1. Einleitung
Reguläre Ausdrücke (englisch regular expression oder regex, selten
regexp), werden in Checkmk für die Angabe von Service-Namen und auch an vielen
anderen Stellen verwendet. Es sind Muster, die auf einen bestimmten Text passen
(match) oder nicht passen (nonmatch). Damit können Sie viele praktische
Dinge anstellen, wie z.B. flexible Regeln formulieren, die
für alle Services greifen, bei denen foo oder bar im Namen vorkommt.
Oft werden reguläre Ausdrücke mit den Suchmustern für Dateinamen verwechselt,
denn die Sonderzeichen * und ?, sowie eckige und geschweifte
Klammern gibt es in beiden.
In diesem Artikel zeigen wir Ihnen die wichtigsten Möglichkeiten der regulären Ausdrücke, selbstverständlich im Kontext von Checkmk. Da Checkmk zwei verschiedene Komponenten für reguläre Ausdrücke nutzt, steckt manchmal der Teufel im Detail. Im wesentlichen nutzt der Monitoring-Kern die C-Bibliothek und alle weiteren Komponenten Python 3. Wo Unterschiede bestehen, erklären wir diese.
Tipp: In Checkmk sind regexp in Eingabefeldern auf unterschiedlichen Seiten erlaubt. Wenn Sie sich unsicher sind, lassen Sie sich die kontextsensitive Hilfe über das Help-Menü einblenden (Help > Show inline help). Dann sehen Sie, ob reguläre Ausdrücke erlaubt sind und wie sie genutzt werden können.
Bei der Arbeit mit älteren Plugins oder Plugins aus externen Quellen kann es mitunter vorkommen, dass diese Python 2 oder Perl nutzen und von den hier geschilderten Konventionen abweichen, bitte beachten Sie daher die jeweilige Plugin-spezifische Dokumentation.
In diesem Artikel zeigen wir Ihnen die wichtigsten Möglichkeiten der regulären Ausdrücke — aber bei weitem nicht alle. Falls Ihnen die hier gezeigten Möglichkeiten nicht weit genug gehen, finden Sie weiter unten Hinweise, wo Sie alle Details nachlesen können. Und dann gibt es ja immer noch das Internet.
Falls Sie eigene Plugins programmieren wollen, die beispielsweise mit regulären Ausdrücken Auffälligkeiten in Log-Dateien finden, können Sie diesen Artikel als Grundlage verwenden. Allerdings ist bei der Suche in großen Datenmengen die Optimierung der Performance ein wichtiger Aspekt. Schlagen Sie daher im Zweifel immer in der Dokumentation der verwendeten Regex-Bibliothek nach.
2. Mit regulären Ausdrücken arbeiten
In diesem Abschnitt zeigen wir anhand konkreter Beispiele die Arbeit mit regulären Ausdrücken, von einfachen Matches einzelner Zeichen oder Zeichenketten, bis hin zu komplexen Gruppen von Zeichen.
2.1. Alphanumerische Zeichen
Bei den regulären Ausdrücken geht es immer darum, ob ein Muster ("Pattern", beziehungsweise der reguläre Ausdruck) auf einen bestimmten Text (z.B. einen Service-Namen) passt (matcht). Der einfachste Anwendungsfall sind Ketten alphanumerischer Zeichen. Diese (und das als Bindestrich verwendete Minus-Zeichen) im Ausdruck matchen einfach sich selbst.
Beim Suchen in der Monitoring-Umgebung unterscheidet Checkmk dabei in der Regel nicht zwischen Groß- und Kleinschreibung. Der Ausdruck CPU load matcht also in den meisten Fällen auf den Text CPU load genauso wie auf cpu LoAd.
Beim Suchen in der Konfigurationsumgebung dagegen wird üblicherweise zwischen Groß- und Kleinschreibung unterschieden. Begründete Ausnahmen von diesen Standards sind möglich und werden in der Inline-Hilfe beschrieben.
Achtung: Bei Eingabefeldern, in denen ohne reguläre Ausdrücke ein exakter Match vorgesehen ist (meistens bei Host-Namen), wird Groß- und Kleinschreibung immer unterschieden!
2.2. Der Punkt als Wildcard
Neben den "Klartext"-Zeichenketten gibt es eine Reihe von Zeichen und
Zeichenfolgen, die "magische" Bedeutung haben. Das wichtigste derartige Zeichen
ist der . (Punkt). Er matcht genau ein einziges beliebiges Zeichen:
| Regulärer Ausdruck | Match | Kein Match |
|---|---|---|
|
|
|
|
|
|
2.3. Wiederholungen von Zeichen
Sehr häufig möchte man definieren, dass eine Folge von Zeichen bestimmter Länge vorkommen darf. Hierfür gibt man in geschweiften Klammern die Zahl der Wiederholungen des vorhergehenden Zeichens an:
| Regulärer Ausdruck | Bedeutung | Match | Kein Match |
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Für die letzten drei Fälle gibt es Abkürzungen: * matcht das
vorhergehende Zeichen beliebig oft, + matcht ein mindestens
einmaliges Auftreten und ? matcht das höchstens einmalige
Auftreten.
Sie können auch den Punkt . mit den Wiederholungsoperatoren verknüpfen, um eine Folge beliebiger Zeichen definierter zu suchen:
| Regulärer Ausdruck | Match | Kein Match |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
2.4. Zeichenklassen, Ziffern und Buchstaben
Zeichenklassen erlauben es, bestimmte Ausschnitte des Zeichensatzes zu matchen, beispielsweise „hier muss eine Ziffer kommen“. Dafür setzen Sie alle zu matchenden Zeichen innerhalb eckiger Klammern. Mit einem Minuszeichen können Sie auch Bereiche angeben. Hinweis: es gilt dabei die Reihenfolge im 7-Bit-ASCII-Zeichensatz.
So steht beispielsweise [abc] für genau eines der Zeichen a, b oder c und
[0-9] für eine beliebige Ziffer - beides lässt sich kombinieren. Auch eine
Negation des Ganzen ist möglich: Mit einem ^ in der Klammer steht [^abc]
dann für ein beliebiges Zeichen außer a, b, c.
Zeichenklassen lassen sich natürlich mit anderen Operatoren kombinieren. Zunächst mal einige abstrakte Beispiele:
| Zeichenklasse | Bedeutung |
|---|---|
|
Genau eines der Zeichen a, b, c. |
|
Genau eine Ziffer, ein Kleinbuchstabe oder ein Unterstrich. |
|
Jedes beliebige Zeichen außer a, b, c. |
|
Genau ein Zeichen aus dem Bereich von Leerzeichen bis Bindestrich gemäß ASCII-Tabelle. In diesem Bereich befinden sich die folgenden Zeichen: |
|
Eine Folge von mindestens einem und maximal 20 Buchstaben und/oder Ziffern in beliebiger Reihenfolge. |
Dazu einige praktische Beispiele:
| Regulärer Ausdruck | Match | Kein Match |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Hinweis: Wenn Sie eines der Zeichen -, [ oder ] brauchen, müssen Sie etwas
tricksen. Das - (Minuszeichen) schreiben Sie ans Ende der Klasse — wie im
letzten Beispiel bereits gezeigt. Beim Auswerten der regulären Ausdrücke wird
das Minuszeichen, wenn es nicht mittleres von drei Zeichen ist, nicht als
Operator, sondern als exakt dieses Zeichen ausgewertet. Eine schließende eckige
Klammer platzieren Sie als erstes Zeichen in der Klasse, eine öffnende
gegebenenfalls als zweites Zeichen. Da keine leeren Klassen erlaubt sind,
wird die schließende eckige Klammer dann als normales Zeichen interpretiert.
Eine Klasse mit diesen Sonderzeichen sähe also so aus: []-], beziehungsweise
[][-] wenn auch die öffnende eckige Klammer benötigt wird.
2.5. Anfang und Ende — Präfix, Suffix und Infix
In vielen Fällen ist es erforderlich, zwischen Matches am Anfang, am Ende oder
einfach irgendwo innerhalb einer Zeichenkette zu unterscheiden. Für den Match
des Anfangs einer Zeichenkette (Präfix-Match) verwenden Sie den ^
(Zirkumflex), für das Ende (Suffix-Match) das $ (Dollarzeichen). Ist
keines der beiden Zeichen angegeben, ist bei den meisten Bibliotheken für
reguläre Ausdrücke Infix-Match Standard — es wird an beliebiger Stelle in der
Zeichenkette gesucht. Für exakte Matches verwenden Sie sowohl ^ als
auch $.
| Regulärer Ausdruck | Match | Kein Match |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
Hinweis: Im Monitoring und der Event Console ist Infix-Match Standard. Ausdrücke, die irgendwo im Text vorkommen, werden gefunden, d.h. die Suche nach "memory" findet auch "Kernel memory". In der Setup-GUI dagegen prüft Checkmk beim Vergleichen von regulären Ausdrücken mit Service-Namen und anderen Dingen grundsätzlich, ob der Ausdruck mit dem Anfang des Textes übereinstimmt (Präfix-Match) – in der Regel ist dies, was Sie suchen:
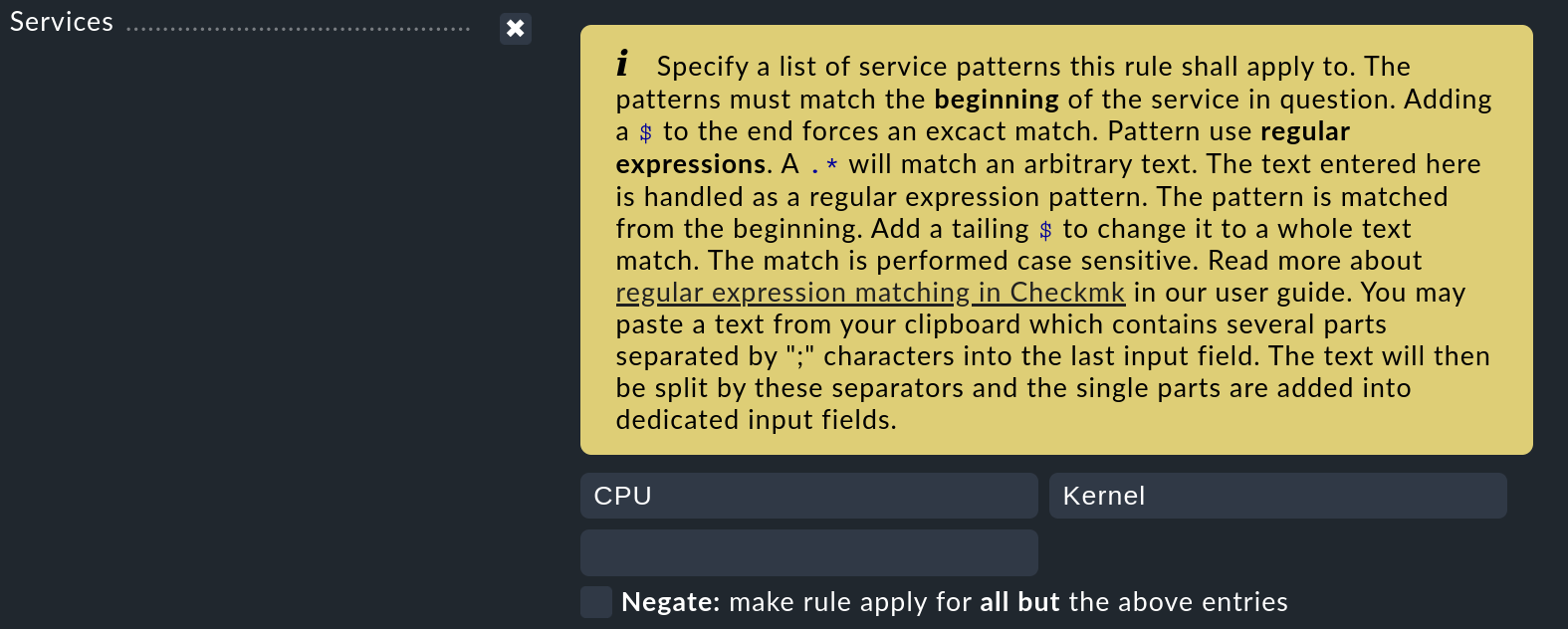
Falls Sie an Stellen, an denen Präfix-Match vorgesehen ist, doch einmal einen
Infix-Match benötigen, erweitern Sie einfach ihren regulären Ausdruck am
Anfang mit .*, um eine beliebige vorangestellte Zeichenkette zu matchen:
| Regulärer Ausdruck | Match | Kein Match |
|---|---|---|
|
|
|
|
|
|
|
|
|
Tipp: Sie können jede Suche am Anfang einer Zeichenkette mit ^ und
jede Suche innerhalb mit .* einleiten, die Interpreter für reguläre
Ausdrücke ignorieren redundante Symbole.
2.6. Sonderzeichen mit Backslash maskieren
Da der Punkt alles matcht, matcht er natürlich auch einen Punkt. Wenn Sie nun
aber genau einen Punkt matchen wollen, so müssen Sie diesen mit einem
\ (Backslash) maskieren (eingedeutscht: „escapen“). Das gilt analog
auch für alle anderen Sonderzeichen.
Dies sind: \ . * + ? { } ( ) [ ] | & ^ und $. Der \
Backslash wertet das nächste dieser Sonderzeichen als normales Zeichen:
| Regulärer Ausdruck | Match | Kein Match |
|---|---|---|
|
|
|
|
|
|
|
|
|
Achtung Python: Da in Python der Backslash in der internen Zeichenkettendarstellung intern mit einem weiteren Backslash maskiert wird, müssen diese beiden Backslashes wiederum maskiert werden, was zu insgesamt vier Backslashes führt:
| Regulärer Ausdruck | Match | Kein Match |
|---|---|---|
|
|
|
2.7. Alternativen
Mit dem senkrechten Strich | können Sie Alternativen definieren, sprich
eine ODER-Verküpfung verwenden: 1|2|3 matcht also 1, 2 oder 3. Wenn Sie die
Alternativen inmitten eines Ausdrucks benötigen, gruppieren Sie diese innerhalb
runder Klammern.
| Regulärer Ausdruck | Match | Kein Match |
|---|---|---|
|
|
|
|
|
|
2.8. Match-Gruppen
Match-Gruppen (englisch match groups oder capture groups) erfüllen zwei Zwecke: Der erste ist — wie im letzten Beispiel gezeigt — die Gruppierung von Alternativen oder
Teil-Matches. Dabei sind auch verschachtelte Gruppierungen möglich. Zudem ist
es zulässig, hinter runden Klammern die Wiederholungsoperatoren *,
+, ? und {…} zu verwenden. So passt der Ausdruck (/local)?/share
sowohl auf /local/share als auch auf /share.
Der zweite Zweck ist das "Einfangen" gematchter Zeichengruppen in Variablen.
In der Event Console (EC), Business Intelligence (BI),
beim Massenumbenennen von Hosts und bei
Piggyback-Zuordnungen besteht die Möglichkeit, den Textteil
der dem regulären Ausdruck in der ersten Klammer entspricht, als \1 zu
verwenden, den der zweiten Klammer entsprechenden als \2 usw. Das letzte
Beispiel der Tabelle zeigt die Verwendung von
Alternativen innerhalb einer Match-Gruppe.
| Regulärer Ausdruck | Zu matchender Text | Gruppe 1 | Gruppe 2 |
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
Folgende Abbildung zeigt eine solche Umbenennung mehrerer
Hosts. Alle Host-Namen, die auf den regulären Ausdruck
server-(.*)\.local passen, werden durch
\1.servers.local ersetzt. Dabei steht das \1 genau für
den Text, der mit dem .* in der Klammer "eingefangen" wurde:
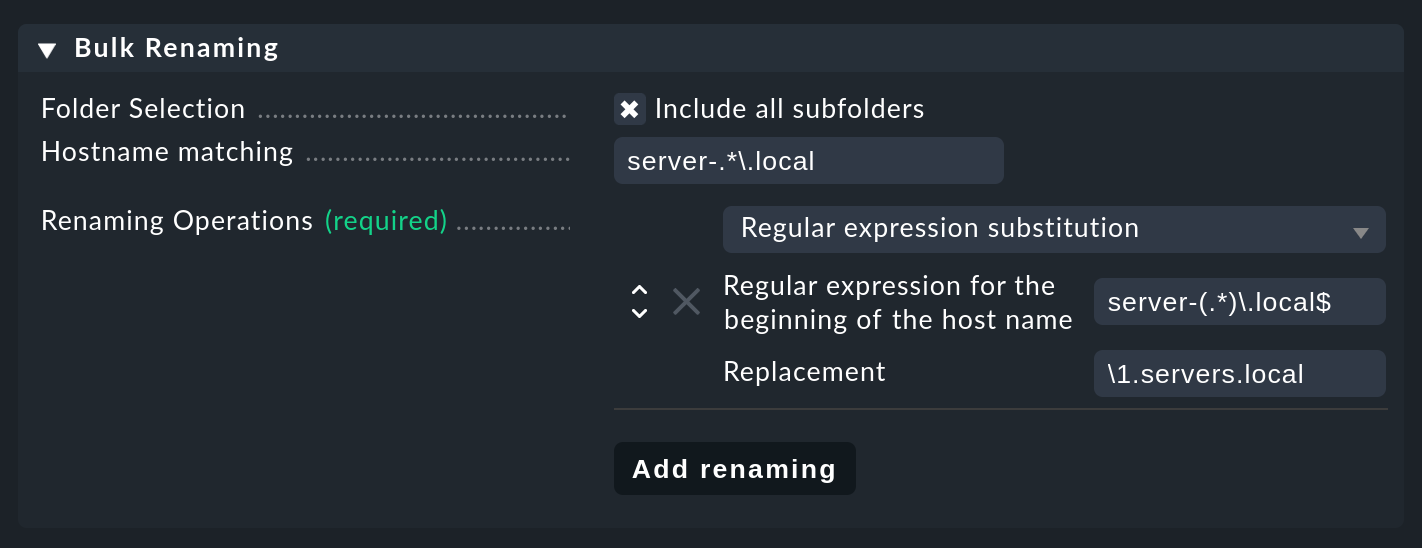
Im konkreten Fall wird also server-lnx02.local in
lnx02.servers.local umbenannt.
3. Tabelle der Sonderzeichen
Hier finden Sie zusammengefasst die Liste von allen oben erklärten Sonderzeichen und Funktionen der regulären Ausdrücke, die Checkmk verwendet:
|
Passt auf ein beliebiges Zeichen. |
|
Wertet das nächste Sonderzeichen als normales Zeichen. |
|
Das vorherige Zeichen muss genau fünfmal vorkommen. |
|
Das vorherige Zeichen muss mindestens fünf- und höchstens zehnmal vorkommen. |
|
Das vorherige Zeichen darf beliebig oft vorkommen (entspricht |
|
Das vorherige Zeichen darf beliebig oft, aber muss mindestens einmal vorkommen (entspricht |
|
Das vorherige Zeichen darf null- oder einmal vorkommen (entspricht |
|
Steht für genau eines der Zeichen |
|
Steht für genau eines der Zeichen |
|
Steht für genau eine Ziffer, einen Kleinbuchstaben oder den Unterstrich. |
|
Steht für genau ein beliebiges Zeichen außer dem einfachen oder doppelten Anführungszeichen. |
|
Matcht das Ende eines Textes. |
|
Matcht den Anfang eines Textes. |
|
Matcht auf |
|
Fasst den Unterausdruck A zu einer Match-Gruppe zusammen. |
|
Matcht einen Tabstop (Tabulator). Dieses Zeichen kommt oft in Log-Dateien oder CSV-Tabellen vor |
|
Matcht alle Leerzeichen (ASCII kennt 5 verschiedene). |
Folgende Zeichen müssen durch Backslash maskiert werden,
wenn sie wörtlich verwendet werden sollen: \ . * + ? { } ( ) [ ] | & ^ $.
3.1. Unicode in Python 3
Insbesondere, wenn Eigennamen in Kommentaren oder beschreibenden Texten per Copy und Paste übernommen wurde und daher Unicode-Zeichen oder verschiedene Typen von Leerzeichen im Text auftreten, sind Pythons erweiterte Klassen sehr hilfreich:
|
Matcht einen Tabstop (Tabulator), teils in Logdateien oder CSV-Tabellen. |
|
Matcht alle Leerzeichen (Unicode kennt 25 verschiedene, ASCII 5). |
|
Invertierung von |
|
Matcht alle Zeichen, die Wortbestandteil sind, also Buchstaben, in Unicode aber auch Akzente, chinesische, arabische oder koreanische Glyphen. |
|
Invertierung von |
An Stellen, an denen Checkmk Unicode-Matching erlaubt, ist \w vor allem zur Suche nach ähnlich geschriebenen Worten in verschiedenen Sprachen hilfreich, beispielsweise Eigennamen, die mal mit und mal ohne Accent geschrieben werden:
| Regular Expression | Match | Kein Match |
|---|---|---|
|
|
|
4. Test regulärer Ausdrücke
Die Logik regulärer Ausdrücke ist nicht immer einfach zu durchschauen, insbesondere bei verschachtelten Match-Gruppen oder der Frage in welcher Reihenfolge von welchem Ende des zu matchenden Strings ausgewertet wird. Besser als Trial and Error in Checkmk sind diese zwei Möglichkeiten zum Test regulärer Ausdrücke: Online-Dienste wie regex101.com bereiten Matches grafisch auf und erklären darüber die Reihenfolge der Auswertung in Echtzeit:
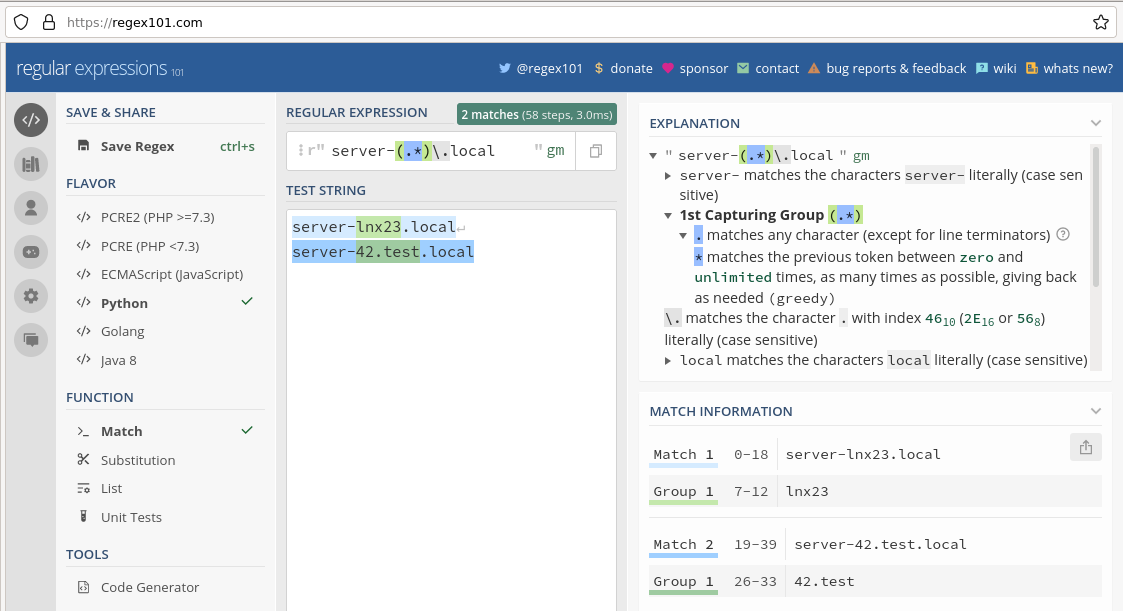
Die zweite Testmöglichkeit ist der Python-Prompt, den jede Python-Installation mitbringt. Unter Linux und auf dem Mac ist Python 3 in der Regel vorinstalliert. Gerade weil reguläre Ausdrücke am Python-Prompt exakt wie in Checkmk ausgewertet werden, gibt es auch bei komplexen Schachtelungen keine Abweichungen bei der Interpretation. Mit dem Test im Python-Interpreter sind Sie damit immer auf der sicheren Seite.
Nach dem Öffnen müssen Sie das Modul re importieren. Im Beispiel schalten wir
zudem mit re.IGNORECASE die Unterscheidung zwischen Groß- und Kleinschreibung
ab:
OMD[mysite]:~$ python3
Python 3.8.10 (default, Jun 2 2021, 10:49:15)
[GCC 9.4.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import re
>>> re.IGNORECASE
re.IGNORECASEUm das Verhalten der regulären Ausdrücke von C nachzubilden, das auch in vielen Python-Komponenten genutzt wird, schränken Sie auf ASCII ein:
>>> re.ASCII
re.ASCIINun können Sie mit der Funktion re.match() direkt einen regulären Ausdruck
gegen einen String matchen und die Match-Gruppe ausgeben,
group(0) steht hierbei für den gesamten Match, mit group(1) wird der
Match ausgegeben, der zum ersten in einer runden Klammer gruppierten
Unterausdruck passt:
>>> x = re.match('M[ae]{1}[iy]{1}e?r', 'Meier')
>>> x.group(0)
'Meier'
>>> x = re.match('M[ae]{1}[iy]{1}e?r', 'Mayr')
>>> x.group(0)
'Mayr'
>>> x = re.match('M[ae]{1}[iy]{1}e?r', 'Myers')
>>> x.group(0)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
IndexError: no such group
>>> x = re.match('server-(.*)\.local', 'server-lnx23.local')
>>> x.group(0)
'server-lnx23.local'
>>> x.group(1)
'lnx23'5. Weitere externe Dokumentation
Ken Thompson, einer der Erfinder von UNIX, hat schon in den 1960ern als erster
reguläre Ausdrücke in der heutigen Form entwickelt — unter anderem im bis
heute gebräuchlichen Unix-Befehl grep. Seitdem wurden zahlreiche
Erweiterungen und Dialekte von regulären Ausdrücken geschaffen — darunter
erweiterter Regexe, Perl-kompatible Regexe und auch eine sehr ähnlich
Variante in Python.
Checkmk verwendet in den Filtern in Ansichten POSIX
erweiterte reguläre Ausdrücke (extended REs).
Diese werden im Monitoring-Kern in C mit der Regexfunktion der C-Bibliothek
ausgewertet. Sie finden eine komplette Referenz dazu in der Linux-Manpage zu
regex(7):
OMD[mysite]:~$ man 7 regex
REGEX(7) Linux Programmer's Manual REGEX(7)
NAME
regex - POSIX.2 regular expressions
DESCRIPTION
Regular expressions ("RE"s), as defined in POSIX.2, come in two forMFS:
modern REs (roughly those of egrep; POSIX.2 calls these "extended" REs)
and obsolete REs (roughly those of *ed*(1); POSIX.2 "basic" REs). Obso-
lete REs mostly exist for backward compatibility in some old programs;An allen anderen Stellen stehen darüber hinaus alle Möglichkeiten der regulären Ausdrücke von Python zur Verfügung. Dies betrifft unter anderem die Konfigurationsregeln, Event Console (EC) und Business Intelligence (BI).
Die regulären Ausdrücke in Python sind eine Erweiterung der extended REs und
sehr ähnlich zu denen aus Perl. Sie unterstützen z.B. den sogenannten
negative Lookahead, einen nicht gierigen * Stern, oder ein
Erzwingen der Unterscheidung von Groß-/Kleinschreibung. Die genauen
Möglichkeiten dieser regulären Ausdrücke finden Sie in der Online-Hilfe von
Python zum Modul re, oder ausführlicher in der
Online-Dokumentation von Python.
OMD[mysite]:~$ pydoc3 re
Help on module re:
NAME
re - Support for regular expressions (RE).
MODULE REFERENCE
https://docs.python.org/3.8/library/re
The following documentation is automatically generated from the Python
source files. It may be incomplete, incorrect or include features that
are considered implementation detail and may vary between Python
implementations. When in doubt, consult the module reference at the
location listed above.
DESCRIPTION
This module provides regular expression matching operations similar to
those found in Perl. It supports both 8-bit and Unicode strings; both
the pattern and the strings being processed can contain null bytes and
characters outside the US ASCII range.
Regular expressions can contain both special and ordinary characters.
Most ordinary characters, like "A", "a", or "0", are the simplest
regular expressions; they simply match themselves. You can
concatenate ordinary characters, so last matches the string 'last'.Eine sehr ausführliche Erklärung zu regulären Ausdrücken finden Sie in Wikipedia.