1. Einleitung
Checkmk Business Intelligence — das klingt zugegeben etwas hochtrabend für eine im Grunde recht einfache Sache. Aber dieser Name trifft den Kern des BI-Moduls von Checkmk recht gut. Hier geht es nämlich darum, aus den vielen einzelnen Statuswerten den Gesamtzustand von geschäftskritischen Anwendungen abzuleiten und übersichtlich darzustellen.
Nehmen Sie als Beispiel den Dienst E-Mail, der in vielen Unternehmen noch immer unverzichtbar ist. Dieser Dienst basiert auf der korrekten Funktion einer Vielzahl von Hardware- und Softwarekomponenten — angefangen bei bestimmten Switchen, über SMTP- und IMAP-Dienste, bis hin zu Infrastrukturdiensten wie LDAP und DNS.
Der Ausfall eines essenziellen Bausteins ist kein Problem, wenn dieser redundant ausgelegt ist. Umgekehrt mag ein Problem bei einem ganz anderen Service, der auf den ersten Blick mit E-Mail nichts zu tun hat, viel schwerwiegendere Auswirkungen haben. Ein einfacher Blick auf eine Liste von Services in Checkmk ist also nicht immer aussagekräftig — zumindest nicht für jeden!
Checkmk BI ermöglicht Ihnen, aus dem aktuellen Zustand von einzelnen Hosts und Services einen Gesamtzustand für eine Anwendung abzuleiten. Dazu definieren Sie über BI-Regeln, wie die Dinge baumartig voneinander abhängen. Jede Anwendung ist dann insgesamt OK, WARN oder CRIT. Die Information über den Zustand und die Abhängigkeiten können Sie auf verschiedene Weise nutzen:
Anzeige des Gesamtstatus einer Anwendung in der GUI.
Berechnung der Verfügbarkeit einer Anwendung.
Benachrichtigungen bei einem Problem oder gar einem Ausfall einer Anwendung.
Impact-Analyse: Ein Service geht auf CRIT — welche Anwendungen sind davon betroffen?
Planung von Wartungszeiten und „Was wäre wenn …“-Analysen.
Daneben gibt es noch die Möglichkeit, die Baumdarstellung von BI für eine „Drilldown“-Ansicht für den Zustand eines Hosts mit allen seinen Services zu verwenden.
Eine Besonderheit von Checkmk BI im Gegensatz zu vergleichbaren Tools im Monitoringumfeld ist, dass Checkmk auch hier regelbasiert arbeitet. Das ermöglicht Ihnen z.B. mit einem generischen Satz von Regeln, dynamisch eine unbestimmte Zahl von ähnlichen Anwendungen zu beschreiben. Das erleichtert immens die Arbeit und hilft, Fehler zu vermeiden — besonders in sehr dynamischen Umgebungen.
2. Konfiguration Teil 1: Das erste Aggregat
2.1. Begriffe
Bevor Sie Schritt für Schritt mit der Praxis anfangen, benötigen Sie zunächst ein paar Begriffe:
Jede mit BI formalisierte Anwendung wird als Aggregation bezeichnet, da hier aus vielen Einzelzuständen ein Gesamtzustand aggregiert wird.
Eine Aggregation ist ein Baum von Objekten. Diese werden Knoten genannt. Die untersten Knoten — also die Blätter des Baums — sind Hosts und Services aus Ihren Checkmk-Instanzen. Die übrigen Knoten sind künstlich erzeugte BI-Objekte.
Jeder Knoten wird durch eine Regel erzeugt. Das gilt auch für die Wurzel des Baums — also den obersten Knoten. Die Regeln legen fest, welche Knoten unter einem Knoten hängen und wie aus deren Zuständen der Zustand des Knotens berechnet werden soll.
Auch der oberste Knoten einer Aggregation (die Wurzel des Baums) wird mit einer Regel erzeugt. Dabei kann eine Regel mehrere Aggregationen erzeugen.
2.2. Ein Beispiel
Am einfachsten geht alles mit einem konkreten Beispiel. Dafür haben wir
uns für diesen Artikel die „Mystery Application“ ausgedacht.
Nehmen Sie an, dass dies eine wichtige Anwendung in einem nicht näher genannten
Unternehmen ist. Dabei spielen unter anderem fünf Server und zwei Netzwerkswitche
eine wichtige Rolle. Damit Sie das Beispiel besser nachvollziehen können,
bekommen diese einfache Namen wie srv-mys-1 oder switch-1.
Folgendes Schaubild gibt den Aufbau grob wieder:
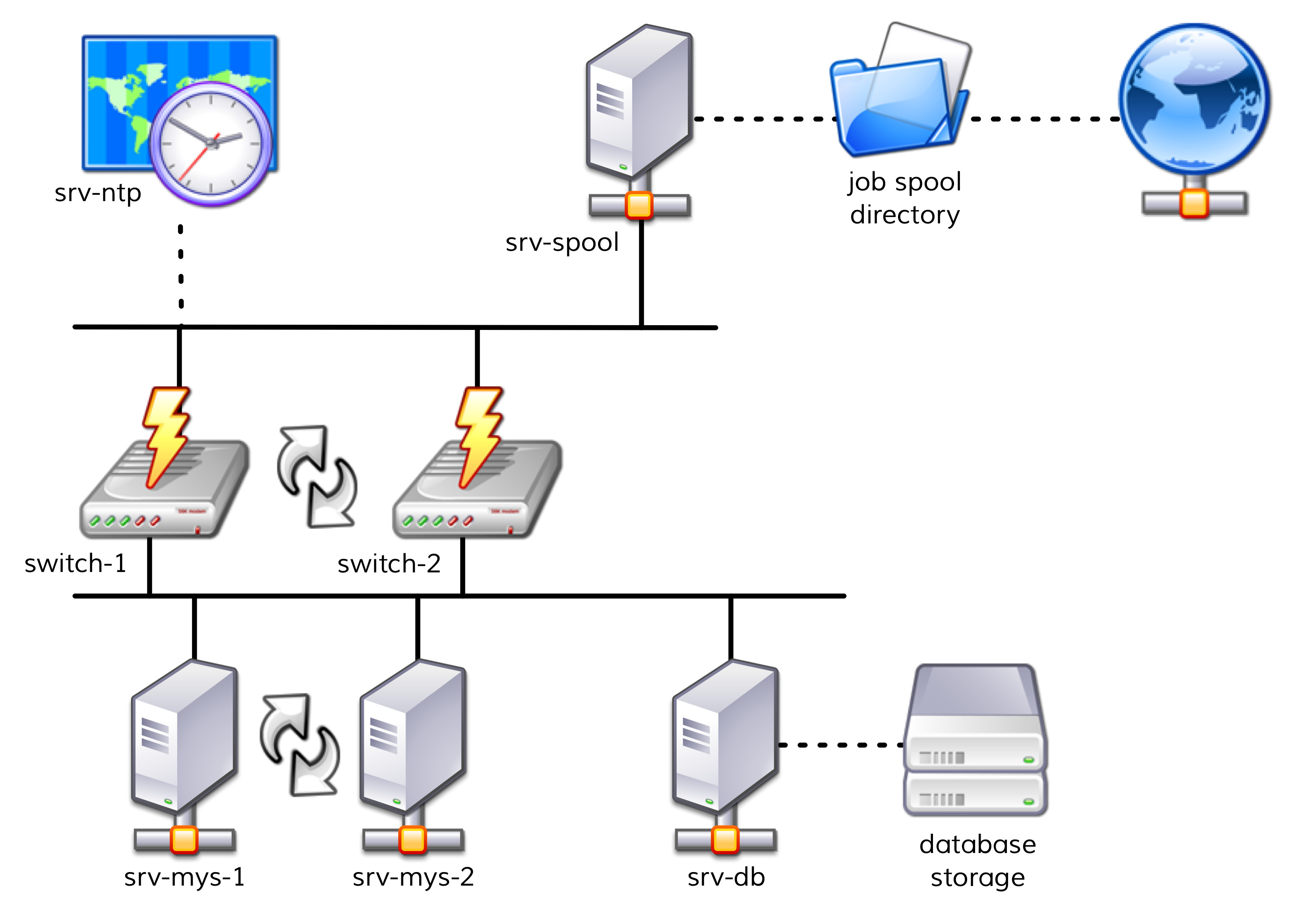
Die beiden Server
srv-mys-1undsrv-mys-2bilden einen redundanten Cluster, auf welchem die eigentliche Anwendung läuft.srv-dbist ein Datenbankserver, welcher die Daten der Anwendung speichert.switch-1undswitch-2sind zwei redundante Router, welche das Servernetz mit einem höheren Netz verbinden.In jenem befindet sich ein Zeitgeber
srv-ntp, welcher für eine exakt synchrone Zeit sorgt.Außerdem arbeitet dort der Server
srv-spool, welcher die von der Mystery Application berechneten Resultate in ein Spool-Verzeichnis befördert.Von dort werden die Daten von einem mysteriösen übergeordneten Dienst abgeholt.
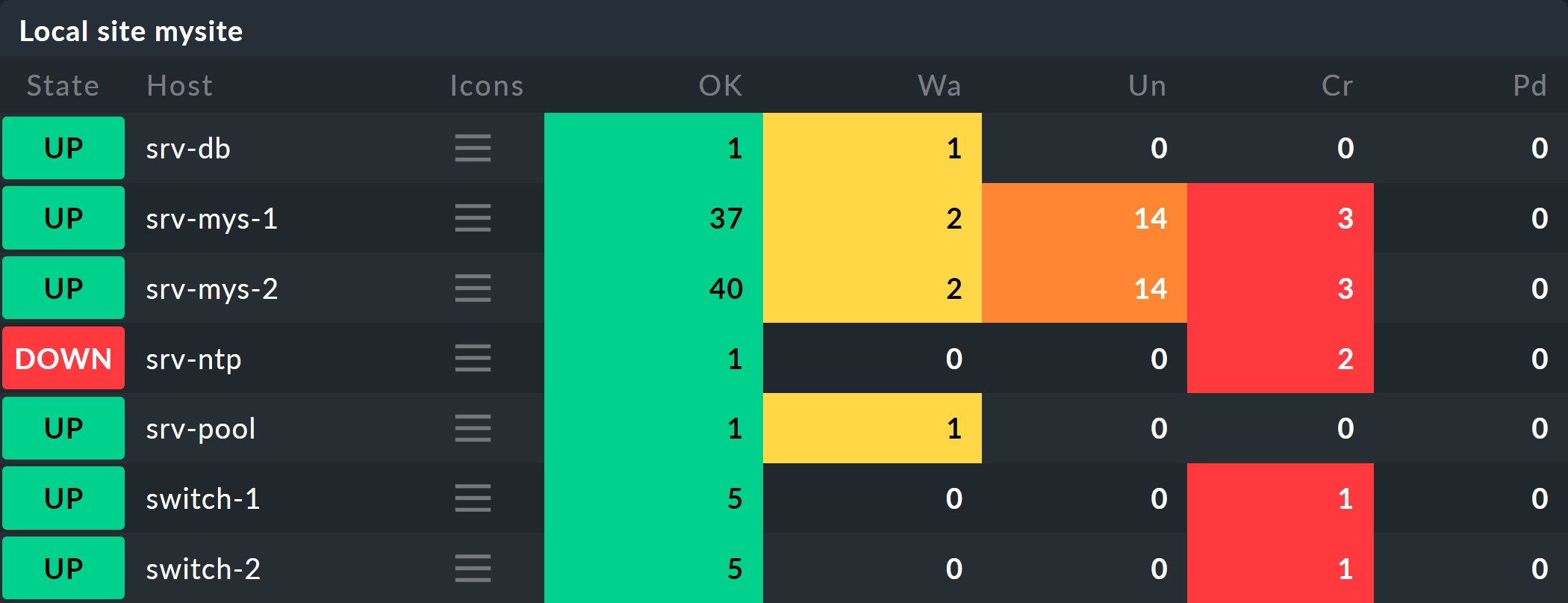
Wenn Sie die nachfolgenden Schritte eins zu eins durchspielen möchten, können Sie die aufgeführten Monitoring-Objekte kurz nachbauen. Zum Testen genügt es dabei, wenn Sie einen vorhandenen Host mehrfach klonen und die Klone entsprechend benennen. Später kommen noch einige wenige Services ins Spiel, die Sie dann bei Zeit für die betroffenen Hosts ins Monitoring aufnehmen können. Auch da können Sie wieder schummeln: Mit simplen Dummy-Local-Checks bekommen Sie schnell passende Services zum Spielen.
Die Hosts im Monitoring sehen in etwa so aus:
2.3. Ihre erste BI-Regel
Beginnen Sie mit etwas Einfachem — quasi der einfachst möglichen sinnvollen
Aggregation überhaupt: einer Aggregation mit nur zwei Knoten. Dabei möchten
Sie den Zustand bei beiden Hosts switch-1 und switch-2
zusammenfassen. Die Aggregation soll Netzwerk heißen und OK sein,
wenn beide Switche erreichbar sind. Bei einem Teilausfall soll sie auf
WARN gehen und wenn beide Switche weg sind auf CRIT.
Legen Sie los: Das BI-Modul erreichen Sie über Setup > Business Intelligence > Business Intelligence. Die Konfiguration der Regeln und Aggregationen geschieht innerhalb von Konfigurationspaketen: den BI Packs. Die Pakete sind nicht nur deswegen praktisch, weil Sie komplexere Konfigurationen damit besser verwalten können. Sie können auch für ein Paket Berechtigungen für bestimmte Kontaktgruppen vergeben und somit Benutzern ohne Adminrechte das Editieren von Teilen der Konfiguration erlauben. Doch dazu später mehr …
Wenn Sie das BI-Modul zum ersten Mal aufrufen, sieht das etwa so aus:

Dort ist bereits ein Paket mit dem Titel Default Pack vorhanden. Es enthält eine Demo für eine Aggregation, die Daten eines einzelnen Hosts zusammenfasst.
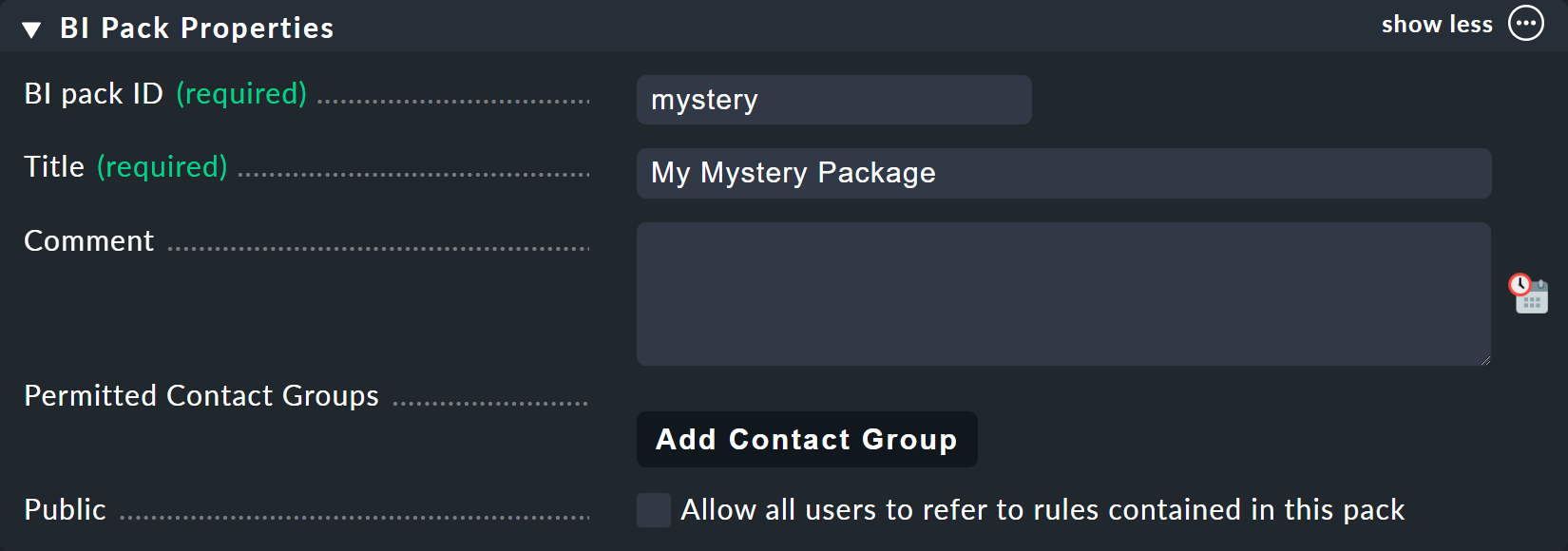
Für das aktuelle Beispiel legen Sie am besten ein neues Paket an (Knopf Add BI pack), welches Sie Mystery nennen.
Wie immer in Checkmk, vergeben Sie eine interne ID (mystery), welche sich später nicht ändern lässt, und einen beschreibenden Titel.
Die Option Public brauchen andere Benutzer, wenn sie Regeln in diesem Paket für ihre eigenen Regeln oder Aggregationen verwenden möchten.
Da Sie Ihre Experimente vermutlich erst mal in Ruhe alleine durchführen wollen, lassen Sie das deaktiviert:
Nach dem Anlegen finden Sie in der Hauptliste jetzt natürlich zwei Pakete:

Vor jedem Eintrag steht ein Symbol zum Editieren der Eigenschaften (![]() ) und eines,
um zum eigentlichen Inhalt des Pakets zu kommen (
) und eines,
um zum eigentlichen Inhalt des Pakets zu kommen (![]() ), wo Sie jetzt auch hin wollen.
Dort angelangt, legen Sie gleich Ihre erste Regel über Add rule an.
), wo Sie jetzt auch hin wollen.
Dort angelangt, legen Sie gleich Ihre erste Regel über Add rule an.
Wie immer in Checkmk, will auch diese Regel eine eindeutige ID und einen Titel haben. Der Titel der Regel hat hier allerdings nicht nur Dokumentationscharakter, sondern wird später auch als Name desjenigen Knotens sichtbar, den diese Regel erzeugt:
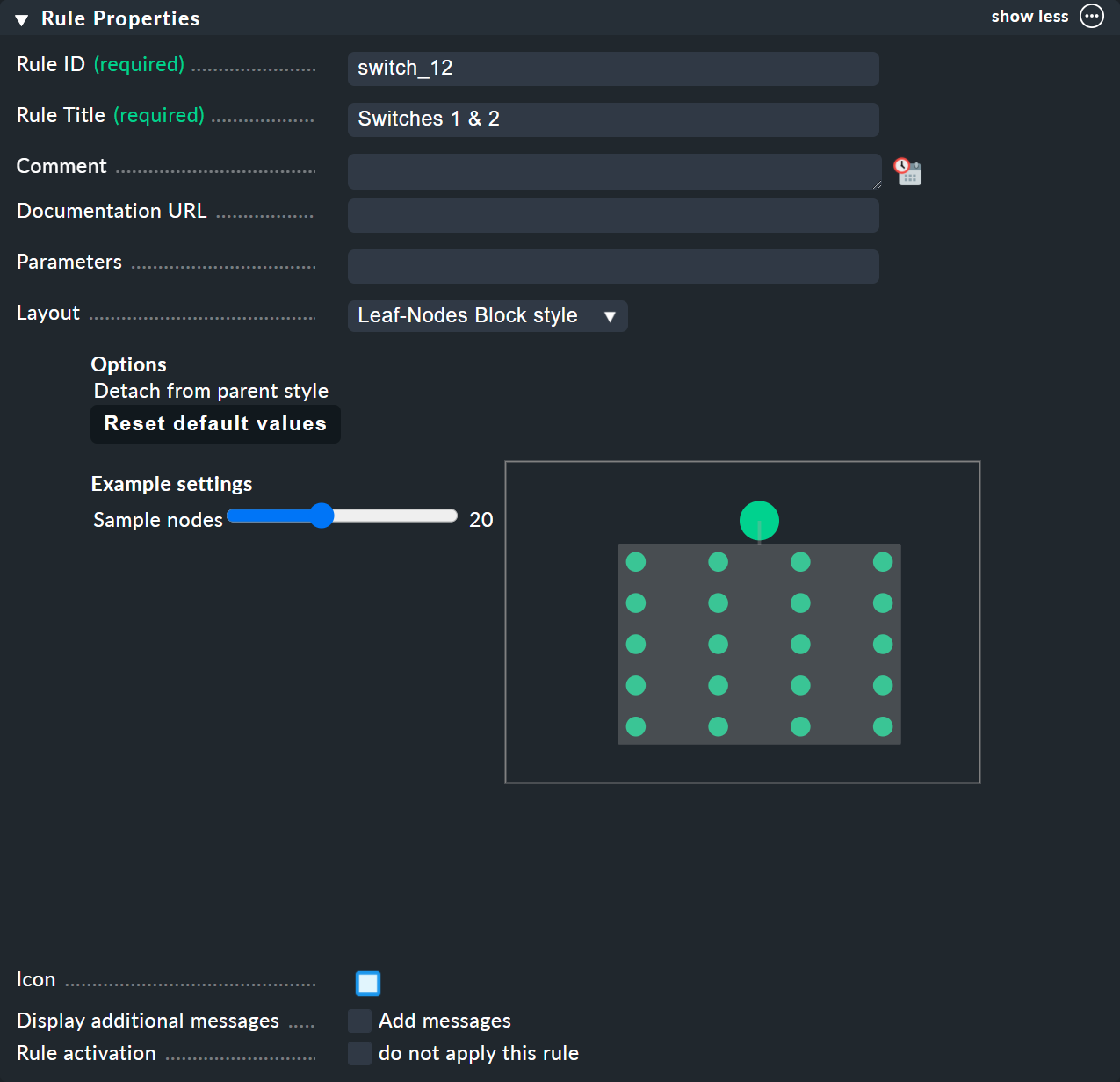
Der darunter folgende Kasten hat den Namen Child Node Generation und ist der wichtigste. Hier legen Sie fest, welche Objekte in diesem Knoten zusammengefasst werden sollen. Das können entweder andere BI-Knoten sein; dazu würden Sie eine andere BI-Regel auswählen. Oder es sind Monitoringobjekte — also Hosts oder Services.
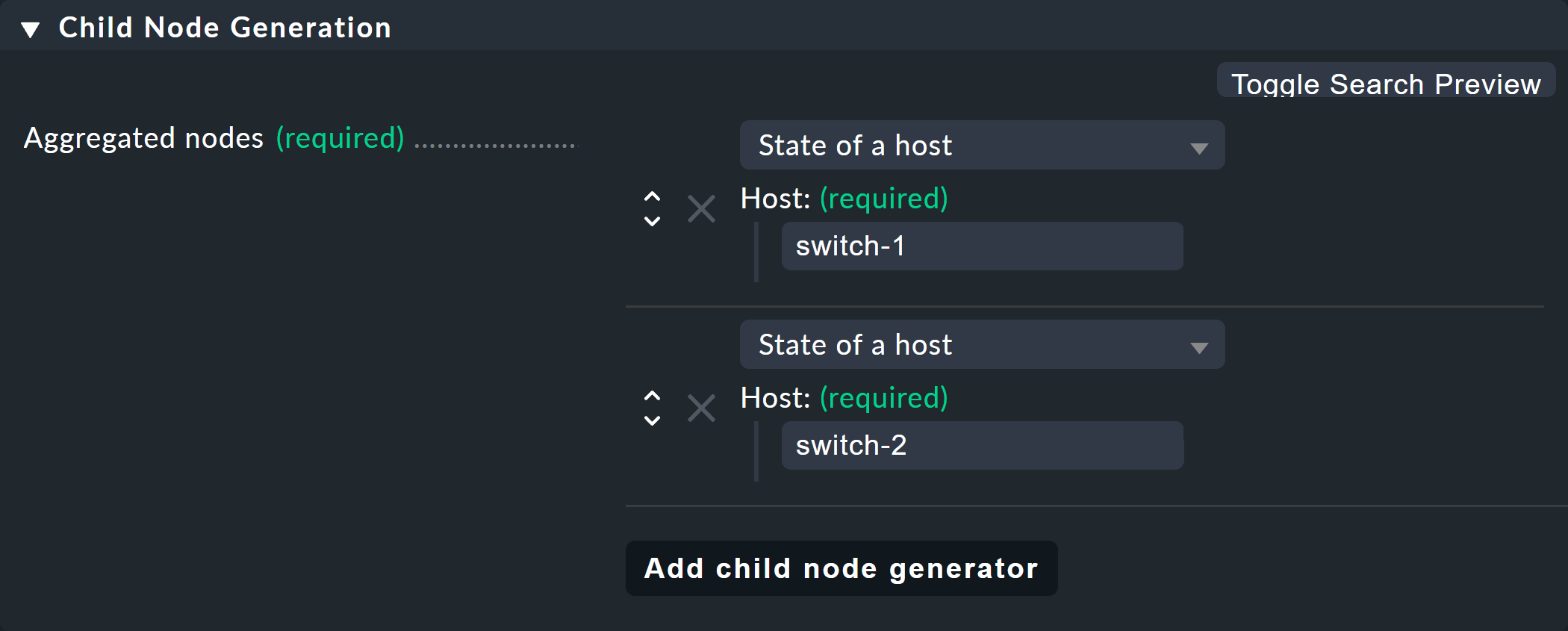
Für das erste Beispiel wählen Sie die zweite Variante (State of a host) und legen
zwei Objekte als Kinder an, nämlich die beiden Hosts switch-1
und switch-2. Das geschieht jeweils mit dem Knopf
Add child node generator. Hier wählen Sie dann logischerweise
State of a host und tragen jeweils den Namen des Hosts ein:
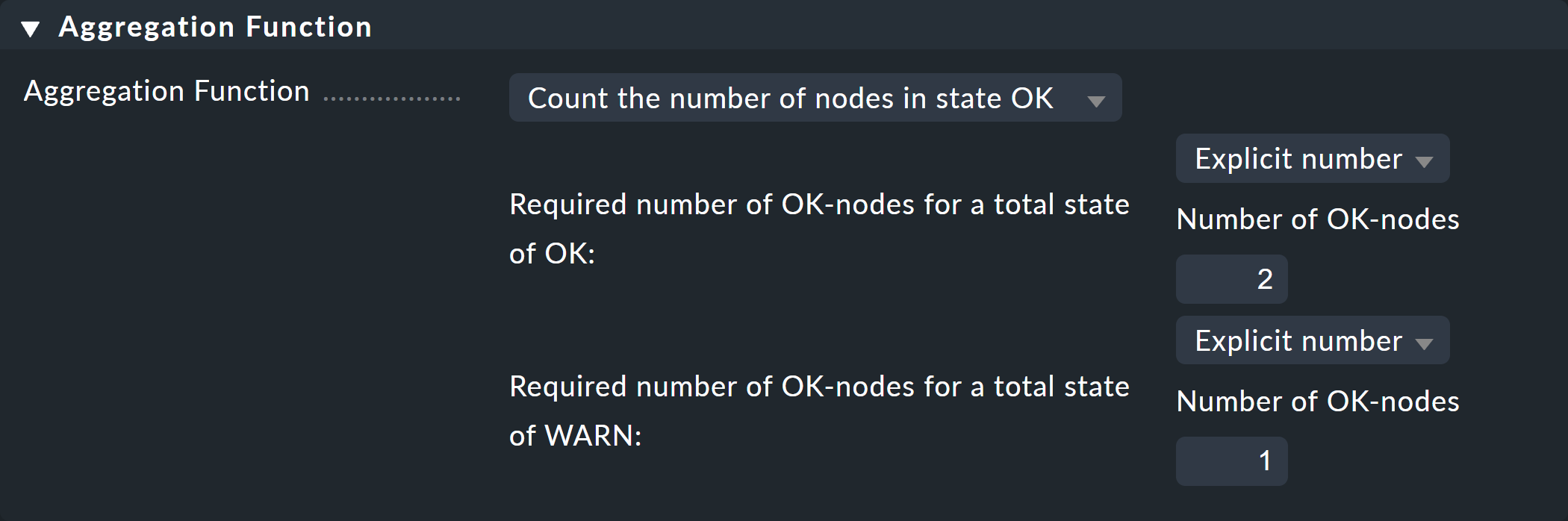
Im dritten und letzten Kasten, Aggregation Function, geben Sie an, wie der Monitoringstatus des Knotens berechnet werden soll. Grundlage dafür ist immer die Liste der Zustände der Unterknoten. Verschiedene logische Verknüpfungen sind möglich.
Vorausgewählt ist Best — take best of all node states. Das würde bedeuten, dass der Knoten erst dann CRIT wird, wenn auch alle Unterknoten CRIT bzw. DOWN sind. Wie oben erwähnt, soll das hier aber nicht der Fall sein. Wählen Sie stattdessen Count the number of nodes in state OK, um die Anzahl der Unterknoten mit Status OK als Maßstab heranzuziehen. Hier werden als Schwellwerte die beiden Zahlen 2 und 1 vorgeschlagen. Das ist prima, denn es ist genau das was Sie brauchen:
Wenn beide Switche UP sind (das wird hier als OK gewertet), soll der Knoten OK werden.
Wenn nur ein Switch UP ist, wird er WARN.
Und wenn beide DOWN sind, wird er CRIT.
Und so sieht die Maske ausgefüllt aus:
Ein Klick auf Create, und schon haben Sie Ihre erste Regel:

2.4. Ihre erste Aggregation
Nun ist es wichtig, dass Sie verstehen, dass eine Regel noch keine Aggregation
ist. Checkmk kann ja noch nicht wissen, ob das hier alles ist oder nur
Teil eines größeren Baums! Wirkliche BI-Objekte werden erst dann erzeugt und
in der Statusoberfläche sichtbar, wenn Sie eine Aggregation anlegen.
Dazu wechseln Sie in die Liste der ![]() Aggregationen.
Aggregationen.
Der Knopf ![]() bringt Sie zu einer Maske zum Anlegen einer neuen Aggregation.
Bei den Aggregation groups können Sie beliebige
Namen angeben. Diese erscheinen dann in der Statusoberfläche als Gruppen, unter denen all
diejenigen Aggregationen sichtbar werden, welche eben diese Gruppenbezeichnung teilen.
Das ist eigentlich das gleiche Konzept wie bei Hashtags oder Schlagworten.
Auch die Aggregation ID können Sie wie gewohnt frei vergeben, später aber nicht mehr ändern.
bringt Sie zu einer Maske zum Anlegen einer neuen Aggregation.
Bei den Aggregation groups können Sie beliebige
Namen angeben. Diese erscheinen dann in der Statusoberfläche als Gruppen, unter denen all
diejenigen Aggregationen sichtbar werden, welche eben diese Gruppenbezeichnung teilen.
Das ist eigentlich das gleiche Konzept wie bei Hashtags oder Schlagworten.
Auch die Aggregation ID können Sie wie gewohnt frei vergeben, später aber nicht mehr ändern.
Den Inhalt der Aggregation legen Sie über Add new element fest. Wählen Sie hier die Einstellung Call a rule und bei Rule: die Regel, die Sie gerade angelegt haben (und davor das Regelpaket, in dem diese sich befindet).
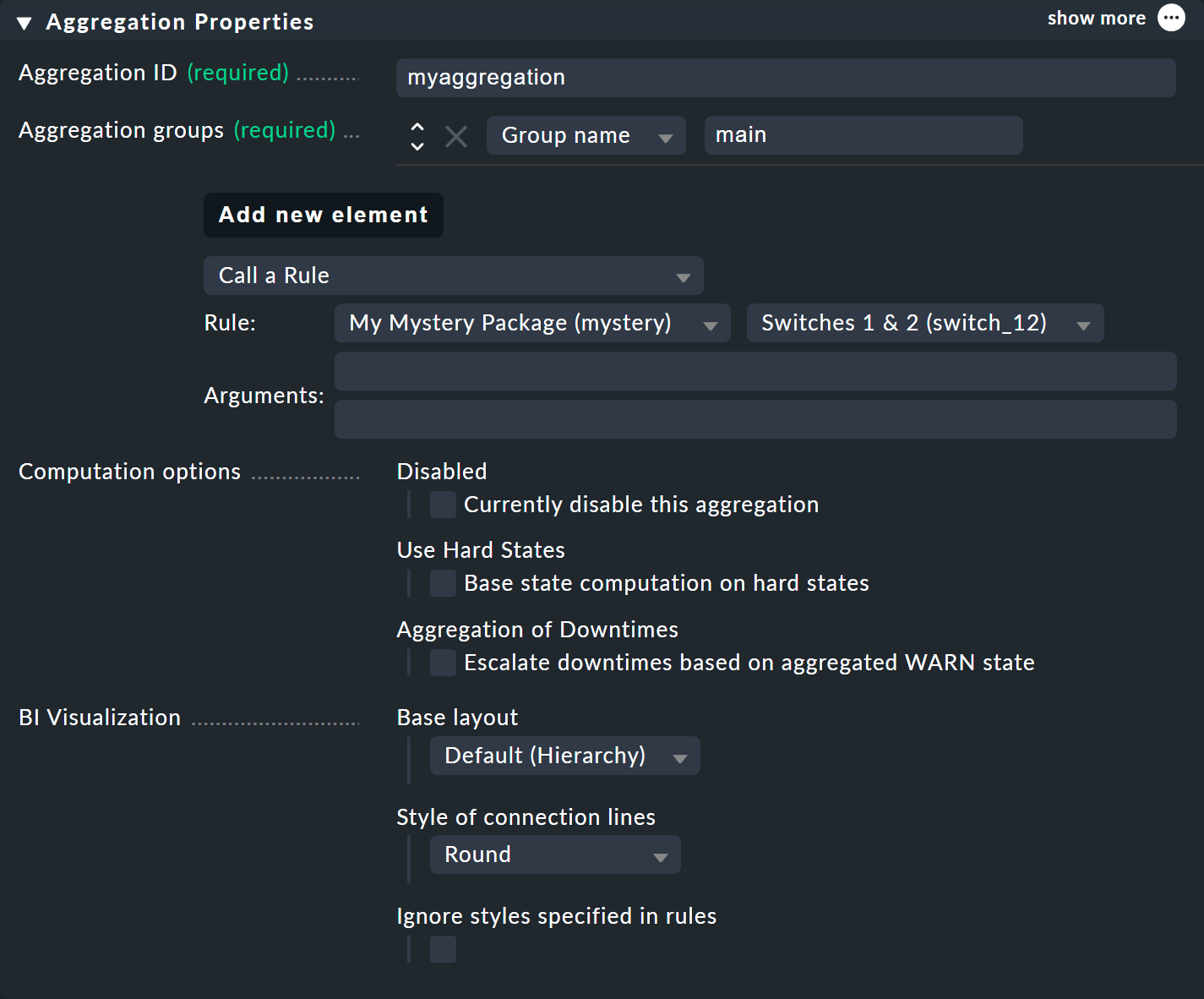
Wenn Sie die Aggregation jetzt mit ![]() speichern, sind Sie fertig!
Ihre erste Aggregation sollte jetzt in der Statusoberfläche auftauchen — vorausgesetzt,
Sie haben auch tatsächlich mindestens einen der Hosts
speichern, sind Sie fertig!
Ihre erste Aggregation sollte jetzt in der Statusoberfläche auftauchen — vorausgesetzt,
Sie haben auch tatsächlich mindestens einen der Hosts switch-1 oder switch-2 im System!
3. BI im Operating Teil 1: Die Statusansicht
3.1. Alle Aggregate anzeigen
Wenn Sie alles richtig gemacht haben, können Sie jetzt Ihr erstes Aggregat über die Statusoberfläche aufrufen. Das geht am einfachsten über Monitor > Business Intelligence > All Aggregations:

Ansichten für BI erstellen
Neben den vorgefertigten BI-Ansichten können Sie auch individuell erstellte Ansichten nutzen. Wählen Sie dazu beim Anlegen einer neuen Ansicht eine der BI-Datenquellen. BI Aggregations liefert Informationen über die Aggregate, BI Hostname Aggregations fügt Filter und Informationen für einzelne Hosts hinzu, BI Aggregations affected by one host zeigt lediglich Aggregate, die sich auf einen einzelnen Host beziehen und BI Aggregations for Hosts by Hostgroups ermöglicht die Unterscheidung nach Hostgruppen.
3.2. Mit dem Baum arbeiten
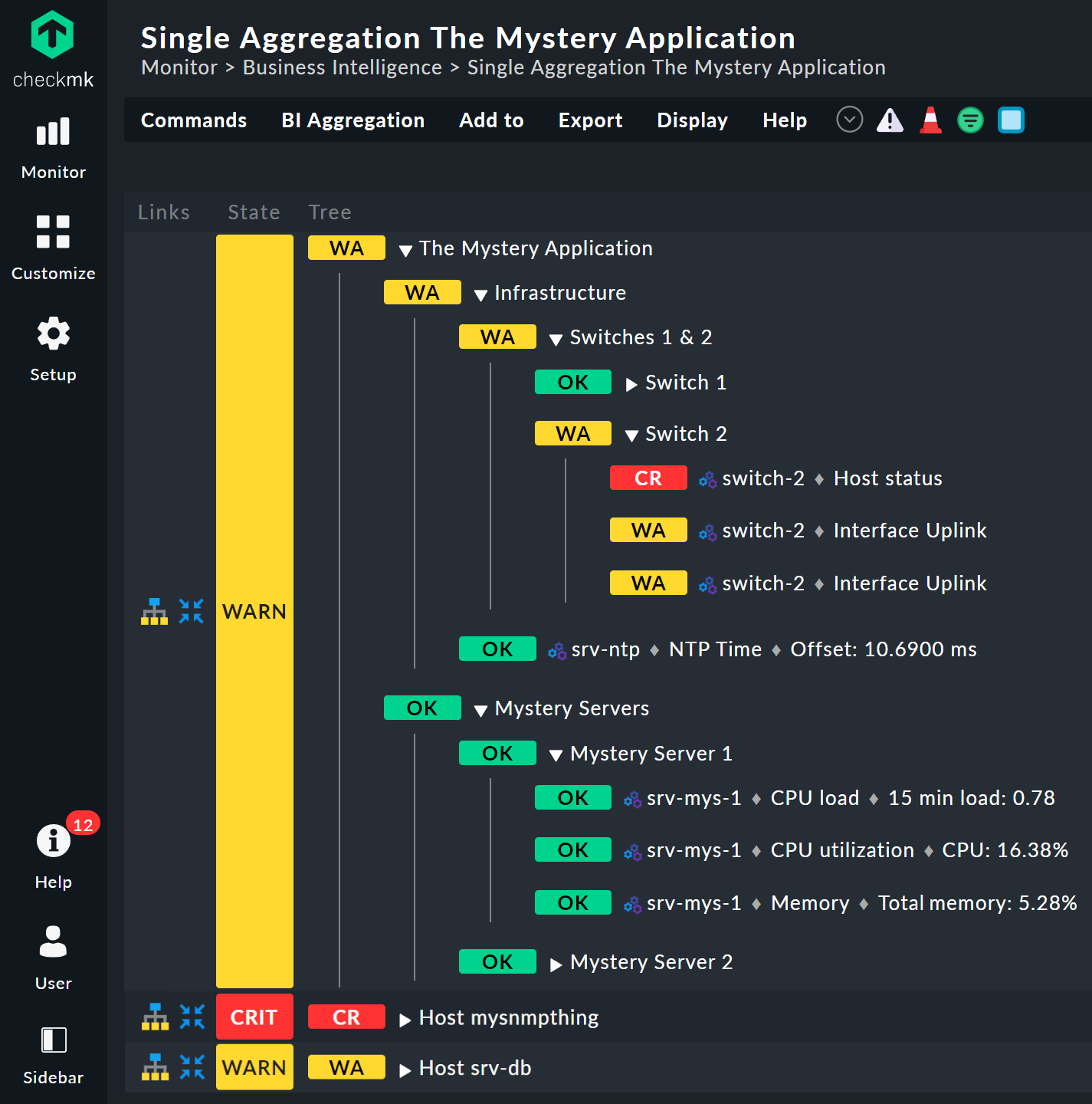
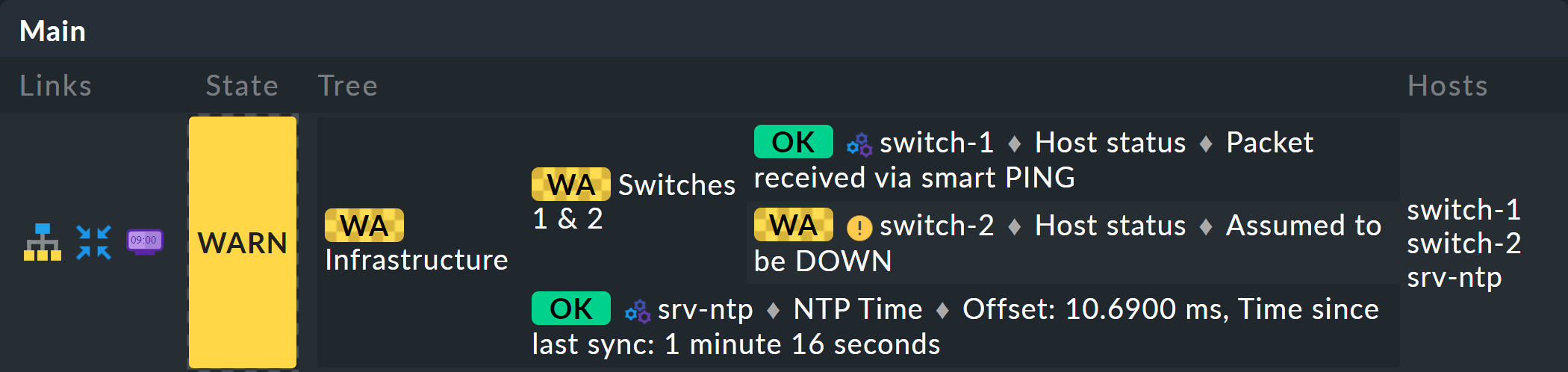
Sehen Sie sich die Darstellung des BI-Baums etwas näher an. Folgendes Beispiel zeigt Ihr Miniaggregat in einer Situation, in der einer der beiden Switches DOWN ist und der andere UP. Wie gewollt, geht das Aggregat dabei in den Zustand WARN:

Dabei sehen Sie auch, dass zur Vereinheitlichung von Hosts und Services ein Host, der DOWN ist, quasi wie ein Service gewertet wird, der CRIT ist. Aus UP wird entsprechend OK.
Die Blätter des Baums zeigen die Zustände von Hosts und Services. Der Hostname — und bei Services auch der Servicename — ist anklickbar und führt Sie zum aktuellen Status des entsprechenden Objekts. Außerdem sehen Sie die letzte Ausgabe des Check-Plugins.
Ganz links neben jedem Aggregat finden Sie zwei Symbole: ![]() und
und ![]() . Mit dem ersten Symbol —
. Mit dem ersten Symbol — ![]() — kommen
Sie zu einer Seite, die nur genau dieses eine Aggregat anzeigt. Das ist natürlich
hauptsächlich dann nützlich, wenn Sie mehr als ein Aggregat angelegt haben. Es eignet
sich z.B. gut für ein Lesezeichen.
— kommen
Sie zu einer Seite, die nur genau dieses eine Aggregat anzeigt. Das ist natürlich
hauptsächlich dann nützlich, wenn Sie mehr als ein Aggregat angelegt haben. Es eignet
sich z.B. gut für ein Lesezeichen. ![]() bringt Sie zur Berechnung
der Verfügbarkeit. Dazu später mehr.
bringt Sie zur Berechnung
der Verfügbarkeit. Dazu später mehr.
3.3. BI ausprobieren: Was wäre wenn?
Links vom Hostnamen finden Sie noch ein interessantes Symbol: ![]() .
Dies ermöglicht eine „Was wäre wenn“-Analyse. Die Idee dahinter ist einfach: Durch
einen Klick auf das Symbol schalten Sie das Objekt testweise auf einen anderen Zustand — allerdings
nur für die BI-Oberfläche, nicht in echt!
Durch mehrfache Klicks gelangen Sie von
.
Dies ermöglicht eine „Was wäre wenn“-Analyse. Die Idee dahinter ist einfach: Durch
einen Klick auf das Symbol schalten Sie das Objekt testweise auf einen anderen Zustand — allerdings
nur für die BI-Oberfläche, nicht in echt!
Durch mehrfache Klicks gelangen Sie von ![]() (OK) über
(OK) über
![]() (WARN),
(WARN), ![]() (CRIT) und
(CRIT) und
![]() (UNKNOWN) wieder zu
(UNKNOWN) wieder zu ![]() zurück.
zurück.
BI berechnet dann den kompletten Baum anhand des angenommenen Status.
Folgende Abbildung zeigt das Minimalaggregat unter der Annahme, dass neben
switch-1, der tatsächlich ausgefallen ist, auch switch-2 DOWN
wäre:

Der Gesamtzustand des Aggregats geht dadurch von WARN auf CRIT. Dabei wird
dessen Farbe mit einem Karomuster hinterlegt. Dieses Muster zeigt Ihnen an,
dass der tatsächliche Zustand eigentlich anders ist. Das ist
keineswegs immer der Fall, denn manche Änderungen bei einem Host oder Service
sind für den Gesamtzustand nicht mehr relevant, z. B. weil dieser sowieso schon
CRIT ist (wie hier im Bild switch-1).
Sie können diese „Was wäre wenn“-Analyse auf verschiedene Arten nutzen, z. B.:
Testen, ob das BI-Aggregat so reagiert, wie Sie das wollen.
Planung der Abschaltung einer Komponente aus Gründen der Wartung.
Bei letzterem Szenario setzen Sie das zu wartende Gerät bzw. dessen Services testweise
auf ![]() . Wenn das Gesamtaggregat dann OK bleibt, muss das
bedeuten, dass der Ausfall aktuell durch Redundanz kompensiert werden kann.
. Wenn das Gesamtaggregat dann OK bleibt, muss das
bedeuten, dass der Ausfall aktuell durch Redundanz kompensiert werden kann.
3.4. BI ausprobieren durch gefakte Zustände
Es gibt noch eine zweite Möglichkeit, die BI-Aggregate zu testen: Das direkte Ändern des tatsächlichen Zustands von Objekten. Das bietet sich vor allem in einem Testsystem an.
Zu diesem Zweck gibt es bei den Kommandos
ein
Host-/Servicekommando mit dem Namen Fake check results. Es ist per Default
nur in der Rolle Administrator verfügbar. Diese Methode wurde z. B. bei der
Erstellung der Screenshots für diesen Artikel genutzt, um switch-1
auf DOWN zu setzen. Daher kommt der verräterische Text
Manually set to Down by cmkadmin.

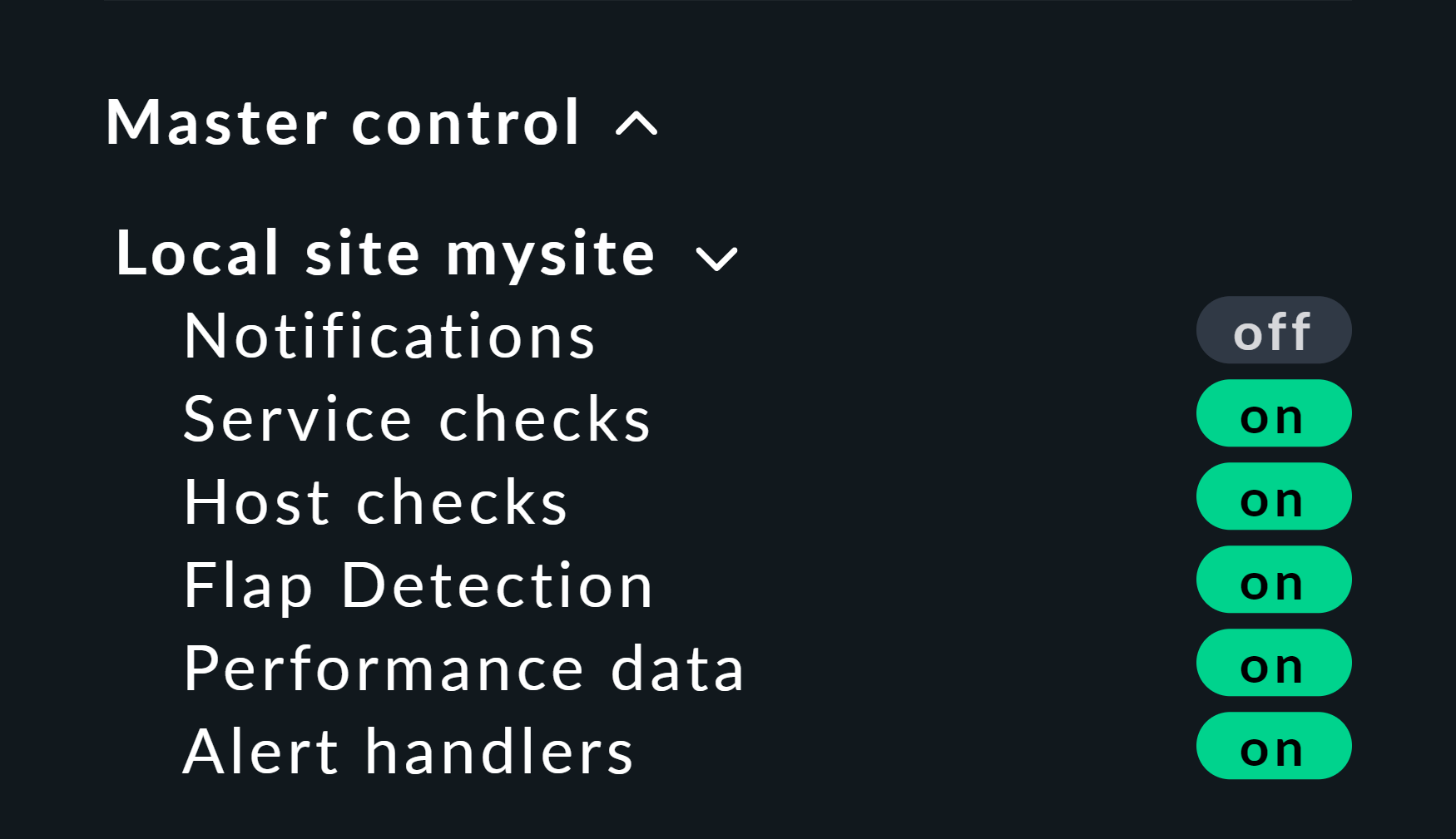
Hier noch ein kleiner Tipp: Wenn Sie mit dieser Methode arbeiten, schalten Sie am besten die aktiven Checks für die betroffenen Hosts und Services aus, denn sonst gehen diese beim nächsten Checkintervall sofort wieder auf den eigentlichen Zustand zurück. Wenn Sie faul sind, machen Sie das einfach global über das Seitenleistenelement Master Control. Bitte vergessen Sie nie, das später wieder zu aktivieren!
3.5. BI-Gruppen
Beim Anlegen des Aggregats haben wir die Eingabemöglichkeit der Aggregation Groups kurz angesprochen. Im Beispiel hatten Sie das vorgeschlagene Main hier einfach bestätigt. Sie sind aber bei der Vergabe der Namen völlig frei und können ein Aggregat auch mehreren Gruppen zuweisen.
Gruppen werden dann wichtig, wenn die Anzahl der Aggregate das übersteigt, was Sie vielleicht auf einem Bildschirm sehen möchten. Sie gelangen zu einer Gruppe, indem Sie bei der Seite All Aggregations auf die angezeigten Namen der Gruppen klicken — also in unserem obigen Beispiel einfach auf die Überschrift Main. Wenn Sie bisher nur dieses eine Aggregat haben, ändert sich natürlich nicht viel. Nur wenn man genau hinsieht merkt man:
Der Titel der Seite heißt jetzt Aggregation group Main.
Die Gruppenüberschrift Main ist verschwunden.
Wenn Sie diese Ansicht öfter besuchen wollen, legen Sie doch einfach ein Lesezeichen davon an — am besten mit dem Bookmarks-Element in der Seitenleiste.
3.6. Vom Host/Service zum Aggregat
Sobald Sie BI-Aggregate eingerichtet haben, werden Sie bei Ihren Hosts und
Services im Kontextmenü ein neues ![]() Symbol finden:
Symbol finden:
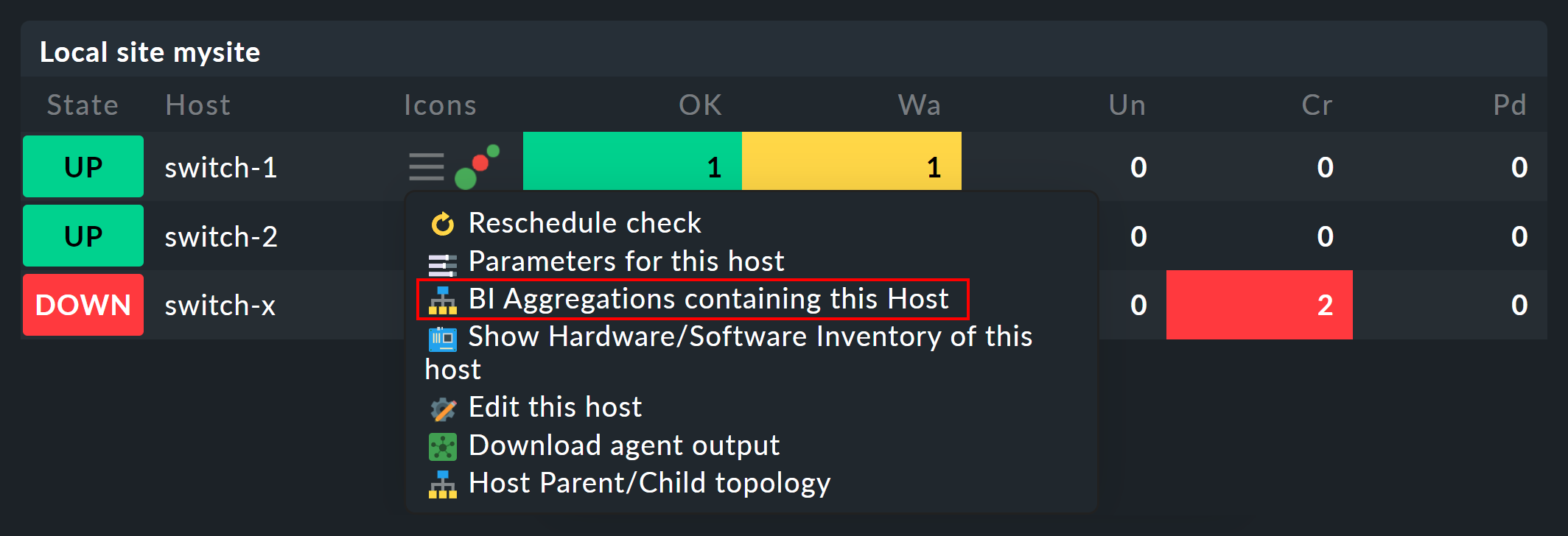
Mit diesem Symbol gelangen Sie zur Liste aller Aggregationen, in denen der betroffene Host oder Service enthalten ist.
4. Konfiguration Teil 2: Mehrstufige Bäume
Nach diesem ersten kurzen Eindruck der BI-Statusoberfläche geht es zurück zur Konfiguration. Denn mit solch einem Miniaggregat können Sie natürlich noch niemanden wirklich beeindrucken.
Es beginnt damit, dass Sie den Baum um eine Ebene erweitern — also von zwei Ebenen (Wurzel und Blätter) auf drei Ebenen (Wurzel, Zwischenebene, Blätter) gehen. Dazu kombinieren Sie Ihren vorhandenen Knoten „Switches 1 & 2“ mit dem Zustand der NTP-Zeitsynchronisation zu einem Oberknoten „Infrastructure“.
Aber der Reihe nach — und zunächst das Ergebnis vorweg:
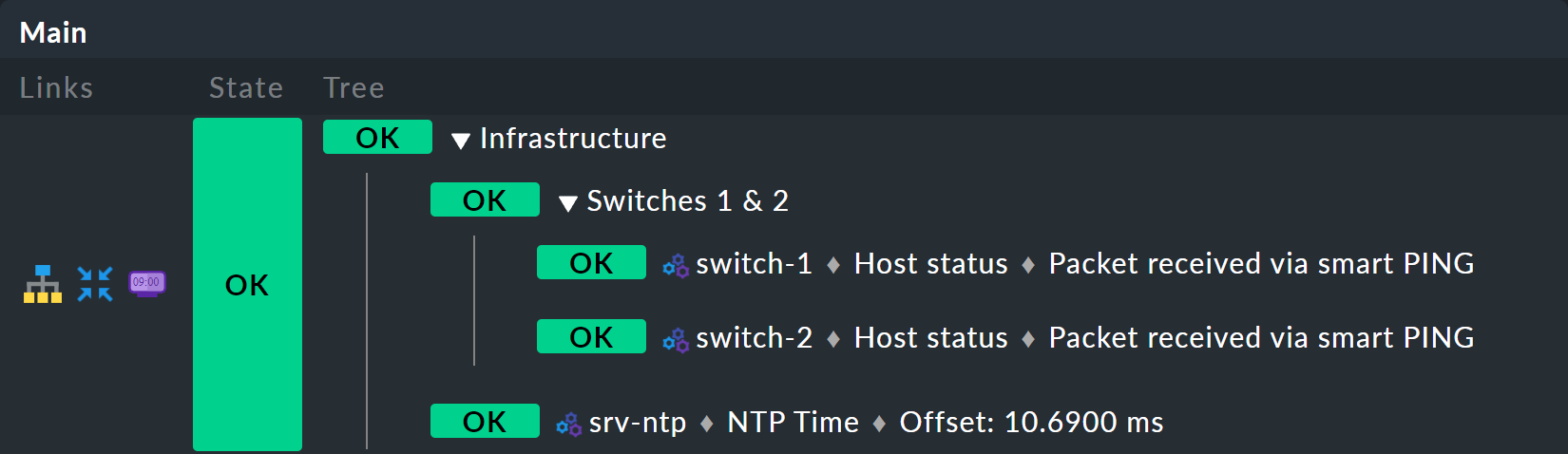
Voraussetzung ist, dass es einen Host srv-ntp gibt, der
einen Service mit dem Namen NTP Time hat:

Legen Sie erst einmal eine BI-Regel an, welche als Unterknoten 1 die Regel „Switches 1 & 2“ bekommt und als Unterknoten 2 direkt den Service NTP Time des Hosts srv-ntp. Im Kopf der Regel wählen Sie infrastructure als Regel-ID und Infrastructure als Namen. Weitere Angaben können Sie sich erst einmal sparen:
Unter Child Node Generation wird es interessant. Der erste Eintrag ist jetzt vom Typ Call a rule und als Regel wählen Sie Ihre Regel von oben aus. Damit „hängen“ Sie diese quasi in den Unterbaum ein.
Der zweite Unterknoten ist vom Typ State of a service, und hier wählen
Sie Ihren NTP-Host per Namen (bitte beachten Sie hier die exakte
Schreibung, inklusive der Groß-/Kleinbuchstaben) sowie den NTP Time-Service per Regex:
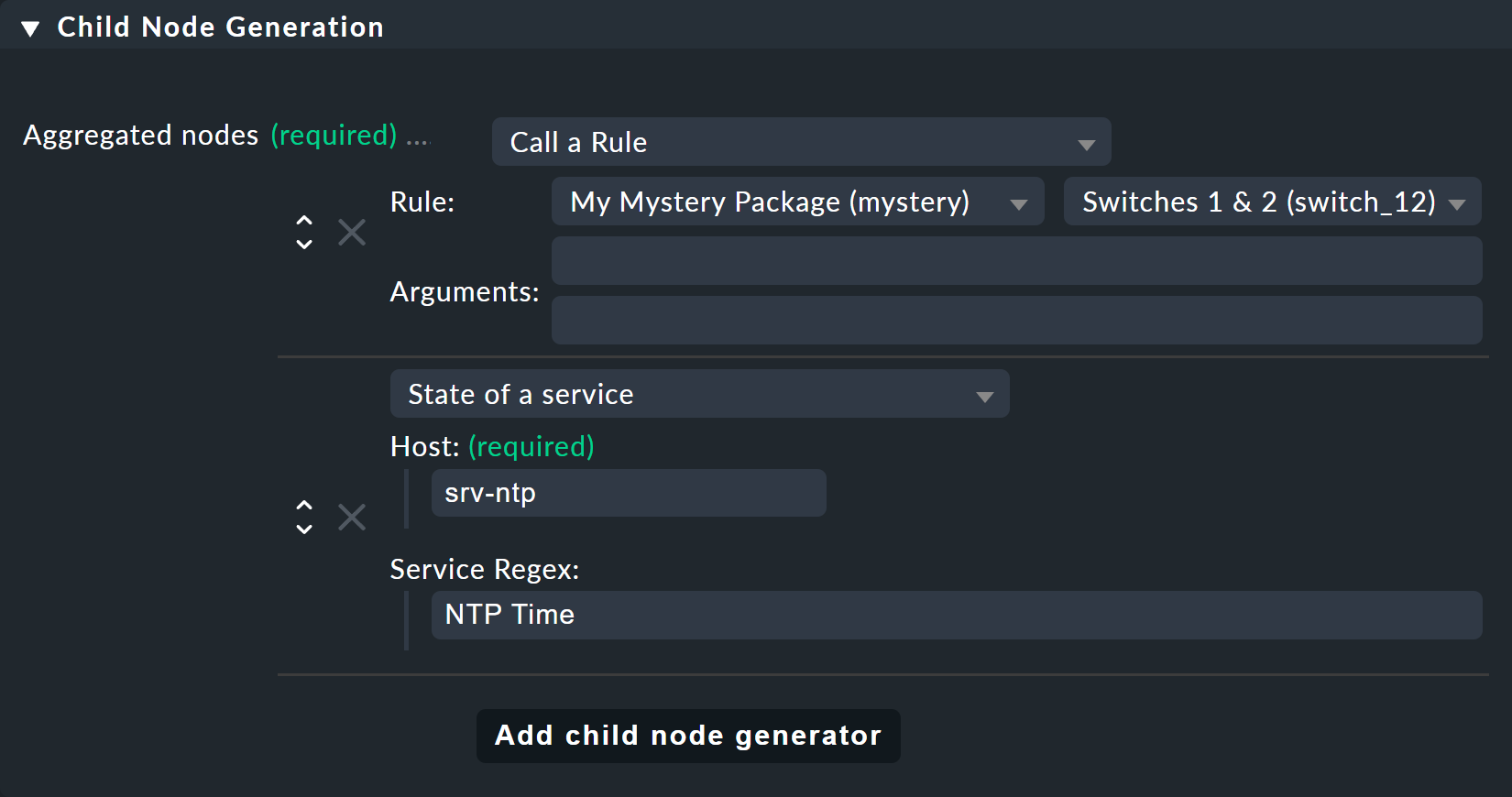
Die Aggregation Function im dritten Kasten setzen Sie dieses Mal auf Worst - take worst state of all nodes.
Der Zustand des Knotens leitet sich bei dieser Funktion also vom schlechtesten
Status eines Services darunter ab. Heißt hier: Geht NTP Time auf CRIT,
geht auch der Knoten auf CRIT.
Damit der neue größere Baum sichtbar wird, müssen Sie natürlich wieder eine Aggregation anlegen. Am besten verändern Sie einfach die bestehende Aggregation, so dass fortan die neue Regel verwendet wird:
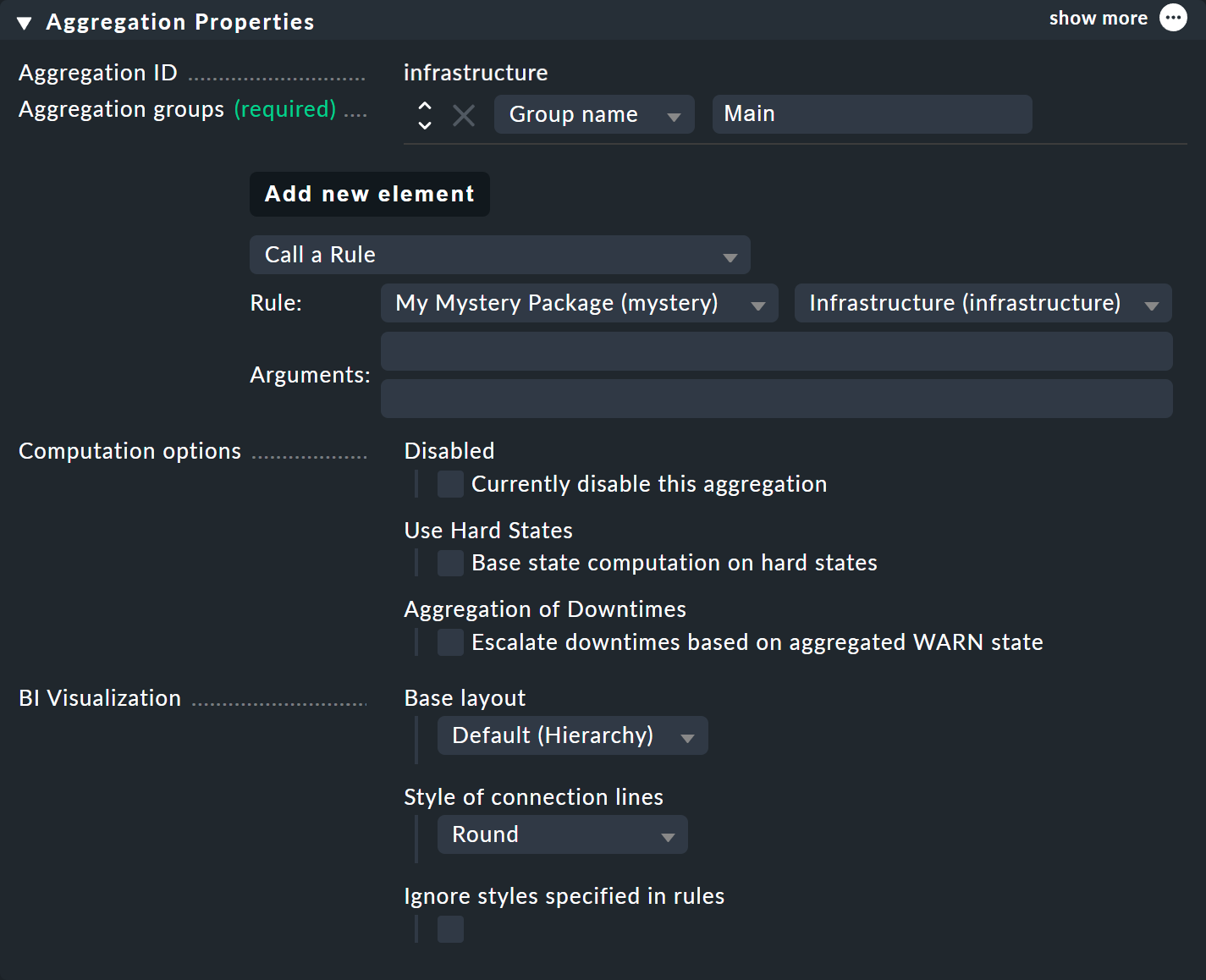
Auf diese Art bleiben Sie bei einer Aggregation. Und die sieht dann so aus (dieses mal sind beide Switches wieder auf OK):
5. BI im Operating Teil 2: Alternative Darstellungen
5.1. Einleitung
Jetzt da Sie einen etwas interessanteren Baum haben, können Sie sich etwas genauer mit den verschiedenen Darstellungsmöglichkeiten befassen, die Checkmk bietet. Ausgangspunkt dafür ist die Funktion Modify display options, welche Sie im Menü Display finden. Diese öffnet einen Kasten mit Optionen. Der Inhalt des Kastens ist immer angepasst auf die Elemente, die auf der Seite dargestellt werden. Im Falle von BI finden Sie aktuell sechs Optionen:
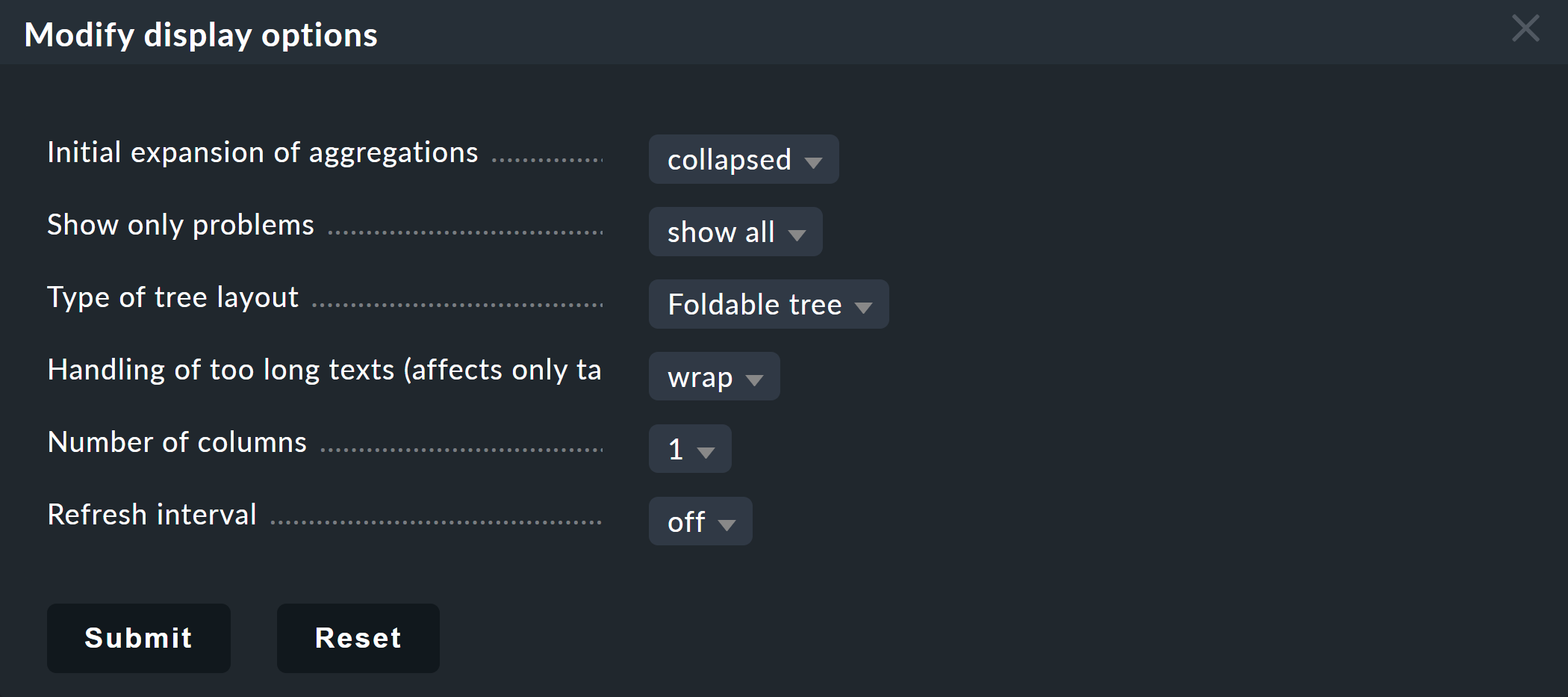
Bäume sofort auf- oder zuklappen
Wenn Sie nicht nur ein Aggregat, sondern sehr viele anzeigen, dann ist die Einstellung Initial expansion of aggregations hilfreich. Hier legen Sie fest, wie weit die Bäume beim ersten Anzeigen aufgeklappt sein sollen. Die Auswahl reicht von geschlossen (collapsed) über die ersten drei Ebenen bis hin zu komplett geöffnet (complete).
Nur Probleme zeigen
Wenn Sie die Option Show only problems aktivieren, werden in den Bäumen nur noch solche Zweige angezeigt, die nicht den Status OK haben. Das sieht dann z.B. so aus:

Art der Baumdarstellung
Unter dem Punkt Type of tree layout finden Sie etliche alternative Darstellungsarten für den Baum. Eine davon heißt Table: top down und sieht so aus:
Extrem platzsparend — vor allem, wenn Sie viele Aggregate gleichzeitig sehen möchten — ist die Darstellung Boxes. Hier ist jeder Knoten ein farbiger Kasten, der per Klick aufgeklappt wird. Die Baumstruktur ist nicht mehr sichtbar, aber Sie können sich so bei minimalem Platzbedarf schnell zu einem Problem durchklicken. Hier im Beispiel sind die Boxen komplett aufgeklappt:

5.2. Weitere Optionen
Letztlich können Sie ein Refresh interval von 30, 60 oder 90 Sekunden setzen und die Anzahl der Spalten über Number of columns bestimmen.
5.3. Visualisierung von BI-Aggregaten
Checkmk beherrscht neben tabellarischen Darstellungen
auch die Visualisierung von BI-Aggregaten. So können Sie Aggregate aus
neuer Perspektive und bisweilen übersichtlicher darstellen. Sie finden die
BI visualization über ![]() in der regulären
Aggregatsansicht.
in der regulären
Aggregatsansicht.

Sie können den Baum frei per Klick auf den Hintergrund bewegen und die gesamte Darstellung per Mausrad skalieren. Sobald der Mauszeiger über den einzelnen Knoten landet, bekommen Sie die zugehörigen Statusinformationen via Hover-Fenster. Per Mausrad skalieren Sie nun die Länge der Zweige des Baums.
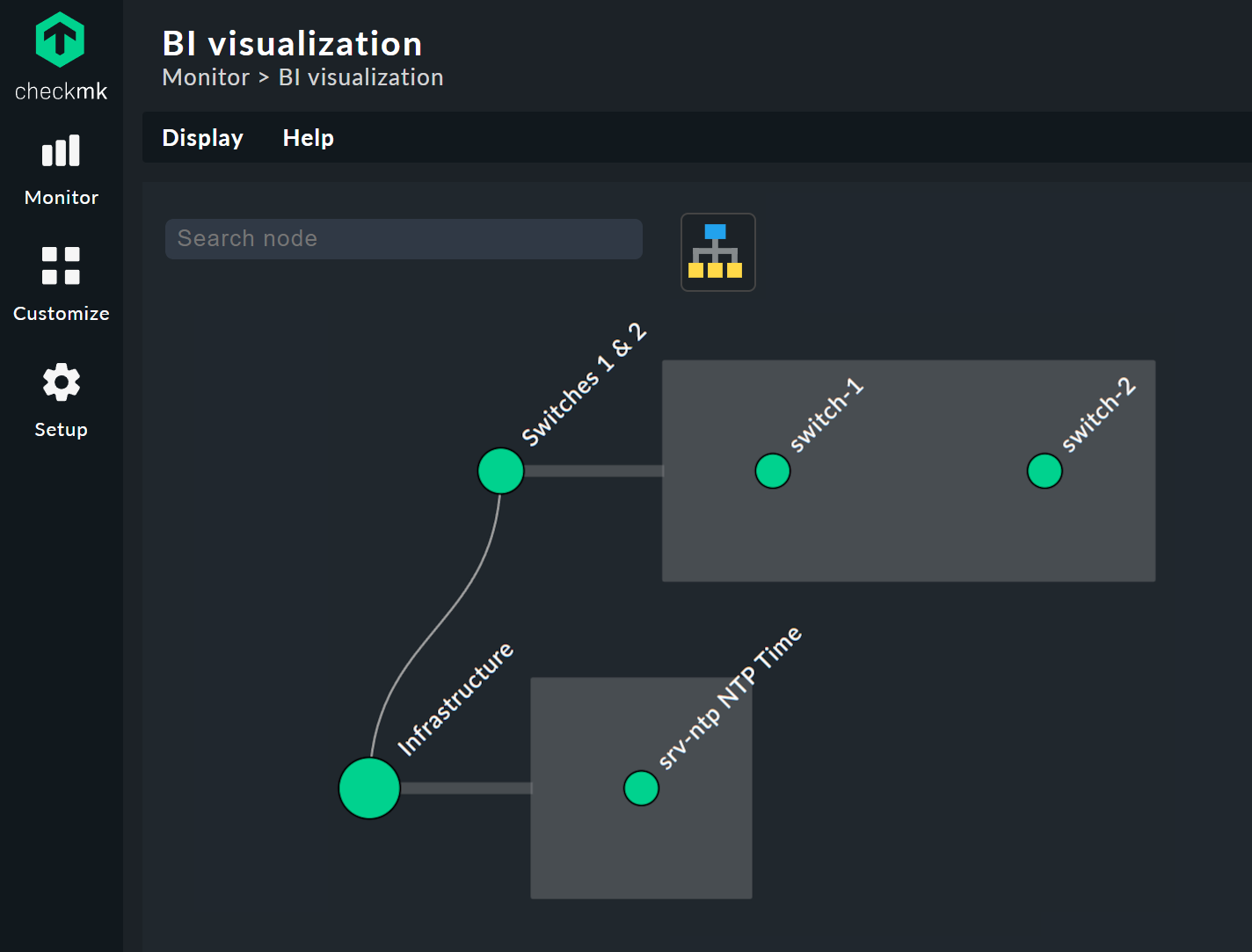
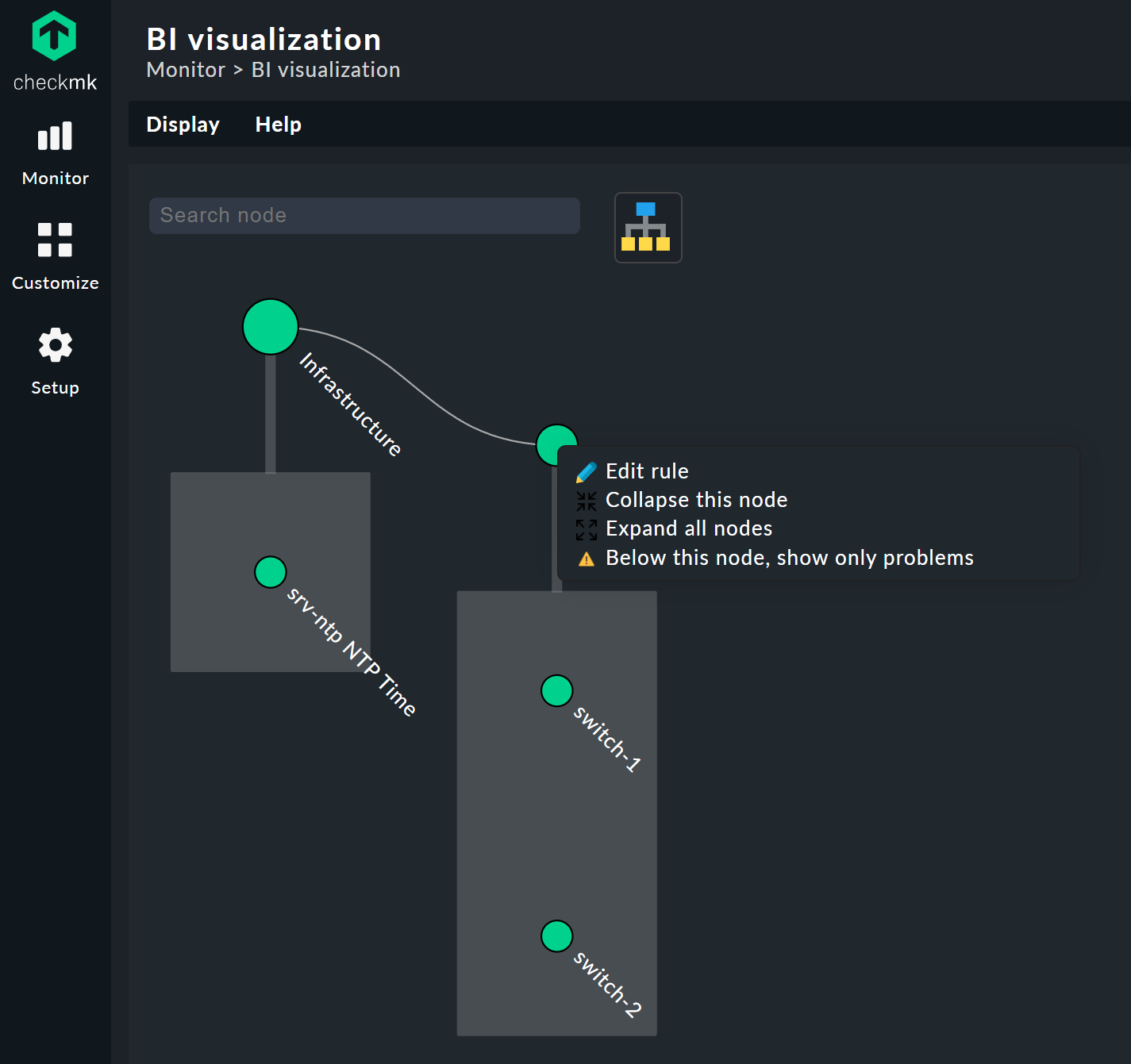
Per Klick auf die Blatt-Knoten gelangen Sie direkt zu den Detailansichten der Hosts oder Services. Per Rechtsklick auf die sonstigen Knoten erhalten Sie, je nach Art des Knotens, Zugriff auf Darstellungsoptionen und beispielsweise die verantwortliche Regel selbst; im Bild über Edit rule.
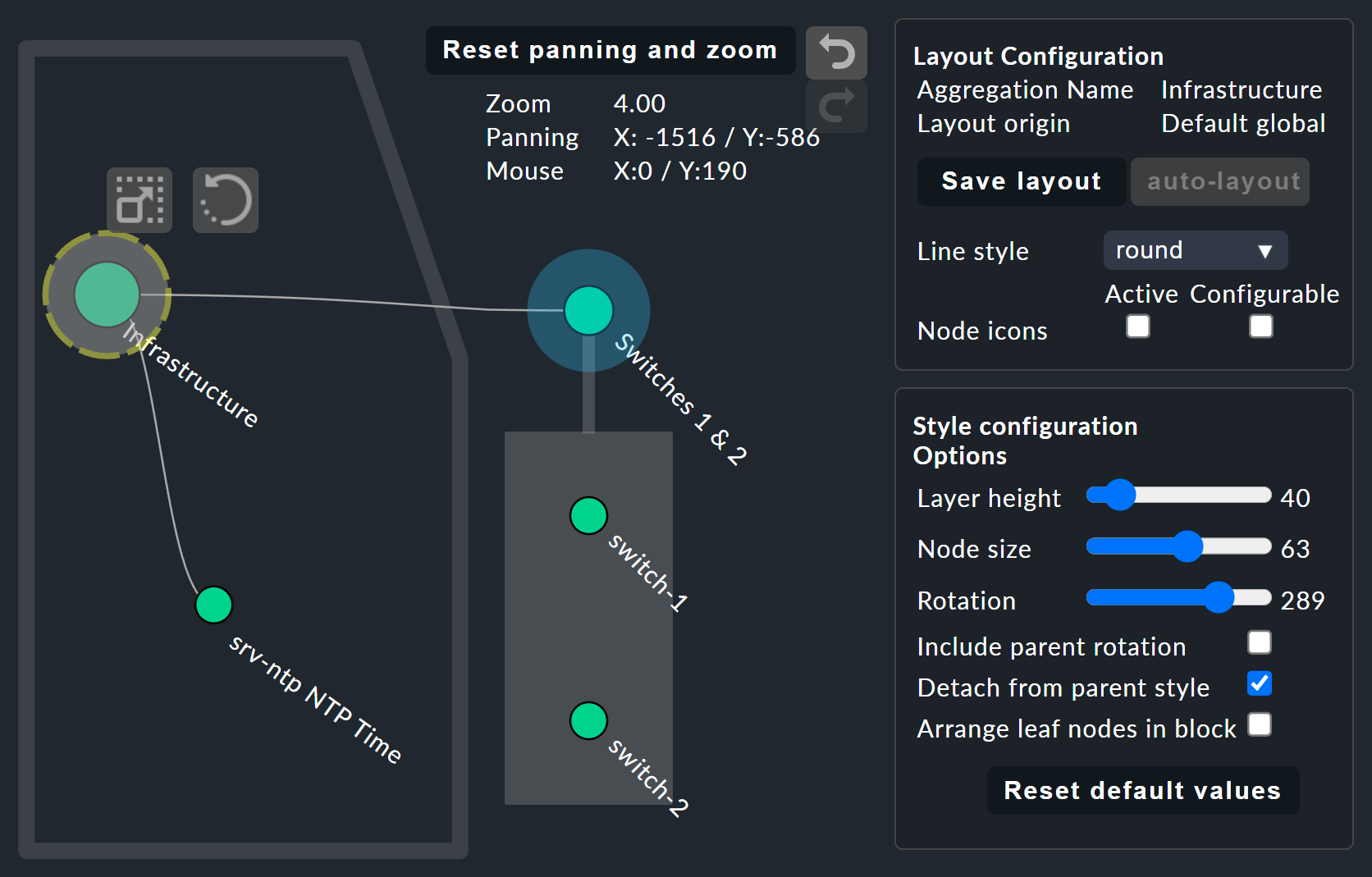
Visualisierung anpassen
Wirklich interessant wird es aber erst mit dem Layout Designer, den
Sie über ![]() oben neben dem Suchfeld öffnen. Zunächst
sehen Sie zwei neue Elemente: Den Kasten Layout Configuration und
zwei neue Icons an der Wurzel,
oben neben dem Suchfeld öffnen. Zunächst
sehen Sie zwei neue Elemente: Den Kasten Layout Configuration und
zwei neue Icons an der Wurzel, ![]() und
und
![]() .
.
In der Konfiguration haben Sie die Wahl
zwischen unterschiedlichen Linienarten und können die Node icons
aktivieren. Damit werden die Icons angezeigt, die Sie in den Regeln von
BI-Aggregaten im Bereich Aggregation Function festlegen dürfen
(direkt zu erreichen über das Kontextmenü des Knotens). Über die Icons
![]() und
und
![]() lässt sich der Baum durch Ziehen mit der Maus drehen beziehungsweise in Länge und Breite skalieren — einmal angeklickt, erscheint zudem der Kasten Style configuration mit
weiteren Darstellungsoptionen. Welche am besten passt, finden Sie durch schlichtes Ausprobieren heraus.
lässt sich der Baum durch Ziehen mit der Maus drehen beziehungsweise in Länge und Breite skalieren — einmal angeklickt, erscheint zudem der Kasten Style configuration mit
weiteren Darstellungsoptionen. Welche am besten passt, finden Sie durch schlichtes Ausprobieren heraus.
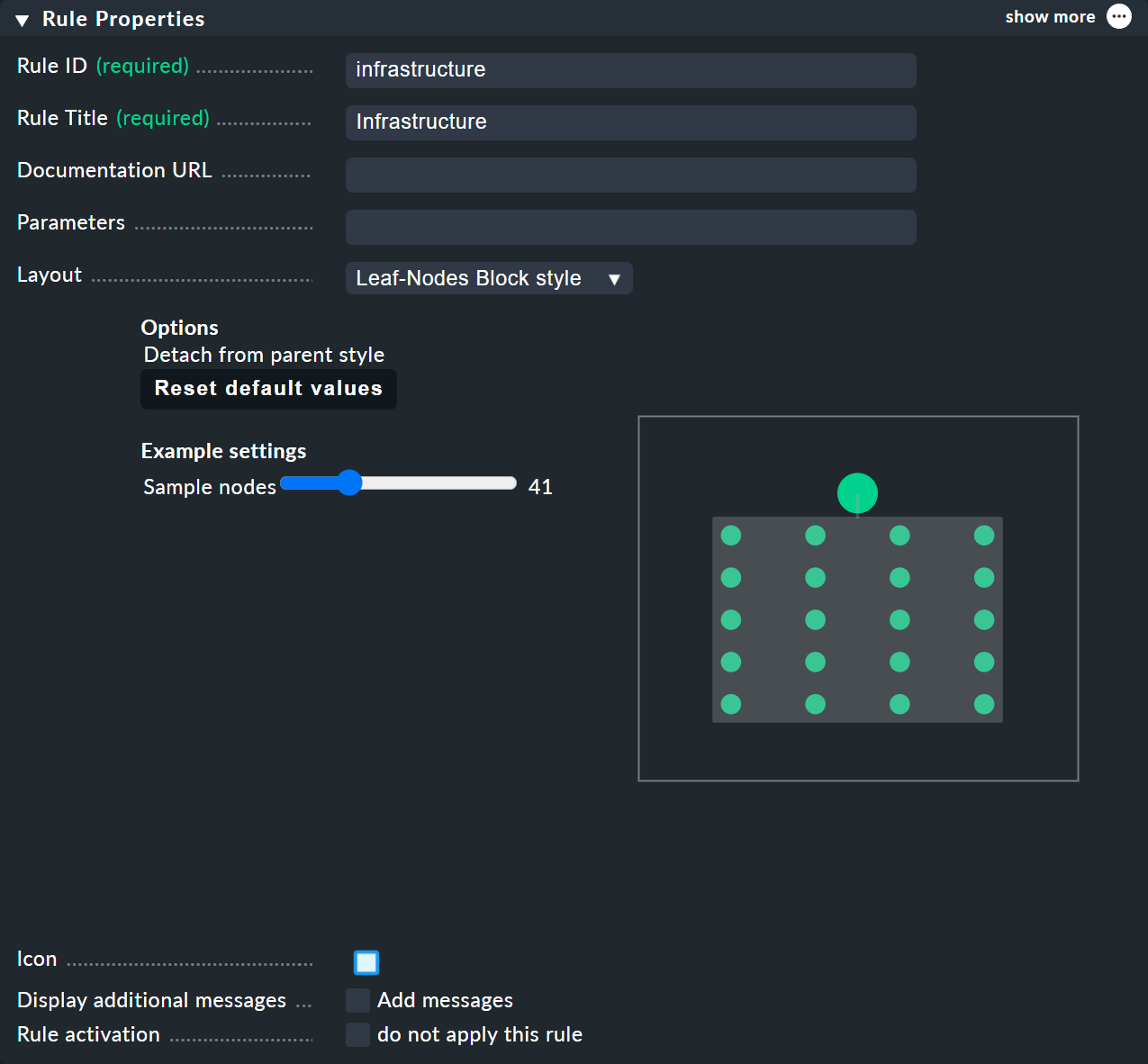
Die größten Anpassungen ermöglichen Ihnen jedoch die Kontextmenüs der Knoten, die im Designer-Modus vier verschiedene Darstellungen für die Hierarchie ab diesem Knoten bieten:
Hierarchical style: Standardeinstellung mit einfacher Hierarchie.
Radial style: Kreisförmige Anordnung mit einstellbarem Kreisausschnitt.
Leaf-Nodes Block style: Blatt-Knoten werden grau unterlegt als Gruppe dargestellt.
Free-Floating style: Dynamisches Layout mit Optionen wie Anziehung, Abständen, Länge der Äste.
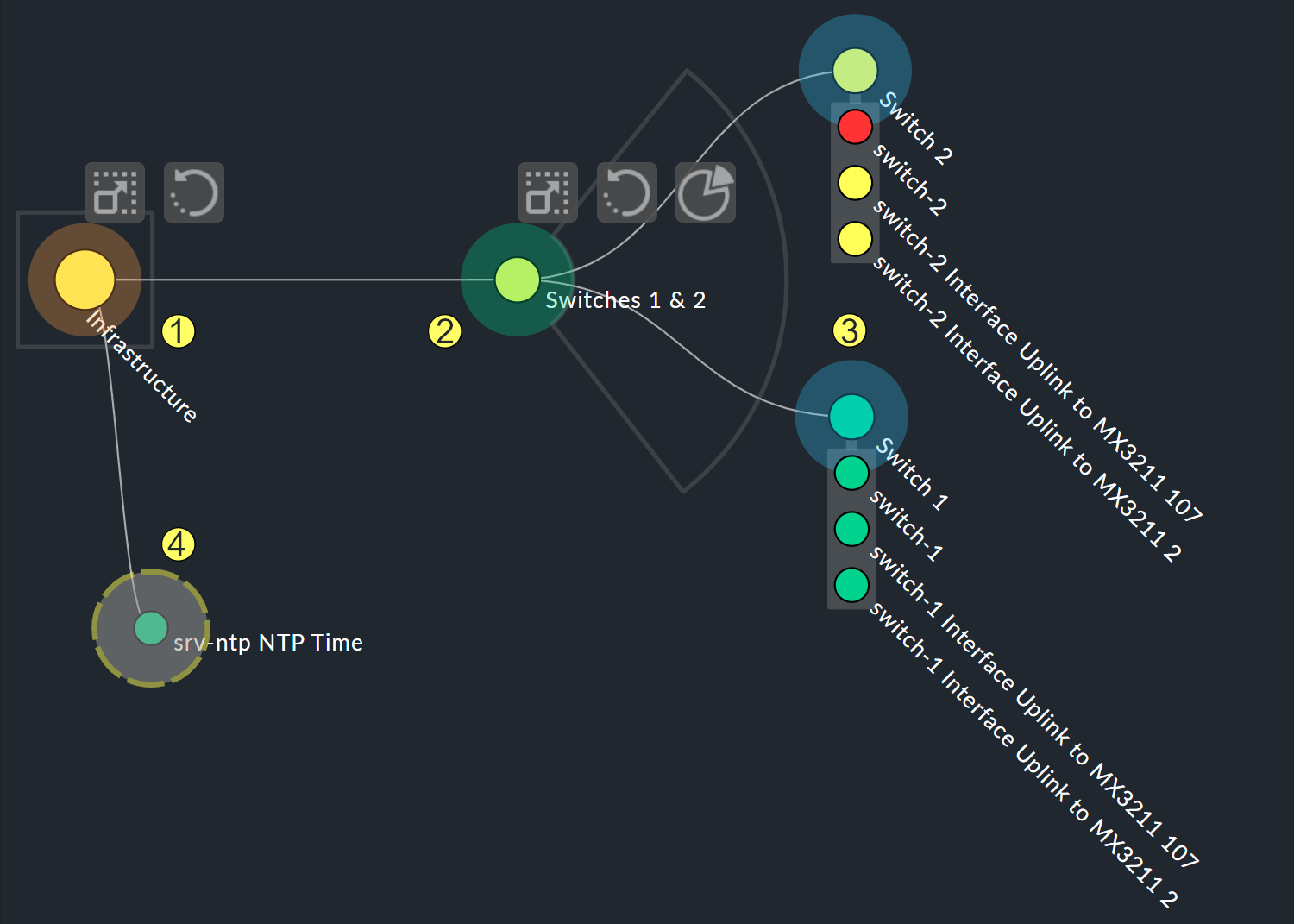
Knoten, denen ein Stil zugeordnet wurde, lassen sich frei platzieren. Je
nach Stil unterscheiden sich auch die Optionen, beim Radial style sehen
Sie am Wurzelknoten etwa ein drittes Icon
![]() , über das Sie die Darstellung auf einen
Kreisausschnitt beschränken können.
, über das Sie die Darstellung auf einen
Kreisausschnitt beschränken können.
Über die Option Detach from parent style können Sie Knoten vom Stil des übergeordneten Knotens lösen, um diese anders zu konfigurieren und frei zu platzieren. In die gleiche Richtung zielt auch Include parent rotation, womit Sie übergeordnete Knoten beim Drehen ein- und ausschließen dürfen.
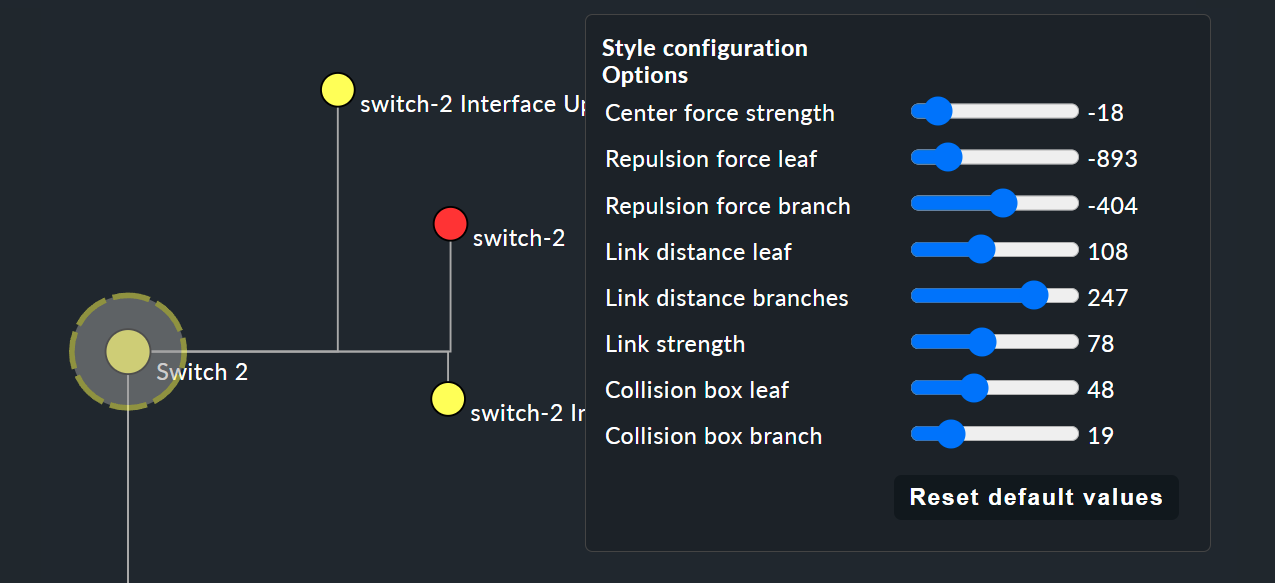
Im Grunde sind alle Stile selbsterklärend, lediglich der Free-Floating style bedarf einiger Erklärungen. Hierbei handelt es sich um ein System aus Anziehung und Abstoßung, wie Sie es von Gravitationssimulationen kennen.
Center force strength |
Anziehungskraft der Mitte auf die Knoten. |
Repulsion force leaf |
Kraft des Abstoßungseffekts von Blättern auf andere Knoten. |
Repulsion force branches |
Kraft der Abstoßung von Knoten auf andere Knoten im selben Zweig. |
Link distance leaf |
Idealer Abstand vom Blattknoten zum vorherigen Knoten. |
Link distance branches |
Idealer Abstand vom Zweigknoten zum vorherigen Knoten. |
Link strength |
Stärke, mit der der ideale Abstand erzwungen wird. |
Collision box leaf |
Größe des Blattknotenbereichs, der andere Knoten abstößt. |
Collision box branch |
Größe des Zweigknotenbereichs, der andere Knoten abstößt. |
Das folgende Bild zeigt einen Zweig im Free-Floating style — die Positionen der einzelnen Blätter ergeben sich dynamisch gemäß der gesetzten Optionen.
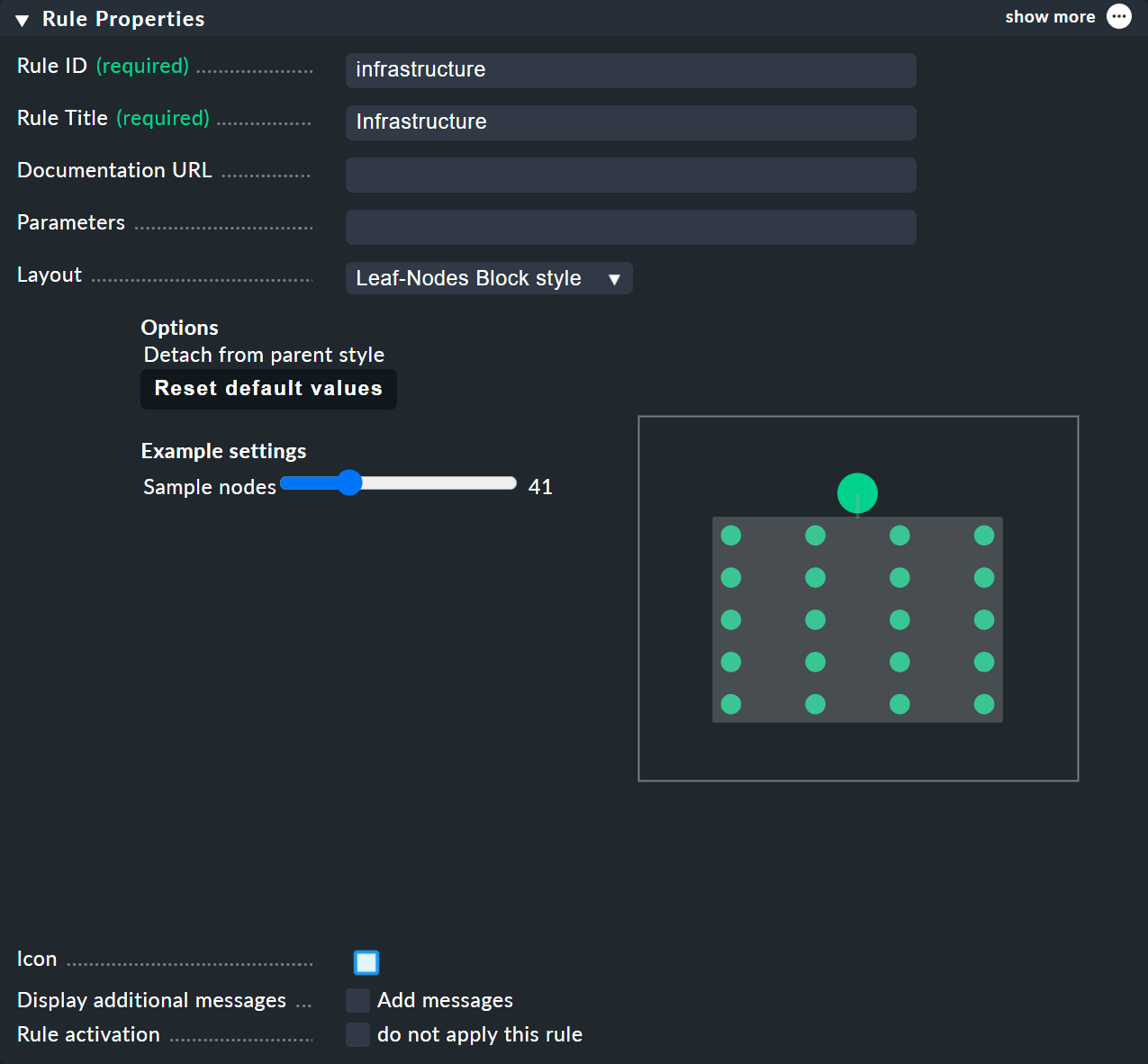
BI-Regeln Layout-Stil vorgeben
Sie können BI-Regeln, die Sie über das Kontextmenü der Knoten erreichen, im Bereich Rule Properties die Layouts Hierarchical, Radial oder Leaf-Nodes Block zuordnen sowie zugehörige Optionen festlegen.
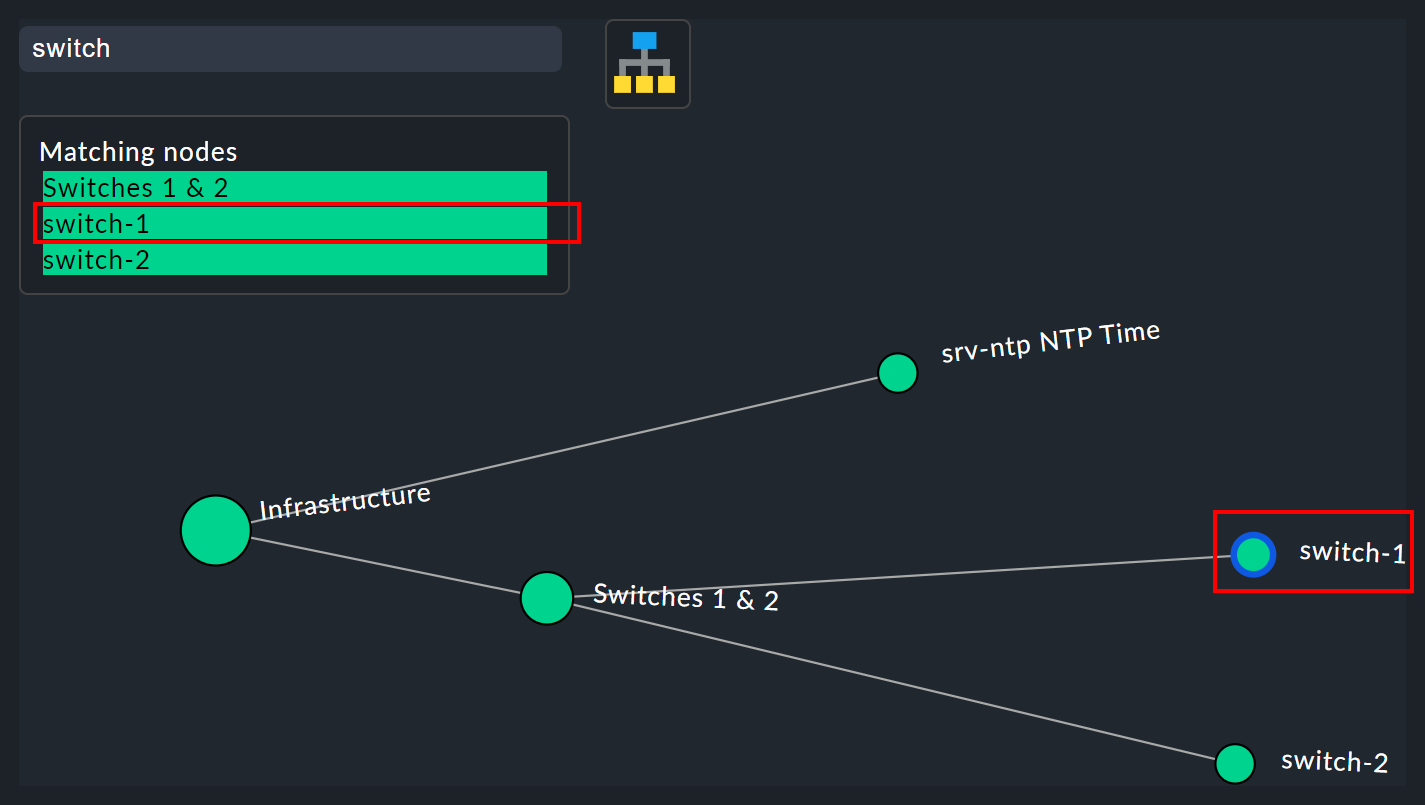
Suchfunktion
In größeren Bäumen ist die Suchfunktion eine enorme Hilfe. Im Suchfeld Search node können Sie einfach einen Namensteil des gewünschten Knotens eingeben und bekommen direkt live eine Liste mit Treffern. Wenn Sie nun mit der Maus über diese Vorschlagsliste fahren, wird der Node unter dem Mauszeiger im Baum durch einen blauen Rand hervorgehoben — das erleichtert eine erste Orientierung. Klicken Sie auf einen Node in der Liste, wird der Baum auf diesen zentriert. So lässt sich auch in Visualisierungen mit Hunderten Nodes schnell der passende Bereich Ihrer Infrastruktur finden.
6. Konfiguration Teil 3: Variablen, Schablonen, Suche
6.1. Konfiguration mit mehr Intelligenz
Weiter geht’s mit der Konfiguration. Und jetzt wird es Zeit, dass es wirklich zur Sache geht. Bisher war das Beispiel nämlich so einfach, dass es ohne Schwierigkeit möglich war, die Objekte in der Aggregation alle einzeln aufzulisten. Aber was, wenn die Dinge komplexer werden? Wenn Sie viele immer wiederkehrende gleiche oder ähnliche Abhängigkeiten formulieren wollen? Wenn es von einer Anwendung nicht nur eine, sondern mehrere Instanzen gibt? Oder wenn Sie mal eben hundert Einzelservices einer Datenbank zu einem BI-Knoten zusammenfassen wollen?
Nun, dann brauchen Sie mächtigere Methoden der Konfiguration. Und die sind genau das, was Checkmk BI gegenüber anderen Tools auszeichnet — und leider auch die Lernkurve etwas steiler gestaltet. Es ist auch der Grund, warum Checkmk BI sich nicht per „Drag-and-Drop“ konfigurieren lässt. Aber wenn Sie die Möglichkeiten erst einmal kennengelernt haben, werden Sie sie sicher nicht mehr missen wollen.
6.2. Parameter
Beginnen Sie mit den Parametern. Nehmen Sie folgende Situation: Sie möchten bei den beiden Switches nicht nur feststellen, ob sie UP sind, sondern auch den Zustand von zwei Ports wissen, die für den Uplink zuständig sind. Insgesamt geht es um folgende vier Services:
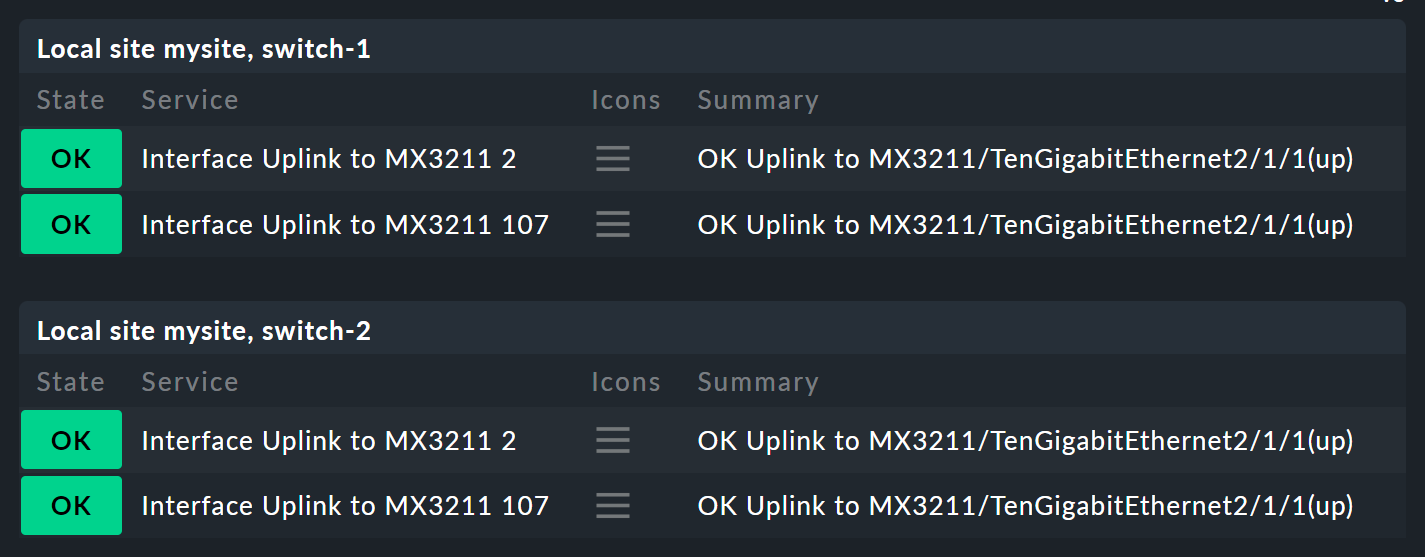
Nun soll der Knoten Switch 1 & 2 so erweitert werden, dass es anstelle der beiden Hostzustände für Switch 1 und 2 jeweils einen Unterknoten gibt, der den Hoststatus und die beiden Uplink-Interfaces zeigt. Diese beiden Unterknoten sollen Switch 1 bzw. Switch 2 heißen.
Eigentlich bräuchten Sie jetzt also zwei neue Regeln — für jeden Switch eine. Besser
geht das, indem Sie eine neue Regel switch erstellen, diese aber mit einem Parameter
ausstatten. Dieser Parameter ist eine Variable, die man beim Aufruf der Regel
aus dem übergeordneten Knoten, hier die alte Regel Switch 1 & 2,
mitgeben kann. Im Beispiel können Sie einfach entweder 1 oder
2 übergeben. Der Parameter bekommt einen Namen, den Sie frei wählen
können. Nehmen Sie hier z. B. den Namen NUMBER. Die Schreibweise mit
Großbuchstaben ist rein willkürlich. Wenn Sie Kleinbuchstaben schöner finden,
können Sie gerne auch diese verwenden.
Und so sieht der Kopf der Regel aus:
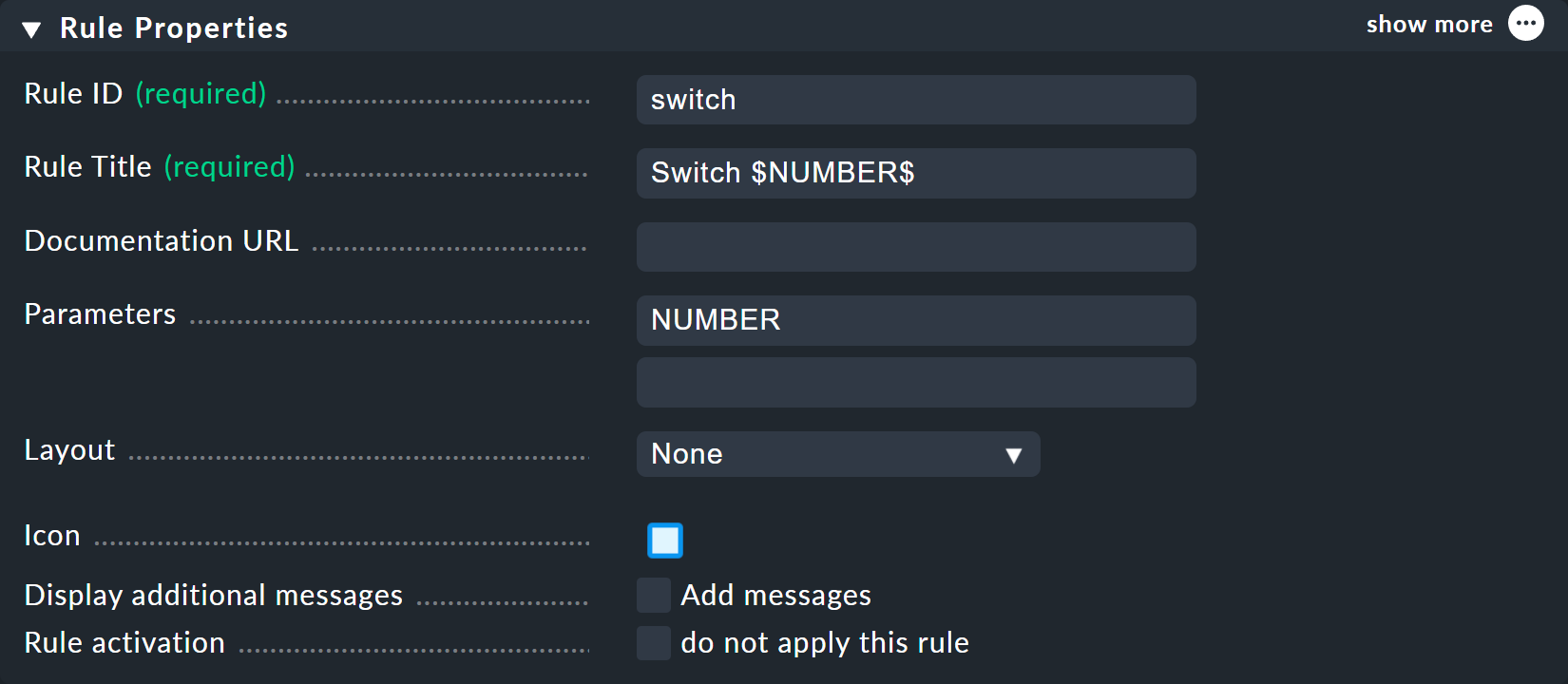
Als ID für die neue Regel können Sie hier switch wählen. Bei Parameter
tragen Sie einfach den Namen der Variablen ein: NUMBER. Wichtig
ist jetzt, dass auch im Rule Title der Regel die Variable eingesetzt
wird, damit nicht beide Knoten einfach nur Switch heißen und so
den gleichen Namen hätten. Beim Verwenden der Variable wird (wie an
vielen Stellen in Checkmk üblich) vorne und hinten ein Dollarzeichen gesetzt.
Als Ergebnis werden die beiden Knoten dann Switch 1 und
Switch 2 heißen.
Präfix-Match ist für Servicenamen Default
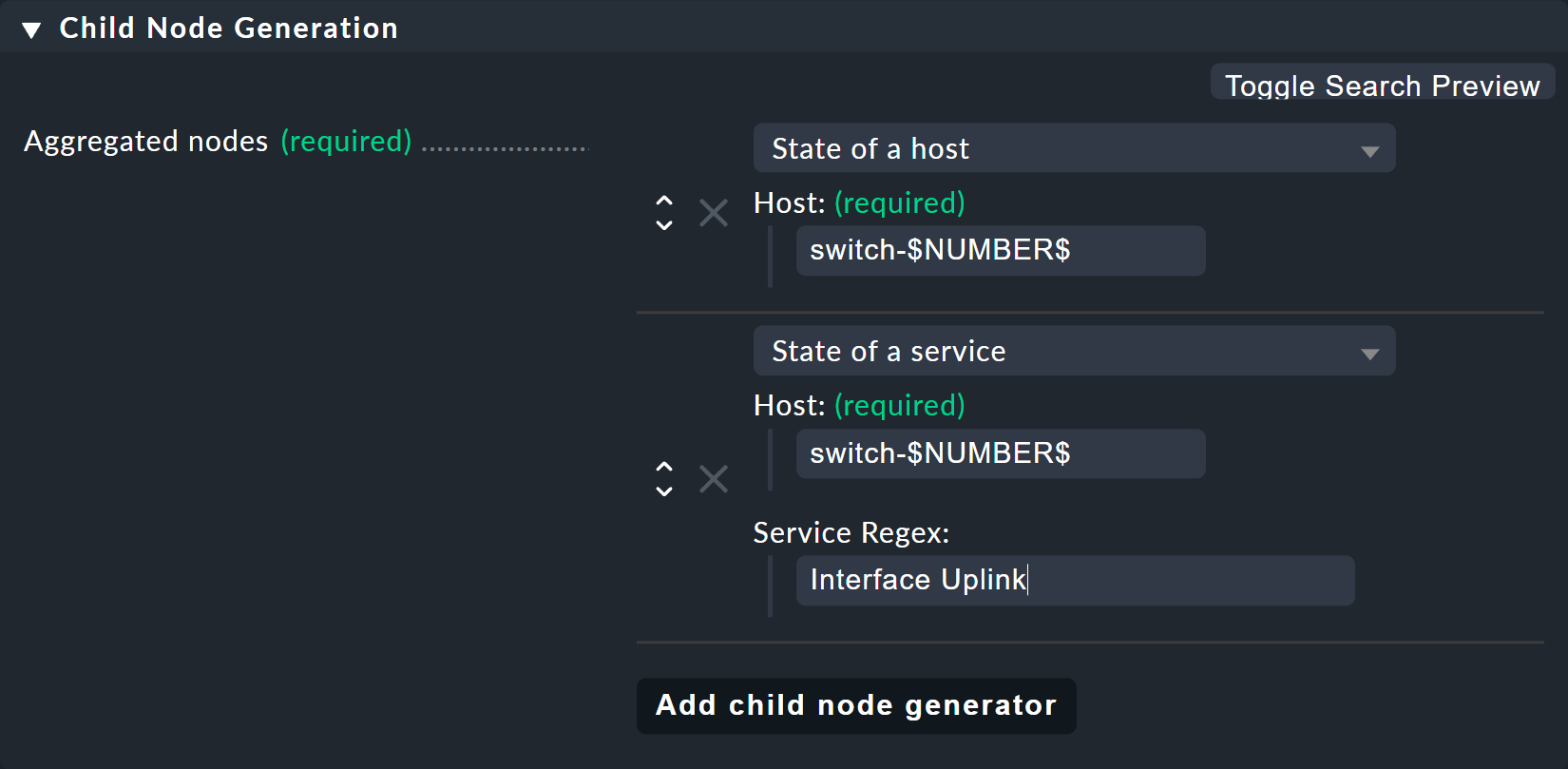
Unter Child Node Generation fügen Sie jetzt als erstes den Hostzustand ein.
Dabei dürfen Sie beim Hostnamen anstelle der 1 oder 2
einfach Ihre Variable einsetzen und zwar auch hier wieder mit je einem
$ hinten und vorne.
Das Gleiche machen Sie bei dem Hostnamen der Uplink-Interfaces. Und hier kommt
gleich noch der zweite Trick. Denn wie Sie vielleicht an der kleinen Serviceliste
oben bemerkt haben, heißen die Services für den Uplink bei beiden Switchen
unterschiedlich! Das ist aber kein Problem, da BI den Servicenamen — ganz
analog zu den bekannten Service-Regeln — immer als Präfix-Match mit
regulären Ausdrücken interpretiert. Schreiben Sie also einfach Interface Uplink,
erwischen Sie so alle Services auf dem jeweiligen Host, die
mit Interface Uplink beginnen:
Übrigens: Durch das Anhängen von $ können Sie das Präfix-Verhalten
abschalten. Ein $ bedeutet bei regulären Ausdrücken — im Kontext der Checkmk-Regeln — soviel wie
„Der Text muss hier enden“. Also matcht Interface 1$ auch
nur auf Interface 1 und nicht z.B. auch auf Interface 10.
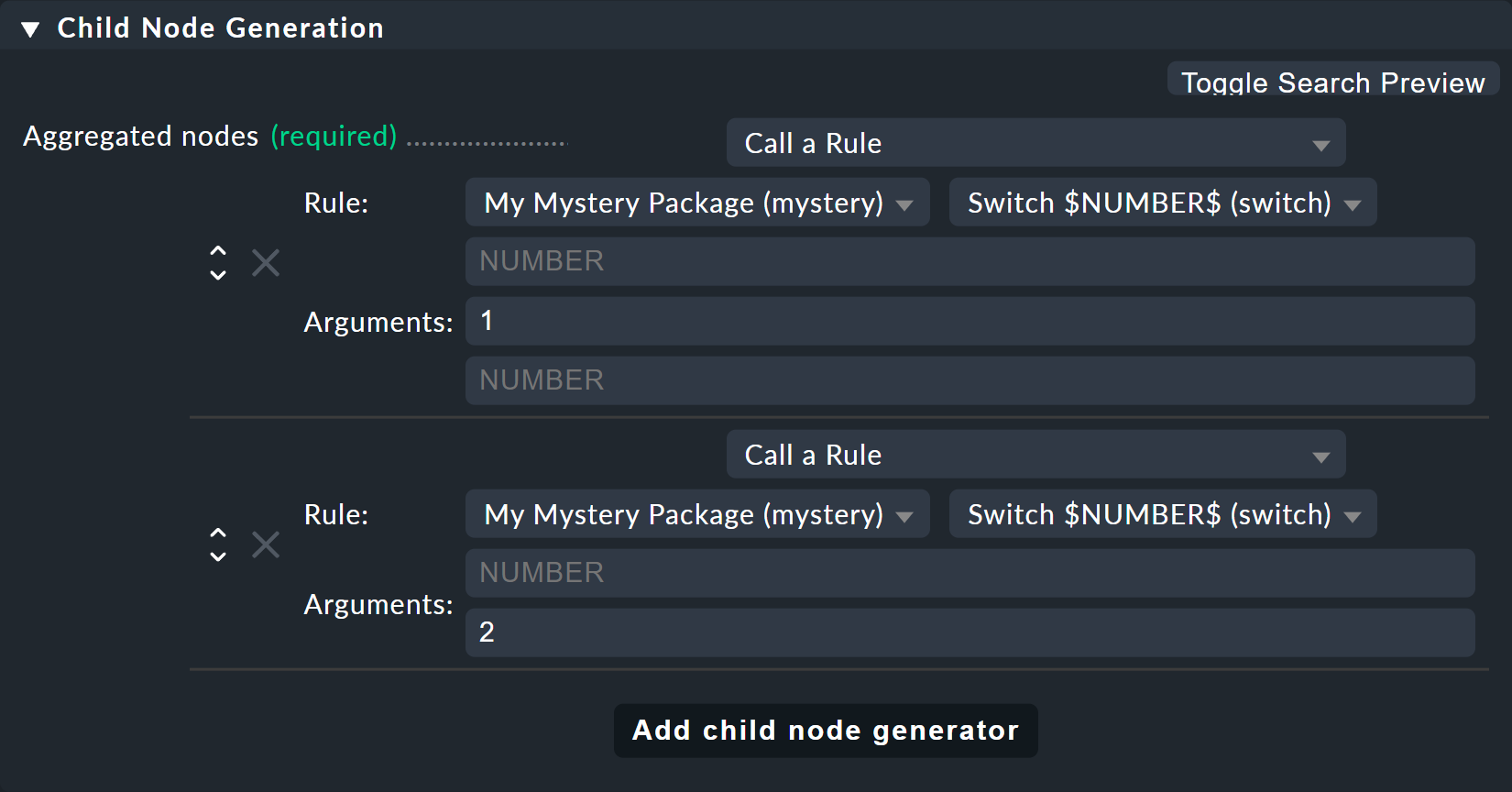
Bauen Sie jetzt noch die alte Regel Switch 1 & 2 so um, dass diese
anstelle der Hostzustände die neue Regel für jeden der beiden Switche je
einmal aufruft. Und hier ist jetzt auch die Stelle, an der Sie die Werte
1 und 2 als Parameter für die Variable NUMBER
übergeben:
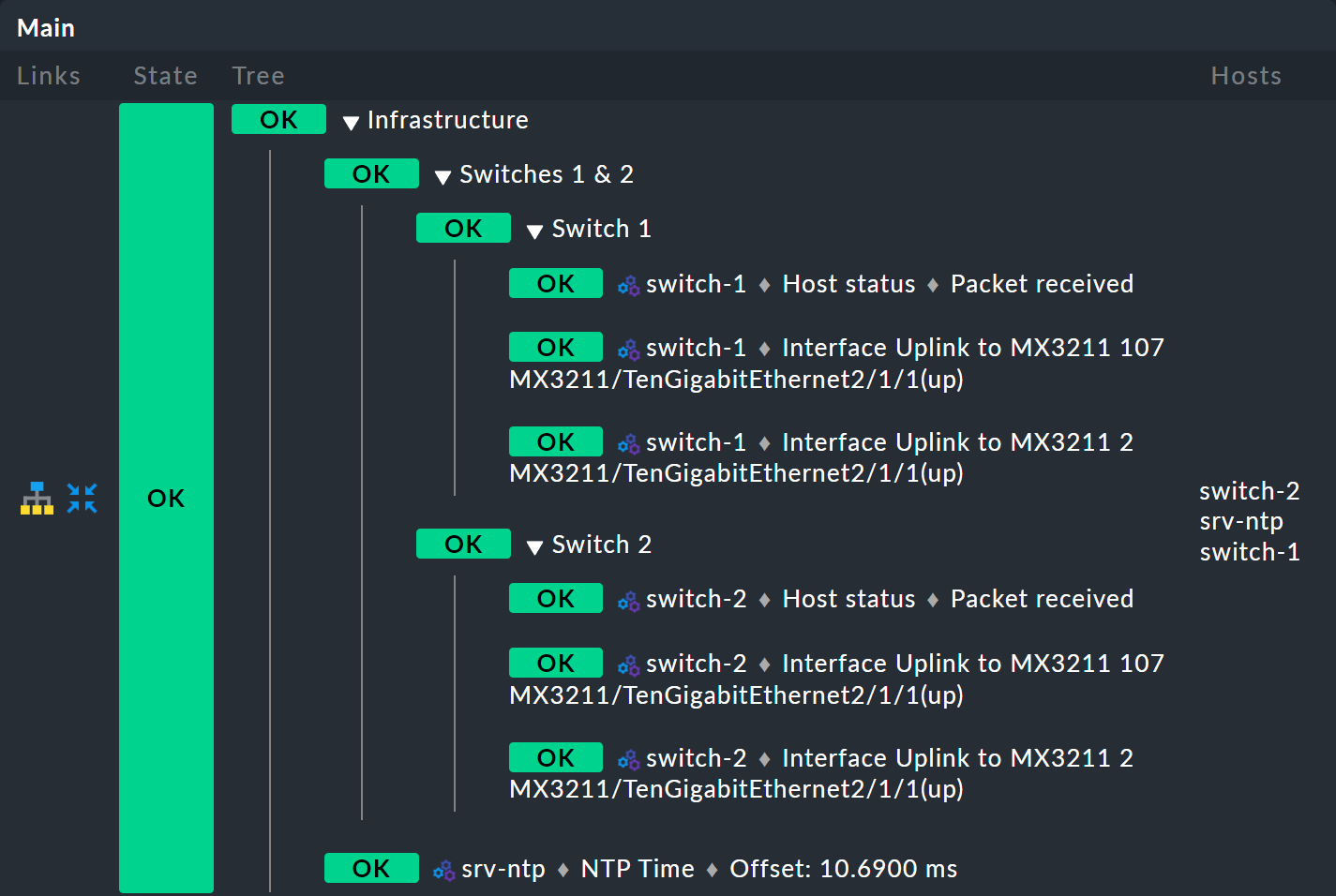
Und voila: Schon haben Sie einen hübschen Baum mit drei Ebenen:
6.3. Reguläre Ausdrücke, fehlende Objekte
Die Sache mit den regulären Ausdrücken ist nochmal einen genaueren Blick wert. Beim Matching der Servicenamen haben wir nämlich am Anfang stillschweigend unterschlagen, dass es sich eben grundsätzlich um reguläre Ausdrücke handelt. Wie gerade erwähnt, findet dabei ein Präfix-Match statt.
Wenn Sie also in einem BI-Knoten beim Servicenamen z. B. Disk angeben,
werden alle Services des betreffenden Hosts eingefangen, die mit
Disk beginnen.
Dabei gelten generell folgende Prinzipien:
Wenn sich ein Knoten auf Objekte bezieht, die es (aktuell) nicht gibt, dann werden diese einfach weggelassen.
Wenn ein Knoten dadurch leer wird, wird er selbst weggelassen.
Ist auch der Wurzelknoten eines Aggregats leer, wird das Aggregat selbst weggelassen.
Vielleicht klingt das für Sie erst einmal etwas verwegen. Ist es nicht gefährlich, einfach Dinge, die da sein sollten, stillschweigend wegzulassen, wenn sie fehlen?
Nun — mit der Zeit werden Sie feststellen, wie praktisch dieses Konzept ist. Denn dadurch können Sie „intelligente“ Regeln schreiben, die auf sehr unterschiedliche Situationen reagieren können. Gibt es einen Service, der nicht bei jeder Instanz einer Anwendung vorhanden ist? Kein Problem — er wird einfach nur dann berücksichtigt, wenn er auch da ist. Oder werden Hosts oder Services vorübergehend aus dem Monitoring genommen? Dann verschwinden diese einfach aus BI, ohne dass es zu Fehlern oder dergleichen kommt. BI ist nicht dafür da, um festzustellen, ob Ihre Monitoringkonfiguration vollständig ist!
Dieses Prinzip gilt übrigens auch bei explizit definierten Services. Denn eigentlich
gibt es diese ja nicht, weil die Servicenamen ja immer als reguläre Ausdrücke
gesehen werden, auch wenn sie keine speziellen Sonderzeichen wie .*
enthalten. Es handelt sich immer automatisch um ein Suchmuster.
6.4. Knoten als Ergebnis einer Suche anlegen
Sie können aber noch weiter automatisieren und vor allem flexibel auf Veränderungen
reagieren. Weiter geht es mit dem Beispiel der beiden Anwendungsserver
srv-mys-1 und srv-mys-2 aus dem Beispiel. Ihr Baum soll
weiter wachsen. Der Knoten Infrastructure soll auf Ebene 2 rutschen.
Und als endgültige Wurzel soll eine Regel mit dem
Titel The Mystery Application dienen, unter der alles hängen wird. Neben
Infrastructure soll es einen Knoten mit dem Namen Mystery Servers
geben.
Unter diesem sollen die (aktuell) zwei Mystery-Server hängen. Von jedem
kommen ein paar exemplarische Services in das Aggregat.
Das Ergebnis soll so aussehen:
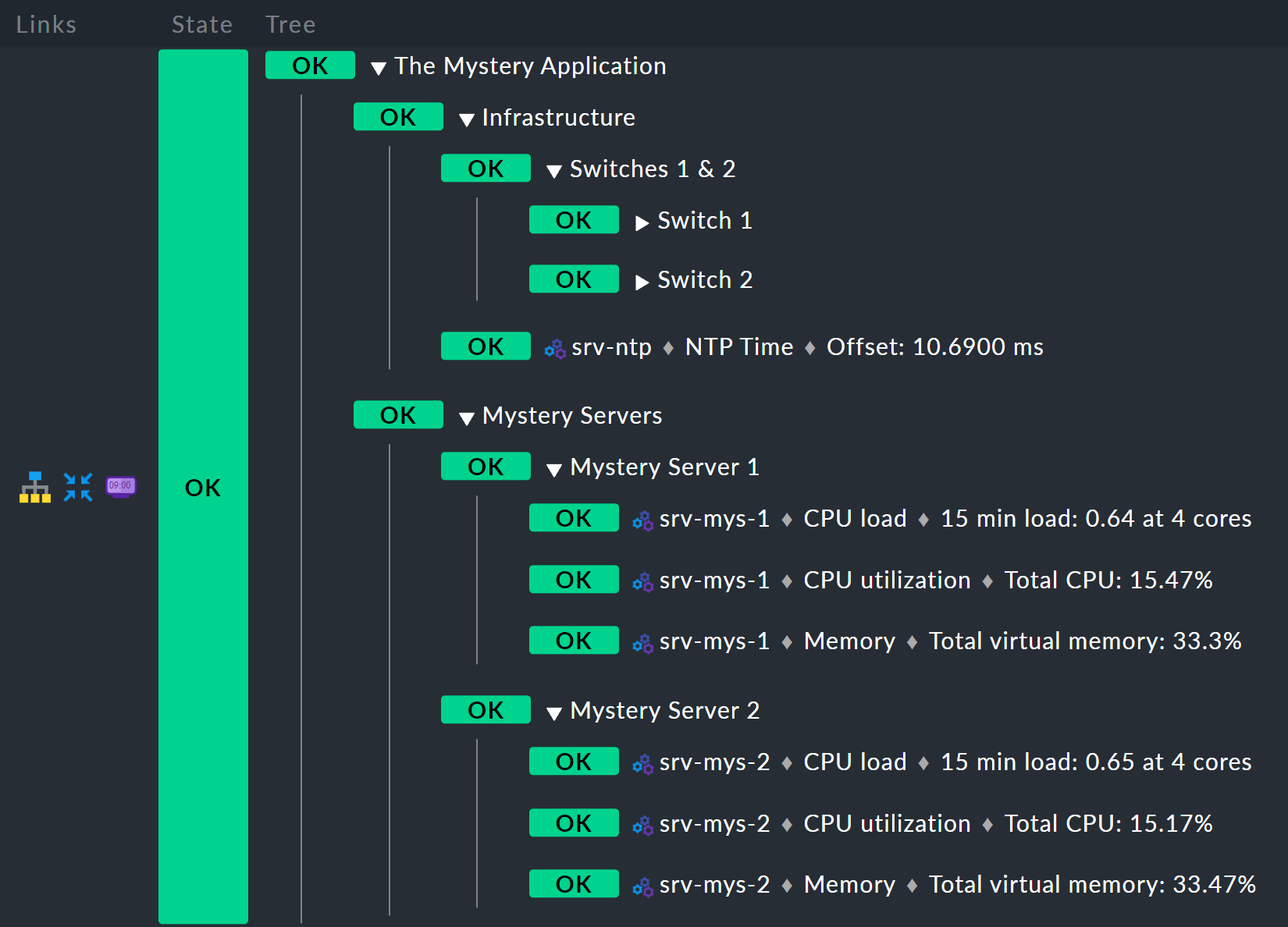
Unterste Regel: Mystery Server X
Fangen Sie von unten an. Denn das ist in BI immer der einfachste Weg.
Unten gibt es die neue Regel Mystery Server X. Natürlich verwenden
Sie einen Parameter, damit Sie nicht für jeden Server eine eigene
Regel brauchen. Den Parameter nennen Sie z. B. wieder NUMBER.
Er soll dann später als Wert 1 oder 2 haben.
Wie bereits oben geschehen, müssen Sie NUMBER abermals
im Kopf der Regel bei Parameters eintragen.
Der folgende Child-Node-Generator sieht dann so aus:
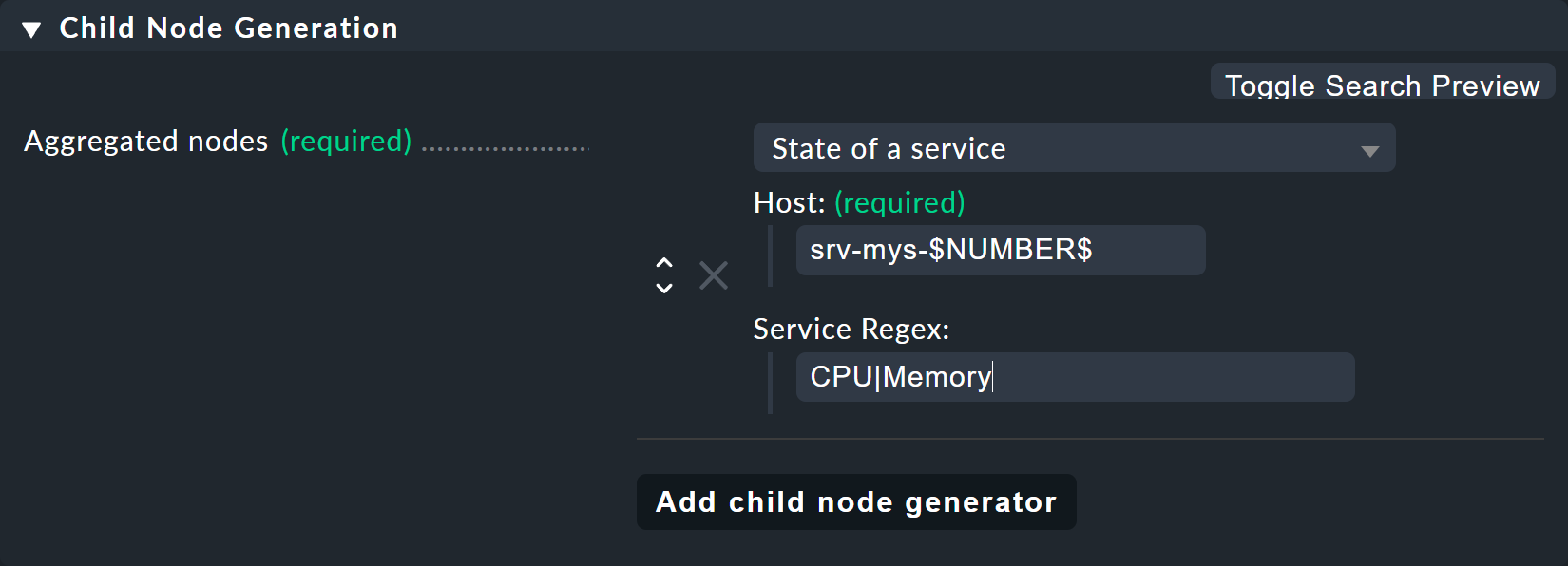
Hier ist Folgendes bemerkenswert:
Beim Hostnamen
srv-mys-$NUMBER$wird die Nummer aus dem Parameter eingesetzt.Bei Service Regex: wird der raffinierte reguläre Ausdruck
CPU|Memoryeingesetzt, der mit einem senkrechten Balken alternative Servicenamen (-anfänge) zulässt und auf alle Services matcht, die mitCPUoderMemorybeginnen. Das spart eine Verdoppelung der Konfiguration!
Übrigens: Dieses Beispiel ist natürlich noch nicht unbedingt perfekt. Zum Beispiel wurde Status des Hosts selbst gar nicht aufgenommen. Wenn also einer der Server DOWN geht, werden die Services auf diesem veralten (stale gehen), aber der Zustand wird OK bleiben und das Aggregat von dem Ausfall nichts „mitbekommen“. Wenn Sie so etwas aber wissen möchten, sollten Sie neben den Services auf jeden Fall auch den Hoststatus aufnehmen.
Mittlere Regel: Mystery Servers
Diese Regel wird interessant. Sie fasst die beiden Mystery-Server zu einem Knoten zusammen. Nun soll es möglich sein, dass die Anzahl der Server nicht festgelegt ist und durchaus später auch mal drei oder mehr sein kann. Oder es könnte gar sein, dass es dutzende Instanzen der Mystery-Anwendung gibt — jede mit einer anderen Anzahl von Servern.
Der Trick liegt im Child-Node-Generator-Typ Create nodes based on a host search. Dieser sucht nach vorhandenen Hosts und erzeugt Knoten auf Basis der gefundenen Hosts. Er sieht hier so aus:
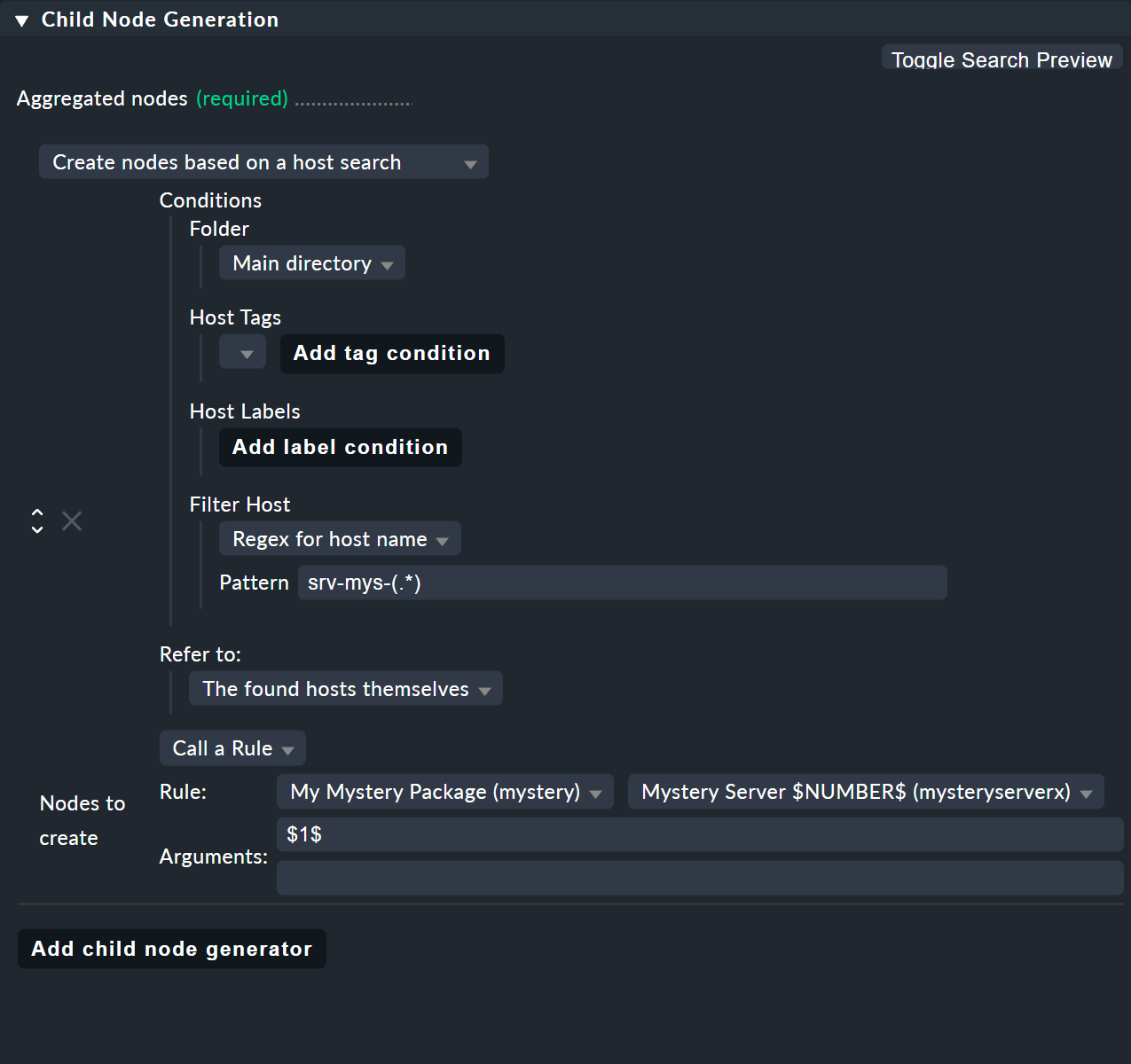
Das Ganze funktioniert so:
Sie formulieren eine Suchbedingung, um Hosts zu finden.
Für jeden gefundenen Host wird ein Child-Node angelegt.
Dabei können Sie aus den gefundenen Hostnamen Teile herausschneiden und als Parameter bereitstellen.
Den Anfang macht das Finden. Hier stehen Ihnen wie üblich Hosttags zur Verfügung. Im
Beispiel können Sie darauf verzichten und stattdessen den regulären Ausdruck srv-mys-(.*)
für den Hostnamen verwenden. Dieser matcht auf alle Hosts, die mit srv-mys- beginnen.
Das .* steht für eine beliebige Zeichenfolge.
Wichtig ist hierbei, dass das .* eingeklammert ist, also (.*). Durch
die Klammerung bildet der Match eine sogenannte Gruppe. In dieser wird genau der Text eingefangen (und gespeichert),
auf den das .* matcht — hier also 1 oder 2.
Die Matchgruppen werden intern durchnummeriert. Hier gibt es nur
eine, welche die Nummer 1 bekommt.
Auf den gematchten Text können Sie später daher mit $1$ zugreifen.
Die Suche wird jetzt zwei Hosts finden:
| Hostname | Wert von $1$
|
|---|---|
srv-mys-1 |
1 |
srv-mys-2 |
2 |
Für jeden gefundenen Host erzeugen Sie einen Unterknoten mit der
Funktion Call a rule. Wählen Sie die Regel Mystery Server $NUMBER$ aus,
die Sie gerade angelegt haben. Als Argument für NUMBER
übergeben Sie die Matchgruppe: $1$.
Jetzt wird also die Unterregel Mystery Server $NUMBER$ zweimal aufgerufen:
einmal mit 1 und einmal mit 2.
Sollte in Zukunft einmal ein neuer Server mit dem Namen srv-mys-3 ins Monitoring
aufgenommen werden, so wird dieser automatisch im BI-Aggregat auftauchen.
Der Zustand des Hosts ist dabei egal.
Auch wenn der Server DOWN ist,
wird er natürlich nicht aus dem Aggregat entfernt!
Zugegeben, das ist hier eine sehr steile Lernkurve. Diese Methode ist wirklich komplex. Aber wenn Sie das erst einmal ausprobiert und verstanden haben, werden Sie auch verstehen, wie mächtig das ganze Konzept ist. Und bislang wurden die Möglichkeiten gerade erst angekratzt!
Oberste Regel
Der neue oberste Knoten The Mystery Application ist jetzt einfach: Dazu ist eine neue Regel notwendig, die zwei Unterknoten der Art Call a rule hat. Diese beiden Regeln sind die bestehende Infrastructure und die gerade neu angelegte Regel mit dem Namen Mystery Servers.
6.5. Knoten mit Servicesuche anlegen
Analog zu der Hostsuche gibt es auch einen Child-Generator-Typ der Create nodes based on a service search heißt. Hier sehen Sie ein Beispiel:
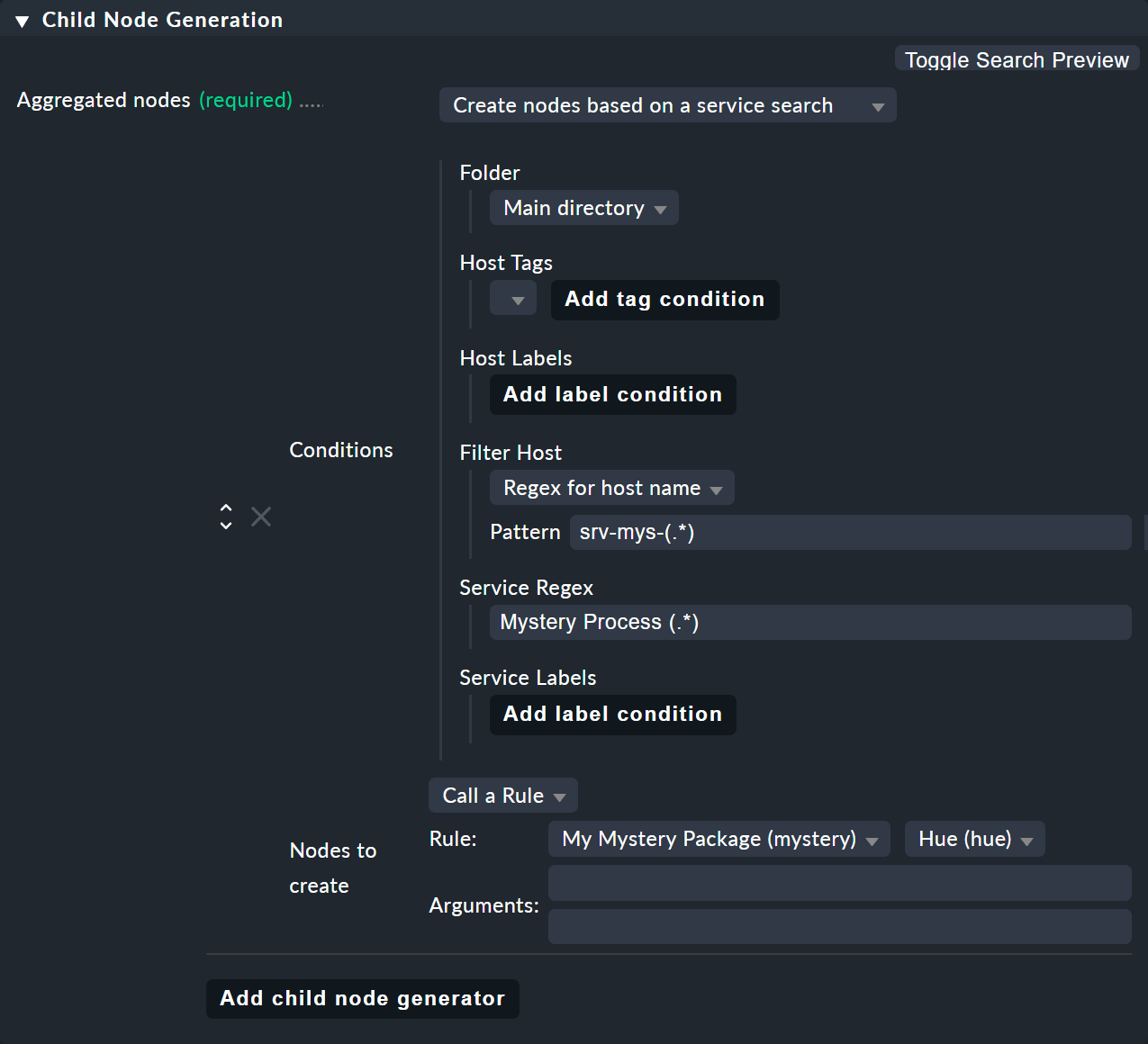
Sie können hier sowohl beim Host als auch beim Service mit ()
Teilausdrücke einklammern. Hierbei gilt:
Wählen Sie Regex for host name, so müssen Sie genau einen Klammerausdruck definieren. Der Matchtext wird dann als
$1$bereitgestellt.Wählen Sie All hosts, so wird der Hostname komplett als
$1$bereitgestellt.Im Servicenamen dürfen Sie mehrere Subgruppen verwenden. Die zugehörigen Matchtexte werden als
$2$,$3$usw. bereitgestellt.
Und bitte vergessen Sie nie, dass Sie mit ![]() stets die Onlinehilfe aufrufen können.
stets die Onlinehilfe aufrufen können.
6.6. Alle übrigen Services
Vielleicht sind Sie bei Ihren Versuchen über den Child-Node-Generator State of remaining services gestolpert. Dieser erzeugt für jeden Service eines Hosts, der in Ihrem BI-Aggregat noch nirgends einsortiert ist, einen Knoten. Dies ist nützlich, wenn Sie BI dazu verwenden, um den Zustand aller Services eines Hosts übersichtlich zu gruppieren — so wie dies im mitgelieferten Beispiel gemacht wird.
7. Die vordefinierte Hostaggregation
Wie erwähnt, können Sie BI auch dazu verwenden, die Services eines Hosts strukturiert anzuzeigen. Dabei fassen Sie alle Services zu einem Baum in einem Aggregat zusammen und verwenden grundsätzlich die Funktion worst. Der Gesamtstatus eines Hosts zeigt dann nur noch, ob es irgendein Problem bei dem Host gibt. Und Sie nutzen BI als übersichtliche „Drilldown“-Methode.
Für diesen Zweck liefert Checkmk bereits einen vordefinierten Satz an
Regeln mit, welchen Sie einfach nur freischalten müssen. Diese Regeln sind
auf die Darstellung von Services auf Windows- oder Linux-Hosts optimiert,
aber Sie können sie natürlich nach Ihren Wünschen anpassen. Sie finden
alle Regeln im Regelpaket Default. Wie üblich gelangen Sie von dort
durch einen Klick auf ![]() zu den Regeln:
zu den Regeln:

Dort finden Sie eine Liste von zwölf Regeln (hier gekürzt):
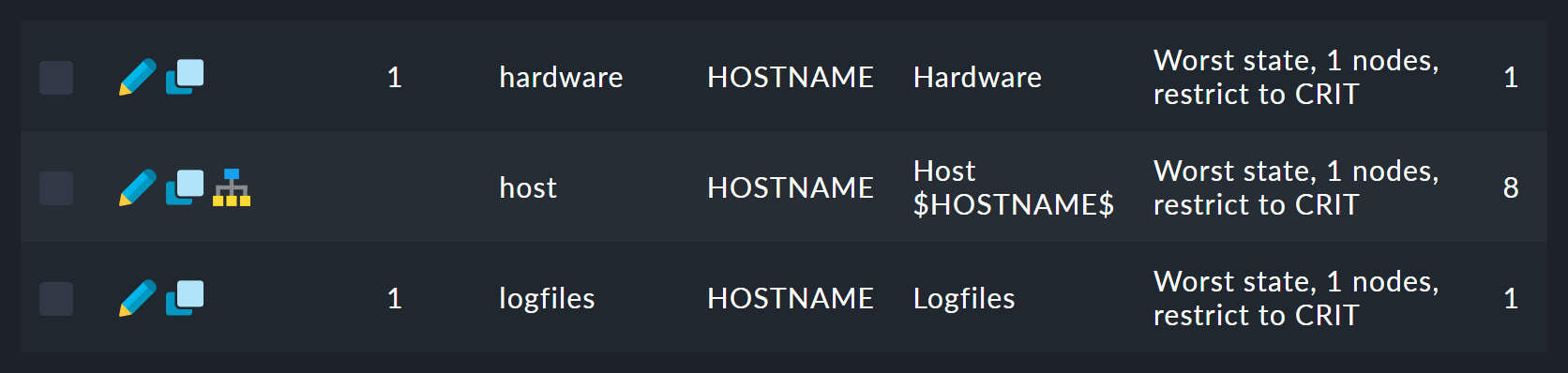
Die erste Regel ist die Regel für die Wurzel des Baums. Das Symbol
![]() bei dieser Regel bringt Sie zu einer Baumdarstellung.
Hier können Sie sehen, wie die Regeln untereinander verschachtelt sind:
bei dieser Regel bringt Sie zu einer Baumdarstellung.
Hier können Sie sehen, wie die Regeln untereinander verschachtelt sind:

Zurück in der Liste der Regeln, gelangen Sie mit dem Knopf ![]() Aggregations
zur Liste der Aggregationen in diesem Regelpaket — welche nur aus einer einzigen
Aggregation besteht. Entfernen Sie in den
Aggregations
zur Liste der Aggregationen in diesem Regelpaket — welche nur aus einer einzigen
Aggregation besteht. Entfernen Sie in den ![]() Details einfach die
Checkbox bei Currently disable this aggregation und sofort bekommen Sie pro
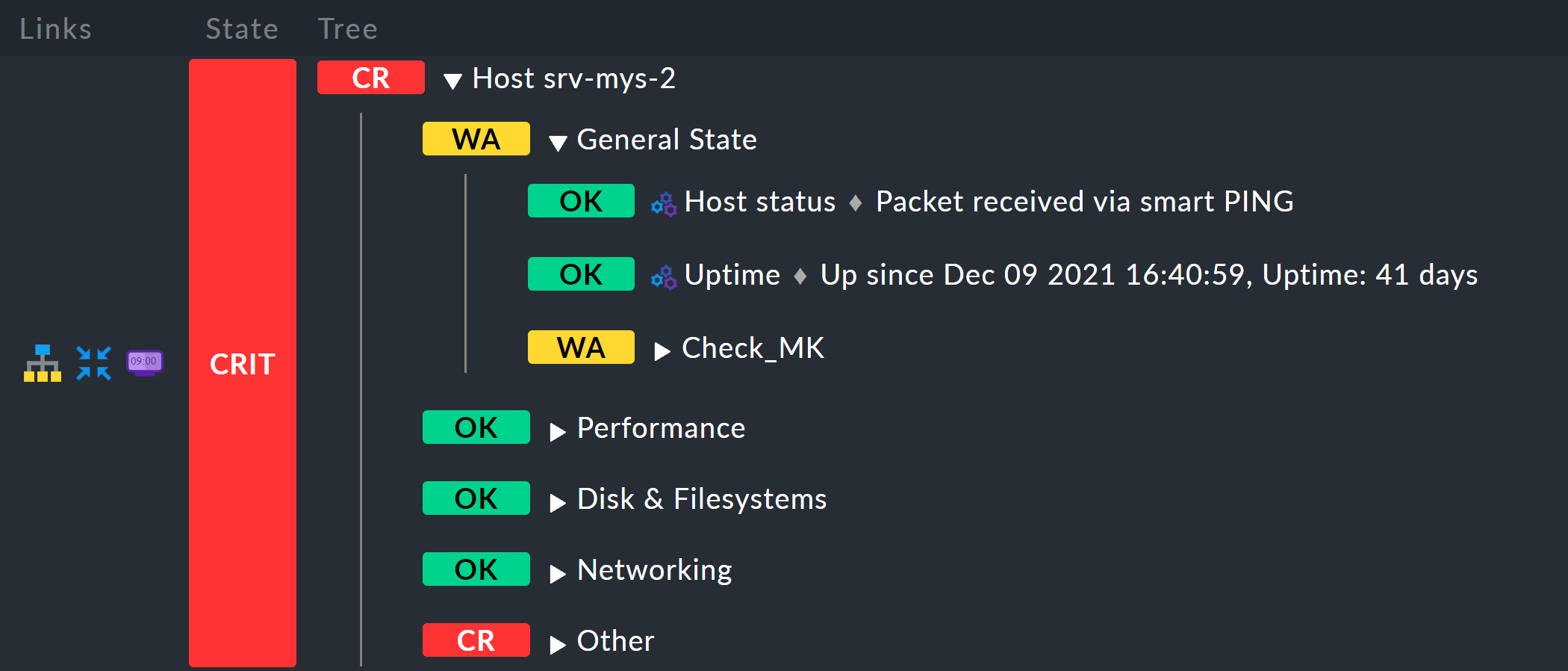
Host eine Aggretation mit dem Titel
Details einfach die
Checkbox bei Currently disable this aggregation und sofort bekommen Sie pro
Host eine Aggretation mit dem Titel Host myhost123. Diese sieht dann
z. B. so aus:
8. Berechtigungen und Sichtbarkeit
8.1. Berechtigungen zum Editieren
Nochmal zurück zu den Regelpaketen. Normalerweise benötigt man für alle Editieraktionen in BI die Rolle Administrator. Genauer gesagt gibt es für BI zwei Berechtigungen, zu finden unter Setup > Users > Roles & permissions:

In der Rolle User ist standardmäßig nur die erste der beiden Berechtigungen
aktiv. Normale
Benutzer können also nur in solchen Regelpaketen arbeiten, in denen sie als
Kontakt hinterlegt sind.
Dies erledigen Sie in den ![]() Details des Regelpakets.
Details des Regelpakets.
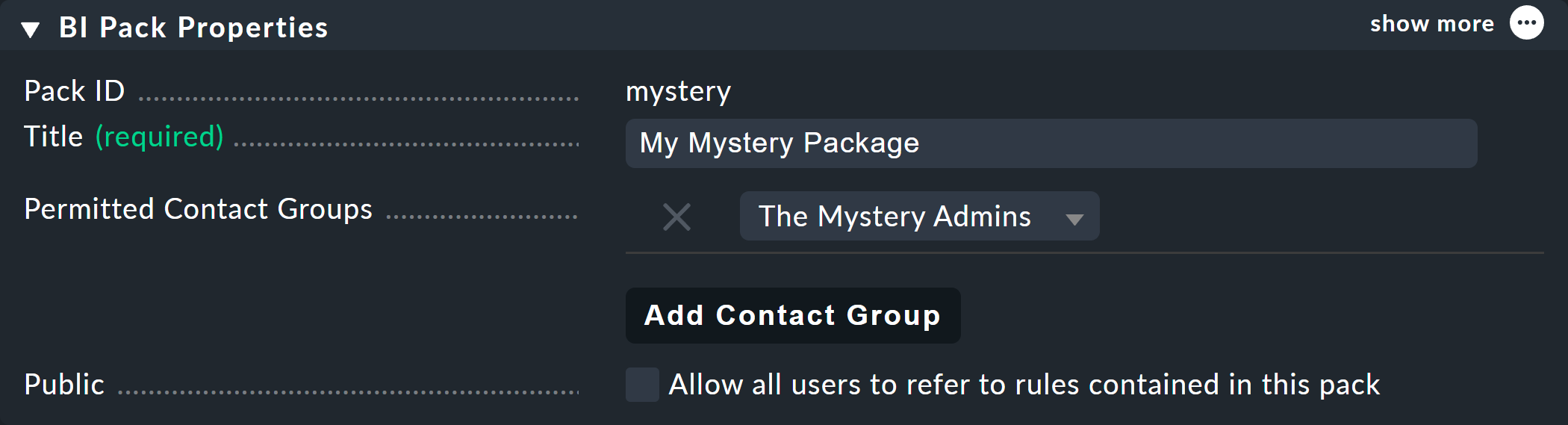
Im folgenden Beispiel ist bei Permitted Contact Groups die Kontaktgruppe The Mystery Admins hinterlegt. Alle Mitglieder dieser Gruppe dürfen jetzt in diesem Paket Regeln editieren:
Übrigens können Sie mit Public > Allow all users to refer to rules contained in this pack anderen Benutzern zumindest erlauben, die hier enthaltenen Regeln zu verwenden — also (woanders) eigene Regeln zu definieren, welche diese Regeln als Unterknoten aufrufen.
8.2. Berechtigungen auf Hosts und Services
Und wie ist es eigentlich mit der Sichtbarkeit der Aggregationen in der Statusoberfläche? Welcher Kontakt darf was sehen?
Nun — in BI-Aggregaten selbst können Sie keine Rechte vergeben. Das geschieht indirekt über die Sichtbarkeit der Hosts und Services und wird geregelt über die Berechtigung See all hosts and services einzelner Rollen unter Setup > Roles & Permissions:

In der Rolle User ist dieses Recht per Default ausgeknipst. Normale Benutzer können nur für sie freigegebene Hosts und Services sehen. Und das drückt sich bei BI so aus, dass sie genau alle BI-Aggregationen sehen, welche mindestens einen freigegebenen Host oder Service enthalten. Diese Aggregate enthalten aber auch nur diese berechtigten Objekte und sind daher eventuell ausgedünnt. Und das wiederum bedeutet, dass sie für unterschiedliche Benutzer einen unterschiedlichen Status haben können!
Ob das jetzt gut oder schlecht ist, hängt davon ab, was Sie möchten. Im Zweifel können Sie die Berechtigung umschalten und manchen oder allen Benutzern erlauben, über den Umweg von BI auch Hosts und Services zu sehen, für die sie kein Kontakt sind — und damit sicherstellen, dass der Status eines Aggregats immer für alle gleich ist.
Das ganze Thema spielt natürlich nur dann eine Rolle, wenn es überhaupt Aggregate gibt, die so bunt zusammengewürfelt sind, dass eben manche Benutzer nur für Teile davon Kontakte sind.
9. BI im Operating Teil 3: Wartungszeiten, Quittierung
9.1. Die generelle Idee
Wie hält es BI eigentlich mit ![]() Wartungszeiten? Nun, hier haben
wir lange nachgedacht und mit vielen Anwendern diskutiert. Das Ergebnis ist
wie folgt:
Wartungszeiten? Nun, hier haben
wir lange nachgedacht und mit vielen Anwendern diskutiert. Das Ergebnis ist
wie folgt:
Sie können ein BI-Aggregat nicht direkt in eine Wartungszeit versetzen — müssen es aber auch nicht, denn …
die Wartungszeit eines BI-Aggregats leitet sich automatisch von den Wartungszeiten seiner Hosts und Services ab.
Um zu verstehen, nach welcher Regel BI den Status „in Wartung“ berechnet, hilft es, wenn Sie sich zurückerinnern, was die eigentliche Idee hinter Wartungszeiten ist: Am betreffenden Objekt wird gerade gearbeitet. Mit Ausfällen ist zu rechnen. Auch wenn das Objekt gerade OK ist, sollte man sich nicht darauf verlassen. Es kann jederzeit CRIT werden. Dies ist bekannt und dokumentiert. Es soll nicht benachrichtigt werden.
Diese Idee kann man 1:1 auf BI übertragen: Im Aggregat gibt es vielleicht ein paar Hosts und Services, welche gerade in Wartung sind. Ob diese gerade OK oder CRIT sind, spielt keine Rolle, denn es ist ja eigentlich Zufall, ob die Objekte während der Wartungsarbeiten ab und zu mal wieder funktionieren oder nicht. Bloß weil im Aggregat aber ein Wartungsobjekt steckt, bedeutet das aber auch nicht gleich, dass die Anwendung, die das Aggregat abbildet, selbst „bedroht“ ist und als „in Wartung“ markiert sein muss. Denn es kann ja Redundanz eingebaut sein, welche den Ausfall der Wartungsobjekte kompensiert. Nur wenn so ein Ausfall tatsächlich zum CRIT-Zustand des Aggregats führen würde — es also eben nicht genug Redundanz gibt und das Aggregat wirklich bedroht ist — genau dann wird es von Checkmk als „in Wartung“ markiert. Wobei auch hier der aktuelle Zustand der Objekte generell keine Rolle spielt.
Knapper formuliert ist die genaue Regel wie folgt:
Wenn ein CRIT-Status eines Hosts/Services zu einem CRIT-Status der Aggregation führen würde, führt ein „in Wartung“-Status dieses Hosts/Services zu einem „in Wartung“-Status der Aggregation.
Wichtig: der wirkliche aktuelle Status der Hosts/Services spielt bei der Berechnung keine Rolle - was in Wartung ist, wird in der BI-Logik als CRIT angenommen. Warum? Weil ein UP- oder OK-Status während einer Wartungszeit reiner Zufall ist, etwa, wenn ein Host zwischen mehreren Neustarts zwischenzeitlich für wenige Sekunden UP meldet.
Und hier haben wir jetzt noch ein Beispiel: Um Platz zu sparen ist dies eine Variante mit nur einem Mystery-Server anstelle von zweien:
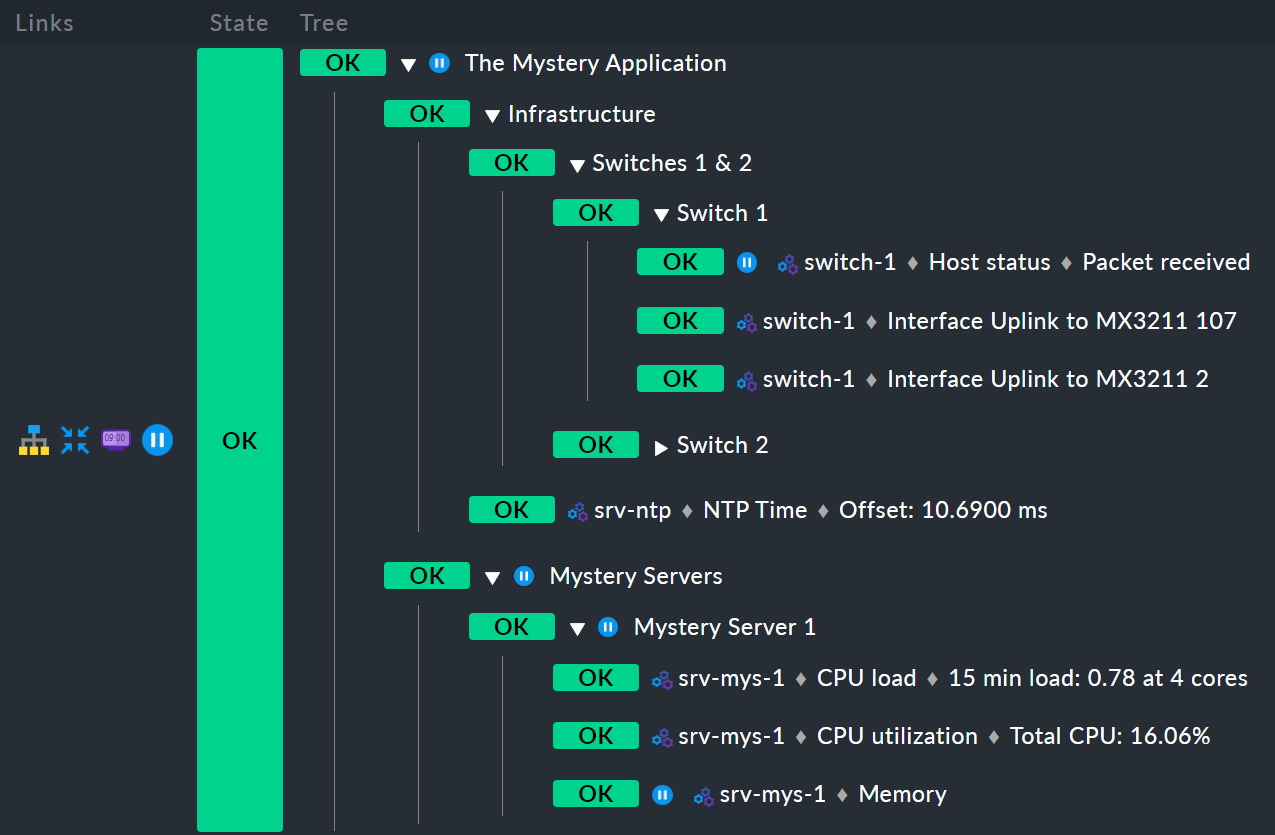
Hier ist zunächst der Host switch-1 in Wartung. Für den Knoten
Infrastructure hat das aber keine Auswirkung. Denn switch-2
ist ja nicht in Wartung. Also ist Infrastructure auch
nicht in Wartung. Dort fehlt das Symbol ![]() für
abgeleitete Wartungszeiten.
für
abgeleitete Wartungszeiten.
Aber: Auch der Service Memory auf srv-mys-1 ist in Wartung.
Dieser ist nicht redundant. Die Wartung vererbt sich daher auf den
Vaterknoten Mystery Server 1, dann weiter auf Mystery Servers
und schließlich auf den obersten Knoten The Mystery Application. Also
ist dieser auch in Wartung.
9.2. Kommando Wartungszeit
Haben wir oben geschrieben, dass Sie ein BI-Aggregat nicht manuell in eine Wartungszeit versetzen können? Das stimmt eigentlich nur halb. Denn Sie werden in der Tat bei BI-Aggregaten ein Kommando zum Setzen von Wartungszeiten finden. Aber das macht nichts anderes, als auf auf jeden einzelnen Host und Service des Aggregats eine Wartung einzutragen. Das führt dann natürlich in der Regel dazu, dass das Aggregat selbst auch als in Wartung gilt. Aber das ist nur indirekt.
9.3. Tuningmöglichkeiten
Oben haben Sie gesehen, dass die Wartungszeitberechnung auf Basis eines angenommenen CRIT-Zustands läuft. In den Eigenschaften eines Aggregats können Sie den Algorithmus so anpassen, dass ein Knoten bereits bei einem angenommenen WARN-Zustand als in Wartung gilt. Die Option hierzu heißt Escalate downtimes based on aggregated WARN state:
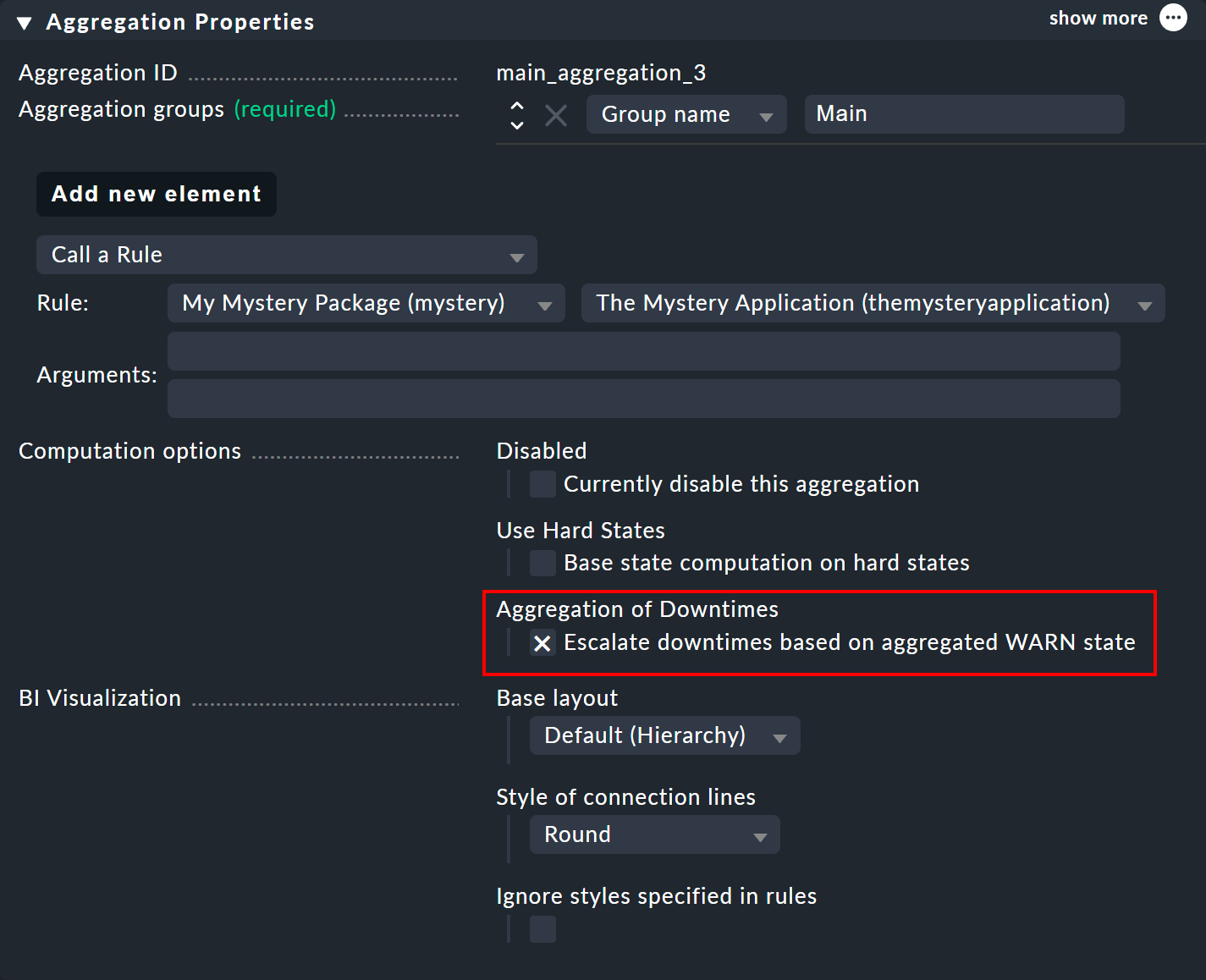
Die Grundannahme, dass die in Wartung befindlichen Objekte CRIT sind, bleibt bestehen. Einen Unterschied gibt es nur dort, wo aufgrund der Aggregatsfunktion aus CRIT ein WARN werden kann — so wie das z. B. beim allerersten Beispiel mit Count the number of nodes in state OK der Fall war. Hier würde eine Wartungszeit bereits dann angenommen werden, wenn auch nur einer der beiden Switche in Wartung wäre.
9.4. Quittierungen
Ganz ähnlich zu den Wartungszeiten wird auch die Information, ob ein Problem
![]() quittiert ist, von BI automatisch berechnet.
Diesmal spielt der Zustand der Objekte durchaus eine Rolle.
quittiert ist, von BI automatisch berechnet.
Diesmal spielt der Zustand der Objekte durchaus eine Rolle.
Die Idee hier ist, folgendes Konzept auf BI zu übertragen: Ein Objekt
hat ein Problem (WARN, CRIT). Aber das ist bekannt und jemand
arbeitet daran (![]() ).
).
Sie können das für ein Aggregat wie folgt selbst berechnen:
Nehmen Sie an, dass alle Hosts und Services, die
 quittierte Probleme haben, wieder OK wären.
quittierte Probleme haben, wieder OK wären.Würde das Aggregat dann selbst auch wieder OK? Genau dann gilt es ebenfalls als
quittiert.
Würde das Aggregat jedoch WARN oder CRIT bleiben, dann gilt es nicht als quittiert. Dann muss es noch mindestens ein weiteres wichtiges Problem geben, das selbst nicht quittiert ist und den OK-Status des Aggregats entfernt.
Übrigens wird Ihnen bei den ![]() Kommandos zu einem
BI-Aggregat angeboten, dessen Probleme zu quittieren. Dies bedeutet aber nur,
dass alle im Aggregat erfassten Hosts und Services quittiert werden
(nur solche, die aktuell auch Probleme haben).
Kommandos zu einem
BI-Aggregat angeboten, dessen Probleme zu quittieren. Dies bedeutet aber nur,
dass alle im Aggregat erfassten Hosts und Services quittiert werden
(nur solche, die aktuell auch Probleme haben).
10. Verfügbarkeit
Genauso wie bei Hosts und Services können Sie auch bei BI die Verfügbarkeit eines oder mehrerer Aggregate für beliebige Zeiträume in der Vergangenheit berechnen lassen. Dazu rekonstruiert das BI-Modul anhand der Historie von Hosts und Services den Zustand des Aggregats für jeden Zeitpunkt in der Vergangenheit. Somit können Sie auch für solche Zeiträume Verfügbarkeiten berechnen, in denen das Aggregat noch gar nicht konfiguriert war!

Alle Einzelheiten zu BI und Verfügbarkeit finden Sie im Artikel zur Verfügbarkeit im Abschnitt zu BI.
11. BI im verteilten Monitoring
Was geschieht eigentlich mit BI in einer verteilten Umgebung? Also wenn die Hosts über mehrere Monitoringserver verteilt sind?
Die Antwort ist relativ einfach: Es funktioniert — und zwar ohne, dass Sie etwas Weiteres beachten müssten. Da BI eine Komponente der Benutzeroberfläche ist und diese von Haus aus eine verteilte Umgebung annimmt, ist dies für BI vollkommen transparent.
Sollte ein Standort aktuell nicht erreichbar oder durch Sie manuell aus der GUI ausgeblendet worden sein, so sind die Hosts des Standorts für BI nicht mehr vorhanden. Das bedeutet dann:
BI-Aggregate, die ausschließlich aus Objekten dieses Standorts aufgebaut sind, verschwinden.
BI-Aggregate, die teilweise aus Objekten dieses Standorts aufgebaut sind, werden ausgedünnt.
In letzterem Fall kann sich das natürlich auf den Status der betroffenen Aggregate auswirken. Wie genau, das hängt von Ihren Aggregierungsfunktionen ab. Wenn Sie z. B. überall worst verwendet haben, kann der Status insgesamt nur gleich bleiben oder besser werden. Denn Objekte des nicht mehr vorhandenen Standorts könnten WARN oder CRIT gewesen sein. Bei anderen Aggregierungsfunktionen können sich natürlich andere Zustände ergeben.
Ob dieses Verhalten für Sie sinnvoll ist oder nicht, müssen Sie im Einzelfall beurteilen. BI ist auf jeden Fall so aufgebaut, dass nicht vorhandene Objekte nicht in einem Aggregat vorkommen können und auch nicht vermisst werden. Denn alle BI-Regeln arbeiten ja, wie bereits oben erklärt, ausschließlich mit Suchmustern.
12. Benachrichtigungen, BI als Service
12.1. Aktive Checks oder Datenquellenprogramm
Kann man bei Statusänderungen in BI-Aggregaten eigentlich benachrichtigen? Nun — auf direktem Wege geht das erst mal nicht, denn BI ist ausschließlich in der GUI vorhanden und hat keinen Bezug zum eigentlichen Monitoring. Aber: Sie können aus BI-Aggregaten normale Services machen. Und diese können dann natürlich wieder Benachrichtigungen auslösen. Dazu gibt es zwei Möglichkeiten:
Mit dem Datenquellenprogramm Check state of BI Aggregations
Mit aktiven Checks vom Typ Check State of BI Aggregation
12.2. Benachrichtigungen über Datenquellenprogramm
Den Anfang macht die Methode „Datenquellenprogramm“, denn diese ist immer dann gut, wenn Sie mehr als nur eine Handvoll Aggregate als Services erzeugen wollen. Dazu finden Sie unter Setup > Agents > Other integrations > BI Aggregations den passenden Regelsatz:
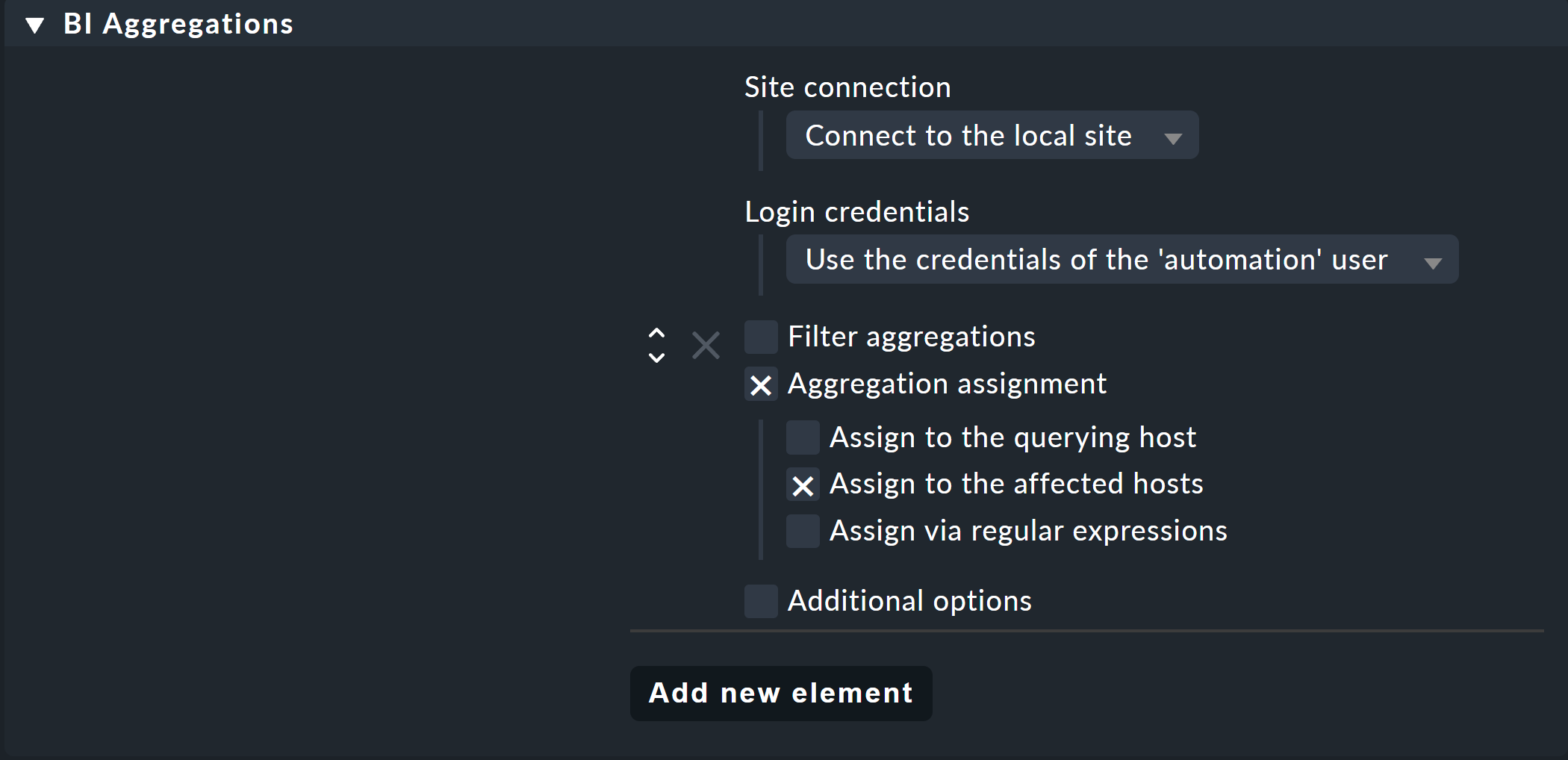
Hier können Sie sogar verschiedene Optionen angeben, zu welchen Hosts die Services hinzugefügt werden sollen. Sie müssen nicht zwingend an dem Host kleben, welcher das Datenquellenprogramm ausführt (Assign to the querying host). Möglich ist auch eine Zuordnung zu den Hosts, welche das Aggregat betrifft (Assign to the affected hosts). Das macht allerdings nur dann wirklich Sinn, wenn es sich dabei immer nur um einen Host handelt. Über reguläre Ausdrücke und Ersetzungen können Sie sogar noch flexibler zuordnen. Das Ganze geschieht dann über den Piggyback-Mechanismus.
Wichtig: Falls der Host, dem Sie diese Regel zuweisen, auch noch über den normalen Agenten überwacht werden soll, müssen Sie unbedingt in dessen Einstellungen dafür sorgen, dass Agent und Datenquellenprogramme ausgeführt werden:

12.3. Benachrichtigungen über einen aktiven Check
Die Benachrichtigung mit einem aktiven Check ist quasi der direktere Weg und erfordert keinen künstlichen „Hilfs-Host“, welcher das Datenquellenprogramm ausführt. Da er jedes Aggregat einzeln abfragen muss, ist er aber bei einer größeren Menge von Aggregaten deutlich weniger performant und dann auch umständlicher aufzusetzen.
Das Ganze geht so: Es gibt einen aktiven Check, welcher per HTTP von der Web-API von Checkmk den Zustand von BI-Aggregaten abrufen kann. Diesen können Sie bequem mit dem Regelsatz Setup > Services > Other services > Check State of BI Aggregation einrichten:
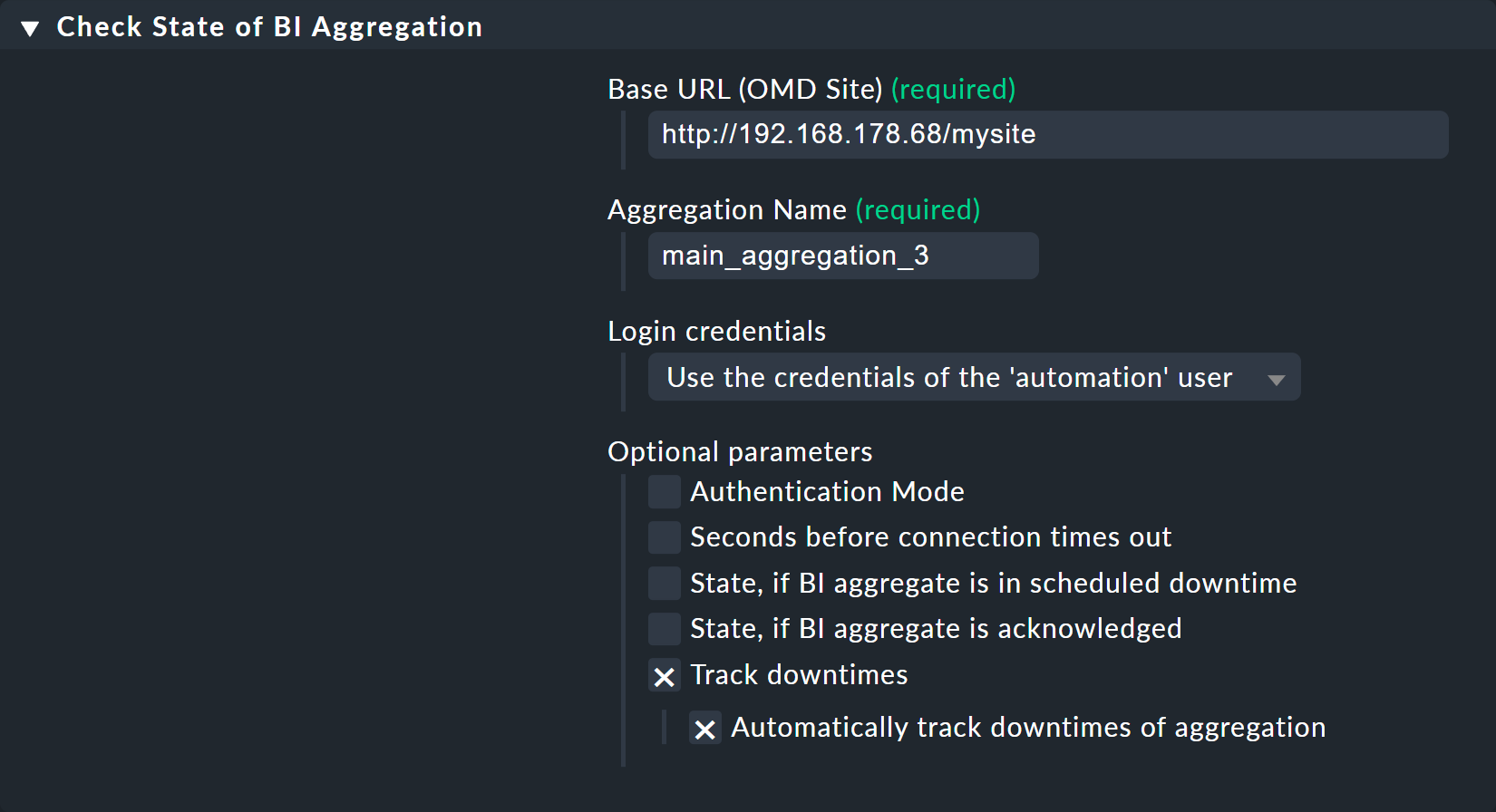
Bitte beachten Sie hierbei Folgendes:
Aktivieren Sie diese Regel nur für den Host, welcher den entsprechenden neuen BI-Service bekommen soll.
Die URL muss diejenige sein, mittels der dieser Host auf die GUI von Checkmk zugreifen kann.
Der Benutzer muss ein Automationsbenutzer sein. Nur solch einer darf die Web-API abrufen. Der Benutzer
automationbietet sich an, da dieser immer automatisch für solche Zwecke angelegt wird.Tragen Sie bei Automation Secret das Automation secret for machine accounts des Benutzers ein, welches Sie in der Konfigurationsmaske der Benutzereigenschaften finden (nur, wenn Sie einen anderen Automationsbenutzer verwenden als
automation).
Im Beispiel ist Automatically track downtimes of aggregation aktiviert. Genau genommen sind damit die scheduled Downtimes gemeint, also die geplanten Wartungszeiten. Damit wird der neue aktive Service automatisch eine Wartungszeit bekommen, wenn auch das BI-Aggregat dies tut.
Der neue Service zeigt dann — natürlich mit einer Verzögerung von bis zu einem
Check-Intervall — den Zustand des Aggregats. Im Beispiel liegt der BI-Check
auf dem Host srv-mys-1:

Diesen Service können Sie dann wie gewohnt Kontakten zuordnen und ihn als Basis für Benachrichtigungen verwenden.