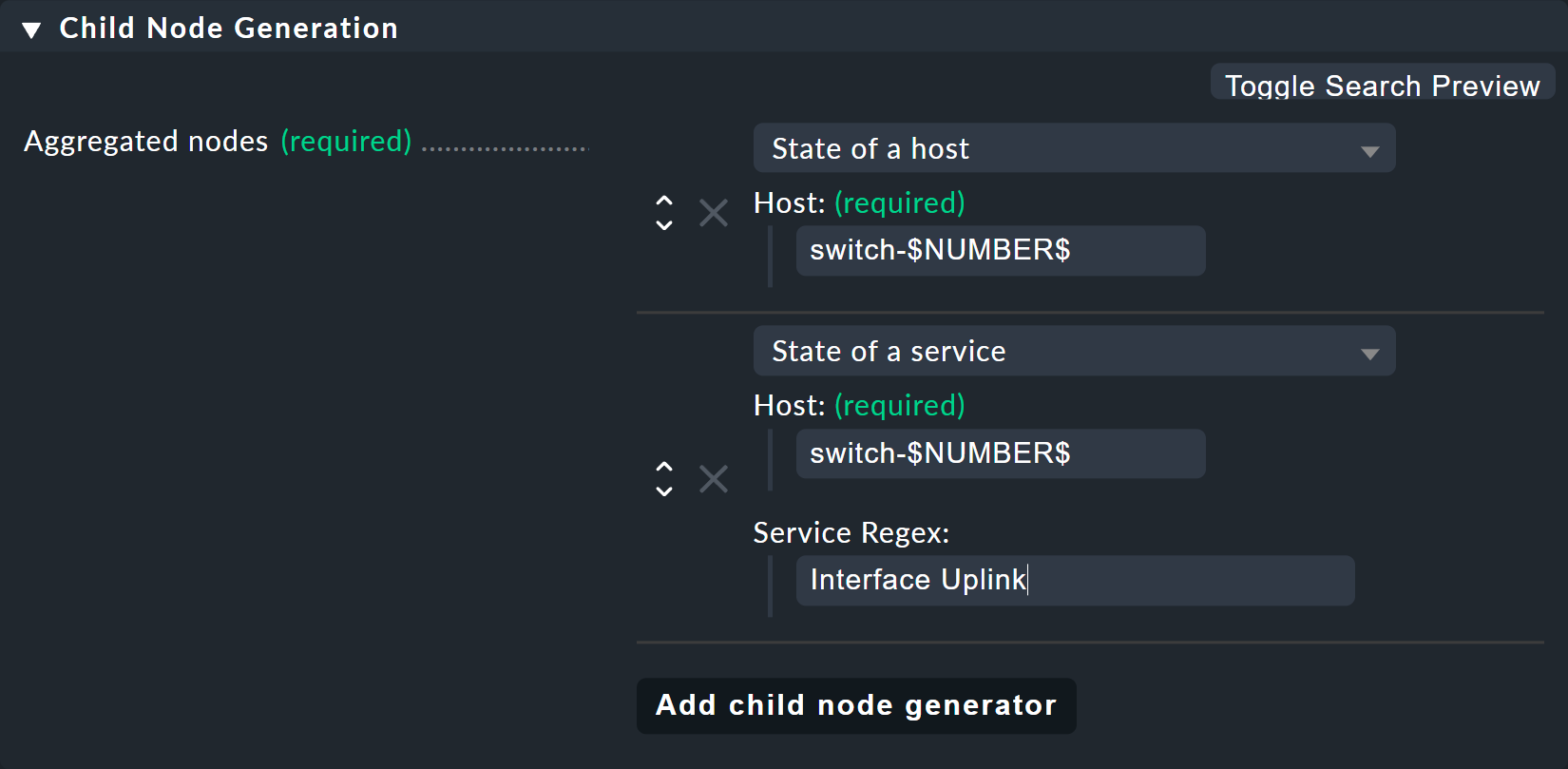
Por cierto: añadiendo $ puedes desactivar el comportamiento del prefijo.
En expresiones regulares, $ significa «El texto debe terminar aquí».
Así que Interface 1$ solo tiene una coincidencia con Interface 1, y no también, por ejemplo, con Interface 10.
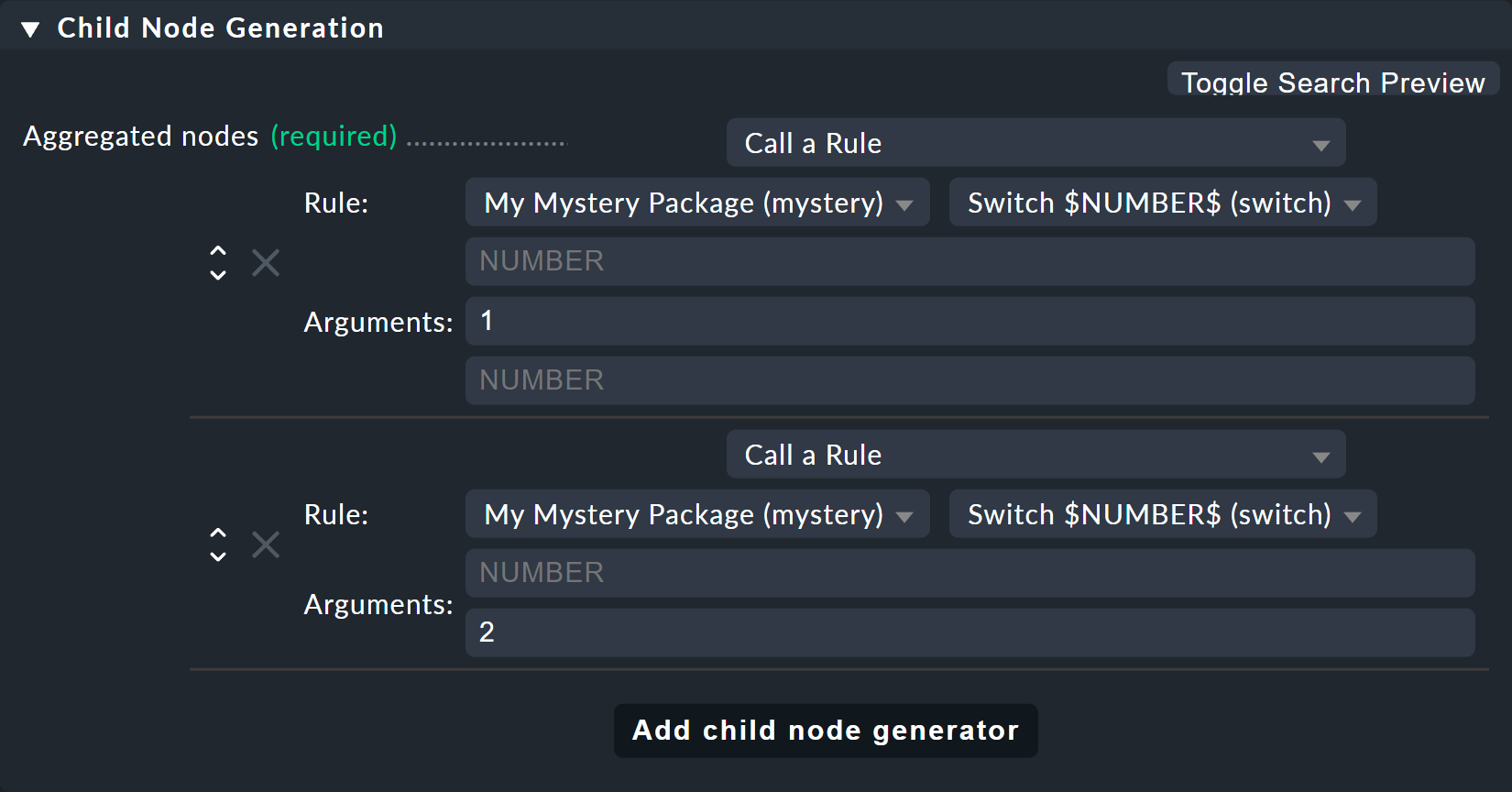
Ahora modifica la antigua regla Switch 1 & 2 para que, en lugar de los estados del host, esta nueva regla solo se invoque una vez para cada uno de los dos switches.
Y aquí es también donde se proporcionan los valores 1 y 2 como parámetros para la variable NUMBER:
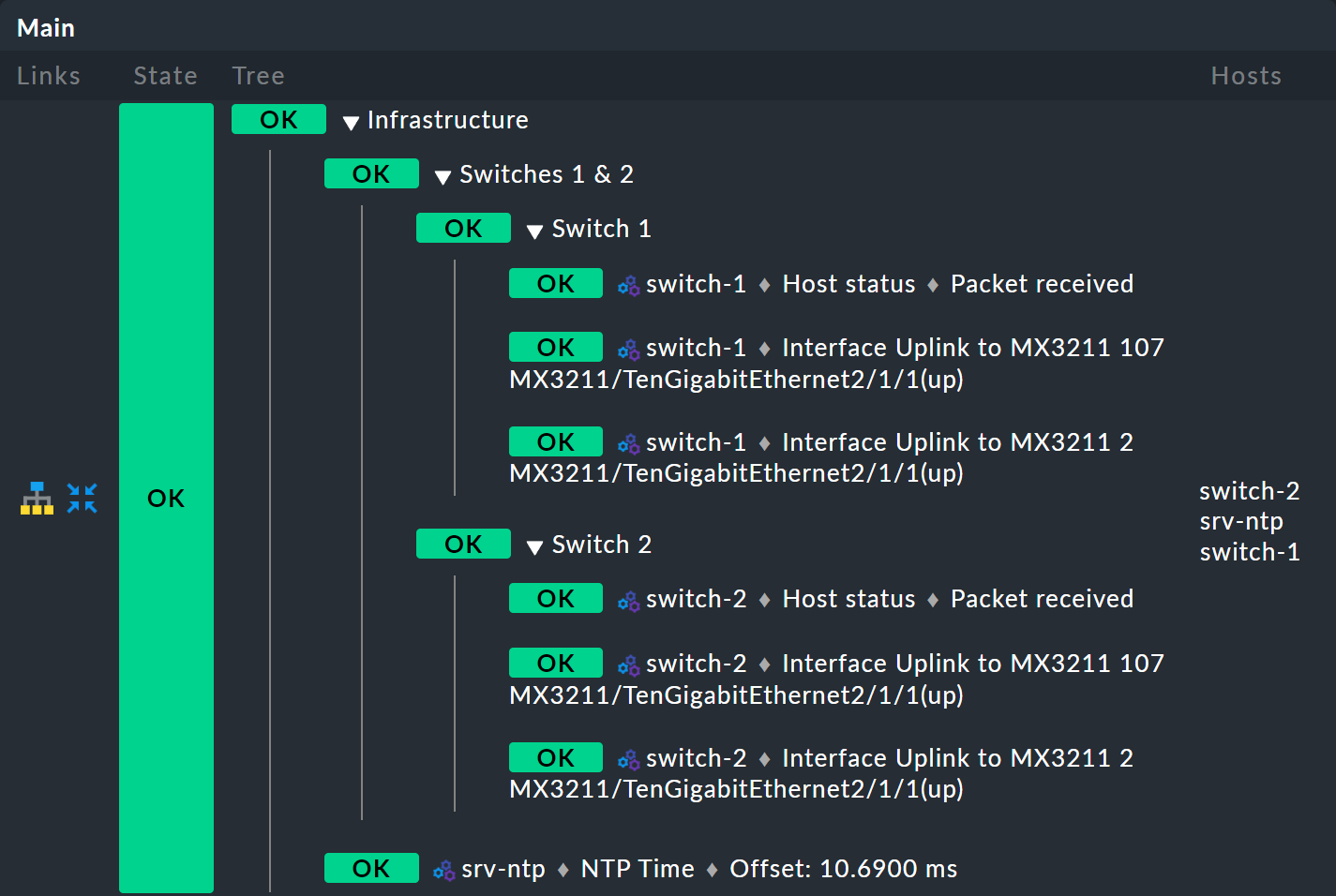
Y voilà: ahora tienes un bonito árbol con tres niveles:
6.3. Expresiones regulares, objetos que faltan
Vale la pena volver a examinar más de cerca el tema de las expresiones regulares. Al hacer coincidir el nombre del servicio, al principio dimos por sentado tácitamente que básicamente solo se trata de expresiones regulares. Como acabamos de mencionar, hay una concordancia de prefijo.
Así que en un nodo BI, si por ejemplo, en el nombre del servicio especificas disk,
se capturarán todos los servicios del host en cuestión que empiecen por Disk.
En general, se aplican los siguientes principios:
Si un nodo hace referencia a objetos que (actualmente) no existen, simplemente se omiten.
Si un nodo queda vacío, se omitirá.
Si el nodo raíz de una agregación también está vacío, se omitirá la propia agregación.
Quizá esto te parezca un poco atrevido al principio, porque ¿no es arriesgado omitir sin más, sin comentarios, items que deberían estar presentes?
Bueno, con el tiempo te darás cuenta de lo práctico que es este concepto, porque te permitirá escribir reglas «inteligentes» que puedan reaccionar ante situaciones muy diferentes. ¿Hay algún servicio que no exista en todos los sites de una aplicación? No hay problema: solo se tendrá en cuenta si está ahí. ¿O se pueden eliminar temporalmente hosts o servicios de la monitorización? En ese caso, simplemente desaparecerán de BI sin provocar errores ni nada por el estilo. ¡BI no está ahí para comprobar si tu configuración de monitorización está completa!
Por cierto, este principio también se aplica a los servicios definidos explícitamente,
ya que estos en realidad no existen porque los nombres de los servicios siempre se consideran expresiones regulares,
incluso si no contienen caracteres especiales como .*.
Siempre es automáticamente un patrón de búsqueda.
6.4. Crear un nodo como resultado de una búsqueda
Pero aún puedes automatizar más y, sobre todo, reaccionar con flexibilidad ante los cambios.
Continúa con el ejemplo de los dos servidores de aplicaciones srv-mys-1 y srv-mys-2 del ejemplo.
Tu árbol debería seguir creciendo.
El nodo Infrastructure debería pasar al nivel 2.
Y como raíz definitiva, debería haber una regla con el título The Mystery Application bajo la cual se agrupará todo.
Junto a Infrastructure debería haber un nodo llamado Mystery Servers.
Se supone que los (actualmente) dos servidores misteriosos deben agruparse bajo este nodo.
En cada uno de ellos se incluyen algunos servicios genéricos en la agregación.
El resultado debería verse así:
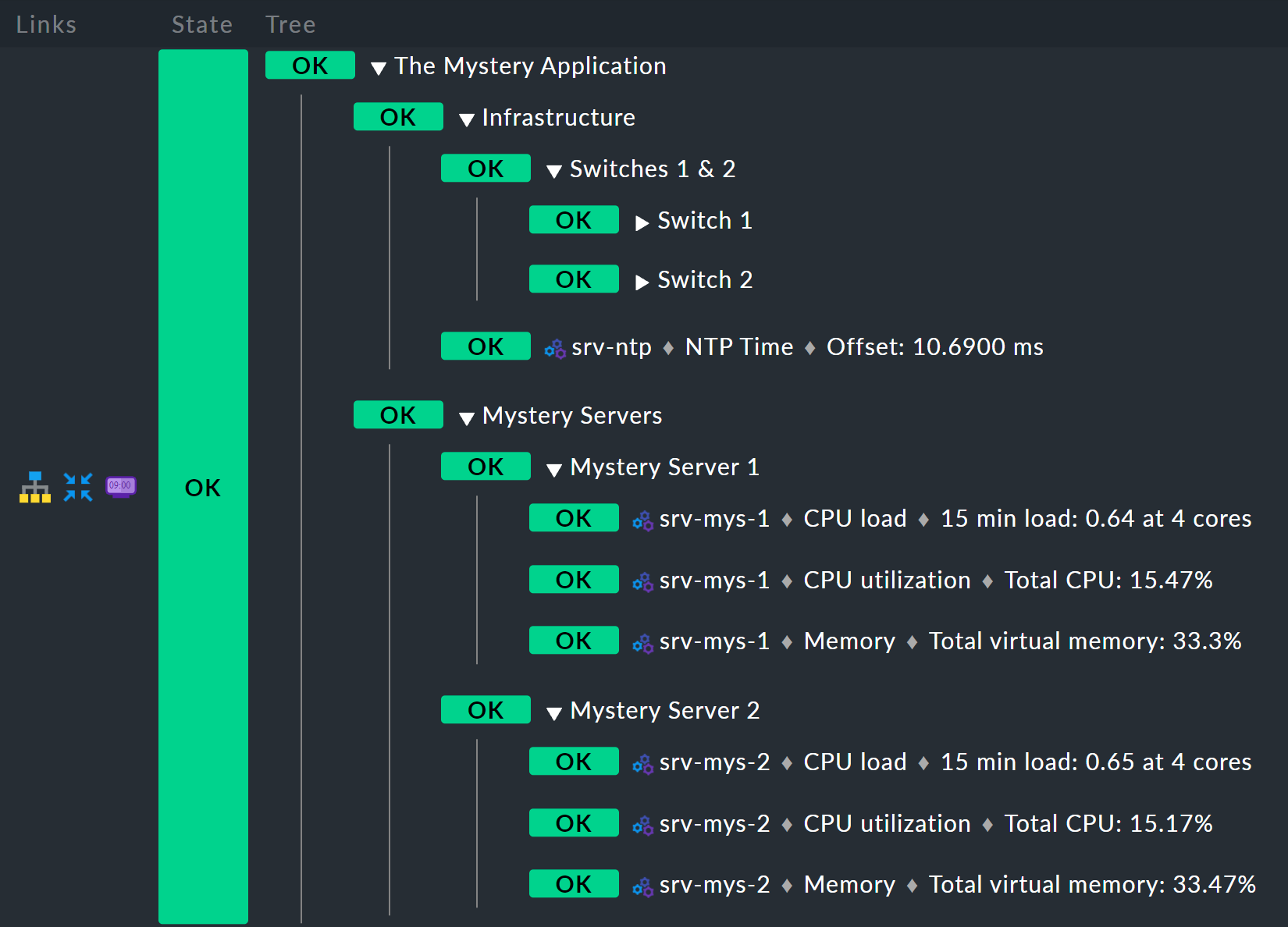
Regla inferior: servidor misterioso X
Empieza por la parte inferior,
porque esa es siempre la forma más fácil en BI.
A continuación se muestra la nueva regla Mystery Server X.
Por supuesto, utiliza un parámetro para no tener que crear una regla separada para cada servidor.
Puedes volver a nombrar el parámetro NUMBER, por ejemplo.
Más adelante debería tener el valor 1 o 2.
Como ya se ha hecho anteriormente, tendrás que volver a introducir NUMBER en el encabezado de Parameters.
El generador de nodos secundarios resultante tendrá este aspecto:
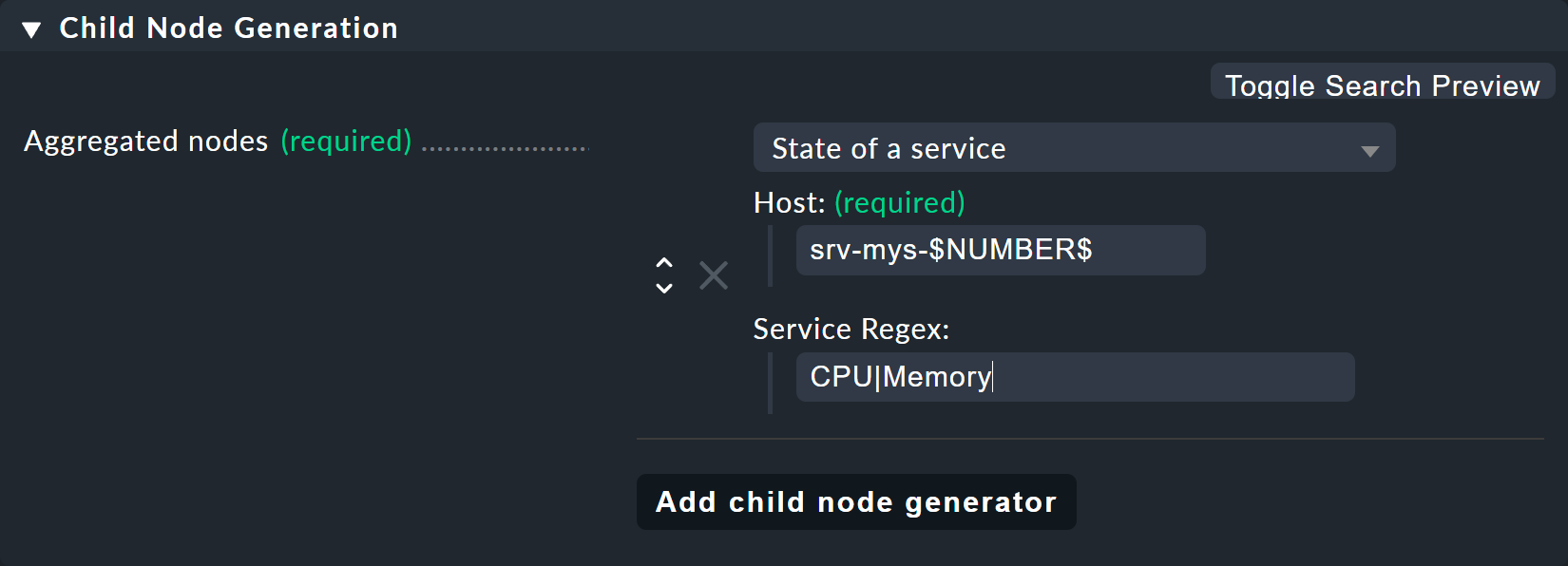
Lo que viene a continuación es interesante:
El nombre del host
srv-mys-$NUMBER$utilizará el número del parámetro.Con Service Regex, se utiliza la sofisticada expresión regular
CPU|Memoryque usa una barra vertical para permitir nombres del servicio alternativos (prefijos), y esto produce una coincidencia con todos los servicios que empiezan porCPUoMemory. ¡Esto evita tener que duplicar la configuración!
Por cierto, este ejemplo no es, por supuesto, necesariamente perfecto. Por ejemplo, el estado del propio host no se ha registrado en absoluto. Así que si uno de los servidores pasa a DOWN, los servicios de este quedarán obsoletos (pasarán a stale), pero el estado seguirá siendo OK, y la agregación no «detectará» ese fallo. Si quieres saber algo así, deberías, en cualquier caso, registrar el estado del host, así como los estados de sus servicios.
Regla intermedia: servidores misteriosos
Esta regla es interesante: resume los dos servidores misteriosos juntos en un nodo. Ahora debería ser posible que el número de servidores no sea fijo, y que más adelante a veces haya tres o más, o podría ser que haya docenas de sitios en la aplicación misteriosa, cada uno con un número diferente de servidores.
El truco está en el tipo de generador de nodos secundarios Create nodes based on a host search. Este busca hosts existentes y crea nodos basados en los hosts encontrados. Se ve así:
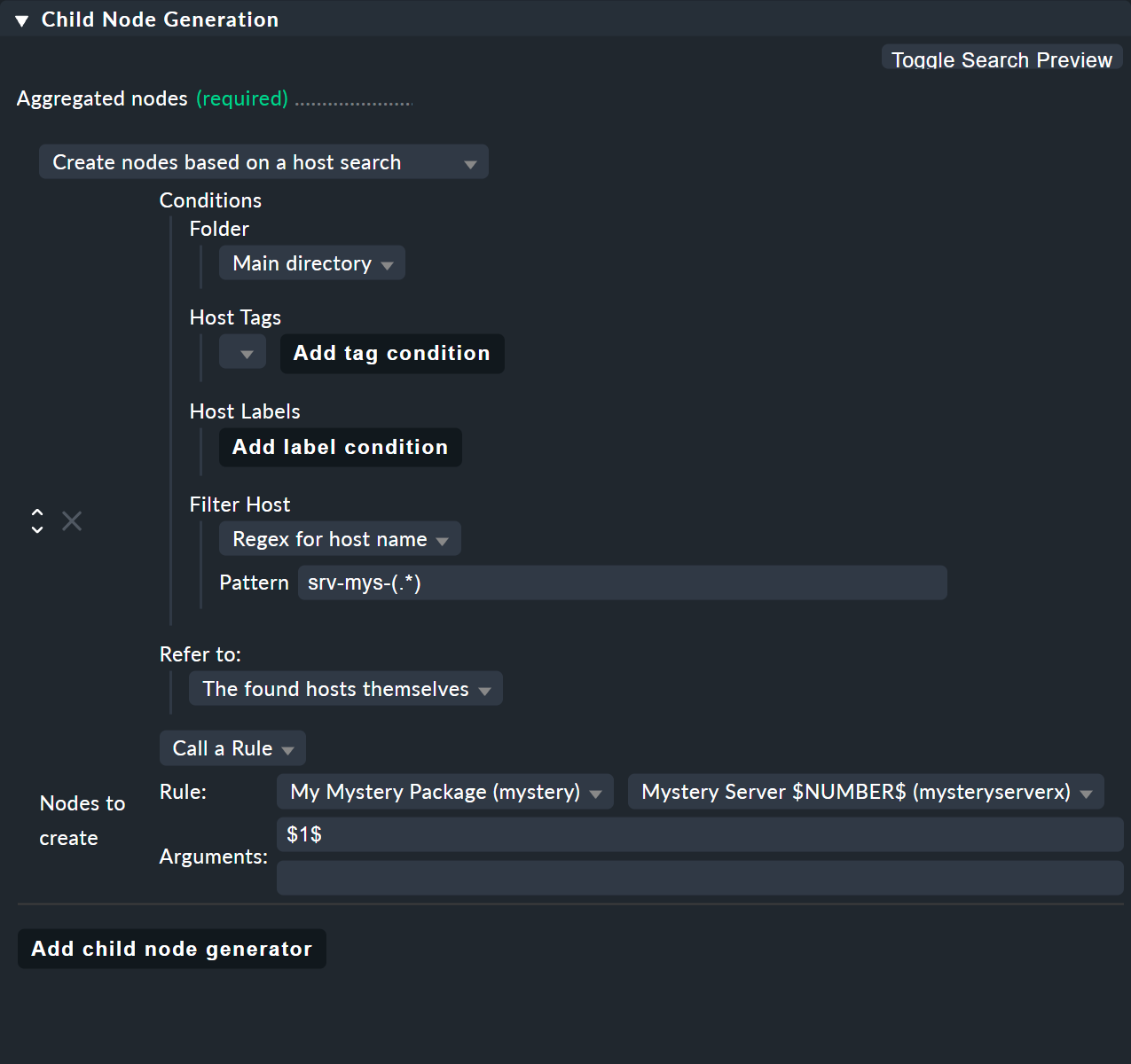
Todo funciona así:
Formulas una condición de búsqueda para encontrar hosts.
Se crea un nodo secundario para cada host encontrado.
Puedes extraer partes de los nombres del host encontrados y proporcionarlas como parámetros.
Encontrarlos es solo el principio.
Como siempre, hay tags del host disponibles.
En el ejemplo puedes omitir esto y, en su lugar, usar la expresión regular srv-mys-(.*) para el nombre del host.
Esto produce una coincidencia con todos los nombres de host que empiezan por srv-mys-.
.* representa cualquier cadena.
Es importante que .* vaya entre corchetes, es decir, (.*).
Al usar los paréntesis, la coincidencia forma lo que se conoce como un grupo de concordancia.
Con esto, se captura (y se almacena) el texto que tiene una concordancia exacta con .* —en este caso, 1 o 2.
Los grupos de concordancia se numeran internamente.
Aquí solo hay uno, que recibe el número 1.
Más tarde podrás acceder al texto coincidente con $1$.
La búsqueda encontrará ahora dos hosts:
| Nombre del host |
Valor de$1$
|
|---|---|
|
1 |
|
2 |
Para cada host encontrado, ahora crearás un subnodo con la función Call a rule.
Selecciona la regla Mystery Server $NUMBER$ que acabas de crear.
Como argumento para NUMBER, pasa ahora el grupo de concordancia: $1$.
Ahora la regla Mystery Server $NUMBER$ se invoca dos veces: una con 1 y otra con 2.
Si en el futuro se añade a la monitorización un nuevo servidor con el nombre srv-mys-3, este aparecerá automáticamente en la Agregación BI.
El estado del host no importa.
Incluso si el servidor es DOWN, por supuesto no se eliminará de la Agregación BI.
Es cierto que la curva de aprendizaje aquí es muy pronunciada. Este método es realmente complejo. Pero una vez que lo hayas probado y lo hayas entendido, te darás cuenta de lo potente que es todo el concepto... ¡y hasta ahora solo hemos arañado la superficie de las posibilidades disponibles!
Regla de nivel superior
El nuevo nodo de nivel superior The Mystery Application ahora es sencillo: se necesita además una nueva regla que tenga dos nodos hijos del tipo Call a rule. Estas dos reglas son la regla existente Infrastructure y la regla Mystery Servers que acabas de crear.
6.5. Crear un nodo con búsqueda de servicio
Al igual que en la búsqueda de host, también hay un tipo de generador secundario llamado Create nodes based on a service search. Aquí tienes un ejemplo:
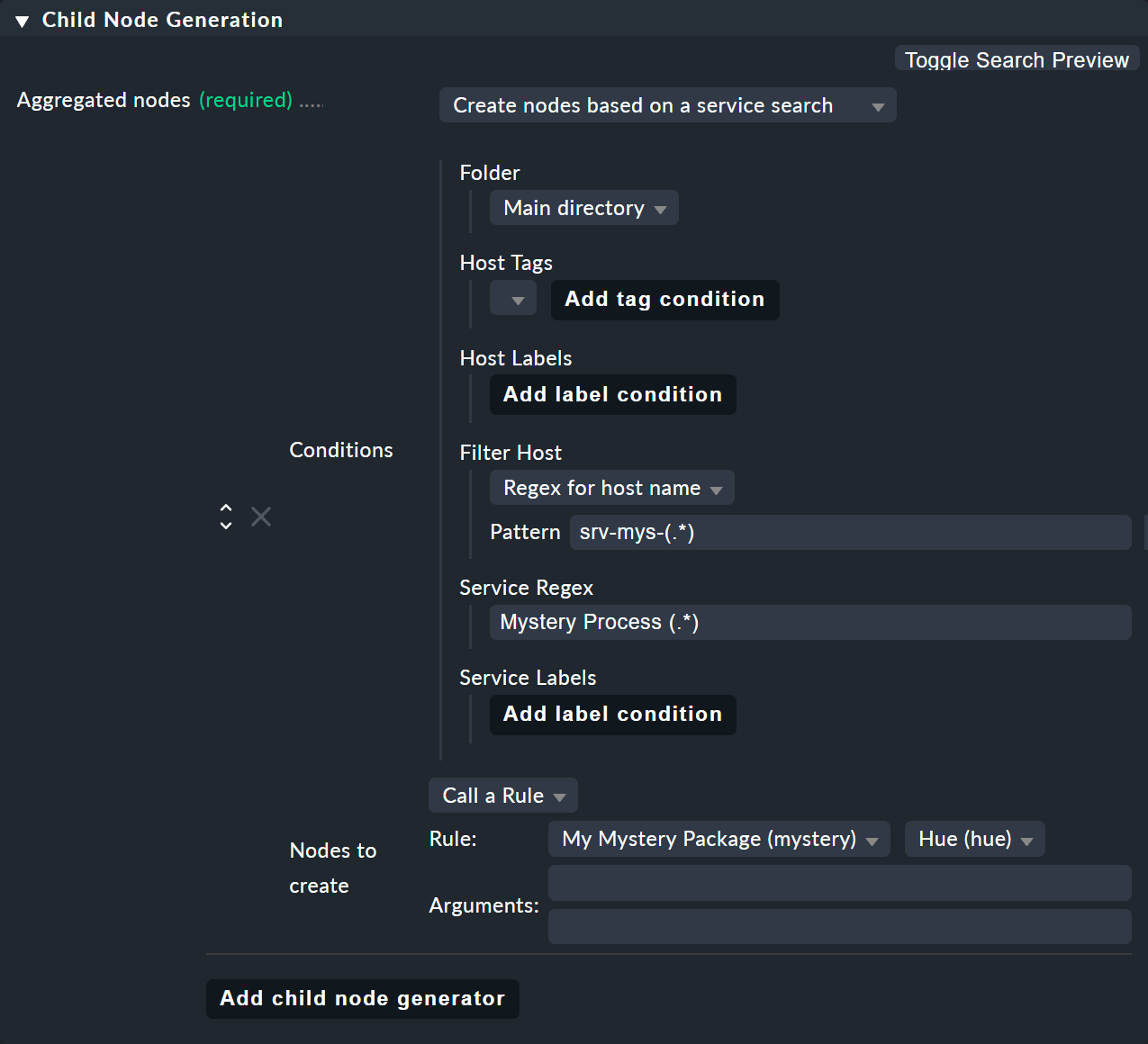
Puedes usar () aquí —encerrando expresiones parciales entre paréntesis— tanto en el host como en el servicio,
donde:
Si eliges «Regex for host name», debes definir exactamente una expresión entre paréntesis. El texto de la coincidencia se proporciona entonces como «
$1$».Si eliges All hosts, el nombre completo del host se proporcionará como
$1$.Puedes utilizar varios subgrupos en el nombre del servicio. Los textos de coincidencia asociados se proporcionan como
$2$,$3$, y así sucesivamente.
Y no olvides que siempre puedes usar ![]() para obtener ayuda en línea.
para obtener ayuda en línea.
6.6. Todos los demás servicios
En tus intentos, es posible que te hayas topado con el generador secundario State of remaining services. Este genera un nodo para cualquiera de los servicios de tu host que aún no se hayan clasificado en tu Agregación BI. Esto resulta útil si utilizas BI para combinar los estados de todos los servicios de un host en grupos claramente organizados, tal y como se hace en nuestro ejemplo incluido.
7. La agregación de hosts predefinida
Como acabamos de mencionar, también puedes usar BI para ofrecer los servicios de un host de forma estructurada. Combinas todos los servicios en un solo árbol en una agregación BI y, básicamente, utilizas la función «worst». El estado general de un host solo se mostrará si hay un problema con él; utilizas BI como un método claro para profundizar.
Para ello, Checkmk ya ofrece un conjunto predefinido de reglas que solo tienes que activar.
Estas reglas están optimizadas para la prestación de servicios en hosts Windows o Linux,
pero, por supuesto, puedes personalizarlas a tu gusto.
Encontrarás todas las reglas en el paquete de reglas «Default».
Como de costumbre, accede a las reglas haciendo clic en «![]() »:
»:

Allí encontrarás una lista de doce reglas (abreviadas aquí):
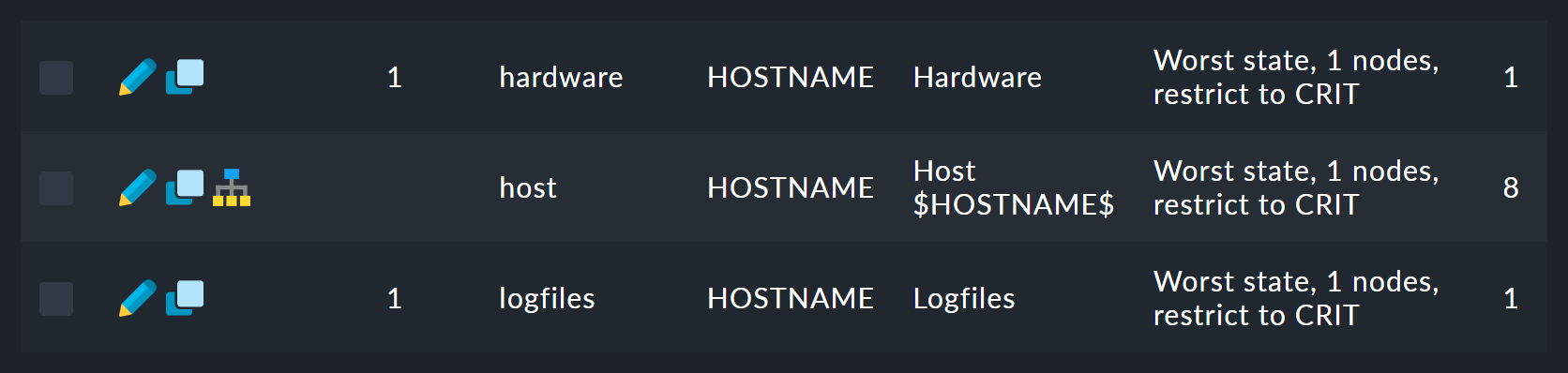
La primera regla es la de la raíz del árbol.
El icono «![]() » de esta regla te lleva a una vista de árbol.
Aquí puedes ver cómo se anidan las reglas entre sí:
» de esta regla te lleva a una vista de árbol.
Aquí puedes ver cómo se anidan las reglas entre sí:

De vuelta en la lista de reglas, con el botón «![]() » (Aggregations) puedes acceder a la lista de agregaciones de este paquete de reglas, que consta de una sola agregación.
En los detalles de «
» (Aggregations) puedes acceder a la lista de agregaciones de este paquete de reglas, que consta de una sola agregación.
En los detalles de «![]() », simplemente desmarca la checkbox en «Currently disable this aggregation»
y obtendrás inmediatamente, por host, una agregación titulada «
», simplemente desmarca la checkbox en «Currently disable this aggregation»
y obtendrás inmediatamente, por host, una agregación titulada «Host myhost123».
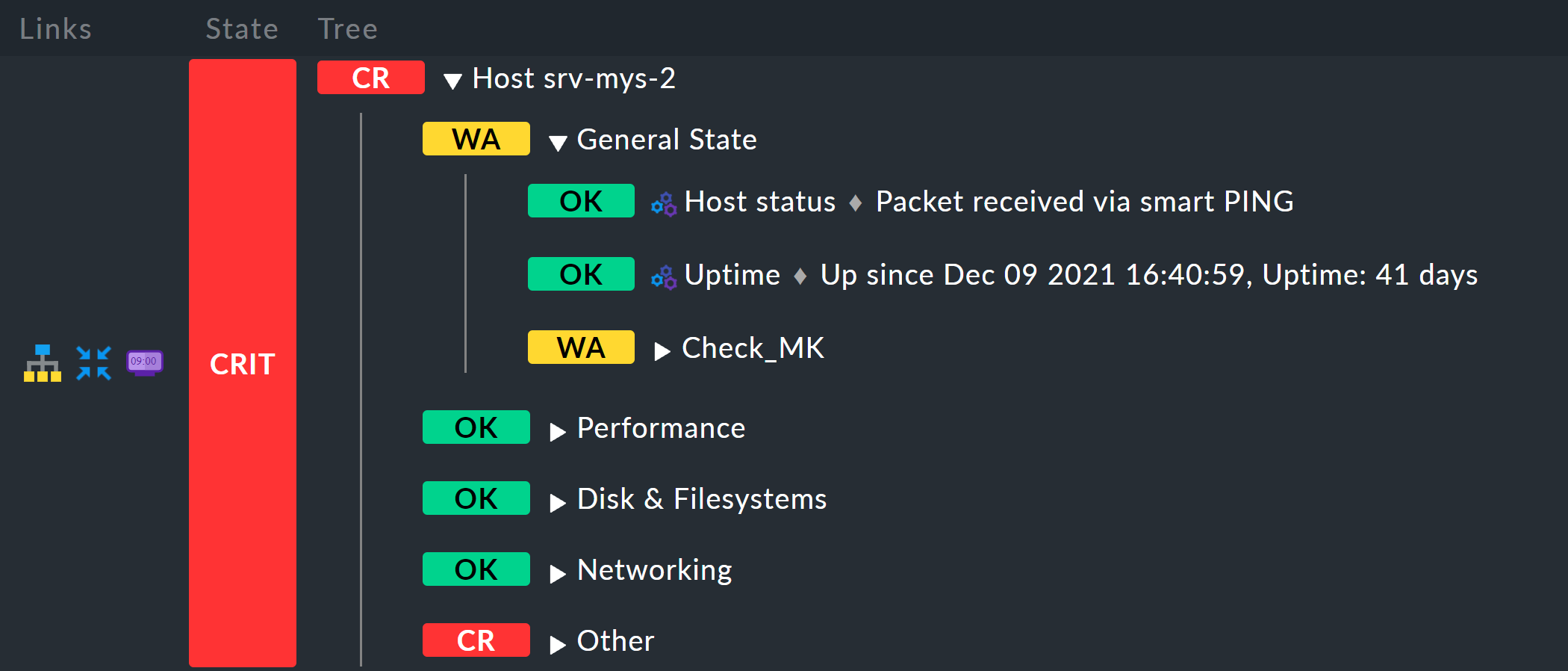
El resultado tendrá entonces este aspecto, por ejemplo:
8. Permisos y visibilidad
8.1. Permisos para la edición
Volvamos de nuevo a los paquetes de reglas. Para todas las acciones de edición en BI, normalmente necesitas tener el rol de administrador. Más concretamente, para BI hay dos permisos, que se encuentran en Setup > Users > Roles & permissions:

En el rol de usuario de monitorización normal, solo el primero de los dos permisos está activo por defecto.
Por lo tanto, los usuarios de monitorización normales solo pueden trabajar en aquellos paquetes de reglas para los que hayan sido definidos como contacto.
Esto se configura en ![]() Detalles del paquete de reglas.
Detalles del paquete de reglas.
En el siguiente ejemplo de Permitted Contact Groups, se ha autorizado al grupo de contacto The Mystery Admins; por lo tanto, todos los miembros de este grupo pueden ahora editar las reglas de este paquete:
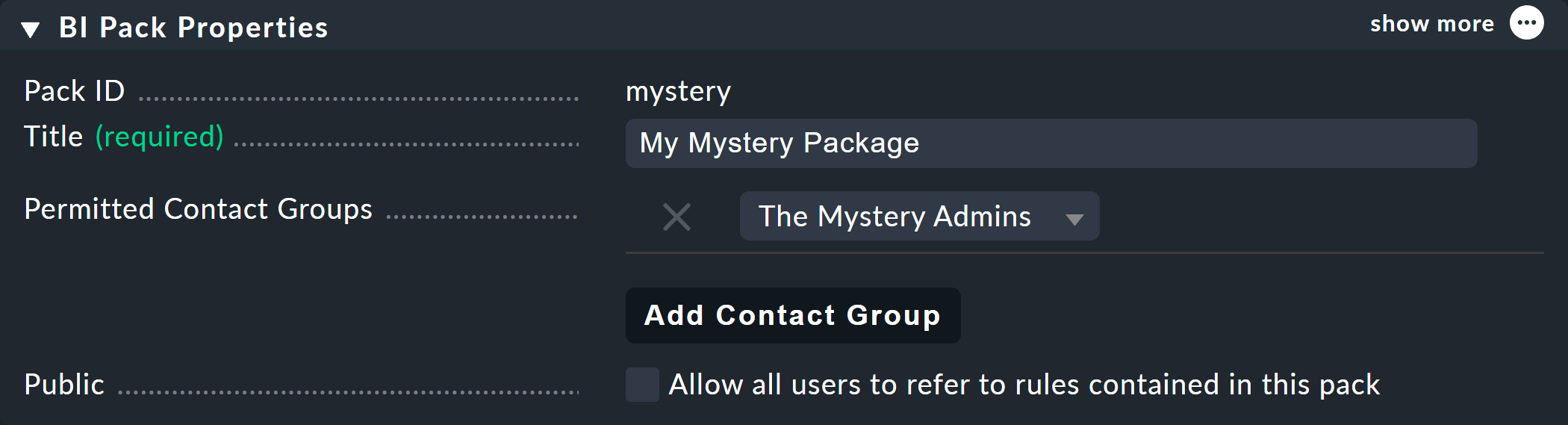
Por cierto, con Public > Allow all users to refer to rules contained in this pack puedes permitir que otros usuarios al menos utilicen las reglas que contiene —es decir, que definan (en otro lugar) sus propias reglas—, las cuales pueden invocar estas reglas como subnodos.
8.2. Permisos en hosts y servicios
¿Cuál es la situación con respecto a la visibilidad real de las agregaciones en la interfaz de estado? ¿Qué contactos pueden ver algo?
Bueno, no puedes asignar ningún permiso en las propias agregaciones BI. Esto se realiza indirectamente a través de la visibilidad de los hosts y servicios, y se rige por la opción «See all hosts and services» en «Setup > Roles & Permissions:»

En el rol «User», este permiso está desactivado por defecto. Los usuarios normales solo pueden ver los hosts y servicios compartidos, y en BI esto se traduce en que pueden ver exactamente todas las Agregaciones BI que contengan al menos un host o servicio compartido. Sin embargo, estas Agregaciones BI solo contienen estos objetos autorizados, por lo que pueden resultar algo «pobres». Y esto, a su vez, significa que pueden tener estados diferentes para distintos usuarios.
Que eso sea bueno o malo depende de lo que quieras. Si tienes dudas, puedes activar o desactivar el permiso y, dando un rodeo por BI, permitir que algunos o todos los usuarios vean hosts y servicios para los que no son contactos —y así asegurarte de que el estado de una agregación sea siempre el mismo para todos.
Por supuesto, todo este tema solo importa si hay, de hecho, agregaciones que están tan mezcladas que solo algunos usuarios son contactos para partes específicas de la misma.
9. BI en funcionamiento, parte 3: tiempo de mantenimiento programado, Reconocimientos
9.1. La idea general
¿Cómo gestiona realmente BI el tiempo de mantenimiento programado de un![]() ?
Hemos reflexionado mucho sobre este tema y lo hemos discutido con muchos usuarios; el resultado es el siguiente:
?
Hemos reflexionado mucho sobre este tema y lo hemos discutido con muchos usuarios; el resultado es el siguiente:
No puedes incluir una Agregación BI directamente en un tiempo de mantenimiento programado, pero tampoco es necesario, porque…
el tiempo de mantenimiento programado para una Agregación BI se deriva automáticamente del tiempo de mantenimiento programado de los hosts y servicios de la Agregación BI.
Para entender con qué regla BI calcula el estado «en tiempo de mantenimiento», te ayudará recordar cuál es la idea real detrás de los tiempos de mantenimiento programados: se está trabajando actualmente en el objeto en cuestión. Es de esperar que se produzcan fallos. Aunque el objeto esté actualmente «OK», no debes confiar en él. Puede pasar a estar «CRIT» en cualquier momento. Esto es algo conocido y documentado, por lo que no debería activar una notificación.
Esta idea se puede trasladar tal cual a BI: En la agregación BI puede haber algunos hosts y servicios que estén actualmente en tiempo de mantenimiento. Que estos estén simplemente «OK» o «CRIT» no importa, porque en realidad es una coincidencia si durante el trabajo de mantenimiento los objetos se apagan y vuelven a encenderse a veces, o no. El mero hecho de que haya un objeto «en tiempo de mantenimiento» en la agregación no significa inmediatamente que la aplicación que realiza el mapeo de la agregación esté «amenazada» y deba marcarse también como «en tiempo de mantenimiento». La aplicación también puede tener una redundancia instalada que compense el fallo de los objetos en «tiempo de mantenimiento». Solo si ese fallo llevara realmente a un estado de «CRIT» para la agregación —es decir, si no hay suficiente redundancia y la agregación está realmente en peligro—, solo entonces Checkmk la marcará como «en tiempo de mantenimiento». Aquí tampoco importa, por lo general, el estado actual de los objetos.
Para decirlo de forma más concisa, la regla exacta es la siguiente:
Si un estado «CRIT» de un host/servicio provocara un estado «CRIT» de la agregación, un estado «en tiempo de mantenimiento» de ese host/servicio provocará un estado «en tiempo de mantenimiento» para la agregación.
Importante: el estado real actual de los hosts/servicios no influye en el cálculo; en la lógica de BI se asume que lo que está «en tiempo de mantenimiento» es «CRIT». ¿Por qué? Porque un estado «UP» o «OK» durante un tiempo de mantenimiento programado es pura coincidencia, por ejemplo, si un host informa de «UP» durante unos segundos entre varios reinicios.
Y aquí tenemos otro ejemplo. Para ahorrar espacio, esta es una variante con un solo servidor misterioso en lugar de dos:
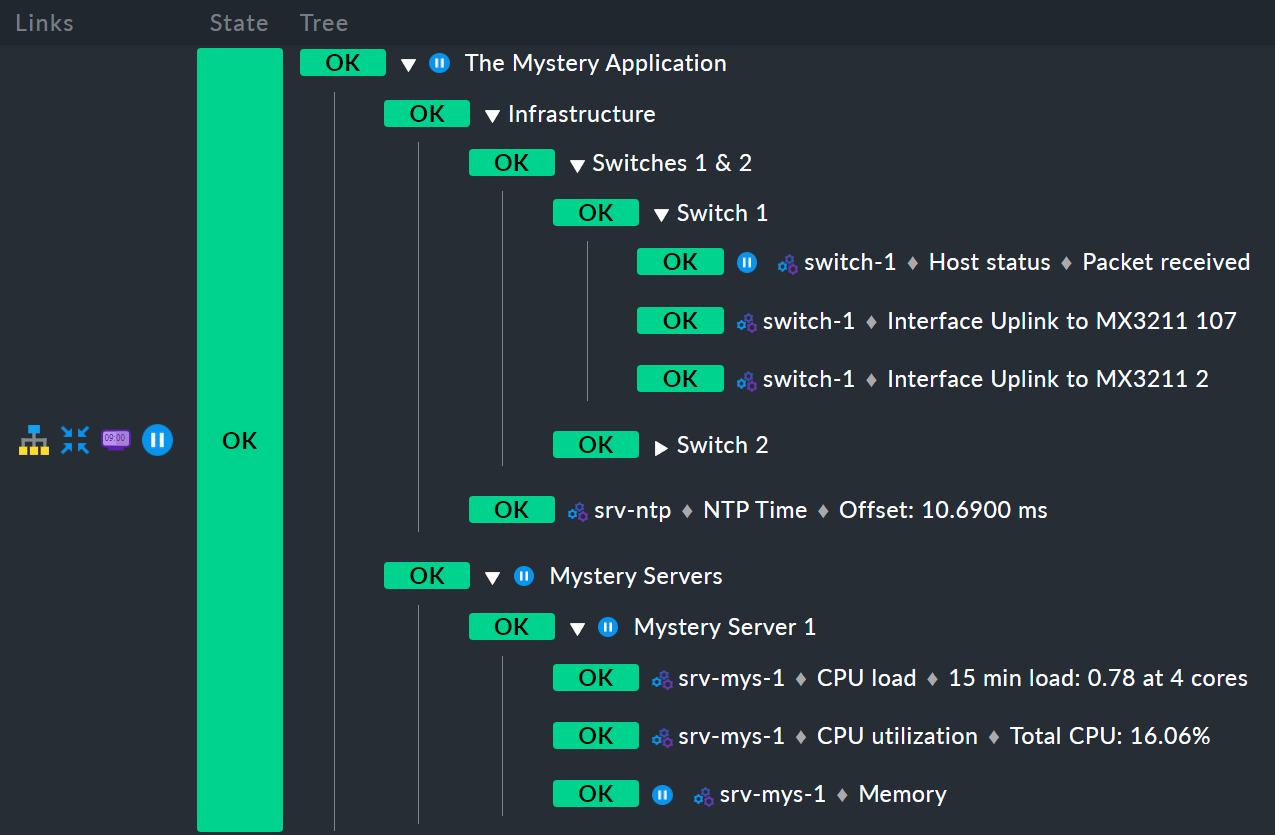
Primero, el host switch-1 está en tiempo de mantenimiento.
Para el nodo Infrastructure esto no tiene ningún efecto, porque switch-2 no está en tiempo de mantenimiento,
y por lo tanto Infrastructure tampoco está en tiempo de mantenimiento.
Por lo tanto, no hay ningún icono de ![]() para tiempos de mantenimiento derivados.
para tiempos de mantenimiento derivados.
Pero el servicio Memory en srv-mys-1 también está en tiempo de mantenimiento.
Este no es redundante.
Por lo tanto, el tiempo de mantenimiento se hereda del nodo padre Mystery Server 1, y luego continúa hasta Mystery Servers, y finalmente hasta el nodo superior The Mystery Application.
Por lo tanto, este nodo superior también estará en tiempo de mantenimiento.
9.2. Comando de tiempo de mantenimiento programado
¿Hemos dicho antes que no puedes poner manualmente una Agregación BI en tiempo de mantenimiento programado?
Eso solo es cierto a medias, ya que, de hecho, existe un comando ![]() para configurar tiempos de mantenimiento programados en las Agregaciones BI.
Pero esto no hace más que registrar una entrada de tiempo de mantenimiento para cada host y servicio de la Agregación BI.
Por supuesto, esto suele provocar que la propia Agregación BI se marque como en tiempo de mantenimiento,
pero se trata solo de un procedimiento indirecto.
para configurar tiempos de mantenimiento programados en las Agregaciones BI.
Pero esto no hace más que registrar una entrada de tiempo de mantenimiento para cada host y servicio de la Agregación BI.
Por supuesto, esto suele provocar que la propia Agregación BI se marque como en tiempo de mantenimiento,
pero se trata solo de un procedimiento indirecto.
9.3. Opciones de ajuste
Como has visto anteriormente, el cálculo del tiempo de mantenimiento programado se basa en un estado «CRIT» (sin datos) supuesto. En las propiedades de una agregación puedes personalizar el algoritmo para que un nodo que asuma el estado «WARN» (sin datos) se marque como en tiempo de mantenimiento. La opción para esto se llama «Escalate downtimes based on aggregated WARN state»:
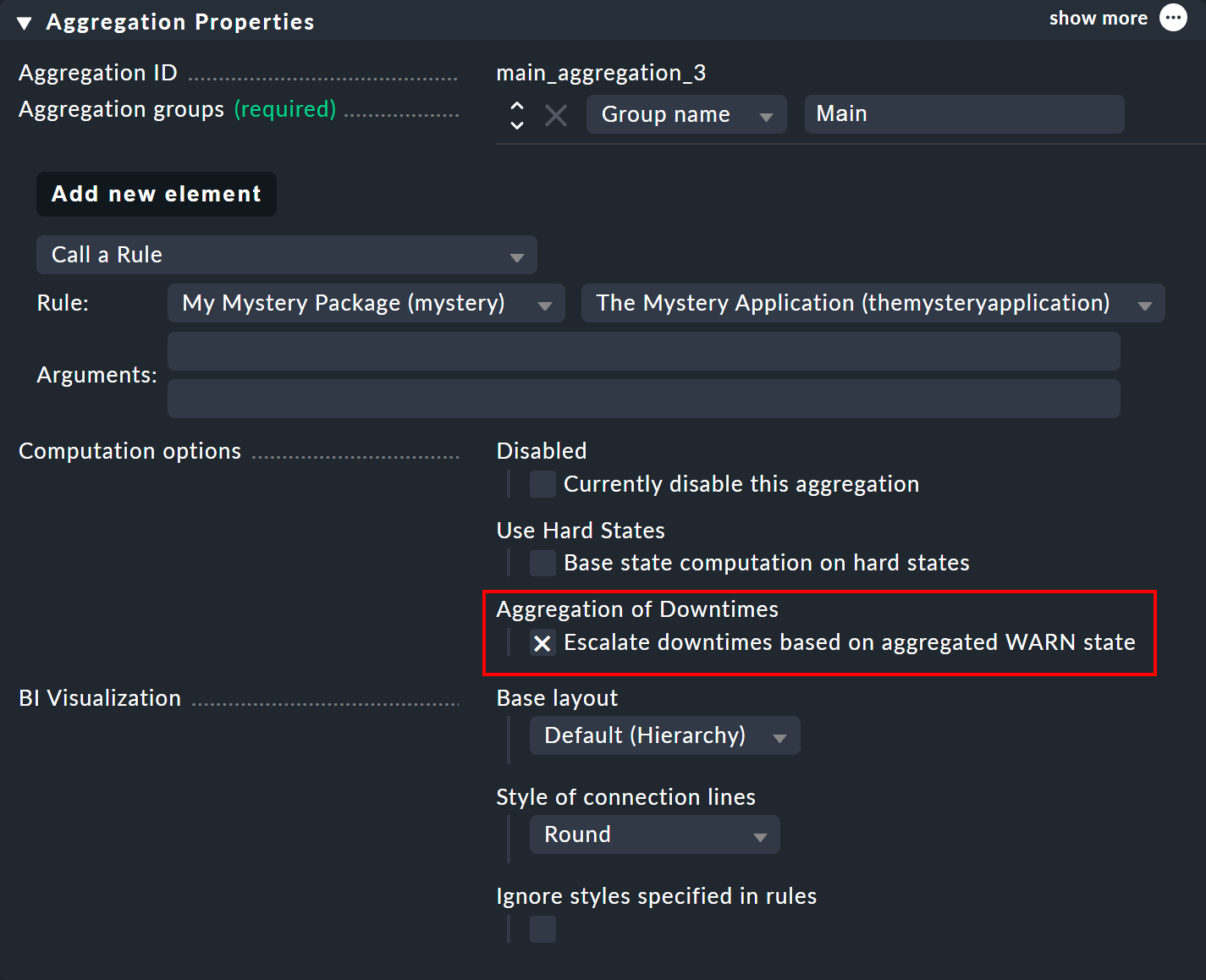
La suposición básica sigue siendo que los objetos en tiempo de mantenimiento están en estado «CRIT». La única diferencia radica en que, debido a la función de agregación, un «CRIT» puede convertirse en un «WARN», como ocurrió en nuestro primer ejemplo con «Count the number of nodes in state OK». En este caso, ya se habría aceptado un tiempo de mantenimiento programado si solo uno de los dos switches estuviera en tiempo de mantenimiento.
9.4. Reconocimientos
De forma muy similar al proceso con el tiempo de mantenimiento programado, si se ha ![]() reconocido un problema, la información también
será calculada automáticamente por BI.
En este caso, el estado de los objetos sin duda influye.
reconocido un problema, la información también
será calculada automáticamente por BI.
En este caso, el estado de los objetos sin duda influye.
La idea aquí es trasladar el siguiente concepto a BI:
Un objeto tiene un problema (WARN, CRIT), pero esto se sabe, y alguien está trabajando en ello (![]() ).
).
Puedes calcular esto para una agregación de la siguiente manera:
Supongamos que todos los hosts y servicios que reconocen problemas en
 vuelven a estar en OK.
vuelven a estar en OK.¿Entonces la agregación en sí volvería a estar en estado «OK»? Precisamente en ese caso, también se realizaría el Reconocimiento en estado «
».
Sin embargo, si la agregación siguiera estando en estado «WARN» o «CRIT», entonces no se consideraría reconocida, porque en ese caso habría al menos un problema importante que no se ha realizado el Reconocimiento, y por lo tanto el estado «OK» se eliminaría de la agregación.
Por cierto, ![]() te ofrecerá un comando para que la Agregación BI reconozca sus problemas,
pero esto solo significa que se reconocerán todos los hosts y servicios detectados en la Agregación BI (solo aquellos que actualmente tienen problemas).
te ofrecerá un comando para que la Agregación BI reconozca sus problemas,
pero esto solo significa que se reconocerán todos los hosts y servicios detectados en la Agregación BI (solo aquellos que actualmente tienen problemas).
10. Hacer visibles los cambios
Los nodos dentro de una agregación a veces pueden cambiar durante el funcionamiento. Al usar agregaciones congeladas, puedes hacer que esos cambios sean visibles.
Aquí tienes un ejemplo: Un switch con 6 puertos debería estar en estado «OK» cuando 5 de sus servicios/puertos están en estado «OK». Sin embargo, como parte de una actualización de firmware, se renombran 2 de los puertos y sus servicios asociados desaparecen de la monitorización.
La agregación consistiría entonces en 4 servicios con el estado «OK», pero la propia agregación aparecería como «WARN» o «CRIT», sin dar ninguna indicación del motivo. Aquí es precisamente donde entran en juego las agregaciones congeladas: Congelas el estado actual y, más tarde, puedes hacer clic para obtener una lista de lo que ha cambiado desde entonces, es decir, qué nodos se han añadido o eliminado. En otras palabras, mientras que las reglas de una agregación indican su estado, las agregaciones congeladas proporcionan información sobre los cambios de estado.
10.1. Congelar y comparar
Usar la función de congelación es muy sencillo: Activa la opción «New aggregations are frozen» en «Aggregation Properties».
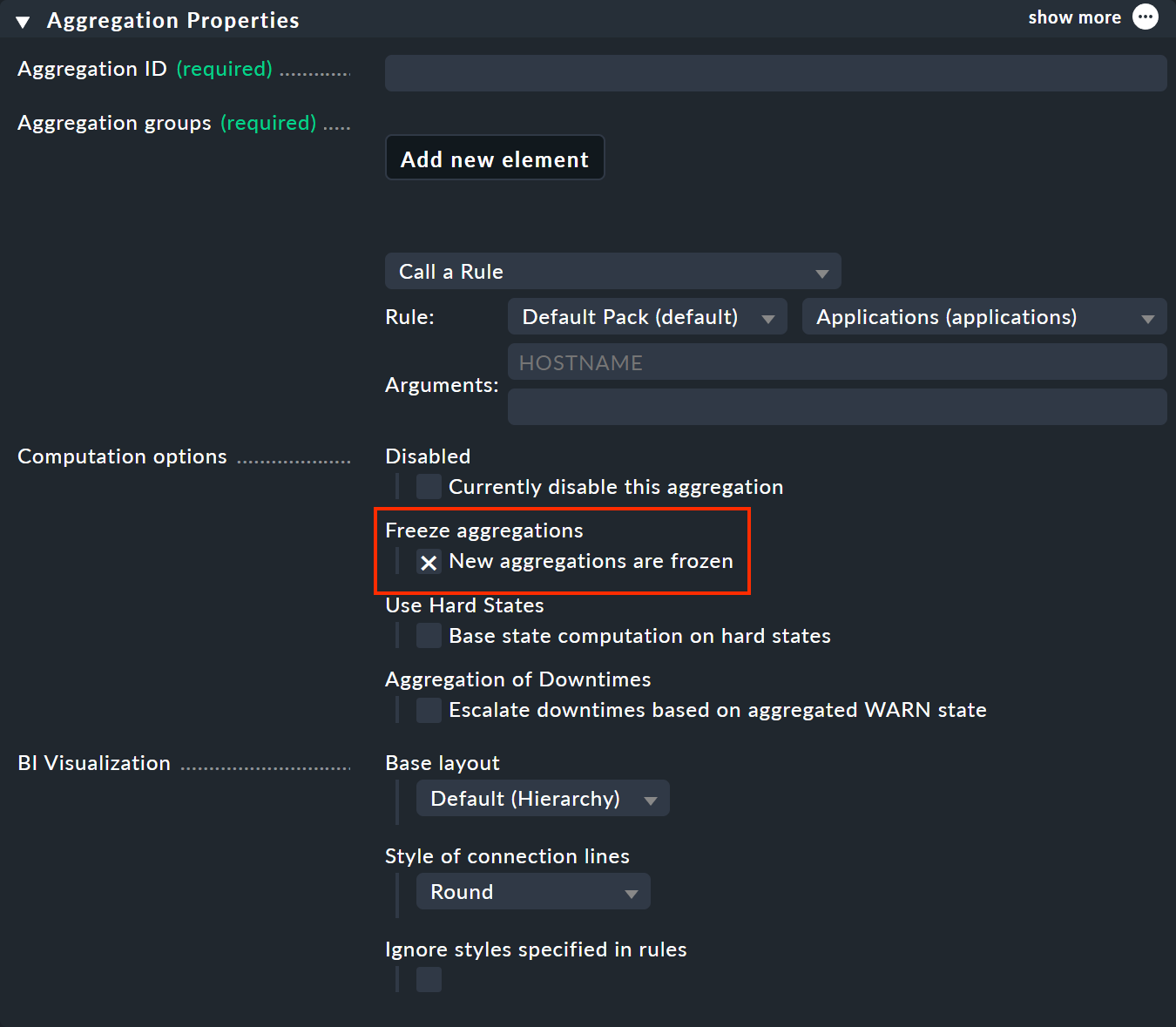
Esto congelará la agregación cuando se guarde, y lo hará cada vez que se marque la checkmark; incluso si la agregación ya existía anteriormente (a pesar de la referencia a «New aggregations …»). Para descongelar el estado congelado, desmarca la checkmark correspondiente.
En la monitorización, ahora verás un nuevo icono de copo de nieve de «![]() » junto a la agregación.
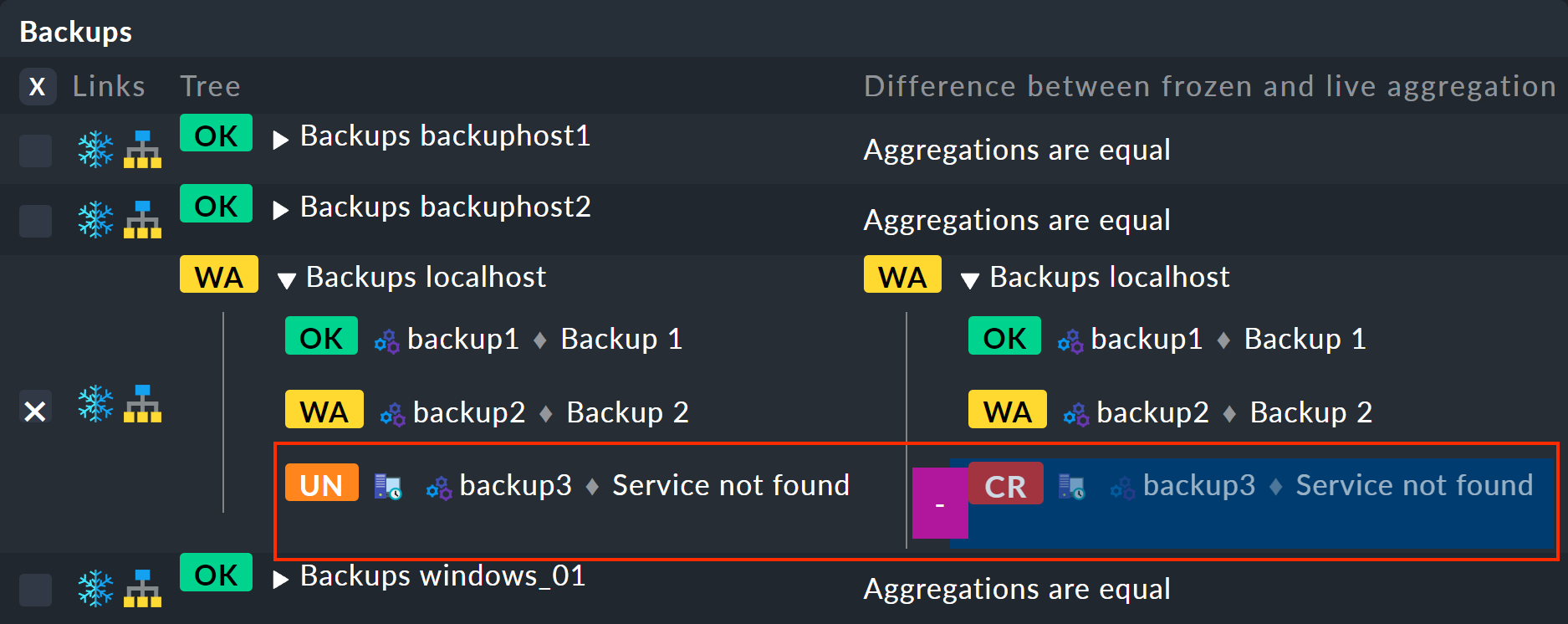
Esto te llevará a la vista de tabla que muestra las diferencias:
A la izquierda, el árbol congelado; a la derecha, el árbol actual con los cambios resaltados (en este caso, la eliminación del servicio «backup3»):
» junto a la agregación.
Esto te llevará a la vista de tabla que muestra las diferencias:
A la izquierda, el árbol congelado; a la derecha, el árbol actual con los cambios resaltados (en este caso, la eliminación del servicio «backup3»):
Si quieres volver a congelar el estado actual, puedes hacerlo a través de Commands > Freeze aggregations. Pero ten cuidado: solo hay un estado actual congelado y no hay historial, incluidos los estados anteriores.
11. Disponibilidad
Al igual que con los hosts y los servicios, también puedes consultar la disponibilidad de BI de una o varias agregaciones para cualquier periodo de tiempo del pasado. Para ello, el módulo de BI reconstruye el estado basándose en el historial de los hosts y servicios de la agregación para cada periodo de tiempo pasado. ¡Así que también puedes calcular la disponibilidad para esos periodos en los que la agregación aún no estaba configurada!

Para obtener todos los detalles sobre BI y la disponibilidad, consulta la sección sobre BI en el artículo sobre disponibilidad.
12. BI en la monitorización distribuida
¿Qué pasa realmente con BI en un entorno distribuido? Es decir, ¿cuando los hosts están repartidos entre varios servidores de monitorización?
La respuesta es relativamente sencilla: funciona, sin que tengas que prestar atención a nada. Dado que BI es un componente de la GUI y, de serie, se entrega con capacidad de soporte para entornos distribuidos, es completamente transparente para BI.
Si una ubicación no está disponible en ese momento o la has ocultado manualmente desde la GUI, los hosts del site ya no existen para BI. Eso significa entonces que:
Las agregaciones BI que se construyen exclusivamente a partir de objetos de esta ubicación desaparecen.
Las agregaciones BI que se construyen parcialmente a partir de objetos de esta ubicación se reducen.
En este último caso, por supuesto, esto puede afectar al estado de las agregaciones afectadas. Los efectos concretos que esto pueda tener dependerán de tus funciones de agregación. Si, por ejemplo, has utilizado worst en todas partes, el estado general simplemente se mantiene igual o mejora, porque los objetos de la ubicación que ya no existe podrían haber tenido ya WARN o CRIT. Por supuesto, también pueden darse otros estados para otras funciones de agregación.
Habrá que evaluar en cada caso concreto si este comportamiento resulta práctico para tu operación. En cualquier caso, BI está diseñado de tal forma que los objetos inexistentes no pueden incluirse en una Agregación BI y, por lo tanto, no pueden pasarse por alto, ya que todas las reglas BI funcionan —como ya se ha explicado anteriormente— exclusivamente con patrones de búsqueda.
13. Notificaciones, BI como servicio
¿Se pueden notificar realmente los cambios de estado en las agregaciones BI? Bueno... eso no es posible directamente al principio, ya que BI existe exclusivamente en la GUI y no tiene relación con la monitorización real. Pero puedes convertir las agregaciones BI en servicios normales, y estos, a su vez, pueden, por supuesto, activar notificaciones.
Para ello, puedes utilizar el agente especial BI Aggregations. Encontrarás el conjunto de reglas adecuado en Setup > Agents > Other integrations > BI Aggregations. Primero, crea una nueva entrada en la caja «BI Aggregations» con «Add new entry».
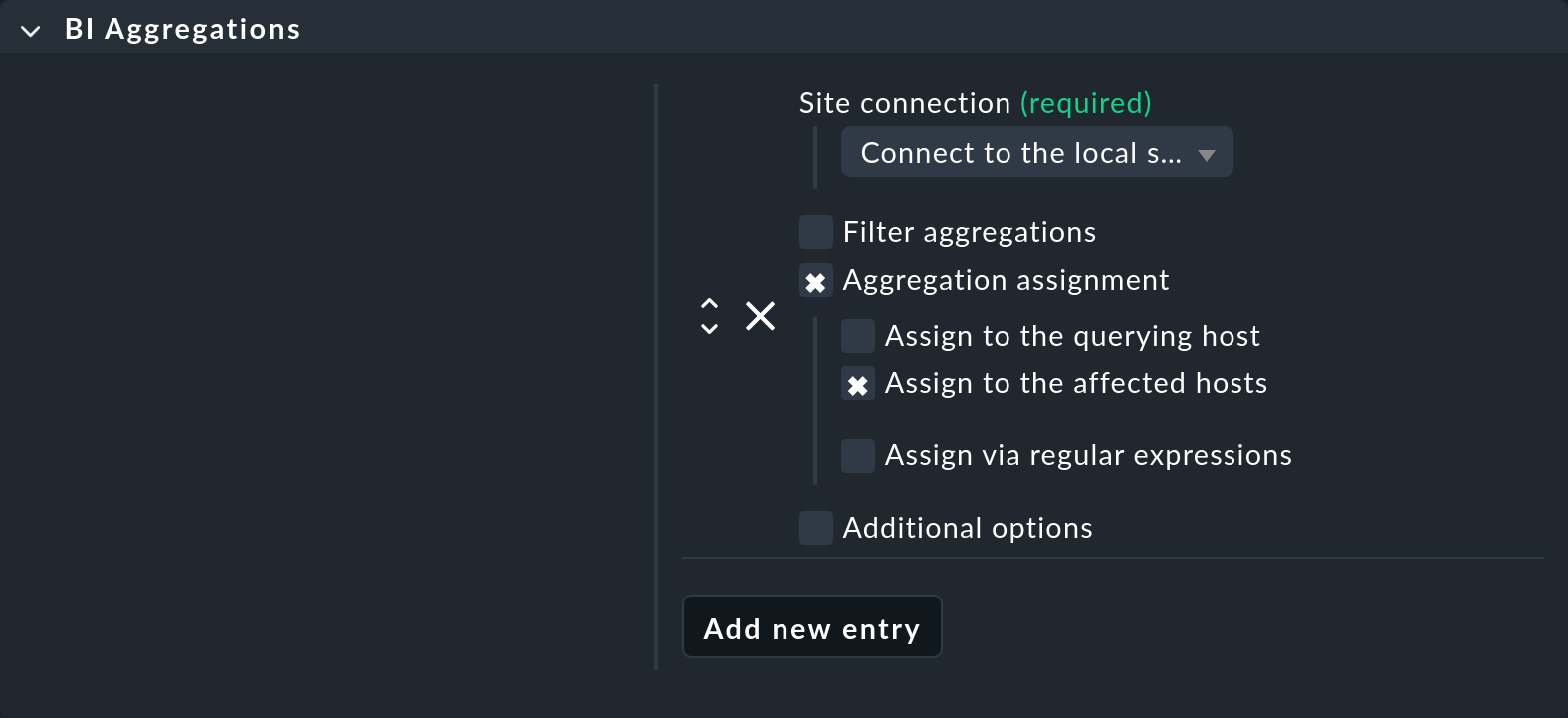
Aquí puedes especificar diferentes opciones sobre a qué hosts se deben añadir los servicios. No tienen por qué estar necesariamente vinculados al host al que está asignado el agente especial (Assign to the querying host). También es posible asignarlos a los hosts que están incluidos en la agregación (Assign to the affected hosts). Sin embargo, eso solo tiene sentido si se trata de un único host. Las expresiones regulares y las sustituciones te permiten ser aún más flexible con las asignaciones. Todo esto se lleva a cabo a través del mecanismo piggyback.
Importante: Si el host al que asignas esta regla debe seguir siendo objeto de monitorización a través del agente normal, asegúrate en su configuración de que se ejecuten tanto el agente normal como los agentes especiales:

El nuevo servicio mostrará entonces —con un retraso de hasta un intervalo de check, por supuesto— el estado de la agregación. Aquí tienes dos ejemplos de nuevos servicios, a los que se añade automáticamente el prefijo Aggr:

Como siempre, puedes asignar este servicio a contactos y utilizarlo como base para las notificaciones.