1. Wichtige Aufgaben im Monitoring
Sie haben Hosts aufgenommen und sich wichtige Werkzeuge angesehen: Jetzt können Sie loslegen mit dem eigentlichen Monitoring. Denn der Sinn von Checkmk ist es ja nicht, sich ständig mit der Konfiguration zu befassen, sondern eine Unterstützung beim IT-Betrieb zu leisten.
Zwar zeigen Ihnen bereits die standardmäßig verfügbaren Ansichten wie z.B. das Snapin Overview sehr genau, wie viele und welche Probleme es gerade gibt. Zur Abbildung eines Arbeitsablaufs (workflow), d.h. dem „richtigen Arbeiten“ mit dem Monitoring, benötigen Sie aber noch etwas mehr Informationen über:
die Quittierung von Problemen
das Senden von Benachrichtigungen im Falle von Problemen
das Setzen von Wartungszeiten
Dieses Kapitel befasst sich nur mit dem ersten und dem letzten Punkt. Die Benachrichtigungen behandelt später ein eigenes Kapitel, da für dieses Thema einige spezielle Vorbereitungen zu treffen sind.
2. Probleme quittieren
Im Overview hatten Sie schon gesehen, dass Probleme entweder unbehandelt (unhandled) oder bearbeitet (handled) sein können. Das Quittieren ist nun genau die Aktion, die aus einem unbehandelten Problem ein bearbeitetes macht. Das muss nicht unbedingt heißen, dass sich wirklich jemand darum kümmert. Manche Probleme verschwinden ja auch von selbst wieder. Aber das Quittieren hilft, einen Überblick zu behalten und einen Workflow zu etablieren.
Was passiert beim Quittieren eines Problems genau?
Im Overview wird das Problem in der Spalte Unhandled beim Host oder Service nicht mehr gezählt.
Die Dashboards listen das Problem ebenfalls nicht mehr auf.
Das Objekt (Host oder Service) wird in Tabellenansichten mit dem Symbol
 markiert.
markiert.Ein Eintrag erfolgt in die Objekt-History, sodass die Aktion später nachvollzogen werden kann.
Wiederholte Benachrichtigungen (falls konfiguriert) werden gestoppt.
Wie quittieren Sie nun ein Problem?
Rufen Sie zunächst eine Tabellenansicht auf, in der das Problem enthalten ist. Am einfachsten ist der Einstieg über die vordefinierten Ansichten im Menü Monitor > Problems > Host problems oder Service problems. Zu diesen gelangen Sie übrigens fast noch schneller, wenn Sie im Overview die Zahl der Probleme anklicken.
Sie können in der Liste den problematischen Host oder Service anklicken und dann auf der Seite mit den Details die Quittierung nur für diesen einzelnen Host oder Service durchführen. Wir bleiben aber auf der Seite mit der Liste, da Sie hier alle Optionen haben, um nur ein Problem oder gleich mehrere auf einmal zu quittieren.
Es ist gar nicht so selten, dass Sie eine Reihe (zusammengehöriger) Probleme auf einmal quittieren wollen. Das geht einfach, indem Sie sich mit einem Klick auf Show checkboxes eine neue erste Spalte in der Liste einblenden lassen, die eine Checkbox vor jeder Zeile enthält. Die Checkboxen sind alle nicht markiert, denn die Auswahl treffen Sie: Markieren Sie die Checkbox für jeden gewünschten Host oder Service.
Wichtig: Wenn Sie auf einer Seite mit einer Liste eine Aktion durchführen, ohne dass Sie Checkboxen eingeblendet haben, dann wird diese Aktion für alle Listeneinträge durchgeführt.
Klicken Sie nun auf Acknowledge problems. Dies blendet am Beginn der Seite den folgenden Bereich ein:
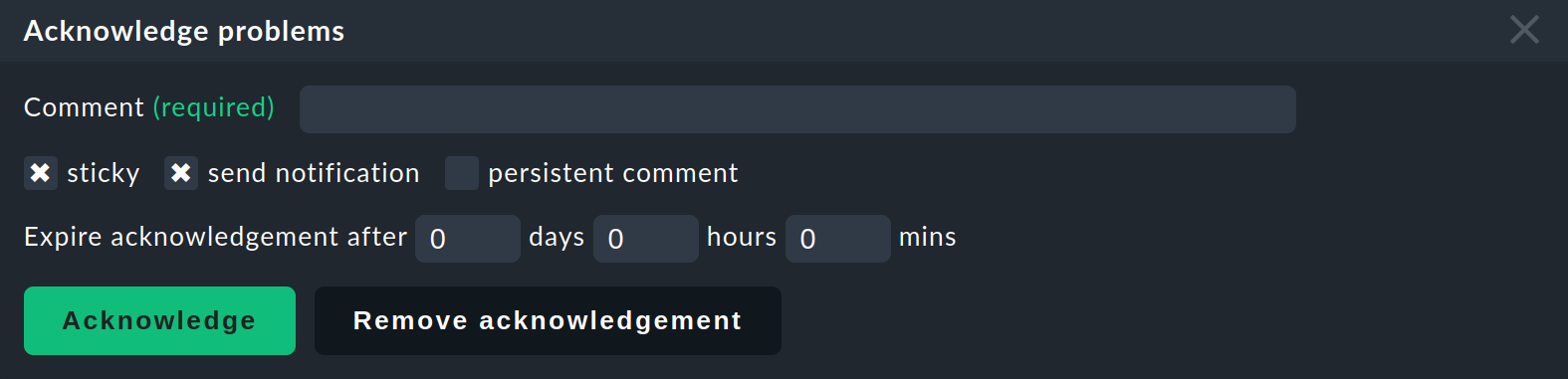
Tragen Sie einen Kommentar ein und klicken Sie auf Acknowledge — und mit der Bestätigung der „Sind Sie sicher?“-Frage …

… gelten alle vorher ausgewählten Probleme als quittiert.
Abschließend noch einige Hinweise:
Mit dem Knopf Remove acknowledgement können Sie eine Quittierung auch wieder entfernen.
Quittierungen können automatisch ablaufen. Dazu dient die Option Expire acknowledgement after, die aber nur in den
 Checkmk Enterprise Editions wirksam ist.
Checkmk Enterprise Editions wirksam ist.
Weitere Informationen zu allen Quittierungsoptionen erhalten Sie im Artikel über die Quittierung.
3. Wartungszeiten einrichten
Manchmal gehen Dinge nicht aus Versehen kaputt, sondern mit Absicht — oder etwas vorsichtiger ausgedrückt, ein Ausfall wird absichtlich in Kauf genommen. Denn jedes Stück Hard- oder Software muss gelegentlich gewartet werden, und während der dazu notwendigen Umbauarbeiten wird der betroffene Host oder Service im Monitoring sehr wahrscheinlich in den Zustand DOWN oder CRIT gehen.
Für diejenigen, die auf Probleme in Checkmk reagieren sollen, ist es dabei natürlich sehr wichtig, dass sie über geplante Ausfälle Bescheid wissen und nicht wertvolle Zeit mit „Fehlalarmen“ verlieren. Um dies zu gewährleisten, kennt Checkmk das Konzept der (geplanten) Wartungszeit (in Englisch scheduled downtime oder kürzer downtime).
Wenn also für ein Objekt eine Wartung ansteht, können Sie dieses in den Wartungszustand versetzen — entweder sofort oder aber auch für einen Zeitraum in der Zukunft.
Die Einrichtung von Wartungszeiten ist sehr ähnlich zum Ablauf der Quittierung von Problemen: Sie starten wieder mit einer Tabellenansicht, in der das gewünschte Objekt (Host oder Service) enthalten ist, für das Sie eine Wartungszeit einrichten wollen. Zum Beispiel können Sie im Overview auf die Zahl der Hosts oder der Services klicken, um sich alle Objekte auflisten zu lassen.
In der dann angezeigten Liste blenden Sie mit Show checkboxes die Checkboxen ein und wählen alle relevanten Einträge aus.
Klicken Sie nun Schedule downtimes. Dies blendet am Beginn der Seite den folgenden Bereich ein:
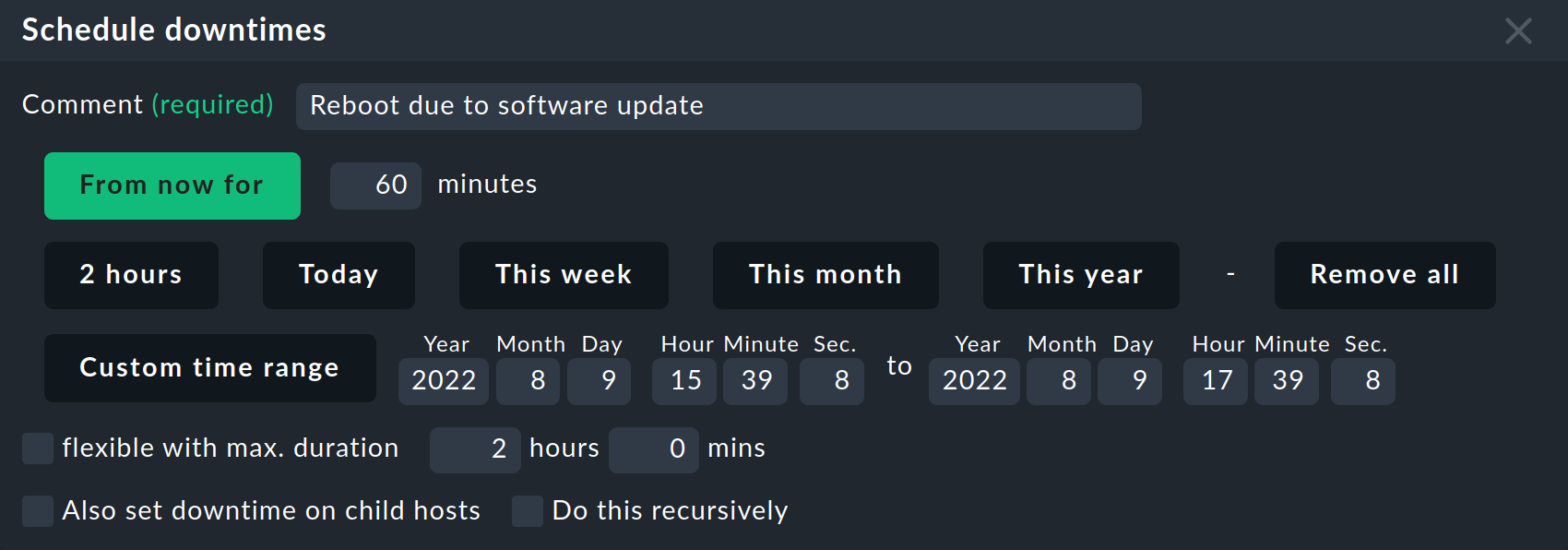
Bei den Wartungszeiten gibt es einen ganzen Haufen von Optionen. Einen Kommentar müssen Sie in jedem Fall eingeben. Durch Anklicken eines Knopfs wählen Sie Beginn und Ende der Wartungszeit. So werden z.B. mit dem Knopf 2 hours die ausgewählten Objekte vom aktuellen Zeitpunkt an für zwei Stunden als „in Wartung“ deklariert. Im Gegensatz zu den Quittungen haben Wartungszeiten grundsätzlich ein Ende, das vorher festgelegt wird.
Hier noch ein paar Hinweise:
Wenn Sie einen Host in die Wartung schicken, werden automatisch auch alle seine Services mitgeschickt. Sparen Sie sich daher die Arbeit, dies doppelt zu tun.
Die flexiblen Wartungszeiten beginnen tatsächlich erst dann, wenn das Objekt in einen anderen Zustand als OK wechselt.
Wenn Sie die
Checkmk Enterprise Editions nutzen, können Sie auch regelmäßige Wartungszeiten definieren (z.B. wegen eines obligatorischen Reboots einmal in der Woche).Einen Überblick über aktuell laufende Wartungszeiten erhalten Sie in Monitor > Overview > Scheduled downtimes.
Die Auswirkungen einer Wartungszeit sind folgende:
Im Overview tauchen die betroffenen Hosts und Services nicht mehr als Probleme auf.
In Tabellenansichten wird ein Service mit dem
 Leitkegel markiert.
Ein Host inklusive der mit ihm in die Wartung geschickten Services erhält das
Leitkegel markiert.
Ein Host inklusive der mit ihm in die Wartung geschickten Services erhält das  blaue Pause-Zeichen.
blaue Pause-Zeichen.Die Benachrichtigungen über Probleme ist während der Wartung abgeschaltet.
Zu Beginn und Ende einer Wartungszeit wird eine spezielle Benachrichtigung ausgelöst.
In der Verfügbarkeitsanalyse werden geplante Wartungszeiten gesondert berücksichtigt.
Eine detaillierte Beschreibung zu allen genannten und weiteren Aspekten finden Sie im Artikel über Wartungszeiten.